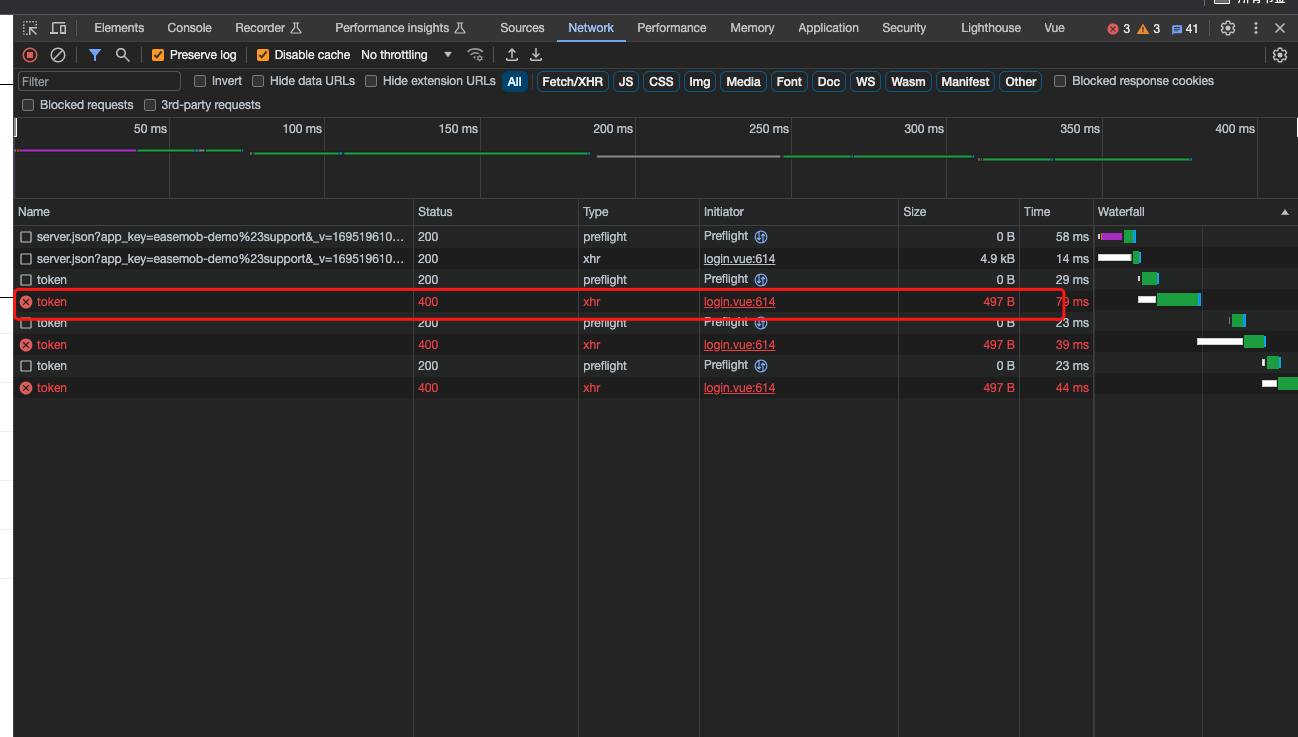
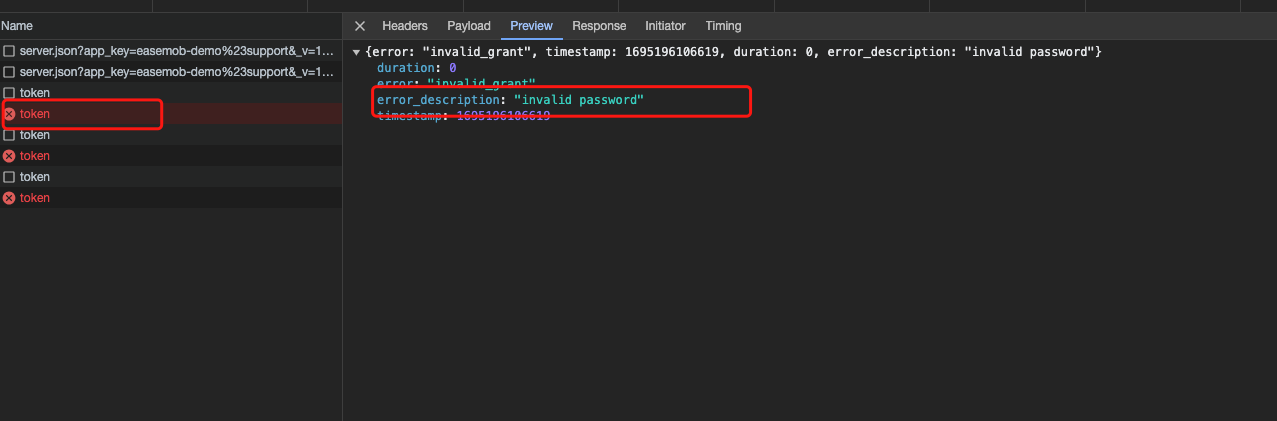
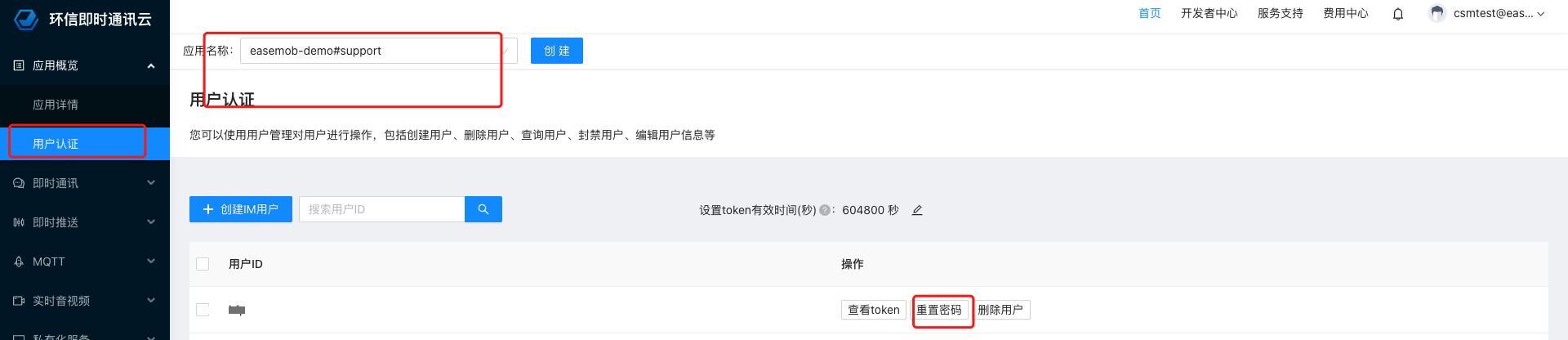
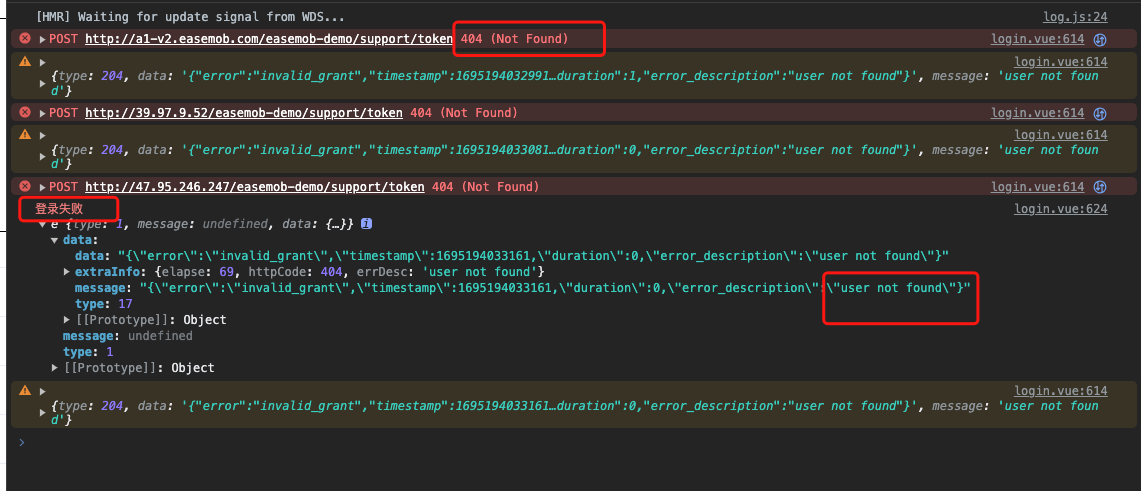
前言
H5页面具有跨平台、开发容易、上线不需要跟随App的版本等优点,但H5页面也有体验不如native好、没有native稳定等问题。所以目前大部分App都是使用Hybrid混合开发的。
当然有了H5页面就少不了H5与native交互,交互就会用到bridge的能力了。WebViewJavascriptBridge是一个native与JS进行消息互通的第三方库,本章会简单解析一下WebViewJavascriptBridge的源码和实现原理。
通讯原理
JavaScriptCore
JavaScriptCore作为iOS的JS引擎为原生编程语言OC、Swift 提供调用 JS 程序的动态能力,还能为 JS 提供原生能力来弥补前端所缺能力。
iOS中与JS通讯使用的是JavaScriptCore库,正是因为JavaScriptCore这种起到的桥梁作用,所以也出现了很多使用JavaScriptCore开发App的框架,比如RN、Weex、小程序、Webview Hybrid等框架。
如图:
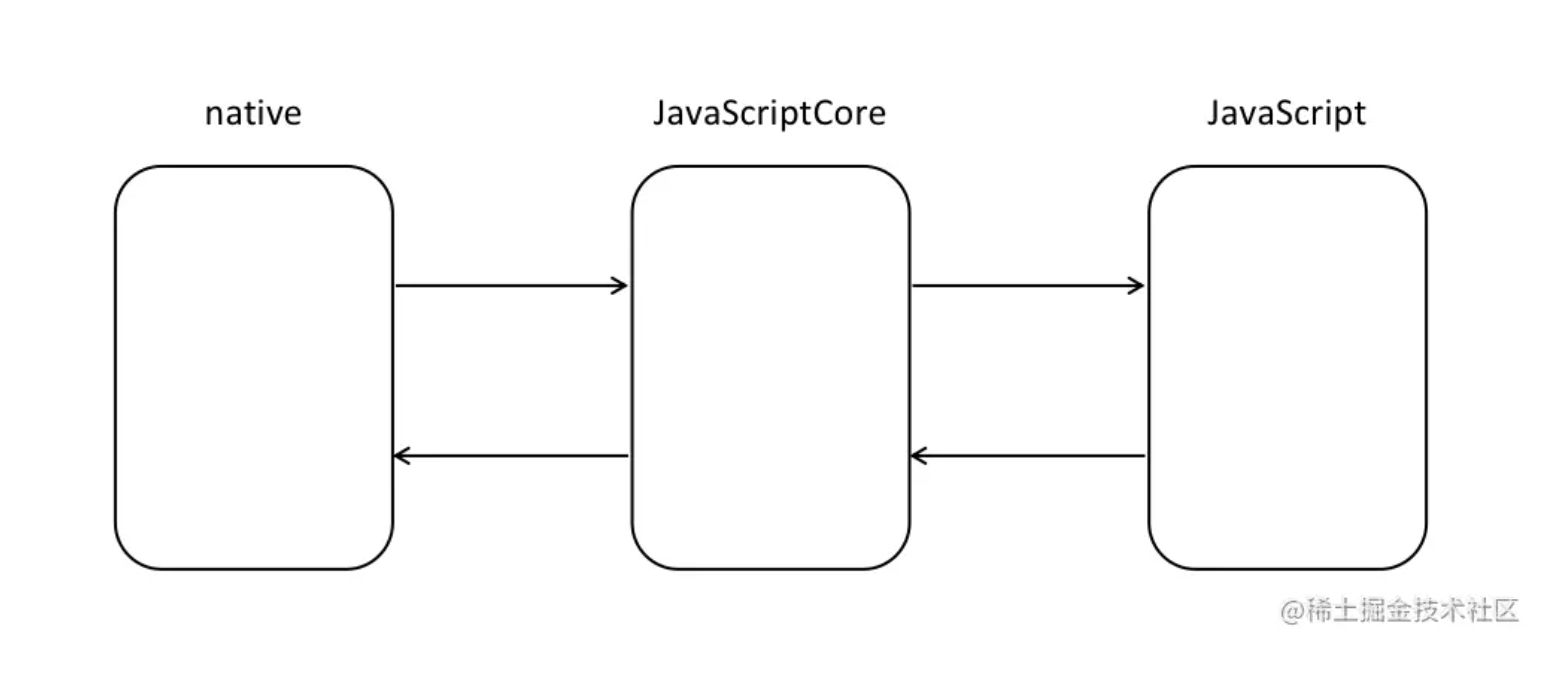
当然JS引擎不光有苹果的JavaScriptCore,谷歌有V8引擎、Mozilla有SpiderMoney
