








【环信公开课第12期视频回放】-所有关于环信IM昵称头像的问题听这课就够了
青年的思想愈被榜样的力量所激动,就愈会发出强烈的光辉-法捷耶夫
在刚刚过去的五四青年节,环信公开课第12期如期举行,这期公开课嘉宾“环信大表哥”一人手写三端,Android/IOS/服务端信手捏来,关于用户体系更是引经据典一番,整场公开课妙语连珠、妙趣横生。加上环信MM的现场答疑,这样一来便消除了拘谨,活跃了气氛,环信小伙伴们在欢快愉悦的气氛中度过了这个有意义的五四青年节!
环信公开课12期讲了什么?
- 如何利用消息扩展属性显示昵称头像?
- 如何通过APP服务器处理昵称头像的显示?
- 昵称头像的本地缓存策略?
- 音视频通话如何显示昵称头像?
关于环信大表哥:
马骏斌丨美国海遇网络CTO,传说中的祖传CTO“环信大表哥”,10年研发经验,现任美国海遇网络CTO。曾就职于北京超图从事GIS研发,负责基于SuperMap平台研究GIS算法以及图形处理工具,优化底层三维渲染引擎,协助产品研发进行数据处理或空间分析工作。
环信简版demo作者,开源了基于环信的直播项目-小马直播间,在imgeek、简书等社区发表了数十篇环信教程,他的教程和开源项目累计帮助了超过1W多名开发者集成环信,自己创建了环信互帮互助群,每天"夜黑风高"活跃在群里回答问题+远程写代码,人送外号“环信大表哥”。
自2011年2月创办www.C3DN.net(中国3D技术开发者社区),并兼任C3DN站长。创办C3DN,不仅为了延续对3D技术的热爱,最主要是想帮助更多需要帮助的人学习3D开发技术;
先放一张大表哥PPT截图,这个style!你们感(la)受(yan)下(jing)。

环信公开课视频回放:视频观看地址
环信公开课第12期讲师PPT在文末下载,最后引用一句某知名互联网公司创始人名言致大表哥“百年之后,你我的肉身终将陨灭,而我们的精神和梦想依然可以在代码中相见”
ios简版demo地址
Android简版demo地址 收起阅读 »
【环信3.0SDK集成小米推送教程】实现离线消息推送和后台视频电话通知
教程所用到的DEMO源码地址:【lzan13 / VMChatDemoCall】
前言
从APP有了聊天功能起,就是为了让用户更畅快的沟通,但有的时候,用户将APP退到了后台,甚至kill掉程序(术语:划掉了应用进程),这种情况下再有消息过来或者有视频通话请求就不能再走之前的聊天通道了,所以就要用到我们今天的主角-推送。苹果手机自带了apns,上传推送证书到环信后台就可以实现ios手机的消息推送,Android虽然也有gcm, 但是在大陆地区是不能正常使用的(海外APP不受影响),那么在国内Android的APP就需要用到第三方推送,环信调研了市场设备情况,选择集成了两家厂商推送,分别是小米推送和华为推送,最大程度保证了应用在后台被杀死的情况下也收到离线消息的通知。

废话不多说,今天就通过集成最新的小米推送来实现下消息的离线推送通知,以及被呼叫方离线时方推送提醒对方启动 app 接听通话;其实都是通过集成推送完成!
准备工作
首先你的项目需要集成环信 sdk,并且已经实现了发送消息以及音视频通话功能(这个可以直接用我上边 github 上的项目);
然后你需要有小米的开发者账户,需要创建一个应用,包名要和你自己的项目一样,然后需要用到的就是应用的appId、appKey、appSecret,这些在环信开发者后台上传小米证书,以及在项目中初始化小米推送需要用到;
开始集成
首先这边先把证书弄好了,证书的名字和秘钥以及包名一定要对应:

然后需要做的就是在代码中集成小米推送,需要做的有两个地方:
在初始化 sdk 的时候调用 options 设置小米的 appId 和 appKey
在 AndroidManifest配置文件配置相应的权限和广播接收器以及服务
/**
* 初始化环信sdk,并做一些注册监听的操作,这里把其他的处理都去掉了只写了小米推送
*/
private void initHyphenate() {
// 初始化sdk的一些配置
EMOptions options = new EMOptions();
// 设置小米推送 appID 和 appKey
options.setMipushConfig("2882303761517573806", "5981757315806");
// 初始化环信SDK,一定要先调用init()
EMClient.getInstance().init(context, options);
// 开启 debug 模式
EMClient.getInstance().setDebugMode(true);
}
然后就是AndroidManifest配置
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.vmloft.develop.app.demo.call">
<!-- 项目权限配置 -->
<!--小米推送相关权限-->
<permission
android:name="com.vmloft.develop.app.demo.call.permission.MIPUSH_RECEIVE"
android:protectionLevel="signature"/>
<uses-permission android:name="com.vmloft.develop.app.demo.call.permission.MIPUSH_RECEIVE"/>
<!--小米推送权限 end-->
<!--程序入口-->
<application
android:name="com.vmloft.develop.app.demo.call.AppApplication"
android:allowBackup="true"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:largeHeap="true"
android:supportsRtl="true"
android:theme="@style/AppTheme">
...
<!--小米推送相关配置-->
<service
android:name="com.xiaomi.push.service.XMJobService"
android:enabled="true"
android:exported="false"
android:permission="android.permission.BIND_JOB_SERVICE"
android:process=":pushservice"/>
<service
android:name="com.xiaomi.push.service.XMPushService"
android:enabled="true"
android:process=":pushservice"/>
<service
android:name="com.xiaomi.mipush.sdk.PushMessageHandler"
android:enabled="true"
android:exported="true"/>
<service
android:name="com.xiaomi.mipush.sdk.MessageHandleService"
android:enabled="true"/>
<!--推送消息广播接收器-->
<receiver
android:name=".push.MIPushReceiver"
android:exported="true">
<intent-filter>
<action android:name="com.xiaomi.mipush.RECEIVE_MESSAGE"/>
</intent-filter>
<intent-filter>
<action android:name="com.xiaomi.mipush.MESSAGE_ARRIVED"/>
</intent-filter>
<intent-filter>
<action android:name="com.xiaomi.mipush.ERROR"/>
</intent-filter>
</receiver>
<receiver
android:name="com.xiaomi.push.service.receivers.NetworkStatusReceiver"
android:exported="true">
<intent-filter>
<action android:name="android.net.conn.CONNECTIVITY_CHANGE"/>
<category android:name="android.intent.category.DEFAULT"/>
</intent-filter>
</receiver>
<receiver
android:name="com.xiaomi.push.service.receivers.PingReceiver"
android:exported="false"
android:process=":pushservice">
<intent-filter>
<action android:name="com.xiaomi.push.PING_TIMER"/>
</intent-filter>
</receiver>
<!--小米推送配置 end-->
</application>
</manifest>
其中MIPushReceiver这个广播接收器可以不用自己实现,环信 sdk 已经集成小米广播接收器EMMipushReceiver实现,可以直接用(这里如果需要自己与自己的业务处理可以继承它去处理自己的逻辑;详细可以根据小米推送官方 sdk 文档进行了解下);
当我们做完这些之后在收到离线消息后就可以收到推送通知了,只不过这个推送通知我们不能自定义,因为这些都是服务器推什么我们接受什么,这点比较坑!
通话的离线通知
上边已经实现了消息的离线通知,我们下边就要做当呼叫对方时,对方却不在线,我们怎么通知对方打开 app 进行接听呢?
曾经集成过环信用户应该知道,在呼叫对方不在线后会马上结束通话,回调对方不在线,在新版3.2.2的 sdk 中新增设置音视频参数及呼叫时对方离线是否发推送的接口,在初始化的时候进行以下设置:
// 设置通话过程中对方如果离线是否发送离线推送通知,默认 false
EMClient.getInstance().callManager().getCallOptions().setIsSendPushIfOffline(true);
// 设置了这个之后就不会在通话状态监听中回调对方不在线,需要实现另外一个回调
...
// 设置音频通话推送提供者,在 onRemoteOffline()回调中给对方发送消息就行了
EMClient.getInstance().callManager().setPushProvider(EMCallManager.EMCallPushProvider {
@Override public void onRemoteOffline(String username) {
EMMessage message = EMMessage.createTxtSendMessage("有人呼叫你,开启 APP 接听吧", username);
// 设置强制推送
message.setAttribute("em_force_notification", "true");
// 设置自定义推送提示
JSONObject extObj = new JSONObject();
try {
extObj.put("em_push_title", "有人呼叫你,开启 APP 接听吧");
extObj.put("extern", "定义推送扩展内容");
} catch (JSONException e) {
e.printStackTrace();
}
message.setAttribute("em_apns_ext", extObj);
message.setMessageStatusCallback(new EMCallBack() {
@Override public void onSuccess() {
// 在这里可以删除消息
}
@Override public void onError(int i, String s) {
// 在这里可以删除消息
}
@Override public void onProgress(int i, String s) {}
});
EMClient.getInstance().chatManager().sendMessage(message);
}
});
实现了上边的这个推送提供者之后,当对方不在线就会回调 onRemoteOffline()方法,就可以发送一条消息给对方,然后上边我们已经集成了小米推送,就可以通过离线推送的方式通知对方有新消息,对方看到后点击通知栏就可以打开 app了,这个时候我们的语音或视频呼叫还在一直呼叫,然后就可以连通了!
结语
OK 到这里基本就已经完成了,大家可以运行自己的项目,或者我上边的 demo 测试下,我这边通过小米5测试 OK;其实集成推送部分并不难,只是有几点需要注意:
环信开发者后台的推送证书设置时一定要注意应用包名和小米推送后台的应用包名以及自己项目的包名,三个地方一定要一致
初始化设置一定要通过环信的 options 去设置小米推送的 appId 和 appKey,不需要用小米的注册方法自己注册;
Androidmanifest 一定要加上环信的广播接收器,或者继承自环信封装的广播接收器
注意以上几点基本推送就没有问题了,如果不行可以先通过小米开发者后台的推送工具测试推送是否通了,然后检查以上几点;
PS:华为推送相关其实一样,不过因为华为不允许个人开发者注册账户,所以这里暂时不赘述
参考资料
【小米推送 Android SDK文档】
【环信推送相关文档】 收起阅读 »
环信移动客服v5.17已发布,客服可以通过名字、昵称搜索会话,查找客户更方便
支持快速搜索客户会话
在进行中会话列表,支持通过客户的名字、昵称进行搜索,以便客服能够快速查找客户的会话。

管理员模式
支持设置上班时间才自动分配会话
新增“只有上班时间才自动分配会话”开关。开关打开时,上班时间开始自动调度会话给客服,下班时间结束自动调度。该开关可以与“允许客服手动接入会话”开关配合使用,以便所有客服均只在上班时间接待会话,使工作量分配更加公平。
可以进入“管理员模式 > 设置 > 系统开关”页面,打开该开关。

公共常用语支持全部删除
公共常用语支持全部删除,方便管理员使用模版批量添加常用语。

在多个页面显示Iframe页签
在客服模式的会话、历史会话页面,管理员模式的历史会话、质量检查页面,均支持显示Iframe页签,方便已集成CRM系统的客户通过Iframe查看、编辑客户资料。
关于如何集成CRM系统,请查看CRM系统对接。

【优化】筛选时支持对客服进行多选
在客服模式的留言页面,管理员模式的留言、历史会话、当前会话页面,对留言、会话进行筛选时,支持同时选择多名客服。
- 留言:点击“自定义留言筛选”,对留言进行筛选;
- 历史会话、当前会话:点击“筛选排序”,对会话进行筛选。
【优化】筛选时支持对渠道、关联进行多选
管理员模式下,在统计查询的工作量、工作质量页面,对统计数据进行筛选时,支持同时选择多条渠道、多个关联。 收起阅读 »
环信SDK3.1.0-3.3.1升级改动
if(EMClient.getInstance().chatManager().isSlientMessage(message)){
return;
} (326, 175, 126)
改为if(EaseCommonUtils.isSilentMessage(messages.get(messages.size()-1))){
// 修改的地方 messages.size()-1)有的参数时message , 请注意
return;
}2. EaseConversationAdapter performFiltering() -- conversationId() 替换 getUserName();3. LnConversationAdapter
(378, 146, 258)(149 本来就存在) conversationId() 替换 getUserName();4. EaseChatFragment
(746) 少去两个方法 (onMessageReadAckReceived, onMessageDeliveryAckReceived)5. EaseChatFragment
添加两个方法(onMessageDelivered, onMessageRead)
EMChatRoomChangeListener -- 全部方法被注释掉了!6. EaseGroupRemoveListener
EaseGroupListener -- (1885)7. CallActivity
(175) EMClient.getInstance().callManager().endCall(); 添加异常处理8. CallActivity
(333) setReceipt() 改为 : setTo ()9. conversationListFragment
(118, 121) -- getUserName() 改为 : conversationId()10. DiagnoseActivity
(67) VERSION 修改!11. GroupDetailsActivity
(1638) 修改了GroupChangeLister12. GroupDetailsActivity
(739) 修改了GroupChangeLister 添加方法 updateGroup(); refreshMembers();13. MainActivity
修改了EMMessageListener()实现的方法 (309)14. MainActivity
修改了EMContactListener()要实现的方法 (435)15. ChatFragment
(750) position = conversation.getAllMessages().indexOf(message);16. PublicChatRooomsActivity
(132) ChatRoomChangeListener修改 -- (206) 复写监听方法17. VideoCallActivity
(274, 235) 电话断了 枚举变量修改18. VideoCallActivity
(431, 432, 433 ) -- getVideoTimedelay 改为 getVideoLatency19. VoiceCallActivity
getVideoFramerate 改为 getVideoFrameRate getVideoLostcnt 改为
(203, )DISCONNNECTED (挂断电话) 改为 DISCONNECTED (249)20. EaseChatRow
ERROR --
(339) 重写updateView方法, 添加多参数方法21. EaseUI
(147) options.setNumberOfMessagesLoaded(1); 方法弃用22. EaseUI
(176, 181) onMessageDeliveryAckReceived() onMessageReadAckReceived()方法弃用 重新添加两个方法23. DemoHelper
onMessageDelivered 和 onMessageRead
(524) 原有方法 : onInvitationReceived, onInvitationAccpted, onInvitationDeclined24. DemoHelper
onUserRemoved, onGroupDestroy, onApplicationReceived, onApplicationAccept, onApplicationDeclined
onAutoAcceptInvitationFromGroup,
onInvitationAccpted, -- 方法名错误 少个Accpted 改为 Accepted
onGroupDestroy 改为onGroupDestroyed
(846) EMContactListener -- onContactAgreed 改为 onFriendRequestAccepted25. DemoHelper
onContactRefused 改为 onFriendRequestDeclined
(1119) onMessageReadAckReceived, onMessageDeliveryAckReceived 去除本文章纯属原创,转载请说明出处! 谢谢!!!!!! 收起阅读 »
添加 onMessageDelivered , onMessageRead
头像昵称的简述和处理方案
从实际角度出发,有几种场景需要使用头像:
1、聊天的详情页面。
2、会话列表页面。
3、好友页面。
针对以上几个场景,
在聊天页面,接受消息的时候,需要知道对方叫什么,所以只需要发送方发消息中,把自己的名字,昵称带过来就行。
这里可以选择用message的属性ext来实现。
message.ext = @{@"nick":@"李明"};

当接收方(韩梅梅)收到消息后,只需要解析message中的ext字段,就可以知道发送方叫李明。
之后再ui上显示就可以了。此处的处理,单聊和群聊是一样的。
注意事项:
发送方设置ext一定要在消息发送之前。
2、会话列表中展示:
上文说道,ext属性是message的,而会话的对象是conversation。此时,如果需要得到对方最后一条消息,可以使用
EMConversation对应的属性lastReceivedMessage。这个属性的描述是
/*!
* \~chinese
* 收到的对方发送的最后一条消息
*
* @result 消息实例
*
* \~english
* Get last received message
*
* @result Message instance
*/
- (EMMessage *)lastReceivedMessage;
这个时候,我们只需要去去 conversation.lastReceivedMessage.ext, 也就可以得到会话列表的头像了。
注意:
群聊里,不能通过最后一条对方发的消息来处理,环信的群属性中,没有头像这一条,所以也不能直接从环信这边取,但是它有群描述。这里提供两个思路:
* 把群属性放到自己的服务器,群头像也放到自己的服务器上,然后根据群id去自己服务器获取。
* 把头像放到群名描述里,之后用自己定义的格式隔开,取头像的时候,就直接从群描述的url来取。
3、好友列表中头像和昵称的获取。
好友列表,好友的信息环信并没有提供多少属性,只提供了环信id。所以这个地方我们就没办法从环信这边获取任何信息了。这个地方说下环信demo的解决方式:
环信demo中,用了一个第三方的云服务叫Parse,Parse的作用,是可以把k-v的键值对存到云服务器上。环信demo就把好友列表中,好友的环信id作为key,其他属性作为value存到了Parse上。这样在展示的时候,就直接去parse上下载,得到对应的昵称和url。
注意:
不过就我了解,国外的Parse服务已经停止了。目前demo里用的是环信自己搭建的一个Parse服务,环信官方也没有承诺该服务始终免费,记得当时也是说过是为了demo展示用才搭建的,所以建议还是自己找一些其他提供类似功能的云服务来使用比较好。
收起阅读 »
APNs证书创建和上传到环信后台
下面大概讲一下如果创建APNs证书和上传到环信。(首先需要有一个付费的苹果开发账号,否则无法创建相关证书)
文章最后有常见问题
1、前期准备
创建根证书很重要,要确保创建根证书的电脑和最好导出P12的电脑是一台,否者可能无法创建成功。
打开电脑的“钥匙串访问”并按照以下操作


邮箱需要符合邮箱格式,名称随意,之后保存到本地。

2、创建支持推送的APP





3、创建推送证书
此处以开发推送证书为例











再用同样的方式创建生产证书,注意命名要有区别。
此时,我们应该有三个文件:

4、制作环信用的P12推送证书
同样以开发证书为例,双击导入aps_development.cer,





以同样的方式再生成生产用推送证书。此时应该一共有5个文件。

5、上传到环信







如果需要填写bundle id,一定要确保填写正确。

注意:此处也需要选择正确,是开发模式还是生产模式。
密码就是到导出证书时候的密码。
注意事项:
app工程里要打开推送开关

==============================
常见问题:
为什么我按照配置后,app后台了还是收不到推送!
环信的长连接存在的情况下,在服务器就属于在线状态,环信不会通过苹果的APNs 给你发推送,而是直接通过环信的长连接,只有app后台被系统挂起或者是进程被杀死了,才会走APNs,先出怎么处理:
在appdelegate文件里,也实现消息的监听,这样有消息了,也能收到回调。
收到回调后,先判断当前app的状态是在前台还是后台,如果是前台就忽视这条消息,如果在后台,就自己从代码里实现一个本地通知,把需要展示的消息内容得到后,自己发localNotifications. 本地通知的实现方式很简单,网上百度就行。
下面我说下这种方式的好处与坏处。
好处:在正常使用场景中,app之间切换很正常,这样的好处就是不需要频繁的断开重连,速度会很快,同时也会比较省电,而且用户体验会更好。
坏处:其他app里,app的icon上的角标和app内部的角标数量是一致的,但是像自己弹出的处理方式,会可能导致角标不一致,因为apns的角标是服务器发过来的,而localNotification的角标是由app自己设置的。
顺便说一句,目前微信的实现方式也是后台的时候长连接保持,app角标也存在不一致的情况。
APP之前没有用推送,现在需要用了,我按照上面设置后还是不行。
需要删除本地的描述文件,重新去开发者中心下载,描述文件就是Provisioning Profile
APP上线之前,如何测试生产的推送是否好用?
这个情况苹果已经替我们想好了,在打包的时候,有一个选项是ad-hoc。这个选项就是打一个生产用的包,并且可以导出保存到本地,之后用itunes安装就可以了。这个地方一定要注意,这个使用使用的证书需要是生产的证书了哦~ 收起阅读 »
【客户世界·洞察者】刘俊彦:观点(二) 跨渠道环境下的客户服务体验是客服行业面对全媒体客服新趋势的主要挑战
“客户世界·洞察者”本期洞察者:刘俊彦 环信CEO
随着信息爆炸的互联网时代的到来,人们阅读习惯的改变,客户世界推出立体化内容呈现方式(图文+短视频)来迎合人们碎片化时间的阅读。那么越来越高标准的阅读需求靠什么来满足?
众所周知《客户世界》做为国内唯一定位于“客户管理”专业研究及其关联产业发展的专业纸媒,在客户中心行业广受赞誉。其精准的内容定位锁定了企业客户管理各级岗位的专业人士。
行业中不乏有思想、有洞察力的行业洞察者,那么他们的观点将是行业人士追捧的话题,这时候就需要一个媒体平台,以猎奇的视角、亲和的形势展示出来。那么客户世界•洞察者就扮演了这个角色。
“客户世界·洞察者”每周一个观点,敬请期待……
刘俊彦毕业于伦敦大学国王学院,计算机硕士。先后任职IONA,RedHat。重度开源软件参与者,JBOSS ESB, SOA-P、Apache CXF、JBOSS Drools、jBPM 等开源项目committer。专注于高并发消息中间件,实时消息系统,异构分布式企业系统集成和应用服务器。
视频观看地址:【客户世界·洞察者】刘俊彦:观点(二)
上一期洞察者讲述的关于工具层面的全媒体接入的各种核心技术问题,本期洞察者谈谈当客户从各种媒体各种渠道接入进来以后,我们应该做些什么来提交效率和客服体验。全媒体客服不仅只是多渠道的接入和各个接入渠道之间的数据打通,更重要的是用户跨媒体、跨渠道、跨部门的体验和跟踪,在海量的数据中发现问题。
多渠道客服接入环境下的客户声音的收集,整理,分析和理解需要一个企业全流程业务部门的参与,包括客服部门、产品研发部门、销售部门和市场部门之间的通力合作。“客户声音”将帮助企业解决四大挑战,请看下图:

为了应对以上四大挑战,厂商推出了客户声音产品。客户声音产品是一款基于人工智能和大数据挖掘的客户体验透析产品。通过对来自多个渠道的非结构化客服数据进行自然语言解析,主题聚类,情感度建模等技术分析手段来挖掘和分析热点话题,发现服务运营问题,寻找畅销或问题产品,洞察销售机会。通过透析客户对企业产品和服务的准确体验,帮助企业识别和改善客户旅程的各个阶段。
一、如何帮助企业倾听客户声音呢?
- 整合多渠道数据源,透析客户对企业产品和服务的准确体验。
- 基于人工智能技术,帮助企业识别和改善客户旅程的各个阶段。
二、“客户声音”产品帮助提高用户体验的一些实践案例:
1,主题及关键词热度分布,实时了解用户最关心的产品和服务。

实例:上述图1显示了某电商主题关键词热度分布。四种颜色代表四个主题,主题和关键词的比例表示该主题或关键词的用户讨论热度,关键词字体越大,表示热度越高,关键词颜色表示情感度。
2,主题及其关键词情感分析,及时追踪到负面情绪。

图2示例:上图是讨论热度最高的主题“注册登录”下头15个关键词的情感估值对比图,绿柱表示用户满意度高。如果用户对某关键词对应的业务充满负面情绪,系统用红柱突出表示出来。黄色表示中性。
3,按关键词或情感度追踪问题并解决问题。

图3示例:某电商按关键词或情感度追踪并解决物流快递问题。
转自客户世界,原文地址阅读原文 收起阅读 »
人工智能,是在砸你饭碗还是在帮你挣钱?

(图为环信CEO刘俊彦)
据刘俊彦介绍,环信是一家经过C轮融资后定位为全媒体智能客服的年轻创业公司,目前有三条产品线,第一个是环信即时通讯云,为企业提供通讯服务。第二个是环信移动客服,是一款针对电商、金融、教育等行业的SaaS客服软件。第三个是环信人工智能机器人,这个产品的产生是因为他们看到了客服行业的一个新“风口”。
客服行业是企业服务市场里面的核心领域之一,而企业级服务这个大市场,刘俊彦认为是“既无内忧又无外患”,为什么这么说?
企业服务在美国是个很成熟的行业, Oracle、微软、SAP等企业加起来已经有4千多亿的市值。而中国,所有的服务企业加起来不超过50亿美金,所以,无内忧是指市场还不成熟,除用友,金蝶外没有什么大公司,这条赛道还是空的,你要做的就是稍微比别人跑的快点。未来发展前景还很广阔。
国家规定个人数据要保留在中国,外资公司不允许在国内建立数据中心。由于牌照问题,也进不来。这样就没有外患。
所以,这么好的市场环境,未来机会很大,根本没有天花板,自己就是天花板,突破自己往前跑就对了!
“近两年,AI很火,就我个人而言,我看到了它目前在工业领域产生的四个价值,自动驾驶、图像识别、医疗影像、再就是客服领域了。这个行业有大量的数据,可是客服行业在当下阶段是个“缺人”的行业。基于这些,我们开发了人工智能这条产品线。目前落地的产品是环信智能客服机器人,对于企业而言,一些简单重复的问题就可以交给机器人来回答,可以大幅降低人工工作量提升效率。”刘俊彦向思路网说道。
目前,人工智能在售前售后都可以发挥价值。售后是以服务,解决问题为导向。比如常见的有简单的退换货和产品售后使用问题,而这种问题智能机器人是可以完全解决的。现在,客服机器人已经可以解决80%的常见问题了。
但是,还有一种相对难的售后问题,像物流问题。举个例子:假如消费者提出:为什么我的宝贝还没到货?机器人回答,对不起,您在等等。这肯定是不行的,一下子就降低了用户体验。
人工客服在解决此问题时,都会问问订单号,然后去物流系统查询再反馈给顾客。其实这块人工智也做的很好了,类似这种物流场景问题,机器人都可以解决,完全不用人工参与,所以在双十一的时候环信的几个用户上了这个功能,发货后,消费者在询问的时候明显是解决了大量的工作量。
在售前环节,有个功能叫“人机协作”,虽然客服机器人做的还不错,但是跟一个优秀的销售比较还是有差距。所以,机器人怎么工作?其实它一直处于“充电”状态,当消费者与销售产生沟通的时候,机器人一直在听,可不是单纯的听,它可以通过分析能给销售推荐下一句适合说的话。
众所周知,客服行业人员流失率很大,那么新人刚上岗第一时间接触消费者会出现不知道如何沟通,而这个时候智能机器人的“人机协作”能力就可以发挥了。除此之外,机器人还可以做产品推荐。
据了解,目前新东方、泰康在线、中信证券、国美在线、链家、神州专车等都为环信用户。
企业服务市场赛道众多,为何环信单单会锁定在客服领域?这个问题,勾起刘俊彦回忆起他的创业初衷。
创业前,我们没想到会聚焦在客服这个领域,本身我是技术出身,之前做通讯方面的产品,对IM比较熟悉。2013年,微信,陌陌火了,很多人都在模仿他们。然后有人就找到我,让我帮忙做一个师生交友的工具,之后很多人都找我帮忙,帮一个两个容易,多了也没精力。就这样,我想是否能出个产品,做个系统框架,当你需要时看看文档看个Demo自己就能搞定。这么一个契机,创立了环信,做了第一个产品环信即时通讯云。
之后我们又发现了一个很有意思的事情,以前是帮助大家做社交,连接人与人,但是有一个场景是之前没想到的,就是连接人和商品,旺旺就是一个最典型的例子,连接的是消费者和商家。这对我们是个很好的启发,由此我们用IM做了个连接人和商业的移动端客服产品。所以,只要是APP里面需要做内置客服的商家,几乎都是环信的用户。
但是,我们又意识到了做APP内置客服更多的是个增量市场,不够大,所以即使达到垄断局面却还是觉得是小水洼里面的霸主。所以最后扩展到全媒体客服,包括网页、微博微信、电话等渠道,不局限于APP。
可是,当产品做到一定程度后,又出现了一个很大的问题。产品趋于成熟,竞争依旧很激烈。在与客户聊天的时候发现大家的产品慢慢都走向驱同。由此,我们盯上了人工智能这条路,意识到这才是拉开各个企业之间差距的关键点!我们不再谈全渠道接入,不再谈报表如何厉害。我们谈什么?我们谈的是人工智能如何在你公司落地,如何降低客服成本,如何帮助客服提升转化率,如何实现精准营销。
就眼前而言,如果你没意识到人工智能的重要,那么很可能就错过了,其实,环信刚开始接触这块的时候,也很犹豫,首先建立这么个团队花费很高,需要长期投入,当时决定做人工智能的时候内部也有很多争论。要不要做?值不值得?最后还是统一了意见,组成了20多人的研发团队专攻这块,决定跑下去。欣慰的是,现在已经产生效益。
人工智能或许在未来更加智能,那么是否有一天可以颠覆传统客服人员?
针对这个问题,刘俊彦有不同的看法“我觉得不会,目前我还没看到哪个企业因为用客服机器人用的好而裁员呢,呵呵,其实,目前互联网企业普遍很重视客户的服务体验。机器人确实解决了一些人力,但是,是将原来的这些人从新分配专注在提升用户体验的其他岗位上。
举个例子,神州专车是我们的客户,现在他们司机端使用的是环信客服机器人,之前他们是由人工客服为司机服务,经常要回答司机遇到的海量紧急问题,比如:乘客下车忘记付款、修车和报销规则等...接通环信客服机器人以后,节约了大量的人工客服工作。
刘俊彦表示,2017年,环信的重心会放在突破大客户上,对于一家企业服务公司,最终拼的还是大客户。其次会服务一些重点行业,例如银行,教育、保险、电商类。最后,会重点推动人工智能在客服行业的落地。
但是,从客服软件行业本身来看,未来面临几大挑战。
首先是移动端的挑战,国内企业客服有四个最常见的通道,电话、官网网页、微信公众号、移动端客服。但是消费者已经表现出一种很明确的趋势,需求点在移动端。那么在手机上最好的客户服务体验是什么?值得客服行业从业者深思。
其次,消费者在线需求渠道目前还处于多样化,以前只是电话沟通,通过质检便可以了解用户的满意度,现在,渠道多样化,需求多样化,所以想关心用户体验变得异常困难,就这样很多企业已经放弃了用户体验这个环节。所以,知道用户说什么,关心什么,吐槽什么,这是以后对于客服软件行业的一个挑战。而环信去年推出了环信客户声音,来解决和提高用户跨媒体、跨渠道环境下的客户服务体验
再次,就是人工智能的挑战,也许有一天人工智能就颠覆了客服软件。那这样,环信不就消失了吗?我认为,我们这种做客服软件的公司最多还能活五年!所以,与其别人颠覆你,不如自己颠覆自己,主动出击迎接挑战!
最后,人力成本对于客服行业来说也是一大挑战。我们有的客户最初是在北京市中心,慢慢的开始搬向周边,甚至开始向其他省市迁移。人力成本提高,从业者逐渐年轻化,不愿意从事客服工作,而客服行业本身又需要较强的心理因素,故此人员短缺。
其实,对于客服软件来说,降低企业人工成本其实是次要的,重点是充当销售提升转化率。很简单的一个道理,你想挣钱,你不能只会省钱!用户真正需要的是通过产品达到赚钱的目的。
例如环信有个客户是做儿童座椅的,以前通过发送短信只有百分之零点几的转化率,用环信的客服软件后达到了百分之二三十的转化率。在客单价较高的情况下,成交量提高了很多。
所以,商家在选择服务商的时候,有些还是值得注意的。刘俊彦也给出了自己的建议。对于大品牌企业来说,真正应该在乎的是这个服务企业是否可以长期陪伴你走下去?是否可以一直保证走在技术前沿?
其次,规模实力也很重要,一个规模完善发展稳定的服务企业是双方合作的基础。
最后,一定要关注移动端业务。选择擅长移动端的服务商,中国的几亿用户几乎都在移动端,商家必须将移动端重视起来! 收起阅读 »
环信入选《创业家》最具价值企业服务商推荐榜,听经纬熊飞聊怎样才是靠谱的企业级生意!
经纬中国投资董事熊飞先生

