1. 前言
最近我需要将网页的DOM输出为PDF文件,我使用的技术是html2Canvas和jsPDF。具体流程是,首先使用html2Canvas将DOM转化为图片,然后将图片添加到jsPDF中进行输出。
const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation: 'p',
});
const canvas = await html2canvas(element,
{
onrendered: function (canvas) {
document.body.appendChild(canvas);
}
}
);
const canvasData = canvas.toDataURL('image/jpeg', 1.0);
pdf.addImage(canvasData, 10, 10);
pdf.save('jecyu.pdf');
遇到了图片导出模糊的问题,解决思路是:
- 先html2canvas 转成高清图片,然后再传一个 scale 配置:
scale: window\.devicePixelRatio \* 3,
- 为了确保图片打印时不会变形,需要按照 PDF 文件的宽高比例进行缩放,使其与 A4 纸张的宽度一致。因为 A4 纸张采用纵向打印方式,所以以宽度为基准进行缩放。
const canvasWidth = canvas.width;
const canvasHeight = canvas.height;
pdf.addImage(data, 'JPEG', 0, 0, width, height);
pdf.save('jecyu.pdf');
要想了解为什么这样设置打印出来的图片变得更加清晰,需要先了解一些有关图像的概念。
2. 一些概念
2.1 英寸
英寸是用来描述屏幕物理大小的单位,以对角线长度为度量标准。常见的例子有电脑显示器的17英寸或22英寸,手机显示器的4.8英寸或5.7英寸等。厘米和英寸的换算是1英寸等于2.54厘米。
2.2 像素
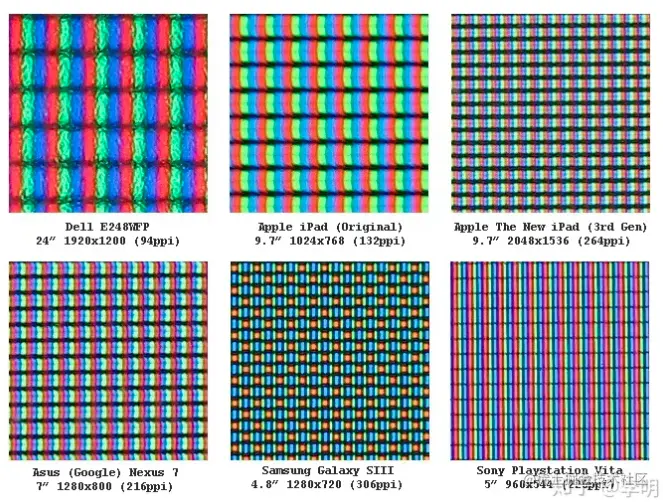
像素是图像显示的基本单元,无法再分割。它是由单一颜色的小方格组成的。每个点阵图都由若干像素组成,这些小方格的颜色和位置决定了图像的样子。