JavaScriptCore本章只简单介绍,后面主要解析WebViewJavascriptBridge。因为uiwebview已经不再使用了,所以后面提到的webview都是wkwebview,demo也是以wkwebview进行解析。
源码解析
代码结构
除了引擎层外,还需要native、h5和WebViewJavascriptBridge三层才能完成一整个信息通路。WebViewJavascriptBridge就是中间那个负责通信的SDK。
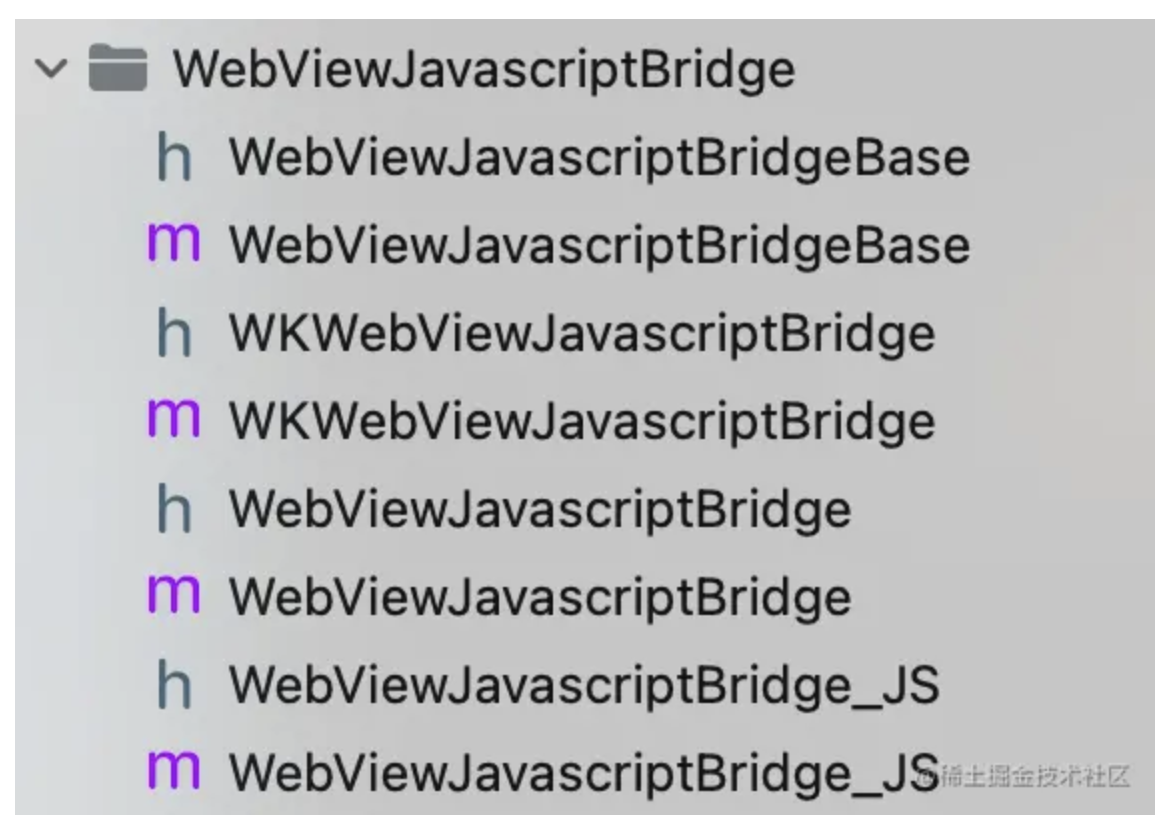
WebViewJavascriptBridge的核心类主要包含几个:
- WebViewJavascriptBridge_JS:是一个JS的字符串,作用是JS环境的Bridge初始化和处理。负责接收native发给JS的消息,并且把JS环境的消息发送给native。
- WKWebViewJavascriptBridge/WebViewJavascriptBridge:主要负责WKWebView和UIWebView相关环境的处理,并且把native环境的消息发送给JS环境。
- WebViewJavascriptBridgeBase:主要实现了native环境的Bridge初始化和处理。
初始化
WebViewJavascriptBridge是如何完成初始化的呢,首先要有webview容器,所以要对webview容器进行初始化,设置代理,初始化WebViewJavascriptBridge对象,加载URL。