口述 | 熊飞
采访 | 李阳林
整理 | 张一、李书娜
首先,我认为(企业服务)行业是非常健康的。对于很多2C的需求,比较容易被大众所理解,因为大部分人都是用户;在2B领域,HR系统所提高HR的效率,一年价值是好几百万,所以创造的价值是很实在的。这是这个行业作为一个系统性的风口起来的一个机会。
在中国,推动企业级服务领域发展的原因主要有两个:一、人力成本的持续上涨;二、中国经济进入新常态,商品市场供大于求导致对于效率的要求提高。
先说人力成本。人力成本应该说是企业级服务发展的动力,中国企业发展已进入第一个拐点,这个拐点像六七年前一个人,每月三千块,一个电脑五千块。现在反过来,一个人每月五千块,一台电脑二千、二千五。企业主很理性,原来不用(工具)觉得贵,现在不用就是傻,人越来越贵,IT越来越便宜。
再看经济模式转型。5年前中国经济的增长方式比较粗放,最近两三年系统性供大于求。以前的企业发展都是拉贷款扩产能,人越多体量越大。现在的市场已经变成了各行各业供大于求、毛利下降,各种各样的产品卖不出去,反过来人力成本还在涨。所以企业主都希望是不是能有一个工具,能够让100人干150人的活。这个市场客观需求在爆发。
判断是否健康的三个标准
三个判断标准在上述大背景下判断一家企业级服务公司是否健康,主要看:一、客户规模的大小;二、客户续费率的高低;三、公司的月、年盈亏是否平衡。
第一:先看供应端企业的大小。企业级服务行业的马太效应比2C要强,巨头们通常资源广阔。但只有这些还不行。在企业级领域行业核心的本质是门槛、有时间的积累。一方面包括产品相对比较复杂;另一方面它需要用户的锤炼,是在跟用户互动的过程中,根据用户反馈去优化产品,包括各种配置,销售也是一个时间积累好的售前,好的实施,好的客户成功。要懂这个领域,不是从零开始,而是需要有很强的行业背景。
市场是后知后觉的,两年前还是企业服务元年,我们喊要中大型客户。很多人都不相信,都去做中小型客户。原来做中大型客户的公司五六千万收入,亏个两三千万,大家觉得SaaS穷途末路,觉得这个东西不挣钱,不能投;两年之后,再看,这个市场并不是那么回事。这是因为你的续约率在那儿。
第二,看客户续费率,用户续费率低于80%,基本上就是一个不太靠谱的生意。举个例子,为什么会要求这么高?我当年在一家零售交易平台(现已成为全球最大的零售交易平台),它的用户续费率是百分之六十几,什么概率?看上去挺高的,三年之后就没啥了,65%×65%×65%,剩不了什么?第二年就剩30%多,第三年剩20%多,你今年好不容易获取很多客户,三年之后这些客户剩二十几个了,这不是一个SaaS所谓长需的生意。
比如:某国内领先Saas公司是90%多的用户续费率,超过100%的金额续费率。其实做大客户服务就符合这么高的续费率,不是说只为了做大客户,而是说大客户的经济性很好,就好像实现梦想有各种方式,做大客户这个方式是实现续约率、实现价值的好生意。
第三,看公司能否实现单月盈亏平衡、全年盈亏平衡。
中国Saas公司开始系统性的进入单月盈亏平衡,全年盈亏平衡。何谓单月盈亏平衡或全年盈亏平衡呢?SaaS收费模式是不同于做其它服务。原来一个三百万的单,现在第一年只能收三五十万,因为客户不太相信,只想先试试,供应端可能连三五十万都收不到,只有客户用好了才会持续买,如果不续约,那客户就流失了。理想性的说,金额续约率百分之百的时候,那么在开始之前企业就已经收到钱了。
续约的维护成本是新销售的五分之一到十分之一。在美国有一个统计,平均你拿新销售一块钱的时候,所有的营销成本加在一起,续约的成本大概两毛钱、一毛七八,因为需求方跟供应方建立联系,需求方用得不错,客户成功,定期跟供应方沟通,帮需求方解决一些问题,收取费用。在这样的过程中,难免会增购其它服务。所以经济性就显著。
中国企业级服务公司的未来
现在是Sass B、C轮公司投资的黄金期,中晚期投资Saas黄金期。为什么是中后期?
在美国,企业服务从时间上划分有三拨:七十年代第一拨,微软,现在是四千亿美金的公司;第二拨是90年代末到2000年,所谓的云计算,如今也算是几十亿到五百亿美金公司;第三拨刚刚开始,中国是三拨合为一拨,三年前没有人谈企业服务,现在所有人在谈企业服务。
如果和美国市场对照,在中国当前这样的环境下,其实是可以出现美国的SAP、微软这样的公司,非常像十五年前2C领域。比如说携程的市值是Priceline、Expedia的总和,为什么?因为在美国爆发互联网旅游的时候,旅行社已经很强大了,所以美国的线上做不起来。但是在中国线下旅行社不强,线上也没有,所以呢,有市场发展空间,所以中国的线上旅行社就发展起来了。再比如,淘宝在中国就比eBay在美国要强大的多了,很大一部分原因是因为美国线下商业形态很成熟,发展空间没那么大。
现在对照企业级服务也是如此。中国企业级服务市场没有SAP,没有相对成熟的企业级服务公司。所以说中国企业级服务公司发展空间很大,没有天花板。现在的北森、销售易、环信,很可能就是未来各个垂直领域的微软和SAP。当然他们最终能不能做到三五千亿或者两三千亿美金,就看它未来的凶悍生长的能力。
未来三到五年之内,一定有估值超一百亿到二百亿人民币的公司出现,十年之内,一定有五百到一千亿人民币估值的公司出现。为什么敢这么说?中国现在最大的SaaS公司,今年确认的收入大概在三到四亿,每年还在上升。
具服务价值的企业服务商推荐榜
为了预见这个市场即将诞生的独角兽,为了给黑马用户推荐最优质的企业级服务商。我们梳理了《冲刺期最具服务价值的企业服务商推荐榜》,排名不分先后,不单一的从估值角度出发,选取C轮、D轮、新三板企业样本,成熟的上市公司不进入参选范畴,由投资人及行业人士推荐,上一轮融资规模。
我们将请这些未来的独角兽,为黑马及广大用户带来最有效的企业服务领域内的创业知识。黑马学吧将会邀请榜单里的18位成员,成立企业级理事会,位大家带来“企业级创业十八招”,敬请期待。
本次榜单成型,感谢蓝海通讯创始人何晓阳、六度人和创始人张星亮、黑马企业级服务分会秘书长万涛、环信唐大欢、北森市场副总裁高燕、销售易市场副总裁Joyce在专业上的支持


本文系创业&黑马原创发布,策划内容创业营,未经授权,转载必究。推荐关注i黑马微信公号(ID:iheima)。
环信成立于2013年4月,是一家国内领先的企业级软件服务提供商,于2016年荣膺“Gartner 2016 Cool Vendor”。产品包括国内上线最早规模最大的即时通讯云平台——环信即时通讯云,以及移动端最佳实践的全媒体智能云客服平台——环信移动客服。截至2016年底,环信即时通讯云共服务了130176家APP客户。环信移动客服共服务了58541家企业客户,现已覆盖包括保险、证券、银行、电商、教育、O2O等领域的众多标杆企业,包括泰康在线、中意人寿、中信证券、国美在线、优信二手车、新东方、新浪微博、链家、58到家、神州专车等典型用户。收起阅读 »
【公开课11回放】环信美女小双mm直播讲解环信客服集成+智能机器人配置
在4月20号这天,通过线上报名参加环信公开课的同学,早早的就收到了公众号、短信的通知。算下时间刚好晚上6点,华灯初上,邀约在这个还没开播的直播间里,那一帘幽蓝色的背景为我们的主角再增添了几分神秘,只有这片刻宁静才能使程序员们忘记在键盘上敲打了一天的劳累。因为大家都有一个共同的期待,小双来!
身高165,温柔体贴,善解人意,会做饭会洗衣,会遛狗会铲屎,英雄联盟一区钻一,会花会活不粘人!
我看着都动心了-某著名互联网公司女产品经理如是说到!
拍摄于4月20号18点40分,公开课工作人员正在做直播最后的调试

众里寻她千百度 那人或在屏幕深处!
小双mm直播现场

环信公开课第11期看点
☞ 教您5分钟快速集成环信移动客服
☞ 我们怎样才能将环信智能机器人用在刀刃上!
☞ 如何高效的生成一份报表让客服绩效一目了然!
环信公开课第11期视频回放观看●5分钟集成环信移动客服+环信智能机器人全解析
收起阅读 »
环信移动客服v5.16已发布,支持根据渠道筛选留言、新增客服账户管理
支持根据渠道筛选留言
支持根据渠道对留言进行筛选,方便根据渠道对留言进行管理。
进入“留言”页面,点击“自定义留言筛选”按钮,选择渠道,并点击“筛选查询”,即可筛选出对应渠道的留言。
管理员模式
新增客服账户管理
新增客服账户管理功能,支持管理员启用或禁用其他管理员和客服账户。一个租户下,在同一时间,最大启用数即为该租户的“购买坐席数”。客服管理功能可以帮助您更好地管理客服团队,在团队成员发生变动时,迅速切换启用的客服账户。
账户处于启用状态时,管理员/客服可以正常登录移动客服系统,并使用角色对应的功能;账户处于禁用状态时,管理员/客服不能登录移动客服系统。
进入“管理员模式 > 成员管理 > 客服”页面,在“账户启用”一列,启用/禁用管理员或客服账户。

进入“管理员模式 > 设置 > 企业信息”页面,查看您的租户的“购买坐席数”和“账户到期日”。

PC客服工作台
当前版本:V2.1.2017.04060
新增转接弹窗提示
当客服收到转接的会话(且“转接会话需要对方确认”开关打开时),PC客服工作台在显示屏右下角弹窗提示:您有新的转接会话。确保客服能够及时处理转接的会话。
移动客服iOS SDK
当前版本:V1.0.2
第二通道支持发送图片、语音消息
移动客服iOS SDK内置第二通道功能,当IM消息通道(第一通道)出现短暂的消息发送失败的情况时,自动调用第二通道将客户消息发送至移动客服系统,确保客户的所有消息均能准时送达。
在之前的版本,移动客服iOS SDK的第二通道仅支持发送文本消息;从该版本开始,第二通道支持发送文本、图片、语音消息。
关于如何集成移动客服iOS SDK,请参考移动客服 iOS SDK 集成。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.16
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
iOS 移动客服
【客户世界·洞察者视频】刘俊彦:全媒体客服的核心是移动端接入,而移动端接入的最佳体验是基于IM(附Gartner报告全文)
移动互联时代,客户正转移至移动端,服务需要紧跟客户步伐。Gartner报告指出:“消费者对移动设备的偏好正在快速发展,对于一些行业而言,到2019年,移动设备的使用将占到所有互联网交互的85%,如果不能改善移动客户服务,企业将遭受损失。”因为技术门槛高目前仅有部分大型企业能够在移动APP上提供端到端的、完整的客户服务支持能力,但是中小型企业的部署热情高涨。同时,在社交媒体上(如Facebook、微博、微信等)入驻的企业都已经开始在平台上提供客户服务能力,相比传统的网页客服和呼叫中心,社交媒体客服更是得到年轻用户的青睐。包括移动APP内置客服、社交媒体客服、网页客服/HTML5客服、传统呼叫中心等接入的全媒体客服已是大势所趋,而全媒体接入的核心在于移动端接入。
环信CEO参加客户世界.洞察者节目录制
当前国内的主要接入渠道包括移动APP内置客服、网页客服/HTML5客服、社交媒体客服(微信、微博)和呼叫中心。由上表可见除开移动APP内置客服以外,其余三个主流的接入门槛较低,技术标准化且成熟,核心难点在于移动端接入。
1.1,全媒体客服主流接入渠道特性:

1.2,支持移动APP内置客户服务的关键技术和最佳实践:
1.2.1,移动APP内置客服帮助企业在移动端保持了品牌和服务的一致性:
在移动APP中内置客户服务,使消费者不需要跳出APP就可以及时得到客户服务支持,而不再需要去寻求第三方比如呼叫中心等传统客服方式。这很好的解决了很多APP运营者,对消费者跳出APP后,可能不再返回APP的忧虑,同时企业保持了品牌和服务的一致性。
1.2.2,移动APP内置客服的最佳体验是基于IM(即时通讯)。
随着IM(即时通讯)类APP如Whatsapp, 微信等在手机上的流行,IM已经被证明是在移动终端上最适合连接人与人的沟通方式。在客服领域,以环信为代表的一批移动APP内置客服技术提供商的成功,也证明了IM同样是移动终端上最适合连接人与服务的沟通方式。将IM方式用于消费者与客服人员沟通有几大优势:
1,支持富媒体消息,表现能力强。比如消费者可以发送位置,图片,订单消息等类型消息。这种类型的富媒体消息,往往很难通过电话描述。
2,IM沟通是典型的异步沟通方式。对客服坐席来说,使用IM,可以和最多几十个消费者同时沟通,相比电话这种传统的一对一同步沟通方式,效率有极大的提高。与此同时,对于消费者来说,使用IM沟通,更符合手机碎片化使用的特点。
3,使用IM客服,只要用户不卸载APP,即使用户离开APP,甚至杀死APP,客服也随时可以将消息以推送方式通知到手机。用户绝不会错过任何有价值的消息。

示例:国美在线APP通过环信提供的APP内置客服很好的服务了上亿用户。
1.2.3移动APP内置IM(即时通讯)客服技术选型建议:

附录:Gartner研究——移动端客户服务 分析师:迈克尔·毛兹
定义:移动端客户服务应用存储在智能手机或平板电脑中、也可通过这些设备进行访问。这些应用的的使用可通过上下文搜索、联系上下文信息、客户定位服务或多模式交互(客户可以进行自助服务,也可以通过语音聊天或同步浏览请求、或得到在线人工支持)。其他技术还包括基于语音的搜索、虚拟客户助理以及触摸式或视觉交互式语音响应(IVR)。
定位和市场接受速度:下载到移动设备上的数亿个移动应用通常缺乏其他渠道中常见的客服支持。它们并非本机自带的移动应用,因此可能无法利用移动平台的所有功能。这种差距将阻碍企业为客户提供丰富且令人满意的移动体验的主动性。因此,尽管移动客户支持尚不成熟,我们仍然认为其将成为IT业界和业务线(LOB)中最重要的优先项目。
用户建议:与客户体验或客户支持副总合作的IT部门,应根据其在移动设备上的关键活动所获得的支持以及客户对各种功能的需求,来调查客户的满意度水平。根据调查结果来提高人们对移动支持当前状态的认知,创建路线图以改善客户支持和评估CRM供应商的移动应用程序和技术。
业务影响:优秀的移动客户服务将促使客户使用公司网站时,从笔记本电脑或台式机转向移动设备。消费者对移动设备的偏好正在快速发展,对于一些行业而言,到2019年,移动设备的使用将占到所有互联网交互的85%,如果不能改善移动客户服务,企业将遭受损失。
好处评级:高关于《客户世界·洞察者》
市场渗透率:目标受众的5%至20%
成熟度:新兴
供应商举例:Creative Virtual;甲骨文;Pegasystems;Salesforce ;SAP;TouchCommerce;
随着信息爆炸的互联网时代的到来,人们阅读习惯的改变,客户世界推出立体化内容呈现方式(图文+短视频)来迎合人们碎片化时间的阅读。那么越来越高标准的阅读需求靠什么来满足?《客户世界》做为国内唯一定位于“客户管理”专业研究及其关联产业发展的专业纸媒,在客户中心行业广受赞誉。其精准的内容定位锁定了企业客户管理各级岗位的专业人士。“客户世界·洞察者”每周一个观点,敬请期待。
收起阅读 »
【环信征文】| 环信的简单接入
然后运行没有报错
下面开始接入
首先是注册和通知//这里的通知只是本地通知
在- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions 方法中添加
//注册环信(注:要让 AppDelegate遵循EMChatManagerDelegate协议)
EMOptions *options = [EMOptions optionsWithAppkey:@"app 的 key"];
options.apnsCertName = @"上传的推送证书的名字";
[[EMClient sharedClient] initializeSDKWithOptions:options];
options.enableDeliveryAck = YES;
//添加监听在线推送消息
[[EMClient sharedClient].chatManager addDelegate:self delegateQueue:nil];
注:环信的通知只有在完全杀死 app 的情况下才会推送 如果只是app 在后台 是不会发推送通知的 所以要监听在线推送消息来发本地推送
下面来实现监听在线推送消息的方法
//监听环信在线推送消息
- (void)messagesDidReceive:(NSArray *)aMessages {
for (EMMessage *message in aMessages) {
EMMessageBody *msgBody = message.body;
switch (msgBody.type) {
case EMMessageBodyTypeText: {
// 收到的文字消息
EMTextMessageBody *textBody = (EMTextMessageBody *)msgBody;
NSString *txt = textBody.text;
UIApplicationState state = [UIApplication sharedApplication].applicationState;
//判断 app 是不是在后台
if (state == UIApplicationStateBackground) {
UILocalNotification *localNote = [[UILocalNotification alloc] init];
//设置通知发出的时间
localNote.fireDate = [NSDate dateWithTimeIntervalSinceNow:5.0];
//设置通知的内容
localNote.alertBody = txt;
//设置锁屏界面的文字
localNote.alertAction = txt;
//设置锁屏界面alertAction是否有效
localNote.hasAction = YES;
//设置应用程序图标右上角的数字
localNote.applicationIconBadgeNumber = 1;
// 调度通知
[[UIApplication sharedApplication] scheduleLocalNotification:localNote];
} else {
// 如果是在前台,这里可以选择增加角标或者其他提示
}
}
break;
case EMMessageBodyTypeImage: {
// 得到一个图片消息body
EMImageMessageBody *body = ((EMImageMessageBody *)msgBody);
UIApplicationState state = [UIApplication sharedApplication].applicationState;
if (state == UIApplicationStateBackground) {
UILocalNotification *localNote = [[UILocalNotification alloc] init];
//设置通知发出的时间
localNote.fireDate = [NSDate dateWithTimeIntervalSinceNow:5.0];
//设置通知的内容
localNote.alertBody = @"收到一张图片";
//设置锁屏界面的文字
localNote.alertAction = @"收到一张图片";
//设置锁屏界面alertAction是否有效
localNote.hasAction = YES;
//设置应用程序图标右上角的数字
localNote.applicationIconBadgeNumber = 1;
//调度通知
[[UIApplication sharedApplication] scheduleLocalNotification:localNote];
}
}
break;
case EMMessageBodyTypeLocation: {
EMLocationMessageBody *body = (EMLocationMessageBody *)msgBody;
NSLog(@"纬度-- %f",body.latitude);
NSLog(@"经度-- %f",body.longitude);
NSLog(@"地址-- %@",body.address);
UIApplicationState state = [UIApplication sharedApplication].applicationState;
if (state == UIApplicationStateBackground) {
UILocalNotification *localNote = [[UILocalNotification alloc] init];
//设置通知发出的时间
localNote.fireDate = [NSDate dateWithTimeIntervalSinceNow:5.0];
//设置通知的内容
localNote.alertBody = @"收到一条消息";
//设置锁屏界面的文字
localNote.alertAction = @"收到一条消息";
//设置锁屏界面alertAction是否有效
localNote.hasAction = YES;
//设置应用程序图标右上角的数字
localNote.applicationIconBadgeNumber = 1;
// 调度通知
[[UIApplication sharedApplication] scheduleLocalNotification:localNote];
}
}
break;
case EMMessageBodyTypeVoice: {
// 音频sdk会自动下载
EMVoiceMessageBody *body = (EMVoiceMessageBody *)msgBody;
NSLog(@"音频remote路径 -- %@" ,body.remotePath);
NSLog(@"音频local路径 -- %@" ,body.localPath); // 需要使用sdk提供的下载方法后才会存在(音频会自动调用)
NSLog(@"音频的secret -- %@" ,body.secretKey);
NSLog(@"音频文件大小 -- %lld" ,body.fileLength);
NSLog(@"音频文件的下载状态 -- %u" ,body.downloadStatus);
NSLog(@"音频的时间长度 -- %u" ,body.duration);
UIApplicationState state = [UIApplication sharedApplication].applicationState;
if (state == UIApplicationStateBackground) {
UILocalNotification *localNote = [[UILocalNotification alloc] init];
//设置通知发出的时间
localNote.fireDate = [NSDate dateWithTimeIntervalSinceNow:5.0];
//设置通知的内容
localNote.alertBody = @"收到一条消息";
//设置锁屏界面的文字
localNote.alertAction = @"收到一条消息";
//设置锁屏界面alertAction是否有效
localNote.hasAction = YES;
//设置应用程序图标右上角的数字
localNote.applicationIconBadgeNumber = 1;
//调度通知
[[UIApplication sharedApplication] scheduleLocalNotification:localNote];
}
}
break;
case EMMessageBodyTypeVideo: {
//视频消息
EMVideoMessageBody *body = (EMVideoMessageBody *)msgBody;
}
break;
case EMMessageBodyTypeFile: {
// 文件消息
EMFileMessageBody *body = (EMFileMessageBody *)msgBody;
}
break;
default:
break;
}
}
}
这里因为我是没有用到视频和文件的功能,所以这里收到之后并没有做处理
//当程序关闭后 通过点击推送弹出的通知
// iOS 10 支持的方法
- (void)jpushNotificationCenter:(UNUserNotificationCenter *)center didReceiveNotificationResponse:(UNNotificationResponse *)response withCompletionHandler:(void (^)())completionHandler {
//在这个方法中实现点击消息进入 app 之后的方法
//我这里是写了一个通知 让 app 进入消息列表界面
[[NSNotificationCenter defaultCenter] postNotificationName:@"jumpToChatListView" object:nil];
}
下面开始聊天
我这里做的是每次开始聊天都要登陆一下 ,也可以选择在用户登陆 app 的时候 或者在 appdelegate 里面登陆
EMError *error = [[EMClient sharedClient] loginWithUsername:@"用户名" password:@"密码"];
if (!error) {
//我在这里做了一个只要和他说话就添加他为好友 这样在后面获取好友列表的时候就有好友啦
MYFMRequestBean* bean = [MyHttpRequest addFriendWithUserId:对方 id currntUserId:自己的 id];
[bean connect:nil success:^(id responseObject) {
} failure:^(NSError *error) {
}];
//这里自定义了一个聊天页面 继承于EaseMessageViewController 定义了两个属性 一个是 talkImg 是对方的头像 一个是 talkName 对方的名字 这个从当前页面就能获取到
ChatViewController *chatController = [[ChatViewController alloc] initWithConversationChatter:对方的环信 idconversationType:EMConversationTypeChat];
chatController.talkImg = 对方的头像的 url 地址;
chatController.talkName = 对方的名字;
chatController.hidesBottomBarWhenPushed=YES;//跳转时隐藏 tabbar
[self.navigationController pushViewController:chatController animated:YES];
} else {
[SVProgressHUD showErrorWithStatus:@"连接失败,请稍后重试"];
}
下面我说一下我自定义的这个ChatViewController
.h 文件就是
#import "EaseMessageViewController.h"
@interface ChatViewController : EaseMessageViewController
@property (nonatomic, copy)NSString *talkName;
@property (nonatomic, copy)NSString *talkImg;
@end
.m 文件:
#import "ChatViewController.h"
//遵循EaseMessageViewController的 DataSource 协议
@interface ChatViewController ()<EaseMessageViewControllerDataSource>
@end
@implementation ChatViewController
- (void)viewDidLoad {
[super viewDidLoad];
self.dataSource = self;
[self.navigationItem setTitle:self.talkName];
}
//这里实现EaseMessageViewController的 DataSource 方法 来改变对方和自己的昵称和头像
- (id<IMessageModel>)messageViewController:(EaseMessageViewController *)viewController
modelForMessage:(EMMessage *)message
{
//用户可以根据自己的用户体系,根据message设置用户昵称和头像
id<IMessageModel> model = nil;
//EaseMessageModel是环信EaseUI提供的model
model = [[EaseMessageModel alloc] initWithMessage:message];
//分两种情况 一种是当为当前用户的时候
if ([model.nickname isEqualToString:[EMClient sharedClient].currentUsername]) {
//默认图
// model.avatarImage = [UIImage imageNamed:@"baseInfo"];
//网络图
model.avatarURLPath = [UserManager userImg];
model.nickname = [UserManager userName];
} else {//当为对方的时候
model.avatarURLPath = _talkImg;//网络图
// model.avatarImage = [UIImage imageNamed:@"baseInfo"];//默认图
model.nickname = _talkName;//用户昵称
}
return model;
}
下面说一下消息列表
自定义了一个ChatListViewController 继承于环信的EaseConversationListViewController
.h文件:
#import "EaseConversationListViewController.h"
@interface ChatListViewController : EaseConversationListViewController
- (void)reloadData;//这里我加了一个刷新方法 如果单击消息进入 app 的时候是在当前页面 要刷新一下,默认是不会刷新的,即使在 viewWillAppear 里面写了也不刷新
@end
.m文件:
#import "ChatListViewController.h"
#import "HPChatListDataModel.h"
#import "NSDate+Category.h"//环信时间分类
#import "ChatViewController.h"
#import "ChatListDataModel.h"//这是自定义的一个 model 类 存放好友的头像昵称和 id
#import "EaseUsersListViewController.h"
@interface ChatListViewController ()<EaseConversationListViewControllerDataSource,EaseConversationListViewControllerDelegate>
@property (nonatomic, strong)NSMutableArray *imageAndNameArray;
@end
@implementation ChatListViewController
- (void)viewDidLoad {
[super viewDidLoad];
[self sendFriendsList];
self.dataSource = self;
self.delegate = self;
[self.navigationItem setTitle:@"聊天列表"];
//打开下来刷新
self.showRefreshHeader = YES;
[self tableViewDidTriggerHeaderRefresh];
}
#pragma mark - 好友列表
- (void)sendFriendsList {
[SVProgressHUD showWithStatus:@"加载中..."];
MYFMRequestBean* bean = [MyHttpRequest friendsListWithUserId:[UserManager userId]];
self.imageAndNameArray = [NSMutableArray array];
__weak typeof(self) weakSelf = self;
[bean connect:nil success:^(id responseObject) {
[SVProgressHUD dismiss];
NSDictionary* dic = responseObject;
if ([dic optIntKey:@"status"] == 1) {
NSArray* arr = dic[@"data"];
for (NSDictionary* dict in arr) {
HPChatListDataModel *model = [[HPChatListDataModel alloc]initWithDictionary:dict];
[weakSelf.imageAndNameArray addObject:model];
}
[self tableViewDidTriggerHeaderRefresh];
} else {
[SVProgressHUD showErrorWithStatus:[dic optStringKey:@"msg"]];
}
} failure:^(NSError *error) {
[SVProgressHUD showErrorWithStatus:@"网络错误"];
}];
}
- (id<IConversationModel>)conversationListViewController:(EaseConversationListViewController *)conversationListViewController
modelForConversation:(EMConversation *)conversation{
//用环信提供的model就可以了
EaseConversationModel *model = [[EaseConversationModel alloc] initWithConversation:conversation];
//然后根据用户名 往上面赋值
//self.imageAndNameArray为自定义的数组,其中存储的是从自己服务器上请求下来的数据
//数据包括,昵称,头像
for (HPChatListDataModel *dataModel in self.imageAndNameArray) {
if ([dataModel.mobile isEqualToString:model.conversation.conversationId]) {//根据用户名对应起来
model.avatarURLPath = dataModel.pic;//头像的网络图片
model.title = dataModel.name;//昵称
}
}
return model;
}
//下拉刷新
- (void)tableViewDidTriggerHeaderRefresh{
//super必须要有 要不会有问题
[super tableViewDidTriggerHeaderRefresh];
}
#pragma mark delegate
- (void)conversationListViewController:(EaseConversationListViewController *)conversationListViewController
didSelectConversationModel:(id<IConversationModel>)conversationModel{
EaseConversationModel *model = (EaseConversationModel *)conversationModel;
//自定义点击cell推出的viewcontroller
ChatViewController *viewController = [[ChatViewController alloc]initWithConversationChatter:model.conversation.conversationId conversationType:(EMConversationTypeChat)];
viewController.talkImg = model.avatarURLPath;
viewController.talkName = model.title;
[self.navigationController pushViewController:viewController animated:YES];
}
- (void)viewWillAppear:(BOOL)animated {
[self tableViewDidTriggerHeaderRefresh];
}
- (void)reloadData {
[self tableViewDidTriggerHeaderRefresh];
}
下面是获取未读消息数量 然后显示小红点
NSArray *conversations = [[EMClient sharedClient].chatManager getAllConversations];
NSInteger unreadCount = 0;
for (EMConversation *converstaion in conversations) {
unreadCount += converstaion.unreadMessagesCount;
}
用 forin 的方式来获取数量
又加了单击聊天的头像然后显示个人信息的功能
so
让ChatViewController 遵循EaseMessageCellDelegate
然后别忘了 self.delegate = self;
然后实现代理方法
- (void)messageViewController:(EaseMessageViewController *)viewController收起阅读 »
didSelectAvatarMessageModel:(id<IMessageModel>)messageModel {
//判断 model 的 nickname 是不是本人的 name 这里因为上面修改昵称的时候把这个 nickname 从 id 改成 name 了 所以这里判断的时候要用 name 来判断 不能用 id 了
if ([messageModel.nickname isEqualToString:@"本人名字"]) {
//跳转到个人信息
} else {
//跳转到对方信息
}
}
我又做了一次面试官
那个人看上去快40了,嫌会议室档次太低,要去演播室面试;进了演播室之后,他直奔中间给主持人和嘉宾坐的两个沙发去了,剩下的另一个沙发我俩谁也没好意思坐,一人搬个板凳坐在他面前--当时的场景像极了他在面试我俩。
我看了看他的简历,1983年出生的,从业以年来的经历写的不是“某大型上市公司”的Leader就是“某大型国企”的专家,但都没写具体公司名,技能写的也像很多从不懂技术的HR写的招聘条件上复制粘贴下来的。
我:(他进来之后应该是我领导,问他点作为Leader该懂的)能简单讲讲敏捷开发吗?
他:敏捷开发……就是开发时候思路和动作都敏捷点,多加点班,快点把结果交出来。
我:(感觉他可能是不太擅长管理的技术专家,问点高难度的)能讲讲需要涉及到Android辅助功能的开发,比如自动抢红包的实现思路吗?
他:不知道什么是“辅助功能”
我:像微信一样在桌面上生成与某人会话的快捷方式怎么做呀?
他:没了解过
我:(感觉他没做过方向性太强的,问点常见的)能讲讲Android事件分发传递机制吗?
他:Android事件分发传递机制呀?不知道
我:能讲讲Android动画分哪几大类吗?
他:Android动画呀?不知道
我:WebView用什么接口与JavaScript交流呀?
他:不知道
我:方法数达到65k以后该怎么办呀?
他:方法少写点就行了吧
我:能说说自定义控件需要用到的方法除了OnDraw()和OnLayout()之外另一个是啥吗?
他:有OnDraw()、OnLayout(),另一个不知道
我:(似乎明白点啥)你有作品吗?
他:有,有(说着打开了手机上一个APP)
(我一看是个简单的新闻客户端,他给我演示了一下Fragment翻页)
我:知道Fragment的懒加载吗?
他:不知道
我:还有别的作品吗?
他:还有,还有(说着打开了手机上的另一个APP)
(我一看是个简单的随手记,他给我演示了一下存储文字)
我:用SharedPerfences保存的?
他:嗯
我:知道SharedPerfences的原理吗?
他:是一个轻量级的数据库
我:你不是四年经验吗?还做过别的APP吗?
他:我……我给公司做的APP都是涉密项目
我:(看他简历上还写着“精通Java”)能说说Java的基本数据类型有哪些吗?比如int和long
他:int…?long…?还有String吧
我:你确定String也是基本数据类型?
他:挺常用的,应该是吧
我:(看他简历上还写着“精通软件工程,精通面向对象,精通设计模式”)能说说面向对象三大特征除了封装和多态之外还有啥吗?
他:封装…?多态…?还有啥我还真不知道
我:(已经确定他是嫌站着工作累去培训班学了几个月的厨师或者洗剪吹了,简历上写的“精通算法”也没必要问了)小刚你问他点问题吧,我有点事先回去了
(后来的对话是小刚告诉我的)
小刚:你知道Android四大组件是啥吗?
他:有个Activity吧?
小刚:能说说Activity生命周期吗?
他:(终于有个知道的了)这个我知道,Activity刚打开的时候调用onCreate(),关闭的时候用finish(),从上一个Activity退回来调用onResume()(也没说对)
小刚:那你期望薪资是多少呀?
他:(瞬间来了精神)必须不低于你俩之和!
如果这个比相声还精彩的面试情景被录下来的话对公司的收视率还是很有帮助的,可惜当天视频部门没开摄像机。 收起阅读 »
环信Android/ios V3.3.1 SDK 已发布,支持token登录,红包集成更快捷!
新功能:
- 新增:使用token登录接口
- 新增:群组群成员进出群组回调
优化:
- Demo中红包集成方式更改为aar,默认支持支付宝渠道支付
修复
- 之前EMChatManager.getMessage对应的消息会保存在缓存中,修改后不缓存getMessage产生的消息。之前的代码会导致loadMoreMessage部分消息不显示。
- 3.3.0版本Demo中群组@键,弹出列表没有包含群组管理员
- 3.3.0版本EMGroup.getMuteList会崩溃
- 3.3.0版本EMChatRoom hash code错误
- 修复音视频被叫时多个应用都会收到通知的错误
iOS V3.3.1 2017-04-07新功能:
- 新增:使用token登录
- 新增:群组群成员进出群组回调
优化:
- 红包改用cocoapods方式集成,支持支付宝和京东支付
修复:
- insertMessage小概率下会崩溃
- [EMMessage setTo:]赋值错误
- 聊天室获取详情接口[IEMChatroomManager fetchChatroomInfo:includeMembersList:error:]第2个参数传入YES时不能获取成员
- 2.x和3.x互通情况下,群组和聊天室的memberlist中出现admin和owner
- 发送消息成功后,对应的EMConversation没有更新最后一条消息
版本历史:AndroidSDK 更新日志 ios SDK更新日志
下载地址:SDK下载 收起阅读 »
环信公开课第11期●5分钟集成环信移动客服+环信智能机器人全解析

