








抓包神器 Charles 使用教程支持mac ios Android
本文以Mac 系统为例进行讲解
- 配置手机代理:
手机和 Mac 连接到同一个 WiFi 网络
1.1 Android 系统:「以华为 P20 手机为例」
- 设置 -> 无线和网络 -> WLAN
- 长按当前 WiFi -> 修改网络
- 勾选显示高级选项
- 代理 -> 手动
- 服务器主机名 -> 填写 Mac 的IP 地址「Mac IP 获取方法:Charles -> Help -> Local IP Address 」
- 服务器端口 -> 8888
- 保存
1.2 IOS 系统:「以 iPhone Xs Max 手机为例」
- 设置 -> 无线局域网
- 点击当前连接的 WiFi
- 最底部 HTTP 代理 -> 配置代理 -> 勾选手动
- 服务器 -> 填写 Mac 的IP 地址「Mac IP 获取方法:Charles -> Help -> Local IP Address 」
- 端口 -> 8888
- 存储
核心功能
一、 抓包「以 iPhone Xs Max 为例」
- Charles 设置
- Proxy -> Proxy Settings -> Port -> 8888
- 勾选 Support HTTP/2
- 勾选 Enable transparent HTTP proxying
- OK
手机设置代理如上「配置手机代理」步骤
打开手机上任意联网的应用,Charles 会弹出请求连接的确认菜单,点击“Allow“即可完成设置
二、 过滤网络请求
- 左侧底部 Filter 栏 -> 过滤关键字
- 在 Charles 的菜单栏选择
Proxy -> Recording Settings -> Include -> add「依次填入协议+主机名+端口号,即可只抓取目标网站的包」
- 切换到 Sequence,在想过滤的网络请求上右击,选择“Focus“,在 Filter 栏勾选上 Focused
三、 分析 HTTPS 包
- Mac 安装证书:
Help -> SSL Proxying -> Install Charles Root Certificate -> 输入系统的帐号密码,即可在钥匙串中看到添加好的证书
如果遇到证书不被信任的问题,解决办法:
Mac本顶栏 前往 -> 实用工具 -> 打开钥匙串访问 -> 找到该证书 -> 双击或右键「显示简介」-> 点开「信任」-> 选择「始终信任」
Charles 设置请求允许 SSL proxying
Charles 默认并不抓取 HTTPS 网络通讯的数据,若想拦截所有 HTTPS 网络请求,需要进行设置:在请求上右击选择 Enable SSL proxying
2. Charles -> Proxy -> SSL Proxying Settings -> SSL Proxying「添加对应的域名和端口号,为方便也可端口号直接添加通配符*」
- 移动端安装证书
a. Charles 选择 Help -> SSL Proxying -> Install Charles Root Certificate on a Mobile Device or Remote Browser
b. 确保手机连上代理的情况下,在手机浏览器栏输入:chls.pro/ssl,下载证书,完成安装。
Android tips:
1.1. 小米机型请注意,如果是 MIUI 9 以上的版本,请不要用自带浏览器下载证书,自带浏览器下载的证书文件格式不对,无法安装,uc 浏览器下载没有问题。
1.2. 若不能直接安装,需要下载下来,到手机设置 -> 安全 -> 从设备存储空间安装 -> 找到下载的证书 .pem 结尾的 -> 点击安装即可
IOS tips:
IOS 需要设置手机信任证书,详见 官方文档。若不能直接安装,需在手机「设置」-> 通用 -> 描述文件与设备管理安装下载的证书,完成安装后 -> 找到关于本机 -> 证书信任设置,打开刚安装的证书的开关。
抓包内容遇到乱码,解决如下:
- Proxy -> SSL Proxy Settings -> Add
- Host:*「代表所有网站都拦截」
- Port:443
- 保存后,在抓包数据就会显示正常
四、 模拟弱网
选择 Proxy -> Throttle Settings -> 勾选 Enable Throttling -> 选择 Throttle Preset 类型
五、 Mock 数据
以 map local 为例,修改返回值
选择目标请求,右键选择 Save All保存请求的 response 内容到本地文件
- 配置 Charles Map Local,Tool -> Map Local -> 勾选 Enable Map Local -> Add 「添加目标请求及需要替换的response 文件地址」-> OK
- 用文本编辑器打开保存的 json 文件,修改内容,进行替换。打开客户端应用重新请求该接口,返回的数据就是本地的文件数据。
链接:https://juejin.cn/post/7215105725387374650
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android打造专有hook,让不规范的代码扼杀在萌芽之中
俗话说,无规矩不成方圆,同样的放在代码里也是十分的贴切,所谓在代码里的规矩,指的就是规范,在一定规范约束下的项目,无论是参与开发还是后期维护,都是非常的直观与便捷,不能说赏心悦目,也可以用健壮可维护来表示;毕竟协同开发的项目,每个人都有自己的一套开发标准,你没有一套规范,或者是规范没有落地执行,想想,长此以往,会发生什么?代码堆积如山?维护成本翻倍增加?新人接手困难?等等,所谓的问题会扑面而来。
正所谓规范是一个项目的基石,也是衡量一个项目,是否健壮,稳定,可维护的标准,可谓是相当重要的。我相信,大部分的公司都有自己的一套规范标准,我也相信,很多可能就是一个摆设,毕竟人员的众多,无法做到一一的约束,如果采取人工的检查,无形当中就会投入大量的时间和人力成本,基于此,所谓的规范,也很难执行下去。
介于人工和时间的投入,我在以往的研究与探索中,开发出了一个可视化的代码检查工具,之前进行过分享,《一个便捷操作的Android可视化规范检查》,想了解的老铁可以看一看,本篇文章不做过多介绍,当时只介绍了工具的使用,没有介绍相关功能的开发过程,后续,有时间了,我会整理开源出来,一直忙于开发,老铁们,多谅解。这个可视化的检查工具,虽然大大提高了检查效率,也节省了人力和时间,但有一个潜在的弊端,就是,只能检查提交之后的代码是否符合规范,对于提交之前没有进行检查,也就说,在提交之前,规范也好,不规范也罢,都能提交上来,用工具检查后,进行修改,更改不规范的地方后然后再提交,只能采取这样的一个模式检查。
这样的一个模式,比较符合,最后的代码检查,适用于项目负责人,开发Leader,对组员提交上来的代码进行规范的审阅,其实并不适用于开发人员,不适用不代表着不可用,只不过相对流程上稍微复杂了几步;应对这样的一个因素,如何适用于开发人员,方便在提交代码之前进行规范检查,便整体提上了研发日程,经过几日的研究与编写,一个简单便捷的Android端Git提交专有hook,便应运而生了。
说它简单,是因为不需要编写任何的代码逻辑,只需要寥寥几步命令,便安装完毕,通过配置文件,便可灵活定制属于自己的检查范围。
为了更好的阐述功能及讲述实现过程,便于大家定制自己的开发规范,再加上篇幅的约束,我总结了四篇文章来进行系统的梳理,还请大家,保持关注,今天这篇,主要讲述最终的开发成果,也就是规范工具如何使用,规范这个东西,其实大差不差,大家完全可以使用我自己已经开发好的这套。
这个工具的开发,利用的是git 钩子(hook),当然也是借助的是Node.js来实现的相关功能,下篇文章会详细介绍,我们先来安装程序,来目睹一下实际的效果,安装程序,只需要执行几步命令即可,无需代码介入,在实际的开发中需要开发人员,分别进行安装。
安装流程
1、安装 Node.js,如果已经安装,可直接第2步:
Node.js中允许使用 JavaScript 开发服务端以及命令行程序,我们可以去官网nodejs.org
下载最新版本的安装程序,然后一步一步进行安装就可以了,这个没什么好说的,都是开发人员。
2、安装android_standard
android_standard是最终的工具,里面包含着拦截代码判断的各种逻辑 , 在项目根目录下执行如下命令:
npm install android_standard --save-dev执行完命令后,你会发现,你的项目下已经多了一个目录,还有两个json文件,如下图所示:
node_modules,用来存放下载安装的包文件夹,里面有我们要使用到的功能,其实和Android中lib目录很类似,都是一些提供功能的库。
package.json文件,是配置文件,比如应用的名字,作者,介绍,还有相关的依赖等,和Android中的build.gradle文件类似。
3、创建git配置文件,执行如下命令
node node_modules/android_standard/gitCommitConfig命令执行成功会返回如下信息:
此命令执行完后,会在项目根目录下创建gitCommitConfig文件,这个文件很重要,是我们执行相关命令的配置文件,内容如下,大家可以根据自己实际项目需要进行更改。
项目下生成gitCommitConfig.android文件,.android是我自己定义的,至于什么格式,等你自己开发的时候,完全可以自定义,是个文件就行。
打开后,文件内容如下,此文件是比较重要的,后续所有的规范检查,都要根据这个文件里的参数来执行,大家在使用的时候,就可以通过这个文件来操作具体的规范检查。
4、更改执行文件,执行如下命令
执行文件,就是需要在上边生成的package.json文件,添加运行程序,使其在git提交时进行hook拦截。
node node_modules/android_standard/package5、添加git过滤
因为执行完上述命令后,会产生几个文件,而这几个文件是不需要我们上传到远程仓库的,所以我们需要在.gitignore文件里添加忽略,直接复制即可。
/node_modules
package.json
package-lock.json
gitCommitConfig.android6、后续如果有更新,可命令进行操作:
注:此命令在更新时执行
npm update android_standard --save-dev7、删除操作
注:后续不想使用了,便可执行如下命令:
npm uninstall android_standard --save-dev具体使用
通过上述的安装流程,短短几个命令,我们的规范检查便安装完毕,后续只需要通过gitCommitConfig.android文件,来动态的更改参数即可,是不是非常的方便,接下来,我们来实际的操作一番。
关于配置文件的相关参数,也都有注释,一看便知,这里简单针对最后的参数,做一个说明,也就是gitCommand这个参数,true为工具,false为命令方式;true也好,false也好,在主要的功能验证上,没有区别,唯一的区别就是,命令行的方式提交,会有颜色区分,后面有效果。
我们先来看下命令行下的执行效果,当配置文件开关gitCommitSwitch已开,并且gitCommand为false,其他的配置参数,大家可以根据需要进行改动,在代码提交的时候如下效果:
在Android studio中提交代码执行效果
TortoiseGit提交代码执行效果:
目前呢,针对Android端的规范检查,无论是java还是Kotlin,还是资源文件,都做了一定的适配,经过多方测试,一切正常,如果大家的公司也需要这样的一个hook工具,欢迎使用,也欢迎继续关注接下来的相关实现逻辑文章。
好了各位老铁,这篇文章先到这里,下篇文章会讲述,具体的实现过程,哦,忘记了,上篇结尾的遗留组件化还未更新,那就更新完组件化,接着更新这个,哈哈,敬请期待!
链接:https://juejin.cn/post/7140963362791227400
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
23年ChatGPT平替方案和开源案例
作为一个老掉牙的全栈程序员,不愿意参与职场的人情世故,只愿意埋头研究技术。是不是大家也有这种想法?这种想法,目前都是扯淡的,那些人情世故会把你挤走~ 想要纯粹的技术环境,可能或许只有大厂了~
现实是:ChatGPT每天都在疯狂地学习,疯狂的进步,也在被开发人员疯狂的使用。至少,我们团队每天总有一个窗口留给了它。由于最近OpenAI服务器频发故障,进入官网的速度越来越慢,难度越来越大。平替或许不是最好的方案,但有时候却是不可或缺的工具。
据悉:OpenAI团队目前正在努力改善模型的性能和速度,想让模型变得更快、更高效。无独有偶,百度也在近期推出了企业专版产品:文心千烦,网友回复:百度果然没有辜负大家,第一时间没有投入技术研究,而是研究出付费方式。
平替案例
以下是群友整理的地址,请勿填写自己的key,以防止被调用。
anzorq-chatgpt-demo.hf.space
chat.openai1s.com [荐]
chat.aifks001.online
gptocean.com
chatgpt.ai [荐]
ai-chat.scholarcn.com
http://www.x5.chat
builtbyjesse.com/lab
http://www.scifmat.work/
aichat.momen.vip/home
开源代码:
github.com/waylaidwand…
github.com/dirk1983/ch…
github.com/Chanzhaoyu/…
github.com/869413421/c…
推荐插件
语音交互插件
Voice Control for ChatGPT:实现语音与chagpt交互,支持多国语言
下载地址:chrome.google.com/webstore/de…
角色提示市场
AIPRM for ChatGPT,可以内嵌角色,输入风格, 输出风格等多种标签支持(貌似开始收费了)
下载地址:chrome.google.com/webstore/de…
聊天工具库-彩蛋
聊天工具,可以支持复制,下载聊天记录,下载图片,转成pdf多种工具
Google浏览器插件
ChatGPT 谷歌助手和高亮显示工具,玩的太嗨了
下载地址:chrome.google.com/webstore/de…
角色脚本插件-彩蛋
可以通过/触发脚本指令,收录近300个专业的角色插件指令,目前尚未发布市场。
接入外网的ChatGPT
可以访问互联网的ChatGPT,数据将不会再停留在2021年9月,而是实时数据检索,通过GPT的语言模型将关键信息提取出来喂养后,给出更加精准的答案
技术研究
案例比较多,就提取一个自己玩的比较好的,用node启动的服务,可以在seveless中快速启动。
设置环境变量:OPENAI_API_KEY为自己key即可
import cloud from '@lafjs/cloud'//这个不用管
import axios from 'axios'//这个测试的
import { ChatGPTAPI } from 'chatgpt'
export async function main(ctx: FunctionContext) {
// body, query 为请求参数, auth 是授权对象
const { auth, body, query } = ctx;
const prompt = body.text.content;
const api = new ChatGPTAPI({ apiKey: cloud.env.OPENAI_API_KEY })
let res = await api.sendMessage('你好')
console.log(res.text)
}
链接:https://juejin.cn/post/7215509220748984376
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 实现计时器
这周接到个新需求,统计用户在线时长,累积到一定时长后上报,可以通过计时器来实现。本篇文章介绍下安卓端实现计时器的三种方式。
Timer、TimerTask
通过Timer和TimerTask实现计时,代码如下:
class TimeChangeExample : BaseGestureDetectorActivity() {
private lateinit var binding: LayoutTimeChangeExampleActivityBinding
private val dateFormat = SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
private var timerHandler = object : Handler(Looper.myLooper() ?: Looper.getMainLooper()) {
override fun handleMessage(msg: Message) {
super.handleMessage(msg)
if (msg.what == 0) {
setCountdownTimeText(msg.obj as Long)
}
}
}
private var timer: Timer? = null
private var timerTask: TimerTask? = null
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.layout_time_change_example_activity)
binding.btnCountdownByTimer.setOnClickListener {
clearText()
binding.tvCountdownText.text = "countdown by timer\n"
startCountdownByTime()
}
binding.btnStopTimer.setOnClickListener {
stopTimer()
}
}
private fun startCountdownByTime() {
stopTimer()
timerTask = object : TimerTask() {
override fun run() {
timerHandler.sendMessage(timerHandler.obtainMessage(0, System.currentTimeMillis()))
}
}
timer = Timer()
timer?.schedule(timerTask, 0, 1000)
}
private fun stopTimer() {
timer?.cancel()
timer = null
timerTask = null
}
private fun setCountdownTimeText(time: Long) {
binding.tvCountdownText.run {
post {
text = text.toString() + "${dateFormat.format(Date(time))}\n"
}
}
}
private fun clearText() {
binding.tvCountdownText.text = ""
}
override fun onDestroy() {
super.onDestroy()
stopTimer()
}
}效果如图:
两次计时之间的误差都是毫秒级的。
BroadCastReceiver
通过注册广播,监听系统时间变化实现计时,但是广播回调触发的间隔固定为一分钟,代码如下:
class TimeChangeExample : BaseGestureDetectorActivity() {
private lateinit var binding: LayoutTimeChangeExampleActivityBinding
private val dateFormat = SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
private val timeChangeBroadcastReceiver = object : BroadcastReceiver() {
override fun onReceive(context: Context?, intent: Intent?) {
if (intent?.action == Intent.ACTION_TIME_TICK) {
setCountdownTimeText(System.currentTimeMillis())
}
}
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.layout_time_change_example_activity)
binding.btnCountdownByBroadcast.setOnClickListener {
clearText()
binding.tvCountdownText.text = "countdown by broadcast\n"
startCountdownByBroadcast()
}
binding.btnStopBroadcast.setOnClickListener {
stopBroadcast()
}
}
private fun startCountdownByBroadcast() {
registerReceiver(timeChangeBroadcastReceiver, IntentFilter().apply {
addAction(Intent.ACTION_TIME_TICK)
})
}
private fun stopBroadcast() {
unregisterReceiver(timeChangeBroadcastReceiver)
}
private fun setCountdownTimeText(time: Long) {
binding.tvCountdownText.run {
post {
text = text.toString() + "${dateFormat.format(Date(time))}\n"
}
}
}
private fun clearText() {
binding.tvCountdownText.text = ""
}
override fun onDestroy() {
super.onDestroy()
stopBroadcast()
}
}效果如图:
两次计时之间的误差都是毫秒级的。
Handler
通过Handler和Runnable来实现计时,代码如下:
class TimeChangeExample : BaseGestureDetectorActivity() {
private lateinit var binding: LayoutTimeChangeExampleActivityBinding
private val dateFormat = SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS")
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = DataBindingUtil.setContentView(this, R.layout.layout_time_change_example_activity)
binding.btnCountdownByHandler.setOnClickListener {
clearText()
binding.tvCountdownText.text = "countdown by handler\n"
startCountdownByHandler()
}
binding.btnStopHandler.setOnClickListener {
stopHandler()
}
}
private val handler = Handler(Looper.myLooper() ?: Looper.getMainLooper())
private val countdownRunnable = object : Runnable {
override fun run() {
setCountdownTimeText(System.currentTimeMillis())
val currentTime = SystemClock.uptimeMillis()
val nextTime = currentTime + (1000 - currentTime % 1000)
handler.postAtTime(this, nextTime)
}
}
private fun startCountdownByHandler() {
val currentTime = SystemClock.uptimeMillis()
val nextTime = currentTime + (1000 - currentTime % 1000)
handler.postAtTime(countdownRunnable, nextTime)
}
private fun stopHandler() {
handler.removeCallbacks(countdownRunnable)
}
private fun setCountdownTimeText(time: Long) {
binding.tvCountdownText.run {
post {
text = text.toString() + "${dateFormat.format(Date(time))}\n"
}
}
}
private fun clearText() {
binding.tvCountdownText.text = ""
}
override fun onDestroy() {
super.onDestroy()
stopHandler()
}
}效果如图:
两次计时之间的误差都是毫秒级的。
示例
在示例Demo中添加了相关的演示代码。
链接:https://juejin.cn/post/7214288126223319100
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 隐私合规检测
目前应用市场的隐私合规检查越来越严格,各大手机厂商的检测标准也不一致,经常有这个平台过审了那个平台还有问题出现,按照工信部的要求,工信部隐私合规说明。隐私合规是个不可不重视的点。
我们通常遇到的主要问题:
在用户同意隐私协议之前,不能有收集用户隐私数据的行为。例如:在用户同意协议之前不能去获取 Android ID、Device ID、MAC 等隐私数据。
在用户同意隐私协议之后,获取权限时必须要符合当前使用场景,例如:我们需要获取手机读写,相机权限,这种需要在真正的读写,打开相机等页面时才能去请求权限。
如上问题处理可分为两种:权限 和 隐私
- 权限 需要在对应页面即 app内获取权限时主动设置弹窗等方式给予app相应的权限
'如电话权限,定位权限,相机权限,浮窗权限,读写权限等。在每个申请危险权限前,都需要弹窗说明权限解释说明。'- 隐私 为app使用过程中与用户个人相关的个人信息
'如位置,Mac地址,设备id等。就Android端而言,多数隐私信息需要对应授权后才能获取,但目前仍存在部分隐私信息无需授权就可以拿到的'如何检测
一、第三方检测
二、静态检测
Lint 检查项目
Lint用于检测静态代码和资源,找到其中不符合预定义规则的地方。可参考网易云隐私合规静态检查
反编译查找对应方法
反编译主要是为了找出第三方的一些不合规方法调用,但是比较麻烦,全局搜索很不方便
三、动态检测(开源)
1、Xposed
优点 :Xposed 是比较早的做hook的框架, Xposed框架可以在不修改APK文件的情况下影响程序运行(修改系统)的框架服务,基于它可以制作出许多功能强大的模块,且在功能不冲突的情况下同时运作。Android中一般存在两种hook:sdk hook和ndk hook。native hook的难点在于理解ELF文件与学习ELF文件,Java层Hook则需要了解虚拟机的特性与java上的反射使用。另外还存在全局hook,即结合sdk hook和ndk hook,xposed就是一种典型的全局hook框架。
缺点:需要手机ROOT
2、VirtualXposed
优点 :VirtualXposed 是基于VirtualApp 和 epic 实现的,能在非ROOT环境下直接运行Xposed模块 (目前支持5.0~10.0)。其实VirtualXposed就是一个支持Xposed的虚拟机,我们把开发好的Xposed模块和对应需要hook的App安装上去就能实现hook功能。
缺点:步骤相对麻烦,de.robv.android.xposed 的依赖需要翻墙。
3、epic
优点 :配置简单,属于运行时hook,说明在动态加载dex也能检测到,也是我目前再用的,可以自定义配置hook 对应的类和方法,并找出当前调用线程堆栈,直接定位到调用的方法。
缺点:兼容问题,Android 11及以上只能支持 64位,不过这个不影响11以下的使用;只检测java类代码,native没有hook 。
接入相对复杂,基于自定义transform , 编译期注解+hook方案,第一个transform收集需要拦截的敏感函数,第二个transform替换敏感函数,运行期收集日志,同时支持游客模式。
有java.util.zip.ZipException: duplicate entry: META-INF/INDEX.LIST 冲突风险。
5、camille
使用
pythonFrida等工具命令,做hook 模块,手机需要Root,功能强大但相对复杂
6、自定义Asm插件,做代码插入检测
可以在class->dex时,对相应的类、调用方法,做检测。添加我们的拦截代码
四、epic落地
- 我这里使用的时 epic 检测,直接依赖:
implementation 'me.weishu:epic:1.0.0'
implementation 'me.weishu.exposed:exposed-xposedapi:0.4.5'主要核心是 DexposedBridge.findAndHookMethod 方法
//targetClass: 传入 需要hook 的类,如:TelephonyManager.class
//targetMethod:类对应的方法,如:getDeviceId
DexposedBridge.findAndHookMethod(targetClass, targetMethod, new XC_MethodHook() {
@Override
protected void beforeHookedMethod(MethodHookParam param) throws Throwable {
super.beforeHookedMethod(param);
//被调用的类名
String className = param.method.getDeclaringClass().getName();
//被调用的函数名
String methodName = param.method.getName();
LogAction.log("检测到 " + className + " 被调用: methodName=" + methodName);
//这里可以搜集当前的线程信息,堆栈等,将调用关系打印出来,例如:
//Thread thread = Thread.currentThread();
//StringBuilder stringBuilder = new StringBuilder();
//获取线程信息
//String threadInfo = getThreadInfo(thread);
//stringBuilder.append(threadInfo);
// 返回表示此线程的堆栈转储的堆栈跟踪元素数组。
// 如果这个线程还没有启动,已经启动但还没有被系统计划运行,或者已经终止,这个方法将返回一个零长度的 数组。
//StackTraceElement[] stackTraceElements = thread.getStackTrace();
//String print = printToString2(stackTraceElements);
//stringBuilder.append("线程堆栈日志:").append(print);
//LogAction.log(stringBuilder);
}
@Override
protected void afterHookedMethod(MethodHookParam param) throws Throwable {
super.afterHookedMethod(param);
}
});例如,我这里用了 leakcanary 做检测时会提示的
因为我对 android.app.ApplicationPackageManager 这个类做了检测,queryIntentActivities 方法被调用时即触发了beforeHookedMethod
五、集成优化处理
我们可以自己定义一个module模块,单独处理合规检测,利用
debugImplementation的方式集成,不会影响到线上
可以使用
ContentProvider做初始化入口,debugImplementation集成进来即可,在ContentProvider onCreate的时候去 start启用 需要hook 的集合类。
可以使用企业微信提供
API Token,在收到 隐私限制方法被调用时,触发消息发送,方便测试和提示,不需要去看log日志。
链接:https://juejin.cn/post/7213642622074273849
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android进程间大数据通信:LocalSocket
前言
说起Android进行间通信,大家第一时间会想到AIDL,但是由于Binder机制的限制,AIDL无法传输超大数据。
那么我们如何在进程间传输大数据呢?
Android中给我们提供了另外一个机制:LocalSocket
它会在本地创建一个socket通道来进行数据传输。
那么它怎么使用?
首先我们需要两个应用:客户端和服务端
服务端初始化
override fun run() {
server = LocalServerSocket("xxxx")
remoteSocket = server?.accept()
...
}先创建一个LocalServerSocket服务,参数是服务名,注意这个服务名需要唯一,这是两端连接的依据。
然后调用accept函数进行等待客户端连接,这个函数是block线程的,所以例子中另起线程。
当客户端发起连接后,accept就会返回LocalSocket对象,然后就可以进行传输数据了。
客户端初始化
var localSocket = LocalSocket()
localSocket.connect(LocalSocketAddress("xxxx"))首先创建一个LocalSocket对象
然后创建一个LocalSocketAddress对象,参数是服务名
然后调用connect函数连接到该服务即可。就可以使用这个socket传输数据了。
数据传输
两端的socket对象是一个类,所以两端的发送和接受代码逻辑一致。
通过localSocket.inputStream和localSocket.outputStream可以获取到输入输出流,通过对流的读写进行数据传输。
注意,读写流的时候一定要新开线程处理。
因为socket是双向的,所以两端都可以进行收发,即读写
发送数据
var pool = Executors.newSingleThreadExecutor()
var runnable = Runnable {
try {
var out = xxxxSocket.outputStream
out.write(data)
out.flush()
} catch (e: Throwable) {
Log.e("xxx", "xxx", e)
}
}
pool.execute(runnable)发送数据是主动动作,每次发送都需要另开线程,所以如果是多次,我们需要使用一个线程池来进行管理
如果需要多次发送数据,可以将其进行封装成一个函数
接收数据
接收数据实际上是进行while循环,循环进行读取数据,这个最好在连接成功后就开始,比如客户端
localSocket.connect(LocalSocketAddress("xxx"))
var runnable = Runnable {
while (localSocket.isConnected){
var input = localSocket.inputStream
input.read(data)
...
}
}
Thread(runnable).start()接收数据实际上是一个while循环不停的进行读取,未读到数据就继续循环,读到数据就进行处理再循环,所以这里只另开一个线程即可,不需要线程池。
传输复杂数据
上面只是简单事例,无法传输复杂数据,如果要传输复杂数据,就需要使用DataInputStream和DataOutputStream。
首先需要定义一套协议。
比如定义一个简单的协议:传输的数据分两部分,第一部分是一个int值,表示后面byte数据的长度;第二部分就是byte数据。这样就知道如何进行读写
写数据
var pool = Executors.newSingleThreadExecutor()
var out = DataOutputStream(xxxSocket.outputStream)
var runnable = Runnable {
try {
out.writeInt(data.size)
out.write(data)
out.flush()
} catch (e: Throwable) {
Log.e("xxx", "xxx", e)
}
}
pool.execute(runnable)读数据
var runnable = Runnable {
var input = DataInputStream(xxxSocket.inputStream)
var outArray = ByteArrayOutputStream()
while (true) {
outArray.reset()
var length = input.readInt()
if(length > 0) {
var buffer = ByteArray(length)
input.read(buffer)
...
}
}
}
Thread(runnable).start()这样就可以传输复杂数据,不会导致数据错乱。
传输超大数据
上面虽然可以传输复杂数据,但是当我们的数据过大的时候,也会出现问题。
比如传输图片或视频,假设byte数据长度达到1228800,这时我们通过
var buffer = ByteArray(1228800)
input.read(buffer)无法读取到所有数据,只能读到一部分。而且会造成后面数据的混乱,因为读取位置错位了。
读取的长度大约是65535个字节,这是因为TCP被IP包包着,也会有包大小限制65535。
但是注意!写数据的时候如果数据过大就会自动进行分包,但是读数据的时候如果一次读取貌似无法跨包,这样就导致了上面的结果,只能读一个包,后面的就错乱了。
那么这种超大数据该如何传输呢,我们用循环将其一点点写入,也一点点读出,并根据结果不断的修正偏移。代码:
写入
var pool = Executors.newSingleThreadExecutor()
var out = DataOutputStream(xxxSocket.outputStream)
var runnable = Runnable {
try {
out.writeInt(data.size)
var offset = 0
while ((offset + 1024) <= data.size) {
out.write(data, offset, 1024)
offset += 1024
}
out.write(data, offset, data.size - offset)
out.flush()
} catch (e: Throwable) {
Log.e("xxxx", "xxxx", e)
}
}
pool.execute(runnable)读取
var input = DataInputStream(xxxSocket.inputStream)
var runnable = Runnable {
var outArray = ByteArrayOutputStream()
while (true) {
outArray.reset()
var length = input.readInt()
if(length > 0) {
var buffer = ByteArray(1024)
var total = 0
while (total + 1024 <= length) {
var count = input.read(buffer)
outArray.write(buffer, 0, count)
total += count
}
var buffer2 = ByteArray(length - total)
input.read(buffer2)
outArray.write(buffer2)
var result = outArray.toByteArray()
...
}
}
}
Thread(runnable).start()这样可以避免因为分包而导致读取的长度不匹配的问题
链接:https://juejin.cn/post/7215100409169625148
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin委托的原理与使用,以及在Android开发中常用的几个场景
Kotlin委托的常见使用场景
前言
在设计模式中,委托模式(Delegate Pattern)与代理模式都是我们常用的设计模式(Proxy Pattern),两者非常的相似,又有细小的区分。
委托模式中,委托对象和被委托对象都是同一类型的对象,委托对象将任务委托给被委托对象来完成。委托模式可以用于实现事件监听器、回调函数等功能。
代理模式中,代理对象与被代理对象是两种不同的对象,代理对象代表被代理对象的功能,代理对象可以控制客户对被代理对象的访问。代理模式可以用于实现远程代理、虚拟代理、安全代理等功能。
以类的委托与代理来举例,委托对象和被委托对象都实现了同一个接口或继承了同一个类,委托对象将任务委托给被委托对象来完成。代理模式中,代理对象与被代理对象实现了同一个接口或继承了同一个类,代理对象代表被代理对象,客户端通过代理对象来访问被代理对象。
两者的区别:
他们虽然都有同一个接口,主要区别在于委托模式中委托对象和被委托对象是同一类型的对象,而代理模式中代理对象与被代理对象是两种不同的对象。总的来说,委托模式是为了将方法的实现交给其他类去完成,而代理模式则是为了控制对象的访问,并在访问前后进行额外的操作。
而我们常用的委托模式怎么使用?在 Java 语言中需要我们手动的实现,而在 Kotlin 语言中直接通过关键字 by 就可以实现委托,其实现更加优雅、简洁了。
我们在开发一个 Android 应用中,常用到的委托分为:
- 接口/类的委托
- 属性的委托
- 结合lazy的延迟委托
- 观察者的委托
- Map数据的委托
下面我们就一起看看不同种类的委托使用以及在 Android 常见的一些场景中的使用。
一、接口/类委托
我们可以选择使用接口来实现类似的效果,也可以直接传参,当然接口的方式更加的灵活,比如我们这里就以接口比如我定义一个攻击与防御的行为接口:
interface IUserAction {
fun attack()
fun defense()
}定义了用户的行为,有攻击和防御两种操作!接下来我们就定义一个默认的实现类:
class UserActionImpl : IUserAction {
override fun attack() {
YYLogUtils.w("默认操作-开始执行攻击")
}
override fun defense() {
YYLogUtils.w("默认操作-开始执行防御")
}
}都是很简单的代码,我们定义一些默认的操作,如果任意类想拥有攻击和防御的能力就直接实现这个接口,如果想自定义攻击和防御则重写对应的方法即可。
如果使用 Java 的方式实现委托,大致代码如下:
class UserDelegate1(private val action: IUserAction) : IUserAction {
override fun attack() {
YYLogUtils.w("UserDelegate1-需要自己实现攻击")
}
override fun defense() {
YYLogUtils.w("UserDelegate1-需要自己实现防御")
}
}如果使用 Kotlin 的方式实现则是:
class UserDelegate2(private val action: IUserAction) : IUserAction by action
如果 Kotlin 的实现不想默认的实现也可以重写部分的操作:
class UserDelegate3(private val action: IUserAction) : IUserAction by action {
override fun attack() {
YYLogUtils.w("UserDelegate3 - 只重写了攻击")
}
}那么使用起来就是这样的:
val actionImpl = UserActionImpl()
UserDelegate1(actionImpl).run {
attack()
defense()
}
UserDelegate2(actionImpl).run {
attack()
defense()
}
UserDelegate3(actionImpl).run {
attack()
defense()
}打印日志如下:
其实在 Android 源码中也有不少委托的使用,例如生命周期的 Lifecycle 委托:
Lifecycle 通过委托机制实现其功能。具体来说,组件可以将自己的生命周期状态委托给 LifecycleOwner 对象,LifecycleOwner 对象则负责管理这些组件的生命周期。
例如,在一个 Activity 中,我们可以通过将 Activity 对象作为 LifecycleOwner 对象,并将该对象传递给需要注册生命周期的组件,从而实现组件的生命周期管理。 页面可以使用 getLifecycle() 方法来获取它所依赖的 LifecycleOwner 对象的 Lifecycle 实例,并在需要时将自身的生命周期状态委托给该 Lifecycle 实例。
通过这种委托机制,Lifecycle 实现了一种方便的方式来管理组件的生命周期,避免了手动管理生命周期带来的麻烦和错误。
class AnimUtil private constructor() : DefaultLifecycleObserver {
...
private fun addLoopLifecycleObserver() {
mOwner?.lifecycle?.addObserver(this)
}
// 退出页面的时候释放资源
override fun onDestroy(owner: LifecycleOwner) {
mAnim?.cancel()
destory()
}
}
除此之外委托还特别适用于一些可配置的功能,比如 Resutl-Api 的封装,如果当前页面需要开启 startActivityForResult 的功能,就实现这个接口,不需要这个功能就不实现接口,达到可配置的效果。
/**
* 定义是否需要SAFLauncher
*/
interface ISAFLauncher {
fun <T : ActivityResultCaller> T.initLauncher()
fun getLauncher(): GetSAFLauncher?
}由于代码是固定的实现,目标Activity也不需要重新实现,我们只需要实现默认的实现即可:
class SAFLauncher : ISAFLauncher {
private var safLauncher: GetSAFLauncher? = null
override fun <T : ActivityResultCaller> T.initLauncher() {
safLauncher = GetSAFLauncher(this)
}
override fun getLauncher(): GetSAFLauncher? = safLauncher
}使用起来我们直接用默认的实现即可:
class DemoActivity : BaseActivity, ISAFLauncher by SAFLauncher() {
override fun init() {
initLauncher() // 实现了接口还需要初始化Launcher
}
fun gotoOtherPage() {
//使用 Result Launcher 的方式启动,并获取到返回值
getLauncher()?.launch<DemoCircleActivity> { result ->
val result = result.data?.getStringExtra("text")
toast("收到返回的数据:$result")
}
}
}这样是不是就非常简单了呢?具体如何使用封装 Result Launcher 可以看看我去年的文章 【传送门】
二、属性委托
除了类与接口对象的委托,我们还常用于属性的委托。
我知道了!这么弄就行了。
private val textStr by "123"哎?怎么报错了?其实不是这么用的。
属性委托和类委托一样,属性的委托其实是对属性的 set/get 方法的委托。
需要我们把 set/get 方法委托给 setValue/getValue 方法,因此被委托类(真实类)需要提供 setValue/getValue 方法,val属性只需要提供 getValue 方法。
我们修改代码如下:
private val textStr by TextDelegate()
class TextDelegate {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String {
return "我是赋值给与的文本"
}
}打印的结果:
而我们定义一个可读写的属性则可以
private var textStr by TextDelegate()
class TextDelegate {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String {
return "我是赋值给与的文本"
}
operator fun setValue(thisRef: Any?, property: KProperty<*>, value: String) {
YYLogUtils.w("设置的值为:$value")
}
}
YYLogUtils.w("textStr:$textStr")
textStr = "abc123"打印则如下:
为了怕大家写错,我们其实可以用接口来限制,只读的和读写的属性,我们分别可以用 ReadOnlyProperty 与 ReadWriteProperty 来限制:
class TextDelegate : ReadOnlyProperty<Any, String> {
override fun getValue(thisRef: Any, property: KProperty<*>): String {
return "我是赋值给与的文本"
}
}
class TextDelegate : ReadWriteProperty<Any, String> {
override fun getValue(thisRef: Any, property: KProperty<*>): String {
return "我是赋值给与的文本"
}
override fun setValue(thisRef: Any, property: KProperty<*>, value: String) {
YYLogUtils.w("设置的值为:$value")
}
}
那么实现的方式和上面自己实现的效果是一样的。如果要使用属性委托可以选用这种接口限制的方式实现。
我们的属性除了委托给类去实现,同时也能委托给其他属性(Kotlin 1.4+)来实现,例如:
private var textStr by TextDelegate2()
private var textStr2 by this::textStr其实是内部委托了对象的 get 和 set 函数。相对委托对象而言性能更好一些。而委托对象去实现,不仅增加了一个委托类,而且还还在初始化时就创建了委托类的实例对象,算起来其实性能并不好。
所以属性的委托不要滥用,如果要用,可以选择委托现成的其他属性来完成,或者使用延迟委托Lazy实现,或者使用更简单的方式实现:
private val industryName: String
get() {
return "abc123"
}对于只读的属性,这种方式也是我们常见的使用方式。
三、延迟委托
如果说使用类来实现委托不那么好的话,其实我们可以使用延迟委托。延迟关键字 lazy 接收一个 lambda 表达式,最后一行代表返回值给被推脱的属性。
默认的 Lazy 实现:
val name: String by lazy {
YYLogUtils.w("第一次调用初始化")
"abc123"
}
YYLogUtils.w(name)
YYLogUtils.w(name)
YYLogUtils.w(name)只有在第一次使用此属性的时候才会初始化,一旦初始化之后就可以直接获取到值。
日志打印:
它的内部其实也是使用的是类的委托实现。
public actual fun <T> lazy(initializer: () -> T): Lazy<T> = SynchronizedLazyImpl(initializer)
最终的实现是由 SynchronizedLazyImpl 类生成并实现的:
private class SynchronizedLazyImpl<out T>(initializer: () -> T, lock: Any? = null) : Lazy<T>, Serializable {
private var initializer: (() -> T)? = initializer
@Volatile private var _value: Any? = UNINITIALIZED_VALUE
// final field is required to enable safe publication of constructed instance
private val lock = lock ?: this
override val value: T
get() {
val _v1 = _value
if (_v1 !== UNINITIALIZED_VALUE) {
@Suppress("UNCHECKED_CAST")
return _v1 as T
}
return synchronized(lock) {
val _v2 = _value
if (_v2 !== UNINITIALIZED_VALUE) {
@Suppress("UNCHECKED_CAST") (_v2 as T)
} else {
val typedValue = initializer!!()
_value = typedValue
initializer = null
typedValue
}
}
}
override fun isInitialized(): Boolean = _value !== UNINITIALIZED_VALUE
override fun toString(): String = if (isInitialized()) value.toString() else "Lazy value not initialized yet."
private fun writeReplace(): Any = InitializedLazyImpl(value)
}我们可以直接看 value 的 get 方法,如果_v1 !== UNINITIALIZED_VALUE 则表明已经初始化过了,就直接返回 value ,否则表明没有初始化过,调用initializer方法,也就是 lazy 的 lambda 表达式返回属性的赋值。
跟我们自己实现类的委托类似,也是实现了getValue方法。只是多了判断是否初始化的一些相关逻辑。
lazy的参数分为三种类型:
- SYNCHRONIZED:添加同步锁,使lazy延迟初始化线程安全
- PUBLICATION:初始化的lambda表达式,可以在同一时间多次调用,但是只有第一次的返回值作为初始化值
- NONE:没有同步锁,非线程安全
默认情况下,对于 lazy 属性的求值是同步锁的(synchronized),是可以保证线程安全的,但是如果不需要线程安全和减少性能花销可以可以使用 lazy(LazyThreadSafetyMode.NONE){} 即可。
四、观察者委托
除了对属性的值进行委托,我们甚至还能对观察到这个变化过程:
使用 observable 委托监听值的变化:
var values: String by Delegates.observable("默认值") { property, oldValue, newValue ->
YYLogUtils.w("打印值: $oldValue -> $newValue ")
}
values = "第一次修改"
values = "第二次修改"
values = "第三次修改"打印:
我们还能使用 vetoable 委托,和 observable 一样可以观察属性的变化,不同的是 vetoable 可以决定是否使用新值。
var age: Int by Delegates.vetoable(18) { property, oldValue, newValue ->
newValue > oldValue
}
YYLogUtils.w("age:$age")
age = 14
YYLogUtils.w("age:$age")
age = 20
YYLogUtils.w("age:$age")
age = 22
YYLogUtils.w("age:$age")
age = 20
YYLogUtils.w("age:$age")我们需要返回 booble 值觉得是否使用新值,比如上述的例子就是当新值大于老值的时候才赋值。那么打印的日志就是如下:
虽然这种方式我们并不常用,一般我们都是使用类似 Flow 之类的工具在源头就处理了逻辑,使用这种方式我们就可以在属性的赋值过程中进行拦截了。在一些特定的场景下还是有用的。
五、Map委托
我们的属性不止可以使用类的委托,延迟的委托,观察的委托,还能委托Map来进行赋值。
当属性的值与 Map 中 key 相同的时候,我们可以把对应 key 的 value 取出来并赋值给属性:
class Member(private val map: Map<String, Any>) {
val name: String by map
val age: Int by map
val dob: Long by map
override fun toString(): String {
return "Member(name='$name', age=$age, dob=$dob)"
}
}使用:
val member = Member(mapOf("name" to "guanyu", "age" to 36, Pair("dob", 1234567890L)))
YYLogUtils.w("member:$member")打印的日志:
但是需要注意的是,map 中的 key 名字必须要和属性的名字一致才行,否则委托后运行解析时会抛出 NoSuchElementException 异常提示。
例如我们在 Member 对象中加入一个并不存在的 address 属性,再次运行就会报错。
而我们把 Int 的 age 属性赋值给为字符串也会报类型转换异常:
所以一定要一一对应才行哦,我怎么感觉有一点 TypeScript 结构赋值的那味道 - - !
总结
委托虽好不要滥用。委托毕竟还是中间多了一个委托类,如果没必要可以直接赋值实现,而不需要多一个中间类占用内存。
我们可以通过接口委托来实现一些可选的配置。通过委托类实现属性的监听与赋值。可以减少一些模板代码,达到低耦合高内聚的效果,可以提高程序的可维护性、可扩展性和可重用性。
对于属性的类委托,我们可以将属性的读取和写入操作委托给另一个对象,或者另一个属性,或者使用延迟委托来推迟对象的创建直到第一次访问。
对于 map 的委托,我们需要仔细对应属性与 key 的一致性。以免出现错误,这是运行时的错误,有可能出现在生产环境上的。
那么大家都是怎么使用的呢?有没有更好的方式呢?或者你有遇到的坑也都可以在评论区交流一下,大家可以互相学习进步。如有本文有一些错漏的地方,希望同学们可以指出。
如果感觉本文对你有一点点的帮助,还望你能点赞支持一下,你的支持是我最大的动力。
本文的部分代码可以在我的 Kotlin 测试项目中看到,【传送门】。你也可以关注我的这个Kotlin项目,我有时间都会持续更新。
Ok,这一期就此完结。
链接:https://juejin.cn/post/7213267574770090039
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
StartService别乱用,小心IllegalStateException
startService可以很方便的启动一个service服务,也可以运行在单独的进程。
但是如果在后台调用了startService,则很可能会抛出一个崩溃。
Caused by: java.lang.IllegalStateException: Not allowed to start service Intent { cmp=com.test.broadservice/.MyService }: app is in background uid UidRecord{b67c471 u0a86 RCVR idle change:uncached procs:1 seq(0,0,0)}
at android.app.ContextImpl.startServiceCommon(ContextImpl.java:1577)
at android.app.ContextImpl.startService(ContextImpl.java:1532)
at android.content.ContextWrapper.startService(ContextWrapper.java:664)
at android.content.ContextWrapper.startService(ContextWrapper.java:664)
at android.app.ActivityThread$H.handleMessage(ActivityThread.java:1661)
at android.os.Handler.dispatchMessage(Handler.java:106)
at android.os.Looper.loop(Looper.java:193)
at android.app.ActivityThread.main(ActivityThread.java:6669)
at java.lang.reflect.Method.invoke(Native Method)
at com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:493)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:858)
错误原因
Android8.0之后,系统增加了对后台Service的限制,如果应用处于后台,调用startService会抛出IllegalStateException。
意思是,在后台的应用,不允许调用startService启动一个后台服务,否则就会抛出异常。
解决方法
1. 使用startForegroundService
使用方法比较简单,这里就不列出代码了。
有几点需要注意:
- 用此方法启动前台服务,会在用户的通知栏上显示
- 必须在
5s内调用服务的startForeground方法,否则会发生ANR
2. 使用JobScheduler
使用JobScheduler可以实现在后台运行任务。
定义一个JobService:
public class MyJobService extends JobService {
@Override
public boolean onStartJob(JobParameters params) {
return false;
}
@Override
public boolean onStopJob(JobParameters params) {
return false;
}
}onStartJob:
- 运行在主进程,需要避免执行耗时的操作。
- 返回true:表示任务还在继续执行
- 返回false:表示任务已执行完
- 执行完之后,可以调jobFinished方法来通知系统任务已完成。
onStopJob:
- 当条件不满足的时候,会回调这个方法。
- 返回true:表示条件满足时,再次执行任务
- 返回false:表示任务完全结束
注册JobService:
<service
android:name=".MyJobService"
android:permission="android.permission.BIND_JOB_SERVICE" />定义一个JobInfo:
JobInfo.Builder builder = new JobInfo.Builder(111, new ComponentName(this, MyJobService.class));
// todo 设置任务的参数将任务发布给系统:
JobScheduler jobScheduler = (JobScheduler) getSystemService(Context.JOB_SCHEDULER_SERVICE);
jobScheduler.schedule(builder.build());3. 使用WorkManager
WorkManager是JobScheduler的升级版本,且支持多进程,可以将任务运行到单独的进程中。具体使用方法可以参考之前的文章:应用退出后继续运行后台任务,来试试WorkManager吧!
总结
Android 8.0版本以上,在后台调用startService会抛出IllegalStateException异常,需要改用其他的方式来使用。
常用的方法有如下三种:
startForegroundService: 这种方式会在用户的通知栏显示UI。JobScheduler:可以实现后台无感知运行任务。WorkManager:Jetpack里的库,JobScheduler的升级版,支持多进程。
链接:https://juejin.cn/post/7212960463730360375
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从SharedPreferences和MMKV看本地数据迁移
1. 前言
之前也有听说过MMKV,但是一直没时间去看,前段时间去简单看看它的相关内容之后觉得挺有意思的,然后就想要不要用MMKV把SP给替换了,这时就又想到了一些数据迁移的问题,所以这次简单谈谈SharedPreferences和MMKV,主要我还是想谈谈数据迁移这个问题。
2. MMKV
腾讯的MMKV,挺牛逼,为什么牛逼,很有想法,这也从侧面体现出想要做出牛逼的东西,你得敢想,然后你想出一套方案之后,还能去实现它。或许你看它的原理你觉得还行,也没多复杂什么的,但你能从0到1的过程想出这个方案然后去实现它吗?
首先要知道它为什么被设计出来,通过官方的介绍:需要一个性能非常高的通用 key-value 存储组件,我们考察了 SharedPreferences、NSUserDefaults、SQLite 等常见组件,发现都没能满足如此苛刻的性能要求。看得出是为了提升性能
那是不是说我觉得MMKV性能比SP好,所以我就用它?并不是这样的,如果你只是用key-value的组件去存状态等少量数据,而且不会频繁的读写,那SP是完全够用的,并且没必要引入MMKV。但是如果你存储的数据大数据复杂,并且频繁读写,假如你这次数据都没写完,又开始写下一次了,那就会有性能上的问题,这时候用MMKV去代替SP完全是一个很好的方案。
因为我当前的项目没有这样的需求,没达到这样的量级,所以暂不需要用到MMKV,但是我简单看了它的原理,比较核心的我觉得就两个思想:mmap和protobuf,其它的append啊这些都是在这基础上进一步优化的操作,核心的就是mmap和protobuf,特别是mmap。所以为什么说牛逼,因为如果是你做,没有参考的情况下,你能想出用mmap这种方案去优化吗?
什么是mmap,内存映射mmap,如果了解过Binder机制,那应该对它多多少少有些印象,如果不知道内存映射是什么,建议可以先去看看Binder机制,了解下一次拷贝的概念,再回来看mmap就知道是什么操作了,就知道为什么它要使用这种思路去做性能提升。
再看看另一个点protobuf,protobuf是一种数据存储格式,它所占用的空间更小,所以也是一个优化的点,占的空间越小,存储时所需要的空间就越小,传送也越快。
2. SharedPreferences
android经常使用的组件,喜欢用它是因为使用起来方便。可以简单看看它是怎么实现的,然后对比一下上面的MMKV。
一般我们调用都是SharedPreferences.Editor的commit()或者apply,然后点进去看发现Editor是一个接口,SharedPreferences也同样是个接口,点它的类看获取它的地方发现在Context里面
public abstract SharedPreferences getSharedPreferences(File file, @PreferencesMode int mode);看它的子类实现在ContextWrapper里面
@Override
public SharedPreferences getSharedPreferences(File file, int mode) {
return mBase.getSharedPreferences(file, mode);
}mBase就是Context,点之后又跳到Context里面了,完了,芭比Q了,死循环了,找不到SharedPreferences的实现类了。为什么要讲这个,其实如果你看源码比较多,你就会发现有个习惯,一般具体的实现类都是在抽象接口的后面加Impl,所以我们找SharedPreferencesImpl,当然你还有个办法能找到,就是百度。然后看SharedPreferencesImpl的commit方法
@Override
public boolean commit() {
......
MemoryCommitResult mcr = commitToMemory();
SharedPreferencesImpl.this.enqueueDiskWrite(
mcr, null /* sync write on this thread okay */);
try {
mcr.writtenToDiskLatch.await();
} catch (InterruptedException e) {
return false;
} finally {
if (DEBUG) {
Log.d(TAG, mFile.getName() + ":" + mcr.memoryStateGeneration
+ " committed after " + (System.currentTimeMillis() - startTime)
+ " ms");
}
}
notifyListeners(mcr);
return mcr.writeToDiskResult;
}commitToMemory里面只是把数据包装成MemoryCommitResult,然后给enqueueDiskWrite方法
private void enqueueDiskWrite(final MemoryCommitResult mcr,
final Runnable postWriteRunnable) {
......
final Runnable writeToDiskRunnable = new Runnable() {
@Override
public void run() {
synchronized (mWritingToDiskLock) {
writeToFile(mcr, isFromSyncCommit);
}
......
}
};
......
QueuedWork.queue(writeToDiskRunnable, !isFromSyncCommit);
}QueuedWork.queue就是放到队列操作,这个就不说的,来看writeToFile(挺长的,我这截取中间一部分)
try {
FileOutputStream str = createFileOutputStream(mFile);
if (DEBUG) {
outputStreamCreateTime = System.currentTimeMillis();
}
if (str == null) {
mcr.setDiskWriteResult(false, false);
return;
}
XmlUtils.writeMapXml(mcr.mapToWriteToDisk, str);
writeTime = System.currentTimeMillis();
FileUtils.sync(str);
fsyncTime = System.currentTimeMillis();
str.close();
ContextImpl.setFilePermissionsFromMode(mFile.getPath(), mMode, 0);
if (DEBUG) {
setPermTime = System.currentTimeMillis();
}
try {
final StructStat stat = Os.stat(mFile.getPath());
synchronized (mLock) {
mStatTimestamp = stat.st_mtim;
mStatSize = stat.st_size;
}
} catch (ErrnoException e) {
// Do nothing
}
if (DEBUG) {
fstatTime = System.currentTimeMillis();
}
// Writing was successful, delete the backup file if there is one.
mBackupFile.delete();
if (DEBUG) {
deleteTime = System.currentTimeMillis();
}
mDiskStateGeneration = mcr.memoryStateGeneration;
mcr.setDiskWriteResult(true, true);
if (DEBUG) {
Log.d(TAG, "write: " + (existsTime - startTime) + "/"
+ (backupExistsTime - startTime) + "/"
+ (outputStreamCreateTime - startTime) + "/"
+ (writeTime - startTime) + "/"
+ (fsyncTime - startTime) + "/"
+ (setPermTime - startTime) + "/"
+ (fstatTime - startTime) + "/"
+ (deleteTime - startTime));
}
long fsyncDuration = fsyncTime - writeTime;
mSyncTimes.add((int) fsyncDuration);
mNumSync++;
if (DEBUG || mNumSync % 1024 == 0 || fsyncDuration > MAX_FSYNC_DURATION_MILLIS) {
mSyncTimes.log(TAG, "Time required to fsync " + mFile + ": ");
}
return;
} catch (XmlPullParserException e) {
Log.w(TAG, "writeToFile: Got exception:", e);
} catch (IOException e) {
Log.w(TAG, "writeToFile: Got exception:", e);
}其实能很明显第一眼就看出,是直接用FileOutputStream写到文件中,然后XmlUtils就是把这个文件写成xml的形式。其实SharedPreferences是用xml的格式存储数据相信大家都懂,我这里只是通过代码简单过一遍这个流程。
能看出SharedPreferences和MMKV的不同之处,SP是用FileOutputStream把数据写进本的,而MMKV是用了内存映射,MMKV明显会更快,存储数据的格式方面,SP是用了xml的格式,而MMKV用的是protobuf,明显也是MMKV会更小。
虽然SharedPreferences调用起来方便,但同样的也了一些缺点,比较多进程环境下,比如在某些快速读写的环境中使用apply等。那是不是说我就必须使用MMKV去代替SharedPreferences?其实并不是,你的功能没涉及多进程环境,没涉及频繁大量的读写数据,比如存就只存一个状态,或者说我隔一段时间才读写一次数据量不大的数据,那直接使用SharedPreferences也不会有什么问题。没必要大动干戈,杀鸡还要用牛刀?
3. 数据迁移
这才是我想讲的重点,什么是数据迁移,和SharedPreferences还有MMKV又有什么关系,数据迁移是一个解决问题的思路,和SP还有MMKV是没有关系,只不过我用它们两个来举例会比较好说明。
虽然MMKV好用是吧,假如说你有什么场景,用SP确实无法支持你的业务了,改用MMKV,但是你的旧版本中还是用的SP去存数据,直接覆盖升级可是不会删除磁盘数据的,那你得把SP之前存的xml格式的数据迁移到MMKV中,这就是一个本地数据迁移的过程。
如果从SP迁移到MMKV中,那应该挺简单,我相信MMKV中有对应的方法提供给你,我想腾讯开发的,肯定会考虑到这一点,如果没有,你自己写这个迁移的逻辑也不难。而且SP是android原生提供的组件,所以不会涉及到删除组件之类的操作。但是假如,我说假如,字节也出个key-value的组件,比如叫ByteKV,假如他不是用protobuf,是另一种能把数据压缩更小的格式。这时候你用MMKV,你想去替换成ByteKV,你要怎么做。
有的人就说了,那如果有这种情况,它们也会考虑兼容其它的组件,如果没有,那就在手动写迁移的逻辑,这个又不复杂。手写迁移的逻辑是不复杂,但有没有想过一个问题,你需要去删除之前的库,比如说你之前依赖MMKV,你现在换这个ByteKV之后,你需要不再依赖MMKV ,不然你就会每次换一个新的库,你都重新依赖,并且不删除旧的依赖。
比如你的1.0版本依赖MMKV,2.0版本改用ByteKV,在依赖ByteKV的同时,你还要依赖MMKV吗?SP是没有这个问题,因为它是原生的代码。
我帮你们想了一个办法,假如1.0版本依赖MMKV,我2.0版本当一个过渡版本依赖ByteKV和MMKV,我3.0再把MMKV的依赖去掉行不行?当然不行,那有些用户直接从1.0升到3.0不就导致没迁移的数据没了吗
那这要怎么处理,其实说来也简单,MMKV把数据存到本地的哪个文件这个你知道吧,它用protobuf的方式去存你也知道吧,那这事不就完了,你知道文件存哪里并以什么方式存,那你就能把内容读取出来,这和存的过程已经没有任何关系了。 所以你读这个文件的内容,根本就不需要MMKV,你只需要判断在这个文件夹下有这个文件,并且这个文件是某个格式的,就手动做迁移,迁移完之后再把文件删了。如果你不知道你所用的框架会把数据存到哪里,又是以什么格式存的,那也简单,去看它的源码就知道了。
这里是拿了MMKV来举例,数据库也一样,你改不同的数据库框架,无所谓,你知道它存在哪里,怎么存的,那你不用对应的库也能把数据提出来。
这其实就是数据迁移的原理,我管你是用什么库存的,你的库做的只不过是对存的过程的优化和决定数据的格式。
还有一个要注意的点是,数据不是一次性迁移完的,是部分部分迁移的,你先迁移一部分,然后删除旧文件的那部分数据。
总结
这篇文章其实主要是想简单介绍SP和MMKV的不同,了解MMKV是为何被设计出来,并且站在开发者的一个角度去思考,如果是你,你要怎样才能像他们一样,设计出这样的一套思路。
其次就是关于本地数据迁移的问题,如果去透过现象看本质,我们平时会用到很多别人写的库,为什么用,因为别人写得好,我自己从0开始设计没办法像他们一样设计得这么好,所以使用他们得。但我同样需要知道这其中的原理,知道他们是怎样去实现的。
链接:https://juejin.cn/post/7208844516950065210
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一看就会,对startActivityForResult的几种实现方案的调用与封装
前言
startActivityForResult 可以说是我们常用的一种操作了,用于启动新页面并拿到这个页面返回的数据,是两个 Activity 交互的基本操作。
虽然可以通过接口,消息总线,单例池,ViewModel 等多种方法来间接的实现这样一个功能,但是 startActivityForResult 还是使用最方便的。
目前有哪些方式实现 startActivityForResult 的功能呢?
有新老两种方式,过时的方法是原生Activity/Fragment的 startActivityForResult 方法。另一种方法是 Activity Result API 通过 registerForActivityResult 来注册回调。
我们一起看看都是如何使用,使用起来方便吗?通常我们又都是如何封装的呢?
一、原生的使用
不管是Activity还是Fragment,我们都可以使用 startActivityForResult
override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {
super.onActivityResult(requestCode, resultCode, data)
if (requestCode == 120 && resultCode == -1) {
toast("接收到返回的数据:" + data?.getStringExtra("text"))
}
}可以看到虽然标记过时了,但是 startActivityForResult 这种方法是可以用的,我们一直这么用的,老项目中有很多页面都是这么定义的。也并没有什么问题。
不过既然谷歌推荐我们使用 Result Api 我们在以后使用 startActivityForResult 的时候还是推荐使用新的方式。
二、对原生的封装Ghost
在之前我们使用 startActivityForResult 这种方式的时候,为了更加方便的私有,有一种很流行的方式 Ghost 。
它使用一种 GhostFragment 的空视图当做一次中转,这种思路在现在看来已经不稀奇了,很多框架如Glide,权限申请等都是用的这种方案。
它的大致实现流程为:
Activty/Fragment -> add GhostFragment -> onAttach 中 startActivityForResult -> GhostFragment onActivityResult接收结果 -> callback回调给Activty/Fragment
总体需要两个类就可以完成这个逻辑,一个是中转Fragment,一个是管理类:
/**
* 封装Activity Result的API
* 使用空Fragemnt的形式调用startActivityForResult并返回回调
*
* Activty/Fragment——>add GhostFragment——>onAttach中startActivityForResult
* ——>GhostFragment onActivityResult接收结果——>callback回调给Activty/Fragment
*/
class GhostFragment : Fragment() {
private var requestCode = -1
private var intent: Intent? = null
private var callback: ((result: Intent?) -> Unit)? = null
fun init(requestCode: Int, intent: Intent, callback: ((result: Intent?) -> Unit)) {
this.requestCode = requestCode
this.intent = intent
this.callback = callback
}
private var activityStarted = false
override fun onAttach(activity: Activity) {
super.onAttach(activity)
if (!activityStarted) {
activityStarted = true
intent?.let { startActivityForResult(it, requestCode) }
}
}
override fun onAttach(context: Context) {
super.onAttach(context)
if (!activityStarted) {
activityStarted = true
intent?.let { startActivityForResult(it, requestCode) }
}
}
override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {
super.onActivityResult(requestCode, resultCode, data)
if (resultCode == Activity.RESULT_OK && requestCode == this.requestCode) {
callback?.let { it1 -> it1(data) }
}
}
override fun onDetach() {
super.onDetach()
intent = null
callback = null
}
}/**
* 管理GhostFragment用于StartActivityForResult
* 启动的时候添加Fragment 返回的时移除Fragment
*/
object Ghost {
var requestCode = 0
set(value) {
field = if (value >= Integer.MAX_VALUE) 1 else value
}
inline fun launchActivityForResult(
starter: FragmentActivity?,
intent: Intent,
crossinline callback: ((result: Intent?) -> Unit)
) {
starter ?: return
val fm = starter.supportFragmentManager
val fragment = GhostFragment()
fragment.init(++requestCode, intent) { result ->
callback(result)
fm.beginTransaction().remove(fragment).commitAllowingStateLoss()
}
fm.beginTransaction().add(fragment, GhostFragment::class.java.simpleName)
.commitAllowingStateLoss()
}
}如此我们就可以使用Kotlin的扩展方法来对它进行进一步的封装
//真正执行AcytivityForResult的方法,使用Ghost的方式执行
inline fun <reified T> FragmentActivity.gotoActivityForResult(
flag: Int = -1,
bundle: Array<out Pair<String, Any?>>? = null,
crossinline callback: ((result: Intent?) -> Unit)
) {
val intent = Intent(this, T::class.java).apply {
if (flag != -1) {
this.addFlags(flag)
}
if (bundle != null) {
//调用自己的扩展方法-数组转Bundle
putExtras(bundle.toBundle()!!)
}
}
Ghost.launchActivityForResult(this, intent, callback)
}使用起来就超级简单了:
gotoActivityForResult<Demo10Activity> {
val text = it?.getStringExtra("text")
toast("拿到返回数据:$text")
}
gotoActivityForResult<Demo10Activity>(bundle = arrayOf("id" to "123", "name" to "zhangsan")) {
val text = it?.getStringExtra("text")
toast("拿到返回数据:$text")
}三、Result Api 的使用
其实看Ghost的原来就看得出,他本质上还是对 startActivityForResult 的调用与封装,还是过期的方法,那么如何使用新的方式,谷歌推荐我们怎么用?
Activity Result API :
它是 Jetpack 的一个组件,这是官方用于替代 startActivityForResult() 和 onActivityResult() 的工具,我们以Activity 1.2.4版本为例:
implementation "androidx.activity:activity-ktx:1.2.4"
那么如何基础的使用它呢:
private val safLauncher = registerForActivityResult(ActivityResultContracts.StartActivityForResult()) { result ->
if (result.resultCode == RESULT_OK) {
val data = result.data?.getStringExtra("text")
toast("拿到返回数据:$data")
}
}
//在方法中使用
safLauncher?.launch(Intent(mActivity, Demo10Activity::class.java))
看起来实现很简单,但是有几点要注意,Launcher 的创建需要在onStart生命周期之前,并且回调是在 Launcher 中处理的。并且 这些 Launcher 并不是只能返回Activity的Result的,还有其他的启动方式:
StartActivityForResult()
StartIntentSenderForResult()
RequestMultiplePermissions()
RequestPermission()
TakePicturePreview()
TakePicture()
TakeVideo()
PickContact()
GetContent()
GetMultipleContents()
OpenDocument()
OpenMultipleDocuments()
OpenDocumentTree()
CreateDocument()可以看到这些方式其实对我们来说很多没必要,在真正的开发中只有 StartActivityForResult 这一种方式是我们的刚需。
为什么?毕竟现在谁还用这种方式申请权限,操作多媒体文件。相信大家也都是使用框架来处理了,所以我们这里只对 StartActivityForResult 这一种方式做处理。毕竟这才是我们使用场景最多的,也是我们比较需要的。
经过分析,对Result Api的封装,我们就剩下的两个重点问题:
- 我们把 Launcher 的回调能在启动的方法中触发。
- 实现 Launcher 在 Activity/Fragment 中的自动注册。
下面我们就来实现吧。
四、Result Api 的封装
我们需要做的是:
第一步我们把回调封装到launch方法中,并简化创建的对象方式
第二步我们尝试自动注册的功能
4.1 封装简化创建方式
首先第一步,我们对 Launcher 对象做一个封装, 把 ActivityResultCallback 回调方法在 launch 方法中调用。
/**
* 对Result-Api的封装,支持各种输入与输出,使用泛型定义
*/
@SuppressWarnings("unused")
public class BaseResultLauncher<I, O> {
private final androidx.activity.result.ActivityResultLauncher<I> launcher;
private final ActivityResultCaller caller;
private ActivityResultCallback<O> callback;
private MutableLiveData<O> unprocessedResult;
public BaseResultLauncher(@NonNull ActivityResultCaller caller, @NonNull ActivityResultContract<I, O> contract) {
this.caller = caller;
launcher = caller.registerForActivityResult(contract, (result) -> {
if (callback != null) {
callback.onActivityResult(result);
callback = null;
}
});
}
public void launch(@SuppressLint("UnknownNullness") I input, @NonNull ActivityResultCallback<O> callback) {
launch(input, null, callback);
}
public void launch(@SuppressLint("UnknownNullness") I input, @Nullable ActivityOptionsCompat options, @NonNull ActivityResultCallback<O> callback) {
this.callback = callback;
launcher.launch(input, options);
}
}上门是对Result的基本封装,由于我们只想要 StartActivityForResult 这一种方式,所以我们定义一个特定的 GetSAFLauncher
/**
* 一般我们用这一个-StartActivityForResult 的 Launcher
*/
class GetSAFLauncher(caller: ActivityResultCaller) :
BaseResultLauncher<Intent, ActivityResult>(caller, ActivityResultContracts.StartActivityForResult()) {
//封装另一种Intent的启动方式
inline fun <reified T> launch(
bundle: Array<out Pair<String, Any?>>? = null,
@NonNull callback: ActivityResultCallback<ActivityResult>
) {
val intent = Intent(commContext(), T::class.java).apply {
if (bundle != null) {
//调用自己的扩展方法-数组转Bundle
putExtras(bundle.toBundle()!!)
}
}
launch(intent, null, callback)
}
}注意这里调用的是 ActivityResultContracts.StartActivityForResult() 并且泛型的两个参数是 Intent 和 ActivityResult。
如果大家想获取文件,可以使用 GetContent() 泛型的参数就要变成 String 和 Uri 。由于我们通常不使用这种方式,所以这里不做演示。
封装第一步之后我们就能这么使用了。
var safLauncher: GetSAFLauncher? = null
//其实就是 onCreate 方法
override fun init() {
safLauncher = GetSAFLauncher(this@Demo16RecordActivity)
}
//AFR
fun resultTest() {
safLauncher?.launch(Intent(mActivity, Demo10Activity::class.java)) { result ->
val data = result.data?.getStringExtra("text")
toast("拿到返回数据:$data")
}
}//或者使用我们自定义的简洁方式
fun resultTest() {
safLauncher?.launch<Demo10Activity> { result ->
val data = result.data?.getStringExtra("text")
toast("拿到返回数据:$data")
}
safLauncher?.launch<Demo10Activity>(arrayOf("id" to "123", "name" to "zhangsan")) { result ->
val data = result.data?.getStringExtra("text")
toast("拿到返回数据:$data")
}
}使用下来是不是简单了很多了,我们只需要创建一个对象就可以了,拿到这个对象调用launch即可实现 startActivityForResult 的功能呢!
4.2 自动注册/按需注册
可以看到相比原始的用法,虽然我们现在的用法就简单了很多,但是我们还是要在oncreate生命周期中创建 Launcher 对象,不然会报错:
LifecycleOwners must call register before they are STARTED.
那我们有哪些方法处理这个问题?
1)基类定义
我们都已经封装成对象使用了,我们把创建的逻辑定义到BaseActivity/BaseFragment不就行了吗?
abstract class AbsActivity() : AppCompatActivity(){
protected var safLauncher: GetSAFLauncher? = null
...
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView()
//Result-Api
safLauncher = GetSAFLauncher(this)
...
}
}这样不就行了吗?可以正常使用的。那有人可能说,你这个对象可能用不到,又不是每一个Activity都会用到 Launcher 对象,你这么无脑创建出来消耗内存。
有办法,按需加载!
2).懒加载
懒加载可以吧,我需要的时候就创建。
abstract class AbsActivity() : AppCompatActivity(){
val safLauncher by lazy { GetSAFLauncher(this) }
...
}额,等等,这样的懒加载貌似是不行的,这在用的时候才初始化,一样会报错:
LifecycleOwners must call register before they are STARTED.
我们只能在页面创建的时候就要明确,这个页面是否需要这个 Launcher 对象,如果要就要在onCreate中创建对象,如果确定不要 Launcher 对象,那么就不必创建对象。
那我们就这么做:
abstract class AbsActivity() : AppCompatActivity(){
protected var safLauncher: GetSAFLauncher? = null
...
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView()
if (needLauncher()) {
//Result-Api
safLauncher = GetSAFLauncher(this)
}
...
}
open protected fun needLauncher(): Boolean = false
}我们使用一个flag判断不就行了吗?这个页面如果需要 Launcher 对象,重写方法返回true就行了。默认是不创建这个对象的。
3).Kotlin委托
我们可以使用Kotlin的委托方式,把初始化的代码和 Launcher 的对象获取用接口封装,然后提供对应的实现类,不就可以完成按需添加 Launcher 的效果了吗?
我们定义一个接口,由于逻辑都封装在了别处,这里就尽量不改动之前的代码,只是定义初始化和提供对象两种方法。
/**
* 定义是否需要SAFLauncher
*/
interface ISAFLauncher {
fun <T : ActivityResultCaller> T.initLauncher()
fun getLauncher(): GetSAFLauncher?
}接着定义这个实现类
class SAFLauncher : ISAFLauncher {
private var safLauncher: GetSAFLauncher? = null
override fun <T : ActivityResultCaller> T.initLauncher() {
safLauncher = GetSAFLauncher(this)
}
override fun getLauncher(): GetSAFLauncher? = safLauncher
}然后我们就可以使用了:
class Demo16RecordActivity : BaseActivity, ISAFLauncher by SAFLauncher() {
//onCreate中直接初始化对象
override fun init() {
initLauncher()
}
//获取到对象直接用即可,还是之前的几个方法,没有变。
fun resultTest() {
getLauncher()?.launch<Demo10Activity> { result ->
val data = result.data?.getStringExtra("text")
toast("拿到返回数据:$data")
}
}
}
效果都是一样的:
这样通过委托的方式,我们就能自己管理初始化,自己随时获取到对象调用launch方法。
如果你当前的Activity不需要 startActivityForResult 这种功能,那么你不实现这个接口即可,如果想要 startActivityForResult 的功能,就实现接口委托实现,从而实现按需加载的逻辑。
我们再回顾一下 Result Api 需要封装的两个痛点与优化步骤:
- 第一步我们把回调封装到launch方法中,并简化创建的对象方式
- 第二步我们尝试自动注册的功能
同时我们还对一些步骤做了更多的可能性分析,对主动注册的方式我们有三种方式,(当然其实还有更多别的方式来实现,我只写了我认为比较简单方便的几种方式)。
到此对 Result Api的封装就此结束。
总结
总的来说 Result Api 的封装其实也不难,使用起来也是很简单了。如果大家是Kotlin项目我推荐使用委托的方式,如果是Java语言开发的也可以用flag的方式实现按需加载的逻辑。
而不想使用 Result Api 那么使用原始的 startActivityForResult 也能实现,那么我推荐你使用 Ghost 框架,可以更加方便快速的实现返回的功能。
本文对于 Result Api 的封装也只是限于 startActivityForResult 这一个场景,不过我们这种方式是很方便扩展的,如果大家想使用Result Api的方式来操作权限,文件等,都可以在 BaseResultLauncher 基础上进行扩展。
本文全部代码均以开源,源码在此。大家可以点个Star关注一波。
好了,本期内容如有错漏的地方,希望同学们可以指出交流。
如果感觉本文对你有一点点点的启发,还望你能点赞支持一下,你的支持是我最大的动力。
Ok,这一期就此完结。
链接:https://juejin.cn/post/7136359176564899877
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android悬浮窗自己踩的2个小坑
最近在做一个全局悬浮窗基于ChatGPT应用快Ai,需要悬浮于在其他应用上面,方便从悬浮窗中,和ChatGPT对话后,对ChatGPT返回的内容拖拽到其他应用内部。快Ai应用本身透明,通过WindowManger添加悬浮窗。类似现在很多应用跳转到其他应用,会悬浮一个小按钮,方便用户点击调回自身一样。只不过快Ai窗口比较大,但不全屏。
碰到以下几个问题:
1、悬浮窗中EditText无法获得弹出键盘
主要是没有明白下面两个属性的作用,在网上搜索之后直接设置了。
WindowManager.LayoutParams.FLAG_NOT_FOCUSABLE
设置FLAG_NOT_FOCUSABLE,悬浮窗外的点击才有效,会把事件分发给悬浮窗底层的其他应用Activity。但设置了FLAG_NOT_FOCUSABLE,屏幕上除悬浮窗之外的地方也可以点击、但是悬浮窗上的EditText会掉不起键盘。
此时悬浮窗外的事件是不会触发悬浮窗内View的onToucheEvent函数,可以通过添加WindowManager.LayoutParams.FLAG_WATCH_OUTSIDE_TOUCH标志位,但无法拦截事件。
WindowManager.LayoutParams.FLAG_NOT_TOUCH_MODAL
屏幕上除了悬浮窗外能够点击、弹窗上的EditText也可以输入、键盘能够弹出来。
所以根据业务需要,我只需要添加WindowManager.LayoutParams.FLAG_NOT_TOUCH_MODAL标志位即可。
2、悬浮窗无法录音
通过Activity调起Service,然后在Service通过WindowManager添加悬浮窗。在没有进行任何操作,正常情况下,可以调起科大讯飞进行录音转成文字发给ChatGPT。
问题点一:同事为了解决我还没来得及修复的windowManger.removeView改成exitProcess问题,强行进行各种修改,最终还调用了activity的finish函数,把activity干掉。最终导致无法调起科大讯飞的语音识别。总是报录音权限问题,找不到任何的问题点,网上资料都说没有给录音权限,其实是有的。最后通过代码回退,定位到是Activity被干掉了,同事也承认他的愚蠢行为。
问题点二:在进行一些操作,例如授权跳转到设置之后,退出设置回到原先界面,科大讯飞调不起录音,还是报权限问题。在有了问题点一的经验后,在Activity的各个生命周期打印日志,发现但onResume函数没有被回调到,也就是应用在后台运行时,该问题必现。
所以就一顿顿顿搜索后,找到官方文档:
Android 9 对后台运行的应用增加了权限限制。
解决方法:
- 声明为系统应用,没问题。但我们想做通用软件。
- 增加前台服务。实测没效果。
- 在2的基础上,再添加一个属性:
android:foregroundServiceType="microphone"。完美。
<service android:name=".ui.service.AiService"
android:foregroundServiceType="microphone"
/>希望本文对君有用!
链接:https://juejin.cn/post/7211116982513811516
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何写一个炫酷的大屏仿真页
前言
之前我写过一遍文章《从阅读页仿真页看贝塞尔曲线》,简要的和大家介绍了仿真页的具体实现思路,正好写完文章的时候,看到 OPPO 发布会里面提到了仿真页,像这样:
看着确实有点炫酷,我平时也接触了很多跟阅读器相关的代码,就零零碎碎花了一些时间撸了一个双页仿真。
看效果:
由于使用录屏,所以看着有点卡顿,实际效果非常流畅!
一、基础知识具备
仿生页里面用到很多自定义 View 的知识,比如:
- 贝塞尔曲线
- 熟悉 Canvas、Paint 和 Path 等常用的Api
- Matrix
具备这些知识以后,我们就可以看懂绝大部分的代码了。这一篇同样并不想和大家过多的介绍代码,具体的可以看一下代码。
二、双仿真和单仿真有什么不同
我写双仿真的时候,感觉和单仿真有两点不同:
- 绘制的页数
- 背部的贴图处理
首先,单仿真只要准备两页的数据:
背部的内容也是第一页的内容,需要对第一页内容进行翻转再平移。
而双仿真需要准备六页的内容,拿左边来说:
我们需要准备上层图片(柯基)、背部图片(阿拉斯加)和底部图片(吉娃娃,看不清),因为我们不知道用户会翻页哪侧,所以两侧一共需要准备六页的数据。
由于翻转机制的不一样,双仿真对于背部的内容只需要平移就行,但是需要新的一页内容,这里相对来说比单仿真简单。
三、我做了哪些优化
主要对翻页的思路进行了优化,
正常的思路是这样的,手指落下的点即页脚:
这样写起来更加简单,但是对于用户来说,可操作的区域比较小,相对来说有点难用。
另外一种思路就是,手指落下的点即到底部同等距离的边:
即手指落位的位置到当前页页脚距离 = 翻动的位置到当前页脚的距离
使用这种方式的好处就是用户可以操作的区域更大,翻书的感觉跟翻实体书的感觉更类似,也更加跟手。
总结
这篇文章就讲到这了,这个 Demo 其实是一个半成品,还有一些手势没处理,阴影的展示还有一些问题。
写仿真比较难的地方在于将一些场景转化成代码,有些地方确实很难去想。
talk is cheap, show me code:
如果觉得本文不错,点赞是对本文最好的肯定,如果你还有任何问题,欢迎评论区讨论!
链接:https://juejin.cn/post/7209625823581978680
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
理解TextView三部曲之番外篇:或许这会是最终的进化
额,为什么会有番外篇呢。。因为新版本上线后,别的同学用我的这个控件,描边显示出问题了-_-!
什么问题呢?
我把问题抽出来,同时把问题放大点,给大家看看(抹眼泪.png)
好嘛,问题不大。。就是描边歪了一点点,对吧。
可是怎么会这样!?,我自己测根本就没有问题,压根就没出现过这样的问题啊。。(抹眼泪.png)
我又去检查了一遍计算描边位置那块的代码,最初是以为其他同学一不小心该了那块的代码,导致描边位置计算出错了,结果发现,代码丝毫没有动过的痕迹。
那怎么会描边出错呢?而且他描边出问题的地方,在我这里这里显示也没什么问题,在他那里会什么会有这么大的偏差呢?
我不信邪,看看那位同学都对StrokeTextView做了哪些设置?结果发现,他多了下面这行代码:
mStrokeTextView.setTypeface(typeface);
我捉摸了一下,发现这行代码很有问题,因为我的StrokeTextView是继承自TextView的,调用setTypeface(),看看它的默认实现:
public void setTypeface(@Nullable Typeface tf) {
if (mTextPaint.getTypeface() != tf) {
mTextPaint.setTypeface(tf);
if (mLayout != null) {
nullLayouts();
requestLayout();
invalidate();
}
}
}看了一眼我就明白了,它只是给TextPaint设置了不同的typeFace,而我们的描边是使用不同的TextPaint,也就是说setTypeface()只是给我们的文本设置了字体,却没有给我们的StrokeTextPaint设置相同的字体,导致了两种不同字体之间,没有办法对齐位置,导致了描边差异。
怎么解决?简单,照葫芦画瓢就行,我们在StrokeTextView重写setTypeface()方法。
setTypeface()的默认实现有两种,我们都要重写:
@Override
public void setTypeface(@androidx.annotation.Nullable Typeface tf) {
// 模仿TextView的设置
// 需在super.setTypeface()调用之前,不然没有效果
if (mStrokePaint != null && mStrokePaint.getTypeface() != tf) {
mStrokePaint.setTypeface(tf);
}
super.setTypeface(tf);
}
另一种比较复杂,不过我们会模仿就行了:
public void setTypeface(@Nullable Typeface tf, int style) {
if (style > 0) {
if (tf == null) {
tf = Typeface.defaultFromStyle(style);
} else {
tf = Typeface.create(tf, style);
}
setTypeface(tf);
// now compute what (if any) algorithmic styling is needed
int typefaceStyle = tf != null ? tf.getStyle() : 0;
int need = style & ~typefaceStyle;
getPaint().setFakeBoldText((need & Typeface.BOLD) != 0);
getPaint().setTextSkewX((need & Typeface.ITALIC) != 0 ? -0.25f : 0);
// 同步设置mStrokeTextPaint
if (mStrokePaint != null) {
mStrokePaint.setFakeBoldText((need & Typeface.BOLD) != 0);
mStrokePaint.setTextSkewX((need & Typeface.ITALIC) != 0 ? -0.25f : 0);
}
} else {
getPaint().setFakeBoldText(false);
getPaint().setTextSkewX(0);
// 同步设置mStrokeTextPaint
if (mStrokePaint != null) {
mStrokePaint.setFakeBoldText(false);
mStrokePaint.setTextSkewX(0);
}
setTypeface(tf);
}
}两步解决,但为什么我这显示没问题,别的同学那里显示就出问题了呢?
我突然想起来,相同字体在不同手机上显示是有差异的,而且有些手机不一定都支持那种字体。
我和那位同学用着不同厂商的真机进行测试,而我的真机是不支持他设置的字体的,所以看着没问题,但他的小米是支持的。难怪我这看着没问题,他那看着就很离谱。
修改完后,我们在运行一遍。
怎一个完美形容!ok,bug解决了,准备提交代码
就这样结束了吗?
时隔多日,我又重新审核了一遍代码,我留意到这样一行代码
float heightWeNeed
= getCompoundPaddingTop() + getCompoundPaddingBottom() + mStrokeWidth + mTextRect.height() + DensityUtil.dp2px(getContext(), 4);
我们需要的高度 = 内边距 + 描边高度 + 文本高度 + 一个额外设定的值 ?
怎么会需要一个额外的值呢?要实现wrap_content的效果,我们的宽度不是只需要加上边距、文本高度和一个描边的高度吗?
好奇怪的逻辑,这不是多余嘛,我当时怎么想的来着哈哈?不符合我wrap_content的预期,把它删了试试,再测一遍
把我之前的测试用例都测了一遍,都运行正常
除了。。除了下面这种情况。
果然,去掉额外的高度,就会有这种高度不够显示的情况。看来当时的我,就是遇到了这种情况,然后一个手快,就给heightWeNeed做了这种适配。
不过这种手快的适配方法貌似不太优雅,为了适配单一的这种情况,要牺牲剩下的所有情况都增加一个额外的高度。
而且因为我们适配的额外高度是一个固定值,如果我们给文本字体大小设置大一点,还是会有高度不够显示的可能,毕竟文本变大了,所需要的高度也就更多了。
好吧,这种适配方法看来是用不得了,要换一个吗?但是计算高度的公式 = 内边距 + 文本高度 + 描边高度,这个公式肯定是没错的。
回到我们最初的问题,我们为什么会需要增加一个额外的固定高度呢?明明公式都是对的,为什么还是会有偏差,难道是公式里的对应的值计算错误了?
我们看看再来看看这个式子:
heightWeNeed = getCompoundPaddingTop() + getCompoundPaddingBottom() +
mStrokeWidth + mTextRect.height();
其中,getCompoundPaddingTop() 和 getCompoundPaddingBottom() 是Android提供的计算内边距的api,这个肯定不至于错吧。
mStrokeWidth是我们的描边宽度,是由用户使用时自定义的,这个没什么需要计算的,就是一个值而已
那么mTextRect.height() 这个呢,我们需要这里返回一个正确的文本高度。
看看这个mTextRect是在哪里赋值的
getPaint().getTextBounds(text, 0, text.length(), mTextRect);
从getTextBounds()里跟下去,发现最后调用测量的是native方法,看不到内部实现,不过我们可以看看getTextBounds()的注释
/**
* Retrieve the text boundary box and store to bounds.
*
* Return in bounds (allocated by the caller) the smallest rectangle that
* encloses all of the characters, with an implied origin at (0,0).
*
* @param text string to measure and return its bounds
* @param start index of the first char in the string to measure
* @param end 1 past the last char in the string to measure
* @param bounds returns the unioned bounds of all the text. Must be allocated by the caller
*/
public void getTextBounds(String text, int start, int end, Rect bounds) {
...
// native 方法
nGetStringBounds(mNativePaint, text, start, end, mBidiFlags, bounds);
}Return in bounds the smallest rectangle that encloses all of the characters
在bounds中返回包含所有字符的最小矩形
也就是说bounds返回的高度,只是能够包含文本的最小高度。
我们在三部曲概览里就讨论过,安卓里文本的描绘,是由几根线来确定的
文本的高度应该为(fontMetrics.bottom -fontMetrics. top),但是,bounds中返回的height也够文本显示啊?怎么会显示成下面这个样子?
比如这样
但实际情况好像是这样的
我想到,安卓绘制文本是有起点坐标的,这个起点由gravity,textAlign,和baseline确定,和内容展示高度好像没有关系。
虽然我们展示高度设小了,但它的起点坐标还在原来的位置(比如y坐标baseline),这才导致了18数字显示不完整,底部好像缺了一块。
问题的根本找到了,看来好像有两种解决方法
- 调整baseline的位置:把我们的baseline位置上移一些,让它和展示区域底部位置重合,这样就能以最小区域显示完整的文本内容。
- 拓宽bounds.height的高度,以(fontMetrics.bottom - fontMetrics.top)作为文本的高度显示,这样就无需改变baseline的位置,但比第一种方案要多需要一些空间。
这里我选了第二种,顺着系统的绘制规则来,图个方便,而且我们的描边也可以利用文本顶部多出来的这些空间。
我们新设个变量 textHeight = fontMetrics.descent - fontMetrics.top
heightWeNeed = getCompoundPaddingTop() + getCompoundPaddingBottom() +
textHeight + mStrokeWidth / 2;
为了最大化利用空间,文字顶部到top线的距离已经足够我们的描边显示了,而bottom线到descent线之间的距离很窄,就可能不够我们的描边显示。
所以只需要在文字底部加一半的描边宽度,同时去掉buttom线和descent线之间的距离,这样就能确保文字和描边都有足够的位置显示了。
好了,番外篇终于结束了,看了眼字数,居然比之前的三部曲系列都要多一些。实在没想到需要这么长的篇幅来讲这两个小优化,谢谢小伙伴们能够看到这里啦。
源码我都已经上传到github了,欢迎小伙伴自取,如果觉得写得不错的,还请给这份工程给个star ~_ <
兄dei,如果觉得我写的还不错,麻烦帮个忙呗 :-)
- 给俺点个赞被,激励激励我,同时也能让这篇文章让更多人看见,(#^.^#)
- 不用点收藏,诶别点啊,你怎么点了?这多不好意思!
- 噢!还有,我维护了一个路由库。。没别的意思,就是提一下,我维护了一个路由库 =.= !!
拜托拜托,谢谢各位同学!
链接:https://juejin.cn/post/7111669608842543135
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
面试官问我:SharedPreference源码中apply跟commit的原理,导致ANR的原因
1.前言
好几年前写过一篇SharedPreference源码相关的文章,对apply跟commit方法讲解的不够透彻,作为颜值担当的天才少年来说,怎么能不一次深入到底呢?
2.正文
为了熟读源码,下班后我约了同事小雪一起探讨,毕竟三人行必有我师焉。哪里来的三个人,不管了,跟小雪研究学术更重要。
小安学长,看了你之前的文章:Android SharedPreference 源码分析(一)对apply(),commit()的底层原理还是不理解,尤其是线程和一些同步锁他里面怎么使用,什么情况下会出现anr?
既然说到apply(),commit()的底层原理,那肯定是老步骤了,上源码。 apply源码如下:
public void apply() {
final long startTime = System.currentTimeMillis();
final MemoryCommitResult mcr = commitToMemory();
final Runnable awaitCommit = new Runnable() {
public void run() {
try {
mcr.writtenToDiskLatch.await();
} catch (InterruptedException ignored) {
}
if (DEBUG && mcr.wasWritten) {
Log.d(TAG, mFile.getName() + ":" + mcr.memoryStateGeneration
+ " applied after " + (System.currentTimeMillis() - startTime)
+ " ms");
}
}
};
// 将 awaitCommit 添加到队列 QueuedWork 中
QueuedWork.addFinisher(awaitCommit);
Runnable postWriteRunnable = new Runnable() {
public void run() {
awaitCommit.run();
QueuedWork.removeFinisher(awaitCommit);// 将 awaitCommit 从队列 QueuedWork 中移除
}
};
SharedPreferencesImpl.this.enqueueDiskWrite(mcr, postWriteRunnable);
// Okay to notify the listeners before it's hit disk
// because the listeners should always get the same
// SharedPreferences instance back, which has the
// changes reflected in memory.
notifyListeners(mcr);
}你这丢了一大堆代码,我也看不懂啊。
别急啊,这漫漫长夜留给我们的事情很多啊,听我一点点给你讲,包你满意。
apply()方法做过安卓的都知道(如果你没有做过安卓,那你点开我博客干什么呢,死走不送),频繁写文件建议用apply方法,因为他是异步存储到本地磁盘的。那么具体源码是如何操作的,让我们掀开他的底裤,不是,让我们透过表面看本质。
我们从下往上看,apply方法最后调用了SharedPreferencesImpl.this.enqueueDiskWrite(mcr, postWriteRunnable);我长得帅我先告诉你,enqueueDiskWrite方法会把存储文件的动作放到子线程,具体怎么放的,我们等下看源码,这边你只要知道他的作用。这个方法的第二个参数 postWriteRunnable做了两件事:
1)让awaitCommit执行,及执行 mcr.writtenToDiskLatch.await();
2)执行QueuedWork.remove(awaitCommit);代码
writtenToDiskLatch是什么,QueuedWork又是什么?
writtenToDiskLatch是CountDownLatch的实例化对象,CountDownLatch是一个同步工具类,它通过一个计数器来实现的,初始值为线程的数量。每当一个线程完成了自己的任务调用countDown(),则计数器的值就相应得减1。当计数器到达0时,表示所有的线程都已执行完毕,然后在等待的线程await()就可以恢复执行任务。
1)countDown(): 对计数器进行递减1操作,当计数器递减至0时,当前线程会去唤醒阻塞队列里的所有线程。
2)await(): 阻塞当前线程,将当前线程加入阻塞队列。 可以看到如果postWriteRunnable方法被触发执行的话,由于 mcr.writtenToDiskLatch.await()的缘故,UI线程会被一直阻塞住,等待计数器减至0才能被唤醒。
QueuedWork其实就是一个基于handlerThread的,处理任务队列的类。handlerThread类为你创建好了Looper和Thread对象,创建Handler的时候使用该looper对象,则handleMessage方法在子线程中,可以做耗时操作。如果对于handlerThread的不熟悉的话,可以看我前面的文章:Android HandlerThread使用介绍以及源码解析
觉得厉害,那咱就继续深入。
enqueueDiskWrite源码如下所示:
private void enqueueDiskWrite(final MemoryCommitResult mcr,
final Runnable postWriteRunnable) {
final boolean isFromSyncCommit = (postWriteRunnable == null);
final Runnable writeToDiskRunnable = new Runnable() {
public void run() {
synchronized (mWritingToDiskLock) {
writeToFile(mcr, isFromSyncCommit);
}
synchronized (mLock) {
mDiskWritesInFlight--;
}
if (postWriteRunnable != null) {
postWriteRunnable.run();
}
}
};
// Typical #commit() path with fewer allocations, doing a write on
// the current thread.
if (isFromSyncCommit) {
boolean wasEmpty = false;
synchronized (mLock) {
wasEmpty = mDiskWritesInFlight == 1;
}
if (wasEmpty) {
writeToDiskRunnable.run();
return;
}
}
QueuedWork.queue(writeToDiskRunnable, !isFromSyncCommit);
}很明显postWriteRunnable不为null,程序会执行QueuedWork.queue(writeToDiskRunnable, !isFromSyncCommit);从writeToDiskRunnable我们可以看到,他里面做了两件事:
1)writeToFile():内容存储到文件;
2)postWriteRunnable.run():postWriteRunnable做了什么,往上看,上面已经讲了该方法做的两件事。
QueuedWork.queue源码:
public static void queue(Runnable work, boolean shouldDelay) {
Handler handler = getHandler();
synchronized (sLock) {
sWork.add(work);
if (shouldDelay && sCanDelay) {
handler.sendEmptyMessageDelayed(QueuedWorkHandler.MSG_RUN, DELAY);
} else {
handler.sendEmptyMessage(QueuedWorkHandler.MSG_RUN);
}
}
}private static class QueuedWorkHandler extends Handler {
static final int MSG_RUN = 1;
QueuedWorkHandler(Looper looper) {
super(looper);
}
public void handleMessage(Message msg) {
if (msg.what == MSG_RUN) {
processPendingWork();
}
}
}这边我默认你已经知道HandlerThread如何使用啦,如果不知道,麻烦花五分钟去看下我之前的博客。
上面的代码很简单,其实就是把writeToDiskRunnable这个任务放到sWork这个list中,并且执行handler,根据HandlerThread的知识点,我们知道handlermessage里面就是子线程了。
接下来我们继续看handleMessage里面的processPendingWork()方法:
private static void processPendingWork() {
long startTime = 0;
if (DEBUG) {
startTime = System.currentTimeMillis();
}
synchronized (sProcessingWork) {
LinkedList<Runnable> work;
synchronized (sLock) {
work = (LinkedList<Runnable>) sWork.clone();
sWork.clear();
// Remove all msg-s as all work will be processed now
getHandler().removeMessages(QueuedWorkHandler.MSG_RUN);
}
if (work.size() > 0) {
for (Runnable w : work) {
w.run();
}
if (DEBUG) {
Log.d(LOG_TAG, "processing " + work.size() + " items took " +
+(System.currentTimeMillis() - startTime) + " ms");
}
}
}
}这代码同样很简单,先是把sWork克隆给work,然后开启循环,执行work对象的run方法,及调用writeToDiskRunnable的run方法。上面讲过了,他里面做了两件事:1)内容存储到文件 2)postWriteRunnable方法回调。 执行run方法的代码:
final Runnable writeToDiskRunnable = new Runnable() {
public void run() {
synchronized (mWritingToDiskLock) {
writeToFile(mcr, isFromSyncCommit);//由于handlermessage在子线程,则writeToFile也在子线程中
}
synchronized (mLock) {
mDiskWritesInFlight--;
}
if (postWriteRunnable != null) {
postWriteRunnable.run();
}
}
};writeToFile方法我们不深入去看,但是要关注,里面有个setDiskWriteResult方法,在该方法里面做了如下的事情:
void setDiskWriteResult(boolean wasWritten, boolean result) {
this.wasWritten = wasWritten;
writeToDiskResult = result;
writtenToDiskLatch.countDown();//计数器-1
}如何上面认真看了的同学,应该可以知道,当调用countDown()方法时,会对计数器进行递减1操作,当计数器递减至0时,当前线程会去唤醒阻塞队列里的所有线程。也就是说,当文件写完时,UI线程会被唤醒。
既然文件写完就会释放锁,那什么情况下会出现ANR呢?
Android系统为了保障在页面切换,也就是在多进程中sp文件能够存储成功,在ActivityThread的handlePauseActivity和handleStopActivity时会通过waitToFinish保证这些异步任务都已经被执行完成。如果这个时候过渡使用apply方法,则可能导致onpause,onStop执行时间较长,从而导致ANR。
private void handlePauseActivity(IBinder token, boolean finished,
boolean userLeaving, int configChanges, boolean dontReport, int seq) {
......
r.activity.mConfigChangeFlags |= configChanges;
performPauseActivity(token, finished, r.isPreHoneycomb(), "handlePauseActivity");
// Make sure any pending writes are now committed.
if (r.isPreHoneycomb()) {
QueuedWork.waitToFinish();
}
......
}你肯定要问,为什么过渡使用apply方法,就有可能导致ANR?那我们只能看QueuedWork.waitToFinish();到底做了什么
public static void waitToFinish() {
long startTime = System.currentTimeMillis();
boolean hadMessages = false;
Handler handler = getHandler();
synchronized (sLock) {
if (handler.hasMessages(QueuedWorkHandler.MSG_RUN)) {
// Delayed work will be processed at processPendingWork() below
handler.removeMessages(QueuedWorkHandler.MSG_RUN);
if (DEBUG) {
hadMessages = true;
Log.d(LOG_TAG, "waiting");
}
}
// We should not delay any work as this might delay the finishers
sCanDelay = false;
}
StrictMode.ThreadPolicy oldPolicy = StrictMode.allowThreadDiskWrites();
try {
processPendingWork();
} finally {
StrictMode.setThreadPolicy(oldPolicy);
}
try {
while (true) {
Runnable finisher;
synchronized (sLock) {
finisher = sFinishers.poll();
}
if (finisher == null) {
break;
}
finisher.run();
}
} finally {
sCanDelay = true;
}
synchronized (sLock) {
long waitTime = System.currentTimeMillis() - startTime;
if (waitTime > 0 || hadMessages) {
mWaitTimes.add(Long.valueOf(waitTime).intValue());
mNumWaits++;
if (DEBUG || mNumWaits % 1024 == 0 || waitTime > MAX_WAIT_TIME_MILLIS) {
mWaitTimes.log(LOG_TAG, "waited: ");
}
}
}
}看着一大坨代码,其实做了两件事:
1)主线程执行processPendingWork()方法,把之前未执行完的内容存储到文件的操作执行完,这部分动作直接在主线程执行,如果有未执行的文件操作并且文件较大,则主线程会因为IO时间长造成ANR。
2)循环取出sFinishers数组,执行他的run方法。如果这时候有多个异步线程或者异步线程时间过长,同样会造成阻塞产生ANR。
第一个很好理解,第二个没有太看明白,sFinishers数组是在什么时候add数据的,而且根据writeToDiskRunnable方法可以知道,先写文件再加锁的,为啥会阻塞呢?
sFinishers的addFinisher方法是在apply()方法里面调用的,代码如下:
@Override
public void apply() {
......
// 将 awaitCommit 添加到队列 QueuedWork 中
QueuedWork.addFinisher(awaitCommit);
Runnable postWriteRunnable = new Runnable() {
@Override
public void run() {
awaitCommit.run();
QueuedWork.removeFinisher(awaitCommit);// 将 awaitCommit 从队列 QueuedWork 中移除
}
};
......
}正常情况下其实是不会发生ANR的,因为writeToDiskRunnable方法中,是先进行文件存储再去阻塞等待的,此时CountDownLatch永远都为0,则不会阻塞主线程。
final Runnable writeToDiskRunnable = new Runnable() {
@Override
public void run() {
synchronized (mWritingToDiskLock) {
writeToFile(mcr, isFromSyncCommit);//写文件,写成功后会调用writtenToDiskLatch.countDown();计数器-1
}
synchronized (mLock) {
mDiskWritesInFlight--;
}
if (postWriteRunnable != null) {
postWriteRunnable.run();//回调到awaitCommit.run();进行阻塞
}
}
};但是如果processPendingWork方法在异步线程在执行时,及通过enqueueDiskWrite方法触发的正常文件保存流程,这时候文件比较大或者文件比较多,子线程则一直在运行中;当用户点击页面跳转时,则触发该Activity的handlePauseActivity方法,根据上面的分析,handlePauseActivity方法里面会执行waitToFinish保证这些异步任务都已经被执行完成。
由于这边主要介绍循环取出sFinishers数组,执行他的run方法造成阻塞产生ANR,我们就重点看下sFinishers数组对象是什么,并且执行什么动作。
private static final LinkedList<Runnable> sFinishers = new LinkedList<>();
@UnsupportedAppUsage
public static void addFinisher(Runnable finisher) {
synchronized (sLock) {
sFinishers.add(finisher);
}
}addFinisher刚刚上面提到是在apply方法中调用,则finisher就是入参awaitCommit,他的run方法如下:
final Runnable awaitCommit = new Runnable() {
@Override
public void run() {
try {
mcr.writtenToDiskLatch.await();//阻塞
} catch (InterruptedException ignored) {
}
if (DEBUG && mcr.wasWritten) {
Log.d(TAG, mFile.getName() + ":" + mcr.memoryStateGeneration
+ " applied after " + (System.currentTimeMillis() - startTime)
+ " ms");
}
}
};不难看出,就是调用CountDownLatch对象的await方法,阻塞当前线程,将当前线程加入阻塞队列。也就是这个时候整个UI线程都阻塞在这边,等待processPendingWork这个异步线程执行完毕,虽然你是在子线程,但是我主线程在等你执行结束才会进行页面切换,所以如果过渡使用apply方法,则可能导致onpause,onStop执行时间较长,从而导致ANR。
小安学长不愧是我的偶像,我都明白了,那继续讲讲同步存储commit()方法吧。
commit方法其实就比较简单了,无非是内存和文件都在UI线程中,我们看下代码证实一下:
@Override
public boolean commit() {
long startTime = 0;
if (DEBUG) {
startTime = System.currentTimeMillis();
}
MemoryCommitResult mcr = commitToMemory();//内存保存
SharedPreferencesImpl.this.enqueueDiskWrite(
mcr, null /* sync write on this thread okay */);//第二个参数为null
try {
mcr.writtenToDiskLatch.await();
} catch (InterruptedException e) {
return false;
} finally {
if (DEBUG) {
Log.d(TAG, mFile.getName() + ":" + mcr.memoryStateGeneration
+ " committed after " + (System.currentTimeMillis() - startTime)
+ " ms");
}
}
notifyListeners(mcr);
return mcr.writeToDiskResult;
}可以看到enqueueDiskWrite的第二个参数为null,enqueueDiskWrite方法其实上面讲解apply的时候已经贴过了,为了不让你往上翻我们继续看enqueueDiskWrite方法:
private void enqueueDiskWrite(final MemoryCommitResult mcr,
final Runnable postWriteRunnable) {
final boolean isFromSyncCommit = (postWriteRunnable == null);//此时postWriteRunnable为null,isFromSyncCommit 则为true
final Runnable writeToDiskRunnable = new Runnable() {
@Override
public void run() {
synchronized (mWritingToDiskLock) {
writeToFile(mcr, isFromSyncCommit);
}
synchronized (mLock) {
mDiskWritesInFlight--;
}
if (postWriteRunnable != null) {
postWriteRunnable.run();
}
}
};
// Typical #commit() path with fewer allocations, doing a write on
// the current thread.
if (isFromSyncCommit) { //当调用commit方法时,isFromSyncCommit则为true
boolean wasEmpty = false;
synchronized (mLock) {
wasEmpty = mDiskWritesInFlight == 1;
}
if (wasEmpty) {
writeToDiskRunnable.run();//主线程回调writeToDiskRunnable的run方法,进行writeToFile文件的存储
return;
}
}
QueuedWork.queue(writeToDiskRunnable, !isFromSyncCommit);
}关键代码已经注释过了,由于postWriteRunnable为null,则isFromSyncCommit为true,代码会在主线程回调writeToDiskRunnable的run方法,进行writeToFile文件的存储。这部分动作直接在主线程执行,如果文件较大,则主线程也会因为IO时间长造成ANR的。
所以SharedPreference 不管是commit()还是apply()方法,如果文件过大或者过多,都会有ANR的风险,那如何规避呢?
