
| 定时任务方式 | 优点 | 缺点 | 使用场景 | 所用的API |
|---|---|---|---|---|
| 普通线程sleep的方式 | 简单易用,可用于一般的轮询Polling | 不精确,不可靠,容易被系统杀死或者休眠 | 需要在App内部执行短时间的定时任务 | Thread.sleep(long) |
| Timer定时器 | 简单易用,可以设置固定周期或者延迟执行的任务 | 不精确,不可靠,容易被系统杀死或者休眠 | 需要在App内部执行短时间的定时任务 | Timer.schedule(TimerTask,long) |
| ScheduledExecutorService | 灵活强大,可以设置固定周期或者延迟执行的任务,并支持多线程并发 | 不精确,不可靠,容易被系统杀死或者休眠 | 需要在App内部执行短时间且需要多线程并发的定时任务 | Executors.newScheduledThreadPool(int).schedule(Runnable,long,TimeUnit) |
| Handler中的postDelayed方法 | 简单易用,可以设置延迟执行的任务,并与UI线程交互 | 不精确,不可靠,容易被系统杀死或者休眠 | 需要在App内部执行短时间且需要与UI线程交互的定时任务 | Handler.postDelayed(Runnable,long) |
| Service + AlarmManger + BroadcastReceiver | 可靠稳定,可以设置精确或者不精确的闹钟,并在后台长期运行 | 需要声明相关权限,并受系统时间影响 | 需要在App外部执行长期且对时间敏感的定时任务 | AlarmManager.set(int,PendingIntent), BroadcastReceiver.onReceive(Context,Intent), Service.onStartCommand(Intent,int,int) |
| WorkManager | 可靠稳定,不受系统时间影响,并可以设置多种约束条件来执行任务 | 需要添加依赖,并不能保证准时执行 | 需要在App外部执行长期且对时间不敏感且需要满足特定条件才能执行的定时任务 | WorkManager.enqueue(WorkRequest), Worker.doWork() |
| RxJava | 简洁、灵活、支持多线程、支持背压、支持链式操作 | 学习曲线较高、内存占用较大 | 需要处理复杂的异步逻辑或数据流 | io.reactivex:rxjava:2.2.21 |
| CountDownTimer | 简单易用、不需要额外的线程或handler | 不支持取消或重置倒计时、精度受系统时间影响 | 需要实现简单的倒计时功能 | android.os.CountDownTimer |
| 协程+Flow | 语法简洁、支持协程作用域管理生命周期、支持流式操作和背压 | 需要引入额外的依赖库、需要熟悉协程和Flow的概念和用法 | 需要处理异步数据流或响应式编程 | kotlinx-coroutines-core:1.5.0 |
使用downTo关键字和Flow实现一个定时任务 | 1、可以使用简洁的语法创建一个倒数的范围 2 、可以使用Flow异步地发射和收集倒数的值3、可以使用onEach等操作符对倒数的值进行处理或转换 | 1、需要注意倒数的范围是否包含0,否则可能会出现偏差 2、需要注意倒数的间隔是否与delay函数的参数一致,否则可能会出现不准确 3、需要注意取消或停止Flow的时机,否则可能会出现内存泄漏或资源浪费 | 1、适合于需要实现简单的倒计时功能,例如显示剩余时间或进度 2、适合于需要在倒计时过程中执行一些额外的操作,例如播放声音或更新UI 3、适合于需要在倒计时结束后执行一些额外的操作,例如跳转页面或弹出对话框 | implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.0" |
| Kotlin 内联函数的协程和 Flow 实现 | 很容易离开主线程,样板代码最少,协程完全活用了 Kotlin 语言的能力,包括 suspend 方法。可以处理大量的异步数据,而不会阻塞主线程。 | 可能会导致内存泄漏和性能问题。 | 处理 I/O 阻塞型操作,而不是计算密集型操作。 | kotlinx.coroutines 和 kotlinx.coroutines.flow |
安卓开发中如何实现一个定时任务
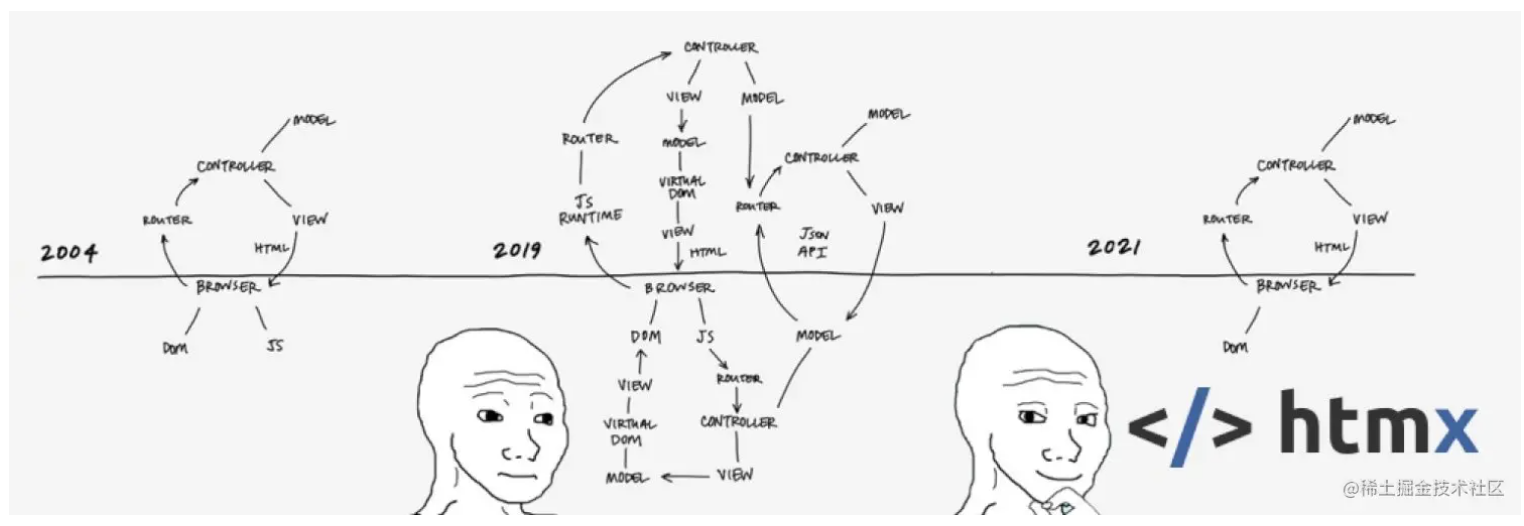
在安卓开发中,我们经常会遇到需要定时执行某些任务的需求,比如轮询服务器数据、更新UI界面、发送通知等等。那么,我们该如何实现一个定时任务呢?本文将介绍安卓开发中实现定时任务的五种方式,并比较它们的优缺点,以及适用场景。
1. 普通线程sleep的方式
这种方式是最简单也最直观的一种实现方法,就是在一个普通线程中使用sleep方法来延迟执行某个任务。例如:
// 创建一个普通线程
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
// 循环执行
while (true) {
// 执行某个任务
doSomething();
