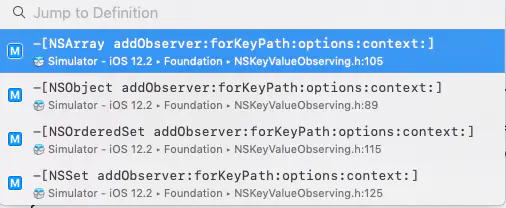
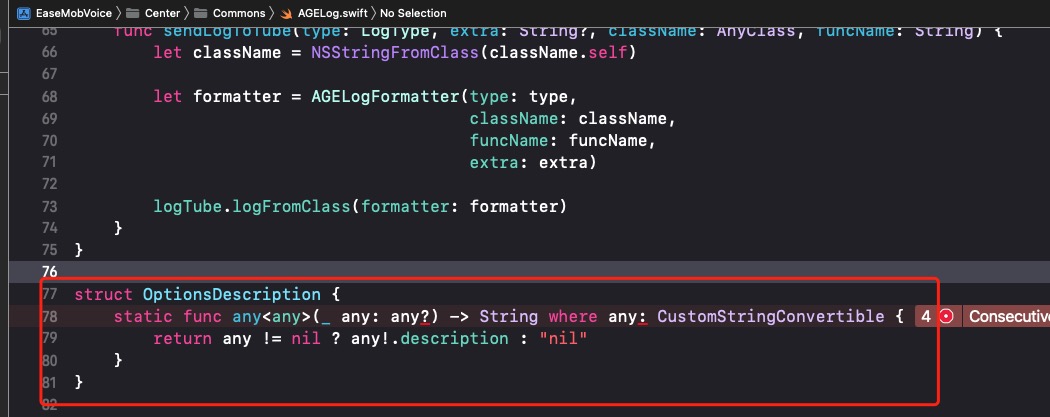
Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '[<__NSArrayM 0x6000033db450> addObserver:forKeyPath:options:context:] is not supported. Key path: count'
OK 说了这么多,好像还是没有解决我们的问题。 为什么监听数组count就抛异常了呢? 带着这个问题 继续往下走。 通过点击array的监听方法 进入到ArrayObserving类中,我们发现,系统给出了注释:NSArrays are not observable, so these methods raise exceptions when invoked on NSArrays.
系统也不期望我们去监听数组的属性。is not supported. Key path: count' 应该就是系统在实现监听方法时,抛出的异常。
var number = 5; var obj = { number: 3, fn1: (function () { var number; this.number *= 2; number = number * 2; number = 3; return function () { var num = this.number; this.number *= 2; console.log(num); number *= 3; console.log(number); } })() } var fn1 = obj.fn1; fn1.call(null); obj.fn1(); console.log(window.number);
functionsayHi(){ console.log('Hello,', this.name);
} var person = {
name: 'YvetteLau',
sayHi: sayHi
} var name = 'Wiliam'; var Hi = person.sayHi;
Hi();
functionsayHi(){ console.log('Hello,', this.name);
} var person = {
name: 'YvetteLau',
sayHi: sayHi
} var name = 'Wiliam'; var Hi = person.sayHi;
Hi.call(person); //Hi.apply(person)
functionsayHi(){ console.log('Hello,', this.name);
} var person = {
name: 'YvetteLau',
sayHi: sayHi
} var name = 'Wiliam'; var Hi = function(fn) {
fn();
}
Hi.call(person, person.sayHi);
functionsayHi(){ console.log('Hello,', this.name);
} var person = {
name: 'YvetteLau',
sayHi: sayHi
} var name = 'Wiliam'; var Hi = function(fn) {
fn.call(this);
}
Hi.call(person, person.sayHi);
ECMAScript 中的函数始终可以作为构造函数实例化一个新对象,也可以作为普通函数被调用。ECMAScript 6 新增了检测函数是否使用 new 关键字调用的 new.target 属性。如果函数是正常调用的,则 new.target 的值是 undefined;如果是使用 new 关键字调用的,则 new.target 将引用被调用的构造函数。
functionKing() { if (!new.target) { throw'King must be instantiated using "new"'
}
console.log('King instantiated using "new"');
} newKing(); // King instantiated using "new"
King(); // Error: King must be instantiated using "new"
这里可以做一些延申,还有没有其他办法来判断函数是否通过new来调用的呢?