图片、电子屏幕和打印机打印的纸张都是由许多特定颜色和位置的小方块拼接而成的。一个像素通常被视为图像的最小完整样本,但它的定义和上下文有关。例如,我们可以在可见像素(打印出来的页面图像)、屏幕上的像素或数字相机的感光元素中使用像素。根据上下文,可以使用更精确的同义词,如像素、采样点、点或斑点。
2.3 PPI 与 DPI
PPI (Pixel Per Inch):每英寸包括的像素数,用来描述屏幕的像素密度。
DPI(Dot Per Inch):即每英寸包括的点数。
在这里,点是一个抽象的单位,可以是屏幕像素点、图片像素点,也可以是打印的墨点。在描述图片和屏幕时,通常会使用DPI,这等同于PPI。DPI最常用于描述打印机,表示每英寸打印的点数。一张图片在屏幕上显示时,像素点是规则排列的,每个像素点都有特定的位置和颜色。当使用打印机打印时,打印机可能不会规则地打印这些点,而是使用打印点来呈现图像,这些打印点之间会有一定的空隙,这就是DPI所描述的:打印点的密度。
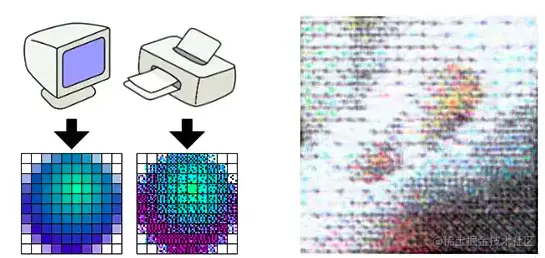
在这张图片中,我们可以清晰地看到打印机是如何使用墨点打印图像的。打印机的DPI越高,打印出的图像就越精细,但同时也会消耗更多的墨点和时间。
2.4 设备像素
设备像素(物理像素)dp:device pixels,显示屏就是由一个个物理像素点组成,屏幕从工厂出来那天物理像素点就固定不变了,也就是我们经常看到的手机分辨率所描述的数字。
一个像素并不一定是小正方形区块,也没有标准的宽高,只是用于丰富色彩的一个“点”而已。
2.5 屏幕分辨率
屏幕分辨率是指一个屏幕由多少像素组成,常说的分辨率指的就是物理像素。手机屏幕的横向和纵向像素点数以 px 为单位。
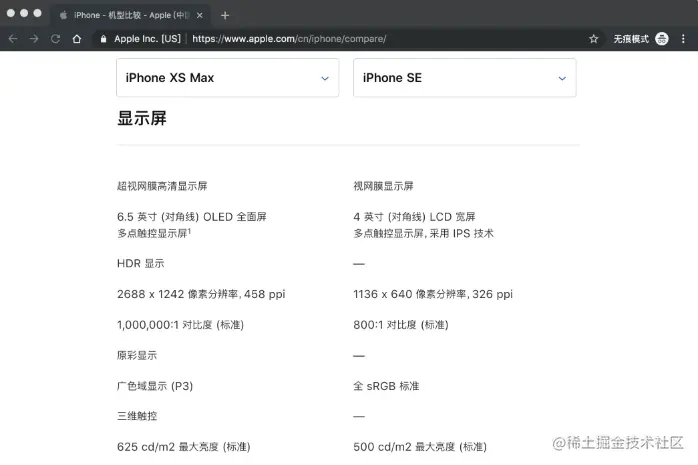
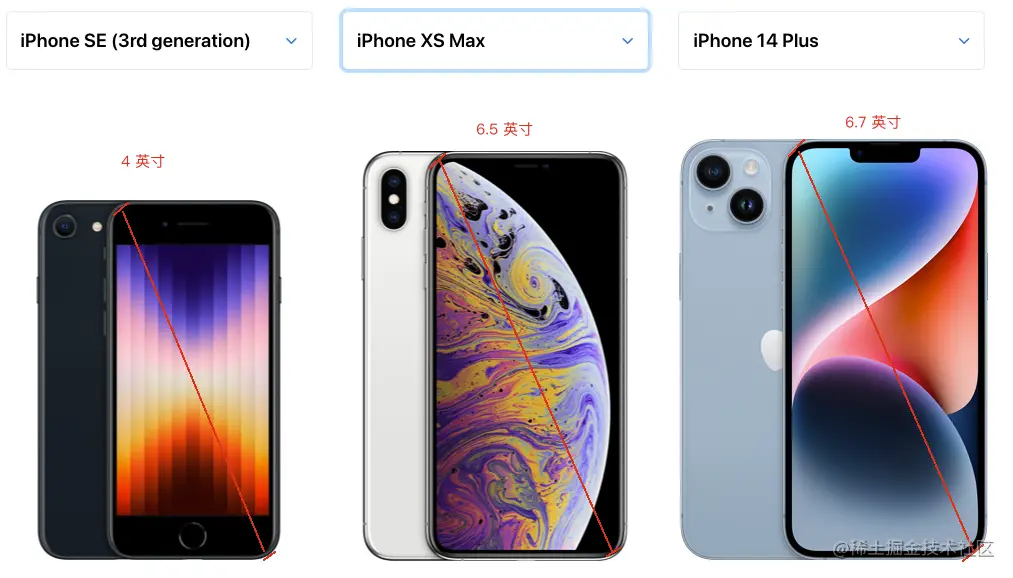
iPhone XS Max 和 iPhone SE 的屏幕分辨率分别为 2688x1242 和 1136x640。分辨率越高,屏幕上显示的像素就越多,单个像素的尺寸也就越小,因此显示效果更加精细。
2.6 图片分辨率
在我们所说的图像分辨率中,指的是图像中包含的像素数量。例如,一张图像的分辨率为 800 x 400,这意味着图像在垂直和水平方向上的像素点数分别为 800 和 400。图像分辨率越高,图像越清晰,但它也会受到显示屏尺寸和分辨率的影响。
