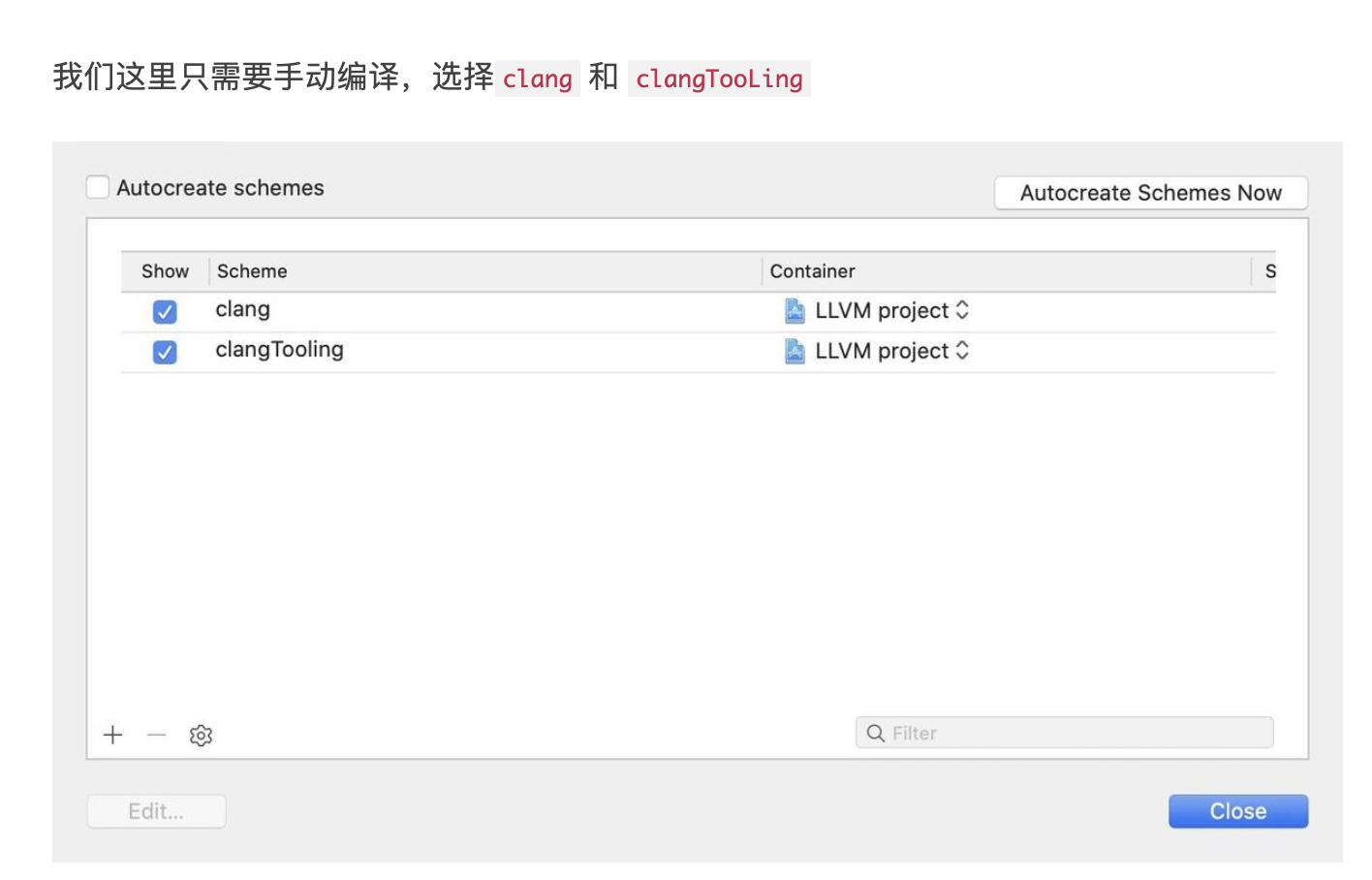
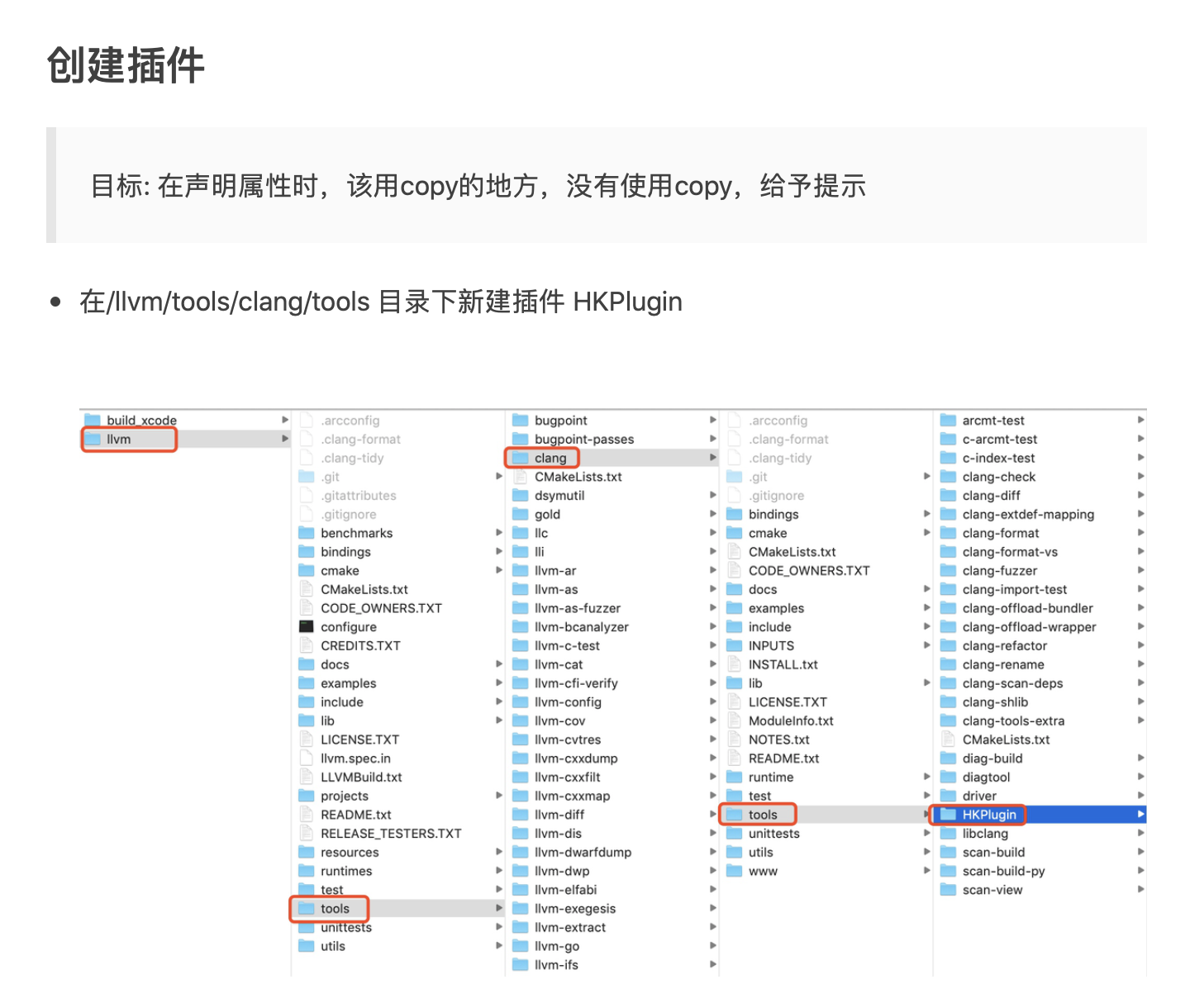
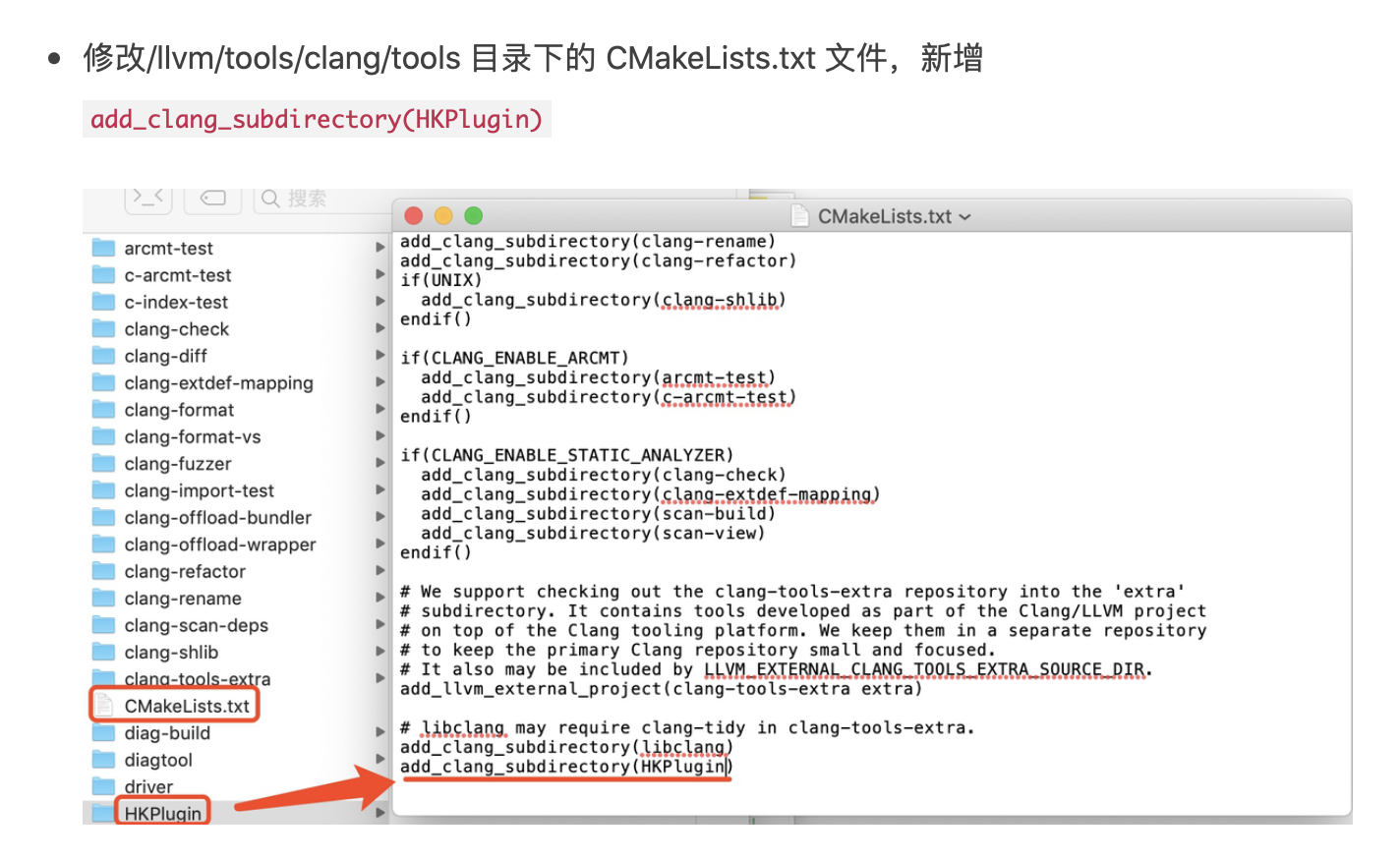
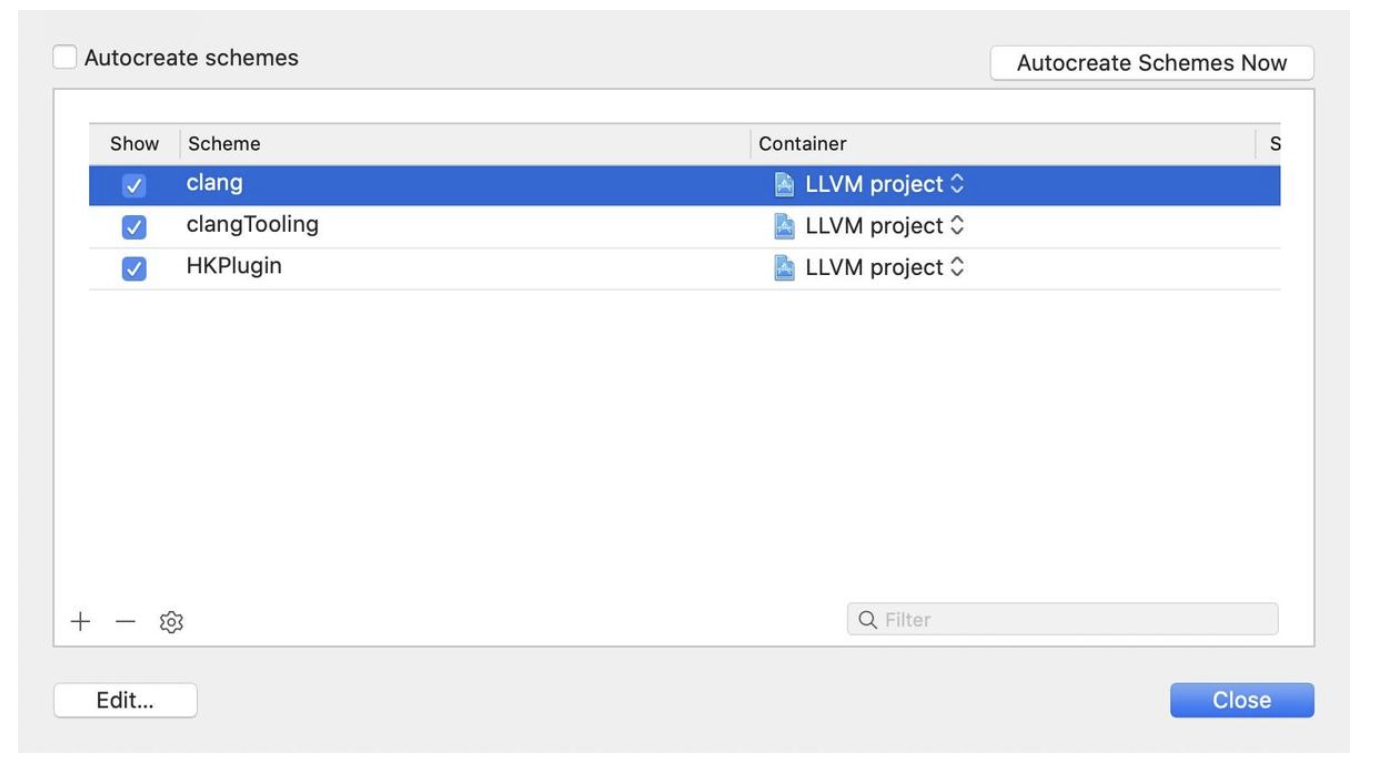
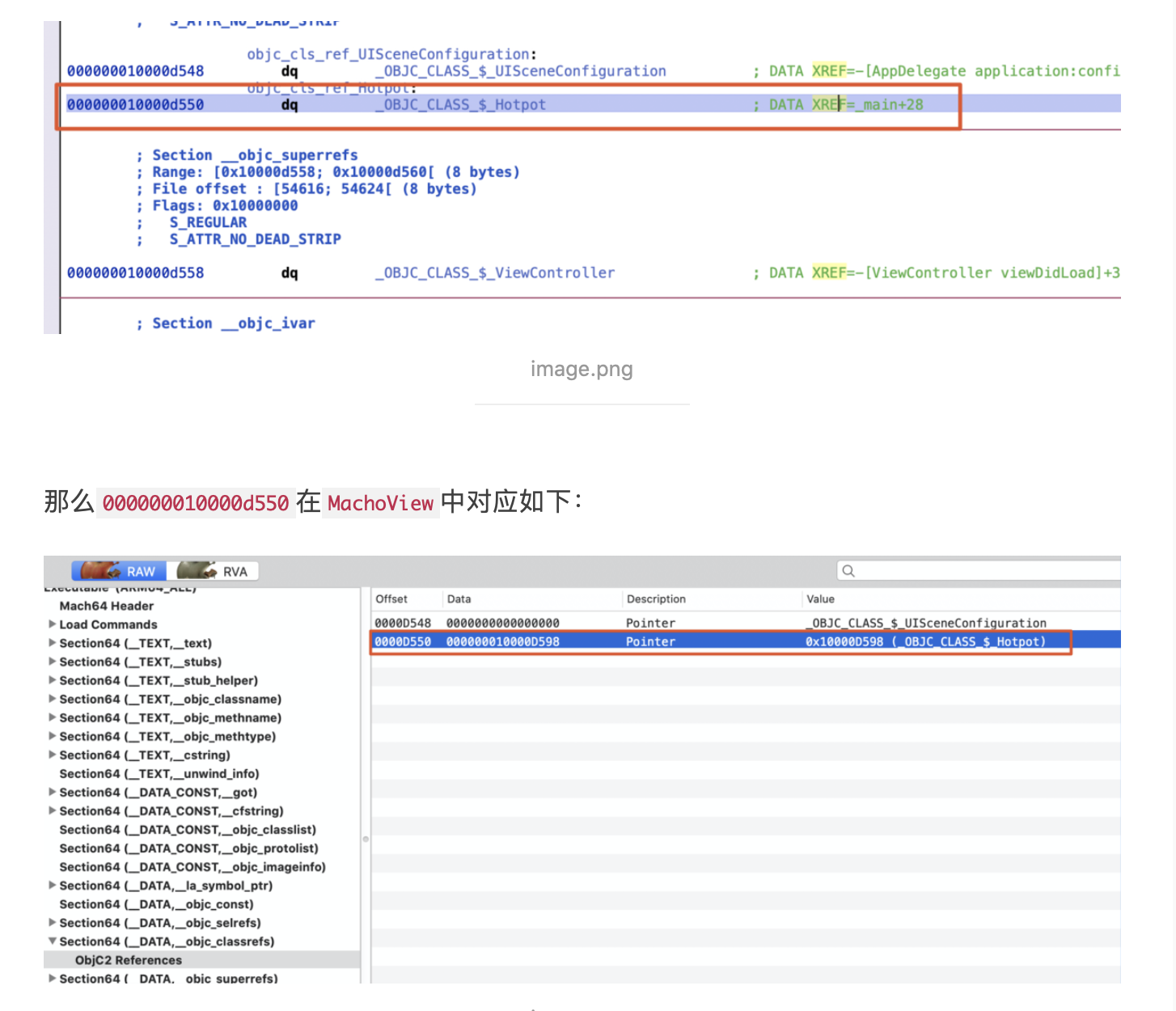
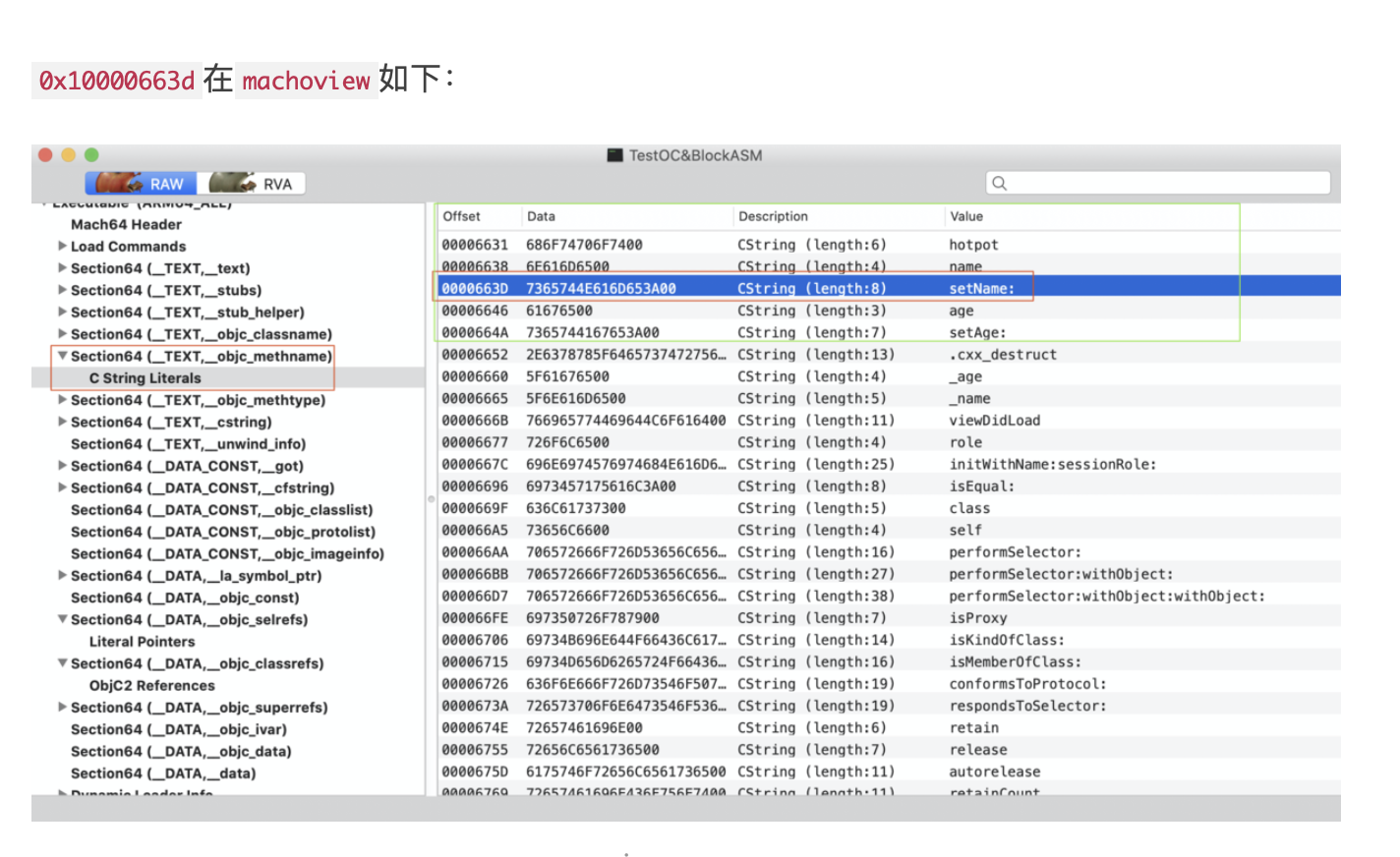
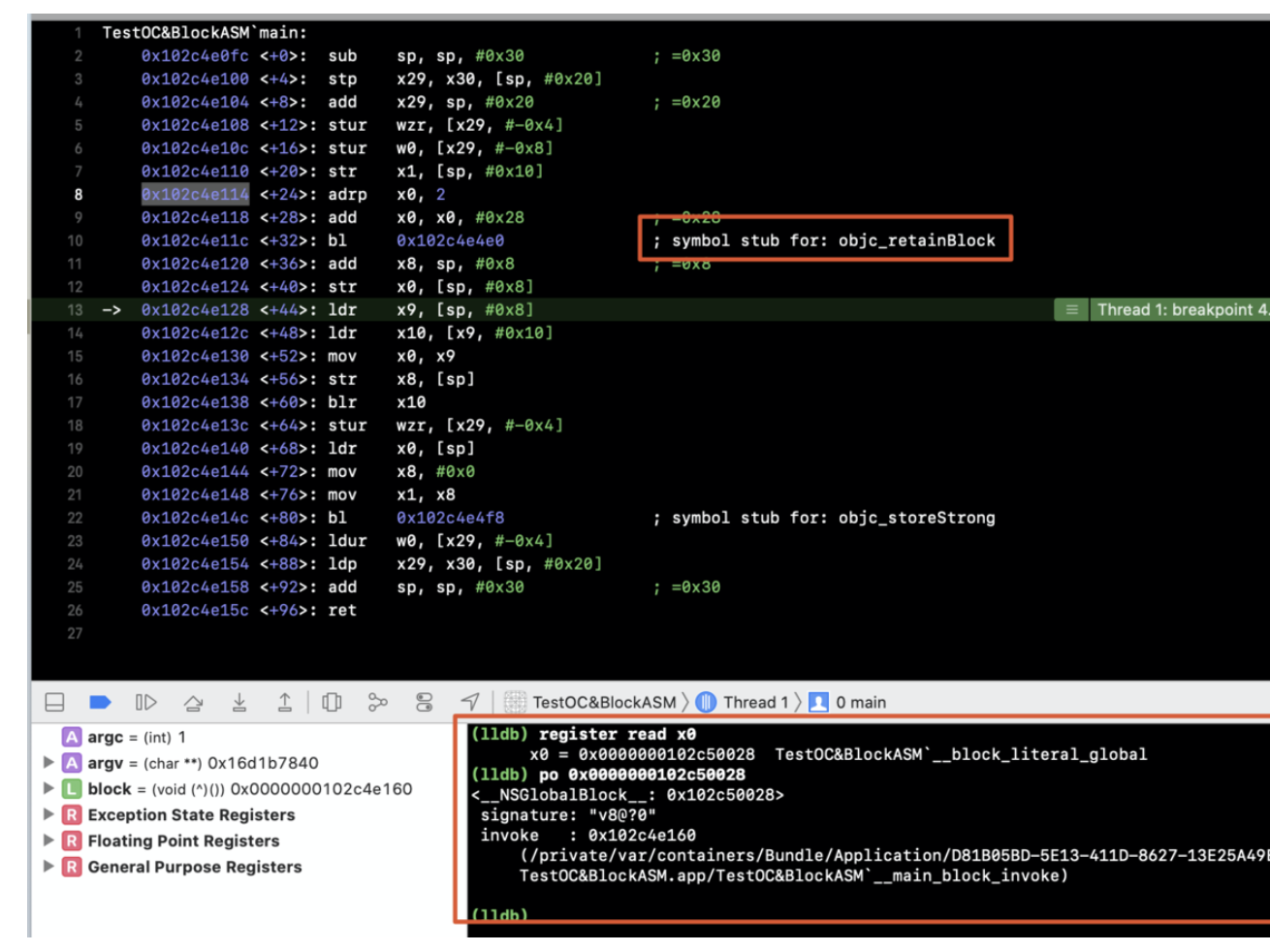
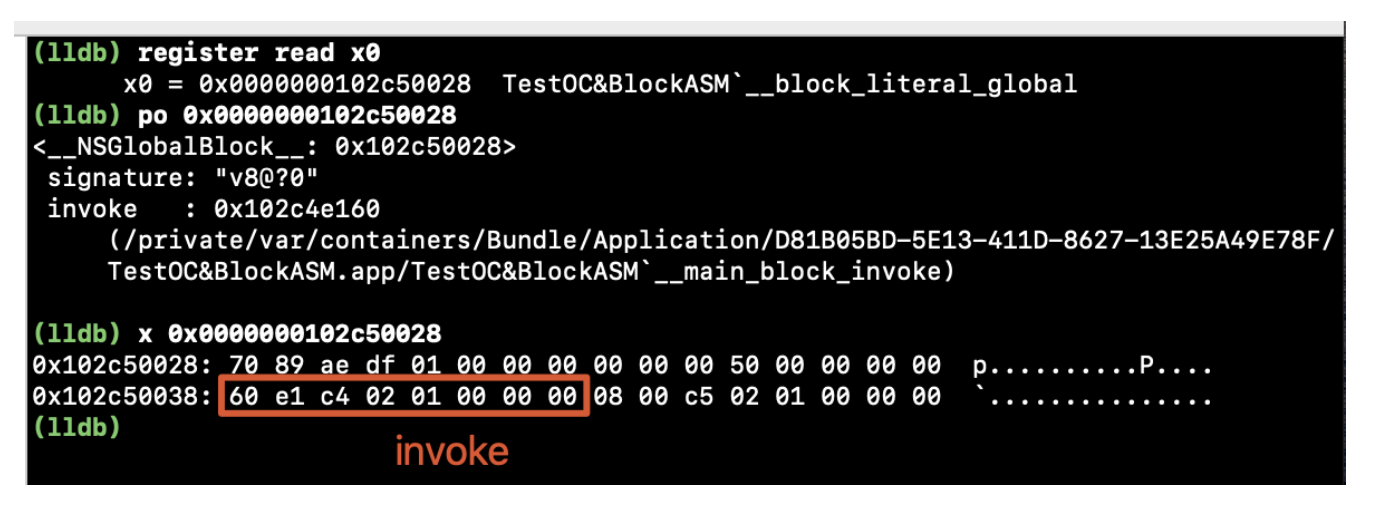
引言
无论你是否用过, wendux 大佬开源的 dio 项目,应该是目前 Flutter 中最 🔥 的网络请求库,在 github 上接近 1W 的 star。
但其实 Dart 中已经有 dart:io 库为我们提供了网络服务,为何 Dio 又如此受到开发者青睐?背后有哪些优秀的设计值得我们学习?