可以使用 instanceof 来判断。我们知道在new的时候发生了哪些操作?用如下代码表示:
var p = new Foo() // 实际上执行的是 // 伪代码
var o = new Object(); // 或 var o = {}
o.__proto__ = Foo.prototype
Foo.call(o)
return o
上述伪代码在MDN是这么说的:
一个继承自 Foo.prototype 的新对象被创建。
使用指定的参数调用构造函数 Foo,并将 this 绑定到新创建的对象。new Foo 等同于 new Foo(),也就是没有指定参数列表,Foo 不带任何参数调用的情况。
由构造函数返回的对象就是 new 表达式的结果。如果构造函数没有显式返回一个对象,则使用步骤1创建的对象。(一般情况下,构造函数不返回值,但是用户可以选择主动返回对象,来覆盖正常的对象创建步骤)
new 的操作说完了 现在我们看一下 instanceof,MDN上是这么说的:instanceof 运算符用于检测构造函数的 prototype 属性是否出现在某个实例对象的原型链上。
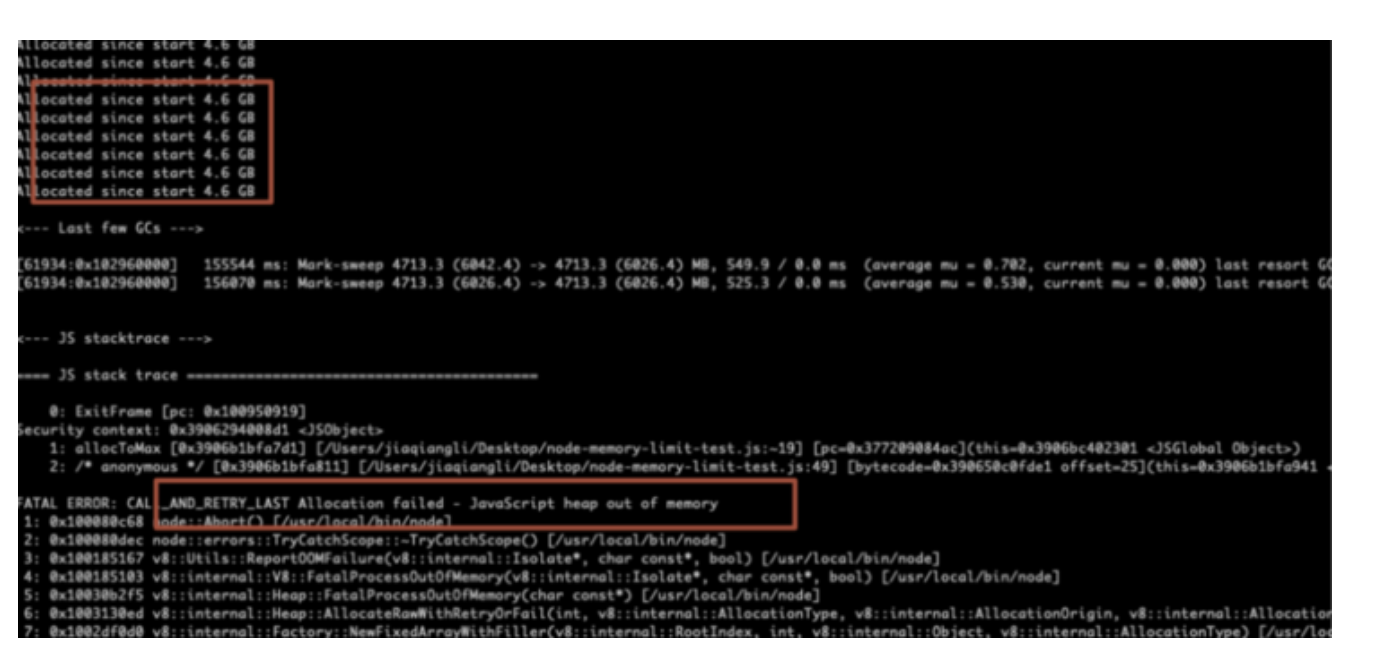
Currently, by default V8 has a memory limit of 512mb on 32-bit systems, and 1gb on 64-bit systems. The limit can be raised by setting --max-old-space-size to a maximum of ~1gb (32-bit) and ~1.7gb (64-bit), but it is recommended that you split your single process into several workers if you are hitting memory limits.
// Small program to test the maximum amount of allocations in multiple blocks. // This script searches for the largest allocation amount.