解决肯定有办法的,下一篇就介绍SharedPreference 的替代方案mmkv的原理,只是今晚有点晚了,咱们早上睡吧,不是,早点回家吧~~~
链接:https://juejin.cn/post/7209447968218382392
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不一样的Android堆栈抓取方案
背景
曾几何时,我们只需要简简单单的一行 Thread.currentThread().getStackTrace() 代码就可以轻轻松松的获取到当前线程的堆栈信息,从而分析各种问题。随着需求的不断迭代,APP 遇到的问题越来越多,卡顿,ANR,异常等等问题接踵而来,那么简简单单某个时刻的堆栈信息已经不能满足我们的需求了,我们的目光逐渐转移到了每个时刻的堆栈上,如果能获取一个时间段内,每个时刻的堆栈信息,那么卡顿,以及 ANR 的问题也将被解决。
抓栈方案
目前对于一段时间内的抓栈方案有两种:
- 方法插桩抓栈
- Native 抓栈
代码插桩抓栈
基本思路
APP 编译阶段,对每个方法进行插桩,在插桩的同时,填入当前方法 ID,发生卡顿或者异常的时候,将之前收集到的方法 ID 进行聚合输出。
插桩流程图:

优点:简单高效,无兼容性问题
缺点:插桩导致所有类都非 preverify,同时 verify 与 optimize 操作会在加载类时被触发。增加类加载的压力照成一定的性能损耗。另外也会导致包体积变大,影响代码 Debug 以及代码崩溃异常后错误行数
Native 抓栈
使用 Native 抓栈之前,我们先了解一下 Java 抓栈的整个流程
JAVA堆栈获取流程图
抓栈当前线程

抓栈其他线程

Java堆栈获取原理分析
由于当前线程抓栈和其他线程抓栈流程类似,这里我们从其他线程抓栈的流程进行分析
首先从入口代码出发,Java 层通过 Thread.currentThread().getStackTrace() 开始获取当前堆栈数据
Thread.java
public StackTraceElement[] getStackTrace() {
StackTraceElement ste[] = VMStack.getThreadStackTrace(this);
return str!=null?ste:EmptyArray.STACK_TRACE_ELEMENT;
}Thread 中的 getStackTrace 只是一个空壳,底层的实现是通过 native 来获取的,继续往下走,通过 VMStack 来获取我们需要的线程堆栈数据
dalvik_system_vmstack.cc
static jobjectArray VMStack_getThreadStackTrace(JNIEnv* env, jclass, jobject javaThread) {
ScopedFastNativeObjectAccess soa(env);
// fn 方法是线程挂起回调
auto fn = [](Thread* thread, const ScopedFastNativeObjectAccess& soaa)
REQUIRES_SHARED(Locks::mutator_lock_) -> jobject {
return thread->CreateInternalStackTrace(soaa);
};
// 获取堆栈
jobject trace = GetThreadStack(soa, javaThread, fn);
if (trace == nullptr) {
return nullptr;
}
// trace 是一个包含 method 的数组,有这个数据之后,我们进行数据反解,就能获取到方法堆栈明文
return Thread::InternalStackTraceToStackTraceElementArray(soa, trace);
}上述代码中,需要注意三个元素
fn={return thread->CreateInternalStackTrace(soaa);}。 // 这个是线程挂起后的回调函数
GetThreadStack(sao,javaThread,fn) // 用来获取实际的线程堆栈信息
Thread::InternalStackTraceToStackTraceElementArray(sao,trace),这里 trace 就是我们拿到的目标产物,这里面就包含了当前线程此时此刻的堆栈信息,需要对堆栈进行进一步的解析,才能获取到可识别的堆栈文本
接下来我们从获取堆栈信息函数着手,看看 GetThreadStack 的具体行为。
dalvik_system_vmstack.cc
static ResultT GetThreadStack(const ScopedFastNativeObjectAccess& soa,jobject peer,T fn){
********
********
********
ThreadList* thread_list = Runtime::Current()->GetThreadList();
// 【Step1】: 挂起线程
Thread* thread = thread_list->SuspendThreadByPeer(peer,SuspendReason::kInternal,&timed_out);
if (thread != nullptr) {
{
ScopedObjectAccess soa2(soa.Self());
// 【Step2】: FN 回调,这里面执行的就是抓栈操作,回到外层的回调函数逻辑中
trace = fn(thread, soa);
}
// 【Step3】: 恢复线程
bool resumed = thread_list->Resume(thread, SuspendReason::kInternal);
}
}
return trace;
}在该操作的三个步骤中,就包含了抓栈的整个流程,
【Step1】: 挂起线程,线程每时每刻都在执行方法,这样就导致当前线程的方法堆栈在不停的增加,如果想要抓到瞬时堆栈,就需要把当前线程暂停,保留瞬时的堆栈信息,这样抓出来的数据才是准确的。
【Step2】: 执行 FN 的回调,这里的 FN 回调,就是上文介绍的回调方法 fn={return thread->CreateInternalStackTrace(soaa)}
【Step3】: 恢复线程的正常运行。
上述流程中,我们需要重点关注一下 FN 回调里面做了什么,以及怎么做到的
thread.cc
jobject Thread::CreateInternalStackTrace(const ScopedObjectAccessAlreadyRunnable& soa) const {
// 创建堆栈回溯观察者
FetchStackTraceVisitor count_visitor(const_cast<Thread*>(this),&saved_frames[0],kMaxSavedFrames);
count_visitor.WalkStack(); // 回溯核心方法
// 创建堆栈回溯观察者 2 号,详细的堆栈数据就是 2 号处理返回的
BuildInternalStackTraceVisitor build_trace_visitor(soa.Self(), const_cast<Thread*>(this), skip_depth);
mirror::ObjectArray<mirror::Object>* trace = build_trace_visitor.GetInternalStackTrace();
return soa.AddLocalReference<jobject>(trace);
}
创建堆回溯观察者 1 号 FetchStackTraceVisitor,最大深度 256 进行回溯,如果深度超过了 256,则使用 2 号继续进行回溯
创建堆回溯观察者 2 号 BuildInternalStackTraceVisitor,承接 1 号的回溯结果,1 号没回溯完,2 号接着回溯。
栈回溯的详细过程
回溯是通过 WalkStack 来实现的。StackVisitor::WalkStack 是一个用于在当前线程堆栈上单步遍历帧的函数。它可以用来收集当前线程堆栈上特定帧的信息,以便进行调试或其他分析操作。 例如,它可以用来找出当前线程堆栈上哪些函数调用了特定函数,或者收集特定函数的参数。 也可以用来找出线程调用的函数层次结构,以及每一层调用的函数参数。 使用这个函数,可以更好地理解代码的执行流程,并帮助进行异常处理和调试。
stack.cc
void StackVisitor::WalkStack(bool include_transitions) {
for (const ManagedStack* current_fragment = thread_->GetManagedStack();current_fragment != nullptr; current_fragment = current_fragment->GetLink()) {
cur_shadow_frame_ = current_fragment->GetTopShadowFrame();
****
****
****
do {
// 通知子类,进行栈帧的获取
bool should_continue = VisitFrame();
cur_depth_++;
cur_shadow_frame_ = cur_shadow_frame_->GetLink();
} while (cur_shadow_frame_ != nullptr);
}
}ManagedStack 是一个单链表,保存了当前 ShadowFrame 或者 QuickFrame 栈指针,先依次遍历 ManagedStack 链表,然后遍历其内部的 ShadowFrame 或者 QuickFrame 还原一个可读的调用栈,从而还原出当前的 Java 堆栈

还原操作是通过 VisitFrame 来实现的,它是一个抽象接口,实现类我们需要看 BuildInternalStackTraceVisitor 的实现
thread.cc
class BuildInternalStackTraceVisitor : public StackVisitor {
mirror::ObjectArray<mirror::Object>* trace_ = nullptr;
bool VisitFrame() override REQUIRES_SHARED(Locks::mutator_lock_) {
****
****
****
// 每循环一帧,将其添加到 arrObj 中
ArtMethod* m = GetMethod();
AddFrame(m, m->IsProxyMethod() ? dex::kDexNoIndex : GetDexPc());
return true;
}
void AddFrame(ArtMethod* method, uint32_t dex_pc) REQUIRES_SHARED(Locks::mutator_lock_) {
ObjPtr<mirror::Object> keep_alive;
if (UNLIKELY(method->IsCopied())) {
ClassLinker* class_linker = Runtime::Current()->GetClassLinker();
keep_alive = class_linker->GetHoldingClassLoaderOfCopiedMethod(self_, method);
} else {
keep_alive = method->GetDeclaringClass();
}
// 添加每一次遍历到的 artMethod 对象,在添加完成之后,进行 count++,进行 Arr 的偏移
trace_->Set<false,false>(static_cast<int32_t>(count_) + 1, keep_alive);
++count_;
}
}在执行 VisitFrame 的过程中,会将每次的 method 拎出来,然后添加至 ObjectArray 的集合中。当所有方法查找完成之后,会进行 method 的反解。
堆栈信息反解关键操作
反解的流程在文章开头,通过 Thread::InternalStackTraceToStackTraceElementArray(soa,trace) 来进行反解。
thread.cc
jobjectArray Thread::InternalStackTraceToStackTraceElementArray(const ScopedObjectAccessAlreadyRunnable& soa,jobject internal,jobjectArray output_array,int* stack_depth) {
int32_t depth = soa.Decode<mirror::Array>(internal)->GetLength() - 1;
for (uint32_t i = 0; i < static_cast<uint32_t>(depth); ++i) {
ObjPtr<mirror::ObjectArray<mirror::Object>> decoded_traces = soa.Decode<mirror::Object>(internal)->AsObjectArray<mirror::Object>();
const ObjPtr<mirror::PointerArray> method_trace = ObjPtr<mirror::PointerArray>::DownCast(decoded_traces->Get(0));
// 【Step1】: 提取数组中的 ArtMethod
ArtMethod* method = method_trace->GetElementPtrSize<ArtMethod*>(i, kRuntimePointerSize);
uint32_t dex_pc = method_trace->GetElementPtrSize<uint32_t>(i + static_cast<uint32_t>(method_trace->GetLength()) / 2, kRuntimePointerSize);
// 【Step2】: 将 ArtMethod 转换成业务上层可识别的 StackTraceElement 对象
const ObjPtr<mirror::StackTraceElement> obj = CreateStackTraceElement(soa, method, dex_pc);
soa.Decode<mirror::ObjectArray<mirror::StackTraceElement>>(result)->Set<false>(static_cast<int32_t>(i), obj);
}
return result;
}
static ObjPtr<mirror::StackTraceElement> CreateStackTraceElement(
const ScopedObjectAccessAlreadyRunnable& soa,
ArtMethod* method,
uint32_t dex_pc) REQUIRES_SHARED(Locks::mutator_lock_) {
// 【Step3】: 获取行号
line_number = method->GetLineNumFromDexPC(dex_pc);
// 【Step4】: 获取类名
const char* descriptor = method->GetDeclaringClassDescriptor();
std::string class_name(PrettyDescriptor(descriptor));
class_name_object.Assign(mirror::String::AllocFromModifiedUtf8(soa.Self(), class_name.c_str()));
// 【Step5】: 获取类路径
const char* source_file = method->GetDeclaringClassSourceFile();
source_name_object.Assign(mirror::String::AllocFromModifiedUtf8(soa.Self(), source_file));
// 【Step6】: 获取方法名
const char* method_name = method->GetInterfaceMethodIfProxy(kRuntimePointerSize)->GetName();
Handle<mirror::String> method_name_object(hs.NewHandle(mirror::String::AllocFromModifiedUtf8(soa.Self(), method_name)));
// 【Step7】: 数据封装回抛
return mirror::StackTraceElement::Alloc(soa.Self(),class_name_object,method_name_object,source_name_object,line_number);
}到这里我们已经分析完一次由 Java 层触发的堆栈调用链路一直到底层的实现逻辑。
核心流程
我们的目标是抓栈,因此我们只需要关注 count_visitor.WalkStack 之后的栈回溯流程。

耗时阶段
这里最后阶段将 ArtMethod 转换成业务上层可识别的 StackTraceElement,由于涉及到大量的字符串操作,给 Java 堆栈的执行贡献了很大的耗时占比。
抓栈新思路
传统的抓栈产生的数据很完善,过程也比较耗时。我们是否可以简化这个流程,提高抓栈效率呢,理论上是可以的,我们只需要自己将这个流程复写一份,然后抛弃部分的数据,优化数据获取时间,同样可以做到更高效的抓栈体验。
Native抓栈逻辑实现
根据系统抓栈流程,我们可以梳理出要做的几个事情点
要做的事情:
挂起线程【获取挂起线程方法内存地址】
进行抓栈【获取抓栈方法内存地址】【优化抓栈耗时】
恢复线程的执行【获取恢复线程方法内存地址】
遇到的问题及解决方案:
- 如何获取系统 threadList 对象
threadList 是线程执行挂起和恢复的关键对象,系统未暴露该对象的直接访问操作,因此我们只能另辟蹊径来获取它,threadList 获取依赖流程图如下:

如果想要执行线程的挂起 thread_->SuspendThreadByPeer 或者恢复 thread_list->Resume ,首先需要获取到 thread_list 系统对象,该对象是通过 Runtime::Current()->getThreadList() 获取而来,,因此我们要先获取 Runtime , Runtime 的获取可以通过 JavaVmExt 来获取,而 JavaVmExt 可以通过 JNI_OnLoad 时的 JavaVM 来获取,完整流程如下代码所示
JNIEXPORT jint JNICALL JNI_OnLoad(JavaVM *vm, void *reserved) {
JNIEnv *env = NULL;
if (vm->GetEnv((void **) &env, JNI_VERSION_1_6) != JNI_OK) {
return -1;
}
JavaVM *javaVM;
env->GetJavaVM(&javaVM);
auto *javaVMExt = (JavaVMExt *) javaVM;
void *runtime = javaVMExt->runtime;
// JavaVMExt 结构
// 10.0 https://android.googlesource.com/platform/art/+/refs/tags/android-10.0.0_r1/runtime/jni/java_vm_ext.h
// 【Step1】. 找到 Runtime_instance_ 的位置
if (api < 30) {
runtime_instance_ = runtime;
} else {
int vm_offset = find_offset(runtime, MAX_SEARCH_LEN, javaVM);
runtime_instance_ = reinterpret_cast<void *>(reinterpret_cast<char *>(runtime) + vm_offset - offsetof(PartialRuntimeR, java_vm_));
}
// 【Step2】. 以 runtime_instance_ 的地址为起点,开始找到 JavaVMExt 在 【https://android.googlesource.com/platform/art/+/refs/tags/android-10.0.0_r29/runtime/runtime.h】中的位置
// 7.1 https://android.googlesource.com/platform/art/+/refs/tags/android-7.1.2_r39/runtime/runtime.h
int offsetOfVmExt = findOffset(runtime_instance_, 0, MAX, (size_t) javaVMExt);
if (offsetOfVmExt < 0) {
ArtHelper::reduce_model = 1;
return;
}
// 【Step3】. 根据 JavaVMExt 的位置,根据各个版本的结构,进行偏移,生成 PartialRuntimeSimpleTenR 的结构
if (ArtHelper::api == ANDROID_P_API || ArtHelper::api == ANDROID_O_MR1_API) {
PartialRuntimeSimpleNineR *simpleR = (PartialRuntimeSimpleNineR *) ((char *) runtime_instance_ + offsetOfVmExt - offsetof(PartialRuntimeSimpleNineR, java_vm_));
thread_list = simpleR->thread_list_;
}else if (ArtHelper::api <= ANDROID_O_API) {
PartialRuntimeSimpleSevenR *simpleR = (PartialRuntimeSimpleSevenR *) ((char *) runtime_instance_ + offsetOfVmExt - offsetof(PartialRuntimeSimpleSevenR, java_vm_));
thread_list = simpleR->thread_list_;
}else{
PartialRuntimeSimpleTenR *simpleR = (PartialRuntimeSimpleTenR *) ((char *) runtime_instance_ + offsetOfVmExt - offsetof(PartialRuntimeSimpleTenR, java_vm_));
thread_list = simpleR->thread_list_;
}
} 经过三个步骤,我们就可以获取到底层的 Runtime 对象,以及最关键的 thread_list 对象,有了它,我们就可以对线程执行暂停和恢复操作。
- 线程的暂停和恢复
因为 SuspendThreadByPeer 和 Resume 方法我们访问不到,但如果我们能够找到这两个方法的内存地址,那么就可以直接执行了,怎么获取到内存地址呢?这里使用 Nougat_dlfunctions 的 fake_dlopen() 和 fake_dlsym() 来获取已被加载到内存的动态链接库 libart.so 中方法内存地址。
WalkStack_ = reinterpret_cast<void (*)(StackVisitor *, bool)>(dlsym_ex(handle,"_ZN3art12StackVisitor9WalkStackILNS0_16CountTransitionsE0EEEvb"));
SuspendThreadByThreadId_ = reinterpret_cast<void *(*)(void *, uint32_t, SuspendReason, bool *)>(dlsym_ex(handle,"_ZN3art10ThreadList23SuspendThreadByThreadIdEjNS_13SuspendReasonEPb"));
Resume_ = reinterpret_cast<bool (*)(void *, void *, SuspendReason)>(dlsym_ex(handle, "_ZN3art10ThreadList6ResumeEPNS_6ThreadENS_13SuspendReasonE"));
PrettyMethod_ = reinterpret_cast<std::string (*)(void *, bool)>(dlsym_ex(handle, "_ZN3art9ArtMethod12PrettyMethodEb"));
到这里,我们已经已经可以完成线程的挂起和恢复了,接下来就是抓栈的操作处理流程。
- 自定义抓栈
同样的,由于我们已经获取到用于栈回溯的 WalkStack 方法地址,我们只需要提供一个自定义的 TraceVisitor 类即可实现栈回溯
class CustomFetchStackTraceVisitor : public StackVisitor {
bool VisitFrame() override {
// 【Step1】: 系统堆栈调用时我们分析到的流程,每帧遍历时会走一次当前流程
void *method = GetMethod();
// 【Step2】: 获取到 Method 对象之后,使用 circular_buffer 存起来,没有多余的过滤逻辑,不反解字符串
if (CustomFetchStackTraceVisitorCallback!= nullptr){
return CustomFetchStackTraceVisitorCallback(method);
}
return true;
}
} 获取到 Method 之后,为了节省本次的抓栈耗时,我们使用固定大小的 circular_buffer 将数据存储起来,新数据自动覆盖老数据,根据需求,进行异步反解 Method 中的详细堆栈数据。到这里,自定义的 Native 抓栈逻辑就完成了。
总结
目前自定义 native 抓栈的多个阶段需要兼容不同系统版本的 thread_list 获取,以及不同版本的线程挂起,线程恢复的函数地址获取。这些都会导致出现或多或少的兼容性问题,这里可以通过两种方案来规避,第一种是过滤读取到的不合法地址,对于这类不合法地址,需要跳过抓栈流程。另外一种就是动态配置下发过滤这些不兼容版本机型。
参考资料
- Nougat_dlfunctions:github.com/avs333/Noug…
- 环形缓冲区:baike.baidu.com/item/%E7%8E…
- Android 平台下的 Method Trace 实现解析:zhuanlan.zhihu.com/p/526960193…
链接:https://juejin.cn/post/7212809255946469432
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
高仿PPT特殊文字效果,TextView实现
事情是这样的,我无聊刷到一个B站视频【旁门左道PPT】我发现了大厂发布会中,少文字PPT还贼高级的秘密!。看到视频中这个特殊的PPT文字效果,个人感觉非常高端。我就想,能不能用TextView来实现。于是就有了这篇文章,效果如下图:
| 简单填充 | 加入文字排版 | 加入动画 |
|---|---|---|
图片填充
在Android中,google提供了 BitmapShader 来实现图片填充的功能。代码如下
public BitmapShader(@NonNull Bitmap bitmap,
@NonNull TileMode tileX,
@NonNull TileMode tileY)
参数介绍:
● bitmap:用来做填充的 Bitmap 对象
● tileX:横向的 TileMode(平铺模式)
● tileY:纵向的 TileMode
TileMode有三种:分别是 Shader.TileMode.CLAMP、Shader.TileMode.MIRROR、Shader.TileMode.REPEAT
● Shader.TileMode.CLAMP:如果着色器超出原始边界范围,会复制边缘颜色。
● Shader.TileMode.MIRROR:横向和纵向的重复着色器的图像,交替镜像图像是相邻的图像总是接合。
● Shader.TileMode.REPEAT: 横向和纵向的重复着色器的图像。
接下来,我们自定义 TextView,让它使用我们定义的Shader,代码如下:
class MaskTextView: androidx.appcompat.widget.AppCompatTextView {
constructor(context: Context) : super(context)
constructor(context: Context, attrs: AttributeSet?) : super(context, attrs)
constructor(context: Context, attrs: AttributeSet?, defStyleAttr: Int) : super(
context,
attrs,
defStyleAttr
)
private var shader: BitmapShader? = null
fun setMaskDrawable(source: Drawable): Unit {
val maskW: Int = source.getIntrinsicWidth()
val maskH: Int = source.getIntrinsicHeight()
val b = Bitmap.createBitmap(maskW, maskH, Bitmap.Config.ARGB_8888)
val c = Canvas(b)
c.drawColor(currentTextColor)
source.setBounds(0, 0, maskW, maskH)
source.draw(c)
shader = BitmapShader(b, Shader.TileMode.REPEAT, Shader.TileMode.CLAMP)
paint.shader = shader
}
}在免费壁纸网站中找到一个你喜欢的图片,调用 setMaskDrawable 方法时,我们就可以看到填充后的效果了。效果如下:
但是光这个效果还不够,还需要设置文字排版。看【旁门左道PPT】我发现了大厂发布会中,少文字PPT还贼高级的秘密!我们知道,有三种文字排版,分别是 高低低高、高低高低、低高低高,它们都需要修改文字的 baseline 来实现。
如何修改单个字符的 baseline 呢?很简单,不需要重写 onDraw 方法。我们可以自定义 Span,然后通过 TextPaint 来实现。在上代码前,先介绍一下 TextPaint,TextPaint 继承 Paint,在绘制和测量文本时给Android一些额外的数据。它的属性介绍如下:
● baselineShift - 基线是文本底部的线。改变baselineShift会使基线向上或向下移动,所以它影响到文本在一条线上的绘制高度。
● bgColor - 这是文本后面的背景颜色。
● density - 暂不清楚它的作用
● drawableState - 暂不清楚它的作用
● linkColor - 一个链接的文本颜色。
可以看到我们只需要修改 baselineShift 就可以改变单个文字的 baseline 了,自定义的Span的代码如下:
class TextUpOrDownSpan(private val isUp:Boolean, private val offset: Int): CharacterStyle() {
override fun updateDrawState(tp: TextPaint?) {
tp?.baselineShift = if(isUp) - offset else offset
}
}效果如下:
添加一个波浪动画
我们也可以给我们的图片填充增加一个动画,其中最常见的就是波浪动画了。效果实现很简单:
第一步:在波浪效果网站上下载一张自己想要的波浪图片
第二步:创建自定义的TextView,加上对应的参数,方便做动画。代码如下:
class AnimatorMaskTextView: androidx.appcompat.widget.AppCompatTextView {
private var shader: BitmapShader? = null
private var shaderMatrix: Matrix = Matrix()
private var offsetY = 0f
var maskX = 0f
set(value) {
field = value
invalidate()
}
var maskY = 0f
set(value) {
field = value
invalidate()
}
fun setMaskDrawable(source: Drawable): Unit {
val maskW: Int = source.getIntrinsicWidth()
val maskH: Int = source.getIntrinsicHeight()
val b = Bitmap.createBitmap(maskW, maskH, Bitmap.Config.ARGB_8888)
val c = Canvas(b)
c.drawColor(currentTextColor)
source.setBounds(0, 0, maskW, maskH)
source.draw(c)
shader = BitmapShader(b, Shader.TileMode.REPEAT, Shader.TileMode.CLAMP)
paint.shader = shader
offsetY = ((height - maskH) / 2).toFloat()
}
override fun onDraw(canvas: Canvas?) {
shaderMatrix.setTranslate(maskX, offsetY + maskY)
shader?.setLocalMatrix(shaderMatrix)
paint.shader = shader
super.onDraw(canvas)
}
}第三步:使用Android的动画api,控制图片的位置。代码如下:
val maskXAnimator: ObjectAnimator =
ObjectAnimator.ofFloat(textView, "maskX", 0f, textView.width.toFloat())
val maskYAnimator: ObjectAnimator =
ObjectAnimator.ofFloat(textView, "maskY", 0f, (-textView.getHeight()).toFloat())
val animatorSet = AnimatorSet()
animatorSet.playTogether(maskXAnimator, maskYAnimator)
animatorSet.start()效果如下:
链接:https://juejin.cn/post/7212418415976529981
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android记一次JNI内存泄漏
记一次JNI内存泄漏
前景
在视频项目播放界面来回退出时,会触发内存LeakCanary内存泄漏警告。
分析
查看leakCanary的日志没有看到明确的泄漏点,所以直接取出leakCanary保存的hprof文件,保存目录在日志中有提醒,需要注意的是如果是android11系统及以上的保存目录和android11以下不同,android11保存的目录在:
/data/media/10/Download/leakcanary-包名/2023-03-14_17-19-45_115.hprof
使用Memory Analyzer Tool(简称MAT) 工具进行分析,需要讲上面的hrof文件转换成mat需要的格式:
hprof-conv -z 转换的文件 转换后的文件
hprof-conv -z 2023-03-14_17-19-45_115.hprof mat115.hprof
打开MAT,导入mat115文件,等待一段时间。
在预览界面打开Histogram,搜索需要检测的类,如:VideoActivity
搜索结果查看默认第一栏,如果没有泄漏,关闭VideoActivity之后,Objects数量一般是零,如果不为零,则可能存在泄漏。
右键Merge Shortest Paths to GC Roots/exclude all phantom/weak/soft etc,references/ 筛选出强引用的对象。
筛选出结果后,出现com.voyah.cockpit.video.ui.VideoActivity$1 @0x3232332 JIN Global 信息,且无法继续跟踪下去。
筛选出结果之后显示有六个VideoActivity对象没有释放,点击该对象也无法看到GC对象路径。(正常的java层内存泄漏能够看到泄漏的对象具体是哪一个)
正常的内存泄漏能够看到具体对象,如图:
这个MegaDataStorageConfig就是存在内存泄漏。
而我们现在的泄漏确实只知道VideoActivity$1 对象泄漏了,没有具体的对象,这样就没有办法跟踪下去了。
解决办法:
虽然无法继续跟踪,但泄漏的位置说明就是这个VideoActivity1这个Class类(class.dex可能有很多,一个个找),打开这个class,查看字节码(可以android studio中快捷打开build中的apk),根据【 .line 406 】等信息定位代码的位置,找到泄漏点。
根据方法名、代码行数、类名,直接定位到了存在泄漏的代码:
红框区内就是内存泄漏的代码,这个回调是一个三方sdk工具,我使用时进行了注册,在onDestory中反注册,但还是存在内存泄漏。(该对象未使用是我代码修改之后的)
修改方法
将这个回调移动到Application中去,然后进行事件或者回调的方式通知VideoActivity,在VideoActivity的onDestory中进行销毁回调。
修改完之后,多次进入VideoAcitivity然后在退出,导出hprof文件到mat中筛选查看,如图:
VideoActiviyty的对象已经变成了零,说明开始存在的内存泄漏已经修改好了,使用android proflier工具也能看到在退出videoactivity界面之后主动进行几次gc回收,内存使用量会回归到进入该界面之前。
总结:
- LeakCanary工具为辅助,MAT工具进行具体分析。因为LeakCanary工具的监听并不准确,如触发leakcanary泄漏警告时代码已经泄漏了很多次。
- 如果能够直接查看泄漏的对象,那是最好修改的,如果不能直接定位泄漏的对象,可以通过泄漏的Class对象在apk解压中找到改class,查看字节码定位具体的代码泄漏位置。
- 使用第三方的sdk时,最好使用Application Context,统一分发统一管理,减少内存泄漏。
链接:https://juejin.cn/post/7210574525665771557
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
告诉ChatGPT,我想读博了
上篇文章详细写了如何体验ChatGPT。在实际使用中发现它对固定模板式的文字工作做的比较好。于是我瞬间想起了毕业前被论文支配的恐惧,我突然有一个大胆的想法,那么ChatGPT是否能帮我写一篇毕业论文呢?
1、论文大纲
以大家最常用的图书管理系统为例。在毕业论文的第一步,我们先根据题目生成一个论文大纲。
唔,感觉还行感觉稍微调整一下就可以用。
2、论文摘要
论文大纲有了,接下来是要写一个中英文的摘要。

看样子只是翻译了一下,和普通的翻译软件也没啥差别。但ChatGPT的强大不止于此,还可以接受我们的“调教”。
3、论文润色
写过论文的同学都知道,初版论文往往经过天翻地覆的修改,因此「论文润色」是写论文时时刻刻都在做的事情。
比如我们对上面的摘要进行润色,我们试着在英文内容前加一个Prompt:
Please proofread and polish the passage from an academic angle and highlight the modification:
请从学术角度对这段话进行校对和润色,并突出修改的内容。
添加完提示后,神奇的事情发生了,不仅给了一个船新版本的摘要翻译,还给出了修改的提示。
那么ChatGPT给的修改建议到底是胡说八道,还是有据可依呢?
我取第一条修改意见,前面加上一个why,作为一个Prompt:
why Replaced "presents" with "proposes" to emphasize the introduction of a new idea ?

oh!有理有据,令人信服。这不比某些不靠谱的导师给你瞎写修改意见强?
4、检查拼写与语法错误
自己写论文时难免会有大量的语法错误,此时也可以通过ChatGPT来检查。
比如我们随便写一个语法错误的句子,然后加一个Prompt。
Please help me to check the spelling and formatting errors and explain the reasons :“I think this song is most poplar of all,and I am very like that。”
看的出来,通过我们自定义的Prompt,ChatGPT不仅将错误的句子修改正确,还帮我把错误的地方列举出来并且给予了详细的解释。相当于你的专属英文老师。
5、总结
简单的体验完之后,可以看出不论是在论文的润色,还是拼写语法的检查,ChatGPT确实都做的很好,可以称之为极其高效率的学术写作练习。感觉有了这么牛的论文写作工具,扶我起来,感觉还能再读个博!

突然,我回忆起自己曾经硕士毕业前写论文时的每一个夜晚,陷入了人生的大思考....
无论是选题还是目录,最后到论文的正文与总结,以往我们的学习方式都是通过搜索引擎进行「单方向信息获取」,大量的时间都用来检索信息,真正留给自己的思考的精力并不多。未来的学习方式定会变成基于AI的**「人机互动加速成长」**,我们通过更高效的方式来获取信息,更多精力留给自己的想法与思考。
即便你读研读博导师是个水货,从不指点你学术写作,你依然可以通过ChatGPT进行训练提高。
虽然最近很多媒体都在扬言AI取代人类的很多职业,但我想,ChatGPT不仅仅可以做为生产力工具,更可以高效的进行学习和工作,未来一定会发挥其教育的属性和价值。
毋庸置疑,人类进入了新的学习时代,新的生产力时代,我很庆幸自己生在了这个时代。
链接:https://juejin.cn/post/7199474323869532219
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我把FlutterWeb渲染模式改成Canvaskit后...
背景
用FLutterWeb开发的网站在使用过程中出现了一些问题,比如在Google浏览器中使用交互、动画流畅,在360浏览器中就卡顿;图标在代码中动态设置颜色的方式在Google浏览器中正常显示,在Safari浏览器中颜色缺失,变为黑色;在有的电脑中Google浏览器也有动画、交互卡顿的现象、页面报错等。很奇怪,一脑袋问号。
优化方案
这些问题的原因是,渲染模式为html导致的,将渲染模式由html改为canvaskit,之前遇到的问题基本就解决了,动画也不卡了,画面也流畅了,图标也正常了,兼容性也提高了,再也不用担心在老板的电脑上卡住了。
渲染模式
简单说说两种模式的区别。
html渲染模式:flutter会采用HTML的custom element,CSS,Canvas和SVG来渲染UI元素。
canvaskit渲染模式:flutter将 Skia 编译成 WebAssembly 格式,并使用 WebGL 渲染。
| html | canvaskit | |
|---|---|---|
| 命令行 | --web-renderer html | --web-renderer canvaskit |
| 优点 | 体积更小 | 渲染性能强;多端一致 |
| 缺点 | 渲染性能差;跨端兼容差 | 体积相较html多2.5M |
所以使用canvaskit会更加流畅,更符合FLutter的气质。但是!也出现了些新的问题。
由Canvaskit引起的问题
图片跨域
报错描述:
Access to XMLHttpRequest at 'https://.../icon/setting_228.webp' from origin 'https://...' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
在html模式下是正常的,而在canvaskit出现了跨域问题,查看日志发现区别。
html的网络请求类型type就是图片本身,不会出现问题。
不会出现跨域的问题原因是在HTML中,有一些标签也可以发起HTTP请求,比如script标签,link标签,img标签,form标签,且被允许跨域。
- link,img标签都是单纯的引入资源文件
- form标签用于收集用户输入并发送,但是发送成功会跳转到新网页,并将服务器响应作为新网页的内容
- script标签可以引入外部js文件,并执行引入的js文件的代码
其中,script标签由于其可以执行引入的js文件的代码,再加上其跨域特性,让script标签可以用来做一些超出其设计初衷的事。script标签会发起HTTP GET去请求服务器上的js文件,所以script标签可以用于实现HTTP GET跨域请求。
而canvaskit模式下,请求类型是xhr,不支持跨域。而我的图片地址和服务地址并不在一个域名,所以出现该问题。
原因是同源策略,它是浏览器特有的一种安全机制,主要用于限制不同的源之间的数据交互。
那如何解决呢?
询问前端大佬后,发现解决问题最快的方法就是放到自身服务的域名下。随后我把图片放在项目中的asset目录中,更改本地引用地址,打包上传部署,解决!
(PS:这个问题在本地debug模式下,并不会出现)
首次打开加载慢
在首次改成canvaskit模式部署后,打开网站,页面一度白屏很长时间,预计有10秒,查看后台日志发现是下载了很多文件,包括canvaskit绘制引擎、字体等。主要耗时是在引擎(约9M)、字体下载,而下载这些的域名都是官方的,所以下载速度也有所限制。
解决办法:
将引擎和字体传值自己的服务器,以加快下载速度。
引擎本地化,查看网络请求详情,可以看到下载地址,单独下载后放到项目中。
我的位置是web/assets/canvaskit/canvaskit.js&wasm。
再设置替换引擎路径,在运行或打包的时候加上以下命令行。等号后面为本地的路径。
--dart-define=FLUTTER_WEB_CANVASKIT_URL=assets/canvaskit/
本地化加载KFOmCnqEu92Fr1Me5WZLCzYlKw.ttf字体文件,同样在请求详情中获取地址,下载至本地,放在本地,
web/assets/canvaskit/。
替换本地地址,在构建完成后的build目录下的main.dart.js中搜索该字体名,把前缀替换成本地路径。
https://fonts.gstatic.com/s/roboto/v20/KFOmCnqEu92Fr1Me5WZLCzYlKw.ttf
替换成
assets/canvaskit/KFOmCnqEu92Fr1Me5WZLCzYlKw.ttf
字体需下载
在打开页面时,会出现字体乱码,原因是正在下载字体,而且引用的字体不一样下载的库也是不同的。同样也可以下载至本地,替换main.dart.js的地址,但下载完体验后,发现不管是第一次还是之后都会出现乱码,只是显示的时间长短,体验也是不很好。
所以我是在pubspec.yaml中设置了本地的字体包的方式解决的,这样在首次加载或后面的刷新,都未出现过乱码。
加载时提示
经过上面两步设置,首次加载时长会有大大缩减,但是也会有白屏,为了更好的体验在白屏时加个提示。
// 在 web/index.html 中的 body 标签下加提示
<div id="text">静态资源加载中...</div>浏览器刷新后页面加载两次
在使用网站时刷新会出现页面加载两次的问题,查看日志发现是web/index.html中的一段代码引起的。
// If service worker doesn't succeed in a reasonable amount of time,
// fallback to plaint <script> tag.
setTimeout(() => {
if (!scriptLoaded) {
console.warn(
'Failed to load app from service worker. Falling back to plain <script> tag.',
);
loadMainDartJs();
}
}, 4000);引起超时的原因是navigator.serviceWorker.register(serviceWorkerUrl)注册失败,而上面的代码是兜底的逻辑。serviceWorker是服务器与浏览器之间的代理,目前用不上,所以将注册逻辑注释掉,直接调用loadMainDartJs()即可。
路由包装url地址方式失效
在canvaskit模式下,刷新后不会停留在当前页面了。之前写过一篇文章《FlutterWeb浏览器刷新后无法回退的解决方案》中的方案看来只适应在html模式下。
解决办法:
在上面的的文章基础上稍微修改下。
// 刷新时回调
_beforeUnload = (event) {
// 本地记录,标记成"已刷新"
DB(DBKey.isRefresh).value = true;
// 记录刷新时的页面,用于还原(本次新增的方法)
List history = get();
DB(DBKey.initRoute).value = history.last;
history.removeLast();
set(history);
// 移除刷新前的实例的监听
html.window.removeEventListener('beforeunload', _beforeUnload);
html.window.removeEventListener('popstate', _popState);
};
// 获取上次最后的页面,(本次新增的方法)
static String initRoute(currentContext) {
return DB(DBKey.initRoute).get(Uri(scheme: RoutePath.scheme, host: RoutePath.home).toString());
}
// 初始化
MaterialApp(
.....
initialRoute: RouterHistory.initRoute(context),//(本次新增的方法)
.....
))这样设置完后也会停留在当前页面了。
最后
如果有遇到其他问题或更好的解决办法欢迎提出讨论
链接:https://juejin.cn/post/7212101192746303544
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 本地存储 —— 基本的键值对存储
前言
在原生的 Android 或 iOS 中,都提供了基本的键值对存储方式,Android 是 SharedPreferences,iOS 是 NSUserDefaults。在 Flutter 中,提供了 shared_preferences 这个插件来实现本地键值对数据存储。实际上,shared_preferences 在 Android 就是使用 SharedPreferences 实现,在 iOS 上则是使用 NSUserDefaults 实现。
基本使用
在 pubspec.yaml 文件中添加以下代码:
dependencies:
flutter:
sdk: flutter
shared_preferences: ^2.0.18我们将基础的计数应用修改为支持从上一次结果(即存储在本地的数值)开始增加。代码如下:
import 'package:flutter/material.dart';
import 'package:shared_preferences/shared_preferences.dart';
class MyApp extends StatefulWidget {
@override
_MyAppState createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
int _counter = 0;
late SharedPreferences _prefs;
@override
void initState() {
super.initState();
_loadCounter();
}
void _loadCounter() async {
_prefs = await SharedPreferences.getInstance();
setState(() {
_counter = (_prefs.getInt('counter') ?? 0);
});
}
void _incrementCounter() async {
setState(() {
_counter++;
});
await _prefs.setInt('counter', _counter);
}
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: Text('Shared Preferences 示例'),
),
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
Text(
'You have pushed the button this many times:',
),
Text(
'$_counter',
style: Theme.of(context).textTheme.headline4,
),
],
),
),
floatingActionButton: FloatingActionButton(
onPressed: _incrementCounter,
tooltip: 'Increment',
child: Icon(Icons.add),
),
),
);
}
}上面的代码是一个基础的计数器应用,我们定义了一个_counter变量来保存计数器的值,并且使用 SharedPreferences 实例来存储和检索_counter变量的值。
在initState方法中,我们使用_loadCounter方法来加载_counter变量的值。在_loadCounter方法中,我们首先使用SharedPreferences.getInstance() 方法来获取 SharedPreferences 实例,然后使用 getInt()方法来检索 _counter 变量的值。如果检索到的值为 null,则将 _counter 变量的值设置为 0。
在 _incrementCounter 方法中,我们使用了setInt方法将 _counter 变量的值保存到 SharedPreferences 实例中来实现本地存储。
运行效果如下:
存储其他类型数据
shared_preferences支持存储的数据类型有整型、浮点型(double)、字符串、布尔型和字符串数组。如果想存储对象,也可以通过 json 序列化和反序列化的方式实现。我们来看一个更复杂点的例子。
class MyApp extends StatefulWidget {
const MyApp({Key? key}) : super(key: key);
@override
_MyAppState createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
// 初始化需要存储的值
int _counter = 0;
String _username = '';
bool _isDarkModeEnabled = false;
final _textController = TextEditingController(text: '');
// SharedPreferences 实例
late SharedPreferences _prefs;
// 加载 SharedPreferences 中存储的值
Future<void> _loadData() async {
_prefs = await SharedPreferences.getInstance();
setState(() {
_counter = _prefs.getInt('counter') ?? 0;
_username = _prefs.getString('username') ?? '';
_textController.text = _username;
_isDarkModeEnabled = _prefs.getBool('isDarkModeEnabled') ?? false;
});
}
void _incrementCounter() async {
setState(() {
_counter++;
});
await _prefs.setInt('counter', _counter);
}
// 保存用户名
void _saveUsername(String username) async {
setState(() {
_username = username;
});
await _prefs.setString('username', _username);
}
// 切换暗黑模式
void _toggleDarkMode(bool isDarkModeEnabled) async {
setState(() {
_isDarkModeEnabled = isDarkModeEnabled;
});
await _prefs.setBool('isDarkModeEnabled', _isDarkModeEnabled);
}
@override
void initState() {
super.initState();
_loadData();
}
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Flutter SharedPreferences 示例',
theme: _isDarkModeEnabled ? ThemeData.dark() : ThemeData.light(),
home: Scaffold(
appBar: AppBar(
title: const Text('Flutter SharedPreferences 示例'),
),
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
Text(
'计数器的值:$_counter',
),
const SizedBox(height: 20),
TextFormField(
decoration: const InputDecoration(
labelText: '请输入您的名字',
),
controller: _textController,
onChanged: (value) {
_saveUsername(value);
},
),
const SizedBox(height: 20),
SwitchListTile(
title: const Text('启用暗黑模式'),
value: _isDarkModeEnabled,
onChanged: (value) {
_toggleDarkMode(value);
},
),
],
),
),
floatingActionButton: FloatingActionButton(
onPressed: _incrementCounter,
tooltip: '递增计数器的值',
child: const Icon(Icons.add),
),
),
);
}
}上述代码增加了两个类型的存储,分别是字符串和布尔型,存储方式其实是类似的,布尔型使用 getBool 获取、setBool 存储;字符串则是使用 getString和 setString。我们通过布尔型变量控制是否启用暗黑模式,使用字符串类存储用户名。下面是运行的结果。
总结
可以看到shared_preferences 非常简单,因此可以应用在简单的键值对存储中,典型的就是我们在本地换成后端的SessionId、记住用户名和密码、或者默认的勾选项等等。然后基于这些存储的数据做默认值显示和业务规则控制、或填充到请求表单里。对于复杂的业务对象存储,则需要使用 SQL数据库或者是 NoSQL 数据库。
链接:https://juejin.cn/post/7212548831723470907
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
究极进化版基于 dio 的网络封装库
可能是 Flutter 上最强的网络框架, 基于dio实现的非侵入式框架(不影响原有功能). 学习成本低、使用简单, 一行代码发起网络请求, 甚至无需初始化。
之前发过两篇关于封装网络库的文章:
距离最早的文章发布时间,已经过去了三年。这期间 dio 也更新到5.x.x了,在使用中也积攒了许多定制需求和优化方案。在确定需求和方案后,修修改改,终于发布了最新最实用的网络请求版本。
欢迎贡献代码/问题
特点
- 个人使用下来感觉开发效率比目前网络请求库都高:最简单易用
- 专为 Flutter 而生,支持全平台
- 遵循设计模式最佳实践,
build模式全局配置 catch请求错误,不需要开发者处理- 优秀的源码/注释/文档/示例
- 类似
kotlin的语法糖:请求结果的when语句和密封类
主要功能
- RESTful API 设计
GET/POST/PUT/HEAH/DELETE/PATCH/DOWNLOAD - 可取消请求
- 异步解析,数据量大不再卡顿
- 全局错误处理(减少崩溃率)
- 自定义解析器,支持全局和单个请求
- 自定义解析方法
- 配置请求参数
- 漂亮的日志打印
- 证书快速配置
- 代理配置
- 拦截器配置
- 强制缓存模式/自定义缓存Key/缓存有效期/LRU缓存算法/缓存任何数据
- 监听上传/下载进度
简单使用
添加依赖:
dependencies:
flutter_nb_net: ^0.0.1像 dio 一样使用,无需配置,返回实体类实现BaseNetworkModel,复写fromJson函数即可,:
class BannerModel extends BaseNetworkModel<BannerModel> {
@override
BannerModel fromJson(Map<String, dynamic> json) {
return BannerModel.fromJson(json);
}
//...
}温馨提示:dart实体类可用freezed、json_serializable生成或者JsonToDart插件一键生成。
/// Get 请求
void requestGet() async {
var appResponse = await get<BannerModel, BannerModel>("banner/json",
responseType: BannerModel());
appResponse.when(success: (BannerModel model) {
var size = model.data?.length;
debugPrint("成功返回$size条");
}, failure: (String msg, int code) {
debugPrint("失败了:msg=$msg/code=$code");
});
}get<BannerModel, BannerModel>这里有两个泛型,前者是接口返回的数据需要序列化的类型,后者是开发关注的需要返回的类型。如果数据类型一致,两个泛型就是一样的。否则,比如接口返回一个用户列表,前面泛型就是User类型,后面是List<User>;又或者接口返回的数据包了几层,我们只需要最里面的数据格式,那么前面就是需要序列化的整个数据类型,第二个泛型是最里面的数据类型。
配置使用
全局配置
在使用前进行全局配置:
NetWrapper.instance
// header
.addHeaders({"aaa": '111'})
// baseUrl
.setBaseUrl("https://www.wanandroid.com/")
// 代理/https
.setHttpClientAdapter(IOHttpClientAdapter()
..onHttpClientCreate = (client) {
client.findProxy = (uri) {
return 'PROXY 192.168.20.43:8888';
};
client.badCertificateCallback =
(X509Certificate cert, String host, int port) => true;
return client;
})
// cookie
.addInterceptor(CookieManager(CookieJar()))
// dio_http_cache
.addInterceptor(DioCacheManager(CacheConfig(
baseUrl: "https://www.wanandroid.com/",
)).interceptor)
// dio_cache_interceptor
.addInterceptor(DioCacheInterceptor(
options: CacheOptions(
store: MemCacheStore(),
policy: CachePolicy.forceCache,
hitCacheOnErrorExcept: [401, 403],
maxStale: const Duration(days: 7),
priority: CachePriority.normal,
cipher: null,
keyBuilder: CacheOptions.defaultCacheKeyBuilder,
allowPostMethod: false,
)))
// 全局解析器
.setHttpDecoder(MyHttpDecoder.getInstance())
// 超时时间
.setConnectTimeout(const Duration(milliseconds: 3000))
// 允许打印log,默认未 true
.enableLogger(true)
.create();如果接口返回的数据格式规范,配置自定义一个全局解析器 .setHttpDecoder(MyHttpDecoder.getInstance()):
/// 默认解码器
class MyHttpDecoder extends NetDecoder {
/// 单例对象
static final MyHttpDecoder _instance = MyHttpDecoder._internal();
/// 内部构造方法,可避免外部暴露构造函数,进行实例化
MyHttpDecoder._internal();
/// 工厂构造方法,这里使用命名构造函数方式进行声明
factory MyHttpDecoder.getInstance() => _instance;
@override
K decode<T extends BaseNetworkModel, K>(
{required Response<dynamic> response, required T responseType}) {
var errorCode = response.data['errorCode'];
/// 请求成功
if (errorCode == 0) {
var data = response.data['data'];
if (data is List) {
var dataList = List<T>.from(
data.map((item) => responseType.fromJson(item)).toList()) as K;
return dataList;
} else {
var model = responseType.fromJson(data) as K;
return model;
}
} else {
var errorMsg = response.data['errorMsg'];
throw NetException(errorMsg, errorCode);
}
}
}如果添加缓存,可以使用dio_cache_interceptor、dio_http_cache等 dio 推荐的缓存库。
// dio_http_cache
.addInterceptor(DioCacheManager(CacheConfig(
baseUrl: "https://www.wanandroid.com/",
)).interceptor)
// dio_cache_interceptor
.addInterceptor(DioCacheInterceptor(
options: CacheOptions(
store: MemCacheStore(),
policy: CachePolicy.forceCache,
hitCacheOnErrorExcept: [401, 403],
maxStale: const Duration(days: 7),
priority: CachePriority.normal,
cipher: null,
keyBuilder: CacheOptions.defaultCacheKeyBuilder,
allowPostMethod: false,
)))因为dio_http_cache依赖的dio和json_annotation是旧版本,所以如果使用dio_http_cache需要解决下依赖冲突:
dependency_overrides:
dio: ^5.0.3
json_annotation: ^4.8.0配置代理和证书:
.setHttpClientAdapter(IOHttpClientAdapter()
..onHttpClientCreate = (client) {
client.findProxy = (uri) {
return 'PROXY 192.168.20.43:8888';
};
client.badCertificateCallback =
(X509Certificate cert, String host, int port) => true;
return client;
})配置cookie:
addInterceptor(CookieManager(CookieJar()))开启 log,默认开启:
.enableLogger(true)特殊配置
有的接口比较特殊,比如返回的数据格式是特殊的,需要单独解析,此时有两种方法实现,第一种适合多个相同的特殊接口,在请求时传入自定义的解析器,第二种是在回调中解析。
解析器httpDecode:
var appResponse = await get<BannerBean, List<BannerBean>>("banner/json",
responseType: BannerBean(), httpDecode: MyHttpDecoder.getInstance());
appResponse.when(success: (List<BannerBean> model) {
var size = model.length;
debugPrint("成功返回$size条");
}, failure: (String msg, int code) {
debugPrint("失败了:$msg");
});回调converter:
var appResponse = await get<BannerModel, List<BannerBean>>("banner/json",
options: buildCacheOptions(const Duration(days: 7)),
responseType: BannerModel(), converter: (response) {
var errorCode = response.data['errorCode'];
/// 请求成功
if (errorCode == 0) {
var data = response.data['data'];
var dataList = List<BannerBean>.from(
data.map((item) => BannerBean.fromJson(item)).toList());
return Result.success(dataList);
} else {
var errorMsg = response.data['errorMsg'];
return Result.failure(msg: errorMsg, code: errorCode);
}
});
appResponse.when(success: (List<BannerBean> model) {
debugPrint("成功返回${model.length}条");
}, failure: (String msg, int code) {
debugPrint("失败了:msg=$msg/code=$code");
});名字的由来
一开始这个库的名字是net,这是我第一次在 pub 上发布,不知道库名称不能重合的规则,一直失败:
`xxx@gmail.com` has insufficient permissions to upload new versions to existing package `net`.说明 pub 上已经有了这个名字的库,改名flutter_net,依然失败:
`xxx@gmail.com` has insufficient permissions to upload new versions to existing package `flutter_net`.
最后改名为flutter_nb_net,终于发布成功了。
链接:https://juejin.cn/post/7212597327579332668
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从Flutter到Compose,为什么都在推崇声明式UI?
Compose推出之初,就曾引发广泛的讨论,其中一个比较普遍的声音就是——“🤨这跟Flutter也长得太像了吧?!”
这里说的长得像,实际更多指的是UI编码的风格相似,而关于这种风格有一个专门的术语,叫做声明式UI。
对于那些已经习惯了命令式UI的Android或iOS开发人员来说,刚开始确实很难理解什么是声明式UI。就像当初刚踏入编程领域的我们,同样也很难理解面向过程编程和面向对象编程的区别一样。
为了帮助这部分原生开发人员完成从命令式UI到声明式UI的思维转变,本文将结合示例代码编写、动画演示以及生活例子类比等形式,详细介绍声明式UI的概念、优点及其应用。
照例,先奉上思维导图一张,方便复习:
命令式UI的特点
既然命令式UI与声明式UI是相对的,那就让我们先来回顾一下,在一个常规的视图更新流程中,如果采用的是命令式UI,会是怎样的一个操作方式。
以Android为例,首先我们都知道,Android所采用的界面布局,是基于View与ViewGroup对象、以树状结构来进行构建的视图层级。
当我们需要对某个节点的视图进行更新时,通常需要执行以下两个操作步骤:
- 使用findViewById()等方法遍历树节点以找到对应的视图。
- 通过调用视图对象公开的setter方法更新视图的UI状态
我们以一个最简单的计数器应用为例:
这个应用唯一的逻辑就是“当用户点击"+"号按钮时数字加1”。在传统的Android实现方式下,代码应该是这样子的:
class CounterActivity : AppCompatActivity() {
var count: Int = 0
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_counter)
val countTv = findViewById<TextView>(R.id.count_tv)
countTv.text = count.toString()
val plusBtn = findViewById<Button>(R.id.plus_btn)
plusBtn.setOnClickListener {
count += 1
countTv.text = count.toString()
}
}
}这段代码看起来没有任何难度,也没有明显的问题。但是,假设我们在下一个版本中添加了更多的需求:
- 当用户点击"+"号按钮,数字加1的同时在下方容器中添加一个方块。
- 当用户点击"-"号按钮,数字减1的同时在下方容器中移除一个方块。
- 当数字为0时,下方容器的背景色变为透明。
现在,我们的代码变成了这样:
class CounterActivity : AppCompatActivity() {
var count: Int = 0
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_counter)
// 数字
val countTv = findViewById<TextView>(R.id.count_tv)
countTv.text = count.toString()
// 方块容器
val blockContainer = findViewById<LinearLayout>(R.id.block_container)
// "+"号按钮
val plusBtn = findViewById<Button>(R.id.plus_btn)
plusBtn.setOnClickListener {
count += 1
countTv.text = count.toString()
// 方块
val block = View(this).apply {
setBackgroundColor(Color.WHITE)
layoutParams = LinearLayout.LayoutParams(40.dp, 40.dp).apply {
bottomMargin = 20.dp
}
}
blockContainer.addView(block)
when {
count > 0 -> {
blockContainer.setBackgroundColor(Color.parseColor("#FF6200EE"))
}
count == 0 -> {
blockContainer.setBackgroundColor(Color.TRANSPARENT)
}
}
}
// "-"号按钮
val minusBtn = findViewById<Button>(R.id.minus_btn)
minusBtn.setOnClickListener {
if(count <= 0) return@setOnClickListener
count -= 1
countTv.text = count.toString()
blockContainer.removeViewAt(0)
when {
count > 0 -> {
blockContainer.setBackgroundColor(Color.parseColor("#FF6200EE"))
}
count == 0 -> {
blockContainer.setBackgroundColor(Color.TRANSPARENT)
}
}
}
}
}已经开始看得有点难受了吧?这正是命令式UI的特点,侧重于描述怎么做,我们需要像下达命令一样,手动处理每一项UI的更新,如果UI的复杂度足够高的话,就会引发一系列问题,诸如:
- 可维护性差:需要编写大量的代码逻辑来处理UI变化,这会使代码变得臃肿、复杂、难以维护。
- 可复用性差:UI的设计与更新逻辑耦合在一起,导致只能在当前程序使用,难以复用。
- 健壮性差:UI元素之间的关联度高,每个细微的改动都可能一系列未知的连锁反应。
声明式UI的特点
而同样的功能,假如采用的是声明式UI,则代码应该是这样子的:
class _CounterPageState extends State<CounterPage> {
int _count = 0;
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text(widget.title),
),
body: Column(
children: [
// 数字
Text(
_count.toString(),
style: const TextStyle(fontSize: 48),
),
Row(
mainAxisSize: MainAxisSize.min,
children: [
// +"号按钮
ElevatedButton(
onPressed: () {
setState(() {
_count++;
});
},
child: const Text("+")),
// "-"号按钮
ElevatedButton(
onPressed: () {
setState(() {
if (_count == 0) return;
_count--;
});
},
child: const Text("-"))
],
),
Expanded(
// 方块容器
child: Container(
width: 60,
padding: const EdgeInsets.all(10),
color: _count > 0 ? const Color(0xFF6200EE) : Colors.transparent,
child: ListView.separated(
itemCount: _count,
itemBuilder: (BuildContext context, int index) {
// 方块
return Container(width: 40, height: 40, color: Colors.white);
},
separatorBuilder: (BuildContext context, int index) {
return const Divider(color: Colors.transparent, height: 10);
},
),
))
],
),
);
}
}
在这样的代码中,我们几乎看不到任何操作UI更新的代码,而这正是声明式UI的特点,它侧重于描述做什么,而不是怎么做,开发者只需要关注UI应该如何呈现,而不需要关心UI的具体实现过程。
开发者要做的,就只是提供不同UI与不同状态之间的映射关系,而无需编写如何在不同UI之间进行切换的代码。
所谓状态,指的是构建用户界面时所需要的数据,例如一个文本框要显示的内容,一个进度条要显示的进度等。Flutter框架允许我们仅描述当前状态,而转换的工作则由框架完成,当我们改变状态时,用户界面将自动重新构建。
下面我们将按照通常情况下,用声明式UI实现一个Flutter应用所需要经历的几个步骤,来详细解析前面计数器应用的代码:
- 分析应用可能存在的各种状态
根据我们前面对于“状态”的定义,我们可以很容易地得出,在本例中,数字(_count值)本身即为计数器应用的状态,其中还包括数字为0时的一个特殊状态。
- 提供每个不同状态所对应要展示的UI
build方法是将状态转换为UI的方法,它可以在任何需要的时候被框架调用。我们通过重写该方法来声明UI的构造:
对于顶部的文本,只需声明每次都使用最新返回的状态(数字)即可:
Text(
_count.toString(),
...
),对于方块容器,只需声明当_count的值为0时,容器的背景颜色为透明色,否则为特定颜色:
Container(
color: _count > 0 ? const Color(0xFF6200EE) : Colors.transparent,
...
)对于方块,只需声明返回的方块个数由_count的值决定:
ListView.separated(
itemCount: _count,
itemBuilder: (BuildContext context, int index) {
// 方块
return Container(width: 40, height: 40, color: Colors.white);
},
...
),- 根据用户交互或数据查询结果更改状态
当由于用户的点击数字发生变化,而我们需要刷新页面时,就可以调用setState方法。setState方法将会驱动build方法生成新的UI:
// "+"号按钮
ElevatedButton(
onPressed: () {
setState(() {
_count++;
});
},
child: const Text("+")),
// "-"号按钮
ElevatedButton(
onPressed: () {
setState(() {
if (_count == 0) return;
_count--;
});
},
child: const Text("-"))
],可以结合动画演示来回顾这整个过程:
最后,用一个公式来总结一下UI、状态与build方法三者的关系,那就是:
以命令式和声明式分别点一杯奶茶
现在,你能了解命令式UI与声明式UI的区别了吗?如果还是有些抽象,我们可以用一个点奶茶的例子来做个比喻:
当我们用命令式UI的思维方式去点一杯奶茶,相当于我们需要告诉制作者,冲一杯奶茶必须按照煮水、冲茶、加牛奶、加糖这几个步骤,一步步来完成,也即我们需要明确每一个步骤,从而使得我们的想法具体而可操作。
而当我们用声明式UI的思维方式去点一杯奶茶,则相当于我们只需要告诉制作者,我需要一杯“温度适中、口感浓郁、有一点点甜味”的奶茶,而不必关心具体的制作步骤和操作细节。
声明式编程的优点
综合以上内容,我们可以得出声明式UI有以下几个优点:
简化开发:开发者只需要维护状态->UI的映射关系,而不需要关注具体的实现细节,大量的UI实现逻辑被转移到了框架中。
可维护性强:通过函数式编程的方式构建和组合UI组件,使代码更加简洁、清晰、易懂,便于维护。
可复用性强:将UI的设计和实现分离开来,使得同样的UI组件可以在不同的应用程序中使用,提高了代码的可复用性。
总结与展望
总而言之,声明式UI是一种更加高层次、更加抽象的编程方式,其最大的优点在于能极大地简化现有的开发模式,因此在现代应用程序中得到广泛的应用,随着更多框架的采用与更多开发者的加入,声明式UI必将继续发展壮大,成为以后构建用户界面的首选方式。
链接:https://juejin.cn/post/7212622837063811109
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android本地化适配之ICU接口
背景:
在多语言项目中,我们经常会遇到本地化适配不规范导致的问题。例如 月份翻译错误、数字显示格式不正确 或者 数字显示形式与本地习惯不符 等。为了寻求一种更精准高效的适配方案,我在网上查阅了相关资料。发现Google提供了一个本地化API接口——ICU API。它可以利用ICU和CLDR提供Unicode和其他国际化支持。从而提升软件的本地化质量。
本地化适配场景
本地化适配所涉及到的问题,基本上都可以归纳为:在不同的语言和地区,同一个信息所显示翻译不同、格式不同或者一个事物表现规则不同。通过归纳总结,我们把常见的本地化适配分为以下几个类型:时间信息、数字信息、文件大小及其单位、历法规则、测量单位和时区信息。
本地化接口使用
针对以上所述本地化场景,我们分别介绍相关接口以及接口使用方法。
常见格式如日期、单位等,在 data/locales 目录中有详细说明。,我们可以下载 data/locales/zh.txt 文件查看不同标签对应内容含义。
例如我们要查看星期在各国翻译下的内容:
- 首先我们在
data/locales/zh.txt中查找星期一对应标签dayNames下面。其中wide表示全称,short表示简称。 - 打开
data/locales其它国家对应语言码txt文件。比如查看法语下翻译情况时打开fr.txt文件。 - 同样查找
dayNames标签对应翻译,并与手机上显示翻译比对是否一致。
除了 data/locales 目录外还有几个目录需要关注:
- data/unit 常用单位
- data/curr 货币单位
- data/lang 语言描述
时间日期格式
DateFormat#getInstanceForSkeleton 、SimpleDateFormat.getDateInstance
说明:
1.这些接口能够解决x年x月x日星期x x时x分x秒这类时间信息格式问题。比如年月日出现先后顺序不同情况。这个格式与本地人使用习惯相关。
好的,我已经输出了你的文章的前半部分,下面是后半部分:
因此使用这个接口能够很好地解决时间显示格式问题。
时间日期格式
DateFormat#getInstanceForSkeleton 、SimpleDateFormat.getDateInstance
说明:
1.这些接口能够解决 x年x月x日 、星期x 、x时x分x秒 这类时间信息格式问题。比如年月日出现先后顺序不同情况,这个格式与本地人使用习惯是相关的。因此使用这个接口能够很好地解决时间显示格式问题。
2.同时这个接口 还能解决时间表述中翻译问题,不用再单独考虑翻译问题。 这个翻译的准确度,往往要高于翻译公司的准确度。
3.使用其中一些特殊接口能够解决一些特殊字串翻译问题。比如使用以下接口可以获取 星期一 、 二月 等相关特殊时间在本地语言翻译字符。这个翻译准确度往往高于翻译公司准确度。希望有类似字串显示场景可以研究这个接口并进行使用。developer.android.com/reference/j…
以下只就说明进行一个简单举例:下面的getDateInstance可以不传第二个参数,那么就会根据当前系统预设来输出结果。
DateFormat df = DateFormat.getDateInstance(DateFormat.LONG, Locale.FRANCE);
myDate = df.parse(myString);
...
January 12, 1952具体格式由第一个参数控制,模块可根据需求自行定制,给出以下使用案例
DateFormat.getInstanceForSkeleton(DateFormat.ABBR_MONTH_DAY, Locale.getDefault()).format(new Date());
...
3月16日
Mar 16
DateFormat.getInstanceForSkeleton(DateFormat.MONTH_WEEKDAY_DAY, Locale.getDefault()).format(new Date());
...
3月16日星期四
Thursday,March 16
DateFormat.getInstanceForSkeleton("MMMEdd", locale1).format(new Date());
...
3月16日星期四
Thursday,Mar 16
DateFormat.getInstanceForSkeleton(DateFormat.YEAR_MONTH_DAY, Locale.getDefault()).format(new Date());
DateFormat.getInstanceForSkeleton(DateFormat.YEAR_MONTH_DAY, Locale.ENGLISH).format(new Date());
...
