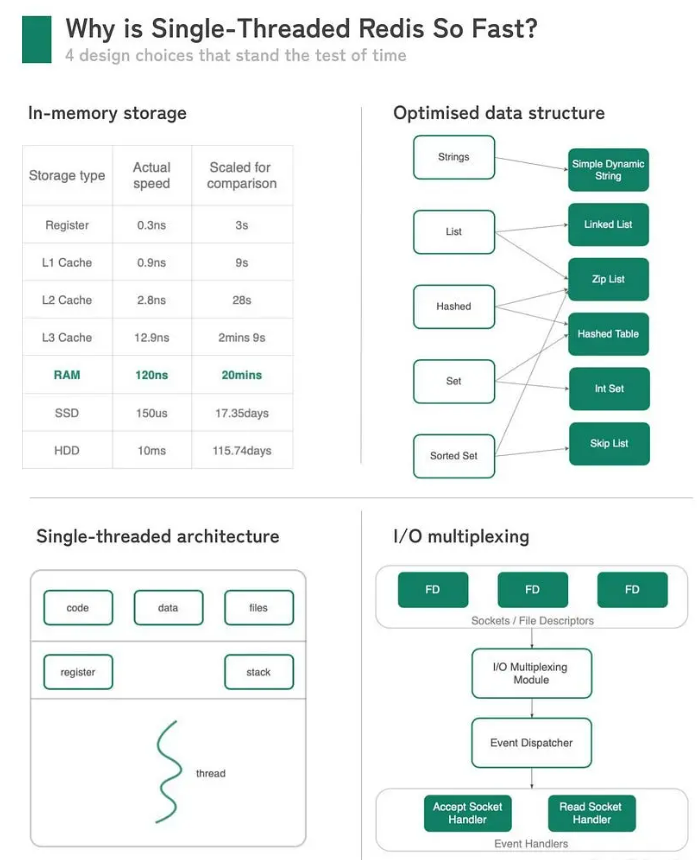
前言
矩阵是人类的瑰宝,矩阵里数字与数字通过关系组在一起。正如大道无形,用不同的视角去解读数的关系,它就有不同的作用。大道至简,难的是解读道的心。(作者发癫中...)
让我们放开的自己的心,不要限制它的解读,(san +++)
下面进行简单的描述。
矩阵 (Matrix)
定义
矩阵由 m 行 n 列 组成的方队,即为 m * n 的矩阵。 其组成的元素可以为实数,虚数。
好了开写。
我这边定义一个枚举类型,因为我想通过矩阵计算对象某个属性。
但是实现实在是有点生草。最开始的时候准备封装个矩阵类,然后通过它进行计算。
但是现实中我那微不足道的 OOP 水平撑不下去了,在矩阵的灵活扩展想法败北了┭┮﹏┭┮。
最后是个四不像的实现。
// 定义矩阵类型
type IMatrix<T = number> = T[][];
class Matrix {
// 获取矩阵常用的坐标集合操作
static getRow<T = number>(matrix: IMatrix<T>, rowIndex: number) {
return matrix?.[rowIndex]
};
static getCol<T = number>(matrix: IMatrix<T>, colIndex: number) {
return matrix.map(row => row[colIndex])
};
static getMatrixLen<T = number>(matrix: IMatrix<T>) {
return {
rowLen: matrix.length,
colLen: Math.max(...matrix.map(row => row.length)),
}
};
}
上面就是获取矩阵常用简化。
这里关于使用类静态方法的考虑是因为我觉得相对比较直观,虽然现在有 esm 现代模块化方案,可以基于文件即模块,但是考虑到更直观的抽象关系,我选择这种方式。第一调用的时候,不会 esm import 那样少了直观的从属关系,esm 的文件即模块确实很方便,但引用代码如果没有插件的话,需要追踪对应的文件模块的话,只能从函数名语义入手。
在项目中有时候会碰到大杂烩语义的文件,比如一个 util文件 会承当各种逻辑封装而失去模块的意义,用类作为一个抽象空间是一种相对方法。
同型矩阵/单位矩阵
同型矩阵就是矩阵之间的行数列数均相同,则视矩阵之间的关系为同型矩阵。符合同型矩阵是一些计算逻辑的前置判断。
单位矩阵是矩阵主对角线之间的数为 1 ,其余为 0 。其实就是行列坐标相同的点就是 1 ,其余就是 0。
interface IGetMatrixValue<T = number> {
(matrixItem: T) : number;
}
//...
static isHomotypeMatrix<T = number>(matrix1: IMatrix<T>, matrix2: IMatrix<T>): boolean {
if (matrix1.length !== matrix2.length) {
return false;
}
if (this.getMatrixLen(matrix1) !== this.getMatrixLen(matrix2)) {
return false;
}
return true;
};
static isUnitMatrix<T = number>(matrix: IMatrix<T>, getMatrixVal?: IGetMatrixValue<T>) {
const handleGetMatrixValue = getMatrixVal || getDefaultMatrixItem;
for (let i = 0; i < matrix.length; i++) {
const row = matrix[i];
for (let j = 0; j < row.length; j++) {
const isSameIdx = i === j;
const val = handleGetMatrixValue(matrix[i][j] as any);
if (isSameIdx && val !== 1) {
return false;
}
if (!isSameIdx && val !== 0) {
return false;
}
}
}
return true;
};
当时写到这里,我感觉脑子乱乱的,可能是经常熬夜吧。
第二个获取单元行数,是不是有点不一样的。其实从这里,我才意识这里正因为我的定义函数因为它太灵活,导致我这边要处理更多的边际逻辑。(当时大脑宕机中...😐)
我希望我的代码可以使用对象运算,但是如何标准的写出可扩展的函数,或许是我要去学习的。 Lodash 源码获取是个不错的选择,但是总有一些事情,让我没有机会。
同型矩阵加/减
同型矩阵同个行列位置的进行加减运算,所以我写道一般,还是抽了一个计算同个位置逻辑的函数,并把其它情况交给调用者自己扩展运算吧。
interface ICustMatrixAWithB<T> {
(matrixAItem: T, matrixBItem: T) : T;
}
static computeHomotypeMatrix<T = number>(matrix1: IMatrix<T>, matrix2: IMatrix<T>, custom: ICustMatrixAWithB<T>): IMatrix<T> {
if (!this.isHomotypeMatrix(matrix1, matrix2)) {
throw new Error('该矩阵非二维数组');
}
const { rowLen, colLen } = this.getMatrixLen(matrix1)
const nextMatrix: T[][] = [];
for (let i = 0; i < rowLen; i++) {
nextMatrix[i] = [];
for (let j = 0; j < colLen; j++) {
nextMatrix[i][j] = custom(matrix1[i]?.[j], matrix2[i]?.[j]);
}
}
return nextMatrix;
};
static addHomotypeMatrix(matrix1: IMatrix<number>, matrix2: IMatrix<number>) {
return this.computeHomotypeMatrix(matrix1, matrix2, (num1, num2) => num1 + num2);
};
static subHomotypeMatrix(matrix1: IMatrix<number>, matrix2: IMatrix<number>) {
return this.computeHomotypeMatrix(matrix1, matrix2, (num1, num2) => num1 - num2);
};
写到这里也说我最纠结的,因为我的封装设计出现了问题,最后一层胶水层没法解决,只能交由调用者使用 computeHomotypeMatrix 去实现自己的加减逻辑。
但我不知道要如何去解决,如果你有办法请留言教教我吧。
这里的逻辑,也让我想起了若川大佬的 vant 组件源码共读中的计算逻辑。只是想不起具体细节,时间真的是改变一切,生物的宿命真是难以跨域。
矩阵乘法 矩阵相乘/矩阵标量
矩阵和标量的乘积,标量指的是一个数,数和矩阵相乘等于数与矩阵的每个元素相乘
矩阵相乘则是比较奇怪,我不太了解原理。是这么一个公式,矩阵1 m * n , 矩阵2 n * p , 当前矩阵的列数等于后矩阵的行数的时候的才可以进行相乘,可以得到这么一个新矩阵 m * p。矩阵的每一项等于 当前行数的前矩阵的列数的项 * 当前的列数的后矩阵的行数的项,两个数组之间的每一元素相乘后累加成项的值
//...
static mapMatralItem<T>(matrix: IMatrix<T>, map: (matrix: T) => T) {
const nextMatrix: IMatrix<T> = [];
for (let i = 0; i < matrix.length; i++) {
const row = matrix[i] || [];
nextMatrix[i] = [];
for (let j = 0; j < row.length; j++) {
const item = row[j];
nextMatrix[i][j] = map(item);
}
}
return nextMatrix;
};
// 数乘
static multipleItemMatrix(matrix: IMatrix<number>, multiple: number) {
return this.mapMatralItem(matrix, (item) => item * multiple);
};
// 矩阵相乘
static multiplyMatrix(matrix1: IMatrix<number>, matrix2: IMatrix<number>) {
const { colLen, rowLen: nexRowLen } = this.getMatrixLen(matrix1);
const { rowLen, colLen: nexColLen } = this.getMatrixLen(matrix2);
if (colLen !== rowLen) {
/** A m * n * B n * p = C m *p */
throw new Error('矩阵乘法必须,前矩阵列数等于后矩阵行数');
}
const nextMatrix: IMatrix = [];
for (let i = 0; i < nexRowLen; i++) {
nextMatrix[i] = [];
const curCol = this.getCol(matrix1, i);
for (let j = 0; j < nexColLen; j++) {
const curRow = this.getRow(matrix2, j);
const len = Math.max(curCol.length, curRow.length);
const computed = Array.from({
length: len,
}, (_, idx) => {
const curColVal = curCol[idx] || 0;
const curRowVal = curRow[idx] || 0;
return curColVal * curRowVal;
});
nextMatrix[i][j] = computed.reduce((acc, cur) => acc + cur, 0);
}
}
return nextMatrix;
};
mapMatralItem 函数封装,它不提供具体的逻辑,只是提供矩阵每个元素的类似数组 map 的能力,但也没有比数组好,因为它再设计的时候少了更多的环境参数。
矩阵转秩
矩阵转秩代表矩阵的行列坐标相互交换,前面有提到的对角线坐标在转秩后仍然还在同一个位置,其它都是 0 交换后也变,所以也可以得出单位矩阵的秩等于单位的结论。
// 矩阵转秩
static randConversionMatrix<T>(matrix: IMatrix<T>) {
const { rowLen, colLen } = this.getMatrixLen(matrix);
const nextMatrix:IMatrix<T> = [];
for (let i = 0; i < colLen; i++) {
nextMatrix[i] = [];
for (let j = 0; j < rowLen; j++) {
nextMatrix[i][j] = matrix[j][i];
}
};
return nextMatrix;
};
矩阵 共轭
这些不懂,暂时跳过,当初不好好学习,上个好的学校 ┭┮﹏┭┮。
矩阵快速幂运算
快速幂是什么,其实就是减少指数,转为同等的底数,来减少计算次数。
看了好久才懂,太菜了。
比方说,一个 2 ** 8 ,我们通过二分指数的方式把底数扩大 (2 ** 2 ) ** 4 -> (4 ** 2) * 2 最后就变小,指数越大效率越高
/**
* 快速幂运算
* @param a 底数
* @param pow 阶乘
*/
const multiQuick = (a: number, pow: number) => {
let curPow = pow, result = 1;
while(curPow) {
if (curPow === 0) {
result *= 1;
} else if (curPow === 1) {
result *= a;
curPow = 0;
} else if (curPow % 2 === 1) {
result *= result * a;
curPow -= 1;
} else if (curPow % 2 === 0) {
result *= result;
curPow >>= 1;
}
};
return result;
};
static multilpyQuiickMatrix(matrix: IMatrix<number>, pow: number) {
return this.mapMatralItem(matrix, (num) => multiQuick(num, pow))
};
这里有小知识点二进制也算复习了,很多东西学了忘,学了忘,只有真正意识到它的价值,才能接纳它。
这里也可以看得出来,虽然我封装得 map 函数不够好,但是确实确实简化很多过程表述。只是从一个数据向另一个数据迁移。
结语
本次文章记录也到到此为止,感谢人生中让我成长的一切,感谢每一个让我快乐的人。
最近行情真的不好,有时候在想,我除了编程还有技能吗?可惜好像没有发现,我学历低,没有大厂背景,真的失业了可能就很难找到工作。
最近也是高考结束了期间,有一批学子成为了准大学生。记得当年报考,我最后还是说服父母说了报考移动应用开发专业。那时候的梦想真的是想学习编程的来开发游戏,然而现在感觉工作了,那股热情却萎了。
人生且叹且前
来源:juejin.cn/post/7258191640564334653