// Allocate a certain size to test if it can be done. function alloc (size) { const numbers = size / 8; const arr = [] arr.length = numbers; // Simulate allocation of 'size' bytes. for (let i = 0; i < numbers; i++) { arr[i] = i; } return arr; };
// Keep allocations referenced so they aren't garbage collected. const allocations = [];
// Allocate successively larger sizes, doubling each time until we hit the limit. function allocToMax () { console.log("Start");
const field = 'heapUsed'; const mu = process.memoryUsage();
// Infinite loop while (true) { // Allocate memory. const allocation = alloc(allocationStep); // Allocate and keep a reference so the allocated memory isn't garbage collected. allocations.push(allocation); // Check how much memory is now allocated. const mu = process.memoryUsage(); const gbNow = mu[field] / 1024 / 1024 / 1024;
module.exports = {
...
plugins: [ new ForkTsCheckerWebpackPlugin()
]
}
在我这个实际的项目中,vue.config.js 修改如下:
configureWebpack: config => { // get a reference to the existing ForkTsCheckerWebpackPlugin const existingForkTsChecker = config.plugins.filter(
p => p instanceof ForkTsCheckerWebpackPlugin,
)[0];
// remove the existing ForkTsCheckerWebpackPlugin // so that we can replace it with our modified version
config.plugins = config.plugins.filter(
p => !(p instanceof ForkTsCheckerWebpackPlugin),
);
// copy the options from the original ForkTsCheckerWebpackPlugin // instance and add the memoryLimit property const forkTsCheckerOptions = existingForkTsChecker.options;
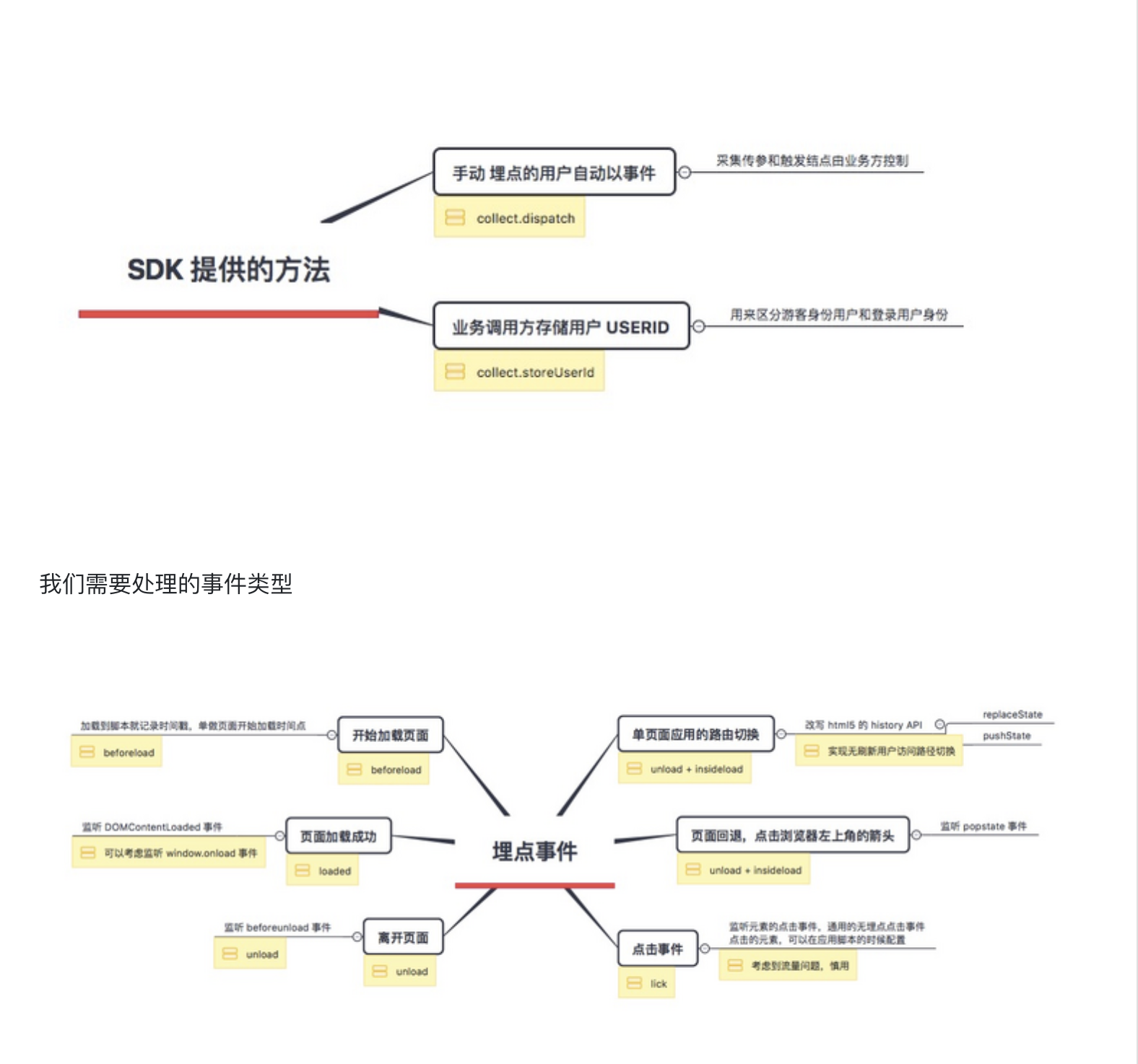
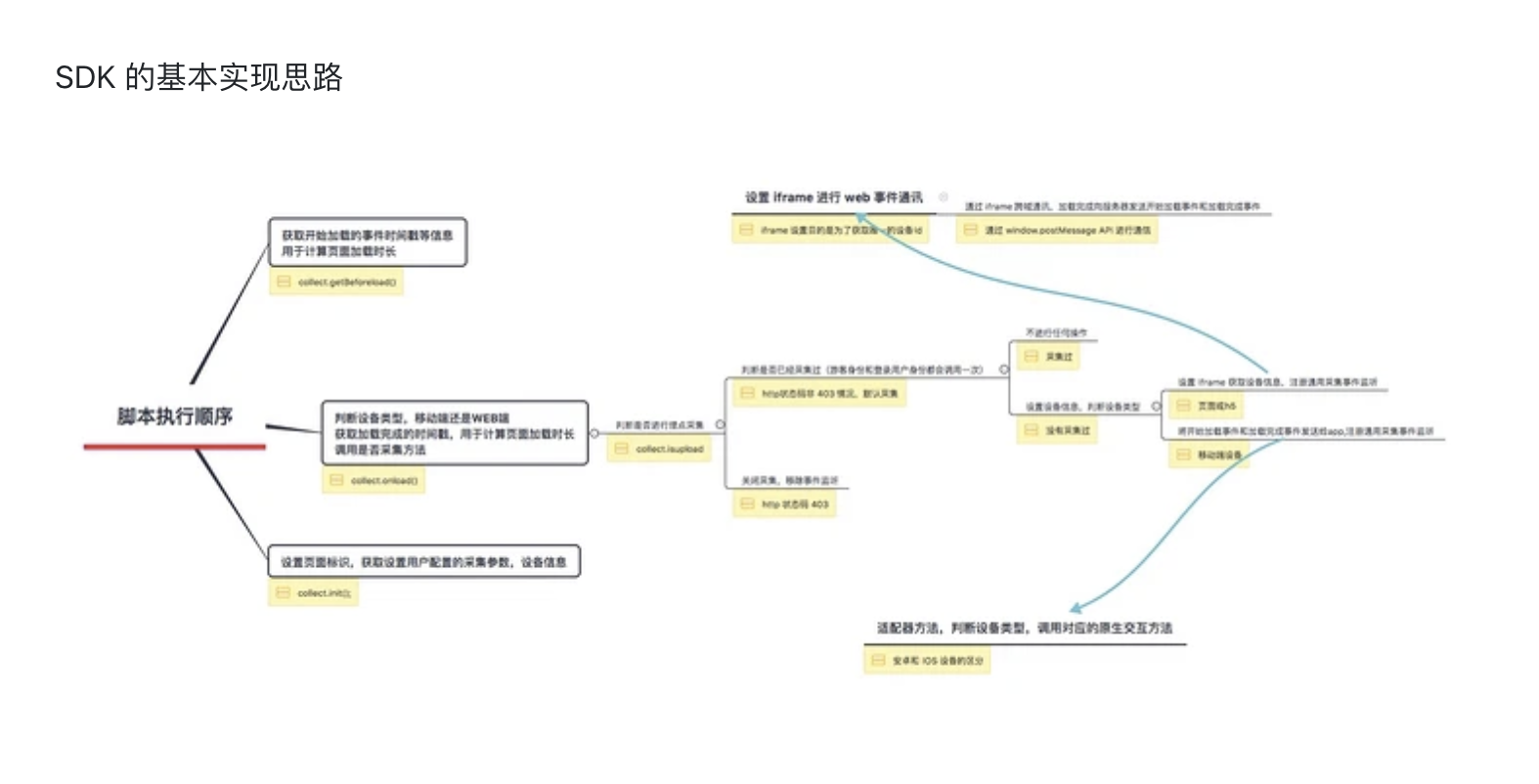
埋点,是网站分析的一种常用的数据采集方法。我们主要用来采集用户行为数据(例如页面访问路径,点击了什么元素)进行数据分析,从而让运营同学更加合理的安排运营计划。现在市面上有很多第三方埋点服务商,百度统计,友盟,growingIO 等大家应该都不太陌生,大多情况下大家都只是使用,最近我研究了下 web 埋点,你要不要了解下。
