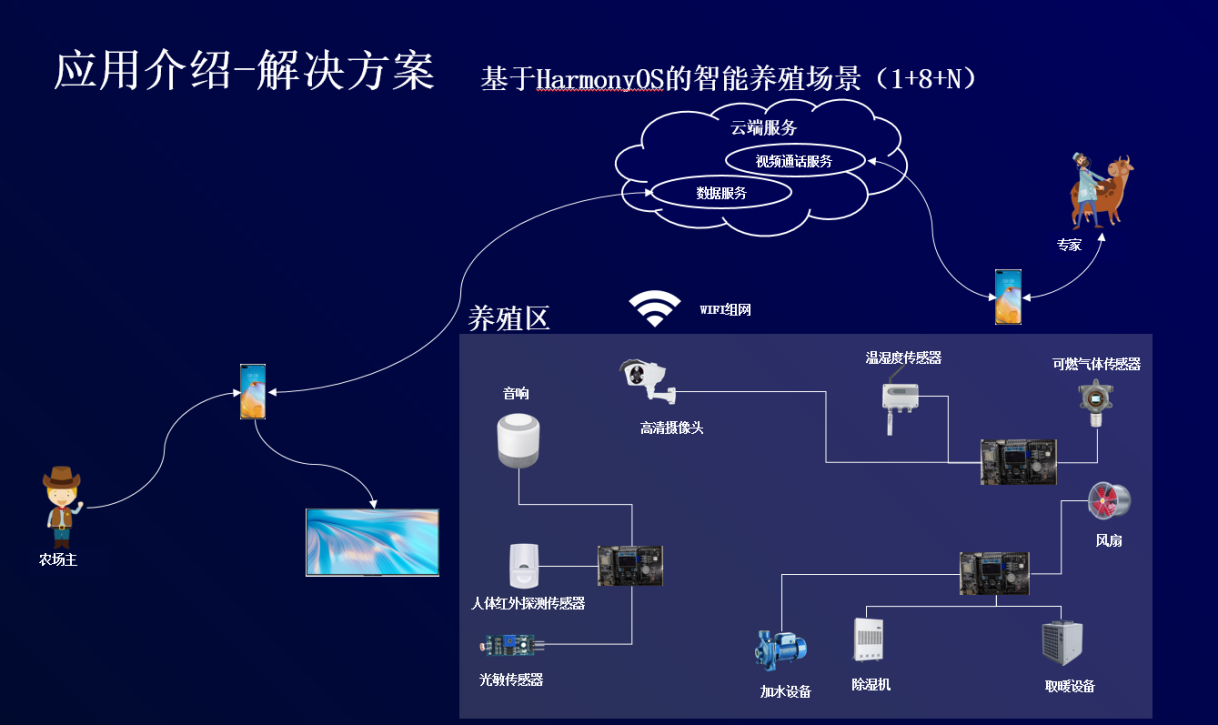
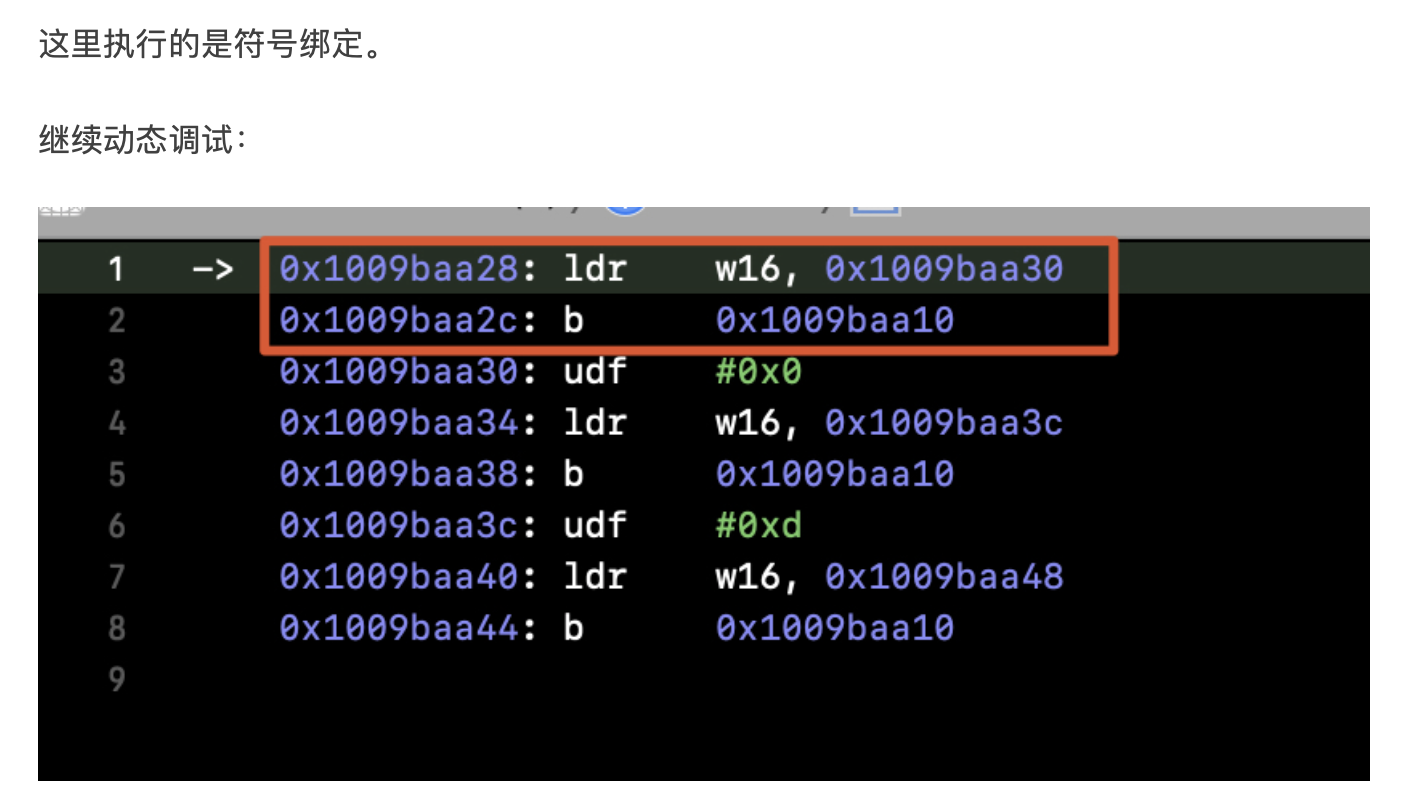
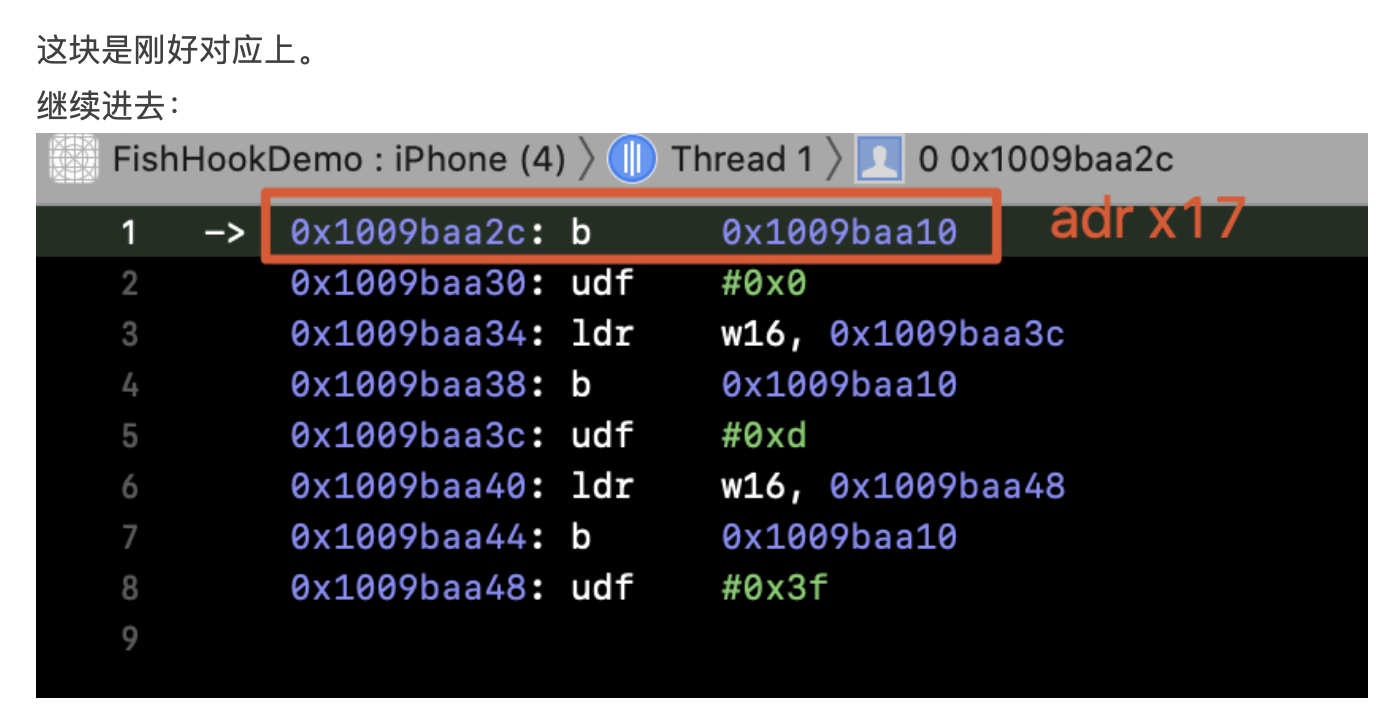
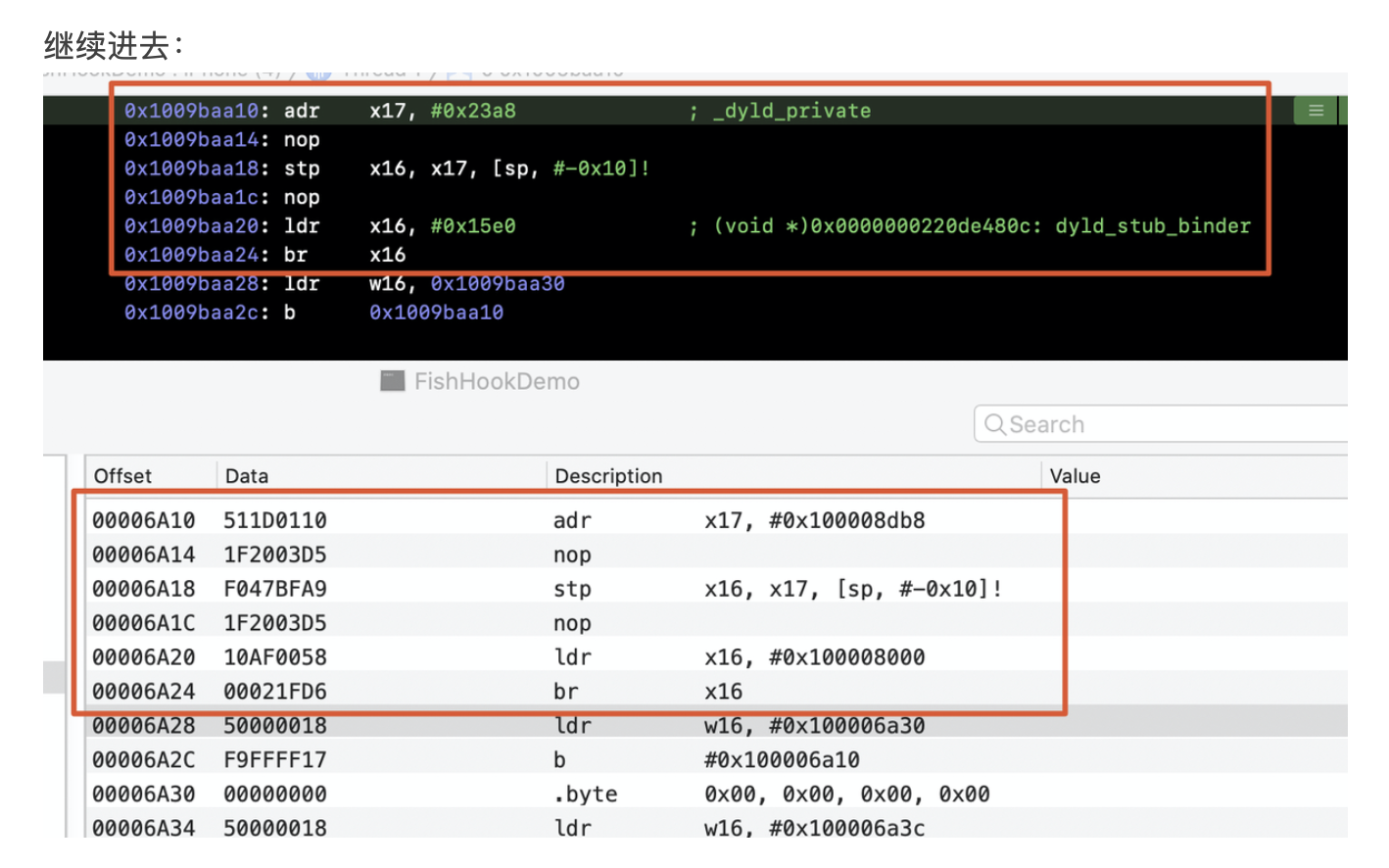
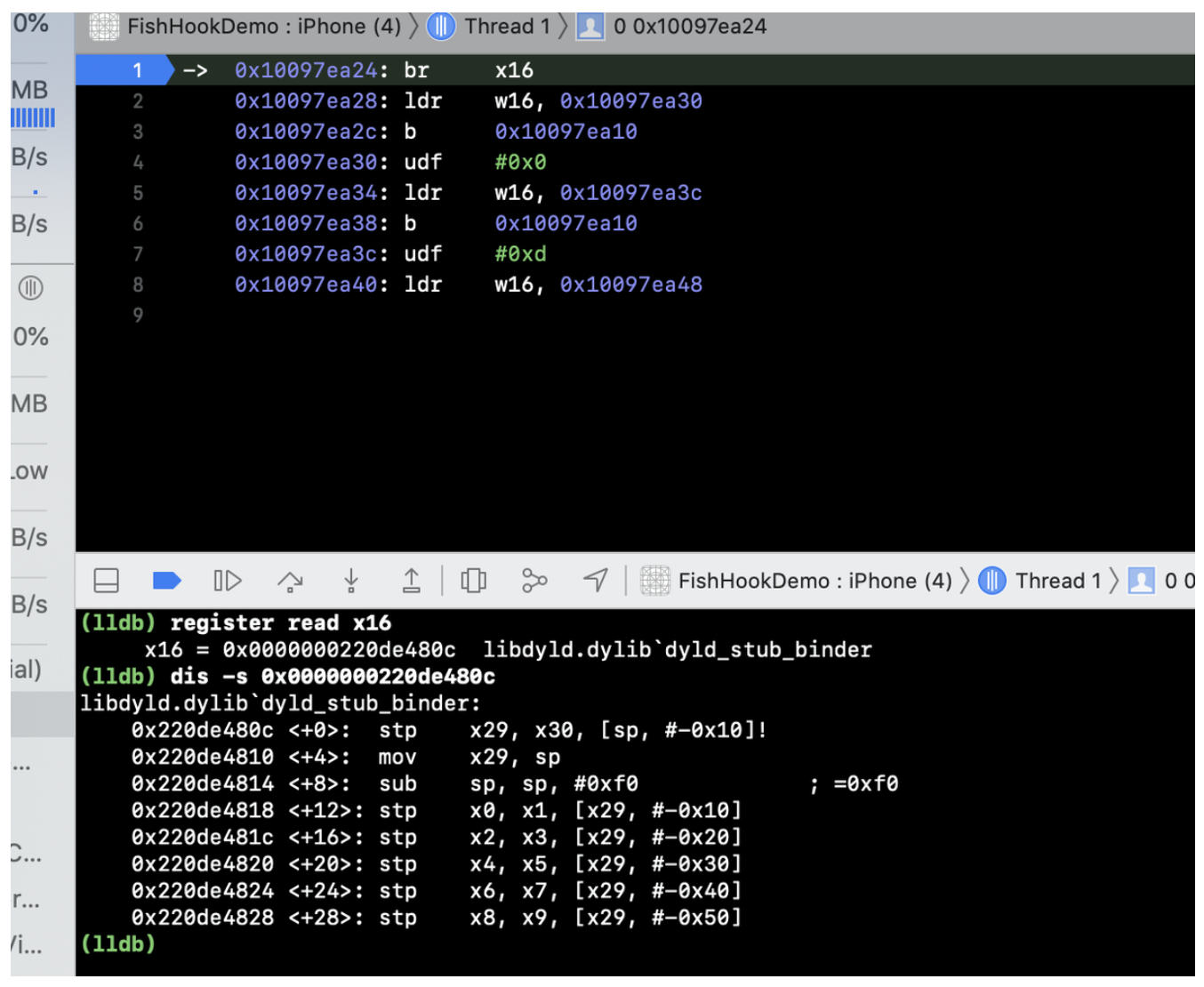
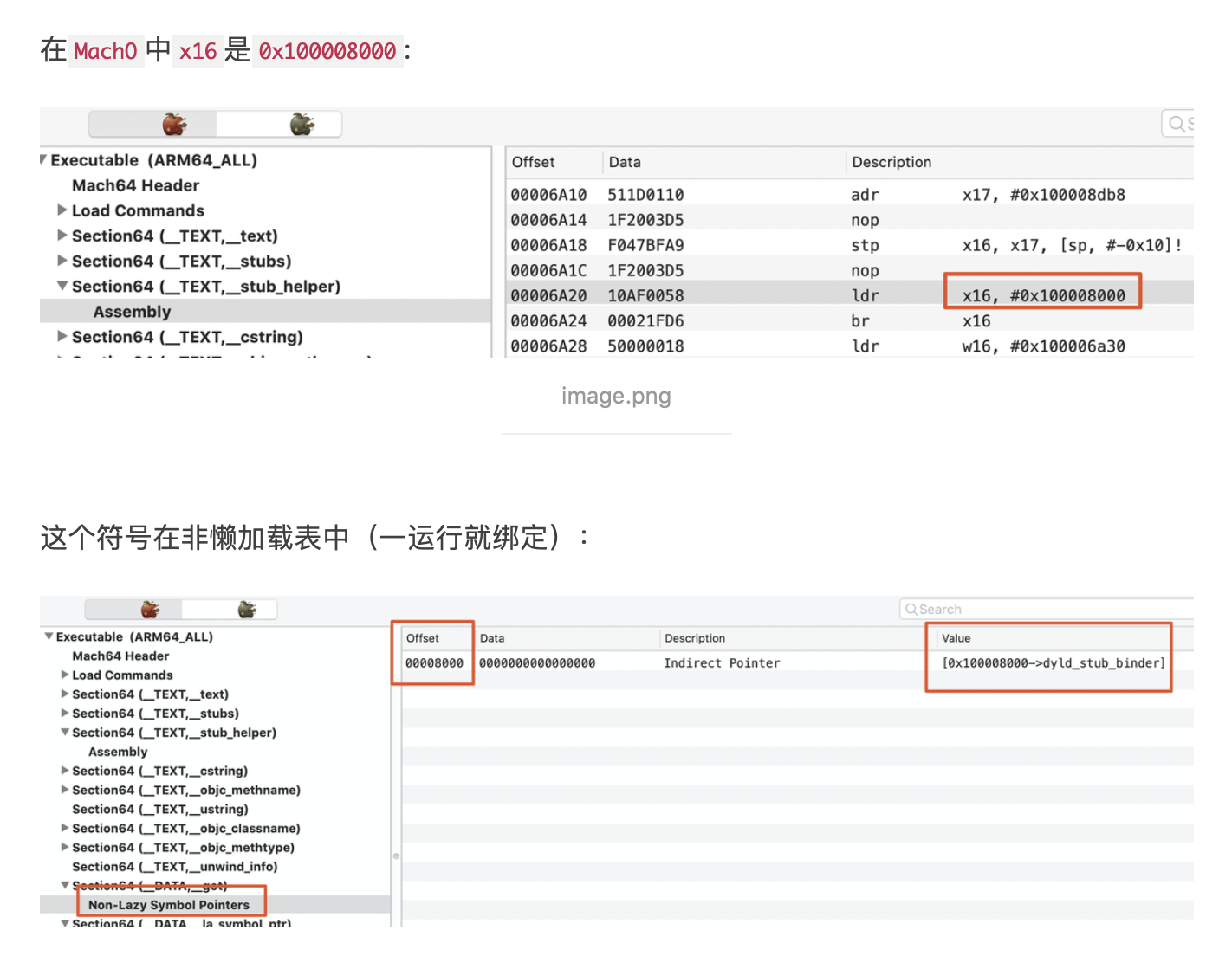