// 延迟10秒
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
// 启动线程
thread.start();
这种方式的优点是简单易懂,不需要借助其他类或组件。但是它也有很多缺点:
- sleep方法会阻塞当前线程,导致资源浪费和性能下降。
- sleep方法不准确,它只能保证在指定时间后醒来,但不能保证立即执行。
- sleep方法受系统时间影响,如果用户修改了系统时间,会导致计时错误。
- sleep方法不可靠,如果线程被异常终止或者进入休眠状态,会导致计时中断。
因此,这种方式只适合一般的轮询Polling场景。
2. Timer定时器
这种方式是使用Java API里提供的Timer类来实现定时任务。Timer类可以创建一个后台线程,在指定的时间或者周期性地执行某个任务。例如:
// 创建一个Timer对象
Timer timer = new Timer();
// 创建一个TimerTask对象
TimerTask task = new TimerTask() {
@Override
public void run() {
// 执行某个任务
doSomething();
}
};
// 设置在5秒后开始执行,并且每隔10秒重复执行一次
timer.schedule(task, 5000, 10000);
这种方式相比第一种方式有以下优点:
- Timer类内部使用wait和notify方法来控制线程的执行和休眠,不会浪费资源和性能。
- Timer类可以设置固定频率或者固定延迟来执行任务,更加灵活和准确。
- Timer类可以取消或者重新安排任务,更加方便和可控。
但是这种方式也有以下缺点:
- Timer类只创建了一个后台线程来执行所有的任务,如果其中一个任务耗时过长或者出现异常,则会影响其他任务的执行。
- Timer类受系统时间影响,如果用户修改了系统时间,会导致计时错误。
- Timer类不可靠,如果进程被杀死或者进入休眠状态,会导致计时中断。
因此,这种方式适合一些不太重要的定时任务。
3. ScheduledExecutorService
这种方式是使用Java并发包里提供的ScheduledExecutorService接口来实现定时任务。ScheduledExecutorService接口可以创建一个线程池,在指定的时间或者周期性地执行某个任务。例如:
// 创建一个ScheduledExecutorService对象
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor();
// 创建一个Runnable对象
Runnable task = new Runnable() {
@Override
public void run() {
// 执行某个任务
doSomething();
}
};
// 设置在5秒后开始执行,并且每隔10秒重复执行一次
service.scheduleAtFixedRate(task, 5, 10, TimeUnit.SECONDS);
这种方式相比第二种方式有以下优点:
- ScheduledExecutorService接口可以创建多个线程来执行多个任务,避免了单线程的弊端。
- ScheduledExecutorService接口可以设置固定频率或者固定延迟来执行任务,更加灵活和准确。
- ScheduledExecutorService接口可以取消或者重新安排任务,更加方便和可控。
但是这种方式也有以下缺点:
- ScheduledExecutorService接口受系统时间影响,如果用户修改了系统时间,会导致计时错误。
- ScheduledExecutorService接口不可靠,如果进程被杀死或者进入休眠状态,会导致计时中断。
因此,这种方式适合一些需要多线程并发执行的定时任务。
4. Handler中的postDelayed方法
这种方式是使用Android API里提供的Handler类来实现定时任务。Handler类可以在主线程或者子线程中发送和处理消息,在指定的时间或者周期性地执行某个任务。例如:
// 创建一个Handler对象
Handler handler = new Handler();
// 创建一个Runnable对象
Runnable task = new Runnable() {
@Override
public void run() {
// 执行某个任务
doSomething();
// 延迟10秒后再次执行该任务
handler.postDelayed(this, 10000);
}
};
// 延迟5秒后开始执行该任务
handler.postDelayed(task, 5000);
这种方式相比第三种方式有以下优点:
- Handler类不受系统时间影响,它使用系统启动时间作为参考。
- Handler类可以在主线程中更新UI界面,避免了线程间通信的问题。
但是这种方式也有以下缺点:
- Handler类只能在当前进程中使用,如果进程被杀死或者进入休眠状态,会导致计时中断。
- Handler类需要手动循环调用postDelayed方法来实现周期性地执行任务。
因此,这种方式适合一些需要在主线程中更新UI界面的定时任务.
