








Android 完整的apk打包流程
在Android Studio中,我们需要打一个apk包,可以在Gradle task 任务中选一个
assembleDebug/assembleRelease 任务,
控制台上就可以看到所有的构建相关task:
可以看到,这么多个task任务,执行是有先后顺序的,其实主要就是以下步骤:
//aidl 转换aidl文件为java文件
> Task :app:compileDebugAidl
//生成BuildConfig文件
> Task :app:generateDebugBuildConfig
//获取gradle中配置的资源文件
> Task :app:generateDebugResValues
// merge资源文件
> Task :app:mergeDebugResources
// merge assets文件
> Task :app:mergeDebugAssets
> Task :app:compressDebugAssets
// merge所有的manifest文件
> Task :app:processDebugManifest
//AAPT 生成R文件
> Task :app:processDebugResources
//编译kotlin文件
> Task :app:compileDebugKotlin
//javac 编译java文件
> Task :app:compileDebugJavaWithJavac
//转换class文件为dex文件
> Task :app:dexBuilderDebug
//打包成apk并签名
> Task :app:packageDebug依靠这些关键步骤最后就能打包出一个apk。
首先看
第一步:aidl(编译aidl文件)
将项目中的aidl文件编译为java文件,AIDL用于进程间通信
第二步:生成BuildConfig文件
在项目中配置了
buildConfigField等信息,会在BuildConfig class类里以静态属性的方式展示:
第三步:合并Resources、assets、manifest、so等资源文件
在我们的项目中会依赖不同的库、组件,也会有多渠道的需求,所以merge这一步操作就是将不同地方的资源文件进行整合。
多个manifest文件也需要整理成一个完整的文件,所以如果有属性冲突这一步就会报错。资源文件也会整理分类到不同的分辨率目录中。
资源处理用的工具是aapt/aapt2
注意:AGP3.0.0之后默认通过AAPT2来编译资源,AAPT2支持了增量更新,大大提升了效率。
AAPT 工具负责编译项目中的这些资源文件,所有资源文件会被编译处理,XML 文件(drawable 图片除外)会被编译成二进制文件,所以解压 apk 之后无法直接打开 XML 文件。但是 assets 和 raw 目录下的资源并不会被编译,会被原封不动的打包到 apk 压缩包中。
资源文件编译之后的产物包括两部分:resources.arsc 文件和一个 R.java。前者保存的是一个资源索引表,后者定义了各个资源 ID 常量。这两者结合就可以在代码中找到对应的资源引用。比如如下的 R.java 文件:
实际上被打包到 apk 中的还有一些其他资源,比如 AndroidManifest.xml 清单文件和三方库中使用的动态库 .so 文件。
第四步:编译java文件(用到的工具 javac )
1、java文件包含之前提到的AIDL 生成的java文件
2、java代码部份:通过Java Compiler 编译项目中所有的Java代码,包括R.java、.aidl文件生成的.java文件、Java源文件,生成.class文件。在对应的build目录下可以找到相关的代码
3、kotlin代码部份:通过Kotlin Compiler编译项目中的所有Kotlin代码,生成.class文件
注:注解处理器(APT,KAPT)生成代码也是在这个阶段生成的。当注解的生命周期被设置为CLASS的时候,就代表该注解会在编译class文件的时候生效,并且生成java源文件和Class字节码文件。
第五步: Class文件打包成DEX(dx/r8/d8等工具编译class文件)
- 在原来
dx是最早的转换工具,用于转换class文件为dex文件。 - Android Studio 3.1之后,引入了
D8编译器和R8工具。 - Android Studio 3.4之后,默认开启 R8
具体的区别可以点击看看
注意:JVM 和 Dalvik(ART) 的区别:JVM执行的是.class文件、Dalvik和ART执行的.dex文件。具体的区别可以点击看看
而在编译class文件过程也常用于编译插桩,比如ASM,通过直接操作字节码文件完成代码修改或生成。
第六步:apkbuilder/zipflinger(生成APK包)
这一步就是生成APK文件,将manifest文件、resources文件、dex文件、assets文件等等打包成一个压缩包,也就是apk文件。
在老版本使用的工具是apkbuilder,新版本用的是 zipflinger。
而在AGP3.6.0之后,使用zipflinger作为默认打包工具来构建APK,以提高构建速度。
第七步: zipalign(对齐处理)
对齐是Android apk 很重要的优化,它会使 APK 中的所有未压缩数据(例如图片或原始文件)在 4 字节边界上对齐。这使得CPU读写就会更高效。
也就是使用工具 zipalign 对 apk 中的未压缩资源(图片、视频等)进行对齐操作,让资源按照 4 字节的边界进行对齐。这种思想同 Java 对象内存布局中的对齐空间非常类似,主要是为了加快资源的访问速度。如果每个资源的开始位置都是上一个资源之后的 4n 字节,那么访问下一个资源就不用遍历,直接跳到 4n 字节处判断是不是一个新的资源即可。
第八步: apk 签名
没有签名的apk 无法安装,也无法发布到应用市场。
大家比较熟知的签名工具是JDK提供的jarsigner,而apksigner是Google专门为Android提供的签名和签证工具。
其区别就在于jarsigner只能进行v1签名,而apksigner可以进行v2、v3、v4签名。
v1签名
v1签名方式主要是利用META-INFO文件夹中的三个文件。
首先,将apk中除了META-INFO文件夹中的所有文件进行进行摘要写到 META-INFO/MANIFEST.MF;然后计算MANIFEST.MF文件的摘要写到CERT.SF;最后计算CERT.SF的摘要,使用私钥计算签名,将签名和开发者证书写到CERT.RSA。
所以META-INFO文件夹中这三个文件就能保证apk不会被修改。
v2签名
Android7.0之后,推出了v2签名,为了解决v1签名速度慢以及签名不完整的问题。
apk本质上是一个压缩包,而压缩包文件格式一般分为三块:
文件数据区,中央目录结果,中央目录结束节。
而v2要做的就是,在文件中插入一个APK签名分块,位于中央目录部分之前,如下图:
这样处理之后,文件就完成无法修改了,这也是为什么 zipalign(对齐处理) 要在签名之前完成。
v3签名
Android 9 推出了v3签名方案,和v2签名方式基本相同,不同的是在v3签名分块中添加了有关受支持的sdk版本和新旧签名信息,可以用作签名替换升级。
v4签名
Android 11 推出了v4签名方案。
最后,apk得以完成打包
PMS 在安装过程中会检查 apk 中的签名证书的合法性,具体安装apk内容稍后介绍。
apk内容包含如下:
总体的打包流程图如下:
链接:https://juejin.cn/post/7206998548343668796
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Lambda - 认识java lambda与kotlin lambda的细微差异
Lambda
这个估计算是一个非常有历史感的话题了,Lambda相关的文章,也有很多了,为啥还要拿出来炒炒冷饭呢?主要是最近有对Lambda的内容进行字节码处理,同时Lambda在java/kotlin/android中,都有着不一样是实现,非常有趣,因此本文算是一个记录,让我们一起去走进lambda的世界吧。当然,本文以java/kotlin视角去记录,在android中lambda的处理还不一样,我们先挖个坑,看看有没有机会填上,当然,部分的我也会夹杂的一起说!
最简单的例子
比如我们常常在写ui的时候,设置一个监听器,就是这么处理
view.setOnClickListener(v -> {
Log.e("hello","123");
});编译后的字节码
INVOKEDYNAMIC onClick()Landroid/view/View$OnClickListener; [
// handle kind 0x6 : INVOKESTATIC
java/lang/invoke/LambdaMetafactory.metafactory(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
// arguments:
(Landroid/view/View;)V,
// handle kind 0x6 : INVOKESTATIC
这里就是我们要的方法
类名.lambda$myFunc$0(Landroid/view/View;)V,
(Landroid/view/View;)Vemmm,密密麻麻,我们先不管这个,这里主要是INVOKEDYNAMIC的这个指令,这里我就不再重复INVOKEDYNAMIC的由来之类的了,我们直接来看,INVOKEDYNAMIC指令执行后的产物是啥?
生成产物类
首先产物之一,肯定是setOnClickListener里面需要的一个实现OnClickListener的对象对吧!我们都知道INVOKEVIRTUAL会在操作数栈的执行一个消耗“对象”的操作,这个从哪里来,其实也很明显,就是从INVOKEDYNAMIC执行后被放入操作数栈的。
当然,这个生成的类还是比较难找的,可以通过以下明=命令去翻翻
java -Djdk.internal.lambda.dumpProxyClasses 类路径当然,在AS中也有相关的生成类,在intermediates/transform目录下,不过高版本的我找不到在哪了,如果知道的朋友也可以告诉一下
调用特定方法
我们的产物类有了,但是我们也知道,lambda不是生成一个对象那么简单,而是要调用到里面的闭包方法,比如我们本例子就是
v -> {
Log.e("hello","123");
}那么我们这个产物的方法在哪呢?
回到INVOKEDYNAMIC指令的里面,我们看到
java/lang/invoke/LambdaMetafactory.metafactory(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
// arguments:
(Landroid/view/View;)V,
// handle kind 0x6 : INVOKESTATIC
类名.lambda$myFunc$0(Landroid/view/View;)V,
(Landroid/view/View;)V
]
INVOKEVIRTUAL android/view/View.setOnClickListener (Landroid/view/View$OnClickListener;)V这里有很多新的东西,比如LambdaMetafactory(java创建运行时类),MethodHandles等,相关概念我不赘述啦!因为有比我写的更好的文章,大家可以观看一下噢!
ASM对匿名内部类、Lambda及方法引用的Hook研究
我这里特地拿出来
INVOKESTATIC 类名.lambda$myFunc$0(Landroid/view/View;)V这里会在生成的产物类中,直接通过INVOKESTATIC方式(当然,这里只针对我们这个例子,后面会继续有说明,不一定是通过INVOKESTATIC方式)方法是lambda0,我们找下这个方法,可以看到,还真的有,如下
private static synthetic lambda$myFunc$0(Landroid/view/View;)V
L0
LINENUMBER 14 L0
LDC "hello"
LDC "123"
INVOKESTATIC android/util/Log.e (Ljava/lang/String;Ljava/lang/String;)I
POP
}这个方法就是lambda要执行的方法,只不过在字节码中包装了一层。
至此,我们就能够大概明白了,lambda究竟干了些什么
java lambda vs Koltin lambda
java lambda
我们刚刚有提到,生成的产物方法不一定通过INVOKESTATIC的方式调用,这也间接说明了,我们的lambda的包装方法,不一定是static,即不一定是静态的。
我们再来一文,
简单来说,java lambda按照情况,生成的方法也不同,比如当前我们的例子,它其实是一个无状态的lambda,即当前块作用域内,就能捕获到所需要的参数,所以就能直接生成一个static的方法
这里我们特地说明了块作用域,比如,下面的方法,setOnClickListener里面的lambda也依赖了一个变量a,但是他们都属于同一个块级别(函数内),
void myFunc(View view){
int a = 1;
view.setOnClickListener(v -> {
Log.e("hello","123" +a );
});
}生成依旧是一个static方法
private static synthetic lambda$myFunc$0(ILandroid/view/View;)V
L0
LINENUMBER 15 L0
LDC "hello"
NEW java/lang/StringBuilder
DUP
INVOKESPECIAL java/lang/StringBuilder.<init> ()V
LDC "123"
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ILOAD 0
INVOKEVIRTUAL java/lang/StringBuilder.append (I)Ljava/lang/StringBuilder;
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
INVOKESTATIC android/util/Log.e (Ljava/lang/String;Ljava/lang/String;)I
POP
}但是,如果我们依赖当前类的一个变量,比如
类属性
public String s;
void myFunc(View view){
view.setOnClickListener(v -> {
Log.e("hello","123" +s);
});
}此时就生成一个当前类的实例方法,在当前类可以调用到该方法
private synthetic lambda$myFunc$0(Landroid/view/View;)V
L0
LINENUMBER 15 L0
LDC "hello"
NEW java/lang/StringBuilder
DUP
INVOKESPECIAL java/lang/StringBuilder.<init> ()V
LDC "123"
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ALOAD 0
GETFIELD com/example/suanfa/TestCals.s : Ljava/lang/String;
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
INVOKESTATIC android/util/Log.e (Ljava/lang/String;Ljava/lang/String;)I
POP
}同时我们也看到,这种方式会引入ALOAD 0,即this指针被捕获,因此,假如外层类与lambda生命周期不同步,就会导致内存泄漏的问题,这点需要注意噢!!同时我们也要注意,并不是所有lambda都会,像上面我们介绍的lambda就不会!
kotlin lambda
这里特地拿kotlin 出来,是因为它有与java层不一样的点,比如同样的代码,lambda依赖了外部类的属性,生成的方法还是一个静态的方法,而不是实例方法
var s: String = 123
fun test(view:View){
view.setOnClickListener {
Log.e("hello","$s")
}
}字节码如下
不一样的点,选择多一个外部类的参数
private final static test$lambda-0(Lcom/example/suanfa/TestKotlin;Landroid/view/View;)V
L0
ALOAD 0
LDC "this$0"
INVOKESTATIC kotlin/jvm/internal/Intrinsics.checkNotNullParameter (Ljava/lang/Object;Ljava/lang/String;)V
L1
LINENUMBER 11 L1
LDC "hello"
ALOAD 0
GETFIELD com/example/suanfa/TestKotlin.s : Ljava/lang/String;
INVOKESTATIC java/lang/String.valueOf (Ljava/lang/Object;)Ljava/lang/String;
INVOKESTATIC android/util/Log.e (Ljava/lang/String;Ljava/lang/String;)I
POP
L2
LINENUMBER 12 L2
RETURN
L3
LOCALVARIABLE this$0 Lcom/example/suanfa/TestKotlin; L0 L3 0
LOCALVARIABLE it Landroid/view/View; L0 L3 1
MAXSTACK = 2
MAXLOCALS = 2
}同样的,同一块作用域的,也当然是静态方法
fun test(view:View){
val s = "123"
view.setOnClickListener {
Log.e("hello","$s")
}
}如下,比起依赖了外部类的属性,没有依赖的话,自然也不用把外部类对象当作参数传入
private final static test$lambda-0(Ljava/lang/String;Landroid/view/View;)V
L0
ALOAD 0
LDC "$s"
INVOKESTATIC kotlin/jvm/internal/Intrinsics.checkNotNullParameter (Ljava/lang/Object;Ljava/lang/String;)V
L1
LINENUMBER 11 L1
LDC "hello"
ALOAD 0
INVOKESTATIC java/lang/String.valueOf (Ljava/lang/Object;)Ljava/lang/String;
INVOKESTATIC android/util/Log.e (Ljava/lang/String;Ljava/lang/String;)I
POP
L2
LINENUMBER 12 L2
RETURN
L3
LOCALVARIABLE $s Ljava/lang/String; L0 L3 0
LOCALVARIABLE it Landroid/view/View; L0 L3 1
MAXSTACK = 2
MAXLOCALS = 2
}因此,我们可以通过这两个差异,可以做一些特定的字节码逻辑。
总结
lambda的水还是挺深的,我们可以通过本文,去初步了解一些lambda的知识,同时我们也需要注意,在android中,也为了兼容lambda,做了一定的骚操作,比如我们常说的d8会对desuger做了一些操作等等。同时android的生成产物类,也会做单例的优化,这在一些场景会有不一样的坑,我们之后再见啦!
链接:https://juejin.cn/post/7206576861052420157
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
来吧!接受Kotlin 协程--线程池的7个灵魂拷问
在Java的世界里支持多线程编程,开启一个线程的方式很简单:
private void startNewThread() {
new Thread(()->{
//线程体
//我在子线程执行...
}).start();
}而Java也是按照此种方式创建线程执行任务。
某天,OS找到Java说到:"你最近的线程创建、销毁有点频繁,我这边切换线程的上下文是要做准备和善后工作的,有一定的代价,你看怎么优化一下?"
Java无辜地答到:"我也没办法啊,业务就是那么多,需要随时开启线程做支撑。"
OS不悦:"你最近态度有点消极啊,说到问题你都逃避,我理解你业务复杂,需要开线程,但没必要频繁开启关闭,甚至有些线程就执行了一会就关闭,而后又立马开启,这不是玩我吗?。这问题必须解决,不然你的KPI我没法打,你回去尽快想想给个方案出来。"
Java悻悻然:"好的,老大,我尽量。"
Java果然不愧是编程界的老手,很快就想到了方案,他兴冲冲地找到OS汇报:"我想到了一个绝佳的方案:建立一个线程池,固定开启几个线程,有任务的时候往线程池里的任务队列扔就完事了,线程池会找到已提交的任务进行执行。当执行完单个任务之后,线程继续查找任务队列,如果没有任务执行的话就睡眠等待,等有任务过来的时候通知线程起来继续干活,这样一来就不用频繁创建与销毁线程了,perfect!"
OS抚掌夸赞:"池化技术,这才是我认识的Java嘛,不过线程也无需一直存活吧?"
Java:"这块我早有应对之策,线程池可以提供给外部接口用来控制线程空闲的时间,如果超过这时间没有任务执行,那就辞退它(销毁),我们不养闲人!"
OS满意点点头:"该方案,我准了,细节之处你再完善一下。"
经过一段时间的优化,Java线程池框架已经比较稳定了,大家相安无事。
某天,OS又把Java叫到办公室:"你最近提交的任务都是很吃CPU,我就只有8个CPU,你核心线程数设置为20个,剩余的12个根本没机会执行,白白创建了它们。"
Java沉吟片刻道:"这个简单,针对计算密集型的任务,我把核心线程数设置为8就好了。"
OS略微思索:"也不失为一个办法,先试试吧,看看效果再说。"
过了几天,OS又召唤了Java,面带失望地道:"这次又是另一个问题了,最近提交的任务都不怎么吃CPU,基本都是IO操作,其它计算型任务又得不到机会执行,CPU天天在摸鱼。"
Java理所当然道:"是呀,因为设置的核心线程数是8,被IO操作的任务占用了,同样的方式对于这种类型任务把核心线程数提高一些,比如为CPU核数的2倍,变为16,这样即使其中一些任务占用了线程,还剩下其它线程可以执行任务,一举两得。"
OS来回踱步,思考片刻后大声道:"不对,你这么设置万一提交的任务都是计算密集型的咋办?又回到原点了,不妥不妥。"
Java似乎早料到OS有此疑问,无奈道:”没办法啊,我只有一个参数设置核心线程,线程池里本身不区分是计算密集型还是IO阻塞任务,鱼和熊掌不可兼得。"
OS怒火中烧,整准备拍桌子,在这关键时刻,办公室的门打开了,翩翩然进来的是Kotlin。
Kotlin看了Java一眼,对OS说到:"我已经知道两位大佬的担忧,食君俸禄,与君分忧,我这里刚好有一计策,解君燃眉之急。"
OS欣喜道:"小K,你有何妙计,速速道来。“
Kotlin平息了一下激动的内心:"我计策说起来很简单,在提交任务的时候指定其是属于哪种类型的任务,比如是计算型任务,则选择Dispatchers.Default,若是IO型任务则选择Dispatchers.IO,这样调用者就不用关注其它的细节了。"
Java说到:"这策略我不是没有想到,只是担忧越灵活可能越不稳定。"
OS打断他说:"先让小K完整说一下实现过程,下来你俩仔细对一下方案,扬长避短,吃一堑长一智,这次务必要充分考虑到各种边界情况。"
Java&Kotlin:"好的,我们下来排期。"
故事讲完,言归正传。
2. Dispatchers.Default 是如何调度的?
Dispatchers.Default 使用
GlobalScope.launch(Dispatchers.Default) {
println("我是计算密集型任务")
}开启协程,指定其运行的任务类型为:Dispatchers.Default。
此时launch函数闭包里的代码将在线程池里执行。
Dispatchers.Default 用在计算密集型的任务场景里,此种任务比较吃CPU。
Dispatchers.Default 原理
概念约定
在解析原理之前先约定一个概念,如下代码:
GlobalScope.launch(Dispatchers.Default) {
println("我是计算密集型任务")
Thread.sleep(20000000)
}在任务里执行线程的睡眠操作,此时虽然线程处于挂起状态,但它还没执行完任务,在线程池里的状态我们认为是忙碌的。
再看如下代码:
GlobalScope.launch(Dispatchers.Default) {
println("我是计算密集型任务")
Thread.sleep(2000)
println("任务执行结束")
}当任务执行结束后,线程继续查找任务队列的任务,若没有任务可执行则进行挂起操作,在线程池里的状态我们认为是空闲的。
调度原理
注:此处忽略了本地队列的场景
由上图可知:
- launch(Dispatchers.Default) 作用是创建任务加入到线程池里,并尝试通知线程池里的线程执行任务
- launch(Dispatchers.Default) 执行并不耗时
3. Dispatchers.IO 是如何调度的?
直接看图:
很明显地看出和Dispatchers.Default的调度很相似,其中标蓝的流程是重点的差异之处。
结合Dispatchers.Default和Dispatchers.IO调度流程可知影响任务执行的步骤有两个:
- 线程池是否有空闲的线程
- 创建新线程是否成功
我们先分析第2点,从源码里寻找答案:
#CoroutineScheduler
private fun tryCreateWorker(state: Long = controlState.value): Boolean {
//线程池已经创建并且还在存活的线程总数
val created = createdWorkers(state)
//当前IO类型的任务数
val blocking = blockingTasks(state)
//剩下的就是计算型的线程个数
val cpuWorkers = (created - blocking).coerceAtLeast(0)
//如果计算型的线程个数小于核心线程数,说明还可以再继续创建
if (cpuWorkers < corePoolSize) {
//创建线程,并返回新的计算型线程个数
val newCpuWorkers = createNewWorker()
//满足条件,再创建一个线程,方便偷任务
if (newCpuWorkers == 1 && corePoolSize > 1) createNewWorker()
//创建成功
if (newCpuWorkers > 0) return true
}
//创建失败
return false
}怎么去理解以上代码的逻辑呢?举个例子:
假设核心线程数为8,初始时创建了8个Default线程,并一直保持忙碌。
此时分别使用Dispatchers.Default 和 Dispatchers.IO提交任务,看看有什么效果。
- Dispatchers.Default 提交任务,此时线程池里所有任务都在忙碌,于是尝试创建新的线程,而又因为当前计算型的线程数=8,等于核心线程数,此时不能创建新的线程,因此该任务暂时无法被线程执行
- Dispatchers.IO 提交任务,此时线程池里所有任务都在忙碌,于是尝试创建新的线程,而当前阻塞的任务数为1,当前线程池所有线程个数为8,因此计算型的线程数为 8-1=7,小于核心线程数,最后可以创建新的线程用以执行任务
这也是两者的最大差异,因为对于计算型(非阻塞)的任务,很占CPU,即使分配再多的线程,CPU没有空闲去执行这些线程也是白搭,而对于IO型(阻塞)的任务,不怎么占CPU,因此可以多开几个线程充分利用CPU性能。
4. 线程池是如何调度任务的?
不论是launch(Dispatchers.Default) 还是launch(Dispatchers.IO) ,它们的目的是将任务加入到队列并尝试唤醒线程或是创建新的线程,而线程寻找并执行任务的功能并不是它们完成的,这就涉及到线程池调度任务的功能。
线程池里的每个线程都会经历上图流程,我们很容易得出结论:
- 只有获得cpu许可的线程才能执行计算型任务,而cpu许可的个数就是核心线程数
- 如果线程没有找到可执行的任务,那么线程将会进入挂起状态,此时线程即为空闲状态
- 当线程再次被唤醒后,会判断是否已经被终止,若是则退出,此时线程就销毁了
处在空闲状态的线程被唤醒有两种可能:
- 线程挂起的时间到了
- 挂起的过程中,有新的任务加入到线程池里,此时将会唤醒线程
5. 据说Dispatchers.Default 任务会阻塞?该怎么办?
在了解了线程池的任务分发与调度之后,我们对线程池的核心功能有了一个比较全面的认识。
接着来看看实际的应用,先看Demo:
假设我们的设备有8核。
先开启8个计算型任务:
binding.btnStartThreadMultiCpu.setOnClickListener {
repeat(8) {
GlobalScope.launch(Dispatchers.Default) {
println("cpu multi...${multiCpuCount++}")
Thread.sleep(36000000)
}
}
}每个任务里线程睡眠了很长时间。
从打印可以看出,8个任务都得到了执行,且都在不同的线程里执行。
此时再次开启一个计算型任务:
var singleCpuCount = 1
binding.btnStartThreadSingleCpu.setOnClickListener {
repeat(1) {
GlobalScope.launch(Dispatchers.Default) {
println("cpu single...${singleCpuCount++}")
Thread.sleep(36000000)
}
}
}先猜测一下结果?
答案是没有任何打印,新加入的任务没有得到执行。
既然计算型任务无法得到执行,那我们尝试换为IO任务:
var singleIoCount = 1
binding.btnStartThreadSingleIo.setOnClickListener {
repeat(1) {
GlobalScope.launch(Dispatchers.IO) {
println("io single...${singleIoCount++}")
Thread.sleep(10000)
}
}
}这次有打印了,说明IO任务得到了执行,并且是新开的线程。
这是为什么呢?
- 计算密集型任务能分配的最大线程数为核心的线程数(默认为CPU核心个数,比如我们的实验设备上是8个),若之前的核心线程数都处在忙碌,新开的任务将无法得到执行
- IO型任务能开的线程默认为64个,只要没有超过64个并且没有空闲的线程,那么就一直可以开辟新线程执行新任务
这也给了我们一个启示:Dispatchers.Default 不要用来执行阻塞的任务,它适用于执行快速的、计算密集型的任务,比如循环、又比如计算Bitmap等。
6. 线程的生命周期是如何确定?
是什么决定了线程能够挂起,又是什么决定了它唤醒后的动作?
先从挂起说起,当线程发现没有任务可执行后,它会经历如下步骤:
重点在于线程被唤醒后确定是哪种场景下被唤醒的,判断方式也很简单:
线程挂起时设定了挂起的结束时间点,当线程唤醒后检查当前时间有没有达到结束时间点,若没有,则说明被新加入的任务动作唤醒的
即使是没有了任务执行,若是当前线程数小于核心线程数,那么也无需销毁线程,继续等待任务的到来即可。
7. 如何更改线程池的默认配置?
上面几个小结涉及到核心线程数,线程挂起时间,最大线程数等,这些参数在Java提供的线程池里都可以动态配置,灵活度很高,而Kotlin里的线程池比较封闭,没有提供额外的接口进行配置。
不过好在我们可以通过设置系统参数来解决这问题。
比如你可能觉得核心线程数为cpu的个数配置太少了,想增加这数量,这想法完全是可以实现的。
先看核心线程数从哪获取的。
internal val CORE_POOL_SIZE = systemProp(
//从这个属性里取值
"kotlinx.coroutines.scheduler.core.pool.size",
AVAILABLE_PROCESSORS.coerceAtLeast(2),//默认为cpu的个数
minValue = CoroutineScheduler.MIN_SUPPORTED_POOL_SIZE//最小值为1
)若是我们没有设置"kotlinx.coroutines.scheduler.core.pool.size"属性,那么将取到默认值,比如现在大部分是8核cpu,那么CORE_POOL_SIZE=8。
若要修改,则在线程池启动之前,设置属性值:
System.setProperty("kotlinx.coroutines.scheduler.core.pool.size", "20")
设置为20,此时我们再按照第5小结的Demo进行测试,就会发现Dispatchers.Default 任务不会阻塞。
当然,你觉得IO任务配置的线程数太多了(默认64),想要降低,则修改属性如下:
System.setProperty("kotlinx.coroutines.io.parallelism", "40")
其它参数也可依此定制,不过若没有强烈的意愿,建议遵守默认配置。
通过以上的7个问题的分析与解释,相比大家都比较了解线程池的原理以及使用了,那么赶紧使用Kotlin线程池来规范线程的使用吧,使用得当可以提升程序运行效率,减少OOM发生。
本文基于Kotlin 1.5.3,文中完整实验Demo请点击
链接:https://juejin.cn/post/7207078219215962170
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单教你Intent如何传大数据
前言
最近想不出什么比较好的内容,但是碰到一个没毕业的小老弟问的问题,那就借机说说这个事。Intent如何传大数据?为什么是简单的说,因为这背后深入的话,有很多底层的细节包括设计思想,我也不敢说完全懂,但我知道当你用Intent传大数据报错的时候应该怎么解决,并且简单聊聊这背后所涉及到的东西。
Intent传大数据
平时可能不会发生这种问题,但比如我之前是做终端设备的,我的设备每秒都会生成一些数据,而长时间的话数据量自然大,这时当我跳到另外一个页面使用intent把数据传过去的时候,就会报错
我们调用
intent.putExtra("key", value) // value超过1M
会报错
android.os.TransactionTooLargeException: data parcel size xxx bytes
这里的xxx就是1M左右,告诉你传输的数据大小不能超过1M,有些话咱也不敢乱说,有点怕误人子弟。我这里是凭印象说的,如果有大佬看到我说错,请狠狠的纠正我。
这个错误描述是这么描述,但真的是限死1M吗,说到这个,就不得不提一样东西,Binder机制,先不要跑,这里不会详细讲Binder,只是提一嘴。
说到Binder那就会联系到mmap内存映射,你可以先简单理解成内存映射是分配一块空间给内核空间和用户空间共用,如果还是不好理解,就简单想成分配一块空间通信用,那在android中mmap分配的空间是多少呢?1M-4K。
那是不是说Intent传输的数据超过1M-4K就会报错,理论上是这样,但实际没到这个值,比如0.8M也可能会报错。所以你不能去走极限操作,比如你的数据到了1M,你觉得只要减少点数据,减到8K,应该就能过了,也许你自己测试是正常的,但是这很危险。
所以能不传大数据就不要传大数据,它的设计初衷也不是为了传大数据用的。如果真要传大数据,也不要走极限操作。
那怎么办,切莫着急,请听我慢慢讲。就这个Binder它是什么玩意,它是Android中独特的进程通信的方式,而Linux中进程通信的方式,在Android中同样也适用。进程间通信有很多方式,Binder、管道、共享内存等。为什么会有这么多种通信方式,因为每种通信方式都有自己的特点,要在不同的场合使用不同的通信方式。
为什么要提这个?因为要看懂这个问题,你需要知道Binder这种通信方式它有什么特点,它适合大量的数据传输吗?那你Binder又与我Intent何干,你抓周树人找我鲁迅干嘛~~所以这时候你就要知道Android四大组件之间是用什么方式通信的。
有点扯远了,现在可以来说说结论了,Binder没办法传大数据,我就1M不到你想怎样?当然它不止1M,只是Android在使用时限制了它只能最多用1M,内核的最大限制是4M。又有点扯远了,你不要想着怎么把限制扩大到4M,不要往这方面想。前面说了,不同的进程通信方式,有自己的特点,适用于某些特定的场景。那Binder不适用于传输大数据,我共享内存行不行?
所以就有了解决办法
bundle.putBinder()有人可能一看觉得,这有什么不同,这在表面上看差别不大,实则内部大大的不同,bundle.putBinder()用了共享内存,所以能传大数据,那为什么这里会用共享内存,而putExtra不是呢?想搞清楚这个问题,就要看源码了。 这里就不深入去分析了,我怕劝退,不是劝退你们,是劝退我自己。有些东西是这样的,你要自己去看懂,看个大概就差不多,但是你要讲出来,那就要看得细致,而有些细节确实会劝退人。所以想了解为什么的,可以自己去看源码,不想看的,就知道这是怎么一回事就行。
那还有没有其它方式呢?当然有,你不懂共享内存,你写到本地缓存中,再从本地缓存中读取行不行?
办法有很多,如果你不知道这个问题怎么解决,你找不到你觉得可行的解决方案,甚至可以通过逻辑通过流程的方式去绕开这个问题。但是你要知道为什么会出现这样的问题,如果你没接触过进程通信,没接触过Binder,让你看一篇文章就能看懂我觉得不切实际,但是至少得知道是怎么一回事。
比如我只说bundle.putBinder()能解决这个问题,你一试,确实能解决,但是不知道为什么,你又怕会不会有其它问题。虽然这篇文章我一直在打擦边球,没有提任何的原理,但我觉得还是能大概让人知道为什么bundle.putBinder()能解决Intent传大数据,你也就能放心去用了。
链接:https://juejin.cn/post/7205138514870829116
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
考研失败,加入国企当程序员,真香!
下面是正文。
最近考研出成绩了,大家考得怎么样?分享一个自己考研失败后,入职国企的故事。
1、考研失败
我是工作了3年后才参加考研的。
老家成都,本科毕业于帝都某所以能歌善舞著称的985学校,哲学专业。
大学选专业时家里人不懂,自己全凭爱好,第一志愿就是哲学。上学时有多快乐,毕业时就多难找工作。
侥幸自己选修过大数据课程,并且听说程序员工资还不错,通过校招加入了隔壁省的一家制造业当程序员。
公司管吃管住,工资1w出头,干了2年,感觉到了危机。自己羞于靠关系上位,但技术上,计算机知识太薄弱也发展有限,于是就想趁着还年轻,考个计算机硕士,提升一下自己。
在工作的第3年决定考研,边工作边考研,压力真是不小。让本来就是学渣的我,从研究生考场走出来就知道了最终的结果:没戏了。
成绩出来后,果然不出所料。
2、加入国企
知道初试成绩以后我难过了几天,认真思考了一下自己的未来发展:旁边的帝都我也回不去了,又不甘心留在这个小城市,于是决定回老家成都发展。
毕业后一直在私企,总是听说国企好、央企不错,所以我这次投简历也想试一下。正好看到一篇讲程序员国企的文章:值得程序员加入的173家国企汇总,网友:这下彻底躺平了,于是就按照文中的思路,找到了成都的一些所谓不错的国企投递试试。
成功加入后发现:真香!
福利真 ** 好!和其它公司谈薪酬,别人都是能压多低压多低,来这家国企,竟然还说我工作年限够长,在我期望的基础上加了3k。六险二金更不用说,平时的各种生活保障也是非常到位。不夸张的说,从私企转到国企的我,有一种刘姥姥进大观园的感觉。
真卷!**是谁告诉我国企适合养老的?**这比我以前在私企工作强度大多了好嘛?而且我第一次听说部门平均加班时长影响个人绩效这种规则。
技术上不激进。可能对于程序员来说,不停的学习新技术是一种常态,但是在这家国企,基本都是传统老技术,我打开代码还看到了我们领导1997年写的头文件。当然,你也可以认为这是一种不好的事。这里的技术对我来说,够了。
同事关系很融洽。我人生中第一次去按摩店找技师,是女同事带我去的,谁能信!不过必须说一句,成都的按摩店是真正规啊!技师可真有劲。
去年回来工作快1年了,我现在对于考研已经释怀了。听说我们部门今年招人开始硕士起步了,**有时候我还挺庆幸自己去年没考研成功的,**不然即使上了研究生,我这实力,也不一定能进入现在的单位了。
3、写在最后
现在回过头来看,有一个不同的体会:考研是一件好事,但如果本身不是沉迷于科研事业,而是更想赚钱的话,有好的工作机会也别错过。
另外,多关注有用的信息很重要,有时候别人的一番话,可能就需要自己经历几年的曲折才能总结出来。
大家有任何程序员求职问题,欢迎在评论区和我交流~
链接:https://juejin.cn/post/7205541247590973499
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
FlutterComponent最佳实践之动画的显和隐
Flutter中包含大量的动画组件和自定义动画方式,所以,在合适的场景下选择合适的动画实现方式就成了决定代码质量好坏的一个重要因素。
动画选择决策树
Flutter中的动画从广义上来讲可以分为两类,一类是基于绘制的动画(Drawing-based animations),另一类是基于代码的动画(Code-based animations)。
下面这个决策树,是Flutter动画选择的总纲,这里梳理了不同的动画的作用场景和功能,我们来看下它具体的实现。
首先,我们需要区分是使用CustomPainter,或者是使用Lottie、Flare这种第三方库,这一类的动画很容易区分——如果你第一感觉,这个动画我做不了,那它大概率就是了。
接下来,就是区分是使用「显示动画」还是「隐式动画」。
简单的说,它们的区别如下:
- 隐式动画:不用循环播放、不用随时中断、不用多个动画协同,它实现的是一种状态到另一种状态的改变
- 显示动画:需要自己控制动画过程
最后,就是看现有组件是否满足需求,如果不行,那么就需要自定义相应的动画。
这就是整个动画决策树的执行过程。它们的开发难度,如下所示。
下面我们就具体来分析下不同的动画实现。本文首先介绍显示动画和隐式动画。
Implicit Animations——隐式动画
在Flutter中,很多常用组件都有其自带的隐式动画版本,例如下图所示的这些组件。
这些组件在Flutter中被称之为隐式动画Widget,下面以AnimatedContainer为例,来看下Implicit Animations的使用。
隐式动画有一个特点,那就是它们都是以「Animated」开头。
基本使用
AnimatedContainer的使用非常简单,甚至和普通的Container没有太大的区别,代码如下所示。
AnimatedContainer(
margin: EdgeInsets.only(top: 20),
width: size,
height: size,
decoration: BoxDecoration(
color: color,
borderRadius: BorderRadius.circular(radius),
),
curve: Curves.easeIn,
duration: Duration(milliseconds: 300),
),当通过setState函数改变AnimatedContainer中的属性时,AnimatedContainer会经过一段动画效果,然后再完成相应的改变。在隐式动画中,你依然可以定义Curve和Duration等参数,但是你无法控制动画,即动画的执行和结束,是由属性改变来驱动的。
使用场景
Implicit Animations可以非常方便的使Widget具有动画效果而不需要写很多额外的动画代码,结合FutureBuilder或者StreamBuilder,甚至不用写setState,下面这个例子就演示了如何将Implicit Animations和FutureBuilder结合起来使用,代码如下所示。
FutureBuilder(
future: future,
builder: (context, snapshot) {
var width = .0;
switch (snapshot.connectionState) {
case ConnectionState.none:
case ConnectionState.waiting:
case ConnectionState.active:
width = .0;
break;
case ConnectionState.done:
width = 100.0;
break;
}
return AnimatedContainer(
width: width,
duration: Duration(seconds: 1),
curve: Curves.easeIn,
child: Image.asset('images/logo.png'),
);
},
),通过FutureBuilder的各种状态回调,就可以设置不同的Widget,并在FutureBuilder完成并显示正常的Widget时,产生一个动画效果,而不是非常生硬的出现。
TweenAnimationBuilder
TweenAnimationBuilder是自定义隐式动画的方式,借助它,你可以给一个指定的Widget作用一个动画效果,一个简单的示例代码如下所示。
TweenAnimationBuilder(
tween: Tween<double>(begin: 0, end: 48),
onEnd: (){}
duration: Duration(seconds: 1),
builder: (BuildContext context, double size, Widget child) {
return IconButton(
iconSize: size,
color: Colors.blue,
icon: child,
);
},
child: Icon(Icons.aspect_ratio),
)借助TweenAnimationBuilder,就可以将一个指定的Tween作用于builder中的Widget,builder中的第二个参数,就是Tween所指定的参数的类型,通过TweenAnimationBuilder,就可以在Widget参数变化的时候产生动画效果。
TweenAnimationBuilder的builder中如果有不变的Child Widget,可以放在TweenAnimationBuilder的child属性中,因为builder在产生动画时会重建,所有不变的Widget,都可以放在TweenAnimationBuilder的child中,再通过builder的第三个参数来传递这个Widget,以避免重建。
通常我们在开发中,会借助Transform来完成动画效果,在builder中,根据Tween返回的数值,使用不同的Transform来修改动画状态。
TweenAnimationBuilder中的begin,只在第一次使用,后面更新时,只看end的值,例如10-30,修改end为50,实际变化是30-50。如果不传begin,那么默认和end相等。
Explicit Animations——显示动画
与隐式动画不同,显示动画给了开发者对动画过程的完全掌控,开发者可以根据自己的需要来控制动画,Flutter中内置了很多显示动画,如下所示。
显示动画也有一个很明显的特点,那就是它们都以「Transition」结尾。
基本使用
以RotationTransition为例,下面来演示下如何使用Flutter中的显示动画。
显示动画是通过AnimationController来进行驱动的,所以,使用显示动画的第一步,就是需要创建AnimationController。有了AnimationController之后,就可以通过控制AnimationController的状态来控制动画的驱动过程,整个代码如下所示。
AnimationController controller;
@override
void initState() {
super.initState();
controller = AnimationController(vsync: this, duration: Duration(seconds: 2))..repeat();
}
@override
void dispose() {
controller.dispose();
super.dispose();
}
@override
Widget build(BuildContext context) {
return Center(
child: GestureDetector(
onTap: () {
if (controller.isAnimating) {
controller.stop();
} else {
controller.repeat();
}
},
child: RotationTransition(
turns: controller,
child: FlutterLogo(
size: 100,
),
),
),
);
}与隐式动画相比,显式动画通过AnimationController来获取动画的行进状态和参数,从而让调用者能够控制动画的行进过程。
显式动画可以实现隐式动画的所有功能,但是比隐式动画多了管理动画生命周期的工作
当Flutter内置显示动画不能满足开发者的需求时,Flutter提供了AnimatedBuilder和AnimatedWidget来让开发者对显示动画进行自定义。
AnimatedWidget
前面提到的都是Flutter中使用动画的最基本方式,但实际上,Flutter提供了很多关于动画的封装组件,可以让开发者更加方便的使用动画,这就是AnimatedWidget。AnimatedWidget也有很多实现类,如图所示。
AnimatedWidget是实现自定义显示动画的另一种方式,它可以将一些动画的逻辑以Widget的形式封装起来,从而让build函数中的代码逻辑更加清晰,下面是AnimatedWidget的示例代码。
@override
Widget build(BuildContext context) {
return Stack(
children: <Widget>[
AnimWidget(animation: controller),
Center(child: FlutterLogo(size: 100)),
],
);
}
class AnimWidget extends AnimatedWidget {
const AnimWidget({
Key? key,
required Animation<double> animation,
}) : super(key: key, listenable: animation);
@override
Widget build(BuildContext context) {
Animation<double> animation = listenable as Animation<double>;
return Container(
decoration: BoxDecoration(
gradient: RadialGradient(
colors: const [Colors.red, Colors.transparent],
stops: [0, animation.value],
),
),
);
}
}那么这种方式和之前直接使用AnimationController和Tween有什么区别呢?细心的读者可能已经发现了,AnimatedWidget不需要自己去监听动画的回调,也不需要通过setState来刷新动画,这些操作,AnimatedWidget已经封装好了,这就是AnimatedWidget的作用。
AnimatedBuilder
AnimatedBuilder是一个特殊的AnimatedWidget,它可以直接指定一个动画作用于Widget上,而不需要重新创建一个自定义的AnimatedWidget,它可以帮助开发者处理动画的监听,当一个Widget Tree中有一些需要动画的Widget,也有一些不需要动画的Widget时,用AnimatedBuilder可以很方便的避免非动画Widget的重绘,所以说,AnimatedBuilder可以更加方便的给一个Widget增加动画效果。
AnimatedBuilder与其它的显示动画一样,也是通过AnimationController驱动的,借助AnimatedBuilder,开发者可以根据需要,自己创建Animation并控制它,下面的代码演示了如何通过控制RadialGradient的stop属性来控制RadialGradient的显示大小,从而形成动画效果,代码如下所示。
@override
Widget build(BuildContext context) {
return AnimatedBuilder(
animation: controller,
builder: (context, widget) {
return Stack(
children: <Widget>[
Container(
decoration: BoxDecoration(
gradient: RadialGradient(
colors: [Colors.red, Colors.transparent],
stops: [0, controller.value],
),
),
),
Center(child: FlutterLogo(size: 100))
],
);
},
);
}上面的代码演示了如何使用AnimatedBuilder,实际上非常简单,与使用内置的显示动画的过程基本一致。
在使用AnimatedBuilder的过程中,需要尽可能多的将需要动画的部分和不需要动画的部分区分开来,这样可以避免多余的重绘,从而提高动画性能,例如上面的代码,可以将FlutterLogo和Stack放置在最外层,这样只需要让RadialGradient产生动画就可以了,代码如下所示。
@override
Widget build(BuildContext context) {
return Stack(
children: <Widget>[
AnimatedBuilder(
animation: controller,
builder: (context, widget) {
return Container(
decoration: BoxDecoration(
gradient: RadialGradient(
colors: [Colors.red, Colors.transparent],
stops: [0, controller.value],
),
),
);
},
),
Center(child: FlutterLogo(size: 100))
],
);
}AnimatedBuilder接收了一个animation,在child中,可以直接使用这个animation的值,其它都和普通的AnimatedWidget类似。
实际上,AnimatedBuilder就是AnimatedWidget的子类,所以在本质上,这两种实现自定义显示动画的方式想相同的,开发者可以根据自己的喜好来选择相应的方式来创建自己的显示动画。
AnimateWidget负责组件的抽离,可以看出组件中杂糅了动画逻辑。而AnimatedBuilder恰好相反,它不在意组件是什么,只是将动画抽离达到复用简单。
Flutter中的显示动画和隐式动画,几乎可以解决大部分我们平时在开发中遇到的动画场景,借助动画选择决策树,我们可以对动画的选择了如指掌,剩下的工作,就是对动画进行拆解,分而治之。
链接:https://juejin.cn/post/7205743525979422779
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android:实现一个自定义View扫描框
扫码功能都用过吧,打开扫码功能后都会有类似封面图的效果。其实就是一个自定义View的遮罩,话不多说,今天这篇我们就来讲解如何实现一个扫面框动效。
首先,我们先分析下动效的组成,有利于待会拆分实现:
- 四周类似角标的白线
- 角标框住的浅白色背景
- 一条由上而下由快到慢移动的扫描线
一经分析,其实非常简单,整体效果就是由这几个简单的元素组成。接下来我们就创建一个ScanView继承自View来实现这个动效。(由于代码古老,这里使用Java)
public final class ScanView extends View {
private Paint paint, scanLinePaint,reactPaint;//三种画笔
private Rect frame;//整个区域
public ScanView(Context context) {
this(context, null);
}
public ScanView(Context context, AttributeSet attrs) {
this(context, attrs, 0);
}
public ScanView(Context context, @Nullable AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
initPaint()
}
private void initPaint() {
/*遮罩画笔*/
paint = new Paint(Paint.ANTI_ALIAS_FLAG);
paint.setColor(color);
paint.setAlpha(CURRENT_POINT_OPACITY);
paint.setStyle(Paint.Style.FILL);
/*边框线画笔*/
reactPaint = new Paint(Paint.ANTI_ALIAS_FLAG);
reactPaint.setColor(reactColor);
reactPaint.setStyle(Paint.Style.FILL);
/*扫描线画笔*/
scanLinePaint = new Paint(Paint.ANTI_ALIAS_FLAG);
scanLinePaint.setStyle(Paint.Style.FILL);
scanLinePaint.setDither(true);
scanLinePaint.setColor(scanLineColor);
}
}三种画笔初始化完成接下来就是使用画笔在画布上绘制效果图了,重写onDraw()方法
public void onDraw(Canvas canvas) {
//绘制取景边框
drawFrameBounds(canvas, frame);
//绘制遮罩
drawMaskView(canvas, frame);
//绘制扫描线
drawScanLight(canvas, frame);
}再来分析,边框的四个角其实拆开来看,就是两条线组成,或者说是两个填充的矩形框垂直相交组成,那么四个角就可以按照这个思路完成,遮罩其实就是一个矩形框。
//绘制四个角,注意是外线而不是内线
private void drawFrameBounds(Canvas canvas, Rect frame) {
// 左上角
canvas.drawRect(frame.left - corWidth, frame.top, frame.left, frame.top + corLength, reactPaint);
canvas.drawRect(frame.left - corWidth, frame.top - corWidth, frame.left + corLength, frame.top, reactPaint);
// 右上角
canvas.drawRect(frame.right, frame.top, frame.right + corWidth,frame.top + corLength, reactPaint);
canvas.drawRect(frame.right - corLength, frame.top - corWidth, frame.right + corWidth, frame.top, reactPaint);
// 左下角
canvas.drawRect(frame.left - corWidth, frame.bottom - corLength,frame.left, frame.bottom, reactPaint);
canvas.drawRect(frame.left - corWidth, frame.bottom, frame.left + corLength, frame.bottom + corWidth, reactPaint);
// 右下角
canvas.drawRect(frame.right, frame.bottom - corLength, frame.right + corWidth, frame.bottom, reactPaint);
canvas.drawRect(frame.right - corLength, frame.bottom, frame.right + corWidth, frame.bottom + corWidth, reactPaint);
}
//绘制遮罩
private void drawMaskView(Canvas canvas, Rect frame) {
canvas.drawRect(frame.left, frame.top, frame.right, frame.bottom, paint);
}到此,我们还剩最后一个扫描线的动画效果,这条线其实就是一张图片,首先需要将图片以Bitmap形式绘制在扫描区域内,然后通过ValueAnimator来控制图片Y坐标点,这样就能达到图片上下移动的效果,至于由快到慢的效果是添加了插值器,这里使用内置的DecelerateInterpolator,同学们可以根据自己想要的效果自己搭配。
if (valueAnimator == null) {
valueAnimator = ValueAnimator.ofInt(frame.top, frame.bottom-10);//图片Y坐标取值范围
valueAnimator.setDuration(3000);//单次动画时间3秒
valueAnimator.setInterpolator(new DecelerateInterpolator());//由快到慢插值器
valueAnimator.setRepeatMode(ValueAnimator.RESTART);//重复动画
valueAnimator.setRepeatCount(ValueAnimator.INFINITE);//无限次数
valueAnimator.addUpdateListener(new ValueAnimator.AnimatorUpdateListener() {
@Override
public void onAnimationUpdate(ValueAnimator animation) {
scanLineTop = (int) animation.getAnimatedValue();//当前时刻获取的Y值
invalidate();//刷新视图
}
});
valueAnimator.start();
}到此就可以实现封面的效果,甚至可以添加别的酷炫效果,只要你敢想敢做。
总结
其实一些动效看似很复杂,但通过认真分析,我们可以将其拆分成多个简单的小块,将每个小块实现后再逐个拼装,最后达到完整的效果。本节主要是通过自定义View实现,用到绘制矩形框(drawRect),属性动画(ValueAnimator),两者使用也是非常简单。另外需要注意动画的使用和释放,避免导致不必要的内存泄漏。
好了,以上便是本篇所有内容,希望对大家有所帮助!