APP、网页等多渠道如何快速接入智能云客服?
客服机器人号称能解决80%的问题,究竟是确有其事还是言过其实?
如何高效的生成一份报表让客服绩效一目了然!
环信公开课第11期(2017.4.20 19:00)●5分钟集成环信移动客服+环信智能机器人全解析
环信公开课 讲师简介

小双mm
疑难投诉处理专家,环信首席程序猿鼓励师
身高165,温柔体贴,善解人意,会做饭会洗衣,会遛狗会铲屎,英雄联盟一区钻一,会花会活不粘人!
环信公开课 活动看点
5分钟集成环信移动客服+环信智能机器人全解析(2017.4.20 19:00)
☞ 教您5分钟快速集成环信移动客服
☞ 我们怎样才能将环信智能机器人用在刀刃上!
☞ 如何高效的生成一份报表让客服绩效一目了然!
☞ 在线问答
环信公开课 活动说明
主讲嘉宾:环信颜值担当小双mm
参会时间:2017.4.20(周四)19:00
活动形式:线上公开课
注意事项:联网手机|电脑均可观看
环信公开课 参会两步走
Step1:在下方填写准确的报名信息
http://mk.meeket.com/flyer/978654/157834.html?source=16
Step2:添加“环信公开课小助手”,小助手拉您进公开课专用微信群,等待开讲。
方法①:长按下方二维码快速添加
方法②:直接添加微信号:huanxin-hh


环信成立于2013年4月,是一家国内领先的企业级软件服务提供商,于2016年荣膺“Gartner 2016 Cool Vendor”。产品包括国内上线最早规模最大的即时通讯云平台——环信即时通讯云,以及移动端最佳实践的全媒体智能云客服平台——环信移动客服。收起阅读 »
环信移动客服v5.15发布——统计数据增加客服的在线时长
统计数据增加客服的在线时长
客服可以查看自己的在线时长数据,包括空闲、忙碌、离开、隐身、在线、离线的时长和占比。
进入客服模式的统计数据页面,选择时间段,查看自己的在线状态分布。

留言支持按创建时间排序
留言支持按创建时间排序,默认为倒序排列,即最新的留言排在前面。可以点击“创建时间”右侧的排序按钮,切换正序/倒序排列方式。

管理员模式
自定义报表
移动客服系统支持自定义报表功能。系统提供90天内的统计数据,管理员可以根据不同的时间段、指标项目和指标维度自由搭配出不同的报表,满足多样化的报表需求。
自定义报表功能为增值服务,如需开通,请提供租户ID并联系环信商务经理。旗舰版客户可以直接使用自定义报表功能。

添加自定义报表
在“管理员模式 > 统计查询 > 自定义报表”页面,点击“添加自定义报表”按钮,填写报表名称,选择时间段、报表类型、指标项目、指标维度,并保存。
每份自定义报表最多可以展示90天内、10个指标项目、2个指标维度的数据。自定义报表会根据您设置的指标实时更新,显示最新的数据。
指标项目包括两类:
- 按会话创建时间计算:排队时长平均值、排队时长最大值、排队总次数、独立访客总数;
- 按会话接起时间计算:质检评分平均值、满意度评分平均值、会话总数、消息总数、会话时长平均值、会话时长最大值、首次响应时长平均值、首次响应时长最大值、响应时长平均值、响应时长最大值。
指标维度包括:客服、访客标签、渠道类型、关联、会话类型、会话有效类型、时间粒度。

查看自定义报表
在“管理员模式 > 统计查询 > 自定义报表”页面,自定义报表以缩略图的形式展示。点击任意报表的内容区域,可以展开该报表,查询更详细的报表内容。
在展开的报表中,您还可以重新设置报表的时间范围,以及对已有的指标项目和指标维度进行筛选。

支持调整最大接待人数上限
目前客服的最大接待人数上限为100,可以设置为0~100之间的数值。当客服的进行中会话数小于最大接待人数时,系统会自动为该客服分配会话。
如果该最大接待人数上限不能满足您的业务需求,移动客服系统支持将最大接待人数上限调整为200。
调整最大接待人数上限为增值服务,如需开通,请提供租户ID并联系环信商务经理。
支持设置历史会话数据的查看权限
支持为自定义角色设置查看全部或所在技能组的历史会话数据的权限,更好地进行技能组的管理。
进入“管理员模式 > 设置 > 权限管理”页面,点击自定义角色,编辑该角色的权限。在管理员模式下,勾选“历史会话(全部)”或“历史会话(技能组)”,并保存。
说明:
- 仅勾选“历史会话(技能组)”时,该角色可以查看其所在的所有技能组的历史会话;若该角色不属于任何技能组,则可以查看“未分组”的历史会话。
- 若同时选择“历史会话(全部)”和“历史会话(技能组)”,使用该角色的坐席在管理员模式可以查看全部历史会话。

Android客服工作台
当前版本:V2.8
新增消息撤回功能
新增消息撤回功能。客服使用Android客服工作台与APP、网页渠道的客户聊天时,可以撤回2分钟内的聊天消息。聊天消息被撤回后,将在APP、网页访客端消失。
注:暂时只有最新版web插件和最新版Android SDK支持消息撤回。
消息撤回功能为增值服务,如需开通,请提供租户ID并联系环信商务经理。
新增锁屏接收消息功能
手机锁屏时,依然可以通过Android客服工作台收到客户的消息。
关于更多Android客服工作台的更新日志,请查看Android 客服工作台 更新日志。
移动客服iOS SDK
当前版本:V1.0.1
支持实时语音、实时视频
移动客服iOS SDK支持实时语音、实时视频(实时音视频)。当客户使用iOS APP联系客服时,可以向客服发起视频聊天。
实时音视频功能需要调用iOS SDK的接口进行集成,集成方式可参考“商城”demo。
注:需要在网页端客服工作台开通“实时视频”这项增值服务后,才能向客服发起视频聊天。
支持发送位置消息
移动客服iOS SDK支持发送地理位置消息。
关于移动客服iOS SDK的集成说明,请查看移动客服 iOS SDK 集成。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.15
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »


使用环信3.xSDK 在 TV 端集成音视频通话功能
项目git源码https://github.com/lzan13/VMChatDemoCall
VMTVCall
使用环信 SDK 开发一款在 TV 上视频通话应用,可以安装在自己的电视上,让爸妈在家和自己进行高清通话
使用版本
- AndrodiStudio 2.3.0
- Gradle 3.3
- SDK Build Tools 25.0.2
- SDK Compile 25
- SDK mini 19
- Leanback 25.3.0
- CardView 25.3.0
- ButterKnife 8.5.1
- EventBus 3.0.0
- 环信 SDK 3.3.0
- 自己封装的工具类库,暂时只能下载源码引用
- 项目首次启动自动注册登录
- 拨号盘实现
- 历史通话记录 TODO
- 视频通话功能(因为电视不需要语音通话以及最小化)
- 视频通话的录制
- 通话截图
其他相关项目
这也实现了一个移动端的音视频小项目,使用环信新版 SDK3.3.0以后版本实现完整的音视频通话功能,本次实现将所有的逻辑操作都放在了 VMCallManager 类中,方便对音视频界面最小化的管理; 此项目实现了音视频过界面的最小化,以及视频通话界面本地和远程画面的大小切换等功能
移动端项目【移动端实现音视频通话项目】
项目截图
首界面

通话界面

收起阅读 »
使用环信3.xSDK 集成音视频通话功能
项目源码git地址https://github.com/lzan13/VMLibraryManager
使用版本
- AndrodiStudio 2.3.0
- Gradle 3.3
- SDK Build Tools 25.0.2
- SDK Compile 25
- SDK mini 19
- Design 25.3.0
- ButterKnife 8.5.1
- EventBus 3.0.0
- 环信 SDK 3.3.0
- 自己封装的工具类库,暂时只能下载源码引用
PS:这边并没有将 libs 目录上传到 github,需要大家自己去环信官网下载最新的 sdk 放在 libs 下 PS:必须使用环信SDK3.3.0以后的版本
实现功能
- 通话界面最小化及恢复
- 通话悬浮窗的实现,可拖动
- 视频通话界面切换
- 视频通话的录制
- 视频通话的截图
- 横竖屏的自动切换
已知问题
- 未接通时切换到悬浮窗,当接通时无法显示画面
- 主叫方接通时无法显示远程图像
项目截图





关联项目
实现有一个 TV 端的应用,可以实现和移动端进行实时通话,给大家在 TV 端使用环信 SDK 进行集成音视频通话加以参考
【TV 端视频通话项目】
收起阅读 »
李理:Theano tutorial和卷积神经网络的Theano实现 Part2
作者:李理
目前就职于环信,即时通讯云平台和全媒体智能客服平台,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。
相关文章:
李理:从Image Caption Generation理解深度学习(part I)
李理:从Image Caption Generation理解深度学习(part II)
李理:从Image Caption Generation理解深度学习(part III)
李理:自动梯度求解 反向传播算法的另外一种视角
李理:自动梯度求解——cs231n的notes
李理:自动梯度求解——使用自动求导实现多层神经网络
李理:详解卷积神经网络
李理:Theano tutorial和卷积神经网络的Theano实现 Part1
接上文。
7. 使用Theano实现CNN
接下来我们继续上文,阅读代码network3.py,了解怎么用Theano实现CNN。
完整的代码参考这里。
7.1 FullyConnectedLayer类
首先我们看怎么用Theano实现全连接的层。
class FullyConnectedLayer(object):7.1.1 init
def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0):
self.n_in = n_in
self.n_out = n_out
self.activation_fn = activation_fn
self.p_dropout = p_dropout
# Initialize weights and biases
self.w = theano.shared(
np.asarray(
np.random.normal(
loc=0.0, scale=np.sqrt(1.0/n_out), size=(n_in, n_out)),
dtype=theano.config.floatX),
name='w', borrow=True)
self.b = theano.shared(
np.asarray(np.random.normal(loc=0.0, scale=1.0, size=(n_out,)),
dtype=theano.config.floatX),
name='b', borrow=True)
self.params = [self.w, self.b]
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):
self.inpt = inpt.reshape((mini_batch_size, self.n_in))
self.output = self.activation_fn(
(1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b)
self.y_out = T.argmax(self.output, axis=1)
self.inpt_dropout = dropout_layer(
inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout)
self.output_dropout = self.activation_fn(
T.dot(self.inpt_dropout, self.w) + self.b)
def accuracy(self, y):
"Return the accuracy for the mini-batch."
return T.mean(T.eq(y, self.y_out))
FullyConnectedLayer类的构造函数主要是定义共享变量w和b,并且随机初始化。参数的初始化非常重要,会影响模型的收敛速度甚至是否能收敛。这里把w和b初始化成均值0,标准差为sqrt(1.0/n_out)的随机值。有兴趣的读者可以参考这里。
此外,这里使用了np.asarray函数。我们用np.random.normal生成了(n_in, n_out)的ndarray,但是这个ndarray的dtype是float64,但是我们为了让它(可能)在GPU上运算,需要用theano.config.floatX,所以用了np.asarray函数。这个函数和np.array不同的一点是它会尽量重用传入的空间而不是深度拷贝。
另外也会把激活函数activation_fn和dropout保存到self里。activation_fn是一个函数,可能使用静态语言习惯的读者不太习惯,其实可以理解为c语言的函数指针或者函数式变成语言的lambda之类的东西。此外,init函数也把参数保存到self.params里边,这样的好处是之后把很多Layer拼成一个大的Network时所有的参数很容易通过遍历每一层的params就行。
7.1.2 set_input
set_inpt函数用来设置这一层的输入并且计算输出。这里使用了变量名为inpt而不是input的原因是input是Python的一个内置函数,容易混淆。注意我们通过两种方式设置输入:self.inpt和self.inpt_dropout。这样做的原因是我们训练的时候需要dropout。我们使用了一层dropout_layer,它会随机的把dropout比例的神经元的输出设置成0。而测试的时候我们就不需要这个dropout_layer了,但是要记得把输出乘以(1-dropout),因为我们训练的时候随机的丢弃了dropout个神经元,测试的时候没有丢弃,那么输出就会把训练的时候大,所以要乘以(1-dropout),模拟丢弃的效果。【当然还有一种dropout的方式是训练是把输出除以(1-dropout),这样预测的时候就不用在乘以(1-dropout)了, 感兴趣的读者可以参考这里】
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):下面我们逐行解读。
self.inpt = inpt.reshape((mini_batch_size, self.n_in))
self.output = self.activation_fn( (1-self.p_dropout)*T.dot(self.inpt, self.w) + self.b)
self.y_out = T.argmax(self.output, axis=1)
self.inpt_dropout = dropout_layer(inpt_dropout.reshape((mini_batch_size, self.n_in)), self.p_dropout)
self.output_dropout = self.activation_fn( T.dot(self.inpt_dropout, self.w) + self.b)
1.reshape inpt
首先把input reshape成(batch_size, n_in),为什么要reshape呢?因为我们在CNN里通常在最后一个卷积pooling层后加一个全连接层,而CNN的输出是4维的tensor(batch_size, num_filter, width, height),我们需要把它reshape成(batch_size, num_filter * width * height)。当然我们定义网络的时候就会指定n_in=num_filter width height了。否则就不对了。
2.定义output
然后我们定义self.output。这是一个仿射变换,然后要乘以(1-p_dropout),原因前面解释过了。这是预测的时候用的输入和输出。【有点读者可能会疑惑(包括我自己第一次阅读时),调用这个函数时会同时传入inpt和inpt_dropout吗?我们在Theano里只是”定义“符号变量从而定义这个计算图,所以不是真的计算。我们训练的时候定义用的是cost损失函数,它用的是inpt_dropout和output_dropout,而test的Theano函数是accuracy,用的是inpt和output以及y_out。
3.定义y_out
这个计算最终的输出,也就是当这一层作为最后一层的时候输出的分类结果。ConvPoolLayer是没有实现y_out的计算的,因为我们不会把卷积作为网络的输出层,但是全连接层是有可能作为输出的,所以通过argmax来选择最大的那一个作为输出。SoftmaxLayer是经常作为输出的,所以也实现了y_out。
4.inpt_dropout 先reshape,然后加一个dropout的op,这个op就是随机的把一些神经元的输出设置成0
def dropout_layer(layer, p_dropout):5.定义output_dropout
srng = shared_randomstreams.RandomStreams(np.random.RandomState(0).randint(999999))
mask = srng.binomial(n=1, p=1-p_dropout, size=layer.shape)
return layer*T.cast(mask, theano.config.floatX)
直接计算
ConvPoolLayer和SoftmaxLayer的代码是类似的,这里就不赘述了。下面会有network3.py的完整代码,感兴趣的读者可以自行阅读。
但是也有一些细节值得注意。对于ConvPoolLayer和SoftmaxLayer,我们需要根据对应的公式计算输出。不过非常幸运,Theano提供了内置的op,如卷积,max-pooling,softmax函数等等。
当我们实现softmax层时,我们没有讨论怎么初始化weights和biases。之前我们讨论过sigmoid层怎么初始化参数,但是那些方法不见得就适合softmax层。这里直接初始化成0了。这看起来很随意,不过在实践中发现没有太大问题。
7.2 ConvPoolLayer类
7.2.1 init
def __init__(self, filter_shape, image_shape, poolsize=(2, 2),首先是参数。
activation_fn=sigmoid):
self.filter_shape = filter_shape
self.image_shape = image_shape
self.poolsize = poolsize
self.activation_fn=activation_fn
# initialize weights and biases
n_out = (filter_shape[0]*np.prod(filter_shape[2:])/np.prod(poolsize))
self.w = theano.shared(
np.asarray(
np.random.normal(loc=0, scale=np.sqrt(1.0/n_out), size=filter_shape),
dtype=theano.config.floatX),
borrow=True)
self.b = theano.shared(
np.asarray(
np.random.normal(loc=0, scale=1.0, size=(filter_shape[0],)),
dtype=theano.config.floatX),
borrow=True)
self.params = [self.w, self.b]
1.filter_shape (num_filter, input_feature_map, filter_width, filter_height)
这个参数是filter的参数,第一个是这一层的filter的个数,第二个是输入特征映射的个数,第三个是filter的width,第四个是filter的height
2.image_shape(mini_batch, input_feature_map, width, height)
输入图像的参数,第一个是mini_batch大小,第二个是输入特征映射个数,必须要和filter_shape的第二个参数一样!第三个是输入图像的width,第四个是height
3.poolsize
pooling的width和height,默认2*2
4.activation_fn
激活函数,默认是sigmoid
代码除了保存这些参数之外就是定义共享变量w和b,然后保存到self.params里。
7.2.2 set_inpt
def set_inpt(self, inpt, inpt_dropout, mini_batch_size):我们逐行解读
self.inpt = inpt.reshape(self.image_shape)
conv_out = conv.conv2d(
input=self.inpt, filters=self.w, filter_shape=self.filter_shape,
image_shape=self.image_shape)
pooled_out = downsample.max_pool_2d(
input=conv_out, ds=self.poolsize, ignore_border=True)
self.output = self.activation_fn(
pooled_out + self.b.dimshuffle('x', 0, 'x', 'x'))
self.output_dropout = self.output # no dropout in the convolutional layers
1.reshape输入
2.卷积
使用theano提供的conv2d op计算卷积
3.max-pooling
使用theano提供的max_pool_2d定义pooled_out
4.应用激活函数
值得注意的是dimshuffle函数,pooled_out是(batch_size, num_filter, out_width, out_height),b是num_filter的向量。我们需要通过broadcasting让所有的pooled_out都加上一个bias,所以我们需要用dimshuffle函数把b变成(1,num_filter, 1, 1)的tensor。dimshuffle的参数’x’表示增加一个维度,数字0表示原来这个tensor的第0维。 dimshuffle(‘x’, 0, ‘x’, ‘x’))的意思就是在原来这个vector的前面插入一个维度,后面插入两个维度,所以变成了(1,num_filter, 1, 1)的tensor。
5.output_dropout
卷积层没有dropout,所以output和output_dropout是同一个符号变量
7.3 Network类
7.3.1 init
def __init__(self, layers, mini_batch_size):参数layers就是网络的所有Layers。
self.layers = layers
self.mini_batch_size = mini_batch_size
self.params = [param for layer in self.layers for param in layer.params]
self.x = T.matrix("x")
self.y = T.ivector("y")
init_layer = self.layers[0]
init_layer.set_inpt(self.x, self.x, self.mini_batch_size)
for j in xrange(1, len(self.layers)):
prev_layer, layer = self.layers[j-1], self.layers[j]
layer.set_inpt(
prev_layer.output, prev_layer.output_dropout, self.mini_batch_size)
self.output = self.layers[-1].output
self.output_dropout = self.layers[-1].output_dropout
比如下面的代码定义了一个三层的网络,一个卷积pooling层,一个全连接层和一个softmax输出层,输入大小是mini_batch_size 1 28 28的MNIST图片,卷积层的输出是mini_batch_size 20 24 24,pooling之后是mini_batch_size 20 12 12。然后接一个全连接层,全连接层的输入就是pooling的输出20 12*12,输出是100。最后是一个softmax,输入是100,输出10。
net = Network([首先是保存layers和mini_batch_size
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
self.params=[param for layer in …]这行代码把所有层的参数放到一个list里。Network.SGD方法会使用self.params来更新所以的参数。self.x=T.matrix(“x”)和self.y=T.ivector(“y”)定义Theano符号变量x和y。这代表整个网络的输入和输出。
首先我们调用init_layer的set_inpt
init_layer = self.layers[0]这里调用第一层的set_inpt函数。传入的inpt和inpt_dropout都是self.x,因为不论是训练还是测试,第一层的都是x。
init_layer.set_inpt(self.x, self.x, self.mini_batch_size)
然后从第二层开始:
for j in xrange(1, len(self.layers)):拿到上一层prev_layer和当前层layer,然后把调用layer.set_inpt函数,把上一层的output和output_dropout作为当前层的inpt和inpt_dropout。
prev_layer, layer = self.layers[j-1], self.layers[j]
layer.set_inpt(
prev_layer.output, prev_layer.output_dropout, self.mini_batch_size)
最后定义整个网络的output和output_dropout`
self.output = self.layers[-1].output7.3.2 SGD函数
self.output_dropout = self.layers[-1].output_dropout
def SGD(self, training_data, epochs, mini_batch_size, eta,有了之前theano的基础和实现过LogisticRegression,阅读SGD应该比较轻松了。
validation_data, test_data, lmbda=0.0):
"""Train the network using mini-batch stochastic gradient descent."""
training_x, training_y = training_data
validation_x, validation_y = validation_data
test_x, test_y = test_data
# compute number of minibatches for training, validation and testing
num_training_batches = size(training_data)/mini_batch_size
num_validation_batches = size(validation_data)/mini_batch_size
num_test_batches = size(test_data)/mini_batch_size
# define the (regularized) cost function, symbolic gradients, and updates
l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers])
cost = self.layers[-1].cost(self)+\
0.5*lmbda*l2_norm_squared/num_training_batches
grads = T.grad(cost, self.params)
updates = [(param, param-eta*grad)
for param, grad in zip(self.params, grads)]
# define functions to train a mini-batch, and to compute the
# accuracy in validation and test mini-batches.
i = T.lscalar() # mini-batch index
train_mb = theano.function(
, cost, updates=updates,
givens={
self.x:
training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
validate_mb_accuracy = theano.function(
, self.layers[-1].accuracy(self.y),
givens={
self.x:
validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
test_mb_accuracy = theano.function(
, self.layers[-1].accuracy(self.y),
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
self.test_mb_predictions = theano.function(
, self.layers[-1].y_out,
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
# Do the actual training
best_validation_accuracy = 0.0
for epoch in xrange(epochs):
for minibatch_index in xrange(num_training_batches):
iteration = num_training_batches*epoch+minibatch_index
if iteration % 1000 == 0:
print("Training mini-batch number {0}".format(iteration))
cost_ij = train_mb(minibatch_index)
if (iteration+1) % num_training_batches == 0:
validation_accuracy = np.mean(
[validate_mb_accuracy(j) for j in xrange(num_validation_batches)])
print("Epoch {0}: validation accuracy {1:.2%}".format(
epoch, validation_accuracy))
if validation_accuracy >= best_validation_accuracy:
print("This is the best validation accuracy to date.")
best_validation_accuracy = validation_accuracy
best_iteration = iteration
if test_data:
test_accuracy = np.mean(
[test_mb_accuracy(j) for j in xrange(num_test_batches)])
print('The corresponding test accuracy is {0:.2%}'.format(
test_accuracy))
print("Finished training network.")
print("Best validation accuracy of {0:.2%} obtained at iteration {1}".format(
best_validation_accuracy, best_iteration))
print("Corresponding test accuracy of {0:.2%}".format(test_accuracy))
虽然看起来代码比较多,但是其实逻辑很清楚和简单,我们下面简单的解读一下。
1. 定义损失函数cost
l2_norm_squared = sum([(layer.w**2).sum() for layer in self.layers])出来最后一层的cost,我们还需要加上L2的normalization,其实就是把所有的w平方和然后开方。注意 self.layers[-1].cost(self),传入的参数是Network对象【函数cost的第一个参数self是对象指针,不要调用者传入的,这里把Network对象自己(self)作为参数传给了cost函数的net参数】。
cost = self.layers[-1].cost(self)+\
0.5*lmbda*l2_norm_squared/num_training_batches
下面是SoftmaxLayer的cost函数:
def cost(self, net):其实net只用到了net.y,我们也可以把cost定义如下:
"Return the log-likelihood cost."
return -T.mean(T.log(self.output_dropout)[T.arange(net.y.shape[0]), net.y])
def cost(self, y):然后调用的时候用
"Return the log-likelihood cost."
return -T.mean(T.log(self.output_dropout)[T.arange(y.shape[0]), y])
cost = self.layers[-1].cost(self.y)+\我个人觉得这样更清楚。
0.5*lmbda*l2_norm_squared/num_training_batches
2. 定义梯度和updates
grads = T.grad(cost, self.params)3. 定义训练函数
updates = [(param, param-eta*grad)
for param, grad in zip(self.params, grads)]
i = T.lscalar() # mini-batch indextrain_mb函数的输入是i,输出是cost,batch的x和y通过givens制定,这和之前的Theano tutorial里的LogisticRegression一样的。cost函数用到的是最后一层的output_dropout,从而每一层都是走计算图的inpt_dropout->output_dropout路径。
train_mb = theano.function(
, cost, updates=updates,
givens={
self.x:
training_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
training_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
4. 定义validation和测试函数
validate_mb_accuracy = theano.function(输出是最后一层的accuracy self.layers[-1].accuracy(self.y)。accuracy使用的是最后一层的output,从而每一层都是用计算图的inpt->output路径。
, self.layers[-1].accuracy(self.y),
givens={
self.x:
validation_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
validation_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
test_mb_accuracy = theano.function(
, self.layers[-1].accuracy(self.y),
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size],
self.y:
test_y[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
5. 预测函数
self.test_mb_predictions = theano.function(输出是最后一层的y_out,也就是softmax的argmax(output)
, self.layers[-1].y_out,
givens={
self.x:
test_x[i*self.mini_batch_size: (i+1)*self.mini_batch_size]
})
7.4 用法
training_data, validation_data, test_data = network3.load_data_shared()至此,我们介绍了Theano的基础知识以及怎么用Theano实现CNN。下一讲将会介绍怎么自己用Python(numpy)实现CNN并且介绍实现的一些细节和性能优化,大部分内容来自CS231N的slides和作业assignment2,敬请关注。 收起阅读 »
mini_batch_size = 10
net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
【公开课第10期视频回放+两个音视频项目源码!】环信公开课第十期--环信3.0实时音视频解析
昨晚环信公开课第十期如约而至,有些小伙伴因为加班等原因(心疼一秒~)没能来到现场,这里公开课小助手环环整理了刘立正老师课件和视频回放,希望小伙伴继续支持我们,关于环信公开课有任何建议欢迎在文章跟帖指出!
先来回顾下公开课内容:
☞ 如何快速实现移动端实时音视频
☞ APP视频聊天横竖屏切换实现
☞ 视频聊天录制保存实现
☞ P2P模式和转发模式的处理
☞ 问答
环信工程师刘立正通过课件和两个开源项目为大家激情讲述了实时音视频的知识点。
课件截图

项目源码一:VMChatDemoCall(实现完整的音视频通话功能)
git源码地址:https://github.com/lzan13/VMChatDemoCall

VMChatDemoCall
使用环信新版 SDK3.3.0以后版本实现完整的音视频通话功能,本次实现将所有的逻辑操作都放在了 VMCallManager 类中,方便对音视频界面最小化的管理; 此项目实现了音视频过界面的最小化,以及视频通话界面本地和远程画面的大小切换等功能
项目源码二:VMTVCall(TV 上视频通话应用,可以安装电视上)
git源码地址:https://github.com/lzan13/VMTVCall

VMTVCall公开课完整视频回放:
使用环信 SDK 开发一款在 TV 上视频通话应用,可以安装在自己的电视上,让爸妈在家和自己进行高清通话
点击附件下载讲师PPT↓↓↓
文末彩蛋!(立正老师在直播现场)