5. Service + AlarmManager + BroadcastReceiver
这种方式是使用Android API里提供的三个组件来实现定时任务. Service组件可以在后台运行某个长期的服务;AlarmManager组件可以设置一个闹钟,在指定的时间发送一个
- Intent,用于指定要启动的Service组件和传递一些参数。
- AlarmManager组件可以设置一个闹钟,在指定的时间发送一个Intent给BroadcastReceiver组件。
- BroadcastReceiver组件可以接收AlarmManager发送的Intent,并启动Service组件来执行任务。
这种方式相比第四种方式有以下优点:
- Service组件可以在后台运行,即使进程被杀死或者进入休眠状态,也不会影响计时。
- AlarmManager组件可以设置精确或者不精确的闹钟,根据不同的需求节省电量。
- BroadcastReceiver组件可以在系统开机后自动注册,实现开机自启动。
但是这种方式也有以下缺点:
- Service组件需要在AndroidManifest.xml文件中声明,并申请相关的权限。
- AlarmManager组件受系统时间影响,如果用户修改了系统时间,会导致计时错误。
- BroadcastReceiver组件需要在代码中动态注册和注销,避免内存泄漏。
因此,这种方式适合一些需要长期在后台执行的定时任务。
6. WorkManager
这种方式是使用Android Jetpack里提供的WorkManager库来实现定时任务. WorkManager库是一个用于管理后台任务的框架,它可以在满足一定条件下执行某个任务,并保证任务一定会被执行。例如:
// 创建一个PeriodicWorkRequest对象
PeriodicWorkRequest request = new PeriodicWorkRequest.Builder(MyWorker.class, 15, TimeUnit.MINUTES)
.setConstraints(new Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build())
.build();
// 获取一个WorkManager对象
WorkManager workManager = WorkManager.getInstance(this);