链接:https://juejin.cn/post/7205585832232403005
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin Collection KTX:让你的集合操作如丝般顺滑
当今移动应用开发,常常需要使用各种集合类型来存储和操作数据。Kotlin 提供了 Collection KTX 扩展库,为我们操作集合提供了非常方便的 API。在本篇文章中,我们将介绍 Collection KTX 中包含的所有扩展函数,让你的集合操作变得更加高效、简单、易读。
除了 Collection KTX,Kotlin 还提供了许多其他扩展库,例如 Android KTX、Coroutines、Serialization KTX 等,它们都可以大大简化我们的开发流程。在接下来的文章中,我们还将为您介绍这些扩展库的详细信息,让你的 Kotlin 开发之路更加畅通无阻
使用
dependencies {
implementation "androidx.collection:collection-ktx:1.2.0"
}用法合集
Collection 扩展函数
filterNot():过滤掉指定元素后的新 Collection。filterNotNull():过滤掉null元素后的新 Collection。
List 扩展函数
sorted():按自然顺序排序后的新 List。sortedBy():按指定方式排序后的新 List。sortedDescending():按自然顺序降序排序后的新 List。sortedByDescending():按指定方式降序排序后的新 List。distinct():去重后的新 List。distinctBy():按指定方式去重后的新 List。minus():删除指定元素后的新 List。plus():添加指定元素后的新 List。drop():去掉前几个元素后的新 List。dropWhile():去掉符合指定条件的元素后的新 List。take():前几个元素组成的新 List。takeWhile():符合指定条件的元素组成的新 List。partition():按指定条件分隔后的 Pair。groupBy():按指定方式分组后的 Map。associate():按指定方式关联后的新 Map。associateBy():按指定方式关联键后的新 Map。associateWith():按指定方式关联值后的新 Map。zip():按指定方式组合后的新 List。
MutableList 扩展函数
removeLast():移除最后一个元素,并返回该元素。removeFirst():移除第一个元素,并返回该元素。move():将指定元素移动到新位置。
Set 扩展函数
minus():删除指定元素后的新 Set。plus():添加指定元素后的新 Set。partition():按指定条件分隔后的 Pair。groupBy():按指定方式分组后的 Map。associate():按指定方式关联后的新 Map。associateBy():按指定方式关联键后的新 Map。associateWith():按指定方式关联值后的新 Map。
MutableSet 扩展函数
remove():移除指定元素,并返回是否移除成功。retainAll():仅保留符合指定条件的元素。addAll():添加指定元素后的新 MutableSet。
Map 扩展函数
minus():删除指定键对应的元素后的新 Map。plus():添加指定键值对后的新 Map。partition():按指定条件分隔后的 Pair。filterKeys():按指定条件过滤键后的新 Map。filterValues():按指定条件过滤值后的新 Map。mapKeys():按指定方式映射键后的新 Map。mapValues(): 按指定方式映射值后的新map
MutableMap 扩展函数
remove():移除指定键对应的元素,并返回该元素。putAll():添加指定键值对后的新 MutableMap。putIfAbsent():仅在指定键不存在时添加指定键值对。compute():更新指定键对应的元素,并返回更新后的值。computeIfAbsent():仅在指定键不存在时更新该键对应的元素。computeIfPresent():仅在指定键存在时更新该键对应的元素。
Iterable 扩展函数
reduceOrNull():对所有元素进行指定操作,如果为 null 则返回 null。reduceIndexedOrNull():对所有元素进行指定操作,同时考虑元素的索引,如果为 null 则返回 null。foldOrNull():对所有元素进行指定操作并给定初始值,如果为 null 则返回 null。foldIndexedOrNull():对所有元素进行指定操作并给定初始值,同时考虑元素的索引,如果为 null 则返回 null。
ListIterator 扩展函数
previousOrNull():返回上一个元素,如果不存在则返回 null。
Sequence 扩展函数
reduceOrNull():对所有元素进行指定操作,如果为 null 则返回 null。reduceIndexedOrNull():对所有元素进行指定操作,同时考虑元素的索引,如果为 null 则返回 null。foldOrNull():对所有元素进行指定操作并给定初始值,如果为 null 则返回 null。foldIndexedOrNull():对所有元素进行指定操作并给定初始值,同时考虑元素的索引,如果为 null 则返回 null。distinct():去重后的新 Sequence。distinctBy():按指定方式去重后的新 Sequence。filterNotNull():过滤掉null元素后的新 Sequence。filterNot():过滤掉指定元素后的新 Sequence。partition():按指定条件分隔后的 Pair。sorted():按自然顺序排序后的新 Sequence。sortedBy():按指定方式排序后的新 Sequence。sortedDescending():按自然顺序降序排序后的新 Sequence。sortedByDescending():按指定方式降序排序后的新 Sequence。take():前几个元素组成的新 Sequence。takeWhile():符合指定条件的元素组成的新 Sequence。zip():按指定方式组合后的新 Sequence
了解工具的尿性
工具的职责就是提高工作效率
- 使用 Collection KTX 可以大大简化集合操作的代码,使代码更加简洁易读,同时可以提高代码的可维护性
- 在使用集合时,应该尽可能使用 Kotlin 标准库中的函数和 Collection KTX 中的扩展函数,而不是手写循环或通过 Java API 进行操作,这可以减少代码量和提高代码可读性。
- 了解不同的集合类型及其特性,选择合适的集合类型可以使代码更加高效。例如,如果需要频繁添加或删除元素,则应该使用可变集合类型。
- 避免频繁进行集合类型的转换,因为这会导致性能降低。如果需要对集合进行不同的操作,可以考虑使用不同的集合类型来解决。
- 尽量避免对空集合进行操作,因为这可能会导致空指针异常。在使用 Collection KTX 时,可以使用非空断言或者空安全操作符来处理可能为空的集合。
当然使用时也要注意,kotlin 的扩展函数让代码的可读性要求增高了少,所以用的使用为了能保证团队的统一,因该注意:
- 对于代码中的扩展函数,应该在函数名称中体现其作用,以便其他开发者更容易理解代码。例如,“find”函数可以改名为“findFirstOrNull”或“findLastOrNull”。
- 在使用 Collection KTX 时,应该注意性能问题。某些操作可能会导致性能下降,例如对大型集合进行循环和操作,因此应该考虑使用 Sequence 和 Flow 来提高性能。
- 避免重复操作。使用 Collection KTX 可以使代码更加简洁和易读,但是不应该过度使用,如果某个操作已经通过一个函数实现了,就不要再手动写同样的操作。
链接:https://juejin.cn/post/7205875448575492152
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 知识集锦 | 基于 Flow 实现滑动显隐层
1. 前言
最近要实现一个小需求,涵盖了很多知识点,比如手势、动画、布局等。挺有意思的,写出来和大家分享一下。如下所示,分为上下两层;当左右滑时,上层会随偏移量而平移,从而让上层产生滑动手势显隐的效果:
| 标题 | |
|---|---|
这里上层通过不透明度 0.2 的蓝色示意,实际使用时可以改为透明色。很多直播间的浮层就是这种交互逻辑,通过右滑来隐藏浮层。
| 直播 | 右滑中 |
|---|---|
2. 实现思路
思路其实非常简单,监听横向滑动的手势事件,根据偏移量让上层组件进行偏移。当放手时,根据偏移量是否达到宽度的一半,使用动画进行移出或者关闭。
偏移的实现方式有很多,但需要自由地进行布局和矩阵变换、透明度,并且需要支持动画的变化,Flow 组件是一个非常不错的选择。 Flow 组件可以通过代理类对子组件进行自定义布局,灵活性极强;如果是 CustomPaint 是 绘制之王 可以绘制万物,那么 Flow 就是 布局之王,可以摆放万物。三年前写过一篇介绍 Flow 使用的文章: 《【Flutter高级玩法- Flow 】我的位置我做主》 。 本文就不对 Flow 的基础使用进行介绍了。
另外,在滑动过程中需要注意限制偏移量,使偏移量在 0~size.width 之内;当放手时,通过动画控制器来驱动动画,使用补间让偏移量运动到 0 (打开) 或 size.width(关闭) 。当关闭时,在右下角展示一个按钮用于点击展开:
3. 布局的代码实现
Flow 组件布局最重要的是实现 FlowDelegate,在其中的 paintChildren 方法中实现布局的逻辑。和 CustomPainter 类似,FlowDelegate 的实现类也可以通过 super 构造为 repaint 入参设置可监听对象。可监听对象的变化会触发 paintChildren 重新绘制:
SwipeFlowDelegate 实现类再构造时传入可监听对象 offsetX,在绘制索引为 1 的孩子时,通过 Matrix4 进行偏移。这样只要在手势水平滑动中,更新 offsetX 值即可。另外,可以根据 offsetX.value 是否达到 size.width 知道是否是关闭状态,如果已经关闭,绘制按钮。
class SwipeFlowDelegate extends FlowDelegate {
final ValueListenable<double> offsetX;
SwipeFlowDelegate(this.offsetX) : super(repaint: offsetX);
@override
void paintChildren(FlowPaintingContext context) {
Size size = context.size;
context.paintChild(0);
Matrix4 offsetM4 = Matrix4.translationValues(offsetX.value, 0, 0);
context.paintChild(1, transform: offsetM4);
// 偏移量对于父级尺寸
if (offsetX.value == size.width) {
Matrix4 m1 = Matrix4.translationValues(size.width / 2 - 30, size.height / 2 - 30, 0);
context.paintChild(2, transform: m1);
Matrix4 m2 = Matrix4.translationValues(size.width / 2 - 30, -(size.height / 2 - 50), 0);
context.paintChild(3, transform: m2);
}
}
@override
bool shouldRepaint(covariant SwipeFlowDelegate oldDelegate) {
return oldDelegate.offsetX.value != offsetX.value;
}
}从这里可以看出,FlowDelegate 的最大优势是可以自定义孩子的绘制与否,还可以在绘制时通过 Matrix4 对孩子进行矩阵变换,还有可选参数可以控制透明度。接下来使用 Flow 组件时,提供 SwipeFlowDelegate ,并在 children 列表中依次放入子组件。其中前两个组件由外界传入,分别是底组件和上层组件,这样组件的布局就完成了,接下来监听事件,更新 factor 即可:
final ValueNotifier<double> factor = ValueNotifier(0);
Flow(
delegate: SwipeFlowDelegate(factor),
children: [
widget.content,
widget.overflow,
GestureDetector(
onTap: open,
child: const Icon(Icons.menu_open_outlined, color: Colors.white)),
GestureDetector(
onTap: () {
Navigator.of(context).pop();
},
child: const Icon(Icons.close, color: Colors.white))
],
)4. 手势的监听
这里手势的处理是非常简单的,通过 GestureDetector 监听水平拖拽事件。在 onHorizontalDragUpdate 中根据拖拽的偏移量更新 factor 的值,其中通过 .clamp(0, widget.width) 可以限制偏移量的取值区间。
@override
Widget build(BuildContext context) {
return GestureDetector(
behavior: HitTestBehavior.opaque,
onHorizontalDragUpdate: _onHorizontalDragUpdate,
onHorizontalDragEnd: _onHorizontalDragEnd,
child: SizedBox(
height: MediaQuery.of(context).size.height,
width: widget.width,
child: Flow( delegate:// 同上,略...
);
}
void _onHorizontalDragUpdate(DragUpdateDetails details) {
double cur = factor.value + details.delta.dx;
factor.value = cur.clamp(0, widget.width);
}
void _onHorizontalDragEnd(DragEndDetails details) {
if (factor.value > widget.width / 2) {
close();
} else {
open();
}
}最后在 _onHorizontalDragEnd 回调中,根据当前偏移量是否大于一般宽度,决定关闭还是打开。期间过程使用动画进行偏移量的过渡变化。
5. 动画的使用
动画的使用,主要是通过 AnimationController 动画控制器来驱动数值的变化;在放手时 Tween 创建补间动画器,监听动画器数值的变化更新偏移量。这样偏移量就可以在指定时间内,在两个值之间渐变,从而产生动画效果。比如抬手时,open 方法是让偏移量从当前位置变化到 0 :
class _ScrollHideWrapperState extends State<ScrollHideWrapper> with SingleTickerProviderStateMixin {
late AnimationController _ctrl;
final ValueNotifier<double> factor = ValueNotifier(0);
@override
void initState() {
super.initState();
_ctrl = AnimationController(
duration: const Duration(milliseconds: 200),
vsync: this,
);
}
@override
Widget build(BuildContext context) {
// 略同...
}
// 动画关闭
Future<void> close() async {
Animation<double> anim = Tween<double>(begin: factor.value, end: widget.width).animate(_ctrl);
anim.addListener(() => factor.value = anim.value);
await _ctrl.forward(from: 0);
}
// 动画打开
Future<void> open() async {
Animation<double> anim = Tween<double>(begin: factor.value, end: 0).animate(_ctrl);
anim.addListener(() => factor.value = anim.value);
await _ctrl.forward(from: 0);
}
}如果想让动画的变化非匀速,可以使用 Curve 来控制动画曲线。这样,基于 Flow 实现的自定义布局,就可以根据手势和动画,完成特定的交互功能。从这里可以看出 Flow 自定义布局的灵活性非常强,很多疑难杂症,都可以使用它来完成。
比如企业微信中:侧滑展示左栏,而且上层不会全部消失,通过 Flow 来自定义布局就很容易实现。大家可以基于本文,自己实现一下作为练习。那本文就到这里,谢谢观看 ~
| 标题 | 关闭 |
|---|---|
链接:https://juejin.cn/post/7205959141562023997
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
迎接35岁,我在美团的22年总结及23年规划
22年10月,喜提二胎,同时儿子还不到两岁,工作中已经苦练写作基本功了,很难有心力在工作外写东西。
但作为一个技术从业者,定期写技术博客和总结规划,是确保高效工作的好习惯。工作已经十年了,越来越认可“选择比努力更重要”。
多数人都不喜欢思考,经常用战术上的勤奋掩饰自己战略上的懒惰,我也是如此,人生才如此被动。
本文不仅会分享自己在2022年所作出的重大人生选择及2023年的规划,还会在字里行间反思自己从高考后一些重大选择的得失。希望自己能以此洗心革面、痛改前非和开启新生,也希望能给有缘人在人生选择上有一些参考。
自我简介
本节主要是流水账的自我回顾,枯燥而乏味,建议读者有选择地看,或者跳过看后面的总结及规划哈~
从小爱学习
我出生于广西一个瑶族自治县的农村家庭,虽然家庭很不富裕,但童年回忆起来还是有很多快乐。但在青少年时期,父母吵闹较多,邻里关系不和,让看似阳光开朗的我,其实在内心已经种下了忧郁的种子,即使成年后,远离家乡,也时常会做相关的噩梦。‘
从小我就喜欢学习,记得小学一二年级,我经常6点多就到学校,有时周末也去学校,还被人笑话,但成绩只有数学还可以。直到四年级,我才开始获得奖状,印象中四至六年级的班主任,总是让我感觉自己很优秀,于是我的成绩真的变好了。
求学之路
初中,通过二婶大姐的帮助,把我安排到了县城最好中学的农村班,开始了住校的生活。初二开始,经常能考全班第一,全校前30。虽然中考不是很好,但还是考上了市里最好的高中。
从高二开始,成绩不时能考全班第一。高考虽然自我感觉发挥不好,但总分还是能排到全校应届第10,全广西一千六百多名。
由于家庭不富裕,高考后我优先考虑读军校,这样大学几年不会让家里负担过重。但因为各种原因,提前批我居然录取上。
于是我就来到了当时随手填的大学及专业,大一时发现可以选拔在校国防生,毕业后和军校生一样直接派到部队任职。于是大二时,我通过选拔加入了国防生队伍。
大学四年的成绩不是很好,因此没有资格保研。但我心中还是很想读研的,但因为国防生的身份,清华不允许报考,丧失了动力后自然考不上,这也成了后来我主动离开部队的原因之一。
军旅生涯
毕业后,我被分配到了北京军区某部的作战部队,在基层连队体验了一个多月后,就被派到南京某军校进行学习培训。军校培训期满后,我回到了北京的部队,开始了指挥军官的工作。
同多数国防生一样,我对基层部队的生活很不适应,被冻晕过几次,加上单位不同意我报考国防大学的研究生,我在13年底提出了复员转业申请。整体还算顺利,提出申请两个多月后,审批就通过了,然后我就离开了部队。
虽然从军入伍有减轻家庭负担的考虑,但离开部队后我还是会经常梦回连队,内心依然很向往部队的工作,也许还有壮志未酬,更有愧疚之情。即使不在部队了,我相信在国防建设上,还是有很多我可以参与的。
离开部队后,我全身心地投入了考研,因为计算机专业考公务员的岗位比较多,所以我选择了跨专业考清华的计算机专业。但没想到我专业课差得太多,只过了国家线,虽有一些院校联系我调剂,但我还是放弃了。
工作履历
然后,我就准备找C++相关的工作,通过大二时就认识的国防生朋友,内推到了一个做3G&4G 通信卡的外企gemalto,正式开启了程序员的生活。
由于做嵌入式操作系统的开发比较乏味,所以我们主动参与了一个小组的 Android 开发工作,学得差不多后,我们都先后离开了外企,他去了360做安卓开发,我去了搜狐做RN开发。
从搜狐开始,我从RN入门大前端,逐步掌握了react web开发、node 中间层或后端开发、vue web 开发、flutter 或 uni-app 跨端开发、PHP、Java、Go和Ruby后端开发。
从2017下半年开始,我的工作主要是管理团队和推进重点项目,团队最多时接近30人,职能上不仅管理过前端、安卓和iOS,也负责过设计团队。
疫情开始的半年多时间,尝试过在线教育创业,后来因为进展不符合预期和需要结婚生娃,在20年下半年入职了美团的前端基建团队。
回顾2022年
2022年初,因为老婆怀上了二胎,我终于做出了两个人生非常重要的选择:一是离开北京;二是从管理者向技术专家转变。
离京的选择
现在想想,有时选对城市,比选对行业或公司都重要。从2007年来到北京上大学,到2022年挥别北京,转眼间,我已经在北京度过了15个春秋。
离开北京时,我居然没有一丝伤感,仔细一想,15年来自己都没有真正考虑过要留在北京。虽然2007年时,就把户口迁到了北京。因为入伍地是北京,离开部队后,只要找到国企接收,也能把户口留在北京。但当时报考的是清华计算机深圳分院,索性就把户口迁回老家了。
21年12月底,父母都在北京,于是全家在北京过了年,但父亲还是不适应北京的气候,春节后就回老家了。而我亲弟在上海,老家只有我爸和爷爷,出了意外不能及时回到他们身边处理,加上老婆怀上了二胎,未来两个孩子的户口及上学问题,使得我不得不考虑离京的问题。
因为我所在的团队,在上海也有很多研发,有时我也需要去上海出差,加上我弟、堂妹、表姐和表弟等都在上海,所以当时优先考虑去上海,这样也不需要换部门或公司。
但由于年初上海的疫情比较严重且排外严重,同时上海离老家还是太远,看到公司在深圳也有岗位,聊了两个部门都有意向后,我选择了深圳,代价是需要换个部门,绩效和调薪都会受影响。选择深圳还有另外一个考虑,去上海的话,至少要缴满一年社保才能有户口,而深圳只需要缴满一个月即可。
三月底发起活水申请并逐步交接工作,四月中旬我就来到了深圳,五一后就把全家接到深圳安定了下来,6月初就办理好了全家的户口迁移。
当时在知乎上,反复看了深圳、上海、广州和北京的城市对比。对我来说,还是深圳最适合我。相比北京,深圳空气质量好很多,我老婆来了深圳后皮肤变好了很多,还有深圳的政务办事效率很高,日常生活很方便。
回想在北京时,早上我得六点前开车上班,否则不知道被五环堵到什么时候,下班时我得八点半前走,否则不知道什么时候可以离开望京。来到深圳后,我就住在公司附近,出门到工位不到10分钟就可以了,有了更多工作时间和关注生活。
回顾城市的选择,我真的很后悔没有早点来到深圳,若不是因为老婆执意要离开北京,因为22年初申请到了工作居住证,很有可能我下半年就在北京买房继续麻木地北漂了。
工作的选择
2022年,全世界所有的互联网公司都不好过,裁员消息层出不穷。作为一个即将35岁的大龄码农,我也是危机感满满,做好了随时被裁的心理建设。
对我来说,留在原部门原团队是最保险的,也是最好的:之前的工作以管理沟通为主,比较得心应手,领导们也比较认可,绩效和调薪也都有保障,同时负责的基本是中后台技术项目或前端基建项目,如组件库、物料管理、提效工具等,既有技术深度又有较好的工作节奏。
但因为原部门不能在深圳放团队,所以我只能通过活水到在深圳有岗位的团队,结合自己长远的职业规划,我选择了人工智能方向的前端团队。虽然团队只有十人上下,但可以做的事情却很有技术深度,同时团队的学历也比较好,60%都是硕士,还有一个是北大的硕士。
来到新团队后,我先加入近期很火的人工智能创作项目,使用 vite2 + vue3 从0开发了一个以图片处理为主要功能的web应用,经常加班赶项目进度,业余时间自学图形渲染。
然而,来到深圳不到半个月,就有一个前端伙伴要离职了,需要开发维护他从零开发的渲染引擎,工作难度比较大加上来深圳后因为燥热一直休息不好,我萌生了先辞职休息一段时间,再重新找工作的想法。
期间虽然没有好好准备面试,抱着了解招聘行情的心态,也和腾讯、字节、虾皮及一些传统行业的公司聊了聊,能拿到offer的基本是管理岗,传统行业一般是大前端总监,管理五十人以上团队,直接向CTO或CEO汇报。
虽然没有调薪,但领导们多次挽留,并给我争取了一些股票,特别是我的直接leader,相当nice,可以让我选择自己想做的事情,并允许我休个长假调整身心,所以我选择留了下来。
做出这个选择的考虑:一是管理岗可遇不可求,毕业后80%的工作都是管理,技术沉淀不够;二是web端的图形渲染和AI推理技术门槛高且非常有趣,并且近几年的人才缺口大,以后即使做管理,招不到人时,自己也得能搞定。
休假回来后:在业务支持上,我调整到了模型训练和管理相关的中后台项目,便于更好地掌握AI应用开发相关的知识技能;在研发提效上,我基于在前端基建团队的建设成果,修订了我们团队的前端工程规范和推进了项目的工程改造;在技术产出上,我主导了web推理引擎的立项,从零实现了 WebAssembly 计算方案,推进了在人脸验证和智能创作等项目的落地。
在新的团队,因为少了很多管理相关的会议,让我有了更多的机会和时间,结合项目需要,系统学习图形渲染和AI应用开发相关的知识技能。
过去的一年,因为两个孩子比较小需要更多精力放在家庭,同时也因为变换城市和岗位,还有新冠的影响,工作产出应该只达到了我预期的70%。但很幸运,让我遇见了一个很好的团队,有了领导的信任和优秀的伙伴们,相信新的一年,我一定会收获满满。
2023年规划
2023年,我首先要养成三一习惯:每周跑一十公里强体魄、每周看一好书启智慧、每周做一公益得快乐。
其次,在生活上,我要好好研究做饭和带娃。虽然我很想为公司的外卖业务贡献力量,但是对孩子们来说,能选择的很少,而且安全和营养都不好保证。生娃养娃容易,但教好孩子很不容易,童年的创伤,我相信一定可以在养育孩子的过程中治愈。同时,带娃也能帮助我理解一些人工智能相关的理论,现在感觉模型训练和教小孩真的很相似~
最后,在工作上:上半年,我要带领小伙伴们进一步完善Web推理引擎,同时提供一系列面向web应用研发同学的AI入门教程;下半年,我将从提升模型部署易用性出发,规划并建设一个全端的AI推理系统。
链接:https://juejin.cn/post/7193289271753572409
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android:面向单Activity开发
记得前一两年很多人都跟风面向单Activity开发,顾名思义,就是整个项目只有一个Activity。一个Activity里面装着N多个Fragment,再给Fragment加上转场动画,效果和多Activity跳转无异。其实想想还比较酷,以前还需要关注多个Acitivity之间的生命周期,现在只需关注一个,但还是需要对Fragment的生命周期进行关注。
其实早在六七年前GitHub上就有单Activity的开源库Fragmentation,后来谷歌也出了一个库Navigation。本来以为官方出品必为经典,当时跟着官方文档一步一步踩坑,最后还是放弃了该方案。理由大概如下:
- 需要创建XML文件,配置导航关系和跳转参数等
- 页面回退是重新创建,需要配合livedata使用
- 貌似还会存在卡顿,一些栈内跳转处理等问题
而Github上Fragmentation库已经停止维护,所幸的是再lssuse中发现了一个基于它继续维护的SFragmentation,于是正是开启了面向单Activity的开发。
提供了可滑动返回的版本
dependencies {
//请使用最新版本
implementation 'com.github.weikaiyun.SFragmentation:fragmentation:latest'
//滑动返回,可选
implementation 'com.github.weikaiyun.SFragmentation:fragmentation_swipeback:latest'
}由于是Fragment之间的跳转,我们需要将原有的Activity跳转动画在框架初始化时设置到该框架中
Fragmentation.builder()
//设置 栈视图 模式为 (默认)悬浮球模式 SHAKE: 摇一摇唤出 NONE:隐藏, 仅在Debug环境生效
.stackViewMode(Fragmentation.BUBBLE)
.debug(BuildConfig.DEBUG)
.animation(
R.anim.public_translate_right_to_center, //进入动画
R.anim.public_translate_center_to_left, //隐藏动画
R.anim.public_translate_left_to_center, //重新出现时的动画
R.anim.public_translate_center_to_right //退出动画
)
.install()因为只有一个Activity,所以需要在这个Activity中装载根Fragment
loadRootFragment(int containerId, SupportFragment toFragment)但现在的APP几乎都是一个页面多个Tab组成的怎么办呢?
loadMultipleRootFragment(int containerId, int showPosition, SupportFragment... toFragments);有了多个Fragment的显示,我们需要切换Tab实际也很简单
showHideFragment(ISupportFragment showFragment);是不是使用起来很简单,首页我们解决了,关于跳转和返回、参数的接受和传递呢?
//启动目标fragment
start(SupportFragment fragment)
//带返回的启动方式
startForResult(SupportFragment fragment,int requestCode)
//接收返回参数
override fun onFragmentResult(requestCode: Int, resultCode: Int, data: Bundle?) {
super.onFragmentResult(requestCode, resultCode, data)
}
//返回到上个页面,和activity的back()类似
pop()对于单Activity而言,我们其实也可以注册一个全局的Fragment监听,这样就能掌控当前的Fragmnet
supportFragmentManager.registerFragmentLifecycleCallbacks(
object : FragmentManager.FragmentLifecycleCallbacks() {
override fun onFragmentAttached(fm: FragmentManager, f: Fragment, context: Context) {
super.onFragmentAttached(fm, f, context)
}
override fun onFragmentCreated(
fm: FragmentManager,
f: Fragment,
savedInstanceState: Bundle?
) {
super.onFragmentCreated(fm, f, savedInstanceState)
}
override fun onFragmentStarted(fm: FragmentManager, f: Fragment) {
super.onFragmentStarted(fm, f)
}
override fun onFragmentResumed(fm: FragmentManager, f: Fragment) {
super.onFragmentResumed(fm, f)
}
override fun onFragmentDestroyed(fm: FragmentManager, f: Fragment) {
super.onFragmentDestroyed(fm, f)
}
},
true
)接下来我们看看Pad应用。对于手机应用来说,一般不会存在局部页面跳转的情况,但是Pad上是常规操作。
如图,点击左边列表的单个item,右边需要显示详情,这时候再点左边的其他item,此时的左边页面是保持不动的,但右边的详情页需要跳转对应的页面。使用过Pad的应该经常见到这种页面,比如Pad的系统设置等页面。这时只使用Activty应该是不能实现的,必须配合Fragment,左右分为两个Fragment。
但问题又出现了,这时候点击back怎么区分局部返回和整个页面返回呢?
//整个页面回退,主要是用于当前装载了Fragment的页面回退
_mActivity.pop()
//局部回退,被装载的Fragment之间回退
pop()如下图,这样的页面我们又应该怎么装载呢?
可以分析,页面最外面是一个Activty,要实现单Activity其内部必装载了一个根Fragment。接着这个根Fragment中使用ViewPage和tablayout完成主页框架。当前tab页要满足右边详情页的单独跳转,还得将右边页面作为主页面,以此装载子Fragment才能实现。
总结
单Activity开发在手机和平板上使用都一样,但在平板上注意的地方更多,尤其是平板一个页面可能是多个页面组成,其局部还能单独跳转的功能,其中涉及到参数回传和栈的回退问题。使用下来,我还是觉得某些页面对硬件要求很高的使用单Activity会出现体验不好的情况,有可能是优化不到位。手机应用我还是使用多Activity方式,平板应用则使用该框架实现单Activity方式。
链接:https://juejin.cn/post/7204100079430123557
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2023也该知道了:kotlin协程取消和异常传播机制
- 什么是结构化并发?
- 说好的异常传播为啥失效了?
- 怎么还有async不抛异常的问题?
1 结构化并发(Structured Concurrency)
1.1 java的"离散性并发"
kotlin 的Coroutine是【结构化并发】,与结构化并发对应的方式是【fire and forget 】姑且称之为【离散性并发】吧,可能不太准确。一个例子解释下离散性并发,java里我们开启一个线程之后,是不具备跟踪管理这个线程的能力的。如下
public void javaThreadFun() {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
//do some work
}
});
thread.setName("child-thread");
thread.start();
}这个例子中,调用javaThreadFun()方法所在的线程,创建并启动child-thread线程之后两个线程没有明确的父子关系,avaThreadFun()方法所在的线程不能天然的感知在自己线程里启动的"子线程",子线程发生异常之后也不会影响到自己。如果父线程要取消中止在自己线程里启动的那些线程也没有现成的方式去供使用。总之,层级关系管理上很离散。
1.2 kotlin 协程的的结构化并发
kotlin的协程天然的具备父协程管理取消子协程、子协程的异常失败影响父协程或者父协程感知子协程错误和失败的能力。如下示例
GlobalScope.launch {
val parentJob = launch {
val childJob = launch {
delay(1_000)//子任务做一些事情
throw NullPointerException() //会导致父协程任务和兄弟协程任务都会被取消
}
delay(5_000)
}
}- childJob失败抛出异常,会影响到父job,进而父job会取消掉其所有的子job。
- 另外,父job也会等待所有的子任务结束后自己才会结束。
与传统的相比
- 有跟踪:在协程左右域里启动协程会作为该协程的子协程,该协程会跟踪这些协程的状态。而不是像线程那些开启之后就忘记没有跟踪。父协程的结束也是要在所有子协程都完成之后自己才会完成,颇有家长负责制的感觉。
- 可取消:取消父协程也会,把其子协程一并取消掉。如上图,取消掉parent-job会导致从属于他的所有子协程取消。
- 能传播:这特性体现在,子协程发生异常,会通知其父协程,父协程会取消掉自己所有的子协程然后再向上传递直到根协程,或者supervisorJob.(这个下文我们会展开分析)
2 取消机制
2.1 父协程的取消会取消子协程
这一章节我们展开聊下Kotlin协程的取消机制,上一节我们提到,父协程/作用域的取消也会取消其子协程我们看个例子。
GlobalScope.launch {
val mParentJOb: Job = this.launch {
val child1Job: Job = this.launch {
this.launch {
delay(300)
}.invokeOnCompletion { throwable ->
println("child1Job 执行完毕,收到了${throwable}")
}
val child2Job = this.launch {
delay(500)
}.invokeOnCompletion { throwable ->
println("child2Job 执行完毕,收到了${throwable}")
}
}
delay(100)
}
mParentJOb.invokeOnCompletion { throwable ->
println("mParentJOb 执行完毕,收到了${throwable}")
}
println("发起取消 mParentJOb")
mParentJOb.cancel()
}.join()运行结果:
发起取消 mParentJOb
child1Job 执行完毕,收到了kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job=StandaloneCoroutine{Cancelling}@100b06de
child2Job 执行完毕,收到了kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job=StandaloneCoroutine{Cancelling}@100b06de
mParentJOb 执行完毕,收到了kotlinx.coroutines.JobCancellationException: StandaloneCoroutine was cancelled; job=StandaloneCoroutine{Cancelled}@100b06de2.2 兄弟协程取消不影响
private suspend fun brotherCoroutine() {
coroutineScope {
launch {
delay(500)
println("is running")
}
launch {
delay(100)
cancel()
}.invokeOnCompletion {
println("job2 is canceled")
}
}
}这似乎没有什么可解释的,某个协程的取消并不会影响到其兄弟协程。
2.3 携程的取消是协作式的
协程的取消是协作式的体现在,对取消的通知需要主动的需要主动嗅探感知做出处理。举个例子
private suspend fun coroutineCanceling() {
coroutineScope {
val job = launch {
var i = 0
while (true) {//1
println(" is running ${i++}")
}
}
job.invokeOnCompletion {
println("job is completion ${it}")
}
delay(50)
job.cancel()
}
}会发现上面这个段代码并不能被取消,原因就是协程并没有感知到自己已经被取消了。这一点跟java thead interrupt机制类似,需要我们感知取消。感知取消的方式有
- 可以使用CoroutineScope.isActive()的方法check是否已经被取消做出反应,代码一处可改成while (isActive)
- 所有的suspend方法内部也会感知cancel。比如delay()方法就是一个suspend方法。
2.4 做好善后取消
协程取消后我们可能会做一些诸如回收资源的动作,但在一个已经处于取消状态的协程里再调用suspend方法就抛出CancellationException异常。此时我们要使用 withContext(NonCancellable) 做取消后的工作
private suspend fun handleCanceling() {
coroutineScope {
val job = launch {
try {
delay(100)//do Something
} finally {
withContext(NonCancellable) {
delay(100)
}
}
}
job.invokeOnCompletion {
println("job is completion ${it}")
}
delay(50)
job.cancel()
}
}另外,还有特别注意的一点是,被取消的协程会向外抛出异常如果使用try-catch捕获但不抛出异常CancellationException,会影响到异常的传播,也就破坏了协程的异常传播机制,具体下一节异常传播机制展开。
2.5 kotlin协程的父子结构
看下面这段代码,思考一个问题,2处字符串会被打印出出来吗,为什么?
private suspend fun parentChildStructTest() {
coroutineScope {
val job1 = launch {
val job2 = launch(Job()) {//1
delay(500)
println("job2 is finish")//2
}
delay(100)
this.cancel()
}
}
}不会打印,不知道你有没有答对。
不是说好的,取消父协程的时候会取消掉其子协程吗?而且子协程里还调用了delay()方式,也会响应取消。问题的关键点在于,job1和job2的父子结构被破坏了。示例代码里1处传入了一个Job对象,此时job2的父层级已经变成了传入的job对象。我们稍加改造下,这里只是为了理解,不建议这么用,会发现job2可以被取消了。
private suspend fun parentChildStructTest() {
coroutineScope {
val job1 = launch {
val j = Job()
val job2 = launch(j) {
delay(500)
println("job2 is finish")
}.invokeOnCompletion {
println("job2 OnCompletion $it")
}
delay(100)
j.cancel() //1
}
}
}新协程的context的组成有两个公式
parentContext = scopeContext + AddionalContext(launch方法传入的context)
childContext = parentConxtext + job(新建)(图来自[Roman Elizarov])
- 新协程的context是【parent context】和【新建job】的相加操作而来。
- 【parent context】是由父层级的context和传入的参数context相加操作而来。
- 子协程的job会和父层级中context的job建立一个父子关系。
当我们使用coroutineScope.launch(Job()){}传入了一个job实例的时候,其实子协程的job和传入的job实例建立了父子结构,破坏了原本的父子结构。
3 异常传播机制
3.1 异常的传播
private suspend fun destroyCoroutineScope() {
coroutineScope {
launch {
launch {
delay(500)
throw NullPointerException()
}.invokeOnCompletion {
println("job-1 invokeOnCompletion $it")
}
launch {
delay(800)
}.invokeOnCompletion {
println("job-2 invokeOnCompletion $it")
}
}.invokeOnCompletion {
println("job-parent completion $it")
}
}
}- 子job异常后,传播到父协程,父协程会取消到自己所有的子协程,然后再往上传播
- 如果是一个取消异常(CancellationException)并不会被取消协程,父协程的处理器会忽略他。也就是在子协程上抛出异常之后,父协程接收到不会做处理。
3.2 监督作用域异常传播(Supervision)
基本表现:使用supervisorScope启动的子协程发生异常时,不影响父协程和兄弟协程。
private suspend fun supervisorJobTest() {
supervisorScope {
launch {
delay(100)
throw NullPointerException()
}
launch {
delay(800)
println("job 2 is running")
}
}
}如上代码,supervisor范围内第一个job抛出异常后,并不会影响第二个job;把错误异常控制在范围内。
- SupervisorCoroutine的子协程发生了异常之后不会影响父协程自身,也不会向上传播。
- 如果 CoroutineContext没有设置CoroutineExceptionHandle,最终异常会传播到ExceptionHandler
但其他的结构化并发特性仍然存在
- 当父协程取消,他的协程也被取消。
- 子协程取消不影响父协程。
- 父协程抛出异常,子协程也会被取消。
- 父协程要等所有子协程完成后才结束。
简单的讲,监督协程具备单向传播的特性,即子协程的异常和取消不影响父协程,父协程的异常和取消会影响子协程
两种方式:
- 构建CoroutineScope时传入SupervisorJob()
- 使用supervisorScope{}产生
注意:
监督协程中的每一个子作业应该通过异常处理机制处理自身的异常。如果不处理异常会被吞掉。
3.3 CoroutineExceptionHandler
用于捕获协程执行过程中未捕获的异常,被用来定义一个全局的异常处理器。
- 不能恢复异常,只是打印、记录、重启应用。
- 只能在【根作用域】或者【supervisorScope的直接子协程】启动协程是传入才生效。
举个例子
suspend fun coroutineExceptionHandlerTest() {
supervisorScope {
val handler = CoroutineExceptionHandler { _, _ -> println("handleException in coroutineExceptionHandler") }
launch(handler) {
delay(100)
throw NullPointerException()
}
}
} 3.4 浅看源码
主从作用域和协作作用域的表现区别上文已经讲到了,通常我们构建一个协程作用域两种方式
val scope = CoroutineScope(Job())
val supervisorJob = CoroutineScope(SupervisorJob())- CourotineScope()方法(没错这是个方法),通过传入Job()SupervisorJob生成的对象最终获得主从作用域和协同作用域。
supervisorScope { scope -> xx }
coroutineScope { scope ->xx }- 通过supervisorScope()或者coroutineScope()构建作用域。
private class SupervisorCoroutine<in T>(
context: CoroutineContext,
uCont: Continuation<T>
) : ScopeCoroutine<T>(context, uCont) {
override fun childCancelled(cause: Throwable): Boolean = false
}
private class SupervisorJobImpl(parent: Job?) : JobImpl(parent) {
override fun childCancelled(cause: Throwable): Boolean = false
}两种作用域在代码上的区别是 fun childCancelled(cause: Throwable) 方法的实现不同,监督作用域直接返回fasle表示不处理子协程的错误异常。让其自己处理
//JobSupport
private fun cancelParent(cause: Throwable): Boolean {
...
return parent.childCancelled(cause) || isCancellation //1
}
private fun finalizeFinishingState(state: Finishing, proposedUpdate: Any?): Any? {
...
val handled = cancelParent(finalException) || handleJobException(finalException)//2
if (handled) (finalState as CompletedExceptionally).makeHandled()
...
}源代码中的核心逻辑,
- 1处的parent.childCanceled的值的最终来源其实就是我们实现的childCancelled方法的返回值
- 2处当我们是一个监督作用域起cancelParent的返回值为false,这种情况下代码就会执行后半句handleJobException(),这半句的内部其实最终是执行了我们设置的CoroutineExceptionHandler。
- 2处cancelParent除了在我们监督作用域的时候返回fasle,在根协程下会返回fasle,这也就是为什么CoroutineExceptionHandler设置在根协程下生效的原因。
代码很多细节不展开有兴趣的自行研究。
4 异常传播需注意问题
4.1 supervisorScope的孙子协程
private suspend fun childChildSupervisorJob() {
supervisorScope { // SupervisorCouroutine
launch { // ScopeCoroutine
val job1 = launch {
delay(100)
throw NullPointerException()
}
val job2 = launch {
delay(800)
println("job 2 is running")
}.invokeOnCompletion {
println("job2 is completion $it")
}
}
}
}- 看上面这个例子job1抛出空指针异常后,job2会不会受影响。
- 是正常的coroutineScope而非supervisorScope,因此supervisorScope的“孙子协程”不遵循互不影响原则
4.2 注意不要破坏父子结构
private suspend fun textSupervisorJob() {
supervisorScope {
launch(SupervisorJob()) {//1
launch {
delay(100)
throw NullPointerException()
}
launch {
delay(800)
println("job 2 is running")
}.invokeOnCompletion {
println("job2 is completion $it")
}
}
}
}- job1抛出异常也会影响job2,原因1处虽然传入了SupervisorJob,但是这个实例其实是作为父context的job传入的,真是job1和job2的parentContext还是job类型,而不是SupervisorJob。具体原理可以看2.5小节
5 关于async的误会
通常构建一个协程除了使用CoroutineScope.launch{}还会使用CoroutineScope.async{}。
经常看到这种说法,async方式启动的协程返回一个Deferred对象,当调用deffered的await()方法的时候才会抛出异常
private suspend fun asyncSample() {
val h = CoroutineScope(CoroutineExceptionHandler { _, _ -> println("发生了异常") })
val d = h.launch {
async {
delay(100)
throw NullPointerException()
}
launch { //job2
delay(500)
println("job 2 is finish")
}
}.join()
}这个例子没有调用await(),实际发现也会立马抛出异常,导致jo2都没执行完。跟我们认为的不一样。
实际情况是这样的:当async被用作构建根协程(由协程作用域直接管理的协程)或者监督作用域直接管理协程时,异常不会主动抛出,而是在调用.await()时抛出。其他情况不等待await就会抛出异常。
6 总结
本文梳理了Kotlin的协程的取消和异常传播处理机制。机制的设置总的来说是服务于结构化并发的。本文应该能让我们了解掌握以下问题才算合格
- kotlin协程结构化并发的特性
- 协程的context是怎么来的?怎么构成的?父协程的context和协程的parentContext是同一个概念吗?
- kotlin的协程是怎么传播的?主从作用域监督作用域的区别?怎么实现
- async方式启动的协程要await()的时候才抛出异常?
链接:https://juejin.cn/post/7205417093973475383
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ProtoBuf 动态拆分Gradle Module
预期
当前安卓的所有proto都生成在一个module中,但是其实业务同学需要的并不是一个大杂烩, 只需要其中他们所关心的proto生成的类则足以。所以我们希望能将这样一个大杂烩的仓库打散,拆解成多个module。
buf.yaml
Protobuf是Protocol Buffers的简称,它是Google公司开发的一种数据描述语言,用于描述一种轻便高效的结构化数据存储格式,并于2008年对外开源。Protobuf可以用于结构化数据串行化,或者说序列化。它的设计非常适用于在网络通讯中的数据载体,很适合做数据存储或 RPC 数据交换格式,它序列化出来的数据量少再加上以 K-V 的方式来存储数据,对消息的版本兼容性非常强,可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。开发者可以通过Protobuf附带的工具生成代码并实现将结构化数据序列化的功能。
在我司proto相关的都是由后端大佬们来维护的,然后这个协议仓库会被android/ios/后端/前端 依赖之后生成对应的代码,然后直接使用。
而proto文件中允许导入对于其他proto文件的依赖,所以这就导致了想要把几个proto转化成一个java-library工程,还需要考虑依赖问题。所以由
我们的后端来定义了一个buf.yaml的数据格式。
version: v1
name: buf.xxx.co/xxx/xxxxxx
deps:
- buf.xxxxx.co/google/protobuf
build:
excludes:
- setting
breaking:
use:
- FILE
lint:
use:
- DEFAULTname代表了这个工程的名字,deps则表示了他依赖的proto的工程名。基于这份yaml内容,我们就可以大概确定一个proto工程编译需要的基础条件。然后我们只需要一个工具或者插件来帮助我们生成对应的工程就够了。
模板工程
现在我们基本已经有了一个单一的proto工程的输入模型了,其中包含工程名依赖的工程还有对应文件夹下的proto文件。然后我们就可以基于这部分输入的模型,生成出第一个模板工程。
plugins {
id 'java-library'
id 'org.jetbrains.kotlin.jvm'
id 'com.google.protobuf'
}
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
sourceSets {
def dirs = new ArrayList<String>()
dirs.add("src/main/proto")
main.proto.srcDirs = dirs
}
protobuf {
protoc {
if (System.getProperty("os.arch").compareTo("aarch64") == 0) {
artifact = "com.google.protobuf:protoc:$version_protobuf_protoc:osx-x86_64"
} else {
artifact = "com.google.protobuf:protoc:$version_protobuf_protoc"
}
}
plugins {
grpc {
if (System.getProperty("os.arch").compareTo("aarch64") == 0) {
artifact = 'io.grpc:protoc-gen-grpc-java:1.36.1:osx-x86_64'
} else {
artifact = 'io.grpc:protoc-gen-grpc-java:1.36.1'
}
}
}
generateProtoTasks {
all().each { task ->
task.generateDescriptorSet = true
task.builtins {
// In most cases you don't need the full Java output
// if you use the lite output.
java {
}
}
task.plugins {
grpc { option 'lite' }
}
}
}
}
afterEvaluate {
project.tasks.findByName("compileJava").dependsOn(tasks.findByName("generateProto"))
project.tasks.findByName("compileKotlin").dependsOn(tasks.findByName("generateProto"))
}
dependencies {
implementation "org.glassfish:javax.annotation:10.0-b28"
def grpcJava = '1.36.1'
compileOnly "io.grpc:grpc-protobuf-lite:${grpcJava}"
compileOnly "io.grpc:grpc-stub:${grpcJava}"
compileOnly "io.grpc:grpc-core:${grpcJava}"
File file = new File(projectDir, "depend.txt")
if (!file.exists()) {
return
}
def lines = file.readLines()
if (lines.isEmpty()) {
return
}
lines.forEach {
logger.lifecycle("project:" + name + " implementation: " + it)
implementation(it)
}
}如果需要将proto编译成java代码,就需要依赖于com.google.protobuf插件,依赖于上面的build.gradle基本就可以将一个proto输入编译成一个jar工程。
另外我们需要把所有的proto文件拷贝到这个壳工程的src/main/proto文件夹下,最后我们会将buf.yaml中的name: buf.xxx.co/xxx/xxxxxx的/xxx/xxxxxx转化成工程名,去除掉一些无法识别的字符。
我们生成的模板工程如下:
其中proto.version会记录proto内的gitsha值还有文件的lastModified时间,如果输入发生变更则会重新进行一次文件拷贝操作,避免重复覆盖的风险。
input.txt则包含了所有proto文件路径,方便我们进行开发调试。
deps 转化
由于proto之间存在依赖,没有依赖则会导致无法将proto转化成java。所以这里我讲buf.yaml中读取出的deps转化成了一个depend.txt.
com.xxxx.api:google-protobuf:7.7.7depend.txt内会逐行写入当前模块的依赖,我们会对name进行一次转化,变成一个可读的gradle工程名。其中7.7.7的版本只是一个缺省而已,并没有实际的价值。
多线程操作
这里我们出现了一点点的性能问题, 如果可以gradle插件中尽量多使用点多线程,尤其是这种需要io的操作中。
这里我通过ForkJoinPool,这个是ExecutorService的实现类。其中submit方法中会返回一个ForkJoinTask,我们可以将获取gitsha值和lastModified放在这个中。之后把所有的ForkJoinTask放到一个数组中。
fun await() {
forkJoins.forEach {
it.join()
}
}然后最后暴露一个await方法,来做到所有的获取方法完成之后再继续向下执行。
另外则就是壳module的生成,我们也放在了子线程内执行。我们这次使用了线程池的invokeAll方法。
protoFileWalk.hashMap.forEach { (_, pbBufYaml) ->
callables.add(Callable<Void> {
val root = FileUtils.getRootProjectDir(settings.gradle)
try {
val file = pbBufYaml.copyLib(File(root, "bapi"))
projects[pbBufYaml.projectName()] = file.absolutePath ?: ""
} catch (e: Exception) {
e.printStackTrace()
e.message.log()
}
null
})
}
executor.invokeAll(callables)这里有个面试经常出现的考点,多线程操作Hashmap,之后我在测试环节随机出现了生成工程和include不匹配的问题。所以最后我更换了ConcurrentHashMap就没有出现这个问题了。
加载壳Module
这部分就和源码编译插件基本是一样的写法。
projects.forEach { (s, file) ->
settings.include(":${s}")
settings.project(":${s}").projectDir = File(file)
}把工程插入settings 即可。
结尾
最终结果大概就是原先一个Module,现在被拆分成100+的Module,而且基于buf.yaml 文件动态生成,基本符合第一期需求。
这部分方案这样也就大概完成了一半,剩下的一半我们需要逐一把生层业务的依赖进行一次变更,这样就可以做到依赖最小化,然后也可以去除掉一部分无用的代码块。
链接:https://juejin.cn/post/7204279791381643322
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter webview_flutter滑动监听
前言
当需要使用webview时,常用的插件有webview_flutter、flutter_webview_plugin、flutter_inappwebview等。
项目中已经使用的是官方的webview_flutter 。
问题:
总的来说webview_flutter可以满足大部分的webview相关需求,直到有一天产品小可爱说网页在顶部时,顶部标题栏背景为白色,之后网页滑动到一定距离的时候需要变成透明。我一听,so easy啊,WebViewController里有相关的方法监听:
我只需要加个Listener手势监听,在move里判断getScrollY()的距离就OK了。
Listener(
child: WebView(initialUrl: "http://www.baidu.com"),
onPointerMove: (PointerMoveEvent event) {
webViewController?.getScrollY().then((value) {
if (value > 200) {
//标题栏背景变白色
} else {
////标题栏背景变透明
}
});
},
);然而....
手势滑动是有惯性的,当快速滑动的时候,手指离开屏幕,会因为惯性继续滑动一段距离。而由于我们监听的是手势操作,当手指离开屏幕,手势监听也就从onPointerMove走到了onPointerUp,也就没办法再监听webViewController?.getScrollY(),惯性滚动的距离就没有监听到,那此时所展现的效果自然就不理想了:
快速下滑屏幕的时候,假设手指离开屏幕的时候监听到getScrollY()=500,但由于惯性网页继续滚动,直到滚回网页顶部。但由于手指离开了屏幕没有继续监听getScrollY(),getScrollY()的最后取值就是500,可此时网页已经惯性滚回到顶部了,此时标题栏依然是白色,而不是变回透明。
解决
遇到问题,咱就解决问题。
反复翻看了webview_flutter的代码,确实没有这个监听,然后联想到即便是在做Android原生开发的时候,webview也是没有提供公开的方法或设置让我们对网页的滚动进行监听的,如果要监听那就需要在原生webview的onScrollChanged增加监听。
修改FlutterWebViewClient,增加方法
void getOffsetY(int offsetY) {
Map<String, Object> args = new HashMap<>();
args.put("offsetY", offsetY);
methodChannel.invokeMethod("getOffsetY", args);
}修改FlutterWebView
@TargetApi(Build.VERSION_CODES.JELLY_BEAN_MR1)
@SuppressWarnings("unchecked")
FlutterWebView(
final Context context,
BinaryMessenger messenger,
int id,
Map<String, Object> params,
View containerView) {
///增加监听
if (webView instanceof CustomWebView){
((CustomWebView)webView).setOnScrollChangedCallback(new CustomWebView.OnScrollChangedCallback() {
@Override
public void onScroll(int dx, int dy) {
flutterWebViewClient.getOffsetY(dy);
Log.d("onScroll",dy+"");
}
});
}
platform_interface.dart里修改WebViewPlatformCallbacksHandler
增加供外部调用的getOffsetY()
void getOffsetY(int offsetY);webview_method_channel.dart修改MethodChannelWebViewPlatform
在_onMethodCall里新增getOffsetY类型
case 'getOffsetY':
_platformCallbacksHandler.getOffsetY(call.arguments['offsetY']);
return null;webview_flutter.dart修改WebView
新增getOffsetY
在_PlatformCallbacksHandler里新增
@override
void getOffsetY(int offsetY){
if (_widget.getOffsetY != null) {
_widget.getOffsetY!(offsetY);
}
}至此,就成功增加了webview的滑动监听
链接:https://juejin.cn/post/7205436102614892604
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单回顾位运算
前言
位运算其实是一个比较常用的操作,有的人可能说,并没有啊,我好像基本就没怎么用过位运算,但如果你经常看源码,你就会发现源码里面有很多位运算的操作,而且这些操作我个人觉得确实是有很意思,所以位运算很重要,平时用不多,也需要经常去回顾复习。
因为临时写的,有些源码的操作我不太记得是出自哪里了,如果以后碰到了,会在评论区进行补充。比如会有一些取反计算再取反回来的操作,比如左移和右移,我现在不太记得是出自哪里了,反正比较经典的。我的个人可能就记得用位运算来表示状态,因为我会经常用这个。
位运算基础
简单来回顾一下基础的计算,位运算会分为一元运算和二元运算。
一元有左移<<,右移>>,无符号右移动>>>和取反~
左移是是什么?比如 0010 左移动一位就变成 0100 (注意这里是二进制的表示),右移动就是 0100 变成 0010。 当然没这么简单啦,二进制也有表示正负值的标志位,右移之后,左边会补标志位的数。而无符号右移动是左边补0。也就是说正数的右移和无符号右移动的结果相同,而负数就不同了。这样说应该好理解吧?那思考一下为什么没有无符号左移
还是不好懂,没关系,我们讲慢些,假如8转成2进制是00001000
而-8就是先取反码,反码就是取反,所以8的反码是11110111,然后再用反码取补码,补码就是+1,所以这里得到补码1111000。即-8转成二进制是11111000
先看看我们对11111000取反码,得00000111,再取补码得00001000,看到从-8到8也是同样的操作。
然后我们看右移一位和无符号右移一位的效果。
-8的二进制11111000,右移一位是11111100,这是多少啊?我们可以用上面的计算看它的正数是多少,反码00000011,补码00000100,这是4吧,所以11111100是-4。
同理看无符号右移,得01111100,反码10000011,补码10000100,这是多少?2的7次方+4,所以是不同的。
取反就好理解了,取反就是逻辑非,比如0010取反就是1101
二元有与&&、或||、异或^
这些都好理解吧,与运算 1010 && 1001 = 1000 , 或运算 1010 || 1001 = 1010 , 异或 1010 ^ 1001 = 0011 ,这没什么好讲的,很基础。
位运算很简单?
一看,哎哟,真的简单,就这?1分钟学会了。学会?那会用吗?
没关系,我们来看一题算法:
一个整型数组里除了两个数字只出现一次,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。例如:
输入:
[1,4,1,6]返回值:
[4,6]明确说了,这题是用位运算,但是怎么做?
开发中位运算的使用
这个我因为临时写的,android源码里确实是有些比较经典的位运算使用场景,我现在不完全记得,只能先列举几个,其它的如果以后想起来,会在评论区中做补充。
用来表示状态
位运算可以用来表示状态,我之前也写过一篇文章 juejin.cn/post/715547… 差不多也是这个意思。
比如window的flags,看看它的定义
public static final int FLAG_LAYOUT_IN_SCREEN = 0x00000100;
public static final int FLAG_LAYOUT_NO_LIMITS = 0x00000200;
public static final int FLAG_FULLSCREEN = 0x00000400;
public static final int FLAG_FORCE_NOT_FULLSCREEN = 0x00000800;
......那他这样做有什么好处,他能一个变量表示多个维度的状态。比如FLAG_LAYOUT_IN_SCREEN|FLAG_LAYOUT_NO_LIMITS|FLAG_FULLSCREEN|FLAG_FORCE_NOT_FULLSCREEN就是 1111 (二进制表示)
如果你要判断这个window是不是同时设置了这4个flag,要怎么判断,就直接if(flags == 15)啊,多简单
但是如果你用多个变量存flag要怎么判断, if(isScreen && isNoLimits && usFullscreen && isForceNot),这样写就很难看,很不方便,我window的flag多着呢,难道你要排火车?
