








Android修炼系列(六),时间与空间复杂度的概念
本来是想将时间复杂度和空间复杂度的内容,放到后面的算法系列,但后想想,其实复杂度的审视应该是贯彻于整个开发过程之中的,应该是属于更大概念的“代码规范”的一部分,而不应局限在某个算法上。当然本文仅是以能用能理解为主,并不会深入到推倒公式的那种程度。
分析
当一个问题的算法被确定以后,那么接下来最重要的当然是评估该算法所用时间和占用内存资源的问题了,如果其运行时间超出了我们所能接受的底线,或者资源的占用多到当前设备不能满足的程度,那么对于我们来说,这个算法就是无用的,即使它能够正确的运行。
相比于执行完程序再事后统计其所用时间和占用空间的方法,理论层面的复杂度分析更有优势,主要表现在两点:
1、算法运行所在的设备,配置不同、运行环境的不同,都会给算法本身运行的实际时间和空间的计算带来偏差;
2、测试数据规模的大小,数据本身的特殊性与否,也会使实际的运行结果不具有普适性,不容易正确的反应算法的性能的一个真实情况。
那怎么从理论层面来分析复杂度呢?
大O标记法
关于 大O 标记法的相关描述,我就直接引用「数据结构与算法分析」的内容了:
一般来说,估计算法资源消耗所需的分析是一个理论问题,因此需要一套正式的系统架构,我们先从某些数学定义开始。
如果存在正常数 c 和 使得当N ≥ 时,T(N) ≤ c f(N),则记为T(N) = O( f(N) )。
定义的目的是建立一种相对的级别。给定两个函数,通常存在一些点,在这些点上一个函数的值小于另一个函数的值,因此,一般地宣称,比如说f(N) < g(N) ,是没有什么意义的。于是,我们比较它们的相对增长率。当将相对增长率应用到算法分析时,我们将会明白为什么它是重要的度量。
虽然对于较小的 N 值,1000N 要比 大,但 以更快的速度增长,因此 最终将是更大的函数。在这种情况下,N = 1000 是转折点。定义是说,最后总会存在某个点 ,从它以后 c · f(N) 总是至少与 T(N) 一样大,从而若忽略常数因子,则 f(N) 至少与 T(N)一样大。
在我们的例子中,T(N) = 1000N,f(N) = , = 1000 而 c=1。我们也可以让 = 10 而 c = 100。因此,可以说 1000N = O()。这种记法称之为 大O标记法。人们常常不说“...级的”,而是说“大O...”。
同理还有下面的几个定义:
| 函数表达式 | 含义 |
|---|---|
| T(N) = O( f(N) ) | 是说T(N) 的增长率小于或等于 f(N) 的增长率(符号读音'大O') |
| T(N) = Ω( g(N) ) | 是说T(N) 的增长率大于或等于 g(N) 的增长率(符号读音'omega') |
| T(N) = Θ( h(N) ) | 是说T(N) 的增长率等于 h(N) 的增长率(符号读音'theta') |
| T(N) = o( p(N) ) | 是说T(N) 的增长率小于 p(N) 的增长率(符号读音'小o') |
还有一点需要知道的是,当 T(N) = O( f(N) ) 时,我们是在保证函数 T(N) 是在以不快于 f(N)的速度增长,因此 f(N) 是T(N)的一个上界。这意味着 f(N) = Ω( T(N) ),于是我们说T(N)是f(N)的一个下界。”
时间复杂度分析
下面我们来看一段非常简单的代码
1 private static int getNum(int n) {
2 int currentNum = 0;
3 for(int i = 0; i < n; i++) {
4 currentNum += i*i;
5 }
6 return currentNum;
7 在分析时,我们可以忽略调用方法、变量的声明和返回值的开销,所以我们只需要分析第2、3、4行的时间开销:
第2行占用1个时间单元;第4行的1次执行实际占用3个时间单元(1次乘法、1次加法、一次赋值),但是这么精确的计算是没有意义的,对于我们分析大O的结果也是无关紧要的,而且随着程序的复杂度提高这种方式也会变得越来越不可操作,(推导过程就省略了,直接上结论了,本节主要是用法层面).
所以我们也记第4行的1次执行时间开销为1个时间单元,则 n 次执行开销为 n 个时间单元;同理第3行执行 n 次的时间开销也为 n 个时间单元,所以执行总开销为 (2n + 1) 个时间单元。所以f(N) = 2n+1,根据上文T(N) = c · f(N)到T(N) = O(2n + 1)的大O表示过程知道,我们可以抛弃一些前导的常数和抛弃低阶项,所以T(N) = O(N)。
知道了分析方法,下面我们再来看看其他复杂度的代码
1 private static void getNum(int n) {
2 int currentNum = 0;
3 for(int i = 0; i < n; i++) {
4 for(int j = 0; j < n; j++) {
5 currentNum++;
6 }
7 }
8 通过上面代码我们可知:第2行1个单元时间,第3行 n 个单元时间,第4行 个单元时间,第5行 个单元时间,所以总时间开销f(N) = 2· + n + 1,所以复杂度T(N) = O(),当然O(N^3^)都是同理的。
1 private static void getNum(int n) {
2 int currentNum = 0;
3 for(int k = 0; k < n; k++) {
4 currentNum++;
5 }
6 for(int i = 0; i < n; i++) {
7 for(int j = 0; j < n; j++) {
8 currentNum++;
9 }
}
通过上面代码我们可知:第2行1个单元时间,第3行 n 个单元时间,第4行 n 个单元时间,第6行 n 个单元时间,第7行 个单元时间,第8行 个单元时间,所以总时间开销f(N) = 2·+3·n + 1,所以复杂度T(N) = O()。
1 if(condition) {
2 S1
3 } else {
4 S2
5 }这是一段伪代码,在这里主要是分析 if 语句的复杂度,在一个 if 语句中,它的运行时间从不超过判断condition的运行时间加上 S1 和 S2 中运行时间长者的总的运行时间。
1 private static void getNum(int n) {
2 int currentNum = 0;
3 currentNum++;
4 if(currentNum > 0) {
5 currentNum--;
6 }
7 通过上面的代码我们可知,第2行1个时间单元,第3行1个时间单元,第4行1个时间单元,第5行1个时间单元,所以总开销4个时间单元,所以复杂度T(N) = O(1),注意这里不是O(4)哦。
1 private static void getNum(int n, int m) {
2 int currentNum = 0;
3 for(int i = 0; i < n; i++) {
4 currentNum++;
5 }
6 for(int j = 0; j < m; j++) {
7 currentNum++;
8 }
9 通过上面的代码我们可知,第2行是1个单元时间,第3行是 n 个单元时间,第4行是 n 个单元时间,第6行是 m 个单元时间,第7行是 m 个时间单元,所以总的时间开销f(N) = 2·n +2·m + 1,所以复杂度T(N) = O(n+m),同理,O(m·n)的复杂度也是同样分析。
1 private static void getNum(int n) {
2 int currentNum = 1;
3 while (currentNum <= n) {
4 currentNum *= 2;
5 }
6 通过上面的代码我们可知,第2行需要1个单元时间;第3行每次执行需要1个单元时间,那么现在需要执行多少次呢?通过分析我们知道当 2=n时 while 循环结束,所以次数 = ,所以第3行总需要 个单元时间;第4行同理也需要 个单元时间,所以总时间开销f(N) = 2· + 1,所以复杂度T(N) = O(logn),注意的是这里不但省略了常数,系数,还省略了底哦。
1 private static void getNum(int n) {
2 int currentNum = 1;
3 for(int i = 0; i < n; i++, currentNum = 1) {
4 while (currentNum <= n) {
5 currentNum *= 2;
6 }
7 }
8 通过上面的代码我们可知,第2行1个单元时间,第3行 n 个单元时间,第4行根据上文我们需要n·个单元时间,第5行也需要n·个单元时间,所以总时间花销f(N) = 2·n· + n + 1,所以复杂度T(N) = O(n·logn)。
空间复杂度分析
上面我们简单介绍了几种常见的时间复杂度,空间的复杂度比时间复杂度要简单许多,下面就来分析一下空间的复杂度:
空间复杂度考量的是算法所需要的存储空间问题,一般情况下,一个程序在机器上执行时,除了需要存储程序本身的指令、常数、变量和输入数据外,还需要存储对数据操作的存储单元,若输入数据所占空间只取决于问题本身,和算法无关,这样只需要分析该算法在实现时所需的辅助单元即可。
1 private static void getNum(int n) {
2 int i = 0;
3 for(; i<n; i++){
4 i*=2;
5 }
6 通过上面的代码我们知道,第2行我们只需要1个空间单元;第3行、第4行不需要额外的辅助空间单元,所以空间复杂度S(N) = O(1),注意不是只有1个空间单元才是O(1)哦,如果空间单元是常量阶的复杂度都是O(1)哦。
1 private static void getNum(int n) {
2 int i = 0;
3 int[] array = new int[n];
4 for(; i<array.length; i++){
5 i*=2;
6 }
7 根据上面的代码我们可知,第2行需要1个空间单元;第3行需要 n 个空间单元;第4行、第5行不需要额外的空间单元,所以总消耗f(n) = n + 1,所以空间复杂度S(N) = O(n),其他情况的分析与时间复杂度分析方法一样,在这里就不详细介绍了。
好了,本文到这里就结束了,关于时间复杂度和空间复杂度的介绍应该够平时所需了。如果本文对你有用,来点个赞吧,大家的肯定也是阿呆i坚持写作的动力。
参考 1、数据结构与算法分析:机械工业出版社
作者:矛盾的阿呆i
链接:https://juejin.cn/post/6938284594076581902
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
在Swift中使用泛型
Swift 5.0 都发布这么久了,而泛型作为该语言的重要特性,还是非常有必要了解一下的。
在 Swift 泛型的运用几乎随处可见,在系统层面,Swift 标准库是通过泛型代码构建出来的,Swift 的数组和字典类型都是泛型集。在主流的轮子里,也是有大量的泛型使用。使用泛型可以提审代码的复用性。
下面就通过实例看看我们的代码怎么写:
1、函数中使用泛型
举个简单的例子哦,比如现在有个简单的需求,就是写一个方法,这个方法需要把传过来的整数参数打印出来。
简单需求卡卡的代码就出来啦:
/// 打印一个整形数字
func myPrintInt(arg:Int){
print(arg)
}看着没啥毛病哦,产品姥爷又说我现在这个方法要支持字符串。
简单再给添加一个方法好啦:
func myPrintString(arg:String){
print(arg)
}产品:现在要支持Float、Array、Dictionary ......
这也好办啊:
// 打印任何东西
func myPrintAny(arg:Any){
print(any1)
}很好,现在我要你传进去两个参数,而且参数类型要一致,你要怎么写。
下面的写法可以不?参数靠大家自觉。
//参数类型千万要一样啊。。。。。
func myPrintAny(any1:Any, any2:Any){
print(any1)
print(any2)
}写成这样的话就可以那赔偿走人啦。
这时候就应该使用泛型了。
// 打印任何东西
func myPrint<T>(any1:T, any2:T){
print(any1)
print(any2)
}方法的使用:
myPrint(any1: 1, any2: 1)
myPrint(any1: "1", any2: "1")
myPrint(any1: ["1","2"], any2: ["3","4"])这里就可以看出泛型的优势所在了,大大提升了代码的可复用性。而且同时也提升了代码的安全性。
泛型和Any的区别
从表面上看,这好像和泛型极其相似。Any 类型和泛型两者都能用于定义接受两个不同类型参数的函数。然而,理解两者之间的区别至关重要:泛型可以用于定义灵活的函数,类型检查仍然由编译器负责;而 Any 类型则可以避开 Swift 的类型系统 (所以应该尽可能避免使用)。
2、类中泛型
实现一个栈,栈里边的元素可以是任何类型,但是所有元素又必须是同一种类型,使用泛型实现的代码就是这样的。
//类作用域
class YJKStack<T>: NSObject {
//栈空间
private var list:[T] = []
//进栈
public func push(item:T){
list.append(item)
}
//出栈
public func pop() -> T{
return list.removeLast()
}
}当你扩展一个泛型类的时候,原始类型定义中声明的类型参数列表在扩展里是可以使用的,并且这些来自原始类型中的参数名称会被用作原始定义中类型参数的引用。
简单说就是类中的泛型,在其扩展中也是可以进行使用的。
extension YJKStack{
/// 获取栈顶元素
public func getLast() -> T?{
return list.last
}
}3、泛型类型约束
在实际运用中,我们的参数虽然可以不是特定的类,但是通常需要这个参数要实现某个协议或者是某个类的子类。这时候就要给泛型添加约束了,代码就是下面这一堆喽
//class YJKProtocolStack<T: A&B> 须实现多个协议的话,用 & 符号链接就好啦。
class YJKProtocolStack<T: A>: NSObject {
//栈空间
private var list:[T] = []
//进栈
public func push(item:T){
list.append(item)
}
//出栈
public func pop() -> T{
return list.removeLast()
}
}
protocol A {}
protocol B {}看了上面的代码,可能有的小伙伴就迷茫啦,既然有YJKProtocolStack<T: A&B>, 为啥没有 YJKProtocolStack<T: A|B>呢,其实想想就可以明白,如果用 | 的话,T 表示的就不是一个指定的类型啦,这样和泛型的定义是不一致的。
4、关联类
在类及函数里都知道泛型怎么玩了,那么在协议里怎么用啦,是不是和类是一样的呢,写个代码看一下:
//Protocols do not allow generic parameters; use associated types instead
//一敲出来,编译器就提示你错误啦,并且告诉你怎么写了。
protocol C<T> {
}
//正确的写法就是下面这样的哦
protocol C {
// Swift 中使用 associatedtype 关键字来设置关联类型实例
// 具体类型由实现类来决定
associatedtype ItemType
func itemAtIndex(index:Int) -> ItemType
func myPrint(item:ItemType)
// 局部作用域的泛型和类的写法是一样的。
func test<T>(a:T)
}
//协议的泛型约束
protocol D {
associatedtype ItemType:A
}再来看看实现类怎么玩:
//遵循了 C 协议的类
class CClassOne<T>:C{
//要指定 C 协议中, ItemType 的具体类型
typealias ItemType = T
public var list:[ItemType] = []
//协议方法的实现
func itemAtIndex(index:Int) -> ItemType{
return list[index]
}
func myPrint(item:ItemType){
}
func test<T>(a: T) {
}
}
//实现2
class CClassTwo:C{
typealias ItemType = Int
public var list:[ItemType] = []
func itemAtIndex(index:Int) -> ItemType{
return list[index]
}
func myPrint(item:ItemType){
}
func test<T>(a: T) {
}
}通过上面两个例子可以看出,只要在实现类中 指定 ItemType 的类型就好啦。这个类型 还可以是个泛型,也可以是具体的数据类型。
还有一点要讲的就是结构体中使用泛型和类是完全一样的处理哦。
5、Where 语句
Where 其实也是做类型约束的,你可以写一个where语句,紧跟在在类型参数列表后面,where语句后跟一个或者多个针对关联类型的约束,以及(或)一个或多个类型和关联类型间的等价(equality)关系。
看看下面几个代码就行啦,不多说了
func test4<T:A>(arg1:T){}
func test5<T>(arg1:T) where T:A{}
// 上面两个方法的作用是一模一样的
//这个方法 arg1 和 arg2 只需是实现 C 协议的对象就好啦
func test6<T1:C, T2:C>(arg1:T1, arg2:T2){}
//这个方法 arg1 和 arg2 需要实现 C 协议, 并且 T1 与 T2 的泛型类型要一致
func test7<T1:C, T2:C>(arg1:T1, arg2:T2) where T1.ItemType == T2.ItemType{}
//这个方法 arg1 和 arg2 需要实现 C 协议, && T1 与 T2 的泛型类型要一致 && T1 的泛型 遵循A协议
func test8<T1:C, T2:C>(arg1:T1, arg2:T2) where T1.ItemType == T2.ItemType, T1.ItemType:A{}本文写到这里就没结束啦,简单介绍啦泛型在 Swift 中的使用,大家想要深入理解泛型,想要融会贯通、运用自如,还需要大家找时间多看看大神写的代码。
转自:https://www.jianshu.com/p/a01f212e628c
收起阅读 »关于 iOS 中各种锁的整理
名词解释
原子:
同一时间只允许一个线程访问
临界区:
指的是一块对公共资源进行访问的代码,并非一种机制或是算法。
自旋锁:
是用于多线程同步的一种锁,线程反复检查锁变量是否可用。由于线程在这一过程中保持执行,因此是一种忙等待。一旦获取了自旋锁,线程会一直保持该锁,直至显式释放自旋锁。 自旋锁避免了进程上下文的调度开销,因此对于线程只会阻塞很短时间的场合是有效的。
互斥锁(Mutex):
是一种用于多线程编程中,防止两条线程同时对同一公共资源(比如全局变量)进行读写的机制。
当线程来到临界区,获取不到锁,就会去睡眠主动让出时间片,让出时间片会导致操作系统切换到另一个线程,这种上下文的切换也耗时
读写锁:
是计算机程序的并发控制的一种同步机制,也称“共享-互斥锁”、多读者-单写者锁) 用于解决多线程对公共资源读写问题。
读操作可并发重入,写操作是互斥的。 读写锁通常用互斥锁、条件变量、信号量实现。
信号量(semaphore):
是一种更高级的同步机制,互斥锁可以说是semaphore在仅取值0/1时的特例。信号量可以有更多的取值空间,用来实现更加复杂的同步,而不单单是线程间互斥。
条件锁:
就是条件变量,当进程的某些资源要求不满足时就进入休眠,也就是锁住了。
当资源被分配到了,条件锁打开,进程继续运行。
递归锁:
递归锁有一个特点,就是同一个线程可以加锁N次而不会引发死锁。
互斥锁 :
互斥锁:线程会从sleep(加锁)——>running(解锁),过程中有上下文的切换,cpu的抢占,信号的发送等开销。
1. NSLock
是 Foundation 框架中以对象形式暴露给开发者的一种锁(Foundation框架同时提供了NSConditionLock,NSRecursiveLock,NSCondition)
NSLock 内部封装了 pthread_mutex 属性为 PTHREAD_MUTEX_ERRORCHECK 它会损失一定的性能来换错误提示。
NSLock 比 pthread_mutex 要慢,因为他还要经过方法调用,但是有缓存多次调用影响不大
NSLock定义如下:
@protocol NSLocking
- (void)lock;
- (void)unlock;
@end
@interface NSLock : NSObject {
@private
void *_priv;
}
- (BOOL)tryLock;
- (BOOL)lockBeforeDate:(NSDate *)limit;
@property (nullable, copy) NSString *name API_AVAILABLE(macos(10.5), ios(2.0), watchos(2.0), tvos(9.0));
@endlock 和 tryLock 方法都会请求加锁, 唯一不同的是 trylock 在没有获得锁的时候可以继续做一些任务和处理,lockBeforeDate方法也比较简单,就是在limit时间点之前获得锁,没有拿到返回NO。
2. pthread_mutex :
pthread 表示 POSIX thread,定义了一组跨平台的线程相关的 API,pthread_mutex 表示互斥锁。
互斥锁的实现原理与信号量非常相似,不是使用忙等,而是阻塞线程并睡眠,需要进行上下文切换,性能不及信号量。
// 初始化属性
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_DEFAULT);
// 初始化锁
pthread_mutex_init(&(_ticketMutex), &attr);
// 销毁属性
pthread_mutexattr_destroy(&attr);
/*
* Mutex type attributes
*/
#define PTHREAD_MUTEX_NORMAL 0
#define PTHREAD_MUTEX_ERRORCHECK 1 // NSLock 使用
#define PTHREAD_MUTEX_RECURSIVE 2 // 递归锁
#define PTHREAD_MUTEX_DEFAULT PTHREAD_MUTEX_NORMAL备注:我们可以不初始化属性,在传属性的时候直接传NULL,表示使用默认属性 PTHREAD_MUTEX_NORMAL。pthread_mutex_init(mutex, NULL);
3. @synchronized :
@synchronized要一个参数,这个参数相当于信号量
// 用在防止多线程访问属性上比较多
- (void)setTestInt:(NSInteger)testInt {
@synchronized (self) {
_testInt = testInt;
}
}自旋锁 :
实现原理 : 保护临界区只有一个线程可以访问
伪代码 :
do {
Acquire Lock // 获取锁
Critical section // 临界区
Release Lock // 释放锁
Reminder section // 不需要锁保护的代码
}实现思路很简单,理论上定义一个全局变量,用来表示锁的状态即可
bool lock = false; // 一开始没有锁上,任何线程都可以申请锁
do {
while(lock); // 如果 lock 为 true 就一直死循环,相当于申请锁
lock = true; // 挂上锁,这样别的线程就无法获得锁
Critical section // 临界区
lock = false; // 相当于释放锁,这样别的线程可以进入临界区
Reminder section // 不需要锁保护的代码
}有一个问题就是一开始有多个线程执行 while 循环, 他们都不会在这里卡住,而是继续执行,这样就无法保证锁的可靠性了,解决思路很简单,就是确保申请锁的过程是原子的。
bool lock = false; // 一开始没有锁上,任何线程都可以申请锁
do {
while(test_and_set(&lock); // test_and_set 是一个原子操作
Critical section // 临界区
lock = false; // 相当于释放锁,这样别的线程可以进入临界区
Reminder section // 不需要锁保护的代码
}如过临界区执行时间过长,使用自旋锁是不合适的。忙等的线程白白占用 CPU 资源。
1. OSSpinLock :
编译器会报警告,大家已经不使用了,在某些场景下已经不安全了,主要是发生在低优先级的线程拿到锁时,高优先级线程进入忙等状态,消耗大量 CPU 时间,从而导致低优先级线程拿不到 CPU 时间,也就无法完成任务并释放锁,这被称为优先级反转
新版 iOS 中,系统维护了 5 个不同的线程优先级/QoS: background,utility,default,user-initiated,user-interactive。
高优先级线程始终会在低优先级线程前执行,一个线程不会受到比它更低优先级线程的干扰。
这种线程调度算法会产生潜在的优先级反转问题,从而破坏了 spin lock。
2. os_unfair_lock:
os_unfair_lock 是苹果官方推荐的替换OSSpinLock的方案,但是它在iOS10.0以上的系统才可以调用,解决了优先级反转问题
两种自旋锁的使用
// 需要导入的头文件
#import
#import
#import
// 自旋锁 实现
- (void)OSSpinLock {
if (@available(iOS 10.0, *)) { // iOS 10以后解决了优先级反转问题
os_unfair_lock_t unfairLock = &(OS_UNFAIR_LOCK_INIT);
NSLog(@"线程1 准备上锁");
os_unfair_lock_lock(unfairLock);
sleep(4);
NSLog(@"线程1执行");
os_unfair_lock_unlock(unfairLock);
NSLog(@"线程1 解锁成功");
} else { // 会造成优先级反转,不建议使用
__block OSSpinLock oslock = OS_SPINLOCK_INIT;
//线程2
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
NSLog(@"线程2 befor lock");
OSSpinLockLock(&oslock);
NSLog(@"线程2执行");
sleep(3);
OSSpinLockUnlock(&oslock);
NSLog(@"线程2 unlock");
});
//线程1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
NSLog(@"线程1 befor lock");
OSSpinLockLock(&oslock);
NSLog(@"线程1 sleep");
sleep(3);
NSLog(@"线程1执行");
OSSpinLockUnlock(&oslock);
NSLog(@"线程1 unlock");
});
// 可以看出不同的队列优先级,执行的顺序不同,优先级越高,越早被执行
}
}
// 需要导入的头文件
#import
#import
#import
// 自旋锁 实现
- (void)OSSpinLock {
if (@available(iOS 10.0, *)) { // iOS 10以后解决了优先级反转问题
os_unfair_lock_t unfairLock = &(OS_UNFAIR_LOCK_INIT);
NSLog(@"线程1 准备上锁");
os_unfair_lock_lock(unfairLock);
sleep(4);
NSLog(@"线程1执行");
os_unfair_lock_unlock(unfairLock);
NSLog(@"线程1 解锁成功");
} else { // 会造成优先级反转,不建议使用
__block OSSpinLock oslock = OS_SPINLOCK_INIT;
//线程2
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
NSLog(@"线程2 befor lock");
OSSpinLockLock(&oslock);
NSLog(@"线程2执行");
sleep(3);
OSSpinLockUnlock(&oslock);
NSLog(@"线程2 unlock");
});
//线程1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0), ^{
NSLog(@"线程1 befor lock");
OSSpinLockLock(&oslock);
NSLog(@"线程1 sleep");
sleep(3);
NSLog(@"线程1执行");
OSSpinLockUnlock(&oslock);
NSLog(@"线程1 unlock");
});
// 可以看出不同的队列优先级,执行的顺序不同,优先级越高,越早被执行
}
}读写锁:
上文有说到,读写锁又称共享-互斥锁
上文有说到,读写锁又称共享-互斥锁
1. pthread_rwlock:
pthread_rwlock经常用于文件等数据的读写操作,需要导入头文件#import
iOS中的读写安全方案需要注意一下场景
- 同一时间,只能有1个线程进行写的操作
- 同一时间,允许有多个线程进行读的操作
- 同一时间,不允许既有写的操作,又有读的操作
//初始化锁
pthread_rwlock_t lock;
pthread_rwlock_init(&_lock, NULL);
//读加锁
pthread_rwlock_rdlock(&_lock);
//读尝试加锁
pthread_rwlock_trywrlock(&_lock)
//写加锁
pthread_rwlock_wrlock(&_lock);
//写尝试加锁
pthread_rwlock_trywrlock(&_lock)
//解锁
pthread_rwlock_unlock(&_lock);
//销毁
pthread_rwlock_destroy(&_lock);
pthread_rwlock经常用于文件等数据的读写操作,需要导入头文件#import
iOS中的读写安全方案需要注意一下场景
- 同一时间,只能有1个线程进行写的操作
- 同一时间,允许有多个线程进行读的操作
- 同一时间,不允许既有写的操作,又有读的操作
//初始化锁
pthread_rwlock_t lock;
pthread_rwlock_init(&_lock, NULL);
//读加锁
pthread_rwlock_rdlock(&_lock);
//读尝试加锁
pthread_rwlock_trywrlock(&_lock)
//写加锁
pthread_rwlock_wrlock(&_lock);
//写尝试加锁
pthread_rwlock_trywrlock(&_lock)
//解锁
pthread_rwlock_unlock(&_lock);
//销毁
pthread_rwlock_destroy(&_lock);用法:实现多读单写
#import
@interface pthread_rwlockDemo ()
@property (assign, nonatomic) pthread_rwlock_t lock;
@end
@implementation pthread_rwlockDemo
- (instancetype)init
{
self = [super init];
if (self) {
// 初始化锁
pthread_rwlock_init(&_lock, NULL);
}
return self;
}
- (void)otherTest{
dispatch_queue_t queue = dispatch_get_global_queue(0, 0);
for (int i = 0; i < 10; i++) {
dispatch_async(queue, ^{
[self read];
});
dispatch_async(queue, ^{
[self write];
});
}
}
- (void)read {
pthread_rwlock_rdlock(&_lock);
sleep(1);
NSLog(@"%s", __func__);
pthread_rwlock_unlock(&_lock);
}
- (void)write
{
pthread_rwlock_wrlock(&_lock);
sleep(1);
NSLog(@"%s", __func__);
pthread_rwlock_unlock(&_lock);
}
- (void)dealloc
{
pthread_rwlock_destroy(&_lock);
}
@end递归锁:
递归锁有一个特点,就是同一个线程可以加锁N次而不会引发死锁。
1. pthread_mutex(recursive):
pthread_mutex_t锁是默认是非递归的。可以通过设置PTHREAD_MUTEX_RECURSIVE属性,将pthread_mutex_t锁设置为递归锁。
pthread_mutex_t lock;
pthread_mutexattr_t attr;
pthread_mutexattr_init(&attr);
pthread_mutexattr_settype(&attr, PTHREAD_MUTEX_RECURSIVE);
pthread_mutex_init(&lock, &attr);
pthread_mutexattr_destroy(&attr);
pthread_mutex_lock(&lock);
pthread_mutex_unlock(&lock);2. NSRecursiveLock:
NSRecursiveLock是对mutex递归锁的封装,API跟NSLock基本一致
#import "RecursiveLockDemo.h"
@interface RecursiveLockDemo()
@property (nonatomic,strong) NSRecursiveLock *ticketLock;
@end
@implementation RecursiveLockDemo
//卖票
- (void)sellingTickets{
[self.ticketLock lock];
[super sellingTickets];
[self.ticketLock unlock];
}
@end条件锁:
1. NSCondition:
定义:
@interface NSCondition : NSObject {
@private
void *_priv;
}
- (void)wait;
- (BOOL)waitUntilDate:(NSDate *)limit;
- (void)signal;
- (void)broadcast;遵循NSLocking协议,使用的时候同样是lock,unlock加解锁,wait是傻等,waitUntilDate:方法是等一会,都会阻塞掉线程,signal是唤起一个在等待的线程,broadcast是广播全部唤起。
NSCondition *lock = [[NSCondition alloc] init];
//Son 线程
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[lock lock];
while (No Money) {
[lock wait];
}
NSLog(@"The money has been used up.");
[lock unlock];
});
//Father线程
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[lock lock];
NSLog(@"Work hard to make money.");
[lock signal];
[lock unlock];
});2.NSConditionLock:
NSConditionLock是对NSCondition的进一步封装,可以设置具体的条件值
定义:
@interface NSConditionLock : NSObject {
@private
void *_priv;
}
- (instancetype)initWithCondition:(NSInteger)condition NS_DESIGNATED_INITIALIZER;
@property (readonly) NSInteger condition;
- (void)lockWhenCondition:(NSInteger)condition;
- (BOOL)tryLock;
- (BOOL)tryLockWhenCondition:(NSInteger)condition; //
- (void)unlockWithCondition:(NSInteger)condition;
- (BOOL)lockBeforeDate:(NSDate *)limit;
- (BOOL)lockWhenCondition:(NSInteger)condition beforeDate:(NSDate *)limit;用法 :
@interface NSConditionLockDemo()
@property (strong, nonatomic) NSConditionLock *conditionLock;
@end
@implementation NSConditionLockDemo
- (instancetype)init
{
if (self = [super init]) {
self.conditionLock = [[NSConditionLock alloc] initWithCondition:1];
}
return self;
}
- (void)otherTest
{
[[[NSThread alloc] initWithTarget:self selector:@selector(__one) object:nil] start];
[[[NSThread alloc] initWithTarget:self selector:@selector(__two) object:nil] start];
}
- (void)__one
{
[self.conditionLock lock];
NSLog(@"__one");
sleep(1);
[self.conditionLock unlockWithCondition:2];
}
- (void)__two
{
[self.conditionLock lockWhenCondition:2];
NSLog(@"__two");
[self.conditionLock unlockWithCondition:3];
}
@end里面有三个常用的方法
* 1、- (instancetype)initWithCondition:(NSInteger)condition; //初始化Condition,并且设置状态值
* 2、- (void)lockWhenCondition:(NSInteger)condition; //当状态值为condition的时候加锁
* 3、- (void)unlockWithCondition:(NSInteger)condition; //当状态值为condition的时候解锁信号量 dispatch_semaphore:
在加锁的过程中,如过线程 1 已经获取了锁,并在执行任务过程中,那么其他线程会被阻塞,直到线程 1 任务结束后完成释放锁。
实现原理 :
信号量的 wait 最终调用到这里
int sem_wait (sem_t *sem) {
int *futex = (int *) sem;
if (atomic_decrement_if_positive (futex) > 0)
return 0;
int err = lll_futex_wait (futex, 0);
return -1;
)首先把信号值减一,并判断是否大于 0,如过大于 0 说明不用等待,立即返回。
否则线程进入睡眠主动让出时间片,让出时间片会导致操作系统切换到另一个线程,这种上下文的切换也耗时,大概 10 微妙,而且还要切回来,如过等待时间很短,那么等待耗时还没有切换耗时长,很不划算。
自旋锁和信号量的实现简单,所以加锁和解锁的效率高
总结
其实本文写的都是一些再基础不过的内容,在平时阅读一些开源项目的时候经常会遇到一些保持线程同步的方式,因为场景不同可能选型不同,这篇就做一下简单的记录吧~我相信读完这篇你应该能根据不同场景选择合适的锁了吧、能够道出自旋锁和互斥锁的区别了吧。
性能排序:
1、os_unfair_lock
2、OSSpinLock
3、dispatch_semaphore
4、pthread_mutex
5、dispatch_queue(DISPATCH_QUEUE_SERIAL)
6、NSLock
7、NSCondition
8、pthread_mutex(recursive)
9、NSRecursiveLock
10、NSConditionLock
11、@synchronized
转自:https://www.jianshu.com/p/eaab05cf0e1c
常用开发加密方法
前言
相信大家在开发中都遇到过,有些隐秘信息需要做加密传输的场景.
A:你就把 XXX 做一下base64加密传过来就行
这些问题相信大家都遇到过,那么在实际开发中我们应该如何选择加密方法呢?
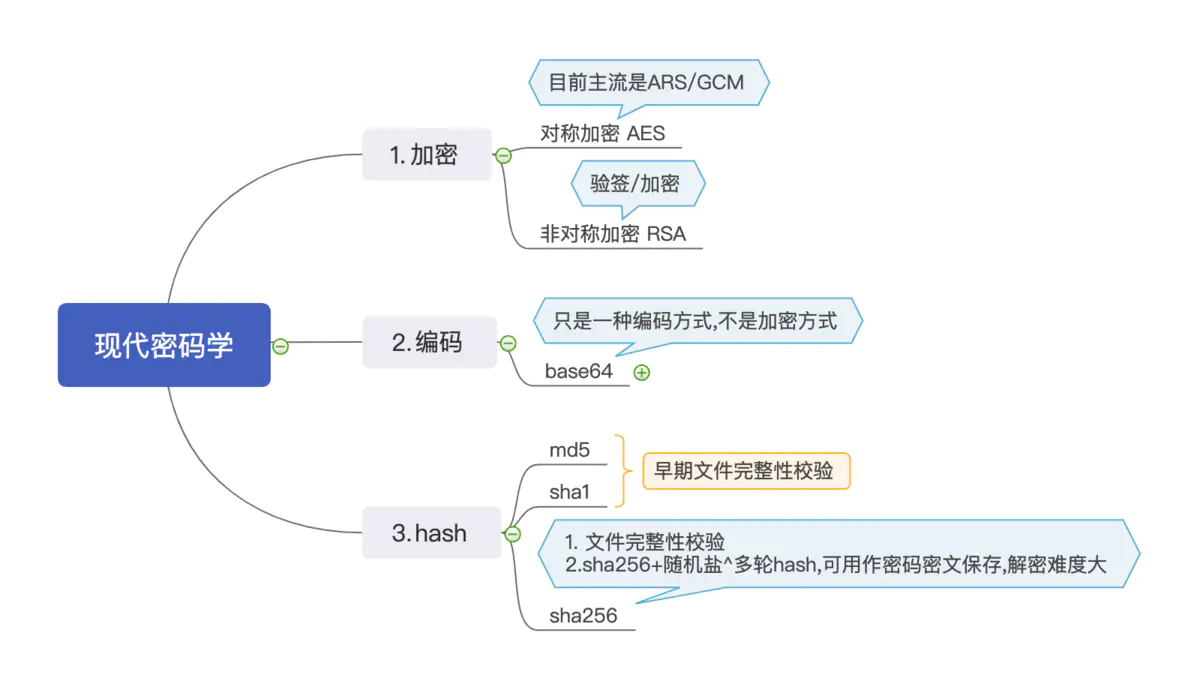
加密
这里我就直接抛出来几个加密规则
AES 对称加密,双方只有同一个秘钥key
RSA 非对称加密,生成一对公私钥.
首先要明确一点, 即使做了加密也不能保证我们的信息就是绝对安全的,只是尽可能的提升破解难度,加密算法的实现都是公开的,所以秘钥如何安全的存储是我们要重点考虑的问题.
关于这两种加密算法大家可以网上查一下原理,这里我不介绍原理,只介绍给大家特定场景下如何选择最优的加密规则,以及一些小Tips.
AES
对称加密,很好理解,生成唯一秘钥key,双方本别可以用key做加密/解密.是比较常用的加密首段,AES只是一种加密规则,具体的加密还有很多种,目前主流使用的是AES/GCM.
RSA
非对称加密,生成一对秘钥,public key/private key,
加解密使用时: public key加密, private key解密.
签名验证时 : private key签名 , public key 验签
这里说一下实际案例:
某某公司,2B的后台支付接口,突然有一天一个商家反馈为什么我账户里钱都没有了,通过日志一查发现都是正常操作刷走了.而某公司并没有办法证明自己的系统是没问题的.理论上这个接口的key下发给商户,但是某某公司也是有这个key的,所以到底是谁泄漏了key又是谁刷走了账户里的钱,谁也无法证明.
这里我们要想一个问题,我们要怎么做才能防止出现此类问题后,商户过来说不是我刷的钱,寻求赔偿的时候, 拿出证据打发他们?
这个问题就可以利用RSA来解决,在接入公司生成APP key 要求接入方自己生成一对RSA秘钥,然后讲 public key上传给我们, private key由接入方自己保存, 而我们只需要验证订单中的签名是否是由private key签名的,而非其他阿猫阿狗签名的订单. 如果出现了上诉问题,那么说明接入方的private key泄漏与我们无关,这样我们就能防止接入方抵赖.
完整性校验.防串改
很多情况下我们需要对数据的完整性做校验, 比如对方发过来一个文件, 我们怎么知道这个问题件就是源文件, 而非被别人恶意拦截串改后的问题?
早些年大家下载程序的时候应该会看到,当前文件的md5值是XXXXX,这个就是为了防止文件被修改的存在的.早期我们都是用md5/sha1来做完整性校验,后来由sha1升级出现了sha256.大家可能不知道应该如何选择.
下面是一个经典故事
Google之前公开过两个不同的PDF,而它们拥有相同的sha1值

两个不同的文件拥有相同sha1值,这意味着我们本地使用的程序sha1是源文件非串改后的,但实际上可能早已偷梁换柱.这是很可怕的.
所以推荐大家在用完整性校验时要使用sha256,会更安全些.
转自:https://www.jianshu.com/p/fa85cbe1027b
收起阅读 »iOS 13:更多系统APP和组件采用Swift编写
苹果在 2014 年 WWDC 发布了全新 Swift 编程语言,Swift 是苹果平台未来的编程语言。自那以后,很多第三方开发者开始使用 Swift 编写程序,不过苹果 iOS 和 macOS 系统,以及各种系统应用还是采用 Objective-C 编写。
这种情况存在很多原因,首先,苹果目前大量的 Objective-C 代码工作的很完美,没有必要为了重写而重写,没有问题就不要创造新的问题。其次,直到 Swift 5.0,ABI 才稳定,Swift 5.1,模块稳定,对于在系统级别大规模部署很重要。
自 iOS 9 之后,开发者 Alexandre Colucci 一直在统计苹果系统中 Swift 的使用情况。最新的数据显示,在 iOS 13 中,一共有 141 个使用 Swift 编写的二进制可执行文件,是 iOS 12 的两倍多,iOS 12 中有 66 个。
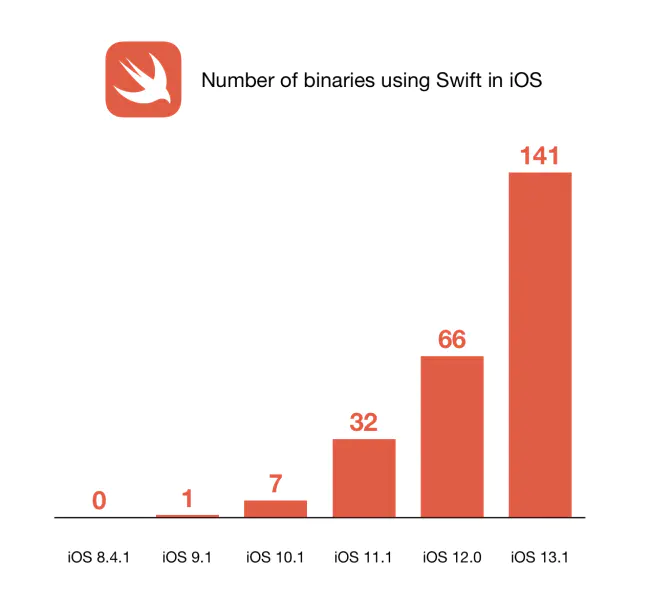
iOS 13 中,Sidecar 副屏、查找和提醒事项等新功能、新应用都采用 Swift 编写,其他使用 Swift 的 app 包括健康、Books 电子书以及一些系统服务,负责 AirPods 和 HomePod 配对的服务,以及查找 App 的离线查找功能等。
转自:https://www.jianshu.com/p/1227b27fcb2c
CoreSimulator与Xcode两个文件夹造成Mac中多了100G的“其他”空间
tips 没有购买cleanMyMac的同学,不要担心,我既然写了文章,肯定是不为了让同学们花钱购买软件的。
CoreSimulator与Xcode两个文件夹造成Mac中多了100G的“其他”空间;
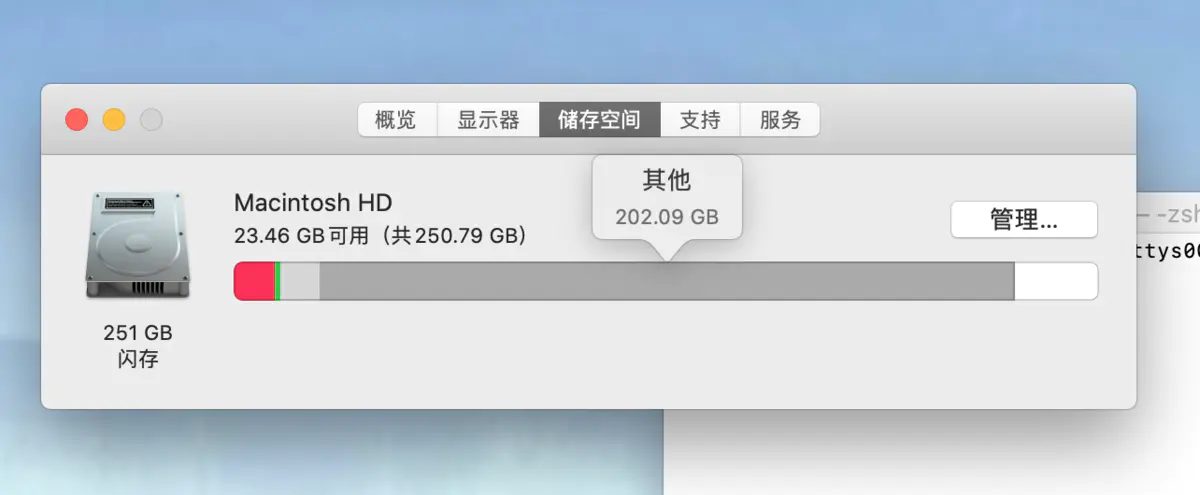
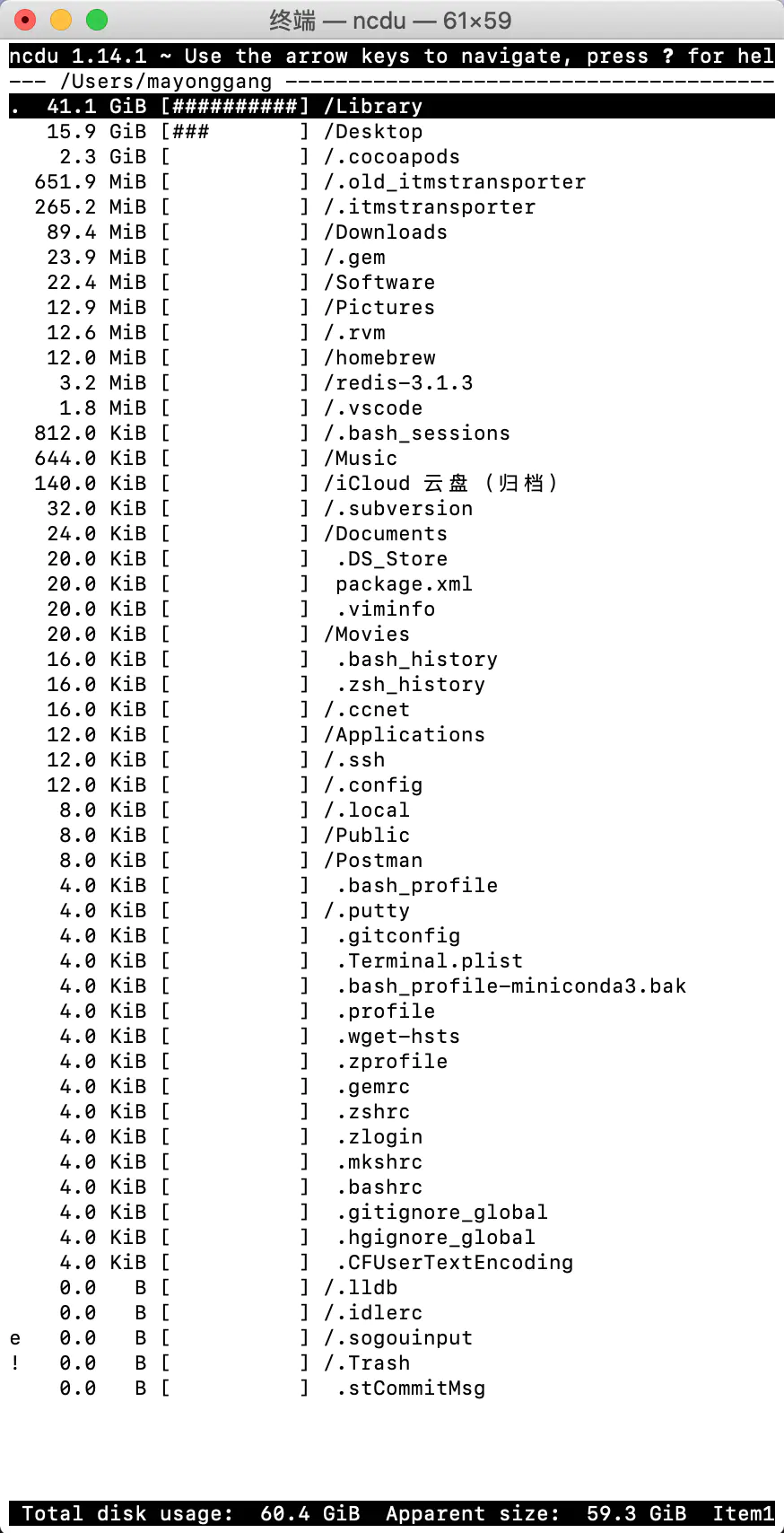
请原谅我表述的不太明白,还是上图吧:
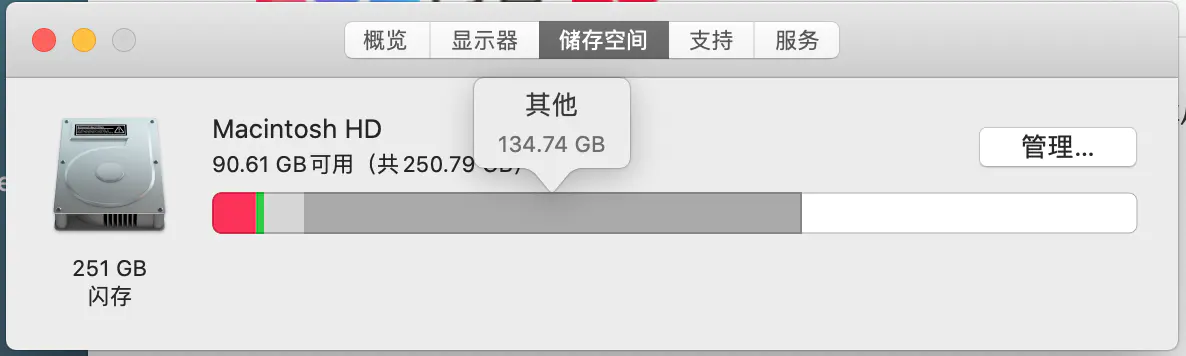
1.清理之前mac电脑只剩下了23.4GB的存储空间可用,“其他”这一项目占了200多GB
2.清理了Xcode文件夹中的部分文件
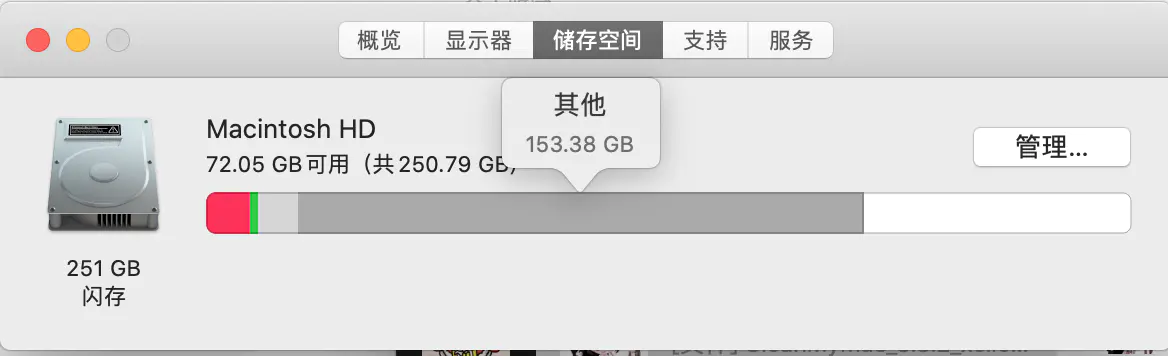
3.清理了CoreSimulator文件夹中的部分文件
使用Clean My Mac 版本4.0.4 中的卸载功能,查看(下边的是我清理之后,清理之前,Xcode占用129GB,现在是37.7GB)
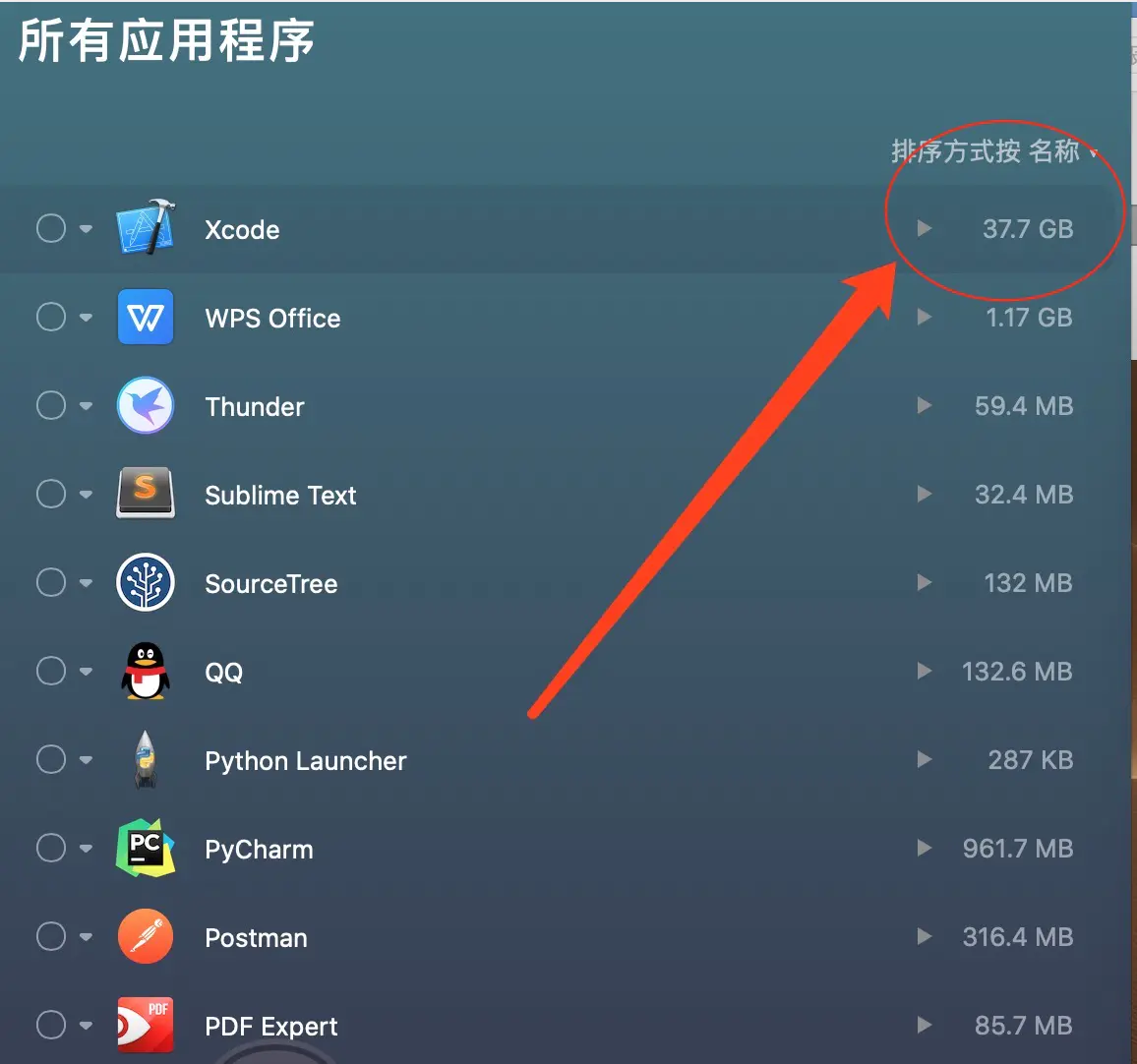
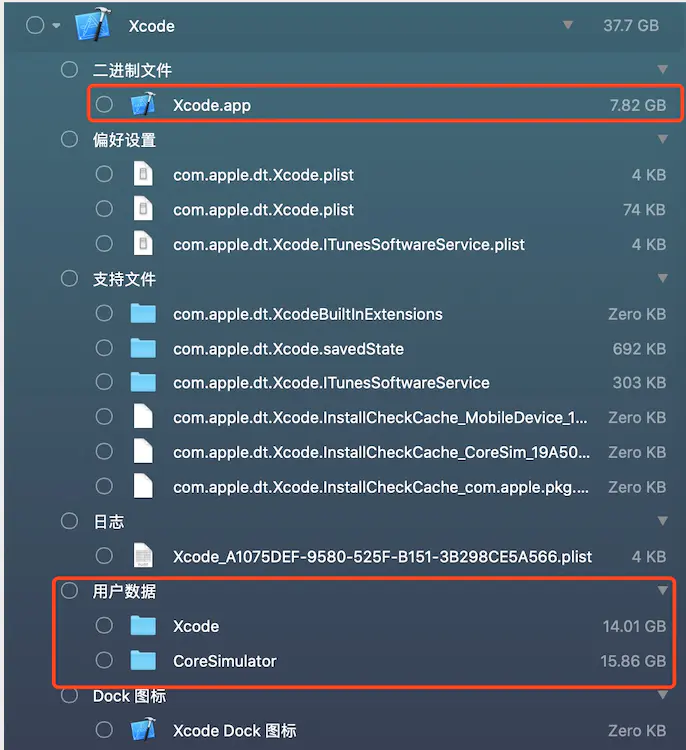
我们通过下图可以得知,Xcode.app本身才7.8个G,可是下边的两个文件夹(清理之前占了120G左右)清理之后还占了30GB左右。
没有购买cleanMyMac的同学,不要担心,我既然写了文章,肯定是不为了让同学们花钱购买软件的。
1.请在电脑上 点击 “前往文件夹”功能,(快捷键:com + shift + g)
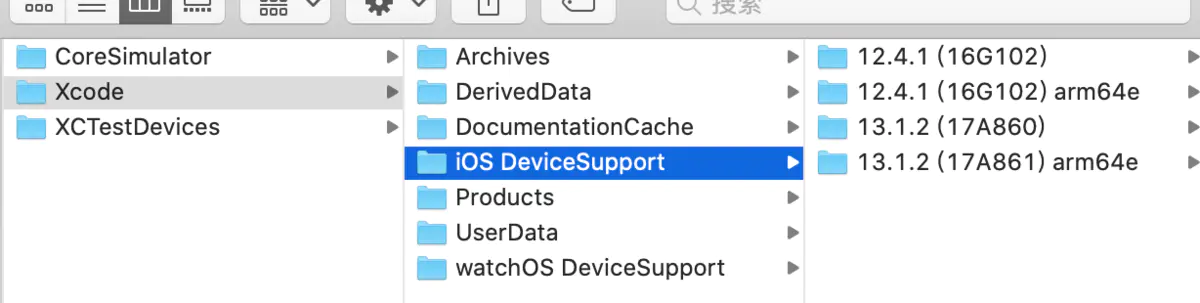
Xcode 文件目录:(不要全部删除整个文件,我们去选择删除DeviceSupport里边老旧的版本就好了)
~/Library/Developer/Xcode/iOS\ DeviceSupportCoreSimulator 文件目录:(不要全部删除整个文件,我们去选择删除Devices里的一些文件就好了)
~/Library/Developer/CoreSimulator/Devices当然也可以在终端输入
open ~/Library/Developer/Xcode/iOS\ DeviceSupport
还有
open ~/Library/Developer/CoreSimulator/Devices
也是一样的;我把12.4以下的都删除了。
想了解这些文件是什么的,可以参照这篇文章 iOS开发-Xcode清理系统内存占用过多的方法
❀
↓ ↓ ↓ ↓ ↓2020年01月08日添加 ↓ ↓ ↓ ↓
❀
感谢评论区的建议。按照建议,亲测后感觉留言里提到ncdu方便快捷,有可取之处。如果有喜欢了解的小伙伴,可以参考这篇文章一个查看MAC硬盘占用的小工具ncdu
转自:https://www.jianshu.com/p/48d8e6870a7c
收起阅读 »iOS websocket接入
接触WebSocket
最近公司的项目中有一个功能 需要服务器主动推数据到APP。
考虑到普通的HTTP 通信方式只能由客户端主动拉取,服务器不能主动推给客户端 。然后就想出的2种解决方案。
1.和后台沟通了一下 他们那里使用的是WebSocket ,所以就使用WebSocket让我们app端和服务器建立长连接。这样就可以事实接受他发过来的消息
2.使用推送,也可以实现接收后台发过来的一些消息
最后还是选择了WebSocket,找到了facebook的 SocketRocket 框架。下面是接入过程中的一些记录
WebSocket
WebSocket 是 HTML5 一种新的协议。它实现了浏览器与服务器全双工通信,能更好的节省服务器资源和带宽并达到实时通讯,它建立在 TCP 之上,同 HTTP 一样通过 TCP 来传输数据,但是它和 HTTP 最大不同是:
WebSocket 是一种双向通信协议,在建立连接后,WebSocket 服务器和 Browser/Client Agent 都能主动的向对方发送或接收数据,就像 Socket 一样;
WebSocket 需要类似 TCP 的客户端和服务器端通过握手连接,连接成功后才能相互通信。
具体在这儿 WebSocket 是什么原理?为什么可以实现持久连接?
用法
我使用的是pod管理库 所以在podfile中加入
pod 'SocketRocket'
在使用命令行工具cd到当前工程 安装
pod install
如果是copy的工程中的 SocketRocket库的github地址:SocketRocket
导入库到工程中以后首先封装一个SocketRocketUtility单例
SocketRocketUtility.m文件中的写法如下:
#import "SocketRocketUtility.h"
#import <SocketRocket.h>
NSString * const kNeedPayOrderNote = @"kNeedPayOrderNote";//发送的通知名称
@interface SocketRocketUtility()<SRWebSocketDelegate>
{
int _index;
NSTimer * heartBeat;
NSTimeInterval reConnectTime;
}
@property (nonatomic,strong) SRWebSocket *socket;
@end
@implementation SocketRocketUtility
+ (SocketRocketUtility *)instance {
static SocketRocketUtility *Instance = nil;
static dispatch_once_t predicate;
dispatch_once(&predicate, ^{
Instance = [[SocketRocketUtility alloc] init];
});
return Instance;
}
//开启连接
-(void)SRWebSocketOpenWithURLString:(NSString *)urlString {
if (self.socket) {
return;
}
if (!urlString) {
return;
}
//SRWebSocketUrlString 就是websocket的地址 写入自己后台的地址
self.socket = [[SRWebSocket alloc] initWithURLRequest:
[NSURLRequest requestWithURL:[NSURL URLWithString:urlString]]];
self.socket.delegate = self; //SRWebSocketDelegate 协议
[self.socket open]; //开始连接
}
//关闭连接
- (void)SRWebSocketClose {
if (self.socket){
[self.socket close];
self.socket = nil;
//断开连接时销毁心跳
[self destoryHeartBeat];
}
}
#pragma mark - socket delegate
- (void)webSocketDidOpen:(SRWebSocket *)webSocket {
NSLog(@"连接成功,可以与服务器交流了,同时需要开启心跳");
//每次正常连接的时候清零重连时间
reConnectTime = 0;
//开启心跳 心跳是发送pong的消息 我这里根据后台的要求发送data给后台
[self initHeartBeat];
[[NSNotificationCenter defaultCenter] postNotificationName:kWebSocketDidOpenNote object:nil];
}
- (void)webSocket:(SRWebSocket *)webSocket didFailWithError:(NSError *)error {
NSLog(@"连接失败,这里可以实现掉线自动重连,要注意以下几点");
NSLog(@"1.判断当前网络环境,如果断网了就不要连了,等待网络到来,在发起重连");
NSLog(@"2.判断调用层是否需要连接,例如用户都没在聊天界面,连接上去浪费流量");
NSLog(@"3.连接次数限制,如果连接失败了,重试10次左右就可以了,不然就死循环了。)";
_socket = nil;
//连接失败就重连
[self reConnect];
}
- (void)webSocket:(SRWebSocket *)webSocket didCloseWithCode:(NSInteger)code reason:(NSString *)reason wasClean:(BOOL)wasClean {
NSLog(@"被关闭连接,code:%ld,reason:%@,wasClean:%d",code,reason,wasClean);
//断开连接 同时销毁心跳
[self SRWebSocketClose];
}
/*
该函数是接收服务器发送的pong消息,其中最后一个是接受pong消息的,
在这里就要提一下心跳包,一般情况下建立长连接都会建立一个心跳包,
用于每隔一段时间通知一次服务端,客户端还是在线,这个心跳包其实就是一个ping消息,
我的理解就是建立一个定时器,每隔十秒或者十五秒向服务端发送一个ping消息,这个消息可是是空的
*/
-(void)webSocket:(SRWebSocket *)webSocket didReceivePong:(NSData *)pongPayload{
NSString *reply = [[NSString alloc] initWithData:pongPayload encoding:NSUTF8StringEncoding];
NSLog(@"reply===%@",reply);
}
- (void)webSocket:(SRWebSocket *)webSocket didReceiveMessage:(id)message {
//收到服务器发过来的数据 这里的数据可以和后台约定一个格式 我约定的就是一个字符串 收到以后发送通知到外层 根据类型 实现不同的操作
NSLog(@"%@",message);
[[NSNotificationCenter defaultCenter] postNotificationName:kNeedPayOrderNote object:message];
}
#pragma mark - methods
//重连机制
- (void)reConnect
{
[self SRWebSocketClose];
//超过一分钟就不再重连 所以只会重连5次 2^5 = 64
if (reConnectTime > 64) {
return;
}
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(reConnectTime * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
self.socket = nil;
[self SRWebSocketOpen];
NSLog(@"重连");
});
//重连时间2的指数级增长
if (reConnectTime == 0) {
reConnectTime = 2;
}else{
reConnectTime *= 2;
}
}
//初始化心跳
- (void)initHeartBeat
{
dispatch_main_async_safe(^{
[self destoryHeartBeat];
__weak typeof(self) weakSelf = self;
//心跳设置为3分钟,NAT超时一般为5分钟
heartBeat = [NSTimer scheduledTimerWithTimeInterval:3*60 repeats:YES block:^(NSTimer * _Nonnull timer) {
NSLog(@"heart");
//和服务端约定好发送什么作为心跳标识,尽可能的减小心跳包大小
[weakSelf sendData:@"heart"];
}];
[[NSRunLoop currentRunLoop]addTimer:heartBeat forMode:NSRunLoopCommonModes];
})
}
//取消心跳
- (void)destoryHeartBeat
{
dispatch_main_async_safe(^{
if (heartBeat) {
[heartBeat invalidate];
heartBeat = nil;
}
})
}
//pingPong机制
- (void)ping{
[self.socket sendPing:nil];
}
#define WeakSelf(ws) __weak __typeof(&*self)weakSelf = self
- (void)sendData:(id)data {
WeakSelf(ws);
dispatch_queue_t queue = dispatch_queue_create("zy", NULL);
dispatch_async(queue, ^{
if (weakSelf.socket != nil) {
// 只有 SR_OPEN 开启状态才能调 send 方法,不然要崩
if (weakSelf.socket.readyState == SR_OPEN) {
[weakSelf.socket send:data]; // 发送数据
} else if (weakSelf.socket.readyState == SR_CONNECTING) {
NSLog(@"正在连接中,重连后其他方法会去自动同步数据");
// 每隔2秒检测一次 socket.readyState 状态,检测 10 次左右
// 只要有一次状态是 SR_OPEN 的就调用 [ws.socket send:data] 发送数据
// 如果 10 次都还是没连上的,那这个发送请求就丢失了,这种情况是服务器的问题了,小概率的
[self reConnect];
} else if (weakSelf.socket.readyState == SR_CLOSING || weakSelf.socket.readyState == SR_CLOSED) {
// websocket 断开了,调用 reConnect 方法重连
[self reConnect];
}
} else {
NSLog(@"没网络,发送失败,一旦断网 socket 会被我设置 nil 的");
}
});
}
-(void)dealloc{
[[NSNotificationCenter defaultCenter] removeObserver:self];
}然后在需要开启socket的地方调用
[[SocketRocketUtility instance] SRWebSocketOpenWithURLString:@"写入自己后台的地址"];
在需要断开连接的时候调用
[[SocketRocketUtility instance] SRWebSocketClose];
使用这个框架最后一个很重要的 需要注意的一点
这个框架给我们封装的webscoket在调用它的sendPing senddata方法之前,一定要判断当前scoket是否连接,如果不是连接状态,程序则会crash。
结语
这里简单的实现了连接和收发数据 后续看项目需求在加上后续的改进 希望能够帮助第一次写的iOSer 。 希望有更好的方法的童鞋可以有进一步的交流 : )
4月10日 更新:
/// Creates and returns a new NSTimer object initialized with the specified block object and schedules it on the current run loop in the default mode.
/// - parameter: ti The number of seconds between firings of the timer. If seconds is less than or equal to 0.0, this method chooses the nonnegative value of 0.1 milliseconds instead
/// - parameter: repeats If YES, the timer will repeatedly reschedule itself until invalidated. If NO, the timer will be invalidated after it fires.
/// - parameter: block The execution body of the timer; the timer itself is passed as the parameter to this block when executed to aid in avoiding cyclical references
+ (NSTimer *)scheduledTimerWithTimeInterval:(NSTimeInterval)interval repeats:(BOOL)repeats block:(void (^)(NSTimer *timer))block API_AVAILABLE(macosx(10.12), ios(10.0), watchos(3.0), tvos(10.0));上面发送心跳包的方法是iOS10才可以用的 其他版本会崩溃 要适配版本 要选择 这个方法
+ (NSTimer *)scheduledTimerWithTimeInterval:(NSTimeInterval)ti target:(id)aTarget selector:(SEL)aSelector userInfo:(nullable id)userInfo repeats:(BOOL)yesOrNo;8月10日 更新demo地址
demo地址
可以下载下来看看哦 :)
注
demo中的后台地址未设置 所以很多同学直接运行就报错了 设置一个自己后台的地址就ok了 :)
转自:https://www.jianshu.com/p/821b777555d3
收起阅读 »iOS 用symbolicatecrash符号化崩溃日志中系统库方法堆栈
说明
现在已经有很多第三方平台支持解析crash日志中的系统方法了,比如bugly。但是万一遇到情况特殊或者公司要求,还是走上传崩溃日志到自己的服务器,然后自己去定期解析的话,就需要用到symbolicatecrash这个工具了。
指令操作均在终端中进行。
另外,每次打包上架提交审核的时候,把对应的.xcarchive与ipa文件一同拷贝一份,按照版本号保存下来是个好习惯。
1.前期准备工作
前期准备工作只需要在第一次尝试解析的时候进行,如果可以成功执行最终的命令行解析日志就不需要重复执行。
确定Xcode路径,执行如下指令
xcode-select --print-path目的:确保Xcode路径存在。如果路径中有空格的存在,请把空格去掉。比如如果Xcode 的名字是“Xcode 9.2”请修改成“Xcode9.2”或者“Xcode”。否则后面你会遇到很多稀奇古怪的错误。
修改方法:应用程序→Xcode→重命名
添加Xcode路径
如果Xcode路径已经存在,或者不需要修改,请跳过这一步。注意如果改过Xcode应用的名字也需要进行这一步操作
执行如下指令
sudo xcode-select -s 路径路径部分直接把Xcode应用内Developer文件夹拖拽进去会自动生成。
Developer文件夹:应用程序→Xcode→右键,显示包内容→Contents文件夹→Developer
确定Xcode command line tools是否安装
执行如下指令
xcode-select --install如果输出以下内容说明已经安装,否则根据提示安装即可。
xcode-select: error: command line tools are already installed, use "Software Update" to install updates2.解析准备工作
解析所需文件
解析崩溃日志需要三个文件
①.崩溃日志文件(通常为.crash如果服务器上面是.txt也没关系,直接下下来把尾缀改成.crash就行)
②.产生崩溃日志的app包对应的.dSYM符号表(注意符号表和包一定要匹配。否则,堆栈方法会错乱)
③.崩溃分析工具symbolicatecrash(Xcode自带)
.dSYM符号表的获取:Xcode→window→organizer 选择Archives→选择想要解析崩溃日志的App包→右键,show in finder→右键(.xcarchive),显示包内容→dSYMs→xxx.app.dSYM
如果自己这里没有app打包文件就只有跟打包的同事要。
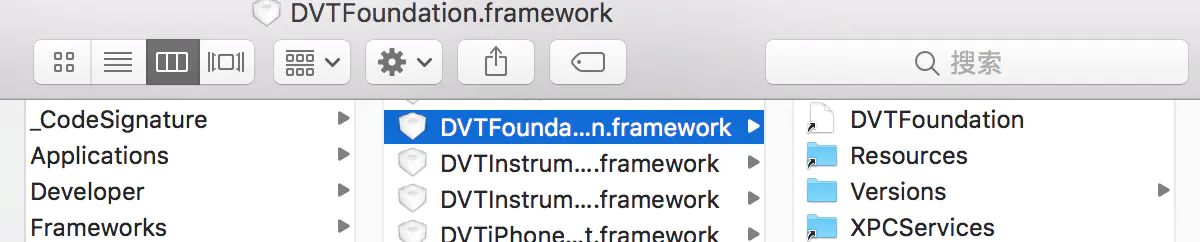
symbolicatecrash的获取:应用程序(Applications)→Xcode→右键,显示包内容→Contents→SharedFrameworks→DVTFoundation.framework→Versions→A→Resources→symbolicatecrash
tips:如果到了DVTFoundation.framework这里打不开下一步了,选择如下浏览方式即可。
3.解析日志
<1>将上述三个文件放在一个文件夹内
文件夹名称可以任意起,路径随意但最好不要出现中文。