// 将PeriodicWorkRequest对象加入到队列中
workManager.enqueue(request);
这种方式相比第五种方式有以下优点:
- WorkManager库不受系统时间影响,它使用系统启动时间作为参考。
- WorkManager库可以设置多种约束条件来执行任务,例如网络状态、电量状态、设备空闲状态等。
- WorkManager库可以取消或者重新安排任务,更加方便和可控。
但是这种方式也有以下缺点:
- WorkManager库需要添加依赖并配置相关的权限。
- WorkManager库不能保证任务准时执行,它会根据系统资源和约束条件来调度任务。
因此,这种方式适合一些对时间不敏感且需要满足特定条件才能执行的定时任务
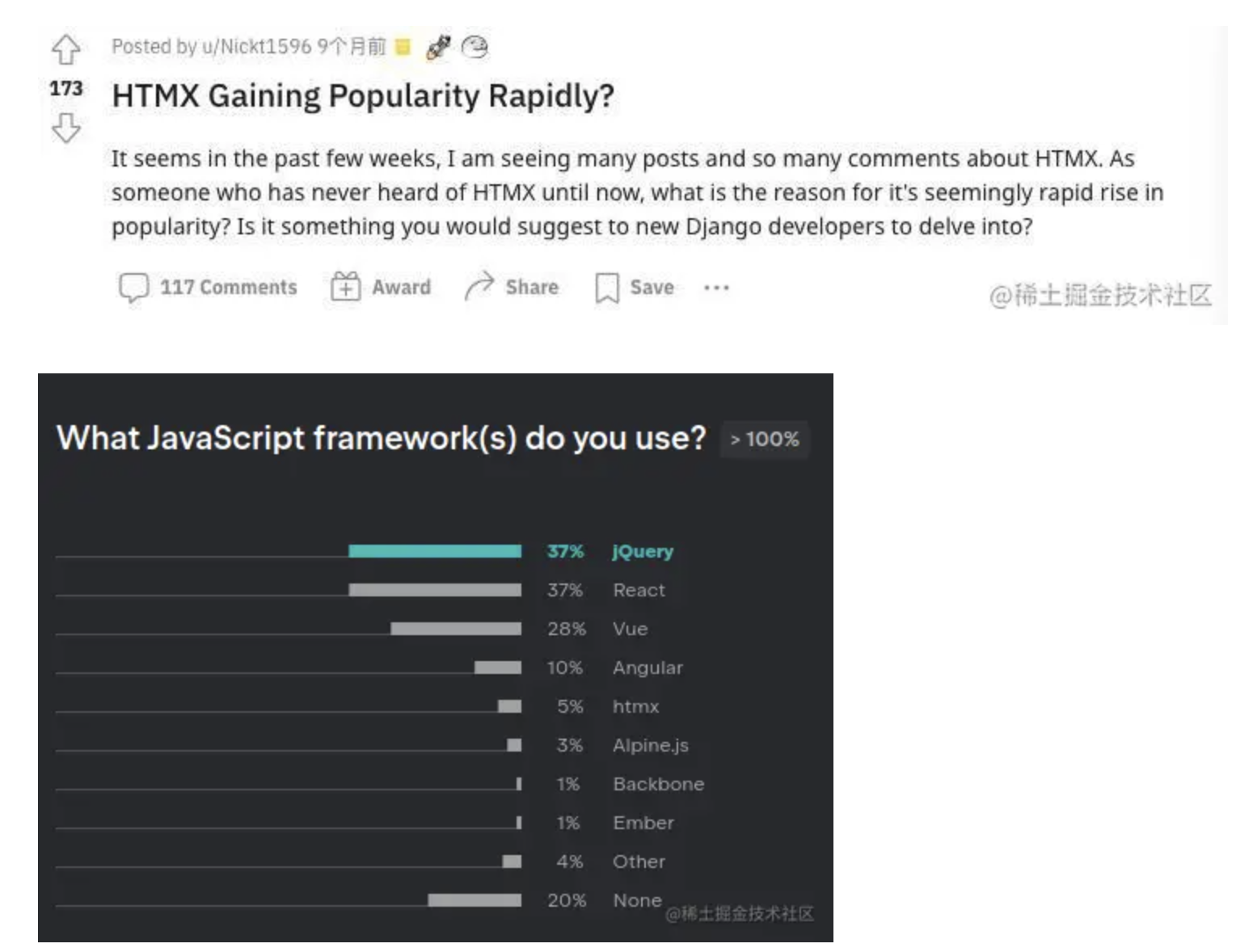
您好,这是必应。我根据您的要求,从网络上搜集了一些关于如何使用RXJAVA、CountDownTimer、协程安卓实现一个定时任务的资料,并整理成了一篇文章。文章的结构如下:
7.如何使用RXJAVA实现定时任务
RXJAVA是一个基于观察者模式和函数式编程的库,它可以用来处理异步事件和数据流。RXJAVA提供了一些操作符,可以用来创建和处理定时任务。其中,interval操作符可以用来创建一个按照固定时间间隔发射整数序列的Observable,可以用来实现周期性的定时任务。例如,以下代码可以实现每隔1秒发射一个整数,从0开始:
//创建一个Observable,每隔1秒发射一个整数,从0开始
Observable timer = Observable.interval(1, TimeUnit.SECONDS);
//订阅这个Observable,打印发射的数据
timer.subscribe(new Observer() {
@Override
public void onSubscribe(Disposable d) {
//订阅时的操作,可以用来取消订阅
}
@Override
public void onNext(Long aLong) {
//收到数据时的操作,可以用来更新UI或者执行其他逻辑
Log.d("RXJAVA", "onNext: " + aLong);
}
@Override
public void onError(Throwable e) {
//发生错误时的操作,可以用来处理异常
}
@Override
public void onComplete() {
//完成时的操作,可以用来释放资源
}
});
如果要实现倒计时的效果,可以使用map操作符,将发射的整数转换为倒计时的秒数。例如,以下代码可以实现一个10秒的倒计时:
//创建一个Observable,每隔1秒发射一个整数,从0开始,共发射10个
Observable timer = Observable.interval(1, TimeUnit.SECONDS).take(10);
//使用map操作符,将发射的整数转换为倒计时的秒数
timer = timer.map(new Function() {
@Override
public Long apply(Long aLong) throws Exception {
//将发射的整数转换为倒计时的秒数,例如0转换为10,1转换为9,以此类推
return 10 - aLong;
}
});
//订阅这个Observable,打印发射的数据
timer.subscribe(new Observer() {
@Override
public void onSubscribe(Disposable d) {
//订阅时的操作,可以用来取消订阅
}
@Override
public void onNext(Long aLong) {
//收到数据时的操作,可以用来更新UI或者执行其他逻辑
Log.d("RXJAVA", "onNext: " + aLong);
}
@Override
public void onError(Throwable e) {
//发生错误时的操作,可以用来处理异常
}
@Override
public void onComplete() {
//完成时的操作,可以用来释放资源
}
});
RXJAVA的优点是可以方便地处理异步事件和数据流,可以使用各种操作符来实现复杂的逻辑,可以避免内存泄漏和线程安全
8.如何使用CountDownTimer实现定时任务
CountDownTimer是Android中提供的一个倒计时器类,它可以用来实现一个在一定时间内递减的倒计时。CountDownTimer的构造方法接受两个参数:总时间和间隔时间。例如,以下代码可以创建一个10秒的倒计时,每隔1秒更新一次:
//创建一个10秒的倒计时,每隔1秒更新一次
CountDownTimer timer = new CountDownTimer(10000, 1000) {
@Override
public void onTick(long millisUntilFinished) {
//每隔一秒调用一次,可以用来更新UI或者执行其他逻辑
Log.d("CountDownTimer", "onTick: " + millisUntilFinished / 1000);
}
@Override
public void onFinish() {
//倒计时结束时调用,可以用来释放资源或者执行其他逻辑
Log.d("CountDownTimer", "onFinish");
}
};
//开始倒计时
timer.start();
//取消倒计时
timer.cancel();
CountDownTimer的优点是使用简单,可以直接在UI线程中更新UI,不需要额外的线程或者Handler。CountDownTimer的缺点是只能实现倒计时的效果,不能实现周期性的定时任务,而且精度受系统时间的影响,可能不够准确。
9.如何使用协程实现定时任务
协程可以用来简化异步编程和线程管理。协程是一种轻量级的线程,它可以在不阻塞线程的情况下挂起和恢复执行。协程安卓提供了一些扩展函数,可以用来创建和处理定时任务。其中,delay函数可以用来暂停协程的执行一段时间,可以用来实现倒计时或者周期性的定时任务。例如,以下代码可以实现一个10秒的倒计时,每隔1秒更新一次:
//创建一个协程作用域,可以用来管理协程的生命周期
val scope = CoroutineScope(Dispatchers.Main)
//在协程作用域中启动一个协程,可以用来执行异步任务
scope.launch {
//创建一个变量,表示倒计时的秒数
var seconds = 10
//循环执行,直到秒数为0
while (seconds > 0) {
//打印秒数,可以用来更新UI或者执行其他逻辑
Log.d("Coroutine", "seconds: $seconds")
//暂停协程的执行1秒,不阻塞线程
delay(1000)
//秒数减一
seconds--
}
//倒计时结束,打印日志,可以用来释放资源或者执行其他逻辑
Log.d("Coroutine", "finish")
}
//取消协程作用域,可以用来取消所有的协程
scope.cancel()
协程安卓的优点是可以方便地处理异步任务和线程切换,可以使用简洁的语法来实现复杂的逻辑,可以避免内存泄漏和回调。协程的缺点是需要引入额外的依赖,而且需要一定的学习成本,不太适合初学者。
10.使用kotlin关键字 ‘downTo’ 搭配Flow
// 创建一个倒计时器,从10秒开始,每秒减一
val timer = object: CountDownTimer(10000, 1000) {
override fun onTick(millisUntilFinished: Long) {
// 在每个间隔,发射剩余的秒数
emitSeconds(millisUntilFinished / 1000)
}
override fun onFinish() {
// 在倒计时结束时,发射0
emitSeconds(0)
}
}
// 创建一个Flow,用于发射倒数的秒数
fun emitSeconds(seconds: Long): Flow = flow {
// 使用downTo关键字创建一个倒数的范围
for (i in seconds downTo 0) {
// 发射当前的秒数
emit(i.toInt())
}
}
11.kotlin内联函数的协程和 Flow 实现
fun FragmentActivity.timerFlow(
time: Int = 60,
onStart: (suspend () -> Unit)? = null,
onEach: (suspend (Int) -> Unit)? = null,
onCompletion: (suspend () -> Unit)? = null
): Job {
return (time downTo 0)
.asFlow()
.cancellable()
.flowOn(Dispatchers.Default)
.onStart { onStart?.invoke() }
.onEach {
onEach?.invoke(it)
delay(1000L)
}.onCompletion { onCompletion?.invoke() }
.launchIn(lifecycleScope)
}
//在activity中使用
val job = timerFlow(
time = 60,
