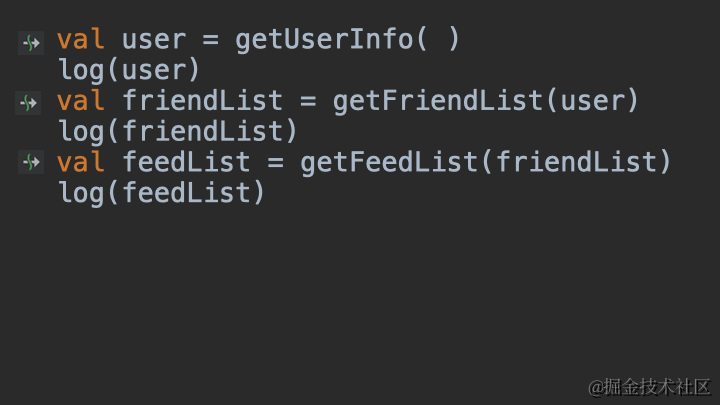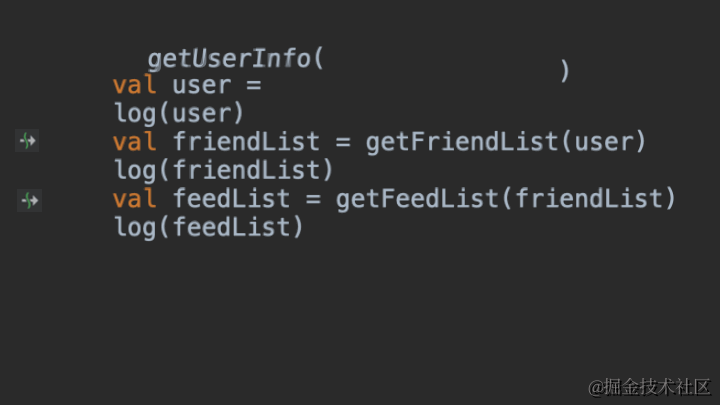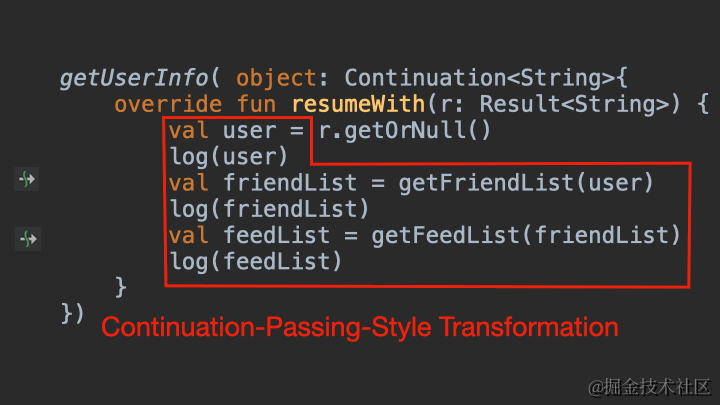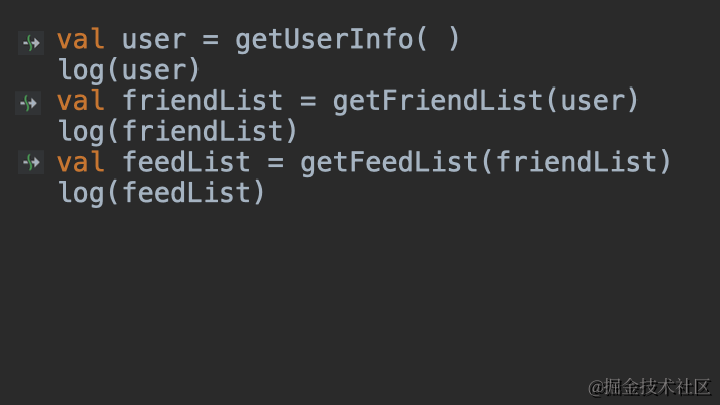
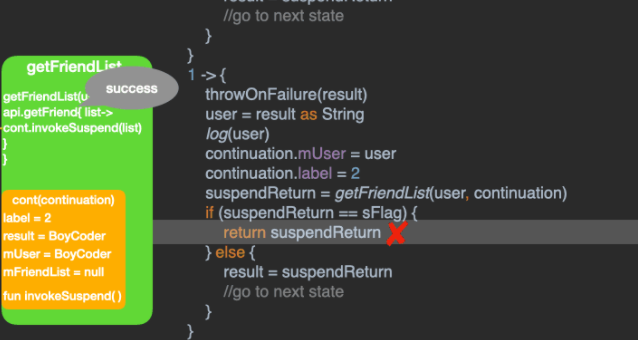
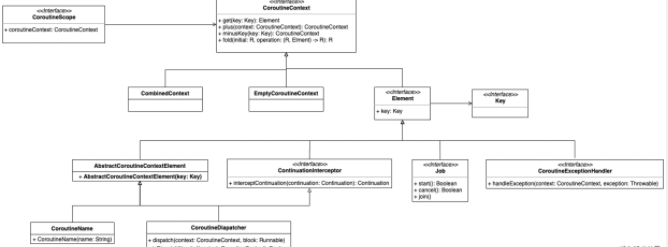
医生推荐了Android最新的Material Motion动画,虽然最终没有给我们的App安排,但给我学习Material Motion动画提供了一次契机。
推荐给大家的学习资料:
什么是转场动画?