2023年3月16
March 16,2023
DateFormat.getInstanceForSkeleton("yyyyMMdd", Locale.getDefault()).format(new Date());
...
2023/03/16
03/16/2023
DateFormat.getInstanceForSkeleton("hhmma", Locale.getDefault()).format(new Date());
...
下午7:51
7:51 PM
SimpleDateFormat.getDateInstance(DateFormat.MEDIUM, Locale.getDefault()).format(new Date());
...
2023年03月16日
Mar 16, 2023
// 使用工具类
DateUtils.formatDateTime(context, time, DateUtils.FORMAT_ABBREV_MONTH);
DateUtils.formatDateTime(context, time, DateUtils.FORMAT_SHOW_YEAR);日期/时间区间:
DateInterval dateInterval = new DateInterval(time1, time2);
DateIntervalFormat.getInstance(DateFormat.YEAR_ABBR_MONTH_DAY, Locale.getDefault()).format(dateInterval, new StringBuffer(""), new FieldPosition(0));
...
2023年3月16日至7月16日
Mar 16 – Jul 16, 2023数字信息格式
NumberFormat#getInstance、NumberFormat#getCurrencyInstance、NumberFormat#getPercentInstance
说明:
1.这些接口能够解决数字信息格式问题。比如数字显示形式应该是本地字母而不是阿拉伯数字、小数点和千分位符号位置不同等。
2.同时这些接口还能解决货币单位和百分比符号的本地化显示问题。
3.使用其中一些特殊接口还能解决一些特殊数字信息的本地化显示问题。比如使用以下接口可以获取本地语言对应的序数词(第一、第二等)或者序列号(1st、2nd等)。
以下只就说明进行一个简单举例:下面的getInstance可以不传参数,那么就会根据当前系统预设来输出结果。
NumberFormat nf = NumberFormat.getInstance(Locale.FRENCH);
myNumber = nf.parse(myString); 输出当地习惯显示的数字格式,或者当地文字
NumberFormat.getInstance(Locale.getDefault()).format(100001.23);
...
100,000.89
100,000.89
DecimalFormat.getPercentInstance(Locale.getDefault()).format(0.53);
...
53%
53%
CompactDecimalFormat.getInstance(locale, CompactDecimalFormat.CompactStyle.SHORT).format(100000);
...
10万
100K文件大小及其单位格式
FileSizeUtils#formatFileSize(Context context,long numberBytes)
说明:
1.这个接口能够解决文件大小及其单位格式问题。比如文件大小显示形式应该是KB而不是kB、单位之间是否有空格等。
2.同时这个接口还能根据当前系统预设自动选择合适的单位和精度来显示文件大小。
给出一个简单举例:
public static String formatFileSize(Context context, long sizeBytes); 将内容大小格式化为字节、千字节、兆字节等形式。 显示的数字,会根据当地习惯,用逗号分开,或者用点号隔开,或者数字用当地字母显示。 文件大小的单位,也会根据当地习惯显示为Mb或者MB等不同形式。
developer.android.com/reference/a…
Android O开始使用标准的单位制 1KB = 1000 bytes
Formatter.formatFileSize(this, 15345);
...
//15.35 KB
//乌克兰语 15,61 КБ
Formatter.formatShortFileSize(this, 15612524);
...
16 MB
16 MB
16 КБ测量单位
MeasureFormat
在需要显示测量单位的场景,可以使用此接口做好本地化信息展示。以下简单介绍毫升的显示。同样的,其他测量单位,都可以采用类似的方式获取, 只是把参数替换一下即可。
说明: 对于长度,质量,体积,货币、卡路里、ml等测量单位的本地化显示。目前基本都基于翻译拼接来完成。后面建议使用google官方接口来实现。 1.数字+单位
支持的测量单位可参考developer.android.google.cn/reference/a… ,调整传参即可
Measure measure = new Measure(30.5, MeasureUnit.CELSIUS);
MeasureFormat.getInstance(Locale.getDefault(),MeasureFormat.FormatWidth.SHORT).format(measure);
...
30.5°C
30.5°C
Measure measure = new Measure(30.5, MeasureUnit.HOUR);
MeasureFormat.getInstance(Locale.getDefault(),MeasureFormat.FormatWidth.SHORT).format(measure);
...
30.5小时
30.5hr
Measure measure = new Measure(224, MeasureUnit.GIGABYTE);
MeasureFormat.getInstance(Locale.getDefault(),MeasureFormat.FormatWidth.SHORT).format(measure);
...
**224吉字节****数字单位常量中文与预期不符,可能需要单独处理**
224GB针对部分场景,需要区分数字和单位大小,可以结合MeasureFormat和NumberFormat,分别拿到完整字符串和数字部分字符串,计算index后设置样式即可(注意:不要拆分成两个字符串分别布局)
NumberFormat instance = NumberFormat.getInstance(Locale.getDefault());
String celsius = MeasureFormat.getInstance(Locale.getDefault(), MeasureFormat.FormatWidth.SHORT, instance).formatMeasures(measure);
String number = instance.format(30.5);
SpannableString spannableString = new SpannableString(celsius);
spannableString.setSpan(new AbsoluteSizeSpan(30, true), celsius.indexOf(number), celsius.indexOf(number) + number.length(), 0);
textView.setText(spannableString);
日期格式符号
说明:获取星期、月份列表等,支持获取format形式和standalone形式,wide、narrow、short
DateFormatSymbols dateFormatSymbols = new DateFormatSymbols(Locale.getDefault);
dateFormatSymbols.getWeekdays();
dateFormatSymbols.getWeekdays(DateFormatSymbols.STANDALONE,DateFormatSymbols.WIDE);
dateFormatSymbols.getMonths();
接口记录:
1、TextUtils#expandTemplate developer.android.google.cn/reference/k…
// string.xml
<string name="storage_size_large_alternate"><xliff:g id="number" example="128">^1</xliff:g> <font size="15"><xliff:g id="unit" example="KB">^2</xliff:g></font></string>
TextUtils.expandTemplate(getText(R.string.storage_size_large_alternate), "128", "GB");
常见问题FAQ
链接:https://juejin.cn/post/7211745375921029181
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于ChatGPT-4,你需要知道什么?
关于ChatGPT-4,你需要知道什么?
开启对话式AI的未来:特性、应用和伦理考虑
ChatGPT-4正以其先进的自然语言理解能力, 改进的上下文保留和更像人类的反应, 对话式AI的世界进行革命. 作为OpenAI开创性的ChatGPT-3的继任者, ChatGPT-4在AI领域树立了新的基准, 在各种应用中为用户提供无缝和高度互动的体验.
自GPT-2推出以来, AI语言模型在理解和生成类似人类的文本的能力方面已经取得了长足的进步. 通过ChatGPT-3, OpenAI推动了AI能够实现的边界, 现在, ChatGPT-4更进一步, 有望实现前所未有的性能改进, 并在AI领域开辟新的可能性.
本文全面介绍了ChatGPT-4的主要特性和改进, 其广泛的应用和用例, 以及围绕该技术的伦理考虑. 无论你是AI爱好者, 开发者还是企业主, 本文将帮助你了解ChatGPT-4是如何改变我们与技术互动的方式, 以及它对各行业的潜在影响.
一 特性和改进
ChatGPT-4最显著的进步之一是它能够产生更自然和类似人类的反应. 通过利用最先进的机器学习算法和大量的训练数据, AI模型现在可以有效地进行复杂的对话, 表现出同情心, 甚至在适当的时候表现出幽默感.
ChatGPT-4对成语表达, 俚语和俗语有更好的理解, 使其在处理不同的沟通方式时更具适应性和通用性. 这种改进的语言理解确保用户可以更自然地与AI模型交谈, 而不必为适应技术而调整他们的语言.
为了提供真正的个性化体验, ChatGPT-4可以根据个人用户的喜好和沟通方式进行定制. 通过先进的机器学习技术, AI模型可以从用户的输入中学习, 并相应地调整其反应, 确保每次互动都感觉真实和定制.
ChatGPT-4的情境感知个性化使它能够理解不同用户情境的细微差别, 如专业, 休闲或教育环境. 这使AI模型能够根据情况调整其语气和风格, 为用户提供更有亲和力和符合背景的对话体验.
二 应用和用例
客户支持和服务 ChatGPT-4可以集成到客户支持系统中, 提供即时, 高效和准确的援助, 减少等待时间, 提高客户满意度. 其先进的语言理解和个性化功能使它能够处理各种查询, 并为用户提供量身定做的解决方案.
内容创作和编辑 ChatGPT-4可以帮助作家, 营销人员和内容创作者生成高质量, 有创意和有吸引力的内容, 从博客文章到社交媒体帖子. 其先进的语言能力可以帮助用户克服写作障碍, 完善他们的想法, 并产生引人注目的内容, 与他们的观众产生共鸣.
虚拟助理 ChatGPT-4增强的对话能力使其成为支持虚拟助手的理想候选者, 为用户提供了与数字伙伴之间更直观, 更像人类的互动. 从安排约会到回答问题和提供建议, ChatGPT-4使虚拟助理变得更有帮助和更全面.
电子学习和辅导 ChatGPT-4的高级语言理解和上下文感知的个性化, 可以用来创建互动和自适应的电子学习平台. 人工智能模型可以帮助学生按照自己的节奏学习, 回答问题, 提供反馈, 并根据他们的独特需求和能力提供个性化的学习路径.
三 伦理顾虑和AI安全
解决人工智能系统中的偏见 OpenAI致力于确保ChatGPT-4的开发是负责任的, 符合道德的. AI系统的主要问题之一是训练数据中存在的偏见, 这可能会导致有偏见的输出. OpenAI积极致力于减少这些偏见, 完善训练过程, 利用多样化和有代表性的数据源, 并不断迭代模型以解决已发现的问题.
隐私和数据保护 随着ChatGPT-4这样的AI模型越来越普遍, 对用户隐私和数据保护的关注也越来越重要. OpenAI遵守严格的数据保护准则, 并确保用户数据得到负责任和安全的处理, 符合相关法规和最佳做法.
防止误用和内容审核 OpenAI认识到滥用AI技术的潜在风险, 如ChatGPT-4. 为了减少这些风险, OpenAI实施了强大的内容审核和滥用预防措施, 确保AI模型的使用是负责任的, 并遵循道德准则.
正在进行的研究和合作 OpenAI致力于推进人工智能安全研究, 解决与部署ChatGPT-4等AI系统相关的挑战, 并促进与其他研究机构, 行业利益相关者和公众的合作. 通过分享知识和合作, AI社区可以为AI安全和伦理制定最佳实践.
四 挑战和未来方向
ChatGPT-4的其余局限性 尽管有了显著的进步, ChatGPT-4仍然有局限性, 比如它的反应偶尔会有不准确或不一致的地方. OpenAI继续致力于完善该模型以解决这些问题并提高其整体性能.
进一步发展的机会 随着AI技术的不断发展, 将不断有机会增强ChatGPT-4的能力, 扩大其应用范围, 并解决其限制. 该模型的未来迭代可能具有更强的语言理解, 语境保持和个性化能力.
五 总结
ChatGPT-4是对话式AI领域的一个重要里程碑, 为用户提供了增强的类人互动和广泛的潜在应用. 其先进的功能和改进有希望改变行业, 彻底改变我们的沟通方式, 并塑造AI驱动的未来体验.
OpenAI邀请用户探索和参与ChatGPT-4, 提供宝贵的反馈和见解, 这将有助于塑造这一突破性技术的持续发展.
随着我们继续见证像ChatGPT-4这样的AI技术的快速发展, 我们必须对这些进展的道德和社会影响保持警惕. 通过促进合作, 透明度和对负责任的发展的共同承诺, 我们可以确保AI技术服务于更大的利益, 并释放其全部潜力以造福人类.
链接:https://juejin.cn/post/7211506841691750437
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【Flutter基础】Dart中的并发Isolate
前言
说到 Flutter 中的异步,我想大家都不陌生。一般我们使用 Future、async-await 来进行网络请求、文件读取等异步加载,但要提到 Isolate ,大家就未必能够说的明白了,今天我就带大家了解下 Dart 中的并发 Isolate。
一、Isolate的基本用法
1.1 Isolate的基本用法
对于 Isolate ,我们一般通过 Isolate.spawn() 来实现并发处理。
const String downloadLink = '下载链接';
final resultPort = ReceivePort();
await Isolate.spawn(readAndParseJson, [resultPort.sendPort, downloadLink]);
String fileContent = await resultPort.first as String;
print('展示文件内容: $fileContent');Isolate.spawn() 内部传递一个 entryPoint 初始化函数,用于执行异步操作。这里我们定义 readAndParseJson 函数,通过设置 延迟2秒 来模拟文件读取。
Future<void> readAndParseJson(List<dynamic> args) async {
SendPort resultPort = args[0];
String fileLink = args[1];
print('获取下载链接: $fileLink');
String fileContent = '文件内容';
await Future.delayed(const Duration(seconds: 2));
Isolate.exit(resultPort, fileContent);
}运行结果:
1.2 Isolate的异常处理
由于 Isolate 开启的是一块新的隔离区,完全和启动的 Isolate 独立,自然是无法通过 try-catch 进行捕获。
好在 Isolate 提供了异常通知的能力,我们依旧可以通过 ReceivePort 来接收 Isolate 产生的异常,代码如下所示:
const String downloadLink = '下载链接';
final resultPort = ReceivePort();
await Isolate.spawn(
readAndParseJsonWithErrorHandle,
[resultPort.sendPort, downloadLink],
onError: resultPort.sendPort,
onExit: resultPort.sendPort,
);
// 获取结果
final response = await resultPort.first;
if (response == null) { // 没有消息
print('没有消息');
} else if (response is List) { // 异常消息
final errorAsString = response[0]; //异常
final stackTraceAsString = response[1]; // 堆栈信息
print('error: $errorAsString \nstackTrace: $stackTraceAsString');
} else { // 正常消息
print(response);
}在readAndParseJsonWithErrorHandle 函数中,我们通过手动 throw Exception 来触发异常处理。
Future<void> readAndParseJsonWithErrorHandle(List<dynamic> args) async {
SendPort resultPort = args[0];
String fileLink = args[1];
String newLink = '文件链接';
await Future.delayed(const Duration(seconds: 2));
throw Exception('下载失败');
Isolate.exit(resultPort, newLink);
}运行结果:
1.3 Isolate.run()
如果我们每次使用时都需要通过 ReceivePort 来实现 Isolate 的消息通信,这样会过于繁琐。好在官方也考虑到了这个问题,通过提供 Isolate.run() 来直接获取返回值:
注意:该方法需要在 Dart 2.19 以上的版本使用,对应 Flutter 3.7.0 以上。
const String downloadLink = '下载链接';
String fileContent = await Isolate.run(() => handleReadAndParseJson(downloadLink));
print('展示文件内容: $fileContent');
/// 处理读取并解析文件内容
Future<String> handleReadAndParseJson(String fileLink) async {
print('获取下载链接: $fileLink');
String fileContent = '文件内容';
await Future.delayed(const Duration(seconds: 2));
return fileContent;
}其原理就是内部通过对 Isolate.spawn() 进行封装,通过 Completer 来实现 Future 的异步回调。关键代码如下:
var result = Completer<R>();
var resultPort = RawReceivePort();
...
try {
Isolate.spawn(_RemoteRunner._remoteExecute,
_RemoteRunner<R>(computation, resultPort.sendPort),
onError: resultPort.sendPort,
onExit: resultPort.sendPort,
errorsAreFatal: true,
debugName: debugName)
.then<void>((_) {}, onError: (error, stack) {
// Sending the computation failed asynchronously.
// Do not expect a response, report the error asynchronously.
resultPort.close();
result.completeError(error, stack);
});
} on Object {
// Sending the computation failed synchronously.
// This is not expected to happen, but if it does,
// the synchronous error is respected and rethrown synchronously.
resultPort.close();
rethrow;
}
Tip:从官方的源码中我们可以学到,在调用
Isolate.spawn()时,建议通过tray-catch捕获可能发生的异常,并且在最后需要关闭 ReceivePort 避免内存泄漏。
二、Flutter中的compute
除了上述在 Dart 中的用法外,我们还可以在 Flutter 中通过 compute() 来实现。并且这也是官方推荐的用法,因为 compute() 允许在非原生平台 Web 上运行。
官方原文:If you’re using Flutter, consider using Flutter’s
compute()function instead ofIsolate.run(). Thecomputefunction allows your code to work on both native and non-native platforms. UseIsolate.run()when targeting native platforms only for a more ergonomic API.
2.1 compute的使用
和 Isolate.run() 的使用方式类似,通过传入 callback 函数让 Isolate 执行:
String content = await compute((link) async {
print('开始下载: $link');
await Future.delayed(const Duration(seconds: 2));
return '下载的内容';
}, '下载链接');
print('完成下载: $content');运行结果:
Tip:在引入 Flutter 包之前,我们可以直接右键
run 'islate.dart' with Coverage在Coverage 运行;在引入 Flutter 包之后,我们就需要在手机上运行,可以通过命令:open -a simulator启动一个 iOS 模拟器运行。
2.2 compute的异常处理
查看 compute() 源码发现,内部使用的是 Isolate.run(),而 Isolate.run() 内部是通过 Completer 来完成异步回调的。因此,我们直接通过 try-catch 即可捕获异常:
try {
await compute((link) async {
await Future.delayed(const Duration(seconds: 2));
throw Exception('下载失败');
}, '下载链接');
} catch (e) {
print('error: $e');
}
print('结束');运行结果:
2.3 compute的源码分析
compute() 实际是对 isolates.compute 的实例化:
const ComputeImpl compute = isolates.compute;而 Isolates 却是通过不同的平台来指定引入的类,这样也印证了为什么官方推荐在 Flutter 中使用 compute()。
import '_isolates_io.dart'
if (dart.library.js_util) '_isolates_web.dart' as isolates;在 _isolates_io.dart 中是通过 Isolate.run() 来实现:
Future<R> compute<Q, R>(isolates.ComputeCallback<Q, R> callback, Q message, {String? debugLabel}) async {
debugLabel ??= kReleaseMode ? 'compute' : callback.toString();
return Isolate.run<R>(() {
return callback(message);
}, debugName: debugLabel);
}在 _isolates_web.dart 中是通过 await null; 抽取单帧来执行函数:
Future<R> compute<Q, R>(isolates.ComputeCallback<Q, R> callback, Q message, { String? debugLabel }) async {
// To avoid blocking the UI immediately for an expensive function call, we
// pump a single frame to allow the framework to complete the current set
// of work.
await null;
return callback(message);
}2.4 compute小结
- 因为
compute()需要引入 flutter/foundation.dart,所以只能在 Flutter 中运行。 - 在 Flutter 中推荐使用
compute()来实现,因为兼容 Web 平台。 - 其内部实现:在平台侧通过
Isolate.run(),在 Web 侧通过await null;抽取单帧来执行函数。
三、Isolate 的工作原理
在 Dart 中,Isolate 是一种类似于线程的概念,可以独立于其他 Isolate 运行,并且具有自己的堆栈和内存空间。这使得 Isolate 可以并行执行代码,并且不会受到其他 Isolate 的影响。
3.1 Future 为何还是会导致卡顿?
有时候我们可能会困惑,为什么明明已经使用了 Future 来异步执行任务,还是会出现卡顿的现象。那是因为 Dart 是单线程的,如果在执行 Future 时遇到耗时的计算任务或者 I/O操作,这些操作会占用当前线程的资源,从而导致应用出现卡顿现象,影响用户体验。
相比之下,Isolate 可以实现多线程并发执行任务,可以利用多核 CPU,因此可以更有效地处理大规模的计算密集型任务、I/O 密集型任务以及处理需要大量计算的算法等。在 Isolate 中执行任务不会占用 UI 线程的资源,从而可以保证应用的流畅性和响应速度。
3.2 Isolate 的工作原理
Isolate 的工作原理是通过使用 Dart 的隔离机制来实现的。每个 Isolate 都运行在独立的隔离环境中,并且与其他 Isolate 共享代码的副本。这意味着Isolate之间不能直接共享数据,而必须使用消息传递机制来进行通信。
其实我们在执行 main() 时,就开始了主 Isolate 的运行,如下图所示:
3.3 Isolate 的生命周期
Isolate的生命周期可以分为三个阶段:创建、运行和终止。
- 创建阶段:使用
Isolate.spawn()方法可以创建一个新的 Isolate,并且将一个函数作为参数传递给这个方法。这个函数将作为新的 Isolate 的入口点,也就是 Isolate 启动时第一个执行的函数。创建 Isolate 时还可以指定其他参数,例如 Isolate 的名称、是否共享代码等等。 - 运行阶段:一旦创建了 Isolate,它就会开始执行入口点函数,并且进入事件循环。在事件循环中,Isolate 会不断地从消息队列中获取消息,并且根据消息的类型执行相应的代码。Isolate 可以同时执行多个任务,并且可以通过消息传递机制来协调这些任务的执行顺序。
- 终止阶段:当 Isolate 完成了它的任务,或者由于某些原因需要停止时,可以调用
Isolate.kill()方法来终止 Isolate。此时,Isolate 会立即停止执行,并且 Isolate 对象和所有与它相关的资源都会被释放。
3.4 Isolate 组
在 Dart 2.15 也就是 Flutter 2.8 版本之后,当一个 Isolate 调用了 Isolate.spawn(),两个 Isolate 将拥有同样的执行代码,并归入同一个 Isolate 组 中。Isolate 组会带来性能优化,例如新的 Isolate 会运行由 Isolate 组持有的代码,即共享代码调用。同时,Isolate.exit() 仅在对应的 Isolate 属于同一组时有效。
其原理是同一个 Isolate 组中的 Isolate 共享同一个堆,避免了对象的重复拷贝。这意味着生成一个新 Isolate 的速度提高了 100 倍,消耗的内存减少了 10-100 倍。
注意不要和前面的概念混淆,Isolate 仍然无法彼此共享内存,仍然需要消息传递。
四、使用场景
4.1 使用原则
- 如果一段代码不会被中断,那么就直接使用正常的同步执行就行。
- 如果代码段可以独立运行而不会影响应用程序的流畅性,建议使用 Future。
- 如果繁重的处理可能要花一些时间才能完成,而且会影响应用程序的流畅性,建议使用 Isolate。
4.2 耗时衡量
通过原则来判断可能过于抽象,我们可以用耗时来衡量:
- 对于耗时不超过
16ms的操作推荐使用 Future。 - 对于耗时超过
16ms以上的操作推荐使用 Isolate。
至于为什么用 16ms 作为衡量呢,因为屏幕一帧的刷新间隔就是 16ms。
compute API文档原文:
/// {@template flutter.foundation.compute.usecase} /// This is useful for operations that take longer than a few milliseconds, and /// which would therefore risk skipping frames. For tasks that will only take a /// few milliseconds, consider [SchedulerBinding.scheduleTask] instead. /// {@endtemplate}
五、结语
至此,我们完成了对 Isolate 概念和用法的认识。项目源码:Fitem/flutter_article
如果觉得这篇文章对你有所帮助的话,不要忘了一键三连哦,大家的点赞是我更新的动力🥰。最后祝大家周末愉快~
参考资料:
链接:https://juejin.cn/post/7211539869805805623
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android应用被抓包?防护手段需知道
为了提高网络数据传输的安全性,业内采用HTTPS的方式取代原来的HTTP,Android的应用开发也不例外,我们似乎只需要修改一下域名就能完成http到https的切换,无需做其他额外的操作,那么这个HTTPS是如何实现的?是否真的就安全了?在不同的Android版本上是否有差异?今天我们就来详细研究一下以上的问题。
Tips:本篇旨在讨论HTTPS传输的安全性,应用本地安全不在讨论范畴。
HTTPS原理
诞生背景
首先就是老生常谈的问题,什么是HTTPS,相信大家有有所了解,这里简单提一下:
由于HTTP协议(HyperText Transfer Protocol,超文本传输协议)中,传输的内容是明文的,请求一旦被劫持,内容就会完全暴露,劫持者可以对其进行窃取或篡改,因此这种数据的传输方式存在极大的安全隐患。
因此,在基于HTTP协议的基础上对传输内容进行加密的HTTPS协议(HyperText Transfer Protocol over Secure Socket Layer)便诞生了,这样即使传输的内容被劫持,由于数据是加密的,劫持者没有对应的密钥也很难对内容进行破解,从而提高的传输的安全性。
密钥协商
既然要对传输的内容进行加密,那就要约定好加密的方式与密钥管理。首先在加密方式的选择上,有对称加密和非对称加密两种,这两种方式各有有缺。
对称加密:
加密和解密使用相同的密钥,这种效率比较高,但是存在密钥维护的问题。如果密钥通过请求动态下发,会有泄漏的风险。如果密钥存放到Client端,那么密钥变更时就要重新发版更新密钥,而且如果要请求多个服务器就要维护多个密钥,对于服务器端也是同理,这种密钥的维护成本极高。
非对称加密:
加密和解密使用不同的密钥,即公钥与私钥,私钥存放在Server端,不对外公开,公钥是对外公开的,这样无论是公钥打包进Client端还是由Server端动态下发,也无需担心泄漏的问题。但是这种加密方式效率较低。
HTTPS协议中,结合了对称加密和非对称加密两种方式,取其精华,弃其糟粕,发挥了两者各自的优势。
假设目前Server端有一对密钥,公钥A和私钥A,在Client端发起请求时,Server端下发公钥A给Client端,Client端生成一个会话密钥B,并使用公钥A对会话密钥B进行加密传到Server端,Server端使用私钥A进行解密得到会话密钥B,这时Client端和Server端完成了密钥协商工作,之后Client和和Server端交互的数据都使用会话密钥B进行对称加解密。在密钥协商过程中,就算被劫持,由于劫持者没有私钥A,也无法获取协商的会话密钥B,因此保证了数据传输的安全性。
密钥协商过程简图如下:
CA证书
上面的过程貌似解决了数据传输的安全问题,但依然有一个漏洞,就是如果劫持者篡改了Server端下发给Client端的公钥的情况。
中间人攻击(MITM攻击)简图如下:
为了解决Client端对Server端下发公钥的信任问题,出现了一个被称作CA(Certificate Authority)的机构。
CA机构同样拥有采用非对称加密的公钥和私钥,公钥加上一些其他的信息(组织单位、颁发时间、过期时间等)信息被制作成一个cer/pem/crt等格式的文件,被称作证书,这些CA机构用来给其他组织单位签发证书的证书叫做根证书,根证书一般都会被预装在我们的设备中,被无条件信任。
以Android设备为例,我们可以在设置 -> 安全 -> 更多安全设置 -> 加密与凭据 -> 信任的凭据中查看当前设备所有的预装的证书。
如果Server端部署的证书是正规CA机构签发的证书(CA机构一般不会直接用根证书为企业签发域名证书,而是使用根证书生成的中间证书,一般情况下证书链是三级,根证书-中间证书-企业证书),那么我们在进行HTTPS请求的时候,不需要做其他额外操作,Client端获取到Server端下发的证书会自动与系统预装的证书进行校验,以确认证书是否被篡改。
如果Server端的证书是自签的,则需要在Client端自行处理证书校验规则,否则无法正常完成HTTPS请求。
这也是为什么,我们在Android开发网络请求时,无需做额外操作便能丝滑切换到HTTPS,但是这样真的就能保证网络请求的安全性了吗?
真的安全了吗?
经过上面的介绍我们可以了解到,如果Client端(手机、浏览器)中预装了大量正规CA机构的根证书,Server端如果是正规CA签发的证书,理论上是解决了HTTPS通信中双端的信任问题,但是还存在一个问题,就是这些Client端一般都会支持用户自行安装证书,这将会给Android端的网络安全带来哪些风险?接下来我们就继续来聊聊。
由于Android版本更新迭代较快,且不同版本之前差异较大,因此分析这个问题的时候一定要基于一个特定的系统版本,区别分析。Android 5.0(21)之前的版本太过古老,这里就不再进行分析,直接分析5.0之后的版本。
在一个只采用默认配置的的测试项目中进行HTTPS请求的抓包测试,发现在5.0(包括)到7.0(不包括)之间的版本,可以通过中间人或VPN的方式进行抓包,而7.0及以上版本则无法正常抓包,抓包情况如下
7.0以下手机代理抓包情况:
7.0及以上手机代理抓包情况:
之所以7.0是个分水岭,是因为在Android7.0之前,系统除了对系统内置CA证书无条件信任外,对用户手动安装的CA证书也无条件信任了。
虽然说7.0及以上的设备不再信用用户自行添加的CA证书,安全性比之前的高很多,但是无门却无法阻止那些抓包的人使用7.0之下的手机,除非提高应用的最小支持版本,但这样就意味着要放弃一些用户,显然也不适用于所有情况。
那么如何在保证低版本兼容性的同时兼顾安全性呢,我们接下来继续探讨。
如何更安全
除了系统默认的安全校验之外,我们也可以通过如下手段来提高请求的安全性,让抓包变得更加困难。
禁用代理
该方式适用于所有Android版本。
在网络请求时,通过调用系统API获取当前网络是否设置了代理,如果设置了就终止请求,达到保护数据安全的目的。因为通过中间人的方式进行抓包,需要把网络请求转发到中间人的代理服务器,如果禁止了代理相当于从源头解决了问题。
优势:设置简单,系统API简单调用即可获取代理状态。
劣势:
会错杀一些因为其他场景而使用代理的用户,导致这样的用户无法正常使用
通过开启VPN在VPN上设置代理转发到中间人服务器的方式绕过
由于设置禁用代理的方式很容易被绕过且有可能影响正常开启VPN用户的使用,因此不推荐使用该方式。
数据加密
该方式适用于所有Android版本。
对请求传输的数据进行加密,然后再通过HTTPS协议传输。HTTPS本身在传输过程中会生成一个会话密钥,但是这个密钥可以被抓包获取,如果对传输的数据进行一次加密后再传输,即使被抓包也没法解析出真实的数据。
优势:安全性较高,只要密钥没有泄漏,数据被破获的风险较低
劣势:
修改同时修改Client端和Server端代码,增加加解密逻辑
加解密操作影响效率且有密钥维护的成本
在对数据安全性要求比较高的接口上,可以采用这种方式对传输内容进行增强保护。
证书单向认证
该方式适用于所有Android版本。
在默认情况下,HTTPS在握手时,Server端下证书等信息到Client端,Client端校验该证书是否为正规CA机构签发,如果是则通过校验。这里我们可以自定义校验规则,可以下载Server端的证书到打包到APK中,在请求时进行证书校验。
优势:安全性高。
劣势:证书容易过期,当前企业证书有效期只有1年,需要每年进行续签,Client需要维护证书更新的问题。
证书双向认证
该方式适用于所有Android版本。
在单向认证中,Client端会验证Server端是否安全,但是Server端并没有对Client进行校验,这里可以让Server端对Client也进行一次认证。这种认证需要在单向认证的基础上再额外创建一套证书B,存放在Client端,并在Client端完成对Server端的校验后,把Client端的公钥证书发送到Server端,由Server端进行校验,校验通过后开始密钥协商等后续步骤。
优势:安全性非常高!
劣势:
Server端要存放Client端公钥证书,如果一个Server对应多个Client则需要维护多套
增加了校验成本,会降低相应速度
网络安全配置文件
该方案为google官方推荐的方案,也是一种证书的单向校验,不过在Android7.0及更高版本上,配置简单,只需要再清单文件的application节点下增加一个networkSecurityConfig项,并指向一个按固定的格式创建一个xml文件,即可完成网络安全的校验,体验相当丝滑,唯一美中不足的是该配置不支持7.0以下的版本。
在7.0及以上版本中,在xml文件夹下创建名为network_security_config_wanandroid的网络安全配置文件:
该文件只需要在清单文件application节点的networkSecurityConfig中引用该文件即可,如此就完成了对wanandroid.com域名及其所有次级域名的证书单向认证。
在7.0以下版本中:
由于networkSecurityConfig是7.0版本新增的,因此在所有7.0以下的设备上无法生效,所以针对7.0以下的设备只能通过代码进行认证。推荐使用OkHttp:
需要注意的是,在通过代码配置指定域名的证书校验时,根域名和次级域名需要分别进行配置。
优势:安全性较高,代码改动少。
劣势:本质还是证书的单向认证。
选择要校验的证书
如果说采取了google推荐的方式进行安全校验,那校验证书链中的哪个证书比较合适呢?
理论上来说,当然是校验企业自己的证书最好,即证书链的第三层企业证书:
但是该层证书的有效期比较短,一般每年都要进行重签,重签之后证书的Sha256就会发生变化,这时候就要及时更新Client端中信息,否则就无法正常完成校验。
为了规避证书频繁过期的问题,我们可以直接对根证书进行校验,一般来说,根证书的有效期是比较长的:
这样就不用担心证书频繁过期的问题了,但是如果再企业证书续签的时候更换了CA机构,那就必须要更新Client端中的根证书信息了,不过这就是另外的一个问题了。
只校验根证书会不会存在风险?
几乎不会,因为正规的CA机构在给一个企业颁发证书的时候,会有审核机制的,一般不会出现错误办法的状况,但在历史上确实出现过CA机构被骗,将证书颁发给了相应域名之外的人。下面截图来自Google官网:
不过这是非常小概率的事件了,因此校验域名+根证书摘要算是即安全又避免了证书频繁过期的问题,再加上google官方的推荐,算的上是最佳解决方案了。
这篇文章就介绍到这里,感谢观看~~
链接:https://juejin.cn/post/7210688688921821221
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android无需权限调起系统相机拍照
在进行一些小型APP的开发,或者是对拍照界面没有自定义要求时,我们可以用调起系统相机的方式快速完成拍照需求
和不需读写权限进行读写操作的方案一样,都是通过Intent启动系统的activity让用户进行操作,系统再将用户操作的结果告诉我们,因为过程对APP是完全透明的,所以不会侵犯用户隐私。
有两种方法可以调起系统相机拍照获取图片,我们先讲比较简单的一种
1、直接获取用户拍照结果
val launcher = registerForActivityResult(ActivityResultContracts.TakePicturePreview()) {bitmap->
bitmap ?: return@registerForActivityResult
vm.process(bitmap)
}
launcher.launch("image/*")这个在旧版本的API中就等于
startActivityForResult(Intent(MediaStore.ACTION_IMAGE_CAPTURE),CODE)等到用户完成拍照,返回我们的activity时,我们就可以得到一张经过压缩的bitmap。这个方法很简单,它的缺点就是获得的bitmap像素太低了,如果对图片像素有要求的话需要使用第二种方法
2、用户拍照之后指定相机将未压缩的图片存放到我们指定的目录
var uri: Uri? = null
val launcher =
registerForActivityResult(ActivityResultContracts.TakePicture()) {
if(it){
uri?.let { it1 -> vm.process(it1) }
}
}
val picture = File(externalCacheDir?.path, "picture")
picture.mkdirs()
uri = FileProvider.getUriForFile(
this,
"${BuildConfig.APPLICATION_ID}.fileprovider",
File(picture, "cache")
)
launcher.launch(uri)这里我逐行进行解释:
- 首先,我们需要指定拍摄的照片要存到哪,所以我们先指定图片的存放路径为externalCacheDir.path/picture/cache 注意这张图片在文件系统中的名字就叫做cache了(没有文件后缀)。
- 然后我们通过FileProvider构建一个有授权的Uri给系统相机,相机程序拿到我们的临时授权,才有权限将文件存放到APP的私有目录。
- 系统相机拍照完成之后就会走到回调,如果resultCode为RESULT_OK才说明用户成功拍照并保存图片了。这样我们就能得到一张系统相机拍出来的原图的Uri,这样我们就可以用这张图片去处理业务了。
注意:使用方法二需要用到FileProvider,所以我们还要在AndroidManifest里声明
<provider
android:name="androidx.core.content.FileProvider"
android:authorities="${applicationId}.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/provider_paths" />
</provider>@xml/provider_paths是我们授权访问的文件路径,这里我写的是
<paths xmlns:android="http://schemas.android.com/apk/res/android">
<external-path name="external_files" path="."/>
</paths>关于这个"path.xml",其实还有一些可以补充说明的,后面有空会补上,这里我简单说明一下:
因为我们创建临时文件的时候,文件指定的目录是externalCacheDir?.path,对应的path就是external-cache-path,表示我们要临时授权的目录是externalCacheDir,如果文件目录指定的是其他路径,那path节点也需要改成代表对应文件夹的节点,这样其他应用才能访问到我们APP的私有目录
链接:https://juejin.cn/post/7211400484104388663
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这几个群,程序员可千万不要进!
震惊!某摸鱼网站惊现肾结石俱乐部!
(图源V2EX)
无关地域、无关性别,各位程序员们在肾结石这个病上面有着出奇一致的反应。诸如此类的各种职业病在我们的生活中更是十分常见。
也可能是到年纪了,在办公室里放眼望去,一群处于亚健康状态的同事们格外显眼:手上戴着护腕的,脖子上贴着膏药的,闲着没事锤两下后背的,甚至还有站着办公时不时嘶哈两声的……
悄悄问了那位站着办公的同事,结果平白遭受了一个白眼:你见过花季少女割痔疮的吗?
没有,不过现在见到了。
不愧是万物生长的季节,那些困扰程序员们的各类职业病也开始逐渐冒头,像“肾结石俱乐部”这样的群,程序员们也许建了成百上千个,不信往下看看?
1、腱鞘炎相亲相爱一家人
专家建议:
腱鞘炎对程序员群体来说已成为一种常见疾病,虽然不会对我们的生命构成威胁,但都或多或少地影响了我们的生活质量:
手部运动不灵活,手腕无力太软弱。
疼痛一来闹心窝,让人意乱难工作。
想知道自己有没有腱鞘炎,分享给大家一个小方法:
腱鞘炎保养可以从这几个方面入手:
休息:保证手腕足够的休息时间,比如每30分钟活动下手腕,避免过多接触冷水。
热敷:温热水泡手,或是热水袋热敷,每天2次,每次30~45分钟。
按摩:对侧拇指沿手指掌面按摩,按摩范围包括整个手掌指背以及手指的掌侧。
如果腱鞘炎比较严重,需要配合一些药物治疗、局部封闭注射治疗或手术治疗,具体需咨询医生。对于还没有腱鞘炎的小伙伴,以下几个手部操送给你,开启腱鞘炎预防之旅吧!
2、颈椎患者大本营
专家建议:
其实随着与手机、电脑相处的时间越来越长,颈椎病的发病人群也逐渐年轻化。当我们在低头玩手机时,脊椎正在承受原本无法承受之重。
举个例子:一个人的头部重约5kg,当我们前倾看手机或低头时,颈部的负重就会大大增加。
看到这里,请大家立刻挺胸抬头并阅读、实践以下内容,减轻颈椎负担!
3、干眼症娱乐部
说起干眼症,大多数程序员都不陌生。引起干眼症的原因比较多,比如过劳致“干”、药物致“干”环境致“干”等等……干眼症很难根治,只能靠日常保养加以改善,从这个意义上讲,干眼症确实可以称为“绝症”。来听听专家的建议吧!
专家建议:
1)调位置
电脑显示器的位置和字体大小,让眼睛距离屏幕50-60厘米,屏幕中心在视线水平或稍向下10-15厘米。
2)多眨眼
多眨眼可以放松睫状肌,滋润眼球。建议每分钟眨眼次数 >15-20次。
3)少看屏幕,多远眺
用电脑或看手机都要注意时间,避免长时间盯着屏幕。参考20原则:用眼20分钟可以盯着20米以外的地方,休息至少20秒。
4)其他小窍门
- 使用蒸汽眼罩或热毛巾热敷,每天1-2次,每次5-10分钟;
- 在医生的建议下使用人工泪液;
- 佩戴隐形眼镜每天应控制在8小时以内,不超过12小时;
- 使用空气加湿器,让空气湿度适宜;
- 增加户外运动。
不说了,眼睛发干,需要摸会儿鱼休息一下(误)~
4、防脱治疗所
身边的程序员们说:一个程序员一生能写的程序行数是有限的,写一行代码就会掉一根头发,直到青丝落尽,就是这个程序员隐退江湖的时候。
当然,这只是玩笑话。引起脱发的原因可能是遗传、压力大、熬夜通宵、 频繁烫染或饮食不均衡等。怎么确定自己的史密斯夫妇还有约翰逊家族们安全,两个步骤测试一下:
保护我们的史密斯夫妇还有约翰逊家族们有这三个妙招:
这些我们眼中的“小病小灾”就像技术债务,短期内选择了忽视,累计到一定程度就会变成身体里的“定时炸弹”。所以,当我们开始长时间的久坐、低头盯手机,当我们压力变大,习惯于加班、熬夜、饮食不规律……更需要停下来想想。
在非洲有个部落
人如果连续赶路三天
就一定要停下来休息一天
因为人们害怕灵魂跟不上自己的脚步
……
——阮靖《风会记得你走过的路》
如果一直忙着赶路,也要记得停下休息,别让健康跟不上我们的脚步。
链接:https://juejin.cn/post/7208817601841250360
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我为什么用TheRouter而不玩Arouter了呢
TheRouter 简介
TheRouter是货拉拉开源的路由框架,针对Android平台实现组件化、跨模块调用、动态化等功能的集成框架。
TheRouter 掘金:juejin.cn/post/713971…
Github: github.com/HuolalaTech…
官网:therouter.cn/
为什么要用TheRouter
| 功能 | TheRouter | ARouter | WMRouter |
|---|---|---|---|
| Fragment路由 | ✔️ | ✔️ | ✔️ |
| 支持依赖注入 | ✔️ | ✔️ | ✔️ |
| 加载路由表 | 无运行时扫描无反射 | 运行时扫描dex反射实例类性能损耗大 | 运行时读文件反射实例类性能损耗中 |
| 注解正则表达式 | ✔️ | ✖️ | ✔️ |
| Activity指定拦截器 | ✔️(四大拦截器可根据业务定制) | ✖️ | ✔️ |
| 导出路由文档 | ✔️(路由文档支持添加注释描述) | ✔️ | ✖️ |
| 动态注册路由信息 | ✔️ | ✔️ | ✖️ |
| APT支持增量编译 | ✔️ | ✔️(开启文档生成则无法增量编译) | ✖️ |
| plugin支持增量编译 | ✔️ | ✖️ | ✖️ |
| 多 Path 对应同一页面(低成本实现双端path统一) | ✔️ | ✖️ | ✖️ |
| 远端路由表下发 | ✔️ | ✖️ | ✖️ |
| 支持单模块独立初始化 | ✔️ | ✖️ | ✖️ |
| 支持使用路由打开第三方库页面 | ✔️ | ✖️ | ✖️ |
上图是从官方获取的介绍,结合自己使用,从以下几点介绍他的好处。
- 使用简易
- 针对后台startActivity的兼容处理
- 直接获取Intent对象
- 动态下发路由表的骚操作
- 和Arouter性能相比
- 使用简易
针对刚入手的同学,很多同学其实需要的功能不多,主要就是跳转页面,原先使用过的Arouter,也能快速适应。想深入学习更多的同学可以再去官网或者官方掘金see see
// 简单的传参和路由跳转
TheRouter.build("test://webview/home")
.withString("url", "http://www.baidu.com")
.navigation(act)
// 如果要打开的是fragment,需要使用 .createFragment();- 针对后台startActivity的兼容处理
Android 10 (级别 29) 及更高版本对后台应用可启动 Activity 的时间施加限制。这些限制有助于最大限度地减少对用户造成的中断(可以更省电),并且可以让用户更好地控制其屏幕上显示的内容。
官方针对Android10以及以上版本调用startActivity的限制,也就是在后台调用该方法是无法跳转的,TheRoute提供兼容处理,先暂停跳转,等APP重新启动了再继续跳转。
// 以下代码只是功能介绍,大家按需自取
// 后台跳转页面
fun goBackActivity(activity: Activity) {
val navigator: Navigator =
TheRouter.build("test://webview/home")
.withString("paramStr", paramStr)
.withInt("paramInt", 0)
if (AndroidVersion.hasQ() && !AppUtils.isAppForeground()) {
// pending() 会标记存入集合LinkedList
navigator.pending().navigation(activity)
} else {
navigator.navigation(activity)
}
}
// Application监听
class ApplicationObserver : DefaultLifecycleObserver {
override fun onResume(owner: LifecycleOwner) {
super.onResume(owner)
// 应用重进onResume,把原先pending()存入集合的navigation,重新取出全部执行
// sendPendingNavigator是Navigator的顶级函数
sendPendingNavigator()
}
}
- 直接获取Intent对象
大部分的路由框架都不提供直接返回Intent,但是有时候我们又只需要对应其他模块的intent对象并不需要跳转,例如构建系统通知栏的点击需要传入PendingIntent,可能需要通过Intent对象构建。
// 获取intent
val intent = TheRouter.build("test://login/hello").createIntent(activity)- 动态下发路由表的『骚操作』
为什么我个人说这是『骚操作』呢?我们以前写一个页面,页面崩溃了,那么我们就想办法修复,让用户先忍忍。可是用你这个APP的人真的能忍受你的崩溃吗?答案是不能的,因此我们想尽各种办法例如热修复等等,但是还是有没有经过热修复的人崩溃了,还是大面积的崩溃。
那动态下发路由表,让这个崩溃页面的路由改下其他页面,例如这个崩溃页面的路由跳转H5页面,告知用户正在紧急修复,这样的过渡会比直接崩溃使用感受好。
当然不止这个场景,再举例一个我们最常见的,例如A页面忘了给相机权限,然后上线了跳转A页面的时候才发现少了这个权限,咋整?重发版呗。但是如果用TheRouter,可以在原工程预留一个过渡页面,我们动态下发路由表,跳到这个过渡页获取权限了再重新跳转原来A页面。
// 获取远端的路由map
/**
[
{
"path": "test://home/webview/pre",
"action": "test://action/start_activity?path=test://app/alert?type=-1&permissionJson={"android.permission.READ_PHONE_STATE": "需要获取您的手机网络状态"}",
"description": "",
"className": "com.test.main.PreWebViewV2Activity",
"params": {
}
}
]
// action说明: 可以写一个test://app/alter权限弹窗页面,传入permissionJson参数授权,授权成功之后再重新执行原来的路由地址
*/
fun getServiceRouterMap() {
try {
val gson = "注释提供的格式"
if (gson.isNullOrEmpty()) {
return
}
Kv.putEnv(LOCAL_ROUTER_MAP, gson) // 本地存储,方便下次取出
mRouteItem = GsonUtils.fromJson(gson, object : TypeToken?>() {}.type)
} catch (e: Exception) {
Log.d("updateRouterMap", e?.toString())
}
}
// 把远端路由遍历添加到本地
fun addMdapRouteMap() {
Log.d("HllMarsConfigTask", "asyncInitRouteMap")
var list = mRouteItem
if (list != null && list.size > 0) {
// 建议远端下发路由表差异部分,用远端包覆盖本地更合理
addRouteMap(list) // TheRouter库RouteMap.kt提供顶级函数
}
}
// 以下是TheRouter库RouteMap.kt类
// 具体实现:如何把远端路由添加到本地
@Synchronized
fun addRouteMap(routeItemArray: Collection?) {
if (routeItemArray != null && !routeItemArray.isEmpty()) {
for (entity in routeItemArray) {
addRouteItem(entity)
}
}
}
@Synchronized
fun addRouteItem(routeItem: RouteItem) {
var path = routeItem.path
if (path.endsWith("/")) {
path = path.substring(0, path.length - 1)
}
debug("addRouteItem", "add $path")
ROUTER_MAP[path] = routeItem
onRouteMapChangedListener?.onChanged(routeItem)
} - 和Arouter性能相比
以阿里的Arouter来说,它是有比较沉重的历史包袱,虽然后面有迭代几个版本来优化,但是更多的还是在历史基础上优化,TheRouter却没有历史包袱。下面是我们自己工程跑的对比效果
链接:https://juejin.cn/post/7148639882401808391
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一个app到底会创建多少个Application对象
问题背景
最近跟群友讨论一个技术问题:
一个应用开启了多进程,最终到底会创建几个application对象,执行几次onCreate()方法?
有的群友根据自己的想法给出了猜想
甚至有的群友直接咨询起了ChatGPT
但至始至终都没有一个最终的结论。于是乎,为了弄清这个问题,我决定先写个demo测试得出结论,然后从源码着手分析原因
Demo验证
首先创建了一个app项目,开启多进程
<?xml version="1.0" encoding="utf-8"?>
<manifest
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools">
<application
android:name=".DemoApplication"
android:allowBackup="true"
android:dataExtractionRules="@xml/data_extraction_rules"
android:fullBackupContent="@xml/backup_rules"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/Theme.Demo0307"
tools:targetApi="31">
<!--android:process 开启多进程并设置进程名-->
<activity
android:name=".MainActivity"
android:exported="true"
android:process=":remote">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
</manifest>然后在DemoApplication的onCreate()方法打印application对象的地址,当前进程名称
public class DemoApplication extends Application {
private static final String TAG = "jasonwan";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "Demo application onCreate: " + this + ", processName=" + getProcessName(this));
}
private String getProcessName(Application app) {
int myPid = Process.myPid();
ActivityManager am = (ActivityManager) app.getApplicationContext().getSystemService(Context.ACTIVITY_SERVICE);
List<ActivityManager.RunningAppProcessInfo> runningAppProcesses = am.getRunningAppProcesses();
for (ActivityManager.RunningAppProcessInfo runningAppProcess : runningAppProcesses) {
if (runningAppProcess.pid == myPid) {
return runningAppProcess.processName;
}
}
return "null";
}
}运行,得到的日志如下
2023-03-07 11:15:27.785 19563-19563/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote
查看当前应用所有进程
说明此时app只有一个进程,且只有一个application对象,对象地址为@fb06c2d
现在我们将进程增加到多个,看看情况如何
<?xml version="1.0" encoding="utf-8"?>
<manifest
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools">
<application
android:name=".DemoApplication"
android:allowBackup="true"
android:dataExtractionRules="@xml/data_extraction_rules"
android:fullBackupContent="@xml/backup_rules"
android:icon="@mipmap/ic_launcher"
android:label="@string/app_name"
android:roundIcon="@mipmap/ic_launcher_round"
android:supportsRtl="true"
android:theme="@style/Theme.Demo0307"
tools:targetApi="31">
<!--android:process 开启多进程并设置进程名-->
<activity
android:name=".MainActivity"
android:exported="true"
android:process=":remote">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
<activity
android:name=".TwoActivity"
android:process=":remote2" />
<activity
android:name=".ThreeActivity"
android:process=":remote3" />
<activity
android:name=".FourActivity"
android:process=":remote4" />
<activity
android:name=".FiveActivity"
android:process=":remote5" />
</application>
</manifest>逻辑是点击MainActivity启动TwoActivity,点击TwoActivity启动ThreeActivity,以此类推。最后我们运行,启动所有Activity得到的日志如下
2023-03-07 11:25:35.433 19955-19955/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote
2023-03-07 11:25:43.795 20001-20001/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote2
2023-03-07 11:25:45.136 20046-20046/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote3
2023-03-07 11:25:45.993 20107-20107/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote4
2023-03-07 11:25:46.541 20148-20148/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote5
查看当前应用所有进程
此时app有5个进程,但application对象地址均为@fb06c2d,地址相同意味着它们是同一个对象。
那是不是就可以得出结论,无论启动多少个进程都只会创建一个application对象呢?并不能妄下此定论,我们将MainActivity的process属性去掉再运行,得到的日志如下
2023-03-07 11:32:10.156 20318-20318/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@5d49e29, processName=com.jason.demo0307
2023-03-07 11:32:15.143 20375-20375/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote2
2023-03-07 11:32:16.477 20417-20417/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote3
2023-03-07 11:32:17.582 20463-20463/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote4
2023-03-07 11:32:18.882 20506-20506/com.jason.demo0307 D/jasonwan: Demo application onCreate: com.jason.demo0307.DemoApplication@fb06c2d, processName=com.jason.demo0307:remote5
查看当前应用所有进程
此时app有5个进程,但有2个application对象,对象地址为@5d49e29和@fb06c2d,且子进程的application对象都相同。
上述所有进程的父进程ID为678,而此进程正是zygote进程
根据上面的测试结果我们目前能得出的结论:
- 结论1:单进程只创建一个
Application对象,执行一次onCreate()方法; - 结论2:多进程至少创建2个
Application对象,执行多次onCreate()方法,几个进程就执行几次;
结论2为什么说至少创建2个,因为我在集成了JPush的商业项目中测试发现,JPush创建的进程跟我自己创建的进程,Application地址是不同的。
这里三个进程,分别创建了三个Application对象,对象地址分别是@f31ba9d,@2c586f3,@fb06c2d
源码分析
这里需要先了解App的启动流程,具体可以参考《App启动流程》
Application的创建位于frameworks/base/core/java/android/app/ActivityThread.java的handleBindApplication()方法中
@UnsupportedAppUsage
private void handleBindApplication(AppBindData data) {
long st_bindApp = SystemClock.uptimeMillis();
//省略部分代码
// Note when this process has started.
//设置进程启动时间
Process.setStartTimes(SystemClock.elapsedRealtime(), SystemClock.uptimeMillis());
//省略部分代码
// send up app name; do this *before* waiting for debugger
//设置进程名称
Process.setArgV0(data.processName);
//省略部分代码
// Allow disk access during application and provider setup. This could
// block processing ordered broadcasts, but later processing would
// probably end up doing the same disk access.
Application app;
final StrictMode.ThreadPolicy savedPolicy = StrictMode.allowThreadDiskWrites();
final StrictMode.ThreadPolicy writesAllowedPolicy = StrictMode.getThreadPolicy();
try {
// If the app is being launched for full backup or restore, bring it up in
// a restricted environment with the base application class.
