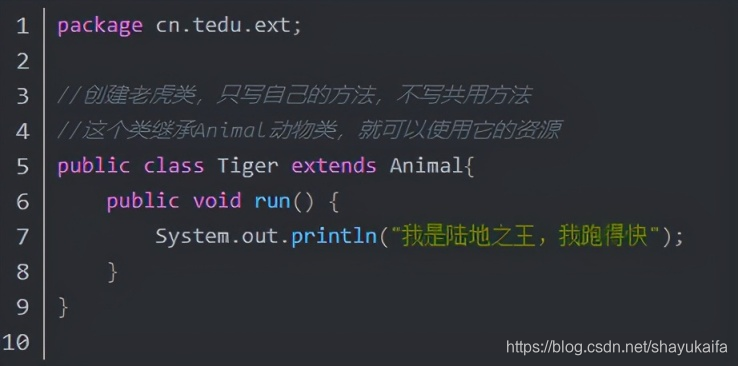
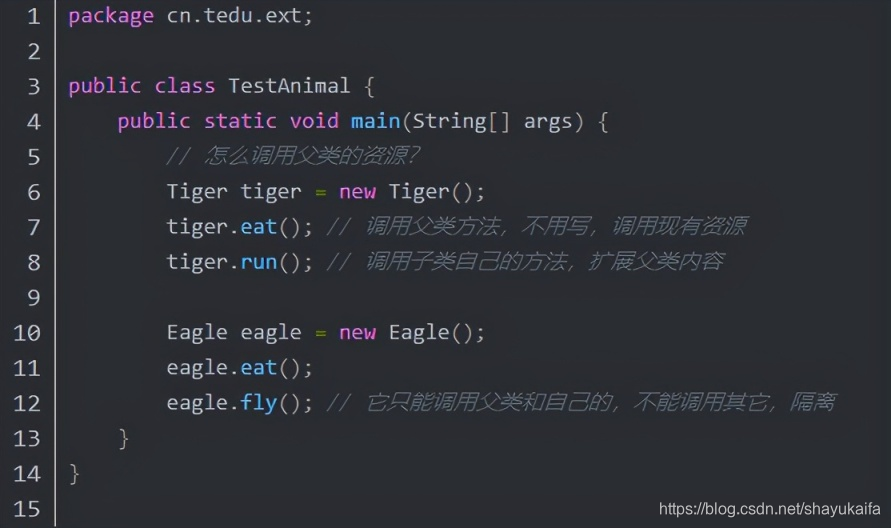
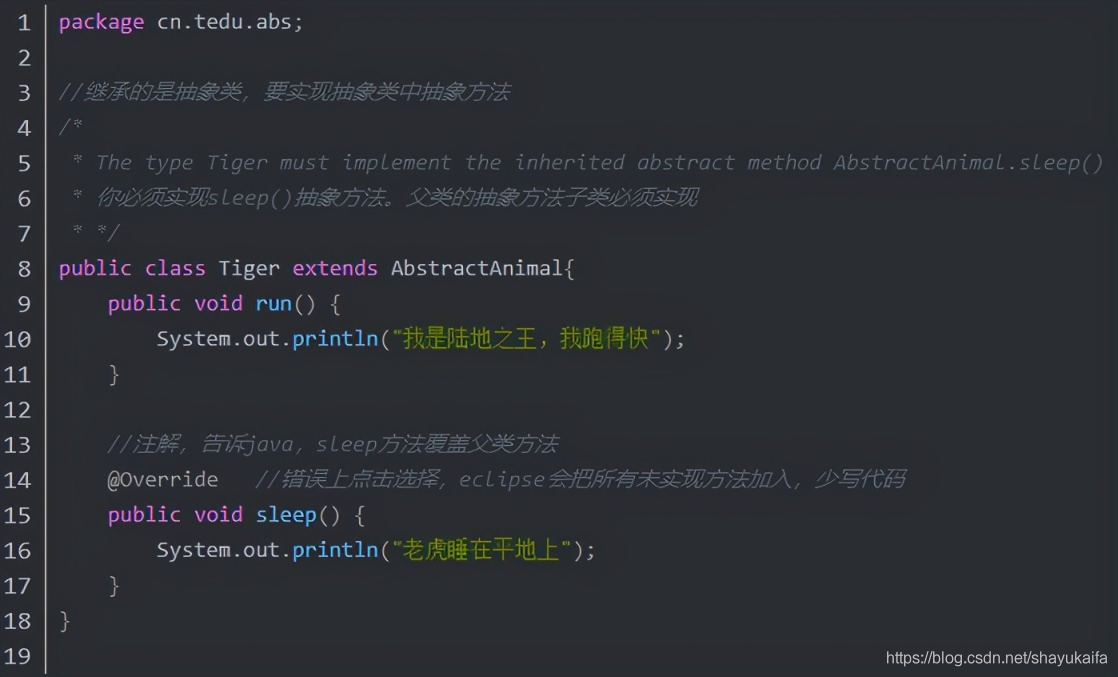
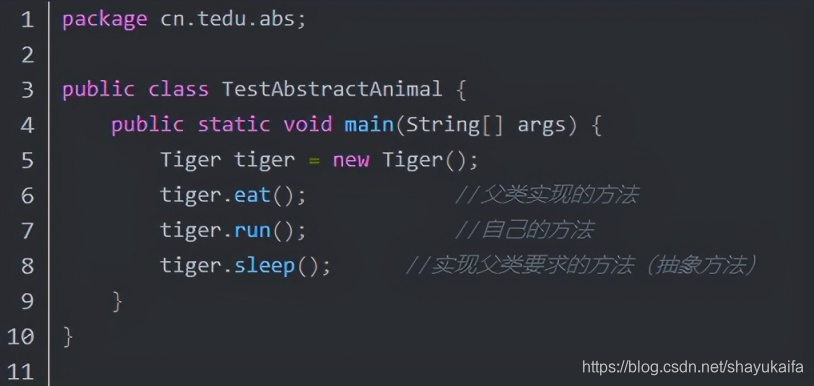
本文由作者FreddyChen原创分享,为了更好的体现文章价值,引用时有少许改动,感谢原作者。
1、写在前面
一直想写一篇关于im即时通讯分享的文章,无奈工作太忙,很难抽出时间。今天终于从公司离职了,打算好好休息几天再重新找工作,趁时间空闲,决定静下心来写一篇文章,毕竟从前辈那里学到了很多东西。
工作了五年半,这三四年来一直在做社交相关的项目,有直播、即时通讯、短视频分享、社区论坛等产品,深知即时通讯技术在一个项目中的重要性,本着开源分享的精神,也趁这机会总结一下,所以写下了这篇文章。
* 重要提示:本文不是一篇即时通讯理论文章,文章内容全部由实战代码组织而成,如果你对即时通讯(IM)技术理论了解的太少,建议先详细阅读:《新手入门一篇就够:从零开发移动端IM》。
本文实践内容将涉及以下即时通讯技术内容:
1)Protobuf序列化;
2)TCP拆包与粘包;
3)长连接握手认证;
4)心跳机制;
5)重连机制;
6)消息重发机制;
7)读写超时机制;
8)离线消息;
9)线程池。
不想看文章的同学,可以直接到Github下载本文源码:
1)原始地址:https://github.com/FreddyChen/NettyChat
2)备用地址:https://github.com/52im/NettyChat
接下来,让我们进入正题。
(本文同步发布于:http://www.52im.net/thread-2671-1-1.html)
2、本文阅读对象
本文适合没有任何即时通讯(IM)开发经验的小白开发者阅读,文章将教你从零开始,围绕一个典型即时通讯(IM)系统的方方面面,手把手为你展示如何基于Netty+TCP+Protobuf来开发出这样的系统。非常适合从零入门的Android开发者。
本文不适合没有编程的准开发者阅读,因为即时通讯(IM)系统属于特定的业务领域,如果你连一般的逻辑代码都很难编写出来,不建议阅读本文。本文显然不是一个编程语言入门教程。
3、关于作者

本文原文内容由FreddyChen原创分享,作者现从事Android程序开发,他的技术博客地址:https://juejin.im/user/5bd7affbe51d4547f763fe72
4、为什么使用TCP?
这里需要简单解释一下,TCP/UDP的区别,简单地总结一下。
优点:
1)TCP:优点体现在稳定、可靠上,在传输数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完之后,还会断开连接用来节约系统资源。
2)UDP:优点体现在快,比TCP稍安全,UDP没有TCP拥有的各种机制,是一个无状态的传输协议,所以传递数据非常快,没有TCP的这些机制,被攻击利用的机制就少一些,但是也无法避免被攻击。
缺点:
1)TCP:缺点就是慢,效率低,占用系统资源高,易被攻击,TCP在传递数据之前要先建立连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞机制等都会消耗大量时间,而且要在每台设备上维护所有的传输连接。
2)UDP:缺点就是不可靠,不稳定,因为没有TCP的那些机制,UDP在传输数据时,如果网络质量不好,就会很容易丢包,造成数据的缺失。
适用场景:
1)TCP:当对网络通讯质量有要求时,比如HTTP、HTTPS、FTP等传输文件的协议, POP、SMTP等邮件传输的协议。
2)UDP:对网络通讯质量要求不高时,要求网络通讯速度要快的场景。
至于WebSocket,后续可能会专门写一篇文章来介绍。综上所述,决定采用TCP协议。
关于TCP和UDP的对比和选型的详细文章,请见:
《简述传输层协议TCP和UDP的区别》
《为什么QQ用的是UDP协议而不是TCP协议?》
《移动端即时通讯协议选择:UDP还是TCP?》
《网络编程懒人入门(四):快速理解TCP和UDP的差异》
《网络编程懒人入门(五):快速理解为什么说UDP有时比TCP更有优势》
《Android程序员必知必会的网络通信传输层协议——UDP和TCP》
或者,如果你对TCP、UDP协议了解的太少,可以阅读一下文章:
《TCP/IP详解 - 第11章·UDP:用户数据报协议》
《TCP/IP详解 - 第17章·TCP:传输控制协议》
《TCP/IP详解 - 第18章·TCP连接的建立与终止》
《TCP/IP详解 - 第21章·TCP的超时与重传》
《脑残式网络编程入门(一):跟着动画来学TCP三次握手和四次挥手》
《技术往事:改变世界的TCP/IP协议(珍贵多图、手机慎点)》
《通俗易懂-深入理解TCP协议(上):理论基础》
《网络编程懒人入门(三):快速理解TCP协议一篇就够》
《迈向高阶:优秀Android程序员必知必会的网络基础》
5、为什么使用Protobuf?
对于App网络传输协议,我们比较常见的、可选的,有三种,分别是json/xml/protobuf,老规矩,我们先分别来看看这三种格式的优缺点。
PS:如果你不了解protobuf是什么,建议详细阅读:《Protobuf通信协议详解:代码演示、详细原理介绍等》。
优点:
1)json:优点就是较XML格式更加小巧,传输效率较xml提高了很多,可读性还不错。
2)xml:优点就是可读性强,解析方便。
3)protobuf:优点就是传输效率快(据说在数据量大的时候,传输效率比xml和json快10-20倍),序列化后体积相比Json和XML很小,支持跨平台多语言,消息格式升级和兼容性还不错,序列化反序列化速度很快。
缺点:
1)json:缺点就是传输效率也不是特别高(比xml快,但比protobuf要慢很多)。
2)xml:缺点就是效率不高,资源消耗过大。
3)protobuf:缺点就是使用不太方便。
在一个需要大量的数据传输的场景中,如果数据量很大,那么选择protobuf可以明显的减少数据量,减少网络IO,从而减少网络传输所消耗的时间。考虑到作为一个主打社交的产品,消息数据量会非常大,同时为了节约流量,所以采用protobuf是一个不错的选择。
更多有关IM相关的协议格式选型方面的文章,可进一步阅读:
《如何选择即时通讯应用的数据传输格式》
《强列建议将Protobuf作为你的即时通讯应用数据传输格式》
《全方位评测:Protobuf性能到底有没有比JSON快5倍?》
《移动端IM开发需要面对的技术问题(含通信协议选择)》
《简述移动端IM开发的那些坑:架构设计、通信协议和客户端》
《理论联系实际:一套典型的IM通信协议设计详解》
《58到家实时消息系统的协议设计等技术实践分享》
《详解如何在NodeJS中使用Google的Protobuf》
《技术扫盲:新一代基于UDP的低延时网络传输层协议——QUIC详解》
《金蝶随手记团队分享:还在用JSON? Protobuf让数据传输更省更快(原理篇)》
《金蝶随手记团队分享:还在用JSON? Protobuf让数据传输更省更快(实战篇)》
>> 更多同类文章 ……
6、为什么使用Netty?
首先,我们来了解一下,Netty到底是个什么东西。网络上找到的介绍:Netty是由JBOSS提供的基于Java NIO的开源框架,Netty提供异步非阻塞、事件驱动、高性能、高可靠、高可定制性的网络应用程序和工具,可用于开发服务端和客户端。
PS:如果你对Java的经典IO、NIO或者Netty框架不了解,请阅读以下文章:
《史上最强Java NIO入门:担心从入门到放弃的,请读这篇!》
《少啰嗦!一分钟带你读懂Java的NIO和经典IO的区别》
《写给初学者:Java高性能NIO框架Netty的学习方法和进阶策略》
《NIO框架详解:Netty的高性能之道》
为什么不用Java BIO?
1)一连接一线程:由于线程数是有限的,所以这样非常消耗资源,最终也导致它不能承受高并发连接的需求。
2)性能低:因为频繁的进行上下文切换,导致CUP利用率低。
3)可靠性差:由于所有的IO操作都是同步的,即使是业务线程也如此,所以业务线程的IO操作也有可能被阻塞,这将导致系统过分依赖网络的实时情况和外部组件的处理能力,可靠性大大降低。
为什么不用Java NIO?
1)NIO的类库和API相当复杂,使用它来开发,需要非常熟练地掌握Selector、ByteBuffer、ServerSocketChannel、SocketChannel等。
2)需要很多额外的编程技能来辅助使用NIO,例如,因为NIO涉及了Reactor线程模型,所以必须必须对多线程和网络编程非常熟悉才能写出高质量的NIO程序。
3)想要有高可靠性,工作量和难度都非常的大,因为服务端需要面临客户端频繁的接入和断开、网络闪断、半包读写、失败缓存、网络阻塞的问题,这些将严重影响我们的可靠性,而使用原生NIO解决它们的难度相当大。
4)JDK NIO中著名的BUG--epoll空轮询,当select返回0时,会导致Selector空轮询而导致CUP100%,官方表示JDK1.6之后修复了这个问题,其实只是发生的概率降低了,没有根本上解决。
为什么用Netty?
1)API使用简单,更容易上手,开发门槛低;
2)功能强大,预置了多种编解码功能,支持多种主流协议;
3)定制能力高,可以通过ChannelHandler对通信框架进行灵活地拓展;
4)高性能,与目前多种NIO主流框架相比,Netty综合性能最高;
5)高稳定性,解决了JDK NIO的BUG;
6)经历了大规模的商业应用考验,质量和可靠性都有很好的验证。
为什么不用第三方SDK,如:融云、环信、腾讯TIM?
这个就见仁见智了,有的时候,是因为公司的技术选型问题,因为用第三方的SDK,意味着消息数据需要存储到第三方的服务器上,再者,可扩展性、灵活性肯定没有自己开发的要好,还有一个小问题,就是收费。比如,融云免费版只支持100个注册用户,超过100就要收费,群聊支持人数有限制等等...

