








优雅的数据统计图表
前言
一直想花时间复刻学习一下Apple产品的原生UI和动画,超级丝滑。
今天,目标是健康的心率数据统计图表。
健康及Android实现效果预览
- Apple健康的图表交互效果:
丝滑,有数据条滑动、滑动查看数据标注两种模式;数据标注位置自适应;两端超出边界会有自动回滚的效果。
- 本文用Android复刻的图表交互效果:
暂时着眼于核心的实现思路,细节有长足的优化空间(如自动回滚的运动曲线、快速滑动、刻度线变化等,但他们对于Demo来说不是重点)😥。
1. 页面内容分析
在开始前,我们不妨先仔细观察一下这个页面所涵盖的信息,再将其转换为我们的业务需求,提前整理好思路再开始上手写。
1.1 图表静态布局
我们把图表打散,它本质上由以下三个组件构成:
- 数据条
- 单个数据条:表示单元时间内的心率分布情况,这里我们将它简化为单元时间内的心率变化范围(最小~最大)
- 数据存储:每个数据条需要涵盖的信息有三点:时间、最小值、最大值,我们使用一个ArrayList将他们放在一起,对于那些空缺的数据,我们可以根据时间来填充数值(设为0),以此实现在图表上的留白。
- 坐标轴 Axis
- 横向:横向坐标轴、背景线及其刻度(0,50,100)几乎是静态的,只有刻度会变化,这里我们暂时忽略这一点。
- 纵向:纵向背景线按照特定的间隔分布,滑动过程中也会跟着变化,与数据条是相对静止的。因此,我们尝试把他们和数据条捆绑在一起来实现。
- 数据标注 IndicatorLabel
- 默认形态:它固定在左上角,取当前可见数据的时间范围、心率变化范围进行展示
- 指示形态:当用户长触摸/点击图表数据条时,它就会展现在其上方;在左右边界会有位置的自适应调整。
- 默认形态和指示形态是非此即彼的,我们可以设置一个boolean值,isShowIndicator来控制他们,true的时候展示指示形态,false就为默认形态,以此简化我们的后续处理逻辑。
1.2 图表动态效果
图表滑动与边界效果
- 滑动变化:图表左右滑动来调整,滑动过程中,上方的 默认形态数据标注的值会发生变化,纵向背景线、刻度值会跟着移动;
- 自动回滚:
- 每次滑动结束后,都会有一个轻微的自动回滚,来保证窗口内呈现的完整的24个数据条。
- 在滑动窗口超出两侧边界后,会进行自动回滚,回到原来的边界。
触摸/点击产生的数据标注
- 用户点击/触摸会触发 指示形态的数据标注,进入此状态后,手指按住屏幕左右滑动可以实现滑动数据标注的效果
- 在进入上述状态后,如果手指快速滑动,则可以恢复标注的默认形态并滑动图表。
2. 页面实现
在使用自定义View实现页面前,结合上述对布局的分析,思考一下我们的工作流程:
- 画一个图表的框架草图,标注出重要的尺寸,确保这些尺寸能够让我们计算出每一个点的坐标;
- 准备一个数据类来容纳每个时间点的数据,用ArrayList打包起来,作为我们的数据源;
- 横向背景线、y轴刻度都是全程静态的,优先绘制它;
- 将纵向背景线、x轴刻度与数据条绑定起来绘制;结合ArrayList中每一个item的索引来计算坐标、使用item的数值计算数据条的y轴位置;
- 实现数据标注的绘制函数,它可以通过指定一个item的索引来展示出对应点的具体信息;
- 通过重写onTouchEvent来实现点击/触摸触发数据标注的效果,实现图表的滑动效果。
脑子里粗略思考一遍每一步的可能难度,发现我们主要面临三个难题😥:
- 使用怎样的布局可以让我们轻松地通过item的索引来计算坐标?
- 该怎么用最简洁优雅的方式让我们的数据条动起来?
- 同样是滑动,有时候用户需要数据条左右滑动,有时候却需要数据条不动,数据标注动,这该怎么区分呢?
为保证阅读体验,实现部分不会列出所有代码并阐述所有细节,代码可以在最下方Ctrl C+V获取。
2.1 图表的基础结构
我们按照拟定的工作流程一步步来:
2.1.1画一个图表的框架草图。
提前拆解思考过图表以后,我们可以快速画出以下结构图:
对于数据条宽度(lineWidth),及数据条间隙宽度(lineSpace)的选取,假设我们最大可视数据条为n个,为了实现规整的页面,需要保证以下等式成立:
其中chartWidth我们在上方结构图中标出的——存放数据条的chart的宽度;
这么做的原因很简单:假设现在n为24,那么这个chart的宽度就是 24* lineWidth +23* lineSpace + 最左侧空白宽度 + 最右侧空白宽度;如上等式保证了左右侧空白宽度都为 0.5 * lineSpace。
2.1.2 准备一个数据类
目前的需求是,存放时间,一个最小值一个最大值,所以创建一个简单的DataClass即可。
data class HeartRateChartEntry(
val time: Date = Date(), val minValue:Int = 66, val maxValue:Int = 88
)
复制代码然后我们创建一些随机数据,用ArrayList存储。
2.1.3 绘制横向背景线、y轴刻度
他们是静态的,直接用绘制出来的结构图计算chart、文本的起讫点坐标直接画就好。
- startX = (getWidth() - chartWidth)/2。当然,你也可以自己定义chart的起点,我建议这个起点的x坐标与lineWidth+lineSpace成正比
- endX = startX + chartWidth
- endY = startY = totalHeight - bottomTextHeight
我们要绘制k条线,就首先计算线之间的距离unitDistance = chartHeight/(k-1),每次绘制让unitDistance*i - startY就可以获取到当前横线的纵坐标了。
(0..mHorizontalLineSliceAmount).forEach{ i ->
//获取当前要写上去的刻度
currentLabel = .....
//计算当前Y
currentY = startY - i * mVerticalUnitDistance
//画线
canvas.drawLine(startX, currentY, endX, currentY, mAxisPaint)
//画text
canvas?.drawText("${currentLabel}", endX + mTextSize/3, currentY+mTextSize/3, mTextLabePaint)
//再画上最左侧的边界线
canvas.drawLine(startX, startY, startX, startY-mChartHeight, mAxisPaint)
}2.1.4绘制数据条与纵向背景线
好,遇到了我们预料的难题,用什么方式绘制数据条,可以让他符合我们的滑动需求呢?
被否定的方案:
假设我们通过onTouchEvent计算手指滑动的距离,用滑动的距离来计算我们需要绘制的数据索引;但这种方式虽然符合我们静态页面的需求,但没法实现顺畅的动画效果,滑动过程中只会不停地闪烁。
究其原因是他实际上没有改变数据条绘制时的横坐标,我们再去根据onTouchEvent的滑动距离来微调他们吗?但这仍然无法避免边缘数据条的闪烁。
更好的方案:窗口
想象我们正对着坐在窗口前,我们把这个窗口假设为一个viewPort,在这个窗口,我们能够看到横向切换的风景,是因为窗口和背景之间的相对移动。
如果我们将其设想为我们的chart和数据条,可不可以把chart理解为窗口,数据条是浮在其表面的风景,然后我们只需要移动数据条,就可以切换风景(数据条滑动的视觉效果),这可以保证不会出现割裂感,毕竟所有东西都已经绘制了,只是位置调整了。
想法看来可以一试,上手前,我们还是先画图理一下思路。
- 我们需要从右往左绘制数据条以展现时间格式
- 初始起点不如设定为chart的最右端
- 如果要向右滑动,是不是把绘图的起始点往右边移就可以了?
看来这个思路没错,我们用viewStartX作为起始点,从右向左画数据条(for循环配合数据下标计算x轴坐标),然后去onTouchEvent的ActionMove里计算滑动的距离,动态调整viewStartX就搞定了。
不过有一点要想一想,如果我们每次都滑动都重新绘制了所有的数据条,如果数据量一大,必定会造成性能问题呀!
不过他很好解决,我们只需要计算当前窗口展示的最左和最右的数据条索引,分别为leftRangeIndex, rightRangeIndex,我们在遍历画数据条的过程中设置为只执行(leftRangeIndex-3, rightRangeIndex+3)范围即可,这就实现了每次只画窗口内+窗口边缘的数据条了。
最后,我们需要在绘制完数据条以后,截取一个窗口下来,放回到我们的chart里,我们可以通过canvas.saveLayer()和canvas.restoreToCount()配对使用来实现。
以下是绘制数据条的核心代码,看个思路就好
- 用saveLayer()来确定一个窗口范围
val windowLayer = canvas?.saveLayer(
left = chartLeftMargin, //chart左边界的x坐标
top = 0F,
right = chartRightBorner, //chart右边界的x坐标
bottom = widthBottom //chart下边界的y坐标
)- 遍历我们存储数据的ArrayList,使用viewStartX和索引来计算每个数据条的横坐标,绘制出来
(0 until mValueArray.size).forEach { it ->
//如果不在我们预期的绘制范围内,那就溜溜球,不画了
if (it > drawRangeRight || it < drawRangeLeft) {
return@forEach
}
//计算坐标x,数据条的y轴起讫点
currentX = mViewStartX - (it) * (mLineWidth + mLineSpace) - chartRightMargin
startY = baseY - mChartHeight / mYAxisRange.second * mValueArray[it].maxValue
endY = baseY - mChartHeight / mYAxisRange.second * mValueArray[it].minValue
if (mValueArray[it].maxValue != 0) {
canvas?.drawLine(currentX, startY, currentX, endY, mLinePaint)
}
在我们既定的特定时间点,绘制纵向背景线和刻度(代码略了,完整版在最下方)
最后,把这个窗口再存储到我们的view里去就完成了
cavas?.restoreToCount(windowLayer!!)2.1.5 数据标注的绘制函数
前文有提到,我们的图表一共有两种数据标注的形式,一是默认形态,二是指示形态,他们是非此即彼的,我们只需要设置一个boolean变量,isShowIndicator,然后在onTouchEvent中动态设置这个变量,就可以实现他们的切换了。
同时,我们在onTouchEvent中维护一个变量indexOnClicked,它用来表示当前被点击的那个数据条的索引,并绘制指示形态的数据标注。
这里的绘制流程不赘述了。
2.2 图表的触摸事件
还是一样,理清思路再上手写代码。
我们希望:
图表能够判定用户的长触摸、快速滑动行为
- 我们的图表需要能够判断以下两个状态值
- 正在数据条滑动状态—isScrolling:表示用户通过快速的手指滑动 来切换 数据条(也就是改变viewStartX的坐标)
- 正在长触摸状态-isLongTouch: 用户的手指一直停留在我们的屏幕上,这是因为他想要查看数据标注,这个状态下的切换不会切换数据条,而是切换数据标注的下标。
- 我们的图表需要能够判断以下两个状态值
图表能够计算每次滑动的距离,动态调整viewStartX与要绘制的数组左右边界
onTouchEvent事件链
为了实现以上需求,我们需要研究一下onTouchEvent(event: MotionEvent?)
对于触摸事件,我们处理以下回调:
- ACTION_DOWN
- 手指按下:无论是点击还是滑动,ACTION_DOWN都是他们的初始动作
- ACTION_MOVE
- 手指滑动:在ACTION_DOWN触发后,如果手指滑动,MOVE就会被触发若干次,以表示手指在图表上的滑动
- ACTION_UP
- 手指抬起:一定是点击事件的结束步,可能是滑动事件的结束步(也可能是ACTION_CANCEL)
- ACTION_CANCEL
- 手势放弃:可能是滑动事件的结束步(也可能是ACTION_UP)
我们先处理该怎么让图表判断是快速滑动:
- 我们维护一个当前时间currentTime
- 每次ACTION_DOWN手指按下的时候,我们就记录那一时刻的时间;
- 在遇到ACTION_MOVE的时候,我们就首先获取当前时间,减去记录的currentTime来获取时间间隔
- 如果这个间隔小于某个时间阈值TIMEDURATION,我们把它认定为是一次快速滑动
- 但是,我们添加限制条件,这一次move的距离必须大于某个阈值,否则视为一次轻微move(手滑产生的,不是用户的内心想法)
- 对于后续的滑动事件来说(上图中的n号ACTION_MOVE),他们时间可能已经超过了阈值,但他们也需要执行这个滑动任务;还记得我们提到的状态变量isScrolling吗,我们在1号ACTION_MOVE中将isScrolling设置为true,后续的n号滑动事件中,只要发现当前是isScrolling==true 是正在滑动状态,它就可以大胆开始执行滑动事件了。
据上,我们有了以下代码:
override fun onTouchEvent(event:MotionEvent?):Boolean{
//获取当前触摸点的横坐标
mCurrentX = event!!.x
when (event.action) {
MotionEvent.ACTION_DOWN -> {
//记录一下触摸的点,用来记录滑动距离
mLastX = mCurrentX
//记录现在的时间,用来判断快速滑动
currentMS = System.currentTimeMillis()
}
MotionEvent.ACTION_MOVE -> {
//获得滑动的距离
mMoveX = mLastX - mCurrentX
//记录一下触摸的点
mLastX = mCurrentX
//如果 move time <Xms and moveX > Xpx, 这是快速滑动
if (((System.currentTimeMillis() - currentMS) < TOUCHMOVEDURATION && (abs(mMoveX) > mLineWidth)) || isScrolling) {
isScrolling = true
//更新viewStartX,实现数据条切换,记得给mViewStartX的setter加invalidate()
mViewStartX -= mMoveX
//更新左右边界
updateCurrentDrawRange()
}
}
}接着,我们来处理该怎么让图表判断是长触摸-isLongTouch:
- 怎样的事件流是长触摸呢?
- 长触摸,就是用户的手放上去以后,没有抬起,只有轻微滑动
- 我们将这个阈值设置为判断快速滑动的时间阈值为TIMEDURATION
- 如果我们在执行ACTION_DOWN后,TIMEDURATION时间内,除了轻微滑动外,没有任何其他ACTION事件触发,那就认定为是长触摸
- 用代码来实现:
- 我们在每次ACTION_DOWN后,都开启一个子线程,在TIMEDURATION后,如果他没有被取消运行,那就将isLongTouch设置为true
- 这样我们就开启了长触摸模式,可以在ACTION_MOVE中增加判断,配合isLongTouch来展示我们的数据标注切换。
- 同样,我们在ACTION_UP和 ACTION_MOVE显著移动的事件中,取消这个子线程。
这里,我用kotlin协程来实现的这个判断长触摸的子线程
开启协程的函数:
fun startIndicatorTimer() {
showIndicatorJob = mScope.launch(Dispatchers.Default) {
//用了hasTimer来辅助外面判断有没有子线程在运行
hasTimer = true
//延时任务进行
delay(TOUCHMOVEDURATION + 10.toLong())
withContext(Dispatchers.Main) {
//长触摸了,那正在滑动状态就必须是false啦
isScrolling = false
//长触摸:轮到我了
isLongTouch = true
//找到当前被触摸的数据条索引
setCurrentIndexOnClicked()
//展示指示形态的数据标签
isShowIndicator = true
//子线程运行完毕,把标记设置为false
hasTimer = false
}
}
}关闭协程的函数:
fun turnOffIndicatorTimer() {
if (hasTimer) {
showIndicatorJob.cancel()
hasTimer = false
}
}触摸事件里的核心代码
//节选
when(event.action){
MotionEvent.ACTION_DOWN->{
//记录坐标,记录时间
mLastX = mCurrentX
currentMS = System.currentTimeMillis()
//开始子线程的任务
startIndicatorTimer()
}
MotionEvent.ACTION_MOVE->{
mMoveX = mLastX - mCurrentX
mLastX = mCurrentX
if(是快速滑动){
//关闭这个长触摸判断线程
turnOffIndicatorTimer()
}
//是长触摸状态,那我们激活isShowIndicator
else if(isLongTouch){
isShowIndicator = true
}
else if(不是轻微滑动){
//关闭长触摸判断事件
turnOffIndicatorTimer()
}
}
}自动回滚
- 我们需要每次滑动结束后去判断,让窗口内呈现完成的N个数据条
- 基于我们的结构,这很容易实现,只需要让我们的viewStartX(绘画初始点)的坐标变为(lineWidth+lineSpace)的整数即可
mViewStartX - (mViewStartX - mInitialStartX).mod(mLineSpace+mLineWidth)
- 我们要在滑动超出边界后,让窗口自动回滚到边界值
- 这同样同意实现,我们通过viewStartX来判断是否出界,然后让viewStartX回到设定的边界值就好了
但我们不能采用直接给viewStartX赋值的方法,而是通过ObjectAnimator来实现顺滑的切换,我们将这个逻辑写在方法drawBackToBorder()中,并把它添加到ACTION_CANCEL和ACTION_UP的回调中,因为只有他们俩可能是触摸事件流的结尾。
别放了给viewStartX的Setter方法添加invalidate(),否则动画不会触发。😈
fun drawBackToBorder(){
var endValue:Float = 0F
endValue =
//out of right borderline
if(mViewStartX < mInitialStartX){
mInitialStartX
//out of left borderline
} else if(mViewStartX > mInitialStartX + (mValueArray.size-24)*(mLineWidth+mLineSpace)){
mInitialStartX + (mValueArray.size-24)*(mLineWidth+mLineSpace)
//does not reach the bound, need reposition to exact place.
} else {
mViewStartX - (mViewStartX - mInitialStartX).mod(mLineSpace+mLineWidth)
}
val anim = ObjectAnimator.ofFloat(mViewStartX, endValue)
anim.interpolator = DecelerateInterpolator()
anim.addUpdateListener {
mViewStartX = it.animatedValue as Float
}
anim.start()
}写在最后
写博客核心是希望能复盘的同时锻炼自己讲清楚思路的能力,相比于贴代码,画图+文字阐述是更我喜欢的做的事。
感谢看到这里,如果有任何疑问,欢迎留言和我交流。😋
3. 附-代码
代码涵盖两个文件:
- HeartRateEntry.kt 数据类
- IsenseChart.kt 自定义view文件,没有添加外部参数StyleValue
YunmaoLeo/AppleHealthChart (github.com)
链接:https://juejin.cn/post/7077960004745199646
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android自定义View的交互,往往都是从星星开始
前言
在前面的学习中,我们基本了解了一些 Canvas 的绘制,那么这一章我们一起复习一下图片的绘制几种方式,和事件的简单交互方式。
我们从易到难,作为基础的进阶控件,我们从最简单的交互开始,那就自定义一个星星评分的控件吧。
一个 App 必不可少的评论系统打分的控件,可以展示评分,可以点击评分,可以滑动评分。它的实现总体上可以分为以下的步骤:
- 强制测量大小为我们指定的大小
- 先绘制Drawable未评分的图片
- 在绘制Bitmap已评分的图片
- 在onTouch中点击和移动的事件中动态计算当前的评分,进而刷新布局
- 回调的处理与属性的抽取
思路我们已经有了,下面一步一步的来实现吧。
话不多说,Let's go
1、测量与图片的绘制
我们需要绘制几个星星,那么我们必须要设置的几个属性:
当前的评分值,总共有几个星星,每一个星星的间距和大小,选中和未选中的Drawable图片:
private int mStarDistance = 0;
private int mStarCount = 5;
private int mStarSize = 20; //每一个星星的宽度和高度是一致的
private float mScoreNum = 0.0F; //当前的评分值
private Drawable mStarScoredDrawable; //已经评分的星星图片
private Drawable mStarUnscoredDrawable; //还未评分的星星图片
private void init(Context context, AttributeSet attrs) {
mScoreNum = 2.1f;
mStarSize = context.getResources().getDimensionPixelSize(R.dimen.d_20dp);
mStarDistance = context.getResources().getDimensionPixelSize(R.dimen.d_5dp);
mStarScoredDrawable = context.getResources().getDrawable(R.drawable.iv_normal_star_yellow);
mStarUnscoredDrawable = context.getResources().getDrawable(R.drawable.iv_normal_star_gray);
}
测量布局的时候,我们就不能根据xml设置的 match_parent 或 wrap_content 来设置宽高,我们需要根据星星的大小与间距来动态的计算,所以不管xml中如何设置,我们都强制性的使用我们自己的测量。
星星的数量 * 星星的宽度再加上中间的间距 * 数量-1,就是我们的控件宽度,控件高度则是星星的高度。
具体的确定测量我们再上一篇已经详细的复习过了,这里直接贴代码:
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
setMeasuredDimension(mStarSize * mStarCount + mStarDistance * (mStarCount - 1), mStarSize);
}这样就可以得到对应的测量宽高 (加一个背景方便看效果):
如何绘制星星?直接绘制Drawable即可,默认的Drawable的绘制为:
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
for (int i = 0; i < mStarCount; i++) {
mStarUnscoredDrawable.setBounds((mStarDistance + mStarSize) * i, 0, (mStarDistance + mStarSize) * i + mStarSize, mStarSize);
mStarUnscoredDrawable.draw(canvas);
}
}如果有5个星星图片,那么就为每一个星星定好位置:
那么已经选中的图片也需要使用这种方法绘制吗?
计算当前的评分,然后计算计算需要绘制多少星星,那么就是这样做:
int score = (int) Math.ceil(mScoreNum);
for (int i = 0; i < score; i++) {
mStarScoredDrawable.setBounds((mStarDistance + mStarSize) * i, 0, (mStarDistance + mStarSize) * i + mStarSize, mStarSize);
mStarScoredDrawable.draw(canvas);
}可是这么做不符合我们的要求啊 ,我们是需要是可以显示评分为2.5之类值,那么我们怎么能绘制半颗星呢?Drawable.draw(canvas) 的方式满足不了,那我们可以使用 BitmapShader 的方式来绘制。
初始化一个 BitmapShader 设置给 Paint 画笔,通过画笔就可以画出对应的形状。
比如此时的场景,我们如果想只画0.5个星星,那么我们就可以
paint = new Paint();
paint.setAntiAlias(true);
paint.setShader(new BitmapShader(drawableToBitmap(mStarScoredDrawable), BitmapShader.TileMode.CLAMP, BitmapShader.TileMode.CLAMP));
@Override
protected void onDraw(Canvas canvas) {
for (int i = 0; i < mStarCount; i++) {
mStarUnscoredDrawable.setBounds((mStarDistance + mStarSize) * i, 0, (mStarDistance + mStarSize) * i + mStarSize, mStarSize);
mStarUnscoredDrawable.draw(canvas);
}
canvas.drawRect(0, 0, mStarSize * mScoreNum, mStarSize, paint);
}那么如果是大于一个星星之后的小数点就可以用公式计算
if (mScoreNum > 1) {
canvas.drawRect(0, 0, mStarSize, mStarSize, paint);
if (mScoreNum - (int) (mScoreNum) == 0) {
//如果评分是3.0之类的整数,那么直接按正常的rect绘制
for (int i = 1; i < mScoreNum; i++) {
canvas.translate(mStarDistance + mStarSize, 0);
canvas.drawRect(0, 0, mStarSize, mStarSize, paint);
}
} else {
//如果是小数例如3.5,先绘制之前的3个,再绘制后面的0.5
for (int i = 1; i < mScoreNum - 1; i++) {
canvas.translate(mStarDistance + mStarSize, 0);
canvas.drawRect(0, 0, mStarSize, mStarSize, paint);
}
canvas.translate(mStarDistance + mStarSize, 0);
canvas.drawRect(0, 0, mStarSize * (Math.round((mScoreNum - (int) (mScoreNum)) * 10) * 1.0f / 10), mStarSize, paint);
}
} else {
canvas.drawRect(0, 0, mStarSize * mScoreNum, mStarSize, paint);
}效果:
关于 BitmapShader 的其他用法,可以翻看我之前的自定义圆角圆形View,和自定义圆角容器的文章,里面都有用到过,主要是方便一些图片的裁剪和缩放等。
2、事件的交互与计算
这里并没有涉及到什么事件嵌套,拦截之类的复杂处理,只需要处理自身的 onTouch 即可。而我们需要处理的就是按下的时候和移动的时候评分值的变化。
在onDraw方法中,我们使用 mScoreNum 变量来绘制的已评分的 Bitmap 绘制。所以这里我们只需要在 onTouch 中计算出对应的 mScoreNum 值,让其重绘即可。
@Override
public boolean onTouchEvent(MotionEvent event) {
//x轴的宽度做一下最大最小的限制
int x = (int) event.getX();
if (x < 0) {
x = 0;
}
if (x > mMeasuredWidth) {
x = mMeasuredWidth;
}
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
case MotionEvent.ACTION_MOVE: {
mScoreNum = x * 1.0f / (mMeasuredWidth * 1.0f / mStarCount);
invalidate();
break;
}
case MotionEvent.ACTION_UP: {
break;
}
}
return super.onTouchEvent(event);
}计算出一颗星的长度,然后计算当前x轴的长度,就可以计算出当前有几颗星,我们默认处理的是 float 类型。就可以根据计算出的 mScoreNum 值来得到对应的动画效果:
3. 回调处理与自定义属性抽取
到此效果的实现算是结束了,但是我们还有一些收尾工作没做,如何监听进度的回调,如何控制整数与浮点数的显示,是否支持触摸等等。然后对其做一些自定义属性的抽取,就可以在应用中比较广泛的使用了。
自定义属性:
private int mStarDistance = 5;
private int mStarCount = 5;
private int mStarSize = 20; //每一个星星的宽度和高度是一致的
private float mScoreNum = 0.0F; //当前的评分值
private Drawable mStarScoredDrawable; //已经评分的星星图片
private Drawable mStarUnscoredDrawable; //还未评分的星星图片
private boolean isOnlyIntegerScore = false; //默认显示小数类型
private boolean isCanTouch = true; //默认支持控件的点击
private OnStarChangeListener onStarChangeListener;自定义属性的赋值与初始化操作:
private void init(Context context, AttributeSet attrs) {
setClickable(true);
TypedArray mTypedArray = context.obtainStyledAttributes(attrs, R.styleable.StarScoreView);
this.mStarDistance = mTypedArray.getDimensionPixelSize(R.styleable.StarScoreView_starDistance, 0);
this.mStarSize = mTypedArray.getDimensionPixelSize(R.styleable.StarScoreView_starSize, 20);
this.mStarCount = mTypedArray.getInteger(R.styleable.StarScoreView_starCount, 5);
this.mStarUnscoredDrawable = mTypedArray.getDrawable(R.styleable.StarScoreView_starUnscoredDrawable);
this.mStarScoredDrawable = mTypedArray.getDrawable(R.styleable.StarScoreView_starScoredDrawable);
this.isOnlyIntegerScore = mTypedArray.getBoolean(R.styleable.StarScoreView_starIsTouchEnable, true);
this.isOnlyIntegerScore = mTypedArray.getBoolean(R.styleable.StarScoreView_starIsOnlyIntegerScore, false);
mTypedArray.recycle();
paint = new Paint();
paint.setAntiAlias(true);
paint.setShader(new BitmapShader(drawableToBitmap(mStarScoredDrawable), BitmapShader.TileMode.CLAMP, BitmapShader.TileMode.CLAMP));
}自定义属性的定义xml文件:
<!-- 评分星星控件 -->
<declare-styleable name="StarScoreView">
<!--星星间距-->
<attr name="starDistance" format="dimension" />
<!--星星大小-->
<attr name="starSize" format="dimension" />
<!--星星个数-->
<attr name="starCount" format="integer" />
<!--星星已评分图片-->
<attr name="starScoredDrawable" format="reference" />
<!--星星未评分图片-->
<attr name="starUnscoredDrawable" format="reference" />
<!--是否可以点击-->
<attr name="starIsTouchEnable" format="boolean" />
<!--是否显示整数-->
<attr name="starIsOnlyIntegerScore" format="boolean" />
</declare-styleable>在OnTouch的时候就可以判断是否能触摸
@Override
public boolean onTouchEvent(MotionEvent event) {
if (isCanTouch) {
//x轴的宽度做一下最大最小的限制
int x = (int) event.getX();
if (x < 0) {
x = 0;
}
if (x > mMeasuredWidth) {
x = mMeasuredWidth;
}
switch (event.getAction()) {
case MotionEvent.ACTION_DOWN:
case MotionEvent.ACTION_MOVE: {
setStarMark(x * 1.0f / (getMeasuredWidth() * 1.0f / mStarCount));
break;
}
case MotionEvent.ACTION_UP: {
break;
}
}
return super.onTouchEvent(event);
} else {
//如果设置不能点击,直接不触发事件
return false;
}
}而 setStarMark 则是设置入口的方法,内部判断是否支持小数点和设置对于的监听,并调用重绘。
public void setStarMark(float mark) {
if (isOnlyIntegerScore) {
mScoreNum = (int) Math.ceil(mark);
} else {
mScoreNum = Math.round(mark * 10) * 1.0f / 10;
}
if (this.onStarChangeListener != null) {
this.onStarChangeListener.onStarChange(mScoreNum); //调用监听接口
}
invalidate();
}一个简单的图片绘制和事件触摸的控件就完成啦,使用起来也是超级方便。
<com.guadou.kt_demo.demo.demo18_customview.star.StarScoreView
android:id="@+id/star_view"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center_horizontal"
android:layout_marginTop="@dimen/d_40dp"
android:background="#f1f1f1"
app:starCount="5"
app:starDistance="@dimen/d_5dp"
app:starIsOnlyIntegerScore="false"
app:starIsTouchEnable="true"
app:starScoredDrawable="@drawable/iv_normal_star_yellow"
app:starSize="@dimen/d_35dp"
app:starUnscoredDrawable="@drawable/iv_normal_star_gray" />Activity中可以设置评分和设置监听:
override fun init() {
val starView = findViewById<StarScoreView>(R.id.star_view)
starView.setOnStarChangeListener {
YYLogUtils.w("当前选中的Star:$it")
}
findViewById<View>(R.id.set_progress).click {
starView.setStarMark(3.5f)
}
}效果:
后记
整个流程走下来是不是很简单呢,此控件不止用于星星类型的评分,任何图片资源都可以使用,现在我们思路打开扩展一下,相似的场景和效果我们可以实现一些图片进度,触摸进度条,圆环的SeekBar,等等类似的控制都是相似的思路。
这一期的比较简单,我并没有上传到 Maven ,如果有需求可以去我的项目里面拿,如果有需求的话也可以自行修改,如果大家有兴趣可以查看源码点击【传送门】。你也可以关注我的这个Kotlin项目,我有时间都会持续更新。
关于事件交互的自定义View后面有时间会再出稍微复杂一点的,帮助大家巩固与复习。我心里的路线是先学绘制再学交互(因为交互的基础就是绘制),然后再学ViewGroup的嵌套、拦截、分发、排版等等,从易到难争取让大家复习个通透,当然如果有人看的话,我会继续更新。
惯例,我如有讲解不到位或错漏的地方,希望同学们可以指出交流。
如果感觉本文对你有一点点的启发,还望你能点赞支持一下,你的支持是我最大的动力。
Ok,这一期就此完结。
链接:https://juejin.cn/post/7167256092051767326
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ConstraintLayout解决的一种布局问题
期望实现的效果
这个效果看上去很简单,但是等到要实现的时候,发现用常规的布局在左侧文字较长的时候,右侧文字标签的控件会控件被左侧文字挤压导致标签控件显示不了(LinearLayout、RelativeLayout都存在一样的问题)
(修改:评论给出了一种用LinearLayout实现的一种方式更便捷,那么这篇文章就当做提供另外一种方案吧- -)
使用ConstraintLayout就能解决这个问题,先贴个代码:
<androidx.constraintlayout.widget.ConstraintLayout
android:layout_width="match_parent"
android:layout_height="wrap_content">
<TextView
android:layout_width="0dp"
android:layout_height="wrap_content"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintRight_toLeftOf="@+id/tv2"
android:ellipsize="end"
android:maxLines="1"
android:id="@+id/tv1"
android:textSize="20dp"
app:layout_constraintHorizontal_chainStyle="packed"
app:layout_constraintHorizontal_bias="0"
app:layout_constraintWidth_default="wrap"
android:text="王小明"
/>
<TextView
app:layout_constraintBottom_toBottomOf="@+id/tv1"
app:layout_constraintRight_toRightOf="parent"
android:background="@drawable/co_border_blue"
app:layout_constraintLeft_toRightOf="@+id/tv1"
app:layout_constraintTop_toTopOf="@id/tv1"
android:id="@+id/tv2"
android:text="父亲"
android:paddingLeft="5dp"
android:paddingRight="5dp"
android:visibility="visible"
android:textSize="15dp"
android:textColor="#59baf5"
android:layout_width="wrap_content"
android:layout_height="wrap_content" />
</androidx.constraintlayout.widget.ConstraintLayout>
核心思路
第一步先把两个文本的对齐方式约束起来
左侧文本需要在右侧文本右侧,右侧文本需要在左侧文本左侧,右侧文本还需要和父布局右对齐
关键代码
<TextView
android:layout_width="0dp"
android:layout_height="wrap_content"
app:layout_constraintRight_toLeftOf="@+id/tv2"
android:id="@+id/tv1"
...
/>
这里tv1设置layout_width="0dp",即match_constraint,如果自适应则按照目前的约束方式两个文本整体会居中
<TextView
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintLeft_toRightOf="@+id/tv1"
android:id="@+id/tv2"
android:text="父亲"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
...
/>
这个时候的效果:
虽然第二种场景下满足了,但是第一种场景下是不符合期望的,这个时候需要考虑再进一步约束:
1)左侧文字需要做到自适应
2)左侧文字自适应后需要对齐到最左侧
3)自适应后左右侧文字需要连接在一起
所以进一步引入了【链条样式】
关键代码:
<TextView
android:id="@+id/tv1"
app:layout_constraintHorizontal_chainStyle="packed"
app:layout_constraintHorizontal_bias="0"
app:layout_constraintWidth_default="wrap"
android:text="王小明"
/>
app:layout_constraintHorizontal_chainStyle="packed" 使链条上的元素都打包到一起
app:layout_constraintHorizontal_bias="0" 使左侧控件最左侧对齐
app:layout_constraintWidth_default="wrap" 使左侧文字自适应大小并且不超过约束限制,默认是“spread”,会占用所有符合约束的控件
这样就完成了目标的效果
链接:https://juejin.cn/post/7041808829113171998
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我代码就加了一行log日志,结果引发了P1的线上事故
线上事故回顾
前段时间新增一个特别简单的功能,晚上上线前review代码时想到公司拼搏进取的价值观临时加一行log日志,觉得就一行简单的日志基本上没啥问题,结果刚上完线后一堆报警,赶紧回滚了代码,找到问题删除了添加日志的代码,重新上线完毕。
情景还原
定义了一个
CountryDTO
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
public Boolean isChinaName() {
return this.country.equals("中国");
}
}
定义测试类
FastJonTest
public class FastJonTest {
@Test
public void testSerialize() {
CountryDTO countryDTO = new CountryDTO();
String str = JSON.toJSONString(countryDTO);
System.out.println(str);
}
}运行时报空指针错误:
通过报错信息可以看出来是 序列化的过程中执行了 isChinaName()方法,这时候this.country变量为空, 那么问题来了:
- 序列化为什么会执行
isChinaName()呢? - 引申一下,序列化过程中会执行那些方法呢?
源码分析
通过debug观察调用链路的堆栈信息
调用链中的ASMSerializer_1_CountryDTO.write是FastJson使用asm技术动态生成了一个类ASMSerializer_1_CountryDTO,
asm技术其中一项使用场景就是通过到动态生成类用来代替
java反射,从而避免重复执行时的反射开销
JavaBeanSerizlier序列化原理
通过下图看出序列化的过程中,主要是调用JavaBeanSerializer类的write()方法。
而JavaBeanSerializer 主要是通过 getObjectWriter()方法获取,通过对getObjectWriter()执行过程的调试,找到比较关键的com.alibaba.fastjson.serializer.SerializeConfig#createJavaBeanSerializer方法,进而找到 com.alibaba.fastjson.util.TypeUtils#computeGetters
public static List<FieldInfo> computeGetters(Class<?> clazz, //
JSONType jsonType, //
Map<String,String> aliasMap, //
Map<String,Field> fieldCacheMap, //
boolean sorted, //
PropertyNamingStrategy propertyNamingStrategy //
){
//省略部分代码....
Method[] methods = clazz.getMethods();
for(Method method : methods){
//省略部分代码...
if(method.getReturnType().equals(Void.TYPE)){
continue;
}
if(method.getParameterTypes().length != 0){
continue;
}
//省略部分代码...
JSONField annotation = TypeUtils.getAnnotation(method, JSONField.class);
//省略部分代码...
if(annotation != null){
if(!annotation.serialize()){
continue;
}
if(annotation.name().length() != 0){
//省略部分代码...
}
}
if(methodName.startsWith("get")){
//省略部分代码...
}
if(methodName.startsWith("is")){
//省略部分代码...
}
}
}从代码中大致分为三种情况:
@JSONField(.serialize = false, name = "xxx")注解getXxx(): get开头的方法isXxx():is开头的方法
序列化流程图
示例代码
/**
* case1: @JSONField(serialize = false)
* case2: getXxx()返回值为void
* case3: isXxx()返回值不等于布尔类型
* case4: @JSONType(ignores = "xxx")
*/
@JSONType(ignores = "otherName")
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
public static void queryCountryList() {
System.out.println("queryCountryList()执行!!");
}
public Boolean isChinaName() {
System.out.println("isChinaName()执行!!");
return true;
}
public String getEnglishName() {
System.out.println("getEnglishName()执行!!");
return "lucy";
}
public String getOtherName() {
System.out.println("getOtherName()执行!!");
return "lucy";
}
/**
* case1: @JSONField(serialize = false)
*/
@JSONField(serialize = false)
public String getEnglishName2() {
System.out.println("getEnglishName2()执行!!");
return "lucy";
}
/**
* case2: getXxx()返回值为void
*/
public void getEnglishName3() {
System.out.println("getEnglishName3()执行!!");
}
/**
* case3: isXxx()返回值不等于布尔类型
*/
public String isChinaName2() {
System.out.println("isChinaName2()执行!!");
return "isChinaName2";
}
}运行结果为:
isChinaName()执行!!
getEnglishName()执行!!
{"chinaName":true,"englishName":"lucy"}代码规范
可以看出来序列化的规则还是很多的,比如有时需要关注返回值,有时需要关注参数个数,有时需要关注@JSONType注解,有时需要关注@JSONField注解;当一个事物的判别方式有多种的时候,由于团队人员掌握知识点的程度不一样,这个方差很容易导致代码问题,所以尽量有一种推荐方案。
这里推荐使用@JSONField(serialize = false)来显式的标注方法不参与序列化,下面是使用推荐方案后的代码,是不是一眼就能看出来哪些方法不需要参与序列化了。
public class CountryDTO {
private String country;
public void setCountry(String country) {
this.country = country;
}
public String getCountry() {
return this.country;
}
@JSONField(serialize = false)
public static void queryCountryList() {
System.out.println("queryCountryList()执行!!");
}
public Boolean isChinaName() {
System.out.println("isChinaName()执行!!");
return true;
}
public String getEnglishName() {
System.out.println("getEnglishName()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public String getOtherName() {
System.out.println("getOtherName()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public String getEnglishName2() {
System.out.println("getEnglishName2()执行!!");
return "lucy";
}
@JSONField(serialize = false)
public void getEnglishName3() {
System.out.println("getEnglishName3()执行!!");
}
@JSONField(serialize = false)
public String isChinaName2() {
System.out.println("isChinaName2()执行!!");
return "isChinaName2";
}
}三个频率高的序列化的情况
以上流程基本遵循 发现问题 --> 原理分析 --> 解决问题 --> 升华(编程规范)。
- 围绕业务上:解决问题 -> 如何选择一种好的额解决方案 -> 好的解决方式如何扩展n个系统应用;
- 围绕技术上:解决单个问题,顺着单个问题掌握这条线上的原理。
链接:https://juejin.cn/post/7156439842958606349
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
安卓APP全局黑白化实现方案
在清明节时各大APP都会进行黑白化处理,当时在接到这个需求的时候感觉好麻烦,是不是又要搞一套皮肤?
然而在一系列搜索之后,找到了两位大神(鸿洋、U2tzJTNE)的实现方案,其实相当的简单!
让我们一起站在巨人的肩膀上来分析一下原理,并思考会不会有更简便的实现?
一、原理
两位大神的置灰方案是相同的,都能看到一段同样的代码:
Paint mPaint = new Paint();
ColorMatrix mColorMatrix = new ColorMatrix();
// 设置饱和度为0
mColorMatrix.setSaturation(0);
mPaint.setColorFilter(new ColorMatrixColorFilter(mColorMatrix));
他们都用了Android提供的ColorMatrix(颜色矩阵),将其饱和度设置为0,这样使用Paint绘制出来的都是没有饱和度的灰白样式!
然而两位在何时使用Paint绘制时选择了不同方案。
1.1 鸿洋:重写draw方法
鸿洋老师分析,如果我们把每个Activity的根布局饱和度设置为0是不是就可以了?
那根布局是谁?
鸿洋老师分析我们的布局最后setContentView最后都会设置到一个R.id.content的FrameLayout当中。
我们去自定义一个GrayFrameLayout,在draw的时候使用这个饱和度为0的画笔,被这个FrameLayout包裹的布局都会变成黑白。
// 转载自鸿洋
// https://blog.csdn.net/lmj623565791/article/details/105319752
public class GrayFrameLayout extends FrameLayout {
private Paint mPaint = new Paint();
public GrayFrameLayout(Context context, AttributeSet attrs) {
super(context, attrs);
ColorMatrix cm = new ColorMatrix();
cm.setSaturation(0);
mPaint.setColorFilter(new ColorMatrixColorFilter(cm));
}
@Override
protected void dispatchDraw(Canvas canvas) {
canvas.saveLayer(null, mPaint, Canvas.ALL_SAVE_FLAG);
super.dispatchDraw(canvas);
canvas.restore();
}
@Override
public void draw(Canvas canvas) {
canvas.saveLayer(null, mPaint, Canvas.ALL_SAVE_FLAG);
super.draw(canvas);
canvas.restore();
}
}然后我们用GrayFrameLayout去替换这个R.id.content的FrameLayout,是不是就可以做到将页面黑白化了?
替换FrameLayout的方法可以去【鸿洋】这篇文章下查看。
1.2 U2tzJTNE:监听DecorView的添加
U2tzJTNE大佬使用了另一种巧妙的方案。
他先创建了一个具有数据变化感知能力的ObservableArrayList(当内容发生变化有回调)。
之后使用反射将WindowManagerGlobal内的mViews容器(ArrayList,该容器会存放所有的DecorView),替换为ObservableArrayList,这样就可以监听到每个DecorView的创建,并且拿到View本身。
拿到DecorView,那就可以为所欲为了!
大佬使用了setLayerType(View.LAYER_TYPE_HARDWARE, mPaint),对布局进行了重绘。至于为什么要用LAYER_TYPE_HARDWARE?因为默认的View.LAYER_TYPE_NONE会把Paint强制设置为null。
// 转载自U2tzJTNE
// https://juejin.cn/post/6892277675012915207
public static void enable(boolean enable) {
try {
//灰色调Paint
final Paint mPaint = new Paint();
ColorMatrix mColorMatrix = new ColorMatrix();
mColorMatrix.setSaturation(enable ? 0 : 1);
mPaint.setColorFilter(new ColorMatrixColorFilter(mColorMatrix));
//反射获取windowManagerGlobal
@SuppressLint("PrivateApi")
Class<?> windowManagerGlobal = Class.forName("android.view.WindowManagerGlobal");
@SuppressLint("DiscouragedPrivateApi")
java.lang.reflect.Method getInstanceMethod = windowManagerGlobal.getDeclaredMethod("getInstance");
getInstanceMethod.setAccessible(true);
Object windowManagerGlobalInstance = getInstanceMethod.invoke(windowManagerGlobal);
//反射获取mViews
Field mViewsField = windowManagerGlobal.getDeclaredField("mViews");
mViewsField.setAccessible(true);
Object mViewsObject = mViewsField.get(windowManagerGlobalInstance);
//创建具有数据感知能力的ObservableArrayList
ObservableArrayList<View> observerArrayList = new ObservableArrayList<>();
observerArrayList.addOnListChangedListener(new ObservableArrayList.OnListChangeListener() {
@Override
public void onChange(ArrayList list, int index, int count) {
}
@Override
public void onAdd(ArrayList list, int start, int count) {
// 拿到DecorView触发重绘
View view = (View) list.get(start);
if (view != null) {
view.setLayerType(View.LAYER_TYPE_HARDWARE, mPaint);
}
}
@Override
public void onRemove(ArrayList list, int start, int count) {
}
});
//将原有的数据添加到新创建的list
observerArrayList.addAll((ArrayList<View>) mViewsObject);
//替换掉原有的mViews
mViewsField.set(windowManagerGlobalInstance, observerArrayList);
} catch (Exception e) {
e.printStackTrace();
}
}只需要在Application里面调用该方法即可。
1.3 方案分析
两位大佬的方案都非常的棒,咱们理性的来对比一下。
鸿洋老师: 使用自定义FrameLayout的方案需要一个BaseActivity统一设置,稍显麻烦,代码侵入性较强。
U2tzJTNE大佬: 方案更加简单、动态,一行代码设置甚至可以做到在当前页从彩色变黑白,但是使用了反射,有一点点性能消耗。
二、简易方案(直接复制)
既然研究明白了大佬的方案,那有没有又不需要反射,设置又简单的方法呢?
能不能使用原生方式获取DecorView的实例呢?
突然灵光一闪,Application里面不是有registerActivityLifecycleCallbacks这个注册监听方法吗?监听里面的onActivityCreated不是可以获取到当前的Activity吗?那DecorView不就拿到了!
搞起!上代码!
public class StudyApp extends Application {
@Override
public void onCreate() {
super.onCreate();
Paint mPaint = new Paint();
ColorMatrix mColorMatrix = new ColorMatrix();
mColorMatrix.setSaturation(0);
mPaint.setColorFilter(new ColorMatrixColorFilter(mColorMatrix));
registerActivityLifecycleCallbacks(new ActivityLifecycleCallbacks() {
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState) {
// 当Activity创建,我们拿到DecorView,使用Paint进行重绘
View decorView = activity.getWindow().getDecorView();
decorView.setLayerType(View.LAYER_TYPE_HARDWARE, mPaint);
}
....
});
}
}这样看起来是不是更简单了!使用了APP原生的方法实现了黑白化!当然也有缺点,因为在Activity级别设置,无法做到在当前页面即时变为黑白。
三、注意事项
这三种方案因为都使用了颜色矩阵,所以坑都是一样的,请注意。
3.1 启动图windowBackground无法变色
在我们可以设置渲染的时候windowBackground已经展示完毕了。
解决方案:只能在当前的包里修改,或者不去理会。
3.2 SurfaceView无法变色
因为我们使用了setLayerType进行重绘,而SurfaceView是有独立的Window,脱离布局内的Window,运行在其他线程,不影响主线程的绘制,所以当前方案无法使SurfaceView变色。
解决方案:
1、使用TextureView。
2、看下这个SurfaceView是否可以设置滤镜,正常都是一些三方或者自制的播放器。
3.3 多进程变色
我们可能会在APP内置小程序,小程序基本是运行在单独的进程中,但是如果我们的黑白配置在运行过程中发生变化,其他进程是无法感知的。
解决方案:使用MMKV存储黑白配置,并设置多进程共享,在开启小程序之前都判断一下黑白展示。
总结
最后咱们再总结一下黑白化方案。
使用了ColorMatrix设置饱和度为0,设置到Paint中,让根布局拿着这个Paint去进行重绘。
这样APP全局黑白化的介绍就结束了,希望大家读完这篇文章,会对APP黑白化有一个更深入的了解。如果我的文章能给大家带来一点点的福利,那在下就足够开心了。
下次再见!
链接:https://juejin.cn/post/7167300200921301028
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android启动优化之多线程依赖线程池
背景
开发中会存在多个任务之间互相依赖,运行非常慢的情况,譬如Android在主线程中初始化多个SDK导致App启动慢的情况,搜索一下发现业界的通用做法是构造任务的有向无环图,拓扑排序生成有序的任务列表,然后用线程池执行任务列表(通俗的说就是先找到没有依赖的任务执行,执行完了以后再找到剩下的没有依赖的任务执行,如此反复直到执行完所有任务),但是这个做法无法解决有的任务需要点击对话框授权的情况,基于这个情况打算再造一个轮子出来。
问题
造轮子之前先梳理了一下对这个轮子的要求,发现除了有向无环图外还是有很多细节要解决的。
-依赖任务多线程启动
-支持交互性任务,先拦截任务,交互完成以后再继续执行
-可视化有向无环图
-可视化任务执行情况
-支持多线程、主线程、主进程、第一个任务、最后一个任务等配置属性
方案
开源
TaskGraph: github.com/JonaNorman/…
线程池只能执行没有依赖关系的任务,TaskGraph开源库用有向无环图实现多线程依赖线程池,用拦截器实现交互式任务
图中添加了A任务,B任务依赖A任务执行完再执行,其中A任务需要点击对话框才能执行。
TaskGraph taskGraph = new TaskGraph();
taskGraph.addTask(new Task("A",new Runnable() {//添加A任务
@Override
public void run() {
}
}).addTaskInterceptor(new Task.TaskInterceptor() {
@Override
public void onIntercept(Task.TaskInterceptorChain interceptorChain) {//拦截A任务,在A任务之前可以插入对话框
AlertDialog.Builder builder = new AlertDialog.Builder(TaskGraphModule.getTopActivity());
builder.setPositiveButton("ok", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
interceptorChain.proceed();//继续
}
});
builder.setNegativeButton("cancel", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialog, int which) {
interceptorChain.cancel();//取消
}
});
builder.show();
}
}));
taskGraph.addTask(new Task("B",new Runnable() {
@Override
public void run() {//添加B任务,B任务依赖A任务先完成
}
}).dependsOn("A").setMainThread(true));
taskGraph.execute();可视化有向图
搜索TASK_GRAPH_LOG: graphviz:会输出有向图日志,复制到 graphviz-visual-editor 可视化查看
可视化任务执行情况
python systrace.py -o trace.html -a packagename sched
复制代码packagename要替换成运行的app的包名 chrome浏览器打开chrome://tracing/,load 按钮加载trace.html
原理
依赖任务多线程启动
正常的线程池只能执行没有依赖关系的任务,怎么才能让线程池支持运行相互依赖的任务呢?
先找到所有没有进来箭头的节点执行,在该图中也就是A,执行完后删除这个节点和边,
变成了下图
继续以上步骤,找到B运行后删除B,变成下图这样
继续以上步骤,找到C D E同时运行,最终所有任务执行完毕。
把上面的步骤翻译成术语
- 有箭头的图叫有向图
- 节点有多少个进来的箭头叫入度
- 没有进来箭头的节点叫入度为0的节点
- 箭头没有形成环的图叫有向无环图
- 依次找到所有入度为0的节点叫拓扑排序
这里有个问题,多线程怎么执行拓扑排序的节点,有两种做法
- 拓扑排序的节点列表作为runnable提交到线程池,依赖的任务线程等待其他任务完成在执行
- 先把入度为0的所有节点提交到线程池,有一个执行完,就触发寻找剩下入度为0的节点继续执行
两种方案我选了方案2,个人感觉方案2找到的节点执行顺序是最优的,并且不需要线程等待,代码简单而且不需要空占有线程池的线程数量
主要思想:
Grpah图有多个node节点,每个Node节点有一个Vertex顶点,多个入边edge,多个出边edge,
拓扑排序就是找所有node节点入度为0的边移除然后继续找直到找完所有节点,核心代码地址
支持交互性任务
有些任务需要交互输入,完成以后再继续执行,为了实现该功能,可以用拦截器的方式来实现。
拦截器的原理就是调用到拦截器时候会用锁等待,如果执行了proceed方法会唤醒锁然后执行下个拦截器,如果执行了cancel会唤醒锁终止所有任务标记cancel状态,每个拦截器必须调用其中一个方法,要不然会一直等待
核心代码如下:代码地址
private void nextIntercept() {
synchronized (sync) {
currentInterceptor = taskInterceptorQueue.poll();//获取下一个拦截器
if (currentInterceptor == null) {
return;
}
currentInterceptor.onIntercept(this);//处罚拦截器
}
while (!graphController.isFinished()) {
synchronized (sync) {
if (cancel) {//调用cancel方法会把cancel赋值为true
throw new TaskCancelException();
} else if (currentInterceptor == proceedInterceptor) {//如果调用了proceed会proceedInterceptor赋值为currentInterceptor
nextIntercept();//执行下一个拦截器
break;
} else {
try {
sync.wait();//等待执行proceed或者cancel方法
} catch (InterruptedException e) {
}
}
}
}
}可视化有向无环图
多个依赖任务添加进去以后如果不能可视化成图就会对影响对任务的把控程度,graphviz是一个图的可视化项目,只要把图的情况写成文本输入就会生成对应图。
digraph pic {
A->B;
B->C;
}可视化任务执行情况
多个任务执行实时运行情况,有助于我们优化任务依赖,主要就是在每个任务执行开始调用Trace.beginSection(name),执行完调用Trace.endSection(),然后用命令
python systrace.py -o trace.html -a packagename sched
生成trace.html,然后用chrome浏览器打开chrome://tracing/点击load按钮加载trace.html就可以查看每个任务的执行情况
支持多线程、主线程、主进程、第一个任务、最后一个任务等配置属性
任务具有多个属性,多线程、主线程、主进程等属性,该实现只要加对应判断就行,第一个任务和最后一个任务则需要遍历所有任务,添加对应依赖关系。
收获
依赖任务多线程调度本身不是很难,在该开源项目中我收获了很多,包括如何实现有向无环图,如何在多线程中实现任务拦截继发,如何使用graphviz实现可视化图,如何用systemtrace可视化任务执行,希望看完文章的同学也可以从中学到什么,谢谢大家的浏览,如果觉得可以,欢迎大家多多star这个开源项目。
链接:https://juejin.cn/post/7168092996133453861
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Lucene源码系列:正排索引文件构建
背景
Lucene中根据term字典和倒排可以快速查找到相关文档的id,那怎么获取文档中的字段内容呢,这就是我们今天要讲的正排数据。
Lucene中对于某个文档的各个字段,可以通过配置来控制是否要存储进正排索引文件中,只有存储到正排索引文件中,查询的时候,有需要才能返回相应的字段。
如果理解了之前介绍过的词向量的索引文件构建,可以发现其实正排索引文件和词向量索引文件构建非常类似。
最终生成的正排索引文件有3个:
- fdt:按chunk存储doc的开启了store的字段
- fdx:chunk的索引文件,记录的是每个chunk的起始docID,以及每个chunk的起始位置,方便根据docID快速定位到chunk。
- fdm:正排索引文件的元信息,用来读取正排索引文件使用的。
前置知识
- 在对字段数据的存储时,对不同的数据类型,有不同的压缩算法,详见《单值编码压缩算法》。
- 构建chunk索引文件的时候会用到工具类FieldsIndexWriter,具体我们已经在《词向量索引文件构建》中详细介绍过了。
索引文件格式
fdm
fdm是正排索引文件的元信息,用来读取的时候使用。
字段详解
Header
文件头部信息,主要是包括:
- 文件头魔数(同一lucene版本所有文件相同)
- 该文件使用的codec名称:Lucene90FieldsIndexMeta
- codec版本
- segment id(也是Segment_N文件中的N)
- segment后缀名(一般为空)
ChunkSize
用来判断是否满足一个chunk的一种条件,如果chunk的大小超过了ChunkSize的限制,则可以构建一个chunk
NumDocs
doc总数
BlockShift
DirectMonotonicWriter需要的参数,DirectMonotonicWriter压缩存储会生成多个block,BlockShift决定了block的大小。
TotalChunks + 1
chunk总数 + 1,在生成fdx索引文件中ChunkStartDocIDs和ChunkOffsets两个字段时,使用DirectMonotonicWriter写入的值的总数。
fdxDocStartFP
fdx索引文件中ChunkStartDocIDs的起始位置
DocBlockMetas
fdx索引文件中ChunkStartDocIDs使用DirectMonotonicWriter编码存储,会生成多个block,这些block的元信息。
tvxOffsetStartFP
fdx中ChunkOffsets的起始位置
OffsetBlockMetas
fdx索引文件中ChunkOffsets使用DirectMonotonicWriter编码存储,会生成多个block,这些block的元信息。
SPEndPoint
fdx文件的结束位置,后面是fdx的footer信息。
MaxPointer
fdt文件的结束位置,后面fdt的footer信息。
NumChunks
chunk总数
NumDirtyChunks
dirtyChunk总数
NumDirtyDocs
dirtyChunk中的doc总数
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
fdt
fdt中按chunk存储各个doc所有的字段数据。
字段详解
Header
文件头部信息,主要是包括:
文件头魔数(同一lucene版本所有文件相同)
该文件使用的codec名称
根据压缩模式的不同有两种:
- Lucene90StoredFieldsFastData
- Lucene90StoredFieldsHighData
codec版本
segment id(也是Segment_N文件中的N)
segment后缀名(一般为空)
chunk
- DocBase:Chunk中Doc的起始编号,Chunk中所有doc的真实编号需要加上这个DocBase
- NumDocsCode:是NumDocs和IsDirty,IsSlice的int组合体
- NumDocs:chunk中的doc总数
- IsDirty:chunk是否是dirtyChunk
- IsSlice:chunk是否被分成多个slice
- DocNumFields:chunk中每个文档的字段个数。
- DocDataLengths:chunk中每个doc占用的存储空间大小。
- Doc:doc中每个store字段的信息
- Field:store的字段
- FieldNumAndTypeCode:FieldNumber和type的long组合体
- FieldNumber:字段的编号
- type:字段的类型
- FieldValue:根据不同的数值类型,有不同的存储方式
- 二进制/string:先存length,再存数据
- byte/short/int:zint存储
- long:tlong存储
- float:zfloat存储
- double:zdouble存储
- FieldNumAndTypeCode:FieldNumber和type的long组合体
- Field:store的字段
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
fdx
fdt中所有chunk的索引信息,可以快速根据docID定位到chunk的位置。
字段详解
Header
文件头部信息,主要是包括:
- 文件头魔数(同一lucene版本所有文件相同)
- 该文件使用的codec名称:Lucene90FieldsIndexIdx
- codec版本
- segment id(也是Segment_N文件中的N)
- segment后缀名(一般为空)
ChunkStartDocIDs
所有chunk的起始docID,使用DirectMonotonicWriter编码存储,会生成多个block。
ChunkOffsets
所有chunk在fdt索引文件中的起始位置,使用DirectMonotonicWriter编码存储,会生成多个block。
Footer
文件尾,主要包括
- 文件尾魔数(同一个lucene版本所有文件一样)
- 0
- 校验码
构建源码
本文源码解析基于lucene-core-9.1.0。
- StoredFieldsConsumer负责调度正排索引文件的构建主要有:启动一个doc的处理,处理doc中的field,结束一个doc的处理,结束正排索引的构建。
- Lucene90CompressingStoredFieldsWriter负责持久化生成正排索引文件
构建涉及到的StoredFieldsConsumer和Lucene90CompressingStoredFieldsWriter逻辑其实非常简单,下面我们一起来看下。
StoredFieldsConsumer
class StoredFieldsConsumer {
final Codec codec;
// 索引文件的目录
final Directory directory;
final SegmentInfo info;
// 实现类是 Lucene90CompressingStoredFieldsWriter,负责正排索引文件的持久化
StoredFieldsWriter writer;
Accountable accountable = Accountable.NULL_ACCOUNTABLE;
// 前一个处理的docID
private int lastDoc;
StoredFieldsConsumer(Codec codec, Directory directory, SegmentInfo info) {
this.codec = codec;
this.directory = directory;
this.info = info;
this.lastDoc = -1;
}
// 创建 Lucene90CompressingStoredFieldsWriter
protected void initStoredFieldsWriter() throws IOException {
if (writer == null) {
this.writer = codec.storedFieldsFormat().fieldsWriter(directory, info, IOContext.DEFAULT);
accountable = writer;
}
}
// 开始处理一个doc
void startDocument(int docID) throws IOException {
assert lastDoc < docID;
initStoredFieldsWriter();
while (++lastDoc < docID) { // 确保doc是连续的
writer.startDocument();
writer.finishDocument();
}
// Lucene90CompressingStoredFieldsWriter中开始处理doc
writer.startDocument();
}
// 每个需要构建的正排字段都会被处理
void writeField(FieldInfo info, IndexableField field) throws IOException {
writer.writeField(info, field);
}
// 结束doc的处理
void finishDocument() throws IOException {
writer.finishDocument();
}
// 结束正排的构建
void finish(int maxDoc) throws IOException {
while (lastDoc < maxDoc - 1) {
startDocument(lastDoc);
finishDocument();
++lastDoc;
}
}
// 持久化正排索引文件
void flush(SegmentWriteState state, Sorter.DocMap sortMap) throws IOException {
try {
writer.finish(state.segmentInfo.maxDoc());
} finally {
IOUtils.close(writer);
}
}
void abort() {
IOUtils.closeWhileHandlingException(writer);
}
}Lucene90CompressingStoredFieldsWriter
成员变量
// 数据文件
public static final String FIELDS_EXTENSION = "fdt";
// 索引文件
public static final String INDEX_EXTENSION = "fdx";
// 元信息文件
public static final String META_EXTENSION = "fdm";
/** Codec name for the index. */
public static final String INDEX_CODEC_NAME = "Lucene90FieldsIndex";
// 不同数据类型编码
static final int STRING = 0x00;
static final int BYTE_ARR = 0x01;
static final int NUMERIC_INT = 0x02;
static final int NUMERIC_FLOAT = 0x03;
static final int NUMERIC_LONG = 0x04;
static final int NUMERIC_DOUBLE = 0x05;
// 数据类型编码的bit数量
static final int TYPE_BITS = PackedInts.bitsRequired(NUMERIC_DOUBLE);
// 提取类型的掩码
static final int TYPE_MASK = (int) PackedInts.maxValue(TYPE_BITS);
static final int VERSION_START = 1;
static final int VERSION_CURRENT = VERSION_START;
static final int META_VERSION_START = 0;
private final String segment;
// 索引生成工具
private FieldsIndexWriter indexWriter;
private IndexOutput metaStream, fieldsStream;
private Compressor compressor;
private final CompressionMode compressionMode;
// chunk的大小
private final int chunkSize;
// 每个chunk最多可以存储多少个doc
private final int maxDocsPerChunk;
// 缓存所有的字段的值
private final ByteBuffersDataOutput bufferedDocs;
// 下标是当前chunk中的docID的偏移量,值是对应doc的字段个数
private int[] numStoredFields;
// 下标是当前chunk中的docID的偏移量,值是对应doc的所有需要store的数据在bufferedDocs中的结束位置
private int[] endOffsets;
// chunk中的起始docID
private int docBase;
// chunk中的doc个数
private int numBufferedDocs;
// chunk总数
private long numChunks;
// dirtyChunk总数,未满足生成chunk的条件时,强制生成的chunk是dirtyChunk
private long numDirtyChunks;
// dirtyDoc总数,dirtyChunk中的doc是dirtyDoc
private long numDirtyDocs;
// 在处理一个doc的时候,统计已经处理的field个数
private int numStoredFieldsInDoc;
核心方法
开始处理一个doc
当前实现中是空操作。
@Override
public void startDocument() throws IOException {}
处理一个field
处理一个field,就是读取field的值,根据值的类型按对应的值的存储方式存入bufferedDocs缓存中。
public void writeField(FieldInfo info, IndexableField field) throws IOException {
++numStoredFieldsInDoc;
int bits = 0;
final BytesRef bytes;
final String string;
Number number = field.numericValue();
if (number != null) { // 如果是数值类型
if (number instanceof Byte || number instanceof Short || number instanceof Integer) {
// byte,short,int都标记为int
bits = NUMERIC_INT;
} else if (number instanceof Long) {
// long
bits = NUMERIC_LONG;
} else if (number instanceof Float) {
// float
bits = NUMERIC_FLOAT;
} else if (number instanceof Double) {
// double
bits = NUMERIC_DOUBLE;
} else {
throw new IllegalArgumentException("cannot store numeric type " + number.getClass());
}
string = null;
bytes = null;
} else {
bytes = field.binaryValue();
if (bytes != null) { // 是二进制
bits = BYTE_ARR;
string = null;
} else { // 是字符串
bits = STRING;
string = field.stringValue();
if (string == null) {
throw new IllegalArgumentException(
"field "
+ field.name()
+ " is stored but does not have binaryValue, stringValue nor numericValue");
}
}
}
// 字段的编号和类型组合体
final long infoAndBits = (((long) info.number) << TYPE_BITS) | bits;
bufferedDocs.writeVLong(infoAndBits);
if (bytes != null) {
bufferedDocs.writeVInt(bytes.length);
bufferedDocs.writeBytes(bytes.bytes, bytes.offset, bytes.length);
} else if (string != null) {
bufferedDocs.writeString(string);
} else {
if (number instanceof Byte || number instanceof Short || number instanceof Integer) {
bufferedDocs.writeZInt(number.intValue());
} else if (number instanceof Long) {
writeTLong(bufferedDocs, number.longValue());
} else if (number instanceof Float) {
writeZFloat(bufferedDocs, number.floatValue());
} else if (number instanceof Double) {
writeZDouble(bufferedDocs, number.doubleValue());
} else {
throw new AssertionError("Cannot get here");
}
}
}结束处理一个doc
结束doc的处理,需要做4件事:
- 如果numBufferedDocs空间不足了,需要扩容
- 记录doc对应的field个数
- 记录doc数据在bufferedDocs中的结束位置
- 判断如果满足一个chunk的生成,则生成chunk
public void finishDocument() throws IOException {
if (numBufferedDocs == this.numStoredFields.length) {
final int newLength = ArrayUtil.oversize(numBufferedDocs + 1, 4);
this.numStoredFields = ArrayUtil.growExact(this.numStoredFields, newLength);
endOffsets = ArrayUtil.growExact(endOffsets, newLength);
}
// 记录doc对应的field个数
this.numStoredFields[numBufferedDocs] = numStoredFieldsInDoc;
numStoredFieldsInDoc = 0;
// 记录当前doc在bufferedDocs中的结束位置
endOffsets[numBufferedDocs] = Math.toIntExact(bufferedDocs.size());
++numBufferedDocs;
if (triggerFlush()) {
flush(false);
}
}生成一个chunk
生成一个chunk的条件:
- bufferDocs缓存超出了chunkSize
- chunk中收集的doc数量超出了maxDocsPerChunk
- 强制生成
// 生成一个chunk的条件
// 1.bufferDocs缓存超出了chunkSize
// 2.chunk中收集的doc数量超出了maxDocsPerChunk
private boolean triggerFlush() {
return bufferedDocs.size() >= chunkSize || numBufferedDocs >= maxDocsPerChunk;
}
private void flush(boolean force) throws IOException {
// chunk数+1
numChunks++;
if (force) { // 如果是强制构建chunk,可能是不满足chunk条件的,这种chunk被定义为dirtyChunk
numDirtyChunks++;
numDirtyDocs += numBufferedDocs;
}
// 生成chunk的索引
indexWriter.writeIndex(numBufferedDocs, fieldsStream.getFilePointer());
// 把各个doc在bufferedDocs中的endOffsets转成length
final int[] lengths = endOffsets;
for (int i = numBufferedDocs - 1; i > 0; --i) {
lengths[i] = endOffsets[i] - endOffsets[i - 1];
}
// 如果当前chunk的大小超出了2倍chunkSize,则需要分片
final boolean sliced = bufferedDocs.size() >= 2 * chunkSize;
final boolean dirtyChunk = force;
writeHeader(docBase, numBufferedDocs, numStoredFields, lengths, sliced, dirtyChunk);
// 下面是压缩处理
byte[] content = bufferedDocs.toArrayCopy();
bufferedDocs.reset();
if (sliced) {
// big chunk, slice it
for (int compressed = 0; compressed < content.length; compressed += chunkSize) {
compressor.compress(
content, compressed, Math.min(chunkSize, content.length - compressed), fieldsStream);
}
} else {
compressor.compress(content, 0, content.length, fieldsStream);
}
// 更新下一个chunk的起始docID
docBase += numBufferedDocs;
// 重置doc数统计
numBufferedDocs = 0;
bufferedDocs.reset();
}
private static void saveInts(int[] values, int length, DataOutput out) throws IOException {
if (length == 1) {
out.writeVInt(values[0]);
} else {
StoredFieldsInts.writeInts(values, 0, length, out);
}
}
private void writeHeader(
int docBase,
int numBufferedDocs,
int[] numStoredFields,
int[] lengths,
boolean sliced,
boolean dirtyChunk)
throws IOException {
final int slicedBit = sliced ? 1 : 0;
final int dirtyBit = dirtyChunk ? 2 : 0;
// save docBase and numBufferedDocs
fieldsStream.writeVInt(docBase);
fieldsStream.writeVInt((numBufferedDocs << 2) | dirtyBit | slicedBit);
// save numStoredFields
saveInts(numStoredFields, numBufferedDocs, fieldsStream);
// save lengths
saveInts(lengths, numBufferedDocs, fieldsStream);
}结束构建
结束构建的时候最重要的就是生成fdx索引文件。
public void finish(int numDocs) throws IOException {
if (numBufferedDocs > 0) { // 如果还有未处理的doc,强制生成一个chunk
flush(true);
} else {
assert bufferedDocs.size() == 0;
}
if (docBase != numDocs) {
throw new RuntimeException(
"Wrote " + docBase + " docs, finish called with numDocs=" + numDocs);
}
// 构建fdx文件
indexWriter.finish(numDocs, fieldsStream.getFilePointer(), metaStream);
// 记录一些元信息
metaStream.writeVLong(numChunks);
metaStream.writeVLong(numDirtyChunks);
metaStream.writeVLong(numDirtyDocs);
CodecUtil.writeFooter(metaStream);
CodecUtil.writeFooter(fieldsStream);
assert bufferedDocs.size() == 0;
}
}链接:https://juejin.cn/post/7166898028941410312
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android中的硬件加速那么好用?为啥没被普及?
