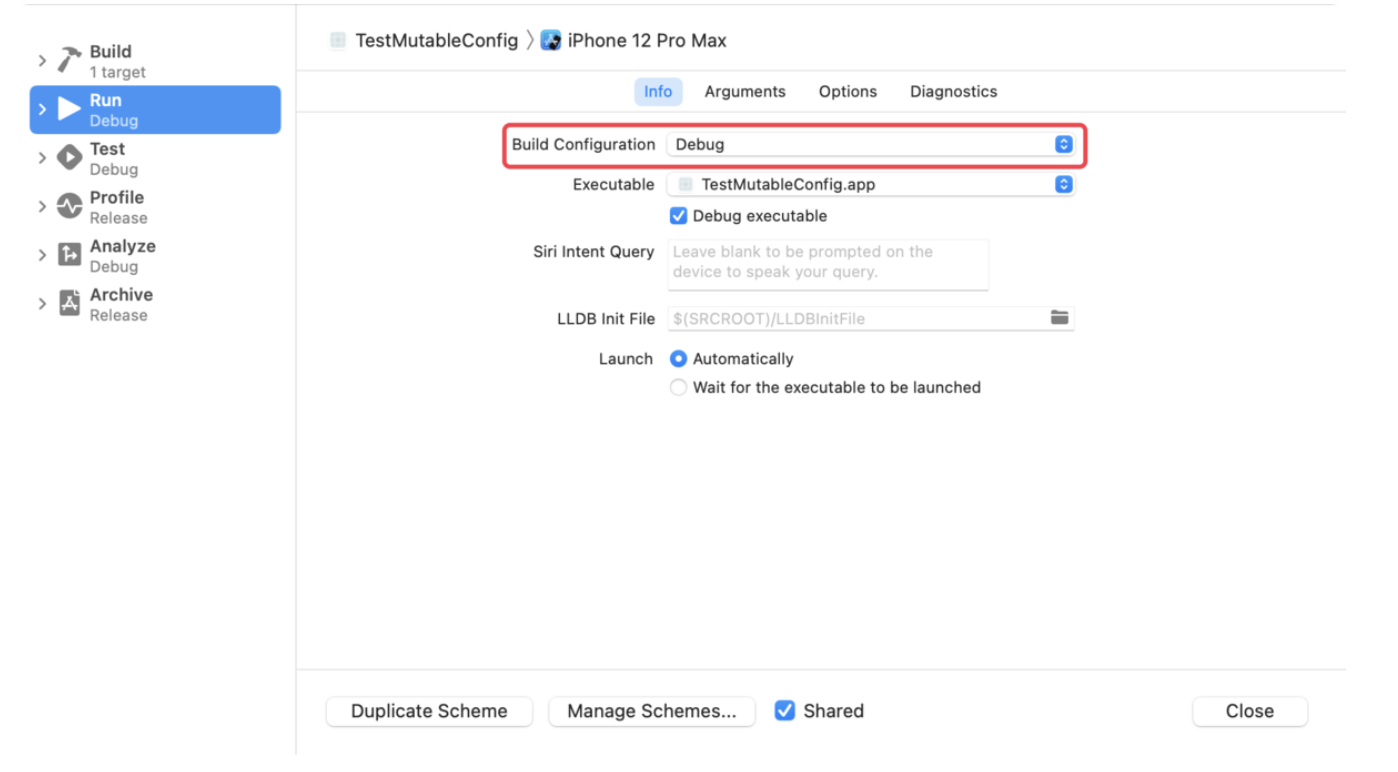
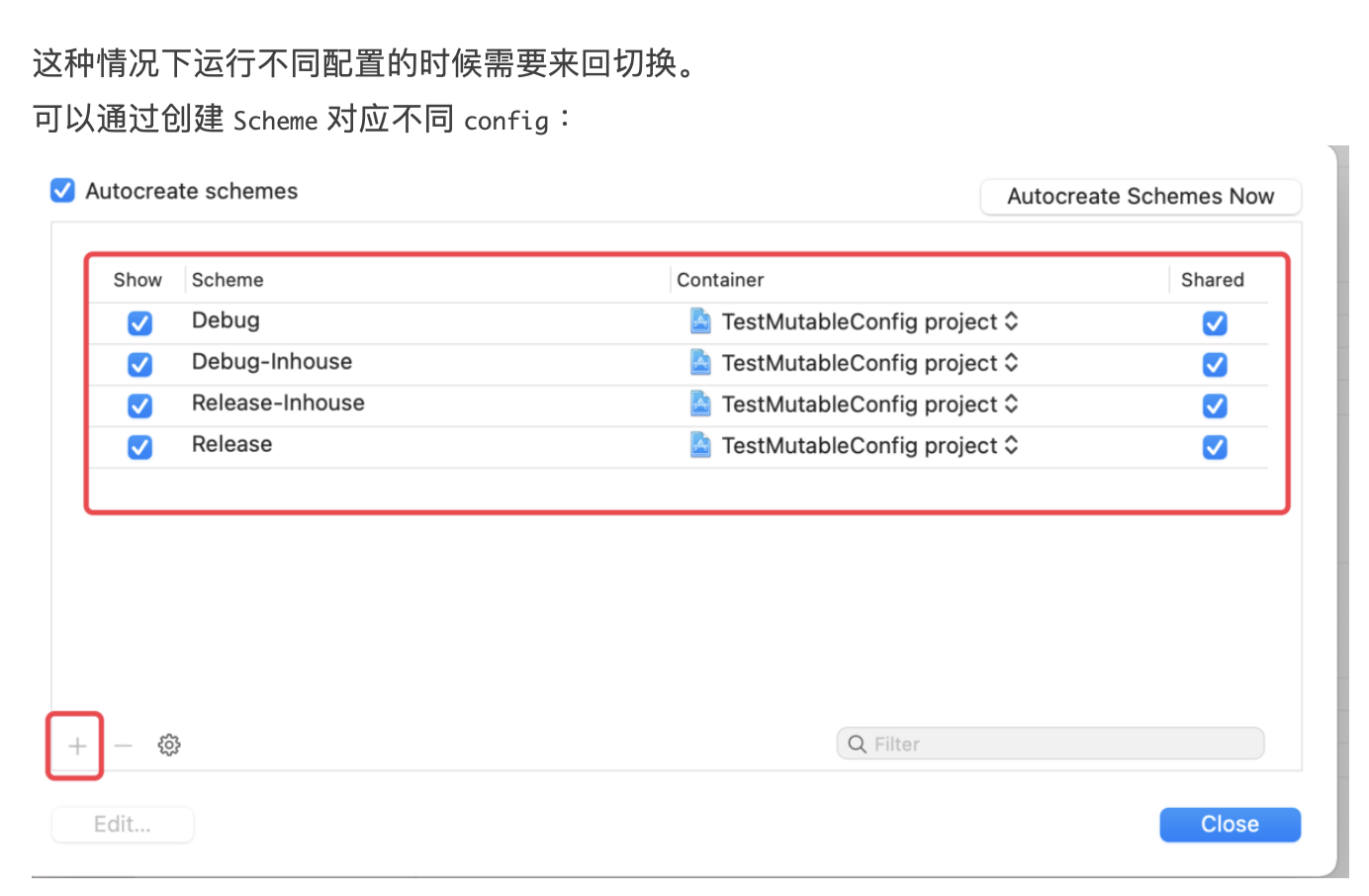
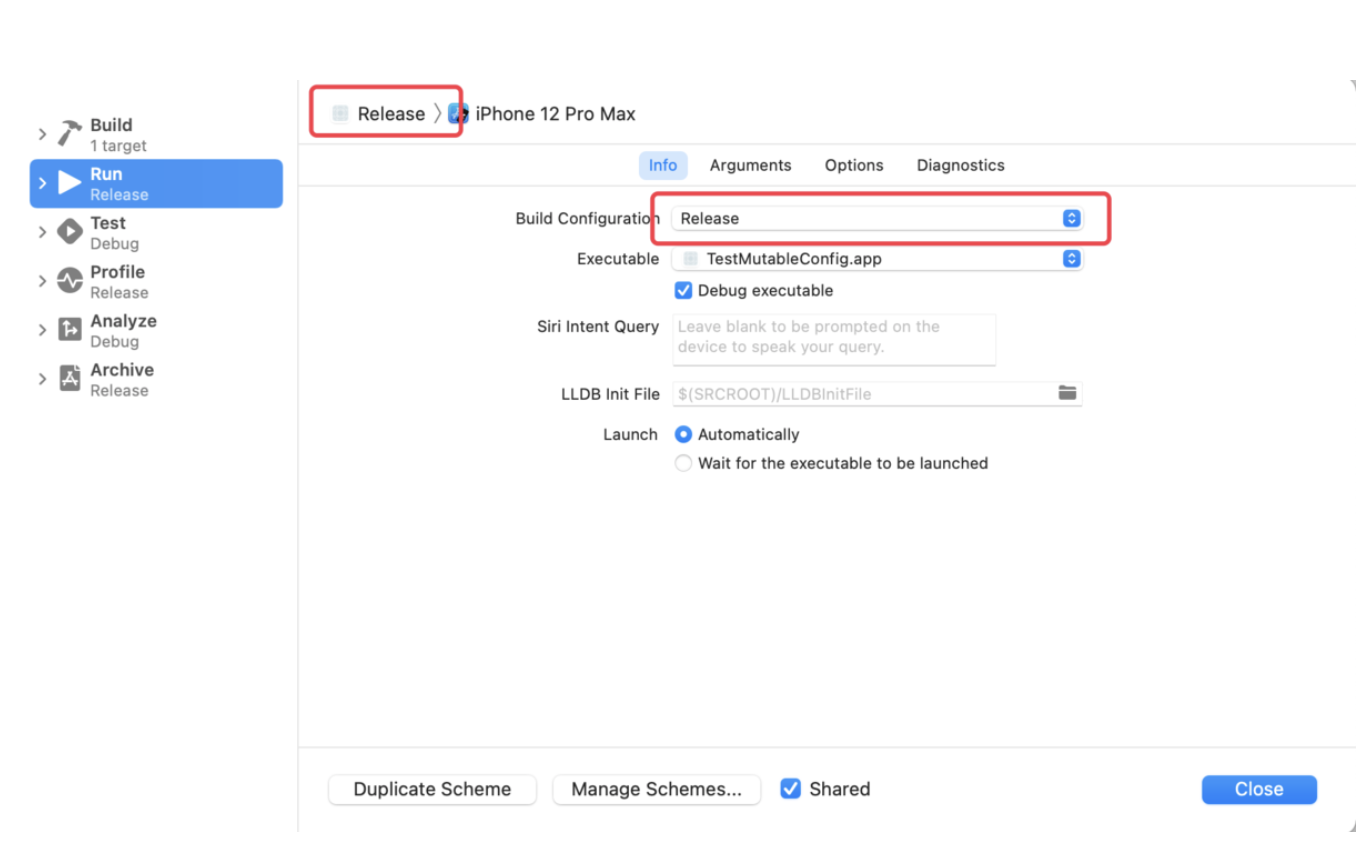