▲ 以上截图内容来自某云IM官网
Mina其实跟Netty很像,大部分API都相同,因为是同一个作者开发的。但感觉Mina没有Netty成熟,在使用Netty的过程中,出了问题很轻易地可以找到解决方案,所以,Netty是一个不错的选择。
PS:有关MINA和Netty框架的关系和对比,详见以下文章:
《有关“为何选择Netty”的11个疑问及解答》
《开源NIO框架八卦——到底是先有MINA还是先有Netty?》
《选Netty还是Mina:深入研究与对比(一)》
《选Netty还是Mina:深入研究与对比(二)》
好了,废话不多说,直接开始吧。
7、准备工作
首先,我们新建一个Project,在Project里面再新建一个Android Library,Module名称暂且叫做im_lib,如图所示:
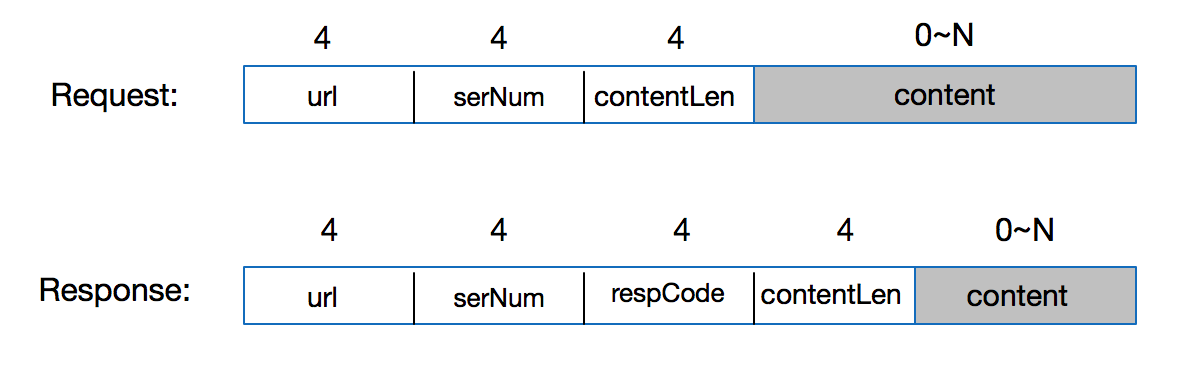
然后,分析一下我们的消息结构,每条消息应该会有一个消息唯一id,发送者id,接收者id,消息类型,发送时间等,经过分析,整理出一个通用的消息类型,如下:
msgId:消息id
fromId:发送者id
toId:接收者id
msgType:消息类型
msgContentType:消息内容类型
timestamp:消息时间戳
statusReport:状态报告
extend:扩展字段
根据上述所示,我整理了一个思维导图,方便大家参考:
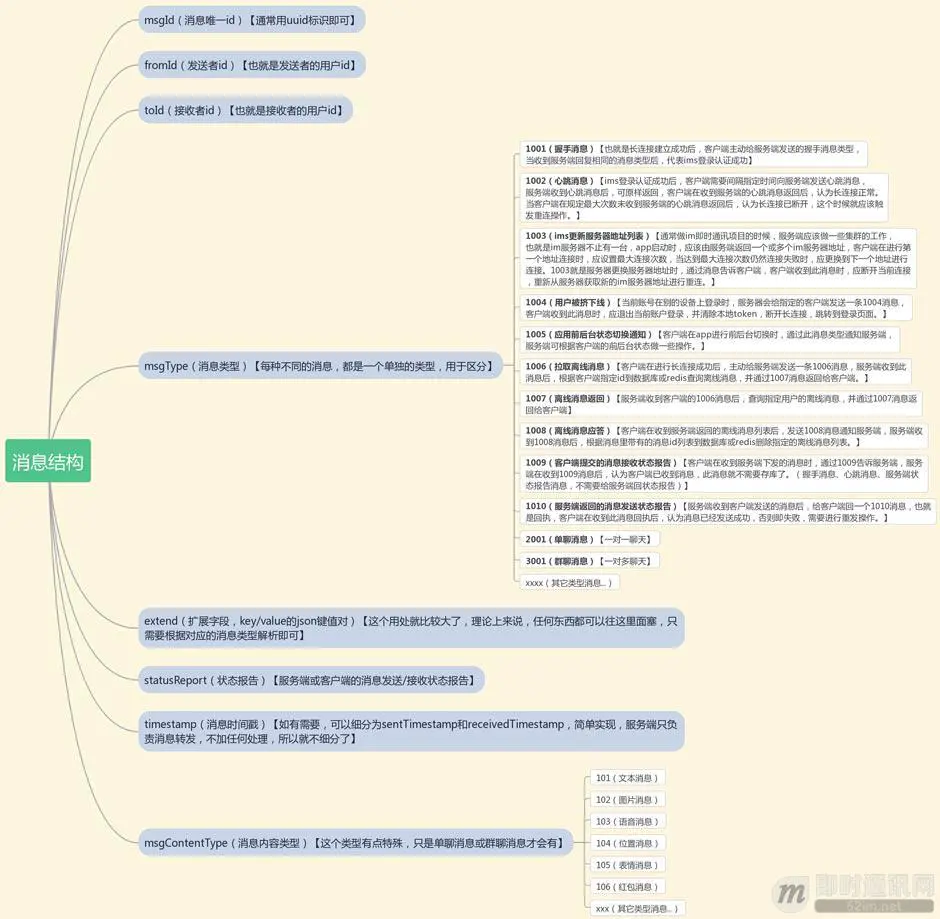
这是基础部分,当然,大家也可以根据自己需要自定义比较适合自己的消息结构。
我们根据自定义的消息类型来编写proto文件:
syntax = "proto3";// 指定protobuf版本
option java_package = "com.freddy.im.protobuf";// 指定包名
option java_outer_classname = "MessageProtobuf";// 指定生成的类名
message Msg {
Head head = 1;// 消息头
string body = 2;// 消息体
}
message Head {
string msgId = 1;// 消息id
int32 msgType = 2;// 消息类型
int32 msgContentType = 3;// 消息内容类型
string fromId = 4;// 消息发送者id
string toId = 5;// 消息接收者id
int64 timestamp = 6;// 消息时间戳
int32 statusReport = 7;// 状态报告
string extend = 8;// 扩展字段,以key/value形式存放的json
}
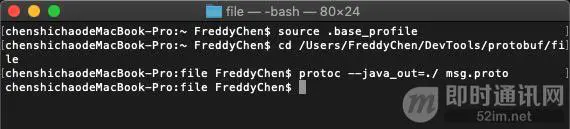
然后执行命令(我用的mac,windows命令应该也差不多):
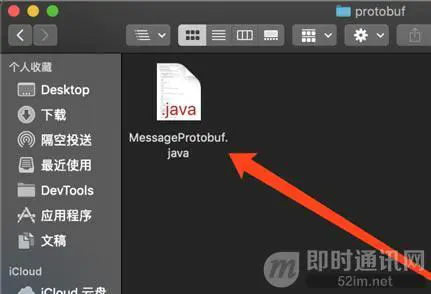
然后就会看到,在和proto文件同级目录下,会生成一个java类,这个就是我们需要用到的东东:
我们打开瞄一眼:
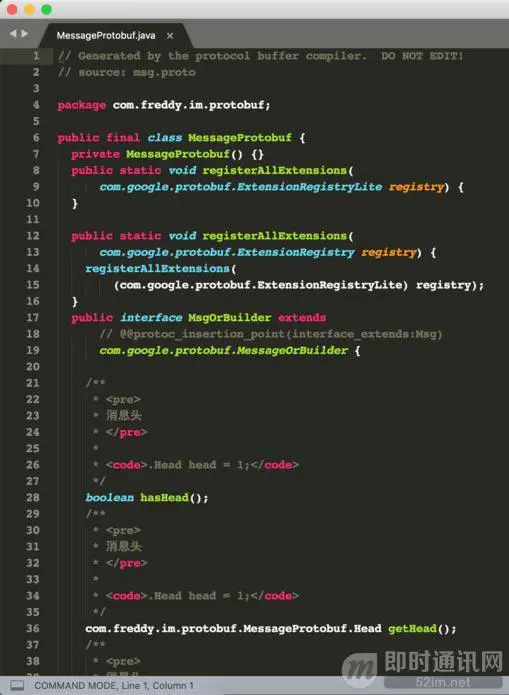
东西比较多,不用去管,这是google为我们生成的protobuf类,直接用就行,怎么用呢?
直接用这个类文件,拷到我们开始指定的项目包路径下就可以啦:
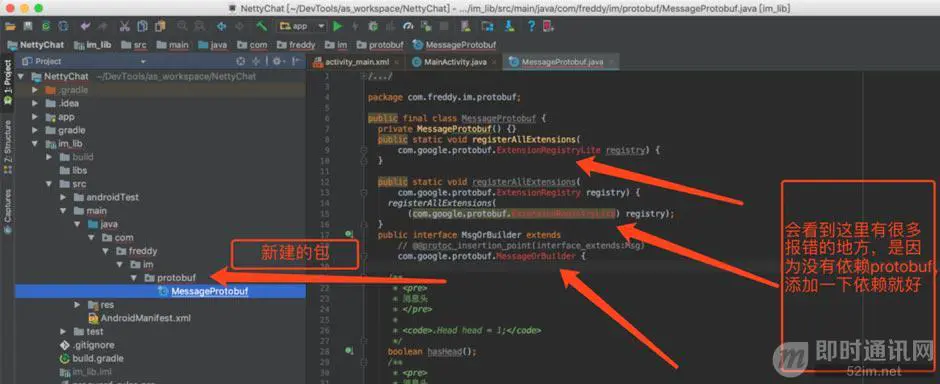
添加依赖后,可以看到,MessageProtobuf类文件已经没有报错了,顺便把netty的jar包也导进来一下,还有fastjson的:
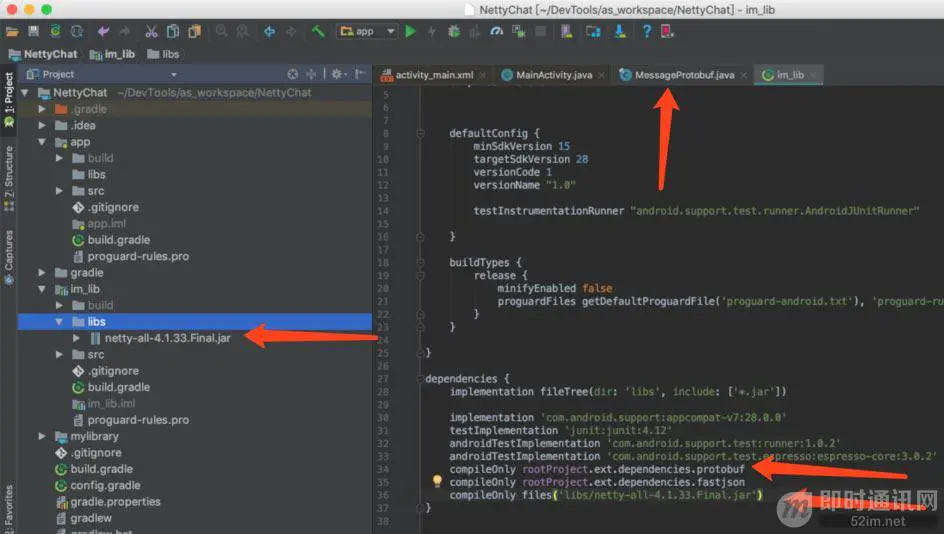
建议用netty-all-x.x.xx.Final的jar包,后续熟悉了,可以用精简的jar包。
至此,准备工作已结束,下面,我们来编写java代码,实现即时通讯的功能。
8、代码封装
为什么需要封装呢?说白了,就是为了解耦,为了方便日后切换到不同框架实现,而无需到处修改调用的地方。
举个栗子,比如Android早期比较流行的图片加载框架是Universal ImageLoader,后期因为某些原因,原作者停止了维护该项目,目前比较流行的图片加载框架是Picasso或Glide,因为图片加载功能可能调用的地方非常多,如果不作一些封装,早期使用了Universal ImageLoader的话,现在需要切换到Glide,那改动量将非常非常大,而且还很有可能会有遗漏,风险度非常高。
那么,有什么解决方案呢?
很简单,我们可以用工厂设计模式进行一些封装,工厂模式有三种:简单工厂模式、抽象工厂模式、工厂方法模式。在这里,我采用工厂方法模式进行封装,具体区别,可以参见:《通俗讲讲我对简单工厂、工厂方法、抽象工厂三种设计模式的理解》。
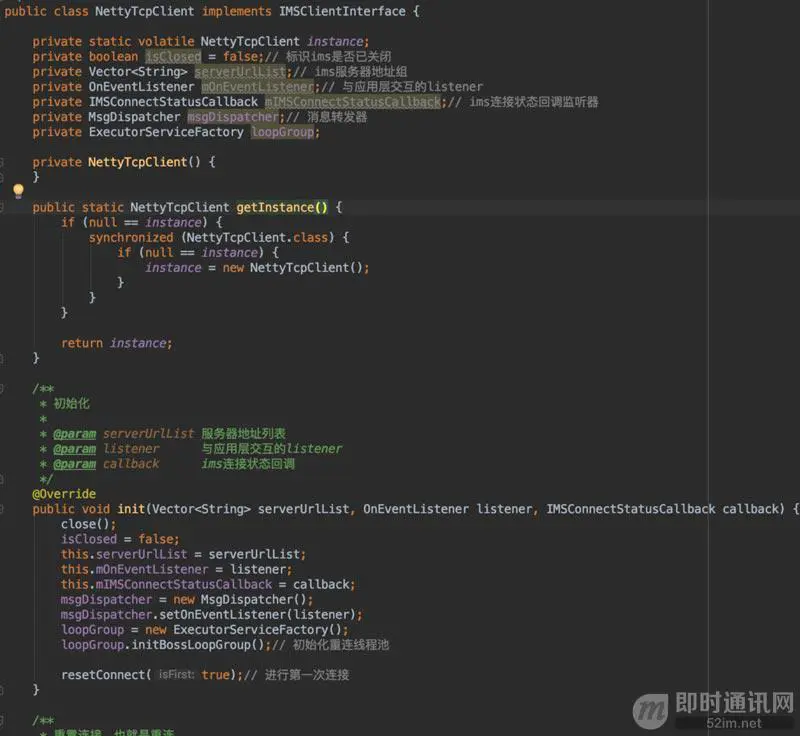
我们分析一下,ims(IM Service,下文简称ims)应该是有初始化、建立连接、重连、关闭连接、释放资源、判断长连接是否关闭、发送消息等功能。
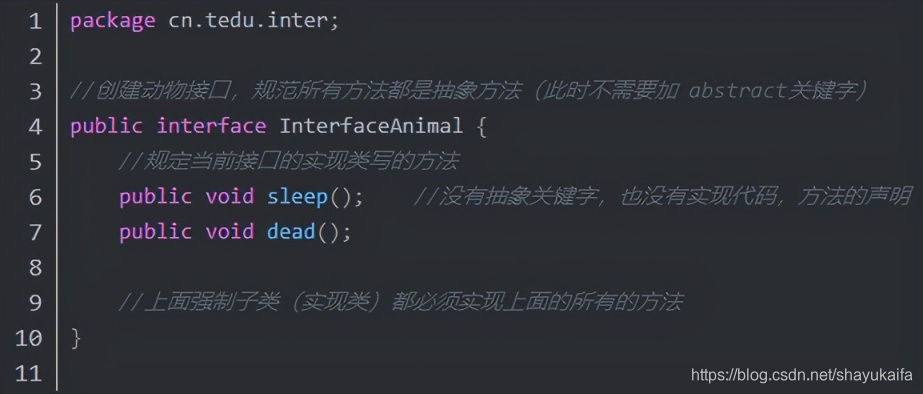
基于上述分析,我们可以进行一个接口抽象:
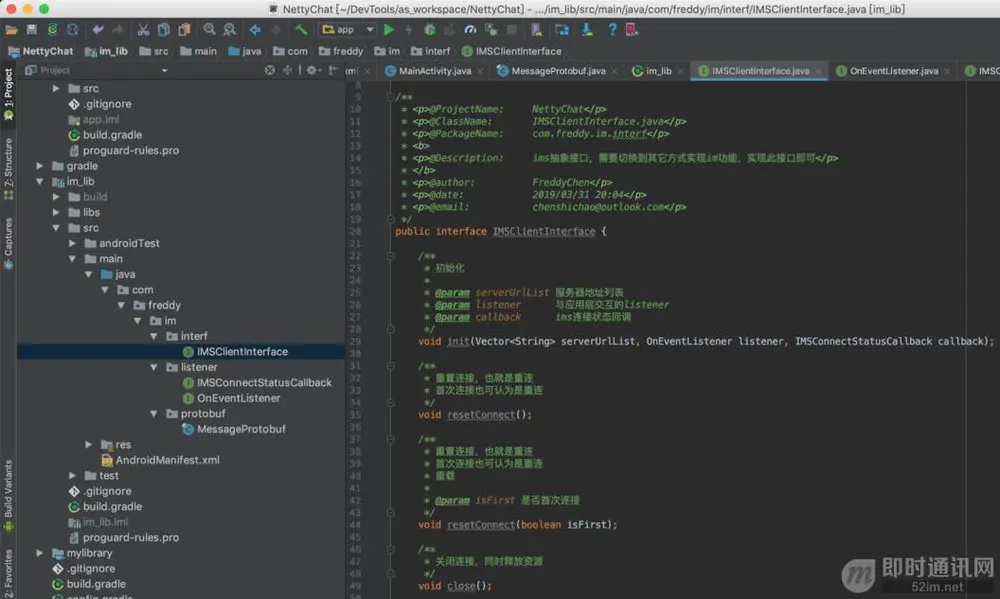
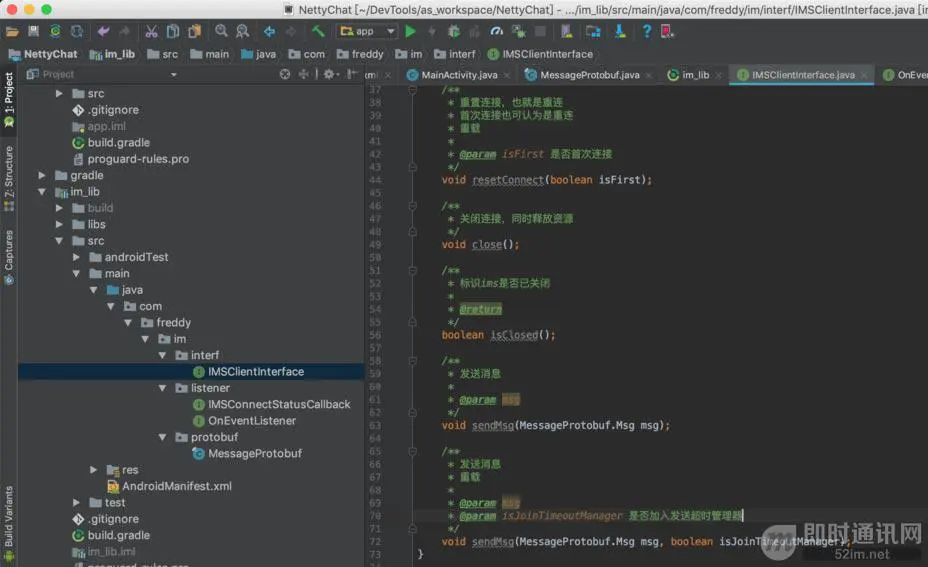
OnEventListener是与应用层交互的listener:
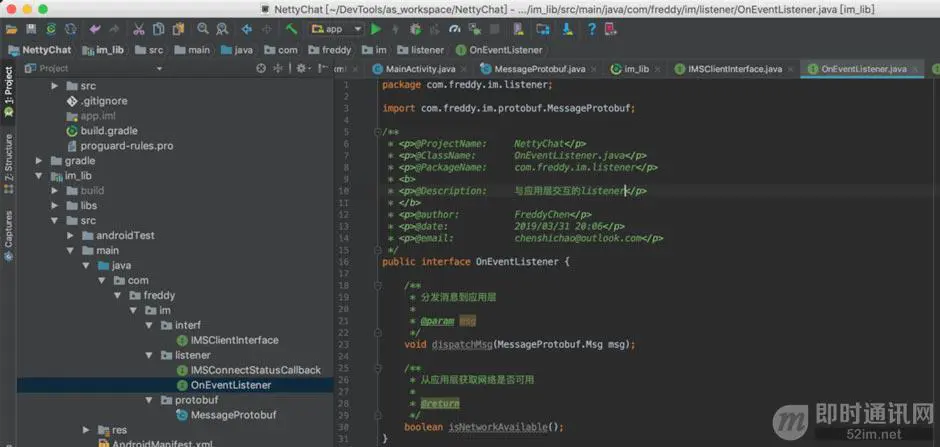
IMConnectStatusCallback是ims连接状态回调监听器:
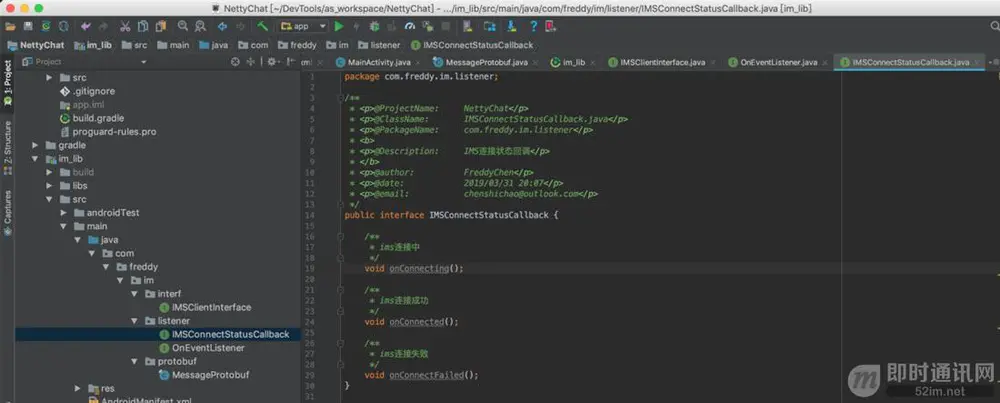
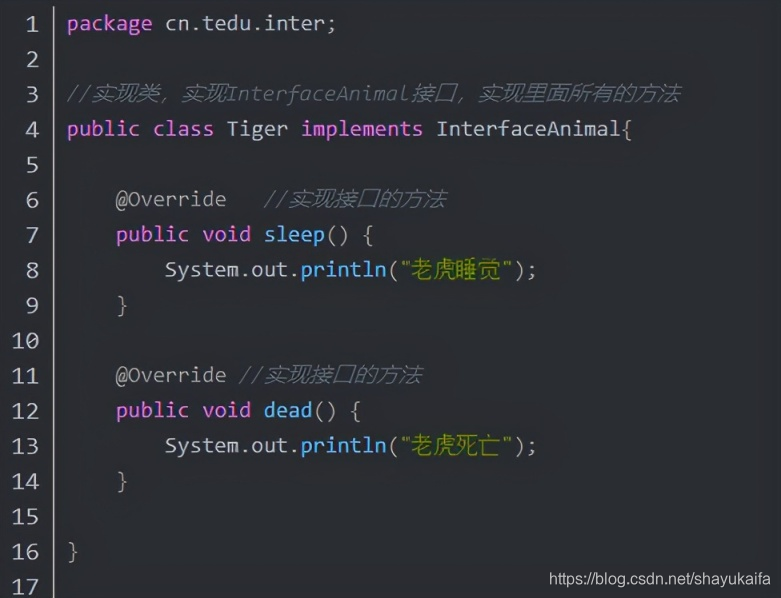
然后写一个Netty tcp实现类:
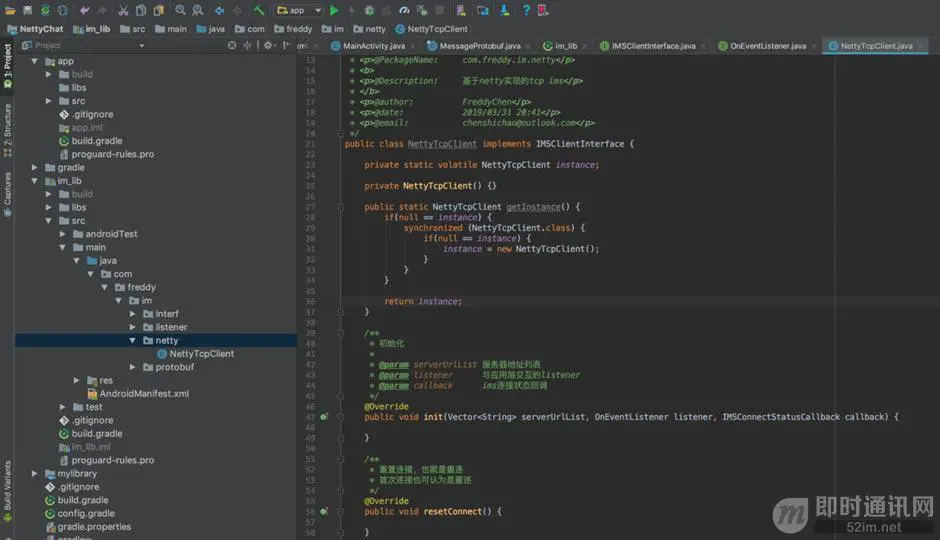
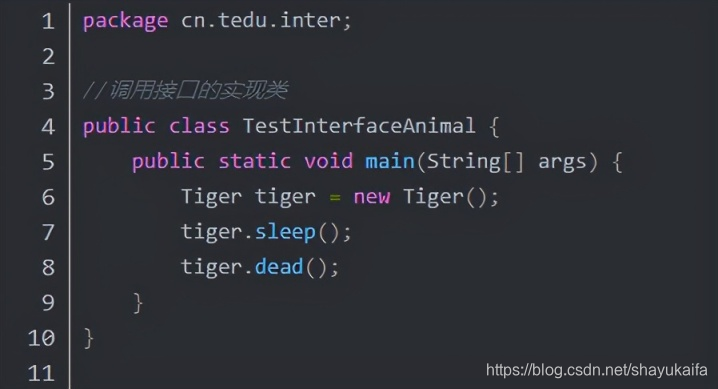
接下来,写一个工厂方法:
封装部分到此结束,接下来,就是实现了。
9、初始化
我们先实现init(Vector serverUrlList, OnEventListener listener, IMSConnectStatusCallback callback)方法,初始化一些参数,以及进行第一次连接等:
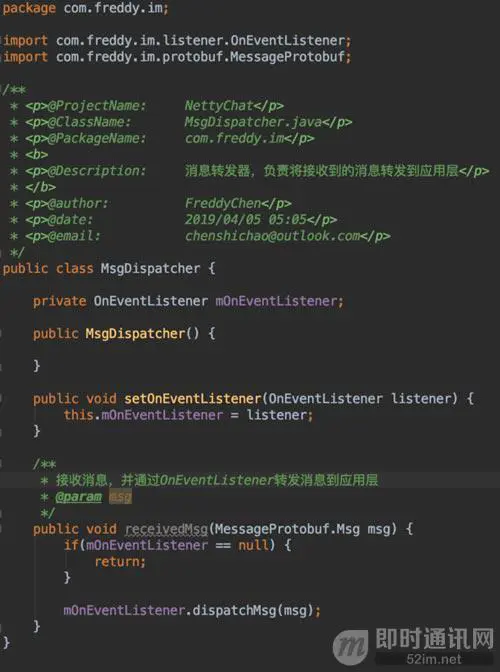
其中,MsgDispatcher是消息转发器,负责将接收到的消息转发到应用层:
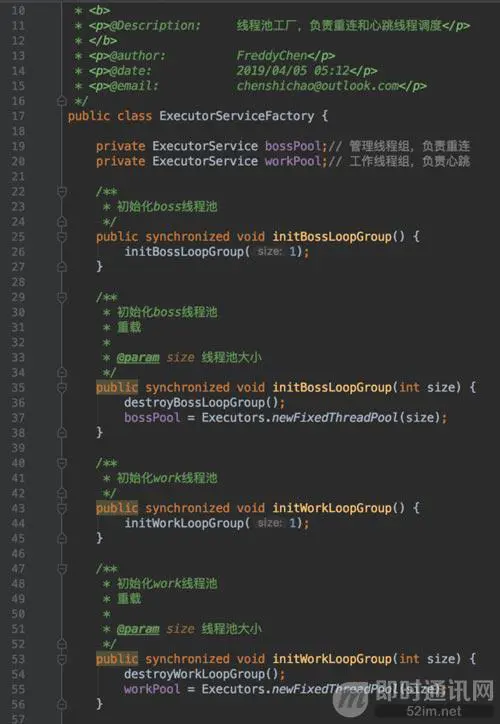
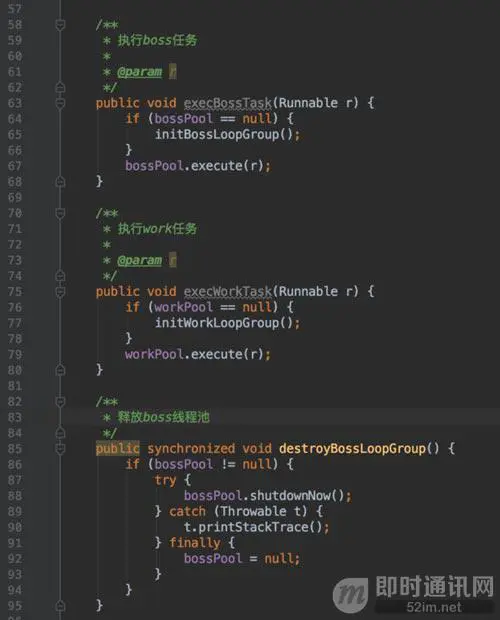
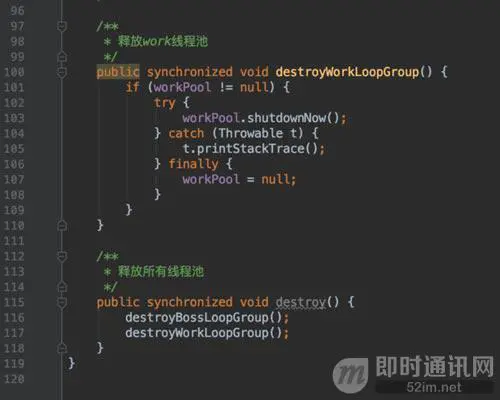
ExecutorServiceFactory是线程池工厂,负责调度重连及心跳线程:
10、连接及重连
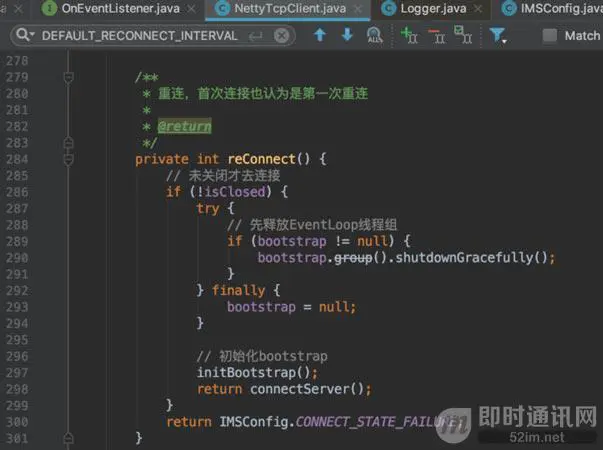
resetConnect()方法作为连接的起点,首次连接以及重连逻辑,都是在resetConnect()方法进行逻辑处理。