用户通过浏览器来访问 web 页面,设备Id需要存储在浏览器上,同一个用户访问不同的业务方网站,设备Id要保持一样。web 变量存储,我们第一时间想到的就是 cookie,sessionStorage,localStorage,但是这3种存储方式都和访问资源的域名相关。我们总不能每次访问一个网站就新建一个设备指纹吧,所以我们需要通过一个方法来跨域共享设备指纹
private fun getAllLauncherApps(): MutableList<AppInfo> {
val list = ArrayList<AppInfo>()
val launchIntent = Intent(Intent.ACTION_MAIN, null)
.addCategory(Intent.CATEGORY_HOME)
val intents = packageManager.queryIntentActivities(launchIntent, 0)
//遍历
for (ri in intents) {
//得到包名
val packageName = ri.activityInfo.applicationInfo.packageName
if (packageName == "com.android.settings") { //不显示原生设置
continue
}
//得到图标
val icon = ri.loadIcon(packageManager)
//得到应用名称
val appName = ri.loadLabel(packageManager).toString()
//封装应用信息对象
val appInfo = AppInfo(icon, appName, packageName)
//添加到list
list.add(appInfo)
}
return list
}
复制代码
public boolean configureContentView(List<Intent> payloadIntents, Intent[] initialIntents,
List<ResolveInfo> rList, boolean alwaysUseOption) {
// The last argument of createAdapter is whether to do special handling
// of the last used choice to highlight it in the list. We need to always
// turn this off when running under voice interaction, since it results in
// a more complicated UI that the current voice interaction flow is not able
// to handle.
mAdapter = createAdapter(this, payloadIntents, initialIntents, rList,
mLaunchedFromUid, alwaysUseOption && !isVoiceInteraction());
final int layoutId;
if (mAdapter.hasFilteredItem()) {
layoutId = R.layout.resolver_list_with_default;
alwaysUseOption = false;
} else {
layoutId = getLayoutResource();
}
mAlwaysUseOption = alwaysUseOption;
int count = mAdapter.getUnfilteredCount();
if (count == 1 && mAdapter.getOtherProfile() == null) {
// Only one target, so we're a candidate to auto-launch!
final TargetInfo target = mAdapter.targetInfoForPosition(0, false);
if (shouldAutoLaunchSingleChoice(target)) {
safelyStartActivity(target);
mPackageMonitor.unregister();