这个系列预计会花 6 期左右从计算机网络原理,到 Dart 中的网络编程,最后再到 Dio 的架构设计,通过原理分析 + 练习的方式,带大家由浅入深的掌握 Dart 中的网络编程与 Dio 库的设计。
本期,我们会通过编写一个简单的本地群聊服务,一起学习计算机网络基础知识与 Dart 中的 Socket 编程。
Socket 是什么
想要了解 Socket 是什么,需要先复习一下网络基础。
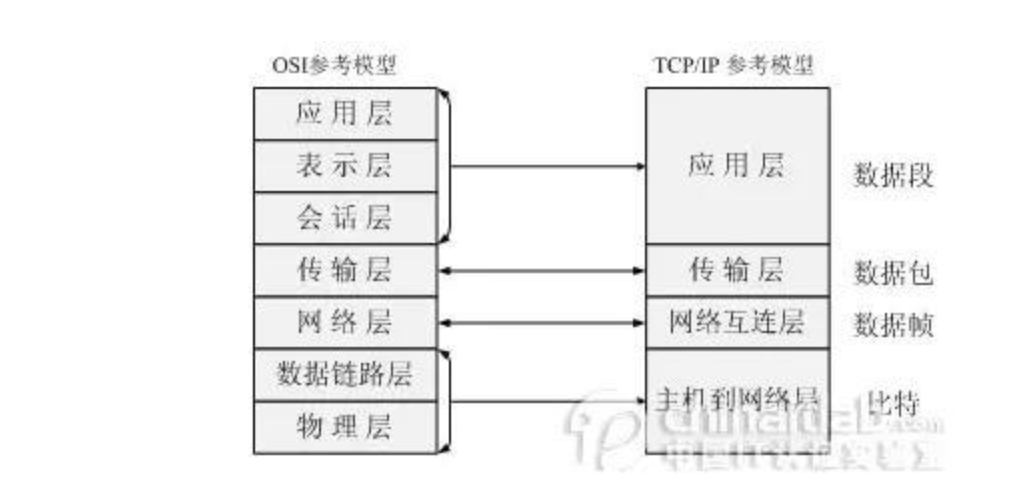
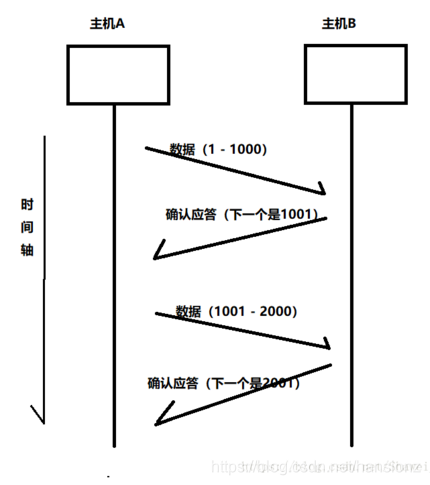
无论微信聊天,观看视频或者打开网页,当我们通过网络进行一次数据传输时。数据根据网络协议进行传输, 在 TCP/IP 协议中,经历如下的流转:
TCP/IP 定义了四层结构,每一层都是为了完成一种功能,为了完成这些功能,需要遵循一些规则,这些规则就是协议,每一层都定义了一些协议。
- 应用层
应用层决定了向用户提供应用服务时通信的活动。TCP/IP 协议族内预存了各类通用的应用服务。比如,FTP(FileTransfer Protocol,文件传输协议)和 DNS(Domain Name System,域名系统)服务就是其中两类。HTTP 协议也处于该层。
- 传输层
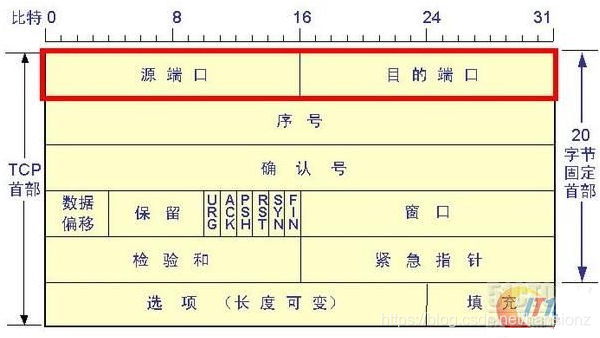
传输层对上层应用层,提供处于网络连接中的两台计算机之间端到端的数据传输。在传输层有两个性质不同的协议:TCP(Transmission ControlProtocol,传输控制协议)和UDP(User Data Protocol,用户数据报协议)。
- 网络层(又名网络互连层)
网络层用来处理在网络上流动的数据包。数据包是网络传输的最小数据单位。该层规定了通过怎样的路径(所谓的传输路线)到达对方计算机,并把数据包传送给对方。与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所起的作用就是在众多的选项内选择一条传输路线。
- 网络访问层(又名链路层)
用来处理连接网络的硬件部分。包括控制操作系统、硬件的设备驱动、NIC(Network Interface Card,网络适配器,即网卡),及光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。
今天的主角 Socket 是应用层 与 TCP/IP 协议族通信的中间软件抽象层,表现为一个封装了 TCP / IP协议族 的编程接口(API)
为什么我们一开始要了解 Socket 编程,因为比起直接使用封装好的网络接口,Socket 能让我们更接近接近网络的本质,同时不用关心底层链路的细节。
如何使用 Dart 中的 Socket
dart:io 库中提供了两个类,第一个是 Socket,我们可以用它作为客户端与服务器建立连接。 第二个是 ServerSocket,我们将使用它创建一个服务器,并与客户端进行连接。
1、Socket 客户端
本系列代码均上传,可直接运行:io_practice/socket_study
Socket 类中有一个静态方法 connect(host, int port) 。第一个参数 host 可以是一个域名或者 IP 的 String,也可以是 InternetAddress 对象。
connect 返回一个 Future<Socket> 对象,当 socket 与 host 完成连接时 Future 对象回调。
// socket_pratice1.dart
void main() {
Socket.connect("www.baidu.com", 80).then((socket) {
print('Connected to: '
'${socket.remoteAddress.address}:${socket.remotePort}');
socket.destroy();
});
}
复制代码这个 case 中,我们通过 80 端口(为 HTTP 协议开放)与 http://www.baidu.com 连接。连接到服务器之后,打印出连接的 IP 地址和端口,最后通过 socket.destroy() 关闭连接。在命令行中 执行 dart socket_pratice1.dart 可以看到如下输出:
➜ socket_study dart socket_pratice1.dart
socket_pratice2.dart: Warning: Interpreting this as package URI, 'package:io_pratice/socket_study/socket_pratice2.dart'.
Connected to: 220.181.38.149:80
复制代码通过简单的函数调用,Dart 为我们完成了 http://www.baidu.com 的 IP 查找与 TCP 建立连接,我们只需要等待即可。 在连接建立之后,我们可以和服务端进行数据交互,为此我们需要做两件事。
1、发起请求 2、响应接受数据
对应 Socket 中提供的两个方法 Socket.write(String data) 和 Socket.listen(void onData(data)) 。
// socket_pratice2.dart
void main() {
String indexRequest = 'GET / HTTP/1.1\nConnection: close\n\n';
//与百度通过 80 端口连接
Socket.connect("www.baidu.com", 80).then((socket) {
print('Connected to: '
'${socket.remoteAddress.address}:${socket.remotePort}');
//监听 socket 的数据返回
socket.listen((data) {
print(new String.fromCharCodes(data).trim());
}, onDone: () {
print("Done");
socket.destroy();
});
//发送数据
socket.write(indexRequest);
});
}
复制代码运行这段代码可以看到 HTTP/1.1 请求头,以及页面数据。这是学习 web 协议很好的一个工具,我们还可以看到设 cookie 等值。(一般不用这种方式连接 HTTP 服务器,Dart 中提供了 HttpClient 类,提供更多能力)
➜ socket_study dart socket_pratice2.dart
socket_pratice2.dart: Warning: Interpreting this as package URI, 'package:io_pratice/socket_study/socket_pratice2.dart'.
Connected to: 220.181.38.150:80
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Content-Length: 14615
Content-Type: text/html
...
...
(headers and HTML code)
...
</script></body></html>
Done
复制代码2、ServerSocket
使用 Socket 可以很容易的与服务器连接,同样我们可以使用 ServerSocket 对象创建一个可以处理客户端请求的服务器。 首先我们需要绑定到一个特定的端口并进行监听,使用 ServerSocket.bind(address,int port) 方法即可。这个方法会返回 Future<ServerSocket> 对象,在绑定成功后返回 ServerSocket 对象。之后 ServerSocket.listen(void onData(Socket event)) 方法注册回调,便可以得到客户端连接的 Socket 对象。注意,端口号需要大于 1024 (保留范围)。
// serversocket_pratice1.dart
void main() {
ServerSocket.bind(InternetAddress.anyIPv4, 4567)
.then((ServerSocket server) {
server.listen(handleClient);
});
}
void handleClient(Socket client) {
print('Connection from '
'${client.remoteAddress.address}:${client.remotePort}');
client.write("Hello from simple server!\n");
client.close();
}
复制代码与客户端不同的是,在 ServerSocket.listen 中我们监听的不是二进制数据,而是客户端连接。 当客户端发起连接时,我们可以得到一个表示客户端连接的 Socket 对象。作为参数调用 handleClient(Socket client) 函数。通过这个 Socket 对象,我们可以获取到客户端的 IP 端口等信息,并且可以与其通信。运行这个程序后,我们需要一个客户端连接服务器。可以将上一个案例中 conect 的地址改为 127.0.0.0.1,端口改为 4567,或者使用 telnet 作为客户端发起。
运行服务端程序:
➜ socket_study dart serversocket_pratice1.dart
serversocket_pratice1.dart: Warning: Interpreting this as package URI, 'package:io_pratice/socket_study/serversocket_pratice1.dart'.
Connection from 127.0.0.1:54555 // 客户端连接之后打印其 ip 与端口
复制代码客户端使用 telnet 请求:
➜ io_pratice telnet localhost 4567
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Hello from simple server! // 来自服务端的消息
Connection closed by foreign host.
复制代码即使客户端关闭连接,服务器程序仍然不会退出,继续等待下一个连接,Dart 已经为我们处理好了一切。
实战:本地群聊服务
1、聊天服务器
有了上面的实践,我们可以尝试编写一个简单的群聊服务。当某个客户端发送消息时,其他所有连接的客户端都可以收到这条消息,并且能优雅的处理错误和断开连接。
如图,我们的三个客户端与服务器保持连接,当其中一个发送消息时,由服务端将消息分发给其他连接者。 所以我们创建一个集合来存储每一个客户端连接对象
List<ChatClient> clients = [];
复制代码每一个 ChatClient 表示一个连接,我们通过对 Socket 进行简单的封装,提供基本的消息监听,退出与异常处理:
class ChatClient {
Socket _socket;
String _address;
int _port;
ChatClient(Socket s){
_socket = s;
_address = _socket.remoteAddress.address;
_port = _socket.remotePort;
_socket.listen(messageHandler,
onError: errorHandler,
onDone: finishedHandler);
}
void messageHandler(List data){
String message = new String.fromCharCodes(data).trim();
// 接收到客户端的套接字之后进行消息分发
distributeMessage(this, '${_address}:${_port} Message: $message');
}
void errorHandler(error){
print('${_address}:${_port} Error: $error');
// 从保存过的 Client 中移除
removeClient(this);
_socket.close();
}
void finishedHandler() {
print('${_address}:${_port} Disconnected');
removeClient(this);
_socket.close();
}
void write(String message){
_socket.write(message);
}
}
复制代码当服务端接受到某个客户端发送的消息时,需要转发给聊天室的其他客户端。
我们通过 messageHandler 中的 distributeMessage 进行消息分发:
...
void distributeMessage(ChatClient client, String message){
for (ChatClient c in clients) {
if (c != client){
c.write(message + "\n");
}
}
}
...
复制代码最后我们只需要监听每一个客户端的连接,将其添加至 clients 集合中即可:
// chatroom.dart
ServerSocket server;
void main() {
ServerSocket.bind(InternetAddress.ANY_IP_V4, 4567)
.then((ServerSocket socket) {
server = socket;
server.listen((client) {
handleConnection(client);
});
});
}
void handleConnection(Socket client){
print('Connection from '
'${client.remoteAddress.address}:${client.remotePort}');
clients.add(new ChatClient(client));
client.write("Welcome to dart-chat! "
"There are ${clients.length - 1} other clients\n");
}
复制代码直接运行程序
➜ dart chatroom.dart
复制代码使用 telnet 测试服务器连接:
➜ socket_study telnet localhost 4567
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
Welcome to dart-chat! There are 0 other clients
复制代码2、聊天客户端
聊天客户端会简单很多,他只需要连接到服务器并接受消息;以及读取用户的输入信息并将其发送至客户端的方法。
前面我们已经实践过如何从服务器接收数据,所以我们只需实现发送消息即可。
通过 dart:io 中的 stdin 能帮助我们轻松的读取键盘输入:
// chatclient.dart
Socket socket;
void main() {
Socket.connect("localhost", 4567)
.then((Socket sock) {
socket = sock;
socket.listen(dataHandler,
onError: errorHandler,
onDone: doneHandler,
cancelOnError: false);
})
.catchError((AsyncError e) {
print("Unable to connect: $e");
exit(1);
});
// 监听键盘输入,将数据发送至服务端
stdin.listen((data) =>
socket.write(
new String.fromCharCodes(data).trim() + '\n'));
}
void dataHandler(data){
print(new String.fromCharCodes(data).trim());
}
void errorHandler(error, StackTrace trace){
print(error);
}
void doneHandler(){
socket.destroy();
exit(0);
}
复制代码之后运行服务器,并通过多个命令行运行多个客户端程序。你可以在某个客户端中输入消息,之后在其他客户端接收到消息。
如果你有多个设备,也可以通过 Socket.connect(host, int port) 与服务器进行连接,当然这需要你提供每个设备的 IP 地址,这该如何做到?下一期我会通过 UDP 与组播协议进一步完善群聊服务。