我们来瞄一眼:
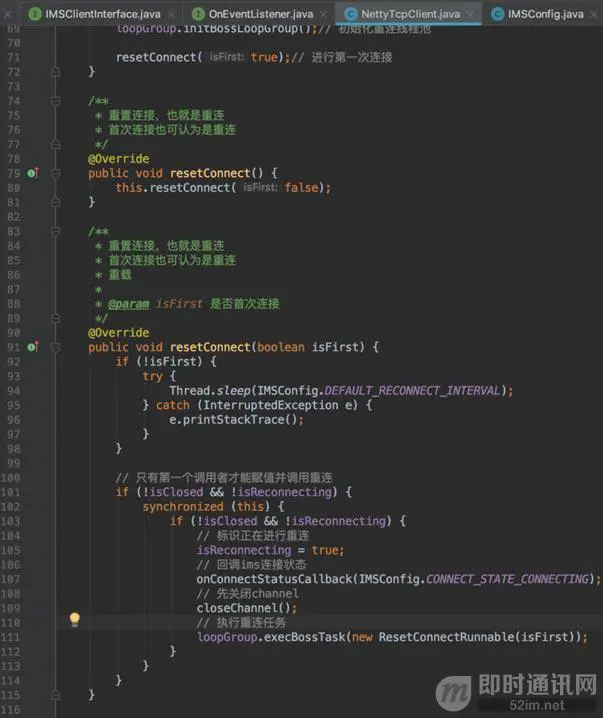
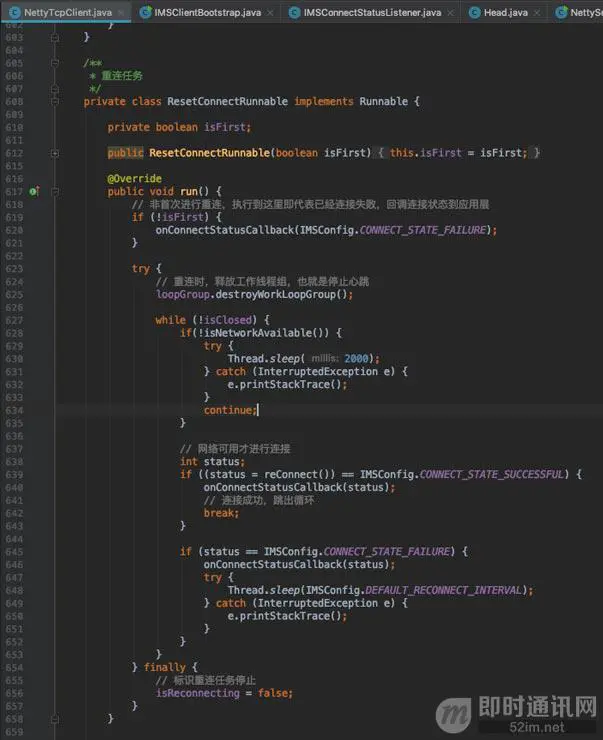
可以看到,非首次进行连接,也就是连接一个周期失败后,进行重连时,会先让线程休眠一段时间,因为这个时候也许网络状况不太好,接着,判断ims是否已关闭或者是否正在进行重连操作,由于重连操作是在子线程执行,为了避免重复重连,需要进行一些并发处理。
开始重连任务后,分四个步骤执行:
1)改变重连状态标识;
2)回调连接状态到应用层;
3)关闭之前打开的连接channel;
4)利用线程池执行一个新的重连任务。
ResetConnectRunnable是重连任务,核心的重连逻辑都放到这里执行:
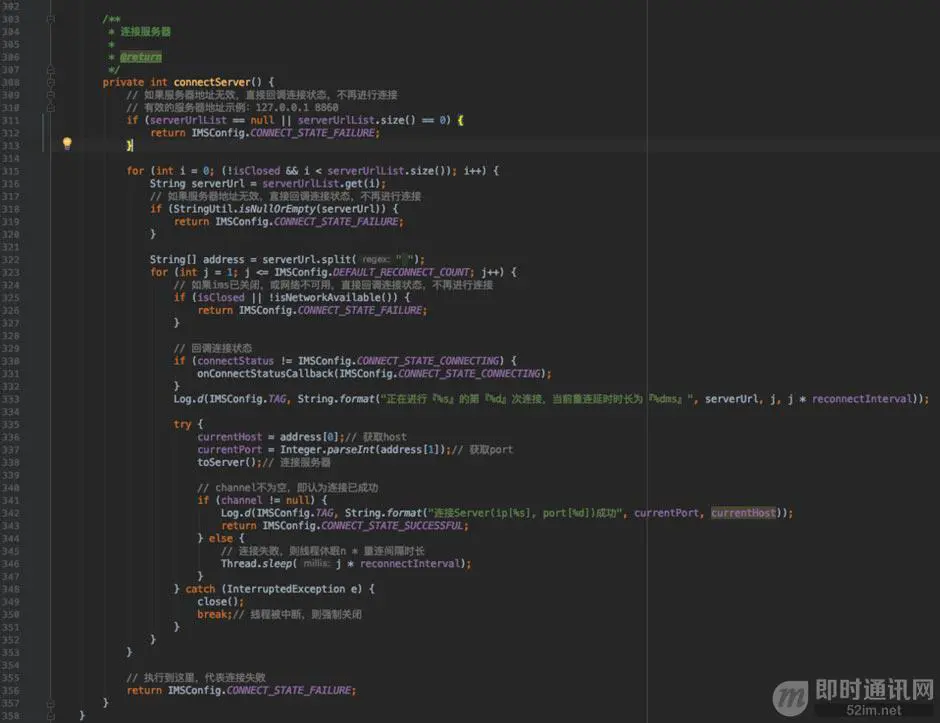
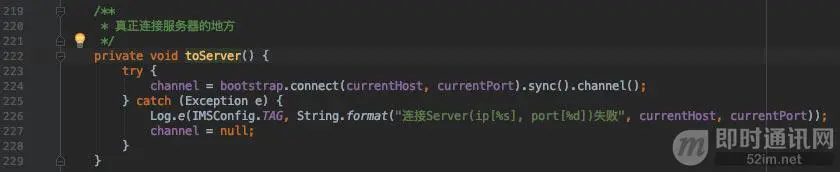
toServer()是真正连接服务器的地方:
initBootstrap()是初始化Netty Bootstrap:
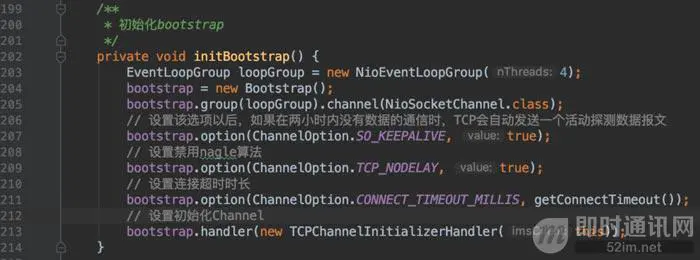
注:NioEventLoopGroup线程数设置为4,可以满足QPS是一百多万的情况了,至于应用如果需要承受上千万上亿流量的,需要另外调整线程数。(参考自:《netty实战之百万级流量NioEventLoopGroup线程数配置》)
接着,我们来看看TCPChannelInitializerHanlder:
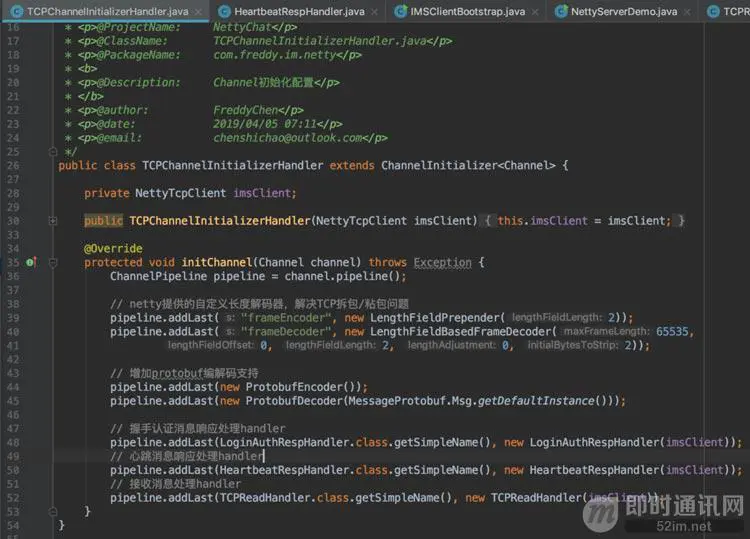
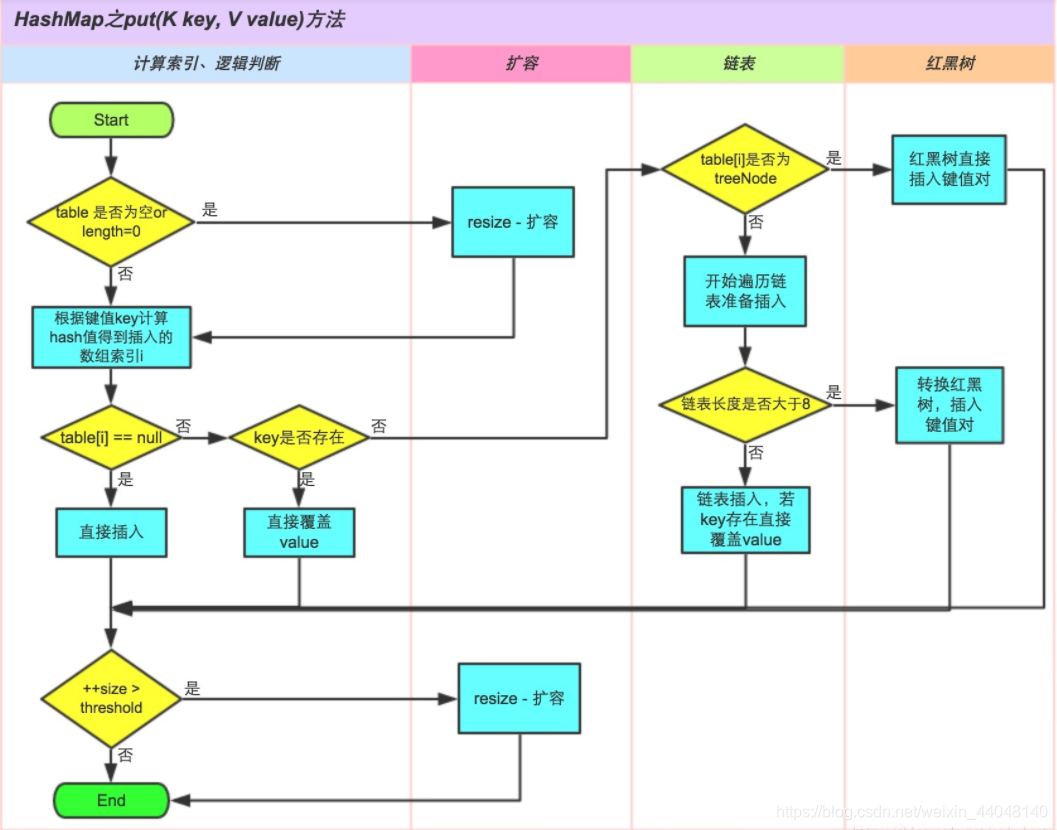
其中,ProtobufEncoder和ProtobufDecoder是添加对protobuf的支持,LoginAuthRespHandler是接收到服务端握手认证消息响应的处理handler,HeartbeatRespHandler是接收到服务端心跳消息响应的处理handler,TCPReadHandler是接收到服务端其它消息后的处理handler,先不去管,我们重点来分析下LengthFieldPrepender和LengthFieldBasedFrameDecoder,这就需要引申到TCP的拆包与粘包啦。
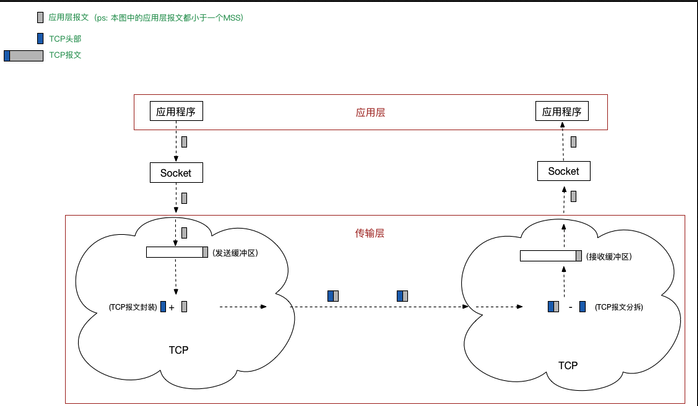
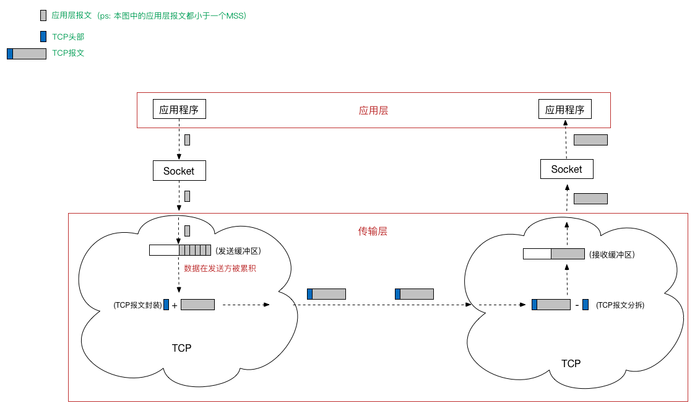
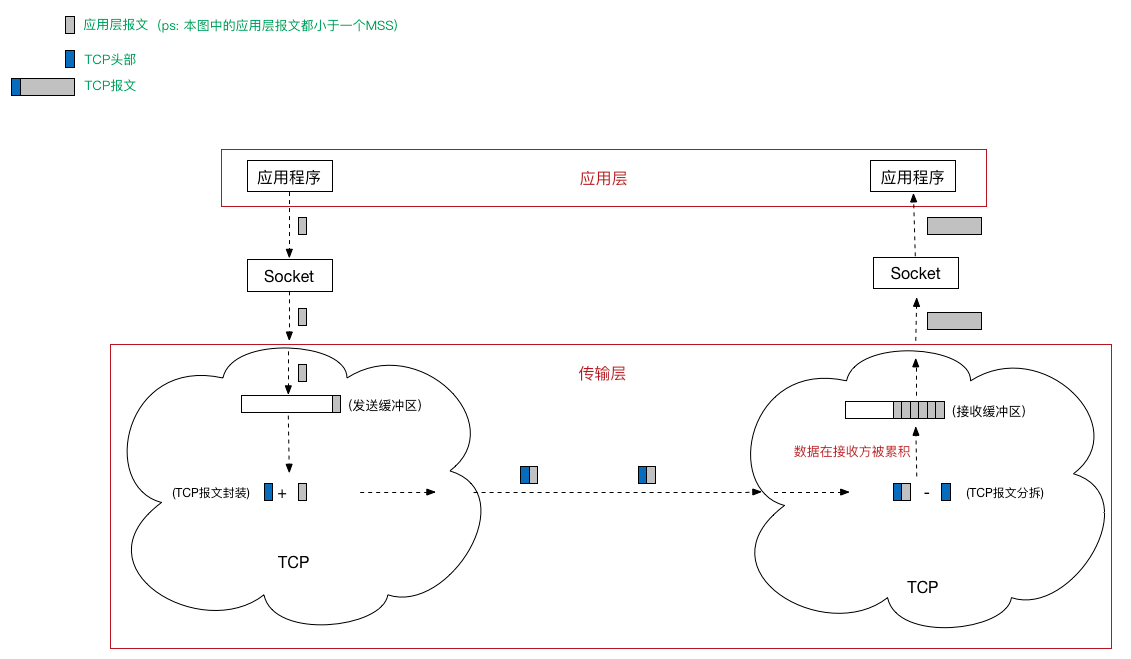
11、TCP的拆包与粘包
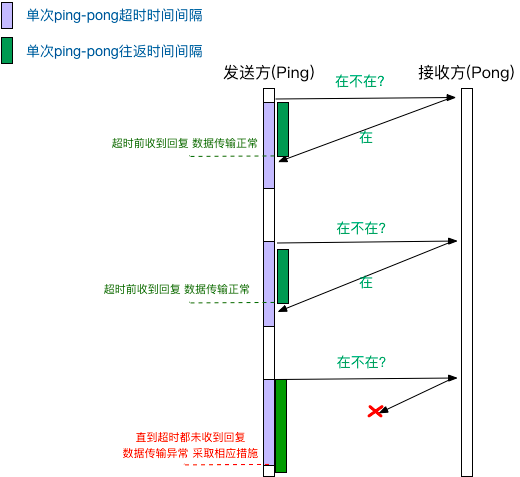
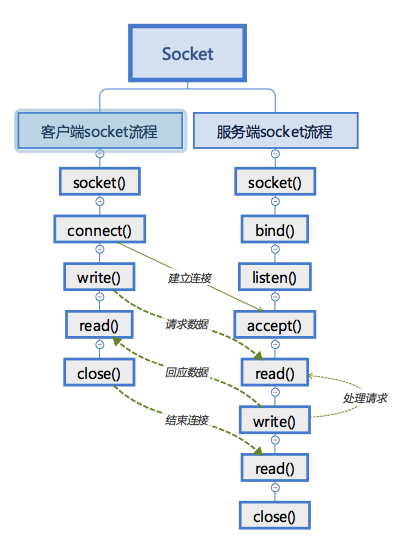
什么是TCP拆包?为什么会出现TCP拆包?
简单地说,我们都知道TCP是以“流”的形式进行数据传输的,而且TCP为提高性能,发送端会将需要发送的数据刷入缓冲区,等待缓冲区满了之后,再将缓冲区中的数据发送给接收方,同理,接收方也会有缓冲区这样的机制,来接收数据。拆包就是在socket读取时,没有完整地读取一个数据包,只读取一部分。
什么是TCP粘包?为什么会出现TCP粘包?
同上。粘包就是在socket读取时,读到了实际意义上的两个或多个数据包的内容,同时将其作为一个数据包进行处理。
引用一张图片来解释一下在TCP出现拆包、粘包以及正常状态下的三种情况:
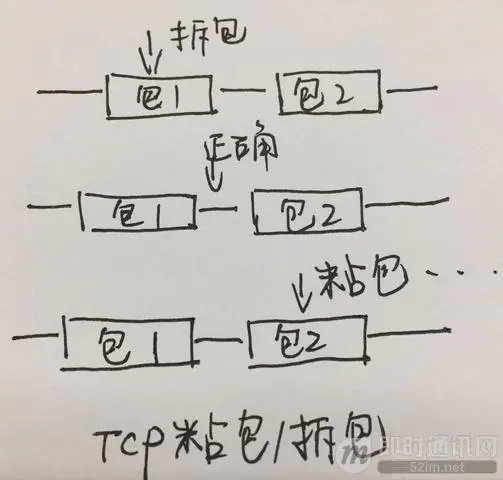
了解了TCP出现拆包/粘包的原因,那么,如何解决呢?
