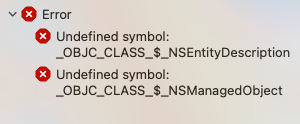
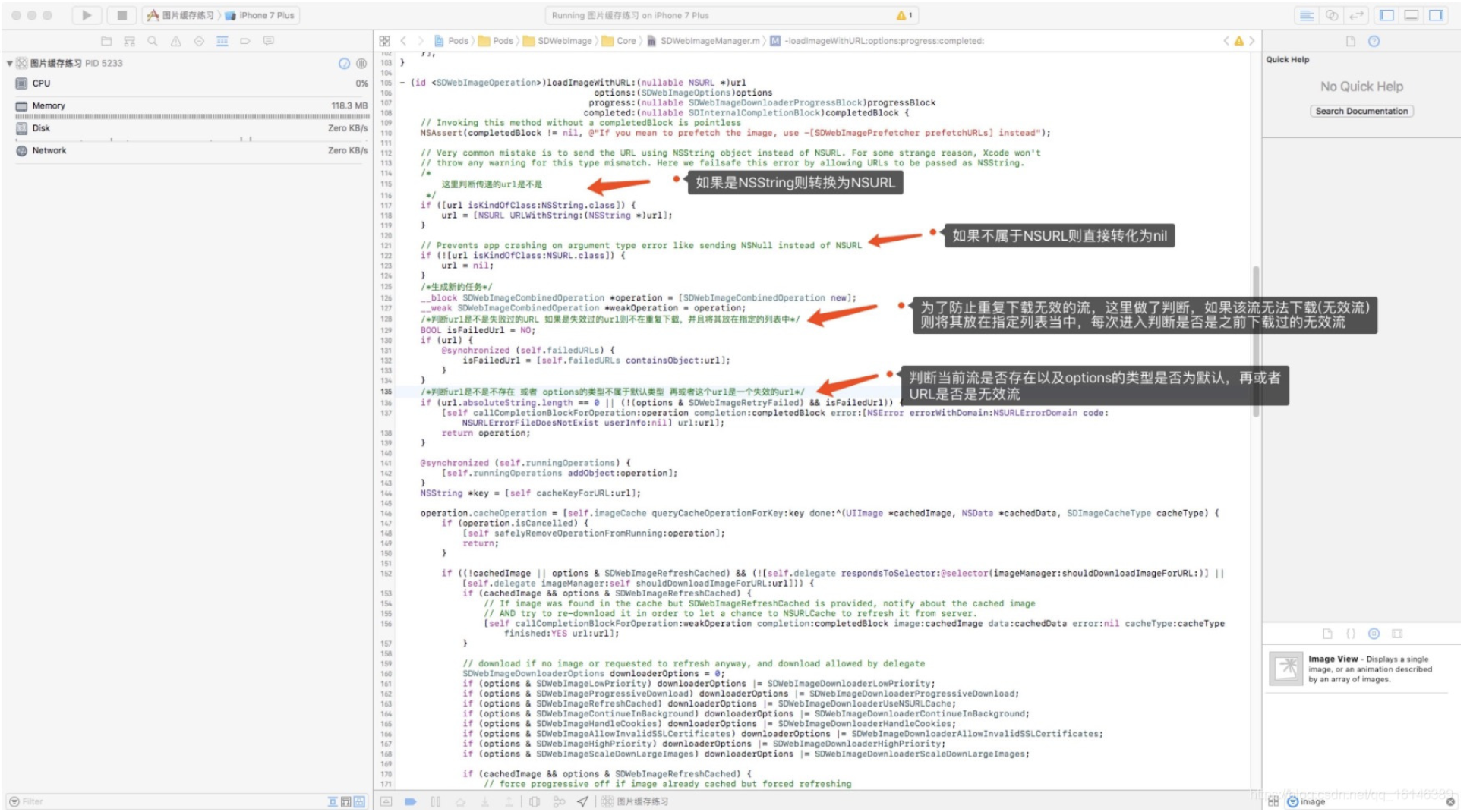
本文解决的问题
- 查看编解码器
- 录制YUV文件
- 将YUV文件编码为MP4视频格式
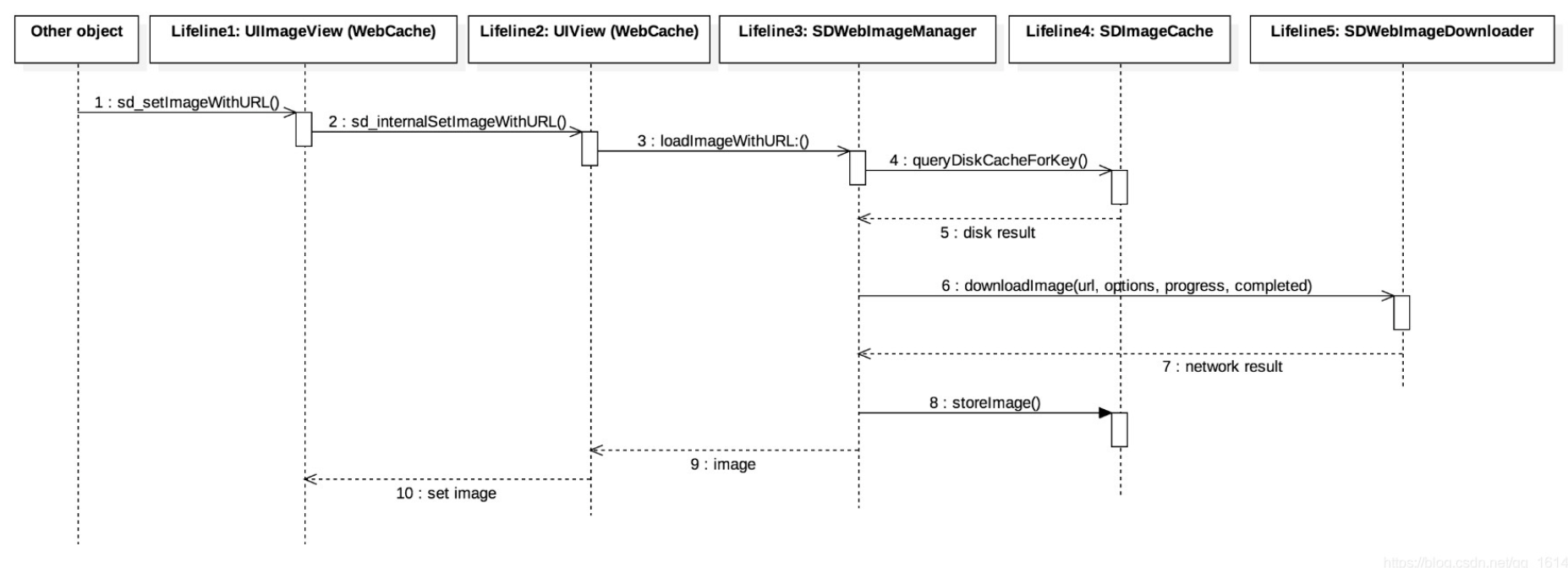
官方的示意图
数据流
input:给解码器输入需要解码或需要编码的数据流
output:解码器输出解码好或编码好的数据给客户端
MediaCodec内部采用异步的方式处理数据,将处理好的数据写入缓冲区,客户端从缓冲区取数据使用,使用后必须手动释放缓冲区,否则无法继续处理数据
状态
- Stopped
- Error
- Uninitialized:新建MediaCodec后,会进入该状态
- Configured:调用configured方法后,进入该状态
- Executing
- Flushed:调用start方法后,进入该状态
- Running:调用dequeueInputBuffer方法后,进入该状态
- End of Stream
- Released
功能描述
打印设备支持的编解码选项
val mediaCodecList = MediaCodecList(MediaCodecList.REGULAR_CODECS)//创建查看设备可以使用的编解码器
val mediaCodecList = MediaCodecList(MediaCodecList.ALL_CODECS)//创建查看所有编解码器
fun printCodecInfo() {
val mediaCodecList = MediaCodecList(MediaCodecList.REGULAR_CODECS)//创建查看设备可以使用的编解码器
val codecInfos = mediaCodecList.codecInfos
codecInfos.forEach { codecInfo ->
if (codecInfo.isEncoder)
println(
"encoder name: ${codecInfo.name} \n" +
" canonicalName: ${codecInfo.canonicalName} \n" +
" isAlias: ${codecInfo.isAlias} \n" +
" isSoftwareOnly: ${codecInfo.isSoftwareOnly} \n" +
" supportedTypes: ${
codecInfo.supportedTypes.map {
println("encoder: $it")
}
} \n" +
" isVendor: ${codecInfo.isVendor} \n" +
" isHardwareAccelerated: ${codecInfo.isHardwareAccelerated}" +
""
)
}
codecInfos.forEach { codecInfo ->
if (!codecInfo.isEncoder)
println(
"decoder name: ${codecInfo.name} \n" +
" canonicalName: ${codecInfo.canonicalName} \n" +
" isAlias: ${codecInfo.isAlias} \n" +
" isSoftwareOnly: ${codecInfo.isSoftwareOnly} \n" +
" supportedTypes: ${
codecInfo.supportedTypes.map {
println("decoder: $it")
}
} \n" +
" isVendor: ${codecInfo.isVendor} \n" +
" isHardwareAccelerated: ${codecInfo.isHardwareAccelerated}" +
""
)
}
}
/*
打印示例
"video/avc":H.264硬件编码器
encoder name: OMX.qcom.video.encoder.avc
canonicalName: OMX.qcom.video.encoder.avc
isAlias: false
isSoftwareOnly: false
supportedTypes: [kotlin.Unit]
isVendor: true
isHardwareAccelerated: true
"video/hevc":H.265软解编码器
encoder name: c2.android.hevc.encoder
canonicalName: c2.android.hevc.encoder
isAlias: false
isSoftwareOnly: true
supportedTypes: [kotlin.Unit]
isVendor: false
isHardwareAccelerated: false
*/
/*查找指定的编解码器*/
val codec = findCodec("video/avc", false, true)//查找H.264硬解码器
fun findCodec(
mimeType: String,
isEncoder: Boolean,
isHard: Boolean = true
): MediaCodecInfo? {
val mediaCodecList = MediaCodecList(MediaCodecList.REGULAR_CODECS)
val codecInfos = mediaCodecList.codecInfos
return codecInfos.find {
it.isEncoder == isEncoder && !it.isSoftwareOnly == isHard && hasThisCodec(
it,
mimeType
)
}
}
private fun hasThisCodec(codecInfo: MediaCodecInfo, mimeType: String): Boolean {
return codecInfo.supportedTypes.find { it.equals(mimeType) } != null
}
复制代码录制yuv文件
打开Camera,通过回调流保存原始YUV数据。简单存几秒即可,1080p下存了225帧,存储占用1080*1920*225*3/2=667.4M字节
示例工程: 地址
示例代码:
val fos = FileOutputStream("$filesDir/test.yuv")
cameraView = findViewById(R.id.cameraview)
cameraView.cameraParams.facing = Camera.CameraInfo.CAMERA_FACING_BACK
cameraView.cameraParams.isFilp = false
cameraView.cameraParams.isScaleWidth = true
cameraView.cameraParams.previewSize.previewWidth = 1920
cameraView.cameraParams.previewSize.previewHeight = 1080
cameraView.addPreviewFrameCallback(object : PreviewFrameCallback {
override fun analyseData(data: ByteArray): Any {
fos.write(data)
return 0
}
override fun analyseDataEnd(t: Any) {}
})
addLifecycleObserver(cameraView)
复制代码YUV视频流编码为h.264码流并通过MediaMuxer保存为mp4文件
编码流程:
- 查询编码队列是否空闲
- 将需要编码的数据复制到编码队列
- 查询编码完成队列是否有完成的数据
- 将已编码完成的数据复制到cpu内存
单线程示例代码:
//TODO YUV视频流编码为H.264/H.265码流并通过MediaMuxer保存为mp4文件
fun convertYuv2Mp4(context: Context) {
val yuvPath = "${context.filesDir}/test.yuv"
val saveMp4Path = "${context.filesDir}/test.mp4"
File(saveMp4Path).deleteOnExit()
val mime = "video/avc" //若设备支持H.265也可以使用'video/hevc'编码器
val format = MediaFormat.createVideoFormat(mime, 1920, 1080)
format.setInteger(
MediaFormat.KEY_COLOR_FORMAT,
MediaCodecInfo.CodecCapabilities.COLOR_FormatYUV420Flexible
)
//width*height*frameRate*[0.1-0.2]码率控制清晰度
format.setInteger(MediaFormat.KEY_BIT_RATE, 1920 * 1080 * 3)
format.setInteger(MediaFormat.KEY_FRAME_RATE, 30)
//每秒出一个关键帧,设置0为每帧都是关键帧
format.setInteger(MediaFormat.KEY_I_FRAME_INTERVAL, 1)
format.setInteger(
MediaFormat.KEY_BITRATE_MODE,
MediaCodecInfo.EncoderCapabilities.BITRATE_MODE_CBR//遵守用户设置的码率
)
//定义并启动编码器
val videoEncoder = MediaCodec.createEncoderByType(mime)
videoEncoder.configure(format, null, null, MediaCodec.CONFIGURE_FLAG_ENCODE)
videoEncoder.start()
// 当前编码帧信息
val bufferInfo = MediaCodec.BufferInfo()
//定义混合器:输出并保存h.264码流为mp4
val mediaMuxer =
MediaMuxer(
"${context.filesDir}/test.mp4",
MediaMuxer.OutputFormat.MUXER_OUTPUT_MPEG_4
);
var muxerTrackIndex = -1
val byteArray = ByteArray(1920 * 1080 * 3 / 2)
var read = 0
var inputEnd = false//数据读取完毕,并且全部都加载至编码器
var pushEnd = false //数据读取完毕,并且成功发出eof信号
val presentTimeUs = System.nanoTime() / 1000
//从文件中读取yuv码流,模拟输入流
FileInputStream("${context.filesDir}/test.yuv").use { fis ->
loop1@ while (true) {
//step1 将需要编码的数据逐帧送往编码器
if (!inputEnd) {
//step1.1 查询编码器队列是否空闲
val inputQueueIndex = videoEncoder.dequeueInputBuffer(30);
if (inputQueueIndex > 0) {
read = fis.read(byteArray)
if (read == byteArray.size) {
//默认从Camera中保存的YUV NV21,编码后颜色成反,手动转为NV12后,颜色正常
val convertCost = measureTimeMillis {
val start = 1920 * 1080
val end = 1920 * 1080 / 4 - 1
for (i in 0..end) {
val temp = byteArray[2 * i + start]
byteArray[2 * i + start] = byteArray[2 * i + start + 1]
byteArray[2 * i + start + 1] = temp
}
}
//step1.2 将数据送往编码器,presentationTimeUs为送往编码器的跟起始值的时间差,单位为微妙
val inputBuffer =
videoEncoder.getInputBuffer(inputQueueIndex)
inputBuffer?.clear()
inputBuffer?.put(byteArray)
videoEncoder.queueInputBuffer(
inputQueueIndex,
0,
byteArray.size,
System.nanoTime() / 1000 - presentTimeUs,
0
)
} else {
inputEnd = true//文件读取结束标记
}
}
}
//step2 将结束标记传给编码器
if (inputEnd && !pushEnd) {
val inputQueueIndex = videoEncoder.dequeueInputBuffer(30);
if (inputQueueIndex > 0) {
val pts: Long = System.nanoTime() / 1000 - presentTimeUs
videoEncoder.queueInputBuffer(
inputQueueIndex,
0,
byteArray.size,
pts,
MediaCodec.BUFFER_FLAG_END_OF_STREAM
)
pushEnd = true
println("数据输入完成,成功发出eof信号")
}
}
//step3 从编码器中取数据,不及时取出,缓冲队列被占用,编码器将阻塞不进行编码工作
val outputQueueIndex = videoEncoder.dequeueOutputBuffer(bufferInfo, 30)
when (outputQueueIndex) {
MediaCodec.INFO_OUTPUT_FORMAT_CHANGED -> {
//step3.1 标记新的解码数据到来,在此添加视频轨道到混合器
muxerTrackIndex = mediaMuxer.addTrack(videoEncoder.outputFormat)
mediaMuxer.start()
}
MediaCodec.INFO_TRY_AGAIN_LATER -> {
}
else -> {
when (bufferInfo.flags) {
MediaCodec.BUFFER_FLAG_CODEC_CONFIG -> {
// SPS or PPS, which should be passed by MediaFormat.
}
MediaCodec.BUFFER_FLAG_END_OF_STREAM -> {
bufferInfo.set(0, 0, 0, bufferInfo.flags)
videoEncoder.releaseOutputBuffer(outputQueueIndex, false)
println("数据解码并获取完成,成功发出eof信号")
break@loop1
}
else -> {
mediaMuxer.writeSampleData(
muxerTrackIndex,
videoEncoder.getOutputBuffer(outputQueueIndex)!!,
bufferInfo
)
}
}
videoEncoder.releaseOutputBuffer(outputQueueIndex, false)
}
}
}
//释放应该释放的具柄
mediaMuxer.release()
videoEncoder.stop()
videoEncoder.release()
}
}
复制代码作者:君子陌路
链接:https://juejin.cn/post/6955080139885838372
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

 、
、