








BOE(京东方)携故宫博物院举办2024“照亮成长路”公益项目落地仪式以创新科技赋能教育可持续发展
2024年9月20日,BOE(京东方)“照亮成长路”智慧教室落成暨百堂故宫传统文化公益课山西活动落地仪式在山西省太原市娄烦县实验小学隆重举行。自“照亮成长路”教育公益项目正式设立以来,BOE(京东方)持续以创新科技赋能偏远地区的教育升级,随着2024年捐赠的23间智慧教室全面圆满竣工并正式投入使用,BOE(京东方)捐建的智慧教室总数已达126间,它们不仅代表了教育创新、文化传承与先进技术的融合,也开启了BOE(京东方)面向新三十年发展征程、积极践行企业社会责任的新起点。
故宫博物院作为“照亮成长路”公益项目的重要合作伙伴,一直致力于促进中华优秀传统文化在青少年中的普及与传播。尤其是与京东方科技集团共同发起的“百堂故宫传统文化公益课”项目是故宫博物院教育推广的又一次重要实践。项目启动后近一年间已为26所学校,2万余名学生送去了400余场线上公益课程。此次落地的山西娄烦实验小学和静乐君宇中学也成为该计划的线下落地试点学校。活动现场,娄烦县委副书记、县长景博,娄烦县委常委、常务副县长任瑛,娄烦县委常委、副县长李学斌,静乐县副县长许龙平,中国乡村发展基金会副秘书长丁亚冬,故宫博物院副院长朱鸿文,京东方科技集团执行副总裁、艺云科技董事长姚项军,京东方科技集团副总裁、首席品牌官司达等出席了本次仪式,共同见证这一重要时刻。
在活动现场,京东方科技集团执行副总裁姚项军表示:“教育数字化是推进教育现代化的关键力量。BOE(京东方)充分发挥自身在物联网创新领域的专长,通过首创的多项类纸护眼显示技术,制定的低蓝光健康显示技术国际标准,推出了一系列智慧校园产品与服务;同时还充分发挥企业产业优势,开发科学与工程教育产品,用科学创新实践支持做公益。BOE(京东方)将携手各界同仁开启‘照亮成长路’教育公益项目的下一个十年篇章,继续推动教育与科技的深度融合,迈向一个更加智慧、更加光明、更加美好的未来!”
中国乡村发展基金会副秘书长丁亚冬在致辞中表示:“BOE(京东方)是我们多年的合作伙伴,持续关注乡村数字化教育的发展,携手实施的‘照亮成长路’教育公益项目已改造完成126间智慧教室,用科技力量助力消弭教育鸿沟,照亮乡村学生的成长之路。未来,我们将继续与BOE(京东方)、故宫博物院及社会各界通力合作,充分发挥各自优势,着力推进教育公平,促进教育均衡发展,为助力全面乡村振兴做出不懈努力。”
故宫博物院副院长朱鸿文在致辞中表示:“故宫博物院作为中华民族五千多年文明的重要承载者、中华优秀传统文化的汇聚地,始终将传承弘扬中华优秀传统文化作为己任,不断探索创新,希望通过丰富多彩的博物馆教育项目,将中华优秀传统文化传递给广大观众。很高兴能够携手京东方这样的科技企业通过传统文化振兴乡村发展,在以科技赋能偏远地区提升数字化水平的基础上,融入传统文化教育,增强师生文化自信,建设文化强国,助力中华民族伟大复兴。”故宫博物院也在活动中向学校的全体师生赠送了《我要去故宫》系列图书。
2024 BOE(京东方)“照亮成长路”教育公益项目的成功落地与本次活动的顺利举办,得益于山西省娄烦县政府和故宫博物院的大力支持,也离不开中国乡村发展基金会在项目推进过程中的通力合作。此次活动过程中,各方领导嘉宾围绕科技文化在教育领域的融合应用、智慧教育的未来趋势以及公益事业的长足发展进行了深入探讨。娄烦县政府相关领导作为代表对BOE(京东方)“百所校园”的公益新里程表示肯定与祝贺,并祝愿“照亮成长路”及“百堂故宫传统文化公益课”在未来能够惠及更多校园,助力更多偏远地区师生了解优秀传统文化、体验智慧教育。
作为一家全球化的科技公司,BOE(京东方)坚持Green+、Innovation+、Community+可持续发展理念,在教育、文化、健康等领域积极开展公益活动,通过引领绿色永续发展、持续驱动科技创新、赋能整个产业和社会。其中,“照亮成长路”是BOE(京东方)2014年启动的教育公益项目,通过智慧教室建设、教育资源融合、教师赋能培训计划等,携手社会各界力量,将技术融入社区公益发展与乡村振兴事业。目前,BOE(京东方)已在全国8大省市地区建成126间智慧教室,为63500余名师生提供软硬融合的智慧教育解决方案和教师赋能计划,切实帮助偏远地区学生群体获得更优质的教育和成长机会,在缩小城乡间数字差距、推动区域教育现代化、促进社会全面进步方面彰显了重要价值。
作为“照亮成长路”的特色项目,“百堂故宫传统文化公益课”让偏远地区的孩子能够通过BOE(京东方)的智慧教育创新技术跨越时间和空间的限制,近距离感受故宫的魅力,了解中国传统文化的精髓。接下来,更多课程将陆续在更为广泛的偏远地区展开,到2025年故宫博物院建院百年之际,双方将联手在北京故宫博物院为孩子们带来第100堂特别课程。
未来,BOE(京东方)与故宫博物院也将继续携手,以科技和文化双重赋能教育,让知识的光芒照亮每一个孩子的未来。
收起阅读 »独家授权!广东盈世获网易邮箱反垃圾服务的独家授权,邮件反垃圾更全面
近日,广东盈世计算机科技有限公司(以下简称“Coremail”)成功获得了网易(杭州)网络有限公司(以下简称“网易”)授予的网易邮箱反垃圾服务独家使用权。这一授权使得Coremail能够在邮件安全产品上运用网易邮箱反垃圾服务,进一步强化其反垃圾能力,邮件反垃圾更全面。
凭借24年的反垃圾反钓鱼技术沉淀,Coremail邮件安全致力于提供一站式邮件安全解决方案,为用户提供安全、可靠的安全解决方案。而网易作为国内邮箱行业的佼佼者,拥有强大的技术实力和丰富的经验,其网易邮箱反垃圾服务更是享有盛誉。
通过合作,网易为Coremail提供Saas在线网关服务,进行进信和外发的在线反垃圾检测。Coremail邮件安全反垃圾服务将以自研反垃圾引擎为主,网易反垃圾服务为辅,以“双引擎”机制保障用户享有最高等级的邮件反垃圾服务。
此外,除网易自身、广州网易计算机系统有限公司及其关联公司外,Coremail是唯一被授权在服务期内独家使用网易邮箱反垃圾服务的公司。这一独家授权充分体现了网易对Coremail的高度认可和信任,同时也彰显了Coremail在邮件安全领域的卓越实力。

此次独家授权,为Coremail带来更多的技术优势和市场竞争优势,进一步巩固其在邮件安全领域的领先地位。同时,对于广大用户来说,这也意味着用户将能够享受到更加安全、高效的邮件安全服务。
未来,Coremail将继续秉持技术创新的精神,致力于为用户提供更优质、安全、智能的邮件安全服务。与此同时,Coremail也将与网易保持紧密的合作关系,为企业的邮件安全保驾护航。
收起阅读 »为什么2.01 变成了 2.00 ,1分钱的教训不可谓不深刻
前些日子,测试提过来一个bug,说下单价格应该是 2.01,但是在订单详情中展示了2.00元。我头嗡的一下子,艹,不会是因为double 的精度问题吧~
果不其然,经过排查代码,最终定位原因订单详情展示金额时,使用double 进行了金额转换,导致金额不准。
我马上排查核心购买和售后链路,发现涉及资金交易的地方没有问题,只有这一处问题,要不然这一口大锅非得扣我身上。
为什么 2.01 变成了 2.0
2.01等小数 在计算机中按照2进制补码存储时,存在除不尽,精度丢失的问题。 例如 2.01的补码为 000000010.009999999999999787 。正如十进制场景存在 1/3等无限小数问题,二进制场景也存在无限小数,所以一定会存在精度问题。
什么场景小数转换存在问题
for (int money = 0; money < 10000; money++) {
String valueYuan = String.format("%.2f", money * 1.0 / 100);
int value = (int) (Double.valueOf(valueYuan) * 100);
if (value != money) {
System.out.println(String.format("原值: %s, 现值:%s", money, value));
}
}
如上代码中,先将数字 除以 100,转为元, 精度为2位,然后将double 乘以100,转为int。 在除以、乘以两个操作后,精度出现丢失。
我把1-10000 的范围测试一遍,共有573个数字出现精度转换错误。 这个概率已经相当大了。
如何转换金额更安全?
Java 提供了BigDecimcal 专门处理精度更高的浮点数。简单封装一下代码,元使用String表示,分使用int表示。提供两个方法实现 元和分的 互转。
public static String change2Yuan(int money) {
BigDecimal base = BigDecimal.valueOf(money);
BigDecimal yuanBase = base.divide(new BigDecimal(100));
return yuanBase.setScale(2, BigDecimal.ROUND_HALF_UP).toString();
}
public static int change2Fen(String money) {
BigDecimal base = new BigDecimal(money);
BigDecimal fenBase = base.multiply(new BigDecimal(100));
return fenBase.setScale(0, BigDecimal.ROUND_HALF_UP).intValue();
}
测试
测试0-1 亿 的金额转换逻辑,均成功转换,不存在精度丢失。
int error = 0;
long time = System.currentTimeMillis();
for (int money = 0; money < 100000000; money++) {
String valueYuan = change2Yuan(money);
int value = change2Fen(valueYuan);
if (value != money) {
error++;
}
}
System.out.println(String.format("时间:%s", (System.currentTimeMillis() - time)));
System.out.println(error);
性能测试
网上很多人说使用 BigDecimcal 存在性能影响,但是我测试性能还是不错的。可能首次耗时略高,大约2ms
| 标题 | 耗时 |
|---|---|
| 0-1亿 | 14.9 秒 |
| 0-100万 | 0.199秒 |
| 0-1万 | 0.59秒 |
| 0-100 | 0.004秒 |
| 0-1 | 0.002秒 |
总结
涉及金额转换的 地方,一定要小心处理,防止出现精度丢失问题。可以使用代码审查工具,查看代码中是否存在使用double 进行金额转换的代码, 同时提供 金额转换工具类。
来源:juejin.cn/post/7399985723673837577
我的 Electron 客户端也可以全量/增量更新了
前言
本文主要介绍 Electron 客户端应用的自动更新,包括全量和增量这两种方式。
全量更新: 运行新的安装包,安装目录所有资源覆盖式更新。
增量更新: 只更新修改的部分,通常是渲染进程和主进程文件。
本文并没有拿真实项目来举例子,而是起一个 新的项目 从 0 到 1 来实现自动更新。
如果已有的项目需要支持该功能,借鉴本文的主要步骤即可。
前置说明:
- 由于业务场景的限制,本文介绍的更新仅支持
Windows操作系统,其余操作系统未作兼容处理。 - 更新流程全部由前端完成,不涉及到后端,没有轮询 更新的机制。
- 发布方式限制为
generic,线上服务需要配置nginx确保访问到资源文件。
准备工作
脚手架搭建项目
我们通过 electron-vite 快速搭建一个基于 Vite + React + TS 的 Electron 项目。

该模板已经包括了我们需要的核心第三方库:electron-builder,electron-updater。
前者是用来打包客户端程序的,后者是用来实现自动更新的。
在项目根目录下,已经自动生成了两份配置文件:electron-builder.yml 和 dev-app-update.yml。
electron-builder.yml
该文件描述了一些 打包配置,更多信息可参考 官网。
在这些配置项中,publish 字段比较重要,因为它关系到更新源。
publish:
provider: generic // 使用一个通用的 HTTP 服务器作为更新源。
url: https://example.com/auto-updates // 存放安装包和描述文件的地址
provider 字段还有其他可选项,但是本文只介绍 generic 这种方式,即把安装包放在 HTTP 服务器里。
dev-app-update.yml
provider: generic
url: https://example.com/auto-updates
updaterCacheDirName: electron-update-demo-updater
其中,updaterCacheDirName 定义下载目录,也就是安装包存放的位置。全路径是C:\Users\用户名\AppData\Local\electron-update-demo-updater,不配置则在C:\Users\用户名\AppData\Local下自动创建文件夹,开发环境下为项目名,生产环境下为项目名-updater。