WKWebView* webView = [[NSClassFromString(@"WKWebView") alloc] initWithFrame:self.view.bounds];
webView.navigationDelegate = self;
[self.view addSubview:webView];
// 开启打印
[WebViewJavascriptBridge enableLogging];
// 创建bridge对象
_bridge = [WebViewJavascriptBridge bridgeForWebView:webView];
// 设置代理
[_bridge setWebViewDelegate:self];
这里加载的就是JSBridgeDemoApp这个本地的html文件。
NSString* htmlPath = [[NSBundle mainBundle] pathForResource:@"JSBridgeDemoApp" ofType:@"html"];
NSString* appHtml = [NSString stringWithContentsOfFile:htmlPath encoding:NSUTF8StringEncoding error:nil];
NSURL *baseURL = [NSURL fileURLWithPath:htmlPath];
[webView loadHTMLString:appHtml baseURL:baseURL];
再看一下JSBridgeDemoApp这个html文件。
function setupWebViewJavascriptBridge(callback) {
// 第一次调用这个方法的时候,为false
if (window.WebViewJavascriptBridge) { return callback(WebViewJavascriptBridge); }
// 第一次调用的时候,为false
if (window.WVJBCallbacks) { return window.WVJBCallbacks.push(callback); }
// 把callback对象赋值给对象
window.WVJBCallbacks = [callback];
// 加载WebViewJavascriptBridge_JS中的代码
// 相当于实现了一个到https://__bridge_loaded__的跳转
var WVJBIframe = document.createElement('iframe');
WVJBIframe.style.display = 'none';
WVJBIframe.src = 'https://__bridge_loaded__';
document.documentElement.appendChild(WVJBIframe);
setTimeout(function() { document.documentElement.removeChild(WVJBIframe) }, 0)
}
// 驱动所有hander的初始化
setupWebViewJavascriptBridge(function(bridge) {
...
