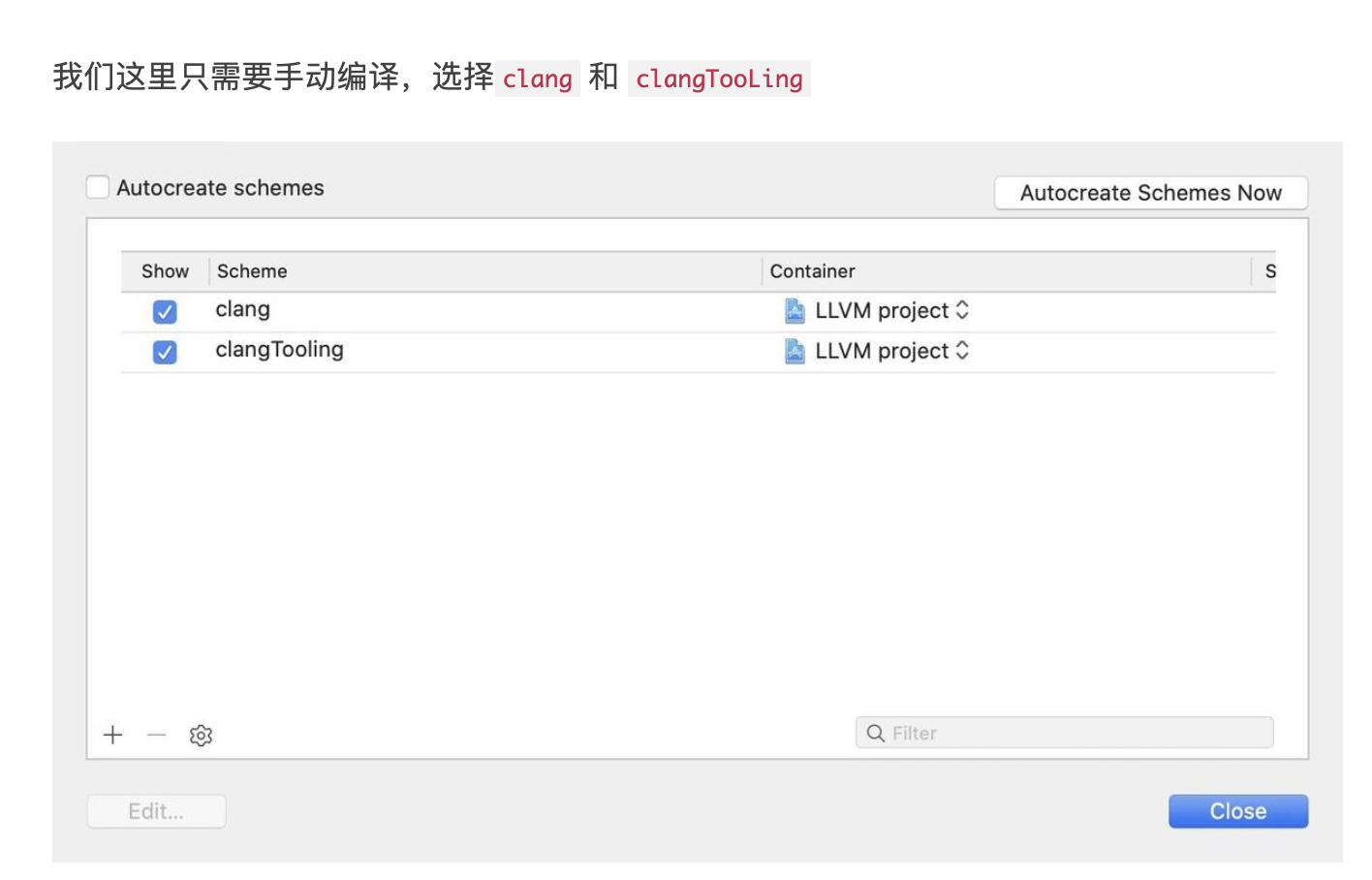
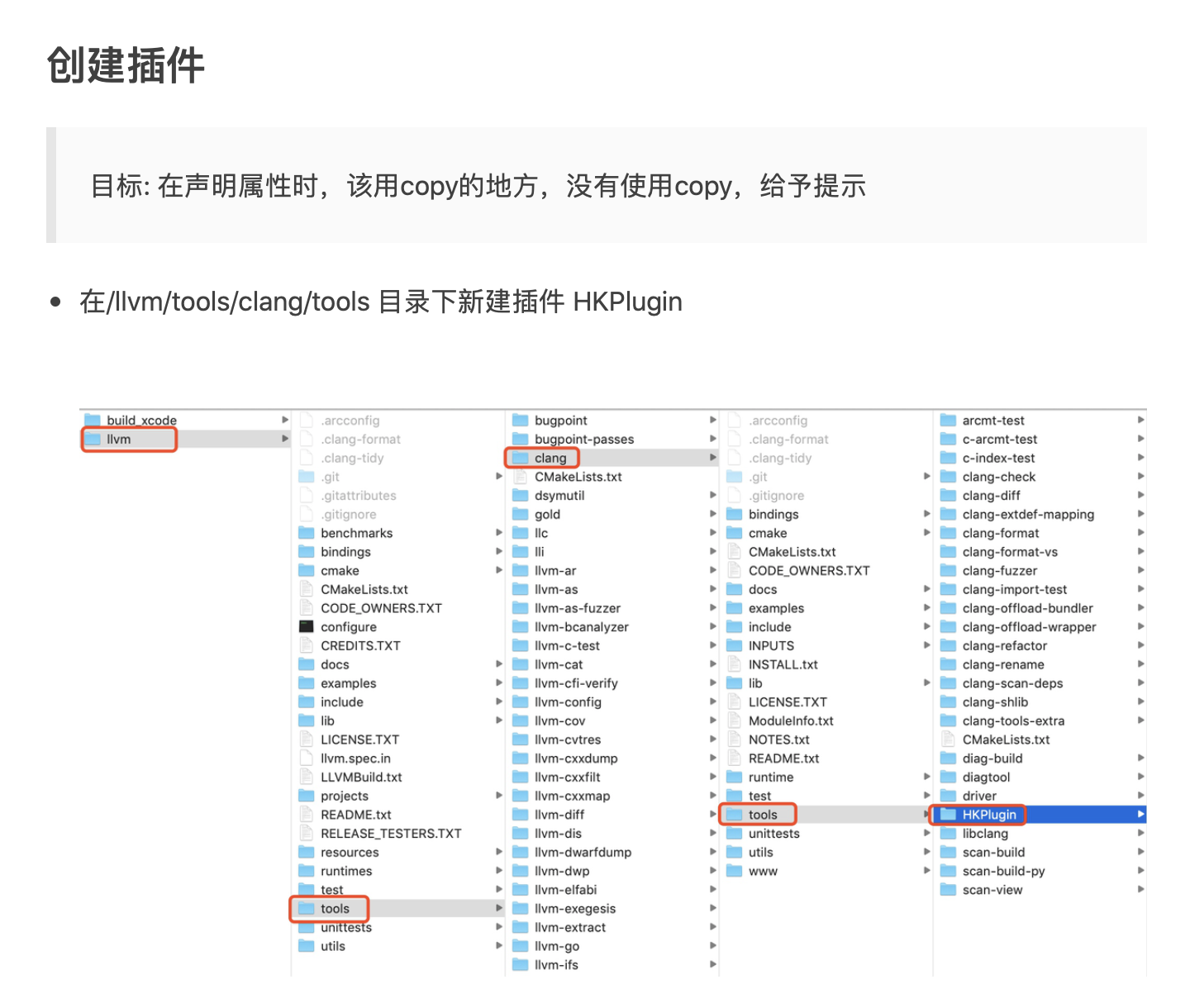
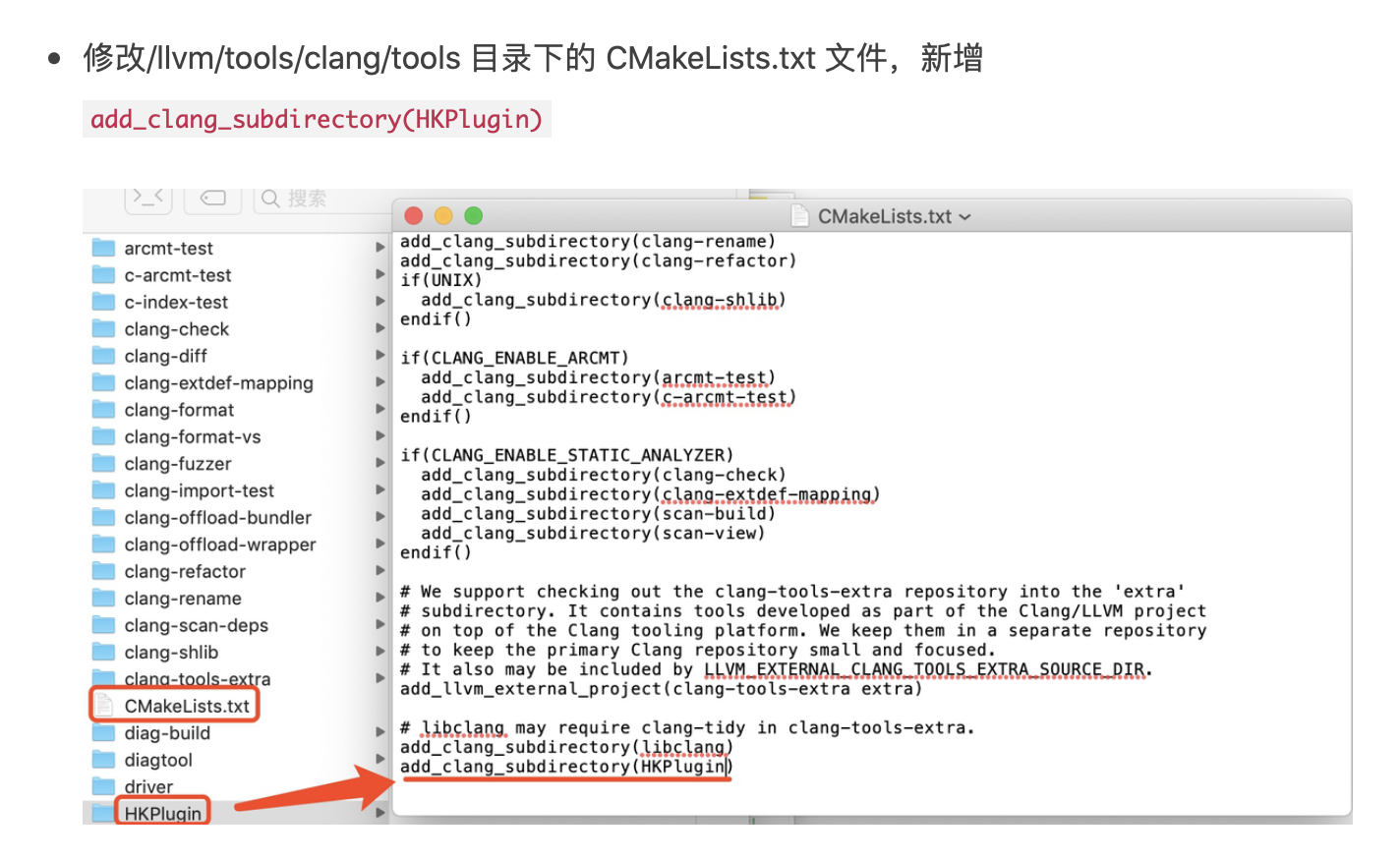
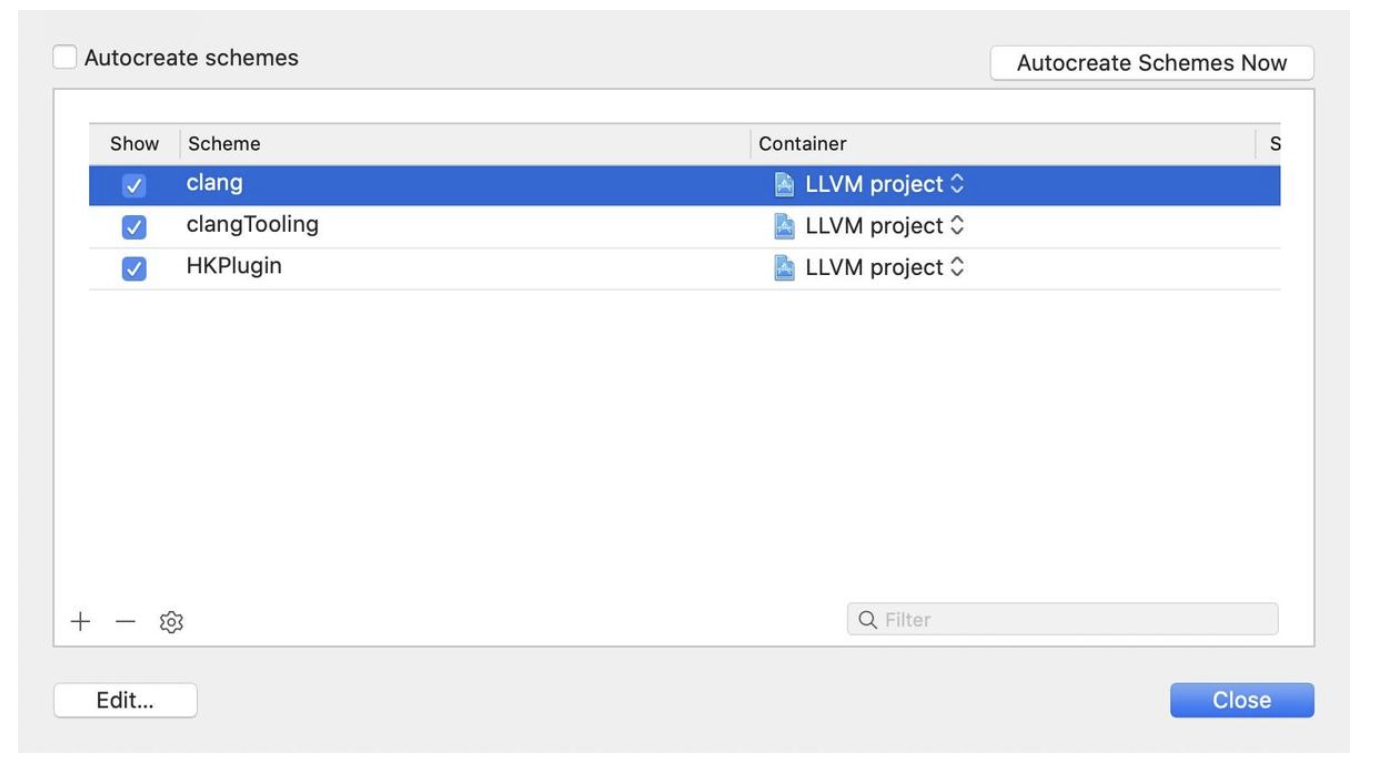
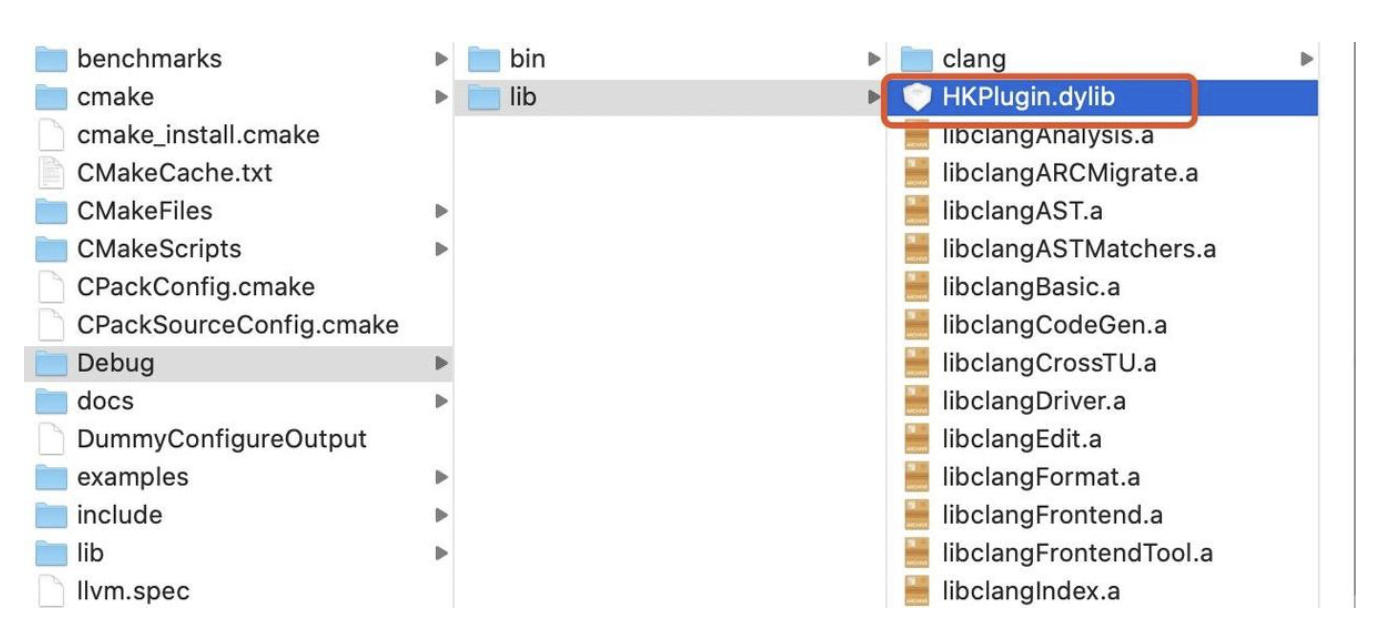
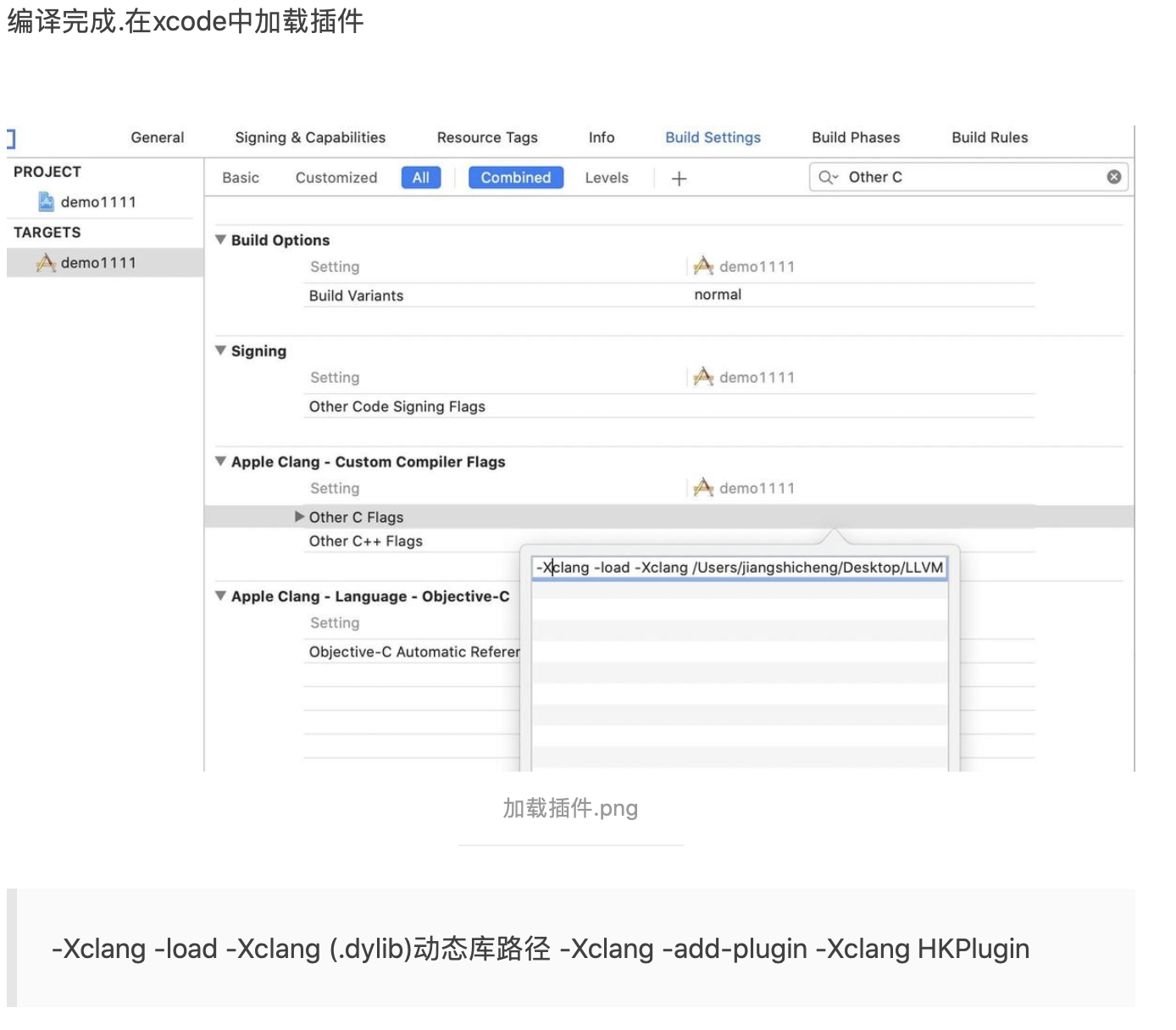
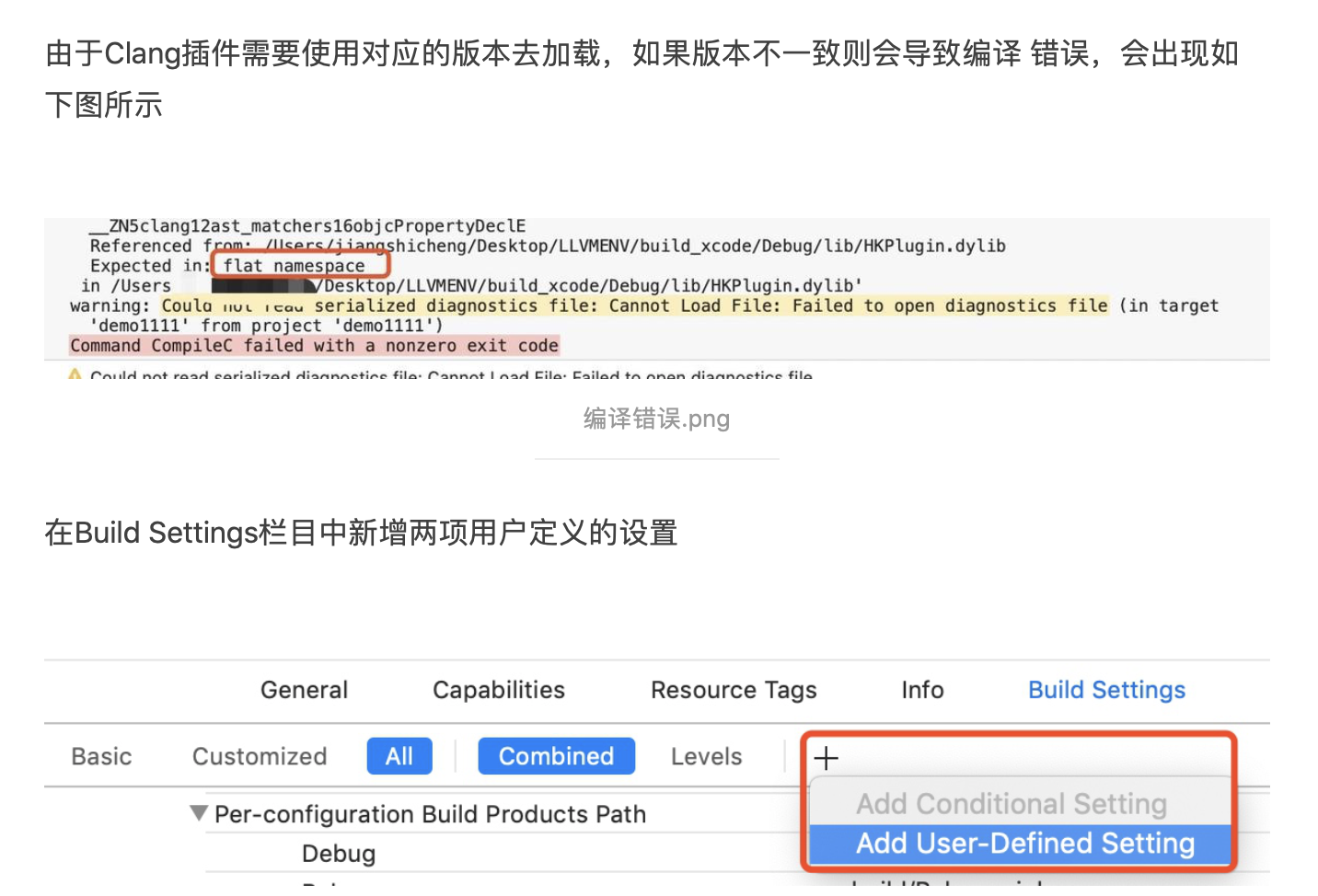
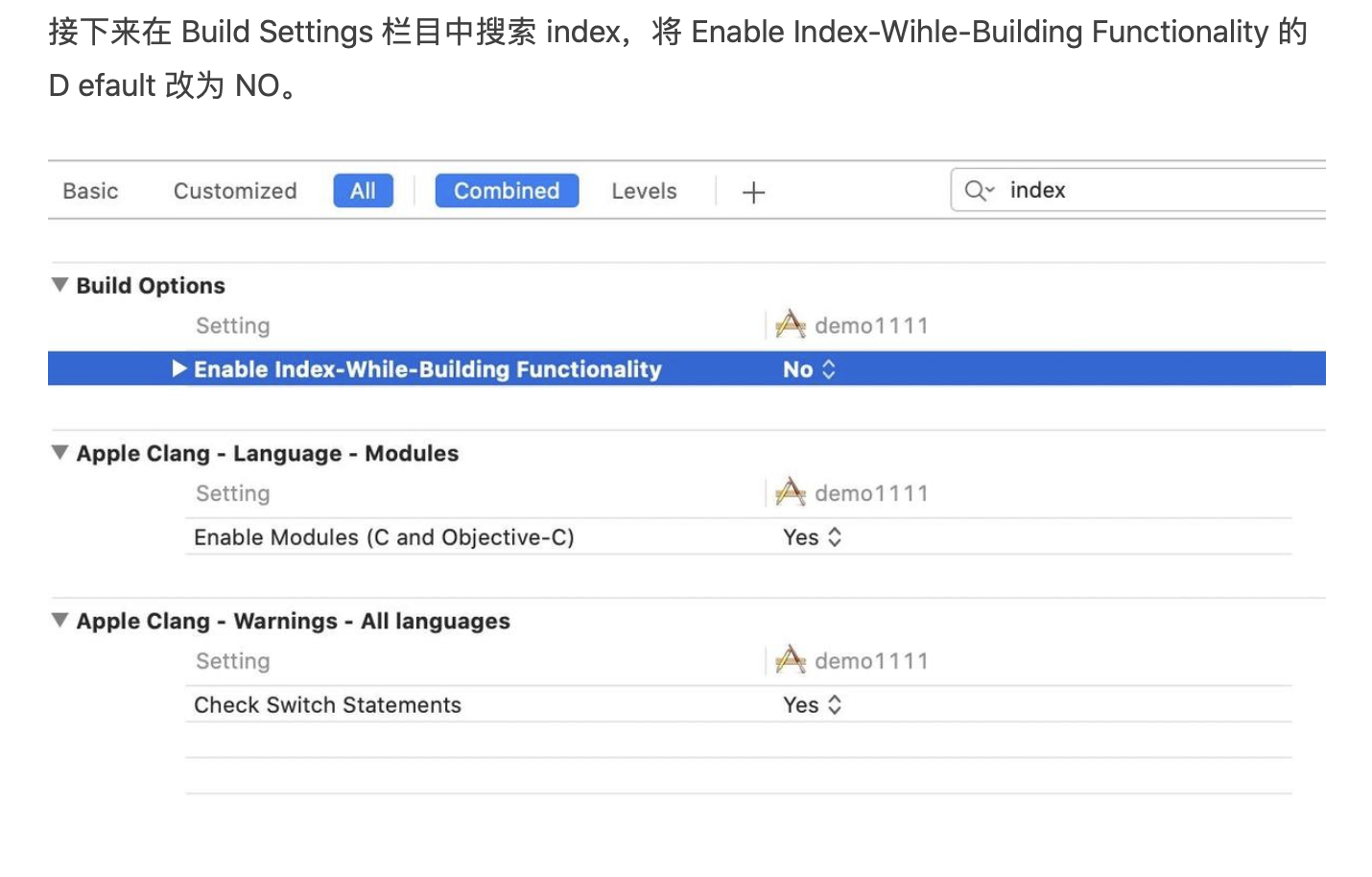
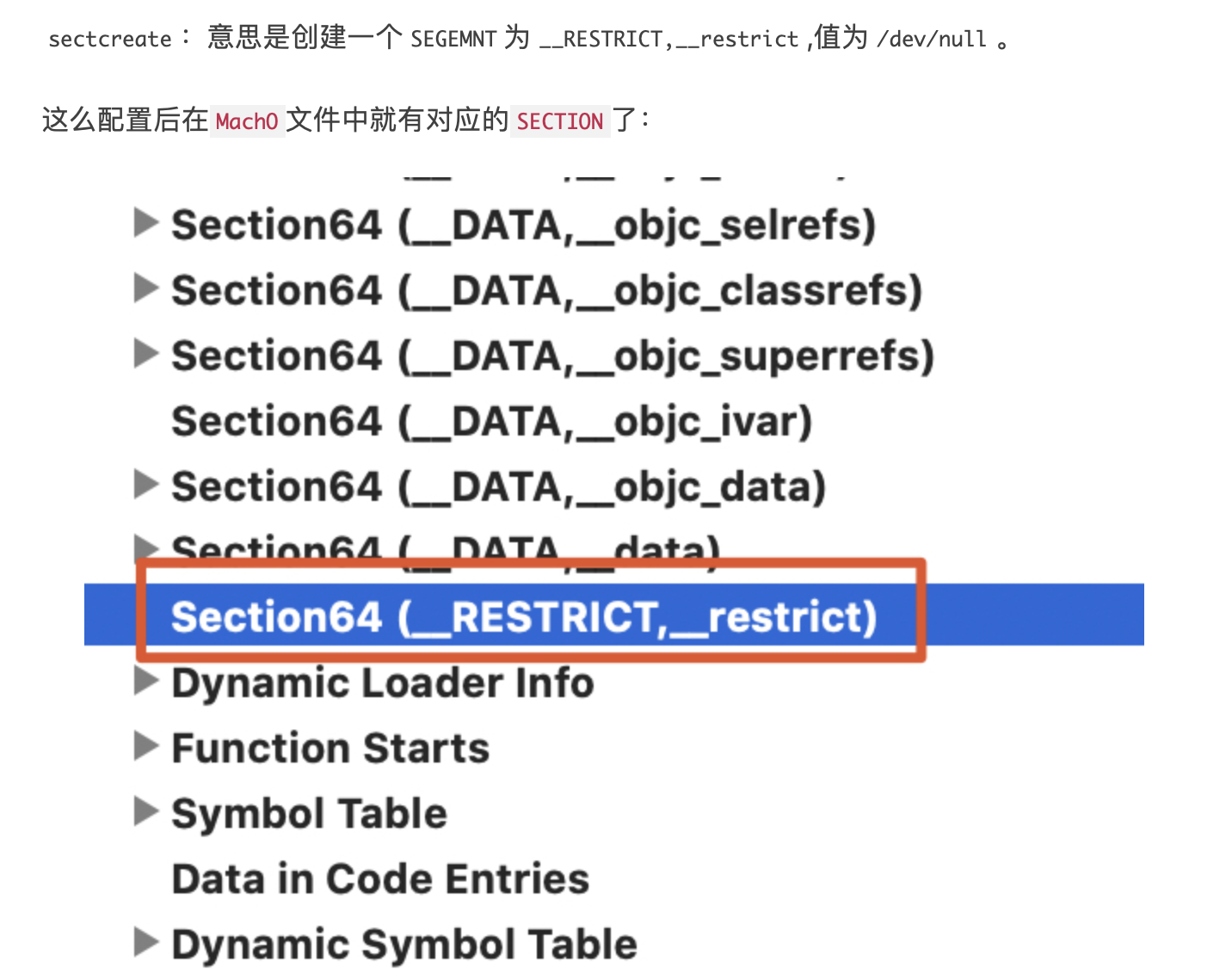
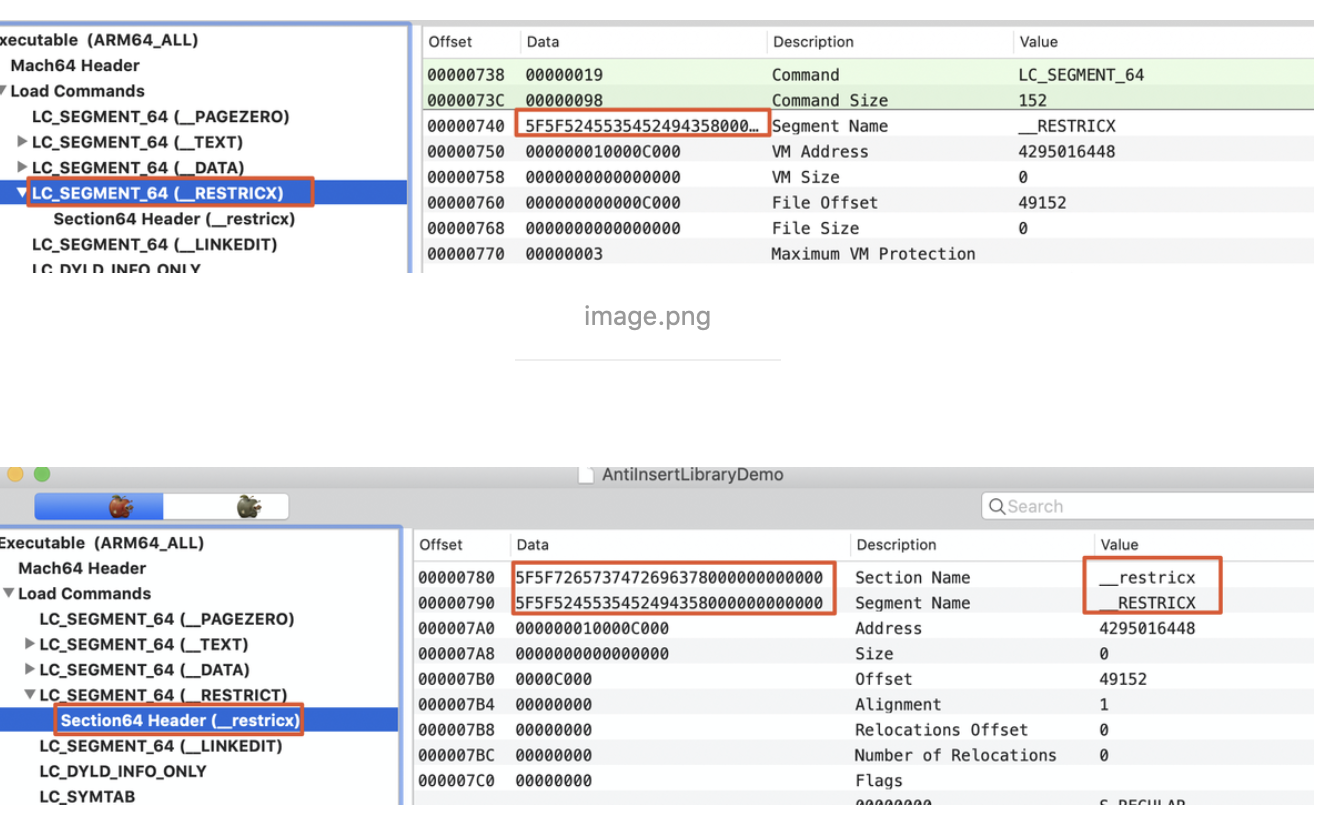
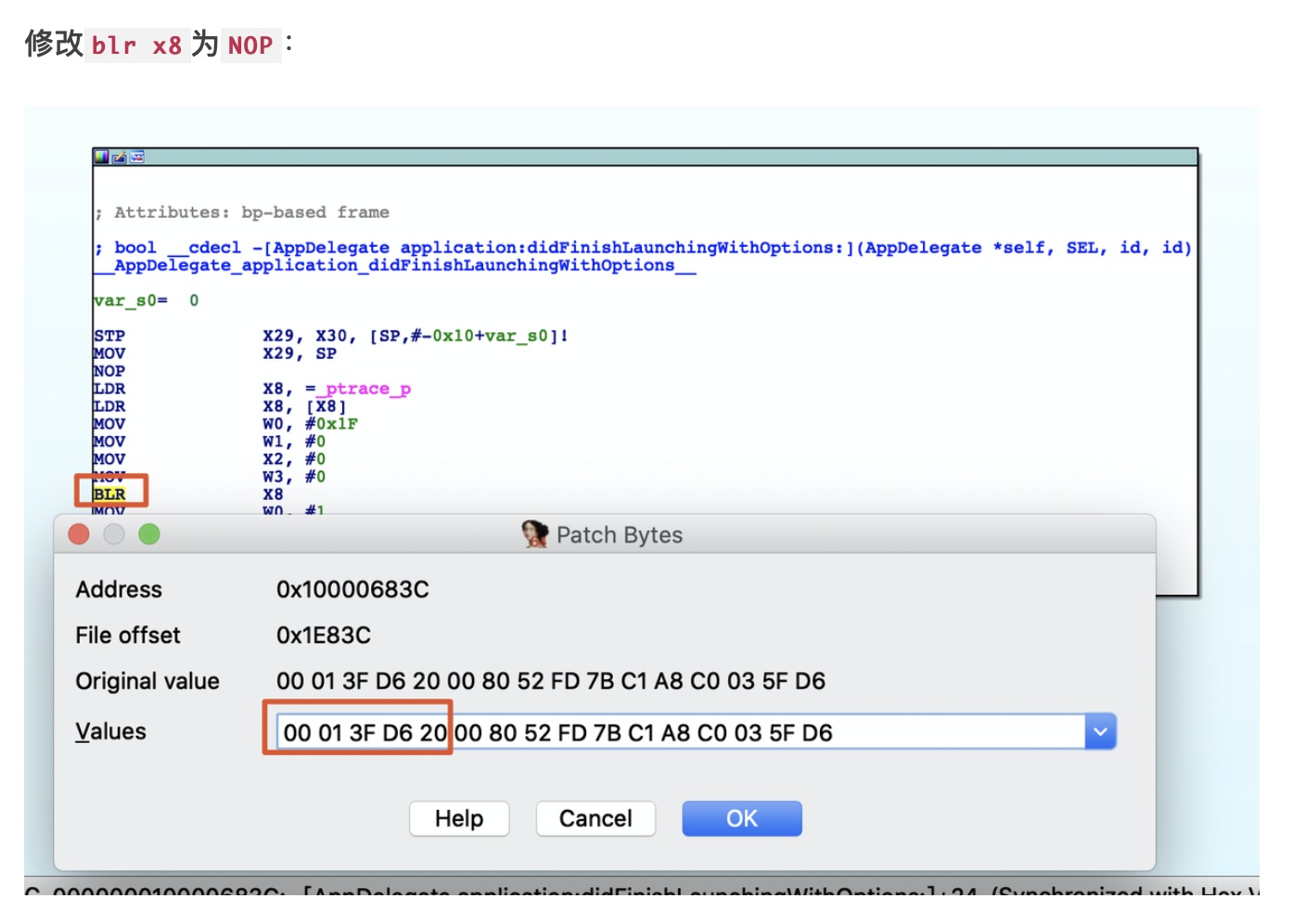
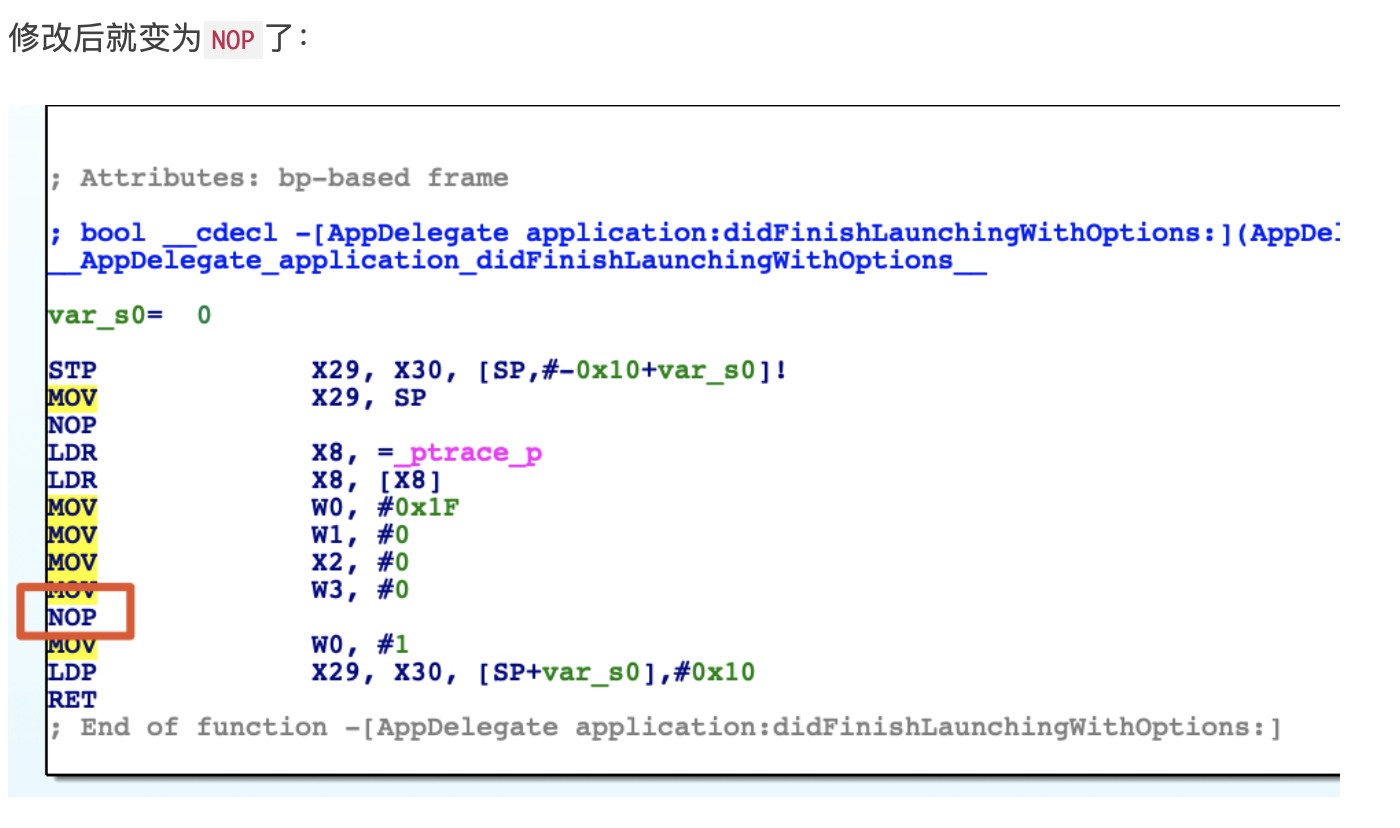
1. 概述
从我们接触前端开始,每个项目的根目录下一般都会有一个package.json文件,这个文件定义了当前项目所需要的各种模块,以及项目的配置信息(比如名称、版本、许可证等)。
当运行npm install命令的时候,会根据package.json文件中的配置自动下载所需的模块,也就是配置项目所需的运行和开发环境。
比如下面这个文件,只存在简单的项目名称和版本号。
{
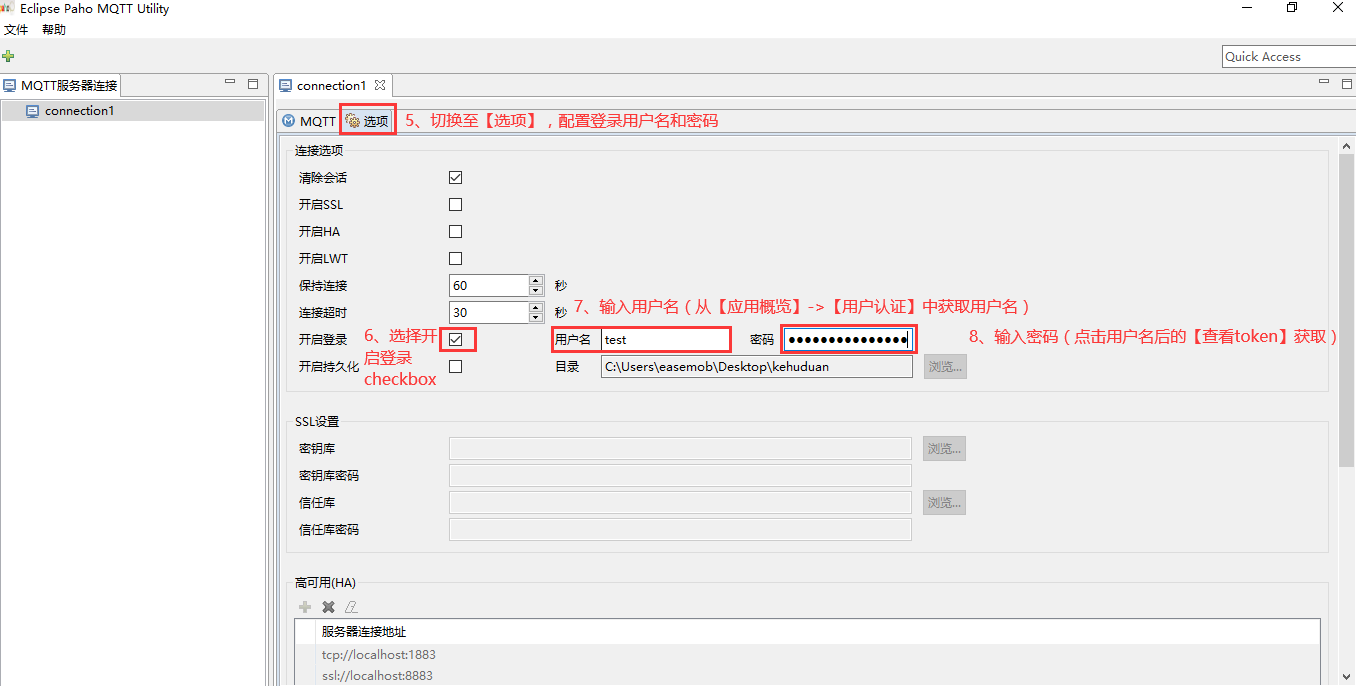
"name" : "yindong",
"version" : "1.0.0",
}
package.json文件是一个JSON对象,这从他的后缀名.json就可以看出来,该对象的每一个成员就是当前项目的一项设置。比如name就是项目名称,version是版本号。