//此处开始创建application对象,注意参数2为null
app = data.info.makeApplication(data.restrictedBackupMode, null);
//省略部分代码
try {
if ("com.jason.demo0307".equals(app.getPackageName())){
Log.d("jasonwan", "execute app onCreate(), app=:"+app+", processName="+getProcessName(app)+", pid="+Process.myPid());
}
//执行application的onCreate方法()
mInstrumentation.callApplicationOnCreate(app);
} catch (Exception e) {
if (!mInstrumentation.onException(app, e)) {
throw new RuntimeException(
"Unable to create application " + app.getClass().getName()
+ ": " + e.toString(), e);
}
}
} finally {
// If the app targets < O-MR1, or doesn't change the thread policy
// during startup, clobber the policy to maintain behavior of b/36951662
if (data.appInfo.targetSdkVersion < Build.VERSION_CODES.O_MR1
|| StrictMode.getThreadPolicy().equals(writesAllowedPolicy)) {
StrictMode.setThreadPolicy(savedPolicy);
}
}
//省略部分代码
}实际创建过程在frameworks/base/core/java/android/app/LoadedApk.java中的makeApplication()方法中,LoadedApk顾名思义就是加载好的Apk文件,里面包含Apk所有信息,像包名、Application对象,app所在的目录等,这里直接看application的创建过程
@UnsupportedAppUsage
public Application makeApplication(boolean forceDefaultAppClass,
Instrumentation instrumentation) {
if ("com.jason.demo0307".equals(mApplicationInfo.packageName)) {
Log.d("jasonwan", "makeApplication: mApplication="+mApplication+", pid="+Process.myPid());
}
//如果已经创建过了就不再创建
if (mApplication != null) {
return mApplication;
}
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "makeApplication");
Application app = null;
String appClass = mApplicationInfo.className;
if (forceDefaultAppClass || (appClass == null)) {
appClass = "android.app.Application";
}
try {
java.lang.ClassLoader cl = getClassLoader();
if (!mPackageName.equals("android")) {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER,
"initializeJavaContextClassLoader");
initializeJavaContextClassLoader();
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
}
ContextImpl appContext = ContextImpl.createAppContext(mActivityThread, this);
//反射创建application对象
app = mActivityThread.mInstrumentation.newApplication(
cl, appClass, appContext);
if ("com.jason.demo0307.DemoApplication".equals(appClass)){
Log.d("jasonwan", "create application, app="+app+", processName="+mActivityThread.getProcessName()+", pid="+Process.myPid());
}
appContext.setOuterContext(app);
} catch (Exception e) {
Log.d("jasonwan", "fail to create application, "+e.getMessage());
if (!mActivityThread.mInstrumentation.onException(app, e)) {
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
throw new RuntimeException(
"Unable to instantiate application " + appClass
+ ": " + e.toString(), e);
}
}
mActivityThread.mAllApplications.add(app);
mApplication = app;
if (instrumentation != null) {
try {
//第一次启动创建时,instrumentation为null,不会执行onCreate()方法
instrumentation.callApplicationOnCreate(app);
} catch (Exception e) {
if (!instrumentation.onException(app, e)) {
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
throw new RuntimeException(
"Unable to create application " + app.getClass().getName()
+ ": " + e.toString(), e);
}
}
}
// 省略部分代码
return app;
}为了看清application到底被创建了几次,我在关键地方埋下了log,TAG为jasonwan的log是我自己加的,编译验证,得到如下log
启动app,进入MainActivity
03-08 17:20:29.965 4069 4069 D jasonwan: makeApplication: mApplication=null, pid=4069
//创建application对象,地址为@c2f8311,当前进程id为4069
03-08 17:20:29.967 4069 4069 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307, pid=4069
03-08 17:20:29.988 4069 4069 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307, pid=4069
03-08 17:20:29.989 4069 4069 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307, pid=4069
03-08 17:20:36.614 4069 4069 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4069
点击MainActivity,跳转到TwoActivity
03-08 17:20:39.686 4116 4116 D jasonwan: makeApplication: mApplication=null, pid=4116
//创建application对象,地址为@c2f8311,当前进程id为4116
03-08 17:20:39.687 4116 4116 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote2, pid=4116
03-08 17:20:39.688 4116 4116 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote2, pid=4116
03-08 17:20:39.688 4116 4116 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote2, pid=4116
03-08 17:20:39.733 4116 4116 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4116
点击TwoActivity,跳转到ThreeActivity
03-08 17:20:41.473 4147 4147 D jasonwan: makeApplication: mApplication=null, pid=4147
//创建application对象,地址为@c2f8311,当前进程id为4147
03-08 17:20:41.475 4147 4147 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote3, pid=4147
03-08 17:20:41.475 4147 4147 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote3, pid=4147
03-08 17:20:41.476 4147 4147 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote3, pid=4147
03-08 17:20:41.519 4147 4147 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4147
点击ThreeActivity,跳转到FourActivity
03-08 17:20:42.966 4174 4174 D jasonwan: makeApplication: mApplication=null, pid=4174
//创建application对象,地址为@c2f8311,当前进程id为4174
03-08 17:20:42.968 4174 4174 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote4, pid=4174
03-08 17:20:42.969 4174 4174 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote4, pid=4174
03-08 17:20:42.969 4174 4174 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote4, pid=4174
03-08 17:20:43.015 4174 4174 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4174
点击FourActivity,跳转到FiveActivity
03-08 17:20:44.426 4202 4202 D jasonwan: makeApplication: mApplication=null, pid=4202
//创建application对象,地址为@c2f8311,当前进程id为4202
03-08 17:20:44.428 4202 4202 D jasonwan: create application, app=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote5, pid=4202
03-08 17:20:44.429 4202 4202 D jasonwan: execute app onCreate(), app=:com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote5, pid=4202
03-08 17:20:44.430 4202 4202 D jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@c2f8311, processName=com.jason.demo0307:remote5, pid=4202
03-08 17:20:44.473 4202 4202 D jasonwan: makeApplication: mApplication=com.jason.demo0307.DemoApplication@c2f8311, pid=4202
结果很震惊,我们在5个进程中创建的application对象,地址均为@c2f8311,也就是至始至终创建的都是同一个Application对象,那么上面的结论2显然并不成立,只是测试的偶然性导致的。
可真的是这样子的吗,这也太颠覆我的三观了,为此我跟群友讨论了这个问题:
不同进程中的多个对象,内存地址相同,是否代表这些对象都是同一个对象?
群友的想法是,java中获取的都是虚拟内存地址,虚拟内存地址相同,不代表是同一个对象,必须物理内存地址相同,才表示是同一块内存空间,也就意味着是同一个对象,物理内存地址和虚拟内存地址存在一个映射关系,同时给出了java中获取物理内存地址的方法Android获取对象地址,主要是利用Unsafe这个类来操作,这个类有一个作用就是直接访问系统内存资源,具体描述见Java中的魔法类-Unsafe,因为这种操作是不安全的,所以被标为了私有,但我们可以通过反射去调用此API, 然后我又去请教了部门搞寄存器的大佬,大佬肯定了群友的想法,于是我添加代码,尝试获取对象的物理内存地址,看看是否相同
public class DemoApplication extends Application {
public static final String TAG = "jasonwan";
@Override
public void onCreate() {
super.onCreate();
Log.d(TAG, "DemoApplication=" + this + ", address=" + addressOf(this) + ", pid=" + Process.myPid());
}
//获取对象的真实物理地址
public static long addressOf(Object o) {
Object[] array = new Object[]{o};
long objectAddress = -1;
try {
Class cls = Class.forName("sun.misc.Unsafe");
Field field = cls.getDeclaredField("theUnsafe");
field.setAccessible(true);
Object unsafe = field.get(null);
Class unsafeCls = unsafe.getClass();
Method arrayBaseOffset = unsafeCls.getMethod("arrayBaseOffset", Object.class.getClass());
int baseOffset = (int) arrayBaseOffset.invoke(unsafe, Object[].class);
Method size = unsafeCls.getMethod("addressSize");
int addressSize = (int) size.invoke(unsafe);
switch (addressSize) {
case 4:
Method getInt = unsafeCls.getMethod("getInt", Object.class, long.class);
objectAddress = (int) getInt.invoke(unsafe, array, baseOffset);
break;
case 8:
Method getLong = unsafeCls.getMethod("getLong", Object.class, long.class);
objectAddress = (long) getLong.invoke(unsafe, array, baseOffset);
break;
default:
throw new Error("unsupported address size: " + addressSize);
}
} catch (Exception e) {
e.printStackTrace();
}
return objectAddress;
}
}运行后得到如下日志
2023-03-10 11:01:54.043 6535-6535/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@930d275, address=8050489105119022792, pid=6535
2023-03-10 11:02:22.610 6579-6579/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119027136, pid=6579
2023-03-10 11:02:36.369 6617-6617/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119029912, pid=6617
2023-03-10 11:02:39.244 6654-6654/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119032760, pid=6654
2023-03-10 11:02:40.841 6692-6692/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119036016, pid=6692
2023-03-10 11:02:52.429 6729-6729/com.jason.demo0307 D/jasonwan: DemoApplication=com.jason.demo0307.DemoApplication@331b3b9, address=8050489105119038720, pid=6729
可以看到,虽然Application的虚拟内存地址相同,都是331b3b9,但它们的真实物理地址却不同,至此,我们可以得出最终结论:
- 单进程,创建1个application对象,执行一次
onCreate()方法 - 多进程(N),创建N个application对象,执行N次
onCreate()方法
链接:https://juejin.cn/post/7208345469658415159
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 可视化预览及编辑Json
项目中涉及到广告开发, 广告的配置是从API动态下发, 广告配置中,有很多业务相关参数,例如关闭或开启、展示间隔、展示时间、重试次数、每日最大显示次数等。
开发时单个广告可能需要多次修改配置来测试,为了方便测试,广告配置的json文件,有两种途径修改并生效
- 每次抓包修改配置
- 本地导入配置,从磁盘读取
但两种方式都有一定弊端
- 首先测试时依赖电脑修改配置
- 无法直观预览广告配置
考虑到开发时经常使用的Json格式化工具,既可以直观的预览Json, 还可以在线编辑
那么就考虑将Json格式化工具移植到项目测试模块中
web网页可以处理Json格式化,同理在Android webView 中同样可行, 只需要引入处理格式化的JS代码即可。
查找资料,发现一个很实用的文章可视化编辑json数据——json editor
开始处理
首先准备好WebView的壳子
//初始化
@SuppressLint("SetJavaScriptEnabled")
private fun initWebView() {
binding.webView.settings.apply {
javaScriptEnabled = true
javaScriptCanOpenWindowsAutomatically = true
setSupportZoom(true)
useWideViewPort = true
builtInZoomControls = true
}
binding.webView.addJavascriptInterface(JsInterface(this@MainActivity), "json_parse")
}
//webView 与 Android 交互
inner class JsInterface(context: Context) {
private val mContext: Context
init {
mContext = context
}
@JavascriptInterface
fun configContentChanged() {
runOnUiThread {
contentChanged = true
}
}
@JavascriptInterface
fun toastJson(msg: String?) {
runOnUiThread { Toast.makeText(mContext, msg, Toast.LENGTH_SHORT).show() }
}
@JavascriptInterface
fun saveConfig(jsonString: String?) {
runOnUiThread {
contentChanged = false
Toast.makeText(mContext, "verification succeed", Toast.LENGTH_SHORT).show()
}
}
@JavascriptInterface
fun parseJsonException(e: String?) {
runOnUiThread {
e?.takeIf { it.isNotBlank() }?.let { alert(it) }
}
}
}
加载json并在WebView中展示
viewModel.jsonData.observe(this) { str ->
if (str?.isNotBlank() == true) {
binding.webView.loadUrl("javascript:showJson($str)")
}
}
WebView 加载预览页面
binding.webView.webViewClient = object : WebViewClient() {
override fun onPageFinished(view: WebView?, url: String?) {
super.onPageFinished(view, url)
viewModel.loadAdConfig(this@MainActivity)
}
}
binding.webView.loadUrl("file:///android_asset/preview_json.html")
Json 预览页, preview_json.html实现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link href="jquery.json-viewer.css"
rel="stylesheet" type="text/css">
</head>
<style type="text/css">
#json-display {
margin: 2em 0;
padding: 8px 15px;
min-height: 300px;
background: #ffffff;
color: #ff0000;
font-size: 16px;
width: 100%;
border-color: #00000000;
border:none;
line-height: 1.8;
}
#json-btn {
display: flex;
align-items: center;
font-size: 18px;
width:100%;
padding: 10;
}
#format_btn {
width: 50%;
height: 36px;
}
#save_btn {
width: 50%;
height: 36px;
margin-left: 4em;
}
</style>
<body>
<div style="padding: 2px 2px 2px 2px;">
<div id="json-btn" class="json-btn">
<button type="button" id="format_btn" onclick="format_btn();">Format</button>
<button type="button" id="save_btn" onclick="save_btn();">Verification</button>
</div>
<div>
<pre id="json-display" contenteditable="true"></pre>
</div>
<br>
</div>
<script type="text/javascript" src="jquery.min.js"></script>
<script type="text/javascript" src="jquery.json-viewer.js"></script>
<script>
document.getElementById("json-display").addEventListener("input", function(){
console.log("json-display input");
json_parse.configContentChanged();
}, false);
function showJson(jsonObj){
$("#json-display").jsonViewer(jsonObj,{withQuotes: true});//format json and display
}
function format_btn() {
var my_json_val = $("#json-display").clone(false);
my_json_val.find("a.json-placeholder").remove();
var jsonval = my_json_val.text();
var jsonObj = JSON.parse(jsonval); //parse string to json
$("#json-display").jsonViewer(jsonObj,{withQuotes: true});//format json and display
}
function save_btn() {
var my_json_val = $("#json-display").clone(false);
my_json_val.find("a.json-placeholder").remove();
var jsonval = my_json_val.text();
var saveFailed = false;
try {
var jsonObj = JSON.parse(jsonval); //parse
} catch (e) {
console.error(e.message);
saveFailed = true;
json_parse.parseJsonException(e.message); // throw exception
}
if(!saveFailed) {
json_parse.saveConfig(jsonval);
}
}
</script>
</body>
</html>
这其中有两个问题需注意
- 如果value的值是url, 格式化后缺少引号
从json-viewer.js源码可以发现,源码中会判断value是否是url,如果是则直接输出
- 如果value的值是url, 格式化后缺少引号
处理方式:在json 左右添加上双引号
if (options.withLinks && isUrl(json)) {
html += '<a href="' + json + '" class="json-string" target="_blank">' + '"' +json + '"' + '</a>';
} else {
// Escape double quotes in the rendered non-URL string.
json = json.replace(/"/g, '\\"');
html += '<span class="json-string">"' + json + '"</span>';
}
- 如果折叠后json-viewer会增加
<a>标签,即使使用text()方法获取到纯文本数据,这里面也包含了“n items”的字符串,那么该如何去除掉这些字符串呢?
- 如果折叠后json-viewer会增加
var my_json_val = $("#json-display").clone(false);
my_json_val.find("a.json-placeholder").remove();
总结
使用时只需将json文件读取,传入preview_json.html的showJson方法
编辑结束后, 点击Save 即可保存
链接:https://juejin.cn/post/7207715311759638589
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
线程池也会导致OOM的原因
1. 前言
我这边从一个问题引出这次的话题,我们可能会在开中碰到一种OOM问题,java.lang.OutOfMemoryError: pthread_create (1040KB stack) failed: Try again
相信很多人碰到过这个错误,很容易从网上搜索到出现这个问题的原因是线程过多,那线程过多为什么会导致OOM?线程什么情况下会释放资源?你又能如何做到让它不释放资源?
有的人可能会想到,那既然创建线程过多会导致OOM,那我用线程池不就行了。但是有没有想过,线程池,也可能会造成OOM。其实这里有个很经典的场景,你使用OkHttp的时候不注意,每次请求都创建OkHttpClient,导致线程池过多出现OOM
2. 简单了解线程池
如何去了解线程池,看源码,直接去看是很难看得懂的,要先了解线程池的原理,对它的设计思想有个大概的掌握之后,再去看源码,就会轻松很多,当然这里只了解基础的原理还不够,还需要有一些多线程相关的基础知识。
本篇文章只从部分源码的角度去分析,线程池如何导致OOM的,而不会全部去看所有线程池的源码细节,因为太多了
首先,要了解线程池,首先需要从它的参数入手:
- corePoolSize:核心线程数量
- maximumPoolSize:最大线程数量
- keepAliveTime,unit:非核心线程的存活时间和单位
- workQueue:阻塞队列
- ThreadFactory:线程工厂
- RejectedExecutionHandler:饱和策略
然后你从网上任何一个地方搜都能知道它大致的工作流程是,当一个任务开始执行时,先判断当前线程池数量是否达到核心线程数,没达到则创建一个核心线程来执行任务,如果超过,放到阻塞队列中等待,如果阻塞队列满了,未达到最大线程数,创建一条非核心线程执行任务,如果达到最大线程数,执行饱和策略。在这个过程中,核心线程不会回收,非核心线程会根据keepAliveTime和unit进行回收。
**这里可以多提一嘴,这个过程用了工厂模式ThreadFactory和策略模式RejectedExecutionHandler,关于策略模式可以看我这篇文章 ** juejin.cn/post/719502…
其实从这里就可以看出为什么线程池也会导致OOM了:核心线程不会回收,非核心线程使用完之后会根据keepAliveTime和unit进行回收 ,那核心线程就会一直存活(我这不考虑shutdown()和shutdownNow()这些情况),一直存活就会占用内存,那你如果创建很多线程池,就会OOM。
所以我这篇文章要分析:核心线程不会释放资源的过程,它内部怎么做到的。 只从这部分的源码去进行分析,不会全部都详细讲。
先别急,为了照顾一些基础不太好的朋友,涉及一些基础知识感觉还是要多讲一下。上面提到的线程回收和shutdown方法这些是什么意思?线程执行完它内部的代码后会主动释放资源吗?
我们都知道开发中有个概念叫生命周期,当然线程池和线程也有生命周期(这很重要),在开发中,我们称之为lifecycle。
生命周期当然是设计这个东西的开发者所定义的,我们先看线程池的生命周期,在ThreadPoolExecutor的注释中有写:
*
* The runState provides the main lifecycle control, taking on values:
*
* RUNNING: Accept new tasks and process queued tasks
* SHUTDOWN: Don't accept new tasks, but process queued tasks
* STOP: Don't accept new tasks, don't process queued tasks,
* and interrupt in-progress tasks
* TIDYING: All tasks have terminated, workerCount is zero,
* the thread transitioning to state TIDYING
* will run the terminated() hook method
* TERMINATED: terminated() has completed
*看得出它的生命周期有RUNNING,SHUTDOWN,STOP,TIDYING和TERMINATED。而shutdown()和shutdownNow()方法会改变生命周期,这里不是对线程池做全面解析,所以先有个大概了解就行,可以暂时理解成这篇文章的所有分析都是针对RUNNING状态下的。
看完线程池的,再看看线程的生命周期。线程的生命周期有:
- NEW:创建,简单来说就是new出来没start
- RUNNABLE:运行,简单来说就是start后执行run方法
- TERMINATED:中止,简单来说就是执行完run方法或者进行中断操作之后会变成这个状态
- BLOCKED:阻塞,就是加锁之后竞争锁会进入到这个状态
- WAITING、TIMED_WAITING:休眠,比如sleep方法
这个很重要,需要了解,你要学会线程这块相关的知识点的话,这些生命周期要深刻理解 。比如BLOCKED和WAITING有什么不同?然后学这块又会涉及到锁那一块的知识。以后有时间可以单独写几篇这类的文章,这里先大概有个概念,只需要能先看懂后面的源码就行。
从生命周期的概念你就能知道线程执行完它内部的代码后会主动释放资源,因为它run执行完之后生命周期会到TERMINATED,那这又涉及到了一个知识点,为什么主线程(ActivityThread),执行完run的代码后不会生命周期变成TERMINATED,这又涉及到Looper,就得了解Handler机制,可以看我这篇文章 juejin.cn/post/715882…
扯远了,现在进入正题,先想想,如果是你,你怎么做让核心线程执行完run之后不释放资源,很明显,只要让它不执行到TERMINATED生命周期就行,如何让它不变成TERMINATED状态,只需要让它进入BLOCKED或者WAITING状态就行。所以我的想法是这样的,当这个核心线程执行完这个任务之后,我让它WAITING,等到有新的任务进来的时候我再唤醒它进入RUNNABLE状态。 这是我从理论这个角度去分析的做法,那看看实际ThreadPoolExecutor是怎么做的
3. 线程池部分源码分析
前面说了,不会全部都讲,这里涉及到文章相关内容的流程就是核心线程的任务执行过程,所以这里主要分析核心线程。
当我们使用线程池执行一个任务时,会调用ThreadPoolExecutor的execute方法
public void execute(Runnable command) {
......
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 我们只看核心线程的流程,所以后面的代码不用管
......
}这个ctl是一个状态相关的代码,可以先不用管,我后面会简单统一做个解释,这里不去管它会比较容易理解,我们现在主要是为了看核心线程的流程。从这里可以看出,当前线程的数量小于核心线程的话执行addWorker方法
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}这个addWorker分为上下两部分,我们分别来做解析
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 下半部分
......
}这里主要是做了状态判断的一些操作,我说过状态相关的我们可以先不管,但是这里的写法我觉得要单独讲一下为什么会这么写。不然它内部很多代码是这样的,我怕劝退很多人。
首先retry: ...... break retry; 这个语法糖,平常我们开发很少用到,可以去了解一下,这里就是为了跳出循环。 其次,这里的compareAndIncrementWorkerCount内部的代码是AtomicInteger ctl.compareAndSet(expect, expect + 1) ,Atomic的compareAndSet操作搭配死循环,这叫自旋,所以说要看懂这个需要一定的java多线程相关的基础。自旋的目的是为了什么?这就又涉及到了锁的分类中有乐观锁,有悲观锁。不清楚的可以去学一下这些知识,你就知道为什么它要这么做了,这里就不一一解释。包括你看它的源码,能看到,它会很多地方用自旋,很多地方用ReentrantLock,但它就是不用synchronized ,这些都是多线程这块基础的知识,这里不多说了。
看看下半部分
private boolean addWorker(Runnable firstTask, boolean core) {
// 上半部分
......
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
......
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
......
}
return workerStarted;
}看到它先创建一个Worker对象,再调用Worker对象内部的线程的start方法,我们看看Worker
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
private static final long serialVersionUID = 6138294804551838833L;
final Thread thread;
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
// 其它方法
......
}看到它内部主要有两个对象firstTask就是任务,thread就是执行这个任务的线程,而这个线程是通过getThreadFactory().newThread(this)创建出来的,这个就是我们创建ThreadPoolExecutor时传的“线程工厂”
外部调t.start();之后就会执行这里的run方法,因为newThread传了this进去,你可以先简单理解调这个线程start会执行到这个run,然后run中调用runWorker(this);
注意,你想想runWorker(this)方法,包括之后的流程,都是执行在哪个线程中?都是执行在子线程中,因为这个run方法中的代码,都是执行在这个线程中。你一定要理解这一步,不然你自己看源码会可能看懵。 因为有些人长期不接触多线程环境的情况下,你会习惯单线程的思维去看问题,那就很容易出现理解上的错误。
我们继续看看runWorker,时刻提醒你自己,之后的流程都是在子线程中进行,这条子线程的生命周期变为RUNNABLE
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {s
w.lock();
// 中断相关的操作
......
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
......
} finally {
afterExecute(task, thrown);
}
} finally {
......
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}先讲讲这里的一个开发技巧,task.run()就是执行任务,它前面的beforeExecute和afterExecute就是模板方法设计模式,方便扩展用。
执行完任务后,最后执行processWorkerExit方法
private void processWorkerExit(Worker w, boolean completedAbruptly) {
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
......
}workers.remove(w)后执行tryTerminate方法尝试将线程池的生命周期变为TERMINATED
final void tryTerminate() {
for (;;) {
int c = ctl.get();
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}先不用管状态的变化,一般一眼都能看得出这里是结束的操作了,我们追踪的核心线程正常在RUNNING状态下是不会执行到这里的。 那我们期望的没任务情况下让线程休眠的操作在哪里?
看回runWorker方法
final void runWorker(Worker w) {
......
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {s
......
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}看到它的while中有个getTask()方法,认真看runWorker方法其实能看出,核心线程执行完一个任务之后会getTask()拿下一个任务去执行,这就是当核心线程满的时候任务会放到阻塞队列中,核心线程执行完任务之后会从阻塞队列中拿下一个任务执行。 getTask()从抽象上来看,就是从队列中拿任务。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
......
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}先把timed当成正常情况下为false,然后会执行workQueue.take(),这个workQueue是阻塞队列BlockingQueue, 注意,这里又需要有点基础了。正常有点基础的人看到这里,已经知道这里就是当没有任务会让核心线程休眠的操作,看不懂的,可以先了解下什么是AQS,可以看看我这篇文章 juejin.cn/post/716801…
如果你说你懒得看,行吧,我随便拿个ArrayBlockingQueue给你举例
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}notEmpty是Condition,这里调用了Condition的await()方法,然后想想执行这步操作的是在哪条线程上?线程进入WAITING状态了吧,不会进入TERMINATED了吧。
然后当有任务添加之后会唤醒它,它继续在循环中去执行任务。
这就验证了我们的猜想,通过让核心线程进入WAITING状态以此来达到执行完run方法中的任务也不会主动TERMINATED而释放线程。所以核心线程一直占用资源,这里说的资源指的是空间,而cpu的时间片是会让出的。
4. 部分线程池的操作解读
为什么线程池也会导致OOM,上面已经通过源码告诉你,核心线程不会释放内存空间,导致线程池多的情况下也会导致OOM。这里为了方便新手阅读ThreadPoolExecutor相关的代码,还是觉得写一些它内部的设计思想,不然没点基础的话确实很难看懂。
首先就是状态,上面源码中都有关线程池的生命中周期状态(ctl字段),可以看看它怎么设计的
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3; // Integer.SIZE是32
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;它这里用了两个设计思想,第一个就是用位来表示状态,关于这类型的设计,可以看我这2篇文章 juejin.cn/post/715547… 和 juejin.cn/post/720550…
另外一个设计思想是:用一个变量的高位置表示状态,低位表示数量。 这里就是用高3位来表示生命周期,剩下的低位表示线程的数量。和这个类似的操作有view中的MeasureSpec,也是一个变量表示两个状态。
然后关于设计模式,可以看到它这里最经典的就是用了策略模式,如果你看饱和策略那块的源码,可以好好看看它是怎么设计的。其它的还有工厂、模板之类的,这些也不难,就是策略还是建议学下它怎么去设计的。
然后多线程相关的基础,这个还是比较重要的,这块的基础不好,看ThreadPoolExecutor的源码会相对吃力。比如我上面提过的,线程的生命周期,锁相关的知识,还有AQS等等。如果你熟悉这些,再看这个源码就会轻松很多。
对于总体的设计,你第一看会觉得它的源码很绕,为什么会这样?因为有中断操作+自旋锁+状态的设计 ,它的这种设计就基本可以说是优化代码到极致,比如说状态的设计,就比普通的能省内存,能更方便通过CAS操作。用自旋就是乐观锁,能节省资源等。有中断操作,能让整个系统更灵活。相对的缺点就是不安全,什么意思呢?已是就是这样写代码很容易出BUG,所以这里的让人觉得很绕的代码,就是很多的状态的判断,这些都是为了保证这个流程的安全。
5. 总结
从部分源码的角度去分析,得到的结论是线程池也可能会导致OOM
那再思考一个问题:不断的创建线程池,“一定”会导致OOM吗? 如果你对线程池已经有一定的了解,相信你也知道这个问题的答案。
链接:https://juejin.cn/post/7210691957790572601
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Jetpack:Android新一代导航管理Navigation
前言
不知道小伙伴们是否注意到,用AS创建一个默认的新项目后,MainActivity已经有了很大的不同,最大的区别就是新增加了两个Fragment,同时我们注意到这两个Fragment之间跳转的时候并没有使用之前FragmentTransaction这种形式,而是使用了NavController和NavHostFragment,这就是新一代导航管理————Navigation。
项目中依赖Navigation:
implementation 'androidx.navigation:navigation-fragment-ktx:2.3.5'
implementation 'androidx.navigation:navigation-ui-ktx:2.3.5'创建导航视图
新建一个Android Resource File,类型选择Navigation即可,输入名称后我们就创建了一个导航视图。
在导航试图中,我们可以通过添加activity/fragment等标签手动添加页面,也支持在Design页面中通过界面添加,如下:
注意:这样添加后手动修改一下label。如果我们将Navigation与ToolBar连接,会在标题栏这个label。
示例中添加了两个页面,添加后代码如下:
<?xml version="1.0" encoding="utf-8"?>
<navigation xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools">
<fragment
android:id="@+id/FirstFragment"
android:name="com.xxx.xxx.FirstFragment"
android:label="@string/first_fragment_label"
tools:layout="@layout/fragment_first">
</fragment>
<fragment
android:id="@+id/SecondFragment"
android:name="com.xxx.xxx.SecondFragment"
android:label="@string/second_fragment_label"
tools:layout="@layout/fragment_second">
</fragment>
</navigation>除了添加Fragment和Activity,Google还提供了一个占位符placeholder,添加加完代码如下:
<fragment android:id="@+id/placeholder" />用于暂时占位以便后面可以替换为Fragment和Activity
添加完页面后,我们还需要添加页面之间的导航,可以手动添加action标签,当然也可以通过拖拽来实现,如下:
这样我们就添加了一个从FirstFragment导航到SecondFragment的动作,我们再添加一个逆向的动作,最终的代码如下:
<?xml version="1.0" encoding="utf-8"?>
<navigation xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools">
<fragment
android:id="@+id/FirstFragment"
android:name="com.xxx.xxx.FirstFragment"
android:label="@string/first_fragment_label"
tools:layout="@layout/fragment_first">
<action
android:id="@+id/action_FirstFragment_to_SecondFragment"
app:destination="@id/SecondFragment" />
</fragment>
<fragment
android:id="@+id/SecondFragment"
android:name="com.xxx.xxx.SecondFragment"
android:label="@string/second_fragment_label"
tools:layout="@layout/fragment_second">
<action
android:id="@+id/action_SecondFragment_to_FirstFragment"
app:destination="@id/FirstFragment" />
</fragment>
</navigation>注意占位符placeholder同样支持添加导航。
这样就实现了两个页面间的导航,最后还需要为这个navigation设置id和默认页面startDestination,如下:
<navigation xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:id="@+id/nav_graph"
app:startDestination="@id/FirstFragment">这样导航视图就创建完成了。可以看到Google力图通过可视化工具来简化开发工作,这对我们开发者来说非常有用,可以省去大量编写同质化代码的时间。
添加NavHost
下一步我们需要向Activity中添加导航宿主,导航宿主是一个空页面,必须实现NavHost接口,我们使用Navigation提供的默认NavHost————NavHostFragment即可。如下:
<fragment
android:id="@+id/nav_host_fragment_content_main"
android:name="androidx.navigation.fragment.NavHostFragment"
android:layout_width="0dp"
android:layout_height="0dp"
app:defaultNavHost="true"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintLeft_toLeftOf="parent"
app:layout_constraintRight_toRightOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:navGraph="@navigation/nav_graph" />在Activity的视图中添加一个fragment标签,android:name设置为实现类,即NavHostFragment;app:navGraph设置为刚才新建的导航视图。
注意app:defaultNavHost="true",设置为true后表示将这个NavHostFragment设置为默认导航宿主,这样就会拦截系统的返回按钮事件。同一布局中如果有多个导航宿主(比如双窗口)则必须制定一个为默认的导航宿主。
这时候我们运行应用,就可以发现Activity中已经可以展示FirstFragment了。
导航
我们还需要为两个fragment添加按钮,是其点击跳转到另外一个页面,代码如下:
binding.buttonFirst.setOnClickListener {
findNavController().navigate(R.id.action_FirstFragment_to_SecondFragment)
}示例中是FirstFragment中的一个按钮,点击时执行了id为action_FirstFragment_to_SecondFragment的动作,这个是我们之前在导航视图中配置好的,会导航到SecondFragment。
注意首先通过findNavController()来获取一个NavController对象,然后调用它的navigate函数即可,当然这个函数有多种重载,比如可以传递参数,如下:
public void navigate(@IdRes int resId, @Nullable Bundle args) {这里不一一列举了,大家自行查看源码即可。
可以看到使用Navigation代码精简了很多,只需要一行代码执行一个函数即可。
findNavController
我们重点来看看findNavController(),它是一个扩展函数,如下:
fun Fragment.findNavController(): NavController =
NavHostFragment.findNavController(this)实际上是NavHostFragment的一个静态函数findNavController:
@NonNull
public static NavController findNavController(@NonNull Fragment fragment) {
...
View view = fragment.getView();
if (view != null) {
return Navigation.findNavController(view);
}
// For DialogFragments, look at the dialog's decor view
Dialog dialog = fragment instanceof DialogFragment
? ((DialogFragment) fragment).getDialog()
: null;
if (dialog != null && dialog.getWindow() != null) {
return Navigation.findNavController(dialog.getWindow().getDecorView());
}
throw new IllegalStateException("Fragment " + fragment
+ " does not have a NavController set");
}通过源码可以看到最终是执行了Navigation的findNavController函数,它的代码如下:
@NonNull
public static NavController findNavController(@NonNull View view) {
NavController navController = findViewNavController(view);
...
return navController;
}这里是通过findViewNavController函数来获取NavController的,它的代码如下:
@Nullable
private static NavController findViewNavController(@NonNull View view) {
while (view != null) {
NavController controller = getViewNavController(view);
if (controller != null) {
return controller;
}
ViewParent parent = view.getParent();
view = parent instanceof View ? (View) parent : null;
}
return null;
}这里可以看到通过view来获取NavController,如果没有则向上层查找(父view)直到找到或到根结点。getViewNavController代码如下:
@Nullable
private static NavController getViewNavController(@NonNull View view) {
Object tag = view.getTag(R.id.nav_controller_view_tag);
NavController controller = null;
if (tag instanceof WeakReference) {
controller = ((WeakReference<NavController>) tag).get();
} else if (tag instanceof NavController) {
controller = (NavController) tag;
}
return controller;
}看到这里获取view中key为R.id.nav_controller_view_tag的tag,这个tag就是NavController,那么这个tag又从哪来的?
其实就是上面我们提到导航宿主————NavHostFragment,在他的onViewCreated中可以看到如下代码:
@Override
public void onViewCreated(@NonNull View view, @Nullable Bundle savedInstanceState) {
super.onViewCreated(view, savedInstanceState);
if (!(view instanceof ViewGroup)) {
throw new IllegalStateException("created host view " + view + " is not a ViewGroup");
}
Navigation.setViewNavController(view, mNavController);
// When added programmatically, we need to set the NavController on the parent - i.e.,
// the View that has the ID matching this NavHostFragment.
if (view.getParent() != null) {
mViewParent = (View) view.getParent();
if (mViewParent.getId() == getId()) {
Navigation.setViewNavController(mViewParent, mNavController);
}
}
}这里的mNavController是在NavHostFragment的onCreate中创建出来的,是一个NavHostController对象,它继承NavController,所以就是NavController。
可以看到onViewCreated中调用了Navigation的setViewNavController函数,它的代码如下:
public static void setViewNavController(@NonNull View view,
@Nullable NavController controller) {
view.setTag(R.id.nav_controller_view_tag, controller);
}这样就将NavController加入tag中了,通过findNavController()就可以得到这个NavController来执行导航了。
注意在onViewCreated中不仅为Fragment的View添加了tag,同时还为其父View也添加了,这样做的目的是在Activity中也可以获取到NavController,这点下面就会遇到。
ToolBar
Google提供了Navigation与ToolBar连接的功能,代码如下:
val navController = findNavController(R.id.nav_host_fragment_content_main)
appBarConfiguration = AppBarConfiguration(navController.graph)
setupActionBarWithNavController(navController, appBarConfiguration)上面我们提到,如果Navigation与ToolBar连接,标题栏会自动显示在导航视图中设定好的label。
注意这里的findNavController是Activity的扩展函数,它最终一样会调用Navigation的对应函数,所以与Fragment的流程是一样的。而上面我们提到了,在NavHostFragment中给上层View也设置了tag,所以在这里才能获取到NavController。
除了这个,我们还可以发现当在切换页面的时候,标题栏的返回按钮也会自动显示和隐藏。当导航到第二个页面SecondFragment,返回按钮显示;当回退到首页时,返回按钮隐藏。
但是此时返回按钮点击无效,因为我们还需要重写一个函数:
override fun onSupportNavigateUp(): Boolean {
val navController = findNavController(R.id.nav_host_fragment_content_main)
return navController.navigateUp(appBarConfiguration)
|| super.onSupportNavigateUp()
}这样当点击标题栏的返回按钮时,会执行NavController的navigateUp函数,就会退回到上一页面。
总结
可以看出通过Google推出的这个Navigation,可以让开发者更加优雅管理导航,同时也简化了这部分的开发工作,可视化功能可以让开发者更直观的进行管理。除此之外,Google还提供了Safe Args Gradle插件,该插件可以生成简单的对象和构建器类,这些类支持在目的地之间进行类型安全的导航和参数传递。关于这个大家可以参考官方文档developer.android.google.cn/guide/navig… 即可。
链接:https://juejin.cn/post/7208711636496400439
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android将so库封装到jar包中并加载其中的so库
说明
因为一些原因,我们提供给客户的sdk,只能是jar包形式的,一些情况下,sdk里面有native库的时候,就不太方便操作了,此篇文章主要解决如何把so库放入jar包里面,如何打包成jar,以及如何加载。
1.如何把so库放入jar包
so库放入jar参考此文章ANDROID将SO库封装到JAR包中并加载其中的SO库
将so库改成.jet后缀,放置和加载so库的SoLoader类同一个目录下面。
2.如何使用groovy打包jar
先把需要打包的class放置到同一个文件夹下面,然后打包即可,利用groovy的copy task完成这项工作非常简单。
3.如何加载jar包里面的so
3.1.首先判断当前jar里面是否存在so
InputStream inputStream = SoLoader.class.getResourceAsStream("/com/dianping/logan/arm64-v8a/liblogan.jet");如果inputStream不为空就表示存在。
3.2.拷贝
判断是否已经把so库拷贝到手机里面了,如果没有拷贝过就进行拷贝,这个代码逻辑很简单。
public class SoLoader {
private static final String TAG = "SoLoader";
/**
* so库释放位置
*/
public static String getPath() {
String path = GlobalCtx.getApp().getFilesDir().getAbsolutePath();
//String path = GlobalCtx.getApp().getExternalFilesDir(null).getAbsolutePath();
return path;
}
public static String get64SoFilePath() {
String path = SoLoader.getPath();
String v8a = path + File.separator + "jniLibs" + File.separator +
"arm64-v8a" + File.separator + "liblogan.so";
return v8a;
}
public static String get32SoFilePath() {
String path = SoLoader.getPath();
String v7a = path + File.separator + "jniLibs" + File.separator +
"armeabi-v7a" + File.separator + "liblogan.so";
return v7a;
}
/**
* 支持两种模式,如果InputStream inputStream = SoLoader.class.getResourceAsStream("/com/dianping/logan/arm64-v8a/liblogan.jet");
* 返回了空,表示可能此库是aar接入的,普通加载so库就行,不为空,需要拷贝so库,动态加载
*/
public static boolean jarMode() {
boolean jarMode = false;
InputStream inputStream = SoLoader.class.getResourceAsStream("/com/dianping/logan/arm64-v8a/liblogan.jet");
if (inputStream != null) {
jarMode = true;
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return jarMode;
}
/**
* 是否已经拷贝过so了
*/
public static boolean alreadyCopySo() {
String v8a = SoLoader.get64SoFilePath();
File file = new File(v8a);
if (file.exists()) {
String v7a = SoLoader.get32SoFilePath();
file = new File(v7a);
return file.exists();
}
return false;
}
/**
* 拷贝logan的so库
*/
public static boolean copyLoganJni() {
boolean load;
File dir = new File(getPath(), "jniLibs");
if (!dir.exists()) {
load = dir.mkdirs();
if (!load) {
return false;
}
}
File subdir = new File(dir, "arm64-v8a");
if (!subdir.exists()) {
load = subdir.mkdirs();
if (!load) {
return false;
}
}
File dest = new File(subdir, "liblogan.so");
//load = copySo("/lib/arm64-v8a/liblogan.so", dest);
load = copySo("/com/dianping/logan/arm64-v8a/liblogan.jet", dest);
if (load) {
subdir = new File(dir, "armeabi-v7a");
if (!subdir.exists()) {
load = subdir.mkdirs();
if (!load) {
return false;
}
}
dest = new File(subdir, "liblogan.so");
//load = copySo("/lib/armeabi-v7a/liblogan.so", dest);
load = copySo("/com/dianping/logan/armeabi-v7a/liblogan.jet", dest);
}
return load;
}
public static boolean copySo(String name, File dest) {
InputStream inputStream = SoLoader.class.getResourceAsStream(name);
if (inputStream == null) {
Log.e(TAG, "inputStream == null");
return false;
}
boolean result = false;
FileOutputStream outputStream = null;
try {
outputStream = new FileOutputStream(dest);
int i;
byte[] buf = new byte[1024 * 4];
while ((i = inputStream.read(buf)) != -1) {
outputStream.write(buf, 0, i);
}
result = true;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return result;
}
}3.3.加载
首先判断当前应用是32位还是64位Process.is64Bit();。然后加载对应的32或者64位的so。
static {
try {
if (SoLoader.jarMode()) {
if (SoLoader.alreadyCopySo()) {
sIsCloganOk = loadLocalSo();
} else {
boolean copyLoganJni = SoLoader.copyLoganJni();
if (copyLoganJni) {
sIsCloganOk = loadLocalSo();
}
}
} else {
System.loadLibrary(LIBRARY_NAME);
sIsCloganOk = true;
}
} catch (Throwable e) {
e.printStackTrace();
sIsCloganOk = false;
}
}
static boolean loadLocalSo() {
boolean bit = Process.is64Bit();
if (bit) {
String v8a = SoLoader.get64SoFilePath();
try {
System.load(v8a);
return true;
} catch (Throwable e) {
e.printStackTrace();
return false;
}
} else {
String v7a = SoLoader.get32SoFilePath();
try {
System.load(v7a);
return true;
} catch (Throwable e) {
e.printStackTrace();
return false;
}
}
}链接:https://juejin.cn/post/7206627150621851707
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
[崩溃] Android应用自动重启
背景
在App开发过程中,我们经常需要自动重启的功能。比如:
- 登录或登出的时候,为了清除缓存的一些变量,比较简单的方法就是重新启动app。
- crash的时候,可以捕获到异常,直接自动重启应用。
- 在一些debug的场景中,比如设置了一些测试的标记位,需要重启才能生效,此时可以用自动重启,方便测试。
那我们如何实现自动重启的功能呢?我们都知道如何杀掉进程,但是当我们的进程被杀掉之后,如何唤醒呢?
这篇文章就来和大家介绍一下,实现应用自动重启的几种方法。
方法1 AlarmManager
private void setAlarmManager(){
Intent intent = new Intent();
intent.setClass(this, MainActivity.class);
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
PendingIntent pendingIntent = PendingIntent.getActivity(this, 0, intent, PendingIntent.FLAG_ONE_SHOT);
AlarmManager alarmManager = (AlarmManager) getSystemService(Context.ALARM_SERVICE);
alarmManager.set(AlarmManager.RTC, System.currentTimeMillis()+100, pendingIntent);
Process.killProcess(Process.myPid());
System.exit(0);
}使用AlarmManager实现自动重启的核心思想:创建一个100ms之后的Alarm任务,等Alarm任务到执行时间了,会自动唤醒App。
缺点:
- 在App被杀和拉起之间,会显示系统
Launcher桌面,体验不好。 - 在高版本不适用
方法2 直接启动Activity
private void restartApp(){
Intent intent = new Intent(this, MainActivity.class);
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
startActivity(intent);
Process.killProcess(Process.myPid());
System.exit(0);
}缺点:
- MainActivity必须是Standard模式
方法3 ProcessPhoenix
JakeWharton大神开源了一个叫ProcessPhoenix的库,这个库可以实现无缝重启app。
实现原理其实很简单,我们先讲怎么使用,然后再来分析源码。
使用方法
首先引入ProcessPhoenix库,这个库不需要初始化,可以直接使用。
implementation 'com.jakewharton:process-phoenix:2.1.2'使用1:如果想重启app后进入首页:
ProcessPhoenix.triggerRebirth(context);使用2:如果想重启app后进入特定的页面,则需要构造具体页面的intent,当做参数传入:
Intent nextIntent = //...
ProcessPhoenix.triggerRebirth(context, nextIntent);有一点需要特别注意。
- 我们通常会在
Application的onCreate方法中做一系列初始化的操作。 - 如果使用
Phoenix库,需要在onCreate方法中判断,如果当前进程是Phoenix进程,则直接return,跳过初始化的操作。
if (ProcessPhoenix.isPhoenixProcess(this)) {
return;
}源码
ProcessPhoenix的原理:
- 当调用
triggerRebirth方法的时候,会启动一个透明的Activity,这个Activity运行在:phoenix进程 Activity启动后,杀掉主进程,然后用:phoenix进程拉起主进程的Activity- 关闭当前
Activity,杀掉:phoenix进程
先来看看Manifest中Activity的注册代码:
<activity
android:name=".ProcessPhoenix"
android:theme="@android:style/Theme.Translucent.NoTitleBar"
android:process=":phoenix"
android:exported="false"
/>可以看到这个Activity确实是在:phoenix进程启动的,且是Translucent透明的。
整个ProcessPhoenix的代码只有不到120行,非常简单。我们来看下triggerRebirth做了什么。
public static void triggerRebirth(Context context) {
triggerRebirth(context, getRestartIntent(context));
}不带intent的triggerRebirth,最后也会调用到带intent的triggerRebirth方法。
getRestartIntent会获取主进程的Launch Activity。
private static Intent getRestartIntent(Context context) {
String packageName = context.getPackageName();
Intent defaultIntent = context.getPackageManager().getLaunchIntentForPackage(packageName);
if (defaultIntent != null) {
return defaultIntent;
}
}所以要调用不带intent的triggerRebirth,必须在当前App的manifest里,指定Launch Activity,否则会抛出异常。
接着来看看真正的triggerRebirth方法:
public static void triggerRebirth(Context context, Intent... nextIntents) {
if (nextIntents.length < 1) {
throw new IllegalArgumentException("intents cannot be empty");
}
// 第一个activity添加new_task标记,重新开启一个新的stack
nextIntents[0].addFlags(FLAG_ACTIVITY_NEW_TASK | FLAG_ACTIVITY_CLEAR_TASK);
Intent intent = new Intent(context, ProcessPhoenix.class);
// 这里是为了防止传入的context非Activity
intent.addFlags(FLAG_ACTIVITY_NEW_TASK); // In case we are called with non-Activity context.
// 将待启动的intent作为参数,intent是parcelable的
intent.putParcelableArrayListExtra(KEY_RESTART_INTENTS, new ArrayList<>(Arrays.asList(nextIntents)));
// 将主进程的pid作为参数
intent.putExtra(KEY_MAIN_PROCESS_PID, Process.myPid());
// 启动ProcessPhoenix Activity
context.startActivity(intent);
}triggerRebirth方法,主要的功能是启动ProcessPhoenix Activity,相当于启动了:phoenix进程。同时,会将nextIntents和主进程的pid作为参数,传给新启动的ProcessPhoenix Activity。
下面我们再来看看,ProcessPhoenix Activity的onCreate方法,看看新进程启动后做了什么。
@Override protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
// 首先杀死主进程
Process.killProcess(getIntent().getIntExtra(KEY_MAIN_PROCESS_PID, -1)); // Kill original main process
ArrayList<Intent> intents = getIntent().getParcelableArrayListExtra(KEY_RESTART_INTENTS);
// 再启动主进程的intents
startActivities(intents.toArray(new Intent[intents.size()]));
// 关闭当前Activity,杀掉当前进程
finish();
Runtime.getRuntime().exit(0); // Kill kill kill!
}:phoenix进程主要做了以下事情:
- 杀死主进程
- 用传入的
Intent启动主进程的Activity(也可以是Service) - 关闭
phoenix Activity,杀掉phoenix进程
总结
如果App有自动重启的需求,比较推荐使用ProcessPhoenix的方法。
原理其实非常简单:
- 启动一个新的进程
- 杀掉主进程
- 用新的进程,重新拉起主进程
- 杀掉新的进程
我们可以直接在工程里引入ProcessPhoenix开源库,也可以自己用代码实现这样的机制,总之都比较简单。
链接:https://juejin.cn/post/7207743145999024165
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android:我是如何优化APP体积的
前言
在日常开发中,随着APP功能迭代发现打出的安装包体积越来越大,这里说的大是猛增的那种大,而并非一点一点增大。从最开始的几兆到后面的几十兆,虽然市面上的很多APP甚至达到上百兆,但毕竟别人功能强大,用到的一些底层库就特别占面积,流量也多所以也可理解。但自研的一些APP可经不住这些考验,所以能压缩就压缩,能优化就尽量优化,以得到用户最好的体验,下面就来说说我在项目中是如何优化APP体积的。
1. 本地资源优化
这里主要是压缩一些图片和视频。项目中本地资源用到最多的应该就是图片,几乎每个页面都离不开图标,甚至一些页面采用大图片的形式。你可知道,正常不经压缩的图片大的可以上大几十兆,小则也是一兆起步。这里做了个实验,同一个文件分别采用svg、png、使用tiny压缩后的png、webp四种类型图片进行展示(顺序是从左到右,从上到下):
可以看到,加载出来的效果几乎没有什么区别,但体积却有很大的差别(其中webp是采取的默认75%转换):
所以,别再使用png格式图片,太浪费资源了,就算经过压缩还是不及svg和webp,这里的webp其实还可以加大转换力度,但个人还是比较喜欢svg。
至于音视频文件也是可以通过其他工具进行压缩再放入本地,如非必要,尽量还是使用网络资源。
2. lib优化
一些三方库会使用底层so文件,一般在配置的时候我们尽量选择一种cpu类型,这里选择armeabi-v7a,其实几乎都兼容
ndk {
//设置支持的SO库架构 armeabi、armeabi-v7a、arm64-v8a、x86、x86_64、mips、mips64
abiFilters 'armeabi-v7a'
}可以看看APK体积分析,每种cpu占用体积都比较大,少配置一种就能省下不少空间。
3. 代码混淆、无用资源的删除
在bulid.gradle中配置minifyEnabled true开启代码混淆,还需要配置混淆规则,否则无法找到目标类。shrinkResources true则是打包时不会将无用资源打入包内,这里有个小坑。之前使用腾讯地图时,某些第三方的静态资源会因为这个操作不被打入包内,导致无法找到资源,所以根据具体情况使用。
release {
buildConfigField "boolean", "LOG_DEBUG", "false"
minifyEnabled true
// shrinkResources true 慎用,可能会导致第三方资源文件找不到
zipAlignEnabled true
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
}4. 代码复用,剔除无用代码
项目中由于多人协同开发会出现各写各的情况,需要抽出一些公共库之类的工具,方便代码复用。一些注释掉的代码该删除就删除。其实这一部分优化的体积相当少,但也得做,也是对代码质量的一种提升。
总结
其实只要做到了以上四步,APP体积优化已经得到了很大程度的提升了,其他再怎么优化效果也不是很明显了,最主要的就是本地资源和第三方so包体积占用较多。图片的使用我们尽量做到:小图标用svg,全屏类的大图可以考虑webp,最好不要使用png。ndk配置最好只配置一款cpu,几乎都可兼容,万不得已再加一个。
以上便是全部内容,希望对大家有所帮助。
链接:https://juejin.cn/post/7206292770277261368
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
【自定义 View】Android 实现物理碰撞效果的徽章墙
前言
在还没有疫情的年代,外出经常会选择高铁,等高铁的时候我就喜欢打开 掌上高铁 的成就,签到领个徽章,顺便玩一下那个类似碰撞小球的徽章墙,当时我就在想这东西怎么实现的,但是吧,实在太懒了/doge,这几年都没尝试去自己实现过。最近有时间倒逼自己做了一些学习和尝试,就分享一下这种功能的实现。
不过,当我为写这篇文章做准备的时候,据不完全考古发现,似乎摩拜的 app 更早就实现了这个需求,但有没有更早的我就不知道了/doge
其实呢,我想起来做这个尝试是我在一个 Android 自定义 View 合集的库 里看到了一个叫 PhysicsLayout 的库,当时我就虎躯一震,我心心念念的徽章墙不就是这个效果嘛,于是也就有了这篇文章。这个 PhysicsLayout 其实是借助 JBox2D 来实现的,但不妨先借助 PhysicsLayout 实现徽章墙,然后再来探索 PhysicsLayout 的实现方式。
实现
添加依赖,
sync
implementation("com.jawnnypoo:physicslayout:3.0.1")
在布局文件中添加
PhysicsLinearLayout,并添加一个子 View,run起来
这里我给
ImageView设置 3 个Physic的属性
layout_shape设置模拟物理形状为圆形layout_circleRadius设置圆形的半径为25dplayout_restitution设置物体弹性的系数,范围为 [0,1],0 表示完全不反弹,1 表示完全反弹
看上去好像效果还行,我们再多加几个试试
子 View试试
有下坠效果了,但是还不能随手机转动自由转动,在我阅读了
PhysicsLayout之后发现其并未提供随陀螺仪自由晃动的方法,那我们自己加一个,在MainActivity给PhysicsLayout添加一个扩展方法
/**
* 随手机的转动,施加相应的矢量
* @param x x 轴方向的分量
* @param y y 轴方向的分量
*/
fun PhysicsLinearLayout.onSensorChanged(x: Float, y: Float) {
for (i in 0..this.childCount) {
Log.d(this.javaClass.simpleName, "input vec2 value : x $x, y $y")
val impulse = Vec2(x, y)
val view: View? = this.getChildAt(i)
val body = view?.getTag(com.jawnnypoo.physicslayout.R.id.physics_layout_body_tag) as? Body
body?.applyLinearImpulse(impulse, body.position)
}
}
在
MainActivity的onCreate()中获取陀螺仪数据,并将陀螺仪数据设置给我们为PhysicsLayout扩展的方法,run
val physicsLayout = findViewById(R.id.physics_layout)
val sensorManager = getSystemService(Context.SENSOR_SERVICE) as SensorManager
val gyroSensor: Sensor? = sensorManager.getDefaultSensor(Sensor.TYPE_GYROSCOPE)
gyroSensor?.also { sensor ->
sensorManager.registerListener(object : SensorEventListener {
override fun onSensorChanged(event: SensorEvent?) {
event?.also {
if (event.sensor.type == Sensor.TYPE_GYROSCOPE) {
Log.d(this@MainActivity.javaClass.simpleName, "sensor value : x ${event.values[0]}, y ${event.values[1]}")
physicsLayout.onSensorChanged(-event.values[0], event.values[1])
}
}
}
override fun onAccuracyChanged(sensor: Sensor?, accuracy: Int) {
}
}, sensor, SensorManager.SENSOR_DELAY_UI)
}
动了,但是好像和预期的效果不太符合呀,而且也不符合用户直觉。
那不知道这时候大家是怎么处理问题的,我是先去看看这个库的
issue,搜索一下和 sensor 相关的提问,第二个就是关于如何让子 view 根据加速度计的数值进行移动,作者给出的答复是使用重力传感器,并在AboutActivity中给出了示例代码。
那我们这里就换用重力传感器来试一试。
val gyroSensor: Sensor? = sensorManager.getDefaultSensor(Sensor.TYPE_GRAVITY)
gyroSensor?.also { sensor ->
sensorManager.registerListener(object : SensorEventListener {
override fun onSensorChanged(event: SensorEvent?) {
event?.also {
if (event.sensor.type == Sensor.TYPE_GRAVITY) {
Log.d(this@MainActivity.javaClass.simpleName, "sensor value : x ${event.values[0]}, y ${event.values[1]}")
physicsLayout.physics.setGravity(-event.values[0], event.values[1])
}
}
}
override fun onAccuracyChanged(sensor: Sensor?, accuracy: Int) {
}
}, sensor, SensorManager.SENSOR_DELAY_UI)
}
这下碰撞效果就正常了,但是好像会卡住不动啊!
不急,回到
issue,看第一个提问:物理效果会在子 view 停止移动后结束 和这里遇到的问题一样,看一下互动,有人提出是由于物理模拟引擎在物体移动停止后将物体休眠了。给出的修改方式是设置bodyDef.allowSleep = false
这个属性,是由
子 View持有,所有现在需要获取子 View的实例并设置对应的属性,这里我就演示修改其中一个的方式,其他类似。
findViewById(R.id.iv_physics_a).apply {
if (layoutParams is PhysicsLayoutParams) {
(layoutParams as PhysicsLayoutParams).config.bodyDef.allowSleep = false
}
}
···
到这里,这个需求基本就算实现了。
原理
看完了徽章墙的实现方式,我们再来看看 PhysicsLayout 是如何实现这种物理模拟效果的。
初看一下代码结构,可以说非常简单
那我们先看一下我上面使用到的
PhysicsLinearLayout
class PhysicsLinearLayout : LinearLayout {
lateinit var physics: Physics
constructor(context: Context) : super(context) {
init(null)
}
constructor(context: Context, attrs: AttributeSet?) : super(context, attrs) {
init(attrs)
}
constructor(context: Context, attrs: AttributeSet?, defStyleAttr: Int) : super(context, attrs, defStyleAttr) {
init(attrs)
}
@TargetApi(21)
constructor(context: Context, attrs: AttributeSet?, defStyleAttr: Int, defStyleRes: Int) : super(context, attrs, defStyleAttr, defStyleRes) {
init(attrs)
}
private fun init(attrs: AttributeSet?) {
setWillNotDraw(false)
physics = Physics(this, attrs)
}
override fun onSizeChanged(w: Int, h: Int, oldw: Int, oldh: Int) {
super.onSizeChanged(w, h, oldw, oldh)
physics.onSizeChanged(w, h)
}
override fun onLayout(changed: Boolean, l: Int, t: Int, r: Int, b: Int) {
super.onLayout(changed, l, t, r, b)
physics.onLayout(changed)
}
override fun onDraw(canvas: Canvas) {
super.onDraw(canvas)
physics.onDraw(canvas)
}
override fun onInterceptTouchEvent(ev: MotionEvent): Boolean {
return physics.onInterceptTouchEvent(ev)
}
@SuppressLint("ClickableViewAccessibility")
override fun onTouchEvent(event: MotionEvent): Boolean {
return physics.onTouchEvent(event)
}
override fun generateLayoutParams(attrs: AttributeSet): LayoutParams {
return LayoutParams(context, attrs)
}
class LayoutParams(c: Context, attrs: AttributeSet?) : LinearLayout.LayoutParams(c, attrs), PhysicsLayoutParams {
override var config: PhysicsConfig = PhysicsLayoutParamsProcessor.process(c, attrs)
}
}
主要有下面几个重点
- 首先是在构造函数创建了
Physics实例 - 然后把
View的绘制,位置,变化,点击事件的处理统统交给了physics去处理 - 最后由
PhysicsLayoutParamsProcessor创建PhysicsConfig的实例
- 首先是在构造函数创建了
那我们先来看一下简单一点的
PhysicsLayoutParamsProcessor
object PhysicsLayoutParamsProcessor {
/**
* 处理子 view 的属性
*
* @param c context
* @param attrs attributes
* @return the PhysicsConfig
*/
fun process(c: Context, attrs: AttributeSet?): PhysicsConfig {
val config = PhysicsConfig()
val array = c.obtainStyledAttributes(attrs, R.styleable.Physics_Layout)
processCustom(array, config)
processBodyDef(array, config)
processFixtureDef(array, config)
array.recycle()
return config
}
/**
* 处理子 view 的形状属性
*/
private fun processCustom(array: TypedArray, config: PhysicsConfig) {
if (array.hasValue(R.styleable.Physics_Layout_layout_shape)) {
val shape = when (array.getInt(R.styleable.Physics_Layout_layout_shape, 0)) {
1 -> Shape.CIRCLE
else -> Shape.RECTANGLE
}
config.shape = shape
}
if (array.hasValue(R.styleable.Physics_Layout_layout_circleRadius)) {
val radius = array.getDimensionPixelSize(R.styleable.Physics_Layout_layout_circleRadius, -1)
config.radius = radius.toFloat()
}
}
/**
* 处理子 view 的刚体属性
* 1. 刚体类型
* 2. 刚体是否可以旋转
*/
private fun processBodyDef(array: TypedArray, config: PhysicsConfig) {
if (array.hasValue(R.styleable.Physics_Layout_layout_bodyType)) {
val type = array.getInt(R.styleable.Physics_Layout_layout_bodyType, BodyType.DYNAMIC.ordinal)
config.bodyDef.type = BodyType.values()[type]
}
if (array.hasValue(R.styleable.Physics_Layout_layout_fixedRotation)) {
val fixedRotation = array.getBoolean(R.styleable.Physics_Layout_layout_fixedRotation, false)
config.bodyDef.fixedRotation = fixedRotation
}
}
/**
* 处理子 view 的刚体描述
* 1. 刚体的摩擦系数
* 2. 刚体的补偿系数
* 3. 刚体的密度
*/
private fun processFixtureDef(array: TypedArray, config: PhysicsConfig) {
if (array.hasValue(R.styleable.Physics_Layout_layout_friction)) {
val friction = array.getFloat(R.styleable.Physics_Layout_layout_friction, -1f)
config.fixtureDef.friction = friction
}
if (array.hasValue(R.styleable.Physics_Layout_layout_restitution)) {
val restitution = array.getFloat(R.styleable.Physics_Layout_layout_restitution, -1f)
config.fixtureDef.restitution = restitution
}
if (array.hasValue(R.styleable.Physics_Layout_layout_density)) {
val density = array.getFloat(R.styleable.Physics_Layout_layout_density, -1f)
config.fixtureDef.density = density
}
}
}
这个类比较简单,就是一个常规的读取设置并创建一个对应的
PhysicsConfig的属性
现在我们来看最关键的
Physics,这个类代码相对比较长,我就不完全贴出来了,一段一段的来分析
- 首先定义了一些伴生对象,主要是预设了几种重力值,模拟世界的边界尺寸,渲染帧率
companion object {
private val TAG = Physics::class.java.simpleName
const val NO_GRAVITY = 0.0f
const val MOON_GRAVITY = 1.6f
const val EARTH_GRAVITY = 9.8f
const val JUPITER_GRAVITY = 24.8f
// Size in DP of the bounds (world walls) of the view
private const val BOUND_SIZE_DP = 20
private const val FRAME_RATE = 1 / 60f
/**
* 在创建 view 对应的刚体时,设置配置参数
* 当布局已经被渲染之后改变 view 的配置需要调用 ViewGroup.requestLayout,刚体才能使用新的配置创建
*/
fun setPhysicsConfig(view: View, config: PhysicsConfig?) {
view.setTag(R.id.physics_layout_config_tag, config)
}
}
- 然后定义了很多的成员变量,这里挑几个重要的说一说吧
/**
* 模拟世界每一步渲染的计算速度,默认是 8
*/
var velocityIterations = 8
/**
* 模拟世界每一步渲染的迭代速度,默认是 3
*/
var positionIterations = 3
/**
* 模拟世界每一米对应多少个像素,可以用来调整模拟世界的大小
*/
var pixelsPerMeter = 0f
/**
* 当前控制着 view 的物理状态的模拟世界
*/
var world: World? = null
private set
- 在
init方法中主要是读取一些Physics配置,另外初始化了一个拖拽手势处理的实例
init {
viewDragHelper = TranslationViewDragHelper.create(viewGroup, 1.0f, viewDragHelperCallback)
density = viewGroup.resources.displayMetrics.density
if (attrs != null) {
val a = viewGroup.context
.obtainStyledAttributes(attrs, R.styleable.Physics)
···
a.recycle()
}
}
- 然后提供了一些物理长度,角度的换算方法
- 在
onLayout中创建了模拟世界,根据边界设置决定是否启用边界,设置碰撞处理回调,根据子 view创建刚体
private fun createWorld() {
// Null out all the bodies
val oldBodiesArray = ArrayList
for (i in 0 until viewGroup.childCount) {
val body = viewGroup.getChildAt(i).getTag(R.id.physics_layout_body_tag) as? Body
oldBodiesArray.add(body)
viewGroup.getChildAt(i).setTag(R.id.physics_layout_body_tag, null)
}
bounds.clear()
if (debugLog) {
Log.d(TAG, "createWorld")
}
world = World(Vec2(gravityX, gravityY))
world?.setContactListener(contactListener)
if (hasBounds) {
enableBounds()
}
for (i in 0 until viewGroup.childCount) {
val body = createBody(viewGroup.getChildAt(i), oldBodiesArray[i])
onBodyCreatedListener?.onBodyCreated(viewGroup.getChildAt(i), body)
}
}
- 在
onInterceptTouchEvent,onTouchEvent中处理手势事件,如果没有开启滑动拖拽,时间继续传递,如果开启了,则由viewDragHelper来处理手势事件。
fun onInterceptTouchEvent(ev: MotionEvent): Boolean {
if (!isFlingEnabled) {
return false
}
val action = ev.actionMasked
if (action == MotionEvent.ACTION_CANCEL || action == MotionEvent.ACTION_UP) {
viewDragHelper.cancel()
return false
}
return viewDragHelper.shouldInterceptTouchEvent(ev)
}
fun onTouchEvent(ev: MotionEvent): Boolean {
if (!isFlingEnabled) {
return false
}
viewDragHelper.processTouchEvent(ev)
return true
}
- 在
onDraw中绘制view的物理效果
先设置世界的物理配置
val world = world
if (!isPhysicsEnabled || world == null) {
return
}
world.step(FRAME_RATE, velocityIterations, positionIterations)
遍历
子 view并获取此前在创建刚体时设置的刚体对象,对于正在被拖拽的view将其移动到对应的位置
translateBodyToView(body, view)
view.rotation = radiansToDegrees(body.angle) % 360f
否则的话,设置
view的物理位置,这里的debugDraw一直是false所以并不会走这段逻辑,且由于是私有属性,外部无法修改,似乎永远不会走这里
view.x = metersToPixels(body.position.x) - view.width / 2f
view.y = metersToPixels(body.position.y) - view.height / 2f
view.rotation = radiansToDegrees(body.angle) % 360f
if (debugDraw) {
val config = view.getTag(R.id.physics_layout_config_tag) as PhysicsConfig
when (config.shape) {
Shape.RECTANGLE -> {
canvas.drawRect(
metersToPixels(body.position.x) - view.width / 2,
metersToPixels(body.position.y) - view.height / 2,
metersToPixels(body.position.x) + view.width / 2,
metersToPixels(body.position.y) + view.height / 2,
debugPaint
)
}
Shape.CIRCLE -> {
canvas.drawCircle(
metersToPixels(body.position.x),
metersToPixels(body.position.y),
config.radius,
debugPaint
)
}
}
}
最后提供了一个接口便于我们在需要的时候修改
JBox2D处理view对应的刚体的物理状态
onPhysicsProcessedListeners.forEach { it.onPhysicsProcessed(this, world) }
- 还有一个测试物理碰撞效果的随机碰撞方法
fun giveRandomImpulse() {
var body: Body?
var impulse: Vec2
val random = Random()
for (i in 0 until viewGroup.childCount) {
impulse = Vec2((random.nextInt(1000) - 1000).toFloat(), (random.nextInt(1000) - 1000).toFloat())
body = viewGroup.getChildAt(i).getTag(R.id.physics_layout_body_tag) as? Body
body?.applyLinearImpulse(impulse, body.position)
}
}
- 首先定义了一些伴生对象,主要是预设了几种重力值,模拟世界的边界尺寸,渲染帧率
Bonus
在上面分析代码的时候,多次提到手势拖拽,那怎么实现这个手势的效果,目前好像对手是没反应嘛~
其实也很简单,将
physics的isFlingEnabled属性设置为true即可。
val physicsLayout = findViewById(R.id.physics_layout).apply {
physics.isFlingEnabled = true
}
在浏览
PhysicsLayoutissue 的时候还意外的发现已经有国人实现了Compose版本的
JetpackComposePhysicsLayout
链接:https://juejin.cn/post/7208508980162101308
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android必知必会-Stetho调试工具
一、背景
Stetho是 Facebook 出品的一个强大的 Android 调试工具,使用该工具你可以在 Chrome Developer Tools查看APP的布局, 网络请求(仅限使用Volle, okhttp的网络请求库), Sqlite, Preference, 一切都是可视化的操作,无须自己在去使用adb, 也不需要root你的设备
本人使用自己的Nubia Z9 Mini作为调试机,由于牵涉到Sqlite数据库,所以尝试了很多办法把它Root了,然而Root之后就无法正常升级系统。
今天得知一调试神器Stetho,无需Root就能查看数据库以及APP的布局(这一点没有Android Device Monitor使用方便,但是Android Device Monitor在Mac上总是莫名其妙出问题),使用起来很方便,大家可以尝试一下。
二、配置流程
1.引入主库
使用Gradle方式:
// Gradle dependency on Stetho
dependencies {
compile 'com.facebook.stetho:stetho:1.3.1'
} 此外还支持Maven方式,这里不做介绍。
2.引入网络请求库
如果需要调试网络且你使用的网络请求库是Volle或者Okhttp,那么你才需要配置,否则跳过此步。
以下根据自己使用的网络请求库情况来导入相应的库:
1.使用okhttp 2.X
dependencies {
compile 'com.facebook.stetho:stetho-okhttp:1.3.1'
} 2.使用okhttp 3.X
dependencies {
compile 'com.facebook.stetho:stetho-okhttp3:1.3.1'
} 3.使用HttpURLConnection
dependencies {
compile 'com.facebook.stetho:stetho-urlconnection:1.3.1'
}3.配置代码
配置Application
public class XXX extends Application {
public void onCreate() {
super.onCreate();
Stetho.initializeWithDefaults(this);
}
}配置网络请求库:
OkHttp 2.2.x+ 或 3.x
//方案一
OkHttpClient client = new OkHttpClient();
client.networkInterceptors().add(new StethoInterceptor());
//方案二
new OkHttpClient.Builder()
.addNetworkInterceptor(new StethoInterceptor())
.build();如果使用的是HttpURLConnection,请查阅相关文档。
4.使用
运行重新编译后的APP程序,保持手机与电脑的连接,然后打开Chrome浏览器,在地址栏里输入:chrome://inspect然后选择自己的设备下运行的APP进程名下的Inspect链接 即可进行调试。
三、遇到的问题
1.okhttp版本问题:
可能你还在使用okhttp 2.x的版本,在引入网络库的时候,你需要去查看一下Stetho当前版本使用的okhttp版本,避免在项目中使用多个不同版本的okhttp。
PS:okhttp2.x和3.x的引入方式略有不同,不可以直接修改版本号来导入:
//2.x
compile 'com.squareup.okhttp:okhttp:2.x.x'
//3.x
compile 'com.squareup.okhttp3:okhttp:3.x.x'2.配置okhttp代码方案一报错:
//方案一
OkHttpClient client = new OkHttpClient();
client.networkInterceptors().add(new StethoInterceptor());
//方案二
OkHttpClient client = new OkHttpClient.Builder()
.addNetworkInterceptor(new StethoInterceptor())
.build();我在使用方案一进行配置okhttp的时候,会报错:
Caused by: java.lang.UnsupportedOperationException不知道是不是兼容的问题,大家在使用的时候请注意。
链接:https://juejin.cn/post/7202164243612860472
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android组件化 这可能是最完美的形态吧?
Android组件化的几种方式
一. 前言
Android开发为什么要组件化,有什么好处?可以看看之前的文章。
组件化的过程中其实都大同小异。结构与功能分为不同的层级:
各模块的跳转和业务通信通过路由转发:
这里讲一下常用的两种方案
二. 修改配置文件的方案
我们都知道组件Module是分为Application和library的:
- application属性,可以独立运行的Android程序,常见的App模块就是Application类型。
- library属性,不可以独立运行,一般是程序依赖的库文件。
那么我们就可以在跟gradle文件中配置,指定当前模块是否需要独立运行。
isNewsFeedModule = true
isProfileModule = true
isPartTimeModule = true
isPromotionModule = true
isWalletModule = true
isYYPayModule = true
isYYFoodModule = true
isRewardsModule = true
isResumeModule = true
isFreelancerModule = true
复制代码在指定的模块如NewsFeed模块中配置是否需要独立运行:
if (isNewsFeedModule.toBoolean()) {
apply plugin: 'com.android.application'
} else {
apply plugin: 'com.android.library'
}
复制代码一个独立运行的application都是要有指定的appid的,那我们也得指定:
defaultConfig {
(!isNewsFeedModule.toBoolean()){
applicationId "com.mygroup.newsfeed"
}
}
复制代码还有可能独立运行和依赖库的方式,它们的清单文件有差异导致不同,那么还得指定清单文件的路径:
sourceSets {
main {
if (isModule.toBoolean()) {
manifest.srcFile 'src/main/module/AndroidManifest.xml'
} else {
manifest.srcFile 'src/main/AndroidManifest.xml'
}
}
}
复制代码最后,如果NesFeed模块是独立运行的,那么App模块不可能依赖一个Application吧。所以App的Build.gradle中也得修改:
if (isNeedHomeModule.toBoolean ()){
implementation project (':newsfeed')
}
复制代码这样每一次想修改对应的模块的时候,就去根目录配置文件修改,然后build之后就能生效。这应该是大多数开发者惯用的组件化方式了吧。
三. 使用框架来实现配置的升级
其实关于配置,关于ApplicationId,清单文件和application与library的判断,都是有迹可循,可以使用代码代替的,由此出现了不少组件化的框架来替我们完成重复的工作。
比较出名的如JIMU。再比如另一个比较火的组件化框架DDComponent,他们替你完成了很大一部分的工作。你只需要引用它的插件
apply plugin: 'com.dd.comgradle'
复制代码指定他独立运行的applicationName就能实现组件化了
combuild {
applicationName = 'com.luojilab.reader.runalone.application.ReaderApplication'
isRegisterCompoAuto = true
}
复制代码其中还自带路由,可谓是方便到家了。
但是一些痛点是,他们基于Gradle插件生成代码,由于AGP7的api有变动,有可能升级到AGP7之后出现问题。还有就是多模块的组合测试不方便,比如我想测试NewsFeed,这个模块中关联了很多Profile模块的东西,那我单独测试就要引入这2个组件,但是他们是平级的。也导致测试不方便,只能运行主app模块来测试。
四. 自定义单独的独立运行模块
我们不使用框架,直接把全部的模块都设置为library,由app模块依赖,我们单独的建立runalone的application类型模块,可以单独的调试ProFile模块 ,也可以添加NewsFeed和Profile模块一起测试。
由于app模块没有依赖runalone的模块,所以对应apk的大小和性能也没有影响,可以说单独用于调试是很方便的。
结构如下:
settings.gradle:
include ':app',
':cs_router',
':cs_baselib',
':cs_cptServices',
':cpt_auth',
':cpt_main',
':cpt_parttime',
':cpt_newsfeed',
':cpt_im',
':cpt_ewallet',
':cpt_profile',
':cs_ninegrid',
':lib_xpopup',
':standalone:parttimerunalone',
':standalone:authrunalone',
':standalone:ewalletrunalone',
':standalone:newsfeedrunalone',
':standalone:profilerunalone'
复制代码优势:
- 同样实现了组件化隔离
- 不需要修改配置反复编译
- 不需要导入第三方库导致开发成本和容错率提高
- 方便不同平级的模块组合调试
内部路由功能的实现:
一些框架都是自带的路由,其实思想都是和ARouter差不多。其他单独的组件化框架也有很多,例如app-joint。另一种方案就是大家耳熟能详的ARouter。
推荐大家使用Arouter,理由还是和上面一样,由gradle生成的代码有风险,AMS生成过程中依赖APG的api,一旦api有变动就无法使用。有可能升级到AGP7之后出现问题。
主要代码如下:
public class ARouterPath {
//App模块路由服务Path
public static final String PATH_SERVICE_APP = "/app/path/service";
//Auth模块路由服务Path
public static final String PATH_SERVICE_AUTH = "/auth/path/service";
//登录页面
public static final String PATH_AUTH_PAGE_LOGIN = "/auth/page/login";
//Main模块路由服务Path
public static final String PATH_SERVICE_MAIN = "/main/path/service";
//首页Main页面
public static final String PATH_MAIN_PAGE_MAIN = "/main/page/main";
//Wallet模块路由服务Path
public static final String PATH_SERVICE_WALLET = "/wallet/path/service";
//IM模块路由服务Path
public static final String PATH_SERVICE_IM = "/im/path/service";
//NewsFeed模块路由服务Path
public static final String PATH_SERVICE_NEWSFEED = "/newsfeed/path/service";
//PartTime模块路由服务Path
public static final String PATH_SERVICE_PARTTIME = "/parttime/path/service";
//Profile模块路由服务Path
public static final String PATH_SERVICE_PROFILE = "/profile/path/service";
//Service模块路由服务Path
public static final String PATH_SERVICE_SERVER = "/service/path/service";
}
复制代码全局保管每个组件的Serivce对象
object YYRouterService {
var appComponentServer: IAppComponentServer? = ARouter.getInstance().navigation(IAppComponentServer::class.java)
var authComponentServer: IAuthComponentServer? = ARouter.getInstance().navigation(IAuthComponentServer::class.java)
...
}
复制代码定义接口:
interface IAppComponentServer : IProvider {
fun initSMS(): IAppComponentServer
//Firebase短信服务-发送短信
fun sendSMSCode(
activity: Activity, phone: String,
sendAction: ((isSuccess: Boolean) -> Unit)?,
verifyAction: ((isSuccess: Boolean) -> Unit)?
)
//Firebase短信服务-验证短信
fun verifySMSCode(activity: Activity, code: String, verifyAction: ((isSuccess: Boolean) -> Unit)?)
fun gotoLoginPage()
}
复制代码ARouter注解标注服务
@Route(path = ARouterPath.PATH_SERVICE_APP, name = "App模块路由服务")
class AppComponentServiceImpl : IAppComponentServer {
override fun initSMS(): IAppComponentServer {
return this
}
override fun sendSMSCode(
activity: Activity, phone: String, sendAction: ((isSuccess: Boolean) -> Unit)?, verifyAction: ((isSuccess: Boolean) -> Unit)?
) {
}
override fun verifySMSCode(activity: Activity, code: String, verifyAction: ((isSuccess: Boolean) -> Unit)?) {
}
override fun gotoLoginPage() {
LoginActivity.startInstance()
}
override fun init(context: Context?) {
}
}
复制代码当然ARouter默认的页面导航也是能做的
@Route(path = ARouterPath.PATH_MAIN_PAGE_MAIN)
@AndroidEntryPoint
class MainActivity : YYBaseVDBActivity<MainViewModel, ActivityMainBinding>() {
companion object {
fun startInstance() {
val intent = Intent(commContext, MainActivity::class.java)
intent.addFlags(Intent.FLAG_ACTIVITY_NEW_TASK)
commContext.startActivity(intent)
}
}
...
}
复制代码至于为什么使用的是IProvide的方式来定义,是因为便于管理,每一个组件自己需要提供的服务或跳转由组件自己定义。没有完全的通过Activity的跳转来搭建路由,有可能你的应用不是基于Activity构建的呢?
基于单Activity+Fragment的构架的话,使用IProvide的方式也不会有影响。比如我们的项目就是把UI也组件化了,每一个组件都是Activity+多Fragment,总共8个组件就只有8个主要的Activity。
感谢看到这里,如果有不同意见,欢迎评论区讨论。
如果觉得不错还请点赞关注。后面可能会讲单Activity+多Fragment的几种方式。
好了,到处完结!
链接:https://juejin.cn/post/7099636408045961224
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
听说Jetpack WorkManager很难用?快来看这篇~
1、什么是WorkManager
按照官方描述,WorkManager 是适合用于持久性工作的推荐解决方案。如果工作始终要通过应用重启和系统重新启动来调度,便是持久性的工作。由于大多数后台处理操作都是通过持久性工作完成的,因此 WorkManager 是适用于后台处理操作的主要推荐 API。
2、任务类型
WorkManager任务类型分为立即运行、长期运行和延期执行,使用方式与周期关系如下所示:
| 立即 | 一次性 | OneTimeWorkRequest 和 Worker。如需处理加急工作,请对 OneTimeWorkRequest 调用 setExpedited()。 |
|---|---|---|
| 长期运行 | 一次性或定期 | 任意 WorkRequest 或 Worker。在工作器中调用 setForeground() 来处理通知。 |
| 可延期 | 一次性或定期 | PeriodicWorkRequest 和 Worker。 |
接下来来看具体的使用方法。
3、入门使用
3.1 添加依赖库
本文代码使用Kotlin编写,所以这里仅引入Kotlin相关的库即可,在build.gradle中添加代码如下所示:
def work_version = "2.7.1"
implementation "androidx.work:work-runtime-ktx:$work_version"如果使用的是Java语言该如何引用呢?听我的,放弃吧~
3.2 定义工作Worker
这里我们以上传日志文件任务为例,新建UploadLogWorker类,继承自Worker,代码如下所示:
class UploadLogWorker(context: Context, workerParams: WorkerParameters) :
Worker(context, workerParams) {
override fun doWork(): Result {
Log.d("打印线程", Thread.currentThread().name)
return Result.success()
}
}继承自Worker的类需要重写doWork方法,我们可以在这个方法中执行具体的任务,这里为了有演示结果打印出线程的名称。
Result用于返回任务的执行结果Result.success表示执行成功;Result.failure、Result.retry则分别表示执行失败和失败后尝试重试。
3.3 创建任务请求WorkRequest
这里我们创建一个一次性的执行任务,代码如下所示:
val uploadLogWorkerRequset: WorkRequest = OneTimeWorkRequestBuilder<UploadLogWorker>()
.build()3.4 将任务提交系统
创建好任务之后,就可以将任务提交系统,执行请求,代码如下所示:
WorkManager.getInstance(this).enqueue(uploadLogWorkerRequset)运行App,运行结果如下图所示。
3.5 为任务传递参数
许多时候我们在执行任务的时候是需要参数的,比如上传日志文件我们要知道日志文件的路径或者其他参数,我们怎么样将参数传递给Worker呢?
我们可以通过WorkRequest的setInputData方法来设置参数,代码如下所示:
val uploadLogWorkerRequset: WorkRequest = OneTimeWorkRequestBuilder<UploadLogWorker>()
.setInputData(workDataOf( "filePath" to "file://***" , "fileName" to "log.txt" ))
.build()这里我们传递了文件路径filePath和文件名fileName,在Worker通过getInputData方法接受,比如我们在doWork中接受参数并打印。代码如下所示:
override suspend fun doWork(): Result {
val filePath = inputData.getString( "filePath" )
val fileName = inputData.getString( "fileName" )
Log.d( "接受的参数" , " $fileName : $filePath " )
return Result.retry()
}运行程序,打印如下图所示。
这样我们就完成了一个最简单的WorkManager使用案例。接着我们来进一步的探索。
4、执行加急工作你所需要知道的
从 WorkManager 2.7 开始,我们可以调用setExpedited方法来告诉系统,我这个任务是加急任务,请尽快执行。修改代码如下所示:
val uploadLogWorkerRequset: WorkRequest = OneTimeWorkRequestBuilder<UploadLogWorker>()
.setExpedited(OutOfQuotaPolicy. RUN_AS_NON_EXPEDITED_WORK_REQUEST )
.build()setExpedited方法中的OutOfQuotaPolicy参数有两个枚举值,含义如下所示。
| 枚举值 | 含义 |
|---|---|
| RUN_AS_NON_EXPEDITED_WORK_REQUEST | 当系统无法为任务加急处理时,任务变成常规任务 |
| DROP_WORK_REQUEST | 当系统无法为任务加急处理时,删除改任务 |
所以我们这里声明为RUN_AS_NON_EXPEDITED_WORK_REQUEST即可。再次运行程序。
OK,完美运行???
不过我的手机是Android 12的,为了确保没问题,我们必须在Android 11 或低版本上执行一次。没崩溃,但是任务却没执行,我们看到了错误日志如下图所示。
Emm.. 一堆乱七八糟的,关键信息在这句话
Expedited WorkRequests require a ListenableWorker to provide an implementation for `getForegroundInfoAsync()`从官方我们获取到了这些信息:在 Android 12 之前,工作器中的 getForegroundInfoAsync() 和 getForegroundInfo() 方法可让 WorkManager 在您调用 setExpedited() 时显示通知。如果您想要请求任务作为加急作业运行,则所有的 ListenableWorker 都必须实现 getForegroundInfo 方法。
如果未能实现对应的 ****getForegroundInfo 方法,那么在旧版平台上调用 setExpedited 时,可能会导致运行时崩溃。
了解到了这些,那我们就来实现getForegroundInfo()方法,修改UploadLogWorker代码如下所示:
class UploadLogWorker(context: Context, workerParams: WorkerParameters) :
Worker(context, workerParams) {
override fun doWork(): Result {
Log.d("打印线程", Thread.currentThread().name)
setForegroundAsync(getForegroundInfo())
return Result.success()
}
@SuppressLint("RestrictedApi")
override fun getForegroundInfoAsync(): ListenableFuture<ForegroundInfo> {
val future = SettableFuture.create<ForegroundInfo>()
future.set(getForegroundInfo())
return future
}
fun getForegroundInfo(): ForegroundInfo {
val notificationManager =
applicationContext.getSystemService(Context.NOTIFICATION_SERVICE) as NotificationManager
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
val channel = NotificationChannel(
"1",
"hh",
NotificationManager.IMPORTANCE_HIGH
)
notificationManager.createNotificationChannel(channel)
}
val notification = NotificationCompat.Builder(applicationContext, "1")
.setSmallIcon(R.drawable.ic_launcher_background)
.setContentTitle(applicationContext.getString(R.string.app_name))
.setContentText("我是一个上传日志的任务")
.build()
return ForegroundInfo(1337, notification)
}
}
再次在Android11 上运行程序,发现打印出了日志,并显示了一个任务通知,如下图所示。
这一点是在执行加急工作时所必须要注意的。
5、协程工作CoroutineWorker
1、将继承类修改为CoroutineWorker
2、实现getForegroundInfo方法,内容与上getForegroundInfo一致
6、定时任务PeriodicWorkRequest
在3.2中我们定义了一次性任务OneTimeWorkRequestBuilder,现在我们将上传日志的这个任务修改为定时任务,代码如下所示:
val uploadLogWorkerRequset: WorkRequest = PeriodicWorkRequestBuilder<UploadLogWorker>(15,TimeUnit.MINUTES)
.build()这里指定了,定时任务的周期是15分钟一次,可以定义的最短重复间隔就是 15 分钟,这一点开发者在测试的时候需要注意,不能傻傻的等着...,这里我就傻傻的等了15分钟,确保定时任务是可以执行的。
7、工作约束、延迟执行和重试策略
7.1 工作约束
很多情况下,我们需要为任务添加工作约束,比如上传日志的任务肯定是在有网络的条件下进行的,当前支持的约束条件如下所示。
| NetworkType | 约束运行工作所需的网络类型。例如 Wi-Fi (UNMETERED)。 |
|---|---|
| BatteryNotLow | 如果设置为 true,那么当设备处于“电量不足模式”时,工作不会运行。 |
| RequiresCharging | 如果设置为 true,那么工作只能在设备充电时运行。 |
| DeviceIdle | 如果设置为 true,则要求用户的设备必须处于空闲状态,才能运行工作。在运行批量操作时,此约束会非常有用;若是不用此约束,批量操作可能会降低用户设备上正在积极运行的其他应用的性能。 |
| StorageNotLow | 如果设置为 true,那么当用户设备上的存储空间不足时,工作不会运行。 |
比如我们现在为一次性任务添加约束为在链接wifi的情况下执行,首先用Constraints构建一个约束实例可以将多个约束条件放在一起。代码如下所示:
val constraints = Constraints.Builder()
.setRequiresCharging(true)
.build()这里设置为仅在充电的时候执行。接着为任务构建器添加约束。
val uploadLogWorkerRequset: WorkRequest = OneTimeWorkRequestBuilder<UploadLogWorker>()
.setConstraints(constraints)
.build()这样一来任务就会在仅充电的时候执行了。
7.2 延迟执行
延迟执行适用于一次性任务和定时任务,但应用在定时任务事仅对第一次执行有效,为啥呢?因为是定时任务呀~
我们为一次性任务设置延迟时间为5秒钟,代码如下所示:
val uploadLogWorkerRequset: WorkRequest = OneTimeWorkRequestBuilder<UploadLogWorker>()
.setConstraints(constraints)
.setInitialDelay( 5 ,TimeUnit.SECONDS)
.build()运行程序,可以看到5秒钟后,程序才打印了日志,这里就不演示了。
7.3 重试策略
在3.2中定义Work中我们提到了Result.retry可以让任务重试,我们也可以自定义任务的重试策略和退避政策,我们通过具体的例子来解释。
val uploadLogWorkerRequset: WorkRequest = OneTimeWorkRequestBuilder<UploadLogWorker>()
.setBackoffCriteria(
BackoffPolicy.EXPONENTIAL, OneTimeWorkRequest.MIN_BACKOFF_MILLIS,
TimeUnit.MILLISECONDS
)
.build()最短退避延迟时间设置为允许的最小值,即 10 秒。由于政策为 LINEAR,每次尝试重试时,重试间隔都会增加约 10 秒。例如,第一次运行以 Result.retry() 结束并在 10 秒后重试;然后,如果工作在后续尝试后继续返回 Result.retry(),那么接下来会在 20 秒、30 秒、40 秒后重试,以此类推。
打印日志如下图所示。
我们可以看到,第一次任务失败后延迟了10秒重新执行,第二次延迟了20秒,第三次延迟了40秒...
8、观察工作执行结果
在任务完成后,我可能需要进行更新UI或者业务逻辑操作。我们可以通过注册监听器来观察 WorkInfo 的变化,以根据ID查询WorkInfo状态为例,代码如下所示:
WorkManager.getInstance(this).getWorkInfoByIdLiveData(uploadLogWorkerRequset.id).observe(this){
if (it.state == WorkInfo.State.SUCCEEDED){
Toast.makeText(this,"任务执行成功,更新UI",Toast.LENGTH_LONG).show()
}else{
//任务失败或重试
}
}除了getWorkInfoByIdLiveData之外还有根据tag、name等查询的转化方法,这里读者可自行查看API。
运行程序,结果如下图所示。
类似的我们还可以通过cancelWorkById等方法来取消任务的执行。这里不做演示了。
9.总结
9.1 特性
- 在早于 Android 12 的 API 版本中,加急工作都是由前台服务执行的,而从 Android 12 开始,它们将由加急作业 (expedited job) 实现。所以在第4小节中,Android12上并不会显示通知栏
- WorkManager 只是一个处理定时任务的工具
- WorkManager 最早兼容到 API 14(Android 4.0)
9.2 注意事项
- 使用WorkManager注册的周期性任务不能保证一定会准时执行,这并不是bug,而是系 统为了减少电量消耗,可能会将触发时间临近的几个任务放在一起执行,这样可以大幅度地减 少CPU被唤醒的次数,从而有效延长电池的使用时间。
- WorkManager官方虽然称它可以保证即使在应用退出甚至手机重启的情况下,之前注册的任务仍然将会得到执行。但是在国产手机中是不可能的,因为系统自己做了改动。但是在国产机上测试退出后,再进来也会执行之前的任务。这个时候可能就会有重复的任务执行。
- 如果任务已经开始执行调用取消任务的方法是无法终止任务的,但是调用取消方法之后,无法再观察到任务结果。
- 执行一个后台任务,在任务结束前杀死APP,再次进来时之前未完成的任务会从头开始执行,且执行结束后无法收到回调。
- 任务添加到队列后,未开始执行前,如果是在onDestory中调用取消任务的方法是不可行的,此种情况下下次进来时仍然会有重复任务开始执行。(原生系统、国产机一样)
9.3 在业务中使用需要关注的问题
- 任务添加到队列后,未开始执行前,如果是在onDestory中调用取消任务的方法是不可行的,此种情况下下次进来时仍然会有重复任务开始执行。
产生原因:cancelWork操作是一个异步操作,调用此操作后取消操作还未执行结束进程便结束了
业务影响: 连续打开关闭多次,会有多个重复的任务执行,且之前的任务无法收到任务进度回调
解决方案: 暂无
链接:https://juejin.cn/post/7207707775774097466
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
是时候弃用 buildSrc ,使用 Composing builds 加快编译速度了
为什么要使用复合构建
依赖管理一直是一个优化痛点,从硬编码到ext,再发展到buildSrc,尽管代码量在发展中增长了,但是对于追求更快更干净的构建来说确实进步了不少。但是buildSrc虽然给了我们相对干净的使用方式,但是依然没有解决最核心的速度问题。编译过程中 Gradle 最大的低效就是它的单线程配置阶段,这意味着每个额外的模块都会对构建产生持续的开销,因此我们依然经历着配置时间的线性增长,通常大型项目编译一次,就要去喝杯咖啡。
使用 Gradle 的复合构建工具就避免了在其他构建模式时很容易观察到的配置时间损失,依赖不再是全量编译了。复合构建将大型项目构建分解为更小、更独立的块,这些块可以根据需要独立或一起工作,包含的构建不与复合构建或其他包含的构建共享任何配置。每个包含的构建都是独立配置和执行的。
更详细的对比,请参考大佬的再见吧 buildSrc, 拥抱 Composing builds 提升 Android 编译速度,这里不再赘述。因为找到的相关使用文档均已过时,所以下面就记录下来最新的创建使用方法。
基本使用
创建版本依赖插件 Module
这个步骤可以手动创建,也可以借助 Android Studio 创建。
手动创建
切换到 Project 视图,创建 version-plugin 文件夹,在 version-plugin 文件夹里创建 src -> main -> java 文件
在 java 文件夹里创建你的包名文件夹,例如 com -> example -> plugin (不想要包名文件夹的话,这一步可以省略),在 plugin 文件夹里创建两个文件
Dependencies.kt和VersionPlugin.kt
在 version-plugin 文件夹下创建
build.gradle.kts文件,这里使用 kotlin DSL 更方便
在
build.gradle.kts里添加所需的插件
plugins {
`kotlin-dsl`
}
在version-plugin 根目录创建
settings.gradle.kts,并添加依赖仓库
dependencyResolutionManagement {
repositories {
google()
mavenCentral()
}
}
rootProject.name = "version-plugin"
include (":version-plugin")
在项目根目录的
settings.gradle里添加includeBuild("version-plugin")引入插件
pluginManagement {
includeBuild("version-plugin")
repositories {
google()
mavenCentral()
gradlePluginPortal()
}
}
dependencyResolutionManagement {
repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
repositories {
google()
mavenCentral()
}
}
rootProject.name = "ComposeBuild"
include ':app'
AS创建
File -> New -> New Module ,选择
Java or kotlin Library,创建一个 Module
创建
Dependencies.kt文件
删除 version-plugin 文件夹下的 libs 文件夹
把
build.gradle转化为build.gradle.kts文件
plugins {
`kotlin-dsl`
}
在 version-plugin 根目录创建
settings.gradle.kts,并添加依赖仓库
dependencyResolutionManagement {
repositories {
google()
mavenCentral()
}
}
rootProject.name = "version-plugin"
include (":version-plugin")
项目根目录
settings.gradle里的include ':version-plugin'替换为includeBuild("version-plugin"),为了规范,把它注册在上面的pluginManagement里
pluginManagement {
includeBuild("version-plugin")
repositories {
google()
mavenCentral()
gradlePluginPortal()
}
}
dependencyResolutionManagement {
repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
repositories {
google()
mavenCentral()
}
}
rootProject.name = "ComposeBuild"
include ':app'
//include ':version-plugin'
完成后的项目目录:
编写插件
Gradle 是一个框架,作为框架,它负责定义流程和规则。而具体的编译工作则是通过插件的方式来完成的,我们要引入插件,而达到获取插件配置的目的。
实现插件类
在VersionPlugin.kt中实现插件
package com.example.plugin
import org.gradle.api.Plugin
import org.gradle.api.Project
class VersionPlugin : Plugin<Project> {
override fun apply(target: Project) {
println("VersionPlugin")
}
}配置依赖
在Dependencies.kt中,我项目的依赖库拷贝在这里:
object Versions {
const val composeUi = "1.3.1"
const val composeVersion = "1.2.0"
const val kotlin = "1.8.0"
const val lifecycle = "2.5.1"
const val activityCompose = "1.5.1"
const val composeMaterial3 = "1.0.0-alpha11"
const val junit = "4.13.2"
const val androidxJunit = "1.1.3"
const val espresso = "3.4.0"
}
object Libraries {
// 依赖库
const val coreKtx = "androidx.core:core-ktx:${Versions.kotlin}"
const val lifecycle = "androidx.lifecycle:lifecycle-runtime-ktx:${Versions.lifecycle}"
const val activityCompose = "androidx.activity:activity-compose:${Versions.activityCompose}"
const val composeUi = "androidx.compose.ui:ui:${Versions.composeUi}"
const val composePreview = "androidx.compose.ui:ui-tooling-preview:${Versions.composeVersion}"
const val composeMaterial3 = "androidx.compose.material3:material3:${Versions.composeMaterial3}"
// 测试库
const val junit = "junit:junit:${Versions.junit}"
const val androidxJunit = "androidx.test.ext:junit:${Versions.androidxJunit}"
const val espresso = "androidx.test.espresso:espresso-core:${Versions.espresso}"
const val uiTestJunit4 = "androidx.compose.ui:ui-test-junit4:${Versions.composeVersion}"
const val uiTooling = "androidx.compose.ui:ui-tooling:${Versions.composeVersion}"
const val uiTestManifest = "androidx.compose.ui:ui-test-manifest:${Versions.composeVersion}"
}注册插件
插件要能被别的 Module 引入,需要注册在插件 Module 的build.gradle.kts中
plugins {
`kotlin-dsl`
}
gradlePlugin {
plugins.register("versionPlugin") {
id = "version-plugin"
implementationClass = "com.example.plugin.VersionPlugin"
}
}使用
在用到的 Module 里添加插件,app 目录下的build.gradle:
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
// 依赖插件
id 'version-plugin'
}这时候就可以引用插件 Module 里定义的依赖了:
implementation Libraries.coreKtx扩展
依赖优化
上面一通操作,在使用的时候,并没有方便多少。为了不再一个一个的引入依赖,我们需要写个扩展优化。为了方便操作和提示,建议使用 Kotlin 的 DSL ,首先把build.gradle转为build.gradle.kts
转化前:
import com.example.plugin.Libraries
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
id 'version-plugin'
}
android {
namespace 'com.example.composingbuilds'
compileSdk 33
defaultConfig {
applicationId "com.example.composingbuilds"
minSdk 24
targetSdk 33
versionCode 1
versionName "1.0"
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
vectorDrawables {
useSupportLibrary true
}
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
}
}
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
kotlinOptions {
jvmTarget = '1.8'
}
buildFeatures {
compose true
}
composeOptions {
kotlinCompilerExtensionVersion '1.1.1'
}
packagingOptions {
resources {
excludes += '/META-INF/{AL2.0,LGPL2.1}'
}
}
}
dependencies {
implementation Libraries.coreKtx
// implementation 'androidx.core:core-ktx:1.7.0'
implementation 'androidx.lifecycle:lifecycle-runtime-ktx:2.3.1'
implementation 'androidx.activity:activity-compose:1.3.1'
implementation "androidx.compose.ui:ui:$compose_version"
implementation "androidx.compose.ui:ui-tooling-preview:$compose_version"
implementation 'androidx.compose.material3:material3:1.0.0-alpha11'
testImplementation 'junit:junit:4.13.2'
androidTestImplementation 'androidx.test.ext:junit:1.1.3'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.4.0'
androidTestImplementation "androidx.compose.ui:ui-test-junit4:$compose_version"
debugImplementation "androidx.compose.ui:ui-tooling:$compose_version"
debugImplementation "androidx.compose.ui:ui-test-manifest:$compose_version"
}转化后:
import com.example.plugin.Libraries
plugins {
id("com.android.application")
id("kotlin-android")
id("version-plugin")
}
android {
namespace = "com.example.composingbuilds"
compileSdk = 33
defaultConfig {
applicationId = "com.example.composingbuilds"
minSdk = 23
targetSdk = 33
versionCode = 1
versionName = "1.0"
testInstrumentationRunner = "androidx.test.runner.AndroidJUnitRunner"
vectorDrawables {
useSupportLibrary = true
}
}
buildTypes {
getByName("release") {
isMinifyEnabled = false
proguardFiles(
getDefaultProguardFile("proguard-android-optimize.txt"),
"proguard-rules.pro"
)
}
}
compileOptions {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
kotlinOptions {
jvmTarget = JavaVersion.VERSION_1_8.toString()
}
buildFeatures {
compose = true
}
composeOptions {
kotlinCompilerExtensionVersion = "1.1.1"
}
packagingOptions {
resources {
excludes += "/META-INF/{AL2.0,LGPL2.1}"
}
}
}
dependencies {
implementation(Libraries.coreKtx)
implementation(Libraries.lifecycle)
implementation(Libraries.activityCompose)
implementation(Libraries.composeUi)
implementation(Libraries.composePreview)
implementation(Libraries.composeMaterial3)
testImplementation(Libraries.junit)
androidTestImplementation(Libraries.androidxJunit)
androidTestImplementation(Libraries.espresso)
androidTestImplementation(Libraries.uiTestJunit4)
debugImplementation(Libraries.uiTooling)
debugImplementation(Libraries.uiTestManifest)
}dependencies里面还是需要一个一个的依赖,有时候项目并不是一个 Module 而是多 Module 的状态,每个build.gradle都要写依赖,要简化这个繁琐的过程,就需要把依赖分类集中处理。
在插件 Module 里新建Extension.kt,可以把依赖库分为kotlin、android、compose、test四部分。扩展DependencyHandlerScope:
fun DependencyHandlerScope.kotlinProject() {
"implementation"(Libraries.coreKtx)
}
fun DependencyHandlerScope.androidProject() {
"implementation"(Libraries.lifecycle)
}
fun DependencyHandlerScope.composeProject() {
"implementation"(Libraries.activityCompose)
"implementation"(Libraries.composeUi)
"implementation"(Libraries.composePreview)
"implementation"(Libraries.composeMaterial3)
}
fun DependencyHandlerScope.androidTest() {
"testImplementation"(Libraries.junit)
"androidTestImplementation"(Libraries.androidxJunit)
"androidTestImplementation"(Libraries.espresso)
"androidTestImplementation"(Libraries.uiTestJunit4)
"debugImplementation"(Libraries.uiTooling)
"debugImplementation"(Libraries.uiTestManifest)
}然后修改项目依赖,调用上面的扩展,短短几行就可实现:
dependencies {
kotlinProject()
androidProject()
composeProject()
androidTest()
// implementation(Libraries.coreKtx)
// implementation(Libraries.lifecycle)
// implementation(Libraries.activityCompose)
// implementation(Libraries.composeUi)
// implementation(Libraries.composePreview)
// implementation(Libraries.composeMaterial3)
//
// testImplementation(Libraries.junit)
// androidTestImplementation(Libraries.androidxJunit)
// androidTestImplementation(Libraries.espresso)
// androidTestImplementation(Libraries.uiTestJunit4)
// debugImplementation(Libraries.uiTooling)
// debugImplementation(Libraries.uiTestManifest)
}插件依赖
上面只优化了dependencies这个闭包,build.gradle.kts依旧很多东西,既然写了一个插件,我们就用插件实现整个配置。
app的build.gradle.kts一共有三个闭包:plugin、android、 dependencies,对应插件其实也是现实这三个配置,回到最开始的VersionPlugin中:
class VersionPlugin : Plugin<Project> {
override fun apply(target: Project) {
with(target){
//配置plugin
//配置android
//配置dependencies
}
}
}1. 首先实现配置plugin
这个闭包就是引入插件,把原 Module 用到的插件搬过来即可,这里要去掉原先加入的自身插件
//配置plugin
plugins.run {
apply("com.android.application")
apply("kotlin-android")
}2. 然后实现配置android
这里用到相关依赖,先添加到插件 Module 的build.gradle.kts里:
plugins {
`kotlin-dsl`
}
dependencies {
implementation("com.android.tools.build:gradle:7.3.1")
implementation("org.jetbrains.kotlin:kotlin-gradle-plugin:1.8.0")
}然后配置android,把 Module 的build.gradle.kts里的android部分搬过来,唯一需要注意的是,插件里没有kotlinOptions,需要自己写一个扩展:
//配置android
extensions.configure<ApplicationExtension> {
applicationId = "com.asi.composingbuild"
compileSdk=33
defaultConfig {
applicationId="com.asi.composingbuild"
minSdk = 23
targetSdk=33
versionCode=1
versionName="1.0"
testInstrumentationRunner= "androidx.test.runner.AndroidJUnitRunner"
vectorDrawables {
useSupportLibrary =true
}
}
buildTypes {
getByName("release") {
isMinifyEnabled = false
proguardFiles(
getDefaultProguardFile("proguard-android-optimize.txt"),
"proguard-rules.pro"
)
}
}
compileOptions {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
kotlinOptions{
jvmTarget = JavaVersion.VERSION_1_8.toString()
}
buildFeatures {
compose = true
}
composeOptions {
kotlinCompilerExtensionVersion = "1.1.1"
}
packagingOptions {
resources {
excludes += "/META-INF/{AL2.0,LGPL2.1}"
}
}
}kotlinOptions扩展:
fun CommonExtension<*, *, *, *>.kotlinOptions(block: KotlinJvmOptions.() -> Unit) {
(this as ExtensionAware).extensions.configure("kotlinOptions", block)
}
首先实现配置
dependencies
//配置dependencies
dependencies {
kotlinProject()
androidProject()
composeProject()
androidTest()
}
依赖插件
把 app Module 的
build.gradle.kts里的内容都删了,只依赖下刚完成的插件:
plugins {
id("version-plugin")
}
是不是很清爽的感觉?
多个插件
如果是多 Module 的项目,每个 Module 的依赖会不一样,所以可以在 version-plugin 中编写多个plugin,然后注册id,在不同的 Module 里使用,修改某个依赖,只构建这个 Module 的依赖,达到隔离构建的目的。
复合构建
上面单一 Module 中单独的插件,依赖的库并没有达到隔离构建的目的,如果我们只是更改了composeUi版本,整个依赖都要重新编译。要实现隔离,需要更精细化的拆分,比如把compose部分单独出来。
新建一个ComposePlugin.kt,把原来插件中的关于compose的配置拷贝过来:
class ComposePlugin : Plugin<Project> {
override fun apply(target: Project) {
with(target) {
//配置compose
extensions.configure<ApplicationExtension> {
buildFeatures {
compose = true
}
composeOptions {
kotlinCompilerExtensionVersion = Versions.kotlinCompilerExtensionVersion
}
}
dependencies {
composeProject()
}
}
}
}插件写完需要注册:
gradlePlugin {
plugins.register("versionPlugin") {
id = "version-plugin"
implementationClass = "com.example.plugin.VersionPlugin"
}
plugins.register("ComposePlugin") {
id = "compose-plugin"
implementationClass = "com.example.plugin.ComposePlugin"
}
}这里可以优化下写法:
gradlePlugin {
plugins{
register("versionPlugin") {
id = "version-plugin"
implementationClass = "com.example.plugin.VersionPlugin"
}
register("ComposePlugin") {
id = "compose-plugin"
implementationClass = "com.example.plugin.ComposePlugin"
}
}
}在 app 模块里引入:
plugins {
id("version-plugin")
id("compose-plugin")
}这样如果修改compose版本,并不会构建别的依赖。
链接:https://juejin.cn/post/7208015274079387707
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
项目中多级缓存设计实践总结
缓存的重要性
简而言之,缓存的原理就是利用空间来换取时间。通过将数据存到访问速度更快的空间里以便下一次访问时直接从空间里获取,从而节省时间。
我们以CPU的缓存体系为例:
CPU缓存体系是多层级的。分成了CPU -> L1 -> L2 -> L3 -> 主存。我们可以得到以下启示。
- 越频繁使用的数据,使用的缓存速度越快
- 越快的缓存,它的空间越小
而我们项目的缓存设计可以借鉴CPU多级缓存的设计。
关于多级缓存体系实现在开源项目中:github.com/valarchie/A…
缓存分层
首先我们可以给缓存进行分层。在Java中主流使用的三类缓存主要有:
- Map(原生缓存)
- Guava/Caffeine(功能更强大的内存缓存)
- Redis/Memcached(缓存中间件)
在一些项目中,会一刀切将所有的缓存都使用Redis或者Memcached中间件进行存取。
使用缓存中间件避免不了网络请求成本和用户态和内核态的切换。 更合理的方式应该是根据数据的特点来决定使用哪个层级的缓存。
Map(一级缓存)
项目中的字典类型的数据比如:性别、类型、状态等一些不变的数据。我们完全可以存在Map当中。
因为Map的实现非常简单,效率上是非常高的。由于我们存的数据都是一些不变的数据,一次性存好并不会再去修改它们。所以不用担心内存溢出的问题。 以下是关于字典数据使用Map缓存的简单代码实现。
/**
* 本地一级缓存 使用Map
*
* @author valarchie
*/
public class MapCache {
private static final Map<String, List<DictionaryData>> DICTIONARY_CACHE = MapUtil.newHashMap(128);
static {
initDictionaryCache();
}
private static void initDictionaryCache() {
loadInCache(BusinessTypeEnum.values());
loadInCache(YesOrNoEnum.values());
loadInCache(StatusEnum.values());
loadInCache(GenderEnum.values());
loadInCache(NoticeStatusEnum.values());
loadInCache(NoticeTypeEnum.values());
loadInCache(OperationStatusEnum.values());
loadInCache(VisibleStatusEnum.values());
}
public static Map<String, List<DictionaryData>> dictionaryCache() {
return DICTIONARY_CACHE;
}
private static void loadInCache(DictionaryEnum[] dictionaryEnums) {
DICTIONARY_CACHE.put(getDictionaryName(dictionaryEnums[0].getClass()), arrayToList(dictionaryEnums));
}
private static String getDictionaryName(Class<?> clazz) {
Objects.requireNonNull(clazz);
Dictionary annotation = clazz.getAnnotation(Dictionary.class);
Objects.requireNonNull(annotation);
return annotation.name();
}
@SuppressWarnings("rawtypes")
private static List<DictionaryData> arrayToList(DictionaryEnum[] dictionaryEnums) {
if(ArrayUtil.isEmpty(dictionaryEnums)) {
return ListUtil.empty();
}
return Arrays.stream(dictionaryEnums).map(DictionaryData::new).collect(Collectors.toList());
}
}Guava(二级缓存)
项目中的一些自定义数据比如角色,部门。这种类型的数据往往不会非常多。而且请求非常频繁。比如接口中经常要校验角色相关的权限。我们可以使用Guava或者Caffeine这种内存框架作为二级缓存使用。
Guava或者Caffeine的好处可以支持缓存的过期时间以及缓存的淘汰,避免内存溢出。
以下是利用模板设计模式做的GuavaCache模板类。
/**
* 缓存接口实现类 二级缓存
* @author valarchie
*/
@Slf4j
public abstract class AbstractGuavaCacheTemplate<T> {
private final LoadingCache<String, Optional<T>> guavaCache = CacheBuilder.newBuilder()
// 基于容量回收。缓存的最大数量。超过就取MAXIMUM_CAPACITY = 1 << 30。依靠LRU队列recencyQueue来进行容量淘汰
.maximumSize(1024)
// 基于容量回收。但这是统计占用内存大小,maximumWeight与maximumSize不能同时使用。设置最大总权重
// 没写访问下,超过5秒会失效(非自动失效,需有任意put get方法才会扫描过期失效数据。但区别是会开一个异步线程进行刷新,刷新过程中访问返回旧数据)
.refreshAfterWrite(5L, TimeUnit.MINUTES)
// 移除监听事件
.removalListener(removal -> {
// 可做一些删除后动作,比如上报删除数据用于统计
log.info("触发删除动作,删除的key={}, value={}", removal.getKey(), removal.getValue());
})
// 并行等级。决定segment数量的参数,concurrencyLevel与maxWeight共同决定
.concurrencyLevel(16)
// 开启缓存统计。比如命中次数、未命中次数等
.recordStats()
// 所有segment的初始总容量大小
.initialCapacity(128)
// 用于测试,可任意改变当前时间。参考:https://www.geek-share.com/detail/2689756248.html
.ticker(new Ticker() {
@Override
public long read() {
return 0;
}
})
.build(new CacheLoader<String, Optional<T>>() {
@Override
public Optional<T> load(String key) {
T cacheObject = getObjectFromDb(key);
log.debug("find the local guava cache of key: {} is {}", key, cacheObject);
return Optional.ofNullable(cacheObject);
}
});
public T get(String key) {
try {
if (StrUtil.isEmpty(key)) {
return null;
}
Optional<T> optional = guavaCache.get(key);
return optional.orElse(null);
} catch (ExecutionException e) {
log.error("get cache object from guava cache failed.");
e.printStackTrace();
return null;
}
}
public void invalidate(String key) {
if (StrUtil.isEmpty(key)) {
return;
}
guavaCache.invalidate(key);
}
public void invalidateAll() {
guavaCache.invalidateAll();
}
/**
* 从数据库加载数据
* @param id
* @return
*/
public abstract T getObjectFromDb(Object id);
}我们将getObjectFromDb方法留给子类自己去实现。以下是例子:
/**
* @author valarchie
*/
@Component
@Slf4j
@RequiredArgsConstructor
public class GuavaCacheService {
@NonNull
private ISysDeptService deptService;
public final AbstractGuavaCacheTemplate<SysDeptEntity> deptCache = new AbstractGuavaCacheTemplate<SysDeptEntity>() {
@Override
public SysDeptEntity getObjectFromDb(Object id) {
return deptService.getById(id.toString());
}
};
}Redis(三级缓存)
项目中会持续增长的数据比如用户、订单等相关数据。这些数据比较多,不适合放在内存级缓存当中,而应放在缓存中间件Redis当中去。Redis是支持持久化的,当我们的服务器重新启动时,依然可以从Redis中加载我们原先存储好的数据。
但是使用Redis缓存还有一个可以优化的点。我们可以自己本地再做一个局部的缓存来缓存Redis中的数据来减少网络IO请求,提高数据访问速度。 比如我们Redis缓存中有一万个用户的数据,但是一分钟之内可能只有不到1000个用户在请求数据。我们便可以在Redis中嵌入一个局部的Guava缓存来提供性能。以下是RedisCacheTemplate.