数组扩容
来看看ArrayList的扩容源码
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}这里的int newCapacity = oldCapacity + (oldCapacity >> 1);就是阔人操作,这个右移是什么?看不懂也没关系,自己套一个数字进去算就知道了,是除2吧,那ArrayList的扩容就是旧容量的一半。
看着简单是吧?那有没有想过一个问题,他写这个代码,为什么不写oldCapacity/2,而写oldCapacity >> 1
那既然右移一位 >> 1 是除2,那左移一位 << 1 是什么操作呢?是什么计算呢?
总结
我这里确实是很久没有用位运算,所以需要复习一下。这个东西对开发来说很重要,比如你是开发应用层的,你觉得这个是底层用到的,你用不到,并不是这样。就拿那个表示状态的来说,自从我看到源码用这一招之后,只要有合适的场景,我也会这样用。
不管是做数学运算,还是逻辑运算,位运算都能适用,它是很简单就能学会,但是学会用,那就是另外一回事,当然不是说看完我这篇文章就开始瞎用,能在合适的场合去使用,那效果十分的好,用不上也没关系,至少要有个意识,这样不管在看源码还是其它时候,都是能帮到你的。
链接:https://juejin.cn/post/7205508171524128828
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一次线上OOM问题分析
现象
线上某个服务有接口非常慢,通过监控链路查看发现,中间的 GAP 时间非常大,实际接口并没有消耗很多时间,并且在那段时间里有很多这样的请求。
原因分析
先从监控链路分析了一波,发现请求是已经打到服务上了,处理之前不知道为什么等了 3s,猜测是不是机器当时负载太大了,通过 QPS 监控查看发现,在接口慢的时候 CPU 突然增高,同时也频繁的 GC ,并且时间很长,但是请求量并不大,并且这台机器很快就因为 Heap满了而被下掉了。
去看了下日志,果然有 OOM 的报错,但是从报错信息上并没办法找到 Root Cause。
system error: org.springframework.web.util.NestedServletException: Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: Java heap space at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1055) at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:943) at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006) at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:909) at javax.servlet.http.HttpServlet.service(HttpServlet.java:681) 另外开发同学提供了线索,在发生问题的时候在跑一个大批量的一次性 JOB,怀疑是不是这个 JOB 导致的,马上把 JOB 代码拉下来分析了下,JOB 做了分批处理,代码也没有发现什么问题。
虽然我们系统加了下面的 JVM 参数,但是由于容器部署的原因,这些文件在 pod 被 kill 掉之后没办法保留下来。
-XX:+HeapDumpOnOutOfMemoryError -XX:ErrorFile=/logs/oom_dump/xxx.log -XX:HeapDumpPath=/logs/oom_dump/xxx.hprof这个现象是最近出现的,猜测是最近提交的代码导致的,于是去分析了最近提交的所有代码,很不幸的都没有发现问题。。。
在分析代码的过程中,该服务又无规律的出现了两次 OOM,只好联系运维同学优先给这个服务加了 EFS (Amazon 文件系统)等待下次出现能抓住这个问题。
刚挂载完 EFS,很幸运的就碰到了系统出现 OOM 的问题。
dump 出来的文件足有 4.8G,话不多说祭出 jvisualvm 进行分析,分析工具都被这个dump文件给搞挂了也报了个java.lang.OutOfMemoryError: Java heap space,加载成功之后就给出了导致OOM的线程。
找到了具体报错的代码行号,翻一下业务代码,竟然是一个查询数据库的count操作,这能有啥问题?
仔细看了下里面有个foreach遍历userId的操作,难道这个userId的数组非常大?
找到class按照大小排序,占用最多的是一个 byte 数组,有 1.07G,char 数组也有1.03G,byte 数组都是数字,直接查看 char 数组吧,点进去查看具体内容,果然是那条count语句,一条 SQL 1.03G 难以想象。。。
这个userId的数据完全是外部传过来的,并没有做什么操作,从监控上看,这个入参有 64M,马上联系对应系统排查为啥会传这么多用户过来查询,经过一番排查确认他们有个bug,会把所有用户都发过来查询。。。到此问题排查清楚。
解决方案
对方系统控制传入userId的数量,我们自己的系统也对userId做一个限制,问题排查过程比较困难,修改方案总是那么的简单。
别急,还有一个
看到这个问题,就想起之前我们还有一个同样类似的问题导致的故障。
也是突然收到很多告警,还有机器 down 机的告警,打开 CAT 监控看的时候,发现内存已经被打满了。
操作和上面的是一样的,拿到 dump 文件之后进行分析,不过这是一个漫长的过程,因为 down了好几台机器,最大的文件有12GB。
通过 MAT 分析 dump 文件发现有几个巨大的 String(熟悉的味道,熟悉的配方)。
接下来就是早具体的代码位置了,去查看了下日志,这台机器已经触发自我保护机制了,把代码的具体位置带了出来。
经过分析代码发现,代码中的逻辑是查询 TIDB(是有同步延迟的),发现在极端情况下会出现将用户表全部数据加载到内存中的现象。
于是找 DBA 拉取了对应时间段 TIDB 的慢查询,果然命中了。
总结
面对 OOM 问题如果代码不是有明显的问题,下面几个JVM参数相当有用,尤其是在容器化之后。
-XX:+HeapDumpOnOutOfMemoryError -XX:ErrorFile=/logs/oom_dump/xxx.log -XX:HeapDumpPath=/logs/oom_dump/xxx.hprof另外提一个参数也很有用,正常来说如果程序出现 OOM 之后,就是有代码存在内存泄漏的风险,这个时候即使能对外提供服务,其实也是有风险的,可能造成更多的请求有问题,所以该参数非常有必要,可以让 K8S 快速的再拉起来一个实例。
-XX:+ExitOnOutOfMemoryError另外,针对这两个非常类似的问题,对于 SQL 语句,如果监测到没有where条件的全表查询应该默认增加一个合适的limit作为限制,防止这种问题拖垮整个系统。
链接:https://juejin.cn/post/7205141492264976445
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
有多少人忘记了gb2312
本想新周摸新鱼,却是早早入坑。看到群友千元求解一个叫当当网的索引瞬间来了兴趣
- 网站地址,大体一看没什么特别的地方就是一个关键字编码问题,打眼一看url编码没跑直接拿去解码无果
-有点惊讶看似url编码实则url编码只是这,滋滋滋...
有点东西,开始抓包,断点,追踪的逆向之路
2. 发现是ajax加载(不简单呀纯纯的吊胃口)先来一波关键字索引(keyword)等一系列基操轻而易举的找到了他
从此开始走向了一条不归路,经过一上午的时间啥也没追到,午休之后继续战斗,经过了一两个半小时+三支长白山牌香烟的努力终于
cihui = '哈哈哈'
js = open("./RSAAA.js", "r", encoding="gbk", errors='ignore')
line = js.readline()
htmlstr = ''
while line:
htmlstr = htmlstr + line
line = js.readline()
ctx = execjs.compile(htmlstr)
result = ctx.call('invokeServer', cihui)
print(result)const jsdom = require("jsdom");
const {JSDOM} = jsdom;
const dom = new JSDOM('<head>\n' +
' <base href="//search.dangdang.com/Standard/Search/Extend/hosts/">\n' +
'<link rel="dns-prefetch" href="//search.dangdang.com">\n' +
'<link rel="dns-prefetch" href="//img4.ddimg.cn">\n' +
'<title>王子-当当网</title>\n' +
'<meta http-equiv="Content-Type" content="text/html; charset=GB2312">\n' +
'<meta name="description" content="当当网在线销售王子等商品,并为您购买王子等商品提供品牌、价格、图片、评论、促销等选购信息">\n' +
'<meta name="keywords" content="王子">\n' +
'<meta name="ddclick_ab" content="ver:429">\n' +
'<meta name="ddclick_search" content="key:王子|cat:|session_id:0b69f35cb6b9ca3e7dee9e1e9855ff7d|ab_ver:G|qinfo:119800_1_60|pinfo:_1_60">\n' +
'<link rel="canonical" href="//search.dangdang.com/?key=%CD%F5%D7%D3\&act=input">\n' +
' <link rel="stylesheet" type="text/css" href="css/theme_1.css">\n' +
' <!--<link rel="Stylesheet" type="text/css" href="css/model/home.css" />-->\n' +
' <link rel="stylesheet" type="text/css" href="css/model/search_pub.css?20211117"> \n' +
'<style>.shop_button {height: 0px;}.children_bg01 a {\n' +
'margin-left: 0px;\n' +
'padding-left: 304px;\n' +
'width: 630px;\n' +
'}\n' +
'.children_bg02 a {\n' +
'margin-left: 0px;\n' +
'padding-left: 304px;\n' +
'width: 660px;\n' +
'}\n' +
'.children_bg03 a {\n' +
'margin-left: 0px;\n' +
'padding-left: 304px;\n' +
'width: 660px;\n' +
'}\n' +
'.narrow_page .children_bg01 a{\n' +
'width: 450px;\n' +
'}\n' +
'.narrow_page .children_bg02 a{\n' +
'width: 450px;\n' +
'}\n' +
'.narrow_page .children_bg03 a{\n' +
'width: 450px;\n' +
'}.price .search_e_price span {font-size: 12px;font-family: 微软雅黑;display: inline-block;background-color: #739cde;color: white;padding: 2px 3px;line-height: 12px;border-radius: 2px;margin: 0 4px 0 5px;}\n' +
'.price .search_e_price:hover {text-decoration: none;}</style> <link rel="stylesheet" href="http://product.dangdang.com/js/lib/layer/3.0.3/skin/default/layer.css?v=3.0.3.3303" id="layuicss-skinlayercss"><script id="temp_script" type="text/javascript" src="//schprompt.dangdang.com/suggest_new.php?keyword=好好&pid=20230227105316030114015279129895799&hw=1&hwps=12&catalog=&guanid=&0.918631418357919"></script><script id="json_script" type="text/javascript" src="//static.dangdang.com/js/header2012/categorydata_new.js?20211105"></script></head>');
window = dom.window;
document = window.document;
function invokeServer(url) {
var scriptOld = document.getElementById('temp_script');
if(scriptOld!=null && document.all)
{
scriptOld.src = url;
return script;
}
var head=document.documentElement.firstChild,script=document.createElement('script');
script.id='temp_script';
script.type = 'text/javascript';
script.src = url;
if(scriptOld!=null)
head.replaceChild(script,scriptOld);
else
head.appendChild(script);
return script
}
完事!当我以为都要结束了的时候恍惚直接看到了源码中的gb2312突然想起了之前做的一个萍乡房产网的网站有过类似经历赶快去尝试结果我**
总结:提醒各位大佬在逆向之路中还是要先从基操开始,没必要一味的去搞攻克扒源码,当然还是要掌握相对全面的内容,其实除了个别大厂有些用些贵的东西据说某数5要20个W随着普遍某数不知道那些用了20w某数的大厂心里是什么感觉或许并不在乎这点零头哈哈毕竟是大厂,小网站的反扒手段并不是很难,俗话说条条大道通北京。
链接:https://juejin.cn/post/7204752219916206140
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android事件冲突解决-悬浮窗拖拽处理
需求场景
最近项目中要做一个音乐播放悬浮按钮的功能,最终实现效果如下:
问题暴露
悬浮窗布局文件就不放了,就是水平LinearLayout里面放几个ImageView。
做的过程当中遇到一个问题,就是悬浮窗是可以任意拖拽的,悬浮窗里面的按钮是可以点击的,比如暂停,下一曲,关闭悬浮窗等。
按常规思路,先给整个悬浮窗setOnTouchListener(),然后再给你里面的按钮setOnClickListener(),点击运行,结果发现,点击事件是可以响应,拖拽也没问题,但是当手指放在ImageView上拖拽时,onTouchListener事件无法响应。
此时第一感觉就是setOnTouchListener()和setOnClickListener()冲突了,需要解决一下冲突。无奈自己对Android事件分发消费机制一直都是一知半解的,一般都是出了问题需要解决,第一时间先百度,没有解决方案就只能去研究Android事件分发消费机制了,但是研究完也都是懵懵懂懂的,今天就决定把这个难点彻底消化掉。
主要研究了这篇文章Android事件分发消费机制,然后对照着写了个demo,一一去验证,加深了自己的理解,最后终于解决了我的问题。
解决思路
先说下解决思路,自定义LinearLayout,当手指处于滑动时,直接拦截事件,交给自己的onTouchEvent处理即可,核心代码如下:
/**
* @author:Jason
* @date:2021/8/24 19:49
* @email:1129847330@qq.com
* @description:可拖拽的LinearLayout,解决子View设置OnClickListener之后无法拖拽的问题
*/
class DraggerbleLinearLayout : LinearLayout {
constructor(context: Context, attr: AttributeSet) : this(context, attr, 0)
constructor(context: Context, attr: AttributeSet, defStyleAttr: Int) : this(context, attr, defStyleAttr, 0)
constructor(context: Context, attr: AttributeSet, defStyleAttr: Int, defStyleRes: Int) : super(context, attr, defStyleAttr, defStyleRes)
override fun onInterceptTouchEvent(ev: MotionEvent?): Boolean {
when (ev?.action) {
MotionEvent.ACTION_MOVE -> {
return true
}
}
return super.onInterceptTouchEvent(ev)
}
}很简单,就是在onInterceptTouchEvent()里面拦截move事件即可,这里你也可以重写onTouchEvent(),在里面实现拖拽功能,但是这样就固定死了,所以我选择在外面setOnTouchListener(),需要拖拽功能时才去实现
/**
* 创建悬浮窗
*/
@SuppressLint("ClickableViewAccessibility")
private fun showWindow() {
//获取WindowManager
windowManager = getSystemService(WINDOW_SERVICE) as WindowManager
val outMetrics = DisplayMetrics()
windowManager.defaultDisplay.getMetrics(outMetrics)
var layoutParam = WindowManager.LayoutParams().apply {
/**
* 设置type 这里进行了兼容
*/
type = if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
WindowManager.LayoutParams.TYPE_APPLICATION_OVERLAY
} else {
WindowManager.LayoutParams.TYPE_PHONE
}
format = PixelFormat.RGBA_8888
flags = WindowManager.LayoutParams.FLAG_NOT_TOUCH_MODAL or WindowManager.LayoutParams.FLAG_NOT_FOCUSABLE
//位置大小设置
width = WRAP_CONTENT
height = WRAP_CONTENT
gravity = Gravity.LEFT or Gravity.TOP
//设置剧中屏幕显示
x = outMetrics.widthPixels / 2 - width / 2
y = outMetrics.heightPixels / 2 - height / 2
}
//在这里设置触摸监听,以实现拖拽功能
floatRootView?.setOnTouchListener(ItemViewTouchListener(layoutParam, windowManager))
// 将悬浮窗控件添加到WindowManager
windowManager.addView(floatRootView, layoutParam)
isAdded = true
}主要是这行代码
//在这里设置触摸监听,以实现拖拽功能
floatRootView?.setOnTouchListener(ItemViewTouchListener(layoutParam, windowManager))
ItemViewTouchListener.kt文件内容
/**
* @author:Jason
* @date: 2021/8/23 19:27
* @email:1129847330@qq.com
* @description:
*/
class ItemViewTouchListener(val layoutParams: WindowManager.LayoutParams, val windowManager: WindowManager) : View.OnTouchListener {
private var lastX = 0.0f
private var lastY = 0.0f
override fun onTouch(view: View, event: MotionEvent): Boolean {
when (event.action) {
MotionEvent.ACTION_DOWN -> {
//这里接收不到Down事件,不要在这里写逻辑
}
MotionEvent.ACTION_MOVE -> {
//重写LinearLayout的OnInterceptTouchEvent之后,这里的Down事件会接收不到,所以初始位置需要在Move事件里赋值
if (lastX == 0.0f || lastY == 0.0f) {
lastX = event.rawX
lastY = event.rawY
}
val nowX: Float = event.rawX
val nowY: Float = event.rawY
val movedX: Float = nowX - lastX
val movedY: Float = nowY - lastY
layoutParams.apply {
x += movedX.toInt()
y += movedY.toInt()
}
//更新悬浮球控件位置
windowManager?.updateViewLayout(view, layoutParams)
lastX = nowX
lastY = nowY
}
MotionEvent.ACTION_UP -> {
lastX = 0.0f
lastY = 0.0f
}
}
return true
}
}这里有一点需要注意的是,重写了LinearLayout的onInterceptTouchEvent()后会导致setOnTouchListener()里面的ACTION_DOWN事件接收不到,所以不要在down事件里面写逻辑。然后onTouch一定要返回true,表示要消费事件,否则当拖拽非ImageView区域时会拖不动。
好了,花了一整天,就解决了这个小问题。
链接:https://juejin.cn/post/7205023631168028730
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
NativeBridge:我在Pub上发布的第一个插件
前沿
坦白地说,在发布 native_bridge 之前,自己从没有想过会在 pub 上发布一款自己开发的 Flutter 插件。一方面是觉得自己水平有限,很难产出比较有实用价值的内容。虽然之前有写过 Plugin 开发相关的文章,但那也只是用来自我学习的 Demo,对大家来说没有太多的应用价值。另一方面也是因为对 pub 的发布流程非常陌生,尤其对大陆开发者来说还会遇到一些额外的问题。
而这次能够促使我去发布 NativeBridge 插件,主要还是之前的 NativeBridge 系列文章在掘金的受欢迎度较高,让我感受到了它存在的价值。另一个原因是之前对掘友的承诺,之前掘友希望 NativeBridge 能够适配 webview_flutter ^4.0.1 以上的版本。
虽然距离上次的回复已经过去了一个多月,但我最终还是完成了许下的承诺^ ^。
NativeBridge 插件
NativeBridge 是基于 webview_flutter 插件来实现 App端 和 H5端 JS 互调能力的插件。 其详细功能说明请跳转 Readme 查看,这里不做过多的介绍。
NativeBridge 目前已成功发布到 pub,需要使用时直接引入即可。
版本更新
这里简述下插件的版本更新内容:
v0.0.2 版本
1. 优化了消息回复后还会导致接收端再次发一条确认消息的问题
原来当 App 收到了 H5 回复的消息后,还会再发送一条消息确认消息。这是没有必要的,这里进行了优化。
通过在消息实体 Message 中新增 isResponseFlag 字段来进行区分,对于 isResponseFlag 为 true 的消息,将不再发送确认消息。
if (isResponseFlag) {
// 是返回的请求消息,则处理H5回调的值
NativeBridgeHelper.receiveMessage(messageJson);
} else {
...
}2. 对于未识别的 Api 新增容错机制处理
随着 App版本 的迭代,可能出现某个新的 Api 老的版本无法支持的情况,对于之前的版本来说,当 Api 不匹配时会直接丢弃消息,等待超时机制处理。这会导致发起端出现 await 情况,直到超时触发回调。这是不适宜的,这次增加了兼容处理。
// 不是返回的请求消息,处理H5端的请求
var callMethod = callMethodMap[messageItem.api];
if (callMethod != null) {
// 有相应的JS方法,则处理
...
} else {
// 若没有对应方法,则返回null,避免低版本未支持Api阻塞H5
messageItem.data = null;
}v1.0.0版本
1. 适配webview_flutter ^4.0.5版本
目前插件引入的 webview_flutter 版本为: ^4.0.5,后续也会随着 webview_flutter 插件的迭代而升级,直到其能力被官方取代为止。
2. 对实现方式进行重构
由于新版本的 webview_flutter 将大部分的 WebView 操作功能移入 WebViewController 处理,因此我们的 NativeBridge 插件也同步进行调整。
现在使用只需要新增 AppBridgeController 继承 NativeBridgeController 实现其对应方法即可正常使用。
class AppBridgeController extends NativeBridgeController {
AppBridgeController(WebViewController controller) : super(controller);
/// 指定JSChannel名称
@override
get name => "nativeBridge";
@override
Map<String, Function?> get callMethodMap => <String, Function?>{
// 版本号
"getVersionCode": (data) async {
return await AppUtil.getVersion();
},
...
};
}
// 初始化AppBridgeController
_appBridgeController = AppBridgeController(_controller);
总结
对于还在使用 webview_flutter 3.0+ 版本的项目,引用 ^0.0.2版本:
native_bridge: ^0.0.2对于使用 webview_flutter 4.0+ 版本的项目,引用 ^1.0.0版本:
native_bridge: ^1.0.0感悟
NativeBridge插件的成功发布,这个过程中也让我受益良多。
开始学会从 SDK 开发者的角度去思考问题,尝试思考如何简化插件的使用、丰富插件的能力,更关注插件的内在结构和对外的协议。也了解到在开源项目中包括开源协议、pub 的 scores 标准、README、CHANGELOG的定义等。
这也是自我的一次成长,愿你我一起共勉!
链接:https://juejin.cn/post/7204349756620210236
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android通知栏适配调研-放弃RemoteViews
问题描述:
项目的通知栏的RemoteViews背景图有些厂商颜色不对,需要一个适配方案,来适配所有机型。
项目现状:
目前的方案是,创建一个新的通知,通过这个通知来获取底色。
其中有一个字段是获取是否是暗黑模式,这段代码是先用按位或忽略掉透明度,系统的字体颜色不会有特别高的同名度,所以这里理论上没什么问题,然后计算两个三维向量的距离,距离越近,颜色越接近。
这里是有误差的,目标向量距离灰色向量rgb(127.5,127.5,127.5)的最大值约为220,而不是180,就会造成纯白色rgb(255,2555,255)的标题字体颜色,理应是黑色背景才能看到,但却被识别成非暗黑模式。
误判了暗黑模式,这里的背景就颜色就会出问题了。
目前项目的解决方案是通过设置RemoteViews的background颜色去做,这里需要适配的问题由RemoteViews实现机制产生:RemoteViews被设计具有跨进城通信的属性,通过Binder传递到SystemService进程,根据它的包名来拿相应的应用的资源,为了提高效率,系统没有直接通过Binder去支持所有的View和View操作,那这里对普通view生效的xml属性,很有可能厂商对系统修改源码后没有完全的适配,可能就不能对其全部生效。
比如对android:background属性进行设置在部分机型上就不会生效,但下面这段代码可以。
RemoteView?.setInt(R.id.ll_root, "setBackgroundColor", ContextCompat.getColor(context, R.color.color_367AF6))接下来来看项目如何设置颜色。
然后来看拿到暗黑模式的布尔字段后,会设置为#FFFFFFFF/#00000000这两个颜色,这两个颜色都是有问题的,首先暗黑模式情况下,#00000000(百分百透明的黑色)不一定会正确解析为透明色,类似问题为启动icon解析时,透明色解析为黑色背景,具体还要观察各厂商系统对源码的修改。
#FFFFFFFF这个颜色也是不对的,不是每个通知栏的背景都是白色,而且这个颜色也不一定会作为背景色,下面鸿蒙系统上就没有生效为白色。
来观察下不同时期的通知样式,可以发现不是每个时期都是固定颜色底色,有白有黑有灰,那就要动态的获取背景色来设置RemoteVies的背景色,下图以安卓1-7为示例。
接着还要考虑不同的系统版本对Notification的改动,如安卓8.0以上加入了Channel这一特性,项目的通知最后是要有一步渠道检查的。这里或许要额外对安卓13的有权限上的适配。
同时如果要考虑通知栏高度的问题的话,以安卓12为例,自定义通知的显示区域比安卓11有调整,折叠态高度上限为64dp,展开时高度上限为256dp,且系统强制显示通知的小图标。所以要考虑到ui层面对高度是否有要求,再来适配各个版本的RemoteViews的高度。下图为展开时示例。
以上,这个方案做不到适合所有机型,要适配所有机型确实是不是个简单的事情。
尝试过程:
核心问题为RemoteViews的背景色不能完美适配所有厂商。首先原安卓系统(非厂商自定义)不需要对其有特定的设置,自动跟随主题颜色;厂商自定义安卓系统,则各不相同,如小米则不会自动更改RemoteViews的颜色。
首先尝试获取背景色,我开始的尝试方式是沿用之前的方式,即build一个Notification,通过遍历其中的text,发现不是所有的都能拿到,参考其他文章列出的类似的表格如下:
虎牙项目目前的方案是,如果没拿到字体,默认就是字体为黑色,这个方法安卓7.0之后就失效了。安卓7.0+修改了Notification,采用 @android:color/primary_text_dark已经获取不到颜色值了。
那既然不能完美解决,这里我使用反编译工具,观察各厂商的逆向工程(以小米为例),这里需要花费大量的时间来阅读源码(前公司的代码真的看不懂= =),最后看到其他文章给出一个方案是在manifest加上这一句才会生效。
<item name="android:forceDarkAllowed" tools:targetApi="q">false</item>
复制代码以上,RemoteViews的确拥有高自定义ui的特性,但很难找到一个方案来适配所有国内厂商的机型,因为Google设计通知栏,或者说其他任何的系统组件的伊始就没考虑过自定以rom的因素。
解决方案:
1. 不使用RemoteViews,改用其他方案解决
2. 使用RemoteViews
先说第一个,如果仅仅是虎牙目前的通知栏用途的话,确实没有使用复杂ui,使用RemoteViews的收益好像不足以掩盖bug多这个缺点。直播间的通知栏提醒完全可以用addAction方法来代替:
其他简单场景的情况下:
第二个,如果坚持使用RemoteViews,基本上网络上大部分的相关的文章我都翻过了,我也没看到业界更好的办法,大概只能反编译去看看抖音和微信是怎么做的吧。
链接:https://juejin.cn/post/7205025712171302973
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
面试题:Android 中 Intent 采用了什么设计模式?
答案是采用了原型模式。
原型模式的好处在于方便地拷贝某个实例的属性进行使用、又不会对原实例造成影响,其逻辑在于对 Cloneable 接口的实现。
话不多说看下 Intent 的关键源码:
// frameworks/base/core/java/android/content/Intent.java
public class Intent implements Parcelable, Cloneable {
...
private static final int COPY_MODE_ALL = 0;
private static final int COPY_MODE_FILTER = 1;
private static final int COPY_MODE_HISTORY = 2;
@Override
public Object clone() {
return new Intent(this);
}
public Intent(Intent o) {
this(o, COPY_MODE_ALL);
}
private Intent(Intent o, @CopyMode int copyMode) {
this.mAction = o.mAction;
this.mData = o.mData;
this.mType = o.mType;
this.mIdentifier = o.mIdentifier;
this.mPackage = o.mPackage;
this.mComponent = o.mComponent;
this.mOriginalIntent = o.mOriginalIntent;
...
if (copyMode != COPY_MODE_FILTER) {
...
if (copyMode != COPY_MODE_HISTORY) {
...
}
}
}
...
}可以看到 Intent 实现的 clone() 逻辑是直接调用了 new 并传入了自身实例,而非调用 super.clone() 进行拷贝。
默认的拷贝策略是 COPY_MODE_ALL,顾名思义,将完整拷贝源实例的所有属性进行构造。其他的拷贝策略是 COPY_MODE_FILTER 指的是只拷贝跟 Intent-filter 相关的属性,即用来判断启动目标组件的 action、data、type、component、category 等必备信息。无视启动 flag、bundle 等数据。
// frameworks/base/core/java/android/content/Intent.java
public class Intent implements Parcelable, Cloneable {
...
public @NonNull Intent cloneFilter() {
return new Intent(this, COPY_MODE_FILTER);
}
private Intent(Intent o, @CopyMode int copyMode) {
this.mAction = o.mAction;
...
if (copyMode != COPY_MODE_FILTER) {
this.mFlags = o.mFlags;
this.mContentUserHint = o.mContentUserHint;
this.mLaunchToken = o.mLaunchToken;
...
}
}
}还有中拷贝策略是 COPY_MODE_HISTORY,不需要 bundle 等历史数据,保留 action 等基本信息和启动 flag 等数据。
// frameworks/base/core/java/android/content/Intent.java
public class Intent implements Parcelable, Cloneable {
...
public Intent maybeStripForHistory() {
if (!canStripForHistory()) {
return this;
}
return new Intent(this, COPY_MODE_HISTORY);
}
private Intent(Intent o, @CopyMode int copyMode) {
this.mAction = o.mAction;
...
if (copyMode != COPY_MODE_FILTER) {
...
if (copyMode != COPY_MODE_HISTORY) {
if (o.mExtras != null) {
this.mExtras = new Bundle(o.mExtras);
}
if (o.mClipData != null) {
this.mClipData = new ClipData(o.mClipData);
}
} else {
if (o.mExtras != null && !o.mExtras.isDefinitelyEmpty()) {
this.mExtras = Bundle.STRIPPED;
}
}
}
}
}总结起来:
| Copy Mode | action 等数据 | flags 等数据 | bundle 等历史 |
|---|---|---|---|
| COPY_MODE_ALL | YES | YES | YES |
| COPY_MODE_FILTER | YES | NO | NO |
| COPY_MODE_HISTORY | YES | YES | NO |
除了 Intent,Android 源码中还有很多地方采用了原型模式。
Bundle也实现了 clone(),提供了 new Bundle(this) 的处理:
public final class Bundle extends BaseBundle implements Cloneable, Parcelable {
...
@Override
public Object clone() {
return new Bundle(this);
}
}
组件信息类
ComponentName也在 clone() 中提供了类似的实现:
public final class ComponentName implements Parcelable, Cloneable, Comparable<ComponentName> {
...
public ComponentName clone() {
return new ComponentName(mPackage, mClass);
}
}
工具类
IntArray亦是如此:
public class IntArray implements Cloneable {
...
@Override
public IntArray clone() {
return new IntArray(mValues.clone(), mSize);
}
}
原型模式也不一定非得实现 Cloneable,提供了类似的实现即可。比如:
Bitmap没有实现该接口但提供了copy(),内部将传递原始 Bitmap 在 native 中的对象指针并伴随目标配置进行新实例的创建:
public final class ComponentName implements Parcelable, Cloneable, Comparable<ComponentName> {
...
public Bitmap copy(Config config, boolean isMutable) {
...
noteHardwareBitmapSlowCall();
Bitmap b = nativeCopy(mNativePtr, config.nativeInt, isMutable);
if (b != null) {
b.setPremultiplied(mRequestPremultiplied);
b.mDensity = mDensity;
}
return b;
}
}
链接:https://juejin.cn/post/7204013918958649405
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android斩首行动——接口预请求
前言
开发同学应该都很熟悉我们页面的渲染过程一般是从Activity#onCreate开始,再发起网络请求,等请求回调回来后,再基于网络数据渲染页面。可以用下面这幅图来粗略描述这个过程:
可以看到,目标页面渲染完成前必须得等待网络请求,导致渲染速度并没有那么快。尤其是当网络并不好的时候感受会更加明显。并且,当目标页面是H5页面或者是Flutter页面的时候,因为涉及到H5容器与Flutter容器的创建,白屏时间会更长。
那么有没有可能提前发起请求,来缩短网络请求这一部分的等待时间呢?这就是我们今天要讲的部分,接口预请求。
目标
我们要达到的目标很简单,就是提前异步发起目标页面的网络请求,从而加快目标页面的渲染速度。改善后的过程可以用下图表示:
并且,我们的预请求能力需要尽量少地侵入业务,与业务解耦,并保证能力的通用性,适用于工程内的任意页面(Android页面、H5页面、Flutter页面)。
方案
整体链路
首先给大家看一下整体链路,具体的细节可以先不用去抠,下面会一一讲到。
预请求时机
预请求时机一般有三种选择:
- 由业务层自行选择时机进行异步预请求
- 点击控件时进行异步预请求
- 路由最终跳转前进行异步预请求
第1种选择,由业务层自行选择时机进行预请求,需要涉及到业务层的改造,以及对时机合理性的把握。一方面是存在改造成本,另一方面是无法保证业务侧调用时机的合理性。
第2种选择,点击控件时进行预请求。若点击时进行预请求,点击事件监听并不是业务域统一的,无法形成有效封装。并且,若后续路由拦截器修改了参数,或是终止了跳转,这次预请求就失去了意义。
因此这里我们选择第3种,基于统一路由框架,在路由最终跳转前进行预请求。既保证了良好的封装性,也实现了对业务的零侵入,同时也做到了懒请求,即用户必然要发起该请求时才会去预请求。这里需要注意的是必须是在最终跳转前进行预请求,可以理解为是路由的最后一个前置异步拦截器。
预请求规则配置
我们通过本地的json文件(当然,有需要也可以上云通过配置后台下发),对预请求的规则进行配置,并将这份配置在App启动阶段异步读入到内存。后续在路由过程中,只有命中了预请求规则,才能发起预请求。配置demo如下:
{
"routeConfig":{
"scheme://domain/path?param1=true&itemId=123":["prefetchKey"],
"route2":["prefetchKey2"],
"route3":["prefetchKey3","prefetchKey4"]
},
"prefetcher":{
"prefetchKey":{
"prefetchType":"network",
"prefetchInfo":{
"api":"network.api.name",
"apiVersion":"1.0",
"method":"post",
"needLogin":"false",
"showLoginUI":"false",
"params": {
"itemId":"$route.itemId",
"firstTime":"true"
},
"headers": {
},
"prefetchImgInResponse": [
{
"imgUrl":"$data.imgData.img",
"imgWidth":"$data.imgData.imgWidth",
"imgHeight":150
}
]
}
},
"prefetchKey2":{
"prefetchType":"network",
"prefetchInfo":{
"api":"network.api.name2",
"apiVersion":"1.0",
"method":"post",
"needLogin":"false",
"showLoginUI":"false",
"params": {
"itemId":"$route.productId",
"firstTime":"false"
},
"headers": {
}
},
"prefetchKey3":{
"prefetchType":"image",
"prefetchInfo":{
"imgUrl":"$route.imgUrl",
"imgWidth":"$route.imgWidth",
"imgHeight": 150
}
},
"prefetchKey4":{
"prefetchInfo":{}
}
}
}规则解读
| 参数名 | 描述 | 备注 |
|---|---|---|
| routeConfig | 路由配置 | 配置路由到预请求的映射 |
| prefetcher | 预请求配置 | 记录所有的预请求 |
| prefetchKey | 预请求的key | |
| prefetchType | 预请求类型 | 分为network类型与image类型,两种类型所需要的参数不同 |
| prefetchInfo | 预请求所需要的信息 | 其中value若为data.param格式,则从响应数据中获取。 |
| params | network请求所需要的请求params | |
| headers | network请求所需要的请求headers | |
| prefetchImgFromResponse | 预请求的响应返回后,需要预加载的图片 | 用于需要预加载图片时,无法确定图片url,图片url只能从预请求响应中获取的场景。 |
举例说明
网络预请求
例如跳转目标页面,它的路由是scheme://domain/path?param1=true&itemId=123。
首先我们在跳转路由时,若跳转的路由是这个目标页面,我们就会尝试去发起预请求。根据上面的demo配置文件,它将匹配到prefetchKey这个预请求。
那么我们详细看prefetchKey这个预请求,预请求类型prefetchType为network,是一个网络预请求,prefetchInfo中具备了请求的基本参数(如apiName、apiVersion、method、请求params与请求headers,不同工程不一样,大家可以根据自己的工程项目进行修改)。具体看params中,有一个参数为itemId:$route.itemId。以$route.开头的意思,就是这个value值要从路由中获取,即itemId=123,那么这个值就是123。
图片预请求
在做网络预请求的过程中,我忽然想到图片做预请求也是可以大大提升用户体验的,尤其是当大图片首次下载到内存中渲染需要的时间会比较长。图片预请求分为url已知与url未知两种场景,下面各举两个例子。
图片url已知
什么是图片url已知呢?比如我们在首页跳转首页的二级页面时,如果二级页面需要预加载的图片跟首页的某张图是一样的(尺寸可能不同),那么首页跳转路由时我们是能够提前知道这个图片的url的,所以我们看到prefetchKey3中配置了prefetchType为image的预请求。image的信息来自于路由参数,需要在跳转时将图片url和宽高作为路由参数之一。
比如scheme://domain/path?imgUrl=${encodeUrl}&imgWidth=200,那么根据配置项,我们将提前将encodeUrl这个图片以宽200,高150的尺寸,加载到内存中去。当目标页面用到这个图片时,将能很快渲染出来。
图片url未知
相反,当跳转目标页面时,目标页面所要加载的图片url没法取到,就对应了图片url未知的场景。
例如闪屏页跳转首页时,如果需要预加载首页顶部的图片,此时闪屏页是无法获取到图片的url的,因为这个图片url是首页接口返回的。这种情况下,我们只能依赖首页的预请求进行。
在demo配置文件中,我们可以看到prefetchImgFromResponse字段。这个字段代表着,当这个预请求响应回来之后,我需要去预请求某张图片。其中,imgUrl是$data.param格式,以$data.开头,代表着这份数据是来自于响应数据的。响应数据就是一串json串,可以凭此,索引到预请求响应中图片url的位置,就能实现图片的提前加载了。
至于图片怎么提前加载到内存中,以及真实图片的加载怎么匹配到内存中的图片,这一部分是通过glide已有的preload机制实现的,感兴趣的同学可以去看一下源码了解一下,这里就不展开了。后面讲的预请求的方案细节,都只限于网络请求。
预请求匹配
预请求匹配指的是实际的业务请求怎样与已经执行的预请求匹配上,从而节省请求的空中时间,直接返回预请求的结果。
首先网络预请求执行前先在内存中生成一份PrefetchRecord,代表着已经执行的预请求,其中的字段跟配置文件中差不多,主要就是记录预请求相关的信息:
class PrefetchRecord {
// 请求信息
String api;
String apiVersion;
String method;
String needLogin;
String showLoginUI;
JSONObject params;
JSONObject headers;
// 预请求状态
int status;
// 预请求结果
ResponseModel response;
// 生成的请求id
String requestId;
boolean isMatch(RealRequest realRequest) {
requestId.equals(realRequest.requestId)
}
}每一个PrefetchRecord生成时,都会生成一个requestId,用于跟实际业务请求进行匹配。requestId的生成规则可以自行制定,比如将所有请求信息包一起做一下md5处理之类。
在实际业务请求发起之前,也会根据同样的规则生成requestId。若内存中存在相同requestId对应的PrefetchRecord,那么就相当于匹配成功了。匹配成功后,再根据预请求的状态进行进一步的处理。
预请求状态
预请求状态分为START、FINISH、ABORT,对应“正在发起预请求”、“已经获得预请求结果”、“预请求被抛弃”。ABORT状态下一节再讲。
为什么要记录这个状态呢?因为我们无法保证,预请求的响应一定在实际请求之前。用图来表示:
因为预请求是一个并发行为。当预请求的空中时间特别长,长到目标页面已经发出实际请求了,预请求的响应还没回来,即预请求状态为START,而非FINISH。那么此时该怎么办?我们就需要让实际请求在一旁等着(记录到内存中,RealRequestRecord),等预请求接收到响应了,再根据requestId去进行匹配,匹配到RealRequestRecord了,就触发RealRequestRecord中的回调,返回数据。
另外,在匹配过程中需要注意一点,因为每次路由跳转,如果发起预请求了,总会生成一个Record在内存中等待匹配。因此在匹配结束后,不管是匹配成功还是匹配失败,都要及时释放将Record从内存中释放掉。
超时重试机制
基于实际请求等待预请求响应的场景,我们再延伸一下。若预请求请求超时,迟迟拿不到响应,该怎么办?用图表示:
假设目前的网络请求,端上默认的超时时间是30s。那么在超时场景下,实际的业务请求在30s内若拿不到预请求的结果,就需要重新发起业务请求,抛弃预请求,并将预请求的状态置为ABORT,这样即使后面预请求响应回来了也不做任何处理。
忽然想到一个很贴切的场景来比喻这个预请求方案。
我们把跳转页面理解为去柜台取餐。
预请求代表着我们人还没到柜台,就先远程下单让柜员去准备食物。
如果柜员准备得比较快,那么我们到柜台后就能直接把食物拿走了,就能快点吃上了(代表着页面渲染速度变快)。
如果柜员准备得比较慢,那么我们到柜台后还是得等一会儿才能取餐,但总体上吃上食物的速度还是要比到柜台后再点餐来得快。
但如果这个柜员消极怠工准备得太慢了,我们到柜台等了很久都没拿到食物,那么我们就只能换个柜员重新点了(超时后发起实际的业务请求),同时还不忘投诉一把(预请求空中时间太慢了)。
总结
通过这篇文章,我们知道了什么是接口预请求,怎么实现接口预请求。我们通过配置文件+统一路由处理+预请求发起、匹配、回调,实现了与业务解耦的,可适用于任意页面的轻量级预请求方案,从而提升页面的渲染速度。
链接:https://juejin.cn/post/7203615594390732855
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 手写热修复dex
现有的热修复框架很多,尤以AndFix 和Tinker比较多
具体的实现方式和项目引用可以参考网络上的文章,今天就不谈,也不是主要目的
今天就来探讨,如何手写一个热修复的功能
对于简单的项目,不想集成其他修复框架的SDK,也不想用第三方平台,只是紧急修复一些bug
还是挺方便的
言归正传,如果一个或多个类出现bug,导致了崩溃或者数据显示异常,如果修复呢,如果熟悉jvm dalvik 类的加载机制,就会清楚的了解 ClassLoader的 双亲委托机制 就可以通过这个
什么是双亲委托机制
- 当前ClassLoader首先从自己已经加载的类中查询是否此类已经加载,如果已经加载则直接返回原来已经加载的类。
每个类加载器都有自己的加载缓存,当一个类被加载了以后就会放入缓存,等下次加载的时候就可以直接返回了。 - 当前classLoader的缓存中没有找到被加载的类的时候,委托父类加载器去加载,父类加载器采用同样的策略,首先查看自己的缓存,然后委托父类的父类去加载,一直到bootstrp ClassLoader.
- 当所有的父类加载器都没有加载的时候,再由当前的类加载器加载,并将其放入它自己的缓存中,以便下次有加载请求的时候直接返回。
突破口来了,看1(如果已经加载则直接返回原来已经加载的类)
对于同一个类,如果先加载修复的类,当后续在加载未修复的类的时候,直接返回修复的类,这样bug不就解决了吗?
Nice ,多看源码和jvm 许多问题可以从framework和底层去解决
话不多说,提出了解决方法,下面着手去实现
public class InitActivity extends FragmentActivity {
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//这里默认在SD卡根目录,实际开发过程中可以把dex文件放在服务器,在启动页下载后加载进来
//第二次进入的时候可以根据目录下是否已经下载过,处理,避免重新下载
//最后根据当前app版本下载不同的修复dex包 等等一系列处理
String dexFilePath = Environment.getExternalStorageDirectory().getAbsolutePath() + "/fix.dex";
DexFile dexFile = null;
try {
dexFile = DexFile.loadDex(dexFilePath, null, Context.MODE_PRIVATE);
} catch (IOException e) {
e.printStackTrace();
}
patchDex(dexFile);
startActivity(new Intent(this, MainActivity.class));
}
/**
* 修复过程,可以放在启动页,这样在等待的过程中,网络下载修复dex文件
*
* @param dexFile
*/
public void patchDex(DexFile dexFile) {
if (dexFile == null) return;
Enumeration<String> enumeration = dexFile.entries();
String className;
//遍历dexFile中的类
while (enumeration.hasMoreElements()) {
className = enumeration.nextElement();
//加载修复后的类,只能修复当前Activity后加载类(可以放入Application中执行)
dexFile.loadClass(className, getClassLoader());
}
}
}方法很简单在启动页,或者Application中提前加载有bug的类
这里写的很简单,只是展示核心代码,实际开发过程中,dex包下载的网络请求,据当前app版本下载不同的修复dex,文件存在的时候可以在Application中先加载一次,启动页就不用加载,等等,一系列优化和判断处理,这里就不过多说明,具体一些处理看github上的代码
###ok 代码都了解了,这个 fix.dex 文件哪里来的呢
熟悉Android apk生成的小伙伴都知道了,跳过这个步骤,不懂的小伙伴继续往下看
上面的InitActivity中startActivity(new Intent(this, MainActivity.class)); 启动了一个MainActivity
看看我的MainActivity
public class MainActivity extends FragmentActivity {
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//0不能做被除数,这里会报ArithmeticException异常
Toast.makeText(this, "结果" + 10 / 0, Toast.LENGTH_LONG).show();
}
}哎呀不小心,写了一个bug 0 咋能做除数呢,app已经上线了,这里必崩啊,咋办
不要急,按照以下步骤:
- 我们要修复这个类
MainActivity,先把bug解决
Toast.makeText(this, "结果" + 10 / 2, Toast.LENGTH_LONG).show();
- 把修复类生成
.class文件(可以先run一次,之后在 build/intermediates/javac/debug/classes/com开的的文件夹,找到生成的class文件,也可以通过javac 命令行生成,也可以通过右边的gradle Task生成)
- 把修复类
.class文件 打包成dex (其他.class删除,只保留修复类) 打开cmd命令行,输入下面命令
D:\Android\sdk\build-tools\28.0.3\dx.bat --dex --output C:\Users\pei\Desktop\dx\fix.dex C:\Users\pei\Desktop\dx\D:\Android\sdk 为自己sdk目录 28.0.3为build-tools版本,可以根据自己已经下载的版本更换
后面两个目录分别是生成.dex文件目录,和.class文件目录
切记
.class文件的目录必须是包名一样的,我的目录是C:\Users\pei\Desktop\dx\com\pei\test\MainActivity.class,不然会报class name does not match path
- 这样dx文件夹下就会生成fix.dex文件了,把fix.dex放进手机根目录试试吧
再次打开App,完美Toast 结果5,完美解决
总结
- 修复方法要在bug类之前执行
- 适合少量bug,太多bug影响性能
- 目前只能修复类,不能修复资源文件
- 目前只能适配单dex的项目,多dex的项目由于当前类和所有的引用类在同一个dex会 当前类被打上CLASS_ISPREVERIFIED标记,被打上这个标记的类不能引用其他dex中的类,否则就会报错
解决办法是在构造方法里引用一个单独的dex中的类,这样不符合规则就不会被标记了
链接:https://juejin.cn/post/7203989318271483960
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
新版Android Studio Logcat view使用简明教程
从Android Studio Dophin开始,Android Studio中的默认展示了新版的logcat。新版的logcat色彩上是更加的好看了,不同的tag会有不同的颜色,不同level等级的log默认也有不同的颜色。log过滤修改的更简洁了,当然使用起来也更加复杂了。原先的log视图只需要勾选就可以选择不同level的log了,只需要选择只展示当前应用的log就可以过滤掉其他应用的log了,但是新版只提供了一个输入框去过滤。在经过几个月的适应和对于官方文档的学习后,终于熟练使用,这里简单分享一下,让更多人更快入门。
定义自己专属的log view
log view 默认提供了两种视图,Standard View 和Compat View。Stand View会展示每一条log的日期,时间,进程线程id,tag,包名,log level以及message。Compat View只展示时间,log level和详细的message。可以通过log view左边的Configure Logcat Formatting Options按钮来修改,同时这个按钮中还有一个Modify Views选项可以来修改standard和 Compat视图的具体展示内容,可以定制自己的logview样式,如下图所示。
个性化的logcat 视图不仅仅是可以自定义展示的内容,还可以修改log和filter的配色方案。前往Settings(Windows)/Preferences(Mac) ->Editor -> Color Scheme,选择Android Logcat即可修改log 的颜色,选择Logcat Filter即可修改filter的颜色。
以上修改的是logcat view的外表,我们还可以修改它的内核,一个是logcat循环滚动区的大小,以及新logcat window的默认filter,可以通过前往Settings(Windows)/Preferences(Mac) -> Tools -> Logcat 设置。
一些操作技巧
在标准布局下,或者我们的log太长的时候,一屏通常展示不下,我们需要不停的向右滑动,滚动才能看到log的信息,我们可以用log view左侧的Soft-Wrap 按钮来让log换行。
左侧的Clear Logcat按钮可以清空logcat。左侧的Pause按钮可以暂停logcat的输出,方便看错误日志,可以避免关心的日志被新的日志冲掉。
新版本中,可以通过点击logcat tab右侧的New tab 按钮来同时创建多个logcat view窗口。这种方式创建的不能同时展示,而利用logcat view左侧的split Panels 按钮则可以创建多个窗口,并且同时展示。每一个窗口都可以设置自己要展示的连接设备,展示样式,以及过滤选项。这样就可以很方便的同时观察多种log。
通过键值对来过滤Log
新的过滤器,看起来简单,实际上更加复杂且强大了。通过Ctrl+Space按键可以查看系统建议的一些查询列表。这里介绍一下查询中会用到的键:
- tag: 匹配日志的tag字段
- package:匹配记录日志的软件包名,其中特殊值mine匹配当前打开项目对应的应用log。
- process:匹配记录日志的进程名
- message:匹配日志中我们自己填写的message的部分。
- level:与指定或者更高级别的日志匹配,比如debug或者error,输入level后as会自动提示可以选择。
- age:让窗口中只保留最近一段时间的log,值为数字加单位,s表示秒,m表示分钟,h表示小时,d表示天。如age:10s就只保留最近10s的日志。
- is: 这个键有两个固定的value取值,
crash匹配应用崩溃日志,stacktrace匹配任意类似java堆栈轨迹的日志,这两个对于看crash查问题是非常好用的。
这么多的键匹配,是可以逻辑组合的。我们可以使用&和|以及圆括号,系统会强制执行常规的运算符优先级。level:ERROR | tag:foo & package:mine 会被强转为level:ERROR | (tag:foo & package:mine ) 。如果我们没有填写逻辑运算符,查询语言会将多个具有相同键的非否定过滤视为OR,其他过滤视为AND。
如:
tag:fa tag:ba package:mine 计算逻辑是 (tag:fa | tag:ba) & package:mine
但tag:fa -tag:ba package:mine 计算逻辑是 tag:fa & -tag:ba & package:mine。这里的-用来表示否定,既tag不包含ba的情况。
新版的logcat view当然也是支持正则的,tag、message、package、process这几项是支持正则的。使用正则需要在键后面加一个~,例如: tag~:My.*Report。
除了正则这个选项之外,这几个键还有完全匹配和包含字符串即可的选项。不加修饰符号就是包含指定的字符串即可匹配。如果后面加=则要完全匹配才可以,例如process=:system_server和process:system_ser可以匹配到system_server的log,但是process=:system_ser则无法匹配到。
同时如上几个匹配选项都支持和前面说的否定符号连用如:-process=:system_server。
既然新版支持了这么复杂和强大过滤功能,如果每次都现想现写,那肯定是头皮发麻。as也为我们提供了收藏和历史记录功能。点击右侧的的星星按钮即可收藏当前的过滤条件,点击左侧的漏斗即可查看历史和收藏,并且可以删除不想要的记录。
切换回旧版log view
最后的最后,如果你觉得新版本适应不了,还是想要切换回旧版本的log view,还想要保留新版的android studio,也还是可以通过修改设置进行切换的。
前往Settings(Windows)/Preferences(Mac) -> Experimental, 反选Enable new logcat tool window 即可,如下图所示。
学习工具的目的,是为了让工具更好的为我们服务。希望大家都能够通过使用as提供的新功能来提高效率,从而有更多的时间去风花雪月。
链接:https://juejin.cn/post/7203336895886819388
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 逆向从入门到入yu
免责声明
本次技术分享仅用于逆向技术的交流与学习,请勿用于其他非法用途;技术是把双刃剑,请善用它。
逆向是什么、可以做什么、怎么做
简单讲,就是将别人打包好的 apk 进行反编译,得到源码并分析代码逻辑,最终达成自己的目的。
可以做的事:
- 修改 smali 文件,使程序达到自己想要的效果,重新编译签名安装,如去广告、自动化操作、电商薅羊毛、单机游戏修改数值、破解付费内容、汉化、抓包等
- 阅读源码,借鉴别人写好的技术实践
- 破解:小组件盒子:http://www.coolapk.com/apk/io.ifte…
怎么做:
- 这是门庞杂的技术活,需要知识的广度、经验、深度
- 需要具体问题,具体分析,有针对性的学习与探索
- 了解打包原理、ARM、Smali汇编语言
- 加固、脱壳
- Xposed、Substrate、Fridad等框架
- 加解密
- 使用好工具## 今日分享涉及工具
apktool:反编译工具
- 反编译:
apktool d <apkPath> o <outputPath> - 重新打包:
apktool b <fileDirPath> -o <apkPath> - 安装:
brew install apktool
- 反编译:
jadx:支持命令行和图形界面,支持apk、dex、jar、aar等格式的文件查看
apksigner:签名工具
Charles:抓包工具
- http://www.charlesproxy.com/
- Android 7 以上抓包 HTTPS ,需要手机 Root 后将证书安装到系统中
- Android 7 以下 HTTPS 直接抓
正题
正向编译
- java -> class -> dex -> apk
反向编译
- apk -> dex -> smali -> java
Smali 是 Android 的 Dalvik 虚拟机所使用的一种 dex 格式的中间语言
官方文档source.android.com/devices/tec…
正题开始,以反编译某瓣App为例:
jadx 查看 Java 源码,找到想修改的代码
反编译得到 smali 源码:
apktool d douban.apk -o doubancode --only-main-classes
修改:找到 debug 界面入口并打开
将修改后的 smali 源码正向编译成 apk:
apktool b doubancode -o douban_mock1.apk
重签名:
jarsigner -verbose -keystore keys.jks test.apk key0
此时的包不能正常访问接口,因为豆瓣 API 做了签名校验,而我们的新 apk 是用了新的签名,看接口抓包
怎么办呢?