当然很多人其实并不关心package.json的配置,他们应用的更多的是dependencies或devDependencies配置。
下面是一个更完整的package.json文件,详细解释一下每个字段的真实含义。
{
"name": "yindong",
"version":"0.0.1",
"description": "antd-theme",
"keywords":["node.js","antd", "theme"],
"homepage": "https://zhiqianduan.com",
"bugs":{"url":"http://path/to/bug","email":"yindong@xxxx.com"},
"license": "ISC",
"author": "yindong",
"contributors":[{"name":"yindong","email":"yindong@xxxx.com"}],
"files": "",
"main": "./dist/default.js",
"bin": "",
"man": "",
"directories": "",
"repository": {
"type": "git",
"url": "https://path/to/url"
},
"scripts": {
"start": "webpack serve --config webpack.config.dev.js --progress"
},
"config": { "port" : "8080" },
"dependencies": {},
"devDependencies": {
"@babel/core": "^7.14.3",
"@babel/preset-env": "^7.14.4",
"@babel/preset-react": "^7.13.13",
"babel-loader": "^8.2.2",
"babel-plugin-import": "^1.13.3",
"glob": "^7.1.7",
"less": "^3.9.0",
"less-loader": "^9.0.0",
"style-loader": "^2.0.0",
"webpack": "^5.38.1",
"webpack-cli": "^4.7.0",
"webpack-dev-server": "^3.11.2"
},
"peerDependencies": {
"tea": "2.x"
},
"bundledDependencies": [
"renderized", "super-streams"
],
"engines": {"node": "0.10.x"},
"os" : [ "win32", "darwin", "linux" ],
"cpu" : [ "x64", "ia32" ],
"private": false,
"publishConfig": {}
}
2. name字段
package.json文件中最重要的就是name和version字段,这两项是必填的。名称和版本一起构成一个标识符,该标识符被认为是完全唯一的。对包的更改应该与对版本的更改一起进行。
name必须小于等于214个字符,不能以.或_开头,不能有大写字母,因为名称最终成为URL的一部分因此不能包含任何非URL安全字符。
npm官方建议我们不要使用与核心节点模块相同的名称。不要在名称中加js或node。如果需要可以使用engines来指定运行环境。
该名称会作为参数传递给require,因此它应该是简短的,但也需要具有合理的描述性。
3. version字段
version一般的格式是x.x.x, 并且需要遵循该规则。
package.json文件中最重要的就是name和version字段,这两项是必填的。名称和版本一起构成一个标识符,该标识符被认为是完全唯一的。每次发布时version不能与已存在的一致。
4. description字段
description是一个字符串,用于编写描述信息。有助于人们在npm库中搜索的时候发现你的模块。