在学习动画的时候,我们总是会听到转场动画,那么,什么是转场动画呢?
首先,对于一个动画而言,两个关键帧是动画的开始帧和动画的结束帧,转场则是两个关键帧之间的过渡。
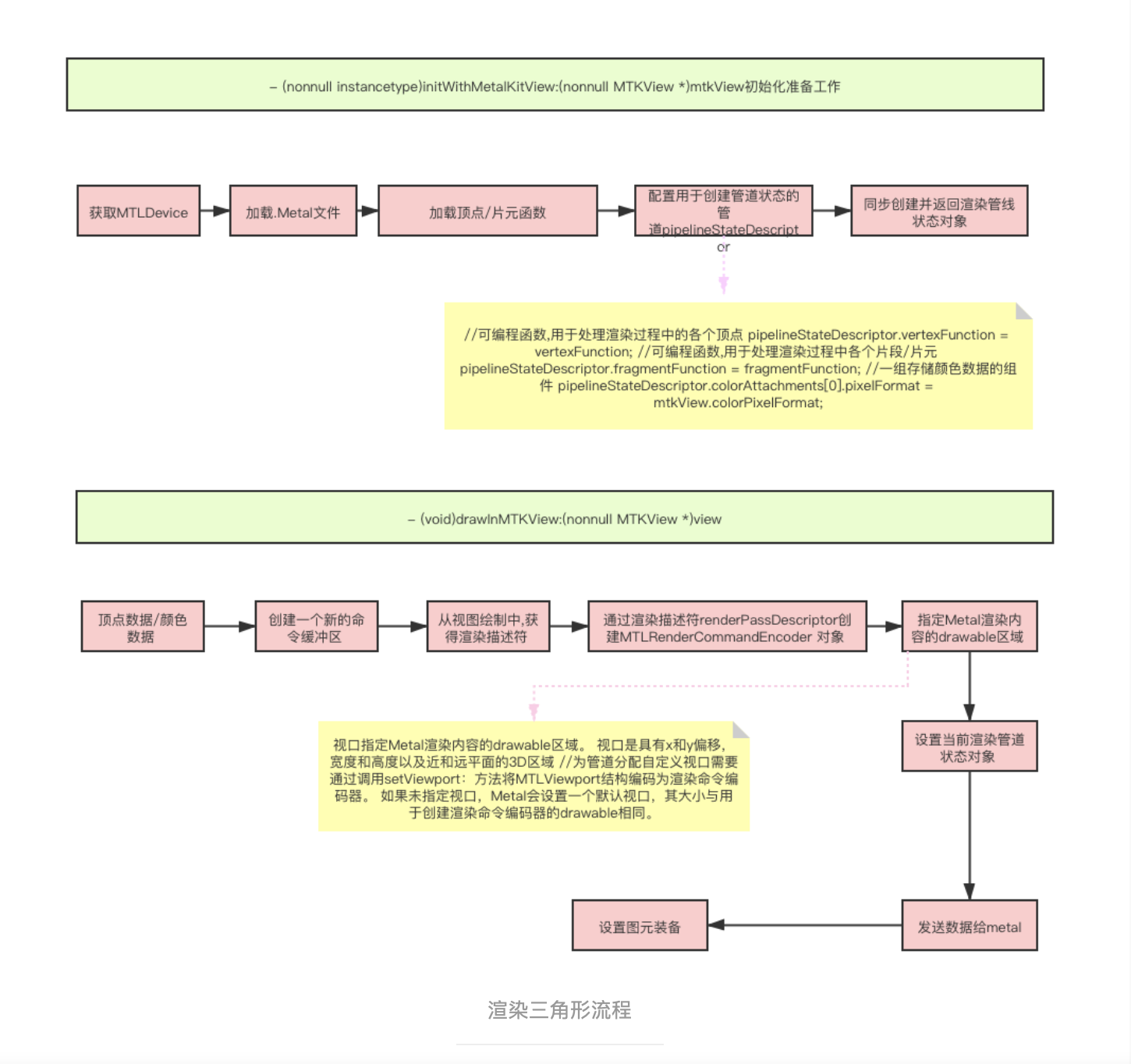
一个完整的转场动画如图:
图片来自《动态设计的转场心法》
一、最初的转场
先教大家一个干货:
adb shell settings put global window_animation_scale 10
adb shell settings put global transition_animation_scale 10
adb shell settings put global animator_duration_scale 10
这个命令可以将动画放慢10倍,方便学习动画的细节,速度恢复则把10改成1。
还记得一开始两个 Activity 怎么过渡的吗?没错就是使用 overridePendingTransition 方法。
Android 2.0 以后可以使用 overridePendingTransition(int enterAnim, int exitAnim) 来完成 Activity 的跳转动画,其中,第一个参数 exitAnim 对应着上述图片转场中的 IN,第二个参数 enterAnim 对应着上述图片中的 OUT。
如果要写一个平移和透明度跳转动画,它通常是这样的:
步骤一 设置进入和退出动画
在资源文件下 anim 目录下新建一个动画的资源文件,Activity 进入动画 anim_in 文件:
<?xml version="1.0" encoding="utf-8"?>
<set xmlns:android="http://schemas.android.com/apk/res/android"
android:duration="500">
<translate
android:fromXDelta="100%p"
android:toXDelta="0"
/>
<alpha
android:fromAlpha="0.0"
android:toAlpha="1.0"
/>
</set>
Activity 退出动画 anim_out 文件:
<?xml version="1.0" encoding="utf-8"?>
<set xmlns:android="http://schemas.android.com/apk/res/android"
android:duration="500">
<translate
android:fromXDelta="0"
android:toXDelta="-100%p"
/>
<alpha
android:fromAlpha="1.0"
android:toAlpha="0.0"
/>
</set>
步骤二 引用动画文件
在界面跳转的时候,调用 overridePendingTransition 方法:
companion object {
fun start(context: Context){
val intent = Intent(context, SecondActivity::class.java)
context.startActivity(intent)
if(context is Activity){
context.overridePendingTransition(R.anim.anim_in, R.anim.anim_out)
}
}
}
效果:
overridePendingTransition写法的问题
和View动画一样,使用虽爽,但只支持平移、旋转、缩放和透明度这四种动画类型,遇到稍微复杂的动画也只能撒手了。