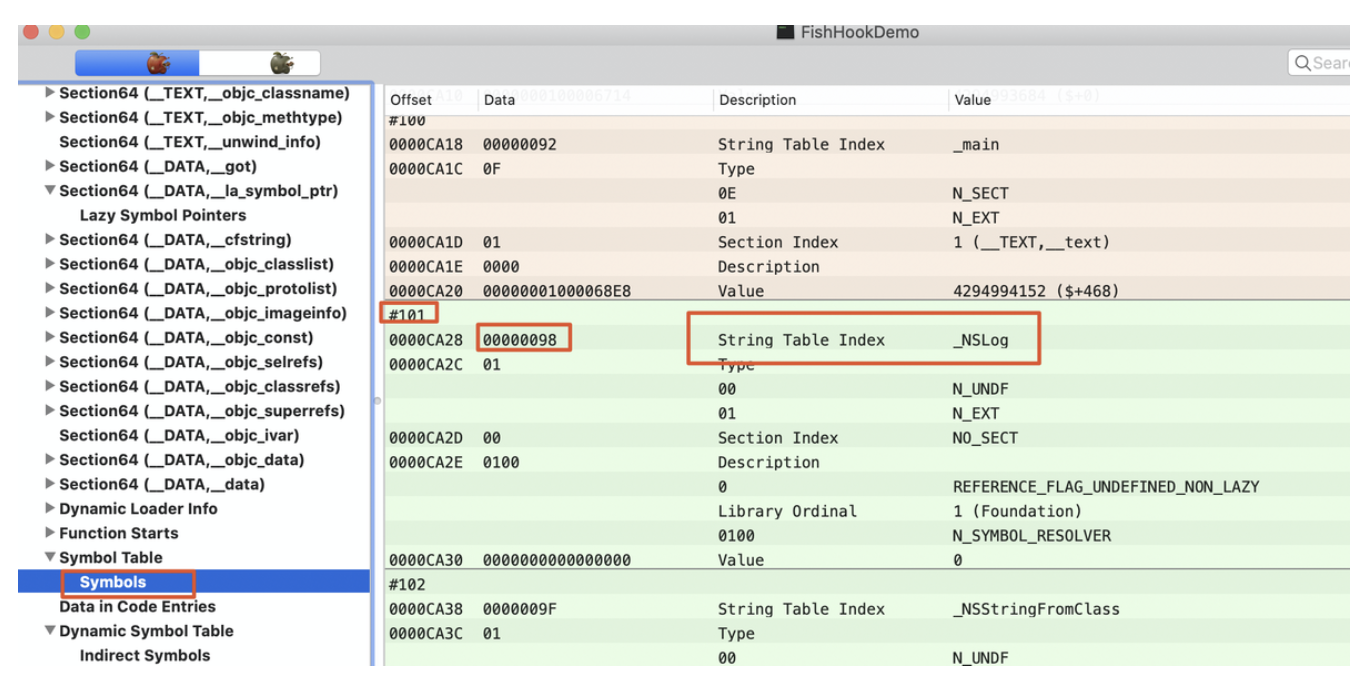
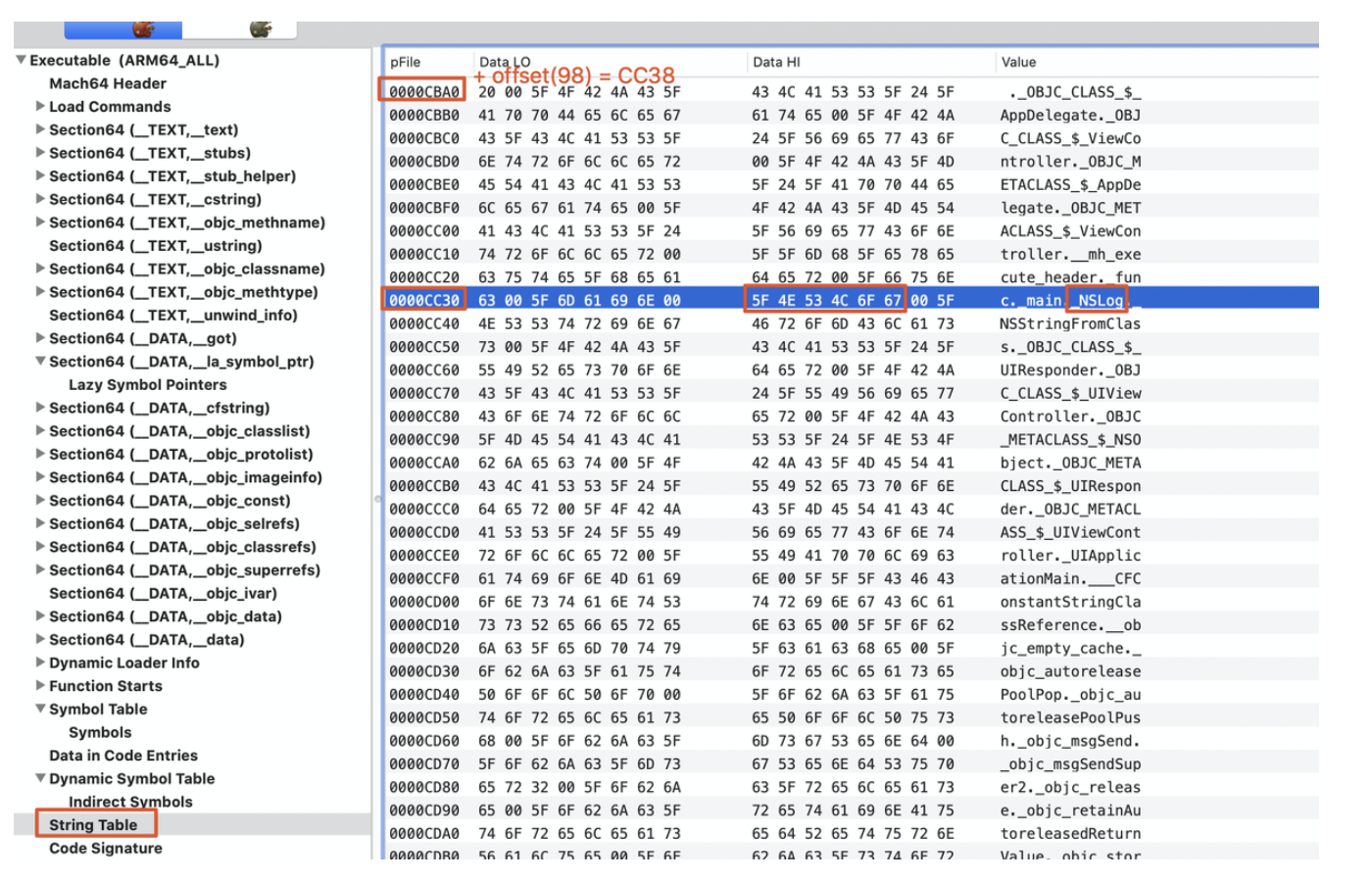
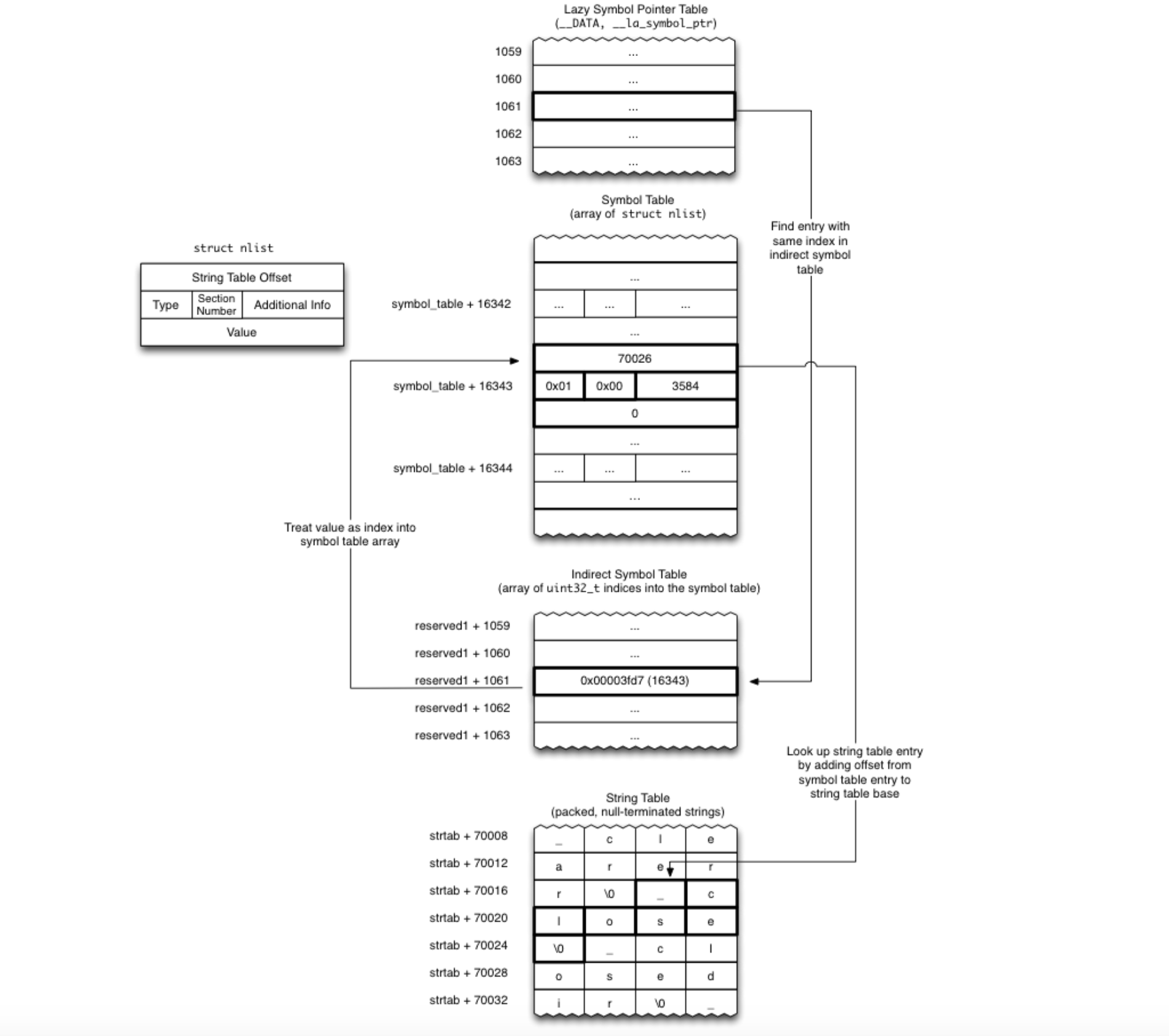
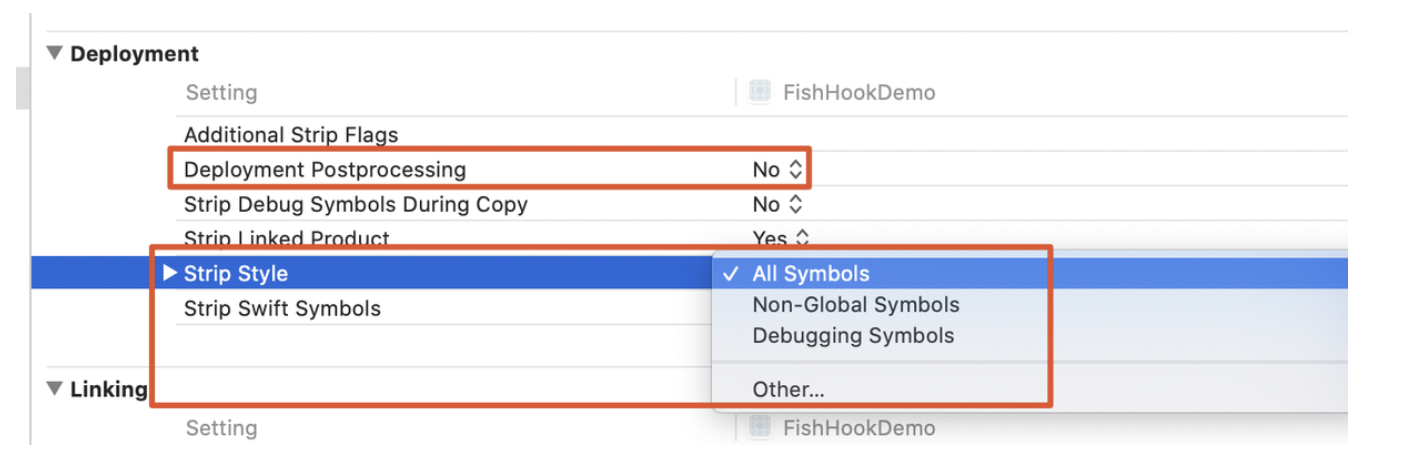
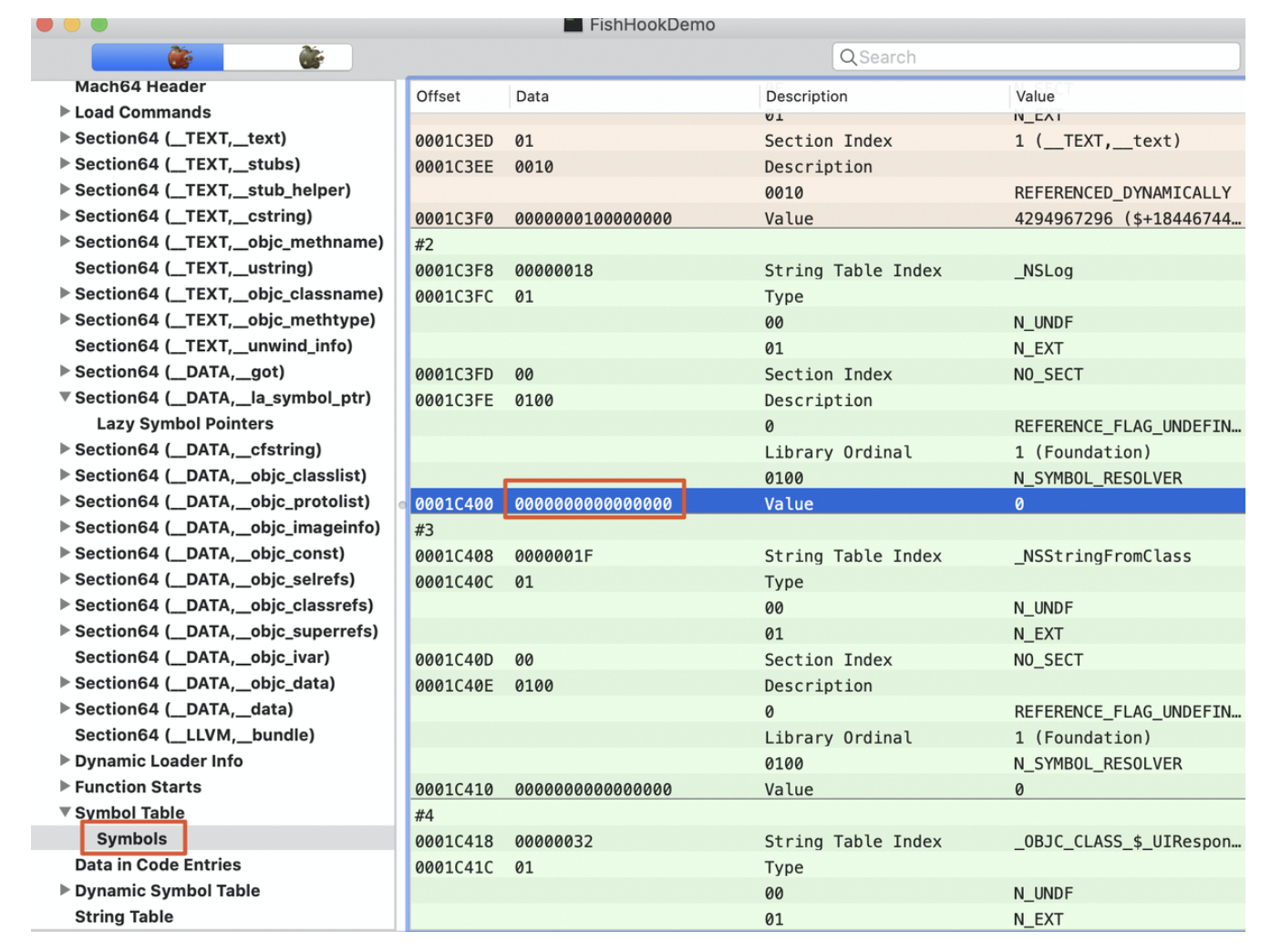
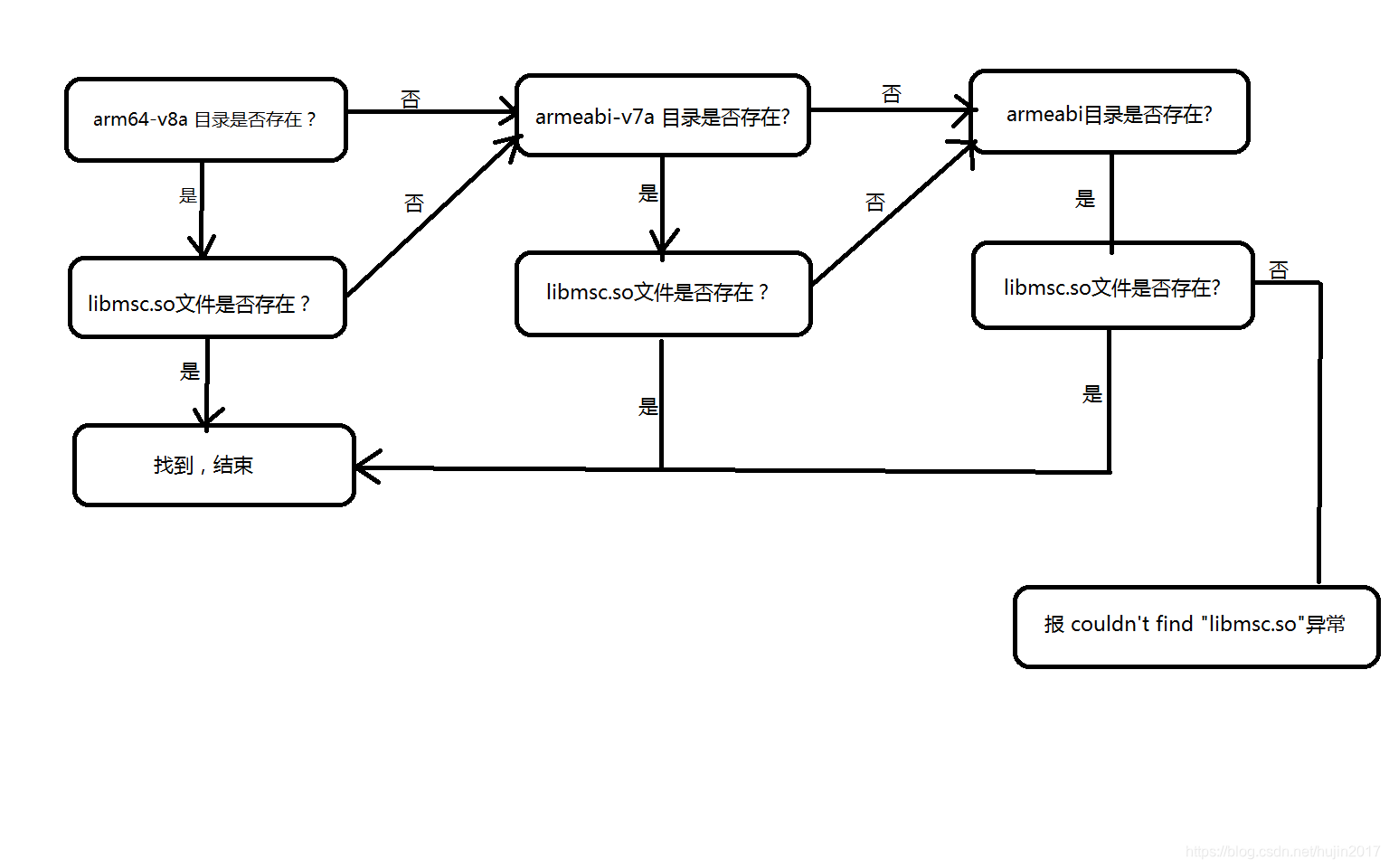
