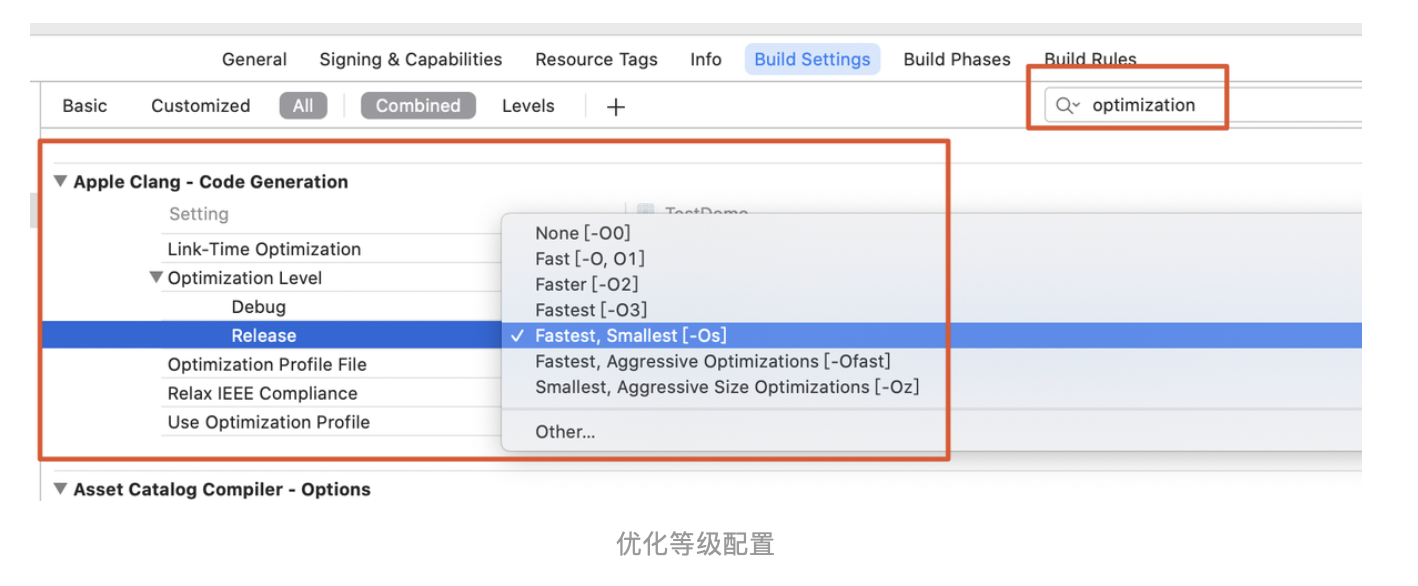
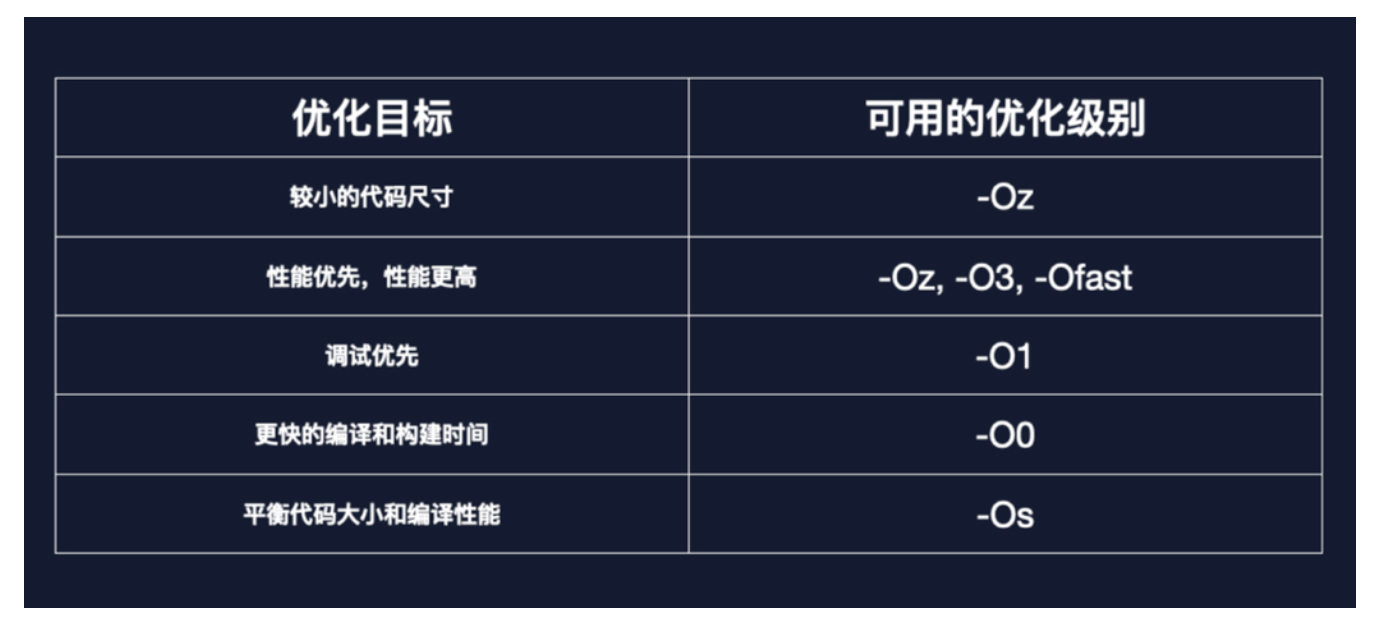
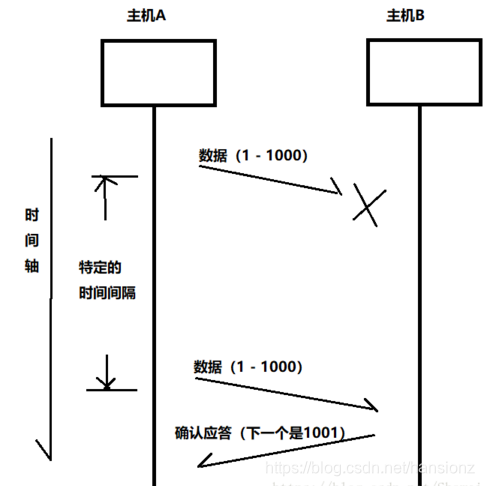
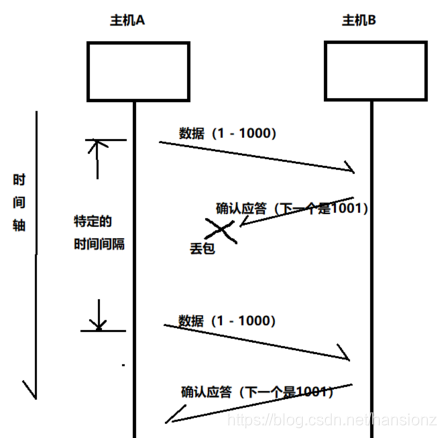
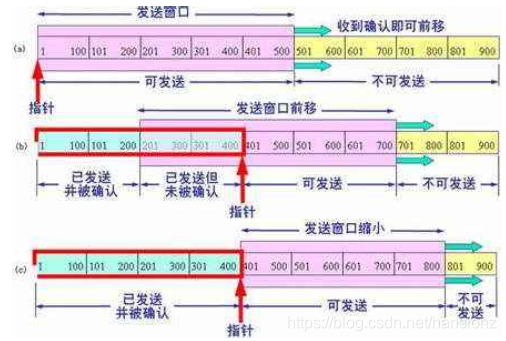
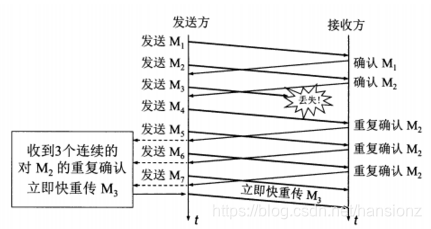
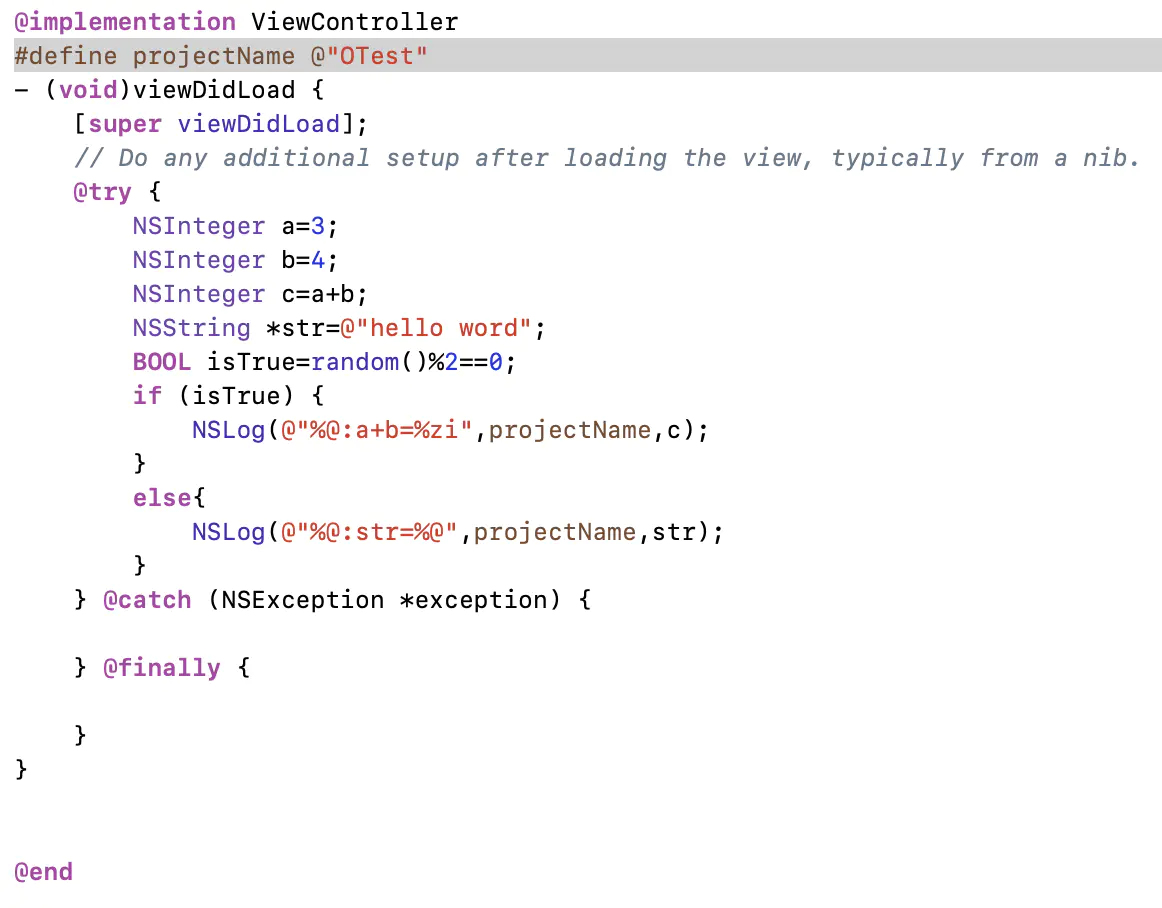
前言
最近Flutter一直比较火,我也它也是非常感兴趣,看了下官网的基础教程后我决定直接上手做一个App,一是这样学的比较快印象更加深刻,二是可以记录其中遇到的一些坑,帮助大家少走一些弯路.本篇文章我会尽可能详细的讲到每一个点上.
项目地址
Github,如果觉得不错,欢迎Star
注意事项