/**
* 缓存接口实现类 三级缓存
* @author valarchie
*/
@Slf4j
public class RedisCacheTemplate<T> {
private final RedisUtil redisUtil;
private final CacheKeyEnum redisRedisEnum;
private final LoadingCache<String, Optional<T>> guavaCache;
public RedisCacheTemplate(RedisUtil redisUtil, CacheKeyEnum redisRedisEnum) {
this.redisUtil = redisUtil;
this.redisRedisEnum = redisRedisEnum;
this.guavaCache = CacheBuilder.newBuilder()
// 基于容量回收。缓存的最大数量。超过就取MAXIMUM_CAPACITY = 1 << 30。依靠LRU队列recencyQueue来进行容量淘汰
.maximumSize(1024)
.softValues()
// 没写访问下,超过5秒会失效(非自动失效,需有任意put get方法才会扫描过期失效数据。
// 但区别是会开一个异步线程进行刷新,刷新过程中访问返回旧数据)
.expireAfterWrite(redisRedisEnum.expiration(), TimeUnit.MINUTES)
// 并行等级。决定segment数量的参数,concurrencyLevel与maxWeight共同决定
.concurrencyLevel(64)
// 所有segment的初始总容量大小
.initialCapacity(128)
.build(new CacheLoader<String, Optional<T>>() {
@Override
public Optional<T> load(String cachedKey) {
T cacheObject = redisUtil.getCacheObject(cachedKey);
log.debug("find the redis cache of key: {} is {}", cachedKey, cacheObject);
return Optional.ofNullable(cacheObject);
}
});
}
/**
* 从缓存中获取对象 如果获取不到的话 从DB层面获取
* @param id
* @return
*/
public T getObjectById(Object id) {
String cachedKey = generateKey(id);
try {
Optional<T> optional = guavaCache.get(cachedKey);
// log.debug("find the guava cache of key: {}", cachedKey);
if (!optional.isPresent()) {
T objectFromDb = getObjectFromDb(id);
set(id, objectFromDb);
return objectFromDb;
}
return optional.get();
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
/**
* 从缓存中获取 对象, 即使找不到的话 也不从DB中找
* @param id
* @return
*/
public T getObjectOnlyInCacheById(Object id) {
String cachedKey = generateKey(id);
try {
Optional<T> optional = guavaCache.get(cachedKey);
log.debug("find the guava cache of key: {}", cachedKey);
return optional.orElse(null);
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
/**
* 从缓存中获取 对象, 即使找不到的话 也不从DB中找
* @param cachedKey 直接通过redis的key来搜索
* @return
*/
public T getObjectOnlyInCacheByKey(String cachedKey) {
try {
Optional<T> optional = guavaCache.get(cachedKey);
log.debug("find the guava cache of key: {}", cachedKey);
return optional.orElse(null);
} catch (ExecutionException e) {
e.printStackTrace();
return null;
}
}
public void set(Object id, T obj) {
redisUtil.setCacheObject(generateKey(id), obj, redisRedisEnum.expiration(), redisRedisEnum.timeUnit());
guavaCache.refresh(generateKey(id));
}
public void delete(Object id) {
redisUtil.deleteObject(generateKey(id));
guavaCache.refresh(generateKey(id));
}
public void refresh(Object id) {
redisUtil.expire(generateKey(id), redisRedisEnum.expiration(), redisRedisEnum.timeUnit());
guavaCache.refresh(generateKey(id));
}
public String generateKey(Object id) {
return redisRedisEnum.key() + id;
}
public T getObjectFromDb(Object id) {
return null;
}
}以下是使用方式:
/**
* @author valarchie
*/
@Component
@RequiredArgsConstructor
public class RedisCacheService {
@NonNull
private RedisUtil redisUtil;
public RedisCacheTemplate<SysUserEntity> userCache;
@PostConstruct
public void init() {
userCache = new RedisCacheTemplate<SysUserEntity>(redisUtil, CacheKeyEnum.USER_ENTITY_KEY) {
@Override
public SysUserEntity getObjectFromDb(Object id) {
ISysUserService userService = SpringUtil.getBean(ISysUserService.class);
return userService.getById((Serializable) id);
}
};
}
}缓存Key以及过期时间
我们可以通过一个枚举类来统一集中管理各个缓存的Key以及过期时间。以下是例子:
/**
* @author valarchie
*/
public enum CacheKeyEnum {
/**
* Redis各类缓存集合
*/
CAPTCHAT("captcha_codes:", 2, TimeUnit.MINUTES),
LOGIN_USER_KEY("login_tokens:", 30, TimeUnit.MINUTES),
RATE_LIMIT_KEY("rate_limit:", 60, TimeUnit.SECONDS),
USER_ENTITY_KEY("user_entity:", 60, TimeUnit.MINUTES),
ROLE_ENTITY_KEY("role_entity:", 60, TimeUnit.MINUTES),
ROLE_MODEL_INFO_KEY("role_model_info:", 60, TimeUnit.MINUTES),
;
CacheKeyEnum(String key, int expiration, TimeUnit timeUnit) {
this.key = key;
this.expiration = expiration;
this.timeUnit = timeUnit;
}
private final String key;
private final int expiration;
private final TimeUnit timeUnit;
public String key() {
return key;
}
public int expiration() {
return expiration;
}
public TimeUnit timeUnit() {
return timeUnit;
}
}统一的使用门面
一般来说,我们在项目中设计好缓存之后就可以让其他同事写业务时直接调用了。但是让开发者去判断这个属于二级缓存还是三级缓存的话,存在心智负担。我们应该让开发者自然地从业务角度去选择某个缓存。比如他正在写部门相关的业务逻辑,就直接使用deptCache。
此时我们可以新建一个CacheCenter来统一按业务划分缓存。以下是例子:
/**
* 缓存中心 提供全局访问点
* @author valarchie
*/
@Component
public class CacheCenter {
public static AbstractGuavaCacheTemplate<String> configCache;
public static AbstractGuavaCacheTemplate<SysDeptEntity> deptCache;
public static RedisCacheTemplate<String> captchaCache;
public static RedisCacheTemplate<LoginUser> loginUserCache;
public static RedisCacheTemplate<SysUserEntity> userCache;
public static RedisCacheTemplate<SysRoleEntity> roleCache;
public static RedisCacheTemplate<RoleInfo> roleModelInfoCache;
@PostConstruct
public void init() {
GuavaCacheService guavaCache = SpringUtil.getBean(GuavaCacheService.class);
RedisCacheService redisCache = SpringUtil.getBean(RedisCacheService.class);
configCache = guavaCache.configCache;
deptCache = guavaCache.deptCache;
captchaCache = redisCache.captchaCache;
loginUserCache = redisCache.loginUserCache;
userCache = redisCache.userCache;
roleCache = redisCache.roleCache;
roleModelInfoCache = redisCache.roleModelInfoCache;
}
}以上就是关于项目中多级缓存的实现。 如有不足恳请评论指出。
链接:https://juejin.cn/post/7208112485764857914
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不同方面浅浅认识一下 Synchronized
Java中的synchronized关键字是一种用于线程同步的机制,它可以确保同一时间只有一个线程能够访问共享资源。本篇博客将从synchronized的基本用法、synchronized锁的对象、synchronized的可重入性、synchronized的锁粒度、synchronized与锁优化等多个方面来深入介绍Java中synchronized关键字的使用。
一、synchronized的基本用法
synchronized关键字可以应用于方法和代码块上,以下是synchronized的基本用法示例:
1.1 修饰方法
synchronized可以用于修饰方法,使得在调用该方法时,只有一个线程能够执行该方法,其他线程需要等待。
public synchronized void syncMethod() {
// synchronized方法体
}1.2 修饰代码块
synchronized还可以用于修饰代码块,只有当线程获取到该代码块的锁时才能进入执行,其他线程需要等待。
public void syncBlock() {
synchronized (this) {
// synchronized代码块
}
}二、synchronized锁的对象
synchronized锁的对象可以是类的实例对象、类对象、任意对象等。以下是synchronized锁的对象示例:
2.1 类的实例对象
当synchronized锁的对象是类的实例对象时,不同的线程对同一个实例对象的同步方法或同步代码块的访问将会被阻塞,因为它们都是使用同一个对象锁。
public synchronized void syncMethod() {
// synchronized方法体
}
public void syncBlock() {
synchronized (this) {
// synchronized代码块
}
}2.2 类对象
当synchronized锁的对象是类对象时,不同的线程对同一个类的同步方法或同步代码块的访问将会被阻塞,因为它们都是使用同一个类锁。
public static synchronized void syncMethod() {
// synchronized方法体
}
public void syncBlock() {
synchronized (SynchronizedDemo.class) {
// synchronized代码块
}
}2.3 任意对象
当synchronized锁的对象是任意对象时,不同的线程对同一个对象的同步方法或同步代码块的访问将会被阻塞,因为它们都是使用同一个对象锁。
public synchronized void syncMethod() {
// synchronized方法体
}
public void syncBlock() {
Object lock = new Object();
synchronized (lock) {
// synchronized代码块
}
}三、synchronized的可重入性
synchronized具有可重入性,即一个线程已经获得了一个对象的锁,再次请求该对象的锁时仍然可以获得该锁。
public synchronized void syncMethod() {
syncMethod2();
// synchronized方法体
}在上面的代码中,syncMethod2()方法也是一个synchronized方法,当syncMethod()方法调用syncMethod2()方法时,它仍然可以获取到该对象的锁,因为锁是可重入的。
四、synchronized的锁粒度
synchronized锁的粒度大小是需要考虑的一个问题,粒度过大会导致性能下降,粒度过小又可能导致死锁。以下是synchronized锁的粒度示例:
4.1 对象锁
对象锁的粒度最细,它只锁定对象中的一个方法或代码块。
public synchronized void syncMethod() {
// synchronized方法体
}
public void syncBlock() {
synchronized (this) {
// synchronized代码块
}
}4.2 类锁
类锁的粒度比对象锁大,它锁定的是整个类的同步方法或同步代码块。
public static synchronized void syncMethod() {
// synchronized方法体
}
public void syncBlock() {
synchronized (SynchronizedDemo.class) {
// synchronized代码块
}
}五、synchronized与锁优化
Java中的synchronized关键字在使用时需要考虑锁的粒度和性能问题,同时也有一些锁优化的技巧可以使用,以下是synchronized与锁优化的示例:
5.1 减小锁粒度
如果使用了对象锁,可以将锁的粒度减小到对象的某个属性上,以减少锁的粒度,从而提高程序的并发性。
public void syncBlock() {
synchronized (lock) {
// synchronized代码块
}
}
public void syncBlock2() {
synchronized (lock.getProperty()) {
// synchronized代码块
}
}5.2 双重检查锁定
双重检查锁定技术可以减少锁的粒度,提高程序的并发性。
public class Singleton {
private volatile static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}在以上代码中,通过双重检查锁定的方式,可以确保Singleton实例只被创建一次,并且提高了程序的并发性能。
5.3 锁消除
在一些情况下,编译器会自动消除一些不必要的锁,以提高程序的并发性能。
public void syncMethod() {
StringBuilder sb = new StringBuilder();
sb.append("a").append("b").append("c");
// sb对象没有被其他线程共享,可以消除锁
synchronized (sb) {
// synchronized代码块
}
}以上代码中,由于sb对象没有被其他线程共享,因此编译器可以自动消除synchronized。
六、synchronized的局限性和替代方案
synchronized虽然是Java中一个非常重要的同步机制,但它也有一些局限性和替代方案。
6.1 局限性
- synchronized只能保证单个线程的同步,无法保证多个线程之间的协作;
- synchronized在多线程并发访问下会导致性能下降;
- synchronized在死锁等异常情况下可能导致程序出现问题。
6.2 替代方案
Java中有许多替代方案可以代替synchronized实现同步,以下是一些常用的替代方案:
- Lock:Lock是Java中提供的一个新的同步机制,它可以替代synchronized实现线程同步,具有更好的扩展性和性能;
- Atomic:Atomic提供了一些原子操作,可以实现一些线程安全的操作;
- ConcurrentHashMap:ConcurrentHashMap是Java中线程安全的Map,可以实现高并发访问;
- Semaphore:Semaphore是一种计数信号量,可以用来控制对公共资源的访问。
七、总结
synchronized是Java中非常重要的同步机制,它可以保证多个线程之间的安全协作,但在使用时需要考虑锁的粒度和性能问题,同时也有一些锁优化的技巧可以使用。
除了synchronized之外,Java中还有许多替代方案可以实现线程同步,包括Lock、Atomic、ConcurrentHashMap等。在实际应用中,需要根据具体的场景选择适合的同步机制来保证程序的正确性和性能。会在后续讲解不同锁结构
链接:https://juejin.cn/post/7208476031135596599
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android Framework源码面试——Activity启动流程
面试的时候,面试官经常同你随便侃侃Activity的启动模式,但Activity启动牵扯的知识点其实很多,并非能单单用四个启动模式就能概括的,
默认的启动模式的表现会随着Intent Flag的设置而改变,因此侃Activity启动模式大多走流程装逼,最多结合项目遇到的问题,随便刁难一下面试者,并不太容易把控,也许最后,面试官跟面试者的答案都是错了,
比如在Service中必须通过设置FLAG_ACTIVITY_NEW_TASK才能启动Activity,这个时候启动Activit会有什么样的表现呢?就这一个问题,答案就要分好几个场景:
Activity的taskAffinity属性的Task栈是否存在
- 如果存在,要看
Activity是否存已经存在于该Task
- 如果已经存在于该
taskAffinity的Task,要看其是不是其rootActivity
- 如果是其
rootActivity,还要看启动该Activity的Intent是否跟当前intent相等
不同场景,所表现的行为都会有所不同,再比如singleInstance属性,如果设置了,大家都知道只有一个实例,将来再启动会复用,但是如果使用Intent.FLAG_ACTIVITY_CLEAR_TASK来启动,仍然会重建,并非完全遵守singleInstance的说明,还有不同Flag在叠加使用时候也会有不同的表现,单一而论Activity启动模式其实是很难的。本文也仅仅是涉及部分启动模式及Flag,更多组合跟场景要自己看源码或者实验来解决了。
1.面试连环炮之说说 Android 的四种启动模式
standard这是Activity的默认启动模式,每次激活Activity的时候都会创建一个新的Activity实例,并放入任务栈中。 使用场景:基本绝大多数地方都可以用。
singleTop这可能也是非常常用的launchMode了。如果在任务的栈顶正好存有该Activity的实例,则会通过调用onNewIntent()方法进行重用,否则就会同 standard 模式一样,创建新的实例并放入栈顶。即便栈中已经存在了该 Activity 的实例,也会创建新的实例,即:A -> B ->A,此时栈内为 A -> B -> A,但 A -> B ->B ,此时栈内为 A -> B。一句话概述就是:当且仅当启动的Activity和上一个Activity一致的时候才会通过调用onNewIntent()方法重用Activity。 使用场景:资讯阅读类 APP 的内容界面。
singleTask这个launchMode专门用于解决上面singleTop的另外一种情况,只要栈中已经存在了该Activity的实例,就会直接调用onNewIntent()方法来实现重用实例。重用时,直接让该Activity的实例回到栈顶,并且移除之前它上面的所有Activity实例。如果栈中不存在这样的实例,则和standard模式相同。即: A ->B -> C -> D -> B,此时栈内变成了 A -> B。而 A -> B -> C,栈内还是 A -> B -> C。 使用场景:浏览器的主页面,或者大部分 APP 的主页面。
singleInstance在一个新栈中创建该Activity的实例,并让多个应用共享该栈中的该Activity实例。一旦该模式的Activity实例已经存在于某个栈中,任何应用再激活该Activity时都会重用该栈中的实例,是的,依然是调用onNewIntent()方法。其效果相当于多个应用共享一个应用,不管是谁激活,该 Activity 都会进入同一个应用中。但值得引起注意的是:singleInstance不要用于中间页面,如果用户中间页面,跳转会出现很难受的问题。 这个在实际开发中我暂未遇到过,不过 Android 系统的来电页面,多次来电均是使用的同一个Activity。
四种模式的背书式理解记忆讲完了,你认为这样就结束了吗?
对,我也一度是这样认为的。
2.面试连环炮之说说 Intent标签起什么作用呢? 简单说一说
我们除了需要知道在 AndroidManifest.xml 里面设置 android:launchMode 属性,我们还需要了解下面这几个Intent标签的用法。
在 Android 中,我们除了在清单文件 AndroidManifest.xml 中配置 launchMode,当然可以用 Intent 标签说事儿。启动 Activity ,我们需要传递一个 Intent,完全可以通过设置 Intent.setFlags(int flags) 来设置启动的 Activity 的启动模式。
需要注意的是:通过代码来设置 Activity 的启动模式的方式,优先级比清单文件设置更高。
FLAG_ACTIVITY_NEW_TASK这个标识会使新启动的Activity独立创建一个Task。
FLAG_ACTIVITY_CLEAR_TOP这个标识会使新启动的Activity检查是否存在于Task中,如果存在则清除其之上的Activity,使它获得焦点,并不重新实例化一个Activity,一般结合FLAG_ACTIVITY_NEW_TASK一起使用。
FLAG_ACTIVITY_SINGLE_TOP等同于在launcherMode属性设置为singleTop。
3.Android 的启动原理,他的流程是什么样的
总的流程图:
1.2.1.进程A与AMS的交互过程
此处以跨进程启动Activity分析一下源码流程:
①A调用startActivity时,需要与AMS交互,此时需要需要获取到AMS的代理对象Binder也就是上图的AMP,
通过ActivityManagerNative.getDefault()获得,并调用AMP的startActivity方法,然后会通过mRemote.transact方法进行Binder通信,在AMS的onTransact方法里面会获取到请求的Activity参数信息:
mRemote.transact(START_ACTIVITY_TRANSACTION,data,reply,0);
@Override
public boolean onTransact(int code, Parcel data, Parcel reply, int flags){
switch(code){
case START_ACTIVITY_TRANSACTION:{ startActivity(app,callingPackage,intent,...)
}
}
}②AMS里面的startActivity方法最主要会去调用startSpecificActivityLocked函数,在此函数里面会去判断目标进程是否已经存在,并且目标向AMS注册过它自己的ApplicationThread也就是上图ATP代理对象,如果这两个条件都满足会去调用realStartActivityLocked方法,这个方法我们后面再看。如果上述条件不满足时,会去调用mService.startProcessLocked(r.processName,...)方法启动进程。
startProcessLocked方法首先调用Process.start("android.app.ActivityThread",)方法会向Zygote发送一个启动进程的请求,并告知Zygote进程启动之后,加载ActivityThread这个类的入口main函数,启动完成后返回进程的pid,并向AMS的Handler发送一个延迟消息,为的是要求目标进程启动后,10秒钟内需要向AMS报告,不然的话AMS就会清除目标进程的相关信息。
Process.start方法会去调用startViaZygote(processClass,)函数,这个函数主要做了两件事,一件就是打开通往Zygote的Socket,第二件事就是通过Socket发送启动进程参数。
Zygote端主要逻辑是在runOnce函数,函数内调用Zygote.forkAndSpecialize(...)创建子进程,创建完成之后就分别在父进程和子进程里面做各自的事情.
父进程通过
hanleParentProc(pid)把子进程的pid通过Socket发送给AMS
子进程调用
handleChildProc函数,做一些通用的初始化,比如启用Binder机制;执行应用程序的入口函数,也就是ActivityThread的Main函数.
ActivityThread的main函数,里面会创建一个ActivityThread对象,并调用thread.attach(false),为的是向AMS报到,上面第一条里面有提到。
attach方法里面,其实是一个跨进程的调用,首先通过
IActivityManager mgr = ActivityManagerNative.getDefault();获取到AMS的Binder代理对象,然后调用
IActivityManager mgr = ActivityManagerNative.getDefault();
mAppThread是应用端的一个Binder对象ApplicationThread,也就是最上面一张图的ATP,这样AMS端就可以调用应用端了。
attachApplication方法里面,最主要有两个方法,一个是通过传入的ApplicationThread对象,调用bindApplication初始化Application对象,另一个就是通过
mStactSupervisor.attachApplicationLoacked(app);
初始化挂起的
Activity对象。
- 在
attachApplicationLoacked函数里,会调用
ActivityRecord hr = stack.topRunningActivityLocked(null);
其中要明白AMS里面有两个栈,一个是
Launch桌面栈,一个就是非桌面栈mFocusedStack,此处的stack就是mFocusedStack,它会将栈顶的ActivityRecord返回出来,我们的目标Activity早就放置在了栈顶,只是一直没有初始化。然后调用方法,来启动Activity
如果我们不是启动另外一个进程,而是同一进程,那么这第二大部分就不会存在了,而是直接调用realStartActivityLocked方法。
realStartActivityLocked(hr,app,true,true);
写到这里是不是有很多码牛的小伙伴们已经坚持不下去了。还剩最后几个步骤
① realStartActivityLocked函数会调用app.thread.scheduleLaunchActivity(new Intent(r.intent),...);也就是通过之前注册的Binder对象ATP,调用scheduleLaunchActivity函数,在scheduleLaunchActivity函数里面:
ActivityClientRecord r = new ActivityClientRecord();
...
sendMessage(H.LAUNCH_ACTIVITY,r);
封装了一个
ActivityClientRecord消息,然后丢到主线程的Handler(mH)里。
②在主线程里面
final ActivityClientRecord r = (ActivityClientRecord)msg.obj ;
r.packageInfo = getPackageInfoNoCheck(...);
handleLaunchActivity(r,null);
getPackageInfoNoCheck函数主要是用来生成一个LoadedApk对象,它用来保存我们的apk信息,因为后面我们需要一个ClassLoader去加载Apk里面的Activity类,所以这里提前准备好。
③handleLaunchActivity里面分为两个部分,一个是performLaunchActivity函数,一个是handleResumeActivity函数。
performLaunchActivity
Activity activity = mInstrumentation.newActivity(...);
//返回之前创建好的
Application app = r.packageInfo.makeApplication(false,mInstrumentation);
//生成ContextImpl
Context appContext = createBaseContextForActivity(r,activity);
//给activity绑定上下文和一些初始化的工作,如createPhoneWindow
activity.attach(appContext,...);
mInstrumentation.callActivityOnCreate(activity,r.state); //生命周期的OnCreate
activity.performStart(); //生命周期的OnStart
return activity④handleResumeActivity:
-> r.activity.performResume()
-> mInstrumentation.callActivityOnResume(this);
-> activity.onResume()链接:https://juejin.cn/post/7208484366954496059
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
提升编程思想,这才是少走十年弯路的学习方式
练习算法和数据结构
熟悉算法和数据结构可以帮助你更好地理解和解决问题,优化你的代码并提高你的代码质量
推荐学习流程
- 了解算法和数据结构的基础概念和术语。在学习任何新的主题之前,首先需要了解其基本概念和术语。对于算法和数据结构,您需要了解什么是算法,什么是数据结构,它们有什么不同,以及它们的主要特征和优缺点。
- 了解常见的数据结构和算法。学习数据结构和算法的最好方法之一是了解它们的常见类型和应用。您可以使用在线资源和参考书籍来了解这些内容。
- 练习编写和实现算法和数据结构。通过编写和实现算法和数据结构来练习可以帮助您更好地理解它们的工作原理和应用。您可以使用在线代码编辑器和调试工具来练习这些技能。
- 解决实际问题和挑战。尝试解决实际问题和挑战可以帮助您将所学的算法和数据结构应用到实践中,并帮助您进一步掌握它们。
纸上得来终觉浅,我们学习之后肯定要进行使用,现在算法学习的网站已经完全为我们考虑了,关于上述的很多步骤天然支持。
那我们在解决算法和数据结构问题时,可以遵循以下步骤:
- 理解问题。阅读问题并确保您完全理解其要求和限制。这可以帮助您确定应该使用的数据结构和算法类型。
- 设计解决方案。根据您对问题的理解,设计一个解决方案。这可以包括确定应该使用的数据结构和算法、解决问题的步骤以及如何处理可能出现的异常情况。
- 实现方案。使用您选择的编程语言和编辑器实现您的解决方案。确保您按照您设计的步骤执行。
- 测试和调试。测试您的实现,并在需要时进行调试。这可以帮助您确定是否存在错误并确保您的代码在各种情况下都能正常工作。
当今时代,忙碌是我们整个社会的代名词,也是我们程序员的天生标签,真的,我从大专毕业到现在,每天早上上班每天下班都在不断的学习,但是结果都是在工作中有机会实战的,一清二楚,不能使用的,真的转眼就忘。
所以我们在学习的过程中要善于总结,总结可以缩小我们记忆搜索的范围,即使忘记了,我们也可以通过最小的代价找回来。
学会总结,学习算法是可以通过以下步骤总结
- 算法和数据结构的定义和区别。了解算法和数据结构的定义和区别可以帮助您更好地理解它们的工作原理和应用。
- 常见的数据结构和算法。了解常见的数据结构和算法可以帮助您更好地应用它们解决实际问题。
- 复杂度分析。了解算法和数据结构的时间和空间复杂度可以帮助您确定其效率和应用场景。
- 优化算法和数据结构。了解如何优化算法和数据结构可以帮助您更好地解决实际问题,并提高效率。
俗话说,专业的都是无味的,此时,我们可以转换思想去记忆
总有一种方法让你记住,因为谁都有故事
- 创造有趣的比喻或类比。将算法或数据结构与某些日常生活中的东西联系起来,可以帮助您更容易地记住它们。例如,您可以将树形数据结构比喻为现实世界中的树木。
- 使用记忆术。使用记忆术,例如联想和图像化,可以帮助您更好地记住算法和数据结构。例如,您可以将联想关键字与算法和数据结构名称相匹配。
- 创建抽象图形和示例。通过使用抽象图形和示例,可以更好地理解和记住算法和数据结构的工作原理和应用。
- 练习并实践。最好的方式是通过不断练习和实践来记住算法和数据结构。通过实际运用它们来解决实际问题,您将更好地理解它们的工作原理和应用,并在大脑中更深刻地记住它们。
学习算法和数据结构需要耐心、练习和实践,使用记忆术、抽象图形和示例来帮助记住算法和数据结构。
来,看个例子
以经常使用的快速排序为例
学习过程
了解快速排序算法的工作原理并熟悉其实现方法是学习快速排序算法的第一步。
快速排序算法是一种分治算法,其基本思想是将一个大问题分解成多个子问题,然后递归地解决这些子问题,最后将它们组合成一个完整的解决方案。
具体来说,快速排序算法将待排序数组分成两部分,其中一部分小于某个基准值,另一部分大于等于基准值。然后,对两部分分别递归地进行快速排序,最终得到一个有序数组。
以下是快速排序算法的核心实现代码:
function quickSort(arr, left, right) {
if (left < right) {
const pivotIndex = partition(arr, left, right);
quickSort(arr, left, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, right);
}
}
function partition(arr, left, right) {
const pivot = arr[right];
let i = left - 1;
for (let j = left; j < right; j++) {
if (arr[j] < pivot) {
i++;
[arr[i], arr[j]] = [arr[j], arr[i]];
}
}
[arr[i + 1], arr[right]] = [arr[right], arr[i + 1]];
return i + 1;
}解决过程
为了更好地理解快速排序算法的实现和工作原理,可以按照以下步骤解决一个简单的示例问题:
问题:给定一个未排序的整数数组 [8, 4, 2, 6, 7, 1, 3, 5],按升序排列。
解决步骤:
Step 1:选择一个基准元素(pivot)。为了简单起见,我们选择数组的最后一个元素 5 作为基准。
Step 2:将数组中小于基准的元素移到基准左侧,大于等于基准的元素移到基准右侧。这可以通过从数组的左侧开始扫描并与基准比较,如果小于基准,则将元素交换到基准左侧。
[4, 2, 3, 5, 7, 1, 8, 6]
^ ^
i j在这个例子中,我们选择数组的第一个元素作为左指针 i,并从第二个元素开始扫描数组。当扫描到元素 4 时,发现其小于基准 5,因此将其交换到 i 处,并将 i 加 1。扫描到元素 2 时,同样将其交换到 i处。继续扫描,直到 j 扫描到基准 5 为止。
Step 3:将基准元素放回正确的位置。由于基准元素是最后一个元素,因此可以将 i+1 位置的元素与基准元素交换。
[4, 2, 3, 5, 7, 1, 6, 8]
^ ^
i+1 right
现在,数组被分成了两个部分:左侧部分 [4, 2, 3, 1] 小于基准值 5,右侧部分 [7, 6, 8] 大于等于基准值 5。
Step 4:对左右两部分分别进行快速排序。这是一个递归过程,直到左右部分的长度都为 1 时停止。
继续对左侧部分进行快速排序,以数组 [4, 2, 3, 1] 为例。
Step 1:选择基准元素。选择数组的最后一个元素 1 作为基准。
Step 2:将小于基准的元素移到基准左侧。在这个例子中,可以看到数组已经有序,因此不需要进行任何交换操作。
Step 3:将基准元素放回正确的位置。将 i+1 位置的元素 1 与基准元素 1 交换。注意,这里 i+1 等于左侧数组的左端点,因为左侧数组中只有一个元素。
Step 4:对左右两部分分别进行快速排序。由于左侧数组只有一个元素,无需进行任何操作。
继续对右侧部分进行快速排序,以数组 [7, 6, 8] 为例。
Step 1:选择基准元素。选择数组的最后一个元素 8 作为基准。
Step 2:将小于基准的元素移到基准左侧。在这个例子中,可以看到只有一个元素小于基准,因此将其与 i 处的元素交换。
[7, 6, 8]
^
i,jStep 3:将基准元素放回正确的位置。将 i+1 位置的元素 7 与基准元素 8 交换。
[7, 8, 6]
^
i+1,rightStep 4:对左右两部分分别进行快速排序。继续对左侧部分 [7] 进行快速排序,无需进行任何操作。对右侧部分 [6] 进行快速排序,同样无需进行任何操作。
综上所述,对于数组 [8, 4, 2, 6, 7, 1, 3, 5],通过快速排序算法的处理,最终得到有序数组 [1, 2, 3, 4, 5, 6, 7, 8]。
核心总结:
快速排序算法是一种高效的排序算法,它的核心在于基准元素的选择和快速分割数组。通过不断选择基准元素,将数组划分成两个部分,并分别对这两个部分进行快速排序,最终将整个数组排序完成。
快速排序算法的时间复杂度为 O(n log n),空间复杂度为 O(log n)。它是一种原地排序算法,不需要额外的空间。
记忆方法:
快速排序算法的核心是基准元素的选择和数组的分割。可以用以下方法记忆:
- 选择基准元素:通常选择数组的最后一个元素作为基准,也可以选择其他位置的元素。
- 分割数组:将数组分割成小于基准的部分和大于等于基准的部分。可以使用双指针法来实现。
- 递归排序:对小于基准的部分和大于等于基准的部分分别进行快速排序,直到数组长度为 1 时停止递归。
记忆口诀:
- 基准元素找末尾,
- 双指针分割快速跑,
- 递归小大排,
- 最后数组有序到。
这个口诀可以快速记忆快速排序算法的核心思想和实现过程。
Android开发怎么融入其中
安卓开发中需要使用算法和数据结构时,可以将以上的学习模板应用到具体的问题中。
- 首先,可以选择适合问题的算法和数据结构。例如,如果你需要对一个数组进行排序,你可以使用快速排序算法。如果你需要快速查找元素,你可以使用二分查找算法。
- 其次,你可以使用学习模板中的学习过程和解决过程来帮助自己理解算法的实现过程和核心思想。通过学习模板,你可以更深入地了解算法和数据结构的实现原理,并将它们应用到实际的开发中。
- 最后,你可以使用学习模板中提供的核心总结和记忆方法来帮助自己记忆算法和数据结构的核心思想和实现过程。这可以帮助你更快速地掌握算法和数据结构,并在实际开发中应用它们。
总结
学而不思则亡 思而不学则殆
使用学习模板可以帮助你更有效地学习算法和数据结构,并将它们应用到实际的安卓开发中。这可以提升你的技能水平,并使你在开发中更加高效和优秀。
链接:https://juejin.cn/post/7201444843137318949
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 中的高阶函数及其应用
前言
前段时间一直在面试,某次面试,面试官看着我的简历说:“看你写的你很了解 kotlin 哦?那你说一说,为什么 kotlin 可以将函数作为参数和返回值,而 java 不行?”
我:“……”。
这次面试我连水都没喝一口就灰溜溜的走了。
回小黑屋的路上,突然想到,这玩意儿好像是叫 “高阶函数” 吧?好像我自己也经常用来着,咋就会啥也说不出来了呢?痛定思痛,赶紧恶补了一下相关的内容。
所以为什么 Kotlin 支持函数作为参数呢?
其实翻看 Kotlin 官方文档 《High-order functions and lambdas》 一节,就会发现它的第一段话就解释了为什么:
Kotlin functions are first-class, which means they can be stored in variables and data structures, and can be passed as arguments to and returned from other higher-order functions. You can perform any operations on functions that are possible for other non-function values.
To facilitate this, Kotlin, as a statically typed programming language, uses a family of function types to represent functions, and provides a set of specialized language constructs, such as lambda expressions.
因为在 Kotlin 中函数是头等公民,所以它们可以被储存在变量中、作为参数传递给其他函数或作为返回值从其他函数返回,就像操作其他普通变量一样操作高阶函数。
而 Kotlin 为了支持这个特性,定义了一系列的函数类型并且提供一些特定的语言结构支持(例如 lambdas 表达式)。
那么要怎么用呢?
高阶函数
首先,先看一段简单的代码:
fun getDataFromNet(onSuccess: (data: String) -> Unit) {
val requestResult = "我是从网络请求拿到的数据"
onSuccess(requestResult)
}
fun main() {
getDataFromNet(
onSuccess = {data: String ->
println("获取到数据:$data")
}
)
}运行代码,输出:
获取到数据:我是从网络请求拿到的数据下面我们来解释一下这段代码是什么意思。
首先看 getDataFromNet 函数的参数 onSuccess ,嗯?这是个什么东西?
哈哈,看起来可能会觉得有点奇怪,其实这里的 onSuccess 也是一个函数,且带有参数 data: String。
大致可以理解成:
fun onSuccess(data: String) {
// TODO
}这么一个函数,不过实际上这个函数是并不叫 onSuccess ,我们是只把这个函数赋值给了变量 onSuccess 。
从上面简单例子,我们可以看出,如果要声明一个个高阶函数,那么我们需要使用形如:
(arg1: String, arg2: Int) -> Unit的函数类型来声明高阶函数。
基本形式就是一个括号 () + -> + Unit 。
其中,() 内可以像普通函数一样声明接收的参数,如果不接收任何参数则可以只写括号:
() -> Unit箭头则是固定表达式,不可省略。
最后的 Unit 表示这个函数返回的类型,不同于普通函数,返回类型不可省略,即使不返回任何数据也必须明确声明 Unit。
当一个普通函数接收到一个作为参数的高阶函数时,可以通过 变量名() 或 变量名.invoke() 调用:
fun getDataFromNet(onSuccess: (data: String) -> Unit, onFail: () -> Unit) {
val requestResult = "我是从网络请求拿到的数据"
// 调用名为 onSuccess 的高阶函数
onSuccess.invoke(requestResult)
// 也可以直接通过括号调用
onSuccess(requestResult)
// 调用名为 onFail 的高阶函数
onFail.invoke()
// 也可以直接通过括号调用
onFail()
}下面再看一个有返回值的高阶函数的例子:
fun getDataFromNet(getUrl: (type: Int) -> String) {
val url = getUrl(1)
println(url)
}
fun main() {
getDataFromNet(
getUrl = {type: Int ->
when (type) {
0 -> "Url0"
1 -> "Url1"
else -> "Err"
}
}
)
}上面的代码会输出:
Url1将高阶函数作为函数返回值或者赋值给变量其实和上面大差不差,只要把一般用法中的返回值和赋值内容换成 函数类型 表示的高阶函数即可:
fun funWithFunReturn(): () -> Unit {
val returnValue: () -> Unit = { }
return returnValue
}在实例化高阶函数时,高阶函数的参数需要使用形如
arg1: String , arg2: Int ->
的形式表示,例如:
fun getDataFromNet(onSuccess: (arg1: String, arg2: Int) -> Unit) {
// do something
}
fun main() {
getDataFromNet(
onSuccess = { arg1: String, arg2: Int ->
println(arg1)
println(arg2)
}
)
}注意,这里的参数名不一定要和函数中定义的一样,可以自己写。
如果参数类型可以推导出来,则可以不用声明类型:
fun getDataFromNet(onSuccess: (arg1: String, arg2: Int) -> Unit) {
// do something
}
fun main() {
getDataFromNet(
onSuccess = { a1, a2 ->
println(a1)
println(a2)
}
)
}同时,如果某些参数没有使用到的话,可以使用 _ 下划线代替:
fun getDataFromNet(onSuccess: (arg1: String, arg2: Int) -> Unit) {
// do something
}
fun main() {
getDataFromNet(
onSuccess = { a1, _ ->
println(a1)
}
)
}用 lambda 表达式简化一下
在上面我们举例的代码中,为了更好理解,我们没有使用 lambda 表达式简化代码。
在实际使用过程中,我们可以大量的使用 lambda 表达式来大大减少代码量,例如:
fun getDataFromNet(onSuccess: (data: String) -> Unit, onFail: () -> Unit) {
val requestResult = "我是从网络请求拿到的数据"
if (requestResult.isNotBlank()) {
onSuccess(requestResult)
}
else {
onFail()
}
}
fun main() {
getDataFromNet(
onSuccess = {data: String ->
println("获取到数据:$data")
},
onFail = {
println("获取失败")
}
)
}可以简化成:
fun main() {
getDataFromNet(
{
println("获取到数据:$it")
},
{
println("获取失败")
}
)
}可以看到,如果高阶函数的参数只有一个的话,可以不用显式声明,默认使用 it 表示。
同时,如果普通函数的参数只有一个高阶函数,且位于最右边,则可以直接提出来,不用写在括号内,并将括号省略:
fun getDataFromNet(onSuccess: (data: String) -> Unit) {
// do something
}
fun main() {
// 这里调用时省略了 ()
getDataFromNet {
println(it)
}
}即使同时有多个参数也不影响把最右边的提出来,只是此时 () 不能省略:
fun getDataFromNet(arg: String, onSuccess: (data: String) -> Unit) {
// do something
}
fun main() {
getDataFromNet("123") {
println(it)
}
}关于使用 lambda 后能把代码简化到什么程度,可以看看这篇文章举的安卓中的点击事件监听的例子:
从最初的
image.setOnClickListener(object: View.OnClickListener {
override fun onClick(v: View?) {
gotoPreview(v)
}
})简化到只有一行:
image.setOnClickListener { gotoPreview(it) }所以它有什么用?
更简洁的回调
在上文中,我们举了使用 lambda 表达式后可以把点击事件监听省略到只有一行的程度,但是这里仅仅只是使用。
众所周知,安卓中写事件监听的代码需要一大串:
public interface OnClickListener {
void onClick(View v);
}
public void setOnClickListener(@Nullable OnClickListener l) {
if (!isClickable()) {
setClickable(true);
}
getListenerInfo().mOnClickListener = l;
}如果我们使用高阶函数配合 lambda 则只需要:
var mOnClickListener: ((View) -> Unit)? = null
fun setOnClickListener(l: (View) -> Unit) {
mOnClickListener = l;
}调用时也只需要:
setOnClickListener {
// do something
}其实,我们最开始举的封装网络请求的例子就是一个很好的事例,如果不使用高阶函数,那么我们为了实现网络请求成功后的回调,还得额外多写一些接口类,得益于高阶函数,我们只需要这样即可:
fun getDataFromNet(onSuccess: (data: String) -> Unit) {
val requestResult = "我是从网络请求拿到的数据"
onSuccess(requestResult)
}
fun main() {
getDataFromNet {
println("获取到数据:$it")
}
}让函数更加多样
有时候,我们可能会有一些比较特殊的需要多重校验的嵌套场景,如果不使用高阶函数的话,可能需要这样写:
fun checkName(data: String): Boolean {
return true
}
fun checkAge(data: String): Boolean {
return true
}
fun checkGender(data: String): Boolean {
return true
}
fun checkId(data: String): Boolean {
return true
}
fun postData(data: String) {
}
fun main() {
val mockData = ""
if (checkName(mockData)) {
if (checkAge(mockData)) {
if (checkGender(mockData)) {
if (checkId(mockData)) {
postData(mockData)
}
}
}
}
}如果使用高阶函数,则可以这么写:
fun checkName(data: String, block: (data: String) -> Unit) {
// if true
block(data)
}
fun checkAge(data: String, block: (data: String) -> Unit) {
// if true
block(data)
}
fun checkGender(data: String, block: (data: String) -> Unit) {
// if true
block(data)
}
fun checkId(data: String, block: (data: String) -> Unit) {
// if true
block(data)
}
fun postData(data: String) {
}
fun main() {
val mockData = ""
checkName(mockData) {
checkAge(it) {
checkGender(it) {
checkId(it) {
postData(it)
}
}
}
}
}额……好像举的这个例子不太恰当,但是大概就是这么个意思。
更好的控制函数执行
在我写的项目中还有一个比上面一个更加奇怪的需求。
这个程序有个后台进程一直在分别请求多个状态,且每个状态返回的数据类型都不同,我们需要分别将这些状态全部请求完成后打包成一个单独的数据,而且这些状态可能并不需要全部都请求,需要根据情况实时调整请求哪些状态,更烦的是,会有一个停止状态,如果收到停止的指令,我们必须立即停止请求,所以不能等待所有请求完成后再停止,必须要立即停止当前所在的请求。如果直接写你会怎么写?
听见都头大了是吧,但是这个就是我之前写工控程序时经常会遇到的问题,需要有一个后台进程实时轮询不同从站的不同数据,并且由于串口通信的特性,如果此时有新的指令需要下发,必须立即停止轮训,优先下发新指令。
所以我是这样写的:
fun getAllStatus(needRequestList: List<Any>, isFromPoll: Boolean = false): StatusData {
val fun0: () -> ResponseData.Status1 = { syncGetStatus1() }
val fun1: () -> ResponseData.Status2 = { syncGetStatus2() }
val fun2: () -> ResponseData.Status3 = { syncGetStatus3() }
val fun3: () -> ResponseData.Status4 = { syncGetStatus4() }
val fun4: () -> ResponseData.Status5 = { syncGetStatus5() }
val fun5: () -> ResponseData.Status6 = { syncGetStatus6() }
val fun6: () -> ResponseData.Status7 = { syncGetStatus7() }
val fun7: () -> Int = { syncGetStatus8() }
val fun8: () -> Int = { syncGetStatus9() }
val funArray = arrayOf(
fun0, fun1, fun2, fun3, fun4, fun5, fun6, fun7, fun8
)
val resultArray = arrayListOf<Any>()
for (funItem in funArray) {
if (isFromPoll && (isPauseNwPoll() || !KeepPolling)) throw IllegalStateException("轮询被中断")
if (funItem in needRequestList) resultArray.add(funItem.invoke())
}
// 后面的省略
}可以看到,我们把需要请求的函数全部作为高阶函数存进 funArray 数组中,然后遍历这个数组开始挨个执行,并且每次执行时都要判断这个请求是否需要执行,以及当前是否被中断请求。
得益于高阶函数的特性,我们可以方便的控制每个函数的执行时机。
总结
因为我讲的比较浅显,读者可能看起来会一头雾水,所以这里推荐结合下面列出的参考资料的文章一起看,同时自己上手敲一敲,就能很好的理解了。
参考资料
链接:https://juejin.cn/post/7208129482095280189
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android AIDL通信DeadObjectException解决
使用过AIDL进行跨进程通信的同学,肯定遇到过DeadObjectException这个崩溃,那么这个崩溃是怎么来的,我们又该如何解决它呢?今天这篇文章就来聊一聊。
崩溃来源
首先,这个崩溃的意思是,多进程在进行跨进程Binder通信的时候,发现通信的Binder对端已经死亡了。
抛出异常的Java堆栈最后一行是BinderProxy.transactNative,所以我们从这个方法入手,看看崩溃是在哪里产生的。
很显现,transactNative对应的是一个native方法,我们找到对应的native方法,在android_util_Binder.cpp中。
static jboolean android_os_BinderProxy_transact(JNIEnv* env, jobject obj,
jint code, jobject dataObj, jobject replyObj, jint flags) // throws RemoteException
{
// 如果data数据为空,直接抛出空指针异常
if (dataObj == NULL) {
jniThrowNullPointerException(env, NULL);
return JNI_FALSE;
}
// 将Java层传入的对象转换为C++层的指针,如果转换出错,中断执行,返回JNI_FALSE
Parcel* data = parcelForJavaObject(env, dataObj);
if (data == NULL) {
return JNI_FALSE;
}
Parcel* reply = parcelForJavaObject(env, replyObj);
if (reply == NULL && replyObj != NULL) {
return JNI_FALSE;
}
// 获取C++层的Binder代理对象指针
// 如果获取失败,会抛出IllegalStateException
IBinder* target = getBPNativeData(env, obj)->mObject.get();
if (target == NULL) {
jniThrowException(env, "java/lang/IllegalStateException", "Binder has been finalized!");
return JNI_FALSE;
}
// 调用BpBinder对象的transact方法
status_t err = target->transact(code, *data, reply, flags);
// 如果成功,返回JNI_TRUE,如果失败,返回JNI_FALSE
if (err == NO_ERROR) {
return JNI_TRUE;
} else if (err == UNKNOWN_TRANSACTION) {
return JNI_FALSE;
}
// 处理异常情况的抛出
signalExceptionForError(env, obj, err, true /*canThrowRemoteException*/, data->dataSize());
return JNI_FALSE;
}可以看到,这个方法主要做的事情是:
- 将
Java层传入的data,转换成C++层的指针 - 获取
C++层的Binder代理对象 - 调用
BpBinder对象的transact方法 - 处理
transact的结果,抛出异常
接下来我们看看,BpBinder的transact方法。
status_t BpBinder::transact(uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
// 首先判断Binder对象是否还存活,如果不存活,直接返回DEAD_OBJECT
if (mAlive) {
...
status = IPCThreadState::self()->transact(binderHandle(), code, data, reply, flags);
return status;
}
return DEAD_OBJECT;
}transact的具体方法,我们这里先不讨论。我们可以看到,在这里会判断当前的Binder对象是否alive,如果不alive,会直接返回DEAD_OBJECT的状态。
返回的结果,在android_util_Binder的signalExceptionForError中处理。
void signalExceptionForError(JNIEnv* env, jobject obj, status_t err,
bool canThrowRemoteException, int parcelSize)
{
// 省略其他异常处理的代码
....
case DEAD_OBJECT:
// DeadObjectException is a checked exception, only throw from certain methods.
jniThrowException(env, canThrowRemoteException
? "android/os/DeadObjectException"
: "java/lang/RuntimeException", NULL);
break;
}这个方法,其实包含非常多异常情况的处理。为了看起来更清晰,这里我们省略了其他异常的处理逻辑,只保留了DEAD_OBJECT的处理。可以很明显的看到,在这里我们抛出了DeadObjectException异常。
解决方法
通过前面的源码分析,我们知道DeadObjectException是发生在,当我们调用transact接口发现Binder对象不再存活的情况。
解决方案也很简单,就是当这个Binder对象死亡之后,不再调用transact接口。
方法1 调用跨进程接口之前,先判断Binder是否存活
这个方案比较简单粗暴,就是在多有调用跨进程接口的地方,都加一个Binder是否存活的判断。
if (mService != null && mService.asBinder().isBinderAlive()) {
mService.test();
}我们来看下isBinderAlive的源码,就是判断mAlive标志位是否为0。
bool BpBinder::isBinderAlive() const
{
return mAlive != 0;
}方法2 监听Binder死亡通知
先初始化一个DeathRecipient,用来监听死亡通知。
private IBinder.DeathRecipient mDeathRecipient = new IBinder.DeathRecipient() {
@Override
public void binderDied() {
// 解绑当前监听,重新启动服务
mService.asBinder().unlinkToDeath(mDeathRecipient, 0);
if (mService != null)
bindService(new Intent("com.service.bind"), mService, BIND_AUTO_CREATE);
}
};在这个死亡监听里,我们可以选择几种处理方式:
- 什么都不做,直接将
mService设置为空 - 再次尝试启动和绑定服务
在onServiceConnected方法中,注册死亡监听:
public void onServiceConnected(ComponentName name, IBinder service) {
mService = IServiceInterface.Stub.asInterface(service);
//获取服务端提供的接口
try {
// 注册死亡代理
if(mService != null){
service.linkToDeath(mDeathRecipient, 0);
}
} catch (RemoteException e) {
e.printStackTrace();
}
}总结
跨进程通信时,无法避免出现Binder对端挂掉的情况,所以在调用相关通信接口时,一定要判断连接是否可用,否则就会出现DeadObjectException的崩溃。
链接:https://juejin.cn/post/7208111879150551096
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter中的异步执行策略
在Flutter中,如何执行一段延迟执行的异步代码?我们可以找到下面这些方法。
- scheduleMicrotask
- Future.microtask
- Future
- Future.delayed
- Timer.run
- WidgetsBinding.addPostFrameCallback
- SchedulerBinding.addPostFrameCallback
你可能会说,这是相当多的选择,但是它们彼此之间有些什么异同呢?