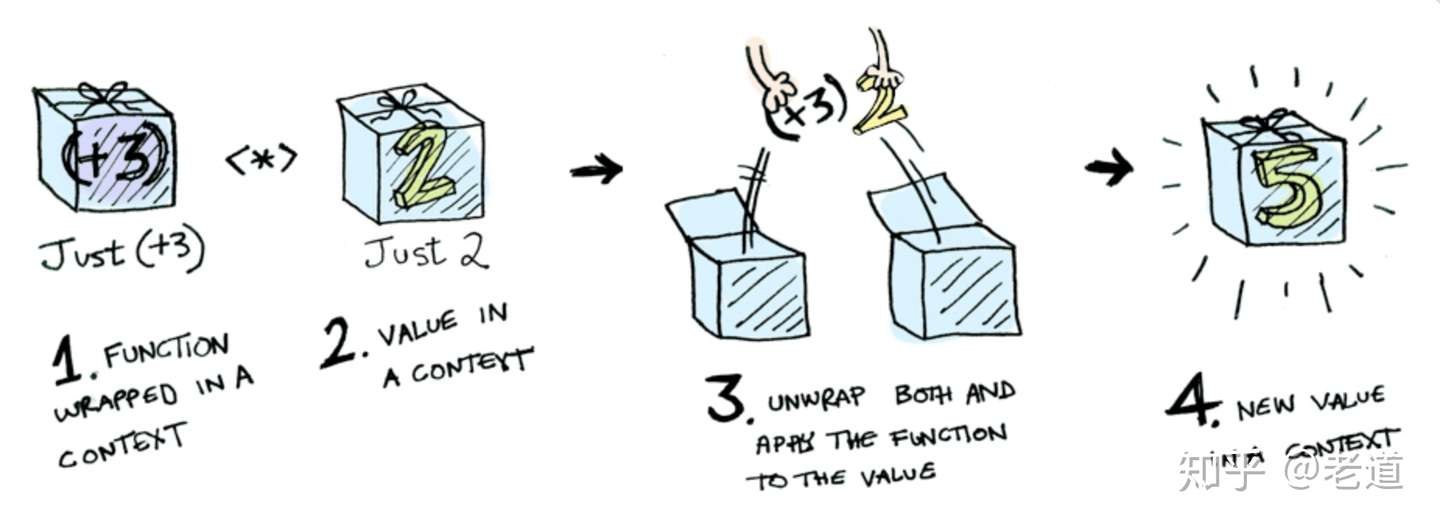
背景

先罗列一些小团队会大概率会遇到的问题:
- 规范
- 代码没有规范,每个人的风格随心所欲,代码交付质量不可控
- 提交 commit 没有规范,无法从 commit 知晓提交开发内容
- 流程
- 研发没有流程,没有 prd,没有迭代的需求管理,这个项目到底做了点啥也不知道
- 效率
- 项目质量
- 项目没有规范就一定没有质量
- 测试功能全部靠人工发现与回归,费时费力
- 部署
- 人工构建、部署,刀耕火种般的操作
- 依赖不统一、人为不可控
- 没有版本追踪、回滚等功能
除了上述比较常见的几点外,其余的一些人为环境因素就不一一列举了,总结出来其实就是混乱 + 不舒服。
同时处在这样的一个团队中,团队自身的规划就不明确,个人就更难对未来有一个清晰的规划与目标,容易全部陷于业务不可自拔、无限循环。
当你处在一个混乱的环境,遇事不要慌(乱世出英雄,为什么不能是你呢),先把事情捋顺,然后定个目标与规划,一步步走。
工程化
上述列举的这些问题可以通过引入工程化体系来解决,那么什么是工程化呢?
广义上,一切以提高效率、降低成本、保障质量为目的的手段,都属于工程化的范畴。
通过一系列的规范、流程、工具达到研发提效、自动化、保障质量、服务稳定、预警监控等等。
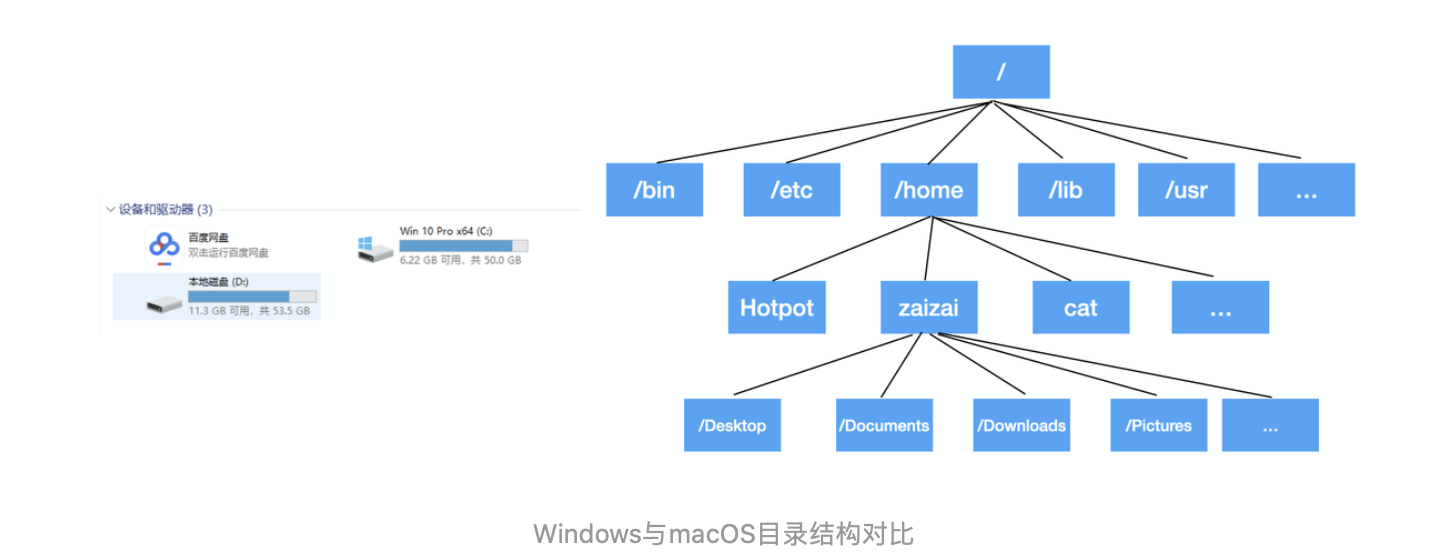
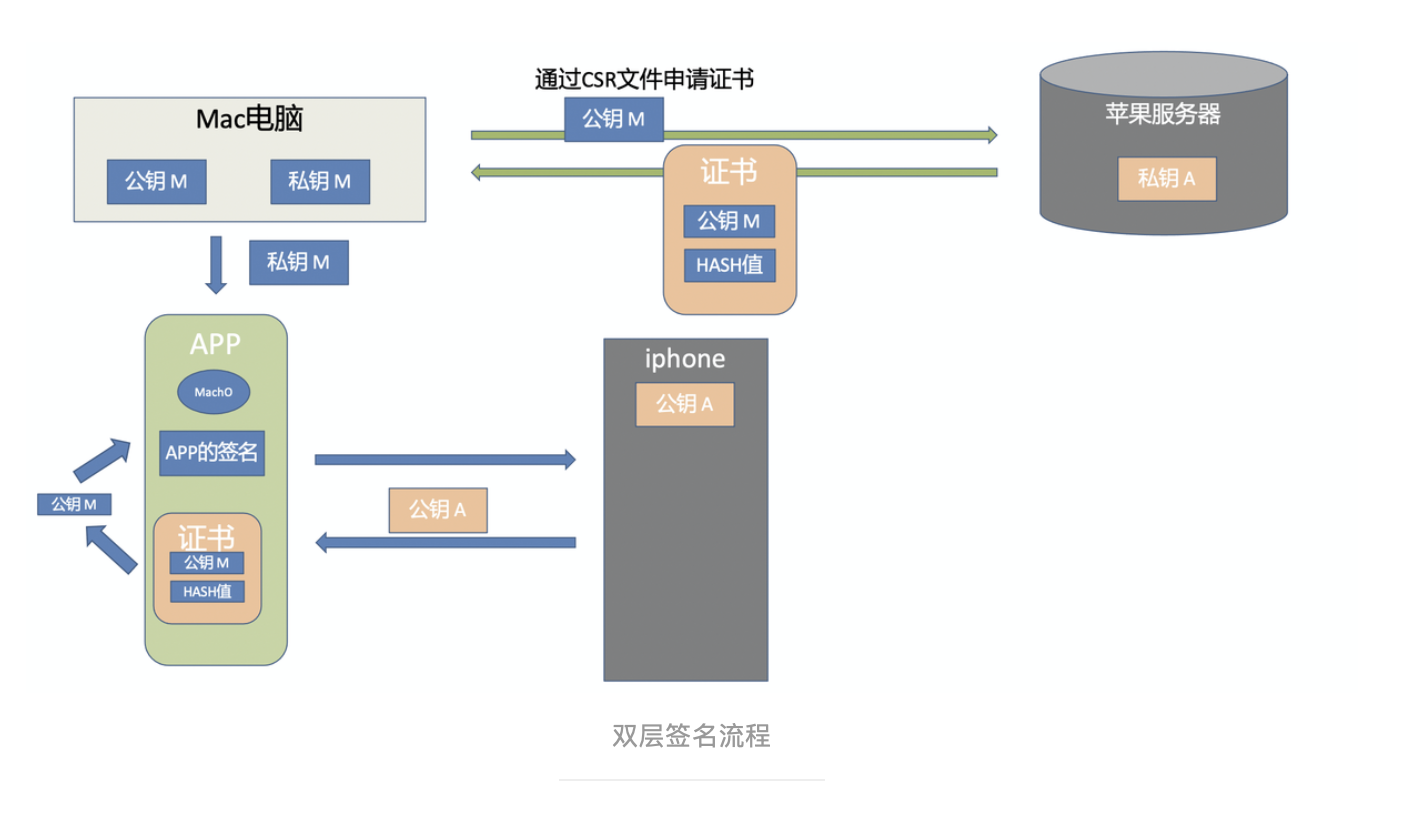
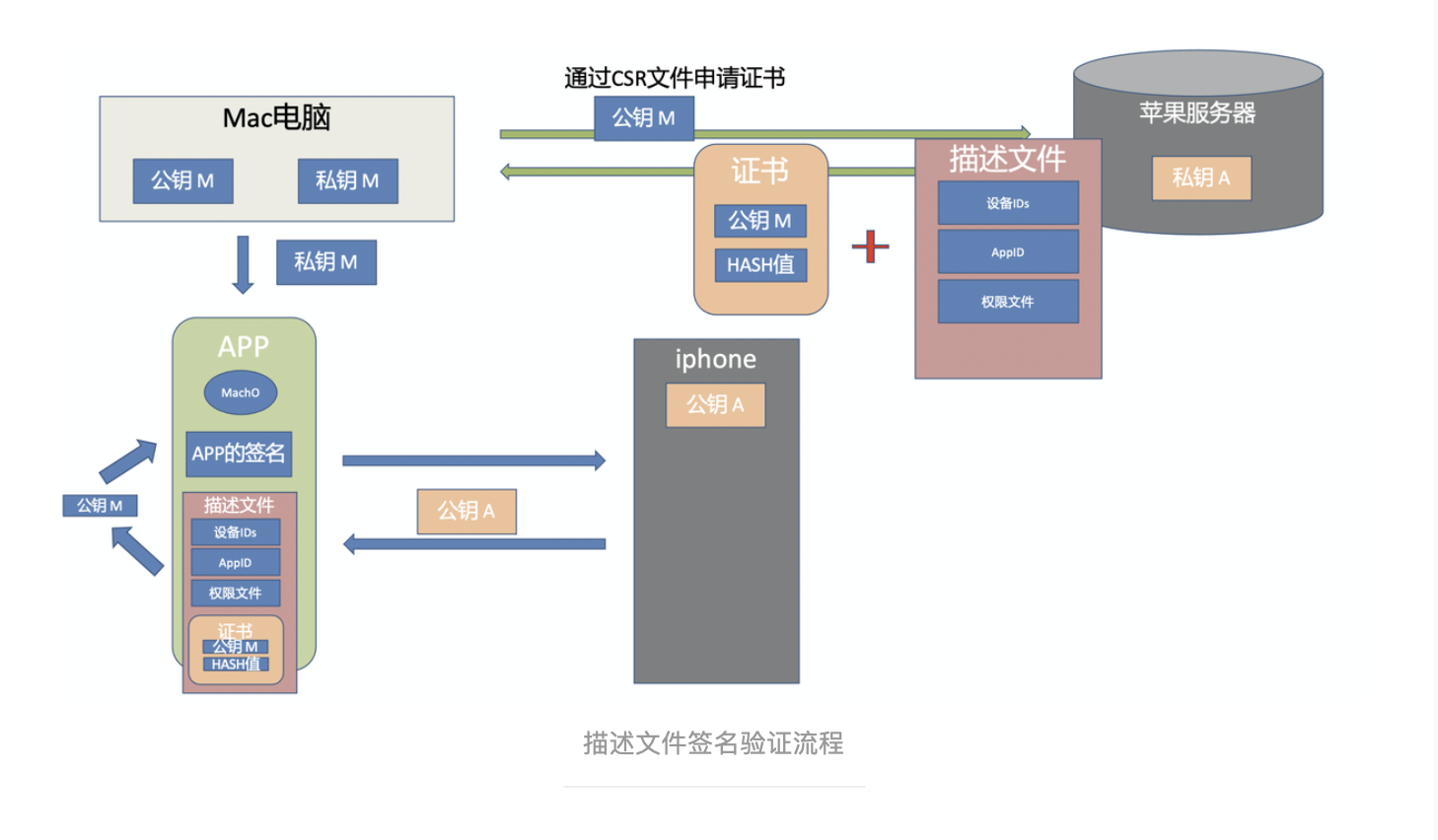
对前端而言,在 Node 出现之后,可以借助于 Node 渗透到传统界面开发之外的领域,将研发链路延伸到整个 DevOps 中去,从而脱离“切图仔”成为前端工程师。
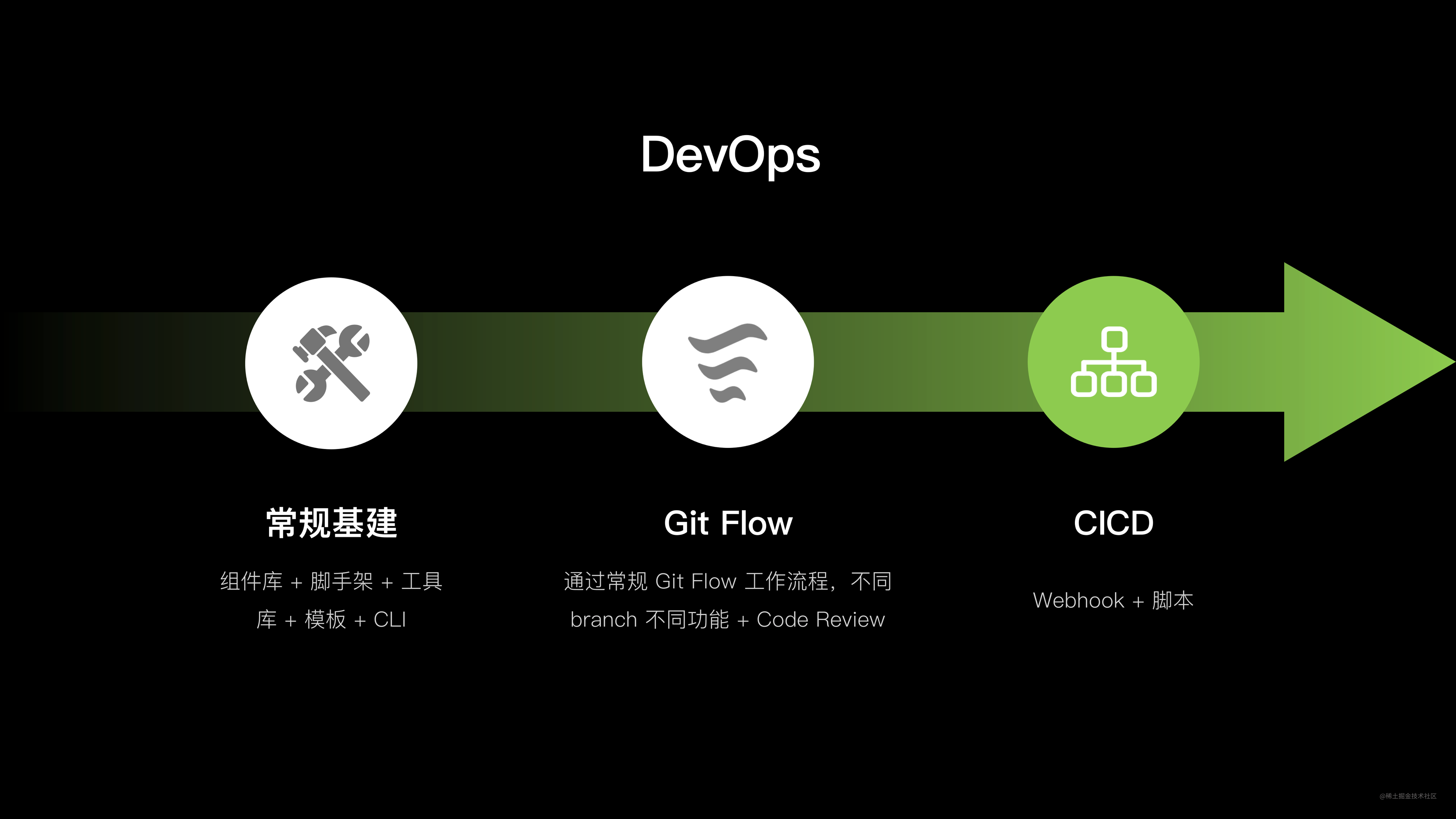
上图是一套简单的 DevOps 流程,技术难度与成本都比较适中,作为小型团队搭建工程化的起点,性价比极高。
在团队没有制定规则,也没有基础建设的时候,通常可以先从最基础的 CLI 工具开始然后切入到整个工程化的搭建。
所以先定一个小目标,完成一个团队、项目通用的 CLI 工具。
CLI 工具分析
小团队里面的业务一般迭代比较快,能抽出来提供开发基建的时间与机会都比较少,为了避免后期的重复工作,在做基础建设之前,一定要做好规划,思考一下当前最欠缺的核心与未来可能需要用到的功能是什么?