收起阅读 »
环信Android自动播放下一条语音
[1]:重写onMessageBubbleClick()
if(type == EMMessage.Type.VOICE.ordinal()&& message.direct() == EMMessage.Direct.RECEIVE){ // 是语音 并且是接受到的
List<EMMessage> emMessages= conversation.getAllMessages();
Log.d("AA", "开始遍历");
position = conversation.getMessagePosition(message); // position 的获取
EaseChatRowVoice easeChatRowVoice = new EaseChatRowVoice(getActivity(), message, position, eAdapter, conversation); // 在EaseChatRowVoice添加参数conversation
easeChatRowVoice.onBubbleClick();
return true; //返回true 自行处理事件
}
参数由来//* EaseChatRowVoice参数介绍: position: conversation.getMessagePosition(message); eAdapter: 通过参数传递过来*/
// ** eAdapter的获取: 在EaseChatMessageList中创建方法 (1). public EaseMessageAdapter getAdapter() { return messageAdapter; }
(1). public EaseMessageAdapter getAdapter() {
return messageAdapter;
}(2). 可以在EaseChatFragment中找到 messageList = (EaseChatMessageList) getView().findViewById(R.id.message_list);控件对象
(3). 在setListItemClickListener------> onBubbleClick()方法中添加
public boolean onBubbleClick(EMMessage message) { // 条目点击事件
if (chatFragmentListener != null) {
eAdapter = messageList.getAdapter();
return chatFragmentListener.onMessageBubbleClick(message, eAdapter); // EaseChatFragmentListener chatFragmentListener
}
return false;
}
(4). 在ChatFragment中的onMessageBubbleClick()即可得到eAdapter!!!!!!!
**********************************不要忘记修改接口EaseChatFragmentListener 中onMessageBubbleClick中的参数*********************
// ** conversation参数或获取: conversation = EMClient.getInstance().chatManager().getConversation(toChatUsername,EaseCommonUtils.getConversationType(chatType), true);[2]: 在EaseChatRowVoice中onBubbleClick()方法
// getConversation参数介绍: toChatUsername: 正要去交谈的对象的环信ID.
chatType: // 判断单聊还是群聊
chatType = fragmentArgs.getInt(EaseConstant.EXTRA_CHAT_TYPE, EaseConstant.CHATTYPE_SINGLE); 注解:/*(EaseConstant.EXTRA_CHAT_TYPE = "chatType")*/
注解: fragmentArgs = getArguments();
注解: 传递增加的参数,改为:
new EaseChatRowVoicePlayClickListener(message, voiceImageView, readStutausView, adapter, activity, position,conversation).onClick(bubbleLayout);[3]: EaseChatRowVoicePlayClickListener构造中获取传递的参数:
conversation adapter 等!! --- > 在EaseChatRowVoicePlayClickListener中的playVoice()中的setOnCompletionListenerbug处理
的onCompletion中添加如下:
public void onCompletion(MediaPlayer mp) {
mediaPlayer.release();
mediaPlayer = null;
stopPlayVoice(); // stop animation
List<EMMessage> emMessages = conversation.getAllMessages(); // 开启下一条语音消息
EMMessage emMessage_last = conversation.getLastMessage();
if(message.equals(emMessage_last)){ // 判断如果是最后一条语音则不做处理
Log.d("AA", "最后一个信息");
}else{
EMMessage emMessage1 = emMessages.get(position + 1);
int type = emMessage1.getType().ordinal();
if(emMessage1 != null){
if(type == EMMessage.Type.VOICE.ordinal()&& message.direct() == EMMessage.Direct.RECEIVE){ // 判断是否是接收到语音
EaseChatRowVoice easeChatRowVoice = new EaseChatRowVoice(activity, emMessage1, position + 1, adapter, conversation);
easeChatRowVoice.onBubbleClick();
}
}
}
}
在操作完所有的步骤之后,会出现语音可以播放但是动画效果却没有执行,原因是:adapter没有刷新,解决办法如下: 在
EaseChatRowVoicePlayClickListener下的showAnimation()中的
voiceIconView.setImageResource(R.anim.voice_from_icon);
(showAnimation()第二行后面)这句话的后面添加此句:
adapter.notifyDataSetChanged();
******* SDK为3.1.0 获取position请用上面的方法, SDK为3.3.1或者其他版本请用 mConversation.getAllMessages().indexOf(message)代替本帖子不收任何费用,代码纯属原创 转载请说明出处 如有运行问题可与我联系 本人姓氏: 侯 邮箱:277667430@qq.com 收起阅读 »
教您5分钟集成环信移动客服SDK
给您的客服账户集成相关渠道后才能使用客服功能呦,试用期短暂,机不可失,快来看看我们的集成攻略!
您可以―― 5 分钟集成环信SDK,轻松处理来自您APP的用户咨询
请先打开客服后台按照以下步骤添加app渠道关联

添加关联后即可开始进行集成
Android SDK:请参考移动客服 Android SDK 集成;
iOS SDK:请参考移动客服 iOS SDK 集成。
也可以直接查看APP集成指南
您还可以――模拟客服场景体验
扫码下方二维码,下载并安装【环信移动客服】app

按照图一添加APP渠道关联
打开【环信移动客服】APP,点击右下角的【设置】按钮后点击右上角【扫一扫】扫描关联app页面下方二维码,将该客服体验DEMO与您的客服账号关联起来,即可体验与客服聊天或与客户聊天
您也可以――为您的其他渠道接入移动客服
微博快速集成指南
微信快速集成指南
网页快速集成指南
在您使用中遇到任何问题,可从以下 4 个途径得到解答!
开发文档 - 常见问题的解决方案在这里都能找到!
开发文档收录了所有常见问题,并按照“新手上路、客服模式、管理员模式、多渠道集成、第三方系统对接”对内容进行分类,同时,提供模糊搜索。
在线技术咨询 - 超快的问题响应机制,专业技术团队在线解答!
点击【客服后台】-【管理员模式】-【技术支持】-【联系客服】,输入您的问题即可。
环信社区- 使用者交流专区,召唤老司机搞定技术难题!
山不在高,有仙则灵,社区不在大,有大神就行!
电话咨询 - 最直接的方式,专职客服一对一解答!
咨询热线:400-612-1986
感谢读到这里的您,下方附上最新鲜的集成说明文档,据说看完走桃花呦
收起阅读 »
李理:Theano tutorial和卷积神经网络的Theano实现 Part1
作者:李理
目前就职于环信,即时通讯云平台和全媒体智能客服平台,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。
相关文章:
李理:从Image Caption Generation理解深度学习(part I)
李理:从Image Caption Generation理解深度学习(part II)
李理:从Image Caption Generation理解深度学习(part III)
李理:自动梯度求解 反向传播算法的另外一种视角
李理:自动梯度求解——cs231n的notes
李理:自动梯度求解——使用自动求导实现多层神经网络
李理:详解卷积神经网络
1. Theano的发音
第一次碰到时很自然的发音是 /θi.ˈæ.noʊ/,不过如果看一些视频可能也有发/te.ˈaː.no/的。这两种都有,比较官方的说法可能是这个:
I think I say roughly /θi.ˈæ.noʊ/ (using the international phonetic alphabet), or /te.ˈaː.no/ when speaking Dutch, which is my native language. I guess the latter is actually closer to the original Greek pronunciation :)另外从这里也有说明:
Theano was written at the LISA lab to support rapid development of efficient machine learning algorithms. Theano is named after the Greek mathematician, who may have been Pythagoras’ wife.维基百科对此作出的解释是:
Theano (/θɪˈænoʊ/; Greek: Θεανώ; fl. 6th-century BC), or Theano of Crotone,[1] is the name given to perhaps two Pythagorean philosophers.因此用英语的发音是 /θɪˈænoʊ/。2. Theano简介
Theano是一个Python库,它可以让你定义,优化以及对数学表达式求值,尤其是多维数组(numpy的ndarray)的表达式的求值。对于解决大量数据的问题,使用Theano可能获得与手工用C实现差不多的性能。另外通过利用GPU,它能获得比CPU上的C实现快很多数量级。
Theano把计算机代数系统(CAS)和优化的编译器结合在一起。 它也可以对许多数学操作生成自定义的c代码。这种CAS和优化编译的组合对于有复杂数学表达式重复的被求值并且求值速度很关键的问题是非常有用的。对于许多不同的表达式只求值一次的场景,Theano也能最小化编译/分析的次数,但是仍然可以提供诸如自动差分这样的符号计算的特性。
Theano的编译器支持这些符号表达式的不同复杂程度的许多优化方法:
- 用GPU来计算
- 常量折叠(constant folding)【编译时的常量表达式计算,参考这里】
- 合并相似的子图,避免重复计算
- 算术简化,比如把x*y/y简化成y,–x【两次求负】简化成x
- 在不同的上下文中插入高效的BLAS函数(比如GEMM)
- 使用Memory Aliasing【详细参考这里】来避免重复计算
- 对于不涉及aliasing的操作尽量使用就地的运算【类似与x*=2 vs y=x*2】
- Elementwise的子表达式的循环的合并(loop fusion)【这是一项编译器优化技巧,简单的说就是把相同下标的循环合并起来,例子可以参考这里】
log(1+exp(x))andlog(∑iexp(x[i]))[/i]
- 【关于这个我们罗嗦一点,读者如果读过的文章,肯定还记得计算softmax时先把向量减去最大的元素,避免exp运算的溢出】
- 更多内容请参考优化部分
>>> import numpy>>> import theano.tensor as T>>> from theano import function>>> x = T.dscalar('x')>>> y = T.dscalar('y')>>> z = x + y>>> f = function([x, y], z)>>> f(2, 3)array(5.0)我们这段代码首先定义了符号变量x和y,它们的类型是double。使用theano.tensor.dscalar(‘x’)定义了一个名字叫x的类型为double的标量(scalar)。注意符号变量的名字是theano看到的,而我们把theano创建的dscalar赋给x是在python里的。在使用theano是我们需要区分普通的python变量和theano的符号变量。theano用符号变量创建出一个computing graph,然后在这个graph上执行各种运算。定义了x和y之后,我们通过操作(op)+定义了符号变量z。接下来我们定义了一个函数(function) f,这个函数的输入是符号变量x和y,输出是符号变量z接下来我们可以”执行“这个函数 f(2,3)运行 f = function([x, y], z)会花费比较长的时间,theano会将函数构建成计算图,并且做一些优化。>>> type(x)<class 'theano.tensor.var.TensorVariable'>>>> x.typeTensorType(float64, scalar)>>> T.dscalarTensorType(float64, scalar)>>> x.type is T.dscalarTruedscalar(‘x’) 返回的对象的类型是theano.tensor.var.TensorVariable,也就是一种符号变量。这种对象有一个type属性,x.type是TensorType。对于dscalar,它的TensorType是64位的浮点数的一个标量。除了变量,我们也可以定义向量(vector)和矩阵matrix。 然后用在前面增加’b’,’w’,’i’,’l’,’f’,’d’,’c’分别表示8位,16位,32位,64位的整数,float,double以及负数。比如imatrix就是32位整数类型的矩阵,dvector就是单精度浮点数的向量。4.2 More Examples 参考这里。这部分会介绍更多的theano的概念,最后包含一个Logistic Regression的例子,包括怎么用theano自动求梯度。4.2.1 Logistic Function函数定义为:
s(x)=11+e−x函数图像为:
 这个函数的特点是它的值域是(0,1),当x趋近 −∞ 时值趋近于0,当x趋近 ∞ 时值趋近于1。我们经常需要对一个向量或者矩阵的每一个元素都应用一个函数,我们把这种操作叫做elementwise的操作(numpy里就叫universal function, ufunc)比如下面的代码对一个矩阵计算logistic函数:
这个函数的特点是它的值域是(0,1),当x趋近 −∞ 时值趋近于0,当x趋近 ∞ 时值趋近于1。我们经常需要对一个向量或者矩阵的每一个元素都应用一个函数,我们把这种操作叫做elementwise的操作(numpy里就叫universal function, ufunc)比如下面的代码对一个矩阵计算logistic函数:>>> import theano>>> import theano.tensor as T>>> x = T.dmatrix('x')>>> s = 1 / (1 + T.exp(-x))>>> logistic = theano.function([x], s)>>> logistic([[0, 1], [-1, -2]])array([[ 0.5 , 0.73105858], [ 0.26894142, 0.11920292]])logistic是elementwise的原因是:定义这个符号变量的所有操作——除法,加法,指数取反都是elementwise的操作。另外logistic函数和tanh函数有如下关系:s(x)=11+e−x=1+tanh(x/2)2我们可以使用下面的代码来验证这个式子:
>>> s2 = (1 + T.tanh(x / 2)) / 2>>> logistic2 = theano.function([x], s2)>>> logistic2([[0, 1], [-1, -2]])array([[ 0.5 , 0.73105858], [ 0.26894142, 0.11920292]])4.2.2 使用共享变量(shared variable)一个函数可以有内部的状态。比如我们可以实现一个累加器,在开始的时候,它的值被初始化成零。然后每一次调用,这个状态会加上函数的参数。首先我们定义这个累加器函数,它把参数加到这个内部状态变量,同时返回这个状态变量老的值【调用前的值】
>>> from theano import shared>>> state = shared(0)>>> inc = T.iscalar('inc')>>> accumulator = function([inc], state, updates=[(state, state+inc)])这里有不少新的概念。shared函数会返回共享变量。这种变量的值在多个函数直接可以共享。可以用符号变量的地方都可以用共享变量。但不同的是,共享变量有一个内部状态的值,这个值可以被多个函数共享。我们可以使用get_value和set_value方法来读取或者修改共享变量的值。另外一个新的概念是函数的updates参数。updates参数是一个list,其中每个元素是一个tuple,这个tuple的第一个元素是一个共享变量,第二个元素是一个新的表达式。updates也可以是一个dict,key是共享变量,值是一个新的表达式。不管用哪种方法,它的意思是:当函数运行完成后,把新的表达式的值赋给这个共享变量。上面的accumulator函数的updates是把state+inc赋给state,也就是每次调用accumulator函数后state增加inc。让我们来试一试!>>> print(state.get_value())0>>> accumulator(1)array(0)>>> print(state.get_value())1>>> accumulator(300)array(1)>>> print(state.get_value())301开始时state的值是0。然后调用一次accumulator(1),这个函数返回state原来的值,也就是0。然后把state更新为1。然后再调用accumulator(300),这一次返回1,同时把state更新为301。我们有可以重新设置state的值。只需要调用set_value方法就行:
>>> state.set_value(-1)>>> accumulator(3)array(-1)>>> print(state.get_value())2我们首先把state设置成-1,然后调用accumulator(3),返回-1,同时吧state更新成了2。我们前面提到过,多个函数可以“共享”一个共享变量,因此我们可以定义如下的函数:
>>> decrementor = function([inc], state, updates=[(state, state-inc)])>>> decrementor(2)array(2)>>> print(state.get_value())0我们定义了decrementor函数,它每次返回之前的state的值,同时把state减去输入参数inc后赋给state。调用decrementor(2),返回state的之前的值2,同时把state更新成0。你可能会奇怪为什么需要updates机制。你也可以让这个函数返回这个新的表达式【当然原来的返回值仍然返回,多返回一个就行】,然后用在numpy更新state。首先updates机制是一种语法糖,写起来更简便。但更重要的是为了效率。共享变量的共享又是可以使用就地(in-place)的算法【符号变量包括共享变量的内存是由Theano来管理的,把它从Theano复制到numpy,然后修改,然后在复制到Theano很多时候是没有必要的,更多Theano的内存管理请参考这里】。另外,共享变量的内存是由Theano来分配和管理,因此Theano可以根据需要来把它放到GPU的显存里,这样用GPU计算时可以避免CPU到GPU的数据拷贝,从而获得更好的性能。有些时候,你可以通过共享变量来定义了一个公式(函数),但是你不想用它的值。这种情况下,你可以用givens这个参数。
>>> fn_of_state = state * 2 + inc>>> # The type of foo must match the shared variable we are replacing>>> # with the ``givens``>>> foo = T.scalar(dtype=state.dtype)>>> skip_shared = function([inc, foo], fn_of_state, givens=[(state, foo)])>>> skip_shared(1, 3) # we're using 3 for the state, not state.valuearray(7)>>> print(state.get_value()) # old state still there, but we didn't use it0首先我们定义了一个符号变量fn_of_state,它用到了共享变量state。然后我们定义skip_shared,他的输入参数是inc和foo,输出是fn_of_state。注意:fn_of_state依赖state和inc两个符号变量,如果参数inc直接给定了。另外一个参数foo取代(而不是赋值给)了inc,因此实际 fn_of_state = foo * 2 + inc。我们调用skip_shared(1,3)会得到7,而state依然是0(而不是3)。如果把这个计算图画出来的话,实际是用foo替代了state。givens参数可以取代任何符号变量,而不只是共享变量【从计算图的角度就非常容易理解了,后面我们会讲到Theano的计算图】。你也可以用这个参数来替代常量和表达式。不过需要小心的是替代的时候不要引入循环的依赖。【比如a=b+c,你显然不能把c又givens成a,这样循环展开就不是有向无环图了】有了上面的基础,我们可以用Theano来实现Logistic Regression算法了。不过这里没有介绍grad,我们先简单的介绍一下,内容来自这里。使用Theano的好处就是auto diff,在前面也介绍过来,几乎所有的深度学习框架/工具都是提供类似的auto diff的功能,只不过定义graph的“语言/语法”和“粒度”不一样。另外除了求梯度,大部分工具还把训练算法都封装好了。而Theano就比较“原始”,它除了自动求梯度,并不会帮你实现sgd或者Adam算法,也不会帮你做dropout,不会帮你做weight decay和normalization,所有这些都得你自己完成。这可能会让那些希望把深度学习当成一个“黑盒”的用户有些失望,对于这样的用户最好用Keras,caffe这样的工具。但是对于想理解更多细节和自己“创造”一种新的网络结构的用户,Theano是个非常好的工具,它提供常见的op,也可以自定义op(python或者c),对于rnn也有非常好的支持。我们下面用Theano来实现对函数
f(x)=x2的导数。
>>> import numpy>>> import theano>>> import theano.tensor as T>>> from theano import pp>>> x = T.dscalar('x')>>> y = x ** 2>>> gy = T.grad(y, x)>>> pp(gy) # print out the gradient prior to optimization'((fill((x ** TensorConstant{2}), TensorConstant{1.0}) * TensorConstant{2}) * (x ** (TensorConstant{2} - TensorConstant{1})))'>>> f = theano.function([x], gy)>>> f(4)array(8.0)>>> numpy.allclose(f(94.2), 188.4)True首先我们定义符号变量x,然后用x定义y,然后使用grad函数求y对x的(偏)导数gy【grad函数返回的仍然只是一个符号变量,可以认为用y和x定义了一个新的符号变量gy】,然后定义函数f,它的输入是x,输出是gy。注意:y是x的函数,gy是x和y的函数,所以最终gy只是x的函数,所以f的输入只有x。 f编译好了之后,给定x,我们就可以求∂y∂x在这个点上的值了。4.2.3 一个实际的例子:Logistic RegressionLogistic Regression(LR)简介LR模型用来进行二分类,它对输入进行仿射变换,然后用logistic函数把它压缩到0和1之间,训练模型就是调整参数,对于类别0,让模型输出接近0的数,对于类别1,让模型输出接近1的数。预测的时候如果大于0.5就输出1,反之输出0。因此我们可以把模型的输出当成概率:
P(y=1|x)=hw(x)=11+exp(−wTx)
P(y=0|x)=1−P(y=1|x)=1−hw(x)对于两个概念分布,cross-entroy是最常见的一种度量方式。【详细介绍参考这里】
loss=−ylogP(y=1|x)−(1−y)logP(y=0|x)=−yloghw(x)−(1−y)log(1−hw(x))如果真实值y=1,那么第二项就是0,
loss=−loghw(x),如果
hw(x)趋近1,那么loss就趋近0;反之如果
hw(x)趋近0,那么loss就趋近无穷大。如果真实值y=0,那么第一项就是0,
loss=−log(1−hw(x)),如果
hw(x)趋近0,
1−hw(x)趋近1,loss趋近0;反之loss趋近无穷大。因此从上面的分析我们发现,这个loss函数是符合直觉的,模型输出
hw(x)越接近真实值,loss越小。有了loss,我们就可以用梯度下降求(局部)最优参数了。【这个loss函数是一个凸函数,所以局部最优就是全局最优,有兴趣的读者可以参考这里,不过对于工程师来说没有必要了解这些细节。我们常见的神经网络是非常复杂的非线性函数,因此loss通常也是非凸的,因此(随机)梯度下降只能得到局部最优解,但是深度神经网络通常能找到比较好的局部最优解,有也一些学者在做研究,有兴趣的读者请参考这里以及这里】接下来是求梯度?有了Theano,我们只需要写出loss就可以啦,剩下的梯度交给Theano就行了。代码分析接下来我们来分析用Theano实现LR算法的代码。每行代码前面都会加上相应的注释,请读者阅读仔细阅读每行代码和注释。
import numpyimport theanoimport theano.tensor as Trng = numpy.randomN = 400 # 训练数据的数量 400feats = 784 # 特征数 784# 生成训练数据: D = ((N, feates), N个随机数值) ,随机数是0或者1D = (rng.randn(N, feats), rng.randint(size=N, low=0, high=2))training_steps = 10000# 定义两个符号变量,x和y,其中x是一个double的matrix,y是一个double的vectorx = T.dmatrix("x")y = T.dvector("y")# 随机初始化参数w,它的大小是feats## 我们把w定义为共享变量,这样可以在多次迭代中共享。w = theano.shared(rng.randn(feats), name="w")# b也是共享变量,我们不需要随机初始化,一般bias出初始化为0就行了。b = theano.shared(0., name="b")print("Initial model:")print(w.get_value())print(b.get_value())# 构造Theano表达式图p_1 = 1 / (1 + T.exp(-T.dot(x, w) - b)) # 模型输出1的概率,一次输出的是N个样本prediction = p_1 > 0.5 # 基于p_1预测分类xent = -y * T.log(p_1) - (1-y) * T.log(1-p_1) # Cross-entropy loss functioncost = xent.mean() + 0.01 * (w ** 2).sum()# loss函数,前面xent是一个向量,所以求mean,然后使用L2 正则化,w越大就惩罚越大gw, gb = T.grad(cost, [w, b]) # 计算cost对w和b的梯度# train是一个函数,它的输入是x和y,输出是分类预测prediction和xent,注意updates参数,每次调用train函数之后都会更新w<-w-0.1*gw, b<-b-0.1*gbtrain = theano.function( inputs=[x,y], outputs=[prediction, xent], updates=((w, w - 0.1 * gw), (b, b - 0.1 * gb)))# pridict是一个函数,输入x,输出predictionpredict = theano.function(inputs=[x], outputs=prediction)# 训练,就是用训练数据x=D[0], y=D[1]进行训练。# 也就算调用train函数,train函数会使用当前的w和b“前向”计算出prediction和xent,同时也计算出cost对w和b的梯度。然后再根据updates参数更新w和bfor i in range(training_steps): pred, err = train(D[0], D[1])print("Final model:")print(w.get_value())print(b.get_value())print("target values for D:")print(D[1])print("prediction on D:")print(predict(D[0]))注意:我们为了提高效率,一次计算N个训练数据,p_1 = 1 / (1 + T.exp(-T.dot(x, w) - b)),这里x是N feats,w是feats 1,-T.dot(x,w)是N 1,而-b是一个1 1的数,所以会broadcasting,N个数都加上-b。然后exp,然后得到p_1,因此p_1是N*1的向量,代表了N个训练数据的输出1的概率。我们可以看到,在Theano里,我们实现一个模型非常简单,我们之需要如下步骤:[list=1]当然这是全量的梯度下降,如果是batch的随机梯度下降,只需要每次循环传入一个batch的输入和输出就行。
5. 计算图
5.1 图的结构
内容来自这里。
如果不了解原理而想在Theano里调试和profiling代码不是件简单的事情。这部分介绍给你关于Theano你必须要了解的一些实现细节。
写Theano代码的第一步是使用符号变量写出所有的数学变量。然后用+,-,*,sum(), tanh()等操作写出各种表达式。所有这些在theano内部都表示成op。一个op表示一种特定的运算,它有一些输入,然后计算出一些输出。你可以把op类比成编程语言中的函数。
Theano用图来表示符号数学运算。这些图的点包括:Apply(实在想不出怎么翻译),变量和op,同时图也包括这些点的连接(有向的边)。Apply代表了op对某些变量的计算【op类比成函数的定义,apply类比成函数的实际调用,变量就是函数的参数】。区分通过op定义的计算和把这个计算apply到某个实际的值是非常重要的。【我们在编程时里定义 x和y,然后定义z=x+y,我们就得到了z的值,但是我们在Theano里定义符号变量x和y,然后定义z=x+y,因为x和y只是一个符号,所以z也只是一个符号,我们需要再定义一个函数,它的输入是x和y输出z。然后”调用“这个函数,传入x和y的实际值,才能得到z的值】。符号变量的类型是通过Type这个类来表示的。下面是一段Theano的代码以及对应的图。
代码:
import theano.tensor as T图:
x = T.dmatrix('x')
y = T.dmatrix('y')
z = x + y

图中的箭头代表了Python对象的引用。蓝色的框是Apply节点,红色的是变量,绿色的是Op,紫色的是Type。
当我们常见符号变量并且用Apply Op来产生更多变量的时候,我们创建了一个二分的有向无环图。如果变量的owner有指向Apply的边,那么说明这个变量是由Apply对应的Op产生的。此外Apply节点的input field和output field分别指向这个Op的输入和输出变量。
x和y的owner是None,因为它不是由其它Op产生的,而是直接定义的。z的owner是非None的,这个Apply节点的输入是x和y,输出是z,Op是+,Apply的output指向了z,z.owner指向Apply,因此它们 是互相引用的。
5.2 自动求导
有了这个图的结构,自动计算导数就很容易了。tensor.grad()唯一需要做的就是从outputs逆向遍历到输入节点【如果您阅读过之前的自动求导部分,就会明白每个Op就是当时我们说的一个Gate,它是可以根据forward阶段的输入值计算出对应的local gradient,然后把所有的路径加起来就得到梯度了】。对于每个Op,它都定义了怎么根据输入计算出偏导数。使用链式法则就可以计算出梯度了。
5.3 优化
当编译一个Theano函数的时候,你给theano.function的其实是一个图(从输出变量遍历到输入遍历)。你通过这个图结构来告诉theano怎么从input算出output,同时这也让theano有机会来优化这个计算图【你可以把theano想像成一个编译器,你通过它定义的符号计算语法来定义函数,然后调用函数。而theano会想方设法优化你的函数(当然前提是保证结果是正确的)】。Theano的优化包括发现图里的一些模式(pattern)然后把他替换新的模式,这些新的模式计算的结果和原来是一样的,但是心模式可能更快更稳定。它也会检测图里的重复子图避免重复计算,还有就是把某些子图的计算生成等价的GPU版本放到GPU里执行。
比如,一个简单的优化可能是把
xyy优化成x。
例子
>>> import theano我们定义
>>> a = theano.tensor.vector("a") # declare symbolic variable
>>> b = a + a ** 10 # build symbolic expression
>>> f = theano.function([a], b) # compile function
>>> print(f([0, 1, 2])) # prints `array([0,2,1026])`
[ 0. 2. 1026.]
>>> theano.printing.pydotprint(b, outfile="./pics/symbolic_graph_unopt.png", var_with_name_simple=True)
The output file is available at ./pics/symbolic_graph_unopt.png
>>> theano.printing.pydotprint(f, outfile="./pics/symbolic_graph_opt.png", var_with_name_simple=True)
The output file is available at ./pics/symbolic_graph_opt.png
b=a+a10,f是函数,输入a,输出b。下面是没有优化的图:

没有优化的图有两个Op,power和add【还有一个DimShuffle,这个是Theano自己增加的一个Op,对于常量10,theano会创建一个TensorConstant。它是0维的tensor,也就是一个scalar。但是a我们定义的是一个vector,power是一个elementwise的操作,底数是一个vector,那么指数也要是同样大小的vector。dimshuffle(‘x’)就是给0维tensor增加一个维度变成1维的tensor(也就是vector),这样维数就对上了,但是x的shape可能是(100,)的,而常量是(1,),大小不一样怎么办呢?这就是broadcasting作的事情了,它会把dimshuffle(‘x’, 10)扩展成(100,)的向量,每一个值都是10【实际numpy不会那么笨的复制100个10,不过我们可以这么理解就好了】。之前我们也学过numpy的broadcasting,theano和numpy的broadcasting使用一些区别的,有兴趣的读者可以参考这里。这里就不过多介绍了,如果后面有用到我们再说。
下面是优化过的图:

优化后变成了一个ElementWise的操作,其实就是把
b=a+a10优化成了
b=a+((a2)2)2+a2关于Theano的简单介绍就先到这里,后面讲到RNN/LSTM会更多的介绍theano的scan函数以及怎么用Theano实现RNN/LSTM。下面我们讲两个实际的例子:用Theano来实现LR和MLP。
6. Classifying MNIST digits using Logistic Regression
参考链接
注意这里说的LR和前面的LR是不同的,很多文献说的Logistic Regression是两类的分类器,这里的LR推广到了多类,有些领域把它叫做最大熵(Max Entropy)模型,有的叫多类LR(multi-class logistic regression)。这里的LR是多类(10)的分类器,前面我们说的是标准的LR,是一个两类的分类器。
6.1 模型定义
Logistic Regression可以认为是一个1层的神经网络,首先是一个仿射变换(没有激活函数),然后接一个softmax。
logistic regression的公式如下:

输出Y是有限的分类。比如对于MNIST数据,Y的取值是0,1,…,9。我们训练的时候如果图片是数字3,那么Y就是one-hot的表示的十维的向量[0,0,0,1,0,0,0,0,0,0]
预测的时候给定一个x,我们会计算出一个十维的向量,比如[0.1, 0.8 , 0.0125, 0.0125,…0.0125]。那么我们会认为这是数字1,因为模型认为输出1的概率是0.8。