<2>在终端中进入该文件夹内
直接拖拽文件夹到路径部分会自动生成
cd 路径<3>解析日志
./symbolicatecrash ./*.crash ./*.app.dSYM>symbol.crash这个方法一次只能解析一个日志文件,然后输出一个解析过后的symbol.crash日志文件(会覆盖之前存在的symbol.crash),这个输出的日志文件就是我们可以直接阅读的日志文件。symbol部分可以任意修改成其他名字。
如果要解析多个日志文件,需要逐一将文件夹内的日志文件替换。或者将所有需要解析的日志文件全部放在文件夹内,但是每次指定需要解析的.crash文件。
如果出现下面类似的错误,报错无法执行
Error: "DEVELOPER_DIR" is not defined at ./symbolicatecrash line xx(数字).执行指令
export DEVELOPER_DIR=Xcode Developer文件夹路径像上面一样把Developer文件夹拖拽到等号后面路径部分就行,然后再执行解析指令就不会报错了。
<4>查看解析结果
<5>给Xcode添加对应固件的符号文件
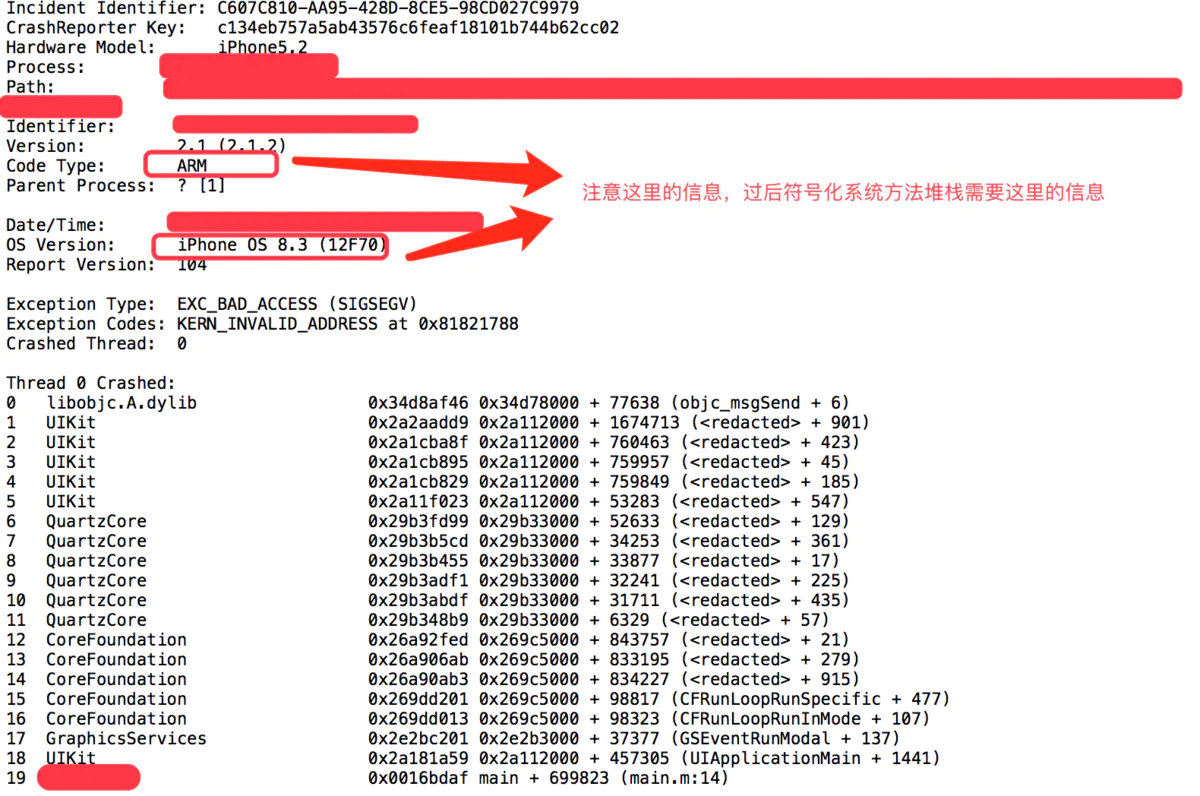
①.下载对应固件符号文件
这个需要结合崩溃日志的信息来,比如这里日志中提到崩溃发生的固件是8.3(12F70)我们就要去找这个固件的符号文件,找的时候还要注意是否区分了CPU架构。下载地址放在后面
②.下载完成后添加进Xcode
打开Finder:点击菜单前往→前往文件夹→输入
~/Library/Developer/Xcode/iOS DeviceSupport→前往
将下载好的符号文件放入定位到的路径里面。
③.再次解析日志文件
<6>固件符号文件下载地址
首先感谢iOS Crash分析必备:符号化系统库方法作者的无私分享。该文章的作者收集了几乎所有固件的符号文件并分享了出来,为了尊重原作者这里就不放下载地址了。大家可以在他的文章当中找到下载地址,以及目前收集了哪些固件符号文件。
转自:https://www.jianshu.com/p/21532aef2811
收起阅读 »关于WKWebView的post请求丢失body问题的解决方案
WKWebView的优点这里不做过多介绍,主要说一下最近解决WKWebView的post请求丢失body问题的解决方案。
WKWebView 通过loadrequest方法加载Post请求会丢失请求体(body)中的内容,进而导致服务器拿不到body中的内容的问题的发生。这个问题的产生主要是因为WKWebView的网络请求的进程与APP不是同一个进程,所以网络请求的过程是这样的:
由APP所在的进程发起request,然后通过IPC通信(进程间通信)将请求的相关信息(请求头、请求行、请求体等)传递给webkit网络线进程接收包装,进行数据的HTTP请求,最终再进行IPC的通信回传给APP所在的进程的。这里如果发起的request请求是post请求的话,由于要进行IPC数据传递,传递的请求体body中根据系统调度,将其舍弃,最终在WKWebView网络进程接受的时候请求体body中的内容变成了空,导致此种情况下的服务器获取不到请求体,导致问题的产生。
为了能够获取POST方法请求之后的body内容,这两天整理了一些解决方案,大致分为三种:
将网络请求交由Js发起,绕开系统WKWebView的网络的进程请求达到正常请求的目的
改变POST请求的方法为GET方法(有风险,不一定服务器会接受GET方法)
将Post请求的请求body内容放入请求的Header中,并通过URLProtocol拦截自定义协议,在拦截中通过NSConnection进行重新请求(重新包装请求body),然后通过回调Client客户端来传递数据内容
三种方法中,我采用了第三种方案,这里说一下第三种方案的实现方式,大致分为三步:
注册拦截的自定义的scheme
重写loadRequest()方法,根据request的method方法是否为POST进行URL的拦截替换
在URLProtocol中进行request的重新包装(获取请求的body内容),使用NSURLConnection进行HTTP请求并将数据回传
这里说明一下为什么要自己去注册自定义的scheme,而不是直接拦截https/http。主要原因是:如果注册了https/http的拦截,那么所有的http(s)请求都会交由系统进程处理,那么此时系统进程会通过IPC的形式传递给实现URLProctol协议的类去处理,在通过IPC传递的过程中丢失body体(上面有讲到),所以在拦截的时候是拿不到POST方法的请求体body的。然而并不是所有的http请求都会走loadrequest()方法(比如js中的ajax请求),所以导致一些POST请求没有被包装(将请求体body内容放到请求头header)就被拦截了,进而丢失请求体body内容,问题一样会产生。所以为了避免这样的问题,我们需要自己去定一个scheme协议,保证不过度拦截并且能够处理我们需要处理的POST请求内容。
以下是具体的实现方式:
注册拦截的自定义的scheme
[NSURLProtocol registerClass:NSClassFromString(@“GCURLProtocol")];
[NSURLProtocol wk_registerScheme:@"gc"];
[NSURLProtocol wk_registerScheme:WkCustomHttp];
[NSURLProtocol wk_registerScheme:WkCustomHttps];重写loadRequest()方法,根据request的method方法是否为POST进行URL的拦截替换
//包装请求头内容
- (WKNavigation *)loadRequest:(NSURLRequest *)request{
NSLog(@"发起请求:%@ method:%@",request.URL.absoluteString,request.HTTPMethod);
NSMutableURLRequest *mutableRequest = [request mutableCopy];
NSMutableDictionary *requestHeaders = [request.allHTTPHeaderFields mutableCopy];
//判断是否是POST请求,POST请求需要包装request中的body内容到请求头中(会有丢失body问题的产生)
//,包装完成之后重定向到拦截的协议中自己包装处理请求数据内容,拦截协议是GCURLProtocol,请自行搜索
if ([mutableRequest.HTTPMethod isEqualToString:@"POST"] && ([mutableRequest.URL.scheme isEqualToString:@"http"] || [mutableRequest.URL.scheme isEqualToString:@"https"])) {
NSString *absoluteStr = mutableRequest.URL.absoluteString;
if ([[absoluteStr substringWithRange:NSMakeRange(absoluteStr.length-1, 1)] isEqualToString:@"/"]) {
absoluteStr = [absoluteStr stringByReplacingCharactersInRange:NSMakeRange(absoluteStr.length-1, 1) withString:@""];
}
if ([mutableRequest.URL.scheme isEqualToString:@"https"]) {
absoluteStr = [absoluteStr stringByReplacingOccurrencesOfString:@"https" withString:WkCustomHttps];
}else{
absoluteStr = [absoluteStr stringByReplacingOccurrencesOfString:@"http" withString:WkCustomHttp];
}
mutableRequest.URL = [NSURL URLWithString:absoluteStr];
NSString *bodyDataStr = [[NSString alloc]initWithData:mutableRequest.HTTPBody encoding:NSUTF8StringEncoding];
[requestHeaders addEntriesFromDictionary:@{@"httpbody":bodyDataStr}];
mutableRequest.allHTTPHeaderFields = requestHeaders;
NSLog(@"当前请求为POST请求Header:%@",mutableRequest.allHTTPHeaderFields);
}
return [super loadRequest:mutableRequest];
}在URLProtocol中进行request的重新包装(获取请求的body内容),使用NSURLConnection进行HTTP请求并将数据回传(以下是主要代码)
+ (BOOL)canInitWithRequest:(NSURLRequest *)request {
NSString *scheme = request.URL.scheme;
if ([scheme isEqualToString:InterceptionSchemeKey]){
if ([self propertyForKey:HaveDealRequest inRequest:request]) {
NSLog(@"已经处理,放行");
return NO;
}
return YES;
}
if ([scheme isEqualToString:WkCustomHttp]){
if ([self propertyForKey:HaveDealWkHttpPostBody inRequest:request]) {
NSLog(@"已经处理,放行");
return NO;
}
return YES;
}
if ([scheme isEqualToString:WkCustomHttps]){
if ([self propertyForKey:HaveDealWkHttpsPostBody inRequest:request]) {
NSLog(@"已经处理,放行");
return NO;
}
return YES;
}
return NO;
}
- (void)startLoading {
//截获 gc 链接的所有请求,替换成本地资源或者线上资源
if ([self.request.URL.scheme isEqualToString:InterceptionSchemeKey]) {
[self htmlCacheRequstLoad];
}
else if ([self.request.URL.scheme isEqualToString:WkCustomHttp] || [self.request.URL.scheme isEqualToString:WkCustomHttps]){
[self postBodyAddLoad];
}
else{
NSMutableURLRequest *newRequest = [self cloneRequest:self.request];
NSString *urlString = newRequest.URL.absoluteString;
[self addHttpPostBody:newRequest];
[NSURLProtocol setProperty:@YES forKey:GCProtocolKey inRequest:newRequest];
[self sendRequest:newRequest];
}
}
- (void)addHttpPostBody:(NSMutableURLRequest *)redirectRequest{
//判断当前的请求是否是Post请求
if ([self.request.HTTPMethod isEqualToString:@"POST"]) {
NSLog(@"post请求");
NSMutableDictionary *headerDict = [redirectRequest.allHTTPHeaderFields mutableCopy];
NSString *body = headerDict[@"httpbody"]?:@"";
if (body.length) {
redirectRequest.HTTPBody = [body dataUsingEncoding:NSUTF8StringEncoding];
NSLog(@"body:%@",body);
}
}
}
- (void)postBodyAddLoad{
NSMutableURLRequest *cloneRequest = [self cloneRequest:self.request];
if ([cloneRequest.URL.scheme isEqualToString:WkCustomHttps]) {
cloneRequest.URL = [NSURL URLWithString:[cloneRequest.URL.absoluteString stringByReplacingOccurrencesOfString:WkCustomHttps withString:@"https"]];
[NSURLProtocol setProperty:@YES forKey:HaveDealWkHttpsPostBody inRequest:cloneRequest];
}else if ([cloneRequest.URL.scheme isEqualToString:WkCustomHttp]){
cloneRequest.URL = [NSURL URLWithString:[cloneRequest.URL.absoluteString stringByReplacingOccurrencesOfString:WkCustomHttp withString:@"http"]];
[NSURLProtocol setProperty:@YES forKey:HaveDealWkHttpPostBody inRequest:cloneRequest];
}
//添加body内容
[self addHttpPostBody:cloneRequest];
NSLog(@"请求body添加完成:%@",[[NSString alloc]initWithData:cloneRequest.HTTPBody encoding:NSUTF8StringEncoding]);
[self sendRequest:cloneRequest];
}
//复制Request对象
- (NSMutableURLRequest *)cloneRequest:(NSURLRequest *)request
{
NSMutableURLRequest *newRequest = [NSMutableURLRequest requestWithURL:request.URL cachePolicy:request.cachePolicy timeoutInterval:request.timeoutInterval];
newRequest.allHTTPHeaderFields = request.allHTTPHeaderFields;
[newRequest setValue:@"image/webp,image/*;q=0.8" forHTTPHeaderField:@"Accept"];
if (request.HTTPMethod) {
newRequest.HTTPMethod = request.HTTPMethod;
}
if (request.HTTPBodyStream) {
newRequest.HTTPBodyStream = request.HTTPBodyStream;
}
if (request.HTTPBody) {
newRequest.HTTPBody = request.HTTPBody;
}
newRequest.HTTPShouldUsePipelining = request.HTTPShouldUsePipelining;
newRequest.mainDocumentURL = request.mainDocumentURL;
newRequest.networkServiceType = request.networkServiceType;
return newRequest;
}
#pragma mark - NSURLConnectionDataDelegate
- (void)connection:(NSURLConnection *)connection didReceiveResponse:(NSURLResponse *)response
{
/**
* 收到服务器响应
*/
NSURLResponse *returnResponse = response;
[self.client URLProtocol:self didReceiveResponse:returnResponse cacheStoragePolicy:NSURLCacheStorageAllowed];
}
- (void)connection:(NSURLConnection *)connection didReceiveData:(NSData *)data
{
/**
* 接收数据
*/
if (!self.recData) {
self.recData = [NSMutableData new];
}
if (data) {
[self.recData appendData:data];
}
}
- (nullable NSURLRequest *)connection:(NSURLConnection *)connection willSendRequest:(NSURLRequest *)request redirectResponse:(nullable NSURLResponse *)response
{
/**
* 重定向
*/
if (response) {
[self.client URLProtocol:self wasRedirectedToRequest:request redirectResponse:response];
}
return request;
}
- (void)connectionDidFinishLoading:(NSURLConnection *)connection
{
[self.client URLProtocolDidFinishLoading:self];
}
- (void)connection:(NSURLConnection *)connection didFailWithError:(NSError *)error
{
/**
* 加载失败
*/
[self.client URLProtocol:self didFailWithError:error];
}转自:https://www.jianshu.com/p/4dfc80ca7db2
收起阅读 »iOS - 同一个workspace下创建多个项目编程
在iOS开发中,相关联的多个项目可能会放在同一个workspace下进行开发,那习惯了一个项目在一个工作空间下的同学该怎么快速开撸呢?
只需要三步而已!
第一步,先用Xcode在目标目录下创建一个workspace文件。见图说话。

第二步,用Xcode打开workspace文件,然后在该workspace下创建多个Project文件。
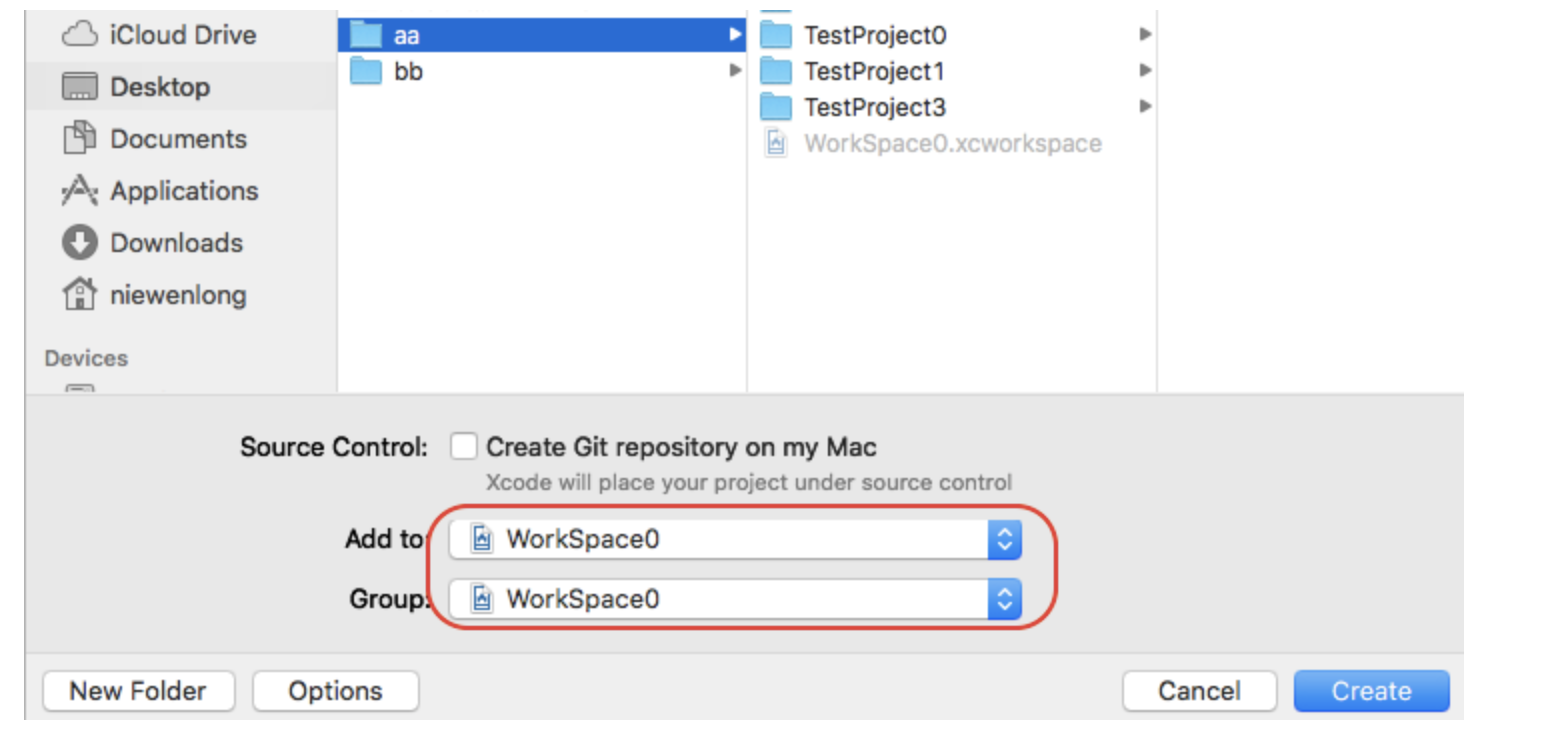
在创建工程的过程中有个主意点:将新建Project添加的目标和组 都是workspace。如图:
第三步,多个工程间文件互相引用问题:多个工程间的文件引用方法:在工程A的Setting选项下的Header Search Paths 下添加“$(SRCROOT)/../B”,这个工程A中即可引用工程B的文件,不过导入文件的方式是:#import <Person.m>
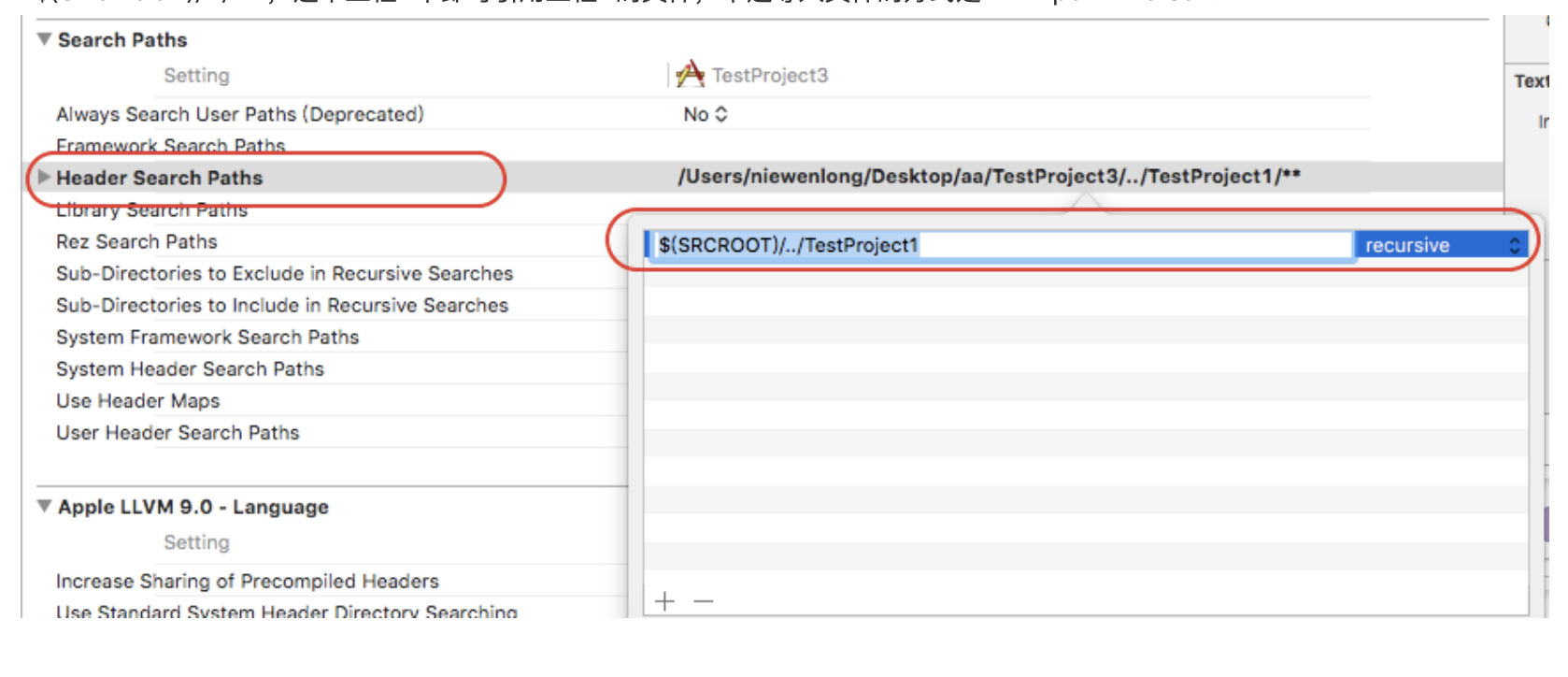
如上设置,多个工程间的类就可以共享使用了。
uniapp实现$router
作为 Vue 重度用户,在使用 uni-app 过程中不可避免的把 Vue 开发习惯带了过去。无论是项目目录结构,还是命名风格,甚至我还封装了一些库,如 https://zhuanlan.zhihu.com/p/141451626 提到的 _request 等。
众所周知,用 Vue 开发项目,其实就是用的 Vue 全家桶。即 Vue + Vuex + VueRouter 。在代码里的体现就是:
this + this.$store + this.$router/$route
然而由于 uni-app 为了保证跨端同时简化语法,用的是微信小程序那套 API。其中就包括路由系统。因为在 uni-app 中,没有 $router/$route。只有 uni[‘路由方法’]。讲真的,这样做确实很容易上手,但同时也是有许多问题:
- 路由传参数只支持字符串,对象参数需要手动JSON序列化
- 传参有长度限制
- 传参不支持特殊符号如 url
- 不支持路由拦截和监听
因此,需要一个工具来将现有的路由使用方式变为 vue-router 的语法,并且完美解决以上几个问题。
vue-router 的语法这里不再赘述。简单的来说就是将路由的用法由:
uni.navigateTo({
url: `../login/login?data=${JSON.stringify({ from: 'index', time:Date.now() })}`
})
变成:
this.$router.push('/login', {
data: {
from: 'index',
time: Date.now()
}
})
同时传参通过一个 $route 对象。因此我们的需求就是事现一个 $router 和 $route 对象。并给定相应方法。比如调用:
push('/login')
其实就是执行了:
uni.navigateTo({ url:`../login/login ` })
实现起来非常简单:
push 方法接收到 '/login' 将其拼接为 `../login/login` 后调用 uni.navigateTo 就可以。
然而这样并不严谨。此时的 push 方法只能在页面内使用。而不能在 pages 文件夹以外的地方使用,因为这里用的是相对路径。只要改成 `pages/login/login` 就好。
$route 的实现就是在路由发生变化时,动态改变一个公共对象 route 的内部值。
而通过全局 mixin onShow 方法,可以实现对路由变化动态监听。
通过 require.context 预引入路由列表实现更好的错误提示。
最后通过一个页面堆栈数据列表实现 route 实时更新。
最后的代码:
import Vue from 'vue'
export const route = { // 当前路由对象所在的 path 等信息。默认为首页
fullPath: '/pages/index/index',
path: '/index',
type: 'push',
query: {}
}
let onchange = () => {} // 路由变化监听函数
const _$UNI_ACTIVED_PAGE_ROUTES = [] // 页面数据缓存
let _$UNI_ROUTER_PUSH_POP_FUN = () => {} // pushPop resolve 函数
const _c = obj => JSON.parse(JSON.stringify(obj)) // 简易克隆方法
const modulesFiles = require.context('@/pages', true, /\.vue$/) // pages 文件夹下所有的 .vue 文件
Vue.mixin({
onShow() {
const pages = getCurrentPages().map(e => `/${e.route}`).reverse() // 获取页面栈
if (pages[0]) { // 当页面栈不为空时执行
let old = _c(route)
const back = pages[0] != route.fullPath
const now = _$UNI_ACTIVED_PAGE_ROUTES.find(e => e.fullPath == pages[0]) // 如果路由没有被缓存就缓存
now ? Object.assign(route, now) : _$UNI_ACTIVED_PAGE_ROUTES.push(_c(route)) // 已缓存就用已缓存的更新 route 对象
_$UNI_ACTIVED_PAGE_ROUTES.splice(pages.length, _$UNI_ACTIVED_PAGE_ROUTES.length) // 最后清除无效缓存
if (back) { // 当当前路由与 route 对象不符时,表示路由发生返回
onchange(route, old)
}
}
}
})
const router = new Proxy({
route: route, // 当前路由对象所在的 path 等信息,
afterEach: to => {}, // 全局后置守卫
beforeEach: (to, next) => next(), // 全局前置守卫
routes: modulesFiles.keys().map(e => e = e.replace(/^\./, '/pages')), // 路由表
_getFullPath(route) { // 根据传进来的路由名称获取完整的路由名称
return new Promise((resolve, reject) => {
const fullPath = this.routes.find(e => RegExp(route + '.vue').test(e))
fullPath ? resolve(fullPath.replace(/\.vue$/, '')) : reject(`路由 ${ route + '.vue' } 不存在于 pages 目录中`)
})
},
_formatData(query) { // 序列化路由传参
let queryString = '?'
Object.keys(query).forEach(e => {
if (typeof query[e] === 'object') {
queryString += `${e}=${JSON.stringify(query[e])}&`
} else {
queryString += `${e}=${query[e]}&`
}
})
return queryString.length === 1 ? '' : queryString.replace(/&$/, '')
},
_beforeEach(path, fullPath, query, type) { // 处理全局前置守卫
return new Promise(resolve => {
this.beforeEach({ path, fullPath, query, type }, resolve)
})
},
_next(next) { // 处理全局前置守卫 next 函数传经来的方法
return new Promise((resolve, reject) => {
if (typeof next === 'function') { // 当 next 为函数时, 表示重定向路由,
reject('在全局前置守卫 next 中重定向路由')
Promise.resolve().then(() => next(this)) // 此处一个微任务的延迟是为了先触发重定向的reject
} else if (next === false) { // 当 next 为 false 时, 表示取消路由
reject('在全局前置守卫 next 中取消路由')
} else {
resolve()
}
})
},
_routeTo(UNIAPI, type, path, query, notBeforeEach, notAfterEach) {
return new Promise((resolve, reject) => {
this._getFullPath(path).then((fullPath) => { // 检查路由是否存在于 pages 中
const routeTo = url => { // 执行路由
const temp = _c(route) // 将 route 缓存起来
Object.assign(route, { path, fullPath, query, type }) // 在路由开始执行前就将 query 放入 route, 防止少数情况出项的 onLoad 执行时,query 还没有合并
UNIAPI({ url }).then(([err]) => {
if (err) { // 路由未在 pages.json 中注册
Object.assign(route, temp) // 如果路由跳转失败,就将 route 恢复
reject(err)
return
} else { // 跳转成功, 将路由信息赋值给 route
resolve(route) // 将更新后的路由对象 resolve 出去
onchange({ path, fullPath, query, type }, temp)
!notAfterEach && this.afterEach(route) // 如果没有禁止全局后置守卫拦截时, 执行全局后置守卫拦截
}
})
}
if (notBeforeEach) { // notBeforeEach 当不需要被全局前置守卫拦截时
routeTo(`${fullPath}${this._formatData(query)}`)
} else {
this._beforeEach(path, fullPath, query, type).then((next) => { // 执行全局前置守卫,并将参数传入
this._next(next).then(() => { // 在全局前置守卫 next 没传参
routeTo(`${fullPath}${this._formatData(query)}`)
}).catch(e => reject(e)) // 在全局前置守卫 next 中取消或重定向路由
})
}
}).catch(e => reject(e)) // 路由不存在于 pages 中, reject
})
},
pop(data) {
if (typeof data === 'object') {
_$UNI_ROUTER_PUSH_POP_FUN(data)
}
uni.navigateBack({ delta: typeof data === 'number' ? data : 1 })
},
// path 路由名 // query 路由传参 // isBeforeEach 是否要被全局前置守卫拦截 // isAfterEach 是否要被全局后置守卫拦截
push(path, query = {}, notBeforeEach, notAfterEach) {
return this._routeTo(uni.navigateTo, 'push', path, query, notBeforeEach, notAfterEach)
},
pushPop(path, query = {}, notBeforeEach, notAfterEach) {
return new Promise(resolve => {
_$UNI_ROUTER_PUSH_POP_FUN(null)
_$UNI_ROUTER_PUSH_POP_FUN = resolve
this._routeTo(uni.navigateTo, 'pushPop', path, query, notBeforeEach, notAfterEach)
})
},
replace(path, query = {}, notBeforeEach, notAfterEach) {
return this._routeTo(uni.redirectTo, 'replace', path, query, notBeforeEach, notAfterEach)
},
switchTab(path, query = {}, notBeforeEach, notAfterEach) {
return this._routeTo(uni.switchTab, 'switchTab', path, query, notBeforeEach, notAfterEach)
},
reLaunch(path, query = {}, notBeforeEach, notAfterEach) {
return this._routeTo(uni.reLaunch, 'reLaunch', path, query, notBeforeEach, notAfterEach)
}
}, {
set(target, key, value) {
if (key == 'onchange') {
onchange = value
}
return Reflect.set(target, key, value)
}
})
Object.setPrototypeOf(route, router) // 让 route 继承 router
export default routeruniapp与flutter,跨平台解决方案你该如何选择
为了做毕设,用了下uniapp与flutter,说真的,这是两款十分优秀的产品,几乎做到了各自领域性能和跨平台的极致。那么这两款产品到底有什么不同,在选型的时候应该如何取舍,这是我写这篇文章的目的。
uniapp与flutter都是为了解决跨平台问题的框架
uniapp是从h5 app到小程序一步步发展过来的,也就是走的html的路线。
html从最早的网页套壳一步步发展至今,为了解决早期套壳的体验问题,我们尝试用js代码调用原生接口,与原生进行交互,出现了一系列如React Native,Cordova,Weex,Framework7,MUI之类的框架,这些框架的出现进一步丰富h5应用的功能。但是这些技术要求很高的优化技巧,要走很多坑,在ios的体验尚可,但是Android上由于更新维护问题,js引擎差别很大,早期Android的js引擎极差,这些框架使用体验都不好,当然也有硬件方面的原因。而且Android上webview存在性能瓶颈,复杂应用不做预加载的情况下使用体验真的不好。后来为了使体验达到h5所能做的极致,小程序出现了,为了性能,屏蔽了dom,规定了独特的规范,按照这些规范去写,编译时框架提前给你优化好,事实证明这样做确实可以提高h5应用的使用体验。
uniapp延续了小程序的思路,和vue结合,屏蔽dom,提前优化,确实很好,也做到了跨平台,这是一款极为优秀的跨各种小程序的解决方案,与它自家的h5+结合也是一个还算不错的h5+ app的前端框架。但是uniapp的定位中有一个极大的问题,就是小程序与h5 app之间的距离太大了,强跨的体验真是极差,得不偿失。举个栗子,3d渲染,多人视频,nfc写卡,这种小程序完全做不到,当然uniapp也可以调h5+ runtime,但是一个复杂的移动端应用可能会加各种各样的东西,你完全预料不到可能出现什么需求,并且这些需求越来越多的情况下,小程序端与移动端分开维护是必然的结果,强行结合只能是结构混乱,难以维护。那么如果分开维护,uniapp与前面提到的那些框架并没有明显优势。
那么接着说flutter,flutter与h5技术栈的思路完全不同,JSCore,V8再怎样优秀,也始终解决不了JavaScript本身语法缺陷和运行在浏览器的事实。
===========================
这里我之前写flutter用dart做了一个渲染引擎,有人言辞激烈的抨击了我的错误,后来我仔细看了一下资料。
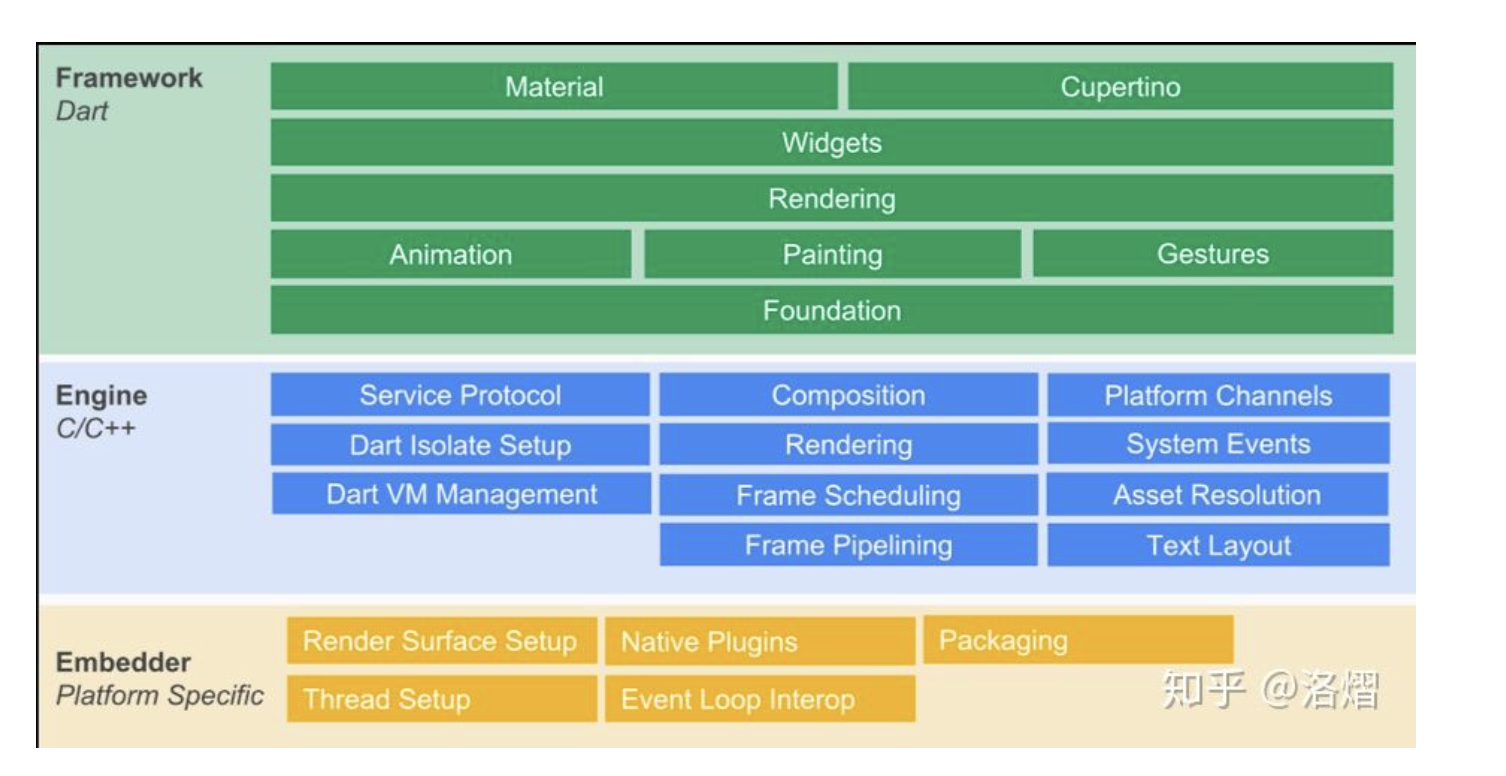
官网上是这样说的
Flutter is built with C, C++, Dart, and Skia (a 2D rendering engine).See this architecture diagram for abetter picture of the main components.
确实,dart只是用来组织各种控件的一个工具,这个图形渲染是用了这个叫Skia的图形库
Skia is an open source 2D graphics library which provides common APIs that work across a variety of hardware and software platforms.
这个Skia,Google旗下,开源2D图形库,提供了多种软硬件平台的通用API。
确实是我的错,没调查清楚,但是这个方式还是令我觉得,很难受。
=================================
也就是说flutter和cocos,unity3d一样,完全可以用来写游戏,突破60fps,而且自己渲染,大大减少了与原生的通信次数,并且使用 Platform Channels 来跟系统通信大大丰富了一些偏门功能的应用,去组件库看了下tcp直连mqtt都支持了,刚好毕设会用到,开心。
所以如果你需要跨平台,技术选型时遇到问题
1.看需求
如果你的应用需求足够简单,像小程序之类的完全可以做到,选uniapp。因为说真的,像点单这种功能,谁没事愿意专门装个肯打鸡,coco之类在手机上,反正我去点单的时候,能用小程序我就不会再装app了,如果有人愿意装app,稍微改改顺便出个app版看着比较好看。
如果你的需求复杂,必然要分开维护,还是和之前一样,uniapp是一个极好的跨各种小程序的解决方案,一次编译,微信小程序,支付宝小程序,百度小程序,多端运行。那app端你可以再选择h5或者flutter。
如果你需要适配横屏,建议用flutter,横屏的交互加上material design的加持,这样和桌面端就没有太大区别了,目前flutter已经可以编译运行在Windows和linux上,虽然目前还很不完善,但是Google的野心和背书能力让我觉得flutter的野心不止于此。未来能附赠一套桌面端,意外之喜。
2.学习成本
flutter的学习成本主要在Dart,而uniapp主要在vue。说真的,我之前做Android和JavaWeb的,Java转Dart真的没有压力,有人说flutter嵌套太多,安卓xml布局嵌套不多吗,公司现在维护的ERP系统jQuery写的跟使一样,各种+ " append。
而我一个传统Java使用者刚开始遇到vue真的难受了好一阵子,这个this的真是vue里令我最难受的,使一样。推荐周围同学学uniapp,学过C++,Java的普遍反映也是vue看不懂。你们再也不是像jQuery一样好单纯好不做作的前端了。
总之前端的uniapp学习成本低,学过后端Java,C++的,flutter上手成本低。
3.社区
刚开始Google要出Fuchsia OS的时候我还嗤之以鼻,真当程序狗们都会乖乖听你话吗,那win phone坟头草都老高了。没想到啊,你们早在苹果骂安卓垃圾的时候就想着今天了吧。
Google在安卓界的背书能力感觉跟Spring在JavaWeb界的背书能力不逞多让,只要Android和Fuchsia不死,Flutter应该不会有太大问题,而且Flutter的社区是真的真的真的很活跃啊,github上问题的解决速度和出视频的速度真是令我叹为观止。
相比之下DCloud出MUI到现在不愠不火就让我不禁对uniapp有些担心,虽然微信,支付宝在后面背书,希望一群国内一线大厂们能给力点吧。而且我在uniapp提的问题一个多月了,无人问津
【报Bug】使用小程序组件,当参数为函数时,传不过去 - DCloud问答
希望你们珍惜你们的银牌赞助者。而且出视频的速度一言难尽,看B站居然没有,讲道理一个好的教学视频真的很重要,干啃API在学习时真是费力不讨好的事情,你学习的思路和文档的思路是不一样的。不过uniapp的QQ群倒是很火,不管怎样,一个国产的优秀产品,希望你们能有一个好的未来。
原文:https://zhuanlan.zhihu.com/p/55466963
收起阅读 »uni-app 的使用体验总结
[实践] uni-app 的使用总结
最近使用 uni-app 的感受。
使用体验
没用之前以为真和 Vue 一样,用了之后才知道。有点类似 Vue 和 小程序结合的感觉。写类似小程序的标签,有着小程序和 Vue 的生命周期钩子。对比 uni-app 文档和微信小程序的文档,不差多少,只是将 wx => uni,熟悉 Vue 和 小程序可以直接上手。
如果看过其他小程序的文档,可以发现,文档主要的三大章节就体现在框架、组件、API 。
uni-app 需要注意看注意事项,文档给出了和 Vue 使用的区别。例如动态的 Class 与 Style 绑定,在 H5 能用,APP 和小程序的体现就不一样。
配置项跟着文档来,开发环境也是现成的,下载 HBuilderX 导入项目就能运行,日常开发习惯了 VSCode,所以 HBuilderX 的主要作用就是用来打包 APK 和起各个端的服务,coding 的话当然还是用 VSCode。
路由
uni-app 的路由全部配置在 pages.json 文件里,就会导致多人开发的时候,路由无法拆分,如果处理的不好,就会发生冲突。
导航
导航栏需要注意的一个问题就是不同端的展示形式会不同,所以要处理兼容问题,导航栏可以自定义,用原生,框架,插件但是兼容性都不同,多端需求一定要在不同设备跑一下看效果。
例如在小程序和 APP 中,原生导航栏取消不了,就不能用自定义的导航栏,要在 pages.json 中配置原生导航栏。
兼容方法就是用 uni-app 提供的条件编译,处理各端不同的差异,我们支付的业务逻辑也是通过条件编译,区分不同端调用不同的支付方式。
生命周期
分为 应用的生命周期、页面的生命周期、组件的生命周期。写过小程序和 Vue 的很好理解,大致上和 Vue 的还是差不多的,页面生命周期针对当前的页面,应用生命周期针对小程序、APP。这些过程可能都要踩一下!
网络请求和环境配置
官方的 uni.request 虽然封装好了基本的请求,但是没有拦截,我们开始也是自己在这基础上加了层壳,简单的封装发送请求。当然也可以选择第三方库的使用,如 flyio、axios。
我们是前端自己封装了 HTTP 请求,并且统一接口的请求方式,所有的接口放到 api.js 文件中进行统一管理。这样大家在页面请求接口的时候风格才统一,包括约定好请求拦截和响应拦截,具体拦截的参数和后台约定好。
资源优化
- 暂时接触不到 Webpack 之类的资源打包优化,但是文档中有提到资源预取、预加载、treeShaking 只需要在配置文件中设置即可,或者在开发工具勾上。小程序也是勾选自动压缩混淆。
- 删除没用到文件和图片资源,因为打包的时候是会算进去的,比如
static目录下的资源文件都会被打包,而且图片资源太大也不好。 - uni-app 运行时的框架主库
chunk-vendors.js文件是经过处理的,部署做gzip。
Web-View 组件
在 uni-app 中使用 Web-View,可以使用本地的资源和网络的资源,不同平台也是有差异的,小程序不支持本地 HTML,且小程序端 Web-View 组件一定有原生导航栏。
需要注意的是网页向应用 postMessage 的时候需要引入 uni.web-view.js,不然是没办法通信拿不到数据。
TODO: 这个坑后面再详细总结下!
全局状态
最开始是直接使用类似小程序的 globalData 来管理我们的全局状态,但是后面发现需求一多,加了各种东西之后,需要取这个状态的时候就很痛苦,做为程序猿嘛,都想偷懒吖,每次都得引入一下 getApp().globalData.data 这样很繁琐可不行,就替换成了 Vuex,需要取这个变量的时候,直接 this.vuex_xxxx 就能拿到这个值。
有段时间重写了 HTTP 请求部分和全局状态管理部分。
小程序中要在每一个页面中添加使用共有的数据,可以有三种方式解决。
Vue.prototype
它的作用是可以挂载到 Vue 的所有实例上,供所有的页面使用。
// main.js
Vue.prototype.$globalVar = "Hello";
然后在 pages/index/index 中使用:
<template>
<view>{{ useGlobalVar }}</view>
</tempalte>
<script>
export default {
data (){
return {
useGlobalVar: $globalVar
}
}
}
</script>
globalData
<!-- App.vue -->
<script>
export default {
globalData:{
data:1
}
onShow() {
getApp().globalData.data; // 使用
getApp().globalData.data = 1; // 更新
};
</script>
Vuex
Vuex 是 Vue 专用的状态管理模式。能够集中管理其数据,并且可观测其数据变化,以及流动。
之前看到一个通俗化比喻:用交通工具来比喻项目中这几种描述全局变量的方式。
下面列举这些方式通俗的理解状态:
Vue 插件 vue-bus 可以来管理一部分全局变量(叫应用状态吧),学习后发现,bus(中文意思:公交车)这名字取得挺形象的。
先罗列一下这些方式,不过这种分类并不严谨。
1、VueBus:公交车 2、Vuex:飞机 3、全局 import
- a.
new Vue():专车; - b.
Vue.use:快车; - c.
Vue.prototype:顺风车。
4、globalData:地铁
首先 VueBus,像公交车一样灵活便捷,随时都可以乘坐;表现在代码里,很轻便,召之即来,缺点就是不好维护,没有一个专门的文件去管理这些变量。想象平时等公交车的心情,知道它回来,但不知道它什么时候来,给人一种很不安的感觉。
而 Vuex,它像飞机,很庄重,塔台要协调飞机运作畅顺,飞机随时向地面报告自己的位置,适合用在大型项目。表现代码中,就是集中式管理所有状态,并且以可预测的方式发生变化。也对应着飞机绝对不能失联的特点。
第三种方式是全局 import,分三种类型,分别是:new Vue()、Vue.use()、Vue.prototype。可以用网约车来比喻,三种类型分别对应:专车、快车、顺风车。都足够灵活,表现在代码里:一处导入,处处可用。
再分别说明:
new Vue() 就像滴滴的礼橙专车,官方运营,安全可靠。表现在代码里,就是只有 Vue 官方维护的库才能使用这种方式。
Vue.use() 就像快车,必须符合滴滴的规范,才能成为专职司机。表现在代码中,就是导入的插件(或者库)必须符合 Vue 的写法(即封装了 Vue 插件写法)。
Vue.prototype 像顺风车,要求没上面两个那么严,符合一般 js 写法就行,就像顺风车的准入门槛稍稍低一点。
当然,uni-app 的项目里还有可以用 globalData 定义全局变量,非要比喻,可以用地铁,首先比 vue-bus 更好管理维护,想象地铁是不是比公交更可靠;其次比 Vuex 更简单,因为 globalData 真的就是简单的定义一些变量。
globalData 是微信小程序发明的,Vue 项目好像没有对应的概念,但是在 uni-app 中一样可用。
上面说到,这种分类方式不严谨,主要体现在原理上,并不是简单的并列关系或包含关系。
插件市场
uni-app 的主要特色也源自于它的插件市场十分丰富。
用得比较好的组件:
uView:我们用了这个库的骨架屏。这个库还是有很多技巧可以学到的。
https://www.uviewui.com/js/intro.html
ColorUI-UniApp:是个样式库,不是组件库。
https://ext.dcloud.net.cn/plugin?id=239
答题模版:左右滑答题模版,单选题、多选项,判断题,填空题,问答题。基于 ColorUI 做的。
https://ext.dcloud.net.cn/plugin?id=451
uCharts 高性能跨全端图表:
https://ext.dcloud.net.cn/plugin?id=271
最后:各端的差异性,很多东西,H5 挺好的,上真机就挂了,真机好着的,换小程序就飘了,不同小程序之间也有差异,重点是仔细阅读文档。
云打包限制,云打包(打 APK) 的每天做了限制,超出次数需要购买。
虽然可能一些原生可以实现的功能 uni-app 实现不了,不过整体开发下来还行,很多的坑还是因为多端不兼容,除了写起来麻烦一点,基本上都还是有可以解决的策略。比之前用 Weex 写 APP 开发体验好一点,比 React Native 的编译鸡肋一点(这点体验不是很好),至于 Flutter 还没有试过,有机会的话会试一下。
原文:https://zhuanlan.zhihu.com/p/153500294
收起阅读 »使用uniapp开发项目来的几点心得体会
先说一下提前须要会的技术
要想快速入手uniapp的话,你最好提前学会vue、微信小程序开发,因为它几乎就是这两个东西的结合体,不然,你就只有慢慢研究吧。
为什么要选择uniapp???
开发多个平台的时候,对,就是开发多端,其中包括安卓、IOS、H5/公众号、微信小程序、百度小程序...等其它小程序时,如果每个平台开发,人力开发成本高,后期维护也难,原生开发周期也长,那Unipp就是你的优先选择,官方是这样介绍的~哈~ 先来说一下uniapp的优点
uniapp优点
优点一,多端支持
当然是多端开发啦,uni-app是一套可以适用多端的开源框架,一套代码可以同时生成ios,Android,H5,微信小程序,支付宝小程序,百度小程序等。
优点二,更新迭代快
用了它的Hbx你就知道,经常会右下角会弹出让你更新,没错,看到它经常更新,这么努力的在先进与优化,还是选良心的了。
优点三,扩张强
你可以把轻松的把uniapp编译到你想要的端,也可以把其它端的转换成uniapp,例如微信小程序,h5等;如果开发app的时候,前端表现不够,你还可以原生嵌套开发。
优点四,开发成本、门槛低
不管你是公司也好,个人也好,如果你想开发多终端兼容的移动端,那uniapp就很适合你,不然以个人的能力要开发多端,哈哈... 洗洗睡觉吧。
优点五,组件丰富
社区还是比较成熟,生态好,组件丰富,支持npm方式安装第三方包,兼容mpvue,DCloud有大量的组件供你使用,当然付费的也不贵,你还可以发布你开发的,赚两个鸡腿钱还是可以的。
开发上的优点暂且不说,大体上的有这么一些,接下来说一下开发过程中的缺点
uniapp缺点
缺点一:爬坑
每个程序前期肯定都会有很多的坑,这里点明一下:腾讯,敢问谁没在微信开发上坑哭过,现在不也爬起来了,2年前有人提的bug,你现在去看,他依然在那,不离不弃呀。uniapp坑也有,一般的都有人解决了,没解决的,你就要慢慢的去琢磨了,官方bug的话,提交反馈,等官方修复。
缺点二:某些组件不成熟
我说的是某些官方组件,像什么地图组件,直播组件等,你要在上面开发一些特别功能的话,那真的是比较费神的。
缺点二:nvue有点蛋疼
某些组件或某些功能,官方明确说,建议用nvue开发,那么问题来了,nvue有很多的局限,特别是css,很多都不支持,什么文字只能是text,只支持class样式,很多的,要看文档来。
暂时从使用上的总结就这么一些,如果你有不同的见解,留言交流交流~~
原文:https://zhuanlan.zhihu.com/p/336773995
收起阅读 »iOS- 安装CocoaPods详细过程
一、简介
什么是CocoaPods
CocoaPods是OS X和iOS下的一个第三类库管理工具,通过CocoaPods工具我们可以为项目添加被称为“Pods”的依赖库(这些类库必须是CocoaPods本身所支持的),并且可以轻松管理其版本。
CocoaPods的好处
1、在引入第三方库时它可以自动为我们完成各种各样的配置,包括配置编译阶段、连接器选项、甚至是ARC环境下的-fno-objc-arc配置等。
2、使用CocoaPods可以很方便地查找新的第三方库,这些类库是比较“标准的”,而不是网上随便找到的,这样可以让我们找到真正好用的类库。
二、Cocoapods安装步骤
注意:在终端输入命令时,取$后面部分输入
1、升级Ruby环境
终端输入:$ gem update --system此时会出现

