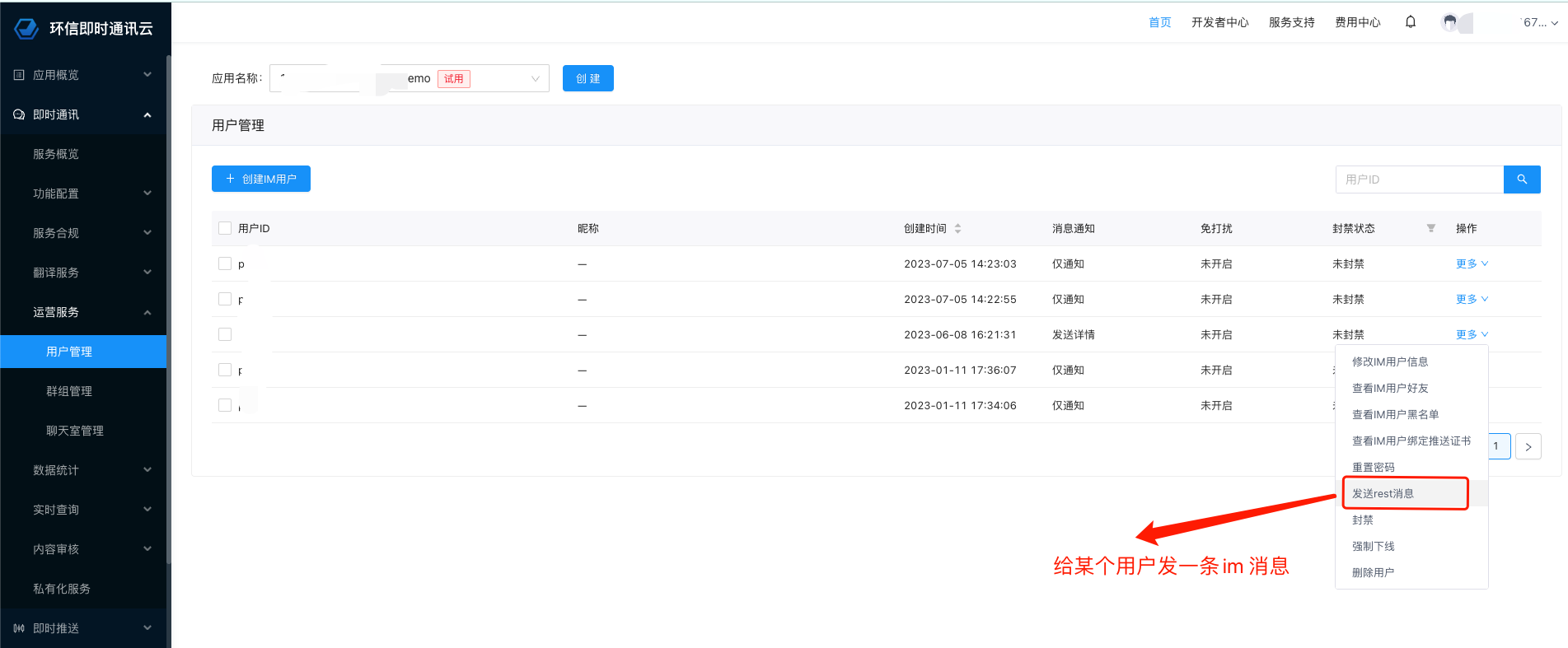
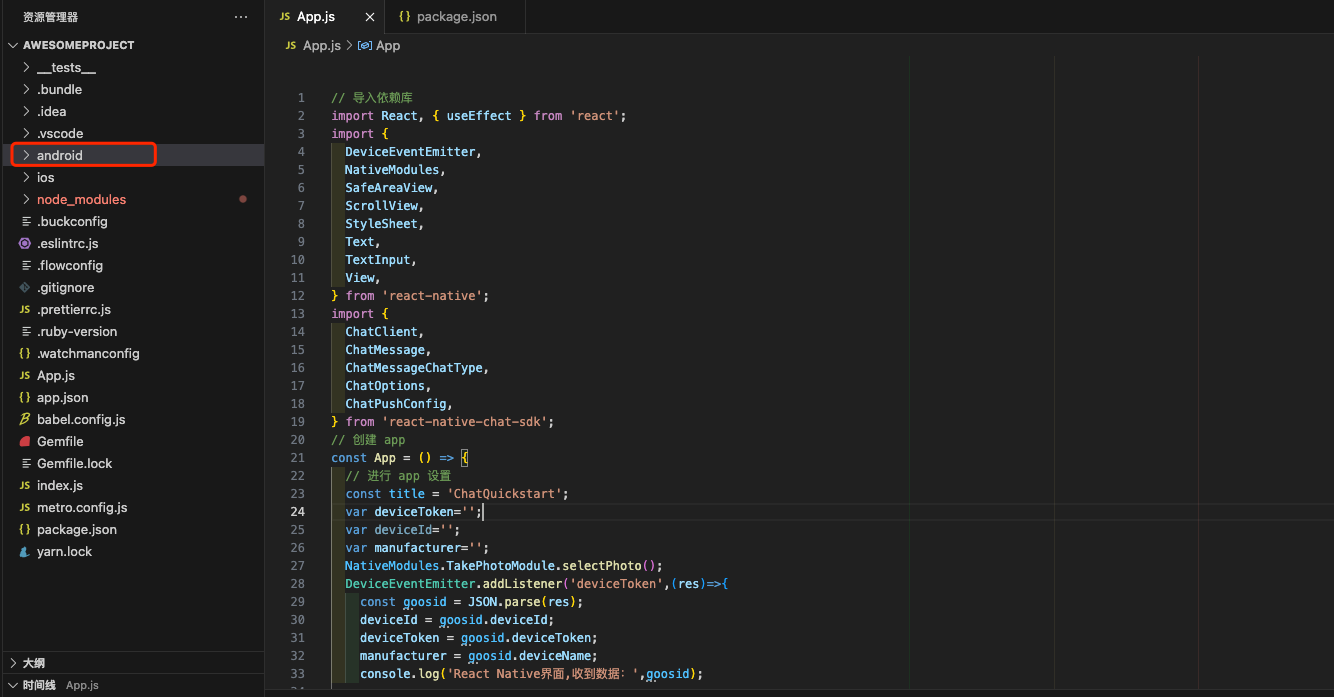
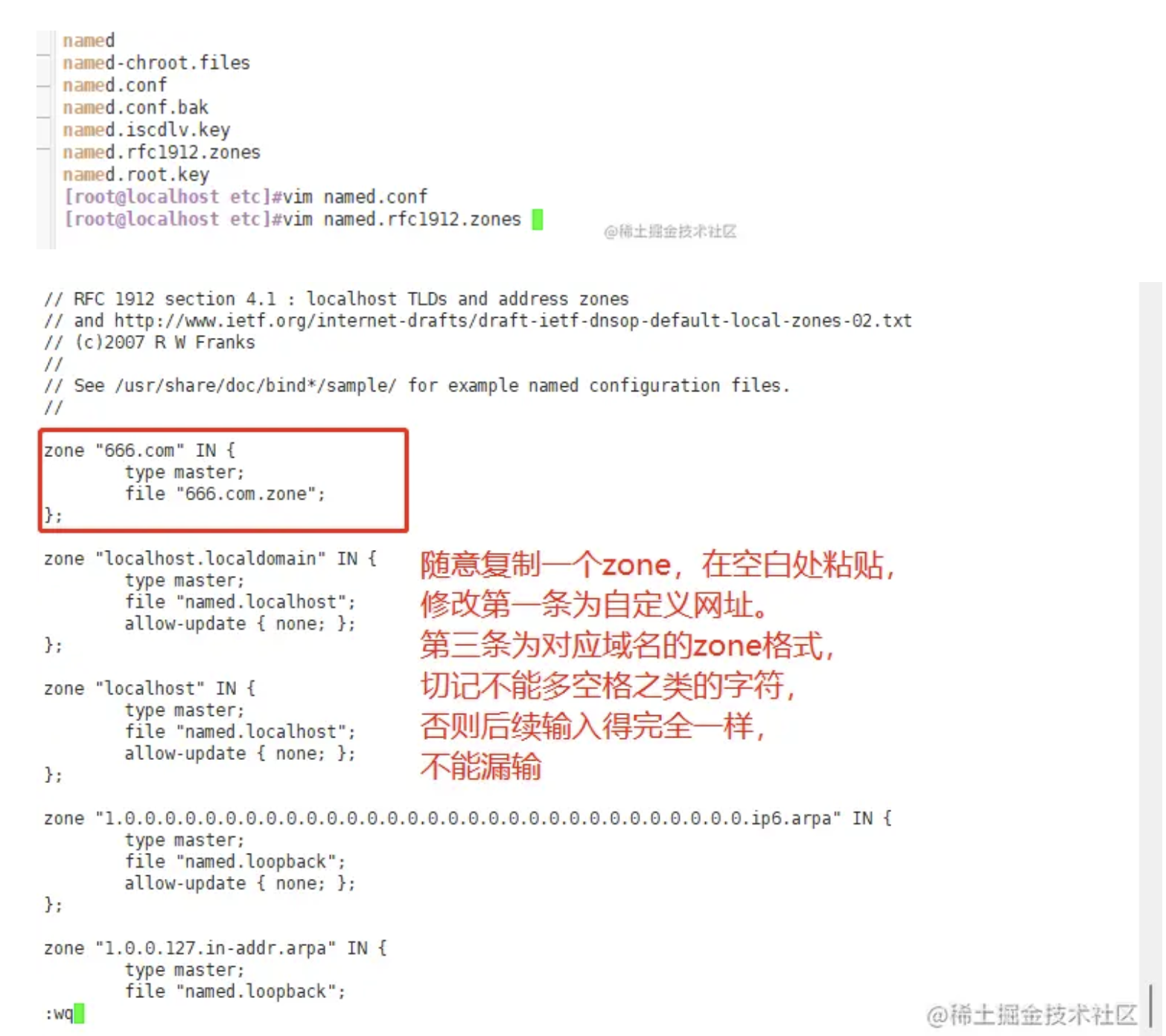