模型定义的代码如下所示:
# initialize with 0 the weights W as a matrix of shape (n_in, n_out)(1) shared函数的value参数
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
# initialize the biases b as a vector of n_out 0s
self.b = theano.shared(
value=numpy.zeros(
(n_out,),
dtype=theano.config.floatX
),
name='b',
borrow=True
)
# symbolic expression for computing the matrix of class-membership
# probabilities
# Where:
# W is a matrix where column-k represent the separation hyperplane for
# class-k
# x is a matrix where row-j represents input training sample-j
# b is a vector where element-k represent the free parameter of
# hyperplane-k
self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b)
# symbolic description of how to compute prediction as class whose
# probability is maximal
self.y_pred = T.argmax(self.p_y_given_x, axis=1)
theano里最重要的就是shared变量,我们一般把模型的参数定义为shared变量,我们可以用numpy的ndarray来定义它的shape并且给这些变量赋初始化的值。
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
上面我们定义了shared变量self.W,用numpy.zeros((n_in, n_out), dtype=theano.config.floatX)来定义了它是二维的数组(也就是矩阵),并且shape是(n_in, n_out),数据类型是theano.config.floatX,这是theano的一个配置项,我们可以在环境变量THEANO_FLAGS或者在$HOME/.theanorc文件里配置。所有的配置选项请参考这里。
config.floatX用来配置使用多少位的浮点数。我们定义shared变量时引用theano.config.floatX,这样就不用在代码里写死到底是用32位还是64位的浮点数,而是可以在环境变量或者配置文件里制定了。
比如我们在允许python是加上 THEANO_FLAGS=’floatX=float32’ python xxx.py,那么W就是32位的浮点数。
(2) shared函数的name参数
shared变量另外一个参数就是name,给变量命名便于调试。
(3) shared函数的borrow参数
使用theano时要区分两部分内存,一部分是我们的代码(包括numpy)的内存,另外就是theano自己管理的内存,这包括shared变量和apply函数时的一些临时内存。所有的theano的函数只能处理它自己管理的内存。那么函数的input呢?默认情况下我们传给theano函数的是python的对象或者numpy的对象,会复制到theano管理的临时变量里。因此为了优化速度,我们有时会把训练数据定义成shared变量,避免重复的内存拷贝。
borrow=True(默认是False)让theano shallow copy numpy的ndarray,从而不节省空间。borrow是True的缺点是复用ndarray的内存空间,如果用同一个ndarray给多个shared变量使用,那么它们是共享这个内存,任何一个人改了,别人都能看得到。我们一般不会用一个ndarray构造多个shared 变量,所以一般设置成True。
更多theano的内存管理请参考这里。
【self.b的定义类似】
接下来我们定义p_y_given_x,首先是仿射变换 T.dot(input, selft.W) + selft.b。然后加一个softmax。
接下来是y_pred:
self.y_pred = T.argmax(self.p_y_given_x, axis=1)我们使用argmax函数来选择概率最大的那个下标。注意axis=1,如果读者follow之前的代码,应该能明白代码的含义,这和numpy里的argmax的axis完全是一样的,原因是因为我们一次求了batch个输入的y。如果不太理解,请读者参考之前的文章。
6.2 定义loss function
前面的文章已经讲过很多次cross entropy的损失函数了。也就是真实分类作为下标去取p_y_given_x 对应的值,然后-log就是这一个训练样本的loss,但是我们需要去一个batch的loss,所以要用两个下标,一个是[0,1, …, batchSize-1],另一个就是样本的真实分类y(每个y都是0-9)。
具体的代码如下:
return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])这里先对所有的p_y_given_x求log,然后在切片出想要的值,其实也可以先切片在求log:
return -T.mean(T.log(self.p_y_given_x[T.arange(y.shape[0]), y]))我自己测试了一下,后者确实快(30s vs 20s),这么一个小小的修改速度就快了很多。
6.3 定义类LogisticRegression
我们可以把上面的所有代码封装成一个LogisticRegression类,以便重复使用。请读者仔细阅读每行代码和注释。
class LogisticRegression(object):我们使用这个类的方法:
"""多类 Logistic Regression 分类器
lr模型由weight矩阵W和biase向量b确定。通过把数据投影到一系列(分类数量个)超平面上,到朝平面的距离就被认为是预测为这个分类的概率
"""
def __init__(self, input, n_in, n_out):
""" 初始化参数
:参数类型 input: theano.tensor.TensorType
:参数说明 input: 符号变量代表输入的一个mini-batch
:参数类型 n_in: int
:参数说明 n_in: 输入神经元的个数,mnist是28*28=784
:参数类型 n_out: int
:参数说明 n_out: 输出的个数,mnist是10
"""
# start-snippet-1
# 把weight W初始化成0,shape是(n_in, n_out)
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
# 把biase初始化成0,shape是(n_out,)
self.b = theano.shared(
value=numpy.zeros(
(n_out,),
dtype=theano.config.floatX
),
name='b',
borrow=True
)
# 给定x,y输出0-9的概率,前面解释过了
self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b)
# 预测
self.y_pred = T.argmax(self.p_y_given_x, axis=1)
# end-snippet-1
# 把模型的参数都保存起来,后面updates会用到
self.params = [self.W, self.b]
# 记下input 为什么要保存到self里?因为我们在预测的时候一般会重新load这个LogisticRegression类,因为模型的参数是LogisticRegression的成员变量(self.W, self.b),使用pickle.load的时候会恢复这些参数,同时也会重新调用__init__方法,所以整个计算图就恢复了。我们预测的时候需要定义predict的函数(还有一张方法就是在LogisticRegression里定义predict函数),这个时候就还需要输入input,所以保存input,具体预测的代码:
#### load the saved model
#### classifier = pickle.load(open('best_model.pkl'))
#### compile a predictor function
#### predict_model = theano.function(
#### inputs=[classifier.input],
#### outputs=classifier.y_pred)
self.input = input
def negative_log_likelihood(self, y):
"""返回预测值在给定真实分布下的负对数似然(也就是cross entropy loss)
参数类型 type y: theano.tensor.TensorType
参数说明 param y: 每个训练数据对应的正确的标签(分类)组成的vecotr(因为我们一次计算一个minibatch)
注意:我们这里使用了平均值而不是求和因为这样的话learning rate就和batch大小无关了【我们调batch的时候可以不影响learning rate】
"""
#前面已经说过了,这里不再解释
return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])
def errors(self, y):
"""返回一个float代表这个minibatch的错误率
:参数类型 type y: theano.tensor.TensorType
:参数说明 param y: 同上面negative_log_likelihood的参数y
"""
# 检查维度是否匹配
if y.ndim != self.y_pred.ndim:
raise TypeError(
'y should have the same shape as self.y_pred',
('y', y.type, 'y_pred', self.y_pred.type)
)
# y必须是int类型的数据
if y.dtype.startswith('int'):
# the T.neq op 返回0和1,如果预测值y_pred和y不同就返回1
# T.neq是一个elementwise的操作,所以用T.mean求评价的错误率
return T.mean(T.neq(self.y_pred, y))
else:
raise NotImplementedError()
# 生成输入的符号变量 (x and y 代表了一个minibatch的数据)有了这个类的对象,接下来就可以定义lost function:
x = T.matrix('x') # 数据
y = T.ivector('y') # labels
# 构造LogisticRegression对象
# MNIST的图片是28*28的,我们把它展开成784的向量
classifier = LogisticRegression(input=x, n_in=28 * 28, n_out=10)
cost = classifier.negative_log_likelihood(y)6.4 模型训练
在大部分编程语言里,我们都需要手工求loss对参数的梯度:
∂ℓ/∂W
∂ℓ/∂b。对于复杂的模型,这非常容易弄错。另外还有很多细节比如数值计算的稳定性(stability)。如果使用Theano,问题就很简单了,因为它会自动求导并且会做一些数学变换来提供数值计算的稳定性。
To get the gradients \partial{\ell}/\partial{W} and \partial{\ell}/\partial{b} in Theano, simply do the following:
在Theano中求
∂ℓ/∂W和
∂ℓ/∂b,只需要如下两行代码:
g_W = T.grad(cost=cost, wrt=classifier.W)g_W and g_b are symbolic variables, which can be used as part of a computation graph. The function train_model, which performs one step of gradient descent, can then be defined as follows:
g_b = T.grad(cost=cost, wrt=classifier.b)
g_W和g_b是符号变量,也是计算图的一部分。函数train_model,没调用一次进行一个minibatch的梯度下降,可以如下定义:
# 参数W和b的更新注意:这个train_model函数的参数是minibatch的下标。为了提高训练速度,我们使用Theano时通常会把所有的训练数据也定义为共享变量,以便把它们放到GPU的显存里,从而避免在cpu和gpu直接来回的复制数据【如果训练数据太大不能放到显存里呢?比较容易想到的就是把训练数据(随机)的切分成能放到内存的一个个window,然后把这个window的数据加载到显存训练,然后再训练下一个window】。而我们每次训练时通过index来从train_set_x里选取这个minibatch的数据:
updates = [(classifier.W, classifier.W - learning_rate * g_W),
(classifier.b, classifier.b - learning_rate * g_b)]
train_model = theano.function(
inputs=[index],
outputs=cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}
)
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}givens之前我们解释过了,就是通过参数index来确定当前的训练数据。为什么要用givens来制定x和y?因为我们没有办法直接把x和y作为参数传给train_model【否则就需要在cpu和gpu复制数据了】我们通过把train_set_x和train_set_y定义为共享变量,然后通过givens和index来制定当前这个minibatch的x和y的值。每次调用train_model,Theano会根据当前的W和b计算loss和梯度g_W和g_b,然后执行updates更新W和b。
6.5 测试模型
要测试模型,首先需要定义错误率:
def errors(self, y):前面是检查y和y_pred的shape是否匹配,因为Theano的Tensor在编译时是没有shape信息的。另外y是运行是传入的,我们也要检查一下它的Type是否int。
if y.ndim != self.y_pred.ndim:
raise TypeError(
'y should have the same shape as self.y_pred',
('y', y.type, 'y_pred', self.y_pred.type)
)
# check if y is of the correct datatype
if y.dtype.startswith('int'):
return T.mean(T.neq(self.y_pred, y))
else:
raise NotImplementedError()
关键的一行代码是:
return T.mean(T.neq(self.y_pred, y))T.neq是个elementwise的函数,如果两个值相等就返回0,不相等返回1,然后调用mean函数就得到错误率。
接下来我们需要定义一个函数来计算错误率,这个函数和训练非常类似,不过用的数据是测试数据和validation数据而已。validation可以帮助我们进行early-stop。我们保留的最佳模型是在validation上表现最好的模型。
test_model = theano.function(
inputs=[index],
outputs=classifier.errors(y),
givens={
x: test_set_x[index * batch_size: (index + 1) * batch_size],
y: test_set_y[index * batch_size: (index + 1) * batch_size]
}
)
validate_model = theano.function(
inputs=[index],
outputs=classifier.errors(y),
givens={
x: valid_set_x[index * batch_size: (index + 1) * batch_size],
y: valid_set_y[index * batch_size: (index + 1) * batch_size]
}
)
6.6 完整的代码
from __future__ import print_function大部分代码都已经解释过来,不过还有两个函数shared_dataset和sgd_optimization_mnist需要再稍微解释一下。
__docformat__ = 'restructedtext en'
import six.moves.cPickle as pickle
import gzip
import os
import sys
import timeit
import numpy
import theano
import theano.tensor as T
class LogisticRegression(object):
def __init__(self, input, n_in, n_out):
# start-snippet-1
# initialize with 0 the weights W as a matrix of shape (n_in, n_out)
self.W = theano.shared(
value=numpy.zeros(
(n_in, n_out),
dtype=theano.config.floatX
),
name='W',
borrow=True
)
# initialize the biases b as a vector of n_out 0s
self.b = theano.shared(
value=numpy.zeros(
(n_out,),
dtype=theano.config.floatX
),
name='b',
borrow=True
)
self.p_y_given_x = T.nnet.softmax(T.dot(input, self.W) + self.b)
self.y_pred = T.argmax(self.p_y_given_x, axis=1)
# end-snippet-1
# parameters of the model
self.params = [self.W, self.b]
# keep track of model input
self.input = input
def negative_log_likelihood(self, y):
# start-snippet-2
return -T.mean(T.log(self.p_y_given_x)[T.arange(y.shape[0]), y])
# end-snippet-2
def errors(self, y):
# check if y has same dimension of y_pred
if y.ndim != self.y_pred.ndim:
raise TypeError(
'y should have the same shape as self.y_pred',
('y', y.type, 'y_pred', self.y_pred.type)
)
# check if y is of the correct datatype
if y.dtype.startswith('int'):
# the T.neq operator returns a vector of 0s and 1s, where 1
# represents a mistake in prediction
return T.mean(T.neq(self.y_pred, y))
else:
raise NotImplementedError()
def load_data(dataset):
''' Loads the dataset
:type dataset: string
:param dataset: the path to the dataset (here MNIST)
'''
#############
# LOAD DATA #
#############
# Download the MNIST dataset if it is not present
data_dir, data_file = os.path.split(dataset)
if data_dir == "" and not os.path.isfile(dataset):
# Check if dataset is in the data directory.
new_path = os.path.join(
os.path.split(__file__)[0],
"..",
"data",
dataset
)
if os.path.isfile(new_path) or data_file == 'mnist.pkl.gz':
dataset = new_path
if (not os.path.isfile(dataset)) and data_file == 'mnist.pkl.gz':
from six.moves import urllib
origin = (
'http://www.iro.umontreal.ca/~lisa/deep/data/mnist/mnist.pkl.gz'
)
print('Downloading data from %s' % origin)
urllib.request.urlretrieve(origin, dataset)
print('... loading data')
# Load the dataset
with gzip.open(dataset, 'rb') as f:
try:
train_set, valid_set, test_set = pickle.load(f, encoding='latin1')
except:
train_set, valid_set, test_set = pickle.load(f)
# train_set, valid_set, test_set format: tuple(input, target)
# input is a numpy.ndarray of 2 dimensions (a matrix)
# where each row corresponds to an example. target is a
# numpy.ndarray of 1 dimension (vector) that has the same length as
# the number of rows in the input. It should give the target
# to the example with the same index in the input.
def shared_dataset(data_xy, borrow=True):
data_x, data_y = data_xy
shared_x = theano.shared(numpy.asarray(data_x,
dtype=theano.config.floatX),
borrow=borrow)
shared_y = theano.shared(numpy.asarray(data_y,
dtype=theano.config.floatX),
borrow=borrow)
return shared_x, T.cast(shared_y, 'int32')
test_set_x, test_set_y = shared_dataset(test_set)
valid_set_x, valid_set_y = shared_dataset(valid_set)
train_set_x, train_set_y = shared_dataset(train_set)
rval = [(train_set_x, train_set_y), (valid_set_x, valid_set_y),
(test_set_x, test_set_y)]
return rval
def sgd_optimization_mnist(learning_rate=0.13, n_epochs=1000,
dataset='mnist.pkl.gz',
batch_size=600):
datasets = load_data(dataset)
train_set_x, train_set_y = datasets[0]
valid_set_x, valid_set_y = datasets[1]
test_set_x, test_set_y = datasets[2]
# compute number of minibatches for training, validation and testing
n_train_batches = train_set_x.get_value(borrow=True).shape[0] // batch_size
n_valid_batches = valid_set_x.get_value(borrow=True).shape[0] // batch_size
n_test_batches = test_set_x.get_value(borrow=True).shape[0] // batch_size
######################
# BUILD ACTUAL MODEL #
######################
print('... building the model')
# allocate symbolic variables for the data
index = T.lscalar() # index to a [mini]batch
# generate symbolic variables for input (x and y represent a
# minibatch)
x = T.matrix('x') # data, presented as rasterized images
y = T.ivector('y') # labels, presented as 1D vector of [int] labels
# construct the logistic regression class
# Each MNIST image has size 28*28
classifier = LogisticRegression(input=x, n_in=28 * 28, n_out=10)
# the cost we minimize during training is the negative log likelihood of
# the model in symbolic format
cost = classifier.negative_log_likelihood(y)
# compiling a Theano function that computes the mistakes that are made by
# the model on a minibatch
test_model = theano.function(
inputs=[index],
outputs=classifier.errors(y),
givens={
x: test_set_x[index * batch_size: (index + 1) * batch_size],
y: test_set_y[index * batch_size: (index + 1) * batch_size]
}
)
validate_model = theano.function(
inputs=[index],
outputs=classifier.errors(y),
givens={
x: valid_set_x[index * batch_size: (index + 1) * batch_size],
y: valid_set_y[index * batch_size: (index + 1) * batch_size]
}
)
# compute the gradient of cost with respect to theta = (W,b)
g_W = T.grad(cost=cost, wrt=classifier.W)
g_b = T.grad(cost=cost, wrt=classifier.b)
# start-snippet-3
# specify how to update the parameters of the model as a list of
# (variable, update expression) pairs.
updates = [(classifier.W, classifier.W - learning_rate * g_W),
(classifier.b, classifier.b - learning_rate * g_b)]
# compiling a Theano function `train_model` that returns the cost, but in
# the same time updates the parameter of the model based on the rules
# defined in `updates`
train_model = theano.function(
inputs=[index],
outputs=cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}
)
# end-snippet-3
###############
# TRAIN MODEL #
###############
print('... training the model')
# early-stopping parameters
patience = 5000 # look as this many examples regardless
patience_increase = 2 # wait this much longer when a new best is
# found
improvement_threshold = 0.995 # a relative improvement of this much is
# considered significant
validation_frequency = min(n_train_batches, patience // 2)
# go through this many
# minibatche before checking the network
# on the validation set; in this case we
# check every epoch
best_validation_loss = numpy.inf
test_score = 0.
start_time = timeit.default_timer()
done_looping = False
epoch = 0
while (epoch < n_epochs) and (not done_looping):
epoch = epoch + 1
for minibatch_index in range(n_train_batches):
minibatch_avg_cost = train_model(minibatch_index)
# iteration number
iter = (epoch - 1) * n_train_batches + minibatch_index
if (iter + 1) % validation_frequency == 0:
# compute zero-one loss on validation set
validation_losses = [validate_model(i)
for i in range(n_valid_batches)]
this_validation_loss = numpy.mean(validation_losses)
print(
'epoch %i, minibatch %i/%i, validation error %f %%' %
(
epoch,
minibatch_index + 1,
n_train_batches,
this_validation_loss * 100.
)
)
# if we got the best validation score until now
if this_validation_loss < best_validation_loss:
#improve patience if loss improvement is good enough
if this_validation_loss < best_validation_loss * \
improvement_threshold:
patience = max(patience, iter * patience_increase)
best_validation_loss = this_validation_loss
# test it on the test set
test_losses = [test_model(i)
for i in range(n_test_batches)]
test_score = numpy.mean(test_losses)
print(
(
' epoch %i, minibatch %i/%i, test error of'
' best model %f %%'
) %
(
epoch,
minibatch_index + 1,
n_train_batches,
test_score * 100.
)
)
# save the best model
with open('best_model.pkl', 'wb') as f:
pickle.dump(classifier, f)
if patience <= iter:
done_looping = True
break
end_time = timeit.default_timer()
print(
(
'Optimization complete with best validation score of %f %%,'
'with test performance %f %%'
)
% (best_validation_loss * 100., test_score * 100.)
)
print('The code run for %d epochs, with %f epochs/sec' % (
epoch, 1. * epoch / (end_time - start_time)))
print(('The code for file ' +
os.path.split(__file__)[1] +
' ran for %.1fs' % ((end_time - start_time))), file=sys.stderr)
def predict():
"""
An example of how to load a trained model and use it
to predict labels.
"""
# load the saved model
classifier = pickle.load(open('best_model.pkl'))
# compile a predictor function
predict_model = theano.function(
inputs=[classifier.input],
outputs=classifier.y_pred)
# We can test it on some examples from test test
dataset='mnist.pkl.gz'
datasets = load_data(dataset)
test_set_x, test_set_y = datasets[2]
test_set_x = test_set_x.get_value()
predicted_values = predict_model(test_set_x[:10])
print("Predicted values for the first 10 examples in test set:")
print(predicted_values)
if __name__ == '__main__':
sgd_optimization_mnist()
前面说过,为了提高训练速度,我们需要把训练数据定义成共享变量。不过GPU里只能存储浮点数【这不是GPU的限制,而是Theano的限制,具体参考这里】,但是我们需要把y当成下标用,所以需要转成int32:
return shared_x, T.cast(shared_y, 'int32')不过即使这样,cast操作(op)还是会把y复制到cpu上进行运算的。所有涉及到y的计算是会放到cpu上的,也就是计算图的loss会在cpu上运行。这是Theano的一个缺陷,不知道为什么会是这样的设计。不过那个stackoverflow的帖子回复里Daniel Renshaw说如果只是把int用作下标,不知会不会能在GPU上。但是计算error肯定是在CPU上了,不过error函数不是在训练阶段,调用的次数也不会太多。
sgd_optimization_mnist实现sgd训练。
其实就是不停的调用train_model函数,每经过一次epoch,就在validation数据上进行一次validation,如果错误率比当前的最佳模型好,就把它保存为最佳模型【用的是pickle】。不过这里使用了一个early-stop的技巧【参考这里】。
除了一个最大的epoch的限制,如果迭代次数iter大于patience,那么就early-stop。patience的初始值是5000,也就是说至少要进行5000次迭代。如果这一次的错误率 < 上一次的错误率乘以improvement_threshold(0.995),那么就认为是比较大的一个提高,patience = max(patience, iter * patience_increase)。patience_increase=2。 大概的idea就是,如果有比较大的提高,那么就多一些”耐心“,多迭代几次。反之如果没有太多提高,咱就没”耐心“了,就early-stop了。
6.7 使用训练好的模型来预测
def predict():前面都解释过了,首先pickle恢复模型的参数和计算图,然后定义predict_model函数,然后进行预测就行了。
"""
An example of how to load a trained model and use it
to predict labels.
"""
# load the saved model
classifier = pickle.load(open('best_model.pkl'))
# compile a predictor function
predict_model = theano.function(
inputs=[classifier.input],
outputs=classifier.y_pred)
# We can test it on some examples from test test
dataset='mnist.pkl.gz'
datasets = load_data(dataset)
test_set_x, test_set_y = datasets[2]
test_set_x = test_set_x.get_value()
predicted_values = predict_model(test_set_x[:10])
print("Predicted values for the first 10 examples in test set:")
print(predicted_values)
7. 使用Theano实现CNN
更新中... 收起阅读 »
视频客服来了!环信移动客服v5.14已发布,支持实时视频、消息回撤功能!
新增实时视频功能
支持客服与客户进行实时视频聊天。当APP或网页渠道的客户发起视频聊天时,客服可以在网页端客服工作台接受邀请,开始与客户进行实时视频聊天。聊天视频支持在会话、历史会话、客户中心等页面进行回放。
注:实时视频功能仅Chrome浏览器在https模式下支持。
实时视频功能为增值服务,如需开通,请提供租户ID并联系环信商务经理。
客服端示例:

APP访客端示例:

新增消息撤回功能
新增消息撤回功能。客服使用网页端客服工作台与APP、网页渠道的客户聊天时,可以撤回2分钟内的聊天消息。聊天消息被撤回后,将在APP、网页访客端消失。
注:移动端客服工作台暂时不支持该功能。
消息撤回功能为增值服务,如需开通,请提供租户ID并联系环信商务经理。
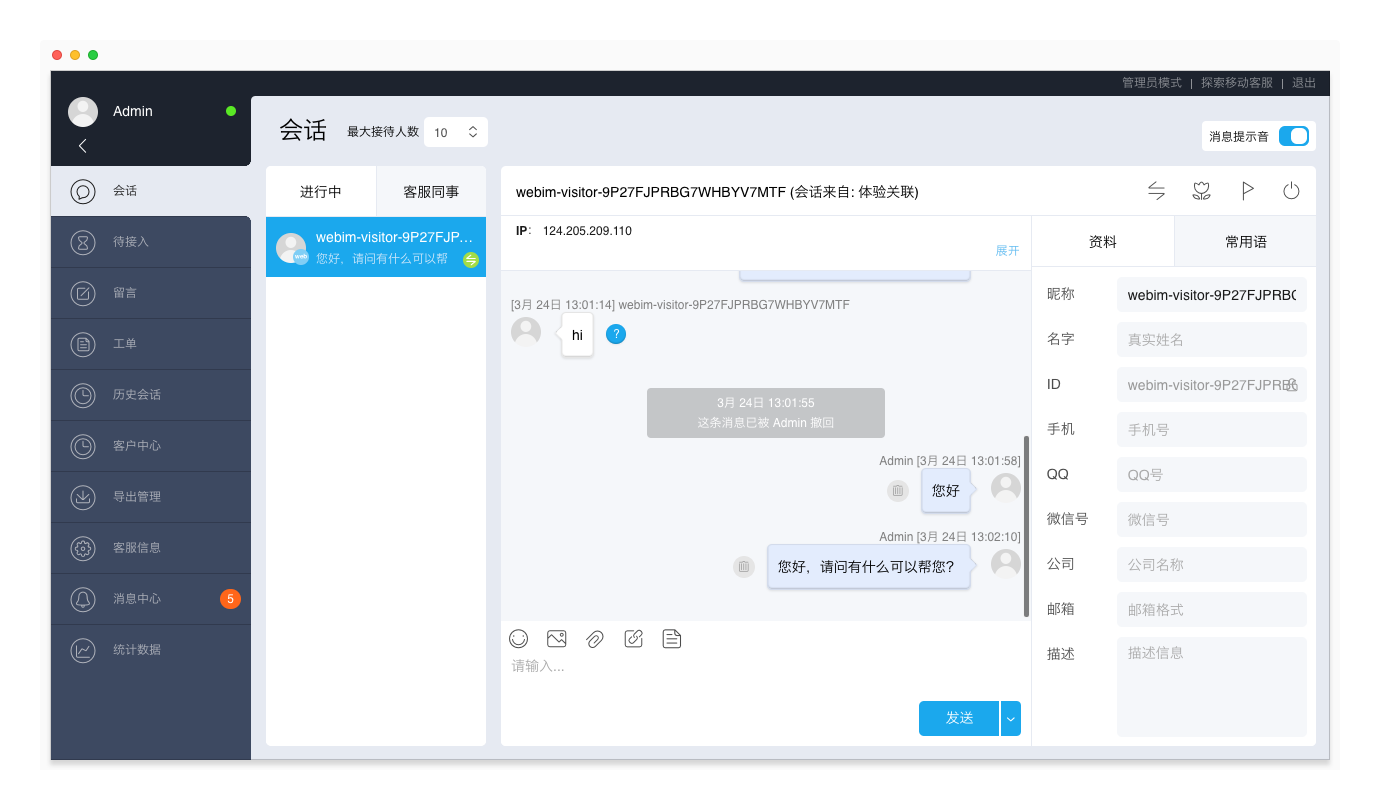
支持显示APP访客端的设备信息
当客服与APP渠道的客户聊天时,会话页面显示客户使用的设备信息,包含IP地址、运营商、操作系统等,帮助客服深入了解服务的客户。
注:暂时仅最新版移动客服Android SDK支持获取用户的设备信息。
获取APP访客端设备信息功能为增值服务,如需开通,请提供租户ID并联系环信商务经理。
【优化】支持显示待接入会话的访客标签
支持在待接入页面显示等待接入的会话的访客标签,帮助客服优先接待重要客户。
访客标签可能来自:
- 重复咨询的客户:该客户之前咨询时,客服为其添加了访客标签;
- 客户被转接技能组:客服将客户的会话转接技能组前为客户添加了访客标签,由于技能组全忙,会话再次进入待接入,此时,管理员可以根据访客标签优先处理该客户的会话。
 【优化】支持保存客服同事之间的聊天消息支持保存客服同事之间的聊天消息。客服在“会话”页面与客服同事聊天后,聊天消息将保存在聊天窗口。注:移动端客服工作台暂时不支持该功能。【优化】支持显示留言的渠道信息支持在留言页面显示留言的渠道信息,即,提交留言的渠道(APP、web等)。管理员模式【优化】支持多次发送访客超时提示语支持多次发送访客超时提示语,优化提醒频率和间隔,提升客户体验。设置方式:进入“管理员模式 > 设置 > 系统开关”页面,打开“访客超时未回复自动结束会话”开关,并设置访客未回复超时时间(第一次发送超时提示语的时间)、提醒次数、提醒间隔、超时提示语,以及自动结束会话的时间(最后一次超时提示语发出x分钟后)。
【优化】支持保存客服同事之间的聊天消息支持保存客服同事之间的聊天消息。客服在“会话”页面与客服同事聊天后,聊天消息将保存在聊天窗口。注:移动端客服工作台暂时不支持该功能。【优化】支持显示留言的渠道信息支持在留言页面显示留言的渠道信息,即,提交留言的渠道(APP、web等)。管理员模式【优化】支持多次发送访客超时提示语支持多次发送访客超时提示语,优化提醒频率和间隔,提升客户体验。设置方式:进入“管理员模式 > 设置 > 系统开关”页面,打开“访客超时未回复自动结束会话”开关,并设置访客未回复超时时间(第一次发送超时提示语的时间)、提醒次数、提醒间隔、超时提示语,以及自动结束会话的时间(最后一次超时提示语发出x分钟后)。 【优化】质量检查增加指标“单次响应时长超过x秒”质量检查增加指标“单次响应时长超过x秒”,考察客服的“最大响应时长”是否在合理区间。在会话详情页的“质检”tab页签显示该会话的最大响应时长,以及单次响应时长超过质检标准的次数。
【优化】质量检查增加指标“单次响应时长超过x秒”质量检查增加指标“单次响应时长超过x秒”,考察客服的“最大响应时长”是否在合理区间。在会话详情页的“质检”tab页签显示该会话的最大响应时长,以及单次响应时长超过质检标准的次数。 Web插件(访客端)当前版本:V43.15支持实时视频访客端Web插件支持实时视频功能,允许客户使用网页端聊天窗口向客服发起视频聊天。发起视频聊天的方法:在聊天窗口点击视频按钮,发起视频邀请,等待客服接受视频邀请,然后在聊天窗口加入视频聊天。注:实时视频功能需要在https模式下工作,仅电脑和Android手机的Chrome浏览器支持。实时视频功能为增值服务,需要在客服端开通才能使用。支持消息撤回访客端Web插件支持消息撤回。当客服在网页端客服工作台撤回消息时,该消息在访客端聊天窗口上消失(桌面聊天窗口和H5网页均支持)。该功能无需额外集成。消息撤回功能为增值服务,需要在客服端开通才能使用。移动客服Android SDK当前版本:V1.0.5支持实时语音、实时视频移动客服Android SDK支持实时语音、实时视频(实时音视频)。当客户使用Android APP联系客服时,可以向客服发起视频聊天。实时音视频功能需要调用Android SDK的接口进行集成,集成方式可参考“商城”demo。支持消息撤回移动客服Android SDK支持消息撤回。当客服在网页端客服工作台撤回消息时,该消息在Android APP上消失。该功能由SDK直接提供,无需额外集成。消息撤回功能为增值服务,需要在客服端开通才能使用。支持获取设备信息移动客服Android SDK支持获取用户的设备信息,如IP地址、运营商、操作系统等。当用户使用Android APP联系客服时,可以在网页端客服工作台看到该用户的设备信息。该功能由SDK直接提供,无需额外集成。获取APP访客端设备信息功能为增值服务,需要在客服端开通才能使用。关于移动客服Android SDK的集成说明,请查看移动客服 Android SDK 集成。“商城”demo (Android)移动客服“商城”demo(Android版)已支持实时视频、消息撤回、获取设备信息这三个增值功能,在网页端客服工作台开通这些功能后,可以先在“商城”demo上体验。体验方法:联系环信商务经理,开通上述增值服务;[list=1]
Web插件(访客端)当前版本:V43.15支持实时视频访客端Web插件支持实时视频功能,允许客户使用网页端聊天窗口向客服发起视频聊天。发起视频聊天的方法:在聊天窗口点击视频按钮,发起视频邀请,等待客服接受视频邀请,然后在聊天窗口加入视频聊天。注:实时视频功能需要在https模式下工作,仅电脑和Android手机的Chrome浏览器支持。实时视频功能为增值服务,需要在客服端开通才能使用。支持消息撤回访客端Web插件支持消息撤回。当客服在网页端客服工作台撤回消息时,该消息在访客端聊天窗口上消失(桌面聊天窗口和H5网页均支持)。该功能无需额外集成。消息撤回功能为增值服务,需要在客服端开通才能使用。移动客服Android SDK当前版本:V1.0.5支持实时语音、实时视频移动客服Android SDK支持实时语音、实时视频(实时音视频)。当客户使用Android APP联系客服时,可以向客服发起视频聊天。实时音视频功能需要调用Android SDK的接口进行集成,集成方式可参考“商城”demo。支持消息撤回移动客服Android SDK支持消息撤回。当客服在网页端客服工作台撤回消息时,该消息在Android APP上消失。该功能由SDK直接提供,无需额外集成。消息撤回功能为增值服务,需要在客服端开通才能使用。支持获取设备信息移动客服Android SDK支持获取用户的设备信息,如IP地址、运营商、操作系统等。当用户使用Android APP联系客服时,可以在网页端客服工作台看到该用户的设备信息。该功能由SDK直接提供,无需额外集成。获取APP访客端设备信息功能为增值服务,需要在客服端开通才能使用。关于移动客服Android SDK的集成说明,请查看移动客服 Android SDK 集成。“商城”demo (Android)移动客服“商城”demo(Android版)已支持实时视频、消息撤回、获取设备信息这三个增值功能,在网页端客服工作台开通这些功能后,可以先在“商城”demo上体验。体验方法:联系环信商务经理,开通上述增值服务;[list=1]环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.14
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
一天轻松集成,环信Unity版SDK帮助游戏APP实现从0到1社交突破!
你辛辛苦苦花大价钱推广的游戏是否还是粘性不够?随着不断的新游戏的冲击用户活跃度每况愈下?如何提升游戏内玩家社交体检已是每个产品经理的必修课。近日,环信宣布Unity版SDK正式发布,只需一天即可轻松集成IM功能,帮助游戏APP实现从0到1的游戏内社交突破。
.jpg")
Unity
Unity SDK是为使用Unity开发的游戏等软件中集成IM功能提供的SDK。依赖Unity的跨平台特性,SDK可以轻松的运行于Android、IOS、MAC、Linux和Window等多个平台产品之上,用户可以用SDK实现IM功能。Unity SDK使用C#进行开发,目前支持登陆、注册、单聊、群聊、文本消息、文件消息,还可以实现群组管理等功能。尚未实现语音通话和视频通话功能。emclient-u3d 为 Open Source, Link to :https://github.com/easemob/emclient-u3d/
Unity SDK 更新日志
版本:V3.0.0 试用版 2017-03-17
- 登陆、登出、注册。
- 聊天:单聊、群聊消息收发。
- 消息类型:
- 可发送:文本、文件。
- 可接受:文本、文件。
环信Unity SDK下载http://www.easemob.com/download/im 收起阅读 »
环信生曦:全媒体客服如何做好信息共享设计
是的,您没看错,上图当年那位最帅的青涩骚年就是现在的老司机生曦