}
在JSBridgeDemoApp的script标签下,声明了一个名为setupWebViewJavascriptBridge的方法,在加载html后直接进行了调用。
setupWebViewJavascriptBridge方法中最核心的代码是:
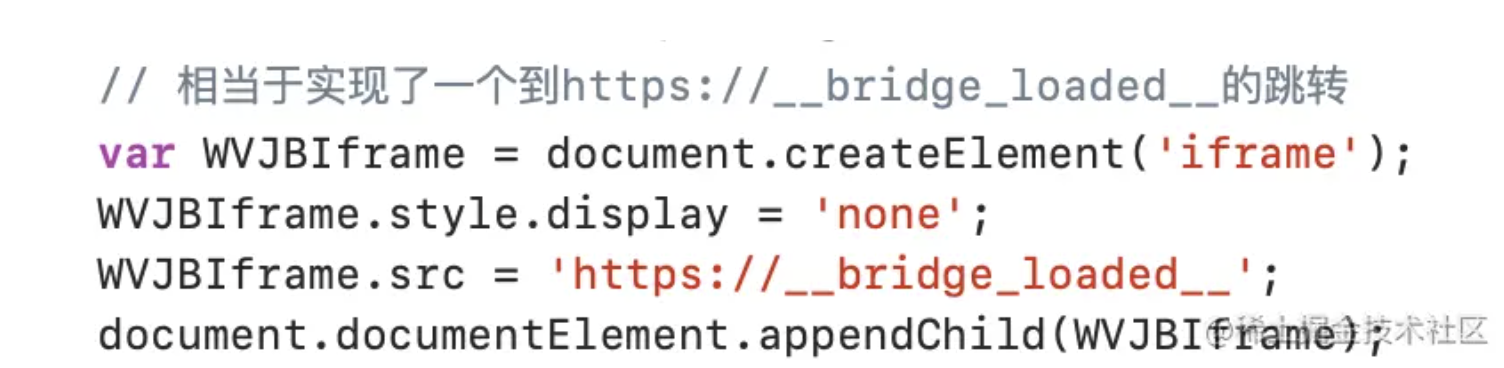
创建一个iframe标签,然后加载了链接为 https://bridge_loaded 的内容。相当于在当前页面内容实现了一个到 https://bridge_loaded 的内部跳转。
ps:iframe标签用于在网页内显示网页,也使用iframe作为链接的目标。
html文件内部实现了这个跳转后native端是如何监听的呢,在webview的代理里有一个方法:decidePolicyForNavigationAction
这个代理方法的作用是只要有webview跳转,就会调用到这个方法。代码如下:
// 只要webview有跳转,就会调用webview的这个代理方法
- (void)webView:(WKWebView *)webView decidePolicyForNavigationAction:(WKNavigationAction *)navigationAction decisionHandler:(void (^)(WKNavigationActionPolicy))decisionHandler {
if (webView != _webView) { return; }
NSURL *url = navigationAction.request.URL;
__strong typeof(_webViewDelegate) strongDelegate = _webViewDelegate;
// 如果是WebViewJavascriptBridge发送或者接收消息,则特殊处理。否则按照正常流程处理
if ([_base isWebViewJavascriptBridgeURL:url]) {
if ([_base isBridgeLoadedURL:url]) {
// 是否是 https://__bridge_loaded__ 这种初始化加载消息
[_base injectJavascriptFile];
} else if ([_base isQueueMessageURL:url]) {
// https://__wvjb_queue_message__
// 处理WEB发过来的消息
[self WKFlushMessageQueue];
} else {
[_base logUnkownMessage:url];
}
decisionHandler(WKNavigationActionPolicyCancel);
return;
}
// webview的正常代理执行流程
...
从上面的代码中可以看到,如果监听的webview跳转不是WebViewJavascriptBridge发送或者接收消息就正常执行流程,如果是WebViewJavascriptBridge发送或者接收消息则对此拦截不跳转,并且针对消息进行处理。
当消息url是https://bridge_loaded 的时候,会去注入WebViewJavascriptBridge_js到JS中:
// 将WebViewJavascriptBrige_JS中的方法注入到webview中并且执行
- (void)injectJavascriptFile {
NSString *js = WebViewJavascriptBridge_js();
// 把javascript代码注入webview中执行
[self _evaluateJavascript:js];
// javascript环境初始化完成以后,如果有startupMessageQueue消息,则立即发送消息
if (self.startupMessageQueue) {
NSArray* queue = self.startupMessageQueue;
self.startupMessageQueue = nil;
for (id queuedMessage in queue) {
[self _dispatchMessage:queuedMessage];
}
}
}
[self _evaluateJavascript:js];就是执行webview中的evaluateJavaScript:方法。把JS写入webview。所以执行完此处代码JS当中就有bridge这个对象了。初始化完成。