如果将 800 x 400 的图像放大到 1600 x 800 的尺寸,它会比原始图像模糊。通过图像分辨率和显示尺寸,可以计算出 dpi,这是图像显示质量的指标。但它还会受到显示屏影响,例如最高显示屏 dpi 为 100,即使图像 dpi 为 200,最高也只能显示 100 的质量。
可以通过 dpi 和显示尺寸,计算出图片原来的像素数。

这张照片的尺寸为 4x4 英寸,分辨率为 300 dpi,即每英寸有 300 个像素。因此它的实际像素数量是宽 1200 像素,高 1200 像素。如果有一张同样尺寸(4x4 英寸)但分辨率为 72 dpi 的照片,那么它的像素数量就是宽 288 像素,高 288 像素。当你放大这两张照片时,由于像素数量的差异,可能会导致细节的清晰度不同。
怎么计算 dpi 呢?dpi = 像素数量 / 尺寸
举个例子说明:
假设您有一张宽为1200像素,高为800像素的图片,您想将其打印成4x6英寸的尺寸。为此,您可以使用以下公式计算分辨率:宽度分辨率 = 1200像素/4英寸 = 300 dpi;高度分辨率 = 800像素/6英寸 = 133.33 dpi。因此,这张图片的分辨率为300 dpi(宽度)和133.33 dpi(高度)。需要注意的是,计算得出的分辨率仅为参考值,实际的显示效果还会受到显示设备的限制。
同一尺寸的图片,同一个设备下,图片分辨率越高,图片越清晰。

2.7 设备独立像素
前面我们说到显示尺寸,可以使用 CSS 像素来描述图片在显示屏上的大小,而 CSS 像素就是设备独立像素。设备独立像素(逻辑像素)dip:device-independent pixels,独立于设备的像素。也叫密度无关像素。
为什么会有设备独立像素呢?
智能手机的发展非常迅速。几年前,我们使用的手机分辨率非常低,例如左侧的白色手机,它的分辨率只有320x480。但是,随着科技的进步,低分辨率手机已经无法满足我们的需求了。现在,我们有更高分辨率的屏幕,例如右侧的黑色手机,它的分辨率是640x960,是白色手机的两倍。因此,如果在这两个手机上展示同一张照片,黑色手机上的每个像素点都对应白色手机上的两个像素点。
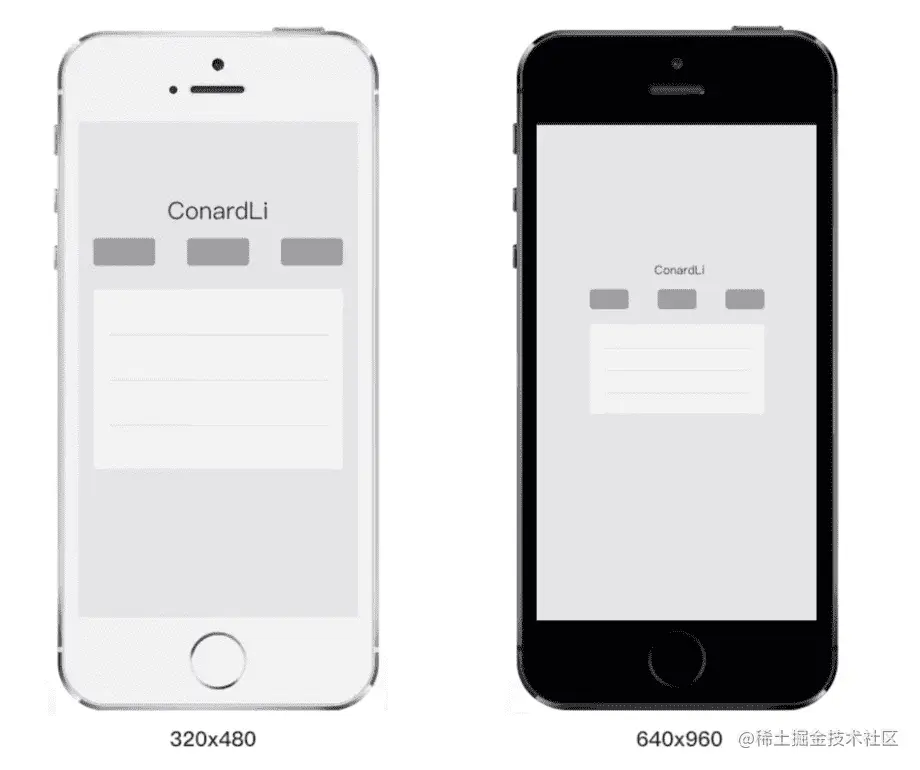
理论上,一个图片像素对应1个设备物理像素,图片才能得到完美清晰的展示。因为黑色手机的分辨率更高,每英寸显示的像素数量增多,缩放因素较大,所以图片被缩小以适应更高的像素密度。而在白色手机的分辨率较低,每英寸显示的像素数量较少,缩放因素较小,所以图片看起来相对较大。
为了解决分辨率越高的手机,页面元素越来越小的问题,确保在白色手机和黑色手机看起来大小一致,就出现了设备独立像素。它可以认为是计算机坐标系统中得到一个点,这个点代表可以由程序使用的虚拟像素。
例如,一个列表的宽度 300 个独立像素,那么在白色手机会用 300个物理像素去渲染它,而黑色手机使用 600个物理像素去渲染它,它们大小是一致的,只是清晰度不同。
那么操作系统是怎么知道 300 个独立像素,应该用多少个物理像素去渲染它呢?这就涉及到设备像素比。
2.8 设备像素比
设备像素比是指物理像素和设备独立像素之间的比例关系,可以用devicePixelRatio来表示。具体而言,它可以按以下公式计算得出。
设备像素比:物理像素 / 设备独立像素
在JavaScript中,可以使用window.devicePixelRatio获取设备的DPR。设备像素比有两个主要目的:
- 1.保持视觉一致性,以确保相同大小的元素在不同分辨率的屏幕上具有一致的视觉大小,避免在不同设备上显示过大或过小的问题。
- 2.支持高分辨率屏幕,以提供更清晰、更真实的图像和文字细节。
开发人员可以使用逻辑像素来布局和设计网页或应用程序,而不必考虑设备的物理像素。系统会根据设备像素比自动进行缩放和适配,以确保内容的一致性和最佳显示效果。
3. 分析原理
3.1 html2canvas 整体流程
在使用html2canvas时,有两种可选的模式:一种是使用foreignObject,另一种是使用纯canvas绘制。
使用第一种模式时,需要经过以下步骤:首先将需要截图的DOM元素进行克隆,并在过程中附上getComputedStyle的style属性,然后将其放入SVG的foreignObject中,最后将SVG序列化成img的src(SVG直接内联)。
img.src = "data:image/svg+xml;charset=utf-8," + encodeURIComponent(new XMLSerializer().serializeToString(svg)); 4.ctx.drawImage(img, ....)