什么是服务设计?与产品设计有哪些不同?
服务设计是基于某个行业的服务需要,以服务流程中的参与者为核心,所涉及的服务场景、交互逻辑以及操作方式等进行的设计。因此,服务设计的衡量标准也是以参与者的服务效率和使用体验进行设定。与产品设计的不同之处在于,服务设计所面对的参与者不仅是为用户,也包含服务人员本身;服务设计不仅是通过产品交互界面(设备的操作界面),也可能会有除产品以外的服务(话术访谈等)。因此对设计师有更高的要求,需要对完成的服务场景有行业化的认识,对客户服务有深度的行业理解。
什么是全媒体服务?
某种行业服务过程中,需要通过不同方式进行服务接入、统一分配服务资源、合理进行服务转化等一系列服务操作中,包含了多种渠道服务的支持。例如,传统的医疗服务行业,通过挂号,缴费,分诊,就医等全线下完成服务。逐渐转化为通过电话、网站、APP等多渠道进行预约、挂号等,选择进行线下就医,或者在线完成医疗咨询、诊治等,后续进行在线回访以及调查等。典型的传统转向数字化的全渠道全媒体服务模式。
全媒体服务如何实现信息共享?
全媒体服务根据每个行业的需要,有不同的服务场景和流程定制,信息同步高效是全媒体服务的基础,设计通常会选择业务信息聚合节点来完成信息聚合。以电商为例,通常以消费者(用户)为维度进行信息聚合,客户服务人员可以通过用户聚合查看到相关的互动记录信息,进行连续不间断的服务支持;以客户服务人员本身作为信息聚合节点,查看相关服务操作过程,来管理和监控服务流程;可以通过服务信息单元进行聚合节点,查看相关涉及的消费者与客户服务人员的行为,来进行服务跟踪和追溯服务状态。当然还有更多信息聚合节点,可以根据行业服务需要进行定制和管理。通过梳理具有行业目的的信息线索,进行节点聚合,是在服务设计中实现信息共享方式最有效的办法。
如何确保和渠道服务能力畅通连贯?
现实生活中,我们经常与遇到一些骚扰的营销电话,其中或多或少可能之前是我们之前有所涉及的服务,但是也许目前不需要的就成了骚扰电话。而有一些可能就成为我们下一次消费的开始,这是渠道营销服务的一种方式。所以营销服务的节点(信息线索)是根据客户信息聚合,如果还有其他渠道方面的节点,我们也许会收到短信或者APP等消息推送,也可能会更有效的完成此次营销服务。所以服务节点聚合的效率是保证服务与服务之间准确、连贯、有效的关键因素。例如,环信移动客服,通过对全渠道消息、语音统一接入,进行服务资源调度与分配,将信息整合为几大重要的信息聚合节点,客户资料中心、云数据计算分析、全媒体接入等等,为客户提供在线服务、管理、追踪、营销等组合业务,高效且系统化的满足行业需求定制。
新生服务如何可以融入现有服务设计中?
这个非常有挑战性的话题,作为设计师,不断的进行设计创新,完善产品、优化服务是产品生命的保证。而技术新模式的加入也在不断改变和推翻低效的工具和实现方式。这不经意间就会落后的技术时代,是与客户一起深入行业发展,共同创新摸索产品的必经之路。现在正在追捧的VR/AR技术,以及AI等人工智能在服务领域的渗透,产品设计也在悄然发生变革。当然,对技术能力的验证不能闭门造车,环信移动客服智能机器人系统中,悄悄然无声融入的智能业务场景应答服务已经在很多大客户身上得到了应用,并迸发出了强大的生产力。在现有产品系统框架的基础上逐渐结合AI与行业服务,以此为基础进行尝试与深入,逐渐可以成长和完善为新的利器。
最后安利一个服务流程设计工具:http://servicedesigntools.org/repository 收起阅读 »
方向
从高考结束到现在,从开始有编程的思想到现在;从我接触游戏到现在,从我第一次开始想,这个程序到底是怎么完成的到现在。
我开始 写Hello World的时候,只知道一个public static void main(String st[]){};然后慢慢的,一个类,一个包,一个 项目,最后 ,一个完整的程序, 波折几百次; 最终不再出现 ANR,那 一瞬间,有一种 释然,一种轻松, 一种成就 包含当时的 心情用最丰盛的庆功会 诠释了这一切。
到我 第一次真正的去理解 一个项目,做一个 项目,一个社交 项目。
一个我 做了一整年的 项目, 在我心里,我是带着遗憾 离开的,我始终 觉得并没有把这个项目 做好,并没有去真正的体现项目的精髓所在, 社交所在;可能我当时 不明白 产品 的思想, 但我思想 倾向于技术不成熟。我觉得一个 好的程序员是要将 产品思想准确 转变成代码的 一个转变器, 所以,当时的心情 也就是我说的 思想一半,技术 一半完成了一个让我非常遗憾的产品。
所以 我会在想,我要在下一个产品做到最好, 做到让自己 百分之百的满意,让这个应用能够 被 许多人认可。 在我 希望下一个产品 能够用得上 社交,用的上sdk的 时候,我真的 等来了一个纯社交的产品;其实我 心里在想,我 要深度去集成 环信sdk,可能我不知道sdk 里面的内容是 什么,并不知道sdk的原理;我却接到了一个自己写即时通讯 项目,以及去实现屏幕同步的项目。
当我听到了自己做这些 东西的 时候,我有点 失望,因为我不能够去好好的,认真的去看,去 实现环信sdk的 即时通讯。
初衷,也许来源于一个 后来才 发现自己喜欢, 愿意跟人去沟通 的自己。
这也就是我 从失望慢慢 变成期待,去体验实现 这个过程的 每一步,我喜欢这样的感觉。
今天早上在车上我想到了一句话,也许,我依然在走环信 即时通讯的路
收起阅读 »
环信公开课第十期--环信3.0实时音视频解析
环信的小伙伴们,还记得那天夕阳下的奔跑吗?“环信直播课堂”回来了!久别半年,环信直播课堂已经升级完成,更名为“环信公开课”,不止在社区,这次加入了微信、QQ群等各种互动,更多新玩法等待你来发掘!
最接地气的实时音视频技术,环信SDK3.0实时音视频解析--环信公开课第十期

课程简介:
APP如何快速实现实时音视频功能?
音视频开发过程中遇到坑怎么处理?
视频聊天想加入更多新玩法?
环信公开课第十期(2017.3.30 19:00)●环信SDK3.0实时音视频讲解,学习环信音视频开发,让你的APP聊起来!
课程看点:
环信SDK3.0实时音视频讲解(2017.3.30 19:00)课程说明:
☞ 如何快速实现移动端实时音视频
☞ APP视频聊天横竖屏切换实现
☞ 视频聊天录制保存实现
☞ P2P模式和转发模式的处理
☞ 自由问答
主讲嘉宾:环信Android工程师 刘立正
参会对象:移动开发者/产品经理/APP开发
参会时间:2017.3.30(周四)19:00
活动形式:线上微课堂
注意事项:联网手机|电脑均可观看
报名地址:点击报名

收起阅读 »
环信移动客服v5.13发布——支持接收并播放微信小视频,支持向工单系统提交工单
支持接收并播放微信小视频
移动客服系统支持接收并播放微信小视频。客服与微信网友聊天时,若收到对方发来的微信小视频,可以直接点击视频进行播放。视频支持全屏切换。
视频消息可以在历史会话等页面查看,并支持导出和下载(导出文件中包含视频消息的下载地址)。
注:目前仅网页版客服工作台支持播放微信小视频,且视频来源为微信授权模式集成的微信公众号。

支持向工单系统提交工单
环信已推出功能强大的支持多人协作的在线工单系统,用于处理邮件、网页、电话渠道提交的工单。环信移动客服系统提供“工单融合”功能,与工单系统连通。
当客户咨询的问题需要后续跟进处理时,客服可以在“工单”页面为客户创建工单,由工单系统的专家继续为客户解答问题。创建工单后,客服可以在工单详情页查看工单进度。
环信工单系统采用私有部署的方式,如需开通“工单融合”功能(增值服务),请联系环信商务经理。

管理员模式
新增权限管理,支持自定义角色和权限
新增权限管理功能,允许管理员自定义角色,并设置该角色可以使用的管理员模式和客服模式的页面。
操作方法:
1. 添加角色。进入“管理员模式 > 设置 > 权限管理”页面,点击“添加角色”按钮,输入角色名称,并保存。

2. 设置自定义角色的权限。点击新添加的角色,在权限页面勾选该角色可以使用的页面,包括管理员模式和客服模式的页面,并保存。
注:如果允许该角色查看“客服模式 > 客户中心”页面,需要同时在“管理员模式 > 设置 > 系统开关”页面打开“客服可以使用访客中心”开关。

3. 设置客服的角色。进入“管理员模式 > 成员管理 > 客服”页面,设置客服的角色。

移动客服系统与工单系统融合
环信已推出功能强大的支持多人协作的在线工单系统,用于处理邮件、网页、电话渠道提交的工单。环信移动客服系统提供“工单融合”功能,与工单系统连通。
在“管理员模式 > 工单”页面,管理员可以为客户创建工单,并查看移动客服系统中已提交的所有工单及其进度。
环信工单系统采用私有部署的方式,如需开通“工单融合”功能(增值服务),请联系环信商务经理。

机器人自定义菜单支持导入/导出
机器人自定义菜单提供菜单模版,并支持导入、导出菜单,便于对菜单进行批量维护。
注:在菜单中添加的多媒体文件不支持导出。

Web插件(访客端)
当前版本:V43.14
显示当前排队人数
网页端的客户联系客服时,支持在网页端聊天窗口显示当前排队人数。桌面聊天窗口和H5网页均支持。
显示当前排队人数为旗舰版功能,如需开通,请提供租户ID并联系环信商务经理。

环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.13
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
【公告】全新的环信移动客服访客端SDK正式发布
全新的环信移动客服访客端SDK正式发布,功能全面升级,性能大幅优化:
- 支持消息传输双通道。当主通道意外受阻时,第二通道自动启用,成倍提升了系统的可靠性,确保消息必达
- 基于MSync协议,更快的连接速度,更小的流量消耗
- 支持消息回撤
- 封装了头像昵称显示,留言,机器人菜单消息/转人工按钮,指定技能组等客服业务功能,极简集成
我们将基于新的移动客服访客端SDK陆续推出消息预知、多端消息漫游、设备信息获取等功能,为您提供最完美的客服体验!
请您尽快升级!
集成指南:
- 安卓:http://docs.easemob.com/cs/300visitoraccess/androidsdk
- iOS: http://docs.easemob.com/cs/300visitoraccess/iossdk
API文档:
- 安卓:http://docs.easemob.com/cs/300visitoraccess/androidsdkapi
- iOS:http://docs.easemob.com/cs/300visitoraccess/iossdkapi
开源的客服Demo:
- 安卓:https://github.com/easemob/kefu-android-demo
- iOS:https://github.com/easemob/helpdeskdemo-ios
如您在集成过程中碰到问题,可以联系我们的支持人员,我们将提供及时周到的支持服务。
敬请您及时更新,享受更优质的服务,谢谢! 收起阅读 »
集成环信demo
2:要记得新建lib文件夹
3:下载libHyphenateFullSDk.a并将其拖入新建的lib文件中,
4:到这步基本ok了,你可以开始浪起~
5:感谢江南孤鹜!
环信移动客服v5.12发布——留言页面改版,支持批量分配留言
留言页面改版,支持批量分配留言
优化留言页面,分类显示未处理、处理中、已解决、未分配的留言;支持选择多个留言,并对留言进行批量分配。
设置方法:
- 勾选多个留言后,点击页面右上角的“处理”按钮,对留言进行批量分配。
- 点击任意一条留言,可以查看留言详情,回复留言、分配留言、修改留言状态。

【优化】进行中会话列表提示转接的会话当客服收到机器人或其他客服转接的会话时,进行中会话列表显示转接标志,提示客服这是一条转接的会话。

【优化】历史会话支持根据技能组进行筛选支持根据技能组筛选历史会话,筛选结果为路由或转接到该技能组并由该技能组的客服结束的会话。【优化】客户中心支持根据客户ID模糊查询在客户中心页面,支持按客户ID模糊查询,即输入客户ID的关键字段,即可查询到该客户的详细资料。注:若在客服模式下显示“客户中心”页面,需要管理员在“管理员模式 > 设置 > 系统开关”页面打开“客服可以使用访客中心功能”开关。【优化】消息中心区分管理员通知和系统消息消息中心增加分类:管理员通知、系统消息,方便客服快速查找管理员通知。【优化】允许客服查看自己的“平均会话时长”“统计数据”页面增加“平均会话时长”指标,允许客服查看自己的“平均会话时长”。 管理员模式留言页面改版,支持批量分配留言优化留言页面,分类显示未处理、处理中、已解决、全部留言;支持选择多个留言,并对留言进行批量分配。设置方法:
- 勾选多个留言后,点击页面右上角的“处理”按钮,对留言进行批量分配。
- 点击任意一条留言,可以查看留言详情,回复留言、分配留言、修改留言状态。

新增访客标签、访客资料、坐席信息变更等“自定义事件”
自定义事件推送新增以下事件:添加访客标签、删除访客标签、更改访客资料、坐席信息变更。当移动客服系统中出现以上事件时,可以实时推送到客户的服务器。
设置方法:进入“管理员模式 > 设置 > 自定义事件推送”页面,创建事件推送,设置服务器地址,勾选需要推送的事件,并保存。
自定义事件推送为增值服务,如需开通,请提供租户ID并联系环信商务经理。

【优化】历史会话支持根据技能组进行筛选
支持根据技能组筛选历史会话,筛选结果为路由或转接到该技能组并由该技能组的客服结束的会话。
【优化】客户中心支持根据客户ID模糊查询
在客户中心页面,支持按客户ID模糊查询,即输入客户ID的关键字段,即可查询到该客户的详细资料。
【优化】消息中心区分管理员通知和系统消息
消息中心增加分类:管理员通知、系统消息,方便客服快速查找管理员通知。
【优化】工作量报表增加指标“接起次数”
“统计查询 > 工作量”页面的客服/技能组工作量详情里,增加“接起次数”,表示客服或技能组在接起的会话中的服务次数。
例如:一条会话被客服A接起,转接至客服B,再次转接至客服A,并由客服A结束。那么,客服A的接起会话数为1,接起次数为2;客服B的接起会话数为1,接起次数为1。

【优化】工作质量报表增加无效人工会话明细
“统计查询 > 工作质量”页面的客服/技能组工作质量详情里,增加无效人工会话明细:客服无消息、访客无消息、均无消息的无效会话数。

iOS客服工作台
当前版本:V2.1.3
支持编辑客户资料中的“自定义字段”。
注:如需添加“自定义字段”,请登录网页版客服工作台,进入“管理员模式 > 设置 > 客户资料自定义”页面进行设置。
关于更多iOS客服工作台的更新日志,请查看iOS 客服工作台 更新日志。
PC客服工作台
当前版本:V2.0.2017.02284
支持消息提示、弹窗和闪烁分开控制,保存文件时支持选择存储路径。
关于更多PC客服工作台的更新日志,请查看PC 客服工作台 更新日志。
Web插件(访客端)
当前版本:V43.13
新增消息预知功能,与网页端客户聊天时,在会话面板显示客户的输入状态及正在输入的内容(下图),使客服能够更高效地解答客户的疑问。

消息预知功能为增值服务,如需开通,请提供租户ID并联系环信商务经理。
关于Web插件的集成说明,请查看网页渠道集成。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.12
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
【环信征文】做一个IOS聊天APP如何实现发送/预览文件功能

导语
在实际项目开发中,用户之间经常需要在聊天窗口发送文件。环信官方IOS版Demo功能很强大,本文主要介绍在IOS版APP中,如何结合iCloud Drive一步步实现【发送文件】和【预览文件】的功能。

一、认识iCloud Drive
iCloud官方文档
这里可以看到iCloud的一些官方介绍以及使用方式,刚开始暂时不必要深入了解。
iCloud Drive, 各类文件,在你的各种设备呈现
http://www.apple.com/cn/icloud/icloud-drive/
iCloud Drive 常见问题
https://support.apple.com/zh-cn/HT201104
为什么我们要用iCloud Drive
由于受ios系统的限制(越狱的iphone当然不受限制),app并不能直接访问系统中的文件,所以只能通过iCloud Drive选取文件。
二、配置项目支持iCloud Drive
我们以环信官方Demo项目为例进行示范操作,V3.3.0版Demo完整源码下载地址:
http://www.easemob.com/download/im
1.下载完项目后,用Xcode打开ChatDemo-UI3.0.xcodeproj,然后更改项目的【Bundle Identifier】为【com.easemob.enterprise.demo.ui.dabiaoge】(自己设置一个独一无二的),并且选择相应的开发证书:
为项目设置一个独一无二的【Bundle Identifier】,才能确保在appstore开发者账户下启用iCloud功能。

2.授权APP使用iCloud服务:选中【Capabilities】标签,点击开关启用【iCloud】服务,勾选【Services】组中的【iCloud Documents】项,下面的容器【Containers】项会自动选上,如下图所示:

授权与容器
容器是存放在服务器的保存所有app数据的一个概念性位置,分为公有数据库与私有数据库。

3.在plist文件中增加配置项:用【Source Code】方式打开项目中的【ChatDemo-UI3.0-Info.plist】文件,在文件末尾新增如下配置:
<key>com.apple.developer.icloud-container-identifiers</key>三、实现【发送文件】功能
<array>
<string>iCloud.$(CFBundleIdentifier)</string>
</array>
<key>com.apple.developer.ubiquity-container-identifiers</key>
<array>
<string>$(AppIdentifierPrefix)$(CFBundleIdentifier)</string>
</array>
<key>com.apple.developer.ubiquity-kvstore-identifier</key>
<string>$(AppIdentifierPrefix)$(CFBundleIdentifier)</string>
1.显示【发送文件】按钮:在聊天窗口的扩展面板中增加【发送文件】的按钮。

(1).在EaseChatBarMoreView.h增加如下代码(具体代码可下载源码参考,文章底下有下载链接):

(3).编译运行项目,进入单聊页面,打开页面底下的扩展面板,就可以看到【发送文件】的按钮已经可以显示出来了。

2.点击【发送文件】按钮,使用UIDocumentPickerViewController打开iCloud文档页面:
文件选择控制器(UIDocumentPickerViewController)可以让用户在程序外访问程序的沙盒。是app间共享文件的一种简单方式。它也支持一些复杂方式,比如用户可能在多个app中编辑同一个文件。
文件选择器可以访问多个文件提供者的文件。比如,iClound可以让你访问其他app存储在iClound的文件,第三方开发者也可以提供文件
(注意:在mac或者windows系统上往icloud drive传文件时,有时候iphone上不能马上显示最新的文件列表,这时候只要在iphone上注销icloud账号重新登录即可)
(1).在EaseMessageViewController.m页面增加如下代码:
// 第1435行
-(void)moreViewFileTransferAction:(EaseChatBarMoreView *)moreView{
// 具体代码,请参考文章提供的源码项目....
....
}
// 选中icloud里的pdf文件
- (void)documentPicker:(UIDocumentPickerViewController *)controller didPickDocumentAtURL:(NSURL *)url {
// 具体代码,请参考文章提供的源码项目....
....
}
// 第2083行
- (void)sendFileMessageWithURL:(NSURL *)url displayName:(NSString*)displayName
{
// 具体代码,请参考文章提供的源码项目....
....
}
在EaseSDKHelper.m文件中添加如下代码:

在EaseSDKHelper.h添加如下代码:

在EaseBubbleView+File.m文件中添加如下代码:

编译运行,效果如下图所示:

四、实现【预览文件】功能
点击聊天窗口中的文件类型消息,使用UIDocumentInteractionController打开文件预览窗口查看文件内容。
文件交互控制器(UIDocumentInteractionController类的实例)为用户提供可接收程序来处理文件,使用起来非常灵活,功能也比较强大。它除了支持同设备上app之间的文档共享外,还可以实现文档的预览、打印、发邮件以及复制。
要使用一个文件交互控制器(UIDocumentInteractionController类的实例),需要以下步骤:
为每个你想打开的文件创建一个UIDocumentInteractionController类的实例;
实现UIDocumentInteractionControllerDelegate代理;
显示预览窗口/显示菜单。
在EaseMessageViewController.m页面增加如下代码:
// 第52行
UIDocumentInteractionController *_fileInteractionController;
// 第872行
// 打开文件
- (void)_fileMessageCellSelected:(id<IMessageModel>)model
{
// 具体代码,请参考文章提供的源码项目....
....
}
// 打开文件
-(void)openFileViewController:(NSString *) file_url {
// 具体代码,请参考文章提供的源码项目....
....
}
- (UIViewController *)documentInteractionControllerViewControllerForPreview:(UIDocumentInteractionController *)controller {
return self;
}
- (UIView *)documentInteractionControllerViewForPreview:(UIDocumentInteractionController *)controller {
return self.view;
}
- (CGRect)documentInteractionControllerRectForPreview:(UIDocumentInteractionController *)controller {
return self.view.frame;
}
// 第1308行
[self _fileMessageCellSelected:model];
// 第45行改为
@interface EaseMessageViewController ()<EaseMessageCellDelegate,UIDocumentPickerDelegate,UIDocumentInteractionControllerDelegate>
点击聊天窗口后,查看文件的效果如下图所示:

这样,一个简单的发送、预览文件功能就完成了。
技巧:如何参考代码实现功能
在百度网盘中下载本项目的完整源码,然后在xcode中打开项目,全局搜索【add by martin】,即可找到作者增加的相关代码。
https://pan.baidu.com/s/1c269Znq
如有问题,请加入【环信互帮互助群】(群号:340452063)提问。
完整源码可参考简书版文章:http://www.jianshu.com/p/034480a08714
相关文章参考
- android中如何显示开发者服务器上的昵称和头像http://www.imgeek.org/article/825307856
- IOS中如何显示开发者服务器上的昵称和头像http://www.imgeek.org/article/825307855
- IOS快速集成环信IM - 基于官方的Demo优化,5分钟集成环信IM功能http://www.imgeek.org/article/825307886
- 草草们的忧伤:环信IM昵称和头像 http://www.imgeek.org/article/825308536
- IOS中环信聊天窗口如何实现文件发送和预览的功能http://www.imgeek.org/question/6260
- 一言不合你就用环信搞个直播APPhttp://blog.csdn.net/mengmakies/article/details/51794248
收起阅读 »
环信稿酬计划
环信稿酬计划,恭喜你,环信能够与你相遇,算得上是走了(狗shi)运了。
想走向人生巅峰先看这里
1、投稿文章内容必须是关于“环信”、“移动开发”和“人工智能”之类的。这里的“环信”可以是即时通讯云,也可以是“环信移动客服”,当然也可以是“大数据、人工智能”等等,智者见智,希望看到你脑洞大开的良心佳作。
2、文章字数在1000至5000为宜。大神作品另论。显然这里“大神”指的是江南孤鹜,午夜狂魔以及李理等作者,或者自认为技术水平超过他们的,也请不吝赐教。
3、文章名字统一规定为《【环信征文】|XXXXXXX》,方便审稿以及打赏。“环信”两个字还是要写在题目上的,万一通过了呢!)
4、文章投稿至我要上周刊。被收录即代表你已通过。
5、投稿文章数量不限。但文章必须是2017年3月之后创作的作品。没错,我们就是这么喜新厌旧。优秀作品会被立即推至环信官网资讯首页,并且有机会被收录至环信开发者周刊、环信博客、环信微博以及环信公众号等平台。
以下内容并不重要,忙的朋友可以退出本文。
文章审核通过,将获得50~500人民币现金奖励(注:具体金额根据文章阅读数和评委评分比重各占一半!阅读数是重要的参考信息,最终决定权依然在评委手中。)

收起阅读 »
java使用Jersey调用rest api实例
我用的版本是1.19,需要以下几个jar包:

首先要写一个网络访问类,这里举了post和delete的例子,其他的方法基本相同:
import java.util.HashMap;使用的例子(创建群组方法,注意这里面使用了设置参数和Header的方法):
import java.util.Map;
import java.util.Set;
import com.google.gson.Gson;
import com.sun.jersey.api.client.Client;
import com.sun.jersey.api.client.WebResource;
import com.sun.jersey.api.client.WebResource.Builder;
public class HXRequest {
private String url;
private Map<String, Object> param = new HashMap<String, Object>();
private Map<String, String> header = new HashMap<String, String>();
public HXRequest(String url){
this.url = url;
}
public void setParam(String key, Object value) {
param.put(key, value);
}
public void setHeader(String key, String value) {
header.put(key, value);
}
/**
* 向指定URL发送POST方法的请求
*/
public String sendPost() {
Client client = Client.create();
WebResource resource = client.resource(url);
Builder builder = resource.header("Content-Type", "application/json");
Set<String> keys = header.keySet();
if(keys != null && keys.size() > 0){
for (String key : keys) {
builder = builder.header(key, header.get(key));
}
}
try {
String result = builder.entity(new Gson().toJson(param)).post(String.class);
System.out.println(result);
return result;
} catch(Exception e){
e.printStackTrace();
return null;
}
}
/**
* 向指定URL发送DELETE方法的请求
*/
public String sendDelete() {
Client client = Client.create();
WebResource resource = client.resource(url);
Builder builder = resource.header("Content-Type", "application/json");
Set<String> keys = header.keySet();
if(keys != null && keys.size() > 0){
for (String key : keys) {
builder = builder.header(key, header.get(key));
}
}
try {
String result = builder.entity(new Gson().toJson(param)).delete(String.class);
System.out.println(result);
return result;
} catch(Exception e){
e.printStackTrace();
return null;
}
}
}
/**收起阅读 »
* 创建群组
* @param hxname
* @return
*/
public static HXResult<HXGroup> createGroup(String hxname, String groupName, String token){
HXRequest request = new HXRequest(createGroupUrl);
request.setParam("groupname", groupName);
request.setParam("desc", groupName);
request.setParam("public", true);
request.setParam("approval", false);
request.setParam("owner", hxname);
request.setHeader("Authorization", "Bearer " + token);
String result = request.sendPost();
if(result == null)
return null;
HXResult<HXGroup> group = new Gson().fromJson(result,
new TypeToken<HXResult<HXGroup>>(){}.getType());
return group;
}
一言不合他就花2小时写了一个Slack的聊天机器人(猛戳下载源码)
2016年作为人工智能元年,聊天机器人(Chatbot)在各大行业的应用方兴未艾。据统计,2016年有超过3万个聊天机器人品牌和6千个相关技能涌入市场。国外包括Facebook Messenger、Slack等均引入了聊天机器人,所以毋庸置疑,聊天机器人将成为我们未来生活中不可或缺的一部分。近日,IMGEEK开源社区热心开发者&朝阳区群众“晨星桑”一言不合他就花2小时写了一个Slack的聊天机器人,猛戳“阅读原文”下载GitHub源码。

简介
什么是Slack
Slack是一个团队沟通的平台,在这里你可以群聊、单聊、甚至打电话。还可以通过简单的拖动,进行文件分享。甚至可以跟Github、Travis、Twitter等等工具和网站进行集成。如果这还不能满足需求,也可以定制自己的APP。Slack也支持强大的搜索功能,所有的消息、通知、文件都可以搜索。
Slack App & Slack Bot
Slack Apps是能提高工作效率的工具,这里已经有很多很好的工具,比如To-do bot,跟他聊天便可以轻松的定制计划任务,在指定的时间做你要求他做的事情。
当你添加To-do bot这个APP之后,你就可与To-do bot的机器人todobot聊天了,在左侧的DIRECT MESSAGES中找到todobot,如果没找到,点击加号,添加todobot,如下图

什么是环信移动客服
环信移动客服是一款国内领先的全媒体智能SaaS客服产品,支持全媒体接入,包括网页在线客服、社交媒体客服(微博、微信)、APP内置客服和呼叫中心等多种渠道均可一键接入。
初始化你的Slack
什时候需要把Slack和客服集成?
星巴克想在Slack上卖咖啡,而Slack的用户都是Team内部的,不可能在每个Team内都安插一个星巴克的服务员。这样就需要把Slack上用户发的消息转到一个集中地方处理,于是我就想到了环信移动客服,消息传递到移动客服,Slack用户可以跟某个客服聊天,并且通过一些定制开发能够看见Slack用户的基本信息(比如:昵称、电话、团队名称等),并且可以二维码支付。
创建你的APP
打开 https://api.slack.com/apps 页面,点击 Create New App 按钮
填写你的 App Name 并选择开发者的Team,你就可以点击Create App按钮了,出现下面界面的时候,你的App就创建好啦