模拟服务器
我们直接运行 npm run build:win,在默认 dist 文件夹下就出现了打包后的一些资源。

其实更新的基本思路就是对比版本号,即对比本地版本和 线上服务器 版本是否一致,若不一致则需要更新。

因此我们在开发调试的时候,需要起一个本地服务器,来模拟真实的情况。
新建一个文件夹 mockServer,把打包后的 setup.exe 安装包和 latest.yml 文件粘贴进去,然后通过 serve 命令默认起了一个 http://localhose:3000 的本地服务器。
既然有了存放资源的本地地址,在开发调试的时候,我们更新下 dev-app-update.yml 文件的 url 字段,也就是修改为 http://localhose:3000。
注:如果需要测试打包后的更新功能,需要同步修改打包配置文件。
全量更新
与主进程文件同级,创建 update.ts 文件,之后我们的更新逻辑将在这里展开。
import { autoUpdater } from 'electron-updater' //核心库
需要注意的是,在我们开发过程中,通过 npm run dev 起来的 Electron 程序其实不能算是打包后的状态。
你会发现在调用 autoUpdater 的一些方法会提示下面的错误:
Skip checkForUpdates because application is not packed and dev update config is not forced
因此我们需要在开发环境去做一些动作,并且手动指定 updateConfigPath:
// update.ts
if (isDev) {
Object.defineProperty(app, 'isPackaged', {
get: () => true
})
autoUpdater.updateConfigPath = path.join(__dirname, '../../dev-app-update.yml')
}
核心对象 autoUpdater 有很多可以主动调用的方法,也有一些监听事件,同时还有一些属性可以设置。
这里只展示了本人项目场景所需的一些配置。
autoUpdater.autoDownload = false // 不允许自动下载更新
autoUpdater.allowDowngrade = true // 允许降级更新(应付回滚的情况)
autoUpdater.checkForUpdates()
autoUpdater.downloadUpdate()
autoUpdater.quitAndInstall()
autoUpdater.on('checking-for-update', () => {
console.log('开始检查更新')
})
autoUpdater.on('update-available', info => {
console.log('发现更新版本')
})
autoUpdater.on('update-not-available', info => {
console.log('不需要全量更新', info.version)
})
autoUpdater.on('download-progress', progressInfo => {
console.log('更新进度信息', progressInfo)
})
autoUpdater.on('update-downloaded', () => {
console.log('更新下载完成')
})
autoUpdater.on('error', errorMessage => {
console.log('更新时出错了', errorMessage)
})
在监听事件里,我们可以拿到下载新版本 整个生命周期 需要的一些信息。
// 新版本的版本信息(已筛选)
interface UpdateInfo {
readonly version: string;
releaseName?: string | null;
releaseNotes?: string | Array<ReleaseNoteInfo> | null;
releaseDate: string;
}
// 下载安装包的进度信息
interface ProgressInfo {
total: number;
delta: number;
transferred: number;
percent: number;
bytesPerSecond: number;
}
在写完这些基本的方法之后,我们需要决定 检验更新 的时机,一般是在应用程序真正启动之后,即 mainWindow 创建之后。
运行项目,预期会提示 不需要全量更新,因为刚才复制到本地服务器的 latest.yml 文件里的版本信息与本地相同。修改 version 字段,重启项目,主进程就会提示有新版本需要更新了。
频繁启动应用太麻烦,除了应用初次启动时主进程主动帮我们检验更新外,还需要用户 手动触发 版本更新检测,此外,由于产品场景需要,当发现有新版本的时候,需要在 渲染进程 通知用户,包括版本更新时间和更新内容。因此我们需要加上主进程与渲染进程的 IPC通信 来实现这个功能。
其实需要的数据主进程都能够提供了,渲染进程具体的展示及交互方式就自由发挥了,这里简单展示下我做的效果。
1. 发现新版本

2. 无需更新

增量更新
为什么要这么做
其实全量更新是一种比较简单粗暴的更新方式,我没有花费太大的篇幅去介绍,基本上就是使用 autoUpdater 封装的一些方法,开发过程中更多的注意力则是放在了渲染进程的交互上。
此外,我们的更新交互用的是一种 用户感知 的方式,即更不更新是由用户自己决定的。而 静默更新 则是用户无感知,在监测到更新后不用去通知用户,而是自行在后台下载,在某个时刻执行安装的逻辑,这种方式往往是一键安装,不会弹出让用户去选择安装路径的窗口。接下去要介绍的增量更新其实是这种 用户无感知 的形式,只不过我们更新的不是整个应用程序。
由于产品迭代比较频繁,我们的业务方经常收到更新提示,意味着他们要经常手动更新应用,以便使用到最新的功能特性。众所周知,Electron 给前端开发提供了一个比较容易上手的客户端开发解决方案,但在享受 跨平台 等特性的同时,还得忍受 臃肿的安装包 。
带宽、流量在当前不是什么大问题,下载和安装的速度也挺快,但这频繁的下载覆盖一模一样的资源文件还是挺糟心的,代码改动量小时,全量更新完全没有必要。我们希望的是,开发更新了什么代码,应用程序就替换掉这部分代码就好了,这很优雅。在 我们的场景 中,这部分代码指的是 —— main、preload、renderer,并不包括 dll、第三方SDK等资源。
网上有挺多种增量更新的 解决方案,例如:
- 通过
win.loadURL(一个线上地址)实现,相当于就套了一层客户端的壳子,与加载的Web端同步更新。这种方法对于简单应用来说是最省心的,但是也有一定的局限性,例如不能使用node去操作一些底层的东西。 - 设置
asar的归档方式,替换app.asar或app.asar.unpack来实现。但后者在我实践过程中存在文件路径不存在的问题。 - 禁用
asar归档,解压渲染进程压缩包后实现替换。简单尝试过,首次执行安装包的时候写入文件很慢,不知道是不是这个方式引起的。 - 欢迎补充。
本文我们采用较普遍的 替换asar 来实现。
优化 app.asar 体积
asar是Electron提供的一种将多个文件合并成一个文件的类tar风格的归档格式,不仅可以缓解Windows下路径名过长的问题, 还能够略微加快一下require的速度, 并且可以隐藏你的源代码。(并非完全隐藏,有方法可以找出来)
Electron 应用程序启动的时候,会读取 app.asar.unpacked 目录中的内容合并到 app.asar 的目录中进行加载。在此之前我们已经打包了一份 Demo 项目,安装到本地后,我们可以根据安装路径找到 app.asar 这个文件。
例如:D:\你的安装路径\electron-update-demo\resources

在这个 Demo 项目中,脚手架生成的模板将图标剥离出来,因此出现了一个 app.asar.unpacked 文件夹。我们不难发现,app.asar 这个文件竟然有 66 MB,再回过头看我们真正的代码文件,甚至才 1 MB !那么到底是什么原因导致的这个文件这么大呢,刚才提到了,asar 其实是一种压缩格式,因此我们只要解压看看就知道了。
npm i -g asar // 全局安装
asar e app.asar folder // 解压到folder文件夹

解压后我们不难发现,out 文件夹里的才是我们打包出来的资源,罪魁祸首竟然是 node_modules,足足有 62.3 MB。
查阅资料得知,Electron 在打包的时候,会把 dependencies 字段里的依赖也一起打包进去。而我们的渲染进程是用 React开发的,这些第三方依赖早就通过 Vite 等打包工具打到资源文件里了,根本不需要再打包一次,不然我们重新下载的 app.asar 文件还是很大的,因此需要尽可能减少体积。
优化应用程序体积 == 减少 node_modules 文件夹的大小 == 减少需要打包的依赖数量 == 减少 dependencies 中的依赖。
1. 移除 dependencies
最开始我想的是把 package.json 中的 dependencies 全都移到 devDependencies,打包后的体积果然减小了,但是在测试过程中会发现某些功能依赖包会缺失,比如 @electron/remote。因此在修改这部分代码的时候,需要特别留意,哪些依赖是需要保留下来的。
由于不想影响 package.json 的版本结构,我只是在写了一个脚本,在 npm i 之后,执行打包命令前修改 devDependencies 就好了。
2. 双 package.json 结构
这是 electron-builder 官网上看到的一种技巧,传送门, 创建 app 文件夹,再创建第二个 package.json,在该文件中配置我们应用的名称、版本、主进程入口文件等信息。这样一来,electron-builder 在打包时会以该文件夹作为打包的根文件夹,即只会打包这个文件夹下的文件。
但是我原项目的主进程和预加载脚本也放在这,尝试修改后出现打包错误的情况,感兴趣的可以试试。

这是我们优化之后的结果,1.32 MB,后面只需要替换这个文件就实现了版本的更新。
校验增量更新
全量更新的校验逻辑是第三方库已经封装好了的,那么对于增量更新,就得由我们自己来实现了。
首先明确一下 校验的时机,package.json 的 version 字段表示应用程序的版本,用于全量更新的判断,那也就意味着,当这个字段保持不变的时候,会触发上文提到的 update-not-available 事件。所以我们可以在这个事件的回调函数里来进行校验。
autoUpdater.on('update-not-available', info => { console.log('不需要全量更新', info.version) })
然后就是 如何校验,我们回过头来看 electron-builder 的打包配置,在 releaseInfo 字段里描述了发行版本的一些信息,目前我们用到了 releaseNotes 来存储更新日志,查阅官网得知还有个 releaseName 好像对于我们而言是没什么用的,那么我们就可以把它作为增量更新的 热版本号。(但其实 官网 配置项还有个 vendor 字段,可是我在用的时候打包会报错,可能是版本的问题,感兴趣的可以试试。)
每次发布新版本的时候,只要不是 Electron自身版本变化 等重大更新,我们都可以通过修改 releaseInfo 的 releaseName 来发布我们的热版本号。现在我们已经有了线上的版本,那 本地热版本号 该如何获取呢。这里我们在每次热更新完成之后,就会把最新的版本号存储在本地的一个配置文件中,通常是 userData 文件夹,用于存储我们应用程序的用户信息,即使程序卸载 了也不会影响里面的资源。在 Windows 下,路径如下:
C:\Users\用户名\AppData\Roaming\electron-update-demo。
因此,整个 校验流程 就是,在打开程序的时候,autoUpdater 触发 update-not-available 事件,拿到线上 latest.yml 描述的 releaseName 作为热版本号,与本地配置文件(我们命名为 config.json)里存储的热版本号(我们命名为 hotVersion)进行对比,若不同就去下载最新的 app.asar 文件。
我们使用 electron-log 来记录日志,代码如下所示。
// 本地配置文件
const localConfigFile = path.join(app.getPath('userData'), 'config.json')
const checkHotVersion = (latestHotVersion: string): boolean => {
let needDownload = false
if (!fs.existsSync(localConfigFile)) {
fs.writeFileSync(localConfigFile, '{}', 'utf8')
log.info('配置文件不存在,已自动创建')
} else {
log.info('监测到配置文件')
}
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
// 对比版本号
if (latestHotVersion !== configData.hotVersion) {
log.info('当前版本不是最新热更版本')
needDownload = true
} else {
log.info('当前为最新版本')
}
} catch (error) {
log.error('读取配置文件时出错', error)
}
return needDownload
}
下载增量更新包
通过刚才的校验,我们已经知道了什么时候该去下载增量更新包。
在开发调试的时候,我们可以把新版本的 app.asar 也放到起了本地服务器的 mockServer 文件夹里来模拟真实的情况。有很多方式可以去下载文件,这里我用了 nodejs 的 http 模块去实现,如果是 https 的需要引用 https 模块。
下载到本地的时候,我是放在了与 app.asar 同级目录的 resources 文件夹,我们不能直接覆盖原文件。一是因为进程权限占用的问题,二是为了容错,所以我们需要以另一个名字来命名下载后的文件(这里我们用的是 app.asar-temp),也就不需要去备份原文件了,代码如下。
const resourcePath = isDev
? path.join('D:\\测试\\electron-update-demo\\resources')
: process.resourcesPath
const localAsarTemp = path.join(resourcePath, 'app.asar-temp')
const asarUrl = 'http://localhost:3000/app.asar'
downloadAsar() {
const fileStream = fs.createWriteStream(localAsarTemp)
http.get(asarUrl, res => {
res.pipe(fileStream)
fileStream
.on('finish', () => {
log.info('asar下载完成')
})
.on('error', error => {
// 删除文件
fs.unlink(localAsarTemp, () => {
log.error('下载出现异常,已中断', error)
})
})
})
}
因此,我们的流程更新为:发现新版本后,下载最新的 app.asar 到 resources 目录,并重命名为 app.asar-temp。这个时候我们启动项目进行调试,找到记录在本地的日志—— C:\Users\用户名\AppData\Roaming\electron-update-demo\logs,会有以下的记录:
[2024-09-20 13:49:22.456] [info] 监测到配置文件
[2024-09-20 13:49:22.462] [info] 当前版本不是最新热更版本
[2024-09-20 13:49:23.206] [info] asar下载完成
在看看项目 resources 文件夹,多了一个 app.asar-temp文件。