1.下载项目后报错是因为没有添加依赖,在pubspec.yaml文件中点击Packages get下载依赖,有时候会在这里出现卡死的情况,可以配置一下环境变量.在终端执行vi ~/.bash_profile,再添加export PUB_HOSTED_URL=https://pub.flutter-io.cn和
export FLUTTER_STORAGE_BASE_URL=https://storage.flutter-io.cn.详情请看修改Flutter环境变量.
2.需要将File Encodings里的Project Encoding设置为UTF-8,否则有时候安卓会报错
3.如果cocoapods不是最新可能会出现Error Running Pod Install,请更新cocoapods.
4.由于flutter_webview_plugin这个插件只支持加载url,于是就需要做一些修改.
iOS 在FlutterWebviewPlugin.m文件中的- (void)navigate:(FlutterMethodCall*)call方法中的最后一排,将[self.webview loadRequest:request]方法改为[self.webview loadHTMLString:url baseURL:nil]
Android 在WebViewManager.java文件中webView.loadUrl(url)方法改为webView.loadData(url, "text/html", "UTF-8"),以及下面那排的void reloadUrl(String url) { webView.loadUrl(url); }改为void reloadUrl(String url) { webView.loadData(url, "text/html", "UTF-8"); }
先看看效果图吧.
iOS效果图
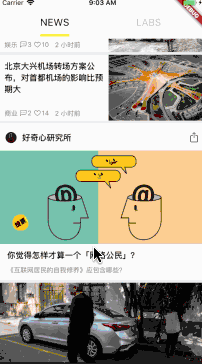
Android效果图

正题
怎么搭建Flutter环境我就不多说了,官网上讲的很详细,还没有搭建开发环境的可以看看这个Flutter中文网.
1导航栏Tabbar

这里我用到了DefaultTabController这个控件,使用DefaultTabController包裹需要用到Tab的页面即可,它的child为Scaffold,Scaffold有个appBar属性,在AppBar中设置具体的样式,大家看代码会更加清楚.相关注释也都写上了.