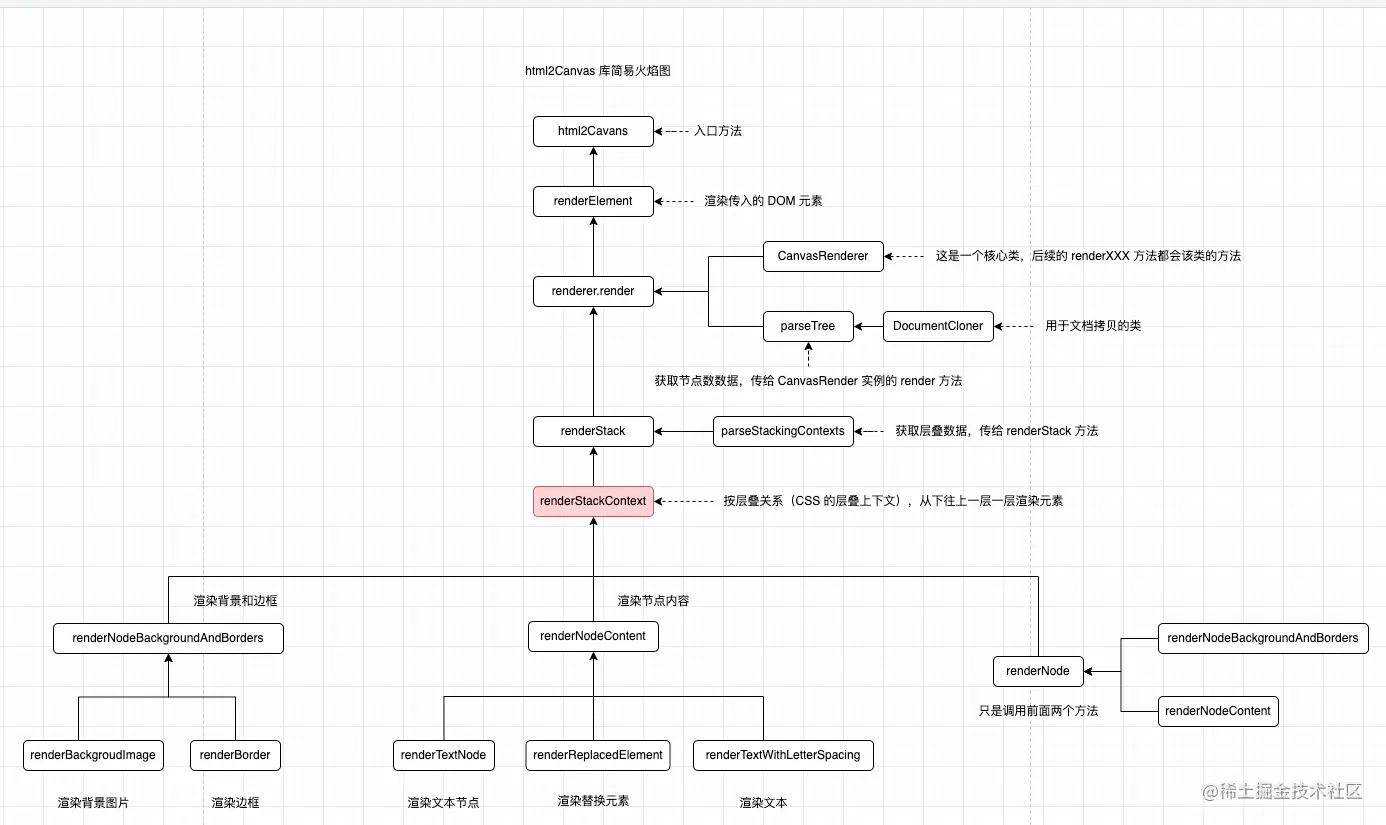
第二种模式是使用纯Canvas进行截图的步骤。具体步骤如下:
- 复制要截图的DOM,并将其附加样式。
- 将复制的DOM转换为类似于VirtualDOM的对象。
- 递归该对象,根据其父子关系和层叠关系计算出一个renderQueue。
- 每个renderQueue项目都是一个虚拟DOM对象,根据之前获取的样式信息,调用ctx的各种方法。
3.2 分析画布属性 width、height、scale
通常情况下,每个位图像素应该对应一个物理像素,才能呈现完美清晰的图片。但是在 retina 屏幕下,由于位图像素点不足,图片就会变得模糊。
为了确保在不同分辨率的屏幕下输出的图片清晰度与屏幕上显示一致,该程序会取视图的 dpr 作为默认的 scale 值,以及取 dom 的宽高作为画布的默认宽高。这样,在 dpr 为 2 的屏幕上,对于 800 * 600 的容器画布,通过 scale * 2 后得到 1600 * 1200 这样的大图。通过缩放比打印出来,它的清晰度是跟显示屏幕一致的。
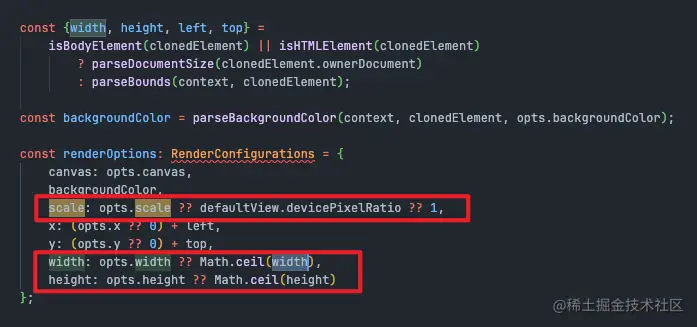
假设在 dpr 为 1 的屏幕,假如这里 scale 传入值为 2,那么宽、高和画布上下文都乘以 2倍。
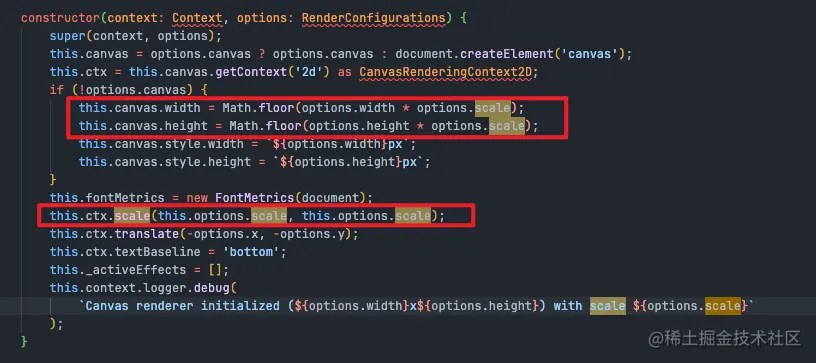
为什么要这样做呢?因为在 canvas 中,默认情况下,一个单位恰好是一个像素,而缩放变换会改变这种默认行为。比如,缩放因子为 0.5 时,单位大小就变成了 0.5 像素,因此形状会以正常尺寸的一半进行绘制;而缩放因子为 2.0 时,单位大小会增加,使一个单位变成两个像素,形状会以正常尺寸的两倍进行绘制。
如下例子,通过放大倍数绘制,输出一张含有更多像素的大图
const canvas = document.createElement('canvas');
canvas.width = 200;
canvas.height = 200;
const ctx = canvas.getContext('2d');
ctx.fillStyle = 'red';
ctx.fillRect(50, 50, 100, 100);
document.body.appendChild(canvas)
const canvas2 = document.createElement('canvas');
canvas2.width = 400;
canvas2.height = 400;
const ctx2 = canvas2.getContext('2d');
ctx2.scale(2, 2);
ctx2.fillStyle = 'blue';
ctx2.fillRect(50, 50, 100, 100);
document.body.appendChild(canvas2)
3.3 为什么 使用 dpr * 倍数进行 scale