至此,下载这一步已经完成了,但这样还会有一个问题,因为文件名没有加上版本号,也没有重复性校验,倘若一直没有更新,那么每次启动应用需要增量更新的时候都需要再次下载。
替换 app.asar 文件
好了,新文件也有了,接下来就是直接替换掉老文件就可以了,但是 替换的时机 很重要。
在 Windows 操作系统下,直接替换 app.asar 会提示程序被占用而导致失败,所以我们应该在程序关闭的时候实现替换。
- 进入应用,下载新版本,自动关闭应用,替换资源,重启应用。
- 进入应用,下载新版本,不影响使用,用户 手动关闭 后替换,下次启动 就是新版本了。
我们有上面两种方案,最终采用了 方案2。
在主进程监听 app.on('quit') 事件,在应用退出的时候,判断 app.asar 和 app.asar-temp 是否同时存在,若同时存在,就去替换。这里替换不能直接用 nodejs 在主进程里去写,因为主进程执行的时候,资源还是被占用的。因此我们需要额外起一个 子进程 去做。
nodejs 可以通过 spawn、exec 等方法创建一个子进程。子进程可以执行一些自定义的命令,我们并没有使用子进程去执行 nodejs,因为业务方的机器上不一定有这个环境,而是采用了启动 exe 可执行文件的方式。可能有人问为什么不直接运行 .bat 批处理文件,因为我调试关闭应用的时候,会有一个 命令框闪烁 的现象,这不太优雅,尽管已经设置 spawn 的 windowsHide: true。
那么如何获得这个 exe 可执行文件呢,其实是通过 bat 文件去编译的,命令如下:
@echo off
timeout /T 1 /NOBREAK
del /f /q /a %1\app.asar
ren %1\app.asar-temp app.asar
我们加了延时,等待父进程完全关闭后,再去执行后续命令。其中 %1 为运行脚本传入的参数,在我们的场景里就是 resources 文件夹的地址,因为每个人的安装地址应该是不一样的,所以需要作为参数传进去。
转换文件的工具一开始用的是 Bat To Exe Converter 下载地址,但是在实际使用的过程中,我的电脑竟然把转换后的 exe 文件 识别为病毒,但在其他同事电脑上没有这种表现,这肯定就不行了,最后还是同事使用 python 帮我转换生成了一份可用的文件(replace.exe)。
这里我们可以选择不同的方式把 replace.exe 存放到 用户目录 上,要么是从线上服务器下载,要么是安装的时候就已经存放在本地了。我们选择了后者,这需要修改 electron-builder 打包配置,指定 asarUnpack, 这样就会存放在 app.asar.unpacked 文件夹中,不经常修改的文件都可以放在这里,不会随着增量更新而替换掉。
有了这个替换脚本之后,开始编写子进程相关的代码。
import { spawn } from 'child_process'
cosnt localExePath = path.join(resourcePath, 'app.asar.unpacked/resources/replace.exe')
replaceAsar() {
if (fs.existsSync(localAsar) && fs.existsSync(localAsarTemp)) {
const command = `${localExePath} ${resourcePath}`
log.info(command)
const logPath = app.getPath('logs')
const childOut = fs.openSync(path.join(logPath, './out.log'), 'a')
const childErr = fs.openSync(path.join(logPath, './err.log'), 'a')
const child = spawn(`"${localExePath}"`, [`"${resourcePath}"`], {
detached: true, // 允许子进程独立
shell: true,
stdio: ['ignore', childOut, childErr]
})
child.on('spawn', () => log.info('子进程触发'))
child.on('error', err => log.error('child error', err))
child.on('close', code => log.error('child close', code))
child.on('exit', code => log.error('child exit', code))
child.stdout?.on('data', data => log.info('stdout', data))
child.stderr?.on('data', data => log.info('stderr', data))
child.unref()
}
}
app.on('quit', () => {
replaceAsar()
})
在这块代码中,创建子进程的配置项比较重要,尤其是路径相关的。因为用户安装路径是不同的,可能会存在 文件夹名含有空格 的情况,比如 Program Files,这会导致在执行的时候将空格识别为分隔符,导致命令执行失败,因此需要加上 双引号。此外,detached: true 可以让子进程独立出来,也就是父进程退出后可以执行,而shell: true 可以将路径名作为参数传过去。
const child = spawn(`"${localExePath}"`, [`"${resourcePath}"`], {
detached: true,
shell: true,
stdio: ['ignore', childOut, childErr]
})
但这块有个 疑惑,为什么我的 close、exit 以及 stdout 都没有触发,以至于不能拿到命令是否执行成功的最终结果,了解的同学可以评论区交流一下。
至此,在关闭应用之后,app.asar 就已经被替换为最新版本了,还差最后一步,更新本地配置文件里的 hotVersion,防止下次又去下载更新包了。
child.on('spawn', () => {
log.info('子进程触发')
updateHotVersion()
})
updateHotVersion() {
fs.writeFileSync(localConfigFile, JSON.stringify({ hotVersion }, null, 2))
}
增量更新日志提示
既然之前提到的全量更新有日志说明,那增量更新可以不用,也应该需要具备这个能力,不然我们神不知鬼不觉帮用户更新了,用户都不知道 新在哪里。
至于更新内容,我们可以复用 releaseInfo 的 releaseNotes 字段,把更新日志写在这里,增量更新完成后展现给用户就好了。
但是总不能每次打开都展示,这里需要用户有个交互,比如点击 知道了 按钮,或者关闭 Modal 后,把当前的热更新版本号保存在本地配置文件,记录为 logVersion。在下次打开程序或者校验更新的时候,我们判断一下 logVersion === hotVersion,若不同,再去提示更新日志。
日志版本 校验和修改的代码如下所示:
checkLogVersion() {
let needShowLog = false
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
const { hotVersion, logVersion } = configData
if (hotVersion !== logVersion) {
log.info('日志版本与当前热更新版本不同,需要提示更新日志')
needShowLog = true
} else {
log.info('日志已是最新版本,无需提示更新日志')
}
} catch (error) {
log.error('读取配置文件失败', error)
}
return needShowLog
}
updateLogVersion() {
try {
const configStr = fs.readFileSync(localConfigFile, 'utf8')
const configData = JSON.parse(configStr || '{}')
const { hotVersion } = configData
fs.writeFileSync(localConfigFile, JSON.stringify({ hotVersion, logVersion: hotVersion }, null, 2))
log.info('日志版本已更新')
} catch (error) {
log.error('读取配置文件失败', error)
}
}
读取 config.json 文件的方法自行封装一下,我这里就重复使用了。主进程 ipcMain.on 监听一下用户传递过来的事件,再去调用 updateLogVersion 即可,渲染进程效果如下:
提示增量更新日志

点击 知道了 后,再次打开应用后就不会提示日志了,因为本地配置文件已经被修改了。

当然可能也有这么个场景,开发就改了一点点无关功能的代码,无需向用户展示日志,我们只需要加一个判断 releaseNotes 是否为空的逻辑就好了,也做到了 静默更新。
小结
不足之处
本文提出的增量更新方案应该算是比较简单的,可能并不适用于所有的场景,考虑也不够全面,例如:
dll、第三方SDK等资源的更新。- 增量更新失败后应该通过全量更新 兜底。
- 用户在使用过程中发布新版本,得等到 第二次打开 才能用到新版本。
流程图
针对本文的解决方案,我简单画了一个 流程图。

参考文章
网上其实有不少关于 Electron 自动更新的文章,在做这个需求之前也是浏览了好多,但也有些没仔细看完,所以就躺在我的标签页没有关闭,在这罗列出来,也当作收藏了。
写这篇文章的目的也是为了记录和复盘,如果能为你提供一些思路那就再好不过了。
鸣谢:
来源:juejin.cn/post/7416311252580352034
国产语言MoonBit崛起,比Rust快9倍,比GO快35倍
在这个技术日新月异的时代,编程语言的更新换代似乎已经成为了家常便饭。但国产语言却一直不温不火,对于程序员来说,拥有一款属于我们自己的语言,一直是大家梦寐以求的事情。
如果我说有一种国产编程语言,它的运行速度比Rust快9倍,比GO快35倍,你会相信吗?
这不是天方夜谭,最近,被称为“国产编程语引领者”的MoonBit(月兔),宣布正式进入Beta预览版本阶段啦!
一听月兔这名字起得挺中式的。
一、初识MoonBit
MoonBit是由粤港澳大湾区数字经济研究院(福田)研发的全新编程语言。
① 官网

② 目前状态
MoonBit是2022年推出的国产编程语言,并在2023年8月18日海外发布后,立即获得国际技术社区的广泛关注。
经过一年多的高速迭代,MoonBit推出了beta预览版。
MoonBit 目前处于 Beta-Preview 阶段。官方希望能在 2024/11/22 达到 Beta 阶段,2025年内达到 1.0 阶段。
③ 由来
诞生于AI浪潮,没有历史包袱:MoonBit 诞生于 ChatGPT 出世之后,使得 MoonBit 团队有更好的机会去重新构想整个程序语言工具链该如何与 AI 友好的协作,不用承担太多的历史包袱
二、MoonBit 语言优势
① 编译与运行速度快
MoonBit在编译速度和运行时性能上表现出色,其编译626个包仅需1.06秒,比Rust快了近9倍;运行速度比GO快35倍!

② 代码体积小
MoonBit 在输出 Wasm 代码体积上相较于传统语言有显著优势。
一个简单的HTTP 服务器时,MoonBit 的输出文件大小仅为 27KB,而 WasmCloud提供的http-hello-world 模板中 Rust 的输出为 100KB,TypeScript 为 8.7MB,Python 更是高达 17MB。

③ 多重安全保障
MoonBit 采用了强大的类型系统,并内置静态检测工具,在编译期检查类型错误,
MoonBit自身的静态控制流分析能在编译器捕获异常的类型,从而提高代码的正确性和可靠性。
④ 高效迭代器
MoonBit创新地使用了零开销的迭代器设计,使得用户能够写出既优雅又高效的代码。
⑤ 创新的泛型系统设计
MoonBit语言在它的测试版里就已经搞定了泛型和特殊的多态性,而且在编译速度特别快的同时,还能做到用泛型时不增加额外负担。
你要知道,这种本事在很多流行的编程语言里,都是正式发布很久之后才慢慢有的,但MoonBit一开始就做到了。这种设计在现在编程语言越来越复杂的大背景下特别关键,因为一个好的类型系统对于整个编程语言生态的健康成长是特别重要的。
三、应用场景
① 云计算
② 边缘计算
③ AI 以及教学领域的发展
四、开发样例
我们在官网 http://www.moonbitlang.cn/gallery/ 可以看到用使用MoonBit 开发的游戏样例
- 罗斯方块游戏
- 马里奥游戏
- 数独求解器
- 贪吃蛇游戏

五、语言学习
5.1 语法文档
如果你也对
MoonBit感兴趣,想学习它,访问官方文档docs.moonbitlang.cn/。文档算是比较详细的了

5.2 在线编译器
无需本地安装编译器即可使用,官方提供了在线编译器
① 在线编辑器地址

② 点击这儿运行代码

5.3 VS Code 中安装插件编写代码、
① 安装插件


② 下载程序
按下shift+cmd+p快捷键(mac快捷键,windows和linux快捷键是ctrl+shift+p),输入 MoonBit:install latest moonbit toolchain,随后会出现提示框,点击“yes”,等待程序下载完成。

③ 创建并打开新项目
下载完成后,点击terminal,输入moon new hello && code hello以创建并打开新项目。
④ 始执行代码
项目启动后,再次打开terminal,输入moon run main命令,即可开始执行代码。
六、小结
下面是晓凡的一些个人看法
MoonBit 作为一款新兴的国产编程语言,其在性能和安全性方面的表现令人印象深刻。
特别是它在编译速度和运行效率上的优化,对于需要处理大量数据和高并发请求的现代应用来说,是一个很大的优势。
同时,它的设计理念符合当前软件开发的趋势,比如对云计算和边缘计算的支持,以及对 AI 应用的适配。
此外,MoonBit 团队在语言设计上的前瞻性思考,比如泛型系统的实现,显示出了其对未来编程语言发展趋势的深刻理解。
而且,提供的游戏开发样例不仅展示了 MoonBit 的实用性,也降低了初学者的学习门槛。
来源:juejin.cn/post/7416604150933733410
花了一天时间帮财务朋友开发了一个实用小工具
大家好,我是晓凡。
写在前面
不知道大家有没有做财务的朋友,我就有这么一位朋友就经常跟我抱怨。一到月底简直就是噩梦,总有加不完的班,熬不完的夜,做不完的报表。

一听到这儿,这不就一活生生的一个“大表哥”么,这加班跟我们程序员有得一拼了,忍不住邪恶一笑,心里平衡了很多。

身为牛马,大家都不容易啊。我不羡慕你数钱数到手抽筋,你也别羡慕我整天写CRUD 写到手起老茧🤣
吐槽归吐槽,饭还得吃,工作还得继续干。于是乎,真好赶上周末,花了一天的时间,帮朋友写了个小工具
一、功能需求
跟朋友吹了半天牛,终于把需求确定下来了。就一个很简单的功能,通过名字,将表一和表二中相同名字的金额合计。
具体数据整合如下图所示

虽然一个非常简单的功能,但如果不借助工具,数据太多,人工来核对,整合数据,还是需要非常消耗时间和体力的。
怪不得,这朋友到月底就消失了,原来时间都耗在这上面了。
二、技术选型
由于需求比较简单,只有excel导入导出,数据整合功能。不涉及数据库相关操作。
综合考虑之后选择了
PowerBuilderPbidea.dll
使用PowerBuilder开发桌面应用,虽然界面丑一点,但是开发效率挺高,简单拖拖拽拽就能完成界面(对于前端技术不熟的小伙伴很友好)
其次,由于不需要数据库,放弃web开发应用,又省去了云服务器费用。最终只需要打包成exe文件即可跑起来
Pbidea.dll 算是Powerbuilder最强辅助开发,没有之一。算是PBer们的福音吧
三、简单界面布局