mRegistered = false;
finish();
return true;
}
}
if (count > 0) {
// add by liuwei,if set my_default_launcher,start default
String defaultlauncher = Settings.Global.getString(this.getContentResolver(), "my_default_launcher");
ENTRY art_quick_lock_object_no_inline
// This is also the slow path for art_quick_lock_object.
SETUP_SAVE_REFS_ONLY_FRAME // save callee saves in case we block
mov x1, xSELF // pass Thread::Current
bl artLockObjectFromCode // (Object* obj, Thread*) <===调用
...
END art_quick_lock_object_no_inline
复制代码
case LockWord::kFatLocked: {
// We should have done an acquire read of the lockword initially, to ensure
// visibility of the monitor data structure. Use an explicit fence instead.
std::atomic_thread_fence(std::memory_order_acquire);
Monitor* mon = lock_word.FatLockMonitor();
if (trylock) {
return mon->TryLock(self) ? h_obj.Get() : nullptr;
} else {
mon->Lock(self);
DCHECK(mon->monitor_lock_.IsExclusiveHeld(self));
return h_obj.Get(); // Success!
}
}
复制代码
{
ScopedThreadSuspension tsc(self, kBlocked); // Change to blocked and give up mutator_lock_.
// Acquire monitor_lock_ without mutator_lock_, expecting to block this time.
// We already tried spinning above. The shutdown procedure currently assumes we stop
// touching monitors shortly after we suspend, so don't spin again here.
monitor_lock_.ExclusiveLock(self);
}
复制代码
class LocalRoomRequestManager :ILocalRequest,IDatabaseRequest{
var studentDao:StudentDao?=null
//相当于Java代码的构造代码块
init{
val studentDatabase=StudentDatabase.getDataBase()
studentDao=studentDatabase?.getStudentDao()
}
companion object{
var INSTANCE: LocalRoomRequestManager? = null
fun getInstance() : LocalRoomRequestManager {
if (INSTANCE == null) {
synchronized(LocalRoomRequestManager::class) {
if (INSTANCE == null) {
INSTANCE = LocalRoomRequestManager()
}
}
}
return INSTANCE!!