继续分析代码,修改网络请求中的 apikey
来看看新的 apk
也可以做爬虫等
启发与防范
- 混淆
- 加固
- 加密
- 运行环境监测
- 不写敏感信息或操作到客户端
- App 运行签名验证
- Api 接口签名验证
One More Thing
工具分享:code.flyleft.cn/posts/3e3d8…
书籍分享:book.douban.com/subject/205…
进阶(下次分享):
- 静态调试
- 动态调试
- 脱壳
- NDK你想
- so文件修改
链接:https://juejin.cn/post/7202573260659163195
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
狂飙!Android 14 第一个预览版已发布~
前言
Android系统的更新速度真的是“一路狂飙”,23年2月8日,Android 14 第一个预览版本发布。Android 14 将继续致力于提高开发人员的工作效率,同时增强性能、隐私、安全性和用户自定义。
预计将会在八月份发布最终的Release版本
获取Android 14
如果你想获取Android 14系统可以使用下列Pixel系列设备
Pixel 4a (5G)
Pixel 5 and 5a
Pixel 6 and 6 Pro
Pixel 6a
Pixel 7 and 7 Pro
或者使用虚拟机的方式,因为家庭困难,所以这里我使用的是虚拟机的方式。
设置SDK
首先我们来安装Android 14 SDK,操作如下图所示。
安装好之后,设置编译版本和目标版本为Android 14 ,代码如下所示
android {
compileSdkPreview "UpsideDownCake"
defaultConfig {
targetSdkPreview "UpsideDownCake"
}
}
复制代码接着我们重点来看,第一个预览版本主要更新了哪些内容,重要分为对所有App的影响和目标版本为14的影响。
更新内容
所有App
安全
- 从Android 14开始,targetSdkVersion低于23的应用无法安装。
也就是说所有App的targetSdkVersion至少等于23,也就是要适配Android 6.0,这是因为Google考虑到部分应用恶意使用低级别的目标版本来规避隐私和安全权限。
辅助功能
- 从 Android 14 开始,系统支持高达 200% 的字体缩放。
这一目的是为弱视用户提供符合 Web 内容无障碍指南 (WCAG) 的额外无障碍选项。如果开发者已经使用缩放像素 (sp) 单位来定义文本大小,那么此更改可能不会对您的应用产生重大影响。
核心功能
- 默认情况下拒绝计划精确警报
精确警报用于用户有意的通知,或用于需要在精确时间发生的操作。 从 Android 14 开始,SCHEDULE_EXACT_ALARM 权限不再预先授予大多数新安装的针对 Android 13 及更高版本的应用程序——该权限默认情况下被拒绝。
- 上下文注册的广播在缓存应用程序时排队
在 Android 14 上,当应用处于缓存状态时,系统可能会将上下文注册的广播放入队列中,也就说,并不是注册之后广播就会直接启动,将根据系统使用情况来等待分配。
目标版本为Android 14的App
核心功能
- 需要前台服务类型
如果应用以 Android 14 为目标平台,则它必须为应用内的每个前台服务指定至少一种前台服务类型。
Android 14 还引入了用于健康和远程消息传递用例的前台服务类型。 该系统还为短服务、特殊用例和系统豁免保留新类型。
前台服务类型有很多,如下列所示:
connectedDevice
dataSync
health
location
mediaPlayback
mediaProjection
microphone
phoneCall
remoteMessaging
shortService
specialUse
systemExempted
其中health、remoteMessaging、shortService、specialUse 和 systemExempted 类型是 Android 14 中提供的新类型。
声明代码如下所示:
<manifest ...>
<uses-permission android:name="android.permission.FOREGROUND_SERVICE_TYPE_MEDIA_PLAYPACK" />
<application ...>
<service
android:name=".MyMediaPlaybackService"
android:foregroundServiceType="mediaPlayback"
android:permission="android.permission.FOREGROUND_SERVICE_TYPE_MEDIA_PLAYPACK"
android:exported="false">
</service>
</application>
</manifest>
Service.startForeground(0, notification, FOREGROUND_SERVICE_TYPE_LOCATION)
安全
对隐式意图的限制
应用程序必须使用明确的意图来交付给未导出的组件,或者将组件标记为已导出。
如果应用程序创建一个可变的挂起意图,但意图未指定组件或包,系统现在会抛出异常。
比如我们在配置文件中声明了一个exported为false的Activity,代码如下所示:
<activity
android:name=".AppActivity"
android:exported="false">
<intent-filter>
<action android:name="com.example.action.APP_ACTION" />
<category android:name="android.intent.category.DEFAULT" />
</intent-filter>
</activity>
然后我们按照意图启动这个Activity,代码如下所示。
context.startActivity(Intent("com.example.action.APP_ACTION"))
那么很抱歉,这里将抛出一个异常。必须改为显示的Intent,代码如下所示:
val explicitIntent =
Intent("com.example.action.APP_ACTION")
explicitIntent.apply {
package = context.packageName
}
context.startActivity(explicitIntent)
- 更安全的动态代码加载
新增功能
联系人
Android 14 增加了以下两个字段:
Contract.Contacts#ENTERPRISE_CONTENT_URI
ContactsContract.CommonDataKinds.Phone#ENTERPRISE_CONTENT_URI
这些字段一起允许具有 READ_CONTACTS 权限的个人应用程序列出所有工作配置文件联系人和电话号码,只要 DevicePolicyManager 中的跨配置文件联系人策略允许。
写在最后
由于,昨天刚刚发布了第一个预览版本,所以我们能感觉到的变化不是太大,不过Android的方向一直都是在权限、隐私等方向。后续如何适配,我们只有等着官方稳定版本出来之后在讨论了~
Android系统更新如此迅速,你觉得这算是狂飙吗?
链接:https://juejin.cn/post/7198067983775973432
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简历写得好,offer不会少!
转眼时间已经到2月下旬了,按照往年各个公司的招聘进度,估计近期各个公司的春招就会开启了。
春招作为校招生们求职的黄金时间,把握好金三银四的招聘季,不仅可以为金九银十的秋招做好铺垫,运气好的话可以直接通过实习转正一步到位免去秋招。
因此,准备在春招中大显身手的朋友,也该把写简历提上日程了!
为什么要写简历
简历作为求职者的名片,是HR衡量求职者岗位匹配度的重要因素,也是面试前留给面试官的第一印象。
一份内容丰富、排版精美的简历不仅可以增大简历筛选的通过率,也能让面试官在面试中更愿意去挖掘出你的闪光点。
毕竟求职者有没有用心、求职意愿是否强烈都是可以从简历中窥探一二的!
与此同时,一份排版混乱、内容随意的简历,如果被石沉大海也就情有可原了。
毕竟简历代表的是一种态度!
如何写简历
简历的目的是向HR和面试官清晰展示自己是否与岗位匹配。
一份简历的制作,通常需要从格式和内容两个方面来考虑。
格式
一份还算不错的简历格式应该考虑到如下几个因素:
最近帮一些同学修改简历,我发现很多同学的简历在排版方面存在如下几个方面的问题:
x 简历色彩太多
理解大家想要突出亮点的心情。但是过于花里胡哨可能会分散阅读者的注意力,从而导致适得其反的结果。
x 内容没有边距
很多同学的经历很丰富,想在简历中充分展现自我,因此密密麻麻写了很多内容。但没有突出亮点,也没有合理的设置边距,这可能会给阅读者带来不好的阅读体验。
x 个人照过于随意
为了在视觉上给招聘官良好的印象,很多同学会放自己的一寸照片在简历上。诚然,良好的求职形象是一个加分项,但是在照片的选择上,大家应该以合适出发,生活照和艺术照确实不太适合在简历上出现。
负责招聘的HR一天可能要阅读上百上千份简历,视觉上的体验也是写简历时需要考虑的因素。
对于理工科的同学们来说,简历排版可能是大家不擅长或者不太care的点,其实目前市面上有很多制作简历的网站,大家可以去这些平台选择合适的模板!
内容
如果说简历的格式只是起到印象分的作用,那么简历的内容就是简历能否选中的决定性因素了!
记得之前去线下招聘会应聘时,HR在拿到我的简历后,手上的笔一直在简历上圈重点,包括我的教育背景、求职意向、实习经历、项目经历、获奖情况等等...
现在回想起来,这应该就是大家常说的star法则吧!
因此,强烈建议大家按照star法则来填充自己简历的内容:
具体到简历中的每个模块,需要包含的内容有以下几个方面:
01 基本信息&求职意向(非常重要)
基本信息是HR联系求职者的主要途径,而求职意向则是岗位匹配度的重要衡量标准。
02 教育背景
成绩好的同学可以放上自己的绩点&排名,学校好的同学可以标注985、211。
03 自我评价&技术栈
自我评价是从性格方面展示求职者的岗位匹配度,技术栈是从能力上体现求职者实力。
对于致力于从事技术岗位的同学,可以在技术栈部分展示出自己的能力。
比如:熟练掌握原生 HTML、CSS、JavaScript 的使用,熟悉 React 框架、了解 Webpack、 TypeScript,熟练使用代码托管工具 Git等等。
如果有持续更新的技术博客或者开源项目,也可以在这里用数字量化加粗体现访问量和star数...
04 实习经历&项目经历(篇幅至少占3/5)
某种程度上说,有和求职岗位相匹配的大厂实习背景的同学在简历筛选中会更容易通过。
如果没有实习经历,有和求职岗位相匹配的项目经历也是star之一。
因为实习经历本质上也是项目经历。
在表述项目经历时,应重点突出自己的工作内容及成果,按照star原则写出技术难点和技术亮点,并量化展示成果,减少口水话的表述。
05 获奖经历和校园经历
获奖经历是软实力的体现, 如果在求职岗位所在的领域获得过有含金量的证书,会给阅读者留下更好的印象。或者在校期间拿到过学业奖学金,也是软实力的体现哦~
总结
一份好的简历,通常会经历多次打磨。
在这期间,我们也可以根据简历来进行阶段性的有效复盘,找出自己的亮点和待提升点,并在下一个版本中进一步提高。
与此同时,建议大家将每个版本的简历保存为word和pdf两个版本。word版本便于进一步修改简历,pdf版本用于求职投递, 防止因设备问题导致格式错乱!
链接:https://juejin.cn/post/7202818813511041082
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
改行后我在做什么?(2022-9-19日晚)
闲言碎语
今天回了趟家里,陪父母一起吃了个饭。父母照例是在唠叨,这个年纪了还不结婚,也没个稳定的工作,巴拉巴拉的一大堆。吃完饭我匆匆的就回到了我租住的地方。在现阶段,其实我对于父母所诉说的很多东西,我都是认同的。
但在我这个年纪,这个阶段,看似有很多选择,但其实我没有选择。能做的也只是多挣点钱。
在这个信息爆炸的时代,我们知道更高的地方在哪里。但当你想要再往上走一步的时候,你发现你的
上限,其实从出生或从你毕业的那一刻就已经注定了。可能少部分人通过自身的努力,的确能突破壁垒达到理想的高度。但这只是小概率事件罢了。在我看来整个社会的发展,其实早就已经陷入了一种怪圈。
在我,早些年刚刚进入社会的时候。那时的想法特别简单。就想着努力工作,努力提升自身的专业素养。被老板赏识,升职加薪成为一名管理者。如果,被淘汰了那应该是自己不够优秀,不够努力,专业技能不过硬,自己为人处事不够圆滑啥的。
当
内卷这个词语引爆网络的时候;当35岁被裁员成为常态的时候。再回头看我以前的那些想法那真的是一个笑话。(我觉得我可能是在为自己被淘汰找借口)
当前的状态
游戏工作室的项目,目前基本处于停滞的状态。我不敢加机器也不敢关机。有时候我都在想,是不是全中国那3-4亿的人都在搞这个?一个国外的游戏,金价直接拉成这个逼样。
汽配这边的话,只能说喝口稀饭。(我花了太多精力在游戏工作室上了)
梦想破灭咯
其实按照正常情况来说,游戏工作室最开始的阶段,我应该是能够稍微挣点钱的。我感觉我天时、地利、人和。我都占的。现在来看的话,其实我只占了
人和。我自己可以编码,脚本还是从驱动层模拟键鼠,写的一套脚本。这样我都没赚钱,我擦勒。
接下来干嘛
接下来准备进厂打螺丝。(开玩笑的)
还是老老实实跟着我弟学着做生意吧。老老实实做汽配吧!在这个时代,好像有一技之长(尤其是IT)的人,好像并不能活得很好。除非,你这一技之长,特别特别长。(当下的中国不需要太多的这类专业技术人员吧。)
我感受到的大环境
我身边有蛮多的大牛。从他们的口中和我自己看到的。我感觉在IT这个领域,国内的环境太恶劣了。在前端,除开UI库,我用到的很多多的库全是老外的。为什么没有国人开源呢?因为,国人都忙着996了。我们可以在什么都不知道的情况下,通过复制粘贴,全局搜索解决大部分问题。 机械视觉、大数据分析、人工智能 等很多东西。这一切的基石很多年前就有了,为什么没人去研究他?为什么我们这波人,不断的在学习:这样、那样的框架。搭积木虽然很好玩。但创造一个积木,不应该也是一件更有挑战性的事情么?
在招聘网站还有一个特别奇怪的现象。看起来这家公司是在招人,但其实是培训机构。 看起来这家公司正儿八经是在招聘兼职,但其实只想骗你去办什么兼职卡。看起来是在招送快递,送外卖的,招聘司机的,但其实只是想套路你买车。我擦勒。这是怎样的一个恶劣的生存环境。这些个B人就不能干点,正经事?
卖菜的、拉车的、搞电商的、搞短视频、搞贷款的、卖保险的、这些个公司市值几百亿。很难看到一些靠创新,靠创造,靠产品质量,发展起来的公司。
链接:https://juejin.cn/post/7144770465741946894
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
DIO源码浅析——揭开面纱后是你印象中的样子吗
DIO源码解析
dio是一个强大的Dart Http请求库,支持Restful API、FormData、拦截器、请求取消、Cookie管理、文件上传/下载、超时、自定义适配器等
Dio版本号:4.0.6
基本使用
final dio = Dio();
final result = await dio.get('https://xxxx.ccc');
源码分析
源码分析通常情况下是一个逆推的过程,首先熟悉api的使用,然后通过api的调用思考功能是如何实现的。这里就从Dio()和get()方法作为切入点,看看Dio的内部实现。切忌直接下载源码通读一遍,容易找不到重点。
Dio
查看源码发现Dio是个抽象类,定义了Dio支持的所有功能。有面向对象经验的应该都知道抽象类无法直接实例化,但是这里却可行其实这是dart的factory语法糖,方便开发者使用工厂模式创建对象。
简化的Dio代码,例举出比较具有代表性的属性和方法。
abstract class Dio {
factory Dio([BaseOptions? options]) => createDio(options);
late BaseOptions options;
Interceptors get interceptors;
late HttpClientAdapter httpClientAdapter;
late Transformer transformer;
...
Future<Response<T>> get<T>(
String path, {
Map<String, dynamic>? queryParameters,
Options? options,
CancelToken? cancelToken,
ProgressCallback? onReceiveProgress,
});
Future<Response<T>> request<T>(
String path, {
data,
Map<String, dynamic>? queryParameters,
CancelToken? cancelToken,
Options? options,
ProgressCallback? onSendProgress,
ProgressCallback? onReceiveProgress,
});
...
}1. 工厂方法创建Dio对象
factory Dio([BaseOptions? options]) => createDio(options);
这是上面提到的为何抽象类能实例化对象,就是个语法糖起了作用,跟进去发现createDio(options)这个方法定义在entry_stub.dart里,并且是个空实现。先不深究,反正最后的实现要么是DioForBrowser、要么是DioForNative至于加了什么魔法不是本期的重点
2. BaseOptions
options保存通用的请求信息,比如baseUrl、headers、超时时间等参数。用来设置全局配置。
3. Interceptors
这就是所有http请求框架里都会用到的拦截器在Dio里的实现,里面的关键源码一个线性列表存储所有的拦截器,和重写的下标操作符。在发起请求时会使用Interceptors存储的拦截器按顺序进行拦截处理。4. HttpClientAdapter
HttpClientAdapter是Dio真正发起请求的地方,他是一个抽象类,实现类通过依赖注入注入进来。Dio这里运用了职责分离的思想进行接耦,Dio定义请求方法和请求拦截等操作,使用HttpClientAdapter建立连接发起请求。这样设计的好处在于,如若对网络请求库有改动的需求可以自己实现一个HttpClientAdapter子类进行替换就行,无需改动原有代码。
5. Transformer
Transformer的作用是在请求前后可以对请求参数,和请求结果进行修改。在请求时生效在请求拦截器之后,响应时发生在响应拦截器之前。对于了解过洋葱模型的同学来说,这很好理解,Transformer处于Interceptors的里面一层。6. 诸如get、post、request...方法
Dio里定义的方法全部都是抽象方法,需要子类来实现。这里的作用是定义一个通用的请求接口,包含http常用的一些方法。按照程序看完抽象类就该看实现类了,Android Studio里在抽象类Dio的左边有个向下的箭头,点击一下发现有三个子类。
1. DioMixin
DioMixin也是一个抽象类,实现了Dio接口几乎所有的方法,只有两个属性未实现:
HttpClientAdapter
BaseOptions
这两个属性交由DioForNative和DioForBrowser各自进行注入。
class DioForBrowser with DioMixin implements Dio {
DioForBrowser([BaseOptions? options]) {
this.options = options ?? BaseOptions();
httpClientAdapter = BrowserHttpClientAdapter();
}
}class DioForNative with DioMixin implements Dio {
singleton.
DioForNative([BaseOptions? baseOptions]) {
options = baseOptions ?? BaseOptions();
httpClientAdapter = DefaultHttpClientAdapter();
}
}这个很好理解,因为native和web的发起请求肯定是不一样的。dio默认使用的http_client来自于dart_sdk暂未直接支持web。所以需要通过创建不同的http_client适配web和native。
好了,到这里基本确定DioMixin这个类就是Dio最重要的实现类了。DioForNative和DioForBrowser只是针对不同平台的适配而已。继续分析DioMixin:
同样从get方法开始跟进
Future<Response<T>> get<T>(
String path, {
Map<String, dynamic>? queryParameters,
Options? options,
CancelToken? cancelToken,
ProgressCallback? onReceiveProgress,
}) {
return request<T>(
path,
queryParameters: queryParameters,
options: checkOptions('GET', options),
onReceiveProgress: onReceiveProgress,
cancelToken: cancelToken,
);
}get方法里设置了一下method为‘GET’,然后把参数全数传递给了request方法,继续看看request方法
Future<Response<T>> request<T>(
String path, {
data,
Map<String, dynamic>? queryParameters,
CancelToken? cancelToken,
Options? options,
ProgressCallback? onSendProgress,
ProgressCallback? onReceiveProgress,
}) async {
options ??= Options();
var requestOptions = options.compose(
this.options,
path,
data: data,
queryParameters: queryParameters,
onReceiveProgress: onReceiveProgress,
onSendProgress: onSendProgress,
cancelToken: cancelToken,
);
requestOptions.onReceiveProgress = onReceiveProgress;
requestOptions.onSendProgress = onSendProgress;
requestOptions.cancelToken = cancelToken;
...
return fetch<T>(requestOptions);
}request方法里主要干了两件事
- 合并BaseOptions和外部传进来的请求参数
- 绑定上传、下载、取消等回调到请求对象
然后将处理好的请求参数交给fetch方法。继续跟进(前方高能,fetch方法是dio的核心了)
Future<Response<T>> fetch<T>(RequestOptions requestOptions) async {
final stackTrace = StackTrace.current;
if (requestOptions.cancelToken != null) {
requestOptions.cancelToken!.requestOptions = requestOptions;
}
//这里是根据请求参数,简单判断下返回的type。意思是T如果声明了类型,要么是普通文本要么是json对象
if (T != dynamic &&
!(requestOptions.responseType == ResponseType.bytes ||
requestOptions.responseType == ResponseType.stream)) {
if (T == String) {
requestOptions.responseType = ResponseType.plain;
} else {
requestOptions.responseType = ResponseType.json;
}
}
//请求拦截包装器:interceptor就是拦截器里的onRequest方法,作为参数传过来
//1.开始分析这个包装器的作用,仅当状态处于next时开始工作
//2.listenCancelForAsyncTask方法作用是,cancelToken的Future和请求的拦截器Future同时执行,cancelToken先执行完成的话就抛出异常终止请求。
//3.创建一个requestHandler,并调用interceptor方法(在request这里就是onRequest方法),然后返回requestHander.future(了解Completer的同学应该都知道,这是可以手动控制future的方法)。这就解释了为何拦截器里的onRequest方法,开发者需要手动调用next等方法进入下一个拦截器。
FutureOr Function(dynamic) _requestInterceptorWrapper(
InterceptorSendCallback interceptor,
) {
return (dynamic _state) async {
var state = _state as InterceptorState;
if (state.type == InterceptorResultType.next) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.requestLock, () {
var requestHandler = RequestInterceptorHandler();
interceptor(state.data as RequestOptions, requestHandler);
return requestHandler.future;
});
}),
);
} else {
return state;
}
};
}
//响应拦截包装器:
//实现方式参考_requestInterceptorWrapper基本类似,但是要注意这里放宽了state的条件多了一个resolveCallFollowing,这个后续再讲
FutureOr<dynamic> Function(dynamic) _responseInterceptorWrapper(
InterceptorSuccessCallback interceptor,
) {
return (_state) async {
var state = _state as InterceptorState;
if (state.type == InterceptorResultType.next ||
state.type == InterceptorResultType.resolveCallFollowing) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.responseLock, () {
var responseHandler = ResponseInterceptorHandler();
interceptor(state.data as Response, responseHandler);
return responseHandler.future;
});
}),
);
} else {
return state;
}
};
}
// 错误拦截包装器
FutureOr<dynamic> Function(dynamic, StackTrace) _errorInterceptorWrapper(
InterceptorErrorCallback interceptor) {
return (err, stackTrace) {
if (err is! InterceptorState) {
err = InterceptorState(
assureDioError(
err,
requestOptions,
),
);
}
if (err.type == InterceptorResultType.next ||
err.type == InterceptorResultType.rejectCallFollowing) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.errorLock, () {
var errorHandler = ErrorInterceptorHandler();
interceptor(err.data as DioError, errorHandler);
return errorHandler.future;
});
}),
);
} else {
throw err;
}
};
}
// Build a request flow in which the processors(interceptors)
// execute in FIFO order.
// Start the request flow
// 初始化请求拦截器第一个元素,第一个InterceptorState的type为next
var future = Future<dynamic>(() => InterceptorState(requestOptions));
// Add request interceptors to request flow
// 这是形成请求拦截链的关键,遍历拦截器的onRequest方法,并且使用_requestInterceptorWrapper对onRequest方法进行包装。
//上面讲到_requestInterceptorWrapper返回的是一个future
//future = future.then(_requestInterceptorWrapper(fun));这段代码就是让拦截器形成一个链表,只有上一个拦截器里的onRequest内部调用了next()才会进入下一个拦截器。
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleRequest
: interceptor.onRequest;
future = future.then(_requestInterceptorWrapper(fun));
});
// Add dispatching callback to request flow
// 发起请求的地方,发起请求时也处在future链表里,方便response拦截器和error拦截器的处理后续。
//1. reqOpt即,经过拦截器处理后的最终请求参数
//2. _dispatchRequest执行请求,并根据请求结果判断执行resolve还是reject
future = future.then(_requestInterceptorWrapper((
RequestOptions reqOpt,
RequestInterceptorHandler handler,
) {
requestOptions = reqOpt;
_dispatchRequest(reqOpt)
.then((value) => handler.resolve(value, true))
.catchError((e) {
handler.reject(e as DioError, true);
});
}));
//request处理执行完成后,进入response拦截处理器,遍历形成response拦截链表
// Add response interceptors to request flow
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleResponse
: interceptor.onResponse;
future = future.then(_responseInterceptorWrapper(fun));
});
// 请求拦截链表添加完成后,添加错误的链表
// Add error handlers to request flow
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleError
: interceptor.onError;
future = future.catchError(_errorInterceptorWrapper(fun));
});
// Normalize errors, we convert error to the DioError
// 最终返回经过了拦截器链表的结果
return future.then<Response<T>>((data) {
return assureResponse<T>(
data is InterceptorState ? data.data : data,
requestOptions,
);
}).catchError((err, _) {
var isState = err is InterceptorState;
if (isState) {
if ((err as InterceptorState).type == InterceptorResultType.resolve) {
return assureResponse<T>(err.data, requestOptions);
}
}
throw assureDioError(
isState ? err.data : err,
requestOptions,
stackTrace,
);
});
}关于fetch的源码分析在关键点写了注释,各位同学自行享用。像这种比较长的源码分析一直在思考该如何写,分块解析怕代码逻辑关联不上来,索性直接全部拿来写上注释。再通过实例问题解释代码,各位如果有好的建议去分析代码,请在评论区留言
关于拦截器的几个实例问题
拦截器不手动调用RequestInterceptorHandler.next会怎么样?
答:根据我们梳理的流程来看,Dio在发起请求时会根据拦截器生成一个future的链表,future只有等到上一个执行完才会执行下一个。如果拦截器里不手动调用next则会停留在链表中的某个节点。
拦截器onError中可以做哪些操作?
interceptors.forEach((Interceptor interceptor) {
var fun = interceptor is QueuedInterceptor
? interceptor._handleError
: interceptor.onError;
future = future.catchError(_errorInterceptorWrapper(fun));
});对这段代码进行分析,可以看到onError的执行,是在future链表的catchError(捕获future里的错误)方法中进行的。
onError的方法签名如下
void onError(DioError err,ErrorInterceptorHandler handler)
可以在onError方法调用 next、resolve、reject三个方法处理。next 使用的completeError,会让future产生一个错误,被catch到交给下一个拦截器处理。
void next(DioError err) {
_completer.completeError(
InterceptorState<DioError>(err),
err.stackTrace,
);
_processNextInQueue?.call();
} resolve 使用complete会正常返回数据,不会触发catchError,所以跳过后续的onError拦截器
void resolve(Response response) {
_completer.complete(InterceptorState<Response>(
response,
InterceptorResultType.resolve,
));
_processNextInQueue?.call();
}reject 和next代码类似,但是设置了状态为InterceptorResultType.reject,结合_errorInterceptorWrapper代码看,包装器里只处理err.type == InterceptorResultType.next ||
err.type == InterceptorResultType.rejectCallFollowing条件,其他状态直接抛出异常。所以reject的效果就是抛出错误直接完成请求
void reject(DioError error) {
_completer.completeError(
InterceptorState<DioError>(
error,
InterceptorResultType.reject,
),
error.stackTrace,
);
_processNextInQueue?.call();
}
//error包装器
FutureOr<dynamic> Function(dynamic, StackTrace) _errorInterceptorWrapper(
InterceptorErrorCallback interceptor) {
return (err, stackTrace) {
if (err is! InterceptorState) {
err = InterceptorState(
assureDioError(
err,
requestOptions,
),
);
}
//仅会处理InterceptorResultType.next和InterceptorResultType.rejectCallFollowing,而reject的类型是reject,所以直接执行elese的throw
if (err.type == InterceptorResultType.next ||
err.type == InterceptorResultType.rejectCallFollowing) {
return listenCancelForAsyncTask(
requestOptions.cancelToken,
Future(() {
return checkIfNeedEnqueue(interceptors.errorLock, () {
var errorHandler = ErrorInterceptorHandler();
interceptor(err.data as DioError, errorHandler);
return errorHandler.future;
});
}),
);
} else {
throw err;
}
};
}- 在onRequest里抛出异常,后续的onRequest和onResponse还会回调吗?
- 在onResponse里抛出异常,后续的onResponse还会回调吗?
答:回顾一下请求的流程,发起请求->onRequest(1)->onRequest(2)->onRequest(3)->http请求->onResponse(1)->onResponse(2)->onResponse(3)->catchError(1)->catchError(2)->catchError(3)。
这就很明显无论是onRequest还是onResponse抛出异常都会被catchError(1)给捕获,跳过了后续的onRequest和onResponse。
补充
- 在requestWrapper、responseWrapper、errorWrapper里都可以看到listenCancelForAsyncTask,第一个参数是cancelToken。这是因为Dio的取消请求是在拦截器里进行的,只要请求还未走完拦截器就可以取消请求。这就有个新的问题,如果咱们未设置拦截器取消请求就无法使用了吗?显然不是。在发起请求的时候还会把cancelToken再次传递进去,监听是否需要取消请求,如果取消的话就关闭连接,感兴趣的同学自行查看相关源码。
Future<Response<T>> _dispatchRequest<T>(RequestOptions reqOpt) async {
var cancelToken = reqOpt.cancelToken;
ResponseBody responseBody;
try {
var stream = await _transformData(reqOpt);
responseBody = await httpClientAdapter.fetch(
reqOpt,
stream,
cancelToken?.whenCancel,
);
...
}- InterceptorResultType在拦截器里发挥的作用,上面也提过了其实就是在调用InterceptorHandler的next,resolve,reject时设着一个标记,用于判断是继续下一个拦截器还是跳过后续拦截方法
2. DioForNative 和 DioForBrowser
下面这段代码是DioMixin发起请求的地方,可以看到真正执行http请求的是HttpClientAdapter的fetch方法。那DioForNative和DioForBrowser是针对不同平台的实现,那最简单的方法就是对fetch方法进行定制就好了。上面也提到了他们各自创建了不同的HttpClientAdapter,感兴趣的同学可以看看BrowserHttpClientAdapter和DefaultHttpClientAdapter
Future<Response<T>> _dispatchRequest<T>(RequestOptions reqOpt) async {
var cancelToken = reqOpt.cancelToken;
ResponseBody responseBody;
try {
var stream = await _transformData(reqOpt);
responseBody = await httpClientAdapter.fetch(
reqOpt,
stream,
cancelToken?.whenCancel,
);
...
}总结
Dio也是一个网络封装库,本身并不负责建立http请求等操作。除此之外还集成了请求拦截,取消请求的功能。采用了面向接口的方式,所以替换http请求库代价很小,只需要自己实现HttpClientAdapter替换下即可。
链接:https://juejin.cn/post/7202793493826781241
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 仿闲鱼动画效果
前言
目前正在做的项目,为了增加用户的体验度,准备增加一些动画效果,其中底部栏中间按钮的点击事件参考了闲鱼的动效,便在此基础上仿写了该动效,并增加了一些新的效果。
动效
闲鱼动效
仿写效果
思路
根据UI的设计图,对每个模块设计好动画效果,本人主要设计了以下四个效果。
1、底部返回键旋转动画
底部返回按钮动画其实就是个旋转动画,利用Transform.rotate设置angle的值即可,这里使用了GetX来对angle进行动态控制。
//返回键旋转角度,初始旋转45度,使其初始样式为 +
var angle = (pi / 4).obs;
///关闭按钮旋转动画控制器
late final AnimationController closeController;
late final Animation<double> closeAnimation;
///返回键旋转动画
closeController = AnimationController(
duration: const Duration(milliseconds: 300),
vsync: provider,
);
///返回键旋转动画
closeController = AnimationController(
duration: const Duration(milliseconds: 300),
vsync: provider,
);
///页面渲染完才开始执行,不然第一次打开不会启动动画
WidgetsBinding.instance.addPostFrameCallback((duration) {
closeAnimation =
Tween(begin: pi / 4, end: pi / 2).animate(closeController)
..addListener(() {
angle.value = closeAnimation.value;
});
closeController.forward();
});
///关闭按钮点击事件
void close() {
///反转动画,并关闭页面
Future.delayed(
const Duration(milliseconds: 120), () {
Get.back();
});
closeController.reverse();
}
IconButton(
onPressed: null,
alignment: Alignment.center,
icon: Transform.rotate(
angle: controller.angle.value,
child: SvgPicture.asset(
"assets/user/ic-train-car-close.svg",
width: 18,
height: 18,
color: Colors.black,
),
))2、底部四个栏目变速上移动画+渐变动画
四个栏目其实就是个平移动画,只不过闲鱼是四个栏目一起平移,而我选择了变速平移,这样视觉效果上会好一点。
//透明度变化
List<AnimationController> opacityControllerList = [];
//上移动画,由于每个栏目的移动速度不一样,需要用List保存四个AnimationController,
//如果想像闲鱼那种整体上移,则只用一个AnimationController即可。
List<AnimationController> offsetControllerList = [];
List<Animation<Offset>> offsetAnimationList = [];
//之所以用addIf,是因为项目中这几个栏目的显示是动态显示的,这里就直接写成true
Column(
children: []
..addIf(
true,
buildItem('assets/user/ic-train-nomal-car.webp',"学车加练","自主预约,快速拿证"))
..addIf(
true,
buildItem('assets/user/ic-train-fuuxn-car.webp',"有证复训","优质陪练,轻松驾车"))
..addIf(
true,
buildItem('assets/user/ic-train-jiaxun-car.webp',"模拟加训","考前加训,临考不惧"))
..addIf(
true,
buildItem('assets/user/ic-train-jiakao-car.webp',"驾考报名","快捷报名无门槛"))
..add(playWidget())
..addAll([
17.space,
]),
)
//仅仅是为了在offsetController全部初始化完后执行play()
Widget playWidget() {
//执行动画
play();
return Container();
}
int i = 0;
Widget buildItem(String img,String tab,String slogan) {
//由于底部栏目是动态显示的,需要在创建Widget时一同创建offsetController和offsetAnimation
i++;
AnimationController offsetController = AnimationController(
duration: Duration(milliseconds: 100 + i * 20),
vsync: this,
);
Animation<Offset> offsetAnimation = Tween<Offset>(
begin: const Offset(0, 2.5),
end: const Offset(0, 0),
).animate(CurvedAnimation(
parent: offsetController,
// curve: Curves.easeInOutSine,
curve: const Cubic(0.12, 0.28, 0.48, 1),
));
AnimationController opacityController = AnimationController(
duration: const Duration(milliseconds: 500),
lowerBound: 0.2,
upperBound: 1.0,
vsync: this);
opacityControllerList.add(opacityController);
offsetControllerList.add(offsetController);
offsetAnimationList.add(offsetAnimation);
return SlideTransition(
position: offsetAnimation,
child: FadeTransition(
opacity: opacityController,
child: Container(
margin: EdgeInsets.only(bottom: 16),
height: 62,
decoration: BoxDecoration(
borderRadius: BorderRadius.all(Radius.circular(12)),
color: const Color(0xfffafafa)),
child:
Row(mainAxisAlignment: MainAxisAlignment.center, children: [
24.space,
Image.asset(img, width: 44, height: 44),
12.space,
Column(
crossAxisAlignment: CrossAxisAlignment.start,
mainAxisSize: MainAxisSize.min,
children: [
Text(tab,
style: const TextStyle(
color: Color(0XFF000000),
fontSize: 16,
fontWeight: FontWeight.bold)),
Text(slogan,
style: const TextStyle(
color: Color(0XFF6e6e6e), fontSize: 12)),
]).expanded,
Image.asset("assets/user/ic-train-arrow.webp",
width: 44, height: 44),
17.space
])).inkWell(
onTap: () {},
delayMilliseconds: 50)),
);
}
//执行动画
void play() async {
for (int i = 0; i < offsetControllerList.length; i++) {
opacityControllerList[i].forward();
///栏目正序依次延迟(40 + 2 * i) * i的时间,曲线速率
Future.delayed(Duration(milliseconds: (40 + 2 * i) * i), () {
offsetControllerList[i]
.forward()
.whenComplete(() => offsetControllerList[i].stop());
});
}
}
///关闭按钮点击事件
void close() {
///反转动画,并关闭页面
Future.delayed(
const Duration(milliseconds: 120), () {
Get.back();
});
for (int i = offsetControllerList.length - 1; i >= 0; i--) {
///栏目倒叙依次延迟(40 + 2 * (offsetControllerList.length-1-i)) * (offsetControllerList.length-1-i))的时间
Future.delayed(
Duration(
milliseconds:
(40 + 2 * (offsetControllerList.length-1-i)) * (offsetControllerList.length-1-i)), () {
offsetControllerList[i].reverse();
});
}
opacityTopController.reverse();
}3、中间图片渐变动画
渐变动画使用FadeTransition即可。
///图片透明度渐变动画控制器
late final AnimationController imgController;
///图片透明度渐变动画
imgController = AnimationController(
duration: const Duration(milliseconds: 500),
lowerBound: 0.0,
upperBound: 1.0,
vsync: provider);
imgController.forward().whenComplete(() => imgController.stop());
///渐变过渡
FadeTransition(
opacity: imgController,
child:
Image.asset("assets/user/ic-traincar-guide.webp"),
),
///关闭按钮点击事件
void close() {
imgController.reverse();
}
4、顶部文案渐变动画+下移动画
///顶部标题下移动画控制器
late final AnimationController offsetTopController;
late final Animation<Offset> offsetTopAnimation;
///顶部标题渐变动画控制器
late final AnimationController opacityTopController;
///顶部标题上移动画
offsetTopController = AnimationController(
duration: const Duration(milliseconds: 300),
vsync: provider,
);
offsetTopController
.forward()
.whenComplete(() => offsetTopController.stop());
offsetTopAnimation = Tween<Offset>(
begin: const Offset(0, -0.8),
end: const Offset(0, 0),
).animate(CurvedAnimation(
parent: offsetTopController,
curve: Curves.easeInOutCubic,
));
offsetTopController
.forward()
.whenComplete(() => offsetTopController.stop());
//UI
SlideTransition(
position: offsetTopAnimation,
child: FadeTransition(
opacity: opacityTopController,
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
mainAxisAlignment: MainAxisAlignment.start,
mainAxisSize: MainAxisSize.min,
children: [
80.space,
const Text(
'练车指南',
style: TextStyle(
color: Color(0XFF141414),
fontSize: 32,
fontWeight: FontWeight.w800,
),
),
2.space,
const Text('易练只为您提供优质教练,为您的安全保驾护航',
style: TextStyle(
color: Color(0XFF141414),
fontSize: 15)),
],
))),
///关闭按钮点击事件
void close() {
offsetTopController.reverse();
opacityTopController.reverse();
}5、注销动画
最后,在关闭页面的时候不要忘记注销动画。
///关闭时注销动画
void dispose() {
for (int i = offsetControllerList.length - 1; i > 0; i--) {
offsetControllerList[i].dispose();
}
offsetTopController.dispose();
opacityTopController.dispose();
imgController.dispose();
closeController.dispose();
}链接:https://juejin.cn/post/7202537103933964346
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android源码—为什么onResume方法中不可以获取View宽高
前言
有一个经典的问题,我们在Activity的onCreate中可以获取View的宽高吗?onResume中呢?
对于这类八股问题,只要看过都能很容易得出答案:不能。
紧跟着追问一个,那为什么View.post为什么可以获取View宽高?
今天来看看这些问题,到底为何?
今日份问题:
- 为什么onCreate和onResume中获取不到view的宽高?
- 为什么View.post为什么可以获取View宽高?
基于Android API 29版本。
问题1、为什么onCreate和onResume中获取不到view的宽高?
首先我们清楚,要拿到View的宽高,那么View的绘制流程(measure—layout—draw)至少要完成measure,【记住这一点】。
还要弄清楚Activity的生命周期,关于Activity的启动流程,后面单独写一篇,本文会带一部分。
另外布局都是通过setContentView(int)方法设置的,所以弄清楚setContentView的流程也很重要,后面也补一篇。
首先要知道Activity的生命周期都在ActivityThread中, 当我们调用startActivity时,最终会走到ActivityThread中的performLaunchActivity
private Activity performLaunchActivity(ActivityClientRecord r, Intent customIntent) {
……
Activity activity = null;
try {
java.lang.ClassLoader cl = appContext.getClassLoader();
// 【关键点1】通过反射加载一个Activity
activity = mInstrumentation.newActivity(
cl, component.getClassName(), r.intent);
……
} catch (Exception e) {
……
}
try {
……
if (activity != null) {
……
// 【关键点2】调用attach方法,内部会初始化Window相关信息
activity.attach(appContext, this, getInstrumentation(), r.token,
r.ident, app, r.intent, r.activityInfo, title, r.parent,
r.embeddedID, r.lastNonConfigurationInstances, config,
r.referrer, r.voiceInteractor, window, r.configCallback,
r.assistToken);
……
if (r.isPersistable()) {
// 【关键点3】调用Activity的onCreate方法
mInstrumentation.callActivityOnCreate(activity, r.state, r.persistentState);
} else {
mInstrumentation.callActivityOnCreate(activity, r.state);
}
……
}
……
return activity;
}performLaunchActivity中主要是创建了Activity对象,并且调用了onCreate方法。
onCreate流程中的setContentView只是解析了xml,初始化了DecorView,创建了各个控件的对象;即将xml中的 转化为一个TextView对象。并没有启动View的绘制流程。
上面走完了onCreate,接下来看onResume生命周期,同样是在ActivityThread中的performResumeActivity
@Override
public void handleResumeActivity(IBinder token, boolean finalStateRequest, boolean isForward,
String reason) {
……
// 【关键点1】performResumeActivity 中会调用activity的onResume方法
final ActivityClientRecord r = performResumeActivity(token, finalStateRequest, reason);
……
final Activity a = r.activity;
……
if (r.window == null && !a.mFinished && willBeVisible) {
r.window = r.activity.getWindow();
View decor = r.window.getDecorView();
decor.setVisibility(View.INVISIBLE); // 设置不可见
ViewManager wm = a.getWindowManager();
WindowManager.LayoutParams l = r.window.getAttributes();
a.mDecor = decor;
……
if (a.mVisibleFromClient) {
if (!a.mWindowAdded) {
a.mWindowAdded = true;
// 【关键点2】在这里,开始做View的add操作
wm.addView(decor, l);
} else {
……
a.onWindowAttributesChanged(l);
}
}
} else if (!willBeVisible) {
……
}
……
}handleResumeActivity中两个关键点
- 调用
performResumeActivity, 该方法中r.activity.performResume(r.startsNotResumed, reason);会调用Activity的onResume方法。 - 执行完Activity的
onResume后调用了wm.addView(decor, l);,到这里,开始将此前创建的DecorView添加到视图中,也就是在这之后才开始布局的绘制流程
到这里,我们应该就能理解,为何onCreate和onResume中无法获取View的宽高了,一句话就是:View的绘制要晚于onResume。
问题2、为什么View.post为什么可以获取View宽高?
那接下来我们开始看第二个问题,先看看View.post的实现。
public boolean post(Runnable action) {
final AttachInfo attachInfo = mAttachInfo;
// 添加到AttachInfo的Handler消息队列中
if (attachInfo != null) {
return attachInfo.mHandler.post(action);
}
// 加入到这个View的消息队列中
getRunQueue().post(action);
return true;
}post方法中,首先判断attachInfo成员变量是否为空,如果不为空,则直接加入到对应的Handler消息队列中。否则走getRunQueue().post(action);
从Attach字面意思来理解,其实就可以知道,当View执行attach时,才会拿到mAttachInfo, 因此我们在onResume或者onCreate中调用view.post(),其实走的是getRunQueue().post(action)。
接下来我们看一下mAttachInfo在什么时机才会赋值。
在View.java中
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
}dispatch相信大家都不会陌生,分发;那么一定是从根布局上开始分发的,我们可以全局搜索,可以看到
不要问为什么一定是这个,因为我看过,哈哈哈
其实ViewRootImpl就是一个布局管理器,这里面有很多内容,可以多看看。
在ViewRootImpl中直接定位到performTraversals方法中;这个方法一定要了解,而且特别长,下面我抽取几个关键点。
private void performTraversals() {
……
// 【关键点1】分发mAttachInfo
host.dispatchAttachedToWindow(mAttachInfo, 0);
……
//【关键点2】开始测量
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
……
//【关键点3】开始布局
performLayout(lp, mWidth, mHeight);
……
// 【关键点4】开始绘制
performDraw();
……
}再强调一遍,这个方法很长,内部很多信息,但其实总结来看,就是View的绘制流程,上面的【关键点2、3、4】。也就是这个方法执行完成之后,我们就能拿到View的宽高了;到这里,我们终于看到和View的宽高相关的东西了。
但还没结束,我们post出去的任务,什么时候执行呢,上面host可以看成是根布局,一个ViewGroup,通过一层一层的分发,最后我们看看View的dispatchAttachedToWindow方法。
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
……
// Transfer all pending runnables.
if (mRunQueue != null) {
mRunQueue.executeActions(info.mHandler);
mRunQueue = null;
}
}这里可以看到调用了mRunQueue.executeActions(info.mHandler);
public void executeActions(Handler handler) {
synchronized (this) {
final HandlerAction[] actions = mActions;
for (int i = 0, count = mCount; i < count; i++) {
final HandlerAction handlerAction = actions[i];
handler.postDelayed(handlerAction.action, handlerAction.delay);
}
mActions = null;
mCount = 0;
}
}这就很简单了,就是将post中的Runnable,转移到mAttachInfo中的Handler, 等待接下来的调用执行。
这里要结合Handler的消息机制,我们post到Handler中的消息,并不是立刻执行,不要认为我们是先dispatchAttachedToWindow的,后执行的测量和绘制,就没办法拿到宽高。实则不是,我们只是将Runnable放到了handler的消息队列,然后继续执行后面的内容,也就是绘制流程,结束后,下一个主线程任务才会去取Handler中的消息,并执行。
结论
- onCreate和onResume中无法获取View的宽高,是因为还没执行View的绘制流程。
- view.post之所以能够拿到宽高,是因为在绘制之前,会将获取宽高的任务放到Handler的消息队列,等到View的绘制结束之后,便会执行。
水平有限,若有不当,请指出!!!