Coding 永远不是最难的,最难的是不知道能使用 code 去做些什么有价值的事情。
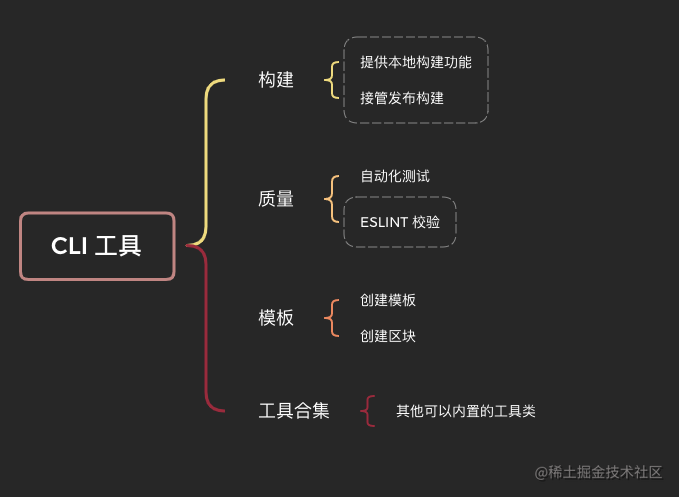
参考上述的 DevOps 流程,本系列先简单规划出 CLI 的四个大模块,后续如果有需求变动再说。
可以根据自己项目的实际情况去设计 CLI 工具,本系列仅提供一个技术架构参考。
构建
通常在小团队中,构建流程都是在一套或者多套模板里面准备多环境配置文件,再使用 Webpack Or Rollup 之类的构建工具,通过 Shell 脚本或者其他操作去使用模板中预设的配置来构建项目,最后再进行部署之类的。
这的确是一个简单、通用的 CI/CD 流程,但问题来了,只要最后一步的发布配置不在可控之内,任意团队的开发成员都可以对发布的配置项做修改。
即使构建成功,也有可能会有一些不可预见的问题,比如 Webpack 的 mode 选择的是 dev 模式、没有对构建代码压缩混淆、没有注入一些全局统一方法等等,此时对生产环境而言是存在一定隐患的。
所以需要将构建配置、过程从项目模板中抽离出来,统一使用 CLI 来接管构建流程,不再读取项目中的配置,而通过 CLI 使用统一配置(每一类项目都可以自定义一套标准构建配置)进行构建。
避免出现业务开发同学因为修改了错误配置而导致的生产问题。
质量
与构建是一样的场景,业务开发的时候为了方便,很多时候一些通用的自动化测试以及一些常规的格式校验都会被忽略。比如每个人开发的习惯不同也会导致使用的 ESLINT 校验规则不同,会对 ESLINT 的配置做一些额外的修改,这也是不可控的一个点。一个团队还是使用同一套代码校验规则最好。
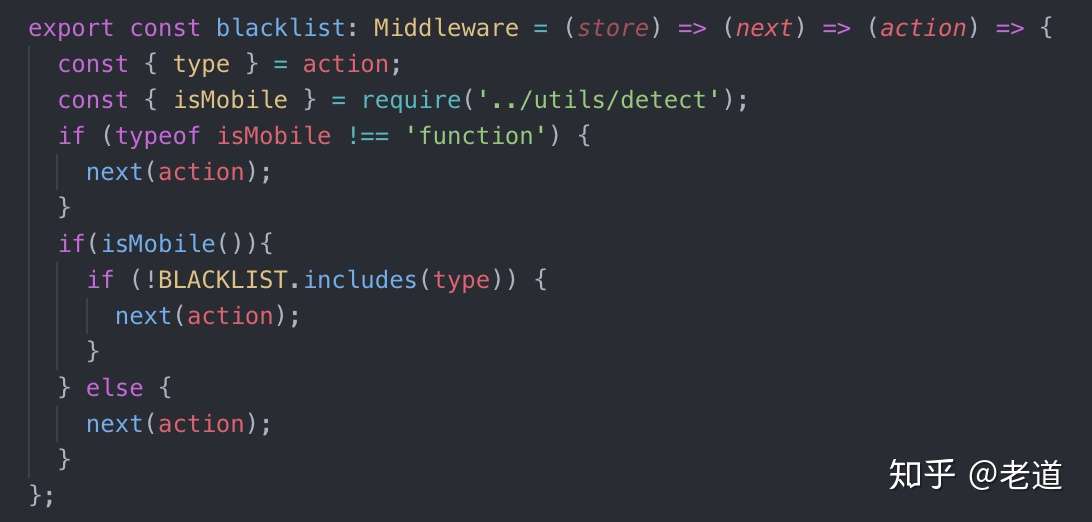
所以也可以将自动化测试、校验从项目中剥离,使用 CLI 接管,从而保证整个团队的某一类项目代码格式的统一性。
模板
至于模板,基本上目前出现的博客中,只要是关于 CLI 的,就必然会有模板功能。
因为这个一个对团队来说,快速、便捷初始化一个项目或者拉取代码片段是非常重要的,也是作为 CLI 工具来说产出最高、收益最明显的功能模块,但本章就不做过多的介绍,放在后面模板的博文统一写。
工具合集
既然是工具合集,那么可以放一些通用的工具类在里面,比如
- 图片压缩(png 压缩的更小的那种)、上传 CDN 等
- 项目升级(比如通用配置更新了,CLI 提供一键升级模板的功能)
- 项目部署、发布 npm 包等操作。
- 等等其他一些重复性的操作,也都可以放在工具合集里面
CLI 开发
前面介绍了 CLI 的几个模块功能设计,接下来可以正式进入开发对应的 CLI 工具的环节。
搭建基础架构
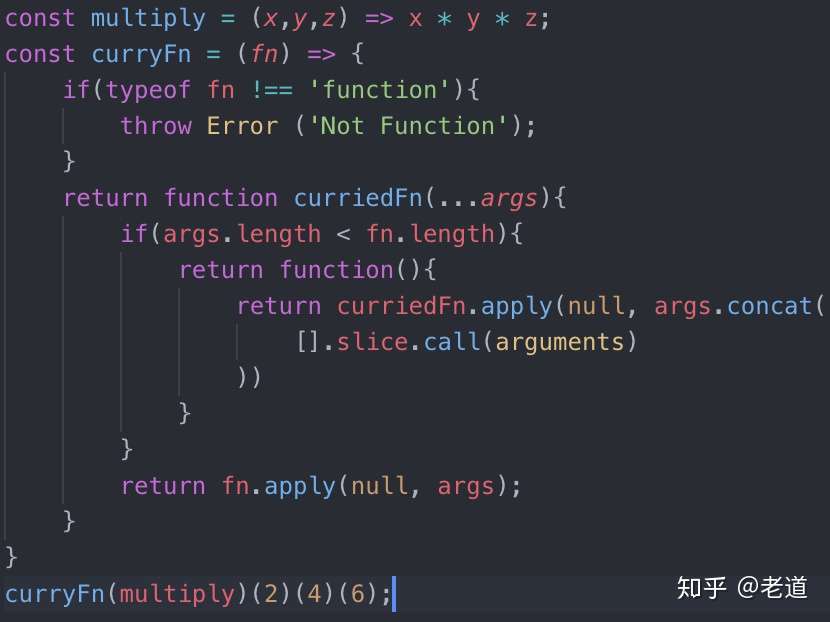
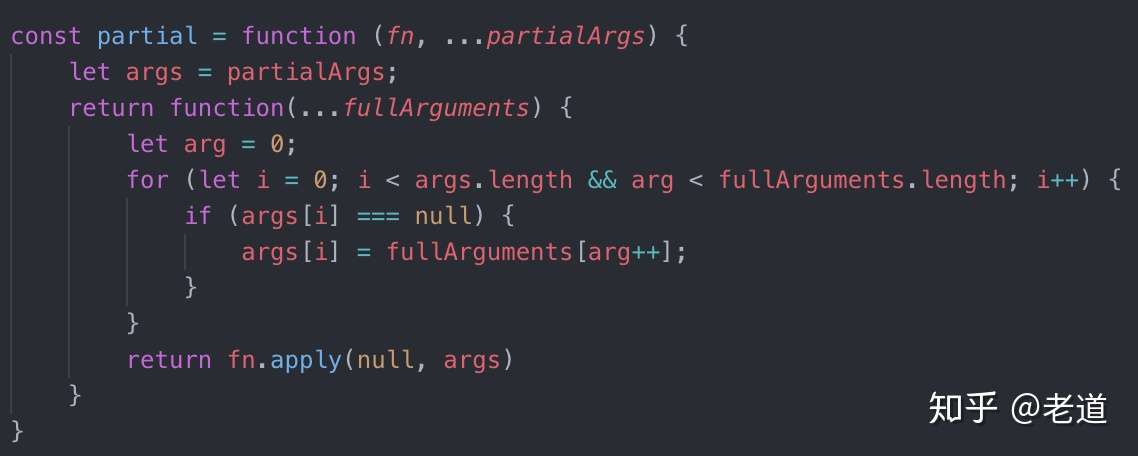
CLI 工具开发将使用 TS 作为开发语言,如果此时还没有接触过 TS 的同学,刚好可以借此项目来熟悉一下 TS 的开发模式。
mkdir cli && cd cli // 创建仓库目录
npm init // 初始化 package.json
npm install -g typescript // 安装全局 TypeScript
tsc --init // 初始化 tsconfig.json
全局安装完 TypeScript 之后,初始化 tsconfig.json 之后再进行修改配置,添加编译的文件夹与输出目录。
{
"compilerOptions": {
"target": "es5", /* Specify ECMAScript target version: 'ES3' (default), 'ES5', 'ES2015', 'ES2016', 'ES2017', 'ES2018', 'ES2019', 'ES2020', 'ES2021', or 'ESNEXT'. */
"module": "commonjs", /* Specify module code generation: 'none', 'commonjs', 'amd', 'system', 'umd', 'es2015', 'es2020', or 'ESNext'. */
"outDir": "./lib", /* Redirect output structure to the directory. */
"strict": true, /* Enable all strict type-checking options. */
"esModuleInterop": true, /* Enables emit interoperability between CommonJS and ES Modules via creation of namespace objects for all imports. Implies 'allowSyntheticDefaultImports'. */
"skipLibCheck": true, /* Skip type checking of declaration files. */
"forceConsistentCasingInFileNames": true /* Disallow inconsistently-cased references to the same file. */
},
"include": [
"./src",
]
}
上述是一份已经简化过的配置,但应对当前的开发已经足够了,后续有需要可以修改 TypeScript 的配置项。
ESLINT
因为是从 0 开发 CLI 工具,可以先从简单的功能入手,例如开发一个 Eslint 校验模块。
npm install eslint --save-dev // 安装 eslint 依赖
npx eslint --init // 初始化 eslint 配置
直接使用 eslint --init 可以快速定制出适合自己项目的 ESlint 配置文件 .eslintrc.json
{
"env": {
"browser": true,
"es2021": true
},
"extends": [
"plugin:react/recommended",
"standard"
],
"parser": "@typescript-eslint/parser",
"parserOptions": {
"ecmaFeatures": {
"jsx": true
},
"ecmaVersion": 12,
"sourceType": "module"
},
"plugins": [
"react",
"@typescript-eslint"
],
"rules": {
}
}
如果项目中已经有定义好的 ESlint,可以直接使用自己的配置文件,或者根据项目需求对初始化的配置进行增改。
创建 ESlint 工具类
第一步,对照文档 ESlint Node.js API,使用提供的 Node Api 直接调用 ESlint。
将前面生成的 .eslintrc.json 的配置项按需加入,同时使用 useEslintrc:fase 禁止使用项目本身的 .eslintrc 配置,仅使用 CLI 提供的规则去校验项目代码。
import { ESLint } from 'eslint'
import { getCwdPath, countTime } from '../util'
// 1. Create an instance.
