








超级全面的Flutter性能优化实践
前言
Flutter是谷歌的移动UI框架,可以快速在iOS和Android上构建高质量的原生用户界面。 Flutter可以与现有的代码一起工作。在全世界,Flutter正在被越来越多的开发者和组织使用,并且Flutter是完全免费、开源的,可以用一套代码同时构建Android和iOS应用,性能可以达到原生应用一样的性能。但是,在较为复杂的 App 中,使用 Flutter 开发也很难避免产生各种各样的性能问题。在这篇文章中,我将介绍一些 Flutter 性能优化方面的应用实践。
一、优化检测工具
flutter编译模式
Flutter支持Release、Profile、Debug编译模式。
Release模式,使用AOT预编译模式,预编译为机器码,通过编译生成对应架构的代码,在用户设备上直接运行对应的机器码,运行速度快,执行性能好;此模式关闭了所有调试工具,只支持真机。
Profile模式,和Release模式类似,使用AOT预编译模式,此模式最重要的作用是可以用DevTools来检测应用的性能,做性能调试分析。
Debug模式,使用JIT(Just in time)即时编译技术,支持常用的开发调试功能hot reload,在开发调试时使用,包括支持的调试信息、服务扩展、Observatory、DevTools等调试工具,支持模拟器和真机。
通过以上介绍我们可以知道,flutter为我们提供 profile模式启动应用,进行性能分析,profile模式在Release模式的基础之上,为分析工具提供了少量必要的应用追踪信息。
如何开启profile模式?
如果是独立flutter工程可以使用flutter run --profile启动。如果是混合 Flutter 应用,在 flutter/packages/flutter_tools/gradle/flutter.gradle 的 buildModeFor 方法中将 debug 模式改为 profile即可。
检测工具
1、Flutter Inspector (debug模式下)
Flutter Inspector有很多功能,其中有两个功能更值得我们去关注,例如:“Select Widget Mode” 和 “Highlight Repaints”。
Select Widget Mode点击 “Select Widget Mode” 图标,可以在手机上查看当前页面的布局框架与容器类型。
通过“Select Widget Mode”我们可以快速查看陌生页面的布局实现方式。
Select Widget Mode模式下,也可以在app里点击相应的布局控件查看
Highlight Repaints
点击 “Highlight Repaints” 图标,它会 为所有 RenderBox 绘制一层外框,并在它们重绘时会改变颜色。
这样做帮你找到 App 中频繁重绘导致性能消耗过大的部分。
例如:一个小动画可能会导致整个页面重绘,这个时候使用 RepaintBoundary Widget 包裹它,可以将重绘范围缩小至本身所占用的区域,这样就可以减少绘制消耗。
2、Performance Overlay(性能图层)
在完成了应用启动之后,接下来我们就可以利用 Flutter 提供的渲染问题分析工具,即性能图层(Performance Overlay),来分析渲染问题了。
我们可以通过以下方式开启性能图层
性能图层会在当前应用的最上层,以 Flutter 引擎自绘的方式展示 GPU 与 UI 线程的执行图表,而其中每一张图表都代表当前线程最近 300 帧的表现,如果 UI 产生了卡顿,这些图表可以帮助我们分析并找到原因。
下图演示了性能图层的展现样式。其中,GPU 线程的性能情况在上面,UI 线程的情况显示在下面,蓝色垂直的线条表示已执行的正常帧,绿色的线条代表的是当前帧:
如果有一帧处理时间过长,就会导致界面卡顿,图表中就会展示出一个红色竖条。下图演示了应用出现渲染和绘制耗时的情况下,性能图层的展示样式:
如果红色竖条出现在 GPU 线程图表,意味着渲染的图形太复杂,导致无法快速渲染;而如果是出现在了 UI 线程图表,则表示 Dart 代码消耗了大量资源,需要优化代码执行时间。
3、CPU Profiler(UI 线程问题定位)
在视图构建时,在 build 方法中使用了一些复杂的运算,或是在主 Isolate 中进行了同步的 I/O 操作。
我们可以使用 CPU Profiler 进行检测:
你需要手动点击 “Record” 按钮去主动触发,在完成信息的抽样采集后,点击 “Stop” 按钮结束录制。这时,你就可以得到在这期间应用的执行情况了。
其中:
x 轴:表示单位时间,一个函数在 x 轴占据的宽度越宽,就表示它被采样到的次数越多,即执行时间越长。
y 轴:表示调用栈,其每一层都是一个函数。调用栈越深,火焰就越高,底部就是正在执行的函数,上方都是它的父函数。
通过上述CPU帧图我们可以大概分析出哪些方法存在耗时操作,针对性的进行优化
一般的耗时问题,我们通常可以 使用 Isolate(或 compute)将这些耗时的操作挪到并发主 Isolate 之外去完成。
例如:复杂JSON解析子线程化
Flutter的isolate默认是单线程模型,而所有的UI操作又都是在UI线程进行的,想应用多线程的并发优势需新开isolate 或compute。无论如何await,scheduleTask 都只是延后任务的调用时机,仍然会占用“UI线程”, 所以在大Json解析或大量的channel调用时,一定要观测对UI线程的消耗情况。
二、Flutter布局优化
Flutter 使用了声明式的 UI 编写方式,而不是 Android 和 iOS 中的命令式编写方式。
声明式:简单的说,你只需要告诉计算机,你要得到什么样的结果,计算机则会完成你想要的结果,声明式更注重结果。
命令式:用详细的命令机器怎么去处理一件事情以达到你想要的结果,命令式更注重执行过程。
flutter声明式的布局方式通过三棵树去构建布局,如图:
Widget Tree: 控件的配置信息,不涉及渲染,更新代价极低。
Element Tree : Widget树和RenderObject树之间的粘合剂,负责将Widget树的变更以最低的代价映射到RenderObject树上。
RenderObject Tree : 真正的UI渲染树,负责渲染UI,更新代价极大。
1、常规优化
常规优化即针对 build() 进行优化,build() 方法中的性能问题一般有两种:耗时操作和 Widget 层叠。
1)、在 build() 方法中执行了耗时操作
我们应该尽量避免在 build() 中执行耗时操作,因为 build() 会被频繁地调用,尤其是当 Widget 重建的时候。
此外,我们不要在代码中进行阻塞式操作,可以将一般耗时操作等通过 Future 来转换成异步方式来完成。
对于 CPU 计算频繁的操作,例如图片压缩,可以使用 isolate 来充分利用多核心 CPU。
2)、build() 方法中堆叠了大量的 Widget
这将会导致三个问题:
1、代码可读性差:画界面时需要一个 Widget 嵌套一个 Widget,但如果 Widget 嵌套太深,就会导致代码的可读性变差,也不利于后期的维护和扩展。
2、复用难:由于所有的代码都在一个 build(),会导致无法将公共的 UI 代码复用到其它的页面或模块。
3、影响性能:我们在 State 上调用 setState() 时,所有 build() 中的 Widget 都将被重建,因此 build() 中返回的 Widget 树越大,那么需要重建的 Widget 就越多,也就会对性能越不利。
所以,你需要 控制 build 方法耗时,将 Widget 拆小,避免直接返回一个巨大的 Widget,这样 Widget 会享有更细粒度的重建和复用。
3)、尽可能地使用 const 构造器
当构建你自己的 Widget 或者使用 Flutter 的 Widget 时,这将会帮助 Flutter 仅仅去 rebuild 那些应当被更新的 Widget。
因此,你应该尽量多用 const 组件,这样即使父组件更新了,子组件也不会重新进行 rebuild 操作。特别是针对一些长期不修改的组件,例如通用报错组件和通用 loading 组件等。
4)、列表优化
尽量避免使用 ListView默认构造方法
不管列表内容是否可见,会导致列表中所有的数据都会被一次性绘制出来
建议使用 ListView 和 GridView 的 builder 方法
它们只会绘制可见的列表内容,类似于 Android 的 RecyclerView。
其实,本质上,就是对列表采用了懒加载而不是直接一次性创建所有的子 Widget,这样视图的初始化时间就减少了。
2、深入光栅化优化
优化光栅线程
屏幕显示器一般以60Hz的固定频率刷新,每一帧图像绘制完成后,会继续绘制下一帧,这时显示器就会发出一个Vsync信号,按60Hz计算,屏幕每秒会发出60次这样的信号。CPU计算好显示内容提交给GPU,GPU渲染好传递给显示器显示。
Flutter遵循了这种模式,渲染流程如图:
flutter通过native获取屏幕刷新信号通过engine层传递给flutter framework
所有的 Flutter 应用至少都会运行在两个并行的线程上:UI 线程和 Raster 线程。
UI 线程
构建 Widgets 和运行应用逻辑的地方。
Raster 线程
用来光栅化应用。它从 UI 线程获取指令将其转换成为GPU命令并发送到GPU。
我们通常可以使用Flutter DevTools-Performance 进行检测,步骤如下:
在 Performance Overlay 中,查看光栅线程和 UI 线程哪个负载过重。
在 Timeline Events 中,找到那些耗费时间最长的事件,例如常见的 SkCanvas::Flush,它负责解决所有待处理的 GPU 操作。
找到对应的代码区域,通过删除 Widgets 或方法的方式来看对性能的影响。
三、Flutter内存优化
1、const 实例化
const 对象只会创建一个编译时的常量值。在代码被加载进 Dart Vm 时,在编译时会存储在一个特殊的查询表里,仅仅只分配一次内存给当前实例。
我们可以使用 flutter_lints 库对我们的代码进行检测提示
2、检测消耗多余内存的图片
Flutter Inspector:点击 “Highlight Oversizeded Images”,它会识别出那些解码大小超过展示大小的图片,并且系统会将其倒置,这些你就能更容易在 App 页面中找到它。
通过下面两张图可以清晰的看出使用“Highlight Oversizeded Images”的检测效果
针对这些图片,你可以指定 cacheWidth 和 cacheHeight 为展示大小,这样可以让 flutter 引擎以指定大小解析图片,减少内存消耗。
3、针对 ListView item 中有 image 的情况来优化内存
ListView 不会销毁那些在屏幕可视范围之外的那些 item,如果 item 使用了高分辨率的图片,那么它将会消耗非常多的内存。
ListView 在默认情况下会在整个滑动/不滑动的过程中让子 Widget 保持活动状态,这一点是通过 AutomaticKeepAlive 来保证,在默认情况下,每个子 Widget 都会被这个 Widget 包裹,以使被包裹的子 Widget 保持活跃。
其次,如果用户向后滚动,则不会再次重新绘制子 Widget,这一点是通过 RepaintBoundaries 来保证,在默认情况下,每个子 Widget 都会被这个 Widget 包裹,它会让被包裹的子 Widget 仅仅绘制一次,以此获得更高的性能。
但,这样的问题在于,如果加载大量的图片,则会消耗大量的内存,最终可能使 App 崩溃。
通过将这两个选项置为 false 来禁用它们,这样不可见的子元素就会被自动处理和 GC。
4、多变图层与不变图层分离
在日常开发中,会经常遇到页面中大部分元素不变,某个元素实时变化。如Gif,动画。这时我们就需要RepaintBoundary,不过独立图层合成也是有消耗,这块需实测把握。
这会导致页面同一图层重新Paint。此时可以用RepaintBoundary包裹该多变的Gif组件,让其处在单独的图层,待最终再一块图层合成上屏。
5、降级CustomScrollView,ListView等预渲染区域为合理值
默认情况下,CustomScrollView除了渲染屏幕内的内容,还会渲染上下各250区域的组件内容,例如当前屏幕可显示4个组件,实际仍有上下共4个组件在显示状态,如果setState(),则会进行8个组件重绘。实际用户只看到4个,其实应该也只需渲染4个, 且上下滑动也会触发屏幕外的Widget创建销毁,造成滚动卡顿。高性能的手机可预渲染,在低端机降级该区域距离为0或较小值。
四、总结
Flutter为什么会卡顿、帧率低?总的来说均为以下2个原因:
UI线程慢了-->渲染指令出的慢
GPU线程慢了-->光栅化慢、图层合成慢、像素上屏慢
所以我们一般使用flutter布局尽量按照以下原则
Flutter优化基本原则:
尽量不要为 Widget 设置半透明效果,而是考虑用图片的形式代替,这样被遮挡的 Widget 部分区域就不需要绘制了;
控制 build 方法耗时,将 Widget 拆小,避免直接返回一个巨大的 Widget,这样 Widget 会享有更细粒度的重建和复用;
对列表采用懒加载而不是直接一次性创建所有的子 Widget,这样视图的初始化时间就减少了。
五、其他
如果大家对flutter动态化感兴趣,我们也为大家准备了flutter动态化平台-Fair
欢迎大家使用 Fair,也欢迎大家为我们点亮star
Github地址:github.com/wuba/fair
Fair官网:fair.58.com
链接:https://juejin.cn/post/7145730792948252686
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
内存优化之掌握 APP 运行时的内存模型
为了让大家深入掌握 App 运行时的内存模型,这一节的内容按照由外到内、逐步深入的原则,分为了 3 个部分:
内存描述指标
内存数据获取
内存模型详解
话不多说,让我们马上开始这一章学习吧!
内存描述指标
在进行内存优化之前,我们必须要先熟悉常用的内存描述指标。内存描述指标可以用来度量一个 App 的内存情况,也可以在我们做内存优化时,更直观地展示出优化前后的效果。
常用的内存描述指标有 6 个,我们先来简单了解一下。
PSS( Proportional Set Size ):实际使用的物理内存,会按比例分配共享的内存。比如一个应用有两个进程都用到了 Chrome 的 V8 引擎,那么每个进程会承担 50% 的 V8 这个 so 库的内存占用。PSS 是我们使用最频繁的一个指标,App 线上的内存数据统计一般都取这个指标。
RSS( Resident Set Size ):PSS 中的共享库会按比例分担,但是 RSS 不会,它会完全算进当前进程,所以把所有进程的 RSS 加总后得出来的内存会比实际高。按比例计算内存占用会有一定的消耗,因此当想要高性能的获取内存数据时便可以使用 RSS,Android 的 LowMemoryKiller 机制就是根据每个进程的 RSS 来计算进程优先级的。
Private Clean / Private Dirty:当我们执行 dump meminfo 时会看到这个指标,Private 内存是只被当前进程独占的物理内存。独占的意思是即使释放之后也无法被其他进程使用,只有当这个进程销毁后其他进程才能使用。Clean 表示该对应的物理内存已经释放了,Dirty 表示对应的物理内存还在使用。
Swap Pss Dirty:这个指标和上面的 Private 指标刚好相反,Swap 的内存被释放后,其他进程也可以继续使用,所以我们在 meminfo 中只看得到 Swap Pss Dirty,而看不到Swap Pss Clean,因为 Swap Pss Clean 是没有意义的。
Heap Alloc:通过 Malloc、mmap 等函数实际申请的虚拟内存,包括 Naitve 和虚拟机申请的内存。
Heap Free:空闲的虚拟内存。
内存描述指标并不多,上面这几个就完全够用了,而且我相信大家或多或少都接触过,所以这里列出来便于我们后面查阅。
内存数据获取
了解了内存的描述指标,我们再来看看如何获取内存的数据,主要有 2 种方式。
① 线下通过 adb 命令获取,一般用于线下调试:
adb shell
dumpsys meminfo 进程名/pid
② 线上通过代码获取,一般用于收集线上的内存数据:
ActivityManager am = (ActivityManager) context.getSystemService(Context.ACTIVITY_SERVICE);
ActivityManager.MemoryInfo memoryInfo = new ActivityManager.MemoryInfo();
虽然获取方法不同,但这两种方式获取数据的原理完全一样,它们调用的都是 android_os_Debug.cpp 对象中的 android_os_Debug_getDirtyPagesPid 接口,它的源码如下:
static jboolean android_os_Debug_getDirtyPagesPid(JNIEnv *env, jobject clazz,
jint pid, jobject object)
{
bool foundSwapPss;
stats_t stats[_NUM_HEAP];
memset(&stats, 0, sizeof(stats));
//1. 加载maps文件,获取
if (!load_maps(pid, stats, &foundSwapPss)) {
return JNI_FALSE;
}
struct graphics_memory_pss graphics_mem;
//2. 获取graphics区域内存数据
if (read_memtrack_memory(pid, &graphics_mem) == 0) {
stats[HEAP_GRAPHICS].pss = graphics_mem.graphics;
stats[HEAP_GRAPHICS].privateDirty = graphics_mem.graphics;
stats[HEAP_GRAPHICS].rss = graphics_mem.graphics;
stats[HEAP_GL].pss = graphics_mem.gl;
stats[HEAP_GL].privateDirty = graphics_mem.gl;
stats[HEAP_GL].rss = graphics_mem.gl;
stats[HEAP_OTHER_MEMTRACK].pss = graphics_mem.other;
stats[HEAP_OTHER_MEMTRACK].privateDirty = graphics_mem.other;
stats[HEAP_OTHER_MEMTRACK].rss = graphics_mem.other;
}
//3. 获取Unkonw区域数据
for (int i=_NUM_CORE_HEAP; i<_NUM_EXCLUSIVE_HEAP; i++) {
stats[HEAP_UNKNOWN].pss += stats[i].pss;
stats[HEAP_UNKNOWN].swappablePss += stats[i].swappablePss;
stats[HEAP_UNKNOWN].rss += stats[i].rss;
stats[HEAP_UNKNOWN].privateDirty += stats[i].privateDirty;
stats[HEAP_UNKNOWN].sharedDirty += stats[i].sharedDirty;
stats[HEAP_UNKNOWN].privateClean += stats[i].privateClean;
stats[HEAP_UNKNOWN].sharedClean += stats[i].sharedClean;
stats[HEAP_UNKNOWN].swappedOut += stats[i].swappedOut;
stats[HEAP_UNKNOWN].swappedOutPss += stats[i].swappedOutPss;
}
//4. 将获取的数据存放到容器中
……
return JNI_TRUE;
}这段源码比较长,我们一起来梳理下里面的逻辑,主要分为 4 部分。
读取 maps 文件,获取该进程的内存详情:通过上一节的学习,我们知道进程使用的内存都是虚拟内存,并且虚拟内存都以页为维度来管理和维护。这个进程的虚拟内存每一页上存放了什么数据,都会记录在 maps 文件中,maps 文件是一个很重要的文件,后面会详细介绍它。
调用 libmemtrack 接口获取 graphics 内存数据:Graphic 内存分配和使用方式具有特殊性,并没有全部映射到应用进程,需要通过 HAL 层(抽象硬件层)libmemtrack 的接口查询,才能完整得到使用的 graphics 内存数据。
分配 Unknow 区域的内存数据:根据前面的知识我们知道,mmap 除了做内存映射,还可以用来申请虚拟内存,如果在申请内存时是私有且匿名的( fd 如果为 -1,flag 入参为MAP_ANONYMOUS 或 MAP_PRIVATE )就会算入 Unknow 中,如果 mmap 申请内存时指定了申请这段内存的名字,就会算入 Other Dev 当中。因此,对这一区域内存问题的排查往往比较复杂,因为我们不知道内存的来源。
存放获取到的内存数据并返回:最后一部分就是将前面获取到的数据放到对应的数据结构中,并返回给接口调用方。
内存模型详解
我们已经知道如何获取内存数据,但是这些数据从哪儿来呢?毕竟只有知道来源,我们才能从源头进行治理。那接下来,我们就对 App 运行时的内存模型进行一个全面且详细的剖析。
我们以系统设置这个 App 为例子,通过 adb 命令获取的内存数据如下:
这里把上面的数据分为两个部分:A 区域和 B 区域。其中 A 区域的数据主要来自前面提到的 android_os_Debug_getMemInfo 接口,B 区域的数据则是对 A 区域中的数据做了汇总处理。
A区域
前面我们已经了解到,android_os_Debug_getMemInfo 接口的数据有两部分来源,一部分是读取 maps 文件解析到每块内存所属的数据,另一部分是读取 libmemtrack 接口的数据获取到的 graphic 内存数据。这两部分的数据来源就组成了 A 区域中的三块数据。下面我们分别来看看这三块数据。
数据 ①:maps 文件数据
maps 文件是分析内存很重要的一个文件,通过 maps 文件我们可以详细知道这个进程的内存中存放了哪些数据。maps 文件存放在 /proc/{ pid }/maps 路径中,该路径除了存放该进程的 maps 文件,还存放了该进程的所有其他信息的数据。如果你感兴趣可以深入了解一下。
对于 root 的手机,我们可以直接查看该目录下的 maps 文件。但是 maps 文件非常长,直接看会很吃力,所以我们一般会通过脚本对 maps 文件中的数据做分析和归类。下面还是以系统设置这个应用为例,它的 maps 文件的部分内容如下:
图中从左至右各个数据段的解释如下:
| 字段 | address | perms offset | offset | dev | inode | pathname |
|---|---|---|---|---|---|---|
| 数据 | 12c00000-32c00000 | rw-p | 00000000 | 00:00 | 0 | main space (region space)] |
| 含义 | 本段内存映射的虚拟地址空间范围 | 读写权限 | 本段映射地址在文件中的偏移 | 所映射的文件所属设备的设备号 | 文件的索引节点号 | 对有名映射而言,pathname 是映射的文件名;对匿名映射来说,pathname 是此段内存在进程中的作用 |
如果手机没有 root 也没关系,我们可以在运行时通过 native 层的 c++ 代码读取该文件,可以看一下android_os_Debug_getMemInfo 接口中调用的 load_maps 方法,该方法读取 maps 文件后,还做了一个详细的分类操作,分完类之后就是我们看到的数据 ① 中的数据,这个方法比较长,所以我精简了部分代码。
static bool load_maps(int pid, stats_t* stats, bool* foundSwapPss)
{
*foundSwapPss = false;
uint64_t prev_end = 0;
int prev_heap = HEAP_UNKNOWN;
std::string smaps_path = base::StringPrintf("/proc/%d/smaps", pid);
auto vma_scan = [&](const meminfo::Vma& vma) {
int which_heap = HEAP_UNKNOWN;
int sub_heap = HEAP_UNKNOWN;
bool is_swappable = false;
std::string name;
if (base::EndsWith(vma.name, " (deleted)")) {
name = vma.name.substr(0, vma.name.size() - strlen(" (deleted)"));
} else {
name = vma.name;
}
uint32_t namesz = name.size();
// 解析Native Heap 内存
if (base::StartsWith(name, "[heap]")) {
which_heap = HEAP_NATIVE;
} else if (base::StartsWith(name, "[anon:libc_malloc]")) {
which_heap = HEAP_NATIVE;
} else if (base::StartsWith(name, "[anon:scudo:")) {
which_heap = HEAP_NATIVE;
} else if (base::StartsWith(name, "[anon:GWP-ASan")) {
which_heap = HEAP_NATIVE;
}
// 解析 stack 部分内存
else if (base::StartsWith(name, "[stack")) {
which_heap = HEAP_STACK;
} else if (base::StartsWith(name, "[anon:stack_and_tls:")) {
which_heap = HEAP_STACK;
}
// 解析 code 部分的内存
else if (base::EndsWith(name, ".so")) {
which_heap = HEAP_SO;
is_swappable = true;
} else if (base::EndsWith(name, ".jar")) {
which_heap = HEAP_JAR;
is_swappable = true;
} else if (base::EndsWith(name, ".apk")) {
which_heap = HEAP_APK;
is_swappable = true;
} else if (base::EndsWith(name, ".ttf")) {
which_heap = HEAP_TTF;
is_swappable = true;
} else if ((base::EndsWith(name, ".odex")) ||
(namesz > 4 && strstr(name.c_str(), ".dex") != nullptr)) {
which_heap = HEAP_DEX;
sub_heap = HEAP_DEX_APP_DEX;
is_swappable = true;
} else if (base::EndsWith(name, ".vdex")) {
which_heap = HEAP_DEX;
……
} else if (base::EndsWith(name, ".oat")) {
which_heap = HEAP_OAT;
is_swappable = true;
} else if (base::EndsWith(name, ".art") || base::EndsWith(name, ".art]")) {
which_heap = HEAP_ART;
……
} else if (base::StartsWith(name, "/dev/")) {
which_heap = HEAP_UNKNOWN_DEV;
// 解析 gl 区域内存
if (base::StartsWith(name, "/dev/kgsl-3d0")) {
which_heap = HEAP_GL_DEV;
}
// 解析 cursor 区域内存
else if (base::StartsWith(name, "/dev/ashmem/CursorWindow")) {
which_heap = HEAP_CURSOR;
} else if (base::StartsWith(name, "/dev/ashmem/jit-zygote-cache")) {
which_heap = HEAP_DALVIK_OTHER;
sub_heap = HEAP_DALVIK_OTHER_ZYGOTE_CODE_CACHE;
}
//解析ashmen匿名共享内存
else if (base::StartsWith(name, "/dev/ashmem")) {
which_heap = HEAP_ASHMEM;
}
} else if (base::StartsWith(name, "/memfd:jit-cache")) {
which_heap = HEAP_DALVIK_OTHER;
sub_heap = HEAP_DALVIK_OTHER_APP_CODE_CACHE;
} else if (base::StartsWith(name, "/memfd:jit-zygote-cache")) {
which_heap = HEAP_DALVIK_OTHER;
sub_heap = HEAP_DALVIK_OTHER_ZYGOTE_CODE_CACHE;
}
//解析java Heap内存
else if (base::StartsWith(name, "[anon:")) {
which_heap = HEAP_UNKNOWN;
if (base::StartsWith(name, "[anon:")) {
which_heap = HEAP_DALVIK_OTHER;
if (base::StartsWith(name, "[anon:dalvik-LinearAlloc")) {
sub_heap = HEAP_DALVIK_OTHER_LINEARALLOC;
} else if (base::StartsWith(name, "[anon:dalvik-alloc space") ||
base::StartsWith(name, "[anon:dalvik-main space")) {
// This is the regular Dalvik heap.
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_NORMAL;
} else if (base::StartsWith(name,
"[anon:dalvik-large object space") ||
base::StartsWith(
name, "[anon:dalvik-free list large object space")) {
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_LARGE;
} else if (base::StartsWith(name, "[anon:dalvik-non moving space")) {
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_NON_MOVING;
} else if (base::StartsWith(name, "[anon:dalvik-zygote space")) {
which_heap = HEAP_DALVIK;
sub_heap = HEAP_DALVIK_ZYGOTE;
} else if (base::StartsWith(name, "[anon:dalvik-indirect ref")) {
sub_heap = HEAP_DALVIK_OTHER_INDIRECT_REFERENCE_TABLE;
} else if (base::StartsWith(name, "[anon:dalvik-jit-code-cache") ||
base::StartsWith(name, "[anon:dalvik-data-code-cache")) {
sub_heap = HEAP_DALVIK_OTHER_APP_CODE_CACHE;
} else if (base::StartsWith(name, "[anon:dalvik-CompilerMetadata")) {
sub_heap = HEAP_DALVIK_OTHER_COMPILER_METADATA;
} else {
sub_heap = HEAP_DALVIK_OTHER_ACCOUNTING; // Default to accounting.
}
}
} else if (namesz > 0) {
which_heap = HEAP_UNKNOWN_MAP;
} else if (vma.start == prev_end && prev_heap == HEAP_SO) {
// bss section of a shared library
which_heap = HEAP_SO;
}
prev_end = vma.end;
prev_heap = which_heap;
const meminfo::MemUsage& usage = vma.usage;
if (usage.swap_pss > 0 && *foundSwapPss != true) {
*foundSwapPss = true;
}
uint64_t swapable_pss = 0;
if (is_swappable && (usage.pss > 0)) {
float sharing_proportion = 0.0;
if ((usage.shared_clean > 0) || (usage.shared_dirty > 0)) {
sharing_proportion = (usage.pss - usage.uss) / (usage.shared_clean + usage.shared_dirty);
}
swapable_pss = (sharing_proportion * usage.shared_clean) + usage.private_clean;
}
// 将获取的数据进行累加
……
};
//for循环函数,执行maps文件的读取
return meminfo::ForEachVmaFromFile(smaps_path, vma_scan);
}通过上面对 maps 的解析函数,我们不仅可以看到 maps 中的数据类型及格式,也可以知道 Dalvik Heap,Native Heap 等数据的组成。在做内存的线上异常监控时,异常情况下,也可以将 maps 文件上传到服务端,服务端对 maps 文件进行解析和分类,这样我们就能非常方便的定位和排查线上内存问题。
数据②:graphic 相关数据
了解了 maps 文件中的内存数据,我们再来看看 graphic 的数据,graphic 的数据有 3 部分。
Gfx dev:绘制时分配,并且已经映射到应用进程虚拟内存中。这里需要注意的是,只有高通的芯片才会将这一块的内存放在 /dev/kgsl-3d0 路径,并映射到进程的虚拟内存中,其他的芯片不会放在这个路径。在上面的 load_maps 方法中,我们也可以看到对这一块内存数据的解析逻辑。
GL mtrack:绘制时分配,没有映射到应用地址空间,包括纹理、顶点数据、shader program 等。
EGL mtrack:应用的 Layer Surface,通过 gralloc 分配,没有映射到应用地址空间。不熟悉 Layer Surface 的话,可以将一个界面理解成一个 Layer Surface,Surface 存储了界面的数据,并交给 GPU 绘制。
上面 1 的数据是通过 load_maps 函数解析获取的,2 和 3 的数据是通过 read_memtrack_memory 函数获取的。该函数会读取和解析路径为 /d/kgsl/proc/{ pid }/mem 的文件,这个文件节点中的数据是gpu driver写入的,该方法的实现可以参考下面高通855源码中的 kgsl_memtrack_get_memory 函数,下面是这个函数的主体逻辑代码。(官方源码:kgsl.c)
int kgsl_memtrack_get_memory(pid_t pid, enum memtrack_type type,
struct memtrack_record *records,
size_t *num_records)
{
……
// 1. 设置目标文件路径
snprintf(tmp, sizeof(tmp), "/d/kgsl/proc/%d/mem", pid);
……
while (1) {
// 2. 读取并解析该文件
……
}
……
return 0;
}我们也可以在 root 手机中,查看 kgsl_memtrack_get_memory 函数读取到该应用进程的数据,下面是系统设置这个应用的部分 graphic 数据。
/d/kgsl/proc/3160 # cat mem
gpuaddr useraddr size id flags type usage sglen mapcount eglsrf eglimg
0000000000000000 0 196608 1 --w---N-- gpumem any(0) 0 0 0 0
0000000000000000 0 16384 2 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 4096 3 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 4 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 5 --w--pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 6 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 7 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 20480 8 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 9 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 10 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 196608 11 --w---N-- gpumem any(0) 0 0 0 0
0000000000000000 0 16384 12 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 4096 13 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 14 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 15 --w--pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 16 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 17 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 32768 18 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 19 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 20 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 65536 21 --w--pY-- gpumem arraybuffer 0 1 0 0
0000000000000000 0 131072 22 --wl-pY-- gpumem command 0 1 0 0
0000000000000000 0 32768 23 --w--pY-- gpumem gl 0 1 0 0
0000000000000000 0 131072 24 --wl-pY-- gpumem gl 0 1 0 0
0000000000000000 0 8192 25 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 8192 26 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 16384 27 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 9469952 28 --wL--N-- ion egl_surface 152 0 1 1
0000000000000000 0 131072 29 --wl-pY-- gpumem command 0 1 0 0
0000000000000000 0 8192 30 --w--pY-- gpumem command 0 1 0 0
0000000000000000 0 4096 31 -----pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 32 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 33 -----pY-- gpumem gl 0 1 0 0
0000000000000000 0 4096 34 --w--pY-- gpumem any(0) 0 1 0 0
0000000000000000 0 4096 35 -----pY-- gpumem gl 0 1 0 0
……数据③:Alloc 内存
在内存描述指标这一部分,我们已经知道数据 ③ 中的数据是调用 malloc、mmap、calloc 等内存申请函数时积累的数据,想要获取这个数据,可以通过下面的接口实现。
- 获取 Java 层申请的内存:会直接去 Art 虚拟机中获取虚拟机已经申请的内存大小。
Runtime runtime = Runtime.getRuntime();
//获取已经申请的Java内存 long usedMemory=runtime.totalMemory() ;
//获取申请但未使用Java内存 long freeMemory = runtime.freeMemory();- 获取 Native 申请的内存:会调用 android_os_Debug.cpp 对象中的android_os_Debug_getNativeHeapSize 接口获取数据,该接口又是调用的 mallinfo 函数,mallinfo 函数会返回 native 层已经申请的内存大小。
//获取已经申请的Native内存
long nativeHeapSize = Debug.getNativeHeapSize()
//获取申请但未使用Native内存
long nativeHeapFreeSize = Debug.getNativeHeapFreeSize()
//Naitve层
static jlong android_os_Debug_getNativeHeapSize(JNIEnv *env, jobject clazz)
{
struct mallinfo info = mallinfo();
return (jlong) info.usmblks;
}我们可以看下 mallinfo 函数的说明文档:
通过上面两个接口获取 Naitve 和 Java 的内存数据效率最高,性能消耗最小,所以适合在代码中做数据监控使用。通过读取和解析 maps 文件来获取内存数据对性能的开销较大,所以从 Android10 开始加了 5 分钟的频控。
B区域
B 区域的数据就是将 A 区域中的 ① 数据做了汇总操作,方便我们查看,并没有太特别的内容,这里就简单列一下了。
Java Heap:(Dalvik Heap 的 Private Dirty 数据) + ( .art mmap 部分的 Private Dirty 和 Private Clean 数据) + getOtherPrivate ( OTHER_ART ) 。这里的 .art 是应用的 dex 文件预编译后的 art 文件,所以也是属于该应用的 JavaHeap。
Native Heap:Native Heap 的 Private Dirty 数据。
Code:.so .jar .apk .ttf .dex .oat 等资源加总。
Stack:getOtherPrivateDirty ( OTHER_STACK )。
Graphics:gl,gfx,egl 的数据加总。
System:( Total Pss ) - ( Private Dirty 和 Private Clean 的总和)。主要是系统占用的内存,如共享的字体、图像资源等。
小结
想要深入掌握 App 运行时的内存模型,夯实内存优化的基础,首先我们要熟悉描述内存的指标,它们是度量我们内存优化效果的重要工具。
常用的指标有 6 个,分别是共享库按比例分担的 Pss;进程在 RAM 中实际保存的总内存 RSS;只被当前进程独占的物理内存 Private Clean / Private Dirty;和 Private 相反的 Swap Pss Dirty;以及 Heap Alloc 和空闲的虚拟内存 Heap Free。获取这些指标的方法有两个,线下可以通过 adb 命令获取,线上可以通过代码获取。
其次,我们需要从原理上深入了解内存的组成,以及这些组成的来源,这样我们才能在内存优化中,做到有的放矢。我们重点掌握 3 类数据:maps 文件数据、graphic 相关数据和 Alloc 内存。
这一章节的内容虽然属于基础知识,但掌握它们可以在后面的实战章节中,帮助我们更容易理解和上手。
链接:https://juejin.cn/post/7175438290324029498
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
算法| Java的int类型最大值为什么是21亿多?
开篇
本文主要介绍在Java中,为什么int类型的最大值为2147483647。
理论值
我们都知道在Java中,int 的长度为32位。
理论上,用二进制表示,32位每一位都是1的话,那么这个数是多少呢?
我们来计算一下,第0位可以用2表示,第1位可以用2表示,第31位可以用231表示,那么32位二进制能够表示的最大值为232 - 1,所以理论上32位数值的取值范围为0 ~ 232 - 1。
那么,Java的int最大值真的为232 - 1吗?
我们知道,232 - 1这个值为42亿多。而在Java中,int的最大值为2147483647也就是21亿多,为什么有这个差距呢?
分析
我们来看下,Java中int的最大值以及这个最大值的二进制数据。
可以看到,int的最大值的最高位为0,而不是1,也就是用31位来表示能够取到的最大值,而不是32位。
因为在Java中,整型是有符号整型,最高位是有特殊含义,代表符号,真正表示数据值的范围为0 ~ 30位。
所以,按照31位来表示的话,其最大值为231 - 1,而这个值就是2147483647即21亿多。
int数据有正负之分,所以最高位用来表示符号,0代表正数,1代表负数。因此Java中,int的数据范围为 -231 ~ 231 - 1。
为啥减1
那为什么都是231, 正数的时候需要减1呢?
我们先来看一下,int的最大值和最小值:
不看符号位的话,最大值比最小值少了1个,这是因为0归到正数里面,所以占用了正数的一个位置。
拓展
负数表示
负数的二进制形式如何表示呢?
先看-100这个数的二进制形式:
最高位为1,就代表负数。值就为符号位后面的值取反再加上1。
二进制1100100对应的10进制就是100.
反码
反码就是,对一个数的二进制除符号位外,按位取反。取反就是二进制数,1变成0,0变成1,这个过程就是取反。
来看一个例子:
可以看到,a、b两个数的二进制是完全相反的。
为什么要取反加1呢?为什么要设计的这么扭曲?到底是人性的扭曲还是道德的沦丧? 这样设计有什么好处?
在计算机系统里,加减乘除的运算,并不是我们想象中10进制的加减乘除,他最后都会被翻译成2进制的位运算来计算。
假如有2个数,a、b都是整数,那么a + b 对应的二进制就是简单的相加。那么如果a为负数,b为正数呢?在执行a + b 的时候,难道还需要特殊处理一下吗?显然是不可能的,在二进制运算中,加减乘除运算只有各自的一套逻辑,无论符号两边的数是什么样子的。
a为负数,那么对a进行取反加1,再与b进行相加,可以按正常的相加逻辑,这样运算结果依然是正确的,而不是说,当a为负数时,计算机去执行另一套的相加逻辑。设计成取反加1,可以让相加运算不去关注两边的数据是正是负,只执行一套相加逻辑就可以了,这对计算机来说是一个性能的提升。
示例
从上面我们得知,负数的二进制表示为数值部分取反加1,以-100为例,那么可以得出-100 等于 ~100 + 1。
知道负数的二进制的样子后,再看int最小值和-1的二进制数据,就不会惊讶了。要不然,当看到int的最小值的二进制居然是一堆0组成,而-1居然是一堆1,看到这样的数据,心里岂不是冒出一堆问号或者一群小羊飘过。
取反加1还是自己的数
有没有一个数,取反加1还是自己?有,0和int的最小值,下面来看下:
先看下Integer.MIN_VALUE的取反加1的过程,可以看到,Integer.MIN_VALUE在取反后加上1,仍然还是他自己。
再看下0的取反加1过程,可以看到0再取反加1后,我嘞个去,居然溢出了!溢出怎么办?溢出就扔了吧不要了,结果还是他自己。
后记
本文主要介绍在Java中,为什么int类型的最大值为什么是21亿多,以及涉及到的知识点的拓展,如有错误欢迎之处。
链接:https://juejin.cn/post/7179455685455773753
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
让人恶心的多线程代码,性能怎么优化!
Java 中最烦人的,就是多线程,一不小心,代码写的比单线程还慢,这就让人非常尴尬。
通常情况下,我们会使用 ThreadLocal 实现线程封闭,比如避免 SimpleDateFormat 在并发环境下所引起的一些不一致情况。其实还有一种解决方式。通过对parse方法进行加锁,也能保证日期处理类的正确运行,代码如图。
1. 锁很坏
但是,锁这个东西,很坏。就像你的贞操锁,一开一闭热情早已烟消云散。
所以,锁对性能的影响,是非常大的。对资源加锁以后,资源就被加锁的线程所独占,其他的线程就只能排队等待这个锁。此时,程序由并行执行,变相的变成了顺序执行,执行速度自然就降低了。
下面是开启了50个线程,使用ThreadLocal和同步锁方式性能的一个对比。
Benchmark Mode Cnt Score Error Units
SynchronizedNormalBenchmark.sync thrpt 10 2554.628 ± 5098.059 ops/ms
SynchronizedNormalBenchmark.threadLocal thrpt 10 3750.902 ± 103.528 ops/ms
========去掉业务影响========
Benchmark Mode Cnt Score Error Units
SynchronizedNormalBenchmark.sync thrpt 10 26905.514 ± 1688.600 ops/ms
SynchronizedNormalBenchmark.threadLocal thrpt 10 7041876.244 ± 355598.686 ops/ms
可以看到,使用同步锁的方式,性能是比较低的。如果去掉业务本身逻辑的影响(删掉执行逻辑),这个差异会更大。代码执行的次数越多,锁的累加影响越大,对锁本身的速度优化,是非常重要的。
我们都知道,Java 中有两种加锁的方式,一种就是常见的synchronized 关键字,另外一种,就是使用 concurrent 包里面的 Lock。针对于这两种锁,JDK 自身做了很多的优化,它们的实现方式也是不同的。
2. synchronied原理
synchronized关键字给代码或者方法上锁时,都有显示的或者隐藏的上锁对象。当一个线程试图访问同步代码块时,它首先必须得到锁,退出或抛出异常时必须释放锁。
给普通方法加锁时,上锁的对象是
this
给静态方法加锁时,锁的是class对象。
给代码块加锁,可以指定一个具体的对象作为锁
monitor,在操作系统里,其实就叫做管程。
那么,synchronized 在字节码中,是怎么体现的呢?参照下面的代码,在命令行执行javac,然后再执行javap -v -p,就可以看到它具体的字节码。可以看到,在字节码的体现上,它只给方法加了一个flag:ACC_SYNCHRONIZED。
synchronized void syncMethod() {
System.out.println("syncMethod");
}
======字节码=====
synchronized void syncMethod();
descriptor: ()V
flags: ACC_SYNCHRONIZED
Code:
stack=2, locals=1, args_size=1
0: getstatic #4
3: ldc #5
5: invokevirtual #6
8: return
我们再来看下同步代码块的字节码。可以看到,字节码是通过monitorenter和monitorexit两个指令进行控制的。
void syncBlock(){
synchronized (Test.class){
}
}
======字节码======
void syncBlock();
descriptor: ()V
flags:
Code:
stack=2, locals=3, args_size=1
0: ldc #2
2: dup
3: astore_1
4: monitorenter
5: aload_1
6: monitorexit
7: goto 15
10: astore_2
11: aload_1
12: monitorexit
13: aload_2
14: athrow
15: return
Exception table:
from to target type
5 7 10 any
10 13 10 any
这两者虽然显示效果不同,但他们都是通过monitor来实现同步的。我们可以通过下面这张图,来看一下monitor的原理。
注意了,下面是面试题目高发地。
如图所示,我们可以把运行时的对象锁抽象的分成三部分。其中,EntrySet 和WaitSet 是两个队列,中间虚线部分是当前持有锁的线程。我们可以想象一下线程的执行过程。
当第一个线程到来时,发现并没有线程持有对象锁,它会直接成为活动线程,进入 RUNNING 状态。
接着又来了三个线程,要争抢对象锁。此时,这三个线程发现锁已经被占用了,就先进入 EntrySet 缓存起来,进入 BLOCKED 状态。此时,从jstack命令,可以看到他们展示的信息都是waiting for monitor entry。
"http-nio-8084-exec-120" #143 daemon prio=5 os_prio=31 cpu=122.86ms elapsed=317.88s tid=0x00007fedd8381000 nid=0x1af03 waiting for monitor entry [0x00007000150e1000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.io.BufferedInputStream.read(java.base@13.0.1/BufferedInputStream.java:263)
- waiting to lock <0x0000000782e1b590> (a java.io.BufferedInputStream)
at org.apache.commons.httpclient.HttpParser.readRawLine(HttpParser.java:78)
at org.apache.commons.httpclient.HttpParser.readLine(HttpParser.java:106)
at org.apache.commons.httpclient.HttpConnection.readLine(HttpConnection.java:1116)
at org.apache.commons.httpclient.HttpMethodBase.readStatusLine(HttpMethodBase.java:1973)
at org.apache.commons.httpclient.HttpMethodBase.readResponse(HttpMethodBase.java:1735)处于活动状态的线程,执行完毕退出了;或者由于某种原因执行了wait 方法,释放了对象锁,就会进入 WaitSet 队列。这就是在调用wait之前,需要先获得对象锁的原因。就像下面的代码:
synchronized (lock){
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}此时,jstack显示的线程状态是 WAITING 状态,而原因是in Object.wait()。
"wait-demo" #12 prio=5 os_prio=31 cpu=0.14ms elapsed=12.58s tid=0x00007fb66609e000 nid=0x6103 in Object.wait() [0x000070000f2bd000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(java.base@13.0.1/Native Method)
- waiting on <0x0000000787b48300> (a java.lang.Object)
at java.lang.Object.wait(java.base@13.0.1/Object.java:326)
at WaitDemo.lambda$main$0(WaitDemo.java:7)
- locked <0x0000000787b48300> (a java.lang.Object)
at WaitDemo$$Lambda$14/0x0000000800b44840.run(Unknown Source)
at java.lang.Thread.run(java.base@13.0.1/Thread.java:830)
发生了这两种情况,都会造成对象锁的释放。进而导致 EntrySet里的线程重新争抢对象锁,成功抢到锁的线程成为活动线程,这是一个循环的过程。
那 WaitSet 中的线程是如何再次被激活的呢?接下来,在某个地方,执行了锁的 notify 或者 notifyAll 命令,会造成WaitSet中 的线程,转移到 EntrySet 中,重新进行锁的争夺。
如此周而复始,线程就可按顺序排队执行。
3. 分级锁
JDK1.8中,synchronized 的速度已经有了显著的提升。那它都做了哪些优化呢?答案就是分级锁。JVM会根据使用情况,对synchronized 的锁,进行升级,它大体可以按照下面的路径:偏向锁->轻量级锁->重量级锁。
锁只能升级,不能降级,所以一旦升级为重量级锁,就只能依靠操作系统进行调度。
和锁升级关系最大的就是对象头里的 MarkWord,它包含Thread ID、Age、Biased、Tag四个部分。其中,Biased 有1bit大小,Tag 有2bit,锁升级就是靠判断Thread Id、Biased、Tag等三个变量值来进行的。
偏向锁
在只有一个线程使用了锁的情况下,偏向锁能够保证更高的效率。
具体过程是这样的。当第一个线程第一次访问同步块时,会先检测对象头Mark Word中的标志位Tag是否为01,以此判断此时对象锁是否处于无锁状态或者偏向锁状态(匿名偏向锁)。
01也是锁默认的状态,线程一旦获取了这把锁,就会把自己的线程ID写到MarkWord中。在其他线程来获取这把锁之前,锁都处于偏向锁状态。
轻量级锁
当下一个线程参与到偏向锁竞争时,会先判断 MarkWord 中保存的线程 ID 是否与这个线程 ID 相等,如果不相等,会立即撤销偏向锁,升级为轻量级锁。
轻量级锁的获取是怎么进行的呢?它们使用的是自旋方式。
参与竞争的每个线程,会在自己的线程栈中生成一个 LockRecord ( LR ),然后每个线程通过 CAS (自旋)的方式,将锁对象头中的 MarkWord 设置为指向自己的 LR 的指针,哪个线程设置成功,就意味着哪个线程获得锁。
当锁处于轻量级锁的状态时,就不能够再通过简单的对比Tag的值进行判断,每次对锁的获取,都需要通过自旋。
当然,自旋也是面向不存在锁竞争的场景,比如一个线程运行完了,另外一个线程去获取这把锁。但如果自旋失败达到一定的次数,锁就会膨胀为重量级锁。
重量级锁
重量级锁即为我们对synchronized的直观认识,这种情况下,线程会挂起,进入到操作系统内核态,等待操作系统的调度,然后再映射回用户态。系统调用是昂贵的,重量级锁的名称由此而来。
如果系统的共享变量竞争非常激烈,锁会迅速膨胀到重量级锁,这些优化就名存实亡。如果并发非常严重,可以通过参数-XX:-UseBiasedLocking禁用偏向锁,理论上会有一些性能提升,但实际上并不确定。
4. Lock
在 concurrent 包里,我们能够发现ReentrantLock和ReentrantReadWriteLock两个类。Reentrant就是可重入的意思,它们和synchronized关键字一样,都是可重入锁。
这里有必要解释一下可重入这个概念,因为在面试的时候经常被问到。它的意思是,一个线程运行时,可以多次获取同一个对象锁。这是因为Java的锁是基于线程的,而不是基于调用的。比如下面这段代码,由于方法a、b、c锁的都是当前的this,线程在调用a方法的时候,就不需要多次获取对象锁。
public synchronized void a(){
b();
}
public synchronized void b(){
c();
}
public synchronized void c(){
}主要方法
LOCK是基于AQS(AbstractQueuedSynchronizer)实现的,而AQS 是基于 volitale 和 CAS 实现的。关于CAS,我们将在下一课时讲解。
Lock与synchronized的使用方法不同,它需要手动加锁,然后在finally中解锁。Lock接口比synchronized灵活性要高,我们来看一下几个关键方法。
lock: lock方法和synchronized没什么区别,如果获取不到锁,都会被阻塞
tryLock: 此方法会尝试获取锁,不管能不能获取到锁,都会立即返回,不会阻塞。它是有返回值的,获取到锁就会返回true
tryLock(long time, TimeUnit unit): 与tryLock类似,但它在拿不到锁的情况下,会等待一段时间,直到超时
lockInterruptibly: 与lock类似,但是可以锁等待可以被中断,中断后返回InterruptedException
一般情况下,使用lock方法就可以。但如果业务请求要求响应及时,那使用带超时时间的tryLock是更好的选择:我们的业务可以直接返回失败,而不用进行阻塞等待。tryLock这种优化手段,采用降低请求成功率的方式,来保证服务的可用性,高并发场景下经常被使用。
读写锁
但对于有些业务来说,使用Lock这种粗粒度的锁还是太慢了。比如,对于一个HashMap来说,某个业务是读多写少的场景,这个时候,如果给读操作也加上和写操作一样的锁的话,效率就会很慢。
ReentrantReadWriteLock是一种读写分离的锁,它允许多个读线程同时进行,但读和写、写和写是互斥的。使用方法如下所示,分别获取读写锁,对写操作加写锁,对读操作加读锁,并在finally里释放锁即可。
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
Lock readLock = lock.readLock();
Lock writeLock = lock.writeLock();
public void put(K k, V v) {
writeLock.lock();
try {
map.put(k, v);
} finally {
writeLock.unlock();
}
}
...那么,除了ReadWriteLock,我们能有更快的读写分离模式么?JDK1.8加入了哪个API?欢迎留言区评论。
公平锁与非公平锁
我们平常用到的锁,都是非公平锁。可以回过头来看一下monitor的原理。当持有锁的线程释放锁的时候,EntrySet里的线程就会争抢这把锁。这个争抢的过程,是随机的,也就是说你并不知道哪个线程会获取对象锁,谁抢到了就算谁的。
这就有一定的概率,某个线程总是抢不到锁,比如,线程通过setPriority 设置的比较低的优先级。这个抢不到锁的线程,就一直处于饥饿状态,这就是线程饥饿的概念。
公平锁通过把随机变成有序,可以解决这个问题。synchronized没有这个功能,在Lock中可以通过构造参数设置成公平锁,代码如下。
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
由于所有的线程都需要排队,需要在多核的场景下维护一个同步队列,在多个线程争抢锁的时候,吞吐量就很低。下面是20个并发之下锁的JMH测试结果,可以看到,非公平锁比公平锁性能高出两个数量级。
Benchmark Mode Cnt Score Error Units
FairVSNoFairBenchmark.fair thrpt 10 186.144 ± 27.462 ops/ms
FairVSNoFairBenchmark.nofair thrpt 10 35195.649 ± 6503.375 ops/ms5. 锁的优化技巧
死锁
我们可以先看一下锁冲突最严重的一种情况:死锁。下面这段示例代码,两个线程分别持有了对方所需要的锁,进入了相互等待的状态,就进入了死锁。面试中手写这段代码的频率,还是挺高的。
public class DeadLockDemo {
public static void main(String[] args) {
Object object1 = new Object();
Object object2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (object1) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (object2) {
}
}
}, "deadlock-demo-1");
t1.start();
Thread t2 = new Thread(() -> {
synchronized (object2) {
synchronized (object1) {
}
}
}, "deadlock-demo-2");
t2.start();
}
}
使用我们上面提到的,带超时时间的tryLock方法,有一方让步,可以一定程度上避免死锁。
优化技巧
锁的优化理论其实很简单,那就是减少锁的冲突。无论是锁的读写分离,还是分段锁,本质上都是为了避免多个线程同时获取同一把锁。我们可以总结一下优化的一般思路:减少锁的粒度、减少锁持有的时间、锁分级、锁分离 、锁消除、乐观锁、无锁等。
减少锁粒度
通过减小锁的粒度,可以将冲突分散,减少冲突的可能,从而提高并发量。简单来说,就是把资源进行抽象,针对每类资源使用单独的锁进行保护。比如下面的代码,由于list1和list2属于两类资源,就没必要使用同一个对象锁进行处理。
public class LockLessDemo {
List<String> list1 = new ArrayList<>();
List<String> list2 = new ArrayList<>();
public synchronized void addList1(String v){
this.list1.add(v);
}
public synchronized void addList2(String v){
this.list2.add(v);
}
}
可以创建两个不同的锁,改善情况如下:
public class LockLessDemo {
List<String> list1 = new ArrayList<>();
List<String> list2 = new ArrayList<>();
final Object lock1 = new Object();
final Object lock2 = new Object();
public void addList1(String v) {
synchronized (lock1) {
this.list1.add(v);
}
}
public void addList2(String v) {
synchronized (lock2) {
this.list2.add(v);
}
}
}减少锁持有时间通过让锁资源尽快的释放,减少锁持有的时间,其他线程可更迅速的获取锁资源,进行其他业务的处理。考虑到下面的代码,由于slowMethod不在锁的范围内,占用的时间又比较长,可以把它移动到synchronized代码快外面,加速锁的释放。
public class LockTimeDemo {
List<String> list = new ArrayList<>();
final Object lock = new Object();
public void addList(String v) {
synchronized (lock) {
slowMethod();
this.list.add(v);
}
}
public void slowMethod(){
}
}
锁分级锁分级指的是我们文章开始讲解的synchronied锁的锁升级,属于JVM的内部优化。它从偏向锁开始,逐渐会升级为轻量级锁、重量级锁,这个过程是不可逆的。
锁分离我们在上面提到的读写锁,就是锁分离技术。这是因为,读操作一般是不会对资源产生影响的,可以并发执行。写操作和其他操作是互斥的,只能排队执行。所以读写锁适合读多写少的场景。
锁消除通过JIT编译器,JVM可以消除某些对象的加锁操作。举个例子,大家都知道StringBuffer和StringBuilder都是做字符串拼接的,而且前者是线程安全的。
但其实,如果这两个字符串拼接对象用在函数内,JVM通过逃逸分析分析这个对象的作用范围就是在本函数中,就会把锁的影响给消除掉。比如下面这段代码,它和StringBuilder的效果是一样的。
String m1(){
StringBuffer sb = new StringBuffer();
sb.append("");
return sb.toString();
}End
Java中有两种加锁方式,一种是使用synchronized关键字,另外一种是concurrent包下面的Lock。本课时,我们详细的了解了它们的一些特性,包括实现原理。下面对比如下:
| 类别 | Synchronized | Lock |
|---|---|---|
| 实现方式 | monitor | AQS |
| 底层细节 | JVM优化 | Java API |
| 分级锁 | 是 | 否 |
| 功能特性 | 单一 | 丰富 |
| 锁分离 | 无 | 读写锁 |
| 锁超时 | 无 | 带超时时间的tryLock |
| 可中断 | 否 | lockInterruptibly |
Lock的功能是比synchronized多的,能够对线程行为进行更细粒度的控制。但如果只是用最简单的锁互斥功能,建议直接使用synchronized。有两个原因:
synchronized的编程模型更加简单,更易于使用
synchronized引入了偏向锁,轻量级锁等功能,能够从JVM层进行优化,同时,JIT编译器也会对它执行一些锁消除动作
多线程代码好写,但bug难找,希望你的代码即干净又强壮,兼高性能与高可靠于一身。
链接:https://juejin.cn/post/7178679092970012731
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
App实现JSBridge的最佳方案
前沿
写这篇文章的主要目的是对 App 的 JSBridge 做一个全面的介绍,同时根据不同的使用场景总结出一份 App 实现 JSBridge 的最佳方案。对于没有接触过 App 的同学能够对 JSBridge 有个大致的概念,对于做过 App 的 JSBridge 开发的同学也能有更系统的认识,也是自己对于相关知识点的归纳总结。
一、概念
什么是 JSBridge ?
JSBridge 的全称:JavaScript Bridge,中文名 JS桥 或 JS桥接器。
JSBridge 是一种用于在 Android 和 iOS 应用与 H5 之间进行通信的技术。它允许应用开发者在原生代码中调用 JavaScript 函数,以及 在JavaScript 中调用原生代码函数。其通常用于移动应用开发中,可以使用 JSBridge 技术在原生应用中嵌入网页,并在网页与原生应用之间进行交互。
二、原理
JSBridge 通过在 WebView 中注册 JavaScript 函数来实现通信。WebView 是一种在应用中嵌入网页的组件,可以在应用中显示网页内容。JSBridge 通过在 WebView 中注册 JavaScript 函数,并在原生代码中调用这些函数来实现通信。
例如,下面是一个使用 JSBridge 实现通信的示例代码:
/* Android 端实现 */
// 在WebView中注册JavaScript函数
webView.loadUrl("javascript:function myFunction() { /* JavaScript code here */ }");
// 在原生代码中调用JavaScript函数
webView.loadUrl("javascript:myFunction()");
/* iOS 端实现 */
// 在WebView中注册JavaScript函数
[self.webView stringByEvaluatingJavaScriptFromString:@"function myFunction() { /* JavaScript code here */ }"];
// 在原生代码中调用JavaScript函数
[self.webView stringByEvaluatingJavaScriptFromString:@"myFunction()"];
上面的代码通过在 WebView 中注册 JavaScript 函数 myFunction,并在原生代码中调用这个函数来实现通信。
在实际开发中,我们一般是创建一个 JSBridge 对象,然后通过 WebView 的 addJavascriptInterface 方法进行注册。
// WebView 的 addJavascriptInterface 方法源码
public void addJavascriptInterface(Object object, String name) {
checkThread();
if (object == null) {
throw new NullPointerException("Cannot add a null object");
}
if (name == null || name.length() == 0) {
throw new IllegalArgumentException("Invalid name");
}
mJavascriptInterfaces.put(name, object);
}该方法首先检查当前线程是否是 UI 线程,以确保添加桥接对象的操作是在 UI 线程中进行的。接着,该方法会检查桥接对象和名称的有效性,确保它们都不为空。最后,该方法会把桥接对象与名称关联起来,并存储到 WebView 的 mJavascriptInterfaces 对象中。
当网页加载完成后,WebView 会把桥接对象的方法注入到网页中,使得网页能够调用这些方法。当网页中的 JavaScript 代码调用桥接对象的方法时,WebView 会把该方法调用映射到原生代码中,从而实现网页与原生应用之间的交互。
addJavascriptInterface 方法的主要作用是把桥接对象的方法注入到网页中,使得网页能够调用这些方法。它的具体实现方式可能会因平台而异,但是它的基本原理是一致的。
三、原生实现
以 H5 获取 App 的版本号为例。Android相关源码
要实现一个获取 App 版本号的 JSBridge,需要在 H5 中编写 JavaScript 代码,并在 Android 原生代码中实现对应的原生方法。
首先,需要在 H5 中编写 JavaScript 代码,用于调用 Android 的原生方法。例如,可以在 H5 中定义一个函数,用于调用 Android 的原生方法:
// assets/index.html
function getAppVersion() {
// 通过JSBridge调用Android的原生方法
JSBridge.getAppVersion(function(version) {
// 在这里处理获取到的Android版本号
});
}然后,需要在 Android 的原生代码中实现对应的原生方法。例如,可以实现一个名为 getAppVersion 的方法,用于在 H5 中调用:
// com.fitem.webviewdemo.AppJSBridge
@JavascriptInterface
public String getAppVersion() {
// 获取App版本号
String version = BuildConfig.VERSION_NAME;
// 将App版本号返回给H5
return version;
}最后通过 Webview 注入定义的 JavascriptInterface 方法的对象,在 H5 生成 window.jsBridge 对象进行调用。
// com.fitem.webviewdemo.MainActivity.kt
webView.addJavascriptInterface(jsBridge, "jsBridge")iOS 的实现和 Android 类似:
- (void)getIOSVersion:(WVJBResponseCallback)callback {
// 获取App版本号
let version = Bundle.main.object(forInfoDictionaryKey:
"CFBundleShortVersionString") as! String
// 将App版本号返回给H5
callback(version);
}
// 在网页加载完成后设置JSBridge
- (void)webViewDidFinishLoad:(UIWebView *)webView {
// 设置JSBridge
[WebViewJavascriptBridge enableLogging];
self.bridge = [WebViewJavascriptBridge bridgeForWebView:webView];
[self.bridge setWebViewDelegate:self];
}
四、跨平台(Flutter)
1. JSBridge 实现
Flutter 实现 JSBridge 功能的插件有很多,但基本上大多数都是基于原生的 JSBridge 能力实现。这里主要介绍官方的 webview_flutter 插件。
webview_flutter 插件实现 App 与 H5 之前的通信分为:App 发送消息到 H5 和 H5 发送消息到 APP 两部分。
H5 发送消息到 APP。首先在 Flutter 应用中添加 WebView 组件,并设置 JavascriptChannel:
WebView(
initialUrl: 'https://www.example.com',
javascriptMode: JavascriptMode.unrestricted,
javascriptChannels: {
// 设置JavascriptChannel
JavascriptChannel(
name: 'JSBridge',
onMessageReceived: (JavascriptMessage message) {
// 在这里处理来自H5的消息
},
),
},
),在H5中,可以通过 JSBridge 对象来调用原生方法:
// 通过JSBridge调用原生方法
window.jsBridge.postMessage('Hello, world!');App 发送消息到 H5。 在 Flutter 中,通过 WebViewController 的 runJavascrip 调用 H5 中 window 对象的方法
controller.runJavascript("receiveMessage(${json.encode(res)})")在 H5 中,可以通过 onmessage 事件来接收来自原生的消息:
// 接收来自原生的消息
window.receiveMessage = function receiveMessage(message) {
console.log(message);
};2. 局限性
webview_flutter 最大的局限在于 App 端与 H5 端之间的通信只支持单向通信,无法通过一次调用直接获取另一端的返回值。
五、App 实现 JSBridge 的最佳方案
1. 实现目标
H5 兼容原生老版本 JSBridge。
支持两端双向通信。针对
webview_flutter的单向通信的局限性进行改造优化,使其能支持返回值的回调。
2. NativeBridge 插件开发
NativeBridge 本质上是对 webview_flutter 的单向通信能力进行扩展和封装。
NativeBridge 插件的使用和实现原理,请阅读之前的文章《Flutter插件之NativeBridge》和《NativeBridge实现原理解析》。
3. 实现效果
- H5 支持原生老版本 JSBridge 兼容。
// 获取app版本号 返回String
async getVersionCode() {
// 是否是新的JSBridge
if (this.isNewJSBridge()) {
return await window.jsBridgeHelper.sendMessage('getVersionCode', null)
} else {
return window.iLotJsBridge.getVersionCode()
}
}- 支持两端双向通信。
// H5 获取 App 的值
const versionNo = await jsBridge.getVersionCode()
// App 获取 H5 的值
var isHome = await NativeBridgeHelper.sendMessage("isHome", null, webViewController).future ?? false;- 新增超时连接机制
就像网络请求一样,我们不能让代码执行一直阻塞在获取返回值的位置上。因为单向发送消息是不可靠的,可能存在消息丢失,或者另一端不响应消息的情况。因此我们需要类似网络请求一样,增加超时回调机制。
// 增加回调异常容错机制,避免消息丢失导致一直阻塞
Future.delayed(const Duration(milliseconds: 100), (){
var completer = _popCallback(callbackId);
completer?.complete(Future.value(null));
});总结
我们首先介绍了 JSBridge 的概念和原理,然后通过在 Android 、iOS 和 Flutter 中实现 JSBridge 来理解原生和 Flutter 之前的差异,最后总结了在 App 中实现 JSBridge 的最佳方案,方案包括支持原生和 Flutter 的兼容,并优化 webview_flutter 只支持单向通信的局限性和增加超时回调机制。
链接:https://juejin.cn/post/7177407635317063735
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Glide 原理探索
implementation 'com.github.bumptech.glide:glide:4.12.0'
annotationProcessor 'com.github.bumptech.glide:compiler:4.12.0'
Glide.with(this).load(url).into(imageView)
上面这行代码,是 Glide 最简单的使用方式了,下面我们来一个个拆解下。
with
with 就是根据传入的 context 来获取图片请求管理器 RequestManager,用来启动和管理图片请求。
public static RequestManager with(@NonNull FragmentActivity activity) {
return getRetriever(activity).get(activity);
}context 可以传入 Application,Activity 和 Fragment,这关系着图片请求的生命周期。通常使用当前页面的 context,这样当我们打开一个页面加载图片,然后退出页面时,图片请求会跟随页面的销毁而被取消,而不是继续加载浪费资源。
当 context 是 Application 时,获得的 RequestManager 是一个全局单例,图片请求的生命周期会跟随整个 APP 。
如果 with 发生在子线程,不管 context 是谁,都返回应用级别的 RequestManager 单例。
private RequestManager getApplicationManager(@NonNull Context context) {
// Either an application context or we're on a background thread.
if (applicationManager == null) {
synchronized (this) {
if (applicationManager == null) {
// Normally pause/resume is taken care of by the fragment we add to the fragment or
// activity. However, in this case since the manager attached to the application will not
// receive lifecycle events, we must force the manager to start resumed using
// ApplicationLifecycle.
// TODO(b/27524013): Factor out this Glide.get() call.
Glide glide = Glide.get(context.getApplicationContext());
applicationManager =
factory.build(
glide,
new ApplicationLifecycle(),
new EmptyRequestManagerTreeNode(),
context.getApplicationContext());
}
}
}
return applicationManager;
}当 context 是 Activity 时,会创建一个无界面的 Fragment 添加到 Activity,用于感知 Activity 的生命周期,同时创建 RequestManager 给该 Fragment 持有。
private RequestManager supportFragmentGet(
@NonNull Context context,
@NonNull FragmentManager fm,
@Nullable Fragment parentHint,
boolean isParentVisible) {
SupportRequestManagerFragment current = getSupportRequestManagerFragment(fm, parentHint);
RequestManager requestManager = current.getRequestManager();
if (requestManager == null) {
// TODO(b/27524013): Factor out this Glide.get() call.