四、核心代码
① 导入excel
string ls_pathName,ls_FileName //路径+文件名,文件名
long ll_Net
long rows
dw_1.reset()
uo_datawindowex dw
dw = create uo_datawindowex
dw_1.setredraw(false)
ll_Net = GetFileSaveName("请选择文件",ls_pathName,ls_FileName,"xlsx","Excel文(*.xlsx),*.xlsx")
rows = dw.ImportExcelSheet(dw_1,ls_pathName,1,0,0)
destroy dw
dw_1.setredraw(true)
MessageBox("提示信息","导入成功 " + string(rows) + "行数据")
② 数据整合
long ll_row,ll_sum1,ll_sum2
long ll_i,ll_j
long ll_yes
string ls_err
//重置表三数据
dw_3.reset()
//处理表一数据
ll_sum1 = dw_1.rowcount( )
if ll_sum1<=0 then
ls_err = "表1 未导入数据,请先导入数据"
goto err
end if
for ll_i=1 to ll_sum1
ll_row = dw_3.insertrow(0)
dw_3.object.num[ll_row] =ll_row //序号
dw_3.object.name[ll_row]=dw_1.object.name[ll_i] //姓名
dw_3.object.salary[ll_row]=dw_1.object.salary[ll_i] //工资
dw_3.object.endowment[ll_row]=dw_1.object.endowment[ll_i] //养老
dw_3.object.medical[ll_row]=dw_1.object.medical[ll_i] //医疗
dw_3.object.injury[ll_row]=dw_1.object.injury[ll_i] //工伤
dw_3.object.unemployment[ll_row]=dw_1.object.unemployment[ll_i] //失业
dw_3.object.publicacc[ll_row]=dw_1.object.publicacc[ll_i] //公积金
dw_3.object.annuity[ll_row]=dw_1.object.annuity[ll_i] //年金
next
//处理表二数据
ll_sum2 = dw_2.rowcount( )
if ll_sum2<=0 then
ls_err = "表2未导入数据,请先导入数据"
goto err
end if
for ll_j =1 to ll_sum2
string ls_name
ls_name = dw_2.object.name[ll_j]
ll_yes = dw_3.Find("name = '"+ ls_name +"' ",1,dw_3.rowcount())
if ll_yes<0 then
ls_err = "查找失败!"+SQLCA.SQLErrText
goto err
end if
if ll_yes = 0 then //没有找到
ll_row = dw_3.InsertRow (0)
dw_3.ScrollToRow(ll_row)
dw_3.object.num[ll_row] = ll_row //序号
dw_3.object.name[ll_row] = dw_1.object.name[ll_j] //姓名
dw_3.object.salary[ll_row] = dw_1.object.salary[ll_j] //工资
dw_3.object.endowment[ll_row] = dw_1.object.endowment[ll_j] //养老
dw_3.object.medical[ll_row] = dw_1.object.medical[ll_j] //医疗
dw_3.object.injury[ll_row] = dw_1.object.injury[ll_j] //工伤
dw_3.object.unemployment[ll_row] = dw_1.object.unemployment[ll_j] //失业
dw_3.object.publicacc[ll_row] = dw_1.object.publicacc[ll_j] //公积金
dw_3.object.annuity[ll_row] = dw_1.object.annuity[ll_j] //年金
end if
if ll_yes >0 then //找到
dec{2} ld_salary,ld_endowment,ld_medical,ld_injury,ld_unemployment,ld_publicacc,ld_annuity
ld_salary = dw_3.object.salary[ll_yes] + dw_2.object.salary[ll_j]
ld_endowment = dw_3.object.endowment[ll_yes] + dw_2.object.endowment[ll_j]
ld_medical = dw_3.object.medical[ll_yes] + dw_2.object.medical[ll_j]
ld_injury = dw_3.object.injury[ll_yes] + dw_2.object.injury[ll_j]
ld_unemployment = dw_3.object.unemployment[ll_yes] + dw_2.object.unemployment[ll_j]
ld_publicacc = dw_3.object.publicacc[ll_yes] + dw_2.object.publicacc[ll_j]
ld_annuity = dw_3.object.annuity[ll_yes] + dw_2.object.annuity[ll_j]
dw_3.object.salary[ll_yes]= ld_salary //工资
dw_3.object.endowment[ll_yes]=ld_endowment //养老
dw_3.object.medical[ll_yes]=ld_medical //医疗
dw_3.object.injury[ll_yes]=ld_injury //工伤
dw_3.object.unemployment[ll_yes]=ld_unemployment //失业
dw_3.object.publicacc[ll_yes]=ld_publicacc //公积金
dw_3.object.annuity[ll_yes]=ld_publicacc //年金
end if
next
return 0
err:
messagebox('错误信息',ls_err)
③ excel导出
string ls_err
string ls_pathName,ls_FileName //路径+文件名,文件名
long ll_Net
if dw_3.rowcount() = 0 then
ls_err = "整合数据为空,不能导出"
goto err
end if
uo_wait_box luo_waitbox
luo_waitbox = create uo_wait_box
luo_waitBox.OpenWait(64,RGB(220,220,220),RGB(20,20,20),TRUE,"正在导出 ", 8,rand(6) - 1)
long rows
CreateDirectory("tmp")
uo_datawindowex dw
dw = create uo_datawindowex
ll_Net = GetFileSaveName("选择路径",ls_pathName,ls_FileName,"xlsx","Excel文(*.xlsx),*.xlsx")
rows = dw.ExportExcelSheet(dw_3,ls_pathName,true,true)
destroy dw
destroy luo_waitbox
MessageBox("提示信息","成功导出 " + string(rows) + " 行数据")
return 0
err:
messagebox('错误信息',ls_err)
五、最终效果

这次分享就到这吧,★,°:.☆( ̄▽ ̄)/$: .°★ 。希望对您有所帮助,也希望多来几个这样的朋友,不多说了, 蹭饭去了
我们下期再见ヾ(•ω•`)o (●'◡'●)
来源:juejin.cn/post/7404036818973245478
37K star!实时后端服务,一个文件实现

如果你经常开发web类的的项目,那你一定经常会接触到后端服务,给项目找一个简单、好用的后端服务可以大大加速开发。
今天我们分享的开源项目,它可以作为SaaS或者是Mobile的后端服务,最简单情况只要一个文件,它就是:PocketBase

PocketBase 是什么
PocketBase是一个开源的Go后端框架,它以单个文件的形式提供了一个实时的后端服务。这个框架特别适合于快速开发小型到中型的Web应用和移动应用。它的设计哲学是简单性和易用性,使得开发者能够专注于他们的产品而不是后端的复杂性。

PocketBase包含以下功能:
- 内置数据库(SQLite)支持实时订阅
- 内置文件和用户管理
- 方便的管理面板 UI
- 简洁的 REST 风格 API
安装使用PocketBase
首先你可以下载PocketBase的预构建版本,你可以在github的release页面下载到对应平台的包。

下载后,解压存档并./pocketbase serve在解压的目录中运行。
启动完成后会3个web服务的路由:
- http://127.0.0.1:8090 - 如果存在pb_public目录,则提供其中的静态内容(html、css、图像等)
- http://127.0.0.1:8090/_/ - Admin的管理页面
- http://127.0.0.1:8090/api/ - Rest API
默认情况下,PocketBase 在端口上运行8090。但您可以通过在 serve 命令后附加--http和--https参数将其绑定到任何端口。
Admin panel
第一次访问管理仪表板 UI 时,它会提示您创建第一个管理员帐户。在管理页面里您可以完全使用 GUI 构建数据架构、添加记录并管理数据库。

API
它带有一个开箱即用的 API,可让您操作任何集合,还具有一个优雅的查询系统,可让您分页搜索记录。这将使您不必自己编写和维护同样无聊的 CRUD 操作,而可以更专注于产品特定的功能。
内置访问规则
PocketBase 可让您通过简单的语法直接从 GUI 定义对资源的访问规则。例如,这有助于定义访问范围和控制对用户特定数据的访问。同样,这将使您无需担心编写身份验证和授权代码。

SDK
使用PocketBase的API可以通过官方SDK,目前官方提供了JS SDK和Dart SDK。
- JavaScript - pocketbase/js-sdk (浏览器和nodejs)
- Dart - pocketbase/dart-sdk(网页、移动、桌面)
它们提供了用于连接数据库、处理身份验证、查询、实时订阅等的库,使开发变得简单。
开发定制应用
PocketBase 作为常规 Go 库包分发,允许您构建自己的自定义应用程序特定的业务逻辑,并且最后仍具有单个可移植的可执行文件。
这是一个简单的例子:
- 首先如果你没有Go的环境,那么需要安装 Go1.21以上版本
- 创建一个新的项目目录,并创建一个main.go文件,文件包含以下内容:
package main
import (
"log"
"net/http"
"github.com/labstack/echo/v5"
"github.com/pocketbase/pocketbase"
"github.com/pocketbase/pocketbase/apis"
"github.com/pocketbase/pocketbase/core"
)
func main() {
app := pocketbase.New()
app.OnBeforeServe().Add(func(e *core.ServeEvent) error {
// add new "GET /hello" route to the app router (echo)
e.Router.AddRoute(echo.Route{
Method: http.MethodGet,
Path: "/hello",
Handler: func(c echo.Context) error {
return c.String(200, "Hello world!")
},
Middlewares: []echo.MiddlewareFunc{
apis.ActivityLogger(app),
},
})
return nil
})
if err := app.Start(); err != nil {
log.Fatal(err)
}
}
- 初始化依赖项,请运行go mod init myapp && go mod tidy。
- 要启动应用程序,请运行go run main.go serve。
- 要构建静态链接的可执行文件,您可以运行CGO_ENABLED=0 go build,然后使用 启动创建的可执行文件./myapp serve。
总结
整体来说PocketBase是一个非常不错的后端服务,它兼顾了易用性和定制的灵活性,如果你有项目的需要或是想要自己开发一个SAAS的服务,都可以选择它来试试。

项目信息
- 项目名称:pocketbase
- GitHub 链接:github.com/pocketbase/…
- Star 数:37K
来源:juejin.cn/post/7415672130190704640
还在用 top htop? 赶紧换 btop 吧,真香!
top
在 Linux 服务器上,或类 Unix 的机器上,一般我们想查看每个进程的 CPU 使用率、内存使用情况以及其他相关信息时会使用 top 命令。

top 是一个标准的 Linux/Unix 工具,实际上我从一开始接触 Linux 就一直使用 top , 一般是两种场景:
- Linux 服务器上用
- 自己的 Mac 电脑上用
top 有一些常用的功能,比如可以动态的显示进程的情况,按照 CPU 、内存使用率排序等。说实话,这么多年了,使用最多的还就是 top ,一来是因为习惯了,工具用惯了很多操作都是肌肉记忆。二来是 top 一般系统自带不用安装,省事儿。
htop
top 挺好的,但 top 对于初学者和小白用户不太友好,尤其是它的用户界面和操作。于是后来有了 htop

htop 是 top 的一个增强替代品,提供了更加友好的用户界面和更多的功能。与 top 相比,htop 默认以颜色区分不同的信息,并且支持水平滚动查看更多的进程信息。htop 还允许用户使用方向键来选择进程,并可以直接发送信号给进程(如 SIGKILL)。htop 支持多种视图和配置选项,使得用户可以根据自己的喜好定制显示的内容。
htop 我也用了几年,确实舒服一些,但由于需要安装和我对 top 的肌肉记忆 ,htop 在我的使用中并未完全替代 top。 直到 btop 的出现
btop
现在,我本机使用的是 btop,有了 btop,top 和 htop 一点儿都不想用了,哈哈。
在服务器上有时候因为懒不想安装,一部分时间还是 top,一部分用 btop。

第一印象是真漂亮啊,然而它不止好看,功能也是很实用,操作还很简单,你说能不喜欢它吗?
说是 btop ,实际上人家真正的名字是 btop++ , 用 C++ 开发的

安装
btop 支持各种类 Unix 系统,你可以在它的文档中找到对应系统的安装方法 github.com/aristocrato…

本文演示,我是用我自己的 Mac 笔记本电脑,用 Mac 安装很简单,用 brew 一行搞定
brew install btop
我的系统情况是这样的:

安装完成后,直接运行 btop 就可以看到如上图的界面了。
功能界面
打开 btop 后不要被它的界面唬住了,其实非常的简单,我们来介绍一下。
打开 btop 后,其实显示的是它给你的 “预置” 界面。 默认有 4 个预置界面,你可以按 p 键进行切换。命令行界面上会分别显示:
- preset 0
- preset 1
- preset 2
- preset 3

你可能注意到了,这 4 个预置界面中有很多内容是重复的,没错,其实 btop 一共就 4 个模块,预置界面只是把不同的模块拼在一起显示罢了。这 4 个模块分别是:
- CPU 模块
- 存储 模块
- 网络 模块
- 进程 模块
这 4 个模块对应的快捷键分别就是 1,2,3,4 你按一下模块显示,再按一下模块隐藏。

所以如果你对预置界面的内容想立刻调整,就可以按快捷键来显示/隐藏 你想要的模块,当然预置界面也是可以通过配置文件调整的,这个我们后面说。
CPU 模块
CPU 模块可以显示 CPU 型号、各内核的使用率、温度,CPU 整体的负载,以及一个直观的图象,所有数据都是实时显示的。

存储 模块
存储模块包括两部分,一个是内存使用情况,一个是磁盘使用情况:

因为比较直观,具体内容我就不解释了。
网络模块
网络模块可以看下网络的整体负载和吞吐情况,主要包括上行和下行数据汇总,你可以通过按快捷键 b和n 来切换看不同的网卡。

进程模块
初始的进程模块可以看到:
- pid
- Program: 进程名称
- Command: 执行命令的路径
- Threads: 进程包含的线程数
- User: 启动进程的用户
- MemB: 进程所占用内存
- Cpu%: 进程所占用 CPU 百分比

你可以按快捷键 e 显示树状视图:

可以按快捷键 r 对进行排序,按一下是倒序,再按一下是正序。具体排序列可以按左右箭头,根据界面显示进行选择,比如我要按照内存使用排序,那么右上角就是这样的:

按 f 键输入你想过滤的内容然后回车,可以过滤一下界面显示的内容,比如我只想看 chrome 的进程情况:

还可以通过 上下箭头选中某一个进程按回车查看进程详情,再次按回车可以隐藏详情:

显示进程详情后可以对进程进行操作,比如 Kill 只需要按快捷键 k 就可以了,然后会弹出提示:

主题
怎么样,是不是很方便,操作简单,上手容易,还好看。关于 btop 的主要操作就这些了,剩下的可以参考 help 和 menu 中显示的内容自行操作和设置都很简单。
btop 的配置文件默认在这里:$HOME/.config/btop ,你可以直接修改配置文件中的详细参数,如我们前文提到的 “预置” 界面以及预置界面内容都可以在配置文件中设置 :

此外 btop 还有很多好看的主题配色,但默认安装的情况下只带了一个 Default 的,如果你想切换用其他的主题,需要先下载这些主题,主题文件在这里:github.com/aristocrato…
下载好以后放到本地对应的文件夹中 ~/.config/btop/themes
然后你就可以要界面上进行主题的切换了,具体流程是先按快捷键 m ,然后选 OPTIONS

接着在 Color theme 中就能看到你当前拥有的 theme 数据,按方向键就可以切换主题配色了:

主题有很多,我这里给大家一个完整的预览:

我目前使用的就是 Default 我觉得最符合我的审美。
最后
用了 btop 后你就再也回不去了,一般情况下再也不会想用 htop 和 top 了,大家没有换的可以直接换了
来源:juejin.cn/post/7415197972009287692
简单实现一个插件系统(不引入任何库),学会插件化思维
插件系统被广泛应用在各个系统中,比如浏览器、各个前端库如vue、webpack、babel,它们都可以让用户自行添加插件。插件系统的好处是允许开发人员在保证内部核心逻辑不变的情况下,以安全、可扩展的方式添加功能。
本文参考了webpack的插件,不引入任何库,写一个简单的插件系统,帮助大家理解插件化思维。
下面我们先看看插件有哪些概念和设计插件的流程。
准备
三个概念
- 核心系统(Core):有着系统的基本功能,这些功能不依赖于任何插件。
- 核心和插件之间的联系(Core <--> plugin):即插件和核心系统之间的交互协议,比如插件注册方式、插件对核心系统提供的api的使用方式。
- 插件(plugin):相互独立的模块,提供了单一的功能。