链接:https://juejin.cn/post/7202231477253095479
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
祖传代码重构:从25万行到5万行的血泪史
背景
一、接手
7 月份组织架构调整后,我们组接手了搜索链路中的 Query 理解基础模块,包括本次重构对象 Query Optimizer,负责 query 的分词、词权、紧密度、意图识别。
二、为什么重构
面对一份 10年+ 历史包袱较重的代码,大多数开发者认为“老项目和人有一个能跑就行”,不愿意对其做较大的改动,而我们选择重构,主要有这些原因:
1.生产工具落后,无法使用现代 C++,多项监控和 TRACE 能力缺失
2.单进程内存消耗巨大——114G
3.服务不定期出现耗时毛刺
4.进程启动需要 18 分钟
5.研效低下,一个简单的功能需要开发 3 人天
基于上述原因,也缘于我们热爱挑战、勇于折腾,我们决定进行拆迁式的重构。
编码实现
一、重写与复用
我们对老 QO 的代码做分析,综合考虑三个因素:是否在使用、是否Query理解功能、是否高频迭代,将代码拆分为四种处理类型:1、删除;2、lib库引入;3、子仓库引入;4、重写引入。
二、整体架构
老服务代码架构堪称灾难,整体遵守“想到哪就写到哪,需要啥就拷贝啥”的设计原则,完全不考虑单一职责、接口隔离、最少知识、模块化、封装复用等。下图介绍老服务的抽象架构:
请求进来先后执行 3 次分词:
1.不带标点符号的分词结果,用于后续紧密度词权算子的计算输入;
2.带标点符号的分词结果,用于后续基于规则的意图算子的计算输入;
3.不带标点符号的分词结果,用于最终结果 XML queryTokens 字段的输出。
1 和 3 的唯一区别,就是调用内核分词的代码位置不同。
下一个环节,请求 Query 分词时,分词接口中竟然包含了 RPC 请求下游 GPU 模型服务获取意图。这是此服务迭代最频繁的功能块,当想要实验模型调整、增减意图时,需要在 QO 仓库进行实验参数解析,将参数万里长征传递到 word_segmentor 仓库的分词接口里,再根据参数修改 RPC 意图调用逻辑。一个简单参数实验,要修改 2个仓库中的多个模块。设计上不符合模块内聚的设计原理,会造成霰弹式代码修改,影响迭代效率,又因为 Query 分词是处理链路中的耗时最长步骤,不必要的串行增加了服务耗时,可谓一举三失。
除此之外,老服务还有其他各类问题:多个函数超过一千行,圈复杂度破百,接口定义 50 多个参数并且毫无注释,代码满地随意拷贝,从以下 CodeCC 扫描结果可见一斑:
新的服务求追架构合理性,确保:
1.类和函数实现遵守单一职责原则,功能内聚;
2.接口设计符合最少知识原则,只传入所需数据;
3. 每个类、接口都附上功能注释,可读性高。
项目架构如下:
CodeCC 扫描结果:
三、核心实现
老服务的请求处理流程:
老服务采用的是原始的线程池模型。服务启动时初始化 20 条线程,每条线程分别持有自身的分词和意图对象,监听任务池中的任务。服务接口收到请求则投入任务池,等待任意一条线程处理。单个请求的处理基本是串行执行,只少量并行处理了几类意图计算。
新服务中,我们实现了一套基于 tRPC Fiber 的简单 DAG 控制器:
1.用算子数初始化 FiberLatch,初始化算子任务间的依赖关系
2.StartFiberDetached 启动无依赖的算子任务,FiberLatch Wait 等待全部算子完成
3.算子任务完成时,FiberLatch -1 并更新此算子的后置算子的前置依赖数
4.计算前置依赖数规 0 的任务,StartFiberDetached 启动任务
通过 DAG 调度,新服务的请求处理流程如下,最大化的提升了算子并行度,优化服务耗时:
DIFF 抹平
完成功能模块迁移开发后,我们进入 DIFF 测试修复期,确保新老模块产出的结果一致。原本预计一周的 DIFF 修复,实际花费三周。解决掉逻辑错误、功能缺失、字典遗漏、依赖版本不一致等问题。如何才能更快的修复 DIFF,我们总结了几个方面:DIFF 对比工具、DIFF 定位方法、常见 DIFF 原因。
一、DIFF 比对工具
工欲善其事必先利其器,通过比对工具找出存在 DIFF 的字段,再针对性地解决。由于老服务对外接口使用 XML 协议,我们开发基于 XML 比对的 DIFF 工具,并根据排查时遇到的问题,为工具增加了一些个性选项:基于XML解析的DIFF工具。
我们根据排查时遇到的问题为工具增加了一些个性选项:
1.支持线程数量与 qps 设置(一些 DIFF 问题可能在多线程下才能复现);
2.支持单个 query 多轮比对(某些模块结果存在一定波动,譬如下游超时了或者每次计算浮点数都有一定差值,初期排查对每个query可重复请求 3-5 轮,任意一轮对上则认为无 DIFF ,待大块 DIFF 收敛后再执行单轮对比测试);
3.支持忽略浮点数漂移误差;
4.在统计结果中打印出存在 DIFF 的字段名、字段值、原始 query 以便排查、手动跟踪复现。
二、DIFF 定位方法
获取 DIFF 工具输出的统计结果后,接下来就是定位每个字段的 DIFF 原因。
逻辑流梳理确认
梳理计算该字段的处理流,确认是否有缺少处理步骤。对流程的梳理也有利于下面的排查。
对处理流的多阶段查看输入输出
一个字段的计算在处理流中一定是由多个阶段组成,检查各阶段的输入输出是否一致,以缩小排查范围,再针对性地到不一致的阶段排查细节。
例如原始的分词结果在 QO 上是调用分词库获得的,当发现最后返回的分词结果不一致时,首先查看该接口的输入与输出是否一致,如果输入输出都有 DIFF,那说明是请求处理逻辑有误,排查请求处理阶段;如果输出无 DIFF,但是最终结果有DIFF,那说明对结果的后处理中存在问题,再去排查后处理阶段。以此类推,采用二分法思想缩小排查范围,然后再到存在 DIFF 的阶段细致排查、检查代码。
查看 DIFF 常见有两种方式:日志打印比对, GDB 断点跟踪。采用日志打印的话,需要在新老服务同时加日志,发版启动服务,而老服务启动需要 18 分钟,排查效率较低。因此我们在排查过程中主要使用 GDB 深入到 so 库中打断点,对比变量值。
三、常见 DIFF 原因
外部库的请求一致,输出不一致
这是很头疼的 case,明明调用外部库接口输入的请求与老模块是完全一致的,但是从接口获取到的结果却是不一致,这种情况可能有以下原因:
1.初始化问题:遗漏关键变量初始化、遗漏字典加载、加载的字典有误,都有可能会造成该类DIFF,因为外部库不一定会因为遗漏初始化而返回错误,甚至外部库的初始化函数加载错字典都不一定会返回 false,所以对于依赖文件数据这块需要细致检查,保证需要的初始化函数及对应字典都是正确的。
有时可能知道是初始化有问题,但找不到是哪里初始化有误,此时可以用 DIFF 的 query,深入到外部库的代码中去,新老两模块一起单步调试,看看结果从哪里开始出现偏差,再根据那附近的代码推测出可能原因。
2.环境依赖:外部库往往也会有很多依赖库,如果这些依赖库版本有 DIFF,也有可能会造成计算结果 DIFF。
外部库的输出一致,处理后结果不一致
这种情况即是对结果的后处理存在问题,如果确认已有逻辑无误,那可能原因是老模块本地会有一些调整逻辑 或 屏蔽逻辑,把从外部库拿出来原始结果结合其他算子结果进行本地调整。例如老 QO 中的百科词权,它的原始值是分词库出的词权,结合老 QO 本地的老紧密度算子进行了 3 次结果调整才得到最终值。
将老模块代码重写后输出不一致
重构过程中对大量的过时写法做重写,如果怀疑是重写导致的 DIFF,可以将原始函数替代掉重写的函数测一下,确认是重写函数带来的 DIFF 后,再细致排查,实在看不出可以在原始函数上一小块一小块的重写。
请求输入不一致
可能原因包括:
1.缺少 query 预处理逻辑:例如 QO 输入分词库的 query 是将原始 query 的各短语经过空格分隔的,且去除了引号;
2.query 编码有误:例如 QO 输入分词库的 query 的编码流程经过了:utf16le → gb13080 → gchar_t (内部自定义类型) → utf16le → char16_t;
3.缺少接口请求参数。
预期内的随机 DIFF
某些库/业务逻辑自身存在预期内的不稳定,譬如排序时未使用 stable_sort,数组元素分数一致时,不能保证两次计算得出的 Top1 是同一个元素。遇到 DIFF 率较低的字段,需根据最终结果的输入值,结果计算逻辑排除业务逻辑预期内的 DIFF。
coredump 问题修复
在进行 DIFF 抹平测试时,我们的测试工具支持多线程并发请求测试,等于同时也在进行小规模稳定性测试。在这段期间,我们基本每天都能发现新的 coredump 问题,其中部分问题较为罕见。下面介绍我们遇到的一些典型 CASE。
一、栈内存被破坏,变量值随机异常
如第 2 章所述,分词库属于不涉及 RPC 且未来不迭代的模块,我们将其在 GCC 8.3.1 下编译成 so 引入。在稳定性测试时,进程会在此库的多个不同代码位置崩溃。没有修改一行代码挂载的 so,为什么老 QO 能稳定运行,而我们会花式 coredump?本质上是因为此代码历史上未重视编译告警,代码存在潜藏漏洞,升级 GCC 后才暴露出来,主要是如下两种漏洞:
1.定义了返回值的函数实际没有 return,栈内存数据异常。
2.sprintf 越界,栈内存数据异常。
排查这类问题时,需要综合上下文检查。以下图老 QO 代码为例:
sprintf 将数字以 16 进制形式输出到 buf_1 ,输出内容占 8 个字节,加上 '\0' 实际需 9 个字节,但 buf_1 和 buf_2 都只申请了 8 个字节的空间,此处将栈内存破坏,栈上的变量 query_words 值就异常了。
异常的表现形式为,while 循环的第一轮,query_words 的数组大小是 x,下一轮 while 循环时,还没有 push 元素,数组大小就变成了 y,因内存被写坏,导致异常新增了 y - x 个不明物体。在后续逻辑中,只要访问到这几个异常元素,就会发生崩溃。
光盯着 query_words 数组,发现不了问题,因为数组的变幻直接不符合基本法。解决此类问题,需联系上下文分析,最好是将代码单独提取出来,在单元测试/本地客户端测试复现,缩小代码范围,可以更快定位问题。而当代码量较少,编译器的 warning 提示也会更加明显,辅助我们定位问题。
上段代码的编译器提示信息如下:(开启了 -Werror 编译选项)
二、请求处理中使用了线程不安全的对象
在代码接手时,我们看到了老的分词模块“怪异”的初始化姿势:一部分数据模型的初始化函数定义为 static 接口,在服务启动时全局调用一次;另一部分则定义为类的 public 接口,每个处理线程中构造一个对象去初始化,为什么不统一定义为 static,在服务启动时进行初始化?每个线程都持有一个对象,不是会浪费内存吗?没有深究这些问题,我们也就错过了问题的答案:因为老的分词模块是线程不安全的,一个分词对象只能同时处理一个请求。
新服务的请求处理实现是,定义全局管理器,管理器内挂载一个唯一分词对象;请求进来后统一调用此分词对象执行分词接口。当 QPS 稍高,两个请求同时进入到线程不安全的函数内部时,就可能把内存数据写坏,进而发生 coredump。
为解决此问题,我们引入了 tRPC 内支持任务窃取的 MQ 线程池,利用 c++11 的 thread_local 特性,为线程池中的每个线程都创建线程私有的分词对象。请求进入后,往线程池内抛入分词任务,单个线程同时只处理一个请求,解决了线程安全问题。
三、tRPC 框架使用问题
函数内局部变量较大 && v0.13.3 版 tRPC 无法正确设置栈大小
稳定性测试过程中,我们发现服务会概率性的 coredump 在老朋友分词 so 里,20 个字以内的 Query 可以稳定运行,超过 20 个字则有可能会崩溃,但老服务的 Query 最大长度是 40 个字。从代码来看,函数中根据 Query 长度定义了不同长度的字节数组,Query 越长,临时变量占据内存越大,那么可能是栈空间不足,引发的 coredump。
根据这个分析,我们首先尝试使用 ulimit -s 命令调整系统栈大小限制,毫无效果。经过在码客上搜寻,了解到 tRPC Fiber 模型有独立的 stack size 参数,我们又满怀希望的给框架配置加上了 fiber stack size 属性,然而还是毫无效果。
无计可施之下,我们将崩溃处相关的函数提取到本地,分别用纯粹客户端(不使用 tRPC), tRPC Future 模型, tRPC Fiber 模型承载这段代码逻辑,循环测试。结果只有 Fiber 模型的测试程序会崩溃,而 Future / 本地客户端的都可以稳定运行。
最后通过在码客咨询,得知我们选用的框架版本 Fiber Stack Size 设置功能恰好有问题,无法正确设置为业务配置值,升级版本后,问题解决。
Redis 连接池模式,不能同时使用一应一答和单向调用的接口
我们尝试打开结果缓存开关后,“惊喜”的发现新的 coredump,并且是 core 在了 tRPC 框架层。与 tRPC 框架开发同事协作排查,发现原因是 Redis 采取连接池模式连接时,不可同时使用一应一答接口和单向调用接口。而我们为了极致性能,在读取缓存执行 Get 命令时使用的是一应一答接口,在缓存更新执行 Set 命令时,采用的是单向调用方式,引发了 coredump。
快速解决此问题,我们将缓存更新执行 Set 命令也改为了应答调用,后续调优再改为异步 Detach 任务方式。
重构效果
最终,我们的成果如下:
【DIFF】
- 算子功能结果无 DIFF
【性能】
- 平均耗时:优化 28.4% (13.01 ms -> 9.31 ms)
- P99 耗时:优化 16.7%(30ms -> 25ms)
- 吞吐率:优化 12%(728qps—>832qps)
【稳定性】
- 上游主调成功率从 99.7% 提升至 99.99% ,消除不定期的 P99 毛刺问题
- 服务启动速度从 18 分钟 优化至 5 分钟
- 可观察可跟踪性提升:建设服务主调监控,缓存命中率监控,支持 trace
- 规范研发流程:单元测试覆盖率从 0% 提升至 60%+,建设完整的 CICD 流程
【成本】
- 内存使用下降 40 G(114 GB -> 76 GB)
- CPU 使用率:基本持平
- 代码量:减少 80%(25 万行—> 5万行)
【研发效率】
- 需求 LeadTime 由 3 天降低至 1 天内
附-性能压测:
(1)不带cache:新 QO 优化平均耗时 26%(13.199ms->9.71ms),优化内存 32%(114.47G->76.7G),提高吞吐率 10%(695qps->775qps)
(2)带cache:新 QO 优化平均耗时 28%(11.15ms->8.03ms),优化内存 33%(114G->76G),提高吞吐率 12%(728qps->832qps)
腾讯工程师技术干货直达:
链接:https://juejin.cn/post/7173485990252642334
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
兔兔按钮——安卓悬浮按钮
前言
安卓的Material库提供了许多样式更精美的控件,其中就有悬浮控件,它表现出一种悬浮在页面的效果,也就是有立体效果的,让人产生这种控件是另一个维度而不是这个维度的感觉,下面我们就来看看兔兔按钮。
正篇
实现过程
首先我们在布局中加上我们的FloatingActionButton控件:
<com.google.android.material.floatingactionbutton.FloatingActionButton
android:id="@+id/fab"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="bottom|end"
android:layout_margin="16dp"
android:src="@drawable/rabbit_logo" />这样预览页面就会出现一个悬浮的圆形按钮,上面是我们的兔兔图案,而且这个控件是出现在屏幕的右下角,接着我们为其增加点击效果:
binding.fab.setOnClickListener {
"FAB Rabbit!".showToast(context)
}其中Toast用到了我们之前文章中的简化方法(安卓开发基础——简化Toast调用方法 - 掘金 (juejin.cn))
运行程序后,我们就可以点击这个兔兔按钮,浮现一句"FAB Rabbit!"的提示。
写的过程很简单,因为其实它的本质还是Button,不过是对其样式进行了不同的改变,有了质感和阴影,使其呈现出浮现的效果。
当然,我们也可以去改变阴影效果的呈现程度:
app:elevation="8dp"我们在XML布局中该控件控制elevation属性,就能为FloatingActionButton指定一个高度,其中,高度值越大,投影范围越大,但投影效果越淡,而高度越小,投影范围越小,反而投影效果越浓。
总结
Material库的确让安卓很多控件效果不一样,但在我们工作设计中还是很少去用它的,因为它的独特效果在公司自己的UI设计师与产品眼中说不定最终还不如和IOS一致好。
链接:https://juejin.cn/post/7197769661455106107
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android深思如何防止快速点击
前言
其实快速点击是个很好解决的问题,但是如何优雅的去解决确是一个难题,本文主要是记录一些本人通过解决快速点击的过程中脑海里浮现的一些对这个问题的深思。
1. AOP
可以通过AOP来解决这个问题,而且AOP解决的方法也很优雅,在开源上也应该是能找到对应的成熟框架。
AOP来解决这类问题其实是近些年一个比较好的思路,包括比如像数据打点,通过AOP去处理,也能得到一个比较优雅的效果。牛逼的人甚至可以不用别人写的框架,自己去封装就行,我因为对这个技术栈不熟,这里就不献丑了。
总之,如果你想快速又简单的处理这种问题,AOP是一个很好的方案
2. kotlin
使用kotlin的朋友有福了,kotlin中有个概念是扩展函数,使用扩展函数去封装放快速点击的操作逻辑,也能很快的实现这个效果。它的好处就是突出两个字“方便”
那是不是我用java,不用kotlin就实现不了kotlin这个扩展函数的效果?当然不是了。这让我想到一件事,我也有去看这类问题的文章,看看有没有哪个大神有比较好的思路,然后我注意到有人就说用扩展函数就行,不用这么麻烦。
OK,那扩展函数是什么?它的原理是什么?不就是静态类去套一层吗?那用java当然能实现,为什么别人用java去封装这套逻辑就是麻烦呢?代码不都是一样,只不过kotlin帮你做了而已。所以我觉得kotlin的扩展函数效果是方便,但从整体的解决思路上看,缺少点优雅。
3. 流
简单来说也有很多人用了Rxjava或者kotlin的flow去实现,像这种实现也就是能方便而已,在底层上并没有什么实质性的突破,所以就不多说了,说白了就是和上面一样。
4. 通过拦截
因为上面已经说了kt的情况,所以接下来的相关代码都会用java来实现。
通过拦截来达到防止快速点击的效果,而拦截我想到有2种方式,第一种是拦截事件,就是基于事件分发机制去实现,第二种是拦截方法。
相对而言,其实我觉得拦截方法会更加安全,举个场景,假如你有个页面,然后页面正在到计算,到计算完之后会显示一个按钮,点击后弹出一个对话框。然后过了许久,改需求了,改成到计算完之后自动弹出对话框。但是你之前的点击按钮弹出对话框的操作还需要保留。那就会有可能因为某些操作导致到计算完的一瞬间先显示按钮,这时你以迅雷不及掩耳的速度点它,那就弹出两次对话框。
(1)拦截事件
其实就是给事件加个判断,判断两次点击的时间如果在某个范围就不触发,这可能是大部分人会用的方式。
正常情况下我们是无法去入侵事件分发机制的,只能使用它提供的方法去操作,比如我们没办法在外部影响dispatchTouchEvent这些方法。当然不正常的情况下也许可以,你可以尝试往hook的方向去思考能不能实现,我这边就不思考这种情况了。
public class FastClickHelper {
private static long beforeTime = 0;
private static Map<View, View.OnClickListener> map = new HashMap<>();
public static void setOnClickListener(View view, View.OnClickListener onClickListener) {
map.put(view, onClickListener);
view.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
long clickTime = SystemClock.elapsedRealtime();
if (beforeTime != 0 && clickTime - beforeTime < 1000) {
return;
}
beforeTime = clickTime;
View.OnClickListener relListener = map.get(v);
if (relListener != null) {
relListener.onClick(v);
}
}
});
}
}简单来写就是这样,其实这个就和上面说的kt的扩展函数差不多。调用的时候就
FastClickHelper.setOnClickListener(view, this);但是能看出这个只是针对单个view去配置,如果我们想其实页面所有view都要放快速点击,只不过某个view需要快速点击,比如抢东西类型的,那肯定不能防。所以给每个view单独去配置就很麻烦,没关系,我们可以优化一下
public class FastClickHelper {
private Map<View, Integer> map;
private HandlerThread mThread;
public void init(ViewGroup viewGroup) {
map = new ConcurrentHashMap<>();
initThread();
loopAddView(viewGroup);
for (View v : map.keySet()) {
v.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN) {
int state = map.get(v);
if (state == 1) {
return true;
} else {
map.put(v, 1);
block(v);
}
}
return false;
}
});
}
}
private void initThread() {
mThread = new HandlerThread("LAZY_CLOCK");
mThread.start();
}
private void block(View v) {
// 切条线程处理
Handler handler = new Handler(mThread.getLooper());
handler.postDelayed(new Runnable() {
@Override
public void run() {
if (map != null) {
map.put(v, 0);
}
}
}, 1000);
}
private void exclude(View... views) {
for (View view : views) {
map.remove(view);
}
}
private void loopAddView(ViewGroup viewGroup) {
for (int i = 0; i < viewGroup.getChildCount(); i++) {
if (viewGroup.getChildAt(i) instanceof ViewGroup) {
ViewGroup vg = (ViewGroup) viewGroup.getChildAt(i);
map.put(vg, 0);
loopAddView(vg);
} else {
map.put(viewGroup.getChildAt(i), 0);
}
}
}
public void onDestroy() {
try {
map.clear();
map = null;
mThread.interrupt();
} catch (Exception e) {
e.printStackTrace();
}
}
}我把viewgroup当成入参,然后给它的所有子view都设置,因为onclicklistener比较常用,所以改成了设置setOnTouchListener,当然外部如果给view设置了setOnTouchListener去覆盖我这的set,那就只能自己做特殊处理了。
在外部直接调用
FastClickHelper fastClickHelper = new FastClickHelper();
fastClickHelper.init((ViewGroup) getWindow().getDecorView());如果要想让某个view不要限制快速点击的话,就调用exclude方法。这里要注意使用完之后释放资源,要调用onDestroy方法释放资源。
关于这个部分的思考,其实上面的大家都会,也基本是这样去限制,但是就是即便我用第二种代码,也要每个页面都调用一次,而且看起来,多少差点优雅。
首先我想的办法是在事件分发下发的过程去做处理,就是在viewgroup的dispatchTouchEvent或者onInterceptTouchEvent这类方法里面,但是我简单看了源码是没有提供方法出来的,也没有比较好去hook的地方,所以只能暂时放弃思考在这个下发流程去做手脚。
补充一下,如果你是自定义view,那肯定不会烦恼这个问题,但是你总不能所有的view都做成自定义的吧。
其次我想怎么能通过不写逻辑代码能实现这个效果,但总觉得这个方向不就是AOP吗,或者不是通过开发层面,在开发结束后想办法去注入字节码等操作,我觉得要往这个方向思考的话,最终的实现肯定不是代码层面去实现的。
(2)拦截方法
上面也说了,相对于拦截事件,假设如果都能实现的情况下,我更倾向于去拦截方法。
因为从这层面上来说,如果实现拦截方法,或者说能实现中断方法,那就不只是能做到防快速点击,而是能给方法去定制相对应的规则,比如某个方法在1秒的间隔内只能调用一次,这个就是防快速点击的效果嘛,比如某个方法我限制只能调一次,如果能实现,我就不用再额外写判断这个方法调用一次过后我设置一个布尔类型,然后下次调用再判断这个布尔类型来决定是否调用,
那现在是没办法实现拦截方法吗?当然有办法,只不过会十分的不优雅,比如一个方法是这样的。
public void fun(){
// todo 第1步
// todo 第2步
// todo ......
// todo 第n步
}那我可以封装一个类,里面去封装一些策略,然后根据策略再去决定方法要不要执行这些步骤,那可能就会写成
public void fun(){
new FunctionStrategy(FunctionStrategy.ONLY_ONE, new CallBack{
@Override
public void onAction() {
// todo 第1步
// todo 第2步
// todo ......
// todo 第n步
}
})
}这样就实现了,比如只调用一次,具体的只调用一次的逻辑就写在FunctionStrategy里面,然后第2次,第n次就不会回调。当然我这是随便乱下来表达这个思路,现实肯定不能这样写。首先这样写就很不优雅,其次也会存在很多问题,扩展性也很差。
那在代码层面还有其它办法拦截或者中断方法吗,在代码层还真有办法中断方法,没错,那就是抛异常,但是话说回来,你也不可能在每个地方都try-catch吧,不切实际。
目前对拦截方法或者中断方法,我是没想到什么好的思路了,但是我觉得如果能实现,对防止快速点击来说,肯定会是一个很好的方案。
链接:https://juejin.cn/post/7197337416096055351
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
KMP—仅需一套代码,使用kotlin也能一站式搭建android, 桌面端,和web端app!
截止上周(本文写于2023.02.07),JetBrains推出Compose跨平台已经发布了1.3.0版本,可以说是很稳定了。很明显这也是跨平台UI的一个很好的方案。
如果你还不了解Compose Multiplatform是什么, 也可以直接参考官网的JetBrains 网站的『长懒看』说明,一句话就是:
Fast reactive Desktop and Web UI framework for Kotlin,JetBrain公司基于Google的 先进工具套件compose,为开发者打造了一套快速响应的桌面端的web端 UI框架,可以完全使用kotlin开发。
因为和jetpack Compose绑定到一起了,相信大部分android 开发者一下子就明白:我们现在可以直接仅用kotlin就打造全平台跨平台的app了。
老哥,为啥不用flutter呢?有区别么?
其实二者还是有相当大的不同的。Kotlin跨平台技术(后文称KMP)和flutter相比,最主要的优势就是不用再学一个新的语言Dart了,直接用koltin就可以搞定,降低了学习成本。除此之外,我还发现了一个有趣的不同之处——他们处理跨平台架构的方案完全不同。
使用Flutter的时候,你需要先写好基础的 业务逻辑、UI逻辑,都只写一次,之后这些基础逻辑就能在不同的平台上直接运行了。你也可以继续写一些对不同平台的适配代码,来优化在特定平台运行的兼容性效果。但,无论你怎么写,真正运行到移动设备、桌面app或者是网页端的时候,你的程序还是由Flutter引擎(由Skia图像处理库构建的引擎)渲染出来而不是直接在操作系统层级渲染的。这就导致它的可移植性很好,但是UI效果并不好,和原生效果还是有些差距。
然而,使用KMP的话,你的业务逻辑还是只写一次,但是后面的UI界面,你需要使用kotlin对目标平台分别编写。虽然大多都可以使用kt语言,但是写法还是有区别的。比如,写android就需要用jetpack Compose框架,iOS就用swift写,桌面端就用compose Multiplatform写,等等。因此,你的app最终会有一个更接近原生的UI效果 —— 只是可移植性就差一些。
最重要的是,这两者提供了不同的方法,怎么用还是得看你的业务场景。
说实话,整体来说还是KMP听起来更好,信我!
理论到此为止!说了这么久,让你有一个初步的感受。但让我们暂时把理论放在一边,关注『怎么用』
新建一个Demo APP
还是得实操一下,要决定开发点什么东西,才能展示所有要了解的实战内容。 Flutter 也有“Hello World” 项目,从这找点儿灵感,制作一个计数器应用程序,允许用户递增和递减一个数值,并记录最新注册的操作是什么。
想要实现上图这个app,我们得决定好使用什么样的架构
选取架构
我们将使用 干净架构(MVVM),这是构建 GUI 应用程序(尤其是在 Android 上)的常用解决方案。 写Android的肯定是对这个架构老生常谈啦。如果你不太了解这个架构,而且感兴趣,也可以先关掉页面去研究一下~比如这个链接-Android干净架构教程
好了,到这就可以开始开工了!我们会用如下几个砖块,构建堆砌我们的app:
Domain:就是Model层,正常应该包括app的全部model,但是这个比较简单,只需要一个data class数据类。
Data:我们的抽象数据源,就是保存这个计数器app的数据的。
Use Cases:所有的用例类,就是:递增计数器、递减计数器并获取其值的方法。
Presentation:界面对应的viewModel,梳理页面操作逻辑。
Framework:数据源实现以及每个平台的用户界面。
注意:上述所有『砖块』,除了只有Framework里面的UI部分,都是可以跨平台复用的。
开始写代码吧
好了,现在可以开始写代码了,我们用Intellij Idea作为示例IDE,如果你用其他惯用IDE也可以找到类似的操作方式。
先创建一个工程,从上面罗列出来的架构开始实现。一个一个类的慢慢写,直到写完全部的平台内容。 Idea这个IDE提供了一些预先构建好的KMP模型应用,我们可以直接使用。不过为了更好的学会内容,我们就先从头开始写吧。
打开IDEA,点击 File > New Project(我的是英文环境,中文类似)。
填上你自己的项目名字就可以运行了。
模块
创建好项目后,第一件事儿,就得创建一下不同的module: common、android、desktop、web。我们就从最基本的common开始写,写好了其他module也可以依赖它。
这时候直接在根目录右键,new module,选择compose MultiPlatform。直接就可以创建相关的模块
创建成功的效果如下:
修改根目录的gradle.properties文件如下:
kotlin.code.style=official
android.useAndroidX=true
kotlin.mpp.enableGranularSourceSetsMetadata=true
kotlin.native.enableDependencyPropagation=false
android.enableJetifier=true这个时候编译应该会很漫长,可以先等待,稍后我们会开始创建数据源集合。
数据集
因为compose的模板已经创建好了相关文件夹,但是需要思考一个问题:
不是说common模块应该是跨平台的嘛?为什么还要在里面创建desktop和android?
可以假定一个虚构的使用场景:你正在开发一个跨平台的app,但是你也需要获取到一些,不同平台特有的API。比如:获取系统版本,连接到底层的日志系统,或者是生成随机的uuid等功能。
KMP还是允许一些简单的方式去获取上面这些底层架构功能的嗯。你可以像如下操作:
// Under Common
expect fun randomUUID(): String// Under Android
import java.util.*
actual fun randomUUID() = UUID.randomUUID().toString()// And so on for all other platforms当然了,这些复杂的底层操作在我们的简单demo中并不会用到~
回到我们的项目中。
可以注意一下我们的compose跨平台module中的 settings.gradle.kts 的文件内容
pluginManagement {
repositories {
google()
gradlePluginPortal()
mavenCentral()
maven("https://maven.pkg.jetbrains.space/public/p/compose/dev")
}
plugins {
kotlin("multiplatform").version(extra["kotlin.version"] as String)
kotlin("android").version(extra["kotlin.version"] as String)
id("com.android.application").version(extra["agp.version"] as String)
id("com.android.library").version(extra["agp.version"] as String)
id("org.jetbrains.compose").version(extra["compose.version"] as String)
}
}
rootProject.name = "composemultidemo"
include(":android", ":desktop", ":common")链接:https://juejin.cn/post/7197714333475553338
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
24 岁技术人不太平凡的一年
一年前,我整夜混迹于魔都淮海中路的酒吧迪厅,而白天,在外滩海景餐厅吃着四位数一顿的西餐。租住的洋房里陈列着各种奢侈品……
一年后,我结婚了,并且买了套房子。
一、魔都
2021 年,是我爸妈非常兴奋的一年。因为那年我去了上海,找了一份年薪 60 几万的工作。他们可以和邻居亲戚们炫耀他们的儿子了。
但我没什么感觉,对我而言,60 万只是手机上的一串数字。而且我知道,60 万并不多。因为那个整日听我汇报的、大腹便便的、看上去不怎么聪明的中年人拿着远比我高的薪水,我和他都一样,只是一条资本家的狗而已。
我一向不打算结婚,也不打算要孩子,也就意味着我不需要存钱。
我不会像我的领导那样为了在上海买一套 1200 万的房子而过得那样抠搜。我可以花一万多租一个小洋房,我可以在家里塞满那些昂贵的电器,我可以每周去国金、恒隆、新天地消费。我会买最新款的苹果全家桶,甚至连手机壳都要买 Lv 的。
但即使这样,钱还是花不完。
别人都因为没钱而烦恼,而我却因为钱花不完而烦恼。
后来,在机缘巧合之下,我开始了绚丽多彩的夜生活。在夜店,只需要花 1 万块钱,就可以当一晚上的王。这种快感是难以描述的。我成了 Myst、LolaClub、Ak、wm、pops 们的常客。开始了一段纸醉金迷的日子。
二、求职
找工作是一件再容易不过的事,因为几乎所有人都有工作。人只要降低要求,就一定能够找到工作。找工作难,是因为你渴望的工作岗位所需要的能力与你当前的能力并不匹配。
刚来到上海的时候,我非常自信,整天到处闲逛。朋友问我为什么不准备面试题?我说没有这种必要,他说不是很理解,我说那算了,不用理解。
因为技术上的知识,就那么多。你有自己的理解,有自己的经验,完全不需要胆怯,也没必要胆怯。合适就去,不合适就再看看。
能否找到好工作,更多的是你和面试官是否聊得来;你所做的事情,是否和这家公司的业务所匹配;你的经历、价值观和这家公司的愿景使命价值观是否契合。
我清楚我的能力究竟如何,我知道我应该去哪种公司。
但我需要了解这些公司的不同。于是我投了很多简历,大小公司都有。像携程、美团、得物、拼多多、小红书、微盟这些公司基本上都有去面试。跑了很多地方,徐家汇、北外滩、五角场、陆家嘴、奉贤岛、静安寺……。
全职面试,一天四五场,很忙。
但不到一周就确定好了 offer。
朋友说我是一个果断的人,我只是觉得没必要消耗时间。
明白自己的能力上限在哪,懂得在合适的环境最大化释放自己的价值。就一定可以收获一份合适的工作,或者说是一份事业。
找到自己的使命,就可战无不胜。
三、爱情
人缺什么,就会去寻找什么。
在 24 岁的年纪里,我缺少的不是梦想、金钱或者使命感,而是爱情。
我遇到了 Emma,她带给我的滋味,与我所有的想象都不一样。
我在上海,她在三亚。我们在相隔千里的城市,我坐着飞机去找她。结果因为晚了几分钟,于是我买了张全价票,硬是要在当天飞过去,因为我等这一天已经等了半个月了。
我们住在三亚的希尔顿。在三亚有两个希尔顿,结果她找错了,去了另一个希尔顿,后来我们很庆幸幸亏没有人开门。
虽然 Emma 笨笨的,但我喜欢她这样。
我们去了亚龙湾、天涯海角和南海观音。
三亚虽然是中国最南方的岛最南侧的城市,但有个外号是东北第四城。前三个是黑龙江、吉林和辽宁。一个城市的名字可能是错的,但外号绝对不会错。海南到处都是东北人。
爱情刚开始都会轰轰烈烈,我会给 Emma 精心挑选手链,去国金帮她挑选面膜,亲手给她写情书,那些情书至今还在我们的衣柜里。后来去全上海只有两个店的 Graff 买了一对情侣对戒。
我不介意给心爱的女人花钱。我觉得,一个男人把钱都花在哪儿了,就知道这个男人的心在哪儿。
当然,认识久了,特别是同居之后,这种轰轰烈烈式的浪漫就会褪去,更多的是生活中的点点滴滴。
有人说过一句话:
和喜欢的人在一起的快乐有两种,一种是一起看电影旅行一起看星星月亮分享所有的浪漫。还有一种则是分吃一盒冰淇淋一起逛超市逛宜家把浪漫落地在所有和生活有关的细节里。
但无论是前者还是后者,我都想和你一起,因为重要的是和你,而不是浪漫。
往事历历在目,虽然现在很难再有当时的那种感觉,可我更享受当下的温馨。
四、旅游
认识 Emma 之后,我们开始养成了旅游的习惯,每个月都会留出两三天时间一起出去旅游。
2 月,去了丽江。爬了玉龙雪山、逛了拉市海和木府。
玉龙雪山真的很神奇,在丽江市任何一个角落,都可以抬头看见白雪皑皑的雪山。
2 月 14 号是情人节,我在丽江的街头给 Emma 买了一束玫瑰。
3 月,我在上海,本来打算去北京,结果发生航变。然后再打算做高铁去杭州西湖,结果杭州顺丰出事了。哪都去不了,只能在上海本地旅游。去了陆家嘴的上海中心大厦。其实很早之前我就和朋友去过一次了,这次去的主要目的是和 Emma 锁同心锁。
我记得我们去的时候,已经是晚上九点五十,工作人员说十点关门,因为疫情原因,明天开始将无限期关停,具体开放时间等通知。如果现在上去,我们只能玩十分钟。没有犹豫,花了四百多买了两张票上去上了把锁。
那时我还不知道,这种繁华将在不久后彻底归于死寂。
后面几天,我们在上海很多地方溜达,外滩、豫园、迪士尼乐园。
迪士尼乐园是上海人流量最大的游乐场,几乎全年都是爆满。但这次疫情期间的迪士尼乐园的游客很少,很多项目都不需要排队。
但那天真的很冷,我们为了看烟花冻得瑟瑟发抖。夜晚的迪士尼城堡真的很美。
4-7 月上海封城,哪儿也没去。
8 月去了博鳌亚洲论坛。如果不是去开会的话,真没什么好玩的。
9 月打算坐轮船去广州徐闻、再坐绿皮火车去拉萨,因为我们认为这样会很浪漫。结果因疫情原因,没办法离开海南,只去了骑驴老街和世纪大桥旁边的云洞书店。
这座书店建在海边,进入看书要提前预约。
实际上没几个看书的,全是美女在拍照。
10 月去了济南大明湖和北京的天安门广场、八大胡同等地方。
很没意思,图我都不想放。
预约了故宫门票,并且打算去八达岭长城。但是在北京土生土长四十年的同事告诉我,他从来没去过故宫,并且不建议去八达岭长城。于是我把故宫的门票退了,并且把八达岭长城的计划也取消了。
11 月一整个月都在忙着买房子的事情,天天跟着中介跑,哪儿也没去。
五、封控、方舱、辞职与离沪
上海疫情暴发,改变了很多事。
这一部分我删掉了,涉及敏感话题。
总结来说就是:封控,挨饿,感染奥密克戎,进方舱,出舱,继续封控。
6 月 1 日,上海终于开放了。
虽然可以离开小区,但离开上海还是很难。
首先我需要收拾家里的东西,然后需要寄回我爸妈家,但当时所有的物流都处于瘫痪状态。当时我也想过直接丢掉,但我的东西真的很多,有二十多个箱子,差不多是我的全部家当了。
再之后需要购买飞机票,但所有的航班都在无限期航变。我给飞机场的工作人员打了很多次电话,没事就问。后来她们有些不耐烦了,告诉我,现在没有一架飞机能从上海飞出去,让我不要再打了。
可我不死心。
最后我选择了乘坐火车。
上海没有直达海口的火车,所以需要在南昌中转。由于我是上海来的,所以当地的政策是要隔离 7 天,除非你不出火车站。上海到南昌的火车是第一天下午到,而南昌到海口的火车是第二天的中午才出发。这也就意味着我要在南昌站睡一晚。而从上海到海口的整个路程,需要花费 3 天。这对以前的我来说是不可思议的。
但爱情赋予我的力量是难以想象的。
我在火车站旁边的超市买了一套被子就上了去南昌的火车,然后躺在按摩椅上睡了一晚。
第四天一大早,我终于到了海南。
六、求职
2022 年,是非常难找工作的。
特别是我准备搬到海南。海南是没有大型互联网公司的,连个月薪上万的工作都找不到。这样估计连自己都养不活。
所以我准备找一份远程工作。相比较于国内,国外远程工作的机会明显更多,可惜我英语不好,连一场基本的面试所需要的词汇都不够。所以我只能找一些国内的远程机会。
机缘巧合之下,终于找到了一家刚在美国融到资的创业公司。
他们需要一位带有产品属性和创造力的前端架构师。前前后后面了大概一周,我成功拿到 offer。这是我第一次加入远程团队。
印象中面试过程中技术相关的点聊了以下几点:
- WebSocket 的弊端。
- Nodejs 的 Stream。
- TLV 相比 JSON 的优劣势。
- HTTP 1.1/2 和 HTTP3(QUIC)的优劣势。
- 对云的看法。
- 真正影响前端性能的点。
- 团队管理方面的一些问题。
因为公司主要业务是做云,所以大多数时间都是在聊云相关的问题。老板是一个拥有 20 年技术背景的老技术人,还是腾讯云 TVP。在一些技术上的观点非常犀利,有自己的独到之处。这一点上我的感受是非常明显的。
全球化边缘云怎么做?
现代应用的性能瓶颈往往不再是渲染性能。但各大前端框架所关注的点却一直是渲染。以至于现代主流前端框架都采用 Island 架构。
但另一个很影响性能的原因是时延。这不仅仅是前端性能的瓶颈,同时也是全球化分布式系统的性能瓶颈。
设想一下,你是做全球化的业务,你的开发团队在芝加哥,所以你在芝加哥买了个机房部署了你们的系统,但你的用户在法兰克福。无论你的系统如何优化,你的用户总是感觉卡顿。因为你们相隔 4000 多英里的物理距离,就一定要遭受 4000 多英里的网络延迟。
那该怎么办呢?很简单,在法兰克福也部署一套一模一样的系统就好了,用户连接距离自己最近的服务器就好了,这样就能避免高网络时延,这就是全球分布式。但如果你的用户也有来自印度的、来自新加坡、来自芬兰的。你该怎么办呢?难道全球 200 多个地区都逐一部署?那样明显不现实,因为成本太高了,99% 的公司都支付不起这笔费用。
所以很多云服务商都提供了全球化的云服务托管,这样就可以以低成本实现上述目标。
但大多数云服务商的做法也并不是在全球那么多地区部署那么多物理服务器。而是在全球主要的十几个地区买十几台 AWS 的裸机就够了。可以以大洲维度划分。有些做得比较好的云服务商可能已经部署了几十个节点,这样性能会更好。
这类云服务商中的一些小而美的团队有 vercel、deno deploy。这也是我们竞争目标之一。
招聘者到底在招什么人?
当时由于各种裁员,大环境不好,面试者非常多,但合适的人又非常少。后来据老板透露,他面试了 48 个人,才找到我。起初我还不信,以为这是常规 PUA,后来我开始负责三面的时候,在面试登记表中发现确实有那么多面试记录。其中竟然有熟人,也有一个前端网红。
后来我总结,很多人抱怨人难招,那他们到底在招什么人?
抛开技术不谈,他们需要有创造力的人。
爱因斯坦说:想象力比知识更重要。想象力是创造力的要素之一,也是创造力的前提。
那些活得不是很实际的人,会比那些活得踏踏实实的人有更大的机会去完成创造。
为什么要抛开技术不谈?因为职业生涯到了一定高度后,已经非唯技术论了。大家的技术都已经到了 80 分以上,单纯谈论技术,已经很难比较出明显差异,这时就要看你能用已有的技术,来做点什么,也就是创造力。这也是为什么我在文中没怎么谈技术面试的原因。
如果将马斯洛需求理论转化为工程师需求理论,那么同样可以有五级:
独立完成系统设计与实现。
具有做产品的悟性,关注易用、性能与稳定。
做极致的产品。对技术、组织能力、市场、用户心理都有很全面深入的理解。代表人物张小龙。
能够给世界带来惊喜的人。代表人物沃兹尼亚克。
推动人类文明进步,开创一个全新行业的人。代表人物马斯克。
绝大多数人都停留在前三个维度上,我也不例外。但我信奉尼采的超人主义,人是可以不断完善自我、超越自我、蜕变与进化的。既然沃兹尼亚克和马斯克能够做到的事情,我为什么不能去做呢?所以我会一直向着他们的方向前进。或许最终我并不能达到那种高度,但我相信我仍然可以做出一些不错的产品。
七、创业
搬到海南之后,时间明显多了起来。不需要上下班通勤,不去夜店酒吧,甚至连下楼都懒得去。三五天出去一次,去小区打一桶纯净水,再去京东超市买一大堆菜和食物,囤在冰箱。如果不好买到的东西,我都会选择网购。我一般会从山姆、网易严选、京东上面网购。
九月份十月份,海南暴发疫情,一共举行了十几轮全员核酸检测,我一轮都没参加。主要是用不到,出不去小区没关系,外卖可以送到小区门口,小区内的京东超市也正常营业,丝毫不影响我的日常起居。
所以我盘算着要做些事情。刚好之前手里经营着几个副业,虽然都没有赚到什么钱。但是局已经布好了。其中一个是互联网 IT 教育机构。是我和我的合伙人在 20 年就开始运营的,现在已经可以在知乎、B 站等渠道花一些营销费用进行招生。我们定价是 4200 一个月(后来涨价到 4800),一期教三个月左右。通过前几期的经验,我们预估,如果一期有十几个人到二十个人报名,就有大概将近 10 万多的收入,还是蛮可观的。所以我准备多花些精力做一下这个教育机构。
培训的内容是前端,目标是零基础就业。因为我在前端这方面有很大的优势,而且当时前端招聘异常火热。初级前端工程师需要掌握的技能也不多,HTML、CSS、JavaScript、Git、Vue,就这么几块内容而已。相比较成型慢的后端,前端是可以速成的,所以我认为这条路非常可行。
我负责的这一期,前期招了将近 20 人。
而下一期还没开课,已经招到了 5 个人。一切都向着好的方向发展。
但很快,十月、十一月左右,招生突然变难了。连知乎上咨询的人都明显变少了。我们复盘了下原因,原来是网上疯传现在是前所未有的互联网寒冬,加上各种大厂裁员的消息频发,搞得人心惶惶。甚至有人扬言,22 年进 IT 行业还不如去养猪。
因为我的合伙人是全职,他在北京生活花费很高,加上前期没有节制地投入营销费用,他已经开始负债了。但是营销费用是不能停的,一旦知+ 停掉,就很难继续招生。
后来经过再三讨论,最终还是决定先停掉。虽然我们笃定 IT 培训是红海,但感觉短期的大环境不行,不适合继续硬撑下去。
目前我带着这期学员即将毕业,而我们也会在 23 年停止招生。
培训的这个过程很累,一边要产出营销内容,一边要完善和设计教材、备课、一边还要批改作业。同时每天完成两个小时的不间断直播授课,不仅仅是对精力的考验,也是对嗓子的考验。
虽然创业未成,但失败是我们成长路上的垫脚石,而且这也谈不上什么失败。
我把经验教训总结如下,希望对你有所启发。
1. 市场和运营太重要了
中国有句谚语叫“酒香不怕巷子深”。意思是如果酒真香,不怕藏于深巷,人们会闻香而至。除了酒,这句话也隐喻好产品自己会说话,真才子自有人赏识。
但实际上,这是大错特错。
随着我阅历、知识、认知的提升,我越发觉得,往往越是这种一说就明白、人人都信的大道理,越是错的。
傅军老师讲过一句话:感受不等于经验、经验不等于知识、知识不等于定律、定律不等于真理。我深受启发。在这个快速发展的信息时代,必须保持独立思考的能力。
我思考的结果是:酒香也怕巷子深。
连可口可乐、路易威登、香奈儿这种世界顶级品牌每年都需要持续不断地花费大量的费用用于营销。由此可见营销的重要性,营销是一定有回报的。
我们的酒要香,同时也不能藏在巷子里。而且,我们的酒不需要特别香,只要不至于苦得无法下咽,就能卖出去。畅销品不一定就是质量好,某些国产品牌的手机就是一个简单的例子。
所以,只需要保证产品是 60 分以上就足够了,剩下的大部分精力都应该放在营销上面。绝大多数只懂得专注于打造 100 分产品的创业公司,基本上都死了。
正确的路径应该是:Poc、Alpha、Beta、MVP。就像下图所示,造车的过程中,产品在任何一个时间点都是可用的。
另外,决定一个公司成功的,一定是运营部或者市场部,绝对不是技术部。但是技术部有可能会让一个公司走向失败。如果一个公司要裁员,技术部门很可能首当其冲。当然这也要看公司文化,但大部分的 Boss 普遍更看重运营与市场。
2. 不要等万事俱备再开始
在创业早期,我们的主要招生渠道是 B 站,但我没有短视频经验。于是我买了暴漫 B 站 UP 主的课程。
本来以为买了课程就意味着学会了做视频,但实际上不是这样的。
做好一个 UP 主需要掌握非常多的知识,选题、文案、表达、拍摄、剪辑、互动,各个环节都有大学问。我很快发现不可能把整个课程全部研究透再去做视频。我需要保持频率地更新视频才能有更多人的关注。
随着业务的发展,后面主战场转到了知乎,工作内容也变成了软文和硬广。UP 主的很多技能还没来得及实践就被搁置了。
知乎也有一个写作训练营,学费大概也要三四千的样子。
我听了试听的三节课,感觉要学习的东西一样很多,所以我没有买这个课程。因为我知道我没有那么多精力。
最重要的是,我发现即使我没有什么技巧和套路,我写的软文一样有很多浏览量和转化率。知+平台的数据可以直接告诉我这篇文章或者回答写得好不好。
同时,很多相关的知识不是一成不变的,它们不是传统知识,需要从实际事物中脚踏实地地学习,我们没办法系统学习。
我们不可能做好所有的准备,但需要先去做。人生也该如此,保持渐进式。
3. 接受糟糕,不要完美主义
初创公司很多东西都是混乱的,缺乏完善的系统和结构,一切似乎都是拍脑袋决定。
报销很混乱、营销费用很混乱、内容管理很混乱、合同很混乱;甚至连招生清单都和实际上课的人对不上……
但我发现这是一个必须接受的现状,如果一切都井井有条,那就不是初创公司了。所以必须要适应这种乱糟糟、混乱的环境。
八、结婚与买房
朋友说我是一个果断的人。
因为从认识,到结婚、买房,一共用了不到一年时间。
其实起初我是强烈不建议买房的,我不看好中国的楼市,而且我们一个月花几千块租房住得非常舒服。而且我的父母在北方的城市也已经有两套房子了。但 Emma 认为没有房子不像个家,没安全感。安全感对一个女人实在太重要了,我想以她对我的了解,她怕我哪天突然悄无声息地就离开她。想了想,确实是这样,所以我就买了。
我们看了海口很多套房子,本来计划买个小两居,但看了几次,都觉得太紧凑了。我是要在家工作的,我有一张很大的双人桌,要单独留一个房间来放它。最后挑了一个三居室的房子。这种感觉和买电脑差不多,本来一台普通 Thinkpad 的预算,最终买了个 MacBookPro 顶配。
房子很漂亮,我们也很喜欢。
不过呢,同时也背负了两百万的贷款。不能再像以前那样随便花钱了。
买房只需要挑房屋布局、装修和地段,其他不需要关心。
买房贷款的注意事项:选择分期,选择还款周期最久的,不要提前还。今年由于疫情原因,房贷大概是 4.5 个点,比前几年要低。买房前保持一年流水,收入大于月供 3 倍。
还需要注意,买完房,还要考虑装修费用和家电的费用。
非刚需不建议买房,刚需的话不会考虑买房的弊端。
至于为什么结婚?
我和 Emma 都是不婚主义者。但是买房子如果不结婚,就只能写一个人的名字。但我们都不愿意写自己的名字。最后没办法,决定去办理结婚证。
但我们没有举办传统的婚礼,我们都不喜欢熙熙攘攘、吵吵闹闹。我们只想过好我们自己的生活,不希望任何人来打扰我们。
这辈子我搬了至少十次家,只有这次是搬进自己的家。
九、学习
今年在学习上主要有四个方面:
- Web3。
- 英语。
- 游戏开发。
- 自媒体。
目前对我来说,Web3 是最重要的事情。虽然我还没有 All in web3,但也差不多了。有人说 Web3 是骗局,但我认为不是骗局。
我承认 Web3 有非常多的漏洞,比如 NFT 的图片压根没上链,链上存储的只是一堆 URL。同时几乎所有用户都没有直接与区块链交互,而是与一堆中心化的平台交互。比如我们使用 MetaMask,其实数据流过了 MetaMask 和 Infura。目前的 Web3 并没有完全去中心化。
没有一个新鲜事物在一诞生就是完美的。正是由于这些不完美的地方,所以才需要我们去完善它们。
目前我已经加入了一个 Web3 团队。虽然团队不大,但是他们做的事情非常吸引我。Web3 是一个高速发展的火箭,对现在的人来说,你先上去再说,何必在乎坐在哪个位置上?
我很期待 2030 年的 Web3。
如果要进入 Web3,需要学习技术有很多,我把一些重要的技术栈列举如下:
- Web3.js or Ethers.js or Wgami:与区块链交互的前端 SDK。
- Solidity:智能合约编程语言。
- Hardhat:以太坊开发环境。
- IPFS:Web3 文件存储系统。
除了上述的技术之外,更多的是概念上的理解,比如 NFT、GameFi 相关的诸多概念等。
学习英语是因为我打算出国,同时我现在的工作环境也有很多英语,我不想让语言成为我继续提升的障碍。
至于游戏开发和自媒体,纯粹是想赚钱。
游戏开发主要是微信小游戏,靠广告费就能赚钱。微信小游戏的制作成本很低,两个人的小型团队就可以开发数款微信小游戏。而且赚钱和游戏质量并不成正比。跳一跳、羊了个羊都是成功案例。当然我的目标不是做那么大,大概只需要做到它们几百分之一的体量就非常不错了,要知道微信有将近 10 亿用户,总有人会玩你的游戏。
另外我学习自媒体和微信小游戏的原因差不多。自媒体的盘子越来越大。在 B 站、抖音这些短视频平台上,有着上千亿甚至更多的市场。这给更多人创造了创造收入的空间。
只要去做,总会有所收获。
在学习的过程中,我会记录大量笔记以及自我思考。但很少会更文。
大概在 9 月份,我参加了掘金的两次更文活动,输出了一些内容。
这个过程很累,但也有所收获。
后来考虑到时间和精力问题,所以很少更文了。
很遗憾,掘金目前只能依靠平台自身给创作者奖励,收入非常有限。如果掘金能够将变现程度发展成像 B 站、公众号或抖音那样,估计也会有更多的创作者加入。连 CSDN、博客园这些老牌产品都做不到。究其原因,还是这种性质的产品受众没有那么广泛,盘子太小了,体量自然无法涨上去。希望未来掘金能够找到属于自己的商业模式。
最后还是很感谢掘金这个平台,给了技术人们一个分享交流的空间。
十、未来
未来三年的计划是出国读硕,并全面转入 Web3 领域。
我不看好中国的经济,并且感觉在中国做生意会越来越难做。而且我更喜欢西方文化、氛围和环境。
在经历了国内疫情反复封控之后,我更加坚定了出国的打算。我不想继续生活在大陆。
我想看看外面的世界,同时系统化地提升一下自己的 CS 知识。
目前出国的思路是申请混合制研究生,F1、OPT、H1B、Green Card。目标是一所在 Chicago QS TOP500 垫底的高校。
另一条出国的路线是直接出国找一份美国的工作,但对目前的我来说是相当难,主要还是因为语言。
之所以是未来三年的计划,也是因为我的英语实在太差,目前按照 CEFR 标准,只达到了 A2。
按照 FSI 英语母语者学习外语的难度排名,中文这类语言是最难学习的。反过来,中文母语者学习英语,也是最难的。真正掌握大概需要 2200 小时,如果每天学习 3-4 小时的话,需要 88 周,将近两年。
FSI 的图片我删掉了,因为那张图上的中国版图有争议。
我的语言天赋很一般,甚至有些差。所以学习效果并不理想。我也不打算短时间内冲刺英语,因为那不太靠谱。我选择花更久的时间去磨它。
之前也想过去 Helsinki,但那边收入不高,税收太高。纠结了很久,还是觉得现在还年轻,多少还是应该有些压力的,去那种地方实在太适合养老了。
以上并不是故事,是我的亲身经历,分享出来的初衷是为大家提供更多职业和人生的思路与思考。希望对你有所帮助!
链接:https://juejin.cn/post/7178816031459115066
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
工作7年的程序员,明白了如何正确的"卷"
大家好,我是大鹅,一名在互联网行业,工作了7年的程序员。
今天和大家聊聊工作7年后,一些感悟吧。
背景
近两年,出台和落地的反垄断法,明确指出要防止资本无序扩张。
这也就导致现在的各大互联网公司,不能再去染指其他已有的传统行业,只能专注自己目前存量的这些业务。或者通过技术创新,开辟出新的行业。
但创新这种东西,可遇不可求,互联网进入到目前这个阶段,能做的,基本都已经有公司在做了。
互联网创造出来的工作机会,例如程序员、产品经理、运营等等,已经进入了一个存量市场的时代。
无意义的卷
我反对的“卷”,是通过疯狂加班,以工作时长换取更高产出的“卷” ,而不是个人学习成长这一方面的“卷”。
这个类型的“卷”,不论是对自己,还是对于这个行业所带动的就业机会,都是不可持续且有害的事情。
对自己:
短期内,因为卷工作时长,的确可以获得了更高的产出,顺带着获得了更多表现自己和让上级看到的机会,这一点是符合逻辑的。
但从长远来看,到了一定岁数,体力肯定不如年轻人了,这时候再被年轻人卷,那真是冤冤相报何时了。。
对就业机会:
正常是下午6点下班,卷的人晚上11-12点才走。
一个业务需求正常开发一个月,硬是压缩到半个月,把1个人当成2个人用。
这样做会进一步缩减这个存量市场的工作机会,因为老板们发现裁掉一部分人,依然可以正常运转。
对于老板来说,他更赚了,因为减少了成本
对于打工人来说,很亏,因为付出了大于1人力的工作时长和产出,得到的却还是1人力的回报。
如果不“卷”,能得到什么?