浅谈
前几天有个朋友问我:Android中硬件加速那么好用,为啥没被普及?,嗯?其实我也想知道。。。
手机开发中最重要的两个点:
- 1.用户点击的流畅性
- 2.界面效果的展示
早期的Android系统这两个事件都是在主线程上执行,导致用户点击的时候,界面绘制停滞或者界面绘制的时候,用户点击半天不响应,体验性很差。
于是在4.0以后,以 “run fast, smooth, and responsively” 为核心目标对 UI 进行了优化,应用开启了硬件加速对UI进行绘制。
1.硬件加速
在之前文章中我们分析过,Android 屏幕的绘制流程分为两部分:
1.生产者:app侧将View渲染到一个buffer中,供SurfaceFlinger消费2.消费者:SurfaceFlinger测将多个buffer合并后放入buffer中,供屏幕显示
其中 第二步一直都是在GPU中实现的,而我们所说的硬件加速就是第一步中的view渲染流程。
早期view的渲染是在主线程中进行的,而硬件加速则使用一个新的线程RenderThread以及硬件GPU进行渲染,
2.CPU / GPU结构对比
- CPU (Central Processing Unit): 中央处理器,计算机设备核心器件,适用于一些复杂的计算。
- GPU (Graphic Processing Unit): 图形处理器,通常所说“显卡”的核心部件就是GPU,主要用于处理图形运算。
CPU和GPU结构对比:
- 黄色代表控制器(Control):用于协调控制整个CPU的运行,包括取指令等操作。
- 绿色的ALU(Arithmetic Logic Unit):算数逻辑单元,主要用于进行数学,逻辑计算。
- 橙色的Cache和DRAM分别为缓存和RAM,用于存储信息。
1.结构上看:CPU的ALU较少,而了解过OpenGl的同学应该知道View的渲染过程中是有大量的浮点数计算的,而浮点数转换为整数计算,可能会消耗大量的ALU单元,这对于CPU是比较难接受的。
2.CPU是串行的,一个CPU同一时间只能做一件事情,(多线程其实也是将CPU时间片分割而已),而GPU内部使用的是几千个小的GPU内核,每个GPU内核处理单元都是并行的,
这就非常符合图形的渲染过程。
GPU是显卡的核心部分,在破解密码方面也非常出色,再知道为啥哪些挖矿的使用的是显卡而不是CPU了吧,一个道理。
硬件加速底层原理:
通过将计算机不擅长的图形计算指令使用特殊的api转换为GPU的专用指令,由GPU完成。这里可能是传统的OpenGL或其他开放语言。
3.OpenGL
Android端一般使用OpenGL ES来实现硬件加速。
这里简单介绍下OpenGL和OpenGL ES。
- OpenGL(Open Graphics Library):开放式图形库,是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API)。这个接口由近350个不同的函数调用组成,
用来绘制从简单的图形比特到复杂的三维景象。 - OpenGL ES(OpenGL for Embedded Systems):是 OpenGL 三维图形 API 的子集,针对手机、PDA和游戏主机等嵌入式设备而设计
如果一个设备支持GPU硬件加速渲染(有可能不支持,看GPU厂商是不是适配了OpenGL 等接口),
那么当Android应用程序调用Open GL接口来绘制UI时,Android应用程序的 UI 就是通过GPU进行渲染的。
4.Android图形系统整体架构
在介绍Android图像系统架构前,我们先来了解几个概念:如果把UI的绘制过程当成一幅画的制作过程:
那么:
1.画笔:
- Skia:CPU用来绘制2D图形
- Open GL /ES:GPU绘制2D和3D图形。
2.画纸:
Surface:所有的绘制和渲染都是在这张画纸上进行,每个窗口都是一个DecorView的容器,同时每个窗口都关联一个Surface
3.画板:
Graphic Buffer :Graphic Buffer是谷歌在4.1以后针对双缓冲的jank问题提出的第三个缓冲,CPU/GPU渲染的内容都将写到这个buffer上。
4.合成
SurfaceFlinger:将所有的Surface合并叠加后显示到一个buffer里面。
简单理解过程:我们使用画笔(Skia、Open GL ES)将内容画到画纸(Surface)中,这个过程可能使用OpenGl ES也可能使用Skia,
使用OpenGl ES表示使用了硬件加速绘制,使用Skia,表示使用的是纯软件绘制。
下面是Android 图形系统的整体架构:
Image Stream Producers:图像数据流生产者,图像或视频数据最终绘制到Surface中。
WindowManager :前面一篇文章《WindowManager体系(上)》笔者说过,每个Surface都有一个Window和他一一对应,而WindowManager则用来管理窗口的各个方面:
动画,位置,旋转,层序,生命周期等。
SurfaceFlinger:用来对渲染后的Surface进行合并,并传递给硬件抽象层处理。
HWC : Hardware Composer,SurfaceFlinger 会委派一些合成的工作给 Hardware Composer 以此减轻 GPU 的负载。这样会比单纯通过 GPU 来合成消耗更少的电量。
Gralloc(Graphics memory allocator):前面讲解的Graphic Buffer分配的内存。
5.软硬件绘制过程源码解析
前面讲解了那么多理论知识,下面从源码角度来分析下硬件加速和软件绘制过程。
“read the fking source”
在前面文章《》中分析过。View最终是在ViewRootImpl的performDraw方法最新渲染的,
而performDraw内部调用的是draw方法。
定位到draw方法:
private void draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) {//1
...
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this);//2
}else {
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {//3
return;
}
}
}
}注释1:如果mThreadedRenderer不为null且isEnabled为true,则调用注释2处的mThreadedRenderer.draw,这个就是硬件绘制的入口
如果其他情况,则调用注释3处的drawSoftware,这里就是软件绘制的入口,再正式对软硬件绘制进行深入之前我们看下mAttachInfo.mThreadedRenderer是在哪里赋值的?
源码全局搜索下:我们发现ViewRootImpl的enableHardwareAcceleration方法中有创建mThreadedRenderer的操作。
private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {
// Try to enable hardware acceleration if requested
...
final boolean hardwareAccelerated =
(attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;
//这里如果attrs.flags设置了WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED,则表示该Window支持硬件加速绘制
if (hardwareAccelerated) {
// Persistent processes (including the system) should not do
// accelerated rendering on low-end devices. In that case,
// sRendererDisabled will be set. In addition, the system process
// itself should never do accelerated rendering. In that case, both
// sRendererDisabled and sSystemRendererDisabled are set. When
// sSystemRendererDisabled is set, PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED
// can be used by code on the system process to escape that and enable
// HW accelerated drawing. (This is basically for the lock screen.)
//Persistent的应用进程以及系统进程不能使用硬件加速
final boolean fakeHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FAKE_HARDWARE_ACCELERATED) != 0;
final boolean forceHwAccelerated = (attrs.privateFlags &
WindowManager.LayoutParams.PRIVATE_FLAG_FORCE_HARDWARE_ACCELERATED) != 0;
if (fakeHwAccelerated) {
mAttachInfo.mHardwareAccelerationRequested = true;
} else if (!ThreadedRenderer.sRendererDisabled
|| (ThreadedRenderer.sSystemRendererDisabled && forceHwAccelerated)) {
if (mAttachInfo.mThreadedRenderer != null) {
mAttachInfo.mThreadedRenderer.destroy();
}
...
//这里创建了mAttachInfo.mThreadedRenderer
mAttachInfo.mThreadedRenderer = ThreadedRenderer.create(mContext, translucent,
attrs.getTitle().toString());
if (mAttachInfo.mThreadedRenderer != null) {
mAttachInfo.mHardwareAccelerated =
mAttachInfo.mHardwareAccelerationRequested = true;
}
}
}
}这里源码告诉我们:
- 1.硬件加速是通过attrs.flags 设置WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED标识来启动的、
- 2、因为硬件加速是一个耗内存的操作,只是硬件加速渲染环境初始化这一操作,就要花掉8M的内存,
所以一般永久性的进程或者系统进程不要使用硬件加速标志,防止出现内存泄露。
再看哪里调用enableHardwareAcceleration方法?
通过源码查找我们注意到ViewRootImpl的setView方法中:
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
//注释1
if (view instanceof RootViewSurfaceTaker) {
mSurfaceHolderCallback =
((RootViewSurfaceTaker)view).willYouTakeTheSurface();
if (mSurfaceHolderCallback != null) {
mSurfaceHolder = new TakenSurfaceHolder();
mSurfaceHolder.setFormat(PixelFormat.UNKNOWN);
mSurfaceHolder.addCallback(mSurfaceHolderCallback);
}
}
...
// If the application owns the surface, don't enable hardware acceleration
if (mSurfaceHolder == null) {//注释2
enableHardwareAcceleration(attrs);
}
}注释1处:表示当前view实现了RootViewSurfaceTaker接口,且view的willYouTakeTheSurface返回的mSurfaceHolderCallback不为null,
则表示应用想自己接管所有的渲染操作,这样创建出来的Activity窗口就类似于一个SurfaceView一样,完全由应用程序自己来控制它的渲染
基本上我们是不会将一个Activity窗口当作一个SurfaceView来使用的,
因此在ViewRootImpl类的成员变量mSurfaceHolder将保持为null值,
这样就会导致ViewRootImpl类的成员函数enableHardwareAcceleration被调用为判断是否需要为当前创建的Activity窗口启用硬件加速渲染。
好了我们回到ViewRootImpl的draw方法:
1.先来看软件绘制
软件绘制调用的是drawSoftware方法。
进入
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty) {
...
canvas = mSurface.lockCanvas(dirty);//1
mView.draw(canvas);//2
surface.unlockCanvasAndPost(canvas);//3
}软件绘制基本就分三步走:
- 步骤1:lockCanvas:每个Window都关联了一个Surface,当有需要绘制UI时,就调用lockCanvas获取一个Canvas对象,这个Canvas封装了Skia提供的2D图形绘制api、
并且向SurfaceFlinger Dequeue了一块Graphic buffer,绘制的内容都会输出到这个buffer中,供SurfaceFlinger合成使用。
步骤2:draw:调用了View的draw方法,这个就会调用到我们自定义组件中View的onDraw方法,传入1中创建的Canvas对象,使用Skia api对图像进行绘制。
步骤3:unlockCanvasAndPost:绘制完成后,通知SurfaceFlinger绘制完成,可以进行buffer的交换,显示到屏幕上了,本质是给SurfaceFlinger queue 一个Graphic buffer、
关于什么是Queue和Dequeue看下图:
软件绘制条形简图:
2.硬件加速分析:
硬件加速分为两个步骤:
- 1.构建阶段
- 2.绘制阶段
构建阶段:
这个阶段用于遍历所有的视图,将需要绘制的Canvas API调用及其参数记录下来,保存在一个Display List,这个阶段发生在CPU主线程上。
Display List本质上是一个缓存区,它里面记录了即将要执行的绘制命令序列,这些命令最终会在绘制阶段被OpenGL转换为GPU渲染指令。
视图构建阶段会将每个View抽象为一个RenderNode,每个View的绘制操作抽象为一系列的DrawOp,
比如:
View的drawLine操作会被抽象为一个DrawLineOp,drawBitmap操作会被抽象成DrawBitmapOp,每个子View的绘制被抽象成DrawRenderNodeOp,每个DrawOp都有对应的OpenGL绘制指令,同时内部也握有需要绘制的数据元。
使用Display List的好处:
- 1、在绘制窗口的下一帧时,如果某个视图UI没有发生变化,则不需要执行与他相关的Canvas API操作,即不用重复执行View的onDraw操作,
而是直接使用上一帧的Display List即可 - 2.如果绘制窗口下一帧时,视图发生了变化,但是只是一些简单属性变化,如位置和透明度等,则只需要修改上次构建的Display List的相关属性即可,也不必重复构建
Display List模型图:
接下来我们从源码角度来看下:
前面我们分析了硬件加速入口是在ThreadedRenderer的draw方法:
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this)进入这个方法看看:
ThreadedRenderer.java
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
...
updateRootDisplayList(view, callbacks);//1
...
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);//2通知RenderThread线程绘制
}ThreadedRenderer主要作用就是在主线程CPU中视图的构建,然后通知RenderThread使用OpenGL进行视图的渲染(注释2处)。
注释1处:updateRootDisplayList看名称应该就是用于视图构建,进去看看
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
//1.构建参数view(DecorView)视图的Display List
updateViewTreeDisplayList(view);
//2
//mRootNodeNeedsUpdate true表示需要更新视图
//mRootNode.isValid() 表示已经构建了Display List
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
//获取DisplayListCanvas
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);//3
try {
//ReorderBarrie表示会按照Z轴坐标值重新排列子View的渲染顺序
canvas.insertReorderBarrier();
//构建并缓存所有的DrawOp
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
canvas.restoreToCount(saveCount);
} finally {
//将所有的DrawOp填充到根RootNode中,作为新的Display List
mRootNode.end(canvas);
}
}
}注释1:updateViewTreeDisplayList对View树Display List进行构建
private void updateViewTreeDisplayList(View view) {
view.mPrivateFlags |= View.PFLAG_DRAWN;
view.mRecreateDisplayList = (view.mPrivateFlags & View.PFLAG_INVALIDATED)
== View.PFLAG_INVALIDATED;
view.mPrivateFlags &= ~View.PFLAG_INVALIDATED;
view.updateDisplayListIfDirty();
view.mRecreateDisplayList = false;
}看View的updateDisplayListIfDirty方法。
/**
* Gets the RenderNode for the view, and updates its DisplayList (if needed and supported)
* @hide
*/
@NonNull
public RenderNode updateDisplayListIfDirty() {
//获取当前mRenderNode
final RenderNode renderNode = mRenderNode;
//2.判断是否需要进行重新构建
if ((mPrivateFlags & PFLAG_DRAWING_CACHE_VALID) == 0
|| !renderNode.isValid()
|| (mRecreateDisplayList)) {
if (renderNode.isValid()
&& !mRecreateDisplayList) {
mPrivateFlags |= PFLAG_DRAWN | PFLAG_DRAWING_CACHE_VALID;
mPrivateFlags &= ~PFLAG_DIRTY_MASK;
//这里用于当前View是ViewGroup,且自身不需要重构,对其子View的DisplayList进行构建
dispatchGetDisplayList();
return renderNode; // no work needed
}
...
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
if (layerType == LAYER_TYPE_SOFTWARE) {
//软件绘制
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
...
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
//View是ViewGroup,需要绘制子View
dispatchDraw(canvas);
...
} else {
draw(canvas);
}
}
} finally {
//将绘制好后的数据填充到renderNode中去
renderNode.end(canvas);
setDisplayListProperties(renderNode);
}
}
}updateDisplayListIfDirty主要作用:
- 1.获取当前View的RenderNode。
- 2.如果需要或者支持则更新当前DisplayList
判断是否需要进行重新构建的条件如下:
- 1.mPrivateFlags 设置了 PFLAG_DRAWING_CACHE_VALID,表明当前缓存已经失效,需要重新构建
- 2.!renderNode.isValid():表明当前Display List的数据不合法,需要重新构建
- 3.mRecreateDisplayList的值等于true,一些其他原因需要重新构建
mRenderNode在View的构造方法中初始化:
public View(Context context) {
...
mRenderNode = RenderNode.create(getClass().getName(), this);
}构建过程如下:
- 1.使用renderNode.start获得一个与当前View关联的DisplayListCanvas。
- 2.使用draw(canvas),将当前View以及子View绘制到当前DisplayListCanvas
- 3.使用renderNode.end(canvas),将已经绘制在 DisplayListCanvas 的 Display List Data 填充到当前 View 关联的 Render Node 中
通过上面几个步骤就将View树对应的DisplayList构建好了。而且这个构建过程会递归构建子View的Display List
我们从绘制流程火焰图中也可以看到大概流程:
红色框中部分:是绘制的DecorView的时候,一直递归updateDisplayListIfDirty方法进行Display List的构建
其他颜色框部分是子View Display List的构建
绘制阶段
这个阶段会调用OpenGL接口将构建好视图进行绘制渲染,将渲染好的内容保存到Graphic buffer中,并提交给SurfaceFlinger。
回到ThreadedRenderer的draw方法:
ThreadedRenderer.java
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks) {
...
updateRootDisplayList(view, callbacks);//1
...
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);//2
}在注释1中创建好视图对应的Display List后,在注释2处调用nSyncAndDrawFrame方法通知RenderThread线程进行绘制
nSyncAndDrawFrame是一个native方法,在讲解nSyncAndDrawFrame方法前我们先来看ThreadedRenderer构造函数中做了哪些事。
ThreadedRenderer(Context context, boolean translucent, String name) {
//这个方法在native层创建RootRenderNode对象并返回对象的地址
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
mRootNode.setClipToBounds(false);
//这个方法在native层创建一个RenderProxy
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
}nCreateRootRenderNode和nCreateProxy方法在android_view_ThreadedRenderer.cpp中实现:
static jlong android_view_ThreadedRenderer_createRootRenderNode(JNIEnv* env, jobject clazz) {
RootRenderNode* node = new RootRenderNode(env);
node->incStrong(0);
node->setName("RootRenderNode");
return reinterpret_cast(node);
}
static jlong android_view_ThreadedRenderer_createProxy(JNIEnv* env, jobject clazz,
jboolean translucent, jlong rootRenderNodePtr) {
RootRenderNode* rootRenderNode = reinterpret_cast(rootRenderNodePtr);
ContextFactoryImpl factory(rootRenderNode);
return (jlong) new RenderProxy(translucent, rootRenderNode, &factory);
}
RenderProxy构造方法:
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())//1
, mContext(nullptr) {
...
} 注意到mRenderThread使用的是RenderThread::getInstance()单例线程,也就说整个绘制过程只有一个RenderThread线程。
接着看RenderThread::getInstance()创建线程的方法:
RenderThread::RenderThread() : Thread(true)
...
Properties::load();
mFrameCallbackTask = new DispatchFrameCallbacks(this);
mLooper = new Looper(false);
run("RenderThread");
}居然也是使用的Looper,是不是和我们的主线程的消息机制一样呢?哈哈
调用run方法会执行RenderThread的threadLoop方法。
bool RenderThread::threadLoop() {
...
int timeoutMillis = -1;
for (;;) {
int result = mLooper->pollOnce(timeoutMillis);
...
nsecs_t nextWakeup;
{
...
while (RenderTask* task = nextTask(&nextWakeup)) {
workQueue.push_back(task);
}
for (auto task : workQueue) {
task->run();
// task may have deleted itself, do not reference it again
}
}
if (nextWakeup == LLONG_MAX) {
timeoutMillis = -1;
} else {
nsecs_t timeoutNanos = nextWakeup - systemTime(SYSTEM_TIME_MONOTONIC);
timeoutMillis = nanoseconds_to_milliseconds(timeoutNanos);
if (timeoutMillis < 0) {
timeoutMillis = 0;
}
}
if (mPendingRegistrationFrameCallbacks.size() && !mFrameCallbackTaskPending) {
...
requestVsync();
}
if (!mFrameCallbackTaskPending && !mVsyncRequested && mFrameCallbacks.size()) {
...
requestVsync();
}
}
return false;
}石锤了就是应用程序主线程的消息机制模型,
- 空闲的时候,Render Thread就睡眠在成员变量mLooper指向的一个Looper对象的成员函数pollOnce中。
- 当其它线程需要调度Render Thread,就会向它的任务队列增加一个任务,然后唤醒Render Thread进行处理。Render Thread通过成员函数nextTask获得需要处理的任务,并且调用它的成员函数run进行处理。
这里做个小结:
ThreadedRenderer构造方法中
- 1.初始化mRootNode指向native层的一个RootRenderNode
- 2.初始化mNativeProxy指向native层的RenderProxy
- 3.在native层创建RenderProxy时,同时也会创建RenderThread线程,这个线程机制和我们主线程消息机制一直,轮询等待获取绘制任务。
好了回头看nSyncAndDrawFrame的native方法
nSyncAndDrawFrame同样也在android_view_ThreadedRenderer.cpp中实现:
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz,
jlong proxyPtr, jlongArray frameInfo, jint frameInfoSize) {
LOG_ALWAYS_FATAL_IF(frameInfoSize != UI_THREAD_FRAME_INFO_SIZE,
"Mismatched size expectations, given %d expected %d",
frameInfoSize, UI_THREAD_FRAME_INFO_SIZE);
RenderProxy* proxy = reinterpret_cast(proxyPtr);
env->GetLongArrayRegion(frameInfo, 0, frameInfoSize, proxy->frameInfo());
return proxy->syncAndDrawFrame();
} 这个方法返回值是proxy->syncAndDrawFrame(),进入RenderProxy的syncAndDrawFrame方法:
int RenderProxy::syncAndDrawFrame() {
return mDrawFrameTask.drawFrame();
}这里的 mDrawFrameTask.drawFrame其实就是向RenderThread的TaskQueue添加一个drawFrame渲染任务,通知RenderThread渲染UI视图。
如下图:
mDrawFrameTask是DrawFrameTask中的函数
int DrawFrameTask::drawFrame() {
...
postAndWait();
return mSyncResult;
}
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
mRenderThread->queue(this);
mSignal.wait(mLock);//锁住等待锁释放
}
void RenderThread::queue(RenderTask* task) {
AutoMutex _lock(mLock);
mQueue.queue(task);
if (mNextWakeup && task->mRunAt < mNextWakeup) {
mNextWakeup = 0;
mLooper->wake();
}
}看到这就知道了drawFrame其实就是往RenderThread线程的任务队列mQueue中按时间顺序加入一个绘制task,并调用mLooper->wake()唤醒RenderThread线程处理。
说到底还是主线程消息机制那套东西。
注意DrawFrameTask在postAndWait的mRenderThread->queue(this)中是将this传入任务队列,所以此任务就是this自己。后面执行绘制任务就使用到了OpenGL对构建好的DisplayList进行渲染。
经过上面的分析,整个硬件绘制流程就有个清晰模型了
点到为止,后面代码大家可以自行找到源码阅读。
绘制阶段这块可能比较复杂些,因为基本上都是native层的东西,有的消化下。
硬件加速和纯软件绘制对比
| 渲染场景 | 纯软件绘制 | 硬件加速 | 加速效果分析 |
|---|---|---|---|
| 页面初始化 | 绘制所有View | 创建所有DisplayList | GPU分担了复杂计算任务 |
| 在一个复杂页面调用背景透明TextView的setText(),且调用后其尺寸位置不变 | 重绘脏区所有View | TextView及每一级父View重建DisplayList | 重叠的兄弟节点不需CPU重绘,GPU会自行处理 |
| TextView逐帧播放Alpha / Translation / Scale动画 | 每帧都要重绘脏区所有View | 除第一帧同场景2,之后每帧只更新TextView对应RenderNode的属性 | 刷新一帧性能极大提高,动画流畅度提高 |
| 修改TextView透明度 | 重绘脏区所有View | 直接调用RenderNode.setAlpha()更新 | 只触发DecorView.updateDisplayListIfDirty,不再往下遍历,CPU执行时间可忽略不计 |
呈现模式分析工具
Android 4.1(API 级别 16)或更高版本的设备上,
执行以下步骤开启工具:
- 1.启动开发者选项;
- 2.在“监控”部分,找到“GPU呈现模式分析”(不同厂商命名有所区别);
- 3.点击“GPU呈现模式分析”,弹出页面中,选择“在屏幕上显示为条形图”即可。
这时,GPU 呈现模式工具已经开启了,接下来,我们可以打开我们要测试的APP来进行观察测试了。
视觉呈现
GPU 渲染模式分析工具以图表(以颜色编码的直方图)的形式显示各个阶段及其相对时间。
Android 10 上显示的彩色部分:
注意点:
- 1.一个应用对应一个图形
- 2.沿水平轴的每个竖条代表一个帧,每个竖条的高度表示渲染该帧所花的时间(以毫秒为单位)。
- 3.中间绿色的线是16.6ms的分割线,高于绿色线表示出现了掉帧
- 4.通过加宽竖条降低透明度来反应比较耗时的帧
- 5.每个竖条都有与渲染管道中某个阶段对应的彩色区段。区段数因设备的 API 级别不同而异。
颜色块含义
Android 6.0 及更高版本的设备时分析器输出中某个竖条的每个区段含义:
4.0(API 级别 14)和 5.0(API 级别 21)之间的 Android 版本具有蓝色、紫色、红色和橙色区段。低于 4.0 的 Android 版本只有蓝色、红色和橙色区段。下表显示的是 Android 4.0 和 5.0 中的竖条区段。
GPU 呈现模式工具,很直观的为我们展示了 APP 运行时每一帧的耗时详情。我们只需要关注代表每一帧的柱状图的颜色详情,就可以分析出卡顿的原因了。
好了,现在来回答标题帧的内容,既然硬件优化这么好用,为啥没被普及?
理由如下:
- 1.稳定性,开启硬件加速后,有小概率出现画面崩溃,所以在一些视频播放器会给个开关让用户手动开关。
- 2.功耗:GPU的功耗远远大于CPU,所以使用场景比较少,一般在游戏端开启硬件加速辅助游戏运行。
- 3.内存消耗:使用OpenGL接口初始化就需要8M作用的内存。
- 4.兼容性:不兼容某些接口和api。
这就是所谓的双刃剑吧!用得好还好,用不好就鸽蛋了。。
链接:https://juejin.cn/post/7166935241108488222
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
实现一个简易Retrofit
前言
作为Android开发,大名鼎鼎的Retrofit网络请求库肯定都用过,而且在Kotlin更新协程后,Retrofit也第一时间更新了协程方式、Flow方式等编码模式,这篇文章我们利用前面的学习知识,尝试着实现一个建议版本的Retrofit,然后看看如何利用挂起函数,来以同步的方式实现异步的代码。
正文
Retrofit涉及的知识点还是蛮多的,包括自定义注解、动态代理、反射等知识点,我们就来复习一下,最后再看如何使用协程来把我们不喜欢的Callback给消灭掉。
定义注解
和Retrofit一样,我们定义俩个注解:
/**
* [Field]注解用在API接口定义的方法的参数上
* */
@Target(AnnotationTarget.VALUE_PARAMETER)
@Retention(AnnotationRetention.RUNTIME)
annotation class Field(val value: String)/**
* [GET]注解用于标记该方法的调用是HTTP的GET方式
* */
@Target(AnnotationTarget.FUNCTION)
@Retention(AnnotationRetention.RUNTIME)
annotation class GET(val value: String)这里我们定义俩个注解,Field用来给方法参数设置,GET用来给方法设置,表明它是一个HTTP的GET方法。
定义ApiService
和Retrofit一样,来定义一个接口文档,里面定义我们需要使用的接口:
/**
* [ApiService]类定义了整个项目需要调用的接口
* */
interface ApiService{
/**
* [reposAsync]用于异步获取仓库信息
*
* @param language 要查询的语言,http真实调用的是[Field]中的lang
* @param since 要查询的周期
*
* @return
* */
@GET("/repo")
fun reposAsync(
@Field("lang") language: String,
@Field("since") since: String
): KtCall<RepoList>
/**
* [reposSync]用于同步调用
* @see [reposSync]
* */
@GET("/repo")
fun reposSync(
@Field("lang") language: String,
@Field("since") since: String
): RepoList
}这里我们查询GitHub上某种语言近期的热门项目,其中reposAsync表示异步调用,返回值类型是KtCall<RepoList>,而reposSync表示同步调用,这里涉及的RepoList就是返回值的数据类型:
data class RepoList(
var count: Int?,
var items: List<Repo>?,
var msg: String?
)
data class Repo(
var added_stars: String?,
var avatars: List<String>?,
var desc: String?,
var forks: String?,
var lang: String?,
var repo: String?,
var repo_link: String?,
var stars: String?
)而KtCall则是用来承载异步调用的回调简单处理:
/**
* 该类用于异步请求承载,主要是用来把[OkHttp]中返回的请求值给转换
* 一下
*
* @param call [OkHttp]框架中的[Call],用来进行网络请求
* @param gson [Gson]的实例,用来反序列化
* @param type [Type]类型实例,用来反序列化
* */
class KtCall<T: Any>(
private val call: Call,
private val gson: Gson,
private val type: Type
){
fun call(callback: CallBack<T>): Call{
call.enqueue(object : okhttp3.Callback{
override fun onFailure(call: Call, e: IOException) {
callback.onFail(e)
}
override fun onResponse(call: Call, response: Response) {
try {
val data = gson.fromJson<T>(response.body?.string(),type)
callback.onSuccess(data)
}catch (e: java.lang.Exception){
callback.onFail(e)
}
}
})
return call
}
}在这里定义了一个泛型类,用来处理T类型的数据,异步调用还是调用OkHttp的Call的enqueue方法,在其中对OkHttp的Callback进行封装和处理,转变为我们定义的Callback类型:
/**
* 业务使用的接口,表示返回的数据
* */
interface CallBack<T: Any>{
fun onSuccess(data: T)
fun onFail(throwable:Throwable)
}这里我们暂时只简单抽象为成功和失败。
单例Http工具类
再接着,我们模仿Retrofit,来使用动态代理等技术来进行处理:
/**
* 单例类
*
* */
object KtHttp{
private val okHttpClient = OkHttpClient
.Builder()
.addInterceptor(HttpLoggingInterceptor().apply {
level = HttpLoggingInterceptor.Level.BASIC
})
.build()
private val gson = Gson()
val baseUrl = "https://trendings.herokuapp.com"
/**
* 利用Java的动态代理,传递[T]类型[Class]对象,可以返回[T]的
* 对象。
* 其中在lambda中,一共有3个参数,当调用[T]对象的方法时,会动态
* 代理到该lambda中执行。[method]就是对象中的方法,[args]是该
* 方法的参数。
* */
fun <T: Any> create(service: Class<T>): T {
return Proxy.newProxyInstance(
service.classLoader,
arrayOf(service)
){ _,method,args ->
val annotations = method.annotations
for (annotation in annotations){
if (annotation is GET){
val url = baseUrl + annotation.value
return@newProxyInstance invoke<T>(url, method, args!!)
}
}
return@newProxyInstance null
} as T
}
/**
* 调用[OkHttp]功能进行网络请求,这里根据方法的返回值类型选择不同的策略。
* @param path 这个是HTTP请求的url
* @param method 定义在[ApiService]中的方法,在里面实现中,假如方法的返回值类型是[KtCall]带
* 泛型参数的类型,则认为需要进行异步调用,进行封装,让调用者传入[CallBack]。假如返回类型是普通的
* 类型,则直接进行同步调用。
* @param args 方法的参数。
* */
private fun <T: Any> invoke(path: String, method: Method, args: Array<Any>): Any?{
if (method.parameterAnnotations.size != args.size) return null
var url = path
val paramAnnotations = method.parameterAnnotations
for (i in paramAnnotations.indices){
for (paramAnnotation in paramAnnotations[i]){
if (paramAnnotation is Field){
val key = paramAnnotation.value
val value = args[i].toString()
if (!url.contains("?")){
url += "?$key=$value"
}else{
url += "&$key=$value"
}
}
}
}
val request = Request.Builder()
.url(url)
.build()
val call = okHttpClient.newCall(request)
//泛型判断
return if (isKtCallReturn(method)){
val genericReturnType = getTypeArgument(method)
KtCall<T>(call, gson, genericReturnType)
} else {
val response = okHttpClient.newCall(request).execute()
val genericReturnType = method.genericReturnType
val json = response.body?.string()
Log.i("zyh", "invoke: json = $json")
//这里这个调用,必须要传入泛型参数
gson.fromJson<Any?>(json, genericReturnType)
}
}
/**
* 判断方法返回类型是否是[KtCall]类型。这里调用了[Gson]中的方法。
*/
private fun isKtCallReturn(method: Method) =
getRawType(method.genericReturnType) == KtCall::class.java
/**
* 获取[Method]的返回值类型中的泛型参数
* */
private fun getTypeArgument(method: Method) =
(method.genericReturnType as ParameterizedType).actualTypeArguments[0]
}上面的代码主要分为俩个部分,第一部分使用Java的动态代理类Porxy,可以通过create方法创建一个接口对象。调用该接口对象的方法,会被代理到lambda中进行处理,在lambda中我们对有GET修饰的方法进行额外处理。
第二部分就是方法的拼接和调用处理,先是针对Field注解修饰的方法参数,给拼接到url中,然后就是重点地方,判断方法的返回值类型,是否是KtCall类型,如果是的话,就认为是异步调用,否则就是同步调用。
对于异步调用,我们封装为一个KtCall的对象,而对于同步调用,我们可以直接利用Gson来解析出我们希望的数据。
Android客户端测试
这样我们就完成了一个简易的既有同步又有异步调用的网络请求封装库,我们写个页面调用一下如下:
//同步调用
private fun sync(){
thread {
val apiService: ApiService = KtHttp.create(ApiService::class.java)
val data = apiService.reposSync(language = "Kotlin", since = "weekly")
runOnUiThread {
findViewById<TextView>(R.id.result).text = data.toString()
Toast.makeText(this, "$data", Toast.LENGTH_SHORT).show()
}
}
}//异步调用
private fun async(){
KtHttp.create(ApiService::class.java).reposAsync(language = "Java", since = "weekly").call(object : CallBack<RepoList>{
override fun onSuccess(data: RepoList) {
runOnUiThread {
findViewById<TextView>(R.id.result).text = data.toString()
Toast.makeText(this@MainActivity, "$data", Toast.LENGTH_SHORT).show()
}
}
override fun onFail(throwable: Throwable) {
runOnUiThread {
findViewById<TextView>(R.id.result).text = throwable.toString()
Toast.makeText(this@MainActivity, "$throwable", Toast.LENGTH_SHORT).show()
}
}
})
}经过测试,这里代码可以正常执行。
协程小试牛刀
在前面我们说过挂起函数可以用同步的代码来写出异步的效果,就比如这里的异步回调,我们可以使用协程来进行简单改造。
首先,想把Callback类型的方式改成挂起函数方式的,有2种方法。第一种是不改变原来代码库的方式,在Callback上面套一层,也是本篇文章所介绍的方法。第二种是修改原来代码块的源码,利用协程的底层API,这个方法等后面再说。
其实在原来Callback上套一层非常简单,我们只需要利用协程库为我们提供的2个顶层函数即可:
/**
* 把原来的[CallBack]形式的代码,改成协程样式的,即消除回调,使用挂起函数来完成,以同步的方式来
* 完成异步的代码调用。
*
* 这里的[suspendCancellableCoroutine] 翻译过来就是挂起可取消的协程,因为我们需要结果,所以
* 需要在合适的时机恢复,而恢复就是通过[Continuation]的[resumeWith]方法来完成。
* */
suspend fun <T: Any> KtCall<T>.await() : T =
suspendCancellableCoroutine { continuation ->
//开始网络请求
val c = call(object : CallBack<T>{
override fun onSuccess(data: T) {
//这里扩展函数也是奇葩,容易重名
continuation.resume(data)
}
override fun onFail(throwable: Throwable) {
continuation.resumeWithException(throwable)
}
})
//当收到cancel信号时
continuation.invokeOnCancellation {
c.cancel()
}
}这里我们推荐使用suspendCancelableCoroutine高阶函数,听名字翻译就是挂起可取消的协程,我们给KtCall扩展一个挂起方法await,在该方法中,我们使用continuation对象来处理恢复的值,同时还可以响应取消,来取消OkHttp的调用。
这里注意的就是resume使用的是扩展函数,与之类似的还有一个suspendCoroutine方法,这个方法无法响应取消,我们不建议使用。
在定义完上面代码后,我们在Android使用一下:
findViewById<TextView>(R.id.coroutineCall).setOnClickListener {
lifecycleScope.launch {
val data = KtHttp.create(ApiService::class.java).reposAsync(language = "Kotlin", since = "weekly").await()
findViewById<TextView>(R.id.result).text = data.toString()
}
}可以发现在这种情况下,我们就可以使用同步的方式写出了异步代码,由于挂起函数的特性,下面那行UI操作会等到挂起函数恢复后才会执行。
总结
本篇文章主要是介绍了一些常用知识点,也让我们对Retrofit的各种方法返回类型兼容性有了一定了解,最后我们使用了在不改变原来代码库的情况下,利用封装一层的方式,来实现以同步的代码写异步的形式。
本篇文章代码地址: github.com/horizon1234…
链接:https://juejin.cn/post/7166799125559083016
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
LeakCanary 浅析
前言
平时我们都有用到LeakCanary来分析内存泄露的情况,这里可以来看看LeakCanary是如何实现的,它的内部又有哪些比较有意思的操作。
LeakCanary的使用
官方文档:square.github.io/leakcanary/…
引用方式
dependencies {
// debugImplementation because LeakCanary should only run in debug builds.
debugImplementation 'com.squareup.leakcanary:leakcanary-android:2.10'
}可以看到LeakCanary的新版本中依赖非常简单,甚至不需要你做什么就可以直接使用。
LeakCanary原理
LeakCanary的封装主要是利用ContentProvider,LeakCanary检测内存泄漏主要是监听Activity和Fragment、view的生命周期,配合弱引用和ReferenceQueue。
源码浅析
初始化
首先debugImplementation只是在Debug的包会依赖,在正式包不会把LeakCanary的内容打进包中。
LeakCanary的初始化是使用了ContentProvider,ContentProvider的onCreate会在Application的onCreate之前,它把ContentProvider写在自己的AndroidMainifest中,打包时会进行合并,所以这整个过程都不需要接入端做初始化操作。
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.squareup.leakcanary.objectwatcher" >
<uses-sdk android:minSdkVersion="14" />
<application>
<provider
android:name="leakcanary.internal.MainProcessAppWatcherInstaller"
android:authorities="${applicationId}.leakcanary-installer"
android:enabled="@bool/leak_canary_watcher_auto_install"
android:exported="false" />
</application>
</manifest>这是它在AndroidManifest所定义的,打包的时候会合并所有的AndroidManifest
这就是它自动初始化的操作,也比较明显了,不用过多解释。
使用
先看看它要监测什么,因为LeakCanary 2.x的代码都是kotlin写的,所以这里得分析kotlin,如果不熟悉kt的朋友,我只能说尽量讲慢一些,因为我想看旧版本的能不能用java来分析,但是简单看了下源码上是有一定的差别,所以还是要分析2.x。
fun appDefaultWatchers(
application: Application,
reachabilityWatcher: ReachabilityWatcher = objectWatcher
): List<InstallableWatcher> {
return listOf(
ActivityWatcher(application, reachabilityWatcher),
FragmentAndViewModelWatcher(application, reachabilityWatcher),
RootViewWatcher(reachabilityWatcher),
ServiceWatcher(reachabilityWatcher)
)
}从这里看到他主要分析Activity、Fragment和Fragment的View、RootView、Service。
看Activity的监听ActivityWatcher
监听Activity调用Destroy时会调用reachabilityWatcher的expectWeaklyReachable方法。
这里可以看看旧版本的做法(正好以前有记录)
private final Application.ActivityLifecycleCallbacks lifecycleCallbacks =
new ActivityLifecycleCallbacksAdapter() {
@Override public void onActivityDestroyed(Activity activity) {
refWatcher.watch(activity);
}
};旧版本是调用refWatcher的watch,虽然代码不同,但是思想一样,再看看旧版本的Fragment
private final FragmentManager.FragmentLifecycleCallbacks fragmentLifecycleCallbacks =
new FragmentManager.FragmentLifecycleCallbacks() {
@Override public void onFragmentViewDestroyed(FragmentManager fm, Fragment fragment) {
View view = fragment.getView();
if (view != null) {
refWatcher.watch(view);
}
}
@Override
public void onFragmentDestroyed(FragmentManager fm, Fragment fragment) {
refWatcher.watch(fragment);
}
};这里监听了Fragment和Fragment的View,所以相比于新版本,旧版本只监听Activity、Fragment和Fragment的View
再回到新版本,分析完Activity的监听之后看看Fragment的
最终Destroy之后也是调用到reachabilityWatcher的expectWeaklyReachable。然后看看RootViewWatcher的操作
private val listener = OnRootViewAddedListener { rootView ->
val trackDetached = when(rootView.windowType) {
PHONE_WINDOW -> {
when (rootView.phoneWindow?.callback?.wrappedCallback) {
is Activity -> false
is Dialog -> {
......
}
else -> true
}
}
POPUP_WINDOW -> false
TOOLTIP, TOAST, UNKNOWN -> true
}
if (trackDetached) {
rootView.addOnAttachStateChangeListener(object : OnAttachStateChangeListener {
val watchDetachedView = Runnable {
reachabilityWatcher.expectWeaklyReachable(
rootView, "${rootView::class.java.name} received View#onDetachedFromWindow() callback"
)
}
......
})
}
}最终也是调用到reachabilityWatcher的expectWeaklyReachabl。最后再看看Service的。
这边因为只是做浅析,不是源码详细分析,所以我这边就不去一个个分析是如何调用到销毁的这个方法的,我们通过上面的方法得到一个结论,Activity、Fragment和Fragment的View、RootView、Service,他们几个,在销毁时都会调用到reachabilityWatcher的expectWeaklyReachabl。所以这些地方就是检测对象是否泄漏的入口。
然后我们来看看expectWeaklyReachable方法
@Synchronized override fun expectWeaklyReachable(
watchedObject: Any,
description: String
) {
// 先从queue中移除一次已回收对象
removeWeaklyReachableObjects()
// 生成随机数当成key
val key = UUID.randomUUID().toString()
val watchUptimeMillis = clock.uptimeMillis()
// 创建弱引用关联ReferenceQueue
val reference =
KeyedWeakReference(watchedObject, key, description, watchUptimeMillis, queue)
......
// 把reference和key 添加到一个Map中
watchedObjects[key] = reference
// 下一步
checkRetainedExecutor.execute {
moveToRetained(key)
}
}你们运气真好,我正好以前也有记录旧版本的refWatcher的watch方法
public void watch(Object watchedReference, String referenceName) {
......
// 生成随机数当成key
String key = UUID.randomUUID().toString();
// 把key 添加到一个Set中
this.retainedKeys.add(key);
// 创建弱引用关联ReferenceQueue
KeyedWeakReference reference = new KeyedWeakReference(watchedReference, key, referenceName, this.queue);
// 下一步
this.ensureGoneAsync(watchStartNanoTime, reference);
}通过对比发现,模板的流程是一样的,但是细节不一样,以前是用Set,现在是用Map,这就是我觉得不能拿旧版本代码来分析的原因。
文章写到这里,突然想到一个很有意思的东西,你要是面试时,面试官看过新版本的代码,你看的是旧版本的代码,结果如果问到一些比较深入的细节,你答出来的和他所理解的不同,那就尴尬了,所以面试时得先说清楚你是看过旧版本的代码
看到用一个弱引用生成一个key和对象绑定起来。然后调用ensureGoneAsync方法
private void ensureGoneAsync(final long watchStartNanoTime, final KeyedWeakReference reference) {
this.watchExecutor.execute(new Retryable() {
public Result run() {
return RefWatcher.this.ensureGone(reference, watchStartNanoTime);
}
});
}execute里面会调用到waitForIdle方法。
我们再回到新版本的代码中
checkRetainedExecutor.execute其实是会执行到这里(kt里面的是写得简单,但是不熟的话可以先别管怎么执行的,只要先知道反正执行到这个地方就行)
这里是做了一个延时发送消息的操作,延时5秒,具体代码在这里
写到这里我感觉有点慌了,因为如果不熟kt的朋友可能真会看困,其实如果看不懂这个代码的话没关系,只要我圈出来的地方,我觉是大概能看懂的,然后流程我会说,我的意思是没必要深入去看每一行是什么意思,我们的目的是找出大概的流程(用游戏的说法,我们是走主线任务,不是要全收集)
延迟5秒后会调回到前面的moveToRetained(key)。那不好意思各位,我又要拿旧版本来对比了,因为细节不同。
private void waitForIdle(final Retryable retryable, final int failedAttempts) {
// 使用IdleHandler来实现在闲时才去执行后面的流程
Looper.myQueue().addIdleHandler(new MessageQueue.IdleHandler() {
@Override public boolean queueIdle() {
postToBackgroundWithDelay(retryable, failedAttempts);
return false;
}
});
}使用IdleHandler来完成闲时触发,我不记得很早之前的版本是不是也用的IdleHandler,这里使用IdleHandler只能说有好有坏吧,好处是闲时触发确实是一个很好的操作,不好的地方是如果一直有异步消息,就一直不会触发后面的流程。
private void postToBackgroundWithDelay(final Retryable retryable, final int failedAttempts) {
long exponentialBackoffFactor = (long) Math.min(Math.pow(2, failedAttempts), maxBackoffFactor);
long delayMillis = initialDelayMillis * exponentialBackoffFactor;
// 根据上下文去计算,这里是5秒
backgroundHandler.postDelayed(new Runnable() {
@Override public void run() {
Retryable.Result result = retryable.run();
if (result == RETRY) {
postWaitForIdle(retryable, failedAttempts + 1);
}
}
}, delayMillis);
}看到旧版本是先用IdelHanlder,在闲时触发的情况下再去延时5秒,而新版本是直接延时5秒,不使用IdelHandler,我没看过这块具体的文档描述,我猜是为了防止饿死,如果用IdelHanlder的话可能会出现一直不触发的情况。
返回看新版本的moveToRetained
@Synchronized private fun moveToRetained(key: String) {
// 从ReferenceQueue中拿出对象移除
removeWeaklyReachableObjects()
// 经过上一步之后判断Map中还有没有这个key,有的话进入下一步操作
val retainedRef = watchedObjects[key]
if (retainedRef != null) {
retainedRef.retainedUptimeMillis = clock.uptimeMillis()
onObjectRetainedListeners.forEach { it.onObjectRetained() }
}
}
private fun removeWeaklyReachableObjects() {
// 从ReferenceQueue中拿出对象,然后从Map中移除
var ref: KeyedWeakReference?
do {
ref = queue.poll() as KeyedWeakReference?
if (ref != null) {
watchedObjects.remove(ref.key)
}
} while (ref != null)
}moveToRetained主要是从ReferenceQueue中找出弱引用对象,然后移除Map中相应的弱引用对象。弱引用+ReferenceQueue的使用,应该不用多说吧,如果弱引用持有的对象被回收,弱引用会添加到ReferenceQueue中。所以watchedObjects代表的是应该将要被回收的对象,queue表示已经被回收的对象,这步操作就是从queue中找出已经回收的对象,然后从watchedObjects移除相应的对象,剩下的的就是应该被回收却没被回收的对象。如果对象被正常回收,那这整个流程就走完了,如果没被回收,会执行到onObjectRetained(),之后就是Dump操作了,之后的就是内存分析、弹出通知那堆操作了,去分析内存的泄漏这些,因为内容比较多,这篇先大概就先到这里。
总结
浅析,就是只做了简单分析LeakCanary的整个工作过程和工作原理。
原理就是用弱引用和ReferenceQueue去判断应该被回收的对象是否已经被回收。大致的工作流程是:监听Activity、Fragment和Fragment的View、RootView、Service对象的销毁,然后将这些对象放入“应该被回收”的容器中,然后5秒后通过弱引用和ReferenceQueue去判断对象是否已被回收,如果被回收则从容器中删除对应的对象,否则进行内存分析。
至于是如何判断不同对象的销毁和如何分析内存情况找出泄漏的引用链,这其中也是细节满满,但是我个人LeakCanary应该是看过两三次源码了,从一开始手动初始化,到旧版本java的实现方式,到现在用kt去实现,能发现它的核心思想其实是一样的,只不过在不断的优化一些细节和不断的扩展可以监测的对象。
2.10版本的源码我也是第一次看,我是一面看一面写这篇文章,如果有哪里流程是我看错的,希望大佬们能及时提出,我也会及时更正。
链接:https://juejin.cn/post/7167026728596946980
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
分享Kotlin协程在Android中的使用
前言
之前我们学了几个关于协程的基础知识,本文将继续分享Kotlin协程的知识点~挂起,同时介绍协程在Android开发中的使用。
正文
挂起
suspend关键字
说到挂起,那么就会离不开suspend关键字,它是Kotlin中的一个关键字,它的中文意思是暂停或者挂起。
以下是通过suspend修饰的方法:
suspend fun suspendFun(){
withContext(Dispatchers.IO){
//do db operate
}
}通过suspend关键字来修饰方法,限制这个方法只能在协程里边调用,否则编译不通过。
suspend方法其实本身没有挂起的作用,只是在方法体力便执行真正挂起的逻辑,也相当于提个醒。如果使用suspend修饰的方法里边没有挂起的操作,那么就失去了它的意义,也就是无需使用。
虽然我们无法正常去调用它,但是可以通过反射去调用:
suspend fun hello() = suspendCoroutine<Int> { coroutine ->
Log.i(myTag,"hello")
coroutine.resumeWith(kotlin.Result.success(0))
}
//通过反射来调用:
fun helloTest(){
val helloRef = ::hello
helloRef.call()
}
//抛异常:java.lang.IllegalArgumentException: Callable expects 1 arguments, but 0 were provided.fun helloTest(){
val helloRef = ::hello
helloRef.call(object : Continuation<Int>{
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: kotlin.Result<Int>) {
Log.i(myTag,"result : ${result.isSuccess} value:${result.getOrNull()}")
}
})
}
//输出:hello挂起与恢复
看一个方法:
public suspend inline fun <T> suspendCancellableCoroutine(
crossinline block: (CancellableContinuation<T>) -> Unit
): T =
suspendCoroutineUninterceptedOrReturn { uCont ->
val cancellable = CancellableContinuationImpl(uCont.intercepted(), resumeMode = MODE_CANCELLABLE)
block(cancellable)
cancellable.getResult()
}这是Kotlin协程提供的api,里边虽然只有短短的三句代码,但是实现甚是复杂而且关键。
继续跟进看看getResult()方法:
internal fun getResult(): Any? {
installParentCancellationHandler()
if (trySuspend()) return COROUTINE_SUSPENDED//返回此对象表示挂起
val state = this.state
if (state is CompletedExceptionally) throw recoverStackTrace(state.cause, this)
if (resumeMode == MODE_CANCELLABLE) {//检查
val job = context[Job]
if (job != null && !job.isActive) {
val cause = job.getCancellationException()
cancelResult(state, cause)
throw recoverStackTrace(cause, this)
}
}
return getSuccessfulResult(state)//返回结果
}最后写一段代码,然后转为Java看个究竟:
fun demo2(){
GlobalScope.launch {
val user = requestUser()
println(user)
val state = requestState()
println(state)
}
}编译后生成的代码大致流程如下:
public final Object invokeSuspend(Object result) {
...
Object cs = IntrinsicsKt.getCOROUTINE_SUSPENDED();//上面所说的那个Any:CoroutineSingletons.COROUTINE_SUSPENDED
switch (this.label) {
case 0:
this.label = 1;
user = requestUser(this);
if(user == cs){
return user
}
break;
case 1:
this.label = 2;
user = result;
println(user);
state = requestState(this);
if(state == cs){
return state
}
break;
case 2:
state = result;
println(state)
break;
}
}当协程挂起后,然后恢复时,最终会调用invokeSuspend方法,而协程的block代码会封装在invokeSuspend方法中,使用状态来控制逻辑的实现,并且保证顺序执行。
通过以上我们也可以看出:
- 本质上也是一个回调,Continuation
- 根据状态进行流转,每遇到一个挂起点,就会进行一次状态的转移。
协程在Android中的使用
举个例子,使用两个UseCase来模拟挂起的操作,一个是网络操作,另一个是数据库的操作,然后操作ui,我们分别看一下代码上面的区别。
没有使用协程:
//伪代码
mNetworkUseCase.run(object: Callback {
onSuccess(user: User) {
mDbUseCase.insertUser(user, object: Callback{
onSuccess() {
MainExcutor.excute({
tvUserName.text = user.name
})
}
})
}
})我们可以看到,用回调的情况下,只要对数据操作稍微复杂点,回调到主线程进行ui操作时,很容易就嵌套了很多层,导致了代码难以看清楚。那么如果使用协程的话,这种代码就可以得到很大的改善。
使用协程:
private fun requestDataUseGlobalScope(){
GlobalScope.launch(Dispatchers.Main){
//模拟从网络获取用户信息
val user = mNetWorkUseCase.requireUser()
//模拟将用户插入到数据库
mDbUseCase.insertUser(user)
//显示用户名
mTvUserName.text = user.name
}
}对以上函数作说明:
- 通过GlobalScope开启一个顶层协程,并制定调度器为Main,也就是该协程域是在主线程中运行的。
- 从网络获取用户信息,这是一个挂起操作
- 将用户信息插入到数据库,这也是一个挂起操作
- 将用户名字显示,这个操作是在主线程中。
由此在这个协程体中就可以一步一步往下执行,最终达到我们想要的结果。
如果我们需要启动的线程越来越多,可以通过以下方式:
private fun requestDataUseGlobalScope1(){
GlobalScope.launch(Dispatchers.Main){
//do something
}
}
private fun requestDataUseGlobalScope2(){
GlobalScope.launch(Dispatchers.IO){
//do something
}
}
private fun requestDataUseGlobalScope3(){
GlobalScope.launch(Dispatchers.Main){
//do something
}
}但是平时使用,我们需要注意的就是要在适当的时机cancel掉,所以这时我们需要对每个协程进行引用:
private var mJob1: Job? = null
private var mJob2: Job? = null
private var mJob3: Job? = null
private fun requestDataUseGlobalScope1(){
mJob1 = GlobalScope.launch(Dispatchers.Main){
//do something
}
}
private fun requestDataUseGlobalScope2(){
mJob2 = GlobalScope.launch(Dispatchers.IO){
//do something
}
}
private fun requestDataUseGlobalScope3(){
mJob3 = GlobalScope.launch(Dispatchers.Main){
//do something
}
}如果是在Activity中,那么可以在onDestroy中cancel掉
override fun onDestroy() {
super.onDestroy()
mJob1?.cancel()
mJob2?.cancel()
mJob3?.cancel()
}可能你发现了一个问题:如果启动的协程不止是三个,而是更多呢?
没错,如果我们只使用GlobalScope,虽然能够达到我们的要求,但是每次我们都需要去引用他,不仅麻烦,还有一点是它开启的顶层协程,如果有遗漏了,则可能出现内存泄漏。所以我们可以使用kotlin协程提供的一个方法MainScope()来代替它:
private val mMainScope = MainScope()
private fun requestDataUseMainScope1(){
mMainScope.launch(Dispatchers.IO){
//do something
}
}
private fun requestDataUseMainScope2(){
mMainScope.launch {
//do something
}
}
private fun requestDataUseMainScope3(){
mMainScope.launch {
//do something
}
}可以看到用法基本一样,但有一点很方便当我们需要cancel掉所有的协程时,只需在onDestroy方法cancel掉mMainScope就可以了:
override fun onDestroy() {
super.onDestroy()
mMainScope.cancel()
}MainScope()方法:
@Suppress("FunctionName")
public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)使用的是一个SupervisorJob(制定的协程域是单向传递的,父传给子)和Main调度器的组合。
在平常开发中,可以的话使用类似于MainScope来启动协程。
结语
本文的分享到这里就结束了,希望能够给你带来帮助。关于Kotlin协程的挂起知识远不止这些,而且也不容易理清,还是会继续去学习它到底用哪些技术点,深入探究原理究竟是如何。
链接:https://juejin.cn/post/7130427677432872968
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
看完这篇,你也可以搞定有趣的动态曲线绘制
前言
接下来我们来了解一下 Path 类的一些特性。Path 类用于描述绘制路径,可以实现绘制线段、曲线、自定义形状等功能。本篇我们介绍 Path 的一个描述类 PathMetric 的应用。通过本篇你会了解以下两方面的内容:
PathMetric类简介。PathMetric的应用。
PathMetric 简介
PathMetric 是一个用于测量 Path 和抽取子路径(sub-paths) 的工具,通过 Path 类的 computeMetrics方法可以返回一组PathMetric 类。为什么是一组,而不是一个呢?这是因为 Path 可能包含多个不连续的子路径,比如通过 moveTo 可以重新开启新的一段路径。
通过 PathMetric 可以获取到 Path 的长度,路径是否闭合,以及某一段路径是否是 Path的子路径。PathMetrics 是一个迭代器,因此在不获取其中的 PathMetric 对象时,并不会实际进行 Path 的相关计算,这样可以提高效率。另外需要注意的是,通过 computeMetrics 方法计算得到的是一个当前Path 对象的快照,如果在之后更改了 Path 对象,并不会进行更新。
我们来看一下 PathMetric 的一些属性和方法。
length:Path对象其中一段(独立的)的长度;isClosed:判断Path对象是否闭合;contourIndex:当前对象在PathMetrics中的次序;getTangentForOffset:这个方法通过距离起点的长度的偏移量(即从0 到length中的某个位置)返回一个Tangent对象,通过这个对象可以获取到Path某一段路径途中的任意一点的位置以及角度。以下面的图形为例,从点(0, 0)到点(2, 2)的线段总长度为2.82,如果我们通过getTangentForOffset获取距离起始点1.41 的位置的Tangent对象,就会得到该位置的坐标是(1, 1),角度是45度(实际以弧度的方式计算)。
extractPath:通过距离 Path 起点的开始距离和结束距离获取这段路劲的子路径,如下图所示。
PathMetric 应用
我们来通过 PathMetric 实现下面动图的效果。
这张图最开始绘制的是一条贝塞尔曲线,是通过 Path 自带的贝塞尔曲线绘制的,代码如下所示。
Path path = Path();
final curveHeight = 60.0;
final stepWidth = size.width / 4;
path.moveTo(0, size.height / 2);
path.quadraticBezierTo(size.width / 2 - stepWidth,
size.height / 2 - curveHeight, size.width / 2, size.height / 2);
path.quadraticBezierTo(size.width / 2 + stepWidth,
size.height / 2 + curveHeight, size.width, size.height / 2);
quadraticBezierTo这个方法就是从 Path 当前的终点到参数3,4(参数名为 x2,y2)绘制一条贝塞尔曲线,控制点为参数1,2(参数名为 x1,y1)。
动画过程中曲线上的红色圆点就是通过 PathMetric 得到的,动画对象 Animation 的值从0-1变化,我们通过这个值乘以曲线的长度就能得到getTangentForOffset方法所需的偏移量,然后就可以确定动画过程中绘制圆点的位置了,代码如下所示。
for (var pathMetric in metrics) {
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * animationValue);
paint.style = PaintingStyle.fill;
canvas.drawCircle(tangent!.position, 4.0, paint);
}接下来是动画过程中的我们看到红色曲线会逐步覆盖蓝色曲线,这就是用 extractPath获取子路径完成的,在动画过程,我们控制 extractPath的结束位置,就可以逐步完成原有曲线的覆盖了,实现代码只有两行,如下所示。
var subPath =
pathMetric.extractPath(0.0, pathMetric.length * animationValue);
canvas.drawPath(subPath, paint);
最后是底下的填充,填充我们使用了渐变色,这个利用了之前我们讲过的Paint 对象的 shader 属性实现,具体可以参考之前的文章。填充其实就是一段闭合的 Path,只是在动画过程中控制右边绘制的边界就可以了,然后上面跟随曲线的部分还是基于子路径完成的。填充部分实现代码如下。
var fillPath = Path();
fillPath.moveTo(0, size.height);
fillPath.lineTo(0, size.height / 2);
fillPath.addPath(subPath, Offset(0, 0));
fillPath.lineTo(tangent.position.dx, size.height);
fillPath.lineTo(0, size.height);
paint.shader = LinearGradient(
begin: Alignment.topCenter,
end: Alignment.bottomCenter,
colors: [Colors.red[400]!, Colors.blue[50]!],
).createShader(Rect.fromLTRB(
0,
size.height / 2 - curveHeight,
size.width,
size.height,
));
canvas.drawPath(fillPath, paint);完整代码已经提交至:绘图相关代码,文件名为:path_metrics_demo.dart。
总结
本篇介绍了 Flutter 路径Path 的工具类 PathMetric的介绍和应用,通过 PathMetric 我们可以定位到 Path 的指定位长度的位置的信息,也可以通过起始点从 Path 中抽取子路径。有了这些基础,就可以实现很多场景的应用,比如曲线上布局标识或填充,标记指定位置的点等等。
链接:https://juejin.cn/post/7122790277315559437
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
10 个有用的 Kotlin flow 操作符
Kotlin 拥有函数式编程的能力,运用得当,可以简化代码,层次清晰,利于阅读,用过都说好。
然而操作符数量众多,根据使用场景选择合适的操作符是一个很大的难题,网上搜索了许久只是学习了一个操作符,还要再去验证它,实在浪费时间,开发效率低下。
一种方式是转至命令式开发,将过程按步骤实现,即可完成需求;另一种方式便是一次学习多个操作符,在下次选择操作符时,增加更多选择。
本篇文章当然关注的是后者,列举一些比较常用 Kotlin 操作符,为提高效率助力,文中有图有代码有讲解,文末有参考资料和一个交互式学习的网站。
让我们开始吧。
1. reduce
reduce 操作符可以将所有数据累加(加减乘除)得到一个结果
listOf(1, 2, 3).reduce { a, b ->
a + b
}
输出:6如果 flow 中没有数据,将抛出异常。如不希望抛异常,可使用 reduceOrNull 方法。
reduce 操作符不能变换数据类型。比如,Int 集合的结果不能转换成 String 结果。
2. fold
fold 和 reduce 很类似,但是 fold 可以变换数据类型
有时候,我们不需要一个结果值,而是需要继续操 flow,可使用 runningFold 。
flowOf(1, 2, 3).runningFold("a") { a, b ->
a + b
}.collect {
println(it)
}
输出:
a
a1
a12
a123同样的,reduce 也有类似的方法 runningReduce
flowOf(1, 2, 3).runningReduce { a, b ->
a + b
}.collect {
println(it)
}
输出:
1
3
63. debounce
debounce 需要传递一个毫秒值参数,功能是:只有达到指定时间后才发出数据,最后一个数据一定会发出。
例如,定义 1000 毫秒,也就是 1 秒,被观察者发出数据,1秒后,观察者收到数据,如果 1 秒内多次发出数据,则重置计算时间。
flow {
emit(1)
delay(590)
emit(2)
delay(590)
emit(3)
delay(1010)
emit(4)
delay(1010)
}.debounce(
1000
).collect {
println(it)
}
输出结果:
3
4rebounce 的应用场景是限流功能
4. sample
sample 和 debounce 很像,功能是:在规定时间内,只发送一个数据
flow {
repeat(4) {
emit(it)
delay(50)
}
}.sample(100).collect {
println(it)
}
输出结果:
1
3sample 的应用场景是截流功能
debounce 和 sample 的限流和截流功能已有网友实现,点击这里
5. flatmapMerge
简单的说就是获得两个 flow 的乘积或全排列,合并并且平铺,发出一个 flow。
描述的仍然不好理解,一看代码便能理解了
flowOf(1, 3).flatMapMerge {
flowOf("$it a", "$it b")
}.collect {
println(it)
}
输出结果:
1 a
1 b
3 a
3 bflatmapMerge 还有一个特性,在下一个操作符里提及。
6. flatmapConcat
先看代码。
flowOf(1, 3).flatMapConcat {
flowOf("a", "b", "c")
}.collect {
println(it)
}功能和 flatmapMerge 一致,不同的是 flatmapMerge 可以设置并发量,可以理解为 flatmapMerge 是线程安全的,而 flatmapConcat 不是线程安全的。
本质上,在 flatmapMerge 的并发参数设置为 1 时,和 flatmapConcat 基本一致,而并发参数大于 1 时,采用 channel 的方式发出数据,具体内容请参阅源码。
7. buffer
介绍 buffer 的时候,先要看这样一段代码。
flowOf("A", "B", "C", "D")
.onEach {
println("1 $it")
}
.collect { println("2 $it") }
输出结果:
1 A
2 A
1 B
2 B
1 C
2 C
1 D
2 D注意输出的内容。
加上 buffer 的代码。
flowOf("A", "B", "C", "D")
.onEach {
println("1 $it")
}
.buffer()
.collect { println("2 $it") }
输出结果:
1 A
1 B
1 C
1 D
2 A
2 B
2 C
2 D输出内容有所不同,buffer 操作符可以改变收发顺序,像有一个容器作为缓冲似的,在容器满了或结束时,下游开始接到数据,onEach 添加延迟,效果更明显。
8. combine
合并两个 flow,长的一方会持续接受到短的一方的最后一个数据,直到结束
flowOf(1, 3).combine(
flowOf("a", "b", "c")
) { a, b -> b + a }
.collect {
println(it)
}
输出结果:
a1
b3
c39. zip
也是合并两个 flow,结果长度与短的 flow 一致,很像木桶原理。
flowOf(1, 3).zip(
flowOf("a", "b", "c")
) { a, b -> b + a }
.collect {
println(it)
}
输出结果:
a1
b310. distinctUntilChanged
就像方法名写的那样,和前一个数据不同,才能收到,和前一个数据想通,会被过滤掉。
flowOf(1, 1, 2, 2, 3, 1).distinctUntilChanged().collect {
println(it)
}
输出结果:
1
2
3
1最后
以上就是今天要介绍的操作符,希望对大家有所帮助。
参考文章:Android — 9 Useful Kotlin Flow Operators You Need to Know
Kotlin 交互式操作符网站:交互式操作符网站
链接:https://juejin.cn/post/7135013334059122719
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
GET 和 POST 有什么区别?
GET 和 POST 是 HTTP 请求中最常用的两种请求方法,在日常开发的 RESTful 接口中,都能看到它们的身影。而它们之间的区别,也是一道常见且经典的面试题,所以我们本文就来详细的聊聊。
HTTP 协议定义的方法类型总共有以下 10 种:
PS:目前大部分的网站使用的都是 HTTP 1.1 的协议。
但在日常开发中,使用频率最高的就属 GET 请求和 POST 请求了,尤其是在中、小型公司,基本只会使用这两种请求来实现一个项目。
1.相同点和最本质的区别
1.1 相同点
GET 请求和 POST 请求底层都是基于 TCP/IP 协议实现的,使用二者中的任意一个,都可以实现客户端和服务器端的双向交互。
1.2 最本质的区别
GET 和 POST 最本质的区别是“约定和规范”上的区别,在规范中,定义 GET 请求是用来获取资源的,也就是进行查询操作的,而 POST 请求是用来传输实体对象的,因此会使用 POST 来进行添加、修改和删除等操作。
当然如果严格按照规范来说,删除操作应该使用 DELETE 请求才对,但在实际开发中,使用 POST 来进行删除的用法更常见一些。
按照约定来说,GET 和 POST 的参数传递也是不同的,GET 请求是将参数拼加到 URL 上进行参数传递的,而 POST 是将请参数写入到请求正文中传递的,如下图所示:
2.非本质区别
2.1 缓存不同
GET 请求一般会被缓存,比如常见的 CSS、JS、HTML 请求等都会被缓存;而 POST 请求默认是不进行缓存的。
2.2 参数长度限制不同
GET 请求的参数是通过 URL 传递的,而 URL 的长度是有限制的,通常为 2k,当然浏览器厂商不同、版本不同这个限制的大小值可能也不同,但相同的是它们都会对 URL 的大小进行限制;而 POST 请求参数是存放在请求正文(request body)中的,所以没有大小限制。
2.3 回退和刷新不同
GET 请求可以直接进行回退和刷新,不会对用户和程序产生任何影响;而 POST 请求如果直接回滚和刷新将会把数据再次提交,如下图所示:
2.4 历史记录不同
GET 请求的参数会保存在历史记录中,而 POST 请求的参数不会保留到历史记录中。
2.5 书签不同
GET 请求的地址可被收藏为书签,而 POST 请求的地址不能被收藏为书签。
总结
GET 和 POST 是 HTTP 请求中最常用的两种请求方法,它们的底层都是基于 TCP/IP 实现的。它们的区别主要体现在 5 个方面:缓存不同、参数长度限制不同、回退和刷新不同、历史记录不同、能否保存为书签不同,但它们最大的区别是规范和约定上的不同,规范中定义 GET 是用来获取信息的,而 POST 是用来传递实体的,并且 GET 请求的参数要放在 URL 上,而 POST 请求的参数要放在请求正文中。
链接:https://juejin.cn/post/7127443645073981476
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
求知 | 聊聊Android资源加载那些事 - Resource的初始化
Hi ,你好 :)
引言
在上一篇,求知 | 聊聊Android资源加载的那些事 - 小试牛刀 中,我们通过探讨 Resource.getx() 等方法,从而解释了相关方法的背后实现。
那么,不知道你有没有好奇 context.resources 与 Resource.getSystem() 有什么不同呢?前者又是在什么时候被初始化的呢?
如果你对上述问题依然存疑,或者你想在复杂中找到一个较清晰的脉络,那本文可能会对你有所帮助。本篇将与你一同探讨关于 Resources 初始化的那些事。
本篇定位中等,主要通过伪源码的方式探索
Resources的初始化过程📌
导航
学完本篇,你将明白以下内容:
Resource(Activity)、Resource(App)初始化流程Context.resource与Resource.getSystem()的不同之处
基础概念
开始本篇前,我们先了解一些必备的基础概念:
ActivityResource
用于持有
Activity或者WindowContext相关联的Resources;
ActivityResources
用于管理
Acitivty的config和其所有ActivityResource,以及当前正在显示的屏幕id;
ResourceManager
用于管理
App所有的resources,内部有一个mActivityResourceReferencesmap保存着所有activity或者windowsToken对应的Resources对象。
Resource(Activity)
在 Activity 中调用 getX() 相关方法时,点进源码不难发现,内部都是调用的 getResource().x ,而 getResource() 又是来自 Context ,所以一切的源头也即从这里开始。
了解 context 的小伙伴应该有印象, context 作为一个顶级抽象类,无论是 Activity 还是 Application 都是其的子类, Context 的实现类又是 ContextImpl,所以当我们要找 Activity 中 resource 在哪里被初始化时🧐,也即是在找:
->
ContextImpl.resource在哪里被初始化? ➡️
顺藤摸瓜,我们去看看 ContextImpl.createActivityContext()。
该方法的调用时机是在构建我们 Activity 之前调用,目的是用于创建 context 实例。
流程分析
具体如下:
ContextImpl.createActivityContext ->
上述总结如下:
内部会获取当前的 分辨率 、
classLoader等配置信息,并调用ResourcesManager.getInstance()从而获取ResourcesManager的单例对象,然后使用其的createBaseTokenResources()去创建最终的Resources。
接着 将resource对象保存到
context中,即赋值给ContextImpl.mResources。
ps: 如果 sdk>=26 ,还会做
CompatResources的判断。
了解了上述流程,我们接着去看 resourcesManager.createBaseTokenResources() 。
ResourceManager.createBaseTokenResources()
上述总结如下:
该方法用于创建当前
activity相对应的resources,内部会经历如下步骤:
先查找或创建当前 token(activity) 所对应的
resources;
Yes -> 什么都不做;
No -> 创建一个
ActivityResources,并将其添加到mActivityResourceReferencesmap中;
接着再去更新该
activity对应resources(内部会再次执行第一步);
再次查找当前的
resources,如果找到,则直接返回;
如果找不到,则重新创建一个
resources(内部又会再执行第一步);
具体的步骤如下所示:
-1. getOrCreateActivityResourcesStructLocked()
ResourcesManager.getOrCreateActivityResourcesStructLocked()
private ActivityResources getOrCreateActivityResourcesStructLocked(
IBinder activityToken) {
// 先从map获取
ActivityResources activityResources = mActivityResourceReferences.get(activityToken);
// 不存在,则创建新的,并以token为key保存到map中,并返回新创建的ActivityResources
if (activityResources == null) {
activityResources = new ActivityResources();
mActivityResourceReferences.put(activityToken, activityResources);
}
return activityResources;
}如题所示,获取或创建 ActivityResources 。如果存在则返回,否则创建并保存到 ResourcesManager.mActivityResourceReferences中。
-2. updateResourcesForActivity()
ResourcesManager.updateResourcesForActivity()
流程如下:
内部会先获取当前
activity对应的resources(如果不存在,则创建),如果当前传入的配置与之前一致,则直接返回。
否则先使用当前 activity 对应的配置 创建一个 [旧]配置对象,接着去更新该 activity 所有的 resources 具体实现类impl。每次更新时会先与先前的配置进行差异更新并返回新的 ReourcesKey ,并使用这个 key 获取其对应的 impl (如果没有则创建),获取到的 resource 实现类 impl 如果与当前的不一致,则更新当前 resources 的 impl。
-3. findResourcesForActivityLocked()
ResourcesManager.findResourcesForActivityLocked()
流程如下:
当通过 findResourcesForActivityLocked() 获取指定的 resources 时,内部会先获取当前 token 对应的 activityResources ,从而拿到其所有的 resources ;然后遍历所有 resources ,如果某个 resouces 对应的 key(ResourcesKey) 与当前查找的一致并且符合其他规则,则直接返回,否则无符合条件时返回null。
–4.createResourcesForActivity()
ResourcesManager.createResourcesForActivity()
流程如下:
在创建
Resources时,内部会先使用key查找相应的ResourcesImpl,如果没找到,则直接返回null,否则调用createResourcesForActivityLocked()创建新的Resources.
总结
当我们在 Activity、Fragment 中调用 getX() 相关方法时,由于 context 只是一个代理,提供了获取 Resources 的 getx() 方法,具体实现在 ContextImpl。所以在我们的 Activity 被创建之前,会先创建 contextImpl,从而调用 createActivityContext() 这个方法内部完成了对 resources 的初始化。内部会先拿到 ResourcesManager(用于管理我们所有resources),从而调用其的createBaseTokenResources() 去创建所需要的 resources ,然后将其赋值给 contextImpl。
在具体的创建过程中分为如下几步:
- 先从
ResourcesManager缓存 (mActivityResourceReferences) 中去找当前 token(Ibinder) 所对应的ActivityResources,如果没找到则重新创建一个,并将其添加到map中; - 接着再去更新当前
token所关联ActivityResources内部(activityResource)所有的resources,如果现有的配置参数与当前要更新的一致,则跳过更新,否则遍历更新所有resources; - 再去获取所需要的
resources,如果找到则返回,否则开始创建新的resources; - 内部会先去获取
ResourcesImpl,如果不存在则会创建一个新的,然后带上所有配置以及 token 去创建相应的resources,内部也同样会执行一遍第一步,然后再创建ActivityResource,并将其添加到第一步创建的activityResouces中。
Resrouces(Application)
Application 级别的,我们应该从哪里找入口呢?🧐
既然是 Application 级别,那就找找 Application 什么时候初始化?而 Resources 来自 Context ,所以我们要寻找的位置又自然是 ContextImpl 了。故此,我们去看看
->
ContexntImpl.createSystemContext()
该方法用于创建 App 的第一个上下文对象,即也就是 AppContext。
流程分析
ContexntImpl.createSystemContext()
fun createSystemContext(mainThread:ActivityThread) {
// 创建和系统包有关的资源信息
val packageInfo = LoadedApk(mainThread)
...
val context = ContextImpl(xxx)
➡️
context.setResources(packageInfo.getResources())
...
return context
}如上所示,当创建系统 Context 时,会先初始化一个 LoadedApk ,用于管理我们系统包相关信息,然后再创建 ContextImpl ,然后调用创建好的 LoadedApk 的 getResources() 方法获取系统资源对象,并将其设置给我们的 ContextImpl 。
➡️ LoadedApk.getResources()
当我们获取 resources 时,内部会先判断是否存在,如果不存在,则调用 ResourcesManager.getResources() 去获取新的 resources 并返回,否则直接返回现有的。相应的,我们再去看看 ResourcesManager.getResources() 。
➡️➡️ ResourcesManager.getResources()
如上所示,内部会对传入的 activityToken 进行判断,如果为 null ,则调用 createResourceForActivity() 去创建;否则调用 createResources() 去创建,具体内部的逻辑和最开始相似,内部会先使用 key 查找相应的 ResourcesImpl ,如果没找到,则分别调用相关方法再去创建 Resources 。
关于 createResourceLocked() ,我们再看一眼,如下所示:
这个方法内部创建了一个新的resources, 最终将其add到了ResourcesManager.mResourceReferences这个List中,以便复用。
总结
当我们的 App 启动后,初始化 Application 时,会调用到 ContexntImpl.createSystemContext() ,该方法内部同时也会完成对我们Resources 的初始化。内部流程如下:
- 先初始化
LoadedApk对象(其用于管理app的信息),再调用其的getResources()方法获取具体的Resources; - 在上述方法内部,会先判断当前
resources是否为 null。 如果为null,则使用ResourcesManager.getResources()去获取,因为这是application的初始化,所以不存在activityToken,故内部会直接调用ResourceManager.createResource()方法,内部会创建一个新的Resources并将其添加到mResourceReferences缓存中。
Resources(System)
大家都应该见过这样的代码,比如 Resources.getSystem().getX() , 而他内部的实现也非常简单,如下所示:
Tips
当我们使用 Resources.getSystem() 时,其实也就是在调用当前 framework 层的资源对象,内部会先判断是否为 null,然后进行初始化,初始化的过程中,因为系统框架层的资源,所以实际的资源管理器直接调用了 AssetManager.getSystem() ,这个方法内部会使用当前系统框架层的apk作为资源路径。所以我们自然也无法用它去加载我们 Apk 内部的资源文件。
小问题
在了解了上述流程后,如果你存在以下问题(就是这么倔强🫡),那么不妨鼓励鼓励自己,[你没掉队]!
- 为什么要存在 ActivityResources 与 ActivityResource ? 我们一直调用的不都是Resources吗?
首先说说
ActivityResource,见名知意,它是作为Resources的包装类型出现,内部持有当前要加载的配置,以及真正的Resources,以便配置变更时更新 resources。
又因为一个
Activity可能关联多个Resources,所以ActivityResources是一个activity(或者windowsContext) 的所有resources合集,内部用一个List维护,而ActivityResources又被ResourcesManager缓存着。
当我们每次初始化Act时,内部都会创建相应的
ActResources,并将其添加到manager中作为缓存。最终的resources 只是一个代理对象,从而供开发者调用, 真正的实现者ResourcesImpl则被全局缓存。
- Resources.getSystem() 获取应用drawable,为什么会报错?
原因也很简单啊,因为
resources相应的AssetManager对应的资源路径时frameWork啊,你让它获取当前应用资源,它不造啊。🥲
结语
最终,让我们反推上去,总体再来回顾一下 Resources 初始化的相关👨🔧:
- 原来我们的
resources都是在context创建时初始化,而且我们所调用的resources实际上被ActivityResource所包装; - 原来我们的
Resources只是一个代理,最终的调用其实是ResourcesImpl,并且被ResourcesManager所缓存。 - 原来每当我们初始化一个
Activity,我们所有的resources都会被刷新,为什么呢,因为我们的 config 配置可能会改变,比如深色模式切换等。 - 原来
Resource.getSystem()无法加载应用资源的原因只是因为AssetManager对应的资源路径是frameWork.apk。
本篇中,我们专注于一个概念,即:resources 到底从何而来,并且从原理上分析了不同context
resources的初始化流程,也明白了他们之间的区别与差异。
细心的小伙伴会发现,从上一篇,我们从应用层
Resources.getx()开始,到现在Resources初始化。我们沿着开发者的使用习惯由浅入深,去探索底层设计,逐渐理清 Android Resources 的整体脉络。
下一篇我将同大家分析
ResourcesManager,并且解释诸多为什么,从而探索其背后的设计思想 :)
关于我
我是 Petterp ,一个 Android工程师 ,如果本文对你有所帮助,欢迎点赞支持,你的支持是我持续创作的最大鼓励!
链接:https://juejin.cn/post/7166243062077718535
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android面试题-2022
1 wait和 sleep 的区别
wait是Object的方法,wait是对象锁,锁定方法不让继续执行,当执行notify方法后就会继续执行,sleep 是Thread的方法,sleep 是使线程睡眠,让出cpu,结束后自动继续执行
2 View和SurfaceView的区别
View基于主线程刷新UI,SurfaceView子线程又可以刷新UI
3. View的绘制原理
View为所有图形控件的基类,View的绘制由3个函数完成
measure,计算视图的大小
layout,提供视图要显示的位置
draw,绘制
4. 简述TCP,UDP,Socket
TCP是经过3次握手,4次挥手完成一串数据的传送
UDP是无连接的,知道IP地址和端口号,向其发送数据即可,不管数据是否发送成功
Socket是一种不同计算机,实时连接,比如说传送文件,即时通讯
5.进程和线程的区别
概念:进程包括多个线程,一个程序一个进程,多线程的优点可以提高执行效率,提高资源利用率
创建:Thread类和Runnable接口,
常用方法有:
start()用于启动线程
run()调用线程对象中的run方法
join()合并插队到当前线程
sellp()睡眠释放cpu资源
setPriority()设置线程优先级
6.RecyclerView和ListView的区别
缓存上:前者缓存的是View+ViewHolder+flag,不用每次调用findViewById,后者则只是缓存View
刷新数据方面,前者提供了局部刷新,后者则全部刷新
7.MVC ,MVP,MVVM
MVC:View是可以直接访问Model的!从而,View里会包含Model信息,不可避免的还要包括一些 业务逻辑。 在MVC模型里,更关注的Model的不变,而同时有多个对Model的不同显示,及View。所以,在MVC模型里,Model不依赖于View,但是 View是依赖于Model的。不仅如此,因为有一些业务逻辑在View里实现了,导致要更改View也是比较困难的,至少那些业务逻辑是无法重用的。
MVP:MVP 是从经典的模式MVC演变而来,它们的基本思想有相通的地方:Controller/Presenter负责逻辑的处理,Model提供数据,View负 责显示。作为一种新的模式,MVP与MVC有着一个重大的区别:在MVP中View并不直接使用Model,它们之间的通信是通过Presenter (MVC中的Controller)来进行的,所有的交互都发生在Presenter内部,而在MVC中View会从直接Model中读取数据而不是通过 Controller。
MVVM:数据双向绑定,通过数据驱动UI,M提供数据,V视图,VM即数据驱动层
8.说下 Activity 跟 跟 window , view 之间的关系?
Activity 创建时通过 attach()初始化了一个 Window 也就是PhoneWindow,一个 PhoneWindow 持有一个DecorView 的实例,DecorView 本身是一个 FrameLayout,继承于 View,Activty 通过setContentView 将xml 布局控件不断 addView()添加到 View 中,最终显示到 Window 于我们交互;
9.Java中堆和栈的理解
在Java中内存分为两种,一种是栈内存,另一种是堆内存
堆内存:用于存储Java中的对象和数组,当我们new一个对象或创建一个数组的时候,就会在堆内存中开辟一段空间给它,用于存放,堆内存的特点:先进先出,后今后出,②可以动态的分配内存的大小,生存期不必告诉编译器,但存取速度较慢;
栈内存:主要用来执行程序用,比如基本类型的变量和对象的引用变量,其特点:①先进后出,后进后出,②存取速度比堆快,仅次于寄存器,栈数据可以共享,但其在栈中的数据大小和生存期必须是确定的;
栈内存和堆内存都属于Java内存的一种,系统会自动去回收它,但对于堆内存开发人员一般会自动回收。
栈是一块和线程紧密相关的内存区域,每个线程都有自己的栈内存,用于存储本地变量、方法参数和栈调用一个线程中存储的变量,对于其他线程是不可见的,而堆是所有线程共享的一个公用内存区域,对象都在堆里创建,但为了提升效率,线程会从堆中拷贝一个缓存到自己的栈中,如果多个线程使用该变量,就可能引发问题,这是volatile修饰变量就可以发挥作用,他要求线程从主存中读取变量的值。
10.Android常用的数据存储方式(4种)
使用SharedPreference存储:保存基于xml文件存储的key-value键值对数据,通常用来存储一些简单的配置信息;
文件存储方式:Context提供了两个方法来打开数据文件的文件IO流;
SQLite存储数据:SQLite是轻量级的嵌入式数据库引擎,支持SQL语言;
网络存储数据:通过网络存储数据;
11.Activity生命周期中的7个方法:
onCreate( ):当Activity被创建时调用;
onStart( ):当Activity被创建后将可见时调用;
onResume( ):(继续开始)当Activity位于设备最前端,对用户可见时调用;
onPause( ):(暂停)当另一个Activity遮挡当前Activity,当前Activity被切换到后台时调用;
onRestart( ):(重新启动)当另一个Activity执行完onStop()方法,又被用户打开时调用;
onStop( ):如果另一个Activity完全遮挡了当前Activity时,该方法被调用;
onDestory( ):当Activity被销毁时调用;
12.Activity的四种启动模式
standard、singleTop、singleTask和singleInstance,他们是在配置文件中通过android:LauchMode属性配置;
standard:默认的启动模式,每次启动会在任务栈中新建一个启动的Activity的实例;
SingleTop:如果要启动的Activity实例已位于栈顶,则不会重新创建该Activity的实例,否则会产生一个新的运行实例;
SingleTask:如果栈中有该Activity实例,则直接启动,中间的Activity实例将会被关闭,关闭的顺序与启动的顺序相同;
SingleInstance:该启动模式会在启动一个Activity时,启动一个新的任务栈,将该Activity实例放置在这个任务栈中,并且该任务栈中不会再保存其他的Activity实例;
Activity任务栈:即存放Activity任务的栈,每打开一个Activity时就会往Activity栈中压入一个Activity
任务,每当销毁一个Activity的时候,就会从Activity任务栈中弹出一个Activity任务,
由于安卓手机的限制,只能从手机屏幕获取当前一个Activity的焦点,即栈顶元素(
最上面的Activity),其余的Activity会暂居后台等待系统的调用;
13.View的绘制原理
View为所有图形控件的基类,View的绘制由3个函数完成
measure,计算视图的大小
layout,提供视图要显示的位置
draw,绘制
14.Okhttp连接池复用机制
15. Rxjava里面有几个角色
Observable:俗称被订阅者,被订阅者是事件的来源,接收订阅者(Observer)的订阅,然后通过发射器(Emitter)发射数据给订阅者。
Observer:俗称订阅者,注册过程传给被订阅者,订阅者监听开始订阅,监听订阅过程中会把Disposable传给订阅者,然后在被订阅者中的发射器(Emitter)发射数据给订阅者(Observer)。
Emitter:俗称发射器,在发射器中会接收下游的订阅者(Observer),然后在发射器相应的方法把数据传给订阅者(Observer)。
Consumer:俗称消费器,消费器其实是Observer的一种变体,Observer的每一个方法都会对应一个Consumer,比如Observer的onNext、onError、onComplete、onSubscribe都会对应一个Consumer。
Disposable:是释放器,通常有两种方式会返回Disposable,一个是在Observer的onSubscribe方法回调回来,第二个是在subscribe订阅方法传consumer的时候会返回
16.RxJava操作符包含的操作符类型有如下几种:
1、创建操作符 :创建被观察者(Observable)对象&发送事件
2、转换操作符:变换被观察者(Observable)发送的事件。将Observable发送的数据按照一定的规则做一些变换,然后再将变换的数据发射出去。变换的操作符有map,flatMap,concatMap,switchMap,buffer,groupBy等等。
3、 合并操作符:组合多个被观察者(Observable)&合并需要发送的事件。包含:concatMap(),concat(), merge(),mergeArray(),concateArray(),reduce(),collect(),startWith(),zip(),count()等
4、功能操作符:辅助被观察者(Observable) 发送事件时实现一些功能性需求,如错误处理,线程调度。
5、过滤操作符:用于将Observable发送的数据进行过滤和选择。让Observable返回我们所需要的数据。过滤操作符有buffer(),filter(),skip(),take(),skipLast(),takeLast(),throttleFirst(),distainctUntilChange()。
链接:https://juejin.cn/post/7166415061089517582
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter如何将文本与图片混合编辑?(功能扩展篇)
前言
一个优秀的富文本,应该包含优秀的排版算法、丰富的功能和渲染的高性能。在上一篇中,我们实现了可扩展的、基础的富文本编辑器。那么在本文中,让我们对富文本进行更多功能的扩展。
注:
— 为了在阅读本文时有更好的体验,请先阅读本专栏第一篇,前文涉及到的知识点,本文不再赘述。(摸鱼的朋友请忽略)
— 完整代码太多, 文章只分析核心代码,需要源码请到 代码仓库
文本与图片混排
在有关富文本的业务需求中,或其他文章渲染中,图文混排的功能是十分重要的。在Flutter中,为了解决这个图文混排的问题,有一个很方便的组件:WidgetSpan。而在本专栏的第一篇的文本基础知识中,已经分析了TextSpan在文本渲染过程中的作用。那么WidgetSpan是如何被渲染的呢,Flutter又是如何将TextSpan与WidgetSpan混合渲染在一起的呢?
—— 效果图完整代码在仓库demo/image_text
因为Flutter提供了WidgetSpan,所以效果图中的布局十分简单:
Widget _widgetSpan() {
return Text.rich(TextSpan(
children: <InlineSpan>[
const TextSpan(text: 'Hello'),
WidgetSpan(
child:
...
//显示本地图片
Image.file(
_image!,
width: width,
height: height,
),
...
),
const TextSpan(text: 'Taxze!'),
],
));
}在之前的文章中,我们已经知道RichText实际上是需要一个InlineSpan,而TextSpan和WidgetSpan(中间还有个PlaceholderSpan)都是InlineSpan的子类实现。RichText最后会将InlineSpan传入RenderParagraph中。那么这个InlineSpan是一个什么样的呢?
InlineSpan树的结构
现在将目光先移到Text()和Text.rich()的构造函数上,我们可以看到,在Text()组件中,它的构造函数只有一个必要参数:data,且textSpan = null,而在Text.rich()的构造函数中,也只有一个必要参数:textSpan。
const Text(
String this.data, {
super.key,
...
}) : textSpan = null;
const Text.rich(
InlineSpan this.textSpan, {
super.key,
...
}) : data = null;然后将目光移到build上,在其主要逻辑中,我们可以发现,RichText在构造时传入的text是一个TextSpan,当采用data作为必要参数传入时,text参数才会有值,当采用textSpan作为参数传入时,children才不会为null。
@override
Widget build(BuildContext context) {
Widget result = RichText(
...
text: TextSpan(
style: effectiveTextStyle,
text: data,
children: textSpan != null ? <InlineSpan>[textSpan!] : null,
),
);
...
return result;
}经过上面的分析之后,我们可以将树的结构总结为两张图:
- 当采用
data作为必要参数传入时,树中只会存在一个根节点
- 当采用
textSpan作为参数传入时,树中会存在多个子树
树中的每一个TextSpan都包含text和style,其中的style是文本样式,如果没有设置某一个节点的样式,那么它会继承父节点中的样式。若根节点也没有自定义样式,那么就会采用默认的样式值。
WidgetSpan混入InlineSpan树结构
将目光移到RichText的createRenderObject方法上,可以看到RichText创建的渲染对象为RenderParagraph,并且将InlineSpan传入。
@override
RenderParagraph createRenderObject(BuildContext context) {
return RenderParagraph(
text, //InlineSpan
...
);
}再将目光移到RenderParagraph的performLayout函数上,它是RenderParagraph的重要逻辑,用于计算RenderParagraph的尺寸和child的绘制位置。
@override
void performLayout() {
final BoxConstraints constraints = this.constraints;
_placeholderDimensions = _layoutChildren(constraints);
_layoutTextWithConstraints(constraints);
_setParentData();
final Size textSize = _textPainter.size;
final bool textDidExceedMaxLines = _textPainter.didExceedMaxLines;
size = constraints.constrain(textSize);
...
}但是,这里计算的child不是TextSpan,而是PlaceholderSpan。通过_extractPlaceholderSpans挑选出所有的PlaceholderSpan,visitChildren是InlineSpan中的方法,通过该方法能遍历InlineSpan树。
late List<PlaceholderSpan> _placeholderSpans;
void _extractPlaceholderSpans(InlineSpan span) {
_placeholderSpans = <PlaceholderSpan>[];
span.visitChildren((InlineSpan span) {
//判断是否为PlaceholderSpan
if (span is PlaceholderSpan) {
_placeholderSpans.add(span);
}
return true;
});
}到这里,对于InlineSpan树的结构已经清晰了,在树中,除了TextSpan,还存在着PlaceholderSpan类型的节点,而WidgetSpan又是继承于PlaceholderSpan的。
不过,PlaceholderSpan只是一个占位节点,RenderParagraph并不会对其进行绘制,RenderParagraph只负责确定它的大小和需要绘制的位置。RenderParagraph只需在布局的时候,将这个绘制的区域预留给WidgetSpan,这样绘制时就不会改变树的结构。
计算WidgetSpan的绘制区域
performLayout是RenderParagraph的布局函数,performLayout内部主要调用了三个函数:
final BoxConstraints constraints = this.constraints;
_placeholderDimensions = _layoutChildren(constraints);
_layoutTextWithConstraints(constraints);
_setParentData();
_layoutChildren函数主要是用于计算确认PlaceholderSpan占位节点的大小。
List<PlaceholderDimensions> _layoutChildren(BoxConstraints constraints, {bool dry = false}) {
final List<PlaceholderDimensions> placeholderDimensions = List<PlaceholderDimensions>.filled(childCount, PlaceholderDimensions.empty);
while (child != null) {
if (!dry) {
...
childSize = child.size;
} else {
childSize = child.getDryLayout(boxConstraints);
}
placeholderDimensions[childIndex] = PlaceholderDimensions(
size: childSize,
alignment: _placeholderSpans[childIndex].alignment,
baseline: _placeholderSpans[childIndex].baseline,
baselineOffset: baselineOffset,
);
child = childAfter(child);
childIndex += 1;
}
return placeholderDimensions;
}
_setParentData此函数用于将父节点的设置给子节点,具体的计算(尺寸计算、偏移计算)都在_layoutTextWithConstraints函数中完成。
void _setParentData() {
...
while (child != null && childIndex < _textPainter.inlinePlaceholderBoxes!.length) {
final TextParentData textParentData = child.parentData! as TextParentData;
textParentData.offset = Offset(
_textPainter.inlinePlaceholderBoxes![childIndex].left,
_textPainter.inlinePlaceholderBoxes![childIndex].top,
);
textParentData.scale = _textPainter.inlinePlaceholderScales![childIndex];
child = childAfter(child);
childIndex += 1;
}
}
_layoutTextWithConstraints此函数包含主要的布局逻辑。其中的_textPainter是RichText将text传入RenderParagraph时,RenderParagraph将text保存在_textPainter中。setPlaceholderDimensions方法用于设置InlineSpan树中每个占位符的尺寸。
void _layoutTextWithConstraints(BoxConstraints constraints) {
_textPainter.setPlaceholderDimensions(_placeholderDimensions);
_layoutText(minWidth: constraints.minWidth, maxWidth: constraints.maxWidth);
}
在
setPlaceholderDimensions将各占位节点尺寸设置完成之后,会调用_layoutText来进行 布局。
void _layoutText({ double minWidth = 0.0, double maxWidth = double.infinity }) {
final bool widthMatters = softWrap || overflow == TextOverflow.ellipsis;
//_textPainter包含节点的尺寸。
_textPainter.layout(
minWidth: minWidth,
maxWidth: widthMatters ?
maxWidth :
double.infinity,
);
}
调用
layout方法,就代表着进入了TextPainter,开始创建ParagraphBuilder,然后进入引擎层开始绘制。
到这里,我们已经了解了图文混排中的图,是如何被混入文本一起渲染的了。下面让我们开始探索,如何将文本与图片放在一起编辑。
文本与图片混合编辑
要想将文本与图片混合编辑,就要在构建InlineSpan树时,在Image()外嵌套一层WidgetSpan,并将其混入InlineSpan树。而其中较为复杂的是对TextRange的位置改变的计算(添加图片、删除图片)。接下让我们一起探索,文本与图片混合编辑的秘密。
输入为图像时的Style处理
若用户操作为插入图片,则该操作不存入Style,若为文本的插入,根据TextRange,判断所需要的Style。
List<TextStyle> getReplacementsAtSelection(TextSelection selection) {
// 只有[left replacement]才会被记录
final List<TextStyle> stylesAtSelection = <TextStyle>[];
for (final TextEditingInlineSpanReplacement replacement in replacements!) {
if (replacement.isWidget == true) {
//若为非编辑文本操作,则暂不处理。
} else {
...
///保存style
stylesAtSelection
.add(replacement.generator('', replacement.range).style!);
...
}
return stylesAtSelection;
}构建InlineSpan树
定义行为添加函数,将用户行为通过该函数保存。
void applyReplacement(TextEditingInlineSpanReplacement replacement) {
if (replacements == null) {
replacements = [];
replacements!.add(replacement);
} else {
replacements!.add(replacement);
}
}
将用户行为映射到生成的
InlineSpan
static void _addToMappingWithOverlaps(
InlineSpanGenerator generator,
TextRange matchedRange,
Map<TextRange, InlineSpan> rangeSpanMapping,
String text,
//非文本编辑行为
{bool? isWidget}) {
// 在某些情况下,应该允许重叠。
// 例如在两个TextSpan匹配相同的替换范围的情况下,
// 尝试合并到一个TextStyle的风格,并建立一个新的TextSpan。
bool overlap = false;
List<TextRange> overlapRanges = <TextRange>[];
//遍历索引
for (final TextRange range in rangeSpanMapping.keys) {
if (math.max(matchedRange.start, range.start) <=
math.min(matchedRange.end, range.end)) {
overlap = true;
overlapRanges.add(range);
}
}
...
//更新TextRanges到InlineSpan的映射。
rangeSpanMapping[uniqueRange] =
TextSpan(text: uniqueRange.textInside(text), style: mergedStyles);
...
}
构建InlineSpan树
@override
TextSpan buildTextSpan({
required BuildContext context,
TextStyle? style,
required bool withComposing,
}) {
//该函数其他逻辑在上一篇文章中已分析
}
通过image_picker插件,实现插入图片
getImage(BuildContext context) async {
//获取Editable的controller
final ReplacementTextEditingController controller =
_data.replacementsController;
//定义当前行为TextRange
final TextRange replacementRange = TextRange(
start: controller.selection.start,
end: controller.selection.end,
);
File? image;
//默认尺寸
double width = 100.0;
double height = 100.0;
//从相册获取图片
var getImage = await ImagePicker().pickImage(source: ImageSource.gallery);
image = File(getImage!.path);
//调用applyReplacement函数,保存用户行为
controller.applyReplacement(
TextEditingInlineSpanReplacement(
replacementRange,
(string, range) => WidgetSpan(
child: GestureDetector(
onTap: () {
...
},
child: Image.file(
image!,
width: width,
height: height,
),
)),
true,
isWidget: true),
);
_data = _data.copyWith(replacementsController: controller);
setState(() {});
}尾述
在这篇文章中,我们实现了将文本与图片混合编辑的功能,其他需要插入的模块也能举一反三实现,例如插入视频。本专栏实现的富文本编辑器对于真实的复杂需求也只是一个小玩意,也有着较多的缺陷,依靠我一个人的力量也是很难实现标题中说的《高性能、多功能的富文本编辑器》,本专栏旨在于引领大家走入Flutter富文本编辑器的世界,而不单单只是学会使用已有的插件,却不了解其中的实现原理,当然这是一个超级大坑🤣。例如文本与图片的排版问题...这些缺陷都需要很多的时间一点点处理解决,也希望在将来能有更多的朋友与我一起探索文本的世界。而在后续的系列文章中,将会把富文本更加的完善,完成一个笔记的Demo,也会有对富文本性能的优化与分析。希望这篇文章能对你有所帮助,有问题欢迎在评论区留言讨论~
参考
关于我
Hello,我是Taxze,如果您觉得文章对您有价值,希望您能给我的文章点个❤️,有问题需要联系我的话:我在这里 ,也可以通过掘金的新的私信功能联系到我。如果您觉得文章还差了那么点东西,也请通过关注督促我写出更好的文章——万一哪天我进步了呢?😝
链接:https://juejin.cn/post/7164162875727020069
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 标准库随处可见的 contract 到底是什么?
Kotlin 的标准库提供了不少方便的实用工具函数,比如 with, let, apply 之流,这些工具函数有一个共同特征:都调用了 contract() 函数。
@kotlin.internal.InlineOnly
public inline fun <T, R> with(receiver: T, block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return receiver.block()
}
@kotlin.internal.InlineOnly
public inline fun repeat(times: Int, action: (Int) -> Unit) {
contract { callsInPlace(action) }
for (index in 0 until times) {
action(index)
}
}contract?协议?它到底是起什么作用?
函数协议
contract 其实就是一个顶层函数,所以可以称之为函数协议,因为它就是用于函数约定的协议。
@ContractsDsl
@ExperimentalContracts
@InlineOnly
@SinceKotlin("1.3")
@Suppress("UNUSED_PARAMETER")
public inline fun contract(builder: ContractBuilder.() -> Unit) { }用法上,它有两点要求:
- 仅用于顶层方法
- 协议描述须置于方法开头,且至少包含一个「效应」(Effect)
可以看到,contract 的函数体为空,居然没有实现,真是一个神奇的存在。这么一来,此方法的关键点就只在于它的参数了。
ContractBuilder
contract的参数是一个将 ContractBuilder 作为接受者的lambda,而 ContractBuilder 是一个接口:
@ContractsDsl
@ExperimentalContracts
@SinceKotlin("1.3")
public interface ContractBuilder {
@ContractsDsl public fun returns(): Returns
@ContractsDsl public fun returns(value: Any?): Returns
@ContractsDsl public fun returnsNotNull(): ReturnsNotNull
@ContractsDsl public fun <R> callsInPlace(lambda: Function<R>, kind: InvocationKind = InvocationKind.UNKNOWN): CallsInPlace
}其四个方法分别对应了四种协议类型,它们的功能如下:
returns:表明所在方法正常返回无异常returns(value: Any?):表明所在方法正常执行,并返回 value(其值只能是 true、false 或者 null)returnsNotNull():表明所在方法正常执行,且返回任意非 null 值callsInPlace(lambda: Function<R>, kind: InvocationKind = InvocationKind.UNKNOWN):声明 lambada 只在所在方法内执行,所在方法执行完毕后,不会再被其他方法调用;可通过 kind 指定调用次数
前面已经说了,contract 的实现为空,所以作为接受着的 ContractBuilder 类型,根本没有实现类 —— 因为没有地方调用,就不需要啊。它的存在,只是为了声明所谓的协议代编译器使用。
InvocationKind
InvocationKind 是一个枚举类型,用于给 callsInPlace 协议方法指定执行次数的说明:
@ContractsDsl
@ExperimentalContracts
@SinceKotlin("1.3")
public enum class InvocationKind {
// 函数参数执行一次或者不执行
@ContractsDsl AT_MOST_ONCE,
// 函数参数至少执行一次
@ContractsDsl AT_LEAST_ONCE,
// 函数参数执行一次
@ContractsDsl EXACTLY_ONCE,
// 函数参数执行次数未知
@ContractsDsl UNKNOWN
}InvocationKind.UNKNOWN,次数未知,其实就是指任意次数。标准工具函数中,repeat 就指定的此类型,因为其「重复」次数由参数传入,确实未知;而除它外,其余像 let、with 这些,都是用的InvocationKind.EXACTLY_ONCE,即单次执行。
Effect
Effect 接口类型,表示一个方法的执行协议约定,其不同子接口,对应不同的协议类型,前面提到的 Returns、ReturnsNotNull、CallsInPlace 均为它的子类型。
public interface Effect
public interface ConditionalEffect : Effect
public interface SimpleEffect : Effect {
public infix fun implies(booleanExpression: Boolean): ConditionalEffect
}
public interface Returns : SimpleEffect
public interface ReturnsNotNull : SimpleEffect
public interface CallsInPlace : Effect简单明了,全员接口!来看一个官方使用,以便理解下这些接口的意义和使用:
public inline fun Array<*>?.isNullOrEmpty(): Boolean {
contract {
returns(false) implies (this@isNullOrEmpty != null)
}
return this == null || this.isEmpty()
}这里涉及到两个 Effect:Returns 和 ConditionalEffect。此方法的功能为:判断数组为 null 或者是无元素空数组。它的 contract 约定是这样的:
- 调用
returns(value: Any?)获得Returns协议(当然也就是SimpleEffect协议),其传入值是 false - 第1步的
Returns调用implies方法,条件是「本对象非空」,得到了一个ConditionalEffect - 于是,最终协议的意思是:函数返回 false 意味着 接受者对象非空
isNullOrEmpty() 的功能性代码给出了返回值为 true 的条件。虽然反过来说,不满足该条件,返回值就是 false,但还是通过 contract 协议里首先说明了这一点。
协议的意义
讲到这里,contract 协议涉及到的基本类型及其使用已经清楚了。回过头来,前面说到,contract() 的实现为空,即函数体为空,没有实际逻辑。这说明,这个调用是没有实际执行效果的,纯粹是为编译器服务。
不妨模仿着 let 写一个带自定义 contract 测试一下这个结论:
// 类比于ContractBuilder
interface Bonjour {
// 协议方法
fun <R> parler(f: Function<R>) {
println("parler something")
}
}
// 顶层协议声明工具,类比于contract
inline fun bonjour(b: Bonjour.() -> Unit) {}
// 模仿let
fun<T, R> T.letForTest(block: (T) -> R): R {
println("test before")
bonjour {
println("test in bonjour")
parler<String> {
""
}
}
println("test after")
return block(this)
}
fun main(args: Array<String>) {
"abc".letForTest {
println("main: $it called")
}
}letForTest() 是类似于 let 的工具方法(其本身功能逻辑不重要)。执行结果:
test before
test after
main: abc called如预期,bonjour 协议以及 Bonjour 协议构造器中的所有日志都未打印,都未执行。
这再一次印证,contract 协议仅为编译器提供信息。那协议对编码来说到底有什么意义呢?来看看下面的场景:
fun getString(): String? {
TODO()
}
fun String?.isAvailable(): Boolean {
return this != null && this.length > 0
}getString() 方法返回一个 String 类型,但是有可能为 null。isAvailable 是 String? 类型的扩展,用以判断是否一个字符串非空且长度大于 0。使用如下:
val target = getString()
if (target.isAvailable()) {
val result: String = target
}按代码的设计初衷,上述调用没问题,target.isAvailable() 为 true,证明 target 是非空且长度大于 0 的字符串,然后内部将它赋给 String 类型 —— 相当于 String? 转换成 String。
可惜,上述代码,编译器不认得,报错了:
Type mismatch.
Required:
String
Found:
String?编译器果然没你我聪明啊!要解决这个问题,自然就得今天的主角上场了:
fun String?.isAvailable(): Boolean {
contract {
returns(true) implies (this@isAvailable != null)
}
return this != null && this.length > 0
}使用 contract 协议指定了一个 ConditionalEffect,描述意思为:如果函数返回true,意味着 Receiver 类型非空。然后,编译器终于懂了,前面的错误提示消失。
这就是协议的意义所在:让编译器看不懂的代码更加明确清晰。
小结
函数协议可以说是写工具类函数的利器,可以解决很多因为编译器不够智能而带来的尴尬问题。不过需要明白的是,函数协议还是实验性质的,还没有正式发布为 stable 功能,所以是有可能被 Kotlin 官方 去掉的。
链接:https://juejin.cn/post/7128258776376803359
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Compose 状态保存:rememberSaveable 原理分析
前言
我曾经在一篇介绍 Compose Navigation 的文章 中提到了 Navigation 的状态保存实际是由 rememberSaveable 实现的,有同学反馈希望单独介绍一下 rememberSaveable 的功能及实现原理。
我们都知道 remember 可以保存数据、避免状态因重组而丢失,但它依然无法避免在 ConfigurationChanged 时的数据丢失。想要在横竖屏切换等场景下依然保存状态,就需要使用 rememberSavable。
从一个报错说起
首先,在代码使用上 rememberSaveable 和 remember 没有区别:
//保存列表状态
val list = rememberSaveable {
mutableListOf<String>()
}
//保存普通状态
var value by rememberSaveable {
mutableStateOf("")
}如上,只要将 remember 改为 rememberSaveable,我们创建的状态就可以跨越横竖屏切换甚至跨越进程持续保存了。不过 rememberSaveable 中并非任何类型的值都可以存储:
data class User(
val name: String = ""
)
val user = rememberSaveable {
User()
}上面代码运行时会发生错误:
java.lang.IllegalArgumentException: User(name=) cannot be saved using the current SaveableStateRegistry. The default implementation only supports types which can be stored inside the Bundle. Please consider implementing a custom Saver for this class and pass it to rememberSaveable().
User 无法存入 Bundle。这非常合理,因为 rememberSaveable 中数据的持久化最终在 ComponentActivity#onSaveInstanceState 中执行,这需要借助到 Bundle 。
rememberSaveable 源码分析
那么,rememberSaveable 是如何关联到 onSaveInstanceState 的呢?接下来简单分析一下内部实现
@Composable
fun <T : Any> rememberSaveable(
vararg inputs: Any?,
saver: Saver<T, out Any> = autoSaver(),
key: String? = null,
init: () -> T
): T {
//...
// 通过 CompositionLocal 获取 SaveableStateRegistry
val registry = LocalSaveableStateRegistry.current
// 通过 init 获取需要保存的数据
val value = remember(*inputs) {
// registry 根据 key 恢复数据,恢复的数据是一个 Saveable
val restored = registry?.consumeRestored(finalKey)?.let {
// 使用 Saver 将 Saveable 转换为业务类型
saver.restore(it)
}
restored ?: init()
}
// 用一个 MutableState 保存 Saver,主要是借助 State 的事务功能避免一致性问题发生
val saverHolder = remember { mutableStateOf(saver) }
saverHolder.value = saver
if (registry != null) {
DisposableEffect(registry, finalKey, value) {
//ValueProvider:通过 Saver#save 存储数据
val valueProvider = {
with(saverHolder.value) { SaverScope { registry.canBeSaved(it) }.save(value) }
}
//试探数值是否可被保存
registry.requireCanBeSaved(valueProvider())
//将ValueProvider 注册到 registry ,等到合适的时机被调用
val entry = registry.registerProvider(finalKey, valueProvider)
onDispose {
entry.unregister()
}
}
}
return value
}如上,逻辑很清晰,主要是围绕 registry 展开的:
- 通过 key 恢复持久化的数据
- 基于 key 注册 ValueProvider,等待合适时机执行数据持久化
- 在 onDispose 中被注销注册
registry 是一个 SaveableStateRegistry 。
恢复 key 的数据
rememberSaveable 是加强版的 remember,首先要具备 remember 的能力,可以看到内部也确实是调用了 remember 来创建数据同时缓存到 Composition 中。init 提供了 remember 数据的首次创建。被创建的数据在后续某个时间点进行持久化,下次执行 rememberSaveable 时会尝试恢复之前持久化的数据。具体过程分为以下两步:
- 通过 registry.consumeRestored 查找 key 获取 Saveable,
- Saveable 经由 saver.restore 转换为业务类型。
上述过程涉及到两个角色:
- SaveableStateRegistry:通过 CompositionLocal 获取,它负责将 Bundle 中的数据反序列化后,返回一个 Saveable
- Saver:Saver 默认有 autoSaver 创建,负责 Saveable 与业务数据之间的转换。
Saveable 并不是一个在具体类型,它可以是可被持久化(写入 Bundle)的任意类型。对于 autoSaver 来说, 这个 Saveable 就是业务数据类型本身。
private val AutoSaver = Saver<Any?, Any>(
save = { it },
restore = { it }
)对于一些复杂的业务结构体,有时并非是所有字段都需要持久化。Saver 为我们提供了这样一个机会机会,可以按照需要将业务类型转化为可序列化类型。Compose 也提供了两个预置的 Saver:ListSaver 和 MapSaver,可以用来转换成 List 或者 Map。
关于恢复数据的 Key :可以看到数据的保存和恢复都依赖一个 key,按道理 key 需要在保存和恢复时严格保持一致 ,但我们平日调用 rememberSaveable 时并没有指定具体的 key,那么在横竖屏切换甚至进程重启后是如何恢复数据的呢?其实这个 key 是 Compose 自动帮我们设置的,它就是编译期插桩生成的基于代码位置的 key ,所以可以保证每次进程执行到此处都保持不变
注册 ValueProvider
SaveableStateRegistry 在 DisposableEffect 中关联 key 注册 ValueProvider。
ValueProvider 是一个 lambda,内部会调用 Saver#save 将业务数据转化为 Saveable。
Saver#save 是 SaverScope 的扩展函数,所以这里需要创建一个 SaverScope 来调用 save 方法。SaverScope 主要用来提供 canBeSaved 方法,我们在自定义 Saver 时可以用来检查类型是否可被持久化
ValueProvider 创建好后紧接着会调用 registry.registerProvider 进行注册,等待合适的时机(比如 Activity 的 onSaveInstanceState)被调用。在注册之前,先调用 requireCanBeSaved 判断数据类型是否可以保存,这也就是文章前面报错的地方。先 mark 一下,稍后我们看一下具体检查的实现。
注销 registry
最后在 onDispose 中调用 unregister 注销之前的注册 。
rememberSaveable 的基本流程理清楚了,可以看见主角就是 registry,因此有必要深入 SaveableStateRegistry 去看一下。我们顺着 LocalSaveableStateRegistry 可以很容易找到 registry 的出处。
DisposableSavableStateRegistry 源码分析
override fun setContent(content: @Composable () -> Unit) {
//...
ProvideAndroidCompositionLocals(owner, content)
//...
}
@Composable
@OptIn(ExperimentalComposeUiApi::class)
internal fun ProvideAndroidCompositionLocals(
owner: AndroidComposeView,
content: @Composable () -> Unit
) {
val view = owner
val context = view.context
//...
val viewTreeOwners = owner.viewTreeOwners ?: throw IllegalStateException(
"Called when the ViewTreeOwnersAvailability is not yet in Available state"
)
val saveableStateRegistry = remember {
DisposableSaveableStateRegistry(view, viewTreeOwners.savedStateRegistryOwner)
}
//...
CompositionLocalProvider(
//...
LocalSaveableStateRegistry provides saveableStateRegistry,
//...
) {
ProvideCommonCompositionLocals(
owner = owner,
//...
content = content
)
}
}如上,我们在 Activity 的 setContent 中设置各种 CompositionLocal,其中就有 LocalSaveableStateRegistry,所以 registry 不仅是一个 SaveableStateRegistry,更是一个 DisposableSaveableStateRegistry 。
接下来看一下 DisposableSaveableStateRegistry 的创建过程 。
saveableStateRegistry 与 SavedStateRegistry
注意下面这个 DisposableSaveableStateRegistry 不是真正的构造函数,它是同名构造函数的一个 Wrapper,在调用构造函数创建实例之前,先调用 androidxRegistry 进行了一系列处理:
internal fun DisposableSaveableStateRegistry(
id: String,
savedStateRegistryOwner: SavedStateRegistryOwner
): DisposableSaveableStateRegistry {
//基于 id 创建 key
val key = "${SaveableStateRegistry::class.java.simpleName}:$id"
// 基于 key 获取 bundle 数据
val androidxRegistry = savedStateRegistryOwner.savedStateRegistry
val bundle = androidxRegistry.consumeRestoredStateForKey(key)
val restored: Map<String, List<Any?>>? = bundle?.toMap()
// 创建 saveableStateRegistry,传入 restored 以及 canBeSaved
val saveableStateRegistry = SaveableStateRegistry(restored) {
canBeSavedToBundle(it)
}
val registered = try {
androidxRegistry.registerSavedStateProvider(key) {
//调用 register#performSave 并且转为 Bundle
saveableStateRegistry.performSave().toBundle()
}
true
} catch (ignore: IllegalArgumentException) {
false
}
return DisposableSaveableStateRegistry(saveableStateRegistry) {
if (registered) {
androidxRegistry.unregisterSavedStateProvider(key)
}
}
}androidxRigistry 跟 rememberSaveable 中的 registry 做的事情类似:
- 基于 key 恢复 bundle 数据,
- 基于 key 注册 SavedStateProvider。
但 androidxRegistry 不是一个 SaveableStateRegistry 而是一个 SavedStateRegistry。名字上有点绕,后者来自 androidx.savedstate ,属于平台代码,而 SaveableStateRegistry 属于 compose-runtime 的平台无关代码。可见这个构造函数的同名 Wrapper 很重要,他就像一个桥梁,解耦和关联了平台相关和平台无关代码。
DisposableSaveableStateRegistry 与 SaveableStateRegistryImpl
DisposableSaveableStateRegistry 真正的构造函数定义如下:
internal class DisposableSaveableStateRegistry(
saveableStateRegistry: SaveableStateRegistry,
private val onDispose: () -> Unit
) : SaveableStateRegistry by saveableStateRegistry {
fun dispose() {
onDispose()
}
}这里用了参数 saveableStateRegistry 作为 SaveableStateRegistry 接口的代理。saveableStateRegistry 实际是一个 SaveableStateRegistryImpl 对象,它像这样创建:
val saveableStateRegistry = SaveableStateRegistry(restored) {
canBeSavedToBundle(it)
}
fun SaveableStateRegistry(
restoredValues: Map<String, List<Any?>>?,
canBeSaved: (Any) -> Boolean
): SaveableStateRegistry = SaveableStateRegistryImpl(restoredValues, canBeSaved)
SaveableStateRegistryImpl 被创建时传入两个参数:
- restoredValues:androidxRegistry 恢复的 bundle 数据,是一个 Map 对象。
- canBeSaved : 用来检查数据是否可持久化,可以的看到这里实际调用了 canBeSavedToBundle。
canBeSavedToBundle
文章开头的报错就是 requireCanBeSaved -> canBeSavedToBundle 检查出来的,通过 canBeSavedToBundle 看一下 rememberSaveable 支持的持久化类型:
private fun canBeSavedToBundle(value: Any): Boolean {
// SnapshotMutableStateImpl is Parcelable, but we do extra checks
if (value is SnapshotMutableState<*>) {
if (value.policy === neverEqualPolicy<Any?>() ||
value.policy === structuralEqualityPolicy<Any?>() ||
value.policy === referentialEqualityPolicy<Any?>()
) {
val stateValue = value.value
return if (stateValue == null) true else canBeSavedToBundle(stateValue)
} else {
return false
}
}
for (cl in AcceptableClasses) {
if (cl.isInstance(value)) {
return true
}
}
return false
}
private val AcceptableClasses = arrayOf(
Serializable::class.java,
Parcelable::class.java,
String::class.java,
SparseArray::class.java,
Binder::class.java,
Size::class.java,
SizeF::class.java
)首先, SnapshotMutableState 允许被持久化,因为我们需要在 rememberSaveable 中调用 mutableStateOf;其次,SnapshotMutableState 的泛型必须是 AcceptableClasses 中的类型,我们自定义的 User 显然不符合要求,因此报了开头的错误。
SaveableStateRegistryImpl 源码分析
前面理清了几个 Registry 类型的关系,整理如下图
SaveableStateRegistry 接口的各主要方法都由 SaveableStateRegistryImpl 代理的:
- consumeRestored:根据 key 恢复数据
- registerProvider:注册 ValueProvider
- canBeSaved:用来检查数据是否是可保存类型
- performSave:执行数据保存
canBeSaved 前面介绍过,其实会回调 canBeSavedToBundle。接下来看一下 SaveableStateRegistryImpl 中其他几个方法是如何实现的:
consumeRestored
override fun consumeRestored(key: String): Any? {
val list = restored.remove(key)
return if (list != null && list.isNotEmpty()) {
if (list.size > 1) {
restored[key] = list.subList(1, list.size)
}
list[0]
} else {
null
}
}我们知道 restored 是从 Bundle 中恢复的数据,实际是一个 Map了类型。而 consumeRestored 就是在 restored 中通过 key 查找数据。restore 的 Value 是 List 类型。当恢复数据时,只保留最后一个只。顺便吐槽一下 consumeRestored 这个名字,将 restore 这个 private 成员信息暴露给了外面,有些莫名其妙。
registerProvider
override fun registerProvider(key: String, valueProvider: () -> Any?): Entry {
require(key.isNotBlank()) { "Registered key is empty or blank" }
@Suppress("UNCHECKED_CAST")
valueProviders.getOrPut(key) { mutableListOf() }.add(valueProvider)
return object : Entry {
override fun unregister() {
val list = valueProviders.remove(key)
list?.remove(valueProvider)
if (list != null && list.isNotEmpty()) {
// if there are other providers for this key return list back to the map
valueProviders[key] = list
}
}
}
}将 ValueProvider 注册到 valueProviders ,valueProviders 也是一个值为 List 的 Map,同一个 Key 可以对应多个 Value。返回的 Entry 用于 onDispose 中调用 unregister。
DisposableSaveableStateRegistry 是一个 CompositionLocal 单例,所以需要 unregister 避免不必要的泄露。注意这里要确保同一个 key 中的 List 中的其它值不被移除
不解:什么情况下同一个 key 会 registerProvider 多个值呢?
performSave
override fun performSave(): Map<String, List<Any?>> {
val map = restored.toMutableMap()
valueProviders.forEach { (key, list) ->
if (list.size == 1) {
val value = list[0].invoke()
if (value != null) {
check(canBeSaved(value))
map[key] = arrayListOf<Any?>(value)
}
} else {
map[key] = List(list.size) { index ->
val value = list[index].invoke()
if (value != null) {
check(canBeSaved(value))
}
value
}
}
}
return map
}在这里调用了 ValueProvider 获取数据后存入 restored ,这里也是有针对 Value 是 List 类型的特别处理。performSave 的调用时机前面已经出现了,是 androidxRegistry 注册的 Provider 中调用:
androidxRegistry.registerSavedStateProvider(key) {
//调用 register#performSave 并且转为 Bundle
saveableStateRegistry.performSave().toBundle()
}SavedStateProvider 会在 onSaveInstance 时被执行。
至此, rememberSaveable 持久化发生的时机与平台进行了关联。
最后回看 androidxRegistry
最后我们再回看一下 DisposableSavableStateRegistry,主要是使用 androidxRegistry 获取 key 对应的数据,并注册 key 对应的 Provider。那么 androidxRegistry 和 key 是怎么来的?
internal fun DisposableSaveableStateRegistry(
id: String,
savedStateRegistryOwner: SavedStateRegistryOwner
): DisposableSaveableStateRegistry {
val key = "${SaveableStateRegistry::class.java.simpleName}:$id"
val androidxRegistry = savedStateRegistryOwner.savedStateRegistry
//...
}先说 key 。key 由 id 唯一决定,而这个 id 其实是 ComposeView 的 layoutId。我们知道 ComposeView 是 Activity/Fragment 承载 Composable 的容器,rememberSaveable 会按照 ComposeView 为单位来持久化数据。
因为你 ComposeView 的 id 决定了 rememberSaveable 存储数据的位置,如果 Activity/Fragment 范围内如果有多个 ComposeView 使用了同一个 id,则只有第一个 ComposeView 能正常恢复数据,这一点要特别注意
再看一下 androidxRegistry,他由 SavedStateRegistryOwner 提供,而这个 owner 是ComposeView 被 attach 到 Activity 时赋的值,就是 Activity 本身:
public class ComponentActivity extends androidx.core.app.ComponentActivity implements
ContextAware,
LifecycleOwner,
ViewModelStoreOwner,
HasDefaultViewModelProviderFactory,
SavedStateRegistryOwner, // ComponentActivity 是一个 SavedStateRegistryOwner
OnBackPressedDispatcherOwner,
ActivityResultRegistryOwner,
ActivityResultCaller {
//...
public final SavedStateRegistry getSavedStateRegistry() {
return mSavedStateRegistryController.getSavedStateRegistry();
}
//...
}mSavedStateRegistryController 会在 Activity 重建时 onCreate 中调用 performRestore;在 onSaveInstanceState 时执行 performSave。
protected void onCreate(@Nullable Bundle savedInstanceState) {
mSavedStateRegistryController.performRestore(savedInstanceState);
//...
}
protected void onSaveInstanceState(@NonNull Bundle outState) {
//...
mSavedStateRegistryController.performSave(outState);
}mSavedStateRegistryController 最终调用到 SavedStateRegistry 的同名方法,看一下 SavedStateRegistry#performSave:
fun performSave(outBundle: Bundle) {
//...
val it: Iterator<Map.Entry<String, SavedStateProvider>> =
this.components.iteratorWithAdditions()
while (it.hasNext()) {
val (key, value) = it.next()
components.putBundle(key, value.saveState())
}
if (!components.isEmpty) {
outBundle.putBundle(SAVED_COMPONENTS_KEY, components)
}
}components 是注册 SavedStateProvider 的 Map。 performSave 中调用 Provider 的 saveState 方法获取到 rememberSaveable 中保存的 bundle,然后存入 outBundle 进行持久化。
至此,rememberSaveable 在 Android 平台完成了横竖屏切换时的状态保存。
最后我们用一个图收尾,红色是保存数据时的数据流流向,绿色是恢复数据时的数据流流向:
链接:https://juejin.cn/post/7166043043651387406
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 如何优雅地阻止系统键盘弹出
前言
开篇先吐槽一下,输入框和文本,一直都是官方每个版本改动的重点,先不说功能上全不全的问题,每次版本升级,必有 breaking change 。对于 extended_text_field | Flutter Package (flutter-io.cn) 和 extended_text | Flutter Package (flutter-io.cn) 来说,新功能都是基于官方的代码,每次版本升级,merge 代码就一个字,头痛,已经有了躺平的想法了。(暂时不 merge 了,能运行就行,等一个稳定点的官方版本,准备做个重构,重构一个相对更好 merge 代码的结构。)
系统键盘弹出的原因
吐槽完毕,我们来看一个常见的场景,就是自定义键盘。要想显示自己自定义的键盘,那么必然需要隐藏系统的键盘。方法主要有如下:
- 在合适的时机调用,
SystemChannels.textInput.invokeMethod<void>('TextInput.hide')。 - 系统键盘为啥会弹出来,是因为某些代码调用了
SystemChannels.textInput.invokeMethod<void>('TextInput.show'),那么我们可以魔改官方代码, 把TextField和EditableText的代码复制出来。
EditableTextState 代码中有一个 TextInputConnection? _textInputConnection;,它会在有需要的时候调用 show 方法。
TextInputConnection 中 show,如下。
/// Requests that the text input control become visible.
void show() {
assert(attached);
TextInput._instance._show();
}TextInput 中 _show,如下。
void _show() {
_channel.invokeMethod<void>('TextInput.show');
}那么问题就简单了,把 TextInputConnection 调用 show 方法的地方全部注释掉。这样子确实系统键盘就不会再弹出来了。
在实际开发过程中,两种方法都有自身的问题:
第一种方法会导致系统键盘上下,会造成布局闪烁,而且调用这个方法的时机也很容易造成额外的 bug 。
第二种方法,就跟我吐槽的一样,复制官方代码真的是吃力不讨好的一件事情,版本迁移的时候,没人愿意再去复制一堆代码。如果你使用的是三方的组件,你可能还需要去维护三方组件的代码。
拦截系统键盘弹出信息
实际上,系统键盘是否弹出,完全是因为 SystemChannels.textInput.invokeMethod<void>('TextInput.show') 的调用,但是我们不可能去每个调用该方法地方去做处理,那么这个方法执行后续,我们有办法拦截吗? 答案当然是有的。
Flutter 的 Framework 层发送信息 TextInput.show 到 Flutter 引擎是通过 MethodChannel, 而我们可以通过重载 WidgetsFlutterBinding 的 createBinaryMessenger 方法来处理Flutter 的 Framework 层通过 MethodChannel 发送的信息。
mixin TextInputBindingMixin on WidgetsFlutterBinding {
@override
BinaryMessenger createBinaryMessenger() {
return TextInputBinaryMessenger(super.createBinaryMessenger());
}
}在 main 方法中初始化这个 binding 。
class YourBinding extends WidgetsFlutterBinding with TextInputBindingMixin,YourBindingMixin {
}
void main() {
YourBinding();
runApp(const MyApp());
}BinaryMessenger 有 3 个方法需要重载.
class TextInputBinaryMessenger extends BinaryMessenger {
TextInputBinaryMessenger(this.origin);
final BinaryMessenger origin;
@override
Future<ByteData?>? send(String channel, ByteData? message) {
// TODO: implement send
throw UnimplementedError();
}
@override
void setMessageHandler(String channel, MessageHandler? handler) {
// TODO: implement setMessageHandler
}
@override
Future<void> handlePlatformMessage(String channel, ByteData? data,
PlatformMessageResponseCallback? callback) {
// TODO: implement handlePlatformMessage
throw UnimplementedError();
}
}- send
Flutter 的 Framework 层发送信息到 Flutter 引擎,会走这个方法,这也是我们需要的处理的方法。
- setMessageHandler
Flutter 引擎 发送信息到 Flutter 的 Framework 层的回调。在我们的场景中不用处理。
- handlePlatformMessage
把 send 和 setMessageHandler 二和一,看了下注释,似乎是服务于 test 的
static const MethodChannel platform = OptionalMethodChannel(
'flutter/platform',
JSONMethodCodec(),
);对于不需要处理的方法,我们做以下处理。
class TextInputBinaryMessenger extends BinaryMessenger {
TextInputBinaryMessenger(this.origin);
final BinaryMessenger origin;
@override
Future<ByteData?>? send(String channel, ByteData? message) {
// TODO: 处理我们自己的逻辑
return origin.send(channel, message);
}
@override
void setMessageHandler(String channel, MessageHandler? handler) {
origin.setMessageHandler(channel, handler);
}
@override
Future<void> handlePlatformMessage(String channel, ByteData? data,
PlatformMessageResponseCallback? callback) {
return origin.handlePlatformMessage(channel, data, callback);
}
}接下来我们可以根据我们的需求处理 send 方法了。当 channel 为 SystemChannels.textInput 的时候,根据方法名字来拦截 TextInput.show。
static const MethodChannel textInput = OptionalMethodChannel(
'flutter/textinput',
JSONMethodCodec(),
); @override
Future<ByteData?>? send(String channel, ByteData? message) async {
if (channel == SystemChannels.textInput.name) {
final MethodCall methodCall =
SystemChannels.textInput.codec.decodeMethodCall(message);
switch (methodCall.method) {
case 'TextInput.show':
// 处理是否需要滤过这次消息。
return SystemChannels.textInput.codec.encodeSuccessEnvelope(null);
default:
}
}
return origin.send(channel, message);
}现在交给我们最后问题就是怎么确定这次消息需要被拦截?当需要发送 TextInput.show 消息的时候,必定有某个 FocusNode 处于 Focus 的状态。那么可以根据这个 FocusNode 做区分。
我们定义个一个特别的 FocusNode,并且定义好一个属性用于判断(也有那种需要随时改变是否需要拦截信息的需求)。
class TextInputFocusNode extends FocusNode {
/// no system keyboard show
/// if it's true, it stop Flutter Framework send `TextInput.show` message to Flutter Engine
bool ignoreSystemKeyboardShow = true;
}这样子,我们就可以根据以下代码进行判断。
Future<ByteData?>? send(String channel, ByteData? message) async {
if (channel == SystemChannels.textInput.name) {
final MethodCall methodCall =
SystemChannels.textInput.codec.decodeMethodCall(message);
switch (methodCall.method) {
case 'TextInput.show':
final FocusNode? focus = FocusManager.instance.primaryFocus;
if (focus != null &&
focus is TextInputFocusNode &&
focus.ignoreSystemKeyboardShow) {
return SystemChannels.textInput.codec.encodeSuccessEnvelope(null);
}
break;
default:
}
}
return origin.send(channel, message);
}最后我们只需要为 TextField 传入这个特殊的 FocusNode。
final TextInputFocusNode _focusNode = TextInputFocusNode()..debugLabel = 'YourTextField';
@override
Widget build(BuildContext context) {
return TextField(
focusNode: _focusNode,
);
}画自己的键盘
这里主要讲一下,弹出和隐藏键盘的时机。你可以通过当前焦点的变化的时候,来显示或者隐藏自定义的键盘。
当你的自定义键盘能自己关闭,并且保存焦点不丢失的,你那还应该在 [TextField]
的 onTap 事件中,再次判断键盘是否显示。比如我写的例子中使用的是 showBottomSheet 方法,它是能通过 drag 来关闭自己的。
下面为一个简单的例子,完整的例子在 extended_text_field/no_keyboard.dart at master · fluttercandies/extended_text_field (github.com)
PersistentBottomSheetController<void>? _bottomSheetController;
final TextInputFocusNode _focusNode = TextInputFocusNode()..debugLabel = 'YourTextField';
@override
void initState() {
super.initState();
_focusNode.addListener(_handleFocusChanged);
}
@override
Widget build(BuildContext context) {
return Scaffold(
body: TextField(
// you must use TextInputFocusNode
focusNode: _focusNode,
),
);
}
void _onTextFiledTap() {
if (_bottomSheetController == null) {
_handleFocusChanged();
}
}
void _handleFocusChanged() {
if (_focusNode.hasFocus) {
// just demo, you can define your custom keyboard as you want
_bottomSheetController = showBottomSheet<void>(
context: FocusManager.instance.primaryFocus!.context!,
// set false, if don't want to drag to close custom keyboard
enableDrag: true,
builder: (BuildContext b) {
// your custom keyboard
return Container();
});
// maybe drag close
_bottomSheetController?.closed.whenComplete(() {
_bottomSheetController = null;
});
} else {
_bottomSheetController?.close();
_bottomSheetController = null;
}
}
@override
void dispose() {
_focusNode.removeListener(_handleFocusChanged);
super.dispose();
}当然,怎么实现自定义键盘,可以根据自己的情况来决定,比如如果你的键盘需要顶起布局的话,你完全可以写成下面的布局。
Column(
children: <Widget>[
// 你的页面
Expanded(child: Container()),
// 你的自定义键盘
Container(),
],
);结语
通过对 createBinaryMessenger 的重载,我们实现对系统键盘弹出的拦截,避免我们对官方代码的依赖。其实 SystemChannels 当中,还有些其他的系统的 channel,我们也能通过相同的方式去对它们进行拦截,比如可以拦截按键。
static const BasicMessageChannel<Object?> keyEvent = BasicMessageChannel<Object?>(
'flutter/keyevent',
JSONMessageCodec(),
);本文相关代码都在 extended_text_field | Flutter Package (flutter-io.cn) 。
爱 Flutter,爱糖果,欢迎加入Flutter Candies,一起生产可爱的Flutter小糖果
链接:https://juejin.cn/post/7166046328609308685
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【Ktor挖坑日记】还在用Retrofit网络请求吗?试试Ktor吧!
Ktor官方对Ktor的描述是:
Create asynchronous client and server applications. Anything from microservices to multiplatform HTTP client apps in a simple way. Open Source, free, and fun!
创建异步客户端和和服务器应用,从微服务到多平台HTTP客户端应用程序都可以用一种简单的方式完成。开源、免费、有趣!
它具有轻量级+可扩展性强+多平台+异步的特性。
轻量级和可扩展性是因为它的内核比较简单,并且当需要一些功能的时候可以加入别的插件到项目中,并不会造成功能冗余。并且Ktor的扩展是使用插拔的方式,使用起来非常简单!
异步,Ktor内部是使用Kotlin协程来实现异步,这对于熟悉Kotlin的Android开发非常友好。
看到这里可能一头雾水,下面将用一个比较简单的例子来带大家入坑Ktor!等看完这篇文章之后就会对Ktor的这些特性有进一步的了解。
小例子 —— 看猫咪
引入依赖
在app模块的gradle中引入依赖
plugins {
...
id 'org.jetbrains.kotlin.plugin.serialization' version "1.7.10" // 跟Kotlin版本一致
}
dependencies {
...
// Ktor
def ktor_version = "2.1.0"
implementation "io.ktor:ktor-client-core:$ktor_version"
implementation "io.ktor:ktor-client-android:$ktor_version"
implementation "io.ktor:ktor-client-content-negotiation:$ktor_version"
implementation "io.ktor:ktor-serialization-kotlinx-json:$ktor_version"
}稍微解释一下这两个依赖
Ktor的客户端内核
由于本APP是部署在Android上的,因此需要引入一个Android依赖,Android平台和其他平台的不同点在于Android具有主线程的概念,Android不允许在主线程发送网络请求,而在Kotlin协程中就是主调度器的概念,其内部是post任务到主线程Handler中,这里就不展开太多。当然如果要使用OkHttp也是可以的!
implementation "io.ktor:ktor-client-okhttp:$ktor_version"
如果想应用到其他客户端平台可以使用CIO
第三个简单来说就是数据转换的插件,例如将远端发送来的数据(可以是CBOR、Json、Protobuf)转换成一个个数据类。
而第四个就是第三个的衍生插件,相信用过
kotlin-serialization的人会比较熟悉,是Kotlin序列化插件,本次引用的是json,类似于Gson,可以将json字符串转换成数据类。
当然,如果需要其他插件可以到官网上看看,例如打印日志Logging
implementation "ch.qos.logback:logback-classic:$logback_version"
implementation "io.ktor:ktor-client-logging:$ktor_version"创建HttpClient
首先创建一个HttpClient实例
val httpClient = HttpClient(Android) {
defaultRequest {
url {
protocol = URLProtocol.HTTP
host = 你的host
port = 你的端口
}
}
install(ContentNegotiation) {
json()
}
}创建的时候是使用DSL语法的,这里解释一下其中使用的两个配置
defaultRequest:给每个HTTP请求加上BaseUrl
例如请求
"/get-cat"就会向"http://${你的host}:${你的端口}/get-cat"发起HTTP请求。
ContentNegotiation:引入数据转换插件。
json:引入自动将json转换数据类的插件。
定义数据类
@Serializable
data class Cat(
val name: String,
val description: String,
val imageUrl: String
)
此处给猫咪定义名字、描述和图片url,需要注意的是需要加上@Serializable注解,这是使用kotlin-serialization的前提条件,而需要正常使用kotlin-serialization,需要在app模块的build.gradle加上以下plugin
plugins {
...
id 'org.jetbrains.kotlin.plugin.serialization' version "1.7.10" // 跟Kotlin版本一致
}创建API
interface CatSource {
suspend fun getRandomCat(): Result<Cat>
companion object {
val instance = CatSourceImpl(httpClient)
}
}
class CatSourceImpl(
private val client: HttpClient
) : CatSource {
override suspend fun getRandomCat(): Result<Cat> = runCatching {
client.get("random-cat").body()
}
}
此处声明一个CatSource接口,接口中声明一个获取随机小猫咪的函数,并且对该接口进行实现。
suspend:HttpClient的方法大多数为suspend函数,例如例子中的get为suspend函数,因此接口也要定义成suspend函数。
Result:Result为Kotlin官方包装类,具有success和failure两个方法,可以包装成功和失败两种数据,可以简单使用runCatching来返回Result
@InlineOnly
@SinceKotlin("1.3")
public inline fun <T, R> T.runCatching(block: T.() -> R): Result<R> {
return try {
Result.success(block())
} catch (e: Throwable) {
Result.failure(e)
}
}
body:获取返回结果,由于内部协程实现,因此不用担心阻塞主线程的问题,由于引入了ContentNegotiation,因此获取到结果之后可以对其进行转换,转换成实际数据类。
展示
ViewModel
class MainViewModel : ViewModel() {
private val catSource = CatSource.instance
private val _catState = MutableStateFlow<UiState<Cat>>(UiState.Loading)
val catState = _catState.asStateFlow()
init {
getRandomCat()
}
fun getRandomCat() {
viewModelScope.launch {
_catState.value = UiState.Loading
// fold 方法可以用来对 Result 的结果分情况处理
catSource.getRandomCat().fold(
onSuccess = {
_catState.value = UiState.Success(it)
}, onFailure = {
_catState.value = UiState.Failure(it)
}
)
}
}
}
sealed class UiState<out T> {
object Loading: UiState<Nothing>()
data class Success<T>(val value: T): UiState<T>()
data class Failure(val exc: Throwable): UiState<Nothing>()
}
inline fun <T> UiState<T>.onState(
onSuccess: (T) -> Unit,
onFailure: (Throwable) -> Unit = {},
onLoading: () -> Unit = {}
) {
when(this) {
is UiState.Failure -> onFailure(this.exc)
UiState.Loading -> onLoading()
is UiState.Success -> onSuccess(this.value)
}
}Activity
界面比较简单,因此用Compose实现
class MainActivity : ComponentActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
KittyTheme {
Column(
modifier = Modifier
.fillMaxWidth()
.padding(32.dp)
) {
val viewModel: MainViewModel = viewModel()
val catState by viewModel.catState.collectAsState()
catState.onState(
onSuccess = { cat ->
AsyncImage(model = cat.imageUrl, contentDescription = cat.name)
Spacer(modifier = Modifier.height(8.dp))
Text(
text = cat.name,
fontWeight = FontWeight.SemiBold,
fontSize = 20.sp
)
Spacer(modifier = Modifier.height(8.dp))
Text(text = cat.description)
},
onFailure = {
Text(text = "Loading Failure!")
},
onLoading = {
CircularProgressIndicator()
}
)
Button(
onClick = viewModel::getRandomCat,
modifier = Modifier.align(Alignment.End)
) { Text(text = "Next Cat!") }
Spacer(modifier = Modifier.height(8.dp))
}
}
}
}
}
对state分情况展示
加载中就展示转圈圈。
成功就展示猫咪图片、猫咪名字、猫咪描述。
失败就展示加载失败。
展示图片的
AsyncImage来自于Coil展示库,传入imageUrl就好啦,使用Kotlin编写,内部使用协程实现异步。
我们运行一下吧!
总结一下
是不是很简单捏!看起来好像很多,其实核心用法就三个
实例HttpClient
在HttpClient中配置插件
调用
get或者post方法
由于内部使用了协程来进行异步,因此不用担心主线程阻塞!令我觉得比较香的是数据转换插件,可以再也不用担心数据转换了。并且支持例如XML、CBOR、Json等等,也不会担心后端会给我们发来什么数据格式了。
还有一个文中没有用到的是Logging插件,可以在logcat打印给服务端发了什么,服务端给客户端发了什么,调试API起来也很方便,跟后端拉扯起来也很有底气!
另外,Android插件不支持WebSocket,但是Okhttp和CIO支持!实际使用中可以用后者创建httpClient!
服务端
创建项目
服务端不是重点就简单提一下,贴一下代码,使用IntelliJ IDEA Ultimate可以直接创建Ktor工程,要是用社区版就去ktor.io/create/创建。
- 工程名字。
2. 配置插件,官方很多插件,不用想着一下子就添加完,需要用的时候再像客户端一样引入依赖就好。
3. 创建项目,下载打开。
编写代码
到Application.kt看一下主函数
fun main() {
embeddedServer(Netty, port = 你的端口, host = "0.0.0.0") {
configureRouting()
configureSerialization()
}.start(wait = true)
}
配置Routing插件
fun Application.configureRouting() {
routing {
randomCat()
static {
resources("static")
}
}
}
fun Route.randomCat() {
get("/random-cat") {
// 随便回一直猫咪给客户端
call.respond(cats.random())
}
}
//本地IPV4地址
private const val BASE_URL = "http://${你的host}:${你的端口}"
private val cats = listOf(
Cat("夺宝1号", "这是一只可爱的小猫咪", "$BASE_URL/cats/cat1.jpg"),
Cat("夺宝2号", "这是一只可爱的小猫咪", "$BASE_URL/cats/cat2.jpg"),
Cat("夺宝3号", "这是一只可爱的小猫咪", "$BASE_URL/cats/cat3.jpg"),
Cat("夺宝4号", "这是一只可爱的小猫咪", "$BASE_URL/cats/cat4.jpg"),
Cat("夺宝5号", "这是一只可爱的小猫咪", "$BASE_URL/cats/cat5.jpg"),
Cat("夺宝6号", "这是一只可爱的小猫咪", "$BASE_URL/cats/cat6.jpg"),
Cat("夺宝7号", "这是一只可爱的小猫咪", "$BASE_URL/cats/cat7.jpg"),
)
@Serializable
data class Cat(
val name: String,
val description: String,
val imageUrl: String
)
配置Serialization插件
fun Application.configureSerialization() {
install(ContentNegotiation) {
json()
}
}
放入图片资源,我放了七只猫咪图片。
然后跑起来就好啦!去手机上看看效果吧!
又总结一次
客户端和服务端使用方式是比较相似的,这也非常友好,由于也是使用Kotlin作为后端,那很多代码都可以拷贝了,例如文中的数据类Cat甚至可以直接拷贝过来。Ktor用起来非常方便,由于其Okhttp插件的存在,在全Kotlin的Android项目中甚至可以考虑Ktor而不是Retrofit(当然Retrofit也是非常优秀的网络请求库)。关于Ktor的坑先开到这啦!
参考
链接:https://juejin.cn/post/7136829279903416333
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
View工作原理 | 理解MeasureSpec和LayoutParams
前言
本篇文章是理解View的测量原理的前置知识,在说View的测量时,我相信很多开发者都会说出重写onMeasure方法,比如下面方法:
override fun onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int) {
super.onMeasure(widthMeasureSpec, heightMeasureSpec)
}但是这时你有没有想过这个方法中的参数即2个Int值是什么意思,以及是谁调用该方法的。
正文
本篇文章就从这个MeasureSpec值的意义以及如何得到MeasureSpec这2个角度来分析。
MeasureSpec
直接翻译就是测量规格,虽然我们在开发中会自己使用Java代码写布局或者在XML中直接进行布局,但是系统在真正测量以及确定其View大小的函数onMeasue中,参数却是MeasureSpec类型,那么它和普通的Int类型有什么区别呢?
其实在测量过程中,系统会将View的布局参数LayoutParams根据父View容器所施加的规则转换为对应的MeasureSpec,然后根据这个MeasureSpec便可以测量出View的宽高。注意一点,测量宽高不一定等于View的最终宽高。
其实这里就可以想一下为什么要如此设计,我们在XML中写布局的时候,在设置View的大小时就是通过下面2个属性:
android:layout_width="match_parent"
android:layout_height="wrap_content"然后再加上padding、margin等共同确定该View的大小;这里虽然没啥问题,但是这个中间转换模式太麻烦了,需要开发者手动读取属性,而且读取各种padding、margin值等,不免会引起错误。
所以Android系统就把这个复杂个转换自己给做了,留给开发者的只有一个宽度MeasureSpec和高度MeasureSpec,可以方便开发者。
MeasureSpec是一个32位Int的值,高2位代表SpecMode,低30位代表SpecSize,SpecMode是指测量模式,而SpecSize是指在某种测量模式下的规格大小。下面是MeasureSpec的源码,比较简单:
//静态类
public static class MeasureSpec {
//移位 30位
private static final int MODE_SHIFT = 30;
//MODE_MASK的值也就是110000...000即11后面跟30个0
private static final int MODE_MASK = 0x3 << MODE_SHIFT;
//UNSPECIFED模式的值也就是00...000即32个0
public static final int UNSPECIFIED = 0 << MODE_SHIFT;
//EXACTLY模式的值也就是01000...000即01后面跟30个0
public static final int EXACTLY = 1 << MODE_SHIFT;
//AT_MOST模式的值也就是10000...000即10后面跟30个0
public static final int AT_MOST = 2 << MODE_SHIFT;
//根据最多30位二进制大小的值以及3个MODE创建出一个32位的MeasureSpec的值
//32位中高2位00 01 10分别表示模式,低30位代表大小
public static int makeMeasureSpec( int size,
@MeasureSpecMode int mode) {
//不考虑这种情况
if (sUseBrokenMakeMeasureSpec) {
return size + mode;
} else {
return (size & ~MODE_MASK) | (mode & MODE_MASK);
}
}
//获取模式
public static int getMode(int measureSpec) {
//noinspection ResourceType
return (measureSpec & MODE_MASK);
}
//获取大小
public static int getSize(int measureSpec) {
return (measureSpec & ~MODE_MASK);
}
}MeasureSpec通过将SpecMode和SpecSize打包成一个int值来避免过多的对象内存分配,为了方便操作,其提供了打包和解包方法。
其中SpecMode有3类,每一类都表示特殊的含义,如下所示:
| SpecMode | 含义 |
|---|---|
| UNSPECIFIED | 表示父容器不对View做任何限制,要多大给多大,这种情况一般用于系统内部,表示一种测量的状态 |
| EXACTLY | 表示父容器已经监测出View所需要的精确大小,这个时候View的最终大小就是SpecSize所指的值。它对于于LayoutParams中的match_parent和具体的数值这俩种模式 |
| AT_MOST | 表示父容器指定了一个可用大小即SpecSize,View的大小不能大于这个值,具体是什么值,需要看View的具体实现。对应于LayoutParams中的wrap_content。 |
从上表格可用发现,一个View的宽高MeasureSpec由它父View和自己的LayoutParams共同决定。
MeasureSpec和LayoutParams的对应关系
上面提到在系统中是以MeasureSpec来确定View测量后的宽高,而正常情况下我们会使用LayoutParams来约束View的大小,所以中间这个转换过程也就是将View的LayoutParams在父容器的MeasureSpec作用下,共同产生View的MeasureSpec。
LayoutParams
这个类在我们平时用代码来设置布局的时候非常常见,其实它就是用来解析XML中一些属性的,我们来看一下源码:
//这个是ViewGroup中的LayoutParams
public static class LayoutParams {
//对应于XML中的match_parent、wrap_parent
public static final int FILL_PARENT = -1;
public static final int MATCH_PARENT = -1;
public static final int WRAP_CONTENT = -2;
//宽度
public int width;
//高度
public int height;
//构造函数
public LayoutParams(Context c, AttributeSet attrs) {
TypedArray a = c.obtainStyledAttributes(attrs, R.styleable.ViewGroup_Layout);
//解析出XML定义的属性,赋值到宽和高2个属性上
setBaseAttributes(a,
R.styleable.ViewGroup_Layout_layout_width,
R.styleable.ViewGroup_Layout_layout_height);
a.recycle();
}
//构造函数,用于代码创建实例
public LayoutParams(int width, int height) {
this.width = width;
this.height = height;
}
//读取XML中的对应属性
protected void setBaseAttributes(TypedArray a, int widthAttr, int heightAttr) {
width = a.getLayoutDimension(widthAttr, "layout_width");
height = a.getLayoutDimension(heightAttr, "layout_height");
}
}这里我们会发现我们在XML中设置的宽高属性就会在这个ViewGroup的LayoutParams给记录起来。
既然说起来LayoutParams,我们就来扩展一下子,因为我们平时在代码中设置这个LayoutParams经常会犯的一个错误就是获取到这个View的LayoutParams,它通常不是ViewGroup.LayoutParams,而是其他的,如果不注意就会强转失败,这里多看2个常见子类。
MarginLayoutParams
第一个就是MarginLayoutParams,一般具体具体View的XXX.LayoutParams都是继承这个父类,代码如下:
public static class MarginLayoutParams extends ViewGroup.LayoutParams {
//4个方向间距的大小
public int leftMargin;
public int topMargin;
public int rightMargin;
public int bottomMargin;
//分别解析XML中的margin、topMargin、leftMargin、bottomMargin和rightMargin属性
public MarginLayoutParams(Context c, AttributeSet attrs) {
super();
TypedArray a = c.obtainStyledAttributes(attrs, R.styleable.ViewGroup_MarginLayout);
setBaseAttributes(a,
R.styleable.ViewGroup_MarginLayout_layout_width,
R.styleable.ViewGroup_MarginLayout_layout_height);
//省略
a.recycle();
}
//省略
}这个不论我们View在啥ViewGroup的里面,在XML中都可以设置其margin,而这些margin的值都会被保存起来。
具体的LayoutParams
第二个就是具体的LayoutParams,比如这里举例LinearLayout.LayoutParams。
首先回顾一下,线性布局的布局参数有什么特点,在XML中在线性布局里写新的View,这时你可以设置宽或者高为0dp,然后设置权重,以及设置layout_gravity这些属性,所以这些属性在解析XML时就会保存到相应的布局参数LayoutParams中,线性布局的布局参数代码如下:
//线性布局的LayoutParams
public static class LayoutParams extends ViewGroup.MarginLayoutParams {
//权重属性
@InspectableProperty(name = "layout_weight")
public float weight;
//layout_gravity属性
@ViewDebug.ExportedProperty(category = "layout", mapping = {
@ViewDebug.IntToString(from = -1, to = "NONE"),
@ViewDebug.IntToString(from = Gravity.NO_GRAVITY, to = "NONE"),
@ViewDebug.IntToString(from = Gravity.TOP, to = "TOP"),
@ViewDebug.IntToString(from = Gravity.BOTTOM, to = "BOTTOM"),
@ViewDebug.IntToString(from = Gravity.LEFT, to = "LEFT"),
@ViewDebug.IntToString(from = Gravity.RIGHT, to = "RIGHT"),
@ViewDebug.IntToString(from = Gravity.START, to = "START"),
@ViewDebug.IntToString(from = Gravity.END, to = "END"),
@ViewDebug.IntToString(from = Gravity.CENTER_VERTICAL, to = "CENTER_VERTICAL"),
@ViewDebug.IntToString(from = Gravity.FILL_VERTICAL, to = "FILL_VERTICAL"),
@ViewDebug.IntToString(from = Gravity.CENTER_HORIZONTAL, to = "CENTER_HORIZONTAL"),
@ViewDebug.IntToString(from = Gravity.FILL_HORIZONTAL, to = "FILL_HORIZONTAL"),
@ViewDebug.IntToString(from = Gravity.CENTER, to = "CENTER"),
@ViewDebug.IntToString(from = Gravity.FILL, to = "FILL")
})
@InspectableProperty(
name = "layout_gravity",
valueType = InspectableProperty.ValueType.GRAVITY)
public int gravity = -1;
//一样从构造函数中获取对应的属性
public LayoutParams(Context c, AttributeSet attrs) {
super(c, attrs);
TypedArray a =
c.obtainStyledAttributes(attrs, com.android.internal.R.styleable.LinearLayout_Layout);
weight = a.getFloat(com.android.internal.R.styleable.LinearLayout_Layout_layout_weight, 0);
gravity = a.getInt(com.android.internal.R.styleable.LinearLayout_Layout_layout_gravity, -1);
a.recycle();
}
}到这里我们就知道了,其实我们在XML布局中的写的各种大小属性,都会被解析为各种LayoutParams实例给保存起来。
转换关系
前面我们知道既然测量的过程需要这个MeasureSpec,而我们平时在开发中在XML里都是使用View的属性,而上面我们可知不论是XML还是代码最终View的宽高等属性都是赋值到了LayoutParams这个类实例中,所以搞清楚MeasureSpec和LayoutParams的转换关系非常重要。
正常来说,View的MeasureSpec由它父View的MeasureSpec和自己的LayoutParams来共同得到,但是对于不同的View,其转换关系是有一点差别的,我们挨个来说一下。
DecorView的MeasureSpec
因为DecorView作为顶级View,它没有父View,所以我们来看一下它的MeasureSpec是如何生成的,在ViewRootImpl的measureHierarchy方法中有,代码如下:
//获取decorView的宽高的MeasureSpec
childWidthMeasureSpec = getRootMeasureSpec(baseSize, lp.width);
childHeightMeasureSpec = getRootMeasureSpec(desiredWindowHeight, lp.height);
//开始对DecorView进行测量
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);看一下这个getRootMeasureSpec方法:
//windowSize就是当前Window的大小
private static int getRootMeasureSpec(int windowSize, int rootDimension) {
int measureSpec;
switch (rootDimension) {
case ViewGroup.LayoutParams.MATCH_PARENT:
//当布局参数是match_parent时,测量模式是EXACTLY
measureSpec = MeasureSpec.makeMeasureSpec(windowSize, MeasureSpec.EXACTLY);
break;
case ViewGroup.LayoutParams.WRAP_CONTENT:
/当布局参数是wrap_content时,测量模式是AT_MOST
measureSpec = MeasureSpec.makeMeasureSpec(windowSize, MeasureSpec.AT_MOST);
break;
default:
//具体宽高时,对应也就是EXACTLY
measureSpec = MeasureSpec.makeMeasureSpec(rootDimension, MeasureSpec.EXACTLY);
break;
}
return measureSpec;
}这里我们就会发现DecorView的Measure的获取非常简单,当DecorView的LayoutParams是match_parent时,测量模式是EXACTLY,值是Window大小;当DecorView的LayoutParams是wrap_content时,测量模式是AT_MOST,值是window大小。
View的MeasureSpec
对于View的MeasureSpec的获取稍微不一样,因为它肯定有父View,所以它的MeasureSpec的创造不仅和自己的LayoutParam有关,还和父View的MeasureSpec有关。
在这里我们先不讨论ViewGroup以及View是如何分发这个测量流程的,后面再说,这里有个我们在自定义ViewGroup时常用的方法,它用来测量它下面的子View,代码如下:
//ViewGroup中的代码,用来自定义ViewGroup时遍历子view,然后挨个进行测量
protected void measureChildWithMargins(
//子View
View child,
//ViewGroup的MeasureSpec,即父View的MeasureSpec
int parentWidthMeasureSpec, int widthUsed,
int parentHeightMeasureSpec, int heightUsed) {
//子View的LayoutParams
final MarginLayoutParams lp = (MarginLayoutParams) child.getLayoutParams();
//获取子View的MeasureSpec
final int childWidthMeasureSpec = getChildMeasureSpec(parentWidthMeasureSpec,
mPaddingLeft + mPaddingRight + lp.leftMargin + lp.rightMargin
+ widthUsed, lp.width);
final int childHeightMeasureSpec = getChildMeasureSpec(parentHeightMeasureSpec,
mPaddingTop + mPaddingBottom + lp.topMargin + lp.bottomMargin
+ heightUsed, lp.height);
//子View进行测量
child.measure(childWidthMeasureSpec, childHeightMeasureSpec);
}这里先不讨论子View如何去测量,只关注在有父View的MeasureSpec和自己的LayoutParams时,它是如何得到自己的MeasureSpec的,代码如下:
//调用的代码
final int childWidthMeasureSpec = getChildMeasureSpec(parentWidthMeasureSpec,
mPaddingLeft + mPaddingRight + lp.leftMargin + lp.rightMargin
+ widthUsed, lp.width);这里注意一下参数,第一个参数是父View的MeasureSpec,第三个参数是当前View的宽度,而这里的宽度有3种:wrap_content为-2,match_parent为-1,具体值大于等于0,虽然说是宽度,也包含了View的LayoutParams信息。
第二个参数表示间距,其中mPaddingLeft和mPaddingRight很重要,因为这个属性是不会记录在LayoutParams中的,而且它的涵义是内间距,这里它是写在父ViewGroup中的属性值,比如加了这个paddingLeft属性后,其子View不会从原点开始绘制,它所可用的宽度就会变小,所以View在测量其大小时要把padding排除在外。
然后看一下源码实现:
public static int getChildMeasureSpec(int spec, int padding, int childDimension) {
//父View的测量模式
int specMode = MeasureSpec.getMode(spec);
//父View的大小
int specSize = MeasureSpec.getSize(spec);
//padding是否大于父View的大小了
int size = Math.max(0, specSize - padding);
//子View的大小
int resultSize = 0;
//子View的测量模式
int resultMode = 0;
//这里要明白layoutParams中的wrap_content是-2,match_parent是-1,具体值才大于0
switch (specMode) {
//父View的测量模式是精确模式
case MeasureSpec.EXACTLY:
if (childDimension >= 0) {
//子View当前写死了大小,所以测量模式必是精确模式
resultSize = childDimension;
resultMode = MeasureSpec.EXACTLY;
} else if (childDimension == LayoutParams.MATCH_PARENT) {
//子View和父View一样大,所以测量模式肯定是精确模式
resultSize = size;
resultMode = MeasureSpec.EXACTLY;
} else if (childDimension == LayoutParams.WRAP_CONTENT) {
//子View是包裹内容,其最大值是父View的大小
resultSize = size;
resultMode = MeasureSpec.AT_MOST;
}
break;
//父View的测量模式是至多模式
case MeasureSpec.AT_MOST:
if (childDimension >= 0) {
//子View大小写死,测量模式必须是精确模式
resultSize = childDimension;
resultMode = MeasureSpec.EXACTLY;
} else if (childDimension == LayoutParams.MATCH_PARENT) {
//和父类一样,也是父类的至多模式
resultSize = size;
resultMode = MeasureSpec.AT_MOST;
} else if (childDimension == LayoutParams.WRAP_CONTENT) {
//这里要稍微注意一下,由于父类最大多少,所以这个View也是至多模式
resultSize = size;
resultMode = MeasureSpec.AT_MOST;
}
break;
// 不分析
case MeasureSpec.UNSPECIFIED:
if (childDimension >= 0) {
// Child wants a specific size... let them have it
resultSize = childDimension;
resultMode = MeasureSpec.EXACTLY;
} else if (childDimension == LayoutParams.MATCH_PARENT) {
// Child wants to be our size... find out how big it should
// be
resultSize = View.sUseZeroUnspecifiedMeasureSpec ? 0 : size;
resultMode = MeasureSpec.UNSPECIFIED;
} else if (childDimension == LayoutParams.WRAP_CONTENT) {
// Child wants to determine its own size.... find out how
// big it should be
resultSize = View.sUseZeroUnspecifiedMeasureSpec ? 0 : size;
resultMode = MeasureSpec.UNSPECIFIED;
}
break;
}
//noinspection ResourceType
return MeasureSpec.makeMeasureSpec(resultSize, resultMode);
}由这里代码可以看出,和DecorView不同的是当前View的MeasureSpec的创建和父View的MeasureSpec和自己的LayoutParams有关。
普通View的MeasureSpec创建规则
对于DecorView的转换我们一般不会干涉,这里有一个普通View的MeasureSpce创建规则总结:
| 子View布局\父View Mode | EXACTLY | AT_MOST | UNSPECIFIED |
|---|---|---|---|
| dp/dx具体值 | EXACTLY+childSize | EXACTLY+childSize | EXACTLY+childSize |
| match_parent | EXACTLY+parentSize | AT_MOST+parentSize | UNSPECIFIIED+0 |
| wrap_conent | AT_MOST+parentSize | AT_MOST+parentSize | UNSPECIFIIED+0 |
这个规则必须牢记,在后面View的绘制中我们将具体解析。
总结
本篇文章主要是理解MeasureSpec的设计初衷以及其含义,然后就是一个View的MeasureSpec是通过什么规则转换而来。后面文章我们将具体分析如何利用MeasureSpce来进行测量,最终确定View的大小。
笔者水平有限,有错误希望大家评论、指正。
链接:https://juejin.cn/post/7051543108516839431
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flow是如何解决背压问题的
前言
随着时间的推移,越来越多的主流应用已经开始全面拥抱
Kotlin,协程的引入,Flow的诞生,给予了开发很多便捷,作为协程与响应式编程结合的流式处理框架,一方面它简单的数据转换与操作符,没有繁琐的操作符处理,广受大部分开发的青睐,另一方面它并没有响应式编程带来的背压问题(BackPressure)的困扰;接下来,本文将会就Flow如何解决背压问题进行探讨
关于背压(BackPressure)
背压问题是什么
首先我们要明确背压问题是什么,它是如何产生的?简单来说,在一般的流处理框架中,消息的接收处理速度跟不上消息的发送速度,从而导致数据不匹配,造成积压。如果不及时正确处理背压问题,会导致一些严重的问题
- 比如说,消息拥堵了,系统运行不畅从而导致崩溃
- 比如说,资源被消耗殆尽,甚至会发生数据丢失的情况
如下图所示,可以直观了解背压问题的产生,它在生产者的生产速率高于消费者的处理速率的情况下出现
定义背压策略
既然我们已经知道背压问题是如何产生的,就要去尝试正确地处理它,大致解决方案策略在于,如果你有一个流,你需要一个缓冲区,以防数据产生的速度快于消耗的速度,所以往往就会针对这个背压策略进行些讨论
- 定义的中间缓冲区需要多大才比较合适?
- 如果缓冲区数据已满了,我们怎么样处理新的事件?
对于以上问题,通过学习Flow里的背压策略,相信可以很快就知道答案了
Flow的背压机制
由于Flow是基于协程中使用的,它不需要一些巧妙设计的解决方案来明确处理背压,在Flow中,不同于一些传统的响应式框架,它的背压管理是使用Kotlin挂起函数suspend实现的,看下源码你会发现,它里面所有的函数方法都是使用suspend修饰符标记,这个修饰符就是为了暂停调度者的执行不阻塞线程。因此,Flow<T>在同一个协程中发射和收集时,如果收集器跟不上数据流,它可以简单地暂停元素的发射,直到它准备好接收更多。看到这,是不是觉得有点难懂.......
简单举个例子,假设我们拥有一个烤箱,可以用来烤面包,由于烤箱容量的限制,一次只能烤4个面包,如果你试着一次烤8个面包,会大大加大烤箱的承载负荷,这已经远远超过了它的内存使用量,很有可能会因此烧掉你的面包。
模拟背压问题
回顾下之前所说的,当我们消耗的速度比生产的速度慢的时候,就会产生背压,下面用代码来模拟下这个过程
首先先创建一个方法,用来每秒发送元素
fun currentTime() = System.currentTimeMillis()
fun threadName() = Thread.currentThread().name
var start: Long = 0
fun createEmitter(): Flow<Int> =
(1..5)
.asFlow()
.onStart { start = currentTime() }
.onEach {
delay(1000L)
print("Emit $it (${currentTime() - start}ms) ")
}
接着需要收集元素,这里我们延迟3秒再接收元素, 延迟是为了夸大缓慢的消费者并创建一个超级慢的收集器。
fun main() {
runBlocking {
val time = measureTimeMillis {
createEmitter().collect {
print("\nCollect $it starts ${start - currentTime()}ms")
delay(3000L)
println(" Collect $it ends ${currentTime() - start}ms")
}
}
print("\nCollected in $time ms")
}
}
看下输出结果,如下图所示
这样整个过程下来,大概需要20多秒才能结束,这里我们模拟了接收元素比发送元素慢的情况,因此就需要一个背压机制,而这正是Flow本质中的,它并不需要另外的设计来解决背压
背压处理方式
使用buffer进行缓存收集
为了使缓冲和背压处理正常工作,我们需要在单独的协程中运行收集器。这就是.buffer()操作符进来的地方,它是将所有发出的项目发送Channel到在单独的协程中运行的收集器。
public fun <T> Flow<T>.buffer(
capacity: Int = BUFFERED,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND
): Flow<T>它还为我们提供了缓冲功能,我们可以指定capacity我们的缓冲区和处理策略onBufferOverflow,所以当Buffer溢出的时候,它为我们提供了三个选项
enum BufferOverflow {
SUSPEND,
DROP_OLDEST,
DROP_LATEST
}- 默认使用
SUSPEND:会将当前协程挂起,直到缓冲区中的数据被消费了 DROP_OLDEST:它会丢弃最老的数据DROP_LATEST: 它会丢弃最新的数据
好的,我们回到上文所展示的模拟示例,这时候我们可以加入缓冲收集buffer,不指定任何参数,这样默认就是使用SUSPEND,它会将当前协程进行挂起
此时当收集器繁忙的时候,程序就开始缓冲,并在第一次收集方法调用结束的时候,两次发射后再次开始收集,此时流程的耗时时长缩短到大约16秒就可以执行完毕,如下图所示输出结果
使用conflate解决
conflate操作符于Channel中的Conflate模式是一直的,新数据会直接覆盖掉旧数据,它不设缓冲区,也就是缓冲区大小为 0,丢弃旧数据,也就是采取 DROP_OLDEST 策略,那么不就等于buffer(0,BufferOverflow.DROP_OLDEST),可以看下它的源码可以佐证我们的判断
public fun <T> Flow<T>.conflate(): Flow<T> = buffer(CONFLATED)在某些情况下,由于根本原因是解决生产消费速率不匹配的问题,我们需要做一些取舍的操作,conflate将丢弃掉旧数据,只有在收集器空闲之前发出的最后一个元素才被收集,将上文的模拟实例改为conflate执行,你会发现我们直接丢弃掉了2和4,或者说新的数据直接覆盖掉了它们,整个流程只需要10秒左右就执行完成了
使用collectLatest解决
通过官方介绍,我们知道collectLatest作用在于当原始流发出一个新的值的时候,前一个值的处理将被取消,也就是不会被接收, 和conflate的区别在于它不会用新的数据覆盖,而是每一个都会被处理,只不过如果前一个还没被处理完后一个就来了的话,处理前一个数据的逻辑就会被取消
suspend fun <T> Flow<T>.collectLatest(action: suspend (T) -> Unit)还是上文的模拟实例,这里我们使用collectLatest看下输出结果:
这样也是有副作用的,如果每个更新都非常重要,例如一些视图,状态刷新,这个时候就不必要用collectLatest ; 当然如果有些更新可以无损失的覆盖,例如数据库刷新,就可以使用到collectLatest,具体详细的使用场景,还需要靠开发者自己去衡量选择使用
小结
对于Flow可以说不需要额外提供什么巧妙的方式解决背压问题,Flow的本质,亦或者说Kotlin协程本身就已经提供了相应的解决方案;开发者只需要在不同的场景中选择正确的背压策略即可。总的来说,它们都是通过使用Kotlin挂起函数suspend,当流的收集器不堪重负时,它可以简单地暂停发射器,然后在准备好接受更多元素时恢复它。
关于挂起函数suspend这里就不过多赘述了,只需要明白的一点是它与传统的基于线程的同步数据管道中背压管理非常相似,无非就是,缓慢的消费者通过阻塞生产者的线程自动向生产者施加背压,简单来说,suspend通过透明地管理跨线程的背压而不阻塞它们,将其超越单个线程并进入异步编程领域。
链接:https://juejin.cn/post/7165380647304282126
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从 internal 修饰符一探 kotlin 的可见性控制
前言
之前探讨过的 sealed class 和 sealed interface 存在 module 的限制,但其主要用于密封 class 的扩展和 interface 的实现。
如果没有这个需求只需要限制 module 的话,使用 Kotlin 中独特的 internal 修饰符即可。
本文将详细阐述 internal 修饰符的特点、原理以及 Java 调用的失效问题,并以此为切入点网罗 Kotlin 中所有修饰符,同时与 Java 修饰符进行对比以加深理解。
- internal 修饰符
- open 修饰符
- default、private 等修饰符
- 针对扩展函数的访问控制
- Kotlin 各修饰符的总结
internal 修饰符
修饰符,modifier,用作修饰如下对象。以展示其在 module 间、package 间、file 间、class 间的可见性。
- 顶层 class、interface
- sub class、interface
- 成员:属性 + 函数
特点
internal 修饰符是 Kotlin 独有的,其在具备了 Java 中 public 修饰符特性的同时,还能做到类似包可见(package private)的限制。只不过范围更大,变成了模块可见(module private)。
首先简单看下其一些基本特点:
上面的特性可以看出来,其不能和
private共存
Modifier 'internal' is incompatible with 'private'
可以和
open共存,但 internal 修饰符优先级更高,需要靠前书写。如果 open 在前的话会收到如下提醒:
Non-canonical modifiers order
其子类只可等同或收紧级别、但不可放宽级别,否则
'public' subclass exposes its 'internal' supertype XXX
说回其最重要的特性:模块可见,指的是 internal 修饰的对象只在相同模块内可见、其他 module 无法访问。而 module 指的是编译在一起的一套 Kotlin 文件,比如:
- 一个 IntelliJ IDEA 模块;
- 一个 Maven 项目;
- 一个 Gradle 源集(例外是
test源集可以访问main的 internal 声明); - 一次
<kotlinc>Ant 任务执行所编译的一套文件。
而且,在其他 module 内调用被 internal 修饰对象的话,根据修饰对象的不同类型、调用语言的不同,编译的结果或 IDE 提示亦有差异:
比如修饰对象为 class 的话,其他 module 调用时会遇到如下错误/提示
Kotlin 中调用:
Cannot access 'xxx': it is internal in 'yyy.ZZZ'
Java 中调用:
Usage of Kotlin internal declaration from different module
修饰对象为成员,比如函数的话,其他 module 调用时会遇到如下错误/提示
Kotlin 中调用:
Cannot access 'xxx': it is internal in 'yyy.ZZZ'(和修饰 class 的错误一样)
Java 中调用:
Cannot resolve method 'xxx'in 'ZZZ'
你可能会发现其他 module 的 Kotlin 语言调用 internal 修饰的函数发生的错误,和修饰 class 一样。而 Java 调用的话,则是直接报找不到,没有 internal 相关的说明。
这是因为 Kotlin 针对 internal 函数名称做了优化,导致 Java 中根本找不到对方,而 Kotlin 还能找到是因为编译器做了优化。
假使将函数名称稍加修改,改为
fun$moduleName的话,Java 中错误/提示会发生变化,和修饰 class 时一样了:
Kotlin 中调用:
Cannot access 'xxx': it is internal in 'yyy.ZZZ'(仍然一样)
Java 中调用:
Usage of Kotlin internal declaration from different module
优化
前面提到了 Kotlin 会针对 internal 函数名称做优化,原因在于:
internal 声明最终会编译成 public 修饰符,如果针对其成员名称做错乱重构,可以确保其更难被 Java 语言错误调用、重载。
比如 NonInternalClass 中使用 internal 修饰的 internalFun() 在编译成 class 之后会被编译成 internalFun$test_debug()。
class NonInternalClass {
internal fun internalFun() = Unit
fun publicFun() = Unit
}
public final class NonInternalClass {
public final void internalFun$test_debug() {
}
public final void publicFun() {
}
}Java 调用的失效
前面提到 Java 中调用 internal 声明的 class 或成员时,IDE 会提示不应当调用跨 module 调用的 IDE 提示,但事实上编译是可以通过的。
这自然是因为编译到字节码里的是 public 修饰符,造成被 Java 调用的话,模块可见的限制会失效。这时候我们可以利用 Kotlin 的其他两个特性进行限制的补充:
使用
@JvmName,给它一个 Java 写不出来的函数名
@JvmName(" zython")
internal fun zython() {
}
Kotlin 允许使用 ` 把一个不合法的标识符强行合法化,而 Java 无法识别这种名称
internal fun ` zython`() { }
open 修饰符
除了 internal,Kotlin 还拥有特殊的 open 修饰符。首先默认情况下 class 和成员都是具备 final 修饰符的,即无法被继承和复写。
如果显式写了 final 则会被提示没有必要:
Redundant visibility modifier
如果可以被继承或复写,需要添加 open 修饰。(当然有了 open 自然不能再写 final,两者互斥)
open 修饰符的原理也很简单,添加了则编译到 class 里即不存在 final 修饰符。
下面抛开 open、final 修饰符的这层影响,着重讲讲 Kotlin 中 default、public、protected、private 的具体细节以及和 Java 的差异。
default、private 等修饰符
除了 internal,open 和 final,Kotlin 还拥有和 Java 一样命名的 default、public 、protected、private修饰符。虽然叫法相同,但在可见性限制的具体细节上存在这样那样的区别。
default
和 Java default visibility 是包可见(package private)不同的是,Kotlin 中对象的 default visibility 是随处可见(visible everywhere)。
public
就 public 修饰符的特性而言,Kotlin 和 Java 是相同的,都是随处可见。只不过 public 在 Kotlin 中是 default visibility,Java 则不是。
正因为此 Kotlin 中无需显示声明 public,否则会提示:Redundant visibility modifier。
protected
Kotlin 中 protected 修饰符和 Java 有相似的地方是可以被子类访问。但也有不同的地方,前者只能在当前 class 内访问,而 Java 则是包可见。
如下在同一个 package 并且是同一个源文件内调用 protected 成员会发生编译错误。
Cannot access 'i': it is protected in 'ProtectedMemberClass'
// TestProtected.kt
open class ProtectedMemberClass {
protected var i = 1
}
class TestProtectedOneFile {
fun test() {
ProtectedMemberClass().run {
i = 2
}
}
}private
Kotlin 中使用 private 修饰顶级类、成员、内部类的不同,visibility 的表现也不同。
当修饰成员的时候,其只在当前 class 内可见。否则提示:
"Cannot access 'xxx': it is private in 'XXX'"
当修饰顶级类的时候,本 class 能看到它,当前文件也能看到,即文件可见(file private)的访问级别。事实上,private 修饰顶级对象的时候,会被编译成 package private,即和 Java 的 default 一样。
但因为 Kotlin 编译器的作用,同 package 但不同 file 是无法访问 private class 的。
Cannot access 'XXX': it is private in file
当修饰的非顶级类,即内部类的话,即便是同文件也无法被访问。比如下面的 test 函数可以访问 TestPrivate,但无法访问 InnerClass。
Cannot access 'InnerClass': it is private in 'TestPrivate'
// TestPrivate.kt
private class TestPrivate {
private inner class InnerClass {
private var name1 = "test"
}
}
class TestPrivateInOneFile: TestGrammar {
override fun test() {
TestPrivate()
TestPrivate().InnerClass() // error
}
}另外一个区别是,Kotlin 中外部类无法访问内部类的 private 成员,但 Java 可以。
Cannot access 'xxx': it is private in 'InnerClass'
针对扩展函数的访问控制
private 等修饰符在扩展函数上也有些需要留意的地方。
扩展函数无法访问被扩展对象的 private / protected 成员,这是可以理解的。毕竟其本质上是静态方法,其内部需要调用实例的成员,而该静态方法是脱离定义 class 的,自然不允许访问访问仅类可见的、子类可见的对象
Cannot access 'xxx': it is private in 'XXX'
Cannot access 'yyy': it is protected in 'XXX'
- 只可以针对 public 修饰的类添加 public 级别的扩展函数,否则会收到如下的错误
'public' member exposes its 'private-in-file' receiver type TestPrivate
扩展函数的原理使得其可以针对目标 class 做些处理,但变相地将文件可见、模块可见的 class 放宽了可见性是不被允许的。但如果将扩展函数定义成 private / internal 是可以通过编译的,但这个扩展函数的可用性会受到限制,需要留意。
Kotlin 各修饰符的总结
对 Kotlin 中各修饰符进行简单的总结:
default 情况下:
- 等同于 final,需要声明 open 才可扩展,这是和 Java 相反的扩展约束策略
- 等同于 public 访问级别,和 Java 默认的包可见不同
- 正因为此,Kotlin 中 final 和 public 无需显示声明
protected 是类可见外加子类可见,而 Java 则是包可见外加子类可见
private 修饰的内部类成员无法被外部类访问,和 Java 不同
internal 修饰符是模块可见,和 Java 默认的包可见有相似之处,也有区别
下面用表格将各修饰符和 Java 进行对比,便于直观了解。
| 修饰符 | Kotlin 中适用场景 | Kotlin | Java |
|---|---|---|---|
| (default) | 随处可见的类、成员 | = public + final | 对象包可见 |
| public | 同上 | = (default) ; 对象随处可见; 无需显示声明 | 对象随处可见 |
| protected | 自己和子类可见 | 对象类可见 + 子类可见 | 对象包可见 + 子类可见 |
| private | 自己和当前文件可见 | 修饰成员:对象类可见; 修饰顶级类:对象源文件可见; 外部类无法访问内部类的 private 成员 | 对象类可见; 外部类可以访问内部类的 private 成员 |
internal | module 内使用的类、成员 | 对象模块可见; 子类只可等同或收紧级别、但不可放宽级别 | - |
open | 可扩展 | 对象可扩展; 和 final 互斥; 优先级低于 internal、protected 等修饰符 | - |
| final | 不可扩展 | = (default) ; 对象不可扩展、复写; 无需显示声明 | 对象不可扩展、复写 |
链接:https://juejin.cn/post/7165443481337331749
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
页面曝光难点分析及应对方案
曝光
曝光埋点分为两种:
- PV
- show
它俩都表示“展示”,但有如下不同:
概念不同:PV = Page View,它特指页面维度的展示。对于 Android 平台来说,可以是一个 Activity 或 Fragment。而 show 可以是任何东西的展示,可以是页面,也可以是一个控件的展示。
上报时机不同:PV 是在离开页面的时候上报,show 是在控件展示的时候上报。
上报参数不同:PV 通常会上报页面停留时长。
消费场景不同:在消费侧,“展示”通常用于形成页面转化率漏斗,PV 和 show 都可用于形成这样的漏斗。但 show 比 PV 更精细,因为可能 A 页面中有 N 个入口可以通往 B页面。
由于产品希望知道更精确的入口信息,遂新增埋点全都是 show。
现有 PV 上报组件
Activity PV
项目中引入了一个第三方库实现了 Activity PV 半自动化上报:
public interface PvTracker {
String getPvEventId();// 生成事件ID
Bundle getPvExtra();// 生成额外参数
default boolean shouldReport() {return true;}
default String getUniqueKey() {return null;}
}该接口定义了如何生成曝光埋点的事件ID和额外参数。
当某 Activity 需要 PV 埋点时实现该接口:
class AvatarActivity : BaseActivity, PvTracker{
override fun getPvEventId() = "avatar.pv"
override fun getPvExtra() = Bundle()
}然后该 pvtracker 库就会自动实现 Activity 的 PV 上报。
它通过如下方式对全局 Activity 生命周期做了监听:
class PvLifeCycleCallback implements Application.ActivityLifecycleCallbacks {
@Override
public void onActivityResumed(Activity activity) {
String eventId = getEventId(activity);
if (!TextUtils.isEmpty(eventId)) {
onActivityVisibleChanged(activity, true); // activity 可见
}
}
@Override
public void onActivityPaused(Activity activity) {
String eventId = getEventId(activity);
if (!TextUtils.isEmpty(eventId)) {
onActivityVisibleChanged(activity, false);// activity 不可见
}
}
// 当 Activity 可见性发生变化
private void onActivityVisibleChanged(Activity activity, boolean isVisible) {
if (activity instanceof PvTracker) {
PvTracker tracker = (PvTracker) activity;
if (!tracker.shouldReport()) {
return;
}
String eventId = tracker.getPvEventId();
Bundle bundle = tracker.getPvExtra();
if (TextUtils.isEmpty(eventId) || mActivityLoadType == null) {
return;
}
String uniqueEventId = PageViewTracker.getUniqueId(activity, eventId);
if (isVisible) {
// 标记曝光开始
PvManager.getInstance().triggerVisible(uniqueEventId, eventId, bundle, loadType);
} else {
// 标记曝光结束,统计曝光时间并上报PV
PvManager.getInstance().triggerInvisible(uniqueEventId);
}
}
}
}PvLifeCycleCallback 是一个全局性的 Activity 生命周期监听器,它会在 Application 初始化的时候注册:
class MyApplication : Application() {
override fun onCreate() {
super.onCreate()
// 在 Application 中初始化
registerActivityLifecycleCallbacks(PvLifeCycleCallback)
}
}这套方案实现了 Activity 层面半自动声明式埋点,即只需要编码埋点数据,不需要手动触发埋点。
Fragment PV
Fragment 生命周期是件非常头痛的事情。
在FragmentManager.FragmentLifecycleCallbacks出现之前没有一个官方的解决方案,Fragment 生命周期处于一片混沌之中。
FragmentManager.FragmentLifecycleCallbacks 为开发者开了一扇窗(但这是一扇破窗):
public abstract static class FragmentLifecycleCallbacks {
public void onFragmentPreAttached(@NonNull FragmentManager fm, @NonNull Fragment f,@NonNull Context context) {}
public void onFragmentAttached(@NonNull FragmentManager fm, @NonNull Fragment f,@NonNull Context context) {}
public void onFragmentPreCreated(@NonNull FragmentManager fm, @NonNull Fragment f,@Nullable Bundle savedInstanceState) {}
public void onFragmentCreated(@NonNull FragmentManager fm, @NonNull Fragment f,@Nullable Bundle savedInstanceState) {}
public void onFragmentActivityCreated(@NonNull FragmentManager fm, @NonNull Fragment f,@Nullable Bundle savedInstanceState) {}
public void onFragmentViewCreated(@NonNull FragmentManager fm, @NonNull Fragment f,@NonNull View v, @Nullable Bundle savedInstanceState) {}
public void onFragmentStarted(@NonNull FragmentManager fm, @NonNull Fragment f) {}
public void onFragmentResumed(@NonNull FragmentManager fm, @NonNull Fragment f) {}
public void onFragmentPaused(@NonNull FragmentManager fm, @NonNull Fragment f) {}
public void onFragmentStopped(@NonNull FragmentManager fm, @NonNull Fragment f) {}
public void onFragmentSaveInstanceState(@NonNull FragmentManager fm, @NonNull Fragment f,@NonNull Bundle outState) {}
public void onFragmentViewDestroyed(@NonNull FragmentManager fm, @NonNull Fragment f) {}
public void onFragmentDestroyed(@NonNull FragmentManager fm, @NonNull Fragment f) {}
public void onFragmentDetached(@NonNull FragmentManager fm, @NonNull Fragment f) {}
}可以通过观察者模式在 Fragment 实例以外的地方全局性地监听所有 Fragment 的生命周期。当其中的 onFragmentResumed() 回调时,意味着 Fragment 可见,而当 onFragmentPaused() 回调时,意味着 Fragment 不可见。
但有如下例外情况:
- 调用
FragmentTransaction的 show()/hide() 方法时,不会走对应的 resume/pause 生命周期回调。(因为它只是隐藏了 Fragment 对应的 View,但 Fragment 还处于 resume 状态,详见FragmentTransaction.hide()- findings | by Nav Singh 🇨🇦 | Nerd For Tech | Medium) - 当 Fragment 和 ViewPager/ViewPager2 共用时,resume/pause 生命周期回调失效。表现为没有展示的 Fragment 会回调 resume,而不可见的 Fragment 不会回调 pause。
pvTracker 的这个库在检测 Fragment 生命周期时也有上述问题。不过它也给出了解决方案:
- 通过监听 ViewPager 页面切换来实现 Fragment + ViewPager 的可见性判断:在 ViewPager 初始化完毕后调用 PageViewTracker.getInstance().observePageChange(viewpager)
- 如果 ViewPager + Fragment 嵌套在一个父 Fragment 还需在父 Fragment.onHiddenChanged() 方法里监听父 Fragment 的显示隐藏状态。
pvTracker 的解决方案是“把皮球踢给上层”,即上层手动调用一个方法来告知库当前 Fragment 的可见性。
全声明式 show 上报
pvtracker 是“半声明式 PV 上报”(Fragment 的可见性需要上层调方法)。
缺少一种“全声明式 show 上报”,即上层无需关注任何上报时机,只需生成埋点参数,就能自动实现 show 的上报。
Fragment 之所以会出现上述例外的情况,是因为 Fragment 的生命周期和其根视图的生命周期不同步。
是不是可以忘掉 Fragment,通过判定其根视图的可见性来表达 Fragment 的可见性?
所以需要一个控件维度全局可见性监听器,引用全网最优雅安卓控件可见性检测 中提供的解决方案:
fun View.onVisibilityChange(
viewGroups: List<ViewGroup> = emptyList(), // 会被插入 Fragment 的容器集合
needScrollListener: Boolean = true,
block: (view: View, isVisible: Boolean) -> Unit
) {
val KEY_VISIBILITY = "KEY_VISIBILITY".hashCode()
val KEY_HAS_LISTENER = "KEY_HAS_LISTENER".hashCode()
// 若当前控件已监听可见性,则返回
if (getTag(KEY_HAS_LISTENER) == true) return
// 检测可见性
val checkVisibility = {
// 获取上一次可见性
val lastVisibility = getTag(KEY_VISIBILITY) as? Boolean
// 判断控件是否出现在屏幕中
val isInScreen = this.isInScreen
// 首次可见性变更
if (lastVisibility == null) {
if (isInScreen) {
block(this, true)
setTag(KEY_VISIBILITY, true)
}
}
// 非首次可见性变更
else if (lastVisibility != isInScreen) {
block(this, isInScreen)
setTag(KEY_VISIBILITY, isInScreen)
}
}
// 全局重绘监听器
class LayoutListener : ViewTreeObserver.OnGlobalLayoutListener {
// 标记位用于区别是否是遮挡case
var addedView: View? = null
override fun onGlobalLayout() {
// 遮挡 case
if (addedView != null) {
// 插入视图矩形区域
val addedRect = Rect().also { addedView?.getGlobalVisibleRect(it) }
// 当前视图矩形区域
val rect = Rect().also { this@onVisibilityChange.getGlobalVisibleRect(it) }
// 如果插入视图矩形区域包含当前视图矩形区域,则视为当前控件不可见
if (addedRect.contains(rect)) {
block(this@onVisibilityChange, false)
setTag(KEY_VISIBILITY, false)
} else {
block(this@onVisibilityChange, true)
setTag(KEY_VISIBILITY, true)
}
}
// 非遮挡 case
else {
checkVisibility()
}
}
}
val layoutListener = LayoutListener()
// 编辑容器监听其插入视图时机
viewGroups.forEachIndexed { index, viewGroup ->
viewGroup.setOnHierarchyChangeListener(object : ViewGroup.OnHierarchyChangeListener {
override fun onChildViewAdded(parent: View?, child: View?) {
// 当控件插入,则置标记位
layoutListener.addedView = child
}
override fun onChildViewRemoved(parent: View?, child: View?) {
// 当控件移除,则置标记位
layoutListener.addedView = null
}
})
}
viewTreeObserver.addOnGlobalLayoutListener(layoutListener)
// 全局滚动监听器
var scrollListener:ViewTreeObserver.OnScrollChangedListener? = null
if (needScrollListener) {
scrollListener = ViewTreeObserver.OnScrollChangedListener { checkVisibility() }
viewTreeObserver.addOnScrollChangedListener(scrollListener)
}
// 全局焦点变化监听器
val focusChangeListener = ViewTreeObserver.OnWindowFocusChangeListener { hasFocus ->
val lastVisibility = getTag(KEY_VISIBILITY) as? Boolean
val isInScreen = this.isInScreen
if (hasFocus) {
if (lastVisibility != isInScreen) {
block(this, isInScreen)
setTag(KEY_VISIBILITY, isInScreen)
}
} else {
if (lastVisibility == true) {
block(this, false)
setTag(KEY_VISIBILITY, false)
}
}
}
viewTreeObserver.addOnWindowFocusChangeListener(focusChangeListener)
// 为避免内存泄漏,当视图被移出的同时反注册监听器
addOnAttachStateChangeListener(object : View.OnAttachStateChangeListener {
override fun onViewAttachedToWindow(v: View?) {
}
override fun onViewDetachedFromWindow(v: View?) {
v ?: return
// 有时候 View detach 后,还会执行全局重绘,为此退后反注册
post {
try {
v.viewTreeObserver.removeOnGlobalLayoutListener(layoutListener)
} catch (_: java.lang.Exception) {
v.viewTreeObserver.removeGlobalOnLayoutListener(layoutListener)
}
v.viewTreeObserver.removeOnWindowFocusChangeListener(focusChangeListener)
if(scrollListener !=null) v.viewTreeObserver.removeOnScrollChangedListener(scrollListener)
viewGroups.forEach { it.setOnHierarchyChangeListener(null) }
}
removeOnAttachStateChangeListener(this)
}
})
// 标记已设置监听器
setTag(KEY_HAS_LISTENER, true)
}有了这个扩展方法,就可以在在项目中的 BaseFragment 中进行全局 Fragment 的可见性监听了:
// 抽象 Fragment
abstract class BaseFragment:Fragment() {
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
if(detectVisibility){
view.onVisibilityChange { view, isVisible ->
onFragmentVisibilityChange(isVisible)
}
}
}
// 抽象属性:是否检测当前 fragment 的可见性
abstract val detectVisibility: Boolean
open fun onFragmentVisibilityChange(show: Boolean) {}
}其子类必须实现抽象属性detectVisibility,表示是否监听当前Fragment的可见性:
class FragmentA: BaseFragment() {
override val detectVisibility: Boolean
get() = true
override fun onFragmentVisibilityChange(show: Boolean) {
if(show) ... else ...
}
}为了让 show 上报不入侵基类,选择了一种可拔插的方案,先定义一个接口:
interface ExposureParam {
val eventId: String
fun getExtra(): Map<String, String?> = emptyMap()
fun isForce():Boolean = false
}该接口用于生成 show 上报的参数。任何需要上报 show 的页面都可以实现该接口:
class MaterialFragment : BaseFragment(), ExposureParam {
abstract val tabName: String
abstract val type: Int
override val eventId: String
get() = "material.show"
override fun getExtra(): Map<String, String?> {
return mapOf(
"tab_name" to tabName,
"type" to type.toString()
)
}
}再自定义一个 Activity 生命周期监听器:
class PageVisibilityListener : Application.ActivityLifecycleCallbacks {
// 页面可见性变化回调
var onPageVisibilityChange: ((page: Any, isVisible: Boolean) -> Unit)? = null
private val fragmentLifecycleCallbacks by lazy(LazyThreadSafetyMode.NONE) {
object : FragmentManager.FragmentLifecycleCallbacks() {
override fun onFragmentViewCreated(fm: FragmentManager, f: Fragment, v: View, savedInstanceState: Bundle?) {
// 注册 Fragment 根视图可见性监听器
if (f is ExposureParam) {
v.onVisibilityChange { view, isVisible ->
onPageVisibilityChange?.invoke(f, isVisible)
}
}
}
}
}
override fun onActivityCreated(activity: Activity, p1: Bundle?) {
// 注册 Fragment 生命周期监听器
(activity as? FragmentActivity)?.supportFragmentManager?.registerFragmentLifecycleCallbacks(fragmentLifecycleCallbacks, true)
}
override fun onActivityDestroyed(activity: Activity) {
// 注销 Fragment 生命周期监听器
(activity as? FragmentActivity)?.supportFragmentManager?.unregisterFragmentLifecycleCallbacks(fragmentLifecycleCallbacks)
}
override fun onActivityStarted(p0: Activity) {
}
override fun onActivityResumed(activity: Activity) {
// activity 可见
if (activity is ExposureParam) onPageVisibilityChange?.invoke(activity, true)
}
override fun onActivityPaused(activity: Activity) {
// activity 不可见
if (activity is ExposureParam) onPageVisibilityChange?.invoke(activity, false)
}
override fun onActivityStopped(p0: Activity) {
}
override fun onActivitySaveInstanceState(p0: Activity, p1: Bundle) {
}
}该监听器同时监听了 Activity 和 Fragment 的可见性变化。其中 Activity 的可见性变化是借助于 ActivityLifecycleCallbacks,而 Fragment 的可见性变化是借助于其视图的可见性。
Activity 和 Fragment 的可见性监听使用同一个onPageVisibilityChange进行回调。
然后在 Application 中页面可见性监听器:
open class MyApplication : Application(){
private val fragmentVisibilityListener by lazy(LazyThreadSafetyMode.NONE) {
PageVisibilityListener().apply {
onPageVisibilityChange = { page, isVisible ->
// 当页面可见时,上报 show
if (isVisible) {
(page as? ExposureParam)?.also { param ->
ReportUtil.reportShow(param.isForce(), param.eventId, param.getExtra())
}
}
}
}
}
override fun onCreate() {
super.onCreate()
registerActivityLifecycleCallbacks(fragmentVisibilityListener)
}这样一来,上报时机已经完全自动化,只需要在上报的页面通过 ExposureParam 声明上报参数即可。
链接:https://juejin.cn/post/7165428849197940749
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 默认可见性为 public,是不是一个好的设计?
前言
众所周知,Kotlin 的默认可见性为 public,而这会带来一定的问题。比如最常见的,library 中的代码被无意中声明为 public 的了,导致用户使用者可以用到我们不想暴露的 API ,这样违背了最小知识原则,也不利于我们后续的变更
那么既然有这些问题,为什么 Kotlin 的默认可见性还被设计成这样呢?又该怎么解决这些问题?
为什么默认为 public
其实在 Kotlin M13 版本之前,Kotlin 的默认可见性是 internal 的,在 M13 版本之后才改成了 public
那么为什么会做这个修改呢?官方是这样说的
In real Java code bases (where public/private decisions are taken explicitly), public occurs a lot more often than private (2.5 to 5 times more often in the code bases that we examined, including Kotlin compiler and IntelliJ IDEA). This means that we’d make people write public all over the place to implement their designs, that would make Kotlin a lot more ceremonial, and we’d lose some of the precious ground won from Java in terms of brevity. In our experience explicit public breaks the flow of many DSLs and very often — of primary constructors. So we decided to use it by default to keep our code clean.
总得来说,官方认为在实际的生产环境中,public 发生的频率要比 private 要高的多,比如在 Kotlin 编译器和 InterlliJ 中是 2.5 倍到 5 倍的差距
这意味着如果默认的不是 public 的话,用户需要到处手动添加 public,会增加不少模板代码,并且会失去简洁性
但是官方这个回答似乎有点问题,我们要对比的是 internal 与 public,而不是 private 与 public
因此也有不少人提出了质疑
反方观点
包括 JakeWharton 在内的很多人对这一改变了提出了质疑,下面我们一起来看下loganj的观点
internal 是安全的默认值
如果一个类或成员最初具有错误的可见性,那么提高可见性要比降低可见性容易得多。也就是说,将 internal 类或成员更改为 public 不需要做什么额外的工作,因为没有外部调用者
在执行相反的操作的成本则很高,如果初始时是 public 的,你要将它修改为 internal 的,就要做很多的兼容工作。
因此,将 internal 设为默认值可以随着代码库的发展而节省大量工作。
分析使用的数据存在缺陷
官方提到 public 发生的频率是 private 的 2.5 倍到 5 倍,但这是建立在有瑕疵的数据上的
由于 Java 提供的可见性选项不足,开发人员被迫两害相权取其轻。更有经验的开发人员倾向于通过命名约定和文档来解决这个问题。经验不足的开发人员往往会直接将可见性设置为 public。
因此,大多数 Java 代码库的 public 类和成员比其作者需要或想要的要多得多。我们不能简单地查看 Java 可见性修饰符在普通代码库中的使用并假设它反映了作者的意愿
例如,我们常用的 Okhttp ,由经验丰富的 Java 开发人员编写的代码库,尽管 Java 存在限制,但他们仍努力将可见性降至最低。
下面是 Okhttp 的 public 包,它们旨在构成 Okhttp 的 API
这里是它的 internal 包,理想情况下只能在模块中被看到。
简单计算可以看到大根有 46% 的公共方法和 71% 的公共类。这已经比一般的代码库好很多,这是我们应该鼓励的方向。
但是 internal 包内部的类根本不应该被公开!而这是因为 Java 的可见性限制引起的(没有模块内可见)
如果 Java 有 Kotlin 的可见性修饰符,我们应该期望接近 24% 的公共方法和 35% 的 public 类。此外,48% 的方法和 65% 的类将是 internal 的!
internal 的潜力被浪费了
在 Java 中,别无选择,只能通过 public 来实现模块内可见,并使用约定和文档来阻止它们的使用。Kotlin 的 internal 可见性修复了 Java 中的这个缺陷,但是选择 public 作为默认可见性忽略了这个重要的修正。
默认 public 会浪费 Kotlin 内部可见性的潜力。它一反常态地鼓励了 Java 实际上不鼓励的不良做法,当 Kotlin 有办法向前迈出一大步时,这样做是从 Java 倒退了一大步。
正方观点
对于一些质疑的观点,官方也做了一些回应
我们曾经将 internal 设置为默认可见性,只是它没有被编译器检查,所以它被像 public 一样被使用。然后我们尝试打开检查,并意识到我们需要在代码中添加很多 public。在应用(Application)代码,而不是库(library)代码中,常常包括很多 public。我们分析了很多 case,结果发现并不是模块边界布局边界不清晰造成的。模块的划分是完全合乎逻辑的,但仍然有很多类由于到处都是 public 关键字而变得非常丑陋。
在主构造函数和基于委托属性的 DSL 中这个情况尤其严重:每个属性都承受着 public 一遍又一遍地重复的视觉负担
因此,我们意识到类的成员在默认情况下必须与类本身一样可见。请注意,如果一个类是内部的,那么它的公共成员实际上也是内部的。所以,我们有两个选择:
默认可见性是公开的
或者类具有与其成员不同的默认可见性。
在后一种情况下,函数的默认值会根据它是在顶层还是在类中声明而改变。我们决定保持一致,因此将默认可见性设置为了 public.
对于库作者,可以通过 lint 规则和 IDE 检查,以确保所有 public 的声明在代码中都是显式的。这会给库代码开发者带来一定的成本,但比起不一致的默认可见性,或者在应用代码中添加大量 public,这似乎并不是一个问题,总得来说优点大于缺点。
如何解决默认可见性的问题
总得来说,双方的观点各有各的道理,不过从 M13 到现在已经很多年了,Kotlin 的可见性一直默认是 public,看样子 Kotlin 官方已经下了结论
那么我们该如何解决库代码默认可见性为 public,导致用户使用者可以用到我们不想暴露的 API 的问题呢?
Kotlin 官方也提供了一个插件供我们使用:binary-compatibility-validator
这个插件可以 dump 出所有的 public API,将代码与 dump 出来的 api 进行对比,可以避免暴露不必要的 api
应用插件
plugins {
id("org.jetbrains.kotlinx.binary-compatibility-validator") version "0.12.1"
}应用插件很简单,只要在 build.gradle 中添加以上代码就好了
插件任务
该插件包括两个任务
apiDump: 构建项目并将其公共 API 转储到项目 api 子文件夹中。API 以人类可读的格式转储。如果 API 转储文件已经存在,它将会被覆盖。apiCheck: 构建项目并检查项目的公共 API 是否与项目 api 子文件夹中的声明相同。如果不同则抛出异常
工作流
我们可以通过以下工作流,确保 library 模块不会无意中暴露 public api
准备阶段(一次性工作):
- 应用插件,配置它并执行 apiDump ,导出项目 public api
- 手动验证您的公共 API (即执行 apiCheck 任务)。
- 提交项目的 api (即 .api 文件) 到您的 VCS。
常规工作流程
- 后续提交代码时,都会构建项目,并将项目的 API 与 .api 文件声明的 api 进行对比,如果两者不同,则 check 任务会失败
- 如果是代码问题,则将可见性修改为 internal 或者 private,再重新提交代码
- 如果的确应该添加新的 public api,则通过 apiDump 更新 .api 文件,并重新提交
与 CI 集成
常规工作流程中,每次提交代码都应该检查 api 是否发生变化,这主要是通过 CI 实现的
以 Github Action 为例,每次提交代码时都会触发检查,如果检查不通过会抛出以下异常
总结
本文主要介绍了为什么 Kotlin 的默认可见性是 public,及其优缺点。同时在这种情况下,我们该如何解决 library 代码容易无意中被声明为 public ,导致用户使用者可以用到我们不想暴露的 API 的问题
如果本文对你有所帮助,欢迎点赞~
示例项目
链接:https://juejin.cn/post/7165659437137395748
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 混淆规则是如何生效的?
前言
记录一下关于 Android 中关于混淆配置文件的生效规则、混淆规则的细节、build 产物中和混淆相关的内容及其作用。
混淆配置生效规则
现在的 Android 项目一般由一个主 app module,n 个子 lib module 共同组成。 app module 通过 dependencies 闭包依赖这些子 module ,或者是将这些子 module 上传到中央仓库之后进行依赖。
if (source_code.toBoolean()) {
implementation project(path: ':thirdlib')
} else {
implementation 'com.engineer.third:thirdlib:1.0.0'
}
implementation project(path: ':compose')
implementation project(path: ':common')
implementation 'androidx.navigation:navigation-fragment-ktx:2.5.2'
...比如对于下图中的几个子 module 可以通过 project(path: 'xxx') 的方式依赖,也可以将这个本地 module 上传到中央仓库之后通过 group_id:artifact_id:version 的方式依赖。
那么这两种方式依赖由哪些差异呢?
- 远程依赖会比直接在本地依赖节省一些编译时间 (当然这不包括下载依赖本身耗费的时间),毕竟可以省去编译源码及资源的时间。
- 对于混淆来说,这两种依赖方式混淆配置规则的生效是有些差异的。这里的差异是说混淆配置文件的差异,而不是说具体的一条混淆配置语法会有差异 。
下面具体来说一下这个差异。关于混淆配置,除了各个 moudle 下我们非常熟悉的肉眼可见 proguard-rules.pro 之外,其实还有别的混淆配置,最终会合并在一起生效。
说到各个 module 的配置文件合并,大家一定会想到 AndroidManifest.xml 。最终打包使用的 AndroidManifest.xml 的内容,就是各个子 module 和主 module merge 后的结果。
需要注意的是,Android 打包过程并不会主动合并本地 module 中的 proguard-rules.pro 文件 。注意,这里说的是本地 module .
也就是说像 common/thirdlib/compose 这类直接在本地依赖的 module, 其内部的 proguard-rules.pro 并不会直接生效。 而通过 implementation group_id:artifact_id:version 依赖的远程 module ,如果其内部有配置 proguard 规则,就会 merge 到最终的混淆配置中。上一篇 发布 Android Lib 到 Maven 解惑 中我们提到, library 通过 gradle 任务发布到中央仓库的时候,会基于本地 consumer-rules.pro 生成最终的 proguard.txt 文件一并打包到 aar 文件中;这里 merge 的就是这个自动生成的 proguard.txt。而最终的混淆配置规则叠加到一起之后,在 app/build/outputs/mapping/huaweiLocalRelease/configuration.txt 这个文件里。
这个文件是有规则的,会按照段落列出编译过招中所涉及的模块。
001:# The proguard configuration file for the following section is D:\workspace\MinApp\app\build\intermediates\default_proguard_files\global\proguard-android-optimize.txt-7.2.1
121:# The proguard configuration file for the following section is D:\workspace\MinApp\app\proguard-rules.pro
182:# The proguard configuration file for the following section is D:\workspace\MinApp\app\build\intermediates\aapt_proguard_file\huaweiLocalRelease\aapt_rules.txt
392:# The proguard configuration file for the following section is D:\workspace\MinApp\common\build\intermediates\consumer_proguard_dir\release\lib0\proguard.txt
395:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\89e35bb901a511dc73379ee56d9a96fb\transformed\navigation-ui-2.3.5\proguard.txt
416:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\ed14b9608e236c3cb341584bd1991f2a\transformed\material-1.5.0\proguard.txt
465:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\38b91e3dad918eabe8ced61c0f881bef\transformed\jetified-stetho-1.6.0\proguard.txt
470:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\380c0daab5f38fa92451c63d6b7f2468\transformed\preference-1.1.1\proguard.txt
494:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\a00816a85507c4640738406281464e4f\transformed\appcompat-1.4.1\proguard.txt
519:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\19a9b30d1e238c7cf954868475b2d87a\transformed\navigation-common-ktx-2.3.5\proguard.txt
541:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\bc1e654ac594a8eec67d83a310d595cd\transformed\rules\lib\META-INF\com.android.tools\r8-from-1.6.0\kotlin-reflect.pro
559:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\822d22c7ed69ccdf4d90c18a483e72c5\transformed\rules\lib\META-INF\com.android.tools\r8-from-1.6.0\coroutines.pro
585:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\555542c94d89a20ac01618f64dfcfed2\transformed\rules\lib\META-INF\proguard\coroutines.pro
608:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\a830f069563364388aaf53b586352be8\transformed\jetified-glide-4.13.1\proguard.txt
625:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\9ce146a7d8708a759f2821d06606c176\transformed\jetified-flexbox-1.0.0\proguard.txt
647:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\003c1e88ccf7eabdb17daba177d5544b\transformed\jetified-hilt-lifecycle-viewmodel-1.0.0-alpha03\proguard.txt
654:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\2675f8213875fddbbb3d30c803c00c9c\transformed\jetified-hilt-android-2.40.1\proguard.txt
665:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\3368f9a73434dea0d4e52626ffd9a8c9\transformed\fragment-1.3.6\proguard.txt
687:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\58278e1b3a97715913034b7b81fae8cb\transformed\jetified-lifecycle-viewmodel-savedstate-2.3.1\proguard.txt
697:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\cb4d77137f22248d78cd200f94d17fc4\transformed\jetified-savedstate-1.1.0\proguard.txt
717:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\6a6fcb77b4395418002e332cd9738bfb\transformed\work-runtime-2.7.0\proguard.txt
728:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\4ab9d68c51a5e06d113a80174817d2cc\transformed\media-1.0.0\proguard.txt
753:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\5599788d3c018cf9be3c21d9a4ff4718\transformed\coordinatorlayout-1.1.0\proguard.txt
778:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\0e108ece111c1c104d1543d98f952017\transformed\vectordrawable-animated-1.1.0\proguard.txt
800:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\19c137c4f40e8110221a03964c21b354\transformed\recyclerview-1.1.0\proguard.txt
827:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\9eb9006bf5796c20208d89f414c860f8\transformed\transition-1.3.0\proguard.txt
848:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\848cc86aa556453b7ae2d77cf1ed69f7\transformed\core-1.7.0\proguard.txt
867:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\c269ff43c6850351c92a4f3de7a5d26d\transformed\jetified-lifecycle-process-2.4.0\proguard.txt
871:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\f082dcda3ea45d057bb4fd056c4b3864\transformed\lifecycle-runtime-2.4.0\proguard.txt
896:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\c78621e75bc17f9e3a8dc4279fe51aed\transformed\rules\lib\META-INF\proguard\retrofit2.pro
928:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\9dd79968324ef9619ccee991ab21aa68\transformed\rules\lib\META-INF\proguard\rxjava2.pro
931:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\9eef9e5128bbcd6232ee9a89f4c5bf00\transformed\lifecycle-viewmodel-2.3.1\proguard.txt
941:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\5875adda5cf6fa792736faf48738cf7c\transformed\jetified-startup-runtime-1.0.0\proguard.txt
952:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\e06b693ee9109a0e8f8d0949e74720e0\transformed\room-runtime-2.4.0\proguard.txt
957:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\6008298b41480f69c56a08890c83e302\transformed\versionedparcelable-1.1.1\proguard.txt
964:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\2810bf2a83f304a3ff02e4019efe065f\transformed\rules\lib\META-INF\proguard\androidx-annotations.pro
985:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\6dc53357fb30238e16dbc902967a8aab\transformed\jetified-annotation-experimental-1.1.0\proguard.txt
1011:# The proguard configuration file for the following section is D:\Android\.gradle\caches\transforms-3\4233f8c9725e3a6760c0e0e606e43b29\transformed\rules\lib\META-INF\proguard\okhttp3.pro
1025:# The proguard configuration file for the following section is <unknown>
可以看到,除了我们熟悉的 app/proguard-rules.pro 之外,其实还使用了其他 module 的 xxx.pro 文件。当然,这里有些文件,可能没有配置任何内容,只是一个默认的配置,就像 app/proguard-rules.pro 刚创建时候的样子,有兴趣的话可以打开文件查看。
在这个最终的混淆配置规则里还有一些值得我们注意的地方。
- proguard-android-optimize.txt-7.2.1
# This is a configuration file for ProGuard.
# http://proguard.sourceforge.net/index.html#manual/usage.html
#
# Starting with version 2.2 of the Android plugin for Gradle, this file is distributed together with
# the plugin and unpacked at build-time. The files in $ANDROID_HOME are no longer maintained and
# will be ignored by new version of the Android plugin for Gradle.
也就是说从 AGP 2.2 开始,在编译阶段会使用当前 AGP 插件所携带的混淆规则,而不在使用本地 Android SDK/tools/proguard/ 目录下的混淆配置了。
这个混淆配置文件里规则都非常通用的,比如对于 enum , Keep 注解,webview Interface 等等之类的规则。 这就意味着 AGP 插件的升级有可能会影响到混淆,如果某个 AGP 版本所携带的混淆规则发了一些变化的话。
- aapt_rules.txt
aapt 顾名思义,就是在执行 AAPT 阶段生成的混淆规则,可以看到里面都是基于 Android 应用层源码的一些配置。会根据代码中的资源文件、布局文件等内容生成相应的规则。比如会基于 AndroidManifest.xml 中声明的四大组件,保留相应的 Activity、Service 等类的构造函数,一些自定义 View 的构造函数等。
- META-INF\proguard\okhttp3.pro
这类混淆规则其实是 xxx.jar 文件内部的混淆规则。Android 开发中非常实用的 okhttp、RxJava、Retrofit 等这些纯 Java/Kotlin 代码的 module 打包之后上传到中央仓库的就是 jar 文件,而不是 aar (毕竟不涉及到 UI,因此也不会有资源文件了)。
对于 java-library 类型的 module, 通过上述配置,最终打包的 jar 文件中将包含这个 thirdlib.pro 混淆配置文件。
剩下的就是一些我们常用的类库自身携带的混淆规则了,可以看到这些 aar 类型的库其混淆配置文件都是 proguard.txt 。
从这里我们可以看到,AGP 已经非常完善了,在打包过程中会在基于实际代码自动生成相应的混淆规则,尤其是关于 Android 自身类及组件的配置。平时在网上看到的各种混淆配置,没必要非得对着里面的内容一条一条的进行配置,一些非常基础且共用的混淆规则都是默认的。我们实际需要关心的还是自身业务相关的混淆规则,比如涉及 Json 序列化操作的 Model 类的,以及自己写的涉及反射操作的类。
那么子 moudle 直接在本地依赖的情况下,混淆配置是如何生效的呢?
子 module 的生效规则
这里我们可以重点关注一下 392:# The proguard configuration file for the following section is D:\workspace\MinApp\common\build\intermediates\consumer_proguard_dir\release\lib0\proguard.txt
从路径就可以猜出来了,这里的 lib0 就是本地依赖的 common module 。
这部分在 configuration.txt 中是这样的。
# The proguard configuration file for the following section is D:\workspace\MinApp\common\build\intermediates\consumer_proguard_dir\release\lib0\proguard.txt
-keep class com.engineer.common.utils.AndroidFileUtils {*;}
# End of content from D:\workspace\MinApp\common\build\intermediates\consumer_proguard_dir\release\lib0\proguard.txt这部分就是子 module 的混淆配置。子 module 混淆配置生效有两种方式,而这两种方式都依赖 consumerProguardFiles 这个属性。
直接使用 consumer-rules.pro
直接在子 module 的 consumer-rules.pro 中配置要混淆的规则。然后在 build.gradle 中通过默认的配置生效
defaultConfig {
minSdk ext.minSdkVersion
targetSdk ext.targetSdkVersion
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
consumerProguardFiles "consumer-rules.pro"
}子 module 创建的时候,会默认在 defaultConfig 闭包中添加 consumerProguardFiles 这个配置,因此只要在 consumer-rules.pro 中配置了混淆规则,就会生效。
使用 proguard-rules.pro
如果你不习惯使用 consumer-rules.pro 的话,也可以使用 proguard-rules.pro ,直接配置一下就可以了。
buildTypes {
release {
minifyEnabled false
consumerProguardFiles "proguard-rules.pro"
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
}
}这两种方式配置的内容,最终都会生效。再次谨记,混淆规则是叠加生效的,并不存在什么先后顺序。打包过程中只要找到了可用的配置文件,就会照单全收
混淆产物
说完了混淆配置生效的规则,可以一并再看一下混淆的产物。打包完成后,会在 app/build/outputs/mapping/{flavor}/ 目录下生成一些混淆相关的文件。
| 文件名 | 作用 |
|---|---|
| configuration.txt | 所有混淆配置的汇总 |
| mapping.txt | 原始与混淆过的类、方法、字段名称间的转换 |
| resources.txt | 资源优化记录文件,哪些资源引用了其他资源,哪些资源在使用,哪些资源被移除 |
| seeds.txt | 未进行混淆的类与成员 |
| usage.txt | APK中移除的代码 |
通过这些文件,我们就可以看到一次打包过程中,混淆具体做了哪些事情。比较常用的是 mapping.txt 文件,当混淆过后的包出现问题时,通过 stacktrace 定位问题的时候,由于代码被混淆会无法识别,这时候就是通过 mappting.txt 文件解混淆。这里使用过 bugly 的同学应该很熟悉了。线上代码出现问题,上传 mapping 文件就可以快速定位到出现问题的具体代码了。
通过 seeds.txt 也可以看到哪些文件没有被混淆,内容是否符合预期。
上面混淆配置生效规则里提到了,打包过程中会综合各个 module 的混淆配置文件。因此,有时候我们会发现,自己明明没有配置某些类的 keep ,但是这些类依然没有被混淆,这时候可能就是由于项目本身依赖的 module 的混淆规则生效了。 比如 configuration.txt 中 Android fragment 包的这条规则
# The proguard configuration file for the following section is /Users/rookie/.gradle/caches/transforms-3/3368f9a73434dea0d4e52626ffd9a8c9/transformed/fragment-1.3.6/proguard.txt
# The default FragmentFactory creates Fragment instances using reflection
-if public class ** extends androidx.fragment.app.Fragment
-keepclasseswithmembers,allowobfuscation public class <1> {
public <init>();
}
# End of content from /Users/rookie/.gradle/caches/transforms-3/3368f9a73434dea0d4e52626ffd9a8c9/transformed/fragment-1.3.6/proguard.txt所有继承自 androidx.fragment.app.Fragment 的类都会随着其构造方法的一起被 keep 。这样最终混淆结果中就会有很多的业务相关的 XXXFragment 类无法被混淆。至于原因,上面的注释解释的很清楚了,需要通过反射创建 Fragment 的实例。
所以,在混淆过程中,如果发现一些没有类没有被混淆,不妨在 configuration.txt 中找找原因。
严格来说,resources.txt 是由于配置了 shrinkResources true 对无效资源文件进行移除操作后产生的结果,不算是混淆,但是这里可以理解为混淆过程
混淆规则
混淆规则本质上非常灵活,很难用一句话概括清楚。这里引用郭神的Android安全攻防战,反编译与混淆技术完全解析(下) 中的表述 ,感觉比较清晰。
keep 关键字规则
| 关键字 | 描述 |
|---|---|
| keep | 保留类和类中的成员,防止它们被混淆或移除。 |
| keepnames | 保留类和类中的成员,防止它们被混淆,但当成员没有被引用时会被移除。 |
| keepclassmembers | 只保留类中的成员,防止它们被混淆或移除。 |
| keepclassmembernames | 只保留类中的成员,防止它们被混淆,但当成员没有被引用时会被移除。 |
| keepclasseswithmembers | 保留类和类中的成员,防止它们被混淆或移除,前提是指名的类中的成员必须存在,如果不存在则还是会混淆。 |
| keepclasseswithmembernames | 保留类和类中的成员,防止它们被混淆,但当成员没有被引用时会被移除,前提是指名的类中的成员必须存在,如果不存在则还是会混淆。 |
通配符规则
| 通配符 | 描述 |
|---|---|
<field> | 匹配类中的所有字段 |
<method> | 匹配类中的所有方法 |
<init> | 匹配类中的所有构造函数 |
* | 匹配任意长度字符,但不含包名分隔符(.)。比如说我们的完整类名是com.example.test.MyActivity,使用com.,或者com.exmaple.都是无法匹配的,因为无法匹配包名中的分隔符,正确的匹配方式是com.exmaple..,或者com.exmaple.test.,这些都是可以的。但如果你不写任何其它内容,只有一个*,那就表示匹配所有的东西。 |
** | 匹配任意长度字符,并且包含包名分隔符(.)。比如proguard-android.txt中使用的-dontwarn android.support.**就可以匹配android.support包下的所有内容,包括任意长度的子包。 |
| *** | 匹配任意参数类型。比如void set*()就能匹配任意传入的参数类型, get*()就能匹配任意返回值的类型。 |
… | 匹配任意长度的任意类型参数。比如void test(…)就能匹配任意void test(String a)或者是void test(int a, String b)这些方法。 |
网上大部分文章提到的混淆配置语法都大同小异,都是从正面出发,这样有时候其实是不太灵活的。比如在某些场景下我们需要保留所有实现了 Serializable 接口的类,因为这些类涉及到序列化操作。
-keep class * implements java.io.Serializable {*;}这条规则本身没问题,但是其实这个规则的范围是很大的。因为我们常用的 enum 的具体实现 Enum 类
public abstract class Enum<E extends Enum<E>>
implements Comparable<E>, Serializable { ....}也是实现了 Serializable 接口的。因此会导致所有的 enum 类型无法被混淆。实际上 Java 集合框架也有很多类实现了这个接口。虽然 Android 官方不建议使用枚举,但是现实中使用的还是挺多的,比如 glide 。这样就会导致原本可以被混淆的类受到牵连。
那么可以避免这种情况吗?其实是有办法的,细心的话你也许已经发现了,在上面 FragmentFactory 的混淆配置语法里有条件判断的逻辑。
# The default FragmentFactory creates Fragment instances using reflection
-if public class ** extends androidx.fragment.app.Fragment
-keepclasseswithmembers,allowobfuscation public class <1> {
public <init>();
}看到这里的 if 你是不是有点想法了呢?强烈建议在需要配置混淆规则的时候多参考一下 configuration.txt 中一些官方库的配置规则,也许会让你打开一扇新的打门。
混淆认知
混淆配置规则看起来简单,但其实结合实际场景会变得有些复杂,尤其是代码包含内部类,匿名内部,静态内部类等等不同场景下。这些具体的规律还是需要结合实际场景通过不断的验证。
关于代码混淆,最好的学习方法就是自己通过写代码,组合各类配置不断验证。打包后可以用 jadx-gui 查看混淆的 apk 文件。
最后再补充一个进行混淆配置验证时的小技巧。
android {
//...
lint {
checkReleaseBuilds false
}
}直接在 app/build.gradle android 闭包下配置关闭 releaseBuild 时的 lint 检查。毕竟混淆规则的修改不会影响代码本身,因此可以通过跳过检测,节省编译时间。毕竟这个 lint 检查的耗时还是很可观的。这样就可以避免每次打包时的等待了。
有些时候临时打 release 包验证一些问题的时候,也可以临时加上这个配置关闭检测。
链接:https://juejin.cn/post/7148456353332215838
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以为很熟悉CountDownLatch的使用了,没想到在生产环境翻车了
前言
大家好,我是小郭,之前分享了CountDownLatch的使用,我们知道用来控制并发流程的同步工具,主要的作用是为了等待多个线程同时完成任务后,在进行主线程任务。
万万没想到,在生产环境中竟然翻车了,因为没有考虑到一些场景,导致了CountDownLatch出现了问题,接下来来分享一下由于CountDownLatch导致的问题。
# 【线程】并发流程控制的同步工具-CountDownLatch
需求背景
先简单介绍下业务场景,针对用户批量下载的文件进行修改上传
为了提高执行的速度,所以在采用线程池去执行 下载-修改-上传 的操作,并在全部执行完之后统一提交保存文件地址到数据库,于是加入了CountDownLatch来进行控制。
具体实现
根据服务本身情况,自定义一个线程池
public static ExecutorService testExtcutor() {
return new ThreadPoolExecutor(
2,
2,
0L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1));
}模拟执行
public static void main(String[] args) {
// 下载文件总数
List<Integer> resultList = new ArrayList<>(100);
IntStream.range(0,100).forEach(resultList::add);
// 下载文件分段
List<List<Integer>> split = CollUtil.split(resultList, 10);
ExecutorService executorService = BaseThreadPoolExector.testExtcutor();
CountDownLatch countDownLatch = new CountDownLatch(100);
for (List<Integer> list : split) {
executorService.execute(() -> {
list.forEach(i ->{
try {
// 模拟业务操作
Thread.sleep(500);
System.out.println("任务进入");
} catch (InterruptedException e) {
e.printStackTrace();
System.out.println(e.getMessage());
} finally {
System.out.println(countDownLatch.getCount());
countDownLatch.countDown();
}
});
});
}
try {
countDownLatch.await();
System.out.println("countDownLatch.await()");
} catch (InterruptedException e) {
e.printStackTrace();
}
}一开始我个人感觉没有什么问题,反正finally都能够做减一的操作,到最后调用await方法,进行主线程任务
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@300ffa5d rejected from java.util.concurrent.ThreadPoolExecutor@1f17ae12[Running, pool size = 2, active threads = 2, queued tasks = 1, completed tasks = 0]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at java.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:112)
at Thread.executor.executorTestBlock.main(executorTestBlock.java:28)
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown
任务进入
countDownLatch.countDown由于任务数量较多,阻塞队列中已经塞满了,所以默认的拒绝策略,当队列满时,处理策略报错异常,
要注意这个异常是线程池,自己抛出的,不是我们循环里面打印出来的,
这也造成了,线上这个线程池被阻塞了,他永远也调用不到await方法,
利用jstack,我们就能够看到有问题
"pool-1-thread-2" #12 prio=5 os_prio=31 tid=0x00007ff6198b7000 nid=0xa903 waiting on condition [0x0000700001c64000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x000000076b2283f8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
"pool-1-thread-1" #11 prio=5 os_prio=31 tid=0x00007ff6198b6800 nid=0x5903 waiting on condition [0x0000700001b61000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x000000076b2283f8> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)
at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)解决方案
调大阻塞队列,但是问题来了,到底多少阻塞队列才是大呢,如果太大了会不由又造成内存溢出等其他的问题
在第一个的基础上,我们修改了拒绝策略,当触发拒绝策略的时候,用调用者所在的线程来执行任务
public static ThreadPoolExecutor queueExecutor(BlockingQueue<Runnable> workQueue){
return new ThreadPoolExecutor(
size,
size,
0L,
TimeUnit.SECONDS,
workQueue,
new ThreadPoolExecutor.CallerRunsPolicy());
}
你可能又会想说,会不会任务数量太多,导致调用者所在的线程执行不过来,任务提交的性能急剧下降
那我们就应该自定义拒绝策略,将这下排队的消息记录下来,采用补偿机制的方式去执行
同时也要注意上面的那个异常是线程池抛出来的,我们自己也需要将线程池进行try catch,记录问题数据,并且在finally中执行countDownLatch.countDown来避免,线程池的使用
总结
目前根据业务部门的反馈,业务实际中任务数不很特别多的情况,所以暂时先采用了第二种方式去解决这个线上问题
在这里我们也可以看到,如果没有正确的关闭countDownLatch,可能会导致一直等待,这也是我们需要注意的。
工具虽然好,但是依然要注意他带来的问题,没有正确的去处理好,引发的一系列连锁反应。
链接:https://juejin.cn/post/7129116234804625421
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
面试必备:ThreadLocal详解
前言
大家好,我是捡田螺的小男孩。
无论是工作还是面试,我们都会跟ThreadLocal打交道,今天就跟大家聊聊ThreadLocal哈~
- ThreadLocal是什么?为什么要使用ThreadLocal
- 一个ThreadLocal的使用案例
- ThreadLocal的原理
- 为什么不直接用线程id作为ThreadLocalMap的key
- 为什么会导致内存泄漏呢?是因为弱引用吗?
- Key为什么要设计成弱引用呢?强引用不行?
- InheritableThreadLocal保证父子线程间的共享数据
- ThreadLocal的应用场景和使用注意点
- github地址,麻烦给个star鼓励一下,感谢感谢
- 公众号:捡田螺的小男孩(欢迎关注,干货多多)
1. ThreadLocal是什么?为什么要使用ThreadLocal?
ThreadLocal是什么?
ThreadLocal,即线程本地变量。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是在操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了并发场景下的线程安全问题。
//创建一个ThreadLocal变量
static ThreadLocal localVariable = new ThreadLocal<>();
为什么要使用ThreadLocal
并发场景下,会存在多个线程同时修改一个共享变量的场景。这就可能会出现线性安全问题。
为了解决线性安全问题,可以用加锁的方式,比如使用synchronized 或者Lock。但是加锁的方式,可能会导致系统变慢。加锁示意图如下:
还有另外一种方案,就是使用空间换时间的方式,即使用ThreadLocal。使用ThreadLocal类访问共享变量时,会在每个线程的本地,都保存一份共享变量的拷贝副本。多线程对共享变量修改时,实际上操作的是这个变量副本,从而保证线性安全。
2. 一个ThreadLocal的使用案例
日常开发中,ThreadLocal经常在日期转换工具类中出现,我们先来看个反例:
/**
* 日期工具类
*/
public class DateUtil {
private static final SimpleDateFormat simpleDateFormat =
new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static Date parse(String dateString) {
Date date = null;
try {
date = simpleDateFormat.parse(dateString);
} catch (ParseException e) {
e.printStackTrace();
}
return date;
}
}我们在多线程环境跑DateUtil这个工具类:
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
executorService.execute(()->{
System.out.println(DateUtil.parse("2022-07-24 16:34:30"));
});
}
executorService.shutdown();
}运行后,发现报错了:
如果在DateUtil工具类,加上ThreadLocal,运行则不会有这个问题:
/**
* 日期工具类
*/
public class DateUtil {
private static ThreadLocal dateFormatThreadLocal =
ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
public static Date parse(String dateString) {
Date date = null;
try {
date = dateFormatThreadLocal.get().parse(dateString);
} catch (ParseException e) {
e.printStackTrace();
}
return date;
}
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 10; i++) {
executorService.execute(()->{
System.out.println(DateUtil.parse("2022-07-24 16:34:30"));
});
}
executorService.shutdown();
}
} 运行结果:
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022
Sun Jul 24 16:34:30 GMT+08:00 2022刚刚反例中,为什么会报错呢?这是因为SimpleDateFormat不是线性安全的,它以共享变量出现时,并发多线程场景下即会报错。
为什么加了ThreadLocal就不会有问题呢?并发场景下,ThreadLocal是如何保证的呢?我们接下来看看ThreadLocal的核心原理。
3. ThreadLocal的原理
3.1 ThreadLocal的内存结构图
为了有个宏观的认识,我们先来看下ThreadLocal的内存结构图
从内存结构图,我们可以看到:
Thread类中,有个ThreadLocal.ThreadLocalMap的成员变量。ThreadLocalMap内部维护了Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型对象值。
3.2 关键源码分析
对照着几段关键源码来看,更容易理解一点哈~我们回到Thread类源码,可以看到成员变量ThreadLocalMap的初始值是为null
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的属性
ThreadLocal.ThreadLocalMap threadLocals = null;
}ThreadLocalMap的关键源码如下:
static class ThreadLocalMap {
static class Entry extends WeakReference> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal k, Object v) {
super(k);
value = v;
}
}
//Entry数组
private Entry[] table;
// ThreadLocalMap的构造器,ThreadLocal作为key
ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
table = new Entry[INITIAL_CAPACITY];
int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
table[i] = new Entry(firstKey, firstValue);
size = 1;
setThreshold(INITIAL_CAPACITY);
}
} ThreadLocal类中的关键set()方法:
public void set(T value) {
Thread t = Thread.currentThread(); //获取当前线程t
ThreadLocalMap map = getMap(t); //根据当前线程获取到ThreadLocalMap
if (map != null) //如果获取的ThreadLocalMap对象不为空
map.set(this, value); //K,V设置到ThreadLocalMap中
else
createMap(t, value); //创建一个新的ThreadLocalMap
}
ThreadLocalMap getMap(Thread t) {
return t.threadLocals; //返回Thread对象的ThreadLocalMap属性
}
void createMap(Thread t, T firstValue) { //调用ThreadLocalMap的构造函数
t.threadLocals = new ThreadLocalMap(this, firstValue); this表示当前类ThreadLocal
}
ThreadLocal类中的关键get()方法
public T get() {
Thread t = Thread.currentThread();//获取当前线程t
ThreadLocalMap map = getMap(t);//根据当前线程获取到ThreadLocalMap
if (map != null) { //如果获取的ThreadLocalMap对象不为空
//由this(即ThreadLoca对象)得到对应的Value,即ThreadLocal的泛型值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue(); //初始化threadLocals成员变量的值
}
private T setInitialValue() {
T value = initialValue(); //初始化value的值
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t); //以当前线程为key,获取threadLocals成员变量,它是一个ThreadLocalMap
if (map != null)
map.set(this, value); //K,V设置到ThreadLocalMap中
else
createMap(t, value); //实例化threadLocals成员变量
return value;
}所以怎么回答ThreadLocal的实现原理?如下,最好是能结合以上结构图一起说明哈~
Thread线程类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,即每个线程都有一个属于自己的ThreadLocalMap。ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型值。- 并发多线程场景下,每个线程
Thread,在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而可以实现了线程隔离。
了解完这几个核心方法后,有些小伙伴可能会有疑惑,ThreadLocalMap为什么要用ThreadLocal作为key呢?直接用线程Id不一样嘛?
4. 为什么不直接用线程id作为ThreadLocalMap的key呢?
举个代码例子,如下:
public class TianLuoThreadLocalTest {
private static final ThreadLocal threadLocal1 = new ThreadLocal<>();
private static final ThreadLocal threadLocal2 = new ThreadLocal<>();
} 这种场景:一个使用类,有两个共享变量,也就是说用了两个ThreadLocal成员变量的话。如果用线程id作为ThreadLocalMap的key,怎么区分哪个ThreadLocal成员变量呢?因此还是需要使用ThreadLocal作为Key来使用。每个ThreadLocal对象,都可以由threadLocalHashCode属性唯一区分的,每一个ThreadLocal对象都可以由这个对象的名字唯一区分(下面的例子)。看下ThreadLocal代码:
public class ThreadLocal {
private final int threadLocalHashCode = nextHashCode();
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
} 然后我们再来看下一个代码例子:
public class TianLuoThreadLocalTest {
public static void main(String[] args) {
Thread t = new Thread(new Runnable(){
public void run(){
ThreadLocal threadLocal1 = new ThreadLocal<>();
threadLocal1.set(new TianLuoDTO("公众号:捡田螺的小男孩"));
System.out.println(threadLocal1.get());
ThreadLocal threadLocal2 = new ThreadLocal<>();
threadLocal2.set(new TianLuoDTO("公众号:程序员田螺"));
System.out.println(threadLocal2.get());
}});
t.start();
}
}
//运行结果
TianLuoDTO{name='公众号:捡田螺的小男孩'}
TianLuoDTO{name='公众号:程序员田螺'} 再对比下这个图,可能就更清晰一点啦:
5. TreadLocal为什么会导致内存泄漏呢?
5.1 弱引用导致的内存泄漏呢?
我们先来看看TreadLocal的引用示意图哈:
关于ThreadLocal内存泄漏,网上比较流行的说法是这样的:
ThreadLocalMap使用ThreadLocal的弱引用作为key,当ThreadLocal变量被手动设置为null,即一个ThreadLocal没有外部强引用来引用它,当系统GC时,ThreadLocal一定会被回收。这样的话,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话(比如线程池的核心线程),这些key为null的Entry的value就会一直存在一条强引用链:Thread变量 -> Thread对象 -> ThreaLocalMap -> Entry -> value -> Object 永远无法回收,造成内存泄漏。
当ThreadLocal变量被手动设置为null后的引用链图:
实际上,ThreadLocalMap的设计中已经考虑到这种情况。所以也加上了一些防护措施:即在ThreadLocal的get,set,remove方法,都会清除线程ThreadLocalMap里所有key为null的value。
源代码中,是有体现的,如ThreadLocalMap的set方法:
private void set(ThreadLocal key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal k = e.get();
if (k == key) {
e.value = value;
return;
}
//如果k等于null,则说明该索引位之前放的key(threadLocal对象)被回收了,这通常是因为外部将threadLocal变量置为null,
//又因为entry对threadLocal持有的是弱引用,一轮GC过后,对象被回收。
//这种情况下,既然用户代码都已经将threadLocal置为null,那么也就没打算再通过该对象作为key去取到之前放入threadLocalMap的value, 因此ThreadLocalMap中会直接替换调这种不新鲜的entry。
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
//触发一次Log2(N)复杂度的扫描,目的是清除过期Entry
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}如ThreadLocal的get方法:
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
//去ThreadLocalMap获取Entry,方法里面有key==null的清除逻辑
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
private Entry getEntry(ThreadLocal key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
return e;
else
//里面有key==null的清除逻辑
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal k = e.get();
if (k == key)
return e;
// Entry的key为null,则表明没有外部引用,且被GC回收,是一个过期Entry
if (k == null)
expungeStaleEntry(i); //删除过期的Entry
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}5.2 key是弱引用,GC回收会影响ThreadLocal的正常工作嘛?
到这里,有些小伙伴可能有疑问,ThreadLocal的key既然是弱引用.会不会GC贸然把key回收掉,进而影响ThreadLocal的正常使用?
- 弱引用:具有弱引用的对象拥有更短暂的生命周期。如果一个对象只有弱引用存在了,则下次GC将会回收掉该对象(不管当前内存空间足够与否)
其实不会的,因为有ThreadLocal变量引用着它,是不会被GC回收的,除非手动把ThreadLocal变量设置为null,我们可以跑个demo来验证一下:
public class WeakReferenceTest {
public static void main(String[] args) {
Object object = new Object();
WeakReferenceFlutter 工程化框架选择 — 状态管理何去何从
这是 《Flutter 工程化框架选择》 系列的第六篇 ,就像之前说的,这个系列只是单纯告诉你,创建一个 Flutter 工程,或者说搭建一个 Flutter 工程脚手架,应该如何快速选择适合自己的功能模块,或者说这是一个指引系列,所以比较适合新手同学。
其实这是我最不想写的一个篇。
状态管理是 Flutter 里 ♾️ 的话题,本质上 Flutter 里的状态管理就是传递状态和基于 setState 的封装,状态管理框架解决的是如何更优雅地共享状态和调用 setState 。
那为什么我不是很想写状态管理的对比内容?
首先因为它很繁,繁体的煩,从 Flutter 发布到现在,scoped_model 、BLoC 、Provider 、 flutter_redux 、MobX、 fish_redux 、Riverpod 、GetX 等各类框架“百花齐放”,虽然这对于社区来说是这是好事,但是对于普通开发者来说很容易造成过度选择困难症,特别早期不少人被各种框架“伤害过”。
其次,状体管理在 Flutter 里一直是一个“敏感”话题,每次聊到状态管理就绕不开 GetX ,但是一旦聊 GetX 又会变成“立场”问题,所以一直以来我都不是很喜欢写状态管理的内容。
所以本来应该在第一篇就出现的内容,一直被拖到现在才放出来,这里提前声明一些,本篇不会像之前一样从大小和性能等方面去做对比,因为对于状态管理框架来说这没什么意义:
- 集成后对大小的影响可能还不如一张图片
- 性能主要取决于开发者的习惯,在状态管理框架上对比性能其实很主观
当然,如果你对集成后对大小的影响真的很在意,那可以在打包时通过 --analyze-size 来生成 analysis.json 文件用于对比分析:
flutter build apk --target-platform android-arm64 --analyze-size
上诉命令在执行之后,会在 /Users/你的用户名/.flutter-devtools/ 目录下生成一个 apk-code-size-analysis_01.json 文件,之后我们只需要打开 Flutter 的 DevTools 下的 App Size Tooling 就可以进行分析。
例如这里是将 Riverpod 和 GetX 在同一项项目集成后导出不同 json 在 Diff 进行对比,可以看到此时差异也就在 78.5kb ,这个差异大小还不如一张 png 资源图片的影响大。
所以本次主要是从这些状体管理框架自身的特点出发,简单列举它们的优劣,至于最后你觉得哪个适合你,那就见仁见智了~
本篇只是告诉你它们的特点和如何去选择,并不会深入详细讲解,如果对实现感兴趣的可以看以前分享过的文章:
Provider
2019 年的 Google I/O 大会 Provider 成了 Flutter 官方新推荐的状态管理方式之一,它的特点就是: 不复杂,好理解,代码量不大的情况下,可以方便组合和控制刷新颗粒度 , 其实一开始官方也有一个 flutter-provide ,不过后来宣告GG , Provider 成了它的替代品。
⚠️注意,
provider比flutter-provide多了个r,所以不要再看着 provide 说 Provider 被弃坑了。
简单来说,Provider 就是针对 InheritedWidget 的一个包装工具,他让 InheritedWidget 的使用变得更简单,在往下共享状态的同时,可以通过 ChangeNotifier 、 Stream 、Future 配合 Consumer* 组合出多样的更新模式。
所以使用 Provider 的好处之一就是简单,同时你可以通过 Consumer* 等来决定刷新的颗粒度,其实也就是 BuildContext 在 of(context) 时的颗粒度控制。
登记到
InheritedWidget里的 context 决定了更新是 rebuild 哪个ComponentElement,感兴趣的可以看 全面理解 State 与 Provider
当然,虽然一直说 Provider 简单,但是其实还是有一些稍微“复杂”的地方,例如 select 。
Provider 里 select 是对 BuildContext 做了 “二次登记” 的行为,就是以前你用 context 是 watch 的时候 ,是直接把这个 Widget 登记到 Element 里,有更新就通知。
但是 select 做了二次处理,就是用 dependOnInheritedElement 做了颗粒化的判断,如果是不等于了才更新,所以它对 context 有要求,如下图对就是对 context 类型进行了判断。
所以 select 算是 Provider 里的“小魔法“之一,总的来说 Provider 是一个符合 Flutter 的行为习惯,但是不大符合前端和原生的开发习惯的优秀状态管理框架。
优点:
- 简单好维护
- read、watch、select 提供更简洁的颗粒度管理
- 官方推荐
缺点:
- 相对依赖 Flutter 和 Widget
- 需要依赖 Context
最后顺带辟个谣,之前有 “传闻” Provider 要被弃坑的说法,作者针对这个也有相应对澄清,所以你还是可以继续安心使用 Provider。
Riverpod
Riverpod 和 Provider 是同个作者,因为 Provider 存在某些局限性,所以作者根据 Provider 这个单词重新排列组合成 Riverpod。
如果说 Provider 是 InheritedWidget 的封装,那 Riverpod 就是在 Provider 的基础上重构出更灵活的操作能力,最直观的就是 Riverpod 中的 Provider 可以随意写成全局,并且不依赖 BuildContext 来编写我们需要的业务逻。
注意: Riverpod 中的 Provider 和前面的 Provider 没有关系。
在 Riverpod 里基本是每一个 “Provider” 都会有一个自己的 “Element” ,然后通过 WidgetRef 去 Hook 后成为 BuildContext 的替代,所以这就是 Riverpod 不依赖 Context 的 “魔法” 之一
⚠️这里的 “Element” 不是 Flutter 概念里三棵树的
Element,它是 Riverpod 里Ref对象的子类。Ref主要提供 Riverpod 内的 “Provider” 之间交互的接口,并且提供一些抽象的生命周期方法,所以它是 Riverpod 里的独有的 “Element” 单位。
另外对比 Provider ,Riverpod 不需要依赖 Flutter ,所以也不需要依赖 Widget,也就是不依赖 BuildContext ,所以可以支持全局变量定义 “Provider” 对象。
优点:
- 在 Provider 的基础上更加灵活的实现,
- 不依赖
BuildContext,所以业务逻辑也无需注入BuildContext - Riverpod 会尽可能通过编译时安全来解决存在运行时异常问题
- 支持全局定义
ProviderReference能更好解决嵌套代码
缺点:
- 实现更加复杂
- 学习成本提高
目前从我个人角度看,我觉得 Riverpod 时当前之下状态管理的最佳选择,它灵活且专注,体验上也更符合 Flutter 的开发习惯。
注意,很多人一开始只依赖
riverpod然后发现一些封装对象不存在,因为riverpod是不依赖 flutter 的实现,所以在 flutter 里使用时不要忘记要依赖flutter_riverpod。
BLoC
BLoC 算是 Flutter 早期比较知名的状态管理框架,它同样是存在 bloc 和 flutter_bloc 这样的依赖关系,它是基于事件驱动来实现的状态管理。
flutter_bloc 基于事件驱动的核心就是 Stream 和 Provider , 是的, flutter_bloc 依赖于 Provider,然后在其基础上设计了基于 Stream 的事件响应机制。
所以严格意义上 BLoC 其实是 Provider + Stream ,如果你一直很习惯基于事件流开发模式,那么 BLoC 就很适合你,但是其实从我个人体验上看,BLoC 在开发节奏上并不是快,相反还有点麻烦,不过优势也很明显,基于 Stream 的封装可以更方便做一些事件状态的监听和转换。
BlocSelector(
selector: (state) {
// return selected state based on the provided state.
},
builder: (context, state) {
// return widget here based on the selected state.
},
)
MultiBlocListener(
listeners: [
BlocListener(
listener: (context, state) {},
),
BlocListener(
listener: (context, state) {},
),
BlocListener(
listener: (context, state) {},
),
],
child: ChildA(),
) 优点:
- 代码更加解耦,这是事件驱动的特性
- 把状态更新和事件绑定,可以灵活得实现状态拦截,重试甚至撤回
缺点:
- 需要写更多的代码,开发节奏会有点影响
- 接收代码的新维护人员,缺乏有效文档时容易陷入对着事件和业务蒙圈
- 项目后期事件容易混乱交织
类似的库还有 rx_bloc ,同样是基于
Stream和 Provider , 不过它采用了 rxdart 的Stream封装。
flutter_redux
flutter_redux 虽然也是 pub 上的 Flutter Favorite 的项目,但是现在的 Flutter 开发者应该都不怎么使用它,而恰好我在刚使用 Flutter 时使用的状态管理框架就是它。
其实前端开始者对 redux 可能会更熟悉一些,当时我恰好用 RN 项目切换到 Flutter 项目,在 RN 时代我就一直在使用 redux,flutter_redux 自然就成了我首选的状态管理框架。
其实这也是 Flutter 最有意思的,很多前端的状态管理框架都可以迁移到 Flutter ,例如 flutter_redux 里就是利用了 Stream特性,通过 redux 单向事件流的设计模式来完成解耦和拓展。
在 flutter_redux 中,开发者的每个操作都只是一个 Action ,而这个行为所触发的逻辑完全由 middleware 和 reducer 决定,这样的设计在一定程度上将业务与UI隔离,同时也统一了状态的管理。
当然缺陷也很明显,你要写一堆代码,开发逻辑一定程度上也不大符合 Flutter 的开发习惯。
优点:
- 解耦
- 对 redux 开发友好
- 适合中大型项目里协作开发
缺点:
- 影响开发速度,要写一堆模版
- 不是很贴合 Flutter 开发思路
说到 redux 就不得不说 fish_redux ,如果说 redux 是搭积木,那闲鱼最早开源的 fish_redux 可以说是积木界的乐高,闲鱼在 redux 的基础上提出了 Comoponent 的概念,这个概念下 fish_redux 是从 Context 、Widget 等地方就开始全面“入侵”你的代码,从而带来“超级赛亚人”版的 redux 。
所以不管是 flutter_redux 还是 fish_redux 都是很适合团队协作的开发框架,但是它的开发体验和开发过程,注定不是很友好。
GetX
GetX 可以说是 Flutter 界内大名鼎鼎,Flutter 不能没有 GetX 就像程序员不能没有 PHP ,GetX 很好用,很具备话题,很全面同时也很 GetX。
严格意义上说现在 GetX 已经不是一个简单的状态管理框架,它是一个统一的 Flutter 开发脚手架,在 GetX 内你可以找到:
- 状态管理
- 路由管理
- 多语言支持
- 页面托管
- Http GetConnect
- Rx GetStream
- 各式各样的 extension
可以说大部分你想到的 GetX 里都有,甚至还有基于 GetX 的 get_storage 实现纯 Dart 文件级 key-value 存储支持。
所以很多时候使用 GetX 开发甚至不需要关心 Flutter ,当然这也导致经常遇到的奇怪情况:大家的问题集中在 GetX 里如何 xxxx,而不是 Flutter 如何 xxxx ,所以 GetX 更像是依附在 Flutter 上的解决方案。
当然,使用 GetX 最直观的就是不需要 BuildContext ,甚至是你在路由跳转时都不需要关心 Context ,这就让你的代码看起来很“干净”,把整个开发过程做到“面向 GetX 开发”的效果 。
另外 GetX 和 Provider 等相比还具备的特色是:
Get.put、Get.find、Get.to等操作完全无需 Widget 介入- 内置的
extension如各类基础类似的*.obs通过GetStream实现了如var count = 0.obs;和Obx(() => Text("${controller.name}"));这样的简化绑定操作
那 GetX 是如何脱离 Context 的依赖?说起来也不复杂,例如 :
GetMaterialApp内通过一个会有一个GlobalKey用于配置MaterialApp的navigatorKey,这样就可以通过全局的navigatorKey获取到Navigator的State,从而调用pushAPI 打开路由
Get.put和Get.find是通过一个内部全局的静态Map来管理,所以在传递和存放时就脱离了InheritedWidget,结合Obx,在对获取到的GetxController的 value 时会有个addListener的操作,从而实现Stream的绑定和更新
可以说 GetX 内部有很多“魔法”,这些魔法或者是对 Flutter API 的 Hook、或者是直接脱离 Flutter 设计的自定义实现,总的来说 GetX “有自己的想法”。
这也就带来一个了个问题,很多人新手一上手就是 GetX ,然后对 Flutter 一知半解,特别是深度解绑了 Context 之后,很多 Flutter 问题就变成了 GetX 上如何 xxxx,例如前面的: Flutter GetX 如何调用谷歌地图这种问题。
如果使用 GetX 而不去思考和理解 GetX 的实现,就很容易在 Flutter 的路上走歪,比如上面各种很基础的问题。
这其实也是 GetX 的最大问题:GetX 做的很多,它入侵到很多领域,而且它拥有很多“魔法”,这些“魔法”让 Flutter 开发者不知布局的脱离了本来应有的轨迹。
当然,你说我就是想完成需求,好用就行,何必关心它们的实现呢?从这个角度看 GetX 无疑是非常不错的选择,只要 GetX 能继续维护下去并把“魔法”继续兼容。
大概就是:GetX “王国” 对初级开发者友好,但是“魔法全家桶”其实对社区的健康发展很致命。
优点:
- 瑞士军刀式护航
- 对新人友好
- 可以减少很多代码
缺点:
- 全家桶,做的太多对于一些使用者来说是致命缺点,需要解决的 Bug 也多
- “魔法”使用较多,脱离 Flutter 原本轨迹
- 入侵性极强
总的来说,GetX 很优秀,他帮你都写好了很多东西,省去了开发者还要考虑如何去组合和思考的过程,从我个人的角度我不喜欢这种风格,但是它总归是可以帮助你提高开发效率。
另外还有一个状态管理库 Mobx ,它库采用了和 GetX 类似的风格,虽然 Mobx 的知名度和关注度不像 GetX 那么高,但是它同样采用了隐式依赖的模式,某种意义上可以把 Mobx 看成是只有状态管理版本的 GetX。
最后
通过上面分享的内容,相信大家对于选哪个状态管理框架应该有自己的理解了,还是那句废话,采用什么方案和框架具体还是取决于你的需求场景,不管是哪个框架目前都有坑和局限,重点还是在于它未来是否持续维护,或者不维护了你自己能否继续维护下去。
链接:https://juejin.cn/post/7163925807893577735
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android仿淘宝、京东Banner滑动查看图文详情
效果图
原理分析
Banner与右侧的查看更多View都是子View,被父View包裹,默认Banner的宽度是match_parent,而查看更多则是在屏幕的右侧,处于不可见状态;- 当
Banner进行左右滑动时,当前的滑动事件是在Banner中消费的,即父View不会进行拦截。 - 当
Banner滑动到最右侧且要继续滑动时,此时父View会进行事件的拦截,从而事件由父View接管,并在父View的onTouchEvent()中消费事件,此时就可以滑动父View中的内容了。怎么滑动呢?在MOVE事件时通过scrollTo()/scrollBy()滑动,而在UP/CANCEL事件时,需要通过Scroller的startScroll()自动滑动到查看更多子View的左侧或右侧,从而完成一次事件的消费; - 当
UP/CANCEL事件触发时,查看更多子View滑动的距离超过一半,认为需要触发查看更多操作了,当然这里的值都可以自行设置。
核心代码
- TJBannerFragment.kt
/**
* 仿淘宝京东宝贝详情Fragment
*/
class TJBannerFragment : BaseFragment() {
private val mModels: MutableList<Any> = mutableListOf()
private val mContainer: VpLoadMoreView by id(R.id.vp2_load_more)
override fun getLayoutId(): Int {
return R.layout.fragment_tx_news_n
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
initVerticalTxScroll()
}
private fun initVerticalTxScroll() {
mModels.add(TxNewsModel(MConstant.IMG_4, "美轮美奂节目", "奥运五环缓缓升起"))
mModels.add(TxNewsModel(MConstant.IMG_1, "精美商品", "9块9包邮"))
mContainer.setData(mModels) {
showToast("打开更多页面")
}
}
}- VpLoadMoreView.kt(父View)
class VpLoadMoreView @JvmOverloads constructor(
context: Context,
attrs: AttributeSet? = null,
defStyle: Int = 0,
) : LinearLayout(context, attrs, defStyle) {
private val mMVPager2: MVPager2 by id(R.id.mvp_pager2)
private var mNeedIntercept: Boolean = false //是否需要拦截VP2事件
private val mLoadMoreContainer: LinearLayout by id(R.id.load_more_container)
private val mIvArrow: ImageView by id(R.id.iv_pull)
private val mTvTips: TextView by id(R.id.tv_tips)
private var mCurPos: Int = 0 //Banner当前滑动的位置
private var mLastX = 0f
private var mLastDownX = 0f //用于判断滑动方向
private var mMenuWidth = 0 //加载更多View的宽度
private var mShowMoreMenuWidth = 0 //加载更多发生变化时的宽度
private var mLastStatus = false // 默认箭头样式
private var mAction: (() -> Unit)? = null
private var mScroller: OverScroller
private var isTouchLeft = false //是否是向左滑动
private var animRightStart = RotateAnimation(0f, -180f,
Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF, 0.5f).apply {
duration = 300
fillAfter = true
}
private var animRightEnd = RotateAnimation(-180f, 0f,
Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF, 0.5f).apply {
duration = 300
fillAfter = true
}
init {
orientation = HORIZONTAL
View.inflate(context, R.layout.fragment_tx_news, this)
mScroller = OverScroller(context)
}
/**
* @param mModels 要加载的数据
* @param action 回调Action
*/
fun setData(mModels: MutableList<Any>, action: () -> Unit) {
this.mAction = action
mMVPager2.setModels(mModels)
.setLoop(false) //非循环模式
.setIndicatorShow(false)
.setLoader(TxNewsLoader(mModels))
.setPageTransformer(CompositePageTransformer().apply {
addTransformer(MarginPageTransformer(15))
})
.setOrientation(ViewPager2.ORIENTATION_HORIZONTAL)
.setAutoPlay(false)
.setOnBannerClickListener(object : OnBannerClickListener {
override fun onItemClick(position: Int) {
showToast(mModels[position].toString())
}
})
.registerOnPageChangeCallback(object : ViewPager2.OnPageChangeCallback() {
override fun onPageScrollStateChanged(state: Int) {
if (mCurPos == mModels.lastIndex && isTouchLeft && state == ViewPager2.SCROLL_STATE_DRAGGING) {
//Banner在最后一页 & 手势往左滑动 & 当前是滑动状态
mNeedIntercept = true //父View可以拦截
mMVPager2.setUserInputEnabled(false) //VP2设置为不可滑动
}
}
override fun onPageSelected(position: Int) {
mCurPos = position
}
})
.start()
}
override fun onLayout(changed: Boolean, l: Int, t: Int, r: Int, b: Int) {
mMenuWidth = mLoadMoreContainer.measuredWidth
mShowMoreMenuWidth = mMenuWidth / 3 * 2
super.onLayout(changed, l, t, r, b)
}
override fun dispatchTouchEvent(ev: MotionEvent?): Boolean {
when (ev?.action) {
MotionEvent.ACTION_DOWN -> {
mLastX = ev.x
mLastDownX = ev.x
}
MotionEvent.ACTION_MOVE -> {
isTouchLeft = mLastDownX - ev.x > 0 //判断滑动方向
}
}
return super.dispatchTouchEvent(ev)
}
override fun onInterceptTouchEvent(ev: MotionEvent?): Boolean {
var isIntercept = false
when (ev?.action) {
MotionEvent.ACTION_MOVE -> isIntercept = mNeedIntercept //是否拦截Move事件
}
//log("ev?.action: ${ev?.action},isIntercept: $isIntercept")
return isIntercept
}
@SuppressLint("ClickableViewAccessibility")
override fun onTouchEvent(ev: MotionEvent?): Boolean {
when (ev?.action) {
MotionEvent.ACTION_MOVE -> {
val mDeltaX = mLastX - ev.x
if (mDeltaX > 0) {
//向左滑动
if (mDeltaX >= mMenuWidth || scrollX + mDeltaX >= mMenuWidth) {
//右边缘检测
scrollTo(mMenuWidth, 0)
return super.onTouchEvent(ev)
}
} else if (mDeltaX < 0) {
//向右滑动
if (scrollX + mDeltaX <= 0) {
//左边缘检测
scrollTo(0, 0)
return super.onTouchEvent(ev)
}
}
showLoadMoreAnim(scrollX + mDeltaX)
scrollBy(mDeltaX.toInt(), 0)
mLastX = ev.x
}
MotionEvent.ACTION_UP, MotionEvent.ACTION_CANCEL -> {
smoothCloseMenu()
mNeedIntercept = false
mMVPager2.setUserInputEnabled(true)
//执行回调
val mDeltaX = mLastX - ev.x
if (scrollX + mDeltaX >= mShowMoreMenuWidth) {
mAction?.invoke()
}
}
}
return super.onTouchEvent(ev)
}
private fun smoothCloseMenu() {
mScroller.forceFinished(true)
/**
* 左上为正,右下为负
* startX:X轴开始位置
* startY: Y轴结束位置
* dx:X轴滑动距离
* dy:Y轴滑动距离
* duration:滑动时间
*/
mScroller.startScroll(scrollX, 0, -scrollX, 0, 300)
invalidate()
}
override fun computeScroll() {
if (mScroller.computeScrollOffset()) {
showLoadMoreAnim(0f) //动画还原
scrollTo(mScroller.currX, mScroller.currY)
invalidate()
}
}
private fun showLoadMoreAnim(dx: Float) {
val showLoadMore = dx >= mShowMoreMenuWidth
if (mLastStatus == showLoadMore) return
if (showLoadMore) {
mIvArrow.startAnimation(animRightStart)
mTvTips.text = "释放查看图文详情"
mLastStatus = true
} else {
mIvArrow.startAnimation(animRightEnd)
mTvTips.text = "滑动查看图文详情"
mLastStatus = false
}
}
}父View的注释很清晰,不用过多解释了,这里需要注意一点,已知在Banner的最后一页滑动时需要判断滑动方向:继续向左滑动,需要父View拦截滑动事件并自己进行消费;向右滑动时,父View不需要处理滑动事件,仍由Banner进行事件消费。
而滑动方向需要起始位置(DOWN事件)的X坐标 - 滑动时的X坐标(MOVE事件) 的差值进行判断,那问题在哪里取起始位置的X坐标呢?在父View的onInterceptTouchEvent()->DOWN事件里吗?这里是不行的,因为滑动方向是在MOVE事件里判断的,在父View的onInterceptTouchEvent()->DOWN事件里拦截的话,后续事件不会往Banner里传递了。这里可以选择在父View的dispatchTouchEvent()->DOWN事件里即可解决。
VpLoadMoreView对应的XML布局:
<?xml version="1.0" encoding="utf-8"?>
<merge xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="@color/white"
android:orientation="horizontal"
tools:parentTag="android.widget.LinearLayout">
<!--ViewPager2-->
<org.ninetripods.lib_viewpager2.MVPager2
android:id="@+id/mvp_pager2"
android:layout_width="match_parent"
android:layout_height="200dp"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintTop_toTopOf="parent" />
<!--加载更多View-->
<LinearLayout
android:id="@+id/load_more_container"
android:layout_width="100dp"
android:layout_height="200dp"
android:gravity="center_vertical"
android:orientation="horizontal">
<ImageView
android:id="@+id/iv_pull"
android:layout_width="18dp"
android:layout_height="18dp"
android:layout_gravity="center_vertical"
android:layout_marginStart="10dp"
android:src="@drawable/icon_arrow_pull" />
<TextView
android:id="@+id/tv_tips"
android:layout_width="16dp"
android:layout_height="match_parent"
android:layout_marginStart="10dp"
android:gravity="center_vertical"
android:text="滑动查看图文详情"
android:textColor="#333333"
android:textSize="14sp"
android:textStyle="bold" />
</LinearLayout>
</merge>这里的父View(VpLoadMoreView)是LinearLayout,且必须是横向布局,XML的顶层布局使用的merge标签,这样既可以优化一层布局,又可以在父View中直接操作加载图文详情的子View。
源码地址
完整代码地址参见:Android仿淘宝、京东Banner滑动至最后查看图文详情
链接:https://juejin.cn/post/7156059973728862238
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
MD5 到底算不算一种加密算法?
本文正在参加「金石计划 . 瓜分6万现金大奖」
hello,大家好,我是张张,「架构精进之路」公号作者。
一旦提到加密算法,经常有人会有这样的疑问:MD5 到底算不算一种加密算法呢?
在回答这个问题之前,我们需要先弄清楚两点:
什么是加密算法?
什么是 MD5?
1、什么是加密算法?
数据加密的基本过程就是对原来为明文的文件或数据按某种算法进行处理,使其成为不可读的一段代码为“密文”,使其只能在输入相应的密钥之后才能显示出原容,通过这样的途径来达到保护数据不被非法人窃取、阅读的目的。 该过程的逆过程为解密,即将该编码信息转化为其原来数据的过程。
-- 来自《百度百科》
使用密码学可以达到以下三个目的:
数据保密性:防止用户的数据被窃取或泄露;
数据完整性:防止用户传输的数据被篡改;
身份验证:确保数据来源与合法的用户。
加密算法分类
常见的加密算法大体可以分为两大类:对称加密和非对称加密。
- 对称加密
对称加密算法就是用一个秘钥进行加密和解密。
- 非对称加密
与对称加密算法不同的是,进行加密与解密使用的是不同的秘钥,有一个公钥-私钥对,秘钥正确才可以正常的进行加解密。
2、什么是MD5?
MD5算法:MD5全称Message Digest Algorithm 5,即消息摘要算法第5版。
MD5 以 512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
MD5算法的主要特点:
- 长度固定
MD5加密后值固定长度是128位,使用32个16进制数字进行表示。
- 单向性
如果告诉原始消息,算法是MD5,迭代次数=1的情况下,我们一样可以得到一摸一样的消息摘要,但是反过来却不行。
- 不可逆
在不知道原始消息的前提下,是无法凭借16个字节的消息摘要(Message Digest),还原出原始的消息的。
下面这个消息摘要,你知道他的原始信息是什么吗?
Message Digest = '454e2624461c206380f9f088b1e55fae'
其实,原始信息是以下长长的字符串:
93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXug
OoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3
CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5z
fhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZ
OEmH0nOnH/0onD- 恒定性
如果按照以上示例的原始信息,大家与我计算出来的消息摘要不一样,那肯定你是使用了一个假的 MD5 工具,哈哈哈。
当原始消息恒定时,每次运行MD5产生的消息摘要都是恒定不变的,无论是谁来计算,结果都应该是一样的。
- 不可预测性
让我们再来尝试一次,「不可逆」中应用到的原始消息的最后一个字母'D',修改成'E',如下所示:
93eyHv2Iw5kbn1dqfBw1BuTE29V2FJKicJSu8iEOpfoafwJISXmz1wnnWL3V/0NxTulfWsXug
OoLfv0ZIBP1xH9kmf22jjQ2JiHhQZP7ZDsreRrOeIQ/c4yR8IQvMLfC0WKQqrHu5ZzXTH4NO3
CwGWSlTY74kE91zXB5mwWAx1jig+UXYc2w4RkVhy0//lOmVya/PEepuuTTI4+UJwC7qbVlh5z
fhj8oTNUXgN0AOc+Q0/WFPl1aw5VV/VrO8FCoB15lFVlpKaQ1Yh+DVU8ke+rt9Th0BCHXe0uZ
OEmH0nOnH/0onE那经 MD5 后产生的消息摘要,是不是和 '454e2624461c206380f9f088b1e55fae' 很相似呢?
让大家失望了,产生的消息摘要没有一丝一毫的关联性,新的消息摘要如下所示:
Message Digest = '8796ed5412b84ff5c4769d080b4a89a2'聊到这里,突然想到一个有意思的问题:
MD5是32位的,理论上是有限的,而世界上的数据是无限的,那会不会生成重复的MD5值?
是不是也有同学产生相似的疑问呢?
理论上来讲,当然会生成重复的MD5值。
分享一个经典的例子:
数据源1:
d131dd02c5e6eec4693d9a0698aff95c2fcab58712467eab4004583eb8fb7f89
55ad340609f4b30283e488832571415a085125e8f7cdc99fd91dbdf280373c5b
d8823e3156348f5bae6dacd436c919c6dd53e2b487da03fd02396306d248cda0
e99f33420f577ee8ce54b67080a80d1ec69821bcb6a8839396f9652b6ff72a70
数据源2:
d131dd02c5e6eec4693d9a0698aff95c2fcab50712467eab4004583eb8fb7f89
55ad340609f4b30283e4888325f1415a085125e8f7cdc99fd91dbd7280373c5b
d8823e3156348f5bae6dacd436c919c6dd53e23487da03fd02396306d248cda0
e99f33420f577ee8ce54b67080280d1ec69821bcb6a8839396f965ab6ff72a70
它们竟然有着共同的MD5值(☞ 注意看,数据源1、2是存在很多细节不同的):
79054025255fb1a26e4bc422aef54eb43、MD5是加密算法吗?
MD5计算,对原始消息(Message)做有损的压缩计算,无论消息(输入值)的长度字节是多少,是1亿字节还是1个字节,都会生成一个固定长度(128位/16字节)的消息摘要(输出值)。
也就是说,MD5 算法和加密算法都可以将信息转换为另外一种内容,但是,MD5 算法对比 加密算法 缺少了解密过程。
好比一头山羊,被层层加工制作成一包包风干羊肉,这个就是一次MD5操作。这种加工过程,势必将羊身体N多部位有损失,故无法通过羊肉干再复原出一头山羊...
使用 加密算法 加密后的消息是完整的,并且基于解密算法后,可以恢复原始数据。而 MD5 算法 得到的消息是不完整的,并且通过摘要的数据也无法得到原始数据。
所以严格意义上来讲,MD5 称为摘要/散列算法更合适,而不是加密算法!
那现实的问题来了,MD5究竟有什么用?
欢迎各位留言补充~
·················· END ··················
希望今天的讲解对大家有所帮助,谢谢!
Thanks for reading!
链接:https://juejin.cn/post/7163264509006577695
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简简单单搞一个实用的Android端搜索框
Hello啊老铁们,今天带来一个非常实用的自定义搜索框,包含了搜索框、热门搜索列表、最近搜索列表等常见的功能,有类似的,大家可以直接复用,将会大大节约您的开发时间,有一点,很负责任的告诉大家,实现这个没什么技术含量,就是很简单的自定义组合View,本文除了使用介绍,我也会把具体的实现过程分享给大家。
今天的内容大概如下:
1、效果展示
2、快速使用及属性介绍
3、具体代码实现
4、开源地址及总结
一、效果展示
效果很常见,就是平常需求中的效果,上面是搜索框,下面是最近和热门搜索列表,为了方便大家在实际需求中使用,配置了很多属性,也进行了上下控件的拆分,也就是上边搜索框和下面的搜索列表的拆分,可以按需进行使用。
二、快速使用及属性介绍
快速使用
目前已经发布至远程Maven,大家可以进行远程依赖使用。
1、在你的根项目下的build.gradle文件下,引入maven。
allprojects {
repositories {
maven { url "https://gitee.com/AbnerAndroid/almighty/raw/master" }
}
}2、在你需要使用的Module中build.gradle文件下,引入依赖。
dependencies {
implementation 'com.vip:search:1.0.0'
}具体代码
1、xml中引入SearchLayout(搜索框)和SearchList(搜索列表),在实际开发中,根据需求可选择使用,二者是互不关联的。
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:paddingLeft="10dp"
android:paddingRight="10dp"
tools:context=".MainActivity">
<com.vip.search.SearchLayout
android:id="@+id/search_layout"
android:layout_width="match_parent"
android:layout_height="40dp"
android:layout_marginTop="10dp"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:search_bg="@drawable/shape_stroke_10" />
<com.vip.search.SearchList
android:id="@+id/search_list"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_marginTop="10dp"
app:is_hot_flex_box_or_grid="true"
app:is_visibility_history_clear="true"
app:layout_constraintTop_toBottomOf="@id/search_layout" />
</androidx.constraintlayout.widget.ConstraintLayout>
2、代码逻辑,以下是测试代码,如用到实际项目,请以实际项目获取控件为主。
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
val searchLayout = findViewById<SearchLayout>(R.id.search_layout)
val searchList = findViewById<SearchList>(R.id.search_list)
searchLayout.setOnTextSearchListener({
//搜索内容改变
}, {
//软键盘点击了搜索
searchList.doSearchContent(it)
})
//设置用于测试的热门搜索列表
searchList.setHotList(getHotList())
//热门搜索条目点击事件
searchList.setOnHotItemClickListener { s, i ->
Toast.makeText(this, s, Toast.LENGTH_SHORT).show()
}
//历史搜索条目点击事件
searchList.setOnHistoryItemClickListener { s, i ->
Toast.makeText(this, s, Toast.LENGTH_SHORT).show()
}
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:模拟热门搜索列表
*/
private val mTestHotList = arrayListOf(
"二流小码农", "三流小可爱", "Android",
"Kotlin", "iOS", "Java", "Python", "Php是世界上最好的语言"
)
private fun getHotList(): ArrayList<SearchBean> {
return ArrayList<SearchBean>().apply {
mTestHotList.forEachIndexed { index, s ->
val bean = SearchBean()
bean.content = s
bean.isShowLeftIcon = true
val drawable: Drawable? = if (index < 2) {
ContextCompat.getDrawable(this@MainActivity, R.drawable.shape_circle_select)
} else if (index == 2) {
ContextCompat.getDrawable(this@MainActivity, R.drawable.shape_circle_ordinary)
} else {
ContextCompat.getDrawable(this@MainActivity, R.drawable.shape_circle_normal)
}
drawable?.setBounds(0, 0, drawable.minimumWidth, drawable.minimumHeight)
bean.leftIcon = drawable
add(bean)
}
}
}
}主要方法介绍
1、搜索框监听
拿到searchLayout控件之后,调用setOnTextSearchListener方法即可,第一个方法是搜索内容发生变化会回调,第二个方法是,点击了软键盘的搜索按钮会回调,如果要在最近搜索里展示,直接调用doSearchContent方法即可。
searchLayout.setOnTextSearchListener({
//搜索内容改变
}, {
//软键盘点击了搜索
searchList.doSearchContent(it)
})2、搜索列表点击事件
热门搜索调用setOnHotItemClickListener方法,历史搜索也就是最近搜索调用setOnHistoryItemClickListener方法,都是两个参数,第一个是文本内容,第二个是索引,也就是点的是哪一个。
//热门搜索条目点击事件
searchList.setOnHotItemClickListener { s, i ->
Toast.makeText(this, s, Toast.LENGTH_SHORT).show()
}
//历史搜索条目点击事件
searchList.setOnHistoryItemClickListener { s, i ->
Toast.makeText(this, s, Toast.LENGTH_SHORT).show()
}3、改变最近(历史)搜索item背景
有的老铁说了,默认的背景我不喜欢,能否可以动态设置,必须能!
默认背景
设置背景,通过setHistoryItemBg方法。
searchList.setHistoryItemBg(R.drawable.shape_solid_d43c3c_10)效果展示
4、动态设置热门搜索热度
可能在很多需求中,需要展示几个热度,有的是按照颜色区分,如下图:
实现起来很简单,在设置热门列表(setHotList)的时候,针对传递的对象设置leftIcon即可。测试代码如下:
private fun getHotList(): ArrayList<SearchBean> {
return ArrayList<SearchBean>().apply {
mTestHotList.forEachIndexed { index, s ->
val bean = SearchBean()
bean.content = s
bean.isShowLeftIcon = true
val drawable: Drawable? = if (index < 2) {
ContextCompat.getDrawable(this@MainActivity, R.drawable.shape_circle_select)
} else if (index == 2) {
ContextCompat.getDrawable(this@MainActivity, R.drawable.shape_circle_ordinary)
} else {
ContextCompat.getDrawable(this@MainActivity, R.drawable.shape_circle_normal)
}
drawable?.setBounds(0, 0, drawable.minimumWidth, drawable.minimumHeight)
bean.leftIcon = drawable
add(bean)
}
}
}具体的哪个数据展示什么颜色,直接设置即可,想怎么展示就怎么展示。当然了除了展示不同的热度之外,还有一些其他的变量,isShowLeftIcon为是否展示文字左边的icon,textColor为当前文字的颜色,根据不同的颜色,我们也可以实现下面的效果。
除了常见的方法之外,还提供了很多的属性操作,具体的大家可以看下面,按需使用即可。
属性介绍
为了让功能灵活多变,也为了满足更多的需求样式,目前自定义了很多属性,大家可以按自己的需要进行设置,或者直接去GitHub中下载源码更改也可以。
SearchLayout(搜索框属性)
| 属性 | 类型 | 概述 |
|---|---|---|
| search_icon | reference | 搜索图标,可直接从drawable或者mipmap中设置 |
| search_icon_width | dimension | 搜索图标的宽 |
| search_icon_height | dimension | 搜索图标的高 |
| search_icon_left | dimension | 搜索图标距离左边的距离 |
| search_icon_delete | reference | 搜索删除图标,右侧的删除 |
| search_icon_delete_width | dimension | 搜索删除图标的宽 |
| search_icon_delete_height | dimension | 搜索删除图标的高 |
| search_icon_delete_right | dimension | 搜索删除图标距离右边的距离 |
| search_hint | string | 搜索框占位字符 |
| search_hint_color | color | 搜索框占位字符颜色 |
| search_color | color | 搜索框文字颜色 |
| search_size | dimension | 搜索框文字大小 |
| search_text_cursor | reference | 搜索框光标 |
| search_bg | reference | 整个搜索框背景 |
SearchList(搜索列表属性)
| 属性 | 类型 | 概述 |
|---|---|---|
| is_hot_flex_box_or_grid | boolean | 热门搜索列表样式,是网格还是流式布局 |
| is_hot_center | boolean | 热门搜索列表样式,内容是否居中 |
| hot_grid_span_count | integer | 热门搜索列表样式,如果是网格布局,条目列数,默认2 |
| hot_item_top_margin | integer | 热门搜索列表 item距离上边的距离 |
| hot_item_color | color | 热门搜索列表 item 文字颜色 |
| hot_item_size | dimension | 热门搜索列表 item 文字大小 |
| hot_item_line | integer | 热门搜索列表 item 文字展示几行 |
| hot_item_bg | reference | 热门搜索列表 item 背景 |
| hot_item_margin_top | reference | 热门搜索列表 item 距离上边的距离 |
| hot_padding_left | dimension | 热门搜索列表 内边距,左 |
| hot_padding_top | dimension | 热门搜索列表 内边距,上 |
| hot_padding_right | dimension | 热门搜索列表 内边距,右 |
| hot_padding_bottom | dimension | 热门搜索列表 内边距,下 |
| is_history_flex_box_or_grid | boolean | 历史搜索列表样式,是网格还是流式布局 |
| history_flex_box_count | integer | 历史搜索列表,最多展示几个item,默认10 |
| is_history_center | boolean | 历史搜索列表样式,内容是否居中 |
| history_grid_span_count | integer | 历史搜索列表样式,如果是网格布局,条目列数,默认2 |
| history_item_top_margin | integer | 历史搜索列表 item距离上边的距离 |
| history_item_color | color | 历史搜索列表 item 文字颜色 |
| history_item_size | dimension | 历史搜索列表 item 文字大小 |
| history_item_margin_top | dimension | 历史搜索列表 item 距离上边的距离 |
| is_visibility_history_clear | boolean | 历史搜索右边是否展示清除小按钮 |
| history_clear_icon | reference | 历史搜索右边的清除小按钮 |
| history_clear_text | string | 历史搜索右边的清除文字 |
| history_clear_size | dimension | 历史搜索右边的清除文字大小 |
| history_clear_color | color | 历史搜索右边的清除文字颜色 |
| history_padding_left | dimension | 历史搜索列表 内边距,左 |
| history_padding_top | dimension | 历史搜索列表 内边距,上 |
| history_padding_right | dimension | 历史搜索列表 内边距,右 |
| history_padding_bottom | dimension | 历史搜索列表 内边距,下 |
三、具体代码实现
关于这个组合View的实现方式,我是分为了两个View,大家在上边的使用中应该也看到了,一个是搜索框SearchLayout,一个是搜索框下面的搜索列表展示SearchList,开头就阐述了,没啥技术含量,简单的罗列下代码实现吧。
SearchLayout是一个组合View,中间是一个EditText,左右两边是一个ImageView,也就是搜索图标和删除图标,如下图:
SearchLayout本身没有啥要说的,无非就是把View组合到了一起,在开发的时候,既然要给别人使用,那么就要拓展出很多的动态属性或者方法出来,这是很重要的,所以,在封装的时候,自定义属性无比的重要,需要精确和认真,这一块没啥好说的,有一点需要注意,也就是EditText绑定软键盘搜索,除了设置属性android:imeOptions="actionSearch",也要设置,android:singleLine="true",方可生效。
SearchList其实也没啥好说的,也是一个组合View,使用的是上下两个RecyclerView来实现的,至于流失布局,采用的是google提供的flexbox,设置布局管理器即可。
recyclerView.layoutManager = FlexboxLayoutManager(mContext)除了这个之外,可能需要阐述的也就是最近搜索的存储机制了,存储呢,Android中提供了很多的存储方式,比如数据库,SharedPreferences,SD卡,还有DataStore,MMKV等,无论哪一种吧,选择适合的即可,这个开源中,不想引入其他的三方了,直接使用的是SharedPreferences。
具体的实现方式,把搜索的内容,转成json串,以json串的形式进行存储,这里借助了原生的JSONArray和JSONObject。流程就是,触发搜索内容后,先从SharedPreferences取出之前存储的内容,放到JSONArray中,当前搜索内容如果存在JSONArray中,那边就要执行删除原来的,再把新的内容插入到第一个的位置,如果不存在JSONArray中,直接添加即可,随后再转成字符串存储即可。
当然了,一般在正常的需求开发中,最近搜索列表肯定不是无限展示的,都有固定的展示个数,比如10个,比如15个,所以,当超过指定的个数,也就是指定的阀门后,就要执行删除的操作。
val searchHistory = getSearchHistory()
if (!TextUtils.isEmpty(it)) {
val jsonArray: JSONArray = if (TextUtils.isEmpty(searchHistory)) {
JSONArray()
} else {
JSONArray(searchHistory)
}
val json = JSONObject()
json.put("content", it)
//如果出现了一样的,删除后,加到第一个
var isEqual = false
var equalPosition = 0
for (i in 0 until jsonArray.length()) {
val item = jsonArray.getJSONObject(i)
val content = item.getString("content")
if (it == content) {
isEqual = true
equalPosition = i
break
}
}
//有一样的
if (isEqual) {
jsonArray.remove(equalPosition)
} else {
//超过了指定的阀门之后,就不在扩充
if (jsonArray.length() >= mHistoryListSize) {
jsonArray.remove(0)
}
}
jsonArray.put(json)
SearchSharedPreUtils.put(mContext!!, "search_history", jsonArray.toString())
}
getSearchHistory()?.let {
eachSearchHistory(it)
}
//两个有一个不为空,展示
if (!TextUtils.isEmpty(it) || !TextUtils.isEmpty(searchHistory)) {
showOrHideHistoryLayout(View.VISIBLE)
}当然了,存储的逻辑,有很多的实现的方式,这里并不是最优的,只是提供了一种思路,大家可以按照自己的方式来操作。
四、开源地址及总结
搜索列表,无论是热门还是最近的搜索列表,均支持网格和流失布局形式展示,大家看属性相关介绍中即可。这个搜索框本身就是很简单的效果还有代码,大家直接看源码或文中介绍即可,就不多赘述了。
链接:https://juejin.cn/post/7163844676556947464
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
浅谈RecyclerView的性能优化
RecyclerView的性能优化
在我们谈RecyclerView的性能优化之前,先让我们回顾一下RecyclerView的缓存机制。
RecyclerView缓存机制
众所周知,RecyclerView拥有四级缓存,它们分别是:
- Scrap缓存:包括mAttachedScrap和mChangedScrap,又称屏内缓存,不参与滑动时的回收复用,只是用作临时保存的变量。
- mAttachedScrap:只保存重新布局时从RecyclerView分离的item的无效、未移除、未更新的holder。
- mChangedScrap:只会负责保存重新布局时发生变化的item的无效、未移除的holder。
- CacheView缓存:mCachedViews又称离屏缓存,用于保存最新被移除(remove)的ViewHolder,已经和RecyclerView分离的视图,这一级的缓存是有容量限制的,默认最大数量为2。
- ViewCacheExtension:mViewCacheExtension又称拓展缓存,为开发者预留的缓存池,开发者可以自己拓展回收池,一般不会用到。
- RecycledViewPool:终极的回收缓存池,真正存放着被标识废弃(其他池都不愿意回收)的ViewHolder的缓存池。这里的ViewHolder是已经被抹除数据的,没有任何绑定的痕迹,需要重新绑定数据。
RecyclerView的回收原理
(1)如果是RecyclerView不滚动情况下缓存(比如删除item)、重新布局时。
- 把屏幕上的ViewHolder与屏幕分离下来,存放到Scrap中,即发生改变的ViewHolder缓存到mChangedScrap中,不发生改变的ViewHolder存放到mAttachedScrap中。
- 剩下ViewHolder会按照
mCachedViews>RecycledViewPool的优先级缓存到mCachedViews或者RecycledViewPool中。
(2)如果是RecyclerView滚动情况下缓存(比如滑动列表),在滑动时填充布局。
- 先移除滑出屏幕的item,第一级缓存mCachedViews优先缓存这些ViewHolder。
- 由于mCachedViews最大容量为2,当mCachedViews满了以后,会利用先进先出原则,把旧的ViewHolder存放到RecycledViewPool中后移除掉,腾出空间,再将新的ViewHolder添加到mCachedViews中。
- 最后剩下的ViewHolder都会缓存到终极回收池RecycledViewPool中,它是根据itemType来缓存不同类型的ArrayList,最大容量为5。
RecyclerView的复用原理
当RecyclerView要拿一个复用的ViewHolder时:
- 如果是预加载,则会先去mChangedScrap中精准查找(分别根据position和id)对应的ViewHolder。
- 如果没有就再去mAttachedScrap和mCachedViews中精确查找(先position后id)是不是原来的ViewHolder。
- 如果还没有,则最终去mRecyclerPool找,如果itemType类型匹配对应的ViewHolder,那么返回实例,让它
重新绑定数据。 - 如果mRecyclerPool也没有返回ViewHolder才会调用
createViewHolder()重新去创建一个。
这里有几点需要注意:
- 在mChangedScrap、mAttachedScrap、mCachedViews中拿到的ViewHolder都是精准匹配。
- mAttachedScrap和mCachedViews没有发生变化,是直接使用的。
- mChangedScrap由于发生了变化,mRecyclerPool由于数据已被抹去,所以都需要调用
onBindViewHolder()重新绑定数据才能使用。
缓存机制总结
- RecyclerView最多可以缓存 N(屏幕最多可显示的item数【Scrap缓存】) + 2 (屏幕外的缓存【CacheView缓存】) + 5*M (M代表M个ViewType,缓存池的缓存【RecycledViewPool】)。
- RecyclerView实际只有两层缓存可供使用和优化。因为Scrap缓存池不参与滚动的回收复用,所以CacheView缓存池被称为一级缓存,又因为ViewCacheExtension缓存池是给开发者定义的缓存池,一般不用到,所以RecycledViewPool缓存池被称为二级缓存。
如果想深入了解RecyclerView缓存机制的同学,可以参考《RecyclerView的回收复用缓存机制详解》 这篇文章。
性能优化方案
根据上面我们对缓存机制的了解,我们可以简单得到以下几个大方向:
- 1.提高ViewHolder的复用,减少ViewHolder的创建和数据绑定工作。【最重要】
- 2.优化
onBindViewHolder方法,减少ViewHolder绑定的时间。由于ViewHolder可能会进行多次绑定,所以在onBindViewHolder()尽量只做简单的工作。 - 3.优化
onCreateViewHolder方法,减少ViewHolder创建的时间。
提高ViewHolder的复用
1.多使用Scrap进行局部更新。
- (1) 使用
notifyItemChange、notifyItemInserted、notifyItemMoved和notifyItemRemoved等方法替代notifyDataSetChanged方法。 - (2) 使用
notifyItemChanged(int position, @Nullable Object payload)方法,传入需要刷新的内容进行局部增量刷新。这个方法一般很少有人知道,具体做法如下:
- 首先在notify的时候,在payload中传入需要刷新的数据,一般使用Bundle作为数据的载体。
- 然后重写
RecyclerView.Adapter的onBindViewHolder(@NonNull RecyclerViewHolder holder, int position, @NonNull List<Object> payloads)方法
@Override
public void onBindViewHolder(@NonNull RecyclerViewHolder holder, int position, @NonNull List<Object> payloads) {
if (CollectionUtils.isEmpty(payloads)) {
Logger.e("正在进行全量刷新:" + position);
onBindViewHolder(holder, position);
return;
}
// payloads为非空的情况,进行局部刷新
//取出我们在getChangePayload()方法返回的bundle
Bundle payload = WidgetUtils.getChangePayload(payloads);
if (payload == null) {
return;
}
Logger.e("正在进行增量刷新:" + position);
for (String key : payload.keySet()) {
if (KEY_SELECT_STATUS.equals(key)) {
holder.checked(R.id.scb_select, payload.getBoolean(key));
}
}
}
详细使用方法可参考XUI中的RecyclerView局部增量刷新 中的代码。
- (3) 使用
DiffUtil、SortedList进行局部增量刷新,提高刷新效率。和上面讲的传入payload原理一样,这两个是Android默认提供给我们使用的两个封装类。这里我以DiffUtil举例说明该如何使用。
- 首先需要实现
DiffUtil.Callback的5个抽象方法,具体可参考DiffUtilCallback.java - 然后调用
DiffUtil.calculateDiff方法返回比较的结果DiffUtil.DiffResult。 - 最后调用
DiffUtil.DiffResult的dispatchUpdatesTo方法,传入RecyclerView.Adapter进行数据刷新。
- 首先需要实现
详细使用方法可参考XUI中的DiffUtil局部刷新 和 XUI中的SortedList自动数据排序刷新 中的代码。
2.合理设置RecyclerViewPool的大小。如果一屏的item较多,那么RecyclerViewPool的大小就不能再使用默认的5,可适度增大Pool池的大小。如果存在RecyclerView中嵌套RecyclerView的情况,可以考虑复用RecyclerViewPool缓存池,减少开销。
3.为RecyclerView设置setHasStableIds为true,并同时重写RecyclerView.Adapter的getItemId方法来给每个Item一个唯一的ID,提高缓存的复用率。
4.视情况使用setItemViewCacheSize(size)来加大CacheView缓存数目,用空间换取时间提高流畅度。对于可能来回滑动的RecyclerView,把CacheViews的缓存数量设置大一些,可以省去ViewHolder绑定的时间,加快布局显示。
5.当两个数据源大部分相似时,使用swapAdapter代替setAdapter。这是因为setAdapter会直接清空RecyclerView上的所有缓存,但是swapAdapter会将RecyclerView上的ViewHolder保存到pool中,这样当数据源相似时,就可以提高缓存的复用率。
优化onBindViewHolder方法
1.在onBindViewHolder方法中,去除冗余的setOnItemClick等事件。因为直接在onBindViewHolder方法中创建匿名内部类的方式来实现setOnItemClick,会导致在RecyclerView快速滑动时创建很多对象。应当把事件的绑定在ViewHolder创建的时候和对应的rootView进行绑定。
2.数据处理与视图绑定分离,去除onBindViewHolder方法里面的耗时操作,只做纯粹的数据绑定操作。当程序走到onBindViewHolder方法时,数据应当是准备完备的,禁止在onBindViewHolder方法里面进行数据获取的操作。
3.有大量图片时,滚动时停止加载图片,停止后再去加载图片。
4.对于固定尺寸的item,可以使用setHasFixedSize避免requestLayout。
优化onCreateViewHolder方法
1.降低item的布局层级,可以减少界面创建的渲染时间。
2.Prefetch预取。如果你使用的是嵌套的RecyclerView,或者你自己写LayoutManager,则需要自己实现Prefetch,重写collectAdjacentPrefetchPositions方法。
其他
以上都是针对RecyclerView的缓存机制展开的优化方案,其实还有几种方案可供参考。
1.取消不需要的item动画。具体的做法是:
((SimpleItemAnimator) recyclerView.getItemAnimator()).setSupportsChangeAnimations(false);2.使用getExtraLayoutSpace为LayoutManager设置更多的预留空间。当RecyclerView的元素比较高,一屏只能显示一个元素的时候,第一次滑动到第二个元素会卡顿,这个时候就需要预留的额外空间,让RecyclerView预加载可重用的缓存。
最后
以上就是RecyclerView性能优化的全部内容,俗话说:百闻不如一见,百见不如一干,大家还是赶紧动手尝试着开始进行优化吧!
链接:https://juejin.cn/post/7164032795310817294
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
计算耗时? Isolate 来帮忙
一、问题引入 - 计算密集型任务
假如现在有个需求,我想要计算 1 亿 个 1~10000 间随机数的平均值,在界面上显示结果,该怎么办?
可能有小伙伴踊跃发言:这还不简单,生成 1 亿 个随机数,算呗。
1. 搭建测试场景
如下,写个简单的测试界面,界面中有计算结果和耗时的信息。点击运行按钮,触发 _doTask 方法进行运算。计算完后将结果展示出来:
代码详见: 【async/isolate/01】
void _doTask() {
int sum = 0;
int startTime = DateTime.now().millisecondsSinceEpoch;
for(int i = 0;i
可以看到,这样是可以实现需求的,总耗时在 8.5 秒左右。细心的朋友可能会发现,在点击按键触发 _doTask 时,FloatingActionButton 的水波纹并没有出现,仿佛是卡死一般。为了应证这点,我们再进行一个对比实验。
请点击前 请点击后 

2. 计算耗时阻塞
如下所示,我们让 CupertinoActivityIndicator 一直处于运动状态,作为界面 未被卡死 的标志。当点击运行时,可以看出指示器被卡住了, 再点击按钮也没有任何的水波纹反映,这说明:
计算的耗时任务会阻塞 Dart 的线程,界面因此无法有任何响应。
未执行前 执行前后 

Row(
mainAxisAlignment: MainAxisAlignment.center,
children: const [Text("动画指示器示意: "), CupertinoActivityIndicator()],
),
3. 计算耗时阻塞的解决方案
有人说,用异步的方式触发 _doTask 呗,比如用 Future 和 scheduleMicrotask 包一下,或 Stream 异步处理。有这个想法的人可以试一试,如果你看懂前面几篇看到了原理,就知道是不可行的,这些工具只不过是回调包装而已。只要计算的任务仍是 Dart 在单线程中处理的,就无法避免阻塞。现在的问题相当于:
一个人无法同时做 洗漱 和 扫地 的任务。
一旦阻塞,界面就无法有任何响应,自然也无法展示加载中的动画,这对于用户体验来说是极其糟糕的。那如何让计算密集型的耗时任务,在处理时不阻塞呢? 我们可以好好品味一下这句话:

这句话言外之意给出了两种解决方案:
【1】. 将计算密集型的耗时任务,从 Dart 端剥离,交由 其他机体 来处理。
【2】. 在 Dart 中通过 多线程 的方式处理,从而不阻塞主线程。
方式一其实很好理解,比如耗时的任务交由服务端来完成,客户端通过 接口请求 ,获取响应结果。这样计算型的密集任务,对于 Flutter 而言,就转换成了一个网络的 IO 任务。或者通过 插件 的方式,将计算的耗时任务交由平台来通过多线程处理,而 Dart 端只需要通过回调处理即可,也不会阻塞。
方式一处理的本质上都是将计算密集型的任务转移到其他机体中,从而让 Dart 避免处理计算密集型的耗时任务。这种方式需要其他语言或后端的支持,想要实现是有一定门槛的。那如何直接在 Flutter 中,通过 Dart 语言处理计算密集型的任务呢?
这就是我们今天的主角: Isolate 。 可能很多人潜意识里 Dart 是单线程模型,无法通过多线程的处理任务,这种认知就狭隘了。其实 Dart 提供了 Isolate, 本质上是通过 C++ 创建线程,隔离出另一份区间来通过 Dart 处理任务。它相当于线程的一种上层封装,屏蔽了很多内部细节,可以通过 Dart 语言直接操作。
二、从 compute 函数认识 Isolate
首先,我们通过 compute 函数认识一下计算密集型的耗时任务该如何处理。 compute 函数字如其名,用于处理计算。只要简单看一下,就知道它本身是 Isolate 的一个简单的封装使用方式。它作为全局函数被定义在 foundation/isolates.dart 中:

1. 认识 compute 函数
既然是函数,那使用时就非常简单,调用就行了。关于函数的调用,比较重要的是 入参 、返回值 和 泛型。从上面函数定义中可以看出,它就是 isolate 包中的 compute 函数, 其中泛型有两个 Q 和 R ,返回值是 R 泛型的 Future 对象,很明显该泛型表示结果 Result;第二入参是 Q 泛型的 message ,表示消息类型;第三入参是可选参数,用于调试时的标签。
---->[_isolates_io.dart#compute]----
/// The dart:io implementation of [isolate.compute].
Future compute(
isolates.ComputeCallback callback,
Q message,
{ String? debugLabel })
async {
看到这里,很自然地就可以想到,这里第一参中传入的 callback 就是计算任务,它将被在其他的 isolate 中被执行,然后返回计算结果。下面我们来看一下在当前场景下的使用方式。在此之前,先封装一下返回的结果。通过 TaskResult 记录结果,作为 compute 的返回值:
代码详见: 【async/isolate/02_compute】
class TaskResult {
final int cost;
final double result;
TaskResult({required this.cost, required this.result});
}
2. compute 函数的使用
在 compute 方法在传入两个参数,其一是 _doTaskInCompute ,也就是计算的耗时任务,其二是传递的信息,这里不需要,传空值字符串。虽然方法的泛型可以不传,但严谨一些的话,可也以把泛型加上,这样可读性更好一些:
void _doTask() async {
TaskResult taskResult = await compute(
_doTaskInCompute, '',
debugLabel: "task1");
setState(() {
result = taskResult.result;
cost = taskResult.cost;
});
}
对于 compute 而言,传入的回调有一个非常重要的注意点:
函数必须是 静态函数 或者 全局函数
static Random random = Random();
static Future _doTaskInCompute(String arg) async {
int count = 100000000;
double result = 0;
int cost = 0;
int sum = 0;
int startTime = DateTime.now().millisecondsSinceEpoch;
for (int i = 0; i < count; i++) {
sum += random.nextInt(10000);
}
int endTime = DateTime.now().millisecondsSinceEpoch;
result = sum / count;
cost = endTime - startTime;
return TaskResult(
result: result,
cost: cost,
);
}
下面看一下用和不用 compute 处理的效果差异,如下左图是使用 compute 的效果,在进行计算的同时指示器的动画仍在运动,桌面计算操作并未影响主线程,界面仍可以触发响应,这就和前面产生了鲜明的对比。
用 compute 不用 compute 
3. 理解 compute 的作用
如下,在 _doTaskInCompute 中打断点调试一下,可以看出此时除了 main 还有一个 task1 的栈帧。此时断点停留在新帧中, main 仍处于运行状态:

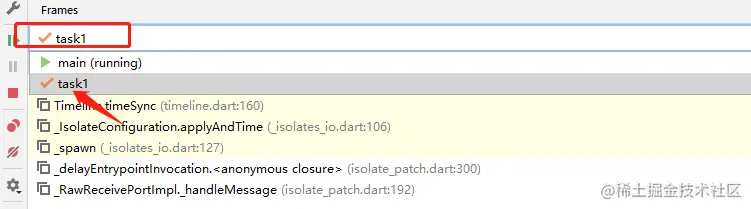
这就相当于计算任务不想自己处理,找另外一个人来做。每块处理任务的单元,就可以视为一个 isolate。它们之间的信息数据在内存中是不互通的,这也是为什么起名为 隔离 isolate 的原因。 这种特性能非常有效地避免多线程中操作同一内存数据的风险。 但同时也需要引入一个 通信机制 来处理两个 isolate 间的通信。
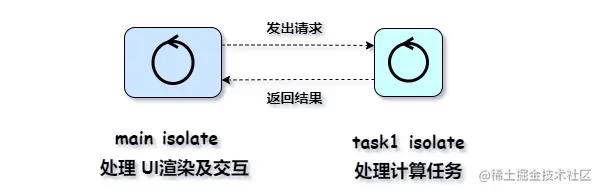
其实这和 客户端 - 服务端 的模型非常相似,通过 发送端 SendPort 发送消息,通过接收端 RawReceivePort 接收消息。从 compute 方法的源码中可以简单地看出,其本质是通过 Isolate.spawn 实现的 Isolate 创建。
这里有个小细节要注意,通过多次测试发现 compute 中的计算耗时要普遍高于主线程中的耗时。这并不是说新建的 isolate 在计算能力上远小于 主 isolate, 毕竟这里是 1 亿 次的计算,任何微小的细节都将被放大 1 亿 倍。这里的关注点应在于 新 isolate 可以独立于 主 isolate 运行,并且可以通过通信机制将结果返回给 主 isolate 。
4. compute 参数传递与多个 isolate
如果是大量的相互独立的计算耗时任务,可以开启多个 isolate 共同处理,最后进行结果汇总。比如这里 1 亿 次的计算,我们可以开 2 个 isolate , 分别处理 5000 万 个计算任务。如下所示,总耗时就是 6 秒左右。当然创建 isolate 也是有资源消耗的,并不是说创建 100 个就能把耗时降低 100 倍。
关于传参非常简单,compute 第一泛型是参数类型,这里可以指定 int类型作为 _doTaskInCompute 任务的入参,指定计算的次数。这里通过两个 compute 创建两个 isolate 同时处理 5000 万 个随机数的的平均值,来模拟那些相互独立的任务:
代码详见: 【async/isolate/03_compute】
最后通过 Future.await 对多个异步任务进行结果汇总,示意图如下,这样就相当于又开了一个 isolate 进行处理计算任务:
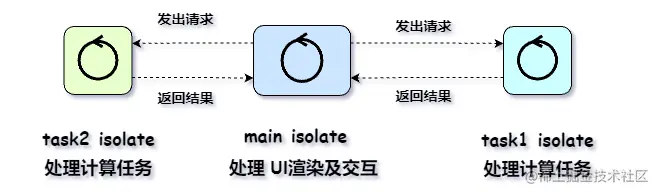
对于 isolate 千万不要盲目使用,一定要认清当前任务是否真有必要使用。比如几百微秒就能处理完成的任务,用 isolate 就是拿导弹打蚊子。或者那些并非由 Dart 端处理的 IO 密集型 任务,用 isolate 就相当于你打开了烧水按钮,又找来一个人专门看着烧水的过程。这种多此一举的行为,都是对于异步不理解的表现。
一般而言,客户端中并没有太多需要处理复杂计算的场景,只有一些特定场景的软件,比如需要进行大量的文字解析、复杂的图片处理等。
三、分析 compute 函数的源码实现
到这可能有人觉得,新开一个 isolate好简单啊,compute 函数处理一下就好啦。但是,简单必然有简单的 局限性,仔细思考一下,会发现 compute 函数有个缺陷:它只会 "闷头干活",只有任务完成才会通过 Future 通知 main isolate 。
也就是说,对于 UI 界面来说无法无法感知到 任务执行进度 信息,处理展示 计算中... 之外没什么能干的。这在某些特别耗时的场景中会造成用户的等待焦虑,我们需要让干活的 isolate 抽空通知一下 main isolate,所以对 isolate 之间的通信方式,是有必要了解的。
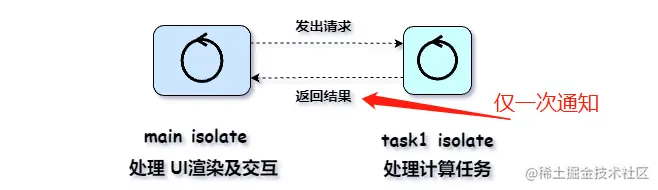
既然 compute 在完成任务时可以进行一次通信,那么就可以从 compute 函数的源码中去分析这种通信的方式。
1. 接收端口的创建与处理器设置
如下所示,在一开始会创建一个 Flow 对象,从该对象的成员中可以看出,它只负责维护两个整型 id 和 _type 的数值信息。接下来会创建 RawReceivePort 对象,是不是有点眼熟?
还记得那个经常在面前晃的 _RawRecivePortImpl类吗? RawReceivePort 的默认工厂构造方法创建的就是 _RawReceivePortImpl 对象,如下代码所示:
---->[isolate_patch.dart/RawReceivePort]----
@patch
class RawReceivePort {
@patch
factory RawReceivePort([Function? handler, String debugName = '']) {
_RawReceivePortImpl result = new _RawReceivePortImpl(debugName);
result.handler = handler;
return result;
}
}
接下来,会创建一个 Completer 对象,并在为 port 设置信息的 handler 处理器,在处理回调中触发 completer#complete 方法,表示异步任务完成。也就是说处理器接收信息之时,就是 completer 中异步任务完成之日。
如果不知道 Completer 和接收端口设置 handler 是干嘛的,可以分别到 【第五篇·第二节】 和 【第六篇·第一节】 温故,这里就不赘述了。
---->[_isolates_io.dart#compute]----
final Completer completer = Completer();
port.handler = (dynamic msg) {
timeEndAndCleanup();
completer.complete(msg);
};
2. 认识 Isolate.spawn 方法
接下来会触发 Isolate.spawn 方法,该方法是生成 isolate 的核心。其中传入的 回调 callback 和 消息 message 以及发送的端口 SendPort 会组合成 _IsolateConfiguration 作为第二参数:
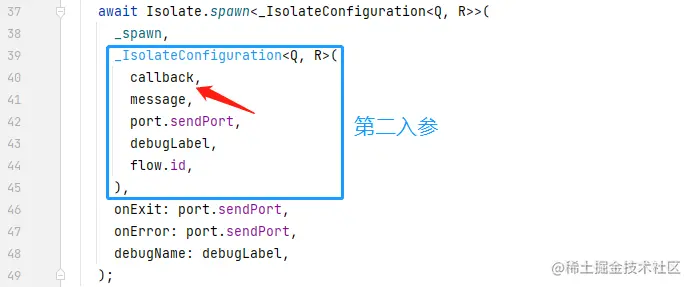
通过 Isolate.spawn 方法的定义可以看出,第一参是一个入口函数,第二参是函数入参。所以上面红框中的对象将作为 _spawn 函数的入参。从这里可以看出第一参 _spawn 函数应该是在新 isolate 中执行的。
external static Future spawn(
void entryPoint(T message), T message,
{bool paused = false,
bool errorsAreFatal = true,
SendPort? onExit,
SendPort? onError,
@Since("2.3") String? debugName});
下面是在耗时任务中打断点的效果,其中很清晰地展现出 _spawn 方法到 _doTaskInCompute 的过程。
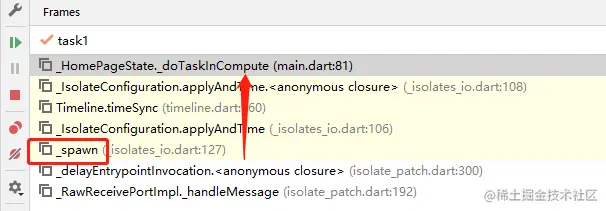
如下,是 _spawn 的处理流程,上面的调试发生在 127 行,此时触发回调方法,获取结果。然后在关闭 isolate 时,将结果发送出去,流程其实并不复杂。

有一个小细节,结果通过 _buildSuccessResponse 方法处理了一下,关闭时发送的消息是列表,后期会根据列表的长度判断任务处理的正确性。
List _buildSuccessResponse(R result) {
return List.filled(1, result);
}
3. 异步任务的结束
从前面测试中可以知道 compute 函数返回值是一个泛型为结果的 Future 对象,那这个返回值是什么呢?如下可以看出当结果列表长度为 1 表示任务成功完成,返回 completer 任务结果的首元素:
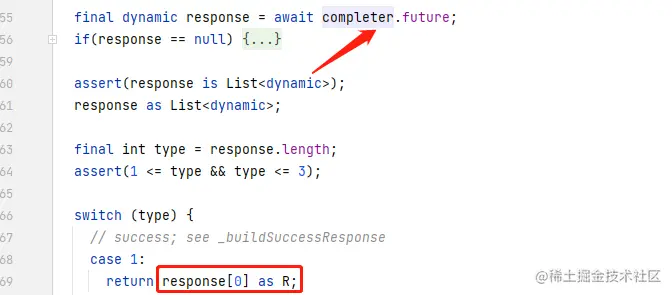
再结合 completer 触发 complete 完成的时机,就不难知道。最终的结果是由接收端接收到的信息,调试如下:
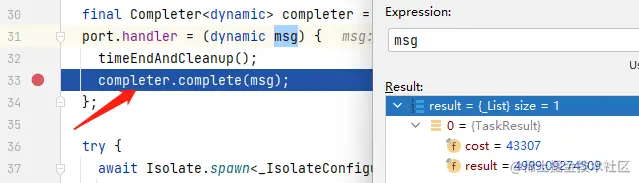
也就是说,isolate 关闭时发送的信息,将会被 接收端的处理器 监听到。这就是 compute 函数源码的全部处理逻辑,总的来看还是非常简单的。就是,使用 Completer ,基于 Isolate.spawn 的简单封装,屏蔽了用户对 RawReceivePort 的感知,从而简化使用。
四、Isolate 发送和接收消息的使用
通过 compute 函数我们知道 isoalte 之间有着一套消息 发送 - 监听 的机制。我们可以利用这个机制在某些时刻发送进度消息传给 main isolate,这样 UI 界面中就可以展示出 耗时任务 的进度。如下所示,每当 100 万次 计算时,发送消息通知 main isolate :
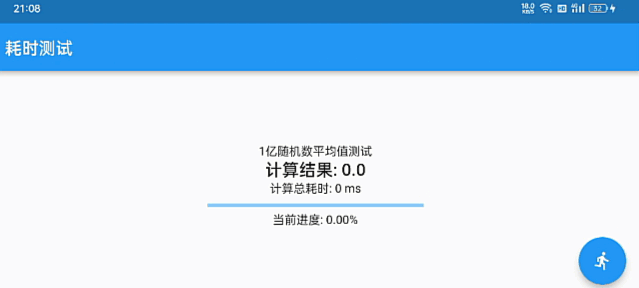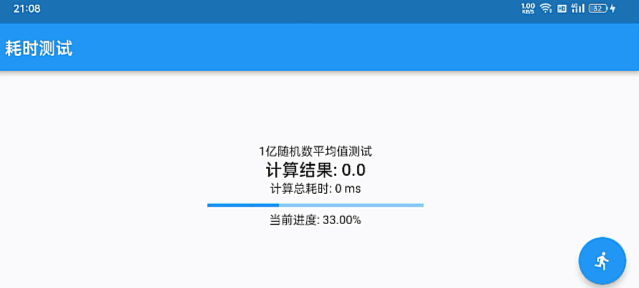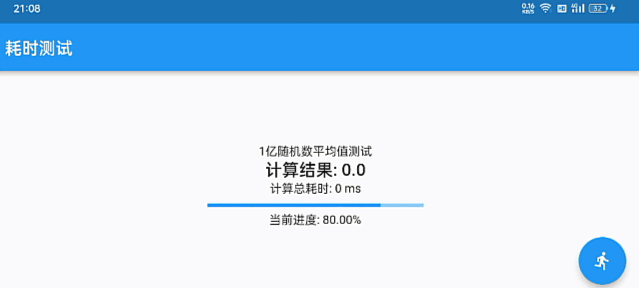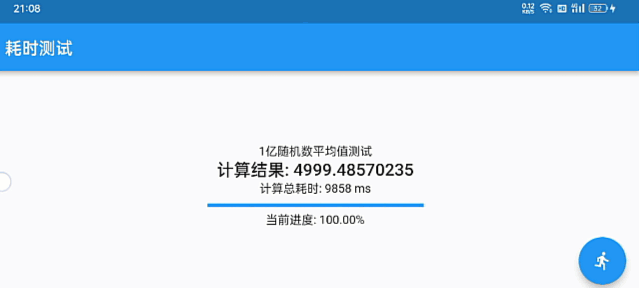
1. 使用 Isolate.spawn
compute 函数为了简化使用,将 发送 - 监听 的处理封装在了内部,用户无法操作。使用为了能使用该功能,我们可以主动来使用 Isolate.spawn 。如下所示,创建 RawReceivePort,并设置 handler 处理器器,这里通过 handleMessage 函数来单独处理。
代码详见: 【async/isolate/04_spawn】
然后调用 Isolate.spawn 来开启新 isolate,其中第一参是在新 isolate 中处理的耗时任务,第二参是任务的入参。这里将发送端口传入 _doTaskInCompute 方法,以便发送消息:
void _doTask() async {
final receivePort = RawReceivePort();
receivePort.handler = handleMessage;
await Isolate.spawn(
_doTaskInCompute,
receivePort.sendPort,
onError: receivePort.sendPort,
onExit: receivePort.sendPort,
);
}
2. 通过端口发送消息
SendPort 传入 _doTaskInCompute 中,如下 tag1 处,可以每隔 1000000 次发送一次进度通知。在任务完成后,使用 Isolate.exit 方法关闭当前 isolate 并发送结果数据。
static void _doTaskInCompute(SendPort port) async {
int count = 100000000;
double result = 0;
int cost = 0;
int sum = 0;
int startTime = DateTime.now().millisecondsSinceEpoch;
for (int i = 0; i < count; i++) {
sum += random.nextInt(10000);
if (i % 1000000 == 0) { // tag1
port.send(i / count);
}
}
int endTime = DateTime.now().millisecondsSinceEpoch;
result = sum / count;
cost = endTime - startTime;
Isolate.exit(port, TaskResult(result: result, cost: cost));
}
3. 通过接收端处理消息
接下来只要在 handleMessage 方法中处理发送端传递的消息即可,可以根据消息的类型判断是什么消息,比如这里如果是 double 表示是进度,通知 UI 更新进度值。另外,如果不同类型的消息非常多,也可以自己定义一套发送结果的规范方便处理。
void handleMessage(dynamic msg) {
print("=========$msg===============");
if (msg is TaskResult) {
progress = 1;
setState(() {
result = msg.result;
cost = msg.cost;
});
}
if (msg is double) {
setState(() {
progress = msg;
});
}
}
其实学会了如何通过 Isolate.spawn 处理计算耗时任务,以及通过 SendPort-RawReceivePort 处理 发送 - 监听 消息,就能满足绝大多数对 Isolate 的使用场景。如果不需要在任务执行过程中发送通知,使用 compute 函数会方便一些。最后还是要强调一点,不要滥用 Isolate ,使用前动动脑子,思考一下是否真的是计算耗时任务,是否真的需要在 Dart 端来完成。开一个 isolate 至少要消耗 30 kb:

作者:张风捷特烈
链接:https://juejin.cn/post/7163431846783483912
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。为什么会发生 Fragment not attached to Activity 异常?
事情是这样的,前两天有位大佬在群里提了个问题,原文如下
一个 Fragment 在点击按钮跳转一个新的 Activity 的时候,报崩溃异常:Fragment not attached to Activity
问:复现路径可能是什么样的呢?
一、回答问题前先审题
我们把这个问题的几个关键词圈出来
首先,可以点击 Fragment 上的按钮,证明这个 Fragment 是可以被看到的,那肯定是处于存活的状态的
其次,在跳转到新的 Activity 的时候发生崩溃,证明 Fragment 调用的是 startActivity() 方法
最后,来看异常信息:”Fragment not attached to Activity“
这个报错我们都已经很熟悉了,在 onAttach() 之前,或者 onDetach() 之后,调用任何和 Context 相关的方法,都会抛出 " not attached to Activity " 异常
发生的原因往往是因为异步任务导致的,比如一个网络请求回来以后,再调用了 startActivity() 进行页面跳转,或者调用 getResources() 获取资源文件等等
解决方案也非常简单:在 Fragment 调用了 Context 相关方法前,先通过 isAdded() 方法检查 Fragment 的存活状态就完事了
到这里,崩溃产生的原因找到了,解决方案也有了,似乎整篇文章就可以结束了
但是,楼主问的是:复现路径可能是什么样的呢?
这勾起了我的好奇心,我也想知道可能的路径是怎样的
于是,在接下来的两个晚上,笔者开始了一场源码之旅..
二、大胆假设,小心求证
审题结束我们就可以开始动手解答了,以下是群里的完整对话
大佬:一个 Fragment 在点击按钮跳转一个新的 Activity 的时候,报崩溃异常:Fragment not attached to Activity 。复现路径可能是什么样的呢?
我:这个问题之前在项目中也有碰到过,当时的解决方案是,通过调用 isAdded() 来检查 Fragment 是否还活着,来避免因为上下文为空导致的崩溃
当时忙于做业务没有深入研究,现在趁着晚上有时间来研究一下下
首先,打开 Fragment 源码,路径在:frameworks/base/core/java/android/app/Fragment.java
用 “not attached to Activity” 作为关键字搜索,可以发现 getResources() 、getLoaderManager() 、startActivity() 等等共计 6 处地方,都可能抛出这个异常
题目明确提到,是跳转 Activity 时发生的错误,那我们直接来看 startActivity() 方法
class Fragment {
void startActivity(){
if (mHost == null)
throw new IllegalStateException("Fragment " + this + " not attached to Activity");
}
}从上面代码可以看出,当 mHost 对象为空时,程序抛出 Fragment not attached to Activity 异常
好,现在我们的问题转变为:
mHost对象什么时候会被赋值?
很显然,如果在赋值前调用了 startActivity() 方法,那程序必然会崩溃
mHost对象赋值以后,可能会被置空吗?如果会,什么时候发生?
我们都知道,Fragment 依赖 Activity 才能生存,那我们有理由怀疑:
当 Activity 执行 stop / destroy ,或者,配置发生变化(比如屏幕旋转)导致 Activity 重建,会不会将 mHost 对象也置空呢?
mHost 对象什么时候会被赋值?
先来看第一个问题,mHost 对象什么时候会被赋值?
平时我们使用 Fragment 开发时,通常都是直接 new 一个对象出来,然后再提交给 FragmentManager 去显示
创建 Fragment 对象的时候,不要求传入 mHost 参数,那 mHost 对象只能是 Android 系统帮我们赋值的了
得,又得去翻源码
打开 FragmentManager.java ,路径在:/frameworks/base/core/java/android/app/FragmentManager.java
class FragmentManager {
FragmentHostCallback mHost; // 内部持有 Context 对象,其本质是宿主 Activity
void moveToState(f,newState){
switch(f.mState){
case Fragment.INITIALIZING:
f.mHost = mHost; // 赋值 Fragment 的 mHost 对象
f.onAttach(mHost.getContext());
}
f.mState = newState;
}
}我们发现源码里只有一个地方会给 mHost 对象赋值,在 FragmetnManager#moveToState() 方法中
如果当前 Fragment 的状态是 INITIALIZING ,那么就把 FragmentManager 自身的 mHost 对象,赋值给 Fragment 的 mHost 对象
这里多说一句,在 Android 系统中,一个 Activity 只会对应一个 FragmentManager 管理者。而 FragmentManager 中的 mHost ,其本质上就是 Activity 宿主。
所以,这里把 FragmentManager 的 mHost 对象,赋值给了 Fragment ,就相当于 Fragment 也持有了宿主 Activity
这也解释了我们之所以能在 Fragment 中调用 getResource() 、startActivity() 等需要 context 的才能访问方法,实际使用的就是 Activity 的上下文
废话说完了,我们来聊正事
FragmentManager#moveToState() 方法会先去判断 Fragment 的状态,那我们首先得知道 Fragment 有哪几种状态
class Fragment {
int INITIALIZING = 0; // Not yet created.
int CREATED = 1; // Created.
int ACTIVITY_CREATED = 2; // The activity has finished its creation.
... // 共6种标识
int mState = INITIALIZING; // 默认为 INITIALIZING
}Google 为 Fragment 共声明了6个状态标识符,各个标识符的含义看注释即可
这里重点关注标识符下面的 mState 变量,它表示的是 Fragment 当前的状态,默认为 INITIALIZING
了解完 Fragment 的状态标识,我们回过头继续来看 FragmentManager#moveToState() 方法
class FragmentManager {
void moveToState(f,newState){
switch(f.mState){
case Fragment.INITIALIZING: // 必走逻辑
f.mHost = mHost; // 赋值 Fragment 的 mHost 对象
f.onAttach(mHost.getContext());
}
f.mState = newState;
}
}
在 moveToState() 方法中,只要当前 Fragment 状态为 INITIALIZING ,即执行 mHost 的赋值操作
巧了不是,前面刚说完,mState 默认值就是 INITIALIZING
也就是说,在第一次调用 moveToState() 方法时,不管接下来 Fragment 要转变成什么状态(根据 newState 的值来判断)
首先,它都得从 INITIALIZING 状态变过去!那么,case = Fragment.INITIALIZING 这个分支必然会被执行!!这时候,mHost 也必然会被赋值!!!
再然后,才会有 onAttach() / onCreate() / onStart() 等等这些生命周期的回调!
因此,我们的第一个猜想:在 mHost 对象赋值前,有没有可能调用 startActivity() 方法?
答案显然是否定的
因为,根据楼主描述,点击按钮以后才发生的崩溃,视图能显示出来,说明 mHost 已经赋值过并且生命周期都正常走
那就只可能是点击按钮后,发生了什么事情,将 mHost 又置为 null 了
mHost 对象什么时候会被置空?
继续,来看第二个问题:mHost 对象赋值以后,可能会被置空吗?如果会,什么时候发生?
我们就不绕弯了,直接说答案,会!
置空 mHost 的逻辑,同样藏在 FragmentManager 的源码里:
class FragmentManager {
void moveToState(f,newState){
if (f.mState < newState) {
switch(f.mState){
case Fragment.INITIALIZING:
f.mHost = mHost; // mHost 对象赋值
}
} else if (f.mState > newState) {
switch (f.mState) {
case Fragment.CREATED:
if (newState < Fragment.CREATED) {
f.performDetach(); // 调用 Fragment 的 onDetach()
if (!f.mRetaining) {
makeInactive(f); // 重点1号,这里会清空 mHost
} else {
f.mHost = null; // 重点2号,这里也会清空 mHost 对象
}
}
}
}
f.mState = newState;
}
void makeInactive(f) {
f.initState(); // 此调用会清空 Fragment 全部状态,包括 mHost
}
}看上面的代码,分发 Fragment 的 performDetach() 方法后,紧接着就会把 mHost 对象置空!
标记为 "重点1号" 和 "重点2号" 的代码都会执行了置空 mHost 对象的逻辑,两者的区别是:
Fragment 有一个保留实例的接口 setRetainInstance(bool) ,如果设置为 true ,那么在销毁重建 Activity 时,不会销毁该 Fragment 的实例对象
当然这不是本节的重点,我们只需要知道:执行完 performDetach() 方法后,无论如何,mHost 也都活不了了
那,什么动作会触发 performDetach() 方法?
1、Activity 销毁重建
不管因为什么原因,只要 Activity 被销毁,Fragment 也不能独善其身,所有的 Fragment 都会被一起销毁,对应的生命周期如下:
Activity#onDestroy()->Fragment#onDestroyView() - >Fragment#onDestroy()- >Fragment#onDetach()
2、调用 FragmentTransaction#remove() 方法移除 Fragment
remove() 方法会移除当前的 Fragment 实例,如果这个 Fragment 正在屏幕上显示,那么 Android 会先移除视图,对应的生命周期如下:
Fragment#onPause()->onStop()->onDestroyView()- >onDestroy()- >onDetach()
3、调用 FragmentTransaction#replace() 方法显示新的 Fragment
replace() 方法会将所有的 Fragment 实例对象都移除掉,只会保留当前提交的 Fragment 对象,生命周期参考 remove() 方法
以上三种场景,是我自己做测试得出来的结果,应该还有其他没测出来的场景,欢迎大佬补充
另外,FragmentTransaction 中还有两个常用的 detach() / hide() 方法,它俩只会将视图移除或隐藏,而不会触发 performDetach() 方法
真相永远只有一个
好了,现在我们知道了 mHost 对象置空的时机,答案已经越来越近了
我们先来汇总下已有的线索
从 FragmentManager 源码来看,只要我们的 startActivity() 页面跳转逻辑写在:
onAttach() 方法执行之后 ,onDetach() 方法执行之前
那结果一定总是能够跳转成功,不会报错!
那么问题就来了
onAttach() 之前,视图不存在,onDetach() 之后,视图都已经销毁了,还点击哪门子按钮?
这句话翻译一下就是:
视图在,Activity 在,点击事件正常响应
视图不在,按钮也不在了呀,也就不存在页面跳转了
这样看起来,似乎永远不会出现楼主说的错误嘛
除非。。。
执行 startActivity() 方法的时候,视图已经不在了!!!
这听起来很熟悉,ummmmmm。。这不就是异步调用吗?
class Fragment {
void onClick(){
//do something
Handler().postDelayed(startActivity(),1000);
}
}上面是一段异步调用的演示代码,为了省事我直接用 Handler 提交了延迟消息
当用户点击跳转按钮后,一旦发生 Activity 销毁重建,或者 Fragment 被移除的情况
等待 1s 执行 startActivity() 方法时,程序就会发生崩溃,这时候终于可以看到我们期待已久的异常:Fragment not attached to Activity
为什么会这样?熟悉 Java 的小伙伴这里肯定要说了,因为提交到 Handler 的 Runnable 会持有外部类呀,也就是宿主 Fragment 的引用。如果在执行 Runnable#run() 方法之前, Fragment 的 mHost 被清空,那程序肯定会发生崩溃的
那我们怎么样才能防止程序崩溃呢?
要么,同步执行 Context 相关方法
要么,异步判空,用到 Context 前调用
isAdded()方法检查 Fragment 存活状态
三、结语
呼~ 这下总算是理清了,我们来尝试回答楼主的问题:发生 not attached to Activity,可能路径是怎样的?
首先,必然存在一个异步任务持有 Fragment 引用,并且内部调用了 startActivity() 方法。
在这个异步任务提交之后,执行之前,一旦发生了下面列表中,一个或多个的情况时,程序就会抛出 not attached to Activity 异常:
- 调用
finishXXX()结束了 Activity,导致 Activity 为空 - 手动调用
Activity#recreate()方法,导致 Activity 重建 - 旋转屏幕、键盘可用性改变、更改语言等配置更改,导致 Activity 重建
- 向 FragmentManager 提交
remove()/replace()请求,导致 Fragment 实例被销毁 - ...
最后,发生这个错误信息的本质,是在 Activity 、Fragment 销毁时,没有同步取消异步任务,这是内存泄漏啊
所以,除了使用 isAdded() 方法判空,避免程序崩溃外,更应该排查哪里可能会长时间引用该 Fragment
如果可能,在 Fragment 的 onDestroy() 方法中,取消异步任务,或者,把 Fragment 改为弱引用
链接:https://juejin.cn/post/7162035153991106597
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
假ArrayList导致的线上事故......
线上事故回顾
晚饭时,当我正沉迷于排骨煲肉质鲜嫩,汤汁浓郁时,产研沟通群内发出一条消息,显示用户存在可用劵,但进去劵列表却什么也没有,并附含了一个视频。于是我一边吃了排骨,一边查看消息点开了视频,en~,视频跟描述一样。但没有系统告警,用户界面也没有明显的报错提示,怀疑是小部分特殊情况导致的,查看消息后几秒,我直接被@来处理问题,擦,只好把外卖盒重新盖好,先去处理问题。
处理经过
通过群内产品发的用户邮箱查到了用户id,再根据接口的相关日志结合uid在日志平台进行关联查询,查到日志后,再拿到traceId进行链路查询,果不其然,发现了异常日志,如下部分日志所示
java.lang.UnsupportedOperationException: null
at java.util.AbstractList.add(AbstractList.java:148) ~[na:1.8.0_151]
at java.util.AbstractList.add(AbstractList.java:108) ~[na:1.8.0_151]
乍一看,这不是空指针嘛,so easy啊
仔细一瞧,这UnsupportedOperationException是个什么玩意
于是,根据日志找到代码中报错的那一行,下面给大家简单模拟下
@Slf4j
@SpringBootTest
public class Demo {
public void test(Context context) {
context.getList().add("Code皮皮虾");
}
}
@Data
class Context {
private List<String> list;
}基本操作就是拿到上下文中的List,然后再add一个元素
讲道理,add操作是不会有问题的,有问题的还得是List,追根溯源,让我康康这个List是怎么来的
于是我一顿狂点,来到了set这个list的位置
@Slf4j
@SpringBootTest
public class Demo {
public void test(Context context) {
context.setList(Arrays.asList("Code皮皮虾"));
}
}
@Data
class Context {
private List<String> list;
}context.setList(Arrays.asList("Code皮皮虾")); 这行看起来好像没问题啊
Arrays.asList(T... a)我们平时也会用,传入一个数组,返回出一个List没啥问题呀
那我再试试add方法
擦,问题复现了,还真是Arrays.asList(T... a)生成的List的add方法报错
由于线上存在问题,则先修改为以下代码上线,也就是修改为我们平时正常的写法
上线后,观察了下日志,群里回复已解决问题,也让用户重试,发现没问题,自此问题解决。
接下来,咱们来看看为啥Arrays.asList(T... a)的add方法会报错
追根溯源
进入asList方法,发现底层new了一个ArrayList,并将数组传入作为List的元素
@SafeVarargs
@SuppressWarnings("varargs")
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}emm,看起来很简单啊,没问题啊,咋会报错呢
别着急,咱们在点开这个ArrayList瞅瞅
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{
private static final long serialVersionUID = -2764017481108945198L;
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
// ... 省略
}擦,这ArrayList是Arrays类的一个静态内部类,不是我们经常用的java.util.ArrayList
真是离谱他妈给离谱开门,离谱大家了,还是我源码看得太少了,呜呜呜~
继续看,这个静态内部类ArrayList继承了AbstractList,而且默认是没有实现add方法的
也就是说调用add方法会直接调用父类,也就是AbstractList的add方法,源码点开一看,真相大白了
AbstractList的add方法直接抛出UnsupportedOperationException异常,跟线上报错一模一样!!!
public boolean add(E e) {
add(size(), e);
return true;
}
public void add(int index, E element) {
throw new UnsupportedOperationException();
}至此,排查结束,继续吃饭去排骨去咯~~~
小彩蛋
在使用Arrays.asList(T... a)方法时,如果只是单个元素的话,Idea会提示我们更建议Collections.singletonList
别用!!!真的别用!!!
因为Collections.singletonList底层跟Arrays.asList(T... a)差不多
SingletonList也是继承了AbstractList的一个内部类,调用add一样会报UnsupportedOperationException异常
public static <T> List<T> singletonList(T o) {
return new SingletonList<>(o);
}
private static class SingletonList<E>
extends AbstractList<E>
implements RandomAccess, Serializable {
private static final long serialVersionUID = 3093736618740652951L;
private final E element;
SingletonList(E obj) {
element = obj;
}
}结尾
当然咯,也不是禁止使用Collections.singletonList和Arrays.asList(T... a),只是我们在使用的时候一定要区分一下场景,如果创建的是一个不会再添加元素的List,那么则可以使用
但我们平时不想写那么麻烦,想要在创建的时候就把元素塞到List中,那咋办呢?
我们其实能使用google的工具类
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>如下写法
@Slf4j
@SpringBootTest
public class Demo {
public static void main(String[] args) {
List<String> strings = Lists.newArrayList("Code皮皮虾", "哈哈哈");
strings.add("憨憨熊");
System.out.println(strings);
}
}其内部已经为我们封装好了,拿来即用即可,哈哈
@SafeVarargs
@CanIgnoreReturnValue // TODO(kak): Remove this
@GwtCompatible(serializable = true)
public static <E> ArrayList<E> newArrayList(E... elements) {
checkNotNull(elements); // for GWT
// Avoid integer overflow when a large array is passed in
int capacity = computeArrayListCapacity(elements.length);
ArrayList<E> list = new ArrayList<>(capacity);
Collections.addAll(list, elements);
return list;
}链接:https://juejin.cn/post/7159839509868183583
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
韩国程序员面试考什么?
大家好,我是老三,在G站闲逛的时候,从每日热门上,看到一个韩国的技术面试项目,感觉有点好奇,忍不住点进去看看。
韩国的面试都考什么?有没有国内的卷呢?
可以看到,有8.k star,2.2k forks,在韩国应该算是顶流的开源项目了。
再看看贡献者,嗯,明显看出来是韩国人。
整体看一下内容。
第一大部分是计算机科学,有这些小类:
- 计算机组成
- 数据结构
数据库
网络
- 操作系统
先不说内容,韩文看起来也够呛,但是基础这一块,内容结构还是比较完整的。
第二大部分是算法:
十大排序、二分查找、DFS\BFS…… 大概也是那些东西。
第三大部分是设计模式,内容不多。
第四大部分是面试题:
终于到了比较感兴趣的部分了,点进语言部分,进去看看韩国人面试都问什么,随便抽几道看看:
- Vector和ArrayList的区别?
- 值传递 vs 引用传递?
- 进程和线程的区别?
- 死锁的四个条件是什么?
- 页面置换算法?
- 数据库是无状态的吗?
- oracle和mysql的区别?
- 说说数据库的索引?
- OSI7层体系结构?
- http和https的区别是?
- DI(Dependency Injection)?
- AOP(Aspect Oriented Programming)?
- ……
定睛一看,有种熟悉的感觉,天下八股都一样么?
第五大部分是编程语言:
包含了C、C++、Java、JavaScript、Python。
稍微看看Java部分,也很熟悉的感觉:
- Java编译过程
- 值传递 vs 引用传递
- String & StringBuffer & StringBuilder
- Thread使用
还有其它的Web、Linux、新技术部分就懒得再一一列出了,大家可以自己去看。
这个仓库,让我来评价评价,好,但不是特别好,为什么呢?大家可以看看国内类似的知识仓库,比如JavaGuide,那家伙,内容丰富的!和国内的相比,这个仓库还是单薄了一些——当然也可能是韩国的IT环境没那么卷,这些就够用了。
再扯点有点没的,我对韩国的IT稍微有一点点了解,通过Kakao。之前对接过Kakao的支付——Kakao是什么呢?大家可以理解为韩国的微信就行了,怎么说呢,有点离谱,他们的支付每天大概九点多到十点多要停服维护,你能想象微信支付每天有一个小时不可用吗?
也有同事对接过Kakao的登录,很简单的一个Oauth2,预估两三天搞定,结果也是各种状况,搞了差不多两周。
可能韩国的IT环境真的没有那么卷吧!
有没有对韩国IT行业、IT面试有更多了解的读者朋友呢?欢迎和老三交流。
链接:https://juejin.cn/post/7162709958574735397
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
封装一个有趣的 Loading 组件
组件定义
loading组件共定义4个入口参数:
- 前景色:绘制图形的前景色;
- 背景色:绘制图形的背景色;
- 图形尺寸:绘制图形的尺寸;
- 加载文字:可选,如果有文字就显示,没有就不显示。
得到的Loading组件类如下所示:
class LoadingAnimations extends StatefulWidget {
final Color bgColor;
final Color foregroundColor;
String? loadingText;
final double size;
LoadingAnimations(
{required this.foregroundColor,
required this.bgColor,
this.loadingText,
this.size = 100.0,
Key? key})
: super(key: key);
@override
_LoadingAnimationsState createState() => _LoadingAnimationsState();
}圆形Loading
我们先来实现一个圆形的loading,效果如下所示。
这里绘制了两组沿着一个大圆运动的轴对称的实心圆,半径依次减小,圆心间距随着动画时间逐步拉大。实际上实现的核心还是基于Path的PathMetrics。具体实现代码如下:
_drawCircleLoadingAnimaion(
Canvas canvas, Size size, Offset center, Paint paint) {
final radius = boxSize / 2;
final ballCount = 6;
final ballRadius = boxSize / 15;
var circlePath = Path()
..addOval(Rect.fromCircle(center: center, radius: radius));
var circleMetrics = circlePath.computeMetrics();
for (var pathMetric in circleMetrics) {
for (var i = 0; i < ballCount; ++i) {
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(
Offset(size.width - tangent.position.dx,
size.height - tangent.position.dy),
ballRadius / (1 + i),
paint);
}
}
}其中路径比例为lengthRatio,通过animationValue乘以一个系数使得实心圆的间距越来越大 ,同时通过Offset(size.width - tangent.position.dx, size.height - tangent.position.dy)绘制了一组对对称的实心圆,这样整体就有一个圆形的效果了,动起来也会更有趣一点。
椭圆运动Loading
椭圆和圆形没什么区别,这里我们搞个渐变的效果看看,利用之前介绍过的Paint的shader可以实现渐变色绘制效果。
实现代码如下所示。
final ballCount = 6;
final ballRadius = boxSize / 15;
var ovalPath = Path()
..addOval(Rect.fromCenter(
center: center, width: boxSize, height: boxSize / 1.5));
paint.shader = LinearGradient(
begin: Alignment.topLeft,
end: Alignment.bottomRight,
colors: [this.foregroundColor, this.bgColor],
).createShader(Offset.zero & size);
var ovalMetrics = ovalPath.computeMetrics();
for (var pathMetric in ovalMetrics) {
for (var i = 0; i < ballCount; ++i) {
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(
Offset(size.width - tangent.position.dx,
size.height - tangent.position.dy),
ballRadius / (1 + i),
paint);
}
}当然,如果渐变色的颜色更丰富一点会更有趣些。
贝塞尔曲线Loading
通过贝塞尔曲线构建一条Path,让一组圆形沿着贝塞尔曲线运动的Loading效果也很有趣。
原理和圆形的一样,首先是构建贝塞尔曲线Path,代码如下。
var bezierPath = Path()
..moveTo(size.width / 2 - boxSize / 2, center.dy)
..quadraticBezierTo(size.width / 2 - boxSize / 4, center.dy - boxSize / 4,
size.width / 2, center.dy)
..quadraticBezierTo(size.width / 2 + boxSize / 4, center.dy + boxSize / 4,
size.width / 2 + boxSize / 2, center.dy)
..quadraticBezierTo(size.width / 2 + boxSize / 4, center.dy - boxSize / 4,
size.width / 2, center.dy)
..quadraticBezierTo(size.width / 2 - boxSize / 4, center.dy + boxSize / 4,
size.width / 2 - boxSize / 2, center.dy);这里实际是构建了两条贝塞尔曲线,先从左边到右边,然后再折回来。之后就是运动的实心圆了,这个只是数量上多了,ballCount为30,这样效果看着就有一种拖影的效果。
var ovalMetrics = bezierPath.computeMetrics();
for (var pathMetric in ovalMetrics) {
for (var i = 0; i < ballCount; ++i) {
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(
Offset(size.width - tangent.position.dx,
size.height - tangent.position.dy),
ballRadius / (1 + i),
paint);
}
}这里还可以改变运动方向,实现一些其他的效果,例如下面的效果,第二组圆球的绘制位置实际上是第一组圆球的x、y坐标的互换。
var lengthRatio = animationValue * (1 - i / ballCount);
var tangent =
pathMetric.getTangentForOffset(pathMetric.length * lengthRatio);
var ballPosition = tangent!.position;
canvas.drawCircle(ballPosition, ballRadius / (1 + i), paint);
canvas.drawCircle(Offset(tangent.position.dy, tangent.position.dx),
ballRadius / (1 + i), paint);组件使用
我们来看如何使用我们定义的这个组件,使用代码如下,我们用Future延迟模拟了一个加载效果,在加载过程中使用loading指示加载过程,加载完成后显示图片。
class _LoadingDemoState extends State<LoadingDemo> {
var loaded = false;
@override
void initState() {
super.initState();
Future.delayed(Duration(seconds: 5), () {
setState(() {
loaded = true;
});
});
}
@override
Widget build(BuildContext context) {
return Scaffold(
backgroundColor: Colors.white,
appBar: AppBar(
title: Text('Loading 使用'),
),
body: Center(
child: loaded
? Image.asset(
'images/beauty.jpeg',
width: 100.0,
)
: LoadingAnimations(
foregroundColor: Colors.blue,
bgColor: Colors.white,
size: 100.0,
),
),
);
}最终运行的效果如下,源码已提交至:绘图相关源码,文件名为loading_animations.dart。
总结
本篇介绍了Loading组件的封装方法,核心要点还是利用Path和动画控制绘制元素的运动轨迹来实现更有趣的效果。在实际应用过程中,也可以根据交互设计的需要,做一些其他有趣的加载动效,提高等待过程的趣味性。
链接:https://juejin.cn/post/7129071400509243423
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
忙里偷闲IdleHandler
在Android中,Handler是一个使用的非常频繁的东西,输入事件机制和系统状态,都通过Handler来进行流转,而在Handler中,有一个很少被人提起但是却很有用的东西,那就是IdleHandler,它的源码如下。
/**
* Callback interface for discovering when a thread is going to block
* waiting for more messages.
*/
public static interface IdleHandler {
/**
* Called when the message queue has run out of messages and will now
* wait for more. Return true to keep your idle handler active, false
* to have it removed. This may be called if there are still messages
* pending in the queue, but they are all scheduled to be dispatched
* after the current time.
*/
boolean queueIdle();
}从注释我们就能发现,这是一个IdleHandler的静态接口,可以在消息队列没有消息时或是队列中的消息还没有到执行时间时才会执行的一个回调。
这个功能在某些重要但不紧急的场景下就非常有用了,比如我们要在主页上做一些处理,但是又不想影响原有的初始化逻辑,避免卡顿,那么我们就需要等系统闲下来的时候再来执行我们的操作,这个时候,我们就可以通过IdleHandler来进行回调。
它的使用也非常简单,代码示例如下。
Looper.myQueue().addIdleHandler {
// Do something
false
}在Handler的消息循环中,一旦队列里面没有需要处理的消息,该接口就会回调,也就是Handler空闲的时候。
这个接口有返回值,代表是否需要持续执行,如果返回true,那么一旦Handler空闲,就会执行IdleHandler中的回调,而如果返回false,那么就只会执行一次。
当返回true时,可以通过removeIdleHandler的方式来移除循环的处理,如果是false,那么在处理完后,它自己会移除。
综上,IdleHandler的使用主要有下面这些场景。
- 低优先级的任务处理:替换之前为了不在初始化的时候影响性能而使用的Handler.postDelayed方法,通过IdleHandler来自动获取空闲的时机。
- Idle时循环处理任务:通过控制返回值,在系统空闲时,不断重复某个操作。
但是要注意的是,如果Handler过于繁忙,那么IdleHandler的执行时机是有可能被延迟很久的,所以,要注意一些比较重要的处理逻辑的处理时机。
在很多第三方库里面,都有IdleHandler的使用,例如LeakCanary,它对内存的dump分析过程,就是在IdleHandler中处理的,从而避免对主线程的影响。
链接:https://juejin.cn/post/7163086937383763975
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
项目维护几年了,为啥还这么卡?
浅谈
前段时间有个客户问我,为啥你们项目都搞了好几年了,为啥线上还会经常反馈卡顿,呃呃呃。。
于是根据自己的理解以及网上大佬们的思路总结了一篇关于卡顿优化这块的文章。
卡顿问题是一个老生常谈的话题了,一个App的好坏,卡顿也许会占一半,它直接决定了用户的留存问题,各大app排行版上,那些知名度较高,但是排行较低的,可能就要思考思考是不是和你app本身有关系了。
卡顿一直是性能优化中相对重要的一个点,因为其涉及了UI绘制、垃圾回收(GC)、线程调度以及Binder,CPU,GPU方面等JVM以及FrameWork相关知识
如果能做好卡顿优化,那么也就间接证明你对Android FrameWork的理解之深。
下面我们就来讲解下卡顿方面的知识。
什么是卡顿:
对用户来讲就是界面不流畅,滞顿。
场景如下:
- 1.视频加载慢,画面卡顿,卡死,黑屏
- 2.声音卡顿,音画不同步。
- 3.动画帧卡顿,交互响应慢
- 4.滑动不跟手,列表自动更新,滚动不流畅
- 5.网络响应慢,数据和画面展示慢、
- 6.过渡动画生硬。
- 7.界面不可交互,卡死,等等现象。
卡顿是如何发生的
卡顿产生的原因一般都比较复杂,如CPU内存大小,IO操作,锁操作,低效的算法等都会引起卡顿。
站在开发的角度看:
通常我们讲,屏幕刷新率是60fps,需要在16ms内完成所有的工作才不会造成卡顿。
为什么是16ms,不是17,18呢?
下面我们先来理清在UI绘制中的几个概念:
SurfaceFlinger:
SurfaceFlinger作用是接受多个来源的图形显示数据Surface,合成后发送到显示设备,比如我们的主界面中:可能会有statusBar,侧滑菜单,主界面,这些View都是独立Surface渲染和更新,最后提交给SF后,SF根据Zorder,透明度,大小,位置等参数,合成为一个数据buffer,传递HWComposer或者OpenGL处理,最终给显示器。
在显示过程中使用到了bufferqueue,surfaceflinger作为consumer方,比如windowmanager管理的surface作为生产方产生页面,交由surfaceflinger进行合成。
VSYNC
Android系统每隔16ms发出VSYNC信号,触发对UI进行渲染,VSYNC是一种在PC上很早就有应用,可以理解为一种定时中断技术。
tearing 问题:
早期的 Android 是没有 vsync 机制的,CPU 和 GPU 的配合也比较混乱,这也造成著名的 tearing 问题,即 CPU/GPU 直接更新正在显示的屏幕 buffer 造成画面撕裂。
后续 Android 引入了双缓冲机制,但是 buffer 的切换也需要一个比较合适的时机,也就是屏幕扫描完上一帧后的时机,这也就是引入 vsync 的原因。
早先一般的屏幕刷新率是 60fps,所以每个 vsync 信号的间隔也是 16ms,不过随着技术的更迭以及厂商对于流畅性的追求,越来越多 90fps 和 120fps 的手机面世,相对应的间隔也就变成了 11ms 和 8ms。
VSYNC信号种类:
- 1.屏幕产生的硬件VSYNC:硬件
VSYNC是一种脉冲信号,起到开关和触发某种操作的作用。 - 2.由
SurfaceFlinger将其转成的软件VSYNC信号,经由Binder传递给Choreographer
Choreographer:
编舞者,用于注册VSYNC信号并接收VSYNC信号回调,当内部接收到这个信号时最终会调用到doFrame进行帧的绘制操作。
Choreographer在系统中流程:
如何通过Choreographer计算掉帧情况:原理就是:
通过给Choreographer设置FrameCallback,在每次绘制前后看时间差是16.6ms的多少倍,即为前后掉帧率。
使用方式如下:
//Application.java
public void onCreate() {
super.onCreate();
//在Application中使用postFrameCallback
Choreographer.getInstance().postFrameCallback(new FPSFrameCallback(System.nanoTime()));
}
public class FPSFrameCallback implements Choreographer.FrameCallback {
private static final String TAG = "FPS_TEST";
private long mLastFrameTimeNanos = 0;
private long mFrameIntervalNanos;
public FPSFrameCallback(long lastFrameTimeNanos) {
mLastFrameTimeNanos = lastFrameTimeNanos;
mFrameIntervalNanos = (long)(1000000000 / 60.0);
}
@Override
public void doFrame(long frameTimeNanos) {
//初始化时间
if (mLastFrameTimeNanos == 0) {
mLastFrameTimeNanos = frameTimeNanos;
}
final long jitterNanos = frameTimeNanos - mLastFrameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if(skippedFrames>30){
//丢帧30以上打印日志
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
}
mLastFrameTimeNanos=frameTimeNanos;
//注册下一帧回调
Choreographer.getInstance().postFrameCallback(this);
}
}UI绘制全路径分析:
有了前面几个概念,这里我们让SurfaceFlinger结合View的绘制流程用一张图来表达整个绘制流程:
- 生产者:APP方构建Surface的过程。
- 消费者:SurfaceFlinger
UI绘制全路径分析卡顿原因:
接下来,我们逐个分析,看看都会有哪些原因可能造成卡顿:
1.渲染流程
1.Vsync 调度:这个是起始点,但是调度的过程会经过线程切换以及一些委派的逻辑,有可能造成卡顿,但是一般可能性比较小,我们也基本无法介入;
2.消息调度:主要是 doframe Message 的调度,这就是一个普通的 Handler 调度,如果这个调度被其他的 Message 阻塞产生了时延,会直接导致后续的所有流程不会被触发
3.input 处理:input 是一次 Vsync 调度最先执行的逻辑,主要处理 input 事件。如果有大量的事件堆积或者在事件分发逻辑中加入大量耗时业务逻辑,会造成当前帧的时长被拉大,造成卡顿,可以尝试通过事件采样的方案,减少 event 的处理
4.动画处理:主要是 animator 动画的更新,同理,动画数量过多,或者动画的更新中有比较耗时的逻辑,也会造成当前帧的渲染卡顿。对动画的降帧和降复杂度其实解决的就是这个问题;
5.view 处理:主要是接下来的三大流程,过度绘制、频繁刷新、复杂的视图效果都是此处造成卡顿的主要原因。比如我们平时所说的降低页面层级,主要解决的就是这个问题;
6.measure/layout/draw:view 渲染的三大流程,因为涉及到遍历和高频执行,所以这里涉及到的耗时问题均会被放大,比如我们会降不能在 draw 里面调用耗时函数,不能 new 对象等等;
7.DisplayList 的更新:这里主要是 canvas 和 displaylist 的映射,一般不会存在卡顿问题,反而可能存在映射失败导致的显示问题;
8.OpenGL 指令转换:这里主要是将 canvas 的命令转换为 OpenGL 的指令,一般不存在问题
9.buffer 交换:这里主要指 OpenGL 指令集交换给 GPU,这个一般和指令的复杂度有关
10.GPU 处理:顾名思义,这里是 GPU 对数据的处理,耗时主要和任务量和纹理复杂度有关。这也就是我们降低 GPU 负载有助于降低卡顿的原因;
11.layer 合成:Android P 修改了 Layer 的计算方法 , 把这部分放到了 SurfaceFlinger 主线程去执行, 如果后台 Layer 过多, 就会导致 SurfaceFlinger 在执行 rebuildLayerStacks 的时候耗时 , 导致 SurfaceFlinger 主线程执行时间过长。
可以选择降低Surface层级来优化卡顿。
- 12.光栅化/Display:这里暂时忽略,底层系统行为;
Buffer 切换:主要是屏幕的显示,这里 buffer 的数量也会影响帧的整体延迟,不过是系统行为,不能干预。
2.系统负载
- 内存:内存的吃紧会直接导致 GC 的增加甚至 ANR,是造成卡顿的一个不可忽视的因素;
- CPU:CPU 对卡顿的影响主要在于线程调度慢、任务执行的慢和资源竞争,比如
1.降频会直接导致应用卡顿;
2.后台活动进程太多导致系统繁忙,cpu \ io \ memory 等资源都会被占用, 这时候很容易出现卡顿问题 ,这种情况比较常见,可以使用dumpsys cpuinfo查看当前设备的cpu使用情况:
3.主线程调度不到 , 处于 Runnable 状态,这种情况比较少见
4.System 锁:system_server 的 AMS 锁和 WMS 锁 , 在系统异常的情况下 , 会变得非常严重 , 如下图所示 , 许多系统的关键任务都被阻塞 , 等待锁的释放 , 这时候如果有 App 发来的 Binder 请求带锁 , 那么也会进入等待状态 , 这时候 App 就会产生性能问题 ; 如果此时做 Window 动画 , 那么 system_server 的这些锁也会导致窗口动画卡顿
- GPU:GPU 的影响见渲染流程,但是其实还会间接影响到功耗和发热;
- 功耗/发热:功耗和发热一般是不分家的,高功耗会引起高发热,进而会引起系统保护,比如降频、热缓解等,间接的导致卡顿。
如何监控卡顿
线下监控:
我们知道卡顿问题的原因错综复杂,但最终都可以反馈到CPU使用率上来
1.使用dumpsys cpuinfo命令
这个命令可以获取当时设备cpu使用情况,我们可以在线下通过重度使用应用来检测可能存在的卡顿点
A8S:/ $ dumpsys cpuinfo
Load: 1.12 / 1.12 / 1.09
CPU usage from 484321ms to 184247ms ago (2022-11-02 14:48:30.793 to 2022-11-02 1
4:53:30.866):
2% 1053/scanserver: 0.2% user + 1.7% kernel
0.6% 934/system_server: 0.4% user + 0.1% kernel / faults: 563 minor
0.4% 564/signserver: 0% user + 0.4% kernel
0.2% 256/ueventd: 0.1% user + 0% kernel / faults: 320 minor
0.2% 474/surfaceflinger: 0.1% user + 0.1% kernel
0.1% 576/vendor.sprd.hardware.gnss@2.0-service: 0.1% user + 0% kernel / faults
: 54 minor
0.1% 286/logd: 0% user + 0% kernel / faults: 10 minor
0.1% 2821/com.allinpay.appstore: 0.1% user + 0% kernel / faults: 1312 minor
0.1% 447/android.hardware.health@2.0-service: 0% user + 0% kernel / faults: 11
75 minor
0% 1855/com.smartpos.dataacqservice: 0% user + 0% kernel / faults: 755 minor
0% 2875/com.allinpay.appstore:pushcore: 0% user + 0% kernel / faults: 744 mino
r
0% 1191/com.android.systemui: 0% user + 0% kernel / faults: 70 minor
0% 1774/com.android.nfc: 0% user + 0% kernel
0% 172/kworker/1:2: 0% user + 0% kernel
0% 145/irq/24-70900000: 0% user + 0% kernel
0% 575/thermald: 0% user + 0% kernel / faults: 300 minor
...2.CPU Profiler
这个工具是AS自带的CPU性能检测工具,可以在PC上实时查看我们CPU使用情况。
AS提供了四种Profiling Model配置:
- 1.
Sample Java Methods:在应用程序基于Java的代码执行过程中,频繁捕获应用程序的调用堆栈
获取有关应用程序基于Java的代码执行的时间和资源使用情况信息。 - 2.
Trace java methods:在运行时对应用程序进行检测,以在每个方法调用的开始和结束时记录时间戳。收集时间戳并进行比较以生成方法跟踪数据,包括时序信息和CPU使用率。
请注意与检测每种方法相关的开销会影响运行时性能,并可能影响性能分析数据。对于生命周期相对较短的方法,这一点甚至更为明显。此外,如果您的应用在短时间内执行大量方法,则探查器可能会很快超过其文件大小限制,并且可能无法记录任何进一步的跟踪数据。
- 3.
Sample C/C++ Functions:捕获应用程序本机线程的示例跟踪。要使用此配置,您必须将应用程序部署到运行Android 8.0(API级别26)或更高版本的设备。 - 4.
Trace System Calls:捕获细粒度的详细信息,使您可以检查应用程序与系统资源的交互方式
您可以检查线程状态的确切时间和持续时间,可视化CPU瓶颈在所有内核中的位置,并添加自定义跟踪事件进行分析。在对性能问题进行故障排除时,此类信息可能至关重要。要使用此配置,您必须将应用程序部署到运行Android 7.0(API级别24)或更高版本的设备。
使用方式:
Debug.startMethodTracing("");
// 需要检测的代码片段
...
Debug.stopMethodTracing();优点:**有比较全面的调用栈以及图像化方法时间显示,包含所有线程的情况
缺点:本身也会带来一点的性能开销,可能会带偏优化方向**
火焰图:可以显示当前应用的方法堆栈:
3.Systrace
Systrace在前面一篇分析启动优化的文章讲解过
这里我们简单来复习下:
Systrace用来记录当前应用的系统以及应用(使用Trace类打点)的各阶段耗时信息包括绘制信息以及CPU信息等。
使用方式:
Trace.beginSection("MyApp.onCreate_1");
alt(200);
Trace.endSection();在命令行中:
python systrace.py -t 5 sched gfx view wm am app webview -a "com.chinaebipay.thirdcall" -o D:\trac1.html记录的方法以及CPU中的耗时情况:
优点:
- 1.轻量级,开销小,CPU使用率可以直观反映
- 2.右侧的Alerts能够根据我们应用的问题给出具体的建议,比如说,它会告诉我们App界面的绘制比较慢或者GC比较频繁。
4.StrictModel
StrictModel是Android提供的一种运行时检测机制,用来帮助开发者自动检测代码中不规范的地方。
主要和两部分相关:
1.线程相关
2.虚拟机相关
基础代码:
private void initStrictMode() {
// 1、设置Debug标志位,仅仅在线下环境才使用StrictMode
if (DEV_MODE) {
// 2、设置线程策略
StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder()
.detectCustomSlowCalls() //API等级11,使用StrictMode.noteSlowCode
.detectDiskReads()
.detectDiskWrites()
.detectNetwork() // or .detectAll() for all detectable problems
.penaltyLog() //在Logcat 中打印违规异常信息
// .penaltyDialog() //也可以直接跳出警报dialog
// .penaltyDeath() //或者直接崩溃
.build());
// 3、设置虚拟机策略
StrictMode.setVmPolicy(new StrictMode.VmPolicy.Builder()
.detectLeakedSqlLiteObjects()
// 给NewsItem对象的实例数量限制为1
.setClassInstanceLimit(NewsItem.class, 1)
.detectLeakedClosableObjects() //API等级11
.penaltyLog()
.build());
}
}
线上监控:
线上需要自动化的卡顿检测方案来定位卡顿,它能记录卡顿发生时的场景。
自动化监控原理:
采用拦截消息调度流程,在消息执行前埋点计时,当耗时超过阈值时,则认为是一次卡顿,会进行堆栈抓取和上报工作
首先,我们看下Looper用于执行消息循环的loop()方法,关键代码如下所示:
/**
* Run the message queue in this thread. Be sure to call
* {@link #quit()} to end the loop.
*/
public static void loop() {
...
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
// 1
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
...
try {
// 2
msg.target.dispatchMessage(msg);
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
} finally {
if (traceTag != 0) {
Trace.traceEnd(traceTag);
}
}
...
if (logging != null) {
// 3
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}在Looper的loop()方法中,在其执行每一个消息(注释2处)的前后都由logging进行了一次打印输出。可以看到,在执行消息前是输出的">>>>> Dispatching to ",在执行消息后是输出的"<<<<< Finished to ",它们打印的日志是不一样的,我们就可以由此来判断消息执行的前后时间点。
具体的实现可以归纳为如下步骤:
- 1、首先,我们需要使用Looper.getMainLooper().setMessageLogging()去设置我们自己的Printer实现类去打印输出logging。这样,在每个message执行的之前和之后都会调用我们设置的这个Printer实现类。
- 2、如果我们匹配到">>>>> Dispatching to "之后,我们就可以执行一行代码:也就是在指定的时间阈值之后,我们在子线程去执行一个任务,这个任务就是去获取当前主线程的堆栈信息以及当前的一些场景信息,比如:内存大小、电脑、网络状态等。
- 3、如果在指定的阈值之内匹配到了"<<<<< Finished to ",那么说明message就被执行完成了,则表明此时没有产生我们认为的卡顿效果,那我们就可以将这个子线程任务取消掉。
这里我们使用blockcanary来做测试:
BlockCanary
APM是一个非侵入式的性能监控组件,可以通过通知的形式弹出卡顿信息。它的原理就是我们刚刚讲述到的卡顿监控的实现原理。
使用方式:
- 1.导入依赖
implementation 'com.github.markzhai:blockcanary-android:1.5.0'- Application的onCreate方法中开启卡顿监控
// 注意在主进程初始化调用
BlockCanary.install(this, new AppBlockCanaryContext()).start();- 3.继承
BlockCanaryContext类去实现自己的监控配置上下文类
public class AppBlockCanaryContext extends BlockCanaryContext {
...
...
/**
* 指定判定为卡顿的阈值threshold (in millis),
* 你可以根据不同设备的性能去指定不同的阈值
*
* @return threshold in mills
*/
public int provideBlockThreshold() {
return 1000;
}
....
}- 4.在Activity的onCreate方法中执行一个耗时操作
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}- 5.结果:
可以看到一个和LeakCanary一样效果的阻塞可视化堆栈图
那有了BlockCanary的方法耗时监控方式是不是就可以解百愁了呢,呵呵。有那么容易就好了
根据原理:我们拿到的是msg执行前后的时间和堆栈信息,如果msg中有几百上千个方法,就无法确认到底是哪个方法导致的耗时,也有可能是多个方法堆积导致。
这就导致我们无法准确定位哪个方法是最耗时的。如图中:堆栈信息是T2的,而发生耗时的方法可能是T1到T2中任何一个方法甚至是堆积导致。
那如何优化这块?
这里我们采用字节跳动给我们提供的一个方案:基于 Sliver trace 的卡顿监控体系
Sliver trace
整体流程图:
主要包含两个方面:
- 检测方案:
在监控卡顿时,首先需要打开 Sliver 的 trace 记录能力,Sliver 采样记录 trace 执行信息,对抓取到的堆栈进行 diff 聚合和缓存。
同时基于我们的需要设置相应的卡顿阈值,以 Message 的执行耗时为衡量。对主线程消息调度流程进行拦截,在消息开始分发执行时埋点,在消息执行结束时计算消息执行耗时,当消息执行耗时超过阈值,则认为产生了一次卡顿。
- 堆栈聚合策略:
当卡顿发生时,我们需要为此次卡顿准备数据,这部分工作是在端上子线程中完成的,主要是 dump trace 到文件以及过滤聚合要上报的堆栈。分为以下几步:
- 1.拿到缓存的主线程 trace 信息并 dump 到文件中。
- 2.然后从文件中读取 trace 信息,按照数据格式,从最近的方法栈向上追溯,找到当前 Message 包含的全部 trace 信息,并将当前 Message 的完整 trace 写入到待上传的 trace 文件中,删除其余 trace 信息。
- 3.遍历当前 Message trace,按照(Method 执行耗时 > Method 耗时阈值 & Method 耗时为该层堆栈中最耗时)为条件过滤出每一层函数调用堆栈的最长耗时函数,构成最后要上报的堆栈链路,这样特征堆栈中的每一步都是最耗时的,且最底层 Method 为最后的耗时大于阈值的 Method。
之后,将 trace 文件和堆栈一同上报,这样的特征堆栈提取策略保证了堆栈聚合的可靠性和准确性,保证了上报到平台后堆栈的正确合理聚合,同时提供了进一步分析问题的 trace 文件。
可以看到字节给的是一整套监控方案,和前面BlockCanary不同之处就在于,其是定时存储堆栈,缓存,然后使用diff去重的方式,并上传到服务器,可以最大限度的监控到可能发生比较耗时的方法。
开发中哪些习惯会影响卡顿的发生
1.布局太乱,层级太深。
- 1.1:通过减少冗余或者嵌套布局来降低视图层次结构。比如使用约束布局代替线性布局和相对布局。
- 1.2:用 ViewStub 替代在启动过程中不需要显示的 UI 控件。
- 1.3:使用自定义 View 替代复杂的 View 叠加。
2.主线程耗时操作
- 2.1:主线程中不要直接操作数据库,数据库的操作应该放在数据库线程中完成。
- 2.2:sharepreference尽量使用apply,少使用commit,可以使用MMKV框架来代替sharepreference。
- 2.3:网络请求回来的数据解析尽量放在子线程中,不要在主线程中进行复制的数据解析操作。
- 2.4:不要在activity的onResume和onCreate中进行耗时操作,比如大量的计算等。
- 2.5:不要在 draw 里面调用耗时函数,不能 new 对象
3.过度绘制
过度绘制是同一个像素点上被多次绘制,减少过度绘制一般减少布局背景叠加等方式,如下图所示右边是过度绘制的图片。
4.列表
RecyclerView使用优化,使用DiffUtil和notifyItemDataSetChanged进行局部更新等。
5.对象分配和回收优化
自从Android引入 ART 并且在Android 5.0上成为默认的运行时之后,对象分配和垃圾回收(GC)造成的卡顿已经显著降低了,但是由于对象分配和GC有额外的开销,它依然又可能使线程负载过重。 在一个调用不频繁的地方(比如按钮点击)分配对象是没有问题的,但如果在在一个被频繁调用的紧密的循环里,就需要避免对象分配来降低GC的压力。
减少小对象的频繁分配和回收操作。
链接:https://juejin.cn/post/7161757546875715615
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
因面试提到 Handler 机制后,引发连环炮轰(我已承受不来~)
因业务繁忙,有段时间没有和大家进行技术分享了,今日特此抽出时间先来分享!!!
今日头条面试题:讲讲ThreadLocal底层原理和Handler的关系
竟然提到了Handler机制就不得不提到这几大将了:Handler,Looper,MessageQueue,Message。延伸重点ThreadLocal!!!
当UI的主线程在初始化第一个 Handler时,就会通过ThreadLocal创建一个Looper,该Looper与UI主线程一一对应。而使用ThreadLocal的目的是保证每一个线程只创建唯一一个Looper。
Looper初始化的时候会创建一个 消息队列MessageQueue。至此,主线程、消息循环、消息队列之间的关系是1:1:1。
Handler、Looper、MessageQueue的初始化流程如下图所示:Hander持有对UI主线程消息队列MessageQueue和消息循环Looper的引用,子线程可以通过 Handler 将消息发送到UI线程的消息队列MessageQueue中。
二问:主线程为啥不用初始化looper呢?
那是因为looper早在ActivityThread初始化的时候就声明好了,可以直接拿来用的。通过分析源码我们知道MessageQueue在Looper中,Looper初始化后作为对象丢给了Handler,并且又存在了 ThreadLocal 里面,ThreadLocal 对象的话作为Key又存在了ThreadLocalMap,ThreadLocalMap对象是Thread里面的一个属性值,也就是说Looper作为桥梁连接了Handler与Looper所在的线程。
三问:Handler机制有了解过没?跟我说说?
在理解Handler 机制前,我们需要先搞懂ThreadLocal。
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的,也就是说该变量是当前线程独有的变量。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
ThreadLocal的原理
想搞懂原理那就得先从源码入手开始分析。
我们先从set方法看起:
从上面的代码不难看出,ThreadLocal set赋值的时候首先会获取当前线程thread,并获取thread线程中的ThreadLocalMap属性。如果map中属性不为空,则直接更新value值,如果map中找不到此ThreadLocal对象,则在threadLocalMap创建一个,并将value值初始化。显然ThreadLocal对象存的值是根据线程走的!
那么ThreadLocalMap又是什么呢,还有createMap又是怎么做的,我们继续往下看。
首先第一步我们得要知道这个东西
每个Thread有一个属性,类型是ThreadLocalMap,从代码不难看出ThreadLocalMap是ThreadLocal的内部静态类。它是与线程所绑定联系在一起的,可以看成一个线程只有一个ThreadLocalMap,知道这一点我们再往下看。
ThreadLocalMap的构成主要是用Entry来保存数据 ,而且还是继承的弱引用。在Entry内部使用ThreadLocal对象作为key,使用我们设置的value作为value。
get的话就比较简单了就是获取当前线程的ThreadLocalMap属性值,在获取Map中对应ThreadLocal对象的value值并返回。
ThreadLocal总结一下就是:每个线程Thread自身有一个属性ThreadLocalMap,然后ThreadLocalMap是一个键值对,它的key值是ThreadLocal对象,它的value值则是我们想要保存处理的数据值。getMap是找到对应线程的ThreadLocalMap属性值,然后通过判断可以初始化或者更新数值。
ThreadLocal分析完了我们接着来看Handler吧。
因为主线程在ActivityThread的main方法中已经创建了Looper,所以主线程使用Handler时可以直接new;子线程使用Handler时需要调用Looper的prepare和loop方法才能进行使用,否则会抛出异常。所以我们从Looper的prepare来分析。
Looper 提供了 Looper.prepare() 方法来创建 Looper ,并且会借助 ThreadLocal 来实现与当前线程的绑定功能。Looper.loop() 则会开始不断尝试从 MessageQueue 中获取 Message , 并分发给对应的 Handler,也就是说 Handler 跟线程的关联是靠 Looper 来实现的。
Looper.loop() 负责对消息的分发,也是和prepare配套使用的方法,两者缺一不可。
msg.target是个啥呢,我们追到Message里面不难发现其实它就是我们发送消息的Handler,这写法是不是很聪明,当从MessageQueen中捞出Message后,我们就能直接调用Handler的dispatchMessage,然后就会走到我们的Handler的handleMessage了。直接上源码:
处理分析完了,我们看个简单点的,消息发送吧。Handler 提供了一些列的方法让我们来发送消息,如 send()系列 post()系列 。不过不管我们调用什么方法,最终都会走到 MessageQueue的enqueueMessage(Message,long) 方法。也就是实现了消息的发送,将Message插入到我们的MessageQueue中。
注意:dispatchMessage() 方法针对 Runnable 的方法做了特殊处理,如果是 ,则会直接执行 Runnable.run() 。(判断依据是上述msg.callback !=null这句)
MessageQueue是个单链表。
MessageQueue里消息按时间排序
MessageQueue的next()是个堵塞方法
总结分析:
Looper.loop() 是个死循环,会不断调用 MessageQueue.next() 获取 Message ,并调用 msg.target.dispatchMessage(msg) 回到了 Handler 来分发消息,以此来完成消息的回调。
四问:Handler什么会出现内存泄漏问题呢?
Handler使用是用来进行线程间通信的,所以新开启的线程是会持有Handler引用的,如果在Activity等中创建Handler,并且是非静态内部类的形式,就有可能造成内存泄漏。
非静态内部类是会隐式持有外部类的引用,所以当其他线程持有了该Handler,线程没有被销毁,则意味着Activity会一直被Handler持有引用而无法导致回收。
MessageQueue中如果存在未处理完的Message,Message的target也是对Activity等的持有引用,也会造成内存泄漏。
解决的办法:
使用静态内部类 + 弱引用的方式: 静态内部类不会持有外部类的的引用,当需要引用外部类相关操作时,可以通过弱引用还获取到外部类相关操作,弱引用是不会造成对象该回收回收不掉的问题,不清楚的可以查阅JAVA的几种引用方式的详细说明。
在外部类对象被销毁时,将MessageQueue中的消息清空。
五问:Looper死循环为什么不会导致应用卡死?
对于线程即是一段可执行的代码,当可执行代码执行完成后,线程生命周期便该终止了,线程退出。而对于主线程,我们是绝不希望会被运行一段时间,自己就退出,那么如何保证能一直存活呢?简单做法就是可执行代码是能一直执行下去的,死循环便能保证不会被退出,例如,binder线程也是采用死循环的方法,通过循环方式不同与Binder驱动进行读写操作,当然并非简单地死循环,无消息时会休眠。但这里可能又引发了另一个问题,既然是死循环又如何去处理其他事务呢?通过创建新线程的方式。真正会卡死主线程的操作是在回调方法onCreate/onStart/onResume等操作时间过长,会导致掉帧,甚至发生ANR,looper.loop本身不会导致应用卡死。
六问:主线程的死循环一直运行是不是特别消耗CPU资源呢?
其实不然,这里就涉及到Linux pipe/epoll机制,简单说就是在主线程的MessageQueue没有消息时,便阻塞在Loop的queue.next()中的nativePollOnce()方法里,此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质同步I/O,即读写是阻塞的。 所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源。
好了,这轮面试中问道的Handler 就问了这么多了,大家可以好好的吸收一下,如有什么疑议欢迎在评论区进行讨论!!!
链接:https://juejin.cn/post/7160681836291555365
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter桌面开发-项目工程化框架搭建
前言
在本专栏前面的几篇文章中,我们对桌面应用实现了可定制的窗口化,适配了多种分辨率的屏幕,并且实现了小组件 “灵动岛”。前面的文章算是一些基础建设的搭建,这篇文章我将基于状态管理库GetX,搭建一个成熟完善的,可投入生产开发的项目架构。这也是我们后面继续开发桌面应用的基础。
搭建原则
此次项目框架的搭建,完全基于GetX库。虽说之前我也分析过GetX的优势和弊端,但对于我们一个开源的项目,GetX这种“全家桶”库再适合不过啦。同时还会提供在Windows开发过程中一些区别于移动端开发的小技巧。
GetX全家桶的搭建
为啥说GetX是全家桶,因为它不仅可以满足MVVM的状态管理,还能满足:国际化、路由配置、网络请求等等,着实方便,而且亲测可靠!GetX
1. 国际化
GetX提供了应用的顶层入口GetMaterialApp,这个控件封装了Flutter的MaterialApp,我们只需要按照GetX给定的规则传入多语言的配置即可。配置也是非常简单的,只需要在类中提供get声明的map对象即可。Map的key由语言的代码和国家地区组成,无需处理系统语言环境变化等事件。
import 'package:get/get.dart';
class Internationalization extends Translations {
@override
Map<String, Map<String, String>> get keys => {
'en_US': {
'appName': 'Flutter Windows',
'hello':'Hello World!'
},
'zh_CN': {
'appName': 'Flutter桌面应用',
'hello':'你好,世界!'
},
'zh_HK': {
'appName': 'Flutter桌面應用',
'hello':'你好,世界!'
},
};
}2. 路由配置
如果没有使用GetX,路由管理很大情况是使用Fluro,大量的define、setting、handle真的配置的很枯燥。在GetX中,你只需要配置路由名称和对应的Widget即可。
class RouteConfig {
/// home模块
static const String home = "/home/homePage";
/// 我的模块
static const String mine = "/mine/myPage";
static final List<GetPage> getPages = [
GetPage(name: home, page: () => HomePage()),
GetPage(name: mine, page: () => MinePage()),
];
}至于参数,可以直接像web端的url一样,使用?、&传递。
同时GetX也提供了路由跳转的方式,相比Flutter Navigator2提供的api,GetX的路由跳转明显更加方便,可以脱离context进行跳转,我们可以在VM层随意处理路由,这点真的很爽。
// 跳转到我的页面
Get.toNamed('${RouteConfig.mine}?userId=123&userName=karl');
// 我的页面接收参数
String? userName = Get.parameters['userName'];
3. GetX状态管理
状态管理才是GetX的重头戏,GetX中实现的Obx机制,能非常轻量级的帮我们定点刷新。Obx是通过创建定向的Stream,来局部setState的。而且作者还提供了ide的插件,我们来创建一个GetX的页面。
通过插件快捷创建之后我们可以得到:logic、state、view的分层结构,通过logic绑定数据和视图,并且实现数据驱动UI刷新。
当然,通过Obx的方式会触发创建较多的Stream,有时使用update()来主动刷新也是可以的。
关于GetX的状态管理,有个细节要提示下:
- 如果listview.build下的item都有自己的状态管理,那么每个item需要向logic传递自己的tag才能产生各自的Obx stream;
Get.put(SwiperItemLogic(), tag: model.key);
GetX相对其他的状态管理,最重点是基于Stream实现了真正的跨组件通信,包括兄弟组件;只需要保证logic层Put一次,其余组件去Find即可直接更新logic的值,实现视图刷新。
4. 网络请求
在网络请求上,GetX的封装其实并没有dio来的好,Get_connect插件集成了REST API请求和GraphQL规范,我们开发过程中其实不会两者都用。虽然GraphQL提高了健壮性,但在定义请求对象的时候,往往会增加一些工作量,特别是对于小项目。
- 我们可以先创建一个基础内容提供,完成通用配置;
/// 网络请求基类,配置公共属性
class BaseProvider extends GetConnect {
@override
void onInit() {
super.onInit();
httpClient.baseUrl = Api.baseUrl;
// 请求拦截
httpClient.addRequestModifier<void>((request) {
request.headers['accept'] = 'application/json';
request.headers['content-type'] = 'application/json';
return request;
});
// 响应拦截;甚至已经把http status都帮我们区分好了
httpClient.addResponseModifier((request, response) {
if (response.isOk) {
return response;
} else if (response.unauthorized) {
// 账户权限失效
}
return response;
});
}
}- 然后按照模块化去配置请求,提高可维护性。
import 'package:get/get.dart';
import 'base_provider.dart';
/// 按照模块去制定网络请求,数据源模块化
class HomeProvider extends BaseProvider {
// get会带上baseUrl
Future<Response> getHomeSwiper(int id) => get('home/swiper');
}日志记录
日志我们采用Logger进行记录,桌面端一般使用txt文件格式。以时间命名,天为单位建立日志文件即可。如果有需要,也可以加一些定时清理的逻辑。
我们需要重写下LogOutput的方法,把颜色和表情都去掉,避免编码错误,然后实现下单例。
Logger? logger;
Logger get appLogger => logger ??= Logger(
filter: CustomerFilter(),
printer: PrettyPrinter(
printEmojis: false,
colors: false,
methodCount: 0,
noBoxingByDefault: true),
output: LogStorage(),
);
class LogStorage extends LogOutput {
// 默认的日志文件过期时间,以小时为单位
static const _logExpiredTime = 72;
/// 日志文件操作对象
File? _file;
/// 日志目录
String? logDir;
/// 日志名称
String? logName;
LogStorage({this.logDir, this.logName});
@override
void destroy() {
deleteExpiredLogs(_logExpiredTime);
}
@override
void init() async {
deleteExpiredLogs(_logExpiredTime);
}
@override
void output(OutputEvent event) async {
_file ??= await createFile(logDir, logName);
String now = CommonUtils.formatDateTime(DateTime.now());
String version = packageInfo.version;
_file!.writeAsStringSync('>>>> $version $now [${event.level.name}]\n',
mode: FileMode.writeOnlyAppend);
for (var line in event.lines) {
_file!.writeAsStringSync('${line.toString()}\n',
mode: FileMode.writeOnlyAppend);
debugPrint(line);
}
}
Future<File> createFile(String? logDir, String? logName) async {
logDir = logDir;
logName = logName;
if (logDir == null) {
Directory documentsDirectory = await getApplicationSupportDirectory();
logDir =
"${documentsDirectory.path}${Platform.pathSeparator}${Constants.logDir}";
}
logName ??=
"${CommonUtils.formatDateTime(DateTime.now(), format: 'yyyy-MM-dd')}.txt";
String path = '$logDir${Platform.pathSeparator}$logName';
debugPrint('>>>>日志存储路径:$path');
File file = File(path);
if (!file.existsSync()) {
file = await File(path).create(recursive: true);
}
return file;
}吐司提示
吐司用的还是fluttertoast的方式。但是windows的实现比较不一样,在windows上的实现toast提示只能显示在应用窗体内。
static FToast fToast = FToast().init(Get.overlayContext!);
static void showToast(String text, {int? timeInSeconds}) {
// 桌面版必须使用带context的FToast
if (Platform.isWindows || Platform.isMacOS) {
cancelToastForDesktop();
fToast.showToast(
toastDuration: Duration(seconds: timeInSeconds ?? 3),
gravity: ToastGravity.BOTTOM,
child: Container(
padding: const EdgeInsets.symmetric(horizontal: 24.0, vertical: 12.0),
decoration: BoxDecoration(
borderRadius: BorderRadius.circular(25.0),
color: const Color(0xff323334),
),
child: Text(
text,
style: const TextStyle(
fontSize: 16,
color: Colors.white,
),
),
),
);
} else {
cancelToast();
Fluttertoast.showToast(
msg: text,
gravity: ToastGravity.BOTTOM,
timeInSecForIosWeb: timeInSeconds ?? 3,
backgroundColor: const Color(0xff323334),
textColor: Colors.white,
fontSize: 16,
);
}
}一些的小技巧
代码注入,更简洁的实现单例和构造引用
在开发过程中,我还会使用get_it和injectable来生成自动单例、工厂构造函数等类。好处是让代码更为简洁可靠,便于维护。下面举个萌友上报的例子,初始配置只需要在create中写入即可,然后业务方调用只需要使用GetIt.get<YouMengReport>().report()上报就行了。这就是一个非常完整的单例,使用维护都很方便。
/// 声明单例,并且自动初始化
@singleton(signalsReady: true)
class YouMengReport {
/// 声明工厂构造函数,自动初始化的时候会自动自行create方法
@factoryMethod
create() {
// 这里可以做一些初始化工作
}
report() {}
}json生成器
由于不支持反射,导致Flutter的json解析一直为人诟病。因此使用json_serializable会是一个不错的选择,其原理是通过AOP注解,帮我们生成json编码和解析。通过插件Json2json_serializable可以帮我们自动生成dart文件,如下图:
链接:https://juejin.cn/post/7159958059006033950
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Dagger2四种使用方式
1. 什么是Dagger2
Dagger2是用来解决对象之间的高度耦合的框架。介绍Dagger2四种方式实现。
具体的四种使用场景
0. 配置
app模块下的build.gradle
dependencies {
//...其他依赖信息
implementation 'com.google.dagger:dagger:2.44'
annotationProcessor 'com.google.dagger:dagger-compiler:2.44'
}
1. 第一种实现方式
自己实现的代码可以在代码的构造函数上通过@Inject修饰,实现代码注入,如下:
1. 实现细节
public class SingleInstance {
@Inject
User user;
@Inject
public SingleInstance() {
DaggerApplicationComponent.create().inject(this);
Log.i("TAG", "SingleInstance === " + user);
}
}
public class User {
//自定义的类通过@Inject注解修饰,在使用的地方使用@Inject初始化时,dagger会去找被@Inject修饰的类进行初始化。
@Inject
public User() {
}
}
@Component
public interface ApplicationComponent {
//指的将对象注入到那个地方,这里指的注入到MainActivity
void inject(MainActivity activity);
//指定将对象注入到什么位置,这里值注入到SingleInstance中
void inject(SingleInstance activity);
}
//TODO 被注入的类
public class MainActivity extends AppCompatActivity {
@Inject
SingleInstance instance;
@Inject
User user;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
DaggerApplicationComponent.create().inject(this);
Log.i("TAG", "instance == " + instance);
Log.i("TAG", "user == " + user);
}
}
2. 小结
- 在需要注入的地方通过
@Inject注解进行标记。 @Component修饰的是一个接口,并在该接口中提供一个将对象注入到哪里的方法。示例中为注入MainActivity和SingleInstance两个类中。- 需要在自定义类的构造函数通过
@Inject注解进行修饰。 - 关键一步是将Component注入到目标类中,在需要实现注入的地方调用由
@Component修饰的接口生成的对应的类。名字规则为Dagger+被@Component修饰的接口名代码为DaggerApplicationComponent.create().inject(this);。
2. 第二种实现方式
第三方库可以Module+主Component的方式实现。该种方式解决对第三方库的初始化。
@Module
public class HttpModule {
//TODO 在module提供实例
@NetScope
@Provides
String providerUrl() {
return "http://www.baidu.com";
}
@NetScope
@Provides
GsonConverterFactory providerGsonConverterFactory() {
return GsonConverterFactory.create();
}
@NetScope
@Provides
RxJava2CallAdapterFactory providerRxjava2CallAdapterFactory() {
return RxJava2CallAdapterFactory.create();
}
/**
* 1. 这里可以通过作用域限制实例使用的范围,这里的作用域必须和自己的Component使用的一样。
* 2. 一个Component只能有一个作用域修饰符。
*
* @return
*/
@NetScope
@Provides
OkHttpClient providerOkHttpClient() {
return new OkHttpClient.Builder()
//TODO 这里可以添加各种拦截器
.build();
}
@NetScope
@Provides
Retrofit providerRetrofit(String url,
OkHttpClient okHttpClient,
GsonConverterFactory gsonConverterFactory,
RxJava2CallAdapterFactory rxJava2CallAdapterFactory) {
return new Retrofit.Builder()
.baseUrl(url)
.client(okHttpClient)
.addConverterFactory(gsonConverterFactory)
.addCallAdapterFactory(rxJava2CallAdapterFactory)
.build();
}
@NetScope
@Provides
ApiService providerApiService(Retrofit retrofit) {
return retrofit.create(ApiService.class);
}
}
@Module
public class DaoModule {
@Name01
@Provides
Student providerStudent01() {
return new Student("tom01");
}
@Name02
@Provides
Student providerStudent02() {
return new Student("tom02", 20);
}
@Named("threeParam")
@Provides
Student providerStudent03() {
return new Student("tom03", 20, 1);
}
}
//NetScope这里的直接是为了限制其作用域
@NetScope
@Component(modules = {HttpModule.class,DaoModule.class})//装载多个Module
public interface HttpComponent {
void inject(MainActivity activity);
}
//被注入的类
public class MainActivity extends AppCompatActivity {
@Inject
ApiService apiService;
@Inject
ApiService apiService2;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
DaggerHttpComponent.builder()
.build()
.inject(this);
Log.i(" TAG", "apiService === " + apiService);
Log.i(" TAG", "apiService2 === " + apiService2);
}
}
小结
- 通过Module提供了创建实例的方法。这里的
@NetScope用于限制了创建实例的作用域。 providerRetrofit方法中的参数是由其他几个方法提供的,如果没有提供@Providers修饰的方法提供实例外,Dagger2会去找被@Inject修饰的构造方法创建实例,如果都没有提供方法参数的实例则会报错。- 如果相同的类型创建不同的对象可以使用
@Named注解解决. @NetScope注解用来使用限定作用域。
3. 第三种实现方式
通过多组件实现相互依赖并提供实例。
//提供了全局的组件
@Component(modules = UserModule.class)
public interface ApplicationComponent {
User createUser();//通过这种方式需要将UserModule中的参数暴露出来,需要提供要暴露出来的相关方法。
// HttpComponent createHttpComponent();
}
//提供基础的实例
@BaseHttpScope
@Component(modules = BaseHttpModule.class, dependencies = ApplicationComponent.class)
public interface BaseHttpComponent {
//TODO 在其他子组件需要依赖时,需要将对应的方法暴露出来
Retrofit providerRetrofit();
}
//这里依赖了BaseHttpComponent组件中提供的实例
@NetScope
@Component(modules = ApiServiceModule.class, dependencies = BaseHttpComponent.class)
public interface ApiServiceComponent {
void inject(MainActivity activity);
}
//具体的实现注入的地方的初始化
public class MainActivity extends AppCompatActivity {
@Inject
ApiService apiService;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
DaggerApiServiceComponent.builder()
.baseHttpComponent(DaggerBaseHttpComponent.builder()
.applicationComponent(DaggerApplicationComponent.create())
.build()).build()
.inject(this);
Log.i("TAG", "apiService == " + apiService);
}
}
小结
- 这里需要注意的是
ApiServiceComponent组件依赖BaseHttpComponent组件,BaseHttpComponent组件以来的是ApplicationComponent组件,结果就是在注入的地方如
DaggerApiServiceComponent.builder()
.baseHttpComponent(DaggerBaseHttpComponent.builder()
.applicationComponent(DaggerApplicationComponent.create())
.build()).build()
.inject(this);
- 需要被子组件使用的实例需要在
XXComponent中暴露出来,如果没有暴露出来会去找被@Inject修饰的构造方法创建实例,如果没有找到则会报错。不能提供对应的实例。
4. 第四种实现方式
跟上面多个Component提供创建实例时,如果在子组件中需要使用父组件中提供的实例,父组件需要手动暴露出提供对应实例的方法。
@Module
public class ApiServiceModule {
//TODO 在module提供实例
@NetScope
@Provides
String providerUrl() {
return "http://www.baidu.com";
}
@NetScope
@Provides
GsonConverterFactory providerGsonConverterFactory() {
return GsonConverterFactory.create();
}
@NetScope
@Provides
RxJava2CallAdapterFactory providerRxjava2CallAdapterFactory() {
return RxJava2CallAdapterFactory.create();
}
/**
* 1. 这里可以通过作用域限制实例使用的范围,这里的作用域必须和自己的Component使用的一样。
* 2. 一个Component只能有一个作用域修饰符。
*
* @return
*/
@NetScope
@Provides
OkHttpClient providerOkHttpClient() {
return new OkHttpClient.Builder()
//TODO 这里可以添加各种拦截器
.build();
}
@NetScope
@Provides
Retrofit providerRetrofit(String url,
OkHttpClient okHttpClient,
GsonConverterFactory gsonConverterFactory,
RxJava2CallAdapterFactory rxJava2CallAdapterFactory) {
return new Retrofit.Builder()
.baseUrl(url)
.client(okHttpClient)
.addConverterFactory(gsonConverterFactory)
.addCallAdapterFactory(rxJava2CallAdapterFactory)
.build();
}
@NetScope
@Provides
ApiService providerApiService(Retrofit retrofit) {
return retrofit.create(ApiService.class);
}
}@NetScope
@Subcomponent(modules = ApiServiceModule.class)
public interface ApiServiceComponent {
@Subcomponent.Factory
interface Factory {
ApiServiceComponent create();
}
void inject(MainActivity activity);
}@Module(subcomponents = ApiServiceComponent.class)
public class ApiServiceComponentModule {
}
@Component(modules = {ApiServiceComponentModule.class})
public interface ApplicationComponent {
//这里在主组件中需要把子组件暴露出来
ApiServiceComponent.Factory createApiServiceComponent();
}
public class MainActivity extends AppCompatActivity {
@Inject
ApiService apiService;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
DaggerApplicationComponent.create()
.createApiServiceComponent()
.create()
.inject(this);
Log.i("TAG", "apiService == " + apiService);
}
}小结
- 这里需要注意的一点是SubComponent装载到主组件中时需要使用一个Module链接。
其他几个使用方法Binds和Lazy 参考demo app05
@Module
public abstract class DaoModule {
/**
* 这里的参数类型决定了调用哪一个实现方法
*
* @param impl01
* @return
*/
@Binds
public abstract BInterface bindBInterface01(Impl01 impl01);
@Provides
static Impl01 providerBInterface01() {
return new Impl01();
}
@Provides
static Impl02 providerBInterface02() {
return new Impl02();
}
}
public class MainActivity extends AppCompatActivity {
@Inject
BInterface impl01;
@Inject
Lazy<BInterface> impl02;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
DaggerApplicationComponent.create()
.inject(this);
Log.i("TAG", "impl01 === " + impl01.getClass().getSimpleName());
Log.i("TAG", "impl02 === " + impl02.getClass().getSimpleName());
Log.i("TAG", "impl02 impl02.get()=== " + impl02.get().getClass().getSimpleName());
}
}
参考资料
demo地址
链接:https://juejin.cn/post/7161042640048226312
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 13这些权限废弃,你的应用受影响了吗?
无论是更改个人头像、分享照片、还是在电子邮件中添加附件,选择和分享媒体文件是用户最常见的操作之一。在听取了 Android 用户反馈之后,我们对应用程序访问媒体文件的方式做了一些改变。
Android 13 已被废弃的权限
许多用户告诉我们,文件和媒体权限让他们很困扰,因为他们不知道应用程序想要访问哪些文件。
在 Android 13 上废弃了 READ_EXTERNAL_STORAGE 和 WRITE_EXTERNAL_STORAGE 权限,用更好的文件访问方式代替这些废弃的 API。
从 Android 10 开始向共享存储中添加文件不需要任何权限。因此,如果你的 App 只在共享存储中添加文件,你可以停止在 Android 10+ 上申请任何权限。
在之前的系统版本中 App 需要申请 READ_EXTERNAL_STORAGE 权限访问设备的文件和媒体,然后选择自己的媒体选择器,这为开发者增加了开发和维护成本,另外 App 依赖于通过 ACTION_GET_CONTENT 或者 ACTION_OPEN_CONTENT 的系统文件选择器,但是我们从开发者那里了解到,它感觉没有很好地集成到他们的 App 中。
图片选择器
在 Android 13 中,我们引入了一个新的媒体工具 Android 照片选择器。该工具为用户提供了一种选择媒体文件的方法,而不需要授予对其整个媒体库的访问权限。
它提供了一个简洁界面,展示照片和视频,按照日期排序。另外在 "Albums" 页面,用户可以按照屏幕截图或下载等等分类浏览,通过指定一些用户是否仅看到照片或视频,也可以设置选择最大文件数量,也可以根据自己的需求定制照片选择器。简而言之,这个照片选择器是为私人设计的,具有干净和简洁的 UI 易于实现。
我们还通过谷歌 Play 系统更新 (2022 年 5 月 1 日发布),将照片选择器反向移植到 Android 11 和 12 上,以将其带给更多的 Android 用户。
开发一个照片选择器是一个复杂的项目,新的照片选择器不需要团队进行任何维护。我们已经在 ActivityX 1.6.0 版本中为它创建了一个 ActivityResultContract。如果照片选择器在你的系统上可用,将会优先使用照片选择器。
// Registering Photo Picker activity launcher with a max limit of 5 items
val pickMultipleVisualMedia = registerForActivityResult(PickMultipleVisualMedia(5)) { uris ->
// TODO: process URIs
}
// Launching the photo picker (photos & video included)
pickMultipleVisualMedia.launch(PickVisualMediaRequest(PickVisualMedia.ImageAndVideo))
如果希望添加类型进行筛选,可以采用这种方式。
// Launching the photo picker (photos only)
pickMultipleVisualMedia.launch(PickVisualMediaRequest(PickVisualMedia.ImageOnly))
// Launching the photo picker (video only)
pickMultipleVisualMedia.launch(PickVisualMediaRequest(PickVisualMedia.VideoOnly))
// Launching the photo picker (GIF only)
pickMultipleVisualMedia.launch(PickVisualMediaRequest(PickVisualMedia.SingleMimeType("image/gif")))可以调用 isPhotoPickerAvailable 方法来验证在当前设备上照片选择器是否可用。
ACTION_GET_CONTENT 将会发生改变
正如你所见,使用新的照片选择器只需要几行代码。虽然我们希望所有的 Apps 都使用它,但在 App 中迁移可能需要一些时间。
这就是为什么我们使用 ACTION_GET_CONTENT 将系统文件选择器转换为照片选择器,而不需要进行任何代码更改,从而将新的照片选择器引入到现有的 App 中。
针对特定场景的新权限
虽然我们强烈建议您使用新的照片选择器,而不是访问所有媒体文件,但是您的 App 可能有一个场景,需要访问所有媒体文件(例如图库照片备份)。对于这些特定的场景,我们将引入新的权限,以提供对特定类型的媒体文件的访问,包括图像、视频或音频。您可以在文档中阅读更多关于它们的内容。
如果用户之前授予你的应用程序 READ_EXTERNAL_STORAGE 权限,系统会自动授予你的 App 访问权限。否则,当你的 App 请求任何新的权限时,系统会显示一个面向用户的对话框。
所以您必须始终检查是否仍然授予了权限,而不是存储它们的授予状态。
下面的决策树可以帮助您更好的浏览这些更改。
我们承诺在保护用户隐私的同时,继续改进照片选择器和整体存储开发者体验,以创建一个安全透明的 Android 生态系统。
新的照片选择器被反向移植到所有 Android 11 和 12 设备,不包括 Android Go 和非 gms 设备。
链接:https://juejin.cn/post/7161230716838084616
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一些有用的技巧帮助你开发 flutter
前言
你好今天给你带来了些有用的建议,让我们开始吧。
正文
1. ElevatedButton.styleFrom 快速样式
你是否厌倦了 container 里那些乏味的 decorations ,想要轻松实现这个美丽的按钮别担心,我给你准备了一些魔法密码。
示例代码
SizedBox(
height: 45,
width: 200,
child: ElevatedButton(
onPressed: () {},
style: ElevatedButton.styleFrom(
elevation: 10, shape: const StadiumBorder()),
child: const Center(child: Text('Elevated Button')),
),
),示例代码
SizedBox(
height: 45,
width: 60,
child: ElevatedButton(
onPressed: () {},
style: ElevatedButton.styleFrom(
elevation: 10, shape: const CircleBorder()),
child: const Center(child: Icon(Icons.add)),
),
),2. TextInputAction.next 焦点切换
你们都知道“焦点节点”。这基本上是用来识别 Flutter 的“焦点树”中特定的 TextField 这允许您在接下来的步骤中将焦点放在 TextField 上。但你知道 Flutter 提供了一个神奇的一行代码同样..。
示例代码
Padding(
padding: const EdgeInsets.all(30.0),
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
TextFormField(
textInputAction: TextInputAction.next,
),
const SizedBox(
height: 50,
),
TextFormField(
textInputAction: TextInputAction.next,
),
const SizedBox(
height: 50,
),
TextFormField(
textInputAction: TextInputAction.done,
),
const SizedBox(
height: 50,
),
],
),
);3. 设置 status Bar 状态栏颜色
你的状态栏颜色破坏了你的页面外观吗? 让我们改变它..。
示例代码
void main() {
WidgetsFlutterBinding.ensureInitialized();
SystemChrome.setSystemUIOverlayStyle(const SystemUiOverlayStyle(
statusBarColor: Colors.transparent, // transparent status bar
));
runApp(const MyApp());
}4.设置 TextStyle.height 段落间距
如果您在页面上显示了一个段落(例如: 产品描述、关于我们的内容等) ,并且它看起来不如 xd 设计那么好!使用这个神奇的代码,使它有吸引力和顺利。
示例代码
Text(
'Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.',
style: TextStyle(
fontSize: 17.0,
height: 1.8,
),
)5. 设置文字 3D
想让你的“标题”文字更有吸引力吗? 给它一个有阴影的 3D 效果..。
示例代码
Center(
child: Text(
'Hello, world!',
style: TextStyle(
fontSize: 50,
color: Colors.pink,
fontWeight: FontWeight.w900,
shadows: <Shadow>[
const Shadow(
offset: Offset(4.0, 4.0),
blurRadius: 3.0,
color: Color.fromARGB(99, 64, 64, 64),
),
Shadow(
offset: const Offset(1.0, 1.0),
blurRadius: 8.0,
color: Colors.grey.shade100),
],
),
),
)6. vscode 插件 Pubspec Assist
你知道 Flutter extensions 吗?你当然是! !我正在分享我最喜欢的 Flutter extensions..。
Pubspec Assist 是一个 VisualStudio 代码扩展,它允许您轻松地向 Dart 和 Flutter 项目的 Pubspec 添加依赖项。Yaml 不需要你编辑。你必须试试。
7. 应用 app 尺寸控制
Application 大小很重要!应用程序大小的 Flutter 应用程序是非常重要的。当它是一个更大的应用程序时,尺寸变得更加重要,因为你需要在设备上有更多的空间。更大的应用程序下载时间也更长。它扩大了 Flutter 应用程序,可以是两个、三个或更多的安装尺寸。因此,在 Android 平台上减小 Flutter 应用程序的大小是非常重要的。
这里有一些减小 Flutter 应用程序大小的技巧 ~ ~ ~
- 减小应用程序元素的大小
- 压缩所有 JPEG 和 PNG 文件
- 使用谷歌字体
- 在 Android Studio 中使用 Analyzer
- 使用命令行中的分析 Analyzer
- 减少资源数量和规模
- 使用特定的 Libraries
谢谢你的阅读...
链接:https://juejin.cn/post/7161311014007341093
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android性能优化 -- 内存优化
内存,是Android应用的生命线,一旦在内存上出现问题,轻者内存泄漏,重者直接crash,因此一个应用保持健壮,内存这块的工作是持久战,而且从写代码这块就需要注意合理性,所以想要了解内存优化如何去做,要先从基础知识开始。
1 JVM内存原理
这一部分确实很枯燥,但是对于我们理解内存模型非常重要,这一块也是面试的常客
从上图中,我将JVM的内存模块分成了左右两大部分,左边属于共享区域(方法区、堆区),所有的线程都能够访问,但也会带来同步问题,这里就不细说了;右边属于私有区域,每个线程都有自己独立的区域。
1.1 方法执行流程
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
execute()
}
private fun execute(){
val a = 2.5f
val b = 2.5f
val c = a + b
val method = Method()
val d = getD()
}
private fun getD(): Int {
return 0
}
}
class Method{
private var a:Int = 0
}我们看到在MainActivity的onCreate方法中,执行了execute方法,因为当前是UI线程,每个线程都有一个Java虚拟机栈,从上图中可以看到,那么每执行一个方法,在Java虚拟机栈中都对应一个栈帧。
每次调用一个方法,都代表一个栈帧入栈,当onCreate方法执行完成之后,会执行execute方法,那么我们看下execute方法。
execute方法在Java虚拟机栈中代表一个栈帧,栈帧是由四部分组成:
(1)局部变量表:局部变量是声明在方法体内的,例如a,b,c,在方法执行完成之后,也会被回收;
(2)操作数栈:在任意方法中,涉及到变量之间运算等操作都是在操作数栈中进行;例如execute方法中:
val a = 2.5f
当执行这句代码时,首先会将 2.5f压入操作数栈,然后给a赋值,依次类推
(3)返回地址:例如在execute调用了getD方法,那么这个方法在执行到到return的时候就结束了,当一个方法结束之后,就要返回到该方法的被调用处,那么该方法就携带一个返回地址,告诉JVM给谁赋值,然后通过操作数栈给d赋值
(4)动态链接:在execute方法中,实例化了Method类,在这里,首先会给Method中的一些静态变量或者方法进行内存分配,这个过程可以理解为动态链接。
1.2 从单例模式了解对象生命周期
单例模式,可能是众多设计模式中,我们使用最频繁的一个,但是单例真是就这么简单吗,使用不慎就会造成内存泄漏!
interface IObserver {
fun send(msg:String)
}class Observable : IObserver {
private val observers: MutableList<IObserver> by lazy {
mutableListOf()
}
fun register(observer: IObserver) {
observers.add(observer)
}
fun unregister(observer: IObserver) {
observers.remove(observer)
}
override fun send(msg: String) {
observers.forEach {
it.send(msg)
}
}
companion object {
val instance: Observable by lazy {
Observable()
}
}
}这里是写了一个观察者,这个被观察者是一个单例,instance是存放在方法区中,而创建的Observable对象则是存在堆区,看下图
因为方法区属于常驻内存,那么其中的instance引用会一直跟堆区的Observable连接,导致这个单例对象会存在很长的时间
btnRegister.setOnClickListener {
Observable.instance.register(this)
}
btnSend.setOnClickListener {
Observable.instance.send("发送消息")
}在MainActivity中,点击注册按钮,注意这里传入的值,是当前Activity,那么这个时候退出,会发生什么?我们先从profile工具里看一下,退出之后,有2个内存泄漏的地方,如果使用的leakcannary(后面会介绍)就应该会明白
那么在MainActivity中,哪个地方发生的了内存泄漏呢?我们紧跟一下看看GcRoot的引用,发现有这样一条引用链,MainActivity在一个list数组中,而且这个数组是Observable中的observers,而且是被instance持有,前面我们说到,instance的生命周期很长,所以当Activity准备被销毁时,发现被instance持有导致回收失败,发生了内存泄漏。
那么这种情况,我们该怎么处理呢?一般来说,有注册就有解注册,所以我们在封装的时候一定要注意单例中传入的参数
override fun onDestroy() {
super.onDestroy()
Observable.instance.unregister(this)
}再次运行我们发现,已经不存在内存泄漏了
1.3 GcRoot
前面我们提到了,因为instance是Gcroot,导致其引用了observers,observers引用了MainActivity,MainActivity退出的时候没有被回收,那么什么样的对象能被看做是GcRoot呢?
(1)静态变量、常量:例如instance,其内存是在方法区的,在方法区一般存储的都是静态的常量或者变量,其生命周期非常长;
(2)局部变量表:在Java虚拟机栈的栈帧中,存在局部变量表,为什么局部变量表能作为gcroot,原因很简单,我们看下面这个方法
private fun execute() {
val a = 2.5f
val method = Method()
val d = getD()
}a变量就是一个局部变量表中的成员,我们想一下,如果a不是gcroot,那么垃圾回收时就有可能被回收,那么这个方法还有什么意义呢?所以当这个方法执行完成之后,gcroot被回收,其引用也会被回收。
2 OOM
在之前我们简单介绍了内存泄漏的场景,那么内存泄漏一旦发生,就会导致OOM吗?其实并不是,内存泄漏一开始并不会导致OOM,而是逐渐累计的,当内存空间不足时,会造成卡顿、耗电等不良体验,最终就会导致OOM,app崩溃
那么什么情况下会导致OOM呢?
(1)Java堆内存不足
(2)没有连续的内存空间
(3)线程数超出限制
其实以上3种状况,前两种都有可能是内存泄漏导致的,所以如何避免内存泄漏,是我们内存优化的重点
2.1 leakcanary使用
首先在module中引入leakcanary的依赖,关于leakcanary的原理,之后会单独写一篇博客介绍,这里我们的主要工作是分析内存泄漏
debugImplementation 'com.squareup.leakcanary:leakcanary-android:2.7'
配置依赖之后,重新运行项目,会看到一个leaks app,这个app就是用来监控内存泄漏的工具
那我们执行之前的应用,打开leaks看一下gcroot的引用,是不是跟我们在as的profiler中看到的是一样的
如果使用过leakcanary的伙伴们应该知道,leakcanary会生成一个hprof文件,那么通过MAT工具,可以分析这个hprof文件,查找内存泄漏的位置,下面的链接能够下载MAT工具
http://www.eclipse.org/mat/downloa…
2.2 内存泄漏的场景
1. 资源性的对象没有关闭
例如,我们在做一个相机模块,通过camera拿到了一帧图片,通常我们会将其转换为bitmap,在使用完成之后,如果没有将其回收,那么就会造成内存泄漏,具体使用完该怎么办呢?
if(bitmap != null){
bitmap?.recycle()
bitmap = null
}调用bitmap的recycle方法,然后将bitmap置为null
2. 注册的对象没有注销
这种场景其实我们已经很常见了,在之前也提到过,就是注册跟反注册要成对出现,例如我们在注册广播接收器的时候,一定要记得,在Activity销毁的时候去解注册,具体使用方式就不做过多的赘述。
3. 类的静态变量持有大数据量对象
因为我们知道,类的静态变量是存储在方法区的,方法区空间有限而且生命周期长,如果持有大数据量对象,那么很难被gc回收,如果再次向方法区分配内存,会导致没有足够的空间分配,从而导致OOM
4. 单例造成的内存泄漏
这个我们在前面已经有一个详细的介绍,因为我们在使用单例的时候,经常会传入context或者activity对象,因为有上下文的存在,导致单例持有不能被销毁;
因此在传入context的时候,可以传入Application的context,那么单例就不会持有activity的上下文可以正常被回收;
如果不能传入Application的context,那么可以通过弱引用包装context,使用的时候从弱引用中取出,但这样会存在风险,因为弱引用可能随时被系统回收,如果在某个时刻必须要使用context,可能会带来额外的问题,因此根据不同的场景谨慎使用。
object ToastUtils {
private var context:Context? = null
fun setText(context: Context) {
this.context = context
Toast.makeText(context, "1111", Toast.LENGTH_SHORT).show()
}
}我们看下上面的代码,ToastUtils是一个单例,我们在外边写了一个context:Context? 的引用,这种写法是非常危险的,因为ToastUtils会持有context的引用导致内存泄漏
object ToastUtils {
fun setText(context: Context) {
Toast.makeText(context, "1111", Toast.LENGTH_SHORT).show()
}
}5. 非静态内部类的静态实例
我们先了解下什么是静态内部类和非静态内部类,首先只有内部类才能设置为静态类,例如
class MainActivity : AppCompatActivity() {
private var a = 10
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main2)
}
inner class InnerClass {
fun setA(code: Int) {
a = code
}
}
}InnerClass是一个非静态内部类,那么在MainActivity声明了一个变量a,其实InnerClass是能够拿到这个变量,也就是说,非静态内部类其实是对外部类有一个隐式持有,那么它的静态实例对象是存储在方法区,而且该对象持有MainActivity的引用,导致退出时无法被释放。
解决方式就是:将InnerClass设置为静态类
class InnerClass {
fun setA(code: Int) {
a = code //这里就无法使用外部类的对象或者方法
}
}大家如果对于kotlin不熟悉的话,就简单介绍一下,inner class在java中就是非静态的内部类;而直接用class修饰,那么就相当于Java中的 public static 静态内部类。
6. Handler
这个可就是老生常谈了,如果使用过Handler的话都知道,它非常容易产生内存泄漏,具体的原理就不说了,感觉现在用Handler真的越来越少了
其实说了这么多,真正在写代码的时候,不能真正的避免,接下来我就使用leakcanary来检测某个项目中存在的内存泄漏问题,并解决
3 从实际项目出发,根除内存泄漏
1. 单例引发的内存泄漏
我们从gcroot中可以看到,在TeachAidsCaptureImpl中传入了LifeCycleOwner,LifeCycleOwner大家应该熟悉,能够监听Activity或者Fragment的生命周期,然后CaptureModeManager是一个单例,传入的mode就是TeachAidsCaptureImpl,这样就会导致一个问题,单例的生命周期很长,Fragment被销毁的时候因为TeachAidsCaptureImpl持有了Fragment的引用,导致无法销毁
fun clear() {
if (mode != null) {
mode = null
}
}所以,在Activity或者Fragment销毁前,将model置为空,那么内存泄漏就会解决了,直到看到这个界面,那么我们的应用就是安全的了
2.使用Toast引发的内存泄漏
在我们使用Toast的时候,需要传入一个上下文,我们通常会传入Activity,那么这个上下文给谁用的呢,在Toast中也有View,如果我们自定过Toast应该知道,那么如果Toast中的View持有了Activity的引用,那么就会导致内存泄漏
Toast.makeText(this,"Toast内存泄漏",Toast.LENGTH_SHORT).show()
那么怎样避免呢?传入Application的上下文,就不会导致Activity不被回收。
链接:https://juejin.cn/post/7134252767379456014
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
线上kafka消息堆积,consumer掉线,怎么办?
线上kafka消息堆积,所有consumer全部掉线,到底怎么回事?
最近处理了一次线上故障,具体故障表现就是kafka某个topic消息堆积,这个topic的相关consumer全部掉线。
整体排查过程和事后的复盘都很有意思,并且结合本次故障,对kafka使用的最佳实践有了更深刻的理解。
好了,一起来回顾下这次线上故障吧,最佳实践总结放在最后,千万不要错过。
1、现象
- 线上kafka消息突然开始堆积
- 消费者应用反馈没有收到消息(没有处理消息的日志)
- kafka的consumer group上看没有消费者注册
- 消费者应用和kafka集群最近一周内没有代码、配置相关变更
2、排查过程
服务端、客户端都没有特别的异常日志,kafka其他topic的生产和消费都是正常,所以基本可以判断是客户端消费存在问题。
所以我们重点放在客户端排查上。
1)arthas在线修改日志等级,输出debug
由于客户端并没有明显异常日志,因此只能通过arthas修改应用日志等级,来寻找线索。
果然有比较重要的发现:
2022-10-25 17:36:17,774 DEBUG [org.apache.kafka.clients.consumer.internals.AbstractCoordinator] - [Consumer clientId=consumer-1, groupId=xxxx] Disabling heartbeat thread
2022-10-25 17:36:17,773 DEBUG [org.apache.kafka.clients.consumer.internals.AbstractCoordinator] - [Consumer clientId=consumer-1, groupId=xxxx] Sending LeaveGroup request to coordinator xxxxxx (id: 2147483644 rack: null)
看起来是kafka-client自己主动发送消息给kafka集群,进行自我驱逐了。因此consumer都掉线了。
2)arthas查看相关线程状态变量
用arthas vmtool命令进一步看下kafka-client相关线程的状态。
可以看到 HeartbeatThread线程状态是WAITING,Cordinator状态是UNJOINED。
此时,结合源码看,大概推断是由于消费时间过长,导致客户端自我驱逐了。
于是立刻尝试修改max.poll.records,减少一批拉取的消息数量,同时增大max.poll.interval.ms参数,避免由于拉取间隔时间过长导致自我驱逐。
参数修改上线后,发现consumer确实不掉线了,但是消费一段时间后,还是就停止消费了。
3、最终原因
相关同学去查看了消费逻辑,发现了业务代码中的死循环,确认了最终原因。
消息内容中的一个字段有新的值,触发了消费者消费逻辑的死循环,导致后续消息无法消费。
消费阻塞导致消费者自我驱逐,partition重新reblance,所有消费者逐个自我驱逐。
这里核心涉及到kafka的消费者和kafka之间的保活机制,可以简单了解一下。
kafka-client会有一个独立线程HeartbeatThread跟kafka集群进行定时心跳,这个线程跟lisenter无关,完全独立。
根据debug日志显示的“Sending LeaveGroup request”信息,我们可以很容易定位到自我驱逐的逻辑。
HeartbeatThread线程在发送心跳前,会比较一下当前时间跟上次poll时间,一旦大于max.poll.interval.ms 参数,就会发起自我驱逐了。
4、进一步思考
虽然最后原因找到了,但是回顾下整个排查过程,其实并不顺利,主要有两点:
- kafka-client对某个消息消费超时能否有明确异常?而不是只看到自我驱逐和rebalance
- 有没有办法通过什么手段发现 消费死循环?
4.1 kafka-client对某个消息消费超时能否有明确异常?
4.1.1 kafka似乎没有类似机制
我们对消费逻辑进行断点,可以很容易看到整个调用链路。
对消费者来说,主要采用一个线程池来处理每个kafkaListener,一个listener就是一个独立线程。
这个线程会同步处理 poll消息,然后动态代理回调用户自定义的消息消费逻辑,也就是我们在@KafkaListener中写的业务。
所以,从这里可以知道两件事情。
第一点,如果业务消费逻辑很慢或者卡住了,会影响poll。
第二点,这里没有看到直接设置消费超时的参数,其实也不太好做。
因为这里做了超时中断,那么poll也会被中断,是在同一个线程中。所以要么poll和消费逻辑在两个工作线程,要么中断掉当前线程后,重新起一个线程poll。
所以从业务使用角度来说,可能的实现,还是自己设置业务超时。比较通用的实现,可以是在消费逻辑中,用线程池处理消费逻辑,同时用Future get阻塞超时中断。
google了一下,发现kafka 0.8 曾经有consumer.timeout.ms这个参数,但是现在的版本没有这个参数了,不知道是不是类似的作用。
4.1.2 RocketMQ有点相关机制
然后去看了下RocketMQ是否有相关实现,果然有发现。
在RocketMQ中,可以对consumer设置consumeTimeout,这个超时就跟我们的设想有一点像了。
consumer会启动一个异步线程池对正在消费的消息做定时做 cleanExpiredMsg() 处理。
注意,如果消息类型是顺序消费(orderly),这个机制就不生效。
如果是并发消费,那么就会进行超时判断,如果超时了,就会将这条消息的信息通过sendMessageBack() 方法发回给broker进行重试。
如果消息重试超过一定次数,就会进入RocketMQ的死信队列。
spring-kafka其实也有做类似的封装,可以自定义一个死信topic,做异常处理
4.2 有没有办法通过什么手段快速发现死循环?
一般来说,死循环的线程会导致CPU飙高、OOM等现象,在本次故障中,并没有相关异常表现,所以并没有联系到死循环的问题。
那通过这次故障后,对kafka相关机制有了更深刻了解,poll间隔超时很有可能就是消费阻塞甚至死循环导致。
所以,如果下次出现类似问题,消费者停止消费,但是kafkaListener线程还在,可以直接通过arthas的 thread id 命令查看对应线程的调用栈,看看是否有异常方法死循环调用。
5、最佳实践
通过此次故障,我们也可以总结几点kafka使用的最佳实践:
使用消息队列进行消费时,一定需要多考虑异常情况,包括幂等、耗时处理(甚至死循环)的情况。
尽量提高客户端的消费速度,消费逻辑另起线程进行处理,并最好做超时控制。
减少Group订阅Topic的数量,一个Group订阅的Topic最好不要超过5个,建议一个Group只订阅一个Topic。
参考以下说明调整参数值:max.poll.records:降低该参数值,建议远远小于<单个线程每秒消费的条数> * <消费线程的个数> * <max.poll.interval.ms>的积。max.poll.interval.ms: 该值要大于<max.poll.records> / (<单个线程每秒消费的条数> * <消费线程的个数>)的值。
链接:https://juejin.cn/post/7161300002403254308
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
深入学习 Kotlin 特色之 Sealed Class 和 Interface
前言
sealed class 以及 1.5 里新增的 sealed interface 可谓是 Kotlin 语言的一大特色,其在类型判断、扩展和实现的限制场景里非常好用。
本文将从特点、场景和原理等角度综合分析 sealed 语法。
- Sealed Class
- Sealed Interface
- Sealed Class & Interface VS Enum
- Sealed Class VS Interface
🏁 Sealed Class
sealed class,密封类。具备最重要的一个特点:
- 其子类可以出现在定义 sealed class 的不同文件中,但不允许出现在与不同的
module中,且需要保证package一致
这样既可以避免 sealed class 文件过于庞大,又可以确保第三方库无法扩展你定义的 sealed class,达到限制类的扩展目的。事实上在早期版本中,只允许在 sealed class 内部或定义的同文件内扩展子类,这些限制在 Kotlin 1.5 中被逐步放开。
如果在不同 module 或 package 中扩展子类的话,IDE 会显示如下的提示和编译错误:
Inheritor of sealed class or interface declared in package xxx but it must be in package xxx where base class is declared
sealed class 还具有如下特点或限制:
sealed class 是抽象类,可以拥有抽象方法,无法直接实例化。否则,编译器将提示如下:
Sealed types cannot be instantiated
sealed class 的构造函数只能拥有两种可见性:默认情况下是
protected,还可以指定成 private,public 是不被允许的。Constructor must be private or protected in sealed class
sealed class 子类可扩展局部以及匿名类以外的任意类型子类,包括普通 class、
data class、object、sealed class 等,子类信息在编译期可知。假使匿名类扩展自 sealed class 的话,会弹出错误提示:
This type is sealed, so it can be inherited by only its own nested classes or objects
sealed class 的实例,可配合
when表达式进行判断,当所有类型覆盖后可以省略else分支如果没有覆盖所有类型,也没有 else 统筹则会发生编译警告或错误
1.7 以前:
Non-exhaustive 'when' statements on sealed class/interface will be prohibited in 1.7.
1.7 及以后:
'when' expression must be exhaustive, add ...
当 sealed class 没有指定构造方法或定义任意属性的时候,建议子类定义成单例,因为即便实例化成多个实例,互相之间没有状态的区别:
'sealed' subclass has no state and no overridden 'equals()'
下面结合代码看下 sealed class 的使用和原理:
示例代码:
// TestSealed.kt
sealed class GameAction(times: Int) {
// Inner of Sealed Class
object Start : GameAction(1)
data class AutoTick(val time: Int) : GameAction(2)
class Exit : GameAction(3)
}除了在 sealed class 内嵌套子类外,还可以在外部扩展子类:
// TestSealed.kt
sealed class GameAction(times: Int) {
...
}
// Outer of Sealed Class
object Restart : GameAction(4)
除了可以在同文件下 sealed class 外扩展子类外,还可以在同包名不同文件下扩展。
// TestExtendedSealedClass.kt
// Outer of Sealed Class file
class TestExtendedSealedClass: GameAction(5)
对于不同类型的扩展子类,when 表达式的判断亦不同:
- 判断 sealed class 内部子类类型自然需要指定父类前缀
- object class 的话可以直接进行实例判断,也可以用
is关键字判断类型匹配 - 普通 class 类型的话则必须加上 is 关键字
- 判断 sealed class 外部子类类型自然无需指定前缀
class TestSealed {
fun test(gameAction: GameAction) {
when (gameAction) {
GameAction.Start -> {}
// is GameAction.Start -> {}
is GameAction.AutoTick -> {}
is GameAction.Exit -> {}
Restart -> {}
is TestExtendedSealedClass -> {}
}
}
}如下反编译的 Kotlin 代码可以看到 sealed class 本身被编译为 abstract class。
扩展自其的内部子类按类型有所不同:
- object class 在 class 内部集成了静态的
INSTANCE实例 - 普通 class 仍是普通 class
- data Class 则是在 class 内部集成了属性的
get、toString以及hashCode函数
public abstract class GameAction {
private GameAction(int times) { }
public GameAction(int times, DefaultConstructorMarker $constructor_marker) {
this(times);
}
// subclass:object
public static final class Start extends GameAction {
@NotNull
public static final GameAction.Start INSTANCE;
private Start() {
super(1, (DefaultConstructorMarker)null);
}
static {
GameAction.Start var0 = new GameAction.Start();
INSTANCE = var0;
}
}
// subclass:class
public static final class Exit extends GameAction {
public Exit() {
super(3, (DefaultConstructorMarker)null);
}
}
// subclass:data class
public static final class AutoTick extends GameAction {
private final int time;
public final int getTime() {
return this.time;
}
public AutoTick(int time) {
super(2, (DefaultConstructorMarker)null);
this.time = time;
}
...
@NotNull
public String toString() {
return "AutoTick(time=" + this.time + ")";
}
public int hashCode() { ... }
public boolean equals(@Nullable Object var1) { ... }
}
}而外部子类则自然是定义在 GameAction 抽象类外部。
public abstract class GameAction {
...
}
public final class Restart extends GameAction {
@NotNull
public static final Restart INSTANCE;
private Restart() {
super(4, (DefaultConstructorMarker)null);
}
static {
Restart var0 = new Restart();
INSTANCE = var0;
}
}文件外扩展子类可想而知。
public final class TestExtendedSealedClass extends GameAction {
public TestExtendedSealedClass() {
super(5, (DefaultConstructorMarker)null);
}
}🏴 Sealed Interface
sealed interface 即密封接口,和 sealed class 有几乎一样的特点。比如:
- 限制接口的实现:一旦含有包含 sealed interface 的 module 经过了编译,就无法再有扩展的实现类了,即对其他 module 隐藏了接口
还有些额外的优势:
帮助密封类、枚举类等类实现多继承和扩展性,比如搭配枚举,以处理更复杂的分类逻辑
Additionally, sealed interfaces enable more flexible restricted class hierarchies because a class can directly inherit more than one sealed interface.
比如 Flappy Bird 游戏的过程中会产生很多 Action 来触发数据的计算以推动 UI 刷新以及游戏的进程,Action 可以用 enum class 来管理。
其中有些 Action 是关联的,有些则没有关联、不是同一层级。但是 enum class 默认扩展自 Enum 类,无法再嵌套 enum。
Enum class cannot inherit from classes
这将导致层级混乱、阅读性不佳,甚至有的时候功能相近的时候还得特意取个不同的名称。
enum class Action {
Tick,
// GameAction
Start, Exit, Restart,
// BirdAction
Up, Down, HitGround, HitPipe, CrossedPipe,
// PipeAction
Move, Reset,
// RoadAction
// 防止和 Pipe 的 Action 重名导致编译出错,
// 将功能差不多的 Road 移动和重置 Action 定义加上了前缀
RoadMove, RoadReset
}
fun dispatch(action: Action) {
when (action) {
Action.Tick -> TODO()
Action.Start -> TODO()
Action.Exit -> TODO()
Action.Restart -> TODO()
Action.Up -> TODO()
Action.Down -> TODO()
Action.HitGround -> TODO()
Action.HitPipe -> TODO()
Action.CrossedPipe -> TODO()
Action.Move -> TODO()
Action.Reset -> TODO()
Action.RoadMove -> TODO()
Action.RoadReset -> TODO()
}
}借助 sealed interface 我们可以给抽出 interface,并将 enum 进行层级拆分。更加清晰、亦不用担心重名。
sealed interface Action
enum class GameAction : Action {
Start, Exit, Restart
}
enum class BirdAction : Action {
Up, Down, HitGround, HitPipe, CrossedPipe
}
enum class PipeAction : Action {
Move, Reset
}
enum class RoadAction : Action {
Move, Reset
}
object Tick: Action使用的时候就可以对抽成的 Action 进行嵌套判断:
fun dispatch(action: Action) {
when (action) {
Tick -> TODO()
is GameAction -> {
when (action) {
GameAction.Start -> TODO()
GameAction.Exit -> TODO()
GameAction.Restart -> TODO()
}
}
is BirdAction -> {
when (action) {
BirdAction.Up -> TODO()
BirdAction.Down -> TODO()
else -> TODO()
}
}
is PipeAction -> {
when (action) {
PipeAction.Move -> TODO()
PipeAction.Reset -> TODO()
}
}
is RoadAction -> {
when (action) {
RoadAction.Move -> TODO()
RoadAction.Reset -> TODO()
}
}
}
}
🤔 总结
1. Sealed Class & Interface VS Enum
总体来说 sealed class 和 interface 和 enum 有相近的地方,也有明显区别,需要留意:
- 每个 enum 常量只能以单例的形式存在
- sealed class 子类可以拥有多个实例,不受限制,每个均可以拥有自己的状态
- enum class 不能扩展自 sealed class 以及其他任何 Class,但他们可以实现 sealed 等 interface
2. Sealed Class VS Interface
Sealed classes and interfaces represent restricted class hierarchies that provide more control over inheritance.
sealed class 和 interface 都意味着受限的类层级结构,便于在继承和实现上进行更多控制。具备如下的共同特性:
- 其 sub class 需要定义在同一 Module 以及同一 package,不局限于 sealed 内部或同文件内
看下对比:
| Sealed | 适用/优势 | 原理 |
|---|---|---|
| Class | 限制类的扩展 | abstract class |
| Interface | 限制接口的实现 帮助类实现多继承和复杂的扩展性 | interface |
链接:https://juejin.cn/post/7160111185201725476
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
带你深入理解Flutter及Dart单线程模型
前言
大家好,我是未央歌,一个默默无闻的移动开发搬砖者~
众所周知,Java 是一种多线程语言,适量并合适地使用多线程,会极大提高资源利用率和运行效率,但缺点也明显,比如开启过多的线程会导致资源和性能的消耗过大以及多线程共享内存容易死锁。
而 Dart 则是一种单线程语言,单线程语言就意味着代码执行顺序是有序的,下面结合一个demo带大家深入了解单线程模型。
demo 示例
点击 APP 右下角的刷新按钮,会调用如下方法,读取一个约 2M 大小的 json 文件。
void loadAssetsJson() async {
var jsonStr = await DefaultAssetBundle.of(context).loadString("assets/list.json");
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
}如下图所示,点击刷新按钮之后,中间的 loading 会卡一下。很多同学一看这个代码就知道,肯定会卡,解析一个 2M 的文件,而且是同步解析,主页面肯定是会卡的。
那如果我换成异步解析呢?还卡不卡?大家可以脑海中思考下这个问题。
异步解析
void loadAssetsJson() async {
var jsonStr = await DefaultAssetBundle.of(context).loadString("assets/list.json");
// 异步解析
Future(() {
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
}).then((value) {});
}大家可以看到,我已经放在异步里解析了,为什么还是会卡呢?大家可以先思考下这个问题。
前面已经提到了 Dart 是一种单线程语言,单线程语言就意味着代码执行顺序是有序的。当然 Dart 也是支持异步的。这两点其实并不冲突。
Dart 线程解析
我们来看看 Dart 的线程,当我们 main() 方法启动之后,Dart已经开启了一个线程,这个线程的名字就叫 Isolate。每一个 Isolate 线程都包含了图示的两个队列,一个 Microtask queue,一个 Event queue。
如图,Isolate 线程会优先执行 Microtask queue 里的事件,当 Microtask queue 里的事件变成空了,才会去执行 Event queue 里的事件。如果正在执行 Microtask queue 里的事件,那么 Event queue 里的事件就会被阻塞,就会导致渲染、手势响应等都得不到响应(绘制图形,处理鼠标点击,处理文件IO等都是在 Event Queue 里完成)。
所以为了保证功能正常使用不卡顿,尽量少在 Microtask queue 做事情,可以放在 Event queue 做。
为什么单线程可以做一个异步操作呢?
- 因为 APP 只有在你滑动或者点击操作的时候才会响应事件。没有操作的时候进入等待时间,两个队列里都是空的。这个时间正是可以进行异步操作的,所以基于这个特点,单线程模型可以在等待过程中做一些异步操作,因为等待的过程并不是阻塞的,所以给我们的感觉就像同时在做多件事情,但自始至终只有一个线程在处理事情。
Future
当方法加上 async 关键字,就代表这个方法开启了一个异步操作,如果这个方法有返回值,就必须要返回一个 Future。
void loadAssetsJson() async {
var jsonStr = await DefaultAssetBundle.of(context).loadString("assets/list.json");
// 异步解析
Future(() {
...
}).then((value) {});
}一个 Future 异步任务的执行,相对简单。在我们声明一个 Future 之后,Dart 会将异步里的代码函数体放在 Event queue 里执行然后返回。这里注意下,Future 和 then 是放在同一个 Event queue 里的。
假设,我执行 Future 代码之后没有立即执行 then 方法,而是等 Future 执行之后5秒,才调用 then 方法,这时候还是放在同一个 Event queue 里吗?显然是不可能的,我们看一下源码是怎么实现的。
Future<R> then<R>(FutureOr<R> f(T value), {Function? onError}) {
...
_addListener(new _FutureListener<T, R>.then(result, f, onError));
return result;
}
bool get _mayAddListener => _state <= (_statePendingComplete | _stateIgnoreError);
void _addListener(_FutureListener listener) {
assert(listener._nextListener == null);
if (_mayAddListener) {
// 待完成
listener._nextListener = _resultOrListeners;
_resultOrListeners = listener;
} else {
// 已完成
...
_zone.scheduleMicrotask(() {
_propagateToListeners(this, listener);
});
}
}
可以看到 then 方法里有一个监听,Future 执行之后5秒才调用,很明显是已完成状态,走 else 那里的 scheduleMicrotask() 方法,就是说把 then 里面的方法放到 Microtask queue 里。
Future 为何卡顿
再来说一下刚刚的问题,我已经放在异步里解析了,为什么还是会卡呢?
其实很简单,Future 里的代码可能需要执行10s,也就是 Event queue 需要10s才能执行完。那这个10s内其他代码肯定就无法执行了。所以 Future 里的代码执行时间过长,还是会卡 UI 的。
以 Android 为例,Android的刷新频率是60帧/秒,Android系统中每隔16.6ms会发送一次 VSYNC(同步)信号,触发UI的渲染。所以我们就要考虑下,一旦代码执行时间超过16.6ms,到底应不应该放在 Future 里执行?
这时候是不是有同学有疑问,我网络请求也是用 Future 写的,为什么就不卡呢?
这个大家就需要注意一下,网络请求不是放在 Dart 层面执行的,它是由操作系统提供的异步线程去执行的,当这个异步执行完系统又返回给 Dart。所以即使 http 请求需要耗时十几秒,也不会感到卡顿。
compute
既然 Future 执行也会卡顿,那要怎么去优化呢?这时候我们可以开一个线程操作,Flutter 为我们封装好了一个 compute()方法,这个方法可以为我们开一个线程。我们用这个方法来优化一下代码,然后再看下执行效果。
void loadAssetsJson() async {
var jsonStr = await DefaultAssetBundle.of(context).loadString("assets/list.json");
var result = compute(parse,jsonStr);
}
static VideoListModel parse(String jsonStr){
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
VideoListModel.fromJson(json.decode(jsonStr));
return VideoListModel.fromJson(json.decode(jsonStr));
}可以看到此时点击刷新按钮,已经不再卡顿了。遇到一些耗时的操作,这确实是一种比较好的解决方式。
我们再看看 DefaultAssetBundle.of(context).loadString("assets/list.json") 方法里面是怎么执行的。
Future<String> loadString(String key, { bool cache = true }) async {
final ByteData data = await load(key);
if (data == null)
throw FlutterError('Unable to load asset: $key');
// 50 KB of data should take 2-3 ms to parse on a Moto G4, and about 400 μs
// on a Pixel 4.
if (data.lengthInBytes < 50 * 1024) {
return utf8.decode(data.buffer.asUint8List());
}
// For strings larger than 50 KB, run the computation in an isolate to
// avoid causing main thread jank.
return compute(_utf8decode, data, debugLabel: 'UTF8 decode for "$key"');
}从官方源码可以看到,当文件的大小超过 50kb 时,也是采用 compute() 方法开一个线程去操作的。
多线程机制
Dart 作为一个单线程语言,虽然提供了多线程的机制,但是在多线程的资源是隔离的,两个线程之间资源是不互通的。
Dart 的多线程数据交互需要从 A 线程传给 B 线程,再由 B 线程返回给 A 线程。而像 Android 在主线程开一个子线程,子线程可以直接拿主线程的数据,而不用让主线程传给子线程。
总结
- Future 适合耗时小于 16ms 的操作
- 可以通过 compute() 进行耗时操作
- Dart 是单线程原因,但也支持多线程,但是线程间数据不互通
链接:https://juejin.cn/post/7161215037078503454
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