通常来说,有以下四种解决方式:
1)消息定长;
2)用回车换行符作为消息结束标志;
3)用特殊分隔符作为消息结束标志,如\t、\n等,回车换行符其实就是特殊分隔符的一种;
4)将消息分为消息头和消息体,在消息头中用字段标识消息总长度。
netty针对以上四种场景,给我们封装了以下四种对应的解码器:
1)FixedLengthFrameDecoder,定长消息解码器;
2)LineBasedFrameDecoder,回车换行符消息解码器;
3)DelimiterBasedFrameDecoder,特殊分隔符消息解码器;
4)LengthFieldBasedFrameDecoder,自定义长度消息解码器。
我们用到的就是LengthFieldBasedFrameDecoder自定义长度消息解码器,同时配合LengthFieldPrepender编码器使用,关于参数配置,建议参考《netty--最通用TCP黏包解决方案:LengthFieldBasedFrameDecoder和LengthFieldPrepender》这篇文章,讲解得比较细致。
我们配置的是消息头长度为2个字节,所以消息包的最大长度需要小于65536个字节,netty会把消息内容长度存放消息头的字段里,接收方可以根据消息头的字段拿到此条消息总长度,当然,netty提供的LengthFieldBasedFrameDecoder已经封装好了处理逻辑,我们只需要配置lengthFieldOffset、lengthFieldLength、lengthAdjustment、initialBytesToStrip即可,这样就可以解决TCP的拆包与粘包,这也就是netty相较于原生nio的便捷性,原生nio需要自己处理拆包/粘包等问题。
12、长连接握手认证
接着,我们来看看LoginAuthHandler和HeartbeatRespHandler。
LoginAuthRespHandler:是当客户端与服务端长连接建立成功后,客户端主动向服务端发送一条登录认证消息,带入与当前用户相关的参数,比如token,服务端收到此消息后,到数据库查询该用户信息,如果是合法有效的用户,则返回一条登录成功消息给该客户端,反之,返回一条登录失败消息给该客户端,这里,就是在接收到服务端返回的登录状态后的处理handler。
比如:
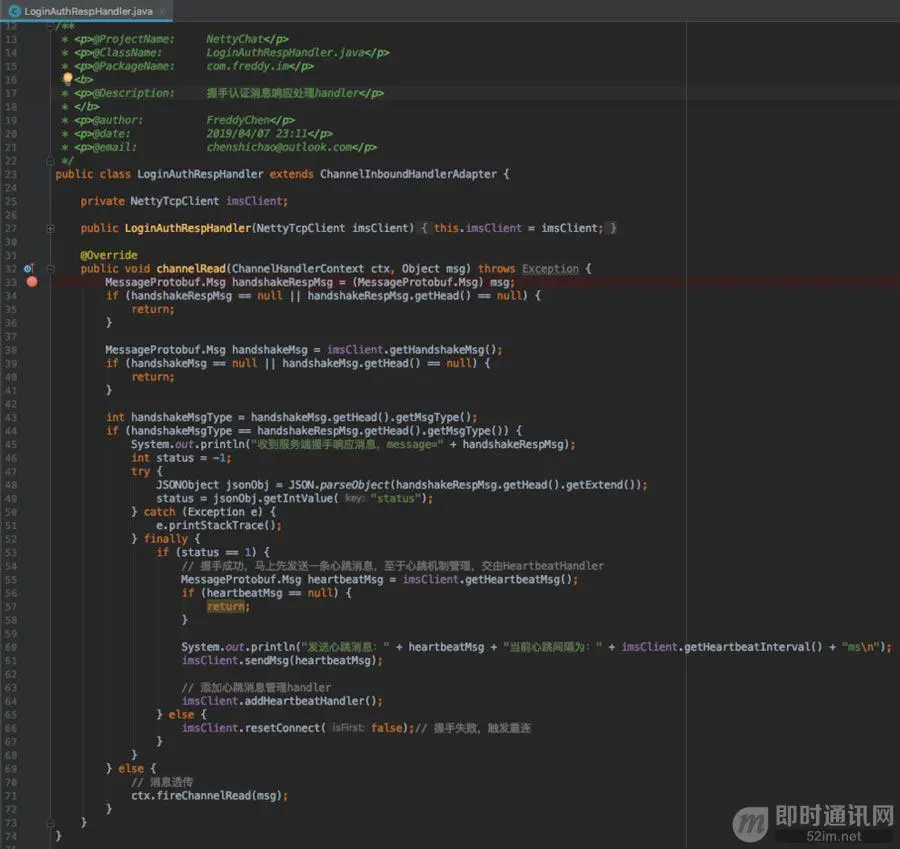
可以看到,当接收到服务端握手消息响应后,会从扩展字段取出status,如果status=1,则代表握手成功,这个时候就先主动向服务端发送一条心跳消息,然后利用Netty的IdleStateHandler读写超时机制,定期向服务端发送心跳消息,维持长连接,以及检测长连接是否还存在等。
HeartbeatRespHandler:是当客户端接收到服务端登录成功的消息后,主动向服务端发送一条心跳消息,心跳消息可以是一个空包,消息包体越小越好,服务端收到客户端的心跳包后,原样返回给客户端,这里,就是收到服务端返回的心跳消息响应的处理handler。
比如:
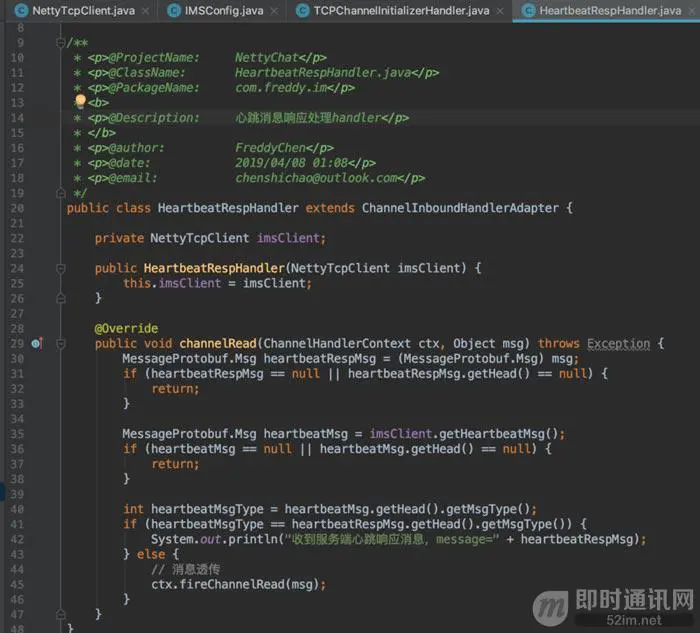
这个就比较简单,收到心跳消息响应,无需任务处理,直接打印一下方便我们分析即可。
13、心跳机制及读写超时机制
心跳包是定期发送,也可以自己定义一个周期,比如:《移动端IM实践:实现Android版微信的智能心跳机制》,为了简单,此处规定应用在前台时,8秒发送一个心跳包,切换到后台时,30秒发送一次,根据自己的实际情况修改一下即可。心跳包用于维持长连接以及检测长连接是否断开等。
PS:更多心跳保活方面的文章请见:
《Android端消息推送总结:实现原理、心跳保活、遇到的问题等》
《为何基于TCP协议的移动端IM仍然需要心跳保活机制?》
《微信团队原创分享:Android版微信后台保活实战分享(网络保活篇)》
《移动端IM实践:WhatsApp、Line、微信的心跳策略分析》
接着,我们利用Netty的读写超时机制,来实现一个心跳消息管理handler:
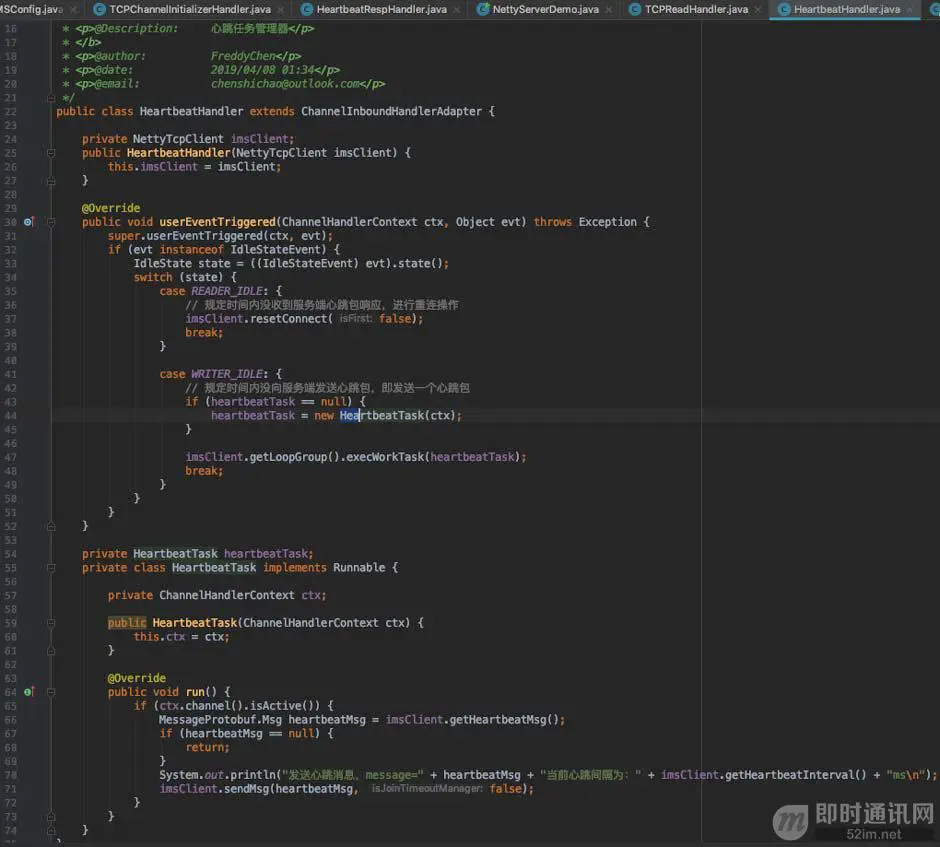
可以看到,利用userEventTriggered()方法回调,通过IdleState类型,可以判断读超时/写超时/读写超时,这个在添加IdleStateHandler时可以配置,下面会贴上代码。
首先我们可以在READER_IDLE事件里,检测是否在规定时间内没有收到服务端心跳包响应,如果是,那就触发重连操作。在WRITER_IDEL事件可以检测客户端是否在规定时间内没有向服务端发送心跳包,如果是,那就主动发送一个心跳包。发送心跳包是在子线程中执行,我们可以利用之前写的work线程池进行线程管理。
addHeartbeatHandler()代码如下:
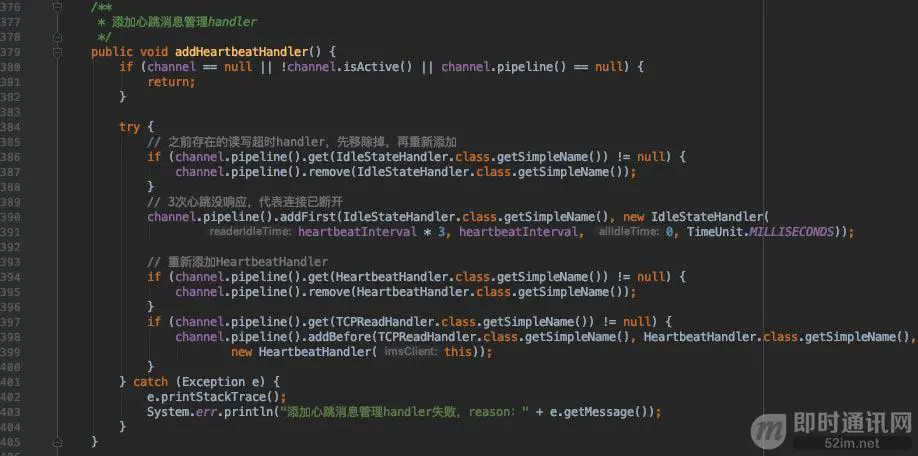
从图上可看到,在IdleStateHandler里,配置的读超时为心跳间隔时长的3倍,也就是3次心跳没有响应时,则认为长连接已断开,触发重连操作。写超时则为心跳间隔时长,意味着每隔heartbeatInterval会发送一个心跳包。读写超时没用到,所以配置为0。
onConnectStatusCallback(int connectStatus)为连接状态回调,以及一些公共逻辑处理:
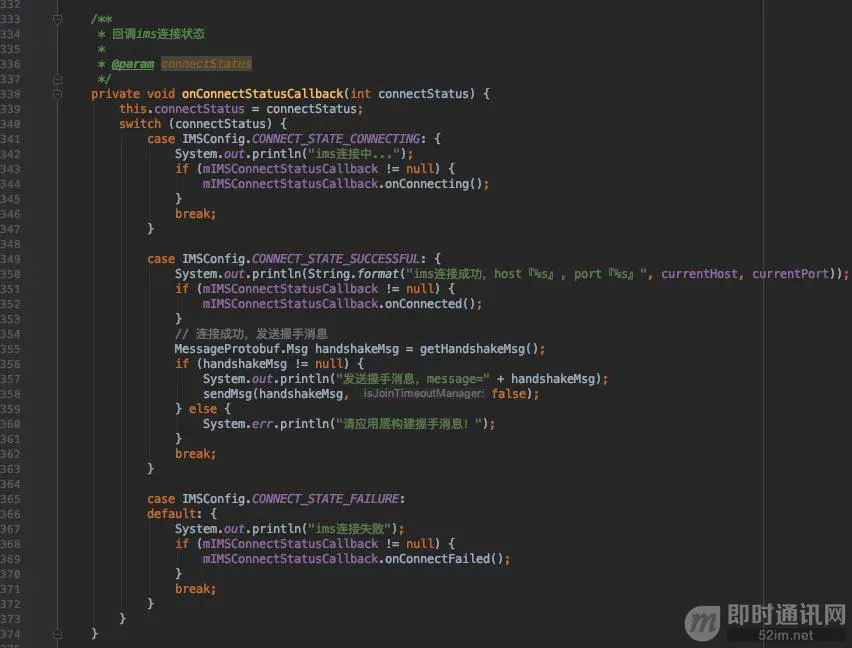
连接成功后,立即发送一条握手消息,再次梳理一下整体流程:
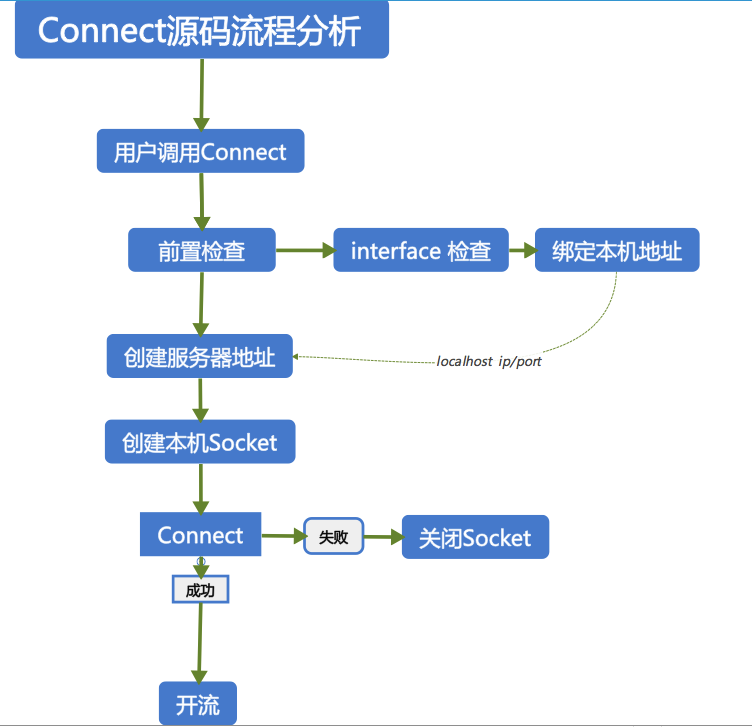
1)客户端根据服务端返回的host及port,进行第一次连接;
2)连接成功后,客户端向服务端发送一条握手认证消息(1001);
3)服务端在收到客户端的握手认证消息后,从扩展字段里取出用户token,到本地数据库校验合法性;
4)校验完成后,服务端把校验结果通过1001消息返回给客户端,也就是握手消息响应;
5)客户端收到服务端的握手消息响应后,从扩展字段取出校验结果。若校验成功,客户端向服务端发送一条心跳消息(1002),然后进入心跳发送周期,定期间隔向服务端发送心跳消息,维持长连接以及实时检测链路可用性,若发现链路不可用,等待一段时间触发重连操作,重连成功后,重新开始握手/心跳的逻辑。
看看TCPReadHandler收到消息是怎么处理的:
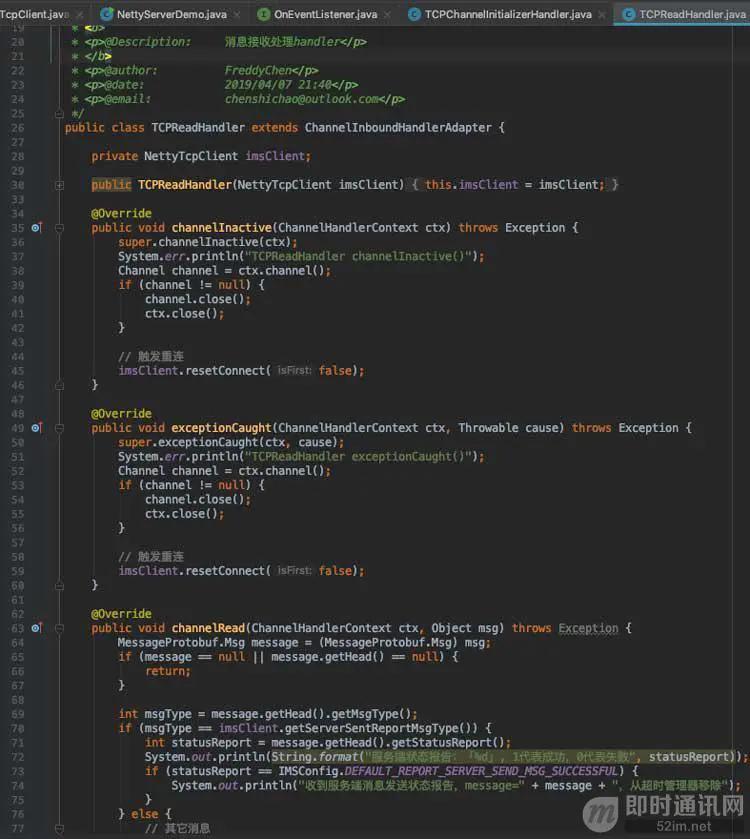
可以看到,在channelInactive()及exceptionCaught()方法都触发了重连,channelInactive()方法在当链路断开时会调用,exceptionCaught()方法在当出现异常时会触发,另外,还有诸如channelUnregistered()、channelReadComplete()等方法可以重写,在这里就不贴了,相信聪明的你一眼就能看出方法的作用。
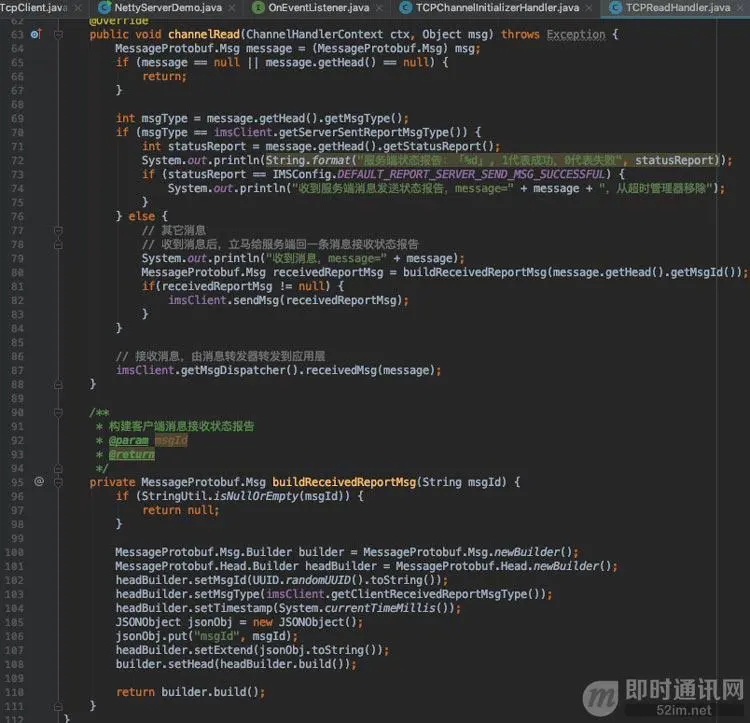
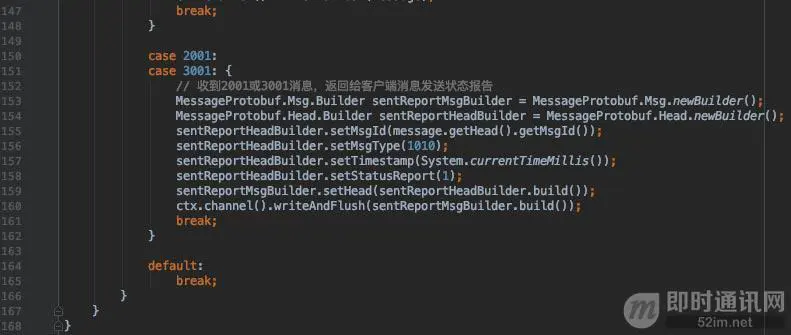
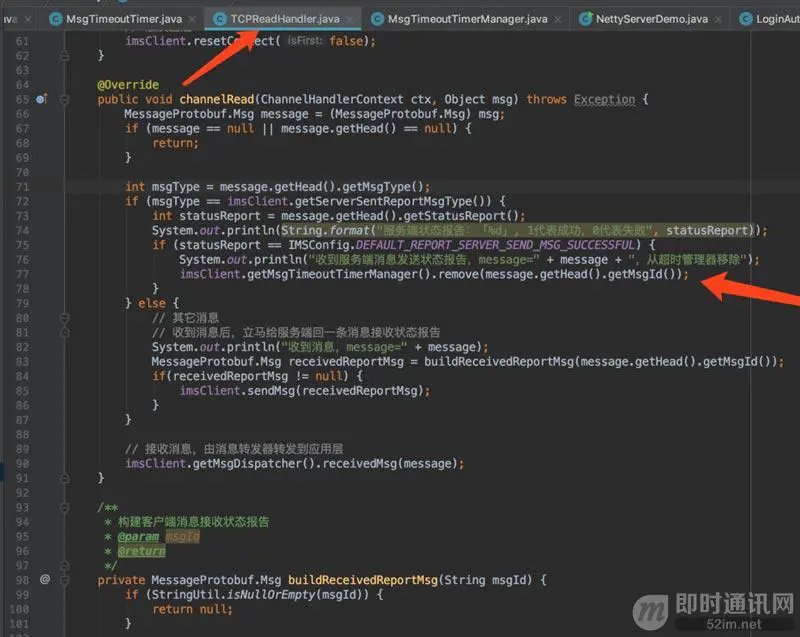
我们仔细看一下channelRead()方法的逻辑,在if判断里,先判断消息类型,如果是服务端返回的消息发送状态报告类型,则判断消息是否发送成功,如果发送成功,从超时管理器中移除,这个超时管理器是干嘛的呢?