}
}
override fun updateStudents(vararg students: Student) {
studentDao?.updateStudents(*students)
}
override fun deleteStudents(vararg students: Student) {
studentDao?.deleteStudent(*students)
}
override fun deleteAllStudent() {
studentDao?.deleteAllStudent()
}
override fun queryAllStudent(): List<Student>? {
return studentDao?.queryAllStudents()
}
override fun insertStudents(vararg students: Student) {
studentDao?.insertStudents(*students)
}
}
复制代码
2.2、Room操作
真正用来操作数据库的代码
初始化数据库
@Database(entities = [Student::class],version = 1)
abstract class StudentDatabase: RoomDatabase() {
abstract fun getStudentDao():StudentDao
companion object{
private var INSTANCE:StudentDatabase?=null
//Application 调用
fun getDatabase(context: Context):StudentDatabase?{
if(INSTANCE==null){
INSTANCE=Room.databaseBuilder(context,StudentDatabase::class.java,"student_database.db")
.allowMainThreadQueries()//允许在主线程查询
.build()
}
return INSTANCE
}
//使用者调用
fun getDataBase():StudentDatabase?= INSTANCE
}
@Dao
interface StudentDao {
/***
* 可变参数,插入数据
*/
@Insert
fun insertStudents(vararg students:Student)
//更新数据
@Update
fun updateStudents(vararg students:Student)
//根据条件删除
@Delete
fun deleteStudent(vararg students:Student)
//删除全部
@Query("delete from student")
fun deleteAllStudent()
//查询全部
@Query("SELECT * FROM student ORDER BY ID DESC")
fun queryAllStudents():List<Student>
}
@Entity
class Student(){
@PrimaryKey(autoGenerate = true)//设置为主键,自动增长
var id:Int=0
@ColumnInfo(name="name")//别名 数据库中的名字如果不设置,默认是属性名称
lateinit var name:String
@ColumnInfo(name ="phoneNumber")
lateinit var phoneNumber:String
//次构造
constructor(name:String,phoneNumber:String): this(){
this.name=name
this.phoneNumber=phoneNumber
}
}
复制代码
inner class MyViewHolder(itemView: View):RecyclerView.ViewHolder(itemView){
var tvID: TextView = itemView.findViewById(R.id.tv_id)
var tvName: TextView = itemView.findViewById(R.id.tv_name)
var tvPhoneNumber: TextView = itemView.findViewById(R.id.tv_phoneNumber)
}
private fun getAllLauncherApps(): MutableList<AppInfo> {
val list = ArrayList<AppInfo>()
val launchIntent = Intent(Intent.ACTION_MAIN, null)
.addCategory(Intent.CATEGORY_HOME)
val intents = packageManager.queryIntentActivities(launchIntent, 0)
//遍历
for (ri in intents) {
//得到包名
val packageName = ri.activityInfo.applicationInfo.packageName
if (packageName == "com.android.settings") { //不显示原生设置
continue
}
//得到图标
val icon = ri.loadIcon(packageManager)
//得到应用名称
val appName = ri.loadLabel(packageManager).toString()
//封装应用信息对象
val appInfo = AppInfo(icon, appName, packageName)
//添加到list
list.add(appInfo)
}
return list
}
复制代码
public boolean configureContentView(List<Intent> payloadIntents, Intent[] initialIntents,
List<ResolveInfo> rList, boolean alwaysUseOption) {
// The last argument of createAdapter is whether to do special handling
// of the last used choice to highlight it in the list. We need to always
// turn this off when running under voice interaction, since it results in
// a more complicated UI that the current voice interaction flow is not able
// to handle.
mAdapter = createAdapter(this, payloadIntents, initialIntents, rList,
mLaunchedFromUid, alwaysUseOption && !isVoiceInteraction());
final int layoutId;
if (mAdapter.hasFilteredItem()) {
layoutId = R.layout.resolver_list_with_default;
alwaysUseOption = false;
} else {
layoutId = getLayoutResource();
}
mAlwaysUseOption = alwaysUseOption;
int count = mAdapter.getUnfilteredCount();
if (count == 1 && mAdapter.getOtherProfile() == null) {
// Only one target, so we're a candidate to auto-launch!
final TargetInfo target = mAdapter.targetInfoForPosition(0, false);
if (shouldAutoLaunchSingleChoice(target)) {
safelyStartActivity(target);
mPackageMonitor.unregister();
mRegistered = false;
finish();
return true;
}
}
if (count > 0) {
// add by liuwei,if set my_default_launcher,start default
String defaultlauncher = Settings.Global.getString(this.getContentResolver(), "my_default_launcher");
/* Copyright 2021 Google LLC.