这是因为你没有权限去升级Ruby
这时应该输入:$ sudo gem update --system
接下来输入密码,注意:输入密码的时候没有任何反应,光标也不会移动,你尽管输入就是了,输完了直接回车。
等一会如果出现
 恭喜你,升级Ruby成功了。
恭喜你,升级Ruby成功了。
2、更换Ruby镜像
首先移除现有的Ruby镜像
终端输入:$ gem sources --remove https://gems.ruby-china.org/然后添加国内最新镜像源(淘宝的Ruby镜像已经不更新了)
终端输入:$ gem sources -a https://gems.ruby-china.com/执行完毕之后输入gem sources -l来查看当前镜像
终端输入:$ gem sources -l如果结果是
*** CURRENT SOURCES ***https://gems.ruby-china.com/
说明添加成功,否则继续执行$ gem source -a https://gems.ruby-china.com/来添加
3、安装CocoaPods
终端输入:$ sudo gem install cocoapods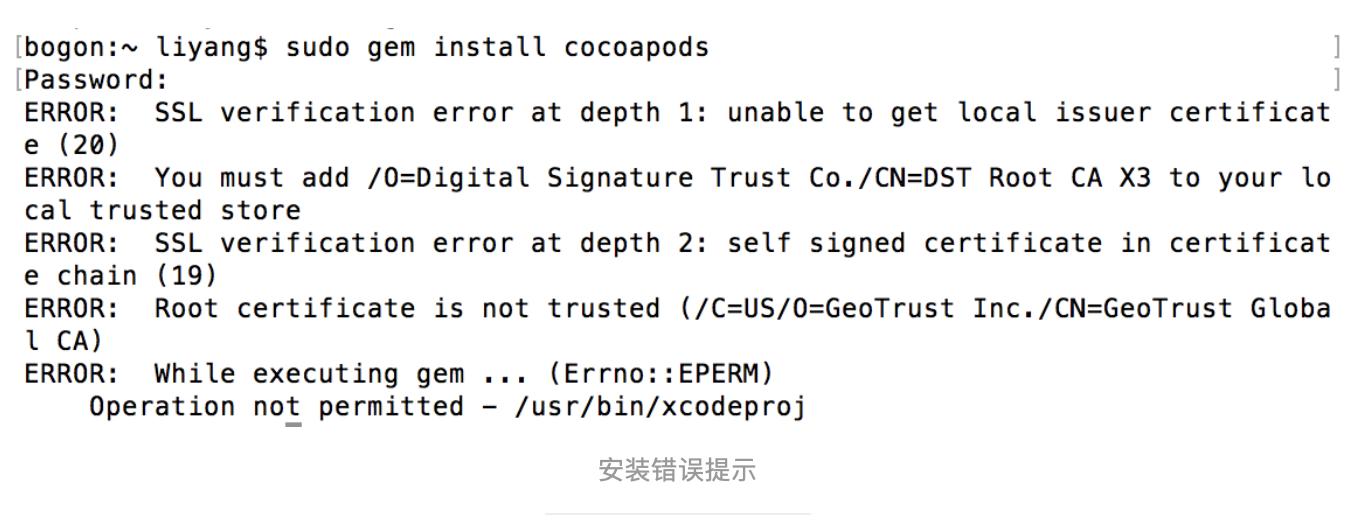
说明没有权限,需要输入
终端输入:$ sudo gem install -n /usr/local/bin cocoapods安装成功如下:

到这之后再执行pod setup(PS:这个过程是漫长的,要有耐心)
终端输入:$ pod setup然后你会看到出现了Setting up CocoaPods master repo,卡住不动了,说明Cocoapods在将它的信息下载到 ~/.cocoapods里。
你可以command+n新建一个终端窗口,执行cd ~/.cocoapods/进入到该文件夹下,然后执行du -sh *来查看文件大小,每隔几分钟查看一次,这个目录最终大小是900多M(我的是930M)
当出现Setup completed的时候说明已经完成了。
4、CocoaPods的使用
终端输入:$ pod search AFNetworking这时有可能出现

执行
rm ~/Library/Caches/CocoaPods/search_index.json来删除该文件然后再次输入
pod search AFNetworking进行搜索这时会提示
Creating search index for spec repo 'master'..等待一会将会出现搜索结果如下:
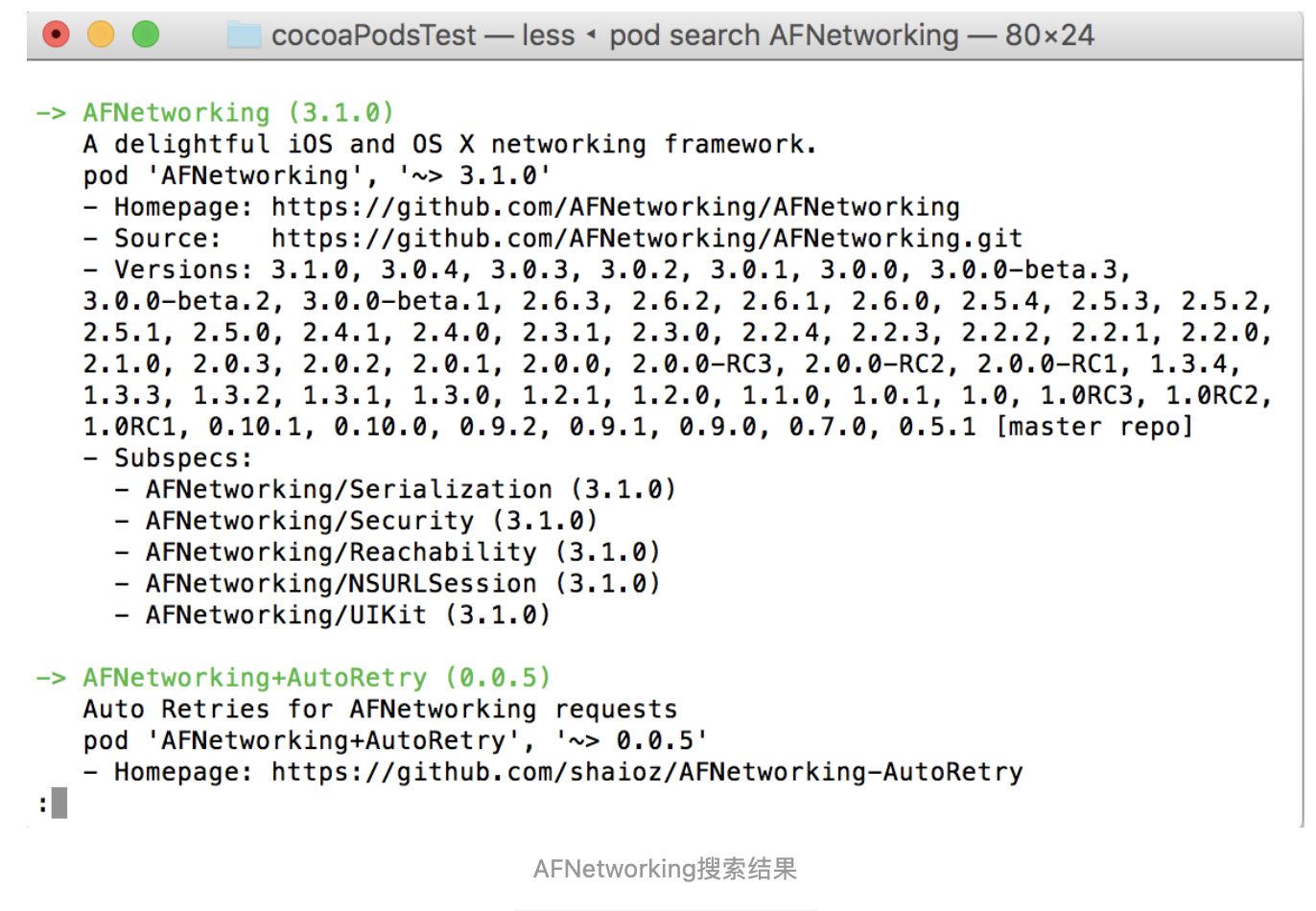
出现这个了就说明搜索成功了,看一下上图中的这一句:pod 'AFNetworking', '~> 3.1.0'
这句话一会我们要用到,这是CocoaPods添加三方库的关键字段
然后退出这个界面(这一步只是验证一下cocoapods有没有安装成功,能不能搜索到你想要的三方库),直接按"q"就退出去了。
2、在工程中创建一个Podfile文件
要想在你的工程中创建Podfile文件,必须先要进到该工程目录下
终端输入:$ cd /Users/liyang/Desktop/CocoaPodsTest
//这是我电脑上的路径,你输入你自己项目的路径或直接拖拽也行进来之后就创建
终端输入:$ touch Podfile然后你在你的工程目录下可以看到多了一个Podfile文件
3、编辑你想导入的第三方库的名称及版本
使用vim编辑Podfile文件
终端输入:$ vim Podfile进入如下界面:
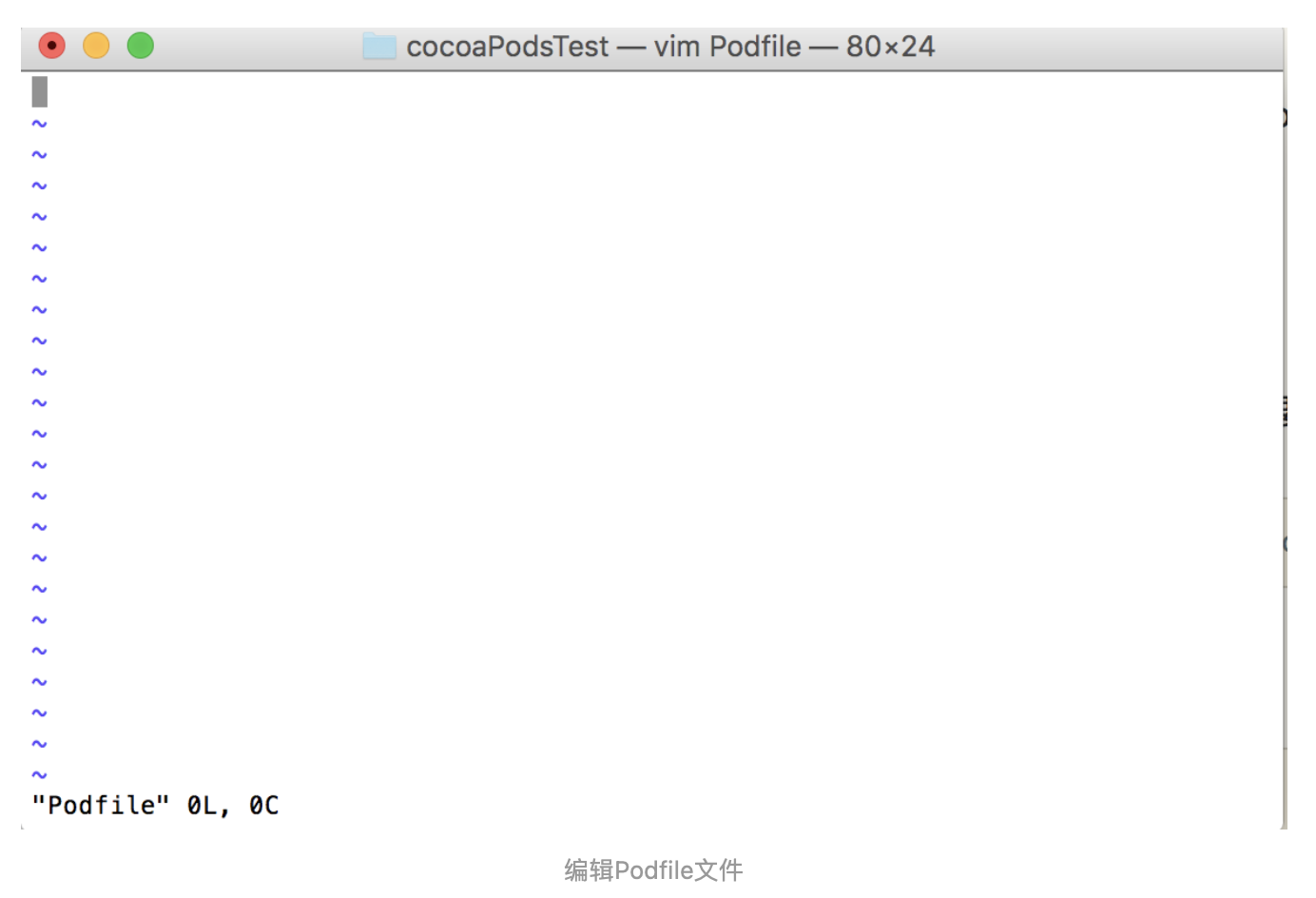
进来之后紧接着按键盘上的英文'i'键
下面的"Podsfile" 0L, 0C将变成-- INSERT --
然后就可以编辑文字了,输入以下文字
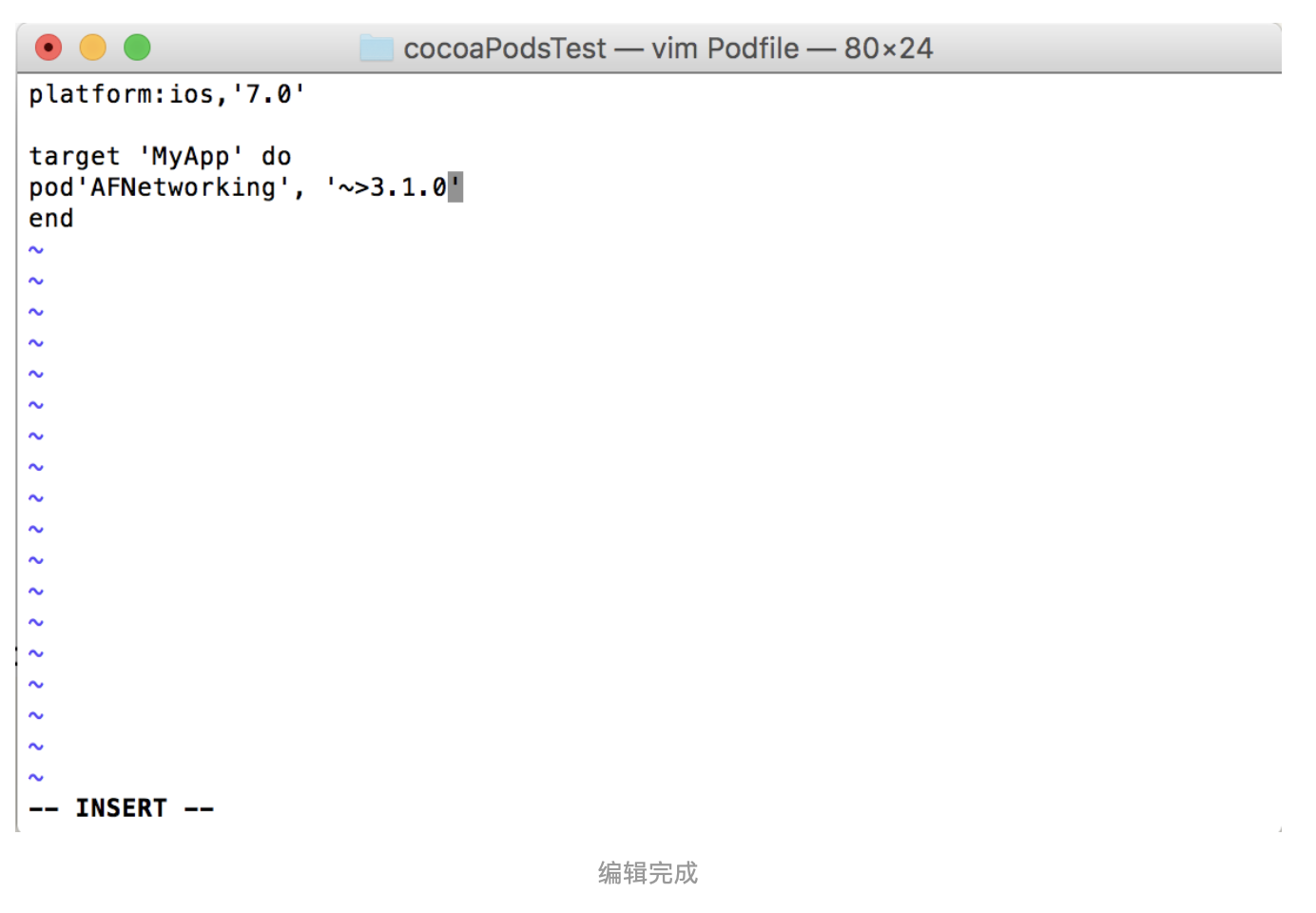
uni-app 悬浮框动效

<view class="menu" :class="{active:menuFlag}">
<image src="../../static/svg/1.svg" class="menuTrigger" @tap="clickMenu"></image>
<image src="../../static/svg/2.svg" class="menuItem menuItem1"></image>
<image src="../../static/svg/3.svg" class="menuItem menuItem2"></image>
<image src="../../static/svg/4.svg" class="menuItem menuItem3"></image>
</view>.menu{
position: fixed;
width: 110rpx;
height: 110rpx;
bottom: 120rpx;
right: 44rpx;
border-radius: 50%;
}
.menuTrigger{
position: absolute;
top: 0;
left: 0;
width: 70rpx;
height: 70rpx;
background-color: green;
border-radius: 50%;
padding: 20rpx;
cursor: pointer;
transition: .35s ease;
}
.menuItem{
position: absolute;
width: 50rpx;
height: 50rpx;
top: 10rpx;
left: 10rpx;
padding: 20rpx;
border-radius: 50%;
background-color: white;
border: none;
box-shadow: 0 0 5rpx 1rpx rgba(0,0,0,.05);
z-index: -1000;
opacity: 0;
}
.menuItem1{
transition: .35s ease;
}
.menuItem2{
transition: .35s ease .1s;
}
.menuItem3{
transition: .35s ease .2s;
}
.menu.active .menuTrigger{
transform: rotateZ(225deg);
background-color: pink;
}
.menu.active .menuItem1{
top: -106rpx;
left: -120rpx;
opacity: 1;
}
.menu.active .menuItem2{
top: 10rpx;
left: -164rpx;
opacity: 1;
}
.menu.active .menuItem3{
top: 126rpx;
left: -120rpx;
opacity: 1;
}data() {
return {
mask: false,
menuFlag: false,
}
},
clickMenu(){
this.menuFlag = !this.menuFlag;
},原文链接:https://zhuanlan.zhihu.com/p/364244176
收起阅读 »async/await 的错误捕获
一、案发现场
为了更好的说明,举一个很常见的例子:
function getData(data) {
return new Promise((resolve, reject) => {
if (data === 1) {
setTimeout(() => {
resolve('getdata success')
}, 1000)
} else {
setTimeout(() => {
reject('getdata error')
}, 1000)
}
})
}
window.onload = async () => {
let res = await getData(1)
console.log(res) //getdata success
}
这样写可以正常打印getdata success 但是如果我们给getData传入的参数不是1,getData会返回一个reject的Promise,而这个地方我们并没有对这个错误进行捕获,则会在控制台看见这样一个鲜红的报错Uncaught (in promise) getdata error
二、尝试捕获它
1. 踹一脚
捕捉错误,首先想到的就是“踹一脚”:
window.onload = async () => {
try {
let res = await getData(3)
console.log(res)
} catch (error) {
console.log(res) //getdata error
}
}
看似问题已经被解决,但是如果我们有一堆请求,每一个await都需要对应一个trycatch,那就多了很多垃圾代码。或许我们可以用一个trycatch将所有的await包起来,但是这样就很不方便对每一个错误进行对应的处理,还得想办法区分每一个错误。
2. then()
因为返回的是一个Promise,那我们首先想到的就是.then()和.catch(),于是很快就能写出以下代码:
window.onload = async () => {
let res = await getData(3).then(r=>r).catch(err=>err);
console.log(res) //getdata error
}
这样看起来比“踹一脚”高大上一点了……
三、有没有更好的方式
上面那种方法是有一定问题的,如果getData()返回是resolve,res则是我们想要的结果,但是如果getData()返回是reject,res则是err,这样错误和正确的结果混在一起了,显然是不行的。
window.onload = async () => {
let res = await getData(3)
.then((res) => [null, res])
.catch((err) => [err, null])
console.log(res) // ["getdata error",null]
}
这种方式有的类似error first的风格。这样可以将错误和正确返回值进行区分了。但是这种方式会让每一次使用await都需要写很长一段冗余的代码,因此考虑提出来封装成一个工具函数:
function awaitWraper(promise) {
return promise.then((res) => [null, res])
.catch((err) => [err, null])
}
window.onload = async () => {
let res = await awaitWraper(getData(3))
console.log(res) // ["getdata error",null]
}
好多了,就先这样吧。
原文链接:https://zhuanlan.zhihu.com/p/114487312
收起阅读 »先看看 VS Code Extension 知识点,再写个 VS Code 扩展玩玩
TL;DR
文章篇幅有点长 ,可以先收藏再看 。要是想直接看看怎么写一个扩展,直接去第二部分 ,或者直接去github看源码 。
第一部分 --- Extension 知识点
一、扩展的启动
- 如何保证性能 --- 扩展激活(Extension Activation) 我们会往VS Code中安装非常多的扩展,VS Code是如何保证性能的呢? 在VS Code中有一个扩展激活(Extension Activation)的概念:VS Code会尽可能晚的加载扩展(懒加载),并且不会加载会话期间未使用的扩展,因此不会占用内存。为了完成扩展的延迟加载,VS Code定义了所谓的激活事件(
activation events)。 VS Code根据特定活动触发激活事件,并且扩展可以定义需要针对哪些事件进行激活。例如,仅当用户打开Markdown文件时,才需要激活用于编辑Markdown的扩展名。 - 如何保证稳定性 --- 扩展隔离(Extension Isolation) 很多扩展都写得很棒 ,但是有的扩展有可能会影响启动性能或VS Code本身的整体稳定性。作为一个编辑器用户可以随时打开,键入或保存文件,确保响应性UI不受扩展程序在做什么的影响是非常重要的。 为了避免扩展可能带来的这些负面问题,VS Code在单独的Node.js进程(扩展宿主进程
extension host process)中加载和运行扩展,以提供始终可用的,响应迅速的编辑器。行为不当的扩展程序不会影响VS Code,尤其不会影响其启动时间 。
四、Activation Events --- package.json
既然扩展是延迟加载(懒加载)的,我们就需要向VS Code提供有关何时应该激活什么扩展程序的上下文,其中比较重要的几个: - onLanguage:${language} - onCommand:${command} - workspaceContains:${toplevelfilename} - *
activationEvents.onLanguage
根据编程语言确定时候激活。比如我们可以这样:
"activationEvents": [
"onLanguage:javascript"
]当检测到是js的文件时,就会激活该扩展。
activationEvents.onCommand
使用命令激活。比如我们可以这样:
"activationEvents": [
"onCommand:extension.sayHello"
]activationEvents.workspaceContains
文件夹打开后,且文件夹中至少包含一个符合glob模式的文件时激活。比如我们可以这样:
"activationEvents": [
"workspaceContains:.editorconfig"
]当打开的文件夹含有.editorconfig文件时,就会激活该扩展。
activationEvents.*
每当VS Code启动,就会激活。比如我们可以这样:
"activationEvents": [
"*"
]五、Contribution Points --- package.json
其中配置的内容会暴露给用户,我们扩展大部分的配置都会写在这里: - configuration - commands - menus - keybindings - languages - debuggers - breakpoints - grammars - themes - snippets - jsonValidation - views - problemMatchers - problemPatterns - taskDefinitions - colors
contributes.configuration
在configuration中配置的内容会暴露给用户,用户可以从“用户设置”和“工作区设置”中修改你暴露的选项。 configuration是JSON格式的键值对,VS Code为用户提供了良好的设置支持。 你可以用vscode.workspace.getConfiguration('myExtension')读取配置值。
contributes.commands
设置命令标题和命令,随后这个命令会显示在命令面板中。你也可以加上category前缀,在命令面板中会以分类显示。
注意:当调用命令时(通过组合键或者在命令面板中调用),VS Code会触发激活事件onCommand:${command}。
六、package.json其他比较特殊的字段
engines:说明扩展程序将支持哪些版本的VS CodedisplayName:在左侧显示的扩展名icon:扩展的图标categories:扩展所属的分类。可以是:Languages, Snippets, Linters, Themes, Debuggers, Formatters, Keymaps, Other
第二部分 --- 自己写个扩展玩玩
我们经常使用console.log来打印日志进行调试,我们就写一个用来美化、简化console.log的扩展玩玩。最终实现的效果:
实现这个扩展,需要注意以下几点: 1. console.log使用css样式 2. VS Code插入内容 3. VS Code光标和选区 4. VS Code删除内容 5. VS Code读取用户配置
下面火速实操(p≧w≦q)。
如何开始
要开始写VS Code扩展,需要两个工具:
- yeoman:有助于启动新项目
- vscode-generator-code:由VS Code团队使用
yeoman构建的生成器 可以使用yarn或npm安装这两个工具,安装完成之后执行yo code,等一会之后它会帮我们生成起始项目,并会询问几个问题:
确认信息之后,会帮我们初始化好整个项目,此时的目录结构是这样的:

我们只需要关注src/extension.ts和package.json即可,其中package.json里面的内容之前已经介绍过。
console.log使用css样式
这里有一篇比较完整的文章:https://www.telerik.com/blogs/how-to-style-console-log-contents-in-chrome-devtools 简单的说,这句代码执行之后打印的是下面图片那样console.log("%cThis is a green text", "color:green");:
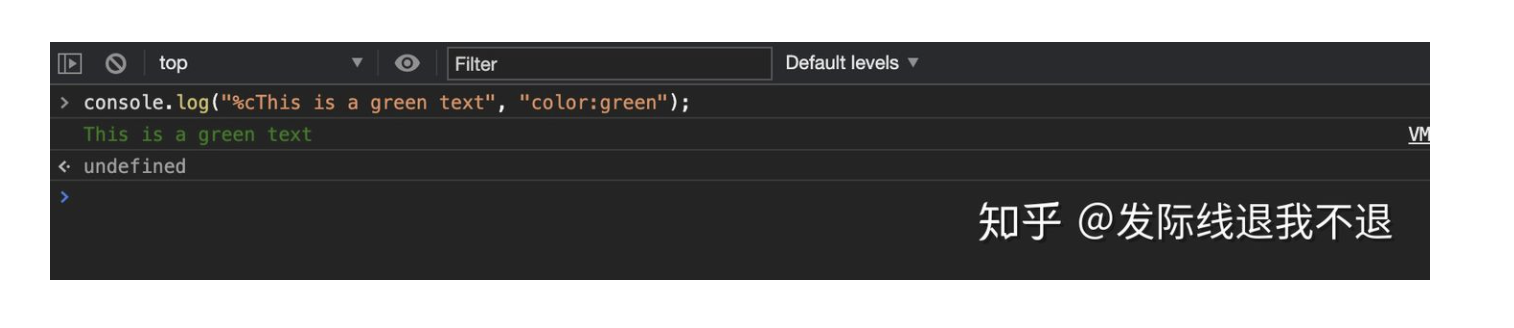
后面的样式会应用在%c后面的内容上
vscode扩展读取用户配置
上文提到过,我们可以在contributes里面定义用户配置:
"contributes": {
"configuration": {
"type": "object",
"title": "Special-console.log",
"properties": {
"special-console.log.projectName": {
"type": "string",
"default": "MyProject",
"description": "Project name"
},
"special-console.log.showLine": {
"type": "boolean",
"default": true,
"description": "Show line number"
},
"special-console.log.deleteAll": {
"type": "boolean",
"default": false,
"description": "delete all logs or delete the log containing [color] and [background]"
}
}
}
},
然后使用vscode.workspace.getConfiguration()读取用户配置
激活扩展
前面提到扩展是延迟加载(懒加载)的,我们只需要向VS Code提供有关何时应该激活什么扩展程序的上下文即可。我们在package.json中定义两个激活的事件:
"activationEvents": [
"onCommand:extension.insertLog",
"onCommand:extension.deleteLogs"
],
接着在contributes中添加快捷键:
"keybindings": [
{
"command": "extension.insertLog",
"key": "shift+ctrl+l",
"mac": "shift+cmd+l",
"when": "editorTextFocus"
},
{
"command": "extension.deleteLogs",
"key": "shift+ctrl+d",
"mac": "shift+cmd+d"
}
],
还可以将命令添加到命令面板里面,也就是按Ctrl +Shift+P弹出来的面板:
"commands": [
{
"command": "extension.insertLog",
"title": "Insert Log"
},
{
"command": "extension.deleteLogs",
"title": "Delete console.log"
}
],
insertLog表示往内容中插入console.log,deleteLogs则表示删除。具体的实现我们放到src/extension.ts的activate中:
export function activate(context: vscode.ExtensionContext) {
const insertLog = vscode.commands.registerCommand('extension.insertLog', () => {})
context.subscriptions.push(insertLog)
const deleteLogs = vscode.commands.registerCommand('extension.deleteLogs', () => {})
context.subscriptions.push(deleteLogs)
}
插入console.log
- 插入
console.log大概的过程是获取当前选区的内容,获取用户配置,根据用户配置和当前选区的内容填充console.log,最后插入到选区的下一行。
const insertLog = vscode.commands.registerCommand('extension.insertLog', () => {
const editor = vscode.window.activeTextEditor
if (!editor) { return }
const selection = editor.selection
const text = editor.document.getText(selection) // 当前选区内容
// 用户配置
if (userConfig) {
projectName = userConfig.projectName || projectName
showLine = userConfig.showLine || showLine
line = showLine?`%cline:${lineNumber}`:'%c'
}
// 设置console.log
...
// 在下一行插入
vscode.commands.executeCommand('editor.action.insertLineAfter')
.then(() => {
insertText(logToInsert, !text, noTextStr.length)
})
})
插入内容:
const insertText = (val: string, cursorMove: boolean, textLen: number) => {
const editor = vscode.window.activeTextEditor
if (!editor) {
vscode.window.showErrorMessage('Can\'t insert log because no document is open')
return
}
editor.edit((editBuilder) => {
editBuilder.replace(range, val) // 插入内容
}).then(() => {
// 修改选区
})
}
删除console.log
删除的时候只需要遍历找一下console.log在判断一下是不是我们加入的内容,是就删除
const deleteLogs = vscode.commands.registerCommand('extension.deleteLogs', () => {
const editor = vscode.window.activeTextEditor
if (!editor) { return }
const document = editor.document
const documentText = editor.document.getText()
let workspaceEdit = new vscode.WorkspaceEdit()
// 获取log
const logStatements = getAllLogs(document, documentText)
// 删除
deleteFoundLogs(workspaceEdit, document.uri, logStatements)
})
删除的时候可以使用workspaceEdit.delete(docUri, log),当然,删除之后我们可以右下角搞个弹窗提示一下用户删除了几个console.log:
vscode.workspace.applyEdit(workspaceEdit).then(() => {
vscode.window.showInformationMessage(`${logs.length} console.log deleted`)
})
具体的代码可以看看github
发布
这个就注册一下账号然后发布就行
原文链接:https://zhuanlan.zhihu.com/p/320220574
收起阅读 »iOS- 集成Bugly详解
SDK 集成
Bugly提供两种集成方式供iOS开发者选择:
- 通过CocoaPods集成
- 手动集成
如果您是从Bugly 2.0以下版本升级过来的,请查看
Bugly iOS SDK 最低兼容系统版本 iOS 7.0
通过CocoaPods集成
在工程的Podfile里面添加以下代码:
pod 'Bugly'保存并执行pod install,然后用后缀为.xcworkspace的文件打开工程。
注意:
命令行下执行pod search Bugly,如显示的Bugly版本不是最新的,则先执行pod repo update操作更新本地repo的内容
关于CocoaPods的更多信息请查看 。
手动集成
- 下载
- 拖拽
Bugly.framework文件到Xcode工程内(请勾选Copy items if needed选项) - 添加依赖库
SystemConfiguration.frameworkSecurity.frameworklibz.dylib或libz.tbdlibc++.dylib或libc++.tbd
初始化SDK
导入头文件
在工程的AppDelegate.m文件导入头文件
#import <Bugly/Bugly.h>如果是
Swift工程,请在对应bridging-header.h中导入
初始化Bugly
在工程AppDelegate.m的application:didFinishLaunchingWithOptions:方法中初始化:
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
[Bugly startWithAppId:@"此处替换为你的AppId"];
return YES;
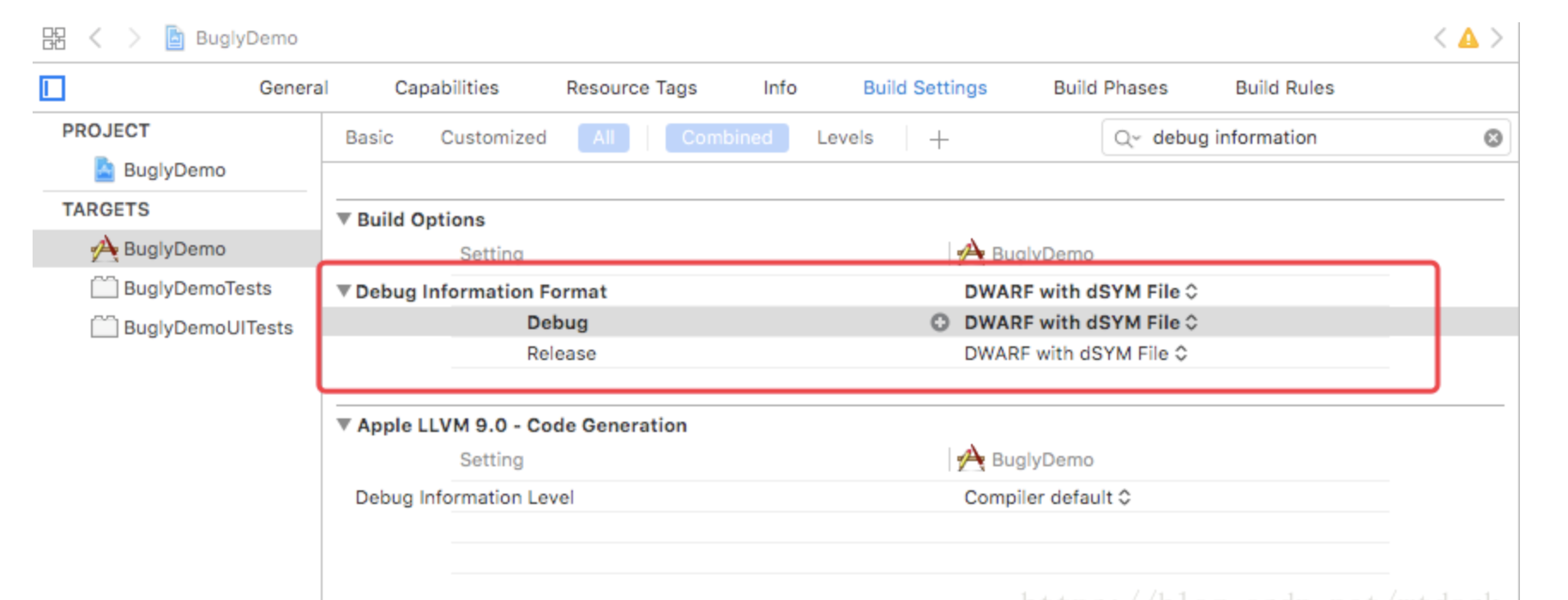
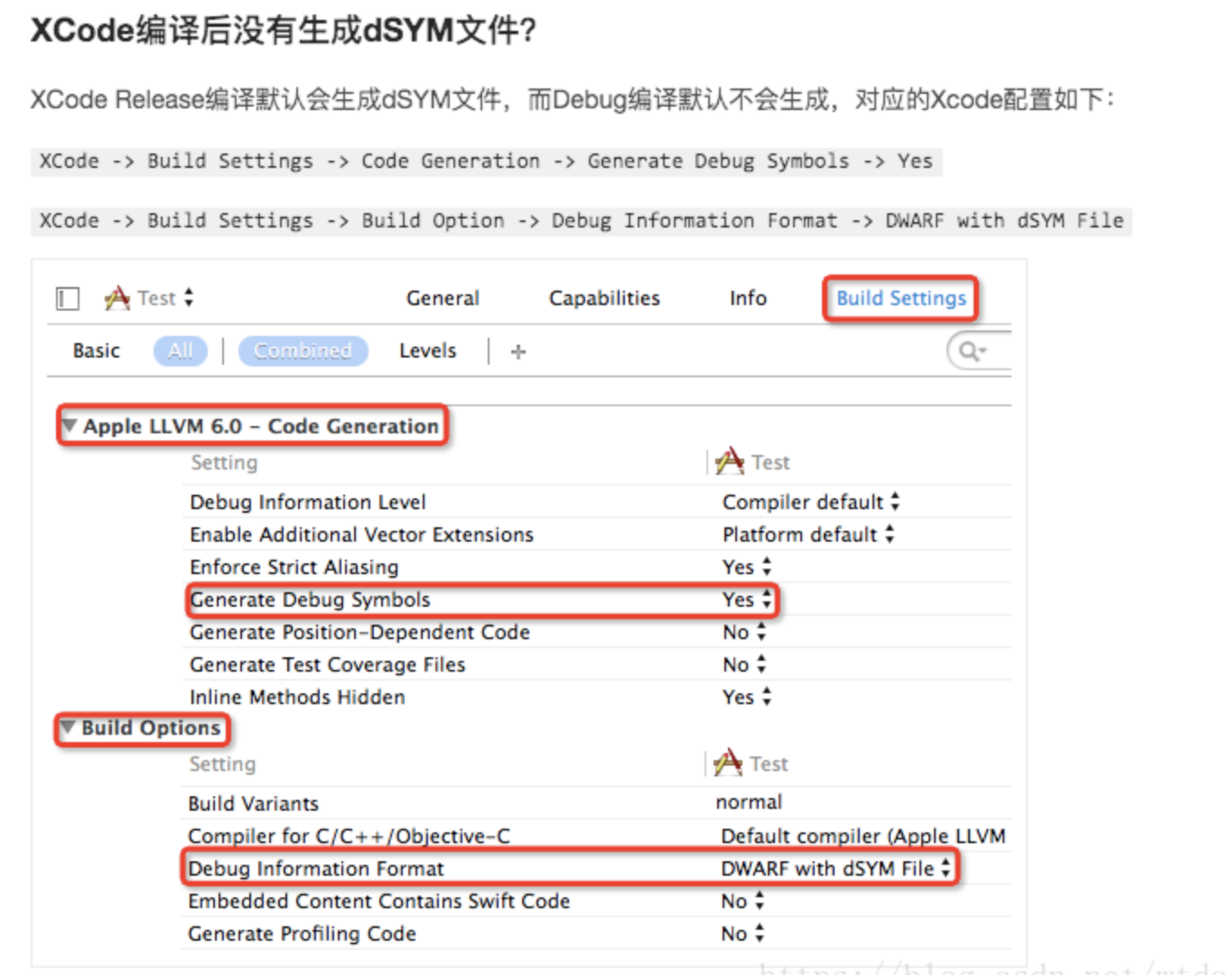
}默认Debug模式,是不会生成dSYM文件,需要开启.重新编译CMD+B,修改配置如下图
Bugly后台显示异常数据
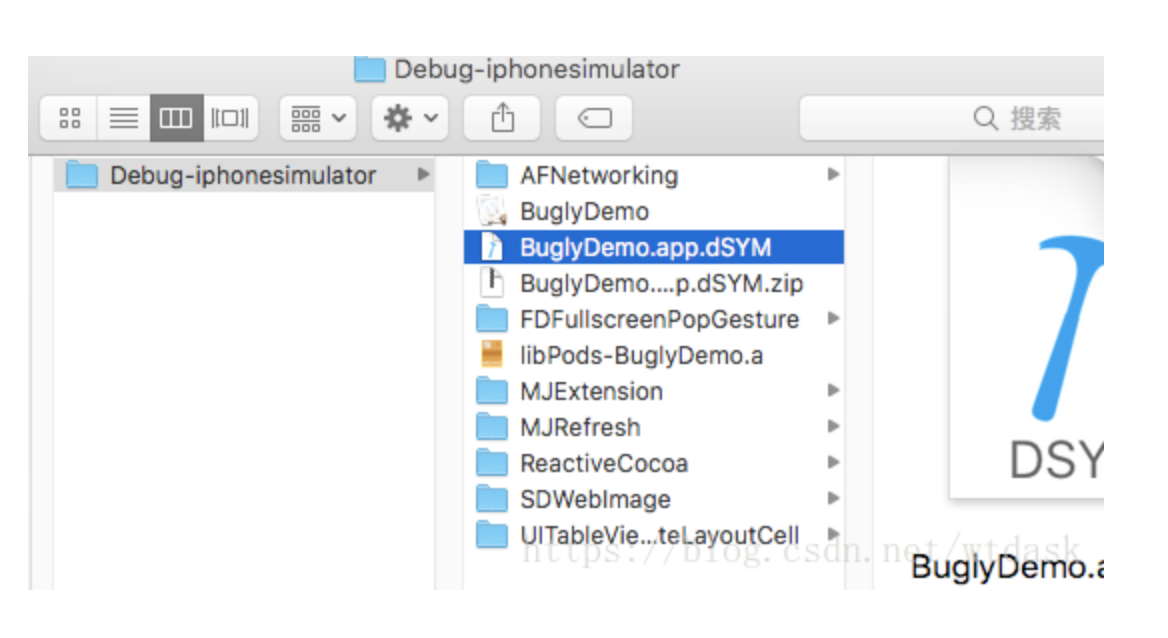
生成后,在哪里可以找到dSYM文件?