const eslint = new ESLint({
fix: true,
extensions: [".js", ".ts"],
useEslintrc: false,
overrideConfig: {
"env": {
"browser": true,
"es2021": true
},
"parser": getRePath("@typescript-eslint/parser"),
"parserOptions": {
"ecmaFeatures": {
"jsx": true
},
"ecmaVersion": 12,
"sourceType": "module"
},
"plugins": [
"react",
"@typescript-eslint",
],
},
resolvePluginsRelativeTo: getDirPath('../../node_modules') // 指定 loader 加载路径
});
export const getEslint = async (path: string = 'src') => {
try {
countTime('Eslint 校验');
// 2. Lint files.
const results = await eslint.lintFiles([`${getCwdPath()}/${path}`]);
// 3. Modify the files with the fixed code.
await ESLint.outputFixes(results);
// 4. Format the results.
const formatter = await eslint.loadFormatter("stylish");
const resultText = formatter.format(results);
// 5. Output it.
if (resultText) {
console.log('请检查===》', resultText);
}
else {
console.log('完美!');
}
} catch (error) {
process.exitCode = 1;
console.error('error===>', error);
} finally {
countTime('Eslint 校验', false);
}
}
创建测试项目
npm install -g create-react-app // 全局安装 create-react-app
create-react-app test-cli // 创建测试 react 项目
测试项目使用的是 create-react-app,当然你也可以选择其他框架或者已有项目都行,这里只是作为一个 demo,并且后期也还会再用到这个项目做测试。
测试 CLI
新建 src/bin/index.ts, demo 中使用 commander 来开发命令行工具。
#!/usr/bin/env node // 这个必须添加,指定 node 运行环境
import { Command } from 'commander';
const program = new Command();
import { getEslint } from '../eslint'
program
.version('0.1.0')
.description('start eslint and fix code')
.command('eslint')
.action((value) => {
getEslint()
})
program.parse(process.argv);
修改 pageage.json,指定 bin 的运行 js(每个命令所对应的可执行文件的位置)
"bin": {
"fe-cli": "/lib/bin/index.js"
},
先运行 tsc 将 TS 代码编译成 js,再使用 npm link 挂载到全局,即可正常使用。
commander 的具体用法就不详细介绍了,基本上市面大部分的 CLI 工具都使用 commander 作为命令行工具开发,也都有这方面的介绍。
命令行进入刚刚的测试项目,直接输入命令 fe-cli eslint,就可以正常使用 Eslint 插件,输出结果如下:

美化输出
可以看出这个时候,提示并没有那么显眼,可以使用 chalk 插件来美化一下输出。
先将测试工程故意改错一个地方,再运行命令 fe-cli eslint
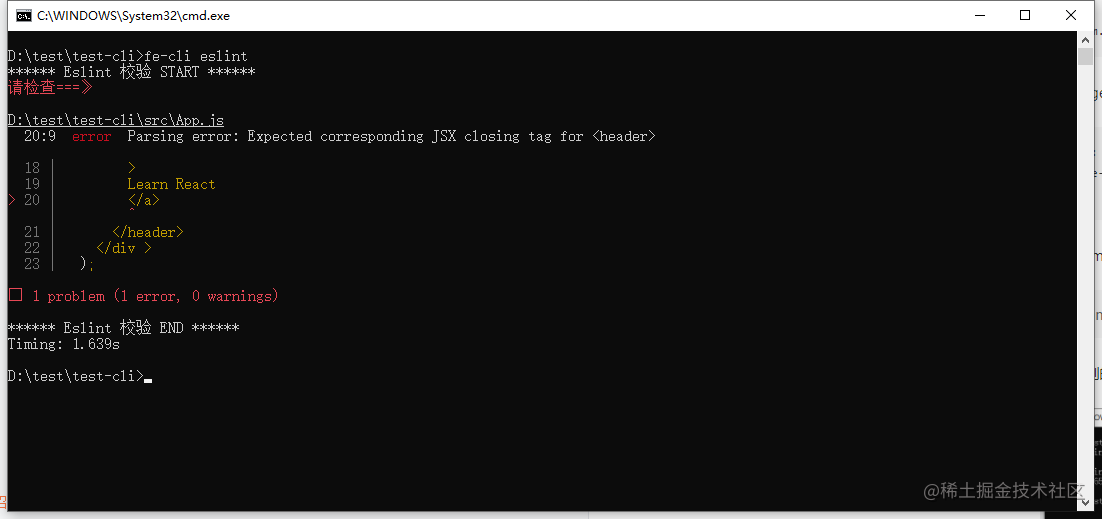
至此,已经完成了一个简单的 CLI 工具,对于 ESlint 的模块,可以根据自己的想法与规划定制更多的功能。
构建模块
配置通用 Webpack
通常开发业务的时候,用的是 webpack 作为构建工具,那么 demo 也将使用 webpack 进行封装。
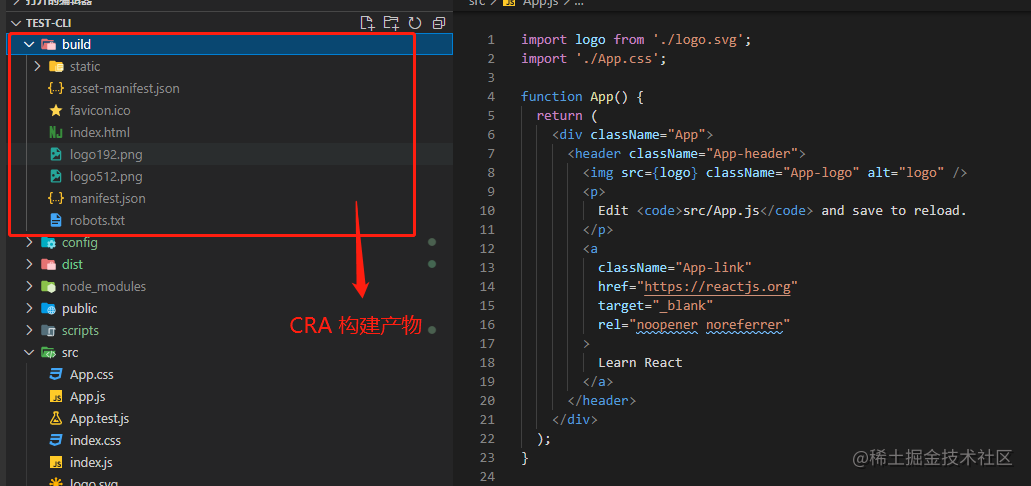
先命令行进入测试项目中执行命令 npm run eject,暴露 webpack 配置项。
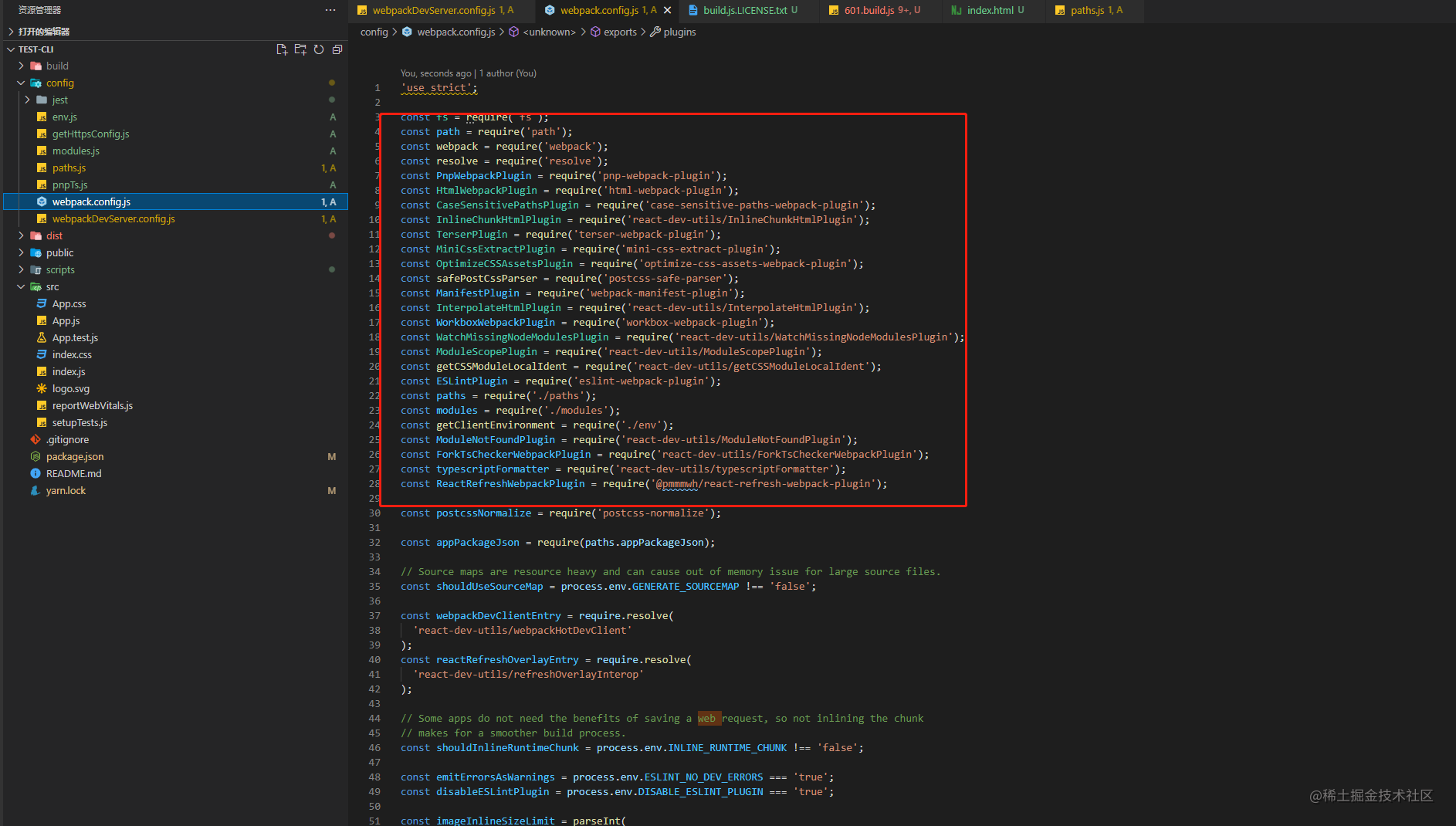
从上图暴露出来的配置项可以看出,CRA 的 webpack 配置还是非常复杂的,毕竟是通用型的脚手架,针对各种优化配置都做了兼容,但目前 CRA 使用的还是 webpack 4 来构建。作为一个新的开发项目,CLI 可以不背技术债务,直接选择 webpack 5 来构建项目。
一般来说,构建工具替换不会影响业务代码,如果业务代码被构建工具绑架,建议还是需要去优化一下代码了。
import path from "path"
const HtmlWebpackPlugin = require('html-webpack-plugin')
const postcssNormalize = require('postcss-normalize');
import { getCwdPath, getDirPath } from '../../util'
interface IWebpack {
mode?: "development" | "production" | "none";
entry: any
output: any
template: string
}
export default ({
mode,
entry,
output,
template
}: IWebpack) => {
return {
mode,
entry,
target: 'web',
output,
module: {
rules: [{