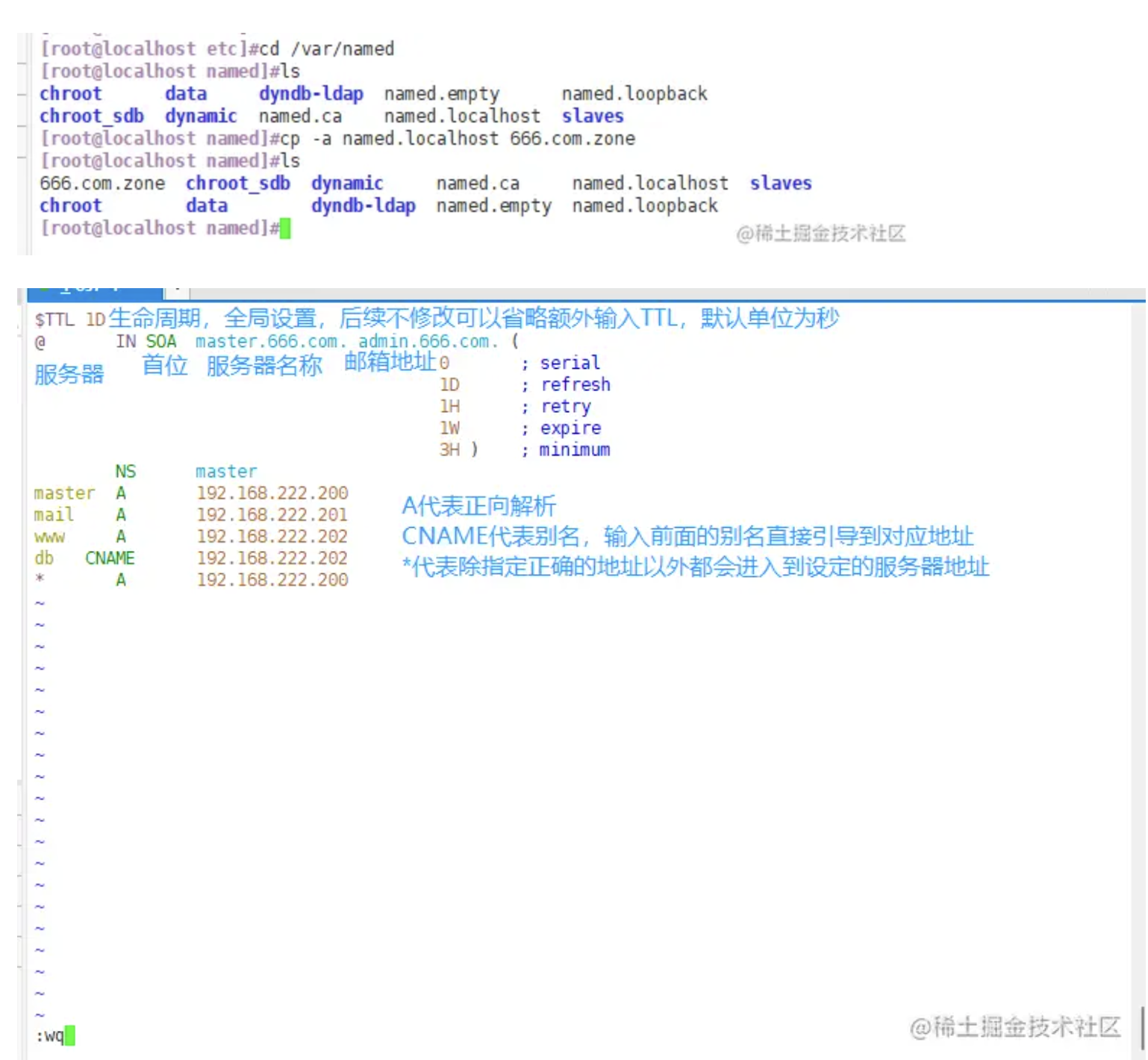
经过 Adobe 工程师多年来的努力,并与 Chrome 等浏览器供应商密切合作,通过 WebAssembly + Emscripten、Web Components + Lit、Service Workers + Workbox 和新的 Web API 的支持,终于在近期推出了 Web 版 Photoshop(photoshop.adobe.com),这在实现高度复杂和图形密集型软件在浏览器中运行方面具有重大意义!