插件系统的设计和执行流程
那么对着上面三个概念,设计插件的流程:
- 首先要有一个核心系统。
- 然后确定核心系统的生命周期和暴露的 API。
- 最后设计插件的结构。
- 插件的注册 -- 安装加载插件到核心系统中。
- 插件的实现 -- 利用核心系统的生命周期钩子和暴露的 API。
最后代码执行的流程是:
- 注册插件 -- 绑定插件内的处理函数到生命周期
- 调用插件 -- 触发钩子,执行对应的处理函数
直接看代码或许更容易理解⬇️
代码实现
准备一个核心系统
一个简单的 JavaScript 计算器,可以做加、减操作。
class Calculator {
constructor(options = {}) {
const { initialValue = 0 } = options
this.currentValue = initialValue;
}
getCurrentValue() {
return this.currentValue;
}
setValue(value) {
this.currentValue = value;
}
plus(addend) {
this.setValue(this.currentValue + addend);
}
minus(subtrahend) {
this.setValue(this.currentValue - subtrahend);
}
}
// test
const calculator = new Calculator()
calculator.plus(10);
calculator.getCurrentValue() // 10
calculator.minus(5);
calculator.getCurrentValue() // 5
确定核心系统的生命周期
实现Hooks
核心系统想要对外提供生命周期钩子,就需要一个事件机制。不妨叫Hooks。(日常开发可以考虑使用webpack的核心库 Tapable )
class Hooks {
constructor() {
this.listeners = {};
}
on(eventName, handler) {
let listeners = this.listeners[eventName];
if (!listeners) {
this.listeners[eventName] = listeners = [];
}
listeners.push(handler);
}
off(eventName, handler) {
const listeners = this.listeners[eventName];
if (listeners) {
this.listeners[eventName] = listeners.filter((l) => l !== handler);
}
}
trigger(eventName, ...args) {
const listeners = this.listeners[eventName];
const results = [];
if (listeners) {
for (const listener of listeners) {
const result = listener.call(null, ...args);
results.push(result);
}
}
return results;
}
destroy() {
this.listeners = {};
}
}
暴露生命周期(通过Hooks)
然后将hooks运用在核心系统中 -- JavaScript 计算器
每个钩子对应的事件:
- pressedPlus 做加法操作
- pressedMinus 做减法操作
- valueWillChanged 即将赋值currentValue,如果执行此钩子后返回值为false,则中断赋值。
- valueChanged 已经赋值currentValue
class Calculator {
constructor(options = {}) {
this.hooks = new Hooks();
const { initialValue = 0 } = options
this.currentValue = initialValue;
}
getCurrentValue() {
return this.currentValue;
}
setValue(value) {
const result = this.hooks.trigger('valueWillChanged', value);
if (result.length !== 0 && result.some( _ => ! _ )) {
} else {
this.currentValue = value;
}
this.hooks.trigger('valueChanged', this.currentValue);
}
plus(addend) {
this.hooks.trigger('pressedPlus', this.currentValue, addend);
this.setValue(this.currentValue + addend);
}
minus(subtrahend) {
this.hooks.trigger('pressedMinus', this.currentValue, subtrahend);
this.setValue(this.currentValue - subtrahend);
}
}
设计插件的结构
插件注册
class Calculator {
constructor(options = {}) {
this.hooks = new Hooks();
const { initialValue = 0, plugins = [] } = options
this.currentValue = initialValue;
// 在options中取出plugins
// 通过plugin执行apply来注册插件 -- apply执行后会绑定(插件内的)处理函数到生命周期
plugins.forEach(plugin => plugin.apply(this.hooks));
}
...
}
插件实现
插件一定要实现apply方法。在Calculator的constructor调用时,才能确保插件“apply执行后会绑定(插件内的)处理函数到生命周期”。
apply的入参是this.hooks,通过this.hooks来监听生命周期并添加处理器。
下面实现一个日志插件和限制最大值插件:
// 日志插件:用console.log模拟下日志
class LogPlugins {
apply(hooks) {
hooks.on('pressedPlus',
(currentVal, addend) => console.log(`${currentVal} + ${addend}`));
hooks.on('pressedMinus',
(currentVal, subtrahend) => console.log(`${currentVal} - ${subtrahend}`));
hooks.on('valueChanged',
(currentVal) => console.log(`结果: ${currentVal}`));
}
}
// 限制最大值的插件:当计算结果大于100时,禁止赋值
class LimitPlugins {
apply(hooks) {
hooks.on('valueWillChanged', (newVal) => {
if (100 < newVal) {
console.log('result is too large')
return false;
}
return true
});
}
}
全部代码
class Hooks {
constructor() {
this.listener = {};
}
on(eventName, handler) {
if (!this.listener[eventName]) {
this.listener[eventName] = [];
}
this.listener[eventName].push(handler);
}
trigger(eventName, ...args) {
const handlers = this.listener[eventName];
const results = [];
if (handlers) {
for (const handler of handlers) {
const result = handler(...args);
results.push(result);
}
}
return results;
}
off(eventName, handler) {
const handlers = this.listener[eventName];
if (handlers) {
this.listener[eventName] = handlers.filter((cb) => cb !== handler);
}
}
destroy() {
this.listener = {};
}
}
class Calculator {
constructor(options = {}) {
this.hooks = new Hooks();
const { initialValue = 0, plugins = [] } = options;
this.currentValue = initialValue;
plugins.forEach((plugin) => plugin.apply(this.hooks));
}
getCurrentValue() {
return this.currentValue;
}
setValue(value) {
const result = this.hooks.trigger("valueWillChanged", value);
if (result.length !== 0 && result.some((_) => !_)) {
} else {
this.currentValue = value;
}
this.hooks.trigger("valueChanged", this.currentValue);
}
plus(addend) {
this.hooks.trigger("pressedPlus", this.currentValue, addend);
this.setValue(this.currentValue + addend);
}
minus(subtrahend) {
this.hooks.trigger("pressedMinus", this.currentValue, subtrahend);
this.setValue(this.currentValue - subtrahend);
}
}
class LogPlugins {
apply(hooks) {
hooks.on("pressedPlus", (currentVal, addend) =>
console.log(`${currentVal} + ${addend}`)
);
hooks.on("pressedMinus", (currentVal, subtrahend) =>
console.log(`${currentVal} - ${subtrahend}`)
);
hooks.on("valueChanged", (currentVal) =>
console.log(`结果: ${currentVal}`)
);
}
}
class LimitPlugins {
apply(hooks) {
hooks.on("valueWillChanged", (newVal) => {
if (100 < newVal) {
console.log("result is too large");
return false;
}
return true;
});
}
}
// run test
const calculator = new Calculator({
plugins: [new LogPlugins(), new LimitPlugins()],
});
calculator.plus(10);
calculator.minus(5);
calculator.plus(1000);
脚本的执行结果如下,大家也可以自行验证一下

看完代码可以回顾一下“插件系统的设计和执行流程”哈。
更多实现
假如要给Calculator设计一个扩展运算方式的插件,支持求平方、乘法、除法等操作,这时候怎么写?
实际上目前核心系统Calculator是不支持的,因为它并没有支持的钩子。那这下只能改造Calculator。
可以自行尝试一下怎么改造。也可以直接看答案:github.com/coder-xuwen…
最后
插件化的好处
在上文代码实现的过程中,可以感受到插件让Calculator变得更具扩展性。
- 核心系统(Core)只包含系统运行的最小功能,大大降低了核心代码的包体积。
- 插件(plugin)则是互相独立的模块,提供单一的功能,提高了内聚性,降低了系统内部耦合度。
- 每个插件可以单独开发,也支持了团队的并行开发。
- 另外,每个插件的功能不一样,也给用户提供了选择功能的能力。
本文的局限性
另外,本文的代码实现很简单,仅供大家理解,大家还可以继续完善:
- 增加ts类型,比如给把所有钩子的类型用emun记录起来
- 支持动态加载插件
- 提供异常拦截机制 -- 处理注册插件插件的情况
- 暴露接口、处理钩子返回的结构时要注意代码安全
参考
Designing a JavaScript Plugin System | CSS-Tricks
干货!撸一个webpack插件(内含tapable详解+webpack流程) - 掘金
来源:juejin.cn/post/7344670957405126695
用了Go的匿名结构体,搬砖效率更高,产量更足了
今天给大家分享一个使用匿名结构体,提升Go编程效率的小技巧,属于在日常写代码过程中积累下来的一个提升自己效率的小经验。
这个技巧之所以提效率主要体现在两方面:
- 减少一些不会复用的类型定义
- 节省纠结该给类型起什么名字的时间
尤其第二项,通过匿名结构体这个名字就能体现出来,它本身没有类型名,这能节省不少想名字的时间。再一个也能减少起错名字给其他人带来的误解,毕竟并不是所有人编程时都会按照英文的词法做命名的。
下面我先从普通结构体说起,带大家看看什么情形下用匿名结构体会带来编码效率的提升。
具名结构体
具名结构体就是平时用的普通结构体。
结构体大家都知道,用于把一组字段组织在一起,来在Go语言里抽象表达现实世界的事物,类似“蓝图”一样。
比如说定义一个名字为Car的结构体在程序里表示“小汽车”
// 定义结构体类型'car'
type car struct {
make string
model string
mileage int
}
用到这个结构体的地方通过其名字引用其即可,比如创建上面定义的结构体的实例
// 创建car 的实例
newCar := car{
make: "Ford",
model: "taurus",
mileage: 200000,
}
匿名结构体
匿名结构体顾名思义就是没有名字的结构体,通常只用于在代码中仅使用一次的结构类型,比如
func showMyCar() {
newCar := struct {
make string
model string
mileage int
}{
make: "Ford",
model: "Taurus",
mileage: 200000,
}
fmt.Printlb(newCar.mode)
}
上面这个函数中声明的匿名结构体赋值给了函数中的变量,所以只能在函数中使用。
如果一个结构体初始化后只被使用一次,那么使用匿名结构体就会很方便,不用在程序的package中定义太多的结构体类型,比如在解析接口的响应到结构体后,就可以使用匿名结构体
用于解析接口响应
func createCarHandler(w http.ResponseWriter, req *http.Request) {
defer req.Body.Close()
decoder := json.NewDecoder(req.Body)
newCar := struct {
Make string `json:"make"`
Model string `json:"model"`
Mileage int `json:"mileage"`
}{}
err := decoder.Decode(&newCar)
if err != nil {
log.Println(err)
return
}
......
return
}
类似上面这种代码一般在控制层写,可以通过匿名结构体实例解析到请求后再去创建对应的DTO或者领域对象供服务层或者领域层使用。
有人会问为什么不直接把API的响应解析到DTO对象里,这里说一下,匿名结构体的使用场景是在觉得定一个Struct 不值得、不方便的情况下才用的。 比如程序拿到接口响应后需要按业务规则加工下才能创建DTO实例这种情况,就很适合用匿名结构体先解析响应。
比用map更健壮
这里再说一点使用匿名结构体的好处。
使用匿名解析接口响应要比把响应解析到map[string]interface{}类型的变量里要好很多,json数据解析到匿名结构体的时候在解析的过程中会进行类型检查,会更安全。使用的时候直接通过s.FieldName访问字段也比map访问起来更方便和直观。
用于定义项目约定的公共字段
除了上面这种结构体初始化后只使用一次的情况,在项目中定义各个接口的返回或者是DTO时,有的公共字段使用匿名结构体声明类型也很方便。
一般在启动项目的时候我们都会约定项目提供的接口的响应值结构,比如响应里必须包含Code、Msg、Data三个字段,每个接口会再细分定义返回的Data的结构,这个时候用匿名结构题能节省一部分编码效率。
比如下面这个Reponse的结构体类型的定义
type UserCouponResponse struct {
Code int64 `json:"code"`
Msg string `json:"message"`
Data []*struct {
CouponId int `json:"couponId"`
ProdCode string `json:"prodCode"`
UserId int64 `json:"userId"`
CouponStatus int `json:"couponStatus"`
DiscountPercentage int `json:"discount"`
} `json:"data"`
}
就省的先去定义一个UserCoupon类型
type UserCoupon struct {
CouponId int `json:"couponId"`
ProdCode string `json:"prodCode"`
UserId int64 `json:"userId"`
CouponStatus int `json:"couponStatus"`
DiscountPercentage int `json:"discount"`
}
再在Response声明里使用定义的UserCoupon了
type UserCouponResponse struct {
Code int64 `json:"code"`
Msg string `json:"message"`
Data []*UserCoupon `json:"data"`
}
当然如果UserCoupon是你的项目其他地方也会用到的类型,那么先声明,顺带在Response结构体里也使用是没问题的,只要会多次用到的类型都建议声明成正常的结构体类型。
还是那句话匿名结构体只在你觉得"这还要定义个类型?”时候使用,用好的确实能提高点代码生产效率。
总结
本次的分享就到这里了,内容比较简单,记住这个口诀:匿名结构体只在你写代码时觉得这还要定义个类型,感觉没必要的时候使用,采纳这个技巧,时间长了还是能看到一些自己效率的提高的。
来源:juejin.cn/post/7359084604663709748
不到50元如何自制智能开关?
前言
家里床头离开关太远了,每次躺在床上玩手机准备睡觉时候还的下去关灯,着实麻烦,所以用目前仅有的一点单片机知识,做了一个小小小的智能开关,他有三个模块构成,如下:
- 主模块是ESP32(20元)
他是一个低成本、低功耗的微控制器,集成了 Wi-Fi 和蓝牙功能,因为我们需要通过网络去开/关灯,还有一个ESP8266,比这个便宜,大概6 块钱,但是他烧录程序的时候比较慢。