Glide glide = Glide.get(context);
requestManager =
factory.build(
glide, current.getGlideLifecycle(), current.getRequestManagerTreeNode(), context);
// This is a bit of hack, we're going to start the RequestManager, but not the
// corresponding Lifecycle. It's safe to start the RequestManager, but starting the
// Lifecycle might trigger memory leaks. See b/154405040
if (isParentVisible) {
requestManager.onStart();
}
current.setRequestManager(requestManager);
}
return requestManager;
}load
load 方法会得到一个图片请求构建器 RequestBuilder,用来创建图片请求。
public RequestBuilder<Drawable> load(@Nullable String string) {
return asDrawable().load(string);
}into
首先是根据 ImageView 的 ScaleType,来配置参数.
public ViewTarget<ImageView, TranscodeType> into(@NonNull ImageView view) {
Util.assertMainThread();
Preconditions.checkNotNull(view);
BaseRequestOptions<?> requestOptions = this;
if (!requestOptions.isTransformationSet()
&& requestOptions.isTransformationAllowed()
&& view.getScaleType() != null) {
// Clone in this method so that if we use this RequestBuilder to load into a View and then
// into a different target, we don't retain the transformation applied based on the previous
// View's scale type.
switch (view.getScaleType()) {
case CENTER_CROP:
requestOptions = requestOptions.clone().optionalCenterCrop();
break;
case CENTER_INSIDE:
requestOptions = requestOptions.clone().optionalCenterInside();
break;
case FIT_CENTER:
case FIT_START:
case FIT_END:
requestOptions = requestOptions.clone().optionalFitCenter();
break;
case FIT_XY:
requestOptions = requestOptions.clone().optionalCenterInside();
break;
case CENTER:
case MATRIX:
default:
// Do nothing.
}
}
return into(
glideContext.buildImageViewTarget(view, transcodeClass),
/*targetListener=*/ null,
requestOptions,
Executors.mainThreadExecutor());
}继续跟进 into,会创建图片请求,获取 Target 载体已有的请求,对比两个请求,如果等效,启动异步请求,然后,图片载体绑定图片请求,也就是 ImageView setTag 为 request 。
private <Y extends Target<TranscodeType>> Y into(
@NonNull Y target,
@Nullable RequestListener<TranscodeType> targetListener,
BaseRequestOptions<?> options,
Executor callbackExecutor) {
Preconditions.checkNotNull(target);
if (!isModelSet) {
throw new IllegalArgumentException("You must call #load() before calling #into()");
}
Request request = buildRequest(target, targetListener, options, callbackExecutor);
Request previous = target.getRequest();
if (request.isEquivalentTo(previous)
&& !isSkipMemoryCacheWithCompletePreviousRequest(options, previous)) {
// If the request is completed, beginning again will ensure the result is re-delivered,
// triggering RequestListeners and Targets. If the request is failed, beginning again will
// restart the request, giving it another chance to complete. If the request is already
// running, we can let it continue running without interruption.
if (!Preconditions.checkNotNull(previous).isRunning()) {
// Use the previous request rather than the new one to allow for optimizations like skipping
// setting placeholders, tracking and un-tracking Targets, and obtaining View dimensions
// that are done in the individual Request.
previous.begin();
}
return target;
}
requestManager.clear(target);
target.setRequest(request);
requestManager.track(target, request);
return target;
}继续跟进异步请求 requestManager.track(target, request)
synchronized void track(@NonNull Target<?> target, @NonNull Request request) {
targetTracker.track(target);
requestTracker.runRequest(request);
} public void runRequest(@NonNull Request request) {
requests.add(request);
if (!isPaused) {
request.begin();//开启图片请求
} else {
request.clear();
if (Log.isLoggable(TAG, Log.VERBOSE)) {
Log.v(TAG, "Paused, delaying request");
}
pendingRequests.add(request);//如果是暂停状态,就把请求存起来。
}
}到这里就启动了图片请求了,我们继续跟进 request.begin()
public void begin() {
synchronized (requestLock) {
//......
if (Util.isValidDimensions(overrideWidth, overrideHeight)) {
//如果有尺寸,开始加载
onSizeReady(overrideWidth, overrideHeight);
} else {
//如果无尺寸就先去获取
target.getSize(this);
}
//......
}
}然后继续瞧瞧 onSizeReady
public void onSizeReady(int width, int height) {
stateVerifier.throwIfRecycled();
synchronized (requestLock) {
//......
loadStatus =
engine.load(
glideContext,
model,
requestOptions.getSignature(),
this.width,
this.height,
requestOptions.getResourceClass(),
transcodeClass,
priority,
requestOptions.getDiskCacheStrategy(),
requestOptions.getTransformations(),
requestOptions.isTransformationRequired(),
requestOptions.isScaleOnlyOrNoTransform(),
requestOptions.getOptions(),
requestOptions.isMemoryCacheable(),
requestOptions.getUseUnlimitedSourceGeneratorsPool(),
requestOptions.getUseAnimationPool(),
requestOptions.getOnlyRetrieveFromCache(),
this,
callbackExecutor);
//......
}
}跟进 engine.load
public <R> LoadStatus load(
GlideContext glideContext,
Object model,
Key signature,
int width,
int height,
Class<?> resourceClass,
Class<R> transcodeClass,
Priority priority,
DiskCacheStrategy diskCacheStrategy,
Map<Class<?>, Transformation<?>> transformations,
boolean isTransformationRequired,
boolean isScaleOnlyOrNoTransform,
Options options,
boolean isMemoryCacheable,
boolean useUnlimitedSourceExecutorPool,
boolean useAnimationPool,
boolean onlyRetrieveFromCache,
ResourceCallback cb,
Executor callbackExecutor) {
long startTime = VERBOSE_IS_LOGGABLE ? LogTime.getLogTime() : 0;
EngineKey key =
keyFactory.buildKey(
model,
signature,
width,
height,
transformations,
resourceClass,
transcodeClass,
options);
EngineResource<?> memoryResource;
synchronized (this) {
//从内存加载
memoryResource = loadFromMemory(key, isMemoryCacheable, startTime);
if (memoryResource == null) { //如果内存里没有
return waitForExistingOrStartNewJob(
glideContext,
model,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
options,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache,
cb,
callbackExecutor,
key,
startTime);
}
}
cb.onResourceReady(
memoryResource, DataSource.MEMORY_CACHE, /* isLoadedFromAlternateCacheKey= */ false);
return null;
} private <R> LoadStatus waitForExistingOrStartNewJob(
GlideContext glideContext,
Object model,
Key signature,
int width,
int height,
Class<?> resourceClass,
Class<R> transcodeClass,
Priority priority,
DiskCacheStrategy diskCacheStrategy,
Map<Class<?>, Transformation<?>> transformations,
boolean isTransformationRequired,
boolean isScaleOnlyOrNoTransform,
Options options,
boolean isMemoryCacheable,
boolean useUnlimitedSourceExecutorPool,
boolean useAnimationPool,
boolean onlyRetrieveFromCache,
ResourceCallback cb,
Executor callbackExecutor,
EngineKey key,
long startTime) {
EngineJob<?> current = jobs.get(key, onlyRetrieveFromCache);
if (current != null) {
current.addCallback(cb, callbackExecutor);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Added to existing load", startTime, key);
}
return new LoadStatus(cb, current);
}
EngineJob<R> engineJob =
engineJobFactory.build(
key,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache);
DecodeJob<R> decodeJob =
decodeJobFactory.build(
glideContext,
model,
key,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
onlyRetrieveFromCache,
options,
engineJob);
jobs.put(key, engineJob);
engineJob.addCallback(cb, callbackExecutor);
engineJob.start(decodeJob);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Started new load", startTime, key);
}
return new LoadStatus(cb, engineJob);
}DecodeJob 是一个 Runnable,它通过一系列的调用,会来到 HttpUrlFetcher 的 loadData 方法。
public void loadData(
@NonNull Priority priority, @NonNull DataCallback<? super InputStream> callback) {
long startTime = LogTime.getLogTime();
try {
//获取输入流,此处使用的是 HttpURLConnection
InputStream result = loadDataWithRedirects(glideUrl.toURL(), 0, null, glideUrl.getHeaders());
//回调出去
callback.onDataReady(result);
} catch (IOException e) {
if (Log.isLoggable(TAG, Log.DEBUG)) {
Log.d(TAG, "Failed to load data for url", e);
}
callback.onLoadFailed(e);
} finally {
if (Log.isLoggable(TAG, Log.VERBOSE)) {
Log.v(TAG, "Finished http url fetcher fetch in " + LogTime.getElapsedMillis(startTime));
}
}
}至此,网络请求结束,最后把图片设置上去就行了,在 SingleRequest 的 onResourceReady 方法,它会把结果回调给 Target 载体。
target.onResourceReady(result, animation);继续跟进它,最终会执行 setResource,把图片设置上去。
protected void setResource(@Nullable Drawable resource) {
view.setImageDrawable(resource);
}总结
with 根据传入的 context 获取图片请求管理器 RequestManager,当传入的 context 是 Application 时,图片请求的生命周期会跟随应用,当传入的是 Activity 时,会创建一个无界面的空 Fragment 添加到 Activity,用来感知 Activity 的生命周期。load 会得到了一个图片请求构建器 RequestBuilder,用来创建图片请求。into 开启加载,先会根据 ImageView 的 ScaleType 来配置参数,创建图片请求,图片载体绑定图片请求,然后开启图片请求,先从内存中加载,如果内存里没有,会创建一个 Runnable,通过一系列的调用,使用 HttpURLConnection 获取网络输入流,把结果回调出去,最后把回调结果设置上去就行了。
缓存
Glide 三级缓存原理:读取一张图片时,顺序是: 弱引用缓存,LruCache,磁盘缓存。
用 Glide 加载某张图片时,先去弱引用缓存中寻找图片,如果有则直接取出来使用,如果没有,则去 LruCache 中寻找,如果 LruCache 中有,则中取出使用,并将它放入弱引用缓存中,如果没有,则从磁盘缓存或网络中加载图片。
private EngineResource<?> loadFromMemory(
EngineKey key, boolean isMemoryCacheable, long startTime) {
if (!isMemoryCacheable) {
return null;
}
EngineResource<?> active = loadFromActiveResources(key); //从弱引用获取图片
if (active != null) {
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from active resources", startTime, key);
}
return active;
}
EngineResource<?> cached = loadFromCache(key); //从 LruCache 获取缓存图片
if (cached != null) {
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from cache", startTime, key);
}
return cached;
}
return null;
}不过,这会产生一个问题:Glide 加载图片时,URL 不变但是图片变了的这种情况,还是用以前的旧图片。因为 Glide 加载图片会将图片缓存到本地,如果 URL 不变则直接读取缓存不会再从网络上加载。
解决方案:
- 清除缓存
- 让后台每次都更改图片的名字
- 图片地址选用 ”url?key="+随机数这种格式
LruCache
LruCache 就是维护一个缓存对象列表,其中对象列表的排列方式是按照访问顺序实现的,即一直没访问的对象,将放在队尾,最先被淘汰,而最近访问的对象将放在队头,最后被淘汰。其内部维护了一个集合 LinkedHashMap,LinkHashMap 继承 HashMap,在 HashMap 的基础上,新增了双向链表结构,每次访问数据的时候,会更新被访问数据的链表指针,该 LinkedHashMap 是以访问顺序排序的,当调用 put 方法时,就会在集合中添加元素,判断缓存是否已满,如果满了就删除队尾元素,即近期最少访问的元素,当调用 LinkedHashMap 的 get 方法时,就会获得对应的集合元素,同时更新该元素到队头。
Glide 会为每个不同尺寸的 Imageview 缓存一张图片,也就是说不管这张图片有没有加载过,只要 Imageview 的尺寸不一样,Glide 就会重新加载一次,这时候,它会在加载 Imageview 之前从网络上重新下载,然后再缓存。举个例子,如果一个页面的 Imageview 是 100 * 100,另一个页面的 Imageview 是 800 * 800,它俩展示同一张图片的话,Glide 会下载两次图片,并且缓存两张图片,因为 Glide 缓存 Key 的生成条件之一就是控件的长宽。
由上可知,在图片加载中关闭页面,此页面也不会造成内存泄漏,因为 Glide 在加载资源的时候,如果是在 Activity 或 Fragment 这类有生命周期的组件上进行的话,会创建一个无界面的 Fragment 加入到 FragmentManager 之中,感知生命周期,当 Activity 或 Fragment 进入不可见或销毁的时候,Glide 会停止加载资源。但是,如果是在非生命周期的组件上进行时,一般会采用 Application 的生命周期贯穿整个应用,此时只有在应用程序关闭的时候才会停止加载。
链接:https://juejin.cn/post/7178370740406714423
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android的线程和线程池
从用途上来说Android的线程主要分为主线程和子线程两类,主线程主要处理和界面相关的工作,子线程主要处理耗时操作。除Thread之外,Android中还有其他扮演线程的角色如AsyncTask、IntentService、HandleThread,其中AsyncTask的底层用到了线程池,IntentService和HandleThread的底层直接使用了线程。
AsyncTask内部封装了线程池和Handler主要是为了方便开发者在在线程中更新UI;HandlerThread是一个具有消息循环的线程,它的内部可以使用Handler;IntentService是一个服务,系统对其进行了封装使其可以更方便的执行后台任务,IntentService内部采用HandleThread来执行任务,当任务执行完毕后IntentService会自动退出。IntentService是一个服务但是它不容易被系统杀死因此它可以尽量的保证任务的执行。
1.主线程和子线程
主线程是指进程所拥有的的线程,在Java中默认情况下一个进程只能有一个线程,这个线程就是主线程。主线程主要处理界面交互的相关逻辑,因为界面随时都有可能更新因此在主线程不能做耗时操作,否则界面就会出现卡顿的现象。主线程之外的线程都是子线程,也叫做工作线程。
Android沿用了Java的线程模型,也有主线程和子线程之分,主线程主要工作是运行四大组件及处理他们和用户的交互,子线程的主要工作就是处理耗时任务,例如网络请求,I/O操作等。Android3.0开始系统要求网络访问必须在子线程中进行否则就会报错,NetWorkOnMainThreadException
2.Android中的线程形态
2.1 AsyncTask
AsyncTask是一个轻量级的异步任务类,它可以在线程池中执行异步任务然后把执行进度和执行结果传递给主线程并在主线程更新UI。从实现上来说AsyncTask封装了Thread和Handler,通过AsyncTask可以很方便的执行后台任务以及主线程中访问UI,但是AsyncTask不适合处理耗时任务,耗时任务还是要交给线程池执行。
AsyncTask的四个核心类如下:
- onPreExecute():主要用于做一些准备工作,在主线程中执行异步任务执行之前
- doInBackground(Params ... params):在线程池执行,此方法用于执行异步任务,params表示输入的参数,在此方法中可以通过publishProgress方法来更新任务进度,publishProgress会调用onProgressUpdate
- onProgressUpdate(Progress .. value):在主线程执行,当任务执行进度发生改变时会调用这个方法
- onPostExecute(Result result):在主线程执行,异步任务之后执行这个方法,result参数是返回值,即doInBackground的返回值。
2.2 AsyncTask的工作原理
2.3 HandleThread
HandleThread继承自Thread,它是一种可以使用Handler的Thread,它的实现在run方法中调用Looper.prepare()来创建消息队列然后通过Looper.loop()来开启消息循环,这样在实际使用中就可以在HandleThread中创建Handler了。
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}HandleThread和Thread的区别是什么?
- Thread的run方法中主要是用来执行一个耗时任务;
- HandleThread在内部创建了一个消息队列需要通过Handler的消息方式来通知HandleThread执行一个具体的任务,HandlerThread的run方法是一个无限循环因此在不使用是调用quit或者quitSafely方法终止线程的执行。HandleTread的具体使用场景是IntentService。
2.4 IntentService
IntentService继承自Service并且是一个抽象的类因此使用它时就必须创建它的子类,IntentService可用于执行后台耗时的任务,当任务执行完毕后就会自动停止。IntentService是一个服务因此它的优先级要比线程高并且不容易被系统杀死,因此可以利用这个特点执行一些高优先级的后台任务,它的实现主要是HandlerThread和Handler,这点可以从onCreate方法中了解。
//IntentService#onCreate
@Override
public void onCreate() {
// TODO: It would be nice to have an option to hold a partial wakelock
// during processing, and to have a static startService(Context, Intent)
// method that would launch the service & hand off a wakelock.
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}当IntentService第一次被启动时回调用onCreate方法,在onCreate方法中会创建HandlerThread,然后使用它的Looper创建一个Handler对象ServiceHandler,这样通过mServiceHandler把消息发送到HandlerThread中执行。每次启动IntentService都会调用onStartCommand,IntentService在onStartCommand中会处理每个后台任务的Intent。
//IntentService#onStartCommand
@Override
public int onStartCommand(@Nullable Intent intent, int flags, int startId) {
onStart(intent, startId);
return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY;
}
//IntentService#onStart
@Override
public void onStart(@Nullable Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}onStartCommand是如何处理外界的Intent的?
在onStartCommand方法中进入了onStart方法,在这个方法中IntentService通过mserviceHandler发送了一条消息,然后这个消息会在HandlerThread中被处理。mServiceHandler接收到消息后会把intent传递给onHandlerIntent(),这个intent跟启动IntentService时的startService中的intent是一样的,因此可以通过这个intent解析出启动IntentService传递的参数是什么然后通过这些参数就可以区分具体的后台任务,这样onHandleIntent就可以对不同的后台任务做处理了。当onHandleIntent方法执行结束后IntentService就会通过stopSelf(int startId)方法来尝试停止服务,这里不用stopSelf()的原因是因为这个方法被调用之后会立即停止服务但是这个时候可能还有其他消息未处理完毕,而采用stopSelf(int startId)方法则会等待所有消息都处理完毕后才会终止服务。调用stopSelf(int startId)终止服务时会根据startId判断最近启动的服务的startId是否相等,相等则立即终止服务否则不终止服务。
每执行一个后台任务就会启动一次intentService,而IntentService内部则通过消息的方式向HandlerThread请求执行任务,Handler中的Looper是顺序处理消息的,这就意味着IntentService也是顺序执行后台任务的,当有多个后台任务同时存在时这些后台任务会按照外界发起的顺序排队执行。
3.Android中的线程池
线程池的优点:
- 线程池中的线程可重复使用,避免因为线程的创建和销毁带来的性能开销;
- 能有效控制线程池中的最大并发数避免大量的线程之间因互相抢占系统资源导致的阻塞现象;
- 能够对线程进行简单的管理并提供定时执行以及指定间隔循环执行等功能。
Android的线程池的概念来自于Java中的Executor,Executor是一个接口,真正的线程的实现是ThreadPoolExecutor,它提供了一些列参数来配置线程池,通过不同的参数可以创建不同的线程池。
3.1 ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}ThreadPoolExecutor是线程池的真正实现,它的构造函数中提供了一系列参数,先看一下每个参数的含义:
- corePoolSize:线程池的核心线程数,默认情况下核心线程会在线程池中一直存活即使他们处于闲置状态。如果将ThreadPoolExecutor的allowCoreThreadTimeOut置为true那么闲置的核心线程在等待新的任务到来时会有超时策略,超时时间由keepAliveTime指定,当等待时间超过keepAliveTime设置的时间后核心线程就会被终止。
- maxinumPoolSize:线程池中所能容纳的最大线程数,当活动线程达到做大数量时后续的新任务就会被阻塞。
- keepAliveTime:非核心线程闲置时的超时时长,超过这个时长非核心线程就会被回收。
- unit:用于指定超时时间的单位,常用单位有毫秒、秒、分钟等。
- workQueue:线程池中的任务队列,通过线程池中的execute方法提交的Runnable对象会存储在这个参数中。
- threadFactory:线程工厂,为线程池提供创建新的线程的功能。
- handler:这个参数不常用,当线程池无法执行新的任务时,这可能是由于任务队列已满或者无法成功执行任务,这个时候ThreadPoolExecutor会调用handler的rejectExecution方法来通知调用者。
ThreadPoolExecutor执行任务时大致遵循如下规则:
- 如果线程池中的线程数量没有达到核心线程的数量那么会直接启动一个核心线程来执行任务;
- 如果线程池中线程数量已经达到或者超过核心线程的数量那么会把后续的任务插入到队列中等待执行;
- 如果任务队列也无法插入那么在基本可以确定是队列已满这时如果线程池中的线程数量没有达到最大值就会立刻创建非核心线程来执行任务;
- 如果非核心线程的创建已经达到或者超过线程池的最大数量那么就拒绝执行此任务,同时ThreadPoolExecutor会通过RejectedExecutionHandler抛出异常rejectedExecution。
3.2线程池的分类
- FixedThreadPool:它是一种数量固定的线程池,当线程处于空闲状态时也不会被回收,除非线程池被关闭。当所有的线程都处于活动状态时,新任务都会处于等待状态,直到有空闲线程出来。FixedThreadPool只有核心线程并且不会被回收因此它可以更加快速的响应外界的请求。
- CacheThreadPool:它是一种线程数量不定的线程池且只有非核心线程,线程的最大数量是Integer.MAX_VALUE,当线程池中的线程都处于活动状态时如果有新的任务进来就会创建一个新的线程去执行任务,同时它还有超时机制,当一个线程闲置超过60秒时就会被回收。
- ScheduleThreadPool:它是一种拥有固定数量的核心线程和不固定数量的非核心线程的线程池,当非核心线程闲置时会立即被回收。
- SignleThreadExecutor:它是一种只有一个核心线程的线程池,所有任务都在同一个线程中按顺序执行。
链接:https://juejin.cn/post/7178847227598045241
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 位图(图片)加载引入的内存溢出问题分析
1.一些定义
在分析具体问题之前,我们先了解一些基本概念,这样可以帮助理解后面的原理部分。当然了,大家对于这部分定义已经了然于胸的,就可以跳过了。
什么是内存泄露?
我们知道Java GC管理的主要区域是堆,Java中几乎所有的实例对象数据实际是存储在堆上的(当然JDK1.8之后,针对于不会被外界调用的数据而言,JVM是放置于栈内的)。针对于某一程序而言,堆的大小是固定的,我们在代码中新建对象时,往往需要在堆中申请内存,那么当系统不能满足需求,于是产生溢出。或者可以这样理解堆上分配的内存没有被释放,从而失去对其控制。这样会造成程序能使用的内存越来越少,导致系统运行速度减慢,严重情况会使程序宕掉。
什么是位图?
位图使用我们称为像素的一格一格的小点来描述图像,计算机屏幕其实就是一张包含大量像素点的网格,在位图中,平时看到的图像将会由每一个网格中的像素点的位置和色彩值来决定,每一点的色彩是固定的,而每个像素点色彩值的种类,产生了不同的位图Config,常见的有:
ALPHA_8, 代表8位Alpha位图,每个像素占用1byte内存
RGB_565,代表8位RGB位图,每个像素占用2byte内存
ARGB_4444 (@deprecated),代表16位ARGB位图,每个像素占用2byte内存
ARGB_8888,代表32位ARGB位图,每个像素占用4byte内存
其实很好理解,我们知道RGB是指红蓝绿,不同的config代表,计算机中每种颜色用几位二进制位来表示,例如:RGB_565代表红5为、蓝6位、绿5为。
2.原理分析
2.1 原理分析一
由第一节的基础定义,我们知道不过JVM还是Android虚拟机,对于每个应用程序可用内存大小是有约束的,而针对于单个程序中Bitmap所占的内存大小也有约束(一般机器是8M、16M,大家可以通过查看build.prop文件去查看这个定义大小),一旦超过了这个大小,就会报OOM错误。
Android编程中,我们经常会使用ImageView 控件,加载图片,例如以下代码:
package com.itbird.BitmapOOM;
import android.graphics.BitmapFactory;
import android.os.Bundle;
import android.widget.ImageView;
import androidx.appcompat.app.AppCompatActivity;
import com.itbird.R;
public class ImageViewLoadBitmapTestActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.imageviewl_load_bitmap_test);
ImageView imageView = findViewById(R.id.imageview);
imageView.setImageResource(R.drawable.bigpic);
imageView.setBackgroundResource(R.drawable.bigpic);
imageView.setImageBitmap(BitmapFactory.decodeFile("path/big.jpg"));
imageView.setImageBitmap(BitmapFactory.decodeResource(getResources(), R.drawable.bigpic));
}
}当图片很小时,一般不会有问题,当图片很大时,就会出现OOM错误,原因是直接调用decodeResource、setImageBitmap、setBackgroundResource时,实际上,这些函数在完成照片的decode之后,都是调用了java底层的createBitmap来完成的,需要消耗更多的内存。至于为什么会消耗那么多内存,如下面的源码分析:
android8.0之前Bitmap源码
public final class Bitmap implements Parcelable {
private static final String TAG = "Bitmap";
...
private byte[] mBuffer;
...
}android8.0之后Bitmap源码
public final class Bitmap implements Parcelable {
...
// Convenience for JNI access
private final long mNativePtr;
...
}对上上述两者,相信大家已经看出点什么了,android8.0之前,Bitmap在Java层保存了byte数组,而且细跟源码的话,您也会发现,8.0之前虽然调用了native函数,但是实际其实就是在native层创建Java层byte[],并将这个byte[]作为像素存储结构,之后再通过在native层构建Java Bitmap对象的方式,将生成的byte[]传递给Bitmap.java对象。(这里其实有一个小知识点,android6.0之前,源码里面很多这样的实现,通过C层来创建Java层对象)。
而android8.0之后,Bitmap在Java层保存的只是一个地址,,Bitmap像素内存的分配是在native层直接调用calloc,所以其像素分配的是在native heap上, 这也是为什么8.0之后的Bitmap消耗内存可以无限增长,直到耗尽系统内存,也不会提示Java OOM的原因。
2.2 原理分析二
看完上面的源码解读,大家一定想知道,那我如果在自己应用中的确有大图片的加载需求,那怎么办呢?调用哪个函数呢?
BitmapFactory.java中有一个Bitmap decodeStream(InputStream is)这个函数,我们可以查看源码,这个函数底层调用了native c函数
在底层进行了decode之后,转换为了bitmap对象,返回给Java层。
3 编程中如何避免图片加载的OOM错误
通过上面章节的知识探索,相信大家已经知道了加载图片时出现OOM错误的原因,其实真正的原因并未是网上很多文章说的,不要使用调用ImageView的某某函数、BitmapFactory的某某函数,真正的原因是,对于大图片,Java堆和Native堆无法申请到可用内存时,就会出现OOM错误,那么针对于不同的系统版本,Android存储、创建图片的方式又有所不同,带来了加载大图片时的OOM错误。
那么接下来,大家最关心的解决方案,有哪些?我们在日常编码中,应该如何编码,才能有效规避此类错误的出现,别急。
3.1 利用BitmapFactory.decodeStream加载InputStream图片字节流的方式显示图片
/**
* 以最省内存的方式读取本地资源的图片
*/
public static Bitmap readBitMap(String path, BitmapFactory.Options opt, InputStream is) {
opt.inPreferredConfig = Bitmap.Config.RGB_565;
if (Build.VERSION.SDK_INT <=android.os.Build.VERSION_CODES.KITKAT ) {
opt.inPurgeable = true;
opt.inInputShareable = true;
}
opt.inSampleSize = 2;//二分之一缩放,可写1即100%显示
//获取资源图片
try {
is = new FileInputStream(path);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
return BitmapFactory.decodeStream(is, null, opt);
}大家可以看到上面的代码,实际上一方面针对Android 4.4之下的直接声明了opt属性,告诉系统可以回收,一方面直接进行了图片缩放。说到这里,大家会有疑问,为什么是android4.4以下加这两个属性,难道之后就不用了了。不要着急,我们看源码:
可以看到源码上说明,此属性4.4之前有用,5.0之后即使设置了,底层也是忽略的。也许大家会问,难道5.0之后Bitmap的源码有什么大的改动吗?的确是,可以看一下以下源码。
8.0之后的Bitmap内存回收机制
NativeAllocationRegistry是Android 8.0引入的一种辅助自动回收native内存的一种机制,当Java对象因为GC被回收后,NativeAllocationRegistry可以辅助回收Java对象所申请的native内存,拿Bitmap为例,如下:
Bitmap(long nativeBitmap, int width, int height, int density,
boolean isMutable, boolean requestPremultiplied,
byte[] ninePatchChunk, NinePatch.InsetStruct ninePatchInsets) {
...
mNativePtr = nativeBitmap;
long nativeSize = NATIVE_ALLOCATION_SIZE + getAllocationByteCount();
<!--辅助回收native内存-->
NativeAllocationRegistry registry = new NativeAllocationRegistry(
Bitmap.class.getClassLoader(), nativeGetNativeFinalizer(), nativeSize);
registry.registerNativeAllocation(this, nativeBitmap);
if (ResourcesImpl.TRACE_FOR_DETAILED_PRELOAD) {
sPreloadTracingNumInstantiatedBitmaps++;
sPreloadTracingTotalBitmapsSize += nativeSize;
}
}当然这个功能也要Java虚拟机的支持,有机会再分析。
**实际使用效果:**3M以内的图片加载没有问题,但是大家注意到一点,没我们代码中是固定缩放了一般,这时大家肯定有疑问,有没有可能,去动态根据图片的大小,决定缩放比例。
3.2 利用BitmapFactory.decodeStream通过按比例压缩方式显示图片
/**
* 以计算的压缩比例加载大图片
*
* @param res
* @param resId
* @param reqWidth
* @param reqHeight
* @return
*/
public static Bitmap decodeCalSampledBitmapFromResource(Resources res, int resId, int reqWidth, int reqHeight) {
// 检查bitmap的大小
final BitmapFactory.Options options = new BitmapFactory.Options();
// 设置为true,BitmapFactory会解析图片的原始宽高信息,并不会加载图片
options.inJustDecodeBounds = true;
options.inPreferredConfig = Bitmap.Config.RGB_565;
BitmapFactory.decodeResource(res, resId, options);
// 计算采样率
options.inSampleSize = calculateInSampleSize(options, reqWidth, reqHeight);
// 设置为false,加载bitmap
options.inJustDecodeBounds = false;
return BitmapFactory.decodeResource(res, resId, options);
}
/*********************************
* @function: 计算出合适的图片倍率
* @options: 图片bitmapFactory选项
* @reqWidth: 需要的图片宽
* @reqHeight: 需要的图片长
* @return: 成功返回倍率, 异常-1
********************************/
private static int calculateInSampleSize(BitmapFactory.Options options, int reqWidth,
int reqHeight) {
// 设置初始压缩率为1
int inSampleSize = 1;
try {
// 获取原图片长宽
int width = options.outWidth;
int height = options.outHeight;
// reqWidth/width,reqHeight/height两者中最大值作为压缩比
int w_size = width / reqWidth;
int h_size = height / reqHeight;
inSampleSize = w_size > h_size ? w_size : h_size; // 取w_size和h_size两者中最大值作为压缩比
Log.e("inSampleSize", String.valueOf(inSampleSize));
} catch (Exception e) {
return -1;
}
return inSampleSize;
}大家可以看到,上面代码实际上使用了一个属性inJustDecodeBounds,当inJustDecodeBounds设为true时,不会加载图片仅获取图片尺寸信息,也就是说,我们先通过不加载实际图片,获取其尺寸,然后再按照一定算法(以需要的图片长宽与实际图片的长宽比例来计算)计算出压缩的比例,然后再进行图片加载。
**实际使用效果:**测试该方法可以显示出来很大的图片,只要你设定的长宽合理。
3,3 及时的回收和释放
直接上代码
/**
* 回收bitmap
*/
private static void recycleBitmap(ImageView iv) {
if (iv != null && iv.getDrawable() != null) {
BitmapDrawable bitmapDrawable = (BitmapDrawable) iv.getDrawable();
iv.setImageDrawable(null);
if (bitmapDrawable != null) {
Bitmap bitmap = bitmapDrawable.getBitmap();
if (bitmap != null) {
bitmap.recycle();
}
}
}
}
/**
* 在Activity或Fragment的onDestory方法中进行回收(必须确保bitmap不在使用)
*/
public static void recycleBitmap(Bitmap bitmap) {
// 先判断是否已经回收
if (bitmap != null && !bitmap.isRecycled()) {
// 回收并且置为null
bitmap.recycle();
bitmap = null;
}
}4.总结
4.1 OOM出现原因
对于大图片,直接调用decodeResource、setImageBitmap、setBackgroundResource时,这些函数在完成照片的decode之后,都是调用了java底层的createBitmap来完成的,需要消耗更多的内存。Java堆和Native堆无法申请到可用内存时,就会出现OOM错误,那么针对于不同的系统版本,Android存储、创建图片的方式又有所不同,带来了加载大图片时的OOM错误。
4.2 解决方案
1.针对于图片小而且频繁加载的,可以直接使用系统函数setImageXXX等
2针对于大图片,在进行ImageView setRes之前,需要先对图片进行处理
1)压缩
2)android4.4之前,需要设置opt,释放bitmap,android5.0之后即使设置,系统也会忽略
3)设置optConfig为565,降低每个像素点的色彩值
4)针对于频繁使用的图片,可以使用inBitmap属性
5)由于decodeStream直接读取的图片字节码,并不会根据各种机型做自动适配,所以需要在各个资源文件夹下放置相应的资源
6)及时回收
链接:https://juejin.cn/post/7179037417704259640
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Handler就是一个简化的邮递系统么?
前置补充
关于本文的初衷不是讲很多细节,主要像聚焦在
Handler的设计理念上,主要想讲述计算机系统中的很多事情在现实中其实有现成的例子可以参考理解,当然现实生活比程序肯定更复杂。
知行合一,想完全理解一个事物,肯定不能光靠看文章,还是要在实际的工作中去使用。
学习是渐进的,可能文中的一些知识点,笔者已经掌握,可能会一笔带过,大家有疑惑 ,建议或者文中的错误,多多提出意见和批评。
ThreadLocal推荐一本书 任玉刚老师的 Android开发艺术探索
关于
Java线程相关知识,推荐 杨冠宝/高海慧 老师的 码出高效:Java开发手册
正文
网上关于Handler的的文章已经有很多了,可能大家看了很多有的同学还是云里雾里,我写这篇文章的理念就是怎样将Handler讲述成我们平常经常使用的事物。
大家已经点进来了,就应该知道Handler是做什么用的,关于它的定义不在多言。
我们用一个爱情故事来模仿这个通信的流程。
1:MainThread(一个人见人爱的女生,我们就叫她
main)。
2:BThread (一个很倾慕
main的男生,我们简称他为B)。
3:剧情设定两个人无法直接通信(具体原因不赘述,大家可以百度一下
ThreadLocal,本文不讲这个了)。
有了设定和人物,那么假如B想给main通信他需要怎么办呢,写信是一种方式。那我们就用写信来比喻Handler。那让我们来分析一下这个通信系统,首先来看Handler。
本文采用6.0源代码
Handler系统
我们平常说的通过Handler进行线程间通信,通常是指的是通过整个Handler系统进行通信,Handler.java只是这个系统的一个入口.
Handler
分析一个东西,我们先从构造函数开始。
public Handler() {
this(null, false);
}
public Handler(Callback callback) {
this(callback, false);
}
public Handler(Looper looper) {
this(looper, null, false);
}
public Handler(Looper looper, Callback callback) {
this(looper, callback, false);
}
public Handler(boolean async) {
this(null, async);
}
public Handler(Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public Handler(Looper looper, Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
上面是Handler所有的构造函数,4个是没有实际的逻辑的,有实际的逻辑只有两个,我们就从这两个构造函数开始分析。
public Handler(Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class<? extends Handler> klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public Handler(Looper looper, Callback callback, boolean async) {
mLooper = looper;
mQueue = looper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
两者的差别就是Looper是否是外部传入的,一个Looper使用的静态函数myLooper() 赋值的,我们暂时先放过这个静态函数一步一步来(放到Looper的环节中讲述)。不过我们看到这个mLooper如果为null就会抛出一个异常,可能很多同志都见到过这个异常Can't create handler inside thread that has not called Looper.prepare(),这个异常就是从这里来的。
分析以上的构造函数,我们发现在Handler整个系统中Looper是必须存在的一个事物。(有的同学会说,我可以在创建Handler的时候手动的传一个null进去,是的,这样的话会得到一个空指针异常)。
如果我们如开头所说,Handler来类比我们现实生活中的通信系统,我们通过它的构造函数得知这个通信系统有4个必须存在的参数,mLooper,mQueue,mCallback,mAsynchronous(mQueue包含在Looper中)。那我们再来一个一个的分析这4个参数,他们究竟在这个通信系统中扮演什么角色。首先先看Looper
Looper
mQueue包含在Looper中,放在一起看。
按照惯例,还是先看构造函数。
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}是一个私有的构造函数,里面讲我们上文提到mQueue给赋值,还有就是将mThread变量赋值为当前所处的线程。Thread.currentThread()不理解请自行百度。
那我们看一下Looper对象既然外部无法通过new关键字直接创建,那么它通过什么方式创建的呢?
在Looper源码中,函数返回类型为Looper的函数只有下面两个。 我们先分析getMainLooper()函数,函数中只是返回了一个sMainLooper。
public static @Nullable Looper myLooper() {
return sThreadLocal.get();
}
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}我们先看sMainLooper。
private static Looper sMainLooper; // guarded by Looper.class
public static void prepareMainLooper() {
prepare(false);
synchronized (Looper.class) {
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
sMainLooper = myLooper();
}
}大家发现饶了一圈,怎么有回到了myLooper()函数,那接下我们看myLooper()函数中的sThreadLocal是什么东西?
static final ThreadLocal<Looper> sThreadLocal = new ThreadLocal<Looper>();
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}我们发现sThreadLocal就是一个ThreadLocal,使用它来存储Looper对象。
- (前文提过
ThreadLocal,它是Java多线程中一个非常非常重要的概念,建议不懂这个的同志,先去看一下这个东西到底是什么?然后再回过头来看这篇文章)。
我们会发现创建Looper对象只能通过唯一入口prepare来创建它。创建Looper的时候,它顺手的将MessageQueue给创建了出来(在上文Looper的构造函数中)。
MessageQueue包含的任务是非常重要的,并且要写入一些c++代码来分析。我们暂且跳过,先得出一个结论之后,在来逆推MessageQueue到底做了什么。
mCallback && mAsynchronous
mCallback:可以从Handler中是可以为null,不传就默认为null,其实是比较容易理解的一个概念,回调函数,不多做解释了,非主线剧情。
mAsynchronous: 从名字来看就是是不是异步的意思,后面会解释一下这个异步的概念。
实际例子
我们上面将Handler想象成一个通信系统,设定了人物,也简单的分析了一下Handler,下面我们来看一个实际的写信流程。
public Thread MainThread = new Thread(new Runnable() {
@Override
public void run() {
}
});
public Thread BThread = new Thread(new Runnable() {
@Override
public void run() {
}
});假如B想通过Handler通信系统给Main写信,那么第一步
- 1: Main得在通信系统中创建
Handler,这个时候Handler可以形容为一个地址。看如下代码:
public Handler mainHandler;
public Thread MainThread = new Thread(new Runnable() {
@Override
public void run() {
if (mainHandler == null) {
Looper.prepare();
mainHandler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
Log.e(TAG, "handleMessage: "+ msg.obj);
}
};
Looper.loop();
}
}
});
2 我们看在创建
Handler之前,需要现在线程中使用Looper.prepare()创建一个Looper出来之后才能创建Handler(前文提到过原因)。那么Looper可以形容为什么呢,这个通信系统中的后台系统,我们接着往下看,看这个形容是否准确。
3 :B拿到Main的
Handler,就使用sendMessage()去给Main传递信息,sendMessage必须发送Message类型的消息,那么Message在通信系统中是什么角色呢,可以理解为信封和邮票,必须以规定好的方式去包装你写得信,这样才可以去发送。这个时候Handler扮演了一个投递入口的角色。
public Thread BThread = new Thread(new Runnable() {
@Override
public void run() {
if (mainHandler != null) {
Message message = Message.obtain();
message.obj= "I LOVE YOU";
mainHandler.sendMessage(message);
Log.e(TAG, "BThread sendMessage 发送了");
}
}
});- 4:从上面的例子代码和上文对
Looper的分析中,我们没有看到Looper.loop()的作用,并且还有一个疑问,B只是投递了信息,谁帮忙传信的呢?我们看下是不是Looper.loop()。只展示关键代码,想看完整代码的同志请自行查看源码。
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
...
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
//这里好像是发送了。
msg.target.dispatchMessage(msg);
...
}
}- 5: 我们在
Looper.loop()中看到了一句msg.target.dispatchMessage(msg),这个从名字看上去很像一个传信的人,但是这个msg.target是个什么鬼东西啊,完全看不懂。从源码得知msg是一个Message类型的对象,那我们去看一下msg.target。
public final class Message implements Parcelable {
...
/*package*/ Handler target;
...
}target就是一个Handler啊,那它是在哪里赋值的呢?其实sendMessage最终会调用到enqueueMessage,具体的调用函数栈,就不贴出来了,有兴趣自行查看源码。
private boolean enqueueMessage(MessageQueue queue, Message msg, long uptimeMillis) {
msg.target = this;
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}在这里我们看到target被赋值为调用者。也就是mainHandler.sendMessage(message);,target就是mainHandler,看了下面的代码你更好理解
Message message = Message.obtain();
message.setTarget(mainHandler);
message.obj= "I LOVE YOU";
mainHandler.sendMessage(message);
Log.e(TAG, "BThread sendMessage 发送了");Message每个信封都支持我们手动写地址的setTarget,但是很多人觉得麻烦,那么通信系统呢,就默认将拿到的地址作为你要传送的地址。也就支持了我们不需要必须调用setTarget()。(有的同学可能比较调皮,我用mainHandler,去发送,target写其他可以么,是可以的,但是系统会帮我们修正,大家可以尝试一下)
MessageQueue,隐藏在内部的工作者
看到这这里,如果不接着深入探究,基本上一个完整的链条已经存在,但是还是有很多疑点,之前提到的MessageQueue还没说到,整个链条就完整了么?其实MessageQueue已经出镜了。loop()函数虽然起了一个死循环,但是每一封信都是从MessageQueue.next()中取出来的。
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
...
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
//这里好像是发送了。
msg.target.dispatchMessage(msg);
...
}
}国际惯例,先看构造函数。
// True if the message queue can be quit.
private final boolean mQuitAllowed;
private long mPtr; // used by native code
MessageQueue(boolean quitAllowed) {
mQuitAllowed = quitAllowed;
mPtr = nativeInit();
}构造函数,从名字来看mQuitAllowed是否允许关闭。退出机制比较复杂不想看的可以跳过,包含的知识点有点多。
1:大家都知道Java的线程机制,1.5之前提供了stop函数,后面移除,移除的原因不赘述,现在线程退出机制就是代码执行完之后就会自动销毁。
2:我们回头看下我们的例子代码,在调用
Looper.loop()函数之后会启动一个死循环不停的取消息,一直到消息为null,才会returen。我们知道了退出的条件,我们看下系统怎么创造这个条件的。
public Thread MainThread = new Thread(new Runnable() {
@Override
public void run() {
Looper.prepare();
if (mainHandler == null) {
mainHandler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
Log.e(TAG, "handleMessage: "+ msg.obj);
}
};
Looper.loop();
}
}
});
Looper.java
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
....
}- 3:调用
Loooper.quit(),来主动退出这个这个死循环,下面就讲述一下这个退出死循环的流程
public void quit() {
mQueue.quit(false);
}
void quit(boolean safe) {
//判断当前是否允许退出,不允许就抛出异常
if (!mQuitAllowed) {
throw new IllegalStateException("Main thread not allowed to quit.");
}
synchronized (this) {
//锁+ 标志位 ,防止重复执行,记住这标志位。 后面还要用到
if (mQuitting) {
return;
}
mQuitting = true;
if (safe) {
removeAllFutureMessagesLocked();
} else {
//退出是这个,清除所有的消息
removeAllMessagesLocked();
}
// We can assume mPtr != 0 because mQuitting was previously false.
//native 函数。 从名字上看是唤醒。
nativeWake(mPtr);
}
}
大家看到了熟悉的一个主动异常"Main thread not allowed to quit.",简单理解主线程不可以退出。主线程创建Looper的流程在本文不赘述,我们接着看调用MessageQueue的quit函数的地方,
- 4: 从上面的代码我们就看到了清除了缓存队列中的所有未发送的消息,然后唤醒?唤醒什么呢?不是退出么? 带着这三个疑问,走向更深的源码。
android_os_MessageQueue.cpp
{ "nativeWake", "(J)V", (void*)android_os_MessageQueue_nativeWake },
static void android_os_MessageQueue_nativeWake(JNIEnv* env, jclass clazz, jlong ptr) {
NativeMessageQueue* nativeMessageQueue = reinterpret_cast<NativeMessageQueue*>(ptr);
nativeMessageQueue->wake();
}
Looper.cpp
void Looper::wake() {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ wake", this);
#endif
uint64_t inc = 1;
ssize_t nWrite = TEMP_FAILURE_RETRY(write(mWakeEventFd, &inc, sizeof(uint64_t)));
if (nWrite != sizeof(uint64_t)) {
if (errno != EAGAIN) {
ALOGW("Could not write wake signal, errno=%d", errno);
}
}
}这是一个到达Native的一个简单的逻辑顺序,Looper.cpp是对epoll的一个封装,我简单的描述一下这个过程
就是有(三个人都活着(线程),要喝水(用CPU),那么三个人要把水给平分(平分Cpu时间片)。
两个人没事干也不累,但是不能die,(还有一些专属任务,需要等待通知),那不干活就不应该喝水,要不就是资源浪费啊,怎么办?
epoll就是干这个的pollOnce就是通知线程进入休眠状态,等到有消息来的时候就会通知对应的人(对应的线程)去干活了,怎么通知呢? 就是通过wake函数。贴一下pollOnce的相关的关键代码,有兴趣的看一下
int Looper::pollOnce(int timeoutMillis, int* outFd, int* outEvents, void** outData) {
int result = 0;
for (;;) {
...
//这里
result = pollInner(timeoutMillis);
}
}
int Looper::pollInner(int timeoutMillis) {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ pollOnce - waiting: timeoutMillis=%d", this, timeoutMillis);
#endif
...
//这里 epoll出现 ,如果想把这个探究明白 建议读这个类的源码,是Android对epoll的封装了
int eventCount = epoll_wait(mEpollFd, eventItems, EPOLL_MAX_EVENTS, timeoutMillis);
// No longer idling.
mPolling = false;
// Acquire lock.
mLock.lock();
// Rebuild epoll set if needed.
if (mEpollRebuildRequired) {
mEpollRebuildRequired = false;
rebuildEpollLocked();
goto Done;
}
// Check for poll error.
if (eventCount < 0) {
if (errno == EINTR) {
goto Done;
}
ALOGW("Poll failed with an unexpected error, errno=%d", errno);
result = POLL_ERROR;
goto Done;
}
// Check for poll timeout.
if (eventCount == 0) {
#if DEBUG_POLL_AND_WAKE
ALOGD("%p ~ pollOnce - timeout", this);
#endif
result = POLL_TIMEOUT;
goto Done;
}
...
}
epoll.h
extern int epoll_wait (int __epfd, struct epoll_event *__events,
int __maxevents, int __timeout);
- 5 :看到这里其实大部分人是很迷惑的,建议迷惑的同志单独深入探究,单独理解上层的同学就看到喝水的故事就好了。那么回到上文说的唤醒,我们知道唤醒之后的线程从休眠的地方开始执行,我们看看陷入休眠的时候在哪里呢?
Message next() {
...
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
//这里休眠的.
nativePollOnce(ptr, nextPollTimeoutMillis);
//唤醒之后从这里开始执行.
synchronized (this) {
...
//还记得这个标志么?在quit函数中赋值为ture的
if (mQuitting) {
dispose();
//这里reture 一个 null
return null;
}
...
}
}
}
(主线程)不会卡死的原因即 Looper退出总结,线程退出机制.
上面描述了退出的一个过程。在简单总结一下
1:
Looper.loop启动死循环,然而实际干的活是从MessageQueue.next()中一直取Message,如果没有Message MessageQueue会调用nativePollOnce让当前线程休眠(这就是为啥死循环不会卡死的原因,很浅显啊,只是简单论述,epoll 可以写好几篇文章了)。
2: 发起退出死循环,终结线程,调用
Looper.quit(),然后还是要调用MessageQueue.quit().
3:
MessageQueue.quit(),先判断当前是否允许退出,允许了将退出的标志位mQuitting设置为true,然后调用removeAllMessagesLocked()清除现在队列中的所有消息。然后唤醒线程
4: 线程被唤醒了就回到第一步,当前没有消息你却唤醒线程,且退出标志位
mQuitting设置为true了,MessageQueue.next()就会返回一个null。
5:
Looper.loop的死循环如果取到了的Message为null,就会returen跳出死循环了。这样一个线程所有的代码执行完成之后,就会自然死亡了,这也是我们Android的Main Thread的MessageQueue不允许退出的原因。
大总结
整个大的线程通信系统
Handler就是一个门面,可以理解为地址。
Message像一个传递员,规定了信的格式和最后一公里的取信和传信。
Looper是一个后台系统,注册什么,所有的入口发起全在这里,让大家以为它把所有的活都干了。
MessageQueue位居后台的一个分拣员,和通知传递员去送信,这个核心就是它,就是所有人都看不到。
链接:https://juejin.cn/post/7049987023662219301
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你真的了解 RSA 加密算法吗?
记得那是我毕业🎓后的第一个秋天,申请了域名,搭建了论坛。可惜好景不长,没多久进入论坛后就出现各种乱七八糟的广告,而这些广告压根都不是我加的。
这是怎么回事?后来我才知道,原来我的论坛没有加 HTTPS 也就是没有 SSL 证书。那这和数学中的素数有啥关系呢?这是因为每一个 SSL 的生成都用到了 RSA 非对称加密,而 RSA 的加解密就是使用了两个互为质数的大素数生成公钥和私钥的。
这就是我们今天要分享的,关于素数在 RSA 算法中的应用。
一、什么是素数
素数(或质数)指的是大于1的且不能通过两个较小的自然数乘积得来的自然数。而大于1的自然数如果不是素数,则称之为合数。例如:7是素数,因为它的乘积只能写成 1 * 7 或者 7 * 1 这样。而像自然数 8 可以写成 2 * 4,因为它是两个较小数字的乘积。
通常在 Java 程序中,我们可以使用下面的代码判断一个数字是否为素数;
boolean isPrime = number > 0;
// 计算number的平方根为k,可以减少一半的计算量
int k = (int) Math.sqrt(number);
for (int i = 2; i <= k; i++) {
if (number % i == 0) {
isPrime = false;
break;
}
}
return isPrime;二、对称加密和非对称加密
假如 Alice 时而需要给北漂搬砖的 Bob 发一些信息,为了安全起见两个人相互协商了一个加密的方式。比如 Alice 发送了一个银行卡密码 142857 给 Bob,Alice 会按照与 Bob 的协商方式,把 142857 * 2 = 285714 的结果传递给 Bob,之后 Bob 再通过把信息除以2拿到结果。
但一来二去,Alice 发的密码、生日、衣服尺寸、鞋子大小,都是乘以2的规律被别人发现。这下这个加密方式就不安全了。而如果每次都给不同的信息维护不同的秘钥又十分麻烦,且这样的秘钥为了安全也得线下沟通,人力成本又非常高。
所以有没有另外一种方式,使用不同的秘钥对信息的加密和解密。当 Bob 想从 Alice 那获取信息,那么 Bob 就给 Alice 一个公钥,让她使用公钥对信息进行加密,而加密后的信息只有 Bob 手里有私钥才能解开。那么这样的信息传递就变得非常安全了。如图所示。
| 对称加密 | 非对称加密 |
|---|---|
三、算法公式推导
如果 Alice 希望更安全的给 Bob 发送的信息,那么就需要保证经过公钥加密的信息不那么容易被反推出来。所以这里的信息加密,会需用到求模运算。像计算机中的散列算法,伪随机数都是求模运算的典型应用。
例如;5^3 mod 7 = 6 —— 5的3次幂模7余6
- 5相当于 Alice 要传递给 Bob 的信息
- 3相当于是秘钥
- 6相当于是加密后的信息
经过求模计算的结果6,很难被推到出秘钥信息,只能一个个去验证;
5^1 mod 7 = 5
5^2 mod 7 = 3
5^3 mod 7 = 6
5^4 mod 7 = 2
...但如果求模的值特别大,例如这样:5^3 mod 78913949018093809389018903794894898493... = 6 那么再想一个个计算就有不靠谱了。所以这也是为什么会使用模运算进行加密,因为对于大数来说对模运算求逆根本没法搞。
根据求模的计算方式,我们得到加密和解密公式;—— 关于加密和解密的公式推到,后文中会给出数学计算公式。
对于两个公式我们做一下更简单的转换;
从转换后的公式可以得知,m 的 ed 次幂,除以 N 求求模可以得到 m 本身。那么 ed 就成了计算公钥加密的重要因素。为此这里需要提到数学中一个非常重要的定理,欧拉定理。—— 1763年,欧拉发现。
欧拉定理:m^φ(n) ≡ 1 (mod n) 对于任何一个与 n 互质的正整数 m,的 φ(n) 次幂并除以 n 去模,结果永远等于1。φ(n) 代表着在小于等于 n 的正整数中,有多少个与 n 互质的数。
例如:φ(8) 小于等于8的正整数中 1、2、3、4、5、6、7、8 有 1、3、5、7 与数字 8 互为质数。所以 φ(8) = 4 但如果是 n 是质数,那么 φ(n) = n - 1 比如 φ(7) 与7互为质数有1、2、3、4、5、6 所有 φ(7) = 6
接下来我们对欧拉公式做一些简单的变换,用于看出ed的作用;
经过推导的结果可以看到 ed = kφ(n) + 1,这样只要算出加密秘钥 e 就可以得到一个对应的解密秘钥 d。那么整套这套计算过程,就是 RSA 算法。
四、关于RSA算法
RSA加密算法是一种非对称加密算法,在公开秘钥加密和电子商业中被广泛使用。
于1977年,三位数学家;罗纳德·李维斯特(Ron Rivest)、阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(Leonard Adleman)设计了一种算法,可以实现非对称加密。这种算法用他们三个人的名字命名,叫做RSA算法。
1973年,在英国政府通讯总部工作的数学家克利福德·柯克斯(Clifford Cocks)在一个内部文件中提出了一个与之等效的算法,但该算法被列入机密,直到1997年才得到公开。
RSA 的算法核心在于取了2个素数做乘积求和、欧拉计算等一系列方式算得公钥和私钥,但想通过公钥和加密信息,反推出来私钥就会非常复杂,因为这是相当于对极大整数的因数分解。所以秘钥越长做因数分解越困难,这也就决定了 RSA 算法的可靠性。—— PS:可能以上这段话还不是很好理解,程序员👨🏻💻还是要看代码才能悟。接下来我们就来编写一下 RSA 加密代码。
五、实现RSA算法
RSA 的秘钥生成首先需要两个质数p、q,之后根据这两个质数算出公钥和私钥,在根据公钥来对要传递的信息进行加密。接下来我们就要代码实现一下 RSA 算法,读者也可以根据代码的调试去反向理解 RSA 的算法过程,一般这样的学习方式更有抓手的感觉。嘿嘿 抓手
1. 互为质数的p、q
两个互为质数p、q是选择出来的,越大越安全。因为大整数的质因数分解是非常困难的,直到2020年为止,世界上还没有任何可靠的攻击RSA算法的方式。只要其钥匙的长度足够长,用RSA加密的信息实际上是不能被破解的。—— 不知道量子计算机出来以后会不会改变。如果改变,那么程序员又有的忙了。
2. 乘积n
n = p * q 的乘积。
public long n(long p, long q) {
return p * q;
}3. 欧拉公式 φ(n)
φ(n) = (p - 1) * (q - 1)
public long euler(long p, long q) {
return (p - 1) * (q - 1);
}4. 选取公钥e
e 的值范围在 1 < e < φ(n)
public long e(long euler){
long e = euler / 10;
while (gcd(e, euler) != 1){
e ++;
}
return e;
}5. 选取私钥d
d = (kφ(n) + 1) / e
public long inverse(long e, long euler) {
return (euler + 1) / e;
}6. 加密
c = m^e mod n
public long encrypt(long m, long e, long n) {
BigInteger bM = new BigInteger(String.valueOf(m));
BigInteger bE = new BigInteger(String.valueOf(e));
BigInteger bN = new BigInteger(String.valueOf(n));
return Long.parseLong(bM.modPow(bE, bN).toString());
}7. 解密
m = c^d mod n
public long decrypt(long c, long d, long n) {
BigInteger bC = new BigInteger(String.valueOf(c));
BigInteger bD = new BigInteger(String.valueOf(d));
BigInteger bN = new BigInteger(String.valueOf(n));
return Long.parseLong(bC.modPow(bD, bN).toString());
}8. 测试
@Test
public void test_rsa() {
RSA rsa = new RSA();
long p = 3, // 选取2个互为质数的p、q
q = 11, // 选取2个互为质数的p、q
n = rsa.n(p, q), // n = p * q
euler = rsa.euler(p, q), // euler = (p-1)*(q-1)
e = rsa.e(euler), // 互为素数的小整数e | 1 < e < euler
d = rsa.inverse(e, euler), // ed = φ(n) + 1 | d = (φ(n) + 1)/e
msg = 5; // 传递消息 5
System.out.println("消息:" + msg);
System.out.println("公钥(n,e):" + "(" + n + "," + e + ")");
System.out.println("私钥(n,d):" + "(" + n + "," + d + ")");
long encrypt = rsa.encrypt(msg, e, n);
System.out.println("加密(消息):" + encrypt);
long decrypt = rsa.decrypt(encrypt, d, n);
System.out.println("解密(消息):" + decrypt);
}测试结果
消息:5
公钥(n,e):(33,3)
私钥(n,d):(33,7)
加密(消息):26
解密(消息):5- 通过选取3、11作为两个互质数,计算出公钥和私钥,分别进行消息的加密和解密。如测试结果消息5的加密后的信息是26,解密后获得原始信息5
六、RSA数学原理
整个 RSA 的加解密是有一套数学基础可以推导验证的,这里小傅哥把学习整理的资料分享给读者,如果感兴趣可以尝试验证。这里的数学公式会涉及到;求模运算、最大公约数、贝祖定理、线性同于方程、中国余数定理、费马小定理。当然还有一些很基础的数论概念;素数、互质数等。以下推理数学内容来自博客:luyuhuang.tech/2019/10/24/…
1. 模运算
1.1 整数除法
定理 1 令 a 为整数, d 为正整数, 则存在唯一的整数 q 和 r, 满足 0⩽r<d, 使得 a=dq+r.
当 r=0 时, 我们称 d 整除 a, 记作 d∣a; 否则称 d 不整除 a, 记作 d∤a
整除有以下基本性质:
定理 2 令 a, b, c 为整数, 其中 a≠0a≠0. 则:
- 对任意整数 m,n,如果 a∣b 且 a∣c, 则 a∣(mb + nc)
- 如果 a∣b, 则对于所有整数 c 都有 a∣bc
- 如果 a∣b 且 b∣c, 则 a∣c
1.2 模算术
在数论中我们特别关心一个整数被一个正整数除时的余数. 我们用 a mod m = b表示整数 a 除以正整数 m 的余数是 b. 为了表示两个整数被一个正整数除时的余数相同, 人们又提出了同余式(congruence).
定义 1 如果 a 和 b 是整数而 m 是正整数, 则当 m 整除 a - b 时称 a 模 m 同余 b. 记作 a ≡ b(mod m)
a ≡ b(mod m) 和 a mod m= b 很相似. 事实上, 如果 a mod m = b, 则 a≡b(mod m). 但他们本质上是两个不同的概念. a mod m = b 表达的是一个函数, 而 a≡b(mod m) 表达的是两个整数之间的关系.
模算术有下列性质:
定理 3 如果 m 是正整数, a, b 是整数, 则有
(a+b)mod m=((a mod m)+(b mod m)) mod m
ab mod m=(a mod m)(b mod m) mod m
根据定理3, 可得以下推论
推论 1 设 m 是正整数, a, b, c 是整数; 如果 a ≡ b(mod m), 则 ac ≡ bc(mod m)
证明 ∵ a ≡ b(mod m), ∴ (a−b) mod m=0 . 那么
(ac−bc) mod m=c(a−b) mod m=(c mod m⋅(a−b) mod m) mod m=0
∴ ac ≡ bc(mod m)
需要注意的是, 推论1反之不成立. 来看推论2:
推论 2 设 m 是正整数, a, b 是整数, c 是不能被 m 整除的整数; 如果 ac ≡ bc(mod m) , 则 a ≡ b(mod m)
证明 ∵ ac ≡ bc(mod m) , 所以有
(ac−bc)mod m=c(a−b)mod m=(c mod m⋅(a−b)mod m) mod m=0
∵ c mod m≠0 ,
∴ (a−b) mod m=0,
∴a ≡ b(mod m) .
2. 最大公约数
如果一个整数 d 能够整除另一个整数 a, 则称 d 是 a 的一个约数(divisor); 如果 d 既能整除 a 又能整除 b, 则称 d 是 a 和 b 的一个公约数(common divisor). 能整除两个整数的最大整数称为这两个整数的最大公约数(greatest common divisor).
定义 2 令 a 和 b 是不全为零的两个整数, 能使 d∣ad∣a 和 d∣bd∣b 的最大整数 d 称为 a 和 b 的最大公约数. 记作 gcd(a,b)
2.1 求最大公约数
如何求两个已知整数的最大公约数呢? 这里我们讨论一个高效的求最大公约数的算法, 称为辗转相除法. 因为这个算法是欧几里得发明的, 所以也称为欧几里得算法. 辗转相除法基于以下定理:
引理 1 令 a=bq+r, 其中 a, b, q 和 r 均为整数. 则有 gcd(a,b)=gcd(b,r)
证明 我们假设 d 是 a 和 b 的公约数, 即 d∣a且 d∣b, 那么根据定理2, d 也能整除 a−bq=r 所以 a 和 b 的任何公约数也是 b 和 r 的公约数;
类似地, 假设 d 是 b 和 r 的公约数, 即 d∣bd∣b 且 d∣rd∣r, 那么根据定理2, d 也能整除 a=bq+r. 所以 b 和 r 的任何公约数也是 a 和 b 的公约数;
因此, a 与 b 和 b 与 r 拥有相同的公约数. 所以 gcd(a,b)=gcd(b,r).
辗转相除法就是利用引理1, 把大数转换成小数. 例如, 求 gcd(287,91) 我们就把用较大的数除以较小的数. 首先用 287 除以 91, 得
287=91⋅3+14
我们有 gcd(287,91)=gcd(91,14) . 问题转换成求 gcd(91,14). 同样地, 用 91 除以 14, 得
91=14⋅6+7
有 gcd(91,14)=gcd(14,7) . 继续用 14 除以 7, 得
14=7⋅2+0
因为 7 整除 14, 所以 gcd(14,7)=7. 所以 gcd(287,91)=gcd(91,14)=gcd(14,7)=7.
我们可以很快写出辗转相除法的代码:
def gcd(a, b):
if b == 0: return a
return gcd(b, a % b)2.2 贝祖定理
现在我们讨论最大公约数的一个重要性质:
定理 4 贝祖定理 如果整数 a, b 不全为零, 则 gcd(a,b)是 a 和 b 的线性组合集 {ax+by∣x,y∈Z}中最小的元素. 这里的 x 和 y 被称为贝祖系数
证明 令 A={ax+by∣x,y∈Z}. 设存在 x0x0, y0y0 使 d0d0 是 A 中的最小正元素, d0=ax0+by0 现在用 d0去除 a, 这就得到唯一的整数 q(商) 和 r(余数) 满足
又 0⩽r<d0, d0 是 A 中最小正元素
∴ r=0 , d0∣a.
同理, 用 d0d0 去除 b, 可得 d0∣b. 所以说 d0 是 a 和 b 的公约数.
设 a 和 b 的最大公约数是 d, 那么 d∣(ax0+by0)即 d∣d0
∴∴ d0 是 a 和 b 的最大公约数.
我们可以对辗转相除法稍作修改, 让它在计算出最大公约数的同时计算出贝祖系数.
def gcd(a, b):
if b == 0: return a, 1, 0
d, x, y = gcd(b, a % b)
return d, y, x - (a / b) * y3. 线性同余方程
现在我们来讨论求解形如 ax≡b(modm) 的线性同余方程. 求解这样的线性同余方程是数论研究及其应用中的一项基本任务. 如何求解这样的方程呢? 我们要介绍的一个方法是通过求使得方程 ¯aa≡1(mod m) 成立的整数 ¯a. 我们称 ¯a 为 a 模 m 的逆. 下面的定理指出, 当 a 和 m 互素时, a 模 m 的逆必然存在.
定理 5 如果 a 和 m 为互素的整数且 m>1, 则 a 模 m 的逆存在, 并且是唯一的.
证明 由贝祖定理可知, ∵ gcd(a,m)=1 , ∴ 存在整数 x 和 y 使得 ax+my=1 这蕴含着 ax+my≡1(modm) ∵ my≡0(modm), 所以有 ax≡1(modm)
∴ x 为 a 模 m 的逆.
这样我们就可以调用辗转相除法 gcd(a, m) 求得 a 模 m 的逆.
a 模 m 的逆也被称为 a 在模m乘法群 Z∗m 中的逆元. 这里我并不想引入群论, 有兴趣的同学可参阅算法导论
求得了 a 模 m 的逆 ¯a 现在我们可以来解线性同余方程了. 具体的做法是这样的: 对于方程 ax≡b(modm)a , 我们在方程两边同时乘上 ¯a, 得 ¯aax≡¯ab(modm)
把 ¯aa≡1(modm) 带入上式, 得 x≡¯ab(modm)
x≡¯ab(modm) 就是方程的解. 注意同余方程会有无数个整数解, 所以我们用同余式来表示同余方程的解.
4. 中国余数定理
中国南北朝时期数学著作 孙子算经 中提出了这样一个问题:
有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二。问物几何?
用现代的数学语言表述就是: 下列同余方程组的解释多少?
孙子算经 中首次提到了同余方程组问题及其具体解法. 因此中国剩余定理称为孙子定理.
定理 6 中国余数定理 令 m1,m2,…,mn 为大于 1 且两两互素的正整数, a1,a2,…,an 是任意整数. 则同余方程组
有唯一的模 m=m1m2…mnm=m1m2…mn 的解.
证明 我们使用构造证明法, 构造出这个方程组的解. 首先对于 i=1,2,…,ni=1,2,…,n, 令
即, MiMi 是除了 mimi 之外所有模数的积. ∵∵ m1,m2,…,mn 两两互素, ∴∴ gcd(mi,Mi)=1. 由定理 5 可知, 存在整数 yiyi 是 MiMi 模 mimi 的逆. 即
上式等号两边同时乘 aiai 得
就是第 i 个方程的一个解; 那么怎么构造出方程组的解呢? 我们注意到, 根据 Mi 的定义可得, 对所有的 j≠ij≠i, 都有 aiMiyi≡0(modmj). 因此我们令
就是方程组的解.
有了这个结论, 我们可以解答 孙子算经 中的问题了: 对方程组的每个方程, 求出 MiMi , 然后调用 gcd(M_i, m_i) 求出 yiyi:
最后求出 x=−2⋅35+3⋅21+2⋅15=23≡23(mod105)
5. 费马小定理
现在我们来看数论中另外一个重要的定理, 费马小定理(Fermat's little theorem)
定理 7 费马小定理 如果 a 是一个整数, p 是一个素数, 那么
当 n 不为 p 或 0 时, 由于分子有质数p, 但分母不含p; 故分子的p能保留, 不被约分而除去. 即 p∣(np).
令 b 为任意整数, 根据二项式定理, 我们有
令 a=b+1, 即得 a^p ≡ a(mod p)
当 p 不整除 a 时, 根据推论 2, 有 a^p−1 ≡ 1(mod p)
6. 算法证明
我们终于可以来看 RSA 算法了. 先来看 RSA 算法是怎么运作的:
RSA 算法按照以下过程创建公钥和私钥:
- 随机选取两个大素数 p 和 q, p≠qp≠q;
- 计算 n=pq
- 选取一个与 (p−1)(q−1) 互素的小整数 e;
- 求 e 模 (p−1)(q−1) 的逆, 记作 d;
- 将 P=(e,n)公开, 是为公钥;
- 将 S=(d,n)保密, 是为私钥.
所以 RSA 加密算法是有效的.
(1) 式表明, 不仅可以用公钥加密, 私钥解密, 还可以用私钥加密, 公钥解密. 即加密计算 C=M^d mod n, 解密计算 M=C^e mod n
RSA 算法的安全性基于大整数的质因数分解的困难性. 由于目前没有能在多项式时间内对整数作质因数分解的算法, 因此无法在可行的时间内把 n 分解成 p 和 q 的乘积. 因此就无法求得 e 模 (p−1)(q−1)的逆, 也就无法根据公钥计算出私钥.
七、常见面试题
- 质数的用途
- RSA 算法描述
- RSA 算法加解密的过程
- RSA 算法使用场景
- 你了解多少关于 RSA 的数学数论知识
链接:https://juejin.cn/post/7173830290812370958
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 组件分析之AspectRatio
引言
AspectRatio 可以根据具体的长宽比约束 child 的布局范围, 从而影响 child 的大小. 通常在视频、图像中会经常使用, 今天我们来分析一下它的实现原理.
AspectRatio
AspectRatio 的参数只有 key、aspectRatio、child. 它会根据 aspectRatio 去重计算约束 child 的布局范围.
我们举一个例子:
Center(
child: AspectRatio(
aspectRatio: 1.0,
child: Image.network('xx'),
),
)以图片长宽比3:2为例子
当 aspectRatio 为1.0时:
由于图片的比例大于 1.0, aspectRatio 取 1.0 时, 以屏宽为基准, 1:1为比例, 构建了一个正方形的布局约束范围. 当图片比大于 1.0 时, 图片以屏宽为图片宽, 而图片高要小于约束高. 因此实际布局中, 图片在约束中央.
当 aspectRatio 为0.2时:
由于图片的比例大于 1.0, aspectRatio 取 0.2 时, 屏幕宽高大于0.2. 以屏高为基准, 1:5为比例, 构建了一个矩形的布局约束范围. 当图片比大于 1.0 时, 图片以屏幕高的1/5为图片宽. 因此实际布局中, 图片会比正常小.
当 aspectRatio 为5.0时:
由于图片的比例大于 1.0, aspectRatio 取 5.0 时, 屏幕宽高小于5.0. 以屏宽为基准, 5:1为比例, 构建了一个矩形的布局约束范围. 当图片比大于 1.0 时, 图片以屏幕高为图片的高. 因此实际布局中, 图片会比正常小.
这一系列的原因都来自于内部的算法, 让我们一起进入源码中学习一下~
RenderAspectRatio
RenderAspectRatio 是 AspectRatio 的 RenderObject . 里面也封装了关于布局的计算规则, AspectRatio 的计算核心在于 _applyAspectRatio.
constraints.isTight
如果尺寸刚刚好合适的话, 会返回满足约束的最小大小
非constraints.isTight
这种情况下, width 会拥有默认赋值. 首先会等于约束的最大宽度. 如果宽度是有限的, 那么高度会根据 _aspectRatio 赋值. 反之, 高度会取约束限制的最大高, 同时将宽根据高度重赋值.在赋值完基础度宽高后, 会通过四个判断获取最后的尺寸.
四个判断如下:
- width > constraints.maxWidth
当宽度大于约束最大宽时, 会重新把宽赋值为约束的最大宽, 并重计算高 - height > constraints.maxHeight
当高度大于约束最大高时, 会重新把高赋值为约束的最大高, 并重计算宽 - width < constraints.minWidth
当宽小于约束的最小值时, 会把宽赋值为约束度最小值, 并重计算高 - height < constraints.minHeight
当高小于约束的最小值时, 会把高赋值为约束度最小值, 并重计算宽
在经过这一系列计算后, 宽高将会根据 aspectRatio 重计算直至符合 aspectRatio 并且能放进约束中.
链接:https://juejin.cn/post/7177559990805217340
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 小技巧之快速理解手势逻辑
GestureDetector
不管你用 InkWell 、InkResponse 、TextButton 还是 ElevatedButton , 它们针对手势的处理逻辑都是来自于 GestureDetector ,也就是理解 Flutter 的手势处理逻辑入门,核心可以从分析 GestureDetector 开始。
其实更严格意义上讲,手势事件是来自
Listener,GestureDetector是针对Listener进行了封装,只是为了避免复杂的源码分析,这里就不做展开,你可以简单理解为:并不是所有的控件都会响应手势,只有带有Listener的才会响应,这主要体现在触摸事件的递归响应上。
在 GestureDetector 里关于事件的响应逻辑主要来自于各种 GestureRecognizer (手势识别)的实现逻辑,不同的手势识别逻辑会响应不同手势结果,相互竞争,最后在 GestureArenaManager (竞技场) 决定出一个胜利者。
简单来说,在竞技场里手势基本遵循两个逻辑:
- 每个 Recognizer 都可以随时选择失败退出,当竞技场只有它一个的时候它就赢了
- 每个 Recognizer 都可以随时宣布自己获得胜利,这时其他 Recognizer 也将不再响应
那么如下图所示,在 GestureDetector 里主要有这 8 种 GestureRecognizer 在处理不同的场景,他们会根据用户使用 GestureDetector 时的参数搭配来参与到事件竞技场里。
举个例子,当你使用了 GestureDetector 并配置了 onTap 、onLongPress 和 onDoubleTap ,它们是如何分别响应手势事件的?
这里的核心逻辑就在于 deadline (时间) 的处理,不管是 onLongPress 还是 onDoubleTap 都是靠 deadline 来判断胜负。
例如,当用户只是普通点击时,如下代码所示,因为默认 LongPressGestureRecognizer 的 deadline 是 500 毫秒,所以在定时器达到 500ms 响应之前,就会因为 PointerUpEvent 导致长按定时器停止,无法触发响应长按事件。
反之如果没有 PointerUpEvent 产生,那么 500 ms 之后 LongPressGestureRecognizer 就会响应,直接宣布胜利(accepted)。
默认情况下
GestureDetector是不支持修改 deadline ,只有直接使用LongPressGestureRecognizer时才可以修改 deadline 的时长。
类似的逻辑在 DoubleTapGestureRecognizer 下也有,DoubleTap 的 deadline 是 300 毫秒,当用户首次点击时会注册一个定时器,如果 300 毫秒以内用户没有产生新的点击,那么 DoubleTapGestureRecognizer 就会宣布“失败“退出竞技,反之如果在 300 毫秒内有新的点击,则直接宣布“获胜”,响应 DoubleTap 回调。
那这时候有人就要问了:“在 DoubleTap 过程中,为什么不会触发 onTap” ? 这就需要说到 TapGestureRecognizer 的触发逻辑。
继续前面 GestureDetector 并配置了 onTap 、onLongPress 和 onDoubleTap 的例子,在用户只做普通点击的时候,前面说过:
LongPressGestureRecognizer的定时器 deadline 还没到 500 毫秒会因为 Up 事件而导致失败退出DoubleTapGestureRecognizer会因为定时器超过 deadline 300 毫秒,没有下一个点击而宣布退出
那么在 Long 和 Double 都失败的情况下,此时 GestureArenaManager (竞技场) 里的成员就只有 TapGestureRecognizer ,这时候竞技场会 close ,会触发竞技场的 sweep 逻辑,直接让最后剩下来的 Recognizer “胜利”,响应 onTap 事件。
所以
TapGestureRecognizer靠的是胜者为王。
所以基于这个例子,配合一开始说的两个逻辑,就可以直观的理解 Flutter 手势竞技场里的响应逻辑和关键 deadline 的作用。
多个 GestureDetector
那么前面都是只有一个 GestureDetector 的场景,如果有两个呢?如下代码所示,在嵌套两个 GestureDetector 下,它们的响应逻辑会是怎么样的?
当区域内有两个 GestureDetector 的时候,用户在普通点击时,因为 deadline 影响,依旧会是在竞技场 close 时才响应 onTap , 但是不同在于此时竞技场里还会有多个 Recognizer 存在,这时候只有排在列表的第一个的 Recognizer 可以赢得事件,也就是上门代码里的红色 200x200 小方块。
因为对于多个 GestureDetector 的情况, Recognizer 在竞技场列表(List<GestureArenaMember)里的顺序和 HitTest 时的递归调用有关系,简单说就是:递归调用会就让我们自下而上的得到一个 HitTestResult 列表,代码里最后的 child 会在最上面。
同时对于单个
GestureDetector而言,TapGestureRecognizer会是_recognizers的第一个,所以first会是响应了TapGestureRecognizer,详细逻辑可以看 《面深入触摸和滑动原理》 。
所以简单理解:
- 两个
GestureDetector在竞技场里的member列表排序时,作为 child 的红色GestureDetector因为 HitTest 递归会被排前面 GestureDetector内部TapGestureRecognizer会在其内部_recognizers排第一
所以 member.first 最终响应了 TapGestureRecognizer ,回到上面两个定律,如果结合多个 GestureDetector 的场景,就应该是:
- 每个 Recognizer 都可以随时选择失败退出,当竞技场只有它一个的时候它就赢了;如果不止一个,那么在竞技场
close时,member.first会获得响应 - 每个 Recognizer 都可以随时宣布自己获得胜利,这是其他 Recognizer 也将不再响应
进阶补充
前面简单介绍了 Flutter 的手势响应的基础逻辑,这里再额外补充两个知识点。
首先,当用户在长按的时候, GestureDetector 何时会发出 onTapDown 事件?
这其实就涉及了另外一个 deadline 参数,当用户在长按的时候,Recognizer 还会触发另外一个定时器,然后通过执行 didExceedDeadline 来发出 onTapDown 事件。
那么问题又来了,既然长按会触发 onTapDown 事件,如果点击区域内有两个 TapGestureRecognizer ,长按的时候因为定时器都触发了 didExceedDeadline ,那是不是两个都会收到 onTapDown 事件 ?
答案是:会的!因为定时器都触发了 didExceedDeadline,从而都发出了 onTapDown 事件,所以两个 onTapDown 回调都会执行,但是后续竞争只会有一个控件能响应 onLongPress 。
另外,如果不是长按导致的 Down 事件, 是不会导致两个
GestureDetector都触发回调onTapDown回调。
第二个补充的是 Listener , 如果你还想深入去看 GestureDetector 的实现,你就会发现 GestureDetector 对 Listener 的封装也许和你想象不大一样, 因为 Listener 的封装只用到了 PointerDown ,并没有用到 onPointerUp ,那 GestureDetector 是怎么响应 Up 和 Move 事件?
这就需要说到前面介绍 《面深入触摸和滑动原理》 里的源码分析,但是为了简单,我们这里只说结论:
因为只有响应了
PointerDown事件,对应的GestureRecognizer才能被添加到GestureBinding的PointerRouter事件路由和GestureArenaManager事件竞技中,而后续的 Up 和 Move 事件主要是通过GestureBinding来处理。
更简单的说,就是只有响应了 PointerDown 事件,控件的 Recognizer 才能响应后续统一处理的其他手势事件,而其他事件不需要在 Listener 这里获取回调。
链接:https://juejin.cn/post/7177283291542880293
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
细节决定成败:探究Mybatis中javaType和ofType的区别
一. 背景描述
今天,壹哥给学生讲解了Mybatis框架,学习了基础的ORM框架操作及多对一的查询。在练习的时候,小张同学突然举手求助,说在做预习作业使用一对多查询时,遇到了ReflectionException 异常 。
二. 情景再现
1. 实体类
为了给大家讲清楚这个异常的产生原因,壹哥先列出今天案例中涉及到的两张表:书籍表和书籍类型表。这两张表中存在着简单的多对一关系,实体类如下:
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Book {
private Integer id;
private String name;
private String author;
private String bookDesc;
private String createTime;
private BookType type;
private String imgPath;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class BookType {
private Integer id;
private String name;
}2.BookMapper.xml映射文件
上课时,壹哥讲解的关联查询是通过查询书籍信息,并同时对书籍类型查询。即在查询Book对象时i,同时查询出BookType对象。BookMapper.xml映射文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.qf.day7.dao.BookDAO">
<resultMap id="booksMap" type="com.qf.day7.entity.Books">
<id property="id" column="id"></id>
<result property="name" column="name"></result>
<result property="author" column="author"></result>
<result property="bookDesc" column="book_desc"></result>
<result property="createTime" column="create_time"></result>
<result property="imgPath" column="img_path"></result>
<!-- 单个对象的关联,javaType是指实体类的类型-->
<association property="type" javaType="com.qf.day7.entity.BookType">
<id property="id" column="type_id"></id>
<result property="name" column="type_name"></result>
</association>
</resultMap>
<select id="findAll" resultMap="booksMap">
SELECT
b.id,
b.`name`,
b.author,
b.book_desc,
b.create_time,
b.img_path,
t.id type_id,
t.`name` type_name
FROM
books AS b
INNER JOIN book_type AS t ON b.type_id = t.id
</select>
</mapper>3. 核心配置
核心配置文件如下:mybatisCfg.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<package name="com.qf.day7.entity"/>
</typeAliases>
<environments default="development">
<environment id="development">
<!-- 事务管理器-->
<transactionManager type="JDBC"></transactionManager>
<!-- 使用mybatis自带连接池-->
<dataSource type="POOLED">
<!-- jdbc四要素-->
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://localhost:3306/books?useUnicode=true&characterEncoding=utf-8&useSSL=false"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/BookMapper.xml"></mapper>
<mapper resource="mapper/BookTypeMapper.xml"></mapper>
</mappers>
</configuration>4. 测试代码
接着我们对上面的配置进行测试。
public class BookDAOTest {
private SqlSessionFactory factory;
@Before
public void setUp() throws Exception {
final InputStream inputStream = Resources.getResourceAsStream("mybatisCfg.xml");
factory = new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void findAll() {
final SqlSession session = factory.openSession();
final BookDAO bookDAO = session.getMapper(BookDAO.class);
final List<Book> list = bookDAO.findAll();
list.stream().forEach(System.out::println);
session.close();
}
}学生按照我讲的内容,测试没有问题。在后续的预习练习中,要求实现在BookType中添加List属性books,在查询BookType对象同时将该类型的Book对象集合查出。小张同学有了如下实现思路。
5. 修改实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class Book {
private Integer id;
private String name;
private String author;
private String bookDesc;
private String createTime;
private String imgPath;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
@Builder
public class BookType {
private Integer id;
private String name;
private List<Book> books;
}6. 添加映射文件BookTypeMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.qf.day7.dao.BookTypeDAO">
<resultMap id="bookTypeMap" type="com.qf.day7.entity.BookType">
<id column="id" property="id"></id>
<result column="name" property="name"></result>
<collection property="books" javaType="com.qf.day7.entity.Book">
<id property="id" column="book_id"></id>
<result property="name" column="book_name"></result>
<result property="author" column="author"></result>
<result property="bookDesc" column="book_desc"></result>
<result property="createTime" column="create_time"></result>
<result property="imgPath" column="img_path"></result>
</collection>
</resultMap>
<select id="findById" resultMap="bookTypeMap">
SELECT
b.id book_id,
b.`name` book_name,
b.author,
b.book_desc,
b.create_time,
b.img_path,
t.id,
t.`name`
FROM
books AS b
INNER JOIN book_type AS t ON b.type_id = t.id
where t.id = #{typeId}
</select>
</mapper>7. 编写测试类
public class BookTypeDAOTest {
private SqlSessionFactory factory;
@Before
public void setUp() throws Exception {
final InputStream inputStream = Resources.getResourceAsStream("mybatisCfg.xml");
factory = new SqlSessionFactoryBuilder().build(inputStream);
}
@Test
public void findById() {
final SqlSession session = factory.openSession();
final BookTypeDAO bookTypeDAO = session.getMapper(BookTypeDAO.class);
BookType bookType = bookTypeDAO.findById(1);
for (Book book : bookType.getBooks()) {
System.out.println(book.getName());
}
session.close();
}然后就出现了一开始提到的异常:
org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: org.apache.ibatis.reflection.ReflectionException: Could not set property 'books' of 'class com.qf.day7.entity.BookType' with value 'Book(id=1, name=Java从入门到精通, author=千锋, bookDesc=很不错的Java书籍, createTime=2022-05-27, type=null, imgPath=174cc662fccc4a38b73ece6880d8c07e)' Cause: java.lang.IllegalArgumentException: argument type mismatch
### The error may exist in mapper/BookTypeMapper.xml
### The error may involve com.qf.day7.dao.BookTypeDAO.findById
### The error occurred while handling results
### SQL: SELECT b.id book_id, b.`name` book_name, b.author, b.book_desc, b.create_time, b.img_path, t.id, t.`name` FROM books AS b INNER JOIN book_type AS t ON b.type_id = t.id where t.id = ?
### Cause: org.apache.ibatis.reflection.ReflectionException: Could not set property 'books' of 'class com.qf.day7.entity.BookType' with value 'Book(id=1, name=Java从入门到精通, author=千锋, bookDesc=很不错的Java书籍, createTime=2022-05-27, type=null, imgPath=174cc662fccc4a38b73ece6880d8c07e)' Cause: java.lang.IllegalArgumentException: argument type mismatch三. 异常分析
上面的 异常提示 , 是 说在 BookType类中的books属性设置有问题 。 我们来仔细查看一下代码,发现是因为直接 复制了之前的关系配置, 在配置文件中 使用javaType 节点 , 但正确的 应该 是 使用ofType。如下图所示:
四. 解析
那么为什么有的关系配置要使用javaType,而有的地方又要使用ofType呢?
这我们就不得不说说Mybatis的底层原理了!在关联映射中,如果是单个的JavaBean对象,那么可以使用javaType;而如果是集合类型,则需要写ofType。以下是Mybatis的官方文档原文:
五. 结尾
虽然上面的代码中只是因为一个单词的不同,却造成了不小的错误。我们的程序是严格的,小问题就可能会耽误你很久的时间。就比如我们的小张同学,在求助壹哥之前已经找bug找了一个小时......最后壹哥一眼就给他看出了问题所在,他都无语凝噎了.....
现在你明白javaType和ofType用法上的区别了吗?如果你还有其他什么问题,可以在评论区留言或私信哦!关注Java架构栈,干货天天都不断。
链接:https://juejin.cn/post/7176860138367057981
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我尝试以最简单的方式帮你梳理 Lifecycle
前言
我们都知道 Activity 与 Fragment 都是有生命周期的,例如:onCreate()、onStop() 这些回调方法就代表着其生命周期状态。我们开发者所做的一些操作都应该合理的控制在生命周期内,比如:当我们在某个 Activity 中注册了广播接收器,那么在其 onDestory() 前要记得注销掉,避免出现内存泄漏。
生命周期的存在,帮助我们更加方便地管理这些任务。但是,在日常开发中光凭 Activity 与 Fragment 可不够,我们通常还会使用一些组件来帮助我们实现需求,而这些组件就不像 Activity 与 Fragment 一样可以很方便地感知到生命周期了。
假设当前有这么一个需求:
开发一个简易的视频播放器组件以供项目使用,要求在进入页面后注册播放器并加载资源,一旦播放器所处的页面不可见或者不位于前台时就暂停播放,等到页面可见或者又恢复到前台时再继续播放,最后在页面销毁时则注销掉播放器。
试想一下:如果现在让你来实现该需求?你会怎么去实现呢?
实现这样的需求,我们的播放器组件就需要获取到所处页面的生命周期状态,在 onCreate() 中进行注册,onResume() 开始播放,onStop() 暂停播放,onDestroy() 注销播放器。
最简单的方法:提供方法,暴露给使用方,供其自己调用控制。
class VideoPlayerComponent(private val context: Context) {
/**
* 注册,加载资源
*/
fun register() {
loadResource(context)
}
/**
* 注销,释放资源
*/
fun unRegister() {
releaseResource()
}
/**
* 开始播放当前视频资源
*/
fun startPlay() {
startPlayVideo()
}
/**
* 暂停播放
*/
fun stopPlay() {
stopPlayVideo()
}
}然后,我们的使用方MainActivity自己,主动在其相对应的生命周期状态进行控制调用相对应的方法。
class MainActivity : AppCompatActivity() {
private lateinit var videoPlayerComponent: VideoPlayerComponent
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
videoPlayerComponent = VideoPlayerComponent(this)
videoPlayerComponent.register(this)
}
override fun onResume() {
super.onResume()
videoPlayerComponent.startPlay()
}
override fun onPause() {
super.onPause()
videoPlayerComponent.stopPlay()
}
override fun onDestroy() {
videoPlayerComponent.unRegister()
super.onDestroy()
}
}虽然实现了需求,但显然这不是最优雅的实现方式。一旦使用方忘记在 onDestroy() 进行注销播放器,就容易造成内存泄漏,而忘记注销显然是一件很容易发生的事情😂 。
回想初衷,之所以将方法暴露给使用方来调用,就是因为我们的组件自身无法感知到使用者的生命周期。所以,一旦我们的组件自身可以感知到使用者的生命周期状态的话,我们就不需要将这些方法暴露出去了。
那么问题来了,组件如何才能感知到生命周期呢?
答:Lifecycle !
直接上案例,借助 Lifecycle 我们改进一下我们的播放器组件👇
class VideoPlayerComponent(private val context: Context) : DefaultLifecycleObserver {
override fun onCreate(owner: LifecycleOwner) {
super.onCreate(owner)
register(context)
}
override fun onResume(owner: LifecycleOwner) {
super.onResume(owner)
startPlay()
}
override fun onPause(owner: LifecycleOwner) {
super.onPause(owner)
stopPlay()
}
override fun onDestroy(owner: LifecycleOwner) {
super.onDestroy(owner)
unRegister()
}
/**
* 注册,加载资源
*/
private fun register(context: Context) {
loadResource(context)
}
/**
* 注销,释放资源
*/
private fun unRegister() {
releaseResource()
}
/**
* 开始播放当前视频资源
*/
private fun startPlay() {
startPlayVideo()
}
/**
* 暂停播放
*/
private fun stopPlay() {
stopPlayVideo()
}
}改进完成后,我们的调用方MainActivity只需要一行代码即可。
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
lifecycle.addObserver(VideoPlayerComponent(this))
}
}这样是不是就优雅多了。
那这 Lifecycle 又是怎么感知到生命周期的呢?让我们这就带着问题,出发探一探它的实现方式与源码!
如果让你来做,你会怎么做
在查看源码前,让我们试着思考一下,如果让你来实现 Jetpack Lifecycle 这样的功能,你会怎么做呢?该从何入手呢?
我们的目的是不通过回调方法即可获取到生命周期,这其实就是解耦,实现解耦的一种很好方法就是利用观察者模式。
利用观察者模式,我们就可以这么设计👇
被观察者对象就是生命周期,而观察者对象则是需要知晓生命周期的对象,例如:我们的三方组件。
接着我们就具体探探源码,看一看Google是如何实现的吧。
Google 实现方式
Lifecycle
一个代表着Android生命周期的抽象类,也就是我们的抽象被观察者对象。
public abstract class Lifecycle {
public abstract void addObserver(@NonNull LifecycleObserver observer);
public abstract void removeObserver(@NonNull LifecycleObserver observer);
public enum Event {
ON_CREATE,
ON_START,
ON_RESUME,
ON_PAUSE,
ON_STOP,
ON_DESTROY,
ON_ANY;
}
public enum State {
DESTROYED,
INITIALIZED,
CREATED,
STARTED,
RESUMED;
}
}内包含 State 与 Event 分别者代表生命周期的状态与事件,同时定义了抽象方法 addObserver(LifecycleObserver) 与removeObserver(LifecycleObserver) 方法用于添加与删除生命周期观察者。
Event 很好理解,就像是 Activity | Fragment 的 onCreate()、onDestroy()等回调方法,它代表着生命周期的事件。
那这 State 又是什么呢?何为状态?他们之间又是什么关系呢?
Event 与 State 之间的关系
关于 Event 与 State 之间的关系,Google官方给出了这么一张两者关系图👇
乍一看,可能第一感觉不是那么直观,我整理了一下👇
INITIALIZED:在ON_CREATE事件触发前。CREATED:在ON_CREATE事件触发后以及ON_START事件触发前;或者在ON_STOP事件触发后以及ON_DESTROY事件触发前。STARTED:在ON_START事件触发后以及ON_RESUME事件触发前;或者在ON_PAUSE事件触发后以及ON_STOP事件触发前。RESUMED:在ON_RESUME事件触发后以及ON_PAUSE事件触发前。DESTROYED:在ON_DESTROY事件触发之后。
Event 代表生命周期发生变化那个瞬间点,而 State 则表示生命周期的一个阶段。这两者结合的好处就是让我们可以更加直观的感受生命周期,从而可以根据当前所处的生命周期状态来做出更加合理操作行为。
例如,在LiveData的生命周期绑定观察者源码中,就会判断当前观察者对象的生命周期状态,如果当前是DESTROYED状态,则直接移除当前观察者对象。同时,根据观察者对象当前的生命周期状态是否 >= STARTED来判断当前观察者对象是否是活跃的。
class LifecycleBoundObserver extends ObserverWrapper implements LifecycleEventObserver {
......
@Override
boolean shouldBeActive() {
//根据观察者对象当前的生命周期状态是否 >= STARTED 来判断当前观察者对象是否是活跃的。
return mOwner.getLifecycle().getCurrentState().isAtLeast(STARTED);
}
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
//根据当前观察者对象的生命周期状态,如果是DESTROYED,直接移除当前观察者
Lifecycle.State currentState = mOwner.getLifecycle().getCurrentState();
if (currentState == DESTROYED) {
removeObserver(mObserver);
return;
}
......
}
......
}其实 Event 与 State 这两者之间的联系,在我们生活中也是处处可见,例如:自动洗车。
想必现在你对 Event 与 State 之间的关系有了更好的理解了吧。
LifecycleObserver
生命周期观察者,也就是我们的抽象观察者对象。
public interface LifecycleObserver {
}所以,我们想成为观察生命周期的观察者的话,就需要具体实现该接口,也就是成为具体观察者对象。
换句话说,就是如果你想成为观察者对象来观察生命周期的话,那就必须实现 LifecycleObserver 接口。
例如Google官方提供的 DefaultLifecycleObserver、 LifecycleEventObserver 。
LifecycleOwner
正如其名字一样,生命周期的持有者,所以像我们的 Activity | Fragment 都是生命周期的持有者。
大白话很好理解,但代码应该如何实现呢?
抽象概念 + 具体实现
抽象概念:定义 LifecycleOwner 接口。
public interface LifecycleOwner {
@NonNull
Lifecycle getLifecycle();
}具体实现:Fragment 实现 LifecycleOwner 接口。
public class Fragment implements ComponentCallbacks, OnCreateContextMenuListener, LifecycleOwner,
ViewModelStoreOwner, HasDefaultViewModelProviderFactory, SavedStateRegistryOwner,
ActivityResultCaller {
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
......
}具体实现:Activity 实现 LifecycleOwner 接口。
public class ComponentActivity extends androidx.core.app.ComponentActivity implements
ContextAware,
LifecycleOwner,
ViewModelStoreOwner,
HasDefaultViewModelProviderFactory,
SavedStateRegistryOwner,
OnBackPressedDispatcherOwner,
ActivityResultRegistryOwner,
ActivityResultCaller {
@NonNull
@Override
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
......
}这样,Activity | Fragment 就都是生命周期持有者了。
疑问?在上方 Activity | Fragment 的类中,getLifecycle() 方法中都是返回 mLifecycleRegistry,那这个 mLifecycleRegistry 又是什么玩意呢?
LifecycleRegistry
是
Lifecycle的一个具体实现类。
LifecycleRegistry 负责管理生命周期观察者对象,并将最新的生命周期事件与状态及时通知给对应的生命周期观察者对象。
添加与删除观察者对象的具体实现方法。
//用户保存生命周期观察者对象
private FastSafeIterableMap<LifecycleObserver, ObserverWithState> mObserverMap = new FastSafeIterableMap<>();
@Override
public void addObserver(@NonNull LifecycleObserver observer) {
enforceMainThreadIfNeeded("addObserver");
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
//将生命周期观察者对象包装成带生命周期状态的观察者对象
ObserverWithState statefulObserver = new ObserverWithState(observer, initialState);
ObserverWithState previous = mObserverMap.putIfAbsent(observer, statefulObserver);
... 省略代码 ...
}
@Override
public void removeObserver(@NonNull LifecycleObserver observer) {
mObserverMap.remove(observer);
}可以从上述代码中发现,LifecycleRegistry 还对生命周期观察者对象进行了包装,使其带有生命周期状态。
static class ObserverWithState {
//生命周期状态
State mState;
//生命周期观察者对象
LifecycleEventObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
//这里确保observer为LifecycleEventObserver类型
mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer);
//并初始化了状态
mState = initialState;
}
//分发事件
void dispatchEvent(LifecycleOwner owner, Event event) {
//根据 Event 得出当前最新的 State 状态
State newState = event.getTargetState();
mState = min(mState, newState);
//触发观察者对象的 onStateChanged() 方法
mLifecycleObserver.onStateChanged(owner, event);
//更新状态
mState = newState;
}
}将最新的生命周期事件通知给对应的观察者对象。
public void handleLifecycleEvent(@NonNull Lifecycle.Event event) {
... 省略代码 ...
ObserverWithState observer = mObserverMap.entrySet().getValue();
observer.dispatchEvent(lifecycleOwner, event);
... 省略代码 ...
mLifecycleObserver.onStateChanged(owner, event);
}那 handleLifecycleEvent() 方法在什么时候被调用呢?
相信看到下方这个代码,你就明白了。
public class FragmentActivity extends ComponentActivity {
......
final LifecycleRegistry mFragmentLifecycleRegistry = new LifecycleRegistry(this);
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_CREATE);
}
@Override
protected void onDestroy() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_DESTROY);
}
@Override
protected void onPause() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_PAUSE);
}
@Override
protected void onStop() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_STOP);
}
......
}在 Activity | Fragment 的 onCreate()、onStart()、onPause()等生命周期方法中,调用LifecycleRegistry 的 handleLifecycleEvent() 方法,从而将生命周期事件通知给观察者对象。
总结
Lifecycle 通过观察者设计模式,将生命周期感知对象与生命周期提供者充分解耦,不再需要通过回调方法来感知生命周期的状态,使代码变得更加的精简。
虽然不通过 Lifecycle,我们的组件也是可以获取到生命周期的,但是 Lifecycle 的意义就是提供了统一的调用接口,让我们的组件可以更加方便的感知到生命周期,方便广达开发者。而且,Google以此推出了更多的生命周期感知型组件,例如:ViewModel、LiveData。正是这些组件,让我们的开发变得越来越简单。
链接:https://juejin.cn/post/7176901382702628924
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Compose 为什么可以跨平台?
前言
Compose 不止能用于 Android 应用开发,借助其分层的架构设计以及 Kotlin 的跨平台优势,也是一个极具潜力的 Kotlin 跨平台框架。本文让我们从 Compose Runtime 的视角出发,看看 Compose 实现跨平台开发的基本原理。
Compose Architecture Layers
Compose 作为一个框架,在架构上从下到上分成多层:
- Compose Compiler:Kotlin 编译器插件,负责对 Composable 函数的静态检查以及代码生成等。
- Compose Runtime:负责 Composable 函数的状态管理,以及执行后的渲染树生成和更新
- Compose UI: 基于渲染树进行 UI 的布局、绘制等 UI 渲染工作
- Compose Foundation: 提供用于布局的基础 Composable 组件,例如
Column,Row等。 - Compose Material:提供上层的面向 Material 设计风格的 Composable 组件。
各层的职责明确,其中 Compose Compiler 和 Runtime 是支撑整个声明式 UI 运转的基石。
Compose Compiler
我们先看一下 Compose Compiler 的作用:
左边的源码是一个非常简单的 Composable 函数,定义了个一大带有状态的 Button,点击按钮,Button 中显示的 count 数增加。
源码经 Compose Compiler 编译后变成右边这样,生成了很多代码。首先函数签名上多了几个参数,特别是多了 %composer 参数。然后函数体中插入了很多对 %composer 的调用,例如 startRestartGroup/endRestartGroup,startReplaceGroup/endReplaceGroup 等。这些生成代码用来完成 Compose Runtime 这一层的工作。接下来我们分析一下 Runtime 具体在做什么
Group & SlotTable
Composable 函数虽然没有返回值,但是执行过程中需要生成服务于 UI 渲染的产物,我们称之为 Composition。参数 %composer 就是 Composition 的维护者,用来创建和更新 Composition。Composition 中包含两棵树,一棵状态树和一棵渲染树。
关于两棵树:如果你了解 React,可以将这两棵树的关系类比成 React 中的 VIrtual DOM Tree 与 Real DOM Tree。Compose 中的这棵 “Virtual DOM” 用来记录 UI 显示所需要的状态信息, 所以我们称之为状态树。
状态树上的节点单元是 Group,编译器生成的 startXXXGroup 本质上就是在创建 Group 单元, startXXXGroup 与 endXXXGroup 之间产生的数据状态都归属当前 Group;产生的 Group 就成为子 Group,因此随着 Composable 的执行,基于 Group 的树型结构就被构建出来了。
关于 Group:Group 都是一些功能单元,比如 RestartGroup 是一个可重组的最小单元,ReplaceableGroup 是可以被动态插入的最小单元等,以 Group 为单位组织状态,可以更灵活的更新状态树。代码中什么位置插入什么样的 startXXXGroup 完全由 Compose Compiler 智能的帮我们生成,我们在写代码时不必付出这方面的思考。
状态树实际是使用一个被称作 Slot Table 的线性数据结构实现的,可以把他理解为一个数组,存储着状态树深度遍历的结果,数组的各个区间存储着对应 UI 节点上的状态。
Comopsable 首次执行时,产生的 Group 以及所瞎的状态会以此填充到 Slot Table 中,填充时会附带一个编译时给予代码位置生成的不重复的 key,所以 Slot Table 中的记录也被称作基于代码位置的存储(Positional Memoization)。当重组发生时, Composable 会再次遍历 SlotTable,并在 startXXXGroup 中根据 key 访问当前代码所需的状态,比如 count 就可以通过 remember 在重组中获取最近的值。
Applier & Node Tree
Slot Table 中的状态不能直接用来渲染,UI 的渲染依赖 Composition 中的另一棵树 - 渲染树。Slot Table 通过 Applier 转换成渲染树。渲染树是真真正的树形结构体 Node Tree。
Applier 是一个接口,从接口定义不难看出,它用于对一棵 Node 类型节点树进行增删改等维护工作。以一个 UI 的插入为例,我们在 Compoable 中的一段 if 语句就可以实现一个 UI 片段的插入。if 代码块在编译期会生成一个 ReplaceGroup,当重组中命中 if 条件执行到 startReplaceGroup 时,发现 Slot Table 中缺少 Group 对应 key 的信息,因此可以识别出是一个插入操作,然后插入新的 Group 以及所辖的 Node 信息,并通过 Applier 转换成 Node Tree 中新插入的节点。
SlotTable 中插入新元素后,后续元素会通过 Gap Buffer 机制进行后移,而不是直接删除。这样可以保证后续元素在 Node Tree 中的对应节点的保留,实现 Node Tree 的增量更新,实现局部刷新,提升性能。
Compose Phases
我们结合前面的介绍,整体看一下 Compose 从源码到上屏的全过程:
Composable 源码经 Compiler 处理后插入了用于更新 Composition 的代码。这部分工作由 Compose Compiler 完成。
当 Compose 框架接收到系统侧发送的帧信号后,从顶层开始执行 Composable 函数,执行过程中依次更新 Composition 中的状态树和渲染树,这个过程即所谓的“组合”。这部分工作由 Compose Runtime 完成。
Compose 在 Android 平台的容器是 AndroidComposeView,当接收到系统发送的 disptachDraw 时,便开始驱动 Composition 的渲染树以及进行 Measure,Lyaout,Drawing 完成 UI 的渲染。这部分工作由 Compose UI 负责完成。
Comopse 渲染一帧的三个阶段 : Composition -> Layout -> Drawing。
传统视图开发中,渲染树(View Tree)的维护需要我们在代码逻辑中完成;Compose 渲染树的维护则交给了框架,所以多了 Composition 这一阶段。这也是 Compose 相对于自定义 View 代码更简单的根本原因。
把这整个过程从中间一分为二来看,Compose Compiler 与 Compose Runtime 负责驱动一棵节点树的更新,这部分与平台无关,节点树也可以是任意类型的节点树甚至是一颗渲染无关的树。不同平台的渲染机制不同,所以 Compose UI 与平台相关。 我们只要在 Compoe UI 这一层,针对不同平台实现自己的 Node Tree 和对应的 Applier,就可以在 Compose Runtime 的驱动下实现 UI 的声明式开发。
Compose for Android View
基于这一结论,我们做一个实验:使用 Compose Runtime 驱动 Android 原生 View 的渲染。
我们首先定义一个基于 View 类型节点的 Applier :ViewApplier
class ViewApplier(val view: FrameLayout) : AbstractApplier<View>(view) {
override fun onClear() {
(view as? ViewGroup)?.removeAllViews()
}
override fun insertBottomUp(index: Int, instance: View) {
(current as? ViewGroup)?.addView(instance, index)
}
override fun insertTopDown(index: Int, instance: View) {
}
override fun move(from: Int, to: Int, count: Int) {
// NOT Supported
TODO()
}
override fun remove(index: Int, count: Int) {
(view as? ViewGroup)?.removeViews(index, count)
}
}然后,我们创建两个 Android View 对应的 Composable,TextView 和 LinearLayout:
@Composable
fun TextView(
text: String,
onClick: () -> Unit = {}
) {
val context = localContext.current
ComposeNode<TextView, ViewApplier>(
factory = {
TextView(context)
},
update = {
set(text) {
this.text = text
}
set(onClick) {
setOnClickListener { onClick() }
}
},
)
}
@Composable
fun LinearLayout(children: @Composable () -> Unit) {
val context = localContext.current
ComposeNode<LinearLayout, ViewApplier>(
factory = {
LinearLayout(context).apply {
orientation = LinearLayout.VERTICAL
layoutParams = ViewGroup.LayoutParams(
ViewGroup.LayoutParams.MATCH_PARENT,
ViewGroup.LayoutParams.MATCH_PARENT,
)
}
},
update = {},
content = children,
)
}
ComposeNode 是 Compose Runtime 提供的 API,用来像 Slot Table 添加一个 Node 信息。Slot Tabl 通过 Applier 创建基于 View 的节点树时,会通过 Node 的 factory 创建对应的 View 节点。
有了上述实验,我们就可以使用 Compose 构建 Android View 了,同时可以通过 Compose 的 SnapshotState 驱动 View 的更新:
@Composable
fun AndroidViewApp() {
var count by remember { mutableStateOf(1) }
LinearLayout {
TextView(
text = "This is the Android TextView!!",
)
repeat(count) {
TextView(
text = "Android View!!TextView:$it $count",
onClick = {
count++
}
)
}
}
}执行效果如下:
同样,我们也可以基于 Compose Runtime 为任意平台打造基于 Compose 的声明式 UI 框架。
Compose for Desktop & Web
JetBrains 在 Compose 多平台应用方面进行了很多尝试,并做出了很多成果。JetBrains 基于谷歌 Jetpack Compose 的 fork 相继发布了 Compose for Desktop 以及 Compose for Web。
Compose Desktop 与 Android 同样基于 LayoutNode 的渲染树,通过 Skia 引擎完成跨平台渲染。所以它们在渲染效果以及开发体验上都保持高度一致。Compose Desktop 依靠 Kotlin/JVM 编译成字节码产物,并使用 Jpackage 和 Jlink 打包成不同桌面系统的( Linux/Mac/Windows)的安装包,可以在脱离 JVM 的环境下直接运行。
Compose Web 使用了基于 W3C 标准的 DomNode 作为渲染树节点,在 Compose Runtime 驱动下生成 DOM Tree 。Compose Web 通过 Kotlin/JS 编译成 JavaScript 最终在浏览器中运行和渲染。Compose Web 中预制了更贴近 HTML 风格的 Composable API,所以 UI 代码上与 Android/Desktop 无法直接复用。
通过 compose-jb 官方的例子,感受一下 Desktop & Web 的不同
上面使用 Compose 在各个平台实现的页面效果,Desktop 和 Android 的渲染效果完全一致,Web 与前两者在现实效果上不同,他们的代码分别如下所示:
Compose Desktop 与 Jetpack Compose 在代码上没有区别,而 Compose Web 使用 Div,Ul 这样与 HTML 标签同名的 Composable,而且使用 style { ...} 这样面向 CSS 的 DSL 替代 Modifier,开发体验更符合前端的习惯。虽然 UI 部分的代码在不同平台有差异,但是在逻辑部分,可以实现完全复用,各平台的 Comopse UI 都使用 component.models.subscribeAsState() 监听状态变化。
Compose for Multiplatform
JetBrains 将 Android,Desktop,Web 三个平台的 Compose 整合成统一 Group Id 的 Kotlin Multiplatform 库,便诞生了 Comopse Multiplatform。
Compose Mutiplatform 作为一个 KM 库,让一个 KMP (Kotlin Multiplatform Project) 中可共享的代码从 Data 层上升到 UI 层以及 UI 相关的 Logic 层。
使用 IntelliJ IDEA 可以创建一个 Compose Multiplatform 工程模版,在结构上与一个普通的 KMP 无异。
android/desktop/web 文件夹是各个平台的工程文件,基于 gradle 编译成目标平台的产物。
common 文件夹是 KMP 的核心。commonMain 中是完全共享的 Kt 代码,通过 expect/actual 关键字实现平台差异化开发。
我们先在 gradle 中依赖 Comopse Multiplatform 库,之后就可以在 commonMain 中开发共享基于 Compose 的 UI 代码了。Comopse Multiplatform 的各个组件将 Jetpack Compose 对应组件的 Group Id 中的 androidx 前缀替换为 org.jertbrains 前缀:
androidx.compose.runtime -> org.jetbrains.compose.runtime
androidx.compose.material -> org.jetbrains.compose.material
androidx.compose.foundation -> org.jetbrains.compose.foundation最后
最后,我们来思考一下 Compose for Multiplatform 与 Compose Multiplatform 这两个词的区别?在我看来,Compose Multiplatform 会让家将焦点放在 Multiplatform 上面,自然会拿来与 Flutter 等同类框架作对比。但是通过本文的介绍,大家已经知道了 Compose 并非一个专门为跨平台打造的框架,现阶段它并不追求渲染效果和开发体验完全一致,它的出现更像是 Kotlin 带来的增值服务。
而 Compose for Multiplatfom 的焦点则更应该放在 Compose 上,它表示 Compose 可以服务于更多平台,依托强大的 Compiler 和 Runtime 层,我们可以为更多平台打造声明式框架。扩大 Kotlin 的应用场景和 Kotlin 开发者的能力边界。希望今后再提到 Compose 跨平台式,大家可以多从 Compose for Multiplatform 的角度去看待他的意义和价值。
链接:https://juejin.cn/post/7176437908935540797
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Suspend函数与回调的互相转换
前言
我们再来一期关于kotlin协程的故事,我们都知道在Coroutine没有出来之前,我们对于异步结果的处理都是采用回调的方式进行,一方面回调层次过多的话,容易导致“回调地狱”,另一方法也比较难以维护。当然,我们并不是否定了回调本身,回调本身同时也是具备很多优点的,比如符合代码阅读逻辑,同时回调本身也是比较可控的。这一期呢,我们就是来聊一下,如何把回调的写法变成suspend函数,同时如何把suspend函数变成回调,从而让我们更加了解kotlin协程背后的故事
回调变成suspend函数
来一个回调
我们以一个回调函数作为例子,当我们normalCallBack在一个子线程中做一些处理,比如耗时函数,做完就会通过MyCallBack回调onCallBack,这里返回了一个Int类型,如下:
var myCallBack:MyCallBack?= null
interface MyCallBack{
fun onCallBack(result: Int)
}
fun normalCallBack(){
thread {
// 比如做一些事情
myCallBack?.onCallBack(1)
}
}转化为suspend函数
此时我们可以通过suspendCoroutine函数,内部其实是通过创建了一个SafeContinuation并放到了我们suspend函数本身(block本身)启动了一个协程,我们之前在聊一聊Kotlin协程"低级"api 这篇文章介绍过
public suspend inline fun <T> suspendCoroutine(crossinline block: (Continuation<T>) -> Unit): T {
contract { callsInPlace(block, InvocationKind.EXACTLY_ONCE) }
return suspendCoroutineUninterceptedOrReturn { c: Continuation<T> ->
val safe = SafeContinuation(c.intercepted())
block(safe)
safe.getOrThrow()
}
}这时候我们就可以直接写为,从而将回调消除,变成了一个suspend函数。
suspend fun mySuspend() = suspendCoroutine<Int> {
thread {
// 比如做一些事情
it.resume(1)
}
}当然,如果我们想要支持一下外部取消,比如当前页面销毁时,发起的网络请求自然也就不需要再请求了,就可以通过suspendCancellableCoroutine创建,里面的Continuation对象就从SafeContinuation(见上文)变成了CancellableContinuation,变成了CancellableContinuation有一个invokeOnCancellation方便,支持在协程体被销毁时的逻辑。
public suspend inline fun <T> suspendCancellableCoroutine(
crossinline block: (CancellableContinuation<T>) -> Unit
): T =
suspendCoroutineUninterceptedOrReturn { uCont ->
val cancellable = CancellableContinuationImpl(uCont.intercepted(), resumeMode = MODE_CANCELLABLE)
/*
* For non-atomic cancellation we setup parent-child relationship immediately
* in case when `block` blocks the current thread (e.g. Rx2 with trampoline scheduler), but
* properly supports cancellation.
*/
cancellable.initCancellability()
block(cancellable)
cancellable.getResult()
}此时我们就可以写出以下代码
suspend fun mySuspend2() = suspendCancellableCoroutine<Int> {
thread {
// 比如做一些事情
it.resume(1)
}
it.invokeOnCancellation {
// 取消逻辑
}
}suspend函数变成回调
见到了回调如何变成suspend函数,那么我们反过来呢?有没有办法?当然有啦!当时suspend函数中有很多种区分,我们一一区分一下
直接返回的suspend函数
suspend fun myNoSuspendFunc():Int{
return 1
}调用suspendCoroutine后直接resume的suspend函数
suspend fun myNoSuspendFunc() = suspendCoroutine<Int> {
continuation ->
continuation.resume(1)
}调用suspendCoroutine后异步执行的suspend函数(这里异步可以是单线程也可以是多线程,跟线程本身无关,只要是异步就会触发挂起)
suspend fun myRealSuspendFunc() = suspendCoroutine<Int> {
thread {
Thread.sleep(300)
it.resume(2)
}那么我们来想一下,这里真正发起挂起的函数是哪个?通过代码其实我们可以猜到,真正挂起的函数只有最后一个myRealSuspendFunc,其他都不是真正的挂起,这里的挂起是什么意思呢?我们从协程的状态就可以知道,当前处于CoroutineSingletons.COROUTINE_SUSPENDED时,就是挂起状态。我们回归一下,一个suspend函数有哪几种情况
这里的1,2,3就分别对应着上文demo中的例子
- 直接返回结果,不需要进入状态机判断,因为本身就没有启动协程
- 进入了协程,但是不需要进行SUSPEND状态就已经有了结果,所以直接返回了结果
- 进入了SUSPEND状态,之后才能获取结果
这里我们就不贴出来源码了,感兴趣可自己看Coroutine的实现,这里我们要明确一个概念,一个Suspend函数的运行机制,其实并不依靠了协程本身。
对应代码表现就是,这个函数的返回结果可能就是直接返回结果本身,另一种就是通过回调本身通知外部(这里我们还会以例子说明)
suspend函数转换为回调
这里有两种情况,我们分别以kotlin代码跟java代码表示:
kotlin代码
由于kotlin可以直接通过suspend的扩展函数startCoroutine启动一个协程,
fun myRealSuspendCallBack(){
::myRealSuspendFunc.startCoroutine(object :Continuation<Int>{
当前环境
override val context: CoroutineContext
get() = Dispatchers.IO
结果
override fun resumeWith(result: Result<Int>) {
if(result.isSuccess){
myCallBack?.onCallBack(result.getOrDefault(0))
}
}
})
}其中Result就是一个内联类,属于kotlin编译器添加的装饰类,在这里我们无论是1,2,3的情况,都可以在resumeWith 中获取到结果,在这里通过callback回调即可
@JvmInline
public value class Result<out T> @PublishedApi internal constructor(
@PublishedApi
internal val value: Any?
) : Serializable {Java代码
这里我们更正一个误区,就是suspend函数只能在kotlin中使用/Coroutine协程只能在kotlin中使用,这个其实是错误的,java代码也能够调起协程,只不过麻烦了一点,至少官方是没有禁止的。
比如我们需要调用startCoroutine,可直接调用
ContinuationKt.startCoroutine();当然,我们也能够直接调用suspend函数
Object result = CallBack.INSTANCE.myRealSuspendFunc(new Continuation<Integer>() {
@NonNull
@Override
public CoroutineContext getContext() {
这里启动的环境其实协程没有用到,读者们可以思考一下为什么!这里就当一个谜题啦!可以在评论区说出你的想法(我会在评论区解答)
return (CoroutineContext) Dispatchers.getIO();
//return EmptyCoroutineContext.INSTANCE;
}
@Override
public void resumeWith(@NonNull Object o) {
情况3
Log.e("hello","resumeWith result is "+ o +" is main "+ (Looper.myLooper() == Looper.getMainLooper()));
// 回调处理即可
myCallBack?.onCallBack(result)
}
});
if(result != IntrinsicsKt.getCOROUTINE_SUSPENDED()){
情况1,2
Log.e("hello","func result is "+ result);
// 回调处理即可
myCallBack?.onCallBack(result)
}这里我们需要注意的是,这里java代码比kotlin多了一个判断,同时resumeWith的参数不再是Result,而是一个Object
if(result != IntrinsicsKt.getCOROUTINE_SUSPENDED()){
}这里脱去了kotlin给我们添加的各种外壳,其实这就是真正的对于suspend结果的处理(只不过kotlin帮我们包了一层)
我们上文说过,suspend函数对应的三种情况,这里的1,2都是直接返回结果的,因为没有走到SUSPEND状态(IntrinsicsKt.getCOROUTINE_SUSPENDED())这里需要读者好好阅读上文,因此
result != IntrinsicsKt.getCOROUTINE_SUSPENDED(),就会直接走到这里,我们就直接拿到了结果
if(result != IntrinsicsKt.getCOROUTINE_SUSPENDED()){
}如果属于情况3,那么这里的result就不再是一个结果,而是当前协程的状态标记罢了,此时当协程完成执行的时候(调用resume的时候),就会回调到resumeWith,这里的Object类型o才是经过SUSPEND状态的结果!
总结
经过我们suspend跟回调的互相状态,能够明白了suspend背后的逻辑与挂起的细节,希望能帮到你!最后本篇还留下了一个小谜题,可以发挥你的理解在评论区说出你的想法!笔者之后会在评论区解答!
链接:https://juejin.cn/post/7175752374458253373
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 线上卡顿监控
1. 卡顿与ANR的关系
卡顿是UI没有及时的按照用户的预期进行反馈,没有及时地渲染出来,从而看起来不连续、不一致。产生卡顿的原因太多了,很难一一列举,但ANR是Google人为规定的概念,产生ANR的原因最多只有4个。分别是:
- Service Timeout:比如前台服务在20s内未执行完成,后台服务Timeout时间是前台服务的10倍,200s;
- BroadcastQueue Timeout:比如前台广播在10s内未执行完成,后台60s
- ContentProvider Timeout:内容提供者,在publish过超时10s;
- InputDispatching Timeout: 输入事件分发超时5s,包括按键和触摸事件。
假如我在一个button的onClick事件中,有一个耗时操作,这个耗时操作的时间是10秒,但这个耗时操作并不会引发ANR,它只是一次卡顿。
一方面,两者息息相关,长时间的UI卡顿是导致ANR的最常见的原因;但另一方面,从原理上来看,两者既不充分也不必要,是两个纬度的概念。
市面上的一些卡顿监控工具,经常被用来监控ANR(卡顿阈值设置为5秒),这其实很不严谨:首先,5秒只是发生ANR的其中一种原因(Touch事件5秒未被及时消费)的阈值,而其他原因发生ANR的阈值并不是5秒;另外,就算是主线程卡顿了5秒,如果用户没有输入任何的Touch事件,同样不会发生ANR,更何况还有后台ANR等情况。真正意义上的ANR监控方案应该是类似matrix里面那样监控signal信号才算。
2. 卡顿原理
主线程从ActivityThread的main方法开始,准备好主线程的looper,启动loop循环。在loop循环内,无消息则利用epoll机制阻塞,有消息则处理消息。因为主线程一直在loop循环中,所以要想在主线程执行什么逻辑,则必须发个消息给主线程的looper然后由这个loop循环触发,由它来分发消息,然后交给msg的target(Handler)处理。举个例子:ActivityThread.H。
public static void loop() {
......
for (;;) {
Message msg = queue.next(); // might block
......
msg.target.dispatchMessage(msg);
}
}loop循环中可能导致卡顿的地方有2个:
- queue.next() :有消息就返回,无消息则使用epoll机制阻塞(nativePollOnce里面),不会使主线程卡顿。
- dispatchMessage耗时太久:也就是Handler处理消息,app卡顿的话大多数情况下可以认为是这里处理消息太耗时了
3. 卡顿监控
- 方案1:WatchDog,往主线程发消息,然后延迟看该消息是否被处理,从而得出主线程是否卡顿的依据。
- 方案2:利用loop循环时的消息分发前后的日志打印(matrix使用了这个)
3.1 WatchDog
开启一个子线程,死循环往主线程发消息,发完消息后等待5秒,判断该消息是否被执行,没被执行则主线程发生ANR,此时去获取主线程堆栈。
- 优点:简单,稳定,结果论,可以监控到各种类型的卡顿
- 缺点:轮询不优雅,不环保,有不确定性,随机漏报
轮询的时间间隔越小,对性能的负面影响就越大,而时间间隔选择的越大,漏报的可能性也就越大。
- UI线程要不断处理我们发送的Message,必然会影响性能和功耗
- 随机漏报:ANRWatchDog默认的轮询时间间隔为5秒,当主线程卡顿了2秒之后,ANRWatchDog的那个子线程才开始往主线程发送消息,并且主线程在3秒之后不卡顿了,此时主线程已经卡顿了5秒了,子线程发送的那个消息也随之得到执行,等子线程睡5秒起床的时候发现消息已经被执行了,它没意识到主线程刚刚发生了卡顿。
假设将间隔时间改为
改进:
- 监控到发生ANR时,除了获取主线程堆栈,再获取一下CPU、内存占用等信息
- 还可结合ProcessLifecycleOwner,app在前台才开启检测,在后台停止检测
另外有些方案的思路,如果我们不断缩小轮询的时间间隔,用更短的轮询时间,连续几个周期消息都没被处理才视为一次卡顿。则更容易监控到卡顿,但对性能损耗大一些。即使是缩小轮询时间间隔,也不一定能监控到。假设每2秒轮询一次,如果连续三次没被处理,则认为发生了卡顿。在02秒之间主线程开始发生卡顿,在第2秒时开始往主线程发消息,这样在到达次数,也就是8秒时结束,但主线程的卡顿在68秒之间就刚好结束了,此时子线程在第8秒时醒来发现消息已经被执行了,它没意识到主线程刚刚发生了卡顿。
3.2 Looper Printer
替换主线程Looper的Printer,监控dispatchMessage的执行时间(大部分主线程的操作最终都会执行到这个dispatchMessage中)。这种方案在微信上有较大规模使用,总体来说性能不是很差,matrix目前的EvilMethodTracer和AnrTracer就是用这个来实现的。
- 优点:不会随机漏报,无需轮询,一劳永逸
- 缺点:某些类型的卡顿无法被监控到,但有相应解决方案
queue.next()可能会阻塞,这种情况下监控不到。
//Looper.java
for (;;) {
//这里可能会block,Printer无法监控到next里面发生的卡顿
Message msg = queue.next(); // might block
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
}
//MessageQueue.java
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
//......
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
//IdleHandler的queueIdle,如果Looper是主线程,那么这里明显是在主线程执行的,虽然现在主线程空闲,但也不能做耗时操作
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
//......
}- 主线程空闲时会阻塞next(),具体是阻塞在nativePollOnce(),这种情况下无需监控
- Touch事件大部分是从nativePollOnce直接到了InputEventReceiver,然后到ViewRootImpl进行分发
- IdleHandler的queueIdle()回调方法也无法监控到
- 还有一类相对少见的问题是SyncBarrier(同步屏障)的泄漏同样无法被监控到
第一种情况我们不用管,接下来看一下后面3种情况下如何监控卡顿。
3.2.1 监控TouchEvent卡顿
首先,Touch是怎么传递到Activity的?给一个view设置一个OnTouchListener,然后看一些Touch的调用栈。
com.xfhy.watchsignaldemo.MainActivity.onCreate$lambda-0(MainActivity.kt:31)
com.xfhy.watchsignaldemo.MainActivity.$r8$lambda$f2Bz7skgRCh8TKh1SZX03s91UhA(Unknown Source:0)
com.xfhy.watchsignaldemo.MainActivity$$ExternalSyntheticLambda0.onTouch(Unknown Source:0)
android.view.View.dispatchTouchEvent(View.java:13695)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
android.view.ViewGroup.dispatchTransformedTouchEvent(ViewGroup.java:3249)
android.view.ViewGroup.dispatchTouchEvent(ViewGroup.java:2881)
com.android.internal.policy.DecorView.superDispatchTouchEvent(DecorView.java:741)
com.android.internal.policy.PhoneWindow.superDispatchTouchEvent(PhoneWindow.java:2013)
android.app.Activity.dispatchTouchEvent(Activity.java:4180)
androidx.appcompat.view.WindowCallbackWrapper.dispatchTouchEvent(WindowCallbackWrapper.java:70)
com.android.internal.policy.DecorView.dispatchTouchEvent(DecorView.java:687)
android.view.View.dispatchPointerEvent(View.java:13962)
android.view.ViewRootImpl$ViewPostImeInputStage.processPointerEvent(ViewRootImpl.java:6420)
android.view.ViewRootImpl$ViewPostImeInputStage.onProcess(ViewRootImpl.java:6215)
android.view.ViewRootImpl$InputStage.deliver(ViewRootImpl.java:5604)
android.view.ViewRootImpl$InputStage.onDeliverToNext(ViewRootImpl.java:5657)
android.view.ViewRootImpl$InputStage.forward(ViewRootImpl.java:5623)
android.view.ViewRootImpl$AsyncInputStage.forward(ViewRootImpl.java:5781)
android.view.ViewRootImpl$InputStage.apply(ViewRootImpl.java:5631)
android.view.ViewRootImpl$AsyncInputStage.apply(ViewRootImpl.java:5838)
android.view.ViewRootImpl$InputStage.deliver(ViewRootImpl.java:5604)
android.view.ViewRootImpl$InputStage.onDeliverToNext(ViewRootImpl.java:5657)
android.view.ViewRootImpl$InputStage.forward(ViewRootImpl.java:5623)
android.view.ViewRootImpl$InputStage.apply(ViewRootImpl.java:5631)
android.view.ViewRootImpl$InputStage.deliver(ViewRootImpl.java:5604)
android.view.ViewRootImpl.deliverInputEvent(ViewRootImpl.java:8701)
android.view.ViewRootImpl.doProcessInputEvents(ViewRootImpl.java:8621)
android.view.ViewRootImpl.enqueueInputEvent(ViewRootImpl.java:8574)
android.view.ViewRootImpl$WindowInputEventReceiver.onInputEvent(ViewRootImpl.java:8959)
android.view.InputEventReceiver.dispatchInputEvent(InputEventReceiver.java:239)
android.os.MessageQueue.nativePollOnce(Native Method)
android.os.MessageQueue.next(MessageQueue.java:363)
android.os.Looper.loop(Looper.java:176)
android.app.ActivityThread.main(ActivityThread.java:8668)
java.lang.reflect.Method.invoke(Native Method)
com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:513)
com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1109)
当有触摸事件时,nativePollOnce()会收到消息,然后会从native层直接调用InputEventReceiver.dispatchInputEvent()。
public abstract class InputEventReceiver {
public InputEventReceiver(InputChannel inputChannel, Looper looper) {
if (inputChannel == null) {
throw new IllegalArgumentException("inputChannel must not be null");
}
if (looper == null) {
throw new IllegalArgumentException("looper must not be null");
}
mInputChannel = inputChannel;
mMessageQueue = looper.getQueue();
//在这里进行的注册,native层会将该实例记录下来,每当有事件到达时就会派发到这个实例上来
mReceiverPtr = nativeInit(new WeakReference<InputEventReceiver>(this),
inputChannel, mMessageQueue);
mCloseGuard.open("dispose");
}
// Called from native code.
@SuppressWarnings("unused")
@UnsupportedAppUsage
private void dispatchInputEvent(int seq, InputEvent event) {
mSeqMap.put(event.getSequenceNumber(), seq);
onInputEvent(event);
}
}InputReader(读取、拦截、转换输入事件)和InputDispatcher(分发事件)都是运行在system_server系统进程中,而我们的应用程序运行在自己的应用进程中,这里涉及到跨进程通信,这里的跨进程通信用的非binder方式,而是用的socket。
InputDispatcher会与我们的应用进程建立连接,它是socket的服务端;我们应用进程的native层会有一个socket的客户端,客户端收到消息后,会通知我们应用进程里ViewRootImpl创建的WindowInputEventReceiver(继承自InputEventReceiver)来接收这个输入事件。事件传递也就走通了,后面就是上层的View树事件分发了。
这里为啥用socket而不用binder?Socket可以实现异步的通知,且只需要两个线程参与(Pipe两端各一个),假设系统有N个应用程序,跟输入处理相关的线程数目是N+1(1是Input Dispatcher线程)。然而,如果用Binder实现的话,为了实现异步接收,每个应用程序需要两个线程,一个Binder线程,一个后台处理线程(不能在Binder线程里处理输入,因为这样太耗时,将会阻塞住发射端的调用线程)。在发射端,同样需要两个线程,一个发送线程,一个接收线程来接收应用的完成通知,所以,N个应用程序需要2(N+1)个线程。相比之下,Socket还是高效多了。
//frameworks/native/services/inputflinger/InputDispatcher.cpp
void InputDispatcher::startDispatchCycleLocked(nsecs_t currentTime,
const sp<Connection>& connection) {
......
status = connection->inputPublisher.publishKeyEvent(dispatchEntry->seq,
keyEntry->deviceId, keyEntry->source,
dispatchEntry->resolvedAction, dispatchEntry->resolvedFlags,
keyEntry->keyCode, keyEntry->scanCode,
keyEntry->metaState, keyEntry->repeatCount, keyEntry->downTime,
keyEntry->eventTime);
......
}
//frameworks/native/libs/input/InputTransport.cpp
status_t InputPublisher::publishKeyEvent(
uint32_t seq,
int32_t deviceId,
int32_t source,
int32_t action,
int32_t flags,
int32_t keyCode,
int32_t scanCode,
int32_t metaState,
int32_t repeatCount,
nsecs_t downTime,
nsecs_t eventTime) {
......
InputMessage msg;
......
msg.body.key.keyCode = keyCode;
......
return mChannel->sendMessage(&msg);
}
//frameworks/native/libs/input/InputTransport.cpp
//调用 socket 的 send 接口来发送消息
status_t InputChannel::sendMessage(const InputMessage* msg) {
size_t msgLength = msg->size();
ssize_t nWrite;
do {
nWrite = ::send(mFd, msg, msgLength, MSG_DONTWAIT | MSG_NOSIGNAL);
} while (nWrite == -1 && errno == EINTR);
......
}
有了上面的知识铺垫,现在回到我们的主问题上来,如何监控TouchEvent卡顿。既然它们是用socket来进行通信的,那么我们可以通过PLT Hook,去Hook这对socket的发送(send)和接收(recv)方法,从而监控Touch事件。当调用到了recvfrom时(send和recv最终会调用sendto和recvfrom,这2个函数的具体定义在socket.h源码),说明我们的应用接收到了Touch事件,当调用到了sendto时,说明这个Touch事件已经被成功消费掉了,当两者的时间相差过大时即说明产生了一次Touch事件的卡顿。
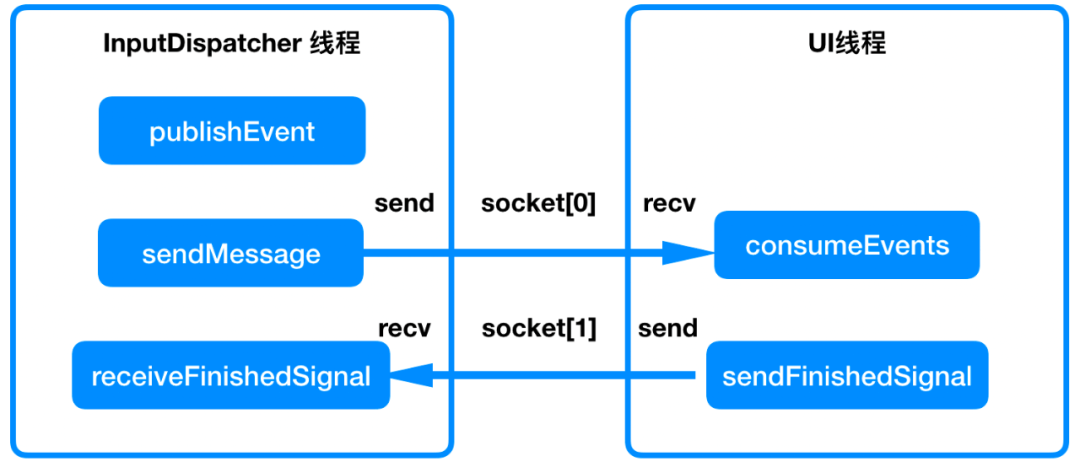
PLT Hook是什么,它是一种native hook,另外还有一种native hook方式是inline hook。PLT hook的优点是稳定性可控,可线上使用,但它只能hook通过PLT表跳转的函数调用,这在一定程度上限制了它的使用场景。
对PLT Hook的具体原理感兴趣的同学可以看一下下面2篇文章:
目前市面上比较流行的PLT Hook开源库主要有2个,一个是爱奇艺开源的xhook,一个是字节跳动开源的bhook。我这里使用xhook来举例,InputDispatcher.cpp最终会被编译成libinput.so(具体Android.mk信息看这里)。那我们就直接hook这个libinput.so的sendto和recvfrom函数。
理论知识有了,直接开干:
ssize_t (*original_sendto)(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
ssize_t my_sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen) {
//应用端已消费touch事件
if (getCurrentTime() - lastTime > 5000) {
__android_log_print(ANDROID_LOG_DEBUG, "xfhy_touch", "Touch有点卡顿");
//todo xfhy 在这里调用java去dump主线程堆栈
}
long ret = original_sendto(sockfd, buf, len, flags, dest_addr, addrlen);
return ret;
}
ssize_t (*original_recvfrom)(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
ssize_t my_recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen) {
//收到touch事件
lastTime = getCurrentTime();
long ret = original_recvfrom(sockfd, buf, len, flags, src_addr, addrlen);
return ret;
}
void Java_com_xfhy_touch_TouchTest_start(JNIEnv *env, jclass clazz) {
xhook_register(".*libinput\\.so$", "__sendto_chk",(void *) my_sendto, (void **) (&original_sendto));
xhook_register(".*libinput\\.so$", "sendto",(void *) my_sendto, (void **) (&original_sendto));
xhook_register(".*libinput\\.so$", "recvfrom",(void *) my_recvfrom, (void **) (&original_recvfrom));
}上面这个是我写的demo,完整代码看这里,这个demo肯定是不够完善的。但方案是可行的。完善的方案请看matrix的Touch相关源码。
3.2.2 监控IdleHandler卡顿
IdleHandler任务最终会被存储到MessageQueue的mIdleHandlers (一个ArrayList)中,在主线程空闲时,也就是MessageQueue的next方法暂时没有message可以取出来用时,会从mIdleHandlers 中取出IdleHandler任务进行执行。那我们可以把这个mIdleHandlers 替换成自己的,重写add方法,添加进来的 IdleHandler 给它包装一下,包装的那个类在执行 queueIdle 时进行计时,这样添加进来的每个IdleHandler在执行的时候我们都能拿到其 queueIdle 的执行时间 。如果超时我们就进行记录或者上报。
fun startDetection() {
val messageQueue = mHandler.looper.queue
val messageQueueJavaClass = messageQueue.javaClass
val mIdleHandlersField = messageQueueJavaClass.getDeclaredField("mIdleHandlers")
mIdleHandlersField.isAccessible = true
//虽然mIdleHandlers在Android Q以上被标记为UnsupportedAppUsage,但居然可以成功设置. 只有在反射访问mIdleHandlers时,才会触发系统的限制
mIdleHandlersField.set(messageQueue, MyArrayList())
}
class MyArrayList : ArrayList<IdleHandler>() {
private val handlerThread by lazy {
HandlerThread("").apply {
start()
}
}
private val threadHandler by lazy {
Handler(handlerThread.looper)
}
override fun add(element: IdleHandler): Boolean {
return super.add(MyIdleHandler(element, threadHandler))
}
}
class MyIdleHandler(private val originIdleHandler: IdleHandler, private val threadHandler: Handler) : IdleHandler {
override fun queueIdle(): Boolean {
log("开始执行idleHandler")
//1. 延迟发送Runnable,Runnable收集主线程堆栈信息
val runnable = {
log("idleHandler卡顿 \n ${getMainThreadStackTrace()}")
}
threadHandler.postDelayed(runnable, 2000)
val result = originIdleHandler.queueIdle()
//2. idleHandler如果及时完成,那么就移除Runnable。如果上面的Runnable得到执行,说明主线程的idleHandler已经执行了2秒还没执行完,可以收集信息,对照着检查一下代码了
threadHandler.removeCallbacks(runnable)
return result
}
}反射完成之后,我们简单添加一个IdleHandler,然后在里面sleep(10000)测试一下,得到结果如下:
2022-10-17 07:33:50.282 28825-28825/com.xfhy.allinone D/xfhy_tag: 开始执行idleHandler
2022-10-17 07:33:52.286 28825-29203/com.xfhy.allinone D/xfhy_tag: idleHandler卡顿
java.lang.Thread.sleep(Native Method)
java.lang.Thread.sleep(Thread.java:443)
java.lang.Thread.sleep(Thread.java:359)
com.xfhy.allinone.actual.idlehandler.WatchIdleHandlerActivity$startTimeConsuming$1.queueIdle(WatchIdleHandlerActivity.kt:47)
com.xfhy.allinone.actual.idlehandler.MyIdleHandler.queueIdle(WatchIdleHandlerActivity.kt:62)
android.os.MessageQueue.next(MessageQueue.java:465)
android.os.Looper.loop(Looper.java:176)
android.app.ActivityThread.main(ActivityThread.java:8668)
java.lang.reflect.Method.invoke(Native Method)
com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:513)
com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1109)
从日志堆栈里面很清晰地看到具体是哪里发生了卡顿。
3.2.3 监控SyncBarrier泄漏
什么是SyncBarrier泄漏?在说这个之前,我们得知道什么是SyncBarrier,它翻译过来叫同步屏障,听起来很牛逼,但实际上就是一个Message,只不过这个Message没有target。没有target,那这个Message拿来有什么用?当MessageQueue中存在SyncBarrier的时候,同步消息就得不到执行,而只会去执行异步消息。我们平时用的Message一般是同步的,异步的Message主要是配合SyncBarrier使用。当需要执行一些高优先级的事情的时候,比如View绘制啥的,就需要往主线程MessageQueue插个SyncBarrier,然后ViewRootlmpl 将mTraversalRunnable 交给 Choreographer ,Choreographer 等到下一个VSYNC信号到来时,及时地去执行mTraversalRunnable ,交给Choreographer 之后的部分逻辑优先级是很高的,比如执行mTraversalRunnable 的时候,这种逻辑是放到异步消息里面的。回到ViewRootImpl之后将SyncBarrier移除。
关于同步屏障和
Choreographer的详细逻辑可以看我之前的文章:Handler同步屏障、Choreographer原理及应用
@UnsupportedAppUsage
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
//插入同步屏障,mTraversalRunnable的优先级很高,我需要及时地去执行它
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
//mTraversalRunnable里面会执行doTraversal
mChoreographer.postCallback(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
void unscheduleTraversals() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
mChoreographer.removeCallbacks(Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
}
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
//移除同步屏障
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
performTraversals();
}
}再来说说什么是同步屏障泄露:我们看到在一开始的时候scheduleTraversals里面插入了一个同步屏障,这时只能执行异步消息了,不能执行同步消息。假设出现了某种状况,让这个同步屏障无法被移除,那么消息队列中就一直执行不到同步消息,可能导致主线程假死,你想想,主线程里面同步消息都执行不了了,那岂不是要完蛋。那什么情况下会导致出现上面的异常情况?
- scheduleTraversals线程不安全,万一不小心post了多个同步屏障,但只移除了最后一个,那有的同步屏障没被移除的话,同步消息无法执行
- scheduleTraversals中post了同步屏障之后,假设某些操作不小心把异步消息给移除了,导致没有移除该同步屏障,也会造成同样的悲剧
问题找到了,怎么解决?有什么好办法能监控到这种情况吗(虽然这种情况比较少见)?微信的同学给出了一种方案,我简单描述下:
- 开个子线程,轮询检查主线程的MessageQueue里面的message,检查是否有同步屏障消息的when已经过去了很久了,但还没得到移除
- 此时可以合理怀疑该同步屏障消息可能已泄露,但还不能确定(有可能是主线程卡顿,导致没有及时移除)
- 这个时候,往主线程发一个同步消息和一个异步消息(可以间隔地多发几次,增加可信度),如果同步消息没有得到执行,但异步消息得到执行了,这说明什么?说明主线程有处理消息的能力,不卡顿,且主线程的MessageQueue中有一个同步屏障一直没得到移除,所以同步消息才没得到执行,而异步消息得到执行了。
- 此时,可以激进一点,把这个泄露的同步泄露消息给移除掉。
下面是此方案的核心代码,完整源码在这里
override fun run() {
while (!isInterrupted) {
val messageHead = mMessagesField.get(mainThreadMessageQueue) as? Message
messageHead?.let { message ->
//该消息为同步屏障 && 该消息3秒没得到执行,先怀疑该同步屏障发生了泄露
if (message.target == null && message.`when` - SystemClock.uptimeMillis() < -3000) {
//查看MessageQueue#postSyncBarrier(long when)源码得知,同步屏障message的arg1会携带token,
// 该token类似于同步屏障的序号,每个同步屏障的token是不同的,可以根据该token唯一标识一个同步屏障
val token = message.arg1
startCheckLeaking(token)
}
}
sleep(2000)
}
}
private fun startCheckLeaking(token: Int) {
var checkCount = 0
barrierCount = 0
while (checkCount < 5) {
checkCount++
//1. 判断该token对应的同步屏障是否还存在,不存在就退出循环
if (isSyncBarrierNotExist(token)) {
break
}
//2. 存在的话,发1条异步消息给主线程Handler,再发1条同步消息给主线程Handler,
// 看一下同步消息是否得到了处理,如果同步消息发了几次都没处理,而异步消息则发了几次都被处理了,说明SyncBarrier泄露了
if (detectSyncBarrierOnce()) {
//发生了SyncBarrier泄露
//3. 如果有泄露,那么就移除该泄露了的同步屏障(反射调用MessageQueue的removeSyncBarrier(int token))
removeSyncBarrier(token)
break
}
SystemClock.sleep(1000)
}
}
private fun detectSyncBarrierOnce(): Boolean {
val handler = object : Handler(Looper.getMainLooper()) {
override fun handleMessage(msg: Message) {
super.handleMessage(msg)
when (msg.arg1) {
-1 -> {
//异步消息
barrierCount++
}
0 -> {
//同步消息 说明主线程的同步消息是能做事的啊,就没有SyncBarrier一说了
barrierCount = 0
}
else -> {}
}
}
}
val asyncMessage = Message.obtain()
asyncMessage.isAsynchronous = true
asyncMessage.arg1 = -1
val syncMessage = Message.obtain()
syncMessage.arg1 = 0
handler.sendMessage(asyncMessage)
handler.sendMessage(syncMessage)
//超过3次,主线程的同步消息还没被处理,而异步消息缺得到了处理,说明确实是发生了SyncBarrier泄露
return barrierCount > 3
}4. 小结
文中详细介绍了卡顿与ANR的关系,以及卡顿原理和卡顿监控,详细捋下来可对卡顿有更深的理解。对于Looper Printer方案来说,是比较完善的,而且微信也在使用此方案,该踩的坑也踩完了。
链接:https://juejin.cn/post/7177194449322606647
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
日常思考,目前Kotlin协程能完全取代Rxjava吗
前言
自从jetbrains公司提出Kotlin协程用来解决异步线程问题,并且衍生出来了Flow作为响应式框架,引来了大量Android开发者的青睐;而目前比较稳定的响应式库当属Rxjava,这样以来目的就很明显了,旨在用Kotlin协程来逐步替代掉Rxjava;
仔细思考下,真的可以完全替代掉Rxjava么,它的复杂性和多样化的操作符,而协程的许多API仍然是实验性的,目前为止,随着kt不断地进行版本迭代,越来越趋于稳定,对此我不能妄下断言;当然Rxjava无疑也是一个非常优秀的框架,值得我们不断深入思考,但是随着协程的出现,就个人而言我会更喜欢使用协程来作为满足日常开发的异步解决方案。
协程的本质和
Rxjava是截然不同的,所以直接拿它们进行对比是比较棘手的;换一种思路,本文我们从日常开发中的异步问题出发,分别观察协程与Rxjava是如何提供相应的解决方案,依次来进行比对,探讨下Kotlin协程是否真的足以取代Rxjava这个话题吧
流类型的比较
现在我们来看下Rxjava提供的流类型有哪些,我们可以使用的基本流类型操作符如下图所示
它们的基本实现在下文会提及到,这里我们简单来讨论下在协程中是怎么定义这些流操作符的
Single<T>其实就是一个返回不可空值的suspend函数
Maybe<T>恰好相反,是一个返回可空的supspend函数
Completable不会发送事件,所以在协程中就是一个不返回任何东西的简单挂起函数
对于
Observable和Flowable,两者都可以发射多个事件,不同在于前者是没有背压管理的,后者才有,而他们在协程中我们可以直接使用Flow来完成,在异步数据流中按顺序发出值,所以只需要一个返回当前Data数据类型的Flow<T>
值得注意的是,该函数本身是不需要
supsend修饰符的,由于Flow是冷流,在进行收集\订阅之前是不会发射数据,只要在collect的时候才需要协程作用域中执行。为什么说Flow足以替代Observable和Flowable原因在与它处理背压(backpressure)的方式。这自然而然来源于协程中的设计与理念,不需要一些巧妙设计的解决方案来处理显示背压,Flow中所有Api基本上都带有suspend修复符,它也成为了解决背压的关键先生。其目的就是在不阻塞线程的情况下暂停调用者的执行,因此,当Flow<T>在同一个协程中发射和收集的时候,如果收集器跟不上数据流,它可以简单地暂停元素的发射,直到它准备好接收更多。
流类型比较的基本实现
好的小伙伴们,上文我们简单用协程写出Rxjava的几个基本流类型,现在让我们用几个详细的实例来看看他们的不同之处吧
Completable ---- 异步任务完成没有结果,可能会抛出错误
在Rxjava中,我们使用Completable.create去创建,里面的CompletableEmitter中有onComplete表示完成的方法和一个onError传递异常的方法,如下代码所示
//completable in Rxjava
fun completableRequest(): Completable {
return Completable.create { emitter->
try {
emitter.onComplete()
}catch (e:Exception) {
emitter.onError(e)
}
}
}
fun main() {
completableRequest()
.subscribe {
println("I,am done")
println()
}
}在协程当中,我们对应的就是调用一个不返回任何内容的挂起函数(returns Unit),就类似于我们调用一个普通函数一样
fun completableCoroutine() = runBlocking {
try {
delay(500L)
println("I am done")
} catch (e: Exception) {
println("Got an exception")
}
}
注意不要在生产环境代码使用
runBlocking,你应该有一个合适的CoroutineScope,由于是测试代码本文都将使用runBlocking来辅助说明测试场景
Single ---- 必须返回或抛出错误的异步任务
在 RxJava 中,我们使用一个Single ,它里面有一个onSuccess传递返回值的方法和一个onError传递异常的方法。
```kotlin
/**
* Single in RxJava
*/
fun main() {
singleResult()
.subscribe(
{ result -> println(result) },
{ println("Got an exception") }
)
}
fun singleResult(): Single<String> {
return Single.create { emitter ->
try {
// process a request
emitter.onSuccess("Some result")
} catch (e: Exception) {
emitter.onError(e)
}
}
```而在协程中,我们调用一个返回非空值的挂起函数:
/**
* Single equivalent in coroutines
*/
fun main() = runBlocking {
try {
val result = getResult()
println(result)
} catch (e: Exception) {
println("Got an exception")
}
}
suspend fun getResult(): String {
// process a request
delay(100)
return "Some result"
}Maybe --- 可能返回结果或抛出错误的异步任务
在 RxJava 中,我们使用一个Maybe. 它里面有一个onSuccess传递返回值的方法onComplete,一个在没有值的情况下发出完成信号的方法,以及一个onError传递异常的方法。
/**
* Maybe in RxJava
*/
fun main() {
maybeResult()
.subscribe(
{ result -> println(result) },
{ println("Got an exception") },
{ println("Completed without a value!") }
)
}
fun maybeResult(): Maybe<String> {
return Maybe.create { emitter ->
try {
// process a request
if (Random.nextBoolean()) {
emitter.onSuccess("Some value")
} else {
emitter.onComplete()
}
} catch (e: Exception) {
emitter.onError(e)
}
}
}在协程中,我们调用一个返回可空值得挂起函数
/**
* Maybe equivalent in coroutines
*/
fun main() = runBlocking {
try {
val result = getNullableResult()
if (result != null) {
println(result)
} else {
println("Completed without a value!")
}
} catch (e: Exception) {
println("Got an exception")
}
}
suspend fun getNullableResult(): String? {
// process a request
delay(100)
return if (Random.nextBoolean()) {
"Some value"
} else {
null
}
}0..N事件的异步流
由于在Rxjava中,Flowable和Observable都是属于0..N事件的异步流,但是Observable几乎没有做相应的背压管理,所以这里我们主要以Flowable为例子,onNext发出下一个流值的方法,一个onComplete表示流完成的方法,以及一个onError传递异常的方法。
/**
* Flowable in RxJava
*/
fun main() {
flowableValues()
.subscribe(
{ value -> println(value) },
{ println("Got an exception") },
{ println("I'm done") }
)
}
fun flowableValues(): Flowable<Int> {
val flowableEmitter = { emitter: FlowableEmitter<Int> ->
try {
for (i in 1..10) {
emitter.onNext(i)
}
} catch (e: Exception) {
emitter.onError(e)
} finally {
emitter.onComplete()
}
}
return Flowable.create(flowableEmitter, BackpressureStrategy.BUFFER)
}在协程中,我们只是创建一个Flow就可以完成这个方法
/**
* Flow in Kotlin
*/
fun main() = runBlocking {
try {
eventFlow().collect { value ->
println(value)
}
println("I'm done")
} catch (e: Exception) {
println("Got an exception")
}
}
fun eventFlow() = flow {
for (i in 1..10) {
emit(i)
}
}
在惯用的
Kotlin中,创建上述流程的方法之一是:fun eventFlow() = (1..10).asFlow()
如上面这些代码所见,我们基本可以使用协程涵盖Rxjava所有的主要基本用法,此外,协程的设计允许我们使用所有标准的Kotlin功能编写典型的顺序代码 ,它还消除了对onComplete或onError回调的需要。我们可以像在普通代码中那样捕获错误或设置协程异常处理程序。并且,考虑到当挂起函数完成时,协程继续按顺序执行,我们可以在下一行继续编写我们的“完成逻辑”。
值得注意的是,当我们进行调用collect收集的时候也是如此,在收集完所有元素后才会执行下一行代码
eventFlow().collect { value ->
println(value)
}
println("I'm done")
Flow收集完所有元素后,才会调用打印I'm done
操作符的比较
总所周知,Rxjava的主要优势在于它拥有非常多的操作符,基本上可以应对日常开发中出现的各种情况,由于它种类特别繁多又比较难记忆,这里我只简单举些常见的操作符进行比较
COMPLETABLE,SINGLE, MAYBE
这里需要强调的是,在Rxjava中Completable,Single和Maybe都有许多相同的操作符,然而在协程中任何类型的操作符其实都是多余的,我们以Single中的map()简单操作符为例来看下:
/**
* Maps Single<String> to
* Single<User> synchronously
*/
fun main() {
getUsername()
.map { username ->
User(username)
}
.subscribe(
{ user -> println(user) },
{ println("Got an exception") }
)
}map作为Rxjava中最常用的操作符,获取一个值并将其转换为另一个值,但是在协程中我们不需要.map()操作符就可以实现这种操作
fun main() = runBlocking {
try {
val username = getUsername() // suspend fun
val user = User(username)
println(user)
} catch (e: Exception) {
println("Got an exception")
}
}使用suspend挂起函数可以挂起当前函数,当执行完毕后在按顺序执行接下来的代码
Flow操作符与Rxjava操作符
现在让我们看看Flow中有哪些操作符,它们与Rxjava相比有什么不同,由于篇幅原因,这里我简单比较下日常开发中最常用的操作符
map()
对于map操作符,Flow中也具有相同的操作符
/**
* Maps Flow<String> to Flow<User>
*/
fun main() = runBlocking {
usernameFlow()
.map { username ->
User(username)
}
.collect { user ->
println(user)
}
}Flow中的map操作符 相当于Rxjava做了一定的简化处理,这是它的一个主要优势,可以看下它的源码
fun <T, R> Flow<T>.map(transform: suspend (T) -> R): Flow<R> = flow {
collect { value -> emit(transform(value)) }
}是不是非常简单,只是重新创建一个新的flow,它从从上游收集值transform并在当前函数应用后发出这些值;事实上大多数Flow的操作符都是这样工作的,不需要遵循严格的协议;对于大多数应用场景,标准Flow操作符就已经足够了,当然编写自定义操作符也是非常简单容易的;相对于Rxjava,如果想要编写自定义操作符,你必须非常了解Rxjava的
flatmap()
另外,在Rxjava中我们经常使用的操作符还有flatmap(),同时还有很多种变体,例如.flatMapSingle(),flatMapObservable(),flatMapIterable()等,简单来说,在Rxjava中我们如果需要对一个值进行同步转换,就使用map,进行异步转换的时候就需要使用flatMap();对此,Flow进行同步或者异步转换的时候不需要不同的操作符,仅仅使用map就足够了,由于它们都有supsend挂起函数进行修饰,不用担心同步性
可以看下在Rxjava中的示例
fun compareFlatMap() {
getUsernames() //Flowable<String>
.flatMapSingle { username ->
getUserFromNetwork(username) // Single<User>
}
.subscribe(
{ user -> println(user) },
{ println("Got an exception") }
)
}好的,我们使用Flow来转换下上述的这一段代码,只需要使用map就可以以任何方式进行转换值,如下代码所示:
runBlocking {
flow {
emit(User("Jacky"))
}.map {
getUserFromName(it) //suspend
}.collect {
println(it)
}
}
suspend fun getUserFromName(user: User): String {
return user.userName
}实际上使用Flow中的map操作符,就可以将上游流发出的值转换为新流,然后将所有流扁平化为一个,这和flatMap的功能几乎可以达到同样的效果
filter()
对于filter操作符,我们在Rxjava中并没有直接的方法进行异步过滤,这需要我们自己编写代码来进行过滤判断,如下所示
fun getUsernames(): Flowable<String> {
val flowableEmitter = { emitter: FlowableEmitter<String> ->
emitter.onNext("Jacky")
}
return Flowable.create(flowableEmitter, BackpressureStrategy.BUFFER)
}
fun isCorrectUserName(userName: String): Single<Boolean> {
return Single.create { emitter ->
runCatching {
//名字判断....
if (userName.isNotEmpty()) {
emitter.onSuccess(true)
} else {
emitter.onSuccess(false)
}
}.onFailure {
emitter.onError(it)
}
}
}
fun compareFilter() {
getUsernames()//Flowable<String>
.flatMapSingle { userName ->
isCorrectUserName(userName)
.flatMap { isCorrect ->
if (isCorrect) {
Single.just(userName)
} else {
Single.never()
}
}
}.subscribe {
println(it)
}
}乍一看,是不是感觉有点麻烦,事实上这确实需要我们使用些小手段才能达到目的;而在Flow中,我们能够轻松地根据同步和异步调用过滤流
runBlocking {
userNameFlow().filter { user ->
isCorrectName(user.userName)
}.collect { user->
println(user)
}
}
suspend fun isCorrectName(userName: String): Boolean {
return userName.isNotEmpty()
}
结语
由于篇幅原因,Rxjava和协程都是一个非常庞大的思考话题,它们之间的不同比较可以永远进行下去;事实上,在Kotlin协程被广泛使用之前,Rxjava作为项目中主要的异步解决方案,以至于到现在工作上还有很多项目用着Rxjava, 所以即使切换到Kotlin协程之后,还有相当长一段时间还在用着Rxjava;这并不代表Rxjava不够好,而是协程让代码变得更易读,更易于使用;
暂时先告一段落了,事实上证明协程确实能够满足我们日常开发的主要需求,下次将会对Rxjava中的背压和之前所讨论的Flow背压问题进行比较探讨,还有非常多的东西要学,共勉!!!!
链接:https://juejin.cn/post/7175803413232844855
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这10张图拿去,别再说学不会RecyclerView的缓存复用机制了!
ViewPager2是在RecyclerView的基础上构建而成的,意味着其可以复用RecyclerView对象的绝大部分特性,比如缓存复用机制等。
作为ViewPager2系列的第一篇,本篇的主要目的是快速普及必要的前置知识,而内容的核心,正是前面所提到的RecyclerView的缓存复用机制。
RecyclerView,顾名思义,它会回收其列表项视图以供重用。
具体而言,当一个列表项被移出屏幕后,RecyclerView并不会销毁其视图,而是会缓存起来,以提供给新进入屏幕的列表项重用,这种重用可以:
避免重复创建不必要的视图
避免重复执行昂贵的findViewById
从而达到的改善性能、提升应用响应能力、降低功耗的效果。而要了解其中的工作原理,我们还得回到RecyclerView是如何构建动态列表的这一步。
RecyclerView是如何构建动态列表的?
与RecyclerView构建动态列表相关联的几个重要类中,Adapter与ViewHolder负责配合使用,共同定义RecyclerView列表项数据的展示方式,其中:
ViewHolder是一个包含列表项视图(itemView)的封装容器,同时也是RecyclerView缓存复用的主要对象。
Adapter则提供了数据<->视图 的“绑定”关系,其包含以下几个关键方法:
- onCreateViewHolder:负责创建并初始化ViewHolder及其关联的视图,但不会填充视图内容。
- onBindViewHolder:负责提取适当的数据,填充ViewHolder的视图内容。
然而,这2个方法并非每一个进入屏幕的列表项都会回调,相反,由于视图创建及findViewById执行等动作都主要集中在这2个方法,每次都要回调的话反而效率不佳。因此,我们应该通过对ViewHolder对象积极地缓存复用,来尽量减少对这2个方法的回调频次。
最优情况是——取得的缓存对象正好是原先的ViewHolder对象,这种情况下既不需要重新创建该对象,也不需要重新绑定数据,即拿即用。
次优情况是——取得的缓存对象虽然不是原先的ViewHolder对象,但由于二者的列表项类型(itemType)相同,其关联的视图可以复用,因此只需要重新绑定数据即可。
最后实在没办法了,才需要执行这2个方法的回调,即创建新的ViewHolder对象并绑定数据。
实际上,这也是RecyclerView从缓存中查找最佳匹配ViewHolder对象时所遵循的优先级顺序。而真正负责执行这项查找工作的,则是RecyclerView类中一个被称为回收者的内部类——Recycler。
Recycler是如何查找ViewHolder对象的?
/**
* ...
* When {@link Recycler#getViewForPosition(int)} is called, Recycler checks attached scrap and
* first level cache to find a matching View. If it cannot find a suitable View, Recycler will
* call the {@link #getViewForPositionAndType(Recycler, int, int)} before checking
* {@link RecycledViewPool}.
*
* 当调用getViewForPosition(int)方法时,Recycler会检查attached scrap和一级缓存(指的是mCachedViews)以找到匹配的View。
* 如果找不到合适的View,Recycler会先调用ViewCacheExtension的getViewForPositionAndType(RecyclerView.Recycler, int, int)方法,再检查RecycledViewPool对象。
* ...
*/
public abstract static class ViewCacheExtension {
...
} public final class Recycler {
...
/**
* Attempts to get the ViewHolder for the given position, either from the Recycler scrap,
* cache, the RecycledViewPool, or creating it directly.
*
* 尝试通过从Recycler scrap缓存、RecycledViewPool查找或直接创建的形式来获取指定位置的ViewHolder。
* ...
*/
@Nullable
ViewHolder tryGetViewHolderForPositionByDeadline(int position,
boolean dryRun, long deadlineNs) {
if (mState.isPreLayout()) {
// 0 尝试从mChangedScrap中获取ViewHolder对象
holder = getChangedScrapViewForPosition(position);
...
}
if (holder == null) {
// 1.1 尝试根据position从mAttachedScrap或mCachedViews中获取ViewHolder对象
holder = getScrapOrHiddenOrCachedHolderForPosition(position, dryRun);
...
}
if (holder == null) {
...
final int type = mAdapter.getItemViewType(offsetPosition);
if (mAdapter.hasStableIds()) {
// 1.2 尝试根据id从mAttachedScrap或mCachedViews中获取ViewHolder对象
holder = getScrapOrCachedViewForId(mAdapter.getItemId(offsetPosition),
type, dryRun);
...
}
if (holder == null && mViewCacheExtension != null) {
// 2 尝试从mViewCacheExtension中获取ViewHolder对象
final View view = mViewCacheExtension
.getViewForPositionAndType(this, position, type);
if (view != null) {
holder = getChildViewHolder(view);
...
}
}
if (holder == null) { // fallback to pool
// 3 尝试从mRecycledViewPool中获取ViewHolder对象
holder = getRecycledViewPool().getRecycledView(type);
...
}
if (holder == null) {
// 4.1 回调createViewHolder方法创建ViewHolder对象及其关联的视图
holder = mAdapter.createViewHolder(RecyclerView.this, type);
...
}
}
if (mState.isPreLayout() && holder.isBound()) {
...
} else if (!holder.isBound() || holder.needsUpdate() || holder.isInvalid()) {
...
// 4.1 回调bindViewHolder方法提取数据填充ViewHolder的视图内容
bound = tryBindViewHolderByDeadline(holder, offsetPosition, position, deadlineNs);
}
...
return holder;
}
...
} 结合RecyclerView类中的源码及注释可知,Recycler会依次从mChangedScrap/mAttachedScrap、mCachedViews、mViewCacheExtension、mRecyclerPool中尝试获取指定位置或ID的ViewHolder对象以供重用,如果全都获取不到则直接重新创建。这其中涉及的几层缓存结构分别是:
mChangedScrap/mAttachedScrap
mChangedScrap/mAttachedScrap主要用于临时存放仍在当前屏幕可见、但被标记为「移除」或「重用」的列表项,其均以ArrayList的形式持有着每个列表项的ViewHolder对象,大小无明确限制,但一般来讲,其最大数就是屏幕内总的可见列表项数。
final ArrayList<ViewHolder> mAttachedScrap = new ArrayList<>();
ArrayList<ViewHolder> mChangedScrap = null;
复制代码但问题来了,既然是当前屏幕可见的列表项,为什么还需要缓存呢?又是什么时候列表项会被标记为「移除」或「重用」的呢?
这2个缓存结构实际上更多是为了避免出现像局部刷新这一类的操作,导致所有的列表项都需要重绘的情形。
区别在于,mChangedScrap主要的使用场景是:
- 开启了列表项动画(itemAnimator),并且列表项动画的
canReuseUpdatedViewHolder(ViewHolder viewHolder)方法返回false的前提下; - 调用了notifyItemChanged、notifyItemRangeChanged这一类方法,通知列表项数据发生变化;
boolean canReuseUpdatedViewHolder(ViewHolder viewHolder) {
return mItemAnimator == null || mItemAnimator.canReuseUpdatedViewHolder(viewHolder,
viewHolder.getUnmodifiedPayloads());
}
public boolean canReuseUpdatedViewHolder(@NonNull ViewHolder viewHolder,
@NonNull List<Object> payloads) {
return canReuseUpdatedViewHolder(viewHolder);
}
public boolean canReuseUpdatedViewHolder(@NonNull ViewHolder viewHolder) {
return true;
}canReuseUpdatedViewHolder方法的返回值表示的不同含义如下:
- true,表示可以重用原先的ViewHolder对象
- false,表示应该创建该ViewHolder的副本,以便itemAnimator利用两者来实现动画效果(例如交叉淡入淡出效果)。
简单讲就是,mChangedScrap主要是为列表项数据发生变化时的动画效果服务的。
而mAttachedScrap应对的则是剩下的绝大部分场景,比如:
- 像notifyItemMoved、notifyItemRemoved这种列表项发生移动,但列表项数据本身没有发生变化的场景。
- 关闭了列表项动画,或者列表项动画的canReuseUpdatedViewHolder方法返回true,即允许重用原先的ViewHolder对象的场景。
下面以一个简单的notifyItemRemoved(int position)操作为例来演示:
notifyItemRemoved(int position)方法用于通知观察者,先前位于position的列表项已被移除, 其往后的列表项position都将往前移动1位。
为了简化问题、方便演示,我们的范例将会居于以下限制:
- 列表项总个数没有铺满整个屏幕——意味着不会触发mCachedViews、mRecyclerPool等结构的缓存操作
- 去除列表项动画——意味着调用notifyItemRemoved后RecyclerView只会重新布局子视图一次
recyclerView.itemAnimator = null理想情况下,调用notifyItemRemoved(int position)方法后,应只有位于position的列表项会被移除,其他的列表项,无论是位于position之前或之后,都最多只会调整position值,而不应发生视图的重新创建或数据的重新绑定,即不应该回调onCreateViewHolder与onBindViewHolder这2个方法。
为此,我们就需要将当前屏幕内的可见列表项暂时从当前屏幕剥离,临时缓存到mAttachedScrap这个结构中去。
等到RecyclerView重新开始布局显示其子视图后,再遍历mAttachedScrap找到对应position的ViewHolder对象进行复用。
mCachedViews
mCachedViews主要用于存放已被移出屏幕、但有可能很快重新进入屏幕的列表项。其同样是以ArrayList的形式持有着每个列表项的ViewHolder对象,默认大小限制为2。
final ArrayList<ViewHolder> mCachedViews = new ArrayList<ViewHolder>();
int mViewCacheMax = DEFAULT_CACHE_SIZE;
static final int DEFAULT_CACHE_SIZE = 2;比如像朋友圈这种按更新时间的先后顺序展示的Feed流,我们经常会在快速滑动中确定是否有自己感兴趣的内容,当意识到刚才滑走的内容可能比较有趣时,我们往往就会将上一条内容重新滑回来查看。
这种场景下我们追求的自然是上一条内容展示的实时性与完整性,而不应让用户产生“才滑走那么一会儿又要重新加载”的抱怨,也即同样不应发生视图的重新创建或数据的重新绑定。
我们用几张流程示意图来演示这种情况:
同样为了简化问题、方便描述,我们的范例将会居于以下限制:
- 关闭预拉取——意味着之后向上滑动时,都不会再预拉取「待进入屏幕区域」的一个列表项放入mCachedView了
recyclerView.layoutManager?.isItemPrefetchEnabled = false- 只存在一种类型的列表项,即所有列表项的itemType相同,默认都为0。
我们将图中的列表项分成了3块区域,分别是被滑出屏幕之外的区域、屏幕内的可见区域、随着滑动手势待进入屏幕的区域。
- 当position=0的列表项随着向上滑动的手势被移出屏幕后,由于mCachedViews初始容量为0,因此可直接放入;
- 当position=1的列表项同样被移出屏幕后,由于未达到mCachedViews的默认容量大小限制,因此也可继续放入;
此时改为向下滑动,position=1的列表项重新进入屏幕,Recycler就会依次从mAttachedScrap、mCachedViews查找可重用于此位置的ViewHolder对象;
mAttachedScrap不是应对这种情况的,自然找不到。而mCachedViews会遍历自身持有的ViewHolder对象,对比ViewHolder对象的position值与待复用位置的position值是否一致,是的话就会将ViewHolder对象从mCachedViews中移除并返回;
此处拿到的ViewHolder对象即可直接复用,即符合前面所述的最优情况。
- 另外,随着position=1的列表项重新进入屏幕,position=7的列表项也会被移出屏幕,该位置的列表项同样会进入mCachedViews,即RecyclerView是双向缓存的。
mViewCacheExtension
mViewCacheExtension主要用于提供额外的、可由开发人员自由控制的缓存层级,属于非常规使用的情况,因此这里暂不展开讲。
mRecyclerPool
mRecyclerPool主要用于按不同的itemType分别存放超出mCachedViews限制的、被移出屏幕的列表项,其会先以SparseArray区分不同的itemType,然后每种itemType对应的值又以ArrayList的形式持有着每个列表项的ViewHolder对象,每种itemType的ArrayList大小限制默认为5。
public static class RecycledViewPool {
private static final int DEFAULT_MAX_SCRAP = 5;
static class ScrapData {
final ArrayList<ViewHolder> mScrapHeap = new ArrayList<>();
int mMaxScrap = DEFAULT_MAX_SCRAP;
long mCreateRunningAverageNs = 0;
long mBindRunningAverageNs = 0;
}
SparseArray<ScrapData> mScrap = new SparseArray<>();
...
}由于mCachedViews默认的大小限制仅为2,因此,当滑出屏幕的列表项超过2个后,就会按照先进先出的顺序,依次将ViewHolder对象从mCachedViews移出,并按itemType放入RecycledViewPool中的不同ArrayList。
这种缓存结构主要考虑的是随着被滑出屏幕列表项的增多,以及被滑出距离的越来越远,重新进入屏幕内的可能性也随之降低。于是Recycler就在时间与空间上做了一个权衡,允许相同itemType的ViewHolder被提取复用,只需要重新绑定数据即可。
这样一来,既可以避免无限增长的ViewHolder对象缓存挤占了原本就紧张的内存空间,又可以减少回调相比较之下执行代价更加昂贵的onCreateViewHolder方法。
同样我们用几张流程示意图来演示这种情况,这些示意图将在前面的mCachedViews示意图基础上继续操作:
假设目前存在于mCachedViews中的仍是position=0及position=1这两个列表项。
当我们继续向上滑动时,position=2的列表项会尝试进入mCachedViews,由于超出了mCachedViews的容量限制,position=0的列表项会从mCachedViews中被移出,并放入RecycledViewPool中itemType为0的ArrayList,即图中的情况①;
同时,底部的一个新的列表项也将随着滑动手势进入到屏幕内,但由于此时mAttachedScrap、mCachedViews、mRecyclerPool均没有合适的ViewHolder对象可以提供给其复用,因此该列表项只能执行onCreateViewHolder与onBindViewHolder这2个方法的回调,即图中的情况②;
- 等到position=2的列表项被完全移出了屏幕后,也就顺利进入了mCachedViews中。
我们继续保持向上滑动的手势,此时,由于下一个待进入屏幕的列表项与position=0的列表项的itemType相同,因此我们可以在走到从mRecyclerPool查找合适的ViewHolder对象这一步时,根据itemType找到对应的ArrayList,再取出其中的1个ViewHolder对象进行复用,即图中的情况①。
由于itemType类型一致,其关联的视图可以复用,因此只需要重新绑定数据即可,即符合前面所述的次优情况。
- ②③ 情况与前面的一致,此处不再赘余。
最后总结一下,
| RecyclerView缓存复用机制 | |
|---|---|
| 对象 | ViewHolder(包含列表项视图(itemView)的封装容器) |
| 目的 | 减少对onCreateViewHolder、onBindViewHolder这2个方法的回调 |
| 好处 | 1.避免重复创建不必要的视图 2.避免重复执行昂贵的findViewById |
| 效果 | 改善性能、提升应用响应能力、降低功耗 |
| 核心类 | Recycler、RecyclerViewPool |
| 缓存结构 | mChangedScrap/mAttachedScrap、mCachedViews、mViewCacheExtension、mRecyclerPool |
| 缓存结构 | 容器类型 | 容量限制 | 缓存用途 | 优先级顺序(数值越小,优先级越高) |
|---|---|---|---|---|
| mChangedScrap/mAttachedScrap | ArrayList | 无,一般为屏幕内总的可见列表项数 | 临时存放仍在当前屏幕可见、但被标记为「移除」或「重用」的列表项 | 0 |
| mCachedViews | ArrayList | 默认为2 | 存放已被移出屏幕、但有可能很快重新进入屏幕的列表项 | 1 |
| mViewCacheExtension | 开发者自己定义 | 无 | 提供额外的可由开发人员自由控制的缓存层级 | 2 |
| mRecyclerPool | SparseArray<ArrayList> | 每种itemType默认为5 | 按不同的itemType分别存放超出mCachedViews限制的、被移出屏幕的列表项 | 3 |
以上的就是RecyclerView缓存复用机制的核心内容了。
链接:https://juejin.cn/post/7173816645511544840
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Gradle 依赖切换源码的实践
最近,因为开发的时候经改动依赖的库,所以,我想对 Gradle 脚本做一个调整,用来动态地将依赖替换为源码。这里以 android-mvvm-and-architecture 这个工程为例。该工程以依赖的形式引用了我的另一个工程 AndroidUtils。在之前,当我需要对 AndroidUtils 这个工程源码进行调整时,一般来说有两种解决办法。
1、一般的修改办法
一种方式是,直接修改 AndroidUtils 这个项目的源码,然后将其发布到 MavenCentral. 等它在 MavenCentral 中生效之后,再将项目中的依赖替换为最新的依赖。这种方式可行,但是修改的周期太长。
另外一种方式是,修改 Gradle 脚本,手动地将依赖替换为源码依赖。此时,需要做几处修改,
修改 1,在 settings.gradle 里面将源码作为子工程添加到项目中,
include ':utils-core', ':utils-ktx'
project(':utils-core').projectDir = new File('../AndroidUtils/utils')
project(':utils-ktx').projectDir = new File('../AndroidUtils/utils-ktx')
修改 2,将依赖替换为工程引用,
// implementation "com.github.Shouheng88:utils-core:$androidUtilsVersion"
// implementation "com.github.Shouheng88:utils-ktx:$androidUtilsVersion"
// 上面的依赖替换为下面的工程引用
implementation project(":utils-core")
implementation project(":utils-ktx")这种方式亦可行,只不过过于繁琐,需要手动修改 Gradle 的构建脚本。
2、通过 Gradle 脚本动态修改依赖
其实 Gradle 是支持动态修改项目中的依赖的。动态修改依赖在上述场景,特别是组件化的场景中非常有效。这里我参考了公司组件化的切换源码的实现方式,用了 90 行左右的代码就实现了上述需求。
2.1 配置文件和工作流程抽象
这种实现方式里比较重要的一环是对切换源码工作机制的抽象。这里我重新定义了一个 json 配置文件,
[
{
"name": "AndroidUtils",
"url": "git@github.com:Shouheng88/AndroidUtils.git",
"branch": "feature-2.8.0",
"group": "com.github.Shouheng88",
"open": true,
"children": [
{
"name": "utils-core",
"path": "AndroidUtils/utils"
},
{
"name": "utils-ktx",
"path": "AndroidUtils/utils-ktx"
}
]
}
]它内部的参数的含义分别是,
name:工程的名称,对应于 Github 的项目名,用于寻找克隆到本地的代码源码url:远程仓库的地址branch:要启用的远程仓库的分支,这里我强制自动切换分支时的本地分支和远程分支同名group:依赖的 group idopen:表示是否启用源码依赖children.name:表示子工程的 module 名称,对应于依赖中的artifact idchildren.path:表示子工程对应的相对目录
也就是说,
- 一个工程下的多个子工程的
group id必须相同 children.name必须和依赖的artifact id相同
上述配置文件的工作流程是,
def sourceSwitches = new HashMap<String, SourceSwitch>()
// Load sources configurations.
parseSourcesConfiguration(sourceSwitches)
// Checkout remote sources.
checkoutRemoteSources(sourceSwitches)
// Replace dependencies with sources.
replaceDependenciesWithSources(sourceSwitches)
- 首先,Gradle 在 setting 阶段解析上述配置文件
- 然后,根据解析的结果,将打开源码的工程通过 project 的形式引用到项目中
- 最后,根据上述配置文件,将项目中的依赖替换为工程引用
2.2 为项目动态添加子工程
如上所述,这里我们忽略掉 json 配置文件解析的环节,直接看拉取最新分支并将其作为子项目添加到项目中的逻辑。该部分代码实现如下,
/** Checkout remote sources if necessary. */
def checkoutRemoteSources(sourceSwitches) {
def settings = getSettings()
def rootAbsolutePath = settings.rootDir.absolutePath
def sourcesRootPath = new File(rootAbsolutePath).parent
def sourcesDirectory = new File(sourcesRootPath, "open_sources")
if (!sourcesDirectory.exists()) sourcesDirectory.mkdirs()
sourceSwitches.forEach { name, sourceSwitch ->
if (sourceSwitch.open) {
def sourceDirectory = new File(sourcesDirectory, name)
if (!sourceDirectory.exists()) {
logd("clone start [$name] branch [${sourceSwitch.branch}]")
"git clone -b ${sourceSwitch.branch} ${sourceSwitch.url} ".execute(null, sourcesDirectory).waitFor()
logd("clone completed [$name] branch [${sourceSwitch.branch}]")
} else {
def sb = new StringBuffer()
"git rev-parse --abbrev-ref HEAD ".execute(null, sourceDirectory).waitForProcessOutput(sb, System.err)
def currentBranch = sb.toString().trim()
if (currentBranch != sourceSwitch.branch) {
logd("checkout start current branch [${currentBranch}], checkout branch [${sourceSwitch.branch}]")
def out = new StringBuffer()
"git pull".execute(null, sourceDirectory).waitFor()
"git checkout -b ${sourceSwitch.branch} origin/${sourceSwitch.branch}"
.execute(null, sourceDirectory).waitForProcessOutput(out, System.err)
logd("checkout completed: ${out.toString().trim()}")
}
}
// After checkout sources, include them as subprojects.
sourceSwitch.children.each { child ->
settings.include(":${child.name}")
settings.project(":${child.name}").projectDir = new File(sourcesDirectory, child.path)
}
}
}
}这里,我将子项目的源码克隆到 settings.gradle 文件的父目录下的 open_sources 目录下面。这里当该目录不存在的时候,我会先创建该目录。这里需要注意的是,我在组织项目目录的时候比较喜欢将项目的子工程放到和主工程一样的位置。所以,上述克隆方式可以保证克隆到的 open_sources 仍然在当前项目的工作目录下。
然后,我对 sourceSwitches,也就是解析的 json 文件数据,进行遍历。这里会先判断指定的源码是否已经拉下来,如果存在的话就执行 checkout 操作,否则执行 clone 操作。这里在判断当前分支是否为目标分支的时候使用了 git rev-parse --abbrev-ref HEAD 这个 Git 指令。该指令用来获取当前仓库所处的分支。
最后,将源码拉下来之后通过 Settings 的 include() 方法加载指定的子工程,并使用 Settings 的 project() 方法指定该子工程的目录。这和我们在 settings.gradle 文件中添加子工程的方式是相同的,
include ':utils-core', ':utils-ktx'
project(':utils-core').projectDir = new File('../AndroidUtils/utils')
project(':utils-ktx').projectDir = new File('../AndroidUtils/utils-ktx')
2.3 使用子工程替换依赖
动态替换工程依赖使用的是 Gradle 的 ResolutionStrategy 这个功能。也许你对诸如
configurations.all {
resolutionStrategy.force 'io.reactivex.rxjava2:rxjava:2.1.6'
}这种写法并不陌生。这里的 force 和 dependencySubstitution 一样,都属于 ResolutionStrategy 提供的功能的一部分。只不过这里的区别是,我们需要对所有的子项目进行动态更改,因此需要等项目 loaded 完成之后才能执行。
下面是依赖替换的实现逻辑,
/** Replace dependencies with sources. */
def replaceDependenciesWithSources(sourceSwitches) {
def gradle = settings.gradle
gradle.projectsLoaded {
gradle.rootProject.subprojects {
configurations.all {
resolutionStrategy.dependencySubstitution {
sourceSwitches.forEach { name, sourceSwitch ->
sourceSwitch.children.each { child ->
substitute module("${sourceSwitch.artifact}:${child.name}") with project(":${child.name}")
}
}
}
}
}
}
}这里使用 Gradle 的 projectsLoaded 这个点进行 hook,将依赖替换为子工程。
此外,也可以将子工程替换为依赖,比如,
dependencySubstitution {
substitute module('org.gradle:api') using project(':api')
substitute project(':util') using module('org.gradle:util:3.0')
}2.4 注意事项
上述实现方式要求多个子工程的脚本尽可能一致。比如,在 AndroidUtils 的独立工程中,我通过 kotlin_version 这个变量指定 kotlin 的版本,但是在 android-mvvm-and-architecture 这个工程中使用的是 kotlinVersion. 所以,当切换了子工程的源码之后就会发现 kotlin_version 这个变量找不到了。因此,为了实现可以动态切换源码,是需要对 Gradle 脚本做一些调整的。
在我的实现方式中,我并没有将子工程的源码放到主工程的根目录下面,也就是将 open_sources 这个目录放到 appshell 这个目录下面。而是放到和 appshell 同一级别。
这样做的原因是,实际开发过程中,通常我们会克隆很多仓库到 open_sources 这个目录下面(或者之前开发遗留下来的克隆仓库)。有些仓库虽然我们关闭了源码依赖,但是因为在 appshell 目录下面,依然会出现在 Android Studio 的工程目录里。而按照上述方式组织目录,我切换了哪个项目等源码,哪个项目的目录会被 Android Studio 加载。其他的因为不在 appshell 目录下面,所以会被 Android Studio 忽略。这种组织方式可以尽可能减少 Android Studio 加载的文本,提升 Android Studio 响应的速率。
总结
上述是开发过程中替换依赖为源码的“无痕”修改方式。不论在组件化还是非组件化需要开发中都是一种非常实用的开发技巧。按照上述开发开发方式,我们可以既能开发 android-mvvm-and-architecture 的时候随时随地打开 AndroidUtils 进行修改,亦可对 AndroidUtil 这个工程独立编译和开发。
源代码参考 android-mvvm-and-architecture 项目(当前是 feature-3.0 分支)的 AppShell 下面的 sources.gradle 文件。
链接:https://juejin.cn/post/7174753036143689787
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
BasicLibrary架构设计旅程(一)—Android必备技能
前言
- 2022年对大部分人来说真的是不容易的一年,有不少粉丝私信问我,今年行情不好,但是现在公司又不好怎么办,我的建议就是学习。无论过去,现在,未来,投资自己一定是不会错的,只有当你足够强大,哪怕生活一地鸡毛,你也能垫起脚尖独揽星空。
- 对于Android来说,我觉得有两个能力和一个态度一定要掌握
- 阅读源码的能力
- 阅读字节码的能力
- 怀疑的态度
阅读源码的能力
- 个人技巧:我个人阅读源码喜欢自己给自己提问题,随后带着问题去读源码的流程,当遇到不确定的可以看看别的大神写的博客和视频。
为什么需要具有阅读源码的能力呢?
当我们通过百度搜索视频,博客,stackOverflow找不到我们问题解决办法的时候,可以通过阅读源码来寻找问题,并解决问题,如以下两个案例
一、AppBarLayout阴影问题
- 源码地址:github.com/Peakmain/Ba…
- 我们每次在项目添加头部的时候,一般做法都是说定义一个公用的布局,但是这其实并不友好,而且每次都需要findVIewById,为了解决上述问题,我用了Builder设计模式设计了NavigationBar,可以动态添加头部
- 其中有个默认的头部设计DefaultNavigationBar,使用的是AppBarLayout+ToolBar,AppBarLayout有个问题就是会存在阴影,我想要在不改变布局的情况下,动态设置取消阴影,在百度中得到的前篇一律的答案是,设置主题,布局中设置阴影
- 既然说布局中设置elevation有效,那么是否可以通过findViewById找到AppBarLayout然后设置elevation=0
findViewById<AppBarLayout>(R.id.navigation_header_container).elevation=0f
运行之后,发现阴影还仍然存在
- 既然布局中设置elevation有效,那它的源码怎么写的呢?
我们可以在AppBarLayout的构造函数中找到这行代码
我们可以发现最终调用的是一个非公平类的静态方法,直接将方法拷贝到我们自己的项目,之后调用该方法
static void setDefaultAppBarLayoutStateListAnimator(
@NonNull final View view, final float elevation) {
final int dur = view.getResources().getInteger(R.integer.app_bar_elevation_anim_duration);
final StateListAnimator sla = new StateListAnimator();
// Enabled and liftable, but not lifted means not elevated
sla.addState(
new int[] {android.R.attr.state_enabled, R.attr.state_liftable, -R.attr.state_lifted},
ObjectAnimator.ofFloat(view, "elevation", 0f).setDuration(dur));
// Default enabled state
sla.addState(
new int[] {android.R.attr.state_enabled},
ObjectAnimator.ofFloat(view, "elevation", elevation).setDuration(dur));
// Disabled state
sla.addState(new int[0], ObjectAnimator.ofFloat(view, "elevation", 0).setDuration(0));
view.setStateListAnimator(sla);
}
二、Glide加载图片读取设备型号问题
- 再比如App加载网络图片时候,App移动应用检测的时候说我们应用自身获取个人信息行为,描述说的是我们有图片上传行为,看了堆栈,主要问题是加载图片的时候,user-Agent有读取设备型号行为
- 关于这篇文章的源码分析,大家可以看我之前的文章:隐私政策整改之Glide框架封装
- glide加载图片默认用的是HttpUrlConnection
- 加载网络图片的时候,默认是在GlideUrl中设置了Headers.DEFAULT,它的内部会在static中添加默认的User-Agent。
小总结
- 优秀的阅读源码能力可以帮我们快速定位并解决问题。
- 优秀的阅读源码能力也可以让我们快速上手任何一个热门框架并了解其原理
阅读字节码的能力的重要性
当我们熟练掌握字节码能力,我们能够深入了解JVM,通过ASM实现一套埋点+拦截第三方频繁调用隐私方法的问题
字节码基础知识
- 由于跨平台性的设计,java的指令都是根据栈来设计的,而这个栈指的就是虚拟机栈
- JVM运行时数据区分为本地方法栈、程序计数器、堆、方法区和虚拟机栈
局部变量表
- 每个线程都会创建一个虚拟机栈,其内部保存一个个栈帧,对应一次次方法的调用
- 栈帧的内部结构是分为:局部变量表、操作数栈、动态链接(指向运行时常量池的方法引用)和返回地址
- 局部变量表内部定义了一个数字数组,主要存储方法参数和定义在方法体内的局部变量
- 局部变量表存储的基本单位是slot(槽),long和double存储的是2个槽,其他都是1个槽
- 非静态方法,默认0槽位存的是this(指的是该方法的类对象)
操作数栈
- 在方法执行过程中,根据字节码指令,往栈中写入数据或提取数据,即入栈和出栈
- 主要用于保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间
- 方法调用的开始,默认的操作数栈是空的,但是操作数栈的数组已经创建,并且大小已知
- 操作数栈并非采用访问索引的方式来进行数据访问的,而是只能通过标准的入栈和出栈操作来完成一次数据访问
一些常用的助记符
- 从局部变量表到操作数栈:iload,iload_,lload,lload_,fload,fload_,dload,dload_,aload,aload
- 操作数栈放到局部变量表:istore,istore_,lstore,lstore_,fstore,fstore_,dstore,dstor_,astore,astore_
- 把常数放到到操作数栈:bipush,sipush,ldc,ldc_w,ldc2_w,aconst_null,iconst_ml,iconst_,lconst_,fconst_,dconst_
- 取出栈顶两个数进行相加,并将结果压入操作数栈:iadd,ladd,fadd,dadd
- iinc:对局部变量表的值进行加1操作
i++和++i区别
public class Test {
public static void main(String[] args) {
int i=10;
int a=i++;
int j=10;
int b=++j;
System.out.println(i);
System.out.println(a);
System.out.println(j);
System.out.println(b);
}
}- 大家可以思考下,这个结果会是什么呢?
- 结果分别是11 10 11 11
字节码结果分析
- 查看字节码命令:javap -v Test.class
- 大家也可以使用idea自带的jclasslib工具,或者ASM Bytecode Viewer工具
0 bipush 10
2 istore_1
3 iload_1
4 iinc 1 by 1
7 istore_2
8 bipush 10
10 istore_3
11 iinc 3 by 1
14 iload_3
15 istore 4
17 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
20 iload_1
21 invokevirtual #3 <java/io/PrintStream.println : (I)V>
24 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
27 iload_2
28 invokevirtual #3 <java/io/PrintStream.println : (I)V>
31 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
34 iload_3
35 invokevirtual #3 <java/io/PrintStream.println : (I)V>
38 getstatic #2 <java/lang/System.out : Ljava/io/PrintStream;>
41 iload 4
43 invokevirtual #3 <java/io/PrintStream.println : (I)V>
46 return- 由于我们是非静态方法,所以局部变量表0的位置存储的是this
- bipush 10:将常量10压入操作数栈
- istore1:将操作数栈的栈顶元素放入到局部变量表1的位置
- iload1:将局部变量表1的位置放入到操作数栈
- iinc 1 by 1:局部变量表1的位置的值+1
- istore2:将操作栈的栈顶元素压入局部变量表2的位置
- 至此最上面两行代码执行完毕,下面的代码我就不再画图阐述了,我相信机智聪敏的你一定已经学会分析了
- 最后来一个小小的总结吧
- i++是先iload1,后局部变量表自增,再istore2,所以a的值还是10
- ++i是先局部变量表自增,随后iload,再istore,所以b的值已经变成了11
ASM 解决隐私方法问题
- 项目地址:github.com/Peakmain/As…
- 大家可以去看下我的源码和文章,具体细节我就不阐述了,里面涉及到了大量的opcodec的操作符,比如Opcode.ILOAD
怀疑的态度
- 无论是视频还是博客,大家对不确认的知识保持一颗怀疑的态度,因为一篇文章或者视频都有可能是不对的,包括我现在写的这篇文章。
kotlin object实现的单例类是懒汉式还是饿汉式
- 以上两个都是网上的文章截取的文章,那kotlin实现的object单例到底是饿汉式还是懒汉式的呢?
- 假设我们有以下代码
object Test {
const val TAG="test"
}通过工具看下反编译后的代码
static代码块什么时候初始化呢?
- 首先我们需要知道JVM的类加载过程:loading->link->初始化
- link又分为:验证、准备、解析
- 而static代码块()是在初始化的过程中调用的
- 虚拟机会必须保证一个类的方法在多线程下被同步加锁
- Java使用方式分为两种:主动和被动
- 主动使用才会导致static代码块的调用
单例的懒汉式和饿汉式的区别是什么呢
- 懒汉式:类加载不会导致该实例被创建,而是首次使用该对象才会被创建
- 饿汉式:类加载就会导致该实例对象被创建
public class Test {
private static Test mInstance;
static {
System.out.println("static:"+mInstance);
}
private Test() {
System.out.println("init:"+mInstance);
}
public static Test getInstance() {
if (mInstance == null) {
mInstance = new Test();
}
return mInstance;
}
public static void main(String[] args) {
Test.getInstance();
}
}- 当调用getInstance的时候,类加载过程中会进行初始化,也就是调用static代码块
- static代码块执行时,由于类没有实例化,所以获取到是null。
- 也就是说,类加载的时候并没有对该实例进行创建(懒汉式)
public class Test1 {
private static final Test1 mInstance=new Test1();
private Test1(){
System.out.println("init:"+mInstance);
}
static {
System.out.println("static:"+mInstance);
}
public static Test1 getInstance(){
return mInstance;
}
public static void main(String[] args) {
Test1.getInstance();
}
}- 类的初始化顺序是由代码的顺序来决定的,上面的代码首先对mInstance进行初始化,但是由于此时构造函数执行完成后才完成类的初始化,所以构造函数返回的是null
- static代码块执行的时候,类实例已经创建完毕
- 正如上面说的static代码块执行的时候还处于类加载中的初始化状态,所以实例是在初始化之前完成(饿汉式)
我们现在回到kotlin的object,我们将其转成Java类
public class Test2 {
public static final String TAG = "test";
private Test2() {
System.out.println("init:" + mInstance);
}
public static Test2 mInstance;
static {
Test2 test2 = new Test2();
mInstance = test2;
System.out.println("static:" + mInstance);
}
public static void main(String[] args) {
System.out.println(Test2.TAG);
}
}- 上面代码在static代码块的时候(类加载的初始化时)进行了类的实例初始化(饿汉式)
总结
- Android必备的技能,其实很多,比如JVM、高并发、binder、泛型、AMS,WMS等等
- 我个人觉得源阅读码能力和掌握字节码属于必备技能,能提高自己知识领域
- 当然如我上面所说,要保持怀疑的态度,本文说的可能也不对。
- 下一篇文章,我将介绍BasicLibrary中基于责任链设计模式搭建的Activity Results API权限封装框架,欢迎大家讨论。
链接:https://juejin.cn/post/7173266221444366372
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为 Kotlin 的函数添加作用域限制(以 Compose 为例)
前言
不知道各位是否已经开始了解 Jetpack Compose?
如果已经开始了解并且上手写过。那么,不知道你们有没有发现,在 Compose 中对于作用域(Scopes)的应用特别多。比如, weight 修饰符只能用在 RowScope 或者 ColumnScope 作用域中。又比如,item 组件只能用在 LazyListScope 作用域中。
如果你还没有了解过 Compose 的话,那你也应该知道,kotlin 标准库中有 5 个作用域函数:let() apply() also() with() run() ,这 5 个函数会以不同的方式持有和返回上下文对象,即调用这些函数时,在它们的 lambda 参数中写的代码将处于特定的作用域。
不知道你们有没有思考过,这些作用域限制是怎么实现的呢?如果我们想自定义一个 Composable 函数,只支持在特定的作用域中使用,应该怎么写呢?
本文将为你解开这个疑惑。
作用域
不过在正式开始之前我们还是先大概补充一点有关 kotlin 中作用域的基本知识。
什么是作用域
其实对于咱们程序员来说,不管学的是什么语言,对于作用域应该都是有一个了解的。
举个简单的例子:
val valueFile = "file"
fun a() {
val valueA = "a"
println(valueFile)
println(valueA)
println(valueB)
}
fun b() {
val valueB = "b"
println(valueFile)
println(valueA)
println(valueB)
}这段代码不用运行都知道肯定会报错,因为在函数 a 中无法访问 valueB ;在函数 b 中无法访问 valueA 。但是这两个函数都可以成功访问 valueFile 。
这是因为 valueFile 的作用域是整个 .kt 文件,也就是说,只要是在这个文件中的代码,都可以访问到它。
而 valueA 和 valueB 的作用域则分别是在函数 a 和 b 中,显然只能在各自的作用域中使用。
同理,如果我们想要调用类的方法或者函数也需要考虑作用域:
class Test {
val valueTest = "test"
fun a(): String {
val valueA = "a"
println(valueTest)
println(valueA)
return "returnA"
}
fun b() {
println(valueA)
println(valueTest)
println(a())
}
}
fun main() {
println(valueTest)
println(valueA)
println(a())
}这里举的例子可能不太恰当,但是这里是为了说明这个情况,不要过多纠结哦~
显然,上面这个代码,在 main 函数中是无法访问到变量 valueTest 和 valueA 的,并且也无法调用函数 a() ;而在 Test 类中的函数 a() 显然可以访问到 valueTest 和 valueA ,并且函数 b() 也可以调用函数 a(),可以访问变量 valueTest 但是无法访问变量 valueA 。
这是因为函数 a() 和 b() 以及变量 valueTest 位于同一个作用域中,即类 Test 的作用域。
而变量 valueA 位于函数 a() 的作用域内,由于 a() 又位于 Test 的作用域内,所以实际上这里的 valueA 的作用域称为嵌套作用域,即同时位于 a() 和 Test 的作用域内。
因为本节只是为了引出我们今天要介绍的内容,所以有关作用域的知识就简单介绍这么多,更多有关作用域的知识可以阅读参考资料 1 。
kotlin 标准库中的作用域函数
在前言中我们说过,kotlin标准库中有5个称之为作用域函数的东西:with、run、let、also、apply 。
它们有什么作用呢?
先看一段我们经常会遇到的代码形式:
val person = Person()
person.fullName = "equationl"
person.lastName = "l"
person.firstName = "equation"
person.age = 24
person.gender = "man"在某些情况下,我们可能会需要多次重复的写一堆 person,可读性很差,写起来也很繁琐。
此时我们就可以使用作用域函数,例如使用 with 改写:
with(person) {
fullName = "equationl"
lastName = "l"
firstName = "equation"
age = 24
gender = "man"
}此时,我们就可以省略掉 person ,直接访问或修改它的属性值,这是因为 with 的第一个参数接收的是需要作为第二个参数的 lambda 上下文对象,即此时,第二个参数 lambda 匿名函数所在的作用域为第一个参数传入的对象,此时 IDE 的提示也指出了此时 with 的匿名函数中的作用域为 Person :
所以在这个匿名函数中能直接访问或修改 Person 的属性。
同理,我们也可以使用 run 函数改写:
person.run {
fullName = "equationl"
lastName = "l"
firstName = "equation"
age = 24
gender = "man"
}可以看出,run 与 with 非常相似,只是 run 是以扩展函数的形式接收上下文对象,它的参数只有一个 lambda 匿名函数。
后面还有 let :
person.let {
it.fullName = "equationl"
it.lastName = "l"
it.firstName = "equation"
it.age = 24
it.gender = "man"
}它与 run 的区别在于,匿名函数中的上下文对象不再是隐式接收器(this),而是作为一个参数(it)存在。
使用 also() 则是:
person.also {
it.fullName = "equationl"
it.lastName = "l"
it.firstName = "equation"
it.age = 24
it.gender = "man"
}和 let 一样,它也是扩展函数,并且上下文也作为参数传入匿名函数,但是不同于 let ,它会返回上下文对象,这样可以方便的进行链式调用,如:
val personString = person
.also {
it.age = 25
}
.toString()最后是 apply :
person.apply {
fullName = "equationl"
lastName = "l"
firstName = "equation"
age = 24
gender = "man"
}与 also 一样,它是扩展函数,也会返回上下文对象,但是它的上下文将作为隐式接收者,而不是匿名函数的一个参数。
下面是它们 5 个函数的对比图和表格:
| 函数 | 上下文形式 | 返回值 | 是否是扩展函数 |
|---|---|---|---|
| with | 隐式接收者(this) | lambda函数(Unit) | 否 |
| run | 隐式接收者(this) | lambda函数(Unit) | 是 |
| let | 匿名函数的参数(it) | lambda函数(Unit) | 是 |
| also | 匿名函数的参数(it) | 上下文对象 | 是 |
| apply | 隐式接收者(this) | 上下文对象 | 是 |
Compose 中的作用域限制
在前言中我们说过,在 Compose 对作用域限制的应用非常多。
例如 Modifier 修饰符,从这个 Compose 修饰符列表 中,我们也能看到很多修饰符的作用域都做了限制:
这里需要对修饰符做限制的原因非常简单:
In the Android View system, there is no type safety. Developers usually find themselves trying out different layout params to discover which ones are considered and their meaning in the context of a particular parent.
在传统的 xml view 体系中就是没有对布局的参数做限制,这就导致所有的参数都可以用在任意布局中,这会导致一些问题。轻则参数无效,写了一堆无用参数;严重的可能会干扰到布局的正常使用。
当然,Modifier 修饰符限制只是 Compose 中其中一个应用,在 Compose 中还有很多作用域限制的例子,例如:
在上图中 item 只能在 LazyListScope 作用域使用,drawRect 只能在 DrawScope 作用域使用。
当然,正如我们前面说的,作用域中不只有函数和方法,还可以访问类的属性,例如,在 DrawScope 作用域提供了一个名为 size 的属性,可以通过它来拿到当前的画布大小:
那么,这些是怎么实现的呢?
自定义我们的作用域限制函数
原理
在开始实现我们自己的作用域函数之前,我们需要先了解一下原理。
这里我们以 Compose 的 Canvas 为例来看看。
首先是 Canvas 的定义:
可以看到这里 Canvas 接收了两个参数:modifier 和 onDraw 的 lambda ,且这个 lambda 的 Receiver(接收者) 为 DrawScope ,也就是说,onDraw 这个匿名函数的作用域被限制在了 DrawScope 内,这也意味着可以在匿名函数内部使用 DrawScope 作用域内的属性、方法等。
再来看看这个 DrawScope 是何方神圣:
可以看到这是一个接口,里面定义了一些属性变量(如我们上面说的 size) 和一些方法(如我们上面说的 drawRect )。
然后再实现这个接口,编写具体实现代码:
实现
所以总结来说,如果我们想实现自己的作用域限制大致分为三步:
- 编写作为作用域的接口
- 实现这个接口
- 在暴露的方法中将 lambda 参数接收者使用上面定义的接口
下面我们举个例子。
假如我们要在 Compose 中实现一个遮罩引导层,用于引导新用户操作,类似这样:
但是我们希望引导层上的提示可以多样化,例如可以支持文字提示、图片提示、甚至播放视频或动图提示,但是我们不希望这些提示 item 在遮罩层以外的地方被调用,因为它们依赖于遮罩层的某些参数,如果在外部调用会出错。
这时候,使用作用域限制就非常合适。
首先,我们编写一个接口:
interface ShowcaseScreenScope {
val isShowOnce: Boolean
@Composable
fun ShowcaseTextItem()
}在这个接口中我们定义了一个属性变量 isShowOnce 用于表示这个引导层是否只显示一次、定义一个方法 ShowcaseTextItem 表示在引导层上显示一串文字,同理我们还可以定义 ShowcaseImageItem 表示显示图片。
然后实现这个接口:
private class ShowcaseScopeImpl: ShowcaseScreenScope {
override val isShowOnce: Boolean
get() = TODO("在这里编写是否只显示一次的逻辑")
@Composable
override fun ShowcaseTextItem() {
// 在这里写你的实现代码
Text(text = "我是说明文字")
}
}在接口实现中,根据我们的需求编写相应的实现逻辑代码。
最后,写一个提供给外部调用的 Composable:
@Composable
fun ShowcaseScreen(content: @Composable ShowcaseScreenScope.() -> Unit) {
// 在这里实现其他逻辑(例如显示遮罩)后调用 content
// ……
ShowcaseScopeImpl().content()
}在这个 composable 中,我们可以先处理完其他逻辑,例如显示遮罩层 UI 或显示动画后再调用 ShowcaseScopeImpl().content() 将我们传递的子 Item 组合上去。
最后,使用时只需要调用:
ShowcaseScreen {
if (!isShowOnce) {
ShowcaseTextItem()
}
}当然,这个 ShowcaseTextItem() 和 isShowOnce 位于 ShowcaseScreenScope 作用域内,在外面是不能调用的:
总结
本文简要介绍了 Kotlin 中的作用域概念和标准库中的作用域函数,并引申到 Compsoe 中关于作用域的应用,最终分析实现原理并讲解如何自定义一个我们自己的 Compose 作用域函数。
本文写的可能比较浅显,很多知识点都是点到为止,没有过多讲解,推荐读者阅读完后,可以看看文末的参考链接中其他大佬写的文章。
链接:https://juejin.cn/post/7173913850230603812
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
检测Android应用使用敏感信息(mac地址、IMEI等)的方法
今天在提交app时,遇到授权前隐私不过的问题,所有的初始化都后置到授权后了,还是被报有获取mac地址和android_id的行为,这很是奇怪,自己也是无处下手,毕竟log里面是没有的,应用商店也没有提供堆栈。
经过一番查找,找到一套自测的工具,这里自己也记录并分享一下,手把手的来一步步操作,就可以自测了,废话不多说,下面按步骤来写了(无需ROOT):
- 下载虚拟系统:VirtualXposed 0.22.0版本这个反正我用有问题,就用了0.20.3了~
- 压缩包里面有
VirtualXposed_for_GameGuardian_0.20.3.apk和VirtualXposed_0.20.3.apk - 将两个apk都安装到手机里面,桌面会看到VirtualXposed图标。
- 自行编译PrivacyCheck检测隐私打点工具或者可以用我编译好的 测试包privacy_check.apk
- 安装要检测的应用,我们这里随便拿个app来测试,就拿掘金来练手吧~ 现在桌面是这样的:
- 打开
VirtualXposed,如果是全面屏记得恢复成普通导航,因为需要菜单功能。做安卓的应该知道菜单怎么调用,小米手机:长按任务键进入设置~~ - 点击添加应用:勾选
PrivacyCheck和稀土掘金,点击下面的安装按钮。 - 弹框选择:
VIRTUALXPOSED,等待安装结束,点击完成! 界面如下: - 点击
Xposed Installer,也就是最右面那个app。安装完成的样子: - 在
Xposed Installerapp里面,左上角点击侧滑栏,点击模块,勾选PrivacyCheck,如图: - 返回到
VirtualXposed界面,进入菜单,最下面有一个重启项,点击重启~ 很快就可以了~ - 返回到这个界面:
- 点击
PrivacyCheckapp,启动完成后,看到就一行字,无需关心,此时切换应用回:VirtualXposed界面。(不要返回,直接应用间切换就好了,保持PrivacyCheck没有杀死。 - 打开终端(mac),输入:
adb logcat | grep PrivacyCheck,回车,会看到这样一行:E PrivacyCheck: 加载app 包名:com.test.privacycheck。 - 打开要测试的app,这里是打开掘金app,不要点击同意,观察log输出:
E PrivacyCheck: 加载app 包名:com.daimajia.gold,只输出了一行,看上去很不错,没有任何问题。 - 参考步骤5,打开其他测试app,比如我之前有问题的app,观察下log:
可以很清楚的看到错误堆栈,看到我这里是因为调用页面start的统计造成的,一下就想起来自己统计根页面时路径导致的,很容易就解决了~~
最后问题改动很简单,但查找的过程还比较麻烦,同时也学到了这种排查隐私的方法,希望也能帮到需要的人~~
链接:https://juejin.cn/post/7106522434261483528
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 一种点赞动画的实现
最近有个需求,需要仿照公司的H5实现一个游戏助手,其中一个点赞的按钮有动画效果,如下图:
分析一下这个动画,点击按钮后,拇指首先有个缩放的效果,然后有5个拇指朝不同的方向移动,其中部分有放大的效果。
点击后的缩放效果
本文通过ScaleAnimation 实现缩放效果,代码如下:
private fun playThumbUpScaleAnimator() {
// x、y轴方向都从1倍放大到2倍,以控件的中心为原点进行缩放
ScaleAnimation(1f, 2f, 1f, 2f, Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF, 0.5f).run {
// 先取消控件当前的动画效果(重复点击时)
view.clearAnimation()
// 设置动画的持续时间
duration = 300
// 开始播放动画
view.startAnimation(this)
}
}拇指的散开效果
有5个拇指分别往不同的方向移动,本文通过动态添加View,并对View设置动画来实现。可以看到在移动的同时还有缩放的效果,所以需要同时播放几个动画。
本文通过ValueAnimator和AnimatorSet来实现该效果,代码如图:
// 此数组控制动画的效果
// 第一个参数控制X轴移动距离
// 第二个参数控制Y轴移动距离
// 第三个参数控制缩放的倍数(基于原大小)
val animatorConfig: ArrayList<ArrayList<Float>> = arrayListOf(
arrayListOf(-160f, 150f, 1f),
arrayListOf(80f, 130f, 1.1f),
arrayListOf(-120f, -170f, 1.3f),
arrayListOf(80f, -130f, 1f),
arrayListOf(-20f, -80f, 0.8f))
private fun playDiffusionAnimator() {
for (index in 0 until 5) {
binding.root.run {
if (this is ViewGroup) {
// 创建控件
val ivThumbUp = AppCompatImageView(context)
ivThumbUp.setImageResource(R.drawable.icon_thumb_up)
// 设置与原控件一样的大小
ivThumbUp.layoutParams = FrameLayout.LayoutParams(DensityUtil.dp2Px(25), DensityUtil.dp2Px(25))
// 先设置为全透明
ivThumbUp.alpha = 0f
addView(ivThumbUp)
// 设置与原控件一样的位置
ivThumbUp.x = binding.ivThumbUp.x
ivThumbUp.y = binding.ivThumbUp.y
AnimatorSet().apply {
// 设置动画集开始播放前的延迟
startDelay = 330L + index * 50L
// 设置动画监听
addListener(object : Animator.AnimatorListener {
override fun onAnimationStart(animation: Animator) {
// 开始播放时把控件设置为不透明
ivThumbUp.alpha = 1f
}
override fun onAnimationEnd(animation: Animator) {
// 播放结束后再次设置为透明,并从根布局中移除
ivThumbUp.alpha = 0f
ivThumbUp.clearAnimation()
ivThumbUp.post { removeView(ivThumbUp) }
}
override fun onAnimationCancel(animation: Animator) {}
override fun onAnimationRepeat(animation: Animator) {}
})
// 设置三个动画同时播放
playTogether(
// 缩放动画
ValueAnimator.ofFloat(1f, animatorConfig[index][2]).apply {
duration = 700
// 设置插值器,速度一开始快,快结束时减慢
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
(values.animatedValue as Float).let { value ->
ivThumbUp.scaleX = value
ivThumbUp.scaleY = value
}
}
},
// X轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.x, ivThumbUp.x + animatorConfig[index][0]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.x = values.animatedValue as Float
}
},
// Y轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.y, ivThumbUp.y + animatorConfig[index][1]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.y = values.animatedValue as Float
}
})
}.start()
}
}
}
}示例
整合之后做了个示例Demo,完整代码如下:
class AnimatorSetExampleActivity : BaseGestureDetectorActivity() {
private lateinit var binding: LayoutAnimatorsetExampleActivityBinding
private val animatorConfig: ArrayList<java.util.ArrayList<Float>> = arrayListOf(
arrayListOf(-160f, 150f, 1f),
arrayListOf(80f, 130f, 1.1f),
arrayListOf(-120f, -170f, 1.3f),
arrayListOf(80f, -130f, 1f),
arrayListOf(-20f, -80f, 0.8f))
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.layout_animatorset_example_activity)
binding.ivThumbUp.setOnClickListener {
playThumbUpScaleAnimator()
playDiffusionAnimator()
}
}
private fun playThumbUpScaleAnimator() {
// x,y轴方向都从1倍放大到2倍,以控件的中心为原点进行缩放
ScaleAnimation(1f, 2f, 1f, 2f, Animation.RELATIVE_TO_SELF, 0.5f, Animation.RELATIVE_TO_SELF, 0.5f).run {
// 先取消控件当前的动画效果(重复点击时)
binding.ivThumbUp.clearAnimation()
// 设置动画的持续时间
duration = 300
// 开始播放动画
binding.ivThumbUp.startAnimation(this)
}
}
private fun playDiffusionAnimator() {
for (index in 0 until 5) {
binding.root.run {
if (this is ViewGroup) {
// 创建控件
val ivThumbUp = AppCompatImageView(context)
ivThumbUp.setImageResource(R.drawable.icon_thumb_up)
// 设置与原控件一样的大小
ivThumbUp.layoutParams = FrameLayout.LayoutParams(DensityUtil.dp2Px(25), DensityUtil.dp2Px(25))
// 先设置为全透明
ivThumbUp.alpha = 0f
addView(ivThumbUp)
// 设置与原控件一样的位置
ivThumbUp.x = binding.ivThumbUp.x
ivThumbUp.y = binding.ivThumbUp.y
AnimatorSet().apply {
// 设置动画集开始播放前的延迟
startDelay = 330L + index * 50L
// 设置动画监听
addListener(object : Animator.AnimatorListener {
override fun onAnimationStart(animation: Animator) {
// 开始播放时把控件设置为不透明
ivThumbUp.alpha = 1f
}
override fun onAnimationEnd(animation: Animator) {
// 播放结束后再次设置为透明,并从根布局中移除
ivThumbUp.alpha = 0f
ivThumbUp.clearAnimation()
ivThumbUp.post { removeView(ivThumbUp) }
}
override fun onAnimationCancel(animation: Animator) {}
override fun onAnimationRepeat(animation: Animator) {}
})
// 设置三个动画同时播放
playTogether(
// 缩放动画
ValueAnimator.ofFloat(1f, animatorConfig[index][2]).apply {
duration = 700
// 设置插值器,速度一开始快,快结束时减缓
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
(values.animatedValue as Float).let { value ->
ivThumbUp.scaleX = value
ivThumbUp.scaleY = value
}
}
},
// Y轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.x, ivThumbUp.x + animatorConfig[index][0]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.x = values.animatedValue as Float
}
},
// X轴的移动动画
ValueAnimator.ofFloat(ivThumbUp.y, ivThumbUp.y + animatorConfig[index][1]).apply {
duration = 700
interpolator = DecelerateInterpolator()
addUpdateListener { values ->
ivThumbUp.y = values.animatedValue as Float
}
})
}.start()
}
}
}
}
}效果如图:
个人感觉还原度还是可以的哈哈。
链接:https://juejin.cn/post/7172867784278769677
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
反思:Google 为何把 SurfaceView 设计的这么难用?
启程
如果你有过 SurfaceView 的使用经历,那么你一定和我一样,曾经被它所引发出 层出不穷的异状 折磨的 怀疑人生—— 毕竟,作为一个有理想的开发者,在深入了解 SurfaceView 之前,你很难想通这样一个问题:
为什么
SurfaceView设计的这么难用?
- 不支持
transform动画;
- 不支持半透明混合;
- 移动,大小改变,隐藏/显示操作引发的各种问题;
另一方面,即使你对 SurfaceView 使用不多,图形系统 的这朵乌云依然笼罩在每一位 Android 开发者的头顶,来看 Google 对其的 描述:
最终我尝试走近这片迷雾,并一点点去思考下列问题的答案:
SurfaceView的设计初衷是为了解决什么问题?
- 实际开发中,
SurfaceView这么 难用 的根本原因是什么?
- 实际开发中,
- 为了解决这些问题,
Google的工程师进行了哪些 尝试 ?
- 为了解决这些问题,
接下来,读者可带着这些问题,跟随笔者一起,再次回顾 SurfaceView 设计和实现的精彩历程。
一、世界观
在了解 SurfaceView 的设计初衷之前,读者首先需要对 Android 现有的图形架构有一个基本的了解。
Android 系统采用一种称为 Surface 的图形架构,简而言之,每一个 Activity 都关联有至少一个 Window(窗口),每一个 Window 都对应有一个 Surface。
Surface 这里直译过来叫做 绘图表面 ,顾名思义,其可在内存中生成一个图形缓冲区队列,用于描述 UI,经与系统服务的WindowServiceManager 通信后、通过 SurfaceFlinger 服务持续合成并送显到显示屏。
读者可通过下图,在印象上对整个流程建立一个简单的轮廓:
由此可见,通常情况下,一个 Activity 的 UI 渲染本质是 系统提供一块内存,并创建一个图形缓冲区进行维护;这块内存就是 Surface,最终页面所有 View 的 UI 状态数据,都会被填充到同一个 Surface 中。
截至目前一切正常,但需要指出的是,现有图形系统的架构设计中还藏了一个线程相关的 隐患 。
二、设计起源
1.线程问题
问题点在于:我们还需保证 Surface 内部 Buffer 缓冲区的 线程安全。
这样的描述,对于读者似乎太过飘渺,但从结论来说,最终,一条 Android开发者 耳熟能详 的规则因此而诞生:
主线程不能执行耗时操作。
我们知道, UI 的所有操作,一定会涉及到视图(View 树) 内部大量状态的维护,而 Surface 内部的缓冲区也会不断地被读写,并交给系统渲染。因此,如果 UI 相关的操作,放在不同的线程中执行,而多线程对这一块内存区域的读写,势必会引发内部状态的混乱。
为了避免这个问题,设计者就需要通过某种手段保证线程同步(比如加锁),而这种同步所带来的巨大开销,对于开发者而言,是不可接受的。
因此,最合理的方案就是保证所有UI相关操作都在同一个线程,而这个线程也被称作 主线程 或 UI 线程。
现在,我们将UI操作限制到主线程去执行,以解决了本小节开始时提到的线程问题,但开发者仍需小心—— 众所周知,主线程除了执行UI相关的操作之外,还负责接收各种各样的 输入事件(比如触摸、按键等),因此,为了保证用户的输入事件能够及时得到响应,我们就要保证 UI 操作的 稳定高效,尽可能避免耗时的 UI 操作。
2.动机
挑战随之而来。
当渲染的缓冲数据来自外部的其它系统服务或API时——比如系统媒体解码器的音视频数据,或者 Camera API 的相机数据等,这时 UI 渲染的效率要求会变得非常高。
开发者有了新的诉求:能否有这样一种特殊的视图,它拥有独立的 Surface ,这样就可以脱离现有 Activity 宿主的限制,在一个独立的线程中进行绘制。
由于该视图不会占用主线程资源,一方面可以实现复杂而高效的 UI 渲染,另一方面可以及时响应用户其它输入事件。
因此,SurfaceView 应运而生:与常规视图控件不同,SurfaceView 拥有独立的 Surface,如果我们将一个 Surface 理解为一个层级 (Layer),最终 SurfaceFlinger 会将前后两者的2个 Layer 进行 合成 和 渲染 :
现在,我们引用官方文档的描述,再次重申适用 SurfaceView 的场景:
在需要渲染到单独的
Surface(例如,使用Camera API或OpenGL ES上下文进行渲染)时,使用SurfaceView进行渲染很有帮助。使用SurfaceView进行渲染时,SurfaceFlinger会直接将缓冲区合成到屏幕上。
如果没有
SurfaceView,您需要将缓冲区合成到屏幕外的Surface,然后该Surface会合成到屏幕上,而使用SurfaceView进行渲染可以省去额外的工作。
3.具体思路
根据当前的设想,我们针对 SurfaceView 设计思路进行细化。
首先,我们需对现有的视图树结构进行改造。为了便于使用,我们允许开发者将 SurfaceView 直接加入到现有的视图树中(即作为控件,它受限于宿主 View Hierachy的结构关系),但在系统服务端中,对于 SurfaceFlinger 而言,SurfaceView 又是完全与宿主完全分离开的:
在上图中,我们可以看到,在 z 轴上,SurfaceView 默认是低于 DecorView 的,也就是说,SurfaceView 通常总是处于当前页面的最下方。
这似乎有些违反直觉,但仔细考虑 SurfaceView 的应用场景,无论是 Camera 相机应用、音视频播放页,亦或者是渲染游戏画面等,SurfaceView 承载的画面似乎总应该在页面的最下面。
实际设计中也是如此,用来描述 SurfaceView 的 Layer 或者 LayerBuffer 的 z 轴位置默认是低于宿主窗口的。与此同时,为了便于最底层的视图可见, SurfaceView 在宿主 Activity 的窗口上设置了一块透明区域(挖了一个洞)。
最终,SurfaceFlinger 把所有的 Layer 通过用统一流程来绘制和合成对应的 UI。
在整个过程中,我们需更进一步深入研究几个细节:
SurfaceView与宿主视图树结构的关系,以及 挖洞 过程的实现;SurfaceView与系统服务的通信创建Surface的实现;SurfaceView具体绘制流程的实现。
三、施工
1. 视图树与挖洞
一句话总结 SurfaceView 与视图树的关系: 在视图树内部,但又没完全在内部 。
首先,SurfaceView 的设计依然遵循 Android 的 View 体系,继承了 View,这意味着使用时,它可以声明在 xml 布局文件中:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View { }
出于安全性的考量,
SurfaceView相关源码并未直接开放出来,开发者只能看到自动生成的一个接口类,源码可以借助梯子在 这里 查阅。
LayoutInflater 布局填充阶段,按既有的布局填充流程,将 SurfaceView 构造并加入到视图树的某个结点;接下来,根布局会通过深度遍历依次执行 onAttachedToWindow() 处理视图挂载窗口的事件:
// /frameworks/base/core/java/android/view/SurfaceView.java
@Override
protected void onAttachedToWindow() {
// ...
mParent.requestTransparentRegion(SurfaceView.this); // 1.
ViewTreeObserver observer = getViewTreeObserver();
observer.addOnPreDrawListener(mDrawListener); // 2.
}
@UnsupportedAppUsage
private final ViewTreeObserver.OnPreDrawListener mDrawListener = new ViewTreeObserver.OnPreDrawListener() {
@Override
public boolean onPreDraw() {
updateSurface(); // 3.
return true;
}
};
protected void updateSurface() {
// ...
mSurfaceSession = new SurfaceSession();
mSurfaceControl = new SurfaceControl.Builder(mSurfaceSession); // 4
//...
}步骤 1 中,SurfaceView 会向父视图依次向上请求创造一份透明区域,根视图统计到最终的信息后,通过 Binder 通知 WindowManagerService 将对应区域设置为透明。
步骤 2、3、4 是在同一个方法的调用栈中,由此可见,SurfaceView 向系统请求透明区域后,会立即创建一个与绘图表面的连接 SurfaceSession ,并创建一个对应的控制器 SurfaceControl,便于对这个独立的绘图表面进行直接通信。
由此可见,Android 自有的视图树体系中,SurfaceView 作为一个普通的 View 被挂载上去之后,通过 Binder 通信,WindowManagerService 将其所在区域设置为透明(挖洞);并建立了与独立绘图表面的连接,后续便可与其直接通信。
2. 子图层类型
在阐述绘制流程之前,读者需简单了解 子图层类型 的概念。
上文说到,SurfaceView 的绝大多数使用场景中,其 z 轴的位置通常是在页面的 最下方 。但在实际开发中,随着业务场景复杂度的上升,仍然有部分场景是无法被满足的,比如:在页面的最上方播放一条全屏的视频广告。
因此,SurfaceView 的设计中引入了一个 子图层类型 的概念,用于定义这个独立的 Surface 相比较当前页面窗口 (即Activity) 的位置:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
// SurfaceView 的子图层类型
int mSubLayer = APPLICATION_MEDIA_SUBLAYER;
// SurfaceView 是否展示在当前窗口的最上方
// 该方法在挖洞和绘制流程中都有使用,最终影响到用户的视觉效果
private boolean isAboveParent() {
return mSubLayer >= 0;
}
}
// /frameworks/base/core/java/android/view/WindowManagerPolicyConstants.java
public interface WindowManagerPolicyConstants {
// ...
int APPLICATION_MEDIA_SUBLAYER = -2;
int APPLICATION_MEDIA_OVERLAY_SUBLAYER = -1;
int APPLICATION_PANEL_SUBLAYER = 1;
int APPLICATION_SUB_PANEL_SUBLAYER = 2;
int APPLICATION_ABOVE_SUB_PANEL_SUBLAYER = 3;
// ...
}如代码所示,mSubLayer 默认值为 -2,这表示 SurfaceView 默认总是在 Activity 的下方,想要让 SurfaceView 展示在 Activity 上方,可以调用 setZOrderOnTop(true) 以修改 mSubLayer 的值:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
public void setZOrderOnTop(boolean onTop) {
if (onTop) {
mSubLayer = APPLICATION_PANEL_SUBLAYER;
} else {
mSubLayer = APPLICATION_MEDIA_SUBLAYER;
}
}
public void setZOrderMediaOverlay(boolean isMediaOverlay) {
mSubLayer = isMediaOverlay ? APPLICATION_MEDIA_OVERLAY_SUBLAYER : APPLICATION_MEDIA_SUBLAYER;
}
}现在,无论是将 SurfaceView 放在页面的上方还是下方,都轻而易举。
但这仍然无法满足所有诉求,比如针对具有 alpha 通道的透明视频进行渲染时,产品希望其所在的图层位置能够更灵活(在两个 View 之间),但由于 SurfaceView 自身设计的原因,其并无法与视图树融合,这也正是 SurfaceView 饱受诟病的主要原因之一。
通过辩证的观点来看, SurfaceView 的这种设计虽然满足不了严苛的业务诉求,但在绝大多数场景下,独立绘图表面 这种设计都能够保证足够的渲染性能,同时不影响主线程输入事件的处理,绝对是一个优秀的设计。
3.子图层类型-插曲
值得一提的是,在 SurfaceView 的设计中,设计者还考虑到了音视频渲染时,字幕相关业务的场景,因此额外提供了一个 setZOrderMediaOverlay() 方法:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
public void setZOrderMediaOverlay(boolean isMediaOverlay) {
mSubLayer = isMediaOverlay ? APPLICATION_MEDIA_OVERLAY_SUBLAYER : APPLICATION_MEDIA_SUBLAYER;
}
}该方法的设计说明了2点:
首先,由于 APPLICATION_MEDIA_SUBLAYER 和 APPLICATION_MEDIA_OVERLAY_SUBLAYER 都小于0,因此,无论如何,字幕始终被渲染在页面的下方。又因为视频理应渲染在字幕的下方,所以 不推荐 开发者在使用 SurfaceView 渲染视频时调用 setZOrderOnTop(true),将视频放在页面视图的顶层。
其次,同时具有 setZOrderOnTop() 和 setZOrderMediaOverlay() 方法,显然是提供给两个不同 SurfaceView 分别使用的,以定义不同的渲染层级,因此同一个页面存在多个 SurfaceView 是正常的,开发者完全可以根据业务场景,合理运用。
4. 令人头大的黑屏问题
在使用 SurfaceView 的过程中,笔者最终也遇到了 默认黑屏 的问题:
由于视频本身的加载和编解码的耗时,用户总是会先看到 SurfaceView 的黑色背景一闪而过,然后视频才开始播放的情况,对于产品而言,这种交互体验是 不可容忍 的。
通过上文读者知道,SurfaceView 拥有独立的绘制表面,因此常规对付 View 的一些手段——比如 setVisibility() 、setAlpha() 、setBackgroundColor() 并不能解决上述问题;因此,想真正解决它,就必须先弄清楚 SurfaceView 底层的绘制流程。
SurfaceView 虽然特殊,但其作为视图树的一个结点,其依然参与到了视图树常规绘制流程,这里我们直接看 SurfaceView 的 draw() 方法:
// /frameworks/base/core/java/android/view/SurfaceView.java
public class SurfaceView extends View {
//...
@Override
public void draw(Canvas canvas) {
if (mDrawFinished && !isAboveParent()) { // 1.
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == 0) {
clearSurfaceViewPort(canvas);
}
}
super.draw(canvas);
}
private void clearSurfaceViewPort(Canvas canvas) {
// ...
canvas.drawColor(0, PorterDuff.Mode.CLEAR); // 2.
}
}由此可见,当满足 !isAboveParent() 的条件——即 SurfaceView 的子图层类型位于宿主视图的下方时,SurfaceView 默认会将绘图表面的颜色指定为黑色。
显然,该问题最简单的解决方式就是对源码进行hook或者反射,遗憾的是,上文我们也提到了,出于安全性的考量,SurfaceView 的源码是没有公开暴露的。
设计者其实也想到了这个问题,因此额外提供了一个 SurfaceHolder 的 API 接口,通过该接口,开发者可以直接拿到独立绘图表面的 Canvas 对象,以及对这个画布进行绘制操作:
// /frameworks/base/core/java/android/view/SurfaceHolder.java
public interface SurfaceHolder {
// ...
public Canvas lockCanvas();
public void unlockCanvasAndPost(Canvas canvas);
//...
}遗憾的是,即使拿到 Canvas,开发者仍然会受到限制:
// /frameworks/base/core/java/com/android/internal/view/BaseSurfaceHolder.java
public abstract class BaseSurfaceHolder implements SurfaceHolder {
private final Canvas internalLockCanvas(Rect dirty, boolean hardware) {
if (mType == SURFACE_TYPE_PUSH_BUFFERS) {
throw new BadSurfaceTypeException("Surface type is SURFACE_TYPE_PUSH_BUFFERS");
}
// ...
}
}这里的代码,笔者引用 罗升阳 的 这篇文章 中的一段来解释:
注意,只有在一个
SurfaceView的绘图表面的类型不是SURFACE_TYPE_PUSH_BUFFERS的时候,我们才可以自由地在上面绘制UI。我们使用SurfaceView来显示摄像头预览或者播放视频时,一般就是会将它的绘图表面的类型设置为SURFACE_TYPE_PUSH_BUFFERS。在这种情况下,SurfaceView的绘图表面所使用的图形缓冲区是完全由摄像头服务或者视频播放服务来提供的,因此,我们就不可以随意地去访问该图形缓冲区,而是要由摄像头服务或者视频播放服务来访问,因为该图形缓冲区有可能是在专门的硬件里面分配的。
由此可见,SurfaceView 黑屏问题的原因是综合且复杂的,无论是通过 setZOrderOnTop() 等方法设置为背景透明(但是会在页面层级的最上方),亦或者调整布局参数,都会有大大小小的一些问题。
小结
综合来看,SurfaceView 这些饱受争议的问题,从设计的角度来看,都是有其自身考量的。
而为了解决这些问题,官方后续提供了 TextureView 以替换 SurfaceView,TextureView 的原理是和 View 一样绘制到当前 Activity 的窗口上,因此不存在 SurfaceView 的这些问题。
换个角度来看,由于 TextureView 渲染依赖于主线程,因此也会导致了新的问题出现。除了性能比较 SurfaceView 会有明显下降外,还会有经常掉帧的问题,有机会笔者会另起一篇进行分享。
参考 & 感谢
细心的读者应该能够发现,关于 参考&感谢 一节,笔者着墨越来越多,原因无他,笔者 从不认为 一篇文章就能够讲一个知识体系讲解的面面俱到,本文亦如是。
因此,读者应该有选择性查看其它优质内容的权利,甚至是为其增加一些简洁的介绍(因为标题大多都很相似),而不是文章末尾甩一堆
https开头的链接不知所云。
这也是对这些内容创作者的尊重,如果你喜欢本文,也同样希望你能够喜欢下面这些文章。
1. Android源码-frameworks-SurfaceView
阅读源码永远是学习最有效的方式,如果你想更进一步深入了解 SurfaceView,选它就对了。
遗憾的是,在笔者学习的过程中,官方文档并未给予到很大的帮助,相当一部分原因是因为文档中的内容太 规范 了,保持内容 精炼 且 准确 的同时,也增加了读者的理解成本。
但无论如何,作为权威的官方文档,仍适合作为复习资料,反复阅读。
3. Android视图SurfaceView的实现原理分析 @罗升阳
神作, 我认为它是 最适合 进阶学习和研究 SurfaceView 源码的文章。
4. Android 5.0(Lollipop)中的SurfaceTexture,TextureView, SurfaceView和GLSurfaceView @ariesjzj
在笔者摸索学习,困惑于标题中这些概念的阶段,本文以浅显易懂的方式对它们进行了简单的总结,推荐。
链接:https://juejin.cn/post/7140191497982312455
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
超有用的Android开发技巧:拦截界面View创建
LayoutInflater.Factory2是个啥?
Activity内界面的创建是由LayoutInflater负责,LayoutInflater最终会交给内部的一个类型为LayoutInflater.Factory2的factory2成员变量进行创建。
这个属性值可以外部自定义传入,默认的实现类为AppCompatDelegateImpl:
然后在AppCompatActivity的初始化构造方法中向LayoutInflater注入AppCompatDelegateImpl:
常见的ImageView、TextView被替换成AppcompatImageView、AppCompatTextView等就是借助AppCompatDelegateImpl进行实现的。
这里有个实现的小细节,在initDelegate()方法中,调用了addOnContextAvailableListener()方法传入一个监听事件实现的factory2注入,这个addOnContextAvailableListener()方法有什么魅力呢?
addOnContextAvailableListener()是干啥用的?
咱们先看下这个方法是干啥用的:
最终是将这个监听对象加入到了ContextAwareHelper类的内部mListeners集合中,咱们接下里看下这个监听对象集合最终是在哪里被调用的。
可以看到,这个集合最终在ComponetActivity的onCreate()方法中调用,请注意,这个调用时机还是在父类的super.onCreate()方法前进行调用的。
所以我们可以得出结论,addOnContextAvailableListener()添加的监听器将在父类onCreate()方法前进行调用。
这个用处的场景还是比较多的,比如我们设置Activity的主题就必须在父类的onCreate()方法前调用,借助这个监听,可以轻松实现。
代码实战
请注意,这个
factory2的设置必须在Activity的onCreate()方法前调用,所以我们可以直接借助addOnContextAvailableListener()进行实现,也可以重写onCreate()方法在指定位置实现。当然了,前者更加的灵活,这里我们还是以后者进行举例。
override fun onCreate(savedInstanceState: Bundle?) {
LayoutInflaterCompat.setFactory2(layoutInflater, object : LayoutInflater.Factory2 {
override fun onCreateView(
parent: View?,
name: String,
context: Context,
attrs: AttributeSet
): View? {
return if (name == "要替换的系统View名称") {
CustumeView()
} else delegate.createView(parent, name, context, attrs)
}
})
}请注意,这里也有一个实现的小细节,如果当某个系统View不属于我们要替换的View,请继续委托给AppCompatDelegateImpl进行处理,这样就保证了实现系统组件特有功能的前提下,又能完成我们的View替换工作。
统一所有界面View的替换工作
如果要替换View的界面非常多,一个Activity一个Activity替换过去太麻烦 ,这个时候就可以使用我们经常使用到的Application的registerActivityLifecycleCallbacks()监听所有Activity的创建流程,其中我们用到的方法就是onActivityPreCreated():
registerActivityLifecycleCallbacks(object : Application.ActivityLifecycleCallbacks {
override fun onActivityPreCreated(activity: Activity, savedInstanceState: Bundle?) {
LayoutInflaterCompat.setFactory2(activity.layoutInflater, object : LayoutInflater.Factory2 {
override fun onCreateView(
parent: View?,
name: String,
context: Context,
attrs: AttributeSet
): View? {
return if (name == "要替换的系统View名称") {
CustumeView()
} else (activity as? AppCompatActivity)?.delegate?.createView(parent, name, context, attrs) ?: null
}
override fun onCreateView(name: String, context: Context, attrs: AttributeSet): View? {
TODO("Not yet implemented")
}
})
}
}不过这个Application.ActivityLifecycleCallbacks接口要重写好多无用的方法,太麻烦了,之前写过一篇关于接口优化相关的文章吗,详情可以参考:接口使用额外重写的无关方法太多?优化它
总结
之前看过很多换肤、埋点统计上报等相关文章,多多少少都介绍了向AppCompatActivity中注入factory2拦截系统View创建的思想,我们设置还可以借助此实现界面黑白化的效果,非常的好用,每个开发者都应该去了解掌握的知识点。
链接:https://juejin.cn/post/7137305357415612452
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
synchronized实现原理
synchronized作为java语言中的并发关键词,其在代码中出现的频率相当高频,大多数开发者在涉及到并发场景时,一般都会下意识得选取synchronized。
synchronized在代码中主要有三类用法,根据其用法不同,所获取的锁对象也不同,如下所示:
- 修饰代码块:这种用法通常叫做同步代码块,获取的锁对象是在synchronized中显式指定的
- 修饰实例方法:这种用法通常叫做同步方法,获取的锁对象是当前的类对象
- 修饰静态方法:这种用法通常叫做静态同步方法,获取的锁对象是当前类的类对象
下面我们一起来测试下三种方式下,对象锁的归属及锁升级过程,SynchronizedTestClass类代码如下:
import org.openjdk.jol.info.ClassLayout;
public class SynchronizedTestClass {
private Object mLock = new Object();
public void testSynchronizedBlock(){
System.out.println("before get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(mLock).toPrintable());
synchronized (mLock) {
System.out.println("testSynchronizedBlock start:"+Thread.currentThread().getName());
System.out.println("after get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(mLock).toPrintable());
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("testSynchronizedBlock end:"+Thread.currentThread().getName());
}
}
public synchronized void testSynchronizedMethod() {
System.out.println("after get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(this).toPrintable());
System.out.println("testSynchronizedMethod start:"+Thread.currentThread().getName());
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("testSynchronizedMethod end:"+Thread.currentThread().getName());
}
public static synchronized void testSynchronizedStaticMethod() {
System.out.println("after get Lock in thread:"+Thread.currentThread().getName()+">>>"+ ClassLayout.parseInstance(SynchronizedTestClass.class).toPrintable());
System.out.println("testSynchronizedStaticMethod start:"+Thread.currentThread().getName());
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("testSynchronizedStaticMethod end:"+Thread.currentThread().getName());
}
}同步代码块
在main函数编写如下代码,调用SynchronizedTestClass类中包含同步代码块的测试方法,如下所示:
public static void main(String[] args) {
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
}运行结果如下:
从上图可以看出在线程2获取锁前,mLock处于无锁状态,等线程2获取锁后,mLock对象升级为轻量级锁,等线程1获取锁后升级为重量级锁,有同学要问了,你在多线程与锁中不是说了synchronized锁升级有四个吗?你是不是写BUG了,当然没有啊,现在我们来看看偏向锁去哪儿了?
偏向锁
对于不同版本的JDK而言,其针对偏向锁的开关和配置均有所不同,我们可以通过执行java -XX:+PrintFlagsFinal -version | grep BiasedLocking来获取偏向锁相关配置,执行命令输出如下:
从上图可以看出在JDK 1.8上,偏向锁默认开启,具有4秒延时,那么我们修改main内容,延时5秒开始执行,看看现象如何,代码如下:
public static void main(String[] args) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
}输出如下:
从上图可以看出在延迟5s执行后,mLock锁变成了无锁可偏向状态,结合上面两个示例,我们可以看出,在轻量级锁和偏向锁阶段均有可能直接升级成重量级锁,是否升级依赖于当时的锁竞争关系,据此我们可以得到synchronized锁升级的常见过程,如下图所示:
可以看出,我们遇到的两种情况分别对应升级路线1和升级路线4。
同步方法
使用线程池调用SynchronizedTestClass类中的同步方法,代码如下:
public static void main(String[] args) {
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedMethod();
}
});
}运行结果如下:
可以看出,在调用同步方法时,直接升级为重量级锁,同一时刻,有且仅有一个线程在同步方法中执行,其他函数在同步方法入口处阻塞等待。
静态同步方法
使用线程池调用SynchronizedTestClass类中的静态同步方法,代码如下
public static void main(String[] args) {
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
SynchronizedTestClass.testSynchronizedStaticMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
SynchronizedTestClass.testSynchronizedStaticMethod();
}
});
}运行结果如下:
可以看出,在调用静态同步方法时,直接升级为重量级锁,同一时刻,有且仅有一个线程在静态同步方法中执行,其他函数在同步方法入口处阻塞等待。
前面我们看的是多个线程竞争同一个锁对象,那么假设我们有三个线程分别执行这三个函数,又会怎样呢?代码如下:
public static void main(String[] args) {
SynchronizedTestClass synchronizedTestClass = new SynchronizedTestClass();
ExecutorService testSynchronizedBlock = Executors.newCachedThreadPool();
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
SynchronizedTestClass.testSynchronizedStaticMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedMethod();
}
});
testSynchronizedBlock.execute(new Runnable() {
@Override
public void run() {
synchronizedTestClass.testSynchronizedBlock();
}
});
}运行结果:
可以看到,3个线程各自运行,互不影响,这也进一步印证了前文所说的锁对象以及MarkWord中标记锁状态的概念。
synchronized实现原理
上面已经学习了synchronized的常见用法,关联的锁对象以及锁升级的过程,接下来我们来看下synchronized实现原理,仍然以上面的SynchronizedTestClass为例,查看其生成的字节码来了解synchronized关键字的实现。
同步代码块
testSynchronizedBlock其所对应的字节码如下图所示:
从上图代码和字节码对应关系可以看出,在同步代码块中获取锁时使用monitorenter指令,释放锁时使用monitorexit指令,且会有两个monitorexit,确保在当前线程异常时,锁正常释放,避免其他线程等待死锁。
所以synchronized的同步机制是依赖monitorenter和monitorexit指令实现的,而这两个指令操作的就是mLock对象的monitor锁,monitorenter尝试获取mLock的monitor锁,如果获取成功,则monitor中的计数器+1,同时记录相关线程信息,如果获取失败,则当前线程阻塞。
Monitor锁就是存储在MarkWord中的指向重量级锁的指针所指向的对象,每个对象在构造时都会创建一个Monitor锁,用于监视当前对象的锁状态以及持锁线程信息,
同步方法
testSynchronizedMethod其所对应的字节码如下图所示:
可以看到同步方法依赖在函数声明时添加ACC_SYNCHRONIZED标记实现,在函数被ACC_SYNCHRONIZED修饰时,调用该函数会申请对象的Monitor锁,申请成功则进入函数,申请失败则阻塞当前线程。
静态同步方法
testSynchronizedStaticMethod其所对应的字节码如下图所示:
和同步方法相同,同步静态方法也是在函数声明部分添加了ACC_SYNCHRONIZED标记,也同步方法不同的是,此时申请的是该类的类对象的Monitor锁。
扩展
上文中针对synchronized的java使用以及字节码做了说明,我们可以看出synchronized是依赖显式的monitorenter,monitorexit指令和ACC_SYNCHRONIZED实现,但是字节码并不是最靠近机器的一层,相对字节码,汇编又是怎么处理synchronized相关的字节码指令的呢?
我们可以通过获取java代码的汇编代码来查看,查看Java类的汇编代码需要依赖hsdis工具,该工具可以从chriswhocodes.com/hsdis/下载(科学上网),下载完成后,在Intellij Idea中配置Main类的编译参数如下图所示:
其中vm options详细参数如下:
-XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly -Xcomp -XX:CompileCommand=compileonly,*SynchronizedTestClass.testSynchronizedBlock -XX:CompileCommand=compileonly,*SynchronizedTestClass.testSynchronizedMethod -XX:+LogCompilation -XX:LogFile=/Volumes/Storage/hotspot.log
其中“compileOnly,”后面跟的是你要抓取的函数名称,格式为:*类名.函数名,LogFile=后指向的是存储汇编代码的文件。
环境变量配置如下:
LIBRARY_PATH=/Volumes/Storage/hsdis
这里的写法是:hsdis存储路径+/hsdis
随后再次运行Main.main即可看到相关汇编代码输出在运行窗口,通过分析运行窗口输出的内容,我们可以看到如下截图:
可以看出在运行时调用SynchronizedTestClass::testSynchronizedMethod时,进入synchronized需要执行lock cmpxchg以确保多线程安全,故synchronized的汇编实现为lock cmpxchg指令。
链接:https://juejin.cn/post/7174054610301091877
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
花里胡哨的文字特效,你学会了吗?
前言
我们的 App 大部分时候的文字都是一种颜色,实际上,文字的颜色也可以多姿多彩。我们今天就来介绍一个能够轻松实现文字渐变色的组件 —— ShaderMask。ShaderMask 能够构建一个着色器(shader),然后覆盖(mask)到它的子组件上,从而改变子组件的颜色。
ShaderMask 实现渐变色文字
ShaderMask 的构造函数定义如下。
const ShaderMask({
Key? key,
required this.shaderCallback,
this.blendMode = BlendMode.modulate,
Widget? child,
})其中关键的参数是 shaderCallback回调方法,通过 回调方法可以构建一个着色器来为子组件着色,典型的做法是使用 Gradient 的子类(如 LinearGradient 和 RadialGradial)来创建着色器。blendMode 参数则用于设置着色的方式。
因此,我们可以利用LinearGradient来实现渐变色文字,示例代码如下,其中 blendMode 选择为 BlendMode.srcIn 是忽略子组件原有的颜色,使用着色器来对子组件着色。
ShaderMask(
shaderCallback: (rect) {
return LinearGradient(
begin: Alignment.centerLeft,
end: Alignment.centerRight,
colors: [
Colors.blue,
Colors.green[300]!,
Colors.orange[400]!,
Colors.red,
],
).createShader(rect);
},
blendMode: BlendMode.srcIn,
child: const Text(
'岛上码农',
style: TextStyle(
fontSize: 36.0,
fontWeight: FontWeight.bold,
),
),
),实现效果如下图。
实际上,不仅仅能够对文字着色,还可以对图片着色,比如我们使用一个 Row 组件在文字前面增加一个Image 组件,可以实现下面的效果。
让渐变色动起来
静态的渐变色着色还不够,Gradient 还有个 transform 来实现三维空间变换的渐变效果,我们可以利用这个参数和动画组件实现动画效果,比如下面这样。
这里其实就是使用了动画控制 transform 实现横向平移。由于 transform 是一个 GradientTransform 类,实现这样的效果需要定义一个GradientTransform子类,如下所示。
@immutable
class SweepTransform extends GradientTransform {
const SweepTransform(this.dx, this.dy);
final double dx;
final double dy;
@override
Matrix4 transform(Rect bounds, {TextDirection? textDirection}) {
return Matrix4.identity()..translate(dx, dy);
}
@override
bool operator ==(Object other) {
if (identical(this, other)) {
return true;
}
if (other.runtimeType != runtimeType) {
return false;
}
return other is SweepTransform && other.dx == dx && other.dy == dy;
}
@override
int get hashCode => dx.hashCode & dy.hashCode;
}然后通过 Animation 动画对象的值控制渐变色平移的距离就可以实现渐变色横向扫过的效果了,代码如下所示。
ShaderMask(
shaderCallback: (rect) {
return LinearGradient(
begin: Alignment.centerLeft,
end: Alignment.centerRight,
colors: [
Colors.blue,
Colors.green[300]!,
Colors.orange[400]!,
Colors.red,
],
transform: SweepTransform(
(_animation.value - 0.5) * rect.width, 0.0),
).createShader(rect);
},
blendMode: BlendMode.srcIn,
child: Row(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Image.asset(
'images/logo.png',
scale: 2,
),
const Text(
'岛上码农',
style: TextStyle(
fontSize: 36.0,
fontWeight: FontWeight.bold,
),
),
],
),
),图片填充
除了使用渐变色之外,我们还可以利用 ImageShader 使用图片填充文字,实现一些其他的文字特效,比如用火焰图片作为背景,让文字看起来像燃烧了一样。
实现的代码如下,其中动效是通过 ImageShader 的构造函数的第4个参数的矩阵matrix4运算实现的,相当于是让填充图片移动来实现火焰往上升的效果。
ShaderMask(
shaderCallback: (rect) {
return ImageShader(
fillImage,
TileMode.decal,
TileMode.decal,
(Matrix4.identity()
..translate(-20.0 * _animation.value,
-150.0 * _animation.value))
.storage);
},
blendMode: BlendMode.srcIn,
child: Row(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Image.asset(
'images/logo.png',
scale: 2,
),
const Text(
'岛上码农',
style: TextStyle(
fontSize: 36.0,
fontWeight: FontWeight.bold,
),
),
],
),
)总结
本篇介绍了 ShaderMask 组件的应用,通过 ShaderMask 组件我们可以对子组件进行着色,从而改变子组件原来的颜色,实现如渐变色填充、图片填充等效果。本篇完整源码已提交至:实用组件相关源码。
链接:https://juejin.cn/post/7172513057044692999
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从阅读仿真页看贝塞尔曲线
前言
一直觉得阅读器里面的仿真页很有意思,最近在看阅读器相关代码的时候发现仿真页是基于贝塞尔曲线去实现的,所以就有了此篇文章。
仿真页一般有两种实现方式:
- 将内容绘制在Bitmap上,基于Canvas去处理仿真页
- OpenGl es
本篇文章我会向大家介绍如何使用Canvas绘制贝塞尔曲线,以及详细的像大家介绍仿真页的实现思路。
后续有机会的话,希望可以再向大家介绍方案二(OpenGL es 学习中...)。
一、贝塞尔曲线介绍
贝塞尔曲线是应用于二维图形应用程序的数学曲线,最初是用在汽车设计的。我们在绘图工具上也常常见到曲线,比如钢笔工具。
为了绘制出更加平滑的曲线,在 Android 中我们也可以使用 Path 去绘制贝塞尔曲线,比如这类曲线图或者描述声波的图:
我们先简单的了解一下基础知识,可以在这个网站先体验一把如何控制贝塞尔曲线:
http://www.jasondavies.com/animated-be…
一阶到四阶都有。
1. 一阶贝塞尔曲线
给定点 P0 和 P1,一阶贝塞尔曲线是两点之间的直线,这条线的公式如下:
图片表示如下:
2. 二阶贝塞尔曲线
从二阶开始,就变得复杂起来,对于给定的 P0、P1 和 P2,都对应的曲线:
图片表示如下:
二阶的公式是如何得出来的?我们可以假设 P0 到 P1 点是 P3,P1 - P2 的点是P4,二阶贝塞尔也只是 P3 - P4 之间的动态点,则有:
P3 = (1-t) P0 + tP1
P4 = (1-t) P1 + tP2
二阶贝塞尔曲线 B(t) = (1-t)P3 + tP4 = (1-t)((1-t)P0 + tP1) + t((1-t)P1 + tP2) = (1-t)(1-t)P0 + 2t(1-t)P1 + ttP2
与最终的公式对应。
3. 三阶贝塞尔曲线
三阶贝塞尔曲线由四个点控制,对于给定的 P0、P1、P2 和 P3,有对应的曲线:
对应的图片:
同样的,三阶贝塞尔可以由二阶贝塞尔得出,从上面的知识我们可以得处,下图中的点 R0 和 R1 的路径其实是二阶的贝塞尔曲线:
对于给定的点 B,有如下的公式,将二阶贝塞尔曲线带入:
R0 = (1-t)(1-t)P0 + 2t(1-t)P1 + ttP2
R1 = (1-t)(1-t)P1 + 2t(1-t)P2 + ttP3
B(t) = (1-t)R0 + tR1 = (1-t)((1-t)(1-t)P0 + 2t(1-t)P1 + ttP2) + t((1-t)(1-t)P1 + 2t(1-t)P2 + ttP3)
最终的结果就是三阶贝塞尔曲线的最终公式。
4. 多阶贝塞尔曲线
多阶贝塞尔曲线我们就不细讲了,可以知道的是,每一阶都可以由它的上一阶贝塞尔曲线推导而出。就像我们之前由一阶推导二阶,由二阶推导出三阶。
二、Android对应的API
Android提供了 Path 供我们去绘制贝塞尔曲线。一阶贝塞尔是一条直线,所以不用处理了。
看一下 Path 对应的 API:
- Path#quadTo(float x1, float y1, float x2, float y2):二阶
- Path#cubicTo(float x1, float y1, float x2, float y2,float x3, float y3):三阶
对于一段贝塞尔曲线来说,由三部分组成:
- 一个开始点
- 一到多个控制点
- 一个结束点
使用的方法也很简单,先挪到开始点,然后将控制点和结束点统统加进来:
class BezierView @JvmOverloads constructor(
context: Context,
attributeSet: AttributeSet? = null,
defStyle: Int = 0
) : View(context, attributeSet, defStyle) {
private val path = Path()
private val paint = Paint()
override fun onDraw(canvas: Canvas?) {
super.onDraw(canvas)
paint.style = Paint.Style.STROKE
paint.strokeWidth = 3f
path.moveTo(0f, 200f)
path.quadTo(200f, 0f, 400f, 200f)
paint.color = Color.BLUE
canvas?.drawPath(path, paint)
path.rewind()
path.moveTo(0f, 600f)
path.cubicTo(100f, 400f, 200f, 800f, 300f, 600f)
paint.color = Color.RED
canvas?.drawPath(path, paint);
}
}最后的结果:
上面是二阶贝塞尔,下面是三阶贝塞尔,可以发现,控制点越多,就能设计出越复杂的曲线。如果想使用二阶贝塞尔实现三阶的效果,就得使用两个二阶贝塞尔曲线。
三、简单案例
既然刚刚画了两个曲线,我们可以利用这个方式简单模拟一个动态声波的曲线,像这样:
这个动画只需要在刚刚的代码的基础上稍微改动一点:
class BezierView @JvmOverloads constructor(
context: Context,
attributeSet: AttributeSet? = null,
defStyle: Int = 0
) : View(context, attributeSet, defStyle) {
private val path = Path()
private val paint = Paint()
private var width = 0f
private var height = 0f
private var quadY = 0f
private var cubicY = 0f
private var per = 1.0f
private var quadHeight = 100f
private var cubicHeight = 200f
private var bezierAnim: ValueAnimator? = null
init {
paint.style = Paint.Style.STROKE
paint.strokeWidth = 3f
paint.isDither = true
paint.isAntiAlias = true
}
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
width = w.toFloat()
height = h.toFloat()
quadY = height / 4
cubicY = height - height / 4
}
fun startBezierAnim() {
bezierAnim?.cancel()
bezierAnim = ValueAnimator.ofFloat(1.0f, 0f, 1.0f).apply {
addUpdateListener {
val value = it.animatedValue as Float
per = value
invalidate()
}
addListener(object :AnimatorListener{
override fun onAnimationStart(animation: Animator?) {
}
override fun onAnimationEnd(animation: Animator?) {
}
override fun onAnimationCancel(animation: Animator?) {
}
override fun onAnimationRepeat(animation: Animator?) {
val random = Random(System.currentTimeMillis())
val one = random.nextInt(400).toFloat()
val two = random.nextInt(800).toFloat()
quadHeight = one
cubicHeight = two
}
})
duration = 300
repeatCount = -1
start()
}
}
override fun onDraw(canvas: Canvas?) {
super.onDraw(canvas)
var quadStart = 0f
path.reset()
path.moveTo(quadStart, quadY)
while (quadStart <= width){
path.quadTo(quadStart + 75f, quadY - quadHeight * per, quadStart + 150f, quadY)
path.quadTo(quadStart + 225f, quadY + quadHeight * per, quadStart + 300f, quadY)
quadStart += 300f
}
paint.color = Color.BLUE
canvas?.drawPath(path, paint)
path.reset()
var cubicStart = 0f
path.moveTo(cubicStart, cubicY)
while (cubicStart <= width){
path.cubicTo(cubicStart + 100f, cubicY - cubicHeight * per, cubicStart + 200f, cubicY + cubicHeight * per, cubicStart + 300f, cubicY)
cubicStart += 300f
}
paint.color = Color.RED
canvas?.drawPath(path, paint);
}
}上面基于二阶贝塞尔曲线,下面基于三阶贝塞尔曲线,加了一层属性动画。
四、仿真页的拆分
我们在本篇文章不会涉及到仿真页的代码,主要做一下仿真页的拆分。
下面的这套方案也是总结自何明桂大佬的方案。
从图中的仿真页中我们可以看出,上下一共两页,我们需要处理:
- 第一页的内容
- 第一页的背面
- 第二页露出来的内容
这三部分中,除了 GE 和 FH 是两段曲线,其他都是直线,直线是比较好计算的,先看两段曲线。
通过观察发现,这里的 GE 和 FH 都是对称的,只有一个平滑的弯,用一个控制点就能应付,所以选择二阶贝塞尔曲线就够了。GE 这段二阶段贝塞尔曲线,对应的控制点是 C,FH 对应的控制点是 D。
1. 第一页正面
再看图片,路径 A - F - H - B - G - E - A 之外的就是第一页正面,将内容页和这个路径的 Path 取反即可。
具体的过程:
- 已知 A 是触摸点,B 是内容页的底角点,可以求出中点 M 的坐标
- AB 和 CD 相互垂直,所以可得 CD 的斜率,从 M 点坐标推出 CD 两点坐标
- E 是 AC 中点,F 是 AD 中点,那么 E 和 F 的点位置很容易推导出来
2. 第二页内容
第二页的重点 KLB 这个三角形,M 是 AB 的中点,J 是 AM 的中点,N 是 JM 的重点,通过斜率很容易推导出与边界相交的KL 两点,之后从内容页上裁出 KLB 这个Path,第二页的内容绘制在这个 Path 即可。
3. 第一页的背面
背面这一块儿绘制的区域是三角形 AOP,AC、AD 和 KL 都已知,求出相交的 KL 点即可。
但是我们还得将第一页底部的内容做一个旋转和偏移,再加上一层蒙层,就可以得到我们想要的背面内容。
总结
可以看出,学会了贝塞尔曲线以后,仿真页其实并不算特别复杂,但是整个数学计算还是很麻烦的。
下篇文章再和大家讨论具体的代码,如果觉得本文有什么问题,评论区见!
参考文章:
链接:https://juejin.cn/post/7173850844977168392
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
什么?还在傻傻地手写Parcelable实现?
什么?还在傻傻地手写Parcelable实现?
缘起
序列化已经是Android司空见惯的东西了,场景太多了。就拿Intent来说吧,extra能放的数据,除了基本类型外,就是序列化的数据了,有两种:
Serializable:Java世界自带的序列化工具,大道至简,是一个无方法接口Parcelable:Android的官配序列化工具
这二者在性能、用法乃至适用场景上均有不同,网上的讨论已经很多了,这里不再赘述。
下面来看看官配正品怎么用的。
Android的Parcelable
首先看看官方示例:
public class MyParcelable implements Parcelable {
private int mData;
public int describeContents() {
return 0;
}
public void writeToParcel(Parcel out, int flags) {
out.writeInt(mData);
}
public static final Parcelable.Creator<MyParcelable> CREATOR
= new Parcelable.Creator<MyParcelable>() {
public MyParcelable createFromParcel(Parcel in) {
return new MyParcelable(in);
}
public MyParcelable[] newArray(int size) {
return new MyParcelable[size];
}
};
private MyParcelable(Parcel in) {
mData = in.readInt();
}
}可以总结,实现Parcelable的数据类,有两个要点:
- 必须有一个 非空的、静态的且名为"CREATOR" 的对象,该对象实现
Parcelable.Creator接口 - 实现方法
describeContents,描述内容;
实现方法writeToParcel,将类数据打入parcel内
示例中,实际的数据只有一个简单的整型。
实验:Intent中的Parcelable传递
这里通过一个案例来说明一下Parcelable的使用。
首先,定义一个数据类User,它包含一个String和一个Int:
class User() : Parcelable {
var name: String? = ""
var updatedTime: Long = 0L
constructor(parcel: Parcel) : this() {
name = parcel.readString()
updatedTime = parcel.readLong()
}
constructor(name: String?, time: Long) : this() {
this.name = name
updatedTime = time
}
override fun writeToParcel(parcel: Parcel, flags: Int) {
Log.d("p-test", "write to")
parcel.writeString(name)
parcel.writeLong(updatedTime)
}
override fun describeContents(): Int {
return 0
}
companion object CREATOR : Parcelable.Creator<User> {
override fun createFromParcel(parcel: Parcel): User {
Log.d("p-test", "createFromParcel")
return User(parcel)
}
override fun newArray(size: Int): Array<User?> {
return arrayOfNulls(size)
}
}
override fun toString(): String = "$name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
}启动方带上User数据:
Log.d("p-test", "navigate to receiver")
context.startActivity(Intent(context, ReceiverActivity::class.java).apply {
putExtra("user", User("Dale", System.currentTimeMillis())) // 调用Intent.putExtra(String name, @Nullable Parcelable value)
})接收方读取并显示User数据:
Log.d("p-test", "onCreate")
val desc: User? = intent?.getParcelableExtra("user")
// 省略展示:desc?.toString()来看看日志:
2022-05-18 11:45:28.280 26148-26148 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 11:45:28.282 26148-26148 p-test com.jacee.example.parcelabletest D write to
2022-05-18 11:45:28.342 26148-26148 p-test com.jacee.example.parcelabletest D onCreate
2022-05-18 11:45:28.343 26148-26148 p-test com.jacee.example.parcelabletest D createFromParcel其过程为:
- 启动
- User类调用
writeToParcel,将数据写入Parcel - 接收
CREATOR调用createFromParcel,从Parcel中读取数据,并构造相应的User数据类对象
界面上,User正确展示:
由此,Parcelable的数据类算是正确实现了。
看起来,虽然没有很难,但是,是真心有点儿烦啊,尤其是相较于Java的Serializable来说。有没有简化之法呢?当然有啊,要知道,现在可是Kotlin时代了!
kotlin-parcelize插件
隆重介绍kotlin-parcelize插件:它提供了一个 Parcelable 的实现生成器。有了此生成器,就不必再写如前的复杂代码了。
怎么使用呢?
首先,需要在gradle里面添加此插件:
plugins {
id 'kotlin-parcelize'
}然后,在需要 Parcelable 的数据类上添加 @kotlinx.parcelize.Parcelize 注解就行了。
来吧,改造前面的例子:
import kotlinx.parcelize.Parcelize
@Parcelize
data class User(
val name: String?,
val updatedTime: Long
): Parcelable {
override fun toString(): String = "new: $name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
}哇,简化如斯,真能实现?还是来看看上述代码对应的字节码吧:
@Metadata(
mv = {1, 6, 0},
k = 1,
d1 = {"\u0000:\n\u0002\u0018\u0002\n\u0002\u0018\u0002\n\u0000\n\u0002\u0010\u000e\n\u0000\n\u0002\u0010\t\n\u0002\b\t\n\u0002\u0010\b\n\u0000\n\u0002\u0010\u000b\n\u0000\n\u0002\u0010\u0000\n\u0002\b\u0003\n\u0002\u0010\u0002\n\u0000\n\u0002\u0018\u0002\n\u0002\b\u0002\b\u0087\b\u0018\u00002\u00020\u0001B\u0017\u0012\b\u0010\u0002\u001a\u0004\u0018\u00010\u0003\u0012\u0006\u0010\u0004\u001a\u00020\u0005¢\u0006\u0002\u0010\u0006J\u000b\u0010\u000b\u001a\u0004\u0018\u00010\u0003HÆ\u0003J\t\u0010\f\u001a\u00020\u0005HÆ\u0003J\u001f\u0010\r\u001a\u00020\u00002\n\b\u0002\u0010\u0002\u001a\u0004\u0018\u00010\u00032\b\b\u0002\u0010\u0004\u001a\u00020\u0005HÆ\u0001J\t\u0010\u000e\u001a\u00020\u000fHÖ\u0001J\u0013\u0010\u0010\u001a\u00020\u00112\b\u0010\u0012\u001a\u0004\u0018\u00010\u0013HÖ\u0003J\t\u0010\u0014\u001a\u00020\u000fHÖ\u0001J\b\u0010\u0015\u001a\u00020\u0003H\u0016J\u0019\u0010\u0016\u001a\u00020\u00172\u0006\u0010\u0018\u001a\u00020\u00192\u0006\u0010\u001a\u001a\u00020\u000fHÖ\u0001R\u0013\u0010\u0002\u001a\u0004\u0018\u00010\u0003¢\u0006\b\n\u0000\u001a\u0004\b\u0007\u0010\bR\u0011\u0010\u0004\u001a\u00020\u0005¢\u0006\b\n\u0000\u001a\u0004\b\t\u0010\n¨\u0006\u001b"},
d2 = {"Lcom/jacee/example/parcelabletest/data/User;", "Landroid/os/Parcelable;", "name", "", "updatedTime", "", "(Ljava/lang/String;J)V", "getName", "()Ljava/lang/String;", "getUpdatedTime", "()J", "component1", "component2", "copy", "describeContents", "", "equals", "", "other", "", "hashCode", "toString", "writeToParcel", "", "parcel", "Landroid/os/Parcel;", "flags", "parcelable-test_debug"}
)
@Parcelize
public final class User implements Parcelable {
@Nullable
private final String name;
private final long updatedTime;
public static final android.os.Parcelable.Creator CREATOR = new User.Creator();
@NotNull
public String toString() {
return "new: " + this.name + " - [" + DateFormat.getInstance().format(new Date(this.updatedTime)) + ']';
}
@Nullable
public final String getName() {
return this.name;
}
public final long getUpdatedTime() {
return this.updatedTime;
}
public User(@Nullable String name, long updatedTime) {
this.name = name;
this.updatedTime = updatedTime;
}
@Nullable
public final String component1() {
return this.name;
}
public final long component2() {
return this.updatedTime;
}
@NotNull
public final User copy(@Nullable String name, long updatedTime) {
return new User(name, updatedTime);
}
// $FF: synthetic method
public static User copy$default(User var0, String var1, long var2, int var4, Object var5) {
if ((var4 & 1) != 0) {
var1 = var0.name;
}
if ((var4 & 2) != 0) {
var2 = var0.updatedTime;
}
return var0.copy(var1, var2);
}
public int hashCode() {
String var10000 = this.name;
return (var10000 != null ? var10000.hashCode() : 0) * 31 + Long.hashCode(this.updatedTime);
}
public boolean equals(@Nullable Object var1) {
if (this != var1) {
if (var1 instanceof User) {
User var2 = (User)var1;
if (Intrinsics.areEqual(this.name, var2.name) && this.updatedTime == var2.updatedTime) {
return true;
}
}
return false;
} else {
return true;
}
}
public int describeContents() {
return 0;
}
public void writeToParcel(@NotNull Parcel parcel, int flags) {
Intrinsics.checkNotNullParameter(parcel, "parcel");
parcel.writeString(this.name);
parcel.writeLong(this.updatedTime);
}
@Metadata(
mv = {1, 6, 0},
k = 3
)
public static class Creator implements android.os.Parcelable.Creator {
@NotNull
public final User[] newArray(int size) {
return new User[size];
}
// $FF: synthetic method
// $FF: bridge method
public Object[] newArray(int var1) {
return this.newArray(var1);
}
@NotNull
public final User createFromParcel(@NotNull Parcel in) {
Intrinsics.checkNotNullParameter(in, "in");
return new User(in.readString(), in.readLong());
}
// $FF: synthetic method
// $FF: bridge method
public Object createFromParcel(Parcel var1) {
return this.createFromParcel(var1);
}
}
}嗯,十分眼熟 —— 这不就是 完美且完整地实现了Parcelable 吗?当然是能正确工作的!
2022-05-18 13:13:30.197 27258-27258 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 13:13:30.237 27258-27258 p-test com.jacee.example.parcelabletest D onCreate复杂的序列化逻辑
如果需要添加更复杂的序列化逻辑,就需要额外通过伴随对象实现,该对象需要实现接口 Parceler:
interface Parceler<T> {
/**
* Writes the [T] instance state to the [parcel].
*/
fun T.write(parcel: Parcel, flags: Int)
/**
* Reads the [T] instance state from the [parcel], constructs the new [T] instance and returns it.
*/
fun create(parcel: Parcel): T
/**
* Returns a new [Array]<T> with the given array [size].
*/
fun newArray(size: Int): Array<T> {
throw NotImplementedError("Generated by Android Extensions automatically")
}
}看样子,Parceler 和原生 Parcelable.Creator 十分像啊,不过多了一个 write 函数 —— 其实就是对应了Parcelable.writeToParcel方法。
简单打印点日志模拟所谓的“复杂的序列化逻辑”:
@Parcelize
data class User(
val name: String?,
val updatedTime: Long
): Parcelable {
override fun toString(): String = "new: $name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
private companion object : Parceler<User> {
override fun create(parcel: Parcel): User {
Log.d("p-test", "new: create")
return User(parcel.readString(), parcel.readLong())
}
override fun User.write(parcel: Parcel, flags: Int) {
Log.d("p-test", "new: write to")
parcel.writeString("【${name}】")
parcel.writeLong(updatedTime)
}
}
}来看看:
2022-05-18 13:24:49.365 29603-29603 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 13:24:49.366 29603-29603 p-test com.jacee.example.parcelabletest D new: write to
2022-05-18 13:24:49.450 29603-29603 p-test com.jacee.example.parcelabletest D onCreate
2022-05-18 13:24:49.450 29603-29603 p-test com.jacee.example.parcelabletest D new: create果然调用了,其中,接收方拿到的name,确实就是write函数改造过的(加了“【】”):
映射序列化
假如数据类不能直接支持序列化,那就可以通过自定义一个Parceler,实现映射序列化。
怎么理解呢?假如有一个数据类A,是一个普通实现,不支持序列化(或者有其他原因,总之是不支持),但是呢,我们又有需求是将它序列化后使用,这时候就可以实现 Parceler<A> 类,然后用包裹A的类B来实现序列化 —— 即,通过Parceler,将普通的A包裹成了序列化的B。
// 目标数据类A
data class User(
val name: String?,
val updatedTime: Long
) {
override fun toString(): String = "new: $name - [${
DateFormat.getInstance().format(Date(updatedTime))
}]"
}
// 实现的Parceler<A>
object UserParceler: Parceler<User> {
override fun create(parcel: Parcel): User {
Log.d("djx_test", "1 new: create")
return User(parcel.readString(), parcel.readLong())
}
override fun User.write(parcel: Parcel, flags: Int) {
Log.d("djx_test", "1 new: write to")
parcel.writeString("【${name}】")
parcel.writeLong(updatedTime)
}
}
// 映射类B
@Parcelize
@TypeParceler<User, UserParceler>
class Target(val value: User): Parcelable // 这个类来实现Parcelable如上就是 A -> B 的序列化映射,同样没问题:
2022-05-18 14:08:26.091 30639-30639 p-test com.jacee.example.parcelabletest D navigate to receiver
2022-05-18 14:08:26.094 30639-30639 p-test com.jacee.example.parcelabletest D 1 new: write to
2022-05-18 14:08:26.148 30639-30639 p-test com.jacee.example.parcelabletest D onCreate
2022-05-18 14:08:26.148 30639-30639 p-test com.jacee.example.parcelabletest D 1 new: create上面的映射类B,还可以这么写:
@Parcelize
class Target(@TypeParceler<User, UserParceler> val value: User): Parcelable
// 或
@Parcelize
class Target(val value: @WriteWith<UserParceler> User): Parcelable总结
说了这么多,其实总结一下就是:
插件kotlin-parcelize接管了套路化、模版化的工作,帮我们自动生成了序列化的实现,它并没有改变 Parcelable 的实现方式。
用它就对了!
链接:https://juejin.cn/post/7098969859777789966
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
聊一聊Kotlin协程"低级"api
聊一聊kotlin协程“低级”api
Kotlin协程已经出来很久了,相信大家都有不同程度的用上了,由于最近处理的需求有遇到协程相关,因此今天来聊一Kotlin协程的“低级”api,首先低级api并不是它真的很“低级”,而是kotlin协程库中的基础api,我们一般开发用的,其实都是通过低级api进行封装的高级函数,本章会通过低级api的组合,实现一个自定义的async await 函数(下文也会介绍kotlin 高级api的async await),涉及的低级api有startCoroutine ,ContinuationInterceptor 等
startCoroutine
我们知道,一个suspend关键字修饰的函数,只能在协程体中执行,伴随着suspend 关键字,kotlin coroutine common库(平台无关)也提供出来一个api,用于直接通过suspend 修饰的函数直接启动一个协程,它就是startCoroutine
@SinceKotlin("1.3")
@Suppress("UNCHECKED_CAST")
public fun <R, T> (suspend R.() -> T).startCoroutine(
作为Receiver
receiver: R,
当前协程结束时的回调
completion: Continuation<T>
) {
createCoroutineUnintercepted(receiver, completion).intercepted().resume(Unit)
}可以看到,它的Receiver是(suspend R.() -> T),即是一个suspend修饰的函数,那么这个有什么作用呢?我们知道,在普通函数中无法调起suspend函数(因为普通函数没有隐含的Continuation对象,这里我们不在这章讲,可以参考kotlin协程的资料)
但是普通函数是可以调起一个以suspend函数作为Receiver的函数(本质也是一个普通函数)
其中startCoroutine就是其中一个,本质就是我们直接从外部提供了一个Continuation,同时调用了resume方法,去进入到了协程的世界
startCoroutine实现
createCoroutineUnintercepted(completion).intercepted().resume(Unit)这个原理我们就不细讲下去原理,之前也有写过相关的文章。通过这种调用,我们其实就可以实现在普通的函数环境,开启一个协程环境(即带有了Continuation),进而调用其他的suspend函数。
ContinuationInterceptor
我们都知道拦截器的概念,那么kotlin协程也有,就是ContinuationInterceptor,它提供以AOP的方式,让外部在resume(协程恢复)前后进行自定义的拦截操作,比如高级api中的Diapatcher就是。当然什么是resume协程恢复呢,可能读者有点懵,我们还是以上图中出现的mySuspendFunc举例子
mySuspendFunc是一个suspned函数
::mySuspendFunc.startCoroutine(object : Continuation<Unit> {
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: Result<Unit>) {
}
})它其实等价于
val continuation = ::mySuspendFunc.createCoroutine(object :Continuation<Unit>{
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: Result<Unit>) {
Log.e("hello","当前协程执行完成的回调")
}
})
continuation.resume(Unit)startCoroutine方法就相当于创建了一个Continuation对象,并调用了resume。创建Continuation可通过createCoroutine方法,返回一个Continuation,如果我们不调用resume方法,那么它其实什么也不会执行,只有调用了resume等执行方法之后,才会执行到后续的协程体(这个也是协程内部实现,感兴趣可以看看之前文章)
而我们的拦截器,就相当于在continuation.resume前后,可以添加自己的逻辑。我们可以通过继承ContinuationInterceptor,实现自己的拦截器逻辑,其中需要复写的方法是interceptContinuation方法,用于返回一个自己定义的Continuation对象,而我们可以在这个Continuation的resumeWith方法里面(当调用了resume之后,会执行到resumeWith方法),进行前后打印/其他自定义操作(比如切换线程)
class ClassInterceptor() :ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>):Continuation<T> by continuation{
override fun resumeWith(result: Result<T>) {
Log.e("hello","MyContinuation start ${result.getOrThrow()}")
continuation.resumeWith(result)
Log.e("hello","MyContinuation end ")
}
}其中的key是ContinuationInterceptor,协程内部会在每次协程恢复的时候,通过coroutineContext取出key为ContinuationInterceptor的拦截器,进行拦截调用,当然这也是kotlin协程内部实现,这里简单提一下。
实战
kotlin协程api中的 async await
我们来看一下kotlon Coroutine 的高级api async await用法
CoroutineScope(Dispatchers.Main).launch {
val block = async(Dispatchers.IO) {
// 阻塞的事项
}
// 处理其他主线程的事务
// 此时必须需要async的结果时,则可通过await()进行获取
val result = block.await()
}我们可以通过async方法,在其他线程中处理其他阻塞事务,当主线程必须要用async的结果的时候,就可以通过await等待,这里如果结果返回了,则直接获取值,否则就等待async执行完成。这是Coroutine提供给我们的高级api,能够将任务简单分层而不需要过多的回调处理。
通过startCoroutine与ContinuationInterceptor实现自定义的 async await
我们可以参考其他语言的async,或者Dart的异步方法调用,都有类似这种方式进行线程调用
async {
val result = await {
suspend 函数
}
消费result
}await在async作用域里面,同时获取到result后再进行消费,async可以直接在普通函数调用,而不需要在协程体内,下面我们来实现一下这个做法。
首先我们想要限定await函数只能在async的作用域才能使用,那么首先我们就要定义出来一个Receiver,我们可以在Receiver里面定义出自己想要暴露的方法
interface AsyncScope {
fun myFunc(){
}
}
fun async(
context: CoroutineContext = EmptyCoroutineContext,
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}
注意这个类,resumeWith 只会跟startCoroutine的这个协程绑定关系,跟await的协程没有关系
class AsyncStub(override val context: CoroutineContext = EmptyCoroutineContext) :
Continuation<Unit>, AsyncScope {
override fun resumeWith(result: Result<Unit>) {
// 这个是干嘛的 == > 完成的回调
Log.e("hello","AsyncStub resumeWith ${Thread.currentThread().id} ${result.getOrThrow()}")
}
}上面我们定义出来一个async函数,同时定义出来了一个AsyncStub的类,它有两个用处,第一个是为了充当Receiver,用于规范后续的await函数只能在这个Receiver作用域中调用,第二个作用是startCoroutine函数必须要传入一个参数completion,是为了收到当前协程结束的回调resumeWith中可以得到当前协程体结束回调的信息
await方法里面
suspend fun<T> AsyncScope.await(block:() -> T) = suspendCoroutine<T> {
// 自定义的Receiver函数
myFunc()
Thread{
切换线程执行await中的方法
it.resumeWith(Result.success(block()))
}.start()
}在await中,其实是一个扩展函数,我们可以调用任何在AsyncScope中定义的方法,同时这里我们模拟了一下线程切换的操作(Dispatcher的实现,这里不采用Dispatcher就是想让大家知道其实Dispatcher.IO也是这样实现的),在子线程中调用it.resumeWith(Result.success(block())),用于返回所需要的信息
通过上面定的方法,我们可以实现
async {
val result = await {
suspend 函数
}
消费result
}这种调用方式,但是这里引来了一个问题,因为我们在await函数中实际将操作切换到了子线程,我们想要将消费result的动作切换至主线程怎么办呢?又或者是加入我们希望获取结果前做一些调整怎么办呢?别急,我们这里预留了一个CoroutineContext函数,我们可以在外部传入一个CoroutineContext
public interface ContinuationInterceptor : CoroutineContext.Element
而CoroutineContext.Element又是继承于CoroutineContext
CoroutineContext.Element:CoroutineContext而我们的拦截器,正是CoroutineContext的子类,我们把上文的ClassInterceptor修改一下
class ClassInterceptor() : ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>) :
Continuation<T> by continuation {
private val handler = Handler(Looper.getMainLooper())
override fun resumeWith(result: Result<T>) {
Log.e("hello", "MyContinuation start ${result.getOrThrow()}")
handler.post {
continuation.resumeWith(Result.success(自定义内容))
}
Log.e("hello", "MyContinuation end ")
}
}同时把async默认参数CoroutineContext实现一下即可
fun async(
context: CoroutineContext = ClassInterceptor(),
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}此后我们就可以直接通过,完美实现了一个类js协程的调用,同时具备了自动切换线程的能力
async {
val result = await {
test()
}
Log.e("hello", "result is $result ${Looper.myLooper() == Looper.getMainLooper()}")
}结果
E start
E MyContinuation start kotlin.Unit
E MyContinuation end
E end
E 执行阻塞函数 test 1923
E MyContinuation start 自定义内容数值
E MyContinuation end
E result is 自定义内容的数值 true
E AsyncStub resumeWith 2 kotlin.Unit最后,这里需要注意的是,为什么拦截器回调了两次,因为我们async的时候开启了一个协程,同时await的时候也开启了一个,因此是两个。AsyncStub只回调了一次,是因为AsyncStub被当作complete参数传入了async开启的协程block.startCoroutine,因此只是async中的协程结束才会被回调。
本章代码
class ClassInterceptor() : ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>) :
Continuation<T> by continuation {
private val handler = Handler(Looper.getMainLooper())
override fun resumeWith(result: Result<T>) {
Log.e("hello", "MyContinuation start ${result.getOrThrow()}")
handler.post {
continuation.resumeWith(Result.success(6 as T))
}
Log.e("hello", "MyContinuation end ")
}
}interface AsyncScope {
fun myFunc(){
}
}
fun async(
context: CoroutineContext = ClassInterceptor(),
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}
class AsyncStub(override val context: CoroutineContext = EmptyCoroutineContext) :
Continuation<Unit>, AsyncScope {
override fun resumeWith(result: Result<Unit>) {
// 这个是干嘛的 == > 完成的回调
Log.e("hello","AsyncStub resumeWith ${Thread.currentThread().id} ${result.getOrThrow()}")
}
}
suspend fun<T> AsyncScope.await(block:() -> T) = suspendCoroutine<T> {
myFunc()
Thread{
it.resumeWith(Result.success(block()))
}.start()
}模拟阻塞
fun test(): Int {
Thread.sleep(5000)
Log.e("hello", "执行阻塞函数 test ${Thread.currentThread().id}")
return 5
}async {
val result = await {
test()
}
Log.e("hello", "result is $result ${Looper.myLooper() == Looper.getMainLooper()}")
}最后
我们通过协程的低级api,实现了一个与官方库不同版本的async await,同时也希望通过对低级api的设计,也能对Coroutine官方库的高级api的实现有一定的了解。
链接:https://juejin.cn/post/7172813333148958728
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter — 仅用三个步骤就能帮你把文本变得炫酷!
前言:
前天,一位不愿意透露姓名的朋友找到我,问我怎么样才能把文本变得炫酷一些,他想用图片嵌入到自己的名字里去,用来当作朋友圈的背景。我直接回了一句,你PS下不就好了。他回我一句:想要这样效果的人比较多,全部都PS的话怕不是电脑要干冒烟...能不能用代码自动生成下(请你喝奶茶🍹)。作为一个乐于助人的人,看到朋友有困难,而且实现起来也不复杂,那我必须要帮忙啊~
注:本文是一篇整活文,让大家看的开心最重要~文章只对核心代码做分析,完整代码在这里
话不多说,直接上图:
填入文本中的可以是手动上传的图片,也可以是彩色小块。
功能实现步骤分析:
1.数据的获取 — 获取输入的文本数据、获取输入的图片数据。
2.将输入的文本生成为图片
3.解析文本图片,替换像素为图片
简单三步骤,实现朴素到炫酷的转换~
1.数据的获取 — 获取输入的文本数据、获取输入的图片数据。
定义需要存放的数据
//用于获取输入的文本
TextEditingController textEditingController = TextEditingController();
//存放输入的图片
List<File> imagesPath = [];输入框
Container(
margin: const EdgeInsets.all(25.0),
child: TextField(
controller: textEditingController,
decoration: const InputDecoration(
hintText: "请输入文字",
border: OutlineInputBorder(
borderRadius: BorderRadius.all(Radius.circular(16.0)))),
),
),九宫格图片封装
@override
Widget build(BuildContext context) {
var maxWidth = MediaQuery.of(context).size.width;
//计算不同数量时,图片的大小
var _ninePictureW = (maxWidth - _space * 2 - 2 * _itemSpace - lRSpace);
...
return Offstage(
offstage: imgData!.length == -1,
child: SizedBox(
width: _bgWidth,
height: _bgHeight,
child: GridView.builder(
gridDelegate: SliverGridDelegateWithFixedCrossAxisCount(
// 可以直接指定每行(列)显示多少个Item
crossAxisCount: _crossAxisCount, // 一行的Widget数量
crossAxisSpacing: _itemSpace, // 水平间距
mainAxisSpacing: _itemSpace, // 垂直间距
childAspectRatio: _childAspectRatio, // 子Widget宽高比例
),
// 禁用滚动事件
physics: const NeverScrollableScrollPhysics(),
// GridView内边距
padding: const EdgeInsets.only(left: _space, right: _space),
itemCount:
imgData!.length < 9 ? imgData!.length + 1 : imgData!.length,
itemBuilder: (context, index) {
if (imgData!.isEmpty) {
return _addPhoto(context);
} else if (index < imgData!.length) {
return _itemCell(context, index);
} else if (index == imgData!.length) {
return _addPhoto(context);
}
return SizedBox();
}),
),
);
}添加图片
使用A佬的
wechat_assets_picker,要的就是效率~Future<void> selectAssets() async {
//获取图片
final List<AssetEntity>? result = await AssetPicker.pickAssets(
context,
);
List<File> images = [];
//循环取出File
if (result != null) {
for (int i = 0; i < result.length; i++) {
AssetEntity asset = result[i];
File? file = await asset.file;
if (file != null) {
images.add(file);
}
}
}
//更新状态,修改存放File的数组
setState(() {
imagesPath = images;
});
}
2.将输入的文本生成为图片
构建输入的文本布局
RepaintBoundary(
key: repaintKey,
child: Container(
color: Colors.white,
width: MediaQuery.of(context).size.width,
height: 300,
//image是解析图片的数据
child: image != null
? PhotoLayout(
n: 1080,
m: 900,
image: image!,
fileImages: widget.images)
:
//将输入的文本布局
Center(
child: Text(
widget.photoText,
style: const TextStyle(
fontSize: 100, fontWeight: FontWeight.bold),
),
),
)),通过
RepaintBoundary将生成的布局生成Uint8List数据/// 获取截取图片的数据,并解码
Future<img.Image?> getImageData() async {
//生成图片数据
BuildContext buildContext = repaintKey.currentContext!;
Uint8List imageBytes;
RenderRepaintBoundary boundary =
buildContext.findRenderObject() as RenderRepaintBoundary;
double dpr = ui.window.devicePixelRatio;
ui.Image image = await boundary.toImage(pixelRatio: dpr);
// image.width
ByteData? byteData = await image.toByteData(format: ui.ImageByteFormat.png);
imageBytes = byteData!.buffer.asUint8List();
var tempDir = await getTemporaryDirectory();
//生成file文件格式
var file =
await File('${tempDir.path}/image_${DateTime.now().millisecond}.png')
.create();
//转成file文件
file.writeAsBytesSync(imageBytes);
//存放生成的图片到本地
// final result = await ImageGallerySaver.saveFile(file.path);
return img.decodeImage(imageBytes);
}
3.解析文本图片,替换像素为图片
判断文本像素,在对应像素位置生成图片
Widget buildPixel(int x, int y) {
int index = x * n + y;
//根据给定的x和y坐标,获取像素的颜色编码
Color color = Color(image.getPixel(y, x));
//判断是不是白色的像素点,如果是,则用SizedBox替代
if (color == Colors.white) {
return const SizedBox.shrink();
}
else {
//如果不是,则代表是文本所在的像素,替换为输入的图片
return Image.file(
fileImages![index % fileImages!.length],
fit: BoxFit.cover,
);
}
}构建最终生成的图片
@override
Widget build(BuildContext context) {
List<Widget> children = [];
//按点去渲染图片的像素位置,每次加10是因为,图像的像素点很多,如果每一个点都替换为图片,第一是效果不好,第二是渲染的时间很久。
for (int i = 0; i < n; i = i+10) {
List<Widget> columnChildren = [];
for (int x = 0; x < m; x = x+10) {
columnChildren.add(
Expanded(
child: buildPixel(x, i),
),
);
}
children.add(Expanded(
child: Column(
crossAxisAlignment: CrossAxisAlignment.stretch,
children: columnChildren,
)));
}
//CrossAxisAlignment.stretch:子控件完全填充交叉轴方向的空间
return Row(
crossAxisAlignment: CrossAxisAlignment.stretch,
children: children,
);
}
这样就实现了文本替换为图片的功能啦~
链接:https://juejin.cn/post/7173112836569169927
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 控件自动贴边实现
最近接到个需求,需要在用户与App交互时,把SDK中之前实现过的悬浮控件贴边隐藏,结束交互后延迟一段时间再自动显示。本篇文章介绍一下实现的思路。
判断交互
用户与App交互、结束交互可以通过监听触摸事件来实现。建议使用的Activity的dispatchTouchEvent,Activity下的所有触摸事件分发时都会回调此方法,代码如下:
class AutoEdgeHideActivity : BaseGestureDetectorActivity() {
override fun dispatchTouchEvent(ev: MotionEvent): Boolean {
when (ev.action) {
MotionEvent.ACTION_DOWN -> {
// 手指按下,开始本次交互
// 在此实现隐藏逻辑
}
MotionEvent.ACTION_UP -> {
// 手指抬起,结束本次交互
// 在此实现延迟显示功能
}
}
return super.dispatchTouchEvent(ev)
}
}隐藏与显示
想要实现的效果是当用户与App交互时,悬浮控件平移贴边,但保留一部分显示。结束交互延迟一段时间后,悬浮控件平移回原来的位置。
此处通过ValueAnimator来实现,计算好控件的起始和结束位置,然后改变控件的x坐标,代码如下:
private fun xCoordinateAnimator(view: View, startX: Float, endX: Float) {
val animator = ValueAnimator.ofFloat(startX, endX)
animator.addUpdateListener {
// 不断更改控件的X坐标
view.x = it.animatedValue as Float
}
// 设置插值器,速度由快变慢
animator.interpolator = DecelerateInterpolator()
// 设置动画的持续时间
animator.duration = 500
animator.start()
}示例
整合之后做了个示例Demo,完整代码如下:
class AutoEdgeHideActivity : BaseGestureDetectorActivity() {
private lateinit var binding: LayoutAutoEdgeHideActivityBinding
private var widthPixels: Int = 0
private val autoShowInterval = 2
private var interacting = false
private var hidden = false
private var lastPositionX: Float = 0f
private val handler = Handler(Looper.myLooper() ?: Looper.getMainLooper())
private val autoShowRunnable = Runnable { autoShow() }
@SuppressLint("SetTextI18n")
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.layout_auto_edge_hide_activity)
widthPixels = resources.displayMetrics.widthPixels
binding.includeTitle.tvTitle.text = "AutoEdgeHideExample"
binding.vFloatView.setOnClickListener {
if (hidden) {
// 当前为隐藏状态,先显示
// 把之前的延迟线程先取消
handler.removeCallbacks(autoShowRunnable)
autoShow()
Toast.makeText(this, "手动显示控件", Toast.LENGTH_SHORT).show()
} else {
// 相应正常的事件
Toast.makeText(this, "点击了浮标控件", Toast.LENGTH_SHORT).show()
}
}
}
override fun dispatchTouchEvent(ev: MotionEvent): Boolean {
when (ev.action) {
MotionEvent.ACTION_DOWN -> {
if (!checkIsTouchFloatView(ev, binding.vFloatView)) {
// 起始ACTION_DOWN事件在浮标控件外,自动隐藏浮标控件,标记正在交互
interacting = true
handler.removeCallbacks(autoShowRunnable)
autoHide()
}
}
MotionEvent.ACTION_UP -> {
if (interacting) {
// 交互结束,一定时间后自动显示,时间可以自由配置
interacting = false
handler.postDelayed(autoShowRunnable, autoShowInterval * 1000L)
}
}
}
return super.dispatchTouchEvent(ev)
}
/**
* 检查是否触摸浮标控件
*/
private fun checkIsTouchFloatView(ev: MotionEvent, view: View): Boolean {
val screenLocation = IntArray(2)
view.getLocationOnScreen(screenLocation)
val viewX = screenLocation[0]
val viewY = screenLocation[1]
return (ev.x >= viewX && ev.x <= (viewX + view.width)) && (ev.y >= viewY && ev.y <= (viewY + view.height))
}
private fun autoShow() {
if (hidden) {
hidden = false
binding.vFloatView.let {
xCoordinateAnimator(it, it.x, lastPositionX)
}
}
}
private fun autoHide() {
if (!hidden) {
hidden = true
binding.vFloatView.let {
// 记录一下显示状态下的x坐标
lastPositionX = it.x
// 隐藏时的x坐标,留一点控件的边缘显示(示例中默认控件在屏幕右侧)
val endX = widthPixels - it.width * 0.23f
xCoordinateAnimator(it, lastPositionX, endX)
}
}
}
private fun xCoordinateAnimator(view: View, startX: Float, endX: Float) {
val animator = ValueAnimator.ofFloat(startX, endX)
animator.addUpdateListener {
view.x = it.animatedValue as Float
}
animator.interpolator = DecelerateInterpolator()
animator.duration = 500
animator.start()
}
}效果如图:
链接:https://juejin.cn/post/7170191911284637727
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
终于理解~Android 模块化里的资源冲突
⚽ 前言
作为 Android 开发者,我们常常需要去管理非常多不同的资源文件,编译时这些资源文件会被统一地收集和整合到同一个包下面。根据官方的《Configure your build》文档介绍的构建过程可以总结这个过程:
- 编译器会将源码文件转换成包含了二进制字节码、能运行在 Android 设备上的 DEX 文件,而其他文件则被转换成编译后资源。
- APK 打包工具则会将 DEX 文件和编译后资源组合成独立的 APK 文件。
但如果资源的命名发生了碰撞、冲突,会对编译产生什么影响?
事实证明这个影响是不确定的,尤其是涉及到构建外部 Library。
本文将探究一些不同的资源冲突案例,并逐个说明怎样才能安全地命名资源。
🇦🇷 App module 内资源冲突
先来看个最简单的资源冲突的案例:同一个资源文件中出现两个命名、类型一样的资源定义,比如:
<!--strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
<string name="hello_world">Hello World!</string>
</resources>试图去编译的话,会导致显而易见的错误提示:
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> /.../strings.xml: Error: Found item String/hello_world more than one time
类似的,另一种常见冲突是在多个文件里定义冲突的资源:
<!--strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
</resources>
<!--other_strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
</resources>我们会收到类似的编译错误,而这次的错误将列出所有发生冲突的具体文件位置。
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> [string/hello_world] /.../other_strings.xml
[string/hello_world] /.../strings.xml: Error: Duplicate resourcesAndroid 平台上资源的运作方式变得愈加清晰。我们需要为 App module 指定在类型、名称、设备配置等限定组合下的唯一资源。也就是说,当 App module 引用 string/hello_world 资源的时候,有且仅有一个值被解析出来。开发者们必须解决发生的资源冲突,可以选择删除那些内容重复的资源、重命名仍然需要的资源、亦或移动到其他限定条件下的资源文件。
更多关于资源和限定的信息可以参考官方的《App resources overview》 文档。
🇩🇪 Library 和 App module 的资源冲突
下面这个案例,我们将研究 Library module 定义了一个和 App module 重复的资源而引发的冲突。
<!--app/../strings.xml-->
<resources>
<string name="hello">Hello from the App!</string>
</resources>
<!--library/../strings.xml-->
<resources>
<string name="hello">Hello from the Library!</string>
</resources>当你编译上面的代码的时候,发现竟然通过了。从我们上个章节的发现来看,我们可以推测 Android 肯定采用了一个规则,去确保在这种场景下仍能够找到一个独有的 string/hello 资源值。
根据官方的《Create an Android library》文档:
编译工具会将来自 Library module 的资源和独立的 App module 资源进行合并。如果双方均具备一个资源 ID 的话,将采用 App 的资源。
这样的话,将会对模块化的 App 开发造成什么影响?比如我们在 Library 中定义了这么一个 TextView 布局:
<!--library/../text_view.xml-->
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@string/hello"
xmlns:android="http://schemas.android.com/apk/res/android" />AS 中该布局的预览是这样的。
现在我们决定将这个 TextView 导入到 App module 的布局中:
<!--app/../activity_main.xml-->
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:gravity="center"
tools:context=".MainActivity"
>
<include layout="@layout/text_view" />
</LinearLayout>无论是 AS 中预览还是实际运行,我们可以看到下面的一个显示结果:
不仅是通过布局访问 string/hello 的 App module 会拿到 “Hello from the App!”,Library 本身拿到的也是如此。基于这个原因,我们需要警惕不要无意覆盖 Lbrary 中的资源定义。
🇧🇷 Library 之间的资源冲突
再一个案例,我们将讨论下当多个 Library 里定义了冲突的资源,会发生什么。
首先来看下如下的布局,如果这样写的话会产生什么结果?
<!--library1/../strings.xml-->
<resources>
<string name="hello">Hello from Library 1!</string>
</resources>
<!--library2/../strings.xml-->
<resources>
<string name="hello">Hello from Library 2!</string>
</resources>
<!--app/../activity_main.xml-->
<TextView
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@string/hello" />string/hello 将会被显示成什么?
事实上这取决于 App build.gradle 文件里依赖这些 Library 的顺序。再次到官方的《Create an Android library》文档里找答案:
如果多个 AAR 库之间发生了冲突,依赖列表里第一个列出(在依赖关系块的顶部)的资源将会被使用。
假使 App module 有这样的依赖列表:
dependencies {
implementation project(":library1")
implementation project(":library2")
...
}最后 string/hello 的值将会被编译成 Hello from Library 1!。
那么如果这两个 implementation 代码调换顺序,比如 implementation project(":library2") 在前、 implementation project(":library1") 在后,资源值则会被编译成 Hello from Library 2!。
从这种微妙的变化可以非常直观地看到,依赖顺序可以轻易地改变 App 的资源展示结果。
🇪🇸 自定义 Attributes 的资源冲突
目前为止讨论的示例都是针对 string 资源的使用,然而需要特别留意的是自定义 attributes 这种有趣的资源类型。
看下如下的 attr 定义:
<!--app/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable">
<attr name="freeText" format="string"/>
</declare-styleable>
<declare-styleable name="CustomStyleable2">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>大家可能都认为上面的写法能通过编译、不会报错,而事实上这种写法必将导致下面的编译错误:
Execution failed for task ':app:mergeDebugResources'.
> /.../attrs.xml: Error: Found item Attr/freeText more than one time但如果 2 个 Library 也采用了这样的自定义 attr 写法:
<!--library1/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>
<!--library2/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable2">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>事实上它却能够通过编译。
然而,如果我们进一步将 Library2 的 attr 做些调整,比如改为 <attr name="freeText" format="boolean"/>。再次编译,它竟然又失败了,而且出现了更多令人费解的错误:
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> A failure occurred while executing com.android.build.gradle.internal.tasks.Workers$ActionFacade
> Android resource compilation failed
/.../library2/build/intermediates/packaged_res/debug/values/values.xml:4:5-6:25: AAPT: error: duplicate value for resource 'attr/freeText' with config ''.
/.../library2/build/intermediates/packaged_res/debug/values/values.xml:4:5-6:25: AAPT: error: resource previously defined here.
/.../app/build/intermediates/incremental/mergeDebugResources/merged.dir/values/values.xml: AAPT: error: file failed to compile.上面错误的一个重点是: mergeDebugResources/merged.dir/values/values.xml: AAPT: error: file failed to compile。
到底是怎么回事呢?
事实上 values.xml 的编译指的是为 App module 生成 R 类。编译期间,AAPT 会尝试在 R 类里为每个资源属性生成独一无二的值。而对于 styleable 类型里的每个自定义 attr,都会在 R 类里生成 2 个的属性值。
第一个是 styleable 命名空间属性值(位于 R.styleable 包下),第二个是全局的 attr 属性值(位于 R.attr 包下)。对于这个探讨的特殊案例,我们则遇到了全局属性值的冲突,并且由于此冲突造成存在 3 个属性值:
R.styleable.CustomStyleable_freeText:来自 Library1,用于解析string格式的、名称为freeText的 attrR.styleable.CustomStyleable2_freeText:来自 Library2,用于解析boolean格式的、名称为freeText的 attrR.attr.freeText:无法被成功解析,源自我们给它赋予了来自 2 个 Library 的数值,而它们的格式不同,造成了冲突
前面能通过编译的示例是因为 Library 间同名的 R.attr.freeText 格式也相同,最终为 App module 编译到的是独一无二的数值。需要注意:每个 module 具备自己的 R 类,我们不能总是指望属性的数值在 Library 间保持一致。
再次看下官方的《Create an Android library》文档的建议:
当你构建依赖其他 Library 的 App module 时,Library module 们将会被编译成 AAR 文件再添加到 App module 中。所以,每个 Library 都会具备自己的
R类,用 Library 的包名进行命名。所有包都会创建从 App module 和 Library module 生成的R类,包括 App module 的包和 Library moudle 的包。
📝 结语
所以我们能从上面的这些探讨得到什么启发?
是资源编译过程的复杂和微妙吗?
确实是的。但是作为开发者,我们能为自己和团队做的是:解释清楚定义的资源想要做什么,也就是说可以加上名称前缀。我们最喜欢的官方文档《Create an Android library》也提到了这宝贵的一点:
通用的资源 ID 应当避免发生资源冲突,可以考虑使用前缀或其他一致的、对 module 来说独一无二的命名方案(抑或是整个项目都是独一无二的命名)。
根据这个建议,比较好的做法是在我们的项目和团队中建立一个模式:在 module 中的所有资源前加上它的 module 名称,例如library_help_text。
这将带来两个好处:
大大降低了名称冲突的概率。
明确资源覆盖的意图。
比如也在 App module 中创建
library_help_text的话,则表明开发者是有意地覆盖 Library module 中的某些定义。有的时候我们的确会想去覆盖一些其他资源,而这样的编码方式可以明确地告诉自己和团队,在编译的时候会发生预期的覆盖。
抛开内部开发不谈,至少是所有公开的资源都应该加上前缀,尤其是作为一个供应商或者开源项目去发布我们的 library。
可以往的经验来看,Google 自己的 library 也没有对所有的资源进行恰当地前缀命名。这将导致意外的副作用:依赖我们发行的 library 可能会因为命名冲突引发 App 编译失败。
Not a great look!
例如,我们可以看到 Material Design library 会给它们的颜色资源统一地添加 mtrl 的前缀。可是 styleable 下嵌套的 attribute resources 却没有使用 material 之类的前缀。
所以你会看到:假使一个 module 依赖了 Material library,同时依赖的另一个 library 中包含了与 Material library 一样名称的 attribute,那么在为这个 moudle 生成 R 类的时候,会发生冲突的可能。
链接:https://juejin.cn/post/7170562275374268447
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter App开发黑白化UI实现方案ColorFiltered
一、相信大家对App黑白化并不陌生,经常可以看到大厂的App在一定的时候会呈现黑白样式如下:
这种效果在原生开发上大家肯定或多或少都了解过,原理都是在根布局绘制的时候将画笔饱和度设置成0;具体实现大家可以搜一搜这里就不贴了。
二、下面就来说说在Flutter这一侧需要怎么实现
- 原理和原生还是一样都是将饱和度设置成0,不过在Flutter这实现起来会比在原生更加的简单。
- Flutter直接为我们提供了ColorFiltered组件(以Color作为源的混合模式Widget)。
- 只需要将ColorFiltered做为根组件(包裹MaterialApp)即可改变整个应用的颜色模式。
实现的最终代码如下
class SaturationWidget extends StatelessWidget {
final Widget child;
///value [0,1]
final double saturation;
const SaturationWidget({
required this.child,
this.saturation = 0,
Key? key,
}) : super(key: key);
@override
Widget build(BuildContext context) {
return ColorFiltered(
colorFilter: ColorFilter.matrix(_saturation(saturation)),
child: child,
);
}
///Default matrix
List<double> get _matrix => [
1, 0, 0, 0, 0, //R
0, 1, 0, 0, 0, //G
0, 0, 1, 0, 0, //B
0, 0, 0, 1, 0, //A
];
///Generate a matrix of specified saturation
///[sat] A value of 0 maps the color to gray-scale. 1 is identity.
List<double> _saturation(double sat) {
final m = _matrix;
final double invSat = 1 - sat;
final double R = 0.213 * invSat;
final double G = 0.715 * invSat;
final double B = 0.072 * invSat;
m[0] = R + sat;
m[1] = G;
m[2] = B;
m[5] = R;
m[6] = G + sat;
m[7] = B;
m[10] = R;
m[11] = G;
m[12] = B + sat;
return m;
}
}- 通过4x5的R、G、B、A、颜色矩阵来生成一个colorFilter
- 最终通过饱和度的值来计算颜色矩阵(饱和度计算算法从Android原生copy过来的)这样就轻松实现了整个App的黑白化(不过iOS的webview是不支持的)
三、最后来看下实现的效果
链接:https://juejin.cn/post/7172022347262590984
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin协程之一文看懂Channel管道
概述
Channel 类似于 Java 的 BlockingQueue 阻塞队列,不同之处在于 Channel 提供了挂起的 send() 和 receive() 方法。另外,通道 Channel 可以被关闭表明不再有数据会进入 Channel, 而接收端可以通过 for 循环取出数据。
Channel 也是生产-消费者模式,这个设计模式在协程中很常见。
基本使用
val channel = Channel<Int>()
// 发送
launch {
repeat(10) {
channel.send(it)
delay(200)
}
// 关闭
channel.close()
}
// 接收
launch {
for (i in channel) {
println("receive: $i")
}
// 关闭后
println("closed")
}produce 和 actor
produce 和 actor 是 Kotlin 提供的构造生产者与消费者的便捷方法。
其中 produce 方法用来启动一个生产者协程,并返回一个 ReceiveChannel 在其他协程中接收数据:
// produce 生产协程
val receiveChannel = CoroutineScope(Dispatchers.IO).produce {
repeat(10) {
send(it)
delay(200)
}
}
// 接收者 1
launch {
for (i in receiveChannel) {
println("receive-1: $i")
}
}
// 接收者 2
launch {
for (i in receiveChannel) {
println("receive-2: $i")
}
}输出:
2022-11-29 10:48:03.045 I/System.out: receive-1: 0
2022-11-29 10:48:03.250 I/System.out: receive-1: 1
2022-11-29 10:48:03.451 I/System.out: receive-2: 2
2022-11-29 10:48:03.654 I/System.out: receive-1: 3
2022-11-29 10:48:03.856 I/System.out: receive-2: 4
2022-11-29 10:48:04.059 I/System.out: receive-1: 5
2022-11-29 10:48:04.262 I/System.out: receive-2: 6
2022-11-29 10:48:04.466 I/System.out: receive-1: 7
2022-11-29 10:48:04.669 I/System.out: receive-2: 8
2022-11-29 10:48:04.871 I/System.out: receive-1: 9
反之也可以用 actor 来启动一个消费协程:
// actor 消费协程
val sendChannel = CoroutineScope(Dispatchers.IO).actor<Int> {
while (true) {
println("receive: ${receive()}")
}
}
// 发送者 1
launch {
repeat(10) {
sendChannel.send(it)
delay(200)
}
}
// 发送者 2
launch {
repeat(10) {
sendChannel.send(it * it)
delay(200)
}
}可以看出 produce 创建的是一个单生产者——多消费者的模型,而 actor 创建的是一个单消费者--多生产者的模型。
不过这些相关的 API 要不就是 ExperimentalCoroutinesApi 实验性标记的,要不就是 ObsoleteCoroutinesApi 废弃标记的,个人感觉暂时没必要使用它们。
Channel 是公平的
发送和接收操作是公平的,它们遵守先进先出原则。官方也给了一个例子:
data class Ball(var hits: Int)
fun main() = runBlocking {
val table = Channel<Ball>() // 一个共享的 table(桌子)
launch { player("ping", table) }
launch { player("pong", table) }
table.send(Ball(0)) // 率先打出第一个球
delay(1000) // 延迟 1 秒钟
coroutineContext.cancelChildren() // 游戏结束,取消它们
}
suspend fun player(name: String, table: Channel<Ball>) {
for (ball in table) { // 在循环中接收球
ball.hits++
println("$name $ball")
delay(300) // 等待一段时间
table.send(ball) // 将球发送回去
}
}由于 ping 协程首先被启动,所以它首先接收到了球,接着即使 ping 协程在将球发送后会立即开始接收,但是球还是被 pong 协程接收了,因为它一直在等待着接收球:
ping Ball(hits=1)
pong Ball(hits=2)
ping Ball(hits=3)
pong Ball(hits=4)带缓冲的 Channel
前面已经说过 Channel 实际上是一个队列,那它当然也存在一个缓存区以及缓存满后的策略(处理背压之类的问题),在创建 Channel 时可以指定两个相关的参数:
public fun <E> Channel(
capacity: Int = RENDEZVOUS,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
onUndeliveredElement: ((E) -> Unit)? = null
): Channel<E>这里的 Channel() 其实并不是构造函数,而是一个顶层函数,它内部会根据不同的入参来创建不同类型的 Channel 实例。其参数含义如下:
- capacity: Channel 缓存区的容量,默认为
RENDEZVOUS = 0 - onBufferOverflow: 缓冲区满后发送端的处理策略,默认挂起。当消费者处理数据比生产者生产数据慢时,新生产的数据会存入缓存区,当缓存区满后,生产者再调用 send() 方法会挂起,等待消费者处理数据。
看个小栗子:
// 创建缓存区大小为 4 的 Channel
val channel = Channel<Int>(4)
// 发送
launch {
repeat(10) {
channel.send(it)
println("send: $it")
delay(200)
}
}
// 接收
launch {
val channel = viewModel.channel
for (i in channel) {
println("receive: $i")
delay(1000)
}
}输出结果:
2022-11-28 17:16:47.905 I/System.out: send: 0
2022-11-28 17:16:47.907 I/System.out: receive: 0
2022-11-28 17:16:48.107 I/System.out: send: 1
2022-11-28 17:16:48.310 I/System.out: send: 2
2022-11-28 17:16:48.512 I/System.out: send: 3
2022-11-28 17:16:48.715 I/System.out: send: 4
2022-11-28 17:16:48.910 I/System.out: receive: 1
2022-11-28 17:16:48.916 I/System.out: send: 5 // 缓存区满了, receive 后才能继续发送
2022-11-28 17:16:49.913 I/System.out: receive: 2
2022-11-28 17:16:49.914 I/System.out: send: 6
2022-11-28 17:16:50.917 I/System.out: receive: 3
2022-11-28 17:16:50.917 I/System.out: send: 7
2022-11-28 17:16:51.920 I/System.out: receive: 4
2022-11-28 17:16:51.920 I/System.out: send: 8
2022-11-28 17:16:52.923 I/System.out: receive: 5
2022-11-28 17:16:52.923 I/System.out: send: 9
2022-11-28 17:16:53.925 I/System.out: receive: 6
2022-11-28 17:16:54.928 I/System.out: receive: 7
2022-11-28 17:16:55.932 I/System.out: receive: 8
2022-11-28 17:16:56.935 I/System.out: receive: 9Channel 构造类型
这一节来简单看看 Channel 构造的几种类型,为防止内容过于枯燥,就不深入剖析一些源码细节了。
Channel 构造
public fun <E> Channel(
capacity: Int = RENDEZVOUS,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
onUndeliveredElement: ((E) -> Unit)? = null
): Channel<E> =
when (capacity) {
RENDEZVOUS -> {
if (onBufferOverflow == BufferOverflow.SUSPEND)
RendezvousChannel(onUndeliveredElement)
else
ArrayChannel(1, onBufferOverflow, onUndeliveredElement)
}
CONFLATED -> {
require(onBufferOverflow == BufferOverflow.SUSPEND) {
"CONFLATED capacity cannot be used with non-default onBufferOverflow"
}
ConflatedChannel(onUndeliveredElement)
}
UNLIMITED -> LinkedListChannel(onUndeliveredElement) // ignores onBufferOverflow: it has buffer, but it never overflows
BUFFERED -> ArrayChannel( // uses default capacity with SUSPEND
if (onBufferOverflow == BufferOverflow.SUSPEND) CHANNEL_DEFAULT_CAPACITY else 1,
onBufferOverflow, onUndeliveredElement
)
else -> {
if (capacity == 1 && onBufferOverflow == BufferOverflow.DROP_OLDEST)
ConflatedChannel(onUndeliveredElement)
else
ArrayChannel(capacity, onBufferOverflow, onUndeliveredElement)
}
}前面我们说了 Channel() 并不是构造函数,而是一个顶层函数,它内部会根据不同的入参来创建不同类型的 Channel 实例。我们看看入参可取的值:
public const val UNLIMITED: Int = Int.MAX_VALUE
public const val RENDEZVOUS: Int = 0
public const val CONFLATED: Int = -1
public const val BUFFERED: Int = -2
public enum class BufferOverflow {
SUSPEND, DROP_OLDEST, DROP_LATEST
}其实光看这个构造的过程,以及两个入参的取值,我们基本上就能知道生成的这个 Channel 实例的表现了。
比如说 UNLIMITED 表示缓存区无限大的管道,它所创建的 Channel 叫 LinkedListChannel; 而 BUFFERED 或指定 capacity 大小的入参,创建的则是 ArrayChannel 实例,这也正是命名为 LinkedList(链表) 和 Array(数组) 的数据结构一个区别,前者可以视为无限大,后者有固定的容量大小。
比如说 SUSPEND 表示缓存区满后挂起, DROP_OLDEST 表示缓存区满后会删除缓存区里最旧的那个元素且把当前 send 的数据存入缓存区, DROP_LATEST 表示缓存区满后会删除缓存区里最新的那个元素且把当前 send 的数据存入缓存区。
Channel 类型
上面创建的这四种 Channel 都有一个共同的基类——AbstractChannel,简单看看他们的继承关系:
在 AbstractSendChannel 中有个重要的成员变量:
protected val queue = LockFreeLinkedListHead()它是一个循环双向链表,形成了一个队列 queue 结构,send() 数据时存入链表尾部,receive() 数据时就从链表头第一个节点取。至于具体的挂起,恢复等流程,感兴趣的可以自己看看源码。
值得一提的是, queue 中的节点类型可以大体分为三种:
- Send
- Receive
- Closed: 当调用
Channel.close()方法时,会往 queue 队列中加入 Closed 节点,这样当send or receive时就知道 Channel 已经关闭了。
另外,对于 ArrayChannel 管道,它有一个成员变量:
private var buffer: Array<Any?> = arrayOfNulls<Any?>(min(capacity, 8)).apply { fill(EMPTY) }这是一个数组类型,用来实现指定 capacity 的缓存区。但是它的初始大小不是 capacity, 主要是用来防止一些不必要的内存分配。
总结
Channel 类似于 BlockingQueue 阻塞队列,其不同之处是默认把阻塞行为换成了挂起,这也是协程的一大特性。它的思想是生产-消费模式(观察者模式)。
简单比较一下四种 Channel 类型:
- RendezvousChannel: 翻译成约会类型,缓存区大小为0,且指定为 SUSPEND 挂起策略。发送者和接收者一对一出现,接收者没出现,则发送者 send 会被挂起;发送者没出现,则接收者 receive 会被挂起。
- ConflatedChannel: 混合类型。发送者不会挂起,它只有一个 value 值,会被新的值覆盖掉;如果没有数据,则接收者会被挂起。
- LinkedListChannel: 不限缓存区大小的类型。发送者不会挂起,能一直往队列里存数据;队列无数据时接收者会被挂起。
- ArrayChannel: 指定缓存区大小的类型。当缓存区满时,发送者根据 BufferOverflow 策略来处理(是否挂起);当缓存区空时,接收者会被挂起。
链接:https://juejin.cn/post/7171272840426029063
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何启动协程
1.launch启动协程
fun main() = runBlocking {
launch {
delay(1000L)
println("World!")
}
println("Hello")
}
fun main() {
GlobalScope.launch {
delay(1000L)
println("World!")
}
println("Hello")
Thread.sleep(2000L)
}
//输出结果
//Hello
//World!上面是两段代码,这两段代码都是通过launch启动了一个协程并且输出结果也是一样的。
第一段代码中的runBlocking是协程的另一种启动方式,这里先看第二段代码中的launch的启动方式;
- GlobalScope.launch
GlobalScope.launch是一个扩展函数,接收者是CoroutineScope,意思就是协程作用域,这里的launch等价于CoroutineScope的成员方法,如果要调用launch来启动一个协程就必须先拿到CoroutineScope对象。GlobalScope.launch源码如下
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}里面有三个参数:
- context: 意思是上下文,默认是
EmptyCoroutineContext,有默认值就可以不传,但是也可以传递Kotlin提供的Dispatchers来指定协程运行在哪一个线程中; - start:
CoroutineStart代表了协程的启动模式,不传则默认使用DEFAULT(根据上下文立即调度协程执行),除DEFAULT外还有其他类型:
- LAZY:延迟启动协程,只在需要时才启动。
- ATOMIC:以一种不可取消的方式,根据其上下文安排执行的协程;
- UNDISPATCHED:立即执行协程,直到它在当前线程中的第一个挂起点;
- block:
suspend是挂起的意思,CoroutineScope.()是一个扩展函数,Unit是一个函数类似于Java的void,那么suspend CoroutineScope.() -> Unit就可以这么理解了:首先,它是一个挂起函数,然后它还是CoroutineScope类的成员或者扩展函数,参数为空,返回值类型为Unit。
- delay(): delay()方法从字面理解就是延迟的意思,在上面的代码中延迟了1秒再执行World,从源码可以看出来它跟其他方法不一样,多了一个
suspend关键字
// 挂起
// ↓
public suspend fun delay(timeMillis: Long) {
if (timeMillis <= 0) return // don't delay
return suspendCancellableCoroutine sc@ { cont: CancellableContinuation<Unit> ->
// if timeMillis == Long.MAX_VALUE then just wait forever like awaitCancellation, don't schedule.
if (timeMillis < Long.MAX_VALUE) {
cont.context.delay.scheduleResumeAfterDelay(timeMillis, cont)
}
}
}suspend的意思就是挂起,被它修饰的函数就是挂起函数, 这也就意味着delay()方法具有挂起和恢复的能力;
- Thread.sleep(2000L)
这个是休眠2秒,那么这里为什么要有这个呢?要解答这疑问其实不难,将Thread.sleep(2000L)删除后在运行代码可以发现只打印了Hello然后程序就结束了,World!并没有被打印出来。
为什么? 将上面的代码转换成线程实现如下:
fun main() {
thread(isDaemon = true) {
Thread.sleep(1000L)
println("Hello World!")
}
}如果不添加isDaemon = true结果输出正常,如果加了那么就没有结果输出。isDaemon的加入后其实是创建了一个【守护线程】,这就意味着主线程结束的时候它会跟着被销毁,所以对于将Thread.sleep删除后导致GlobalScope创建的协程不能正常运行的主要原因就是通过launch创建的协程还没开始执行程序就结束了。那么Thread.sleep(2000L)的作用就是为了不让主线程退出。
另外这里还有一点需要注意:程序的执行过程并不是按照顺序执行的。
fun main() {
GlobalScope.launch { // 1
println("Launch started!") // 2
delay(1000L) // 3
println("World!") // 4
}
println("Hello") // 5
Thread.sleep(2000L) // 6
println("Process end!") // 7
}
/*
输出结果:
Hello
Launch started!
World!
Process end!
*/上面的代码执行顺序是1、5、6、2、3、4、7,这个其实好理解,首先执行1,然后再执行5,执行6的时候等待2秒,在这个等待过程中协程创建完毕了开始执行2、3、4都可以执行了,当2、3、4执行完毕后等待6执行完毕,最后执行7,程序结束。
2.runBlocking启动协程
fun main() {
runBlocking { // 1
println("launch started!") // 2
delay(1000L) // 3
println("World!") // 4
}
println("Hello") // 5
Thread.sleep(2000L) // 6
println("Process end!") // 7
}上面这段代码只是将GlobalScope.launch改成了runBlocking,但是执行顺序却完全不一样,它的执行顺讯为代码顺序1~7,这是因为runBlocking是带有阻塞属性的,它会阻塞当前线程的执行。这是它跟launch的最大差异。
runBlocking与lanuch的另外一个差异是GlobalScope,从代码中可以看出runBlocking并不需要这个,这点可以从源码中分析
public actual fun <T> runBlocking(
context: CoroutineContext,
block: suspend CoroutineScope.() -> T): T {
...
}顶层函数:类似于Java中的静态函数,在Java中常用与工具类,例如StringUtils.lastElement();
runBlocking是一个顶层函数,因此可以直接使用它;在它的第二个参数block中有一个返回值类型:T,它刚好跟runBlocking的返回值类型是一样的,因此可以推测出runBlocking是可以有返回值的
fun main() {
val result = test(1)
println("result:$result")
}
fun test(num: Int) = runBlocking {
return@runBlocking num.toString()
}
//输出结果:
//result:1但是,Kotlin在文档中注明了这个函数不应该从协程中使用。它的设计目的是将常规的阻塞代码与以挂起风格编写的库连接起来,以便在主函数和测试中使用。 因此在正式环境中这种方式最好不用。
3.async启动协程
在 Kotlin 当中,可以使用 async{} 创建协程,并且还能通过它返回的句柄拿到协程的执行结果。
fun main() = runBlocking {
val deferred = async {
1 + 1
}
println("result:${deferred.await()}")
}
//输出结果:
//result:2上面的代码启动了两个协程,启动方式是runBlocking和async,因为async的调用需要一个作用域,而runBlocking恰好满足这个条件,GlobalScope.launch也可以满足这个条件但是GlobalScope也不建议在生产环境中使用,因为GlobalScope 创建的协程没有父协程,GlobalScope 通常也不与任何生命周期组件绑定。除非手动管理,否则很难满足我们实际开发中的需求。
上面的代码多了一个deferred.await()它就是获取最终结果的关键。
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyDeferredCoroutine(newContext, block) else
DeferredCoroutine<T>(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}async和launch一样也是一个扩展函数,也有三个参数,和launch的区别在于两点:
- block的函数类型:
launch返回的是Unit类型,async返回的是泛型T - 返回值不同:
launch返回的是Job,async返回的是Deffered<T>,而async可以返回执行结果的关键就在这里。
启动协程的三种方式都讲完了,这里存在一个疑问,launch和async都有返回值,为什么async可以获取执行结果,launch却不行?
这主要跟launch的返回值有关,launch的返回值Job代表的是协程的句柄,而句柄并不能返回协程的执行结果。
句柄: 句柄指的是中间媒介,通过这个中间媒介可以控制、操作某样东西。举个例子,door handle 是指门把手,通过门把手可以去控制门,但 door handle 并非 door 本身,只是一个中间媒介。又比如 knife handle 是刀柄,通过刀柄可以使用刀。
协程的三中启动方式区别如下:
- launch:无法获取执行结果,返回类型Job,不会阻塞;
- async:可获取执行结果,返回类型Deferred,调用await()会阻塞不调用则不会但也无法获取执行结果;
- runBlocking:可获取执行结果,阻塞当前线程的执行,多用于Demo、测试,官方推荐只用于连接线程与协程。
链接:https://juejin.cn/post/7171981069720223751
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android-多套环境的维护
记录一下项目中多套环境维护的一种思路。
一、多套环境要注意的问题
1、方便使用灵活配置
2、配置安全不会被覆写
3、扩展灵活
4、安装包可动态切换环境,方便测试人员使用
二、解决思路
1、Android中的Properties文件是只读的,打包后不可修改,所以用Properties文件维护所有的配置。
2、在一个安装包内动态切换环境,方便测试人员切换使用,这一点用MMKV来动态存储。为了防止打包时可能出现的错误,这一点也需要Properties文件来控制。
三、Properties文件的封装
package com.abc.kotlinstudio
import android.content.Context
import java.io.IOException
import java.util.*
object PropertiesUtil {
private var pros: Properties? = null
fun init(c: Context) {
pros = Properties()
try {
val input = c.assets.open("appConfig.properties")
pros?.load(input)
} catch (e: IOException) {
e.printStackTrace()
}
}
private fun getProperty(key: String, default: String): String {
return pros?.getProperty(key, default) ?: default
}
/**
* 判断是否是国内版本
*/
fun isCN(): Boolean {
return getProperty("isCN", "true").toBoolean()
}
/**
* 判断是否是正式环境
*/
fun isRelease(): Boolean {
return getProperty("isRelease", "false").toBoolean()
}
/**
* 获取版本的环境 dev test release
* 如果isRelease为true就读Properties文件,为false就读MMKV存储的值
*/
fun getEnvironment(): Int = if (isRelease()) {
when (getProperty("environment", "test")) {
"dev" -> {
GlobalUrlConfig.EnvironmentConfig.DEV.value
}
"test" -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
"release" -> {
GlobalUrlConfig.EnvironmentConfig.RELEASE.value
}
else -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
}
} else {
when (CacheUtil.getEnvironment(getProperty("environment", "test"))) {
"dev" -> {
GlobalUrlConfig.EnvironmentConfig.DEV.value
}
"test" -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
"release" -> {
GlobalUrlConfig.EnvironmentConfig.RELEASE.value
}
else -> {
GlobalUrlConfig.EnvironmentConfig.TEST.value
}
}
}
/**
* 获取国内外环境
*/
fun getCN(): Int = if (isRelease()) {
when (getProperty("isCN", "true")) {
"true" -> {
GlobalUrlConfig.CNConfig.CN.value
}
"false" -> {
GlobalUrlConfig.CNConfig.I18N.value
}
else -> {
GlobalUrlConfig.CNConfig.CN.value
}
}
} else {
when (CacheUtil.getCN(getProperty("isCN", "true"))) {
"true" -> {
GlobalUrlConfig.CNConfig.CN.value
}
"false" -> {
GlobalUrlConfig.CNConfig.I18N.value
}
else -> {
GlobalUrlConfig.CNConfig.CN.value
}
}
}
}注意二点,打包时如果Properties文件isRelease为true则所有配置都读Properties文件,如果为false就读MMKV存储的值;如果MMKV没有存储值,默认值也是读Properties文件。
内容比较简单:
isCN = true //是否国内环境
isRelease = false //是否release,比如日志的打印也可以用这个变量控制
#dev test release //三种环境
environment = dev //环境切换
四、MMKV封装
package com.abc.kotlinstudio
import android.os.Parcelable
import com.tencent.mmkv.MMKV
import java.util.*
object CacheUtil {
private var userId: Long = 0
//公共存储区的ID
private const val STORAGE_PUBLIC_ID = "STORAGE_PUBLIC_ID"
//------------------------公共区的键------------------
//用户登录的Token
const val KEY_PUBLIC_TOKEN = "KEY_PUBLIC_TOKEN"
//------------------------私有区的键------------------
//用户是否第一次登录
const val KEY_USER_IS_FIRST = "KEY_USER_IS_FIRST"
/**
* 设置用户的ID,根据用户ID做私有化分区存储
*/
fun setUserId(userId: Long) {
this.userId = userId
}
/**
* 获取MMKV对象
* @param isStoragePublic true 公共存储空间 false 用户私有空间
*/
fun getMMKV(isStoragePublic: Boolean): MMKV = if (isStoragePublic) {
MMKV.mmkvWithID(STORAGE_PUBLIC_ID)
} else {
MMKV.mmkvWithID("$userId")
}
/**
* 设置登录后token
*/
fun setToken(token: String) {
put(KEY_PUBLIC_TOKEN, token, true)
}
/**
* 获取登录后token
*/
fun getToken(): String = getString(KEY_PUBLIC_TOKEN)
/**
* 设置MMKV存储的环境
*/
fun putEnvironment(value: String) {
put("environment", value, true)
}
/**
* 获取MMKV存储的环境
*/
fun getEnvironment(defaultValue: String): String {
return getString("environment", true, defaultValue)
}
/**
* 设置MMKV存储的国内外环境
*/
fun putCN(value: String) {
put("isCN", value, true)
}
/**
* 获取MMKV存储的国内外环境
*/
fun getCN(defaultValue: String): String {
return getString("isCN", true, defaultValue)
}
//------------------------------------------基础方法区-----------------------------------------------
/**
* 基础数据类型的存储
* @param key 存储的key
* @param value 存储的值
* @param isStoragePublic 是否存储在公共区域 true 公共区域 false 私有区域
*/
fun put(key: String, value: Any?, isStoragePublic: Boolean): Boolean {
val mmkv = getMMKV(isStoragePublic)
return when (value) {
is String -> mmkv.encode(key, value)
is Float -> mmkv.encode(key, value)
is Boolean -> mmkv.encode(key, value)
is Int -> mmkv.encode(key, value)
is Long -> mmkv.encode(key, value)
is Double -> mmkv.encode(key, value)
is ByteArray -> mmkv.encode(key, value)
else -> false
}
}
/**
* 这里使用安卓自带的Parcelable序列化,它比java支持的Serializer序列化性能好些
* @param isStoragePublic 是否存储在公共区域 true 公共区域 false 私有区域
*/
fun <T : Parcelable> put(key: String, t: T?, isStoragePublic: Boolean): Boolean {
if (t == null) {
return false
}
return getMMKV(isStoragePublic).encode(key, t)
}
/**
* 存Set集合的数据
* @param isStoragePublic 是否存储在公共区域 true 公共区域 false 私有区域
*/
fun put(key: String, sets: Set<String>?, isStoragePublic: Boolean): Boolean {
if (sets == null) {
return false
}
return getMMKV(isStoragePublic).encode(key, sets)
}
/**
* 取数据,因为私有存储区用的多,所以这里给了默认参数为私有区域,如果公共区域取要记得改成true.下同
*/
fun getInt(key: String, isStoragePublic: Boolean = false, defaultValue: Int = 0): Int {
return getMMKV(isStoragePublic).decodeInt(key, defaultValue)
}
fun getDouble(
key: String,
isStoragePublic: Boolean = false,
defaultValue: Double = 0.00
): Double {
return getMMKV(isStoragePublic).decodeDouble(key, defaultValue)
}
fun getLong(key: String, isStoragePublic: Boolean = false, defaultValue: Long = 0L): Long {
return getMMKV(isStoragePublic).decodeLong(key, defaultValue)
}
fun getBoolean(
key: String,
isStoragePublic: Boolean = false,
defaultValue: Boolean = false
): Boolean {
return getMMKV(isStoragePublic).decodeBool(key, defaultValue)
}
fun getFloat(key: String, isStoragePublic: Boolean = false, defaultValue: Float = 0F): Float {
return getMMKV(isStoragePublic).decodeFloat(key, defaultValue)
}
fun getByteArray(key: String, isStoragePublic: Boolean = false): ByteArray? {
return getMMKV(isStoragePublic).decodeBytes(key)
}
fun getString(
key: String,
isStoragePublic: Boolean = false,
defaultValue: String = ""
): String {
return getMMKV(isStoragePublic).decodeString(key, defaultValue) ?: defaultValue
}
/**
* getParcelable<Class>("")
*/
inline fun <reified T : Parcelable> getParcelable(
key: String,
isStoragePublic: Boolean = false
): T? {
return getMMKV(isStoragePublic).decodeParcelable(key, T::class.java)
}
fun getStringSet(key: String, isStoragePublic: Boolean = false): Set<String>? {
return getMMKV(isStoragePublic).decodeStringSet(key, Collections.emptySet())
}
fun removeKey(key: String, isStoragePublic: Boolean = false) {
getMMKV(isStoragePublic).removeValueForKey(key)
}
fun clearAll(isStoragePublic: Boolean = false) {
getMMKV(isStoragePublic).clearAll()
}
}五、URL的配置
假设有国内外以及host、h5_host环境 :
object GlobalUrlConfig {
private val BASE_HOST_CN_DEV = "https://cn.dev.abc.com"
private val BASE_HOST_CN_TEST = "https://cn.test.abc.com"
private val BASE_HOST_CN_RELEASE = "https://cn.release.abc.com"
private val BASE_HOST_I18N_DEV = "https://i18n.dev.abc.com"
private val BASE_HOST_I18N_TEST = "https://i18n.test.abc.com"
private val BASE_HOST_I18N_RELEASE = "https://i18n.release.abc.com"
private val BASE_HOST_H5_CN_DEV = "https://cn.dev.h5.abc.com"
private val BASE_HOST_H5_CN_TEST = "https://cn.test.h5.abc.com"
private val BASE_HOST_H5_CN_RELEASE = "https://cn.release.h5.abc.com"
private val BASE_HOST_H5_I18N_DEV = "https://i18n.dev.h5.abc.com"
private val BASE_HOST_H5_I18N_TEST = "https://i18n.test.h5.abc.com"
private val BASE_HOST_H5_I18N_RELEASE = "https://i18n.release.h5.abc.com"
private val baseHostList: List<List<String>> = listOf(
listOf(
BASE_HOST_CN_DEV,
BASE_HOST_CN_TEST,
BASE_HOST_CN_RELEASE
), listOf(
BASE_HOST_I18N_DEV,
BASE_HOST_I18N_TEST,
BASE_HOST_I18N_RELEASE
)
)
private val baseHostH5List: List<List<String>> = listOf(
listOf(
BASE_HOST_H5_CN_DEV,
BASE_HOST_H5_CN_TEST,
BASE_HOST_H5_CN_RELEASE
), listOf(
BASE_HOST_H5_I18N_DEV,
BASE_HOST_H5_I18N_TEST,
BASE_HOST_H5_I18N_RELEASE
)
)
//base
var BASE_HOST: String =
baseHostList[PropertiesUtil.getCN()][PropertiesUtil.getEnvironment()]
//base_h5
var BASE_H5_HOST: String =
baseHostH5List[PropertiesUtil.getCN()][PropertiesUtil.getEnvironment()]
enum class CNConfig(var value: Int) {
CN(0), I18N(1)
}
enum class EnvironmentConfig(var value: Int) {
DEV(0), TEST(1), RELEASE(2)
}六、测试人员可在打好的App动态切换
可以弹Dialog动态切换环境,下面为测试代码:
//初始化
PropertiesUtil.init(this)
MMKV.initialize(this)
CacheUtil.setUserId(1000L)
val btSetCn = findViewById<AppCompatButton>(R.id.bt_set_cn)
val btSeti18n = findViewById<AppCompatButton>(R.id.bt_set_i8n)
val btSetDev = findViewById<AppCompatButton>(R.id.bt_set_dev)
val btSetTest = findViewById<AppCompatButton>(R.id.bt_set_test)
val btSetRelease = findViewById<AppCompatButton>(R.id.bt_set_release)
//App内找个地方弹一个Dialog动态修改下面的参数即可。
btSetCn.setOnClickListener {
CacheUtil.putCN("true")
//重启App(AndroidUtilCode工具类里面的方法)
AppUtils.relaunchApp(true)
}
btSeti18n.setOnClickListener {
CacheUtil.putCN("false")
AppUtils.relaunchApp(true)
}
btSetDev.setOnClickListener {
CacheUtil.putEnvironment("dev")
AppUtils.relaunchApp(true)
}
btSetTest.setOnClickListener {
CacheUtil.putEnvironment("test")
AppUtils.relaunchApp(true)
}
btSetRelease.setOnClickListener {
CacheUtil.putEnvironment("release")
AppUtils.relaunchApp(true)
}总结
一般会有4套环境: 开发环境,测试环境,预发布环境,正式环境。如果再区分国内外则乘以2。除了base的主机一般还会引入其他主机,比如h5的主机,这样会导致整个环境复杂多变。
刚开始是给测试打多渠道包,测试抱怨切环境,频繁卸载安装App很麻烦,于是做了这个优化。上线时记得把Properties文件isRelease设置为true,则发布的包就不会有问题,这个一般都不会忘记,风险很小。相比存文件或者其他形式安全很多。
写的比较匆忙,代码略粗糙,主要体现思路。以上!
链接:https://juejin.cn/post/7168497103516205069
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
线程池封装及拒绝策略
前文提到线程的使用以及线程间通信方式,通常情况下我们通过new Thread或者new Runnable创建线程,这种情况下,需要开发者手动管理线程的创建和回收,线程对象没有复用,大量的线程对象创建与销毁会引起频繁GC,那么事否有机制自动进行线程的创建,管理和回收呢?线程池可以实现该能力。
线程池的优点:
- 线程池中线程重用,避免线程创建和销毁带来的性能开销
- 能有效控制线程数量,避免大量线程抢占资源造成阻塞
- 对线程进行简单管理,提供定时执行预计指定间隔执行等策略
线程池的封装实现
在java.util.concurrent包中提供了一系列的工具类以方便开发者创建和使用线程池,这些类的继承关系及说明如下:
| 类名 | 说明 | 备注 |
|---|---|---|
| Executor | Executor接口提供了一种任务提交后的执行机制,包括线程的创建与运行,线程调度等,通常不直接使用该类 | / |
| ExecutorService | ExecutorService接口,提供了创建,管理,终止Future执行的方法,用于跟踪一个或多个异步任务的进度,通常不直接使用该类 | / |
| ScheduledExecutorService | ExecutorService的实现接口,提供延时,周期性执行Future的能力,同时具备ExecutorService的基础能力,通常不直接使用该类 | / |
| AbstractExecutorService | AbstractExecutorService是个虚类,对ExecutorService中方法进行了默认实现,其提供了newTaskFor函数,用于获取RunnableFuture对象,该对象实现了submit,invokeAny和invokeAll方法,通常不直接使用该类 | / |
| ThreadPoolExecutor | 通过创建该类对象就可以构建一个线程池,通过调用execute方法可以向该线程池提交任务。通常情况下,开发者通过自定义参数,构造该类对象就来获得一个符合业务需求的线程池 | / |
| ScheduledThreadPoolExecutor | 通过创建该类对象就可以构建一个可以周期性执行任务的线程池,通过调用schedule,scheduleWithFixedDelay等方法可以向该线程池提交任务并在指定时间节点运行。通常情况下,开发者通过构造该类对象就来获得一个符合业务需求的可周期性执行任务的线程池 | / |
由上表可知,对于开发者而言,通常情况下我们可以通过构造ThreadPoolExecutor对象来获取一个线程池对象,通过其定义的execute方法来向该线程池提交任务并执行,那么怎么创建线程池呢?让我们一起看下
ThreadPoolExecutor
ThreadPoolExecutor完整参数的构造函数如下所示:
/**
* Creates a new {@code ThreadPoolExecutor} with the given initial
* parameters.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @param maximumPoolSize the maximum number of threads to allow in the
* pool
* @param keepAliveTime when the number of threads is greater than
* the core, this is the maximum time that excess idle threads
* will wait for new tasks before terminating.
* @param unit the time unit for the {@code keepAliveTime} argument
* @param workQueue the queue to use for holding tasks before they are
* executed. This queue will hold only the {@code Runnable}
* tasks submitted by the {@code execute} method.
* @param threadFactory the factory to use when the executor
* creates a new thread
* @param handler the handler to use when execution is blocked
* because the thread bounds and queue capacities are reached
* @throws IllegalArgumentException if one of the following holds:
* {@code corePoolSize < 0}
* {@code keepAliveTime < 0}
* {@code maximumPoolSize <= 0}
* {@code maximumPoolSize < corePoolSize}
* @throws NullPointerException if {@code workQueue}
* or {@code threadFactory} or {@code handler} is null
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
} 从上述代码可以看出,在构建ThreadPoolExecutor时,主要涉及以下参数:
- corePoolSize:核心线程个数,一般情况下可以使用 处理器个数/2 作为核心线程数的取值,可以通过Runtime.getRuntime().availableProcessors()来获取处理器个数
- maximumPoolSize:最大线程个数,该线程池支持同时存在的最大线程数量
- keepAliveTime:非核心线程闲置时的超时时长,超过这个时长,非核心线程就会被回收,我们也可以通过allowCoreThreadTimeOut(true)来设置核心线程闲置时,在超时时间到达后回收
- unit:keepAliveTime的时间单位
- workQueue:线程池中的任务队列,当核心线程数满或最大线程数满时,通过线程池的execute方法提交的Runnable对象存储在这个参数中,遵循先进先出原则
- threadFactory:创建线程的工厂 ,用于批量创建线程,统一在创建线程时进行一些初始化设置,如是否守护线程、线程的优先级等。不指定时,默认使用Executors.defaultThreadFactory() 来创建线程,线程具有相同的NORM_PRIORITY优先级并且是非守护线程
- handler:任务拒绝处理策略,当线程数量等于最大线程数且等待队列已满时,就会采用拒绝处理策略处理新提交的任务,不指定时,默认的处理策略是AbortPolicy,即抛弃该任务
综上,我们可以看出创建一个线程池最少需要明确核心线程数,最大线程数,超时时间及单位,等待队列这五个参数,下面我们创建一个核心线程数为1,最大线程数为3,5s超时回收,等待队列最多能存放5个任务的线程池,代码如下:
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5));随后我们使用for循环向该executor中提交任务,代码如下:
public static void main(String[] args) {
// 创建线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5));
for (int i=0;i<10;i++) {
int finalI = i;
System.out.println("put runnable "+ finalI +"to executor");
// 向线程池提交任务
executor.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"start");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"executed");
}
});
}
}输出如下:
从输出可以看到,当提交一个任务到线程池时,其执行流程如下:
线程池拒绝策略
线程池拒绝策略有四类,定义在ThreadPoolExecutor中,分别是:
- AbortPolicy:默认拒绝策略,丢弃提交的任务并抛出RejectedExecutionException,在该异常输出信息中,可以看到当前线程池状态
- DiscardPolicy:丢弃新来的任务,但是不抛出异常
- DiscardOldestPolicy:丢弃队列头部的旧任务,然后尝试重新执行,如果再次失败,重复该过程
- CallerRunsPolicy:由调用线程处理该任务
当然,如果上述拒绝策略不能满足需求,我们也可以自定义异常,实现RejectedExecutionHandler接口,即可创建自己的线程池拒绝策略,下面是使用自定义拒绝策略的示例代码:
public static void main(String[] args) {
RejectedExecutionHandler handler = new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("runnable " + r +" in executor "+executor+" is refused");
}
};
ThreadPoolExecutor executor = new ThreadPoolExecutor(1,3,5,TimeUnit.SECONDS,new LinkedBlockingQueue<>(5),handler);
for (int i=0;i<10;i++) {
int finalI = i;
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"start");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName()+",runnable "+ finalI +"executed");
}
};
System.out.println("put runnable "+ runnable+" index:"+finalI +" to executor:"+executor);
executor.execute(runnable);
}
}输出如下:
任务队列
对于线程池而言,任务队列需要是BlockingQueue的实现类,BlockingQueue接口的实现类类图如下:
下面我们针对常用队列做简单了解:
ArrayBlockingQueue:ArrayBlockingQueue是基于数组的阻塞队列,在其内部维护一个定长数组,所以使用ArrayBlockingQueue时必须指定任务队列长度,因为不论对数据的写入或者读取都使用的是同一个锁对象,所以没有实现读写分离,同时在创建时我们可以指定锁内部是否采用公平锁,默认实现是非公平锁。
非公平锁与公平锁
公平锁:多个任务阻塞在同一锁时,等待时长长的优先获取锁
非公平锁:多个任务阻塞在同一锁时,锁可获取时,一起抢锁,谁先抢到谁先执行
LinkedBlockingQueue:LinkedBlockingQueue是基于链表的阻塞队列,在创建时可不指定任务队列长度,默认值是Integer.MAX_VALUE,在LinkedBlockingQueue中读锁和写锁实现了分支,相对ArrayBlockingQueue而言,效率提升明显。
SynchronousQueue:SynchronousQueue是一个不存储元素的阻塞队列,也就是说当需要插入元素时,必须等待上一个元素被移出,否则不能插入,其适用于任务多但是执行比较快的场景。
PriorityBlockingQueue:PriorityBlockingQueue是一个支持指定优先即的阻塞队列,默认初始化长度为11,最大长度为Integer.MAX_VALUE - 8,可以通过让装入队列的对象实现Comparable接口,定义对象排序规则来指定队列中元素优先级,优先级高的元素会被优先取出。
DelayQueue:DelayQueue是一个带有延迟时间的阻塞队列,队列中的元素,只有等待延时时间到了才可以被取出,由于其内部用PriorityBlockingQueue维护数据,故其长度与PriorityBlockingQueue一致。一般用于定时调度类任务。
下表从一些角度对上述队列进行了比较:
| 队列名称 | 底层数据结构 | 默认长度 | 最大长度 | 是否读写分离 | 适用场景 |
|---|---|---|---|---|---|
| ArrayBlockingQueue | 数组 | 0 | 开发者指定大小 | 否 | 任务数量较少时使用 |
| LinkedBlockingQueue | 链表 | Integer.MAX_VALUE | Integer.MAX_VALUE | 是 | 大量任务时使用 |
| SynchronousQueue | 公平锁-队列/非公平锁-栈 | 0 | / | 否 | 任务多但是执行速度快的场景 |
| PriorityBlockingQueue | 对象数组 | 11 | Integer.MAX_VALUE-8 | 否 | 有任务需要优先处理的场景 |
| DelayQueue | 对象数组 | 11 | Integer.MAX_VALUE-8 | 否 | 定时调度类场景 |
链接:https://juejin.cn/post/7171813123286892557
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单封装一个易拓展的Dialog
Dialog,每个项目中多多少少都会用到,肯定也会有自己的一套封装逻辑,无论如何封装,都是奔着简单复用的思想,有的是深层次的封装,也就是把相关的UI效果直接封装好,暴露可以修改的属性和方法,让调用者根据实际业务,调用修改即可,当然也有简单的封装,只封装基本的功能,其UI和实际的动作,交给调用者,两种封装方式,各有利弊,前者调用者不用自己创建UI和实现相关动作,只需要简单的调用即可,但是不易于扩展,效果比较局限,想要拓展其他的效果,就不得不自己动手实现;后者扩展性强,因为只提供基本的调用方式,也就是说,你想要什么效果都行,毕竟是所有的UI和动作都是你自己来实现,优点是它,其缺点也是它。
前者的封装司空见惯,大多数的公司也都是采取的这样的封装,毕竟调用者实现起来也是很方便,这里就不详细说了,具体我们谈一下后者的封装,后者的封装虽然调用者需要自己来实现,但是扩展性是很强的。
今天的内容大致如下:
1、效果及代码具体调用。
2、如何封装一个Dialog。
3、开源地址。
4、总结及注意事项。
一、效果及代码具体调用
通过Kotlin的扩展函数,参数以类做为扩展,封装之后,调用非常的便捷,只需要传递你要的视图即可,我们先看下具体的案例,代码如下:
showVipDialog {
addLayout(R.layout.layout_dialog_custom)//传递dialog视图
set {
//Dialog操作,获取View及绑定数据
}
}通过以上的代码,我们就实现了一个Dialog的弹出,addLayout方法传递视图,set扩展函数进行获取View和绑定数据,这样的一个简单的封装,我们就实现了Dialog的扩展操作,针对不同的Dialog样式,传递不同的xml视图即可。
1、快速使用
为了方便大家使用,目前已经上传到了远程maven,大家可以进行依赖使用,或者下载源码依赖也可以。
根项目build.gradle
allprojects {
repositories {
……
maven { url "https://gitee.com/AbnerAndroid/almighty/raw/master" }
}
}在需要的Module下引入依赖
dependencies {
……
implementation "com.vip:dialog:1.0.0"
}2、代码案例
源码下载之后,运行项目,就可以看到给大家提供的相关Demo,当然了,由于做到了可扩展,大家想实现什么样的效果都是可以的,毕竟视图都是自己传递的。
由于所有的案例都是调用开头的代码,就不一一列举了,简单的列举几个。
普通的提示框
普通的提示框,可以按照下面的代码逻辑进行调用。
showVipDialog {
addLayout(R.layout.layout_dialog_custom)//添加弹出的视图
set {//逻辑处理,获取view,绑定数据
setDialogCancelable(false)//点击空白不消失
val btnConfirm = findView<TextView>(R.id.dialog_button_confirm)//获取View
btnConfirm.setOnClickListener {
toast("确定")
dismiss()
}
}
}方法一览
| 方法名 | 参数类型 | 概述 |
|---|---|---|
| addLayout | int | xml视图 |
| set | 无参 | 逻辑处理 |
| style | 无参 | dialog设置样式 |
| setDialogCancelable | Boolean | 点击空白是否消失,默认true消失,false为不消失 |
| findView | int | 控件id,泛型为控件 |
| dismiss | 无参 | 隐藏dialog |
| getDialogView | 无参 | 获取当前View视图 |
DataBinding形式的提示框
DataBinding形式和普通的区别在于,不用再获取View视图,由普通的set扩展函数改为bind扩展函数,泛型为Binding,记得把xml视图进行convert to data binding layout。
showVipDialog {
addLayout(R.layout.layout_dialog_custom)//添加弹出的视图
bind<LayoutDialogCustomBinding> {//逻辑处理,获取view,绑定数据
it.dialogButtonConfirm.setOnClickListener {
toast("确定")
dismiss()
}
}
}方法一览
除了普通的方法调用之外,还可以调用下面的方法。
| 方法名 | 参数类型 | 概述 |
|---|---|---|
| bind | 无参 | 和set一样进行逻辑处理,泛型为ViewDataBinding |
| getDataBinding | 无参 | 获取当前的DataBinding,用于更新视图 |
| setPendingBindings | int | 传递的BR,用于xml和Data数据进行绑定 |
具体的案例大家直接可以看源码,源码中提供了很多常见的效果,都是可以自定义实现的,具体的就不罗列了,本身没有多少难度。
确认框
输入框
底部列表
菊花加载
二、如何封装一个Dialog
这样的一个简单的Dialog如何进行封装呢?在封装之前,我们首先要明确封装思路,1、视图由调用者传递,2、逻辑操作由调用者处理,3、样式也由调用者进行设置,也就是说,我们只封装基本的dialog使用,也就是一个壳,具体的内容,统统交给调用者进行处理,有了这三个思路我们就可以进行着手封装了。
1、封装BaseDialog
封装Base的原因,在于统一管理子类,在于简化子类的代码逻辑,便于提供公共的方法让子类实现或调用,BaseDialog这里继承的是DialogFragment,最大的原因就是,容易通过生命周期回调来管理弹窗,还有对于复杂样式的弹窗,使用DialogFragment会更加方便和高效。
和之前封装Activity一样,做为一个抽象父类,子类要实现的无非就是,视图的传递和逻辑的处理,我们就可以在父类中进行定义抽象方法,Dialog一般有自己定义的样式,我们也可以定义一个初始化样式的方法。
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
abstract fun initData()
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化样式
*/
abstract fun initStyle()
/**
* AUTHOR:AbnerMing
* INTRODUCE:传递的视图
*/
abstract fun getLayoutId(): Int除了必要实现的方法之外,我们还可以把一些公用的方法,定义到Base里,如获取View的方法,获取控件的方法等,这么做的目的,便于子类自定义实现一些效果以及减少findViewById的调用次数。
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取View视图
*/
fun <V> findView(id: Int): View {
var view = mViewSparseArray[id]
if (view == null) {
view = mView?.findViewById(id)
mViewSparseArray.put(id, view)
}
return view
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取当前View视图
*/
fun getDialogView(): View {
return mView!!
}以上只是列举了几个实现的方法,完整的代码,大家可以看源码中的BaseDialog类。
2、拓展ViewDataBinding形式Dialog
正常的普通Dialog就可以继承BaseDialog,基本就可以满足需要的,若是要和ViewDataBinding进行结合,那么就需要拓展需求了,具体的拓展也很简单,一是绑定View,二是绑定数据,完整的代码,大家可以看源码中BaseBindingDialog类。
绑定View
通过DataBindingUtil的bind方法,得到ViewDataBinding。
mBinding = DataBindingUtil.bind(getDialogView())
复制代码绑定数据
完成xml视图和数据的绑定。
mBinding.setVariable(variableId, t)
mBinding.executePendingBindings()3、封装工具类,拓展相关功能
为了更加方便的让调用者使用,封装拓展函数是很有必要的,要不然,调用者每次都得要继承上边的两个父类,这样的代码就会增加很多,还会创建很多的类,我们需要单独的创建一个工具类,来实例化我们需要简化的功能逻辑。
提供添加xml视图的方法
很简单的一个普通方法,没什么好说的,把传递的xml,赋值给重写的getLayoutId方法即可。
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置layout
* @param mLayoutId xml布局
*/
fun addLayout(mLayoutId: Int): VipDialog {
this.mLayoutId = mLayoutId
return this
}提供普通使用和DataBinding形式使用方法
普通和DataBinding方法,这里用到了接口回调,接口的实现则在initVMData方法里,两个方法本身功能是一样的,无非就是一个是普通,一个是返回ViewDataBinding。
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun <VB : ViewDataBinding> bind(block: (bind: VB) -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke(getDataBinding())
}
})
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun set(block: () -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke()
}
})
return this
}提供设置样式的方法
样式的设置也就是使用了接口回调。
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置样式
*/
fun style(style: () -> Unit): VipDialog {
setStyleCallBackListener(object : OnStyleCallBackListener {
override fun styleCallback() {
style.invoke()
}
})
return this
}提供获取ViewDataBinding的方法
这个方法的提供是便于拿到ViewDataBinding,有效的更新视图数据。
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取ViewDataBinding
*/
fun <VB : ViewDataBinding> getDataBinding(): VB {
return mBinding as VB
}我们看下整体的代码,如下:
/**
*AUTHOR:AbnerMing
*DATE:2022/11/22
*INTRODUCE:实例化功能
*/
class VipDialog : BaseBindingDialog<ViewDataBinding>() {
companion object {
fun init(): VipDialog {
return VipDialog()
}
}
private var mLayoutId = 0
override fun initVMData() {
mOnDialogDataCallbackListener?.dataCallback()
}
override fun initStyle() {
mOnStyleCallBackListener?.styleCallback()
}
override fun getLayoutId(): Int {
return mLayoutId
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:获取ViewDataBinding
*/
fun <VB : ViewDataBinding> getDataBinding(): VB {
return mBinding as VB
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置layout
* @param mLayoutId xml布局
*/
fun addLayout(mLayoutId: Int): VipDialog {
this.mLayoutId = mLayoutId
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun <VB : ViewDataBinding> bind(block: (bind: VB) -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke(getDataBinding())
}
})
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:初始化数据
*/
fun set(block: () -> Unit): VipDialog {
setDataCallBackListener(object : OnDialogDataCallbackListener {
override fun dataCallback() {
block.invoke()
}
})
return this
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:设置样式
*/
fun style(style: () -> Unit): VipDialog {
setStyleCallBackListener(object : OnStyleCallBackListener {
override fun styleCallback() {
style.invoke()
}
})
return this
}
private var mOnDialogDataCallbackListener: OnDialogDataCallbackListener? = null
private fun setDataCallBackListener(mOnDialogDataCallbackListener: OnDialogDataCallbackListener) {
this.mOnDialogDataCallbackListener = mOnDialogDataCallbackListener
}
private var mOnStyleCallBackListener: OnStyleCallBackListener? = null
private fun setStyleCallBackListener(mOnStyleCallBackListener: OnStyleCallBackListener) {
this.mOnStyleCallBackListener = mOnStyleCallBackListener
}
}4、封装拓展函数,简化调用
dialog的弹出可能有很多场景,比如Activity里,比如Fragment里,比如一个工具类中,我们可以根据已知的场景,来定义我们的调用方式,目前,我定义了两种,在Activity或者Fragment里可以直接进行调用,也就是开头的调用方式,当然了,大家也可以自己拓展。
/**
* AUTHOR:AbnerMing
* INTRODUCE:Activity显示Dialog
*/
fun AppCompatActivity.showVipDialog(vipDialog: VipDialog.() -> Unit): VipDialog {
val dialog = VipDialog.init()
dialog.apply(vipDialog)
setActivityDialog(this.supportFragmentManager, dialog)
return dialog
}
/**
* AUTHOR:AbnerMing
* INTRODUCE:Fragment显示Dialog
*/
fun Fragment.showVipDialog(vipDialog: VipDialog.() -> Unit): VipDialog {
val dialog = VipDialog.init()
dialog.apply(vipDialog)
setActivityDialog(this.childFragmentManager, dialog)
return dialog
}通过以上几步,我们就可以实现开头的简单调用,具体的大家可以查看相关源码。
三、开源地址
四、总结及注意事项
在开头已经阐述,这种方式易于拓展,但是代码量相对比较多,毕竟所有的UI和逻辑都必须独自来处理,在项目中的解决方式为,如果很多的弹框效果一样,建议再封装一层,抽取公共的工具类。
还有一个需要注意的,本身扩展函数showVipDialog返回的就是调用的类,也就是一个Dialog,大家可以直接获取变量,在其他的地方做更新Dialog或者销毁的操作。
val dialog=showVipDialog {
……
}链接:https://juejin.cn/post/7171983903228428318
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 玩转彩虹, 吃定彩虹
闲暇时,又听到了这首歌. 抑郁质性格的人难免会惆怅,美好的东西转瞬即逝.不过谁叫咱们是程序员呢~ 这就安排上.整上一个想看就看的彩虹!
玩转彩虹
彩虹,是气象中的一种光学现象,当太阳光照射到半空中的水滴,光线被折射及反射,在天空上形成拱形的七彩光谱,由外圈至内圈呈红、橙、黄、绿、蓝、靛蓝、蓝紫七种颜色. 相信小伙伴们在大雨过后的不经意间都见过吧! 接下来,我们就自己手动绘制一下.一般这种, 我们都会分析一下绘制的步骤.
分析步骤
彩虹实际上就是7道拱桥型状的颜色堆积,绘制彩虹第一步我们不如先绘制一道拱桥形状的颜色块.也就是说, 本质上我们绘制一个半圆环即可解决问题.
绘制半圆环
在Flutter中, 半圆环都绘制有很多方法. 比如canvas中,有drawOval(rect,paint) 的方法,这种方法可以绘制出一整个圆环, 我们可以对它作切割即可. 不过这种方法不便利的是它控制不了圆环的进度, 有没有一种方法可以让我们自己去控制圆环绘制的进度呢? 答案就是Path, 好多伙伴们应该都对Path 有过或多或少都了解, 它不仅可以画直线、三角形、圆锥,更可以画优美的贝塞尔曲线. 这里我们调用它的acrTo(Rect rect, double startAngle, double sweepAngle, bool forceMoveTo) 方法, 它的参数:
- rect: 给定一个矩形范围,在矩形范围中绘制弧形. 也就是我们如果是正方形的话,实际上绘制的便是一个圆形,如果是长方形的话最终产物就是椭圆形.
- startAngle: 起始的角度
- sweepAngle: 扫过的角度
实际上这里的坐标系和笛卡尔坐标系是一样的, 所以是从x轴开始算的, 也就是顺时针方向分别是0 -> pi/2 -> pi -> 3/2pi-> 2pi. 我们假设startAngle是0的话, sweepAngle为1/3pi, 那么最终的圆弧如图左示.
- forceMoveTo: false的时候,添加一个线段开始于当前点,结束于弧的起点.true时为原点.
理论知识了解完毕以后,我们通过如下代码进行绘制试一下:
{
Path path = Path();
path.moveTo(-width, 0.0);
path.arcTo(
Rect.fromCenter(center: Offset.zero, width: width, height: width),
-pi,
pi,
true,
);
}结果如图:
第一道圆弧已经出来了, 说明理论上这样做可行.
多道圆弧
一道圆弧既然可以了, 我们首先记录下彩虹的颜色
final List<Color> colors = const [
Color(0xFF8B00FF),
Color(0xFF0000FF),
Color(0xFF00FFFF),
Color(0xFF00FF00),
Color(0xFFFFFF00),
Color(0xFFFF7F00),
Color(0xFFFF0000),
];记录好颜色后, 我们首先回顾一下. 刚刚一道圆弧是怎么绘制的呢? 通过path的arcTo()方法,起始在负x轴, 终止于x轴.也就是说我们重复的绘制上七道, 只需要半径不一样即可绘制出相互连接的颜色体.
for (var color in colors) {
_paint.color = color;
// 绘制圆弧
drawArc();
canvas.drawPath(path, _paint);
// width 为每到圆弧的半径
width += widthStep;
}嗯~ 没错, 结果确实和意料的一样
但是,总觉得有些不完美. 彩虹似乎都是有光晕的吧~
添加光晕
好, 光晕说来这不就来了.实际上我们可以通过画笔绘制周围部分作模糊当作光晕的形成, 恰恰Paint的mastFilter 也提供了这个方法.
{
_paint.maskFilter = const MaskFilter.blur(BlurStyle.solid, 6);
}我们先简要分析一下MaskFilter.blur() 提供了参数有哪些用处吧~实际上也就是style和sigma.style控制最终绘制出来的效果.sigma控制效果的大小.这里我们使用BlurStyle.solid就可以绘制出光晕的效果
光晕也有了, 但是我感觉不够个性. 我希望它可以像扇子一样展开收起. 我们来看看怎么实现.
动画
实际上控制它的展开收起也就是在path中sweepAngle.我们最小扫过是0弧度,最大是pi.
我们控制了弧度变化也就控制了彩虹的展示大小.直接安排上repeat()动画
{
AnimationController _controller = AnimationController(
vsync: this,
// 这里需要把最大值改成pi, 这样才会完全展开
upperBound: pi,
duration: const Duration(seconds: 2),
);
_controller.repeat(reverse: true);
}链接:https://juejin.cn/post/7169872546936913934
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这一篇让你搞定 Flutter 的数据表格
前言
目前,越来越多的管理层(所谓的领导)都希望在手机端查看各种各样的数据报表,以达到随时随地关注经营业绩(监督干活)的目的。这就要求移动端能够提供数据表来满足这类诉求,本篇我们就来介绍 Flutter 的数据表格的使用。通过本篇你会了解到:
- Flutter 自带的
DataTable的使用; - 第三方强大的数据表
SfDataGrid的使用。
组成DataTable的基本元素
DataTable 是 Flutter 自带的数据表组件,支持定义表头和行数据来实现数据表格,同时支持列排序、选中行等操作,对于基础的数据表格展示基本能够满足,DataTable类的定义如下。
DataTable({
Key? key,
required this.columns,
this.sortColumnIndex,
this.sortAscending = true,
this.onSelectAll,
this.decoration,
this.dataRowColor,
this.dataRowHeight,
this.dataTextStyle,
this.headingRowColor,
this.headingRowHeight,
this.headingTextStyle,
this.horizontalMargin,
this.columnSpacing,
this.showCheckboxColumn = true,
this.showBottomBorder = false,
this.dividerThickness,
required this.rows,
this.checkboxHorizontalMargin,
this.border,
}) 常用的属性说明如下:
columns:是一个DataColumn数组,用于定义表头。rows:是一个DataRow数组,用于定义每一行要显示的数据。sortColumnIndex:要排序的列,可以通过该值设定当前使用那一列进行排序。指定的列会有一个向上或向下的箭头指示当前的排序方式。sortAscending:排序的方式,默认为升序排序。onSelectAll:全选回调事件,如果全选携带的参数为true,否则为false。
DataColumn 是数据列组件,包括了如下4个属性:
label:可以是任意组件,通常我们使用的是Text组件,也可以使用其他组件。tooltip:列的描述文字,用于列宽受限时展示完整的列内容。numeric:是否是数字列,如果是数字列会采用右对齐方式呈现。onSort:排序事件回调,携带两个参数指示当前实用第几列排序,排序方式是升序还是降序。我们可以通过这个方法来响应排序操作对要展示的行数据进行排序。
DataRow是数据行组件,包括如下5个属性:
cells:DataCell数组,用于定义每一列对应的元素。selected:行的选中状态,默认为不选中。onSelectChanged:行选中状态改变时的回调函数。onLongPress:长按行的回调,我们可以用来做长按删除、上移、下移类的操作。color:MaterialStateProperty<Color?>类,可以用来定义不同状态下的行的颜色。
DataCell是数据单元格组件,用于定义要显示的单元格内容以及响应单元格的交互(包括点击、长按、双击等)。
由此我们就得到了一个完整的 DataTable 所需要的元素。
DataTable 示例
首先说一下,Flutter 提供的 DataTable 如果超出屏幕范围默认是不支持滚动的,因此如果要支持滚动,就需要用 SingleChildScrollView 包裹,然后定义滚动的方向来实现横向或纵向滚动。如果要同时支持横向和纵向滚动,就需要使用两个SingleChildScrollView来包裹。下面的示例代码就是实用了两个SingleChildScrollView实现了列表的横向和纵向滚动。
class _DataTableDemoState extends State<DataTableDemo> {
var _sortAscending = true;
int? _sortColumn;
final dataModels = <DataModel>[
DataModel(nation: '中国', population: 14.1, continent: '亚洲'),
DataModel(nation: '美国', population: 2.42, continent: '北美洲'),
DataModel(nation: '俄罗斯', population: 1.43, continent: '欧洲'),
DataModel(nation: '巴西', population: 2.14, continent: '南美洲'),
DataModel(nation: '印度', population: 13.9, continent: '亚洲'),
DataModel(nation: '德国', population: 0.83, continent: '欧洲'),
DataModel(nation: '埃及', population: 1.04, continent: '非洲'),
DataModel(nation: '澳大利亚', population: 0.26, continent: '大洋洲'),
DataModel(nation: '印度', population: 13.9, continent: '亚洲'),
DataModel(nation: '德国', population: 0.83, continent: '欧洲'),
DataModel(nation: '埃及', population: 1.04, continent: '非洲'),
DataModel(nation: '澳大利亚', population: 0.26, continent: '大洋洲'),
];
Function(int, bool)? _sortCallback;
@override
void initState() {
super.initState();
_sortCallback = (int column, bool isAscending) {
setState(() {
_sortColumn = column;
_sortAscending = isAscending;
});
};
}
@override
Widget build(BuildContext context) {
return Scaffold(
backgroundColor: Colors.white,
appBar: AppBar(
title: const Text('DataTable'),
backgroundColor: Colors.red[400]!,
),
body: SingleChildScrollView(
scrollDirection: Axis.vertical,
child: SingleChildScrollView(
scrollDirection: Axis.horizontal,
child: DataTable(
horizontalMargin: 10.0,
showBottomBorder: true,
sortAscending: _sortAscending,
sortColumnIndex: _sortColumn,
showCheckboxColumn: true,
headingTextStyle: const TextStyle(
fontWeight: FontWeight.bold,
color: Colors.black,
),
columns: [
const DataColumn(label: Text('国家')),
DataColumn(
label: const Text('人口(亿)'),
numeric: true,
onSort: _sortCallback,
),
DataColumn(
label: const Text('大洲'),
onSort: _sortCallback,
),
const DataColumn(label: Text('说明')),
],
rows: sortDataModels(),
),
),
),
);
}
List<DataRow> sortDataModels() {
dataModels.sort((dataModel1, dataModel2) {
bool isAscending = _sortAscending;
var result = 0;
if (_sortColumn == 0) {
result = dataModel1.nation.compareTo(dataModel2.nation);
}
if (_sortColumn == 1) {
result = dataModel1.population.compareTo(dataModel2.population);
}
if (_sortColumn == 2) {
result = dataModel1.continent.compareTo(dataModel2.continent);
}
if (isAscending) {
return result;
}
return -result;
});
return dataModels
.map((dataModel) => DataRow(
onSelectChanged: (selected) {},
cells: [
DataCell(
Text(dataModel.nation),
),
DataCell(
Text('${dataModel.population}'),
),
DataCell(
Text(dataModel.continent),
),
const DataCell(
Text('这是详细介绍'),
),
],
))
.toList();
}
}上述代码的实现效果如下图所示。
可以看到,使用 DataTable 能够满足我们基本的数据表格的需求,但是我们如果希望表头固定或者列固定,实现起来就有点麻烦了。复杂表格的场景,推荐大家一个好用的第三方库:SfDataGrid。
SfDataGrid
SfDataGrid 同时支持移动端、Web 端和桌面端,基本上和前端 Web 表格功能有的它都有,比如固定某些列或某些行、自动滚动、编辑单元格、设置行高和列宽、排序、单击选择单行或多行、自定义样式、合并单元格、调整列宽、上拉加载或分页浏览、导出到 Excel 文件等等。可以说,用 SfDataGrid 可以满足绝大多数数据表格的场景,更重要的是,官方提供了详细的文档(点此查看使用文档)和示例代码,可以让我们轻松上手。下面是实用 SfDataGrid实现的一个示例效果(移动端列宽调整需要使用长按功能)。
总结
本篇介绍了 Flutter 中的数据表格组件 DataTable 的使用,并介绍了一个很强大的数据表格库 SfDataGrid。如果是简单的数据表格可以使用 Flutter 自带的 DataTable,如果涉及到复杂的样式和交互效果,建议实用 SfDataGrid 来搞定。
链接:https://juejin.cn/post/7168430613891842055
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
温故知新--MV*系列架构模型
下文仅代表个人理解,可能会有偏差或错误,欢迎评论或私信讨论。
MVC
从软件架构模型角度
MVC 是比较“古老”的架构模型,后面的 MV* 都是基于它进行拓展。MVC 出现的意义是为了提高程序的可维护性与拓展性。在 View 层与 Model 层中添加了 Controller 层作为中转层。
从实现角度
在 Android 中关于 MVC 的实现比较简单粗暴,View 层就是 xml 布局文件,Controller 层就是 Activity/Fragment。但由于 xml 布局文件功能性比较差,与 UI 有关的操作主要靠 Activity/Fragment。所以, Activity/Fragment 同时承载了 View 层与 Controller 层的任务。
优缺点
- 优点:
- 通过分层思想划分不同职责,提高了程序的拓展性与可维护性
- 缺点:
- 在 Android 中由于 xml 文件功能性太低,导致 Activity/Fragment 承载了 View 与 Controller 职责,导致其复杂度太高,降低了程序可维护性。
- 三层间是互相持有,耦合度太高。
MVP
从软件架构模型角度
MVP 是从 MVC 派生出来的。Presenter 层相较于 MVC 的 Controller 层除了中转外,还承载了数据处理任务(将从 Model 层中获取的数据处理成 View 层需要的格式)。
从实现角度
在 Android 中 MVP 模型是通过接口实现的,通过定义 View 层与 Presenter 层接口,提高程序拓展性。将页面逻辑处理至 Presenter 层,降低了 Activity/Fragment 的复杂度,提高程序的可维护性。
优缺点
- 优点:
- 将页面逻辑抽离到 Presenter 层,降低了 Activity/Fragment 内部的复杂度,使其替代 xml 布局文件承担了 View 层任务。
- 通过面向接口开发,提高了代码拓展性。
- 缺点:
- View 层接口中的方法定义粒度无法保证,太细导致逻辑分散,出现"改不全"问题,太粗导致代码维护性退化。
- View 层接口仅支持单一实现,例如 Activity 和 Fragment 需要单独实现,导致无法实现跨页面通信。
- View 层与 Presenter 层相互持有,增加了耦合度,同时由于 Presenter 层持有 View 层(Activity/Fragment) 也会存在内存泄露的风险。
- Presenter 层生命周期与 Activity 一致,无法处理屏幕旋转等场景。
MVVM
关于 MVVM 架构的理解分歧还是蛮大的,主要有两种:
- MVVM 指的是 DataBinding
- MVVM 指的是 View(Activity/Fragment) + ViewModel(Jetpack组件) + Model
其实这两种理解都是对的,只是站在的角度不同。
从软件架构模型角度
MVVM 的核心就是数据绑定,借助数据绑定将 View 层与 Model 层进行解耦。ViewModel 层的作用是一个数据中转站,负责暴露 Model 层数据。所以 MVVM 也是一种数据驱动模式。
从实现角度
MVVM 在 Android 中的实现可借助 Jetpack 组件库。但要注意区分 ViewModel 层并不是指 ViewModel 组件,怎么理解这句话呢?
如果按照严格的软件架构模型实现,那么这里的 ViewModel 层需要依靠 ViewMode + DataBinding 实现。但目前 DataBinding 在大多数的项目中落地情况不是很好,所以大部分项目是通过 ViewModel + LiveData 来实现。
优缺点
- 优点:
- 借助 Jetpack 组件库可以实现生命周期感应,并且 ViewModel 生命周期长于 Activity,可处理屏幕旋转等场景。
- 通过监听/绑定方式,将 View 层与 ViewModel 层进行解耦。
- 缺点:
- 通过数据驱动的方式,并且 LiveData 仅支持单一数据类型,导致在复杂页面时 LiveData 的维护成本增加。
MVI
从软件架构模型角度
关于 MVI 目前没有明确的定义。主流的解释是“基于响应式编程实现的事件(状态)驱动模式”。这里与 MVVM 的主要区别就在于,MVVM 是数据驱动,而 MVI 是事件(状态)驱动。
从实现角度
实现 MVI 模型可以通过 View + Presenter + Model 或者 View + JetPack(ViewModel + LiveData/Flow) + Model 方式都实现。关键在于 Model 层与 View 层之间的传递的状态。
怎么理解数据驱动与事件(状态)驱动呢?(以 JetPack 实现为例)
- 数据驱动:ViewModel 持有的是数据,View 通过监听数据变化触发页面逻辑。
- 事件(状态)驱动:ViewModel 持有的是页面状态,View 通过监听状态触发页面变换。
关于具体的实现,这里推荐两个示例:
- 通过 MVP 实现 MVI(这是一篇海外博客)
- 通过 Jetpack 实现 MVI (这是 Airbnb 开源的框架)
Google 推荐框架模式
目前通过官方最新架构指南中可以发现,官方推荐通过 Jetpack 来实现 MVI 模型。
- UI Layer: 用于处理页面逻辑。内部包含了 Activity/Fragment(UI Element)、ViewModel(State Holder)
- Domain Layer: 用于处理 DataLayer 获取的数据,提高代码的复用性。
- Data Layer: 用于处理业务逻辑。内部包含了数据处理(Repositories)、数据存储(Data Sources)
链接:https://juejin.cn/post/7167288478487543816
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 官方项目是怎么做模块化的?快来学习下
本篇文章将会以 Now in Android 项目为例,讲解 Android 官方 App 模块化相关知识及策略。
概述
模块化是将单一模块代码结构拆分为高内聚内耦合的多模块的一种编码实践。
模块化的好处
模块化有以下好处:
- 可扩展性:在高耦合的单一代码库中,牵一发而动全身。模块化项目当采用关注点分离原则。这会赋予了贡献者更多的自主权,同时也强制执行架构模式。
- 支持并行工作:模块化有助于减少代码冲突,为大型团队中的开发人员提供更高效的并行工作。
- 所有权:一个模块可以有一个专门的 owner,负责维护代码和测试、修复错误和审查更改。
- 封装:独立的代码更容易阅读、理解、测试和维护。
- 减少构建时间:利用 Gradle 的并行和增量构建可以减少构建时间。
- 动态交付:模块化是 Play 功能交付 的一项要求,它允许有条件地交付应用程序的某些功能或按需下载。
- 可重用性:模块化为代码共享和构建多个应用程序、跨不同平台、从同一基础提供了机会。
模块化的误区
模块化也可能会被滥用,需要注意以下问题:
- 太多模块:每个模块都有其成本,如 Gradle 配置的复杂性增加。这可能会导致 Gradle 同步及编译时间的增加,并产生持续的维护成本。此外,与单模块相比,添加更多模块会增加项目 Gradle 设置的复杂性。这可以通过使用约定插件来缓解,将可重用和可组合的构建配置提取到类型安全的 Kotlin 代码中。在 Now in Android 应用程序中,可以在 build-logic文件夹 中找到这些约定插件。
- 没有足够的模块:相反,如果你的模块很少、很大并且紧密耦合,最终会产生另外的大模块。这将失去模块化的一些好处。如果您的模块臃肿且没有单一的、明确定义的职责,您应该考虑将其进一步拆分。
- 太复杂了:模块化并没有灵丹妙药 -- 一种方案解决所有项目的模块化问题。事实上,模块化你的项目并不总是有意义的。这主要取决于代码库的大小和相对复杂性。如果您的项目预计不会超过某个阈值,则可扩展性和构建时间收益将不适用。
模块化策略
需要注意的是没有单一的模块化方案,可以确保其对所有项目都适用。但是,可以遵循一般准则,可以尽可能的享受其好处并规避其缺点。
这里提到的模块,是指 Android 项目中的 module,通常会包含 Gradle 构建脚本、源代码、资源等,模块可以独立构建和测试。如下:
一般来说,模块内的代码应该争取做到低耦合、高内聚。
- 低耦合:模块应尽可能相互独立,以便对一个模块的更改对其他模块的影响为零或最小。他们不应该了解其他模块的内部工作原理。
- 高内聚:一个模块应该包含一组充当系统的代码。它应该有明确的职责并保持在某些领域知识的范围内。例如,Now in Android 项目中的core-network模块负责发出网络请求、处理来自远程数据源的响应以及向其他模块提供数据。
Now in Android 项目中的模块类型
注:模块依赖图(如下)可以在模块化初期用于可视化各个模块之间的依赖关系。
Now in Android 项目中有以下几种类型的模块:
- app 模块: 包含绑定其余代码库的应用程序级和脚手架类,
app例如和应用程序级受控导航。一个很好的例子是通过导航设置和底部导航栏设置。该模块依赖于所有模块和必需的模块。 feature-模块: 功能特定的模块,其范围可以处理应用程序中的单一职责。这些模块可以在需要时被任何应用程序重用,包括测试或其他风格的应用程序,同时仍然保持分离和隔离。如果一个类只有一个feature模块需要,它应该保留在该模块中。如果不是,则应将其提取到适当的core模块中。一个feature模块不应依赖于其他功能模块。他们只依赖于core他们需要的模块。core-模块:包含辅助代码和特定依赖项的公共库模块,需要在应用程序中的其他模块之间共享。这些模块可以依赖于其他核心模块,但它们不应依赖于功能模块或应用程序模块。- 其他模块 - 例如和模块
sync、benchmark、test以及app-nia-catalog用于快速显示我们的设计系统的目录应用程序。
项目中的主要模块
基于以上模块化方案,Now in Android 应用程序包含以下模块:
| 模块名 | 职责 | 关键类及核心示例 |
|---|---|---|
app | 将应用程序正常运行所需的所有内容整合在一起。这包括 UI 脚手架和导航。 | NiaApp, MainActivity 应用级控制导航通过 NiaNavHost, NiaTopLevelNavigation |
feature-1, feature-2 ... | 与特定功能或用户相关的功能。通常包含从其他模块读取数据的 UI 组件和 ViewModel。如:feature-author在 AuthorScreen 上显示有关作者的信息。feature-foryou它在“For You” tab 页显示用户的新闻提要和首次运行期间的入职。 | AuthorScreen AuthorViewModel |
core-data | 保存多个特性模块中的数据。 | TopicsRepository AuthorsRepository |
core-ui | 不同功能使用的 UI 组件、可组合项和资源,例如图标。 | NiaIcons NewsResourceCardExpanded |
core-common | 模块之间共享的公共类。 | NiaDispatchers Result |
core-network | 发出网络请求并处理对应的结果。 | RetrofitNiANetworkApi |
core-testing | 测试依赖项、存储库和实用程序类。 | NiaTestRunner TestDispatcherRule |
core-datastore | 使用 DataStore 存储持久数据。 | NiaPreferences UserPreferencesSerializer |
core-database | 使用 Room 的本地数据库存储。 | NiADatabase DatabaseMigrations Dao classes |
core-model | 整个应用程序中使用的模型类。 | Author Episode NewsResource |
core-navigation | 导航依赖项和共享导航类。 | NiaNavigationDestination |
Now in Android 的模块化
Now in Android 项目中的模块化方案是在综合考虑项目的 Roadmap、即将开展的工作和新功能的情况下定义的。Now in Android 项目的目标是提供一个接近生产环境的大型 App 的模块化方案,并且要让方案看起来并没有过度模块化,希望是在两者之间找到一种平衡。
这种方法与 Android 社区进行了讨论,并根据他们的反馈进行了改进。这里并没有一个绝对的正确答案。归根结底,模块化 App 有很多方法和方法,没有唯一的灵丹妙药。这就需要在模块化之前考虑清楚目标、要解决的问题已经对后续工作的影响,这些特定的情况会决定模块化的具体方案。可以绘制出模块依赖关系图,以便帮助更好地分析和规划。
这个项目就是一个示例,并不是一个需要固守不可改变固定结构,相反而是可以根据需求就行变化的。根据 Now in Android 这是我们发现最适合我们项目的一般准则,并提供了一个示例,可以在此基础上进一步修改、扩展和构建。如果您的数据层很小,则可以将其保存在单个模块中。但是一旦存储库和数据源的数量开始增长,可能值得考虑将它们拆分为单独的模块。
最后,官方对其他方式的模块化方案也是持开发态度,有更好的方案及建议也可以反馈出来。
总结
以上内容是根据 Modularization learning journey 翻译整理而得。整体上是提供了一个示例,对一些初学者有一个可以参考学习的工程,对社区中模块化开发起到的积极的作用。说实话,这部分技术在国内并不是什么新技术了。
下面讲一个我个人对这个模块化方案的理解,以下是个人观点,请批判性看待。
首先是好的点提供了通用的 Gradle 配置,简化了各个模块的配置步骤,各种方式预计会在之后的一些项目中流行开来。
不足的点就是没有明确模块化的整体策略,是应采取按照功能还是按照特性分,类似讨论还有我们平时的类文件是按照功能来分还是特性来分,如下是按照特性区分:
# DO,建议方式
- Project
- feature1
- ui
- domain
- data
- feature2
- ui
- domain
- data
- feature3
按照功能区分的方式大致如下:
# DO NOT,不建议方式
- Project
- ui
- feature1
- feature2
- feature3
- domain
- feature1
- feature2
- feature3
- data
我个人是倾向去按照特性的方式区分,而示例中看上去是偏后者,或者是一个混合体,比如有的模块是添加 feature 前缀的,但是 core-model 模块又是在统一的一个模块中集中管理。个人建议的方式应该是将各个模块中各自使用的模型放到自己的模块中,否则项目在后续进行组件化时将会遇到频繁发版的问题。当然,这种方式在模块化的阶段并没有什么大问题。
模块化之后就是组件化,组件化之后就是壳工程,每个技术阶段对应到团队发展的阶段,有机会的话后面可以展开聊聊。
链接:https://juejin.cn/post/7128069998978793509
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
货拉拉客户端通用日志组件 - Glog
Glog 是货拉拉移动端监控系统中的日志存储组件,Glog 意即 General log - 通用日志。为了满足我们对日志格式的多种需求,我们在存储方式、归档方式上做了一些探索和实践,使得 Glog 的通用性和性能优于常见的日志方案。Glog 已经在货拉拉全线 App 中稳定运行了 1 年多,现在将其开源,我们希望 Glog 的开源能够为移动开发者提供一种更加通用的日志方案,同时希望 Glog 能够从社区中汲取养分,不断得到优化和完善。GitHub 地址:https://github.com/huolalatech/hll-wp-glog
背景简介
移动端日志系统通常来说,主要的目标是辅助开发同学排查线上问题,这些问题包括但不限于
- 客诉渠道反馈的 App 使用问题;
- Crash 系统上报的崩溃问题;
- 其他线上冒烟问题。
为了能够尽快定位问题,我们希望能够快速、详细的还原问题现场,这就需要在代码中 App 运行的关键节点埋入日志,将出现问题时的运行状态快速上报。这对日志系统提出了两个关键的要求,信息完整性以及实时性。
在移动端,公司之前存在一套简单的日志系统,收集的日志信息比较有限,我们通过 App 的常见使用流程来看其覆盖的关键节点
另外,之前的日志系统只能通过下发任务回捞,实时性较差,还存在 I/O 性能等问题。
为了解决这些问题,我们开发了新的移动端日志系统,覆盖了上面 App 使用流程的全节点信息
另一方面,为了提升日志的实时性,我们增加了实时日志,通过短轮询来进行定时上报,此外还补充了监控日志来支撑 App 的横向数据对比、评估 App 的性能指标,最终的方案如下
系统主要组成包括
- Android/iOS 上层日志采集 SDK
- 跨平台的储存组件 Glog
- 负责日志存储过滤的日志后端
- 负责日志展示的日志前端
新的监控系统包括实时性要求较高的实时日志,信息较完整的离线日志以及为大盘数据服务的监控日志
- 实时日志,快速上传,信息精简,能够接近实时的查看,快速定位、排查用户反馈的问题;
- 离线日志,通过后台任务触发上传,按天归档,作为实时日志的兜底,要求信息完整详尽;
- 监控日志,支持采样,作为监控大盘的信息源,实时性要求最高,日志只包括监控信息。
为了适配不同日志的存储格式,我们希望存储组件能够在格式上尽量通用,最好做到格式无关;另一方面我们也希望其性能、可靠和安全方面能够对齐一线水平,在调研了市面上流行的日志组件后,我们发现并没有现成方案满足我们的需求,因此我们自研了自己的日志存储组件 Glog。
方案概览
应用上层对不同类型的日志序列化(推荐 Protobuf)之后,将二进制数据存储到 Glog,对于上传频次较高的实时日志和监控日志,采用重命名缓存的方式快速归档;对于信息较全而上传频次不高的离线日志,我们采用 mmap 偏移映射的方式归档,相较标准 I/O 复制归档的方式,提升了性能。在可靠性和安全性方面我们也借鉴了当前的流行方案,例如 mmap I/O 提升性能和可靠性、流式的加密和压缩防止 CPU 突发峰值,另外我们在日志中加入了同步标记支持读取容错。
存储方式
为了适应不同的日志格式,Glog 存储二进制数据,上层依据自己的需要,将数据序列化后交给 Glog
具体的文件格式:使用 2 个字节描述每条日志长度,在每条日志末尾加入一个同步标志,用于文件损坏时的读取容错。

归档方式
回顾一下常见的日志组件中 mmap 的使用方式,首先 mmap I/O 需要映射一片大小为 page size (通常为 4KB) 整数倍大小的缓存,随着数据的写入将这片空间耗尽后,我们无法持续扩展这片空间的大小(由于它占用的是 App 的运行内存空间),因此需要将其中的数据归档,常见的方式是将其中内容 flush 追加到另一个归档文件当中,之后再清空 mmap 缓存,这个 flush 的过程一般使用标准 I/O
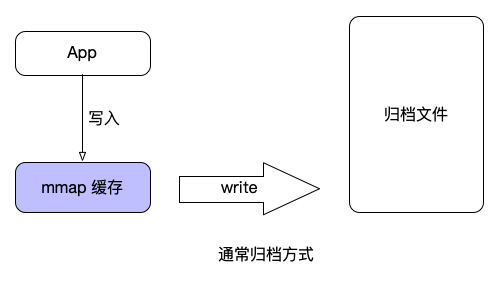
而我们的实时、监控日志为了快速上传保证数据实时性,采用间隔较短的轮询来触发 flush 并上传,这将导致 flush 频率变得很高;而通常的 flush 方式采用标准 I/O 来复制数据,性能相对较低,后续的日志写入需要等待 flush 完成,这将影响我们的写入性能,因此我们考虑两种方案来提升 flush 速度以优化写入性能
- mmap 偏移映射,通过 mmap 映射归档文件的末尾,之后通过内存拷贝将 mmap 缓存追加到归档文件末尾。这种方式将文件复制变成内存复制,性能较好。
- 文件重命名,对于可以快速上传并删除的日志,我们可以在需要时将 mmap 缓存重命名成归档文件,之后重建缓存。这种方式直接去除了复制的环节,但是在日志量较大时,可能产生很多零碎的归档文件。
这两种方案可以在我们的不同日志场景应用,对于实时、监控日志来说,对性能要求最高,选用第 2 种方案,这个方案带来的零碎归档文件问题,由于上传和删除较快,在这里并不会堆积,另一方面,考虑到实时、监控日志上传周期较短,零碎的归档文件也便于控制上传的数据量;而离线日志选用第 1 种方案,可以将每天的日志归档在一个文件中,相对常见的标准 I/O 也有性能上的优势。
加密方式
Glog 使用了 ECDH + AES CFB-128,对每条日志进行单独加密。具体来说通过 ECDH 协商加密秘钥,之后 AES CFB-128 进行对称加密。
选择 CFB-128 是因为 AES 通用性和安全性较好,加解密只需执行相同块加密算法,对 IV 随机性要求低,ECC 相对 RSA 在加密强度相同的前提下,秘钥更短。
| Security(In Bits) | RSA Key Length Required(In Bits) | ECC Key Length Required(In Bits) |
|---|---|---|
| 80 | 1024 | 160-223 |
| 112 | 2048 | 224-255 |
| 128 | 3072 | 256-383 |
| 192 | 7680 | 384-511 |
| 256 | 15360 | 512+ |
压缩方式
考虑到解压缩的便捷性和通用性,Glog 使用了常见的 Deflate 无损压缩算法,对日志进行流式压缩,即以每条日志为压缩单元,在每次写入时进行同步压缩。这样避免了归档时对整个 mmap 缓存做压缩带来的 CPU 波峰,具体的原理下面做一些解释。
Deflate 算法是 LZ77 与哈夫曼编码的组合
LZ77
LZ77 将数据(短语)通过前向缓冲区,然后移动到滑动窗口中成为字典的一部分,之后从字典中搜索能与前向缓冲区匹配的最长短语,如果能够命中,则成为短语标记作为结果保存起来,不能命中则作为字符标记保存。
解压时,如果是字符标记则直接拷贝到滑动窗口中,如果是短语标记则在滑动窗口中查找相应的偏移量,之后将滑动窗口中相应长度的短语拷贝到结果中。
短语标记包括了
- 滑动窗口中的偏移量
- 匹配命中的字符长度
- 匹配结束后前向缓冲区的第一个字符
下面展示了对字符 LABLALALABLA 进行 LZ77 压缩和解压缩的过程,
接下来霍夫曼编码对 LZ77 的处理结果(包括前面提到的偏移量、长度、字符),按照出现频率越高,占用空间越少的方式进行编码存储。
在简要说明原理之后,我们知道影响压缩率的几个因素:滑动窗口(字典)大小,输入的数据(短语)长度、以及短语中字符的重复率。字典越大、短语越长,越容易从字典中找到匹配短语进而变成短语标记,那么流式压缩以每条日志作为压缩单元,输入数据长度变短,我们如何保证压缩率呢?
这里我们能做的是尽量保证字典的大小,不频繁重置字典,具体做法是只在 mmap 缓存归档时重置字典,对于归档前 mmap 缓存的数据,复用字典来保证压缩率。
消息队列
mmap 相对标准 I/O 在性能上有较大优势,主要是由于其减少了内核空间与用户空间的拷贝、以及 write lseek 系统调用带来的上下文切换开销
但在系统资源不足时 mmap 仍有可能出现性能问题,举个例子,我们知道 mmap 与标准 I/O 一样也需要通过 Page Cache 回写到磁盘
Page Cache 的生命周期:
当用户通过标准 I/O 从用户缓冲区向内核空间拷贝数据时,如果内核缓冲区中没有这个 Page,将发生缺页中断分配一个 Page,之后拷贝数据,结束后这个 Page Cache 变成一个脏页,然后该脏页同步到磁盘中,同步结束后,这个 Page Cache 变成 Clean Page 保存在系统中。
Android 中可以通过 showmap 命令观察 mmap 写入了 Page Cache
当系统内存不足时,系统将回收 Page Cache 来释放内存,引起频繁的磁盘回写,mmap 性能也会受到影响。
另一方面由于实时日志、监控日志需要高频归档,而归档会阻塞后续的写入。因此我们在 Glog 底层加入了消息队列来处理写入和归档等操作,进一步提升性能,避免卡顿。
性能对比
| 手机型号 | 日志 SDK | 1w 条日志耗时 | 10w 条日志耗时 |
|---|---|---|---|
| Samsung Galaxy S10+ Android 11 | glog | 21 ms | 182 ms |
| glog+pb | 54 ms | 335 ms | |
| xlog | 207 ms | 1961 ms | |
| logan | 250 ms | 6469 ms | |
| Huawei Honor Magic 2 Android 10 | glog | 38 ms | 286 ms |
| glog+pb | 84 ms | 505 ms | |
| xlog | 263 ms | 2165 ms | |
| logan | 242 ms | 3643 ms | |
| Xiaomi 10 Android 11 | glog | 27 ms | 244 ms |
| xlog | 198 ms | 1863 ms | |
| logan | 210 ms | 4238 ms | |
| Huawei Mate 40 pro HarmonyOS 2.0.0 | glog | 30 ms | 257 ms |
| xlog | 275 ms | 2484 ms | |
| logan | 260 ms | 4020 ms | |
| OPPO R11 Android 8.1.0 | glog | 63 ms | 324 ms |
| glog+pb | 234 ms | 1611 ms | |
| xlog | 464 ms | 3625 ms | |
| logan | 430 ms | 5355 ms | |
| iPhone 12 128G iOS 14.8 | glog | 7 ms | 29 ms |
| xlog | 152 ms | 1079 ms | |
| logan | 162 ms | 12821 ms | |
| iPhone 8 64G iOS 13.7 | glog | 12 ms | 50 ms |
| xlog | 242 ms | 2106 ms | |
| logan | 251 ms | 38312 ms |
Glog 使用异步模式、按天归档
通过对比数据来看,Glog 异步模式由于使用了消息队列,即使累加上 Protobuf 的序列化时间,写入性能相对来说依然有较大优势。
遇到的问题
- 使用 mmap 偏移映射方式拷贝数据时,需要通过 mmap 映射文件末尾,其偏移量也需要是 page size 的整数倍,而归档文件和复制数据大小通常情况下都不是 page size 的整数倍,需要做额外的计算;
- 如果只对归档文件总体积作为阈值来清理,在重命名归档这种情况下零碎文件较多,可能在收集文件列表的过程中导致 JNI 本地引用超限,需要限制文件总个数、及时回收 JNI 本地引用;
- 在跨天写入日志的情况下,mmap 缓存中的数据可能无法及时归档,造成部分日志误写入次日的归档文件当中,需要在归档轮询中增加时间窗口的判定;
- 为了便于上层上传日志,在底层需要添加日志解析模块。
总结
通过上面的介绍,可以看到 Glog 相较其他流行方案的主要区别是:
- 存储的是格式无关的二进制数据,具有更好的定制性;
- 底层实现的消息队列,性能更优使用也更方便;
- 新的归档方式一方面提升性能,另一方面也便于高频读取。
当然这些手段也带来了一些妥协,比如由于存储的是二进制数据,使用 Glog 需要额外添加序列化代码;异步模式下,消息队列中的任务在 Crash 或断电时可能丢失,这些问题在我们的使用场景基本可以忽略。
为了实现货拉拉的业务需求,我们参考流行的日志方案,站在巨人的肩膀上,在移动端存储组件高性能、可靠、安全的基本要求之外,提供了更多的特性和额外的优化。在开源之后,也希望能够反哺社区,为移动开发者提供一种更为通用的日志方案。
以 Glog 为存储模块的日志系统,目前已经接入了公司的全线 app,实时日志的单日日志量达到数十亿条,稳定运行在百万级别的 App 上。为线上用户反馈问题解决、App 崩溃排查提供了有力的帮助,除此之外,还为风控系统、监控大盘提供了数据支撑。
链接:https://juejin.cn/post/7168662263337861133
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【杰哥带你玩转Android自动化】AccessibilityService基础
0x1、引言
Hi,我是杰哥,忙了好一阵子,终于有点时间来继续填坑啦~
间隔太久没更新,读者估计都忘记这个专栏了,所以在开始本节前,再重复下这段话:
所有Android自动化框架和工具中 操作Android设备的功能实现 都基于 adb 和 无障碍服务AccessibilityService。
前面所学的 adb 更倾向于 PC端控制Android设备自动化,无论有线连接还是无线连接,你都需要一台PC 来跑脚本。它的 不方便 还体现在:你写了一个很屌的脚本,跟亲朋好友Share,他们还得 安装配置一波运行环境 才能用。
而本节要学的 无障碍服务AccessibilityService 则更倾向于 APP控制Android设备自动化,把编写好的脚本打包成 Android APK安装包,直接把apk发给别人,安装了启动下无障碍服务,直接能用,相比之下方便得不是一星半点。当然,编写脚本需要一点 一点基本的Android开发经验。
AccessibilityService,别看名字长,其实一点都不难,本节学习路线如下:
- 简单了解下AccessibilityService是什么东西;
- AccessibilityService的基本使用,先跑起来再说;
- 掌握一些常用伎俩;
- 动手写个超简单的案例:自动登录Windows/Mac微信
没有前戏,我直接开始~
0x2、AccessibilityService简介
Android官方文档中有个专题 → 【打造无障碍应用】 其中包含了对 无障碍相关 的一系列解读,在Android开发者的公号里也有两篇讲解的文章:
感兴趣的可移步至相关文章进行阅读,这里不展开讲,我们更关注的是 无障碍服务的使用。点开官方文档:《创建自己的无障碍服务》,这样介绍到:
无障碍服务是一种应用,可提供界面增强功能,来协助残障用户或可能暂时无法与设备进行全面互动的用户完成操作。例如,正在开车、照顾孩子或参加喧闹聚会的用户可能需要其他或替代的界面反馈方式。Android 提供了标准的无障碍服务(包括 TalkBack),开发者也可以创建和分发自己的服务。
简而言之就是:优化残障人士使用Android设备和应用程序的体验
读者看完这段话,估计是一脸懵逼,落地一下就是:利用这个服务自动控制其它APP的各种操作,如点击、滑动、输入等。然后文档下面有一个 注意:
只能是为了!!!
2333,在国内是不存在的,它的应用场景五花八门,凡是和 自动点 有关的都离不开它,如:灰产微商工具、开屏广告跳过、自动点击器、红包助手、自动秒杀工具、一键XX、第三方应用监听等等。em...读者暂且把它理解成一个可以拿来帮助我们自动点点点的工具就好,接着说下怎么用。
0x3、AccessibilityService基本使用
AccessibilityService无障碍服务 说到底,还是一个 服务,那妥妥滴继承 Service,并具有它的生命周期和一些特性。
用户手动到设置里启动无障碍服务,系统绑定服务后,会回调 onServiceConnected(),而当用户在设置中手动关闭、杀死进程、或开发者调用 disableSelf() 时,服务会被关闭销毁。
关于它的基本用法非常简单,四步走~
① 自定义AccessibilityService
继承 AccessibilityService,重写 onInterrupt() 和 onAccessibilityEvent() 方法,示例代码如下:
import android.accessibilityservice.AccessibilityService
import android.util.Log
import android.view.accessibility.AccessibilityEvent
class JumpAdAccessibilityService: AccessibilityService() {
val TAG = javaClass.simpleName
override fun onAccessibilityEvent(event: AccessibilityEvent?) {
Log.d(TAG, "onAccessibilityEvent:$event")
}
override fun onInterrupt() {
Log.d(TAG, "onInterrupt")
}
}上述两个方法是 必须重写 的:
onInterrupt()→ 服务中断时回调;onAccessibilityEvent()→ 接收到系统发送AccessibilityEvent时回调,如:顶部Notification,界面更新,内容变化等,我们可以筛选特定的事件类型,执行不同的响应。比如:顶部出现WX加好友的Notification Event,跳转到加好友页自动通过。
具体的Event类型可参见文尾附录,另外两个 可选 的重写方法:
onServiceConnected()→ 当系统成功连接无障碍服务时回调,可在此调用 setServiceInfo() 对服务进行配置调整onUnbind()→ 系统将要关闭无障碍服务时回调,可在此进行一些关闭流程,如取消分配的音频管理器
② Service注册
上面说了AccessbilityService本质还是Service,所以需要在 AndroidManifest.xml 中进行注册:
<service
android:name=".JumpAdAccessibilityService"
android:exported="false"
android:label="跳过广告哈哈哈哈"
android:permission="android.permission.BIND_ACCESSIBILITY_SERVICE">
<intent-filter>
<action android:name="android.accessibilityservice.AccessibilityService" />
</intent-filter>
</service>
Tips:设置 android:permission="android.permission.BIND_ACCESSIBILITY_SERVICE" 是为了确保只有系统可以绑定此服务。而 android:label 是设置在无障碍服务那里文案,其它照抄。
③ 监听相关配置
就是监听什么类型的Event,监听什么app等的配置,配置方法有两种,二选一 即可~
动态配置
重写 onServiceConnected(),配置代码示例如下:
override fun onServiceConnected() {
val serviceInfo = AccessibilityServiceInfo().apply {
eventTypes = AccessibilityEvent.TYPES_ALL_MASK
feedbackType = AccessibilityServiceInfo.FEEDBACK_GENERIC
flags = AccessibilityServiceInfo.DEFAULT
packageNames = arrayOf("com.tencent.mm") //监听的应用包名,支持多个
notificationTimeout = 10
}
setServiceInfo(serviceInfo)
}属性与可选值详解可见文尾附录,接着说另一种配置方式~
静态配置
Android 4.0 后,可以在AndroidManifest.xml中添加一个引用配置文件的<meta-data>元素:
<service android:name=".JumpAdAccessibilityService"
...
<meta-data
android:name="android.accessibilityservice"
android:resource="@xml/accessible_service_config_jump_ad" />
可以看到resource属性会引用了一个xml文件,我们来创建这个文件:
在 res 文件夹下 新建xml文件夹 (有的话不用建),然后 新建一个配置xml文件 (名字自己定),如:
内容如下:
<?xml version="1.0" encoding="utf-8"?>
<accessibility-service xmlns:android="http://schemas.android.com/apk/res/android"
android:accessibilityEventTypes="typeAllMask"
android:accessibilityFeedbackType="feedbackGeneric"
android:accessibilityFlags="flagDefault"
android:canRetrieveWindowContent="true"
android:description="@string/accessibility_desc"
android:notificationTimeout="100"
android:packageNames="com.tencent.mm"
android:settingsActivity="cn.coderpig.jumpad.MainActivity" />
属性与可选值详解可见文尾附录,说下两种配置方式的优缺点:
静态配置可配置属性更多,适合参数不需要动态改变的场景,动态配置属性有限,但灵活性较高,可按需修改参数,可以搭配使用。
④ 启用无障碍服务
二选一配置完毕后,运行APP,然后依次打开手机 (不同手机系统会有些许差异):设置 → 无障碍 → 找到我们的APP → 显示关闭说明无障碍服务没起来,点开:
开关打开后,会弹出授权窗口,点击允许:
上面我们设置监听的包名是com.tencent.mm,打开微信,也可以看到控制台陆续输出一些日志信息:
可以,虽然没具体干点啥,但服务算是支棱起来了!!!
0x3、一些常用伎俩
无障碍服务的常用伎俩有这四个:判断无障碍服务是否开启、结点查找、结点交互、全局交互。接着一一讲解:
① 判断无障碍服务是否打开
这个没啥好讲的,直接上工具代码:
fun Context.isAccessibilitySettingsOn(clazz: Class<out AccessibilityService?>): Boolean {
var accessibilityEnabled = false // 判断设备的无障碍功能是否可用
try {
accessibilityEnabled = Settings.Secure.getInt(
applicationContext.contentResolver,
Settings.Secure.ACCESSIBILITY_ENABLED
) == 1
} catch (e: Settings.SettingNotFoundException) {
e.printStackTrace()
}
val mStringColonSplitter = SimpleStringSplitter(':')
if (accessibilityEnabled) {
// 获取启用的无障碍服务
val settingValue: String? = Settings.Secure.getString(
applicationContext.contentResolver,
Settings.Secure.ENABLED_ACCESSIBILITY_SERVICES
)
if (settingValue != null) {
// 遍历判断是否包含我们的服务
mStringColonSplitter.setString(settingValue)
while (mStringColonSplitter.hasNext()) {
val accessibilityService = mStringColonSplitter.next()
if (accessibilityService.equals(
"${packageName}/${clazz.canonicalName}",
ignoreCase = true
)
) return true
}
}
}
return false
}每次打开我们的APP都调用下这个方法判断无障碍服务是否打开,没有弹窗或者给提示,引导用户去 无障碍设置页设置下,跳转代码如下:
startActivity(Intent(Settings.ACTION_ACCESSIBILITY_SETTINGS))设置完返回APP,再获取一次服务状态,所以建议在 onResume() 中调用,并做一些对应的UI更新操作。
② 节点查找
比如我要点击某个按钮,我需要先查找到节点,然后再触发点击交互,所以得先定位到节点。下述两个方法可以 获取当前页面节点信息AccessibilityNodeInfo:
AccessibilityEvent.getSource()AccessibilityService.getRootInActiveWindow()
但要注意两个节点个数不一定相等,而获取到 AccessibilityNodeInfo 实例后可以通过下述方法定位结点(可能匹配到多个,所以返回类型是List<AccessibilityNodeInfo>):
AccessibilityNodeInfo.findAccessibilityNodeInfosByText()→ 通过Text查找;AccessibilityNodeInfo.findAccessibilityNodeInfosByViewId()→ 通过节点ID查找
根据文本匹配就不用说了,注意它是contain()包含匹配,不是equals()的方式就好,这里主要说下如何获取 节点ID,需要用到一些工具,前三个是最常见的工具,从旧到新依次是:
1、HierarchyView
老牌分析工具,早期Android SDK有快捷方式,新版找不到了,得自己点击:android-sdk目录下的tools\monitor.bat 启动 Android Device Monitor:
然后点击生成节点数,会dump出节点树,点击相应节点获取所需数据:
直接生成当前页面节点树,方便易用,而且不止布局分析,还有方法调用跟踪、文件管理器等,百宝箱啊,不过小卡,用的时候鼠标一直显示Loading。
2、UI Automator Viewer
比HierarchyView更纯粹,只有生成当前页面节点树的功能,新版同样找不到快捷方式了,得点击
android-sdk目录下的 tools\bin\uiautomatorviewer.bat 启动:
用法也同样简单,而且支持保存节点树,不卡~
3、LayoutInspector
AS 3.0后取消了老旧的DDMS后提供的界面更友好的全新工具,依次点击:Tools → Layout Inspector 打开:
然后选择要监听的进程:
选择完可能会一直转加载不出来,因为默认勾选了 Enable Live Layout Inspector 它会实时加载布局内容,关掉它。
依次点击:File → Settings → Experimental → 找到Layout Inspector → 取消勾选
确定后,此时入口变成了这个:
选择要查看的进程,OK,有多个Windows还可以自行选择:
这里笔者试了几次没load出微信的布局,不知道电脑太辣鸡还是手机问题:
试了一个简单页面倒可以:
还有一点,选进程只能选可debug的进程,所以想调所有进程的话,要么虚拟机,要么Root了的真机,2333,虽然高档,但是用起来没前两个顺手。
4、其它工具
除上面三个之外其它都是一些小众工具了,如 autojs,划出左侧面板 → 打开悬浮框 → 点击悬浮图标展开扇形菜单 → 点击蓝色的 → 选择布局范围分析 → 点击需要获得结点信息的区域。具体步骤如下图所示:
开发者助手等工具获取方式也是类型。这里顺带安利一波笔者在《学亿点有备无患的"姿势"》 写的工具代码 → 获取当前页面所有控件信息,直接调用下方法:
解析好的节点树直接dump出来,获取id就是这么so easy~
③ 节点交互
除了根据ID或文本定位到节点的方法外,还可以调用下述方法进行循环迭代:
- getParent() → 获取父节点;
- getChild() → 获取子节点;
- getChildCount() → 获取节点的子节点数;
获取节点后,可以调用 performAction() 方法对节点执行一个动作,如点击、长按、滑动等,直接上工具代码:
// 点击
fun AccessibilityNodeInfo.click() = performAction(AccessibilityNodeInfo.ACTION_CLICK)
// 长按
fun AccessibilityNodeInfo.longClick() =
performAction(AccessibilityNodeInfo.ACTION_LONG_CLICK)
// 向下滑动一下
fun AccessibilityNodeInfo.scrollForward() =
performAction(AccessibilityNodeInfo.ACTION_SCROLL_FORWARD)
// 向上滑动一下
fun AccessibilityNodeInfo.scrollBackward() =
performAction(AccessibilityNodeInfo.ACTION_SCROLL_BACKWARD)
// 填充文本
fun AccessibilityNodeInfo.input(content: String) = performAction(
AccessibilityNodeInfo.ACTION_SET_TEXT, Bundle().apply {
putCharSequence(AccessibilityNodeInfo.ACTION_ARGUMENT_SET_TEXT_CHARSEQUENCE, content)
}
)④ 全局交互
除了控件触发事件外,AccessibilityService提供了一个 performGlobalAction() 来执行一些通用交互,示例如下:
performGlobalAction(GLOBAL_ACTION_BACK) // 返回键
performGlobalAction(GLOBAL_ACTION_HOME) // Home键关于AccessibilityService常用伎俩就这些,接着写个超简单的例子来练练手~
0x4、超简单案例:自动登录Windows/Mac微信
登录过微信的PC,下次登录需要在手机上点击确定登录:
我有强迫症,每次下班都会退掉PC的微信,上班再重新登,每次都要点一下,不得不说有点蠢。
完全可以用本节学的姿势写一个自动登录的小jio本啊,简单,也好演示脚本开发的基本流程~
① 判断无障碍服务是否开启
直接在《AccessibilityService基本使用》的代码基础上进行开发,先撸出一个骚气的设置页:
接着是控件初始化,事件设置的一些简单逻辑:
运行下看看效果:
② 看下需要监听什么类型的Event
先把无障碍配置文件里的 android:accessibilityEventTypes 设置为 typeAllMask,即监听所有类型的Event。接着直接把 onAccessibilityEvent() 的参数 event 打印出来:
运行后,开启无障碍服务,接着点击登录/或者扫二维码,微信弹出登录页面,可以看到下述日志:
即打开登录页会触发 TYPE_WINDOW_STATE_CHANGED 类型的 Event,且页面为 ExtDeviceWXLoginUI。
行吧,那就只关注这类型的Event,把 android:accessibilityFeedbackType 设置为 typeWindowStateChanged,改下 onAccessibilityEvent() 里的处理逻辑:
③ 找到登录按钮并触发点击
懒得用工具扣,直接用adb的脚本打印出节点树,直接就定位要找的节点了:
行吧,可以根据文本查找,也可以根据id查找,前者是contain()的方式匹配,包含登录文本的节点都会被选中:
而这里的id是唯一的,所以直接根据id进行查找,找到后触发点击:
运行下看看效果:
脚本检测到登录页面,自动点击登录按钮,迅雷不及掩耳之势页面就关了~
0x5、小结
本节过了一下 AccessibilityService无障碍服务 的基础姿势,并写了一个超简单的微信自动登录案例演示脚本编写的大概过程,相信读者学完可以动手尝试编写一些简单的脚本。而在实际开发中还会遇到一些问题,如:获取到控件,但无法点击,在后续实战环节中会一一涉猎,剧透下,下一节会带着大家来开发一个:微信僵尸好友检测工具,敬请期待~
参考文献
- 官方文档:《创建自己的无障碍服务》
- AccessibilityService使用入门
- (AccessibilityService) Android 辅助功能笔记
- 辅助功能 AccessibilityService笔记(2)
附录:属性、参数、可选值详解
Tips:下述内容可能过时,或者有部分不准确,建议以官方文档和源码为准
android:accessibilityEventTypes → AccessibilityServiceInfo.eventTypes
服务监听的事件类型,可选值有这些,支持多个,属性值用|分隔,代码设置值用or分隔
| 描述 | xml属性值 | 代码设置值 |
|---|---|---|
| 所有类型的事件 | typeAllMask | xxx |
| 一个应用产生一个通知事件 | typeAnnouncement | TYPE_ANNOUNCEMENT |
| 辅助用户读取当前屏幕事件 | typeAssistReadingContext | TYPE_ASSIST_READING_CONTEXT |
| view中上下文点击事件 | typeContextClicked | TYPE_VIEW_CONTEXT_CLICKED |
| 监测到的手势事件完成 | typeGestureDetectionEnd | TYPE_GESTURE_DETECTION_END |
| 开始手势监测事件 | typeGestureDetectionStart | TYPE_GESTURE_DETECTION_START |
| Notification变化事件 | typeNotificationStateChanged | TYPE_NOTIFICATION_STATE_CHANGED |
| 触摸浏览事件完成 | typeTouchExplorationGestureEnd | TYPE_TOUCH_EXPLORATION_GESTURE_END |
| 触摸浏览事件开始 | typeTouchExplorationGestureStart | TYPE_TOUCH_EXPLORATION_GESTURE_START |
| 用户触屏事件结束 | typeTouchInteractionEnd | TYPE_TOUCH_INTERACTION_END |
| 触摸屏幕事件开始 | typeTouchInteractionStart | TYPE_TOUCH_INTERACTION_START |
| 无障碍焦点事件清除 | typeViewAccessibilityFocusCleared | TYPE_VIEW_ACCESSIBILITY_FOCUS_CLEARED |
| 获得无障碍的焦点事件 | typeViewAccessibilityFocused | TYPE_VIEW_ACCESSIBILITY_FOCUSED |
| View被点击 | typeViewClicked | TYPE_VIEW_CLICKED |
| View被长按 | typeViewLongClicked | TYPE_VIEW_LONG_CLICKED |
| View被选中 | typeViewSelected | TYPE_VIEW_SELECTED |
| View获得焦点 | typeViewFocused | TYPE_VIEW_FOCUSED |
| 一个View进入悬停 | typeViewHoverEnter | TYPE_VIEW_HOVER_ENTER |
| 一个View退出悬停 | typeViewHoverExit | TYPE_VIEW_HOVER_EXIT |
| View滚动 | typeViewScrolled | TYPE_VIEW_SCROLLED |
| View文本变化 | typeViewTextChanged | TYPE_VIEW_TEXT_CHANGED |
| View文字选中发生改变事件 | typeViewTextSelectionChanged | TYPE_VIEW_TEXT_SELECTION_CHANGED |
| 窗口的内容发生变化,或子树根布局发生变化 | typeWindowContentChanged | TYPE_WINDOW_CONTENT_CHANGE |
| 新的弹出层导致的窗口变化(dialog、menu、popupwindow) | typeWindowStateChanged | TYPE_WINDOW_STATE_CHANGED |
| 屏幕上的窗口变化事件,需要API 21+ | typeWindowsChanged | TYPE_WINDOWS_CHANGED |
| UIanimator中在一个视图文本中进行遍历会产生这个事件,多个粒度遍历文本。一般用于语音阅读context | typeViewTextTraversedAtMovementGranularity | TYPE_VIEW_TEXT_TRAVERSED_AT_MOVEMENT_GRANULARITY |
android:accessibilityFeedbackType → AccessibilityServiceInfo.feedbackType
操作相关按钮后,服务给用户的反馈类型,可选值如下:
| 描述 | xml属性值 | 代码设置值 |
|---|---|---|
| 取消所有的反馈方式,一般用这个 | feedbackAllMask | FEEDBACK_ALL_MASK |
| 可听见的(非语音反馈) | feedbackAudible | FEEDBACK_AUDIBLE |
| 通用反馈 | feedbackGeneric | FEEDBACK_GENERIC |
| 触觉反馈(震动) | feedbackHaptic | FEEDBACK_HAPTIC |
| 语音反馈 | feedbackSpoken | FEEDBACK_SPOKEN |
| 视觉反馈 | feedbackVisual | FEEDBACK_VISUAL |
| 盲文反馈 | 不支持 | FEEDBACK_BRAILLE |
android:accessibilityFlags → AccessibilityServiceInfo.flags
辅助功能附加的标志,可选值有这些,支持多个,属性值用|分隔,代码设置值用or分隔:
| 描述 | xml属性值 | 代码设置值 |
|---|---|---|
| 默认配置 | flagDefault | DEFAULT |
| 为WebView中呈现的内容提供更好的辅助功能支持 | flagRequestEnhancedWebAccessibility | FLAG_REQUEST_ENHANCED_WEB_ACCESSIBILITY |
| 使用该flag表示可获取到view的ID | flagReportViewIds | FLAG_REPORT_VIEW_IDS |
| 获取到一些被表示为辅助功能无权获取到的view | flagIncludeNotImportantViews | FLAG_INCLUDE_NOT_IMPORTANT_VIEWS |
| 监听系统的物理按键 | flagRequestFilterKeyEvents | FLAG_REQUEST_FILTER_KEY_EVENTS |
| 监听系统的指纹手势 API 26+ | flagRequestFingerprintGestures | FLAG_REQUEST_FINGERPRINT_GESTURES |
| 系统进入触控探索模式,出现一个鼠标在用户的界面 | flagRequestTouchExplorationMode | FLAG_REQUEST_TOUCH_EXPLORATION_MODE |
| 如果辅助功能可用,提供一个辅助功能按钮在系统的导航栏 API 26+ | flagRequestAccessibilityButton | FLAG_REQUEST_ACCESSIBILITY_BUTTON |
| 要访问所有交互式窗口内容的系统,这个标志没有被设置时,服务不会收到TYPE_WINDOWS_CHANGE事件 | flagRetrieveInteractiveWindows | FLAG_RETRIEVE_INTERACTIVE_WINDOWS |
| 系统内所有的音频通道,使用由STREAM_ACCESSIBILTY音量控制USAGE_ASSISTANCE_ACCESSIBILITY | flagEnableAccessibilityVolume | FLAG_ENABLE_ACCESSIBILITY_VOLUME |
android:canRetrieveWindowContent
服务是否能取回活动窗口内容的属性,与flagRetrieveInteractiveWindows搭配使用,无法在运行时更改此配置。
android:notificationTimeout → AccessibilityServiceInfo.notificationTimeout
同一类型的两个辅助功能事件发送到服务的最短间隔(毫秒,两个辅助功能事件之间的最小周期)
android:packageNames → AccessibilityServiceInfo.packageNames
监听的应用包名,多个用逗号(,)隔开,两种方式设置监听所有应用的事件:
- 不设置此属性;
- 赋值null → android:packageNames="@null"
网上一堆说空字符串的,都是没经过验证的,用空字符串你啥都捕获不到!!!
android:settingsActivity → AccessibilityServiceInfo.settingsActivityName
允许修改辅助功能的activity类名,就是你自己的无障碍服务的设置页。
android:description
该服务的简单说明,会显示在无障碍服务说明页:
android:canPerformGestures
是否可以执行手势,API 24新增
链接:https://juejin.cn/post/7169033859894345765
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin Flow啊,你将流向何方?
前言
前边一系列的协程文章铺垫了很久,终于要分析Flow了。如果说协程是Kotlin的精华,那么Flow就是协程的精髓。
通过本篇文章,你将了解到:
- 什么是流?
- 为什么引进Flow?
- Fow常见的操作
- 为什么说Flow是冷流?
1. 什么是流
自然界的流水,从高到低,从上游到下游流动。
而对于计算机世界的流:
数据的传递过程构成了数据流,简称流
比如想要查找1~1000内的偶数,可以这么写:
var i = 0
var list = mutableListOf<Int>()
while (i < 1000) {
if (i % 2 == 0)
list.add(i)
i++
}此处对数据的处理即为找出其中的偶数。
若想要在偶数中找到>500的数,则继续筛选:
var i = 0
var list = mutableListOf<Int>()
while (i < 1000) {
if (i > 500 && i % 2 == 0)
list.add(i)
i++
}可以看出,原始数据是1~1000,我们对它进行了一些操作:过滤偶数、过滤>500的数。当然还可以进行其它操作,如映射、变换等。
提取上述过程三要素:
- 原始数据
- 对数据的一系列操作
- 最终的数据
把这一系列的过程当做流:
从流的方向来观察,我们称原始数据为上流,对数据进行一系列处理后,最终的数据为下流。
从流的属性来观察,我们认为生产者在上流生产数据,消费者在下流消费数据。
2. 为什么引进Flow?
由前面的文章我们知道,Java8提供了StreamAPI,专用来操作流,而Kotlin也提供了Sequence来处理流。
那为什么还要引进Flow呢?
在Kotlin的世界里当然不会想再依赖Java的StreamAPI了,主要来对比Kotlin里的各种方案选择。
先看应用场景的演变。
a、集合获取多个值
想要获取多个值,很显而易见的想到了集合。
fun testList() {
//构造集合
fun list(): List<Int> = listOf(1, 2, 3)
list().forEach {
//获取多个值
println("value = $it")
}
}以上函数功能涉及两个对象:生产者和消费者。
生产者:负责将1、2、3构造为集合。
消费者:负责从集合里将1、2、3取出。
若此时想要控制生产者的速度,比如先将1放到集合里,过1秒后再讲2放进集合,在此种场景下该函数显得不那么灵活了。
b、Sequence控制生成速度
Sequence可以生产数据,先看看它是怎么控制生产速度的。
fun testSequence() {
fun sequence():Sequence<Int> = sequence {
for (i in 1..3) {
Thread.sleep(1000)
yield(i)
}
}
sequence().forEach {
println("value = $it")
}
}通过阻塞线程控制了生产者的速度。
你可能会说:在协程体里为啥要用Thread.sleep()阻塞线程呢,用delay()不香吗?
看起来很香,我们来看看实际效果:
直接报编译错误了,提示是:受限制的挂起函数只能调用自己协程作用域内的成员和其它挂起函数。
而sequence的作用域是SequenceScope,查看其定义发现:
究其原因,SequenceScope 被RestrictsSuspension 修饰限制了。
c、集合配合协程使用
sequence 因为协程作用域的限制,不能异步生产数据,而使用集合却没此限制。
suspend fun testListDelay() {
suspend fun list():List<Int> {
delay(1000)
return listOf(1, 2, 3)
}
list().forEach {
println("value = $it")
}
}但也暴露了一个缺陷,只能一次性的返回集合元素。
综上所述:
不管是集合还是Sequence,都不能完全覆盖流的需求,此时Flow闪亮登场了
3. Fow常见的操作
最简单的Flow使用
suspend fun testFlow1() {
//生产者
var flow = flow {
//发射数据
emit(5)
}
//消费者
flow.collect {
println("value=$it")
}
}通过flow函数构造一个flow对象,然后通过调用flow.collect收集数据。
flow函数的闭包为生产者的生产逻辑,collect函数的闭包为消费者的消费逻辑。
当然,还有更简单的写法:
suspend fun testFlow2() {
//生产者
flow {
//发射数据
emit(5)
}.collect {
//消费者
println("value=$it")
}
}执行流程:
Flow操作符
上面只提到了flow数据的发送以及接收,并没有提及对flow数据的操作。
flow提供了许多操作符方便我们对数据进行处理(对流进行加工)。
我们以寻找1~1000内大于500的偶数为例:
suspend fun testFlow3() {
//生产者
var flow = flow {
for (i in 1..1000) {
emit(i)
}
}.filter { it > 500 && it % 2 == 0 }
//消费者
flow.collect {
println("value=$it")
}
}filter函数的作用根据一定的规则过滤数据,一般称这种函数为flow的操作符。
当然还可以对flow进行映射、变换、异常处理等。
suspend fun testFlow3() {
//生产者
var flow = flow {
for (i in 1..1000) {
emit(i)
}
}.filter { it > 500 && it % 2 == 0 }
.map { it - 500 }
.catch {
//异常处理
}
//消费者
flow.collect {
println("value=$it")
}
}中间操作符
前面说过流的三要素:原始数据、对数据的操作、最终数据,对应到Flow上也是一样的。
flow的闭包里我们看做是原始数据,而filter、map、catch等看做是对数据的操作,collect闭包里看做是最终的数据。
filter、map等操作符属于中间操作符,它们负责对数据进行处理。
中间操作符仅仅只是预先定义一些对流的操作方式,并不会主动触发动作执行
末端操作符
末端操作符也叫做终端操作符,调用末端操作符后,Flow将从上流发出数据,经过一些列中间操作符处理后,最后流到下流形成最终数据。
如上面的collect操作符就是其中一种末端操作符。
怎么区分中间操作符和末端操作符呢?
和Sequence操作符类似,可以通过返回值判断。
先看看中间操作符filter:
public inline fun <T> Flow<T>.filter(crossinline predicate: suspend (T) -> Boolean): Flow<T> = transform { value ->
if (predicate(value)) return@transform emit(value)
}
internal inline fun <T, R> Flow<T>.unsafeTransform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = unsafeFlow { // Note: unsafe flow is used here, because unsafeTransform is only for internal use
collect { value ->
// kludge, without it Unit will be returned and TCE won't kick in, KT-28938
return@collect transform(value)
}
}可以看出,filter操作符仅仅只是构造了Flow对象,并重写了collect函数。
再看末端操作符collect:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})返回值为Unit,并且通过调用collect最终调用了emit,触发了流。
Flow相比Sequence、Collection的优势
Sequence对于协程的支持不够好,不能调用其作用域外的suspend函数,而Collection生产数据不够灵活,来看看Flow是如何解决这些问题的。
suspend fun testFlow4() {
//生产者
var flow = flow {
for (i in 1..1000) {
delay(1000)
emit(i)
}
}.flowOn(Dispatchers.IO)//切换到io线程执行
//消费者
flow.collect {
delay(1000)
println("value=$it")
}
}如上,flow的生产者、消费者闭包里都支持调用协程的suspend函数,同时也支持切换线程执行。
再者,flow可以将集合里的值一个个发出,可调整其流速。
当然,flow还提供了许多操作符帮助我们实现各种各样的功能,此处限于篇幅就不再深入。
万变不离其宗,知道了原理,一切迎刃而解。
4. 为什么说Flow是冷流?
flow 的流动
在sequence的分析里有提到过sequence是冷流,那么什么是冷流呢?
没有消费者,生产者不会生产数据
没有观察者,被观察者不会发送数据
suspend fun testFlow5() {
//生产者
var flow = flow {
println("111")
for (i in 1..1000) {
emit(i)
}
}.filter {
println("222")
it > 500 && it % 2 == 0
}.map {
println("333")
it - 500
}.catch {
println("444")
//异常处理
}如上代码,只要生产者没有消费者,该函数运行后不会有任何打印语句输出。
这个时候将消费者加上,就会触发流的流动。
还是以最简单的flow demo为例,看看其调用流程:
图上1~6步骤即为最简单的flow调用流程。
可以看出,只有调用了末端操作符(如collect)之后才会触发flow的流动,因此flow是冷流。
flow 的原理
suspend fun testFlow1() {
//生产者
var flow = flow {
//发射数据
emit(5)
}
//消费者
flow.collect {
println("value=$it")
}
}以上代码涉及到三个关键函数(flow、emit、collect),两个闭包(flow闭包、collect闭包。
从上面的调用图可知,以上五者的调用关系:
flow-->collect-->flow闭包-->emit-->collect闭包
接下来逐一分析在代码里的关系。
先看生产者动作(flow函数)
flow函数实现:
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
传入的参数类型为:FlowCollector的扩展函数,而FlowCollector是接口,它有唯一的函数:emit(xx)。因此在flow函数的闭包里可以调用emit(xx)函数,flow闭包作为SafeFlow的成员变量block。
flow 函数返回SafeFlow,SafeFlow继承自AbstractFlow,并实现了collect函数:
#Flow.kt
public final override suspend fun collect(SafeCollector: FlowCollector<T>) {
//构造SafeCollector
//collector 作为SafeCollector的成员变量
val safeCollector = SafeCollector(collector, coroutineContext)
try {
//抽象函数,子类实现
collectSafely(safeCollector)
} finally {
safeCollector.releaseIntercepted()
}
}collect的闭包作为SafeCollector的成员变量collector,后面会用到。
由此可见:flow函数仅仅只是构造了flow对象并返回。
再看消费者动作(collect)
当消费者调用flow.collect函数时:
public suspend inline fun <T> Flow<T>.collect(crossinline action: suspend (value: T) -> Unit): Unit =
collect(object : FlowCollector<T> {
override suspend fun emit(value: T) = action(value)
})此时调用的collect即为flow里定义的collect函数,并构造了匿名对象FlowCollector,实现了emit函数,而emit函数的真正实现为action,也就是外层传入的collect的闭包。
上面分析到的collect源码里调用了collectSafely:
private class SafeFlow<T>(private val block: suspend FlowCollector<T>.() -> Unit) : AbstractFlow<T>() {
override suspend fun collectSafely(collector: FlowCollector<T>) {
collector.block()
}
}此处的block即为在构造flow对象时传入的闭包。
此时,消费者通过collect函数已经调用到生产者的闭包里
还剩下最后一个问题:生产者的闭包是如何流转到消费者的闭包里呢?
最后看发射动作(emit)
在生产者的闭包里调用了emit函数:
override suspend fun emit(value: T) {
//挂起函数
return suspendCoroutineUninterceptedOrReturn sc@{ uCont ->
try {
//uCont为当前协程续体
emit(uCont, value)
} catch (e: Throwable) {
// Save the fact that exception from emit (or even check context) has been thrown
lastEmissionContext = DownstreamExceptionElement(e)
throw e
}
}
}
private fun emit(uCont: Continuation<Unit>, value: T): Any? {
val currentContext = uCont.context
currentContext.ensureActive()
// This check is triggered once per flow on happy path.
val previousContext = lastEmissionContext
if (previousContext !== currentContext) {
checkContext(currentContext, previousContext, value)
}
completion = uCont
//collector.emit 最终调用collect的闭包
return emitFun(collector as FlowCollector<Any?>, value, this as Continuation<Unit>)
}如此一来,生产者的闭包里调用emit函数后,将会调用到collect的闭包里,此时数据从flow的上游流转到下游。
总结以上步骤,其实本质还是对象调用。
中间操作符的原理
以filter为例:
public inline fun <T> Flow<T>.filter(crossinline predicate: suspend (T) -> Boolean): Flow<T> = transform { value ->
//判断过滤条件是否满足,若是则发送数据
if (predicate(value)) return@transform emit(value)
}
internal inline fun <T, R> Flow<T>.unsafeTransform(
@BuilderInference crossinline transform: suspend FlowCollector<R>.(value: T) -> Unit
): Flow<R> = unsafeFlow { // Note: unsafe flow is used here, because unsafeTransform is only for internal use
//调用当前对象collect
collect { value ->
// kludge, without it Unit will be returned and TCE won't kick in, KT-28938
return@collect transform(value)
}
}
internal inline fun <T> unsafeFlow(@BuilderInference crossinline block: suspend FlowCollector<T>.() -> Unit): Flow<T> {
//构造flow,重写collect
return object : Flow<T> {
override suspend fun collect(collector: FlowCollector<T>) {
collector.block()
}
}
}filter操作符构造了新的flow对象,该对象重写了collect函数。
当调用flow.collect时,先调用到filter对象的collect,进而调用到原始flow的collect,接着调用到原始flow对象的闭包,在闭包里调用的emit即为filter的闭包,若filter闭包里条件满足则调动emit函数,最后调用到collect的闭包。
理解中间操作符的要点:
- 中间操作符返回新的flow对象,重写了collect函数
- collect函数会调用当前flow(调用filter的flow对象)的collect
- collect函数做其它的处理
与sequence类似,使用了装饰者模式。
以上以filter为例阐述了原理,其它中间操作符的原理类似,此处就不再细说。
下篇将分析Flow的背压与线程切换,相信分析的逻辑会让大家耳目一新,敬请期待~
本文基于Kotlin 1.5.3,文中完整Demo请点击
链接:https://juejin.cn/post/7168511169781563428
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter富文本性能优化 — 渲染
文本的排版与绘制
在经过之前文章的学习后,我们可以知道RichText主要是通过构建InlineSpan树来实现图文混排的功能。对InlineSpan树的结构我们也已经很清晰,在树中,除了TextSpan,还存在着PlaceholderSpan类型的节点,而WidgetSpan又是继承于PlaceholderSpan的,PlaceholderSpan会在文字排版的时候作为占位符参与排版,WidgetSpan就可以在排版完之后得到位置信息,然后绘制在正确的地方。
RichText继承的是MultiChildRenderObjectWidget,对应的RenderObject就是负责文本的排版和渲染的RenderParagraph。RenderParagraph负责文本的Layout和Paint,但RenderParagraph并不会直接的绘制文本,它最终都是调用TextPainter对象,再由TextPainter去触发Engine层中的排版和渲染。
那么文本具体的排版和绘制过程是怎么样的呢? ——知道它的原理实现过程,才能更好的优化它
我们已经知道PlaceholderSpan会在文字排版的时候作为占位符参与排版,那么editable.dart中的_layoutChildren方法就是用来收集PlaceholderSpan的信息,用于后续的文本排版。
///如果没有PlaceholderSpan(WidgetSpan),这个方法不会做任何事
List<PlaceholderDimensions> _layoutChildren(BoxConstraints constraints, {bool dry = false}) {
if (childCount == 0) {
_textPainter.setPlaceholderDimensions(<PlaceholderDimensions>[]);
return <PlaceholderDimensions>[];
}
RenderBox? child = firstChild;
final List<PlaceholderDimensions> placeholderDimensions = List<PlaceholderDimensions>.filled(childCount, PlaceholderDimensions.empty);
int childIndex = 0;
//将宽度设置为PlaceholderSpan所在段落的最大宽度,若不做限制,会溢出。
BoxConstraints boxConstraints = BoxConstraints(maxWidth: constraints.maxWidth);
...
//遍历InlineSpan树下PlaceholderSpan的所有子节点,收集它的尺寸信息(PlaceholderDimensions)
placeholderDimensions[childIndex] = PlaceholderDimensions(
size: childSize,
alignment: _placeholderSpans[childIndex].alignment,
baseline: _placeholderSpans[childIndex].baseline,
baselineOffset: baselineOffset,
);
child = childAfter(child);
childIndex += 1;
}
return placeholderDimensions;
}通过paragraph.dart下的_layoutTextWithConstraints方法,将收集的PlaceholderSpan信息更新到TextPainter。
void _layoutTextWithConstraints(BoxConstraints constraints) {
//设置每个占位符(PlaceholderSpan)的尺寸,传入的PlaceholderDimensions必须与PlaceholderSpan的数量对应。
_textPainter.setPlaceholderDimensions(_placeholderDimensions);
//用于计算需要绘制的文本的位置
_layoutText(minWidth: constraints.minWidth, maxWidth: constraints.maxWidth);
}当PlaceholderSpan信息更新到TextPainter后,我们在看到layout方法,
void layout({ double minWidth = 0.0, double maxWidth = double.infinity }) {
...
//_rebuildParagraphForPaint用于判断是否需要重建文本段落。
//_paragraph为空则意味着样式发生改变,文本需要重新布局。
if (_rebuildParagraphForPaint || _paragraph == null) {
//重建文本段落
_createParagraph();
}
...
//TextBox会在Paint时被绘制。
_inlinePlaceholderBoxes = _paragraph!.getBoxesForPlaceholders();
}在layout中调用的_createParagraph,主要来添加TextSpan和计算PlaceholderDimensions。
void _createParagraph() {
...
//遍历InlineSpan树,如果是TextSpan就将其添加到builder中。
//如果是PlaceholderSpan(WidgetSpan和自定义span),就计算PlaceholderDimensions。
final ui.ParagraphBuilder builder = ui.ParagraphBuilder(_createParagraphStyle());
text.build(builder, textScaleFactor: textScaleFactor, dimensions: _placeholderDimensions);
_inlinePlaceholderScales = builder.placeholderScales;
_paragraph = builder.build();
_rebuildParagraphForPaint = false;
}在计算完PlaceholderDimensions后,需要将它更新到对应的节点。
void _setParentData() {
RenderBox? child = firstChild;
int childIndex = 0;
//循环遍历布局的子节点,给每一个子节点的占位符设置parentData的偏移量
while (child != null && childIndex < _textPainter.inlinePlaceholderBoxes!.length) {
final TextParentData textParentData = child.parentData! as TextParentData;
//主要计算offset和scale
textParentData.offset = Offset(
_textPainter.inlinePlaceholderBoxes![childIndex].left,
_textPainter.inlinePlaceholderBoxes![childIndex].top,
);
textParentData.scale = _textPainter.inlinePlaceholderScales![childIndex];
child = childAfter(child);
childIndex += 1;
}
}在layout被调用后(计算好需要绘制的区域后),将进行paint,paint主要为两个部分:文本的绘制和占位符的绘制。·
void _paintContents(PaintingContext context, Offset offset) {
//断言,如果最后绘制的宽高与最大宽高的约束不相同,则抛出一个异常。(断言只在debug模式下运行有效,如果在release模式运行,断言不会执行)
debugAssertLayoutUpToDate();
//绘制的偏移
final Offset effectiveOffset = offset + _paintOffset;
if (selection != null && !_floatingCursorOn) {
//计算插入的文本的偏移量
_updateSelectionExtentsVisibility(effectiveOffset);
}
final RenderBox? foregroundChild = _foregroundRenderObject;
final RenderBox? backgroundChild = _backgroundRenderObject;
//绘制child的RenderObject
if (backgroundChild != null) {
context.paintChild(backgroundChild, offset);
}
//绘制layout布局好的文本
//调用canvas.drawParagraph()将文本绘制到指定的区域中
_textPainter.paint(context.canvas, effectiveOffset);
RenderBox? child = firstChild;
int childIndex = 0;
//循环遍历InlineSpan树,其中每一个TextBox都对应一个PlaceholderSpan
while (child != null && childIndex < _textPainter.inlinePlaceholderBoxes!.length) {
//parentData的偏移量
final TextParentData textParentData = child.parentData! as TextParentData;
final double scale = textParentData.scale!;
//绘制占位的child
//在pushTransform中,用了TransformLayer包裹了一层,用于对排版进行变换,主要是包含offset和scale
context.pushTransform中,用了(
needsCompositing,
effectiveOffset + textParentData.offset,
Matrix4.diagonal3Values(scale, scale, scale),
(PaintingContext context, Offset offset) {·
context.paintChild(
child!,
offset,
);
},
);
child = childAfter(child);
childIndex += 1;
}
if (foregroundChild != null) {
//绘制RenderObject
context.paintChild(foregroundChild, offset);
}
}在了解Flutter文本的排版和绘制后,我们会发现,在文本的排版和绘制过程中,有着许多位置计算和构建文本段落的逻辑,这是非常耗时的过程,为了程序的高性能,我们是不可能每一帧都去重新排版渲染的。当然,我们能想到,Flutter官方肯定也能想到,所以Flutter在更新文本时,会通过比较文本信息,更具文本信息的更新状态来判断下一帧是否要进行文本的重新排版渲染。
enum RenderComparison {
//更新后的InlineSpan树与更新前完全一样
identical,
//更新后的InlineSpan树与更新前一样(布局一样),只是像一些点击事件发生改变
metadata,
//更新后的InlineSpan树与更新前存在TextSpan的样式变化,但是树的结构没有变化,布局没有改变
paint,
//更新后的InlineSpan树与更新前发生了布局变化,例如文本大小改变,或插入了图片...
layout,
}四种状态的变化情况是越来越大的,identical与metadata的状态是不会对RenderObject渲染对象进行改变的,paint是需要重新绘制文本,layout是需要重新排版文本。了解了Flutter对文本更新状态的定义,再让我们了解下,Flutter是如何判断文本更新的状态的。
@override
RenderComparison compareTo(InlineSpan other) {
...
//判断Text或子child数量是否发生变化,若发生变化则需要重新排版
if (textSpan.text != text ||
children?.length != textSpan.children?.length ||
(style == null) != (textSpan.style == null)) {
//返回文本更新状态
return RenderComparison.layout;
}
RenderComparison result = recognizer == textSpan.recognizer ?
RenderComparison.identical :
RenderComparison.metadata;
//比较textSpan.style
if (style != null) {
//style!.compareTo()用于比较样式,若只是color这些属性的修改,只需要重新绘制即可
//若是字体大小这样属性发生变化,则需要重新进行排版
final RenderComparison candidate = style!.compareTo(textSpan.style!);
if (candidate.index > result.index) {
result = candidate;
}
if (result == RenderComparison.layout) {
return result;
}
}
//递归比较子child节点
if (children != null) {
for (int index = 0; index < children!.length; index += 1) {
final RenderComparison candidate = children![index].compareTo(textSpan.children![index]);
if (candidate.index > result.index) {
result = candidate;
}
if (result == RenderComparison.layout) {
return result;
}
}
}
return result;
}文本渲染优化探索
结论 —— 按段落(块)渲染文本。
文本渲染最头疼的问题就在于长文本(超十万字)的渲染,这样的长文本在渲染时往往会占用很大的内存,滚动卡顿,给用户带来极差的体验。如果你对长文本渲染没有概念,那么可以和我一起看下这个测试例子(所有测试代码均在Profile模式下运行):
代码实现如下:模拟将长文本渲染进一个Text的操作。
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text("长文本渲染 — 测试"),
),
body: Center(
child: ListView(
children: <Widget>[
//创建一个Iterable,通过序列来动态生成元素
Text(Iterable.generate(100000, (i) => "Hello Flutter $i").join('\n'))
],
),
),
);
}我们可以在效果图中看到,在快速滑动时,页面有明显卡顿。通过计算得到帧率在15帧左右。这在现在动不动就屏幕刷新率为144的手机中,体验十分糟糕。
优化:对于渲染时,在一个Text组件中渲染10万条文本,不如生成10万个Text组件,每个组件渲染一行文本。不要以我们的思维去理解Flutter,认为Flutter做某件事会很累。Flutter渲染一个和渲染10万个Text,在性能上没有太多的差距。
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text("Flutter 长文本渲染测试"),
),
body: Center(
child: ListView(
children: <Widget>[
// 三个点...是dart的语法糖,用于拼接集合(List、Map...),可以将其拼接到一个ListView(Column、Row)上面
...Iterable.generate(100000, (i) => Text("Hello Taxze $i"))
],
),
),
);
}这样优化后,帧率基本保持在60帧。
但是,这不是较好的优化方式,属于暴力解法。如果你只需要显示文本的话,你可以使用ListView.build用来逐行动态加载文本,同时给列表指定itemExtent或prototypeItem会有更高的性能,所以当我们知道列表项的高度都相同时,强烈建议指定itemExtent或prototypeItem。使用prototypeItem是在我们知道列表组件高度相同,但不确定列表组件的具体高度时使用。
body: Center(
child: ListView.builder(
prototypeItem: const Text(''),
itemCount: 100000,
itemBuilder: (BuildContext context, int index) {
return Text("Hello Taxze $index");
},
),
)当需要像富文本这样,需要图文混排或编辑文本的功能时,那渲染的基本框架像下面这样比较好:
SingleChildScrollView(
child: Column(
children: <Widget>[
...Iterable.generate(100000, (i) => Text("Hello Taxze $i"))
],
),
)当然,真实的业务需求中肯定不是这么简单的,一般需要我们自己魔改SingleChildScrollView,例如在SingleChildScrollView添加一些其他的参数。
富文本块结构定义
知道了文本渲染优化的一些点,那么我们再看向富文本。想要高性能的渲染富文本,那么我们同样不能将所有文本放在一个Editable下渲染。我们需要定义富文本的块状规则,将同一块样式的文本渲染在一个RichText中,将该RichText定义为一个TextLine,一个文本段落。若有图片等WidgetSpan,则将其插入在段落中。遇到单段落文本为长文本时,选择将其分行、分多个RichText渲染。段落规则定义的实现逻辑我们可以参考Quill:
//Quill文档中的一行富文本。输入一个新样式的文本时,会渲染新的一行,且完全占用该行。
class Line extends Container<Leaf?> {
//判断该行是否嵌入其他元素,例如图片
bool get hasEmbed {
return children.any((child) => child is Embed);
}
//判断是否为最后一行·
Line? get nextLine {
if (!isLast) {
return next is Block ? (next as Block).first as Line? : next as Line?;
}
if (parent is! Block) {
return null;
}
if (parent!.isLast) {
return null;
}
...
}
@override
void insert(int index, Object data, Style? style) {
final text = data as String;
//判断是否换行符,如果没有,则不需要更新段落块
final lineBreak = text.indexOf('\n');
if (lineBreak < 0) {
_insertSafe(index, text, style);
return;
}
// 如果输入一个文本超过了一行的宽度,则自动换行且继承该行样式。这样就能把TextLine变为Block
final nextLine = _getNextLine(index);
// 设置新的格式且重新布局
_format(style);
// 继续插入剩下的文本
final remain = text.substring(lineBreak + 1);
nextLine.insert(0, remain, style);
}
...
}具体的段落规则(插入、删除、嵌入Widget到段落、删除Widget),都需要根据自己的业务来定义。Quill的实现方式只是单做一个参考。
尾述
在这篇文章中,我们分析了Flutter文本的排版与绘制原理,且对文本的渲染进行优化分析。最后的目的都是将这些知识、优化的点结合到富文本中。在对富文本块状规则的定义时,需要结合真实的业务逻辑,避免段落规则的计算部分过于复杂,否则容易造成UI绘制时间过长。希望这篇文章能对你有所帮助,有问题欢迎在评论区留言讨论~
链接:https://juejin.cn/post/7168248386545451016
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【造轮子】自定义一个随意拖拽可吸边的悬浮View
1、效果
2、前言
在开发中,随意拖拽可吸边的悬浮View还是比较常见的,这种功能网上也有各种各样的轮子,其实写起来并不复杂,看完本文,你也可以手写一个,而且不到400行代码就能实现一个通用的随意拖拽可吸边的悬浮View组件。
3、功能拆解
4、功能实现
4.1、基础实现
4.1.1、自定义view类
先定义一个FloatView类,继承自FrameLayout,实现构造方法。
创建一个ShapeableImageView,并添加到这个FloatView中。
class FloatView : FrameLayout {
constructor(context: Context) : this(context, null)
constructor(context: Context, attributeSet: AttributeSet?) : this(context, attributeSet, 0)
constructor(context: Context, attributeSet: AttributeSet?, defStyle: Int) : super(context, attributeSet, defStyle) {
initView()
}
private fun initView() {
val lp = LayoutParams(LayoutParams.WRAP_CONTENT, LayoutParams.WRAP_CONTENT)
layoutParams = lp
val imageView = ShapeableImageView(context)
imageView.setImageResource(R.mipmap.ic_avatar)
addView(imageView)
}
}4.1.2、添加到window
在页面的点击事件中,通过DecorView把这个FloatView添加到window中
mBinding.btnAddFloat.setOnClickListener {
val contentView = this.window.decorView as FrameLayout
contentView.addView(FloatView(this))
}来看下效果:
默认在左上角,盖住了标题栏,也延伸到了状态栏,不是很美观。
从这个视图层级关系中可以看出,我们是把FloatView添加到DecorView的根布局(rootView)里面了,实际下面还有一层contentView,contentView是不包含状态栏、导航栏和ActionBar的。
我们改一下添加的层级(content):
val contentView = this.window.decorView.findViewById(android.R.id.content) as FrameLayout
contentView.addView(FloatView(this))再看下效果:
此时,是默认显示在状态栏下面了,但还是盖住了标题栏。
这是因为标题栏是在activity的layout中加的toolbar,不是默认的ActionBar,app主题是Theme.Material3.DayNight.NoActionBar,所以显示效果其实是正确的。
手动加上ActionBar看看效果:
这就验证了我们之前的论点了。
不管我们添加的根布局是rootView还是contentView,实际上可能都有需求不要盖住原有页面上的某些元素,这时候可以通过margin或者x/y坐标位置来限制view显示的位置。
4.1.3、视图层级关系
4.2、拖拽
4.2.1、View.OnTouchListener
实现View.OnTouchListener接口,重写onTouch方法,在onTouch方法中根据拖动的坐标实时修改view的位置。
override fun onTouch(v: View, event: MotionEvent): Boolean {
val x = event.x
val y = event.y
when (event.action) {
MotionEvent.ACTION_DOWN -> {
mDownX = event.x
mDownY = event.y
}
MotionEvent.ACTION_MOVE -> {
offsetTopAndBottom((y - mDownY).toInt())
offsetLeftAndRight((x - mDownX).toInt())
}
MotionEvent.ACTION_UP -> {
}
}
return true
}- MotionEvent.ACTION_DOWN 手指按下
- MotionEvent.ACTION_MOVE 手指滑动
- MotionEvent.ACTION_UP 手指抬起
效果:
ok,这就实现随意拖拽了。
4.2.2、动态修改view坐标
上面我们修改view坐标用的是offsetTopAndBottom和offsetLeftAndRight,分别是垂直方向和水平方向的偏移,当然也还有别的方式可以修改坐标
- view.layout()
- view.setX/view.setY
- view.setTranslationX/view.setTranslationY
- layoutParams.topMargin...
- offsetTopAndBottom/offsetLeftAndRight
4.2.3、view坐标系
上面我们获取坐标用的是event.x,实际上还有event.rawX,他们的区别是什么,view在视图上的坐标又是怎么定义的?
搞清楚了这些,在做偏移计算时,就能达到事半功倍的效果,省去不必要的调试工作。
一图胜千言:
4.3、吸边
吸边的场景基本可以分为两种:
- 上下吸边
- 左右吸边
要么左右吸,要么上下吸,上下左右同时吸一般是违背交互逻辑的(四象限),用户也会觉得很奇怪。
吸边的效果其实就是当手指抬起(MotionEvent.ACTION_UP)的时候,根据滑动的距离,以及初始的位置,来决定view最终的位置。
比如默认在顶部,向下滑动的距离不足半屏,那就还是吸附在顶部,超过半屏,则自动吸附在底部,左右同理。
4.3.1、上下吸边
计算公式:
1.上半屏:
1.1.滑动距离<半屏=吸顶
1.2.滑动距离>半屏=吸底
2.下半屏:
2.1.滑动距离<半屏=吸底
2.2.滑动距离>半屏=吸顶先看下效果:
可以看到基础效果我们已经实现了,但是顶部盖住了ToolBar,底部也被NavigationBar遮住了,我们再优化一下,把ToolBar和NavigationBar的高度也计算进去。
看下优化后的效果:
这样看起来就好很多了。
上图效果最终代码:
private fun adsorbTopAndBottom(event: MotionEvent) {
if (isOriginalFromTop()) {
// 上半屏
val centerY = mViewHeight / 2 + abs(event.rawY - mFirstY)
if (centerY < getScreenHeight() / 2) {
//滑动距离<半屏=吸顶
val topY = 0f + mToolBarHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(topY).start()
} else {
//滑动距离>半屏=吸底
val bottomY = getContentHeight() - mViewHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(bottomY.toFloat()).start()
}
} else {
// 下半屏
val centerY = mViewHeight / 2 + abs(event.rawY - mFirstY)
if (centerY < getScreenHeight() / 2) {
//滑动距离<半屏=吸底
val bottomY = getContentHeight() - mViewHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(bottomY.toFloat()).start()
} else {
//滑动距离>半屏=吸顶
val topY = 0f + mToolBarHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(topY).start()
}
}
}4.3.2、左右吸边
计算公式:
1.左半屏:
1.1.滑动距离<半屏=吸左
1.2.滑动距离>半屏=吸右
2.右半屏:
2.1.滑动距离<半屏=吸右
2.2.滑动距离>半屏=吸左看下效果:
左右吸边的效果相对上下吸边来说要简单些,因为不用计算ToolBar和NavigationBar,计算逻辑与上下吸边相通,只不过参数是从屏幕高度变为屏幕宽度,Y轴变为X轴。
代码:
private fun adsorbLeftAndRight(event: MotionEvent) {
if (isOriginalFromLeft()) {
// 左半屏
val centerX = mViewWidth / 2 + abs(event.rawX - mFirstX)
if (centerX < getScreenWidth() / 2) {
//滑动距离<半屏=吸左
val leftX = 0f
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(leftX).start()
} else {
//滑动距离<半屏=吸右
val rightX = getScreenWidth() - mViewWidth
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(rightX.toFloat()).start()
}
} else {
// 右半屏
val centerX = mViewWidth / 2 + abs(event.rawX - mFirstX)
if (centerX < getScreenWidth() / 2) {
//滑动距离<半屏=吸右
val rightX = getScreenWidth() - mViewWidth
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(rightX.toFloat()).start()
} else {
//滑动距离<半屏=吸左
val leftX = 0f
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).x(leftX).start()
}
}
}
Author:yechaoa
5、进阶封装
为什么要封装一下呢,因为现在的计算逻辑、参数配置都是在FloatView这一个类里,定制化太强反而不具备通用性,可以进行一个简单的抽取封装,向外暴露一些配置和接口,这样在其他的业务场景下也可以复用,避免重复造轮子。
5.1、View封装
5.1.1、BaseFloatView
把FloatView改成BaseFloatView,然后把一些定制化的能力交给子view去实现。
这里列举了3个方法:
/**
* 获取子view
*/
protected abstract fun getChildView(): View
/**
* 是否可以拖拽
*/
protected abstract fun getIsCanDrag(): Boolean
/**
* 吸边的方式
*/
protected abstract fun getAdsorbType(): Int5.1.2、子view
class AvatarFloatView(context: Context) : BaseFloatView(context) {
override fun getChildView(): View {
val imageView = ShapeableImageView(context)
imageView.setImageResource(R.mipmap.ic_avatar)
return imageView
}
override fun getIsCanDrag(): Boolean {
return true
}
override fun getAdsorbType(): Int {
return ADSORB_VERTICAL
}
}这样稍微抽一下,代码看起来就简洁很多了,只需要配置一下就可以拥有随意拖拽的能力了。
5.1.3、吸边距离可配
目前吸边的逻辑是判断拖拽距离是否超过半屏,来决定吸哪边,为了更好的通用性,可以把这个距离参数变为可配置的,比如不一定要以半屏为界限,也可以是屏幕的30%。
先定义一个距离系数的变量,默认为屏幕的一半,取值范围0-1
private var mDragDistance = 0.5 // 默认吸边需要的拖拽距离为屏幕的一半然后定义一个设置这个距离系数的方法
/**
* 设置吸边需要的拖拽距离,默认半屏修改吸边方向,取值0-1
*/
fun setDragDistance(distance: Double) {
mDragDistance = distance
}再定义获取实际需要拖拽距离的方法
/**
* 获取上下吸边时需要拖拽的距离
*/
private fun getAdsorbHeight(): Double {
return getScreenHeight() * mDragDistance
}
/**
* 获取左右吸边时需要拖拽的距离
*/
private fun getAdsorbWidth(): Double {
return getScreenWidth() * mDragDistance
}最后修改判断的地方
if (centerY < getAdsorbHeight()) {
//滑动距离<半屏=吸顶
val topY = 0f + mToolBarHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(topY).start()
} else {
//滑动距离>半屏=吸底
val bottomY = getContentHeight() - mViewHeight
animate().setInterpolator(DecelerateInterpolator()).setDuration(300).y(bottomY.toFloat()).start()
}由if (centerY < getScreenHeight() / 2)改为if (centerY < getAdsorbHeight())
这样,在调用的时候就可以根据需要,来配置拖拽吸边的界限了。
比如屏幕的30%:
mFloatView?.setDragDistance(0.3)5.2、调用封装
5.2.1、管理类
新建一个FloatManager的管理类,它来负责FloatView的显示隐藏,以及回收逻辑。
设计模式还是使用单例,我们需要在这个单例类里持有Activity,因为需要通过Activity的window获取decorView然后把FloatView添加进去,但是Activity与单例的生命周期是不对等的,这就很容易造成内存泄露。
怎么解?也好办,管理一下activity的生命周期就好了。
在之前分析LifecycleScope源码的文章中有提到关于Activity生命周期的管理,得益于lifecycle的强大,这个问题解起来也变得更简单。
private fun addLifecycle(activity: ComponentActivity?) {
activity?.lifecycle?.addObserver(mLifecycleEventObserver)
}
private var mLifecycleEventObserver = LifecycleEventObserver { _, event ->
if (event == Lifecycle.Event.ON_DESTROY) {
hide()
}
}
fun hide() {
if (::mContentView.isInitialized && mFloatView != null && mContentView.contains(mFloatView!!)) {
mContentView.removeView(mFloatView)
}
mFloatView?.release()
mFloatView = null
mActivity?.lifecycle?.removeObserver(mLifecycleEventObserver)
mActivity = null
}- 添加生命周期的监听
- 在ON_DESTROY的时候处理回收逻辑
5.2.2、FloatManager完整代码
@SuppressLint("StaticFieldLeak")
object FloatManager {
private lateinit var mContentView: FrameLayout
private var mActivity: ComponentActivity? = null
private var mFloatView: BaseFloatView? = null
fun with(activity: ComponentActivity): FloatManager {
mContentView = activity.window.decorView.findViewById(android.R.id.content) as FrameLayout
mActivity = activity
addLifecycle(mActivity)
return this
}
fun add(floatView: BaseFloatView): FloatManager {
if (::mContentView.isInitialized && mContentView.contains(floatView)) {
mContentView.removeView(floatView)
}
mFloatView = floatView
return this
}
fun setClick(listener: BaseFloatView.OnFloatClickListener): FloatManager {
mFloatView?.setOnFloatClickListener(listener)
return this
}
fun show() {
checkParams()
mContentView.addView(mFloatView)
}
private fun checkParams() {
if (mActivity == null) {
throw NullPointerException("You must set the 'Activity' params before the show()")
}
if (mFloatView == null) {
throw NullPointerException("You must set the 'FloatView' params before the show()")
}
}
private fun addLifecycle(activity: ComponentActivity?) {
activity?.lifecycle?.addObserver(mLifecycleEventObserver)
}
private var mLifecycleEventObserver = LifecycleEventObserver { _, event ->
if (event == Lifecycle.Event.ON_DESTROY) {
hide()
}
}
fun hide() {
if (::mContentView.isInitialized && mFloatView != null && mContentView.contains(mFloatView!!)) {
mContentView.removeView(mFloatView)
}
mFloatView?.release()
mFloatView = null
mActivity?.lifecycle?.removeObserver(mLifecycleEventObserver)
mActivity = null
}
}5.2.3、调用方式
- 显示
FloatManager.with(this).add(AvatarFloatView(this)).show()- 隐藏
FloatManager.hide()- 带点击事件
FloatManager.with(this).add(AvatarFloatView(this))
.setClick(object : BaseFloatView.OnFloatClickListener {
override fun onClick(view: View) {
Toast.makeText(this@FloatViewActivity, "click", Toast.LENGTH_SHORT).show()
}
})
.show()6、Github
链接:https://juejin.cn/post/7126475397645991972
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin常用的by lazy你真的了解吗
前言
在使用Kotlin语言进行开发时,我相信很多开发者都信手拈来地使用by或者by lazy来简化你的属性初始化,但是by lazy涉及的知识点真的了解吗 假如让你实现这个功能,你会如何设计。
正文
话不多说,我们从简单的属性委托by来说起。
委托属性
什么是委托属性呢,比较官方的说法就是假如你想实现一个比较复杂的属性,它们处理起来比把值保存在支持字段中更复杂,但是却不想在每个访问器都重复这样的逻辑,于是把获取这个属性实例的工作交给了一个辅助对象,这个辅助对象就是委托。
比如可以把这个属性的值保存在数据库中,一个Map中等,而不是直接调用其访问器。
看完这个委托属性的定义,假如你不熟悉Kotlin也可以理解,就是我这个类的实例由另一个辅助类对象来提供,但是这时你可能会疑惑,上面定义中说的支持字段和访问器是什么呢,这里顺便给不熟悉Kotlin的同学普及一波。
Java的属性
当你定义一个Java类时,在定义字段时并不是所有字段都是属性,比如下面代码:
//Java类
public class Phone {
//3个字段
private String name;
private int price;
private int color;
//name字段访问器
private String getName() {
return name;
}
private void setName(String name){
this.name = name;
}
//price字段访问器
private int getPrice() {
return price;
}
private void setPrice(int price){
this.price = price;
}
}上面我在Phone类中定义了3个字段,但是只有name和price是Phone的属性,因为这2个字段有对应的get和set,也只有符合有getter和setter的字段才叫做属性。
这也能看出Java类的属性值是保存在字段中的,当然你也可以定义setXX函数和getXX函数,既然XX属性没有地方保存,XX也是类的属性。
Kotlin的属性
而对于Kotlin的类来说,属性定义就非常简单了,比如下面类:
class People(){
val name: String? = null
var age: Int? = null
}在Kotlin的类中只要使用val/var定义的字段,它就是类的属性,然后会自带getter和setter方法(val属性相当于Java的final变量,是没有set方法的),比如下面:
val people = People()
//调用name属性的getter方法
people.name
//调用age属性的setter方法
people.age = 12这时就有了疑问,为什么上面代码定义name时我在后面给他赋值了即null值,和Java一样不赋值可以吗 还有个疑问就是在Java中是把属性的值保存在字段中,那Kotlin呢,比如name这个属性的值就保存给它自己吗
带着问题,我们继续分析。
Kotlin属性访问器
前面我们可知Java中的属性是保存在字段中,或者不要字段,其实Kotlin也可以,这个就是给属性定义自定义setter方法和getter方法,如下代码:
class People(){
val name: String? = null
var age: Int = 0
//定义了isAbove18这个属性
var isAbove18: Boolean = false
get() = age > 18
}比如这里自定义了get访问器,当再访问这个属性时,便会调用其get方法,然后进行返回值。
Kotlin属性支持字段field
这时一想那Kotlin的属性值保存在哪里呢,Kotlin会使用一个field的支持字段来保存属性。如下代码:
class People{
val name: String? = null
var age: Int = 0
//返回field的值
get() = field
//设置field的值
set(value){
Log.i("People", "旧值是$field 新值是$value ")
field = value
}
var isAbove18: Boolean = false
get() = age > 18
}可以发现每个属性都会有个支持字段field来保存属性的值。
好了,为了介绍为什么Kotlin要有委托属性这个机制,假如我在一个类中,需要定义一个属性,这时获取属性的值如果使用get方法来获取,会在多个类都要写一遍,十分不符合代码设计,所以委托属性至关重要。
委托属性的实现
在前面说委托属性的概念时就说了,这个属性的值需要由一个新类来代理处理,这就是委托属性,那我们也可以大概猜出委托属性的底层逻辑,大致如下面代码:
class People{
val name: String? = null
var age: Int = 0
val isAbove18: Boolean = false
//email属性进行委托,把它委托给ProduceEmail类
var email: String by ProduceEmail()
}假如People的email属性需要委托,上面代码编译器会编译成如下:
class People{
val name: String? = null
var age: Int = 0
val isAbove18: Boolean = false
//委托类的实例
private val productEmail = ProduceEmail()
//委托属性
var email: String
//访问器从委托类实例获取值
get() = productEmail.getValue()
//设置值把值设置进委托类实例
set(value) = productEmail.setValue(value)
}当然上面代码是编译不过的,只是说一下委托的实现大致原理。那假如想使ProduceEmail类真的具有这个功能,需要如何实现呢。
by约定
其实我们经常使用 by 关键字它是一种约定,是对啥的约定呢 是对委托类的方法的约定,关于啥是约定,一句话说明白就是简化函数调用,具体可以查看我之前的文章:
# Kotlin invoke约定,让Kotlin代码更简洁
那这里的by约定简化了啥函数调用呢 其实也就是属性的get方法和set方法,当然委托类需要定义相应的函数,也就是下面这2个函数:
//by约定能正常使用的方法
class ProduceEmail(){
private val emails = arrayListOf("111@qq.com")
//对应于被委托属性的get函数
operator fun getValue(people: People, property: KProperty<*>): String {
Log.i("zyh", "getValue: 操作的属性名是 ${property.name}")
return emails.last()
}
//对于被委托属性的get函数
operator fun setValue(people: People, property: KProperty<*>, s: String) {
emails.add(s)
}
}定义完上面委托类,便可以进行委托属性了:
class People{
val name: String? = null
var age: Int = 0
val isAbove18: Boolean = false
//委托属性
var email: String by ProduceEmail()
}然后看一下调用地方:
val people = People()
Log.i("zyh", "onCreate: ${people.email}")
people.email = "222@qq.com"
Log.i("zyh", "onCreate: ${people.email}")打印如下:
会发现每次调用email属性的访问器方法时,都会调用委托类的方法。
关于委托类中的方法,当你使用by关键字时,IDE会自动提醒,提醒如下:
比如getValue方法中的参数,第一个就是接收者了,你这个要委托的属性是哪个类的,第二个就是属性了,关于KProperty不熟悉的同学可以查看文章:
# Kotlin反射全解析3 -- 大展身手的KProperty
它就代表这属性,可以调用其中的一些方法来获取属性的信息。
而且方法必须使用operator关键字修饰,这是重载操作符的必须步骤,想使用约定,就必须这样干。
by lazy的实现
由前面明白了by的原理,我们接着来看一下我们经常使用的by lazy是个啥,直接看代码:
//这里使用by lazy惰性初始化一个实例
val instance: DataStoreManager by lazy(mode = LazyThreadSafetyMode.SYNCHRONIZED) {
DataStoreManager(store) }比如上面代码,使用惰性初始化初始了一个实例,我们来看一下这个by的实现:
//by代码
@kotlin.internal.InlineOnly
public inline operator fun <T> Lazy<T>.getValue(thisRef: Any?, property: KProperty<*>): T = value哦,会发现它是Lazy类的一个扩展函数,按照前面我们对by的理解,它就是把被委托的属性的get函数和getValue进行配对,所以可以想象在Lazy< T >类中,这个value便是返回的值,我们来看一下:
//惰性初始化类
public interface Lazy<out T> {
//懒加载的值,一旦被赋值,将不会被改变
public val value: T
//表示是否已经初始化
public fun isInitialized(): Boolean
}到这里我们注意一下 by lazy的lazy,这个就是一个高阶函数,来创建Lazy实例的,lazy源码:
//lazy源码
public actual fun <T> lazy(mode: LazyThreadSafetyMode, initializer: () -> T): Lazy<T> =
when (mode) {
LazyThreadSafetyMode.SYNCHRONIZED -> SynchronizedLazyImpl(initializer)
LazyThreadSafetyMode.PUBLICATION -> SafePublicationLazyImpl(initializer)
LazyThreadSafetyMode.NONE -> UnsafeLazyImpl(initializer)
}这里会发现第一个参数便是线程同步的模式,第二个参数是初始化器,我们就直接看一下最常见的SYNCHRONIZED的模式代码:
//线程安全模式下的单例
private class SynchronizedLazyImpl<out T>(initializer: () -> T, lock: Any? = null) : Lazy<T>, Serializable {
private var initializer: (() -> T)? = initializer
//用来保存值,当已经被初始化时则不是默认值
@Volatile private var _value: Any? = UNINITIALIZED_VALUE
//锁
private val lock = lock ?: this
override val value: T
//见分析1
get() {
//第一次判空,当实例存在则直接返回
val _v1 = _value
if (_v1 !== UNINITIALIZED_VALUE) {
@Suppress("UNCHECKED_CAST")
return _v1 as T
}
//使用锁进行同步
return synchronized(lock) {
//第二次判空
val _v2 = _value
if (_v2 !== UNINITIALIZED_VALUE) {
@Suppress("UNCHECKED_CAST") (_v2 as T)
} else {
//真正初始化
val typedValue = initializer!!()
_value = typedValue
initializer = null
typedValue
}
}
}
//是否已经完成
override fun isInitialized(): Boolean = _value !== UNINITIALIZED_VALUE
override fun toString(): String = if (isInitialized()) value.toString() else "Lazy value not initialized yet."
private fun writeReplace(): Any = InitializedLazyImpl(value)
}分析1:这个单例实现是不是有点眼熟,没错它就是双重校验锁实现的单例,假如你对双重校验锁的实现单例方式还不是很明白可以查看文章:
这里实现懒加载单例的模式就是双重校验锁,2次判空以及volatile关键字都是有作用的,这里不再赘述。
总结
先搞明白by的原理,再理解by lazy就非常好理解了,虽然这些关键字我们经常使用,不过看一下其源码实现还是很舒爽的,尤其是Kotlin的高阶函数的一些SDK写法还是很值的学习。
链接:https://juejin.cn/post/7057675598671380493
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