onStart = { Log.d("Timer", "Starting timer...") },
onEach = { Log.d("Timer", "Seconds remaining: $it") },
onCompletion = { Log.d("Timer", "Timer completed.") }
)
//取消计时
job.cancel()
来源:juejin.cn/post/7270173192789737487





































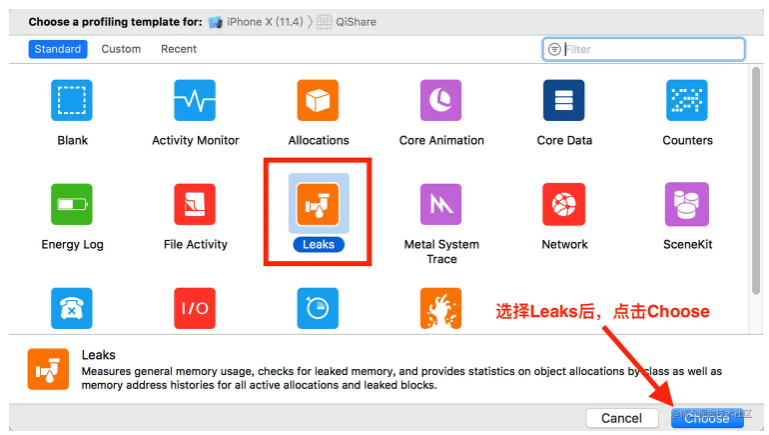
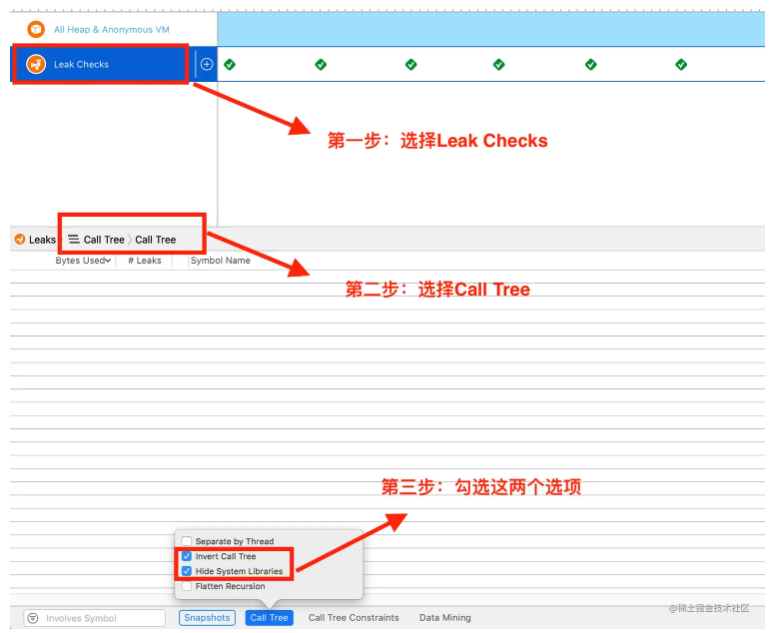
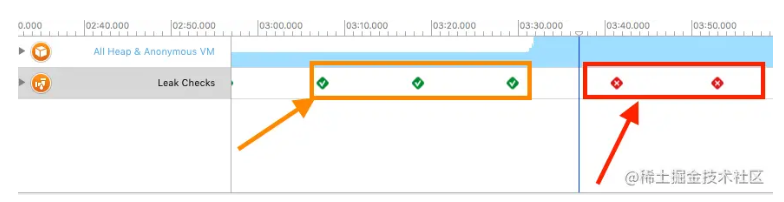
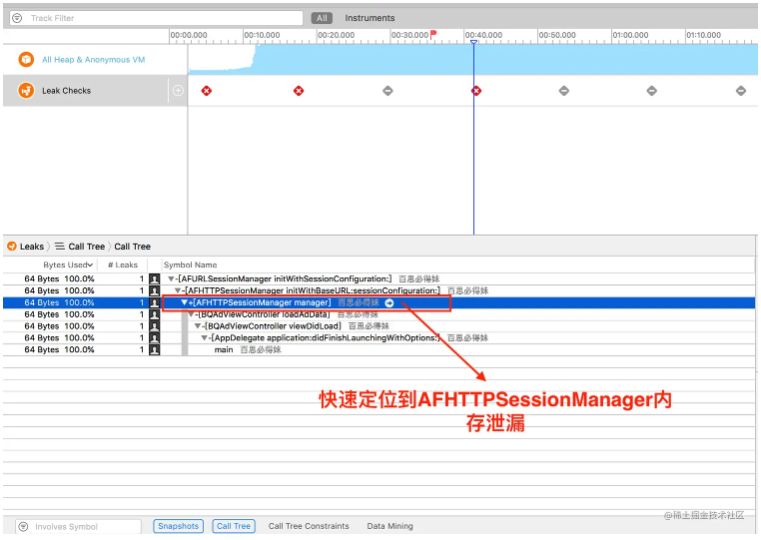

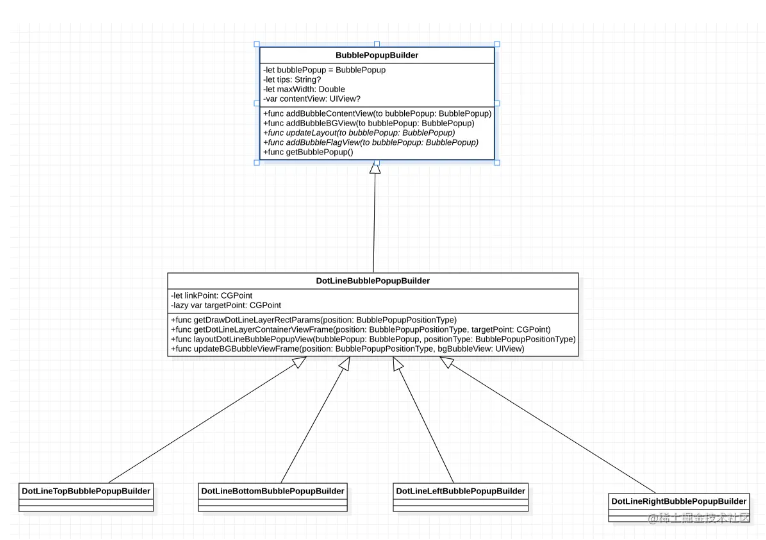
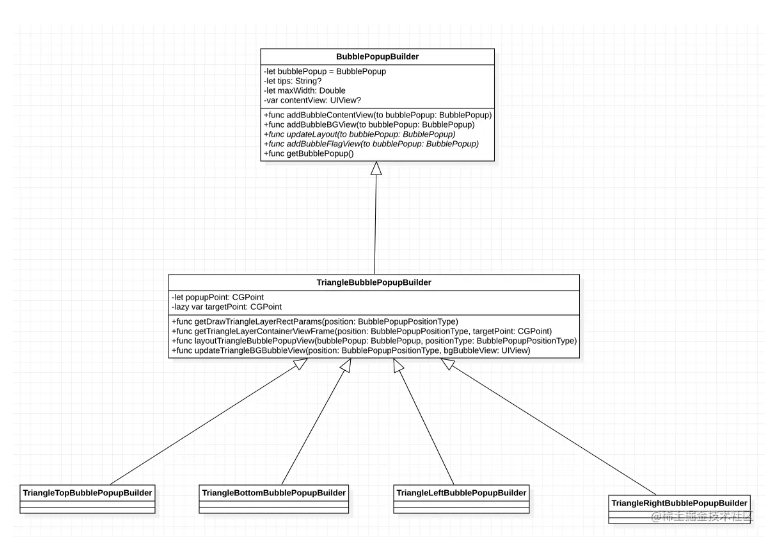
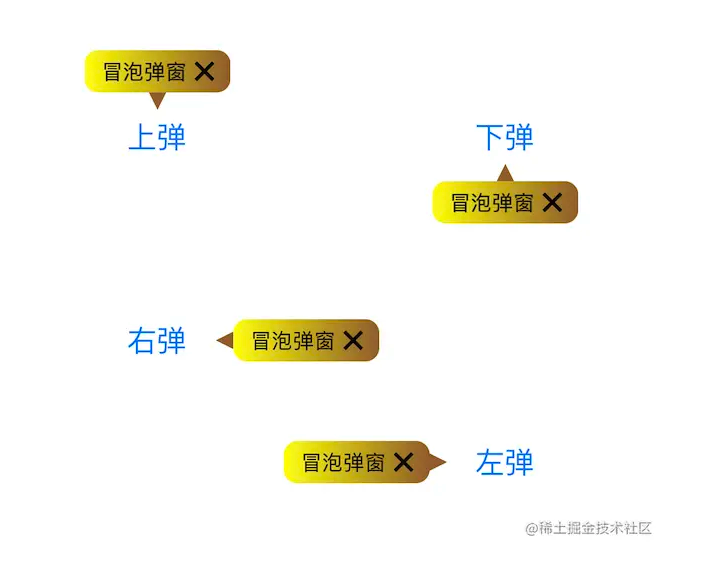
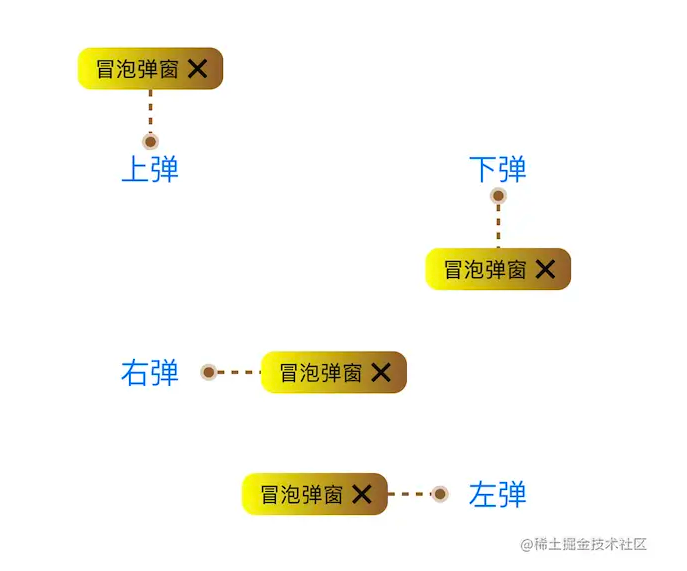














 在2.17入职之后,也算是正式开启了社畜的角色。奈何在公司工作不到半个月之后,开始迎来了为期三个多月的疫情,疫情不仅是对公司有着强烈的冲击,对打工人也是晴天霹雳。
在2.17入职之后,也算是正式开启了社畜的角色。奈何在公司工作不到半个月之后,开始迎来了为期三个多月的疫情,疫情不仅是对公司有着强烈的冲击,对打工人也是晴天霹雳。














































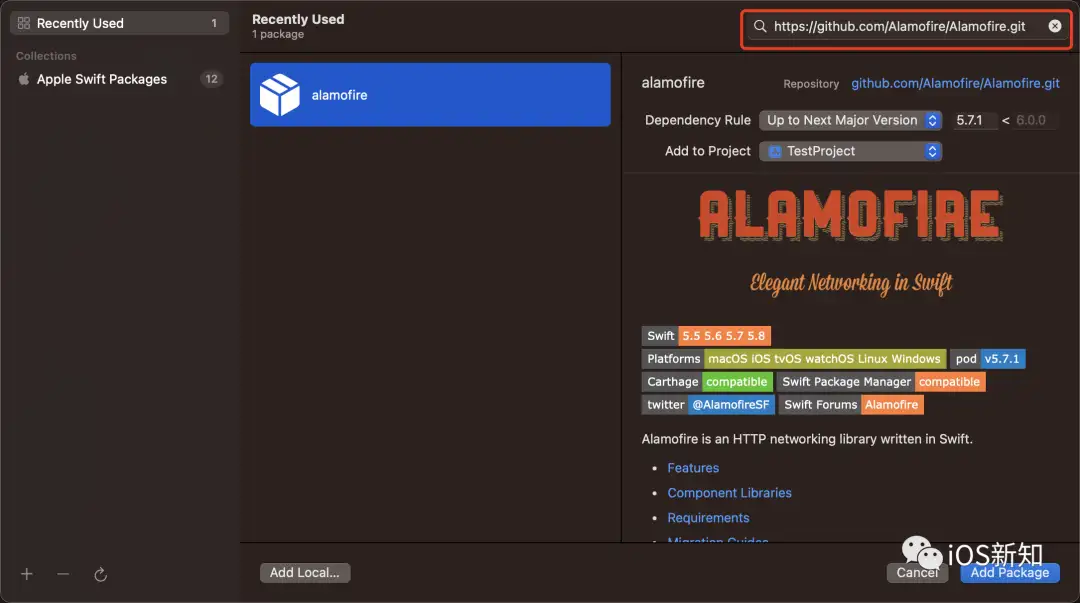
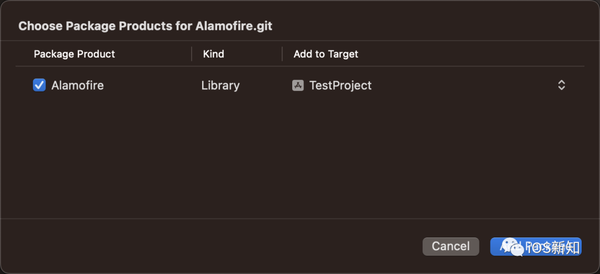
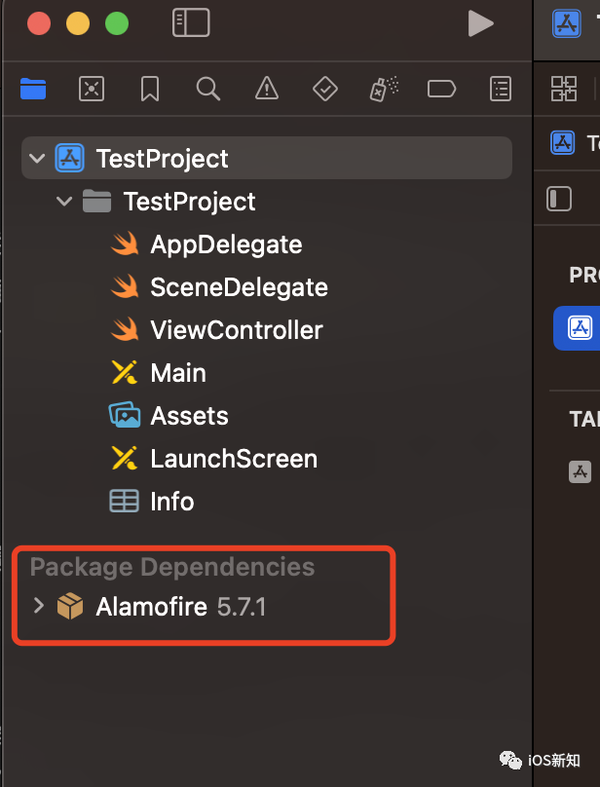
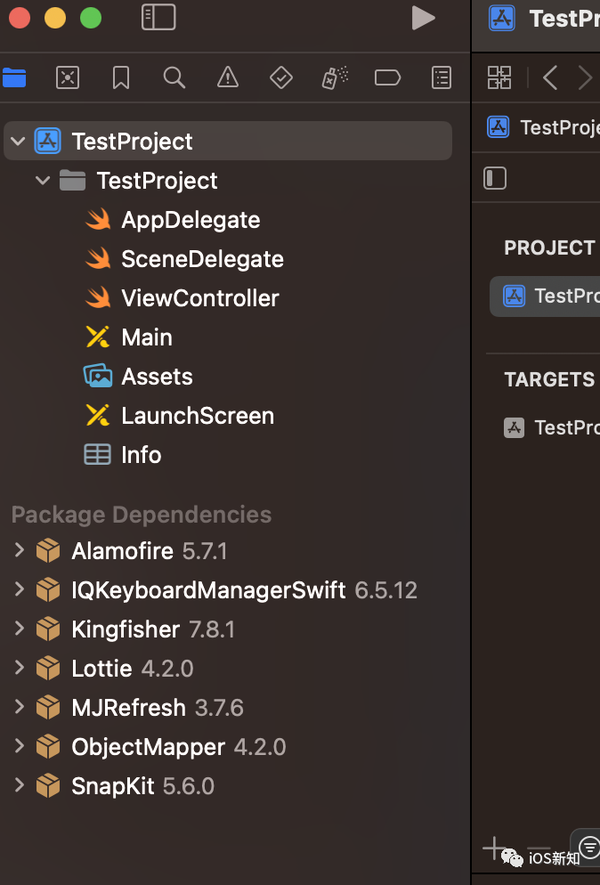
































































 而使用
而使用