本文就来看看 Photoshop 所使用的 Web 能力、进行的性能优化以及未来可能的发展方向。
愿景:在浏览器中使用 Photoshop
Adobe 的愿景就是将 Photoshop 带到浏览器中,让更多的用户能够方便地使用它进行图像编辑和平面设计。过去几十年,Photoshop一直是图像编辑和平面设计的黄金标准,但它只能在桌面上运行。现在,通过将它移植到浏览器中,就打开一个全新的世界。
Web 版 Photoshop 承诺了无处不在、无摩擦的访问体验。用户只需打开浏览器,就能即时开始使用 Photoshop 进行编辑和协作,而不需要安装任何软件。而且,由于Web是一个跨平台的运行环境,它可以屏蔽底层操作系统的差异,使Photoshop 能够在不同的平台上与用户进行互动。

另外,通过链接的功能,共享工作流变得更加方便。Photoshop文档可以通过URL直接访问。这样,创作者可以轻松地将链接发送给协作者,实现更加便捷的合作。
但是,实现这个愿景面临着重大的技术挑战,要求重新思考像Photoshop这样强度大的应用如何在Web上运行。
使用新的 Web 能力
最近几年出现了一些新的 Web 平台能力,可以通过标准化和实现最终使类似于Photoshop这样的应用成为可能。Adobe工程师们创新地利用了几个关键的下一代API。
使用 OPFS 实现高性能本地文件访问
Photoshop 操作涉及读写可能非常大的PSD文件。这要求有效访问本地文件系统,新的Origin Private File System API (OPFS) 提供了一个快速、特定于源的虚拟文件系统。
Origin Private File System (OPFS) 是一个提供了快速、安全的本地文件系统访问能力的 Web API。它允许Web应用以原生的方式读取和写入本地文件,而无需将文件直接暴露给Web环境。OPFS通过在浏览器中运行一个本地代理和使用特定的文件系统路径来实现文件的安全访问。
const opfsRoot = await navigator.storage.getDirectory();
使用 OPFS 可以快速创建、读取、写入和删除文件。例如:
// 创建文件
const file = await opfsRoot.getFileHandle('image.psd', { create: true });
// 获取读写句柄
const handle = await file.createSyncAccessHandle();
// 写入内容
handle.write(buffer);
// 读取内容
handle.read(buffer);
// 删除文件
await file.remove();
为了实现绝对快的同步操作,可以利用Web Workers获取 FileSystemSyncAccessHandle。
这个本地高性能文件系统在浏览器中实现Photoshop所需的高要求文件工作流程非常关键。它能够提供快速而可靠的文件读写能力,使得Photoshop能够更高效地处理大型文件。这种优化的文件系统为用户带来更流畅的图像编辑和处理体验。
释放WebAssembly的强大潜力
WebAssembly是重新在JavaScript中实现Photoshop计算密集型图形处理的关键因素之一。为了将现有的 C/C++ 代码库移植到 JavaScript 中,Adobe使用了Emscripten编译器生成WebAssembly模块代码。
在此过程中,WebAssembly具备了几个至关重要的能力:
- SIMD:使用SIMD向量指令可以加速像素操作和滤波。
- 异常处理:Photoshop的代码库中广泛使用C++异常。
- 流式实例化:由于Photoshop的WASM模块大小超过80MB,因此需要进行流式编译。
- 调试:Chrome浏览器在DevTools中提供的WebAssembly调试支持是非常有用的
- 线程:Photoshop使用工作线程进行并行执行任务,例如处理图像块:
// 线程函数
void* tileProcessor(void* data) {
// 处理图像块数据
return NULL;
}
// 启动工作线程
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, tileProcessor, NULL);
pthread_create(&thread2, NULL, tileProcessor, NULL);
// 等待线程结束
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
利用 P3 广色域
P3色域比sRGB色域更广阔,能够显示更多的颜色范围。然而长时间以来,在 Web 上sRGB一直是唯一的色域标准,其他更宽广的色域如P3并没有被广泛采用。

Photoshop利用新的color()函数和Canvas API来充分发挥P3色域的鲜艳度,从而实现更准确的颜色呈现。通过使用这些功能,Photoshop能够更好地展示P3色域所包含的更丰富、更生动的颜色。
color: color(display-p3 1 0.5 0)
Web Components 提供UI的灵活性
Photoshop是 Adobe Creative Cloud 生态系统中的一部分。通过使用基于 Lit[1] 构建的标准化 Web Components 策略,可以实现应用之间 UI 的一致性。
Lit 是一个构建快速、轻量级 Web Components 库。它的核心是一个消除样板代码的组件基础类,它提供了响应式状态、作用域样式和声明性模板系统,这些系统都非常小、快速且具有表现力。

Photoshop 的 UI 元素来自于Adobe 的 Web Components 库:Spectrum[2],该库实现了Adobe的设计系统。
Spectrum Web Components 具有以下特点:
- 默认支持无障碍访问:开发时考虑到现有和新兴浏览器规范,以支持辅助技术。
- 轻量级:使用 Lit Element 实现,开销最小。
- 基于标准:基于 Web Components 标准,如自定义元素和 Shadow DOM 构建。
- 框架无关:由于浏览器级别的支持,可以与任何框架一起使用。
此外,整个 Photoshop 应用都是使用基于 Lit 的 Web Components 构建的。Lit的模板和虚拟DOM差异化使得UI更新效率高。当需要时,Web Components 的封装性也使得轻松地集成其他团队的 React 代码成为可能。
总体而言,Web Components 的浏览器原生自定义元素结合Lit的性能,为Adobe构建复杂的 Photoshop UI 提供了所需的灵活性,同时保持了高效性。
优化 Photoshop 在浏览器中的性能
尽管新的 Web Components 提供了基础,但像Photoshop这样的密集型桌面应用仍然需要进行广泛的跟踪和性能优化工作,以提供一流的在线体验。

使用 Service Workers 缓存资源和代码
Service Workers 可以让 Web 应用在用户首次访问后将其代码和资源等缓存到本地,以便在后续加载时可以更快地呈现。尽管 Photoshop 目前还不支持完全离线使用,但它已经利用了 Service Workers 来缓存其 WebAssembly 模块、脚本和其他资源,以提高加载速度。

Chrome DevTools Application 面板 > Cache storage 展示了 Photoshop 预缓存的不同类型资源,包括在Web上进行代码拆分后本地缓存的许多JavaScript代码块。这些被本地缓存的JavaScript代码块使得后续的加载非常快速。这种缓存机制对于加载性能有着巨大的影响。在第一次访问之后,后续的加载通常非常快速。
Adobe 使用了 Workbox[3] 库,以更轻松地将 Service Worker 缓存集成到构建过程中。
当资源从Service Worker缓存中返回时,V8引擎使用一些优化策略:
- 安装期间缓存的资源会被立即进行编译,并立即进行代码缓存,以实现一致且快速的性能表现。
- 通过Cache API 进行缓存的资源,在第二次加载时会经过优化的缓存处理,比普通缓存更快速。
- V8能够根据资源的缓存重要性进行更积极的编译优化。
这些优化措施使得 Photoshop 庞大的缓存 WebAssembly 模块能够获得更高的性能。

流式编译和缓存大型WebAssembly模块
Photoshop的代码库需要多个大型的WebAssembly模块,其中一些大小超过80MB。V8和Chrome中的流式编译支持高效处理这些庞大的模块。
此外,当第一次从 Service Worker 请求 WebAssembly 模块时,V8会生成并存储一个优化版本以供缓存使用,这对于 Photoshop 庞大的代码尺寸至关重要。
并行图形操作的多线程支持
在 Photoshop 中,许多核心图像处理操作(如像素变换)可以通过在多个线程上进行并行执行来大幅提速。WebAssembly 的线程支持能够利用多核设备进行计算密集型图形任务。
这使得 Photoshop 可以将性能关键的图像处理函数移植到 WebAssembly,并使用与桌面端相同的多线程方法来实现并行处理。
通过 WebAssembly 调试优化
对于开发过程中的诊断和解决性能瓶颈来说,WebAssembly 调试支持非常重要。Chrome DevTools 具备分析 WASM 代码、设置断点和检查变量等一系列功能,这使得WASM的调试与JavaScript有着相同的可调试性。

将设备端机器学习与 TensorFlow.js 集成
Photoshop 最近的 Web 版本包括了使用 TensorFlow.js[4] 提供 AI 功能的能力。在设备上运行模型而不是在云端运行,可以提高隐私、延迟和成本效益。
TensorFlow.js 是一款面向JavaScript开发者的开源机器学习库,能够在浏览器客户端中运行。它是 Web 机器学习方案中最成熟的选项,支持全面的 WebGL 和 WebAssembly 后端算子,并且未来还将可选用WebGPU后端以实现更快的性能,以适应新的Web标准。
“选择主题”功能利用机器学习技术,在图像中自动提取主要前景对象,大大加快了复杂选区的速度。
下面是一幅日落的插图,想将它改成夜晚的场景。使用了"选择主题"和 AI prompt 来尝试选择最感兴趣的区域以进行更新。

Photoshop 能够根据 AI prompt 生成一幅更新后的插图:

根据 AI prompt,Photoshop 生成了一幅基于此的更新插图:

该模型已从 TensorFlow 转换为 TensorFlow.js 以启用本地执行:
// 加载选择主题模型
const model = wait tf.loadGraphModel('select_subject.json');
// 对图像张量运行推理
const {mask, background} = model.execute(imgTensor);
// 从掩码中细化选择
Adobe 和 Google 合作通过为 Emscripten 开发代理 API 来解决 Photoshop 的 WebAssembly 代码和 TensorFlow.js 之间的同步问题。这使的框架之间可以无缝集成。
由于Google团队通过其各种支持的后端(WebGL,WASM,Web GPU)改进了 TensorFlow.js 的硬件执行性能,这使模型的性能提高了30%到200%,在浏览器中能够实现接近实时的性能。
关键模型针对性能关键的操作进行了优化,例如Conv2D。Photoshop 可以根据性能需求选择在设备上还是在云端运行模型。
Photoshop 未来在 Web 上的发展
Photoshop 在 Web 上的普遍应用是一个巨大的里程碑,但这只是可能性的冰山一角。
随着浏览器厂商不断发展和完善标准和性能,Photoshop 将继续在 Web 上扩展,通过渐进增强来上线更多功能。而且,Photoshop 只是一个开始。Adobe计划在网络上积极构建其整个 Creative Cloud 套件,在浏览器中解锁更多复杂的设计应用。
Adobe 与浏览器工程师的合作将持续推动 Web 平台的进步,通过提升标准和改进性能,开发出更具雄心的应用。前方等待着我们的,是充满无限可能性的未来!
Photoshop 网页版目前可以在以下桌面版浏览器上使用:
- Chrome 102+
- Edge 102+
- Firefox 111+
来源:juejin.cn/post/7285942684174778431






















![Screenshot_20230927-131444[1].png](https://www.imgeek.net/uploads/article/20230928/59c85cb06624536f820d632d3e12813d.jpg)