test: /\.(js|jsx)$/,
use: {
loader: getRePath('babel-loader'),
options: {
presets: [
''@babel/preset-env',
],
},
},
exclude: [
getCwdPath('./node_modules') // 由于 node_modules 都是编译过的文件,这里做过滤处理
]
},
{
test: /\.css$/,
use: [
'style-loader',
{
loader: 'css-loader',
options: {
importLoaders: 1,
},
},
{
loader: 'postcss-loader',
options: {
postcssOptions: {
plugins: [
[
'postcss-preset-env',
{
ident: "postcss"
},
],
],
},
}
}
],
},
{
test: /\.(woff(2)?|eot|ttf|otf|svg|)$/,
type: 'asset/inline',
},
{
test: [/\.bmp$/, /\.gif$/, /\.jpe?g$/, /\.png$/],
loader: 'url-loader',
options: {
limit: 10000,
name: 'static/media/[name].[hash:8].[ext]',
},
},
]
},
plugins: [
new HtmlWebpackPlugin({
template,
filename: 'index.html',
}),
],
resolve: {
extensions: [
'',
'.js',
'.json',
'.sass'
]
},
}
}
上述是一份简化版本的 webpack 5 配置,再添加对应的 commander 命令。
program
.version('0.1.0')
.description('start eslint and fix code')
.command('webpack')
.action((value) => {
buildWebpack()
})
现在可以命令行进入测试工程执行 fe-cli webpack 即可得到下述构建产物
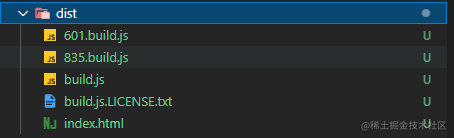
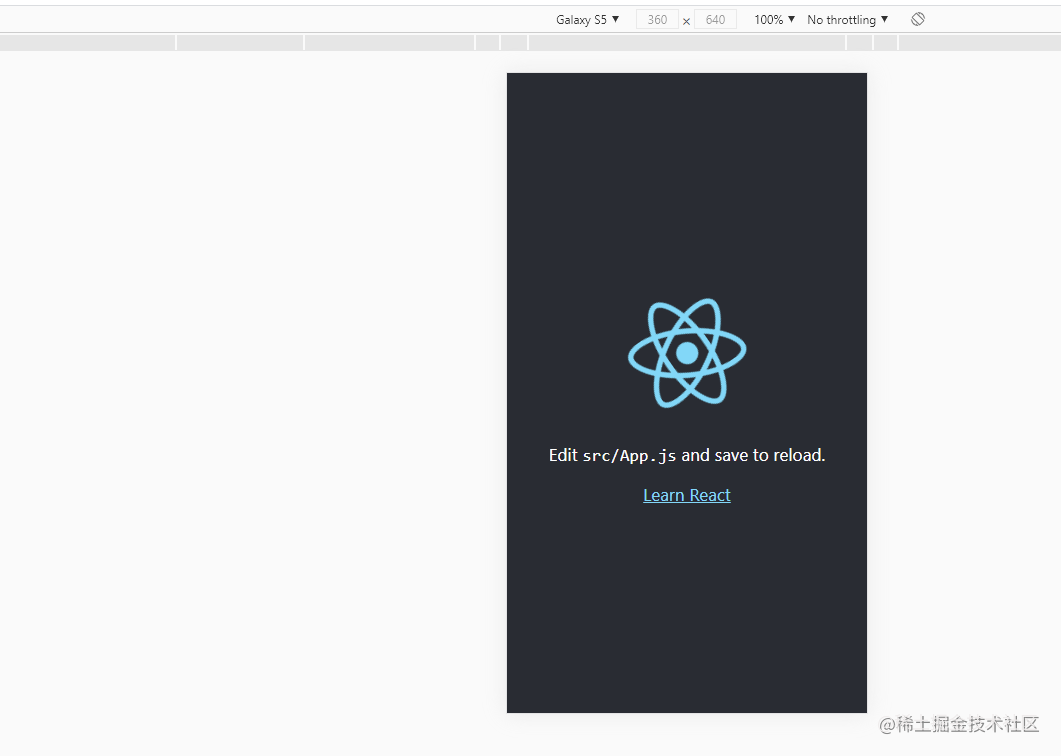
下图是使用 CRA 构建出来的产物,跟上图的构建产物对一下,能明显看出使用简化版本的 webpack 5 配置还有很多可优化的地方,那么感兴趣的同学可以再自行优化一下,作为 demo 已经完成初步的技术预研,达到了预期目标。
此时,如果熟悉构建这块的同学应该会想到,除了 webpack 的配置项外,构建中绝大部分的依赖都是来自测试工程里面的,那么如何确定 React 版本或者其他的依赖统一呢?
常规操作还是通过模板来锁定版本,但是业务同学依然可以自行调整版本依赖导致不一致,并不能保证依赖一致性。
既然整个构建都由 CLI 接管,只需要考虑将全部的依赖转移到 CLI 所在的项目依赖即可。
解决依赖
Webpack 配置项新增下述两项,指定依赖跟 loader 的加载路径,不从项目所在 node_modules 读取,而是读取 CLI 所在的 node_modules。
resolveLoader: {
modules: [getDirPath('../../node_modules')]
}, // 修改 loader 依赖路径
resolve: {
modules: [getDirPath('../../node_modules')],
}, // 修改正常模块依赖路径
同时将 babel 的 presets 模块路径修改为绝对路径,指向 CLI 的 node_modules(presets 会默认从启动路劲读取依赖)。
{
test: /\.(js|jsx)$/,
use: {
loader: getRePath('babel-loader'),
options: {
presets: [
getRePath('@babel/preset-env'),
[
getRePath("@babel/preset-react"),
{
"runtime": "automatic"
}
],
],
},
},
exclude: [
[getDirPath('../../node_modules')]
]
}
完成依赖修改之后,一起测试一下效果,先将测试工程的依赖 node_modules 全部删除
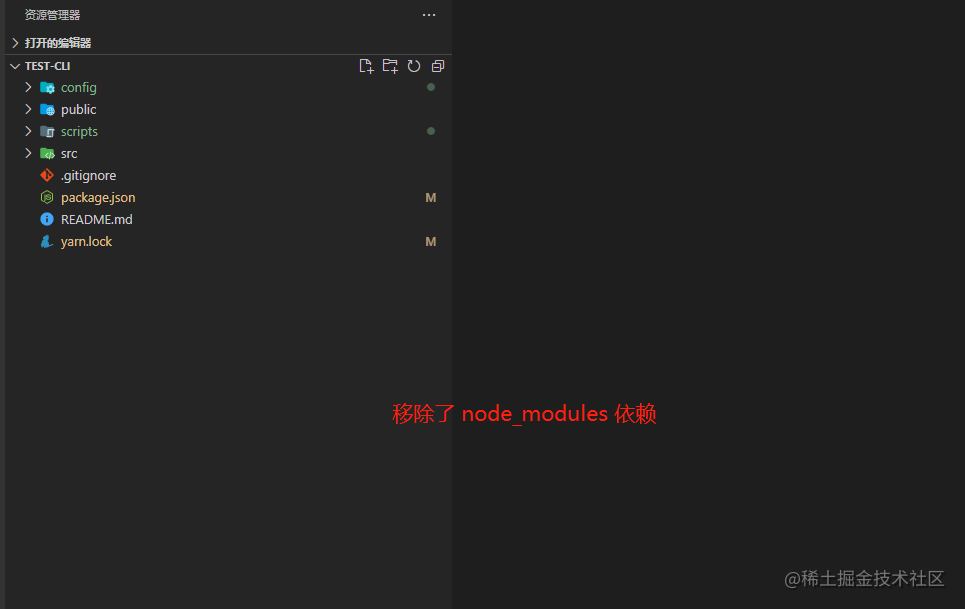
再执行 fe-cli webpack,使用 CLI 依赖来构建此项目。
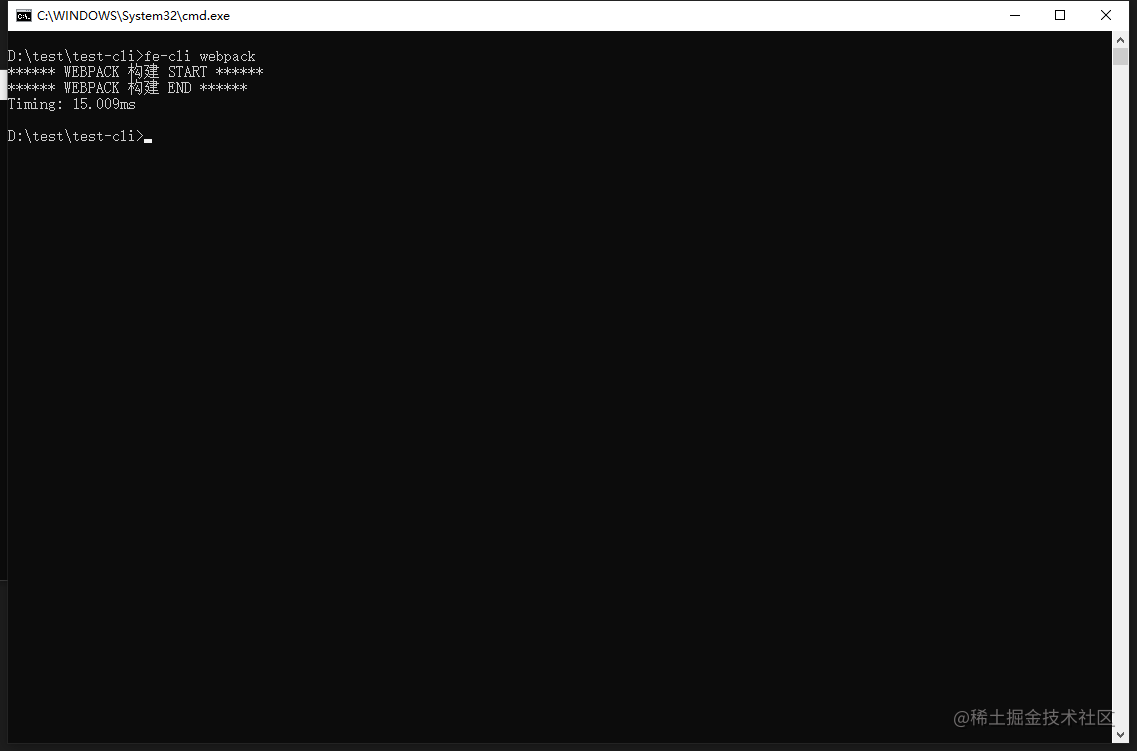
可以看出,已经可以在项目不安装任何依赖的情况,使用 CLI 也可以正常构建项目了。
那么目前所有项目的依赖、构建已经全部由 CLI 接管,可以统一管理依赖与构建流程,如果需要升级依赖的话可以使用 CLI 统一进行升级,同时业务开发同学也无法对版本依赖进行改动。
这个解决方案要根据自身的实际需求来实施,所有的依赖都来源于 CLI 工具的话,版本升级影响会非常大也会非常被动,要做好兼容措施。比如哪些依赖可以取自项目,哪些依赖需要强制通用,做好取舍。
写给迷茫 Coder 们的一段话
如果遇到最开始提到那些问题的同学们,应该会经常陷入到业务中无法自拔,而且写这种基础项目,是真的很花时间也很枯燥。容易对工作厌烦,对 coding 感觉无趣。
这是很正常的,绝大多数人都有这段经历与类似的想法,但还是希望你能去多想想,在枯燥、无味、重复的工作中去发现痛点、机会。只有接近业务、熟悉业务,才有机会去优化、革新、创造。
所有的基建都是要依托业务才能发挥最大的作用。
每天抽个半小时思考一下今天的工作还能在哪些方面有所提高,提高效率的不仅仅是你的代码也可以是其他的工具或者是引入新的流程。
同时也不要仅仅限制在思考阶段,有想法就争取落地,再多抽半小时进行 coding 或者找工具什么的,但凡能够提高个几分钟的效率,即使是个小工具、多几行代码、换个流程这种也值得去尝试一下。
等你把这些零碎的小东西、想法一点点全部积累起来,到最后整合到一个体系中去,那么此时你会发现已经可以站在更高一层的台阶去思考、规划下一阶段需要做的事情,而这其中所有的经历都是你未来成长的基石。
一直相信一句话:努力不会被辜负,付出终将有回报。此时敲下去的每一行代码在未来都将是你登高的一步步台阶。