初始化设置你的App
点击OAuth & Permissions页面,在下面会有Permission Scope,这里我们搜索bot,然后选择并 Save Changes
在上面的Redirect URLS中填写OAuth认证成功之后的回调地址,比如 https://xxx.xxx/oauth/callback,当然这会儿你可能也不知道你的地址是什么呢,记得之后会用得上
点击Event Subscriptions,这是设置Slack 事件订阅的,有了它,我们就可以接收到用户在Slack上发的消息了。
进入页面后打开开关,在下面的Subscribe to Team Events中,我们搜索并添加message.channel和message.im,分别是群聊和单聊的消息事件订阅
当然,光订阅是不行的,我们还要设置订阅的地址,在上面的Request Url中设置好你的订阅地址就可以李,比如 https://xxx.xxx/events/callback
创建Bot User,在BotUsers页面,创建一个BotUser
然后你就可以在OAuth & Permissions页面,点击Install App to Team按钮,把App安装到你的Team了
Hello World
Step 1:事件订阅初始化
在设置事件订阅地址的时候,Slack会尝试进行一次检查,需要你他们的请求中携带的challenge原封不动的返回给服务器
Slack进行事件订阅验证的请求体Step 2: 处理消息的事件
{
"type": "url_verification",
"challenge": "xxxxxxxxxxxxxx",
"token": "slack verify token"
}
当我们想处理用户发来的消息的时候,我们需要处理消息的事件订阅。
最外层的type为event_callback,event为事件内容,根据event中的type能区分event的类型,channel为消息投递的channel id,user为发送人的id,text为消息的内容
要小心:如果是机器人发送的消息,event中会有bot_id,如果处理不当会导致消息循环发送(不要问我怎么知道的……)
Step 3: 把消息发送到移动客服
Step 3.1: 获取发消息的Token
方法:POSTStep 3.2:发送文本消息
地址:https://a1.easemob.com/{org}/{app}/token
请求体:
{
"client_id": "client_id",
"client_secret": "client_secret",
"grant_type": "client_credentials"
}
响应体:
{
"accessToken": "ABCDEFG"
}
from为发送消息的人,目前以slackTeamId_slackUserId_slackChannelId为格式
方法:POSTStep 4: 让Slack App接收移动客服消息
地址:https://a1.easemob.com/{org}/{app}/messages
请求头:
Authorization: Bearer accessToken
请求体:
{
"from": "teamId_userid_channelId",
"targetType": "users",
"target": ["imServiceNumber"],
"msg": {
"msg": "你好",
"type": "txt"
},
"ext": {
"weichat": {
"visitor": {
"userNickname": "这里可以填写昵称,也可为空",
"companyName": "这里填写公司名称,也可以为空"
}
}
}
}
如果你想使用移动客服回调的方式接收消息,你需要跟你的移动客服客户经理申请开通;当然你也可以使用环信即时通讯云的SDK开发,使用长连接接收消息。
以下以回调模式举例,简单的集成只需要关心如下几个字段
- eventType应该为chat
- from 消息的发送人,应该就是imServiceNumber,要跟集成移动客服的保持一致
- payload是消息的内容,简单的可以先支持txt类型的
- to是接收消息的人,目前以slackTeamId_slackUserId_slackChannelId为格式
消息回调的bodyStep 5: 处理OAuth回调
{
"callId": "xxxxxxxx#xxxxxx_305833766880810084",
"chat_type": "chat",
"eventType": "chat",
"from": "im-channel",
"msg_id": "305833766880810084",
"payload": {
"bodies": [
{
"msg": "啊啊啊",
"type": "txt"
}
],
"ext": {
"weichat": {
"ack_for_msg_id": null,
"agent": {
"avatar": "",
"userNickname": "Admin"
}
}
}
},
"security": "xxxxxxxxxxxxxxxxx",
"timestamp": 1488772272814,
"to": "teamId_userid_channelId"
}
OAuth回调的时候,slack会传给我们一个code,这个code相当于一个临时令牌,来换取accessToken等信息,下面的API就是如何使用code来获取这些信息
方法:POSTStep 6: 把收到的消息发给Slack 用户
地址:https://slack.com/api/oauth.access
请求参数:
client_id
client_secret
code
响应体:
{
"access_token": "xoxp-139740849892-139751631381-146013991078-XXXXXXXXXXXXXXXXXXXXXXX",
"bot": {
"bot_access_token": "xoxb-144002817952-XXXXXXXXXXXXXXXXXXXXXXX",
"bot_user_id": "UXXXXXXXXX"
},
"ok": true,
"scope": "identify,bot",
"team_id": "TXXXXXXX",
"team_name": "91chenxing",
"user_id": "UXXXXXXX"
}
发消息需要以SlackBot的身份发送,需要根据teamId获取到SlackBot,获取bot的accessToken。什么时候能获取到SlackBot信息呢?在Slack用户安装App的时候,进行完OAuth认证,Slack Bot信息就会通过 OAuth 回调传给我们了
方法:GET至此你就可以在移动客服中和Slack中的用户聊天啦
地址:https://slack.com/api/chat.postMessage
请求参数:
token botAccessToken
channel 填写用户名中的channelId
text 消息内容
as_user 设置为true,就会以bot身份显示,而不是app
如果还需要获取User、Team的信息,可以使用Slack Api获取
如果需要的Api权限不够,则需要用户在授权的时候给予更多的权限
注意
- 一定要注意消息收发,一不小心会导致消息循环发送,形成死循环
- Slack的中Channel可以分为3中:Public Channel、Direct Message Channel、Private Channel,可以根据channel的第一个字母进行区分,C开头的是Public Channel,D开头的是Direct MessageChannel、G开头的是Private Channel
项目源码:https://github.com/sheepstarli/slack2easemobkefu 收起阅读 »



炸窝了,苹果禁止使用热更新

有开发者质疑可能是项目中使用了JSPatch、weex以及ReactNative等热更新技术。对于修复bug提交审核的开发者来说,热更新技术可以帮开发者避免长时间的审核等待以及多次被拒造成的成本开销。但也给黑客留了后门,也就违反了苹果的安全和隐私政策。
不过这次苹果只是对使用热更新的应用进行了警告,并没有开发者反应产品因此问题被下架。
对此,开发者表示:
舞小月:苹果注重的就是流畅性和用户体验,混编做的东西肯定没有native的流畅,这就违背了苹果本来的意愿,被禁也是正常的,而且苹果自己的蛋糕为何要分给竞争对手?以前没混编的时候你该怎么做不还是做了,现在没有,不代表以后没有,就像之前没有混编,后来有了混编。新的框架苹果自然也会去完善,苹果既然做了这个决定,他肯定会优化自己的东西。
Gilbertat:苹果爸爸会不会在自己的生态中搞死js啊
luohui8891:我们也是昨天收到的,目前没有什么对策。我们的APP只是用JSPatch做热修复,并不修改应用的功能行为等(但我觉得Apple并不care这个)。
lsllsllsl:没用RN没用JSPatch,同样收到警告。
luohui8891:@tcathy 根据邮件里说是你下次提交前请去掉这样远程下载代码运行的机制。所以应该就是下个版本如果不删除就reject
Loooren:早上收到邮件,itunesconnect站内信,电话通知....用到了weex
xiaofuyesnew:昨天晚上微软发布了Visual Studio 2017,自带基于React Native的iOS开发功能。鉴于微软这两年来开源的力度,发布这一功能似乎是在抢占开发者的市场,基于vs2017,在非苹果上开发ios应用更容易了。所以,苹果在这个节骨眼发出这个警告邮件,就有点威胁现有开发者的意思。暗地里想跟微软互怼。
对于那些已经在学习RN、weex、JSPatch的同学来说,这是个悲惨的故事


从苹果的角度看,禁止应用使用热更新技术更多是为了保护用户隐私、数据安全以及其全力打造的生态圈。对于用户来说,出于安全起见,应谨慎授予应用权限;对于开发者来说,为了审核以及长远的用户体验考虑,不要轻易触碰苹果拉的那条红线。

以上内容来源于CocoaChina,GitHub 收起阅读 »
Android ios V3.3.0 SDK 已发布,增加群组、聊天室管理员权限

Android V3.3.0 2017-03-07
新功能:
- 群组和聊天室改造:增加管理员权限,新增禁言,增减管理员的功能,支持使用分批的方式获取成员,禁言,管理员列表,支持完善的聊天室功能。新增加API请查看链接3.3.0 api修改
- 优化dns劫持时的处理
- 增加EMConversation.latestMessageFromOthers,表示收到对方的最后一条消息
- 增加EMClient.compressLogs,压缩log,Demo中增加通过邮件发送log的示例
- libs.without.audio继续支持armeabi,解决armeabi-v5te的支持问题
bug 修订:
- 修复2.x升级3.x消息未读数为0的bug
- Demo在视频通话时,主叫方铃声没有播放的问题
- Demo在视频通话时,主叫方在建立连接成功后,文字提示不正确
- Demo在聊天窗口界面,清空消息后,收到新的消息,返回会话列表,未读消息数显示不正确
- 修复在Oppo和Vivo手机上出现的JobService报错。
- EMGroupManager.createGroup成员列表数超过512产生的overflow错误
- 修复部分手机在网络切换时发消息慢的bug
ios V3.3.0 2017-03-07
新功能:
- 新增:群组改造,增加一系列新接口,具体查看iOS iOS 3.3.0 api修改
- 新增:获取SDK日志路径接口,将日志文件压缩成.gz文件,返回gz文件路径,[EMClient getLogFilesPath:]
- 更新:使用视频通话录制功能时,必须在开始通话之前调用[EMVideoRecorderPlugin initGlobalConfig]
优化:
- 优化DNS劫持时的处理
- 切换网络时,减小消息重发的等待时间
修复:
- 音视频通话丢包率(以前返回的是丢包数)
- IOS动态库用H264编码在iPhone6s上崩溃
- 实时音视频新旧版互通崩溃
版本历史:Android SDK更新日志 ios SDK更新日志
下载地址:SDK下载 收起阅读 »
环信完成C轮1.03亿元融资,深耕BI和AI层!
3月8日,企业级软件服务提供商环信今日对外宣布,完成C轮103000000元人民币融资,本轮融资由经纬领投,银泰嘉禾跟投。环信创始人、CEO刘俊彦表示:“本轮融资资金将用于环信BI和AI层的产品打磨、完善生态圈建设以及提升垂直行业解决方案能力。”

环信CEO宣布完成由经纬领投的C轮1.03亿元融资
1. 顶级风投持续看好,资本、客户规模、产品、大客户等核心维度均领先行业。
一直将环信视为中国企业级服务潜在“独角兽”公司的经纬中国合伙人左凌烨表示:“客服是企业服务软件的最大市场之一。随着用户体验和技术演进,对客服产品提出更多挑战,包括全渠道,实时性,移动化和AI辅助等等。环信作为该领域的绝对领先的创业公司,率先满足这些需求,推出并不断优化其一流产品。先后获得泰康,中信证券,中意人寿,国美在线等多家国内500强标杆客户,年收入保持250%以上的增长,取得骄人的市场认可和业务增长。经纬非常看好客服市场在中国的前景,并坚信环信将保持势头,成为该领域的领军企业。”
环信目前有三条产品线,包括环信即时通讯云、环信移动客服和环信人工智能。在2013年成立之初,环信推出PaaS通讯能力平台“环信即时通讯云”,用即时通讯“连接人与人”。2015年环信推出SaaS客服云产品“环信移动客服”,用即时通讯“连接人与商业”。随后,环信移动客服又拓展包括微信、微博、网页端、呼叫中心等全渠道客服接入能力,帮助企业和消费者多点接触。
移动互联时代,当用户能够在任何时间、任意地点,跨渠道、跨媒体、跨平台联系商家获得服务以后,客服请求必然激增。“我们希望能通过人工智能解决商家日益增长的客服成本和海量客服请求之间的天然矛盾,人工智能显然是绝佳的手段。”刘俊彦这样评价人工智能产品线。从最初的连接人与人,到连接人与商业,再到如今的人工智能,环信的主线关键词一直都是“连接”。
截至2016年底,环信即时通讯云共服务了130176家APP客户。环信移动客服共服务了58541家企业客户,包括泰康在线、中意人寿、中信证券、国美在线、优信二手车、新东方、新浪微博、链家、58到家、神州专车等。
2. SaaS公司四个竞争层面,深耕细作BI和AI层,深度连接人与商业。
环信CEO刘俊彦认为如果从核心竞争力的角度,可以将SaaS企业的发展划分为四个层面。分为工具层、BI层(数据层)、生态圈和AI层。SaaS产品在工具层面的竞争将越来越难以差异化。BI层(数据层)是将工作流里产生的数据和知识变成产品。一旦用户的个性化数据和知识也变成了产品的一部分,用户的迁移成本将变得更高,这时企业才开始有了自己独特的竞争壁垒。SaaS企业的终极竞争层面是AI层,这是一个大趋势。
对于产品的优势,刘俊彦表示环信已经做到了工具层面的领先,在第二个层面即BI层面,环信也推出了相应的产品,如环信客户声音。环信客户声音是基于人工智能和大数据挖掘的客户体验透析产品。Gartner联合环信发布的《下一代客户服务软件趋势》报告显示:“客户声音(VOC)是企业有关客户体验管理(CEM)战略需要考量的核心维度。全媒体客服的最佳体验不仅是多渠道的接入,更重要的是跨渠道环境下的用户体验保证。”环信认为理解客户声音是保证客户体验的最重要一环,环信客户声音运用NLP(自然语言解析),深度学习等人工智能技术,对来自多种渠道的非结构化数据源进行客服业务的特征提取,主题聚类解析,情感分析建模。从而帮助企业挖掘和分析客户服务中的热点话题,发现服务运营问题,寻找畅销或问题产品,洞察销售机会。
在第四层即AI层面,环信推出了环信智能客服机器人和环信智能质检。环信客服机器人基于机器学习技术和自然语言处理,辅助、替代人工客服回答常见、高频的问题,从而降低人力成本。环信智能质检则是基于环信在线客服积累的各个领域的海量用户对话,提取出数百个客服对话特征,并用这些特征训练得到的几十种常见通用质检模型,从而将质检从过去人工、抽样,转变为自动、全面的工作。刘俊彦认为:“软件正在吃掉世界,而AI正在吃掉软件。客户服务行业因为其劳动力密集,有海量数据等特点,是现阶段AI能够真实落地并能产生巨大价值的几个行业之一。”
环信在客户互动这一主线上,从连接消费者,到客服的效率工具,已经完成主要的布局。下一步是紧紧把握住客户服务全面转向移动端,以及对话经济(Conversation As A Commerce)的新趋势,产品继续深耕细作,深度连接人与商业,全力发展BI和AI,引导SaaS客服行业的发展进入到一个新的层面。
3. 完善生态圈,推出五大垂直行业智能客户互动解决方案,服务好大型客户。
SaaS企业的核心竞争力的第三层是生态圈,只有建立生态圈,SaaS企业才能真正筑起足够高的竞争门槛。Salesforce目前拥有上百家企业在其force.com平台上进行软件、插件的开发,已形成自己的生态,其他公司基本无法与之抗衡。比如要颠覆Salesforce,就不再只是颠覆掉Salesforce的产品本身,还要同时颠覆Salesforce生态中的几百家合作伙伴公司。
只有完善生态圈推出行业垂直解决方案才能更好的服务大客户。环信已经陆续推出了针对五大垂直行业的智能客户互动解决方案,同时大客户战略的执行也初见成效。2016年环信平均客单价已经达到6.2万左右,2017年将会持续提升,预计将进入10万到20万区间。同时,在金融、证券、银行、教育等行业均实现了大客户的重要突破,签约了众多500强行业标杆客户,标志着中国的新兴SaaS企业,开始和中科软,恒生电子这样的传统大型IT系统供应商同场竞技,获得了主流大型传统企业的认可。
4. 诗和远方是中国的Salesforce,这一代明星SaaS公司是下代中国SaaS创业者的天花板。
中国企业级软件服务市场和北美市场最大的不同就是,在北美除了Salesforce和Oracle等巨头外,大部分SaaS企业只能做巨头看不上的中小客户市场,上升空间天花板明显。中国企业级服务市场既没有本土巨头,又因为国外巨头企业服务公司进入中国有天然政策壁垒,可谓既无内忧也无外患。所以包括客服云、销售云、HR云、财务云、协同云等核心企业级服务赛道这几年都在野蛮生长,各赛道格局也已初定,成长起来了一批明星公司。
环信的诗和远方是中国的Salesforce,中国这一代各个赛道的领先SaaS企业因为没有既有的天花板,都有可能最终成为中国的Salesforce,这一批企业也将成为下一代中国SaaS创业者的天花板。 收起阅读 »
李理:详解卷积神经网络
作者:李理
目前就职于环信,即时通讯云平台和全媒体智能客服平台,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。
相关文章:
李理:从Image Caption Generation理解深度学习(part I)
李理:从Image Caption Generation理解深度学习(part II)
李理:从Image Caption Generation理解深度学习(part III)
李理:自动梯度求解 反向传播算法的另外一种视角
李理:自动梯度求解——cs231n的notes
李理:自动梯度求解——使用自动求导实现多层神经网络
接下来介绍一种非常重要的神经网络——卷积神经网络。这种神经网络在计算机视觉领域取得了重大的成功,而且在自然语言处理等其它领域也有很好的应用。深度学习受到大家的关注很大一个原因就是Alex等人实现的AlexNet(一种深度卷积神经网络)在LSVRC-2010 ImageNet这个比赛中取得了非常好的成绩。此后,卷积神经网络及其变种被广泛应用于各种图像相关任务。
这里主要参考了Neural Networks and Deep Learning和cs231n的课程来介绍CNN,两部分都会有理论和代码。前者会用theano来实现,而后者会使用我们前一部分介绍的自动梯度来实现。下面首先介绍Michael Nielsen的部分(其实主要是翻译,然后加一些我自己的理解)。
前面的话
如果读者自己尝试了上一部分的代码,调过3层和5层全连接的神经网络的参数,我们会发现神经网络的层数越多,参数(超参数)就越难调。但是如果参数调得好,深的网络的效果确实比较浅的好(这也是为什么我们要搞深度学习的原因)。所以深度学习有这样的说法:“三个 bound 不如一个 heuristic,三个 heuristic 不如一个trick”。以前搞机器学习就是feature engineering加调参,现在就剩下调参了。网络的结构,参数的初始化,learning_rate,迭代次数等等都会影响最终的结果。有兴趣的同学可以看看Michael Nielsen这个电子书的相应章节,cs231n的Github资源也有介绍,另外《Neural Networks: Tricks of the Trade》这本书,看名字就知道讲啥的了吧。
不过我们还是回到正题“卷积神经网络”吧。
CNN简介
在之前的章节我们使用了神经网络来解决手写数字识别(MNIST)的问题。我们使用了全连接的神经网络,也就是前一层的每一个神经元都会连接到后一层的每一个神经元,如果前一层有m个节点,后一层有n个,那么总共有m*n条边(连接)。连接方式如下图所示:

具体来讲,对于输入图片的每一个像素,我们把它的灰度值作为对应神经元的输入。对于28×28的图像来说,我们的网络有784个输入神经元。然后我们训练这个网络的weights和biases来使得它可以正确的预测对应的数字。
我们之前设计的神经网络工作的很好:在MNIST手写识别数据集上我们得到了超过98%的准确率。但是仔细想一想的话,使用全连接的网络来识别图像有一些奇怪。因为这样的网络结构没有考虑图像的空间结构。比如,它对于空间上很近或者很远的像素一样的对待。这些空间的概念【比如7字会出现某些像素在某个水平方向同时灰度值差不多,也就是上面的那一横】必须靠网络从训练数据中推测出来【但是如果训练数据不够而且图像没有做居中等归一化的话,如果训练数据的7的一横都出现在图像靠左的地方,而测试数据把7写到右下角,那么网络很可能学不到这样的特征】。那为什么我们不能设计一直网络结构考虑这些空间结构呢?这样的想法就是下面我们要讨论的CNN的思想。
这种神经网络利用了空间结构,因此非常适合用来做图片分类。这种结构训练也非常的快,因此也可以训练更“深”的网络。目前,图像识别大都使用深层的卷积神经网络及其变种。
卷积神经网络有3个基本的idea:局部感知域(Local Recpetive Field),权值共享和池化(Pooling)。下面我们来一个一个的介绍它们。
局部感知域
在前面图示的全连接的层里,输入是被描述成一列神经元。而在卷积网络里,我们把输入看成28×28方格的二维神经元,它的每一个神经元对应于图片在这个像素点的强度(灰度值),如下图所示:

和往常一样,我们把输入像素连接到隐藏层的神经元。但是我们这里不再把输入的每一个像素都连接到隐藏层的每一个神经元。与之不同,我们把很小的相临近的区域内的输入连接在一起。
更加具体的来讲,隐藏层的每一个神经元都会与输入层一个很小的区域(比如一个5×5的区域,也就是25个像素点)相连接。隐藏对于隐藏层的某一个神经元,连接如下图所示:

输入图像的这个区域叫做那个隐藏层神经元的局部感知域。这是输入像素的一个小窗口。每个连接都有一个可以学习的权重,此外还有一个bias。你可以把那个神经元想象成用来分析这个局部感知域的。
我们然后在整个输入图像上滑动这个局部感知域。对于每一个局部感知域,都有一个隐藏层的神经元与之对应。为了具体一点的展示,我们首先从最左上角的局部感知域开始:

然后我们向右滑动这个局部感知域:

以此类推,我们可以构建出第一个隐藏层。注意,如果我们的输入是28×28,并且使用5×5的局部关注域,那么隐藏层是24×24。因为我们只能向右和向下移动23个像素,再往下移动就会移出图像的边界了。【说明,后面我们会介绍padding和striding,从而让图像在经过这样一次卷积处理后尺寸可以不变小】
这里我们展示了一次向右/下移动一个像素。事实上,我们也可以使用一次移动不止一个像素【这个移动的值叫stride】。比如,我们可以一次向右/下移动两个像素。在这篇文章里,我们只使用stride为1来实验,但是请读者知道其他人可能会用不同的stride值。
共享权值
之前提到过每一个隐藏层的神经元有一个5×5的权值。这24×24个隐藏层对应的权值是相同的。也就是说,对于隐藏层的第j,k个神经元,输出如下:
σ(b+∑l=04∑m=04wl,maj+l,k+m)这里,σ是激活函数,可以是我们之前提到的sigmoid函数。b是共享的bias,Wl,m 是5×5的共享权值。ax,y 是输入在x,y的激活。
【从这个公式可以看出,权值是5×5的矩阵,不同的局部感知域使用这一个参数矩阵和bias】
这意味着这一个隐藏层的所有神经元都是检测同一个特征,只不过它们位于图片的不同位置而已。比如这组weights和bias是某个局部感知域学到的用来识别一个垂直的边。那么预测的时候不管这条边在哪个位置,它都会被某个对于的局部感知域检测到。更抽象一点,卷积网络能很好的适应图片的位置变化:把图片中的猫稍微移动一下位置,它仍然知道这是一只猫。
因为这个原因,我们有时把输入层到隐藏层的映射叫做特征映射(feature map)。我们把定义特征映射的权重叫做共享的权重(shared weights),bias叫做共享的bias(shared bais)。这组weights和bias定义了一个kernel或者filter。
上面描述的网络结构只能检测一种局部的特征。为了识别图片,我们需要更多的特征映射。隐藏一个完整的卷积神经网络会有很多不同的特征映射:

在上面的例子里,我们有3个特征映射。每个映射由一个5×5的weights和一个biase确定。因此这个网络能检测3种特征,不管这3个特征出现在图像的那个局部感知域里。
为了简化,上面之展示了3个特征映射。在实际使用的卷积神经网络中我们会使用非常多的特征映射。早期的一个卷积神经网络——LeNet-5,使用了6个特征映射,每一个都是5×5的局部感知域,来识别MNIST数字。因此上面的例子和LeNet-5很接近。后面我们开发的卷积层将使用20和40个特征映射。下面我们先看看模型学习到的一些特征:

这20个图片对应了20个不同的特征映射。每个映射是一个5×5的图像,对应于局部感知域的5×5个权重。颜色越白(浅)说明权值越小(一般都是负的),因此对应像素对于识别这个特征越不重要。颜色越深(黑)说明权值越大,对应的像素越重要。
那么我们可以从这些特征映射里得出什么结论呢?很显然这里包含了非随机的空间结构。这说明我们的网络学到了一些空间结构。但是,也很难说它具体学到了哪些特征。我们学到的不是一个 Gabor滤波器 的。事实上有很多研究工作尝试理解机器到底学到了什么样的特征。如果你感兴趣,可以参考Matthew Zeiler 和 Rob Fergus在2013年的论文 Visualizing and Understanding Convolutional Networks。。
共享权重和bias的一大好处是它极大的减少了网络的参数数量。对于每一个特征映射,我们只需要 25=5×5 个权重,再加一个bias。因此一个特征映射只有26个参数。如果我们有20个特征映射,那么只有20×26=520个参数。如果我们使用全连接的神经网络结构,假设隐藏层有30个神经元(这并不算很多),那么就有784*30个权重参数,再加上30个bias,总共有23,550个参数。换句话说,全连接的网络比卷积网络的参数多了40倍。
当然,我们不能直接比较两种网络的参数,因为这两种模型有本质的区别。但是,凭直觉,由于卷积网络有平移不变的特性,为了达到相同的效果,它也可能使用更少的参数。由于参数变少,卷积网络的训练速度也更快,从而相同的计算资源我们可以训练更深的网络。
“卷积”神经网络是因为公式(1)里的运算叫做“卷积运算”。更加具体一点,我们可以把公式(1)里的求和写成卷积:$a^1 = \sigma(b + w * a^0)$。*在这里不是乘法,而是卷积运算。这里不会讨论卷积的细节,所以读者如果不懂也不要担心,这里只不过是为了解释卷积神经网络这个名字的由来。【建议感兴趣的读者参考colah的博客文章 《Understanding Convolutions》】
池化(Pooling)
除了上面的卷积层,卷积神经网络也包括池化层(pooling layers)。池化层一般都直接放在卷积层后面池化层的目的是简化从卷积层输出的信息。
更具体一点,一个池化层把卷积层的输出作为其输入并且输出一个更紧凑(condensed)的特征映射。比如,池化层的每一个神经元都提取了之前那个卷积层的一个2×2区域的信息。更为具体的一个例子,一种非常常见的池化操作叫做Max-pooling。在Max-Pooling中,这个神经元选择2×2区域里激活值最大的值,如下图所示:

注意卷积层的输出是24×24的,而池化后是12×12的。
就像上面提到的,卷积层通常会有多个特征映射。我们会对每一个特征映射进行max-pooling操作。因此,如果一个卷积层有3个特征映射,那么卷积加max-pooling后就如下图所示:

我们可以把max-pooling看成神经网络关心某个特征在这个区域里是否出现。它忽略了这个特征出现的具体位置。直觉上看,如果某个特征出现了,那么这个特征相对于其它特征的精确位置是不重要的【精确位置不重要,但是大致的位置是重要的,比如识别一个猫,两只眼睛和鼻子有一个大致的相对位置关系,但是在一个2×2的小区域里稍微移动一下眼睛,应该不太影响我们识别一只猫,而且它还能解决图像拍摄角度变化,扭曲等问题】。而且一个很大的好处是池化可以减少特征的个数【2×2的max-pooling让特征的大小变为原来的1/4】,因此减少了之后层的参数个数。
Max-pooling不是唯一的池化方法。另外一种常见的是L2 Pooling。这种方法不是取2×2区域的最大值,而是2×2区域的每个值平方然后求和然后取平方根。虽然细节有所不同,但思路和max-pooling是类似的:L2 Pooling也是从卷积层压缩信息的一种方法。在实践中,两种方法都被广泛使用。有时人们也使用其它的池化方法。如果你真的想尝试不同的方法来提供性能,那么你可以使用validation数据来尝试不同池化方法然后选择最合适的方法。但是这里我们不在讨论这些细节。【Max-Pooling是用的最多的,甚至也有人认为Pooling并没有什么卵用。深度学习一个问题就是很多经验的tricks由于没有太多理论依据,只是因为最早的人用了,而且看起来效果不错(但可能换一个数据集就不一定了),所以后面的人也跟着用。但是过了没多久又被认为这个trick其实没啥用】
放到一起
现在我们可以把这3个idea放到一起来构建一个完整的卷积神经网络了。它和之前我们看到的结构类似,不过增加了一个有10个神经元的输出层,这个层的每个神经元对应于0-9直接的一个数字:

这个网络的输入的大小是28×28,每一个输入对于MNIST图像的一个像素。然后使用了3个特征映射,局部感知域的大小是5×5。这样得到3×24×24的输出。然后使用对每一个特征映射的输出应用2×2的max-pooling,得到3×12×12的输出。
最后一层是全连接的网络,3×12×12个神经元会连接到输出10个神经元中的每一个。这和之前介绍的全连接神经网络是一样的。
卷积结构和之前的全连接结构有很大的差别。但是整体的图景是类似的:一个神经网络有很多神经元,它们的行为有weights和biase确定。并且整体的目标也是类似的:使用训练数据来训练网络的weights和biases使得网络能够尽量好的识别图片。
和之前介绍的一样,这里我们仍然使用随机梯度下降来训练。不过反向传播算法有所不同。原因是之前bp算法的推导是基于全连接的神经网络。不过幸运的是求卷积和max-pooling的导数是非常简单的。如果你想了解细节,请自己推导。【这篇文章不会介绍CNN的梯度求解,后面实现使用的是theano,后面介绍CS231N的CNN是会介绍怎么自己来基于自动求导来求这个梯度,而且还会介绍高效的算法,感兴趣的读者请持续关注】
CNN实战
前面我们介绍了CNN的基本理论,但是没有讲怎么求梯度。这里的代码是用theano来自动求梯度的。我们可以暂时把cnn看出一个黑盒,试试用它来识别MNIST的数字。后面的文章会介绍theano以及怎么用theano实现CNN。
代码
首先得到代码: git clone
安装theano
参考这里 ;如果是ubuntu的系统,可以参考这里 ;如果您的机器有gpu,请安装好cuda以及让theano支持gpu。
默认的network3.py的第52行是 GPU = True,如果您的机器没有gpu,请把这一行改成GPU = False
baseline
首先我们实现一个baseline的系统,我们构建一个只有一个隐藏层的3层全连接网络,隐藏层100个神经元。我们训练时60个epoch,使用learning rate $\eta = 0.1$,batch大小是10,没有正则化:
$cd src
$ipython
>>> import network3
>>> from network3 import Network
>>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
>>> training_data, validation_data, test_data = network3.load_data_shared()
>>> mini_batch_size = 10
>>> net = Network([
FullyConnectedLayer(n_in=784, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
得到的分类准确率是97.8%。这是在test_data上的准确率,这个模型使用训练数据训练,并根据validation_data来选择当前最好的模型。使用validation数据来可以避免过拟合。读者运行时可能结果会有一些差异,因为模型的参数是随机初始化的。
改进版本1
我们首先在输入的后面增加一个卷积层。我们使用5 5的局部感知域,stride等于1,20个特征映射。然后接一个2 2的max-pooling层。之后接一个全连接的层,最后是softmax(仿射变换加softmax):