1、首先应该可以释放出一部分新的工作机会出来,让这个行业可以容纳更多的人。
因为之前通过疯狂加班,1个人干2个人的事情这种情况得到制止,意味着需要新增人员才能完成以前的工作量。
2、不用疯狂加班,身体好了,也有时间了。
我认为正确的“卷”
背景交代清楚了,回到主题,如何正确的“卷”
这里没有什么长篇大论,我认为正确的卷,应该是想清楚自己的方向,坚持不断的学习和积累,让自己拥有这个领域足够的专业度和深度,这才是自己的核心优势。卷的是毅力和积累,而不是体力。
同时,还可以对外输出自己的知识,让自己在这个行业拥有一定的知名度,这可以很大的提高自己的抗风险能力。
写在最后
我个人的力量有限,我不觉得我能影响多少人,但能影响一点,也总是好的。
也希望看到这个文章的你,能一起帮助这个行业,让它的风气,变得更好一点。
链接:https://juejin.cn/post/7201046007441227832
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
上手试试 Compose for ios
前言
前段时间看了阿黄哥的一篇介绍Compose for ios 的文章
Compose跨平台第三弹:体验Compose for iOS(黄林晴)
才知道 compose 已经可以跨ios端了,自己也打算上手试试。等自己实际上手之后,才发现有很多坑,尤其是配置环境方面,所以打算写一篇文章记录一下。
开始
接下来,我会从新建一个项目,依赖配置,环境配置,一直到可以使用Compose 写一个Hello Word的Demo, 这样的步骤来介绍一个我曾遇见的坑以及解决方法。
如果要尝试ios方面的东西,一定是需要mac系统的,无论是用mac 电脑 还是使用虚拟机,并且还需要Xocde 这个巨无霸。
首先来介绍一个我使用的环境:
mac os 12.6.3Xcode 13.2.1Kotlin 1.8.0Compsoe 1.3.0
我之前研究过KMM,曾尝试写了一个Demo,当时的mac 系统是 10.17 版本,最多只能下载Xcode 12.3,而这个版本的Xcode 只能编译 Kotlin 1.5.31,想要用高版本的kotlin 就得需要使用 12.5版本的Xcdoe,所以我就是直接将mac 系统升级到了 12.6.3,Xcode 我是下载的13.2.1,直接下载最新版的Xcode14 应该也可以。这是关于环境版本需要注意的一些点。
现在开始正式的搭建项目。
首先要安装一个Android Studio 插件,直接 在插件市场搜索 Kotlin Multiplatform Mobile 就可以。
安装完成之后,在新建项目的时候 就可以看到在最后多出来两个项目模板,
这里使用第一个模板。
创建出来目录结构大概是这个样子的:
androidApp就是运行在Android平台上的。iosApp就是运行在ios平台上的。shared就是两者通用的部分。
shared 中又分为androidMain,iosMain和 commonMain 三个部分。
主要是在commonMain中定义行为,然后分别在androidMain和iosMain 中分别实现,这个Demo 中主要是展示系统版本。
interface Platform {
val name: String
}
expect fun getPlatform(): Platformexpect 关键字是将此声明标记为是平台相关的,并期待从模块中实现。
然后在对应模块中实现:
//android
class AndroidPlatform : Platform {
override val name: String = "Android ${android.os.Build.VERSION.SDK_INT}"
}
actual fun getPlatform(): Platform = AndroidPlatform()
//ios
class IOSPlatform: Platform {
override val name: String = UIDevice.currentDevice.systemName() + " " + UIDevice.currentDevice.systemVersion
}
actual fun getPlatform(): Platform = IOSPlatform()
actual : 表示多平台项目中的一个平台相关实现
Kotlin关键字 参见:
http://www.kotlincn.net/docs/refere…
引用自:http://www.kotlincn.net/docs/refere…
这个模板项目大概就了解这么多,接下我们开始引入Compose相关依赖。
首先在settings.gradle.kts 中添加仓库:
pluginManagement {
repositories {
google()
gradlePluginPortal()
mavenCentral()
//添加这两行
maven(uri("https://plugins.gradle.org/m2/")) // For kotlinter-gradle
maven("https://maven.pkg.jetbrains.space/public/p/compose/dev")
}
}
dependencyResolutionManagement {
repositories {
google()
mavenCentral()
// 添加这个
maven("https://maven.pkg.jetbrains.space/public/p/compose/dev")
}
}然后引入插件和依赖:
根目录build.gradle.kts
plugins {
//trick: for the same plugin versions in all sub-modules
id("com.android.application").version("7.4.1").apply(false)
id("com.android.library").version("7.4.1").apply(false)
kotlin("android").version("1.8.0").apply(false)
kotlin("multiplatform").version("1.8.0").apply(false)
//添加此行
id("org.jetbrains.compose") version "1.3.0" apply false
}
share Module 的 build.gradle.kts
plugins {
kotlin("multiplatform")
id("com.android.library")
//添加此行
id("org.jetbrains.compose")
}
sourceSets {
val commonMain by getting{
//添加依赖
dependencies {
with(compose) {
implementation(ui)
implementation(foundation)
implementation(material)
implementation(runtime)
}
}
}
....
}然后再进行编译的时候,这里会报错:
ERROR: Compose targets '[uikit]' are experimental and may have bugs!
But, if you still want to use them, add to gradle.properties:
org.jetbrains.compose.experimental.uikit.enabled=true
这里是需要在gradle.properties 中添加:
org.jetbrains.compose.experimental.uikit.enabled=true然后在编译ios module的时候,可以选择直接从这列选择iosApp:
有时候可能因为Xcode环境问题,这里的iosApp 会标记着一个红色的x号,提示找不到设别,或者其他关于Xcode的问题,此时可以直接点击iosApp module 下的 iosApp.xcodeproj ,可以直接用Xcode 来打开编译。还可以直接直接跑 linkDebugFrameworkIosX64 这个task 来直接编译。
此时编译我是碰见了一个异常:
e: Module "org.jetbrains.compose.runtime:runtime-saveable (org.jetbrains.compose.runtime:runtime-saveable-uikitx64)" has a reference to symbol androidx.compose.runtime/remember|-2215966373931868872[0]. Neither the module itself nor its dependencies contain such declaration.
This could happen if the required dependency is missing in the project. Or if there is a dependency of "org.jetbrains.compose.runtime:runtime-saveable (org.jetbrains.compose.runtime:runtime-saveable-uikitx64)" that has a different version in the project than the version that "org.jetbrains.compose.runtime:runtime-saveable (org.jetbrains.compose.runtime:runtime-saveable-uikitx64): 1.3.0" was initially compiled with. Please check that the project configuration is correct and has consistent versions of all required dependencies.出现这个错误是需要在gradle.properties 中添加:
kotlin.native.cacheKind=none然后编译出现了一个报错信息巨多的异常:
//只粘贴了最主要的一个异常信息
Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/ld invocation reported errors这里是需要在share的build.gradle.kts中加上这个配置:
listOf(
iosX64(),
iosArm64(),
iosSimulatorArm64()
).forEach {
it.binaries.framework {
baseName = "shared"
//加上此行
isStatic = true
}
}
/**
* Specifies if the framework is linked as a static library (false by default).
* 指定框架是否作为静态库链接(默认情况下为false)。
*/
var isStatic = false然后再编译的时候还遇到一个异常信息:
//org.gradle.api.UnknownDomainObjectException: KotlinTarget with name 'uikitX64' not found.这个是在share的build.gradle.kts中加上如下配置:
kotlin{
val args = listOf(
"-linker-option", "-framework", "-linker-option", "Metal",
"-linker-option", "-framework", "-linker-option", "CoreText",
"-linker-option", "-framework", "-linker-option", "CoreGraphics"
)
//org.gradle.api.UnknownDomainObjectException: KotlinTarget with name 'uikitX64' not found.
iosX64("uikitX64") {
binaries {
executable {
entryPoint = "main"
freeCompilerArgs = freeCompilerArgs + args
}
}
}
iosArm64("uikitArm64") {
binaries {
executable {
entryPoint = "main"
freeCompilerArgs = freeCompilerArgs + args
freeCompilerArgs = freeCompilerArgs + "-Xdisable-phases=VerifyBitcode"
}
}
}
}然后再编译就可以正常编译通过了。
下面我们就可以在两端使用Compose了。
首先在commonMain中写一个Composable,用来供给两端调用:
@Composable
internal fun KMMComposeView(device:String){
Box(contentAlignment = Alignment.Center) {
Text("Compose跨端 $device view")
}
}这里一定要写上internal 关键字,internal 是将一个声明 标记为在当前模块可见。
internal 官方文档
http://www.kotlincn.net/docs/refere…
不然在ios 调用定义好的Compose 的时候产生下面的异常:
Undefined symbols for architecture x86_64:
"_kfun:com.xl.kmmdemo#KMMComposeView(kotlin.String){}", referenced from:
_objc2kotlin_kfun:com.xl.kmmdemo#KMMComposeView(kotlin.String){} in shared(result.o)然后再两端添加各自的调用:
androidMain的 Platform.kt
@Composable
fun MyKMMView(){
KMMComposeView("Android")
}
iosMain的 Platform.kt
fun MyKMMView(): UIViewController = Application("ComposeMultiplatformApp") {
KMMComposeView(UIDevice.currentDevice.systemName())
}最后在androidApp module中直接调用 MyKMMView() 就行了,iosApp 想要使用的话,我们还得修改一下iosApp moudle的代码:
我们呢需要将 iosApp/iosApp/iOSApp.swift 的原有代码:
import SwiftUI
@main
struct iOSApp: App {
var body: some Scene {
WindowGroup {
ContentView()
}
}
}替换为:
import SwiftUI
import shared
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
var myWindow: UIWindow?
func application(
_ application: UIApplication,
didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?
) -> Bool {
myWindow = UIWindow(frame: UIScreen.main.bounds)
//主要关注这一行, 这里是调用我们自己在iosMain里面定义的 KMMViewController
let mainViewController = PlatformKt.KMMViewController()
myWindow?.rootViewController = mainViewController
myWindow?.makeKeyAndVisible()
return true
}
func application(
_ application: UIApplication,
supportedInterfaceOrientationsFor supportedInterfaceOrientationsForWindow: UIWindow?
) -> UIInterfaceOrientationMask {
return UIInterfaceOrientationMask.all
}
}最后来看看效果:
用来演示效果的代码非常简单,就是使用一个Text 组件来展示 设备的类型。
写在最后
自己在上手的时候本以为很简单,结果就是不断踩坑,同时ios相关知识也比较匮乏,有些问题的解决方案网上的答案也非常少,最后是四五天才能正常跑起来这个Demo。现在是将这些坑都记录下来,希望能给其他的同学能够提供一些帮助。
后面的计划会尝试使用ktor接入一些网络请求,然后写一个跨端的开源项目,如果再遇见什么坑会继续分享这个踩坑系列。
关于Compose for Desktop 之前也有过尝试,是写了一个adb GUI的工具项目,非常简单 ,没遇见什么坑,就是Compose的约束布局没有。目前工作中经常用到的一些工具 也是使用Compose写的。
今天的碎碎念就到这里了,这次写的也比较细,比较碎,大家要是有什么问题,欢迎一起交流。
链接:https://juejin.cn/post/7201831630603976741
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 3.7 之快速理解 toImageSync 是什么?能做什么?
随着 Flutter 3.7 的更新, dart:ui 下多了 Picture.toImageSync 和 Scene.toImageSync 这两个方法,和Picture.toImage 以及 Scene.toImage 不同的是 ,toImageSync 是一个同步执行方法,所以它不需要 await 等待,而调用 toImageSync 会直接返回一个 Image 的句柄,并在 Engine 后台会异步对这个 Image 进行光栅化处理。
前言
那 toImageSync 有什么用?不是有个 toImage 方法了,为什么要多一个 Sync 这样的同步方法?
目前
toImageSync最大的特点就是图像会在 GPU 中常驻 ,所以对比toImage生成的图像,它的绘制速度会更快,并且可以重复利用,提高效率。
toImage生成的图像也可以实现 GPU 常驻,但目前没有未实现而已。
toImageSync是一个同步方法,在某些场景上弥补了toImage必须是异步的不足。

而 toImageSync 的使用场景上,官方也列举了一些用途,例如:
- 快速捕捉一张昂贵的栅格化图片,用户支持跨多帧重复使用
- 应用在图片的多路过滤器上
- 应用在自定义着色器上
具体在 Flutter Framework 里,目前 toImageSync 最直观的实现,就是被使用在 Android 默认的页面切换动画 ZoomPageTransitionsBuilder 上,得意于 toImageSync 的特性,Android 上的页面切换动画的性能,几乎减少了帧光栅化一半的时间,从而减少了掉帧和提高了刷新率。
当然,这是通过牺牲了一些其他特性来实现,后面我们会讲到。
SnapshotWidget
前面说了 toImageSync 让 Android 的默认页面切换动画性能得到了大幅提升,那究竟是如何实现的呢?这就要聊到 Flutter 3.7 里新增加的 SnapshotWidget 。
其实一开始 SnapshotWidget 是被定义为 RasterWidget ,从初始定义上看它的 Target 更大,但是最终在落地的时候,被简化处理为了 SnapshotWidget ,而从使用上看确实 Snapshot 更符合它的设定。
概念
SnapshotWidget 的作用是可以将 Child 变成的快照(ui.Image)从而替换它们进行显示,简而言之就是把子控件都变成一个快照图片,而 SnapshotWidget 得到快照的办法就是 Scene.toImageSync 。
那么到这里,你应该知道为什么
toImageSync可以提高 Android 上的页面切换动画的性能了吧?因为SnapshotWidget会在页面跳转时把 Child 变成的快照,而toImageSync栅格化的图片还可以跨多帧重复使用。
那么问题来了,SnapshotWidget 既然是通过 toImageSync 将 Child 变成的快照(ui.Image)来提高性能,那么带来的副作用是什么?
答案是动画效果,因为子控件都变成了快照,所以如果 Child 控件带有动画效果,会呈现“冻结”状态,更形象的对比如下图所示:
| FadeUpwardsPageTransitionsBuilder | ZoomPageTransitionsBuilder |
|---|---|
 |  |
默认情况下 Flutter 在 Android 上的页面切换效果使用的是 ZoomPageTransitionsBuilder ,而 ZoomPageTransitionsBuilder 里在页面切换时会开启 SnapshotWidget 的截图能力,所以可以看到,它在页面跳转时,对比 FadeUpwardsPageTransitionsBuilder 动图, ZoomPageTransitionsBuilder 的红色方块和掘金动画会停止。
因为动画很短,所以可以在代码里设置
timeDilation = 40.0;和SchedulerBinding.resetEpoch来全局减慢动画执行的速度,另外可以配置MaterialApp的ThemeData下对应的pageTransitionsTheme来切换页面跳转效果。
所以在官方的定义中,SnapshotWidget 是用来协助执行一些简短的动画效果,比如一些 scale 、 skew 或者 blurs 动画在一些复杂的 child 构建上开销会很大,而使用 toImageSync 实现的 SnapshotWidget 可以依赖光栅缓存:
对于一些简短的动画,例如
ZoomPageTransitionsBuilder的页面跳转,SnapshotWidget会将页面内的 children 都转化为快照(ui.Image),尽管页面切换时会导致 child 动画“冻结”,但是实际页面切换时长很短,所以看不出什么异常,而带来的切换动画流畅度是清晰可见的。
再举个更直观的例子,如下代码所示,运行后我们可以看到一个旋转的 logo 在屏幕上随机滚动,这里分别使用了 AnimatedSlide 和 AnimatedRotation 执行移动和旋转动画。
Timer.periodic(const Duration(seconds: 2), (timer) {
final random = Random();
x = random.nextInt(6) - 3;
y = random.nextInt(6) - 3;
r = random.nextDouble() * 2 * pi;
setState(() {});
});
AnimatedSlide(
offset: Offset(x.floorToDouble(), y.floorToDouble()),
duration: Duration(milliseconds: 1500),
curve: Curves.easeInOut,
child: AnimatedRotation(
turns: r,
duration: Duration(milliseconds: 1500),
child: Image.asset(
'static/test_logo.png',
width: 100,
height: 100,
),
),
)
如果这时候在 AnimatedRotation 上层加多一个 SnapshotWidget ,并且打开 allowSnapshotting ,可以看到此时 logo 不再转动,因为整个 child 已经被转化为快照(ui.Image)。
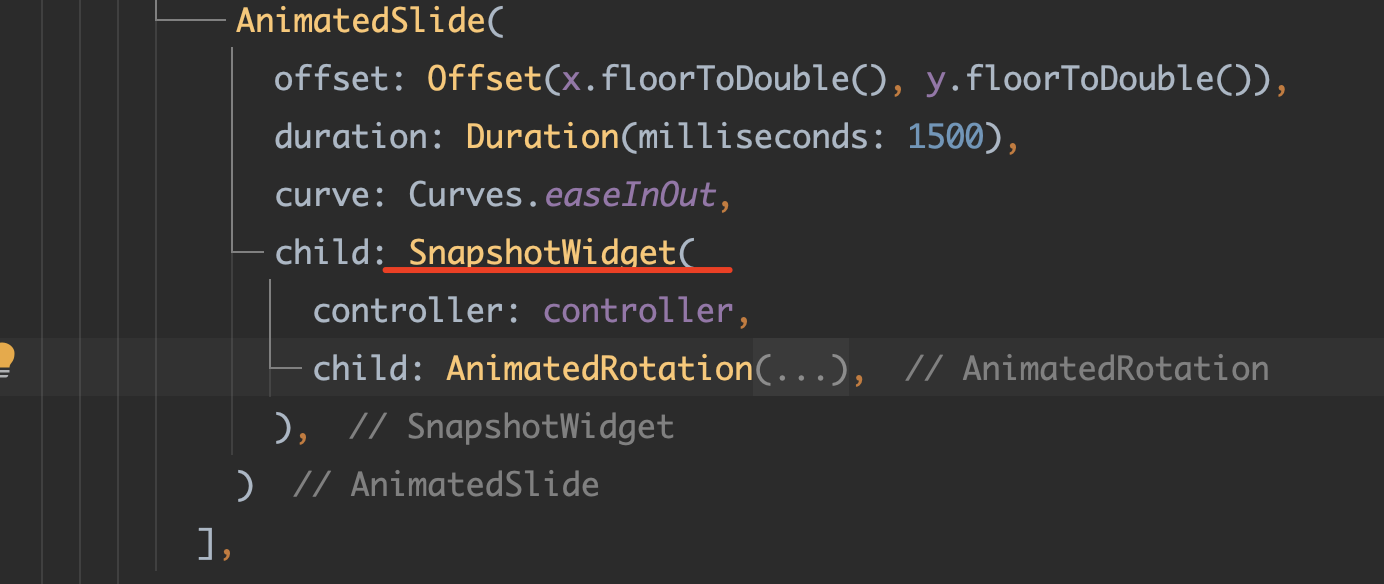 |  |
|---|
所以
SnapshotWidget不适用于子控件还需要继续动画或有交互响应的地方,例如轮播图。
使用
如之前的代码所示,使用 SnapshotWidget 也相对简单,你只需要配置 SnapshotController ,然后通过 allowSnapshotting 控制子控件是否渲染为快照即可。
controller.allowSnapshotting = true;SnapshotWidget 在捕获快照时,会生成一个全新的 OffsetLayer 和 PaintingContext,然后通过 super.paint 完成内容捕获(这也是为什么不支持 PlatformView 的原因之一),之后通过 toImageSync 得到完整的快照(ui.Image)数据,并交给 SnapshotPainter 进行绘制。
 |  |
|---|
所以 SnapshotWidget 完成图片绘制会需要一个 SnapshotPainter ,默认它是通过内置的 _DefaultSnapshotPainter 实现,当然我们也可以自定义实现 SnapshotPainter 来完成自定义逻辑。
从实现上看,
SnapshotPainter用来绘制子控件快照的接口,正如上面代码所示,会根据 child 是否支持捕获(_childRaster == null),从而选择调用paint或paintSnapshot来实现绘制。
另外,目前受制于 toImageSync 的底层实现, SnapshotWidget 无法捕获 PlatformView 子控件,如果遇到 PlatformView,SnapshotWidget 会根据 SnapshotMode 来决定它的行为:
| normal | 默认行为,如果遇到无法捕获快照的子控件,直接 thrown |
|---|---|
| permissive | 宽松行为,遇到无法捕获快照的子控件,使用未快照的子对象渲染 |
| forced | 强制行为,遇到无法捕获快照的子控件直接忽略 |
另外 SnapshotPainter 可以通过调用 notifyListeners 触发 SnapshotWidget 使用相同的光栅进行重绘,简单来说就是:
你可以在不需要重新生成新快照的情况下,对当然快照进行一些缩放、模糊、旋转等效果,这对性能会有很大提升。
所以在 SnapshotPainter 里主要需要实现的是 paint 和 paintSnapshot 两个方法:
paintSnapshot 是绘制 child 快照时会被调用
paint 方法里主要是通过
painter(对应super.paint)这个 Callback 绘制 child ,当快照被禁用或者permissive模式下遭遇 PlatformView 时会调用此方法

举个例子,如下代码所示,在 paintSnapshot 方法里,通过调整 Paint ..color ,可以在前面的小 Logo 快照上添加透明度效果:
class TestPainter extends SnapshotPainter {
final Animation<double> animation;
TestPainter({
required this.animation,
});
@override
void paint(PaintingContext context, ui.Offset offset, Size size,
PaintingContextCallback painter) {}
@override
void paintSnapshot(PaintingContext context, Offset offset, Size size,
ui.Image image, Size sourceSize, double pixelRatio) {
final Rect src = Rect.fromLTWH(0, 0, sourceSize.width, sourceSize.height);
final Rect dst =
Rect.fromLTWH(offset.dx, offset.dy, size.width, size.height);
final Paint paint = Paint()
..color = Color.fromRGBO(0, 0, 0, animation.value)
..filterQuality = FilterQuality.low;
context.canvas.drawImageRect(image, src, dst, paint);
}
@override
void dispose() {
super.dispose();
}
@override
bool shouldRepaint(covariant TestPainter oldDelegate) {
return oldDelegate.animation.value != animation.value;
}
}
其实还可以把移动的动画部分挪到 paintSnapshot 里,然后通过对 animation 的状态进行管理,然后通过 notifyListeners 直接更新快照绘制,这样在性能上会更有优势,Android 上的 ZoomPageTransitionsBuilder 就是类似实现。
animation.addListener(notifyListeners);
animation.addStatusListener(_onStatusChange);
void _onStatusChange(_) {
notifyListeners();
}
@override
void paintSnapshot(PaintingContext context, Offset offset, Size size, ui.Image image, Size sourceSize, double pixelRatio) {
_drawMove(context, offset, size);
}
@override
void paint(PaintingContext context, ui.Offset offset, Size size, PaintingContextCallback painter) {
switch (animation.status) {
case AnimationStatus.completed:
case AnimationStatus.dismissed:
return painter(context, offset);
case AnimationStatus.forward:
case AnimationStatus.reverse:
}
....
}
更多详细可以参考系统
ZoomPageTransitionsBuilder里的代码实现。
拓展探索
其实除了 SnapshotWidget 之外,RepaintBoundary 也支持了 toImageSync , 因为 toImageSync 获取到的是 GPU 中的常驻数据,所以在实现类似控件截图和高亮指引等场景绘制上,理论上应该可以得到更好的性能预期。
final RenderRepaintBoundary boundary =
globalKey.currentContext!.findRenderObject()! as RenderRepaintBoundary;
final ui.Image image = boundary.toImageSync();除此之外,dart:ui 里的 Scene 和 _Image 对象其实都是 NativeFieldWrapperClass1 ,以前我们解释过:NativeFieldWrapperClass1 就是它的逻辑是由不同平台的 Engine 区分实现 。
 | 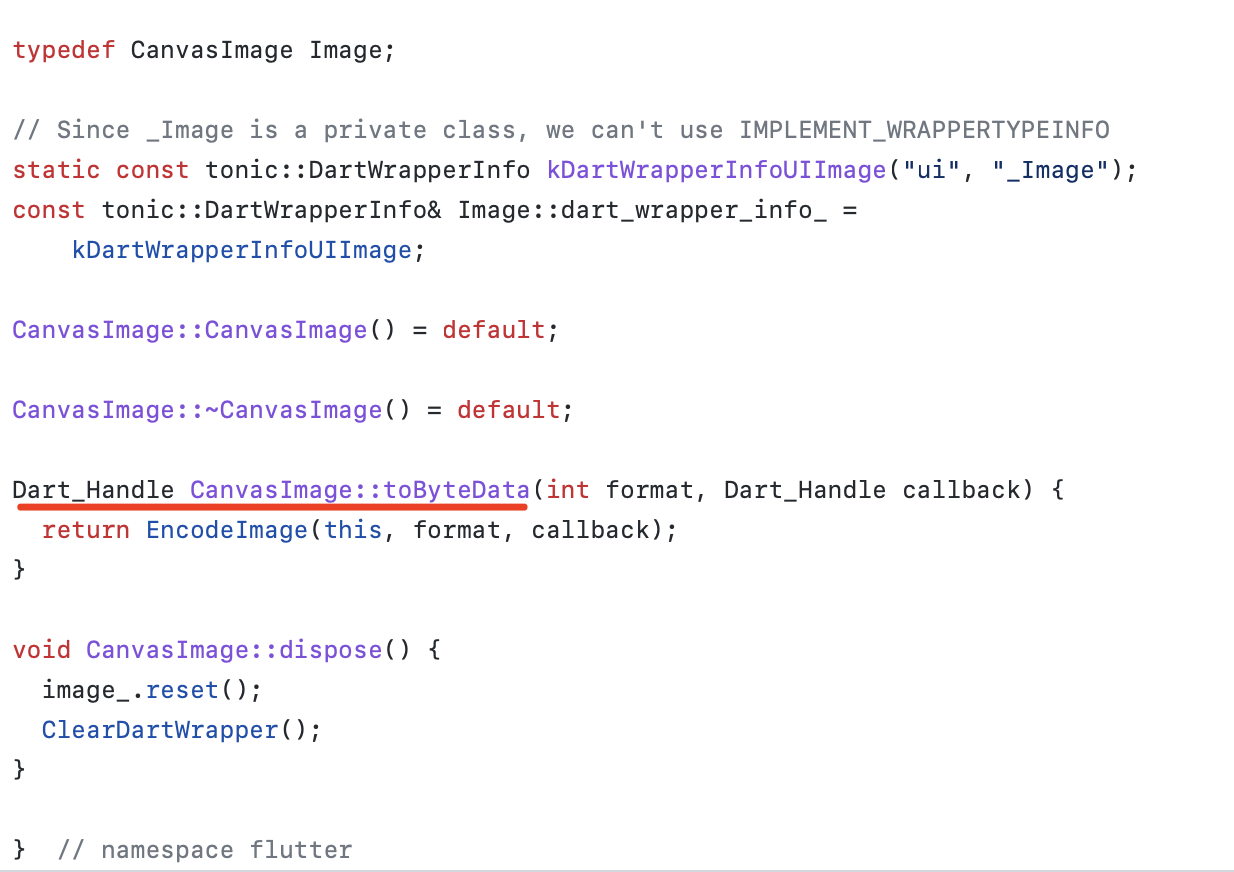 |
|---|
所以如果你直接在
flutter/bin/cache/pkg/sky_engine/lib/ui/compositing.dart下去断点toImageSync是无法成功执行到断点位置的,因为它的真实实现在对应平台的 Engine 实现。
另外,前面我们一直说 toImageSync 对比 toImage 是 GPU 常驻,那它们的区别在哪里?从上图我们就可以看出:
toImageSync执行了Scene:RasterizeToImage并返回Dart_Null句柄toImage执行了Picture:RasterizeLayerTreeToImage并直接返回
简单展开来说,就是:
toImageSync最终是通过SkImage::MakeFromTexture通过纹理得到一个 GPUSkImage图片toImage是通过makeImageSnapshot和makeRasterImage生成SkImage,makeRasterImage是一个复制图像到 CPU 内存的操作。
 |  |  | 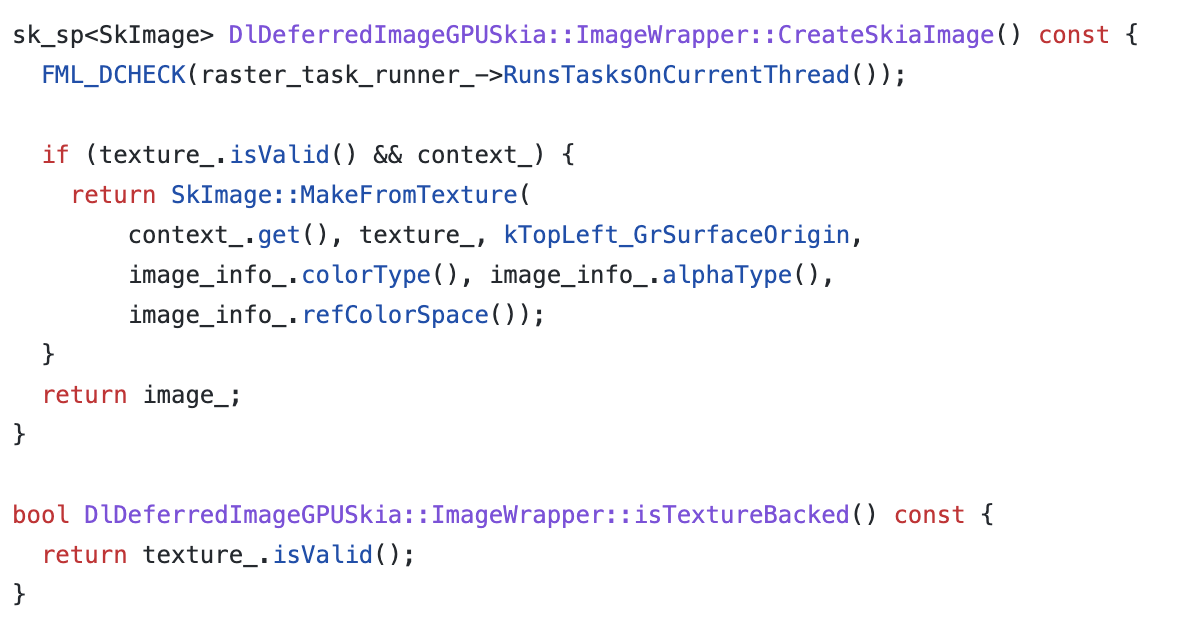 |
|---|
其实一开始 toImageSync 是被命令为 toGpuImage ,但是为了更形象通用,最后才修改为 toImageSync 。

而 toImageSync 等相关功能的落地可以说同样历经了漫长的讨论,关于是否提供这样一个 API 到最终落地,其执行难度丝毫不比 background isolate 简单,比如:是否定义异常场景,遇到错误是否需要在Framwork 层消化,是否真的需要这样的接口来提高性能等等。
 |  |  |  |
|---|
而 toImageSync 等相关功能最终能落地,其中最重要的一点我认为是:
toGoulmagegives the framework the ability to take performance into their own hands, which is important given that our priorities don't always line up.
最后
toImageSync 只是一个简单的 API ,但是它的背后经历了很多故事,同时 toImageSync 和它对应的封装 SnapshotWidget ,最终的目的就是提高 Flutter 运行的性能。
也许目前对于你来说 toImageSync 并不是必须的,甚至 SnapshotWidget 看起来也很鸡肋,但是一旦你需要处理复杂的绘制场景时, toImageSync 就是你必不可少的菜刀。
链接:https://juejin.cn/post/7197326179933372476
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
final的那些事儿
final作为java中基础常用的关键字,相信大家都很熟悉,大家都晓得final可以修饰类,方法和变量且具有以下特性:
- final修饰类时,该类不可被继承
- final修饰方法时,该方法不可被重写
- final修饰变量时,如果该变量是基础数据类型,则只能赋值一次,如果该变量是对象类型,则其指向的地址只能赋值一次
那么除了这些就没有了吗?看以下问题:
- 当匿名内部类引用函数中的局部变量时,局部变量是基础数据类型会怎样?对象类型会怎样?为什么需要final修饰?
- 当匿名内部类引用函数中的局部变量时,这个变量在堆上还是栈上?
- 当对象类型局部变量用final修饰后,如果被子线程持有,在子线程的属性值修改能被主线程感知吗?
如果这些问题你都晓得,那么恭喜你,不用继续往下看了。
当匿名内部类引用函数局部变量时,为什么需要final修饰?
内部类中不修改函数局部变量值
要验证该问题,我们先来简单编写一个内部类引用函数中局部变量的示例,代码如下:
public interface Callback {
void doWork();
}
public class FinalTest {
public FinalTest() {
}
public void execute() {
int variable = 10;
setCallback(new Callback() {
@Override
public void doWork() {
System.out.println("method variable is:" + variable);
}
});
}
public void setCallback(Callback callback) {
}
}
public class Main {
public static void main(String[] args) {
FinalTest finalTest = new FinalTest();
finalTest.execute();
}
}可以看到在上述代码中,我们在FinalTest的execute方法中,通过Callback这个匿名内部类引用了execute函数中的variable变量,此时虽然variable没有被final修饰,但是代码仍然是可以运行的(基于JDK 1.8)。
有同学要说了,你又乱说,看看你的问题,问的是当内部类引用函数局部变量时,为什么需要final修饰?这没有final不照样跑的好好的?别急,我们来看下该程序的字节码,FinalTest类对应的字节码如下所示:
可以看到编译后自动为variable变量添加了final关键词修饰,那么为什么需要使用final关键词来修饰呢?主要有以下几点原因:
- 生命周期不同: 从运行时内存分区一文中可知,函数中的局部变量作为线程的私有数据,被存储在虚拟机栈对应的栈帧中,当函数结束执行后出栈,而Callback类的doWork方法其调用时机与execute函数的执行结束时机明显不一致,故如果不使用final修饰,不能保证doWork方法执行时variable变量仍然存在。
- 数据不同步: 从变量数据同步的角度来看,局部变量在传递到内部类时,是以备份的形式拷贝到自己的构造函数中,加以存储利用,如果不添加final修饰,则内外部修改互不同步,造成脏数据。
那么为什么使用fina就能解决以上问题呢?(仅针对基础类型讨论,对象类型见下一部分)
生命周期不同
继续查看FinalTest类字节码,可以看到当variable变量使用final修饰后,其被存储于常量池中,而常量池存储于方法区中,进而生命周期必然是大于Callback类的,variable变量相关字节码如下图:
数据不同步
查看通过new Callback创建的FinalTest匿名内部类的字节码,代码如下所示:
可以看到编译生成的 FinalTest$1这个匿名内部类继承自Callback接口,其通过构造函数持有了外部类FinalTest的引用以及int类型的var2,当variable被final修饰时,由于其值不可修改,故外部的variable变量和 FinalTest$1构造函数中传入的var2值始终保持一致,故而不存在数据不同步的问题。
从这里我们明显可以看出匿名内部类会持有外部类的引用,Handler导致的Activity内部泄漏的场景就是这样引发的
同理也可以看出,为什么匿名内部类访问外部类的成员变量不需要final修饰,主要是这种访问关系都可以转化为通过外部类引用间接访问
内部类中修改函数局部变量值
仍以上文中代码为例,我们在doWork中修改variable变量的值,来看下会怎么样?
从上图可以看出编译器提示我们将variable转化成一个单元素的数组,按照编译器提示修改,果然可以正常运行了
那么这是为什么呢?不是说final修饰的变量值不能变吗?编译器bug了?
当然不是,这里我们需要明白单元素数组它不是一个基础类型变量,它指向的是一块内存地址,当其被final修饰时,说的是该变量不能重新指向一块新的内存地址,而不是内存地址处存储的内容不可以变化,也就是说我们不能再次执行variable = {20}这种赋值操作(PS:类对象同理,变量不可以重新赋值成新的对象,但是对象的成员属性取值可以发生变化)。
为对对象的指向地址修改和成员属性修改做区分,下文中将成员属性修改简称为内容修改,将地址修改简称为值修改
同时我们也可以从这里了解到当匿名内部类持有函数的局部变量时,是通过符号引用获取的(类结构中常量池中字段说明可以参考<<深入理解Java虚拟机>>), FinalTest$1类中val$variable变量声明及在常量池中引用如下图所示:
子线程修改final修饰局部变量内容,是否可同步?
仍以上文代码为例,修改FinalTest类如下所示:
public class FinalTest {
public FinalTest() {
}
public void execute() {
int variable = 10;
setCallback(new Callback() {
@Override
public void doWork() {
System.out.println("method variable is:" + variable);
}
});
}
public void execute2() {
final int[] variable = {10};
ExecutorService executorService = Executors.newFixedThreadPool(5);
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println("variable[0] is:" + variable[0]);
variable[0] = 100;
System.out.println("change variable[0] is:" + variable[0]);
}
});
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("after change variable[0] is:" + variable[0]);
}
public void setCallback(Callback callback) {
}
}在Main中运行execute2,执行结果如下图所示:
可以看到,数组元素的值确定发生了改变,这也就意味着被final修饰的变量,其内容修改在多线程环境下具有可见性。
final在多线程环境下具有可见性
总结
final,static与synchronized
| 关键词 | 修饰类型 | 作用 |
|---|---|---|
| final | 类,方法,变量 | 修饰类,则类不可继承; 修饰方法,则方法不可被子类重写; 修饰变量,则变量只能初始化一次 |
| static | 内部类,方法,变量,代码段 | 修饰内部类,则该类只能访问外部类的静态成员变量和方法,在Handler内存泄漏的修复方案中就有静态内部类的方式; 修饰方法,则该方法可以直接通过类名访问 修饰变量,则该变量可以直接通过类名访问,在类的实例中,静态变量共享同一份内存空间,故其具有全局性质 修饰代码段,则该代码段在类加载的时候就会执行,由于类加载是多线程安全的,所以可以通过静态代码段实现一些初始化操作而不用担心多线程问题 |
| synchronized | 方法,代码段 | 修饰方法时,则该方法为同步方法,使用该方法所在的类对象做为锁对象,多线程环境下,排队执行 修饰代码段时,一般会指定所使用的锁对象,多线程环境下,该代码段排队执行 |
链接:https://juejin.cn/post/7201665010199003197
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
拥有思想,你就是高级、资深、专家、架构师
当然要想成为高级工程师或者架构师,光看书是不行的,书本上来的东西都是工具型编程的体现,何为工具型编程呢?
就是说可以依据书本、网络等渠道就能完成的编程就是工具型编程,那怎么解决呢?
为什么要提升编程思想
这个问题我想大家都有答案,编程思想就是一个程序员的灵魂,没有灵魂的程序员,只配ctrl + C/V.
专业一点来讲,提升编程思想的重要性在于它能够帮助开发者更好地解决问题、提高效率、减少错误,并提高代码的可读性、可维护性和可扩展性,而这些点位就是成为一个高级Android工程师或者架构师必不可少的技能,也是每一个程序员应该具备的技能。在国外,很多面试更看重的是学习能力和编程思想,其实也是,一个10年的经验丰富的程序员学习一门新的语言或者技术如同探囊取物,对于一个公司、一个团队、一个业务成本来讲,有这样一个人是最经济的。更具体来讲:
- 解决问题能力:良好的编程思想能够帮助开发者更好地理解问题,设计出高效、可靠、可扩展的解决方案。
- 代码质量提升:优秀的编程思想可以帮助开发者写出易于阅读、易于维护的代码,并使其更加健壮、可靠、可测试。
- 工作效率提高:合理的编程思想可以使开发者更加高效地编写代码,并降低代码调试和修复的时间。
- 技术实力提升:良好的编程思想可以使开发者更加深入地理解编程语言和计算机科学原理,并在实践中掌握更多的技能和技巧。
- 职业发展:具备良好编程思想的开发者在技术水平和职业发展方面具有更好的竞争力和前景。
良好的编程思想可以帮助开发者更好地解决问题、提高效率、提高代码质量和可维护性,并在职业发展中具有更好的前景和竞争力,这也就成了了中、高、架构等分级程序员的区别之分。
如何提升自己的编程思想
- 练习算法和数据结构:熟悉算法和数据结构可以帮助你更好地理解和解决问题,优化你的代码并提高你的代码质量。
- 阅读源代码:阅读其他优秀项目的源代码可以帮助你学习其他开发人员的编程思想,理解他们是如何解决问题的,进而提高自己的编程思维。
- 学习设计模式:设计模式是一种常用的编程思想,它可以帮助你更好地组织你的代码,提高代码的可维护性和可扩展性。
- 参与开源项目:参与开源项目可以帮助你学习其他开发人员的编程思想,理解他们是如何解决问题的,同时也可以帮助你获取更多的开发经验和知识。
- 持续学习:跟上Android开发的最新技术和趋势可以让你更好地了解开发环境和市场需求,并提升自己的编程思想。
- 经常review自己的代码:经常review自己的代码可以帮助你发现自己代码中的问题并及时改进,同时也可以帮助你学习其他开发人员的编程思想。
接下来,我们对这些步骤的项目进行分析和说明,
练习算法和数据结构
熟悉算法和数据结构可以帮助你更好地理解和解决问题,优化你的代码并提高你的代码质量, Android 这种移动平台,性能要求是非常高的,但是他的机型众多,系统不一,所以我们应该从编程角度就减少不必要的麻烦。怎么练习呢?
- 选择适合自己的算法练习平台:例如LeetCode、HackerRank、Codeforces等。这些平台都提供了大量的算法题目,可以帮助你提高算法水平。
- 学习基础算法:如排序、查找、树、图等算法,这些算法是其他算法的基础,掌握好基础算法对于提高算法能力非常有帮助。
- 练习算法的具体类型:例如贪心算法、动态规划、分治算法等,这些算法在实际开发中非常常见,掌握好这些算法可以让你更好地解决实际问题。
- 尝试实现算法:通过手写实现一些经典算法,你可以更好地理解算法的思想和实现方式,并加深对算法的理解。
- 参与算法竞赛:参与算法竞赛可以帮助你提高算法能力,同时也可以认识到其他优秀的算法工程师。
很多人在开发过程中公司是不会要求有算法参与的,特别是在Android端,也很少有人在开发中精心设计一款算法用于Android业务,Android的数据量级都在可控范围内,但是优秀的程序员不是应公司要求而编程的,我们因该在面对数据的时候,自然而然的想到算法,想到时间复杂度、空间复杂度的问题算法-时间复杂度 这是之前我在公司分享过的一篇文章,大家可以参考一下,基本涵盖了时间复杂度及在不同场景中的计算方式以及在特殊场景下的计算概念。
举几个例子,怎么将算法运用到平时的开发中呢?
- 优化算法复杂度:在实际开发中,我们常常需要处理大量数据,如果算法复杂度高,就容易导致程序运行缓慢。因此,优化算法复杂度是非常重要的。比如,在ListView或RecyclerView中使用二分查找算法可以快速查找到指定位置的数据。
- 应用动态规划算法:动态规划算法可以用于解决一些经典问题,例如最长公共子序列、背包问题等。在实际开发中,我们也可以应用动态规划算法解决一些问题,例如路径规划、字符串匹配等。
- 应用贪心算法:贪心算法是一种可以获得近似最优解的算法,可以用于一些优化问题。在Android开发中,例如布局优化、图片压缩等方面,也可以应用贪心算法来达到优化的效果。
- 应用其他常用算法:除了上述算法外,其他常用算法也可以应用于Android开发中,例如图像处理算法、机器学习算法等。对于一些比较复杂的问题,我们也可以引入其他算法来解决。
反正就是学之前要理解对应算法的大致用途,在类似场景中,直接尝试搬套,先在伪代码中演算其结果,结果正趋向时果断使用。
阅读源码
阅读其他优秀项目的源代码可以帮助你学习其他开发人员的编程思想,理解他们是如何解决问题的,进而提高自己的编程思维
前边不是说了,工具型编程可以不用看吗,是的,但是阅读源码不是查看工具,而是提升你的编程思想,借鉴思想是人类进化的最主要体现之一,多个思想的碰撞也能造就更成功的事件。那怎么阅读源码呢?这个每个人都有自己的方法,阅读后要善于变通,运用到自己的项目中,我是这么做的。
- 选择合适的开源项目:选择一个合适的开源项目非常重要。你可以选择一些知名度比较高的项目,例如Retrofit、OkHttp、Glide等,这些项目通常质量比较高,也有一定的文档和教程。
- 确定目标和问题:在阅读源码前,你需要明确自己的目标和问题。例如,你想了解某个库的实现原理,或者你想解决一个具体的问题。
- 仔细阅读源码:在阅读源码时,需要仔细阅读每一个类、方法、变量的注释,了解每一个细节。同时也需要了解项目的整体结构和运行流程。
- 了解技术背景和思路:在阅读源码时,你需要了解作者的技术背景和思路,了解为什么选择了某种实现方式,这样可以更好地理解代码。
- 实践运用:通过阅读源码,你可以学到许多好的编程思想和技巧,你需要将这些思想和技巧运用到自己的开发中,并且尝试创新,将这些思想和技巧进一步发扬光大。
阅读源码需要持之以恒,需要不断地实践和思考,才能真正学习到他人的编程思想,并将其运用到自己的开发中。
学习设计模式
设计模式本就是编程思想的总结,是先辈们的经验绘制的利刃,它可以帮助你更好地组织你的代码,提高代码的可维护性和可扩展性。
- 学习设计模式的基本概念:学习设计模式前,需要了解面向对象编程的基本概念,例如继承、多态、接口等。同时也需要掌握一些基本的设计原则,例如单一职责原则、开闭原则等。
- 学习设计模式的分类和应用场景:学习设计模式时,需要了解每个设计模式的分类和应用场景,例如创建型模式、结构型模式、行为型模式等。你需要了解每个模式的特点,以及何时应该选择使用它们。
- 练习设计模式的实现:练习实现设计模式是学习设计模式的关键。你可以使用一些例子,例如写一个简单的计算器、写一个文件读写程序等,通过练习来加深对设计模式的理解。
- 将设计模式应用到实际项目中:将设计模式应用到实际项目中是学习设计模式的最终目标。你需要从项目需求出发,结合实际场景选择合适的设计模式。举例来说,下面是一些在Android开发中常用的设计模式:
- 单例模式:用于创建全局唯一的实例对象,例如Application类和数据库操作类等。
- 适配器模式:用于将一个类的接口转换成客户端期望的另一个接口,例如ListView的Adapter。
- 工厂模式:用于创建对象,例如Glide中的RequestManager和RequestBuilder等。
- 观察者模式:用于实现事件机制,例如Android中的广播机制、LiveData等。
学习设计模式需要不断练习和思考,通过不断地练习和实践,才能真正将设计模式灵活运用到自己的项目中。
参与开源或者尝试商业SDK开发
参与开源,很多同学是没有时间的,并且国内缺少很多开发团队项目,都是以公司或者团队模式开源的,个人想在直接参与比较困难,所以有条件的同学可以参与商业SDK的开发,
商业SDK比较特殊的点在于受众不同,但是他所涉及的编程思想较为复杂,会涉及到很多设计模式和架构模式。
比如,Android商业SDK开发涉及到很多方面,下面列举一些常见的考虑点以及经常使用的架构和设计模式:
- 安全性:SDK需要考虑用户隐私保护和数据安全,确保不会泄露敏感信息。
- 稳定性:SDK需要保证在不同的环境下运行稳定,不会因为异常情况而崩溃。
- 可扩展性:SDK需要考虑未来的扩展和升级,能够方便地添加新的功能和支持更多的设备和系统版本。
- 性能:SDK需要保证在各种设备和网络条件下,响应速度和性能都有足够的表现。
- 兼容性:SDK需要考虑在不同版本的Android系统和各种厂商的设备上,都能够正常运行。
经常用到的架构和设计模式包括:
- MVVM架构:MVVM是Model-View-ViewModel的简称,通过将视图、模型和视图模型分离,可以实现更好的代码组织和更容易的测试。
- 单例模式:单例模式是一种创建全局唯一对象的模式,在SDK中常用于创建全局的配置、管理器等。
- 工厂模式:工厂模式是一种创建对象的模式,SDK中常用于创建和管理复杂的对象。
- 观察者模式:观察者模式是一种事件机制,SDK中常用于通知应用程序有新的数据或事件到达。
- 适配器模式:适配器模式用于将一个接口转换成另一个接口,SDK中常用于将SDK提供的接口适配成应用程序需要的接口。
- 策略模式:策略模式是一种动态地改变对象的行为的模式,SDK中常用于在运行时选择不同的算法实现。
Android商业SDK开发需要综合考虑多个方面,选择适合的架构和设计模式能够提高代码质量、开发效率和维护性。
了解市场、了解业务,不要埋头敲代码
掌握最新的市场需求,比如网络框架的发展历程,从开始的HttpURLConnection的自己封装使用,到okhttp,再到retrofit, 再后来的结构协程、Flow等等,其实核心没有变化就是网络请求,但是,从高内聚到,逐层解耦,变的是其编程的思想。
CodeReview
可以参考该文章,此文章描述了CodeReview 的流程和方法,值得借鉴,CodeReview 是一个天然的提升自己业务需求的过程,
zhuanlan.zhihu.com/p/604492247
经常写开发文档
设计和编写开发文档是一个很重要的工作,它不仅能够提升自己的编程思想,也能够帮助团队提高协作效率和减少沟通成本.
如果要求你在开发一个需求前对着墙或者对着人讲一遍开发思路,你可能讲不出来,也不好意思,且没有留存,开发文档可以满足你,当你写开发文档时,你记录了你的对整个需求的开发,以及你编程的功底,日益累积后,你的思想自然会水涨船高,因为你写开发文档的过程就是在锻炼自己,比如我在前公司开发国际化适配时写的文档(当然只是我的粗鄙想法国际化ICU4J 适配及SDK设计,我会先分析问题,为什么?然后设计,并且会思考可能遇到的问题,也一并解决了。时间长了,设计模式、思想也会得到提升。
当然,也要分场景去设计,按需求去设计,可以采纳以下建议:
设计和编写开发文档是一个很重要的工作,它不仅能够提升自己的编程思想,也能够帮助团队提高协作效率和减少沟通成本。下面是一些关于如何设计一份好的开发文档的建议:
- 明确文档的目标和受众:在编写文档之前,需要明确文档的目标和受众,确定文档需要包含的内容和写作风格
- 使用清晰的语言和示例:使用简洁、清晰的语言描述问题,使用示例代码和截图帮助读者理解问题。
- 分层次组织文档:文档应该按照逻辑和功能分层次组织,每一层都有明确的目标和内容。
- 使用图表和图形化工具:图表和图形化工具能够有效地展示复杂的概念和数据,帮助读者更好地理解文档内容。
- 定期更新和维护文档:开发文档需要定期更新和维护,以反映最新的代码和功能。
通过设计一份好的开发文档,可以提升自己的编程思想,使得代码更加清晰和易于维护,同时也能够提高团队的协作效率和代码质量。
向上有组织的反馈
经常向领导有组织的汇报开发进度、问题、结果,不仅可以提升编程思想,还能够提高自己的工作效率和沟通能力
首先,向领导汇报开发进度、问题和结果,可以让自己更加清晰地了解项目的进展情况和任务的优先级,帮助自己更好地掌控项目进度和管理时间。
其次,通过向领导汇报问题,可以促使自己更加深入地了解问题的本质和解决方案,同时也能够得到领导的反馈和指导,帮助自己更快地解决问题。
最后,向领导汇报开发结果,可以帮助自己更好地总结经验和教训,促进自己的成长和提高编程思想。同时,也能够让领导更清晰地了解自己的工作成果,提高领导对自己的认可和评价。
向领导有组织地汇报开发进度、问题和结果,不仅能够提升编程思想,还能够提高工作效率和沟通能力,促进自己的成长和发展。
总结
- 编程思想的提升
- 学习数据结构和算法,尤其是常见的算法类型和实际应用
- 阅读优秀开源代码,理解代码架构和设计思想,学习开发最佳实践
- 学习设计模式,尤其是常见的设计模式和应用场景
- 实际项目开发中的应用
- 通过代码重构,优化代码质量和可维护性
- 运用算法解决实际问题,例如性能优化、数据处理、机器学习等
- 运用设计模式解决实际问题,例如代码复用、扩展性、灵活性等
- 沟通与协作能力的提高
- 与团队成员保持良好的沟通,及时反馈问题和进展情况
- 向领导有组织地汇报开发进度、问题和结果,以提高工作效率和沟通能力
- 参加技术社区活动,交流分享经验和知识,提高团队的技术实力和协作能力
以上是这些方面的核心点,当然每个方面都有很多细节需要关注和完善,需要持续学习和实践。
附件
以下是我之前为项目解决老项目的图片框架问题而设计的文档,因名称原因只能图片展示
首先,交代了背景,存在的问题
针对问题,提出设计思想
开始设计,从物理结构到架构
链接:https://juejin.cn/post/7200944831114264637
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【设计模式】Kotlin 与 Java 中的单例
单例模式
单例模式是一个很常见的设计模式,尤其是在 Java 中应用非常广泛。单例模式的定义是保证一个类仅有一个实例,并提供一个访问它的全局访问点。
Java 中的单例模式
Java 中存在多种单例模式的实现方案,最经典的包括:
懒汉式
饿汉式
双重校验锁
饿汉式 / 静态单例
Java 中懒汉式单例如其名一样,“饿” 体现在不管单例对象是否存在,都直接进行初始化:
public final class SingleManager {
@NotNull
public static final SingleManager INSTANCE = new SingleManager();
private SingleManager() {}
public static SingleManager getInstance() {
return INSTANCE;
}
}实际上,这也是静态单例。
懒汉式 / 延迟初始化
Java 中的懒汉式核心特点在于“懒” ,它不像饿汉式,无论 INSTANCE 是否已经存在值,都进行初始化;而是在调用 get 方法时,检查引用对象是否为空,如果为空再去初始化:
public final class SingleManager {
public static SingleManager INSTANCE;
private SingleManager() {}
public static SingleManager getInstance() {
if (INSTANCE == null) {
INSTANCE = new SingleManager();
}
return INSTANCE;
}
}双重校验锁
public final class SingleManager {
// volatile 防止指令重排,确保原子操作的顺序性
public volatile static SingleManager INSTANCE;
private SingleManager() {}
public static SingleManager getInstance() {
// 第一次判空,减少进入同步锁的次数,提高效率
if (INSTANCE == null) {
// 确保同步
synchronized (SingleManager.class) {
// 确保加锁后,引用仍是空的
if (INSTANCE == null) {
INSTANCE = new SingleManager();
}
}
}
return INSTANCE;
}
}Kotlin 中的单例模式
object 关键字
Kotlin 提供了比 Java 更方便的语法糖 object 关键字,能够更方便地实现单例模式:
object SingleManager {
fun main() {}
}使用:
// used in kotlin
SingleManager.main()
// used in java
SingleManager.Companion.main();
如果要在 Java 中的使用方式与 Kotlin 使用方式一致,可以在方法上添加
@JvmStatic注解:
object SingleManager {
@JvmStatic
fun main() {}
}
// used in java
SingleManager.main();
object 关键字实现的单例,编译为 Java 字节码的实现是:
public final class SingleManager {
@NotNull
public static final SingleManager INSTANCE;
public final void main() {
}
private SingleManager() {
}
static {
SingleManager var0 = new SingleManager();
INSTANCE = var0;
}
}这是一种标准的 Java 静态单例实现。
Kotlin 懒汉式
在一些特殊的情况,例如你的单例对象要保存一些不适合放在静态类中的引用,那么使用 object 就不是合适的方案了,例如,Android 中的上下文 Context 、View 都不适合在静态类中进行引用,IDE 也会提醒你这样会造成内存泄漏:
一种好的解决方案是在 Kotlin 中使用懒汉式的写法:
class SingleManager {
companion object {
private var instance: SingleManager? = null
fun getInstance(): SingleManager {
if (instance == null) {
instance = SingleManager()
}
return instance!!
}
}
var view: View? = null
}但是这样仍然会提醒你不要引用:
但如果引用的对象是你自定义的 View :
class BaseView @JvmOverloads constructor(
context: Context, attrs: AttributeSet? = null
) : FrameLayout(context, attrs)
在 kotlin 中懒汉式是不会提示你的:
可以看出,使用 object 关键字,仍然会飘黄,提醒你可能存在内存泄漏。
本质上来说,没有提示实际上也是存在内存泄漏的隐患的。 虽然可以骗过 IDE 但不应该欺骗自己。
写在最后
Kotlin 作为一门更新的 JVM 语言,它提供了很多语法糖突破了 Java 的一些固定写法,有些设计模式已经不再适合新的语言(例如 Builder 模式在 Kotlin 中很少会出现了)。虽然新语言简化了代码的复杂度、简化了写法,但不能简化知识点,例如,使用 Kotlin 需要一个线程安全的单例,仍然可以使用双重校验锁的写法。本质上还是要搞清楚底层逻辑。
链接:https://juejin.cn/post/7200708877389070395
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter WebView 性能优化,让 h5 像原生页面一样优秀
WebView 页面的体验上之所以不如原生页面,主要是因为原生页面可以马上显示出页面骨架,一下子就能看到内容。WebView 需要先根据 url 去加载 html,加载到 html 后才能加载 css ,css 加载完成后才能正常显示页面内容,至少多出两步网络请求。有的页面是用 js 渲染的,这样时间会更长。要想让 WebView 页面能接近 Flutter 页面的体验,主要就是要省掉网络请求的时间。
做优化要考虑到很多方面,在成本与收益之间做平衡。如果不是新开项目,需要考虑项目当前的情况。下面分两种情况讨论一下。
服务端渲染
页面 html 已经在服务端拼接完成。只需要 html,css 就可以正常查看页面(主要内容不受影响)。如果你的项目的页面是这样的,那么我们已经有了一个好的起点。
WebView 要显示一个页面,需要串行下面的过程。通过 url 加载到 html 后再加载 css,css 加载完成后显示页面。
url -> html -> css -> 显示我们可以对 css 的请求做一下优化。优化方案有两种
- 内联 css 到 html
- 把 css 缓存到本地。
第一种方案比较容易做,修改一下页面的打包方案即可。很容易实现一份代码打包出两个页面,一个外链 css ,一个内联css。但坏处也是很明显的,每次都加载同样的 css,会增加网络传输,如果网络不佳的话,对首屏时间可能会产生明显的影响。就算抛开首屏时间,也会对用户的流量造成浪费。
第二种方案可以解决 css 重复打包的问题。首先要考虑的问题是:css 放在本地的哪个地方?
css 放哪里
有两个地方可以放
- 放在 asset,和 app 一起打包发布,好处是简单可靠,坏处是不方便更新。
- 放在 文档目录,好处是可以随时更新,坏处是逻辑上会复杂一些。
文档目录用于存储只能由该应用访问的文件,系统不会清除该目录,只有在删除应用时才会消失。
从技术上来说,这两种方案都是可以的。先说下不方便更新的问题:既然 app 的其它页面都不能随便更新,为什么不能接受这个页面的样式不能随便更新?如果是害怕版本冲突,那也好解决,发一次版,更新一次页面地址,每个版本都有其对应的页面地址,这样就不会冲突了。根本原因是掌控的诱惑,即使你能控制住诱惑,你的老板也控制不住。所以还是老老实实选第二种方案吧。
放哪里的问题解决了,接下来要考虑的是如何更新 css 的问题。
更新 css
因为有可能 app 启动后第一个展示的就是这个页面,所以要在 app 启动后第一时间就更新 css。但又有一个问题,每次启动都更新同样的内容是在浪费流量。解决办法是加一个配置,每次启动后第一时间加载这个配置,通过配置信息来判断要不要更新 css。
这个配置一定要很小,比如可以用二进制 01 表示true false,当然了可能不需要这么极端,用一个 map 就好。
如何利用本地 css 快速显示页面
在 app 上启动一个本地 http server 提供 css。 我们可以在打包的时候把 css 的外链写成本地 http,比如 http://localhost:8080/index.css 。
除了 css,页面的重要图片,字体等静态资源也可以放在本地,只要加载到 html 就可以立即显示页面,省了一步需要串行的网络请求。
到这里服务端渲染页面的优化就完成了,还是很简单的吧,示例代码在后面。
浏览器渲染
近年来,随着 vue,react 的兴起,由 js 在浏览器中拼接 html 逐渐成为主流。虽然可以用同构的方案,但那样会增加成本,除非必须,一般都是只在浏览器渲染。可能你的页面正是这样的。我们来分析一下。
WebView 要显示一个页面,需要串行下面的过程。通过 url 加载到 html 后再加载 css、js,js 请求完数据后才能显示页面。
url -> html -> css,js -> js 去加载数据 -> 显示和服务端渲染的页面相比,首次请求时间更长。多出了 js 加载数据的时间。除了要缓存 css,还要缓存 js 和数据。缓存 js 是必须的,缓存数据是可选的。好消息是 html 只有骨架,没有内容,可以连 html 也一起缓存。
缓存 js,html 的方案和缓存 css 的方案是一样的。缓存数据会面临数据更新的难题,所以只可以缓存少量不需要时时更新的少量重要数据,不需要所有数据都缓存。app 的原生页面也是需要加载数据的,也不是每种数据都要缓存。
数据更新之所以说是一个难题,是因为很多内容数据是需要即时更新的。但数据已经下发到客户端,已经缓存起来,客户端不再发起新的请求,如何通知客户端进行数据更新?虽然有轮询,socket,服务端推送等方案可以尝试,但开发成本都比较高,和获得的收益相比,代价太大。
当缓存了 html,css,js 等静态资源后,h5 就已经和原生页面站在同一起跑线上了,对于只读的页面,体验上相差无几。
加载数据后还有js 拼接 html 的时间,和加载的时间相比,只要硬件还可以的情况下,消耗的时间可以忽略
图片不适合用缓存 css 的方案,因为图片太大也太多。只能预加载少量最重要的图片,其它大量图片只能对二次加载做优化,我们会在后面讨论
浏览器渲染的页面也需要打包的配合,需要把所有的要缓存的静态资源地址都换成本地地址,这就要求发布的时候一份代码需要发布两个页面。一个是给浏览器用的,资源都通过网络加载。一个是给 WebView 用的,资源都从本地获取。
思路已经有了,具体实现就简单了。下面我给出关键环节的示例代码,供大家参考。
如何启动本地server
本地不需要 https,用 http 用行了,但是需要在 AndroidManifest.xml 的 applictation 中做如下配置 android:usesCleartextTraffic="true"
import 'package:shelf/shelf_io.dart' as io;
import 'package:shelf_static/shelf_static.dart';
import 'package:path_provider/path_provider.dart';
Future<void> initServer(webRoot) async {
var documentDirectory = await getApplicationDocumentsDirectory();
var handler =
createStaticHandler('${documentDirectory.path}/$webRoot', defaultDocument: 'index.html');
io.serve(handler, 'localhost', 8080);
}createStaticHandler 负责处理静态资源。
如果要兼容 windows 系统,路径需要用 path 插件的 join 方法拼接
如何让 WebView 的页面请求走本地服务
两种方案:
- 打包的时候需要缓存的页面的地址都改成本地地址
- 对页面请求 在 WebView 中进行拦截,让已经缓存的页面走本地 server。
相比之下,第 2 种方案都好一些。可以通过配置文件灵活修改哪些页面需要缓存。
在下面的示例代码中 ,cachedPagePaths 存储着需要缓存的页面的 path。
import 'dart:async';
import 'package:flutter/material.dart';
import 'package:webview_flutter/webview_flutter.dart';
class MyWebView extends StatefulWidget {
const MyWebView({super.key, required this.url, this.cachedPagePaths = const []});
final String url;
final List<String> cachedPagePaths;
@override
State<MyWebView> createState() => _MyWebViewState();
}
class _MyWebViewState extends State<MyWebView> {
late final WebViewController controller;
@override
void initState() {
controller = WebViewController()
..setJavaScriptMode(JavaScriptMode.unrestricted)
..setNavigationDelegate(NavigationDelegate(
onNavigationRequest: (request) async {
var uri = Uri.parse(request.url);
// TODO: 还应该判断下 host
if (widget.cachedPagePaths.contains(uri.path)) {
var url = 'http://localhost:8080/${uri.path}';
Future.microtask(() {
controller.loadRequest(Uri.parse(url));
});
return NavigationDecision.prevent;
} else {
return NavigationDecision.navigate;
}
},
))
..loadRequest(Uri.parse(widget.url));
super.initState();
}
@override
void didUpdateWidget(covariant MyWebView oldWidget) {
if(oldWidget.url!=widget.url){
controller.loadRequest(Uri.parse(widget.url));
}
super.didUpdateWidget(oldWidget);
}
@override
Widget build(BuildContext context) {
return Column(
children: [Expanded(child: WebViewWidget(controller: controller))],
);
}
}优化图片请求
如果页面中有很多图片,你会发现,体验上还是不如 Flutter 页面,为什么呢?原来 Flutter Image Widget 使用了缓存,把请求到的图片都缓存了起来。 要达到相同的体验,h5 页面也需要实现相同的缓存功能。
关于 Flutter 图片请参见 快速掌握 Flutter 图片开发核心技能
代码实现
要如何实现呢?只需要两步。
- 打包的时候需要把图片的外链请求改成本地请求
- 本地 server 对图片请求进行拦截,优先读缓存,没有再去请求网络。
第 1 条我举个例子,比如图片的地址为 https://juejin.com/logo.png ,打包的时候需要修改为 http://localhost:8080/logo.png
第 2 条的实现上,我们取个巧,借用 Flutter 中的 NetworkImage,NetworkImage 有缓存的功能。
下面给出完整示例代码,贴到 main.dart 中就能运行。运行代码后看到一段文字和一张图片。
注意先安装相关的插件,插件的名字 import 里有。
import 'dart:io';
import 'package:flutter/material.dart';
import 'package:path_provider/path_provider.dart';
import 'dart:async';
import 'dart:typed_data';
import 'package:shelf/shelf.dart';
import 'package:shelf/shelf_io.dart' as io;
import 'package:shelf_static/shelf_static.dart';
import 'dart:ui' as ui;
import 'package:webview_flutter/webview_flutter.dart';
const htmlString = '''
<!DOCTYPE html>
<head>
<title>webview demo | IAM17</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0,
maximum-scale=1.0, user-scalable=no,viewport-fit=cover" />
<style>
*{
margin:0;
padding:0;
}
body{
background:#BBDFFC;
text-align:center;
color:#C45F84;
font-size:20px;
}
img{width:90%;}
p{margin:30px 0;}
</style>
</head>
<html>
<body>
<p>大家好,我是 17</p>
<img src='http://localhost:8080/tos-cn-i-k3u1fbpfcp/
c6208b50f419481283fcca8c44a2e3af~tplv-k3u1fbpfcp-watermark.image'/>
</body>
</html>
''';
void main() async {
runApp(const MyApp());
}
class MyApp extends StatefulWidget {
const MyApp({super.key});
@override
State<MyApp> createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
WebViewController? controller;
@override
void initState() {
init();
super.initState();
}
init() async {
var server = Server17(remoteHost: 'p6-juejin.byteimg.com');
await server.init();
var filePath = '${server.webRoot}/index.html';
var indexFile = File(filePath);
await indexFile.writeAsString(htmlString);
setState(() {
controller = WebViewController()
..loadRequest(Uri.parse('http://localhost:${server.port}/index.html'));
});
}
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
body: SafeArea(
child: controller == null
? Container()
: WebViewWidget(controller: controller!),
),
));
}
}
class Server17 {
Server17(
{this.remoteSchema = 'https',
required this.remoteHost,
this.port = 8080,
this.webFolder = 'www'});
final String remoteSchema;
final String remoteHost;
final int port;
final String webFolder;
String? _webRoot;
String get webRoot {
if (_webRoot == null) throw Exception('请在初始化后读取');
return _webRoot!;
}
init() async {
var documentDirectory = await getApplicationDocumentsDirectory();
_webRoot = '${documentDirectory.path}/$webFolder';
await _createDir(_webRoot!);
var handler = Cascade()
.add(getImageHandler)
.add(createStaticHandler(_webRoot!, defaultDocument: 'index.html'))
.handler;
io.serve(handler, InternetAddress.loopbackIPv4, port);
}
_createDir(String path) async {
var dir = Directory(path);
var exist = dir.existsSync();
if (exist) {
return;
}
await dir.create();
}
Future<Uint8List?> loadImage(String url) async {
Completer<ui.Image> completer = Completer<ui.Image>();
ImageStreamListener? listener;
ImageStream stream = NetworkImage(url).resolve(ImageConfiguration.empty);
listener = ImageStreamListener((ImageInfo frame, bool sync) {
final ui.Image image = frame.image;
completer.complete(image);
if (listener != null) {
stream.removeListener(listener);
}
});
stream.addListener(listener);
var uiImage = await completer.future;
var pngBytes = await uiImage.toByteData(format: ui.ImageByteFormat.png);
if (pngBytes != null) {
return pngBytes.buffer.asUint8List();
}
return null;
}
FutureOr<Response> getImageHandler(Request request) async {
if (RegExp(
r'\.(png|image)$',
).hasMatch(request.url.path)) {
var url = '$remoteSchema://$remoteHost/${request.url.path}';
var imageData = await loadImage(url);
//TODO: 如果 imageData 为空,改成错误图片
return Response.ok(imageData);
} else {
return Response.notFound('next');
}
}
}
代码逻辑
- 在本地文档目录的 www 文件夹中准备了一个 index.html 文件
- 启动本地 server,通过访问 http://localhost:8080/index.html 请求本地页面。
- server 收到请求后,对图片请求进行拦截,通过 NetworkImage 返回图片。
第 2 条。本例中是直接访问的 localhost,实际应用中,页面地址是外链地址,通过拦截的方式请求本地。如何做页面地址拦截前面已经给出示例了。
第 3 条。打包后的时候对所有图片地址都写成了本地地址,改成本地地址的目的就是为了让图片请求都由本地 server 响应。本地 server 拿到 图片地址后,再改回网络地址,通过 NetworkImage 请求图片。NetworkImage 会首先判断有没有缓存,有直接用,没有就发起网络请求,然后再缓存。
可能你觉得有点绕,既然最后还要用网络地址,为什么还要先写成本地地址,象拦截页面请求那样拦截图片请求不香吗?答案是不可以。两个原因。
- webview_flutter 只能拦截页面请求。
- 本地 server 不方便拦截 443 端口。
对比于拦截 443 端口,修改打包方案要容易的多。
关于图片类型
在示例代码中,用 RegExp( r'\.(png|image)$',) 判断是否要响应请求。从正则可以看出,以 png 或 image 结果的图片都能响应请求。判断 image 是因为示例中的图片地址是以 image 结尾的。
示例代码只能支持 png 格式的图片,示例图片虽然是 image 结尾,但格式也是 png 格式。如果要支持更多格式的图片,需要用到第三方库。
关于图片地址
如果图片地址失改,可以自行换一个,随使在网上找个 png 图片 地址就行。
把图片缓存到磁盘。
我们演示了把图片缓存到内存,当 app 被杀掉,缓存都没了,除非缓存到磁盘。这项工作已经有插件帮我们做了。
用 cached_network_image 替换 NetworkImage,稍加改动就可以实现磁盘缓存了。
总结一下
服务端染页面方案
- 打包的时候需要打出两个页面,一个页面的 css 外链接是外网,一个页面的 css 链接是本地。
- 在 App 启动的时候根据配置信息预加载 css 存到文档目录。
- 启动本地 server 响应 css 的请求。
浏览器渲染方案
- 打包的时候需要打出两个页面,一个页面的 css,js 链接是外网,一个页面的 css,js 链接是本地。
- 在 App 启动的时候根据配置信息预加载 html,css,js 存到文档目录。
- 根据配置信息拦截页面请求,已经缓存的页面改走本地 server。
- 启动本地 server 响应 html,css,js 的请求
图片缓存
如果不做图片缓存,通过前面两个方案,h5 速度就已经得到大大提高了。如果有余力,可以做图片缓存。图片缓存是可选的,是对前面两种方案的加强。
- 给 app 用的页面打包的时候把图片地址换成本地地址。
- 启动本地 server 响应图片请求,有缓存就读缓存,没有缓存走网络。
可能你的项目不同,有不同的方案,欢迎一起讨论。
本文到这里就结束了,谢谢观看。
番外
为了给自己一点压力,上一篇 在 Flutter 中使用 webview_flutter 4.0 | js 交互 中我就预告说今天要发这篇性能优化的文章。结果压力是有的了,但却没能按时完工(理想情况是周日下午完工,这样可以休息一下)。一个原因是 升级 flutter 报错,浪费了一个上午,再有就是写了一版后,并不满意,又重写了一版,最后才定稿。一直写到深夜才把主要内容写完。早上起来又做了补充修改。
由于时间紧,有不妥之处,还请各位大佬雅正。
链接:https://juejin.cn/post/7199298121792749628
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在 Flutter 中使用 webview_flutter 4.0 | js 交互
大家好,我是 17。
已经有很多关于 Flutter WebView 的文章了,为什么还要写一篇。两个原因:
- Flutter WebView 是 Flutter 开发的必备技能
- 现有的文章都是关于老版本的,新版本 4.x 有了重要变化,基于 3.x 的代码很多要重写。
本篇讲 js 交互。首先了解下 4.0 有哪些重大变化。
- 最大的变化就是 WebView 类已被删除,其功能已拆分为 WebViewController 和 WebViewWidget。让我们可以提前初始化 WebViewController。
- Android 的 PlatformView 的实现目前不再可配置。它在版本 23+ 上使用 Texture Layer Hybrid Compositiond,在版本 19-23 回退到 Hybrid Composition。
第 2 条的变化让我们不需要再写判断 android 的代码了。
还有 api 的变化。总的来说,让我们的编码更加容易了。
写本文的时候,Flutter WebView 的版本是 4.0.2
环境准备
虽然文档上写的是支持 addroid SDK 19+ or 20+, 但我们最好写 21 或更高,不是说会影响 Flutter WebView 的使用,而是太低了会影响其它插件的使用。如果能写 23 就更好了,这样可以用 Texture Layer Hybrid Compositiond 了。
android {
defaultConfig {
minSdkVersion 21
}
}iOS 支持 9.0 以上,新版本的 flutter 默认配置是 ios 11.0 ,所以我们按 Flutter 默认的配置就好。
安装 webview_flutter
flutter pub add webview_flutter最简示例
一般举例都是先发一个 hello world,咱们也发一个最简单的,先跑起来。
完整代码,贴到 main.dart 就能运行
- 引用 webview_flutter 插件
- 创建 controller
- 用 WebViewWidget 展示内容
import 'package:flutter/material.dart';
import 'package:webview_flutter/webview_flutter.dart';
const htmlString = '''
<!DOCTYPE html>
<head>
<title>webview demo | IAM17</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0,
maximum-scale=1.0, user-scalable=no,viewport-fit=cover" />
<style>
*{
margin:0;
padding:0;
}
body{
background:#BBDFFC;
display:flex;
justify-content:center;
align-items:center;
height:100px;
color:#C45F84;
font-size:20px;
}
</style>
</head>
<html>
<body>
<div >大家好,我是 17</div>
</body>
</html>
''';
void main() {
runApp(const MyApp());
}
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return const MaterialApp(
home: Scaffold(
body: SafeArea(child: MyWebView()),
));
}
}
class MyWebView extends StatefulWidget {
const MyWebView({super.key});
@override
State<MyWebView> createState() => _MyWebViewState();
}
class _MyWebViewState extends State<MyWebView> {
late final WebViewController controller;
double height = 0;
@override
void initState() {
controller = WebViewController()
..setJavaScriptMode(JavaScriptMode.unrestricted)
..loadHtmlString(htmlString);
super.initState();
}
@override
Widget build(BuildContext context) {
return Column(
children: [Expanded(child: WebViewWidget(controller: controller))],
);
}
}执行代码,你将看到如下内容
WebView 内容的可以通过网址获取,但这样不方便演示各种效果,所以直接用 htmlString 替代了,效果是一样的。
默认情况下 javascript 是被禁用的。必须手动开启 setJavaScriptMode(JavaScriptMode.unrestricted),否则对于绝大多数的网页都没法用了。
WebView 的小大
WebViewWidget 会尝试让自己获得最大高度和最大宽度,所以 WebView 必须放在有限宽度和有限高度的 Widget 中。一般会用 SizedBox 这样的容器把 WebView 包起来。但是 WebView 内容的高度是未知的,要如何设置 SizedBox 的 height 呢?
一种方案是 height 采用固定高度,如果 WebView 内容过多,可以用上下滑动的方式来查看所有内容。如果 WebView 的内容高度是变化的,用固定高度可能会产生大块空白,这个时候应该把 height 设置成 WebView 内容的高度。
那么问题来了,如何获得 WebView 内容的高度?最理想的情况是网页是自己能控制的,让网页自己报告高度。
网页自己报告高度
在 htmlString 中 增加 js
<body>
<div class="content">大家好,我是 17</div>
<script>
const resizeObserver = new ResizeObserver(entries =>
Report.postMessage(document.scrollingElement.scrollHeight))
resizeObserver.observe(document.body)
</script>
</body>
如果WebView 不支持 ResizeObserver 可以直接在合适的时机调用 Report.postMessage(document.scrollingElement.scrollHeight))
dart 代码中
- 增加一个变量 height ,初始值为 0。
- 增加 ScriptChannel,注意名字和前面 script 中的名字必须一样,本例中名字叫 Report
- 用 SizedBox 替换 Expanded,限定 WebViewWidget 的高度。
class _MyWebViewState extends State<MyWebView> {
late final WebViewController controller;
double height = 0;
@override
void initState() {
controller = WebViewController()
..setJavaScriptMode(JavaScriptMode.unrestricted)
..addJavaScriptChannel('Report', onMessageReceived: (message) {
setState(() {
height = double.parse(message.message);
});
})
..loadHtmlString(htmlString);
super.initState();
}
@override
Widget build(BuildContext context) {
return Column(
children: [
SizedBox(height: height, child: WebViewWidget(controller: controller)),
],
);
}
}修改 html 代码中的 body 的样式 height:100px 为 height:200px;,重新运行代码(restart,hot reload 不生效 ),发现 SizedBox 也变为 200px 高了。
无法修改页面
如果页面我们无权修改也没有办法协调修改,那就只能通过注入 js 方式获取了。
如果页面的高度只由静态 css 决定,可以简单的加一个小延时,直接获取高度即可。
controller.setNavigationDelegate(NavigationDelegate(
onPageFinished: (url) async {
await Future.delayed(Duration(milliseconds: 50));
var message = await controller.runJavaScriptReturningResult(
'document.scrollingElement.scrollHeight');
setState(() {
height =double.parse(message.toString());
});
},
));如果页面加载完成后 js 又对页面进行了修改,这个时间就很难预估了。js 可以随时修改页面,导致高度改变,所以要想时时跟踪页面高度,只能靠监听。如果 webview 不支持 ResizeObserver,还可以用 setInterval。
void initState() {
controller = WebViewController()
..setJavaScriptMode(JavaScriptMode.unrestricted)
..addJavaScriptChannel('Report', onMessageReceived: (message) {
var msgHeight = double.parse(message.message);
setState(() {
height = msgHeight;
});
})
..setNavigationDelegate(NavigationDelegate(
onPageFinished: (url) async {
// 注入 js
controller.runJavaScript(
'''const resizeObserver = new ResizeObserver(entries =>
Report.postMessage(document.scrollingElement.scrollHeight))
resizeObserver.observe(document.body)''');
},
))
..loadHtmlString(htmlString);
super.initState();
}必须等到页面加载完成后再注入 js,否则页面文档还不存在,往哪里注入啊。
因为代码都在 dart 这边,免去了和页面开发沟通的成本。既使 WebView 加载的页面中可能还有链接,跳到另一个地址,js 注入的代码依然有效!
页面的高度可能会在很短时间内连续变化,我们可以只对最后一次的高度变化做更新,用 Timer 可以做到。页面高度要限制一个最大值,否则超出最大允许的高度就报错了。
可能你会觉得既然注入的方式这么多优点,不需要页面报告那种方式了,都用这种注入的方式就可以了。实际上每种方式都有它的利弊,不然我就不会介绍了。页面报告的方式在于灵活,想什么时候报告就什么时候报告,页面高度变化了,也可以不报告。在页面没有内容的时候可以先报告一个预估的高度,会让页面避免从 0 开始突然变高。尽量把主动权交给页面,因为页面是可以随时修改的,app 不能!
在网页中调用 Flutter 页面
拦截 url
url 以 /android 结尾时,跳到对应的原生页面。否则继续原来的请求。
onNavigationRequest: (request) {
if (request.url.endsWith('/android')) {
// 跳到原生页面
return NavigationDecision.prevent;
} else {
// 继续原来的请求
return NavigationDecision.navigate;
}
},触发方式有两种
- 用 A 标签
<a href='/ios'>跳到 Flutter 页面</a> - 用 js 跳转
window.location.href='完整页面地址'
用 js 跳转的地址一定是完整的页面地址。比如这样写都是可以的
https://juejin.cnaa:/bb
schema 可以自定义,但不能没有。这样写是无效的 /android
js 调用 JavaScriptChannel 定义的方法
先定义跳转的通道对象为 Jump
void initState() {
controller = WebViewController()
..setJavaScriptMode(JavaScriptMode.unrestricted)
..addJavaScriptChannel('Jump', onMessageReceived: (message) {
//根据 message 信息跳转
})
..loadHtmlString(htmlString);
super.initState();
}在页面中执行 Jump.postMessage('video');
实际上,flutter 拿到页面传过来的信息后,除了可以跳转到 flutter 页面,还可以执行其它功能,比如调取相机。
总结
通过两个示例演示了页面与 flutter 通信的 3 种方式
- flutter 拦截 url
- flutter 设置 JavaScriptChannel
- flutter 向页面注入 js
向页面注入 js 需要等页面加载完成后再注入。注入 js 的能力非常强大的。几乎可以对页面做任意修改。比如
- 删除页面中不想要的部分
- 修改页面的样式
- 增加页面的功能,比如给页面增加一个按钮,点按钮跳到原生页面,就好像原来的页面就有这个功能一样。
删除页面中不想要的部分,这是有实际意义的。页面都会有页头,这可能和 app 的头部冲突。有了注入 js 这个利器,可以在不修改页面的情况下,直接在 app 中不显示页头。
修改页面样式,这个你懂的,既然能注入 js ,也就是能注入 css 了。相比于直接用 js 修改页面样式,注入 css 的方式更加容易维护。
当然了,凡事有利有弊,不要滥用这个功能。在 app 单方面修改页面,将来页面修改的时候可能会翻车,即使做好沟通,也会给页面开发造成限制或麻烦,所以如何做一定要权衡各方面的得失。
app 不像页面那样可以随时修改,所以要优先考虑让页面实现功能,尽量把控制权交给页面(说两遍了,因为很重要)。js 注入这种操作不是万不得已不要做,把它做为最后的选项。
最后说一点,示例中为了方便演示用 loadHtmlString,实际应用中一般是用 loadRequest 加载网址。
loadHtmlString(htmlString) loadRequest(Uri.parse('https://juejin.cn'))
本文到这里就结束了。谢谢观看!
链接:https://juejin.cn/post/7196698315835260984
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
鹅厂组长,北漂 10 年,有房有车,做了一个违背祖宗的决定
前几天是 10 月 24 日,有关注股票的同学,相信大家都过了一个非常难忘的程序员节吧。在此,先祝各位朋友们身体健康,股票基金少亏点,最重要的是不被毕业。
抱歉,当了回标题党,不过在做这个决定之前确实纠结了很久,权衡了各种利弊,就我个人而言,不比「3Q 大战」时腾讯做的「艰难的决定」来的轻松。如今距离这个决定过去了快 3 个月,我也还在适应着这个决定带来的变化。
按照工作汇报的习惯,先说结论:
在北漂整整 10 年后,我回老家合肥上班了
做出这个决定的唯一原因:
没有北京户口,积分落户陪跑了三年,目测 45 岁之前落不上
户口搞不定,意味着孩子将来在北京只能考高职,这断然是不能接受的;所以一开始是打算在北京读几年小学后再回老家,我也能多赚点钱,两全其美。
因为我是一个人在北京,如果在北京上小学,就得让我老婆或者让我父母过来。可是我老婆的职业在北京很难就业,我父母年龄大了,北京人生地不熟的,而且那 P 点大的房子,住的也憋屈。而将来一定是要回去读书的,这相当于他们陪着我在北京折腾了。
或者我继续在北京打工赚钱,老婆孩子仍然在老家?之前的 6 年基本都是我老婆在教育和陪伴孩子,我除了逢年过节,每个月回去一到两趟。孩子天生过敏体质,经常要往医院跑,生病时我也帮不上忙,所以时常被抱怨”丧偶式育儿“,我也只能跟渣男一样说些”多喝热水“之类的废话。今年由于那啥,有整整 4 个多月没回家了,孩子都差点”笑问客从何处来“了。。。
5月中旬,积分落户截止,看到贴吧上网友晒出的分数和排名,预计今年的分数线是 105.4,而实际分数线是 105.42,比去年的 100.88 多了 4.54 分。而一般人的年自然增长分数是 4 分,这意味着如果没有特殊加分,永远赶不上分数线的增长。我今年的分数是 90.8,排名 60000 左右,每年 6000 个名额,即使没有人弯道超车,落户也得 10 年后了,孩子都上高一了,不能在初二之前搞到户口,就表示和大学说拜拜了。
经过我的一番仔细的测算,甚至用了杠杆原理和人品守恒定理等复杂公式,最终得到了如下结论:
我这辈子与北京户口无缘了
所以,思前想后,在没有户口的前提下,无论是老婆孩子来北京,还是继续之前的异地,都不是好的解决方案。既然将来孩子一定是在合肥高考,为了减少不必要的折腾,那就只剩唯一的选择了,我回合肥上班,兼顾下家里。
看上去是个挺自然的选择,但是:
我在腾讯是组长,团队 20 余人;回去是普通工程师,工资比腾讯打骨折
不得不说,合肥真的是互联网洼地,就没几个公司招人,更别说薪资匹配和管理岗位了。因此,回合肥意味着我要放弃”高薪“和来之不易的”管理“职位,从头开始,加上合肥这互联网环境,基本是给我的职业生涯判了死刑。所以在 5 月底之前就没考虑过这个选项,甚至 3 月份时还买了个显示器和 1.6m * 0.8m 的大桌子,在北京继续大干一场,而在之前的 10 年里,我都是用笔记本干活的,从未用过外接显示器。
5 月初,脉脉开始频繁传出毕业的事,我所在的部门因为是盈利的,没有毕业的风险。但是营收压力巨大,作为底层的管理者,每天需要处理非常非常多的来自上级、下级以及甲方的繁杂事务,上半年几乎都是凌晨 1 点之后才能睡觉。所以,回去当个普通工程师,每天干完手里的活就跑路,貌似也不是那么不能接受。毕竟自己也当过几年 leader 了,leader 对自己而言也没那么神秘,况且我这还是主动激流勇退,又不是被撸下来的。好吧,也只能这样安慰自己了,中年人,要学会跟自己和解。后面有空时,我分享下作为 leader 和普通工程师所看到的不一样的东西。
在艰难地说服自己接受之后,剩下的就是走各种流程了:
1. 5月底,联系在合肥工作的同学帮忙内推;6月初,通过面试。我就找了一家,其他家估计性价比不行,也不想继续面了
2. 6月底告诉总监,7月中旬告诉团队,陆续约或被约吃散伙饭
3. 7月29日,下午办完离职手续,晚上坐卧铺离开北京
4. 8月1日,到新公司报道7 月份时,我还干了一件大事,耗时两整天,历经 1200 公里,不惧烈日与暴雨,把我的本田 125 踏板摩托车从北京骑到了合肥,没有拍视频,只能用高德的导航记录作为证据了:
这是导航中断的地方,晚上能见度不行,在山东花了 70 大洋,随便找了个宾馆住下了,第二天早上出发时拍的,发现居然是水泊梁山附近,差点落草为寇:
骑车这两天,路上发生了挺多有意思的事,以后有时间再分享。到家那天,是我的结婚 10 周年纪念日,我没有提前说我要回来,更没说骑着摩托车回来,当我告诉孩子他妈时,问她我是不是很牛逼,得到的答复是:
我觉得你是傻逼
言归正传,在离开北京前几天,我找团队里的同学都聊了聊,对我的选择,非常鲜明的形成了两个派系:
1. 未婚 || 工作 5 年以内的:不理解,为啥放弃管理岗位,未来本可以有更好的发展的,太可惜了,打骨折的降薪更不能接受
2. 已婚 || 工作 5 年以上的:理解,支持,甚至羡慕;既然迟早都要回去,那就早点回,多陪陪家人,年龄大了更不好回;降薪很正常,跟房价也同步,不能既要又要
复制代码确实,不同的人生阶段有着不同的想法,我现在是第 2 阶段,需要兼顾家庭和工作了,不能像之前那样把工作当成唯一爱好了。
在家上班的日子挺好的,现在加班不多,就是稍微有点远,单趟得 1 个小时左右。晚上和周末可以陪孩子玩玩,虽然他不喜欢跟我玩🐶。哦,对了,我还有个重要任务 - 做饭和洗碗。真的是悔不当初啊,我就不应该说会做饭的,更不应该把饭做的那么好吃,现在变成我工作以外的最重要的业务了。。。
比较难受的是,现在公司的机器配置一般,M1 的 MBP,16G 内存,512G 硬盘,2K 显示器。除了 CPU 还行,内存和硬盘,都是快 10 年前的配置了,就这还得用上 3 年,想想就头疼,省钱省在刀刃上了,属于是。作为对比,腾讯的机器配置是:
M1 Pro MBP,32G 内存 + 1T SSD + 4K 显示器
客户端开发,再额外配置一台 27寸的 iMac(i9 + 32G内存 + 1T SSD)
由奢入俭难,在习惯了高配置机器后,现在的机器总觉得速度不行,即使很多时候,它和高配机没有区别。作为开发,尤其是客户端开发,AndroidStudio/Xcode 都是内存大户,16G 实在是捉襟见肘,非常影响搬砖效率。公司不允许用自己的电脑,否则我就自己买台 64G 内存的 MBP 干活用了。不过,换个角度,编译时间变长,公司提供了带薪摸鱼的机会,也可以算是个福利🐶
另外,比较失落的就是每个月发工资的日子了,比之前少了太多了,说没感觉是不可能的,还在努力适应中。不过这都是小事,毕竟年底发年终奖时,会更加失落,hhhh😭😭😭😭
先写这么多吧,后面有时间的话,再分享一些有意思的事吧,工作上的或生活上的。
遥想去年码农节时,我还在考虑把房子从昌平换到海淀,好让孩子能有个“海淀学籍”,当时还做了点笔记:
没想到,一年后的我回合肥了,更想不到一年后的腾讯,股价竟然从 500 跌到 206 了(10月28日,200.8 了)。真的是世事难料,大家保重身体,好好活着,多陪陪家人,一起静待春暖花开💪🏻💪🏻
链接:https://juejin.cn/post/7159837250585362469
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Activity生命周期监控方案
实际开发中,我们经常需要在Activity的onResume或者onStop中进行全局资源的获取或释放,那么怎么去监控Activity生命周期变化呢?
实际开发中,我们经常需要在Activity的onResume或者onStop中进行全局资源的获取或释放,那么怎么去监控Activity生命周期变化呢?
通知式监控
一般情况下,我们可以在资源管理类中提供onActivityResume,onActivityStop之类的公共接口来实现该需求,这种情况下,需要在Activity内部的各个生命周期函数中手动调用资源管理类的对应函数,实现如下所示:
// 资源管理类
public class ResourceManager {
private static final String TAG = "ResourceManager";
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
}
public class NotifyAcLifecycleActivity extends AppCompatActivity {
private ResourceManager mResourceManager = new ResourceManager();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_notify_ac_lifecycle);
}
@Override
protected void onResume() {
super.onResume();
mResourceManager.onActivityResume();
}
@Override
protected void onStop() {
super.onStop();
mResourceManager.onActivityStop();
}
}
可以看出,通知式实现的生命周期监控具有以下显著缺陷:
- 代码侵入性强:需要在Activity中手动调用资源管理类的对应公共方法
- 耦合严重:资源管理类的公共方法和Activity生命周期函数强耦合,当资源管理类的数量发生变化时,新增或者删除,都需改动Activity代码
一般情况下,我们可以在资源管理类中提供onActivityResume,onActivityStop之类的公共接口来实现该需求,这种情况下,需要在Activity内部的各个生命周期函数中手动调用资源管理类的对应函数,实现如下所示:
// 资源管理类
public class ResourceManager {
private static final String TAG = "ResourceManager";
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
} public class NotifyAcLifecycleActivity extends AppCompatActivity {
private ResourceManager mResourceManager = new ResourceManager();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_notify_ac_lifecycle);
}
@Override
protected void onResume() {
super.onResume();
mResourceManager.onActivityResume();
}
@Override
protected void onStop() {
super.onStop();
mResourceManager.onActivityStop();
}
}可以看出,通知式实现的生命周期监控具有以下显著缺陷:
- 代码侵入性强:需要在Activity中手动调用资源管理类的对应公共方法
- 耦合严重:资源管理类的公共方法和Activity生命周期函数强耦合,当资源管理类的数量发生变化时,新增或者删除,都需改动Activity代码
监听式监控
即然通知式监控具有那么多的缺陷,那么我们怎么来解决该问题呢?从操作意图可以看出,我们期望在Activity生命周期变化的时候资源管理类能收到通知,换句话说就是资源管理类可以监听到Activity的生命周期变更,说到监听,我们自然而言的想到了设计模式中的观察者模式。
观察者模式包含了被观察者和观察者两个角色,描述的是当被观察者状态发生变化时,所有依赖于该被观察者的观察者都可以接收到通知并根据需要完成操作
由观察者模式定义来看,Activity应该是被观察者,资源管理器应该是观察者,为进一步解耦,我们引入接口,定义观察者接口如下所示:
public interface LifecycleObserver {
void onActivityResume();
void onActivityStop();
}
在被观察者(Activity)中通知观察者,修改的代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private LifecycleObserver mObserver;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
}
public void setObserver(LifecycleObserver observer) {
mObserver = observer;
}
@Override
protected void onResume() {
super.onResume();
if (mObserver != null) {
mObserver.onActivityResume();
}
}
@Override
protected void onStop() {
super.onStop();
if (mObserver != null) {
mObserver.onActivityStop();
}
}
}
使需要观察的对象实现观察者接口,并在onCreate中完成观察,代码如下:
public class ResourceManager implements LifecycleObserver{
private static final String TAG = "ResourceManager";
@Override
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
@Override
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
setObserver(new ResourceManager());
}
这样就通过LifecycleObserver完成了ResourceManager观察Activity生命周期变化的操作,如果不需要接收通知,不调用setObserver方法即可。
简单业务中,上述实现没问题,单随着业务的逐步扩大,资源管理器可能不止一个,而且并不一定需要一直监听变化,在一定情况下,可能需要移除,接下来我们进一步修改被观察者中关于观察者的管理,使其支撑多个观察者以及动态移除观察者,代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private List<LifecycleObserver> mObservers = new ArrayList<>();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
addObserver(new ResourceManager());
}
public void addObserver(LifecycleObserver observer) {
mObservers.add(observer);
}
public void removeObserver(LifecycleObserver observer) {
mObservers.remove(observer);
}
@Override
protected void onResume() {
super.onResume();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityResume();
}
}
}
@Override
protected void onStop() {
super.onStop();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityStop();
}
}
}
}
从上述实现可以看出,该方案具有以下缺点:
- 不适用于多Activity场景
- 仍然需要耦合Activity的addObserver和removeObserver方法
即然通知式监控具有那么多的缺陷,那么我们怎么来解决该问题呢?从操作意图可以看出,我们期望在Activity生命周期变化的时候资源管理类能收到通知,换句话说就是资源管理类可以监听到Activity的生命周期变更,说到监听,我们自然而言的想到了设计模式中的观察者模式。
观察者模式包含了被观察者和观察者两个角色,描述的是当被观察者状态发生变化时,所有依赖于该被观察者的观察者都可以接收到通知并根据需要完成操作
由观察者模式定义来看,Activity应该是被观察者,资源管理器应该是观察者,为进一步解耦,我们引入接口,定义观察者接口如下所示:
public interface LifecycleObserver {
void onActivityResume();
void onActivityStop();
}在被观察者(Activity)中通知观察者,修改的代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private LifecycleObserver mObserver;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
}
public void setObserver(LifecycleObserver observer) {
mObserver = observer;
}
@Override
protected void onResume() {
super.onResume();
if (mObserver != null) {
mObserver.onActivityResume();
}
}
@Override
protected void onStop() {
super.onStop();
if (mObserver != null) {
mObserver.onActivityStop();
}
}
}使需要观察的对象实现观察者接口,并在onCreate中完成观察,代码如下:
public class ResourceManager implements LifecycleObserver{
private static final String TAG = "ResourceManager";
@Override
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
@Override
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
} @Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
setObserver(new ResourceManager());
}这样就通过LifecycleObserver完成了ResourceManager观察Activity生命周期变化的操作,如果不需要接收通知,不调用setObserver方法即可。
简单业务中,上述实现没问题,单随着业务的逐步扩大,资源管理器可能不止一个,而且并不一定需要一直监听变化,在一定情况下,可能需要移除,接下来我们进一步修改被观察者中关于观察者的管理,使其支撑多个观察者以及动态移除观察者,代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private List<LifecycleObserver> mObservers = new ArrayList<>();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
addObserver(new ResourceManager());
}
public void addObserver(LifecycleObserver observer) {
mObservers.add(observer);
}
public void removeObserver(LifecycleObserver observer) {
mObservers.remove(observer);
}
@Override
protected void onResume() {
super.onResume();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityResume();
}
}
}
@Override
protected void onStop() {
super.onStop();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityStop();
}
}
}
}从上述实现可以看出,该方案具有以下缺点:
- 不适用于多Activity场景
- 仍然需要耦合Activity的addObserver和removeObserver方法
ActivityLifecycleCallbacks
上面都是开发者实现的,那么系统内部有没有已经实现的方案呢?查看源码,可以找到ActivityLifecycleCallbacks,其定义如下:
public interface ActivityLifecycleCallbacks {
/**
* Called as the first step of the Activity being created. This is always called before
* {@link Activity#onCreate}.
*/
default void onActivityPreCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called when the Activity calls {@link Activity#onCreate super.onCreate()}.
*/
void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState);
/**
* Called as the last step of the Activity being created. This is always called after
* {@link Activity#onCreate}.
*/
default void onActivityPostCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called as the first step of the Activity being started. This is always called before
* {@link Activity#onStart}.
*/
default void onActivityPreStarted(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStart super.onStart()}.
*/
void onActivityStarted(@NonNull Activity activity);
/**
* Called as the last step of the Activity being started. This is always called after
* {@link Activity#onStart}.
*/
default void onActivityPostStarted(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being resumed. This is always called before
* {@link Activity#onResume}.
*/
default void onActivityPreResumed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onResume super.onResume()}.
*/
void onActivityResumed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being resumed. This is always called after
* {@link Activity#onResume} and {@link Activity#onPostResume}.
*/
default void onActivityPostResumed(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being paused. This is always called before
* {@link Activity#onPause}.
*/
default void onActivityPrePaused(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onPause super.onPause()}.
*/
void onActivityPaused(@NonNull Activity activity);
/**
* Called as the last step of the Activity being paused. This is always called after
* {@link Activity#onPause}.
*/
default void onActivityPostPaused(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being stopped. This is always called before
* {@link Activity#onStop}.
*/
default void onActivityPreStopped(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStop super.onStop()}.
*/
void onActivityStopped(@NonNull Activity activity);
/**
* Called as the last step of the Activity being stopped. This is always called after
* {@link Activity#onStop}.
*/
default void onActivityPostStopped(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity saving its instance state. This is always
* called before {@link Activity#onSaveInstanceState}.
*/
default void onActivityPreSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called when the Activity calls
* {@link Activity#onSaveInstanceState super.onSaveInstanceState()}.
*/
void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState);
/**
* Called as the last step of the Activity saving its instance state. This is always
* called after{@link Activity#onSaveInstanceState}.
*/
default void onActivityPostSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called as the first step of the Activity being destroyed. This is always called before
* {@link Activity#onDestroy}.
*/
default void onActivityPreDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onDestroy super.onDestroy()}.
*/
void onActivityDestroyed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being destroyed. This is always called after
* {@link Activity#onDestroy}.
*/
default void onActivityPostDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity configuration was changed.
* @hide
*/
default void onActivityConfigurationChanged(@NonNull Activity activity) {
}
}
从接口函数可以看出这是用于监听Activity生命周期事件的回调,我们可以在Application中使用registerActivityLifecycleCallbacks注册Activity生命周期的全局监听,当有Activity的生命周期发生变化时,就会回调该接口中的方法,代码如下:
registerActivityLifecycleCallbacks(new ActivityLifecycleCallbacks() {
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState) {
}
@Override
public void onActivityStarted(@NonNull Activity activity) {
}
@Override
public void onActivityResumed(@NonNull Activity activity) {
}
@Override
public void onActivityPaused(@NonNull Activity activity) {
}
@Override
public void onActivityStopped(@NonNull Activity activity) {
}
@Override
public void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState) {
}
@Override
public void onActivityDestroyed(@NonNull Activity activity) {
}
});
随后我们就可以根据回调的Activity对象判定应该由哪个资源管理器响应对应的生命周期变化。
通常情况下,我们可以依赖该方法实现以下需求:
- 自定义的全局的Activity栈管理
- 用户行为统计收集
- Activity切入前后台后的资源申请或释放
- 应用前后台判定
- 页面数据保存与恢复
- ... etc
上面都是开发者实现的,那么系统内部有没有已经实现的方案呢?查看源码,可以找到ActivityLifecycleCallbacks,其定义如下:
public interface ActivityLifecycleCallbacks {
/**
* Called as the first step of the Activity being created. This is always called before
* {@link Activity#onCreate}.
*/
default void onActivityPreCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called when the Activity calls {@link Activity#onCreate super.onCreate()}.
*/
void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState);
/**
* Called as the last step of the Activity being created. This is always called after
* {@link Activity#onCreate}.
*/
default void onActivityPostCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called as the first step of the Activity being started. This is always called before
* {@link Activity#onStart}.
*/
default void onActivityPreStarted(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStart super.onStart()}.
*/
void onActivityStarted(@NonNull Activity activity);
/**
* Called as the last step of the Activity being started. This is always called after
* {@link Activity#onStart}.
*/
default void onActivityPostStarted(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being resumed. This is always called before
* {@link Activity#onResume}.
*/
default void onActivityPreResumed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onResume super.onResume()}.
*/
void onActivityResumed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being resumed. This is always called after
* {@link Activity#onResume} and {@link Activity#onPostResume}.
*/
default void onActivityPostResumed(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being paused. This is always called before
* {@link Activity#onPause}.
*/
default void onActivityPrePaused(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onPause super.onPause()}.
*/
void onActivityPaused(@NonNull Activity activity);
/**
* Called as the last step of the Activity being paused. This is always called after
* {@link Activity#onPause}.
*/
default void onActivityPostPaused(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being stopped. This is always called before
* {@link Activity#onStop}.
*/
default void onActivityPreStopped(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStop super.onStop()}.
*/
void onActivityStopped(@NonNull Activity activity);
/**
* Called as the last step of the Activity being stopped. This is always called after
* {@link Activity#onStop}.
*/
default void onActivityPostStopped(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity saving its instance state. This is always
* called before {@link Activity#onSaveInstanceState}.
*/
default void onActivityPreSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called when the Activity calls
* {@link Activity#onSaveInstanceState super.onSaveInstanceState()}.
*/
void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState);
/**
* Called as the last step of the Activity saving its instance state. This is always
* called after{@link Activity#onSaveInstanceState}.
*/
default void onActivityPostSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called as the first step of the Activity being destroyed. This is always called before
* {@link Activity#onDestroy}.
*/
default void onActivityPreDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onDestroy super.onDestroy()}.
*/
void onActivityDestroyed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being destroyed. This is always called after
* {@link Activity#onDestroy}.
*/
default void onActivityPostDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity configuration was changed.
* @hide
*/
default void onActivityConfigurationChanged(@NonNull Activity activity) {
}
}从接口函数可以看出这是用于监听Activity生命周期事件的回调,我们可以在Application中使用registerActivityLifecycleCallbacks注册Activity生命周期的全局监听,当有Activity的生命周期发生变化时,就会回调该接口中的方法,代码如下:
registerActivityLifecycleCallbacks(new ActivityLifecycleCallbacks() {
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState) {
}
@Override
public void onActivityStarted(@NonNull Activity activity) {
}
@Override
public void onActivityResumed(@NonNull Activity activity) {
}
@Override
public void onActivityPaused(@NonNull Activity activity) {
}
@Override
public void onActivityStopped(@NonNull Activity activity) {
}
@Override
public void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState) {
}
@Override
public void onActivityDestroyed(@NonNull Activity activity) {
}
});随后我们就可以根据回调的Activity对象判定应该由哪个资源管理器响应对应的生命周期变化。
通常情况下,我们可以依赖该方法实现以下需求:
- 自定义的全局的Activity栈管理
- 用户行为统计收集
- Activity切入前后台后的资源申请或释放
- 应用前后台判定
- 页面数据保存与恢复
- ... etc
Lifecycle in Jetpack
Lifecycle相关内容可以参考前面发布的系列文章:
Lifecycle相关内容可以参考前面发布的系列文章:
Instrumentation
从Activity启动流程可知每个Activity生命周期变化时,ActivityThread都会通过其内部持有的Instrumentation类的对象进行分发,如果我们能自定义Instrumentation类,用我们自定义的Instrumentation类对象替换这个成员变量,那么自然可以通过这个自定义Instrumentation类对象来监听Activity生命周期变化。
那么怎么修改ActivityThread类的mInstrumentation成员呢?自然要用反射实现了。
自定义Instrumentation类如下所示:
public class CustomInstrumentation extends Instrumentation {
private static final String TAG = "CustomInstrumentation";
private Instrumentation mBaseInstrumentation;
public CustomInstrumentation(Instrumentation instrumentation) {
super();
mBaseInstrumentation = instrumentation;
}
@Override
public void callActivityOnResume(Activity activity) {
super.callActivityOnResume(activity);
Log.d(TAG, "callActivityOnResume " + activity.toString());
}
@Override
public void callActivityOnStop(Activity activity) {
super.callActivityOnStop(activity);
Log.d(TAG, "callActivityOnStop " + activity.toString());
}
}
在Application的attachBaseContext函数中反射修改ActivityThread的mInstrumentation成员为CustomInstrumentation类的对象,相关代码如下:
@Override
protected void attachBaseContext(Context base) {
hookInstrumentation();
super.attachBaseContext(base);
}
public void hookInstrumentation() {
Class<?> activityThread;
try{
activityThread = Class.forName("android.app.ActivityThread");
Method sCurrentActivityThread = activityThread.getDeclaredMethod("currentActivityThread");
sCurrentActivityThread.setAccessible(true);
//获取ActivityThread 对象
Object activityThreadObject = sCurrentActivityThread.invoke(null);
//获取 Instrumentation 对象
Field mInstrumentation = activityThread.getDeclaredField("mInstrumentation");
mInstrumentation.setAccessible(true);
Instrumentation instrumentation = (Instrumentation) mInstrumentation.get(activityThreadObject);
CustomInstrumentation customInstrumentation = new CustomInstrumentation(instrumentation);
//将我们的 customInstrumentation 设置进去
mInstrumentation.set(activityThreadObject, customInstrumentation);
}catch (Exception e){
e.printStackTrace();
}
}
编写两个Activity分别为MainActivity和NotifyAcLifecycleActivity,在MainActivity中点击按钮跳转到NotifyAcLifecycleActivity,日志输出如下:
可以拿出,虽然正常代理到了Activity的生命周期变更,但是每次Activity启动都会爆出Uninitialized ActivityThread, likely app-created Instrumentation, disabling AppComponentFactory的异常,查看源码,查找该问题的原因:
// Instrumentation.java
private ActivityThread mThread = null;
private AppComponentFactory getFactory(String pkg) {
if (pkg == null) {
Log.e(TAG, "No pkg specified, disabling AppComponentFactory");
return AppComponentFactory.DEFAULT;
}
if (mThread == null) {
Log.e(TAG, "Uninitialized ActivityThread, likely app-created Instrumentation,"
+ " disabling AppComponentFactory", new Throwable());
return AppComponentFactory.DEFAULT;
}
LoadedApk apk = mThread.peekPackageInfo(pkg, true);
// This is in the case of starting up "android".
if (apk == null) apk = mThread.getSystemContext().mPackageInfo;
return apk.getAppFactory();
}
final void basicInit(ActivityThread thread) {
mThread = thread;
}
可以看到当mThread成员为空时,会抛出该问题,mThread是在basicInit中赋值的,由于我们创建的CustomInstrumentation对象没有调用该函数,故mThread必然为空,那么如何规避该问题呢?方案主要有两个方向
初始化CustomInstrumentation对象的mThread对象
反射获取原始Instrumentation对象的mThread取值,然后设置到自定义的CustomInstrumentation对象中
针对getFactory方法使用的函数,将函数重写,调用原始Instrumentation对应的函数
这里我们使用第二个方案,在CustomInstrumentation中重写newActivity方法,使用原始的Instrumentation对象代理,代码如下:
public Activity newActivity(ClassLoader cl, String className,
Intent intent)
throws InstantiationException, IllegalAccessException,
ClassNotFoundException {
return mBaseInstrumentation.newActivity(cl, className, intent);
}
再次运行,可以看到日志中不再打印该异常,同时我们也能正常监听到Activity生命周期变化了,详细日志如下:

综上,我们就可以在自定义Instrumentation类的callActivityOnStop方法中过滤某些Activity,在其切入后台时进行资源的释放。
不难看出,自定义Instrumentation走通后,我们可以在该类中接管系统的Activity启动,进而将某个目标Activity替换成我们自己的Activity,这也是插件化实现中的一个核心步骤
作者:小海编码日记
链接:https://juejin.cn/post/7199609821980229691
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
收起阅读 »
从Activity启动流程可知每个Activity生命周期变化时,ActivityThread都会通过其内部持有的Instrumentation类的对象进行分发,如果我们能自定义Instrumentation类,用我们自定义的Instrumentation类对象替换这个成员变量,那么自然可以通过这个自定义Instrumentation类对象来监听Activity生命周期变化。
那么怎么修改ActivityThread类的mInstrumentation成员呢?自然要用反射实现了。
自定义Instrumentation类如下所示:
public class CustomInstrumentation extends Instrumentation {
private static final String TAG = "CustomInstrumentation";
private Instrumentation mBaseInstrumentation;
public CustomInstrumentation(Instrumentation instrumentation) {
super();
mBaseInstrumentation = instrumentation;
}
@Override
public void callActivityOnResume(Activity activity) {
super.callActivityOnResume(activity);
Log.d(TAG, "callActivityOnResume " + activity.toString());
}
@Override
public void callActivityOnStop(Activity activity) {
super.callActivityOnStop(activity);
Log.d(TAG, "callActivityOnStop " + activity.toString());
}
}在Application的attachBaseContext函数中反射修改ActivityThread的mInstrumentation成员为CustomInstrumentation类的对象,相关代码如下:
@Override
protected void attachBaseContext(Context base) {
hookInstrumentation();
super.attachBaseContext(base);
}
public void hookInstrumentation() {
Class<?> activityThread;
try{
activityThread = Class.forName("android.app.ActivityThread");
Method sCurrentActivityThread = activityThread.getDeclaredMethod("currentActivityThread");
sCurrentActivityThread.setAccessible(true);
//获取ActivityThread 对象
Object activityThreadObject = sCurrentActivityThread.invoke(null);
//获取 Instrumentation 对象
Field mInstrumentation = activityThread.getDeclaredField("mInstrumentation");
mInstrumentation.setAccessible(true);
Instrumentation instrumentation = (Instrumentation) mInstrumentation.get(activityThreadObject);
CustomInstrumentation customInstrumentation = new CustomInstrumentation(instrumentation);
//将我们的 customInstrumentation 设置进去
mInstrumentation.set(activityThreadObject, customInstrumentation);
}catch (Exception e){
e.printStackTrace();
}
}编写两个Activity分别为MainActivity和NotifyAcLifecycleActivity,在MainActivity中点击按钮跳转到NotifyAcLifecycleActivity,日志输出如下:
可以拿出,虽然正常代理到了Activity的生命周期变更,但是每次Activity启动都会爆出Uninitialized ActivityThread, likely app-created Instrumentation, disabling AppComponentFactory的异常,查看源码,查找该问题的原因:
// Instrumentation.java
private ActivityThread mThread = null;
private AppComponentFactory getFactory(String pkg) {
if (pkg == null) {
Log.e(TAG, "No pkg specified, disabling AppComponentFactory");
return AppComponentFactory.DEFAULT;
}
if (mThread == null) {
Log.e(TAG, "Uninitialized ActivityThread, likely app-created Instrumentation,"
+ " disabling AppComponentFactory", new Throwable());
return AppComponentFactory.DEFAULT;
}
LoadedApk apk = mThread.peekPackageInfo(pkg, true);
// This is in the case of starting up "android".
if (apk == null) apk = mThread.getSystemContext().mPackageInfo;
return apk.getAppFactory();
}
final void basicInit(ActivityThread thread) {
mThread = thread;
}可以看到当mThread成员为空时,会抛出该问题,mThread是在basicInit中赋值的,由于我们创建的CustomInstrumentation对象没有调用该函数,故mThread必然为空,那么如何规避该问题呢?方案主要有两个方向
初始化CustomInstrumentation对象的mThread对象
反射获取原始Instrumentation对象的mThread取值,然后设置到自定义的CustomInstrumentation对象中
针对getFactory方法使用的函数,将函数重写,调用原始Instrumentation对应的函数
这里我们使用第二个方案,在CustomInstrumentation中重写newActivity方法,使用原始的Instrumentation对象代理,代码如下:
public Activity newActivity(ClassLoader cl, String className,
Intent intent)
throws InstantiationException, IllegalAccessException,
ClassNotFoundException {
return mBaseInstrumentation.newActivity(cl, className, intent);
}再次运行,可以看到日志中不再打印该异常,同时我们也能正常监听到Activity生命周期变化了,详细日志如下:
综上,我们就可以在自定义Instrumentation类的callActivityOnStop方法中过滤某些Activity,在其切入后台时进行资源的释放。
不难看出,自定义Instrumentation走通后,我们可以在该类中接管系统的Activity启动,进而将某个目标Activity替换成我们自己的Activity,这也是插件化实现中的一个核心步骤
链接:https://juejin.cn/post/7199609821980229691
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
浅谈开发中对数据的编码和封装
前言
前几天写了一篇对跨端通讯的思考,当时顺便想到了数据这一块,所以也可以整理一下,单独拿出来说说平时开发中涉及到哪些对数据的处理方式。
Base64
之前详细写过一篇关于Base64的文章
简单来说,Base64就是把你的数据转成只有64个无特殊符号的字符,主要常用于加密后之类的生成的字节数组,转成Base64方便进行数据传输,如果不转的话就会是乱码,会看得很难受,这些乱码在某些编码下展示出来的是豆腐块,有点扯远了。
还有就是比如中文啊,emoji啊这类的字符,在某些情况下也需要转成Base64进行传输。
缺点就是只用64个字符表示,还有我之前分析过base64的转换原理,通过其原理能很容易看出,最终的转换结果相比转换前的数据更加长。
JSON/XML
这些就比较常见了,对数据按照一定的格式进行封装。为什么要说这个呢?因为他这些封装是约定熟成的方式,和上面的Base64的转换方式就不同,相当于是大家约定好按照这个格式包装数据,然后传输,自己再按照这个格式去解开拿到数据。
多数用于跨端传输,像客户端请求服务端拿数据,那不也就是跨端嘛,其实这个所有人都用到,但为什么说这个呢?还是那个跨端通信的问题,跨端通信没办法直接传对象,实际传对象的效果是转json传的String,然后另外一端再创建一个自己端的对象,解析json,把json数据填充进去。
还有,既然是约定的,那其实我们自己也可以按照我们自己的约定去做跨端的数据传送,只不过json这种格式,是已经设计得很好了,你很难再去约定一种比这个格式更好的封装。
PS:不要觉得json大家都在用,都形成肌肉记忆了,没有什么难的。其实比如像gson\fastjson这些,人家去研究解析json的算法,也是一个技术点。你觉得简单,那是因为你在使用,但让你从0去做,你不一定能做出来。
URL编码
又叫做urlencode,顾名思义用于url连接中的一种对数据的操作。
它将特殊字符转成16进制并且在前面加%,那同理解析拿数据的时候也是根据%去做判断。
为什么会出现这种编码呢?主要是为了防止冲突,我们都知道比如get请求都会在url链接后面拼参数,防止在传输中出现问题,所以把特殊字符都进行编码。
比如http://www.baidu.com/?aaaaaaa 会编码成https%3A%2F%2Fwww.baidu.com%2F%3Faaaaaaa
该编码主要用于对url的处理。
驼峰和下划线
这其实是一个命名方式,不同的端有不同的命名习惯,比如java习惯就是用驼峰,但是还是跨端问题,有些时候存在写死的情况,当然这个代码不是你写的,也可能是前人留下的(我没有暗示什么)。但如果你的代码中出现两种命名方式会让代码看着比较乱。没关系我们可以做个转换,我这里以下划线转驼峰为例
private String lineToHump(String str) {
if (TextUtils.isEmpty(str)) {
return str;
}
String[] strs = str.split("_");
if (strs.length < 2) {
return str;
}
StringBuilder result = new StringBuilder(strs[0]);
for (int i = 1; i < strs.length; i++) {
String upper = (strs[i].charAt(0) + "").toUpperCase();
if (strs[i].length() > 1) {
result.append(upper).append(strs[i].substring(1));
} else {
result.append(upper);
}
}
return result.toString();
}可以写个转换方法,我这里只是随便写个Demo,这段代码是还能进行优化的,主要大概就是这个意思。
上面说的json主要是为了说数据的封装和解封,这里主要是说数据的转换,我的意思是在开发中,我们也会出现不同端的数据形式不同,我们不需要在代码中向其它端进行妥协,只用写个方法去做数据的转换,在本端还是正常写本端的代码就行。
摘要
摘要算法,简单来说就是将原数据以一种算法生成一段很小的新数据,这段新数据主要是用来标识这段原数据。怎么还有点绕,总之就是生成一个字符串来标识原数据 。对任意一组输入数据进行计算,得到一个固定长度的输出。
也可称之为哈希算法,最重要的是它取决于它的这个设计思想,它是一个不可能逆的过程,一般不能根据摘要拿到原数据,注意我用了一般,因为这个世界上存在很多老六。
摘要算法中当前最经典的是SHA算法和MD算法,SHA-1、SHA-256和MD5。其中他们加密过程可以单独写一篇文章来说,这里就不过多解释。
摘要算法最主要的运用场景是校验数据的完整性和是否有被篡改。比如CA证书的校验,android签名的校验,会拿原数据做摘要和传过来的摘要相对比,是否一样,如果不一样说明数据有被篡改过。再比如我本地有个视频,我怎么判断后台这个视频是不是更新了,要不要下载,可以对视频文件做MD5,然后和后台文件的MD5进行对比,如果一样说明视频没有更新,如果不一样说明视频有更新或者本地的视频不完整(PS:对文件做摘要可是一个耗时的过程。)
加密
讲完摘要可以趁热打铁说说加密,加密顾名思义就是把明文数据转成密文,然后另一方拿到密文之后再转成明文。
加密和摘要不同在于,它们的本质都不同,摘要是为了验证数据,加密是为了安全传输数据。它们在表现上的不同体现在,摘要是不可逆,加密是可逆的。
加密在当前的设计上又分为对称加密和非对称加密,主流的对称加密是AES算法,主流的非对称加密是RSA算法。对称加密的加密和解密使用的密钥是相同的,非对称是不同的 ,所以非对称加密更为安全,但是也会更耗时。
当然你也可以不用这些算法,如果你是直接接触这些算法,好像是要付专利费的,每年给多少钱别人才给你用这个算法,资本家不就喜欢搞这种东西吗?扯远了。你也可以使用自己约定的算法,只不过在高手面前可能你的算法相当于裸奔,要是你真能设计出和这些算法旗鼓相当的算法,你也不会来看我这么捞的文章。
所以加密,是为了保证数据的安全,如果你传输的数据觉得被看了也无所谓,那就不用加密,因为它耗时。如果你只是为了防止数据被改,也不用加密,用摘要就行。如果你是为了传输seed,那我建议你加密[狗头]
通信协议
json那里我们有说,它就是双方约定好的数据格式。以小见大,通信协议也是双方约定的一种数据传输的过程。通信协议会更为严谨,而且会很多不同,各家有各家的通信协议,不是像json这种就是大家都用一样的。
比如我们的网络传输,就有很多协议,http协议、tcpip协议等,这些在网络中是规定好的,大家都用这一套。再比如蓝牙协议,也是要按照同一个规范去使用。但是硬件的协议就多种多样了,不同的硬件厂商会定义不同的通信协议。
二维码
二维码也是对数据封装的一种形式,可以通过把数据变成图像,然后是扫码后再获取到数据,这么一种模式我感觉能想出这个法子的人挺牛逼的。
它所涉及的内容很多,具体可以参考这篇文章,我觉得这个大佬写得挺好的 二维码生成原理 - 知乎 (zhihu.com)
我之前自己去用java实现,最终没画出来,感觉原理是没问题的,应该是我哪里细节没处理好,这里就简单介绍一下就行。其实简单来说,它就是有一个模板的情况下,把数据填充到模板里面。
这里借大佬的图,模板就是这样的
然后按照规则去填充数据
这样去填充,其实会让黑点分布不均匀,填充之后还会做一个转换。
但是二维码也有缺点,缺点就是数据量大的时候,你的二维码很难被识别出,但是不得不说能想出这个方法,能设计出这个东西的人,确实牛逼。
链接:https://juejin.cn/post/7199862924830670904
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
七道Android面试题,先来简单热个身
马上就要到招(tiao)聘(cao)旺季金三银四了,一批一批的社会精英在寻找自己的下一家的同时,也开始着手为面试做准备,回想起自己这些年,也大大小小经历过不少面试,有被面试过,也有当过面试官,其中也总结出了两个观点,一个就是不花一定的时间背些八股文还真的不行,一些扯皮的话别去听,都是在害人,另一个就是面试造火箭,入职拧螺丝毕竟都是少数,真正一场合格的面试问的东西,都是实际开发过程中会遇到的,下面我就说几个我遇到过的面试题吧
为什么ArrayMap比HashMap更适合Android开发
我们一般习惯在项目当中使用HashMap去存储键值队这样的数据,所以往往在android面试当中HashMap是必问环节,但有次面试我记得被问到了有没有有过ArrayMap,我只能说有印象,毕竟用的最多的还是HashMap,然后那个面试官又问我,觉得Android里面更适合用ArrayMap还是HashMap,我就说不上来了,因为也没看过ArrayMap的源码,后来回去看了下才给弄明白了,现在就简单对比下ArrayMap与HashMap的特点
HashMap
- HashMap的数据结构为数组加链表的结构,jdk1.8之后改为数组加链表加红黑树的结构
- put的时候,会先计算key的hashcode,然后去数组中寻找这个hashcode的下标,如果数据为空就先resize,然后检查对应下标值(下标值=(数组长度-1)&hashcode)里面是否为空,空则生成一个entry插入,否就判断hascode与key值是否分别都相等,如果相等则覆盖,如果不等就发生哈希冲突,生成一个新的entry插入到链表后面,如果此时链表长度已经大于8且数组长度大于64,则先转成树,将entry添加到树里面
- get的时候,也是先去查找数组对应下标值里面是否为空,如果不为空且key与hascode都相等,直接返回value,否就判断该节点是否为一个树节点,是就在树里面返回对应entry,否就去遍历整个链表,找出key值相等的entry并返回
ArrayMap
- 内部维护两个数组,一个是int类型的数组(mHashes)保存key的hashcode,另一个是Object的数组(mArray),用来保存与mHashes对应的key-value
- put数据的时候,首先用二分查找法找出mHashes里面的下标index来存放hashcode,在mArray对应下标index<<1与(index<<1)+1的位置存放key与value
- get数据的时候,同样也是用二分查找法找出与key值对应的下标index,接着再从mArray的(index<<1)+1位置将value取出
对比
- HashMap在存放数据的时候,无论存放的量是多少,首先是会生成一个Entry对象,这个就比较浪费内存空间,而ArrayMap只是把数据插入到数组中,不用生成新的对象
- 存放大量数据的时候,ArrayMap性能上就不如HashMap,因为ArrayMap使用的是二分查找法找的下标,当数据多了下标值找起来时间就花的久,此外还需要将所有数据往后移再插入数据,而HashMap只要插入到链表或者树后面即可
所以这就是为什么,在没有那么大的数据量需求下,Android在性能角度上比较适合用ArrayMap
为什么Arrays.asList后往里add数据会报错
这个问题我当初问过不少人,不缺乏一些资历比较深的大佬,但是他们基本都表示不清楚,这说明平时我们研究Glide,OkHttp这样的三方库源码比较多,而像一些比较基础的往往会被人忽略,而有些问题如果被忽略了,往往会产生一些捉摸不透的问题,比如有的人喜欢用Arrays.asList去生成一个List
val dataList = Arrays.asList(1,2,3)
dataList.add(4)但是当我们往这个List里面add数据的时候,我们会发现,crash了,看到的日志是
不被支持的操作,这让首次遇到这样问题的人肯定是一脸懵,List不让添加数据了吗?之前明明可以的啊,但是之前我们创建一个List是这样创建的
它所在的包是java.util.ArrayList里面,我们看下里面的代码
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}是存在add方法的,我们再回头再去看看asList生成的List
是在java.util.Arrays包里面的,而这里面的ArrayList我们看到了,并没有去实现List接口,所以也就没有add,get等方法,另外在kotlin里面,我们会看到一个细节,当你敲完Arrays.asList的时候,编译器会提示你,可以转换成listof函数,而这个还是我们知道生成的list都是只能读取,不能往里写数据
Thread.sleep(0)到底“睡没睡”
记得在上上家公司,接手的第一个需求就是做一个动画,这个动画需要一个延迟启动的功能,我那个时候想都没想加了个Thread.sleep(3000),后来被领导批了,不可以用Thread.sleep实现延迟功能,那会还不太明白,后来知道了,Thread.sleep(3000)不一定真的暂停三秒,我们来举个例子
println("start:${System.currentTimeMillis()}")
Thread(Runnable {
Thread.sleep(3000)
println("end:${System.currentTimeMillis()}")
}).start()我们在主线程先打印一条数据展示时间,然后开启一个子线程,在里面sleep三秒以后在打印一下时间,我们看下结果如何
start:1675665421590
end:1675665424591好像对了又好像没对,为什么是过了3001毫秒才打印出来呢?有的人会说,1毫秒而已,忽略嘛,那我们把上面的代码改下再试试
println("start:${System.currentTimeMillis()}")
Thread(Runnable {
Thread.sleep(0)
println("end:${System.currentTimeMillis()}")
}).start()现在sleep了0毫秒,那是不是两条打印日志应该是一样的呢,我们看看结果
start:1675666764475
end:1675666764477这下子给整不会了,明明sleep0毫秒,那么多出来的2毫秒是怎么回事呢?其实在Android操作系统中,每个线程使用cpu资源都是有优先级的,优先级高的才有资格使用,而操作系统则是在一个线程释放cpu资源以后,重新计算所有线程的优先级来重新分配cpu资源,所以sleep真正的意义不是暂停,而是在接下去的时间内不参与cpu的竞争,等到cpu重新分配完资源以后,如果优先级没变,那么继续执行,所以sleep(0)秒的真正含义是触发cpu资源重新分配
View.post为什么可以获取控件的宽高
我们都知道在onCreate里面想要获取一个控件的宽高,如果直接获取是拿不到的
val mWith = bindingView.mainButton.width
val mHeight = bindingView.mainButton.height
println("按钮宽:$mWith,高:$mHeight")
......
按钮宽:0,高:0而如果想要获取宽高,则必须调用View.post的方法
bindingView.mainButton.post {
val mWith = bindingView.mainButton.width
val mHeight = bindingView.mainButton.height
println("按钮宽:$mWith,高:$mHeight")
}
......
按钮宽:979,高:187很神奇,加个post就可以在同样的地方获取控件宽高了,至于为什么呢?我们来分析一下
简单的来说
Activity生命周期,onCreate方法里面视图还在绘制过程中,所以没法直接获取宽高,而在post方法中执行,就是在线程里面获取宽高,这个线程会在视图没有绘制完成的时候放在一个等待队列里面,等到视图绘制执行完毕以后再去执行队列里面的线程,所以在post里面也可以获取宽高
复杂的来说
我们首先从View.post方法里面开始看
这个代码里面的两个框子,说明了post方法做了两件事情,当mAttachInfo不为空的时候,直接让mHandler去执行线程action,当mAttachInfo为空的时候,将线程放在了一个队列里面,从注释里面的第一个单词Postpone就可以知道,这个action是要推迟进行,什么时候进行呢,我们在慢慢看,既然是判断当mAttachInfo不为空才去执行线程,那我们找找什么时候对mAttachInfo赋值,整个View的源码里面只有一处是对mAttachInfo赋值的,那就是在dispatchAttachedToWindow
这个方法里面,我们看下
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
...省略部分源码...
// Transfer all pending runnables.
if (mRunQueue != null) {
mRunQueue.executeActions(info.mHandler);
mRunQueue = null;
}
}当走到dispatchAttachedToWindow这个方法的时候,mAttachInfo才不为空,也就是从这里开始,我们就可以获取控件的宽高等信息了,另外我们顺着这个方法往下看,可以发现,之前的那个队列在这里开始执行了,现在就关键在于,什么时候执行dispatchAttachedToWindow这个方法,这个时候就要去ViewRootIml类里面查看,发现只有一处调用了这个方法,那就是在performTraversals这个方法里面
private void performTraversals() {
...省略部分源码...
host.dispatchAttachedToWindow(mAttachInfo, 0);
...省略部分源码...
// Ask host how big it wants to be
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
...省略部分源码...
performLayout(lp, mWidth, mHeight);
...省略部分源码...
performDraw();
}performTraversals这个方法我们就很熟悉了,整个View的绘制流程都在里面,所以只有当mAttachInfo在这个环节赋值了,才可以得到视图的信息
IdleHandler到底有啥用
Handler是面试的时候必问的环节,除了问一下那四大组件之外,有的面试官还会问一下IdleHandler,那IdleHandler到底是什么呢,它是干什么用的呢,我们来看看
Message next() {
...省略部分代码...
synchronized (this) {
// If first time idle, then get the number of idlers to run.
// Idle handles only run if the queue is empty or if the first message
// in the queue (possibly a barrier) is due to be handled in the future.
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
}只有在MessageQueue中的next方法里面出现了IdleHandler,作用也很明显,当消息队列在遍历队列中的消息的时候,当消息已经处理完了,或者只存在延迟消息的时候,就会去处理mPendingIdleHandlers里面每一个idleHandler的事件,而这些事件都是通过方法addIdleHandler注册进去的
Looper.myQueue().addIdleHandler {
false
}addIdlehandler接受的参数是一个返回值为布尔类型的函数类型参数,至于这个返回值是true还是false,我们从next()方法中就能了解到,当为false的时候,事件处理完以后,这个IdleHandler就会从数组中删除,下次再去遍历执行这个idleHandler数组的时候,该事件就没有了,如果为true的话,该事件不会被删除,下次依然会被执行,所以我们按需设置。现在我们可以利用idlehandler去解决上面讲到的在onCreate里面获取控件宽高的问题
Looper.myQueue().addIdleHandler {
val mWith = bindingView.mainButton.width
val mHeight = bindingView.mainButton.height
println("按钮宽:$mWith,高:$mHeight")
false
}当MessageQueue中的消息处理完的时候,我们的视图绘制也完成了,所以这个时候肯定也能获取控件的宽高,我们在IdleHandler里面执行了同样的代码之后,运行后的结果如下
按钮宽:979,高:187除此之外,我们还可以做点别的事情,比如我们常说的不要在主线程里面做一些耗时的工作,这样会降低页面启动速度,严重的还会出现ANR,这样的场景除了开辟子线程去处理耗时操作之外,我们现在还可以用IdleHandler,这里举个例子,我们在主线程中给sp塞入一些数据,然后在把这些数据读取出来,看看耗时多久
println(System.currentTimeMillis())
val testData = "aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhas" +
"jkhdaabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd"
sharePreference = getSharedPreferences(packageName, MODE_PRIVATE)
for (i in 1..5000) {
sharePreference.edit().putString("test$i", testData).commit()
}
for (i in 1..5000){
sharePreference.getString("test$i","")
}
println(System.currentTimeMillis())
......运行结果
1676260921617
1676260942770我们看到在塞入5000次数据,再读取5000次数据之后,一共耗时大概20秒,同时也阻塞了主线程,导致的现象是页面一片空白,只有等读写操作结束了,页面才展示出来,我们接着把读写操作的代码用IdleHandler执行一下看看
Looper.myQueue().addIdleHandler {
sharePreference = getSharedPreferences(packageName, MODE_PRIVATE)
val editor = sharePreference.edit()
for (i in 1..5000) {
editor.putString("test$i", testData).commit()
}
for (i in 1..5000){
sharePreference.getString("test$i","")
}
println(System.currentTimeMillis())
false
}
......运行结果
1676264286760
1676264308294运行结果依然耗时二十秒左右,但区别在于这个时候页面不会受到读写操作的阻塞,很快就展示出来了,说明读写操作的确是等到页面渲染完才开始工作,上面过程没有放效果图主要是因为时间太长了,会影响gif的体验,有兴趣的可以自己试一下
如何让指定视图不被软键盘遮挡
我们通常使用android:windowSoftInputMode属性来控制软键盘弹出之后移动界面,让输入框不被遮挡,但是有些场景下,键盘永远都会挡住一些我们使用频次比较高的控件,比如现在我们有个登录页面,大概的样子长这样
它的布局文件是这样
<RelativeLayout
android:id="@+id/mainroot"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:layout_width="200dp"
android:layout_height="200dp"
android:layout_centerHorizontal="true"
android:layout_marginTop="100dp"
android:src="@mipmap/ic_launcher_round" />
<androidx.appcompat.widget.LinearLayoutCompat
android:id="@+id/ll_view1"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:layout_marginBottom="120dp"
android:gravity="center"
android:orientation="vertical">
<EditText
android:id="@+id/main_edit"
android:layout_width="match_parent"
android:layout_height="40dp"
android:hint="请输入用户名"
android:textColor="@color/black"
android:textSize="15sp" />
<EditText
android:id="@+id/main_edit2"
android:layout_width="match_parent"
android:layout_height="40dp"
android:layout_marginTop="30dp"
android:hint="请输入密码"
android:textColor="@color/black"
android:textSize="15sp" />
<Button
android:layout_width="match_parent"
android:layout_height="50dp"
android:layout_marginHorizontal="10dp"
android:layout_marginTop="20dp"
android:text="登录" />
</androidx.appcompat.widget.LinearLayoutCompat>
</RelativeLayout>在这样一个页面里面,由于输入框与登录按钮都比较靠页面下方,导致当输入完内容想要点击登录按钮时候,必须再一次关闭键盘才行,这样的操作在体验上就比较大打折扣了
现在希望可以键盘弹出之后,按钮也展示在键盘上面,这样就不用收起弹框以后才能点击按钮了,这样一来,windowSoftInputMode这一个属性已经不够用了,我们要想一下其他方案
- 首先,需要让按钮也展示在键盘上方,那只能让布局整体上移把按钮露出来,在这里我们可以改变LayoutParam的bottomMargin参数来实现
- 其次,需要知道键盘什么时候弹出,我们都知道android里面并没有提供任何监听事件来告诉我们键盘什么时候弹出,我们只能从其他角度入手,那就是监听根布局可视区域大小的变化
ViewTreeObserver
我们先获取视图树的观察者,使用addOnGlobalLayoutListener去监听全局视图的变化
bindingView.mainroot.viewTreeObserver.addOnGlobalLayoutListener {
}接下去就是要获取根视图的可视化区域了,如何来获取呢?View里面有这么一个方法,那就是getWindowVisibleDisplayFrame,我们看下源码注释就知道它是干什么的了
一大堆英文没必要都去看,只需要看最后一句就好了,大概意思就是获取能够展示给用户的可用区域,所以我们在监听器里面加上这个方法
bindingView.mainroot.viewTreeObserver.addOnGlobalLayoutListener {
val rect = Rect()
bindingView.mainroot.getWindowVisibleDisplayFrame(rect)
}当键盘弹出或者收起的时候,rect的高度就会跟着变化,我们就可以用这个作为条件来改变bottomMargin的值,现在我们增加一个变量oldDelta来保存前一个rect变化的高度值,用来做比较,完整的代码如下
var oldDelta = 0
val params:RelativeLayout.LayoutParams = bindingView.llView1.layoutParams as RelativeLayout.LayoutParams
val originBottom = params.bottomMargin
bindingView.mainroot.viewTreeObserver.addOnGlobalLayoutListener {
val rect = Rect()
bindingView.mainroot.getWindowVisibleDisplayFrame(rect)
val deltaHeight = r.height()
if (oldDelta != deltaHeight) {
if (oldDelta != 0) {
if (oldDelta > deltaHeight) {
params.bottomMargin = oldDelta - deltaHeight
} else if (oldDelta < deltaHeight) {
params.bottomMargin = originBottom
}
bindingView.llView1.layoutParams = params
}
oldDelta = deltaHeight
}
}最终效果如下
弹出后页面有个抖动是因为本身有个页面平移的效果,然后再去计算layoutparam,如果不想抖动可以在布局外层套个scrollView,用smoothScrollTo把页面滑上去就可以了,有兴趣的可以业余时间试一下
为什么LiveData的postValue会丢失数据
LiveData已经问世好多年了,大家都很喜欢用,因为它上手方便,一般知道塞数据用setValue和postValue,监听数据使用observer就可以了,然而实际开发中我遇到过好多人,一会这里用setValue一会那里用postValue,或者交替着用,这种做法也不能严格意义上说错,毕竟运行起来的确没问题,但是这种做法确实是存在风险隐患,那就是连续postValue会丢数据,我们来做个实验,连续setValue十个数据和连续postValue十个数据,收到的结果都分别是什么
var testData = MutableLiveData<Int>()
fun play(){
for (i in 1..10) {
testData.value = i
}
}
mainViewModel.testData.observe(this) {
println("收到:$it")
}
//执行结果
收到:1
收到:2
收到:3
收到:4
收到:5
收到:6
收到:7
收到:8
收到:9
收到:10setValue十次数据都可以收到,现在把setValue改成postValue再来试试
var testData = MutableLiveData<Int>()
fun play(){
for (i in 1..10) {
testData.postValue(i)
}
}得到的结果是
收到:10只收到了最后一条数据10,这是为什么呢?我们进入postValue里面看看里面的源码就知道了
主要看红框里面,有一个synchronized同步锁锁住了一个代码块,我们称为代码块1,锁的对象是mDataLock,代码块1做的事情先是给postTask这个布尔值赋值,接着把传进来的值赋给mPendingData,那我们知道了,postTask除了第一个被执行的时候,值是true,结下去等mPendingData有值了以后就都为false,前提是mPendingData没有被重置为NOT_SET,然后我们顺着代码往下看,会看到代码接下来就要到一个mPostValueRunnable的线程里面去了,我们看下这个线程
发现同样的锁,锁住了另一块代码块,我们称为代码块2,这个代码块里面恰好是把mPendingData的值赋给newValue以后,重置为NOT_SET,这样一来,postValue又可以接受新的值了,所以这也是正常情况下每次postValue都可以接受到值的原因,但是我们想想连续postValue的场景,我们知道如果synchronized如果修饰一段代码块,那么当这段代码块获取到锁的时候,就具有优先级,只有当全部执行完以后才会释放锁,所以当代码块1连续被访问时候,代码块2是不会被执行的,只有等到代码块1执行完,释放了锁,代码块2才会被执行,而这个时候,mPendingData已经是最新的值了,之前的值已经全部被覆盖了,所以我们说的postValue会丢数据,其实说错了,应该是postValue只会发送最新数据
总结
这篇文章讲到的面试题还仅仅只是过去几年遇到的,现在面试估计除了一些常规问题之外,比重会更倾向于Kotlin,Compose,Flutter的知识点,所以只有不断的日积月累,让自己的知识点更加的全面,才能在目前竞争激烈的行情趋势下逆流而上,不会被拍打在沙滩上
链接:https://juejin.cn/post/7199537072302374969
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2022年终总结——迷茫摆烂
前言
如果要用两个关键词来概括2022全年,我认为是“迷茫”和“摆烂”。迫于对未来的迷茫无措,我写下了这些文字。原本没有打算发出来,但是仔细想想,这又何尝不是一种逃避?所以我发了出来,希望老哥们可以在看完文章后帮我指引前路,不在迷茫。标志性事件太多,麻烦认出来的哥哥,可以给我个面子。
求助
我有两个路线,不知道走哪个。一个是考研,一个是学习,来年跳槽。求指导。
考研的话,北京的学校难度咋样?非全日制的会被承认吗?毕业后大约29岁了,还来得及吗?
学习的话,应该学什么技术呀?应该深入还是全栈?
流水账
关于工作
我在2021年毕业,在年底进入公司,是安卓开发岗位。一直到2月过年那段时间,我摸清了自己的工作内容,接手了以往的项目。我们部门只有我一个安卓开发,其他部门不熟,但是好像也没有安卓岗。没有人教,所以我一直都是靠前任的代码和百度来学习的。我的定位就是应对项目可能会出现的安卓需求,不涉及核心。看似多余,不过工资低(6000),公司养得起。
公司氛围很轻松,朝九晚六。我们同事一直都在忙项目,有点顾不上我。偶尔有人给我派发学习任务,我简单学完之后,面对大把时间就开始手足无措。好多事想干,又不知道先干什么,于是我开始摆烂逃避。看资讯、看小说、刷论坛、刷贴吧,一混就是一天,很爽,深陷其中。
日子就这样混到了三月底。部长看我太闲了,让我跟其中一个项目。这是和安卓风马牛不相及的项目,我也很慌,就开始百度教程学习,慢慢不再混日子。后来正式上手,太难,摸不到门路。只好向同事要了一份他们的做参考,慢慢的上手了,越做越快。于是,在知道截止日期的情况下,我开始摆烂了。玩一会儿,做一点儿。但我还是在截止前一天完成了,耗时一个月。
四月底,部长好像觉得我做的很可以,又给我派了一部分任务。这部分更难,更多。我一开始遇到了点难题,卡了我好久。在百度疯狂的cv了一周之后才解决。然后我又开始摆烂了,这次摆烂的更狠。再加上后面因为疫情开始居家,于是越加肆无忌惮。发觉的时候已经过了20多天了,也居家半个月了。然后我就只能疯狂加班补,最终还是在截止那天完成了,耗时一个半月。
那是六月初,我们刚结束隔离,重新上班。我感到很内疚,因为其他人的工作量是我的两倍,而且部长也催过我。然后我决定发愤图强,然后接过了学习任务。学习完了之后,开始摆烂。后面给我安排了新的任务,需要用到上面学习的内容,然后我就一边学习,一边做,一边摸鱼。
然后就摸鱼摸到了八月,两个月过去了。这时候给我安排了一个安卓项目,我当时真的差点喜极而泣。但是同时,我也真的很慌。因为我除了毕设,就没有再单独开发一个安卓项目了。然后我就结束摆烂,一边偶尔摸鱼,一边努力干活。
一直努力到十月,我终于完成了。其实现在仔细想想,难度也不是很难。之所以耗费两个月时间,多半是因为我经常前半天摸鱼,后半天干活吧。然后就又没事了,放假回来之后就提了点意见让我修改。然后我就又不知道干啥了,就继续摸鱼摆烂。
摆烂到十一月,我们又因为疫情被迫居家了,我直接毫无顾忌的开始疯玩了。后面有新冠什么的,写在生活里了。总之,一直摆烂到现在,偶尔完成一下工作。
总结
总的来说,基本上就是有任务的时候就干活,不忙的时候就迷茫摆烂。
每天都过得浑浑噩噩的,白天迷茫摆烂,夜里焦虑失眠。在公司也没什么师傅来指导,东学一点西学一点的。整个技术成长过程特别碎片化,知识结构不成体系,技术深度严重不足。稍微遇到一些开放性的有难度的问题,就没有足够的信心搞定,产生明显的畏难情绪和自卑心理,觉得自己技不如人,开始逃避,继而摆烂。
每次开会,同事的任务都很高深,到了我就是学习***,感觉自己像个边缘人。
我看不清前面的路该怎么走,未来的技术路线该怎么制定,最近几个月要关注什么,学习什么,自己身上那么多的问题,要优先解决哪一个。
关于生活
因为公司朝九晚六,所以我空闲时间还不少。基本上就是下班回家打游戏、做饭、看小说。我几乎没有自控能力,所以一玩就玩到半夜两三点再睡,因此经常迟到。不过因为公司制度,所以还没有扣过钱。但是睡的太少,前半天只能靠摸鱼看论坛来维持精神。然后午休睡2个小时,后半天在工作。这个状态会在有任务的时候减轻,在没任务的时候加重。
在四月份的时候换了房子。原先住的隔断,虽然双方都很安静,但是因为不隔音,对自控能力极差的我来说简直是折磨(对方是女的,色色不方便)。所以我搬到了离公司很近,房租1800的7平米厨房改的小房间。之前地铁通勤要300元,起床要7:30,这次我血赚。
换了房子之后就更加没有节制了。因为房间小,也就不再做饭了,每天都是打游戏、看小说、刷视频来回换。但是,每当很晚的时候,我好像没事做了该睡觉了,我就感觉空虚茫然。感觉之前做的那些都没有让我真的快乐起来。明明到了该睡觉的时间了,可是心里却很慌,觉得我还没有真的放松一下,可是我不知道做什么。然后就只能继续干刚才那些,等我不知不觉的睡着为止。所以我第二天就经常起不来床,一天都很累,可是回到家里又不知道干什么才能真正地放松自己,只能重复以前的生活,恶性循环了。
打游戏、看小说、刷视频,在一开始确实是快乐的,但是时间长了就开始坐牢了。我明明已经感觉不到快乐了,却不舍得离去,总会觉得接下来一定还有地方可以继续获得快乐,下一个视频、故事情节一定更有趣。因为,如果我退出去了,我就又会迷茫空虚,不知所措。我下意识的想要逃避,不想面对,因为逃避真的有用。但是也因为没有解决根本问题而恶性循环,这都是自己的决定导致的结果。尼采说所有过去的事情是你的意志选择的结果,积极接受,因为这是你的命运。
转而到了六月,中介给我埋得雷爆了。我看房的时候是毛坯房,中介说后面都会给安装空调的,但是房东没给安。一整个夏天我都是靠两个风扇熬过去的。偶尔受不了了,就去隔壁屋蹭一蹭空调。
我在家里读小说只读长度100到200章之间的,因为我会控制不住一直读下去,沉浸于人物中无法自拔,导致晚睡。我一开始喜欢读言情重生种田爽文,毕竟我从小从农村长大,很有代入感。后面也开始读其他类型的,但是也逃不过言情种田爽文这一块。对于从小贫穷吃不起饭,社交能力有问题的我来说,我真的需要飞黄腾达,也需要一个住在心里的人。我一直都梦想有个像小说主角一样有能力的人,带我走出泥潭。后来读的小说多了,我也走出来了,知道自己为什么沉迷了。现实做不到的,只能靠小说了。
我走出小说是七月份的事情了。因为迷茫却又不再读小说,所以我只能多开游戏。我那时候手里在玩三款游戏,玩完正好0点,奖励一下正好睡觉。但是现实不会这么如人愿。一开始还好,时间一长,游戏玩的和上班一样了。玩完还是很累,想休息。可是不知道咋休息,只能刷短视频到3点。
后来我加入了一个游戏交流群,群里人好多都是成年土豪,却又很和善。他们每天当黑奴带本,却没有怨言。人的成长来源,或是经历,或是社交,或是阅读。在高中之后,我终于迎来了一个稳定且长期的社交途径。我跟着一起谈论游戏,也会谈论自己的生活,以求指点。但是成长是缓慢的,我还没有摆脱困境,就进入了一个更大的困境。
一切的转折点是十二月初,我被诈骗了。
具体经过很蠢,我就不发了。我攒了几年的积蓄全没了,还背上了1万的网贷。虽然第一时间就报了警,但是我知道,我这4万多,回不来了。出了警察局我才发现,我要交下个季度的房租了。我之前经常有朋友向我借钱,我圣母心蛮重的,看不得别人受苦,所以我陆陆续续的借出去了2万。所以事发之后,我第一时间联系他们。但是,就要回来一千,甚至有些垃圾人都不回消息了。
我很难过,不敢和家里说,只能看看能不能靠12月要发的工资撑过去,实在不行就网贷。
过了几天,我例行和父母打微信视频。这时候我才知道我爸爸和几个亲戚来北京的工地干活了,而且阳了。他们买不到药,只能困在工地里面干熬着。我很心疼,第二天就很早去楼下药铺排队买药,想着给他们送过去。买完药已经十一点了,想着先回家吃点饭,顺便问问地址。结果正吃着饭呢,突然就感觉特别难受,特别冷,还十分不清醒。我爸爸也说不用给他们送药,他们都快好了。我赶紧给自己贴了好多的暖宝宝,盖着被子睡觉了。虽然措施不少,但还是觉得冷的不行。我以为我是排队的时候,穿的少了,被冻着了。好不容易睡着,再醒来还是冷。我觉得不对了,一看体温计,39.5度。我居然就这么阳了。刚买的药,全给自己用了。
我躺在床上,很委屈,难受的想哭。我到手就6000块钱,我在这刚工作一年攒下4万容易吗?我除了房租水电等必要的花销,几乎不消费的。之前借我钱的那些人,有些还是在大学的时候借的。我家里在农村也是最底下的那一档了,我大学四年努力打零工去实习,省吃俭用才存下了一点儿钱。我穿着高中买的烂衣服,他们还向我借钱,我以为他们可能真缺钱,才借给他们的。谁知道他们转头拿去买苹果,花天酒地了。在我真的需要帮助的时候,却只有一个人还了钱。
我把我被诈骗、要不回钱、阳了这些事说在了群里,求到了许多的指点。我之后就去要钱了。也不是没有进展,要回来一部分。只是,我说话的时候,他们苹果手机的灵动岛一直在跳动,很刺眼。仿佛在嘲笑我,我现在吃饭的工具,用的还是2017年花4000买的电脑。手机也是三年前花了2000买的。我对自己并不好,对别人那么好干嘛,又不是土豪。人不为己天诛地灭。
我不敢乱消费。我知道我看不清自己,现在消费主义盛行,谁知道这些需求到底是不是真正的自己的需求。就像是,我已经单身26年了,早就分不清自己是真的喜欢,还是只想色色了。更何况,我家里真的穷,在我毕业挣钱之后才搬离我住了20多年的土坯房。我爸爸已经50多了,也去不了几天工地搬砖了,我只能指望我自己。
我经常在想,我死了之后会发生什么。我死了以后,这世界的所有事情全都和我无关了。我的后事如何处理,亲人会不会难过,过了几年他们还会不会记得我?我的后代会如何发展,会越来越好还是最终都消散了?我们国家呢,会越来越昌盛,还是功亏一篑,全族消失?那地球呢,会不会最终被太阳吞噬?那银河最终会不会被黑洞吞噬?那宇宙最终会不会热寂呢?还是宇宙最终会变成一个互相吞噬而成的大黑洞,最终大爆炸?
一般我想到这里就不敢继续往下想了。但在我阳的最严重的时候,在我以为我快死了的时候,我反而胆子大了起来。我不敢想下去是因为我不甘心。很多事情我注定无法亲眼见证,很多事情我可以却没有尝试过。也许这就是会有很多人相信轮回的原因吧。人总是会因为各种原因而产生遗憾。贫苦者寄希望于来生过上富裕的生活,痴情者寄希望于来生可以再续前缘。我想明白了,我不甘心,我想见见那些美丽的风景,我想尝尝那些神奇的美食,我想试试双人到底比单人爽在哪里,我想让父母过上好的生活。我也想享受人生,享受生活。然后我打开京东,下单,余额不足。
从大四开始,也就是我开始步入社会的时候,每个冬天我都会因为轻信他人而受到严重损失。算上这次,已经是三次了。金额越来越大,后果越来越严重。第一次借钱给他人却要不回来,第二次被实习公司坑,第三次被诈骗。
我开始仔细反思自己究竟为什么被骗,因为我一开始就觉得有问题,我却一直跟着对方的脚步走,我当时想暂停,我为什么没有暂停?我性格有问题,我喜欢被动,胆小怕事。我不会主动找人聊天,我只会等被人来找我。我不会找事情做,只会等事情来找我。所以我一直跟着骗子的脚步走,知道有问题却不敢停止。
为什么不主动,为什么胆小怕事呢?
我从小家里就很穷,住土坯房里,睡一张炕上,吃院子里种的菜。平时穿堂哥剩下来的衣服,冬天才有新衣服,才有肉吃。我最苦的时候是高中的时候。那时候家里变故也多,我一个月只能拿200块钱在食堂吃饭。每天吃馒头蘸酱,偶尔吃3块钱的白菜和西红柿。不知道为什么,我明明一直吃不饱,体重却越来越高。家里人也开始说我,觉得我乱花钱。河北的高中压力太大了,我每天晚上睡不着,哗哗的掉头发。精神身体双层打压之下,我变得胆小懦弱。因为我没有试错空间,我要是错了,就真的完了。
我那时候真是给我饿坏了,现在还有影响,我已经分不清我是不是吃饱了,我只能等吃不下了才会停手,给我多少,我就一定都吃了。高中饿的时间太久导致的,已经是潜意识了。
我被动是因为我没有一个目标,啥都可以,所以就开始等着别人摆布。我挺胸无大志的。我以前觉得,能吃饱有住的地方就行,攒点钱以后回村,毕竟成长期我一直吃不饱。
从我进入大学之后,我突然就没事干了。之前一直都有一双无形的手推着我走向大学,现在这双手消失了。高中是我最痛苦的时光,所以我厌学了,开始摆烂。
我分不清好坏,分不清冷热,分不清是否吃饱,分不清是否喜欢,分不清是否需要。推着我的手消失了,我就不知道应该怎么办了。我曾经想天降主角,帮我制定规则,推着我走。但是,这是不可能的。因为我没有一个目标,所以我迷茫,所以我被动。所以有人推我时,我即使知道那是骗子,我也会下意识的由着他推着走。
我也知道自己胆小怕事的原因是自身不够强大。阳的时候,我多想有个人,可以带我走出泥潭,仿佛小说主角一般。但是,我阳过了也没人来。我最后才知道,我只能靠自己。有人指点我说,不管你目标是什么,不管最终能不能实现,你都要先写出来,先说出来。只有这样你才会为之努力,想办法去实现他。畏畏缩缩在心里不敢提出来,只会让人踌躇不前,最终会导致觉得自己会做不到,不断否定自己。长此以往,就会变得胆小怕事。
归根到底,我一直都在忽视自己真正的感受,从来没有认清自己。明白自己真正想要什么很难,人生得意须尽欢,我这时候才真正地明白。
既然不知道自己真正想要什么,那就多尝试吧,全都试试就知道了。我想尝试很多的新鲜事物,我想过优质的生活,我想强大起来不再懦弱,我不想父母劳累了。这些都需要钱。
所以,我当前阶段的主要目标就是搞钱!
不幸中的万幸,我被骗之后,大数据知道我缺钱,疯狂给我发垃圾短信,让我网贷。然后我看到了保险的短信,然后我想起来我买了好几年的保险。一切很顺利,3小时就理赔成功了。给了我2.7万,可以回家过年了。
但是回家之后又出了很多事。就不细谈了,说起来就生气。我以为天底下还是好人多,但这次为数不多的坏人都让我家碰上了。
总结
不抱怨,三思后行,学会享受人生,努力赚钱!!
明白自己真正想要什么很难,人生得意须尽欢,我想尝试很多的新鲜事物,我想过优质的生活,我想强大起来不再懦弱,我不想父母劳累了。这些都需要钱。
所以,我当前阶段的主要目标就是搞钱!
2023年计划
如果说“迷茫”和“摆烂”是2022全年的两个关键词,那么我希望2023全年的两个关键词是“尝试”和“积累”。
既然不知道自己真正想要什么,那就多尝试吧,全都试试就知道了。我想尝试很多的新鲜事物,我想过优质的生活,我想强大起来不再懦弱,我不想父母劳累了。这些都需要钱。
既然不知道路,那就多尝试吧,把想尝试的都去试试,不再压抑自己。人生得意须尽欢!
找到路之后就一路积累,一路走下去吧。
关于工作
我有两个路线,不知道走哪个。一个是考研,一个是学习,来年跳槽。
我今年26了,要是考研的话,毕业就得29。程序员吃青春饭,我怕到时候跟不上了。而且北京的研究生不知道好不好考。
学习积累方面也不知道学啥。因为公司需求不大,所以我想往全栈那边走一下。我今年的计划是,先学uni-app,再学flutter。系统学习一下安卓,更新一下技术,并使用新技术重新写一遍自己的毕设。学一下主流的后端技术,重新写一遍自己的毕设的后端。
关于生活
明白自己真正想要什么,多多尝试新鲜事物。
开始健身,至少今年要减20斤肥,变成健康的身体。新冠太可怕了,我被折磨怕了。
学习一下护肤品相关知识,准备尝试找对象,不想单身了。(我看他们都开始捣鼓化妆了,难道现在流行男生化妆了吗)
规律生活,不要再熬夜了。
后言
想说的太多了,文字总是太过苍白,无法表达万一。
其实由于各种原因,时间并不站在我这里。我已经26了,这个时候才开窍似乎是晚了。
但是,最好的开始时刻就是当下。
我之前也有想改变的时候,但是“晚了”这两个字让我给自己判了死刑。不停否定自己,不再进步。
这次,我不想再放弃了。
这次,我不想再放弃了。
链接:https://juejin.cn/post/7194456242910462008
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
7年老菜鸟平凡的2022
前言
嗨,大家好,我是希留。一个被迫致力于成为一名全栈开发的菜鸟。
2022年对于大多数人而言是难忘的一年,受疫情影响、经历行业寒冬。裁员、失业等情况总是笼罩着本就焦虑不安的生活。
而我的2022,用一个关键词就可以概括:“平凡”。既没有升职加薪,也没有被裁失业。就像是一潭湖水,没有什么波澜。可即便如此,也得默默的努力着。下面就来盘点一下属于我的2022。
工作技能上
付出
这一年,本本分分的完成工作上的功能开发,业余时间则在几个技术平台上更新一些文章,几乎都是一篇文章手动同步发送几个平台。
累计在CSDN上写了31篇文章,掘金上更新了28篇文章,公众号更新了26篇文章,头条号更新了26篇文章。
除了更新文章外,还利用业余时间帮朋友开发了一款租房小程序,包含管理后台以及微信小程序。目前还在开发当中,感兴趣的朋友也可以体验一下。后台体验账号: test/123456
小程序端:
收获
CSDN
csdn平台就只收获了访问数据以及粉丝数的增加。
掘金
在掘金平台除了收获一些访问数据的增加外,还切切实实的参与创作活动薅到一些马克杯、抱枕、现金等羊毛,在此感谢掘金平台让我体会到了写作真的能够带来价值,感谢~
微信公众号
微信公众号收获了一些粉丝。
头条号
头条号收获了一些粉丝,以及微薄的收益。
副业拓展上
付出
不知道是受大环境影响还是年龄大了,老是会有各种焦虑。所以也萌生了想要开展副业的想法,于是参加了几个付费社群,也跟着入局实践了两个项目,一个是闲鱼电商,一个是外卖cps。
有朋友入局过这种副业项目的也可以评论区交流一下。
收获
咸鱼上的GMV是2w多,利润有3k多,有这个收益还是比较满意的,希望可以越来越好。
外卖CPS虽然也有一点收益,但是还不够微信300块的认证费,这个项目算是费了。
总的来说,想要做副业也不是那么容易的,虽然眼前有一点点小收益,但是想要放大太难了。
2023未来展望
- 完成租房小程序的开发并上线。
- 更新不少于25篇技术类文章
- 寻找一个更适合技术人员的副业项目
- 完成人生大事
总结
好了,以上就是我的2022总结和未来展望了,感谢大家的阅读。
生活如果不宠你,更要自己善待自己。这一路,风雨兼程,就是为了遇见最好的自己,如此而已。
链接:https://juejin.cn/post/7194432987587412029
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