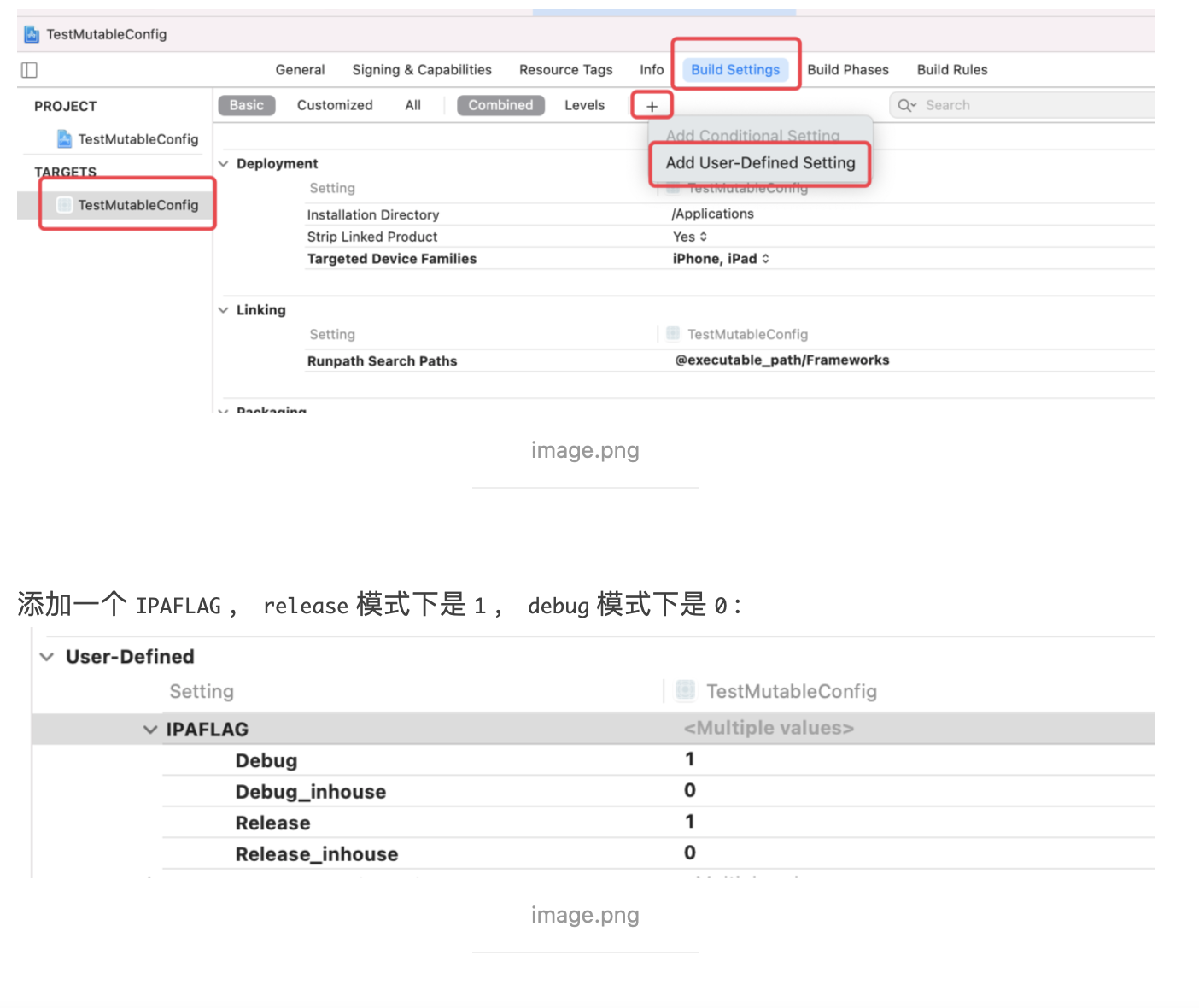
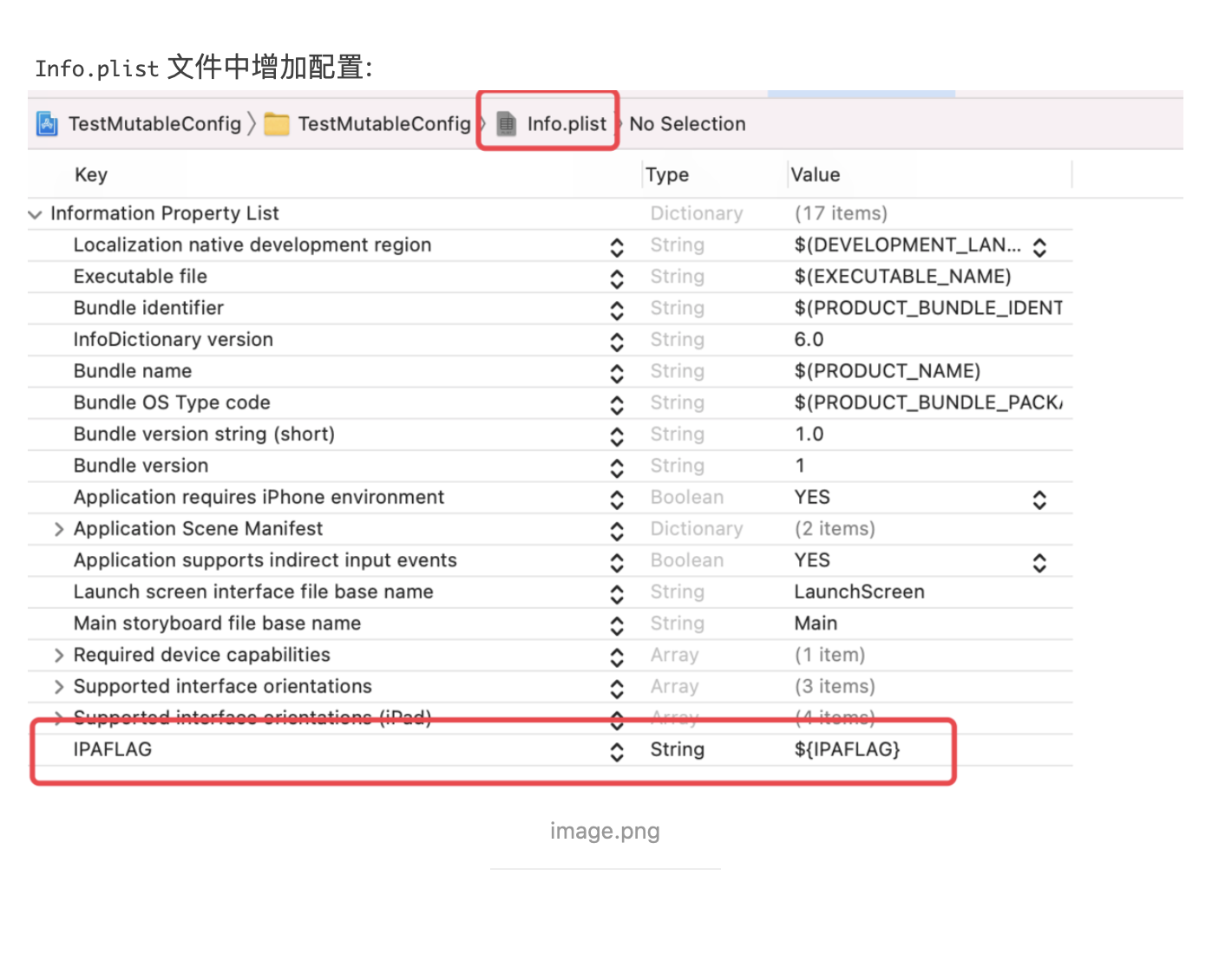