在使用html2Canvas时,默认会根据设备像素比例(dpr)来输出与屏幕上显示的图片清晰度相同的图像。但是,如果需要打印更高分辨率的图像,则需要将dpr乘以相应的倍数。例如,如果我们想要将一张800像素宽,600像素高,72dpi分辨率的屏幕图片打印在一张8x6英寸,300dpi分辨率的纸上,我们需要确保图片像素与打印所需像素相同,以保证清晰度。
步骤 1: 将纸的尺寸转换为像素
可以使用打印分辨率来确定转换后的像素尺寸。
假设打印分辨率为 300 dpi,纸的尺寸为 8x6 英寸,那么:
纸的宽度像素 = 8 英寸 * 300 dpi = 2400 像素
纸的高度像素 = 6 英寸 * 300 dpi = 1800 像素
步骤 2: 计算图片在纸上的实际尺寸
将图片的尺寸与纸的尺寸进行比例缩放,以确定在纸上的实际打印尺寸 。
图片在纸上的宽度 = (图片宽度 / 屏幕像素每英寸) * 打印分辨率
图片在纸上的高度 = (图片高度 / 屏幕像素每英寸) * 打印分辨率
图片在纸上的宽度 = (800 / 72) * 300 = 3333.33 像素(约为 3334 像素)
图片在纸上的高度 = (600 / 72) * 300 = 2500 像素
步骤 3: 调整图片大小和打印分辨率
根据计算出的实际尺寸,可以将图片的大小调整为适合打印的尺寸,并设置适当的打印分辨率。
图片在纸上的宽度为 3334 像素,高度为 2500 像素。
也就是说,在保持分辨率为 72 dpi 的情况下,需要把原来 800*600 的图片,调整像素为 3334 * 2500。如果是位图直接放大,就会变糊。如果是矢量图,就不会有问题。这也是 html2Canvas 最终通过放大 scale 来提高打印清晰度的原因。
在图片调整像素为 *3334 * 2500,虽然屏幕宽高变大了,但通过打印尺寸的换算,最终还是 6 8 英寸,分辨率 为 300dpi。
在本案例中,我们需要打印出一个可以正常查看的 pdf,对于 A4尺寸,我们可以用 pt 作为单位,其尺寸为 595pt * 841pt。 实际尺寸为 595/72 = 8.26英寸,841/72 = 11.68英寸。为了打印高清图片,需要确保每英寸有300个像素,也就是8.26 * 300 = 2478像素,11.68 * 300 = 3504 像素,也就是说 canvas 转出的图片必须要这么大,最终打印的像素才这么清晰。
而在绘制 DOM 中,由于调试时不需要这么大,我们可以缩放比例,比如缩小至3倍,这样图片大小就为826像素 * 1168像素。如果高度超过1168像素,则需要考虑分页打印。
下面是 pt 转其他单位的计算公式
function convertPointsToUnit(points, unit) {
var multiplier;
switch(unit) {
case 'pt':
multiplier = 1;
break;
case 'mm':
multiplier = 72 / 25.4;
break;
case 'cm':
multiplier = 72 / 2.54;
break;
case 'in':
multiplier = 72;
break;
case 'px':
multiplier = 96 / 72;
break;