总结:在加载h5页面后会调用setupWebViewJavascriptBridge方法,该方法内创建了一个iframe加载内容为 https://bridge_loaded ,该消息被decidePolicyForNavigationAction监听到,然后执行injectJavascriptFile去读取WebViewJavascriptBridge_js将WebViewJavascriptBridge对象注入到当前h5中。
WebViewJavascriptBridge 对象
整个WebViewJavascriptBridge_js文件其实就是一个字符串形式的js代码,里面包含WebViewJavascriptBridge和相关bridge调用的方法。
// 初始化Bridge对象,OC可以通过WebViewJavascriptBridge来调用JS里面的各种方法
window.WebViewJavascriptBridge = {
registerHandler: registerHandler, // JS中注册方法
callHandler: callHandler, // JS中调用OC的方法
disableJavscriptAlertBoxSafetyTimeout: disableJavscriptAlertBoxSafetyTimeout,
_fetchQueue: _fetchQueue, // 把消息转换成JSON串
_handleMessageFromObjC: _handleMessageFromObjC // OC调用JS的入口方法
};
WebViewJavascriptBridge对象里核心的方法有:
- registerHandler:JS中注册方法
- callHandler: JS中调用native的方法
- _fetchQueue: 把消息转换成JSON字符串
- _handleMessageFromObjC:native调用JS的入口方法
当初始化完成后,WebViewJavascriptBridge对象和对象里的方法就已经存在并且可用了。
JS和native是如何相互传递消息的呢?从上面的代码中可以看到如果JS想要发送消息给native就会调用callHandler方法;如果native想要调用JS方法那JS侧就必须先注册一个registerHandler方法。
相对应的我们看一下native侧是如何与JS传递消息的,其实接口标准是一致的,native调JS的方法使用callHandler方法:
id data = @{ @"dataFromOC": @"aaaa!" };
[_bridge callHandler:@"OCToJSHandler" data:data responseCallback:^(id response) {
NSLog(@"JS回调的数据是:%@", response);
}];
JS调native方法在native侧就必须先注册一个registerHandler方法:
// 注册事件(h5调App)
[_bridge registerHandler:@"JSTOOCCallback" handler:^(id data, WVJBResponseCallback responseCallback) {
NSLog(@"JSTOOCCallback called: %@", data);
responseCallback(@"Response from JSTOOCCallback");
}];
也就是说native像JS发送消息的话,JS侧要先注册该方法registerHandler,native侧调用callHandler;
JS像native发送消息的话,native侧要先注册registerHandler,JS侧调用callHandler。这样才能完成双端通信。
如图:
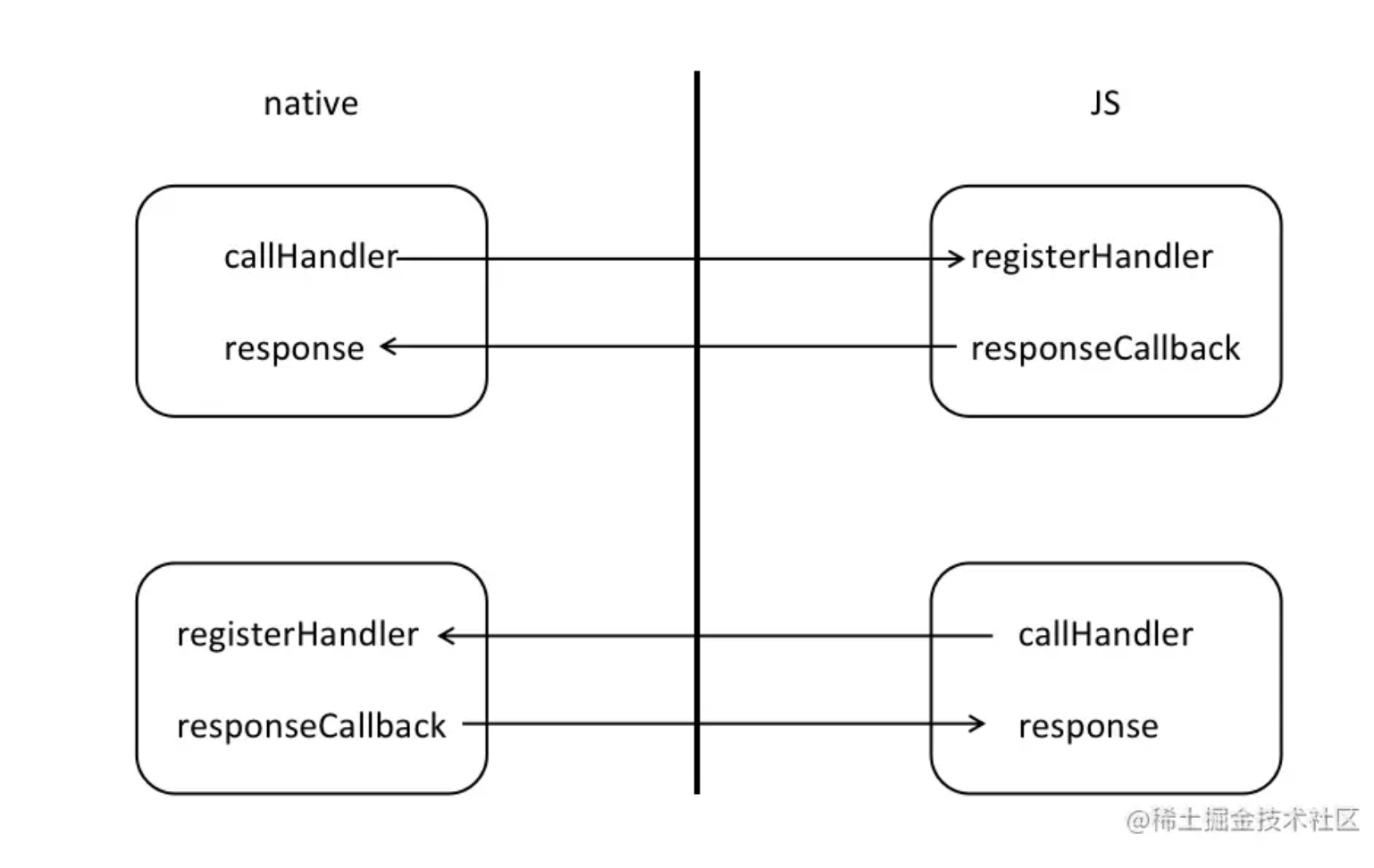
native向JS发送消息
现在要从native侧向JS侧发送一条消息,方法名为:"OCToJSHandler",并且拿到JS的回调,具体实现细节如下:
JS侧
native向JS发送数据,首先要在JS侧去注册这个方法:
bridge.registerHandler('OCToJSHandler', function(data, responseCallback) {
...