5. keywords字段
keywords是一个字符串组成的数组,有助于人们在npm库中搜索的时候发现你的模块。
6. homepage字段
homepage项目的主页地址。
7. bugs字段
bugs用于项目问题的反馈issue地址或者一个邮箱。
"bugs": {
"url" : "https://github.com/owner/project/issues",
"email" : "project@hostname.com"
}
8. license字段
license是当前项目的协议,让用户知道他们有何权限来使用你的模块,以及使用该模块有哪些限制。
"license" : "BSD-3-Clause"
9. author字段 contributors字段
author是具体一个人,contributors表示一群人,他们都表示当前项目的共享者。同时每个人都是一个对象。具有name字段和可选的url及email字段。
"author": {
"name" : "yindong",
"email" : "yindong@xx.com",
"url" : "https://zhiqianduan.com/"
}
也可以写成一个字符串
"author": "yindong yindong@xx.com (https://zhiqianduan.com/)"
10. files字段
files属性的值是一个数组,内容是模块下文件名或者文件夹名,如果是文件夹名,则文件夹下所有的文件也会被包含进来(除非文件被另一些配置排除了)
可以在模块根目录下创建一个.npmignore文件,写在这个文件里边的文件即便被写在files属性里边也会被排除在外,这个文件的写法与.gitignore类似。
11. main字段
main字段指定了加载的入口文件,require导入的时候就会加载这个文件。这个字段的默认值是模块根目录下面的index.js。
12. bin字段
bin项用来指定每个内部命令对应的可执行文件的位置。如果你编写的是一个node工具的时候一定会用到bin字段。
当我们编写一个cli工具的时候,需要指定工具的运行命令,比如常用的webpack模块,他的运行命令就是webpack。
"bin": {
"webpack": "bin/index.js",
}
当我们执行webpack命令的时候就会执行bin/index.js文件中的代码。
在模块以依赖的方式被安装,如果存在bin选项。在node_modules/.bin/生成对应的文件,
Npm会寻找这个文件,在node_modules/.bin/目录下建立符号链接。由于node_modules/.bin/目录会在运行时加入系统的PATH变量,因此在运行npm时,就可以不带路径,直接通过命令来调用这些脚本。
所有node_modules/.bin/目录下的命令,都可以用npm run [命令]的格式运行。在命令行下,键入npm run,然后按tab键,就会显示所有可以使用的命令。
13. man字段
man用来指定当前模块的man文档的位置。
"man" :[ "./doc/calc.1" ]
14. directories字段
directories制定一些方法来描述模块的结构, 用于告诉用户每个目录在什么位置。
15. repository字段
指定一个代码存放地址,对想要为你的项目贡献代码的人有帮助
"repository" : {
"type" : "git",
"url" : "https://github.com/npm/npm.git"
}
16. scripts字段
scripts指定了运行脚本命令的npm命令行缩写,比如start指定了运行npm run start时,所要执行的命令。
"scripts": {
"start": "node ./start.js"
}
使用scripts字段可以快速的执行shell命令,可以理解为alias。
scripts可以直接使用node_modules中安装的模块,这区别于直接运行需要使用npx命令。
"scripts": {
"build": "webpack"
}
// npm run build
// npx webpack
17. config字段
config字段用于添加命令行的环境变量。
{
"name" : "yindong",
"config" : { "port" : "8080" },
"scripts" : { "start" : "node server.js" }
}
然后,在server.js脚本就可以引用config字段的值。
console.log(process.env.npm_package_config_port); // 8080
用户可以通过npm config set来修改这个值。
npm config set yindong:port 8000
18. dependencies字段, devDependencies字段
dependencies字段指定了项目运行所依赖的模块,devDependencies指定项目开发所需要的模块。
它们的值都是一个对象。该对象的各个成员,分别由模块名和对应的版本要求组成,表示依赖的模块及其版本范围。
当安装依赖的时候使用--save参数表示将该模块写入dependencies属性,--save-dev表示将该模块写入devDependencies属性。
"devDependencies": {
"webpack": "^5.38.1",
}
对象的每一项通过一个键值对表示,前面是模块名称,后面是对应模块的版本号。版本号遵循“大版本.次要版本.小版本”的格式规定。
版本说明
固定版本: 比如5.38.1,安装时只安装指定版本。
波浪号: 比如~5.38.1, 表示安装5.38.x的最新版本(不低于5.38.1),但是不安装5.39.x,也就是说安装时不改变大版本号和次要版本号。
插入号: 比如ˆ5.38.1, ,表示安装5.x.x的最新版本(不低于5.38.1),但是不安装6.x.x,也就是说安装时不改变大版本号。需要注意的是,如果大版本号为0,则插入号的行为与波浪号相同,这是因为此时处于开发阶段,即使是次要版本号变动,也可能带来程序的不兼容。
latest: 安装最新版本。
19. peerDependencies字段
当我们开发一个模块的时候,如果当前模块与所依赖的模块同时依赖一个第三方模块,并且依赖的是两个不兼容的版本时就会出现问题。
比如,你的项目依赖A模块和B模块的1.0版,而A模块本身又依赖B模块的2.0版。
大多数情况下,这不构成问题,B模块的两个版本可以并存,同时运行。但是,有一种情况,会出现问题,就是这种依赖关系将暴露给用户。
最典型的场景就是插件,比如A模块是B模块的插件。用户安装的B模块是1.0版本,但是A插件只能和2.0版本的B模块一起使用。这时,用户要是将1.0版本的B的实例传给A,就会出现问题。因此,需要一种机制,在模板安装的时候提醒用户,如果A和B一起安装,那么B必须是2.0模块。
peerDependencies字段,就是用来供插件指定其所需要的主工具的版本。可以通过peerDependencies字段来限制,使用myless模块必须依赖less模块的3.9.x版本.
{
"name": "myless",
"peerDependencies": {
"less": "3.9.x"
}
}
注意,从npm 3.0版开始,peerDependencies不再会默认安装了。就是初始化的时候不会默认带出。
20. bundledDependencies字段
bundledDependencies指定发布的时候会被一起打包的模块.
21. optionalDependencies字段
如果一个依赖模块可以被使用, 同时你也希望在该模块找不到或无法获取时npm继续运行,你可以把这个模块依赖放到optionalDependencies配置中。这个配置的写法和dependencies的写法一样,不同的是这里边写的模块安装失败不会导致npm install失败。
22. engines字段