二、Android 5.0 Material 转场动画
在 Android 5.0 之后,我们可以使用 Material Design 为我们带来的转场动画。
不说别的,先看几个案例:
| 官方Demo | 掘金App | 我的App |
|---|---|---|
从左到右依次是官方Demo、掘金App和我的开源项目Hoo,与最初的转场的不同点如下:
- 如果说 overridePendingTransition 对应着 View 动画,那么 Material 转场对应着的是属性动画,所以可以自定义界面过渡动画。
- 除了进入、退出场景,Material 转场为我们增加一种新的场景,共享元素,上述三图的动画过渡都用到了共享元素。
- 不仅仅能用在Activity,还可以用在Fragment和View之间。
三张图中都使用了ImageView作为共享元素(Hoo中使用更加复杂的PhotoView),共享元素的动画看着十分有趣,看着就像图片从A界面中跳到了B界面上。
为什么我可以判断掘金也是使用的 Material 转场?因为 Material 共享元素动画开始的时候默认会将 StartView 的 Alpha 设置为0,仔细看掘金大图打开的一瞬间,后面的图已经没了~,并且一开始过渡还有一点小瑕疵。
1. 进入和退出动画
进入和退出动画不包括共享元素的动画,只支持三种动画类型:
| 动画 | 解释 |
|---|---|
Explode(爆炸式) | 将视图移入场景中心或从中移出 |
Slide(滑动式) | 将视图从场景的其中一个边缘移入或移出 |
Fade(淡入淡出式) | 通过更改视图的不透明度,在场景中添加视图或从中移除视图 |
细心的同学可能发现,Material Design没有支持 Scale 和 Rotation 这两种类型的动画,可能这两种类型的过渡动画使用场景实在太少,如果实在想用,可以自定义实现。
步骤一 创建Material Bundle
startActivity(intent,
ActivityOptions.makeSceneTransitionAnimation(this).toBundle())
步骤二 设置动画
override fun onCreate(savedInstanceState: Bundle?) {
// 开启Material动画
window.requestFeature(Window.FEATURE_ACTIVITY_TRANSITIONS)
super.onCreate(savedInstanceState)
//setContentView(R.layout.detail_activity)
// 设置进入的动画
window.enterTransition = Slide()
// 设置退出动画
window.exitTransition = Slide()
}
除了这种方式,还可以通过设置主题的方式设置进入和退出动画,同样也适用于共享动画。
2. 共享元素动画
启用共享元素动画的步骤跟之前的步骤稍有不同。
步骤一 设置Activity A
先给 View 设置 transitionName:
ivShoe.transitionName = transitionName
接着,它需要提供共享的 View 和 TransitionName。
其实,就是想让你告诉系统,什么样的 View 需要做动画,那如果有多个 View 呢?所以,你还得给View 绑定一个 TransitionName,防止动画做混了。
代码:
val options = ActivityOptions.makeSceneTransitionAnimation(this, binding.ivShoe, transitionName)