})
这个registerHandler的实现在WebViewJavascriptBridge_JS是:
// web端注册一个消息方法,将注册的方法存储起来
function registerHandler(handlerName, handler) {
messageHandlers[handlerName] = handler;
}
就是将这个注册的方法存储到messageHandlers这个map中,key为方法名称,value为function(data, responseCallback) {}这个方法。
native侧
native侧调用bridge的callHandler方法,传参为data和一个callback回调
id data = @{ @"dataFromOC": @"aaaa!" };
[_bridge callHandler:@"OCToJSHandler" data:data responseCallback:^(id response) {
NSLog(@"JS回调的数据是:%@", response);
}];
接下来会走到WebViewJavascriptBridgeBase的-sendData: responseCallback: handlerName:方法,该方法中将"data"和"handlerName"存入到一个message字典中,如果存在callback会生成一个callbackId一并存入到message字典中,并且将该回调存入到responseCallbacks中,key为callbackId,value为这个callback。代码如下:
// 所有信息存入字典
NSMutableDictionary* message = [NSMutableDictionary dictionary];
if (data) {
message[@"data"] = data;
}
if (responseCallback) {
NSString* callbackId = [NSString stringWithFormat:@"objc_cb_%ld", ++_uniqueId];
self.responseCallbacks[callbackId] = [responseCallback copy];
message[@"callbackId"] = callbackId;
}
if (handlerName) {
message[@"handlerName"] = handlerName;
}
[self _queueMessage:message];
将message存储到队列等待执行,执行该条message时会先将message进行序列化,序列化完成后将message拼接到字符串WebViewJavascriptBridge._handleMessageFromObjC('%@');中,然后执行_evaluateJavascript执行该js方法。
// 把OC消息序列化、并且转化为JS环境的格式,然后在主线程中调用_evaluateJavascript
- (void)_dispatchMessage:(WVJBMessage*)message {
NSString *messageJSON = [self _serializeMessage:message pretty:NO];
NSString* javascriptCommand = [NSString stringWithFormat:@"WebViewJavascriptBridge._handleMessageFromObjC('%@');", messageJSON];
[self _evaluateJavascript:javascriptCommand];
}
_handleMessageFromObjC方法会将messageJSON传递给_dispatchMessageFromObjC进行处理。
首先将messageJSON进行解析,根据handlerName取出存储在messageHandlers中的方法。如果该message中存在callbackId,将callbackId作为参数生成一个回调放到responseCallback中。
代码如下:
function _doDispatchMessageFromObjC() {
// 解析发送过来的JSON
var message = JSON.parse(messageJSON);
var messageHandler;
var responseCallback;
// 主动调用
// 如果有callbackid
if (message.callbackId) {
// 将callbackid当做callbackResponseId再返回回去
var callbackResponseId = message.callbackId;
responseCallback = function(responseData) {
// 把消息从JS发送到OC,执行具体的发送操作
_doSend({ handlerName:message.handlerName, responseId:callbackResponseId, responseData:responseData });
};
// 获取JS注册的函数,取出消息里的handlerName
var handler = messageHandlers[message.handlerName];
// 调用JS中的对应函数处理
handler(message.data, responseCallback);
}
}
handler方法其实就是名为"OCToJSHandler"的方法,这时就走到了registerHandler里的那个function(data, responseCallback) {}方法了。我们看一下方法内部的具体实现:
bridge.registerHandler('OCToJSHandler', function(data, responseCallback) {
// OC中传过来的数据
log('从OC传过来的数据是:', data)
// JS返回数据
var responseData = { 'dataFromJS':'bbbb!' }
responseCallback(responseData)
})
data就是从native传过来的数据,responseCallback就是保存的回调,然后又生成了新数据作为参数给到了这个回调。
responseCallback的实现是:
responseCallback = function(responseData) {
// 把消息从JS发送到OC,执行具体的发送操作
_doSend({ handlerName:message.handlerName, responseId:callbackResponseId, responseData:responseData });
};
将该方法的handlerName、生成的callbackResponseId(也就是callbackId)以及JS返回的数据一起给到_doSend方法。
_doSend方法将message存储到sendMessageQueue消息列表中,并使用messagingIframe加载了一次https://wvjb_queue_message。
// 把消息从JS发送到OC,执行具体的发送操作
function _doSend(message, responseCallback) {
// 把消息放入消息列表
sendMessageQueue.push(message);
// 发出js对oc的调用,让webview执行跳转操作,可以在decidePolicyForNavigationAction:中拦截到js发给oc的消息
messagingIframe.src = CUSTOM_PROTOCOL_SCHEME + '://' + QUEUE_HAS_MESSAGE;
}
这时webview的监听方法decidePolicyForNavigationAction监听到了https://wvjb_queue_message 消息后还是执行WebViewJavascriptBridge._fetchQueue()去取数据,取到数据后根据responseId当初在_responseCallbacks中存储的callback,然后执行callback、移除responseCallbacks中的数据。到此为止,整个native向JS发送消息的过程就完成了。
总结:
- JS中先调用registerHandler将方法存储到messageHandlers中
- native调用callHandler:方法,将消息内容存储到message中,回调存储到responseCallbacks中。
- 将message消息序列化通过_evaluateJavascript方法执行_handleMessageFromObjC
- 将message解析,通过message.handlerName从messageHandlers取出该方法;根据message.callbackId生成回调
- 执行该方法,回调
JS向native发送消息
从JS向native发消息其实和native向JS发消息的接口层面是差不多的。
native侧
native侧首先要注册一个JSTOOCCallback方法
[_bridge registerHandler:@"JSTOOCCallback" handler:^(id data, WVJBResponseCallback responseCallback) {
responseCallback(@"Response from JSTOOCCallback");
}];
该方法也同样是将该方法的callback存储起来,存储到messageHandlers当中,key就是方法名"JSTOOCCallback",value就是callback。
JS侧
JS侧会调用callHandler方法:
// 调用oc中注册的那个方法
bridge.callHandler('JSTOOCCallback', {'foo': 'bar'}, function(response) {
log('JS 取到的回调是:', response)
})
这个callHandler方法同样会调用_doSend方法:将callback存储到responseCallbacks中,key为callbakid;将消息存储到sendMessageQueue中;messagingIframe执行https://wvjb_queue_message
native的decidePolicyForNavigationAction方法监听到该消息后同样通过WebViewJavascriptBridge._fetchQueue()去取消息。
根据callbackId创建一个responseCallback,根据message的handlerName从messageHandlers取出该回调,然后执行:
WVJBResponseCallback responseCallback = NULL;
NSString* callbackId = message[@"callbackId"];
if (callbackId) {
responseCallback = ^(id responseData) {
if (responseData == nil) {
responseData = [NSNull null];
}
WVJBMessage* msg = @{ @"responseId":callbackId, @"responseData":responseData };
[self _queueMessage:msg];
};
} else {
responseCallback = ^(id ignoreResponseData) {
// Do nothing
};
}
WVJBHandler handler = self.messageHandlers[message[@"handlerName"]];
handler(message[@"data"], responseCallback);
调用完这个方法后,该消息已经收到,然后将回调的内容回调给JS。
通过上面的代码可以看到,回调JS的内容就是callbackId和responseData生成的message,调用_queueMessage方法。
_queueMessage方法上面已经看过了,就是序列化消息、加入队列、执行WebViewJavascriptBridge._handleMessageFromObjC('%@');方法。
JS收到该消息后,处理返回的消息,从responseCallbacks中根据message中的responseId取出callback并且执行。最后删除responseCallbacks中的数据,JS向native发送数据就完成了。
总结:
- native侧调用registerHandler方法注册方法,方法名为JSTOOCCallback,将消息存储到messageHandlers中,key为方法名,value为callback。
- JS侧调用callHandler方法:将responseCallback存储到responseCallbacks中;将message存储到sendMessageQueue中;messagingIframe执行 http://wvjb_queue_message
- native侧监听到该消息后调用WebViewJavascriptBridge._fetchQueue()去取数据
- 根据handlerName从messageHandlers中取出该callback;根据callbackId创建callback对象作为参数放到handlerName的方法中;执行该回调。
总结
综上,WebViewJavascriptBridge的核心流程就分析完了,最核心的点是JS通过加载iframe来通知native侧;native侧通过evaluateJavaScript方法去执行JS。
从整个SDK来看,设计的非常好,值得借鉴学习:
- 使用外观模式统一调用接口,比如初始化WebViewJavascriptBridge的时候,不需要关心使用方使用的是UIWebView还是WKWebView,内部已经处理好了。
- 接口统一,不管是native侧还是JS侧,调用方法就是callHandler、注册方法就是registerHandler,不需要关注内部实现,使用非常方便。
- 代码简洁,逻辑清晰,层次分明。从类的分布就能很清晰的看出各自的功能是什么。
- 职责单一,比如decidePolicyForNavigationAction方法只负责监听事件、_fetchQueue是负责把消息转换成JSON字符串返回、_doSend是发送消息到native、_dispatchMessageFromObjC是负责处理从OC返回的消息等。虽然decidePolicyForNavigationAction也能接收消息,但这样就不会这么精简了。
- 扩展性好,目前decidePolicyForNavigationAction虽然只有初始化和发消息两个事件,如果有其他事件还可以再扩展,这也得益于方法设计的职责单一,扩展对原有方法影响会很小。