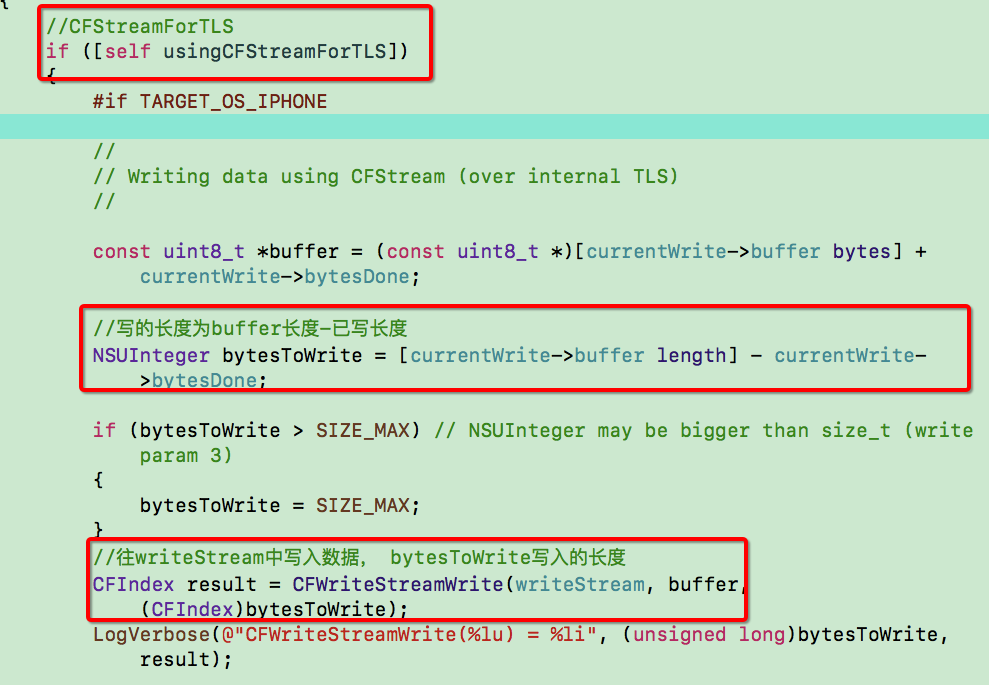
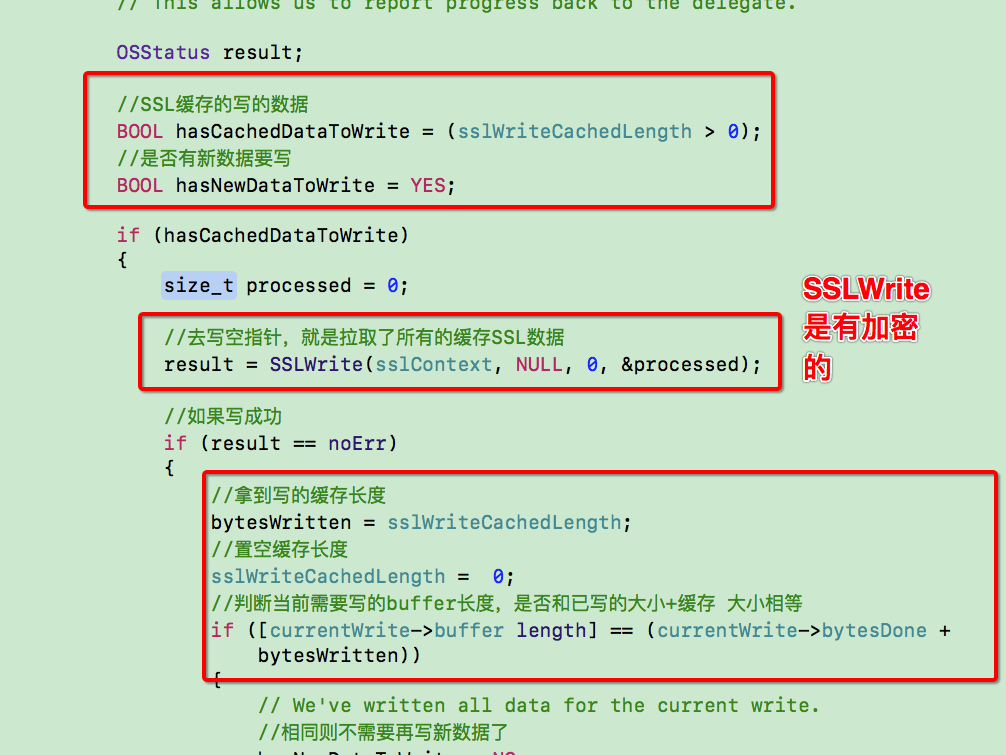
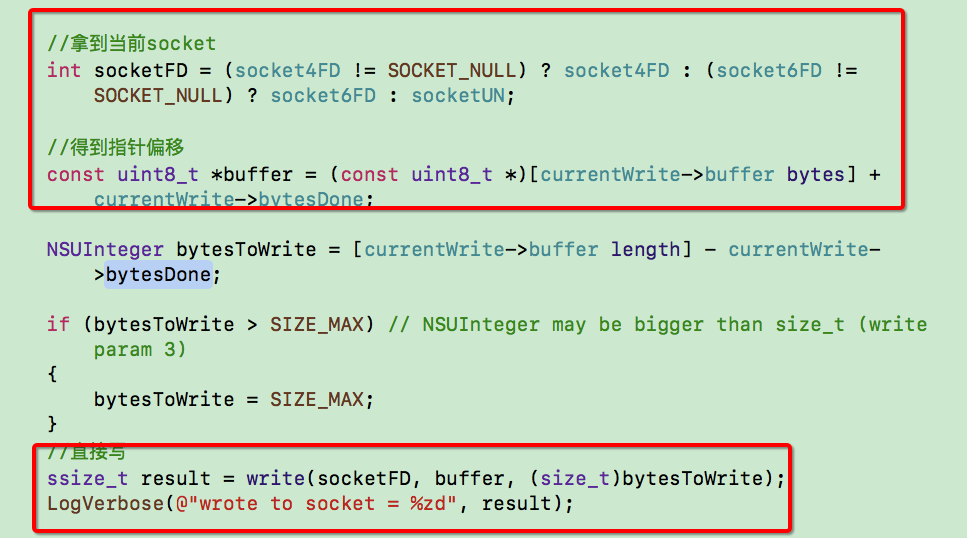
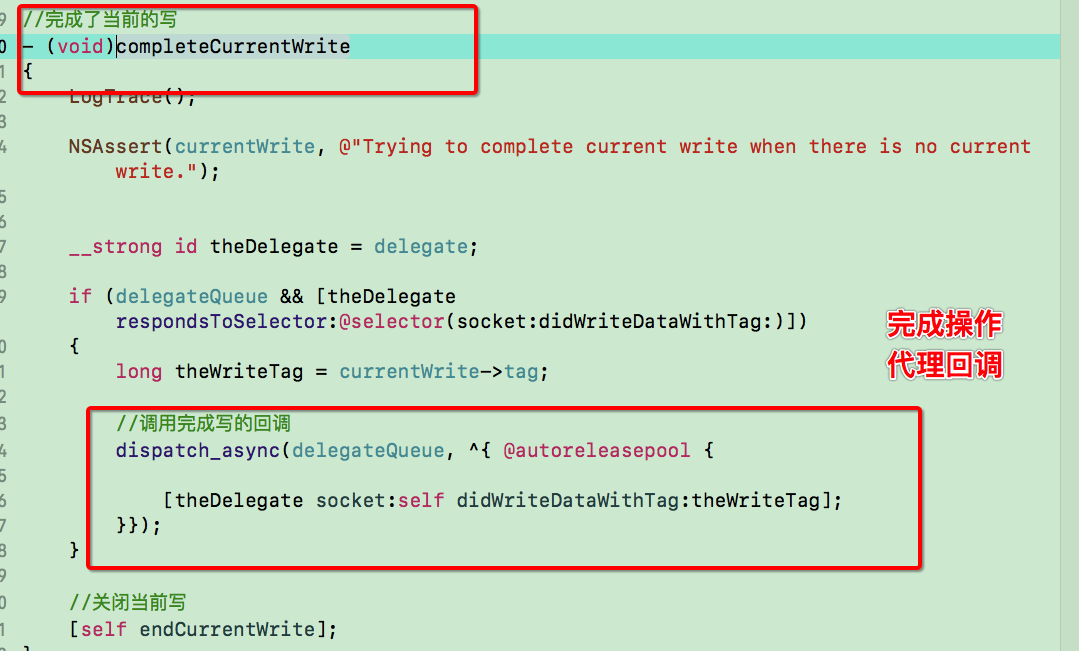
路由的概念
路由这个词本身应该是互联网协议中的一个词,维基百科对此的解释如下:
路由(routing)就是通过互联的网络把信息从源地址传输到目的地址的活动。路由发生在OSI网络参考模型中的第三层即网络层。
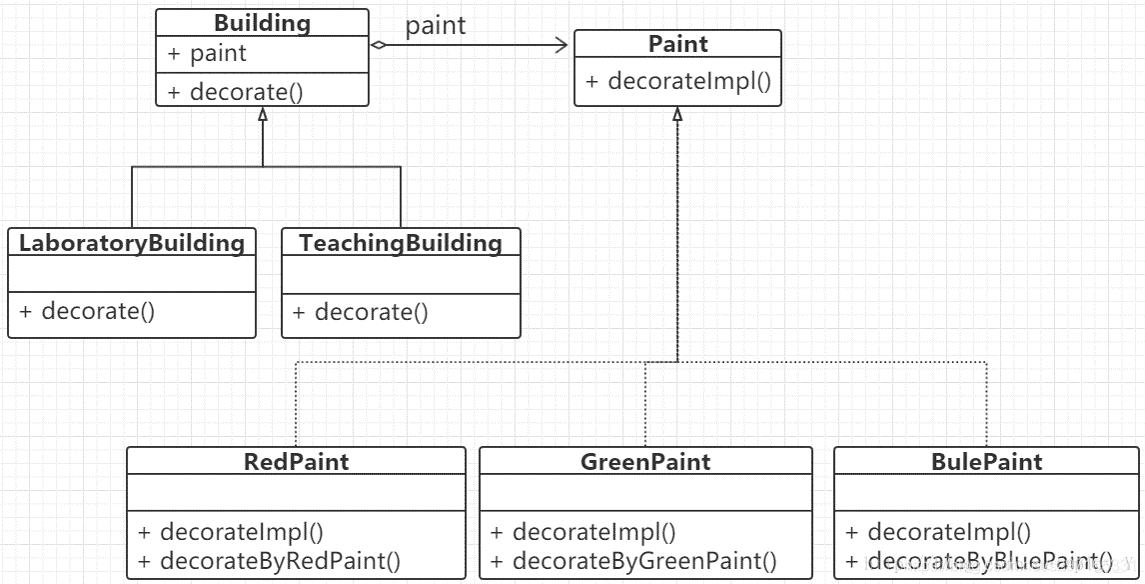
个人理解,在前端开发中,路由就是通过一串字符串映射到对应业务的能力。APP的路由框首先能够搜集各组件的路由scheme,并生成路由表,然后,能够根据外部输入字符串在路由表中匹配到对应的页面或者服务,进行跳转或者调用,并提供会获取返回值等,示意如下
所以一个基本路由框架要具备如下能力:
- APP路由的扫描及注册逻辑
- 路由跳转target页面能力
- 路由调用target服务能力
APP中,在进行页面路由的时候,经常需要判断是否登录等一些额外鉴权逻辑所以,还需要提供拦截逻辑等,比如:登陆。
三方路由框架是否是APP强需求
答案:不是,系统原生提供路由能力,但功能较少,稍微大规模的APP都采用三方路由框架。
Android系统本身提供页面跳转能力:如startActivity,对于工具类APP,或单机类APP,这种方式已经完全够用,完全不需要专门的路由框架,那为什么很多APP还是采用路由框架呢?这跟APP性质及路由框架的优点都有关。比如淘宝、京东、美团等这些大型APP,无论是从APP功能还是从其研发团队的规模上来说都很庞大,不同的业务之间也经常是不同的团队在维护,采用组件化的开发方式,最终集成到一个APK中。多团队之间经常会涉及业务间的交互,比如从电影票业务跳转到美食业务,但是两个业务是两个独立的研发团队,代码实现上是完全隔离的,那如何进行通信呢?首先想到的是代码上引入,但是这样会打破了低耦合的初衷,可能还会引入各种问题。例如,部分业务是外包团队来做,这就牵扯到代码安全问题,所以还是希望通过一种类似黑盒的方式,调用目标业务,这就需要中转路由支持,所以国内很多APP都是用了路由框架的。其次我们各种跳转的规则并不想跟具体的实现类扯上关系,比如跳转商详的时候,不希望知道是哪个Activity来实现,只需要一个字符串映射过去即可,这对于H5、或者后端开发来处理跳转的时候,就非常标准。
原生路由的限制:功能单一,扩展灵活性差,不易协同
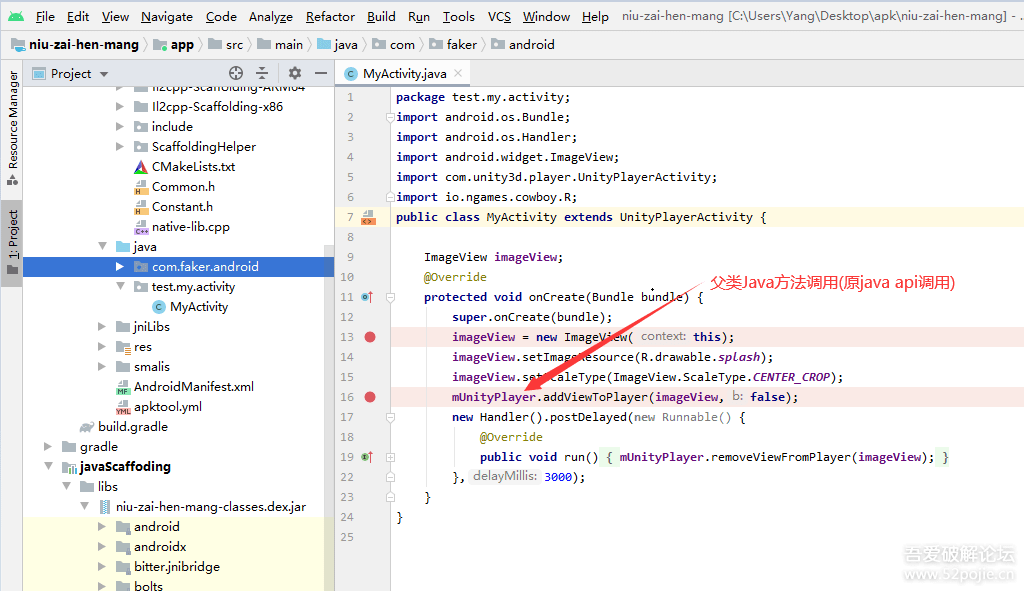
传统的路由基本上就限定在startActivity、或者startService来路由跳转或者启动服务。拿startActivity来说,传统的路由有什么缺点:startActivity有两种用法,一种是显示的,一种是隐式的,显示调用如下:
import com.snail.activityforresultexample.test.SecondActivity;
public class MainActivity extends AppCompatActivity {
void jumpSecondActivityUseClassName(){
Intent intent =new Intent(MainActivity.this, SecondActivity.class);
startActivity(intent);
}
显示调用的缺点很明显,那就是必须要强依赖目标Activity的类实现,有些场景,尤其是大型APP组件化开发时候,有些业务逻辑出于安全考虑,并不想被源码或aar依赖,这时显式依赖的方式就无法走通。再来看看隐式调用方法。
第一步:manifest中配置activity的intent-filter,至少要配置一个action
第二步:调用
void jumpSecondActivityUseFilter() {
Intent intent = new Intent();
intent.setAction("com.snail.activityforresultexample.SecondActivity");
startActivity(intent);
}
如果牵扯到数据传递写法上会更复杂一些,隐式调用的缺点有如下几点:
- 首先manifest中定义复杂,相对应的会导致暴露的协议变的复杂,不易维护扩展。
- 其次,不同Activity都要不同的action配置,每次增减修改Activity都会很麻烦,对比开发者非常不友好,增加了协作难度。
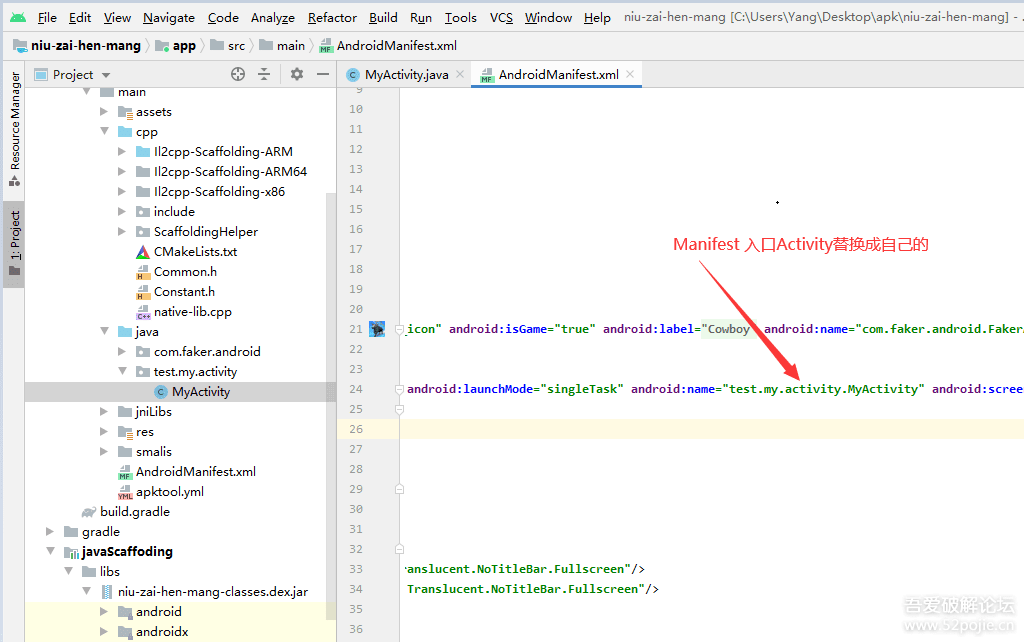
- 最后,Activity的export属性并不建议都设置成True,这是降低风险的一种方式,一般都是收归到一个Activity,DeeplinkActivitiy统一处理跳转,这种场景下,DeeplinkActivitiy就兼具路由功能,隐式调用的场景下,新Activitiy的增减势必每次都要调整路由表,这会导致开发效率降低,风险增加。
可以看到系统原生的路由框架,并没太多考虑团队协同的开发模式,多限定在一个模块内部多个业务间直接相互引用,基本都要代码级依赖,对于代码及业务隔离很不友好。如不考虑之前Dex方法树超限制,可以认为三方路由框架完全是为了团队协同而创建的。
APP三方路由框架需具备的能力
目前市面上大部分的路由框架都能搞定上述问题,简单整理下现在三方路由的能力,可归纳如下:
- 路由表生成能力:业务组件**[UI业务及服务]**自动扫描及注册逻辑,需要扩展性好,无需入侵原有代码逻辑
- scheme与业务映射逻辑 :无需依赖具体实现,做到代码隔离
- 基础路由跳转能力 :页面跳转能力的支持
- 服务类组件的支持 :如去某个服务组件获取一些配置等
- [扩展]路由拦截逻辑:比如登陆,统一鉴权
- 可定制的降级逻辑:找不到组件时的兜底
可以看下一个典型的Arouter用法,第一步:对新增页面添加Router Scheme 声明,
@Route(path = "/test/activity2")
public class Test2Activity extends AppCompatActivity {
...
}
build阶段会根据注解搜集路由scheme,生成路由表。第二步使用
ARouter.getInstance()
.build("/test/activity2")
.navigation(this);
如上,在ARouter框架下,仅需要字符串scheme,无需依赖任何Test2Activity就可实现路由跳转。
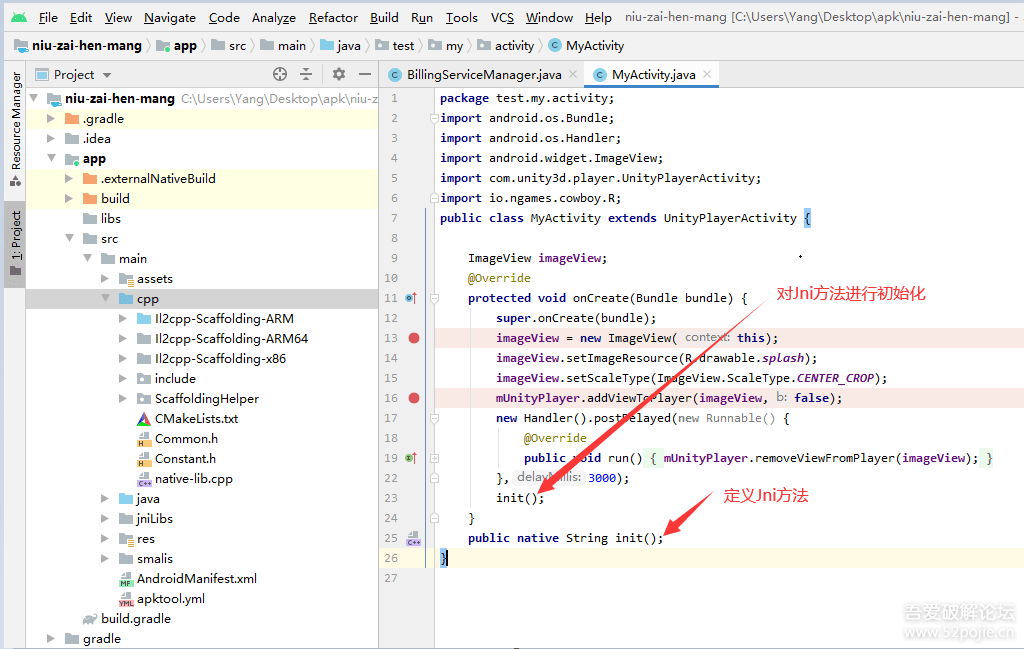
APP路由框架的实现
路由框架实现的核心是建立scheme和组件**[Activity或者其他服务]**的映射关系,也就是路由表,并能根据路由表路由到对应组件的能力。其实分两部分,第一部分路由表的生成,第二部分,路由表的查询
路由表的自动生成
生成路由表的方式有很多,最简单的就是维护一个公共文件或者类,里面映射好每个实现组件跟scheme,
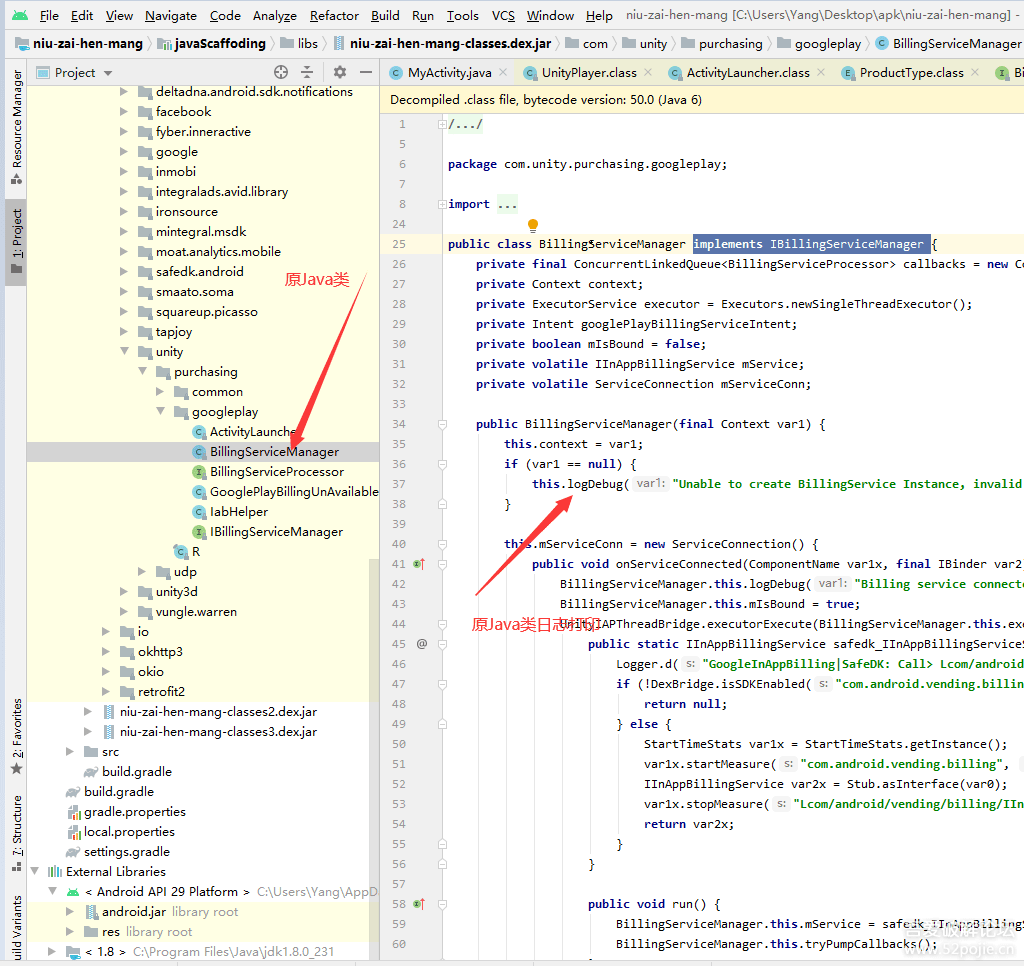
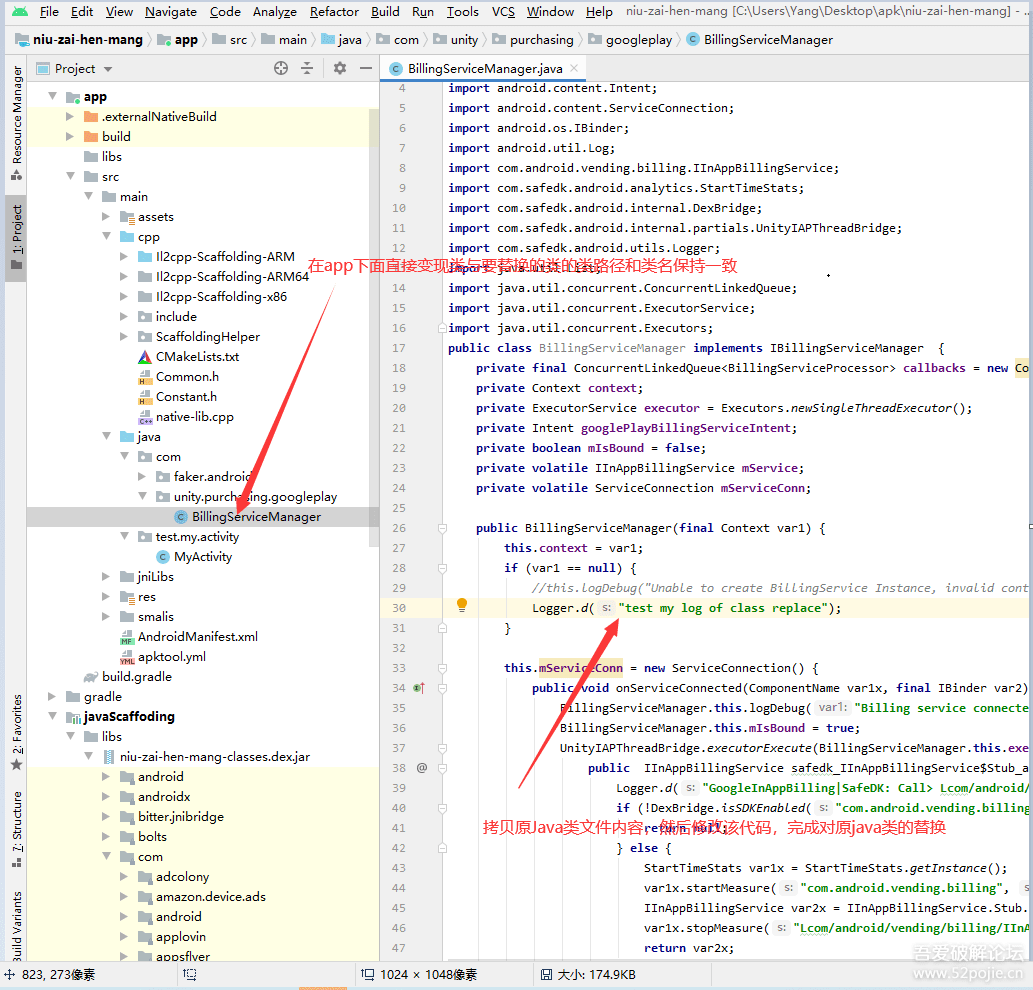
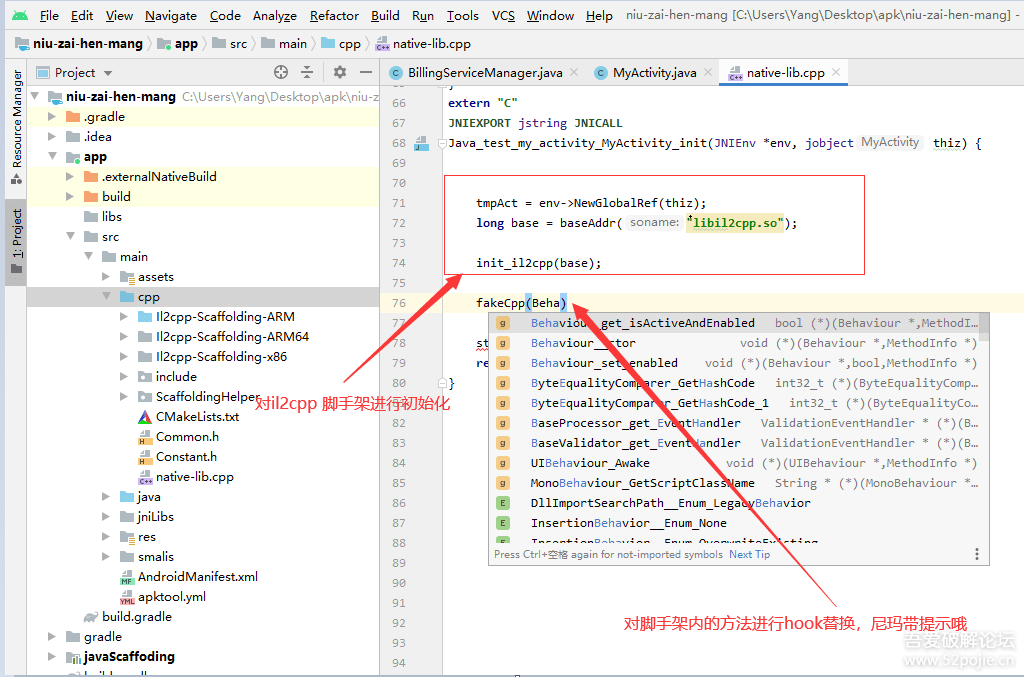
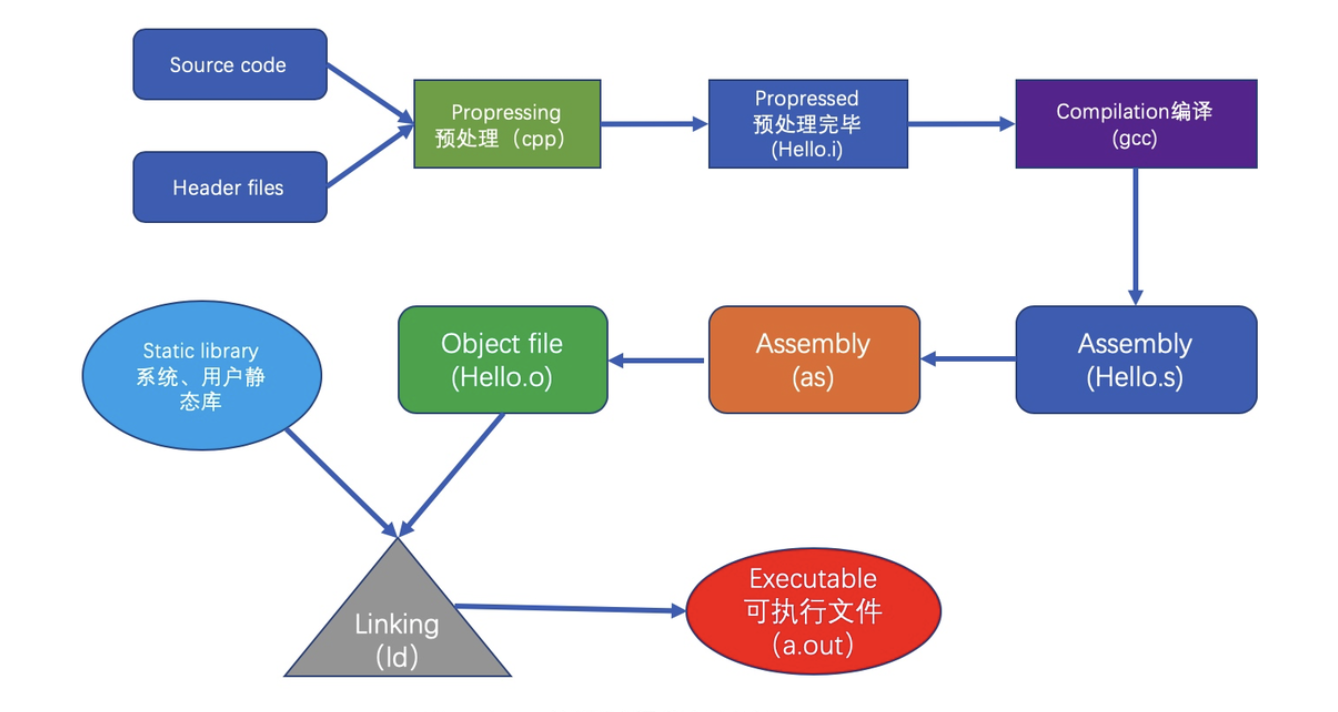
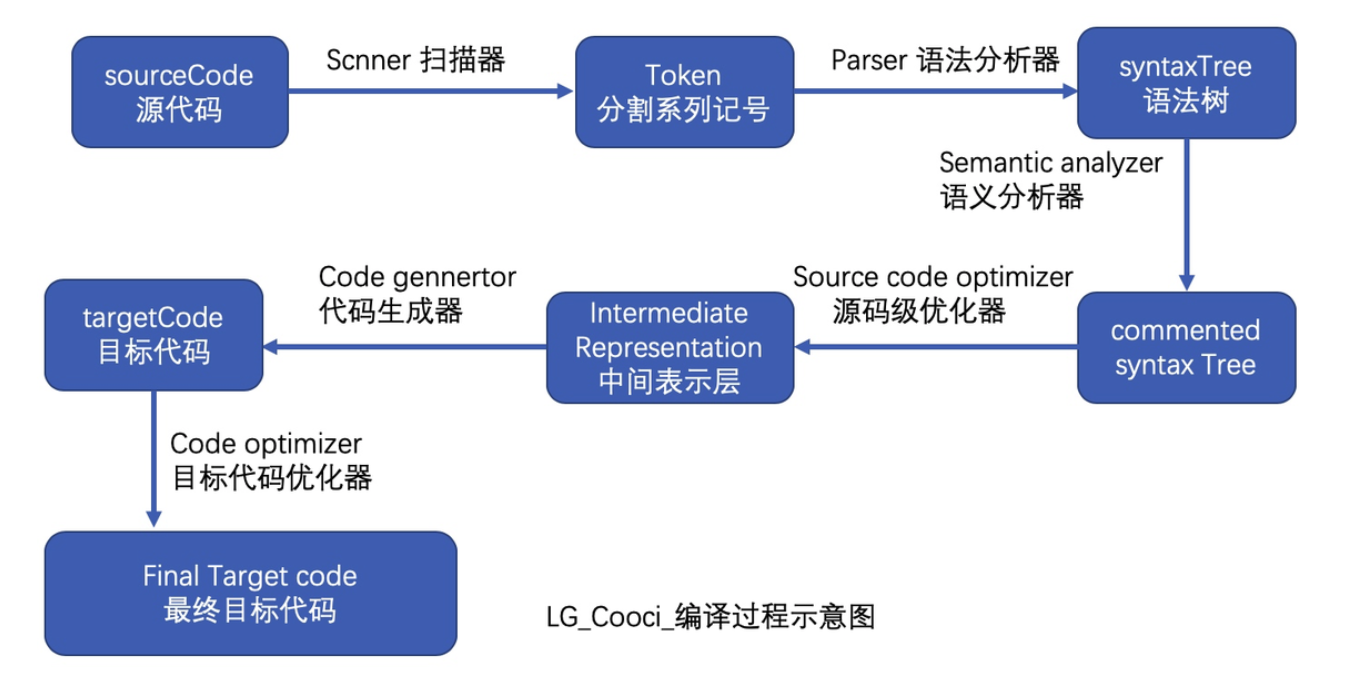
不过,这种做法缺点很明显:每次增删修改都要都要修改这个表,对于协同非常不友好,不符合解决协同问题的初衷。不过,最终的路由表倒是都是这条路,就是将所有的Scheme搜集到一个对象中,只是实现方式的差别,目前几乎所有的三方路由框架都是借助注解+APT[Annotation Processing Tool]工具+AOP(Aspect-Oriented Programming,面向切面编程)来实现的,基本流程如下:
其中牵扯的技术有注解、APT(Annotation Processing Tool)、AOP(Aspect-Oriented Programming,面向切面编程)。APT常用的有JavaPoet,主要是遍历所有类,找到被注解的Java类,然后聚合生成路由表,由于组件可能有很多,路由表可能也有也有多个,之后,这些生成的辅助类会跟源码一并被编译成class文件,之后利用AOP技术【如ASM或者JavaAssist】,扫描这些生成的class,聚合路由表,并填充到之前的占位方法中,完成自动注册的逻辑。
JavaPoet如何搜集并生成路由表集合?
以ARouter框架为例,先定义Router框架需要的注解如:
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.CLASS)
public @interface Route {
/**
* Path of route
*/
String path();
该注解用于标注需要路由的组件,用法如下:
@Route(path = "/test/activity1", name = "测试用 Activity")
public class Test1Activity extends BaseActivity {
@Autowired
int age = 10;
之后利用APT扫描所有被注解的类,生成路由表,实现参考如下:
@Override
public boolean process(Set annotations, RoundEnvironment roundEnv) {
if (CollectionUtils.isNotEmpty(annotations)) {
Set routeElements = roundEnv.getElementsAnnotatedWith(Route.class);
this.parseRoutes(routeElements);
...
return false;
}
private void parseRoutes(Set routeElements) throws IOException {
...
// Generate groups
String groupFileName = NAME_OF_GROUP + groupName;
JavaFile.builder(PACKAGE_OF_GENERATE_FILE,
TypeSpec.classBuilder(groupFileName)
.addJavadoc(WARNING_TIPS)
.addSuperinterface(ClassName.get(type_IRouteGroup))
.addModifiers(PUBLIC)
.addMethod(loadIntoMethodOfGroupBuilder.build())
.build()
).build().writeTo(mFiler);
产物如下:包含路由表,及局部注册入口。
自动注册:ASM搜集上述路由表并聚合插入Init代码区
为了能够插入到Init代码区,首先需要预留一个位置,一般定义一个空函数,以待后续填充:
public class RouterInitializer {
public static void init(boolean debug, Class webActivityClass, IRouterInterceptor... interceptors) {
...
loadRouterTables();
}
//自动注册代码
public static void loadRouterTables() {
}
}
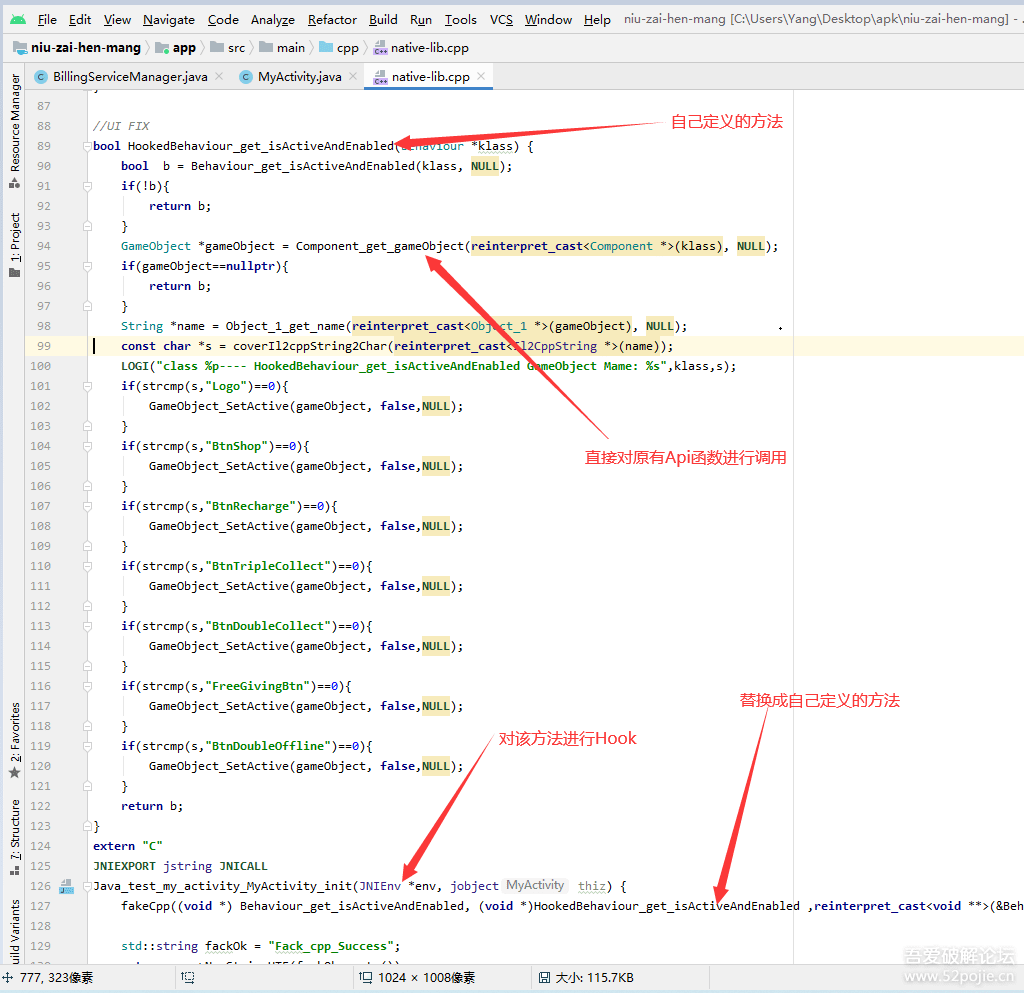
首先利用AOP工具,遍历上述APT中间产物,聚合路由表,并注册到预留初始化位置,遍历的过程牵扯是gradle transform的过程,
搜集目标,聚合路由表
/**扫描jar*/
fun scanJar(jarFile: File, dest: File?) {
val file = JarFile(jarFile)
var enumeration = file.entries()
while (enumeration.hasMoreElements()) {
val jarEntry = enumeration.nextElement()
if (jarEntry.name.endsWith("XXRouterTable.class")) {
val inputStream = file.getInputStream(jarEntry)
val classReader = ClassReader(inputStream)
if (Arrays.toString(classReader.interfaces)
.contains("IHTRouterTBCollect")
) {
tableList.add(
Pair(
classReader.className,
dest?.absolutePath
)
)
}
inputStream.close()
} else if (jarEntry.name.endsWith("HTRouterInitializer.class")) {
registerInitClass = dest
}
}
file.close()
}
对目标Class注入路由表初始化代码
fun asmInsertMethod(originFile: File?) {
val optJar = File(originFile?.parent, originFile?.name + ".opt")
if (optJar.exists())
optJar.delete()
val jarFile = JarFile(originFile)
val enumeration = jarFile.entries()
val jarOutputStream = JarOutputStream(FileOutputStream(optJar))
while (enumeration.hasMoreElements()) {
val jarEntry = enumeration.nextElement()
val entryName = jarEntry.getName()
val zipEntry = ZipEntry(entryName)
val inputStream = jarFile.getInputStream(jarEntry)
//插桩class
if (entryName.endsWith("RouterInitializer.class")) {
//class文件处理
jarOutputStream.putNextEntry(zipEntry)
val classReader = ClassReader(IOUtils.toByteArray(inputStream))
val classWriter = ClassWriter(classReader, ClassWriter.COMPUTE_MAXS)
val cv = RegisterClassVisitor(Opcodes.ASM5, classWriter,tableList)
classReader.accept(cv, EXPAND_FRAMES)
val code = classWriter.toByteArray()
jarOutputStream.write(code)
} else {
jarOutputStream.putNextEntry(zipEntry)
jarOutputStream.write(IOUtils.toByteArray(inputStream))
}
jarOutputStream.closeEntry()
}
//结束
jarOutputStream.close()
jarFile.close()
if (originFile?.exists() == true) {
Files.delete(originFile.toPath())
}
optJar.renameTo(originFile)
}
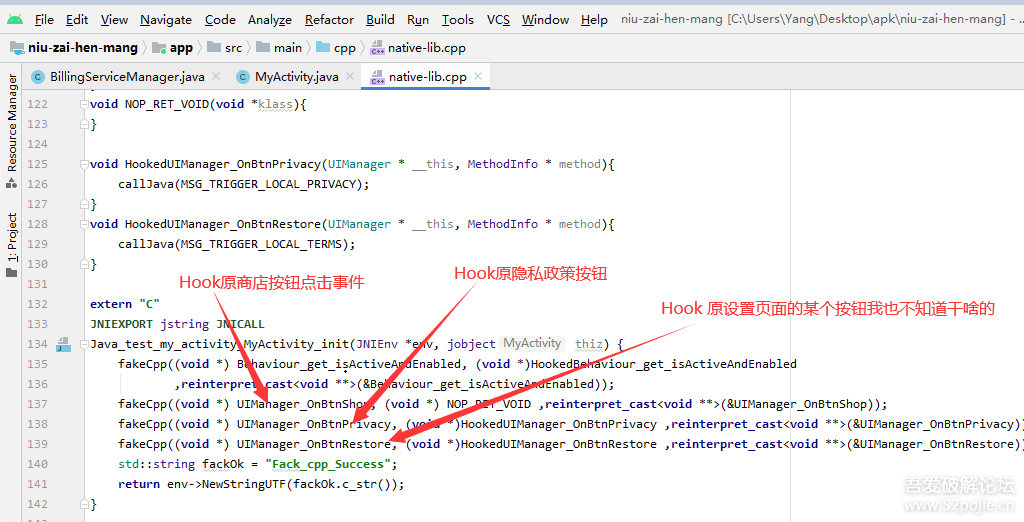
最终RouterInitializer.class的 loadRouterTables会被修改成如下填充好的代码:
public static void loadRouterTables() {
register("com.alibaba.android.arouter.routes.ARouter$$Root$$modulejava");
register("com.alibaba.android.arouter.routes.ARouter$$Root$$modulekotlin");
register("com.alibaba.android.arouter.routes.ARouter$$Root$$arouterapi");
register("com.alibaba.android.arouter.routes.ARouter$$Interceptors$$modulejava");
...
}
如此就完成了路由表的搜集与注册,大概的流程就是如此。当然对于支持服务、Fragment等略有不同,但大体类似。
Router框架对服务类组件的支持
通过路由的方式获取服务属于APP路由比较独特的能力,比如有个用户中心的组件,我们可以通过路由的方式去查询用户是否处于登陆状态,这种就不是狭义上的页面路由的概念,通过一串字符串如何查到对应的组件并调用其方法呢?这种的实现方式也有多种,每种实现方式都有自己的优劣。
- 一种是可以将服务抽象成接口,沉到底层,上层实现通过路由方式映射对象
- 一种是将实现方法直接通过路由方式映射
先看第一种,这种事Arouter的实现方式,它的优点是所有对外暴露的服务都暴露接口类【沉到底层】,这对于外部的调用方,也就是服务使用方非常友好,示例如下:
先定义抽象服务,并沉到底层
public interface HelloService extends IProvider {
void sayHello(String name);
}
实现服务,并通过Router注解标记
@Route(path = "/yourservicegroupname/hello")
public class HelloServiceImpl implements HelloService {
Context mContext;
@Override
public void sayHello(String name) {
Toast.makeText(mContext, "Hello " + name, Toast.LENGTH_SHORT).show();
}
使用:利用Router加scheme获取服务实例,并映射成抽象类,然后直接调用方法。
((HelloService) ARouter.getInstance().build("/yourservicegroupname/hello").navigation()).sayHello("mike");
这种实现方式对于使用方其实是很方便的,尤其是一个服务有多个可操作方法的时候,但是缺点是扩展性,如果想要扩展方法,就要改动底层库。
再看第二种:将实现方法直接通过路由方式映射
服务的调用都要落到方法上,参考页面路由,也可以支持方法路由,两者并列关系,所以组要增加一个方法路由表,实现原理与Page路由类似,跟上面的Arouter对比,不用定义抽象层,直接定义实现即可:
定义Method的Router
public class HelloService {
@MethodRouter(url = {"arouter://sayhello"})
public void sayHello(String name) {
Toast.makeText(mContext, "Hello " + name, Toast.LENGTH_SHORT).show();
}
使用即可
RouterCall.callMethod("arouter://sayhello?name=hello");
上述的缺点就是对于外部调用有些复杂,尤其是处理参数的时候,需要严格按照协议来处理,优点是,没有抽象层,如果需要扩展服务方法,不需要改动底层。
上述两种方式各有优劣,不过,如果从左服务组件的初衷出发,第一种比较好:对于调用方比较友好。另外对于CallBack的支持,Arouter的处理方式可能也会更方便一些,可以比较方便的交给服务方定义。如果是第二种,服务直接通过路由映射的方式,处理起来就比较麻烦,尤其是Callback中的参数,可能要统一封装成JSON并维护解析的协议,这样处理起来,可能不是很好。
路由表的匹配
路由表的匹配比较简单,就是在全局Map中根据String输入,匹配到目标组件,然后依赖反射等常用操作,定位到目标。
组件化与路由的关系
组件化是一种开发集成模式,更像一种开发规范,更多是为团队协同开发带来方便。组件化最终落地是一个个独立的业务及功能组件,这些组件之间可能是不同的团队,处于不同的目的在各自维护,甚至是需要代码隔离,如果牵扯到组件间的调用与通信,就不可避免的借助路由,因为实现隔离的,只能采用通用字符串scheme进行通信,这就是路由的功能范畴。
组件化需要路由支撑的根本原因:组件间代码实现的隔离
总结
- 路由不是一个APP的必备功能,但是大型跨团队的APP基本都需要
- 路由框架的基本能力:路由自动注册、路由表搜集、服务及UI界面路由及拦截等核心功能
- 组件化与路由的关系:组件化的代码隔离导致路由框架成为必须