Event Loop and Multithreading
Dart是一个单线程模型。但是你的Flutter应用同样可以同时做多件事情,这就是「Event Loop」发挥作用的地方。Event Loop是一个无尽的循环,它执行预定的events。这些events(或者只是代码块)必须是轻量级的,否则,你的应用程序会感觉卡顿。
每个event,如按下按钮或网络请求,都被安排在一个事件队列中,等待被事件循环捡起并执行。这种设计模式在UI和其他处理任何类型事件的系统中相当常见。
在Dart的单线程模型中,还有一个Microtask。它组成了Event Loop中的另一一个队列,即Microtask Queue。关于这个队列你唯一需要记住的是,在事件本身被执行之前,所有安排在Microtask Queue的任务都将在Event Loop循环的一次迭代中被执行。
可以通过这个链接查看更多内容:dart.cn/articles/ar…
Events
任何进入event queue的东西都被称之为Event。这是Flutter中调度异步任务的默认方法。为了调度一个Event,我们把它添加到event queue中,由Event Loop来接收。这种方法被许多Flutter机制所使用,如I/O、手势事件、Timer等。
Timer
Timer是Flutter中异步任务的基础。它被用来安排event queue中的代码执行,无论是否有延迟执行的需要。由此产生的有趣的事实是,如果当前队列很忙,你的定时器将永远不会被执行,即使时间到了。
Timer.run(() {
print("Timer");
});Future and Future.delayed
Future是Dart中使用的非常广泛的一个异步方法,它的内部实现,实际上也就是基于Timer的。
Future<void>(() {
print("Future Event");
});
Future<void>.delayed(Duration.zero, () {
print("Future.delayed Event");
});Microtasks
如前所述,所有调度的microtasks都会在下一个调度的Event之前执行。建议避免使用这个队列,除非绝对需要异步执行代码,而且要在event queue的下一个事件之前处理。你也可以把这个队列看成是属于前一个事件的任务队列,因为它们将在下一个事件之前完成。如果这个队列不断膨胀,就会完全冻结你的应用程序,因为它必须先执行这个队列中的所有内容,然后才能进行其事件队列的下一次迭代,例如处理用户输入,甚至渲染应用程序本身。
scheduleMicrotask
顾名思义,在microtask queue中调度一个块代码。与Timer类似,如果出错,会使应用程序崩溃。
scheduleMicrotask(() {
print("Microtask");
});Future.microtask
与我们之前看到的类似,但它将我们的microtask包裹在一个try-catch块中,以一种漂亮而干净的方式返回执行结果或异常。
Future<void>.microtask(() {
print("Microtask");
});
复制代码Post Frame Callback
前面两种方法只涉及到lower-level Event Loop,而现在我们要转到Flutter领域。这个Callback会在渲染管道完成时被调用,所以它与widget的生命周期相管理。当它被调度时,它只会被调用一次,而不是在每一帧都回调。使用addPostFrameCallback方法,你可以安排一个或多个回调,在界面渲染完成后被调用。
所有预定的Callback将在frame结束时按照它们被添加的顺序执行。到这个回调被调用的时候,可以保证Widget的构建过程已经完成。通过一些方法,你甚至可以访问Widget(RenderBox)的布局信息,比如它的大小,并做其他的一些事情。Callback本身将在正常的event queue中运行,Flutter默认使用该队列来处理几乎所有事情。
SchedulerBinding
这是一个负责绘图回调的mixin类,实现了我们感兴趣的方法。
SchedulerBinding.instance.addPostFrameCallback((_) {
print("SchedulerBinding");
});WidgetsBinding
我特意包括这个,因为它经常和SchedulerBinding一起被提及。它从SchedulerBinding中继承了这个方法,并有与我们的主题无关的一些额外方法。一般来说,你使用SchedulerBinding或WidgetsBinding并不重要,两者将执行位于SchedulerBinding中的完全相同的代码。
WidgetsBinding.instance.addPostFrameCallback((_) {
print("WidgetsBinding");
});总结
由于我们今天学到了很多理论知识,我强烈建议大家多玩一会儿,以确保我们能正确地掌握它。我们可以在之前的initState中使用下面的代码,并尝试预测它将以何种顺序被执行,这并不是一件看起来很容易的事情。
SchedulerBinding.instance.addPostFrameCallback((_) {
print("SchedulerBinding");
});
WidgetsBinding.instance.addPostFrameCallback((_) {
print("WidgetsBinding");
});
Timer.run(() {
print("Timer");
});
scheduleMicrotask(() {
print("scheduleMicrotask");
});
Future<void>.microtask(() {
print("Future Microtask");
});
Future<void>(() {
print("Future");
Future<void>.microtask(() {
print("Microtask from Event");
});
});
Future<void>.delayed(Duration.zero, () {
print("Future.delayed");
Future<void>.microtask(() {
print("Microtask from Future.delayed");
});
});输出结果如下所示。
I/flutter (31989): scheduleMicrotask
I/flutter (31989): Future Microtask
I/flutter (31989): SchedulerBinding
I/flutter (31989): WidgetsBinding
I/flutter (31989): Timer
I/flutter (31989): Future
I/flutter (31989): Microtask from Event
I/flutter (31989): Future.delayed
I/flutter (31989): Microtask from Future.delayed现在我们了解了这么多细节,你可以对如何安排你的代码做出深思熟虑的决定。作为一个经验法则,如果你需要你的上下文或与Layout或UI相关的东西,请使用addPostFrameCallback。在任何其他情况下,用Future或Future.delayed在标准的event queue中进行调度应该是足够的。microtask queue是非常小众的东西,你可能永远不会遇到,但它仍然值得了解。当然,如果你有一个繁重的任务,你就会考虑创建一个Isolate。
链接:https://juejin.cn/post/7208222652619948069
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Disruptor 高性能队列原理浅析
介绍
Disruptor 是英国外汇交易公司 LMAX 开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与 I/O 操作处于同样的数量级)。基于Disruptor 开发的系统单线程能支撑每秒 600 万订单,2010 年在 QCon 演讲后,获得了业界关注。2011 年,企业应用软件专家 Martin Fowler 专门撰写长文介绍。同年它还获得了 Oracle 官方的 Duke 大奖。
本文主要参考它 2011 年的论文 《LMAX Disruptor: High performance alternative to bounded queues for exchanging data between concurrent threads》还结合了美团技术团队对它分析的文章。论文中文翻译参考了肥兔子爱豆畜子翻译的中文版。
这里所说的队列是系统内部的内存队列,而不是Kafka这样的分布式队列。
许多应用程序依靠队列在处理阶段之间交换数据。我们的性能测试表明,当以这种方式使用队列时,其延迟成本与磁盘(基于RAID或SSD的磁盘系统)的IO操作成本处于同一数量级都很慢。如果在一个端到端的操作中有多个队列,这将使整个延迟增加数百微秒。
测试表明,使用 Disruptor 的三阶段流水线的平均延迟比基于队列的同等方法低 3 个数量级。此外,在相同的配置下,Disruptor 处理的吞吐量约为 8 倍。
并发问题
在本文以及在一般的计算机科学理论中,并发不仅意味着两个以上任务同时并行发生,而且意味着它们在访问资源时相互竞争。争用的资源可以是数据库、文件、socket,甚至是内存中的一个位置。
代码的并发执行涉及两件事:互斥和内存可见性。互斥是关于如何管理保证某些资源的独占式使用。内存可见性是关于控制内存更改何时对其他线程可见。如果你可以避免多线程竞争的去更新共享资源,那么就可以避免互斥。如果您的算法可以保证任何给定的资源只被一个线程修改,那么互斥是不必要的。读写操作要求所有更改对其他线程可见。但是,只有争用的写操作需要对更改进行互斥。
在任何并发环境中,最昂贵的操作是争用写访问。要让多个线程写入同一资源,需要复杂而昂贵的协调。通常,这是通过采用某种锁策略来实现的。
但是锁的开销是非常大的,在论文中设计了一个实验:
- 这个测试程序调用了一个函数,该函数会对一个 64 位的计数器循环自增 5 亿次。
- 机器环境:2.4G 6 核
- 运算: 64 位的计数器累加 5 亿次
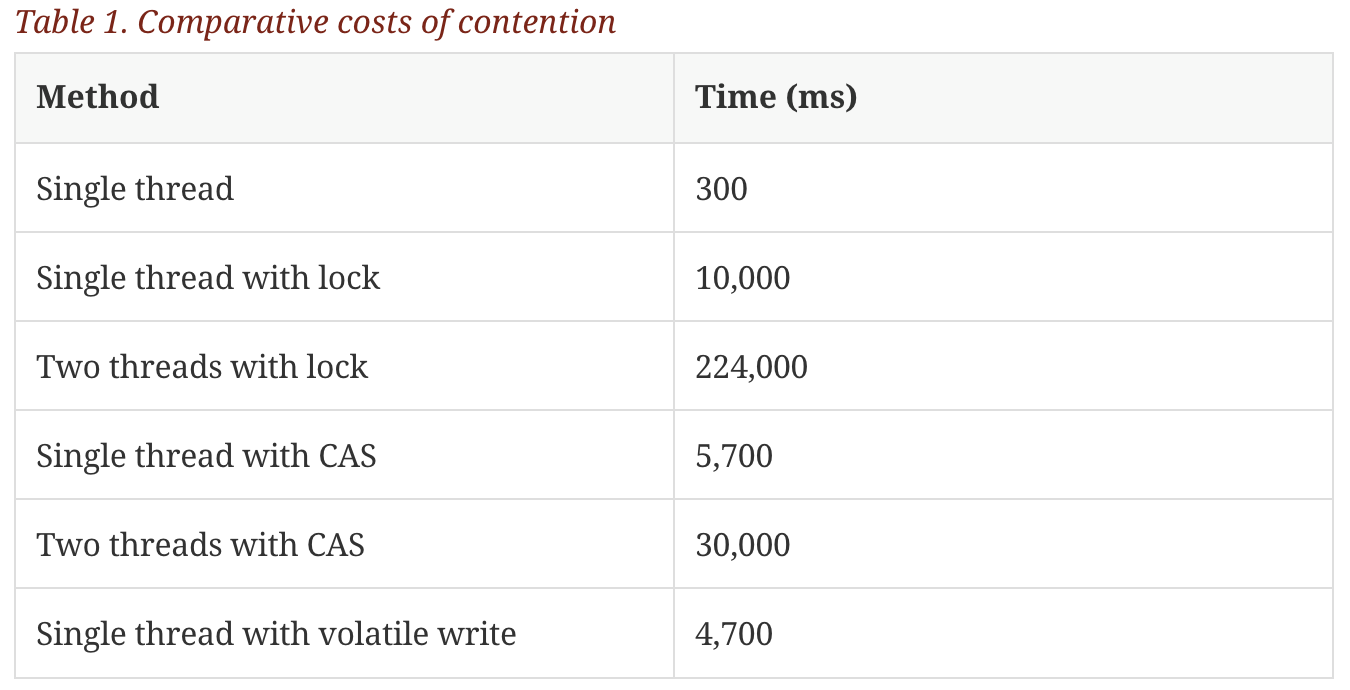
单线程情况下,不加锁的性能 > CAS 操作的性能 > 加锁的性能。
在多线程情况下,为了保证线程安全,必须使用 CAS 或锁,这种情况下,CAS 的性能超过锁的性能,前者大约是后者的 8 倍。
保证线程安全一般使用锁或者原子变量。
采取加锁的方式,默认线程会冲突,访问数据时,先加上锁再访问,访问之后再解锁。通过锁界定一个临界区,同时只有一个线程进入。
原子变量能够保证原子性的操作,意思是某个任务在执行过程中,要么全部成功,要么全部失败回滚,恢复到执行之前的初态,不存在初态和成功之间的中间状态。例如 CAS 操作,要么比较并交换成功,要么比较并交换失败。由 CPU 保证原子性。
通过原子变量可以实现线程安全。执行某个任务的时候,先假定不会有冲突,若不发生冲突,则直接执行成功;当发生冲突的时候,则执行失败,回滚再重新操作,直到不发生冲突。
CAS 操作是一种特殊的机器代码指令,它允许将内存中的字有条件地设置为原子操作。比如对于前面的“递增计数器实验”例子,每个线程都可以在一个循环中自旋,读取计数器,然后尝试以原子方式将其设置为新的递增值。
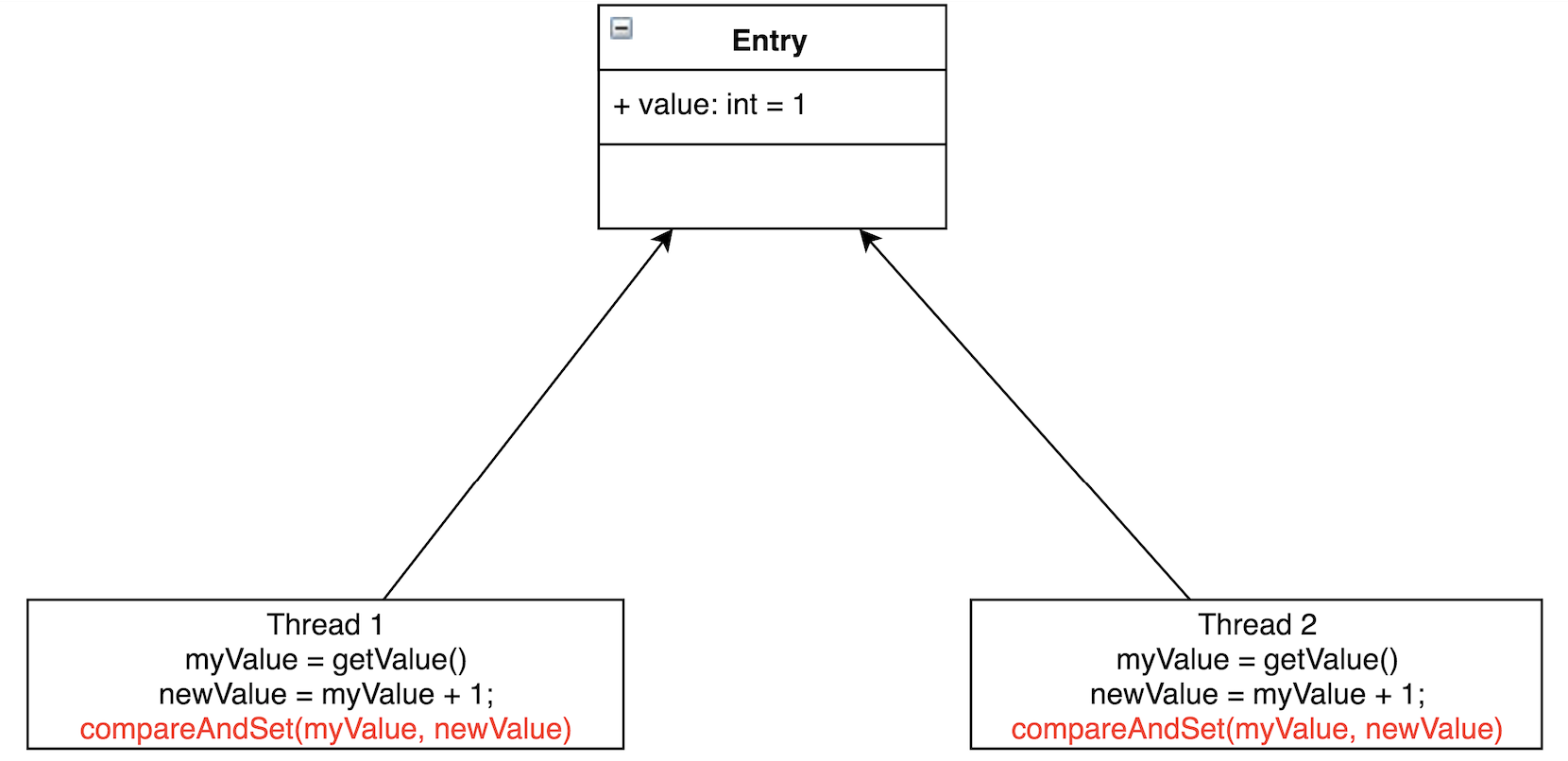
如图所示,Thread1 和 Thread2 都要把 Entry 加 1。若不加锁,也不使用 CAS,有可能 Thread1 取到了myValue=1,Thread2 也取到了 myValue=1,然后相加,Entry 中的 value 值为 2。这与预期不相符,我们预期的是 Entry 的值经过两次相加后等于3。
CAS 会先把 Entry 现在的 value 跟线程当初读出的值相比较,若相同,则赋值;若不相同,则赋值执行失败。一般会通过 while/for 循环来重新执行,直到赋值成功。CAS无需线程进行上下文切换到内核态去执行,在用户态执行了 CPU 的原语指令 cmpxchg,CAS 相当于在用户态代码里边插入了一个 cmpxchg 指令,这样 CPU 一直在用户态执行,执行到 cmpxchg 指令就开始执行内核态内存空间的操作系统的代码。执行指令要比上下文切换的开销要小,所以 CAS 要比重量级互斥锁性能要高。(用户态和内核态没有切换)
如果程序的关键部分比计数器的简单增量更复杂,则可能需要使用多个CAS操作的复杂状态机来编排争用。使用锁开发并发程序是困难的;而使用 CAS 操作和内存屏障开发无锁算法要更加复杂多倍,而且难于测试和证明正确性。
内存屏障和缓存问题
出于提升性能的原因,现代处理器执行指令、以及内存和执行单元之间数据的加载和存储都是不保证顺序的。不管实际的执行顺序如何,处理器只需保证与程序逻辑的顺序产生相同的结果即可。这在单线程的程序中不是一个问题。但是,当线程共享状态时,为了确保数据交换的成功与正确,在需要的时候、内存的改变能够以正确的顺序显式是非常重要的。处理器使用内存屏障来指示内存更新顺序很重要的代码部分。它们是在线程之间实现硬件排序和更改可见性的方法。
内存屏障(英语:Memory barrier),也称内存栅栏,内存栅障,屏障指令等,是一类同步屏障指令,它使得 CPU 或编译器在对内存进行操作的时候, 严格按照一定的顺序来执行, 也就是说在内存屏障之前的指令和之后的指令不会由于系统优化等原因而导致乱序。
大多数处理器提供了内存屏障指令:
- 完全内存屏障(full memory barrier)保障了早于屏障的内存读写操作的结果提交到内存之后,再执行晚于屏障的读写操作。
- 内存读屏障(read memory barrier)仅确保了内存读操作;
- 内存写屏障(write memory barrier)仅保证了内存写操作。
现代的 CPU 现在比当前一代的内存系统快得多。为了弥合这一鸿沟,CPU 使用复杂的高速缓存系统,这些系统是有效的快速硬件哈希表,无需链接。这些缓存通过消息传递协议与其他处理器缓存系统保持一致。此外,处理器还具有“存储缓冲区”(store buffer/load buffer,比 L1 缓存更靠近 CPU,跟寄存器同一个级别,用来当作 CPU 与高速缓存之间的缓冲。毕竟高速缓存由于一致性的问题也会阻塞)来缓冲对这些缓存的写入,以及作为“失效队列”,以便缓存一致性协议能够在即将发生写入时快速确认失效消息,以提高效率。
这对数据意味着,任何值的最新版本在被写入后的任何阶段都可以位于寄存器、存储缓冲区、L1/L2/L3 缓存之一或主内存中。如果线程要共享此值,则需要以有序的方式使其可见,这是通过协调缓存一致性消息的交换来实现的。这些信息的及时产生可以通过内存屏障来控制。
L1、L2、L3 分别表示一级缓存、二级缓存、三级缓存,越靠近 CPU 的缓存,速度越快,容量也越小。所以 L1 缓存很小但很快,并且紧靠着在使用它的 CPU 内核;L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用;L3 更大、更慢,并且被单个插槽上的所有 CPU 核共享;最后是主存,由全部插槽上的所有 CPU 核共享。
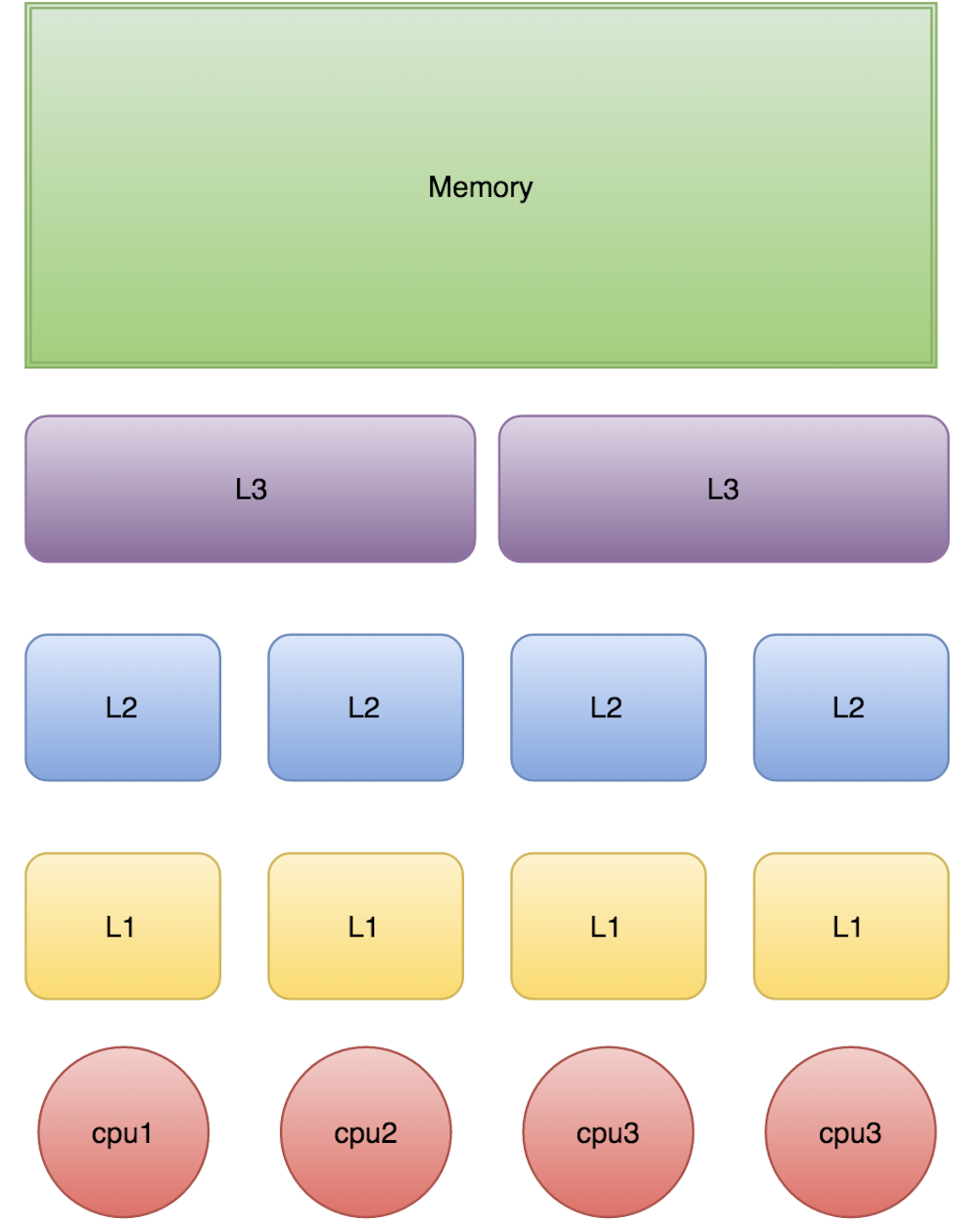
当 CPU 执行运算的时候,它先去 L1 查找所需的数据、再去 L2、然后是 L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要尽量确保数据在 L1 缓存中。
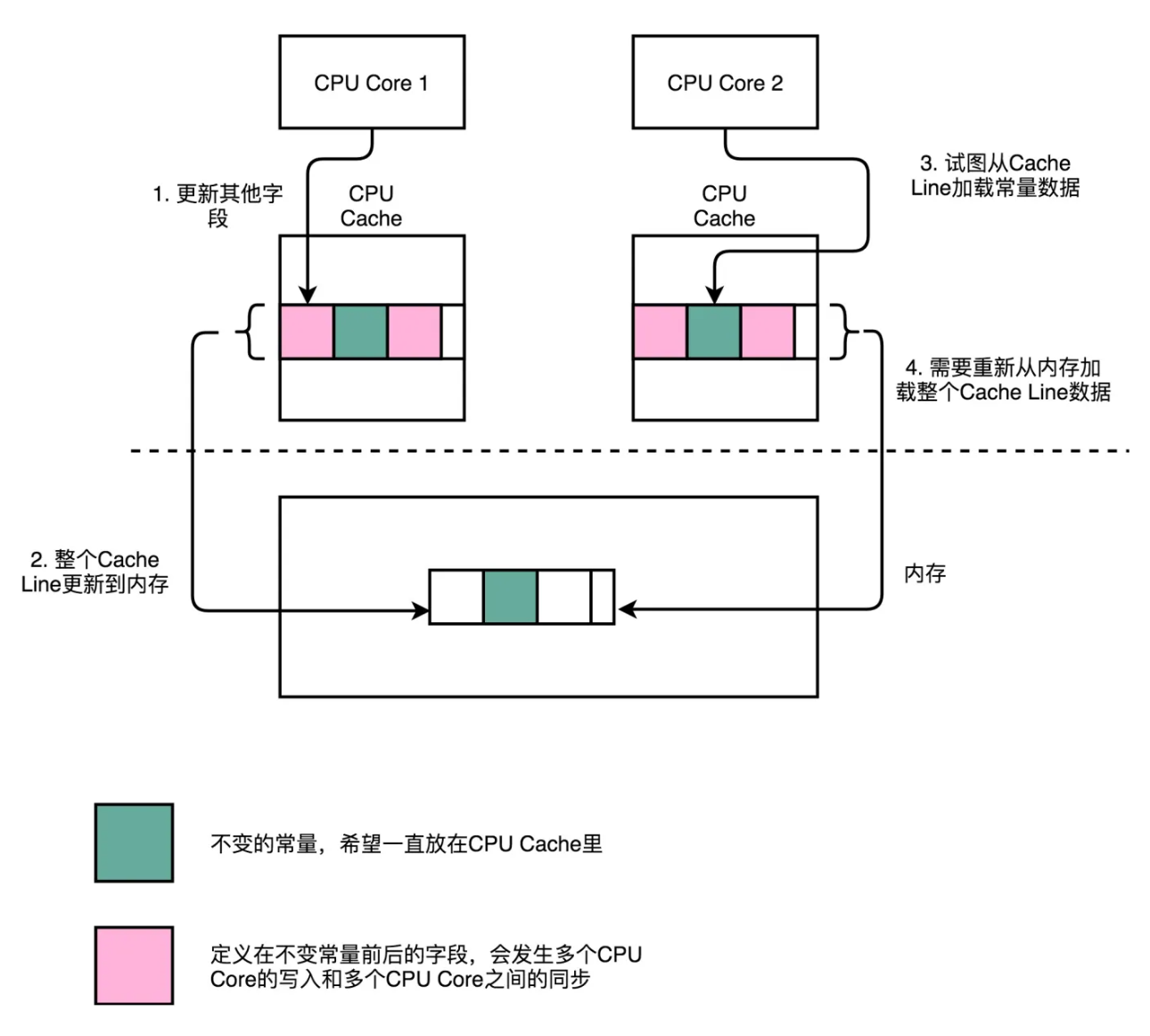
另外,线程之间共享一份数据的时候,需要一个线程把数据写回内存,而另一个线程访问内存中相应的数据。
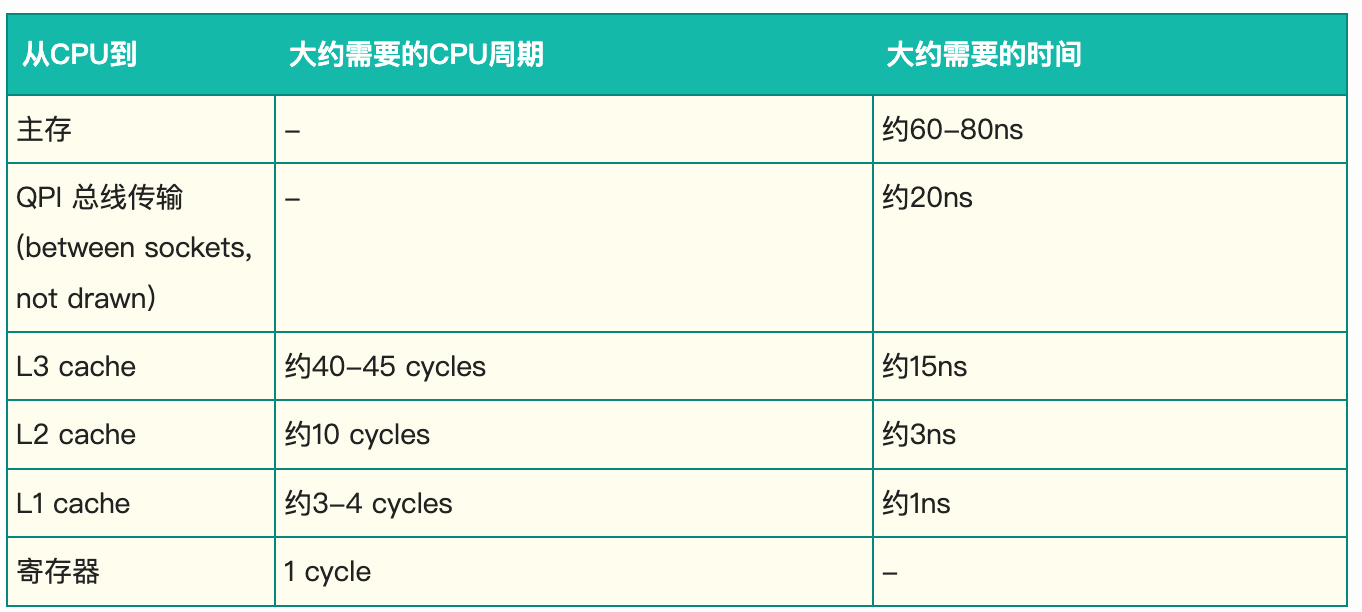
如果你用一种能被预测的方式访问内存的话,CPU 可以预测下个可能访问的值从内存先缓存到缓存中,来降低下次访问的延迟。但是如果是一些非顺序的、步长无法预测的结构,让 CPU 只能访问内存,性能上与访问缓存差很多。所以为了有效利用 CPU 高速缓存的特性,我们应当尽量使用顺序存储结构。
队列的问题
队列通常使用链表或数组作为元素的底层存储。如果允许内存中的队列是无界的,那么对于许多类的问题,它可以不受约束地增长,直到耗尽内存而达到灾难性的后果,当生产者超过消费者时就会发生这种情况。无界队列在可以在生产者可以保证不超过消费者的系统中使用,因为内存是一种宝贵的资源,但是如果这种假设不成立,而队列增长没有限制,那么总是有风险的。为了避免这种灾难性的结果,队列的大小通常要受到限制(有界)。要使队列保持有界,就需要对其底层选择数组结构或主动跟踪其大小。
队列的实现往往要在 head、tail 和 size 变量上有写争用。在使用时,由于消费者和生产者之间的速度差异,队列通常总是接近于满或接近于空。它们很少在生产和消费速率均衡的中间地带运作。这种总是满的或总是空的倾向会导致高级别的争用、和/或昂贵的缓存一致性。问题在于,即使 head 和 tail 使用不同的并发对象(如锁或CAS变量)来进行读写锁分离,它们通常也占用相同的 cacheline。
管理生产者申请队列的 head,消费者申请队列的 tail,以及中间节点的存储,这些问题使得并发实现的设计非常复杂,除了在队列上使用一个粗粒度的锁之外,还难以管理。对于 put 和 take 操作,使用整个队列上的粗粒度锁实现起来很简单,但对吞吐量来说是一个很大的瓶颈。如果并发关注点在队列的语义中被分离开来,那么对于除单个生产者-单个消费者之外的任何场景,实现都变得非常复杂。
而使用相同的 cacheline 会产生伪共享问题。比如 ArrayBlockingQueue 有三个成员变量:
- takeIndex:需要被取走的元素下标;
- putIndex:可被元素插入的位置的下标;
- count:队列中元素的数量;
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。

如上图所示,当生产者线程 put 一个元素到 ArrayBlockingQueue 时,putIndex 会修改,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。一般的解决方案是,增大数组元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间。
Disruptor 解决思路
启动时,将预先分配环形缓冲区的所有内存。环形缓冲区可以存储指向 entry 的指针数组,也可以存储表示 entry 的结构数组。这些 entry 中的每一个通常不是传递的数据本身,类似对象池机制,而是它的容器。这种 entry 的预分配消除了支持垃圾回收的语言中的问题,因为 entry 将被重用,并在整个 Disruptor 实例存活期间都有效。这些 entry 的内存是同时分配的。
一般的数据结构是像下面这样的:
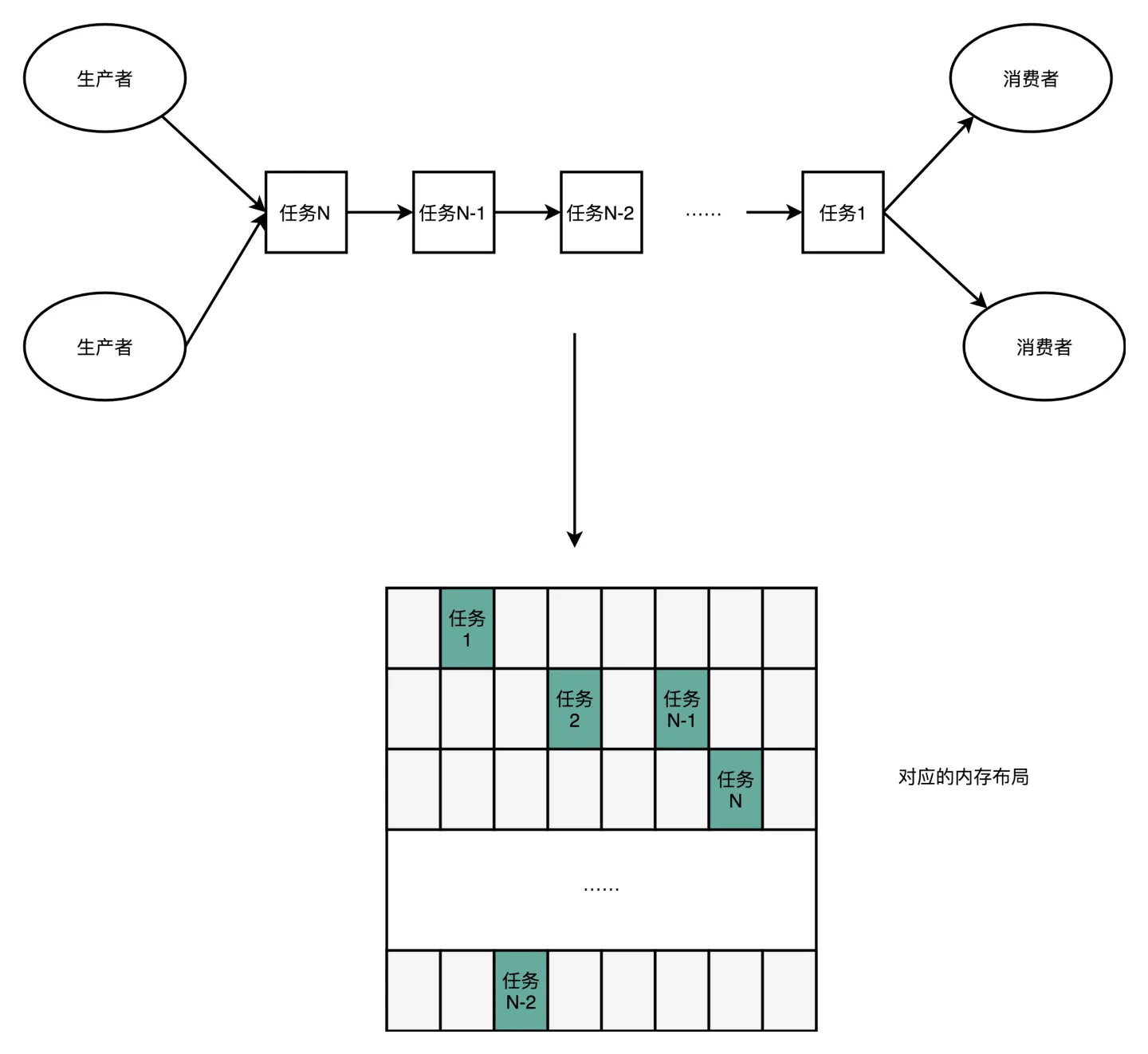
我们可以使用一个环状的数组结构改进成下面这样:
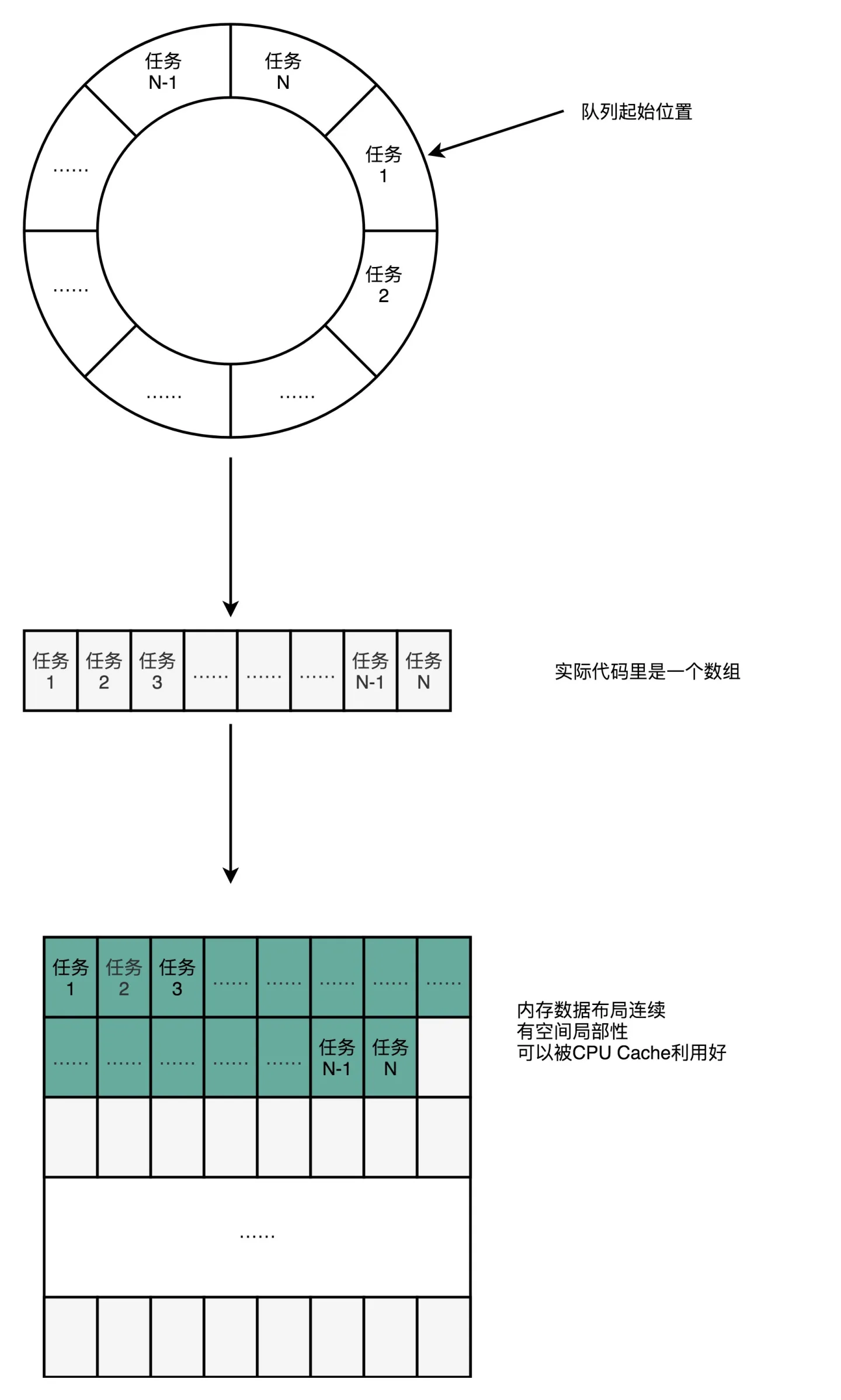
数组的连续多个元素会一并加载到 CPU Cache 里面来,所以访问遍历的速度会更快。而链表里面各个节点的数据,多半不会出现在相邻的内存空间,自然也就享受不到整个 Cache Line 加载后数据连续从高速缓存里面被访问到的优势。遍历访问时 CPU 层面的分支预测会很准确。这可以使得我们更有效地利用了 CPU 里面的多级流水线,我们的程序就会跑得更快。
在像 Java 这样的托管运行时环境中开发低延迟系统时,垃圾收集机制可能会带来问题。分配的内存越多,给垃圾收集器带来的负担就越大。当对象的寿命很短或实际上是常驻的时候,垃圾收集器工作得最好。在环形缓冲区中预先分配 entry 意味着它对于垃圾收集器来说是常驻内存的,垃圾回收的负担就很轻。同时,数组结构对处理器的缓存机制更加友好。数组长度 2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心 index 溢出的问题。index 是 long 类型,即使 100 万 QPS 的处理速度,也需要 30 万年才能用完。
一般的 Cache Line 大小在 64 字节左右,然后 Disruptor 在非常重要的字段前后加了很多额外的无用字段。可以让这一个字段占满一整个缓存行,这样就可以避免未共享导致的误杀。
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
下面用非环形的结构模拟无锁读写。
一个生产者的流程
- 申请写入m个元素;
- 若是有m个元素可以入,则返回最大的序列号。这儿主要判断是否会覆盖未读的元素;
- 若是返回的正确,则生产者开始写入元素。
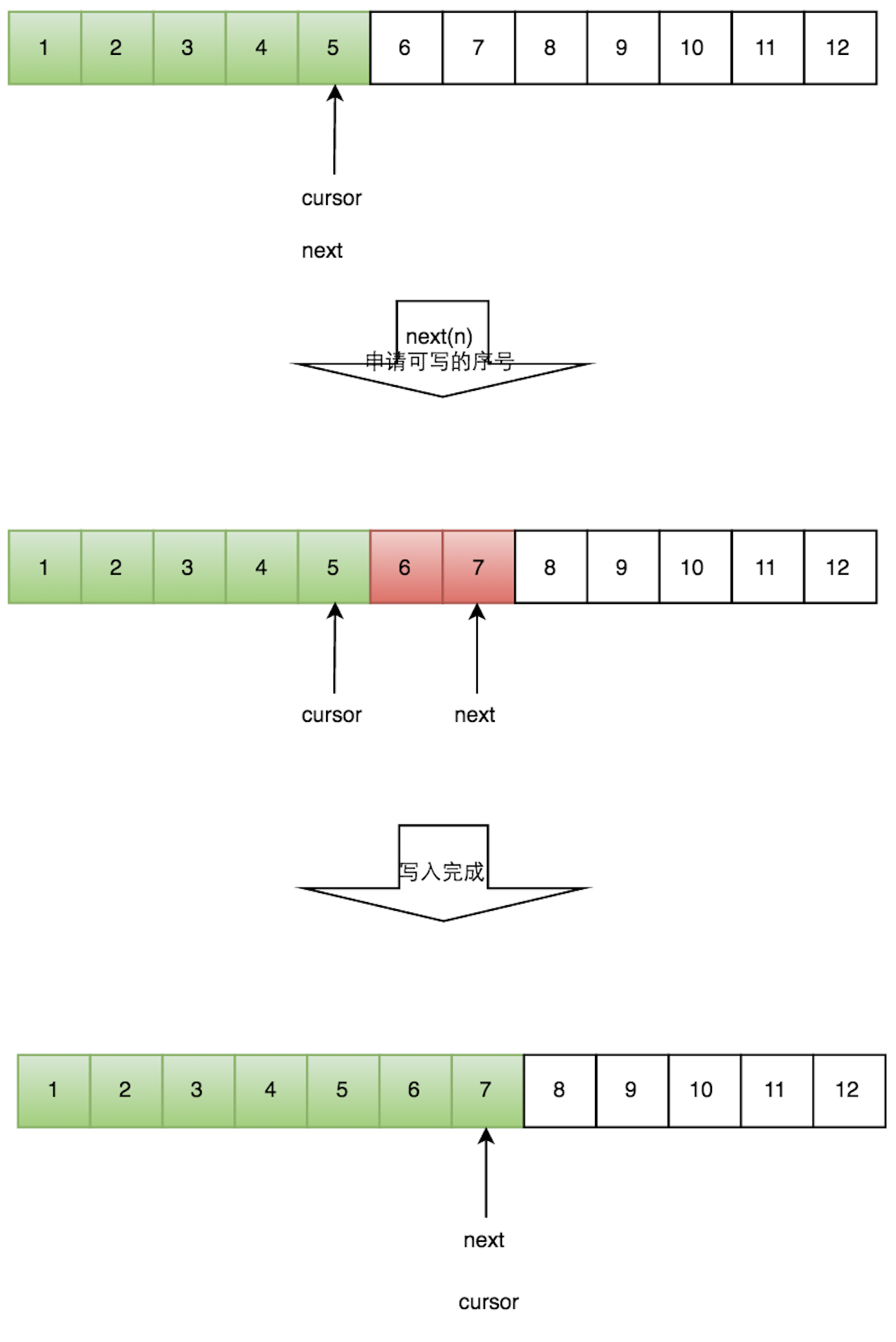
多个生产者流程
多个生产者的情况下,会遇到“如何防止多个线程重复写同一个元素”的问题。Disruptor 的解决方法是,每个线程获取不同的一段数组空间进行操作。这个通过 CAS 很容易达到。只需要在分配元素的时候,通过 CAS 判断一下这段空间是否已经分配出去即可。
但如何防止读取的时候,读到还未写的元素。Disruptor 在多个生产者的情况下,引入了一个与 Ring Buffer 大小相同的 buffer,Available Buffer。当某个位置写入成功的时候,便把 Availble Buffer 相应的位置置位,标记为写入成功。读取的时候,会遍历 Available Buffer,来判断元素是否已经就绪。
读数据流程
生产者多线程写入的情况会复杂很多:
- 申请读取到序号n;
- 若 writer cursor >= n,这时仍然无法确定连续可读的最大下标。从 reader cursor 开始读取 available Buffer,一直查到第一个不可用的元素,然后返回最大连续可读元素的位置;
- 消费者读取元素。
如下图所示,读线程读到下标为 2 的元素,三个线程 Writer1/Writer2/Writer3 正在向 RingBuffer 相应位置写数据,写线程被分配到的最大元素下标是 11。
读线程申请读取到下标从3到11的元素,判断 writer cursor>=11。然后开始读取 availableBuffer,从 3 开始,往后读取,发现下标为7的元素没有生产成功,于是WaitFor(11)返回6。
然后,消费者读取下标从 3 到 6 共计 4 个元素(多个生产者情况下,消费者消费过程示意图)。
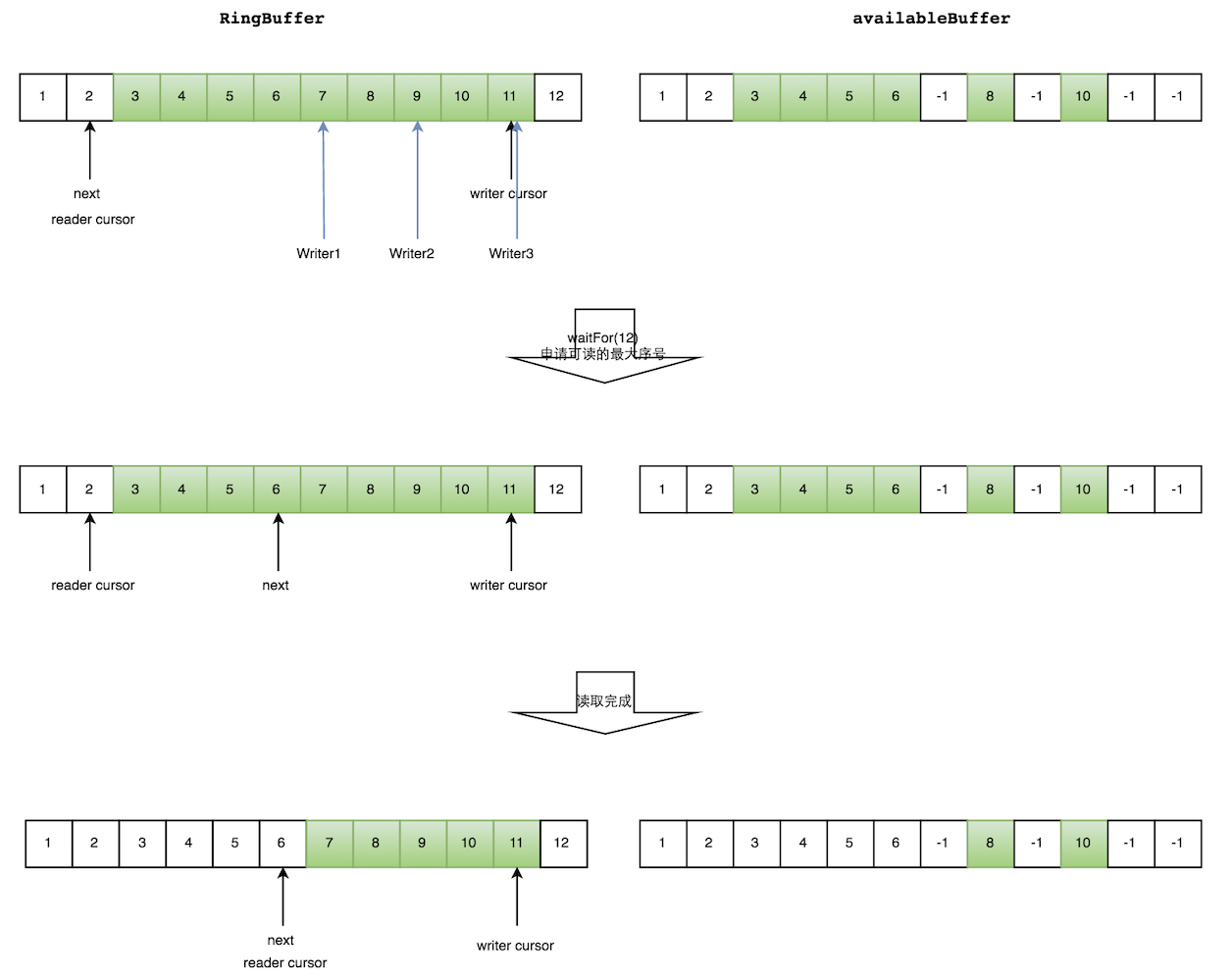
写数据流程
多个生产者写入的时候:
- 申请写入 m 个元素;
- 若是有 m 个元素可以写入,则返回最大的序列号。每个生产者会被分配一段独享的空间;
- 生产者写入元素,写入元素的同时设置 available Buffer 里面相应的位置,以标记自己哪些位置是已经写入成功的。
如下图所示,Writer1 和 Writer2 两个线程写入数组,都申请可写的数组空间。Writer1 被分配了下标 3 到下表 5 的空间,Writer2 被分配了下标 6 到下标 9 的空间。
Writer1 写入下标 3 位置的元素,同时把 available Buffer 相应位置置位,标记已经写入成功,往后移一位,开始写下标 4 位置的元素。Writer2 同样的方式。最终都写入完成。
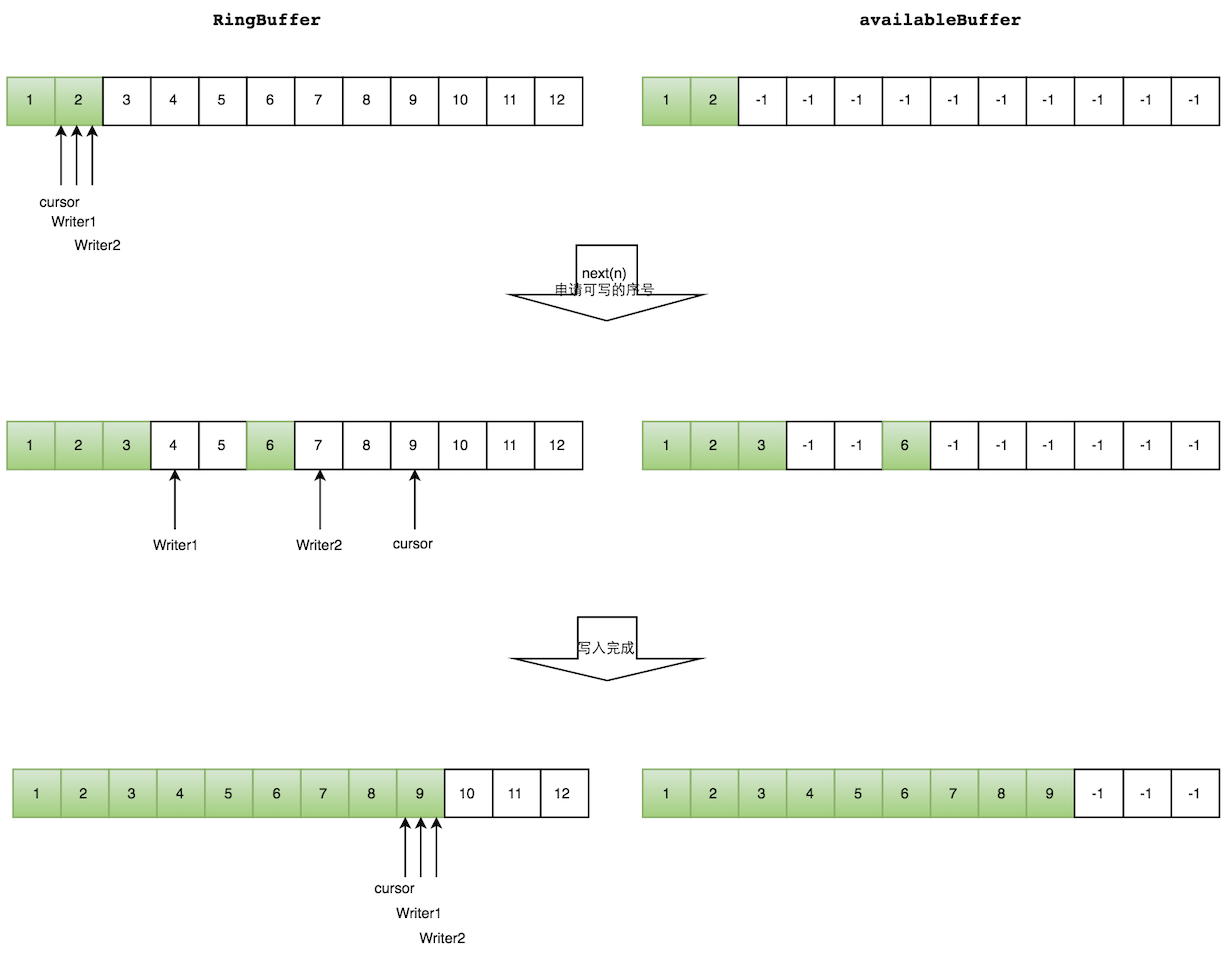
总结
整体上来看 Disruptor 在提高吞吐量、减少并发执行损耗上做出了很大贡献,通过贴合硬件机制的方式进行设计,消除写争用,最小化读争用,并确保代码与现代处理器使用的 Cache 特性良好配合。我们可以看下 Log4j 2 的性能数据,Log4j 2 的 Loggers all async 就是基于 Disruptor 的。
总结来说 Disruptor 是性能极高的无锁队列,提供了一种很好的利用硬件特性实现尽可能从缓存读取来加速访问的无锁方案。
链接:https://juejin.cn/post/7206540113571364920
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android音频播放AudioTrick详解
Android 中常用的播放音频的接口有MediaPlayer、AudioTrack和SoundPool,音频的渲染最常用的是AudioTrack和OpenSL ES ,下面将介绍下AudioTrack相关知识,主要内容如下:
- AudioTrack介绍
- AudioTrack的创建
- AudioTrack音频数据写入
- AudioTrack生命周期
- AudioTrack的使用
AudioTrack介绍
AudioTrack用来点播放原始 pcm格式的音频数据,AudioTrack有两种播放模式:
MODE_STATIC:这种模式会将音频数据一次写入音频缓冲区,适合处理内存少及尽可能小的延迟播放的短声音场景,如播放的游戏音效、铃声、系统提示音等,此时这种模式开销最小。MODE_STREAM:这种模式会不断的写入音频数据,适用于需要不断接受音频数据的场景,这种模式主要是由于某些音频数据持续时间长、或者音频特性(高采样率、更高位深等)导致不能一次性写入内存而出现的,正常播放PCM原始音频数据就选择这种模式。
与MediaPlayer相比较,MediaPlayer可以播放不同类型、不同格式的声音文件,会在底层创建与之对应的音频解码器,而AudioTrack只接收PCM原始音频数据,MediaPlayer在底层还是会创建AudioTrack,把解码后的PCM数流传递给AudioTrack,AudioTrack再传递给AudioFlinger进行混音,然后才传递给硬件播放。
AudioTrack的创建
AudioTrack的创建使用如下方式:
// Android5.0开始
AudioTrack(
attributes: AudioAttributes!,
format: AudioFormat!,
bufferSizeInBytes: Int,
mode: Int,
sessionId: Int)上面构造方法对应的参数含义如下:
- attributes:表示音频流信息的属性集合,自从 Android5.0 开始使用
AudioAttributes来取代流类型的设置,可以比流类型设置传达更多信息,常用来设置音频的用途、音频的内容等。 - format:表示
AudioTrack接受的音频格式,对于线性PCM来说,反应每个样本大小(8、16、32位)及表现形式(整型、浮点型),音频格式定义在AudioFormat中,常见的音频数据格式中只有AudioFormat.ENCODING_PCM_16BIT可以保证在所有的设备上正常使用,像AudioFormat.ENCODING_PCM_8BIT不能保证在所有设备上正常使用。 - bufferSizeInBytes:表示音频数据缓冲区的大小,单位事字节,其大小一般是音频帧大小的非零倍数,如果播放模式是
MODE_STATIC,则缓冲区大小是本次播放的音频的大小,如果播放模式是MODE_STREAM,则缓冲区大小不能小于最小缓冲区大小,也就是不能小于getMinBufferSize返回的大小。 - mode:表示播放模式,
AudioTrack提供了MODE_STATIC和MODE_STREAM两种方式,MODE_STATIC会将音频资源一次性写入音频缓冲区,适用于铃声、系统提示音等延时小、音频资源内存占用少的场景,,MODE_STREAM则适用于需要不断通过write方法写入数据的场景,相较MODE_STATIC会有一定延时,但是可以持续不断的接收音频数据。 - sessionId:音频会话 Id,这里使用
AudioManager.AUDIO_SESSION_ID_GENERATE有底层音频框架自己生成sessionId。
AudioTrack音频数据写入
无论是流模式(STREAM_MODE)还是静态缓冲模式(STATIC_MODE)模式,都需通过write方式写入音频数据来进行播放,主要的write方式如下:
// AudioTrack构造函数中指定的格式应为AudioFormat#ENCODING_PCM_8BIT
open fun write(audioData: ByteArray, offsetInBytes: Int, sizeInBytes: Int): Int
// AudioTrack构造函数中指定的格式应为AudioFormat#ENCODING_PCM_16BIT
open fun write(audioData: ShortArray, offsetInShorts: Int, sizeInShorts: Int): Int
// AudioTrack构造函数中指定的格式应为AudioFormat#ENCODING_PCM_FLOAT
open fun write(audioData: FloatArray, offsetInFloats: Int, sizeInFloats: Int, writeMode: Int): Int写入音频数据的返回值大于等于 0,读取音频数据常见异常如下:
- ERROR_INVALID_OPERATION:表示
AudioTrack未初始化。 - ERROR_BAD_VALUE:表示参数无效。
- ERROR_DEAD_OBJECT:表示已经传输了一些音频数据的情况下不返回错误码,将在下次
write返回处返回错误码。
这个跟AudioRecord中的 read 函数有点类似,具体细节查看官方文档。
AudioTrack生命周期
AudioTrack的生命周期主要是STATE_UNINITIALIZED、STATE_INITIALIZED和STATE_NO_STATIC_DATA,其中STATE_INITIALIZED对应STREAM_MODE,STATE_NO_STATIC_DATA对应STATIC_MODE,至于播放状态不怎么重要,如下图所示:
AudioTrack的使用
AudioTrack的使用主要就是从PCM文件中读取数据,然后将读取到的音频写入AudioTrack进行播放,其关键代码如下:
// 初始化AudioTrack
private fun initAudioTrack() {
bufferSize = AudioTrack
.getMinBufferSize(SAMPLE_RATE, CHANNEL_CONFIG, AUDIO_FORMAT)
attributes = AudioAttributes.Builder()
.setUsage(AudioAttributes.USAGE_MEDIA) // 设置音频的用途
.setContentType(AudioAttributes.CONTENT_TYPE_MUSIC) // 设置音频的内容类型
.build()
audioFormat = AudioFormat.Builder()
.setSampleRate(SAMPLE_RATE)
.setChannelMask(AudioFormat.CHANNEL_OUT_MONO)
.setEncoding(AudioFormat.ENCODING_PCM_16BIT)
.build()
audioTrack = AudioTrack(
attributes, audioFormat, bufferSize,
AudioTrack.MODE_STREAM, AudioManager.AUDIO_SESSION_ID_GENERATE
)
}
// AudioTrack写入音频数据
private fun writeAudioData(){
scope.launch(Dispatchers.IO){
val pcmFile = File(pcmFilePath)
val ins = FileInputStream(pcmFile)
val bytes = ByteArray(bufferSize)
var len: Int
while (ins.read(bytes).also { len = it } > 0){
audioTrack.write(bytes, 0, len)
}
audioTrack.stop()
}
}
// 开始播放
private fun start(){
audioTrack.play()
writeAudioData()
}AudioTrack的使用基本如上,AudioTrack播放音频的相关代码可以在回复关键字【audiotrack】关键字获取,案例中用到的本地PCM文件可以回复关键字【pcm】获取。
链接:https://juejin.cn/post/7204485453570867259
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