home: new DefaultTabController(
length: titleList.length,
child: new Scaffold(
appBar: new AppBar(
elevation: 0.0,//导航栏下面那根线
title: new TabBar(
isScrollable: false,//是否可滑动
unselectedLabelColor: Colors.black26,//未选中按钮颜色
labelColor: Colors.black,//选中按钮颜色
labelStyle: TextStyle(fontSize: 18),//文字样式
indicatorSize: TabBarIndicatorSize.label,//滑动的宽度是根据内容来适应,还是与整块那么大(label表示根据内容来适应)
indicatorWeight: 4.0,//滑块高度
indicatorColor: Colors.yellow,//滑动颜色
indicatorPadding: EdgeInsets.only(bottom: 1),//与底部距离为1
tabs: titleList.map((String text) {//tabs表示具体的内容,是一个数组
return new Tab(
text: text,
);
}).toList(),
),
),
//body表示具体展示的内容
body:TabBarView(children: [News(url: 'http://app3.qdaily.com/app3/homes/index_v2/'),News(url: 'http://app3.qdaily.com/app3/papers/index/')]) ,
),
),
大家也可以看看官网的示例Flutter官网示例
2. 不同样式的item
样式一
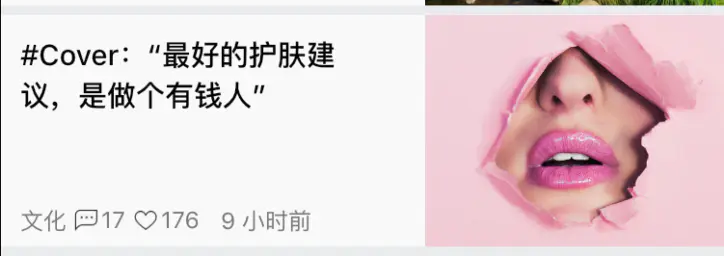
这种布局的大概结构如下
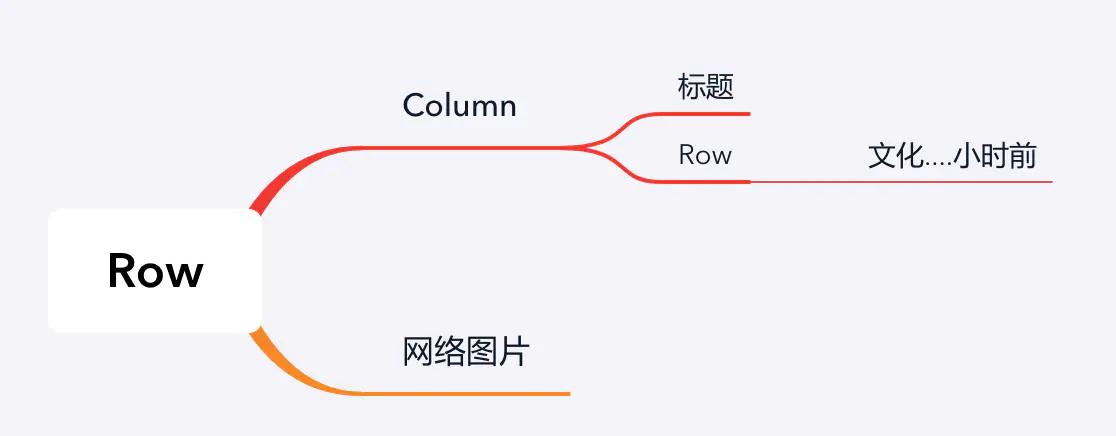
注意这里图片是紧贴着右边屏幕的,所以这里需要用到Expanded控件,用于自动填充子控件.
样式二

这个样式的控件布局就很简单了,结构如下
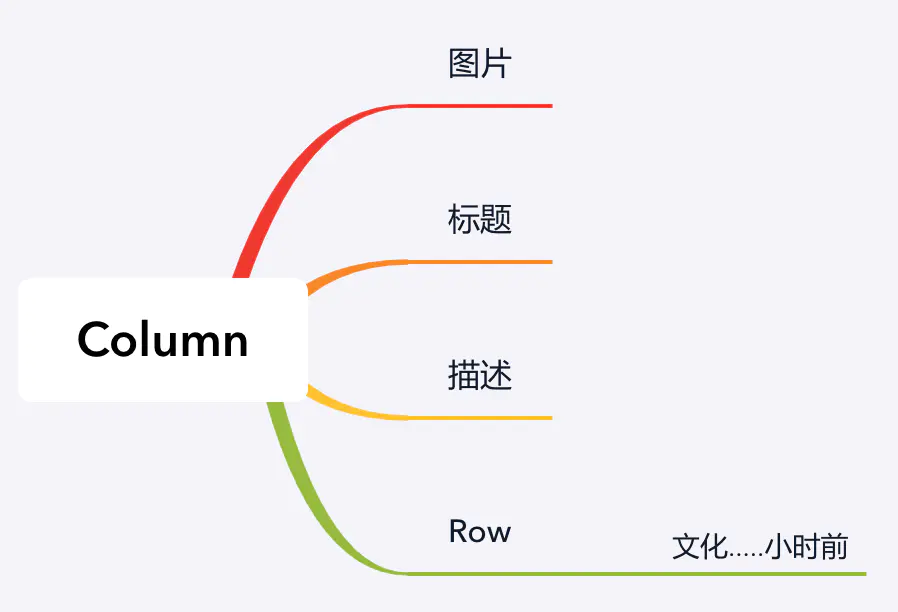
样式三

这个和样式二差不多,只不过最上面多了一块.