下面讲到消息重发机制的时候会详细地讲。在else里,收到其他消息后,会立马给服务端返回一个消息接收状态报告,告诉服务端,这条消息我已经收到了,这个动作,对于后续需要做的离线消息会有作用。如果不需要支持离线消息功能,这一步可以省略。最后,调用消息转发器,把接收到的消息转发到应用层即可。
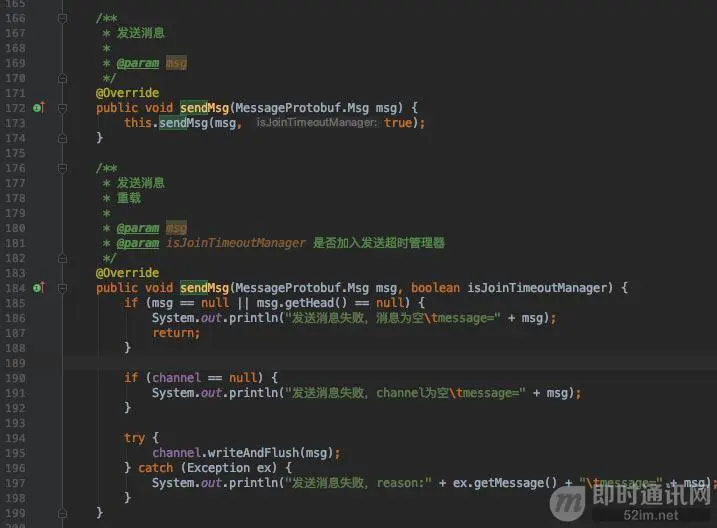
代码写了这么多,我们先来看看运行后的效果,先贴上缺失的消息发送代码及ims关闭代码以及一些默认配置项的代码。
发送消息:
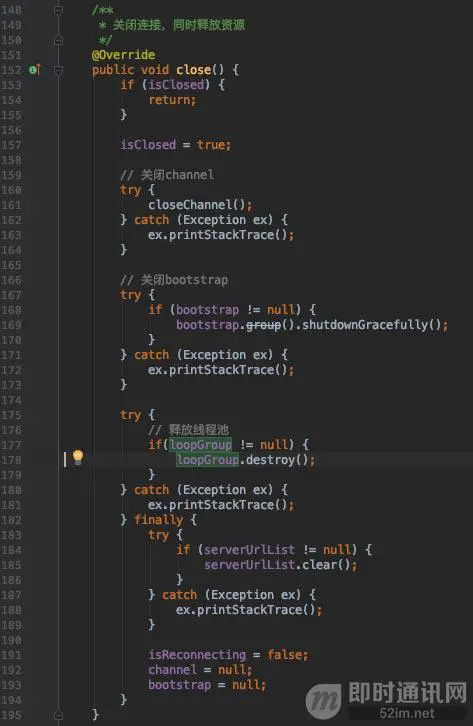
关闭ims:
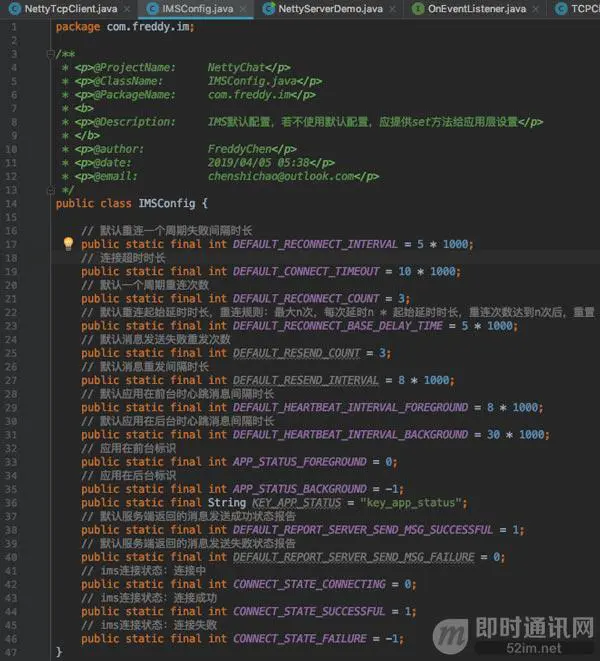
ims默认配置:
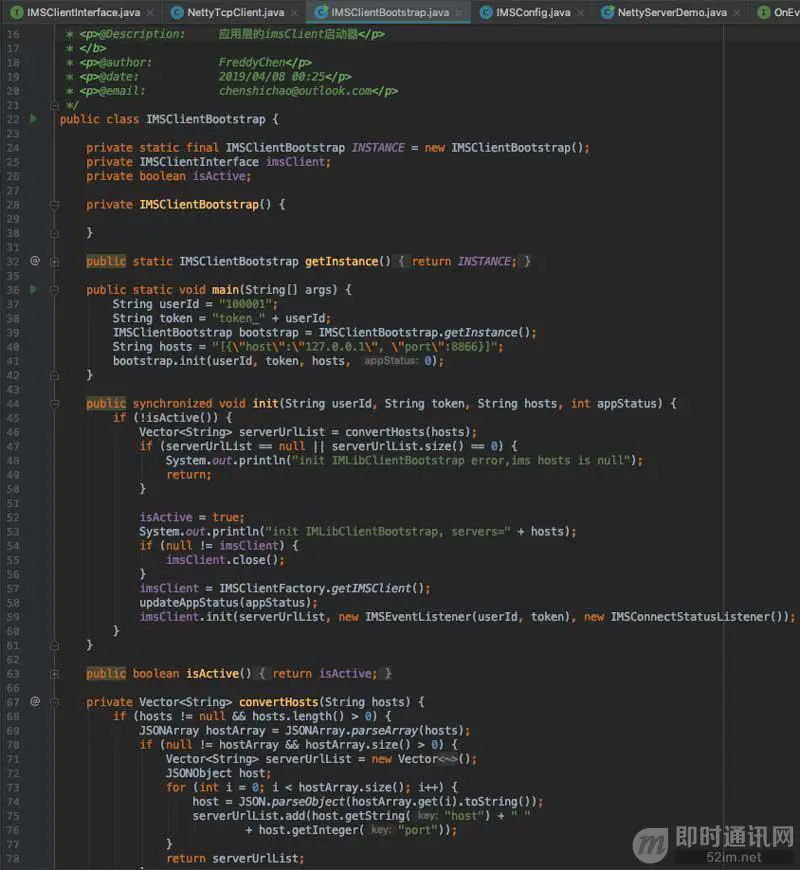
还有,应用层实现的ims client启动器:
由于代码有点多,不太方便全部贴上,如果有兴趣可以下载本文的完整demo进行体验。
额,对了,还有一个简易的服务端代码,如下:
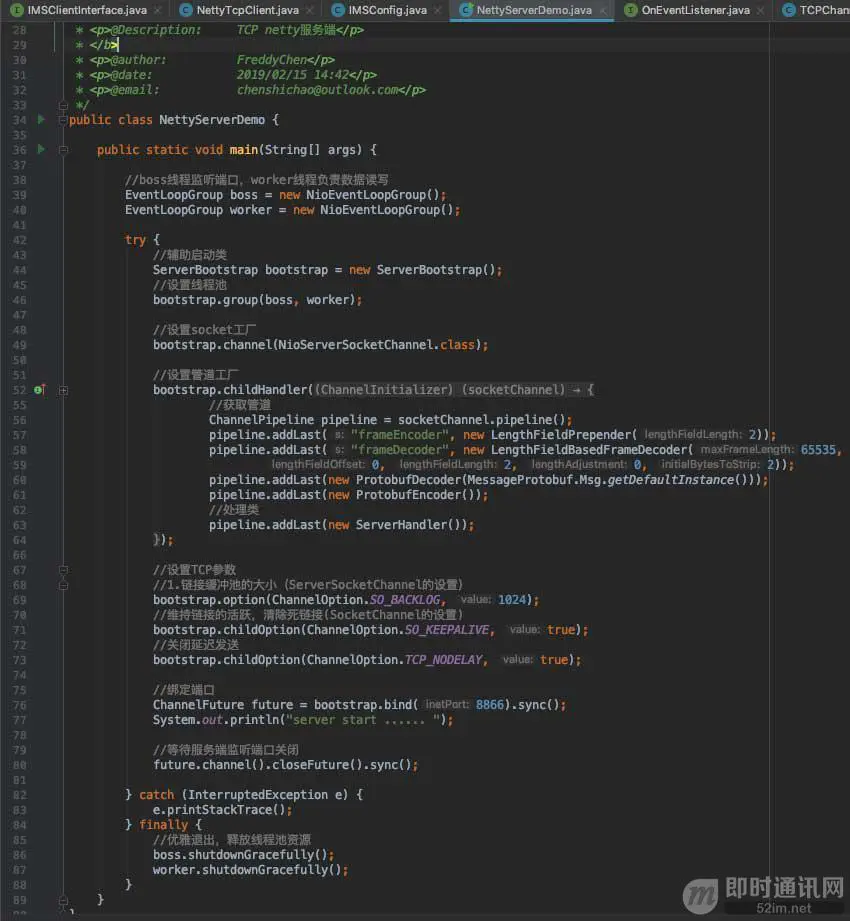
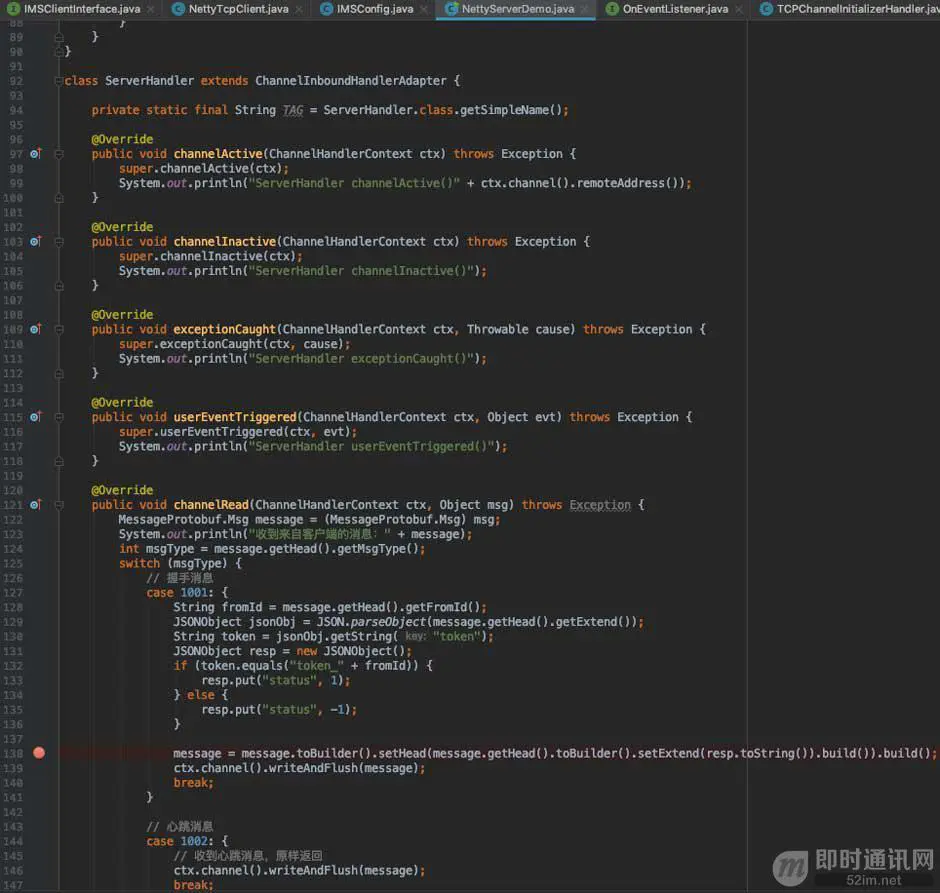
14、运行调试
我们先来看看连接及重连部分(由于录制gif比较麻烦,体积较大,所以我先把重连间隔调小成3秒,方便看效果)。
启动服务端:

启动客户端:

可以看到,正常的情况下已经连接成功了,接下来,我们来试一下异常情况。
比如服务端没启动,看看客户端的重连情况:
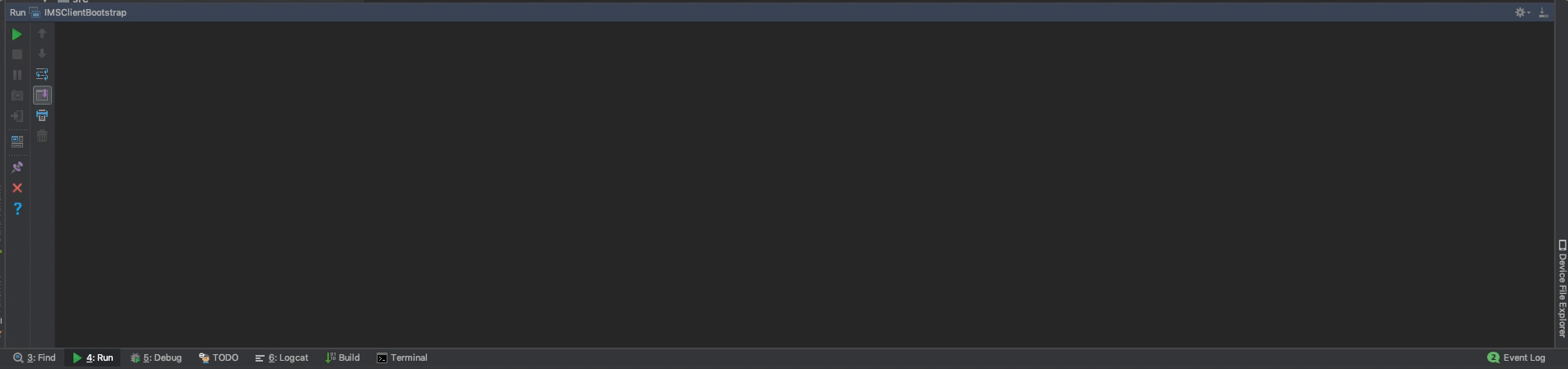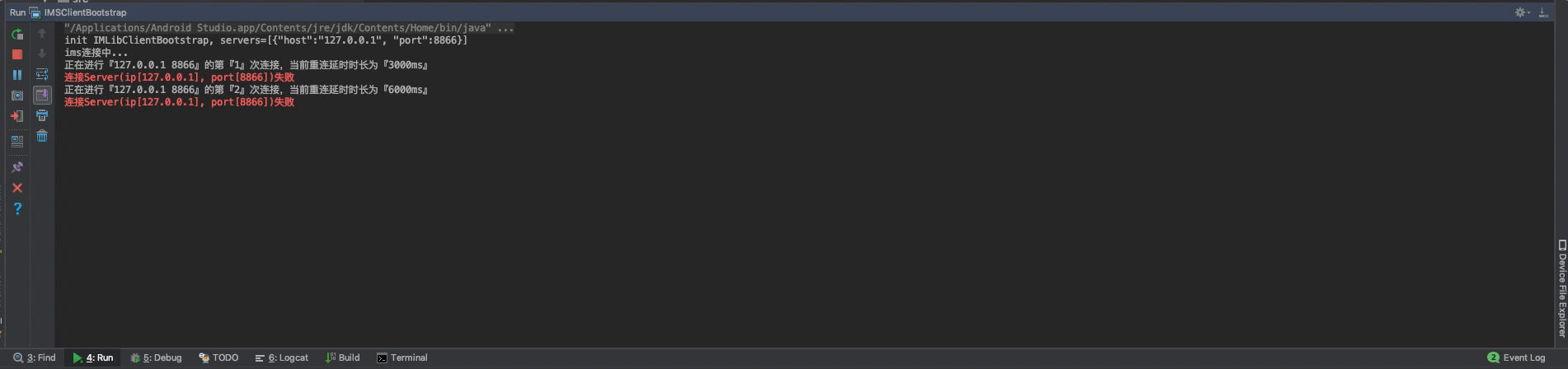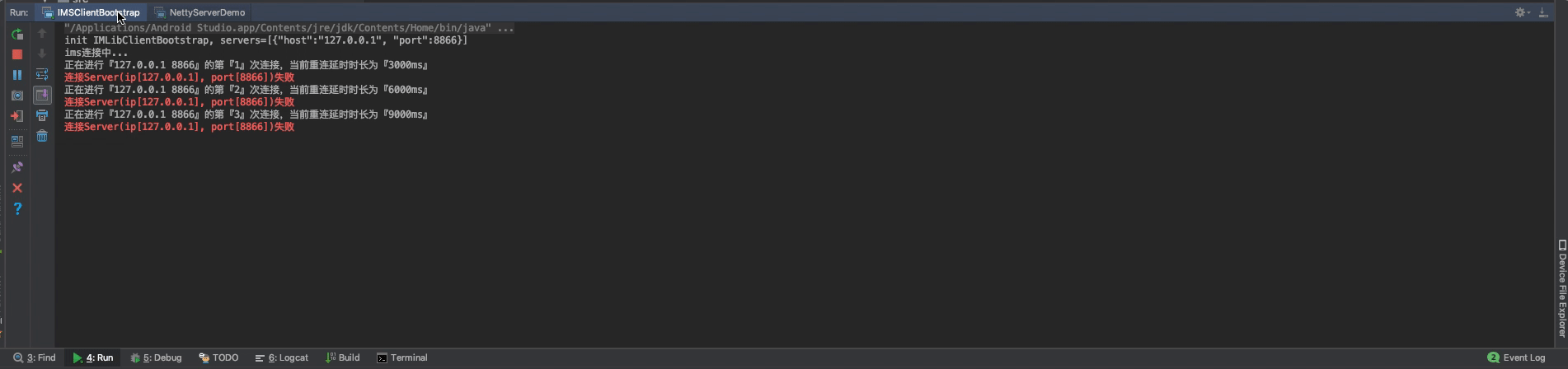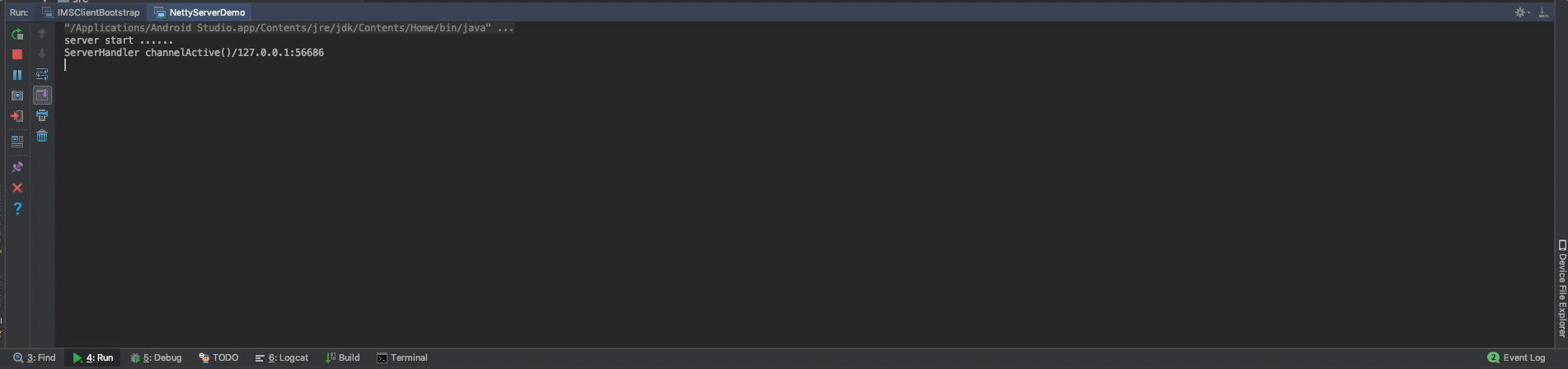
这次我们先启动的是客户端,可以看到连接失败后一直在进行重连,由于录制gif比较麻烦,在第三次连接失败后,我启动了服务端,这个时候客户端就会重连成功。
然后,我们再来调试一下握手认证消息即心跳消息:
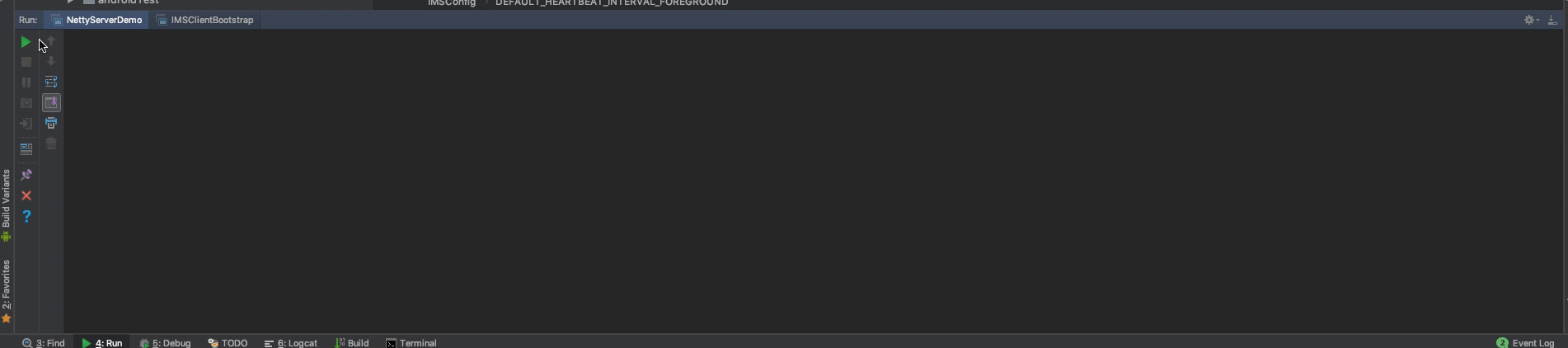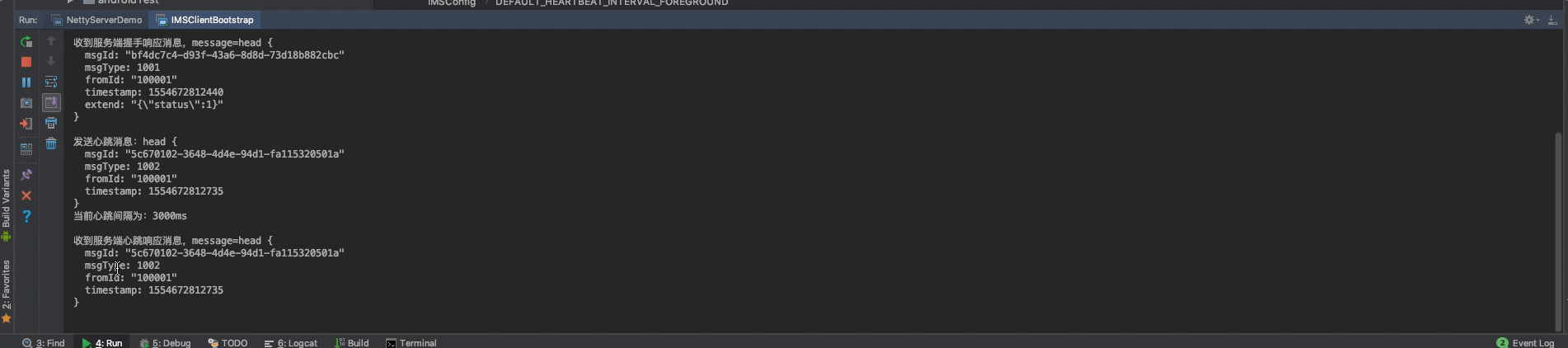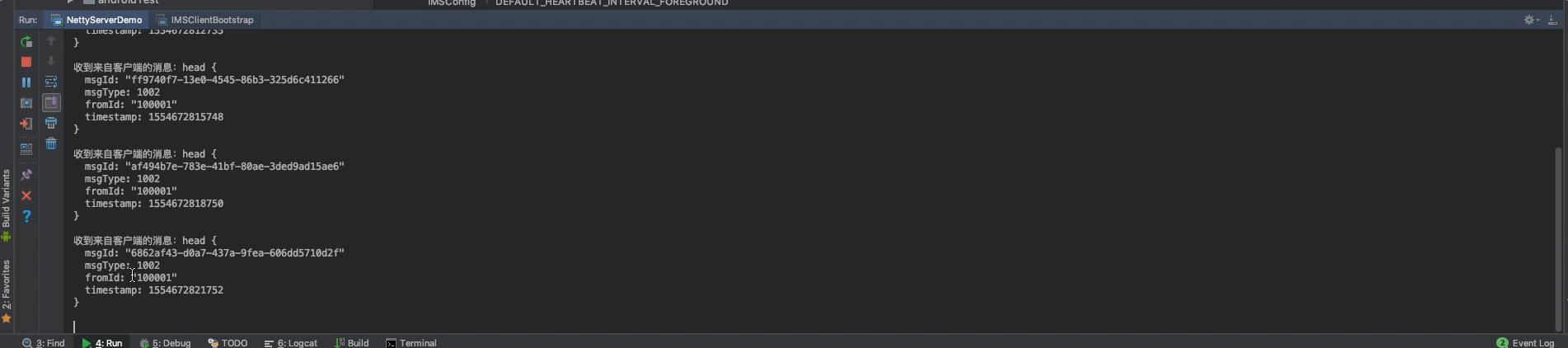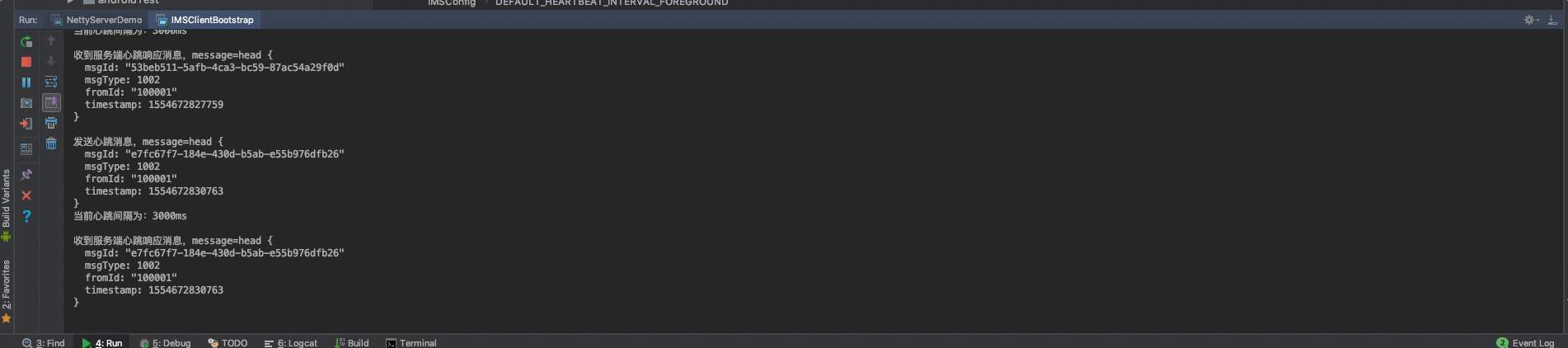
可以看到,长连接建立成功后,客户端会给服务端发送一条握手认证消息(1001),服务端收到握手认证消息会,给客户端返回了一条握手认证状态消息,客户端收到握手认证状态消息后,即启动心跳机制。gif不太好演示,下载demo就可以直观地看到。
接下来,在讲完消息重发机制及离线消息后,我会在应用层做一些简单的封装,以及在模拟器上运行,这样就可以很直观地看到运行效果。
15、消息重发机制
消息重发,顾名思义,即使对发送失败的消息进行重发。考虑到网络环境的不稳定性、多变性(比如从进入电梯、进入地铁、移动网络切换到wifi等),在消息发送的时候,发送失败的概率其实不小,这时消息重发机制就很有必要了。
有关即时通讯(IM)应用中的消息送达保证机制,可以详细阅读以下文章:
《IM消息送达保证机制实现(一):保证在线实时消息的可靠投递》
《IM群聊消息如此复杂,如何保证不丢不重?》
《完全自已开发的IM该如何设计“失败重试”机制?》
我们先来看看实现的代码逻辑。
MsgTimeoutTimer:
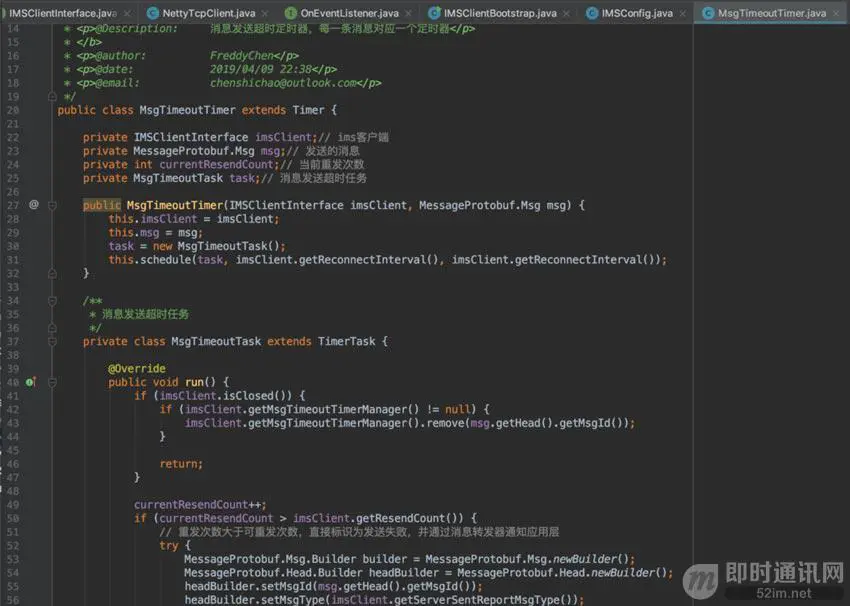
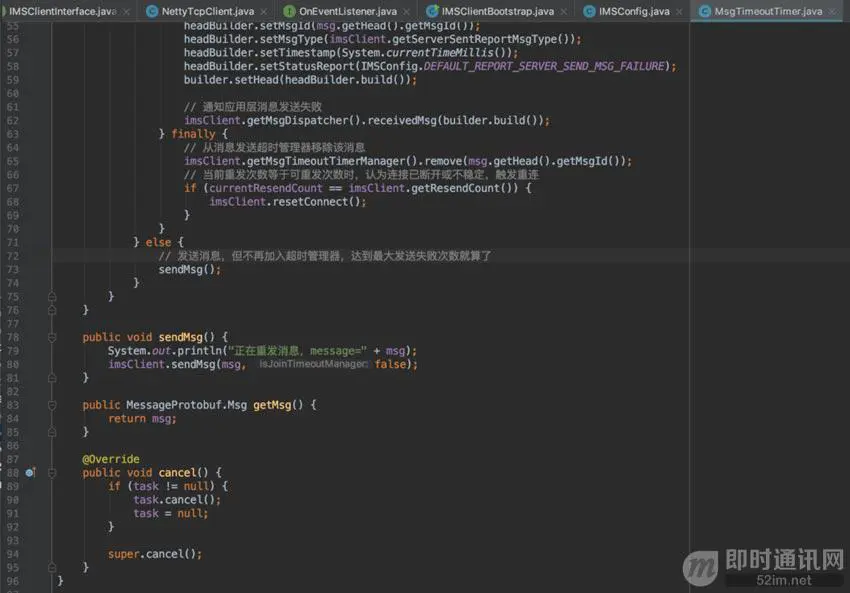
MsgTimeoutTimerManager:
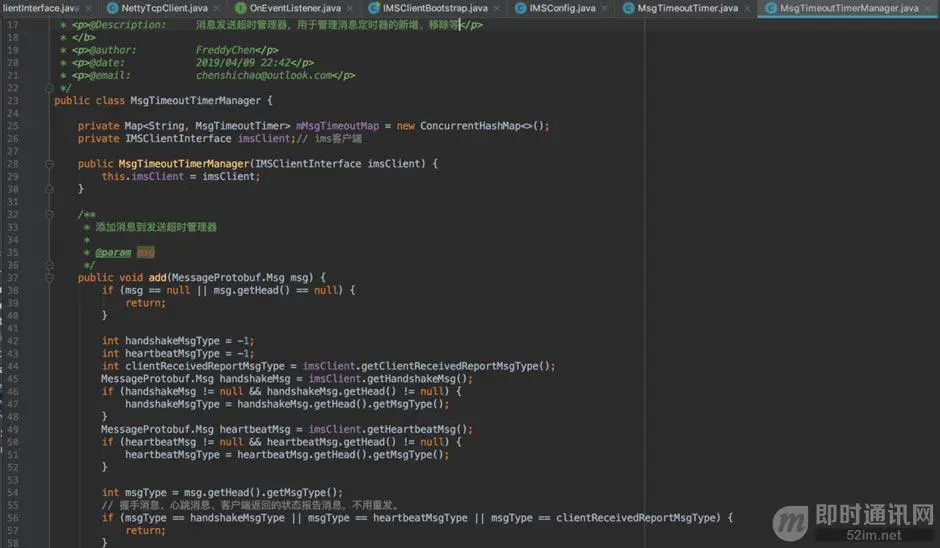
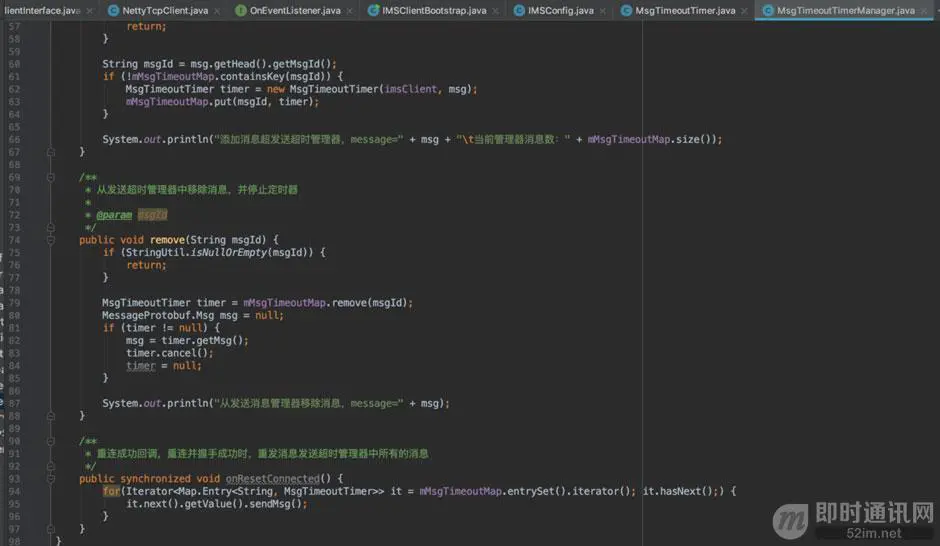
然后,我们看看收消息的TCPReadHandler的改造:
最后,看看发送消息的改造:
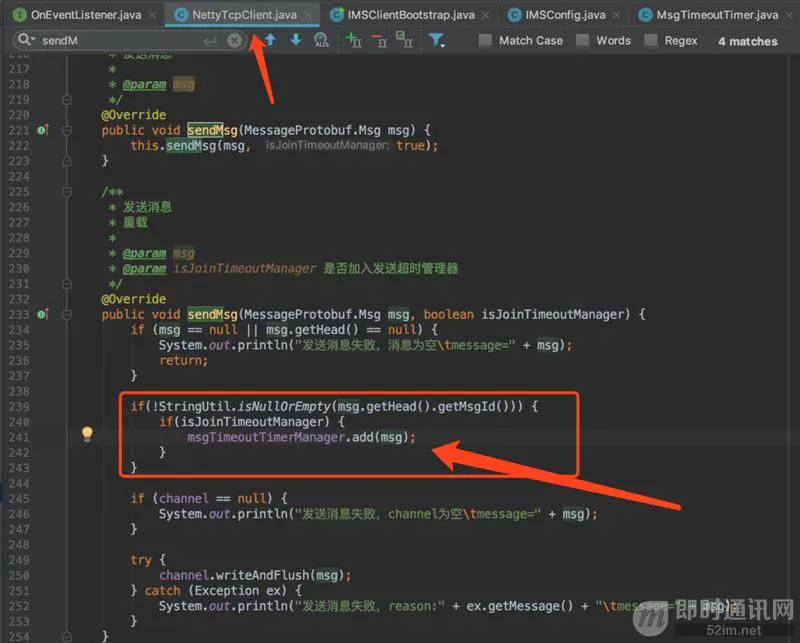
说一下逻辑吧:发送消息时,除了心跳消息、握手消息、状态报告消息外,消息都加入消息发送超时管理器,立马开启一个定时器,比如每隔5秒执行一次,共执行3次,在这个周期内,如果消息没有发送成功,会进行3次重发,达到3次重发后如果还是没有发送成功,那就放弃重发,移除该消息,同时通过消息转发器通知应用层,由应用层决定是否再次重发。如果消息发送成功,服务端会返回一个消息发送状态报告,客户端收到该状态报告后,从消息发送超时管理器移除该消息,同时停止该消息对应的定时器即可。
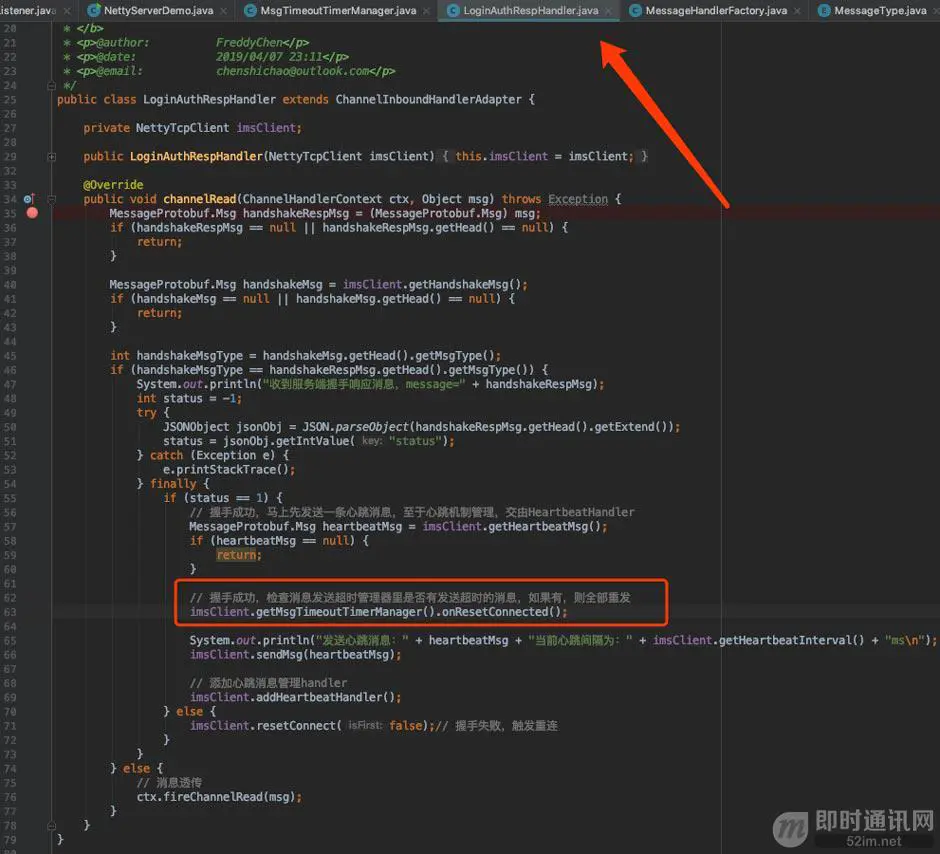
另外,在用户握手认证成功时,应该检查消息发送超时管理器里是否有发送超时的消息,如果有,则全部重发:
16、离线消息
由于离线消息机制,需要服务端数据库及缓存上的配合,代码就不贴了,太多太多。
我简单说一下实现思路吧:客户端A发送消息到客户端B,消息会先到服务端,由服务端进行中转。
这个时候,客户端B存在两种情况:
1)长连接正常,就是客户端网络环境良好,手机有电,应用处在打开的情况;
2)废话,那肯定就是长连接不正常咯。这种情况有很多种原因,比如wifi不可用、用户进入了地铁或电梯等网络不好的场所、应用没打开或已退出登录等,总的来说,就是没有办法正常接收消息。
如果是长连接正常,那没什么可说的,服务端直接转发即可。
如果长连接不正常,需要这样处理:
服务端接收到客户端A发送给客户端B的消息后,先给客户端A回复一条状态报告,告诉客户端A,我已经收到消息,这个时候,客户端A就不用管了,消息只要到达服务端即可。然后,服务端先尝试把消息转发到客户端B,如果这个时候客户端B收到服务端转发过来的消息,需要立马给服务端回一条状态报告,告诉服务端,我已经收到消息,服务端在收到客户端B返回的消息接收状态报告后,即认为此消息已经正常发送,不需要再存库。
如果客户端B不在线,服务端在做转发的时候,并没有收到客户端B返回的消息接收状态报告,那么,这条消息就应该存到数据库,直到客户端B上线后,也就是长连接建立成功后,客户端B主动向服务端发送一条离线消息询问,服务端在收到离线消息询问后,到数据库或缓存去查客户端B的所有离线消息,并分批次返回,客户端B在收到服务端的离线消息返回后,取出消息id(若有多条就取id集合),通过离线消息应答把消息id返回到服务端,服务端收到后,根据消息id从数据库把对应的消息删除即可。
以上是单聊离线消息处理的情况,群聊有点不同,群聊的话,是需要服务端确认群组内所有用户都收到此消息后,才能从数据库删除消息,就说这么多,如果需要细节的话,可以私信我。
更多有关离线消息处理思路的文章,可以详细阅读:
《IM消息送达保证机制实现(二):保证离线消息的可靠投递》
《IM群聊消息如此复杂,如何保证不丢不重?》
《浅谈移动端IM的多点登陆和消息漫游原理》
不知不觉,NettyTcpClient中定义了很多变量,为了防止大家不明白变量的定义,还是贴上代码吧:
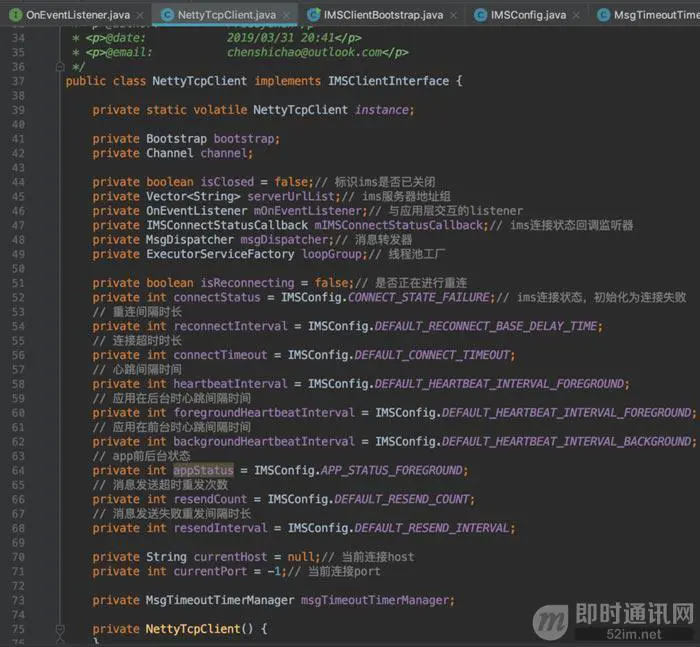
18、最终运行
运行一下,看看效果吧:
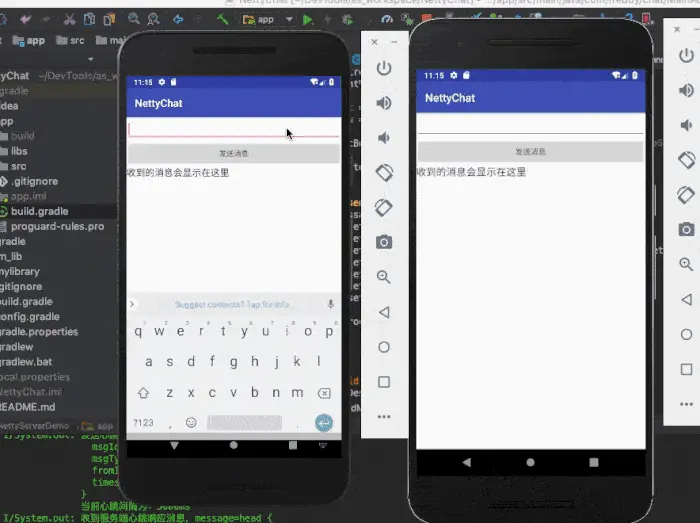
运行步骤是:
1)首先,启动服务端。
2)然后,修改客户端连接的ip地址为192.168.0.105(这是我本机的ip地址),端口号为8855,fromId,也就是userId,定义成100001,toId为100002,启动客户端A。
3)再然后,fromId,也就是userId,定义成100002,toId为100001,启动客户端B。
4)客户端A给客户端B发送消息,可以看到在客户端B的下面,已经接收到了消息。
5)用客户端B给客户端A发送消息,也可以看到在客户端A的下面,也已经接收到了消息。
至于,消息收发测试成功。至于群聊或重连等功能,就不一一演示了,还是那句话,下载demo体验一下吧:https://github.com/52im/NettyChat。