ImageGalleryActivity.start(this, it, options.toBundle(), transitionName)
如果有多个共享元素,可以将关系存进 Pair,然后把 Pair 放进去,不懂的可以看一下 Api。
步骤二 为Activity B设置共享元素动画
默认支持的共享元素的动画也是有限的,支持的种类有:
| 动画 | 说明 |
|---|---|
changeBounds | 为目标视图布局边界的变化添加动画效果 |
changeClipBounds | 为目标视图裁剪边界的变化添加动画效果 |
changeTransform | 为目标视图缩放和旋转方面的变化添加动画效果 |
changeImageTransform | 为目标图片尺寸和缩放方面的变化添加动画效果 |
通过 Window 设置 sharedElementEnterTransition 和 sharedElementExitTransition:
override fun onCreate(savedInstanceState: Bundle?) {
// 开启Material动画
window.requestFeature(Window.FEATURE_ACTIVITY_TRANSITIONS)
val transitionSet = TransitionSet()
transitionSet.addTransition(ChangeBounds())
transitionSet.addTransition(ChangeClipBounds())
transitionSet.addTransition(ChangeImageTransform())
window.sharedElementEnterTransition = transitionSet
window.sharedElementExitTransition = transitionSet
super.onCreate(savedInstanceState)
// 我这里的transitionName是通过Intent传进去的
val transitionName = intent.getStringExtra(CUS_TRANSITION_NAME)
// 给ImageView设置transitionName
binding.ivShoe.transitionName = transitionName
}
这样写完大部分场景都是可以用的,但是,如果你是通过 Glide 加载或者其他图片库加载的网络图片,恭喜你,大概率会遇到这样的问题:
为什么会出现这样的情况?因为加载网络图片是需要时间的,我们可以等 B 页面的图片加载好了,再去开启动画,Material 装厂就支持这样的操作。
在 onCreate 中调用 postponeEnterTransition() 方法表明我们的动画需要延迟执行,等我们需要的时机,再调用 Activity 中的 startPostponedEnterTransition() 方法来开始执行动画,所以,即便是在 A 界面中,跳转到 B 界面中的 Fragment,动画也是一样可以执行的。
到这儿,界面就可以正常跳转了,图片就不放了。
共享元素动画原理其实也很简单,如果是 A 跳到 B,会先把 A 和 B 的共享元素的状态分别记录下来,之后跳到 B,根据先前记录的状态执行属性动画,虽然是叫共享元素,它们可是不同的 View。
不仅仅 Activity 可以支持 Material 转场动画,Fragment 和 View 也都是可以的(之前我一直以为是不可以的~),感兴趣的同学可以自行研究。
三、Android Material Motion动画
新出的 Motion 动画是什么呢?