- 光电开关(10元)
这个可有可无,这个是用来当晚上下班回家后,开门自动开灯使用的,如果在他前面有遮挡,他的信号线会输出高/低电压,这个取决于买的是常开还是常闭,我买的是常开,当有物体遮挡时,会输出低电压,所以当开门时,门挡住了它,它输出低电压给ESP32,ESP32读取到电压状态后触发开灯动作。
家里床头离开关太远了,每次躺在床上玩手机准备睡觉时候还的下去关灯,着实麻烦,所以用目前仅有的一点单片机知识,做了一个小小小的智能开关,他有三个模块构成,如下:
- 主模块是ESP32(20元)
他是一个低成本、低功耗的微控制器,集成了 Wi-Fi 和蓝牙功能,因为我们需要通过网络去开/关灯,还有一个ESP8266,比这个便宜,大概6 块钱,但是他烧录程序的时候比较慢。
- 光电开关(10元)
这个可有可无,这个是用来当晚上下班回家后,开门自动开灯使用的,如果在他前面有遮挡,他的信号线会输出高/低电压,这个取决于买的是常开还是常闭,我买的是常开,当有物体遮挡时,会输出低电压,所以当开门时,门挡住了它,它输出低电压给ESP32,ESP32读取到电压状态后触发开灯动作。

- 舵机 SG90(5元)
这是用来触发开/关灯动作的设备,需要把它用胶粘在开关上,他可以旋转0-180度,力度也还行,对于开关足够了。还有一个MG90舵机,力度特别大,但是一定要买180度的,360度的舵机只能正转和反转,不能控制角度。


- 杜邦线(3元)

Arduino Ide
Arduino是什么就不说了,要烧录代码到ESP32,需要使用官方乐鑫科技提供的ESP-IDF工具,它是用来开发面向ESP32和ESP32-S系列芯片的开发框架,但是,Arduino Ide提供了一个核心,封装了ESP-IDF一些功能,便于我们更方便的开发,当然Arduino还有适用于其他开发板的库。
Arduino配置ESP32的开发环境比较简单,就是点点点、选选选即可。
接线
下面就是接线环节,先看下ESP32的引脚,他共有30个引脚,有25个GPIO(通用输入输出)引脚,如下图中紫色的引脚,在我们的这个设备里,舵机和光电开关都需要接入正负级到下图中的红色(VCC)和黑色(GND)引脚上,而他们都需要在接入一个信号作为输出/输入点,可以在着25个中选择一个,但还是有几个不能使用的,比如有一些引脚无法配置为输出,只用于作输入,还有RX和TX,我们这里使用26(光电开关)和27(舵机)引脚就可以了。

esp32代码
下面写一点点代码,主要逻辑很简单,创建一个http服务器,用于通过外部去控制舵机的转向,外部通过http请求并附带一个角度参数,在通过ESP32Servo这个库去使舵机角度发生改变。
esp32的wifi有以下几种模式。
- Station Mode(STA模式): 在STA模式下,esp32可以连接到一个wifi,获取一个ip地址,并且可以与网络中的其他设备进行通信。
- Access Point Mode(AP模式): 在AP模式下,它充当wifi热点,其他设备可以连接到esp32,就像连接到普通路由器一样,一般用作配置模式使用,经常买到的智能设备,进入配置模式和后,他会开一个热点,你的手机连接到这个热点后,在通过他们提供的app去配置,就是用这种模式。
- Soft Access Point Mode(SoftAP模式): 同时工作在STA模式和AP模式下。
下一步根据自己的逻辑,比如当光电开关被遮挡时,并且又是xxxx时,就开灯,或者当xxx点后就关灯。
#include
#include
#include
#include
#include
#define SERVO_PIN_NUMBER 27
#define STATE_PIN_NUMBER 26
#define CLOSE_VALUE 40
#define OPEN_VALUE 150
const char* ssid = "wifi名称";
const char* password = "wifi密码";
AsyncWebServer server(80);
Servo systemServo;
bool openState = false;
void setup() {
Serial.begin(115200);
WiFi.mode(WIFI_AP_STA);
WiFi.begin(ssid, password);
Serial.println("\nConnecting");
while (WiFi.status() != WL_CONNECTED) {
Serial.print(".");
delay(100);
}
systemServo.attach(SERVO_PIN_NUMBER);
systemServo.write(90);
openState = false;
write_state(CLOSE_VALUE);//启动时候将灯关闭
Serial.print("Local ESP32 IP: ");
Serial.println(WiFi.localIP());
pinMode(STATE_PIN_NUMBER, INPUT);
int timezone = 8 * 3600;
configTime(timezone, 0, "pool.ntp.org");
server.on("/set_value", HTTP_GET, [](AsyncWebServerRequest * request) {
if (request->hasParam("value")) {
String value = request->getParam("value")->value();
int intValue = value.toInt();
write_state(intValue);
request->send(200, "text/plain", "value: " + String(intValue));
} else {
request->send(400, "text/plain", "error");
}
});
server.begin();
}
void write_state(int value) {
openState = value < 90 ? false : true;
systemServo.write(value);
delay(100);
systemServo.write(90);
}
void loop() {
time_t now = time(nullptr);
struct tm *timeinfo;
timeinfo = localtime(&now);
//指定时间关灯
int currentMin = timeinfo->tm_min;
int currentHour = timeinfo->tm_hour;
if (currentHour == 23 && currentMin == 0 && openState ) {
write_state(CLOSE_VALUE);
openState = false;
}
//下班开灯
if (digitalRead(STATE_PIN_NUMBER) == 0 && currentHour > 18 && !openState) {
write_state(OPEN_VALUE);
openState = true;
}
}
Android下控制
当然,还得需要通过外部设备进行手动开关,这里就简单写一个Android程序,上面写了一个http服务,访问esp32的ip地址,发起一个http请求就可以了,所以浏览器也可以,但更方便的是app,效果如下。

package com.example.composedemo
import android.content.Context
import android.content.SharedPreferences
import android.os.Bundle
import android.util.Log
import android.view.View
import android.widget.TextView
import androidx.activity.ComponentActivity
import androidx.activity.compose.setContent
import androidx.compose.foundation.layout.Row
import androidx.compose.foundation.layout.fillMaxSize
import androidx.compose.material.*
import androidx.compose.runtime.*
import androidx.compose.ui.Modifier
import androidx.compose.ui.graphics.Color
import androidx.compose.ui.tooling.preview.Preview
import com.example.composedemo.ui.theme.ComposeDemoTheme
import kotlinx.coroutines.Dispatchers
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.launch
import kotlinx.coroutines.withContext
import java.net.HttpURLConnection
import java.net.URL
class MainActivity : ComponentActivity() {
private val state = State()
private lateinit var sharedPreferences: SharedPreferences
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
sharedPreferences = getPreferences(Context.MODE_PRIVATE)
state.ipAddressChange = {
with(sharedPreferences.edit()) {
putString("ipAddress", it)
apply()
}
}
state.slideChange = {setValue(it) }
state.lightChange = {
Log.i(TAG, "onCreate: $it")
if (it) openLight()
if (!it) closeLight()
}
state.esp32IpAddress.value = sharedPreferences.getString("ipAddress", "")!!
setContent {
ComposeDemoTheme {
Surface(
modifier = Modifier.fillMaxSize(),
color = MaterialTheme.colors.background
) {
SlidingOvalLayout(state)
}
}
}
}
private fun closeLight() =setValue(40)
private fun openLight() = setValue(150)
private fun setValue(value: Int) {
sendHttpRequest("http://${state.esp32IpAddress.value}/set_value/?value=$value:")
}
private fun sendHttpRequest(url: String) {
GlobalScope.launch(Dispatchers.IO) {
try {
val connection = URL(url).openConnection() as HttpURLConnection
connection.requestMethod = "GET"
connection.connect()
if (connection.responseCode == HttpURLConnection.HTTP_OK) {
val response = connection.inputStream.bufferedReader().readText()
withContext(Dispatchers.Main) {
}
} else {
withContext(Dispatchers.Main) {
}
}
connection.disconnect()
} catch (e: Exception) {
e.printStackTrace()
withContext(Dispatchers.Main) {
}
}
}
}
}
@Preview(showBackground = true)
@Composable
fun DefaultPreview() {
ComposeDemoTheme {
}
}
ui组件
package com.example.composedemo
import androidx.compose.foundation.background
import androidx.compose.foundation.clickable
import androidx.compose.foundation.layout.*
import androidx.compose.foundation.shape.RoundedCornerShape
import androidx.compose.material.*
import androidx.compose.runtime.*
import androidx.compose.ui.Alignment
import androidx.compose.ui.Modifier
import androidx.compose.ui.draw.shadow
import androidx.compose.ui.geometry.Offset
import androidx.compose.ui.graphics.Color
import androidx.compose.ui.graphics.graphicsLayer
import androidx.compose.ui.input.pointer.pointerInput
import androidx.compose.ui.layout.layout
import androidx.compose.ui.tooling.preview.Preview
import androidx.compose.ui.unit.Dp
import androidx.compose.ui.unit.IntOffset
import androidx.compose.ui.unit.dp
import com.example.composedemo.ui.theme.ComposeDemoTheme
const val TAG = "TAG"
@Composable
fun SlidingOvalLayout(state: State) {
var offset by remember { mutableStateOf(Offset(0f, 0f)) }
var parentWidth by remember { mutableStateOf(0) }
var sliderValue by remember { mutableStateOf(0) }
var closeStateColor by remember { mutableStateOf(Color(0xFFDF2261)) }
var openStateColor by remember { mutableStateOf(Color(0xFF32A34B)) }
Box(
modifier = Modifier
.fillMaxSize()
.padding(40.dp)
.width(100.dp)
) {
Column(
modifier = Modifier
.fillMaxSize()
.padding(16.dp),
verticalArrangement = Arrangement.SpaceBetween,
horizontalAlignment = Alignment.CenterHorizontally
) {
Column {
Box() {
TextField(
value = state.esp32IpAddress.value,
onValueChange = {
state.esp32IpAddress.value = it
state.ipAddressChange(it)
},
colors = TextFieldDefaults.textFieldColors(
disabledTextColor = Color.Transparent,
backgroundColor = Color(0xFFF1EEF1),
focusedIndicatorColor = Color.Transparent,
unfocusedIndicatorColor = Color.Transparent,
disabledIndicatorColor = Color.Transparent
),
modifier = Modifier
.fillMaxWidth()
.background(color = Color(0xFFF1EEF1))
)
}
Box() {
Column() {
Text(text = sliderValue.toString())
Row(
verticalAlignment = Alignment.CenterVertically,
horizontalArrangement = Arrangement.spacedBy(8.dp)
) {
Slider(
value = sliderValue.toFloat(),
onValueChange = {
sliderValue = it.toInt()
state.slideChange(sliderValue)},
valueRange = 0f..180f,
onValueChangeFinished = {
},
colors = SliderDefaults.colors(
thumbColor = Color.Blue,
activeTrackColor = Color.Blue
)
)
}
}
}
}
Box(
modifier = Modifier
.fillMaxWidth()
.height(70.dp)
.shadow(10.dp, shape = RoundedCornerShape(100.dp))
.background(color = Color(0xFFF1EEF1))
.layout { measurable, constraints ->
val placeable = measurable.measure(constraints)
parentWidth = placeable.width
layout(placeable.width, placeable.height) {
placeable.place(0, 0)
}
}
) {
Box(
modifier = Modifier
.offset {
if (state.lightValue.value) {
IntOffset((parentWidth - 100.dp.toPx()).toInt(), 0)
} else {
IntOffset(0, 0)
}
}
.graphicsLayer {
translationX = offset.x
}
.clickable() {
state.lightValue.value = !state.lightValue.value
state.lightChange(state.lightValue.value )
}
.pointerInput(Unit) {
}
.background(
color = if(state.lightValue.value) openStateColor else closeStateColor,
shape = RoundedCornerShape(100.dp)
)
.size(Dp(100f), Dp(80f))
)
}
}
}
}
@Preview
@Composable
fun PreviewSlidingOvalLayout() {
ComposeDemoTheme {
}
}
class State {
var esp32IpAddress: MutableState = mutableStateOf("")
var lightValue :MutableState<Boolean> = mutableStateOf(false)
var ipAddressChange :(String)->Unit={}
var slideChange:(Int)->Unit={}
var lightChange:(Boolean)->Unit={}
}
来源:juejin.cn/post/7292245569482407988
Java音视频文件解析工具
@[toc]
小伙伴们知道,松哥平时录了蛮多视频课程,视频录完以后,就想整理一个视频文档出来,在整理视频文档的时候,就会遇到一个问题,就是怎么统计视频时长?
特别是有时候为了方便大家看到每一集视频的时长,我要把视频目录整理成下面这个样子:

这个逐集去查看就很麻烦,一套视频动辄几百集,挨个统计不现实,也不符合咱们程序员做事风格。
那么怎么办呢?
一开始我是使用 Python 去解决的,Python 做这样一个小工具其实特别方便,简简单单 30 行代码左右就能搞定了。之前的课程的这些时间统计我基本上都是用 Python 去完成的。
不过最近松哥发现 Java 里边其实也有一个视频处理的库,做这个事情也是非常方便,而且使用 Java 属于主场作战,就能够更加灵活的扩展功能了。
一 jave-all-deps
在 Java 开发中,处理音视频文件经常需要复杂的编解码操作,开发者通常需要依赖于外部库来实现这些功能,其中最著名的是 FFmpeg。然而,直接在 Java 中使用 FFmpeg 并不是一件容易的事,因为它需要处理本地库和复杂的命令行接口。
幸运的是,jave-all-deps 库提供了一个简洁而强大的解决方案,让 Java 开发者能够轻松地进行音视频文件的转码和处理。
jave-all-deps 是 JAVE2(Java Audio Video Encoder)项目的一部分,它是一个基于 ffmpeg 项目的 Java 封装库。JAVE2 通过提供一套简单易用的 API,允许 Java 开发者在不直接处理 ffmpeg 复杂命令的情况下,进行音视频文件的格式转换、转码、剪辑等操作。
jave-all-deps 库特别之处在于它集成了核心 Java 代码和所有支持平台的二进制可执行文件,使得开发者无需手动配置 ffmpeg 环境,即可在多个操作系统上无缝使用。
是不是非常方便?
整体上来说,jave-all-deps 帮我们解决了三大类问题:
- 跨平台兼容性问题:音视频处理往往涉及到不同的操作系统和硬件架构,jave-all-deps 库提供了针对不同平台的预编译 ffmpeg 二进制文件,使得开发者无需担心平台兼容性问题。
- 复杂的命令行操作:ffmpeg 虽然功能强大,但其命令行接口复杂且难以记忆。jave-all-deps 通过封装 ffmpeg 的命令行操作,提供了简洁易用的 Java API,降低了使用门槛。
- 依赖管理:在项目中集成音视频处理功能时,往往需要处理多个依赖项。jave-all-deps 库将核心代码和所有必要的二进制文件打包在一起,简化了依赖管理。
简单来说,就是你想在项目中使用 ffmpeg,但是又嫌麻烦,那么就可以使用 jave-all-deps 这个工具封装后的 ffmpeg,简单快捷!
二 具体用法
jave-all-deps 库提供了多种音视频处理功能,松哥这里来和大家演示几个常见的。
2.1 添加依赖
添加依赖有两种方式,一种就是添加所有的依赖库,如下:
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-all-deps</artifactId>
<version>3.5.0</version>
</dependency>
这个库中包含了不同平台所依赖的库的内容。
也可以根据自己平台选择不同的依赖库,这种方式需要首先添加 java-core:
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-core</artifactId>
<version>3.5.0</version>
</dependency>
然后再根据自己使用的不同平台,继续添加不同依赖库:
Linux 64 位 amd/intel:
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-nativebin-linux64</artifactId>
<version>3.5.0</version>
</dependency>
Linux 64 位 arm:
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-nativebin-linux-arm64</artifactId>
<version>3.5.0</version>
</dependency>
Linux 32 位 arm:
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-nativebin-linux-arm32</artifactId>
<version>3.5.0</version>
</dependency>
Windows 64 位:
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-nativebin-win64</artifactId>
<version>3.5.0</version>
</dependency>
MacOS 64 位:
<dependency>
<groupId>ws.schild</groupId>
<artifactId>jave-nativebin-osx64</artifactId>
<version>3.5.0</version>
</dependency>
2.2 视频转音频
将视频文件从一种格式转换为另一种格式,例如将 AVI 文件转换为 MPEG 文件。
File source = new File("D:\\AI智能体\\mp4\\01.大模型有什么缺陷.mp4");
File target = new File("D:\\AI智能体\\mp4\\01.大模型有什么缺陷.mp3");
AudioAttributes audio = new AudioAttributes();
audio.setCodec("libmp3lame");
audio.setBitRate(128000);
audio.setChannels(2);
audio.setSamplingRate(44100);
EncodingAttributes attrs = new EncodingAttributes();
attrs.setOutputFormat("mp3");
attrs.setAudioAttributes(audio);
Encoder encoder = new Encoder();
encoder.encode(new MultimediaObject(source), target, attrs);
2.3 视频格式转换
将一种视频格式转换为另外一种视频格式,例如将 mp4 转为 flv:
File source = new File("D:\\AI智能体\\mp4\\01.大模型有什么缺陷.mp4");
File target = new File("D:\\AI智能体\\mp4\\01.大模型有什么缺陷.flv");
AudioAttributes audio = new AudioAttributes();
audio.setCodec("libmp3lame");
audio.setBitRate(64000);
audio.setChannels(1);
audio.setSamplingRate(22050);
VideoAttributes video = new VideoAttributes();
video.setCodec("flv");
video.setBitRate(160000);
video.setFrameRate(15);
video.setSize(new VideoSize(400, 300));
EncodingAttributes attrs = new EncodingAttributes();
attrs.setOutputFormat("flv");
attrs.setAudioAttributes(audio);
attrs.setVideoAttributes(video);
Encoder encoder = new Encoder();
encoder.encode(new MultimediaObject(source), target, attrs);
2.4 获取视频时长
这个就是松哥的需求了,我这块举个简单例子。
public class App {
static SimpleDateFormat DATE_FORMAT = new SimpleDateFormat("mm:ss");
public static void main(String[] args) throws EncoderException {
System.out.println("输入视频目录:");
String dir = new Scanner(System.in).next();
File folder = new File(dir);
List<String> files = sort(folder);
outputVideoTime(files);
}
private static void outputVideoTime(List<String> files) throws EncoderException {
for (String file : files) {
File video = new File(file);
if (video.isFile() && !video.getName().startsWith(".") && video.getName().endsWith(".mp4")) {
MultimediaObject multimediaObject = new MultimediaObject(video);
long duration = multimediaObject.getInfo().getDuration();
String s = "%s %s";
System.out.println(String.format(s, video.getName(), DATE_FORMAT.format(duration)));
} else if (video.isDirectory()) {
System.out.println(video.getName());
outputVideoTime(sort(video));
}
}
}
public static List<String> sort(File folder) {
return Arrays.stream(folder.listFiles()).map(f -> f.getAbsolutePath()).sorted(String.CASE_INSENSITIVE_ORDER).collect(Collectors.toList());
}
}
这段代码基本上都是 Java 基础语法,没啥难的,我也就不多说了。有不明白的地方欢迎加松哥微信讨论。
其实 Java 解决这个似乎也不难,也就是 20 行代码左右,似乎和 Python 不相上下。
三 总结
jave-all-deps 库是 Java 音视频处理领域的一个强大工具,它通过封装 ffmpeg 的复杂功能,为 Java 开发者提供了一个简单易用的音视频处理解决方案。该库解决了跨平台兼容性问题、简化了复杂的命令行操作,并简化了项目中的依赖管理。无论是进行格式转换、音频转码还是其他音视频处理任务,jave-all-deps 库都是一个值得考虑的选择。
通过本文的介绍,希望能够帮助读者更好地理解和使用 jave-all-deps 库。
来源:juejin.cn/post/7415723701947154473
127.0.0.1 和 localhost,如何区分?
在实际开发中,我们经常会用到 127.0.0.1 和 localhost,那么,两者到底有什么区分呢?这篇文章,我们来详细了解 127.0.0.1 和 localhost。
127.0.0.1
127.0.0.1 是一个特殊的 IPv4 地址,通常被称为“环回地址”或“回送地址”。它被用于测试和调试网络应用程序。
当你在计算机上向 127.0.0.1 发送数据包时,数据不会离开计算机,而是直接返回到本地。这种机制允许开发者测试网络应用程序而不需要实际的网络连接。
127.0.0.1 是一个专用地址,不能用于实际的网络通信,仅用于本地通信。除了 127.0.0.1,整个 127.0.0.0/8(即 127.0.0.1 到 127.255.255.255)范围内的地址都是保留的环回地址。
在 IPv6 中,类似的环回地址是 ::1。如下图,为 MacOS的 /etc/hosts 文件中的内容:

使用场景
1. 开发和测试
- 开发人员常常使用
127.0.0.1来测试网络应用程序,因为它不需要实际的网络连接。 - 可以在本地机器上运行服务器和客户端,进行开发和调试。
2. 网络配置和诊断: - 使用
ping 127.0.0.1可以测试本地网络栈是否正常工作。 - 一些服务会绑定到
127.0.0.1以限制访问范围,仅允许本地访问。
示例
运行一个简单的 Python HTTP 服务器并访问它:
python -m http.server --bind 127.0.0.1 8000
然后在浏览器中访问 http://127.0.0.1:8000,你会看到服务器响应。通过 127.0.0.1,开发人员和系统管理员可以方便地进行本地网络通信测试和开发工作,而不需要依赖实际的网络连接。
优点
- 快速测试:可以快速测试本地网络应用程序。
- 独立于网络:不依赖于实际的网络连接或外部网络设备。
- 安全:由于数据包不离开本地计算机,安全性较高。
缺点
- 局限性:只能用于本地计算机,不适用于与其他计算机的网络通信。
- 调试范围有限:无法测试跨网络的通信问题。
localhost
localhost 是一个特殊的域名,指向本地计算机的主机名。
- 在 IPv4 中,
localhost通常映射到 IP 地址127.0.0.1。 - 在 IPv6 中,
localhost通常映射到 IP 地址::1。
localhost 被定义在 hosts 文件中(例如,在 Linux 系统中是 /etc/hosts 文件)。如下图,为 MacOS的 /etc/hosts 文件中的内容:

因此,当你在应用程序中使用 localhost 作为目标地址时,系统会将其解析为 127.0.0.1,然后进行相同的环回处理。
使用场景
- 开发和测试:开发人员常使用
localhost来测试应用程序,因为它不需要实际的网络连接。 - 本地服务:一些服务(如数据库、Web 服务器等)可以配置为只在
localhost上监听,以限制访问范围仅限于本地计算机,增强安全性。 - 网络调试:使用
localhost可以帮助诊断网络服务问题,确保服务在本地环境中正常运行。
优点
- 易记:相对 IP 地址,
localhost更容易记忆和输入。 - 一致性:在不同操作系统和环境中,
localhost通常都被解析为127.0.0.1。
缺点
- 依赖 DNS 配置:需要正确的 hosts 文件配置,如果配置错误可能导致问题。
- 与 127.0.0.1 相同的局限性:同样只能用于本地计算机。
两者对比
- 本质:
127.0.0.1是一个 IP 地址,而localhost是一个主机名。 - 解析方式:
localhost需要通过 DNS 或 hosts 文件解析为127.0.0.1,而127.0.0.1是直接使用的 IP 地址。 - 易用性:
localhost更容易记忆和输入,但依赖于正确的 DNS/hosts 配置。 - 性能:通常情况下,两者在性能上没有显著差异,因为
localhost最终也会解析为127.0.0.1。
结论
127.0.0.1 和 localhost都是指向本地计算机的地址,适用于本地网络应用程序的测试和调试。选择使用哪个主要取决于个人偏好和具体需求。在需要明确指定 IP 地址的场景下,127.0.0.1 更为直接;而在需要易记和通用的主机名时,localhost 更为合适。两者在实际使用中通常是等价的,差别微乎其微。
来源:juejin.cn/post/7413189674107273257
桌面端Electron基础配置
机缘
机缘巧合之下获取到一个桌面端开发的任务。
为了最快的上手速度,最低的开发成本,选择了electron。

介绍
Electron是一个使用 JavaScript、HTML 和 CSS 构建桌面应用程序的框架。 嵌入 Chromium 和 Node.js 到 二进制的 Electron 允许您保持一个 JavaScript 代码代码库并创建 在Windows上运行的跨平台应用 macOS和Linux——不需要本地开发 经验。
主要结构

electron主要有一个主进程和一个或者多个渲染进程组成,方便的脚手架项目有
electron-vite
安装方式
npm i electron-vite -D
electron-vite分为3层结构
main // electron主进程
preload // electron预加载进程 node
renderer // electron渲染进程 vue
创建项目
npm create @quick-start/electron
项目创建完成启动之后
会在目录中生成一个out目录

out目录中会生成项目文件代码,在electron-vite中使用ESmodel来加载文件,启动的时候会被全部打包到out目录中合并在一起。所以一些使用CommonJs的node代码复制进来需要做些修改。npm安装的依赖依然可以使用CommonJs的方式引入。
node的引入

在前面的推荐的几篇文章中都有详细的讲解,无需多言。electron是以chrom+node,所以node的加入也非常的简单。
nodeIntegration: true,
main主进程中的简单配置

preload目录下引入node代码,留一个口子在min主进程中调用。
配置数据库
以sequelize为例
npm install --save sequelize
npm install --save sqlite3
做本地应用使用推荐sqlite3,使用本地数据库,当然了用其他的数据也没问题,用法和node中一样。需要注意的是C++代码编译的问题,可能会存在兼容性问题,如果一直尝试还是报错就换版本吧。electron-vite新版本问题不大,遇到过老版本一直编译失败的问题
测试能让用版本
- "electron": "^25.6.0",
- "electron-vite": "^1.0.27",
- "sequelize": "^6.33.0",