case 'pc':
multiplier = 12;
break;
case 'em':
multiplier = 12;
break;
case 'ex':
multiplier = 6;
break;
default:
throw ('Invalid unit: ' + unit);
}
return points \* multiplier; }
4. 扩展
4.1 为什么使用大图片 Icon 打印出来还模糊
在理论上,一个位图像素应该对应一个物理像素,这样图片才能完美清晰地展示。在普通屏幕上,这没有问题,但在Retina屏幕上,由于位图像素点不足,图片会变得模糊。

所以,对于图片高清问题,比较好的方案是两倍图片(@2x)。
如:200x300(css pixel)img标签,就需要提供 400x600 的图片。
如此一来,位图像素点个数就是原来的 4 倍,在 retina 屏幕下,位图像素个数就可以跟物理像素个数
形成 1:1 的比例,图片自然就清晰了(这也解释了为啥视觉稿的画布需要 x2)
这里还有另一个问题,如果普通屏幕下,也用了两倍图片 ,会怎么样呢?
很明显,在普通屏幕下(dpr1),200X300(css pixel)img 标签,所对应的物理像素个数就是 200x300 个。而两倍图的位图像素。则是200x300*4,所以就出现一个物理像素点对应4个位图像素点,所以它的取色也只能通过一定的算法(显示结果就是一张只有原像素总数四分之一)
我们称这个过程叫做(downsampling),肉眼看上去虽然图片不会模糊,但是会觉得图片缺失一些锐利度。

通常在做移动端开发时,对于没那么精致的app,统一使用 @2x 就好了。

上面 100x100的图片,分别放在 100x100、50x50、25x25的 img 容器中,在 retina 屏幕下的显示效果
条码图,通过放大镜其实可以看出边界像素点取值的不同:
图片1,就近取色,色值介于红白之间,偏淡,图片看上去可能会模糊(可以理解为图片拉伸)。
图片2,没有就近取色,色值要么红,要么是白,看上去很清晰。
图片3,就近取色,色值位于红白之间,偏重,图片看上去有色差,缺失锐利度(可以理解为图片挤压)。
要想大的位图 icon 缩小时保证显示质量,那就需要这样设置:
img {
image-rendering:-moz-crisp-edges;
image-rendering:-o-crisp-edges;
image-rendering:-webkit-optimize-contrast;
image-rendering: crisp-edges;
-ms-interpolation-mode: nearest-neighbor;
-webkit-font-smooting: antialiased;
}
5. 总结
本文介绍了如何通过使用 html2Canvas 来打印高清图片,并解释了一些与图片有关的术语,包括英寸、像素、PPI 与 DPI、设备像素、分辨率等,同时逐步分析了 html2Canvas 打印高清图片的原理。
demo: github.com/jecyu/pdf-d…
参考资料