1. Android Motion 简介
其实它就是新支持的四种动画类型,分别是:
1.1 Container transform
Container transform 也是基于共享元素的动画,跟之前共享元素动画最大的不同点在于它的 Start View可以是一个 ViewGroup,也可以是一个 View,如图一中所看到的那样,它的 Start View 是一个 CardView。
1.2 Shared axis
Shared axis 看上去像平移动画,官方展示的三个例子分别是,横向平移、纵向平移和Z轴平移。
1.3 Fade Through
Fade Through 本质上是一个透明度+缩放动画,官方的建议是用在两个关联性不强的界面的跳转中。
1.4 Fade
乍一看,Fade 动画和上面的 Fade Through 是一致的,就动画本质而言,它们的确是一样的透明度+缩放动画,但是官方建议,如果发生在同一个界面,比如弹出Dialog、Menu等这类的弹框可以考虑这种动画。
Google 提供了两种库供大家使用。
一种是 AndroidX 包,特点是:
- 兼容到 API 14
- 仅支持 Fragment 和 View 之间的过渡
- 行为一致性
另外一种是 Platform 包,特点是:
- 兼容到 API 21
- 支持 Fragment、View、Activity 和 Window
- 在不同的 API 上,可能会有点差异
现在的 App,最低版本应该都在 21 了,而且支持 Activity,所以建议还是选择 Platform。
2. Material Motion 初体验
我们以 Container transform 为例,来个 Activity 之间的 Android Motion 动画的初体验:
步骤一 引入依赖
implementation 'com.google.android.material:material:1.4.0-alpha01'
步骤二 设置Activity A
这里的 Activity A 对应着 MainActivity,在 MainActivity 中启用转场动画:
class MainActivity : AppCompatActivity() {
//...
override fun onCreate(savedInstanceState: Bundle?) {
window.requestFeature(Window.FEATURE_ACTIVITY_TRANSITIONS)
setExitSharedElementCallback(MaterialContainerTransformSharedElementCallback())
window.sharedElementsUseOverlay = false
super.onCreate(savedInstanceState)
//...
}
}
步骤三 设置跳转事件
跟创建共享元素的步骤一样,先设置 TransitionName:
private fun onCreateListener(id: Long, url: String): View.OnClickListener {
return View.OnClickListener {
val transitionName = "${id}-${url}"
it.transitionName = transitionName
DetailActivity.start(context, id, it as ConstraintLayout, transitionName)
}
}
这里偷了懒,将 TransitionName 的设置放在了点击事件中,接着创建 Bundle:
const val CUS_TRANSITION_NAME: String = "transition_name"
class DetailActivity : AppCompatActivity() {
companion object {
fun start(context: Context, id: Long, viewGroup: ConstraintLayout, transitionName: String){
val intent = Intent(context, DetailActivity::class.java)
intent.putExtra(BaseConstant.DETAIL_SHOE_ID, id)
intent.putExtra(CUS_TRANSITION_NAME, transitionName)
if(context is Activity){
context.startActivity(intent, ActivityOptions.makeSceneTransitionAnimation(context, viewGroup, transitionName).toBundle())
}else {
context.startActivity(intent)
}
}
}
}
步骤四 设置Activity B
Demo 中的 Activity B 对应着 DetailActivity,这一步主要给进入和退出的共享动画设置 MaterialContainerTransform,具体的代码是:
override fun onCreate(savedInstanceState: Bundle?) {
// 1. 设置动画
window.requestFeature(Window.FEATURE_ACTIVITY_TRANSITIONS)
setEnterSharedElementCallback(MaterialContainerTransformSharedElementCallback())
super.onCreate(savedInstanceState)
//...
// 2. 设置transitionName
binding.mainContent.transitionName = intent.getStringExtra(CUS_TRANSITION_NAME)
// 3. 设置具体的动画
window.sharedElementEnterTransition = MaterialContainerTransform().apply {
addTarget(binding.mainContent)
duration = 300L
}
window.sharedElementExitTransition = MaterialContainerTransform().apply {
addTarget(binding.mainContent)
duration = 300L
}
}
Demo 中使用了 DataBinding,不过你只需要了解 binding.mainContent 是一个 ViewGroup。到这儿,你就可以成功的看到 Demo 中的效果了。
Material Motion 其实 Android 5.0 中加入的转场动画一样,它们也继承自 Transition,但给我们的使用带来了很大的方便。
四、总结
在 Android 转场的过程中:
- 最初的 View 转场带给我们平移、缩放、旋转和透明度四种基本能力的支持;
- 接着,Android 5.0 Material 转场给我们带来了共享元素动画的惊喜,并具备了自定义转场动画的能力,升级了Android转场的玩法;
- 最后是出来不久的 Android Motion,通过封装了四种动画,降低了我们转场的使用难度。
虽然起点的图片查看器的专场没有使用 Material 转场,但是过度依然丝滑,感兴趣的话我会在后面单独开一篇。