由于gif录制体积较大,所以只能简单演示一下消息收发,具体下载demo体验吧。如果有需要应用层UI实现(就是聊天页及会话页的封装)的话,我再分享出来吧。
19、写在最后
终于写完了,这篇文章大概写了10天左右,有很大部分的原因是自己有拖延症,每次写完一小段,总静不下心来写下去,导致一直拖到现在,以后得改改。第一次写技术分享文章,有很多地方也许逻辑不太清晰,由于篇幅有限,也只是贴了部分代码,建议大家把源码下载下来看看。一直想写这篇文章,以前在网上也尝试过找过很多im方面的文章,都找不到一篇比较完善的,本文谈不上完善,但包含的模块很多,希望起到一个抛砖引玉的作用,也期待着大家跟我一起发现更多的问题并完善,最后,如果这篇文章对你有用,希望在github上给我一个star哈。。。
应大家要求,精简了netty-all-4.1.33.Final.jar包,原netty-all-4.1.33.Final.jar包大小为3.9M。
经测试发现目前im_lib库只需要用到以下jar包:
netty-buffer-4.1.33.Final.jar
netty-codec-4.1.33.Final.jar
netty-common-4.1.33.Final.jar
netty-handler-4.1.33.Final.jar
netty-resolver-4.1.33.Final.jar
netty-transport-4.1.33.Final.jar
所以,抽取以上jar包,重新打成了netty-tcp-4.1.33-1.0.jar(已经上传到github工程了),目前自测没有问题,如果发现bug,请告诉我,谢谢。
附上原jar及裁剪后jar包的大小对比:


代码已更新到Github:
https://github.com/52im/NettyChat
附录:更多网络编程/即时通讯/消息推送的实战入门文章
《手把手教你用Netty实现网络通信程序的心跳机制、断线重连机制》
《NIO框架入门(一):服务端基于Netty4的UDP双向通信Demo演示》
《NIO框架入门(二):服务端基于MINA2的UDP双向通信Demo演示》
《NIO框架入门(三):iOS与MINA2、Netty4的跨平台UDP双向通信实战》
《NIO框架入门(四):Android与MINA2、Netty4的跨平台UDP双向通信实战》
《微信小程序中如何使用WebSocket实现长连接(含完整源码)》
《Web端即时通讯安全:跨站点WebSocket劫持漏洞详解(含示例代码)》
《解决MINA数据传输中TCP的粘包、缺包问题(有源码)》
《开源IM工程“蘑菇街TeamTalk”2015年5月前未删减版完整代码 [附件下载]》
《用于IM中图片压缩的Android工具类源码,效果可媲美微信 [附件下载]》
《高仿Android版手机QQ可拖拽未读数小气泡源码 [附件下载]》
《一个WebSocket实时聊天室Demo:基于node.js+socket.io [附件下载]》
《Android聊天界面源码:实现了聊天气泡、表情图标(可翻页) [附件下载]》
《高仿Android版手机QQ首页侧滑菜单源码 [附件下载]》
《开源libco库:单机千万连接、支撑微信8亿用户的后台框架基石 [源码下载]》
《分享java AMR音频文件合并源码,全网最全》
《微信团队原创Android资源混淆工具:AndResGuard [有源码]》
《一个基于MQTT通信协议的完整Android推送Demo [附件下载]》
《Android版高仿微信聊天界面源码 [附件下载]》
《高仿手机QQ的Android版锁屏聊天消息提醒功能 [附件下载]》
《高仿iOS版手机QQ录音及振幅动画完整实现 [源码下载]》
《Android端社交应用中的评论和回复功能实战分享[图文+源码]》
《Android端IM应用中的@人功能实现:仿微博、QQ、微信,零入侵、高可扩展[图文+源码]》
《仿微信的IM聊天时间显示格式(含iOS/Android/Web实现)[图文+源码]》
(本文同步发布于:http://www.52im.net/thread-2671-1-1.html)
收起阅读 »