这里需要注意的是,那个你猜这个图片是堆叠在整个大图上面的,所以需要用到Stack这个控件,其中Stack中有个属性const FractionalOffset(double dx, double dy)用于表示子控件相对于父控件的位置
样式四
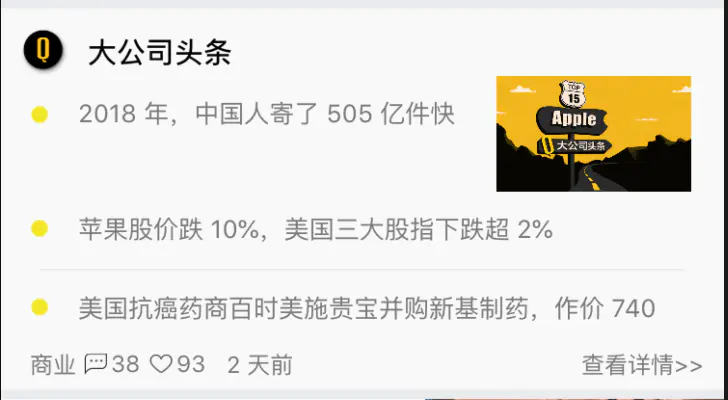
这种样式稍微复杂一点,结构如下
3、数据抓取
用青花瓷抓取了好奇心数据.青花瓷使用教程
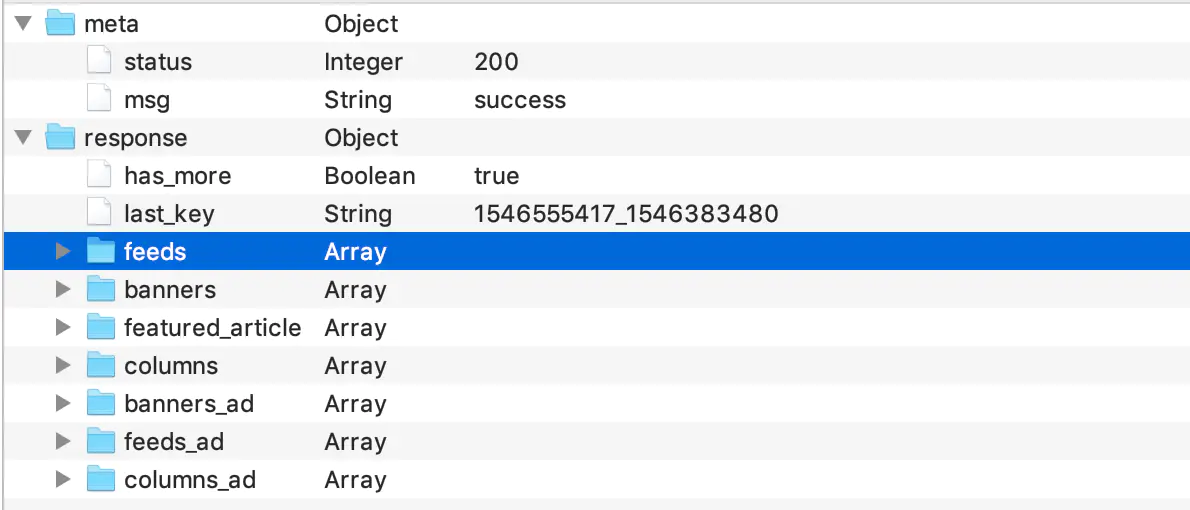
简单分析一下,has_more表示是否可以加载更多,last_key用于上拉加载的时候请求用的,feeds就是每一条数据,banners就是轮播图的信息,columns就是横向滚动的ListView的相关数据,这个后面讲.接下来就做json序列化相关的了.
4.Json序列化
首先在pubspec.yaml中导入
dependencies:
json_annotation: ^2.0.0
dev_dependencies:
build_runner: ^1.0.0
json_serializable: ^2.0.0
创建一个model.dart文件
引入文件
import 'package:json_annotation/json_annotation.dart';
part 'model.g.dart';
其中这个model.g.dart等会儿会自动生成.这里需要掌握两个知识点
1.@JsonSerializable() 这是表示告诉编译器这个类是需要生成Model类的
2,@JsonKey 由于服务器返回的部分数据名称在Dart语言中是不被允许的,比如has_more,Dart中命名不能出现下划线,所以就需要用到@JsonKey来告诉编译器这个参数对于json中的哪个字段
@JsonSerializable()
class Feed {
String image;
int type;
@JsonKey(name: 'index_type')
int indexType;
Post post;
@JsonKey(name: 'news_list')
List<News> newsList;
Feed(this.image,this.type,this.post,this.indexType,this.newsList);
factory Feed.fromJson(Map<String,dynamic> json) => _$FeedFromJson(json);
Map<String, dynamic> toJson() => _$FeedToJson(this);
}
好了,写完后会报错,因为FeedFromJson和FeedToJson没有找到,这个时候在控制到输入flutter packages pub run build_runner build指令后会自动生成一个moded.g.dart文件,于是在网络请求下来数据后就可以用Feed feed = Feed.fromJson(data)这个方法来将Json中数据转换保存在Feed这个实例中了.在model类中还有些复杂的Json嵌套,但是也都很简单,大家看一眼应该就会了,哈哈.JSON和序列化具体教程
5.轮播图
Flutter中的轮播图我用到了Fluuter_Swiper这个组件,这里设置小圆点属性的时候稍微麻烦了点,网上好像也没有讲到,我这里讲一下.
首先要创建DotSwiperPaginationBuilder
DotSwiperPaginationBuilder builder = DotSwiperPaginationBuilder(
color: Colors.white,//未选中圆点颜色
activeColor: Colors.yellow,//选中圆点颜色
size:7,//未选中大小
activeSize: 7,//选中圆点大小
space: 5//圆点间距
);
然后在Swiper中的pagination属性中设置它
pagination: new SwiperPagination(
builder: builder,
),
6.网络请求
首先,展示页面要继承自StatefulWidget,因为需要动态更新数据和列表.
网络请求插件我用的Dio,非常好用.
在initState方法中请求数据表示刚加载页面的时候进行网络请求,请求数据方法如下
void getData()async{
if (lastKey == '0'){
dataList = [];//下拉刷新的时候将DataList制空
}
Dio dio = new Dio();
Response response = await dio.get("$url$lastKey.json");
Reslut reslut = Reslut.fromJson(response.data);
if(!reslut.response.hasMore){
return;//如果没有数据就不继续了
}
if(reslut.response.columns != null) {
columnList = reslut.response.columns;
}
lastKey = reslut.response.lastKey;//更新lastkey
setState(() {
if (reslut.response.banners != null){
banners = reslut.response.banners;//给轮播图赋值
}
dataList.addAll(reslut.response.feeds);//给数据源赋值
});
}
因为用到了setState()方法,所以在该方法中改变了的数据会对其相应的地方进行刷新,比如设置了ListView的itemCount个数为dataList.length,如果在SetState方法中dataList.length改变了,那么ListView的itemCount树也会自动改变并刷新ListView.
7. 上拉刷新与加载
Flutter中有RefreshIndicator用于下拉刷新,它有个onRefresh闭包方法,表示下拉的时候执行的方法,一般用于网络请求.onRefresh方法如下
Future<void> _handleRefresh() {
final Completer<void> completer = Completer<void>();
Timer(const Duration(seconds: 1), () {
completer.complete();
});
return completer.future.then<void>((_) {
lastKey = '0';
getData();
});
}
下拉加载的话需要初始化一个ScrollController,将它设为ListView的controller,并对其进行监听,当滑动到最底部的时候进行网络请求.
@override
void initState() {
url = widget.url;
getData();
_scrollController.addListener(() {
///判断当前滑动位置是不是到达底部,触发加载更多回调
if (_scrollController.position.pixels == _scrollController.position.maxScrollExtent) {
getData();
}
});
}
final ScrollController _scrollController = new ScrollController();
上拉加载loading框用到了flutter_spinkit插件,提供了大量的加载样式.
代码如下
///上拉加载更多
Widget _buildProgressIndicator() {
///是否需要显示上拉加载更多的loading
Widget bottomWidget = new Row(mainAxisAlignment: MainAxisAlignment.center, children: <Widget>[
///loading框
new SpinKitThreeBounce(color: Color(0xFF24292E)),
new Container(
width: 5.0,
),
]);
return new Padding(
padding: const EdgeInsets.all(20.0),
child: new Center(
child: bottomWidget,
),
);
}
8. ListView赋值
由于最上面有一个轮播图,最下面有加载框,所以ListView的itemCount个数为dataList.length+2,又因为每个item之间都有一个浅灰色的风格线,所以需要用到ListView.separated,具体代码如下:
Widget build(BuildContext context) {
return RefreshIndicator(
onRefresh:(()=> _handleRefresh()),
color: Colors.yellow,//刷新控件的颜色
child: ListView.separated(
physics: const AlwaysScrollableScrollPhysics(),
itemCount: _getListCount(),//item个数
controller: _scrollController,//用于监听是否滑到最底部
itemBuilder: (context,index){
if(index == 0){
return SwiperWidget(context, banners);//如果是第一个,则展示banner
}else if(index < dataList.length + 1){
return WidgetUtils.GetListWidget(context, dataList[index - 1]);//展示数据
}else {
return _buildProgressIndicator();//展示加载loading框
}
},
separatorBuilder: (context,idx){//分割线
return Container(
height: 5,
color: Color.fromARGB(50,183, 187, 197),
);
},
),
);
}
9. ListView嵌套横向滑动ListView
这种的话也稍微复杂一点,有两种样式.并且到滑到最右边的时候可以继续请求并加载数据.

首先来分析一下数据
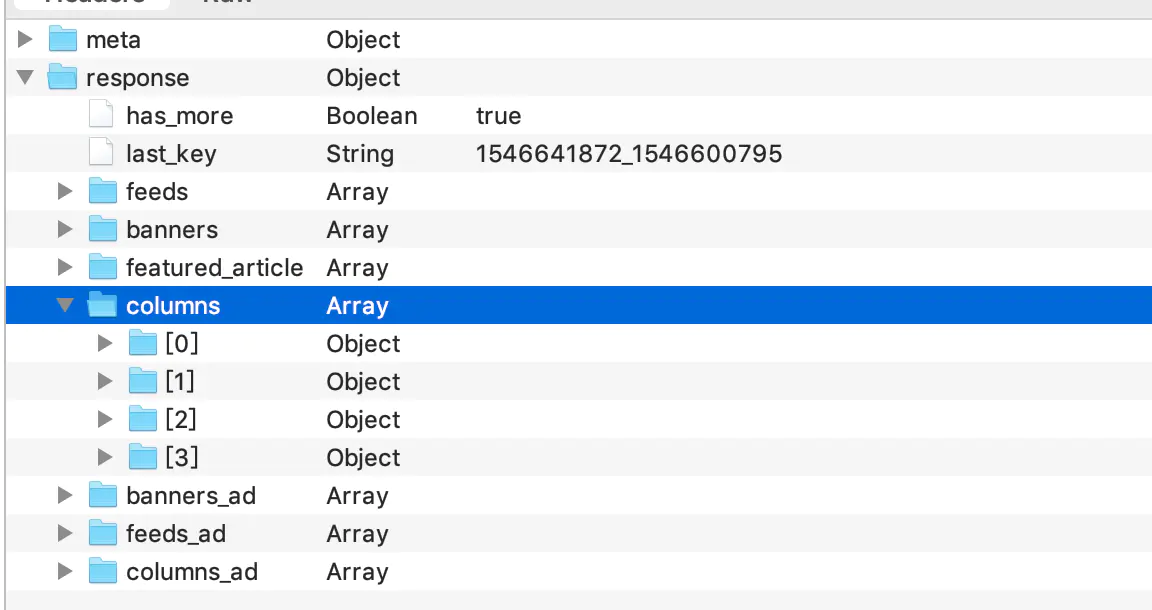
这个colunmns就是横向滑动列表的重要数据.
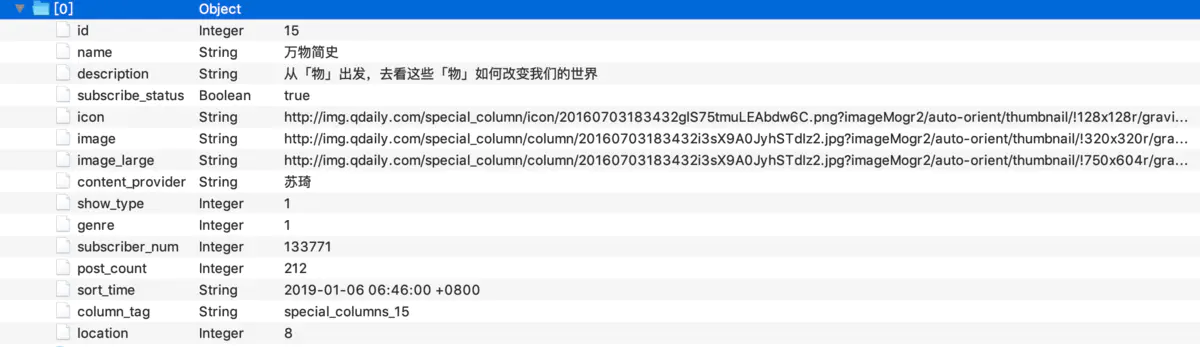
里面的id是请求参数,show_type表示列表的样式,location表示插入的位置.而且通过抓取接口发现,当横向列表快要展示出来的时候,才会去请求横向列表的具体接口.
那么思路就很清晰了,在请求获得数据后遍历colunmns,根据每个colunmn的location插入一个Map,如下
data.insert(colunm.location, {'id':colunm.id,'showType':colunm.showType});
再创建一个ColumnsListWidget类,继承自StatefulWidget,是一个新item,在滑动到该列表的位置的时候,会将该Map数据传给ColumnsListWidget,这个时候ColumnsListWidget就会加载数据并展示出来了,滑到最右边的时候加载和滑到最底部加载的方法一样,就不多说了.具体可以查看源码,关键代码如下:
static Widget GetListWidget(BuildContext context, dynamic data) {
Widget widget;
if(data.runtimeType == Feed) {
if (data.indexType != null) {
widget = NewsListWidget(context, data);
} else if (data.type == 2) {
widget = ListImageTop(context, data);
} else if (data.type == 0) {
widget = ActivityWidget(context, data);
} else if (data.type == 1) {
widget = ListImageRight(context, data);
}
}else{
widget = ColumnsListWidget(id: data['id'],showType: data['showType'],);
}
1.横向ListView外需要用Flexible包裹,Flexible组件可以使Row、Column、Flex等子组件在主轴方向有填充可用空间的能力(例如,Row在水平方向,Column在垂直方向),但是它与Expanded组件不同,它不强制子组件填充可用空间。
2.ListView初始位置用到padding: new EdgeInsets.symmetric(horizontal: 12.0),用padding: EdgeInsets.only(left: 12)的话会让ListView和最左边一直有条线
10.webview加载复杂的Html字段

获取到网页详情的数据发现是Html字段,并且其中的css是url地址,试了很多Flutter加载Html的插件发现样式都不正确,最后决定使用原生和Flutter混编,这时候发现flutter_webview_plugin这个插件是使用原生网页的,不过它只支持加载url,于是就需要做一些修改.
iOS
在FlutterWebviewPlugin.m文件中的- (void)navigate:(FlutterMethodCall*)call方法中的最后一排,将[self.webview loadRequest:request]方法改为[self.webview loadHTMLString:url baseURL:nil]
Android
在WebViewManager.java文件中webView.loadUrl(url)方法改为webView.loadData(url, "text/html", "UTF-8"),以及下面那排的void reloadUrl(String url) { webView.loadUrl(url); }改为void reloadUrl(String url) { webView.loadData(url, "text/html", "UTF-8"); }
由于服务器端返回的Html中的css和js文件地址是/assets/app3开头的,所以需要替换成绝对路径,所以要用到这个方法htmlBody.replaceAll( '/assets/app3','http://app3.qdaily.com/assets/app3')
好了,这下就可以呈现出漂亮的网页了.
11.ListView嵌套GridView
在点击横向滑动列表的总标题的时候,会进入到相关栏目的详情页,如图
这个ListView包含上下两部分.上面这部分为:
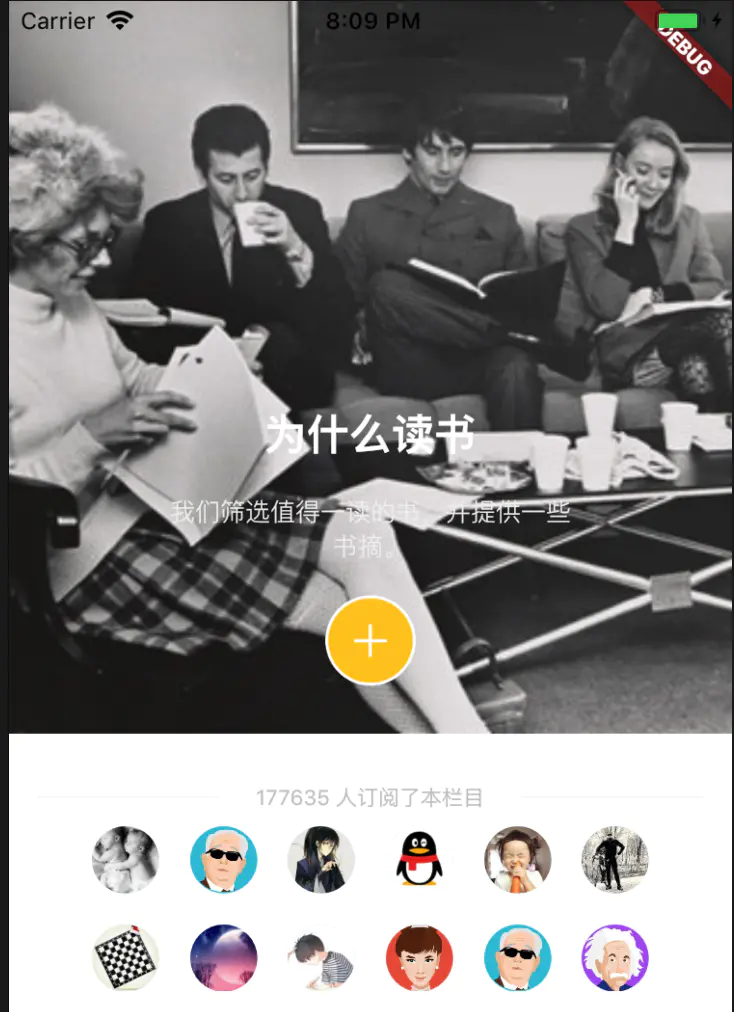
结构如下
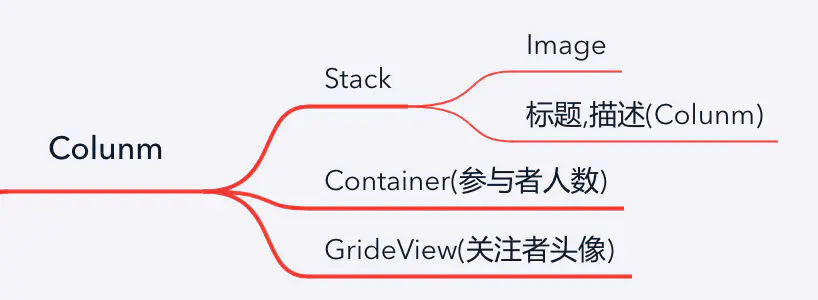
下面就是一个GridView,不过有时候下面会是ListView,根据shouwType字段来判断,GridView的代码如下:
Widget ColumnsDetailTypeTwo(BuildContext context,List<Feed> feesList){
return GridView.count(
physics: NeverScrollableScrollPhysics(),
crossAxisCount: 2,
shrinkWrap: true,
mainAxisSpacing: 10.0,
crossAxisSpacing: 15.0,
childAspectRatio: 0.612,
padding: new EdgeInsets.symmetric(horizontal: 20.0),
children: feesList.map((Feed feed) {
return ColumnsTypeTwoTile(context, feed);
}).toList()
);
}
其中 childAspectRatio表示宽高比.
圆角头像需要用到
CircleAvatar(backgroundImage:NetworkImage(url),),这个控件
12、在切换Tab的时候防止执行initState
在切换顶部tab的时候会发现下面的界面会自动滑动到顶(位置重置)并执行initState,同时每次滑到横向ListView的时候,它也会执行initState并且位置也会重置,要让它只执行一次initState方法的话需要这么做.
class _XXXState extends State<XXX> with AutomaticKeepAliveClientMixin{
@override
bool get wantKeepAlive => true;
这样它就会只执行一次initState方法了.
总结
做了这个项目最大的感受就是界面布局是真的很方便很简单,因为做了一遍对很多知识点也理解的更深了.如果觉得有帮助到你的话,希望可以给个 Star
项目地址
Github
链接:https://www.jianshu.com/p/4a0185b5a8f5
收起阅读 »