SPDX-License-Identifier: Apache-2.0 */
data class MyData(
- val nums: List<Int>
+ val nums: PersistentList<Int>
)
- val myInts = mutableListOf(1, 2, 3, 4)
- val myObj = MyData(myInts)
- myInts.add(5) // Fails to compile with PersistentList, but mutates with List
+ val newData = myObj.copy(
+ nums = myObj.nums.mutate { it += 5 } // Mutate returns a new PersistentList
+ )
复制代码
/* Copyright 2021 Google LLC.
SPDX-License-Identifier: Apache-2.0 */
val Context.dataStore by dataStore("my_file.json", serializer = UserPreferencesSerializer)
复制代码
其读取数据看起来与使用 protos 进行读取一样:
/* Copyright 2021 Google LLC.
SPDX-License-Identifier: Apache-2.0 */
suspend fun getShowCompleted(): Boolean {
context.dataStore.data.first().showCompleted
}
复制代码
您可以使用生成的 .copy() 函数更新数据:
/* Copyright 2021 Google LLC.
SPDX-License-Identifier: Apache-2.0 */
suspend fun setShowCompleted(newShowCompleted: Boolean) {
// This will leave the sortOrder value untouched:
context.dataStore.updateData { it.copy(newShowCompleted = showCompleted) }
}
复制代码
ENTRY art_quick_lock_object_no_inline
// This is also the slow path for art_quick_lock_object.
SETUP_SAVE_REFS_ONLY_FRAME // save callee saves in case we block
mov x1, xSELF // pass Thread::Current
bl artLockObjectFromCode // (Object* obj, Thread*) <===调用
...
END art_quick_lock_object_no_inline
复制代码
case LockWord::kFatLocked: {
// We should have done an acquire read of the lockword initially, to ensure
// visibility of the monitor data structure. Use an explicit fence instead.
std::atomic_thread_fence(std::memory_order_acquire);
Monitor* mon = lock_word.FatLockMonitor();
if (trylock) {
return mon->TryLock(self) ? h_obj.Get() : nullptr;
} else {
mon->Lock(self);
DCHECK(mon->monitor_lock_.IsExclusiveHeld(self));
return h_obj.Get(); // Success!
}
}
复制代码
{
ScopedThreadSuspension tsc(self, kBlocked); // Change to blocked and give up mutator_lock_.
// Acquire monitor_lock_ without mutator_lock_, expecting to block this time.
// We already tried spinning above. The shutdown procedure currently assumes we stop
// touching monitors shortly after we suspend, so don't spin again here.
monitor_lock_.ExclusiveLock(self);
}
复制代码
setState() 将对组件 state 的更改排入队列,并通知 React 需要使用更新后的 state 重新渲染此组件及其子组件。这是用于更新用户界面以响应事件处理器和处理服务器数据的主要方式 将 setState() 视为请求而不是立即更新组件的命令。为了更好的感知性能,React 会延迟调用它,然后通过一次传递更新多个组件。React 并不会保证 state 的变更会立即生效。
我希望调用 API 时,有着和调用系统自带 API 一样的体验,所以我并没有为 Category 方法添加前缀。我已经用工具扫描过这个项目中的 API,确保没有对系统 API 产生影响。我知道没有前缀的 Category 可能会带来麻烦(比如可能和其他某些类库产生冲突),所以如果你只需要其中少量代码,那最好将那段代码取出来,而不是导入整个库。
task.display = ^(CGContextRef context, CGSize size, BOOL(^isCancelled)(void)) { if (isCancelled()) return; NSArray *lines = CreateCTLines(text, font, size.width); if (isCancelled()) return;
for (int i = 0; i < lines.count; i++) {
CTLineRef line = line[i]; CGContextSetTextPosition(context, 0, i * font.pointSize * 1.5); CTLineDraw(line, context); if (isCancelled()) return;
}
};
var arr = [1,2,3]; var arr1 =newArray(1,2,3) var a = {}; // 检测某个实例对象是否属于某个对象类型 console.log(arr instanceofArray);//true console.log(arr1 instanceofArray);//true console.log(a instanceofArray);//true
function fun () {
console.log(1);
}
console.log(fun instanceofFunction);//true
// 添加一个比较函数 arr.sort(function(a,b) { if (a > b) { return-1;//表示 a 要排在 b 前面 } elseif (a < b) { return1;//表示 a 要排在 b后面 } else { return0;;//表示 a 和 b 保持原样,不换位置 }
});
console.log(arr);//[30,20,10,9,8,7,6,5,4,3,2,1] (添加函数之后) // 想要从小到大排序只要将函数 大于小于 号,反向即可