engines字段指明了该模块运行的平台,比如Node或者npm的某个版本或者浏览器。
{ "engines" : { "node" : ">=0.10.3 <0.12", "npm" : "~1.0.20" } }
23. os字段
可以指定你的模块只能在哪个操作系统上运行
"os" : [ "darwin", "linux", "win32" ]
24. cpu字段
限制模块只能在某种架构的cpu下运行
"cpu" : [ "x64", "ia32" ]
25. private字段
如果这个属性被设置为true,npm将拒绝发布它,这是为了防止一个私有模块被无意间发布出去。
"private": true
26. publishConfig字段
这个配置是会在模块发布时生效,用于设置发布用到的一些值的集合。如果你不想模块被默认标记为最新的,或者默认发布到公共仓库,可以在这里配置tag或仓库地址。
通常publishConfig会配合private来使用,如果你只想让模块被发布到一个特定的npm仓库,如一个内部的仓库。
"private": true,
"publishConfig": {
"tag": "1.0.0",
"registry": "https://registry.npmjs.org/",
"access": "public"
}
27. preferGlobal字段
preferGlobal的值是布尔值,表示当用户不将该模块安装为全局模块时(即不用–global参数),要不要显示警告,表示该模块的本意就是安装为全局模块。
"preferGlobal": false
28. browser字段
browser指定该模板供浏览器使用的版本。Browserify这样的浏览器打包工具,通过它就知道该打包那个文件。
"browser": {
"tipso": "./node_modules/tipso/src/tipso.js"
},
链接:https://juejin.cn/post/6987179395714646024