在这种网络结构中,我们可以认为卷积和池化层可以学会输入图片的局部的空间特征,而全连接的层整合全局的信息,学习出更抽象的特征。这是卷积神经网络的常见结构。
下面是代码:
>>> net = Network([【注意图片的大小,开始是(mini_batch_size, 1, 28 ,28),经过一个20个5 5的卷积池层后变成了(mini_batch_size, 20, 24,24),然后在经过2 2的max-pooling后变成了(mini_batch_size, 20, 12, 12),然后接全连接层的时候可以理解成把所以的特征映射展开,也就是20 12 12,所以FullyConnectedLayer的n_in是20 12 12】
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=20*12*12, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
这个模型得到98.78%的准确率,这相对之前的97.8%是一个很大的提高。事实上我们的错误率减少了1/3,这是一个很大的提高。【准确率很高的时候就看错误率的减少,这样比较有成就感,哈哈】
如果要用gpu,可以把上面的命令保存到一个文件test.py,然后:
$THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32 python test.py在这个网络结构中,我们吧卷积和池化层看出一个整体。这只是一种习惯。network3.py会把它们当成一个整体,每个卷积层后面都会跟一个池化层。但实际的一些卷积神经网络并不都要接池化层。
改进版本2
我们再加入第二个卷积-池化层。这个卷积层插入在第一个卷积层和全连接层中间。我们使用同样的5×5的局部感知域和2×2的max-pooling。代码如下:
>>> net = Network([【注意图片的大小,开始是(mini_batch_size, 1, 28 ,28),经过一个20个5 5的卷积池层后变成了(mini_batch_size, 20, 24,24),然后在经过2 2的max-pooling后变成了(mini_batch_size, 20, 12, 12)。然后是40个5*5的卷积层,变成了(mini_batch_size, 40, 8, 8),然后是max-pooling得到(mini_batch_size, 40, 4, 4)。然后是全连接的层】
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2)),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2)),
FullyConnectedLayer(n_in=40*4*4, n_out=100),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.1,
validation_data, test_data)
这个模型得到99.6%的准确率!
这里有两个很自然的问题。第一个是:加第二个卷积-池化层有什么意义呢?事实上,你可以认为第二个卷积层的输入是12*12的”图片“,它的”像素“代表某个局部特征。【比如你可以认为第一个卷积层识别眼睛鼻子,而第二个卷积层识别脸,不同生物的脸上面鼻子和眼睛的相对位置是有意义的】
这是个看起来不错的解释,那么第二个问题来了:第一个卷积层的输出是不同的20个不同的局部特征,因此第二个卷积层的输入是20 12 12。这就像我们输入了20个不同的”图片“,而不是一个”图片“。那第二个卷积层的神经元学到的是什么呢?【如果第一层的卷积网络能识别”眼睛“,”鼻子“,”耳朵“。那么第二层的”脸“就是2个眼睛,2个耳朵,1个鼻子,并且它们满足一定的空间约束。所以第二层的每一个神经元需要连接第一层的每一个输出,如果第二层只连接”眼睛“这个特征映射,那么只能学习出2个眼睛,3个眼睛这样的特征,那就没有什么用处了】
改进版本3
使用ReLU激活函数。ReLU的定义是:
ReLU(x)=max(0,x)
>>> from network3 import ReLU
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
使用ReLU后准确率从99.06%提高到99.23%。从作者的经验来看,ReLU总是要比sigmoid激活函数要好。
但为什么ReLU就比sigmoid或者tanh要好呢?目前并没有很好的理论介绍。ReLU只是在最近几年开始流行起来的。为什么流行的原因是经验:有一些人尝试了ReLU,然后在他们的任务里取得了比sigmoid好的结果,然后其他人也就跟风。理论上没有人证明ReLU是更好的激活函数。【所以说深度学习有很多tricks,可能某几年就流行起来了,但过几年又有人认为这些tricks没有意义。比如最早的pretraining,现在几乎没人用了。】
改进版本4
扩展数据。
深度学习非常依赖于数据。我们可以根据任务的特点”构造“新的数据。一种简单的方法是把训练数据里的数字进行一下平移,旋转等变换。虽然理论上卷积神经网络能学到与位置无关的特征,但如果训练数据里数字总是出现在固定的位置,实际的模型也不一定能学到。所以我们构造一些这样的数据效果会更好。
$ python expand_mnist.pyexpand_mnist.py这个脚本就会扩展数据。它只是简单的把图片向上下左右各移动了一个像素。扩展后训练数据从50000个变成了250000个。
接下来我们用扩展后的数据来训练模型:
>>> expanded_training_data, _, _ = network3.load_data_shared(这个模型的准确率是99.37%。扩展数据看起来非常trival,但是却极大的提高了识别准确率。
"../data/mnist_expanded.pkl.gz")
>>> net = Network([
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
改进版本5
接下来还有改进的办法吗?我们的全连接层只有100个神经元,增加神经元有帮助吗? 作者尝试了300和1000个神经元的全连接层,得到了99.46%和99.43%的准确率。相对于99.37%并没有本质的提高。
那再加一个全连接的层有帮助吗?我们了尝试一下:
>>> net = Network([在第一个全连接的层之后有加了一个100个神经元的全连接层。得到的准确率是99.43%,把这一层的神经元个数从100增加到300个和1000个得到的准确率是99.48 %和99.47%。有一些提高但是也不明显。
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU),
SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
>>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda=0.1)
为什么增加更多层提高不多呢,按说它的表达能力变强了,可能的原因是过拟合。那怎么解决过拟合呢?一种方法就是dropout。drop的详细解释请参考这里。简单来说,dropout就是在训练的时候随机的让一些神经元的激活“丢失”,这样网络就能学到更加鲁棒的特征,因为它要求某些神经元”失效“的情况下网络仍然能工作,因此就不会那么依赖某一些神经元,而是每个神经元都有贡献。
下面是在两个全连接层都加入50%的dropout:
>>> net = Network([使用dropout后,我们得到了99.60%的一个模型。
ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
filter_shape=(20, 1, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
filter_shape=(40, 20, 5, 5),
poolsize=(2, 2),
activation_fn=ReLU),
FullyConnectedLayer(
n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
FullyConnectedLayer(
n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],
mini_batch_size)
>>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03,
validation_data, test_data)
这里有两点值得注意:
- 训练的epoch变成了40.因为dropout减少了过拟合,所以我们不需要60个epoch。
- 全连接层使用了1000个神经元。因为dropout会丢弃50%的神经元,所以从直觉来看1000个神经元也相当于只有500个。如果过用100个神经元感觉太少了点。作者经过验证发现有了dropout用1000个比300个的效果好。
改进版本6
ensemble多个神经网络。作者分别训练了5个神经网络,每一个都达到了99.6%的准确率,然后用它们来投票,得到了99.67%准确率的模型。
这是一个非常不错的模型了,10000个测试数据只有33个是错误的,我们把错误的图片都列举了出来:

图片的右上角是正确的分类,右下角是模型的分类。可以发现有些错误可能人也会犯,因为有些数字人也很难分清楚。
【为什么只对全连接的层使用dropout?】
如果读者仔细的阅读代码,你会发现我们只对全连接层进行了dropout,而卷积层没有。当然我们也可以对卷积层进行dropout。但是没有必要。因为卷积层本身就有防止过拟合的能力。原因是权值共享强制网络学到的特征是能够应用到任何位置的特征。这让它不太容易学习到特别局部的特征。因此也就没有必要对它进行的dropout了。
更进一步
感兴趣的读者可以参考这里,列举了MNIST数据集的最好结果以及对应的论文。目前最好的结果是99.79%
What’s Next?
接下来的文章会介绍theano,一个非常流行的深度学习框架,然后会讲解network3.py,也就是怎么用theano实现CNN。敬请关注。
收起阅读 »
两会专题报道:从北京到天津,他们改变了什么?看环信天津研发中心负责人赵贵斌的花样人生

年近40岁的北京人赵贵斌,去年10月带着组建环信天津研发中心的任务来到天津于家堡,和同事们一起,让已经在北京生根的环信延伸到天津。早在来天津之前,这名清华北大双料高材生就已经属于“外溢”的人才,曾跟随妻子在宁波工作过几年。他是跟随着工作走,也是跟随着自己的心走。 如今,环信正在快速地发展,招聘到更多的人才,是他面临的最大难题。
.jpg")
对于家堡这个地方,赵贵斌有着很高的评价。他和妻子居住在公寓,周围有购物中心、菜市场、高铁站,干什么都很方便。平时闲下来,赵贵斌还喜欢在河边散步、跑步。这周边人少,安静,不堵车,他说在这样的环境中,他能够很快地高效率地投入到工作,更能有许多独立思考问题的时间。
.jpg")
如今,赵贵斌的公司正在快速地发展,招聘到更多的人才,是他们面临的最大难题。赵贵斌希望,那些盲目地想要去“北漂”的年轻人,应该好好地算一笔账,说不定算明白之后就会发现,北京之外,还有更多更明智的选择。 (来自:腾讯大燕网·天津站) 收起阅读 »
环信移动客服v5.11发布——机器人渠道设置变更为路由规则“渠道指定”,管理员可以发通知给所有客服
【优化】历史会话支持查询会话转接情况
在“历史会话”页面可以查看会话是否经过转接,并且可以根据“是否转接”对会话进行筛选。
【优化】导出管理提供下载记录
在“导出管理”页面,可以查看每个导出文件的下载记录,包括客服名称、下载时间、IP地址。
管理员模式
机器人渠道设置变更为路由规则“渠道指定”
机器人渠道设置从“智能机器人 > 机器人设置”页面转移到“设置 > 会话分配规则”页面的路由规则“渠道指定”,并增加为渠道指定技能组。
数据迁移
版本更新后,原来的“机器人开关”中渠道设置将完全同步至“渠道指定”,工作时间设置变化为:
- “全天接会话”:对应“全天指定机器人”;
- “上班时间客服全忙以及下班时间接会话”和“仅下班时间接会话”:均对应“上班时间不指定”和“下班时间指定机器人”。

各路由规则说明如下:
- 渠道指定:为APP、网页、微信、微博这四种渠道分别指定机器人或技能组,支持全天指定和分上下班时间指定。
- 关联指定:为各个渠道内的关联分别指定机器人或技能组,支持全天指定和分上下班时间指定。
- 入口指定:通过网页和APP的访客端指定会话分配的技能组。
- 默认指定:将没有指定技能组的会话统一分配至未分组。
- 渠道指定、关联指定、入口指定这三种路由规则可以上下拖动,排在上方的路由规则优先级高;
- 当优先级高的路由规则指定机器人,优先级低的路由规则指定技能组,那么,机器人转人工时,分两种情况:
- 当优先级高的路由规则指定技能组,优先级低的路由规则指定机器人,那么,会话由指定的技能组接待,不会再转给机器人。
管理员可以发通知给所有客服
在管理员模式的“消息中心”页面,管理员可以向客服团队成员发布通知,内容可以是文字或附件,通知将展示在收件人的消息中心。
在“消息中心”页面,点击“发送新通知”,从右侧选择客服同事,并填写主题、内容或添加附件,点击“发送通知”,向收件人发送一条通知。

新增技术支持模块
移动客服系统新增“技术支持”页面,提供查看文档、常见问题的快捷入口,网络检测功能,以及联系环信官网客服的按钮。

【优化】机器人菜单增加“返回上一级”选项
支持创建4级机器人菜单,第2-4级菜单增加“返回上一级”选项,优化机器人接待时的用户体验。

【优化】增加开关控制仅机器人接待会话时是否自动发送满意度评价邀请
在“设置 > 系统开关”页面,当“会话结束自动发送满意度评价邀请”开关打开时,可以进一步选择仅机器人接待会话时,是否自动发送满意度评价邀请。

【优化】客户资料自定义中系统字段默认打开且不可关闭
在客户资料自定义页面,系统字段默认打开且不可关闭,避免误操作。原本处于关闭状态的系统字段会自动打开,并显示在“资料”页签。
说明:仍然可以手动控制自定义字段的“字段开关”。

【优化】客户中心导出文件包含“自定义字段”
在“客户中心”页面,点击“导出基本资料”按钮,可以导出客户的基本资料,导出文件中包含在“设置 > 客户资料自定义”页面添加并打开的自定义字段。
【优化】模糊搜索支持导出会话
在“搜索”页面,对会话进行搜索后,可以点击“导出”按钮,导出搜索结果。
生成导出文件后,请前往“导出管理”页面下载。
【优化】历史会话支持查询会话转接情况
在“历史会话”页面可以查看会话是否经过转接,并且可以根据“是否转接”对会话进行筛选。
管理员模式下,可以在会话详情页查看详细的转接记录。
【优化】导出管理提供下载记录
在“导出管理”页面,可以查看每个导出文件的下载记录,包括客服名称、下载时间、IP地址,以备企业内部安全审核。
Android客服工作台
当前版本:V2.7
新增客服可以发送所有类型的文件。
关于更多Android客服工作台的更新日志,请查看Android 客服工作台 更新日志。
PC客服工作台
当前版本:V2.0.2017.02150
新增下载导出功能,支持在“导出管理”页面下载导出文件。并且,修复消息提示音,支持播放语音消息。
关于更多PC客服工作台的更新日志,请查看PC 客服工作台 更新日志。
移动客服Android SDK
当前版本:V1.0.4
移动客服Android SDK支持对留言评论进行翻页查询。
关于移动客服Android SDK的集成说明,请查看移动客服 Android SDK 集成。
移动客服iOS SDK
当前版本:V1.0.0
移动客服iOS SDK发布!该iOS SDK基于IM SDK 3.x,登录、发消息速度更快。提供内置会话相关UI,集成后可立即给移动客服发送文本、语音、图片、文件消息。
支持双通道:已集成双通道功能,确保不丢消息;
极简集成:集成移动客服通用功能,只需5分钟。
关于移动客服iOS SDK的集成说明,请查看移动客服 iOS SDK 集成。
环信移动客服更新日志http://docs.easemob.com/cs/releasenote/5.11
环信移动客服登陆地址http://kefu.easemob.com/ 收起阅读 »
产品同质化?SaaS制胜之道本就不在工具层!
环信从2013年成立,从一开始的“即时通讯云”到移动客服,再到入选“Gartner 2016Cool Vendor”,环信的成绩着实令人惊诧。直到上周五,牛透社获取了来自Gartner和环信联合发布的《下一代客户服务软件趋势》报告,我们开始重新审视客服领域,重新审视带给我们诸多震撼的环信。
连接:从即时通讯云到人工智能,让连接价值更深入
“目前的环信,其实有三条产品线,分别是:即时通讯云、移动客服、人工智能。”当我问及环信当下的产品结构时,刘俊彦给出了这样的答案。
环信在2013年成立时,开始做即时通讯云,让企业的APP拥有像微信一样的聊天沟通能力,这个场景是“连接人和人”。
但当产品上线后,他们很快发现,IM其实天然的还适用在第二个场景——“连接人和商业”。最典型的例子就是淘宝旺旺。旺旺作为一款聊天工具,很好地连接了消费者和企业客服,这样的场景,用户黏性会更强,在商业上的价值也更高。这个场景离企业更近,也更适合商业化,环信移动客服应运而生,其核心就是用即时通讯工具连接人和商业。随后,环信又推出了全媒体客服,让用户可以通过各种通道联系到企业。
实际上,牛透社此前对于环信的印象就止步于此了,看起来,环信似乎就是做了这两件事情,并凭此声名大噪。但刘俊彦说,环信还有第三条产品线——环信人工智能。
当环信在做移动客服的时候,发现他们在一开始构建的“蓝图”其实还不够完美,有个最大的问题——当你真的将工具做得很出色,让任何一个消费者在任何地点都能很容易地与企业聊天沟通的时候,所有的压力和责任就会转移到商家身上。在手机时代,每个人都能24小时联系到商家,但商家的客服人员其实是有限的,用户需求的激增难以满足,所以回过头来看,这样的客服工具并没能真的提升用户体验,反而让商家倍感压力。
“我们希望能通过人工智能解决商家日益高涨的客服成本和用户需求不断增长的天然矛盾,人工智能显然是绝佳的手段。”刘俊彦这样评价道人工智能产品线。

环信创始人兼CEO 刘俊彦
从一开始的IM试图连接人和人,再到连接人和商业,打造了一款完整的客服产品,到如今的人工智能,环信的主线其实并没有发生任何变化——连接。以刘俊彦的话来说,环信的基因就是连接与对话,环信希望用对话的方式将人和人、人和商业连接在一起,这是环信公司的主线或者说愿景。
引领:结合“土壤”引领创新,缔造移动客服时代
牛透社早在去年7月份就得知了环信入选“Gartner 2016 Cool Vendor”,但仅通过过往的一些通稿并不能了解太多讯息,直到近期环信与Gartner联合发布的《下一代客户服务软件趋势》报告出炉,坐在环信的会议室里,和刘俊彦面对面交流,我们才从行业的角度,看到了一个更真实的环信。
“Gartner每年5月的Cool Vendor评选,都是从四五十家被不同分析师所提企业中筛选出的寥寥几家上榜企业,环信到底‘酷’在哪,能成为中国唯一入选的SaaS客服企业?”我抛出了牛透社对此最想了解的问题。
“在我看来,有两点非常关键——环信的创新和我们所扎根的‘土壤’。创新让我们始终走在行业前列,而‘土壤’则带来了更多契机。”刘俊彦这样答道,“Gartner几年前就作出预测,发生在移动端上的客户服务在未来将达到什么规模,在市场上占据多少比例,但实际的数据始终落后于预测,于是不断修正数据。从北美市场来看,不论是移动互联网的发展还是基于IM的商业文化,都还不足以支撑Gartner所预测的数据。但纵观全球,Gartner发现中国的市场做到了——不论是其预测的移动端客服的快速兴起还是客服机器人在客户服务中的大规模应用,美国都没能实现,但中国都实现了。而且Gartner发现,在中国引领世界的这一波客户服务的创新浪潮背后,主要的推动企业是一家叫环信的公司。”
环信达到了Gartner几年前预测的行业数据,做到了全球诸多企业都没能做到的事情,听起来有些不可思议,但Gartner以其报告严谨性享誉全球,这又是毋庸置疑的。
环信之所以能有这样的成绩,也正如刘俊彦所说:一方面是来源于环信不断的创新,这让环信始终保持着足够的敏锐度;另一方面,中国有着很独特的“土壤”,移动互联网的发展非常迅速,这是其它国家,包括美国在内都不能及的,而基于IM的商业文化、社交文化,也让环信移动客服获得了快速发展。
挑战:解析用户之难,让服务能力不止于工具
“当下的国内企业客服部门面临三大挑战:
一是移动化的挑战。过去的消费者都是通过电话、网页的方式联系客服,而现在则更多地转移到了微信公众号、APP上,许多企业的IT架构难以适应移动时代。
二是来自服务体验的挑战。过去以电话呼叫中心为主的客服部门,通常采用录音和抽样质检方式来监控服务质量。当用户服务请求激增,且服务请求来自微信、APP、网页、电话等多个渠道,每个渠道的数据格式都不一样,都是非结构化数据,且数据量极大,企业就不能像过去一样做抽样人工质检,也就失去了对服务体验最基本的监测。
三是客服人力成本与用户量激增的天然矛盾。当用户量越来越大,如何匹配足够的客服资源,这让许多公司头疼。”
当问及国内企业客服部门所面临的挑战,刘俊彦给出了这样的答案。
对于环信而言,专注在移动端即时通讯领域已经许久,所谓移动化的挑战,自然并不难应对。刘俊彦也表示,环信的全渠道客服,其移动端体验是颠覆性的,用户的痛点问题能得到很好的解决。
但他显然并不认为这是多末大的优势,在他看来,所谓全渠道客服,只是一个工具,一个相对专业的团队,有足够的资金,两年时间,基本都能将工具属性的全渠道客服做得很不错。
刘俊彦将客服领域的竞争分为三个层面:工具层面、BI层面、AI层面。
工具层面
在工具层面,诸多厂商的差距在变小,从表面来看,产品趋于同质化。
BI和AI层面
在这两个层面,是要通过数据分析和人工智能的能力,提供更好的用户体验。
全媒体客服的最佳体验不仅只是多渠道的接入,更重要的是用户跨渠道的体验和跟踪,在海量的数据中发现问题。而要做到这一点,企业首先需要理解客户到底体验到了什么。倾听客户声音的能力决定了他们在客户体验这个领域上的竞争力。
Gartner报告也指出:“VOC(客户声音)是企业有关客户体验管理(CEM)战略需要考量的核心维度。CEM是个很大的话题,覆盖了企业交付給用户的客户体验的方方面面,是未来五年全球CEO所关注的排名前三的重点领域之一。”
正是基于此,环信推出了“环信客户声音”——一款基于人工智能和大数据挖掘的客户体验透析产品。通过对多渠道的非结构化数据源进行客服业务的特征提取,发现服务运营的问题。通俗地来说,就是可以将系统中每天产生的数十万会话都转化成文本分析,主题关键词热度越高,说明用户关注度越高,加上对关键词做情感分析,了解用户对于某件事所带有的情绪。由此,企业就可以优先解决用户最关心、最影响体验的问题。
突围:纵观SaaS竞争格局,生态圈方为制胜之道
将目光聚焦在整个SaaS软件领域,刘俊彦认为,存在四个层面的竞争:
工具层竞争
所有SaaS软件的第一个竞争层面都是工具层,在工作流层面。也就说你做一个SaaS软件,主要是帮助企业实现它的工作流,比如客服的工作流,比如销售团队管理的工作流。目前大部分中国的SaaS企业公司都从工具开始起家。但在美国这个充分竞争的市场上,你只做第一个层面的SaaS企业,基本是没人会投资的。中国的SaaS行业还不像美国那样成熟,在这个层面还存在一些机会。而具体到客服领域来看,这一层面的竞争已经快结束了,开始进入第二层面的竞争。
数据层竞争
在这一层面,是数据的竞争,或者说知识的竞争。工具层面拉不开差距,而工作流中沉淀了大量数据,要把这些数据变为产品。
像环信现在做BI,竞争中我们不是比较谁的报表数量多,而是比较是否有探索式BI自定义报表的能力。想象一下,如果一个用户,在你的平台上自己生成了很多自定义的报表和BI数据,那么他就很难迁移走了。一旦用户的个性化数据和知识变成了产品的一部分,这将让用户的迁移成本变得更高,这时企业间的竞争才开始有了自己独特的壁垒。但中国目前能够做到这个层面的SaaS公司不多,因为第一层面的工具竞争还没有结束。
生态圈的竞争
最典型的例子就是Salesforce。Salesforce的成功并不仅仅是因为其产品很出色,还在于它的生态圈很完善。Salesforce目前拥有上百家企业在其force.com平台上进行软件、插件的开发,已形成自己的生态,其他公司基本无法与之抗衡。比如美国有一家著名的生命科技公司,viva,目前市值是17亿美金,但他自己没有底层平台,他把底层平台搭建在Salesforce上并基于此开发自己使用的软件。当你要颠覆Salesforce,就不再只是颠覆掉Salesforce的产品本身,还要同时颠覆Salesforce生态中的几百家合作伙伴公司。
AI层竞争
“SaaS企业的终极竞争层面是AI层,这是一个大趋势。环信的智能客服机器人、客户声音、环信智能质检,都是AI团队打造出来的。所有的数据、业务流程最终都以AI形式展现出来,这是最终决定所有SaaS公司生死的核心关键。”刘俊彦坚定地说到,“环信目前处于第二层到第三层的竞争阶段,对于第四层的AI也一直在努力。”
还是以客服行业为例子。客服行业在10年前,只有呼叫中心这一种形式。呼叫中心最初是解决基本沟通的问题,让消费者能找到我。所以第一阶段是解决沟通与通信问题,即通讯设备厂商阶段,出现Avaya、中兴、华为等销售通讯设备的企业;第二阶段是如何管理客服人员,促发了一批以提供管理和效率工具软件为主的客服企业。这阶段的主要挑战是如何使人像机器一样高效标准;第三阶段是机器替代人,由于不断提高的人力成本和不断增加的客户请求之间的不可调和的矛盾,我们只能用AI来代替人。这阶段的主要挑战是如何让机器像人一样智能、灵活。
“您认为中国SaaS市场会不会出现Salesforce这样的巨头企业?”临走前我问到。
“其实在中国企业服务的各主要赛道已经出现巨头了,格局也相对清晰,如果这些领头羊不出现什么重大失误,相信能一直居于前列。而当大家将第三层生态圈做好之后,或许就会是中国的Salesforce。”
收起阅读 »
一家SaaS客服企业要做AI,环信打的是什么算盘?

从SaaStr回来后,环信以CEO刘俊彦的口吻,连续对外做了几次观点发声,关于SaaS创业的9种正确姿势、AI正在吃掉软件……其中有些观点引起了笔者的兴趣,笔者也查找梳理了这家近两年在移动客服领域风生水起的创业企业的资料。全媒体客服、客服移动化、智能化、营销化是其突出的特点,然而在这一次与刘俊彦的采访中,他更想强调的是环信在数据层面的战略优势以及对AI的认知和布局。
笔者将环信所发出的观点和这次采访做了一些结合,以展示环信CEO刘俊彦以及环信对SaaS和自身发展的看法、布局。
从行业焦点看SaaS发展三大阶段
“在中国,不知道是不是因为SaaS企业有准确的数学模型,可以用一大串公式表达,直接戳中了资本的甜点,反正在过去1,2年的资本寒冬里,SaaS企业已经成为了很多资本寻求低风险高质量投资标的的热门选择。”这是一篇文章中提到的一句话,实质上也确实是前两年,尤其是2015下半年、2016上半年的SaaS市场行业状况,无论是哪个领域,无论是CEO、COO等CXO,还是市场经理、销售业务员等相对基层的员工,都会时不时拽出“CAC”“LTV”等高大上的词汇。
然而刘俊彦认为,这种现象正在逐渐削弱。他将近几年这一波SaaS的发展分为三个阶段,第一个是野蛮生长的阶段,SaaS浪潮涌起后,大波创业者入海,各自发展、野蛮生长;第二个是经典SaaS理论大行其道的阶段,CAC、LTV、续约率、客单价等等。美国SaaS企业已经发展了10多年,形成了一整套完整的理论体系,这为国内野蛮生长的市场打开了一扇经验之门,行业逐渐褪去虚热,开始转向理性阶段;然而,从去年下半年开始,很多SaaS创业公司开始发现美国经典SaaS理论并不完全适用,很多企业开始明确做大客户的思路,这就进入了SaaS发展的第三个阶段。
中国企业服务市场和北美市场存在很大的不同:在北美,除了Salesforce和Oracle等巨头外,大部分SaaS企业只能做巨头看不上的中小客户市场;而在中国,企业服务的6个核心赛道,客服云、市场云、销售云、HR云、财务云、协同云,都没有历史巨头。这就意味着中国的这一批SaaS企业都有可能成长为各自赛道上的巨头,都有机会做大客户。针对大客户的SaaS运营体系和针对中小企业的体系是不太一样的,而大家目前讨论比较多的经典SaaS理论体系主要针对中小客户,原因也很简单:在美国,绝大部分SaaS企业都是在做中小客户,愿意出来分享的也是这部分SaaS企业,而Oracle、Salesforce这样的巨头通常是不出来分享经验的。

从核心竞争力看SaaS的四级阶梯
如果从核心竞争力的角度,可以将SaaS企业的发展划分为四个阶段。
第一阶段的重点在工具层面,所有的产品都是为解决工作流的问题而开发的工具。工具的核心在于技术,技术本身并不是不可突破的壁垒,那么如果仅仅局限于工具层面,就很难让竞争产生差异化。
第二阶段的重点在数据层面,将工作流里产生的数据和知识变成产品。比如企业要做定制BI,数据源的挖掘聚合、数据清洗、数据的视图展现,这些部分往往要根据企业需求来进行定制。一旦用户的个性化数据和知识也变成了产品的一部分,用户的迁移成本将变得更高,这时企业才开始有了自己独特的竞争壁垒。
第三阶段的重点是生态圈的建设。只有建立生态圈,SaaS企业才能真正筑起足够高的竞争门槛。比如要颠覆Salesforce,就不再只是颠覆掉Salesforce的产品本身,还要同时颠覆Salesforce生态中的几百家合作伙伴公司。
第四阶段的重点是AI,严格来讲这是刘俊彦个人对SaaS未来技术发展方向的看法。“个人觉得SaaS的终极竞争在AI”,正如刘俊彦在谈论AI的文章中提到的,“AI正在吃掉软件,也正在深刻的影响着SaaS客服行业,在客服领域AI正逐渐发挥着重要的作用,有望成为一股颠覆性的力量从而被整个行业寄予厚望”。
AI很可能彻底颠覆SaaS客服软件
为什么这么说?刘俊彦以SaaS客服为例子,说明了为什么AI可能会彻底颠覆现在的SaaS客服软件。简单来讲,现在市场上所有SaaS客服软件的核心功能都是把一个服务请求按特定的规则分配给客服,然后给客服提供一个好用的效率工具,并提供各种报表来考核和管理客服的绩效。进入到智能客服机器人时代后,一个机器人可以秒级处理上百万的服务请求,所以不需要分配。机器人也不需要管理和发工资,所以也不再需要各种绩效管理和报表。那么目前市场上的这些传统SaaS客服软件还有存在的意义吗?
“当然,完全用客服机器人代替人,技术还不成熟,还需要5到10年时间,所以环信做SaaS客服软件,一二三层的能力还是要持续加强的”,刘俊彦补充到。基于这种思考和AI的发展趋势,刘俊彦将AI提到了环信的发展战略层面,并很早组建了AI团队。
进击二三四级技术力量,环信要做下一个Salesforce
回到环信,客服移动化、全媒体客服、客服智能化、客服营销化等,是环信移动客服的特点。对于产品的优势,刘俊彦表示环信已经做到了工具层面的领先,在第二个层面即数据层面,环信也推出了相应的数据产品,如环信客户声音。
环信客户声音是基于人工智能和大数据挖掘的客户体验透析产品。全媒体客服的最佳体验不仅是多渠道的接入,更重要的是跨渠道环境下,如何保证用户体验。环信认为,理解客户声音是保证客户体验的最重要一环。环信客户声音通过NLP(自然语言解析)、主题聚类、情感分析等技术手段,对来自多个渠道的非结构化文本数据进行挖掘和分析热点话题,发现服务运营问题,寻找畅销或者问题产品,洞察销售机会。
在第四层即AI层面,环信推出了环信智能客服机器人和环信智能质检。
环信客服机器人是环信基于自然语言处理和机器学习技术所推出的产品,其主要功能是辅助、替代人工客服回答常见、高频的问题,从而降低人力成本。
环信智能质检则是基于环信在线客服积累的各个领域的海量用户对话,提取出数百个客服对话特征,并用这些特征训练得到的几十种常见通用质检模型,从而将质检从过去人工、抽样,转变为自动、全面的工作。
令刘俊彦感到振奋的是,Gartner对于下一代客户服务软件的趋势预测和环信的实践是完全吻合的。Gartner报告指出“消费者对移动设备的偏好正在快速发展,到2019年,移动设备的使用将占到所有互联网交互的85%,如果不能改善移动客户服务,企业将遭受损失。” 。Gartner报告还指出,“VOC(客户声音)是企业有关客户体验管理(CEM)战略需要考量的核心维度。CEM是未来五年全球CEO所关注的排名前三的重点领域之一。”
应该说,这几条预测都在环信身上得到了有效地验证。相比于北美市场,中国有着很独特的“土壤”,移动互联网的发展非常迅速,这是包括美国在内的其它国家都不能及的,而基于IM的商业文化、社交文化,也让环信移动客服获得了快速发展。

2017年,环信的重点是加大二三四层核心竞争力的建设:将数据产品做得更好,在生态圈建设方面继续建设自身的PaaS平台,并在AI层面加大投入。
总的来说,刘俊彦认为客服是中国企业级服务市场六大核心赛道——客服云、市场云、销售云、HR云、财务云、协同云之一,环信希望能够在这一赛道上深耕细作并筑起足够高的竞争壁垒,成为像Salesforce一样的SaaS企业巨头。 收起阅读 »