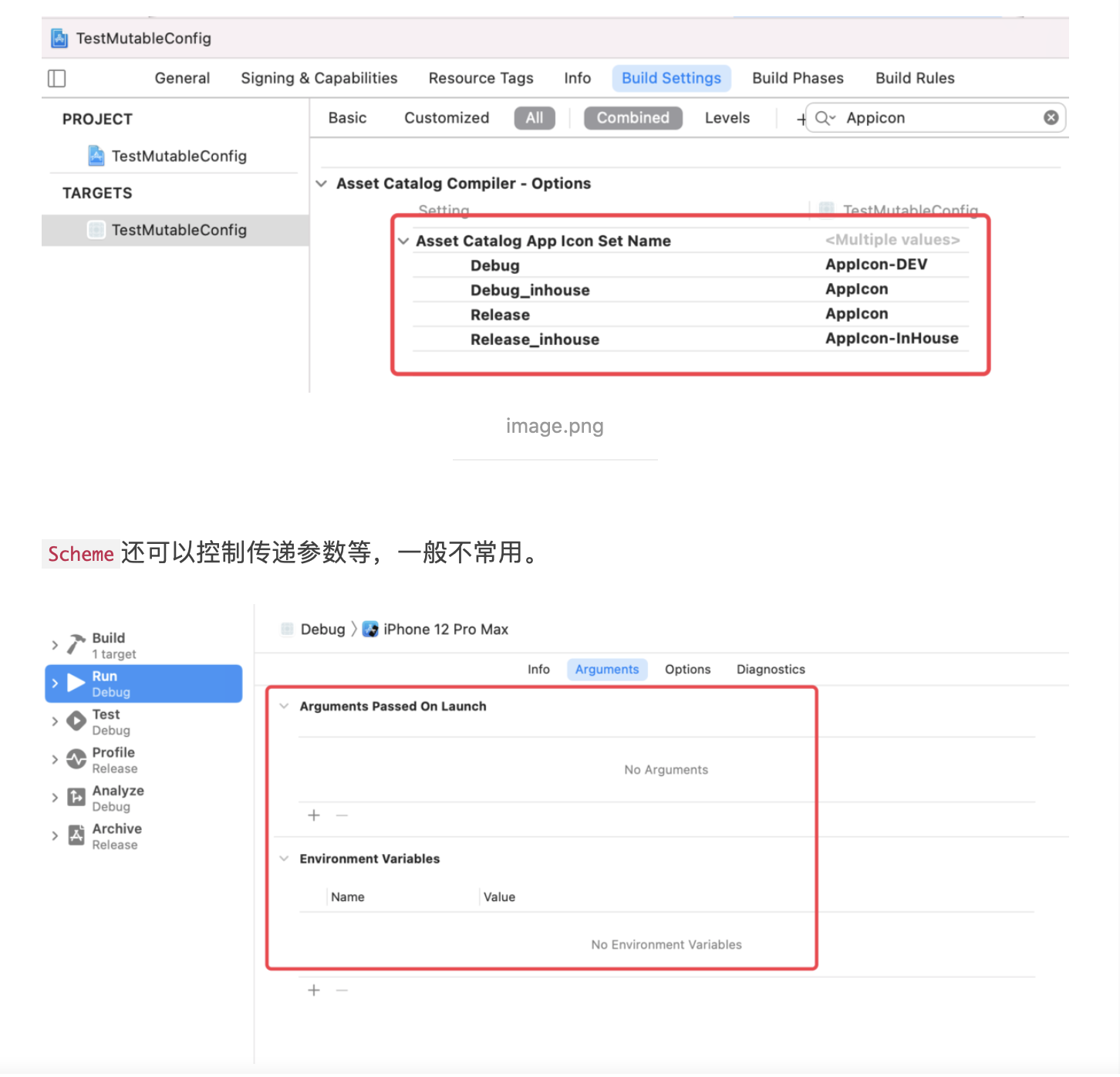
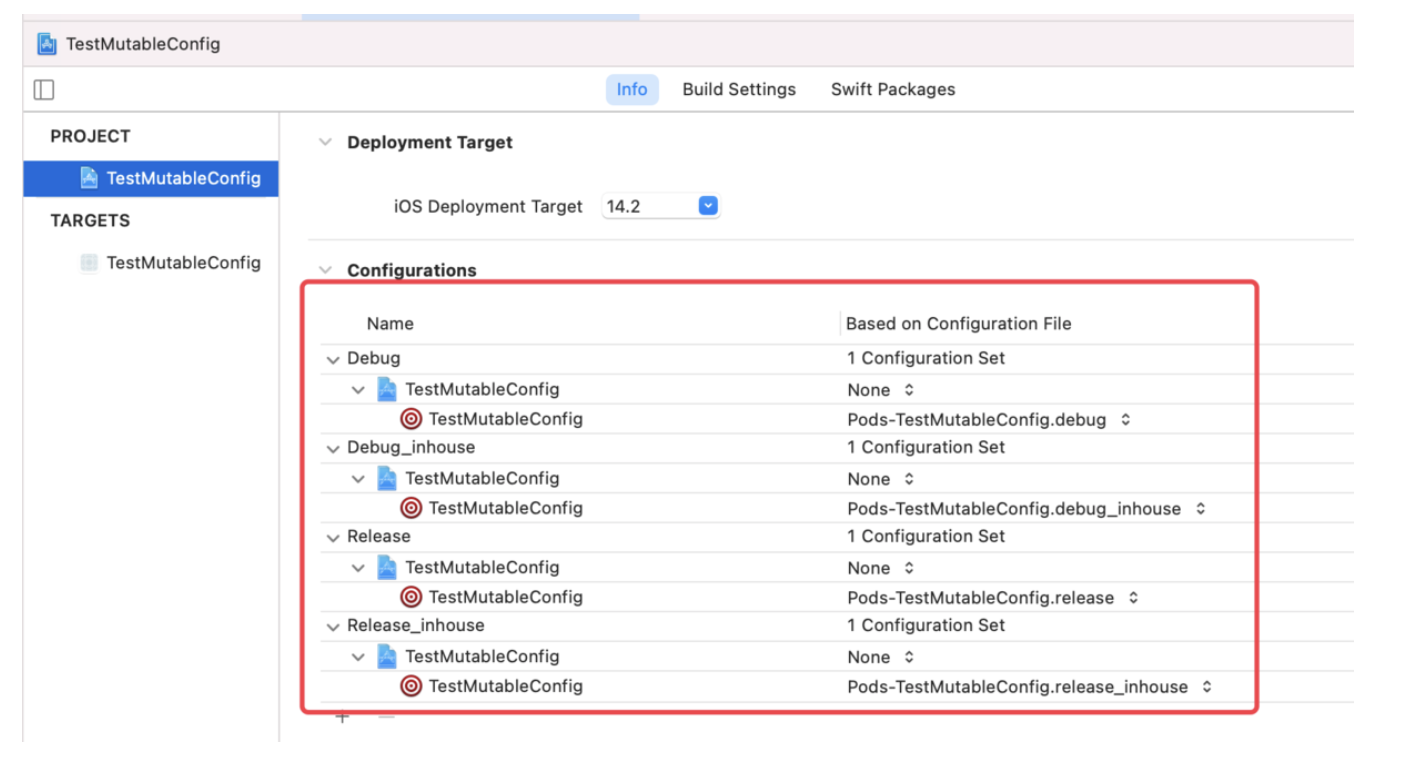
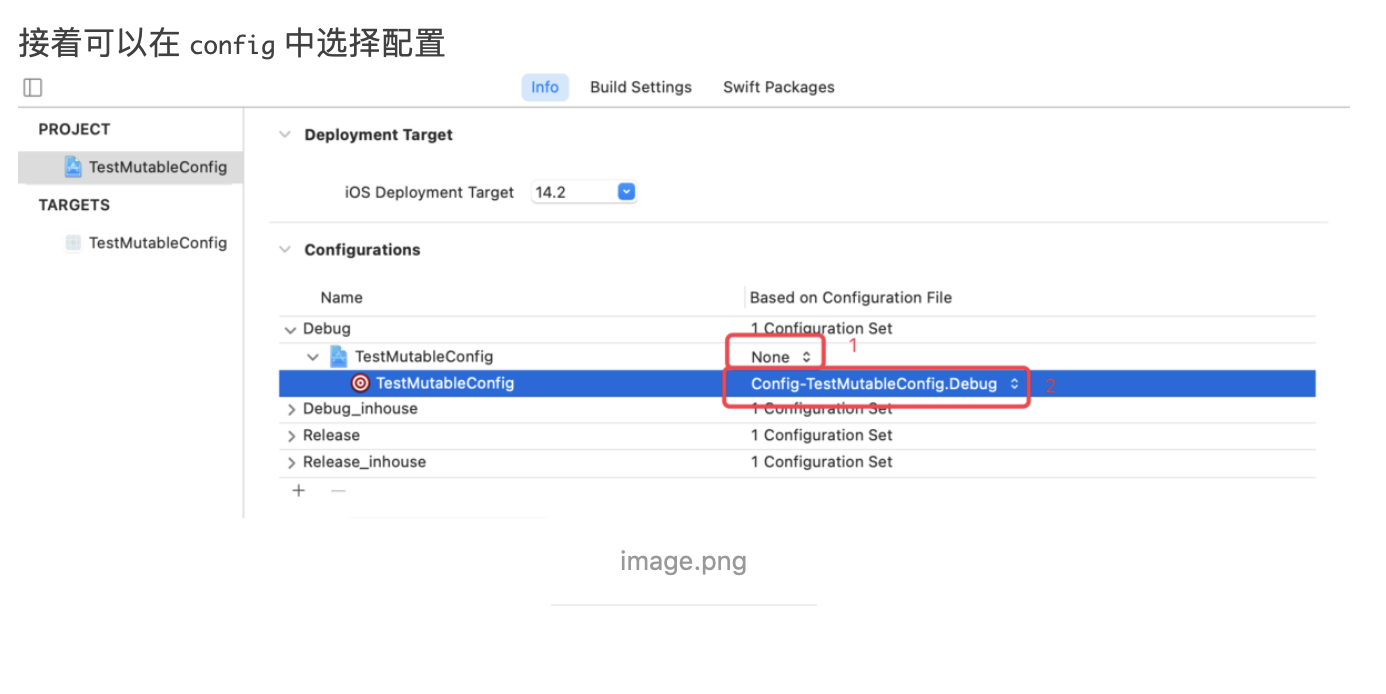