转字符串方法:将数组的所有元素连接到一个字符串中
join() 通过参数作为连字符将数组中的每一项用连字符连成一个完整的字符串
var arr = [1,2,3,4,5,6,7,8,9,10,20,30];
// 转字符串方法 var str = arr.join();
console.log(str);//1,2,3,4,5,6,7,8,9,10,20,30 var str = arr.join("*");
console.log(str);//1*2*3*4*5*6*7*8*9*10*20*30 var str = arr.join("");
console.log(str);//123456789102030
/* arguments展示形式是一个伪数组,因此可以进行遍历,伪数组有如下特点: 具有length属性 按照索引方式存储数据 不具有数组的 push pop 等方法 */
案例:利用 arguments 求一组数最大值
function getMax() { var max = arguments[0]; var arry = arguments; for (var i =0; i < arry.length; i++) { if (arry[i] > max) {
max = arry[i];
}
} return max;
}
遍历:遍及所有,对数组的每一个元素都访问一次就叫遍历。利用 for 循环,将数组中的每一项单独拿出来,进行一些操作
根据下标在 0 到 arr.length-1 之间,进行 for 循环遍历
//遍历数组就是把数组的元素从头到尾访问一遍 var arry = ['red','blue','green'] for(var i =0; i <3; i++){
console.log(arry[i]);
} //1.因为索引号从0开始,所以计数器i必须从0开始 //2.输出时计数器i当索引号使用
// 通用写法 var arry = ['red','blue','green'] for(var i =0; i < arry.length; i++){ //也可以写成: i <= arry.length - 1 console.log(arry[i]);
}
数组应用案例
求一组数中的所有数的和以及平均值
var arry = [2, 6, 7, 9, 11]; var sum =0; var average =0; for (var i =0; i < arry.length; i++) {
sum += arry[i];
}
average = sum / arry.length;
console.log(sum,average);//同时输出多个变量用逗号隔开
2、当内层循环结束时,在数组最后一位的元素,就一定是这个数组中最大的元素了,这时候除了最后一个元素不用再动以外(所以内层循环每循环一次就可以少循环一次)我们还要再来确定这个数组中第二大的元素,第三大的元素,以此类推,因此我们还需要一层外层循环。如果这个数组有 n 个元素我们就要确定 n - 1 个元素的位置,所以外层循环需要循环的次数就是 n - 1 次
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
复制代码
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
复制代码
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
//拒绝策略的接口
RejectedExecutionHandler handler) {
复制代码
public static class CustomDiscardOldestPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardOldestPolicy} for the given executor.
*/
public CustomDiscardOldestPolicy() {
}
/**
* Obtains and ignores the next task that the executor
* would otherwise execute, if one is immediately available,
* and then retries execution of task r, unless the executor
* is shut down, in which case task r is instead discarded.
*
* @param r the runnable task requested to be executed
* @param e the executor attempting to execute this task
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
System.out.println("被拒绝的任务 " + r.toString());
Runnable runnable = e.getQueue().poll();
if (runnable != null)
System.out.println("队列中拿到的任务 " + runnable.toString());
else
System.out.println("队列中拿到的任务 null");
e.execute(r);
}
}
}
public static void main(String[] args) {
ThreadPoolExecutor pool = new ThreadPoolExecutor(
1,
2,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(2),
new CustomDiscardOldestPolicy()
);
for (int i = 0; i < 5; i++) {
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("任务执行---开始" + Thread.currentThread().getName() + " 任务 " + this.toString());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
System.out.println("添加任务 " + runnable.toString());
pool.execute(runnable);
}
}
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory, defaultHandler);
}
复制代码
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
复制代码
当打包成功后,我们获取apk的classes.dex的crc32值,随后将该crc32值赋予R.string.classes_txt,最后通过AndroidStudio再重新打包即可(因为更改资源文件并不会改变classe.dex的crc32值,改变代码才会)。获取classes.dex的crc32值的方法,可使用 Windows CRC32命令工具,使用方法如下:
本节主要介绍下我们常用的 javadoc tag ,虽然内容比较简单,但若正确使用,真的能使我们的代码高大上不少。不仅如此,只要我们按照Javadoc 注释规则,在编码完成后,Javadoc 也能够帮我们从源代码中生成相应的 Html 格式的 API 开发文档。可以点击Oracle规范,我将常用的javadoc tag 根据自己的习惯进行了整理,见下: