








因为买不到烟花,所以我想用Compose来放烟花
再过几天就要过大年了,最近周围也是一到晚上就是到处都在放烟花,看得我十分眼馋也想搞点烟花来放放,可惜周围实在是买不到,一打听全是托人在外省买的,算了太麻烦了,那真的烟花放不了,我就干脆决定写个烟花出来吧,应应景,也烘托点年味儿出来~刚好最近学了点Compose的动画,所以这个烟花就拿Compose来写,先上个最终效果图
不好意思...放错效果图了...这个才是
gif有点卡,真实效果还要流畅点,这些我们先不说,先来看看这个动画我们需要做些什么
- 一闪一闪(对..在闪)的小星星
- 逐渐上升的烟花火苗
- 烟花炸开的效果
- 炸开后闪光效果
开始开发
闪烁的星星
首先我们放烟花肯定是在晚上放烟花的,所以整体画布首先背景色就是黑色,模拟一个夜空的场景
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
) {
}确定好了画布以后,我们先来想想如何画星星,夜空中的星星其实就是在画布上画几个小圆点,然后小圆点的颜色是白色的,最后星星看起来都是有大有小的,因为距离我们的距离不一样,所以我们的小圆点也要看起来大小不一样,也就是圆点的半径不一样,知道这些以后我们开始设计代码,先确定好需要的变量,比如画布的中心点xy坐标,星星的xy坐标,以及星星的颜色
val drawColor = colorResource(id = R.color.white)
val centerX = screenWidth() / 2
val centerY = screenHeight() / 2
val starXList = listOf(
screenWidth() / 12, screenWidth() / 6, screenWidth() / 4,
screenWidth() / 3, screenWidth() * 5 / 12, screenWidth() / 2, screenWidth() * 7 / 12,
screenWidth() * 2 / 3, screenWidth() * 3 / 4, screenWidth() * 5 / 6, screenWidth() * 11 / 12
)
val starYList = listOf(
centerY / 12, centerY / 6, centerY / 4,
centerY / 3, centerY * 5 / 12, centerY / 2, centerY * 7 / 12,
centerY * 2 / 3, centerY * 3 / 4, centerY * 5 / 6, centerY * 11 / 12
)starXList放星星的横坐标,横坐标就是把画布宽十二等分,starYList放星星的纵坐标,纵坐标就是把画布高的二分之一再十二等分,这样作法的目的就是最终画圆点的时候,两个List可以随机选取下标值,达到星星随机散布在夜空的效果
drawCircle(drawColor, 5f, Offset(starXList[0], starYList[10]))
drawCircle(drawColor, 4f, Offset(starXList[1], starYList[9]))
drawCircle(drawColor, 3f, Offset(starXList[2], starYList[4]))
drawCircle(drawColor, 5f, Offset(starXList[3], starYList[6]))
drawCircle(drawColor, 6f, Offset(starXList[4], starYList[3]))
drawCircle(drawColor, 5f, Offset(starXList[5], starYList[7]))
drawCircle(drawColor, 6f, Offset(starXList[6], starYList[2]))
drawCircle(drawColor, 2f, Offset(starXList[7], starYList[1]))
drawCircle(drawColor, 5f, Offset(starXList[8], starYList[0]))
drawCircle(drawColor, 2f, Offset(starXList[9], starYList[5]))
drawCircle(drawColor, 2f, Offset(starXList[10], starYList[8]))然后一闪一闪的效果怎么做呢,一闪一闪也就是圆点的半径循环在变大变小,所以我们需要用到Compose的循环动画rememberInfiniteTransition,这个函数可以通过它的animateXXX函数来创建循环动画,它里面有三个这样的函数
我们这里就使用animateFloat来创建可以变化的半径
val startRadius by transition.animateFloat(
initialValue = 0f,
targetValue = 1f,
animationSpec = infiniteRepeatable(tween(1000, easing = LinearEasing))
)这个函数返回的是一个Float类型的值,前两个参数很好理解,初始值跟最终值,第三个参数是一个
InfiniteRepeatableSpec的对象,它决定这个循环动画的一些参数,duration决定动画持续时间,delayMillis延迟执行的时间,easing决定动画执行的速度
- LinearEasing 匀速执行
- FastOutLinearInEasing 逐渐加速
- FastOutSlowInEasing 先加速后减速
- LinearOutSlowInEasing 逐渐减速
这里的星星的动画就选择匀速执行就好,我们把starRadius设置到星星的绘制流程里面去
drawCircle(drawColor, 5f + startRadius, Offset(starXList[0], starYList[10]))
drawCircle(drawColor, 4f + startRadius, Offset(starXList[1], starYList[9]))
drawCircle(drawColor, 3f + startRadius, Offset(starXList[2], starYList[4]))
drawCircle(drawColor, 5f + startRadius, Offset(starXList[3], starYList[6]))
drawCircle(drawColor, 6f + startRadius, Offset(starXList[4], starYList[3]))
drawCircle(drawColor, 5f + startRadius, Offset(starXList[5], starYList[7]))
drawCircle(drawColor, 6f + startRadius, Offset(starXList[6], starYList[2]))
drawCircle(drawColor, 2f + startRadius, Offset(starXList[7], starYList[1]))
drawCircle(drawColor, 5f + startRadius, Offset(starXList[8], starYList[0]))
drawCircle(drawColor, 2f + startRadius, Offset(starXList[9], starYList[5]))
drawCircle(drawColor, 2f + startRadius, Offset(starXList[10], starYList[8]))效果就是这样的
烟花火苗
现在开始绘制烟花部分,首先是上升的火苗,火苗也是个小圆点,它的起始坐标跟终点坐标很好确定,横坐标都是centerX即画布的一半,纵坐标开始位置是在画布高度位置,结束是在centerY即画布一半高度位置,而一次放烟花的过程中,烟花炸开的次数有很多次,伴随着火苗上升次数也很多次,所以这个也是个循环动画,整个过程代码实现如下
val fireDuration = 3000
val shootHeight by transition.animateFloat(
screenHeight(),
screenHeight() / 2,
animationSpec = InfiniteRepeatableSpec(tween(fireDuration,
easing = FastOutSlowInEasing))
)
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
由于火苗上升会随着重力逐渐减速,所以这里选择的是先快后慢的动画效果,效果如下
烟花炸开
这一部分难度开始增加了,因为烟花炸开这个效果是要等到火苗上升到最高点的位置然后在炸开的,这两个动画有个先后关系,用惯了Androi属性动画的我刚开始还不以为然,认为肯定会有个动画回调或者监听器之类的东西,然而看了下循环动画的源码发现并没有找到想要的监听器
那只能换个思路了,刚刚说到炸开的动画是在火苗上升到最高点的时候才开始的,那这个最高点就是个开关,当火苗到达最高点的时候,让火苗的动画“暂停”,然后开始炸开的动画,现在问题的关键是,如何让火苗的动画“暂停”,我们知道火苗的动画是一个循环动画,循环动画是从初始值到最终值循环变化的过程,那么我们是不是只要让这两个值都为同一个,让它们没有变化的空间,是不是就等于让这个动画“暂停”了呢,我们开始设计这个过程
var turnOn by remember { mutableStateOf(false) }
val distance = remember { Animatable(screenHeight().dp, Dp.VectorConverter) }
LaunchedEffect(turnOn) {
distance.snapTo(if (turnOn) screenHeight().dp else 0.dp)
}turnOn是个开关,true的时候表示火苗动画开始,false的时候表示火苗动画已经到达最高点,distance是一个Animatable的对象,Animatable是啥呢,从字面上就能理解它也是个动画,但与我们刚刚接触的循环动画不一样,它只有从初始值到最终值的单向变化,而后面的LaunchedEffect是啥呢,我们点到里面去看下它的源码
fun LaunchedEffect(
key1: Any?,
block: suspend CoroutineScope.() -> Unit
) {
val applyContext = currentComposer.applyCoroutineContext
remember(key1) { LaunchedEffectImpl(applyContext, block) }
}这里我们看到key1是任何值,被remember保存了起来,block是个挂起的函数类型对象,也就是block是运行在协程里面的,我们再去LaunchedEffectImpl里面看看
我们看到了这个协程是在被remember的值发生改变以后才去执行的,那现在清楚了,每次改变turnOn的值,distance就会来回从screenHeight()和0之间切换,而切换的条件就是火苗上升高度到达了画布的一半,我们改一下刚刚火苗的动画,让shootHeight随着distance变化而变化,另外我们给画布添加个点击事件,每次点击让turnOn的值发生改变,目的让动画多进行几次
val shootHeight by transition.animateFloat(
distance.value.value,
distance.value.value / 2,
animationSpec = InfiniteRepeatableSpec(tween(fireDuration,
easing = FastOutSlowInEasing))
)
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
turnOn = false
}
}我们看下效果是不是我们想要的
So far so good~动画已经分离开来了,现在就要开始炸开效果的开发,我们先脑补下炸开是什么样子的,是由火苗开始,向四周延伸出去若干条烟火,或者换句话说就是以火苗为圆心,向四周画线条,这样说我们思路有了,这是一个由圆心开始向外drawLine的过程,drawLine这个api大家很熟悉了,最主要的就是确定开始跟结束两处的坐标,但是无论开始还是结束,这两个坐标都是分布在一个圆周上的,所以我们第一步先要确定在哪几个角度上面画线
val anglist = listOf(30, 75, 120, 165, 210, 255, 300, 345)
知道了角度以后,就要去计算xy坐标了,这个就要用到正弦余弦公式
private fun calculateX(centerX: Float, fl: Int, endCor: Boolean): Float {
val angle = Math.toRadians(fl.toDouble())
return centerX - cos(angle).toFloat() * (if (endCor) screenWidth() / 2 else screenWidth() / 12)
}
private fun calculateY(centerY: Float, fl: Int, endCor: Boolean): Float {
val angle = Math.toRadians(fl.toDouble())
return centerY - sin(angle).toFloat() * (if (endCor) screenWidth() / 2 else screenWidth() / 12)
}其中endColor是true就是画终点的坐标,false就是起点的坐标,我们先画一条线,剩下的线的代码都相同
val startfireOneX = calculateX(centerX, anglist[0], false)
val startfireOneY = calculateY(centerY, anglist[0], false)
val endfireOneX = calculateX(centerX, anglist[0], true)
val endfireOneY = calculateY(centerY, anglist[0], true)
var fireColor = colorResource(id = R.color.color_03DAC5)
var fireOn by remember { mutableStateOf(false) }
val fireOneXValue = remember { Animatable(startfireOneX, Float.VectorConverter) }
val fireOneYValue = remember { Animatable(startfireOneY, Float.VectorConverter) }
val fireStroke = remember { Animatable(0f, Float.VectorConverter) }
LaunchedEffect(fireOn){
fireStroke.snapTo(if(fireOn) 20f else 0f)
fireOneXValue.snapTo(if(fireOn) endfireOneX else startfireOneX)
fireOneYValue.snapTo(if(fireOn) endfireOneY else startfireOneY)
}
fireOneXValue是第一条线横坐标的变化动画,fireOneYValue是纵坐标的变化动画,它们的改变都有fireOn去控制,fireOn打开的时机就是火苗上升到最高点的时候,同时我们也增加了fireStroke,表示线条粗细的变化动画,也随着fireOn的改变而改变,我们现在去创建横坐标,纵坐标以及线条粗细的循环动画
val fireOneX by transition.animateFloat(
startfireOneX, fireOneXValue.value,
infiniteRepeatable(tween(fireDuration, easing = FastOutSlowInEasing))
)
val fireOneY by transition.animateFloat(
startfireOneY, fireOneYValue.value,
infiniteRepeatable(tween(fireDuration, easing = FastOutSlowInEasing))
)
val strokeW by transition.animateFloat(
initialValue = fireStroke.value/20,
targetValue = fireStroke.value,
animationSpec = infiniteRepeatable(tween(fireDuration,
easing = FastOutSlowInEasing))
)我们现在可以去绘制第一根线了,在Canvas里面增加第一个drawLine
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
turnOn = false
fireOn = true
}
drawLine(
fireColor, Offset(startfireOneX, startfireOneY),
Offset(fireOneX, fireOneY), cap = StrokeCap.Round, strokeWidth = strokeW
)
}到了这一步,我们应该考虑的是,如何让动画衔接起来,也就是炸开动画完成以后,继续执行火苗动画,那么我们就要找出炸开动画结束的那个点,这里总共有三个值,我们选择strokeW,当线条粗细到达最大值的时候,将fireOn关闭,将turnOn打开,我们在drawLine后面加上这段逻辑
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
turnOn = false
fireOn = true
}
drawLine(
fireColor, Offset(startfireOneX, startfireOneY),
Offset(fireOneX, fireOneY), cap = StrokeCap.Round, strokeWidth = strokeW
)
if(strokeW == 19){
fireOn = false
turnOn = true
}
}这个时候,两个动画就连起来了,我们运行下看看效果
一条线完成了,那么其余几根线道理也是一样的,代码有点多篇幅关系就不贴出来了,直接看效果图吧
基本的样子已经出来了,现在给这个烟花优化一下,我们知道放烟花时候,每次炸开的样子都是不一样的,红橙黄绿啥颜色都有,我们这边也让每次炸开时候,颜色都不一样,那首先我们要弄一个颜色的集合
val colorList = listOf(
colorResource(id = R.color.color_03DAC5), colorResource(id = R.color.color_BB86FC),
colorResource(id = R.color.color_E6A639), colorResource(id = R.color.color_01B9FF),
colorResource(id = R.color.color_FF966B), colorResource(id = R.color.color_FFEBE7),
colorResource(id = R.color.color_FF4252), colorResource(id = R.color.color_EC4126)
)并且让fireColor在每次炸开之前,更换一次颜色,随机换也行,按照下标顺序替换也行,这边我选择顺序换了,位置就是炸开动画开始的地方
var colorIndex by remember { mutableStateOf(0) }
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
if (strokeW.toInt() == 0) {
colorIndex += 1
if (colorIndex > 7) colorIndex = 0
fireColor = colorList[colorIndex]
}
turnOn = false
fireOn = true
}
drawLine(
fireColor, Offset(startfireOneX, startfireOneY),
Offset(fireOneX, fireOneY), cap = StrokeCap.Round, strokeWidth = strokeW
)
if(strokeW == 19){
fireOn = false
turnOn = true
}
}我们再想想看,烟花结束以后是不是还会有一些闪光,有的烟花的闪光还会有声音,声音我们弄不出来,但是闪光还是可以的,还记得我们星星怎么画的吗,不就是几个圆圈在那里不断绘制,然后一闪一闪的效果就是不断改变圆圈的半径,那我们烟花的闪光效果也可以这么做,首先我们先确定好需要绘制圆圈的坐标
val endXAnimList = listOf(
calculatePointX(centerX, anglist[0]),
calculatePointX(centerX, anglist[1]),
calculatePointX(centerX, anglist[2]),
calculatePointX(centerX, anglist[3]),
calculatePointX(centerX, anglist[4]),
calculatePointX(centerX, anglist[5]),
calculatePointX(centerX, anglist[6]),
calculatePointX(centerX, anglist[7])
)
val endYAnimList = listOf(
calculatePointY(centerY, anglist[0]),
calculatePointY(centerY, anglist[1]),
calculatePointY(centerY, anglist[2]),
calculatePointY(centerY, anglist[3]),
calculatePointY(centerY, anglist[4]),
calculatePointY(centerY, anglist[5]),
calculatePointY(centerY, anglist[6]),
calculatePointY(centerY, anglist[7])
)然后烟花放完以后会有个逐渐暗淡的过程,在这里我们就让圆圈的半径也有个逐渐变小的过程,那我们就创建个变小的动画
val pointDuration = 3000
val firePointRadius = remember{ Animatable(0f, Float.VectorConverter) }
val pointRadius by transition.animateFloat(
initialValue = firePointRadius.value,
targetValue = firePointRadius.value / 6,
animationSpec = infiniteRepeatable(tween(pointDuration,
easing = FastOutLinearInEasing))
)有了这个闪光的动画以后,接下去就要让它跟炸开的动画衔接起来了,这边也跟其他动画一样,增加一个开关去控制,当开关打开之后,firePointRadius设置成最大,开启这个闪光动画,当开关关闭以后,就让firePointRadius设置为0,也就是关闭闪光动画,代码如下
var pointOn by remember { mutableStateOf(false) }
LaunchedEffect(pointOn) {
firePointRadius.snapTo(if (pointOn) 12f else 0f)
}参数都设置好了以后,我们可以去绘制闪光的圆圈了,这边我们让闪光的开关在炸开动画完毕之后打开,原本要开启的火苗动画我们暂时先不打开,而闪光动画的颜色我们让它跟炸开的动画颜色一致,让整个过程看上去像是烟花自己炸开然后变成小颗粒的样子
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
....此处省略前面两个烟花动画的绘制过程.....
if(strokeW == 19){
fireOn = false
pointOn = true
}
if(pointOn){
repeat(endXAnimList.size) {
drawCircle(
colorList[colorIndex], pointRadius,
Offset(endXAnimList[it], endYAnimList[it])
)
}
}
}到了这里感觉好像漏了点什么,没错,之前我们暂时把火苗开关打开的时机取消了,那这个开关得打开呀,不然我们的烟花没办法连在一起放,现在就是要找到这个临界值,我们发现这个绘制圆圈的过程,只有圆圈的半径在随着时间的递进逐渐变小的,它的最小值是当pointOn开关打开之后,targetValue的值也就是2,所以我们可以判断当pointRadius变成2的时候,将闪光动画关闭,火苗动画打开,我们将这个判断加到绘制圆圈的后面
if(pointOn){
repeat(endXAnimList.size) {
drawCircle(
colorList[colorIndex], pointRadius,
Offset(endXAnimList[it], endYAnimList[it])
)
}
if (pointRadius.toInt() == 2) {
pointOn = false
turnOn = true
}
}现在动画已经都衔接起来了,我们看下效果吧
额~~感觉怪怪的,说好的闪光呢,但就动画而言圆圈的确是完成了半径逐渐变小的绘制过程,那么问题出在哪里呢?我们回到代码中再检查一遍,发现了这一处代码
Offset(endXAnimList[it], endYAnimList[it])
复制代码这个圆点绘制的位置是均匀分布在一个圆周上的,也就是只绘制了八个圆点,但是真实效果里面的圆点有很多个,那我们是不是只要将endXAnimList,endYAnimList这两个数组里面的坐标打乱随机组成一个圆点不就好了,这样一来最多会绘制出64个圆点,再配合动画不就能达到闪光的效果了吗,所以我们先写一个随机函数
private fun randomCor(): Int {
return (Math.random() * 8).toInt()
}然后将原来绘制圆点的坐标的下标改成随机数
if(pointOn){
repeat(endXAnimList.size) {
drawCircle(
colorList[colorIndex], pointRadius,
Offset(endXAnimList[randomCor()], endYAnimList[randomCor()])
)
}
if (pointRadius.toInt() == 2) {
pointOn = false
turnOn = true
}
}现在我们再来看看效果如何
总结
完整的动画效果已经出来了,整个开发过程还是相对来讲比较吃力的,我想这应该是刚开始接触Compose动画这一部分吧,后面再多开发几个动画应该会得心应手一些,但还是有点收获的,比如
- 循环动画如果中途需要暂停,然后过段时间再打开的话,不能直接对它的initValue跟targetValue设置值,这样是无效的,必须搭配着Animatable动画一起使用才行
- LaunchedEffect虽说是在Compose里面是提供给协程运行的函数,不看源码的话以为它里面只能做一件事情,其他事情会被堵塞,其实LaunchedEffect已经封装好了,它的block就是一个协程,所以无论在LaunchedEffect做几件事情,它们都只是运行在一个协程里面
也有一些遗憾与不足
- 动画衔接的地方都是判断一个值有没有到达一个具体值,然后用开关去控制,感觉应该有更好的方式,比如可以配合着delayMillis,让动画延迟一会再开始
- 烟花本身其实可以用曲线来代替直线,比如贝塞尔,这个是在开发过程中才想到的,我先去试试看,等龙年再画个更好的烟花~~
链接:https://juejin.cn/post/7190213271826694199
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
快速排序和归并排序的时间复杂度分析——通俗易懂
快速排序和归并排序的时间复杂度分析——通俗易懂
一、前言
今天面试的时候,被问到归并排序的时间复杂度,这个大家都知道是O(nlogn),但是面试官又继续问,怎么推导出来的。这我就有点懵了,因为之前确实没有去真正理解这个时间复杂度是如何得出的,于是就随便答了一波(理解了之后,发现面试的时候答错了......)。
归并排序和快速排序,是算法中,非常重要的两个知识点,同时也是在面试中被问的非常频繁的内容,我明知如此,却没有彻底理解,真是太不应该了。所以,今天这篇博客就来分析一下这两种排序算法的时间复杂度是如何得出的。我查了许多篇博客,很多都是通过公式进行分析,十分难理解,下面我就结合自己的理解,使用通俗易懂的方式进行描述(为了好理解,可能会有些啰嗦)。
二、正文
2.1 归并排序的时间复杂度分析
了解归并排序的应该都知道,归并排序的时间复杂度是O(nlogn),且这个时间复杂度是稳定的,不随需要排序的序列不同而产生波动。那这个时间复杂度是如何得来的呢?我们可以这样分析,假设我们需要对一个包含n个数的序列使用归并排序,并且使用的是递归的实现方式,那么过程如下:
- 递归的第一层,将
n个数划分为2个子区间,每个子区间的数字个数为n/2; - 递归的第二层,将
n个数划分为4个子区间,每个子区间的数字个数为n/4; - 递归的第三层,将
n个数划分为8个子区间,每个子区间的数字个数为n/8;
......
- 递归的第
logn层,将n个数划分为n个子区间,每个子区间的数字个数为1;
我们知道,归并排序的过程中,需要对当前区间进行对半划分,直到区间的长度为1。也就是说,每一层的子区间,长度都是上一层的1/2。这也就意味着,当划分到第logn层的时候,子区间的长度就是1了。而归并排序的merge操作,则是从最底层开始(子区间为1的层),对相邻的两个子区间进行合并,过程如下:
- 在第
logn层(最底层),每个子区间的长度为1,共n个子区间,每相邻两个子区间进行合并,总共合并n/2次。n个数字都会被遍历一次,所有这一层的总时间复杂度为O(n);
......
- 在第二层,每个子区间长度为
n/4,总共有4个子区间,每相邻两个子区间进行合并,总共合并2次。n个数字都会被遍历一次,所以这一层的总时间复杂度为O(n); - 在第一层,每个子区间长度为
n/2,总共有2个子区间,只需要合并一次。n个数字都会被遍历一次,所以这一层的总时间复杂度为O(n);
通过上面的过程我们可以发现,对于每一层来说,在合并所有子区间的过程中,n个元素都会被操作一次,所以每一层的时间复杂度都是O(n)。而之前我们说过,归并排序划分子区间,将子区间划分为只剩1个元素,需要划分logn次。每一层的时间复杂度为O(n),共有logn层,所以归并排序的时间复杂度就是O(nlogn) 。
上面的描述算是非常详细了,应该不会太难理解。如果上面的过程还是不太理解,那么我们通过另外一种更直观的方式进行分析。上面描述的是递归的过程,下面我们通过非递归(迭代)方式实现的归并排序,再来分析一波,这种方式更加直观(为什么不直接通过非递归的方式描述,而是先通过递归的方式分析,是因为上面的过程也可以用来分析快速排序)。下面是通过非递归方式实现的归并排序代码,其中有两处分析时间复杂度的关键点,我标注出来了(重点关注注释):
**
/**
* 此方法用来定义子区间大小,子区间大小从1->2->4->8 ... ->n/2
* 可以近似地认为进行了logn次
*/
public static void merge(int[] arr) {
// 关键点1:划分子区间,每一次的子区间长度是上一次的两倍,所以这个循环需要执行logn次
for(int i = 1;i<arr.length;i *= 2){
// 关键点2:此方法每次执行的时间复杂度为O(n),具体看下方
mergeSort(arr,i);
}
}
/**
* 以下方法,每次执行的时间复杂度都是O(n),
* 因为需要将arr数组的每gap个数子,作为一个子区间,
* 然后对相邻的两个子区间执行归并排序的merge操作,
* 所以在这个方法中,arr数组中的每一个数都会在merge操作中,
* 被处理一次,所以下面这个方法的时间复杂度为O(n)
*/
public static void mergeSort(int[] arr, int gap) {
int[] tmp = new int[arr.length];
int index = 0;
int start1 = 0;
int end1 = start1 + gap - 1;
int start2 = end1 + 1;
int end2 = (start2 + gap - 1)>=arr.length?arr.length-1:start2+gap-1;
while(start2<arr.length){
while(start1<=end1&&start2<=end2){
if(arr[start1]<arr[start2]){
tmp[index++] = arr[start1++];
}else{
tmp[index++] = arr[start2++];
}
}
while(start1<=end1){
tmp[index++] = arr[start1++];
}
while(start2<=end2){
tmp[index++] = arr[start2++];
}
start1 = end2+1;
end1 = start1 + gap - 1;
start2 = end1 + 1;
end2 = (start2 + gap - 1)>=arr.length?arr.length-1:start2+gap-1;
}
while(start1<arr.length){
tmp[index++] = arr[start1++];
}
for(int j = 0;j<tmp.length;j++){
arr[j] = tmp[j];
}
} 上面的代码,merge方法中的循环需要循环logn次,每次循环都调用一次mergeSort方法,mergeSort方法的时间复杂度为O(n),所以很容易得出归并排序的时间复杂度为O(nlogn)。
2.2 快速排序的时间复杂度
了解快速排序的应该知道,快速排序的时间复杂度在O(nlogn)~ O(n^2)之间,下面我就来分别分析这两种情况:
(一)快速排序的最好情况O(nlogn)
这种情况下,其实和上面通过递归分析的归并排序很类似,理解了归并排序的时间复杂度分析,那这里应该也很好理解。快速排序的实现方式,就是在当前区间中选择一个轴,区间中所有比轴小的数都需要放到轴的左边,而比轴大的数则放到轴的右边。在理想的情况下,我们选取的轴刚好就是这个区间的中位数。也就是说,在操作之后,正好将区间分成了数字个数相等的左右两个子区间。此时就和归并排序基本一致了:
- 递归的第一层,
n个数被划分为2个子区间,每个子区间的数字个数为n/2; - 递归的第二层,
n个数被划分为4个子区间,每个子区间的数字个数为n/4; - 递归的第三层,
n个数被划分为8个子区间,每个子区间的数字个数为n/8;
......
- 递归的第
logn层,n个数被划分为n个子区间,每个子区间的数字个数为1;
以上过程与归并排序基本一致,而区别就是,归并排序是从最后一层开始进行merge操作,自底向上;而快速排序则是从第一层开始,交换区间中数字的位置,也就是自顶向下。但是,merge操作和快速排序的调换位置操作,时间复杂度是一样的,对于每一个区间,处理的时候,都需要遍历一次区间中的每一个元素。这也就意味着,快速排序和归并排序一样,每一层的总时间复杂度都是O(n),因为需要对每一个元素遍历一次。而且在最好的情况下,同样也是有logn层,所以快速排序最好的时间复杂度为O(nlogn)。
(二)快速排序的最坏情况O(n^2)
下面我们再来说一说快速排序的最坏情况,这种情况就比较好理解了。什么是快速排序的最坏情况,那就是,对于每一个区间,我们在处理的时候,选取的轴刚好就是这个区间的最大值或者最小值。比如我们需要对n个数排序,而每一次进行处理的时候,选取的轴刚好都是区间的最小值。于是第一次操作,在经过调换元素顺序的操作后,最小值被放在了第一个位置,剩余n-1个数占据了2到n个位置;第二次操作,处理剩下的n-1个元素,又将这个子区间的最小值放在了当前区间的第1个位置,以此类推......每次操作,都只能将最小值放到第一个位置,而剩下的元素,则没有任何变化。所以对于n个数来说,需要操作n次,才能为n个数排好序。而每一次操作都需要遍历一次剩下的所有元素,这个操作的时间复杂度是O(n),所以总时间复杂度为O(n^2)。
其实上面的过程,我们可以换一个角度理解:每次操作,找出最小值放到剩余区间的第一个位置,这不就是选择排序的实现方式吗?而选择排序的时间复杂度就是O(n^2),所以上面的过程也就O(n^2)。
三、总结
以上内容,就是我基于自己的理解,对快速排序和归并排序时间复杂度的分析。为了更好理解,我的描述都尽可能的详细,所以可能会有点啰嗦,但是我认为还是很通俗易懂的。希望这篇博客能够为之前对这两种排序算法理解不是特别清晰的人提供帮助,同时,若上面的内容存在错误或不足,欢迎指正或补充。
链接:https://juejin.cn/post/7192214624748601401
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android SplashScreen API使用
在Android 12 出现了一个SplashScreen新功能,它为所有应用添加了新的应用启动动画,可以通过SplashScreen API来定制专属应用启动动画。
默认情况下,新的应用启动动画为白色背景,中心为应用图标。
接下去将一一介绍如何使用SplashScreen API来定制专属应用启动动画。
由于这是Android 12新增功能,所以所有相关API都要求api 31才能使用,因此需要额外创建一个values-v31,并将themes.xml拷贝一份放入其中。
背景颜色
默认情况下,应用启动动画背景为白色。
在应用所使用的主题中设置以下代码,可以定制应用启动动画的背景颜色。
<item name="android:windowSplashScreenBackground">@color/splash_screen_background</item>
<color name="splash_screen_background">#7B5AB6</color>
需要注意一点,目前使用android:windowSplashScreenBackground设置的颜色不能带透明度,必须为6位或者是8位且透明度为FF,如果使用了带透明度的颜色将不生效。
启动图标
默认情况下,应用启动动画的中心为应用图标。
在应用所使用的主题中设置以下代码,可以定制应用启动动画的中心图标。
<item name="android:windowSplashScreenAnimatedIcon">@drawable/cat</item>
这是原始图片:
- 可以发现启动图标需要保留一定的内边距,因为会被部分裁剪。
- 除了设置静态图片,也可以设置动画形式,配置使用android:windowSplashScreenAnimationDuration设置动画时长。
- 如果设置的图标是透明背景的,可以另外设置android:windowSplashScreenIconBackgroundColor来定制中心图标的背景颜色。
底部图片(Google不推荐使用)
使用android:windowSplashScreenBrandingImage可以设置底部图片,图片尺寸比例需要为2.5:1。
延缓启动时间
使用android:windowSplashScreenAnimationDuration可以设置启动动画时长,但是最长只能设置1000毫秒。
很多时候需要在启动的时候拉取一些应用配置,需要有更长时间的启动效果。
可以在代码中实现,通过ViewTreeObserver.OnPreDrawListener:
class MainActivity : AppCompatActivity() {
private var isAppReady = false
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
val content: View = findViewById(android.R.id.content)
content.viewTreeObserver.addOnPreDrawListener(object : ViewTreeObserver.OnPreDrawListener {
override fun onPreDraw(): Boolean {
if (isAppReady) {
content.viewTreeObserver.removeOnPreDrawListener(this)
}
return isAppReady
}
})
delayBootTime()
}
private fun delayBootTime() {
lifecycleScope.launch {
delay(3000)
isAppReady = true
}
}
}当应用配置已准备好,onPreDraw返回true,并且移除监听。这里使用delay3秒来模拟拉取应用配置的耗时操作。
需要注意,一定要在准备好后onPreDraw返回true,否则会一直卡在启动页上。
启动退出动画
Android 12 SplashScreen新功能提供了setOnExitAnimationListener方法可以定制启动退出时的动画效果,该API只能在版本12及以上使用:
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.S) {
splashScreen.setOnExitAnimationListener { splashScreenView ->
val slideUp = ObjectAnimator.ofFloat(
splashScreenView,
View.TRANSLATION_Y,
0f,
-splashScreenView.height.toFloat()
)
slideUp.duration = 2000
// 在自定义动画结束时调用splashScreenView.remove()
slideUp.addListener(object : AnimatorListenerAdapter() {
override fun onAnimationEnd(animation: Animator?) {
splashScreenView.remove()
}
})
slideUp.start()
}
}低版本兼容
在Android 12以下版本没有SplashScreen启动动画,显示的空白背景页面,这在用户体验上很不好。因此,Google在AndroidX中提供了一个向下兼容的SplashScreen库。
配置
implementation 'androidx.core:core-splashscreen:1.0.0'
复制代码设置主题
定义一个新的主题并给应用使用:
<style name="SplashScreenTheme" parent="Theme.SplashScreen">
<item name="windowSplashScreenBackground">@color/splash_screen_background</item>
<item name="windowSplashScreenAnimatedIcon">@drawable/cat</item>
<item name="postSplashScreenTheme">@style/Theme.SplashScreenDemo</item>
</style>需要注意几点:
- 必须以R.style.Theme_SplashScreen 为父级
- 启动图标动画形式失效
- windowSplashScreenBackground、windowSplashScreenAnimatedIcon前面都没有 android:
- postSplashScreenTheme指定应用原来的主题,这样,当SplashScreen结束时,应用主题能够被恢复
在启动Activity中设置
一定要在setContentView方法之前调用installSplashScreen方法
super.onCreate(savedInstanceState)
installSplashScreen()
setContentView(R.layout.activity_main)
至此,在低版本上也能有同样效果的SplashScreen动画了,当然一些启动退出动画这些Android 12特有的API仍然是无法使用的。
链接:https://juejin.cn/post/7189908561336467515
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
学之前“flow?狗都不学”学之后“狗不学正好我学”
标题皮一下,个人项目引入Kotlin Flow一段时间了,这篇文章想写写个人理解到的一点皮毛,有错欢迎在评论区指出。
Flow基础知识
Flow可理解为数据流,使用起来比较简单,看几个demo就可以直接上手了,除了提几个点之外也不再赘述。
- Flow为冷流。在Flow知识体系中,生产(获取)数据的可称为生产者(producer),消费(使用)数据的可称为消费者(consumer),冷流即有消费者消费数据,生产者才会生产数据。
- Flow中生产者与消费者为一对一的关系,即消费者不share(共享)同一个Flow,新加一个消费者,就会新创建一个Flow。
上面两个点可以通过个简单的demo进行验证。
val timerFlow = flow {
val start = 0
var current = start
while (true) {
emit(current)
current++
delay(1000)
}
}
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
var firstTimer by mutableStateOf(0)
var secondTimer by mutableStateOf(0)
var thirdTimer by mutableStateOf(0)
val fontSize: TextUnit = 30.sp
lifecycleScope.launch {
while (true) {
delay(1000)
firstTimer++
}
}
setContent {
var secondTimerIsVisible by remember {
mutableStateOf(false)
}
var thirdTimerIsVisible by remember {
mutableStateOf(false)
}
Column(
modifier = Modifier.fillMaxSize(),
horizontalAlignment = Alignment.CenterHorizontally,
verticalArrangement = Arrangement.Center
) {
Text(
text = "屏幕启动时间为${firstTimer}秒",
textAlign = TextAlign.Center, fontSize = fontSize
)
if (secondTimerIsVisible) {
Text(
"第一个自定义计时器的时间为${secondTimer}秒。",
textAlign = TextAlign.Center,
fontSize = fontSize
)
} else {
Button(
onClick = {
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
timerFlow.collect {
secondTimer = it
}
}
}
secondTimerIsVisible = true
},
) {
Text(
text = "启动第一个自定义计时器",
textAlign = TextAlign.Center,
fontSize = fontSize
)
}
}
if (thirdTimerIsVisible) {
Text(
"第二个自定义计时器的时间为${thirdTimer}秒。",
textAlign = TextAlign.Center,
fontSize = fontSize
)
} else {
Button(
modifier = Modifier.padding(10.dp),
onClick = {
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
timerFlow.collect {
thirdTimer = it
}
}
}
thirdTimerIsVisible = true
},
) {
Text(
text = "启动第二个自定义计时器",
textAlign = TextAlign.Center,
fontSize = fontSize
)
}
}
}
}
}
}运行一下。
在上面的demo中,创建了三个计时器,第一个计时器用协程来实现,来计时屏幕的启动时间,第二,第三个计时器用flow来实现,为自定义计时器,需要手动启动。
- 在屏幕启动几秒后,才启动第二个计时器,该计时器是从0秒开始启动的,这说明flow并不是屏幕一启动就产生数据,而是有消费者消费数据,才会产生数据。
- 第二个计时器和第三个计时器的时间不一样,说明它们尽管用了同一个timerFlow变量,却不是共享同一个flow,新加一个消费者,就会新创建一个Flow。
SharedFlow
稍微了解设计模式的读者应该知道,Flow其实是用了观察者模式,生产者对应subject(被观察者),消费者对应observer(观察者),只是flow中每个subject只允许有一个observer,但在实际项目中,一个subject有多个observer的情况再正常不过,于是乎就有了SharedFlow。
SharedFlow是共享流,它的特性与flow刚好反着来。
- SharedFlow是热流,即使没有消费者也会一直产生数据,该产生数据的策略是可变的,后面会详细讲。
- 多个消费者会共享同一个Flow。
对上面代码进行修改,将Flow转换为SharedFlow,并将其移动到新建的MainViewModel中。
class MainViewModel : ViewModel() {
val timerFlow = flow {
val start = 0
var current = start
while (true) {
emit(current)
current++
delay(1000)
}
}.shareIn(viewModelScope, SharingStarted.Eagerly,0)
}修改MainActivity的代码,添加viewModel的实例化代码private val viewModel: MainViewModel = MainViewModel() ,并timerFlow.collect改成viewModel.timerFlow.collect,改动较少,就不放出全部源码了,需要注意的是,将MainViewModel直接实例化的做法是错误的,理由是当Activity由于某种原因,如屏幕旋转而销毁时,MainViewModel会重新实例化,这样就达不到ViewModel数据持久化的目的了,本文是为了方便演示SharedFlow是热流的特性才直接实例化。
运行一下。
效果图有两个点是比较关键的。
- 自定义计时器的时间与屏幕启动时间是一样的,说明SharedFlow不管有没有消费者,都会产生数据。
- 两个自定义计时器的时间是一样的,说明两个计时器共享了同一个SharedFlow。
先看看shareIn()方法的源码。
public fun <T> Flow<T>.shareIn(
scope: CoroutineScope,
started: SharingStarted,
replay: Int = 0
): SharedFlow<T>
scope参数为指定SharedFlow在哪个协程域启动。
replay参数指定当有新的消费者出现时,发送多少个之前的数据给该消费者。
started为启动策略。
有三个启动策略可选。
SharingStarted.Eagerly 。SharedFlow会立即产生数据,即使连第一个消费者还没出现,demo中使用的就是该启动策略。
SharingStarted.Lazily。SharedFlow只有在第一个消费者消费数据后才产生数据。
WhileSubscribed。WhileSubscribed的源码如下所示。
public fun SharingStarted.Companion.WhileSubscribed(
stopTimeout: Duration = Duration.ZERO,
replayExpiration: Duration = Duration.INFINITE
)
- stopTimeOut。当SharedFlow一个消费者也没有的时候,等待多久才停止流。
- replayExpiration。用来指定replay个数量的缓存在等待多少时间后无效,当你不想用户看到较旧的数据时,可使用这个参数。
此外,SharedFlow也可以直接创建。
class MainViewModel : ViewModel() {
val timerFlow = MutableSharedFlow<Int>()
init {
viewModelScope.launch {
val start = 0
var current = start
while (true) {
timerFlow.emit(current)
current++
delay(1000)
}
}
}
}StateFlow
StateFlow是SharedFlow的一个特殊变种,其特性有:
- 始终有值且值唯一。
- 可以有多个消费者。
- 永远只把最新的值给到消费者。
第二,第三特性比较好理解,就是replay参数为1的SharedFlow,那第一个特性需要结合demo才更好理解。
先将flow转化为StateFlow。
class MainViewModel : ViewModel() {
val timerFlow = flow {
val start = 0
var current = start
while (true) {
emit(current)
current++
delay(1000)
}
}.stateIn(viewModelScope, SharingStarted.Eagerly,0)
}sharedIn()的源码如下所示。
public fun <T> Flow<T>.stateIn(
scope: CoroutineScope,
started: SharingStarted,
initialValue: T//初始值
): StateFlow<T>{
}运行一下。
与SharedFlow比较,最大的不同就是SharedFlow demo中的自定义计时器是从0开始的,之后才和屏幕启动时间一致,而这个StateFlow demo中的自定义计时器是一启动就和屏幕启动时间一致,出现这种情况的原因是:
- SharedFlow并不存储值,MainActivity只有在 SharedFlow emit()出最新值的时候,才能collect()到值。
- 根据StateFlow的第一点特性,其始终有值且值唯一,在MainActivity一订阅StateFlow的时候,就立马就将最新的值给到了MainActivity,所以StateFlow demo中的计时器没有经历0的阶段。
可以看到,StateFlow与之前的LiveData比较相似的。
StateFlow还有另一种在实际项目中更常用的使用方式,修改MainViewModel的代码。
class MainViewModel : ViewModel() {
private val _timerFlow: MutableStateFlow<Int> = MutableStateFlow(0)
val timerFlow: StateFlow<Int> = _timerFlow.asStateFlow()
init {
viewModelScope.launch {
val start = 0
var current = start
while (true) {
_timerFlow.value = current
current++
delay(1000)
}
}
}
}代码中先创建私有MutableStateFlow实例_timerFlow,再将其转化为公共StateFlow实例timerFlow,因为timerFlow只可读,不能修改,暴露给Main Activity使用更符合规范。
collect Flow的规范做法
官方推荐我们用lifeCycle.repeatOnLifecycle()去collect flow。
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.timerFlow.collect {
...
}
}
}Activity会在onStart()开始收集数据,在onStop()结束数据的收集。
如下图所示,如果直接使用lifecycleScope.launch去collect flow,那么在应用进入后台后,也会持续进行数据的收集,这样将造成资源的浪费。
要是嫌上述代码繁琐,也可以添加以下依赖。
implementation "androidx.lifecycle:lifecycle-runtime-compose:2.6.0-alpha01"
然后将collect代码改成下述代码也能达到同样的效果,不过该方法只适用于StateFlow。
viewModel.timerFlow.collectAsStateWithLifecycle()
该方法的源码如下所示。
fun <T> StateFlow<T>.collectAsStateWithLifecycle(
lifecycleOwner: LifecycleOwner = LocalLifecycleOwner.current,
minActiveState: Lifecycle.State = Lifecycle.State.STARTED,
context: CoroutineContext = EmptyCoroutineContext
): State<T>从第二个参数可以知道默认是从onStart()开始收集数据。
项目真的需要引入Flow吗?
谷歌对Flow的推崇力度很大,Android官网中除了Flow相关的文章之外,很多代码示例也多多少少用了Flow,大有一种Flow放之四海而皆准的态势,但使用一段时间后,我发现Flow的应用场景其实也是有一定局限的。
以我个人项目中的之前Repository类中某段代码为例。
override suspend fun getCategory(): Flow<List<Category>?> {
return flow {
when (val response = freeApi.getCategoryList()) {
is ApiSuccess -> {
val categories = response.data
withContext(Dispatchers.IO) {
Timber.v("cache categories in db")
categoryDao.insertCategoryList(categories)
}
emit(categories)//1
}
else -> {
Timber.d(response.toString())
val cacheCategories = withContext(Dispatchers.IO) {
categoryDao.getCategoryList()
}
if (cacheCategories.isNotEmpty()) {
Timber.d("load categories from db")
emit(cacheCategories)//2
} else {
Timber.d("fail to load category from db")
emit(null)//3
}
}
}
}
}其实上面代码并不适合用Flow,因为尽管代码1,2,3处都有emit,但最终getCategory()只会emit一次值,Flow是数据流,但一个数据并不能流(Flow)起来,这样无法体现出Flow的好处,徒增资源的消耗。
除此之外,在一个屏幕需要获取从多个api获取数据的时候,如果强行用Flow就会出现繁琐重复的代码,像下面的代码会有好几处。
getXXX().catch{
//进行异常处理
}.collect{
//得到数据
}我也去查阅了相关的资料,发现确实如此,具体可见参考资料1和2。
参考资料
本文主要参考了资料4,与资料4在排版,内容有较多相似地方。
链接:https://juejin.cn/post/7190005859034857532
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
android 原生安全音量逻辑设计
前言
接到一个开发需求,需要定制化开发一个安全音量功能;此前有了解过为了符合欧盟等有关国家和地区的规定,原生Android是有自带一个安全音量功能的,想要定制则先要了解这个功能原先长什么样子,下面我们就从一个系统工程师的角度出发去探寻一下,原生Android的安全音量功能是如何实现的。
安全音量配置
安全音量的相关配置都在framework的config.xml里面,可以直接修改或者overlay配置修改其默认值。
<!-- Whether safe headphone volume is enabled or not (country specific). -->
<bool name="config_safe_media_volume_enabled">true</bool>
<!-- Safe headphone volume index. When music stream volume is below this index
the SPL on headphone output is compliant to EN 60950 requirements for portable music
players. -->
<integer name="config_safe_media_volume_index">10</integer>
config_safe_media_volume_enabled是安全音量功能的总开关,config_safe_media_volume_index则是表明触发安全音量弹框的音量大小值。
安全音量相关流程
安全音量的主要流程都在AudioService里面,其大致流程如下图所示:
onSystemReady 初始化
系统启动过程略去不表,在系统启动完成后会调用onSystemReady;在onSystemReady中,service会发送一个MSG_CONFIGURE_SAFE_MEDIA_VOLUME_FORCED的msg,强制配置安全音量。
public void onSystemReady() {
...
sendMsg(mAudioHandler,
MSG_CONFIGURE_SAFE_MEDIA_VOLUME_FORCED,
SENDMSG_REPLACE,
0,
0,
TAG,
SystemProperties.getBoolean("audio.safemedia.bypass", false) ?
0 : SAFE_VOLUME_CONFIGURE_TIMEOUT_MS);
...
}发送的MSG_CONFIGURE_SAFE_MEDIA_VOLUME_FORCED会调用onConfigureSafeVolume()来进行安全音量的配置
onConfigureSafeVolume() 安全音量配置
private void onConfigureSafeVolume(boolean force, String caller) {
synchronized (mSafeMediaVolumeStateLock) {
//Mobile contry code,国家代码,主要用来区分不同国家,部分国家策略可能会不一致
int mcc = mContext.getResources().getConfiguration().mcc;
if ((mMcc != mcc) || ((mMcc == 0) && force)) {
//从config_safe_media_volume_index中获取回来的安全音量触发阈值
mSafeMediaVolumeIndex = mContext.getResources().getInteger(
com.android.internal.R.integer.config_safe_media_volume_index) * 10;
mSafeUsbMediaVolumeIndex = getSafeUsbMediaVolumeIndex();
//根据audio.safemedia.force属性值或者value配置的值来决定是否使能安全音量
boolean safeMediaVolumeEnabled =
SystemProperties.getBoolean("audio.safemedia.force", false)
|| mContext.getResources().getBoolean(
com.android.internal.R.bool.config_safe_media_volume_enabled);
//确认是否需要bypass掉安全音量功能
boolean safeMediaVolumeBypass =
SystemProperties.getBoolean("audio.safemedia.bypass", false);
// The persisted state is either "disabled" or "active": this is the state applied
// next time we boot and cannot be "inactive"
int persistedState;
if (safeMediaVolumeEnabled && !safeMediaVolumeBypass) {
persistedState = SAFE_MEDIA_VOLUME_ACTIVE; //这个值只能是disable或者active,不能是inactive,主要用于下次启动。
// The state can already be "inactive" here if the user has forced it before
// the 30 seconds timeout for forced configuration. In this case we don't reset
// it to "active".
if (mSafeMediaVolumeState != SAFE_MEDIA_VOLUME_INACTIVE) {
if (mMusicActiveMs == 0) { //mMusicActiveMs主要用于计数,当安全音量弹框弹出时,如果按了确定,这个值便开始递增,当其达到UNSAFE_VOLUME_MUSIC_ACTIVE_MS_MAX时,则重新使能安全音量
mSafeMediaVolumeState = SAFE_MEDIA_VOLUME_ACTIVE;
enforceSafeMediaVolume(caller);
} else {
//跑到这里则表示已经弹过安全音量警示了,并且按了确定,所以把值设置为inactive
// We have existing playback time recorded, already confirmed.
mSafeMediaVolumeState = SAFE_MEDIA_VOLUME_INACTIVE;
}
}
} else {
persistedState = SAFE_MEDIA_VOLUME_DISABLED;
mSafeMediaVolumeState = SAFE_MEDIA_VOLUME_DISABLED;
}
mMcc = mcc;
//持久化当前安全音量的状态
sendMsg(mAudioHandler,
MSG_PERSIST_SAFE_VOLUME_STATE,
SENDMSG_QUEUE,
persistedState,
0,
null,
0);
}
}
}由上可知,onConfigureSafeVolume()主要用于配置和使能安全音量功能,并且通过发送MSG_PERSIST_SAFE_VOLUME_STATE来持久化安全音量配置的值,这个持久化的值只能是active或者disabled。
case MSG_PERSIST_SAFE_VOLUME_STATE:
onPersistSafeVolumeState(msg.arg1);
break;
....
....
private void onPersistSafeVolumeState(int state) {
Settings.Global.putInt(mContentResolver,
Settings.Global.AUDIO_SAFE_VOLUME_STATE,
state);
}
安全音量触发
从实际操作可知,安全音量触发条件是:音量增大到指定值。
从调节音量的代码出发,在调用mAudioManager.adjustStreamVolume和mAudioManager.setStreamVolume时,最终会调用到AudioService中的同名方法,在执行该方法的内部:
protected void adjustStreamVolume(int streamType, int direction, int flags,
String callingPackage, String caller, int uid) {
...
...
...
} else if ((direction == AudioManager.ADJUST_RAISE) &&
!checkSafeMediaVolume(streamTypeAlias, aliasIndex + step, device)) {
Log.e(TAG, "adjustStreamVolume() safe volume index = " + oldIndex);
mVolumeController.postDisplaySafeVolumeWarning(flags);
....
...
private void setStreamVolume(int streamType, int index, int flags, String callingPackage,
String caller, int uid) {
....
....
if (!checkSafeMediaVolume(streamTypeAlias, index, device)) {
mVolumeController.postDisplaySafeVolumeWarning(flags);
mPendingVolumeCommand = new StreamVolumeCommand(
streamType, index, flags, device);
} else {
onSetStreamVolume(streamType, index, flags, device, caller);
index = mStreamStates[streamType].getIndex(device);
}
....
....由以上代码可以看出,其安全音量弹框警告的触发地方就在checkSafeMediaVolume方法附近处,并且都是通过mVolumeController这个远程服务去调用UI显示安全音量弹框警告,但两种调节音量的方法,触发效果略有不同:
- adjustStreamVolume:当音量步进方向是上升并且checkSafeMediaVolume返回false时,直接弹出警告框;由于警告框占据了焦点,此时无法进行UI操作,并且再按音量+键时,会继续触发这个弹框,导致无法实质性地调整音量;
- setStreamVolume:当传入的音量形参大于安全音量阈值,会触发checkSafeMediaVolume返回false,弹出安全音量警告框;并且会通过mPendingVolumeCommand保存设置的音量值,待关掉安全音量后再赋回来。
private boolean checkSafeMediaVolume(int streamType, int index, int device) {
synchronized (mSafeMediaVolumeStateLock) {
if ((mSafeMediaVolumeState == SAFE_MEDIA_VOLUME_ACTIVE) &&
(mStreamVolumeAlias[streamType] == AudioSystem.STREAM_MUSIC) &&
((device & mSafeMediaVolumeDevices) != 0) &&
(index > safeMediaVolumeIndex(device))) {
return false;
}
return true;
}
}以上是安全音量判断条件checkSafeMediaVolume,可以看出其判断主要根据以下条件:
- mSafeMediaVolumeState是否为active,这个是安全音量功能的开关变量;
- 音频流是否为STREAM_MUSIC,只针对该音频流做安全音量;
- 设备类型,默认mSafeMediaVolumeDevices值如下:
/*package*/ final int mSafeMediaVolumeDevices = AudioSystem.DEVICE_OUT_WIRED_HEADSET
| AudioSystem.DEVICE_OUT_WIRED_HEADPHONE
| AudioSystem.DEVICE_OUT_USB_HEADSET;
由上可知,只针对耳机播放或者USB耳机才做安全音量功能,如有需要系统工程师可自行配置其他设备;
- 音量大小,只有音量index超过safeMediaVolumeIndex获取的值,才需要弹出安全音量警示框,而safeMediaVolumeIndex的值则是本文开头在config.xml中配置的config_safe_media_volume_index所得出的;
UI部分
上面有提到,当满足安全音量警示框的触发条件时,会通过mVolumeController这个远程服务去调用UI显示安全音量弹框警告,其调用链条有点长,中途略过不表,其最终会走到VolumeDialogImpl.java的showSafetyWarningH,如下:
public class VolumeDialog {
...
private void showSafetyWarningH(int flags) {
if ((flags & (AudioManager.FLAG_SHOW_UI | AudioManager.FLAG_SHOW_UI_WARNINGS)) != 0
|| mShowing) {
synchronized (mSafetyWarningLock) {
if (mSafetyWarning != null) {
return;
}
mSafetyWarning = new SafetyWarningDialog(mContext, mController.getAudioManager()) {
@Override
protected void cleanUp() {
synchronized (mSafetyWarningLock) {
mSafetyWarning = null;
}
recheckH(null);
}
};
mSafetyWarning.show();
}
recheckH(null);
}
rescheduleTimeoutH();
}
...
}UI配置部分主要在SafetyWarningDialog.java,代码就不贴了,可自行查看,其本质是一个对话框,在弹出时会抢占UI焦点,如果不点击确定或取消,则无法操作其他UI;点击确定后,会调用mAudioManager.disableSafeMediaVolume()来暂时关闭安全音量警告功能,但上面有提到,当点击确定之后其实是启动了一个变量mMusicActiveMs的计数,当这个计数到达一定值(默认是20个小时),安全音量会重新启动;但如果点击了取消,再继续调大音量时,安全音量弹框还是会继续弹出;
disableSafeMediaVolume()
上面有提到,在安全音量弹框弹出后,点击确定可以暂时关闭安全音量警告功能,其实最终会调用到AudioService中的disableSafeMediaVolume(),代码如下:
public void disableSafeMediaVolume(String callingPackage) {
enforceVolumeController("disable the safe media volume");
synchronized (mSafeMediaVolumeStateLock) {
setSafeMediaVolumeEnabled(false, callingPackage);
if (mPendingVolumeCommand != null) {
onSetStreamVolume(mPendingVolumeCommand.mStreamType,
mPendingVolumeCommand.mIndex,
mPendingVolumeCommand.mFlags,
mPendingVolumeCommand.mDevice,
callingPackage);
mPendingVolumeCommand = null;
}
}
}一方面是调用setSafeMediaVolumeEnabled来暂时关闭安全音量功能,另一方面会把此前临时挂起的设置音量mPendingVolumeCommand重新设置回去。
小结
简单来讲,Android原生的安全音量功能默认强制打开,在插入耳机后,音量调节到指定阈值时,会触发音量警告弹框,该弹框会抢走焦点,不点击确定或取消无法进行其他操作;在点击确定后,默认操作者本人允许设备音量继续往上调,但此时系统会开始一个默认为20分钟的倒计时,在这20分钟内音量随意调节都不会触发安全音量弹框,但20分钟结束后,音量大于阈值时会继续触发安全音量弹框,提醒使用者注意。
链接:https://juejin.cn/post/7178817360810737722
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
落地 Kotlin 代码规范,DeteKt 了解一下~
前言
各个团队多少都有一些自己的代码规范,但制定代码规范简单,困难的是如何落地。如果完全依赖人力Code Review难免有所遗漏。
这个时候就需要通过静态代码检查工具在每次提交代码时自动检查,本文主要介绍如何使用DeteKt落地Kotlin代码规范,主要包括以下内容
- 为什么使用
DeteKt? IDE接入DeteKt插件CLI命令行方式接入DeteKtGradle方式接入DeteKt- 自定义
Detekt检测规则 Github Action集成Detekt检测
为什么使用DeteKt?
说起静态代码检查,大家首先想起来的可能是lint,相比DeteKt只支持Kotlin代码,lint不仅支持Kotlin,Java代码,也支持资源文件规范检查,那么我们为什么不使用Lint呢?
在我看来,Lint在使用上主要有两个问题:
- 与
IDE集成不够好,自定义lint规则的警告只有在运行./gradlew lint后才会在IDE上展示出来,在clean之后又会消失 lint检查速度较慢,尤其是大型项目,只对增量代码进行检查的逻辑需要自定义
而DeteKt提供了IDE插件,开启后可直接在IDE中查看警告,这样可以在第一时间发现问题,避免后续检查发现问题后再修改流程过长的问题
同时Detekt支持CLI命令行方式接入与Gradle方式接入,支持只检查新增代码,在检查速度上比起lint也有一定的优势
IDE接入DeteKt插件
如果能在IDE中提示代码中存在的问题,应该是最快发现问题的方式,DeteKt也贴心的为我们准备了插件,如下所示:
主要可以配置以下内容:
DeteKt开关- 格式化开关,
DeteKt直接使用了ktlint的规则 Configuration file:规则配置文件,可以在其中配置各种规则的开关与参数,默认配置可见:default-detekt-config.ymlBaseline file:基线文件,跳过旧代码问题,有了这个基线文件,下次扫描时,就会绕过文件中列出的基线问题,而只提示新增问题。Plugin jar: 自定义规则jar包,在自定义规则后打出jar包,在扫描时就可以使用自定义规则了
DeteKt IDE插件可以实时提示问题(包括自定义规则),如下图所示,我们添加了自定义禁止使用kae的规则:
对于一些支持自动修复的格式问题,DeteKt插件支持自动格式化,同时也可以配置快捷键,一键自动格式化,如下所示:
CLI命令行方式接入DeteKt
DeteKt支持通过CLI命令行方式接入,支持只检测几个文件,比如本次commit提交的文件
我们可以通过如下方式,下载DeteKt的jar然后使用
curl -sSLO https://github.com/detekt/detekt/releases/download/v1.22.0-RC1/detekt-cli-1.22.0-RC1.zip
unzip detekt-cli-1.22.0-RC1.zip
./detekt-cli-1.22.0-RC1/bin/detekt-cli --help
DeteKt CLI支持很多参数,下面列出一些常用的,其他可以参见:Run detekt using Command Line Interface
Usage: detekt [options]
Options:
--auto-correct, -ac
支持自动格式化的规则自动格式化,默认为false
Default: false
--baseline, -b
如果传入了baseline文件,只有不在baseline文件中的问题才会掘出来
--classpath, -cp
实验特性:传入依赖的class路径和jar的路径,用于类型解析
--config, -c
规则配置文件,可以配置规则开关及参数
--create-baseline, -cb
创建baseline,默认false,如果开启会创建出一个baseline文件,供后续使用
--input, -i
输入文件路径,多个路径之间用逗号连接
--jvm-target
EXPERIMENTAL: Target version of the generated JVM bytecode that was
generated during compilation and is now being used for type resolution
(1.6, 1.8, 9, 10, 11, 12, 13, 14, 15, 16 or 17)
Default: 1.8
--language-version
为支持类型解析,需要传入java版本
--plugins, -p
自定义规则jar路径,多个路径之间用,或者;连接
在命令行可以直接通过如下方式检查
java -jar /path/to/detekt-cli-1.21.0-all.jar # detekt-cli-1.21.0-all.jar所在路径
-c /path/to/detekt_1.21.0_format.yml # 规则配置文件所在路径
--plugins /path/to/detekt-formatting-1.21.0.jar # 格式化规则jar,主要基于ktlint封装
-ac # 开启自动格式化
-i $FilePath$ # 需要扫描的源文件,多个路径之间用,或者;连接
通过如上方式进行代码检查速度是非常快的,根据经验来说一般就是几秒之内可以完成,因此我们完成可以将DeteKt与git hook结合起来,在每次提交commit的时候进行检测,而如果是一些比较耗时的工具比如lint,应该是做不到这一点的
类型解析
上面我们提到了,DeteKt的--classpth参数与--language-version参数,这些是用于类型解析的。
类型解析是DeteKt的一项功能,它允许 Detekt 对您的 Kotlin 源代码执行更高级的静态分析。
通常,Detekt 在编译期间无法访问编译器语义分析的结果,我们只能获取Kotlin源代码的抽象语法树,却无法知道语法树上符号的语义,这限制了我们的检查能力,比如我们无法判断符号的类型,两个符号究竟是不是同一个对象等
通过启用类型解析,Detekt 可以获取Kotlin编译器语义分析的结果,这让我们可以自定义一些更高级的检查。
而要获取类型与语义,当然要传入依赖的class,也就是classpath,比如android项目中常常需要传入android.jar与kotlin-stdlib.jar
Gradle方式接入DeteKt
CLI方式检测虽然快,但是需要手动传入classpath,比较麻烦,尤其是有时候自定义规则需要解析我们自己的类而不是kotlin-stdlib.jar中的类时,那么就需要将项目中的代码的编译结果传入作为classpath了,这样就更麻烦了
DeteKt同样支持Gradle插件方式接入,这种方式不需要我们另外再配置classpath,我们可以将CLI命令行方式与Gradle方式结合起来,在本地通过CLI方式快速检测,在CI上通过Gradle插件进行完整的检测
接入步骤
// 1. 引入插件
plugins {
id("io.gitlab.arturbosch.detekt").version("[version]")
}
repositories {
mavenCentral()
}
// 2. 配置插件
detekt {
config = files("$projectDir/config/detekt.yml") // 规则配置
baseline = file("$projectDir/config/baseline.xml") // baseline配置
parallel = true
}
// 3. 自定义规则
dependencies {
detektPlugins "io.gitlab.arturbosch.detekt:detekt-formatting:1.21.0"
detektPlugins project(":customRules")
}
// 4. 配置 jvmTarget
tasks.withType(Detekt).configureEach {
jvmTarget = "1.8"
}
// DeteKt Task用于检测,DetektCreateBaselineTask用于创建Baseline
tasks.withType(DetektCreateBaselineTask).configureEach {
jvmTarget = "1.8"
}
// 5. 只分析指定文件
tasks.withType<io.gitlab.arturbosch.detekt.Detekt>().configureEach {
// include("**/special/package/**") // 只分析 src/main/kotlin 下面的指定目录文件
exclude("**/special/package/internal/**") // 过滤指定目录
}
如上所示,接入主要需要做这么几件事:
- 引入插件
- 配置插件,主要是配置
config与baseline,即规则开关与老代码过滤 - 引入
detekt-formatting与自定义规则的依赖 - 配置
JvmTarget,用于类型解析,但不用再配置classpath了。 - 除了
baseline之外,也可以通过include与exclude的方式指定只扫描指定文件的方式来实现增量检测
通过以上方式就接入成功了,运行./gradlew detektDebug就可以开始检测了,扫描结果可在终端直接查看,并可以直接定位到问题代码处,也可以在build/reprots/路径下查看输出的报告文件:
自定义Detekt检测规则
要落地自己制定的代码规范,不可避免的需要自定义规则,当然我们首先要看下DeteKt自带的规则,是否已经有我们需要的,只需把开关打开即可.
DeteKt自带规则
DeteKt自带的规则都可以通过开关配置,如果没有在 Detekt 闭包中指定 config 属性,detekt 会使用默认的规则。这些规则采用 yaml 文件描述,运行 ./gradlew detektGenerateConfig 会生成 config/detekt/detekt.yml 文件,我们可以在这个文件的基础上制定代码规范准则。
detekt.yml 中的每条规则形如:
complexity: # 大类
active: true
ComplexCondition: # 规则名
active: true # 是否启用
threshold: 4 # 有些规则,可以设定一个阈值
# ...更多关于配置文件的修改方式,请参考官方文档-配置文件
Detekt 的规则集划分为 9 个大类,每个大类下有具体的规则:
| 规则大类 | 说明 |
|---|---|
| comments | 与注释、文档有关的规范检查 |
| complexity | 检查代码复杂度,复杂度过高的代码不利于维护 |
| coroutines | 与协程有关的规范检查 |
| empty-blocks | 空代码块检查,空代码应该尽量避免 |
| exceptions | 与异常抛出和捕获有关的规范检查 |
| formatting | 格式化问题,detekt直接引用的 ktlint 的格式化规则集 |
| naming | 类名、变量命名相关的规范检查 |
| performance | 检查潜在的性能问题 |
| potentail-bugs | 检查潜在的BUG |
| style | 统一团队的代码风格,也包括一些由 Detekt 定义的格式化问题 |
表格引用自:cloud.tencent.com/developer/a…
更细节的规则说明,请参考:官方文档-规则集说明
自定义规则
接下来我们自定义一个检测KAE使用的规则,如下所示:
// 入口
class CustomRuleSetProvider : RuleSetProvider {
override val ruleSetId: String = "detekt-custom-rules"
override fun instance(config: Config): RuleSet = RuleSet(
ruleSetId,
listOf(
NoSyntheticImportRule(),
)
)
}
// 自定义规则
class NoSyntheticImportRule : Rule() {
override val issue = Issue(
"NoSyntheticImport",
Severity.Maintainability,
"Don’t import Kotlin Synthetics as it is already deprecated.",
Debt.TWENTY_MINS
)
override fun visitImportDirective(importDirective: KtImportDirective) {
val import = importDirective.importPath?.pathStr
if (import?.contains("kotlinx.android.synthetic") == true) {
report(
CodeSmell(
issue,
Entity.from(importDirective),
"'$import' 不要使用kae,推荐使用viewbinding"
)
)
}
}
}代码其实并不复杂,主要做了这么几件事:
- 添加
CustomRuleSetProvider作为自定义规则的入口,并将NoSyntheticImportRule添加进去 - 实现
NoSyntheticImportRule类,主要包括issue与各种visitXXX方法 issue属性用于定义在控制台或任何其他输出格式上打印的ID、严重性和提示信息visitImportDirective即通过访问者模式访问语法树的回调,当访问到import时会回调,我们在这里检测有没有添加kotlinx.android.synthetic,发现存在则报告异常
支持类型解析的自定义规则
上面的规则没有用到类型解析,也就是说不传入classpath也能使用,我们现在来看一个需要使用类型解析的自定义规则
比如我们需要在项目中禁止直接使用android.widget.Toast.show,而是使用我们统一封装的工具类,那么我们可以自定义如下规则:
class AvoidToUseToastRule : Rule() {
override val issue = Issue(
"AvoidUseToastRule",
Severity.Maintainability,
"Don’t use android.widget.Toast.show",
Debt.TWENTY_MINS
)
override fun visitReferenceExpression(expression: KtReferenceExpression) {
super.visitReferenceExpression(expression)
if (expression.text == "makeText") {
// 通过bindingContext获取语义
val referenceDescriptor = bindingContext.get(BindingContext.REFERENCE_TARGET, expression)
val packageName = referenceDescriptor?.containingPackage()?.asString()
val className = referenceDescriptor?.containingDeclaration?.name?.asString()
if (packageName == "android.widget" && className == "Toast") {
report(
CodeSmell(
issue, Entity.from(expression), "禁止直接使用Toast,建议使用xxxUtils"
)
)
}
}
}
}可以看出,我们在visitReferenceExpression回调中检测表达式,我们不仅需要判断是否存在Toast.makeTest表达式,因为可能存在同名类,更需要判断Toast类的具体类型,而这就需要获取语义信息
我们这里通过bindingContext来获取表达式的语义,这里的bindingContext其实就是Kotlin编译器存储语义信息的表,详细的可以参阅:K2 编译器是什么?世界第二高峰又是哪座?
当我们获取了语义信息之后,就可以获取Toast的具体类型,就可以判断出这个Toast是不是android.widget.Toast,也就可以完成检测了
Github Action集成Detekt检测
在完成了DeteKt接入与自定义规则之后,接下来就是每次提交代码时在CI上进行检测了
一些大的开源项目每次提交PR都会进行一系列的检测,我们也用Github Action来实现一个
我们在.github/workflows目录添加如下代码
name: Android CI
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
detekt-code-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
distribution: 'temurin'
cache: gradle
- name: Grant execute permission for gradlew
run: chmod +x gradlew
- name: DeteKt Code Check
run: ./gradlew detektDebug
这样在每次提交PR的时候,就都会自动调用该workflow进行检测了,检测不通过则不允许合并,如下所示:
点进去也可以看到详细的报错,具体是哪一行代码检测不通过,如图所示:
总结
本文主要介绍了DeteKt的接入与如何自定义规则,通过IDE集成,CLI命令行方式与Gradle插件方式接入,以及CI自动检测,可以保证代码规范,IDE提示,CI检测三者的统一,方便提前暴露问题,提高代码质量。
如果本文对你有所帮助,欢迎点赞~
链接:https://juejin.cn/post/7152886037746827277
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
请求量突增一下,系统有效QPS为何下降很多?
简介
最近我观察到一个现象,当服务的请求量突发的增长一下时,服务的有效QPS会下降很多,有时甚至会降到0,这种现象网上也偶有提到,但少有解释得清楚的,所以这里来分享一下问题成因及解决方案。
队列延迟
目前的Web服务器,如Tomcat,请求处理过程大概都类似如下:
这是Tomcat请求处理的过程,如下:
- Acceptor线程:线程名类似http-nio-8080-Acceptor-0,此线程用于接收新的TCP连接,并将TCP连接注册到NIO事件中。
- Poller线程:线程名类似http-nio-8080-ClientPoller-0,此线程一般有CPU核数个,用于轮询已连接的Socket,接收新到来的Socket事件(如调用端发请求数据了),并将活跃Socket放入exec线程池的请求队列中。
- exec线程:线程名类似http-nio-8080-exec-0,此线程从请求队列中取出活跃Socket,并读出请求数据,最后执行请求的API逻辑。
这里不用太关心Acceptor与Poller线程,这是nio编程时常见的线程模型,我们将重点放在exec线程池上,虽然Tomcat做了一些优化,但它还是从Java原生线程池扩展出来的,即有一个任务队列与一组线程。
当请求量突发增长时,会发生如下的情况:
- 当请求量不大时,任务队列基本是空的,每个请求都能得到及时的处理。
- 但当请求量突发时,任务队列中就会有很多请求,这时排在队列后面的请求,就会被处理得越晚,因而请求的整体耗时就会变长,甚至非常长。
可是,exec线程们还是在一刻不停歇的处理着请求的呀,按理说服务QPS是不会减少的呀!
简单想想的确如此,但调用端一般是有超时时间设置的,不会无限等待下去,当客户端等待超时的时候,这个请求实际上Tomcat就不用再处理了,因为就算处理了,客户端也不会再去读响应数据的。
因此,当队列比较长时,队列后面的请求,基本上都是不用再处理的,但exec线程池不知道啊,它还是会一如既往地处理这些请求。
当exec线程执行这些已超时的请求时,若又有新请求进来,它们也会排在队尾,这导致这些新请求也会超时,所以在流量突发的这段时间内,请求的有效QPS会下降很多,甚至会降到0。
这种超时也叫做队列延迟,但队列在软件系统中应用得太广泛了,比如操作系统调度器维护了线程队列,TCP中有backlog连接队列,锁中维护了等待队列等等。
因此,很多系统也会存在这种现象,平时响应时间挺稳定的,但偶尔耗时很高,这种情况有很多都是队列延迟导致的。
优化队列延迟
知道了问题产生的原因,要优化它就比较简单了,我们只需要让队列中那些长时间未处理的请求暂时让路,让线程去执行那些等待时间不长的请求即可,毕竟这些长时间未处理的请求,让它们再等等也无防,因为客户端可能已经超时了而不需要请求结果了,虽然这破坏了队列的公平性,但这是我们需要的。
对于Tomcat,在springboot中,我们可以如下修改:
使用WebServerFactoryCustomizer自定义Tomcat的线程池,如下:
@Component
public class TomcatExecutorCustomizer implements WebServerFactoryCustomizer<TomcatServletWebServerFactory> {
@Resource
ServerProperties serverProperties;
@Override
public void customize(TomcatServletWebServerFactory factory) {
TomcatConnectorCustomizer tomcatConnectorCustomizer = connector -> {
ServerProperties.Tomcat.Threads threads = serverProperties.getTomcat().getThreads();
TaskQueue taskqueue = new SlowDelayTaskQueue(1000);
ThreadPoolExecutor executor = new org.apache.tomcat.util.threads.ThreadPoolExecutor(
threads.getMinSpare(), threads.getMax(), 60L, TimeUnit.SECONDS,
taskqueue, new CustomizableThreadFactory("http-nio-8080-"));
taskqueue.setParent(executor);
ProtocolHandler handler = connector.getProtocolHandler();
if (handler instanceof AbstractProtocol) {
AbstractProtocol<?> protocol = (AbstractProtocol<?>) handler;
protocol.setExecutor(executor);
}
};
factory.addConnectorCustomizers(tomcatConnectorCustomizer);
}
}注意,这里还是使用的Tomcat实现的线程池,只是将任务队列TaskQueue扩展为了SlowDelayTaskQueue,它的作用是将长时间未处理的任务移到另一个慢队列中,待当前队列中无任务时,再把慢队列中的任务移回来。
为了能记录任务入队列的时间,先封装了一个记录时间的任务类RecordTimeTask,如下:
@Getter
public class RecordTimeTask implements Runnable {
private Runnable run;
private long createTime;
private long putQueueTime;
public RecordTimeTask(Runnable run){
this.run = run;
this.createTime = System.currentTimeMillis();
this.putQueueTime = this.createTime;
}
@Override
public void run() {
run.run();
}
public void resetPutQueueTime() {
this.putQueueTime = System.currentTimeMillis();
}
public long getPutQueueTime() {
return this.putQueueTime;
}
}然后队列的扩展实现如下:
public class SlowDelayTaskQueue extends TaskQueue {
private long timeout;
private BlockingQueue<RecordTimeTask> slowQueue;
public SlowDelayTaskQueue(long timeout) {
this.timeout = timeout;
this.slowQueue = new LinkedBlockingQueue<>();
}
@Override
public boolean offer(Runnable o) {
// 将任务包装一下,目的是为了记录任务放入队列的时间
if (o instanceof RecordTimeTask) {
return super.offer(o);
} else {
return super.offer(new RecordTimeTask(o));
}
}
public void pullbackIfEmpty() {
// 如果队列空了,从慢队列中取回来一个
if (this.isEmpty()) {
RecordTimeTask r = slowQueue.poll();
if (r == null) {
return;
}
r.resetPutQueueTime();
this.add(r);
}
}
@Override
public Runnable poll(long timeout, TimeUnit unit) throws InterruptedException {
pullbackIfEmpty();
while (true) {
RecordTimeTask task = (RecordTimeTask) super.poll(timeout, unit);
if (task == null) {
return null;
}
// 请求在队列中长时间等待,移入慢队列中
if (System.currentTimeMillis() - task.getPutQueueTime() > this.timeout) {
this.slowQueue.offer(task);
continue;
}
return task;
}
}
@Override
public Runnable take() throws InterruptedException {
pullbackIfEmpty();
while (true) {
RecordTimeTask task = (RecordTimeTask) super.take();
// 请求在队列中长时间等待,移入慢队列中
if (System.currentTimeMillis() - task.getPutQueueTime() > this.timeout) {
this.slowQueue.offer(task);
continue;
}
return task;
}
}
}逻辑其实挺简单的,如下:
- 当任务入队列时,包装一下任务,记录一下入队列的时间。
- 然后线程从队列中取出任务时,若发现任务等待时间过长,就将其移入慢队列。
- 而pullbackIfEmpty的逻辑,就是当队列为空时,再将慢队列中的任务移回来执行。
为了将请求的队列延迟记录在access.log中,我又修改了一下Task,并加了一个Filter,如下:
- 使用ThreadLocal将队列延迟先存起来
@Getter
public class RecordTimeTask implements Runnable {
private static final ThreadLocal<Long> WAIT_IN_QUEUE_TIME = new ThreadLocal<>();
private Runnable run;
private long createTime;
private long putQueueTime;
public RecordTimeTask(Runnable run){
this.run = run;
this.createTime = System.currentTimeMillis();
this.putQueueTime = this.createTime;
}
@Override
public void run() {
try {
WAIT_IN_QUEUE_TIME.set(System.currentTimeMillis() - this.createTime);
run.run();
} finally {
WAIT_IN_QUEUE_TIME.remove();
}
}
public void resetPutQueueTime() {
this.putQueueTime = System.currentTimeMillis();
}
public long getPutQueueTime() {
return this.putQueueTime;
}
public static long getWaitInQueueTime(){
return ObjectUtils.defaultIfNull(WAIT_IN_QUEUE_TIME.get(), 0L);
}
}- 再在Filter中将队列延迟取出来,放入Request对象中
@WebFilter
@Component
public class WaitInQueueTimeFilter extends HttpFilter {
@Override
public void doFilter(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws
IOException,
ServletException {
long waitInQueueTime = RecordTimeTask.getWaitInQueueTime();
// 将等待时间设置到request的attribute中,给access.log使用
request.setAttribute("waitInQueueTime", waitInQueueTime);
// 如果请求在队列中等待了太长时间,客户端大概率已超时,就没有必要再执行了
if (waitInQueueTime > 5000) {
response.sendError(503, "service is busy");
return;
}
chain.doFilter(request, response);
}
}- 然后在access.log中配置队列延迟
server:
tomcat:
accesslog:
enabled: true
directory: /home/work/logs/applogs/java-demo
file-date-format: .yyyy-MM-dd
pattern: '%h %l %u %t "%r" %s %b %Dms %{waitInQueueTime}rms "%{Referer}i" "%{User-Agent}i" "%{X-Forwarded-For}i"'
注意,在access.log中配置%{xxx}r表示取请求xxx属性的值,所以,%{waitInQueueTime}r就是队列延迟,后面的ms是毫秒单位。
优化效果
我使用接口压测工具wrk压了一个测试接口,此接口执行时间100ms,使用1000个并发去压,1s的超时时间,如下:
wrk -d 10d -T1s --latency http://localhost:8080/sleep -c 1000
然后,用arthas看一下线程池的队列长度,如下:
[arthas@619]$ vmtool --action getInstances \
--classLoaderClass org.springframework.boot.loader.LaunchedURLClassLoader \
--className org.apache.tomcat.util.threads.ThreadPoolExecutor \
--express 'instances.{ #{"ActiveCount":getActiveCount(),"CorePoolSize":getCorePoolSize(),"MaximumPoolSize":getMaximumPoolSize(),"QueueSize":getQueue().size()} }' \
-x 2
可以看到,队列长度远小于1000,这说明队列中积压得不多。
再看看access.log,如下:
可以发现,虽然队列延迟任然存在,但被控制在了1s以内,这样这些请求就不会超时了,Tomcat的有效QPS保住了。
而最后面那些队列延迟极长的请求,则是被不公平对待的请求,但只能这么做,因为在请求量超出Tomcat处理能力时,只能牺牲掉它们,以保全大局。
链接:https://juejin.cn/post/7189258947688136764
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
新年兔兔送祝福——SearchRabbit(安卓app)
前言
2023年到来,今年过年格外早,没几天就要迎新年了,因为是兔年,所以我创建了一个Rabbit为主题的App,里面以兔子为主题而添加各种相关内容,目前仅有十条2023兔年祝福语,后面会增加其他功能,下面,我们看看这个App的样子。
正篇
UI设计
首先,这个App因为这两天才创建的,所以只是UI上看起来和兔子相关,内容并不是很充实。主要是找了一张兔子的图片做App的logo,以及找了几张动态图作为app内部的装饰UI,如下:
勉强符合此次“兔了个兔”的主题。
内容设计
内部我是利用LottieAnimation去展示动图(让UI忙碌的安卓Lottie动画渲染库(一) - 掘金 (juejin.cn) & 让UI忙碌的安卓Lottie动画渲染库(二) - 掘金 (juejin.cn)),然后使用之前掘友推荐的刘强东写的列表神器BRV(liangjingkanji/BRV: [文档详细] Android上最好的RecyclerView框架, 比 BRVAH 更简单强大 (github.com)),琢磨了半天最后还是没有成功使用库作者推荐的DataBinding方式,我使用RecyclerView中使用BRV去加载10条祝福语。
这是使用作者推荐方式后运行不起来的截图:
看文档上的解决方法依次尝试还是没成功,所以还是采用ViewBinding的方式了。
代码与效果展示
部分XML布局如下,我虽然启用了DataBinding但目前还不会用,所以我也同时启用了ViewBinding:
<?xml version="1.0" encoding="utf-8"?>
<layout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools">
<data>
</data>
<LinearLayout
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical"
tools:context=".MainActivity">
...
...
<com.airbnb.lottie.LottieAnimationView
android:id="@+id/rabbit_easter_egg_slider"
android:layout_width="match_parent"
android:layout_height="100dp"
android:layout_gravity="center"
app:lottie_autoPlay="true"
app:lottie_fileName="lottie/rabbit_easter_egg_slider.json"
app:lottie_loop="true"
app:lottie_repeatMode="restart" />
<androidx.core.widget.NestedScrollView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_gravity="center"
tools:ignore="SpeakableTextPresentCheck">
<LinearLayout
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:orientation="vertical">
...
...
<com.airbnb.lottie.LottieAnimationView
android:id="@+id/rabbit_2023"
android:layout_width="200dp"
android:layout_height="200dp"
android:layout_gravity="center"
app:lottie_autoPlay="true"
app:lottie_fileName="lottie/rabbit_2023.json"
app:lottie_loop="true"
app:lottie_repeatMode="restart" />
</LinearLayout>
</androidx.core.widget.NestedScrollView>
<androidx.recyclerview.widget.RecyclerView
android:id="@+id/vMainList"
android:layout_width="match_parent"
android:layout_height="wrap_content" >
</androidx.recyclerview.widget.RecyclerView>
</LinearLayout>
</layout>我的activity中部分代码如下,很笨拙地使用列表的方式存了10条祝福语,后面还会优化一下并加上复制按钮:
...
...
class MainActivity : AppCompatActivity() {
private lateinit var binding: ActivityMainBinding
private var text = arrayOf("兔年!...",
...
....,
....,
....")
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
window.attributes.softInputMode = WindowManager.LayoutParams.SOFT_INPUT_ADJUST_PAN
binding.vMainList.linear().setup {
addType<SimpleModel>(R.layout.item_simple)
setAnimation(AnimationType.SLIDE_BOTTOM)
onBind {
val binding = getBinding<ItemSimpleBinding>() // 使用ViewBinding/DataBinding都可以使用本方法
binding.tvName.text = getModel<SimpleModel>().name
}
}.models = getData()
}
private fun getData(): MutableList<Any> {
// 在Model中也可以绑定数据
return mutableListOf<Any>().apply {
for (i in 1..10) {
val simpleModel = SimpleModel(
"$i、${text[i-1]}"
, i)
add(simpleModel)
// add(SimpleModel())
}
}
}
}运行后目前只可以滑动查看列表:
项目代码
总之就是这个App目前还非常简陋,但是已经放到了GitHub上了,后续会逐渐添加优化一些功能和代码。
项目地址:ObliviateOnline/RabbitApp: 2023 rabbit app (github.com)
总结
本来是想做一个搜索类的App,结果发现做着做着就偏离了方向,但是本来就是为了新年添个彩头,又是自己弄着玩的,加之看起来还是像那么回事,所以就这么直接发出来献丑了,希望大家喜欢!
链接:https://juejin.cn/post/7188887146344742969
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
介绍一个令强迫症讨厌的小红点组件
前言
在 App 的运营中,活跃度是一个重要的指标,日活/月活……为了提高活跃度,就发明了小红点,然后让强迫症用户“没法活”。
小红点虽然很讨厌,但是为了 KPI,程序员也不得不屈从运营同学的逼迫(讨好),得想办法实现。这一篇,来介绍一个徽标(Badge)组件,能够快速搞定应用内的小红点。
Badge 组件
Badge 组件被 Flutter 官方推荐,利用它让小红点的实现非常轻松,只需要2个步骤就能搞定。
- 引入依赖
在 pubspec.yaml文件种引入相应版本的依赖,如下所示。
badges: ^2.0.3- 将需要使用小红点的组件使用 Badge 作为上级组件,设置小红点的位置、显示内容、颜色(没错,也可以改成小蓝点)等参数,示例代码如下所示。
Badge(
badgeContent: Text('3'),
position: BadgePosition.topEnd(top: -10, end: -10),
badgeColor: Colors.blue,
child: Icon(Icons.settings),
)position可以设置徽标在组件的相对位置,包括右上角(topEnd)、右下角(bottomEnd)、左上角(topStart)、左下角(bottomStart)和居中(center)等位置。并可以通过调整垂直方向和水平方向的相对位置来进行位置的细微调整。当然,Badge 组件考虑了很多应用场景,因此还有其他的一些参数:
elevation:阴影偏移量,默认为2,可以设置为0消除阴影;gradient:渐变色填充背景;toAnimate:徽标内容改变后是否启用动效哦,默认有动效。shape:徽标的形状,默认是原型,也可以设置为方形,设置为方形的时候可以使用borderRadius属性设置圆角弧度。borderRadius:圆角的半径。animationType:内容改变后的动画类型,有渐现(fade)、滑动(slide)和缩放(scale)三种效果。showBadge:是否显示徽标,我们可以利用这个控制小红点的显示与否,比如没有提醒的时候该值设置为false即可隐藏掉小红点。
总的来说,这些参数能够满足所有需要使用徽标的场景了。
实例
我们来看一个实例,我们分别在导航栏右上角、内容区和底部导航栏使用了三种类型的徽标,实现效果如下。
其中导航栏的代码如下,这是 Badge 最简单的实现方式了。
AppBar(
title: const Text('Badge Demo'),
actions: [
Badge(
showBadge: _badgeNumber > 0,
padding: const EdgeInsets.all(4.0),
badgeContent: Text(
_badgeNumber < 99 ? _badgeNumber.toString() : '99+',
textAlign: TextAlign.center,
style: const TextStyle(
color: Colors.white,
fontSize: 11.0,
),
),
position: BadgePosition.topEnd(top: 4, end: 4),
child: IconButton(
onPressed: () {},
icon: const Icon(
Icons.message_outlined,
color: Colors.white,
),
),
),
],
),内容区的徽标代码如下,这里使用了渐变色填充,动画形式为缩放,并且将徽标放到了左上角,注意如果使用了渐变色那么会覆盖 badgeColor 指定的背景色。
Badge(
showBadge: _badgeNumber > 0,
padding: const EdgeInsets.all(6.0),
badgeContent: Text(
_badgeNumber < 99 ? _badgeNumber.toString() : '99+',
textAlign: TextAlign.center,
style: const TextStyle(
color: Colors.white,
fontSize: 10.0,
),
),
position: BadgePosition.topStart(top: -10, start: -10),
badgeColor: Colors.blue,
animationType: BadgeAnimationType.scale,
elevation: 0.0,
gradient: const LinearGradient(
begin: Alignment.topCenter,
end: Alignment.bottomCenter,
colors: [
Colors.red,
Colors.orange,
Colors.green,
],
),
child: Image.asset(
'images/girl.jpeg',
width: 200,
height: 200,
),
),底部导航栏的代码如下所示,这里需要注意,Badge 组件会根据内容区的尺寸自动调节大小,底部导航栏的显示控件有限,推荐使用小红点(不用数字标识)即可。
BottomNavigationBar(items: [
BottomNavigationBarItem(
icon: Badge(
showBadge: _badgeNumber > 0,
padding: const EdgeInsets.all(2.0),
badgeContent: Text(
_badgeNumber < 99 ? _badgeNumber.toString() : '99+',
textAlign: TextAlign.center,
style: const TextStyle(
color: Colors.white,
fontSize: 11.0,
),
),
position: BadgePosition.topEnd(top: -4, end: -6),
animationType: BadgeAnimationType.fade,
child: const Icon(Icons.home_outlined)),
label: '首页',
),
const BottomNavigationBarItem(
icon: Icon(
Icons.star_border,
),
label: '推荐',
),
const BottomNavigationBarItem(
icon: Icon(
Icons.account_circle_outlined,
),
label: '我的',
),
]),总结
本篇介绍了使用 Badge 组件实现小红点徽标组件。可以看到,Badge 组件的使用非常简单,相比我们自己从零写一个 Badge 组件来说,使用它可以让我们省时省力、快速地完成运营同学要的小红点。本篇源码已上传至:实用组件相关代码。
链接:https://juejin.cn/post/7188124857958137911
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 原生混合 Flutter 开发初体验之一
前言
最近公司的项目用Flutter技术栈比较多,有些需求可能还需要一些Android原生的支持,所以我做了一些Android原生混合Flutter开发的尝试,参考了一些文章,也遇到了一些问题,这里把总结的经验分享出来。
本文是针对 Android 项目添加 Flutter 模块的情况编写的。
开发环境
- PC with Win10 20H2
- Android Studio Arctic Fox | 2020.3.1 Patch 2(试过小松鼠版本,太不喜欢了,电鳗就更没去尝试)
- AGP 7.0.2
创建一个Android项目
直接贴图带过了哈,这步应该都熟练的吧
创建一个Flutter模块
这里就有区别了,较新版的AS中提供直接创建Flutter模块的模板,但是我的北极狐版本没有,因此这里演示两种方式:
AS模板创建
在你的当前项目中,使用AS菜单中的 File > New > New Module… 创建一个新的Flutter模块,或者选择一个此前就已准备好的Flutter模块。
如果你选择创建一个新的模块,你可以使用向导来帮助你设置模块的名称,模块存放的位置之类的配置项。
- 由于我这里还是北极狐版的
AS,所以我并未实践官方提供的模板创建方式,按照官方的说法,它会自动帮你配置好依赖关系,但我也不确定会不会遇到问题,没有最好,有的话应该也都和手动创建的方式差不多。
手动创建Flutter模块
在Terminal执行下方命令
```
flutter create -t module --org com.randalldev fluttermodule
```
复制代码然后官方提供了两种方式添加依赖关系:
AAR依赖模式
AAR模式有个好处就是团队中的其他成员不需要安装Flutter SDK,最少只需要一个人输出AAR即可。
但是我个人不喜欢这种方式,我更倾向于
git submodule的项目管理方式,并且安装Flutter SDK的成本实在算不上高,因此,这种方式,我按下不表。
模块代码依赖模式
这种方式确保了一步完成
Android项目和Flutter模块的编译。这种方式对于你的开发同时涉及两个部分并且快速迭代很方便,但这需要团队的每个人成员都安装Flutter SDK来确保顺利编译这个混合app。
在主项目的
settings.gradle中将Flutter模块作为子项目引入。
// Include the host app project.
include ':app' // 默认已有的配置
setBinding(new Binding([gradle: this])) // 新增
evaluate(new File( // 新增
settingsDir.parentFile, // 新增
'${root_project}/fluttermodule/.android/include_flutter.groovy' // 新增
)) // 新增
此时
AS会提示你gradle配置变更了,需要重新sync,别急,先别点!
假设
fluttermodule是和app目录同层级的。
在
app的build.gradle中添加flutter模块的依赖
dependencies {
implementation project(':flutter')
}
官方的指南就到此为止了,与此同时,坑也来了/doge
排雷
此时当你点了sync会出现如下报错
* What went wrong:
A problem occurred evaluating script.
> Failed to apply plugin class 'FlutterPlugin'.
> Build was configured to prefer settings repositories over project repositories but repository 'maven' was added by plugin class 'FlutterPlugin'
将project的setting.gradle的
dependencyResolutionManagement {
repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
repositories {
google()
mavenCentral()
jcenter() // Warning: this repository is going to shut down soon
}
}
改为
dependencyResolutionManagement {
repositoriesMode.set(RepositoriesMode.PREFER_PROJECT)
repositories {
google()
mavenCentral()
jcenter() // Warning: this repository is going to shut down soon
}
}
此时当你点了sync会出现如下报错
A problem occurred evaluating project ':app'.
> Project with path ':fluttermodule' could not be found in project ':app'.
在project的setting.gradle的末尾添加
include ':fluttermodule'
此时当你点了sync编译大概率能成功,但是会有很严重的警告
Failed to resolve: androidx.core:core-ktx:1.9.0
Add Google Maven repository and sync project
Show in Project Structure dialog
Affected Modules: app
在project的build.gradle的
task clean(type: Delete) {
delete rootProject.buildDir
}上方添加
allprojects {
repositories {
google()
mavenCentral()
maven { url 'https://jitpack.io' }
}
}至此,大体上一个混合的Android原生+Flutter项目的初步构建就完成了。
页面跳转
Android原生打开Flutter页面
默认的跳转方式会出现明显的白屏,体验上很不好,这里直接给出优化后的方式
使用FlutterEngine缓存并复用
在
app的AndroidManifest.xml中注册FlutterActivity
<activity
android:name="io.flutter.embedding.android.FlutterActivity"
android:configChanges="orientation|keyboardHidden|keyboard|screenSize|locale|layoutDirection|fontScale|screenLayout|density|uiMode"
android:hardwareAccelerated="true"
android:theme="@style/Theme.HybridFlutter"
android:windowSoftInputMode="adjustResize" >
</activity>
在
app中创建一个App.kt继承Application并在AndroidManifest.xml中配置给application节点的name属性
class App : Application() {
···
}
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.randalldev.hybridflutter">
<application
android:name=".App"
···
</manifest>
在
App.kt中准备好FlutterEngine
创建
FlutterEngine实例
private val flutterEngine by lazy {
FlutterEngine(this).apply {
dartExecutor.executeDartEntrypoint(DartExecutor.DartEntrypoint.createDefault())
}
}
重写
onCreate()并将实例存储在FlutterEngineCache中
override fun onCreate() {
super.onCreate()
FlutterEngineCache.getInstance().put("your_engine_id", flutterEngine)
}
重写
onTerminate()并将实例销毁
override fun onTerminate() {
super.onTerminate()
flutterEngine.destroy()
}
在业务需要的地方使用
FlutterEngine中的Intent实例进行跳转
findViewById<TextView>(R.id.textView).setOnClickListener {
startActivity(FlutterActivity.withCachedEngine("your_engine_id").build(this))
}
选择
app进行run
如果遇到如下
Java版本问题,请进行如下配置变更
A problem occurred evaluating project ':flutter'.
> Failed to apply plugin 'com.android.internal.library'.
> Android Gradle plugin requires Java 11 to run. You are currently using Java 1.8.
You can try some of the following options:
- changing the IDE settings.
- changing the JAVA_HOME environment variable.
- changing `org.gradle.java.home` in `gradle.properties`.
选择 Project Structure > SDK location > Gradle Settings 设置
Gradle JDK为11
在
./gradle.properties中添加上文中对应的java.home路径
# replace with your own jdk11 or above
org.gradle.java.home=C\:\\Softwares\\Google\\Android\\Android_Studio\\jre
sync后应该就可以顺利的run了
链接:https://juejin.cn/post/7187979205215748156
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android Studio 如何更便捷开发系统 App
System App
最近接触系统App相关的开发,刚开始得知在系统源码中,开发系统应用,As 引用库的时候,居然不能代码联想,布局也不能预览,实在不习惯。后面搜了下网上的资源,有一些介绍,也不是特别完整,于是自己把这些零碎的点,整理出来,方面后续自己看看。
本文主要解决以下几个问题:
- 代码移植、资源移植
- 系统隐藏代码未找到
- aidl 代码问题
- protobuf 代码问题
- lint 警告提示
代码移植、资源移植
这一步,就是把系统App的代码拷贝出来(例如:/packages/apps/Settings),相当于移植到一个新的项目。创建一个新的 As 工程,然后按照源码的目录层级创建,记得包名跟源码一致,尽可能保存目录层级一致,接着就是各种 copy 操作了,把 src、res 等目录都搬过去新项目中。在移植的过程,需要将 Android.bp 文件里面依赖的库,按照 gradle 的方式来依赖进去。例如:
static_libs: [
"com.google.android.material_material",
"androidx.transition_transition",
"androidx-constraintlayout_constraintlayout",
"androidx.core_core",
"androidx.media_media",
"androidx.legacy_legacy-support-core-utils",
"androidx.legacy_legacy-support-core-ui",
"androidx.fragment_fragment",
"androidx.appcompat_appcompat",
"androidx.preference_preference",
"androidx.recyclerview_recyclerview",
"androidx.legacy_legacy-preference-v14",
"androidx.leanback_leanback",
"androidx.leanback_leanback-preference",
"androidx.lifecycle_lifecycle-extensions",
"androidx.lifecycle_lifecycle-common-java8",
"kotlin-stdlib",
"kotlinx-coroutines-android",
"androidx.navigation_navigation-common-ktx",
"androidx.navigation_navigation-fragment-ktx",
"androidx.navigation_navigation-runtime-ktx",
"androidx.navigation_navigation-ui-ktx",
]对应到 gradle 代码,这个过程十分麻烦,因为很多资源缺失,需要一个个的寻找,以及代码的移植还会关联其他工程代码。而且库的版本也是需要注意的。所以需要耐心解决。
compileOnly files('libs/framework.jar')
implementation "org.jetbrains.kotlin:kotlin-stdlib:$kotlin_version"
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.1.1'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.1.1'
implementation 'androidx.core:core-ktx:1.6.0'
implementation 'androidx.appcompat:appcompat:1.3.1'
implementation 'com.google.android.material:material:1.4.0'
implementation 'com.android.support:multidex:1.0.0'
implementation 'androidx.constraintlayout:constraintlayout:2.1.1'
implementation "com.google.protobuf:protobuf-javalite:3.13.0"
def nav_version = "2.3.5"
// Java language implementation
implementation "androidx.navigation:navigation-fragment-ktx:$nav_version"
implementation "androidx.navigation:navigation-ui-ktx:$nav_version"
// Feature module Support
implementation "androidx.navigation:navigation-dynamic-features-fragment:$nav_version"
def lifecycle_version = "2.3.1"
def arch_version = "2.1.0"
// ViewModel
implementation "androidx.lifecycle:lifecycle-viewmodel-ktx:$lifecycle_version"
// LiveData
implementation "androidx.lifecycle:lifecycle-livedata-ktx:$lifecycle_version"
// Lifecycles only (without ViewModel or LiveData)
implementation "androidx.lifecycle:lifecycle-runtime-ktx:$lifecycle_version"
// ???
implementation "android.arch.lifecycle:extensions:1.1.1"
// Saved state module for ViewModel
implementation "androidx.lifecycle:lifecycle-viewmodel-savedstate:$lifecycle_version"
// Annotation processor
kapt "androidx.lifecycle:lifecycle-compiler:$lifecycle_version"
// alternately - if using Java8, use the following instead of lifecycle-compiler
implementation "androidx.lifecycle:lifecycle-common-java8:$lifecycle_version"
// optional - helpers for implementing LifecycleOwner in a Service
implementation "androidx.lifecycle:lifecycle-service:$lifecycle_version"
// optional - ProcessLifecycleOwner provides a lifecycle for the whole application process
implementation "androidx.lifecycle:lifecycle-process:$lifecycle_version"
// optional - ReactiveStreams support for LiveData
implementation "androidx.lifecycle:lifecycle-reactivestreams-ktx:$lifecycle_version"
// optional - Test helpers for LiveData
testImplementation "androidx.arch.core:core-testing:$arch_version"
def leanback_version = "1.2.0-alpha01"
implementation "androidx.leanback:leanback:$leanback_version"
// leanback-preference is an add-on that provides a settings UI for TV apps.
implementation "androidx.leanback:leanback-preference:$leanback_version"
// leanback-paging is an add-on that simplifies adding paging support to a RecyclerView Adapter.
implementation "androidx.leanback:leanback-paging:1.1.0-alpha08"
// leanback-tab is an add-on that provides customized TabLayout to be used as the top navigation bar.
implementation "androidx.leanback:leanback-tab:1.1.0-beta01"
如果项目源码存在多个 src 目录,需要在 gradle 中指定 java 目录
sourceSets {
main {
java.srcDirs = ['src/main/src', 'src/main/src2', 'src/main/src_gen']
// 定义proto文件目录
proto {
// srcDir 'src/main/java'
srcDir 'src/main/src'
include '**/*.proto'
}
}
}系统隐藏代码未找到
系统源码编译之后,找到/out/target/common/obj/JAVA_LIBRARIES/framework_intermediates 目录下的 classes.jar 文件,更名为 framework.jar ,按照jar包的引用方式,依赖进去工程。
同时需要更改jar的加载顺序,在工程目录的 gradle 添加如下代码
allprojects {
repositories {
google()
jcenter()
}
gradle.projectsEvaluated {
tasks.withType(JavaCompile) {
options.compilerArgs << "-Xlint:unchecked" << "-Xlint:deprecation"
// options.compilerArgs.add('-Xbootclasspath/p:app/libs/framework.jar')
Set<File> fileSet = options.bootstrapClasspath.getFiles()
List<File> newFileList = new ArrayList<>();
//"../framework.jar" 为相对位置,需要参照着修改,或者用绝对位置
// 我这里用的是绝对路径,注意区分 linux 系统与 window 系统的反斜杠
newFileList.add(new File("/xxx/framework.jar"))
newFileList.addAll(fileSet)
options.bootstrapClasspath = files(newFileList.toArray())
// options.bootstrapClasspath.getFiles().forEach(new Consumer<File>() {
// @Override
// void accept(File file) {
// println(file.name)
// }
// })
//options.compilerArgs.add('-Xbootclasspath/p:app\\libs\\framework.jar')
}
}
}aidl 代码问题
aidl 代码可以用两种方式处理,一种是直接拷贝aidl的生成物,本质还是java代码,另一种方式是按源码那样创建aidl文件。
protobuf 代码问题
需要正确引入对应的 protobuf 的版本,以及生成代码的目录,我记得我当时还因为版本不匹配导致一些错误,具体时间太久了,当时也没存记录。
plugins {
id 'com.android.application'
id 'com.google.protobuf'
id 'kotlin-android'
id 'kotlin-kapt'
}
protobuf {
protoc {
artifact = "com.google.protobuf:protoc:3.13.0"
}
generateProtoTasks {
all().each { task ->
task.builtins {
java {
option "lite"
}
}
}
}
}
···
// 工程 gradle 配置
buildscript {
ext.kotlin_version = "1.4.32"
repositories {
google()
jcenter()
}
dependencies {
classpath "com.android.tools.build:gradle:4.1.3"
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version"
classpath "com.google.protobuf:protobuf-gradle-plugin:0.8.13"
}
}lint 警告提示
源码中会使用一些过时的方法,在打包过程会导致失败。需要在 gradle 中配置,错误不中断
lintOptions {
abortOnError false
}小结
整个过程,就是多次修改,拷贝,然后编译的过程,直到没有错误提示,能够成功生成apk的时候,就成功了。之后就可以愉快的关联代码,以及布局预览了。
链接:https://juejin.cn/post/7056403090706169886
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
「Android」用 Spotless 让你的代码 “一尘不染“
Spotless 是什么?
这是一个代码格式化工具,我们可以定义自己想要的代码规则在需要的时候去应用它,整个过程完全自动且可以应用于整个工程。
Spotless 支持多种语言:c、c++、java、kotlin、python 等等更多,应用广泛的开发语言基本都支持。
插件丰富,支持 Gradle、Maven、SBT。并且有 IDE 插件,如:VS Code、Intellij。
社区活跃,很多优秀的开源贡献者,如:ktlint、ktfmt、prittier 等, Github 上的提交经常是几天前。
为什么要用 Spotless?
编写代码时我们都希望遵循固定的代码风格,我们使用的 IDE 也都有代码格式化功能。但是很遗憾,代码格式化都需要开发者手动触发,所以你肯定会有忘记格式化的时候。
如果你的团队有 code review 的过程,你的小伙伴或许能纠正这些问题,当然,也有可能看不到,某段代码就这样”脏“了。
虽然良好、统一的代码风格并不能提高代码性能,即使代码风格很糟糕代码也能正确编译,且运行结果并无二致。但是当你的代码有良好统一风格时,代码会更美观,有更好的阅读性,小伙伴 code review 时可以完全不用关注代码风格。
而 [Spotless](diffplug/spotless: Keep your code spotless (github.com)) 就是这样一个能让你不用关注代码风格的工具,因为它会自动帮你格式化代码。
项目整合
Gradle 配置
首先在 project build.gradle 中添加 Spotless 插件
classpath "com.diffplug.spotless:spotless-plugin-gradle:$spotless_version"然后在 project 或 module 的 build.gradle 中做如下配置
apply plugin: 'com.diffplug.spotless'
spotless {
java{
target 'src/*/java/**/*.java'
googleJavaFormat()
}
kotlin {
target 'src/*/java/**/*.kt'
ktlint('0.43.2')
}
format 'misc', {
target '**/*.gradle', '**/*.md', '**/.gitignore'
}
format 'xml', {
target '**/*.xml'
}
}结束了,就是这么简单,你需要的仅仅是去配置你想要的代码规则。具体规则配置请参考 [Spotless GitHub](spotless/plugin-gradle at main · diffplug/spotless (github.com))
Java (google-java-format, eclipse jdt, clang-format, prettier, palantir-java-format, formatAnnotations)
Kotlin (ktfmt, ktlint, diktat, prettier)Spotless gradle task
使用 Spotless 非常简单,一般我们只需要使用两个 task
./gradlew spotlessCheck执行 spotlessCheck 可以校验代码风格,如果有问题会报错并列出异常代码的位置
./gradlew spotlessApply执行 spotlessApply 可以在全工程范围内自动修复代码不合规的地方。不过它只能格式化代码,如果规则需要修改代码,比如要删除某个导入的包是需要手动操作的。
从以上两步操作:配置、执行,可以看到 Spotless 的依赖成本是非常低的,使用也非常简单。它带来的好处在我看来有两点:
- 保证全工程代码风格一致,且是遵循官方代码风格规范
- 开发者编码阶段完全不需要关心代码风格问题,也不会在 review 阶段花时间更正代码风格,只关注业务价值本身
所以如果你或你的团队在关注代码风格问题,那么 Spotless 一定适合你,请尝试使用吧!
对于 Android 开发最关心的就是 java 和 kotlin 了,这两个语言都有非常多的代码规范支持,不过使用较多的是 Java「google-java-format」和 kotlin「ktlint」。随着 kotlin 在 Android 开发的占比增长,kotlin 的代码规范就显得更受关注,并且如果你关注 Google 的官方源码,你会发现 Google 的这些工程大多都是使用 ktlint 约束代码风格,这是因为 ktlin 同时支持 official Kotlin coding conventions 和 Android Kotlin Style Guide 两种风格,Android 开发者可以用 ktlint 方便的遵循 Google 代码风格。
更多 ktlint 内容请关注 [ktlint](Ktlint (pinterest.github.io))。
Android Studio lint 插件
前文提到的 google-java-format、ktlint 是都有 IDE 插件的,可以在 plugins market 中安装。
个人目前开发比较少涉及到 java ,所以 AS 并没有安装 google-java-format,有 java code format 的开发者可以在市场中安装此工具。下面我简单介绍下 AS ktlint 插件的使用体验。
比如此处多了一个空行,ktlint 会醒目标红,鼠标移过去会展示可操作的选项,可以选择 ktlint format 或禁用此规则。
安装插件后 AS 会增加一个菜单 Refactor -> Format With Ktlint,此菜单可以格式化整个文件,就与 AS 的格式化操作一样,你也可以为 Format With Ktlint 指定快捷键,操作会更方便。
在 ktlint 的 gradle 、AS 插件加持下,相信代码风格在开发中不需要特别花时间去处理了。如果代码风格不正确首先是 AS 的 error 醒目提醒,如果看到了可以一键修复。如果看不到,在执行 ./gradlew spotlessApply之后还可以全工程修复,让“脏”代码无所遁形。
Git hooks
上文介绍的配置,可能已经满足很多人了,不过还是有人会觉得,只要是手动操作的内容,那一定会有可能会忘记,有没有不需要手动操作的格式化操作。
有的有的,方案就是本小结标题 Git hooks。Ktlint 官网有一键安装 git hooks的操作,可以参考 [ktlint git hooks](Command line - Ktlint (pinterest.github.io))。
关于 git hooks 是什么可以参考这篇博文: [git hooks 简介与使用](git hooks 简介与使用 - 简书 (jianshu.com))
不过这个需要每个人都要手动去操作,其实我们可以把 git hooks 脚本文件放到我们工程里,然后通过 gradle 将脚本文件拷贝至 .git 目录
首先在项目下新建hooks目录,新建pre-commit文件:
#!/bin/sh
#
# An example hook script to verify what is about to be committed.
# Called by "git commit" with no arguments. The hook should
# exit with non-zero status after issuing an appropriate message if
# it wants to stop the commit.
#
# To enable this hook, rename this file to "pre-commit".
./gradlew spotlessCheck
result=$?
printf "the spotlessCheck result code is $result"
if [[ "$result" = 0 ]] ; then
echo "\033[32m
....
....
SpotlessCheck Pass!!
....
....
\033[0m"
exit 0
else
./gradlew spotlessApply
echo "\033[31m
....
....
SpotlessCheck Failed!!
代码格式有问题;
....
已经自动调整格式,review代码后再git add . && git commit
....
....
\033[0m"
exit 1
fipre-commit 脚本可以根据自己需要作调整,这边仅仅是一个示例。
下一步需要将此文件拷贝至项目目录下 .git/hooks 目录,可以用 gradle 来处理拷贝事件。
task copyHooks(type: Copy) {
println 'copyHooks task'
from("hooks") {
include "**"
}
into ".git/hooks"
}执行此 task 就可以将项目 hooks 目录内容拷贝至 .git
完成上述操作之后,在每次执行 git commit 之前都会先执行 pre-commit,在校验失败后会自动格式化代码,开发者在 reivew 之后再重新提交。
总结
如果你在开发过程中时不时会因为代码格式化问题造成困扰,那 Spotless 及 ktlint 会完全解放你。让你无需关注代码格式的同时也能保证代码风格的一致。
ktlint 的优秀远不止此篇文中所述,这仅仅是一篇指导文,大家可以去探索更适合自己项目的方法。
希望此文能让大家了解 Spotless 并尝试使用,谢谢!
链接:https://juejin.cn/post/7187600446902435898
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin Flow 探索
响应式编程
因为 Kotlin Flow 是基于 响应式编程 的实现,所以先了解一下 响应式编程 的概念。
首先看下百度百科解释:
响应式编程是一种面向数据流和变化传播的编程范式。这意味着可以在编程语言中很方便地表达静态或动态的数据流,而相关的计算模型会自动将变化的值通过数据流进行传播。
这个释义很抽象,难以理解。只知道它的核心是:数据流。
如何理解这个数据流,先看下响应式编程 ReactiveX 下的一个框架 RxJava 。
RxJava 是基于响应式编程的实现,它的定义:
RxJava 是 Reactive Extensions 的 Java VM 实现:一个通过使用可观察序列来组合异步和基于事件的程序的库。
它扩展了观察者模式以支持数据/事件序列,并添加了运算符,允许您以声明方式组合序列,同时消除了对低级线程、同步、线程安全和并发数据结构等问题的担忧。
看完这个定义,脑袋中也很模糊。下面从 RxJava 应用的一个简单例子来分析:
Observable.just(bitmap).map { bmp->
//在子线程中执行耗时操作,存储 bitmap 到本地
saveBitmap(bmp)
}.subscribeOn(Schedulers.io()).observeOn(AndroidSchedulers.mainThread()).subscribe { bitmapLocalPath ->
//在主线程中处理存储 bitmap 后的本地路径地址
refreshImageView(bitmapLocalPath)
}上面例子中: 将一个 bitmap 存储到本地并返回本地路径,从源数据 bitmap → 存储 btimap 到本地操作 → 获取本地图片路径值刷新UI。其实,就可以把这整个过程中按时间发生的事件序列理解为数据流。
数据流包含提供方(生产者),中介(中间操作),使用方(消费者):
- 提供方(生产者):源数据,将数据添加到数据流中;
- 中介(中间操作):可以修改发送到数据流的值,或修正数据流本身;
- 使用方(消费者):结果数据,使用数据流中的值。
那么,上面例子中的数据流是:
- 提供方(生产者):源数据 bitmap;
- 中介(中间操作):map 操作,存储 btimap 到本地;
- 使用方(消费者):本地图片路径。
再看下 RxJava 中的数据流解释:
RxJava 中的数据流由源、零个或多个中间步骤组成,然后是数据消费者或组合器步骤(其中该步骤负责通过某种方式消费数据流):
source.operator1().operator2().operator3().subscribe(consumer);
source.flatMap(value -> source.operator1().operator2().operator3());
在这里,如果我们想象自己在操作符 operator2 上,向左看 source 被称为上游。向右看 subscriber/consumer 称为下游。当每个元素都写在单独的行上时,这一点通常更为明显:
source
.operator1()
.operator2()
.operator3()
.subscribe(consumer)这也是 RxJava 的上游、下游概念。
其实,Flow 数据流中参看 RxJava,也可以有这样类似的上游和下游概念:
flow
.operator1()
.operator2()
.operator3()
.collect(consumer)了解了 响应式编程 的核心 数据流 后,对 响应式编程 有了初步印象。但是 响应式编程 的实现远不止如此,它还涉及观察者模式,线程调度等。不管原理这些,用它来做开发有什么好处呢?其实,它主要优点是:
- 对于并发编程,线程切换,没有 callback hell,简化了异步执行的代码;
- 代码优雅,简洁,易阅读和维护。
下面看两个业务例子:
Observable.just(bitmap).map { bmp ->
//在子线程中执行耗时操作,存储 bitmap 到本地
saveBitmap(bmp)
}.map { path ->
//在子线程中执行耗时操作,上传图片到服务端
uploadBitmap(path)
}.subscribeOn(Schedulers.io()).observeOn(AndroidSchedulers.mainThread())
.subscribe { downloadUrl ->
//在主线程中处理获取图片下载地址
} //从服务端批量下载文件
Observable.from(downloadUrls).flatMap { downloadUrl ->
//下载单个文件,返回本地文件
Observable.just(downloadUrl).map {url-> downloadResource(url) }
}.map { file ->
//对文件解压
unzipFile(file)
}.subscribeOn(Schedulers.io()).observeOn(AndroidSchedulers.mainThread())
.subscribe { folderPath ->
//拿到文件夹路径
}所以 响应式编程 的实现,主要是帮我们解决了 并发编程问题,能用优雅简洁的代码做异步事件处理。
Kotlin 协程 和 Flow,它们结合在一起也实现了 响应式编程。在 Kotlin 环境中,再结合 Android 提供 Lifecycle, ViewModel, Flow 的扩展,能让我们在 Android 中做并发编程,异步事件管理如鱼得水。
Kotlin Flow
Kotlin Flow 就是 Kotlin 数据流,它基于 Kotlin 协程构建。上一篇 Kotlin 协程探索 分析了 协程 的大致原理,知道协程就是 Kotlin 提供的一套线程 API 框架,方便做并发编程。那么 Kotlin 协程 和 Flow (数据流)的结合,和 RxJava 框架就有异曲同工之妙。
下面使用 Kotlin 协程 和 Flow 来实现上面 RxJava 的两个业务例子:
GlobalScope.launch(Dispatchers.Main) {
flowOf(bitmap).map { bmp ->
//在子线程中执行耗时操作,存储 bitmap 到本地
Log.d("TestFlow", "saveBitmap: ${Thread.currentThread()}")
saveBitmap(bmp)
}.flowOn(Dispatchers.IO).collect { bitmapLocalPath ->
//在主线程中处理存储 bitmap 后的本地路径地址
Log.d("TestFlow", "bitmapLocalPath=$bitmapLocalPath: ${Thread.currentThread()}")
}
}
//从服务端批量下载文件
GlobalScope.launch(Dispatchers.Main) {
downloadUrls.asFlow().flatMapConcat { downloadUrl ->
//下载单个文件,返回本地文件
flowOf(downloadUrl).map { url ->
Log.d("TestFlow", "downloadResource:url=$url: ${Thread.currentThread()}")
downloadResource(url)
}
}.map { file ->
//对文件解压
Log.d("TestFlow", "unzipFile:file=${file.path}: ${Thread.currentThread()}")
unzipFile(file)
}.flowOn(Dispatchers.IO).collect { folderPath ->
//拿到文件夹路径
Log.d("TestFlow", "folderPath=$folderPath: ${Thread.currentThread()}")
}
}
控制台结果输出:
TestFlow: saveBitmap: Thread[DefaultDispatcher-worker-1,5,main]
TestFlow: bitmapLocalPath=/mnt/sdcard/Android/data/com.wangjiang.example/files/images/flow.png: Thread[main,5,main]
TestFlow: downloadResource:url=https://www.wangjiang.example/coroutine.zip: Thread[DefaultDispatcher-worker-1,5,main]
TestFlow: unzipFile:file=/mnt/sdcard/Android/data/com.wangjiang.example/files/zips/coroutine.zip: Thread[DefaultDispatcher-worker-1,5,main]
TestFlow: downloadResource:url=https://www.wangjiang.example/flow.zip: Thread[DefaultDispatcher-worker-1,5,main]
TestFlow: unzipFile:file=/mnt/sdcard/Android/data/com.wangjiang.example/files/zips/flow.zip: Thread[DefaultDispatcher-worker-1,5,main]
TestFlow: folderPath=/mnt/sdcard/Android/data/com.wangjiang.example/files/zips/coroutine: Thread[main,5,main]
TestFlow: folderPath=/mnt/sdcard/Android/data/com.wangjiang.example/files/zips/flow: Thread[main,5,main]可以看到,和 RxJava 实现的效果是一致的。首先,使用launch启动一个协程,然后使用源数据创建一个 Flow(数据生产),再经过 flatMapConcat, map 变换(多个中间操作),最后通过collect获取结果数据(数据消费),这其中还包括线程切换:在主线程中启动子线程执行耗时任务,并将耗时任务结果返回给主线程(flowOn 指定了中间操作在 IO 线程中执行)。所以 协程 和 Flow(数据流) 结合,就是 响应式编程 的实现,这对我们来说,使用它可以在 Kotlin 环境中写出优雅的异步代码来做并发编程。
下面再分别来熟悉一下 协程 和 Flow。
协程概念
首先来看一下协程中的一些概念和 API。
CoroutineScope: 定义协程的 scope。
CoroutineScope 会跟踪它使用 launch 或 async 创建的所有协程。您可以随时调用 scope.cancel() 以取消正在进行的工作(即正在运行的协程)。在 Android 中,某些 KTX 库为某些生命周期类提供自己的 CoroutineScope。例如,ViewModel 有 viewModelScope,Lifecycle 有 lifecycleScope。不过,与调度程序不同,CoroutineScope 不运行协程。
Kotlin 提供了为 UI 组件使用的 MainScope:
public fun MainScope(): CoroutineScope = ContextScope(SupervisorJob() + Dispatchers.Main)为应用程序整个生命周期使用的 GlobalScope:
public object GlobalScope : CoroutineScope {
/**
* Returns [EmptyCoroutineContext].
*/
override val coroutineContext: CoroutineContext
get() = EmptyCoroutineContext
}因为是应用程序整个生命周期,所以要慎重使用。
也可以自定义 Scope:
val scope = CoroutineScope(Job() + Dispatchers.Main)另外,Android KTX 库针对 CoroutineScope 做了扩展,所以在 Android 中通常会使用 Activity 或 Fragment 生命周期相关的 lifecycleScope,和 ViewModel 生命周期相关的viewModelScope 。
public val Lifecycle.coroutineScope: LifecycleCoroutineScope
get() {
while (true) {
val existing = mInternalScopeRef.get() as LifecycleCoroutineScopeImpl?
if (existing != null) {
return existing
}
val newScope = LifecycleCoroutineScopeImpl(
this,
SupervisorJob() + Dispatchers.Main.immediate
)
if (mInternalScopeRef.compareAndSet(null, newScope)) {
newScope.register()
return newScope
}
}
}public val ViewModel.viewModelScope: CoroutineScope
get() {
val scope: CoroutineScope? = this.getTag(JOB_KEY)
if (scope != null) {
return scope
}
return setTagIfAbsent(
JOB_KEY,
CloseableCoroutineScope(SupervisorJob() + Dispatchers.Main.immediate)
)
}
internal class CloseableCoroutineScope(context: CoroutineContext) : Closeable, CoroutineScope {
override val coroutineContext: CoroutineContext = context
override fun close() {
coroutineContext.cancel()
}
}启动协程: launch 和 async
启动协程有两种方式:
launch:启动一个新的协程,并返回一个Job,这个Job是可以取消的Job.cancel;async:也会启动一个新的协程,并返回一个Deferred接口实现,这个接口其实也继承了Job接口,可以使用await挂起函数等待返回结果。
CoroutineContext: 协程上下文
val scope = CoroutineScope(Job() + Dispatchers.Main)在 CoroutineScope 中定义了 plus 操作:
public operator fun CoroutineScope.plus(context: CoroutineContext): CoroutineScope =
ContextScope(coroutineContext + context)因为 Job 和 Dispatchers 顶层都继承了接口 Element,而 Element 又继承了接口 CoroutineContext:
public interface Element : CoroutineContext所以 Job() 和 Dispatchers.Main 可以相加。这里 CoroutineScope 的构造方法中是必须要有 Job(),如果没有,它自己也会创建一个 Job():
public fun CoroutineScope(context: CoroutineContext): CoroutineScope =
ContextScope(if (context[Job] != null) context else context + Job())Job 和 CoroutineDispatcher 在 CoroutineContext 中的作用是:
Job:控制协程的生命周期。
CoroutineDispatcher:将工作分派到适当的线程。
CoroutineDispatcher:协程调度器与线程
- Dispatchers.Default:默认调度器,指示此协程应在为 cpu 计算操作预留的线程上执行;
- Dispatchers.Main:指示此协程应在为 UI 操作预留的主线程上执行;
- Dispatchers.IO:指示此协程应在为 I/O 操作预留的线程上执行。
GlobalScope.launch(Dispatchers.Main) {
}withContext(Dispatchers.IO){
}.flowOn(Dispatchers.IO)小结
要使用协程,首先创建一个 scope: CoroutineScope 来负责管理协程,定义scope 时需要指定控制协程的生命周期的 Job和将工作分派到适当线程的CoroutineDispatcher。定义好 scope 后, 可通过 scope.launch启动一个协程,也可以多次使用scope.launch启动多个协程,启动的协程可通过 scope.cancel取消,但它取消的是 scope 启动的所有协程。如果要取消单个协程,需要使用scope.launch返回的 Job 来取消Job.cancel,这个 Job 控制着单个协程的生命周期。当启动协程后,主线程中的任务依然可以继续执行,在执行launch{}时,可以通过 withContext(Dispatchers.IO)将协程的执行操作移至一个 I/O 子线程,子线程执行完任务,再将结果返回主线程继续执行。
简单示例:
//主线程分派任务
private val scope = CoroutineScope(Job() + Dispatchers.Main)
//管理对应的协程的生命周期
private var job1: Job? = null
fun exec() {
//启动一个协程
job1 = scope.launch {
//子线程执行耗时任务
withContext(Dispatchers.IO){
}
}
//启动一个协程
val job2 = scope.launch {
//启动一个协程
val taskResult1 = async {
//子线程执行耗时任务
withContext(Dispatchers.IO){
}
}
val taskResult2 = async {
//子线程执行耗时任务
withContext(Dispatchers.IO){
}
}
//taskResult1 和 taskResult2 都返回结果才会继续执行
taskResult1.await() + taskResult2.await()
}
}
fun cancelJob() {
//取消 job1 对应的协程
job1?.cancel("cancel job1")
}
fun cancelScope() {
//取消 scope 对应的所有协程
scope.cancel("cancel scope")
}在上面的例子中:
scope:定义主线程分派任务的 scope 来跟踪它使用 launch 或 async 创建的所有协程;job1:管理它对应的协程的生命周期;withContext(Dispatchers.IO):切换到子线程执行耗时任务;cancelJob会取消 job1 对应的协程;cancelScope会取消 scope 启动的所有协程。
Flow 数据流
了解了 Kotlin 协程的一些基础 概念和 API 后,知道了协程的基本使用。接下来,再了解一下 Kotlin Flow 相关的概念和 API。
Kotlin 中的 Flow API 旨在异步处理按顺序执行的数据流。Flow 本质上是一个 Sequence。我们可以像对 Kotlin 中 Sequence 一样来操作Flow:变换,过滤,映射等。Kotlin Sequences 和 Flow 的主要区别在于 Flow 可以挂起。
如果有理解 Kotlin Sequence,那其实很好理解 Kotlin Flow。刚好,在前面一篇 Kotlin 惰性集合操作-序列 Sequence文章中,有分析 Sequence 的原理,这里也可以把 Flow 按照类似的原理进行理解。
val sequenceResult = intArrayOf(1, 2, 3).asSequence().map { it * it }.toList()
MainScope().launch{
val flowResult = intArrayOf(1, 2, 3).asFlow().map { it * it }.toList(mutableListOf())
}上面 sequenceResult 和 flowResult 的值都是:[1, 4, 9]。
在 Sequence 中,如果没有末端操作,中间操作不会被执行。在 Flow 中也是一样,如果数据流没有数据消费collect ,中间操作也不会被执行。
flowOf(bitmap).map { bmp ->
//在子线程中执行耗时操作,存储 bitmap 到本地
saveBitmap(bmp)
}.flowOn(Dispatchers.Default)上面代码中,map 操作不会被执行。
一个完整的数据流应该包含:数据生产( flowOf , asFlow, flow{} )→ 中间操作(map, filter等)→ 数据消费(collect,asList,asSet等)。下面将分别了解相关操作。
数据流:数据生产
数据生产主要是通过数据源构建数据流。可以使用 Builders.kt 中提供的 Flow 相关扩展方法,如:
intArrayOf(1, 2, 3).asFlow().map { it * it }val downloadUrl = "https://github.com/ReactiveX/RxJava"
flowOf(downloadUrl).map { downloadZip(it) }(1..10).asFlow().filter { it % 2 == 0 }通常使用 flowOf 和 asFlow方法直接构建数据流。它们创建的都是冷流:
冷流:这段 flow 构建器中的代码直到流被收集(collect)的时候才运行。
也可以通过 flow{} 来构建数据流,使用emit方法将数据源添加到数据流中:
flow<Int> {
emit(1)
withContext(Dispatchers.IO){
emit(2)
}
emit(3)
}.map { it * it }不管是 flowOf,asFlow 还是 flow{},它们都会实现接口 FlowCollector:
public fun <T> flow(@BuilderInference block: suspend FlowCollector<T>.() -> Unit): Flow<T> = SafeFlow(block)
internal inline fun <T> unsafeFlow(@BuilderInference crossinline block: suspend FlowCollector<T>.() -> Unit): Flow<T> {
return object : Flow<T> {
override suspend fun collect(collector: FlowCollector<T>) {
collector.block()
}
}
}接口 FlowCollector 提供的 emit 方法,负责将源数据添加到数据流中:
public fun interface FlowCollector<in T> {
/**
* Collects the value emitted by the upstream.
* This method is not thread-safe and should not be invoked concurrently.
*/
public suspend fun emit(value: T)
}总结:构建数据流可以使用 Flow 相关扩展方法: flowOf , asFlow, flow{},它们都是通过接口 FlowCollector 提供的 emit 方法,将源数据添加到数据流中。
数据流:中间操作
中间操作主要修改发送到数据流的值,或修正数据流本身。如 filter, map, flatMapConcat 操作等:
intArrayOf(1, 2, 3).asFlow().map { it * it }.collect{ }
(1..100).asFlow().filter { it % 2 == 0 }.collect{ }
val data = hashMapOf<String, List<String>>(
"Java" to arrayListOf<String>("xiaowang", "xiaoli"),
"Kotlin" to arrayListOf<String>("xiaozhang", "xiaozhao")
)
flow<Map<String, List<String>>> {
emit(data)
}.flatMapConcat {
it.values.asFlow()
}.collect{ }中间操作符有很多,根据使用场景大概可分为:
- 转换操作符:简单转换可以使用过滤
filter,映射map操作,复杂转换可以使用变换transform操作; - 限长过渡操作符:在流触及相应限制的时候会将它的执行取消,可以使用获取
take操作,take(2)表示只获取前两个值; - 丢弃操作符:丢弃流中结果值,可以使用丢弃
drop操作,drop(2)表示丢弃前两个值; - 展平操作符:将给定的流展平为单个流,
flatMapConcat与flattenConcat操作表示顺序收集传入的流操作,flatMapMerge与flattenMerge操作表示并发收集所有传入的流,并将它们的值合并到一个单独的流,以便尽快的发射值操作,flatMapLatest操作表示以展平的方式收集最新的流操作; - 组合操作符:将多个流组合,
zip操作表示组合两个流的值,两个流都有值才进行组合操作,combine操作表示组合两个流最新的值,每次组合的时候都是使用每个流最新的值; - 缓冲操作符:当数据生产比数据消费快的时候,可以使用缓冲
buffer操作,在数据消费的时候可以缩短时间; - 合并操作符:合并发射项,不对每个值进行处理,可以使用合并
conflate操作,跳过中间值; - flowOn 操作符:更改流发射的上下文,会将
flowOn操作前的操作切换到 flowOn 指定的上下文Dispatchers.Default,Dispatchers.IO,Dispatchers.Main,也就是指定前面的操作所执行的线程;
上面介绍了主要的操作符的大致使用场景,操作符详细解释可以查看官方文档:异步流。
中间操作符代码示例:
(1..3).asFlow().take(2).collect{
//收集到结果值 1,2
}(1..3).asFlow().drop(2).collect{
//收集到结果值 3
} private fun downloadVideo(videoUrl: String): Pair<String, String> {
return Pair(videoUrl, "videoFile")
}
private fun downloadAudio(audioUrl: String): Pair<String, String> {
return Pair(audioUrl, "audioFile")
}
private fun downloadImage(imageUrl: String): Pair<String, String> {
return Pair(imageUrl, "imageFile")
}
MainScope().launch {
val imageDownloadUrls = arrayListOf<String>("image1", "image2")
val audioDownloadUrls = arrayListOf<String>("audio1", "audio2", "audio3")
val videoDownloadUrls = arrayListOf<String>("video1", "video2", "video3", "video4")
val imageFlows = imageDownloadUrls.asFlow().map {
downloadImage(it)
}
val audioFlows = audioDownloadUrls.asFlow().map {
downloadAudio(it)
}
val videoFlows = videoDownloadUrls.asFlow().map {
downloadVideo(it)
}
merge(imageFlows, audioFlows, videoFlows).flowOn(Dispatchers.IO).onEach {
Log.d("TestFlow", "result=$it")
}.collect()
}
控制台输出结果:
TestFlow: result=(image1, imageFile)
TestFlow: result=(image2, imageFile)
TestFlow: result=(audio1, audioFile)
TestFlow: result=(audio2, audioFile)
TestFlow: result=(audio3, audioFile)
TestFlow: result=(video1, videoFile)
TestFlow: result=(video2, videoFile)
TestFlow: result=(video3, videoFile)
TestFlow: result=(video4, videoFile)
merge 操作符将多个流合并到一个流,支持并发。类似 RxJava 的 zip 操作(1..3).asFlow().onStart {
Log.d("TestFlow", "onStart:${Thread.currentThread()}")
}.flowOn(Dispatchers.Main).map {
Log.d("TestFlow", "map:$it,${Thread.currentThread()}")
if (it % 2 == 0)
throw IllegalArgumentException("fatal args:$it")
it * it
}.catch {
Log.d("TestFlow", "catch:${Thread.currentThread()}")
emit(-1)
}.flowOn(Dispatchers.IO)
.onCompletion { Log.d("TestFlow", "onCompletion:${Thread.currentThread()}") }
.onEach {
Log.d("TestFlow", "onEach:$it,${Thread.currentThread()}")
}.collect()
控制台输出结果:
TestFlow: onStart:Thread[main,5,main]
TestFlow: map:1,Thread[DefaultDispatcher-worker-3,5,main]
TestFlow: map:2,Thread[DefaultDispatcher-worker-3,5,main]
TestFlow: catch:Thread[DefaultDispatcher-worker-3,5,main]
TestFlow: onEach:1,Thread[main,5,main]
TestFlow: onEach:-1,Thread[main,5,main]
TestFlow: onCompletion:Thread[main,5,main]
flowOn 指定 onStart 在主线程中执行(Dispatchers.Main),指定 map 和 catch 在 IO 线程中执行(Dispatchers.IO)总结:中间操作其实就是数据流的变换操作,与 Sequence 和 RxJava 的变换操作类似。
数据流:数据消费
数据消费就是使用数据流的结果值。末端操作符最常使用 collect来收集流结果值:
(1..3).asFlow().collect{
//收集到结果值 1,2,3
}除了 collect 操作符外,还有一些操作符可以获取数据流结果值:
collectLatest:使用数据流的最新值;toList或toSet等:将数据流结果值转换为集合;first:获取数据流的第一个结果值;single:确保流发射单个(single)值;reduce:累积数据流中的值;fold:给定一个初始值,再累积数据流中的值。
末端操作符代码示例:
(1..3).asFlow().collectLatest {
delay(300)
//只能获取到3
}//转换为 List 集合 [1,2,3]
val list = (1..3).asFlow().toList()
//转换为 Set 集合 [1,2,3]
val set = (1..3).asFlow().toSet()val first = (1..3).asFlow().first()
//first 为第一个结果值 1val single = (1..3).asFlow().single()
//流不是发射的单个值,会抛异常val reduce = (1..3).asFlow().reduce { a, b ->
a + b
}
//reduce 的值为6=1+2+3 val fold = (1..3).asFlow().fold(10) { a, b ->
a + b
}
//fold 的值为16=10+1+2+3 除了上面这些末端操作符,在末端之前还关联着一些操作符:
onStart:在数据流结果值收集之前调用;onCompletion:在数据流结果值收集之后调用;onEmpty:在数据流完成而不发出任何元素时调用;onEach:在数据流结果值收集时迭代流的每个值;catch:在收集数据流结果时,声明式捕获异常。
末端关联操作符代码示例:
(1..3).asFlow().onStart {
Log.d("TestFlow", "onStart")
}.map {
if (it % 2 == 0)
throw IllegalArgumentException("fatal args:$it")
it * it
}.catch { emit(-1) }.onCompletion { Log.d("TestFlow", "onCompletion") }.onEach {
Log.d("TestFlow", "onEach:$it")
}.collect()
控制台输出结果:
TestFlow: onStart
TestFlow: onEach:1
TestFlow: onEach:-1
TestFlow: onCompletion总结:数据流进行数据消费时,可以结合末端操作符输出集合,累积值等,当要监听数据流收集结果值开始或结束,可以使用 onStart 和 onCompletion,当遇到流抛出异常,可以声明 catch进行异常处理。
总结
响应式编程,可以理解为一种面向数据流编程的方式,也就是使用数据源构建数据流 → 修改数据流中的值 → 处理数据流结果值,在这个过程中,一系列的事件或操作都是按顺序发生的。在 Java 环境中,RxJava 框架实现了响应式编程,它结合了数据流、观察者模式、线程框架;在 Kotlin 环境中,Kotlin 协程和 Flow 结合在一起实现了响应式编程,其中协程就是线程框架,Flow 就是数据流。不管是 RxJava 还是 Kotlin 协程和 Flow 的实现的响应式编程,它们的目的都是为了:使用优雅,简洁,易阅读,易维护的代码来编写并发编程,处理异步操作事件。另外,Android LifeCycle 和 ViewModel 对 Kotlin 协程和 Flow 进行了扩展支持,这也对异步事件进行生命周期管理更方便。
参考文档:
- GitHub RxJava:RxJava
- Kotlin Flow 操作符:异步流
- Google Android developer Kotlin Flow :Android 上的 Kotlin 数据流
下一篇将探索 Kotlin Flow 冷流和热流。
链接:https://juejin.cn/post/7187586519534829623
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
基于 Android 系统方案适配 Night Mode 后,老板要再加一套皮肤?
背景说明
原本已经基于系统方案适配了暗黑主题,实现了白/黑两套皮肤,以及跟随系统。后来老板研究学习友商时,发现友商 App 有三套皮肤可选,除了常规的亮白和暗黑,还有一套暗蓝色。并且在跟随系统暗黑模式下,用户可选暗黑还是暗蓝。这不,新的需求马上就来了。
其实我们之前两个 App 的换肤方案都是使用 Android-skin-support 来做的,在此基础上再加套皮肤也不是难事。但在新的 App 实现多皮肤时,由于前两个 App 做了这么久都只有两套皮肤,而且新的 App 需要实现跟随系统,为了更好的体验和较少的代码实现,就采用了系统方案进行适配暗黑模式。
以 Android-skin-support 和系统两种方案适配经验来看,系统方案适配改动的代码更少,所花费的时间当然也就更少了。所以在需要新添一套皮肤的时候,也不可能再去切方案了。那么在使用系统方案的情况下,如何再加一套皮肤呢?来,先看源码吧。
源码分析
以下源码基于 android-31
首先,在代码中获取资源一般通过 Context 对象的一些方法,例如:
// Context.java
@ColorInt
public final int getColor(@ColorRes int id) {
return getResources().getColor(id, getTheme());
}
@Nullable
public final Drawable getDrawable(@DrawableRes int id) {
return getResources().getDrawable(id, getTheme());
}可以看到 Context 是通过 Resources 对象再去获取的,继续看 Resources:
// Resources.java
@ColorInt
public int getColor(@ColorRes int id, @Nullable Theme theme) throws NotFoundException {
final TypedValue value = obtainTempTypedValue();
try {
final ResourcesImpl impl = mResourcesImpl;
impl.getValue(id, value, true);
if (value.type >= TypedValue.TYPE_FIRST_INT
&& value.type <= TypedValue.TYPE_LAST_INT) {
return value.data;
} else if (value.type != TypedValue.TYPE_STRING) {
throw new NotFoundException("Resource ID #0x" + Integer.toHexString(id) + " type #0x" + Integer.toHexString(value.type) + " is not valid");
}
// 这里调用 ResourcesImpl#loadColorStateList 方法获取颜色
final ColorStateList csl = impl.loadColorStateList(this, value, id, theme);
return csl.getDefaultColor();
} finally {
releaseTempTypedValue(value);
}
}
public Drawable getDrawable(@DrawableRes int id, @Nullable Theme theme)
throws NotFoundException {
return getDrawableForDensity(id, 0, theme);
}
@Nullable
public Drawable getDrawableForDensity(@DrawableRes int id, int density, @Nullable Theme theme) {
final TypedValue value = obtainTempTypedValue();
try {
final ResourcesImpl impl = mResourcesImpl;
impl.getValueForDensity(id, density, value, true);
// 看到这里
return loadDrawable(value, id, density, theme);
} finally {
releaseTempTypedValue(value);
}
}
@NonNull
@UnsupportedAppUsage(maxTargetSdk = Build.VERSION_CODES.R, trackingBug = 170729553)
Drawable loadDrawable(@NonNull TypedValue value, int id, int density, @Nullable Theme theme)
throws NotFoundException {
// 这里调用 ResourcesImpl#loadDrawable 方法获取 drawable 资源
return mResourcesImpl.loadDrawable(this, value, id, density, theme);
}到这里我们知道在代码中获取资源时,是通过 Context -> Resources -> ResourcesImpl 调用链实现的。
先看 ResourcesImpl.java:
/**
* The implementation of Resource access. This class contains the AssetManager and all caches
* associated with it.
*
* {@link Resources} is just a thing wrapper around this class. When a configuration change
* occurs, clients can retain the same {@link Resources} reference because the underlying
* {@link ResourcesImpl} object will be updated or re-created.
*
* @hide
*/
public class ResourcesImpl {
...
}虽然是 public 的类,但是被 @hide 标记了,意味着想通过继承后重写相关方法这条路行不通了,pass。
再看 Resources.java,同样是 public 类,但没被 @hide 标记。我们就可以通过继承 Resources 类,然后重写 Resources#getColor 和 Resources#getDrawableForDensity 等方法来改造获取资源的逻辑。
先看相关代码:
// SkinResources.kt
class SkinResources(context: Context, res: Resources) : Resources(res.assets, res.displayMetrics, res.configuration) {
val contextRef: WeakReference<Context> = WeakReference(context)
override fun getDrawableForDensity(id: Int, density: Int, theme: Theme?): Drawable? {
return super.getDrawableForDensity(resetResIdIfNeed(contextRef.get(), id), density, theme)
}
override fun getColor(id: Int, theme: Theme?): Int {
return super.getColor(resetResIdIfNeed(contextRef.get(), id), theme)
}
private fun resetResIdIfNeed(context: Context?, resId: Int): Int {
// 非暗黑蓝无需替换资源 ID
if (context == null || !UIUtil.isNightBlue(context)) return resId
var newResId = resId
val res = context.resources
try {
val resPkg = res.getResourcePackageName(resId)
// 非本包资源无需替换
if (context.packageName != resPkg) return newResId
val resName = res.getResourceEntryName(resId)
val resType = res.getResourceTypeName(resId)
// 获取对应暗蓝皮肤的资源 id
val id = res.getIdentifier("${resName}_blue", resType, resPkg)
if (id != 0) newResId = id
} finally {
return newResId
}
}
}主要原理与逻辑:
- 所有资源都会在
R.java文件中生成对应的资源 id,而我们正是通过资源 id 来获取对应资源的。 Resources类提供了getResourcePackageName/getResourceEntryName/getResourceTypeName方法,可通过资源 id 获取对应的资源包名/资源名称/资源类型。- 过滤掉无需替换资源的场景。
Resources还提供了getIdentifier方法来获取对应资源 id。- 需要适配暗蓝皮肤的资源,统一在原资源名称的基础上加上
_blue后缀。 - 通过
Resources#getIdentifier方法获取对应暗蓝皮肤的资源 id。如果没找到,改方法会返回0。
现在就可以通过 SkinResources 来获取适配多皮肤的资源了。但是,之前的代码都是通过 Context 直接获取的,如果全部替换成 SkinResources 来获取,那代码改动量就大了。
我们回到前面 Context.java 的源码,可以发现它获取资源时,都是通过 Context#getResources 方法先得到 Resources 对象,再通过其去获取资源的。而 Context#getResources 方法也是可以重写的,这意味着我们可以维护一个自己的 Resources 对象。Application 和 Activity 也都是继承自 Context 的,所以我们在其子类中重写 getResources 方法即可:
// BaseActivity.java/BaseApplication.java
private Resources mSkinResources;
@Override
public Resources getResources() {
if (mSkinResources == null) {
mSkinResources = new SkinResources(this, super.getResources());
}
return mSkinResources;
}到此,基本逻辑就写完了,马上 build 跑起来。
咦,好像有点不太对劲,有些 color 或 drawable 没有适配成功。
经过一番对比,发现 xml 布局中的资源都没有替换成功。
那么问题在哪呢?还是先从源码着手,先来看看 View 是如何从 xml 中获取并设置 background 属性的:
// View.java
public View(Context context, @Nullable AttributeSet attrs, int defStyleAttr, int defStyleRes) {
this(context);
// AttributeSet 是 xml 中所有属性的集合
// TypeArray 则是经过处理过的集合,将原始的 xml 属性值("@color/colorBg")转换为所需的类型,并应用主题和样式
final TypedArray a = context.obtainStyledAttributes(
attrs, com.android.internal.R.styleable.View, defStyleAttr, defStyleRes);
...
Drawable background = null;
...
final int N = a.getIndexCount();
for (int i = 0; i < N; i++) {
int attr = a.getIndex(i);
switch (attr) {
case com.android.internal.R.styleable.View_background:
// TypedArray 提供一些直接获取资源的方法
background = a.getDrawable(attr);
break;
...
}
}
...
if (background != null) {
setBackground(background);
}
...
}再接着看 TypedArray 是如何获取资源的:
// TypedArray.java
@Nullable
public Drawable getDrawable(@StyleableRes int index) {
return getDrawableForDensity(index, 0);
}
@Nullable
public Drawable getDrawableForDensity(@StyleableRes int index, int density) {
if (mRecycled) {
throw new RuntimeException("Cannot make calls to a recycled instance!");
}
final TypedValue value = mValue;
if (getValueAt(index * STYLE_NUM_ENTRIES, value)) {
if (value.type == TypedValue.TYPE_ATTRIBUTE) {
throw new UnsupportedOperationException(
"Failed to resolve attribute at index " + index + ": " + value);
}
if (density > 0) {
// If the density is overridden, the value in the TypedArray will not reflect this.
// Do a separate lookup of the resourceId with the density override.
mResources.getValueForDensity(value.resourceId, density, value, true);
}
// 看到这里
return mResources.loadDrawable(value, value.resourceId, density, mTheme);
}
return null;
}TypedArray 是通过 Resources#loadDrawable 方法来加载资源的,而我们之前写 SkinResources 的时候并没有重写该方法,为什么呢?那是因为该方法是被 @UnsupportedAppUsage 标记的。所以,这就是 xml 布局中的资源替换不成功的原因。
这个问题又怎么解决呢?
之前采用 Android-skin-support 方案做换肤时,了解到它的原理,其会替换成自己的实现的 LayoutInflater.Factory2,并在创建 View 时替换生成对应适配了换肤功能的 View 对象。例如:将 View 替换成 SkinView,而 SkinView 初始化时再重新处理 background 属性,即可完成换肤。
AppCompat 也是同样的逻辑,通过 AppCompatViewInflater 将普通的 View 替换成带 AppCompat- 前缀的 View。
其实我们只需能操作生成后的 View,并且知道 xml 中写了哪些属性值即可。那么我们完全照搬 AppCompat 这套逻辑即可:
- 定义类继承
LayoutInflater.Factory2,并实现onCreateView方法。 onCreateView主要是创建 View 的逻辑,而这部分逻辑完全 copyAppCompatViewInflater类即可。- 在
onCreateView中创建 View 之后,返回 View 之前,实现我们自己的逻辑。 - 通过
LayoutInflaterCompat#setFactory2方法,设置我们自己的 Factory2。
相关代码片段:
public class SkinViewInflater implements LayoutInflater.Factory2 {
@Nullable
@Override
public View onCreateView(@Nullable View parent, @NonNull String name, @NonNull Context context, @NonNull AttributeSet attrs) {
// createView 方法就是 AppCompatViewInflater 中的逻辑
View view = createView(parent, name, context, attrs, false, false, true, false);
onViewCreated(context, view, attrs);
return view;
}
@Nullable
@Override
public View onCreateView(@NonNull String name, @NonNull Context context, @NonNull AttributeSet attrs) {
return onCreateView(null, name, context, attrs);
}
private void onViewCreated(@NonNull Context context, @Nullable View view, @NonNull AttributeSet attrs) {
if (view == null) return;
resetViewAttrsIfNeed(context, view, attrs);
}
private void resetViewAttrsIfNeed(Context context, View view, AttributeSet attrs) {
if (!UIUtil.isNightBlue(context)) return;
String ANDROID_NAMESPACE = "http://schemas.android.com/apk/res/android";
String BACKGROUND = "background";
// 获取 background 属性值的资源 id,未找到时返回 0
int backgroundId = attrs.getAttributeResourceValue(ANDROID_NAMESPACE, BACKGROUND, 0);
if (backgroundId != 0) {
view.setBackgroundResource(resetResIdIfNeed(context, backgroundId));
}
}
}// BaseActivity.java
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
SkinViewInflater inflater = new SkinViewInflater();
LayoutInflater layoutInflater = LayoutInflater.from(this);
// 生成 View 的逻辑替换成我们自己的
LayoutInflaterCompat.setFactory2(layoutInflater, inflater);
}至此,这套方案已经可以解决目前的换肤需求了,剩下的就是进行细节适配了。
其他说明
自定义控件与第三方控件适配
上面只对 background 属性进行了处理,其他需要进行换肤的属性也是同样的处理逻辑。如果是自定义的控件,可以在初始化时调用 TypedArray#getResourceId 方法先获取资源 id,再通过 context 去获取对应资源,而不是使用 TypedArray#getDrawable 类似方法直接获取资源对象,这样可以确保换肤成功。而第三方控件也可通过 background 属性同样的处理逻辑进行适配。
XML <shape> 的处理
<!-- bg.xml -->
<shape xmlns:android="http://schemas.android.com/apk/res/android">
<corners android:radius="8dp" />
<solid android:color="@color/background" />
</shape>上面的 bg.xml 文件内的 color 并不会完成资源替换,根据上面的逻辑,需要新增以下内容:
<!-- bg_blue.xml -->
<shape xmlns:android="http://schemas.android.com/apk/res/android">
<corners android:radius="8dp" />
<solid android:color="@color/background_blue" />
</shape>如此,资源替换才会成功。
设计的配合
这次对第三款皮肤的适配还是蛮轻松的,主要是有以下基础:
- 在适配暗黑主题的时候,设计有出设计规范,后续开发按照设计规范来。
- 暗黑和暗蓝共用一套图片资源,大大减少适配工作量。
- 暗黑和暗蓝部份共用颜色值含透明度,同样减少了工作量,仅少量颜色需要新增。
这次适配的主要工作量还是来自 <shape> 的替换。
暗蓝皮肤资源文件的归处
我知道很多换肤方案都会将皮肤资源制作成皮肤包,但是这个方案没有这么做。一是没有那么多需要替换的资源,二是为了减少相应的工作量。
我新建了一个资源文件夹,与 res 同级,取名 res-blue。并在 gradle 配置文件中配置它。编译后系统会自动将它们合并,同时也能与常规资源文件隔离开来。
// build.gradle
sourceSets {
main {
java {
srcDir 'src/main/java'
}
res.srcDirs += 'src/main/res'
res.srcDirs += 'src/main/res-blue'
}
}有哪些坑?
WebView 资源缺失导致闪退
版本上线后,发现有 android.content.res.Resources$NotFoundException 异常上报,具体异常堆栈信息:
android.content.res.ResourcesImpl.getValue(ResourcesImpl.java:321)
android.content.res.Resources.getInteger(Resources.java:1279)
org.chromium.ui.base.DeviceFormFactor.b(chromium-TrichromeWebViewGoogle.apk-stable-447211483:4)
org.chromium.content.browser.selection.SelectionPopupControllerImpl.n(chromium-TrichromeWebViewGoogle.apk-stable-447211483:1)
N7.onCreateActionMode(chromium-TrichromeWebViewGoogle.apk-stable-447211483:8)
Gu.onCreateActionMode(chromium-TrichromeWebViewGoogle.apk-stable-447211483:2)
com.android.internal.policy.DecorView$ActionModeCallback2Wrapper.onCreateActionMode(DecorView.java:3255)
com.android.internal.policy.DecorView.startActionMode(DecorView.java:1159)
com.android.internal.policy.DecorView.startActionModeForChild(DecorView.java:1115)
android.view.ViewGroup.startActionModeForChild(ViewGroup.java:1087)
android.view.ViewGroup.startActionModeForChild(ViewGroup.java:1087)
android.view.ViewGroup.startActionModeForChild(ViewGroup.java:1087)
android.view.ViewGroup.startActionModeForChild(ViewGroup.java:1087)
android.view.ViewGroup.startActionModeForChild(ViewGroup.java:1087)
android.view.ViewGroup.startActionModeForChild(ViewGroup.java:1087)
android.view.View.startActionMode(View.java:7716)
org.chromium.content.browser.selection.SelectionPopupControllerImpl.I(chromium-TrichromeWebViewGoogle.apk-stable-447211483:10)
Vc0.a(chromium-TrichromeWebViewGoogle.apk-stable-447211483:10)
Vf0.i(chromium-TrichromeWebViewGoogle.apk-stable-447211483:4)
A5.run(chromium-TrichromeWebViewGoogle.apk-stable-447211483:3)
android.os.Handler.handleCallback(Handler.java:938)
android.os.Handler.dispatchMessage(Handler.java:99)
android.os.Looper.loopOnce(Looper.java:233)
android.os.Looper.loop(Looper.java:334)
android.app.ActivityThread.main(ActivityThread.java:8333)
java.lang.reflect.Method.invoke(Native Method)
com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:582)
com.android.internal.os.ZygoteInit.main(ZygoteInit.java:1065)经查才发现在 WebView 中长按文本弹出操作菜单时,就会引发该异常导致 App 闪退。
这是其他插件化方案也踩过的坑,我们只需在创建 SkinResources 之前将外部 WebView 的资源路径添加进来即可。
@Override
public Resources getResources() {
if (mSkinResources == null) {
WebViewResourceHelper.addChromeResourceIfNeeded(this);
mSkinResources = new SkinResources(this, super.getResources());
}
return mSkinResources;
}
RePlugin/WebViewResourceHelper.java 源码文件
具体问题分析可参考
Fix ResourceNotFoundException in Android 7.0 (or above)
最终效果图
总结
这个方案在原本使用系统方式适配暗黑主题的基础上,通过拦截 Resources 相关获取资源的方法,替换换肤后的资源 id,以达到换肤的效果。针对 XML 布局换肤不成功的问题,复制 AppCompatViewInflater 创建 View 的代码逻辑,并在 View 创建成功后重新设置需要进行换肤的相关 XML 属性。同一皮肤资源使用单独的资源文件夹独立存放,可以与正常资源进行隔离,也避免了制作皮肤包而增加工作量。
目前来说这套方案是改造成本最小,侵入性最小的选择。选择适合自身需求的才是最好的。
链接:https://juejin.cn/post/7187282270360141879
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
使用 Jetpack Compose 做一个年度报告页面
刚刚结束的 2022 年,不少应用都给出了自己的 2022 年度报告。趁着这股热潮,我自己维护的应用《译站》 也来凑个热闹,用 Jetpack Compose 写了个报告页面。效果如下:
效果还算不错?如果需要实际体验的,可以前往 这里 下载翻译后打开底部最右侧 tab,即可现场看到。
制作过程
观察上图,需要完成的有三个难点:
- 闪动的数字
- 淡出 + 向上位移的微件们
- 有一部分微件不参与淡出(如 Spacer)
下面将详细介绍
闪动的数字
在我的上一篇文章 Jetpack Compose 十几行代码快速模仿即刻点赞数字切换效果 中,我基于 AnimatedContent 实现了 数字增加时自动做动画 的 Text,它的效果如下:
诶,既然如此,那实现这个数字跳动不就简单了吗?我们只需要让数字自动从 0 变成 目标数字,不就有了动画的效果吗?
此处我选择 Animatable ,并且使用 LauchedEffect 让数字自动开始递增,并把数字格式化为 0013(长度为目标数字的长度)传入到上次完成的微件中,这样一个自动跳动的动画就做好啦。
代码如下:
@Composable
fun AutoIncreaseAnimatedNumber(
modifier: Modifier = Modifier,
number: Int,
durationMills: Int = 10000,
textPadding: PaddingValues = PaddingValues(horizontal = 8.dp, vertical = 12.dp),
textSize: TextUnit = 24.sp,
textColor: Color = Color.Black,
textWeight: FontWeight = FontWeight.Normal
) {
// 动画,Animatable 相关介绍可以见 https://compose.funnysaltyfish.fun/docs/design/animation/animatable?source=trans
val animatedNumber = remember {
androidx.compose.animation.core.Animatable(0f)
}
// 数字格式化后的长度
val l = remember {
number.toString().length
}
// Composable 进入 Composition 阶段时开启动画
LaunchedEffect(number) {
animatedNumber.animateTo(
targetValue = number.toFloat(),
animationSpec = tween(durationMillis = durationMills)
)
}
NumberChangeAnimatedText(
modifier = modifier,
text = "%0${l}d".format(animatedNumber.value.roundToInt()),
textPadding = textPadding,
textColor = textColor,
textSize = textSize,
textWeight = textWeight
)
}
@OptIn(ExperimentalAnimationApi::class)
@Composable
fun NumberChangeAnimatedText(
modifier: Modifier = Modifier,
text: String,
textPadding: PaddingValues = PaddingValues(horizontal = 8.dp, vertical = 12.dp),
textSize: TextUnit = 24.sp,
textColor: Color = Color.Black,
textWeight: FontWeight = FontWeight.Normal,
) {
Row(modifier = modifier) {
text.forEach {
AnimatedContent(
targetState = it,
transitionSpec = {
slideIntoContainer(AnimatedContentScope.SlideDirection.Up) with
fadeOut() + slideOutOfContainer(AnimatedContentScope.SlideDirection.Up)
}
) { char ->
Text(text = char.toString(), modifier = modifier.padding(textPadding), fontSize = textSize, color = textColor, fontWeight = textWeight)
}
}
}
}这样就完成啦~
淡出 + 向上位移的微件们
实际上,这个标题的难点在于“们”这个字,这意味着不但要完成“向上+淡出”的效果,还要有序,一个一个来。
对于这个问题,因为我的需求很简单:所有微件竖着排列,自上而下逐渐淡出。因此,我选择的解决思路是:自定义布局。(这不一定是唯一的思路,如果你有更好的方法,也欢迎一起探讨)。下面我们慢慢拆解:
微件竖着放
这其实是最简单的一步,你可以阅读我曾经写的 深入Jetpack Compose——布局原理与自定义布局(一) 来了解。简单来说,我们只需要依次摆放所有微件,然后把总宽度设为宽度最大值,总高度设为高度之和即可。代码如下:
@Composable
fun AutoFadeInComposableColumn(
modifier: Modifier = Modifier,
content: @Composable FadeInColumnScope.() -> Unit
) {
val measurePolicy = MeasurePolicy { measurables, constraints ->
val placeables = measurables.map { measurable ->
measurable.measure(constraints.copy(minHeight = 0, minWidth = 0))
}
var y = 0
// 宽度:父组件允许的最大宽度,高度:微件高之和
layout(constraints.maxWidth, placeables.sumOf { it.height }) {
// 依次摆放
placeables.forEachIndexed { index, placeable ->
placeable.placeRelativeWithLayer(0, y){
alpha = 1
}
y += placeable.height
}.also {
// 重置高度
y = 0
}
}
}
Layout(modifier = modifier, content = { FadeInColumnScopeInstance.content() }, measurePolicy = measurePolicy)
}上面的例子就是最简单的自定义布局了,它可以实现内部的 Composable 从上到下竖着排列。注意的是,在 place 的时候,我们使用了 placeRelativeWithLayer ,它可以调整组件的 alpha(还有 rotation/transform),这个未来会被用于实现淡出效果。
一个一个淡出
到了关键的一步了。我们不妨想一想,淡出就是 alpha 从 0->1,y 偏移从 offsetY -> 0 的过程,因此我们只需要在 place 时控制一下两者的值就行。作为一个动画过程,自然可以使用 Animatable。现在的问题是:需要几个 Animatable 呢?
自然,你可以选择使用 n 个 Animatable 分别控制 n 个微件,不过考虑到同一时刻其实只有一个 @Composable 在做动画,因此我选择只用一个。因此我们需要增加一些变量:
- currentFadeIndex 记录当前是哪个微件在播放动画
- finishedFadeIndex 记录播放完成的最后一个微件的 index,用于检查动画是否结束了
实话说这两个变量或许可以合成一个,不过既然写成了两个,那就先这样写下去吧。
两个状态可以只放到 Layout 里面,也可以放到专门的 State 中,考虑到外部可能要用到(嘿嘿,其实是真的要用到)两个值,我们单独写一个 State 吧
class AutoFadeInColumnState {
var currentFadeIndex by mutableStateOf(-1)
var finishedFadeIndex by mutableStateOf(0)
companion object {
val Saver = listSaver<AutoFadeInColumnState, Int>(
save = { listOf(it.currentFadeIndex, it.finishedFadeIndex) },
restore = {
AutoFadeInColumnState().apply {
currentFadeIndex = it[0]; finishedFadeIndex = it[1]
}
}
)
}
}
@Composable
fun rememberAutoFadeInColumnState(): AutoFadeInColumnState {
return rememberSaveable(saver = AutoFadeInColumnState.Saver) { AutoFadeInColumnState() }
}接下来,为我们的自定义 Composable 添加几个参数吧
@Composable
fun AutoFadeInComposableColumn(
modifier: Modifier = Modifier,
state: AutoFadeInColumnState = rememberAutoFadeInColumnState(),
fadeInTime: Int = 1000, // 单个微件动画的时间
fadeOffsetY: Int = 100, // 单个微件动画的偏移量
content: @Composable FadeInColumnScope.() -> Unit
)接下来就是关键,修改 place 的代码完成动画效果。
// ...
placeables.forEachIndexed { index, placeable ->
// @1 实际的 y,对于动画中的微件减去偏移量,对于未动画的微件不变
val actualY = if (state.currentFadeIndex == index) {
y + (( 1 - fadeInAnimatable.value) * fadeOffsetY).toInt()
} else {
y
}
placeable.placeRelativeWithLayer(0, actualY){
// @2
alpha = if (index == state.currentFadeIndex) fadeInAnimatable.value else
if (index <= state.finishedFadeIndex) 1f else 0f
}
y += placeable.height
}.also {
y = 0
}相较于之前,代码有两处主要更改。@1 处更改微件的 y,对于动画中的微件减去偏移量,对于未动画的微件不变,以实现 “位移” 的效果; @2 处则设置 alpha 值实现淡出效果,具体逻辑如下:
- 如果是正在动画的那个,alpha 就是当前动画的值,实现渐渐淡出的效果
- 否则,对于已经执行完动画的,alpha 正常为 1;否则为 0(还没轮到它们显示)
接下来,问题在于执行完一个如何执行下一个了。我的思路是这样的:添加一个 LauchedState(state.currentFadeIndex) 使得在 currentFadeIndex 变化时(这表示当前执行动画的微件变了)重新把 Animatable 置0,开启动画效果。动画完成后又把 currentFadeIndex 加一,直至完成所有。代码如下:
@Composable
fun xxx(...){
LaunchedEffect(state.currentFadeIndex){
if (state.currentFadeIndex == -1) {
// 找到第一个需要渐入的元素
state.currentFadeIndex = 0
}
// 开始动画
fadeInAnimatable.animateTo(
targetValue = 1f,
animationSpec = tween(
durationMillis = fadeInTime,
easing = LinearEasing
)
)
// 动画播放完了,更新 finishedFadeIndex
state.finishedFadeIndex = state.currentFadeIndex
// 全部动画完了,退出
if(state.finishedFadeIndex >= whetherFadeIn.size - 1) return@LaunchedEffect
state.currentFadeIndex += 1
fadeInAnimatable.snapTo(0f) // snapTo(0f) 无动画直接置0
}
}到这里,一个 内部子微件依次淡出 的自定义布局已经基本完成了。下面问题来了:在 Compose 中,我们使用 Spacer 创建间隔,但是往往 Spacer 是不需要动画的。因此我们需要支持一个特性:允许设置某些 Composable 不做动画,也就是直接跳过它们。这种子微件告诉父微件信息的时期,当然要交给 ParentData 来做
允许部分 Composable 不做动画
要了解 ParentData,您可以参考我的文章 深入Jetpack Compose——布局原理与自定义布局(四)ParentData,此处不再赘述。
我们添加一个 class FadeInColumnData(val fade: Boolean = true) 和 对应的 Modifier,用于指定某些 Composable 跳过动画。考虑到这个特定的 Modifier 只能用在我们这个布局,因此需要加上 scope 的限制。这些代码如下:
class FadeInColumnData(val fade: Boolean = true) : ParentDataModifier {
override fun Density.modifyParentData(parentData: Any?): Any =
this@FadeInColumnData
}
interface FadeInColumnScope {
@Stable
fun Modifier.fadeIn(whetherFadeIn: Boolean = true): Modifier
}
object FadeInColumnScopeInstance : FadeInColumnScope {
override fun Modifier.fadeIn(whetherFadeIn: Boolean): Modifier = this.then(FadeInColumnData(whetherFadeIn))
}有了这个,我们上面的布局也得做相应的更改,具体来说:
- 需要增加一个列表
whetherFadeIn记录ParentData提供的值 - 开始的动画 index 不再是
0,而是找到的第一个需要做动画的元素 currentFadeIndex的更新需要找到下一个需要做动画的值
具体代码如下:
@Composable
fun AutoFadeInComposableColumn() {
var whetherFadeIn: List<Boolean> = arrayListOf()
// ...
LaunchedEffect(state.currentFadeIndex){
// 等待初始化完成
while (whetherFadeIn.isEmpty()){ delay(50) }
if (state.currentFadeIndex == -1) {
// 找到第一个需要渐入的元素
state.currentFadeIndex = whetherFadeIn.indexOf(true)
}
// 开始动画
// - state.currentFadeIndex = 0
for (i in state.finishedFadeIndex + 1 until whetherFadeIn.size){
if (whetherFadeIn[i]){
state.currentFadeIndex = i
fadeInAnimatable.snapTo(0f)
break
}
}
}
val measurePolicy = MeasurePolicy { measurables, constraints ->
// ...
whetherFadeIn = placeables.map { placeable ->
((placeable.parentData as? FadeInColumnData) ?: FadeInColumnData()).fade
}
// 宽度:父组件允许的最大宽度,高度:微件高之和
layout(constraints.maxWidth, placeables.sumOf { it.height }) {
// ...
}
}
Layout(modifier = modifier, content = { FadeInColumnScopeInstance.content() }, measurePolicy = measurePolicy)
}完成啦!
一点小问题
事实上,整个布局的大体到目前已经趋于完成,不过目前有点小问题:对于 AutoIncreaseAnimatedNumber ,它的动画执行时机是错误的。你可以想象:尽管数字没有显示出来(alpha 为 0),但实际上它已经被摆放了,因此数字跳动的动画已经开始了。对于这个问题,我的解决方案是为 AutoIncreaseAnimatedNumber 额外添加一个 Boolean 参数 startAnim,只有该值为 true 时才真正开始执行动画。
那么 startAnim 什么时候为 true 呢?就是 currentFadeIndex == 这个微件的 Index 时,这样就可以手工指定什么时候开始动画了。
代码如下:
@Composable
fun AutoIncreaseAnimatedNumber(
startAnim: Boolean = true,
...
) {
// Composable 进入 Composition 阶段,且 startAnim 为 true 时开启动画
LaunchedEffect(number, startAnim) {
if (startAnim)
animatedNumber.animateTo(
targetValue = number.toFloat(),
animationSpec = tween(durationMillis = durationMills)
)
}
NumberChangeAnimatedText(
...
)
}实际使用时
Row(verticalAlignment = Alignment.CenterVertically) {
AnimatedNumber(number = 110, startAnim = state.currentFadeIndex == 7) // 或者 >=,如果动画时间长于 fadeInTime 的话
ResultText(text = "次")
}完工!
Pager?
如你所想,整体的布局是用 Pager 实现的,这个用的是 google/accompanist: A collection of extension libraries for Jetpack Compose 内的实现。鉴于不是本篇重点,此处略过,感兴趣的可以看下面的代码。
代码
完整代码见 FunnyTranslation/AnnualReportScreen.kt at compose。
如果有用,欢迎 Star仓库 / 此处点赞 / 评论 ~
链接:https://juejin.cn/post/7186937474931753020
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何优雅的在Fragment中使用ViewBinding
前言
在Fragment中控制View十分简单,只需要声明+findViewById即可:
class FragmentA : Fragment() {
private lateinit var imageView: ImageView
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
super.onViewCreated(view, savedInstanceState)
imageView = view.findViewById(R.id.imageView)
}
}但这样同时也遇到了一个问题:在使用Navigation或者使用replace并addToBackStack进行FragmentA切换到FragmentB时,FragmentA会走到onDestroyView,但不会destory。FragmentA走到onDestroyView时,Fragment对根View的引用会置空,由于imageView被Fragment持有,所以此时imageView并未被释放,从而导致了内存泄漏。
当页面变的复杂时,变量的声明以及赋值也会变成一个重复的工作。比较成熟的框架如Butter Knife通过@BindView注解生成代码,以避免手工编写findViewById代码,同时也提供了Unbinder用以在onDestoryView中进行解绑以防止内存泄漏。不过在Butter Knife的官方文档中提到目前Butter Knife已不再维护,推荐使用ViewBinding作为视图绑定工具:
Attention: This tool is now deprecated. Please switch to view binding. Existing versions will continue to work, obviously, but only critical bug fixes for integration with AGP will be considered. Feature development and general bug fixes have stopped.
在ViewBinding的官方文档中,推荐的写法如下:
class TestFragment : Fragment() {
private var _binding: FragmentTestBinding? = null
// 只能在onCreateView与onDestoryView之间的生命周期里使用
private val binding: FragmentTestBinding get() = _binding!!
override fun onCreateView(
inflater: LayoutInflater,
container: ViewGroup?,
savedInstanceState: Bundle?
): View {
_binding = FragmentTestBinding.inflate(inflater, container, false)
return binding.root
}
override fun onDestroyView() {
super.onDestroyView()
_binding = null
}
}这种方式虽然防止了内存泄漏,但仍然需要手工编写一些重复代码,大部分人甚至可能直接声明lateinit var binding,从而导致更严重的内存泄漏问题。下面我们将介绍两种解放方案:
Fragment基类
如果项目中存在一个BaseFragment的话,我们完全可以将上面的逻辑放在BaseFragment中:
open class BaseFragment<T : ViewBinding> : Fragment() {
protected var _binding: T? = null
protected val binding: T get() = _binding!!
override fun onDestroyView() {
super.onDestroyView()
_binding = null
}
}或者更进一步,将onCreateView的逻辑也放在父类中:
abstract class BaseFragment<T : ViewBinding> : Fragment() {
private var _binding: T? = null
protected val binding: T get() = _binding!!
abstract val bindingInflater: (LayoutInflater, ViewGroup?, Bundle?) -> T
override fun onCreateView(
inflater: LayoutInflater,
container: ViewGroup?,
savedInstanceState: Bundle?
): View {
_binding = bindingInflater.invoke(inflater, container, savedInstanceState)
return binding.root
}
override fun onDestroyView() {
super.onDestroyView()
_binding = null
}
}子类使用时:
class TestFragment : BaseFragment<FragmentTestBinding>() {
override val bindingInflater: (LayoutInflater, ViewGroup?, Bundle?) -> FragmentTestBinding
get() = { layoutInflater, viewGroup, _ ->
FragmentTestBinding.inflate(layoutInflater, viewGroup, false)
}
}不过这种方式由于给基类增加了泛型,所以对于已有项目的侵入性比较高。
生命周期委派
借助Kotlin的by关键字,我们可以将binding置空的任务交给Frament生命周期进行处理,比较简单的版本如下:
class LifecycleAwareViewBinding<F : Fragment, V : ViewBinding> : ReadWriteProperty<F, V>, LifecycleEventObserver {
private var binding: V? = null
override fun getValue(thisRef: F, property: KProperty<*>): V {
binding?.let {
return it
}
throw IllegalStateException("Can't access ViewBinding before onCreateView and after onDestroyView!")
}
override fun setValue(thisRef: F, property: KProperty<*>, value: V) {
if (thisRef.viewLifecycleOwner.lifecycle.currentState == Lifecycle.State.DESTROYED) {
throw IllegalStateException("Can't set ViewBinding after onDestroyView!")
}
thisRef.viewLifecycleOwner.lifecycle.addObserver(this)
binding = value
}
override fun onStateChanged(source: LifecycleOwner, event: Lifecycle.Event) {
if (event == Lifecycle.Event.ON_DESTROY) {
binding = null
source.lifecycle.removeObserver(this)
}
}
}在使用时可以直接通过by关键字,但仍需在onCreateView中进行赋值:
class TestFragment : Fragment() {
private var binding: FragmentTestBinding by LifecycleAwareViewBinding()
override fun onCreateView(
inflater: LayoutInflater,
container: ViewGroup?,
savedInstanceState: Bundle?
): View {
binding = FragmentTestBinding.inflate(inflater, container, false)
return binding.root
}
}如果想省略onCreateView中的创建ViewBinding的重复逻辑,有两种思路,一个是Fragment构造时传入布局Id,通过viewBinding生成的bind函数创建ViewBinding;另外一种思路则是通过反射调用ViewBinding的inflate方法。两种思路的主要不同就是创建ViewBinding的方式不一样,而核心代码一样,实现如下:
class LifecycleAwareViewBinding<F : Fragment, V : ViewBinding>(
private val bindingCreator: (F) -> V
) : ReadOnlyProperty<F, V>, LifecycleEventObserver {
private var binding: V? = null
override fun getValue(thisRef: F, property: KProperty<*>): V {
binding?.let {
return it
}
val lifecycle = thisRef.viewLifecycleOwner.lifecycle
if (lifecycle.currentState == Lifecycle.State.DESTROYED) {
this.binding = null
throw IllegalStateException("Can't access ViewBinding after onDestroyView")
} else {
lifecycle.addObserver(this)
val viewBinding = bindingCreator.invoke(thisRef)
this.binding = viewBinding
return viewBinding
}
}
override fun onStateChanged(source: LifecycleOwner, event: Lifecycle.Event) {
if (event == Lifecycle.Event.ON_DESTROY) {
binding = null
source.lifecycle.removeObserver(this)
}
}
}然后创建函数返回LifecycleAwareViewBinding即可:
// 1. 通过bind函数
fun <V : ViewBinding> Fragment.viewBinding(binder: (View) -> V): LifecycleAwareViewBinding<Fragment, V> {
return LifecycleAwareViewBinding { binder.invoke(it.requireView()) }
}
// 使用
class TestFragment : Fragment(R.layout.fragment_test) {
private val binding: FragmentTestBinding by viewBinding(FragmentTestBinding::bind)
}
// 2. 通过反射的方式
inline fun <reified V : ViewBinding> Fragment.viewBinding(): LifecycleAwareViewBinding<Fragment, V> {
val method = V::class.java.getMethod("inflate", LayoutInflater::class.java, ViewGroup::class.java, Boolean::class.java)
return LifecycleAwareViewBinding { method.invoke(null, layoutInflater, null, false) as V }
}
// 使用
class TestFragment : Fragment() {
private val binding: FragmentTestBinding by viewBinding()
override fun onCreateView(
inflater: LayoutInflater,
container: ViewGroup?,
savedInstanceState: Bundle?
): View {
return binding.root
}
}需要注意的是第一种方式使用了Fragment#requireView方法,所以需要将布局id传给Fragment的构造方法(将布局id传给Fragment实际上是借助了Fragment默认的onCreateView实现,虽然不传布局Id、手动实现也可以,但这样实际上和最上面提到的方法差不多了)。
上面的两种思路GitHub中已经有作者实现了,并且考虑了一些边界case以及优化,感兴趣的可以去看看:ViewBindingPropertyDelegate
总结
对于ViewBinding为了防止内存泄漏而出现的模板代码,可以将模板代码提取至基类Fragment中或者借助Fragment的viewLifecycleOwner的生命周期进行自动清理;对于onCreateView中为了创建ViewBinding而出现的模板代码,可以借助Fragment#onCreateView的默认实现以及ViewBinding生成的bind函数进行创建,或者通过反射调用ViewBinding生成的inflate方法创建ViewBinding。
链接:https://juejin.cn/post/7057144897060470815
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
kotlin-object关键字与单例模式
object 关键字有三种不同的语义:匿名内部类、伴生对象、单例模式。因为 Kotlin 的设计者认为,这三种语义本质上都是在定义一个类的同时还创建了对象。在这样的情况下,与其分别定义三种不同的关键字,还不如将它们统一成 object 关键字。
一、 匿名内部类
Android中用java写View的点击事件:
findViewById(R.id.tv).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
//do something
}
});在 Kotlin 当中,我们会使用 object 关键字来创建匿名内部类。同样,在它的内部,我们也必须要实现它内部未实现的方法。这种方式不仅可以用于创建接口的匿名内部类,也可以创建抽象类的匿名内部类:
findViewById<TextView>(R.id.tv).setOnClickListener(object : View.OnClickListener {
override fun onClick(v: View?) {
//do something
}
})
//上面的代码可以用SAM转换简化,IDE会提示
Java 和 Kotlin 相同的地方就在于,它们的接口与抽象类,都不能直接创建实例。想要创建接口和抽象类的实例,我们必须通过匿名内部类的方式。
在 Kotlin 中,匿名内部类还有一个特殊之处,就是我们在使用 object 定义匿名内部类的时候,其实还可以在继承一个抽象类的同时,来实现多个接口:
//抽象类和抽象方法
abstract class Person{
abstract fun isAdult()
}
//接口
interface AListener {
fun getA()
}
//接口
interface BListener {
fun getB()
}
//继承一个抽象类的同时,来实现多个接口
private val item = object :Person(),AListener,BListener{
override fun isAdult() {
//do something
}
override fun getA() {
//do something
}
override fun getB() {
//do something
}
}在日常的开发工作当中,我们有时会遇到这种情况:我们需要继承某个类,同时还要实现某些接口,为了达到这个目的,我们不得不定义一个内部类,然后给它取个名字。但这样的类,往往只会被用一次就再也没有其他作用了。所以针对这种情况,使用 object 的这种语法就正好合适。我们既不用再定义内部类,也不用想着该怎么给这个类取名字,因为用过一次后就不用再管了。
引申:可以把函数当做参数简化定义接口的操作。以前写java时应该都写过很多如下的接口回调:
class DownloadFile {
//携带token下载文件
fun downloadFile(token:String) {
val filePath = ""
listener?.onSuccess(filePath)
}
//定义成员变量
private var listener: OnDownloadResultListener? = null
//写set方法
fun setOnDownloadResultListener(listener: OnDownloadResultListener){
this.listener = listener
}
//定义接口
interface OnDownloadResultListener {
fun onSuccess(filePath:String)
}
}通过函数当做参数就不需要定义接口了:
class DownloadFile {
private var onSuccess: ((String?) -> Unit)? = null
fun downloadFile(token:String) {
val filePath = ""
onSuccess?.invoke(filePath)
}
fun setOnDownloadResultListener(method:((String?) -> Unit)? = null){
this.onSuccess = method
}
}
//调用
DownloadFile().downloadFile("")
DownloadFile().setOnDownloadResultListener { filePath ->
print("$filePath")
}二、单例模式
在 Kotlin 当中,要实现单例模式其实非常简单,我们直接用 object 修饰类即可:
object StringUtils {
fun getLength(text: String?): Int = text?.length ?: 0
}
//反编译
public final class StringUtils {
@NotNull
public static final StringUtils INSTANCE; //静态单例对象
public final int getLength(@Nullable String text) {
return text != null ? text.length() : 0;
}
private StringUtils() {
}
static { //静态代码块
StringUtils var0 = new StringUtils();
INSTANCE = var0;
}
}这种方式定义的单例模式,虽然简洁,但存在两个缺点:
1、不支持懒加载。
2、不支持传参构造单例。写构造方法会报错,会提示object修饰的类不允许有构造方法。
三、伴生对象
1、深入分析伴生对象
Kotlin 当中没有 static 关键字,所以我们没有办法直接定义静态方法和静态变量。不过,Kotlin 还是为我们提供了伴生对象,来帮助实现静态方法和变量。
我们先来看看 object 定义单例的一种特殊情况,看看它是如何演变成“伴生对象”的:
class User() {
object InnerClass {
fun foo() {}
}
}用object修饰嵌套类,看下反编译的结果:
public final class User {
//object修饰的内部类为静态内部类
public static final class Inner {
@NotNull
public static final User.Inner INSTANCE; //静态单例对象
public final void foo() {
}
private Inner() {
}
//通过static静态代码块创建了单例对象
static {
User.Inner var0 = new User.Inner();
INSTANCE = var0;
}
}
}调用的时候的代码
User.InnerClass.foo()
可以看到foo方法并不是静态方法,那加上@JvmStatic这个注解试试:
class User() {
object InnerClass {
@JvmStatic
fun foo() {}
}
}
//反编译结果
public final class User {
public static final class InnerClass {
@NotNull
public static final User.InnerClass INSTANCE;
@JvmStatic
public static final void foo() { //foo方法变成了静态方法
}
private InnerClass() {
}
static {
User.InnerClass var0 = new User.InnerClass();
INSTANCE = var0;
}
}
}foo方法变成了一个静态方法,但是在使用的时候还是要User.InnerClass.foo(),而User类中的静态方法应该是直接User.foo()调用才对,这还是不符合定义静态方法的初衷。那在 Kotlin 如何实现这样的静态方法呢?我们只需要在前面例子当中的 object 关键字前面,加一个 companion 关键字即可。
①不加@JvmStatic注解
//假如不加@JvmStatic注解
class User() {
companion object InnerClass {
fun foo() {}
}
}
//反编译
public final class User {
@NotNull
public static final User.InnerClass InnerClass = new User.InnerClass((DefaultConstructorMarker)null);
public static final class InnerClass {
public final void foo() {
}
private InnerClass() {
}
// $FF: synthetic method
public InnerClass(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
//调用
User.foo()
//反编译调用的代码
User.InnerClass.foo();如果不加上@JvmStatic注解调用的时候只是省略了前面的单例对象InnerClass,foo仍然不是User的静态方法。
②加@JvmStatic注解
//假如加@JvmStatic注解
class User() {
companion object InnerClass {
@JvmStatic
fun foo() {}
}
}
//反编译
public final class User {
@NotNull
public static final User.InnerClass InnerClass = new User.InnerClass((DefaultConstructorMarker)null);
@JvmStatic
public static final void foo() { //多生成了一个foo方法,但其实还是调用的下面的foo方法
InnerClass.foo();
}
public static final class InnerClass {
@JvmStatic
public final void foo() { //实际的foo方法
}
private InnerClass() {
}
// $FF: synthetic method
public InnerClass(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}可以看到这个时候多生成了一个静态的foo方法,可以通过User.foo()真正去调用了,而不是省略掉了InnerClass单例对象(把InnerClass对象放在了静态方法的实现中)。
那又有问题来了,上面二种方式应该如何选择,哪种情况下哪个好,什么时候该加注解什么时候不该加注解?
解析:1、用companion修饰的对象会创建一个Companion的实例:
class User {
companion object {
fun foo() {}
}
}
//反编译
public final class User {
@NotNull
public static final User.Companion Companion = new User.Companion((DefaultConstructorMarker)null);
public static final class Companion {
public final void foo() {
}
private Companion() {
}
// $FF: synthetic method
public Companion(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
//java中调用
User.Companion.foo();如果不加@JvmStatic,java调用kotlin代码会多创建这个Companion实例,会多一部分内存开销,所以如果这个静态方法java需要调用,那务必要把@JvmStatic加上。
2、多创建一个静态foo方法会不会多内存开销? 答案是不会,因为这个静态的foo方法调用的也是Companion中的方法foo方法,所以不会有多的内存开销。
2、用伴生对象实现工厂模式
所谓的工厂模式,就是指当我们想要统一管理一个类的创建时,我们可以将这个类的构造函数声明成 private,然后用工厂模式来暴露一个统一的方法,以供外部使用。Kotlin 的伴生对象非常符合这样的使用场景:
// 私有的构造函数,外部无法调用
class User private constructor(name: String) {
companion object {
@JvmStatic
fun create(name: String): User? {
// 统一检查,比如敏感词过滤
return User(name)
}
}
}3、用伴生对象实现单例模式
(1)、借助懒加载委托
class MainActivity : AppCompatActivity() {
//借助懒加载委托实现单例
private val people by lazy { People("张三", 18) }
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
}
//反编译后
public final class MainActivity extends AppCompatActivity {
private final Lazy people$delegate;
private final People getPeople() {
Lazy var1 = this.people$delegate;
Object var3 = null;
return (People)var1.getValue();
}
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
this.setContentView(1300000);
}
public MainActivity() { //构造方法
this.people$delegate = LazyKt.lazy((Function0)null.INSTANCE); //lazy方法有线程安全的实现
}
}
在MainActivity的构造方法中通过LazyKt.lazy获取类的代理对象,看下LazyKt.lazy的源码实现:
/**
* Creates a new instance of the [Lazy] that uses the specified initialization function [initializer]
* and the default thread-safety mode [LazyThreadSafetyMode.SYNCHRONIZED]. //线程安全模式
*
* If the initialization of a value throws an exception, it will attempt to reinitialize the value at next access.
*
* Note that the returned instance uses itself to synchronize on. Do not synchronize from external code on
* the returned instance as it may cause accidental deadlock. Also this behavior can be changed in the future.
*/
public actual fun <T> lazy(initializer: () -> T): Lazy<T> = SynchronizedLazyImpl(initializer)
/**
* Creates a new instance of the [Lazy] that uses the specified initialization function [initializer]
* and thread-safety [mode].
*
* If the initialization of a value throws an exception, it will attempt to reinitialize the value at next access.
*
* Note that when the [LazyThreadSafetyMode.SYNCHRONIZED] mode is specified the returned instance uses itself
* to synchronize on. Do not synchronize from external code on the returned instance as it may cause accidental deadlock.
* Also this behavior can be changed in the future.
*/
public actual fun <T> lazy(mode: LazyThreadSafetyMode, initializer: () -> T): Lazy<T> =
when (mode) {
LazyThreadSafetyMode.SYNCHRONIZED -> SynchronizedLazyImpl(initializer)
LazyThreadSafetyMode.PUBLICATION -> SafePublicationLazyImpl(initializer)
LazyThreadSafetyMode.NONE -> UnsafeLazyImpl(initializer)
}(2)、伴生对象 Double Check
class UserManager private constructor(name: String) {
companion object {
@Volatile
private var INSTANCE: UserManager? = null
fun getInstance(name: String): UserManager =
// 第一次判空
INSTANCE?: synchronized(this) {
// 第二次判空
INSTANCE?:UserManager(name).also { INSTANCE = it }
}
}
}
// 使用
UserManager.getInstance("Tom")我们定义了一个伴生对象,然后在它的内部,定义了一个 INSTANCE,它是 private的,这样就保证了它无法直接被外部访问。同时它还被注解“@Volatile”修饰了,这可以保证INSTANCE的可见性,而getInstance()方法当中的synchronized,保证了INSTANCE的原子性。因此,这种方案还是线程安全的。
同时,我们也能注意到,初始化情况下,INSTANCE 是等于 null 的。这也就意味着,只有在getInstance() 方法被使用的情况下,我们才会真正去加载用户数据。这样,我们就实现了整个UserManager的懒加载,而不是它内部的某个参数的懒加载。
另外,由于我们可以在调用getInstance(name) 方法的时候传入初始化参数,因此,这种方案也是支持传参的。
单例模式最多的写法,注意如果参数是上下文,不能传递Activity或Fragment的上下文,不然会有内存泄漏。(单例的内存泄漏)
(3)、抽象类模板
如果有多个类似于上面的单例,那么就会有很多重复代码,于是尝试抽象成模板代码:
//要实现单例类,就只需要继承这个 BaseSingleton 即可
//P为参数,T为返回值
abstract class BaseSingleton<in P, out T> {
@Volatile
private var instance: T? = null
//抽象方法,需要我们在具体的单例子类当中实现此方法
protected abstract fun creator(param: P): T
fun getInstance(param: P): T =
instance ?: synchronized(this) {
instance ?: creator(param).also { instance = it }
}
}通过伴生对象实现抽象类,并给出具体实现
//构建UploadFileManager对象需要一个带参数的构造方法
class UploadFileManager(val param: String) {
//伴生对象实现BaseSingleton抽象类
companion object : BaseSingleton<String, UploadFileManager>() {
//重写方法并给出具体实现
override fun creator(param: String): UploadFileManager {
return UploadFileManager(param)
}
}
fun foo(){
print("foo")
}
}
//调用
UploadFileManager.getInstance("张三").foo()
因为构造方法的限制这种封装也有一定的局限性。
链接:https://juejin.cn/post/7186854600257830970
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
由浅入深,详解 ViewModel 的那些事
引言
关于 ViewModel ,Android 开发的小伙伴应该都非常熟悉,无论是新项目还是老项目,基本都会使用到。而 ViewModel 作为 JetPack 核心组件,其本身也更是承担着不可或缺的作用。
因此,了解 ViewModel 的设计思想更是每个应用层开发者必不可缺的基本功。
随着这两年 ViewModel 的逐步迭代,比如 SaveStateHandle 的加入等,ViewModel 也已经不是最初版本的样子。要完全理解其设计体系,往往也要伴随着其他组件的基础,所以并不是特别容易能被开发者吃透。
故本篇将以最新视角开始,与你一起,用力一瞥 ViewModel 的设计原理。
本文对应的组件版本:
- Activity-ktx-1.5.1
- ViewModel-ktx-2.5.1
本篇定位中等,将从背景与使用方式开始,再到源码解读。由浅入深,解析
ViewModel的方方面面。
导航
学完本篇,你将了解或明白以下内容:
ViewModel的使用方式;SavedStateHandle的使用方式;ViewModel创建与销毁流程;SavedStateHandle创建流程;
好了,让我们开始吧! 🐊
基础概念
在开始本篇前,我们先解释一些基础概念,以便更加清晰的了解后续的状态保存相关。
何谓配置变更?
配置变更指的是,应用在运行时,内置的配置参数变更从而触发的Activity重新创建。
常见的场景有:旋转屏幕、深色模式切换、屏幕大小变化、更改了默认语言或者时区、更改字体大小或主题颜色等。
何谓异常重建?
异常重建指的是非配置变更情况下导致的 Activity 重新创建。
常见场景大多是因为 内存不足,从而导致后台应用被系统回收 ,当我们切换到前台时,从而触发的重建,这个机制在Android中为 Low Memory Killer 机制,简称 LMK。
可以在开发者模式,限制后台任务数为1,从而测试该效果。
ViewModel存在之前的世界
在 ViewModel 出现之前,对于 View 逻辑与数据,我们往往都是直接存在 Activity 或者 Fragment 中,优雅一点,会细分到具体的单独类中去承载。当配置变更时,无可避免,会触发界面重绘。相应的,我们的数据在没有额外处理的情况下,往往也会被初始化,然后在界面重启时重新加载。
但如果当前页面需要维护某些状态不被丢失呢,比如 选择、上传状态 等等? 此时问题就变得棘手起来。
稍有经验同学会告诉你,在 onSaveInstanceState 中重写,使用bundle去存储相应的状态啊?➡️
但状态如果少点还可以,多一点就非常头痛,更别提包含继承关系的状态保存。 😶🌫️
所以,不出意外的话,我们 App 的 Activity-manifest 中通常默认都是下列写法:
android:configChanges="keyboard|orientation|uiMode|..."
这也是为啥Android程序普遍不支持屏幕旋转的一部分原因,从源头扼杀因部分配置变更导致的状态丢失问题。🐶保命
VideModel存在之后的世界
随着 ViewModel 组件推出之后,上述因配置变更而导致的状态丢失问题就迎刃而解。
ViewModel 可以做到在配置变更后依然持有状态。所以,在现在的开发中,我们开始将 View数据 与 逻辑 藏于 ViewModel 中,然后对外部暴漏观察者,比如我们常常会搭配 LiveData 一起使用,以此更容易的保持状态同步。
关于 ViewModel 的生命周期,具体如下图所示:
虽然 ViewModel 非常好用,但 ViewModel 也不是万能,其只能避免配置变更时避免状态丢失。比如如果我们的App是因为 内存不足 而被系统kill 掉,此时 ViewModel 也会被清除 🔺 。
不过对于这种情况,仍然有以下三个方法可以依然保存我们的状态:
- 重写
onSaveInstanceState()与onRestoreInstanceState(); - 使用
SavedState,本质上其实还是onSaveInstanceState(); - 使用
SavedStateHandle,本质上是依托于SaveState的实现;
上述的后两种都是随着 JetPack 逐步被推出,可以理解为是对原有的onSavexx的封装简化,从而使其变得更易用。
关于这三种方法,我们会在 SavedStateHandle 流程解析中再进行具体叙述,这里先提出来,留个伏笔。
ViewModel使用方式
作为文章的开始,我们还是要先聊一聊 ViewModel 的使用方式,如下例所示:
当然,你也可以选择引入 activity-ktx ,从而以更简便的写法去写:
implementation 'androidx.activity:activity-ktx:1.5.1'
private val mainModel by viewModels()
示例比较简单,我们创建了一个 ViewModel ,如上所示,并在 MainActivity 的 onCreate() 中进行了初始化。
这也是我们日常的使用方式,具体我们这里就不再做阐述。
SavedStateHandle使用方式
我们知道,ViewModel 可以处理因为配置更改而导致的的状态丢失,但并不保证异常终止的情况,而官方的 SavedStateHandle 正是用于这种情况的解决方式。
SavedStateHandle ,如名所示,用于保存状态的手柄。再细化点就是,用于保存状态的工具,从而配合 ViewModel 而使用,其内部使用一个 map 保存我们要存储的状态,并且其本身使用 operator 重载了 set() 与 get() 方法,所以对于我们来说,可以直接使用 键值对 的形式去操作我们要保存的状态,这也是官方为什么称 SavedStateHandle 是一个 具有键值映射Map 特性的原因。
在 Fragment1.2 及 Activity1.1.0 之后,
SavedStateHandle可以作为 ViewModel 的构造函数,从而反射创建带有SavedStateHandle的 ViewModel 。
具体使用方式如下:
我们在 MainViewModel 构造函数中新增了一个参数 state:SavedStateHandle ,这个参数在 ViewModel 初始化时,会帮我们自动进行注入。从而我们可以利用 SavedStateHandle 以key-value的形式去保存一些 自定义状态 ,从而在进程异常终止,Act重建后,也能获取到之前保存的状态。
至于为什么能实现保存状态呢?
主要是因为 SavedStateHandle 内部默认有一个 SavedStateRegistry.SavedStateProvider 状态保存提供者对象,该对象会在我们创建ViewModel 时绑定到 SavedStateRegistry 中,从而在我们 Activity 异常重建时做到状态的 恢复 与 绑定 (通过重写 onSavexx() 与 onCreate() 方法监听)。
关于这部分内容,我们下面的源码解析部分也会再聊到,这里我们只需要知道是这么回事即可。
ViewModel源码解析
本章节,我们将从 ViewModelProvider() 开始,理清 ViewModel 的 创建 与 销毁 流程,从而理解其背后的 [魔法]。
不过 ViewModel 的源码其实并不是很复杂,所以别担心😉。
仔细想想,要解析ViewModel的源码,应该从哪里入手呢?
ViewModelProvider(this).get(MainViewModel::class.java)
最简单的方式还是初始化这里,所以我们直接从 ViewModelProvider() 初始化开始->
ViewModelProvider(this)
public constructor(owner: ViewModelStoreOwner)
: this(owner.viewModelStore, defaultFactory(owner), defaultCreationExtras(owner))相应的,这里开始,我们就涉及到了三个方面,即 viewModelStore 、 Factory、 Exras 。所以接下来我们就顺藤摸瓜,分别看看这三处的实现细节。
owner.viewModelStore
ViewModelStoreOwner 顾名思义,用于保存 ViewModelStore 对象。
而 ViewModelStore 是负责维护我们 ViewModel 实例的具体类,内部有一个 map 的合集,用于保存我们创建的所有 ViewModel ,并对外提供了 clear() 方法,以 便于非配置变更时清除缓存 。
defaultFactory(owner)
该方法用于初始化 ViewModel 默认的创造工厂🏭 。默认有两个实现,前者是 HasDefaultViewModelProviderFactory ,也是我们 Fragment 或者 ComponentActivity 都默认实现的接口,而后者是是指全局 NewInstanceFactory 。
两者的不同点在于,后者只能创建 空构造函数 的 ViewModel ,而前者没有这个限制。
示例源码:
HasDefaultViewModelProviderFactory 在 ComponentActivity 中的实现如下:
defaultCreationExtras(owner)
用于辅助 ViewModel 初始化时需要传入的参数,具体源码如下:
如上所示,默认有两个实现,前者是 HasDefaultViewModelProviderFactory ,也就是我们 ComponentActivity 实现的接口,具体的实现如下:
默认会帮我们注入 application 以及 intent 等,注意这里还默认使用了 getIntent().getExtras() 作为 ViewModel 的 默认状态 ,如果我们 ViewModel 构造函数中有 SavedStateHandle 的话。
更多关于 CreationExtras 可以了解这篇 创建 ViewModel 的新方式,CreationExtras 了解一下?
get(ViewModel::xx)
从缓存中获取现有的 ViewModel 或者 反射创建 新的 ViewModel。
示例源码如下:
当我们使用 get() 方法获取具体的 ViewModel 对象时,内部会先利用 当前包名+ViewModel类名 作为 key ,然后从 viewModelStore 中取。如果当前已创建,则直接使用;反之则调用我们的 ViewModel工厂 create() 方法创建新的 ViewModel。 创建完成后,并将其保存到 ViewModelStore 中。
create(modelClass,extras)
具体的创造逻辑里,这里的 factory 正是我们在 ViewModelProvider 初始化时,默认构造函数 defaultFactory() 方法中生成的SavedStateViewModelFactory ,所以我们直接去看这个工厂类即可。
具体源码如下:
create(key,modelClass)
兼容旧的版本以及用户操作行为。
相应的,这里我们还需要再提一下,LegacySavedStateHandleController.create() 方法:
当我们调用创建 ViewModel 时,内部会调用具体的 ViewModel 工厂去创建,如果当前 ViewModel 已创建,则直接返回,否则调用其 create() 方法创建新的 ViewModel 。在具体的创建方法中,需要判断当前构造函数是不是带 application 或者 SaveStateHandle ,从而调用合适的 newInstance() 方法,最后再将创建好的 ViewModel 添加到 ViewModelStore 的 缓存 中。
销毁流程
在初始化 ViewModelProvider 时,还记得我们需要传递的 ViewModelStoreOwner 吗?
而这个接口正是被我们的 ComponentActivity 或者 Fragment 各自实现,相应的 ViewModelStore 也是存在于我们的 ComponentActivity 中,所以我们直接去看示例代码即可:
以ComponentActivity为例,具体的源码如下:
如上所示:在初始化Activity时,内部会使用 lifecycle 添加一个生命周期观察者,并监听 onDestory() 通知(Act销毁),如果当前销毁的原因非配置更改导致,则调用 ViewModeltore.clear() ,即清空我们的ViewModel缓存列表,从而这也是为什么 ViewModel 不支持非配置更改的实例保存。
你可能会惊讶,那还怎么借助SavedStateHandle保存状态,viewModel已经被清空了啊🤔?
如果你记得 Activity 传统处理状态的方式,此时也就能理解为什么了?因为源头都是一个地方,而 SavedStateHandle 仅仅只是一个更简便的封装而已。不过关于这个问题具体解析,我们将在下面继续进行探讨,从而理解 SavedStateHandle 的完整流程。
SavedStateHandle流程解析
关于 SavedStateHandle 的使用方法我们在上面已经叙述过了,其相关的 api 使用源码也不是我们所关注的重点,因为并不复杂,而我们主要要探讨的是其整个流程。
要摸清 SavedStateHandle 的流程,无非就两个方向,即 从何而来 ,又 在哪里进行使用 🤔。
在上面探索 ViewModel 创建流程时,我们发现,在 get(ViewModel:xx) 方法内部,最终的 create() 方法里,存在两个分支:
- 存在附加参数extras(viewModel2.5.0新增);
- 不存在附加参数extras(兼容历史版本或者用户自定义的行为);
相应的,如果 ViewModel 的构造函数中存在 SavedStateHandle ,则各自的流程如下所示:
- CreationExtras.createSavedStateHandle() ;
- LegacySavedStateHandleController.create(xx).handle ;
前者使用了 CreationExtras 的扩展函数 createSavedStateHandle() :
而后者使用了 LegacySavedStateHandleController 控制器去创建:
总结:
上述流程中,两者大致是一样的,都需要先调用 consumeRestoredStateForKey(key) 拿到要还原的 Bundle , 再调用 SavedStateHandle.createHandle() 去创建 SavedStateHandle 。
那 SavedStateRegistry 又是什么呢?
我们的插入点也就在于此开始。
我们暂时先不关注如何还原状态,而是先搞清楚 SavedStateRegistry 是什么,它又是从哪来而传递来的。然后再来看 状态如何被还原,以及 SavedStateHandle 的创建流程,最后再搞清与 SavedStateRegistry 又是如何进行关联。
SavedStateRegistry
其是一个用于保存状态的注册表,往往由 SavedStateRegistryOwner 接口所提供实现,从而以便与拥有生命周期的组件相关联。
比如我们常用的 ComponentActivity 或者 Fragment 默认都实现了该接口。
源码如下所示:
分析上面的代码不难发现,SavedStateRegistry 本身提供了状态 还原 与 保存 的具体能力,并使用一个 map 保存当前所有的状态提供者,具体的状态提供者由 SavedStateProvider 接口实现。
SavedStateRegistryOwner
相当于是拥有 SavedStateRegistry 的具体类,因为本身继承了 LifecycleOwner 接口,故其也具备 生命感知 能力,如下所示:
interface SavedStateRegistryOwner : LifecycleOwner {
val savedStateRegistry: SavedStateRegistry
}以 ComponentActivity 为例,我们会发现,ComponentActivity 默认实现 SavedStateRegistryOwner 接口。即 SavedStateRegistry 的创造以及状态的保存,肯定也是 经过我们Activity转发处理(不然它自己怎么处理呢😅)。
而在上面探索 ViewModel 初始化时,我们了解到,ComponentActivity 默认实现了 HasDefaultViewModelProviderFactory 接口,用于创建ViewModel工厂 。相应的,其接口方法 getDefaultViewModelProviderFactory() 默认返回的是 SavedStateViewModelFactory ,即支持状态保存的ViewModel工厂。而该工厂构造函数中正是需要接受一个 SavedStateRegistry 变量,也正是我们 ComponentActivity 中默认保存的实例,所以也不难猜测 ViewModel工厂 是如何与 SavedStateRegistry 如何关联的。
以 ComponentActivity 的实现为例,源码如下:
ComponentActivity 初始化时,会创建一个 用于保存状态注册表的控制器 SavedStateRegistryController 对象,见面知意,不难猜出,其是用于控制 SavedStateRegistry 的具体类。并且该控制器对象会在 onCreate() 中调用 performRestore() 还原状态,并在onSaveInstanceState() 中去保存状态,此时也就解释了为什么 SavedStateRegistry 能做到状态保存。
相应的,我们还是要再去看看 SavedStateRegistryController ,以便更好的理解。
SavedStateRegistryController
用于控制 SavedStateRegistry ,对外提供了 初始化 ,状态 还原、保存 等方法,如下所示:
简而言之,其主要用于辅助 SavedStateRegistry 进行状态保存与还原。
小结
我们再回顾一下上面的步骤,在只关心 SavedStateHandle 如何被创建这样一个大背景下,我们大致可以梳理出这样的流程:
因为我们的 ComponentActivity 或者 Fragment 默认已经实现了 SavedStateRegistryOwner 接口,而且默认是由 SavedStateRegistryController 作为 SavedStateRegistry 的具体控制,因此具体的状态保存与还原都由该控制器去操作。
当我们的 Activity 因为异常生命周期重建时,此时会回调 onSaveInstanceState() 去保存状态,此时 SavedStateRegistryController 就会调用 performSave() 去保存当前状态(即将我们ViewModel的状态保存到bundle里),然后在 Activity 重建时,在 onCreate() 方法里进行还原(即从bundle里取出我们保存的状态)。
当我们创建 ViewModel 时,默认使用的 ViewModel 工厂是支持保存状态的 SavedStateViewModelFactory 。在初始化该工厂时,需要显式传递 SavedStateRegistryOwner 接口对象到该工厂中,而该工厂的构造函数内,会将 SavedStateRegistry 自行保存起来。
最后,如果要创建的 ViewModel 需要保存状态(即构造函数中存在SavedStateHadnle),则使用保存的 SavedStateRegistry 变量去获取我们将要还原的状态,然后再调用 SavedStateHandle.createHandle() 去创建具体的 SavedStateHadnle。
由此结合 ViewModel 创建的流程,我们可以总结 SavedStateRegistry 的传递流程伪代码如下:
SavedStateHandle如何创建
在上面,我们聊完了 SavedStateRegistry 是如何被创建以及被传递给我们的 ViewModel工厂 ,而这一小节,我们将要聊聊 SavedStateHandle 如何被创建,以及状态是如何被还原的。
我们知道,当创建 SavedStateHandle 前,需要先获取已保存的状态,也即 consumeRestoredStateForKey() 方法,所以我们本章节的插入点也就是从这里开始。
而与 consumeRestoredStateForKey() 关联的类有两个, SavedStateHandlesProvider 与 SavedStateRegistry 。
前者是
viewModel(2.5.0) 新提供的 创建SavedStateHandle 的方式,后者则是用于 适配 2.5.0 之前的方式。
以 SavedStateHandlesProvider 为例,源码如下:
当我们调用 consumeRestoredStateForKey() 获取具体状态时,内部先会调用 performRestore() 从 SavedStateRegistry 获取我们保存的状态集,然后将其保存到 provider 中。再从这个总的 状态bundle 中获取我们当前 viewModel 所对应的状态。
相应的,我们再去看看 SavedStateHandle.createHandle() 方法,即 SavedStateHandle 最终被怎么创建出来。
源码如下:
上述的逻辑也比较简单,具体如源码中所示,当我们创建 SavedStateHandle 时,需要先从 SavedStateRegistry 获取我们的状态Bundle,然后再调用 createHandle() 方法创建具体的 SavedStateHandle。并在其 createHandle() 内将我们传入的 bundle 转为 Map 形式,从而传入 SavedStateHandle 的构造函数中用于初始化。
总结
在这一章节,我们主要探讨的是 SavedStateHandle 的创建流程,以 ComponentActivity 为例:
我们知道 Android 中关于状态的保存与还原,官方建议使用 onSaveInstanceState() 与 onRestoreInstanceState() ,但随着JetPack组件库的完善,官方在这两个方法的基础上新增了 SavedState ,目的是简化状态保存的成本。从原理上,其创建了一个 状态保存的的注册表 SavedStateRegistry ,内部缓存着具体的 状态提供者合集(key为string,value为SavedStateProvider)。
当我们 Activity 因为配置更改或者不可控原因需要重建时,系统此时会主动调用 onSaveInstanceState() 方法,从而触发调用 savedStateRegistry.performSave() 去保存状态。该方法内部会创建一个新的 Bundle 对象,用于保存所有状态,然后再调用所有缓存的状态提供者(SavedStateProvider)的 saveState() 方法,从而将所有需要需要保存的状态以 key-value 的方式存到 Bundle 中去。最后再将这个整体的 bundle 存入 onSaveInstanceState() 方法参数提供的 bundle 中。
当我们的 Activity 重建完成后,在 onCreate() 方法中,再使用 SavedStateRegistry 还原我们自己保存的状态 restoredState。
最后当我们创建 ViewModel 时,因为我们的 ViewModel工厂(SavedStateViewModelFactory) 持有了 SavedStateRegistry ,也即持有着我们要还原的状态(如果有)。在创建具体的 ViewModel 时,如果我们要创建的 ViewModel 构造函数中存在 SavedStateHandle 参数,则该 ViewModel 支持保存状态,所以需要先去使用 SavedStateRegistry 获取我们保存的状态,最后再调用 SavedStateHandle.create() 去创建具体 SaveStateHandle ,从而创建出支持保存状态 ViewModel 。
结语
在本篇中,我们从 ViewModel 的背景开始,再到 ViewModel 与 SavedStateHandle 的使用方式,最后又从源码层级分析了两者的具体流程,从而较完整的解析了 ViewModel 的底层实现与 SavedStateHandle 的整体创建流程。
至于更加详细的使用方式,这也非本篇要深入探索的细节,具体可参照其他同学的教程即可。
至此,关于 ViewModel 设计思想 以及 状态保存原理 到这里就结束了。也相信读过本篇的你也将不会再有所疑惑 :)
链接:https://juejin.cn/post/7186680109384859706
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
兔年了,一起用Compose来画兔子吧
准备工作
兔子主要还是画在画布上面,所以我们首先得生成个Canvas,然后确定Canvas的宽高跟画笔颜色
val drawColor = colorResource(id = R.color.color_EC4126)
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
}宽高这边只是写死的两个数值,我们也可以用系统api来获取真实的屏幕宽高,画笔颜色选用偏红的颜色,毕竟要过年了,喜庆点~,接下去开始准备画兔子
脑袋
脑袋其实就是个椭圆,我们用canvas的drawPath方法去绘制,我们需要做的就是确定这个椭圆的中心点坐标,以及绘制这个椭圆的左上坐标以及右下坐标
val startX = screenWidth() / 4
val startY = screenHeight() / 3
val headPath = Path()
headPath.moveTo(screenWidth() / 2, screenHeight() / 2)
headPath.addOval(Rect(startX, startY, screenWidth() - startX, screenHeight() - startY))
headPath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = headPath, color = drawColor, style = Stroke(width = 12f))
}
脑袋的中心点坐标x轴跟y轴分别就是画布宽高的一半,左上的x坐标就是画布宽的四分之一,y坐标就是画布高的三分之一,右下的x坐标就是画布宽减去左上的x坐标,右下的y坐标就是减去左上的y坐标,最终在Canvas里面将这个椭圆的path绘制出来,我们看下效果图
耳朵
画完脑袋我们接着画耳朵,两只耳朵其实也就是两个椭圆,分别以中心线左右对称,绘制思路同画脑袋一样,确定两个path的中心点坐标,以及各自左上跟右下的xy坐标
val leftEarPath = Path()
val leftEarPathX = screenWidth() * 3 / 8
val leftEarPathY = screenHeight() / 6
leftEarPath.moveTo(leftEarPathX, leftEarPathY)
leftEarPath.addOval(
Rect(
leftEarPathX - 60f,
leftEarPathY / 2,
leftEarPathX + 60f,
startY + 30f
)
)
leftEarPath.close()
val rightEarPath = Path()
val rightEarPathX = screenWidth() * 5 / 8
val rightEarPathY = screenHeight() / 6
rightEarPath.moveTo(rightEarPathX, rightEarPathY)
rightEarPath.addOval(
Rect(
rightEarPathX - 60f,
rightEarPathY / 2,
rightEarPathX + 60f,
startY + 30f
)
)
rightEarPath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = leftEarPath, color = drawColor, style = Stroke(width = 10f))
drawPath(path = rightEarPath, color = drawColor, style = Stroke(width = 10f))
}看下效果图
内耳
这样感觉耳朵不是很立体,看起来有点平面,毕竟兔耳朵会有点往里凹的感觉,所以我们给这副耳朵加个内耳增加点立体感,内耳其实很简单,道理同外面的耳朵一样,只是中心点跟左上点,右下点的xy坐标会小一点,我们稍微改一下外耳的path就可以了
val leftEarSubPath = Path()
val leftEarSubPathX = screenWidth() * 3 / 8
val leftEarSubPathY = screenHeight() / 4
leftEarSubPath.moveTo(leftEarSubPathX, leftEarSubPathY)
leftEarSubPath.addOval(
Rect(
leftEarSubPathX - 30f,
screenHeight() / 6,
leftEarSubPathX + 30f,
startY + 30f
)
)
leftEarSubPath.close()
val rightEarSubPath = Path()
val rightEarSubPathX = screenWidth() * 5 / 8
val rightEarSubPathY = screenHeight() / 4
rightEarSubPath.moveTo(rightEarSubPathX, rightEarSubPathY)
rightEarSubPath.addOval(
Rect(
rightEarSubPathX - 30f,
screenHeight() / 6,
rightEarSubPathX + 30f,
startY + 30f
)
)
rightEarSubPath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = leftEarSubPath, color = drawColor, style = Stroke(width = 6f))
drawPath(path = rightEarSubPath, color = drawColor, style = Stroke(width = 6f))
}看下效果图
有内味儿了,内耳的画笔粗细稍微调小了一点,为了突出个近大远小嘛哈哈哈,我们接着下一步
眼睛
画完耳朵我们开始画眼睛了,眼睛也很好画,主要是先找到中心点位置就好,中心点的x坐标其实跟耳朵的x坐标是一样的,y坐标在脑袋中心点y坐标稍微靠上一点的位置
val leftEyePath = Path()
val leftEyePathX = screenWidth() * 3 / 8
val leftEyePathY = screenHeight() * 11 / 24
leftEyePath.moveTo(leftEyePathX, leftEyePathY)
leftEyePath.addOval(
Rect(
leftEyePathX - 35f,
leftEyePathY - 35f,
leftEyePathX + 35f,
leftEyePathY + 35f
)
)
leftEyePath.close()
val rightEyePath = Path()
val rightEyePathX = screenWidth() * 5 / 8
val rightEyePathY = screenHeight() * 11 / 24
rightEyePath.moveTo(rightEyePathX, rightEyePathY)
rightEyePath.addOval(
Rect(
rightEyePathX - 35f,
rightEyePathY - 35f,
rightEyePathX + 35f,
rightEyePathY + 35f
)
)
rightEyePath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = leftEyePath, color = drawColor, style = Stroke(width = 10f))
drawPath(path = rightEyePath, color = drawColor, style = Stroke(width = 10f))
}效果图如下
眼神有点空洞,无神是不,缺个眼珠子,那我们再给小兔子画上眼珠吧,眼珠就在眼睛的中心点位置,画一个圆点,圆点就要用到drawCircle,它有这些属性
fun drawCircle(
color: Color,
radius: Float = size.minDimension / 2.0f,
center: Offset = this.center,
/*@FloatRange(from = 0.0, to = 1.0)*/
alpha: Float = 1.0f,
style: DrawStyle = Fill,
colorFilter: ColorFilter? = null,
blendMode: BlendMode = DefaultBlendMode
)我们不需要用到全部,只需要用到颜色color,也就是红色,圆点半径radius,肯定要比眼睛的半径要小一点,我们就设置为10f,圆点中心坐标center,就是眼睛的中心点坐标,知道了以后我们开始绘制眼珠
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawCircle(color = drawColor, radius = 10f, center = Offset(leftEyePathX,leftEyePathY))
drawCircle(color = drawColor, radius = 10f, center = Offset(rightEyePathX,rightEyePathY))
}我们再看下效果图
鼻子
接下去我们画鼻子,鼻子肯定在脑袋的中间,所以中心点x坐标就是脑袋中心点的x坐标,那鼻子的y坐标就设置成比中心点y坐标稍微高一点的位置,代码如下
val nosePath = Path()
val nosePathX = screenWidth() / 2
val nosePathY = screenHeight() * 13 / 24
nosePath.moveTo(nosePathX, nosePathY)
nosePath.addOval(Rect(nosePathX - 15f, nosePathY - 15f, nosePathX + 15f, nosePathY + 15f))
nosePath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = nosePath, color = drawColor, style = Stroke(width = 10f))
}
我们看下效果图
兔唇
兔子的样子逐渐出来了,画完鼻子我们接着画啥呢?没错,兔子最有特点的位置也就是兔唇,我们脑补下兔唇长啥样子,首先位置肯定是在鼻子的下面,然后从鼻子开始往两边分叉,也就是两个扇形,扇形怎么画呢,我们也有现成的api,drawArc,我们看下drawArc都提供了哪些属性
fun drawArc(
color: Color,
startAngle: Float,
sweepAngle: Float,
useCenter: Boolean,
topLeft: Offset = Offset.Zero,
size: Size = this.size.offsetSize(topLeft),
/*@FloatRange(from = 0.0, to = 1.0)*/
alpha: Float = 1.0f,
style: DrawStyle = Fill,
colorFilter: ColorFilter? = null,
blendMode: BlendMode = DefaultBlendMode
)我们需要用到的就是颜色color,这个扇形起始角度startAngle,扇形终止的角度sweepAngle,是否扇形两端跟中心点连接起来的布尔值useCenter,扇形的左上位置topLeft以及扇形的大小size也就是设置半径,知道这些以后我们开始逐个代入参数吧
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawArc(
color = drawColor,
0f,
120f,
style = Stroke(width = 10f),
useCenter = false,
size = Size(120f, 120f),
topLeft = Offset(nosePathX - 120f, nosePathY)
)
drawArc(
color = drawColor,
180f,
-120f,
style = Stroke(width = 10f),
useCenter = false,
size = Size(120f, 120f),
topLeft = Offset(nosePathX + 10f, nosePathY)
)
}画兔唇的时候其实就是在鼻子的两端各画一个坐标轴,左边的兔唇起始角度就是从x轴开始也就是0度,顺时针旋转120度,左上位置的x坐标刚好离开鼻子一个半径的位置,右边的兔唇刚好相反,逆时针旋转120度,起始角度是180度,左上位置的x坐标刚好在鼻子的位置那里,稍微加个10f让兔唇可以对称一些,我们看下效果图
胡须
脸上好像空了点,兔子的胡须还没有呢,胡须其实就是两边各画三条线,用drawLine这个api,起始位置的x坐标跟眼睛中心点的x坐标一样,中间胡须起始位置的y坐标跟鼻子的y坐标一样,上下胡须的y坐标各减去一定的数值
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawLine(
color = drawColor,
start = Offset(leftEyePathX, nosePathY - 60f),
end = Offset(leftEyePathX - 250f, nosePathY - 90f),
strokeWidth = 5f,
cap = StrokeCap.Round
)
drawLine(
color = drawColor,
start = Offset(leftEyePathX, nosePathY),
end = Offset(leftEyePathX - 250f, nosePathY),
strokeWidth = 5f,
cap = StrokeCap.Round
)
drawLine(
color = drawColor,
start = Offset(leftEyePathX, nosePathY + 60f),
end = Offset(leftEyePathX - 250f, nosePathY + 90f),
strokeWidth = 5f,
cap = StrokeCap.Round
)
drawLine(
color = drawColor,
start = Offset(rightEyePathX, nosePathY - 60f),
end = Offset(rightEyePathX + 250f, nosePathY - 90f),
strokeWidth = 5f,
cap = StrokeCap.Round
)
drawLine(
color = drawColor,
start = Offset(rightEyePathX, nosePathY),
end = Offset(rightEyePathX + 250f, nosePathY),
strokeWidth = 5f,
cap = StrokeCap.Round
)
drawLine(
color = drawColor,
start = Offset(rightEyePathX, nosePathY + 60f),
end = Offset(rightEyePathX + 250f, nosePathY + 90f),
strokeWidth = 5f,
cap = StrokeCap.Round
)
}很简单的画了六条线,线的粗细也稍微设置的小一点,毕竟胡须还是比较细的,我们看下效果图
就这样兔子脑袋部分所有元素都画完了,我们接着给兔子画身体
身体
身体其实也是个椭圆,位置刚好在画布下方三分之一的位置,左上x坐标比脑袋左上x坐标大一点,y坐标就是画布三分之二的位置处,右下x坐标比脑袋右下x坐标稍微小一点,y坐标就是画布的底端,知道以后我们就仿照着脑袋画身体
val bodyPath = Path()
val bodyPathX = screenWidth() / 2
val bodyPathY = screenHeight() * 5 / 6
bodyPath.moveTo(bodyPathX, bodyPathY)
bodyPath.addOval(
Rect(
startX + 50f,
screenHeight() * 2 / 3,
screenWidth() - startX - 50f,
screenHeight()
)
)
bodyPath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = bodyPath, color = drawColor, style = Stroke(width = 10f))
}效果图如下
双爪
画完身体我们再画兔子的双爪,双爪其实也是画两个椭圆,椭圆中心点的x坐标同两只眼睛的x坐标一样,y坐标在画布六分之五的位置
val leftHandPath = Path()
val leftHandPathX = screenWidth() * 3 / 8
val leftHandPathY = screenHeight() * 5 / 6
leftHandPath.moveTo(leftHandPathX, leftHandPathY)
leftHandPath.addOval(
Rect(
leftHandPathX - 35f,
leftHandPathY - 90f,
leftHandPathX + 35f,
leftHandPathY + 90f
)
)
leftHandPath.close()
val rightHandPath = Path()
val rightHandPathX = screenWidth() * 5 / 8
val rightHandPathY = screenHeight() * 5 / 6
rightHandPath.moveTo(rightHandPathX, rightHandPathY)
rightHandPath.addOval(
Rect(
rightHandPathX - 35f,
rightHandPathY - 90f,
rightHandPathX + 35f,
rightHandPathY + 90f
)
)
rightHandPath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = leftHandPath, color = drawColor, style = Stroke(width = 10f))
drawPath(path = rightHandPath, color = drawColor, style = Stroke(width = 10f))
}我们看下效果图
尾巴
还差最后一步,我们给兔子画上尾巴,尾巴的中心点x坐标就是画布宽度减去脑袋右边x轴坐标,尾巴中心点的y坐标就是画布高度减去一定的数值,我们看下代码
val tailPath = Path()
val tailPathX = screenWidth() - startX
val tailPathY = screenHeight() - 200f
tailPath.moveTo(tailPathX, tailPathY)
tailPath.addOval(Rect(tailPathX - 60f, tailPathY - 90f, tailPathX + 60f, tailPathY + 90f))
tailPath.close()
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawPath(path = tailPath, color = drawColor, style = Stroke(width = 10f))
}就这样一只兔子画完了,我们看下最终效果图
看起来像那么回事了,我们再稍微点缀下,背景我们发现还有点单调,毕竟是过年了嘛,虽然多地不让放烟花,但我们看看还是可以的,网上找张烟花图片给兔子当背景吧,刚好也有drawImage这样的api可以将图片绘制到画布上,代码如下
val bgBitmap = ImageBitmap.imageResource(id = R.drawable.firework_night)
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.White)
) {
drawImage(image = bgBitmap,
srcOffset = IntOffset(0,0),
srcSize = IntSize(bgBitmap.width,bgBitmap.height),
dstSize = IntSize(screenWidth().toInt()*5/4,screenHeight().toInt()*5/4),
dstOffset = IntOffset(0,0)
)
}我们来看下效果怎么样
嗯~~大功告成~~好像也不是很好看哈哈哈,不过重点咱也不是为了美观,而是一个过年了图个寓意,另一个就是用下Compose里面Canvas这些api,毕竟随着kotlin逐步成熟,个人感觉Compose很有可能成为Android以后主流的UI开发模式
最后给大家拜个早年了,祝大家兔年大吉,“兔”飞猛进~~
链接:https://juejin.cn/post/7186454742950740028
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 弹性布局的基石: Flex 和 Flexible
Flutter 弹性布局的基石 是 Flex 和 Flexible。理解了这两个 widget,后面的 Row,Column 就都轻而易举了。本文用示例的方式详细介绍 Flex 的布局算法。
Flex 布局算法
小写字母开头的 flex 是指 Flexible 的 属性 flex。
先布局 flex 为 0 或 null 的 child。在 main 轴上 child 受到的约束是 unbounded。如果 crossAxisAlignment 是 CrossAxisAlignment.stretch, 在 cross 轴上的约束是 tight,值是 cross 轴上约束的最大值。否则,在 cross 轴上的约束是 loose。
为 flex 不为 0 的 child 申请空间,flex 值越大,按比例得到的可以占用的空间越大。
为 flex 不为 0 的 child 分配空间。main 轴方向的最大值是第二步申请到的空间的值。如果 child 的 fit 参数为 FlexFit.tight,child 在主轴方向 受到 tight 约束,值为第二步申请到的空间的值。如果 child 的 fit 参数为 FlexFit.loose,child 在主轴方向 受到 loose 约束。child 在主轴方向可以任意小,但不能超第二步申请到的空间的值。
Flex cross 轴的高度是能包住所有 child,并不超过最大约束。
Flex main 轴的宽度与 mainAxisSize 有关。如果 mainAxisSize 是 MainAxisSize.max,main 轴的宽度是最大约束值,否则是能包住所有 child ,但不超过最大约束。
Flex 自己的尺寸和 child 的尺寸确认后,根据 mainAxisAlignment 和 crossAxisAlignment 摆放 child。
看了算法并不直观,下面通过实例讲解。
非弹性组件在 main 轴受到的约束是 unbounded
Flex(
direction: Axis.horizontal,
children: [
Container(
width: 1000,
height: 100,
color: Colors.red[200],
),
],
)我们看到,Flex 在主轴的约束是 unbounded,所以 container 可以取值 1000,超出屏幕,显示警告。
flex 值越高,可以分到的空间越大,但能否占满空间取决于 fit 参数
Flex(
direction: Axis.horizontal,
children: [
Flexible(flex:2 ,child: Container(width: 50,height: 80,color: Colors.green,),),
Flexible(flex:1, child: Container(width: 100,height: 50,color: Colors.blue[300],),),
Container(width: 50,height: 100,color: Colors.red[200],
),
],
)假设宽一共 200,布局过程:
- 先分配非弹性 child 红色块 50。
- 绿色和蓝色块是弹性块,它们会瓜分剩下的 150,按 flex 值,绿色块应该分 100,蓝色块分 50。
- 绿色块的 fit 值是 loose,flex 不强制它把空间占满,所以它只点了 50。蓝色块的 fit 值 是 loose,它的 width 比 50 大 flex 会强制它的宽度为 50。效果就是右边还剩下 50,那本来是分给绿色块的。
如果绿色块的 fit 值修改为 FlexFit.tight,剩下的空间就会被占满了,这个时候 width 会被忽略。
Flexible 的作用就是为了修改 child 的 parentData,给 child 增加 fit, flex 布局信息。让 Flex 根据这些信息为 child 布局。
Expanded
class Expanded extends Flexible {
const Expanded({
super.key,
super.flex,
required super.child,
}) : super(fit: FlexFit.tight);
}Expanded 其实就是 fit 固定为 FlexFit.tight 的 Flexible。其实可以直接用 Flexible 的,但因为 Expanded 太常用了,所以单独加了一个类。同时 Expanded 也更加有语义。Expanded 和 Flexible 的关系就像 Center 和 Align的一样。
Spacer
class Spacer extends StatelessWidget {
const Spacer({super.key, this.flex = 1})
: assert(flex != null),
assert(flex > 0);
final int flex;
@override
Widget build(BuildContext context) {
return Expanded(
flex: flex,
child: const SizedBox.shrink(),
);
}
}Spacer 的 child 是 SizedBox.shrink(),用来占位,没有实际的意义。Spacer 是 Expanded 的包装,就是为了占空位用的。
至于摆放 child 的规则大同小异,如果有不明白的同学可以看 这篇 Flutter Wrap 图例
Flex 和 Flexible 如果都掌握了,Row 和 Colmn 自然就会了。因为 Row 只是 direction 为 Axis.horizontal 的 Flex,Column 只是 direction 为 Axis.vertical 的 Flex。
链接:https://juejin.cn/post/7180962741950087224
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 蒙层控件 ModalBarrier
ModalBarrier 是一个蒙层控件,可以对他后面的 UI 进行遮挡,阻止用户和后面的 UI 发生交互。
ModalBarrier 介绍
在实现上,核心代码是 是一个 ConstrainedBox 包了一个 ColoredBox 。ConstrainedBox 的作用是让 ModalBarrier 拥有允许范围内的最大尺寸。ColoredBox 就是画一个背景色。
ConstrainedBox(
constraints: const BoxConstraints.expand(),
child: color == null ? null : ColoredBox(
color: color!,
),
),参数主要有 3 个 color 设置背景色,dismissible 决定点击的时候是否隐藏,onDismiss 是一个回调,当隐藏的时候调用。
使用 ModalBarrier
使用 ModalBarrier 需要 用到 Stack,下面是一个例子。开始的时候 ModalBarrier 不显示,点击按钮的时候,显示 ModalBarrier,过几秒后自动消失。显示 ModalBarrier 的时候,尝试点击按钮,是点不到的,因为已经被 ModalBarrier 遮挡了。
class MyWidget extends StatefulWidget {
const MyWidget({super.key});
@override
State<MyWidget> createState() => _MyWidgetState();
}
class _MyWidgetState extends State<MyWidget> {
var showBarrier = false;
@override
void initState() {
super.initState();
}
@override
void dispose() {
super.dispose();
}
@override
Widget build(BuildContext context) {
return SizedBox(
width: 300,
height: 300,
child: Stack(
alignment: Alignment.center,
children: [
ElevatedButton(
onPressed: (() async {
setState(() {
showBarrier = true;
});
await Future.delayed(Duration(seconds: 5));
setState(() {
showBarrier = false;
});
}),
child: Text('显示 barrier')),
if (showBarrier)
ModalBarrier(
color: Colors.black38,
),
],
));
}
}在这个例子中,你点遮罩,遮罩 是不消失的。因为让遮罩消失执行的代码是 Navigator.maybePop(context)。我们并没有 push ,所以 pop 也就没有反应了。
一般来说,如果想要全屏遮罩,直接用 Dialog 为好。想部分遮罩,才需要直接用 ModalBarrier,这个时候自己控制显隐。
if (onDismiss != null) {
onDismiss!();
} else {
Navigator.maybePop(context);
}
}ModalBarrier 源码的逻辑是这样的,所以我们可以添加 onDismiss 回调,在回调函数里隐藏遮罩,这样就不会再走 Navigator.maybePop(context); 了。
ModalBarrier(
dismissible: true,
onDismiss: () {
setState(() {
showBarrier = false;
});
},
color: Colors.black38,
);链接:https://juejin.cn/post/7184675957805072440
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
比 Flutter ListView 更灵活的布局方式
大家好,我是 17。
在 Flutter 中,涉及到滚动布局的时候,很多同学会大量使用 ListView。
ListView 的局限
没错,在实现效果的方面 ListView 确实能做到大多数,但是有些情况下会很别扭,性能也不好。你可能遇到过下面的设计:
banner 和下面的列表是一起滚动的。如果用 ListView ,你一定可以马上写出代码:
ListView.builder(
itemBuilder: (context, index) {
if (index == 0) {
return Container(
height: 100,
color: Colors.blue,
child: Text('banner'),
);
} else {
return ListTile(title: Text('${index - 1}'));
}
},
itemCount: 100
)上面的代码会有一个问题,banner 的高度和下面列表的高度不一样,导致无法使用定高列表,造成性能下降。需要 if else,如果有多个 banner,if else 也要多个,那就相当复杂了。
还有一个问题,在你没有设置任何边距的情况下,ListView 和上面的 Widget 可能会一段空白。
你需要这样去除空白。
ListView.builder(
padding: EdgeInsets.zero,为什么会有空白呢?这是因为 ListView 继承自 BoxScrollView,它的主要贡献就是加了这个空白!
这个空白的值是多少呢?就是取的 mediaQuery 的 padding。因为浏海屏的出现,ios 中,上面和下面会有一部分不适合显示主要内容,所以就有了这个安全 padding。BoxScrollView 在设计的时候也考虑到了这一点,于是就默认加了这个 padding。但实际上,如果 listView 不是在最顶部,反而是帮了倒忙。
ListView 最理想的使用场景是展示的 item 都一样高,但多数情况下,item 是不一样高的。ListView 出现的目的是为了方便使用,但却是牺牲了灵活性。它只能有一个 SliverChild,这会导致 itemBuilder 函数逻辑的复杂和性能的下降。
更灵活的布局方式
其实我们可以直接从 ScrollView 继承,根据实际情况定制需要的组件。说到定制你可能会觉得一定很复杂,实际上是非常简单的,而且因为我们是根据业务量身定做的组件,所以用起来会特别顺手。
要用 ScrollView 实现上面的设计,只需要下面的代码:
class MyListView extends ScrollView {
const MyListView(
{Key? key,
this.banner,
required this.itemBuilder,
required this.itemExtent,
required this.itemCount})
: super(key: key);
final Widget? banner;
final IndexedWidgetBuilder itemBuilder;
final double itemExtent;
final int itemCount;
@override
List<Widget> buildSlivers(BuildContext context) {
List<Widget> list = [];
if (banner != null) {
list.add(SliverToBoxAdapter(child: banner!));
}
list.add(SliverFixedExtentList(
delegate: SliverChildBuilderDelegate(itemBuilder, childCount: itemCount),
itemExtent: itemExtent,
));
return list;
}
}很简单吧。实际上,我们只是 override buildSlivers 方法,生成一个 list。SliverToBoxAdapter 可以看作是一个转换器,把普通的 Widget 转换为 Sliver Widget。虽然 buildSlivers 的返回值是 List<Widget> ,但实际上,Widget 应该是 Sliver Widget,否则无法滚动。
MyListView 使用起来也很方便,代码更简洁,没有了讨厌的 if else 了。
MyListView(
banner: Container(color: Colors.green, height: 100),
itemExtent: 20,
itemCount: 100,
itemBuilder: (context, index) => Text('$index'),
)现在 banner 和 item 的逻辑是分开的,代码更加清晰,也更好维护。把 banner 这个高度不一样的 widget 分开后,剩下的 item 高度都是一样的,本例中,我们设置固定高度 itemExtent: 20,每个 item 的高度都是 20,在 buildSlivers 中用 itemExtent 做为参数,用 SliverFixedExtentList 生成定高列表,性能得到大大提高。
老板说,把第 10 条数据显示在第一的位置
这个需求还是很常见的,在某个时刻,需要把某条数据显示在第一的位置。如果用 ListView 实现起来不容易,你可能想要调整数据的位置,但需求是数据的位置不变,只是想让 ViewPort 滚动到 第 10 条数据的位置。你可能还想到了用 ListView 的 controller 来控制滚动位置,尝试一下可以知道并不方便实现,或者实现了也不方便维护。
直接用 ScrollView 就很简单了。 ScrollView 有一个参数可以直接实现在这样的功能,这个参数就是 center。你可能很奇怪,ListView 是从 BoxScrollView 继承,BoxScrollView 是从 ScrollView 继承,但是在 ListView 中没有发现这个参数啊?为了方便使用,BoxScrollView 只有一个 Sliver Child,center 参数没有了用武之地,在 ListView 中找不到这个参数也就不奇怪了。
实现功能
先看下效果,不使用 center 参数,banner 在第一个位置显示。
使用 center 参数后,第 10 条数据,自动显示在第一个位置。
下面是完整代码,贴到 main.dart 就能运行
import 'package:flutter/material.dart';
void main() => runApp(const MyApp());
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return const MaterialApp(
home: Scaffold(body: MyWidget()),
);
}
}
class MyWidget extends StatefulWidget {
const MyWidget({super.key});
@override
State<MyWidget> createState() => _MyWidgetState();
}
class _MyWidgetState extends State<MyWidget> {
@override
Widget build(BuildContext context) {
return SafeArea(
child: MyListView(
banner: Container(
color: Colors.blue[100],
alignment: Alignment.center,
height: 100,
child: const Text(
'IAM17 Flutter 天天更新',
),
),
itemBuilder: (context, index) {
return ListTile(
title: Text('$index'),
);
},
center: const ValueKey(9),
itemExtent: 20,
itemCount: 100));
}
}
class MyListView extends ScrollView {
const MyListView(
{Key? key,
this.banner,
required this.itemBuilder,
required this.itemExtent,
required this.itemCount,
Key? center})
: super(key: key, center: center);
final Widget? banner;
final IndexedWidgetBuilder itemBuilder;
final double itemExtent;
final int itemCount;
@override
List<Widget> buildSlivers(BuildContext context) {
List<Widget> list = [];
if (banner != null) {
list.add(SliverToBoxAdapter(child: banner!));
}
if (center == null) {
list.add(SliverFixedExtentList(
delegate:
SliverChildBuilderDelegate(itemBuilder, childCount: itemCount),
itemExtent: itemExtent,
));
} else {
for (var i = 0; i < itemCount; i++) {
list.add(SliverToBoxAdapter(
key: ValueKey(i),
child: itemBuilder(context, i),
));
}
}
return list;
}
}当 center 不为 null 的时候,放弃使用 SliverFixedExtentList,只能把 child 一个一个加到 list 中。这样会损失一些性能,但能快速实现需求,还是值得的。
center 参数是如何影响位置的?
在 ViewPort 的构造函数中有一个 assert,如果 center 不为空,那么在 slivers 中必须要找到 key 为 center 的 child。
Viewport({
...
this.center,
...
}) :
assert(center == null || slivers.where((Widget child) => child.key == center).length == 1),最终是给 ViewPort 对应的 renderObject 的 center 赋值。
代码位置 : flutter/lib/src/widgets/viewport.dart
void _updateCenter() {
// TODO(ianh): cache the keys to make this faster
final Viewport viewport = widget as Viewport;
if (viewport.center != null) {
int elementIndex = 0;
for (final Element e in children) {
if (e.widget.key == viewport.center) {
renderObject.center = e.renderObject as RenderSliver?;
break;
}
elementIndex++;
}
assert(elementIndex < children.length);
_centerSlotIndex = elementIndex;
} else if (children.isNotEmpty) {
renderObject.center = children.first.renderObject as RenderSliver?;
_centerSlotIndex = 0;
} else {
renderObject.center = null;
_centerSlotIndex = null;
}
}
总之,就是通过 key 找到对应的 Sliver Widget,对应到 renderObject,实现 center 的功能。
通过这个简单的案例说明,我们应该自己动手定制适合自己项目的 ”ListView“!通过简单的封装,就能让我们的代码更简洁,更容易维护,性能也会更好。
更多关于滚动的参数介绍可以看这篇 flutter 滚动的基石 Scrollable。
回答下 @法的空间 提的问题:CustomScrollView 的意义何在?
BoxScrollView 和 CustomScrollView 都是 ScrollView 的 子类。BoxScrollView 只能创建一块滑动内容,CustomScrollView 可以支持滑动列表,这就是 CustomScrollView 的意义。
之所以没有直接用 CustomScrollView ,而是直接从 ScrollView 继承是为了可以把一些属性和滑动列表一起封装起来,方便使用。
如果代码不需要复用,直接用 CustomScrollView 也是可以的,而且也是最简单的方式。
CustomScrollView 的代码就一句:
@override
List<Widget> buildSlivers(BuildContext context) => slivers;
ScrollView 是抽象类,不能直接用,CustomScrollView 的意义在于:我们不需要每次都要 extends 一个类出来,用 CustomScrollView 就可以支持滑动列表。
希望已经解答了你的问题,谢谢提问!
链接:https://juejin.cn/post/7184955986224873531
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flow 转 LiveData,数据丢了,肿么回事?
前言
最近我在负责一段代码库,需要在使用 Flow 的 Data 层和仍然依赖 LiveData 暴露 State 数据的 UI 层之间实现桥接。好在 androidx.lifecycle 框架已经提供了一个叫做 asLiveData() 的方法,可以让你毫不费力地将 Flow 转为 LiveData。
然而使用这种方式得到的 LiveData 需要牢记一点:在拥有一个及以上活跃的观察者的条件下,它才会发射数据。假使上游的 flow 产生了更新,但对应的 LiveData 并非活跃的状态,那么它将无法获得最新的数值。
让我通过如下的实例,向你展示我们可能会遇到的这种潜在问题。
示例
我们有一个简单的 Activity,它持有 AAC ViewModel 的实例:
class MainActivity : AppCompatActivity() {
private val viewModel: MainViewModel by viewModels()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
}该 ViewModel 的实现是这样的:
class MainViewModel : ViewModel() {
private val repository = Repository()
val state: LiveData<Int> = repository.state.asLiveData()
}它持有一个 Repository 实例,充当琐碎的数据层。
同时 ViewModel 还通过前面提到的 asLiveData() 方法,将 Repository 持有的 StateFlow 转为了 LiveData 并对外暴露了其 State 数据。
Repository 的实现如下:
class Repository {
private val _state = MutableStateFlow(-1)
val state: StateFlow<Int> = _state
suspend fun update() {
_state.emit(Random.nextInt(until = 1000))
}
}它拥有一个包裹着 Integer 数据(初始值为 -1)的 StateFlow 示例,同时对外提供了一个方法允许外界更新它的 State:从 0 到 1000 之间取得一个新的随机数。
试想一下,假使希望 Activity 创建的时候就能执行这个数据更新。我们可以这么实现:
- 在
MainViewModel内创建一个init()来做这个操作 - Activity 的
onCreate()里调用该方法
// MainViewModel
fun init() {
// update() is suspending, so we launch a new coroutine here
viewModelScope.launch {
repository.update()
}
}
// MainActivity
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
viewModel.init()
}这样的话,Activity 创建的时候一个新的协程将被启动,最终会调用 Repository 的 update() ,生成一个随机数并发射到它的 State。
此外,我们可能还需要在 ViewModel 中去发送包含了新生成数值的事件出去。可以在 ViewModel 中添加一个sendAnalyticalEvent() ,这样可以在执行完 Repository 的 update() 之后立即调用它。
// MainViewModel
fun init() {
viewModelScope.launch {
repository.update()
sendAnalyticalEvent() // <-- NEW
}
}
private fun sendAnalyticalEvent() {
// Typically, we would schedule a network request here
val liveDataValue = state.value
val flowValue = repository.state.value
Log.d("Current number in LiveData", "$liveDataValue")
Log.d("Current number in StateFlow", "$flowValue")
}该方法内,我们可以做些典型的操作,比如向后端服务器发送网络请求。这里,让我们仅仅在 Logcat 里打印来自 LiveData and Flow 的数值即可。
上面的运行结果相当出乎意料。你可能会争辩道:LiveData 没有获取到最新的数值,是因为没有足够的时间从上游的 flow 中收集数据,不然的话肯定能够拿到正确的数值。
但这个 case 里,不仅仅是 LiveData 获得到的是错误的数值,它获得到的是 null。而且请别忘了,它的存放在 Repository 里的初值是 -1。这只能代表一个意思:这里的 LiveData 压根没有从 StateFlow 里收集任何数据。
原因是我们还没有开始观察这个 LiveData,它自然会被当作是非活跃的。而且根据 asLiveData() 方法的文档可以知道,在这种情况下 LiveData 不会从上游的 flow 收集任何数据。
asLiveData:Creates a
LiveDatathat has values collected from the originFlow.
上游 flow 数据的收集发生在
LiveData变成活跃的时候,即LiveData.onActive。如果 flow 尚未完成,而LiveData变成了非激活状态,即LiveData.onActive,那么 flow 的数据收集将在timeoutInMs参数指定的时间后被取消。除非在超时之前,LiveData变成活跃状态。
一旦我们开始在 Activity 里观察 LiveData 的数据(因此将促使 LiveData 变成活跃状态),它就能够拥有正确的、最新的数值了。
// MainActivity
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
viewModel.init()
viewModel.state.observe(this) { // <-- NEW
Log.d("Current number in MainActivity", "$it")
}
}如下是 Logcat 里新的输出。
上面的示例里,我们采用的是 StateFlow,但规则同样适用于 SharedFlow。
而且,情况将更加糟糕,因为当 LiveData 处于非激活状态的时候,任何发送给 SharedFlow 的事件都将永久丢失(默认情况下 SharedFlow 不会将任何数值重新发送给新的订阅者)。
总结
请时刻记住采用 asLiveData() 方法转换 Flow 得到的 LiveData 将会和预期的稍稍不同:它只会在注册了活跃观察者的情况下发射数据。
就我个人而言,这种行为无可厚非:因为我们都还没有观察它、自然不会在意 LiveData 的数值是啥、能不能获取得到。但话说回来,确实存在一些场景,需要在你尚未开始观察的时候,去访问 ViewModel 中 LiveData 的当前数值。
通过阅读这篇文章,我希望你在遇到这种获取不到正确数值的情况时,不要惊讶、心中有数。
链接:https://juejin.cn/post/7186249265138794551
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Compose跨平台第一弹:体验Compose for Desktop
前言
Compose是Android官方提供的声明式UI开发框架,而Compose Multiplatform是由JetBrains 维护的,对于Android开发来说,个人认为学习Jetpack Compose是必须的,因为它会成为Android主流的开发模式,而compose-jb作为一个扩展能力,我们可以有选择的去尝试。今天我们先来了解一下使用compose-jb开发一个桌面端应用的流程。
接下来还会有第二弹,第三弹...
环境要求
开发Compose for Desktop环境要求主要有两点:
JDK 11或更高版本
IntelliJ IDEA 2020.3 或更高版本(也可以使用AS,这里为了使用IDEA提供的项目模板)
接着我们来一步步体验Compose for Desktop的开发流程。
开发流程
创建项目
下载好IDEA后,我们直接新建项目,选择Compose Multipalteform类型,输入项目名称,这里只选择Single platform且平台为Desktop即可。
创建好项目后,来看项目目录结构,目录结构如下图所示。
在配置文件中指定了程序入口为MainKt以及包名、版本号等。MainKt文件代码如下所示。
@Composable
@Preview
fun App() {
var text by remember { mutableStateOf("Hello, World!") }
MaterialTheme {
Button(onClick = {
text = "Hello, Desktop!"
}) {
Text(text)
}
}
}
fun main() = application {
Window(onCloseRequest = ::exitApplication) {
App()
}
}在MainKt文件中,入口处调用了App()方法,App方法中绘制了一个按钮,运行程序,结果如下图所示。
我们可以看到一个Hello World的桌面端程序就显示出来了。接下来我们来添加一些页面元素。
添加输入框
为了让桌面端程序更“像样子”,我们首先修改桌面程序的标题为“学生管理系统”,这毕竟是我们学生时代最喜欢的名字。代码如下所示:
fun main() = application {
Window(onCloseRequest = ::exitApplication, title = "学生管理系统") {
App()
}
}在App方法中,添加两个输入框分别为学号、密码,添加一个登陆按钮,写法与Android中的Compose一致,代码如下所示。
MaterialTheme {
var name by remember {
mutableStateOf("")
}
var password by remember {
mutableStateOf("")
}
Column {
TextField(name, onValueChange = {
name = it
}, placeholder = {
Text("请输入学号")
})
TextField(password, onValueChange = {
password = it
}, placeholder = {
Text("请输入密码")
})
Button(onClick = {
}) {
Text("登陆")
}
}
}再次运行程序,页面如下所示。
添加头像
接着我们再来添加头像显示,我们将下载好的图片资源放在resources目录下
然后使用Image组件将头像显示出来即可,代码如下所示。
Image(
painter = painterResource("photo.png"),
contentDescription = null,
modifier = Modifier.size(width = 100.dp, height = 100.dp)
.clip(CircleShape)
)再次运行程序,结果如下所示。
当然我们还可以将布局稍微修饰一下,使得布局看起来更好看一些。但这并不是这里的重点。
添加退出弹窗
当我们点击左上角(macOS)的X号时,应用程序就直接退出了,这是因为在Window函数中指定了退出事件,再来看一下这部分代码,如下所示。
fun main() = application {
Window(onCloseRequest = ::exitApplication, title = "学生管理系统") {
App()
}
}接下来我们增加一个确认退出的弹窗提醒。代码如下所示。
fun main() = application {
var windowsOpen by remember {
mutableStateOf(true)
}
var isClose by remember {
mutableStateOf(false)
}
if (windowsOpen) {
Window(onCloseRequest = { isClose = true }, title = "学生管理系统") {
App()
if (isClose) {
Dialog(onCloseRequest = { isClose = false }, title = "确定退出应用程序吗?") {
Row {
Button(onClick = {
windowsOpen = false
}) {
Text("确定")
}
}
}
}
}
}
}这里我们新增了两个变量windowsOpen、isClose分别用来控制应用程序的Window是否显示与确认弹窗的显示。这部分代码相信使用过Jetpack Compose的都可以看得懂。
运行程序,点击X号,弹出退出确认弹窗,点击确定,应用程序将退出。效果如下图所示。
实现一个网络请求功能
在 KMM入门 中我们借用「wanandroid」中「每日一问」接口实现了一个网络请求,现在我们将这部分功能移植到Desktop程序中,网络请求框架仍然使用Ktor,当然其实你也可以使用Retrofit,这一点并不重要。
首先添加Ktor的依赖,代码如下所示。
val jvmMain by getting {
dependencies {
implementation(compose.desktop.currentOs)
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
val ktorVersion = "2.1.2"
implementation("io.ktor:ktor-client-core:$ktorVersion")
implementation("io.ktor:ktor-client-content-negotiation:$ktorVersion")
implementation("io.ktor:ktor-serialization-kotlinx-json:$ktorVersion")
implementation("io.ktor:ktor-client-android:$ktorVersion")
}
}添加一个Api接口
object Api {
val dataApi = "https://wanandroid.com/wenda/list/1/json"
}创建HttpUtil类,用于创建HttpClient对象和获取数据的方法,代码如下所示。
import io.ktor.client.*
import io.ktor.client.call.*
import io.ktor.client.plugins.contentnegotiation.*
import io.ktor.client.request.*
import io.ktor.serialization.kotlinx.json.*
import kotlinx.serialization.json.Json
class HttpUtil {
private val httpClient = HttpClient {
install(ContentNegotiation) {
json(Json {
prettyPrint = true
isLenient = true
ignoreUnknownKeys = true
})
}
}
/**
* 获取数据
*/
suspend fun getData(): String {
val rockets: DemoReqData =
httpClient.get(Api.dataApi).body()
return "${rockets.data} "
}
}DemoReqData是接口返回数据对应映射的实体类,这里就不再给出了。
然后我们编写UI,点击按钮开始网络请求,代码如下所示。
Column() {
val scope = rememberCoroutineScope()
var demoReqData by remember { mutableStateOf(DemoReqData()) }
Button(onClick = {
scope.launch {
try {
demoReqData = HttpUtil().getData()
} catch (e: Exception) {
}
}
}) {
Text(text = "请求数据")
}
LazyColumn {
repeat(demoReqData.data?.datas?.size ?: 0) {
item {
Message(demoReqData.data?.datas?.get(it))
}
}
}
}获取数据后,通过
Message方法
将数据展示出来,这里只将作者与标题内容显示出来,代码如下所示。
@Composable
fun Message(data: DemoReqData.DataBean.DatasBean?) {
Card(
modifier = Modifier
.background(Color.White)
.padding(10.dp)
.fillMaxWidth(), elevation = 10.dp
) {
Column(modifier = Modifier.padding(10.dp)) {
Text(
text = "作者:${data?.author}"
)
Text(text = "${data?.title}")
}
}
}运行程序,点击“请求数据”,结果如下图所示。
这样我们就实现了一个简单的桌面端数据请求与显示功能。
写在最后
当然,在Compose For Desktop中还有许多的组件,比如Tooltips、Context Menu等等,这里无法一一介绍,需要我们在使用的时候去实践,我们将在后面的N弹中持续探索...
链接:https://juejin.cn/post/7185423734864347193
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
实测分析Const在Flutter中的性能表现
在实际的Flutter开发中,可以发现编辑器AS会提示在组件之前加上const关键字,
这是因为Flutter2之后,多了一个linter规则,prefer_const_constructors,官方建议首选使用const来实例化常量构造函数。
那const作用是什么?并且在性能方面对整个app有多大的提升?
一、Const的作用
const 是 constant 的缩写,本意是不变的,不易改变的意思,包括C++、go中都有此关键字,同样的,在Flutter中也是表示不变的意思。具体来看看下面的代码。
Row(
children: [
Image(image: NetworkImage('https://flutter.github.io/assets-for-api-docs/assets/widgets/owl.jpg')),
Text("$_counter")
],
);这是一个水平布局,内部排列了一个Image和Text,注意这个Text的是有一个动态的值_counter。
为了能够更新_counter,必然要调用setState() 方法。我们都知道,如果调用setState() ,那么整个Row包括Image和Text都会自动递归重建。每调用一次,父widget和子widget都会重建一次,那么在复杂的UI和业务场景下,就加深了app的不稳定性。
这就是为什么在开发中,要尽量在小的范围去使用setState,避免不必要的重建任务。为了优化这个问题,官方就更新出了const关键字,被const修饰的widget,就代表永远不会被重建。
比如在上述代码中Image是不可变的,Text是可变的,那么在Image之间加上const修饰,当调用setState() 时,只会更新Text,Image不会被重新构建。
Row(
children: [
const Image(image: NetworkImage('https://flutter.github.io/assets-for-api-docs/assets/widgets/owl.jpg')),
Text("$_counter")
],
);二、性能分析
2.1 widget rebuild状态
DevTools提供了一个查询widget rebuild状态的工具,在 Widget rebuild stats 中勾选 Track widget rebuilds 来查看 widget 的重建信息。重建信息包括 Widget 名字、源码位置、上一帧中重建次数、当前页面中重建次数。
在每个widget之前都有一个小图标,
- 黄色旋转圆圈 - 重建次数过多
- 灰色圆圈 - 未重建
- 灰色旋转圆圈 - 重建
为了进行const对比,我们以上面代码为例,
Row(
children: [
const Image(image: NetworkImage('https://flutter.github.io/assets-for-api-docs/assets/widgets/owl.jpg')),
Text("$_counter")
],
);在Image前加上const,Text则不加,当调用setState时,观察两个widget的情况。
清楚的发现,没加const的Image widget前面的圆圈在旋转,则表示Image在重建,且重建次数+1。
2.2 内存占用
关于内存,DevTool同样提供了内存分析工具Memory,接下来结合案例进行分析。
在项目中新建两个类,内部不做额外的动作,
void _buildConstObject(){
const ConstObject();
}
void _buildConstObjectNot(){
ConstObjectNot();
}其中ConstObject 加上const修饰,ConstObjectNot则不进行修饰,在触发build时,两个对象同时进行1000次的创建,
void _doBuild(){
for(var i = 0; i< 1000;i++){
_buildConstObject();
_buildConstObjectNot();
}
}打开内存分析工具,可以发现未加Const修饰的ConstObjectNot创建了1000个对象,所占用内存约16k,而加了const的ConstObject则可以忽略不计。
注意这里ConstObjectNot和ConstObject内部是没有做任何widget创建的,如果在实际复杂的项目中,未使用const,内存将成倍增加。
2.3 流畅性
在DevTool中打开performance overlay, 在app顶部就会出现性能图层,这两张图表显示的是应用的耗时信息。如果 UI 产生了卡顿(跳帧),这些图表可以帮助分析应用中卡顿,每一张图表都代表当前线程的最近 300 帧表现。
如上图,第一张图属于raster 线程的性能情况即GPU性能,第二张图显示的UI线程性能表现。
当中垂直的绿色条条代表的是当前帧。每一帧都应该在 1/60 秒(大约 16 ms)内创建并显示。如果有一帧超时(任意图像)而无法显示,就导致了卡顿,图表之一就会展示出来一个红色竖条。如果是在 UI 图表出现了红色竖条,则表明 Dart 代码消耗了大量资源。而如果红色竖条是在 GPU 图表出现的,意味着场景太复杂导致无法快速渲染。
为了验证流畅性,我们开启了一个动画,动画在规定时间内进行重复性的放大缩小动作,且分为两个场景,一个场景是在所有widget以及对象前加上const修饰,另外一个场景则什么都不做,对比查看每帧的耗时。
class AnLogo extends AnimatedWidget {
static final _opacityTween = Tween<double>(begin: 0.1, end: 1.0);
static final _sizeTween = Tween<double>(begin: 0.0, end: 300.0);
const AnLogo({Key? key, required Animation<double> animation})
: super(key: key, listenable: animation);
@override
Widget build(BuildContext context) {
Animation<double> animation1 = listenable as Animation<double>;
return Scaffold(
appBar: AppBar(
title: const Text("动画"),
),
body: Center(
child: Opacity(
opacity: _opacityTween.evaluate(animation1),
child: Container(
margin: const EdgeInsets.symmetric(vertical: 10.0),
height: _sizeTween.evaluate(animation1),
width: _sizeTween.evaluate(animation1),
child: Image.asset("images/ic_1.jpeg"),
),
),
),
);
}
}| no const | const |
|---|---|
| no const | const |
|---|---|
GPU帧率:
| GPU | |
|---|---|
| no const平均最大耗时/帧 | 9.9ms/frame |
| const平均最大耗时/帧 | 7.6ms/frame |
UI线程帧率:
| UI线程 | |
|---|---|
| no const平均最大耗时/帧 | 7.8ms/frame |
| const平均最大耗时/帧 | 7.1ms/frame |
从实验结果上看,没有加const的GPU帧率平均最大达到9.9ms/帧,而加了const的GPU帧率比之降低了约2.3ms;UI帧率(CPU)加const与不加const相差不大,约0.7ms。
三、总结
从上面的测试看,不管是内存占用还是流畅性,添加const修饰的性能都是优于未添加const修饰的性能,const减少了组件的重建以及对象的创建,进行flutter开发时,在合适的时机去使用const以减少不必要的开销。
推荐阅读:
链接:https://juejin.cn/post/7186439056358637605
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RxJava加Retrofit文件分段上传
前言
本文基于 RxJava 和 Retrofit 库,设计并实现了一种用于大文件分块上传的工具,并对其进行了全面的拆解分析。抛砖引玉,对同样有处理文件分块上传诉求的读者,可能会起到一定的启发作用。
文章主体由四部分构成:
- 首先分析问题,问题拆解为:多线程分段读取文件、构建和发出文件片段上传请求
- 基于 JDK 随机读取文件的类库,设计本地多线程分段读取文件的单元
- 基于 Retrofit 设计由文件片段构建上传的网络请求
- 从上述设计演变而来的完整代码实现
另外,在文章提供的完整代码中,还附了一段由 PHP 编写,用来接收多线程分段数据的服务端接口实现,其中处理了因客户端都线程上传片段,导致服务端接收的文件片段无序,故需在适当时机合并分块构成目标文件。
受限于笔者的开发经验与理论理解,文章的思路和代码难免可能有偏颇,对于有改进和优化的部分,欢迎大家讨论区提出。
问题拆解
要完成文件分段上传到服务端,第一步是分段读取本地文件。通常分段是为了多线程同时执行上传,提高设备计算和网络资源利用率,减少上传时间优化体验,这样即需要一个支持多线程的文件分段读取工具。由于文件可能超过设备内存大小,在读取这类超大文件时需要控制最大读取量防止内存溢出。此时文件已从磁盘数据转换为内存中的字节数据,只需要将这些内存数据传给服务端即可。这样问题被分成 3 个子问题:
- 分段读取文件到内存中
- 控制多线程数量
- 将文件片段传给服务端
问题 1 很好解决,利用 Java 的 RandomAccessFile 可对文件的随机读取的特性,即可按需读取文件片段到内存中。问题 2 相对复杂一点,但如果有阅读过 JDK 中线程池源码的读者,就会发现这个问题的和控制线程池中线程数量其实是类似的。问题 3 就不复杂了,Retrofit 基于 OKhttp ,OkHttp是很容易基于字节数组构建 multipart/form-data 请求的。
分块并发读取文件
根据上述对问题 1、2 的拆解,可将读取抽象为一个文件读取器,构建时传入文件对象和分段大小以及最大并发数,以及分段数据的回调。当外部启动读取时将根据文件大小和配置的分段大小构建若干个 Task 用于读取对应片段的数据。
public BlockReader(@NotNull File file, @NotNull BlockCallback callback, int poolSize, int blockSize) {
mFile = file;
mCallback = callback;
mPoolSize = poolSize;
mBlockSize = blockSize;
}
public void start(@Nullable BlockFilter filter) {
Observable.empty().observeOn(Schedulers.computation()).doOnComplete(() -> {
long length = mFile.length();
for (long offset = 0; offset < length; offset += mBlockSize) {
if (null != filter && filter.ignore(offset)) {
continue;
}
mQueue.offer(new ReadTask(offset));
}
for (int i = 0; i < Math.min(mPoolSize, mQueue.size()); i++) {
Observable.empty().observeOn(Schedulers.io()).doOnComplete(this::schedule).subscribe();
}
}).subscribe();
}多线程调度部分,可通过加锁和记录状态变量统计当前正运行的线程数,则可控制字节数组数,这样就相当于控制住了最大内存占用。
private void schedule() {
if (mRunning.get() >= mPoolSize) {
return;
}
ReadTask task;
synchronized (mQueue) {
if (mRunning.get() >= mPoolSize) {
return;
}
task = mQueue.poll();
if (null != task) {
mRunning.incrementAndGet();
}
}
if (null != task) {
task.run();
}
} 最后是文件随机读取,直接调用 RandomAccessFile 的 API 即可:
private class ReadTask implements Action {
@Override
public void run() {
try (RandomAccessFile raf = new RandomAccessFile(mFile, RAF_MODE);
ByteArrayOutputStream out = new ByteArrayOutputStream(mBlockSize)) {
raf.seek(mOffset);
byte[] buf = new byte[DEF_BLOCK_SIZE];
long cnt = 0;
for (int bytes = raf.read(buf); bytes != -1 && cnt < mBlockSize; bytes = raf.read(buf)) {
out.write(buf, 0, bytes);
cnt += bytes;
}
out.flush();
mCallback.onFinished(mOffset, out.toByteArray());
} catch (IOException e) {
mCallback.onFinished(mOffset, null);
} finally {
mRunning.decrementAndGet();
schedule();
}
}
}文件片段上传
上传部分则使用 Retrofit 提供的注解和 OKHttp 的类库构建请求。但值得一提的是需要在磁盘IO线程同步完成网络IO,这样可以避免网络IO速度落后磁盘IO太多而导致任务堆积造成内存溢出。
public interface BlockUploader {
@POST("test/upload.php")
@Multipart
Single<Response<ResponseBody>> upload(@Header("filename") String filename,
@Header("total") long total,
@Header("offset") long offset,
@Part List<MultipartBody.Part> body);
}
private static void syncUpload(String fileName, long fileLength, long offset, byte[] bytes) {
RequestBody data = RequestBody.create(MediaType.parse("application/octet-stream"), bytes);
MultipartBody body = new MultipartBody.Builder()
.addFormDataPart("file", fileName, data)
.setType(MultipartBody.FORM)
.build();
retrofit.create(BlockUploader.class).upload(fileName, fileLength, offset, body.parts()).subscribe(resp -> {
if (resp.isSuccessful()) {
System.out.println("✓ offset: " + offset + " upload succeed " + resp.code());
} else {
System.out.println("✗ offset: " + offset + " upload failed " + resp.code());
}
}, throwable -> {
System.out.println("! offset: " + offset + " upload failed");
});
}完整代码
为控制篇幅,完整代码请移步 Github,服务端部分处理形如:
链接:https://juejin.cn/post/7183887127992598585
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
运动APP视频轨迹回放分享实现
喜欢户外运动的朋友一般都应该使用过运动APP(keep, 咕咚,悦跑圈,国外的Strava等)的一项功能,就是运动轨迹视频分享,分享到朋友圈或是运动群的圈子里。笔者本身平常也是喜欢户外跑、骑行、爬山等户外运动,也跑过半马、全马,疫情原因之前报的杭州的全马也延期了好几次了。回归正题,本文笔者基于自己的思想实现运动轨迹回放的一套算法策略,实现本身是基于Mapbox地图的,但是其实可以套用在任何地图都可以实现,基本可以脱离地图SDK的API。Mapbox 10 版本之后的官方给出的Demo里已经有类似轨迹回放的Case了,但是深度地依赖地图SDK本身的API,倘若在高德上实现很难可以迁移的。
这里先看下gif动图的效果,这是我在奥森跑的10KM的一个轨迹:
整个的实现包含了轨迹的回放,视频的录制,然后视频的录制这块不再笔者这篇文章的介绍的范畴内。所以这里主要介绍轨迹的回放,这个回放过程其实也是包含了大概10多种动画在里面的,辅助信息距离的文字跳转动画;距离下面配速、运动时间等的flap in 及 out的动画;播放button,底部button的渐变Visibility; 地图的缩放以及视觉角度的变化等;以上的这些也不做讨论。主要介绍轨迹回放、整公里点的显示(起始、结束), 回放过程中窗口控制等,作为主要的讲解范畴。
首先介绍笔者最开始的一种实现,假如以上轨迹List 有一百个点,每相邻的两个点做Animation之后,在AnimationEnd的Listener里开起距离下一个点的Animation,直到所有点结束,这里有个问题每次的运动轨迹的点的数量不一样,所以开起Animation的次数也不一样,整个轨迹回放的时间等于所有的Animation执行的时间和,每次动画启动需要损耗20~30ms。倘若要分享到微信朋友圈,视频的时间是限制的,但之前的那种方式时间上显然不可控,每次动画启动的损耗累加导致视频播放不完。
紧接着换成AnimationSet, 将各个线段Animation的动画放入Set里,然后playSequentially执行,同样存在上面的问题。假如只执行一次动画,那么这次动画start的损耗在整个视频播放上时长上的占比就可以忽略不计了,那如何才能将整个List的回放在一个Animation下执行完呢?假如轨迹只是一个普通的 Path,那么我们就可以基于Path的 length一个属性动画了,当转化到地图运动轨迹上去时,又如何去实现呢?
基于Path Length的属性动画
- 计算List对应的Path
- 通过PathMeasure获取 Path 的 Length
- 对Path做 Length的属性动画
这里有两套Point体系,一个是View的Path对应的Points, 然后就是Map上的List对应的Points,运动轨迹原始数据是Map上的List 点,上面的第一步就是将Map上的Points 转成屏幕Pixel对应的点并生成Path; 第二部通过PathMeasure 计算Path的Length; 最后在Path Length上做属性动画,然而这里并非将属性动画中每次渐变的值(这里对应的是View的Point点)绘制成View对应的Path,而是将渐变中的点又通过Map的SDK转成地图Location点,绘制地图轨迹。这里一共做了两道转换,中间只是借助View的Path做了一个依仗Length属性做的一个动画。因为基本上每种地图SDK都有Pixel 跟Location Point点互相transform的API,所以这个可以直接迁移到其它地图上,例如高德地图等。
下面具体看下代码,先将Location 转成View的Point体系,这里保存了总的一个Path,以及List 中两两相邻点对应的分段Path的一个list.
- 生成Path:
其中用到 Mapbox地图API Location 点转View的PointF 接口API toScreenLocation(LatLng latlng), 这里生成List, 然后计算得到Path.
- 基于Length做属性动画:
首先创建属性动画的 Instance:
ValueAnimator.ofObject(new DstPathEvaluator(), 0, mPathMeasure.getLength());
将每次渐变的值经过 calculateAnimPathData(value) 计算后存入到 以下的四个变量中,这里除了Length的渐变值,还附带有角度的一个二元组值。
dstPathEndPoint[0] = 0;//x坐标
dstPathEndPoint[1] = 0;//y坐标
dstPathTan[0] = 0;//角度值
dstPathTan[1] = 0;//角度值
然后将dstPathEndPoint 的值转成Mapbox的 Location的 Latlng 经纬度点,
PointF lastPoint = new PointF(dstPathEndPoint[0], dstPathEndPoint[1]);
LatLng lastLatLng = mapboxMap.getProjection().fromScreenLocation(lastPoint);
Point point = Point.fromLngLat(lastLatLng.getLongitude(), lastLatLng.getLatitude());
过滤掉一些动画过程中可能产生的异常点,最后加入到Mapbox的轨迹绘制的Layer中形成轨迹的一个渐变:
Location curLocation = mLocationList.get(animIndex);
float degrees = MapBoxPathUtil.getRotate(curLocation, point);
if (animIndex < 5 || Math.abs(degrees - curRotate) < 5) {//排除异常点
setMarkerRecord(point);
}setMarkerRecord(point) 方法调用加入到 Map 轨迹的绘制Layer中
动画过程中,当加入到Path中的点超过一定占比时,做了一个窗口显示的动画,窗口List跟整个List的一个计算:
//这里可以取后半段的数据,滑动窗口,保持 moveCamera 的窗口值不变。
int moveSize = passedPointList.size();
List<LatLng> windowPassList = passedPointList.subList(moveSize - windowLength, moveSize);接下来看整公里点的绘制,看之前先看下上面的calculateAnimPathData()方法的逻辑
如上,length为当前Path走过的距离,假设轨迹一共100点,当前走到 49 ~ 50 点之间,那么calculateLength就是0到50这个点的Path的长度,它是大于length的,offsetLength = calculateLength - length; 记录的是 当前点到50号点的一个长度offsetLength,animIndex值当前值对应50,recordPathList为一开始提到的跟计算总Path时一个分段Path的List, 获取到49 ~ 50 这个Path对应的一个model.
RecordPathBean recordPathBean = recordPathList.get(animIndex);
获得Path(49 ~ 50) 的长度减去 当前点到 50的Path(cur ~ 50)的到 Path(49 ~ cur) 的长度
float stopD = (float) (pathMeasure.getLength() - offsetLengthCur);
然后最终通过PathMeasure的 getPosTan 获得dstPathEndPoint以及dstPathTan数据。
pathMeasure.getSegment(0, stopD, dstPath, false);
mDstPathMeasure = new PathMeasure(dstPath, false);
//这里有个参数 tan
mDstPathMeasure.getPosTan(mDstPathMeasure.getLength(), dstPathEndPoint, dstPathTan);
- 整公里点的绘制
原始数据中的List的Location中存储了一个字段kilometer, 当某个Location是整公里点时该字段就有对应的值,每次Path属性渐变时,上面的逻辑里记录了lastAnimIndex, animIndex。当 animIndex > lastAnimIndex时, 上面的calculateAnimPathData() 方法里分析animIndex有可能还没走到,所以在animIndex > lastAnimIndex时lastAnimIndex肯定走到了。
当lastAnimIndex对应的点是 整公里时,做一个响应的属性动画。
至此,运动轨迹回放的一个动画执行逻辑分析完了,如文章开始所说,整个过程中其实还包含了好多种其它的动画,处理它们播放的一个时序问题,如何编排实现等等也是一个难点。另外还就是轨迹播放时的一个Camera的一个视觉跟踪的效果没有实现,这个用地图本身的Camera 的API是一种实现,但是如何跟上面的这些结合到一块;然后就是自行通过计算角度偏移,累计到一定的旋转角度时,转移地图的指南针;以上是笔者想到的方案,以上有计算角度的,但需要找准那个累计的角度值,然后大量实际数据适配。
最后,有需要了解轨迹回放功能其它实现的,可留言或私信笔者进行一起探讨。
链接:https://juejin.cn/post/7183602475591548986
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RxJava2 事件分发&消费绑定逻辑 简析
前言
重温RxJava2源码,做个简单的记录,本文仅分析事件的发射与消费简单逻辑,从源码角度分析被观察者(上游事件)是如何与观察者(下游事件)进行关联的。
事件发射
Observable.just(1,2,3)
.subscribe();Observable.create(new ObservableOnSubscribe<Integer>() {
@Override
public void subscribe(@NonNull ObservableEmitter<Integer> emitter) throws Exception {
emitter.onNext(1);
emitter.onNext(2);
emitter.onNext(3);
}
}).subscribe();上述两种方式都是由被观察者发出3个事件,交给观察者(下游事件)去处理。这里分析一下Observable.just 与Observable.create 方法的区别
Observable被观察者(上游事件)
just方式
public static <T> Observable<T> just(T item1, T item2, T item3) {
return fromArray(item1, item2, item3);
}这里将传入的item…继续传入fromArray方法
public static <T> Observable<T> fromArray(T... items) {
return RxJavaPlugins.onAssembly(new ObservableFromArray<T>(items));
}最终将参数传入实例化的ObservableFromArray对象中,并将该对象返回,此处可先不关注RxJavaPlugins类,继续探索ObservableFromArray类都做了什么;
public final class ObservableFromArray<T> extends Observable<T> {
final T[] array;
public ObservableFromArray(T[] array) {
this.array = array;
}
@Override
public void subscribeActual(Observer<? super T> observer) {
FromArrayDisposable<T> d = new FromArrayDisposable<T>(observer, array);
observer.onSubscribe(d);
if (d.fusionMode) {
return;
}
d.run();
}
}作为Observable的子类,每个被观察者都要实现自己的subscribeActual方法,这里才是真正与观察者进行绑定的具体实现,其中实例化了FromArrayDisposable对象,并将observer(观察者)与array传入,方法结尾调用了其run方法。
void run() {
T[] a = array;
int n = a.length;
for (int i = 0; i < n && !isDisposed(); i++) {
T value = a[i];
if (value == null) {
downstream.onError(new NullPointerException("The element at index " + i + " is null"));
return;
}
downstream.onNext(value);
}
if (!isDisposed()) {
downstream.onComplete();
}
}可以看到其中对于最初传入的1、2、3,以此进行了onNext方法的调用,分发结束后调用了onComplete,事件结束。
create方式
首先从上面的实例代码可以看到,create方法中还需要传入ObservableOnSubscribe的实例对象,暂且不管,我们来挖掘一下create方法
public static <T> Observable<T> create(ObservableOnSubscribe<T> source) {
return RxJavaPlugins.onAssembly(new ObservableCreate<T>(source));
}最终将上述我们创建的ObservableOnSubscribe对象传入新实例化的ObservableCreate对象中,并将该对象返回;
public final class ObservableCreate<T> extends Observable<T> {
final ObservableOnSubscribe<T> source;
public ObservableCreate(ObservableOnSubscribe<T> source) {
this.source = source;
}
@Override
protected void subscribeActual(Observer<? super T> observer) {
CreateEmitter<T> parent = new CreateEmitter<T>(observer);
observer.onSubscribe(parent);
try {
source.subscribe(parent);
} catch (Throwable ex) {
Exceptions.throwIfFatal(ex);
parent.onError(ex);
}
}
}看到在subscribeActual方法中,创建了CreateEmitter对象,接着分别调用observer#onSubscribe方法和source#subscribe方法,这里要搞清楚其中的3个变量分别是什么
source:被观察者(上游事件),最初我们create方法中传入的接口对象,我们就是在source中进行事件分发的observer:观察者(下游事件),我们的事件最终交给observer去处理,这里将observer传入了CreateEmitter,就是要在Emitter中进行中转分发事件给observerparent:理解为一个上下游的中转站,上游事件发射后在这里交给下游去处理
最后我们看一下CreateEmitter类中的实现
static final class CreateEmitter<T>
extends AtomicReference<Disposable>
implements ObservableEmitter<T>, Disposable {
private static final long serialVersionUID = -3434801548987643227L;
final Observer<? super T> observer;
CreateEmitter(Observer<? super T> observer) {
this.observer = observer;
}
@Override
public void onNext(T t) {
if (t == null) {
onError(new NullPointerException("onNext called with null. Null values are generally not allowed in 2.x operators and sources."));
return;
}
if (!isDisposed()) {
observer.onNext(t);
}
}
}这里只贴出了onNext方法,可以看到当onNext方法被调用后,其中就会去调用observer的onNext方法,而onNext最初的触发就是在实例代码中我们实例化的ObservableOnSubscribe其中的subscribe方法中
事件消费
...
.subscribe(new Consumer<Integer>() {
@Override
public void accept(Integer integer) throws Exception {
}
});...
.subscribe(new Observer<Integer>() {
@Override
public void onSubscribe(@NonNull Disposable d) {
}
@Override
public void onNext(@NonNull Integer integer) {
}
@Override
public void onError(@NonNull Throwable e) {
}
@Override
public void onComplete() {
}
});上述两种方式都是接收被观察者(上游事件)发出的事件,进行处理消费。这里分析一下Consumer与Observer的区别
Observer观察者(下游事件)
Consumer
public interface Consumer<T> {
/**
* Consume the given value.
* @param t the value
* @throws Exception on error
*/
void accept(T t) throws Exception;
}Consumer仅为一个接口类,其中accept方法接收事件并消费,我们需要去到上游事件订阅下游事件时的subscribe方法,根据下游事件的参数类型与数量,会进入不同的subscribe重载方法中;
subscribe(Consumer<? super T> onNext) : Diposable
public final Disposable subscribe(Consumer<? super T> onNext) {
return subscribe(onNext, Functions.ON_ERROR_MISSING, Functions.EMPTY_ACTION, Functions.emptyConsumer());
}public final Disposable subscribe(Consumer<? super T> onNext, Consumer<? super Throwable> onError,
Action onComplete, Consumer<? super Disposable> onSubscribe) {
LambdaObserver<T> ls = new LambdaObserver<T>(onNext, onError, onComplete, onSubscribe);
subscribe(ls);
return ls;
}该方法中包装了一个LambdaObserver,将我们传入的onNext方法再传入其中
public final class LambdaObserver<T> extends AtomicReference<Disposable>
implements Observer<T>, Disposable, LambdaConsumerIntrospection {
private static final long serialVersionUID = -7251123623727029452L;
final Consumer<? super T> onNext;
final Consumer<? super Throwable> onError;
final Action onComplete;
final Consumer<? super Disposable> onSubscribe;
public LambdaObserver(Consumer<? super T> onNext, Consumer<? super Throwable> onError,
Action onComplete,
Consumer<? super Disposable> onSubscribe) {
super();
this.onNext = onNext;
this.onError = onError;
this.onComplete = onComplete;
this.onSubscribe = onSubscribe;
}
@Override
public void onNext(T t) {
if (!isDisposed()) {
try {
onNext.accept(t);
} catch (Throwable e) {
Exceptions.throwIfFatal(e);
get().dispose();
onError(e);
}
}
}可以看到LambdaObserver实际上就是Observer的实现类,其中实现了onSubscribe onNext onError onComplete 方法,上述代码中我们看到我们最初的Consumer对象实际上就是其中的onNext变量,在LambdaObserver收到onNext事件消费时,再将事件交给Consumer去处理。Consumer相当于一种简易模式的观察者,根据被观察者的subscribe订阅方法消费特定的事件(onNext或onError等)。
Observer
public interface Observer<T> {
void onSubscribe(@NonNull Disposable d);
void onNext(@NonNull T t);
void onError(@NonNull Throwable e);
void onComplete();
}Observer是最原始的观察者,是所有Observer的顶层接口,其中方法为观察者可以消费的四个事件
subscribe(Observer<? super T> observer)
该方法也是其他所有订阅观察者方法最终会进入的方法
public final void subscribe(Observer<? super T> observer) {
ObjectHelper.requireNonNull(observer, "observer is null");
try {
observer = RxJavaPlugins.onSubscribe(this, observer);
subscribeActual(observer);
} catch (NullPointerException e) { // NOPMD
...
} catch (Throwable e) {
...
}
}最终在subscribeActual方法中进行被观察者与观察者(上游与下游事件)的绑定。
写在结尾
抛开所有的操作符、线程切换来说,RxJava的上下游事件绑定逻辑还是十分清晰易读的,可以通过源码了解每个事件是如何从上游传递至下游的。至于其他逻辑,另起篇幅分析。
链接:https://juejin.cn/post/7184749810484772923
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 协程探索
Kotlin 协程是什么?
本文只是自己经过研究后,对 Kotlin 协程的理解概括,如有偏差,还请斧正。
简要概括:
协程是 Kotlin 提供的一套线程 API 框架,可以很方便的做线程切换。 而且在不用关心线程调度的情况下,能轻松的做并发编程。也可以说协程就是一种并发设计模式。
下面是使用传统线程和协程执行任务:
Thread{
//执行耗时任务
}.start()
val executors = Executors.newCachedThreadPool()
executors.execute {
//执行耗时任务
}
GlobalScope.launch(Dispatchers.IO) {
//执行耗时任务
}在实际应用开发中,通常是在主线中去启动子线程执行耗时任务,等耗时任务执行完成,再将结果给主线程,然后刷新UI:
Thread{
//执行耗时任务
runOnMainThread {
//获取耗时任务结果,刷新UI
}
}.start()
val executors = Executors.newCachedThreadPool()
executors.execute {
//执行耗时任务
runOnMainThread {
//获取耗时任务结果,刷新UI
}
}
Observable.unsafeCreate<Unit> {
//执行耗时任务
}.subscribeOn(Schedulers.io()).observeOn(AndroidSchedulers.mainThread()).subscribe {
//获取耗时任务结果,刷新UI
}
GlobalScope.launch(Dispatchers.Main) {
val result = withContext(Dispatchers.IO){
//执行耗时任务
}
//直接拿到耗时任务结果,刷新UI
refreshUI(result)
}从上面可以看到,使用Java 的 Thread 和 Executors 都需要手动去处理线程切换,这样的代码不仅不优雅,而且有一个重要问题,那就是要去处理与生命周期相关的上下文判断,这导致逻辑变复杂,而且容易出错。
RxJava 是一套优雅的异步处理框架,代码逻辑简化,可读性和可维护性都很高,很好的帮我们处理线程切换操作。这在 Java 语言环境开发下,是如虎添翼,但是在 Kotlin 语言环境中开发,如今的协程就比 RxJava 更方便,或者说更有优势。
下面看一个 Kotlin 中使用协程的例子:
GlobalScope.launch(Dispatchers.Main) {
Log.d("TestCoroutine", "launch start: ${Thread.currentThread()}")
val numbersTo50Sum = withContext(Dispatchers.IO) {
//在子线程中执行 1-50 的自然数和
Log.d("TestCoroutine", "launch:numbersTo50Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo50 = naturalNumbers.takeWhile { it <= 50 }
numbersTo50.sum()
}
val numbers50To100Sum = withContext(Dispatchers.IO) {
//在子线程中执行 51-100 的自然数和
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
val result = numbersTo50Sum + numbers50To100Sum
Log.d("TestCoroutine", "launch end:result=$result ${Thread.currentThread()}")
}
Log.d("TestCoroutine", "Hello World!,${Thread.currentThread()}")
控制台输出结果:
2023-01-02 16:05:45.846 10153-10153/com.wangjiang.example D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-02 16:05:48.058 10153-10153/com.wangjiang.example D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-02 16:05:48.059 10153-10322/com.wangjiang.example D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-02 16:05:49.114 10153-10322/com.wangjiang.example D/TestCoroutine: launch:numbers50To100Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-02 16:05:50.376 10153-10153/com.wangjiang.example D/TestCoroutine: launch end:result=5050 Thread[main,5,main]在上面的代码中:
launch是一个函数,用于创建协程并将其函数主体的执行分派给相应的调度程序。Dispatchers.MAIN指示此协程应在为 UI 操作预留的主线程上执行。Dispatchers.IO指示此协程应在为 I/O 操作预留的线程上执行。withContext(Dispatchers.IO)将协程的执行操作移至一个 I/O 线程。
从控制台输出结果中,可以看出在计算 1-50 和 51-100 的自然数和的时候,线程是从主线程(Thread[main,5,main])切换到了协程的线程(DefaultDispatcher-worker-1,5,main),这里计算 1-50 和 51-100 都是同一个子线程。
在这里有一个重要的现象,代码从逻辑上看起来是同步的,并且启动协程执行任务的时候,没有阻塞主线程继续执行相关操作,而且在协程中的异步任务执行完成之后,又自动切回了主线程。这就是 Kotlin 协程给开发做并发编程带来的好处。这也是有个概念的来源: Kotlin 协程同步非阻塞。
同步非阻塞”是真的“同步非阻塞” 吗?下面探究一下其中的猫腻,通过 Android Studio ,查看 .class 文件中的上面一段代码:
BuildersKt.launch$default((CoroutineScope)GlobalScope.INSTANCE, (CoroutineContext)Dispatchers.getMain(), (CoroutineStart)null, (Function2)(new Function2((Continuation)null) {
int I$0;
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var10000;
int numbersTo50Sum;
label17: {
Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
Function2 var10001;
CoroutineContext var6;
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch start: " + Thread.currentThread());
var6 = (CoroutineContext)Dispatchers.getIO();
var10001 = (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch:numbersTo50Sum: " + Thread.currentThread());
this.label = 1;
if (DelayKt.delay(1000L, this) == var4) {
return var4;
}
break;
case 1:
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
Sequence naturalNumbers = SequencesKt.generateSequence(Boxing.boxInt(0), (Function1)null.INSTANCE);
Sequence numbersTo50 = SequencesKt.takeWhile(naturalNumbers, (Function1)null.INSTANCE);
return Boxing.boxInt(SequencesKt.sumOfInt(numbersTo50));
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
});
this.label = 1;
var10000 = BuildersKt.withContext(var6, var10001, this);
if (var10000 == var5) {
return var5;
}
break;
case 1:
ResultKt.throwOnFailure($result);
var10000 = $result;
break;
case 2:
numbersTo50Sum = this.I$0;
ResultKt.throwOnFailure($result);
var10000 = $result;
break label17;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
numbersTo50Sum = ((Number)var10000).intValue();
var6 = (CoroutineContext)Dispatchers.getIO();
var10001 = (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch:numbers50To100Sum: " + Thread.currentThread());
this.label = 1;
if (DelayKt.delay(1000L, this) == var4) {
return var4;
}
break;
case 1:
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
Sequence naturalNumbers = SequencesKt.generateSequence(Boxing.boxInt(51), (Function1)null.INSTANCE);
Sequence numbers50To100 = SequencesKt.takeWhile(naturalNumbers, (Function1)null.INSTANCE);
return Boxing.boxInt(SequencesKt.sumOfInt(numbers50To100));
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
});
this.I$0 = numbersTo50Sum;
this.label = 2;
var10000 = BuildersKt.withContext(var6, var10001, this);
if (var10000 == var5) {
return var5;
}
}
int numbers50To100Sum = ((Number)var10000).intValue();
int result = numbersTo50Sum + numbers50To100Sum;
Log.d("TestCoroutine", "launch end:result=" + result + ' ' + Thread.currentThread());
return Unit.INSTANCE;
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
}), 2, (Object)null);
Log.d("TestCoroutine", "Hello World!," + Thread.currentThread());
虽然上面 .class 文件中的代码比较复杂,但是从大体逻辑可以看出,Kotlin 协程也是通过回调接口来实现异步操作的,这也解释了 Kotlin 协程只是让代码逻辑是同步非阻塞,但是实际上并没有,只是 Kotlin 编译器为代码做了很多事情,这也是说 Kotlin 协程其实就是一套线程 API 框架的原因。
再看一个上面例子的变种:
GlobalScope.launch(Dispatchers.Main) {
Log.d("TestCoroutine", "launch start: ${Thread.currentThread()}")
val numbersTo50Sum = async {
withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbersTo50Sum: ${Thread.currentThread()}")
delay(2000)
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo50 = naturalNumbers.takeWhile { it <= 50 }
numbersTo50.sum()
}
}
val numbers50To100Sum = async {
withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(500)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
}
// 计算 1-50 和 51-100 的自然数和是两个并发操作
val result = numbersTo50Sum.await() + numbers50To100Sum.await()
Log.d("TestCoroutine", "launch end:result=$result ${Thread.currentThread()}")
}
Log.d("TestCoroutine", "Hello World!,${Thread.currentThread()}")
控制台输出结果:
2023-01-02 16:32:12.637 13303-13303/com.wangjiang.example D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-02 16:32:13.120 13303-13303/com.wangjiang.example D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-02 16:32:14.852 13303-13444/com.wangjiang.example D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-2,5,main]
2023-01-02 16:32:14.853 13303-13443/com.wangjiang.example D/TestCoroutine: launch:numbers50To100Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-02 16:32:17.462 13303-13303/com.wangjiang.example D/TestCoroutine: launch end:result=5050 Thread[main,5,main]
async 创建了一个协程,它让计算 1-50 和 51-100 的自然数和是两个并发操作。上面控制台输出结果可以看到计算 1-50 的自然数和是在线程 Thread[DefaultDispatcher-worker-2,5,main] 中,而计算 51-100 的自然数和是在另一个线程Thread[DefaultDispatcher-worker-1,5,main]中。
从上面的例子,协程在异步操作,也就是线程切换上:主线程启动子线程执行耗时操作,耗时操作执行完成将结果更新到主线程的过程中,代码逻辑简化,可读性高。
suspend 是什么?
suspend 直译就是:挂起
suspend 是 Kotlin 语言中一个 关键字,用于修饰方法,当修饰方法时,表示这个方法只能被 suspend 修饰的方法调用或者在协程中被调用。
下面看一下将上面代码案例拆分成几个 suspend 方法:
fun getNumbersTo100Sum() {
GlobalScope.launch(Dispatchers.Main) {
Log.d("TestCoroutine", "launch start: ${Thread.currentThread()}")
val result = calcNumbers1To100Sum()
Log.d("TestCoroutine", "launch end:result=$result ${Thread.currentThread()}")
}
Log.d("TestCoroutine", "Hello World!,${Thread.currentThread()}")
}
private suspend fun calcNumbers1To100Sum(): Int {
return calcNumbersTo50Sum() + calcNumbers50To100Sum()
}
private suspend fun calcNumbersTo50Sum(): Int {
return withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbersTo50Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo50 = naturalNumbers.takeWhile { it <= 50 }
numbersTo50.sum()
}
}
private suspend fun calcNumbers50To100Sum(): Int {
return withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
}
控制台输出结果:
2023-01-03 14:47:57.047 11349-11349/com.wangjiang.example D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-03 14:47:59.311 11349-11349/com.wangjiang.example D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-03 14:47:59.312 11349-11537/com.wangjiang.example D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-3,5,main]
2023-01-03 14:48:00.336 11349-11535/com.wangjiang.example D/TestCoroutine: launch:numbers50To100Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-03 14:48:01.339 11349-11349/com.wangjiang.example D/TestCoroutine: launch end:result=5050 Thread[main,5,main]
suspend 关键字标记方法时,其实是告诉 Kotlin 从协程内调用方法。所以这个“挂起”,并不是说方法或函数被挂起,也不是说线程被挂起。
假设一个非 suspend 修饰的方法调用 suspend 修饰的方法会怎么样呢?
private fun calcNumbersTo100Sum(): Int {
return calcNumbersTo50Sum() + calcNumbers50To100Sum()
}此时,编译器会提示:
Suspend function 'calcNumbersTo50Sum' should be called only from a coroutine or another suspend function
Suspend function 'calcNumbers50To100' should be called only from a coroutine or another suspend function下面查看 .class 文件中的上面方法 calcNumbers50To100Sum 代码:
private final Object calcNumbers50To100Sum(Continuation $completion) {
return BuildersKt.withContext((CoroutineContext)Dispatchers.getIO(), (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch:numbers50To100Sum: " + Thread.currentThread());
this.label = 1;
if (DelayKt.delay(1000L, this) == var4) {
return var4;
}
break;
case 1:
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
Sequence naturalNumbers = SequencesKt.generateSequence(Boxing.boxInt(51), (Function1)null.INSTANCE);
Sequence numbers50To100 = SequencesKt.takeWhile(naturalNumbers, (Function1)null.INSTANCE);
return Boxing.boxInt(SequencesKt.sumOfInt(numbers50To100));
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
}), $completion);
}可以看到 private suspend fun calcNumbers50To100Sum() 经过 Kotlin 编译器编译后变成了private final Object calcNumbers50To100Sum(Continuation $completion), suspend 消失了,方法多了一个参数 Continuation $completion,所以 suspend修饰 Kotlin 的方法或函数,编译器会对此方法做特殊处理。
另外,suspend 修饰的方法,也预示着这个方法是耗时方法,告诉方法调用者要使用协程。当执行 suspend 方法,也预示着要切换线程,此时主线程依然可以继续执行,而协程里面的代码可能被挂起了。
下面再稍为修改 calcNumbers50To100Sum 方法:
private suspend fun calcNumbers50To100Sum(): Int {
Log.d("TestCoroutine", "launch:numbers50To100Sum:start: ${Thread.currentThread()}")
val sum= withContext(Dispatchers.Main) {
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
Log.d("TestCoroutine", "launch:numbers50To100Sum:end: ${Thread.currentThread()}")
return sum
}
控制台输出结果:
2023-01-03 15:28:04.349 15131-15131/com.bilibili.studio D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-03 15:28:04.803 15131-15131/com.bilibili.studio D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-03 15:28:04.804 15131-15266/com.bilibili.studio D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-3,5,main]
2023-01-03 15:28:06.695 15131-15131/com.bilibili.studio D/TestCoroutine: launch:numbers50To100Sum:start: Thread[main,5,main]
2023-01-03 15:28:06.696 15131-15131/com.bilibili.studio D/TestCoroutine: launch:numbers50To100Sum: Thread[main,5,main]
2023-01-03 15:28:07.700 15131-15131/com.bilibili.studio D/TestCoroutine: launch:numbers50To100Sum:end: Thread[main,5,main]
2023-01-03 15:28:07.700 15131-15131/com.bilibili.studio D/TestCoroutine: launch end:result=5050 Thread[main,5,main]主线程不受协程线程的影响。
总结
Kotlin 协程是一套线程 API 框架,在 Kotlin 语言环境下使用它做并发编程比传统 Thread, Executors 和 RxJava 更有优势,代码逻辑上“同步非阻塞“,而且简洁,易阅读和维护。
suspend 是 Kotlin 语言中一个关键字,用于修饰方法,当修饰方法时,该方法只能被 suspend 修饰的方法和协程调用。此时,也预示着该方法是一个耗时方法,告诉调用者需要在协程中使用。
参考文档:
下一篇,将研究 Kotlin Flow。
链接:https://juejin.cn/post/7184628421010391095
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android实现RecyclerView嵌套流式布局
前言
Android开发中,列表页面是常见需求,流式布局的标签效果也是常见需求,那么两者结合的效果啥样呢?这篇文章简单实现一下。
实现过程
- 添加流式布局依赖,在app/build.gradle文件中添加如下代码
implementation 'com.google.android.flexbox:flexbox:3.0.0'
- 新建Activity文件RecyclerViewActivity.class
package com.example.androidstudy;
import androidx.appcompat.app.AppCompatActivity;
import androidx.recyclerview.widget.LinearLayoutManager;
import androidx.recyclerview.widget.RecyclerView;
import android.os.Bundle;
import android.widget.Toast;
import com.example.androidstudy.adapter.MyRecyclerAdapter;
import com.example.androidstudy.bean.TestData;
import java.util.ArrayList;
import java.util.List;
public class RecyclerViewActivity extends AppCompatActivity {
private RecyclerView recyclerView;
private MyRecyclerAdapter adapter;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_recycler_view);
initViews();
initListener();
}
private void initListener() {
adapter.setItemCellClicker(tag -> Toast.makeText(RecyclerViewActivity.this, tag, Toast.LENGTH_SHORT).show());
}
private void initViews() {
recyclerView = findViewById(R.id.recyclerview);
// 设置布局管理器
recyclerView.setLayoutManager(new LinearLayoutManager(this, LinearLayoutManager.VERTICAL, false));
List<String> sss = new ArrayList<>();
sss.add("重型卡车1");
sss.add("重车11");
sss.add("重型卡车3445");
sss.add("重型卡车6677");
List<String> sss1 = new ArrayList<>();
sss1.add("轻型卡车1");
sss1.add("轻车11");
sss1.add("轻型卡车3445");
sss1.add("轻型卡车6677");
List<String> sss2 = new ArrayList<>();
sss2.add("其他1");
sss2.add("其他2");
List<TestData> list = new ArrayList<>();
list.add(new TestData("重型",sss));
list.add(new TestData("轻型", sss1));
list.add(new TestData("其他", sss2));
// 实例化Adapter对象
adapter = new MyRecyclerAdapter(this, list);
// 设置Adapter
recyclerView.setAdapter(adapter);
adapter.notifyDataSetChanged();
}
}Activity页面布局activity_recycler_view.xml
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".RecyclerViewActivity">
<androidx.recyclerview.widget.RecyclerView
android:id="@+id/recyclerview"
android:layout_width="match_parent"
android:layout_height="match_parent"/>
</androidx.constraintlayout.widget.ConstraintLayout>
- 创建Adapter文件MyRecyclerAdapter.class
package com.example.androidstudy.adapter;
import android.content.Context;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.widget.TextView;
import androidx.annotation.NonNull;
import androidx.recyclerview.widget.RecyclerView;
import com.example.androidstudy.R;
import com.example.androidstudy.bean.TestData;
import com.google.android.flexbox.FlexboxLayout;
import java.util.List;
public class MyRecyclerAdapter extends RecyclerView.Adapter<MyRecyclerAdapter.MyViewHolder>{
private List<TestData> data;
private Context myContext;
public MyRecyclerAdapter(Context context, List<TestData> data) {
this.myContext = context;
this.data = data;
}
@NonNull
@Override
public MyViewHolder onCreateViewHolder(@NonNull ViewGroup parent, int viewType) {
View inflate = LayoutInflater.from(parent.getContext()).inflate(R.layout.item_cell, parent, false);
return new MyViewHolder(inflate);
}
public interface ItemCellClicker{
void onItemClick(String tag);
}
// 流式布局标签点击事件
public ItemCellClicker itemCellClicker;
// 设置点击事件回调
public void setItemCellClicker(ItemCellClicker itemCellClicker){
this.itemCellClicker = itemCellClicker;
}
@Override
public void onBindViewHolder(@NonNull MyViewHolder holder, int position) {
TextView title = holder.itemView.findViewById(R.id.tv_title);
FlexboxLayout flexboxLayout = holder.itemView.findViewById(R.id.flexbox_layout);
TestData data = this.data.get(position);
List<String> tags = data.getTag();
flexboxLayout.removeAllViews();
// flexbox布局动态添加标签
for (int i = 0; i < tags.size(); i++) {
String temp = tags.get(i);
View tagView = LayoutInflater.from(myContext).inflate(R.layout.item_tag_cell, null, false);
TextView tag = tagView.findViewById(R.id.tv_tag);
tag.setText(temp);
// 设置标签点击事件
tag.setOnClickListener(view -> itemCellClicker.onItemClick(temp));
flexboxLayout.addView(tagView);
}
title.setText(data.getTitle());
}
@Override
public int getItemCount() {
return data.size();
}
public static class MyViewHolder extends RecyclerView.ViewHolder{
public MyViewHolder(@NonNull View itemView) {
super(itemView);
}
}
}列表项布局item_cell.xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:orientation="vertical"
android:padding="10dp"
tools:context=".MyActivity">
<TextView
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintLeft_toLeftOf="parent"
android:id="@+id/tv_title"
android:text="Hello android"
android:textSize="20sp"
android:textColor="@color/black"
android:layout_width="wrap_content"
android:layout_height="wrap_content"/>
<!--流式布局-->
<com.google.android.flexbox.FlexboxLayout
android:id="@+id/flexbox_layout"
android:orientation="horizontal"
app:flexWrap="wrap"
android:layout_width="match_parent"
android:layout_height="wrap_content"/>
</LinearLayout>列表中标签布局item_tag_cell.xml
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:padding="10dp"
tools:context=".MyActivity">
<TextView
android:id="@+id/tv_tag"
android:paddingHorizontal="12dp"
android:background="@drawable/item_tag_bg"
android:gravity="center"
android:text="Hello android"
android:textSize="20sp"
android:textColor="@color/black"
android:layout_width="wrap_content"
android:layout_height="32dp"/>
</LinearLayout>效果
链接:https://juejin.cn/post/7179921554141577272
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何搞一个在线的Shape生成
Shape是Android中一个必不可少的资源,很多的背景,比如圆角,分割线、渐变等等效果,几乎都有它的影子存在,毕竟写起来简单便捷,使用起来也是简单便捷,又占用内存小,谁能不爱?无论是初级,还是中高级,创建一个shape文件,相信大家都是信手拈来。
虽然在项目里,我们可以直接复制一个Shape文件,改一改,就能很简单的实现,但是为了更方便的创建,直接拿来可以用,于是搞了一个在线的Shape生成,目前包含了,实心、空心、渐变的模式,希望可以帮助到大家,虽然是属于造轮子了,但猜测一下,估计有需要的人,哈哈~
今天的内容大致如下:
1、在线生成Shape效果
2、如何实现这样一个在线生成平台
3、具体的主要代码实现
4、总结及问题须知
一、在线生成Shape效果
效果不是很好,毕竟咱也不是搞UI的,不过功能均可用,问题不大,目前就是左侧功能选择区域,右侧是效果及代码展示区域,包含文件的下载操作。
在线地址:abnerming888.github.io/vip/shape/s…
实际效果如下:
二、如何实现这样一个在线生成平台
其实大家可以发现,虽然是辅助生成的Android功能,但本身就是网页,所以啊,懂得Web这是最基本的,不要求多么精通,但基本的页面得需要掌握,其次就是,清楚自己要实现什么功能,得有思路,比如这个Shape,那么你就要罗列常用的几种Shape类型,其主要的代码是如何呈现的,这是最重要的,搞定下面两步问题不大。
1、Shape代码模板
Shape的生成,其实是根据模板来的,只不过根据动态配置,改其中的参数而已,所以啊,是非常简单的,罗列基本的模板后,就可以选择性的更改。
实心模板
<?xml version="1.0" encoding="utf-8"?>
<shape xmlns:android="http://schemas.android.com/apk/res/android">
<corners android:radius="10dp"></corners>
<solid android:color="#ff0000" />
</shape>空心模板
<?xml version="1.0" encoding="utf-8"?>
<shape xmlns:android="http://schemas.android.com/apk/res/android"
>
<stroke
android:width="1dp"
android:color="#ff0000" />
<corners android:radius="10dp" />
<solid android:color="#171616"/>
</shape>渐变模板
<?xml version="1.0" encoding="utf-8"?>
<shape xmlns:android="http://schemas.android.com/apk/res/android">
<gradient
android:angle="90"
android:centerColor="#000000"
android:endColor="#ff0000"
android:startColor="#ff0000"
android:type="linear" />
<corners android:radius="10dp"></corners>
</shape>在上边的模板中,其实需要更改的元素并不是很多,无非就是,颜色值,角度大小,边框等信息,这些信息,需要用户自己选择,所以需要抛给用户触发。
2、Web页面编写及上传平台
有了相关模板,那么就需要绘制UI进行实现了,其实在Android studio里的插件最合适不过了,插件也已经实现了,这个我们后面说,目前的在线,就需要大家进行Web绘制了,也就是Html、Css、JavaScript相关的技术了,相对于Android而言,还是比较简单的,编码思想都是一样的,具体的编写,大家可以自行发挥。
其实大家最关心的是,我们的页面,如何让别人进行使用,一般的情况下,服务器是必须的,如果我们没有服务器,其实也有很多的三方免费的托管,比如Github上,Github搭建静态网站,大家可以去搜,网上很多资料,按照步骤来就可以轻松实现了。
三、具体的主要代码实现
1、颜色选择实现
颜色用到了coloris插件,它可以在触摸输入框的时候,弹出颜色选择框,效果如下图:
使用起来也是很简答,在标签后面增加data-coloris属性即可。
<input type="text" style="width: 75%" class="input_color" value="#ff0000" data-coloris/>
2、下载代码实现
下载代码是用到了一个三方插件,FileSaver.js,下载的时候,也是非常的简单:
let blob = new Blob([code], {type: "text/plain;charset=utf-8"});
saveAs(blob, fileName + ".xml");
3、常规代码实现
常规代码,确实没啥好说的,无非就是Html、Css、JavaScript,大家可以直接右键看源代码即可。
四、总结及问题须知
其实大家可以发现,目前的生成,颜色也好,角度边框也好,都是固定写死的,其实,在实际的项目开发中,这些都是在资源里进行配置好的,直接选择资源里的即可,其实应该加个,可配置的参数,只配置一次,就可以动态的选择项目中的资源。
在线的毕竟还不是很方便,其实自己一直在搞一个自动化脚手架,可以直接生成到项目中,目前是针对公司里架构,不太方便开源出来,但2023年,改为自己的框架后,会给大家开源出来,很多代码,真的可以自动生成,真是方便了很多。
链接:https://juejin.cn/post/7175065117107683387
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 字节码插桩全流程解析
1 准备工作
但凡涉及到gradle开发,我一般都是会在buildSrc文件夹下进行,还有没有伙伴不太了解buildSrc的,其实buildSrc是Android中默认的插件工程,在gradle编译的时候,会编译这个项目并配置到classpath下。这样的话在buildSrc中创建的插件,每个项目都可以引入。
在buildSrc中可以创建groovy目录(如果对groovy或者kotlin了解),也可以创建java目录,对于插件开发个人更便向使用groovy,因为更贴近gradle。
1.1 创建插件
创建插件,需要实现Plugin接口,在引入这个插件后,项目编译的时候,就会执行apply方法。
class ASMPlugin implements Plugin<Project>{
@Override
void apply(Project project) {
def ext = project.extensions.getByType(AppExtension)
if (ext != null){
ext.registerTransform(new ASMTransform())
}
}
}在apply方法中,可以执行自定义的Task,也可以执行自定义的Transform(其实也可以看做是一种特殊的Task),这里我们自定义了插桩相关的Transform。
1.2 创建Transform
什么是Transform呢?就是在class文件打包生成dex文件的过程中,对class字节码做处理,最终生成新的dex文件,那么有什么方式能够对字节码操作呢?ASM是一种方式,使用Javassist也可以织入字节码。
class ASMTransform extends Transform {
@Override
String getName() {
return "ASMTransform"
}
@Override
Set<QualifiedContent.ContentType> getInputTypes() {
return TransformManager.CONTENT_CLASS
}
@Override
Set<QualifiedContent.Scope> getScopes() {
return TransformManager.SCOPE_FULL_PROJECT
}
@Override
boolean isIncremental() {
return false
}
@Override
void transform(Context context, Collection<TransformInput> inputs, Collection<TransformInput> referencedInputs, TransformOutputProvider outputProvider, boolean isIncremental) throws IOException, TransformException, InterruptedException {
inputs.each { input ->
input.directoryInputs.each { dic ->
/**这里会拿到两个路径,分别是java代码编译后的javac/debug/classes,以及kotlin代码编译后的 tmp/kotlin-classes/debug */
println("dic path == >${dic.file.path}")
/**所有的class文件的根路径,我们已经拿到了,接下来就是分析这些文件夹下的class文件*/
findAllClass(dic.file)
/**这里一定不能忘记写*/
def dest = outputProvider.getContentLocation(dic.name, dic.contentTypes, dic.scopes, Format.DIRECTORY)
FileUtils.copyDirectory(dic.file, dest)
}
input.jarInputs.each { jar ->
/**这里也一定不能忘记写*/
def dest = outputProvider.getContentLocation(jar.name,jar.contentTypes,jar.scopes,Format.JAR)
FileUtils.copyFile(jar.file,dest)
}
}
}
/**
* 查找class文件
* @param file 可能是文件也可能是文件夹
*/
private void findAllClass(File file) {
if (file.isDirectory()) {
file.listFiles().each {
findAllClass(it)
}
} else {
modifyClass(file)
}
}
/**
* 进行字节码插桩
* @param file 需要插桩的字节码文件
*/
private void modifyClass(File file) {
println("最终的class文件 ==> ${file.absolutePath}")
/**如果不是.class文件,抛弃*/
if (!file.absolutePath.endsWith(".class")) {
return
}
/**BuildConfig.class文件以及R文件都抛弃*/
if (file.absolutePath.contains("BuildConfig.class") || file.absolutePath.contains("R")) {
return
}
doASM(file)
}
/**
* 进行ASM字节码插桩
* @param file 需要插桩的class文件
*/
private void doASM(File file) {
def fis = new FileInputStream(file)
def cr = new ClassReader(fis)
def cw = new ClassWriter(ClassWriter.COMPUTE_MAXS)
cr.accept(new ASMClassVisitor(Opcodes.ASM9, cw), ClassReader.SKIP_FRAMES | ClassReader.SKIP_DEBUG)
/**重新覆盖*/
def bytes = cw.toByteArray()
def fos = new java.io.FileOutputStream(file.absolutePath)
fos.write(bytes)
fos.flush()
fos.close()
}
}如果想要使用Transform,那么需要引入transform-api,其实在transform 1.5之后gradle就支持Transform了。
implementation 'com.android.tools.build:transform-api:1.5.0'
当执行Transform任务的时候,最终会执行到transform方法,在这个方法中可以获取TransformInput的输入,主要包括两种:文件夹和Jar包;对于Jar包,我们不需要处理,只需要拷贝到目标文件夹下即可。
对于文件夹我们是需要处理的,因为这里包含了我们要处理的.class文件,对于Java编译后的class文件是存在javac/debug/classes根文件夹下,对于kotlin编译后的class文件是存在temp/classes根文件下。
所以在整个编译的过程中,只要是.class文件都会执行doASM这个方法,在这个方法中就是我们在上节提到的对于字节码的插桩。
1.3 ASM字节码插桩
class ASMClassVisitor extends ClassVisitor {
ASMClassVisitor(int api) {
super(api)
}
@Override
MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) {
println("visitMethod==>$name")
/**所有的方法都会在ASMMethodVisitor中插入字节码*/
def method = super.visitMethod(access, name, descriptor, signature, exceptions)
return new ASMMethodVisitor(api, method, access, name, descriptor)
}
ASMClassVisitor(int api, ClassVisitor classVisitor) {
super(api, classVisitor)
}
@Override
FieldVisitor visitField(int access, String name, String descriptor, String signature, Object value) {
return super.visitField(access, name, descriptor, signature, value)
}
@Override
AnnotationVisitor visitAnnotation(String descriptor, boolean visible) {
return super.visitAnnotation(descriptor, visible)
}
}class ASMMethodVisitor extends AdviceAdapter {
private def methodName
/**
* Constructs a new {@link AdviceAdapter}.
*
* @param api the ASM API version implemented by this visitor. Must be one of {@link
* Opcodes#ASM4}, {@link Opcodes#ASM5}, {@link Opcodes#ASM6} or {@link Opcodes#ASM7}.
* @param methodVisitor the method visitor to which this adapter delegates calls.
* @param access the method's access flags (see {@link Opcodes}).
* @param name the method's name.
* @param descriptor the method's descriptor (see {@link Type Type}).
*/
protected ASMMethodVisitor(int api, MethodVisitor methodVisitor, int access, String name, String descriptor) {
super(api, methodVisitor, access, name, descriptor)
this.methodName = name
}
@Override
protected void onMethodEnter() {
super.onMethodEnter()
visitFieldInsn(GETSTATIC,
"com/lay/learn/base_net/LoggUtils",
"INSTANCE",
"Lcom/lay/learn/base_net/LoggUtils;")
visitMethodInsn(INVOKEVIRTUAL, "com/lay/learn/base_net/LoggUtils", "start", "()V", false)
}
@Override
protected void onMethodExit(int opcode) {
super.onMethodExit(opcode)
visitFieldInsn(GETSTATIC,
"com/lay/learn/base_net/LoggUtils",
"INSTANCE",
"Lcom/lay/learn/base_net/LoggUtils;")
visitLdcInsn(methodName)
visitMethodInsn(INVOKEVIRTUAL, "com/lay/learn/base_net/LoggUtils", "end", "(Ljava/lang/String;)V",false)
}
}这里就不再细说了,贴上源码大家可以借鉴一下哈。
最终在编译的过程中,对所有的方法插入了我们自己的耗时计算逻辑,当运行之后
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
}
}虽然我们没有显示地在MainActivity的onCreate中插入耗时检测代码,但是在控制台中我们可以看到,onCreate方法耗时180ms
2022-12-28 19:50:19.243 13665-13665/com.lay.learn.asm E/LoggUtils: <init> 耗时==>0
2022-12-28 19:50:19.458 13665-13665/com.lay.learn.asm E/LoggUtils: onCreate 耗时==>180
1.4 插件配置
当我们完成一个插件之后,需要在META-INF文件夹下创建一个gradle-plugins文件夹,并在properties文件中声明插件全类名。
implementation-class=com.lay.asm.ASMPlugin
要注意插件id就是properties文件的名字。
这样只要某个工程中需要字节码插桩,只需要引入asm_plugin这个插件即可在编译的时候扫描整个工程。
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
id 'asm_plugin'
}附上buildSrc中的gradle配置文件
plugins{
id 'groovy'
}
repositories {
google()
mavenCentral()
}
dependencies {
implementation gradleApi()
implementation localGroovy()
implementation 'org.apache.commons:commons-io:1.3.2'
implementation "com.android.tools.build:gradle:7.0.3"
implementation 'com.android.tools.build:transform-api:1.5.0'
implementation 'org.ow2.asm:asm:9.1'
implementation 'org.ow2.asm:asm-util:9.1'
implementation 'org.ow2.asm:asm-commons:9.1'
}
java {
sourceCompatibility = JavaVersion.VERSION_1_8
targetCompatibility = JavaVersion.VERSION_1_8
}
最后需要说一点就是,在Transform任务执行时,一定要将文件夹或者jar包传递到下一级的Transform中,否则会导致apk打包时缺少文件导致apk无法运行。
链接:https://juejin.cn/post/7182178552207376421
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 惰性集合操作-序列 Sequence
集合操作函数 和 序列
在了解 Kotlin 惰性集合之前,先看一下 Koltin 标准库中的一些集合操作函数。
定义一个数据模型 Person 和 Book 类:
data class Person(val name: String, val age: Int)
data class Book(val title: String, val authors: List<String>)
filter 和 map 操作:
val people = listOf<Person>(
Person("xiaowang", 30),
Person("xiaozhang", 32),
Person("xiaoli", 28)
)
//大于 30 岁的人的名字集合列表
people.filter { it.age >= 30 }.map(Person::name)
count 操作:
val people = listOf<Person>(
Person("xiaowang", 30),
Person("xiaozhang", 32),
Person("xiaoli", 28)
)
//小于 30 岁人的个数
people.count { it.age < 30 }
flatmap 操作:
val books = listOf<Book>(
Book("Java 语言程序设计", arrayListOf("xiaowang", "xiaozhang")),
Book("Kotlin 语言程序设计", arrayListOf("xiaoli", "xiaomao")),
)
// 所有书的名字集合列表
books.flatMap { it.authors }.toList()
在上面这些函数,每做一步操作,都会创建中间集合,也就是每一步的中间结果都被临时存储在一个临时集合中。
filter 函数源码:
public inline fun <T> Iterable<T>.filter(predicate: (T) -> Boolean): List<T> {
//创建一个新的集合列表
return filterTo(ArrayList<T>(), predicate)
}
public inline fun <T, C : MutableCollection<in T>> Iterable<T>.filterTo(destination: C, predicate: (T) -> Boolean): C {
for (element in this) if (predicate(element)) destination.add(element)
return destination
}map 函数源码:
public inline fun <T, R> Iterable<T>.map(transform: (T) -> R): List<R> {
//创建一个新的集合列表
return mapTo(ArrayList<R>(collectionSizeOrDefault(10)), transform)
}
public inline fun <T, R, C : MutableCollection<in R>> Iterable<T>.mapTo(destination: C, transform: (T) -> R): C {
for (item in this)
destination.add(transform(item))
return destination
}
如果被操作的元素过多,假设 people 或 books 超过 50个、100个,那么 函数链式调用 如:fliter{}.map{} 就会变得低效,且浪费内存。
Kotlin 为解决上面这种问题,提供了惰性集合操作 Sequence 接口。这个接口表示一个可以逐个列举的元素列表。Sequence 只提供了一个 方法, iterator,用来从序列中获取值。
public interface Sequence<out T> {
/**
* Returns an [Iterator] that returns the values from the sequence.
*
* Throws an exception if the sequence is constrained to be iterated once and `iterator` is invoked the second time.
*/
public operator fun iterator(): Iterator<T>
}
public inline fun <T> Sequence(crossinline iterator: () -> Iterator<T>): Sequence<T> = object : Sequence<T> {
override fun iterator(): Iterator<T> = iterator()
}
/**
* Creates a sequence that returns all elements from this iterator. The sequence is constrained to be iterated only once.
*
* @sample samples.collections.Sequences.Building.sequenceFromIterator
*/
public fun <T> Iterator<T>.asSequence(): Sequence<T> = Sequence { this }.constrainOnce()
序列中的元素求值是惰性的。因此,可以使用序列更高效地对集合元素执行链式操作,而不需要创建额外的集合来保存过程中产生的中间结果。关于这个惰性是怎么来的,后面再详细解释。
可以调用扩展函数 asSequence 把任意集合转换成序列,调用 toList 来做反向的转换。
val people = listOf<Person>(
Person("xiaowang", 30),
Person("xiaozhang", 32),
Person("xiaoli", 28)
)
people.asSequence().filter { it.age >= 30 }.map(Person::name).toList()
val books = listOf<Book>(
Book("Java 语言程序设计", arrayListOf("xiaowang", "xiaozhang")),
Book("Kotlin 语言程序设计", arrayListOf("xiaoli", "xiaomao")),
)
books.asSequence().flatMap { it.authors }.toList()
序列中间和末端操作
序列操作分为两类:中间的和末端的。一次中间操作返回的是另一个序列,这个新序列知道如何变换原始序列中的元素。而一次末端返回的是一个结果,这个结果可能是集合、元素、数字,或者其他从初始集合的变换序列中获取的任意对象。
中间操作始终是惰性的。
下面从例子来理解这个惰性:
listOf(1, 2, 3, 4).asSequence().map {
println("map${it}")
it * it
}.filter {
println("filter${it}")
it % 2 == 0
}上面这段代码在控制台不会输出任何内容(因为没有末端操作)。
listOf(1, 2, 3, 4).asSequence().map {
println("map${it}")
it * it
}.filter {
println("filter${it}")
it % 2 == 0
}.toList()
控制台输出:
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map1
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter1
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map2
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter4
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map3
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter9
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: map4
2023-01-01 20:23:05.071 17000-17000/com.wangjiang.example D/TestSequence: filter16
在末端操作 .toList()的时候,map 和 filter 变换才被执行,而且元素是被逐个执行的。并不是所有元素经在 map 操作执行完成后,再执行 filter 操作。
为什么元素是逐个被执行,首先看下 toList() 方法:
public fun <T> Sequence<T>.toList(): List<T> {
return this.toMutableList().optimizeReadOnlyList()
}
public fun <T> Sequence<T>.toMutableList(): MutableList<T> {
return toCollection(ArrayList<T>())
}
public fun <T, C : MutableCollection<in T>> Sequence<T>.toCollection(destination: C): C {
for (item in this) {
destination.add(item)
}
return destination
}最后的 toCollection 方法中的 for (item in this),其实就是调用 Sequence 中的迭代器 Iterator 进行元素迭代。其中这个 this 来自于 filter,也就是使用 filter 的 Iterator 进行元素迭代。来看下 filter :
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate)
}
internal class FilteringSequence<T>(
private val sequence: Sequence<T>,
private val sendWhen: Boolean = true,
private val predicate: (T) -> Boolean
) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
val iterator = sequence.iterator()
var nextState: Int = -1 // -1 for unknown, 0 for done, 1 for continue
var nextItem: T? = null
private fun calcNext() {
while (iterator.hasNext()) {
val item = iterator.next()
if (predicate(item) == sendWhen) {
nextItem = item
nextState = 1
return
}
}
nextState = 0
}
override fun next(): T {
if (nextState == -1)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem
nextItem = null
nextState = -1
@Suppress("UNCHECKED_CAST")
return result as T
}
override fun hasNext(): Boolean {
if (nextState == -1)
calcNext()
return nextState == 1
}
}
}filter 中又会使用上一个 Sequence 的 sequence.iterator() 进行元素迭代。再看下 map :
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
internal class TransformingSequence<T, R>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> R) : Sequence<R> {
override fun iterator(): Iterator<R> = object : Iterator<R> {
val iterator = sequence.iterator()
override fun next(): R {
return transformer(iterator.next())
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun <E> flatten(iterator: (R) -> Iterator<E>): Sequence<E> {
return FlatteningSequence<T, R, E>(sequence, transformer, iterator)
}
}也是使用上一个 Sequence 的 sequence.iterator() 进行元素迭代。所以以此类推,最终会使用转换为 asSequence() 的源 iterator()。
下面自定义一个 Sequence 来验证上面的猜想:
listOf(1, 2, 3, 4).asSequence().mapToString {
Log.d("TestSequence","mapToString${it}")
it.toString()
}.toList()
fun <T> Sequence<T>.mapToString(transform: (T) -> String): Sequence<String> {
return TransformingStringSequence(this, transform)
}
class TransformingStringSequence<T>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> String) : Sequence<String> {
override fun iterator(): Iterator<String> = object : Iterator<String> {
val iterator = sequence.iterator()
override fun next(): String {
val next = iterator.next()
Log.d("TestSequence","next:${next}")
return transformer(next)
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
}
控制台输出:
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:1
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString1
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:2
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString2
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:3
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString3
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: next:4
2023-01-01 20:43:43.899 21797-21797/com.wangjiang.example D/TestSequence: mapToString4
所以这就是 Sequence 为什么在获取结果的时候才会被应用,也就是末端操作被调用的时候,才会依次处理每个元素,这也是 被称为惰性集合操作的原因。
经过一系列的 序列操作,每个元素逐个被处理,那么优先处理 filter 序列,其实可以减少变换的总次数。因为每个序列都是使用上一个序列的 sequence.iterator() 进行元素迭代。
创建序列
在集合操作上,可以使用集合直接调用 asSequence() 转换为序列。那么不是集合,有类似集合一样的变换,该怎么操作呢。
下面以求 1到100 的所有自然数之和为例子:
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo100 = naturalNumbers.takeWhile { it <= 100 }
val sum = numbersTo100.sum()
println(sum)
控制台输出:
5050先看下 generateSequence 源码:
public fun <T : Any> generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T> =
if (seed == null)
EmptySequence
else
GeneratorSequence({ seed }, nextFunction)
private class GeneratorSequence<T : Any>(private val getInitialValue: () -> T?, private val getNextValue: (T) -> T?) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
var nextItem: T? = null
var nextState: Int = -2 // -2 for initial unknown, -1 for next unknown, 0 for done, 1 for continue
private fun calcNext() {
//getInitialValue 获取的到就是 generateSequence 的第一个参数 0
//getNextValue 获取到的就是 generateSequence 的第二个参数 it+1,这个it 就是 nextItem!!
nextItem = if (nextState == -2) getInitialValue() else getNextValue(nextItem!!)
nextState = if (nextItem == null) 0 else 1
}
override fun next(): T {
if (nextState < 0)
calcNext()
if (nextState == 0)
throw NoSuchElementException()
val result = nextItem as T
// Do not clean nextItem (to avoid keeping reference on yielded instance) -- need to keep state for getNextValue
nextState = -1
return result
}
override fun hasNext(): Boolean {
if (nextState < 0)
calcNext()
return nextState == 1
}
}
}上面代码其实就是创建一个 Sequence 接口实现类,并实现它的 iterator 接口方法,返回一个 Iterator 迭代器。
public fun <T> Sequence<T>.takeWhile(predicate: (T) -> Boolean): Sequence<T> {
return TakeWhileSequence(this, predicate)
}
internal class TakeWhileSequence<T>
constructor(
private val sequence: Sequence<T>,
private val predicate: (T) -> Boolean
) : Sequence<T> {
override fun iterator(): Iterator<T> = object : Iterator<T> {
val iterator = sequence.iterator()
var nextState: Int = -1 // -1 for unknown, 0 for done, 1 for continue
var nextItem: T? = null
private fun calcNext() {
if (iterator.hasNext()) {
//iterator.next() 调用的就是上一个 GeneratorSequence 的 next 方法,而返回值就是它的 it+1
val item = iterator.next()
//判断条件,也就是 it <= 100 -> item <= 100
if (predicate(item)) {
nextState = 1
nextItem = item
return
}
}
nextState = 0
}
override fun next(): T {
if (nextState == -1)
calcNext() // will change nextState
if (nextState == 0)
throw NoSuchElementException()
@Suppress("UNCHECKED_CAST")
val result = nextItem as T
// Clean next to avoid keeping reference on yielded instance
nextItem = null
nextState = -1
return result
}
override fun hasNext(): Boolean {
if (nextState == -1)
calcNext() // will change nextState
return nextState == 1
}
}
}在 TakeWhileSequence 的 next 方法中,会优先调用内部方法 calcNext,而这个方法内部又是调用 GeneratorSequence的 next方法,这样就 拿到了当前值 it+1(上一个是0+1,下一个就是1+1),拿到值后再判断 it <= 100 -> item <= 100。
public fun Sequence<Int>.sum(): Int {
var sum: Int = 0
for (element in this) {
sum += element
}
return sum
}sum 方法是序列的末端操作,也就是获取结果。for (element in this) ,调用上一个 Sequence 中的迭代器 Iterator 进行元素迭代,以此类推,直到调用 源 Sequence 中的迭代器 Iterator 进行元素迭代。
总结
Kotlin 标准库提供的集合操作函数:filter,map, flatmap 等,在操作的时候会创建存储中间结果的临时列表,当集合元素较多时,这种链式操作就会变得低效。为了解决这种问题,Kotlin 提供了惰性集合操作 Sequence 接口,只有在 末端操作被调用的时候,也就是获取结果的时候,序列中的元素才会被逐个执行,处理完第一个元素后,才会处理第二个元素,这样中间操作是被延期执行的。而且因为是顺序地去执行每一个元素,所以可以先做 filter 变换,再做 map 变换,这样有助于减少变换的总次数。
链接:https://juejin.cn/post/7184250146933178405
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
深入flutter布局约束原理
刚开始接触flutter的时候,Container组件是用得最多的。它就像HTML中的div一样普遍,专门用来布局页面的。
但是使用Container嵌套布局的时候,经常出现一些令人无法理解的问题。就如下面代码,在一个固定的容器中,子组件却铺满了全屏。
/// 例一
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}然后要加上alignment属性,子组件正常显示了,但容器还是铺满全屏。
/// 例二
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}而在容器外层添加一个Scaffold组件,它就正常显示了。
/// 例三
@override
Widget build(BuildContext context) {
return Scaffold(
body: Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
),
);
}这一切的怪异行为困扰了我很久,直到我深入了flutter布局的学习,才渐渐解开这些疑惑。
1、flutter的widget类型
flutter的widget可以分为三类,组合类ComponentWidget、代理类ProxyWidget和绘制类RenderObjectWidget
组合类:如Container、Scaffold、MaterialApp还有一系列通过继承StatelessWidget和StatefulWidget的类。组合类是我们开发过程中用得最多的组件。
代理类:InheritedWidget,功能型组件,它可以高效快捷的实现共享数据的跨组件传递。如常见的Theme、MediaQuery就是InheritedWidget的应用。
绘制类:屏幕上看到的UI几乎都会通过RenderObjectWidget实现。通过继承它,可以进行界面的布局和绘制。如Align、Padding、ConstrainedBox等都是通过继承RenderObjectWidget,并通过重写createRenderObject方法来创建RenderObject对象,实现最终的布局(layout)和绘制(paint)。
2、Container是个组合类
显而易见Container继承StatelessWidget,它是一个组合类,同时也是一个由DecoratedBox、ConstrainedBox、Transform、Padding、Align等组件组合的多功能容器。可以通过查看Container类,看出它实际就是通过不同的参数判断,再进行组件的层层嵌套来实现的。
@override
Widget build(BuildContext context) {
Widget? current = child;
if (child == null && (constraints == null || !constraints!.isTight)) {
current = LimitedBox(
maxWidth: 0.0,
maxHeight: 0.0,
child: ConstrainedBox(constraints: const BoxConstraints.expand()),
);
} else if (alignment != null) {
current = Align(alignment: alignment!, child: current);
}
final EdgeInsetsGeometry? effectivePadding = _paddingIncludingDecoration;
if (effectivePadding != null) {
current = Padding(padding: effectivePadding, child: current);
}
if (color != null) {
current = ColoredBox(color: color!, child: current);
}
if (clipBehavior != Clip.none) {
assert(decoration != null);
current = ClipPath(
clipper: _DecorationClipper(
textDirection: Directionality.maybeOf(context),
decoration: decoration!,
),
clipBehavior: clipBehavior,
child: current,
);
}
if (decoration != null) {
current = DecoratedBox(decoration: decoration!, child: current);
}
if (foregroundDecoration != null) {
current = DecoratedBox(
decoration: foregroundDecoration!,
position: DecorationPosition.foreground,
child: current,
);
}
if (constraints != null) {
current = ConstrainedBox(constraints: constraints!, child: current);
}
if (margin != null) {
current = Padding(padding: margin!, child: current);
}
if (transform != null) {
current = Transform(transform: transform!, alignment: transformAlignment, child: current);
}
return current!;
}
组合类基本不参与ui的绘制,都是通过绘制类的组合来实现功能。
3、flutter布局约束
flutter中有两种布局约束BoxConstraints盒约束和SliverConstraints线性约束,如Align、Padding、ConstrainedBox使用的是盒约束。
BoxConstraints盒约束是指flutter框架在运行时遍历整个组件树,在这过程中 「向下传递约束,向上传递尺寸」,以此来确定每个组件的尺寸和大小。
BoxConstraints类由4个属性组成,最小宽度minWidth、最大宽度maxWidth、最小高度minHeight、最大高度maxHeight。
BoxConstraints({
this.minWidth,
this.maxWidth,
this.minHeight,
this.maxHeight,
});根据这4个属性的变化,可以分为“紧约束(tight)”、“松约束(loose)”、“无界约束”、“有界约束”。
紧约束:最小宽(高)度和最大宽(高)度值相等,此时它是一个固定宽高的约束。
BoxConstraints.tight(Size size)
: minWidth = size.width,
maxWidth = size.width,
minHeight = size.height,
maxHeight = size.height;
松约束:最小宽(高)值为0,最大宽(高)大于0,此时它是一个约束范围。
BoxConstraints.loose(Size size)
: minWidth = 0.0,
maxWidth = size.width,
minHeight = 0.0,
maxHeight = size.height;
无界约束:最小宽(高)和最大宽(高)值存在double.infinity(无限)。
BoxConstraints.expand({double? width, double? height})
: minWidth = width ?? double.infinity,
maxWidth = width ?? double.infinity,
minHeight = height ?? double.infinity,
maxHeight = height ?? double.infinity;
有界约束:最小宽(高)和最大宽(高)值均为固定值。
BoxConstraints(100, 300, 100, 300)
4、Container布局行为解惑
了解了BoxConstraints布局约束,回到本文最开始的问题。
/// 例一
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}例一中,两个固定宽高的Container,为什么子容器铺满了全屏?
根据BoxConstraints布局约束,遍历整个组件树,最开始的root是树的起点,它向下传递的是一个紧约束。因为是移动设备,root即是屏幕的大小,假设屏幕宽414、高896。于是整个布局约束如下:
这里有个问题,就是Container分明已经设置了固定宽高,为什么无效?
因为父级向下传递的约束,子组件必须严格遵守。这里Container容器设置的宽高超出了父级的约束范围,就会自动被忽略,采用符合约束的值。
例一两上Container都被铺满屏幕,而最底下的红色Container叠到了最上层,所以最终显示红色。
/// 例二
@override
Widget build(BuildContext context) {
return Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
);
}例二也同样可以根据布局约束求证,如下图:
这里Container为什么是ConstrainedBox和Align组件?前面说过Container是一个组合组件,它是由多个原子组件组成的。根据例二,它是由ConstrainedBox和Align嵌套而成。
Align提供给子组件的是一个松约束,所以容器自身设置50宽高值是在合理范围的,因此生效,屏幕上显示的就是50像素的红色方块。ConstrainedBox受到的是紧约束,所以自身的300宽高被忽略,显示的是铺满屏幕的黄色块。
/// 例三
@override
Widget build(BuildContext context) {
return Scaffold(
body: Container(
width: 300,
height: 300,
color: Colors.amber,
alignment: Alignment.center,
child: Container(width: 50, height: 50, color: Colors.red,),
),
);
}例三中Scaffold向下传递的是一个松约束,所以黄色Container的宽高根据自身设置的300,在合理的范围内,有效。Container再向下传递的也是松约束,最终红色Container宽高为50。
这里还有个问题,怎么确定组件向下传递的是紧约束还是松约束?
这就涉及到组件的内部实现了,这里通过Align举个例。
Align是一个绘制组件,它能够进行界面的布局和绘制,这是因为Align的继承链为:
Align -> SingleChildRenderObjectWidget -> RenderObjectWidget
Align需要重写createRenderObject方法,返回RenderObject的实现,这里Align返回的是RenderPositionedBox,所以核心内容就在这个类中
class Align extends SingleChildRenderObjectWidget {
/// ...
@override
RenderPositionedBox createRenderObject(BuildContext context) {
return RenderPositionedBox(
alignment: alignment,
widthFactor: widthFactor,
heightFactor: heightFactor,
textDirection: Directionality.maybeOf(context),
);
}
/// ...
}而RenderPositionedBox类中,重写performLayout方法,该方法用于根据自身约束条件,计算出子组件的布局,再根据子组件的尺寸设置自身的尺寸,形成一个至下而上,由上到下的闭环,最终实现界面的整个绘制。
RenderPositionedBox -> RenderAligningShiftedBox -> RenderShiftedBox -> RenderBox
class RenderPositionedBox extends RenderAligningShiftedBox {
/// ...
@override
void performLayout() {
final BoxConstraints constraints = this.constraints; // 自身的约束大小
final bool shrinkWrapWidth = _widthFactor != null || constraints.maxWidth == double.infinity;
final bool shrinkWrapHeight = _heightFactor != null || constraints.maxHeight == double.infinity;
/// 存在子组件
if (child != null) {
/// 开始布局子组件
child!.layout(constraints.loosen(), parentUsesSize: true);
/// 根据子组件的尺寸设置自身尺寸
size = constraints.constrain(Size(
shrinkWrapWidth ? child!.size.width * (_widthFactor ?? 1.0) : double.infinity,
shrinkWrapHeight ? child!.size.height * (_heightFactor ?? 1.0) : double.infinity,
));
/// 计算子组件的位置
alignChild();
} else {
/// 不存在子组件
size = constraints.constrain(Size(
shrinkWrapWidth ? 0.0 : double.infinity,
shrinkWrapHeight ? 0.0 : double.infinity,
));
}
}
/// ...
}根据Align中performLayout方法的实现,可以确定该组件最终会给子组件传递一个怎么样的约束。
/// constraints.loosen提供的是一个松约束
child!.layout(constraints.loosen(), parentUsesSize: true);
/// loosen方法
BoxConstraints loosen() {
assert(debugAssertIsValid());
/// BoxConstraints({double minWidth = 0.0, double maxWidth = double.infinity, double minHeight = 0.0, double maxHeight = double.infinity})
return BoxConstraints(
maxWidth: maxWidth,
maxHeight: maxHeight,
);
}其它绘制类的组件基本跟Align大同小异,只要重点看performLayout方法的实现,即可判断出组件提供的约束条件。
总结
1、flutter的widget分为,组合类、代理类和绘制类。
2、Container是一个组合类,由DecoratedBox、ConstrainedBox、Transform、Padding、Align等绘制组件组合而成。
3、flutter中有两种布局约束BoxConstraints盒约束和SliverConstraints线性约束。
4、BoxConstraints的约束原理是: 「向下传递约束,向上传递尺寸」。
5、BoxConstraints的约束类型为:紧约束、松约束、无界约束、有界约束。
6、判断一个绘制组件的约束行为可以通过查看performLayout方法中layout传入的约束值。
链接:https://juejin.cn/post/7183549888406224955
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android App封装 —— 实现自己的EventBus
背景
在项目中我们经常会遇到跨页面通信的需求,但传统的EventBus都有各自的缺点,如EventBus和RxBus需要自己管理生命周期,比较繁琐,基于LiveData的Bus切线程比较困难等。于是我参考了一些使用Flow实现EventBus的文章,结合自身需求,实现了极简的EventBus。
EventBus
EventBus是用于 Android 和 Java 的发布/订阅事件总线。Publisher可以将事件Event post给每一个订阅者Subscriber中接收,从而达到跨页面通信的需求。
可以看出EventBus本身就是一个生产者消费者模型,而在我们第一篇搭建MVI框架的时候,用到的Flow天然就支持生产者和消费者模型,所以我们可以自己用Flow搭建一个自己的EventBus
基于Flow搭建EventBus
根据EventBus的架构图,我们来用Flow搭建,需要定义一下几点
- 定义事件Event
- 发送者 Publisher 如何发送事件
- 如何存储Event并且分发
- 如何订阅事件
1. 定义事件
sealed class Event {
data class ShowInit(val msg: String) : Event()
}这个和之前搭建MVI框架类似,用一个sleaed class和data class或者object来定义事件,用来传递信息
2. 发送事件
fun post(event: Event, delay: Long = 0) {
...
}发送事件定义一个这样的函数就可以了,传入事件和延迟时间
3. 存储Event并且分发
对于同一种Event,我们可以用一个SharedFlow来存储,依次发送给订阅方。而在整个App中,我们会用到各种不同种类的Event,所以这时候我们就需要用到HashMap去存储这些Event了。数据结构如下:
private val flowEvents = ConcurrentHashMap<String, MutableSharedFlow<Event>>()
4. 订阅事件
inline fun <reified T : Event> observe(
lifecycleOwner: LifecycleOwner,
minState: Lifecycle.State = Lifecycle.State.CREATED,
dispatcher: CoroutineDispatcher = Dispatchers.Main,
crossinline onReceived: (T) -> Unit
)lifecycleOwner,用来定义订阅者的生命周期,这样我们就不需要额外管理注册与反注册了minState,定义执行订阅的生命周期Statedispatcher,定义执行所在的线程onReceived,收到Event后执行的Lamda
使用
//任何地方
FlowEventBus.post(Event.ShowInit("article init"))
// Activity或者Fragment中
FlowEventBus.observe<Event.ShowInit>(this, Lifecycle.State.STARTED) {
binding.button.text = it.msg
}完整代码
object FlowEventBus {
//用HashMap存储SharedFlow
private val flowEvents = ConcurrentHashMap<String, MutableSharedFlow<Event>>()
//获取Flow,当相应Flow不存在时创建
fun getFlow(key: String): MutableSharedFlow<Event> {
return flowEvents[key] ?: MutableSharedFlow<Event>().also { flowEvents[key] = it }
}
// 发送事件
fun post(event: Event, delay: Long = 0) {
MainScope().launch {
delay(delay)
getFlow(event.javaClass.simpleName).emit(event)
}
}
// 订阅事件
inline fun <reified T : Event> observe(
lifecycleOwner: LifecycleOwner,
minState: Lifecycle.State = Lifecycle.State.CREATED,
dispatcher: CoroutineDispatcher = Dispatchers.Main,
crossinline onReceived: (T) -> Unit
) = lifecycleOwner.lifecycleScope.launch(dispatcher) {
getFlow(T::class.java.simpleName).collect {
lifecycleOwner.lifecycle.whenStateAtLeast(minState) {
if (it is T) onReceived(it)
}
}
}
}链接:https://juejin.cn/post/7182399245859684412
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android App封装 —— DI框架 Hilt?Koin?
背景
前面的项目Github wanandroid例子我们可以看到,我们创建Repository和ViewModel的时候,都是直接创建的
class MainViewModel : BaseViewModel<MainState, MainIntent>() {
private val mWanRepo = HomeRepository()
...
}
class MainActivity : BaseActivity<ActivityMainBinding>() {
override fun onCreate(savedInstanceState: Bundle?) {
mViewModel = ViewModelProvider(this).get(MainViewModel::class.java)
}
}但是一般一个repository会被多个viewModel使用,我们不想创建多个同样类型的repository实例,这时候我们需要将WanRepository设置为单例。但是当代码越来越多,对象的共享、依赖关系以及生命周期越来越复杂的时候,我们全部自己手写显然是比较复杂的。
所以Goolge强推我们使用DI(Dependency Injection)依赖注入来管理对象的创建,之前推出了强大的Dagger,但是由于难学难用,很少有人用到这个框架。后面又推出了Hilt,基于Dagger实现,针对于Android平台简化了使用方式,原理和Dagger是一致的。
本来准备将Hilt引用到项目中,后来发现了一个轻量级的DI框架koin,两者学习对比了一下之后还是决定使用Koin这个轻量级的框架,koin和Hilt的详细对比就不在此展开了,网上有很多文章。
那么就开始动工,准备在项目中集成koin吧。
koin
koin官网,官网永远是学习一个东西的最佳途径
1. 依赖
网上看到很多koin的使用案例,我看依赖的都是2.X的包
implementation "org.koin:koin-android:$koin_version"
implementation "org.koin:koin-android-viewmodel:$koin_version"
后面我去官网看了下文档,发现koin已经升级到3.x了,合并所有 Scope/Fragment/ViewModel API,只需要引用一个包就可以了
implementation "io.insert-koin:koin-android:$koin_version" //3.3.1
2. 启动
添加好依赖后,可以在Application中启动koin,初始化koin的配置,代码如下
class App : Application() {
override fun onCreate() {
super.onCreate()
startKoin {
//开始启动koin
androidLogger()
androidContext(this@App)//这边传Application对象,这样你注入的类中,需要app对象的时候,可以直接使用
modules(appModule)//这里面传各种被注入的模块对象,支持多模块注入
}
}
}3. 模块Module
上文中的modules(appModule),是用来配置koin使用的Module有哪些,那么Module是什么呢?
Koin是以Module的形式组织依赖项,我们可以将可能用到的依赖项定义在Module中,也就是对象的提供者
val repoModule = module {
single { HomeRepository() }
}
val viewModelModule = module {
viewModel { MainViewModel(get()) }
}
val appModule = listOf(viewModelModule, repoModule)
上面这段代码就是定义了两个Module,一个我专门用来定义repository,一个专门用来定义viewModel。
然后通过get()、inject(),表示在需要注入依赖项,也就是对象的使用者,这时就会在Module里面检索对应的类型,然后自动注入。
所以之前Repository的创建变为
val mWanRepo: HomeRepository by inject(HomeRepository::class.java)
并且依据single定义为了单例
进一步简化可以将repository写到ViewModel的构造方法中
class MainViewModel(private val homeRepo: HomeRepository) : BaseViewModel<MainState, MainIntent>() {
...
}
根据viewModel { MainViewModel(get()) }的定义,在构造MainViewModel的时候会自动因为get()填充HomeRepository对象
4. Activity中使用ViewModel
class MainActivity : BaseActivity<ActivityMainBinding>() {
private val mViewModel by viewModel<MainViewModel>()
}总结
koin和Hilt,大家可以看自己的习惯使用,Hilt的特点主要是利用注解生成代码,使用方便,效率也挺高的。koin我主要是看中它比较轻量级,可以快速入门使用。
项目地址:Github wanandroid。
链接:https://juejin.cn/post/7179151577864175671
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android App封装 —— ViewBinding
一、背景
在前面的Github wanandroid项目中可以看到,我获取控件对象还是用的findviewbyId
button = findViewById(R.id.button)
viewPager = findViewById(R.id.view_pager)
recyclerView = findViewById(R.id.recycler_view)
现在肯定是需要对这个最常用的获取View的findViewById代码进行优化,主要是有两个原因
过于冗余
findViewById对应所有的View都要书写findViewById(R.id.xxx)的方法,代码过于繁琐
不安全
强制转换不安全,findViewById获取到的是一个View对象,是需要强转的,一旦类型给的不对则会出现异常,比如将TextView错转成ImageView
所以我们需要一个框架解决这个问题,大致是有三个方案
二、方案
方案一 butterkniife
这个应该很多人都用过,由大大佬JakeWharton开发,通过注解生成findViewById的代码来获取对应的View。
@BindView(R.id.button)
EditText mButton;但是2020年3月份,大佬已在GitHub上说明不再维护,推荐使用 ViewBinding了。
方案二 kotlin-android-extensions(KAE)
kotlin-android-extensions只需要直接引入布局可以直接使用资源Id访问View,节省findviewbyid()。
import kotlinx.android.synthetic.main.<布局>.*
button.setOnClickListener{...} 但是这个插件也已经被Google废弃了,会影响效率并且安全性和兼容性都不太友好,Google推荐ViewBinding替代
方案三 ViewBinding
既然都推荐ViewBinding,那现在来看看ViewBinding是啥。官网是这么说的
通过ViewBinding功能,您可以更轻松地编写可与视图交互的代码。在模块中启用视图绑定之后,系统会为该模块中的每个 XML 布局文件生成一个绑定类。绑定类的实例包含对在相应布局中具有 ID 的所有视图的直接引用。在大多数情况下,视图绑定会替代 findViewById。
简而言之就是就是替代findViewById来获取View的。那我们来看看ViewBinding如何使用呢?
三、ViewBinding使用
1. 条件
确保你的Android Studio是3.6或更高的版本
ViewBinding在 Android Studio 3.6 Canary 11 及更高版本中可用
2. 启用ViewBinding
在模块build.gradle文件android节点下添加如下代码
android {
viewBinding{
enabled = true
}
}Android Studio 4.0 中,viewBinding 变成属性被整合到了 buildFeatures 选项中,所以配置要改成:
// Android Studio 4.0
android {
buildFeatures {
viewBinding = true
}
}配置好后就已经启用好了ViewBinding,重新编译后系统会为每个布局生成对应的Binding类,类中包含布局ID对应的View引用,并采取驼峰式命名。
3. 使用
以activity举例,我们的MainActivity的布局是activity_main,之前我们布局代码是:
class MainActivity : BaseActivity() {
private lateinit var button: Button
private lateinit var viewPager: ViewPager2
private lateinit var recyclerView: RecyclerView
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
button = findViewById(R.id.button)
button.setOnClickListener { ... }
}
}现在就要改为
- 对应的Binding类如ActivityMainBinding类去用inflate加载布局
- 然后通过getRoot获取到View
- 将View传入到setContentView(view:View)中
Activity就能显示activity_main.xml这个布局的内容了,并可以通过Binding对象直接访问对应View对象。
class MainActivity : BaseActivity() {
private lateinit var mBinding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
mBinding = ActivityMainBinding.inflate(layoutInflater)
setContentView(mBinding.root)
mBinding.button.setOnClickListener { ... }
}
}而在其他UI elements中,如fragment、dialog、adapter中,使用方式大同小异,都是通过inflate去加载出View,然后后面加以使用。
四、原理
生成的类可以在/build/generated/data_binding_base_class_source_out下找到
public final class ActivityMainBinding implements ViewBinding {
@NonNull
private final ConstraintLayout rootView;
@NonNull
public final Button button;
@NonNull
public final RecyclerView recyclerView;
@NonNull
public final ViewPager2 viewPager;
private ActivityMainBinding(@NonNull ConstraintLayout rootView, @NonNull Button button,
@NonNull RecyclerView recyclerView, @NonNull ViewPager2 viewPager) {
this.rootView = rootView;
this.button = button;
this.recyclerView = recyclerView;
this.viewPager = viewPager;
}
@Override
@NonNull
public ConstraintLayout getRoot() {
return rootView;
}
@NonNull
public static ActivityMainBinding inflate(@NonNull LayoutInflater inflater) {
return inflate(inflater, null, false);
}
@NonNull
public static ActivityMainBinding inflate(@NonNull LayoutInflater inflater,
@Nullable ViewGroup parent, boolean attachToParent) {
View root = inflater.inflate(R.layout.activity_main, parent, false);
if (attachToParent) {
parent.addView(root);
}
return bind(root);
}
@NonNull
public static ActivityMainBinding bind(@NonNull View rootView) {
// The body of this method is generated in a way you would not otherwise write.
// This is done to optimize the compiled bytecode for size and performance.
int id;
missingId: {
id = R.id.button;
Button button = ViewBindings.findChildViewById(rootView, id);
if (button == null) {
break missingId;
}
id = R.id.recycler_view;
RecyclerView recyclerView = ViewBindings.findChildViewById(rootView, id);
if (recyclerView == null) {
break missingId;
}
id = R.id.view_pager;
ViewPager2 viewPager = ViewBindings.findChildViewById(rootView, id);
if (viewPager == null) {
break missingId;
}
return new ActivityMainBinding((ConstraintLayout) rootView, button, recyclerView, viewPager);
}
String missingId = rootView.getResources().getResourceName(id);
throw new NullPointerException("Missing required view with ID: ".concat(missingId));
}
}可以看到关键的方法就是这个bind方法,里面通过ViewBindings.findChildViewById获取View对象,而继续查看这个方法
public class ViewBindings {
private ViewBindings() {
}
/**
* Like `findViewById` but skips the view itself.
*
* @hide
*/
@Nullable
public static <T extends View> T findChildViewById(View rootView, @IdRes int id) {
if (!(rootView instanceof ViewGroup)) {
return null;
}
final ViewGroup rootViewGroup = (ViewGroup) rootView;
final int childCount = rootViewGroup.getChildCount();
for (int i = 0; i < childCount; i++) {
final T view = rootViewGroup.getChildAt(i).findViewById(id);
if (view != null) {
return view;
}
}
return null;
}
}可见还是使用的findViewById,ViewBinding这个框架只是帮我们在编译阶段自动生成了这些findViewById代码,省去我们去写了。
五、优缺点
优点
- 对比kotlin-extension,可以控制访问作用域,kotlin-extension可以访问不是该布局下的view;
- 对比butterknife,减少注解以及id的一对一匹配
- 兼容Kotlin、Java;
- 官方推荐。
缺点
- 增加编译时间,因为ViwBinding是在编译时生成的,会产生而外的类,增加包的体积;
- include的布局文件无法直接引用,需要给include给id值,然后间接引用;
整体来说ViewBinding的优点还是远远大于缺点的,所以可以放心使用。
六、 封装
既然选择了方案ViewBinding,那我们要在项目中使用,肯定还需要对他加一些封装,我们可以用泛型封装setContentView的代码
abstract class BaseActivity<T : ViewBinding> : AppCompatActivity() {
private lateinit var _binding: T
protected val binding get() = _binding;
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
_binding = getViewBinding()
setContentView(_binding.root)
initViews()
initEvents()
}
protected abstract fun getViewBinding(): T
open fun initViews() {}
open fun initEvents() {}
}class MainActivity : BaseActivity<ActivityMainBinding>() {
override fun getViewBinding() = ActivityMainBinding.inflate(layoutInflater)
override fun initViews() {
binding.button.setOnClickListener {
...
}
}
}这样在Activity中使用起来就很方便,fragment也可以做类似的封装
abstract class BaseFragment<T : ViewBinding> : Fragment() {
private var _binding: T? = null
protected val binding get() = _binding!!
override fun onCreateView(
inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?
): View? {
_binding = getViewBinding(inflater, container)
return binding.root
}
protected abstract fun getViewBinding(inflater: LayoutInflater, container: ViewGroup?): T
override fun onDestroyView() {
super.onDestroyView()
_binding = null
}
}注意:
这里会发现Fragment和Activity的封装方式不一样,没有用lateinit。
因为binding变量只有在onCreateView与onDestroyView才是可用的,而fragment的生命周期和activity的不同,fragment可以超出其视图的生命周期,比如fragment hide的时候,如果不将这里置为空,有可能引起内存泄漏。
所以我们要在onCreateView中创建,onDestroyView置空。
七、总结
ViewBinding相比优点还是很多的,解决了安全性问题和兼容性问题,所以我们可以放心大胆的使用。
项目源码地址: Github wanandroid
链接:https://juejin.cn/post/7177673339517796413
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android App封装 ——架构(MVI + kotlin + Flow)
一、背景
最近看了好多MVI的文章,原理大多都是参照google发布的 应用架构指南,但是实现方式有很多种,就想自己封装一套自己喜欢用的MVI架构,以供以后开发App使用。
说干就干,准备对标“玩Android”,利用提供的数据接口,搭建一个自己习惯使用的一套App项目,项目地址:Github wanandroid。
二、MVI
先简单说一下MVI,从MVC到MVP到MVVM再到现在的MVI,google是为了一直解决痛点所以不断推出新的框架,具体的发展流程就不多做赘诉了,网上有好多,我们可以选择性适合自己的。
应用架构指南中主要的就是两个架构图:
2.1 总体架构
Google推荐的是每个应用至少有两层:
- UI Layer 界面层: 在屏幕上显示应用数据
- Data Layer 数据层: 提供所需要的应用数据(通过网络、文件等)
- Domain Layer(optional)领域层/网域层 (可选):主要用于封装数据层的逻辑,方便与界面层的交互,可以根据User Case
图中主要的点在于各层之间的依赖关系是单向的,所以方便了各层之间的单元测试
2.2 UI层架构
UI简单来说就是拿到数据并展示,而数据是以state表示UI不同的状态传送给界面的,所以UI架构分为
- UI elements层:UI元素,由
activity、fragment以及包含的控件组成 - State holders层: state状态的持有者,这里一般是由
viewModel承担
2.3 MVI UI层的特点
MVI在UI层相比与MVVM的核心区别是它的两大特性:
- 唯一可信数据源
- 数据单向流动。
从图中可以看到,
- 数据从Data Layer -> ViewModel -> UI,数据是单向流动的。ViewModel将数据封装成
UI State传输到UI elements中,而UI elements是不会传输数据到ViewModel的。 - UI elements上的一些点击或者用户事件,都会封装成
events事件,发送给ViewModel
2.4 搭建MVI要注意的点
了解了MVI的原理和特点后,我们就要开始着手搭建了,其中需要解决的有以下几点
- 定义
UI State、events - 构建
UI State单向数据流UDF - 构建事件流
events UI State的订阅和发送
三、搭建项目
3.1 定义UI State、events
我们可以用interface先定义一个抽象的UI State、events,event和intent是一个意思,都可以用来表示一次事件。
@Keep
interface IUiState
@Keep
interface IUiIntent
然后根据具体逻辑定义页面的UIState和UiIntent。
data class MainState(val bannerUiState: BannerUiState, val detailUiState: DetailUiState) : IUiState
sealed class BannerUiState {
object INIT : BannerUiState()
data class SUCCESS(val models: List<BannerModel>) : BannerUiState()
}
sealed class DetailUiState {
object INIT : DetailUiState()
data class SUCCESS(val articles: ArticleModel) : DetailUiState()
}通过MainState将页面的不同状态封装起来,从而实现唯一可信数据源
3.2 构建单向数据流UDF
在ViewModel中使用StateFlow构建UI State流。
_uiStateFlow用来更新数据uiStateFlow用来暴露给UI elements订阅
abstract class BaseViewModel<UiState : IUiState, UiIntent : IUiIntent> : ViewModel() {
private val _uiStateFlow = MutableStateFlow(initUiState())
val uiStateFlow: StateFlow<UiState> = _uiStateFlow
protected abstract fun initUiState(): UiState
protected fun sendUiState(copy: UiState.() -> UiState) {
_uiStateFlow.update { copy(_uiStateFlow.value) }
}
}class MainViewModel : BaseViewModel<MainState, MainIntent>() {
override fun initUiState(): MainState {
return MainState(BannerUiState.INIT, DetailUiState.INIT)
}
}3.3 构建事件流
在ViewModel中使用 Channel构建事件流
_uiIntentFlow用来传输Intent- 在viewModelScope中开启协程监听
uiIntentFlow,在子ViewModel中只用重写handlerIntent方法就可以处理Intent事件了 - 通过sendUiIntent就可以发送Intent事件了
abstract class BaseViewModel<UiState : IUiState, UiIntent : IUiIntent> : ViewModel() {
private val _uiIntentFlow: Channel<UiIntent> = Channel()
val uiIntentFlow: Flow<UiIntent> = _uiIntentFlow.receiveAsFlow()
fun sendUiIntent(uiIntent: UiIntent) {
viewModelScope.launch {
_uiIntentFlow.send(uiIntent)
}
}
init {
viewModelScope.launch {
uiIntentFlow.collect {
handleIntent(it)
}
}
}
protected abstract fun handleIntent(intent: IUiIntent)
class MainViewModel : BaseViewModel<MainState, MainIntent>() {
override fun handleIntent(intent: IUiIntent) {
when (intent) {
MainIntent.GetBanner -> {
requestDataWithFlow()
}
is MainIntent.GetDetail -> {
requestDataWithFlow()
}
}
}
}3.4 UI State的订阅和发送
3.4.1 订阅UI State
在Activity中订阅UI state的变化
- 在
lifecycleScope中开启协程,collectuiStateFlow。 - 使用
map来做局部变量的更新 - 使用
distinctUntilChanged来做数据防抖
class MainActivity : BaseMVIActivity() {
private fun registerEvent() {
lifecycleScope.launchWhenStarted {
mViewModel.uiStateFlow.map { it.bannerUiState }.distinctUntilChanged().collect { bannerUiState ->
when (bannerUiState) {
is BannerUiState.INIT -> {}
is BannerUiState.SUCCESS -> {
bannerAdapter.setList(bannerUiState.models)
}
}
}
}
lifecycleScope.launchWhenStarted {
mViewModel.uiStateFlow.map { it.detailUiState }.distinctUntilChanged().collect { detailUiState ->
when (detailUiState) {
is DetailUiState.INIT -> {}
is DetailUiState.SUCCESS -> {
articleAdapter.setList(detailUiState.articles.datas)
}
}
}
}
}
}3.4.2 发送Intent
直接调用sendUiIntent就可以发送Intent事件
button.setOnClickListener {
mViewModel.sendUiIntent(MainIntent.GetBanner)
mViewModel.sendUiIntent(MainIntent.GetDetail(0))
}3.4.3 更新Ui State
调用sendUiState发送Ui State更新
需要注意的是: 在UiState改变时,使用的是copy复制一份原来的UiState,然后修改变动的值。这是为了做到 “可信数据源”,在定义MainState的时候,设置的就是val,是为了避免多线程并发读写,导致线程安全的问题。
class MainViewModel : BaseViewModel<MainState, MainIntent>() {
private val mWanRepo = WanRepository()
override fun initUiState(): MainState {
return MainState(BannerUiState.INIT, DetailUiState.INIT)
}
override fun handleIntent(intent: IUiIntent) {
when (intent) {
MainIntent.GetBanner -> {
requestDataWithFlow(showLoading = true,
request = { mWanRepo.requestWanData() },
successCallback = { data -> sendUiState { copy(bannerUiState = BannerUiState.SUCCESS(data)) } },
failCallback = {})
}
is MainIntent.GetDetail -> {
requestDataWithFlow(showLoading = false,
request = { mWanRepo.requestRankData(intent.page) },
successCallback = { data -> sendUiState { copy(detailUiState = DetailUiState.SUCCESS(data)) } })
}
}
}
}其中 requestDataWithFlow 是封装的一个网络请求的方法
protected fun <T : Any> requestDataWithFlow(
showLoading: Boolean = true,
request: suspend () -> BaseData<T>,
successCallback: (T) -> Unit,
failCallback: suspend (String) -> Unit = { errMsg ->
//默认异常处理
},
) {
viewModelScope.launch {
val baseData: BaseData<T>
try {
baseData = request()
when (baseData.state) {
ReqState.Success -> {
sendLoadUiState(LoadUiState.ShowMainView)
baseData.data?.let { successCallback(it) }
}
ReqState.Error -> baseData.msg?.let { error(it) }
}
} catch (e: Exception) {
e.message?.let { failCallback(it) }
}
}
}至此一个MVI的框架基本就搭建完毕了
3.5运行效果
四、 总结
不管是MVC、MVP、MVVM还是MVI,主要就是View和Model之间的交互关系不同
- MVI的核心是 数据的单向流动
- MVI使用kotlin flow可以很方便的实现 响应式编程
- MV整个View只依赖一个State刷新,这个State就是 唯一可信数据源
目前搭建了基础框架,后续还会在此项目的基础上继续封装jetpack等更加完善这个项目。
链接:https://juejin.cn/post/7177619630050000954
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
90%的Java开发人员都会犯的5个错误
前言
作为一名java开发程序员,不知道大家有没有遇到过一些匪夷所思的bug。这些错误通常需要您几个小时才能解决。当你找到它们的时候,你可能会默默地骂自己是个傻瓜。是的,这些可笑的bug基本上都是你忽略了一些基础知识造成的。其实都是很低级的错误。今天,我总结一些常见的编码错误,然后给出解决方案。希望大家在日常编码中能够避免这样的问题。
1. 使用Objects.equals比较对象
这种方法相信大家并不陌生,甚至很多人都经常使用。是JDK7提供的一种方法,可以快速实现对象的比较,有效避免烦人的空指针检查。但是这种方法很容易用错,例如:
Long longValue = 123L;
System.out.println(longValue==123); //true
System.out.println(Objects.equals(longValue,123)); //false
为什么替换==为Objects.equals()会导致不同的结果?这是因为使用==编译器会得到封装类型对应的基本数据类型longValue,然后与这个基本数据类型进行比较,相当于编译器会自动将常量转换为比较基本数据类型, 而不是包装类型。
使用该Objects.equals()方法后,编译器默认常量的基本数据类型为int。下面是源码Objects.equals(),其中a.equals(b)使用的是Long.equals()会判断对象类型,因为编译器已经认为常量是int类型,所以比较结果一定是false。
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
public boolean equals(Object obj) {
if (obj instanceof Long) {
return value == ((Long)obj).longValue();
}
return false;
}知道了原因,解决方法就很简单了。直接声明常量的数据类型,如Objects.equals(longValue,123L)。其实如果逻辑严密,就不会出现上面的问题。我们需要做的是保持良好的编码习惯。
2. 日期格式错误
在我们日常的开发中,经常需要对日期进行格式化,但是很多人使用的格式不对,导致出现意想不到的情况。请看下面的例子。
Instant instant = Instant.parse("2021-12-31T00:00:00.00Z");
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("YYYY-MM-dd HH:mm:ss")
.withZone(ZoneId.systemDefault());
System.out.println(formatter.format(instant));//2022-12-31 08:00:00
以上用于YYYY-MM-dd格式化, 年从2021 变成了 2022。为什么?这是因为 java 的DateTimeFormatter 模式YYYY和yyyy之间存在细微的差异。它们都代表一年,但是yyyy代表日历年,而YYYY代表星期。这是一个细微的差异,仅会导致一年左右的变更问题,因此您的代码本可以一直正常运行,而仅在新的一年中引发问题。12月31日按周计算的年份是2022年,正确的方式应该是使用yyyy-MM-dd格式化日期。
这个bug特别隐蔽。这在平时不会有问题。它只会在新的一年到来时触发。我公司就因为这个bug造成了生产事故。
3. 在 ThreadPool 中使用 ThreadLocal
如果创建一个ThreadLocal 变量,访问该变量的线程将创建一个线程局部变量。合理使用ThreadLocal可以避免线程安全问题。
但是,如果在线程池中使用ThreadLocal ,就要小心了。您的代码可能会产生意想不到的结果。举个很简单的例子,假设我们有一个电商平台,用户购买商品后需要发邮件确认。
private ThreadLocal<User> currentUser = ThreadLocal.withInitial(() -> null);
private ExecutorService executorService = Executors.newFixedThreadPool(4);
public void executor() {
executorService.submit(()->{
User user = currentUser.get();
Integer userId = user.getId();
sendEmail(userId);
});
}如果我们使用ThreadLocal来保存用户信息,这里就会有一个隐藏的bug。因为使用了线程池,线程是可以复用的,所以在使用ThreadLocal获取用户信息的时候,很可能会误获取到别人的信息。您可以使用会话来解决这个问题。
4. 使用HashSet去除重复数据
在编码的时候,我们经常会有去重的需求。一想到去重,很多人首先想到的就是用HashSet去重。但是,不小心使用 HashSet 可能会导致去重失败。
User user1 = new User();
user1.setUsername("test");
User user2 = new User();
user2.setUsername("test");
List<User> users = Arrays.asList(user1, user2);
HashSet<User> sets = new HashSet<>(users);
System.out.println(sets.size());// the size is 2
细心的读者应该已经猜到失败的原因了。HashSet使用hashcode对哈希表进行寻址,使用equals方法判断对象是否相等。如果自定义对象没有重写hashcode方法和equals方法,则默认使用父对象的hashcode方法和equals方法。所以HashSet会认为这是两个不同的对象,所以导致去重失败。
5. 线程池中的异常被吃掉
ExecutorService executorService = Executors.newFixedThreadPool(1);
executorService.submit(()->{
//do something
double result = 10/0;
});上面的代码模拟了一个线程池抛出异常的场景。我们真正的业务代码要处理各种可能出现的情况,所以很有可能因为某些特定的原因而触发RuntimeException 。
但是如果没有特殊处理,这个异常就会被线程池吃掉。这样就会导出出现问题你都不知道,这是很严重的后果。因此,最好在线程池中try catch捕获异常。
链接:https://juejin.cn/post/7182184496517611576
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
快速上手Compose约束布局
前言
今天对Compose中约束布局的使用方法进行一下记录,我发现在学习Compose的过程中,像Column,Row等布局可以很快上手,可以理解怎样使用,但是对于ConstraintLayout 还是得额外学习一下,所以总结一下进行记录。其实Compose-ConstraintLayout 完全是我对传统布局使用习惯的迁移,已经习惯了约束的思维方式。
接下来我们就看Compose中ConstraintLayout 是怎样使用的。
使用
首先我们先引入依赖
Groovy
implementation "androidx.constraintlayout:constraintlayout-compose:1.0.1"
Kotlin
implementation("androidx.constraintlayout:constraintlayout-compose:1.0.1")
在传统布局中,我们对约束布局的使用都是通过id进行相互约束的,那在Compose中我们同样需要先创建一个类似id功能一样的引用。
val (text) = createRefs()
在Compose中有两种创建引用的方式:createRefs() 和createRef()。createRef()只能创建一个,createRefs()每次能创建多个(最多16个)。
然后对我们的组件设置约束,这里我用了一个Text()做示例。
ConstraintLayout(modifier = Modifier.fillMaxSize()) {
val (text) = createRefs()
Text("Hello Word", modifier = Modifier.constrainAs(text) {
start.linkTo(parent.start)
top.linkTo(parent.top)
})
}
这样就实现了 Text() 组件在我们布局的左上角。
当我们同时也对end 做出约束,就会达到一个Text()组件在布局中横向居中的效果。
Text("Hello Word", modifier = Modifier.constrainAs(text) {
start.linkTo(parent.start)
end.linkTo(parent.end)
top.linkTo(parent.top)
})
当我们想有一个Button按钮 在文字的下方居中显示,我们可以这样做:
ConstraintLayout(modifier = Modifier.fillMaxSize()) {
val (text, button) = createRefs()
Text("Hello Word", modifier = Modifier.constrainAs(text) {
start.linkTo(parent.start)
end.linkTo(parent.end)
top.linkTo(parent.top)
})
Button(onClick = {}, modifier = Modifier.constrainAs(button) {
start.linkTo(text.start)
end.linkTo(text.end)
top.linkTo(text.bottom)
}) {
Text("按钮")
}
}
将Button组件相对于文字组件做出前,后,顶部约束。
实践
接下来我们尝试使用约束布局来做一个个人信息显示的效果。我们先看下我们要实现的效果:
我们先分解一下这个效果,一个Image图片,一个Text 名称,一个Text 微信号, 还有一个 二维码。
接下来我们就一步步来实现一下。
先是头像部分,我们对Image头像,先进行上,下,前约束,再设置一下左边距,能够留出空间来。
Image(painter = painterResource(R.drawable.logo8), "head",
contentScale = ContentScale.Crop,
modifier = Modifier.constrainAs(head) {
start.linkTo(parent.start)
top.linkTo(parent.top)
bottom.linkTo(parent.bottom)
}.padding(start = 20.dp).size(60.dp).clip(CircleShape)
)
然后我们开始添加名称和id。
Text()名称组件是顶部和头像顶部对齐,start 和 头像的end 进行对齐;Id 是对于名称 start对齐,顶部与名称底部对齐。
Text("Android开发那点事儿",
style = TextStyle(fontSize = 16.sp,
color = Color.Black, fontWeight = FontWeight(600)),
modifier = Modifier.constrainAs(name) {
top.linkTo(head.top)
start.linkTo(head.end)
}.padding(start = 10.dp)
)
Text("微信号:android-blog",
style = TextStyle(fontSize = 12.sp,
color = Color.DarkGray, fontWeight = FontWeight(400)),
modifier = Modifier.constrainAs(id) {
top.linkTo(name.bottom)
start.linkTo(name.start)
}.padding(start = 10.dp, top = 5.dp)
)
效果:
最后我们来加载二维码,二维码图标和右箭头图标都是从“阿里icon”中找的图标。
将图标相对于头像上下居中,紧靠右边,然后留出间距,然后是箭头上下都跟二维码图标对齐,左侧紧贴二维码的右侧。
ConstraintLayout(modifier = Modifier.width(300.dp)
.height(80.dp).background(Color.LightGray)) {
........
Image(
painter = painterResource(R.drawable.qr),"",
modifier = Modifier.size(20.dp).constrainAs(qr) {
top.linkTo(head.top)
bottom.linkTo(head.bottom)
end.linkTo(parent.end, 30.dp)
})
Image(
painter = painterResource(R.drawable.left), "",
modifier = Modifier.size(20.dp).constrainAs(left) {
top.linkTo(qr.top)
bottom.linkTo(qr.bottom)
start.linkTo(qr.end)
})
}
我们来看下最后完成的效果。
至此,我们就通过ConstraintLayout完成了一个简单的效果,如果有传统布局的使用基础,Compose的使用起来还是可以很快上手的。
最后
ConstraintLayout 最基础的用法我们就写到这里,另外还有一些进阶用法会在后续的文章中给大家详细介绍。
链接:https://juejin.cn/post/7181455100374679589
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
订单30分钟未支付自动取消怎么实现?
目录
- 了解需求
- 方案 1:数据库轮询
- 方案 2:JDK 的延迟队列
- 方案 3:时间轮算法
- 方案 4:redis 缓存
- 方案 5:使用消息队列
了解需求
在开发中,往往会遇到一些关于延时任务的需求。
例如
- 生成订单 30 分钟未支付,则自动取消
- 生成订单 60 秒后,给用户发短信
对上述的任务,我们给一个专业的名字来形容,那就是延时任务。那么这里就会产生一个问题,这个延时任务和定时任务的区别究竟在哪里呢?一共有如下几点区别
定时任务有明确的触发时间,延时任务没有
定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
定时任务一般执行的是批处理操作是多个任务,而延时任务一般是单个任务
下面,我们以判断订单是否超时为例,进行方案分析
方案 1:数据库轮询
思路
该方案通常是在小型项目中使用,即通过一个线程定时的去扫描数据库,通过订单时间来判断是否有超时的订单,然后进行 update 或 delete 等操作
实现
可以用 quartz 来实现的,简单介绍一下
maven 项目引入一个依赖如下所示
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.2</version>
</dependency>调用 Demo 类 MyJob 如下所示
package com.rjzheng.delay1;
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class MyJob implements Job {
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println("要去数据库扫描啦。。。");
}
public static void main(String[] args) throws Exception {
// 创建任务
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("job1", "group1").build();
// 创建触发器 每3秒钟执行一次
Trigger trigger = TriggerBuilder
.newTrigger()
.withIdentity("trigger1", "group3")
.withSchedule(
SimpleScheduleBuilder
.simpleSchedule()
.withIntervalInSeconds(3).
repeatForever())
.build();
Scheduler scheduler = new StdSchedulerFactory().getScheduler();
// 将任务及其触发器放入调度器
scheduler.scheduleJob(jobDetail, trigger);
// 调度器开始调度任务
scheduler.start();
}
}运行代码,可发现每隔 3 秒,输出如下
要去数据库扫描啦。。。优点
简单易行,支持集群操作
缺点
- 对服务器内存消耗大
- 存在延迟,比如你每隔 3 分钟扫描一次,那最坏的延迟时间就是 3 分钟
- 假设你的订单有几千万条,每隔几分钟这样扫描一次,数据库损耗极大
方案 2:JDK 的延迟队列
思路
该方案是利用 JDK 自带的 DelayQueue 来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入 DelayQueue 中的对象,是必须实现 Delayed 接口的。
DelayedQueue 实现工作流程如下图所示
其中 Poll():获取并移除队列的超时元素,没有则返回空
take():获取并移除队列的超时元素,如果没有则 wait 当前线程,直到有元素满足超时条件,返回结果。
实现
定义一个类 OrderDelay 实现 Delayed,代码如下
package com.rjzheng.delay2;
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
public class OrderDelay implements Delayed {
private String orderId;
private long timeout;
OrderDelay(String orderId, long timeout) {
this.orderId = orderId;
this.timeout = timeout + System.nanoTime();
}
public int compareTo(Delayed other) {
if (other == this) {
return 0;
}
OrderDelay t = (OrderDelay) other;
long d = (getDelay(TimeUnit.NANOSECONDS) - t.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) ? 0 : ((d < 0) ? -1 : 1);
}
// 返回距离你自定义的超时时间还有多少
public long getDelay(TimeUnit unit) {
return unit.convert(timeout - System.nanoTime(), TimeUnit.NANOSECONDS);
}
void print() {
System.out.println(orderId + "编号的订单要删除啦。。。。");
}
}运行的测试 Demo 为,我们设定延迟时间为 3 秒
package com.rjzheng.delay2;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.TimeUnit;
public class DelayQueueDemo {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("00000001");
list.add("00000002");
list.add("00000003");
list.add("00000004");
list.add("00000005");
DelayQueue<OrderDelay> queue = newDelayQueue < OrderDelay > ();
long start = System.currentTimeMillis();
for (int i = 0; i < 5; i++) {
//延迟三秒取出
queue.put(new OrderDelay(list.get(i), TimeUnit.NANOSECONDS.convert(3, TimeUnit.SECONDS)));
try {
queue.take().print();
System.out.println("After " + (System.currentTimeMillis() - start) + " MilliSeconds");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}输出如下
00000001编号的订单要删除啦。。。。
After 3003 MilliSeconds
00000002编号的订单要删除啦。。。。
After 6006 MilliSeconds
00000003编号的订单要删除啦。。。。
After 9006 MilliSeconds
00000004编号的订单要删除啦。。。。
After 12008 MilliSeconds
00000005编号的订单要删除啦。。。。
After 15009 MilliSeconds可以看到都是延迟 3 秒,订单被删除
优点
效率高,任务触发时间延迟低。
缺点
- 服务器重启后,数据全部消失,怕宕机
- 集群扩展相当麻烦
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现 OOM 异常
- 代码复杂度较高
方案 3:时间轮算法
思路
先上一张时间轮的图(这图到处都是啦)
时间轮算法可以类比于时钟,如上图箭头(指针)按某一个方向按固定频率轮动,每一次跳动称为一个 tick。这样可以看出定时轮由个 3 个重要的属性参数,ticksPerWheel(一轮的 tick 数),tickDuration(一个 tick 的持续时间)以及 timeUnit(时间单位),例如当 ticksPerWheel=60,tickDuration=1,timeUnit=秒,这就和现实中的始终的秒针走动完全类似了。
如果当前指针指在 1 上面,我有一个任务需要 4 秒以后执行,那么这个执行的线程回调或者消息将会被放在 5 上。那如果需要在 20 秒之后执行怎么办,由于这个环形结构槽数只到 8,如果要 20 秒,指针需要多转 2 圈。位置是在 2 圈之后的 5 上面(20 % 8 + 1)
实现
我们用 Netty 的 HashedWheelTimer 来实现
给 Pom 加上下面的依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.24.Final</version>
</dependency>测试代码 HashedWheelTimerTest 如下所示
package com.rjzheng.delay3;
import io.netty.util.HashedWheelTimer;
import io.netty.util.Timeout;
import io.netty.util.Timer;
import io.netty.util.TimerTask;
import java.util.concurrent.TimeUnit;
public class HashedWheelTimerTest {
static class MyTimerTask implements TimerTask {
boolean flag;
public MyTimerTask(boolean flag) {
this.flag = flag;
}
public void run(Timeout timeout) throws Exception {
System.out.println("要去数据库删除订单了。。。。");
this.flag = false;
}
}
public static void main(String[] argv) {
MyTimerTask timerTask = new MyTimerTask(true);
Timer timer = new HashedWheelTimer();
timer.newTimeout(timerTask, 5, TimeUnit.SECONDS);
int i = 1;
while (timerTask.flag) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(i + "秒过去了");
i++;
}
}
}输出如下
1秒过去了
2秒过去了
3秒过去了
4秒过去了
5秒过去了
要去数据库删除订单了。。。。
6秒过去了优点
效率高,任务触发时间延迟时间比 delayQueue 低,代码复杂度比 delayQueue 低。
缺点
- 服务器重启后,数据全部消失,怕宕机
- 集群扩展相当麻烦
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现 OOM 异常
方案 4:redis 缓存
思路一
利用 redis 的 zset,zset 是一个有序集合,每一个元素(member)都关联了一个 score,通过 score 排序来取集合中的值
添加元素:ZADD key score member [score member …]
按顺序查询元素:ZRANGE key start stop [WITHSCORES]
查询元素 score:ZSCORE key member
移除元素:ZREM key member [member …]
测试如下
添加单个元素
redis> ZADD page_rank 10 google.com
(integer) 1
添加多个元素
redis> ZADD page_rank 9 baidu.com 8 bing.com
(integer) 2
redis> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"
5) "google.com"
6) "10"
查询元素的score值
redis> ZSCORE page_rank bing.com
"8"
移除单个元素
redis> ZREM page_rank google.com
(integer) 1
redis> ZRANGE page_rank 0 -1 WITHSCORES
1) "bing.com"
2) "8"
3) "baidu.com"
4) "9"那么如何实现呢?我们将订单超时时间戳与订单号分别设置为 score 和 member,系统扫描第一个元素判断是否超时,具体如下图所示
实现一
package com.rjzheng.delay4;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.Tuple;
import java.util.Calendar;
import java.util.Set;
public class AppTest {
private static final String ADDR = "127.0.0.1";
private static final int PORT = 6379;
private static JedisPool jedisPool = new JedisPool(ADDR, PORT);
public static Jedis getJedis() {
return jedisPool.getResource();
}
//生产者,生成5个订单放进去
public void productionDelayMessage() {
for (int i = 0; i < 5; i++) {
//延迟3秒
Calendar cal1 = Calendar.getInstance();
cal1.add(Calendar.SECOND, 3);
int second3later = (int) (cal1.getTimeInMillis() / 1000);
AppTest.getJedis().zadd("OrderId", second3later, "OID0000001" + i);
System.out.println(System.currentTimeMillis() + "ms:redis生成了一个订单任务:订单ID为" + "OID0000001" + i);
}
}
//消费者,取订单
public void consumerDelayMessage() {
Jedis jedis = AppTest.getJedis();
while (true) {
Set<Tuple> items = jedis.zrangeWithScores("OrderId", 0, 1);
if (items == null || items.isEmpty()) {
System.out.println("当前没有等待的任务");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
continue;
}
int score = (int) ((Tuple) items.toArray()[0]).getScore();
Calendar cal = Calendar.getInstance();
int nowSecond = (int) (cal.getTimeInMillis() / 1000);
if (nowSecond >= score) {
String orderId = ((Tuple) items.toArray()[0]).getElement();
jedis.zrem("OrderId", orderId);
System.out.println(System.currentTimeMillis() + "ms:redis消费了一个任务:消费的订单OrderId为" + orderId);
}
}
}
public static void main(String[] args) {
AppTest appTest = new AppTest();
appTest.productionDelayMessage();
appTest.consumerDelayMessage();
}
}此时对应输出如下
可以看到,几乎都是 3 秒之后,消费订单。
然而,这一版存在一个致命的硬伤,在高并发条件下,多消费者会取到同一个订单号,我们上测试代码 ThreadTest
package com.rjzheng.delay4;
import java.util.concurrent.CountDownLatch;
public class ThreadTest {
private static final int threadNum = 10;
private static CountDownLatch cdl = newCountDownLatch(threadNum);
static class DelayMessage implements Runnable {
public void run() {
try {
cdl.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
AppTest appTest = new AppTest();
appTest.consumerDelayMessage();
}
}
public static void main(String[] args) {
AppTest appTest = new AppTest();
appTest.productionDelayMessage();
for (int i = 0; i < threadNum; i++) {
new Thread(new DelayMessage()).start();
cdl.countDown();
}
}
}输出如下所示
显然,出现了多个线程消费同一个资源的情况。
解决方案
(1)用分布式锁,但是用分布式锁,性能下降了,该方案不细说。
(2)对 ZREM 的返回值进行判断,只有大于 0 的时候,才消费数据,于是将 consumerDelayMessage()方法里的
if(nowSecond >= score){
String orderId = ((Tuple)items.toArray()[0]).getElement();
jedis.zrem("OrderId", orderId);
System.out.println(System.currentTimeMillis()+"ms:redis消费了一个任务:消费的订单OrderId为"+orderId);
}修改为
if (nowSecond >= score) {
String orderId = ((Tuple) items.toArray()[0]).getElement();
Long num = jedis.zrem("OrderId", orderId);
if (num != null && num > 0) {
System.out.println(System.currentTimeMillis() + "ms:redis消费了一个任务:消费的订单OrderId为" + orderId);
}
}在这种修改后,重新运行 ThreadTest 类,发现输出正常了
思路二
该方案使用 redis 的 Keyspace Notifications,中文翻译就是键空间机制,就是利用该机制可以在 key 失效之后,提供一个回调,实际上是 redis 会给客户端发送一个消息。是需要 redis 版本 2.8 以上。
实现二
在 redis.conf 中,加入一条配置
notify-keyspace-events Ex
运行代码如下
package com.rjzheng.delay5;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPubSub;
public class RedisTest {
private static final String ADDR = "127.0.0.1";
private static final int PORT = 6379;
private static JedisPool jedis = new JedisPool(ADDR, PORT);
private static RedisSub sub = new RedisSub();
public static void init() {
new Thread(new Runnable() {
public void run() {
jedis.getResource().subscribe(sub, "__keyevent@0__:expired");
}
}).start();
}
public static void main(String[] args) throws InterruptedException {
init();
for (int i = 0; i < 10; i++) {
String orderId = "OID000000" + i;
jedis.getResource().setex(orderId, 3, orderId);
System.out.println(System.currentTimeMillis() + "ms:" + orderId + "订单生成");
}
}
static class RedisSub extends JedisPubSub {
@Override
public void onMessage(String channel, String message) {
System.out.println(System.currentTimeMillis() + "ms:" + message + "订单取消");
}
}
}输出如下
可以明显看到 3 秒过后,订单取消了
ps:redis 的 pub/sub 机制存在一个硬伤,官网内容如下
原:Because Redis Pub/Sub is fire and forget currently there is no way to use this feature if your application demands reliable notification of events, that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.
翻: Redis 的发布/订阅目前是即发即弃(fire and forget)模式的,因此无法实现事件的可靠通知。也就是说,如果发布/订阅的客户端断链之后又重连,则在客户端断链期间的所有事件都丢失了。因此,方案二不是太推荐。当然,如果你对可靠性要求不高,可以使用。
优点
(1) 由于使用 Redis 作为消息通道,消息都存储在 Redis 中。如果发送程序或者任务处理程序挂了,重启之后,还有重新处理数据的可能性。
(2) 做集群扩展相当方便
(3) 时间准确度高
缺点
需要额外进行 redis 维护
方案 5:使用消息队列
思路
我们可以采用 rabbitMQ 的延时队列。RabbitMQ 具有以下两个特性,可以实现延迟队列
RabbitMQ 可以针对 Queue 和 Message 设置 x-message-tt,来控制消息的生存时间,如果超时,则消息变为 dead letter
lRabbitMQ 的 Queue 可以配置 x-dead-letter-exchange 和 x-dead-letter-routing-key(可选)两个参数,用来控制队列内出现了 deadletter,则按照这两个参数重新路由。结合以上两个特性,就可以模拟出延迟消息的功能,具体的,我改天再写一篇文章,这里再讲下去,篇幅太长。
优点
高效,可以利用 rabbitmq 的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。
缺点
本身的易用度要依赖于 rabbitMq 的运维.因为要引用 rabbitMq,所以复杂度和成本变高。
链接:https://juejin.cn/post/7181297729979547705
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为什么计算机中的负数要用补码表示?
思维导图:
1. 为什么计算机要使用二进制数制?
所谓数制其实就是一种 “计数的进位方式”。
常见的数制有十进制、二进制、八进制和十六进制:
十进制是我们日常生活中最熟悉的进位方式,它一共有 0、1、2、3、4、5、6、7、8 和 9 十个符号。在计数的过程中,当某一位满 10 时,就需要向它临近的高位进一,即逢十进一;
二进制是程序员更熟悉的进位方式,也是随着计算机的诞生而发展起来的,它只有 0 和 1 两个符号。在计数的过程中,当某一位满 2 时,就需要向它临近的高位进一,即逢二进一;
八进制和十六进制同理。
那么,为什么计算机要使用二进制数制,而不是人类更熟悉的十进制呢?其原因在于二进制只有两种状态,制造只有 2 个稳定状态的电子元器件可以使用高低电位或有无脉冲区分,而相比于具备多个状态的电子元器件会更加稳定可靠。
2.有符号数与无符号数
在计算机中会区分有符号数和无符号数,无符号数不需要考虑符号,可以将数字编码中的每一位都用来存放数值。有符号数需要考虑正负性,然而计算机是无法识别符号的 “正+” 或 “负-” 标志的,那怎么办呢?
好在我们发现 “正 / 负” 是两种截然不同的状态,正好可以映射到计算机能够理解的 “0 / 1” 上。因此,我们可以直接 “将符号数字化”,将 “正+” 数字化为 “0”,将 “负-” 数字化为 “1”,并将数字化后的符号和数值共同组成数字编码。
另外,为了计算方便,我们额外再规定将 “符号位” 放在数字编码的 “最高位”。例如,+1110 和 -1110 用 8 位二进制表示就是:
- 0000, 1110(符号作为编码的一部分,最高位 0 表示正数)
- 1000, 1110(符号作为编码的一部分,最高位 1 表示负数)
从中我们也可以看出无符号数和有符号数的区别:
1、最高位功能不同: 无符号数的编码中的每一位都可以用来存放数值信息,而有符号数需要在编码的最高位留出一位符号位;
2、数值范围不同: 相同位数下有符号数和无符号数表示的数值范围不同。以 16 位数为例,无符号数可以表示 0
65536,而有符号数可以表示 -3276832768。
提示: 无符号数和有符号数表示的数值范围大小是一样大的,n 位二进制最多只能表示 个信息量,这是无法被突破的。
3. 机器数的运算效率问题
在计算机中,我们会把带 “正 / 负” 符号的数称为真值(True Value),而把符号化后的数称为机器数(Computer Number)。
机器数才是数字在计算机中的二进制表示。 例如在前面的数字中, +1110 是真值,而 0000, 1110 是机器数。新的问题来了:将符号数字化后的机器数,在运算的过程中符号位是否与数值参与运算,又应该如何运算呢?
我们先举几个加法运算的例子:
- 两个正数相加:
0000, 1110 + 0000, 0001 = 0000, 1111 // 14 + 1 = 15 正确
^ ^ ^
符号位 符号位 符号位
- 两个负数相加:
1000, 1110 + 1000, 0001 = 0000, 1111 // (-14) + (-1) = 15 错误
^ ^ ^
符号位 符号位 符号位(最高位的 1 溢出)
- 正负数相加:
0000, 1110 + 1000, 0001 = 1001, 1111 // 14 + (-1) = -15 错误
^ ^ ^
符号位 符号位 符号位
可以看到,在对机器数进行 “按位加法” 运算时,只有两个正数的加法运算的结果是正确的,而包含负数的加法运算的结果却是错误的,会出现 -14 - 1 = 15 和 14 - 1 = -15 这种错误结果。
所以,带负数的加法运算就不能使用常规的按位加法运算了,需要做特殊处理:
两个正数相加:
- 直接做按位加法。
两个负数相加:
- 1、用较大的绝对值 + 较小的绝对值(加法运算);
- 2、最终结果的符号为负。
正负数相加:
- 1、判断两个数的绝对值大小(数值部分);
- 2、用较大的绝对值 - 较小的绝对值(减法运算);
- 3、最终结果的符号取绝对值较大数的符号。
哇🤩?好好的加法运算给整成减法运算? 运算器的电路设计不仅要多设置一个减法器,而且运算步骤还特别复杂。那么,有没有不需要设置减法器,而且步骤简单的方案呢?
4. 原码、反码、补码
为了解决有符号机器数运算效率问题,计算机科学家们提出多种机器数的表示法:
| 机器数 | 正数 | 负数 |
|---|---|---|
| 原码 | 符号位表示符号 数值位表示真值的绝对值 | 符号位表示数字的符号 数值位表示真值的绝对值 |
| 反码 | 无(或者认为是原码本身) | 符号位为 1 数值位是对原码数值位的 “按位取反” |
| 补码 | 无(或者认为是原码本身) | 在负数反码的基础上 + 1 |
1、原码: 原码是最简单的机器数,例如前文提到从
+1110和-1110转换得到的0000, 1110和1000, 1110就是原码表示法,所以原码在进行数字运算时会存在前文提到的效率问题;
2、反码: 反码一般认为是原码和补码转换的中间过渡;
3、补码: 补码才是解决机器数的运算效率的关键, 在计算机中所有 “整型类型” 的负数都会使用补码表示法;
正数的补码是原码本身;- 零的补码是零;
- 负数的补码是在反码的基础上再加 1。
很多教材和网上的资料会认为正数的原码、反码和补码是相同的,这么说倒也不影响什么。 但结合补码的设计原理,小彭的观点是正数是没有反码和补码的,负数使用补码是为了找到一个 “等价” 的正补数代替负数参与计算,将加减法运算统一为两个正数加法运算,而正数自然是不需要替换的,所以也就没有补码的形式。
提示: 为了便于你理解,小彭后文会继续用
“正数的补码是原码本身”这个观点阐述。
5. 使用补码消除减法运算
理解补码表示法后,似乎还是不清楚补码有什么用❓
我们重新计算上一节的加法运算试试:
| 举例 | 真值 | 原码 | 反码 | 补码 |
|---|---|---|---|---|
| +14 | +1110 | 0000, 1110 | 0000, 1110 | 0000, 1110 |
| +13 | +1101 | 0000, 1101 | 0000, 1101 | 0000, 1101 |
| -14 | +1110 | 1000, 1110 | 1111, 0001 | 1111, 0010 |
| -15 | -1110 | 1000, 1111 | 1111, 0000 | 1111, 0001 |
| +1 | +0001 | 0000, 0001 | 0000, 0001 | 0000, 0001 |
| -1 | -0001 | 1000, 0001 | 1111, 1110 | 1111, 1111 |
- 两个正数相加:
// 补码表示法
0000, 1110 + 0000, 0001 = 0000, 1111 // 14 + 1 = 15 正确
^ ^ ^
符号位 符号位 符号位
- 两个负数相加:
// 补码表示法
1111, 0010 + 1111, 1111 = 1111, 0001 // (-14) + (-1) = -15 正确
^ ^ ^
符号位 符号位 符号位(最高位的 1 溢出)
- 正负数相加:
// 补码表示法
0000, 1110 + 1111, 1111 = 0000, 1101 // 14 + (-1) = 13 正确
^ ^ ^
符号位 符号位 符号位(最高位的 1 溢出)
可以看到,使用补码表示法后,有符号机器数加法运算就只是纯粹的加法运算,不会因为符号的正负性而采用不同的计算方法,也不需要减法运算。因此电路设计中只需要设置加法器和补数器,就可以完成有符号数的加法和减法运算,能够简化电路设计。
除了消除减法运算外,补码表示法还实现了 “0” 的机器数的唯一性:
在原码表示法中,“+0” 和 “-0” 都是合法的,而在补码表示法中 “0” 只有唯一的机器数表示,即 0000, 0000 。换言之补码能够比原码多表示一个最小的负数 1000, 0000。
最后提供按照不同表示法解释二进制机器数后得到的真值对比:
| 二进制数 | 无符号真值 | 原码真值 | 反码真值 | 补码真值 |
|---|---|---|---|---|
| 0000, 0000 | 0 | +0 | +0 | +0 |
| 0000, 0001 | 1 | +1 | +1 | +1 |
| … | … | … | … | … |
| 1000, 0000 | 128 | -0(负零,无意义) | -127 | -128(多表示一个数) |
| 1000, 0001 | 129 | -1 | -126 | -127 |
| … | … | … | … | … |
| 1111, 1110 | 254 | -126 | -1 | -2 |
| 1111, 1111 | 255 | -127 | -0(负零) | -1 |
6. 补码我懂了,但是为什么?
理解原码和补码的定义不难,理解补码作用也不难,难的是理解补码是怎么设计出来的,总不可能是被树上的苹果砸到后想到的吧?
这就要提到数学中的 “补数” 概念:
- 1、当一个正数和一个负数互为补数时,它们的绝对值之和就是模;
- 2、一个负数可以用它的正补数代替。
6.1 时钟里的补数
听起来很抽象对吧❓其实生活中,就有一个更加形象的例子 —— 时钟,时钟里就蕴含着补数的概念!
比如说,现在时钟的时针刻度指向 6 点,我们想让它指向 3 点,应该怎么做:
- 方法 1 : 逆时针地拨动 3 个点数,让时针指向 3 点,这相当于做减法运算 -3;
- 方法 2: 顺时针地拨动 9 个点数,让时针指向 3 点,这相当于做加法运算 +9。
可以看到,对于时钟来说 -3 和 +9 竟然是等价的! 这是因为时钟只能 12 个小时,当时间点数超过 12 时就会自动丢失,所以 15 点和 3 点在时钟看来是都是 3 点。如果我们要在时钟上进行 6 - 3 减法运算,我们可以将 -3 等价替换为它的正补数 +9 后参与计算,从而将减法运算替换为 6 + 9 加法运算,结果都是 3。
6.2 十进制的例子
理解了补数的概念后,我们再多看一个十进制的例子:我们要计算十进制 354365 - 95937 = 的结果,怎么做呢?
- 方法 1 - 借位做减法: 常规的做法是利用连续向前借位做减法的方式计算,这没有问题;
- 方法 2 - 减模加补: 使用补数的概念后,我们就可以将减法运算消除为加法运算。
具体来说,如果我们限制十进制数的位长最多只有 6 位,那么模就是 1000000,-95937 对应的正补数就是 1000000 - 95937 = 904063 。此时,我们可以直接用正补数代替负数参与计算,则有:
354365 - 95937 // = 258428
= 354365 - (1000000 - 904063)
= 354365 - 1000000 + 904063 【减整加补】
= 258428可以看到,把 -95937 等价替换为 +904063 后,就把减法运算替换为加法运算。细心的你可能要举手提问了,还是需要减去 1000000 呀?🙋🏻♀️
其实并不用,因为 1000000 是超过位数限制的,所以减去 1000000 这一步就像时针逆时针拨动一整圈一样是无效的。所以实际上需要计算的是:
// 实际需要计算的是:
354365 + 904063
= 1258428 = 258428
^
最高位 1 超出位数限制,直接丢弃
6.3 为什么要使用补码?
继续使用前文提到的 14 + (-1) 正负数相加的例子:
// 原码表示法
0000, 1110 + 1000, 0001 = 1001, 1111 // 14 + (-1) = -15 错误
^ ^ ^
符号位 符号位 符号位
// 补码表示法
0000, 1110 + 1111, 1111 = 1, 0000, 1101 // 14 + (-1) = 13 正确
^ ^ ^
符号位 符号位 最高位 1 超出位数限制,直接丢弃
如果我们限制二进制数字的位长最多只有 8 位,那么模就是 1, 0000, 0000 ,此时,-1 的二进制数 1000, 0001 的正补数就是 1111, 1111。
我们使用正补数 1111, 1111 代替负数 1000, 0001 参与运算,加法运算后的结果是 1, 0000, 1101。其中最高位 1 超出位数限制,直接丢弃,所以最终结果是 0000, 1101,也就是 13,计算正确。
补码示意图
到这里,相信补码的设计原理已经很清楚了。
补码的关键在于:找到一个与负数等价的正补数,使用该正补数代替负数,从而将减法运算替换为两个正数加法运算。 补码的出现与运算器的电路设计有关,从设计者的角度看,希望尽可能简化电路设计和计算复杂度。而使用正补数代替负数就可以消除减法器,实现简化电路的目的。
所以,小彭认为只有负数才存在补码,正数本身就是正数,根本就没必要使用补数,更不需要转为补码。而且正数使用补码的话,还不能把负数转补码的算法用在正数上,还得强行加一条 “正数的补码是原码本身” 的规则,就离谱好吧。
7. 总结
1、无符号数的编码中的每一位都可以用来存放数值信息,而有符号数需要在最高位留出一位符号位;
2、在有符号数的机器数运算中,需要对正数和负数采用不同的计算方法,而且需要引入减法器;
3、为了解决有符号机器数运算效率问题,计算机科学家们提出多种机器数的表示法:原码、反码、补码和移码;
4、使用补码表示法后,运算器可以消除减法运算,而且实现了 “0” 的机器数的唯一性;
5、补码的关键是找到一个与负数等价的正补数,使用该正补数代替负数参与计算,从而将减法运算替换为加法运算。
在前文讲补码的地方,我们提到计算机所有 “整型类型” 的负数都会使用补码表示法,刻意强调 “整数类型” 是什么原因呢,难道浮点数和整数在计算机中的表示方法不同吗?这个问题我们在 下一篇文章 里讨论,请关注。
参考资料
- 计算机组成原理教程(第 2、6 章) —— 尹艳辉 王海文 邢军 著
- 深入浅出计算机组成原理(第 11 ~ 16 讲) —— 徐文浩 著,极客时间 出品
- 10分钟速成课 计算机科学 —— Carrie Anne 著
- Binary number —— Wikipedia
链接:https://juejin.cn/post/7169966346753540103
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
掌握这17张图,没人比你更懂RecyclerView的预加载
实际上,预拉取(prefetch)机制作为RecyclerView的重要特性之一,常常与缓存复用机制一起配合使用、共同协作,极大地提升了RecyclerView整体滑动的流畅度。
并且,这种特性在ViewPager2中同样得以保留,对ViewPager2滑动效果的呈现也起着关键性的作用。因此,我们ViewPager2系列的第二篇,就是要来着重介绍RecyclerView的预拉取机制。
预拉取是指什么?
在计算机术语中,预拉取指的是在已知需要某部分数据的前提下,利用系统资源闲置的空档,预先拉取这部分数据到本地,从而提高执行时的效率。
具体到RecyclerView预拉取的情境则是:
- 利用UI线程正好处于空闲状态的时机
- 预先拉取待进入屏幕区域内的一部分列表项视图并缓存起来
- 从而减少因视图创建或数据绑定等耗时操作所引起的卡顿。
预拉取是怎么实现的?
正如把缓存复用的实际工作委托给了其内部的Recycler类一样,RecyclerView也把预拉取的实际工作委托给了一个名为GapWorker的类,其内部的工作流程,可以用以下这张思维导图来概括:
接下来我们就循着这张思维导图,来一一拆解预拉取的工作流程。
1.发起预拉取工作
通过查找对GapWorker对象的引用,我们可以梳理出3个发起预拉取工作的时机,分别是:
- RecyclerView被拖动(Drag)时
@Override
public boolean onTouchEvent(MotionEvent e) {
...
switch (action) {
...
case MotionEvent.ACTION_MOVE: {
...
if (mScrollState == SCROLL_STATE_DRAGGING) {
...
// 处于拖动状态并且存在有效的拖动距离时
if (mGapWorker != null && (dx != 0 || dy != 0)) {
mGapWorker.postFromTraversal(this, dx, dy);
}
}
}
break;
...
}
...
return true;
}
- RecyclerView惯性滑动(Fling)时
class ViewFlinger implements Runnable {
...
@Override
public void run() {
...
if (!smoothScrollerPending && doneScrolling) {
...
} else {
...
if (mGapWorker != null) {
mGapWorker.postFromTraversal(RecyclerView.this, consumedX, consumedY);
}
}
}
...
} - RecyclerView嵌套滚动时
private void nestedScrollByInternal(int x, int y, @Nullable MotionEvent motionEvent, int type) {
...
if (mGapWorker != null && (x != 0 || y != 0)) {
mGapWorker.postFromTraversal(this, x, y);
}
...
}2.执行预拉取工作
GapWorker是Runnable接口的一个实现类,意味着其执行工作的入口必然是在run方法。
final class GapWorker implements Runnable {
@Override
public void run() {
...
prefetch(nextFrameNs);
...
}
}在run方法内部我们可以看到其调用了一个prefetch方法,在进入该方法之前,我们先来分析传入该方法的参数。
// 查询最近一个垂直同步信号发出的时间,以便我们可以预测下一个
final int size = mRecyclerViews.size();
long latestFrameVsyncMs = 0;
for (int i = 0; i < size; i++) {
RecyclerView view = mRecyclerViews.get(i);
if (view.getWindowVisibility() == View.VISIBLE) {
latestFrameVsyncMs = Math.max(view.getDrawingTime(), latestFrameVsyncMs);
}
}
...
// 预测下一个垂直同步信号发出的时间
long nextFrameNs = TimeUnit.MILLISECONDS.toNanos(latestFrameVsyncMs) + mFrameIntervalNs;
prefetch(nextFrameNs);由该方法的实参命名nextFrameNs可知,传入的是下一帧开始绘制的时间。
了解过Android屏幕刷新机制的人都知道,当GPU渲染完图形数据并放入图像缓冲区(buffer)之后,显示屏(Display)会等待垂直同步信号(Vsync)发出,随即交换缓冲区并取出缓冲数据,从而开始对新的一帧的绘制。
所以,这个实参同时也表示下一个垂直同步信号(Vsync)发出的时间,这是个预测值,单位为纳秒。由最近一个垂直同步信号发出的时间(latestFrameVsyncMs),加上每一帧刷新的间隔时间(mFrameIntervalNs)计算而成。
其中,每一帧刷新的间隔时间是这样子计算得到的:
// 如果取自显示屏的刷新率数据有效,则不采用默认的60fps
// 注意:此查询我们只静态地执行一次,因为它非常昂贵(>1ms)
Display display = ViewCompat.getDisplay(this);
float refreshRate = 60.0f; // 默认的刷新率为60fps
if (!isInEditMode() && display != null) {
float displayRefreshRate = display.getRefreshRate();
if (displayRefreshRate >= 30.0f) {
refreshRate = displayRefreshRate;
}
}
mGapWorker.mFrameIntervalNs = (long) (1000000000 / refreshRate); // 1000000000纳秒=1秒也即假定在默认60fps的刷新率下,每一帧刷新的间隔时间应为16.67ms。
再由该方法的形参命名deadlineNs可知,传入的参数表示的是预抓取工作完成的最后期限:
void prefetch(long deadlineNs) {
...
}综合一下就是,预抓取的工作必须在下一个垂直同步信号发出之前,也即下一帧开始绘制之前完成。
什么意思呢?
这是由于从Android 5.0(API等级21)开始,出于提高UI渲染效率的考虑,Android系统引入了RenderThread机制,即渲染线程。这个机制负责接管原先主线程中繁重的UI渲染工作,使得主线程可以更加专注于与用户的交互,从而大幅提高页面的流畅度。
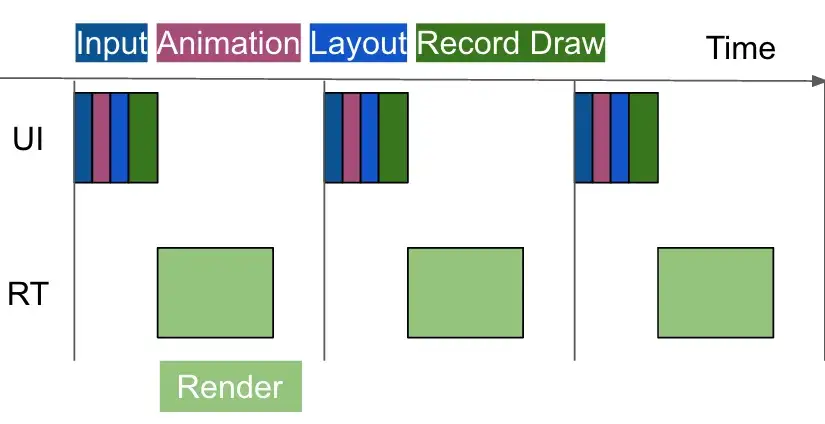
但这里有一个问题。
当UI线程提前完成工作,并将一个帧传递给RenderThread渲染之后,就会进入所谓的休眠状态,出现了大量的空闲时间,直至下一帧开始绘制之前。如图所示:
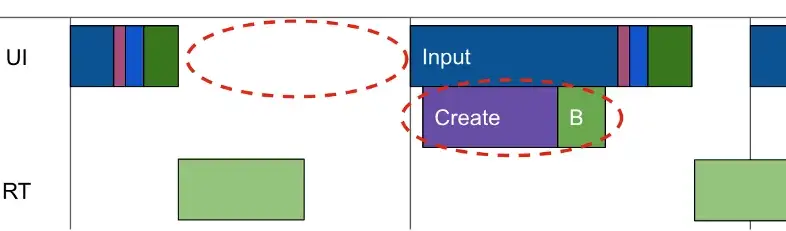
一方面,这些UI线程上的空闲时间并没有被利用起来,相当于珍贵的线程资源被白白浪费掉;
另一方面,新的列表项进入屏幕时,又需要在UI线程的输入阶段(Input)就完成视图创建与数据绑定的工作,这会推迟UI线程及RenderThread上的其他工作,如果这些被推迟的工作无法在下一帧开始绘制之前完成,就有可能造成界面上的丢帧卡顿。
GapWorker正是选择在此时间窗口内安排预拉取的工作,也即把创建和绑定的耗时操作,移到UI线程的空闲时间内完成,与原先的RenderThread并行执行。
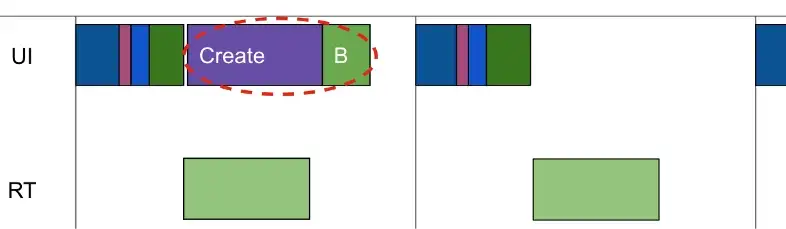
但这个预拉取的工作同样必须在下一帧开始绘制之前完成,否则预拉取的列表项视图还是会无法被及时地绘制出来,进而导致丢帧卡顿,于是才有了前面表示最后期限的传入参数。
了解完这个参数的含义后,让我们继续往下阅读源码。
2.1 构建预拉取任务列表
void prefetch(long deadlineNs) {
buildTaskList();
...
}进入prefetch方法后可以看到,预拉取的第一个动作就是先构建预拉取的任务列表,其内部又可分为以下3个事项:
2.1.1 收集预拉取的列表项数据
private void buildTaskList() {
// 1.收集预拉取的列表项数据
final int viewCount = mRecyclerViews.size();
int totalTaskCount = 0;
for (int i = 0; i < viewCount; i++) {
RecyclerView view = mRecyclerViews.get(i);
// 仅对当前可见的RecyclerView收集数据
if (view.getWindowVisibility() == View.VISIBLE) {
view.mPrefetchRegistry.collectPrefetchPositionsFromView(view, false);
totalTaskCount += view.mPrefetchRegistry.mCount;
}
}
...
} static class LayoutPrefetchRegistryImpl
implements RecyclerView.LayoutManager.LayoutPrefetchRegistry {
...
void collectPrefetchPositionsFromView(RecyclerView view, boolean nested) {
...
// 启用了预拉取机制
if (view.mAdapter != null
&& layout != null
&& layout.isItemPrefetchEnabled()) {
if (nested) {
...
} else {
// 基于移动量进行预拉取
if (!view.hasPendingAdapterUpdates()) {
layout.collectAdjacentPrefetchPositions(mPrefetchDx, mPrefetchDy,
view.mState, this);
}
}
...
}
}
}public class LinearLayoutManager extends RecyclerView.LayoutManager implements
ItemTouchHelper.ViewDropHandler, RecyclerView.SmoothScroller.ScrollVectorProvider {
public void collectAdjacentPrefetchPositions(int dx, int dy, RecyclerView.State state,
LayoutPrefetchRegistry layoutPrefetchRegistry) {
// 根据布局方向取水平方向的移动量dx或垂直方向的移动量dy
int delta = (mOrientation == HORIZONTAL) ? dx : dy;
...
ensureLayoutState();
// 根据移动量正负值判断移动方向
final int layoutDirection = delta > 0 ? LayoutState.LAYOUT_END : LayoutState.LAYOUT_START;
final int absDelta = Math.abs(delta);
// 收集与预拉取相关的重要数据,并存储到LayoutState
updateLayoutState(layoutDirection, absDelta, true, state);
collectPrefetchPositionsForLayoutState(state, mLayoutState, layoutPrefetchRegistry);
}
}这一事项主要是依据RecyclerView滚动的方向,收集即将进入屏幕的、待预拉取的列表项数据,其中,最关键的2项数据是:
- 待预拉取项的position值——用于预加载项位置的确定
- 待预拉取项与RecyclerView可见区域的距离——用于预拉取任务的优先级排序
我们以最简单的LinearLayoutManager为例,看一下这2项数据是怎样收集的,其最关键的实现就在于前面的updateLayoutState方法。
假定此时我们的手势是向上滑动的,则其进入的是layoutToEnd == true的判断:
private void updateLayoutState(int layoutDirection, int requiredSpace,
boolean canUseExistingSpace, RecyclerView.State state) {
...
if (layoutToEnd) {
...
// 步骤1,获取滚动方向上的第一个项
final View child = getChildClosestToEnd();
// 步骤2,确定待预拉取项的方向
mLayoutState.mItemDirection = mShouldReverseLayout ? LayoutState.ITEM_DIRECTION_HEAD
: LayoutState.ITEM_DIRECTION_TAIL;
// 步骤3,确认待预拉取项的position
mLayoutState.mCurrentPosition = getPosition(child) + mLayoutState.mItemDirection;
mLayoutState.mOffset = mOrientationHelper.getDecoratedEnd(child);
// 步骤4,确认待预拉取项与RecyclerView可见区域的距离
scrollingOffset = mOrientationHelper.getDecoratedEnd(child)
- mOrientationHelper.getEndAfterPadding();
} else {
...
}
...
mLayoutState.mScrollingOffset = scrollingOffset;
}步骤1,获取RecyclerView滚动方向上的第一项,如图中①所示:
步骤2,确定待预拉取项的方向。不用反转布局的情况下是ITEM_DIRECTION_TAIL,该值等于1,如图中②所示:
步骤3,确认待预拉取项的position值。由滚动方向上的第一项的position值加上步骤2确定的方向值相加得到,对应的是RecyclerView待进入屏幕区域的下一个项,如图中③所示:
步骤4,确认待预拉取项与RecyclerView可见区域的距离,该值由以下2个值相减得到:
getEndAfterPadding:指的是RecyclerView去除了Padding后的底部位置,并不完全等于RecyclerView的高度。getDecoratedEnd:指的是由列表项的底部位置,加上列表项设立的外边距,再加上列表项间隔的高度计算得到的值。
我们用一张图来说明一下:
首先,图中的①表示一个完整的屏幕可见区域,其中:
- 深灰色区域对应的是RecyclerView设立的上下内边距,即Padding值。
- 中灰色区域对应的是RecyclerView的列表项分隔线,即Decoration。
- 浅灰色区域对应的是每一个列表项设立的外边距,即Margin值。
RecyclerView的实际可见区域,是由虚线a和虚线b所包围的区域,即去除了上下内边距之后的区域。getEndAfterPadding方法返回的值,即是虚线b所在的位置。
图中的②是对RecyclerView底部不可见区域的透视图,假定现在position=2的列表项的底部正好贴合到RecyclerView可见区域的底部,则getDecoratedEnd方法返回的值,即是虚线c所在的位置。
接下来,如果按前面的步骤4进行计算,即用虚线c所在的位置减去的虚线b所在的位置,得到的就是图中的③,即刚好是列表项的外边距加上分隔线的高度。
这个结果就是待预拉取列表项与RecyclerView可见区域的距离。随着向上滑动的手势这个距离值逐渐变小,直到正好进入RecyclerView的可见区域时变为0,随后开始预加载下一项。
这2项数据收集到之后,就会调用GapWorker的addPosition方法,以交错的形式存放到一个int数组类型的mPrefetchArray结构中去:
@Override
public void addPosition(int layoutPosition, int pixelDistance) {
...
// 根据实际需要分配新的数组,或以2的倍数扩展数组大小
final int storagePosition = mCount * 2;
if (mPrefetchArray == null) {
mPrefetchArray = new int[4];
Arrays.fill(mPrefetchArray, -1);
} else if (storagePosition >= mPrefetchArray.length) {
final int[] oldArray = mPrefetchArray;
mPrefetchArray = new int[storagePosition * 2];
System.arraycopy(oldArray, 0, mPrefetchArray, 0, oldArray.length);
}
// 交错存放position值与距离
mPrefetchArray[storagePosition] = layoutPosition;
mPrefetchArray[storagePosition + 1] = pixelDistance;
mCount++;
}需要注意的是,RecyclerView每次的预拉取并不限于单个列表项,实际上,它可以一次获取多个列表项,比如使用了GridLayoutManager的情况。
2.1.2 根据预拉取的数据填充任务列表
private void buildTaskList() {
...
// 2.根据预拉取的数据填充任务列表
int totalTaskIndex = 0;
for (int i = 0; i < viewCount; i++) {
RecyclerView view = mRecyclerViews.get(i);
...
LayoutPrefetchRegistryImpl prefetchRegistry = view.mPrefetchRegistry;
final int viewVelocity = Math.abs(prefetchRegistry.mPrefetchDx)
+ Math.abs(prefetchRegistry.mPrefetchDy);
// 以2为偏移量进行遍历,从mPrefetchArray中分别取出前面存储的position值与距离
for (int j = 0; j < prefetchRegistry.mCount * 2; j += 2) {
final Task task;
if (totalTaskIndex >= mTasks.size()) {
task = new Task();
mTasks.add(task);
} else {
task = mTasks.get(totalTaskIndex);
}
final int distanceToItem = prefetchRegistry.mPrefetchArray[j + 1];
// 与RecyclerView可见区域的距离小于滑动的速度,该列表项必定可见,任务需要立即执行
task.immediate = distanceToItem <= viewVelocity;
task.viewVelocity = viewVelocity;
task.distanceToItem = distanceToItem;
task.view = view;
task.position = prefetchRegistry.mPrefetchArray[j];
totalTaskIndex++;
}
}
...
}Task是负责存储预拉取任务数据的实体类,其所包含属性的含义分别是:
position:待预加载项的Position值distanceToItem:待预加载项与RecyclerView可见区域的距离viewVelocity:RecyclerView的滑动速度,其实就是滑动距离immediate:是否立即执行,判断依据是与RecyclerView可见区域的距离小于滑动的速度view:RecyclerView本身
从第2个for循环可以看到,其是以2为偏移量进行遍历,从mPrefetchArray中分别取出前面存储的position值与距离的。
2.1.3 对任务列表进行优先级排序
填充任务列表完毕后,还要依据实际情况对任务进行优先级排序,其遵循的基本原则就是:越可能快进入RecyclerView可见区域的列表项,其预加载的优先级越高。
private void buildTaskList() {
...
// 3.对任务列表进行优先级排序
Collections.sort(mTasks, sTaskComparator);
} static Comparator sTaskComparator = new Comparator() {
@Override
public int compare(Task lhs, Task rhs) {
// 首先,优先处理未清除的任务
if ((lhs.view == null) != (rhs.view == null)) {
return lhs.view == null ? 1 : -1;
}
// 然后考虑需要立即执行的任务
if (lhs.immediate != rhs.immediate) {
return lhs.immediate ? -1 : 1;
}
// 然后考虑滑动速度更快的
int deltaViewVelocity = rhs.viewVelocity - lhs.viewVelocity;
if (deltaViewVelocity != 0) return deltaViewVelocity;
// 最后考虑与RecyclerView可见区域距离最短的
int deltaDistanceToItem = lhs.distanceToItem - rhs.distanceToItem;
if (deltaDistanceToItem != 0) return deltaDistanceToItem;
return 0;
}
};
2.2 调度预拉取任务
void prefetch(long deadlineNs) {
...
flushTasksWithDeadline(deadlineNs);
}预拉取的第二个动作,则是将前面填充并排序好的任务列表依次调度执行:
private void flushTasksWithDeadline(long deadlineNs) {
for (int i = 0; i < mTasks.size(); i++) {
final Task task = mTasks.get(i);
if (task.view == null) {
break; // 任务已完成
}
flushTaskWithDeadline(task, deadlineNs);
task.clear();
}
} private void flushTaskWithDeadline(Task task, long deadlineNs) {
long taskDeadlineNs = task.immediate ? RecyclerView.FOREVER_NS : deadlineNs;
RecyclerView.ViewHolder holder = prefetchPositionWithDeadline(task.view,
task.position, taskDeadlineNs);
...
}2.2.1 尝试根据position获取ViewHolder对象
进入prefetchPositionWithDeadline方法后,我们终于再次见到了上一篇的老朋友——Recycler,以及熟悉的成员方法tryGetViewHolderForPositionByDeadline:
private RecyclerView.ViewHolder prefetchPositionWithDeadline(RecyclerView view,
int position, long deadlineNs) {
...
RecyclerView.Recycler recycler = view.mRecycler;
RecyclerView.ViewHolder holder;
try {
...
holder = recycler.tryGetViewHolderForPositionByDeadline(
position, false, deadlineNs);
...
}
这个方法我们在上一篇文章有介绍过,作用是尝试根据position获取指定的ViewHolder对象,如果从缓存中查找不到,就会重新创建并绑定。
2.2.2 根据绑定成功与否添加到mCacheViews或RecyclerViewPool
private RecyclerView.ViewHolder prefetchPositionWithDeadline(RecyclerView view,
int position, long deadlineNs) {
...
if (holder != null) {
if (holder.isBound() && !holder.isInvalid()) {
// 如果绑定成功,则将该视图进入缓存
recycler.recycleView(holder.itemView);
} else {
//没有绑定,所以我们不能缓存视图,但它会保留在池中直到下一次预取/遍历。
recycler.addViewHolderToRecycledViewPool(holder, false);
}
}
...
return holder;
}接下来,如果顺利地获取到了ViewHolder对象,且该ViewHolder对象已经完成数据的绑定,则下一步就该立即回收该ViewHolder对象,缓存到mCacheViews结构中以供重用。
而如果该ViewHolder对象还未完成数据的绑定,意味着我们没能在设定的最后期限之前完成预拉取的操作,列表项数据不完整,因而我们不能将其缓存到mCacheViews结构中,但它会保留在mRecyclerViewPool结构中,以供下一次预拉取或重用。
预拉取机制与缓存复用机制的怎么协作的?
既然是与缓存复用机制共用相同的缓存结构,那么势必会对缓存复用机制的流程产生一定的影响,同样,让我们用几张流程示意图来演示一下:
假定现在position=5的列表项的底部正好贴合到RecyclerView可见区域的底部,即还要滑动超过该列表项的外边距+分隔线高度的距离,下一个列表项才可见。
随着向上拖动的手势,GapWorker开始发起预加载的工作,根据前面梳理的流程,它会提前创建并绑定position=6的列表项的ViewHolder对象,并将其缓存到mCacheViews结构中去。
- 继续保持向上拖动,当position=6的列表项即将进入屏幕时,它会按照上一篇缓存复用机制的流程,从mCacheViews结构取出可复用的ViewHolder对象,无需再次经历创建和绑定的过程,因此滑动的流畅度有了提升。
- 同时,随着position=6的列表项进入屏幕,GapWorker也开始了对position=7的列表项的预加载
- 之后,随着拖动距离的增大,position=0的列表项也将被移出屏幕,添加到mCachedViews结构中去。
上一篇文章我们讲过,mCachedViews结构的默认大小限制为2,从这里就可以看出,其这样设计是想刚好能缓存一个被移出屏幕的可复用ViewHolder对象+一个待进入屏幕的预拉取ViewHolder对象的。
不知道你们注意到没有,在步骤5的示意图中,可复用ViewHolder对象是添加到预拉取ViewHolder对象前面的,之所以这样子画是遵循了源码中的实现:
// 添加之前,先移除最老的一个ViewHolder对象
int cachedViewSize = mCachedViews.size();
if (cachedViewSize >= mViewCacheMax && cachedViewSize > 0) { // 当前已经放满
recycleCachedViewAt(0); // 移除mCachedView结构中的第1个
cachedViewSize--; // 总数减1
}
// 默认从尾部添加
int targetCacheIndex = cachedViewSize;
// 处理预拉取的情况
if (ALLOW_THREAD_GAP_WORK
&& cachedViewSize > 0
&& !mPrefetchRegistry.lastPrefetchIncludedPosition(holder.mPosition)) {
// 从最后一个开始,跳过所有最近预拉取的对象排在其前面
int cacheIndex = cachedViewSize - 1;
while (cacheIndex >= 0) {
int cachedPos = mCachedViews.get(cacheIndex).mPosition;
// 添加到最近一个非预拉取的对象后面
if (!mPrefetchRegistry.lastPrefetchIncludedPosition(cachedPos)) {
break;
}
cacheIndex--;
}
targetCacheIndex = cacheIndex + 1;
}
mCachedViews.add(targetCacheIndex, holder);也就是说,虽然缓存复用的对象和预拉取的对象共用同一个mCachedViews结构,但二者是分组存放的,且缓存复用的对象是排在预拉取的对象前面的。这么说或许还是很难理解,我们用几张示意图来演示一下就懂了:
1.假定现在mCachedViews中同时有2种类型的ViewHolder对象,黑色的代表缓存复用的对象,白色的代表预拉取的对象;
2.现在,有另外一个缓存复用的对象想要放到mCachedViews中,按源码的做法,默认会从尾部添加,即targetCacheIndex = 3:
3.随后,需要进一步确认放入的位置,它会从尾部开始逐个遍历,判断是否是预拉取的ViewHolder对象,判断的依据是该ViewHolder对象的position值是否存在mPrefetchArray结构中:
boolean lastPrefetchIncludedPosition(int position) {
if (mPrefetchArray != null) {
final int count = mCount * 2;
for (int i = 0; i < count; i += 2) {
if (mPrefetchArray[i] == position) return true;
}
}
return false;
}
4.如果是,则跳过这一项继续遍历,直到找到最近一个非预拉取的对象,将该对象的索引+1,即targetCacheIndex = cacheIndex + 1,得到确认放入的位置。
5.虽然二者是分组存放的,但二者内部仍是有序的,即按照加入的顺序正序排列。
开启预拉取机制后的实际效果如何?
最后,我们还剩下一个问题,即预拉取机制启用之后,对于RecyclerView的滑动展示究竟能有多大的性能提升?
关于这个问题,已经有人做过相关的测试验证,这里就不再大量贴图了,只概括一下其方案的整体思路:
- 测量工具:开发者模式-GPU渲染模式
- 该工具以滚动显示的直方图形式,直观地呈现渲染出界面窗口帧所需花费的时间
- 水平轴上的每个竖条即代表一个帧,其高度则表示渲染该帧所花的时间。
- 绿线表示的是16.67毫秒的基准线。若想维持每秒60帧的正常绘制,则需保证代表每个帧的竖条维持在此线以下。
- 耗时模拟:在onBindViewHolder方法中,使用Thread.sleep(time)来模拟页面渲染的复杂度。复杂度的大小,通过time时间的长短来体现。时间越长,复杂度越高。
- 测试结果:对比同一复杂度下的RecyclerView滑动,未启用预拉取机制的一侧流畅度明显更低,并且随着复杂度的增加,在16ms内无法完成渲染的帧数进一步增多,延时更长,滑动卡顿更明显。
最后总结一下:
| 预加载机制 | |
|---|---|
| 概念 | 利用UI线程正好处于空闲状态的时机,预先拉取一部分列表项视图并缓存起来,从而减少因视图创建或数据绑定等耗时操作所引起的卡顿。 |
| 重要类 | GapWorker:综合滑动方向、滑动速度、与可见区域的距离等要素,构建并调度预拉取任务列表。 |
| Recycler:获取ViewHolder对象,如果缓存中找不到,则重新创建并绑定 | |
| 结构 | mCachedViews:顺利获取到了ViewHolder对象,且已完成数据的绑定时放入 |
| mRecyclerPool:顺利获取到了ViewHolder对象,但还未完成数据的绑定时放入 | |
| 发起时机 | 被拖动(Drag)、惯性滑动(Fling)、嵌套滚动时 |
| 完成期限 | 下一个垂直同步信号发出之前 |
链接:https://juejin.cn/post/7181979065488769083
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android URL Scheme数据还原流程与踩坑分享
前言
最近在搞URL Scheme数据还原相关代码的重构工作,借此梳理一下整体的流程。并且在重构过程中呢,还遇到了一个天坑,拿出来与大家分享一下。如果大家有更好的方案,欢迎评论或私信我让我学习一下~
前置知识点
首先我们对齐一下所需要的前置知识点,避免后面造成理解上的冲突。
URL Scheme
URL Scheme指的是遵守以下格式的URL:
{scheme://action?param1=value1¶m2=value2...}
APP识别到URL Scheme数据后,会根据action去执行相应的逻辑。
scheme通常由业务定义好,一般以app层级划分或业务域层级划分,比如"taobao://"、"douyin://",或者"tbSearch://"、"douyinSearch://"。action指的是行为,比如"user/detail"是打开个人详情页面,"item/detail"是打开商品详情页面等。再由后面的参数决定具体的页面数据。举个例子:
{wodeApp://user/detail?userId=123}
wodeApp识别到这个Url Scheme以wodeApp开头,就知道是它需要的数据,进而解析数据,打开userId为123的用户页面。
URL Scheme来源
Scheme数据的来源可以有很多,最常见的就是剪贴板、H5页面唤端、消息通知唤端、短信通知唤端等。因为后面的内容会涉及到数据来源,场景又比较复杂可能会比较混乱,所以这里我们先理清一下。
我们把所有的唤端(包括H5页面唤端、消息通知唤端、短信通知唤端)统一一下,都称为Intent唤端,因为他们最终给到App的数据都是放在Intent中的,所以后面讲到唤端就不再一一区分了。
那么我们现在能拿到URL Scheme的场景就分为四种:
- 冷启动时从剪贴板获取
- 热启动时从剪贴板获取
- 冷启动时从唤端Intent中获取
- 热启动时从唤端Intent中获取
为什么要分冷热启动呢?因为冷热启动,URL Scheme获取的方式是不一样的,具体后面会说到。
数据还原
数据还原,在产品上是非常重要的。最基本的一种数据还原,就是跳转目标页面。比如用户被消息推送了某个商品,点击进来后根据解析得到的Scheme数据我们需要跳转到指定的商品详情页面。另外,我们可能还需要根据解析的Scheme数据向服务端发起某个请求,比如从平价商品页面唤端来的用户我们需要打上用户标签。
所有的根据action指定的业务逻辑,我们都称之为数据还原。
产品的迭代历程
上面也讲到了,我是因为重构才有机会写这篇文章的。那为什么要重构呢?自然是代码hold不住产品的迭代速度了,这就要从产品的需求讲起。(当然,需求的迭代只是重构的原因之一,更主要的原因是之前的代码没封装,写的很乱,职责不清晰,所以才把重构提上日程的..)
有一天,PD找上门来
PD:咱们做个简单的唤端哈,从消息通知进来,或者从H5页面唤端进来,我们能打开相应的页面就行。另外,如果剪贴板里有这样的数据,也要能达到一样的效果。
程序员A:没问题,这项技术已经很成熟了,马上给你搞出来
最终这个需求的实现,也基本上不存在什么问题。唤端的Intent数据从闪屏页拿到后,传递到首页,首页再根据数据执行相应的Action。另外在首页onResume生命周期中获取剪贴板数据,如果符合Scheme数据协议,也去做相应的Action。
过了一个月,PD又找上门来
PD:咱们唤端需要再做一个通用能力哈。如果唤端数据带了某个api的某个参数,需要在下次请求这个api的时候把这个参数给带上,从而满足服务端数据的定制化能力。当然了,还是跟上次一样,如果剪贴板里有这样的数据,也要能达到一样的效果。
程序员A:为啥要这样搞啊?有啥用?
PD:你想啊,比如首页的推荐流理论上对每个人都是不一样的。那如何实现更精准地推送呢?唤端就是一个手段。每个唤端页面唤端的时候,都带上用户相关的数据,然后把这份数据作为接口参数传给服务端,不就可以实现定向推送了嘛。
程序员A:你很有想法,但是我得想一想...
糟了,之前的剪贴板相关的代码要重写了。为什么呢?因为之前是在首页onResume生命周期中获取剪贴板数据,如果剪贴板数据符合Scheme数据协议,就去做相应的Action。但这个新的需求,又必须保证得在首页请求发出去之前,就要拿到剪贴板数据并预埋好接口参数,否则就不会起作用了。比如用户冷启App时,如果不在闪屏页预先拿到剪贴板数据并预埋上首页的接口参数的话,到首页做这个逻辑就没法保证是在首页接口请求前完成参数的预埋了。
那这个逻辑是要放在闪屏页么?也不对,因为在热启App时,是不会经过闪屏页的,但热启时也要有这样的能力,这就要我们必须把解析剪贴板的这段逻辑放在BaseActivity中去。
下面就来分享一下URL Scheme数据还原改善后的流程。
数据还原流程
剪贴板
冷启:闪屏页onWindowFocusChanged获取剪贴板数据->解析scheme数据(执行预埋接口参数等Action)->跳转首页->首页跳转至目标页面->清空剪贴板
热启:BaseActivity#onWindowFocusChanged获取剪贴板数据->解析(执行预埋接口参数等Action)->跳转目标页面->清空剪贴板
因为某些原因,我们的项目中闪屏页没有继承BaseActivity,所以这里分开了两个部分。如果大家都是统一继承BaseActivity的,那么这部分解析scheme的逻辑是可以合二为一的。
唤端
冷启:闪屏页onCreate获取唤端Intent->解析scheme数据(执行预埋接口参数等Action)->跳转首页->首页跳转至目标页面->清空剪贴板
热启:闪屏页onCreate获取唤端Intent->解析scheme数据(执行预埋接口参数等Action)->跳转目标页面->清空剪贴板
总结
- 唤端的逻辑全部在闪屏页的onCreate生命周期做。只有在冷启唤端时需要先跳转至首页,首页再跳转至模板页面。
- 剪贴板的逻辑,冷启时在闪屏页做剪贴板的获取与解析,热启时在页面基类做剪贴板的获取与解析,解析完数据后统一在页面基类进行目标页面的跳转。之所以放在页面基类而不是首页,是因为热启回APP后可能处于任意一个页面,所以这段逻辑只能放到基类里面去处理。
另外需要注意的一点是,闪屏页的LaunchMode需要设置为singleTask,否则唤端启动时新创建的闪屏页会到浏览器的栈去,不符合业务需求。
踩坑分享
在这个过程中,我也踩了一个大坑..没想到Android对剪贴板的获取有这样的限制。细心的同学可能已经发现了,在重构前我们是在首页的onResume生命周期去获取剪贴板的,去网上一搜获取剪贴板数据,大部分的回答都是这样:
override fun onResume() {
window.decorView.post{
val content = ClipboardService.getInstance().clipboardContent
}
}那为什么在方案设计中,却是在onWindowFocusChanged回调中才去获取剪贴板数据呢?因为上面的代码,在部分场景(尤其是闪屏页),是没法保证能拿到剪贴板数据的。
原因
Android获取剪贴板存在限制,必须在当前Activity获得焦点的情况下才能成功获取到。
闪屏页的生命周期:onCreate->onResume->跳转页面->onPause
闪屏页获取焦点时的回调:onWindowFocusChanged(boolean hasFocus);当回调中hasFocus收到true时,表面当前Activity窗口获取到了焦点。
经试验,当闪屏页跳转页面过快,部分机型(如Redmi k40 pro)onWindowFocusChanged会回调false,收不到true,即一直没有获得过焦点,那么这种情况下就无法获取剪贴板数据(拿到是空字符串)。所以获取剪贴板数据的时机,不能太早,也不能太晚。不能在onCreate中去获取剪贴板数据,也不能等到发生跳转了再去拿。
其次,因为onWindowFocusChanged回调时机必在onResume之后,所以即使我们在onResume中post去拿剪贴板,我们也没法保证post的Runnable执行的时机是正正好的。有可能Runnable执行时,闪屏页已经发生跳转了。也有可能Runnable执行时,闪屏页还未获取到焦点。
所以呢,我们应该把获取剪贴板数据的时机放到onWindowFocusChanged中去,而闪屏页冷启跳转首页的逻辑,也要放到onWindowFocusChanged之后,保证闪屏页已经获取到焦点了,且成功获取到剪贴板数据了。
总结
通过这篇文章,我们知道了URL Scheme数据还原的整体流程。如果大家实际业务中没有类似“根据唤端数据,预埋首页接口参数”这样的需求,其实可以比较简单地就实现了。另外,分享了一下Android上获取剪贴板数据所存在的限制,以及在实际业务中遇到的坑该怎么解决。
文章不足之处,还望大家多多海涵,多多指点,先行谢过!
链接:https://juejin.cn/post/7177315439532310584
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android代码静态检查(lint、Checkstyle、ktlint、Detekt)
Android代码静态检查(lint、Checkstyle、ktlint、Detekt)
在Android项目开发过程中,开发团队往往要花费大量的时间和精力发现并修改代码缺陷。
静态代码分析工具能够在代码构建过程中帮助开发人员快速、有效的定位代码缺陷并及时纠正这些问题,从而极大地提高软件可靠性
节省软件开发和测试成本。
Android目前主要使用的语言为kotlin、java,所以我们需要尽可能支持这两种语言。
Lint
Android Studio 提供的代码扫描工具。通过进行 lint 检查来改进代码
能检测什么?是否包含潜在错误,以及在正确性、安全性、性能、易用性、便利性和国际化方面是否需要优化改进,帮助我们发现代码结/质量问题,同时提供一些解决方案。每个问题都有信息描述和等级。
支持【300+】检测规则,支持Manifest文件、XML、Java、Kotlin、Java字节码、Gradle文件、Proguard文件、Propetty文件和图片资源;
基于抽象语法树分析,经历了LOMBOK-AST、PSI、UAST三种语法分析器;
主要包括以下几个方面
Correctness:不够完美的编码,比如硬编码、使用过时 API 等;Performance:对性能有影响的编码,比如:静态引用,循环引用等;Internationalization:国际化,直接使用汉字,没有使用资源引用等;Security:不安全的编码,比如在WebView中允许使用JavaScriptInterface等
在module下的build.gradle中添加以下代码:
android {
lintOptions {
// true--关闭lint报告的分析进度
quiet true
// true--错误发生后停止gradle构建
abortOnError false
// true--只报告error
ignoreWarnings true
// true--忽略有错误的文件的全/绝对路径(默认是true)
//absolutePaths true
// true--检查所有问题点,包含其他默认关闭项
checkAllWarnings true
// true--所有warning当做error
warningsAsErrors true
// 关闭指定问题检查
disable 'TypographyFractions','TypographyQuotes'
// 打开指定问题检查
enable 'RtlHardcoded','RtlCompat', 'RtlEnabled'
// 仅检查指定问题
check 'NewApi', 'InlinedApi'
// true--error输出文件不包含源码行号
noLines true
// true--显示错误的所有发生位置,不截取
showAll true
// 回退lint设置(默认规则)
lintConfig file("default-lint.xml")
// true--生成txt格式报告(默认false)
textReport true
// 重定向输出;可以是文件或'stdout'
textOutput 'stdout'
// true--生成XML格式报告
xmlReport false
// 指定xml报告文档(默认lint-results.xml)
//xmlOutput file("lint-report.xml")
// true--生成HTML报告(带问题解释,源码位置,等)
htmlReport true
// html报告可选路径(构建器默认是lint-results.html )
//htmlOutput file("lint-report.html")
// true--所有正式版构建执行规则生成崩溃的lint检查,如果有崩溃问题将停止构建
checkReleaseBuilds true
// 在发布版本编译时检查(即使不包含lint目标),指定问题的规则生成崩溃
fatal 'NewApi', 'InlineApi'
// 指定问题的规则生成错误
error 'Wakelock', 'TextViewEdits'
// 指定问题的规则生成警告
warning 'ResourceAsColor'
// 忽略指定问题的规则(同关闭检查)
ignore 'TypographyQuotes'
}
}运行./gradlew lint,检测结果在build/reports/lint/lint.html可查看详情。
CheckStyle
Java静态代码检测工具,主要用于代码的编码规范检测 。
CheckStyle是Gralde自带的Plugin,The Checkstyle Plugin
通过分析源码,与已知的编码约定进行对比,以html或者xml的形式将结果展示出来。
其原理是使用Antlr库对源码文件做词语发分析生成抽象语法树,遍历整个语法树匹配检测规则。
目前不支持用户自定义检测规则,已有的【100+】规则中,有一部分规则是有属性的支持设置自定义参数。
在module下的build.gradle中添加以下代码:
/**
* The Checkstyle Plugin
*
* Gradle plugin that performs quality checks on your project's Java source files using Checkstyle
* and generates reports from these checks.
*
* Tasks:
* Run Checkstyle against {rootDir}/src/main/java: ./gradlew checkstyleMain
* Run Checkstyle against {rootDir}/src/test/java: ./gradlew checkstyleTest
*
* Reports:
* Checkstyle reports can be found in {project.buildDir}/build/reports/checkstyle
*
* Configuration:
* Checkstyle is very configurable. The configuration file is located at {rootDir}/config/checkstyle/checkstyle.xml
*
* Additional Documentation:
* https://docs.gradle.org/current/userguide/checkstyle_plugin.html
*/
apply plugin: 'checkstyle'
checkstyle {
//configFile = rootProject.file('checkstyle.xml')
configProperties.checkstyleSuppressionsPath = rootProject.file("suppressions.xml").absolutePath
// The source sets to be analyzed as part of the check and build tasks.
// Use 'sourceSets = []' to remove Checkstyle from the check and build tasks.
//sourceSets = [project.sourceSets.main, project.sourceSets.test]
// The version of the code quality tool to be used.
// The most recent version of Checkstyle can be found at https://github.com/checkstyle/checkstyle/releases
//toolVersion = "8.22"
// Whether or not to allow the build to continue if there are warnings.
ignoreFailures = true
// Whether or not rule violations are to be displayed on the console.
showViolations = true
}
task projectCheckStyle(type: Checkstyle) {
group 'verification'
classpath = files()
source 'src'
//include '**/*.java'
//exclude '**/gen/**'
reports {
html {
enabled = true
destination file("${project.buildDir}/reports/checkstyle/checkstyle.html")
}
xml {
enabled = true
destination file("${project.buildDir}/reports/checkstyle/checkstyle.xml")
}
}
}
tasks.withType(Checkstyle).each { checkstyleTask ->
checkstyleTask.doLast {
reports.all { report ->
// 检查生成报告中是否有错误
def outputFile = report.destination
if (outputFile.exists() && outputFile.text.contains("<error ") && !checkstyleTask.ignoreFailures) {
throw new GradleException("There were checkstyle errors! For more info check $outputFile")
}
}
}
}
// preBuild的时候,执行projectCheckStyle任务
//project.preBuild.dependsOn projectCheckStyle
project.afterEvaluate {
if (tasks.findByName("preBuild") != null) {
project.preBuild.dependsOn projectCheckStyle
println("project.preBuild.dependsOn projectCheckStyle")
}
}默认情况下,Checkstyle插件希望将配置文件放在根项目中,但这可以更改。
<root>
└── config
└── checkstyle
└── checkstyle.xml //Checkstyle 配置
└── suppressions.xml //主Checkstyle配置文件执行preBuild就会执行checkstyle并得到结果。
支持Kotlin
怎么实现Kotlin的代码检查校验呢?我找到两个富有意义的方法。
1. Detekt — https://github.com/arturbosch/detekt 2. ktlint — https://github.com/shyiko/ktlint
KtLint
添加插件依赖
buildscript {
dependencies {
classpath "org.jlleitschuh.gradle:ktlint-gradle:11.0.0"
}
}引入插件,完善相关配置:
apply plugin: "org.jlleitschuh.gradle.ktlint"
ktlint {
android = true
verbose = true
outputToConsole = true
outputColorName = "RED"
enableExperimentalRules = true
ignoreFailures = true
//["final-newline", "max-line-length"]
disabledRules = []
reporters {
reporter "plain"
reporter "checkstyle"
reporter "sarif"
reporter "html"
reporter "json"
}
}
project.afterEvaluate {
if (tasks.findByName("preBuild") != null) {
project.preBuild.dependsOn tasks.findByName("ktlintCheck")
println("project.preBuild.dependsOn tasks.findByName(\"ktlintCheck\")")
}
}运行prebuild,检测结果在build/reports/ktlint/ktlintMainSourceSetCheck/ktlintMainSourceSetCheck.html可查看详情。
Detekt
添加插件依赖
buildscript {
dependencies {
classpath "io.gitlab.arturbosch.detekt:detekt-gradle-plugin:1.22.0"
}
}引入插件,完善相关配置(PS:可以在yml文件配置相关的规则):
apply plugin: 'io.gitlab.arturbosch.detekt'
detekt {
// Version of Detekt that will be used. When unspecified the latest detekt
// version found will be used. Override to stay on the same version.
toolVersion = "1.22.0"
// The directories where detekt looks for source files.
// Defaults to `files("src/main/java", "src/test/java", "src/main/kotlin", "src/test/kotlin")`.
source = files(
"src/main/kotlin",
"src/main/java"
)
// Builds the AST in parallel. Rules are always executed in parallel.
// Can lead to speedups in larger projects. `false` by default.
parallel = false
// Define the detekt configuration(s) you want to use.
// Defaults to the default detekt configuration.
config = files("$rootDir/config/detekt/detekt-ruleset.yml")
// Applies the config files on top of detekt's default config file. `false` by default.
buildUponDefaultConfig = false
// Turns on all the rules. `false` by default.
allRules = false
// Specifying a baseline file. All findings stored in this file in subsequent runs of detekt.
//baseline = file("path/to/baseline.xml")
// Disables all default detekt rulesets and will only run detekt with custom rules
// defined in plugins passed in with `detektPlugins` configuration. `false` by default.
disableDefaultRuleSets = false
// Adds debug output during task execution. `false` by default.
debug = false
// If set to `true` the build does not fail when the
// maxIssues count was reached. Defaults to `false`.
ignoreFailures = true
// Android: Don't create tasks for the specified build types (e.g. "release")
//ignoredBuildTypes = ["release"]
// Android: Don't create tasks for the specified build flavor (e.g. "production")
//ignoredFlavors = ["production"]
// Android: Don't create tasks for the specified build variants (e.g. "productionRelease")
//ignoredVariants = ["productionRelease"]
// Specify the base path for file paths in the formatted reports.
// If not set, all file paths reported will be absolute file path.
//basePath = projectDir
}
tasks.named("detekt").configure {
reports {
// Enable/Disable XML report (default: true)
xml.required.set(true)
xml.outputLocation.set(file("build/reports/detekt/detekt.xml"))
// Enable/Disable HTML report (default: true)
html.required.set(true)
html.outputLocation.set(file("build/reports/detekt/detekt.html"))
// Enable/Disable TXT report (default: true)
txt.required.set(true)
txt.outputLocation.set(file("build/reports/detekt/detekt.txt"))
// Enable/Disable SARIF report (default: false)
sarif.required.set(true)
sarif.outputLocation.set(file("build/reports/detekt/detekt.sarif"))
// Enable/Disable MD report (default: false)
md.required.set(true)
md.outputLocation.set(file("build/reports/detekt/detekt.md"))
custom {
// The simple class name of your custom report.
reportId = "CustomJsonReport"
outputLocation.set(file("build/reports/detekt/detekt.json"))
}
}
}
project.afterEvaluate {
if (tasks.findByName("preBuild") != null) {
project.preBuild.dependsOn tasks.findByName("detekt")
println("project.preBuild.dependsOn tasks.findByName(\"detekt\")")
}
}运行prebuild,检测结果在build/reports/detekt/detekt.html可查看详情。
总结
CheckStyle不支持kotlin,Ktlin和Detekt两者对比Ktlint它的规则不可定制,Detekt 工作得很好并且可以定制,尽管插件集成看起来很新。虽然输出的格式都支持html,但显然Detekt输出的结果的阅读体验更好一些。
以上相关的插件因为都支持命令行运行,所以都可以结合Git 钩子,它用于检查即将提交的快照,例如,检查是否有所遗漏,确保测试运行,以及核查代码。
不同团队的代码的风格不尽相同,不同的项目对于代码的规范也不一样。目前项目开发中有很多同学几乎没有用过代码检测工具,但是对于一些重要的项目中代码中存在的缺陷、性能问题、隐藏bug都是零容忍的,所以说静态代码检测工具尤为重要。
链接:https://juejin.cn/post/7181424552583364645
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 实现手写签名效果
如何使用Flutter实现手写签名的效果
思路
- 需要监听用户触摸的起始点和结束点,并记录途经点,这里我使用了
StreamController - 将途经点从起始位置到结束位置绘制出来,这里用到
CustomPainter
绘制流程
- 获取触摸点作为画笔的起始点
- 手机途经点
- 绘制途径路线
- 结束触摸点重置画笔
具体实现
需要一个Listener用来监听用户行为,并将这些行为的点添加到StreamController中,
两个变量
final List _points = []; //承载对应的点
final StreamController _controller = StreamController(); //数据通信
Widget _buildWriteWidget() {
return Stack(
children: [
Listener( //用来监听用户的触摸行为
child: Container(
color: Colors.transparent,
),
onPointerDown: (PointerDownEvent event) {
_points.add(event.localPosition);
_controller.sink.add([_points]); //起始点的记录
},
onPointerMove: (PointerMoveEvent event) {
_points.add(event.localPosition);
_controller.sink.add([_points]); //添加途经点
},
onPointerUp: (PointerUpEvent event) {
_points.add(Offset.zero); //结束的标记
},
),
StreamBuilder(
stream: _controller.stream,
builder: (BuildContext context, AsyncSnapshot snapshot) {
return snapshot.hasData
? CustomPaint(painter: LinePainter(snapshot.data)) //关联数据到Painter
: const SizedBox();
}),
Positioned(
bottom: 50,
right: 50,
child: FloatingActionButton(
onPressed: () {
_clear();
},
child: const Icon(Icons.cleaning_services),
))
],
);
}清除StreamController的内容,重置数据
void _clear() {
_points.clear();
_controller.add(null);
}dispose时释放StreamController
@override
void dispose() {
_controller.close();
super.dispose();
}画笔Painter
class LinePainter extends CustomPainter {
final List<List<Offset>> lines;
final Color paintColor = Colors.black;
final Paint _paint = Paint();
LinePainter(this.lines);
@override
void paint(Canvas canvas, Size size) {
_paint.strokeCap = StrokeCap.round;
_paint.strokeWidth = 5.0;
if (lines.isEmpty) {
canvas.drawPoints(PointMode.polygon, [Offset.zero, Offset.zero], _paint);
} else {
for (int i = 0; i < lines.length; i++) {
for (int j = 0; j < lines[i].length - 1; j++) {
if (lines[i][j] != Offset.zero && lines[i][j + 1] != Offset.zero) {
canvas.drawLine(lines[i][j], lines[i][j + 1], _paint); //绘制相应的点
}
}
}
}
}
@override
bool shouldRepaint(covariant CustomPainter oldDelegate) => true;
}链接:https://juejin.cn/post/7180186082489663547
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RxJava观察者模式
1.RxJava的观察者模式
RxJava的观察者模式是扩展的观察者模式,扩展的地方主要体现在事件通知的方式有很多种
2.RxJava的观察者模式涉及到几个类
- Observable:被观察者
- Observer:观察者
- Subscribe:订阅
- Event:被观察者通知观察者的事件
3.Obsercerable与Observer通过Subscribe实现关联,Event主要向Observer通知Observeble的变化,Event有几个通知方式
- Next:常规事件,可以传递各种各样的数据
- Error:异常事件,当被观察者发送异常事件后那么其他的事件就不会再继续发送了
- Completed:结束事件,当观察者接收到这个事件后就不会再接收后续被观察者发送过来的事件
4.代码实现
- 首先定义一个观察者Observer
public abstract class Observer<T> {
//和被观察者订阅后,会回调这个方法
public static void onSubscribe(Emitter emitter);
// 传递常规事件,用于传递数据
public abstract void onNext(T t);
// 传递异常事件
public abstract void onError(Throwable e);
// 传递结束事件
public abstract void onComplete();
}
Observer中的方法都是回调,其中多了一个Emitter的接口类,他是一个发射器
public interface Emitter<T> {
void onNext(T t);
void onError(Throwable error);
void onCompleted();
}
实现逻辑就是通过包装Observer,里面最终是通过Observer进行回调的
public class CreateEmitter<T> implements Emitter<T> {
final Observer<T> observer;
CreateEmitter(Observer<T> observer) {
this.observer = observer;
}
@Override
public void onNext(T t) {
observer.onNext(t);
}
@Override
public void onError(Throwable error) {
observer.onError(error);
}
@Override
public void onComplete() {
observer.onComplete();
}
} - 被观察者的实现
public abstract class Observable<T>{
public void subscribe(Observer<T> observer) {
//通过传入的Observer包装成CreateEmitter,用于回调
CreateEmitter emitter = new CreateEmitter(observer);
//回调订阅成功的方法
observer.onSubscribe(emitter);
//回调发射器emitter
subscribe(emitter);
}
/**
* 订阅成功后,进行回调
*/
public abstract void subscribe(Emitter<T> emitter);
}
就两步,第一步用于订阅,第二步用于回调- 具体的使用
private void observer() {
// 第一步,创建被观察者
Observable<String> observable = new Observable<String>() {
@Override
public void subscribe(Emitter<String> emitter) {
emitter.onNext("第一次");
emitter.onNext("第二次");
emitter.onNext("第三次");
emitter.onComplete();
}
};
// 第二步,创建观察者
Observer<String> observer = new Observer<String>() {
@Override
public void onSubscribe(Emitter emitter) {
Log.i("TAG", " onSubscribe ");
}
@Override
public void onNext(String s) {
Log.i("TAG", " onNext s:" + s);
}
@Override
public void onError(Throwable e) {
Log.i("TAG", " onError e:" + e.toString());
}
@Override
public void onComplete() {
Log.i("TAG", " onComplete ");
}
};
// 第三步,被观察者订阅观察者
observable.subscribe(observer);
}
被订阅成功后,被观察者的subscribe里面就可以通过发射器发送事件了,最终在观察者的方法里进行回调。RxJava也是观察者和被观察者订阅的过程,只不过被观察者有变化的时候是由发射器进行发送的,这样就不止有一种事件了
1.RxJava的装饰者模式
- 装饰者模式:在不改变原有的架构基础上添加一些新的功能,是作为其原有结构的包装,这个过程称为装饰。
- RxJava的装饰者模式主要是用于实现Observable和Observer的包装,主要是为了与RxJava的观察者模式配合实现代码的方式更简洁。
- 拆解RxJava的装饰器模式
- 被观察者Observable
参考手机包装的例子
第一步:要有一个抽象接口,在RxJava中这个抽象接口是ObservableSource,里面有一个方法subscribe
public interface ObservableSource<T> {
/**
* Subscribes the given Observer to this ObservableSource instance.
* @param observer the Observer, not null
* @throws NullPointerException if {@code observer} is null
*/
void subscribe(@NonNull Observer<? super T> observer);
}
第二步:要有一个包装类,实现了ObservableSource的,RxJava的包装类是Observable,实现了对应的接口,
并且在subscribe方法里通过调用抽象方法subscribeActual,来对观察者进行订阅
public abstract class Observable<T> implements ObservableSource<T> {
...
@Override
public final void subscribe(Observer<? super T> observer) {
...
subscribeActual(observer);
...
}
protected abstract void subscribeActual(Observer<? super T> observer);
...
}
第三步:这就是具体的包装类了如图所示2.观察者Observer:
- 第一步:要有一个抽象接口,而RxJava的接口是Emitter和Observer,里面有好几个方法基本一样,onNext,onError,onComplete,用于被观察者进行回调;
- 第二步:要有一个包装类,实现了Emitter或者Observer,但是观察者比较特殊,没有一个基础的包装类,而是直接封装了很多的包装类
RxJava的的被观察者是在创建的时候进行包装的,例如第一步的Observable.create方法,通过Observable.create的创建后进行了第一层包装,结构如下
第二步的subscribeO方法调用时进行了第二层的包装,此时结构如下:
第三步的observerOn方法调用时,进行了第四层的包装,那么结构就是下面的样子
最终调用订阅方法的时候已经进行了四次包装,那么可以理解每调用一次操作符就会进行一层被观察者的包装。
那么这样包装的好处是什么呢?
这就是装饰者模式的特性,在不改变原有功能的基础上添加额外的功能。
5.总结
我们在创建被观察者的时候,会对被观察者做一层包装,创建几次就包装几次,然后在被观察者调用subscribe方法时,一层层回调被观察者的subscribeAcutal方法,而在被观察者的subscribeAcutal方法里,会对观察者做一层包装;
也就是说被观察者是在创建的时候进行包装,然后在subscribeActual中实现额外的功能;
而观察者是在被观察者调用subscribeActual方法里进行包装的,然后针对观察者实现自己额外的功能;
流程图如下:
链接:https://juejin.cn/post/7180698264251924536
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RxJava装饰者模式
1.装饰者模式
- 装饰者模式时在保留原有结构的前提下添加新的功能,这些功能作为其原有结构的包装。
2.RxJava的装饰者模式
1.被观察者Observable
- 根据
Observerable的源码可知Observable的结构接口是Observerablesource<T>,里面有一个方法subscribe用于和观察者实现订阅,源码如下
/**
* Represents a basic, non-backpressured {@link Observable} source base interface,
* consumable via an {@link Observer}.
*
* @param <T> the element type
* @since 2.0
*/
public interface ObservableSource<T> {
/**
* Subscribes the given Observer to this ObservableSource instance.
* @param observer the Observer, not null
* @throws NullPointerException if {@code observer} is null
*/
void subscribe(Observer<? super T> observer);
}- 然后需要一个包装类,就是实现
ObservableSource接口的类,就是Observable<T>,它实现了ObservableSource并在subscribe方法中调用了subscribeActual方法与观察者实现订阅关系,源码如下
public abstract class Observable<T> implements ObservableSource<T> {
@Override
public final void subscribe(Observer<? super T> observer) {
...
subscribeActual(observer);
...
}
protected abstract void subscribeActual(Observer<? super T> observer);
}- 第三步就是包装类了,包装类有很多有一百多个,如
ObservableAll、ObservableAny、ObservableCache
2.观察者Observer
- 第一步,
Observer的结构的接口有Emitter和Observer,两个接口中的方法差不多,都是onNext、OnError、OnComplete,用于被观察者的回调 - 第二步,实现
Emitter或者Observer接口的包装类,观察者中没有实现这两个接口的基础包装类,而是直接封装了很多包装类
3.被观察者和观察者的包装类有在创建的时候进行包装也有在调用的时候包装,那么他们的结构又是怎么样的
以RxJava的最基础用法来分析,Observable.create().subscribeOn().observeOn().subscribe()为例,层层调用后它的结构如下:
- 首先是
Observable.create,通过创建ObservableCreate对象进行第一层包装,把ObservableOnSubscribe包在了里面
- 然后是
Observable.create().subscribeOn(),调用时又进行了一层包装,把ObservableCreate包进去了
- 再然后就分别是
observeOn()了,结构如下
- 总共进行了4层包装,可以理解为每调用一次操作符就会进行一层被观察者的包装,这样包装的好处就是为了添加额外的功能,那么每一层又添加了哪些额外的功能呢
4.被观察者的subscribe方法
调用subscribe方法后会从最外层的包装类一步一步的往里面调用,从被观察者的subscribe方法中可以得知额外功能的实现是在subscribeActual方法中,那么上面几层包装的subscribeActual方法中又做了什么呢,分析如下
- 先看最外层的包装
observerOn的subscribeActual方法做了什么,先看源码:
public final class ObservableObserveOn<T> extends AbstractObservableWithUpstream<T, T> {
final Scheduler scheduler;
final boolean delayError;
final int bufferSize;
public ObservableObserveOn(ObservableSource<T> source, Scheduler scheduler, boolean delayError, int bufferSize) {
super(source);
this.scheduler = scheduler;
this.delayError = delayError;
this.bufferSize = bufferSize;
}
@Override
protected void subscribeActual(Observer<? super T> observer) {
if (scheduler instanceof TrampolineScheduler) {
source.subscribe(observer);
} else {
Scheduler.Worker w = scheduler.createWorker();
source.subscribe(new ObserveOnObserver<T>(observer, w, delayError, bufferSize));
}
}
...
}- 源码中有一个
source,这个source是上一层包装类的实例,在source.subscribe()中对观察者进行了一层包装,也就是ObserveOnObserver,它在onNext方法里面实现了线程切换,这个onNext是在被观察者在通知观察者时会被回调,然后通过包装类实现额外的线程切换,这里是切换到了主线程执行。此时观察者的结构如下:
@Override
public void onNext(T t) {
if (done) {
return;
}
if (sourceMode != QueueDisposable.ASYNC) {
queue.offer(t);
}
schedule();
}- 再看下一层的包装
subscribeOn的subscribeActual方法做了什么,先看源码
public final class ObservableSubscribeOn<T> extends AbstractObservableWithUpstream<T, T> {
final Scheduler scheduler;
public ObservableSubscribeOn(ObservableSource<T> source, Scheduler scheduler) {
super(source);
this.scheduler = scheduler;
}
@Override
public void subscribeActual(final Observer<? super T> s) {
final SubscribeOnObserver<T> parent = new SubscribeOnObserver<T>(s);
s.onSubscribe(parent);
parent.setDisposable(scheduler.scheduleDirect(new Runnable() {
@Override
public void run() {
source.subscribe(parent);
}
}));
}
...
}这里又对观察者进行了一层包装,也就是SubscribeOnObserver,这里面的额外功能就是资源释放,包装完后的结构如下
static final class SubscribeOnObserver<T> extends AtomicReference<Disposable> implements Observer<T>, Disposable {
private static final long serialVersionUID = 8094547886072529208L;
...
@Override
public void dispose() {
DisposableHelper.dispose(s);
DisposableHelper.dispose(this);
}
@Override
public boolean isDisposed() {
return DisposableHelper.isDisposed(get());
}
void setDisposable(Disposable d) {
DisposableHelper.setOnce(this, d);
}
}在subscribeActual方法中有一个调用是source.subscribe(parent),这个source就是它的上一层的包装类ObservableCreate,那么ObservableCreate的subscribeActual方法就会在子线程执行。
ObservableCreate的subscribeActual方法做了什么,先看源码
public final class ObservableCreate<T> extends Observable<T> {
final ObservableOnSubscribe<T> source;
public ObservableCreate(ObservableOnSubscribe<T> source) {
this.source = source;
}
@Override
protected void subscribeActual(Observer<? super T> observer) {
CreateEmitter<T> parent = new CreateEmitter<T>(observer);
observer.onSubscribe(parent);
try {
source.subscribe(parent);
} catch (Throwable ex) {
Exceptions.throwIfFatal(ex);
parent.onError(ex);
}
}
...
}源码中的source就是创建最原始的ObservableOnSubscribe,这里会回调到ObservableOnSubscribe的subscribe方法,在subscribeActual方法中又对观察者进行了一层包装也就是CreateEmitter,这个类里面做的事情是判断线程是否被释放,如果释放了则不再进行回调,这时候结构如下图
@Override
public void onNext(T t) {
if (t == null) {
onError(new NullPointerException("onNext called with null. Null values are generally not allowed in 2.x operators and sources."));
return;
}
if (!isDisposed()) {
observer.onNext(t);
}
}这里由于上面的包装类已经切换到了子线程所以ObservableOnSubscribe的subscribe方法的执行也是在子线程;
3.总结
在创建被观察者的时候会对被观察者进行层层的包装,创建几次就包装几次,然后在被观察者调用subscribe方法时,一层层回调被观察者的subscribeActual方法,而在被观察者subscribeActual方法中会对观察者做一层包装。也就是说被观察者是创建的时候包装,在subscribeActual方法中实现额外的功能,观察者是在被观察者调用subscribeActual方法时进行包装的,然后针对观察者实现自己的额外的功能,流程图如下:
最终的结构如下:
- 第一步:创建被观察者时或者使用操作符时会对被观察者进行包装
- 第二步:当被观察者和观察者产生订阅关系后,被观察者会一层层的回调被观察者的
subscribeActual方法,在这个方法中对观察者进行包装,此时被观察者的功能实现是在subscribeActual中,观察者的实现是在包装类里
- 第三步:被观察者和观察者不同的是,被观察者是在订阅成功后就执行了包装类相应的功能,而观察者是在事件回调的时候,会在观察者的包装类里实现相应的功能
- 最终流程图
链接:https://juejin.cn/post/7180695827252248633
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 源码阅读 - StatefulWidget 源码分析 & State 生命周期
一、StatefulWidget
StatefulWidget 也是继承自 Widget,重写了 createElement,并且添加了一个新的接口 createState,下面我们看一下它的源码:
看起来是不是很简单,代码不足十行。
createElement方法返回一个StatefulElement类型的Element。createState抽象方法返回一个State类型的实例对象。在给定的位置为StatefulWidget创建可变状态(state)。框架可以在StatefulWidget生命周期内多次调用此方法,比如:将StatefulWidget插入到Widget Tree中的多个位置时,会创建多个单独的State实例,如果将StatefulWidget从Widget Tree中删除,稍后再次将琦插入到Widget Tree中,框架将会再次调用createState创建一个新的State实例对象。
StatefulWidget 我们暂时就先讲到这里, 关于 State 和 StatefulElement 我们在下面会进行分析。
二、StatefulElement
上面讲到 StatefulWidget 中 createElement 会创建一个 StatefulElement 类型的 Element。下面我们就一起看下 StatefulElement 的源码。
在执行 StatefulWidget#createElement 时会把 this 传递进去,此时执行 StatefulElement 的构造方法中我们可以看出会做以下三件事情:
- 首先通过
_state = widget.createState()执行StatefulWidget中的createState进行闯将State实例; - 其次通过
state._element = this将当前对象赋值给State中的_element属性; - 最后通过
state._widget = widget,将StatefulWidget赋值给State中的_widget属性。
通过以上分析我们相应的可以得出以下结论:
StatefulElement持有State状态;State中又会反过来持有StatefulElement和StatefulWidget(当然,State的源码我们还没有看到);StatefulWidget只是负责创建StatefulElement和State,但是并不持有它们。
至此我们已经理清了 StatefulWidget、StatefulElement 和 State 三者之间的关系,关于 State 我们会在后面讲到。现在我们已经知道 StatefulWidget 中的 createState 在何时执行,那么 StatefulElement#createElement 又是在何时执行的呢?下面我们来看一个例子:
import 'package:flutter/material.dart';
void main() {
runApp(
const MyApp(),
);
}
class MyApp extends StatefulWidget {
const MyApp({super.key});
@override
State<MyApp> createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
@override
Widget build(BuildContext context) {
return const ColoredBox(
color: Colors.red,
);
}
}通过断点调试可以看出在 Element#inflateWidget 中 通过 newWidget.createElement() 来进行触发 StatefulWidget#createElement 的执行,进而执行 StatefulElement 的构造函数。
关于更多 StatefulElement 内部方法,将在 State 源码以及相关案例中穿插进行。
三、State
State 是一个抽象类,它只定义了一个 build 抽象方法,由于构建 Widget 对象。它是通过StatefulElement#build 方法进行调用的。
如下是 State 源码的部分截图:
从源码中我们也可以对上面的结论得到验证,State 持有 StatefulElement 、StatefulWidget,这里的泛型 T必须是 StatefulWidget 类型,如下图所示:
除此之外 State 中还持有 BuildContext,通过源码我们可以看出 BuildContext 其实就是 StatefulElement 。
BuildContext get context {
return _element!;
}那么现在我们可以思考一下 State 中的生命周期方法在何时调用以及在哪里调用呢?从上面我们得出的结论:StatefulElement 持有 State 状态,State 中又会反过来持有 StatefulElement 和 StatefulWidget,StatefulWidget 只是负责创建 StatefulElement 和 State,但是并不持有它们。不难猜测出,应该是在 StatefulElement 中来触发的,下面我通过一个小的案例来进行研究一下:
void main() {
runApp(
const WrapWidget(),
);
}class WrapWidget extends StatelessWidget {
const WrapWidget({
Key? key,
}) : super(key: key);
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text("StatefulWidget Demo"),
),
body: MyApp(),
),
);
}
}class MyApp extends StatefulWidget {
const MyApp({
super.key,
});
@override
// ignore: no_logic_in_create_state
State<MyApp> createState() {
debugPrint("createState");
return _MyAppState();
}
}
class _MyAppState extends State<MyApp> {
late int _count = 0;
@override
void initState() {
debugPrint("initState");
super.initState();
}
@override
void didChangeDependencies() {
debugPrint("didChangeDependencies");
super.didChangeDependencies();
}
@override
void didUpdateWidget(MyApp oldWidget) {
debugPrint("didUpdateWidget");
super.didUpdateWidget(oldWidget);
}
@override
void deactivate() {
debugPrint("deactivate ");
super.deactivate();
}
@override
void dispose() {
debugPrint("dispose");
super.dispose();
}
@override
void reassemble() {
debugPrint("reassemble");
super.reassemble();
}
@override
Widget build(BuildContext context) {
debugPrint("build");
return Column(
children: [
Text('$_count'),
OutlinedButton(
onPressed: () {
setState(() {
_count++;
});
},
child: const Text('OnPress'),
),
],
);
}
}程序刚运行时打印日志如下:
然后我们点击⚡️按钮热重载,控制台输出日志如下:
我们再次点击 OnPress 按钮时,打印日志如下:
此时我们注释掉 WrapWidget 中的 body: MyApp() 这行代码,打印日志如下:
此时结合源码,我们来一起看下各个生命周期函数:
initState: 当Widget第一次插入到Widget Tree中,会执行一次,我们一般在这里可以做一些初始化状态的操作以及订阅通知事件等,通过源码我们可以看出它是在Statefulelement#_firstBuild中执行的;didChangeDependencies: 当State对象的依赖发生变化时会进行调用,例如:例如系统语言Locale或者应用主题等,通过源码我们可以看出它在Statefulelement#_firstBuild和Statefulelement#performRebuild中都会执行;build:在以下场景中都会调用:initState调用之后didUpdateWidget调用之后setState调用之后didChangeDependencies调用之后- 调用
deactivate之后,然后又重新插入到Widtget Tree中
通过源码可以看出它是在
Statefulelement#build中执行的;reassemble:专门为了开发调试而提供的,在hot reload时会被调用,在Release模式下永远不会被调用,通过源码可以看出它是在Statefulelement#reassemble中执行的;didUpdateWidget:在 Widget 重新构建时,Flutter 框架会在Element#updateChild中通过Widget.canUpdate判断是否需要进行更新,如果为 true 则进行更新;在
canUpdate源码中,新旧 widget 的key和runtimeType同时相等时会返回true,也就是说在在新旧widget的key和runtimeType同时相等时didUpdateWidget()就会被调用;deactivate:当 State 对象从树中被移除时将会调用,它将会在Statefulelement#deactivate中进行调用;dispose:当 State 对象从树中被永久移除时调用;通常在此回调中释放资源,它将会在Statefulelement#unmount中进行调用。
总结
至此,结合一些小的案例和源码阅读,我们大致明白了 StatefulWidget、State 以及 StatefulElement 他们三者之间的关系以及 State 的生命周期,相信在以后的实际应用中会更加得心应手。
链接:https://juejin.cn/post/7180626500951998520
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Jetpack Compose 十几行代码快速模仿即刻点赞数字切换效果
缘由
四点多刷掘金的时候,看到这样一篇文章:
自定义View模仿即刻点赞数字切换效果,作者使用自定义绘制的技术完成了数字切换的动态效果,也就是如图:
两图分别为即刻的效果和作者的实现
不得不说,作者模仿的很像,自定义绘制玩的炉火纯青,非常优秀。不过,即使是这样简单的动效,使用 View 体系实现起来仍然相对麻烦。对上文来说,作者使用的 Kotlin 代码也达到了约 170 行。
Composable
如果换成 Compose 呢?作为声明式框架,在处理这类动画上会不会有奇效?
答案是肯定的!下面是最简单的实现:
Row(modifier = modifier) {
text.forEach {
AnimatedContent(
targetState = it,
transitionSpec = {
slideIntoContainer(AnimatedContentScope.SlideDirection.Up) with
fadeOut() + slideOutOfContainer(AnimatedContentScope.SlideDirection.Up)
}
) { char ->
Text(text = char.toString(), modifier = modifier.padding(textPadding), fontSize = textSize, color = textColor)
}
}
}你没看错,这就是 Composable 对应的简单模仿,核心代码不过十行。它的大致效果如下:
能看到,在数字变化时,相应的动画效果已经非常相似。当然他还有小瑕疵,比如在 99 - 100 时,最后一位的 0 没有初始动画;比如在数字减少时,他的动画方向应该相反。但这两个问题都是可以加点代码解决的,这里核心只是思路
原理
与上文作者将每个数字当做一个整体对待不同,我将每一位独立处理。观察图片,动画的核心在于每一位有差异时要做动画处理,因此将每一位单独处理能更好的建立状态。
Jetpack Compose 是声明式 UI,状态的变化自然而然就导致 UI 的变化,我们所需要做的只是在 UI 变化时加个动画就可以。而刚好,对于这种内容的改变,Compose 为我们提供了开箱即用的微件:AnimatedContent
AnimatedContent
此 Composable 签名如下:
@Composable
fun <S> AnimatedContent(
targetState: S,
modifier: Modifier = Modifier,
transitionSpec: AnimatedContentScope<S>.() -> ContentTransform = {
...
},
contentAlignment: Alignment = Alignment.TopStart,
content: @Composable() AnimatedVisibilityScope.(targetState: S) -> Unit
)重点在于 targetState,在 content 内部,我们需要获取到用到这个值,根据值的不同,呈现不同的 UI。AnimatedContent 会在 targetState 变化使自动对上一个 Composable 执行退出动画,并对新 Composable 执行进入动画 (有点幻灯片切换的感觉hh),在这里,我们的动画是这样的:
slideIntoContainer(AnimatedContentScope.SlideDirection.Up)
with
fadeOut() + slideOutOfContainer(AnimatedContentScope.SlideDirection.Up)上半部分的 slideIntoContainer 会执行进入动画,方向为自下向上;后半部分则是退出动画,由向上的路径动画和淡出结合而来。中缀函数 with 连接它们。这也体现了 Kotlin 作为一门现代化语言的优雅。
关于 Compose 的更多知识,可以参考 Compose 中文社区的大佬们共同维护的 Jetpack Compose 博物馆。
代码
本文的所有代码如下:
import androidx.compose.animation.*
import androidx.compose.foundation.layout.*
import androidx.compose.material.Text
import androidx.compose.material.TextButton
import androidx.compose.runtime.*
import androidx.compose.ui.Alignment
import androidx.compose.ui.Modifier
import androidx.compose.ui.graphics.Color
import androidx.compose.ui.unit.TextUnit
import androidx.compose.ui.unit.dp
import androidx.compose.ui.unit.sp
@OptIn(ExperimentalAnimationApi::class)
@Composable
fun NumberChangeAnimationText(
modifier: Modifier = Modifier,
text: String,
textPadding: PaddingValues = PaddingValues(horizontal = 8.dp, vertical = 12.dp),
textSize: TextUnit = 24.sp,
textColor: Color = Color.Black
) {
Row(modifier = modifier) {
text.forEach {
AnimatedContent(
targetState = it,
transitionSpec = {
slideIntoContainer(AnimatedContentScope.SlideDirection.Up) with
fadeOut() + slideOutOfContainer(AnimatedContentScope.SlideDirection.Up)
}
) { char ->
Text(text = char.toString(), modifier = modifier.padding(textPadding), fontSize = textSize, color = textColor)
}
}
}
}
@Composable
fun NumberChangeAnimationTextTest() {
Column(horizontalAlignment = Alignment.CenterHorizontally) {
var text by remember { mutableStateOf("103") }
NumberChangeAnimationText(text = text)
Row(Modifier.fillMaxWidth(), horizontalArrangement = Arrangement.SpaceEvenly) {
// 加一 和 减一
listOf(1, -1).forEach { i ->
TextButton(onClick = {
text = (text.toInt() + i).toString()
}) {
Text(text = if (i == 1) "加一" else "减一")
}
}
}
}
}这个示例也被收录到了我的 JetpackComposeStudy: 本人 Jetpack Compose 主题文章所包含的示例,包括自定义布局、部分组件用法等 里,感兴趣的可以去那里查看更多代码。
最近掘金开启了2022的年度人气创作者评选,如果您对我的文章认可的话,欢迎投给我宝贵的一票,感谢!本文有帮助的话,也欢迎点赞交流。
(现在6点13分,连写代码加写文章共用了一个多小时,嗯,收工~)
链接:https://juejin.cn/post/7179543408347152442
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