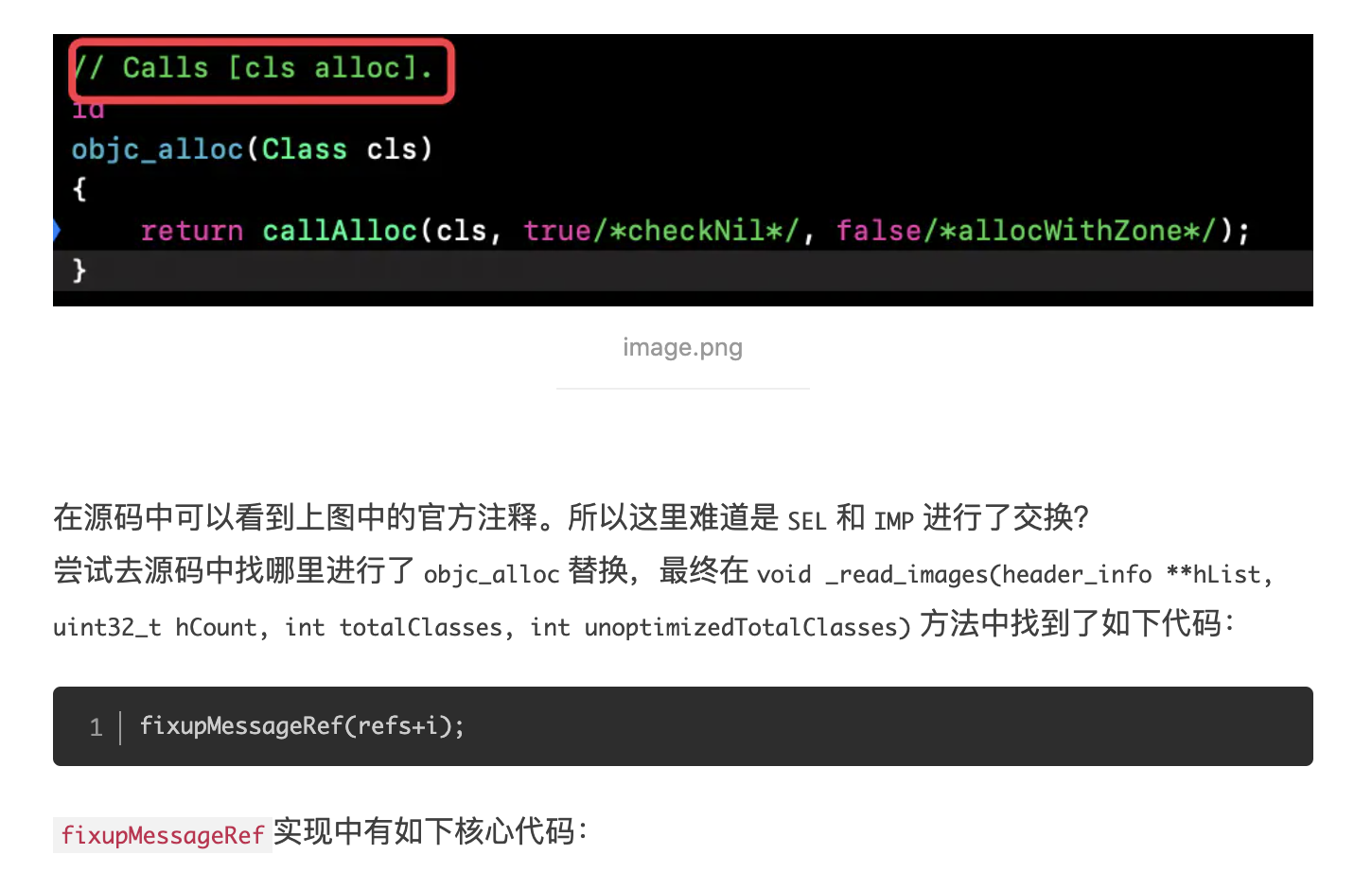
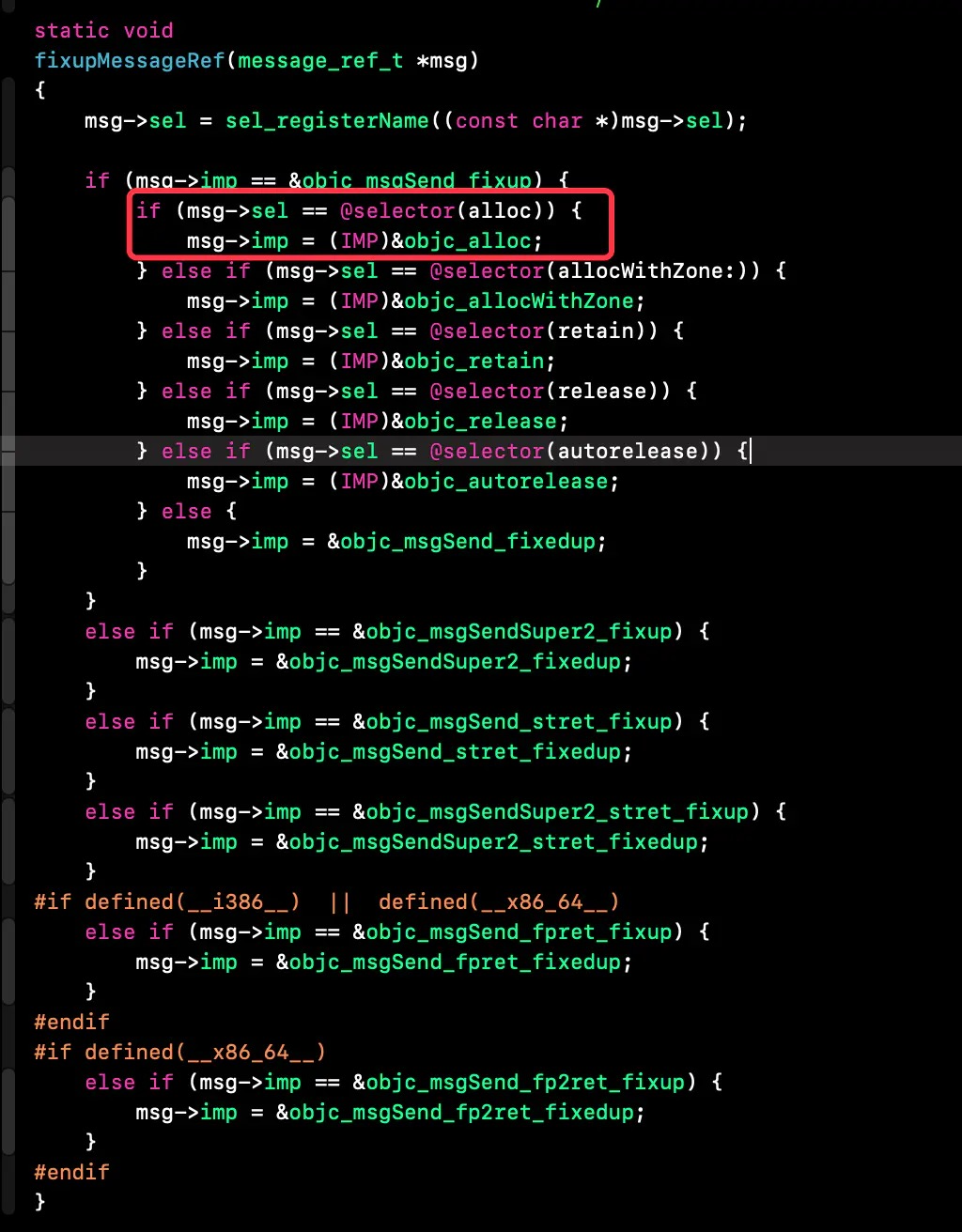
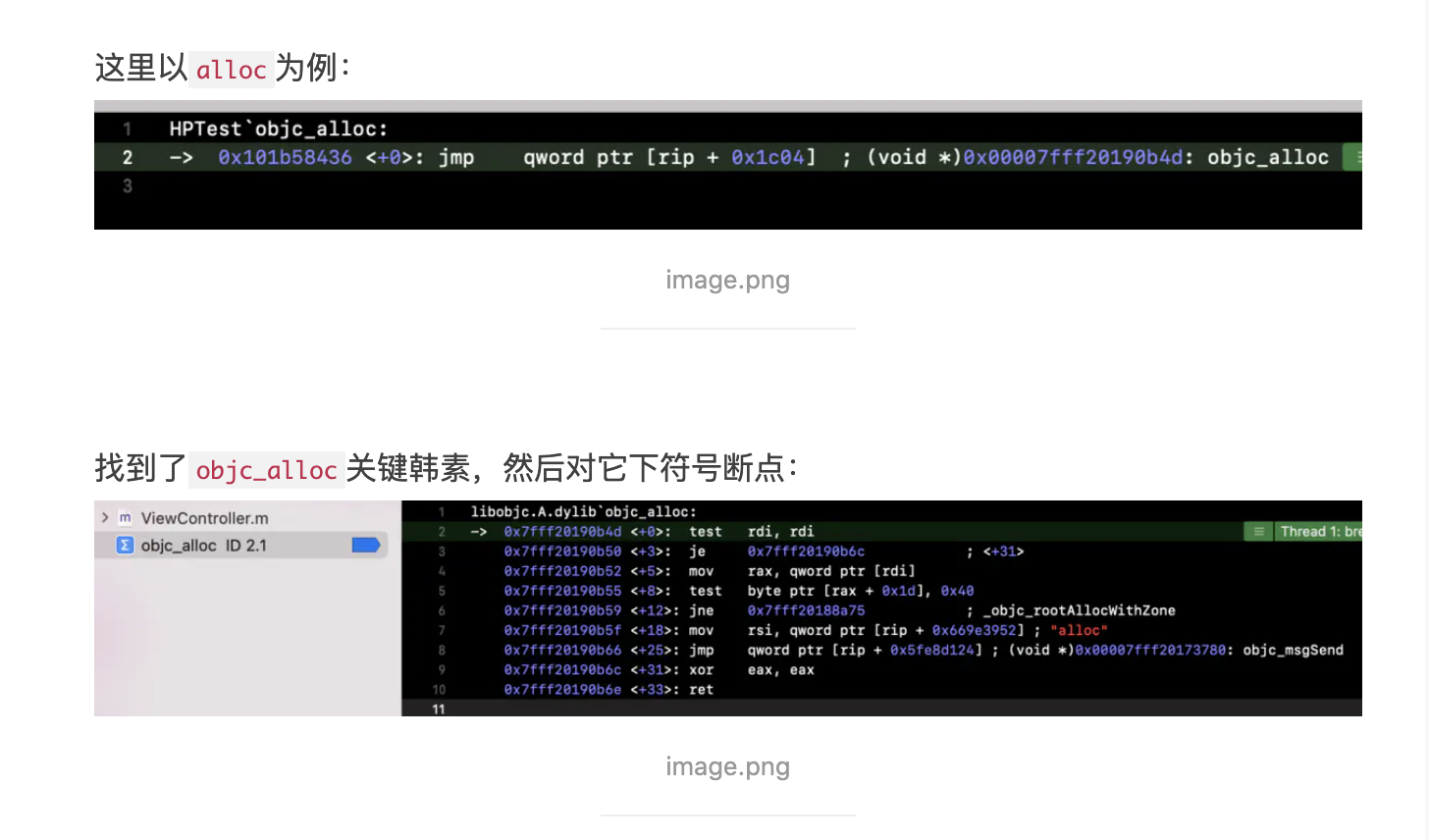
稍有 iOS 开发经验的人应该都是用过 CocoaPods,而对于 CI、CD 有了解的同学也都知道 Fastlane。而这两个在 iOS 开发中非常便捷的第三方库都是使用 Ruby 来编写的,这是为什么?