@interface AppDelegate ()<BuglyDelegate>2.设置代理对象
BuglyConfig *config = [[BuglyConfig alloc] init];
config.delegate = self;
[Bugly startWithAppId:@"你的AppId" config:config];3.实现代理方法attachmentForException
#pragma mark - Bugly代理 - 捕获异常,回调(@return 返回需上报记录,随 异常上报一起上报)
- (NSString *)attachmentForException:(NSException *)exception {
#ifdef DEBUG // 调试
return [NSString stringWithFormat:@"我是携带信息:%@",[self redirectNSLogToDocumentFolder]];
#endif
return nil;
}
#pragma mark - 保存日志文件
- (NSString *)redirectNSLogToDocumentFolder{
//如果已经连接Xcode调试则不输出到文件
if(isatty(STDOUT_FILENO)) {
return nil;
}
UIDevice *device = [UIDevice currentDevice];
if([[device model] hasSuffix:@"Simulator"]){
//在模拟器不保存到文件中
return nil;
}
//获取Document目录下的Log文件夹,若没有则新建
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSDocumentDirectory, NSUserDomainMask, YES);
NSString *logDirectory = [[paths objectAtIndex:0] stringByAppendingPathComponent:@"Log"];
NSFileManager *fileManager = [NSFileManager defaultManager];
BOOL fileExists = [fileManager fileExistsAtPath:logDirectory];
if (!fileExists) {
[fileManager createDirectoryAtPath:logDirectory withIntermediateDirectories:YES attributes:nil error:nil];
}
NSDateFormatter *formatter = [[NSDateFormatter alloc] init];
[formatter setLocale:[[NSLocale alloc] initWithLocaleIdentifier:@"zh_CN"]];
[formatter setDateFormat:@"yyyy-MM-dd HH:mm:ss"]; //每次启动后都保存一个新的日志文件中
NSString *dateStr = [formatter stringFromDate:[NSDate date]];
NSString *logFilePath = [logDirectory stringByAppendingFormat:@"/%@.txt",dateStr];
// freopen 重定向输出输出流,将log输入到文件
freopen([logFilePath cStringUsingEncoding:NSASCIIStringEncoding], "a+", stdout);
freopen([logFilePath cStringUsingEncoding:NSASCIIStringEncoding], "a+", stderr);
return [[NSString alloc] initWithContentsOfFile:logFilePath encoding:NSUTF8StringEncoding error:nil];
}Bugly iOS 符号表配置
<起始地址> <结束地址> <函数> [<文件名:行号>]

UPLOAD_DEBUG_SYMBOLS=0iOS- 研发助手DoraemonKit技术实现(二)
一、前言
- 第一、很多测试同学比较关注App质量,但是他们却没有Xcode运行环境,他们对于质量数据无法很有效的查看。
- 第二、App端实时的查看App的质量数据,不依赖IDE,方便快捷直观。
- 第三、实时采集性能数据,为后期结合测试平台产生性能数据报表提供数据来源。
二、技术实现
3.1:帧率展示
- (void)startRecord{
if (_link) {
_link.paused = NO;
}else{
_link = [CADisplayLink displayLinkWithTarget:self selector:@selector(trigger:)];
[_link addToRunLoop:[NSRunLoop mainRunLoop] forMode:NSRunLoopCommonModes];
_record = [DoraemonRecordModel instanceWithType:DoraemonRecordTypeFPS];
_record.startTime = [[NSDate date] timeIntervalSince1970];
}
}
- (void)trigger:(CADisplayLink *)link{
if (_lastTime == 0) {
_lastTime = link.timestamp;
return;
}
_count++;
NSTimeInterval delta = link.timestamp - _lastTime;
if (delta < 1) return;
_lastTime = link.timestamp;
CGFloat fps = _count / delta;
_count = 0;
NSInteger intFps = (NSInteger)(fps+0.5);
// 0~60 对应 高度0~200
[self.record addRecordValue:fps time:[[NSDate date] timeIntervalSince1970]];
[_oscillogramView addHeightValue:fps*200./60. andTipValue:[NSString stringWithFormat:@"%zi",intFps]];
}3.2:CPU展示
- 使用task_threads函数,获取当前App行程中所有的线程列表。
- 对于第一步中获取的线程列表进行遍历,通过thread_info函数获取每一个非闲置线程的cpu使用率,进行相加。
- 使用vm_deallocate函数释放资源。
+ (CGFloat)cpuUsageForApp {
kern_return_t kr;
thread_array_t thread_list;
mach_msg_type_number_t thread_count;
thread_info_data_t thinfo;
mach_msg_type_number_t thread_info_count;
thread_basic_info_t basic_info_th;
// get threads in the task
// 获取当前进程中 线程列表
kr = task_threads(mach_task_self(), &thread_list, &thread_count);
if (kr != KERN_SUCCESS)
return -1;
float tot_cpu = 0;
for (int j = 0; j < thread_count; j++) {
thread_info_count = THREAD_INFO_MAX;
//获取每一个线程信息
kr = thread_info(thread_list[j], THREAD_BASIC_INFO,
(thread_info_t)thinfo, &thread_info_count);
if (kr != KERN_SUCCESS)
return -1;
basic_info_th = (thread_basic_info_t)thinfo;
if (!(basic_info_th->flags & TH_FLAGS_IDLE)) {
// cpu_usage : Scaled cpu usage percentage. The scale factor is TH_USAGE_SCALE.
//宏定义TH_USAGE_SCALE返回CPU处理总频率:
tot_cpu += basic_info_th->cpu_usage / (float)TH_USAGE_SCALE;
}
} // for each thread
// 注意方法最后要调用 vm_deallocate,防止出现内存泄漏
kr = vm_deallocate(mach_task_self(), (vm_offset_t)thread_list, thread_count * sizeof(thread_t));
assert(kr == KERN_SUCCESS);
return tot_cpu;
}测试结果基本和Xcode测量出来的cpu使用率是一样的,还是比较准确的。
3.3:内存展示
//当前app消耗的内存
+ (NSUInteger)useMemoryForApp{
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
kern_return_t kernelReturn = task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count);
if(kernelReturn == KERN_SUCCESS)
{
int64_t memoryUsageInByte = (int64_t) vmInfo.phys_footprint;
return memoryUsageInByte/1024/1024;
}
else
{
return -1;
}
}
//设备总的内存
+ (NSUInteger)totalMemoryForDevice{
return [NSProcessInfo processInfo].physicalMemory/1024/1024;
}3.4:流量监控
@interface DoraemonNSURLProtocol()<NSURLConnectionDelegate,NSURLConnectionDataDelegate>
@property (nonatomic, strong) NSURLConnection *connection;
@property (nonatomic, assign) NSTimeInterval startTime;
@property (nonatomic, strong) NSURLResponse *response;
@property (nonatomic, strong) NSMutableData *data;
@property (nonatomic, strong) NSError *error;
@end
@implementation DoraemonNSURLProtocol
+ (BOOL)canInitWithRequest:(NSURLRequest *)request{
if ([NSURLProtocol propertyForKey:kDoraemonProtocolKey inRequest:request]) {
return NO;
}
if (![DoraemonNetFlowManager shareInstance].canIntercept) {
return NO;
}
if (![request.URL.scheme isEqualToString:@"http"] &&
![request.URL.scheme isEqualToString:@"https"]) {
return NO;
}
//NSLog(@"DoraemonNSURLProtocol == %@",request.URL.absoluteString);
return YES;
}
+ (NSURLRequest *)canonicalRequestForRequest:(NSURLRequest *)request{
//NSLog(@"canonicalRequestForRequest");
NSMutableURLRequest *mutableReqeust = [request mutableCopy];
[NSURLProtocol setProperty:@YES forKey:kDoraemonProtocolKey inRequest:mutableReqeust];
return [mutableReqeust copy];
}
- (void)startLoading{
//NSLog(@"startLoading");
self.connection = [[NSURLConnection alloc] initWithRequest:[[self class] canonicalRequestForRequest:self.request] delegate:self];
[self.connection start];
self.data = [NSMutableData data];
self.startTime = [[NSDate date] timeIntervalSince1970];
}
- (void)stopLoading{
//NSLog(@"stopLoading");
[self.connection cancel];
DoraemonNetFlowHttpModel *httpModel = [DoraemonNetFlowHttpModel dealWithResponseData:self.data response:self.response request:self.request];
if (!self.response) {
httpModel.statusCode = self.error.localizedDescription;
}
httpModel.startTime = self.startTime;
httpModel.endTime = [[NSDate date] timeIntervalSince1970];
httpModel.totalDuration = [NSString stringWithFormat:@"%f",[[NSDate date] timeIntervalSince1970] - self.startTime];
[[DoraemonNetFlowDataSource shareInstance] addHttpModel:httpModel];
}
#pragma mark - NSURLConnectionDelegate
- (void)connection:(NSURLConnection *)connection didFailWithError:(NSError *)error{
[[self client] URLProtocol:self didFailWithError:error];
self.error = error;
}
- (BOOL)connectionShouldUseCredentialStorage:(NSURLConnection *)connection {
return YES;
}
- (void)connection:(NSURLConnection *)connection didReceiveAuthenticationChallenge:(NSURLAuthenticationChallenge *)challenge {
[[self client] URLProtocol:self didReceiveAuthenticationChallenge:challenge];
}
- (void)connection:(NSURLConnection *)connection didCancelAuthenticationChallenge:(NSURLAuthenticationChallenge *)challenge {
[[self client] URLProtocol:self didCancelAuthenticationChallenge:challenge];
}
#pragma mark - NSURLConnectionDataDelegate
- (void)connection:(NSURLConnection *)connection didReceiveResponse:(NSURLResponse *)response{
[[self client] URLProtocol:self didReceiveResponse:response cacheStoragePolicy:NSURLCacheStorageAllowed];
self.response = response;
}
- (void)connection:(NSURLConnection *)connection didReceiveData:(NSData *)data{
[[self client] URLProtocol:self didLoadData:data];
[self.data appendData:data];
}
- (NSCachedURLResponse *)connection:(NSURLConnection *)connection willCacheResponse:(NSCachedURLResponse *)cachedResponse{
return cachedResponse;
}
- (void)connectionDidFinishLoading:(NSURLConnection *)connection {
[[self client] URLProtocolDidFinishLoading:self];
}3.5:自定义监控
DoraemonKit项目地址:github.com/didi/Doraem…
摘自:https://blog.csdn.net/weixin_33847182/article/details/91472599
iOS- 研发助手DoraemonKit技术实现(一)
一、前言
- 常用工具 : App信息展示,沙盒浏览、MockGPS、H5任意门、子线程UI检查、日志显示。
- 性能工具 : 帧率监控、CPU监控、内存监控、流量监控、自定义监控。
- 视觉工具 : 颜色吸管、组件检查、对齐标尺。
- 业务专区 : 支持业务测试组件接入到DoraemonKit面板中。
二、技术实现
2.1:App信息展示
我们要看一些手机信息或者App的一些基本信息的时候,需要到系统设置去找,比较麻烦。特别是权限信息,在我们app装的比较多的时候,我们很难快速找到我们app的权限信息。而这些信息从代码角度都是比较容易获取的。我们把我们感兴趣的信息列表出来直接查看,避免了去手机设置里查看或者查看源代码的麻烦。
获取手机型号
+ (NSString *)iphoneType{
struct utsname systemInfo;
uname(&systemInfo);
NSString *platform = [NSString stringWithCString:systemInfo.machine encoding:NSUTF8StringEncoding];
//iPhone
if ([platform isEqualToString:@"iPhone1,1"]) return @"iPhone 1G";
...
//其他对应关系请看下面对应表
return platform;
}
获取手机系统版本
//获取手机系统版本
NSString *phoneVersion = [[UIDevice currentDevice] systemVersion];
复制代码获取App BundleId
一个app分为测试版本、企业版本、appStore发售版本,每一个app长得都一样,如何对他们进行区分呢,那就要用到BundleId这个属性了。
//获取bundle id
NSString *bundleId = [[NSBundle mainBundle] bundleIdentifier];
获取App 版本号
//获取App版本号
NSString *bundleVersionCode = [[[NSBundle mainBundle]infoDictionary] objectForKey:@"CFBundleVersion"];权限信息查看
- NotDetermined => 用户还没有选择。
- Restricted => 该权限受限,比如家长控制。
- Denied => 用户拒绝使用该权限。
- Authorized => 用户同意使用该权限。
2.2:沙盒浏览
以前如果我们要去查看App缓存、日志信息,都需要访问沙盒。由于iOS的封闭性,我们无法直接查看沙盒中的文件内容。如果我们要去访问沙盒,基本上有两种方式,第一种使用Xcode自带的工具,从Windows-->Devices进入设备管理界面,通过Download Container的方式导出整个app的沙盒。第二种方式,就是自己写代码,访问沙盒中指定文件,然后使用NSLog的方式打印出来。这两种方式都比较麻烦。
- (void)shareFileWithPath:(NSString *)filePath{
NSURL *url = [NSURL fileURLWithPath:filePath];
NSArray *objectsToShare = @[url];
UIActivityViewController *controller = [[UIActivityViewController alloc] initWithActivityItems:objectsToShare applicationActivities:nil];
NSArray *excludedActivities = @[UIActivityTypePostToTwitter, UIActivityTypePostToFacebook,
UIActivityTypePostToWeibo,
UIActivityTypeMessage, UIActivityTypeMail,
UIActivityTypePrint, UIActivityTypeCopyToPasteboard,
UIActivityTypeAssignToContact, UIActivityTypeSaveToCameraRoll,
UIActivityTypeAddToReadingList, UIActivityTypePostToFlickr,
UIActivityTypePostToVimeo, UIActivityTypePostToTencentWeibo];
controller.excludedActivityTypes = excludedActivities;
[self presentViewController:controller animated:YES completion:nil];
}
2.3:MockGPS
/*
* locationManager:didUpdateLocations:
*
* Discussion:
* Invoked when new locations are available. Required for delivery of
* deferred locations. If implemented, updates will
* not be delivered to locationManager:didUpdateToLocation:fromLocation:
*
* locations is an array of CLLocation objects in chronological order.
*/
- (void)locationManager:(CLLocationManager *)manager
didUpdateLocations:(NSArray<CLLocation *> *)locations API_AVAILABLE(ios(6.0), macos(10.9));- (void)doraemon_swizzleLocationDelegate:(id)delegate {
if (delegate) {
//1、让所有的CLLocationManager的代理都设置为[DoraemonGPSMocker shareInstance],让他做中间转发
[self doraemon_swizzleLocationDelegate:[DoraemonGPSMocker shareInstance]];
//2、绑定所有CLLocationManager实例与delegate的关系,用于[DoraemonGPSMocker shareInstance]做目标转发用。
[[DoraemonGPSMocker shareInstance] addLocationBinder:self delegate:delegate];
//3、处理[DoraemonGPSMocker shareInstance]没有实现的selector,并且给用户提示。
Protocol *proto = objc_getProtocol("CLLocationManagerDelegate");
unsigned int count;
struct objc_method_description *methods = protocol_copyMethodDescriptionList(proto, NO, YES, &count);
NSMutableArray *array = [NSMutableArray array];
for(unsigned i = 0; i < count; i++)
{
SEL sel = methods[i].name;
if ([delegate respondsToSelector:sel]) {
if (![[DoraemonGPSMocker shareInstance] respondsToSelector:sel]) {
NSAssert(NO, @"你在Delegate %@ 中所使用的SEL %@,暂不支持,请联系DoraemonKit开发者",delegate,sel);
}
}
}
free(methods);
}else{
[self doraemon_swizzleLocationDelegate:delegate];
}
} "0x2800a07a0_binder" = "<CLLocationManager: 0x2800a07a0>";
"0x2800a07a0_delegate" = "<MAMapLocationManager: 0x2800a04d0>";
"0x2800b59a0_binder" = "<CLLocationManager: 0x2800b59a0>";
"0x2800b59a0_delegate" = "<KDDriverLocationManager: 0x2829d3bf0>";
}2.4:H5任意门
有的时候Native和H5开发同时开发一个功能,H5依赖native提供入口,而这个时候Native还没有开发好,这个时候H5开发就没法在App上看到效果。再比如,有些H5页面处于的位置比较深入,就像我们代驾司机端,做单流程比较多,有的H5界面需要很繁琐的操作才能展示到App上,不方便我们查看和定位问题。 这个时候我们可以为app做一个简单的浏览器,输入url,使用自带的容器进行跳转。因为每一个app的H5容器基本上都是自定义过得,都会有自己的bridge定制化,所以这个H5容器没有办法使用系统原生的UIWebView或者WKWebView,就只能交给业务方自己去完成。我们在DorameonKit初始化的时候,提供了一个回调让业务方用自己的H5容器去打开这个Url:
[[DoraemonManager shareInstance] addH5DoorBlock:^(NSString *h5Url) {
//使用自己的H5容器打开这个链接
}];2.5:子线程UI检查
@implementation UIView (Doraemon)
+ (void)load{
[[self class] doraemon_swizzleInstanceMethodWithOriginSel:@selector(setNeedsLayout) swizzledSel:@selector(doraemon_setNeedsLayout)];
[[self class] doraemon_swizzleInstanceMethodWithOriginSel:@selector(setNeedsDisplay) swizzledSel:@selector(doraemon_setNeedsDisplay)];
[[self class] doraemon_swizzleInstanceMethodWithOriginSel:@selector(setNeedsDisplayInRect:) swizzledSel:@selector(doraemon_setNeedsDisplayInRect:)];
}
- (void)doraemon_setNeedsLayout{
[self doraemon_setNeedsLayout];
[self uiCheck];
}
- (void)doraemon_setNeedsDisplay{
[self doraemon_setNeedsDisplay];
[self uiCheck];
}
- (void)doraemon_setNeedsDisplayInRect:(CGRect)rect{
[self doraemon_setNeedsDisplayInRect:rect];
[self uiCheck];
}
- (void)uiCheck{
if([[DoraemonCacheManager sharedInstance] subThreadUICheckSwitch]){
if(![NSThread isMainThread]){
NSString *report = [BSBacktraceLogger bs_backtraceOfCurrentThread];
NSDictionary *dic = @{
@"title":[DoraemonUtil dateFormatNow],
@"content":report
};
[[DoraemonSubThreadUICheckManager sharedInstance].checkArray addObject:dic];
}
}
}
@end2.6:日志显示
收起阅读 »移动架构 (八) 人人都能看得懂的动态化加载插件技术模型实现
移动架构 (二) Android 中 Handler 架构分析,并实现自己简易版本 Handler 框架
移动架构 (四) EventBus 3.1.1 源码分析及实现自己的轻量级 EventBus 框架,根据 TAG 发送接收事件。
移动架构 (五) 仅仅对 Java Bean 的操作,就能完成对数据持久化
基本概念
插件化其实也就是 模块化->组件化 演变而来, 属于动态加载技术,主要用于解决应用越来越庞大以及功能模块的解耦,小项目中一般用的不多。
原理: 插件化的原理其实就是在 APP 壳运行过程中,动态加载一些程序中原本不存在的可执行文件并运行这些文件中的代码逻辑。可执行文件总的来说分为两个,其一是动态链接库 so,其二是 dex 相关文件包括 jar/apk 文件。
发展历史
很早以前插件化这项技术已经有公司在研究了,淘宝,支付宝做的是比较早,但是淘宝这项技术一直都是保密的,直到 2015 年左右市面上才出现了一些关于插件化的框架,Android 插件化分为很多技术流派,实现的方式都不太一样。下面我就简单以时间线来举例几个比较有代表性的插件框架:
| 时间 | 框架名称 | 作者 | 框架简介 |
|---|---|---|---|
| 2014年底 | dynamic-load-apk | 主席任玉刚 | 动态加载技术 + 代理实现 |
| 2015年 8 月 | DroidPlugin | 360 手机助手 | 可以直接运行第三方的独立 APK 文件,完全不需要对 APK 进行修改或安装。一种新的插件机制,一种免安装的运行机制,是一个沙箱(但是不完全的沙箱。就是对于使用者来说,并不知道他会把 apk 怎么样), 是模块化的基础。 |
| 2015年底 | Small | wequick | Small 是一种实现轻巧的跨平台插件化框架,基于“轻量、透明、极小化、跨平台”的理念 |
| 2017年 6 月 | VirtualAPK | 滴滴 | VirtualAPK 对插件没有额外的约束,原生的 apk 即可作为插件。插件工程编译生成 apk 后,即可通过宿主 App 加载,每个插件 apk 被加载后,都会在宿主中创建一个单独的 LoadedPlugin 对象。通过这些 LoadedPlugin 对象,VirtualAPK 就可以管理插件并赋予插件新的意义,使其可以像手机中安装过的 App 一样运行。 |
| 2017年 7 月 | RePlgin | 360手机卫士 | RePlugin 是一套完整的、稳定的、适合全面使用的,占坑类插件化方案,由 360 手机卫士的RePlugin Team 研发,也是业内首个提出”全面插件化“(全面特性、全面兼容、全面使用)的方案。 |
| 2019 | Shadow | 腾讯 | Shadow 是一个腾讯自主研发的 Android 插件框架,经过线上亿级用户量检验。 Shadow 不仅开源分享了插件技术的关键代码,还完整的分享了上线部署所需要的所有设计(零反射) |
插件化必备知识
- Binder
- APP 打包流程
- APP 安装流程
- APP 启动流程
- 资源加载机制
- 反射,ClassLoader
- ...
实现简易版本插件化框架
今天我们这里就以动态加载技术,ClassLoader + 反射 + 代理模式 等基本技术来实现动态加载 APK 中的(Activity, Broadcast, Service ,资源)项目地址
先来看一个我们最终实现的效果
加载插件 APK
在加载 APK 之前我们先来了解下 ClassLoader 家族,继承关系图
DexClassLoader 加载流程
从上面 2 张图中,我们得知动态加载 APK 需要用到 DexClassLoader ,既然知道了用 DexClassLoader 来加载 APK , 那么native 中将 apk -> dex 解析出来,class 又怎么加载勒? 通过 DexClassLoader 流程图得知可以直接调用 loadClass(String classPath) 来加载,下面我们就正式进行今天的主题了。
代码实现加载 APK
/**
* 加载插件 APK
*/
public boolean loadPlugin(Context context, String filePath) {
if (context == null || filePath == null || filePath.isEmpty())
throw new NullPointerException("context or filePath is null ?");
this.mContext = context.getApplicationContext();
this.apkFilePath = filePath;
//拿到 包管理
packageManager = mContext.getPackageManager();
if (getPluginPackageInfo(apkFilePath) == null) {
return false;
}
//从包里获取 Activity
pluginPackageInfo = getPluginPackageInfo(apkFilePath);
//存放 DEX 路径
mDexPath = new File(Constants.IPluginPath.PlugDexPath);
if (mDexPath.exists())
mDexPath.delete();
else
mDexPath.mkdirs();
//通过 DexClassLoader 加载 apk 并通过 native 层解析 apk 输出 dex
//第二个参数可以为 null
if (getPluginClassLoader(apkFilePath, mDexPath.getAbsolutePath()) == null || getPluginResources(filePath) == null)
return false;
this.mDexClassLoader = getPluginClassLoader(apkFilePath, mDexPath.getAbsolutePath());
this.mResources = getPluginResources(filePath);
return true;
}
复制代码/**
* @return 得到对应插件 APK 的 Resource 对象
*/
public Resources getPluginResources() {
return getPluginResources(apkFilePath);
}
/**
* 得到对应插件 APK 中的 加载器
*
* @param apkFile
* @param dexPath
* @return
*/
public DexClassLoader getPluginClassLoader(String apkFile, String dexPath) {
return new DexClassLoader(apkFile, dexPath, null, mContext.getClassLoader());
}
/**
* 得到对应插件 APK 中的 加载器
*
* @return
*/
public DexClassLoader getPluginClassLoader() {
return getPluginClassLoader(apkFilePath, mDexPath.getAbsolutePath());
}
/**
* 得到插件 APK 中 包信息
*/
public PackageInfo getPluginPackageInfo(String apkFilePath) {
if (packageManager != null)
return packageManager.getPackageArchiveInfo(apkFilePath, PackageManager.GET_ACTIVITIES);
return null;
}
/**
* 得到插件 APK 中 包信息
*/
public PackageInfo getPluginPackageInfo() {
return getPluginPackageInfo(apkFilePath);
}
复制代码加载插件中 Activity
实现流程
代码实现流程
代理类 ProxyActivity 实现
public class ProxyActivity extends AppCompatActivity {
/**
* 需要加载插件的全类名
*/
protected String activityClassName;
private String TAG = this.getClass().getSimpleName();
private IActivity iActivity;
private ProxyBroadcast receiver;
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
activityClassName = getLoadClassName();
//拿到加载插件的的全类名 通过反射实例化
try {
Class<?> pluginClassName = getClassLoader().loadClass(activityClassName);
//拿到构造函数
Constructor<?> constructor = pluginClassName.getConstructor(new Class[]{});
//实例化 拿到插件 UI
Object pluginObj = constructor.newInstance(new Object[]{});
if (pluginObj != null) {
iActivity = (IActivity) pluginObj;
iActivity.onActivityCreated(this, savedInstanceState);
}
} catch (Exception e) {
Log.e(TAG, e.getMessage());
}
}
}
复制代码
重写代理类中的 startActivity
/**
* 这里的 startActivity 是插件促使调用的
*/
@Override
public void startActivity(Intent intent) {
//需要开启插件 Activity 的全类名
String className = getLoadClassName(intent);
Intent proxyIntent = new Intent(this, ProxyActivity.class);
proxyIntent.putExtra(Constants.ACTIVITY_CLASS_NAME, className);
super.startActivity(proxyIntent);
}
复制代码
插件 Activity 实现 IActivity 的生命周期并且重写一些重要函数,都交于插件中处理
public class BaseActivityImp extends AppCompatActivity implements IActivity {
private final String TAG = getClass().getSimpleName();
/**
* 代理 Activity
*/
protected Activity that;
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle bundle) {
this.that = activity;
Log.i(TAG, " onActivityCreated");
onCreate(bundle);
}
/**
* 通过 View 方式加载
*
* @param view
*/
@Override
public void setContentView(View view) {
Log.i(TAG, " setContentView --> view");
if (that != null) {
that.setContentView(view);
} else {
super.setContentView(view);
}
}
/**
* 通过 layoutID 加载
*
* @param layoutResID
*/
@Override
public void setContentView(int layoutResID) {
Log.i(TAG, " setContentView --> layoutResID");
if (that != null) {
that.setContentView(layoutResID);
} else {
super.setContentView(layoutResID);
}
}
/**
* 通过代理 去找布局 ID
*
* @param id
* @param <T>
* @return
*/
@Override
public <T extends View> T findViewById(int id) {
if (that != null)
return that.findViewById(id);
return super.findViewById(id);
}
/**
* 通过 代理去开启 Activity
*
* @param intent
*/
@Override
public void startActivity(Intent intent) {
if (that != null) {
Intent tempIntent = new Intent();
tempIntent.putExtra(Constants.ACTIVITY_CLASS_NAME, intent.getComponent().getClassName());
that.startActivity(tempIntent);
} else
super.startActivity(intent);
}
@Override
public String getPackageName() {
return that.getPackageName();
}
@Override
public void onActivityStarted(@NonNull Activity activity) {
Log.i(TAG, " onActivityStarted");
onStart();
}
@Override
public void onActivityResumed(@NonNull Activity activity) {
Log.i(TAG, " onActivityResumed");
onResume();
}
@Override
public void onActivityPaused(@NonNull Activity activity) {
Log.i(TAG, " onActivityPaused");
onPause();
}
@Override
public void onActivityStopped(@NonNull Activity activity) {
Log.i(TAG, " onActivityStopped");
onStop();
}
@Override
public void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle bundle) {
onSaveInstanceState(bundle);
Log.i(TAG, " onActivitySaveInstanceState");
}
@Override
public void onActivityDestroyed(@NonNull Activity activity) {
Log.i(TAG, " onActivityDestroyed");
onDestroy();
}
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
}
@Override
protected void onStart() {
}
@Override
protected void onResume() {
}
@Override
protected void onStop() {
}
@Override
protected void onPause() {
}
@Override
protected void onSaveInstanceState(Bundle outState) {
}
@Override
protected void onDestroy() {
}
@Override
public void onBackPressed() {
}
}
复制代码
加载插件中 Broadcast
流程图
代码实现
代理 ProxyActivity 中重写注册广播
@Override
public Intent registerReceiver(BroadcastReceiver receiver, IntentFilter filter) {
IntentFilter proxyIntentFilter = new IntentFilter();
for (int i = 0; i < filter.countActions(); i++) {
//内部是一个数组
proxyIntentFilter.addAction(filter.getAction(i));
}
//交给代理广播去注册
this.receiver = new ProxyBroadcast(receiver.getClass().getName(), this);
return super.registerReceiver(this.receiver, filter);
}
复制代码
加载插件中需要注册的广播全路径
public ProxyBroadcast(String broadcastClassName, Context context) {
this.broadcastClassName = broadcastClassName;
this.iBroadcast = iBroadcast;
//通过加载插件的 DexClassLoader loadClass
try {
Class<?> pluginBroadcastClassName = PluginManager.getInstance().getPluginClassLoader().loadClass(broadcastClassName);
Constructor<?> constructor = pluginBroadcastClassName.getConstructor(new Class[]{});
iBroadcast = (IBroadcast) constructor.newInstance(new Object[]{});
//返回给插件中广播生命周期
iBroadcast.attach(context);
} catch (Exception e) {
e.printStackTrace();
Log.e(TAG, e.getMessage());
}
}
复制代码
接收到消息返回给插件中
@Override
public void onReceive(Context context, Intent intent) {
iBroadcast.onReceive(context, intent);
}
复制代码
插件中广播注册
/**
* 动态注册广播
*/
public void register() {
//动态注册广播
IntentFilter intentFilter = new IntentFilter();
intentFilter.addAction("_DevYK");
receiver = new PluginBroadReceiver();
registerReceiver(receiver, intentFilter);
}
/**
* 通过代理去注册广播
*
* @param receiver
* @param filter
* @return
*/
@Override
public Intent registerReceiver(BroadcastReceiver receiver, IntentFilter filter) {
if (that != null) {
return that.registerReceiver(receiver, filter);
} else
return super.registerReceiver(receiver, filter);
}
复制代码
插件中实现代理广播中的生命周期并实现接收函数
public class BaseBroadReceiverImp extends BroadcastReceiver implements IBroadcast {
//代理广播中绑定成功插件广播
@Override
public void attach(Context context) {
}
//代理广播接收到数据转发给插件中
@Override
public void onReceive(Context context, Intent intent) {
}
}
复制代码
加载插件中 Service
流程图
代码实现
ProxyAcitivy 开启插件中服务
/**
* 加载插件中 启动服务
* @param service
* @return
*/
@Override
public ComponentName startService(Intent service) {
String className = getLoadServiceClassName(service);
Intent intent = new Intent(this,ProxyService.class);
intent.putExtra(Constants.SERVICE_CLASS_NAME,className);
return super.startService(intent);
}
复制代码ProxyService.java
public class ProxyService extends Service {
private IService iService;
@Override
public IBinder onBind(Intent intent) {
return iService.onBind(intent);
}
@Override
public void onCreate() {
super.onCreate();
}
@Override
public int onStartCommand(Intent intent, int flags, int startId) {
if (iService == null)
init(intent);
return iService.onStartCommand(intent, flags, startId);
}
@Override
public void onStart(Intent intent, int startId) {
super.onStart(intent, startId);
iService.onStart(intent,startId);
}
@Override
public boolean onUnbind(Intent intent) {
iService.onUnbind(intent);
return super.onUnbind(intent);
}
@Override
public void onDestroy() {
super.onDestroy();
iService.onDestroy();
}
//初始化
public void init(Intent proIntent) {
//拿到需要启动服务的全类名
String serviceClassName = getServiceClassName(proIntent);
try {
Class<?> pluginService = PluginManager.getInstance().getPluginClassLoader().loadClass(serviceClassName);
Constructor<?> constructor = pluginService.getConstructor(new Class[]{});
iService = (IService) constructor.newInstance(new Object[]{});
iService.onCreate(getApplicationContext());
} catch (Exception e) {
//加载 class
}
}
@Override
public ClassLoader getClassLoader() {
return PluginManager.getInstance().getPluginClassLoader();
}
public String getServiceClassName(Intent intent) {
return intent.getStringExtra(Constants.SERVICE_CLASS_NAME);
}
}
复制代码
插件服务实现 IService
public class BaseServiceImp extends Service implements IService {
...
}
复制代码
插件中重写 startService 交于代理中处理
/**
* 加载插件中服务,交于代理处理
* @param service
* @return
*/
@Override
public ComponentName startService(Intent service) {
String className = getLoadServiceClassName(service);
Intent intent = new Intent(this,ProxyService.class);
intent.putExtra(Constants.SERVICE_CLASS_NAME,className);
return super.startService(intent);
}
复制代码
总结
动态加载 Activity, Broadcast , Service 其实基本原理就是将插件中需要启动四大组件的信息告诉代理类中,让代理类来负责处理插件中的逻辑,代理类中处理完之后通过 IActivity, IBroadcast, IService 来通知插件。
动态加载插件我们这篇文章就讲到这里了,感兴趣的可以参考项目地址 ,这个实现方案不适合线上商业项目,使用需谨慎。如果项目中只用到了插件中的生命周期可以选择性的使用。
感谢阅览本篇文章,谢谢!
参考文章
作者:DevYK
链接:https://juejin.cn/post/6844903924000882695
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
移动架构 (六) 轻量级进程间通信框架设计
移动架构 (二) Android 中 Handler 架构分析,并实现自己简易版本 Handler 框架
移动架构 (四) EventBus 3.1.1 源码分析及实现自己的轻量级 EventBus 框架,根据 TAG 发送接收事件。
移动架构 (五) 仅仅对 Java Bean 的操作,就能完成对数据持久化
概述
现在多进程传递数据使用越来越广泛了,在 Android 中进程间通信提供了 文件 、AIDL 、Binder 、Messenger 、ContentProvider 、Socket 、MemoryFile 等,实际开发中使用最多的应该是 AIDL ,但是 AIDL 需要编写 aidl 文件,如果使用 AIDL 仅仅是为了传递数据, 那么 YKProBus 是你不错的选择。
YKProBus
怎么使用?
1. root/build.gradle 中添加框架 maven
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
复制代码2. app/build.gradle 中添加框架 依赖
dependencies {
implementation 'com.github.yangkun19921001:YKProBus:1.0.1'
}
复制代码3. 发送进程绑定接收进程服务
EventManager.getInstance().bindApplication(Context context,String proName);
复制代码4. 发送消息
EventManager.getInstance().sendMessage(int messageTag,Bundle bundle);
复制代码5. 接收进程中需要在清单文件注册服务
<service
android:name="com.devyk.component_eventbus.proevent.service.MessengerService"
android:enabled="true"
android:exported="true">
<intent-filter>
<action android:name="com.devyk.component_eventbus.service"></action>
<category android:name="android.intent.category.DEFAULT" />
</intent-filter>
</service>
复制代码6. 接收消息
6.1 在需要接收消息的类中实现 IMessageHandler 并实例化一个 Handler 用于接收发送进程发来的消息
public class MainActivity extends Activity implements IMessageHandler{
...
/**
* 接收其它进程发送过来的消息
*
* @return
*/
@Override
public Handler getHandler() {
return new Handler() {
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
switch (msg.what) {
case 0x001:
...
break;
}
}
};
}
...
}
复制代码6.2 注册当前类需要接收消息
EventManager.getInstance().registerMessager(int messageTag, Object obj);
复制代码框架设计大概流程
Messenger 源码分析
Messenger 内部其实也是依赖 aidl 实现的进程间通信。
服务端
@Override
public IBinder onBind(Intent intent) {
return mServiceMessenger.getServiceMessenger().getBinder();
}
复制代码getBinder() 跟进去
public IBinder getBinder() {
return mTarget.asBinder();
}
复制代码mTarget 从何而来,从源码找找
public Messenger(Handler target) {
mTarget = target.getIMessenger();
}
复制代码这里是我们实例化 服务端 Messenger 传入的 Handler target
/**
* 初始化服务端 Messenger
*/
public MessengerManager() {
if (null == mServiceMessenger)
mServiceMessenger = new Messenger(mMessengerServiceHandler);
}
复制代码那么我们在点击 getIMessenger() 在看看内部实现
final IMessenger getIMessenger() {
synchronized (mQueue) {
if (mMessenger != null) {
return mMessenger;
}
mMessenger = new MessengerImpl();
return mMessenger;
}
}
复制代码继续点击 MessengerImple
private final class MessengerImpl extends IMessenger.Stub {
public void send(Message msg) {
msg.sendingUid = Binder.getCallingUid();
Handler.this.sendMessage(msg);
}
}
复制代码这个是一个内部实现的类,可以看到继承的是 IMessenger.Stub 然后实现 send (Message msg) 函数,然后通过 mTarget.sendMessage(msg) 发送消息,最后在我们传入进去的 mMessengerServiceHandler 的 handleMessage (Message) 接收发来的消息。
既然这里内部帮我们写了 aidl 文件 ,并且也继承了 IMessenger.Stub 我们今天就要看到 aidl 才死心 , 好吧我们来找找 IMessenger aidl 文件。
可以看到是在 framework/base/core/java/android/os 路径中,我们点击在来看下文件中怎么写的
内部就一个 send 函数,看到这,大家应该都明白了,Messenger 其实也没什么大不了,就是系统内部帮我们写了 aidl 并且也实现了 aidl ,最后又帮我们做了一个 Handler 线程间通信,所以服务端收到了客服端发来的消息。
客服端
客服端需要在 bindServicer onServiceConnected 回调中拿到 servicer, 平时我们自己写 应该是这么拿到 Ibinder 对象吧
IMessenger mServiceMessenger = IMessenger.Stub.asInterface(service);
复制代码但是我们实际客服端是这样拿到服务端的 Messenger
/**
* 服务端消息是否连接成功
*/
private class EventServiceConnection implements ServiceConnection {
@Override
public void onServiceConnected(ComponentName name, IBinder service) {
isBindApplication = true;
// 得到服务信使对象
mServiceMessenger = new Messenger(service);
//将本地信使告诉服务端
registerMessenger();
String proName = ProcessUtils.getProName(mApplicationContext);
Log.d(TAG, " EventServiceConnection " + proName);
}
@Override
public void onServiceDisconnected(ComponentName name) {
isBindApplication = false;
}
}
复制代码// 得到服务信使对象
mServiceMessenger = new Messenger(service);
复制代码跟进去
public Messenger(IBinder target) {
mTarget = IMessenger.Stub.asInterface(target);
}
复制代码这不就是我们刚刚说的自己实现的那种写法吧,到这里我们都懂了吧,我们平时写的 aidl android 中已经帮我们写了,想当于在 aidl 中封装下就变成了现在的 Messenger , 而我们又在 Messenger 上封装了下,想当于 三次封装了,为了使用更简单。封装才是王道!
总结
我们自己的 YKProBus 为了进程间通信使用更简单方便,其实相当于在 AIDL 中的三次封装。想要了解的可以去看下我具体的封装或者 Messenger 源码。
感谢大家抽空阅览文章,谢谢!
作者:DevYK
链接:https://juejin.cn/post/6844903910587498510
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
iOS使用RunLoop监控线上卡顿
通过iOS性能优化 我们知道,简单来说App卡顿,就是FPS达不到60帧率,丢帧现象,就会卡顿。但是很多时候,我们只知道丢帧了。具体为什么丢帧,却不是很清楚,那么我们要怎么监控呢,首先我们要明白,要找出卡顿,就是要找出主线程做了什么,而线程消息,是依赖RunLoop的,所以我们可以使用RunLoop来监控。
RunLoop是用来监听输入源,进行调度处理的。如果RunLoop的线程进入睡眠前方法的执行时间过长而导致无法进入睡眠,或者线程唤醒后接收消息时间过长而无法进入下一步,就可以认为是线程受阻了。如果这个线程是主线程的话,表现出来的就是出现了卡顿。
RunLoop和信号量
我们可以使用CFRunLoopObserverRef来监控NSRunLoop的状态,通过它可以实时获得这些状态值的变化。
runloop
关于runloop,可以参照 RunLoop详解之源码分析 这篇文章详细了解。这里简单总结一下:
runloop的状态
/* Run Loop Observer Activities */
typedef CF_OPTIONS(CFOptionFlags, CFRunLoopActivity) {
kCFRunLoopEntry = (1UL << 0), // 即将进入Loop
kCFRunLoopBeforeTimers = (1UL << 1), //即将处理Timer
kCFRunLoopBeforeSources = (1UL << 2), //即将处理Source
kCFRunLoopBeforeWaiting = (1UL << 5), //即将进入休眠
kCFRunLoopAfterWaiting = (1UL << 6), //刚从休眠中唤醒
kCFRunLoopExit = (1UL << 7), //即将退出Loop
kCFRunLoopAllActivities = 0x0FFFFFFFU //所有状态改变
};CFRunLoopObserverRef 的使用流程
设置Runloop observer的运行环境
CFRunLoopObserverContext context = {0, (__bridge void *)self, NULL, NULL};2. 创建Runloop observer对象
第一个参数:用于分配observer对象的内存
第二个参数:用以设置observer所要关注的事件
第三个参数:用于标识该observer是在第一次进入runloop时执行还是每次进入runloop处理时均执行
第四个参数:用于设置该observer的优先级
第五个参数:用于设置该observer的回调函数
第六个参数:用于设置该observer的运行环境
// 创建Runloop observer对象
_observer = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
0,
&runLoopObserverCallBack,
&context);
3. 将新建的observer加入到当前thread的runloop
CFRunLoopAddObserver(CFRunLoopGetMain(), _observer, kCFRunLoopCommonModes);
4. 将observer从当前thread的runloop中移除
CFRunLoopRemoveObserver(CFRunLoopGetMain(), _observer, kCFRunLoopCommonModes);
5. 释放 observer
CFRelease(_observer); _observer = NULL;信号量
关于信号量,可以详细参考 GCD信号量-dispatch_semaphore_t
简单来说,主要有三个函数
dispatch_semaphore_create(long value); // 创建信号量
dispatch_semaphore_signal(dispatch_semaphore_t deem); // 发送信号量
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout); // 等待信号量dispatch_semaphore_create(long value);和GCD的group等用法一致,这个函数是创建一个dispatch_semaphore_类型的信号量,并且创建的时候需要指定信号量的大小。
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout); 等待信号量。如果信号量值为0,那么该函数就会一直等待,也就是不返回(相当于阻塞当前线程),直到该函数等待的信号量的值大于等于1,该函数会对信号量的值进行减1操作,然后返回。
dispatch_semaphore_signal(dispatch_semaphore_t deem); 发送信号量。该函数会对信号量的值进行加1操作。
通常等待信号量和发送信号量的函数是成对出现的。并发执行任务时候,在当前任务执行之前,用dispatch_semaphore_wait函数进行等待(阻塞),直到上一个任务执行完毕后且通过dispatch_semaphore_signal函数发送信号量(使信号量的值加1),dispatch_semaphore_wait函数收到信号量之后判断信号量的值大于等于1,会再对信号量的值减1,然后当前任务可以执行,执行完毕当前任务后,再通过dispatch_semaphore_signal函数发送信号量(使信号量的值加1),通知执行下一个任务……如此一来,通过信号量,就达到了并发队列中的任务同步执行的要求。
监控卡顿
原理: 利用观察Runloop各种状态变化的持续时间来检测计算是否发生卡顿
一次有效卡顿采用了“N次卡顿超过阈值T”的判定策略,即一个时间段内卡顿的次数累计大于N时才触发采集和上报:举例,卡顿阈值T=500ms、卡顿次数N=1,可以判定为单次耗时较长的一次有效卡顿;而卡顿阈值T=50ms、卡顿次数N=5,可以判定为频次较快的一次有效卡顿
主要代码
// minimum
static const NSInteger MXRMonitorRunloopMinOneStandstillMillisecond = 20;
static const NSInteger MXRMonitorRunloopMinStandstillCount = 1;
// default
// 超过多少毫秒为一次卡顿
static const NSInteger MXRMonitorRunloopOneStandstillMillisecond = 50;
// 多少次卡顿纪录为一次有效卡顿
static const NSInteger MXRMonitorRunloopStandstillCount = 1;
@interface YZMonitorRunloop(){
CFRunLoopObserverRef _observer; // 观察者
dispatch_semaphore_t _semaphore; // 信号量
CFRunLoopActivity _activity; // 状态
}
@property (nonatomic, assign) BOOL isCancel; //f是否取消检测
@property (nonatomic, assign) NSInteger countTime; // 耗时次数
@property (nonatomic, strong) NSMutableArray *backtrace;-(void)registerObserver{
// 1. 设置Runloop observer的运行环境
CFRunLoopObserverContext context = {0, (__bridge void *)self, NULL, NULL};
// 2. 创建Runloop observer对象
// 第一个参数:用于分配observer对象的内存
// 第二个参数:用以设置observer所要关注的事件
// 第三个参数:用于标识该observer是在第一次进入runloop时执行还是每次进入runloop处理时均执行
// 第四个参数:用于设置该observer的优先级
// 第五个参数:用于设置该observer的回调函数
// 第六个参数:用于设置该observer的运行环境
_observer = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
0,
&runLoopObserverCallBack,
&context);
// 3. 将新建的observer加入到当前thread的runloop
CFRunLoopAddObserver(CFRunLoopGetMain(), _observer, kCFRunLoopCommonModes);
// 创建信号 dispatchSemaphore的知识参考:https://www.jianshu.com/p/24ffa819379c
_semaphore = dispatch_semaphore_create(0); ////Dispatch Semaphore保证同步
__weak __typeof(self) weakSelf = self;
// dispatch_queue_t queue = dispatch_queue_create("kadun", NULL);
// 在子线程监控时长
dispatch_async(dispatch_get_global_queue(0, 0), ^{
// dispatch_async(queue, ^{
__strong __typeof(weakSelf) strongSelf = weakSelf;
if (!strongSelf) {
return;
}
while (YES) {
if (strongSelf.isCancel) {
return;
}
// N次卡顿超过阈值T记录为一次卡顿
// 等待信号量:如果信号量是0,则阻塞当前线程;如果信号量大于0,则此函数会把信号量-1,继续执行线程。此处超时时间设为limitMillisecond 毫秒。
// 返回值:如果线程是唤醒的,则返回非0,否则返回0
long semaphoreWait = dispatch_semaphore_wait(self->_semaphore, dispatch_time(DISPATCH_TIME_NOW, strongSelf.limitMillisecond * NSEC_PER_MSEC));
if (semaphoreWait != 0) {
// 如果 RunLoop 的线程,进入睡眠前方法的执行时间过长而导致无法进入睡眠(kCFRunLoopBeforeSources),或者线程唤醒后接收消息时间过长(kCFRunLoopAfterWaiting)而无法进入下一步的话,就可以认为是线程受阻。
//两个runloop的状态,BeforeSources和AfterWaiting这两个状态区间时间能够监测到是否卡顿
if (self->_activity == kCFRunLoopBeforeSources || self->_activity == kCFRunLoopAfterWaiting) {
if (++strongSelf.countTime < strongSelf.standstillCount){
NSLog(@"%ld",strongSelf.countTime);
continue;
}
[strongSelf logStack];
[strongSelf printLogTrace];
NSString *backtrace = [YZCallStack yz_backtraceOfMainThread];
NSLog(@"++++%@",backtrace);
[[YZLogFile sharedInstance] writefile:backtrace];
if (strongSelf.callbackWhenStandStill) {
strongSelf.callbackWhenStandStill();
}
}
}
strongSelf.countTime = 0;
}
});
}demo测试
我把demo放在了github demo地址
使用时候,只需要
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
// Override point for customization after application launch.
[[YZMonitorRunloop sharedInstance] startMonitor];
[YZMonitorRunloop sharedInstance].callbackWhenStandStill = ^{
NSLog(@"eagle.检测到卡顿了");
};
return YES;
}控制器中,每次点击屏幕,休眠1秒钟,如下
#import "ViewController.h"
@interface ViewController ()
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event{
usleep(1 * 1000 * 1000); // 1秒
}
@end点击屏幕之后,打印如下
YZMonitorRunLoopDemo[10288:1915706] ==========检测到卡顿之后调用堆栈==========
(
"0 YZMonitorRunLoopDemo 0x00000001022c653c -[YZMonitorRunloop logStack] + 96",
"1 YZMonitorRunLoopDemo 0x00000001022c62a0 __36-[YZMonitorRunloop registerObserver]_block_invoke + 484",
"2 libdispatch.dylib 0x00000001026ab6f0 _dispatch_call_block_and_release + 24",
"3 libdispatch.dylib 0x00000001026acc74 _dispatch_client_callout + 16",
"4 libdispatch.dylib 0x00000001026afad4 _dispatch_queue_override_invoke + 876",
"5 libdispatch.dylib 0x00000001026bddc8 _dispatch_root_queue_drain + 372",
"6 libdispatch.dylib 0x00000001026be7ac _dispatch_worker_thread2 + 156",
"7 libsystem_pthread.dylib 0x00000001b534d1b4 _pthread_wqthread + 464",
"8 libsystem_pthread.dylib 0x00000001b534fcd4 start_wqthread + 4"
)
libsystem_kernel.dylib 0x1b52ca400 __semwait_signal + 8
libsystem_c.dylib 0x1b524156c nanosleep + 212
libsystem_c.dylib 0x1b5241444 usleep + 64
YZMonitorRunLoopDemo 0x1022c18dc -[ViewController touchesBegan:withEvent:] + 76
UIKitCore 0x1e1f4fcdc <redacted> + 336
UIKitCore 0x1e1f4fb78 <redacted> + 60
UIKitCore 0x1e1f5e0f8 <redacted> + 1584
UIKitCore 0x1e1f5f52c <redacted> + 3140
UIKitCore 0x1e1f3f59c <redacted> + 340
UIKitCore 0x1e2005714 <redacted> + 1768
UIKitCore 0x1e2007e40 <redacted> + 4828
UIKitCore 0x1e2001070 <redacted> + 152
CoreFoundation 0x1b56bf018 <redacted> + 24
CoreFoundation 0x1b56bef98 <redacted> + 88
CoreFoundation 0x1b56be880 <redacted> + 176
CoreFoundation 0x1b56b97即可定位到卡顿位置
-[ViewController touchesBegan:withEvent:]
卡顿日志写入本地
上面已经监控到了卡顿,和调用堆栈。如果是debug模式下,可以直接看日志,如果想在线上查看的话,可以写入本地,然后上传到服务器
写入本地数据库
创建本地路径
-(NSString *)getLogPath{
NSArray *paths = NSSearchPathForDirectoriesInDomains(NSCachesDirectory,NSUserDomainMask,YES);
NSString *homePath = [paths objectAtIndex:0];
NSString *filePath = [homePath stringByAppendingPathComponent:@"Caton.log"];
return filePath;
}如果是第一次写入,带上设备信息,手机型号等信息
NSString *filePath = [self getLogPath];
NSFileManager *fileManager = [NSFileManager defaultManager];
if(![fileManager fileExistsAtPath:filePath]) //如果不存在
{
NSString *str = @"卡顿日志";
NSString *systemVersion = [NSString stringWithFormat:@"手机版本: %@",[YZAppInfoUtil iphoneSystemVersion]];
NSString *iphoneType = [NSString stringWithFormat:@"手机型号: %@",[YZAppInfoUtil iphoneType]];
str = [NSString stringWithFormat:@"%@\n%@\n%@",str,systemVersion,iphoneType];
[str writeToFile:filePath atomically:YES encoding:NSUTF8StringEncoding error:nil];
}如果本地文件已经存在,就先判断大小是否过大,决定是否直接写入,还是先上传到服务器
float filesize = -1.0;
if ([fileManager fileExistsAtPath:filePath]) {
NSDictionary *fileDic = [fileManager attributesOfItemAtPath:filePath error:nil];
unsigned long long size = [[fileDic objectForKey:NSFileSize] longLongValue];
filesize = 1.0 * size / 1024;
}
NSLog(@"文件大小 filesize = %lf",filesize);
NSLog(@"文件内容 %@",string);
NSLog(@" ---------------------------------");
if (filesize > (self.MAXFileLength > 0 ? self.MAXFileLength:DefaultMAXLogFileLength)) {
// 上传到服务器
NSLog(@" 上传到服务器");
[self update];
[self clearLocalLogFile];
[self writeToLocalLogFilePath:filePath contentStr:string];
}else{
NSLog(@"继续写入本地");
[self writeToLocalLogFilePath:filePath contentStr:string];
}压缩日志,上传服务器
因为都是文本数据,所以我们可以压缩之后,打打降低占用空间,然后进行上传,上传成功之后,删除本地,然后继续写入,等待下次写日志
压缩工具
使用 SSZipArchive具体使用起来也很简单,
// Unzipping
NSString *zipPath = @"path_to_your_zip_file";
NSString *destinationPath = @"path_to_the_folder_where_you_want_it_unzipped";
[SSZipArchive unzipFileAtPath:zipPath toDestination:destinationPath];
// Zipping
NSString *zippedPath = @"path_where_you_want_the_file_created";
NSArray *inputPaths = [NSArray arrayWithObjects:
[[NSBundle mainBundle] pathForResource:@"photo1" ofType:@"jpg"],
[[NSBundle mainBundle] pathForResource:@"photo2" ofType:@"jpg"]
nil];
[SSZipArchive createZipFileAtPath:zippedPath withFilesAtPaths:inputPaths];代码中
NSString *zipPath = [self getLogZipPath];
NSString *password = nil;
NSMutableArray *filePaths = [[NSMutableArray alloc] init];
[filePaths addObject:[self getLogPath]];
BOOL success = [SSZipArchive createZipFileAtPath:zipPath withFilesAtPaths:filePaths withPassword:password.length > 0 ? password : nil];
if (success) {
NSLog(@"压缩成功");
}else{
NSLog(@"压缩失败");
}具体如果上传到服务器,使用者可以用AFN等将本地的 zip文件上传到文件服务器即可,就不赘述了。
至此,我们做到了,用runloop,监控卡顿,写入日志,然后压缩上传服务器,删除本地的过程。
详细代码见demo地址
转自:https://www.jianshu.com/p/05ae5ff5a9c1
移动架构 (五) 仅仅对 Java Bean 的操作,就能完成对数据持久化
移动架构 (二) Android 中 Handler 架构分析,并实现自己简易版本 Handler 框架
移动架构 (四) EventBus 3.1.1 源码分析及实现自己的轻量级 EventBus 框架,根据 TAG 发送接收事件。
前言
GitHub 上面开源了多个 Android 数据库,比如 GreenDao , LitePal , ORMLite 等,开源的数据库一般都是使用非常简单,不用开发者写 SQL,创建 table 等一些繁琐的操作,都是基于对对象的一些操作。那么我们自己可以设计一款不用自己来写 SQL 的轻量级数据库吗?当然可以,下面我们就来开干。
使用
给一个 Object 对象定义协定好的注解 table ,id
@YKTable("tb_police")
public class Police {
/**
* 人员 id
*/
@YKField("_id")
private String id;
/**
* 人员姓名
*/
private String name;
public Police(String id, String name) {
this.id = id;
this.name = name;
}
public Police() {
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Police{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
'}';
}
}
复制代码
插入数据
BaseDaoFactory.getOurInstance().getBaseDao(Police.class).insert(new Police("01", "DevYK"));
复制代码
删除数据
BaseDaoFactory.getOurInstance().getBaseDao(Police.class).delete(new Police("01", "DevYK"));
复制代码
更新数据
BaseDaoFactory.getOurInstance().getBaseDao(Police.class).updata(new Police("02", "BaseDevYK"), new Police("01", "DevYK"));
复制代码
查询数据
BaseDaoImp<Police> mBaseDao BaseDaoFactory.getOurInstance().getBaseDao(Police.class);
Police police = new Police();
police.setId("02");
List<Police> policeLists = mBaseDao.query(police);
复制代码
到这里,增删改查咱们都已经操作完了,使用是不是非常的简单,不用使用者写一行 SQL 语句,基本上一行代码解决,下面我们来看看源码实现,它到底做了些什么?
自动创建 table
流程
创建表核心代码
/**
* 初始化
*
* @param sqLiteDatabase
* @param entityClass
*/
public void init(SQLiteDatabase sqLiteDatabase, Class<T> entityClass) {
this.mSQLiteDatabase = sqLiteDatabase;
this.mEntityClass = entityClass;
if (!isInit) {
//自动建表,取得表名
if (entityClass != null && (entityClass.getAnnotation(YKTable.class) == null)) {
//通过反射得到类名
this.mTableName = entityClass.getSimpleName();
} else {
if (TextUtils.isEmpty(entityClass.getAnnotation(YKTable.class).value())) {
//如果有注解但是注解为空的话,就取当前 类名
this.mTableName = entityClass.getSimpleName();
} else {
//取得注解上面的表名
this.mTableName = entityClass.getAnnotation(YKTable.class).value();
}
}
//执行创建表的操作, 使用 getCreateTabeSql () 生成 sql 语句
String autoCreateTabSql = getCreateTableSql();
Log.i(TAG, "tagSQL-->" + autoCreateTabSql);
//执行创建表的 SQL
this.mSQLiteDatabase.execSQL(autoCreateTabSql);
mCacheMap = new HashMap<>();
initCacheMap();
isInit = true;
}
}
复制代码insert 插入数据
流程
插入核心代码
/**
* 插入数据
* @param entity
* @return
*/
@Override
public long insert(T entity) {
//1. 准备好 ContentValues 中需要的数据
Map<String, String> map = getValues(entity);
if (map == null || map.size() == 0) return 0;
//2. 把数据转移到 ContentValues 中
ContentValues values = getContentValues(map);
//将数据插入表中
return mSQLiteDatabase.insert(mTableName, null, values);
}
复制代码- 首先接收外部传入的数据对象。
- 对数据对象进行解析,拿到数据库表中对应字段的值,拿到之后将字段 key,对应的值 values 存入 map。
- 将 map 解析为 ContentValues。
- 进行数据库插入 mSQLiteDatabase.insert。
delete 删除数据
流程图
核心代码流程
拿到对应字段的值
/**
* key(字段) - values(成员变量) ---》getValues 后 ---》key (成员变量的名字) ---values 成员变量的值 id 1,name alan , password 123
*
* @param entity
* @return
*/
private Map<String, String> getValues(T entity) {
HashMap<String, String> map = new HashMap<>();
//返回所有的成员变量
Iterator<Field> iterator = mCacheMap.values().iterator();
while (iterator.hasNext()) {
Field field = iterator.next();
field.setAccessible(true);
try {
Object object = field.get(entity);
if (object == null) {
continue;
}
String values = object.toString();
String key = "";
if (field.getAnnotation(YKField.class) != null) {
key = field.getAnnotation(YKField.class).value();
} else {
key = field.getName();
}
if (!TextUtils.isEmpty(key) && !TextUtils.isEmpty(values)) {
map.put(key, values);
}
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
return map;
}
复制代码
将拿到要删除的 key,values 字段对应的值,自动生成 SQL
public Condition(Map<String,String> whereCasue) {
//whereArgs 里面的内容存入的 list
ArrayList list = new ArrayList();
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("1=1");
//取得所有成员变量的名字
Set<String> keys = whereCasue.keySet();
Iterator<String> iterator = keys.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
String value = whereCasue.get(key);
if (value != null){
stringBuffer.append(" and " + key + "=?");
list.add(value);
}
}
this.whereClause = stringBuffer.toString();
this.whereArgs = (String[]) list.toArray(new String[list.size()]);
}
复制代码
根据生成的 SQL 条件删除数据
int delete = mSQLiteDatabase.delete(mTableName, condition.getWhereClause(), condition.getWhereArgs());
复制代码
query 查询数据
流程图
核心代码流程
拿到查询的条件的对象,转为 key,values 的 map 对象
Map<String, String> values = getValues(where);
private Map<String, String> getValues(T entity) {
HashMap<String, String> map = new HashMap<>();
//返回所有的成员变量
Iterator<Field> iterator = mCacheMap.values().iterator();
while (iterator.hasNext()) {
//拿到成员变量
Field field = iterator.next();
//设置可操作的权限
field.setAccessible(true);
try {
//拿到成员变量对应的值 values
Object object = field.get(entity);
if (object == null) {
continue;
}
String values = object.toString();
String key = "";
//如果成员变量上声明了注解,直接拿到该值 key,反之反射拿
if (field.getAnnotation(YKField.class) != null) {
key = field.getAnnotation(YKField.class).value();
} else {
key = field.getName();
}
//将类中拿到的 key values 存入 map 中
if (!TextUtils.isEmpty(key) && !TextUtils.isEmpty(values)) {
map.put(key, values);
}
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
return map;
}
复制代码
将 map 转为自动生成 SQL 对象
public Condition(Map<String,String> whereCasue) {
//whereArgs 里面的内容存入的 list
ArrayList list = new ArrayList();
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("1=1");
//取得所有成员变量的名字
Set<String> keys = whereCasue.keySet();
Iterator<String> iterator = keys.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
String value = whereCasue.get(key);
if (value != null){
//查询的条件 sql
stringBuffer.append(" and " + key + "=?");
//查询的条件对应的 值
list.add(value);
}
}
this.whereClause = stringBuffer.toString();
this.whereArgs = (String[]) list.toArray(new String[list.size()]);
}
复制代码
查询数据,并遍历 Cursor 取出数据
Cursor cursor = mSQLiteDatabase.query(mTableName,null,condition.getWhereClause(), condition.getWhereArgs(), null, limitString, orderBy);
List<T> result = getResult(cursor, where);
复制代码
update 更新数据
流程图
核心代码流程
拿到需要更新的值,转为 map
Map<String, String> values = getValues(entity);
复制代码
将需要更新的 map 转为 ContentValues
ContentValues contentValues = getContentValues(values);
复制代码
将条件转为 map
//条件
Map<String, String> whereMp = getValues(where);
复制代码
将条件 map 转为 sql
public Condition(Map<String,String> whereCasue) {
//whereArgs 里面的内容存入的 list
ArrayList list = new ArrayList();
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("1=1");
//取得所有成员变量的名字
Set<String> keys = whereCasue.keySet();
Iterator<String> iterator = keys.iterator();
while (iterator.hasNext()) {
String key = iterator.next();
String value = whereCasue.get(key);
if (value != null){
//查询的条件 sql
stringBuffer.append(" and " + key + "=?");
//查询的条件对应的 值
list.add(value);
}
}
this.whereClause = stringBuffer.toString();
this.whereArgs = (String[]) list.toArray(new String[list.size()]);
}
复制代码
总结
通过上面的步骤,我们不编写 SQL ,完全是依赖数据对象来做操作,对 SQL 不太熟悉的很友好。对于那些开源框架为什么可以自动建表,不用填写 SQL ,仅仅通过数据 Bean 就能操作数据库的好奇,在没有了解它们内部实现的原理下,看看自己能不能实现,结果也没那么难嘛。但是实际项目还是建议在了解内部实现原理的情况下使用开源框架。在这里推荐下 郭霖大神的 LitePal 框架非常稳定,使用非常简单,易上手。
如果对上面源码感兴趣的可以去我的代码仓库YKDB详细了解。
作者:DevYK
链接:https://juejin.cn/post/6844903907613753351
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
收起阅读 »
移动架构 (四) EventBus 3.1.1 源码分析及实现自己的轻量级 EventBus 框架,根据 TAG 发送接收事件。
移动架构 (一) 架构第一步,学会画各种 UML 图
移动架构 (二) Android 中 Handler 架构分析,并实现自己简易版本 Handler 框架
EventBus 我相信大家不会很默认,应该也都在项目中使用过,虽然 EventBus 在项目中不便于管理,发射出去的消息不便于跟踪或者阅读,但是不可否认它是一个优秀的开源项目,还是值得我们大家学习的,我个人感觉唯一不足的就是 EventBus 功能上不能根据 TAG 来进行发射和接收消息,只能通过注解 + 消息类型进行找消息。那么我们自己可以实现这个功能吗?不可否认,当然可以! 想要实现这个功能,我们先大概简要的了解下 EventBus 使用及源码是怎么实现的。
EventBus 简单使用
EventBus 可以代替 Android 传统的 Intent, Handler, Broadcast 或接口函数, 在 Fragment, Activity, Service 线程间进行数据传递。
添加 EventBus 到项目中
implementation 'org.greenrobot:eventbus:3.1.1'
复制代码register
EventBus.getDefault().register(this);
复制代码注解实现接收的 Event
@Subscribe(threadMode = ThreadMode.MAIN)
public void receive(String event){
Log.d(TAG,"接收到 EventBus post message:" + event);
}
复制代码发射数据
EventBus.getDefault().post("发射一个测试消息");
复制代码注销注册的事件
EventBus.getDefault().unregister(this);
复制代码这里就简单介绍下 EventBus 使用,想详细了解的可以看 EventBus GitHub
EventBus 3.1.1 源码分析
上面小节咱们学习了 EventBus 的简单使用,那么我们就根据上面使用到的来进行源码分析。
register
流程图:
register 代码:
/**
*
*EventBus register
*/
public void register(Object subscriber) {
//1. 拿到当前注册 class
Class<?> subscriberClass = subscriber.getClass();
//2. 查找当前 class 类中所有订阅者的方法
List<SubscriberMethod> subscriberMethods = subscriberMethodFinder.findSubscriberMethods(subscriberClass);
synchronized (this) {
for (SubscriberMethod subscriberMethod : subscriberMethods) {
//3.
subscribe(subscriber, subscriberMethod);
}
}
}
复制代码subscribe(x,x)代码:
//必须加锁调用
private void subscribe(Object subscriber, SubscriberMethod subscriberMethod) {
//拿到订阅者参数类型
Class<?> eventType = subscriberMethod.eventType;
Subscription newSubscription = new Subscription(subscriber, subscriberMethod);
//根据参数类型,拿到当前所有订阅者
CopyOnWriteArrayList<Subscription> subscriptions = subscriptionsByEventType.get(eventType);
//4. 如果没有拿到,则存进去缓存中
if (subscriptions == null) {
subscriptions = new CopyOnWriteArrayList<>();
subscriptionsByEventType.put(eventType, subscriptions);
} else {
//如果已经存在相同类型的注册事件,就抛出异常
if (subscriptions.contains(newSubscription)) {
throw new EventBusException("Subscriber " + subscriber.getClass() + " already registered to event "
+ eventType);
}
}
......
}
复制代码
拿到当前传入进来的 this 对象。
查找当前 this 类中所有订阅的函数。
subscriptionsByEventType 完成数据初始化。
subscriptionsByEventType = new HashMap();
复制代码// 参考上图注释 4 ,根据参数类型存储订阅者和订阅方法
post
流程图:
代码
/** 发送事件*/
public void post(Object event) {
//在当前线程中取出变量数据
PostingThreadState postingState = currentPostingThreadState.get();
//将需要发送的数据添加进当前线程的队列中
List<Object> eventQueue = postingState.eventQueue;
eventQueue.add(event);
if (!postingState.isPosting) {
postingState.isMainThread = isMainThread();
postingState.isPosting = true;
if (postingState.canceled) {
throw new EventBusException("Internal error. Abort state was not reset");
}
try {
while (!eventQueue.isEmpty()) {
//开启取出数据
postSingleEvent(eventQueue.remove(0), postingState);
}
} finally {
postingState.isPosting = false;
postingState.isMainThread = false;
}
}
}
复制代码 private void postSingleEvent(Object event, PostingThreadState postingState) throws Error {
Class<?> eventClass = event.getClass();
boolean subscriptionFound = false;
if (eventInheritance) {
//查找所有的事件类型
List<Class<?>> eventTypes = lookupAllEventTypes(eventClass);
int countTypes = eventTypes.size();
for (int h = 0; h < countTypes; h++) {
Class<?> clazz = eventTypes.get(h);
subscriptionFound |= postSingleEventForEventType(event, postingState, clazz);
}
} else {
//发送事件
subscriptionFound = postSingleEventForEventType(event, postingState, eventClass);
}
if (!subscriptionFound) {
if (logNoSubscriberMessages) {
logger.log(Level.FINE, "No subscribers registered for event " + eventClass);
}
if (sendNoSubscriberEvent && eventClass != NoSubscriberEvent.class &&
eventClass != SubscriberExceptionEvent.class) {
post(new NoSubscriberEvent(this, event));
}
}
}
复制代码 private boolean postSingleEventForEventType(Object event, PostingThreadState postingState, Class<?> eventClass) {
CopyOnWriteArrayList<Subscription> subscriptions;
synchronized (this) {
//这里的容器就是 register 的时候添加进行去的,现在拿出来
subscriptions = subscriptionsByEventType.get(eventClass);
}
if (subscriptions != null && !subscriptions.isEmpty()) {
for (Subscription subscription : subscriptions) {
postingState.event = event;
postingState.subscription = subscription;
boolean aborted = false;
try {
//发送到订阅者哪里去
postToSubscription(subscription, event, postingState.isMainThread);
aborted = postingState.canceled;
} finally {
postingState.event = null;
postingState.subscription = null;
postingState.canceled = false;
}
if (aborted) {
break;
}
}
return true;
}
return false;
}
复制代码 private void postToSubscription(Subscription subscription, Object event, boolean isMainThread) {
//根据订阅者 threadMode 来进行发送
switch (subscription.subscriberMethod.threadMode) {
case POSTING:
//通过反射发送
invokeSubscriber(subscription, event);
break;
case MAIN:
//如果是主线程直接在当前线程发送
if (isMainThread) {
invokeSubscriber(subscription, event);
} else {
//开启一个子线程发送
mainThreadPoster.enqueue(subscription, event);
}
break;
case MAIN_ORDERED:
if (mainThreadPoster != null) {
mainThreadPoster.enqueue(subscription, event);
} else {
// temporary: technically not correct as poster not decoupled from subscriber
invokeSubscriber(subscription, event);
}
break;
case BACKGROUND:
if (isMainThread) {
backgroundPoster.enqueue(subscription, event);
} else {
invokeSubscriber(subscription, event);
}
break;
case ASYNC:
asyncPoster.enqueue(subscription, event);
break;
default:
throw new IllegalStateException("Unknown thread mode: " + subscription.subscriberMethod.threadMode);
}
}
复制代码步骤
- post
- 获取事件类型
- 根据类型,获取订阅者和订阅方法
- 根据订阅者的 threadMode 来判断线程
- 通过反射直接调用订阅者的订阅方法来完成本次通信息
Subscribe
这里是订阅者的意思,通过自定义注解实现
@Documented
@Retention(RetentionPolicy.RUNTIME) //注解会在class字节码文件中存在,在运行时可以通过反射获取到
@Target({ElementType.METHOD}) //只能在方法上声明
public @interface Subscribe {
ThreadMode threadMode() default ThreadMode.POSTING; //默认在 post 线程
boolean sticky() default false; //默认不是粘性事件
int priority() default 0; //线程优先级默认
}
复制代码threadMode
package org.greenrobot.eventbus;
public enum ThreadMode {
POSTING, // post 线程
MAIN,//指定主线程
MAIN_ORDERED,
BACKGROUND,//后台进行
ASYNC;//异步
private ThreadMode() {
}
}
复制代码unregister
流程:
EventBus 源码总结
到这里我们就简单的分析了 注册 - > 订阅 - > 发送 - >接收事件 简单的流程就是这样了,如果想更深入的话,建议下载源码来看 EventBus GitHub 架构方面还是要注重基础知识,比如 注解 + 反射 + 设计模式 (设计模式的话建议去看 《Android 源码设计模式》一书 ),现在开源项目几乎离不开这几项技术。只有我们掌握了基础 + 实现原理。我们模仿着也能写出来同样的项目。
下面我们就简单模仿下 EventBus 原理,实现自己的 EventBus 框架。
YEventBus 根据 TAG 实现接收消息架构实现
说明一点,这里我们还是根据 EventBus 的核心原理实现,并不会有 EventBus 那么多功能,我们只是学习 EventBus 原理的同时,能根据它的原理,自己写一套轻量级的 EventBus 架构。
最后一共差不多 300 行代码实现根据 TAG 发送/接收事件,下面是效果图:
以下我就直接贴代码了 每一步代码都有详细的注释,相信应该不难理解。
使用方式
添加依赖
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
dependencies {
implementation 'com.github.yangkun19921001:YEventBus:Tag'
}
复制代码
注册事件
//开始注册事件。模仿 EventBus
YEventBus.getDefault().register(this);
复制代码
订阅消息
/**
* 这里是自定义的注册,最后通过反射来获取当前类里面的订阅者
*
* @param meg
*/
@YSubscribe(threadMode = YThreadMode.MAIN, tag = Constants.TAG_1)
public void onEvent(String meg) {
Toast.makeText(getApplicationContext(), "收到:" + meg, Toast.LENGTH_SHORT).show();
}
复制代码
发送消息
YEventBus.getDefault().post(Constants.TAG_1, "发送 TAG 为 1 的消息");
复制代码
register
/**
* 注册方法
*/
public void register(Object subscriber) {
//拿到当前注册的所有的订阅者
List<YSubscribleMethod> ySubscribleMethods = mChacheSubscribleMethod.get(subscriber);
//如果订阅者已经注册了 就不需要再注册了
if (ySubscribleMethods == null) {
//开始反射找到当前类的订阅者
ySubscribleMethods = getSubscribleMethods(subscriber);
//注册了就存在缓存中,避免多次注册
mChacheSubscribleMethod.put(subscriber, ySubscribleMethods);
}
}
/**
* 拿到当前注册的所有订阅者
*
* @param subscriber
* @return
*/
private List<YSubscribleMethod> getSubscribleMethods(Object subscriber) {
//拿到注册的 class
Class<?> subClass = subscriber.getClass();
//定义一个容器,用来装订阅者
List<YSubscribleMethod> ySubscribleMethodList = new ArrayList<>();
//开始循环找到
while (subClass != null) {
//1. 开始进行筛选,如果是系统的就不需要进行下去
String subClassName = subClass.getName();
if (subClassName.startsWith(Constants.JAVA) ||
subClassName.startsWith(Constants.JAVA_X) ||
subClassName.startsWith(Constants.ANDROID) ||
subClassName.startsWith(Constants.ANDROID_X)
) {
break;
}
//2. 遍历拿到当前 class
Method[] declaredMethods = subClass.getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
//3. 检测当前方法中是否有 我们的 订阅者 注解也就是 YSubscribe
YSubscribe annotation = declaredMethod.getAnnotation(YSubscribe.class);
//如果没有直接跳出查找
if (annotation == null)
continue;
// check 这个方法的参数是否有多个
Class<?>[] parameterTypes = declaredMethod.getParameterTypes();
if (parameterTypes.length > 1) {
throw new RuntimeException("YEventBus 只能接收一个参数");
}
//4. 符合要求,最后添加到容器中
//4.1 拿到需要在哪个线程中接收事件
YThreadMode yThreadMode = annotation.threadMode();
//只能在当前 tag 相同下才能接收事件
String tag = annotation.tag();
YSubscribleMethod subscribleMethod = new YSubscribleMethod(tag, declaredMethod, yThreadMode, parameterTypes[0]);
ySubscribleMethodList.add(subscribleMethod);
}
//去父类找订阅者
subClass = subClass.getSuperclass();
}
return ySubscribleMethodList;
}
复制代码post (这里不是粘性事件)
/**
* post 方法
*/
public void post(String tag, Object object) {
//拿到当前所有订阅者持有的类
Set<Object> subscriberClass = mChacheSubscribleMethod.keySet();
//拿到迭代器,
Iterator<Object> iterator = subscriberClass.iterator();
//进行循环遍历
while (iterator.hasNext()) {
//拿到注册 class
Object subscribleClas = iterator.next();
//获取类中所有添加订阅者的注解
List<YSubscribleMethod> ySubscribleMethodList = mChacheSubscribleMethod.get(subscribleClas);
for (YSubscribleMethod subscribleMethod : ySubscribleMethodList) {
//判断这个方法是否接收事件
if (!TextUtils.isEmpty(tag) && subscribleMethod.getTag().equals(tag) //注解上面的 tag 是否跟发送者的 tag 相同,相同就接收
&& subscribleMethod.getEventType().isAssignableFrom(object.getClass() //判断类型
)
) {
//根据注解上面的线程类型来进行切换接收消息
postMessage(subscribleClas, subscribleMethod, object);
}
}
}
}
private void postMessage(final Object subscribleClas, final YSubscribleMethod subscribleMethod, final Object message) {
//根据需要的线程来进行切换
switch (subscribleMethod.getThreadMode()) {
case MAIN:
//如果接收的是主线程,那么直接进行反射,执行订阅者的方法
if (isMainThread()) {
postInvoke(subscribleClas, subscribleMethod, message);
} else {//如果接收消息在主线程,发送线程在子线程那么进行线程切换
mHandler.post(new Runnable() {
@Override
public void run() {
postInvoke(subscribleClas, subscribleMethod, message);
}
});
}
break;
case ASYNC://需要在子线程中接收
if (isMainThread())
//如果当前 post 是在主线程中,那么切换为子线程
ThreadUtils.executeByCached(new ThreadUtils.Task<Boolean>() {
@Nullable
@Override
public Boolean doInBackground() throws Throwable {
postInvoke(subscribleClas, subscribleMethod, message);
return true;
}
@Override
public void onSuccess(@Nullable Boolean result) {
Log.i(TAG, "执行成功");
}
@Override
public void onCancel() {
}
@Override
public void onFail(Throwable t) {
}
});
else
postInvoke(subscribleClas, subscribleMethod, message);
break;
case POSTING:
case BACKGROUND:
case MAIN_ORDERED:
postInvoke(subscribleClas, subscribleMethod, message);
break;
default:
break;
}
}
/**
* 反射调用订阅者
*
* @param subscribleClas
* @param subscribleMethod
* @param message
*/
private void postInvoke(Object subscribleClas, YSubscribleMethod subscribleMethod, Object message) {
Log.i(TAG, "post message: " + "TAG:" + subscribleMethod.getTag() + " 消息体:" + message);
Method method = subscribleMethod.getMethod();
//执行
try {
method.invoke(subscribleClas, message);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
复制代码Subscribe 订阅者
/**
* <pre>
* author : devyk on 2019-07-27 18:05
* blog : https://juejin.im/user/3368559355637566/posts
* github : https://github.com/yangkun19921001
* mailbox : yang1001yk@gmail.com
* desc : This is YSubscribe
* </pre>
*/
@Target(ElementType.METHOD) //target 描述此注解在哪里使用
@Retention(RetentionPolicy.RUNTIME) //retention 描述此注解保留的时长 这里是在运行时
public @interface YSubscribe {
YThreadMode threadMode() default YThreadMode.POSTING; //默认是在 post 线程接收数据
String tag() default "";//根据消息来接收事件
}
复制代码TreadMode 线程模式
/**
* <pre>
* author : devyk on 2019-07-27 18:14
* blog : https://juejin.im/user/3368559355637566/posts
* github : https://github.com/yangkun19921001
* mailbox : yang1001yk@gmail.com
* desc : This is YThreadMode
* </pre>
*/
public enum YThreadMode {
/**
* Subscriber will be called directly in the same thread, which is posting the event. This is the default. Event delivery
* implies the least overhead because it avoids thread switching completely. Thus this is the recommended mode for
* simple tasks that are known to complete in a very short time without requiring the main thread. Event handlers
* using this mode must return quickly to avoid blocking the posting thread, which may be the main thread.
*/
POSTING,
/**
* On Android, subscriber will be called in Android's main thread (UI thread). If the posting thread is
* the main thread, subscriber methods will be called directly, blocking the posting thread. Otherwise the event
* is queued for delivery (non-blocking). Subscribers using this mode must return quickly to avoid blocking the main thread.
* If not on Android, behaves the same as {@link #POSTING}.
*/
MAIN,
/**
* On Android, subscriber will be called in Android's main thread (UI thread). Different from {@link #MAIN},
* the event will always be queued for delivery. This ensures that the post call is non-blocking.
*/
MAIN_ORDERED,
/**
* On Android, subscriber will be called in a background thread. If posting thread is not the main thread, subscriber methods
* will be called directly in the posting thread. If the posting thread is the main thread, EventBus uses a single
* background thread, that will deliver all its events sequentially. Subscribers using this mode should try to
* return quickly to avoid blocking the background thread. If not on Android, always uses a background thread.
*/
BACKGROUND,
/**
* Subscriber will be called in a separate thread. This is always independent from the posting thread and the
* main thread. Posting events never wait for subscriber methods using this mode. Subscriber methods should
* use this mode if their execution might take some time, e.g. for network access. Avoid triggering a large number
* of long running asynchronous subscriber methods at the same time to limit the number of concurrent threads. EventBus
* uses a thread pool to efficiently reuse threads from completed asynchronous subscriber notifications.
*/
ASYNC
}
复制代码unRegister取消注册
/**
* 取消注册订阅者
*/
public void unRegister(Object subscriber) {
Log.i(TAG, "unRegister start:当前注册个数" + mChacheSubscribleMethod.size());
Class<?> subClas = subscriber.getClass();
List<YSubscribleMethod> ySubscribleMethodList = mChacheSubscribleMethod.get(subClas);
if (ySubscribleMethodList != null)
mChacheSubscribleMethod.remove(subscriber);
Log.i(TAG, "unRegister success:当前注册个数" + mChacheSubscribleMethod.size());
}
复制代码框架怎么实现根据 TAG 接收消息
这个其实很简单,拿到 post 发送的 tag,跟订阅者的 tag 比较下就行了。其实只要了解原理也没有那么难得。
//判断这个方法是否接收事件
if (!TextUtils.isEmpty(tag) && subscribleMethod.getTag().equals(tag) //注解上面的 tag 是否跟发送者的 tag 相同,相同就接收
&& subscribleMethod.getEventType().isAssignableFrom(object.getClass() //判断类型
)
复制代码总结
最后我们根据开源项目 EventBus 实现了自己 代码传送阵 YEventBus 框架,可以根据 TAG 发送/接收消息。只要了解开源框架原理,根据自己需求改动原有框架或者实现自己的框架都不是太难,加油!
作者:DevYK
链接:https://juejin.cn/post/6844903901129342989
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
收起阅读 »
移动架构 (三) AMS 源码分析
移动架构 (一) 架构第一步,学会画各种 UML 图
移动架构 (二) Android 中 Handler 架构分析,并实现自己简易版本 Handler 框架
AMS 介绍
ActivityManagerService 简称 AMS , 是 Android 内核中核心功能之一,由 com.android.server.SystemService.java 启动。
AMS 启动流程
以下流程因为涉及的源代码太多了 , 我这里以 UML 流程图跟代码截图以示
Android 系统启动
应用进程启动
ServiceManager 启动
AMS 注册
AMS 启动详解
代码流程:
AMS 具体是在 SystemService 进中启动的,主要是在
com/android/server/SystemServer.javamain() 函数中进行。
/**
* 这里的 main 函数 主要是 zygote 通过反射调用
*/
public static void main(String[] args) {
new SystemServer().run();
}
复制代码
从上图可以得知 main 方法主要是执行的
com/android/server/SystemServer.javarun() 函数,我们具体来看下 run() 到底干了什么?
private void run() {
try {
....
//加载了动态库libandroid_servers.so
System.loadLibrary("android_servers");
//创建SystemServiceManager,它会对系统的服务进行创建、启动和生命周期管理
mSystemServiceManager = new SystemServiceManager(mSystemContext);
mSystemServiceManager.setRuntimeRestarted(mRuntimeRestart);
LocalServices.addService(SystemServiceManager.class, mSystemServiceManager);
} finally {
}
// 启动各种服务
try {
traceBeginAndSlog("StartServices");
//启动了ActivityManagerService、PowerManagerService、PackageManagerService 等服务
startBootstrapServices();
// 启动了BatteryService、UsageStatsService和WebViewUpdateService 等服务
startCoreServices();
// 启动了CameraService、AlarmManagerService、VrManagerService等服务
startOtherServices();
SystemServerInitThreadPool.shutdown();
....
} catch (Throwable ex) {
throw ex;
} finally {
traceEnd();
}
// Loop forever.
Looper.loop();
throw new RuntimeException("Main thread loop unexpectedly exited");
}
复制代码run () 函数核心任务就是初始化一些事务和核心服务启动,这里核心服务初略有 80 多个,系统把核心服务大概分为了 3 类,分别是引导服务、核心服务和其他服务,因为这小节主要研究 AMS 启动,所以我们只关注 startBootstrapServices(); 内容就行了。
startBoostrapService() 这个函数的主要作用,根据官方的意思就是启动需要获得的小型的关键服务。 这些服务具有复杂的相互依赖性,这就是我们在这里将它们全部初始化的原因。 除非您的服务也与这些依赖关系缠绕在一起,否则应该在其他一个函数中初始化它。
public void startBootstrapServices(){
...
//启动 AMS 服务
mActivityManagerService = mSystemServiceManager.startService(
ActivityManagerService.Lifecycle.class).getService();
//设置管理器
mActivityManagerService.setSystemServiceManager(mSystemServiceManager);
//设置安装器
mActivityManagerService.setInstaller(installer);
...
}
复制代码这里主要调用 SystemServiceManager 的 startService 方法,方法的参数是
ActivityManagerService.Lifecycle.classcom/android/server/SystemServiceManager.java我们再来看看 SSM 的 startService 方法主要干嘛了?
SSM startService(Class serviceClass)
publicT startService(Class serviceClass) {
try {
...
final T service;
try {
Constructorconstructor = serviceClass.getConstructor(Context.class);
//实例化对象
service = constructor.newInstance(mContext);
} catch (InvocationTargetException ex) {
throw new RuntimeException("Failed to create service " + name
+ ": service constructor threw an exception", ex);
}
startService(service);
return service;
} finally {
Trace.traceEnd(Trace.TRACE_TAG_SYSTEM_SERVER);
}
}
复制代码跟踪代码可以得知 startService 方法传入的参数是 Lifecycle.class,Lifecycle 继承自 SystemService 。首先,通过反射来创建 Lifecycle 实例,得到传进来的 Lifecycle 的构造器 constructor ,接着又调用 constructor 的newInstance 方法来创建 Lifecycle 类型的 service 对象。接着将刚创建的 service 添加到 ArrayList 类型的mServices 对象中来完成注册。最后在调用 service 的 onStart 方法来启动 service ,并返回该 service 。Lifecycle 是 AMS 的内部类。
Lifecycle 走向
public static final class Lifecycle extends SystemService {
private final ActivityManagerService mService;
public Lifecycle(Context context) {
super(context);
mService = new ActivityManagerService(context);
}
@Override
public void onStart() {
mService.start();
}
public ActivityManagerService getService() {
return mService;
}
}
复制代码主要执行 Lifecyle onStart()
public void startService(@NonNull final SystemService service) {
// 把 AMS 服务添加到系统服务中
mServices.add(service);
// Start it.
long time = System.currentTimeMillis();
try {
//执行 Lifecyle 重 onStart 函数方法
service.onStart();
} catch (RuntimeException ex) {
throw new RuntimeException("Failed to start service " + service.getClass().getName()
+ ": onStart threw an exception", ex);
}
warnIfTooLong(System.currentTimeMillis() - time, service, "onStart");
}
复制代码上面第四步调用 constructor 的 newInstance 方法已经实例化了 Lifecycle 并创建 new
ActivityManagerService(context); 对象,接着又在第四步 startService(service) 调用了 service.start();实际上是调用了 Lifecyle onStart 函数方法。
ActivityManagerService getService()
mActivityManagerService = mSystemServiceManager.startService(
ActivityManagerService.Lifecycle.class).getService();
复制代码从上面代码得知实际上是调用了 AMS 中内部类 Lifecycle 中的 getService 函数返回了 AMS 实例,那么 AMS 实例就相当于创建了。
最后启动 AMS 进程是在 Zygote 中执行的,可以参考应用进程中的流程图。
作者:DevYK
链接:https://juejin.cn/post/6844903894166798349
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
iOS序列化的进阶方案——Protocol Buffer
前言
最近项目需要,引入Protocol Buffer来做对象序列化。
正文
Protocol Buffer是Google出的序列化数据格式,下面简称pb。
我们更常用的序列化数据格式应该是json,json和pb本质上都是对象的序列化和反序列化,在项目中json也是前后端通信的主要数据格式。
在本地存储时,我们可以使用YYModel将对象转成json对应的NSData,也可以使用NSKeyedArchiver结合实现NSCoding协议把对象转成NSData,进而将二进制数据存储在沙盒中或者数据库。
那么为什么不使用json,而要用pb?
因为项目中序列化数据到沙盒是一个高频场景,尝试过数据库、NSCoding+NSKeyedArchiver、YYModel等方法都有各自瓶颈:数据内容比较大数据库会造成体积膨胀过快不便管理,NSCoding+NSKeyedArchiver在序列化数据量较大的情况下性能不佳,YYModel在变动的时候不太友好。
相对而言,pb有以下特点:
pb是一种可扩展的序列化数据数据格式,新老版本的数据可以相互读取;
pb是使用字节流方式进行序列化,体积小速度快;(相对而言json是用字符串表示的,光表示字符串的""符号就有很多)
pb的代码是由描述文件proto生成,proto是文本文件便于做版本管理;
pb的使用
使用pb首先要定义proto的数据结构,语法非常简单,可以直接上手写:
syntax = "proto3";
message LYItemData {
uint32 itemId = 1;
string itemContentStr = 2;
}这里定义一个最简单的message,第一行是声明proto的版本,然后添加两个属性itemId和itemContentStr;
使用的时候,用[LYItemData parseFromData:data error:nil];可以将NSData转换成对象,访问LYItemData类的data属性,可以拿到其序列化之后的二进制数据;
代码很简单, 序列化和反序列化都只有一行,使用样例:
NSString *path = [NSHomeDirectory() stringByAppendingPathComponent:@"test_data"];
NSData *data = [[NSData alloc] initWithContentsOfFile:path];
LYItemData *itemData;
if (data) {
itemData = [LYItemData parseFromData:data error:nil]; // 反序列化
}
else {
itemData = [LYItemData new];
itemData.itemId = (int)time(NULL);
itemData.itemContentStr = [self timeStampConversionNSString:itemData.itemId];
[[NSFileManager defaultManager] createFileAtPath:path contents:itemData.data attributes:nil]; // 访问itemData.data属性时会做一次序列化
}message可以定义容器类型,包括数组、map等;
定义数组使用repeated,表示该元素是重复的,数量从0到若干个不等;
定义字典使用map,map里面带两个参数,分别表示key和value的type;
message LYArrayData {
repeated LYItemData items = 1;
map<int32, string> idToContentStrMap = 2;
}也可以在message中声明另外一个message 的属性
message LYProtobufLocalData {
uint64 dataId = 1;
string dataContentStr = 2;
uint32 updateTime = 3;
LYArrayData arrData = 4;
}了解这些常见的message定义方式,就可以满足大多数开发,其他用到再学也不迟。
其他使用方式例如any、oneof、reserved、enum、import、package可以自行探究,我们项目中没有使用到。
不管哪种定义方式,在定义成员属性的时候,都需要指定一个数字,这个数字是tag,需要保证在类中是唯一的。
tag是属性的唯一标识符,pb会在存储和读取的时候用到这个属性。
了解这些常见的message定义方式,就可以满足大多数开发,其他用到再学也不迟。
其他使用方式例如any、oneof、reserved、enum、import、package可以自行探究,我们项目中没有使用到。
不管哪种定义方式,在定义成员属性的时候,都需要指定一个数字,这个数字是tag,需要保证在类中是唯一的。
tag是属性的唯一标识符,pb会在存储和读取的时候用到这个属性。
代码生成
代码生成可以和Xcode结合,在每次编译之后自动生成。
在 Build Phases 里面添加一段脚本(下图中的Run Proto):先cd到proto所在的目录,然后运行脚本即可。
cd ${SOURCE_ROOT}/LearnProtoBuf/PB/
./protoc ProtobufData.proto --objc_out=./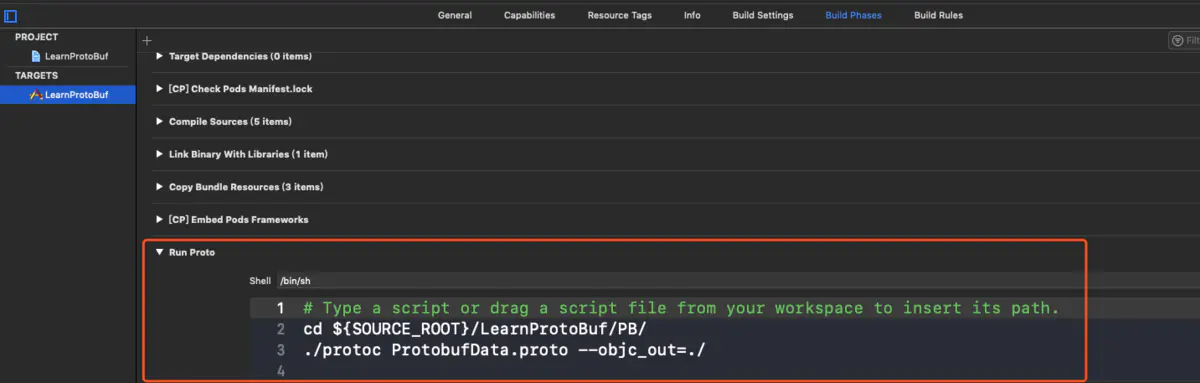
如果项目中有多个proto,此处可以使用sh脚本,把路径名作为参数传入,在sh脚本里面分别对每个proto文件做代码生成。
如果不想使用这种方式,也可以按照传统方法先安装protobuf,网上教程比较多,这里不再赘述。
总结
在Restful架构逐渐被RPC架构淘汰的现在,pb取代json作为前后端的通信数据格式也是时代的潮流。
json最大的优势或许是后端已有的很多服务都是用json通信,一时间无法完全替换。
pb简单易用,对持续变更更加友好。
一次定义,多端使用;
版本更迭,格式兼容。
附录
官方参考文档--OC代码生成
PB-Github
二进制encode原理
转自:https://www.jianshu.com/p/e2baa9bb4f5e
探讨SWIFT 5.2的新功能特性
从表面上看,SWIFT 5.2在新的语言特性方面肯定是一个小版本,因为这个新版本的大部分重点是提高SWIFT底层基础结构的速度和稳定性,例如如何报告编译器错误,以及如何解决构建级依赖。
然而,斯威夫特5.2总数新的语言特性可能相对较小,它确实包括两个新功能,它们可能会对SWIFT的整体功能产生相当大的影响。函数式程序设计语言.
本周,让我们探讨这些特性,以及我们如何可能使用它们来接受一些在函数式编程世界中非常流行的不同范例--在面向对象的SWIFT代码库中,它们可能会感觉更加一致和熟悉。
在我们开始之前,作为Xcode 11.4的一部分,SWIFT5.2仍然处于测试版,请注意,本文是一篇非常探索性的文章,代表了我对这些新语言特性的第一印象。随着我在生产中使用新特性获得更多经验,我的观点可能会发生变化,尽管我将尝试在这种情况下更新这篇文章,但我建议您使用本文作为灵感,亲自探索这些新特性,而不是直接使用以原样呈现的解决方案。
有了这个小小的免责声明,让我们开始探索吧!
一个开发者,有一个学习的氛围跟一个交流圈子特别重要,这是一个我的iOS交流群:1012951431, 分享BAT,阿里面试题、面试经验,讨论技术, 大家一起交流学习成长!希望帮助开发者少走弯路。
调用类型为函数
尽管SWIFT并不是一种严格的函数式编程语言,但毫无疑问,函数在其总体设计和使用中扮演着非常重要的角色。从闭包如何作为异步回调使用,到集合如何大量使用典型的函数模式(如map和reduce-职能无处不在。
SWIFT5.2的有趣之处在于它开始模糊函数和类型之间的界限。尽管我们一直能够将任何给定类型的实例方法作为函数传递(因为SWIFT支持一级函数),我们现在能够调用某些类型,就好像它们本身是函数一样。.
让我们先来看看一个使用Cache我们内置的类型“SWIFT中的缓存”-这提供了一个更多的“快速友好”包装上的APINSCache:
class Cache {
private let wrapped = NSCache()
private let dateProvider: () -> Date
private let entryLifetime: TimeInterval
...
func insert(_ value: Value, forKey key: Key) {
...
}
} 假设我们想要向上面的类型添加一个方便的API--让我们自动使用插入值的id作为它的缓存键,以防当前Value类型符合标准库的Identifiable协议。虽然我们可以简单地命名新的apiinsert还有,我们要给它起一个非常特别的名字-callAsFunction:
extension Cache where Value: Identifiable, Key == Value.ID {
func callAsFunction(_ value: Value) {
insert(value, forKey: value.id)
}
}这似乎是一种奇怪的命名约定,但通过这样命名我们的新方便方法,我们实际上已经给出了Cache输入一个有趣的新功能--它现在可能被称为函数--如下所示:
let document: Document = ...
let cache = Cache()
// We can now call our 'cache' variable as if it was referencing a
// function or a closure:
cache(document) 可以说,这既很酷,也很奇怪。但问题是-它有什么用呢?让我们继续探索,看看DocumentRenderer协议,它为用于呈现的各种类型定义了一个公共接口。Document应用程序中的实例:
protocol DocumentRenderer {
func render(_ document: Document,
in context: DocumentRenderingContext,
enableAnnotations: Bool)
}类似于我们之前向我们的Cache类型,让我们在这里做同样的事情-只是这一次,我们将扩展上面的协议,以允许任何符合的类型被调用为一个函数,其中包含一组默认参数:
extension DocumentRenderer {
func callAsFunction(_ document: Document) {
render(document,
in: .makeDefaultContext(),
enableAnnotations: false
)
}
}上述两个变化在孤立的情况下看起来可能不那么令人印象深刻,但是如果我们将它们放在一起,我们就可以看到为一些更复杂的类型提供基于功能的方便API的吸引力。例如,我们在这里构建了一个DocumentViewController-使用我们的Cache类型,以及基于核心动画的DocumentRenderer协议--在加载文档时,这两种协议现在都可以简单地作为函数调用:
class DocumentViewController: UIViewController {
private let cache: Cache
private let render: CoreAnimationDocumentRenderer
...
private func documentDidLoad(_ document: Document) {
cache(document)
render(document)
}
}这很酷,特别是如果我们的目标是轻量级API设计或者如果我们在建造某种形式的领域专用语言。虽然通过传递实例方法来实现类似的结果一直是可能的好像它们是封闭的-通过允许直接调用我们的类型,我们都避免了手动传递这些方法,并且能够保留API可能使用的任何外部参数标签。
例如,假设我们还想做一个PriceCalculator变成一个可调用的类型。为了维护原始API的语义,我们将保留for外部参数标签,即使在声明callAsFunction执行情况-如下:
extension PriceCalculator {
func callAsFunction(for product: Product) -> Int {
calculatePrice(for: product)
}
}下面是上述方法与存储对类型的引用的比较calculatePrice方法-请注意第一段代码是如何丢弃参数标签的,而第二段代码是如何保留参数标签的:
// Using a method reference:
let calculatePrice = PriceCalculator().calculatePrice
...
calculatePrice(product)
// Calling our type directly:
let calculatePrice = PriceCalculator()
...
calculatePrice(for: product)让类型像函数一样被调用是一个非常有趣的概念,但也许更有趣的是,它还使我们能够走相反的方向--并将函数转换为适当的类型。
面向对象的函数式编程
虽然在许多函数式编程概念中有着巨大的威力,但当使用大量面向对象的框架(就像大多数Apple的框架一样)时,应用这些概念和模式往往是很有挑战性的。让我们看看SWIFT5.2的新可调用类型功能是否可以帮助我们改变这种状况。
后续精彩内容请转到我的博客继续观看
转自:https://www.jianshu.com/p/c8f0f4ae63e5
收起阅读 »iOS- WMZDropDownMenu:App各种类型筛选菜单
软件介绍
一个能几乎实现所有 App 各种类型筛选菜单的控件,可悬浮。目前已实现 闲鱼 / 美团 / Boss直聘 / 京东 / 饿了么 / 淘宝 / 拼多多 / 赶集网 / 美图外卖 等等的筛选菜单,可以自由调用代理实现自己想组装的筛选功能和 UI,且控件的生命周期自动管理,悬浮自动管理。实现功能
- 组合自定义功能
- 支持自定义多选|单选|复选
- 支持自定义弹出的动画 (目前已实现向下,向左全屏,向右全屏,拼多多对话框弹出,boss直聘全屏弹出)
- 支持自定义tableView/collectionView头尾视图
- 支持自定义全局头尾视图
- 支持自定义collectionCell/tableViewCell视图
- 支持自定义标题
- 支持自定义点击回收视图
- 支持自定义回收列表
- 支持任意级的联动(由于数据比较庞杂,暂时自动适配不了无限级的联动,所以需要你调用一个方法更新数据传给我,详情看Demo)
- 支持嵌套使用,即两个筛选菜单可以连着使用
- 支持放在放在任意视图上,tableviewHeadView毫无疑问支持且无须写其他代码只要放上去即可
- 支持控制器消失自动关闭视图,无须再控制器消失方法里手动关闭
- 链式实现所有配置的自定义修改 (总之,你想要的基本都有,不想要的也有)
效果图

用法:
组装全在一些代理里,代理方法可能有点多~ ~,不过只有两个是必实现的,其他的都是可选的)
WMZDropMenuDelegate
@required 一定实现的方法
*/
- (NSArray*)titleArrInMenu:(WMZDropDownMenu *)menu;
/*
*返回WMZDropIndexPath每行 每列的数据
*/
- (NSArray*)menu:(WMZDropDownMenu *)menu
dataForRowAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
@optional 可选实现的方法
/*
*返回setion行标题有多少列 默认1列
*/
- (NSInteger)menu:(WMZDropDownMenu *)menu numberOfRowsInSection:
(NSInteger)section;
/*
*自定义tableviewCell内容 默认WMZDropTableViewCell 如果要使用默认的
cell返回 nil
*/
- (UITableViewCell*)menu:(WMZDropDownMenu *)menu
cellForUITableView:(WMZDropTableView*)tableView AtIndexPath:
(NSIndexPath*)indexpath dataForIndexPath:(WMZDropTree*)model;
/*
*自定义tableView headView
*/
- (UITableViewHeaderFooterView*)menu:(WMZDropDownMenu *)menu
headViewForUITableView:(WMZDropTableView*)tableView
AtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*自定义tableView footView
*/
- (UITableViewHeaderFooterView*)menu:(WMZDropDownMenu *)menu
footViewForUITableView:(WMZDropTableView*)tableView
AtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*自定义collectionViewCell内容
*/
- (UICollectionViewCell*)menu:(WMZDropDownMenu *)menu
cellForUICollectionView:(WMZDropCollectionView*)collectionView
AtDropIndexPath:(WMZDropIndexPath*)dropIndexPath AtIndexPath:
(NSIndexPath*)indexpath dataForIndexPath:(WMZDropTree*)model;
/*
*自定义collectionView headView
*/
- (UICollectionReusableView*)menu:(WMZDropDownMenu *)menu
headViewForUICollectionView:(WMZDropCollectionView*)collectionView
AtDropIndexPath:(WMZDropIndexPath*)dropIndexPath AtIndexPath:
(NSIndexPath*)indexpath;
/*
*自定义collectionView footView
*/
- (UICollectionReusableView*)menu:(WMZDropDownMenu *)menu
footViewForUICollectionView:(WMZDropCollectionView*)collectionView
AtDropIndexPath:(WMZDropIndexPath*)dropIndexPath AtIndexPath:
(NSIndexPath*)indexpath;
/*
*headView标题
*/
- (NSString*)menu:(WMZDropDownMenu *)menu
titleForHeadViewAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*footView标题
*/
- (NSString*)menu:(WMZDropDownMenu *)menu
titleForFootViewAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*返回WMZDropIndexPath每行 每列 indexpath的cell的高度 默认35
*/
- (CGFloat)menu:(WMZDropDownMenu *)menu heightAtDropIndexPath:
(WMZDropIndexPath*)dropIndexPath AtIndexPath:
(NSIndexPath*)indexpath;
/*
*自定义headView高度 collectionView默认35
*/
- (CGFloat)menu:(WMZDropDownMenu *)menu
heightForHeadViewAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*自定义footView高度
*/
- (CGFloat)menu:(WMZDropDownMenu *)menu
heightForFootViewAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
#pragma -mark 自定义用户交互的每行的头尾视图
/*
*自定义每行全局头部视图 多用于交互事件
*/
- (UIView*)menu:(WMZDropDownMenu *)menu
userInteractionHeadViewInSection:(NSInteger)section;
/*
*自定义每行全局尾部视图 多用于交互事件
*/
- (UIView*)menu:(WMZDropDownMenu *)menu
userInteractionFootViewInSection:(NSInteger)section;
#pragma -mark 样式动画相关代理
/*
*返回WMZDropIndexPath每行 每列的UI样式 默认MenuUITableView
注:设置了dropIndexPath.section 设置了 MenuUITableView 那么row则全部
为MenuUITableView 保持统一风格
*/
- (MenuUIStyle)menu:(WMZDropDownMenu *)menu
uiStyleForRowIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*返回section行标题数据视图出现的动画样式 默认
MenuShowAnimalBottom
注:最后一个默认是筛选 弹出动画为 MenuShowAnimalRight
*/
- (MenuShowAnimalStyle)menu:(WMZDropDownMenu *)menu
showAnimalStyleForRowInSection:(NSInteger)section;
/*
*返回section行标题数据视图消失的动画样式 默认 MenuHideAnimalTop
注:最后一个默认是筛选 消失动画为 MenuHideAnimalLeft
*/
- (MenuHideAnimalStyle)menu:(WMZDropDownMenu *)menu
hideAnimalStyleForRowInSection:(NSInteger)section;
/*
*返回WMZDropIndexPath每行 每列的编辑类型 单选|多选 默认单选
*/
- (MenuEditStyle)menu:(WMZDropDownMenu *)menu
editStyleForRowAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*返回WMZDropIndexPath每行 每列 显示的个数
注:
样式MenuUITableView 默认4个
样式MenuUICollectionView 默认1个 传值无效
*/
- (NSInteger)menu:(WMZDropDownMenu *)menu
countForRowAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*WMZDropIndexPath是否显示收缩功能 default >参数
wCollectionViewSectionShowExpandCount 显示
*/
- (BOOL)menu:(WMZDropDownMenu *)menu
showExpandAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*WMZDropIndexPath上的内容点击 是否关闭视图 default YES
*/
- (BOOL)menu:(WMZDropDownMenu *)menu
closeWithTapAtDropIndexPath:(WMZDropIndexPath*)dropIndexPath;
/*
*是否关联 其他标题 即选中其他标题 此标题会不会取消选中状态 default
YES 取消,互不关联
*/
- (BOOL)menu:(WMZDropDownMenu *)menu
dropIndexPathConnectInSection:(NSInteger)section;
#pragma -mark 交互自定义代理
/*
*cell点击方法
*/
- (void)menu:(WMZDropDownMenu *)menu
didSelectRowAtDropIndexPath:(WMZDropIndexPath *)dropIndexPath
dataIndexPath:(NSIndexPath*)indexpath data:(WMZDropTree*)data;
/*
*标题点击方法
*/
- (void)menu:(WMZDropDownMenu *)menu didSelectTitleInSection:
(NSInteger)section btn:(WMZDropMenuBtn*)selectBtn;
/*
*确定方法 多个选择
selectNoramalData 转化后的的模型数据
selectData 字符串数据
*/
- (void)menu:(WMZDropDownMenu *)menu didConfirmAtSection:
(NSInteger)section selectNoramelData:(
NSMutableArray*)selectNoramalData selectStringData:
(NSMutableArray*)selectData;
/*
*自定义标题按钮视图 返回配置 参数说明
offset 按钮的间距
y 按钮的y坐标 自动会居中
*/
- (NSDictionary*)menu:(WMZDropDownMenu *)menu
customTitleInSection:
(NSInteger)section withTitleBtn:(WMZDropMenuBtn*)menuBtn;
/*
*自定义修改默认collectionView尾部视图
*/
- (void)menu:(WMZDropDownMenu *)menu
customDefauultCollectionFootView:(WMZDropConfirmView*)confirmView;下载地址:https://gitee.com/mirrors/WMZDropDownMenu
收起阅读 »IOS-图片浏览之YBImageBrowser的简单使用
1.安装
第一种方式 使用 cocoapods
第二种方式 手动导入
pod 'SDWebImage', '~> 4.3.3'
pod 'FLAnimatedImage', '~> 1.0.12'2.使用
我这里是采用代理数据源的方式,完整代码如下:
#import "ViewController.h"
#import "YBImageBrowser.h"
#import
@interface ViewController (){
NSArray *imageArray;
NSMutableArray *imageViewArray;
NSInteger currentIndex;
}
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
imageViewArray = [[NSMutableArray alloc]init];
imageArray = @[
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118687954&di=d92e4024fe4c2e4379cce3d3771ae105&imgtype=0&src=http%3A%2F%2Fimg3.duitang.com%2Fuploads%2Fitem%2F201605%2F18%2F20160518181939_nCZWu.gif",
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118772581&di=29b994a8fcaaf72498454e6d207bc29a&imgtype=0&src=http%3A%2F%2Fimglf2.ph.126.net%2F_s_WfySuHWpGNA10-LrKEQ%3D%3D%2F1616792266326335483.gif",
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118803027&di=beab81af52d767ebf74b03610508eb36&imgtype=0&src=http%3A%2F%2Fe.hiphotos.baidu.com%2Fbaike%2Fpic%2Fitem%2F2e2eb9389b504fc2995aaaa1efdde71190ef6d08.jpg",
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118823131&di=aa588a997ac0599df4e87ae39ebc7406&imgtype=0&src=http%3A%2F%2Fimg3.duitang.com%2Fuploads%2Fitem%2F201605%2F08%2F20160508154653_AQavc.png",
@"https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=722693321,3238602439&fm=27&gp=0.jpg",
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118892596&di=5e8f287b5c62ca0c813a548246faf148&imgtype=0&src=http%3A%2F%2Fwx1.sinaimg.cn%2Fcrop.0.0.1080.606.1000%2F8d7ad99bly1fcte4d1a8kj20u00u0gnb.jpg",
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118914981&di=7fa3504d8767ab709c4fb519ad67cf09&imgtype=0&src=http%3A%2F%2Fimg5.duitang.com%2Fuploads%2Fitem%2F201410%2F05%2F20141005221124_awAhx.jpeg",
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118934390&di=fbb86678336593d38c78878bc33d90c3&imgtype=0&src=http%3A%2F%2Fi2.hdslb.com%2Fbfs%2Farchive%2Fe90aa49ddb2fa345fa588cf098baf7b3d0e27553.jpg",
@"https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1524118984884&di=7c73ddf9d321ef94a19567337628580b&imgtype=0&src=http%3A%2F%2Fimg5q.duitang.com%2Fuploads%2Fitem%2F201506%2F07%2F20150607185100_XQvYT.jpeg"
];
[self initUI];
// Do any additional setup after loading the view, typically from a nib.
}
-(void)initUI{
NSInteger rowCount = 3;
CGFloat width = self.view.bounds.size.width;
CGFloat imgW = width/rowCount;
CGFloat imgH = imgW;
CGFloat xPoint = 0;
CGFloat yPoint = 100;
NSInteger index = 0;
for (NSString *imgUrl in imageArray) {
UIButton *button = [[UIButton alloc] initWithFrame:CGRectMake(xPoint, yPoint, imgW, imgH)];
button.userInteractionEnabled = YES;
button.tag = index;
//点击图片放大
[button addTarget:self action:@selector(imgViewClick:) forControlEvents:UIControlEventTouchUpInside];
UIImageView *img = [[UIImageView alloc] initWithFrame:CGRectMake(0, 0, imgW, imgH)];
[button addSubview:img];
[img sd_setImageWithURL:[NSURL URLWithString:imgUrl] placeholderImage:[UIImage imageNamed:@"no_img.png"]];
[imageViewArray addObject:img];
xPoint += imgW;
if ((index+1)%rowCount==0) {
yPoint += imgH;
xPoint = 0;
}
[self.view addSubview:button];
index++;
}
}
-(void)imgViewClick:(UIButton *)btn{
currentIndex = btn.tag;
YBImageBrowser *browser = [YBImageBrowser new];
browser.dataSource = self;
browser.currentIndex = btn.tag;
//展示
[browser show];
}
//YBImageBrowserDataSource 代理实现赋值数据
- (NSInteger)numberInYBImageBrowser:(YBImageBrowser *)imageBrowser {
return imageArray.count;
}
- (YBImageBrowserModel *)yBImageBrowser:(YBImageBrowser *)imageBrowser modelForCellAtIndex:(NSInteger)index {
NSString *urlStr = [imageArray objectAtIndex:index];
YBImageBrowserModel *model = [YBImageBrowserModel new];
model.url = [NSURL URLWithString:urlStr];
//model.sourceImageView = [imageViewArray objectAtIndex:index];
return model;
}
- (UIImageView *)imageViewOfTouchForImageBrowser:(YBImageBrowser *)imageBrowser {
return [imageViewArray objectAtIndex:currentIndex];
}
- (void)didReceiveMemoryWarning {
[super didReceiveMemoryWarning];
// Dispose of any resources that can be recreated.
}
@end 3.效果

git地址:https://github.com/indulgeIn/YBImageBrowser
移动架构 (二) Android 中 Handler 架构分析,并实现自己简易版本 Handler 框架
Android 中消息机制
Android 的消息机制主要指 Handler 的运行机制,先来看下 Handler 的一张运行架构图来对 Handler 有个大概的了解。
Handler 消息机制图:
Handler 类图:
以上图的解释:
- 以 Handler 的 sendMessage () 函数为例,当发送一个 message 后,会将此消息加入消息队列 MessageQueue 中。
- Looper 负责去遍历消息队列并且将队列中的消息分发非对应的 Handler 进行处理。
- 在 Handler 的 handlerMessage 方法中处理该消息,这就完成了一个消息的发送和处理过程。
这里从图中可以看到 Android 中 Handler 消息机制最重要的四个对象分别为 Handler 、Message 、MessageQueue 、Looper。
ThreadLocal 的工作原理
ThreadLocal 是一个线程内部的数据存储类,通过它可以在指定的线程中存储数据, 数据存储以后,只有再指定线程中可以获取到存储的数据,对于其它线程来说则是无法获取到存储的对象。下面就是我们验证 ThreadLocal 存取是否是按照刚刚那样所说。
子线程中存,子线程中取
// 代码测试
new Thread("thread-1"){
@Override
public void run() {
ThreadLocal<String> mThread_A = new ThreadLocal();
mThread_A.set("thread-1");
System.out.println("mThread_A :"+mThread_A.get());
}
}.start();
//打印结果
mThread_A :thread-1
复制代码主线程中存,子线程取
//主线程中存,子线程取
final ThreadLocal<String> mThread_B = new ThreadLocal();
mThread_B.set("thread_B");
new Thread(){
@Override
public void run() {
System.out.println("mThread_B :"+mThread_B.get());
}
}.start();
//打印结果
mThread_B :null
复制代码主线程存,主线程取
//主线程存,主线程取
ThreadLocal<String> mThread_C = new ThreadLocal();
mThread_C.set("thread_C");
System.out.println("mThread_C :"+mThread_C.get());
//打印结果
mThread_C :thread_C
复制代码
结果是不是跟上面我们所说的答案一样,那么为什么会是这样勒?现在我们带着问题去看下 ThreadLocal 源码到底做了什么?
从上图可以 ThreadLocal 主要函数组成部分,这里我们用到了 set , get 那么就从 set , get 入手吧。
ThreadLocal set(T):
(图 1)
(图 2)
(图 3)
(图 四)
从 (图一) 得知 set 函数里面获取了当前线程,这里我们主要看下 getMap(currentThread) 主要干什么了?
从 (图二) 中我们得知 getMap 主要是从当前线程拿到 ThreadLocalMap 这个实例对象,如果当前线程的 ThreadLocalMap 为 NULL ,那么就 createMap ,这里的 ThreadLocalMap 可以暂时理解为一个集合对象就行了,它 (图四) 底层是一个数组实现的添加数据。
ThreadLocal T get():
这里的 get() 函数其实已经能够说明为什么在不同线程存储的数据拿不到了。因为存储是在当前线程存储的,取数据也是在当前所在的线程取得,所以不可能拿到的。带着问题我们找到了答案。是不是有点小激动呀?(^▽^)
Android 消息机制源码分析
这里我们就直接看源码,一下是我看源码的流程。
创建全局唯一的 Looper 对象和全局唯一 MessageQueue 消息对象。
Activity 中创建 Handler。
Handler sendMessage 发送一个消息的走向。
Handler 消息处理。
消息阻塞和延时
阻塞和延时
Looper 的阻塞主要是靠 MessageQueue 来实现的,在 MessageQueue -> next() nativePollOnce(ptr, nextPollTimeoutMillis) 进行阻塞 , 在 MessageQueue -> enqueueMessage() -> nativeWake(mPtr) 进行唤醒。主要依赖 native 层的 looper epoll 进制进行的。
阻塞和延时,主要是 next() 的 nativePollOnce(ptr , nextPollTimeoutMillis) 调用 native 方法来操作管道,由 nextPollTimeoutMillis 决定是否需要阻塞 , nextPollTimeoutMilis 为 0 的时候表示不阻塞 , 为 -1 的时候表示一直阻塞直到被唤醒,其它时间表示延时。
唤醒
主要是指 enqueueMessage () @MessageQueue 进行唤醒。
阻塞 -> 唤醒 消息切换
总结
简单的理解阻塞和唤醒就是在主线程的 MessageQueue 没有消息时,便阻塞在 Loop 的 queue.next() 中的 nativePollOnce() 方法里面,此时主线程会释放 CPU 资源进入休眠状态,直到下一个消息到达或者有消息的时候才触发,通过往 pipe 管道写端写入数据来唤醒主线程工作。
这里采用的 epoll 机制,是一种 IO 多路复用机制,可以同时监控多个描述符,当某个描述符就绪 (读或写就绪) , 则立刻通知相应程序进行读或者写操作,本质同步 I/O , 即读写是阻塞的。所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量的 CPU 资源。
延时入队
主要指 enqueueMessage() 消息入队列(Message 单链表),上图代码对 message 对象池重新排序,遵循规则 ( when 从小到大) 。
此处 for 死循环退出情况分为两种
- p == null 表示对象池中已经运行到了最后一个,无需要再循环。
- 碰到下一个消息 when 小于前一个,立马退出循环 (不管对象池中所有 message 是否遍历完) 进行重新排序。
好了,到了这里 Handler 源码分析算是告一段落了,下面我们来看下面试中容易被问起的问题。
常见问题分析
为什么不能在子线程中更新 UI ,根本原因是什么?
mThread 是主线程,这里会检查当前线程是否是主线程,那么为什么没有在 onCreate 里面没有进行这个检查呢?这个问题原因出现在 Activity 的生命周期中 , 在 onCreate 方法中, UI 处于创建过程,对用户来说界面还不可见,直到 onStart 方法后界面可见了,再到 onResume 方法后页面可以交互,从某种程度来讲, 在 onCreate 方法中不能算是更新 UI,只能说是配置 UI,或者是设置 UI 属性。 这个时候不会调用到 ViewRootImpl.checkThread () , 因为 ViewRootImpl 没有创建。 而在 onResume 方法后, ViewRootImpl 才被创建。 这个时候去交户界面才算是更新 UI。
setContentView 知识建立了 View 树,并没有进行渲染工作 (其实真正的渲染工作实在 onResume 之后)。也正是建立了 View 树,因此我们可以通过 findViewById() 来获取到 View 对象,但是由于并没有进行渲染视图的工作,也就是没有执行 ViewRootImpl.performTransversal。同样 View 中也不会执行 onMeasure (), 如果在 onResume() 方法里直接获取 View.getHeight() / View.getWidth () 得到的结果总是 0。
为什么主线程用 Looper 死循环不会引发 ANR 异常?
简单来说就是在主线程的 MessageQueue 没有消息时,便阻塞在 loop 的 queue.next() 中的 nativePollOnce() 方法,此时主线程会释放 CPU 资源进入休眠状态,直到下个消息到达或者有事务发生,通过往 pipe 管道写入数据来唤醒主线程工作。这里采用的是 epoll 机制,是一种 IO 多路复用机制。
为什么 Handler 构造方法里面的 Looper 不是直接 new ?
如果在 Handler 构造方法里面直接 new Looper(), 可能是无法保证 Looper 唯一,只有用 Looper.prepare() 才能保证唯一性,具体可以看 prepare 方法。
MessageQueue 为什么要放在 Looper 私有构造方法初始化?
因为一个线程只绑定一个 Looper ,所以在 Looper 构造方法里面初始化就可以保证 mQueue 也是唯一的 Thread 对应一个 Looper 对应一个 mQueue。
Handler . post 的逻辑在哪个线程执行的?是由 Looper 所在线程还是 Handler 所在线程决定的?
由 Looper 所在线程决定的。逻辑是在 Looper.loop() 方法中,从 MessageQueue 中拿出 message ,并且执行其逻辑,这里在 Looper 中执行的,因此有 Looper 所在线程决定。
MessageQueue.next() 会因为发现了延迟消息,而进行阻塞。那么为什么后面加入的非延迟消息没有被阻塞呢?
可以参考 消息阻塞和延时 -> 唤醒
Handler 的 dispatchMessage () 分发消息的处理流程?
属于 Runnable 接口。
通过下面代码形式调用。
private static Handler mHandler = new Handler(new Handler.Callback() {
@Override
public boolean handleMessage(Message msg) {
return true;
}
});
复制代码如果第一步,第二部都不满足直接走下面 handlerMessage 参考下面代码实现方式
private static Handler mHandler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
}
};
复制代码
也可以通过 debug 方式来具体看 dispatchMessage 执行状态。
实现自己的 Handler 简单架构
主要实现测试代码
作者:DevYK
链接:https://juejin.cn/post/6844903892828815367
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
移动架构 (一) 架构第一步,学会画各种 UML 图
注意: 文章中 UML 图开始用是 Windows PowerDesigner 工具,后来换电脑了用的 StarUML。
UML
定义
UML 是统一建模语言, 是一种开放的方法,用于说明、可视化、构建和编写一个正在开发的、面向对象的、软件密集系统的制品的开放方法。
作用
- 帮组开发团队以一种可视化的方式理解系统的功能需求。
- 有利于开发团队队员之间在各个开发环节间确立沟通的标准,便于系统文档的制定和项目的管理。因为 UML 的简单、直观和标准性,在一个团队中用 UML 来交流比用文字说明的文档要好的多。
- UML 为非专业编程人士理解软件的功能和构造,提供了一种直白、简单、通俗的方法。
- 使用 UML 可以方便的理解各种框架的设计方式。
面向对象模型
用例图 (User Case Diagram)
概述
- 用例图主要模拟系统中的动态行为,并且描述了用户、需求、以及系统功能单元之间的关系。
- 用例图由参与者 (用户) ,用例 (功能) 和它们之间的关系组成。
目的
- 用来收集系统的要求。
- 用于获取系统的外观图。
- 识别外部和内部影响因素。
- 显示要求之间的相互作用是参与者。
构成元素
| 组成元素 | 说明 | 符号表示 |
|---|---|---|
| 参与者 (Actor) | 表示与你自己的程序或者系统进行正在交互的动作。用一个小人表示 | |
| 用例 (User Case) | 表示在一个系统或者程序中某个功能的描述。用一个椭圆代表 | |
| 关联关系 (Association) | 表示参与者与用例之间的关系。用一个箭头表示 | |
| 包含关系 (Include) | 表示一个大的功能分解成多个小模块的动作。用一个带包含文字的虚线箭头表示 | |
| 扩展关系 (Extend) | 表示用例功能的延伸,相当于是为用例提供附加功能。用一个带扩展文字的虚线箭头表示 | |
| 依赖 (dependency) | 表示一个用例依赖于另一个用例(相当于程序里面的一个类引用另一个类的关系)。用一个带依赖文字的虚线箭头表示 | |
| 泛化 (Generalization) | 相当于程序里面的继承关系。用一个箭头表示 |
用例图例子
需求: 以一个登录的例子来画一个用例图
- 包含 登录/注册/
- 登录/注册 支持手机号码、第三方 QQ/weichat/GitHub 登录注册
效果图:
提供的登录用例基本上已经包含了刚刚所学的组成元素部分。
结构图
类图 (Class Diagram)
概念
类图 (Class Diagram) 是显示了模型的静态结构,特别是模型中存在的类、类的内部结构以及它们与其它类的关系等。
类图不显示暂时性的信息,类图是面向对象建模的主要组成部分。它即用于应用程序的系统分类的一般概念建模,也用于详细建模,将模型转换成编程代码。
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 泛化 (Generalization) | 是一种继承关系, 表示一般与特殊的关系, 它指定了子类如何特化父类的所有特征和行为。用一个带三角箭头的实线,箭头指向父类表示 | |
| 实现 (Realization) | 是一种类与接口的关系, 表示类是接口所有特征和行为的实现。用一个带三角箭头的虚线,箭头指向接口表示. | |
| 关联 (Association) | 1. 是一种拥有的关系, 它使一个类知道另一个类的属性和方法. 2.关联可以是双向的,也可以是单向的。双向的关联可以有两个箭头或者没有箭头,单向的关联有一个箭头。用一个带普通箭头的实心线,指向被拥有者 | |
| 依赖 (Dependency) | 是一种使用的关系, 即一个类的实现需要另一个类的协助, 所以要尽量不使用双向的互相依赖.用一个带箭头的虚线,指向被使用者 | |
| 聚合 (Aggregation) | 聚合是一种特殊的关联 (Association) 形式,表示两个对象之间的所属 (has-a) 关系。所有者对象称为聚合对象,它的类称为聚合类;从属对象称为被聚合对象,它的类称为被聚合类。例如,一个公司有很多员工就是公司类 Company 和员工类Employee 之间的一种聚合关系。被聚合对象和聚合对象有着各自的生命周期,即如果公司倒闭并不影响员工的存在。用一个带空心菱形的实心线,菱形指向整体 | |
| 组合 (Composition) | 是整体与部分的关系, 但部分不能离开整体而单独存在. 如公司和部门是整体和部分的关系, 没有公司就不存在部门。用一个带实心菱形的实线,菱形指向整体表示。 |
类图例子
需求: 基于 google 官方 MVP 架构 绘制一个基本的 MVP 类图架构
组合结构图 (Composite Structure Diagram)
概念
用来显示组合结构或部分系统的内部构造,包括类、接口、包、组件、端口和连接器等元素。比类图更抽象的表示,一般来说先画组合结构图,再画类图。
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 类 (Class) | 表示对某件事物的描述 | |
| 接口 (Interface) | 表示用于对 Class 的说明 | |
| 端口 (port) | 表示部件和外部环境的交互点 | |
| 部件 (part) | 表示被描述事物所拥有的内部成分 | |
| 泛化 (Generalication) | 是一种继承关系, 表示一般与特殊的关系, 它指定了子类如何特化父类的所有特征和行为。用一个带三角箭头的实线,箭头指向父类表示 | |
| 实现 (Realization) | 是一种类与接口的关系, 表示类是接口所有特征和行为的实现。用一个带三角箭头的虚线,箭头指向接口表示. | |
| 关联 (Association) | 1. 是一种拥有的关系, 它使一个类知道另一个类的属性和方法. 2.关联可以是双向的,也可以是单向的。双向的关联可以有两个箭头或者没有箭头,单向的关联有一个箭头。用一个带普通箭头的实心线,指向被拥有者 | |
| 依赖 (Dependency) | 是一种使用的关系, 即一个类的实现需要另一个类的协助, 所以要尽量不使用双向的互相依赖.用一个带箭头的虚线,指向被使用者 | |
| 聚合 (Aggregation) | 聚合是一种特殊的关联 (Association) 形式,表示两个对象之间的所属 (has-a) 关系。所有者对象称为聚合对象,它的类称为聚合类;从属对象称为被聚合对象,它的类称为被聚合类。例如,一个公司有很多员工就是公司类 Company 和员工类Employee 之间的一种聚合关系。被聚合对象和聚合对象有着各自的生命周期,即如果公司倒闭并不影响员工的存在。用一个带空心菱形的实心线,菱形指向整体 | |
| 组合 (Composition) | 是整体与部分的关系, 但部分不能离开整体而单独存在. 如公司和部门是整体和部分的关系, 没有公司就不存在部门。用一个带实心菱形的实线,菱形指向整体表示。 |
注意事项
侧重类的整体特性,就用类图;侧重类的内部结构,就使用组合结构图。
组合结构图例子
对象图 (Object Diagram)
概念
显示某时刻对象和对象之间的关系
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 对象 (Object) | 代表某个事物 | |
| 实例链接 (Instance Link) | 链是类之间关系的实例 | |
| 依赖 (Dependency) | 想当于 A 对象使用 B 对象里面的属性 |
对象图例子
包图 (Package Diagram)
概念
包与包的之间的关系
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 包 (Package) | 当对一个比较复杂的软件系统进行建模时,会有大量的类、接口、组件、节点和图需要处理;如果放在同一个地方的话,信息量非常的大,显得很乱,不方便查询,所以就对这些信息进行分组,将语义或者功能相同的放在同一个包中,这样就便于理解和处理整个模型 | |
| 泛化 (Generalization) | 是一种继承关系, 表示一般与特殊的关系, 它指定了子类如何特化父类的所有特征和行为。用一个带三角箭头的实线,箭头指向父类表示 | |
| 依赖 (Dependency) | 是一种使用的关系, 即一个类的实现需要另一个类的协助, 所以要尽量不使用双向的互相依赖.用一个带箭头的虚线,指向被使用者 |
包图例子
动态图
时序图 (Sequence Diagram)
概念
时序图(Sequence Diagram) , 又名序列图、循序图、顺序图,是一种UML交互图。
它通过描述对象之间发送消息的时间顺序显示多个对象之间的动态协作。
它可以表示用例的行为顺序,当执行一个用例行为时,其中的每条消息对应一个类操作或状态机中引起转换的触发事件。
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 参与者 (Actor) | 表示与你自己的程序或者系统进行正在交互的动作。用一个小人表示 | |
| 对象 (Object) | 代表某个事物 | |
| 控制焦点 (Activation) | 控制焦点是顺序图中表示时间段的符号,在这个时间段内对象将执行相应的操作。用小矩形表示 | |
| 消息 (Message) | 消息一般分为同步消息(Synchronous Message),异步消息(Asynchronous Message)和返回消息(Return Message) |
时序图例子
需求:这里为了简单就用一个登陆的时序图为参考
通讯图 (Communication Diagram)
概念
顺序图强调先后顺序,通信图则是强调相互之间的关系。顺序图和通信图基本同构,但是很少使用通信图,因为顺序图更简洁,更直观。
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 参与者 (Actor) | 表示与你自己的程序或者系统进行正在交互的动作。用一个小人表示 | |
| 对象 (Object) | 代表某个事物 | |
| 实例链接 (Instance Link) | 链是类之间关系的实例 | |
| 消息 (Message) | 消息一般分为同步消息(Synchronous Message),异步消息(Asynchronous Message)和返回消息(Return Message) |
通讯图例子
活动图 (Activity Diagram)
概念
活动图是 UML 用于对系统的动态行为建模的另一种常用工具,它描述活动的顺序,展现从一个活动到另一个活动的控制流。活动图在本质上是一种流程图。活动图着重表现从一个活动到另一个活动的控制流,是内部处理驱动的流程。
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 活动 (Activity) | 活动状态用于表达状态机中的非原子的运行 | |
| 对象节点 (Object Node) | 某件事物的具体代表 | |
| 判断 (Decision) | 对某个事件进行判断 | |
| 同步 (synchronization) | 指发送一个请求,需要等待返回,然后才能够发送下一个请求,有个等待过程; | |
| 开始 (final) | 表示成实心黑色圆点 | |
| 结束 (Flow Final) | 分为活动终止节点(activity final nodes)和流程终止节点(flow final nodes)。而流程终止节点表示是子流程的结束。 |
活动图例子
需求: 点开直播 -> 观看直播的动作
状态图 (Statechart Diagram)
概念
描述了某个对象的状态和感兴趣的事件以及对象响应该事件的行为。转换 (transition) 用标记有事件的箭头表示。状态(state)用圆角矩形表示。通常的做法会包含一个初始状态,当实例创建时,自动从初始状态转换到另外一个状态。
状态图显示了对象的生命周期:即对象经历的事件、对象的转换和对象在这些事件之间的状态。当然,状态图不必要描述所有的事件。
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 开始 (final) | 表示成实心黑色圆点 | |
| 结束 (Flow Final) | 分为活动终止节点(activity final nodes)和流程终止节点(flow final nodes)。而流程终止节点表示是子流程的结束。 | |
| 状态 (state) | 某一时刻变化的记录 | |
| 过渡 (Transition) | 相当于 A 点走向 B 点的过渡 | |
| 同步 (synchronization) | 共同执行一个指令 |
状态图例子
需求: 这里直接借鉴 Activity 官方状态图
交错纵横图 (Interaction overview Diagram)
概念
用来表示多张图之间的关联
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 开始 (final) | 表示成实心黑色圆点 | |
| 结束 (Flow Final) | 分为活动终止节点(activity final nodes)和流程终止节点(flow final nodes)。而流程终止节点表示是子流程的结束。 | |
| 同步 (synchronization) | 共同执行一个指令 | |
| 判断 (Decision) | 对某个事件进行判断 | |
| 流 (Flow) | 事件流的走向 | 可以参考,开始跟结束 |
交错纵横图例子
交互图
组件图 (Component Diagram)
概念
组件图(component diagram)是用来反映代码的物理结构。从组件图中,您可以了解各软件组件(如源代码文件或动态链接库)之间的编译器和运行时依赖关系。使用组件图可以将系统划分为内聚组件并显示代码自身的结构
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 组件 (Component) | 组件用一个左侧带有突出两个小矩形的矩形来表示 | |
| 接口 (Interface) | 接口由一组操作组成,它指定了一个契约,这个契约必须由实现和使用这个接口的构件的所遵循 |
组件图例子
部署图 (Deployment Diagram)
概念
部署图可以用于描述规范级别的架构,也可以描述实例级别的架构。这与类图和对象图有点类似,做系统集成很方便。
构成元素
| 构成元素 | 说明 | 表示符号 |
|---|---|---|
| 节点 (node) | 结点是存在与运行时的代表计算机资源的物理元素,可以是硬件也可以是运行其上的软件系统 | |
| 节点实例 (Node Instance) | 与结点的区别在于名称有下划线 | |
| 物件(Artifact) | 物件是软件开发过程中的产物,包括过程模型(比如用例图、设计图等等)、源代码、可执行程序、设计文档、测试报告、需求原型、用户手册等等。 |
部署图例子
经典例子
微信支付时序图
总结
只要掌握常用的几种图 (用例图、类图、时序图、活动图) ,就已经迈向架构第一步了,加油!
作者:DevYK
链接:https://juejin.cn/post/6844903891067207693
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
iOS- 多页面嵌套(JXPagerView、JXCategoryView)
目录
1. 示例
2. 详细说明Podfile中导入
pod 'JXPagingView/Pager'
pod 'JXCategoryView'1. 示例
VC
// 头部View高
#define JXTableHeaderViewHeight (kIs_iPhoneX?200+44:200)
// 菜单项View高
#define JXheightForHeaderInSection 40
#import <JXPagingView/JXPagerView.h>
#import <JXCategoryView/JXCategoryView.h>
<JXPagerViewDelegate, JXCategoryViewDelegate>
/**
顶部View(自定义View)
*/
@property (nonatomic,strong) ZYTeamplayerHeadView *teamplayerHeadV;
/**
菜单项View
*/
@property (nonatomic,strong) JXCategoryTitleView *categoryView;
/**
内容View
*/
@property (nonatomic, strong) JXPagerView *pagingView;
/**
内容View,建议这里使用控制器
*/
@property (nonatomic, strong) NSArray <ZYTeamplayerContentView *> *listViewArray;
/**
菜单项标题数组
*/
@property (nonatomic,copy) NSArray *itemArr;-(void)viewDidLoad{
[super viewDidLoad];
[self.view addSubview:self.pagingView];
}
#pragma mark - JXPagingViewDelegate
/**
自定义头部视图
*/
- (UIView *)tableHeaderViewInPagerView:(JXPagerView *)pagerView {
return self.teamplayerHeadV;
}
/**
自定义头部视图高
@param pagerView pagerView
@return 头部视图高
*/
- (NSUInteger)tableHeaderViewHeightInPagerView:(JXPagerView *)pagerView {
return JXTableHeaderViewHeight;
}
/**
菜单项View
@param pagerView pagerView
@return 菜单项View
*/
- (UIView *)viewForPinSectionHeaderInPagerView:(JXPagerView *)pagerView {
return self.categoryView;
}
/**
菜单项View高
@param pagerView pagerView
@return 菜单项View高
*/
- (NSUInteger)heightForPinSectionHeaderInPagerView:(JXPagerView *)pagerView {
return JXheightForHeaderInSection;
}
/**
内容子视图数组
@param pagerView pagerView
@return 内容子视图数组
*/
- (NSArray<UIView<JXPagerViewListViewDelegate> *> *)listViewsInPagerView:(JXPagerView *)pagerView {
return self.listViewArray;
}
/**
上下滚动后调用
*/
- (void)mainTableViewDidScroll:(UIScrollView *)scrollView {
//计算偏移量
CGFloat P = scrollView.contentOffset.y/(JXTableHeaderViewHeight-kNavBarAndStatusBarHeight);
}
#pragma mark - JXCategoryViewDelegate
/**
选中菜单项后调用
@param categoryView 菜单项View
@param index 下表
*/
- (void)categoryView:(JXCategoryBaseView *)categoryView didSelectedItemAtIndex:(NSInteger)index {
self.navigationController.interactivePopGestureRecognizer.enabled = (index == 0);
}
/**
滑动并切换内容视图后调用
@param categoryView 菜单项View
@param index 下表
*/
- (void)categoryView:(JXCategoryBaseView *)categoryView didScrollSelectedItemAtIndex:(NSInteger)index{
}
#pragma mark 懒加载
/**
总视图
*/
-(JXPagerView *)pagingView{
if(!_pagingView){
//
_pagingView = [[JXPagerView alloc] initWithDelegate:self];
_pagingView.frame = self.view.bounds;
}
return _pagingView;
}
/**
自定义头部视图
*/
-(ZYTeamplayerHeadView *)teamplayerHeadV{
if(!_teamplayerHeadV){
_teamplayerHeadV=[ZYTeamplayerHeadView new];
[_teamplayerHeadV setFrame:CGRectMake(0, 0, kScreenWidth, JXTableHeaderViewHeight)];
}
return _teamplayerHeadV;
}
/**
菜单项视图View
*/
-(JXCategoryTitleView *)categoryView{
if(!_categoryView){
//
_categoryView = [[JXCategoryTitleView alloc] initWithFrame:CGRectMake(0, 0, kScreenWidth, JXheightForHeaderInSection)];
// dele
_categoryView.delegate = self;
// 设置菜单项标题数组
_categoryView.titles = self.itemArr;
// 背景色
_categoryView.backgroundColor = [UIColor whiteColor];
// 标题色、标题选中色、标题字体、标题选中字体
_categoryView.titleColor = kTitleColor;
_categoryView.titleSelectedColor = kTintClolor;
_categoryView.titleFont=kFont(16);
_categoryView.titleSelectedFont=kFontBold(16);
// 标题色是否渐变过渡
_categoryView.titleColorGradientEnabled = YES;
// 下划线
JXCategoryIndicatorLineView *lineView = [[JXCategoryIndicatorLineView alloc] init];
// 下划线颜色
lineView.indicatorLineViewColor = kTintClolor;
// 下划线宽度
lineView.indicatorLineWidth = 35;
_categoryView.indicators = @[lineView];
// 联动(categoryView和pagingView)
_categoryView.contentScrollView = self.pagingView.listContainerView.collectionView;
// 返回上一页侧滑手势(仅在index==0时有效)
self.navigationController.interactivePopGestureRecognizer.enabled = (_categoryView.selectedIndex == 0);
}
return _categoryView;
}
/**
内容视图数组
*/
-(NSArray<ZYTeamplayerContentView *> *)listViewArray{
if(!_listViewArray){
// 内容视图(通过PageType属性区分页面)
CGRect rect=CGRectMake(0, 0, kScreenWidth, kScreenHeight-kNavBarAndStatusBarHeight-JXTableHeaderViewHeight-JXheightForHeaderInSection);
ZYTeamplayerContentView *playerView = [[ZYTeamplayerContentView alloc] initWithFrame:rect];
[playerView setPageType:ZYTeamplayerContentViewTypePlayer];
ZYTeamplayerContentView *infoView = [[ZYTeamplayerContentView alloc] initWithFrame:rect];
[infoView setPageType:ZYTeamplayerContentViewTypeTeam];
_listViewArray = @[playerView, infoView];
}
return _listViewArray;
}
/**
菜单项标题数组
*/
-(NSArray *)itemArr{
if(!_itemArr){
_itemArr=@[@"球员",@"信息"];
}
return _itemArr;
}添加下拉刷新
__weak typeof(self)weakSelf = self;
self.pagingView.mainTableView.mj_header = [MJRefreshNormalHeader headerWithRefreshingBlock:^{
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(2 * NSEC_PER_SEC)), dispatch_get_main_queue(), ^{
// 修改
// [self.categoryView reloadData];
// [self.pagingView reloadData];
[weakSelf.pagingView.mainTableView.mj_header endRefreshing];
});
}];自定义内容视图View
#import "JXPagerView.h"
typedef enum{
ZYTeamplayerContentViewTypePlayer, // 球员
ZYTeamplayerContentViewTypeTeam, // 信息
}ZYTeamplayerContentViewType;
<JXPagerViewListViewDelegate>
/**
页面类型
*/
@property (nonatomic,assign) ZYTeamplayerContentViewType pageType;@property (nonatomic, copy) void(^scrollCallback)(UIScrollView *scrollView);
// 必须加(用于联动)
- (void)scrollViewDidScroll:(UIScrollView *)scrollView {
self.scrollCallback(scrollView);
}
#pragma mark - JXPagingViewListViewDelegate
- (UIView *)listView {
return self;
}
/**
返回一个可滚动的视图
*/
- (UIScrollView *)listScrollView {
return self.contentTableView;
}
/**
用于联动
*/
- (void)listViewDidScrollCallback:(void (^)(UIScrollView *))callback {
self.scrollCallback = callback;
}
-(void)layoutSubviews{
[self.contentTableView setFrame:self.bounds];
}
-(UITableView *)contentTableView{
if(!_contentTableView){
_contentTableView=[[UITableView alloc]initWithFrame:CGRectZero style:UITableViewStyleGrouped];
[_contentTableView setDelegate:self];
[_contentTableView setDataSource:self];
[_contentTableView setSeparatorStyle:UITableViewCellSeparatorStyleNone];
[_contentTableView setBackgroundColor:[UIColor whiteColor]];
[_contentTableView setContentInset:UIEdgeInsetsMake(0, 0, kNavBarAndStatusBarHeight, 0)]; //
[self addSubview:_contentTableView];
[_contentTableView mas_makeConstraints:^(MASConstraintMaker *make) {
make.left.right.top.bottom.mas_equalTo(0);
}];
}
return _contentTableView;
}2. 详细说明
菜单项
JXCategoryTitleView 文本菜单项
收起阅读 »
美团外卖Android Crash治理之路
Crash率是衡量一个App好坏的重要指标之一,如果你忽略了它的存在,它就会愈演愈烈,最后造成大量用户的流失,进而给公司带来无法估量的损失。本文讲述美团外卖Android客户端团队在将App的Crash率从千分之三做到万分之二过程中所做的大量实践工作,抛砖引玉,希望能够为其他团队提供一些经验和启发。
面临的挑战和成果
面对用户使用频率高,外卖业务增长快,Android碎片化严重这些问题,美团外卖Android App如何持续的降低Crash率,是一项极具挑战的事情。通过团队的全力全策,美团外卖Android App的平均Crash率从千分之三降到了万分之二,最优值万一左右(Crash率统计方式:Crash次数/DAU)。
美团外卖自2013年创建以来,业务就以指数级的速度发展。美团外卖承载的业务,从单一的餐饮业务,发展到餐饮、超市、生鲜、果蔬、药品、鲜花、蛋糕、跑腿等十多个大品类业务。目前美团外卖日完成订单量已突破2000万,成为美团点评最重要的业务之一。美团外卖客户端所承载的业务模块越来越多,产品复杂度越来越高,团队开发人员日益增加,这些都给App降低Crash率带来了巨大的挑战。
Crash的治理实践
对于Crash的治理,我们尽量遵守以下三点原则:
- 由点到面。一个Crash发生了,我们不能只针对这个Crash的去解决,而要去考虑这一类Crash怎么去解决和预防。只有这样才能使得这一类Crash真正被解决。
- 异常不能随便吃掉。随意的使用try-catch,只会增加业务的分支和隐蔽真正的问题,要了解Crash的本质原因,根据本质原因去解决。catch的分支,更要根据业务场景去兜底,保证后续的流程正常。
- 预防胜于治理。当Crash发生的时候,损失已经造成了,我们再怎么治理也只是减少损失。尽可能的提前预防Crash的发生,可以将Crash消灭在萌芽阶段。
常规的Crash治理
常规Crash发生的原因主要是由于开发人员编写代码不小心导致的。解决这类Crash需要由点到面,根据Crash引发的原因和业务本身,统一集中解决。常见的Crash类型包括:空节点、角标越界、类型转换异常、实体对象没有序列化、数字转换异常、Activity或Service找不到等。这类Crash是App中最为常见的Crash,也是最容易反复出现的。在获取Crash堆栈信息后,解决这类Crash一般比较简单,更多考虑的应该是如何避免。下面介绍两个我们治理的量比较大的Crash。
NullPointerException
NullPointerException是我们遇到最频繁的,造成这种Crash一般有两种情况:
- 对象本身没有进行初始化就进行操作。
- 对象已经初始化过,但是被回收或者手动置为null,然后对其进行操作。
针对第一种情况导致的原因有很多,可能是开发人员的失误、API返回数据解析异常、进程被杀死后静态变量没初始化导致,我们可以做的有:
- 对可能为空的对象做判空处理。
- 养成使用@NonNull和@Nullable注解的习惯。
- 尽量不使用静态变量,万不得已使用SharedPreferences来存储。
- 考虑使用Kotlin语言。
针对第二种情况大部分是由于Activity/Fragment销毁或被移除后,在Message、Runnable、网络等回调中执行了一些代码导致的,我们可以做的有:
- Message、Runnable回调时,判断Activity/Fragment是否销毁或被移除;加try-catch保护;Activity/Fragment销毁时移除所有已发送的Runnable。
- 封装LifecycleMessage/Runnable基础组件,并自定义Lint检查,提示使用封装好的基础组件。
- 在BaseActivity、BaseFragment的onDestory()里把当前Activity所发的所有请求取消掉。
IndexOutOfBoundsException
这类Crash常见于对ListView的操作和多线程下对容器的操作。
针对ListView中造成的IndexOutOfBoundsException,经常是因为外部也持有了Adapter里数据的引用(如在Adapter的构造函数里直接赋值),这时如果外部引用对数据更改了,但没有及时调用notifyDataSetChanged(),则有可能造成Crash,对此我们封装了一个BaseAdapter,数据统一由Adapter自己维护通知, 同时也极大的避免了The content of the adapter has changed but ListView did not receive a notification,这两类Crash目前得到了统一的解决。
另外,很多容器是线程不安全的,所以如果在多线程下对其操作就容易引发IndexOutOfBoundsException。常用的如JDK里的ArrayList和Android里的SparseArray、ArrayMap,同时也要注意有一些类的内部实现也是用的线程不安全的容器,如Bundle里用的就是ArrayMap。
系统级Crash治理
众所周知,Android的机型众多,碎片化严重,各个硬件厂商可能会定制自己的ROM,更改系统方法,导致特定机型的崩溃。发现这类Crash,主要靠云测平台配合自动化测试,以及线上监控,这种情况下的Crash堆栈信息很难直接定位问题。下面是常见的解决思路:
- 尝试找到造成Crash的可疑代码,看是否有特异的API或者调用方式不当导致的,尝试修改代码逻辑来进行规避。
- 通过Hook来解决,Hook分为Java Hook和Native Hook。Java Hook主要靠反射或者动态代理来更改相应API的行为,需要尝试找到可以Hook的点,一般Hook的点多为静态变量,同时需要注意Android不同版本的API,类名、方法名和成员变量名都可能不一样,所以要做好兼容工作;Native Hook原理上是用更改后方法把旧方法在内存地址上进行替换,需要考虑到Dalvik和ART的差异;相对来说Native Hook的兼容性更差一点,所以用Native Hook的时候需要配合降级策略。
- 如果通过前两种方式都无法解决的话,我们只能尝试反编译ROM,寻找解决的办法。
我们举一个定制系统ROM导致Crash的例子,根据Crash平台统计数据发现该Crash只发生在vivo V3Max这类机型上,Crash堆栈如下:
java.lang.RuntimeException: An error occured while executing doInBackground()
at android.os.AsyncTask$3.done(AsyncTask.java:304)
at java.util.concurrent.FutureTask.finishCompletion(FutureTask.java:355)
at java.util.concurrent.FutureTask.setException(FutureTask.java:222)
at java.util.concurrent.FutureTask.run(FutureTask.java:242)
at android.os.AsyncTask$SerialExecutor$1.run(AsyncTask.java:231)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1112)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:587)
at java.lang.Thread.run(Thread.java:818)
Caused by: java.lang.NullPointerException: Attempt to invoke interface method 'int java.util.List.size()' on a null object reference
at android.widget.AbsListView$UpdateBottomFlagTask.isSuperFloatViewServiceRunning(AbsListView.java:7689)
at android.widget.AbsListView$UpdateBottomFlagTask.doInBackground(AbsListView.java:7665)
at android.os.AsyncTask$2.call(AsyncTask.java:292)
at java.util.concurrent.FutureTask.run(FutureTask.java:237)
... 4 more
复制代码我们发现原生系统上对应系统版本的AbsListView里并没有UpdateBottomFlagTask类,因此可以断定是vivo该版本定制的ROM修改了系统的实现。我们在定位这个Crash的可疑点无果后决定通过Hook的方式解决,通过源码发现AsyncTask$SerialExecutor是静态变量,是一个很好的Hook的点,通过反射添加try-catch解决。因为修改的是final对象所以需要先反射修改accessFlags,需要注意ART和Dalvik下对应的Class不同,代码如下:
public static void setFinalStatic(Field field, Object newValue) throws Exception {
field.setAccessible(true);
Field artField = Field.class.getDeclaredField("artField");
artField.setAccessible(true);
Object artFieldValue = artField.get(field);
Field accessFlagsFiled = artFieldValue.getClass().getDeclaredField("accessFlags");
accessFlagsFiled.setAccessible(true);
accessFlagsFiled.setInt(artFieldValue, field.getModifiers() & ~Modifier.FINAL);
field.set(null, newValue);
}
复制代码private void initVivoV3MaxCrashHander() {
if (!isVivoV3()) {
return;
}
try {
setFinalStatic(AsyncTask.class.getDeclaredField("SERIAL_EXECUTOR"), new SafeSerialExecutor());
Field defaultfield = AsyncTask.class.getDeclaredField("sDefaultExecutor");
defaultfield.setAccessible(true);
defaultfield.set(null, AsyncTask.SERIAL_EXECUTOR);
} catch (Exception e) {
L.e(e);
}
}
复制代码美团外卖App用上述方法解决了对应的Crash,但是美团App里的外卖频道因为平台的限制无法通过这种方式,于是我们尝试反编译ROM。
Android ROM编译时会将framework、app、bin等目录打入system.img中,system.img是Android系统中用来存放系统文件的镜像 (image),文件格式一般为yaffs2或ext。但Android 5.0开始支持dm-verity后,system.img不再提供,而是提供了三个文件system.new.dat,system.patch.dat,system.transfer.list,因此我们首先需要通过上述的三个文件得到system.img。但我们将vivo ROM解压后发现厂商将system.new.dat进行了分片,如下图所示:
经过对system.transfer.list中的信息和system.new.dat 1 2 3 ... 文件大小对比研究,发现一些共同点,system.transfer.list中的每一个block数*4KB 与对应的分片文件的大小大致相同,故大胆猜测,vivo ROM对system.patch.dat分片也只是单纯的按block先后顺序进行了分片处理。所以我们只需要在转化img前将这些分片文件合成一个system.patch.dat文件就可以了。最后根据system.img的文件系统格式进行解包,拿到framework目录,其中有framework.jar和boot.oat等文件,因为Android4.4之后引入了ART虚拟机,会预先把system/framework中的一些jar包转换为oat格式,所以我们还需要将对应的oat文件通过ota2dex将其解包获得dex文件,之后通过dex2jar和jd-gui查看源码。
OOM
OOM是OutOfMemoryError的简称,在常见的Crash疑难排行榜上,OOM绝对可以名列前茅并且经久不衰。因为它发生时的Crash堆栈信息往往不是导致问题的根本原因,而只是压死骆驼的最后一根稻草。
导致OOM的原因大部分如下:
- 内存泄漏,大量无用对象没有被及时回收导致后续申请内存失败。
- 大内存对象过多,最常见的大对象就是Bitmap,几个大图同时加载很容易触发OOM。
内存泄漏
内存泄漏指系统未能及时释放已经不再使用的内存对象,一般是由错误的程序代码逻辑引起的。在Android平台上,最常见也是最严重的内存泄漏就是Activity对象泄漏。Activity承载了App的整个界面功能,Activity的泄漏同时也意味着它持有的大量资源对象都无法被回收,极其容易造成OOM。
常见的可能会造成Activity泄漏的原因有:
- 匿名内部类实现Handler处理消息,可能导致隐式持有的Activity对象无法回收。
- Activity和Context对象被混淆和滥用,在许多只需要Application Context而不需要使用Activity对象的地方使用了Activity对象,比如注册各类Receiver、计算屏幕密度等等。
- View对象处理不当,使用Activity的LayoutInflater创建的View自身持有的Context对象其实就是Activity,这点经常被忽略,在自己实现View重用等场景下也会导致Activity泄漏。
对于Activity泄漏,目前已经有了一个非常好用的检测工具:LeakCanary,它可以自动检测到所有Activity的泄漏情况,并且在发生泄漏时给出十分友好的界面提示,同时为了防止开发人员的疏漏,我们也会将其上报到服务器,统一检查解决。另外我们可以在debug下使用StrictMode来检查Activity的泄露、Closeable对象没有被关闭等问题。
大对象
在Android平台上,我们分析任一应用的内存信息,几乎都可以得出同样的结论:占用内存最多的对象大都是Bitmap对象。随着手机屏幕尺寸越来越大,屏幕分辨率也越来越高,1080p和更高的2k屏已经占了大半份额,为了达到更好的视觉效果,我们往往需要使用大量高清图片,同时也为OOM埋下了祸根。
对于图片内存优化,我们有几个常用的思路:
- 尽量使用成熟的图片库,比如Glide,图片库会提供很多通用方面的保障,减少不必要的人为失误。
- 根据实际需要,也就是View尺寸来加载图片,可以在分辨率较低的机型上尽可能少地占用内存。除了常用的BitmapFactory.Options#inSampleSize和Glide提供的BitmapRequestBuilder#override之外,我们的图片CDN服务器也支持图片的实时缩放,可以在服务端进行图片缩放处理,从而减轻客户端的内存压力。
分析App内存的详细情况是解决问题的第一步,我们需要对App运行时到底占用了多少内存、哪些类型的对象有多少个有大致了解,并根据实际情况做出预测,这样才能在分析时做到有的放矢。Android Studio也提供了非常好用的Memory Profiler,堆转储和分配跟踪器功能可以帮我们迅速定位问题。
AOP增强辅助
AOP是面向切面编程的简称,在Android的Gradle插件1.5.0中新增了Transform API之后,编译时修改字节码来实现AOP也因为有了官方支持而变得非常方便。
在一些特定情况下,可以通过AOP的方式自动处理未捕获的异常:
- 抛异常的方法非常明确,调用方式比较固定。
- 异常处理方式比较统一。
- 和业务逻辑无关,即自动处理异常后不会影响正常的业务逻辑。典型的例子有读取Intent Extras参数、读取SharedPreferences、解析颜色字符串值和显示隐藏Window等等。
这类问题的解决原理大致相同,我们以Intent Extras为例详细介绍一下。读取Intent Extras的问题在于我们非常常用的方法 Intent#getStringExtra 在代码逻辑出错或者恶意攻击的情况下可能会抛出ClassNotFoundException异常,而我们平时在写代码时又不太可能给所有调用都加上try-catch语句,于是一个更安全的Intent工具类应运而生,理论上只要所有人都使用这个工具类来访问Intent Extras参数就可以防止此类型的Crash。但是面对庞大的旧代码仓库和诸多的业务部门,修改现有代码需要极大成本,还有更多的外部依赖SDK基本不可能使用我们自己的工具类,此时就需要AOP大展身手了。
我们专门制作了一个Gradle插件,只需要配置一下参数就可以将某个特定方法的调用替换成另一个方法:
WaimaiBytecodeManipulator {
replacements(
"android/content/Intent.getIntExtra(Ljava/lang/String;I)I=com/waimai/IntentUtil.getInt(Landroid/content/Intent;Ljava/lang/String;I)I",
"android/content/Intent.getStringExtra(Ljava/lang/String;)Ljava/lang/String;=com/waimai/IntentUtil.getString(Landroid/content/Intent;Ljava/lang/String;)Ljava/lang/String;",
"android/content/Intent.getBooleanExtra(Ljava/lang/String;Z)Z=com/waimai/IntentUtil.getBoolean(Landroid/content/Intent;Ljava/lang/String;Z)Z",
...)
}
}
复制代码上面的配置就可以将App代码(包括第三方库)里所有的Intent.getXXXExtra调用替换成IntentUtil类中的安全版实现。当然,并不是所有的异常都只需要catch住就万事大吉,如果真的有逻辑错误肯定需要在开发和测试阶段及时暴露出来,所以在IntentUtil中会对App的运行环境做判断,Debug下会将异常直接抛出,开发同学可以根据Crash堆栈分析问题,Release环境下则在捕获到异常时返回对应的默认值然后将异常上报到服务器。
依赖库的问题
Android App经常会依赖很多AAR, 每个AAR可能有多个版本,打包时Gradle会根据规则确定使用的最终版本号(默认选择最高版本或者强制指定的版本),而其他版本的AAR将被丢弃。如果互相依赖的AAR中有不兼容的版本,存在的问题在打包时是不能发现的,只有在相关代码执行时才会出现,会造成NoClassDefFoundError、NoSuchFieldError、NoSuchMethodError等异常。如图所示,order和store两个业务库都依赖了platform.aar,一个是1.0版本,一个是2.0版本,默认最终打进APK的只有platform 2.0版本,这时如果order库里用到的platform库里的某个类或者方法在2.0版本中被删除了,运行时就可能发生异常,虽然SDK在升级时会尽量做到向下兼容,但很多时候尤其是第三方SDK是没法得到保证的,在美团外卖Android App v6.0版本时因为这个原因导致热修复功能丧失,因此为了提前发现问题,我们接入了依赖检查插件Defensor。
Defensor在编译时通过DexTask获取到所有的输入文件(也就是被编译过的class文件),然后检查每个文件里引用的类、字段、方法等是否存在。
除此之外我们写了一个Gradle插件SVD(strict version dependencies)来对那些重要的SDK的版本进行统一管理。插件会在编译时检查Gradle最终使用的SDK版本是否和配置中的一致,如果不一致插件会终止编译并报错,并同时会打印出发生冲突的SDK的所有依赖关系。
Crash的预防实践
单纯的靠约定或规范去减少Crash的发生是不现实的。约定和规范受限于组织架构和具体执行的个人,很容易被忽略,只有靠工程架构和工具才能保证Crash的预防长久的执行下去。
工程架构对Crash率的影响
在治理Crash的实践中,我们往往忽略了工程架构对Crash率的影响。Crash的发生大部分原因是源于程序员的不合理的代码,而程序员工作中最直接的接触的就是工程架构。对于一个边界模糊,层级混乱的架构,程序员是更加容易写出引起Crash的代码。在这样的架构里面,即使程序员意识到导致某种写法存在问题,想要去改善这样不合理的代码,也是非常困难的。相反,一个层级清晰,边界明确的架构,是能够大大减少Crash发生的概率,治理和预防Crash也是相对更容易。这里我们可以举几个我们实践过的例子阐述。
业务模块的划分
原来我们的Crash基本上都是由个别同学关注解决的,团队里的每个同学都会提交可能引起Crash的代码,如果负责Crash的同学因为某些事情,暂时没有关注App的Crash率,那么造成Crash的同学也不会知道他的代码引起了Crash。
对于这个问题,我们的做法是App的业务模块化。业务模块化后,每个业务都有都有唯一包名和对应的负责人。当某个模块发生了Crash,可以根据包名提交问题给这个模块的负责人,让他第一时间进行处理。业务模块化本身也是工程架构优先需要考虑的事情之一。
页面跳转路由统一处理页面跳转
对外卖App而言,使用过程中最多的就是页面间的跳转,而页面间跳转经常会造成ActivityNotFoundException,例如我们配了一个scheme,但对方的scheme路径已经发生了变化;又例如,我们调用手机上相册的功能,而相册应用已被用户自己禁用或移除了。解决这一类Crash,其实也很简单,只需要在startActivity增加ActivityNotFoundException异常捕获即可。但一个App里,启动Activity的地方,几乎是随处可见,无法预测哪一处会造成ActivityNotFoundException。
我们的做法是将页面的跳转,都通过我们封装的scheme路由去分发。这样的好处是,通过scheme路由,在工程架构上所有业务都是解耦,模块间不需要相互依赖就可以实现页面的跳转和基本类型参数的传递;同时,由于所有的页面跳转都会走scheme路由,我们只需要在scheme路由里一处加上ActivityNotFoundException异常捕获即可解决这种类型的Crash。路由设计示意图如下:
网络层统一处理API脏数据
客户端的很大一部分的Crash是因为API返回的脏数据。比如当API返回空值、空数组或返回不是约定类型的数据,App收到这些数据,就极有可能发生空指针、数组越界和类型转换错误等Crash。而且这样的脏数据,特别容易引起线上大面积的崩溃。
最早我们的工程的网络层用法是:页面监听网络成功和失败的回调,网络成功后,将JSON数据传递给页面,页面解析Model,初始化View,如图所示。这样的问题就是,网络虽然请求成功了,但是JSON解析Model这个过程可能存在问题,例如没有返回数据或者返回了类型不对的数据,而这个脏数据导致问题会出现在UI层,直接反应给用户。
根据上图,我们可以看到由于网络层只承担了请求网络的职责,没有承担数据解析的职责,数据解析的职责交给了页面去处理。这样使得我们一旦发现脏数据导致的Crash,就只能在网络请求的回调里面增加各种判断去兼容脏数据。我们有几百个页面,补漏完全补不过来。通过几个版本的重构,我们重新划分了网络层的职责,如图所示:
从图上可以看出,重构后的网络层负责请求网络和数据解析,如果存在脏数据的话,在网络层就会发现问题,不会影响到UI层,返回给UI层的都是校验成功的数据。这样改造后,我们发现这类的Crash率有了极大的改善。
大图监控
上面讲到大对象是导致OOM的主要原因之一,而Bitmap是App里最常见的大对象类型,因此对占用内存过大的Bitmap对象的监控就很有必要了。
我们用AOP方式Hook了三种常见图片库的加载图片回调方法,同时监控图片库加载图片时的两个维度:
- 加载图片使用的URL。外卖App中除静态资源外,所有图片都要求发布到专用的图片CDN服务器上,加载图片时使用正则表达式匹配URL,除了限定CDN域名之外还要求所有图片加载时都要添加对应的动态缩放参数。
- 最终加载出的图片结果(也就是Bitmap对象)。我们知道Bitmap对象所占内存和其分辨率大小成正比,而一般情况下在ImageView上设置超过自身尺寸的图片是没有意义的,所以我们要求显示在ImageView中的Bitmap分辨率不允许超过View自身的尺寸(为了降低误报率也可以设定一个报警阈值)。
开发过程中,在App里检测到不合规的图片时会立即高亮出错的ImageView所在的位置并弹出对话框提示ImageView所在的Activity、XPath和加载图片使用的URL等信息,如下图,辅助开发同学定位并解决问题。在Release环境下可以将报警信息上报到服务器,实时观察数据,有问题及时处理。
Lint检查
我们发现线上的很多Crash其实可以在开发过程中通过Lint检查来避免。Lint是Google提供的Android静态代码检查工具,可以扫描并发现代码中潜在的问题,提醒开发人员及早修正,提高代码质量。
但是Android原生提供的Lint规则(如是否使用了高版本API)远远不够,缺少一些我们认为有必要的检测,也不能检查代码规范。因此我们开始开发自定义Lint,目前我们通过自定义Lint规则已经实现了Crash预防、Bug预防、提升性能/安全和代码规范检查这些功能。如检查实现了Serializable接口的类,其成员变量(包括从父类继承的)所声明的类型都要实现Serializable接口,可以有效的避免NotSerializableException;强制使用封装好的工具类如ColorUtil、WindowUtil等可以有效的避免因为参数不正确产生的IllegalArgumentException和因为Activity已经finish导致的BadTokenException。
Lint检查可以在多个阶段执行,包括在本地手动检查、编码实时检查、编译时检查、commit时检查,以及在CI系统中提Pull Request时检查、打包时检查等,如下图所示。更详细的内容可参考《美团外卖Android Lint代码检查实践》。
资源重复检查
在之前的文章《美团外卖Android平台化架构演进实践》中讲述了我们的平台化演进过程,在这个过程中大家很大的一部分工作是下沉,但是下沉不完全就会导致一些类和资源的重复,类因为有包名的限制不会出现问题。但是一些资源文件如layout、drawable等如果同名则下层会被上层覆盖,这时layout里view的id发生了变化就可能导致空指针的问题。为了避免这种问题,我们写了一个Gradle插件通过hook MergeResource这个Task,拿到所有library和主库的资源文件,如果检查到重复则会中断编译过程,输出重复的资源名及对应的library name,同时避免有些资源因为样式等原因确实需要覆盖,因此我们设置了白名单。同时在这个过程中我们也拿到了所有的的图片资源,可以顺手做图片大小的本地监控,如下图所示:
Crash的监控&止损的实践
监控
在经过前面提到的各种检查和测试之后,应用便开始发布了。我们建立了如下图的监控流程,来保证异常发生时能够及时得到反馈并处理。首先是灰度监控,灰度阶段是增量Crash最容易暴露的阶段,如果这个阶段没有很好的把握住,会使得增量变存量,从而导致Crash率上升。如果条件允许的话,可以在灰度期间制定一些灰度策略去提高这个阶段Crash的暴露。例如分渠道灰度、分城市灰度、分业务场景灰度、新装用户的灰度等等,尽量覆盖所有的分支。灰度结束之后便开始全量,在全量的过程中我们还需要一些日常Crash监控和Crash率的异常报警来防止突发情况的发生,例如因为后台上线或者运营配置错误导致的线上Crash。除此之外还需要一些其他的监控,例如,之前提到的大图监控,来避免因为大图导致的OOM。具体的输出形式主要有邮件通知、IM通知、报表。
止损
尽管我们在前面做了那么多,但是Crash还是无法避免的,例如,在灰度阶段因为量级不够,有些Crash没有被暴露出来;又或者某些功能客户端比后台更早上线,而这些功能在灰度阶段没有被覆盖到;这些情况下,如果出现问题就需要考虑如何止损了。
问题发生时首先需要评估重要性,如果问题不是很严重而且修复成本较高可以考虑在下个版本再修复,相反如果问题比较严重,对用户体验或下单有影响时就必须要修复。修复时首先考虑业务降级,主要看该部分异常的业务是否有兜底或者A/B策略,这样是最稳妥也是最有效的方式。如果业务不能降级就需要考虑热修复了,目前美团外卖Android App接入的热修复框架是自研的Robust,可以修复90%以上的场景,热修成功率也达到了99%以上。如果问题发生在热修复无法覆盖的场景,就只能强制用户升级。强制升级因为覆盖周期长,同时影响用户的体验,只在万不得已的情况下才会使用。
展望
Crash的自我修复
我们在做新技术选型时除了要考虑是否能满足业务需求、是否比现有技术更优秀和团队学习成本等因素之外,兼容性和稳定性也非常重要。但面对国内非富多彩的Android系统环境,在体量百万级以上的的App中几乎不可能实现毫无瑕疵的技术方案和组件,所以一般情况下如果某个技术实现方案可以达到0.01‰以下的崩溃率,而其他方案也没有更好的表现,我们就认为它是可以接受的。但是哪怕仅仅十万分之一的崩溃率,也代表还有用户受到影响,而我们认为Crash对用户来说是最糟糕的体验,尤其是涉及到交易的场景,所以我们必须本着每一单都很重要的原则,尽最大努力保证用户顺利执行流程。
实际情况中有一些技术方案在兼容性和稳定性上做了一定妥协的场景,往往是因为考虑到性能或扩展性等方面的优势。这种情况下我们其实可以再多做一些,进一步提高App的可用性。就像很多操作系统都有“兼容模式”或者“安全模式”,很多自动化机械机器都配套有手动操作模式一样,App里也可以实现备用的降级方案,然后设置特定条件的触发策略,从而达到自动修复Crash的目的。
举例来讲,Android 3.0中引入了硬件加速机制,虽然可以提高绘制帧率并且降低CPU占用率,但是在某些机型上还是会有绘制错乱甚至Crash的情况,这时我们就可以在App中记录硬件加速相关的Crash问题或者使用检测代码主动检测硬件加速功能是否正常工作,然后主动选择是否开启硬件加速,这样既可以让绝大部分用户享受硬件加速带来的优势,也可以保障硬件加速功能不完善的机型不受影响。
还有一些类似的可以做自动降级的场景,比如:
- 部分使用JNI实现的模块,在SO加载失败或者运行时发生异常则可以降级为Java版实现。
- RenderScript实现的图片模糊效果,也可以在失败后降级为普通的Java版高斯模糊算法。
- 在使用Retrofit网络库时发现OkHttp3或者HttpURLConnection网络通道失败率高,可以主动切换到另一种通道。
这类问题都需要根据具体情况具体分析,如果可以找到准确的判定条件和稳定的修复方案,就可以让App稳定性再上一个台阶。
特定Crash类型日志自动回捞
外卖业务发展迅速,即使我们在开发时使用各种工具、措施来避免Crash的发生,但Crash还是不可避免。线上某些怪异的Crash发生后,我们除了分析Crash堆栈信息之外,还可以使用离线日志回捞、下发动态日志等工具来还原Crash发生时的场景,帮助开发同学定位问题,但是这两种方式都有它们各自的问题。离线日志顾名思义,它的内容都是预先记录好的,有时候可能会漏掉一些关键信息,因为在代码中加日志一般只是在业务关键点,在大量的普通方法中不可能都加上日志。动态日志(Holmes)存在的问题是每次下发只能针对已知UUID的一个用户的一台设备,对于大量线上Crash的情况这种操作并不合适,因为我们并不能知道哪个发生Crash的用户还会再次复现这次操作,下发配置充满了不确定性。
我们可以改造Holmes使其支持批量甚至全量下发动态日志,记录的日志等到发生特定类型的Crash时才上报,这样一来可以减少日志服务器压力,同时也可以极大提高定位问题的效率,因为我们可以确定上报日志的设备最后都真正发生了该类型Crash,再来分析日志就可以做到事半功倍。
总结
业务的快速发展,往往不可能给团队充足的时间去治理Crash,而Crash又是App最重要的指标之一。团队需要由一个个Crash个例,去探究每一个Crash发生的最本质原因,找到最合理解决这类Crash的方案,建立解决这一类Crash的长效机制,而不能饮鸩止渴。只有这样,随着版本的不断迭代,我们才能在Crash治理之路上离目标越来越近。
作者:美团技术团队
链接:https://juejin.cn/post/6844903620920492046
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin集成Arouter
使用场景
为了软件间的解耦操作,确保模块之间
Activity的相互跳转不受影响。故引用阿里巴巴的Arouter。但官网上还没有针对Kotlin的集成说明,故在此记录下来
如何使用
gradle配置- 目录配置,常量类配置
- 在
Application中进行Arouter初始化 Activity的配置
1. gradle配置
注意需要在两个地方进行配置
1.根目录下的build.gradle中配置,在dependencies中增加arouter-register引用
dependencies {
classpath "com.alibaba:arouter-register:1.0.2"
}
复制代码2.在模块所在的build.gradle中添加引用及编译配置
plugins {
// 1.增加kotlin-kapt引用
id 'kotlin-kapt'
}
android {
// 2.增加Arouter编译配置,注意顺序。此处应该在android{}中
kapt {
arguments {
arg("AROUTER_MODULE_NAME", project.getName())
}
}
}
dependencies {
// 3. 添加gradle引用
implementation 'com.alibaba:arouter-api:1.5.1'
kapt "com.alibaba:arouter-compiler:1.5.1"
}
复制代码注意:此处的与官网教程不一样。官网的配置是针对java的,所以我没有使用
javaCompileOptions和annotationProcessor'com.alibaba:arouter-compiler:1.5.1'这两个配置对kotlin不生效。
2. 目录配置,常量类配置
新建一个ui包用于存放需要跳转的Activity,随后新建一个Constant的Object文件。添加Activity的常量资源
常量类Constants
object Constants {
object Activitys{
const val RECYCLELIST_ACTIVITY = "/ui/RecycleListActivity"
}
}
复制代码目录结构
3. 在Application中进行Arouter初始化
class App : Application() {
override fun onCreate() {
super.onCreate()
if (BuildConfig.DEBUG){
ARouter.openLog()
ARouter.openDebug()
}
ARouter.init(this)
}
override fun onTerminate() {
super.onTerminate()
ARouter.getInstance().destroy()
}
}
复制代码**注意:**此处有两个小坑。
- 重写的
APP类需要在Manifest中进行添加,否则不会执行。(只需要在application节点中添加name并指向这个类即可) - 注意
BuildConfig这个类是引用谁的,因为Arouter本身也有BuildConfig。此处需要引用Anroid的BuildConfig。博主引用错了后,一直无法跳转。而且也一直没有报错,坑了很久
4. Activity的配置
以上工作做完后,就可以在需要跳转的Activity进行配置了。
跳转到的Activity,增加@Route注解
@Route(path = Constants.Activitys.RECYCLELIST_ACTIVITY)
class RecycleListActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_recycle_list)
}
}
复制代码需要进行跳转的Activity,调用Arouter单例进行跳转
mBtnList.setOnClickListener {
ARouter.getInstance().build(Constants.Activitys.RECYCLELIST_ACTIVITY).navigation()
}作者:约束№证
链接:https://juejin.cn/post/6955465825809760286
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Object类和Any详解
Any
Any类是kotlin类结构的跟,每个kotlin都继承或间接继承于Any类
/**
* The root of the Kotlin class hierarchy. Every Kotlin class has [Any] as a superclass.
*/
public open class Any {
// kotlin的函数可以没有函数体,其不是Abstract方法,所以子类不必重写。
public open operator fun equals(other: Any?): Boolean
public open fun hashCode(): Int
public open fun toString(): String
}
复制代码里面有三个open的方法equals、hashCode和toString,其中equals和hashCode如果需要修改就必须同时修改。
Object
同样java中Object也是class结构的根,每个类继承或者间接继承于Object
package java.lang;
public class Object {
public Object() {
}
private static native void registerNatives();
public final native Class<?> getClass();
public native int hashCode();
public boolean equals(Object var1) {
return this == var1;
}
protected native Object clone() throws CloneNotSupportedException;
public String toString() {
return this.getClass().getName() + "@" + Integer.toHexString(this.hashCode());
}
public final native void notify();
public final native void notifyAll();
public final native void wait(long var1) throws InterruptedException;
public final void wait(long var1, int var3) throws InterruptedException {
if (var1 < 0L) {
throw new IllegalArgumentException("timeout value is negative");
} else if (var3 >= 0 && var3 <= 999999) {
if (var3 > 0) {
++var1;
}
this.wait(var1);
} else {
throw new IllegalArgumentException("nanosecond timeout value out of range");
}
}
public final void wait() throws InterruptedException {
this.wait(0L);
}
protected void finalize() throws Throwable {
}
static {
registerNatives();
}
}
复制代码相比于Kotlin,java中的class方法丰富的多,十二个。其中7个本地方法包含一个静态本地方法,5个可以被子类覆盖的方法
private static native void registerNatives();
static {
registerNatives();
}
复制代码静态本地方法在类加载时执行。该方法的作用是通过类加载器加载一些本地方法到JVM中。Object类在被加载时,会加载一些methods中的本地方法到JVM中如下:
static JNINativeMethod methods[] = {
{“hashCode”, “()I”, (void *)&JVM_IHashCode},
{“wait”, “(J)V”, (void *)&JVM_MonitorWait},
{“notify”, “()V”, (void *)&JVM_MonitorNotify},
{“notifyAll”, “()V”, (void *)&JVM_MonitorNotifyAll},
{“clone”, “()Ljava/lang/Object;”, (void *)&JVM_Clone},
};
复制代码@Contract(pure = true) public final native Class<?> getClass();
返回该对象的类的Class对象。Class对象可以用于反射等场景。
public native int hashCode();
返回对象的哈希值,主要用于HashMap的hash tables。
哈希需要注意的几点:
相等的对象必须要有相同的哈希码
不相等的对象一定有着不同的哈希码——错!
有同一个哈希值的对象一定相等——错!
重写equals时必须重写hashCode
equals
public boolean equals(Object var1) {
return this == var1;
}
复制代码判断引用是否指向同一个地址,就是判断两个引用指向的对象是否是同一个对象, String重写了该方法,判断字符串是否相等。
protected native Object clone() throws CloneNotSupportedException;
该方法用于拷贝。要调用该方法需要类实现Cloneable接口,否则抛出CloneNotSupportedException。
浅拷贝,重写clone方法,调用super.clone():
public class TestOne implements Cloneable {
@NonNull
@Override
protected TestOne clone() {
TestOne obj = null;
try {
obj = (TestOne) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return obj;
}
}
复制代码深拷贝
public class TestTwo implements Cloneable {
public TestOne var;
@NonNull
@Override
protected TestTwo clone() {
TestTwo obj = null;
try {
obj = (TestTwo) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
obj.var = obj.var.clone();
return obj;
}
}
复制代码public String toString()
返回类名和对象的哈希值的十六进制字符串,推荐子类重写该方法。
notify()、notifyAll()、wait()方法
从1.0版开始,Java中的每一个对象都有一个内部锁。如果一个方法用synchronized关键字声明,那么对象的锁将保护整个方法。也就是说,要调用该方法,线程必须获得内部的对象锁。
public synchronize void method(){
method body
}
等同于
public void method(){
this.intrinsicLock.lock();
try{
method body
}
finally{ this.intrinsicLock.unlock();}
}
复制代码从这个示例我们即可看出上面几个方法的作用。
public final native void notify();
随机选择一个在该对象上调用wait方法的线程,解除其阻塞状态。该方法只能在一个同步方法或同步块中调用。如果当前线程不是对象锁的持有者,该方法抛出一个IllegalMonitorStateException异常。
public final native void notifyAll();
解除那些在该对象上调用wait方法的线程的阻塞状态。该方法只能在同步方法或同步块内部调用。如果当前线程不是对象锁的持有者,该方法抛出一个IllegalMonitorStateException异常。
public final void wait() throws InterruptedException
使线程进入等待状态直到它被通知。该方法只能在一个同步方法中调用。如果当前线程不是对象锁的持有者,该方法抛出一个IllegalMonitorStateException异常。
public final void wait(long millis, int nanos) throws InterruptedException
public final native void wait(long millis) throws InterruptedException;
参数:millis 毫秒数 nanos 纳秒数 < 1000 000
使线程进入等待状态直到它被通知或者经过指定的时间。这些方法只能在一个同步方法中调用。如果当前线程不是对象锁的持有者该方法抛出一个IllegalMonitorStateException异常。
protected void finalize() throws Throwable
当一个堆空间中的对象没有被栈空间变量指向的时候,这个对象会等待被java回收。
GC特点:
- 当对象不再被程序所使用的时候,垃圾回收器将会将其回收
- 垃圾回收是在后台运行的,我们无法命令垃圾回收器马上回收资源,但是我们可以告诉他可以尽快回收资源(System.gc()和Runtime.getRuntime().gc())
- 垃圾回收器在回收某个对象的时候,首先会调用该对象的finalize()方法
- GC主要针对堆内存
- 单例模式的缺点
Any和Object相同点
Kotlin中的Any只存在于编译期,运行期就不存在了。
val any = Any()
println("any:$any ")
println("anyClass:${any.javaClass} ")
val obj = any as Object
synchronized(obj){
obj.wait()
}
println("obj:$obj ")
println("obj:${any.`class`} ")
I/System.out: any:java.lang.Object@d12ebc1
I/System.out: anyClass:class java.lang.Object
I/System.out: obj:java.lang.Object@d12ebc1
I/System.out: obj:class java.lang.Object
复制代码从上面的示例可以看出在runtime,Any变成了Object,在kotlin中也可以将Any强转为Object。
从Kolitn的官方文档 kotlinlang.org/docs/java-i… 可以看到Object对应的就是Any
Kotlin专门处理一些Java类型。这些类型不是按原样从Java加载的,而是映射到相应的Kotlin类型。映射只在编译时起作用,运行时表示保持不变。Java的原语类型映射到相应的Kotlin类型(保持平台类型)
从上面的示例可以看出obj可以any混用,any强转后不仅可以使用notify()等方法,还可以使用Any的扩展方法,如使用 obj.apply { }
作者:zbt
链接:https://juejin.cn/post/6955413784143855629
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
iOS-TZImagePickerController获取图片视频
TZImagePickerControllerDemo
项目介绍
TZImagePickerControllerDemo
使用说明
1. 定义 类变量:
UIImagePickerController* picker_library_;
2.实现 UIImagePickerControllerDelegate 这个delegate,还需要UINavigationControllerDelegate 这个代理
3. 以模态的方式,显示 图片选取器
picker_library_ = [[UIImagePickerController alloc] init];
picker_library_.sourceType = UIImagePickerControllerSourceTypePhotoLibrary;
picker_library_.allowsEditing = YES;
picker_camera_.allowsImageEditing=YES;
picker_library_.delegate = self;
[self presentModalViewController: picker_library_
animated: YES];其中,sourceType 指定了 几种 图片的来源:
UIImagePickerControllerSourceTypePhotoLibrary:表示显示所有的照片
UIImagePickerControllerSourceTypeCamera:表示从摄像头选取照片
UIImagePickerControllerSourceTypeSavedPhotosAlbum:表示仅仅从相册中选取照片。
allowEditing和allowsImageEditing 设置为YES,表示 允许用户编辑图片,否则,不允许用户编辑。
选照片
//MaxImagesCount 可以选着的最大条目数
TZImagePickerController *imagePicker = [[TZImagePickerController alloc] initWithMaxImagesCount:1 delegate:self];
// 是否显示可选原图按钮
imagePicker.allowPickingOriginalPhoto = NO;
// 是否允许显示视频
imagePicker.allowPickingVideo = NO;
// 是否允许显示图片
imagePicker.allowPickingImage = YES;
// 这是一个navigation 只能present
[self presentViewController:imagePicker animated:YES completion:nil];选择照片的回调
// 选择照片的回调
-(void)imagePickerController:(TZImagePickerController *)picker
didFinishPickingPhotos:(NSArray<UIImage *> *)photos
sourceAssets:(NSArray *)assets
isSelectOriginalPhoto:(BOOL)isSelectOriginalPhoto{
}选视频
//MaxImagesCount 可以选着的最大条目数
TZImagePickerController *imagePicker = [[TZImagePickerController alloc] initWithMaxImagesCount:2 delegate:self];
// 是否显示可选原图按钮
imagePicker.allowPickingOriginalPhoto = NO;
// 是否允许显示视频
imagePicker.allowPickingVideo = YES;
// 是否允许显示图片
imagePicker.allowPickingImage = NO;
// 这是一个navigation 只能present
[self presentViewController:imagePicker animated:YES completion:nil];选择视频的回调
// 选择视频的回调
-(void)imagePickerController:(TZImagePickerController *)picker
didFinishPickingVideo:(UIImage *)coverImage
sourceAssets:(PHAsset *)asset{
}Android修炼系列(五),写一篇超全面的annotation讲解(2)
自定义编译期注解(CLASS)
为什么要最后说编译期注解呢,因为相对前面的自定义注解来说,编译期注解有些难度,涉及到的东西比较多,但却是平时用到的最多的注解,因为编译期注解不存在反射,所以对性能没有影响。
本来也想用绑定 View 的例子讲解,但是现在这样的 demo 网上各种泛滥,而且还有各路大牛写的,所以我就没必要班门弄斧了。在这里以跳转界面为例:
Intent intent = new Intent (this, NextActivity.class);
startActivity (intent);
复制代码本着方便就是改进的原则,让我们定义一个编译期注解,来自动生成上述的代码,想想每次需要的时候只需要一个注解就能跳转到想要跳转的界面是不是很刺激。
1.首先新建一个 android 项目,在创建两个 java module(File -> New -> new Module ->java Module),因为有的类在android项目中不支持,建完后项目结构如下:
其中 annotation 中盛放自定义的注解,annotationprocessor 中创建注解处理器并做相关处理,最后的 app 则为我们的项目。
注意:MyFirstProcessor类为上文讲解 AbstractProcessor 所建的类,可以删去,跟本项目没有关系。
2.处理各自的依赖
3.编写自定义注解,这是一个应用到字段之上的注解,被注解的字段为传递的参数
/**
* 这是一个自定义的跳转传值所用到的注解。
* value 表示要跳转到哪个界面activity的元素,传入那个界面的名字。
*/
@Retention(RetentionPolicy.CLASS)
@Target(ElementType.FIELD)
public @interface IntentField {
String value () default " ";
}
复制代码4.自定义注解处理器,获取被注解元素的类型,进行相应的操作。
@AutoService(javax.annotation.processing.Processor.class)
public class MyProcessot extends AbstractProcessor{
private Map<Element, List<VariableElement>> items = new HashMap<>();
private List<Generator> generators = new LinkedList<>();
// 做一些初始化工作
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
super.init(processingEnvironment);
Utils.init();
generators.add(new ActivityEnterGenerator());
generators.add(new ActivityInitFieldGenerator());
}
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
// 获取所有注册IntentField注解的元素
for (Element elem : roundEnvironment.getElementsAnnotatedWith(IntentField.class)) {
// 主要获取ElementType 是不是null,即class,interface,enum或者注解类型
if (elem.getEnclosingElement() == null) {
// 直接结束处理器
return true;
}
// 如果items的key不存在,则添加一个key
if (items.get(elem.getEnclosingElement()) == null) {
items.put(elem.getEnclosingElement(), new LinkedList<VariableElement>());
}
// 我们这里的IntentField是应用在一般成员变量上的注解
if (elem.getKind() == ElementKind.FIELD) {
items.get(elem.getEnclosingElement()).add((VariableElement)elem);
}
}
List<VariableElement> variableElements;
for (Map.Entry<Element, List<VariableElement>> entry : items.entrySet()) {
variableElements = entry.getValue();
if (variableElements == null || variableElements.isEmpty()) {
return true;
}
// 去通过自动javapoet生成代码
for (Generator generator : generators) {
generator.genetate(entry.getKey(), variableElements, processingEnv);
generator.genetate(entry.getKey(), variableElements, processingEnv);
}
}
return false;
}
// 指定当前注解器使用的Java版本
@Override public SourceVersion getSupportedSourceVersion() {
return SourceVersion.latestSupported();
}
// 指出注解处理器 处理哪种注解
@Override
public Set<String> getSupportedAnnotationTypes() {
Set<String> annotations = new LinkedHashSet<>(2);
annotations.add(IntentField.class.getCanonicalName());
return annotations;
}
}
复制代码5.这是一个工具类方法,提供了本 demo 中所用到的一些方法,其实实际里面的方法都很常见,只不过做了一个封装而已.
public class Utils {
private static Set<String> supportTypes = new HashSet<>();
/** 当getIntent的时候,每种类型写的方式都不一样,所以把每种方式都添加到了Set容器中。*/
static void init() {
supportTypes.add(int.class.getSimpleName());
supportTypes.add(int[].class.getSimpleName());
supportTypes.add(short.class.getSimpleName());
supportTypes.add(short[].class.getSimpleName());
supportTypes.add(String.class.getSimpleName());
supportTypes.add(String[].class.getSimpleName());
supportTypes.add(boolean.class.getSimpleName());
supportTypes.add(boolean[].class.getSimpleName());
supportTypes.add(long.class.getSimpleName());
supportTypes.add(long[].class.getSimpleName());
supportTypes.add(char.class.getSimpleName());
supportTypes.add(char[].class.getSimpleName());
supportTypes.add(byte.class.getSimpleName());
supportTypes.add(byte[].class.getSimpleName());
supportTypes.add("Bundle");
}
/** 获取元素所在的包名。*/
public static String getPackageName(Element element) {
String clazzSimpleName = element.getSimpleName().toString();
String clazzName = element.toString();
return clazzName.substring(0, clazzName.length() - clazzSimpleName.length() - 1);
}
/** 判断是否是String类型或者数组或者bundle,因为这三种类型getIntent()不需要默认值。*/
public static boolean isElementNoDefaultValue(String typeName) {
return (String.class.getName().equals(typeName) || typeName.contains("[]") || typeName.contains("Bundle"));
}
/**
* 获得注解要传递参数的类型。
* @param typeName 注解获取到的参数类型
*/
public static String getIntentTypeName(String typeName) {
for (String name : supportTypes) {
if (name.equals(getSimpleName(typeName))) {
return name.replaceFirst(String.valueOf(name.charAt(0)), String.valueOf(name.charAt(0)).toUpperCase())
.replace("[]", "Array");
}
}
return "";
}
/**
* 获取类的的名字的字符串。
* @param typeName 可以是包名字符串,也可以是类名字符串
*/
static String getSimpleName(String typeName) {
if (typeName.contains(".")) {
return typeName.substring(typeName.lastIndexOf(".") + 1, typeName.length());
}else {
return typeName;
}
}
/** 自动生成代码。*/
public static void writeToFile(String className, String packageName, MethodSpec methodSpec, ProcessingEnvironment processingEnv, ArrayList<FieldSpec> listField) {
TypeSpec genedClass;
if(listField == null) {
genedClass = TypeSpec.classBuilder(className)
.addModifiers(Modifier.PUBLIC, Modifier.FINAL)
.addMethod(methodSpec).build();
}else{
genedClass = TypeSpec.classBuilder(className)
.addModifiers(Modifier.PUBLIC, Modifier.FINAL)
.addMethod(methodSpec)
.addFields(listField).build();
}
JavaFile javaFile = JavaFile.builder(packageName, genedClass)
.build();
try {
javaFile.writeTo(processingEnv.getFiler());
} catch (IOException e) {
e.printStackTrace();
}
}
}
复制代码6.自定义一个接口,把需要自动生成的每个java文件的方法都独立出去。
public interface Generator {
void genetate(Element typeElement
, List<VariableElement> variableElements
, ProcessingEnvironment processingEnv);
}
复制代码7.编写自动生成文件的格式,生成后的类格式如下:
上图为本例中的MainActivity$Enter类,如果你想生成一个类,那么这个类的格式和作用肯定已经在你的脑海中有了定型,如果你自己都不知道想要生成啥,那还玩啥。
/**
* 这是一个要自动生成跳转功能的.java文件类
* 主要思路:1.使用javapoet生成一个空方法
* 2.为方法加上实参
* 3.方法的里面的代码拼接
* 主要需要:获取字段的类型和名字,获取将要跳转的类的名字
*/
public class ActivityEnterGenerator implements Generator{
private static final String SUFFIX = "$Enter";
private static final String METHOD_NAME = "intentTo";
@Override
public void genetate(Element typeElement, List<VariableElement> variableElements, ProcessingEnvironment processingEnv) {
MethodSpec.Builder methodBuilder = MethodSpec.methodBuilder(METHOD_NAME)
.addModifiers(Modifier.PUBLIC)
.returns(void.class);
// 设置生成的METHOD_NAME方法第一个参数
methodBuilder.addParameter(Object.class, "context");
methodBuilder.addStatement("android.content.Intent intent = new android.content.Intent()");
// 获取将要跳转的类的名字
String name = "";
// VariableElement 主要代表一般字段元素,是Element的一种
for (VariableElement element : variableElements) {
// Element 只是一种语言元素,本身并不包含信息,所以我们这里获取TypeMirror
TypeMirror typeMirror = element.asType();
// 获取注解在身上的字段的类型
TypeName type = TypeName.get(typeMirror);
// 获取注解在身上字段的名字
String fileName = element.getSimpleName().toString();
// 设置生成的METHOD_NAME方法第二个参数
methodBuilder.addParameter(type, fileName);
methodBuilder.addStatement("intent.putExtra(\"" + fileName + "\"," +fileName + ")");
// 获取注解上的元素
IntentField toClassName = element.getAnnotation(IntentField.class);
String name1 = toClassName.value();
if(null != name && "".equals(name)){
name = name1;
}
// 理论上每个界面上的注解value一样,都是要跳转到的那个类名字,否则提示错误
else if(name1 != null && !name1.equals(name)){
processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR, "同一个界面不能跳转到多个活动,即value必须一致");
}
}
methodBuilder.addStatement("intent.setClass((android.content.Context)context, " + name +".class)");
methodBuilder.addStatement("((android.content.Context)context).startActivity(intent)");
/**
* 自动生成.java文件
* 第一个参数:要生成的类的名字
* 第二个参数:生成类所在的包的名字
* 第三个参数:javapoet 中提供的与自动生成代码的相关的类
* 第四个参数:能够为注解器提供Elements,Types和Filer
*/
Utils.writeToFile(typeElement.getSimpleName().toString() + SUFFIX, Utils.getPackageName(typeElement), methodBuilder.build(), processingEnv,null);
}
}
复制代码当我们定义了跳转的类,那么接下来肯定就是在另一个界面获取传递过来的数据了,参考格式如下,这是本demo中自动生成的MainActivity$Init 类。
/**
* 要生成一个.Java文件,在这个Java文件里生成一个获取上个界面传递过来数据的方法
* 主要思路:1.使用Javapoet生成一个空的的方法
* 2.为方法添加需要的形参
* 3.拼接方法内部的代码
* 主要需要:获取传递过来字段的类型
*/
public class ActivityInitFieldGenerator implements Generator {
private static final String SUFFIX = "$Init";
private static final String METHOD_NAME = "initFields";
@Override
public void genetate(Element typeElement, List<VariableElement> variableElements, ProcessingEnvironment processingEnv) {
MethodSpec.Builder methodBuilder = MethodSpec.methodBuilder(METHOD_NAME)
.addModifiers(Modifier.PROTECTED)
.returns(Object.class);
final ArrayList<FieldSpec> listField = new ArrayList<>();
if (null != variableElements && variableElements.size() != 0) {
VariableElement element = variableElements.get(0);
// 当前接收数据的字段的名字
IntentField currentClassName = element.getAnnotation(IntentField.class);
String name = currentClassName.value();
methodBuilder.addParameter(Object.class, "currentActivity");
methodBuilder.addStatement(name + " activity = (" + name + ")currentActivity");
methodBuilder.addStatement("android.content.Intent intent = activity.getIntent()");
}
for (VariableElement element : variableElements) {
// 获取接收字段的类型
TypeName currentTypeName = TypeName.get(element.asType());
String currentTypeNameStr = currentTypeName.toString();
String intentTypeName = Utils.getIntentTypeName(currentTypeNameStr);
// 字段的名字,即key值
Name filedName = element.getSimpleName();
// 创建成员变量
FieldSpec fieldSpec = FieldSpec.builder(TypeName.get(element.asType()),filedName+"")
.addModifiers(Modifier.PUBLIC)
.build();
listField.add(fieldSpec);
// 因为String类型的获取 和 其他基本类型的获取在是否需要默认值问题上不一样,所以需要判断是哪种
if (Utils.isElementNoDefaultValue(currentTypeNameStr)) {
methodBuilder.addStatement("this."+filedName+"= intent.get" + intentTypeName + "Extra(\"" + filedName + "\")");
} else {
String defaultValue = "default" + element.getSimpleName();
if (intentTypeName == null) {
// 当字段类型为null时,需要打印错误信息
processingEnv.getMessager().printMessage(Diagnostic.Kind.ERROR, "the type:" + element.asType().toString() + " is not support");
} else {
if ("".equals(intentTypeName)) {
methodBuilder.addStatement("this." + filedName + "= (" + TypeName.get(element.asType()) + ")intent.getSerializableExtra(\"" + filedName + "\")");
} else {
methodBuilder.addParameter(TypeName.get(element.asType()), defaultValue);
methodBuilder.addStatement("this."+ filedName +"= intent.get"
+ intentTypeName + "Extra(\"" + filedName + "\", " + defaultValue + ")");
}
}
}
}
methodBuilder.addStatement("return this");
Utils.writeToFile(typeElement.getSimpleName().toString() + SUFFIX, Utils.getPackageName(typeElement), methodBuilder.build(), processingEnv, listField);
}
}
复制代码8、在Activity中使用刚才的自定义注解。
public class MainActivity extends AppCompatActivity {
@IntentField("NextActivity")
int count = 10;
@IntentField("NextActivity")
String str = "编译器注解";
@IntentField("NextActivity")
StuBean bean = new StuBean(1,"No1");
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
addOnclickListener();
}
public void addOnclickListener() {
findViewById(R.id.tvnext).setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
// 从哪个界面进行跳转,则以哪个界面打头,enter 结尾
// 例如 MainActivity$Enter
new MainActivity$Enter()
.intentTo(MainActivity.this, count, str, bean);
}
});
}
}
复制代码9.这是实体bean
public class StuBean implements Serializable{
public StuBean(int id , String name) {
this.id = id;
this.name = name;
}
//学号
public int id;
//姓名
public String name;
}
复制代码10、在NextActivity接收并打印数据:
public class NextActivity extends AppCompatActivity {
private TextView textView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_next);
textView = (TextView) findViewById(R.id.tv);
// 想获取从哪个界面传递过来的数据,就已哪个类打头,init结尾
// 例如 MainActivity$Init
MainActivity$Init formIntent = (MainActivity$Init)new MainActivity$Init().initFields(this,0);
textView.setText(formIntent.count + "---" + formIntent.str + "---" +formIntent.bean.name);
// 打印上个界面传递过来的数据
Log.i("Tag",formIntent.count + "---" + formIntent.str + "---" + formIntent.bean.name);
}
}
复制代码11.运行结果:
总结
好了,看到这里,你应该对注解有所了解了,但是看的再懂也不如自己动手练一下。如果你仔细研究了,你会发现一个非常奇怪的事情,当我们设置 RetentionPolicy.CLASS 级别的时候,仍能通过反射获取注解信息,当我们设置 RetentionPolicy.SOURCE 级别的时候,仍能走通编译期注解,是不是非常迷惑。
之后只能又找了一些资料(非权威),看到了一个比较受认同的解释:这个属性主要给IDE 或者编译器开发者准备的,一般应用级别上不太会用到。
好了,本文到这里就结束了,关于注解的讲解应该非常全面了。如果本文对你有用,来点个赞吧,大家的肯定也是阿呆i坚持写作的动力。
参考 1、B.E,Java编程思想:机械工业出版社
作者:矛盾的阿呆i
链接:https://juejin.cn/post/6936609673416015908
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android修炼系列(五),写一篇超全面的annotation讲解(1)
不学注解,也许是因为平时根本不需要没事自定义个这玩意玩,可随着Android形势越来越内卷,不学点东西是真不行了。而通过本文的学习,可以让你对于注解有个全面的认识,你会发现,小小的注解,大有可为,编不下去了..
注解不同于注释,注释的作用是为了方便自己或者别人的阅读,能够利用 javadoc 提取源文件里的注释来生成人们所期望的文档,对于代码本身的运行是没有任何影响的。
而注解的功能就要强大很多,不但能够生成描述符文件,而且有助于减轻编写“样板”代码的负担,使代码干净易读。通过使用扩展的注解(annotation)API 我们能够在 编译期 和 运行期 对代码进行操控。
注解(也被称为元数据)为我们在代码中添加信息提供了一种形式化的方法,使我们可以在稍后的某个时刻非常方便的使用这些数据。 —Jeremy Meyer
本文主要对于下面几个方面进行讲解,篇幅很长,建议收藏查看:
Java 最初内置的三种标准注解
注解是 java SE5中的重要的语言变化之一,你可能对注解的原理不太理解,但你每天的开发中可能无时无刻不在跟注解打交道,最常见的就是 @Override 注解,所以注解并没有那么神秘,也没有那么冷僻,不要害怕使用注解(虽然使用的注解大部分情况都是根据需要自定义的注解),用的多了自然就熟了。为什么说最初的三种标准注解呢,因为在后续的 java 版本中又陆陆续续的增加了一些注解,不过原理都是一样的。
| java SE5内置的标准注解 | 含义 |
|---|---|
| @Override | 表示当前的方法定义将覆盖超类中的方法,如果方法拼写错误或者方法签名不匹配,编译器便会提出错误提示 |
| @Deprecated | 表示当前方法已经被弃用,如果开发者使用了注解为它的元素,编译器便会发出警告信息 |
| @SuppressWarnings | 可以关闭不当的编译器警告信息 |
Java 提供的四种元注解和一般注解
所谓元注解(meta-annotation)也是一种注解,只不过这种注解负责注解其他的注解。所以再说元注解之前我们来看一下普通的注解:
public @interface LogClassMessage {}
这是一个最普通的注解,注解的定义看起来很像一个接口,在 interface 前加上 @ 符号。事实上在语言级别上,注解也和 java 中的接口、类、枚举是同一个级别的,都会被编译成 class 文件。而前面提到的元注解存在的目的就是为了修饰这些普通注解,但是要明确一点,元注解只是给普通注解提供了作用,并不是必须存在的。
| java 提供的元注解 | 作用 |
|---|---|
| @Target | 定义你的注解应用到什么地方(详见下文解释) |
| @Retention | 定义该注解在哪个级别可用(详见下文解释) |
| @Documented | 将此注解包含在 javadoc 中 |
| @Inherited | 允许子类继承超类中的注解 |
〔1〕@Target使用的时候添加一个 ElementType 参数,表示当前注解可以应用到什么地方,即可以指定一种,也可以同时指定多种,使用方法如下:
// 表示当前的注解只能应用到类、接口(包括注解)、enum上面
@Target(ElementType.TYPE)
public @interface LogClassMessage {}
复制代码 // 表示当前的注解只能应用到方法和成员变量上面
@Target({ElementType.METHOD,ElementType.FIELD})
public @interface LogClassMessage {}
复制代码下面来看一下 ElementType 的全部参数含义:
| ElementType 参数 | 说明 |
|---|---|
| ElementType.CONSTRUCTOR | 构造器的声明 |
| ElementType.FIELD | 域的声明(包括enum的实例) |
| ElementType.LOCATION_VARLABLE | 局部变量的声明 |
| ElementType.METHOD | 方法的声明 |
| ElementType.PACKAGE | 包的声明 |
| ElementType.PARAMETER | 参数的声明 |
| ElementType.TYPE | 类、接口(包括注解类型)、enum声明 |
〔2〕@Retention用来注解在哪一个级别可用,需要添加一个 RetentionPolicy 参数,用来表示在源代码中(SOURCE),在类文件中(CLASS)或者运行时(RUNTIME):
// 表示当前注解运行时可用
@Retention(RetentionPolicy.RUNTIME)
public @interface LogClassMessage {}
复制代码下面来看一下 RetentionPolicy 的全部参数含义:
| RetentionPolicy 参数 | 说明 |
|---|---|
| RetentionPolicy.SOURCE | 注解将被编译器丢弃,只能存于源代码中 |
| RetentionPolicy.CLASS | 注解在class文件中可用,能够存于编译之后的字节码之中,但会被VM丢弃 |
| RetentionPolicy.RUNTIME | VM在运行期也会保留注解,因此运行期注解可以通过反射获取注解的相关信息 |
在注解中,一般都会包含一些元素表示某些值,并且可以为这些元素设置默认值,没有元素的注解也称为标记注解(marker annotation)
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD,ElementType.FIELD})
public @interface LogClassMessage {
public int id () default -1;
public String message() default "";
}
复制代码注:虽然上面的 id 和 message 定义和接口的方法定义很类似,但是在注解中将 id 和 message 称为:int 元素 id , String 元素 message。而且注解元素的类型是有限制的,并不是任何类型都可以,主要包括:基本数据类型(理论上是没有基本类型的包装类型的,但是由于自动封装箱,所以也不会报错)、String 类型、enum 类型、Class 类型、Annotation 类型、以及以上类型的数组,(没有等字,说明目前注解的元素类型只支持上面列出的这几种),否则编译器便会提示错误。
invalid type 'void ' for annotation member // 例如注解类型为void的错误信息
对于默认值限制 ,Bruce Eckel 在其书中是这样描述的:编译器对元素的默认值有些过分挑剔,首先,元素不能有不确定的值。也就是说,元素必须要么具有默认值,要么在使用注解时提供注解的值。其次,对于非基本类型的元素,无论在源代码声明中,或者在注解接口中定义默认值时,都不能以 null 作为其值。这个约束使得处理器很难表现一个元素的存在或缺失的状态,因为在每个注解的声明中,所有元素都存在,并且都具有相应的值。为了绕开这个约束,我们只能自己定义一些特殊的值,例如空字符串或者负数,以此表示某个元素的不存在,这算得上是一个习惯用法。
参考系统的标准注解
怎么说呢,接触一种知识的途径有很多,可能每一种的结果都是大同小异的,都能让你学到东西,但是实现的方式、实现过程中的规范、方法和思路却并不一定是最佳的。
上文讲到的是注解的基本语法,那么系统是怎么用的呢?首先让我们来看一下使用频率最高的 @Override :
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {}
复制代码〔1〕首先系统定义一个没有元素的标记注解 Override ,随后使用元注解 @Target 指明 Override 注解只能应用于方法之上(你可以细想想,是不是在我们实际使用这个注解的时候,只能是重写方法,没有见过重写类或者字段的吧),使用注解 @Retention 表示当前注解只能存在源代码中,并不会出现在编译之后的 class 文件之中。
@Override
protected void onResume() {
super.onResume();
}
复制代码〔2〕如在 Activity 中我们可以重写 onResume() 方法,添加注解 @override 之后编译器便会去检查父类中是否存在相同方法,如果不存在便会报错。
〔3〕也许到这里你会感到很疑惑,注解到底是怎么工作的,怎么系统这样定义一个注解 Override 它就能工作了?黑魔法吗,擦擦,完成看不到实现过程嘛(泪流满面),经过查阅了一些资料(非权威)了解到,其实处理过程都编写在了编译器里面,也就是说编译器已经给我们写好了处理方法,当编译器进行检查的时候就会调用相应的处理方法。
注解处理器
介绍之前,先引用 Jeremy Meyer 的一段话:如果没有用来读取注解的工具,那么注解也不会比注释更有用。使用注解的过程中,很重要的一个部分就是创建与使用注解处理器。Java SE5 扩展了反射机制的API,以帮助程序员构造这类工具。同时,它还提供了一个外部工具 apt帮助程序员解析带有注解的 java 源代码。
根据上面描述我们可以知道,注解处理器并不是一个特定格式,并不是只有继承了 AbstractProcessor 这个抽象类才叫注解处理器,凡是根据相关API 来读取注解的类或者方法都可以称为注解处理器。
反射机制下的处理器
最简单的注解处理器莫过于,直接使用反射机制的 getDeclaredMethods 方法获取类上所有方法(字段原理是一样的),再通过调用 getAnnotation 获取每个方法上的特定注解,有了注解便可以获取注解之上的元素值,方法如下:
public void getAnnoUtil(Class<?> cl) {
for(Method m : cl.getDeclaredMethods()) {
LogClassMessage logClassMessage = m.getAnnotation(LogClassMessage .class);
if(null != logClassMessage) {
int id = logClassMessage.id();
String method = logClassMessage.message();
}
}
}
复制代码由于反射对性能会有一定的损耗,所以上述类型的注解处理器并不占主流,现在使用最多的还是 AbstractProcessor 自定义注解处理器,因为后者并不需要通过反射实现,效率和直接调用普通方法没有区别,这也是为什么编译期注解比运行时注解更受欢迎。
但是并不是说为了性能运行期注解就不能用了,只能说不能滥用,要在性能方面给予考虑。目前主要的用到运行期注解的框架差不多都有缓存机制,只有在第一次使用时通过反射机制,当再次使用时直接从缓存中取出。
好了,说着说着就跑题,还是来聊一下这个 AbstractProcessor 类吧,到底有何魅力让这么多人为她沉迷,方法如下:
public class MyFirstProcessor extends AbstractProcessor {
/**
* 做一些初始化工作,注释处理工具框架调用了这个方法,给我们传递一个 ProcessingEnvironment 类型的实参。
*
* <p>如果在同一个对象多次调用此方法,则抛出IllegalStateException异常。
*
* @param processingEnvironment 这个参数里面包含了很多工具方法
*/
@Override
public synchronized void init(ProcessingEnvironment processingEnvironment) {
// 返回用来在元素上进行操作的某些工具方法的实现
Elements es = processingEnvironment.getElementUtils();
// 返回用来创建新源、类或辅助文件的Filer
Filer filer = processingEnvironment.getFiler();
// 返回用来在类型上进行操作的某些实用工具方法的实现
Types types = processingEnvironment.getTypeUtils();
// 这是提供给开发者日志工具,我们可以用来报告错误和警告以及提示信息
// 注意 message 使用后并不会结束过程,Kind 参数表示日志级别
Messager messager = processingEnvironment.getMessager();
messager.printMessage(Diagnostic.Kind.ERROR, "例如当默认值为空则提示一个错误");
// 返回任何生成的源和类文件应该符合的源版本
SourceVersion version = processingEnvironment.getSourceVersion();
super.init(processingEnvironment);
}
/**
* @return 如果返回true 不要求后续Processor处理它们,反之,则继续执行处理。
*/
@Override
public boolean process(Set<? extends TypeElement> set, RoundEnvironment roundEnvironment) {
/**
* TypeElement 这表示一个类或者接口元素集合常用方法不多,TypeMirror getSuperclass()返回直接超类。
*
* <p>详细介绍下 RoundEnvironment 这个类,常用方法:
* boolean errorRaised() 如果在以前的处理round中发生错误,则返回true
* Set<? extends Element> getElementsAnnotatedWith(Class<? extends Annotation> a)
* 这里的 a 即你自定义的注解class类,返回使用给定注解类型注解的元素的集合
* Set<? extends Element> getElementsAnnotatedWith(TypeElement a)
*
* <p>Element 的用法:
* TypeMirror asType() 返回此元素定义的类型 如int
* ElementKind getKind() 返回元素的类型 如 e.getkind() = ElementKind.FIELD 字段
* boolean equals(Object obj) 如果参数表示与此元素相同的元素,则返回true
* Name getSimpleName() 返回此元素的简单名称
* List<? extends Elements> getEncloseElements 返回元素直接封装的元素
* Element getEnclosingElements 返回此元素的最里层元素,如果这个元素是个字段等,则返回为类
*/
return false;
}
/**
* 指出注解处理器 处理哪种注解
* 在 jdk1.7 中,我们可以使用注解 {@SupportedAnnotationTypes()} 代替
*/
@Override
public Set<String> getSupportedAnnotationTypes() {
return super.getSupportedAnnotationTypes();
}
/**
* 指定当前注解器使用的Jdk版本。
* 在 jdk1.7 中,我们可以使用注解{@SupportedSourceVersion()}代替
*/
@Override
public SourceVersion getSupportedSourceVersion() {
return super.getSupportedSourceVersion();
}
}
复制代码自定义运行期注解(RUNTIME)
我们在开发中经常会需要计算一个方法所要执行的时间,以此来直观的比较哪个实现方式最优,常用方法是开始结束时间相减
System.currentTimeMillis()
但是当方法多的时候,是不是减来减去都要减的怀疑人生啦,哈哈,那么下面我就来写一个运行时注解来打印方法执行的时间。
1.首先我们先定义一个注解,并给注解添加我们需要的元注解:
/**
* 这是一个自定义的计算方法执行时间的注解。
* 只能作用于方法之上,属于运行时注解,能被VM处理,可以通过反射得到注解信息。
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface CalculateMethodRunningTime {
// 要计算时间的方法的名字
String methodName() default "no method to set";
}
复制代码2.利用反射方法在程序运行时,获取被添加注解的类的信息:
public class AnnotationUtils {
// 使用反射通过类名获取类的相关信息。
public static void getClassInfo(String className) {
try {
Class c = Class.forName(className);
// 获取所有公共的方法
Method[] methods = c.getMethods();
for (Method m : methods) {
Class<CalculateMethodRunningTime> ctClass = CalculateMethodRunningTime.class;
if (m.isAnnotationPresent(ctClass)) {
CalculateMethodRunningTime anno = m.getAnnotation(ctClass);
// 当前方法包含查询时间的注解时
if (anno != null) {
final long beginTime = System.currentTimeMillis();
m.invoke(c.newInstance(), null);
final long time = System.currentTimeMillis() - beginTime;
Log.i("Tag", anno.methodName() + "方法执行所需要时间:" + time + "ms");
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
复制代码3.在 activity 中使用注解,注意咱们的注解是作用于方法之上的:
public class ActivityAnnotattion extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_anno);
AnnotationUtils.getClassInfo("com.annotation.zmj.annotationtest.ActivityAnnotattion");
}
@CalculateMethodRunningTime(methodName = "method1")
public void method1() {
long i = 100000000L;
while (i > 0) { i--; }
}
}
复制代码4.运行结果:
作者:矛盾的阿呆i
链接:https://juejin.cn/post/6936609673416015908
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android修炼系列(四),谈起泛型,大家都很佛性
当我们new了一个对象,会发生什么呢?来段代码:
public class Tested {
public static int T = 10;
public int c = 1;
}
复制代码类初始化
在编译期,编译器会将 Tested.java类转换成 Tested.class 字节码文件。当虚拟机接收到new 字节码指令时,如果此时类还未被初始化,则虚拟机会先进行类的初始化过程。
在类加载完成后。虚拟机会为new Tested() 的Tested对象,在java堆中分配内存。而对象所需要的内存大小在类加载完成后就被确定了。
指针碰撞
如果 java 中的内存是规整的,即使用过的放在一边,空闲的在另一边,中间放着指针作为分界点的指示器。那所分配的内存就仅仅是将指针像空闲空间挪动一段与对象大小相等的距离。这种方式内称为指针碰撞。
空闲列表
如果 java 中的内存是不工整的,使用过的和空闲的内存相互交错,那么虚拟机就必须维护一个列表记录哪些内存是可用的。在分配的时候从列表中找到一块足够大的空间给对象示例,并更新表的记录。这种分配方式称为空闲列表。
对象初始化
当我们的对象内存被分配完毕后,虚拟机就会对对象进行初始化操作。
此时Tested 对象在我们眼里就算出生了,在虚拟机眼里就是真正可用的了。可对象的生命并不是无穷的,它也会经历自己的死亡。
可达性分析
在主流实现中,我们通过可达性分析来判断一个对象是否存活。实现思路是:通过一系列被称为 “GC Roots” 的对象作为起始点,从这些节点开始像下搜索,搜索所走的路径被称为引用链,当一个对象到GC Roots没有任何引用链相连,则证明此对象是不可用的。见图:
即使 Obj5 与 Obj4 由于与 GC Roots 没有引用链相连,所以我们称 GC Roots 到对象 Obj4 和 Obj5 不可达。所以 Obj4 和 Obj5 就是可回收的。
既然Obj4 和 Obj5 是可回收的,那么是否一定会被回收呢?不一定。此时虚拟机会进行第一次的标记过程。因为 java 内能够重写 finalize() 方法(在这里只是分析特例,不推荐在任何情况下使用此方法),当对象重写了此方法,并且 finalize() 方法还未被虚拟机调用,那么虚拟机就会将此对象放入一个专门的F-Queue队列,由一个单独的 Finalizer 线程去执行它,如果队列中对象的 finalize() 方法在虚拟机第二次标记之前执行,并在此次执行过程中又将自己与GC Roots 引用链相连,那么虚拟机在进行第二次标记时,就会将该对象从 F-Queue队列移除,否则就宣告该对象死亡。注意:finalize() 方法只会被执行一次,所以一个对象一生只有一次机会进入F-Queue队列,有机会逃脱本此死亡。
如果对象已经宣告死亡了,那么虚拟机怎么来回收它吗?
标记-清除算法
这是最基础的收集算法,主要分为标记和清除两个阶段。首先标记出所以需要回收的对象,在标记完成后统一回收所有被标记的对象。可以参考上面的空闲列表。其有两点不足:
a. 效率问题,标记和清除两个过程效率都不高。
b. 空间问题,因为堆中的内存不是规整的,已使用的和空闲的内存相互交错,这也就导致了每次GC回收后,产生大量的内存碎片,而当再次分配一个大对象时,如果无法找到足够的连续内存,又会再此触发GC回收。
复制算法
复制算法是将堆内存分成大小相等的两块,每次只使用其中一块,这样内存就是规整的了,参考指针碰撞。每当一块内存使用完了,就将该块内存中存活的对象复制到另一边,随后将该块内存一次清理掉。
现在的虚拟机都采用这种方式来回收新生代,只是并不是按照1:1的比例来划分内存,而是将内存分为一块较大的 Eden 空间,和两块较小的 Survivor 空间(HotSpot虚拟机默认Eden:Survivor = 8 :1)。每次只使用 Eden 和 其中一块 Survivor 空间,当回收时,将 Eden 空间和当前正使用的 Survivor 空间内存活的对象复制到另一块空闲的 Survivor空间,随后清空 Eden 和 刚才用过的 Survivor 内存。
注意:由于我们无法保证每次 存活的对象所占内存一直都不大于 Survivor 内存值,所以就会有溢出风险。所以在 分代收集算法 中,虚拟机会将内存先划分为一块新生代内存和一块为老年代内存。而在新生代内存中,会采用这种8:1:1的内存分配方式,如果溢出了,就将该情况下的存活对象全部放在老年代内存里,说白了就是一种兜底策略。这里要注意的是,不是溢出的那部分,而是全部的存活对象。
标记-整理算法
标记-整理算法中的标记过程,与标记-清除算法中的标记过程一样,不同的是,当标记完成并清理回收完对象后,会将当前不连续的碎片内存就行整理,即存活的对象都移到一端,来保证接下来要分配的内存的规整性。我们的 分代收集算法 中的老年代内存块,就是采用的该算法(当然也可以是标记-清除算法,不同虚拟机的策略不同)。所以就不再对分代收集算法就行赘述了。
好了,本文到这里,关于“对象”的生命周期的讲解就结束了。如果本文对你有用,来点个赞吧,大家的肯定也是阿呆i坚持写作的动力。
参考
1、周志明,深入理解JAVA虚拟机:机械工业出版社
作者:矛盾的阿呆i
链接:https://juejin.cn/post/6935481800365981727
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
iOS-MBprogressHUD的使用
看开发文档中,涉及到六种基础的提示框
typedef NS_ENUM(NSInteger, MBProgressHUDMode) {
/**使用UIActivityIndicatorView显示进度。这是菊花默认值。 */
MBProgressHUDModeIndeterminate,
/** 使用圆形的饼图来显示进度。 */
MBProgressHUDModeDeterminate,
/** 使用水平进度条显示进度 */
MBProgressHUDModeDeterminateHorizontalBar,
/** 使用圆环进度视图显示进度。*/
MBProgressHUDModeAnnularDeterminate,
/** 自定义的view*/
MBProgressHUDModeCustomView,
/** 仅显示标签 */
MBProgressHUDModeText
};使用函数
+ (void)showToast:(NSString *)title withView:(UIView *)view {
MBProgressHUD *hud = [MBProgressHUD showHUDAddedTo:view animated:YES];
hud.mode = MBProgressHUDModeIndeterminate;
hud.labelText = title;
[hud hide:YES afterDelay:1];
}运行例子:

//1,设置背景框的透明度 默认0.8
hud.opacity = 1;
//2,设置背景框的背景颜色和透明度, 设置背景颜色之后opacity属性的设置将会失效
hud.color = [UIColor redColor];
hud.color = [HUD.color colorWithAlphaComponent:1];
//3,设置背景框的圆角值,默认是10
hud.cornerRadius = 20.0;
//4,设置提示信息 信息颜色,字体
hud.labelColor = [UIColor blueColor];
hud.labelFont = [UIFont systemFontOfSize:13];
hud.labelText = @"Loading...";
//5,设置提示信息详情 详情颜色,字体
hud.detailsLabelColor = [UIColor blueColor];
hud.detailsLabelFont = [UIFont systemFontOfSize:13];
hud.detailsLabelText = @"LoadingLoading...";
//6,设置菊花颜色 只能设置菊花的颜色
hud.activityIndicatorColor = [UIColor blackColor];
//7,设置一个渐变层
hud.dimBackground = YES;
//9,设置提示框的相对于父视图中心点的便宜,正值 向右下偏移,负值左上
hud.xOffset = -80;
hud.yOffset = -100;
//10,设置各个元素距离矩形边框的距离
hud.margin = 0;
//11,背景框的最小大小
hud.minSize = CGSizeMake(50, 50);
//12设置背景框的实际大小 readonly
CGSize size = HUD.size;
//13,是否强制背景框宽高相等
hud.square = YES;WKWebView 使用问题整理
一. WKWebView处理window.open问题
WKWebView加载页面, 当页面使用window.open跳转时候, 无响应, 需要实现WKUIDelegate协议实现
-(WKWebView *)webView:(WKWebView *)webView createWebViewWithConfiguration:(WKWebViewConfiguration *)configuration forNavigationAction:(WKNavigationAction *)navigationAction windowFeatures:(WKWindowFeatures *)windowFeatures{
WKFrameInfo *frameInfo = navigationAction.targetFrame;
if (![frameInfo isMainFrame]) {
//1. 本页跳转
[webView loadRequest:navigationAction.request];
//2. 获取url 打开新的 vc 实现跳转到新页面
//NSString *urlStr = [[navigationAction.request URL] absoluteString];
}
return nil;
}注意 :
1- 使用 window.open 在移动端可能引发兼容问题, 建议前端对移动端标签使用location.href处理
2- ajax 处理window.open时候, 同步时可以响应跳转, 异步时不会响应跳转
$.ajax({
url: '',
async: true,
complete: function (xhr) {
window.open("http://www.baidu.com");
}
});二. WKWebView处理a标签问题
方案1: 不建议使用
- (void)webView:(WKWebView *)webView didFinishNavigation:(null_unspecified WKNavigation *)navigation{
// 将a标签 跳转方式全部改为本页
[webView evaluateJavaScript:@"var aArr = document.getElementsByTagName('a');for(var i=0;i} 方案2: WKNavigationDelegate协议实现
-(void)webView:(WKWebView *)webView decidePolicyForNavigationAction:(WKNavigationAction *)navigationAction decisionHandler:(void (^)(WKNavigationActionPolicy))decisionHandler{
// webview 本页重新加载
if (navigationAction.targetFrame == nil) {
[webView loadRequest:navigationAction.request];
}
decisionHandler(WKNavigationActionPolicyAllow);
return;
}方案3: WKUIDelegate协议实现
-(WKWebView *)webView:(WKWebView *)webView createWebViewWithConfiguration:(WKWebViewConfiguration *)configuration forNavigationAction:(WKNavigationAction *)navigationAction windowFeatures:(WKWindowFeatures *)windowFeatures{
WKFrameInfo *frameInfo = navigationAction.targetFrame;
if (![frameInfo isMainFrame]) {
// 可创建新页面打开 [WebView new]
// 也可重新加载本页面 [webView loadRequest:navigationAction.request];
}
return nil;
}注意 : 如果方案2与方案3 代码中均实现, 程序会先执行方案2
三. WKWebView处理alert 问题
WKWebView加载页面, 当页面使用alert()、confirm()和prompt(),默认无响应. 若要正常使用这三个方法,需要实现WKUIDelegate中的三个方法模拟JS的这三个方法
JS 处理实现方法
function showAlert() {
alert("js_alertMessage");
}
function showConfirm() {
confirm("js_confirmMessage");
}
function showPrompt() {
prompt("js_prompt", "js_prompt_defaultMessage");
}
App 处理
//! alert(message)
- (void)webView:(WKWebView *)webView runJavaScriptAlertPanelWithMessage:(NSString *)message initiatedByFrame:(WKFrameInfo *)frame completionHandler:(void (^)(void))completionHandler {
completionHandler();
}
//! confirm(message)
- (void)webView:(WKWebView *)webView runJavaScriptConfirmPanelWithMessage:(NSString *)message initiatedByFrame:(WKFrameInfo *)frame completionHandler:(void (^)(BOOL))completionHandler {
completionHandler();
}
//! prompt(prompt, defaultText)
- (void)webView:(WKWebView *)webView runJavaScriptTextInputPanelWithPrompt:(NSString *)prompt defaultText:(NSString *)defaultText initiatedByFrame:(WKFrameInfo *)frame completionHandler:(void (^)(NSString *))completionHandler {
completionHandler();
}注意: completionHandler();需要被执行, 不然会引发crash.
四. WKWebView与JS简单交互
-WKWebView加载页面, 当需要给js简单交互, 可如下处理
// JS 处理
document.getElementById("btn").onclick = function () {
var url = "APP://action?params";
window.location.href = url;
}
// App 处理
-(void)webView:(WKWebView *)webView decidePolicyForNavigationAction:(WKNavigationAction *)navigationAction decisionHandler:(void (^)(WKNavigationActionPolicy))decisionHandler{
if ([navigationAction.request.URL.scheme caseInsensitiveCompare:@"APP"] == NSOrderedSame) {
// 进行业务处理
decisionHandler(WKNavigationActionPolicyCancel);
}else{
if (navigationAction.targetFrame == nil) {
[webView loadRequest:navigationAction.request];
}
decisionHandler(WKNavigationActionPolicyAllow);
}
return;
}// App 处理
NSString *func = [NSString stringWithFormat:@"loadData('%@', '%@')", @"aaa", @"bbb"];
[webView evaluateJavaScript:func completionHandler:nil];
// JS 处理
function loadData(action, params){
document.getElementById("returnValue").innerHTML = action + '?' + params;
}注意:
1 webView调用 evaluateJavaScript:completionHandler:方法, 要确保前端的JS方法不在闭包中, 如window.onload = function() {} 中的方法就无法调用.
2 如果交互复杂 可以使用 WebViewJavascriptBridge 实现
五. WKWebView相关文档
转自:https://www.jianshu.com/p/b9a88a537d87
iOS面试题(四)
1. OC 的消息机制
消息机制可以分为三个部分
1. 消息传递
当我么调用方法的时候,方法的调用都会转化为objc_msgSend这样来传递。
第一步会根据对象的isa指针找到所属的类(也就是类对象)
第二步,会根据类对象里面的catch里面查找。catch是个散列表,是根据@selector(方法名)来获取对应的IMP,从而开始调用
第三步,如果第二步没有找到,会继续查找到类对象里面的class_rw_t里面的methods(方法列表),从而遍历,找到方法所属的IMP,如果查找到则会添加到catch表里面
第四步,如果第三部也没有找到,会根据类对象里面的superclass指针,查找super的catch,如果也是没有查找,会继续查找到superclass里面的class_rw_t里面的methods(方法列表),从而遍历,找到方法所属的IMP,如果查找到则会添加到catch表里面
第五步,如果第四部还是没有查找到,此时会根据类的superclass,继续第四部操作
.......
第六步。如果一直查找到基类都没有找到响应的方法,则会进入动态解析里面
2. 动态解析
当消息传递,没有找到对应的IMP的时候,会进入的动态解析中
此时会根据方法是类方法,还是实例方法分别调用+(BOOL)resolveClassMethod:(SEL)sel、+(BOOL)resolveInstanceMethod:(SEL)sel
我们可以实现这两个方法,使用Runtime的class_addMethod来添加对应的IMP
如果添加后,返回true,没有添加则调用父类方法
注意:其实返回true或者false,结果都是一样的,再次掉消息传递步骤
3. 消息转发
如果我们没有实现动态解析方法,就会走到消息转发这里
第一步,会调用-(id)forwardingTargetForSelector:(SEL)aSelector方法,我们可以在这里,返回一个响应aSelector的对象。当返回不为nil时候,系统会继续再次走消息转发,继续查找对应的IMP
第二步,如果第一步返回nil或者self(自己),此时系统会继续走这里-(NSMethodSignature *)methodSignatureForSelector:(SEL)aSelector,需要返回aSelector的一个签名
第三步,如果返回了签名,就会到这里-(void)forwardInvocation:(NSInvocation *)anInvocation,相应的我们可以根据anInvocation,可以获取到参数、target、方法名等,再次操作的空间就很多了,看你需求喽。此时我们什么都不操作也是没问题的,
注意:当我们是类方法的时候,其实我们可以将以上方法的-改为+,即可实现了类方法的转发
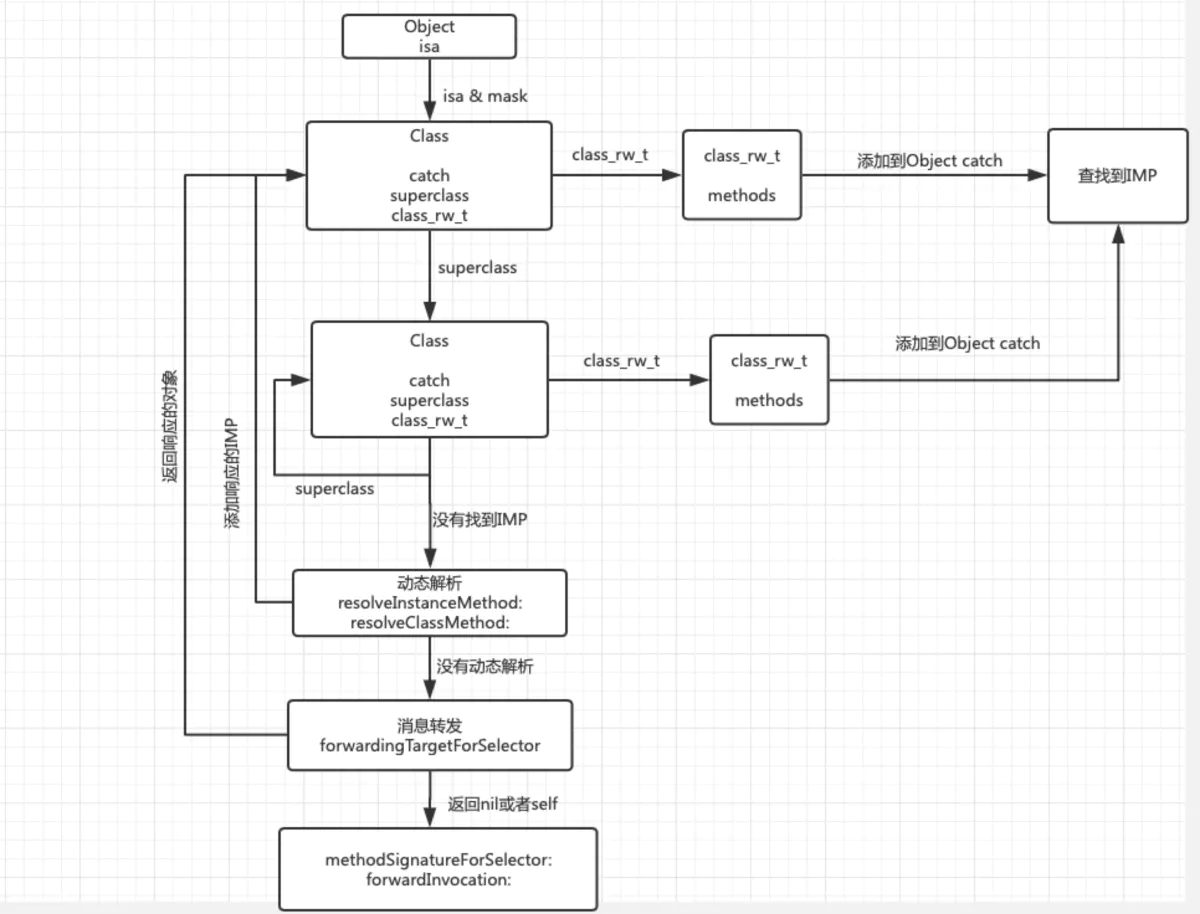
2.weak表是如何存储__weak指针的
weak关键字,我们都知道,当对象销毁的时候,也会将指针赋值为nil,而weak的底层也是将指针和对象以键值对的形式存储在哈希表里面
当使用__weak修饰的时候,底层会调用id objc_storeWeak(id *location, id newObj)传递两个参数
第一个参数为指针,第二个参数为所指向的对象
第二步,继续调用storeWeak(location, (objc_object *)newObj)
1. 第一个参数是指针,第二个参数是对象的地址
2. 再次方法里面会根据对象地址生成一个SideTables对象
第三步,调用id weak_register_no_lock(weak_table_t *weak_table, id referent_id, id *referrer_id, bool crashIfDeallocating)
1. weak_table则为SideTables的一个属性,referent_id为对象,referrer_id则为那个弱引用的指针
2. 在此里面会根据对象地址和指针生成一个weak_entry_t
第四步,会继续调用static void weak_entry_insert(weak_table_t *weak_table, weak_entry_t *new_entry)
重点:在此方法里面会根据对象 & weak_table->mask(表示weak表里面可以存储的大小减一,例如:表可以存储10个对象,那么mask就是9), 生成对应的index,如果index对应已经存储上对象,则会index++的方式找到未存储的对应,并将new_entry存储进去,储存在weak_table里的weak_entries属 性里面
注意:当一个对象多个weak指针指向的时候,生成的也是一个entry,多个指针时保存在entry里面referrers属性里面
以下为简易的源码:
id
objc_storeWeak(id *location, id newObj)
{
return storeWeak
(location, (objc_object *)newObj);
}
static id
storeWeak(id *location, objc_object *newObj) {
// 根据对象生成新的SideTable
SideTable *newTable = &SideTables()[newObj];
newObj = (objc_object *)
weak_register_no_lock(&newTable->weak_table, (id)newObj, location, crashIfDeallocating);
}
id
weak_register_no_lock(weak_table_t *weak_table, id referent_id,
id *referrer_id, bool crashIfDeallocating){
objc_object *referent = (objc_object *)referent_id;
objc_object **referrer = (objc_object **)referrer_id;
// 根据对象和指针生成一个entry
weak_entry_t new_entry(referent, referrer);
// 检查是是否该去扩容
weak_grow_maybe(weak_table);
// 将新的entry 插入到表里面
weak_entry_insert(weak_table, &new_entry);
}
static void weak_entry_insert(weak_table_t *weak_table, weak_entry_t *new_entry)
{
weak_entry_t *weak_entries = weak_table->weak_entries;
size_t begin = hash_pointer(new_entry->referent) & (weak_table->mask);
size_t index = begin;
size_t hash_displacement = 0;
while (weak_entries[index].referent != nil) {
index = (index+1) & weak_table->mask;
if (index == begin) bad_weak_table(weak_entries);
hash_displacement++;
}
weak_entries[index] = *new_entry;
weak_table->num_entries++;
}weak_table的扩容,根据存储条数 >= 最大存储条数的3/4时,就会按照两倍的方式进行扩容,并且会将已经有的条目再次生成新的index(因为扩容后,weak_table的mask发生了改变)。进行保存
以下为简易的源码:
static void weak_grow_maybe(weak_table_t *weak_table)
{
size_t old_size = (weak_table->mask ? weak_table->mask + 1 : 0);
if (weak_table->num_entries >= old_size * 3 / 4) {
weak_resize(weak_table, old_size ? old_size*2 : 64);
}
}
static void weak_resize(weak_table_t *weak_table, size_t new_size)
{
size_t old_size = TABLE_SIZE(weak_table);
weak_entry_t *old_entries = weak_table->weak_entries;
// calloc 分配新的控件
weak_entry_t *new_entries = (weak_entry_t *)
calloc(new_size, sizeof(weak_entry_t));
// mask 就是大小减一
weak_table->mask = new_size - 1;
weak_entry_t *entry;
weak_entry_t *end = old_entries + old_size;
for (entry = old_entries; entry < end; entry++) {
if (entry->referent) {
weak_entry_insert(weak_table, entry);
}
}
}3. 方法catch表是如何存储方法的
我们都是知道调用方法的时候,会根据对象的isa查找到对象类对象,并开始在catch表里面查询对应的IMP
其实catch是个散列表,是根据方法的@selector(方法名) & catch->mask(catck表最大数量 - 1)得到index,如果index已经存储了新的方法,那么就会index++,如果index对应的值为nil时,将响应的方法,插入到catch表里面
核心代码
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver) {
// 获取类对象的catch地址
cache_t *cache = &cls->cache
// 获取key
cache_key_t key = (cache_key_t)sel;
// 找到bucket
bucket_t *bucket = cache->find(key, receiver);
}
bucket_t * cache_t::find(cache_key_t k, id receiver)
{
// catch表的buckets属性
bucket_t *b = buckets();
// catch 表示的mask 最大值 - 1
mask_t m = mask();
mask_t begin = cache_hash(k, m);
mask_t i = begin;
do {
if (b[i].key() == 0 || b[i].key() == k) {
return &b[i];
}
} while ((i = cache_next(i, m)) != begin);
}
static inline mask_t cache_next(mask_t i, mask_t mask) {
return (i+1) & mask;
}注意:catch表的扩容,同样也是和weak_table一样按照2倍的方式进行扩容,但是注意:扩容后,以前缓存的方法则会被删除掉。
简易代码
void cache_t::expand() {
uint32_t oldCapacity = capacity();
uint32_t newCapacity = oldCapacity ? oldCapacity*2 : INIT_CACHE_SIZE;
reallocate(oldCapacity, newCapacity);
}
void cache_t::reallocate(mask_t oldCapacity, mask_t newCapacity)
{
// 获取旧的oldBuckets
bucket_t *oldBuckets = buckets();
// 重新分配新的
bucket_t *newBuckets = allocateBuckets(newCapacity);
// free 掉旧的
cache_collect_free(oldBuckets, oldCapacity);
}4. 优化后isa指针是什么样的?存储都有哪些内容?
最新的Objective-C的对象里面的isa指针已经不是单单的指向所属类的地址了的指针了,而时变成了一个共用体,并且使用位域来存储更多的信息

5. App启动流程,以及如何优化?
启动顺序
1. dyld,Apple的动态连接器,可以用来装载Mach-O文件(可执行文件、动态库)
1.1、装载App的可执行文件,同事递归加载所有依赖的动态库
1.2 、当dyld把可执行文件、动态库装载完毕后,会通知Runtime进行下一步的处理
Runtime
1. 调用map_images进行可执行文件内容的解析和处理
2. 在load_images里面调用call_load_methods,调用所有class和category的+load方法
3. 进行各种objc结构的初始化(注册Objc类,初始化类对象等等)
4. 到目前未知,可执行文件和动态库中所有的符号(Class,Protocol,Selector,IMP..)都已经按照格式成功加载到内存中,被runtime管理
main函数调用
1. 所有初始化工作结束后,dyld就会调用main函数
2. 截下来就是UIApplicationMan函数,AppDelegate的application:didFinishLaunchingWithOptions:的
- App启动速度优化
1. dyld
1.1、减少动态库,合并一些自定义的动态库,以及定期清理一些不需要的动态库
1.2、较少Objc类、category的数量、以及定期清理一些不必要的类和分类
1.3、Swift尽量使用struct
2. Runtime
2.1、使用+initialize和dispatch_once取代Objc的+load方法、C++的静态构造器
3. main
3.1、再不印象用户体验的情况下面,尽可能的将一些操作延迟,不要全部放到finishLaunching
3.2、一些网络请求
3.3、一些第三方的注册
3.4、以及window的rootViewController 的viewDidload方法,也别做耗时操作
4. 注意:我们可以添加环境变量可以打印出App的启动时间分析(Edit scheme -> Run -> Arguments)
4.1、DYLD_PRINT_STATISTICS设置为1,可以打印出来每个阶段的时间
4.2、如果需要更详细的信息,那就设置DYLD_PRINT_STATISTICS_DETAILS为1
6. App瘦身
资源(图片、音频、视频等)
1. 可以采取无损压缩
2. 使用LSUnusedResources去除没有用的资源 LSUnusedResources
可执行文件瘦身
1. Strip Linked Product、Make Strings Read-Only、Symbols Hidden by Default设置为true
2. 去掉一些异常支持 Enable C++ Exceptions、Enable Objective-C Exceptions设置为false
3. 使用AppCode检测未使用的代码:菜单栏 -> Code -> Inspect Code,等编译完成后,会看到未使用的类
生成LinkMap文件,可以查看可执行文件的具体组成
1. 可借助第三方工具解析LinkMap文件LinkMap
Link Map解析结果
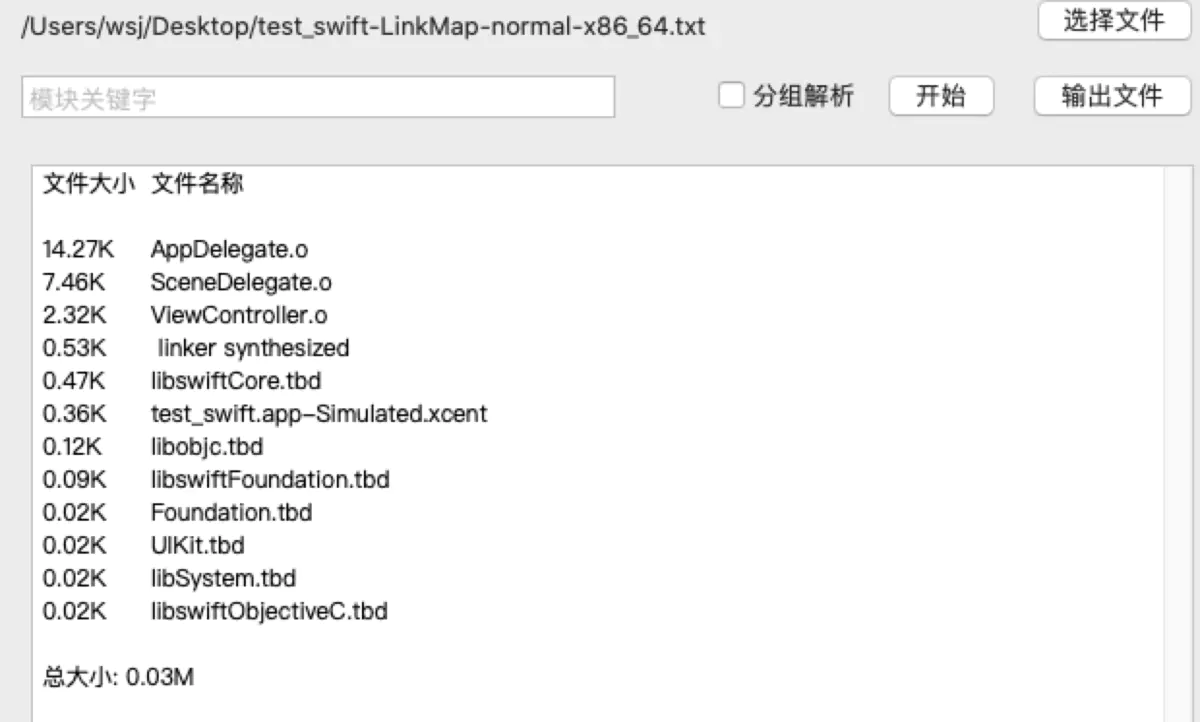
iOS面试题(三)
1. ARC帮我们做了什么?
使用LLVM + Runtime 结合帮我管理对象的生命周期
LLVM 帮我们在代码合适的地方添加release、retarn、autorelease等添加计数器或者减少计数器操作
Runtime 帮我们像__weak、copy等关键字的操作
2.initialize和load是如何调用的?它们会多次调用吗?
load方法说在应用加载的时候,Runtime直接拿到load的IMP直接去调用的,而不是像其他方式根据objc_msgSend(消息机制)来调用方法的
load方法调用的顺序是根据类的加载的前后进行调用的,但是每个类调用的顺序是superclass->class->category顺序调用的,每个load方法只会调用一次(手动调用不算)
一下为Runtime源码的主要代码:
load_images(const char *path __unused, const struct mach_header *mh) {
// 准备class 和category
prepare_load_methods((const headerType *)mh);
// 调用load方法
call_load_methods();
}
void prepare_load_methods(const headerType *mhdr) {
classref_t *classlist =
_getObjc2NonlazyClassList(mhdr, &count);
for (i = 0; i < count; i++) {
schedule_class_load(remapClass(classlist[i]));
}
category_t **categorylist = _getObjc2NonlazyCategoryList(mhdr, &count);
for (i = 0; i < count; i++) {
category_t *cat = categorylist[i];
add_category_to_loadable_list(cat);
}
}
static void schedule_class_load(Class cls) {
// 开始递归,加载superclass
schedule_class_load(cls->superclass);
add_class_to_loadable_list(cls);
}
void call_load_methods(void) {
do {
while (loadable_classes_used > 0) {
call_class_loads();
}
more_categories = call_category_loads();
} while (loadable_classes_used > 0 || more_categories);
}
static void call_class_loads(void) {
// 在此add_class_to_loadable_list 里面准备了所有重写load的方法的类
struct loadable_class *classes = loadable_classes;
// Call all +loads for the detached list.
for ( int i = 0; i < used; i++) {
Class cls = classes[i].cls;
// 获取到load 方法的imp
load_method_t load_method = (load_method_t)classes[i].method;
// 调用laod 方法
(*load_method)(cls, SEL_load);
}
}
static bool call_category_loads(void) {
// 在prepare_load_methods 方法里面准备了所有重新load方法的category
struct loadable_category *cats = loadable_categories;
for (int i = 0; i < used; i++) {
// 获取到catgegory
Category cat = cats[i].cat;
// 获取category 的load 方法的IMP实现
load_method_t load_method = (load_method_t)cats[i].method;
cls = _category_getClass(cat);
if (cls && cls->isLoadable()) {
// 调用load方法
(*load_method)(cls, SEL_load);
}
}
}initialize方法的调用其实和其他方法调用一样的,objc_msgSend(消息机制)来调用的。调用的数序是:没有初始话的superclass -> 实现initialize的categort 或者 实现了initialize的class,如果class没有实现initialize 方法,则会调用superclass的initialize,因为initialize的底层是使用了objc_msgSend
看下Runtime底层调用_class_initialize的源码
void _class_initialize(Class cls) {
supercls = cls->superclass;
if (supercls && !supercls->isInitialized()) {
// 又是个递归
_class_initialize(supercls);
}
// 调用 initialize方法
callInitialize(cls);
}
// objc_msgSend 调用 initialize 方法
void callInitialize(Class cls) {
// **注意:因为使用了objc_msgSend,有可能调用class的 initialize **
objc_msgSend(cls, SEL_initialize);
}总结:
load方法一个类只会调用一次(除去手动调用),而调用的数序是,从superclass -> class -> category,category里面的顺序是先编译,先调用
initialize方法,一个类可能会调用多次,如果子类没有实现initialize方法,当第一次使用此类的时候,会调用superclass。而调用的顺序是,superclass -> 实现initialize的category 或者 实现了initialize方法(没有category实现initialize) 或者 superclass的initialize (没有子类和category实现initialize方法)
3.说下autoreleasepool
在MRC下,当对象调用autorerelease方法时候,会将对象加入到对象前面的哪一个autoreleasepool里面,并且当autoreleasepool作用域释放的时候,会对里面的所有的对象进行一次release操作。
autoreleasepool底层是使用了AutoreleasePoolPage对象来管理的,AutoreleasePoolPage是一个双向的链表,每个AutoreleasePoolPage都有4096个字节,除了用来存放内部的成员变量,剩下的控件都会用来存放autorelease对象的地址
/// AutoreleasePoolPage 的简化的结构
class AutoreleasePoolPage {
magic_t const magic;
// 下一次可以存储对象的地址
id *next;
pthread_t const thread;
// 标识上一个page对象
AutoreleasePoolPage * const parent;
// 标识下一个page对昂
AutoreleasePoolPage *child;
uint32_t const depth;
uint32_t hiwat;
}当autoreleasepool开始的时候,会调用AutorelasePoolPage的push方法,会讲一个标识POOL_BOUNDARY添加到AutoreleasePoolPage对象里面,并且返回POOL_BOUNDARY的地址r1(暂且这样叫)
当对像进行relase的时候,会将对象的地址添加到当前AutorelasePoolPage里面,依次添加。
当autoreleasepool作用域结束的时候,会调用AutorelasePoolPage的pop(r1)方法(r1为当前aotoreleasepool开始的加入标识POOL_BOUNDARY的地址),AutorelasePoolPage则会将里面保存的对象的从左后一个开始进行release操作,当碰到r1时候,标识当前那个autoreleasepool里面所有的对象都进行了一次release操作。
@autoreleasepool {
// 此处会调用
void *ctxt = AutoreleasePoolPage::push();
// 添加到最近的一个autoreleasepool中
[[[NSObject alloc]init] autorelease];
//移除作用域的时候调用
AutoreleasePoolPage:pop(ctxt)
}
// autoreleasepool 作用域开始会调用AutoreleasePoolPage::push()
static inline void *push() {
id *dest;
if (DebugPoolAllocation) {
// 创建一个心的page对象
dest = autoreleaseNewPage(POOL_BOUNDARY);
} else {
// 已经有了page对象,讲`pool_boundary`添加进去
dest = autoreleaseFast(POOL_BOUNDARY);
}
}
static inline id *autoreleaseFast(id obj)
{
// 获取正在使用的page对昂
AutoreleasePoolPage *page = hotPage();
// page还没有装满
if (page && !page->full()) {
return page->add(obj);
} else if (page) {
// 已经添加满了
return autoreleaseFullPage(obj, page);
} else {
// 没有page对象,创建心的page对象
return autoreleaseNoPage(obj);
}
}
// 对象调用release 的简介源码
id objc_object::rootAutorelease2() {
return AutoreleasePoolPage::autorelease((id)this);
}
static inline id autorelease(id obj) {
// 同样也是添加进去
id *dest = autoreleaseFast(obj);
return obj;
}
// page调用pop简介源码 *token 表示结束的标识
static inline void pop(void *token) {
AutoreleasePoolPage *page;
id *stop;
page = pageForPointer(token);
stop = (id *)token;
page->releaseUntil(stop);
}
// 释放对象的源码
void releaseUntil(id *stop) {
// next 标识当前page可以存储对象的下一个地址
while (this->next != stop) {
AutoreleasePoolPage *page = hotPage();
// 因为page是个双向链表,当page为空的时候,需要往上查找parent的page对象里面存储的睇相
while (page->empty()) {
page = page->parent;
setHotPage(page);
}
id obj = *--page->next;
if (obj != POOL_BOUNDARY) {// obj 不是刚开始传入的POOL_BOUNDARY及表示对象,所以需要调用一次操作
objc_release(obj);
}
}
}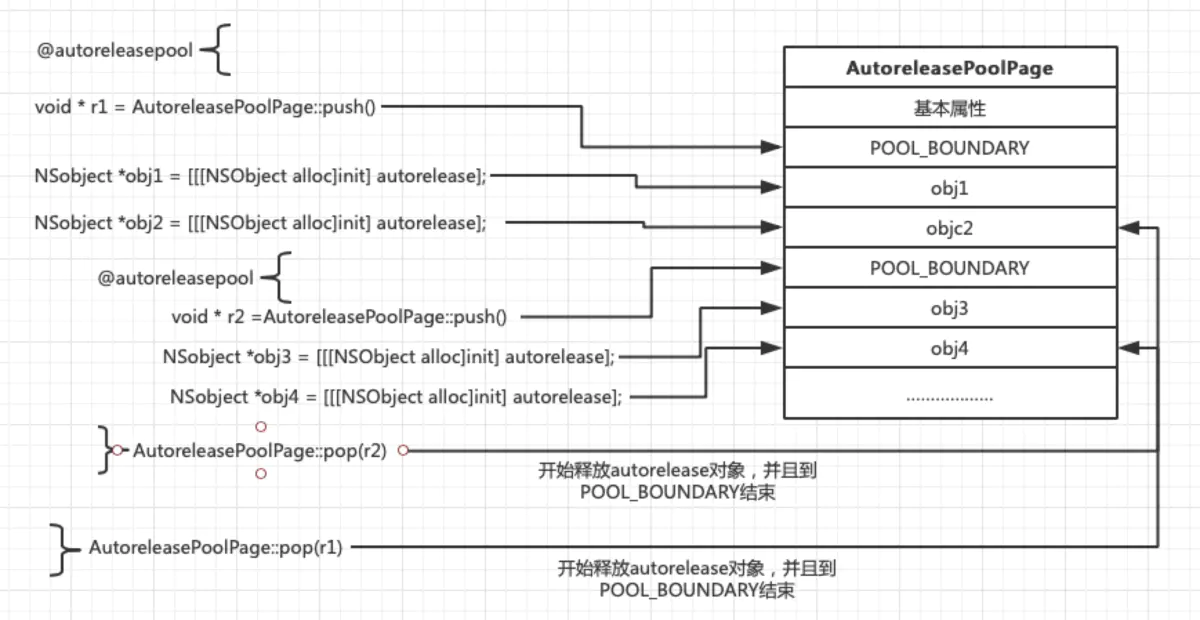
autoreleasepool和runloop的关系
runloop里面会注册两个Observer来监听runloop的状态变化
其中一个Observer监听的状态为kCFRunLoopEntry进入runloop的状态,则会调用AutoreleasePoolPage::push()方法
另外中一个Observer监听的状态为kCFRunLoopBeforeWaiting、kCFRunLoopExit,即将休眠和退出当前的runloop。
在kCFRunLoopBeforeWaiting的回掉里面会调用AutoreleasePoolPage::pop(ctxt)和AutoreleasePoolPage::(push)方法,释放上一个autoreleasepool里面添加的对象,并开启下一个autoreleasepool。
在kCFRunLoopExit的Observer回掉里面会调用AutoreleasePoolPage::(push)释放autoreleasepool里面的对象
4.category属性是存储在那里?
我们都知道可以使用Runtime的objc_setAssociatedObject、objc_getAssociatedObject两个方法给category的属性重写get、set方法,而此属性的值是存储在那里呢?
其实此属性的值保存在一个AssociationsManager里面。
我们也是可以根据源码看一下
void _object_set_associative_reference(id object, void *key, id value, uintptr_t policy) {
// 一下为精简的代码
id new_value = value ? acquireValue(value, policy) : nil;
{
AssociationsManager manager;
AssociationsHashMap &associations(manager.associations());
disguised_ptr_t disguised_object = DISGUISE(object);
if (new_value) {
ObjectAssociationMap *refs = new ObjectAssociationMap;
associations[disguised_object] = refs;
(*refs)[key] = ObjcAssociation(policy, new_value);
}
}
}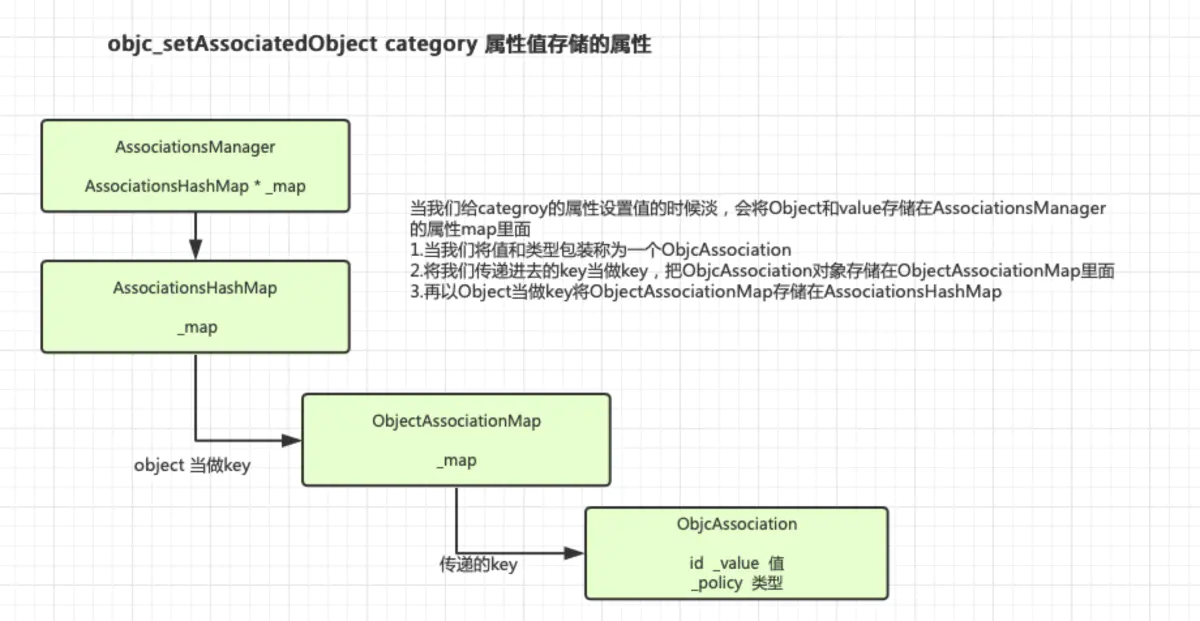
5.category方法是如何添加的?
当我们给分类添加相同的方法的时候,会调用category里面的方法,而不是调用我们class里面的方法
当编译器编译的时候,编译器会将category编译成category_t这样的结构体,等类初始化的时候,会将分类的信息同步到class_rw_t里面,包含:method、property、protocol等,同步的时候会将category里面的信息添加到class的前面(而不是替换掉class里面的方法),而方法调用的时候,而是遍历class_rw_t里面的方法,所以找到分类里面的IMP则返回。
- 使用memmove,将类方法移动到后面
- 使用memcpy,将分类的方法copy到前面
- 当多个分类有相同的方法的时候,调用的顺序是后编译先调用
- 当类初始化同步category的时候,会使用while(i--)的倒序循环,将后编译的category添加到最前面。
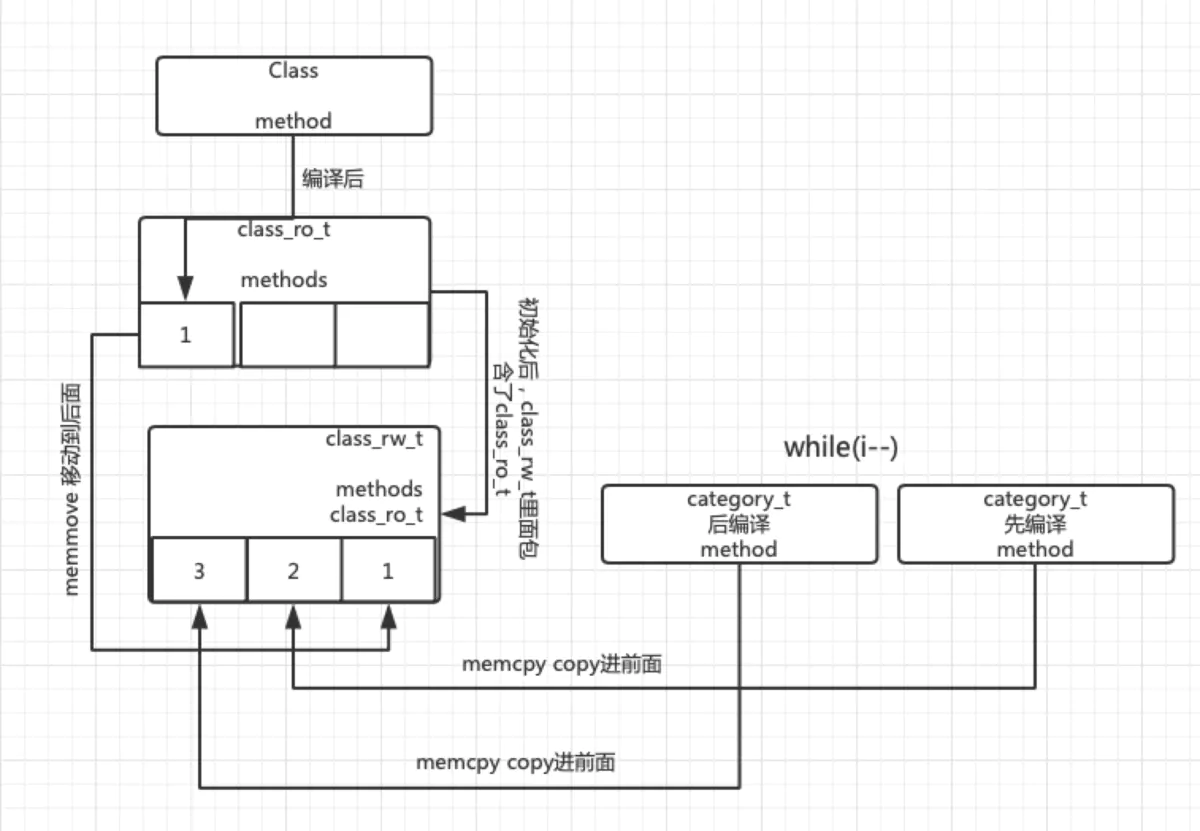
react中的组件设计
react的组件设计有很多模式。下面列举几种常见的:
完全受控组件
这种组件设计的特点是,组件的所有state和action都来自props,组件自身没有状态,只负责展示UI层。model层完全交给全局状态管理库比如redux或mobx。不推荐这种组件设计,因为后期不好维护。这是典型的滥用全局状态管理库的现象。
什么叫滥用全局状态管理库?
就是没有认识到状态管理库的作用,或者说我们什么时候需要状态管理库?
拿 react 来说,react 是有组内状态的,状态可以通过 props 传递。但是,但当 app 比较庞大的时候,兄弟组件,远亲组件这些的交流就变得困难起来,
它们必须依赖相同的父组件来完成信息的传递。这时,就是我们使用状态管理库的时候。
但是,很多人把所有状态都往 redux 里面丢,虽然这方便了开发,但缺点却很明显:
- 组件很难复用:因为状态只有一份。
- 耦合度高:根据高内聚低耦合的设计原则,一个模块应该有独立的功能,不依赖外部,在内部实现复杂度,只暴露接口来与外界交流。但如果把组内的一些状态放在全局 model,就提供了让其他组件修改的能力,并且代码没有内聚。
非受控组件
划分好状态的等级,尽量把状态放在组件内。当遇到共享组内状态困难的场景时,提升状态到全局状态管理库。
这种组件,有view层、model层、services层。因为它是有独立功能的,然后通过向外界暴露api来提供自己的能力,同时把复杂度隐藏在内部。
例如一个列表组件:
// 方案一
// ListDemo.jsx
import React,{useEffect} from 'react';
import {getData} from 'services/api';
export default function ListDemo({requestId}){
// model
const [data,setData] = useState([]);
const [visible,setVisible] = useState(false);
useEffect(()=>{
// services 层
getData().then(data=>{
setData(data)
});
/**
* 当requestId变化时,列表会重新请求
* 这里的requestId是组件向外界暴露的一个api
**/
},[requestId])
useEffect(()=>{
if(visible===true){
// clearState
setVisible(false);
}
},[requestId])
return (
// view
<div>
{
data.map(item=><li>{item}</li>
}
{
visible && (
<div>
this is a modal
</div>
)
}
</div>
)
)
}
// app.jsx
<ListDemo />
这种组件设计的特点是,组件可以重置自身状态的时机是由自身控制的。如果你觉得这样麻烦,你可以把重置自身状态的时机交给外部,通过key来 “销毁组件”=>“重新渲染组件”。上面的代码可以简化成:
// 方案二
// ListDemo.jsx
import React,{useEffect} from 'react';
import {getData} from 'services/api';
export default function ListDemo({requestId}){
// model
const [data,setData] = useState([]);
const [visible,setVisible] = useState(false);
useEffect(()=>{
// services 层
getData().then(data=>{
setData(data)
});
},[])
return (
// view
<div>
{
data.map(item=><li>{item}</li>
}
{
visible && (
<div>
this is a modal
</div>
)
}
</div>
)
)
}
// app.jsx
/*
*当requestId变化时,ListDemo会重新渲染
*/
<ListDemo key={requestId} />
方案二的代码比较整洁,且出错率比方案一低,但是方案二存在重新渲染组件的一个环节,性能开支会比方案一多一点点(大部分情况你都可以忽略不计)。
很多情况下,我们应该采用方案二。
原文:https://zhuanlan.zhihu.com/p/88593781
收起阅读 »如何用webpack优化moment.js的体积
本篇为转译,原出处。
当你在代码中写了var moment = require('moment') 然后再用webpack打包, 打出来的包会比你想象中的大很多,因为打包结果包含了各地的local文件.
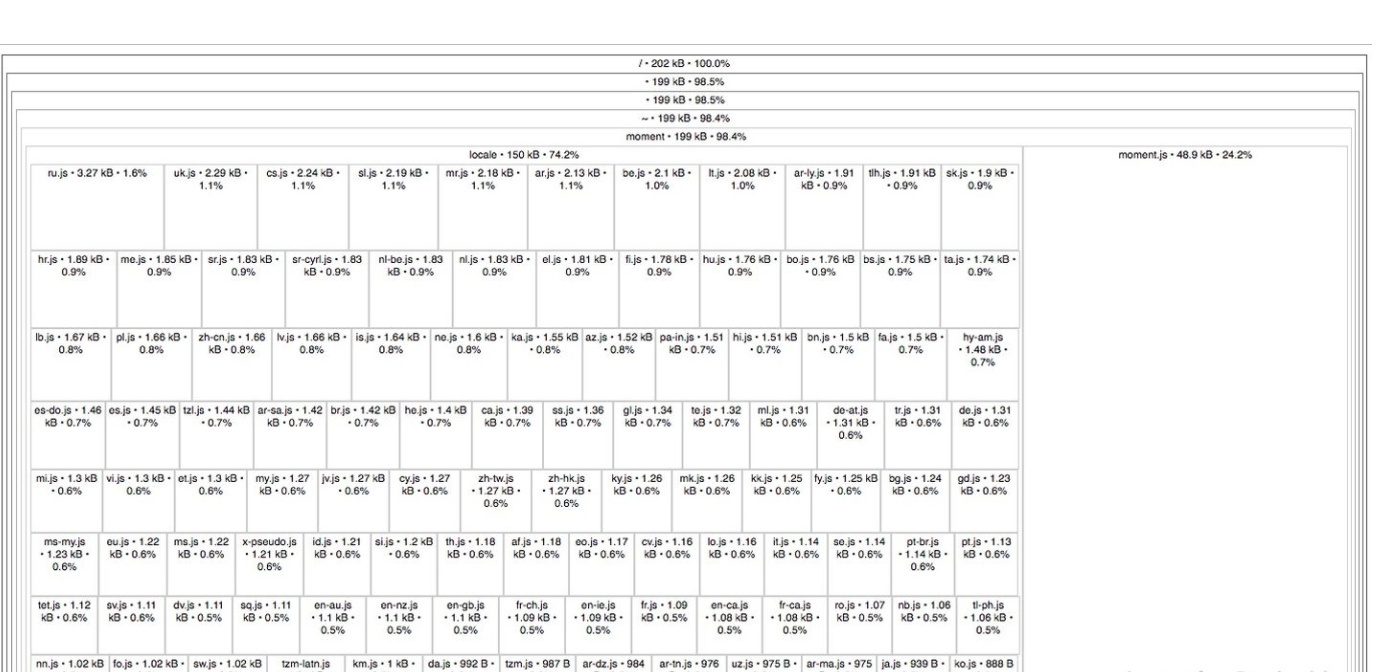
解决方案是下面的两个webpack插件,任选其一:
IgnorePluginContextReplacementPlugin
方案一:使用 IgnorePlugin插件
IgnorePlugin的原理是会移除moment的所有本地文件,因为我们很多时候在开发中根本不会使用到。 这个插件的使用方式如下:
const webpack = require('webpack');
module.exports = {
//...
plugins: [
// 忽略 moment.js的所有本地文件
new webpack.IgnorePlugin(/^\.\/locale$/, /moment$/),
],
};那么你可能会有疑问,所有本地文件都被移除了,但我想要用其中的一个怎么办。不用担心,你依然可以在代码中这样使用:
const moment = require('moment');
require('moment/locale/ja');
moment.locale('ja');
...这个方案被用在 create-react-app.
方案二:使用 ContextReplacementPlugin
这个方案其实跟方案一有点像。原理是我们告诉webpack我们会使用到哪个本地文件,具体做法是在插件项中这样添加ContextReplacementPlugin:
const webpack = require('webpack');
module.exports = {
//...
plugins: [
// 只加载 `moment/locale/ja.js` 和 `moment/locale/it.js`
new webpack.ContextReplacementPlugin(/moment[/\\]locale$/, /ja|it/),
],
};值得注意的是,这样你就不需要在代码中再次引入本地文件了:
const moment = require('moment');
// 不需要
moment.locale('ja');
...体积对比
对比条件:
- webpack: v3.10.0
- moment.js: v2.20.1
具体表现:
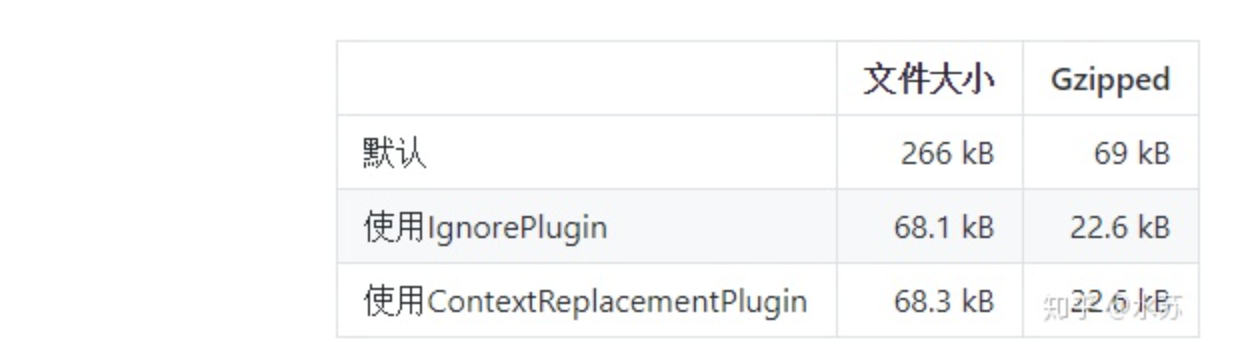
可见,处理后的体积小了很多。
原文链接:https://zhuanlan.zhihu.com/p/90748774
git 撤销对文件的追踪
撤销暂存区(index)区的track
当我们新增加文件时,使用git status会打印出:
Untracked files:
(use "git add ..." to include in what will be committed)
hello.txt
nothing added to commit but untracked files present (use "git add" to track) 可见,git add 命令可以用来追踪文件。
当我们使用 git add hello.txt后,再使用git status后,会打印出:
Changes to be committed:
(use "git restore --staged ..." to unstage)
new file: hello.txt 可见,文件已经被追踪了,只是还没提交到本地仓库。此时可以使用git restore来撤销这个追踪。
> git restore hello.txt --staged
> git status
On branch master
Your branch is up to date with 'origin/master'.
Untracked files:
(use "git add ..." to include in what will be committed)
hello.txt 撤销“已经提交到本地仓库的文件”的追踪
当一个文件(例如hello.txt)已经提交到本地仓库时。后续你再往.gitignore添加它,也不会起作用。怎么解除这种追踪呢?最常见的做法是直接删除这个文件,流程是:本地删除,提交删除这个commit到仓库。
但这样本地的也会被删除。有时我们只是想删除仓库的副本,可以使用git rm --cached。git rm经常被用来删除工作区和暂存区的文件。它可以携带一个cache参数,作用如下(摘自文档):
git rm --cached
Use this option to unstage and remove paths only from the index. Working tree files, whether modified or not, will be left alone.
使用这个项来解除暂存区的缓存,工作区的文件将保持不动。意思就是不会在实际上删掉这个文件,只是解除它的追踪关系。
举例:
> git rm --cached hello.txt
// rm 'hello.txt'
> git status
On branch master
Your branch is up to date with 'origin/master'.
Changes to be committed:
(use "git restore --staged ..." to unstage)
deleted: hello.txt
工作区的hello.txt还在,但已经没有被git追踪了。之后,只要我们把hello.txt添加到.gitignore后,修改hello.txt并不会产生改动。
接下来我们提交下这个改动。
git commit -m 'delete hello.txt'
[master d7a2e3e] delete hello.txt
1 files changed, 17 deletions(-)
delete mode 100644 hello.txt使用rm这个命令时,我们经常会用到-r这个命令。-r是递归的意思,表示删除整个文件夹,包括它的子文件夹。
原文:https://zhuanlan.zhihu.com/p/139950341
web前端常见的三种manifest文件
manifest.json
manifest.json经常被用在PWA,用来 告知浏览器 关于PWA应用的一些信息如应用图标、启动应用的画面。举例:
{
"short_name": "React App",
"name": "Create React App Sample",
"icons": [
{
"src": "favicon.ico",
"sizes": "64x64 32x32 24x24 16x16",
"type": "image/x-icon"
},
{
"src": "logo192.png",
"type": "image/png",
"sizes": "192x192"
},
{
"src": "logo512.png",
"type": "image/png",
"sizes": "512x512"
}
],
"start_url": ".",
"display": "standalone",
"theme_color": "#000000",
"background_color": "#ffffff"
}assets-manifest.json
assets-manifest.json经常会在create-react-app这个脚手架的打包文件上看到,由webpack-manifest-plugin这个webpack插件产生。举例:
{
"files": {
"main.css": "/static/css/main.491bee12.chunk.css",
"main.js": "/static/js/main.14bfbead.chunk.js",
"main.js.map": "/static/js/main.14bfbead.chunk.js.map",
"runtime-main.js": "/static/js/runtime-main.e89362ac.js",
"runtime-main.js.map": "/static/js/runtime-main.e89362ac.js.map",
"static/js/2.017bb613.chunk.js": "/static/js/2.017bb613.chunk.js",
"static/js/2.017bb613.chunk.js.map": "/static/js/2.017bb613.chunk.js.map",
"index.html": "/index.html",
"precache-manifest.33b41575e0c64a21bca1a6091e8a5c6d.js": "/precache-manifest.33b41575e0c64a21bca1a6091e8a5c6d.js",
"service-worker.js": "/service-worker.js",
"static/css/main.491bee12.chunk.css.map": "/static/css/main.491bee12.chunk.css.map",
"static/media/logo.svg": "/static/media/logo.25bf045c.svg"
},
"entrypoints": [
"static/js/runtime-main.e89362ac.js",
"static/js/2.017bb613.chunk.js",
"static/css/main.491bee12.chunk.css",
"static/js/main.14bfbead.chunk.js"
]
}wepack-mainfest-plugin对它自身的介绍是:
This will generate amanifest.jsonfile in your root output directory with a mapping of all source file names to their corresponding output file。意思就是assets-manifest.json其实只是源文件和加哈希后文件的一个对比表,仅此而已。它不会对应用的运行产生任何影响,浏览器也不会去请求它。
precache-manifest.js
这个文件由workbox-webpack-plugin插件生成, 用来告诉workbox哪些静态文件可以缓存。例如:
/**
* The workboxSW.precacheAndRoute() method efficiently caches and responds to
* requests for URLs in the manifest.
* See https://goo.gl/S9QRab
*/
self.__precacheManifest = [].concat(self.__precacheManifest || []);
workbox.precaching.precacheAndRoute(self.__precacheManifest, {});
其中self.__precacheManifest的值就是precache-manifest.js的内容。
原文链接:https://zhuanlan.zhihu.com/p/90829472
收起阅读 »

