背景
flutter版本要实现一个渐变的圆弧指示器,如图
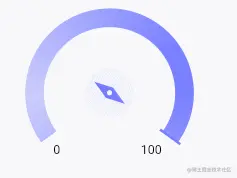
颜色需要有个渐变,而且根据百分比的不同,中间的菱形指向还不一样
1.自定义CustomPainter
class PlatePainter extends CustomPainter {
@override
void paint(Canvas canvas, Size size) {
// 画图逻辑
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) {
// 是否需要重绘的判断 ,可以先返回false
return false;
}
}
然后加入一点点画图的细节:
import 'dart:math';
import 'dart:ui' as ui;
import 'package:flutter/material.dart';
class PlatePainter3 extends CustomPainter {
final Paint _paintProgress = Paint()
..strokeWidth = 15
..style = PaintingStyle.stroke;
final Paint _paintBg = Paint()
..strokeWidth = 15
..color = const Color(0xFFC8CAFF).withAlpha(22)
..style = PaintingStyle.stroke;
final Paint _paintLine = Paint()
..strokeWidth = 2
..color = const Color(0Xff7A80FF)
..style = PaintingStyle.fill;
final Path _path = Path();
final Paint _paintCenter = Paint()
..strokeWidth = 2
..color = const Color(0xFF767DFF).withAlpha(14)
..style = PaintingStyle.fill;
@override
void paint(Canvas canvas, Size size) {
final width = size.width;
final height = size.height;
final center = Offset(width / 2, height * 3 / 4);
final rect = Rect.fromCircle(
center: center,
radius: 60,
);
canvas.drawArc(rect, pi * 0.8, pi * 2 * (0.1 + 0.1 + 0.5), false, _paintBg);
_paintProgress.shader = ui.Gradient.sweep(
center,
[
const Color(0XffCACCFF),
const Color(0Xff7A80FF),
],
);
canvas.drawArc(rect, pi * 0.8, (pi * 2 * 0.7) , false, _paintProgress);
TextPainter textPainter = TextPainter(
text: const TextSpan(text: '0', style: TextStyle(color: Colors.black, fontSize: 10)),
textDirection: TextDirection.ltr,
);
textPainter.layout(maxWidth: width);
textPainter.paint(canvas, Offset(width / 2 - 60 + 15, height - 5));
textPainter.text = const TextSpan(text: '100', style: TextStyle(color: Colors.black, fontSize: 10));
textPainter.layout(maxWidth: width);
textPainter.paint(canvas, Offset(width / 2 + 60 - 15 - 20, height - 5));
Offset c = Offset(width / 2, height * 3 / 4);
var angle = pi * 0.8 + pi * 2 * (0.1 + 0.1 + 0.5) ;
canvas.drawLine(c + _calXYByRadius(angle, 50), c + _calXYByRadius(angle, 70), _paintLine);
final o1 = c+_calXYByRadius(angle, 15);
final o2 = c+_calXYByRadius(angle + pi, 15);
final o3 = c+_calXYByRadius(angle + 0.5 * pi, 5);
final o4 = c+_calXYByRadius(angle + pi + 0.5 * pi, 5);
_path.reset();
_path.moveTo(o1.dx, o1.dy);
_path.lineTo(o3.dx, o3.dy);
_path.lineTo(o2.dx, o2.dy);
_path.lineTo(o4.dx, o4.dy);
_path.close();
_paintCenter.color = const Color(0xFF767DFF);
canvas.drawPath(_path, _paintCenter);
_paintCenter.color = const Color(0xFF767DFF).withAlpha(14);
canvas.drawCircle(c, 20, _paintCenter);
_paintCenter.color = Colors.white;
canvas.drawCircle(c, 2, _paintCenter);
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) {
return false;
}
Offset _calXYByRadius(double angle, double radius) {
final y = sin(angle) * radius;
final x = cos(angle) * radius;
return Offset(x, y);
}
}
中间颜色的渐变用到了Paint的方法shader,设置的属性为 dart:ui包下的Gradient,不要导错包了,应该import的时候加入 as ui,才可以如代码中设置的样式.
import 'dart:ui' as ui;
满心欢喜的运行一下,Duang
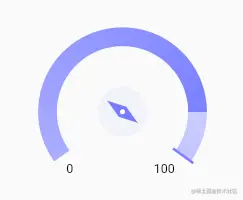
渐变颜色没有按照想象中的开始和结束.
2.关于 paint的shader属性
/// The shader to use when stroking or filling a shape.
///
/// When this is null, the [color] is used instead.
///
/// See also:
///
/// * [Gradient], a shader that paints a color gradient.
/// * [ImageShader], a shader that tiles an [Image].
/// * [colorFilter], which overrides [shader].
/// * [color], which is used if [shader] and [colorFilter] are null.
Shader? get shader {
return _objects?[_kShaderIndex] as Shader?;
}
set shader(Shader? value) {
_ensureObjectsInitialized()[_kShaderIndex] = value;
}
直接查看Gradient类的sweep方法,参数如下
Gradient.sweep(
Offset center,
List<Color> colors, [
List<double>? colorStops,
TileMode tileMode = TileMode.clamp,
double startAngle = 0.0,
double endAngle = math.pi * 2,
Float64List? matrix4,
])
翻译如下
创建一个以 center 为中心、从 startAngle 开始到 endAngle 结束的扫描渐变。 startAngle 和 endAngle 应该以弧度提供,零弧度是 center 右侧的水平线,正角度围绕 center 顺时针方向。如果提供了 colorStops,colorStops[i] 是一个从 0.0 到 1.0 的数字,它指定了 color[i] 在渐变中的开始位置。如果 colorStops 没有提供,那么只有两个停止点,在 0.0 和 1.0,是隐含的(因此 color 必须只有两个条目)。 startAngle 之前和 endAngle 之后的行为由 tileMode 参数描述。有关详细信息,请参阅 [TileMode] 枚举。
哦哦,应该修改startAngle和endAngle方法,然后按照开始和结束的颜色结束.修改
_paintProgress.shader = ui.Gradient.sweep(
center,
[
const Color(0XffCACCFF),
const Color(0Xff7A80FF),
],
[0, 1],
TileMode.clamp,
0.8 * pi,
2.2 * pi,
);
然后运行
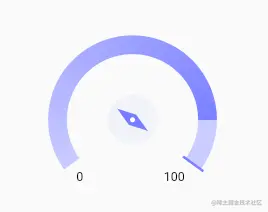
好像开始的颜色正常了,但是结束颜色还是一样的问题.
3.两种解决方法
3.1 设置shader属性(推荐)
_paintProgress.shader = ui.Gradient.sweep(
center,
[
const Color(0Xff7A80FF),
const Color(0XffCACCFF),
const Color(0Xff7A80FF),
],
[0.0, 0.5, 0.9],
TileMode.clamp,
);
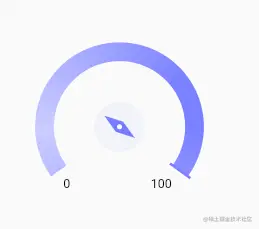
运行如图:
3.2 旋转控件,开始绘制从0开始
painter修改代码
import 'dart:math';
import 'dart:ui' as ui;
import 'package:flutter/material.dart';
class PlatePainter4 extends CustomPainter {
final Paint _paintProgress = Paint()
..strokeWidth = 15
..style = PaintingStyle.stroke;
final Paint _paintBg = Paint()
..strokeWidth = 15
..color = const Color(0xFFC8CAFF).withAlpha(22)
..style = PaintingStyle.stroke;
final Paint _paintLine = Paint()
..strokeWidth = 2
..color = const Color(0Xff7A80FF)
..style = PaintingStyle.fill;
final Path _path = Path();
final Paint _paintCenter = Paint()
..strokeWidth = 2
..color = const Color(0xFF767DFF).withAlpha(14)
..style = PaintingStyle.fill;
@override
void paint(Canvas canvas, Size size) {
final width = size.width;
final height = size.height;
final center = Offset(width / 2, height /2);
final rect = Rect.fromCircle(
center: center,
radius: 60,
);
canvas.drawArc(rect, 0, (pi * 1.4), false, _paintBg);
_paintProgress.shader = ui.Gradient.sweep(
center,
[
const Color(0XffCACCFF),
const Color(0Xff7A80FF),
// const Color(0Xff7A80FF),
// Colors.white,
// Colors.black,
],
);
canvas.drawArc(rect, 0, (pi * 1.4) , false, _paintProgress);
// TextPainter textPainter = TextPainter(
// text: const TextSpan(text: '0', style: TextStyle(color: Colors.black, fontSize: 10)),
// textDirection: TextDirection.ltr,
// );
// textPainter.layout(maxWidth: width);
// textPainter.paint(canvas, Offset(width / 2 - 60 + 15, height - 5));
// textPainter.text = const TextSpan(text: '100', style: TextStyle(color: Colors.black, fontSize: 10));
// textPainter.layout(maxWidth: width);
// textPainter.paint(canvas, Offset(width / 2 + 60 - 15 - 20, height - 5));
Offset c = Offset(width / 2, height / 2);
var angle = pi * 1.4 ;
canvas.drawLine(c + _calXYByRadius(angle, 50), c + _calXYByRadius(angle, 70), _paintLine);
final o1 = c+_calXYByRadius(angle, 15);
final o2 = c+_calXYByRadius(angle + pi, 15);
final o3 = c+_calXYByRadius(angle + 0.5 * pi, 5);
final o4 = c+_calXYByRadius(angle + pi + 0.5 * pi, 5);
_path.reset();
_path.moveTo(o1.dx, o1.dy);
_path.lineTo(o3.dx, o3.dy);
_path.lineTo(o2.dx, o2.dy);
_path.lineTo(o4.dx, o4.dy);
_path.close();
_paintCenter.color = const Color(0xFF767DFF);
canvas.drawPath(_path, _paintCenter);
_paintCenter.color = const Color(0xFF767DFF).withAlpha(14);
canvas.drawCircle(c, 20, _paintCenter);
_paintCenter.color = Colors.white;
canvas.drawCircle(c, 2, _paintCenter);
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) {
return false;
}
Offset _calXYByRadius(double angle, double radius) {
final y = sin(angle) * radius;
final x = cos(angle) * radius;
return Offset(x, y);
}
}
页面代码加入旋转代码:
Transform.rotate(
angle: 0.8 * pi,
child: CustomPaint(
painter: PlatePainter4(),
size: const Size(180, 180),
),
),
运行如下图第二个:
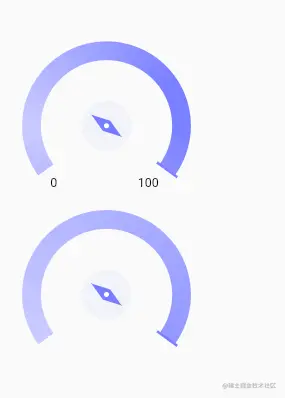
缺点:画文字的坐标还需要重新计算和旋转
4.加上动画,动起来
效果图:
最终代码:
Page:
import 'dart:math';
import 'package:demo4/widgets/plate_painter.dart';
import 'package:demo4/widgets/plate_painter3.dart';
import 'package:flutter/material.dart';
import '../widgets/plate_painter2.dart';
import '../widgets/plate_painter4.dart';
class Page6 extends StatefulWidget {
const Page6({Key? key}) : super(key: key);
@override
State<Page6> createState() => _Page6State();
}
class _Page6State extends State<Page6> with TickerProviderStateMixin{
late AnimationController _animationController;
static final Animatable<double> _iconTurnTween =
Tween<double>(begin: 0.0, end: 1.0).chain(CurveTween(curve: Curves.fastOutSlowIn));
@override
void initState() {
_animationController = AnimationController(vsync: this, duration: const Duration(seconds: 6));
_animationController.drive(_iconTurnTween);
_animationController.forward();
super.initState();
}
@override
void dispose() {
_animationController.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('自定义圆盘'),
),
body: Column(
children: [
AnimatedBuilder(
animation: _animationController.view,
builder: (_, __) {
final progress = _animationController.value;
return CustomPaint(
painter: PlatePainter(progress),
size: const Size(180, 180),
);
},
),
AnimatedBuilder(
animation: _animationController.view,
builder: (_, __) {
final progress = _animationController.value;
return Transform.rotate(
angle: 0.8 * pi,
child: CustomPaint(
painter: PlatePainter2(progress),
size: const Size(180, 180),
),
);
},
),
],
),
);
}
}
方法一:
import 'dart:math';
import 'dart:ui' as ui;
import 'package:flutter/material.dart';
class PlatePainter extends CustomPainter {
PlatePainter(
this.progress,
);
final num progress;
final Paint _paintProgress = Paint()
..strokeWidth = 15
..style = PaintingStyle.stroke;
final Paint _paintBg = Paint()
..strokeWidth = 15
..color = const Color(0xFFC8CAFF).withAlpha(22)
..style = PaintingStyle.stroke;
final Paint _paintLine = Paint()
..strokeWidth = 2
..color = const Color(0Xff7A80FF)
..style = PaintingStyle.fill;
final Path _path = Path();
final Paint _paintCenter = Paint()
..strokeWidth = 2
..color = const Color(0xFF767DFF).withAlpha(14)
..style = PaintingStyle.fill;
@override
void paint(Canvas canvas, Size size) {
final width = size.width;
final height = size.height;
final center = Offset(width / 2, height * 3 / 4);
final rect = Rect.fromCircle(
center: center,
radius: 60,
);
canvas.drawArc(rect, pi * 0.8, pi * 2 * (0.1 + 0.1 + 0.5), false, _paintBg);
_paintProgress.shader = ui.Gradient.sweep(
center,
[
const Color(0Xff7A80FF),
const Color(0XffCACCFF),
const Color(0Xff7A80FF),
],
[0.0, 0.5, 0.9],
TileMode.clamp,
);
canvas.drawArc(rect, pi * 0.8, (pi * 2 * 0.7) * progress, false, _paintProgress);
TextPainter textPainter = TextPainter(
text: const TextSpan(text: '0', style: TextStyle(color: Colors.black, fontSize: 10)),
textDirection: TextDirection.ltr,
);
textPainter.layout(maxWidth: width);
textPainter.paint(canvas, Offset(width / 2 - 60 + 15, height - 5));
textPainter.text = const TextSpan(text: '100', style: TextStyle(color: Colors.black, fontSize: 10));
textPainter.layout(maxWidth: width);
textPainter.paint(canvas, Offset(width / 2 + 60 - 15 - 20, height - 5));
Offset c = Offset(width / 2, height * 3 / 4);
var angle = pi * 0.8 + pi * 2 * (0.1 + 0.1 + 0.5) * progress;
canvas.drawLine(c + _calXYByRadius(angle, 50), c + _calXYByRadius(angle, 70), _paintLine);
final o1 = c+_calXYByRadius(angle, 15);
final o2 = c+_calXYByRadius(angle + pi, 15);
final o3 = c+_calXYByRadius(angle + 0.5 * pi, 5);
final o4 = c+_calXYByRadius(angle + pi + 0.5 * pi, 5);
_path.reset();
_path.moveTo(o1.dx, o1.dy);
_path.lineTo(o3.dx, o3.dy);
_path.lineTo(o2.dx, o2.dy);
_path.lineTo(o4.dx, o4.dy);
_path.close();
_paintCenter.color = const Color(0xFF767DFF);
canvas.drawPath(_path, _paintCenter);
_paintCenter.color = const Color(0xFF767DFF).withAlpha(14);
canvas.drawCircle(c, 20, _paintCenter);
_paintCenter.color = Colors.white;
canvas.drawCircle(c, 2, _paintCenter);
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) {
return (oldDelegate as PlatePainter).progress != progress;
}
Offset _calXYByRadius(double angle, double radius) {
final y = sin(angle) * radius;
final x = cos(angle) * radius;
return Offset(x, y);
}
}
方法二:
import 'dart:math';
import 'dart:ui' as ui;
import 'package:flutter/material.dart';
class PlatePainter2 extends CustomPainter {
PlatePainter2(
this.progress,
);
final num progress;
final Paint _paintProgress = Paint()
..strokeWidth = 15
..style = PaintingStyle.stroke;
final Paint _paintBg = Paint()
..strokeWidth = 15
..color = const Color(0xFFC8CAFF).withAlpha(22)
..style = PaintingStyle.stroke;
final Paint _paintLine = Paint()
..strokeWidth = 2
..color = const Color(0Xff7A80FF)
..style = PaintingStyle.fill;
final Path _path = Path();
final Paint _paintCenter = Paint()
..strokeWidth = 2
..color = const Color(0xFF767DFF).withAlpha(14)
..style = PaintingStyle.fill;
@override
void paint(Canvas canvas, Size size) {
final width = size.width;
final height = size.height;
final center = Offset(width / 2, height /2);
final rect = Rect.fromCircle(
center: center,
radius: 60,
);
canvas.drawArc(rect, 0, (pi * 1.4), false, _paintBg);
_paintProgress.shader = ui.Gradient.sweep(
center,
[
const Color(0XffCACCFF),
const Color(0Xff7A80FF),
// const Color(0Xff7A80FF),
// Colors.white,
// Colors.black,
],
);
canvas.drawArc(rect, 0, (pi * 1.4) * progress, false, _paintProgress);
// TextPainter textPainter = TextPainter(
// text: const TextSpan(text: '0', style: TextStyle(color: Colors.black, fontSize: 10)),
// textDirection: TextDirection.ltr,
// );
// textPainter.layout(maxWidth: width);
// textPainter.paint(canvas, Offset(width / 2 - 60 + 15, height - 5));
// textPainter.text = const TextSpan(text: '100', style: TextStyle(color: Colors.black, fontSize: 10));
// textPainter.layout(maxWidth: width);
// textPainter.paint(canvas, Offset(width / 2 + 60 - 15 - 20, height - 5));
Offset c = Offset(width / 2, height /2);
var angle = pi * 1.4 * progress;
canvas.drawLine(c + _calXYByRadius(angle, 50), c + _calXYByRadius(angle, 70), _paintLine);
final o1 = c+_calXYByRadius(angle, 15);
final o2 = c+_calXYByRadius(angle + pi, 15);
final o3 = c+_calXYByRadius(angle + 0.5 * pi, 5);
final o4 = c+_calXYByRadius(angle + pi + 0.5 * pi, 5);
_path.reset();
_path.moveTo(o1.dx, o1.dy);
_path.lineTo(o3.dx, o3.dy);
_path.lineTo(o2.dx, o2.dy);
_path.lineTo(o4.dx, o4.dy);
_path.close();
_paintCenter.color = const Color(0xFF767DFF);
canvas.drawPath(_path, _paintCenter);
_paintCenter.color = const Color(0xFF767DFF).withAlpha(14);
canvas.drawCircle(c, 20, _paintCenter);
_paintCenter.color = Colors.white;
canvas.drawCircle(c, 2, _paintCenter);
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) {
return (oldDelegate as PlatePainter2).progress != progress;
}
Offset _calXYByRadius(double angle, double radius) {
final y = sin(angle) * radius;
final x = cos(angle) * radius;
return Offset(x, y);
}
}