先抛开这个话题不谈,我们来看一下 CocoaPods 和 Fastlane 是如何使用的,首先是 CocoaPods,在每一个工程使用 CocoaPods 的工程中都有一个 Podfile:
source 'https://github.com/CocoaPods/Specs.git'
target 'Demo' do
pod 'Mantle', '~> 1.5.1'
pod 'SDWebImage', '~> 3.7.1'
pod 'BlocksKit', '~> 2.2.5'
pod 'SSKeychain', '~> 1.2.3'
pod 'UMengAnalytics', '~> 3.1.8'
pod 'UMengFeedback', '~> 1.4.2'
pod 'Masonry', '~> 0.5.3'
pod 'AFNetworking', '~> 2.4.1'
pod 'Aspects', '~> 1.4.1'
end
这是一个使用 Podfile 定义依赖的一个例子,不过 Podfile 对约束的描述其实是这样的:
source('https://github.com/CocoaPods/Specs.git')
target('Demo') do
pod('Mantle', '~> 1.5.1')
...
end
Ruby 代码在调用方法时可以省略括号。
Podfile 中对于约束的描述,其实都可以看作是对代码简写,上面的代码在解析时可以当做 Ruby 代码来执行。
Fastlane 中的代码 Fastfile 也是类似的:
lane :beta do
increment_build_number
cocoapods
match
testflight
sh "./customScript.sh"
slack
end
使用描述性的”代码“编写脚本,如果没有接触或者使用过 Ruby 的人很难相信上面的这些文本是代码的。
Ruby 概述
在介绍 CocoaPods 的实现之前,我们需要对 Ruby 的一些特性有一个简单的了解,在向身边的朋友“传教”的时候,我往往都会用优雅这个词来形容这门语言(手动微笑)。
除了优雅之外,Ruby 的语法具有强大的表现力,并且其使用非常灵活,能快速实现我们的需求,这里简单介绍一下 Ruby 中的一些特性。
一切皆对象
在许多语言,比如 Java 中,数字与其他的基本类型都不是对象,而在 Ruby 中所有的元素,包括基本类型都是对象,同时也不存在运算符的概念,所谓的 1 + 1,其实只是 1.+(1) 的语法糖而已。
得益于一切皆对象的概念,在 Ruby 中,你可以向任意的对象发送 methods 消息,在运行时自省,所以笔者在每次忘记方法时,都会直接用 methods 来“查文档”:
2.3.1 :003 > 1.methods
=> [:%, :&, :*, :+, :-, :/, :<, :>, :^, :|, :~, :-@, :**, :<=>, :<<, :>>, :<=, :>=, :==, :===, :[], :inspect, :size, :succ, :to_s, :to_f, :div, :divmod, :fdiv, :modulo, :abs, :magnitude, :zero?, :odd?, :even?, :bit_length, :to_int, :to_i, :next, :upto, :chr, :ord, :integer?, :floor, :ceil, :round, :truncate, :downto, :times, :pred, :to_r, :numerator, :denominator, :rationalize, :gcd, :lcm, :gcdlcm, :+@, :eql?, :singleton_method_added, :coerce, :i, :remainder, :real?, :nonzero?, :step, :positive?, :negative?, :quo, :arg, :rectangular, :rect, :polar, :real, :imaginary, :imag, :abs2, :angle, :phase, :conjugate, :conj, :to_c, :between?, :instance_of?, :public_send, :instance_variable_get, :instance_variable_set, :instance_variable_defined?, :remove_instance_variable, :private_methods, :kind_of?, :instance_variables, :tap, :is_a?, :extend, :define_singleton_method, :to_enum, :enum_for, :=~, :!~, :respond_to?, :freeze, :display, :send, :object_id, :method, :public_method, :singleton_method, :nil?, :hash, :class, :singleton_class, :clone, :dup, :itself, :taint, :tainted?, :untaint, :untrust, :trust, :untrusted?, :methods, :protected_methods, :frozen?, :public_methods, :singleton_methods, :!, :!=, :__send__, :equal?, :instance_eval, :instance_exec, :__id__]
比如在这里向对象 1 调用 methods 就会返回它能响应的所有方法。
一切皆对象不仅减少了语言中类型的不一致,消灭了基本数据类型与对象之间的边界;这一概念同时也简化了语言中的组成元素,这样 Ruby 中只有对象和方法,这两个概念,这也降低了我们理解这门语言的复杂度:
block
Ruby 对函数式编程范式的支持是通过 block,这里的 block 和 Objective-C 中的 block 有些不同。
首先 Ruby 中的 block 也是一种对象,所有的 Block 都是 Proc 类的实例,也就是所有的 block 都是 first-class 的,可以作为参数传递,返回。
def twice(&proc)
2.times { proc.call() } if proc
end
def twice
2.times { yield } if block_given?
end
yield 会调用外部传入的 block,block_given? 用于判断当前方法是否传入了 block。
在这个方法调用时,是这样的:
twice do
puts "Hello"
end
eval
最后一个需要介绍的特性就是 eval 了,早在几十年前的 Lisp 语言就有了 eval 这个方法,这个方法会将字符串当做代码来执行,也就是说 eval 模糊了代码与数据之间的边界。
有了 eval 方法,我们就获得了更加强大的动态能力,在运行时,使用字符串来改变控制流程,执行代码;而不需要去手动解析输入、生成语法树。
手动解析 Podfile
在我们对 Ruby 这门语言有了一个简单的了解之后,就可以开始写一个简易的解析 Podfile 的脚本了。
在这里,我们以一个非常简单的 Podfile 为例,使用 Ruby 脚本解析 Podfile 中指定的依赖:
source 'http://source.git'
platform :ios, '8.0'
target 'Demo' do
pod 'AFNetworking'
pod 'SDWebImage'
pod 'Masonry'
pod "Typeset"
pod 'BlocksKit'
pod 'Mantle'
pod 'IQKeyboardManager'
pod 'IQDropDownTextField'
end
因为这里的 source、platform、target 以及 pod 都是方法,所以在这里我们需要构建一个包含上述方法的上下文:
# eval_pod.rb
$hash_value = {}
def source(url)
end
def target(target)
end
def platform(platform, version)
end
def pod(pod)
end
使用一个全局变量 hash_value 存储 Podfile 中指定的依赖,并且构建了一个 Podfile 解析脚本的骨架;我们先不去完善这些方法的实现细节,先尝试一下读取 Podfile 中的内容并执行会不会有什么问题。
在 eval_pod.rb 文件的最下面加入这几行代码:
content = File.read './Podfile'
eval content
p $hash_value
这里读取了 Podfile 文件中的内容,并把其中的内容当做字符串执行,最后打印 hash_value 的值。
运行这段 Ruby 代码虽然并没有什么输出,但是并没有报出任何的错误,接下来我们就可以完善这些方法了:
def source(url)
$hash_value['source'] = url
end
def target(target)
targets = $hash_value['targets']
targets = [] if targets == nil
targets << target
$hash_value['targets'] = targets
yield if block_given?
end
def platform(platform, version)
end
def pod(pod)
pods = $hash_value['pods']
pods = [] if pods == nil
pods << pod
$hash_value['pods'] = pods
end
在添加了这些方法的实现之后,再次运行脚本就会得到 Podfile 中的依赖信息了,不过这里的实现非常简单的,很多情况都没有处理:
$ ruby eval_pod.rb
{"source"=>"http://source.git", "targets"=>["Demo"], "pods"=>["AFNetworking", "SDWebImage", "Masonry", "Typeset", "BlocksKit", "Mantle", "IQKeyboardManager", "IQDropDownTextField"]}
CocoaPods 中对于 Podfile 的解析与这里的实现其实差不多,接下来就进入了 CocoaPods 的实现部分了。
CocoaPods 的实现
在上面简单介绍了 Ruby 的一些语法以及如何解析 Podfile 之后,我们开始深入了解一下 CocoaPods 是如何管理 iOS 项目的依赖,也就是 pod install 到底做了些什么。
Pod install 的过程
pod install 这个命令到底做了什么?首先,在 CocoaPods 中,所有的命令都会由 Command 类派发到将对应的类,而真正执行 pod install 的类就是 Install:
module Pod
class Command
class Install < Command
def run
verify_podfile_exists!
installer = installer_for_config
installer.repo_update = repo_update?(:default => false)
installer.update = false
installer.install!
end
end
end
end
这里面会从配置类的实例 config 中获取一个 Installer 的实例,然后执行 install! 方法,这里的 installer 有一个 update 属性,而这也就是 pod install 和 update 之间最大的区别,其中后者会无视已有的 Podfile.lock 文件,重新对依赖进行分析:
module Pod
class Command
class Update < Command
def run
...
installer = installer_for_config
installer.repo_update = repo_update?(:default => true)
installer.update = true
installer.install!
end
end
end
end
Podfile 的解析
Podfile 中依赖的解析其实是与我们在手动解析 Podfile 章节所介绍的差不多,整个过程主要都是由 CocoaPods-Core 这个模块来完成的,而这个过程早在 installer_for_config 中就已经开始了:
def installer_for_config
Installer.new(config.sandbox, config.podfile, config.lockfile)
end
这个方法会从 config.podfile 中取出一个 Podfile 类的实例:
def podfile
@podfile ||= Podfile.from_file(podfile_path) if podfile_path
end
类方法 Podfile.from_file 就定义在 CocoaPods-Core 这个库中,用于分析 Podfile 中定义的依赖,这个方法会根据 Podfile 不同的类型选择不同的调用路径:
Podfile.from_file
`-- Podfile.from_ruby
|-- File.open
`-- eval
from_ruby 类方法就会像我们在前面做的解析 Podfile 的方法一样,从文件中读取数据,然后使用 eval 直接将文件中的内容当做 Ruby 代码来执行。
def self.from_ruby(path, contents = nil)
contents ||= File.open(path, 'r:utf-8', &:read)
podfile = Podfile.new(path) do
begin
eval(contents, nil, path.to_s)
rescue Exception => e
message = "Invalid `#{path.basename}` file: #{e.message}"
raise DSLError.new(message, path, e, contents)
end
end
podfile
end
在 Podfile 这个类的顶部,我们使用 Ruby 的 Mixin 的语法来混入 Podfile 中代码执行所需要的上下文:
include Pod::Podfile::DSL
Podfile 中的所有你见到的方法都是定义在 DSL 这个模块下面的:
module Pod
class Podfile
module DSL
def pod(name = nil, *requirements) end
def target(name, options = nil) end
def platform(name, target = nil) end
def inhibit_all_warnings! end
def use_frameworks!(flag = true) end
def source(source) end
...
end
end
end
这里定义了很多 Podfile 中使用的方法,当使用 eval 执行文件中的代码时,就会执行这个模块里的方法,在这里简单看一下其中几个方法的实现,比如说 source 方法:
def source(source)
hash_sources = get_hash_value('sources') || []
hash_sources << source
set_hash_value('sources', hash_sources.uniq)
end
该方法会将新的 source 加入已有的源数组中,然后更新原有的 sources 对应的值。
稍微复杂一些的是 target 方法:
def target(name, options = nil)
if options
raise Informative, "Unsupported options `#{options}` for " \
"target `#{name}`."
end
parent = current_target_definition
definition = TargetDefinition.new(name, parent)
self.current_target_definition = definition
yield if block_given?
ensure
self.current_target_definition = parent
end
这个方法会创建一个 TargetDefinition 类的实例,然后将当前环境系的 target_definition 设置成这个刚刚创建的实例。这样,之后使用 pod 定义的依赖都会填充到当前的 TargetDefinition 中:
def pod(name = nil, *requirements)
unless name
raise StandardError, 'A dependency requires a name.'
end
current_target_definition.store_pod(name, *requirements)
end
当 pod 方法被调用时,会执行 store_pod 将依赖存储到当前 target 中的 dependencies 数组中:
def store_pod(name, *requirements)
return if parse_subspecs(name, requirements)
parse_inhibit_warnings(name, requirements)
parse_configuration_whitelist(name, requirements)
if requirements && !requirements.empty?
pod = { name => requirements }
else
pod = name
end
get_hash_value('dependencies', []) << pod
nil
end
总结一下,CocoaPods 对 Podfile 的解析与我们在前面做的手动解析 Podfile 的原理差不多,构建一个包含一些方法的上下文,然后直接执行 eval 方法将文件的内容当做代码来执行,这样只要 Podfile 中的数据是符合规范的,那么解析 Podfile 就是非常简单容易的。
安装依赖的过程
Podfile 被解析后的内容会被转化成一个 Podfile 类的实例,而 Installer 的实例方法 install! 就会使用这些信息安装当前工程的依赖,而整个安装依赖的过程大约有四个部分:
- 解析 Podfile 中的依赖
- 下载依赖
- 创建 Pods.xcodeproj 工程
- 集成 workspace
def install!
resolve_dependencies
download_dependencies
generate_pods_project
integrate_user_project
end
在上面的 install 方法调用的 resolve_dependencies 会创建一个 Analyzer 类的实例,在这个方法中,你会看到一些非常熟悉的字符串:
def resolve_dependencies
analyzer = create_analyzer
plugin_sources = run_source_provider_hooks
analyzer.sources.insert(0, *plugin_sources)
UI.section 'Updating local specs repositories' do
analyzer.update_repositories
end if repo_update?
UI.section 'Analyzing dependencies' do
analyze(analyzer)
validate_build_configurations
clean_sandbox
end
end
在使用 CocoaPods 中经常出现的 Updating local specs repositories 以及 Analyzing dependencies 就是从这里输出到终端的,该方法不仅负责对本地所有 PodSpec 文件的更新,还会对当前 Podfile 中的依赖进行分析:
def analyze(analyzer = create_analyzer)
analyzer.update = update
@analysis_result = analyzer.analyze
@aggregate_targets = analyzer.result.targets
end
analyzer.analyze 方法最终会调用 Resolver 的实例方法 resolve:
def resolve
dependencies = podfile.target_definition_list.flat_map do |target|
target.dependencies.each do |dep|
@platforms_by_dependency[dep].push(target.platform).uniq! if target.platform
end
end
@activated = Molinillo::Resolver.new(self, self).resolve(dependencies, locked_dependencies)
specs_by_target
rescue Molinillo::ResolverError => e
handle_resolver_error(e)
end
这里的 Molinillo::Resolver 就是用于解决依赖关系的类。
解决依赖关系(Resolve Dependencies)
CocoaPods 为了解决 Podfile 中声明的依赖关系,使用了一个叫做 Milinillo 的依赖关系解决算法;但是,笔者在 Google 上并没有找到与这个算法相关的其他信息,推测是 CocoaPods 为了解决 iOS 中的依赖关系创造的算法。
Milinillo 算法的核心是 回溯(Backtracking) 以及 向前检查(forward check)),整个过程会追踪栈中的两个状态(依赖和可能性)。
在这里并不想陷入对这个算法执行过程的分析之中,如果有兴趣可以看一下仓库中的 ARCHITECTURE.md 文件,其中比较详细的解释了 Milinillo 算法的工作原理,并对其功能执行过程有一个比较详细的介绍。
Molinillo::Resolver 方法会返回一个依赖图,其内容大概是这样的:
Molinillo::DependencyGraph:[
Molinillo::DependencyGraph::Vertex:AFNetworking(#<Pod::Specification name="AFNetworking">),
Molinillo::DependencyGraph::Vertex:SDWebImage(#<Pod::Specification name="SDWebImage">),
Molinillo::DependencyGraph::Vertex:Masonry(#<Pod::Specification name="Masonry">),
Molinillo::DependencyGraph::Vertex:Typeset(#<Pod::Specification name="Typeset">),
Molinillo::DependencyGraph::Vertex:CCTabBarController(#<Pod::Specification name="CCTabBarController">),
Molinillo::DependencyGraph::Vertex:BlocksKit(#<Pod::Specification name="BlocksKit">),
Molinillo::DependencyGraph::Vertex:Mantle(#<Pod::Specification name="Mantle">),
...
]
这个依赖图是由一个结点数组组成的,在 CocoaPods 拿到了这个依赖图之后,会在 specs_by_target 中按照 Target 将所有的 Specification 分组:
{
#<Pod::Podfile::TargetDefinition label=Pods>=>[],
#<Pod::Podfile::TargetDefinition label=Pods-Demo>=>[
#<Pod::Specification name="AFNetworking">,
#<Pod::Specification name="AFNetworking/NSURLSession">,
#<Pod::Specification name="AFNetworking/Reachability">,
#<Pod::Specification name="AFNetworking/Security">,
#<Pod::Specification name="AFNetworking/Serialization">,
#<Pod::Specification name="AFNetworking/UIKit">,
#<Pod::Specification name="BlocksKit/Core">,
#<Pod::Specification name="BlocksKit/DynamicDelegate">,
#<Pod::Specification name="BlocksKit/MessageUI">,
#<Pod::Specification name="BlocksKit/UIKit">,
#<Pod::Specification name="CCTabBarController">,
#<Pod::Specification name="CategoryCluster">,
...
]
}
而这些 Specification 就包含了当前工程依赖的所有第三方框架,其中包含了名字、版本、源等信息,用于依赖的下载。
下载依赖
在依赖关系解决返回了一系列 Specification 对象之后,就到了 Pod install 的第二部分,下载依赖:
def install_pod_sources
@installed_specs = []
pods_to_install = sandbox_state.added | sandbox_state.changed
title_options = { :verbose_prefix => '-> '.green }
root_specs.sort_by(&:name).each do |spec|
if pods_to_install.include?(spec.name)
if sandbox_state.changed.include?(spec.name) && sandbox.manifest
previous = sandbox.manifest.version(spec.name)
title = "Installing #{spec.name} #{spec.version} (was #{previous})"
else
title = "Installing #{spec}"
end
UI.titled_section(title.green, title_options) do
install_source_of_pod(spec.name)
end
else
UI.titled_section("Using #{spec}", title_options) do
create_pod_installer(spec.name)
end
end
end
end
在这个方法中你会看到更多熟悉的提示,CocoaPods 会使用沙盒(sandbox)存储已有依赖的数据,在更新现有的依赖时,会根据依赖的不同状态显示出不同的提示信息:
-> Using AFNetworking (3.1.0)
-> Using AKPickerView (0.2.7)
-> Using BlocksKit (2.2.5) was (2.2.4)
-> Installing MBProgressHUD (1.0.0)
...
虽然这里的提示会有三种,但是 CocoaPods 只会根据不同的状态分别调用两种方法:
- install_source_of_pod
- create_pod_installer
create_pod_installer 方法只会创建一个 PodSourceInstaller 的实例,然后加入 pod_installers 数组中,因为依赖的版本没有改变,所以不需要重新下载,而另一个方法的 install_source_of_pod 的调用栈非常庞大:
installer.install_source_of_pod
|-- create_pod_installer
| `-- PodSourceInstaller.new
`-- podSourceInstaller.install!
`-- download_source
`-- Downloader.download
`-- Downloader.download_request
`-- Downloader.download_source
|-- Downloader.for_target
| |-- Downloader.class_for_options
| `-- Git/HTTP/Mercurial/Subversion.new
|-- Git/HTTP/Mercurial/Subversion.download
`-- Git/HTTP/Mercurial/Subversion.download!
`-- Git.clone
在调用栈的末端 Downloader.download_source 中执行了另一个 CocoaPods 组件 CocoaPods-Download 中的方法:
def self.download_source(target, params)
FileUtils.rm_rf(target)
downloader = Downloader.for_target(target, params)
downloader.download
target.mkpath
if downloader.options_specific?
params
else
downloader.checkout_options
end
end
方法中调用的 for_target 根据不同的源会创建一个下载器,因为依赖可能通过不同的协议或者方式进行下载,比如说 Git/HTTP/SVN 等等,组件 CocoaPods-Downloader 就会根据 Podfile 中依赖的参数选项使用不同的方法下载依赖。
大部分的依赖都会被下载到 ~/Library/Caches/CocoaPods/Pods/Release/ 这个文件夹中,然后从这个这里复制到项目工程目录下的 ./Pods 中,这也就完成了整个 CocoaPods 的下载流程。
生成 Pods.xcodeproj
CocoaPods 通过组件 CocoaPods-Downloader 已经成功将所有的依赖下载到了当前工程中,这里会将所有的依赖打包到 Pods.xcodeproj 中:
def generate_pods_project(generator = create_generator)
UI.section 'Generating Pods project' do
generator.generate!
@pods_project = generator.project
run_podfile_post_install_hooks
generator.write
generator.share_development_pod_schemes
write_lockfiles
end
end
generate_pods_project 中会执行 PodsProjectGenerator 的实例方法 generate!:
def generate!
prepare
install_file_references
install_libraries
set_target_dependencies
end
这个方法做了几件小事:
- 生成 Pods.xcodeproj 工程
- 将依赖中的文件加入工程
- 将依赖中的 Library 加入工程
- 设置目标依赖(Target Dependencies)
这几件事情都离不开 CocoaPods 的另外一个组件 Xcodeproj,这是一个可以操作一个 Xcode 工程中的 Group 以及文件的组件,我们都知道对 Xcode 工程的修改大多数情况下都是对一个名叫 project.pbxproj 的文件进行修改,而 Xcodeproj 这个组件就是 CocoaPods 团队开发的用于操作这个文件的第三方库。
生成 workspace
最后的这一部分与生成 Pods.xcodeproj 的过程有一些相似,这里使用的类是 UserProjectIntegrator,调用方法 integrate! 时,就会开始集成工程所需要的 Target:
def integrate!
create_workspace
integrate_user_targets
warn_about_xcconfig_overrides
save_projects
end
对于这一部分的代码,也不是很想展开来细谈,简单介绍一下这里的代码都做了什么,首先会通过 Xcodeproj::Workspace 创建一个 workspace,之后会获取所有要集成的 Target 实例,调用它们的 integrate! 方法:
def integrate!
UI.section(integration_message) do
XCConfigIntegrator.integrate(target, native_targets)
add_pods_library
add_embed_frameworks_script_phase
remove_embed_frameworks_script_phase_from_embedded_targets
add_copy_resources_script_phase
add_check_manifest_lock_script_phase
end
end
方法将每一个 Target 加入到了工程,使用 Xcodeproj 修改 Copy Resource Script Phrase 等设置,保存 project.pbxproj,整个 Pod install 的过程就结束了。
总结
最后想说的是 pod install 和 pod update 区别还是比较大的,每次在执行 pod install 或者 update 时最后都会生成或者修改 Podfile.lock 文件,其中前者并不会修改 Podfile.lock 中显示指定的版本,而后者会会无视该文件的内容,尝试将所有的 pod 更新到最新版。
CocoaPods 工程的代码虽然非常多,不过代码的逻辑非常清晰,整个管理并下载依赖的过程非常符合直觉以及逻辑。
作者:Draveness
链接:https://zhuanlan.zhihu.com/p/22652365
收起阅读 »