node-gyp vscode 这些安装环境网上找找也很多就不多说了。
import { Sequelize } from 'sequelize'
import log from '../config/log/log'
const path = require('path')
let documentsPath
if (process.env['ELECTRON_RENDERER_URL']) {
documentsPath = './out/config/sqlite/sqlite.db'
} else {
documentsPath = path.join(process.env.USERPROFILE, 'Documents') + '\\sqlite\\sqlite.db'
}
console.log('documentsPath-------------****-----------', documentsPath)
export const seq = new Sequelize({
dialect: 'sqlite',
storage: documentsPath
})
seq
.authenticate()
.then(() => {
log.info('数据库连接成功')
})
.catch((err) => {
log.error('数据库连接失败' + err)
})
终端乱码问题
"dev:win": "chcp 65001 && electron-vite dev",
chcp 65001只在win环境下添加
electron多页签
electron日志
import logger from 'electron-log'
logger.transports.file.level = 'debug'
logger.transports.file.maxSize = 30 * 1024 * 1024 // 最大不超过10M
logger.transports.file.format = '[{y}-{m}-{d} {h}:{i}:{s}.{ms}] [{level}]{scope} {text}' // 设置文件内容格式
var dayjs = require('dayjs')
const date = dayjs().format('YYYY-MM-DD') // 格式化日期为 yyyy-mm-dd
logger.transports.file.fileName = date + '.log' // 创建文件名格式为 '时间.log' (2023-02-01.log)
// 可以将文件放置到指定文件夹中,例如放到安装包文件夹中
const path = require('path')
let logsPath
if (process.env['ELECTRON_RENDERER_URL']) {
logsPath = './out/config/logs/' + date + '.log'
} else {
logsPath = path.join(process.env.USERPROFILE, 'Documents') + '\\logs\\' + date + '.log'
}
console.log('logsPath-------------****-----------', logsPath) // 获取到安装目录的文件夹名称
// 指定日志文件夹位置
logger.transports.file.resolvePath = () => logsPath
// 有六个日志级别error, warn, info, verbose, debug, silly。默认是silly
export default {
info(param) {
logger.info(param)
},
warn(param) {
logger.warn(param)
},
error(param) {
logger.error(param)
},
debug(param) {
logger.debug(param)
},
verbose(param) {
logger.verbose(param)
},
silly(param) {
logger.silly(param)
}
}
对应用做好日志维护是一个很重要的事情
主进程中也可以在main文件下监听
app.on('activate', function () {
// On macOS it's common to re-create a window in the app when the
// dock icon is clicked and there are no other windows open.
if (BrowserWindow.getAllWindows().length === 0) createWindow()
})
// 渲染进程崩溃
app.on('renderer-process-crashed', (event, webContents, killed) => {
log.error(
`APP-ERROR:renderer-process-crashed; event: ${JSON.stringify(event)}; webContents:${JSON.stringify(
webContents
)}; killed:${JSON.stringify(killed)}`
)
})
// GPU进程崩溃
app.on('gpu-process-crashed', (event, killed) => {
log.error(`APP-ERROR:gpu-process-crashed; event: ${JSON.stringify(event)}; killed: ${JSON.stringify(killed)}`)
})
// 渲染进程结束
app.on('render-process-gone', async (event, webContents, details) => {
log.error(
`APP-ERROR:render-process-gone; event: ${JSON.stringify(event)}; webContents:${JSON.stringify(
webContents
)}; details:${JSON.stringify(details)}`
)
})
// 子进程结束
app.on('child-process-gone', async (event, details) => {
log.error(`APP-ERROR:child-process-gone; event: ${JSON.stringify(event)}; details:${JSON.stringify(details)}`)
})
应用更新
在Electron中实现自动更新,需要使用electron-updater
npm install electron-updater --save
需要知道服务器地址,单版本号有可更新内容的时候可以通过事件监听控制更新功能
provider: generic
url: 'http://localhost:7070/urfiles'
updaterCacheDirName: 111-updater
import { autoUpdater } from 'electron-updater'
import log from '../config/log/log'
export const autoUpdateInit = (mainWindow) => {
let result = {
message: '',
result: {}
}
autoUpdater.setFeedURL('http://localhost:50080/latest.yml')
//设置自动下载
autoUpdater.autoDownload = false
autoUpdater.autoInstallOnAppQuit = false
// 监听error
autoUpdater.on('error', function (error) {
log.info('检测更新失败' + error)
result.message = '检测更新失败'
result.result = error
mainWindow.webContents.send('update', JSON.stringify(result))
})
// 检测开始
autoUpdater.on('checking-for-update', function () {
result.message = '检测更新触发'
result.result = ''
// mainWindow.webContents.send('update', JSON.stringify(result))
log.info(`检测更新触发`)
})
// 更新可用
autoUpdater.on('update-available', (info) => {
result.message = '有新版本可更新'
result.result = info
mainWindow.webContents.send('update', JSON.stringify(result))
log.info(`有新版本可更新${JSON.stringify(info)}${info}`)
})
// 更新不可用
autoUpdater.on('update-not-available', function (info) {
result.message = '检测更新不可用'
result.result = info
mainWindow.webContents.send('update', JSON.stringify(result))
log.info(`检测更新不可用${info}`)
})
// 更新下载进度事件
autoUpdater.on('download-progress', function (progress) {
result.message = '检测更新当前下载进度'
result.result = progress
mainWindow.webContents.send('update', JSON.stringify(result))
log.info(`检测更新当前下载进度${JSON.stringify(progress)}${progress}`)
})
// 更新下载完毕
autoUpdater.on('update-downloaded', function () {
//下载完毕,通知应用层 UI
result.message = '检测更新当前下载完毕'
result.result = {}
mainWindow.webContents.send('update', result)
autoUpdater.quitAndInstall()
log.info('检测更新当前下载完毕,开始安装')
})
}
export const updateApp = (ctx) => {
let message
if (ctx.params == 'inspect') {
console.log('检测是否有新版本')
message = '检测是否有新版本'
autoUpdater.checkForUpdates() // 开始检查是否有更新
}
if (ctx.params == 'update') {
message = '开始更新'
autoUpdater.downloadUpdate() // 开始下载更新
}
return (ctx.body = {
code: 200,
message,
result: {
currentVersion: 0
}
})
}
dev下想测试更新功能,可以在主进程main文件中添加
Object.defineProperty(app, 'isPackaged', {
get() {
return true
}
})
接口封装
eletron中可以像node一样走http的形式编写接口,但是更推荐用IPC走内存直接进行主进程和渲染进程之间的通信
前端
import { ElMessage } from 'element-plus'
import router from '../router/index'
export const getApi = (url: string, params: object) => {
return new Promise(async (resolve, rej) => {
try {
console.log('-------------------url+params', url, params)
// 如果有token的话
let token = sessionStorage.getItem('token')
// 走ipc
if (window.electron) {
const res = await window.electron.ipcRenderer.invoke('getApi', JSON.stringify({ url, params, token }))
console.log('res', res)
if (res?.code == 200) {
return resolve(res.result)
} else {
// token校验不通过退出登录
if (res?.error == 10002 || res?.error == 10002) {
router.push({ name: 'loginPage' })
}
// 添加接口错误的处理
ElMessage.error(res?.message || res || '未知错误')
rej(res)
}
} else {
// 不走ipc
}
} catch (err) {
console.error(url + '接口请求错误----------', err)
rej(err)
}
})
}
后端
ipcMain.handle('getApi', async (event, args) => {
const { url, params, token } = JSON.parse(args)
//
})
electron官方文档中提供的IPC通信的API有好几个,每个使用的场景不一样,根据情况来选择
node中使用的是esmodel和一般的node项目写法上还有些区别,得适应一下。
容易找到的都是渲染进程发消息,也就是vue发消息给node,但是node发消息给vue没有写
这时候就需要使用webContents方法来实现
this.mainWindow.webContents.send('receive-tcp', JSON.stringify({ code: key, data: res.data }))
使用webContents的时候在vue中一样是通过事件监听‘receive-tcp’事件来获取
本地图片读取
// node中IO操作是异步所以得订阅一下
const subscribeImage = new Promise((res, rej) => {
// 读取图片文件进行压缩
sharp(imagePath)
.webp({ quality: 80 })
.toBuffer((err, buffer) => {
if (err) {
console.error('读取本地图片失败Error converting image to buffer:', err)
rej(
(ctx.body = {
error: 10003,
message: '本地图片读取失败'
})
)
} else {
log.info(`读取本地图片成功:${ctx.params}`)
res({
code: 200,
msg: '读取本地图片成功:',
result: buffer.toString('base64')
})
}
})
})
TCP
既然写了桌面端,那数据交互的方式可能就不局限于http,也会有WS,TCP,等等其他的通信协议。
node中提供了Tcp模块,net
const net = require('net')
const server = net.createServer()
server.on('listening', function () {
//获取地址信息
let addr = server.address()
tcpInfo.TcpAddress = `ip:${addr.port}`
log.info(`TCP服务启动成功---------- ip:${addr.port}`)
})
//设置出错时的回调函数
server.on('error', function (err) {
if (err.code === 'EADDRINUSE') {
console.log('地址正被使用,重试中...')
tcpProt++
setTimeout(() => {
server.close()
server.listen(tcpProt, 'ip')
}, 1000)
} else {
console.error('服务器异常:', err)
}
})
TCP链接成功获取到数据之后在data事件中,就可以使用webContents方法来主动传递消息给渲染进程
也得对Tcp数据包进行解析,一般都是和外部系统协商沟通的数据格式。一般是十六进制或者是二进制数据,需要对数据进行解析,切割,缓存。
使用 Bufferdata = Buffer.concat([overageBuffer, data]) 对数据进行处理
根据数据的长度对数据进行切割,判断数据的完整性质,对数据进行封包和拆包
粘包处理网上都有
处理完.toString()一下 over
socket.on('data', async (data) => {
...
let buffer = data.slice(0, packageLength) // 取出整个数据包
data = data.slice(packageLength) // 删除已经取出的数据包
// 数据处理
let key = buffer.slice(4, 8).reverse().toString('hex')
console.log('data', key, buffer)
let res = await isFunction[key](buffer)
this.mainWindow.webContents.send('receive-tcpData', JSON.stringify({ code: key, data: res.data }))
})
// 获取包长度的方法
getPackageLen(buffer) {
let bufferCopy = Buffer.alloc(12)
buffer.copy(bufferCopy, 0, 0, 12)
let bufferSize = bufferCopy.slice(8, this.headSize).reverse().readInt32BE(0)
console.log('bufferSize', bufferSize, bufferSize + this.headSize, buffer.length)
if (bufferSize > buffer.length - this.headSize) {
return -1
}
if (buffer.length >= bufferSize + this.headSize) {
return bufferSize + this.headSize // 返回实际长度 = 消息头长度 + 消息体长度
}
}
打完收工

来源:juejin.cn/post/7338265878289301567
短信接口被爆破了,一晚上差点把公司干破产了
背景
某天夜里,你正睡着觉,与周公神游。
老板打来电话:“小李,快看一下,系统出故障了,一个小时发了200条短信,再搞下去,我要破产了..."
巴拉巴拉...
于是,你赶紧跳下床,查了一个后台日志,发送短信API接口5s发送一次,都已经发送了500条了。在达到每日限额后,自动终止了。很明显被黑客攻击了。
500 * 0.1 * 8 = 400
一晚上约干掉了400元人民币
睡意全无,赶紧起来排查原因
故障分析
我司是做国外业务的,用的短信厂家是RingRing, 没有阿里云那种自带的强悍的预警和封禁功能。黑客通过伪造IP地址和手机号然后攻破了APP的短信接口,然后顺藤摸瓜的拿到相关发布的全部应用。于是,一个晚上,单个APP的每日短信限额和全部短信限额都攻破了。
APP使用的是https双向加密,黑客也不是单纯的爆破,没有大量的验证码错误日志。我们现在都不清楚黑客是通过什么方式绕过我们系统的,或者直接攻破了验证码
可能有懂这方面的掘友,可以分享一下哈
我们先上了一个临时方案,如果10分钟内,发送短信超过30条,且手机号超过60%都是同一个国家,我们关闭短信发送功能10分钟,并推送告警
然后抓紧时间去升级验证码,提高安全标准
验证码
文字验证码

我司最开始用的就是这种,简单易用。但是任你把噪点和线条铺满,整的面目全非,都防不住机器的识别,这种验证码直接pass了
优点:简易,具有一定的防爆破功能
缺点:防君子不防小人,在黑客面前,GG
滑块验证码

我司对于滑块验证码有几点考虑:
- 安全有待商榷,
- 背景图片需要符合国外市场和审美,需要UI介入,增加人工成本
- 不确定是否符合国外的习惯
基于这几点考虑,我司放弃了这个方案。但平心而论,国内用滑块验证码的是最多的,原因如下:
- 用户体验好
- 防破解性更强
- 适应移动设备
- 适用性广
npm install rc-slider-captcha
import SliderCaptcha from 'rc-slider-captcha';
const Demo = () => {
return (
<SliderCaptcha
request={async () => {
return {
bgUrl: 'background image url',
puzzleUrl: 'puzzle image url'
};
}}
onVerify={async (data) => {
console.log(data);
// verify data
return Promise.resolve();
}}
/>
);
};
滑块验证码是用的最多的验证码,操作简单,基本平替了图片验证码
图形顺序验证码 & 图形匹配验证码 & 语顺验证码


我司没有采用这种方案的原因如下:
- 我们的APP是多语言,点击文字这种方案不适用
- 没有找到免费且合适的APP插件
- 时间紧,项目紧急,没有功夫就研究
总结:
安全性更强,用户量越大的网站越受青睐
难度相对更大,频繁验证会流失一些用户
reCAPTCHA v3
综上,我司使用了reCAPTCHA

理由如下:
- 集成简单
- 自带控制台,方便管理和查看
- 谷歌出品,值得信赖,且有保障
<script src="https://www.google.com/recaptcha/api.js?render=reCAPTCHA_site_key"></script>
<script>
function onClick(e) {
e.preventDefault();
grecaptcha.ready(function() {
grecaptcha.execute('reCAPTCHA_site_key', {action: 'submit'}).then(function(token) {
// Add your logic to submit to your backend server here.
});
});
}
</script>
// 返回值
{
score: 1 // 评分0 到 1。1:确认为人类,0:确认为机器人。
hostname: "localhost"
success: true,
challenge_ts: "2024-xx-xTxx:xx:xxZ"
action: "homepage"
}
紧急上线后,安全性大大增强,再也没有遭受黑客袭击了。本以为可以睡个安稳觉了,又有其他的问题了,听我细讲
根据官方文档,建议score取0.5, 我们根据测试的情况,降低了标准,设置为0.3。上线后,很多用户投诉安全度过低,请30分后重试。由于我们当时的业务是出行和游乐, APP受限后,用户生活受到了很大限制,很多用户预约了我们的产品,却用不了,导致收到了大量的投诉。更糟糕的时候,我们的评分标准0.3是写死的,只能重新发布,一来二去,3天过去了。客服被用户骂了后,天天来我们技术部骂我们。哎,想想都是泪
我们紧急发布了一版,将评分标准设置成可配置的,通过API获取, 暂定0.1。算是勉强度过了这一关
reCAPTCHA v2
把分数调整到0.1后,我们觉得不是很安全,有爆破的风险,于是在下个版本使用了v2

使用v2,一切相对平稳,APP短信验证码风波也算平安度过了
2FA
双因素验证(Two-factor authentication,简称2FA,又名二步验证、双重验证),是保证账户安全的一道有效防线。在登录或进行敏感操作时,需要输入验证器上的动态密码(类似于银行U盾),进一步保护您的帐户免受潜在攻击者的攻击。双因素验证的动态密码生成器分为软件和硬件两种,最常用的软件有OTP Auth和谷歌验证器 (Google Authenticator)


经市场调用,客户要求,后续的APP,我们的都采用2fa方案,一人一码,安全可靠。
实现起来也比较简单,后端使用sha1加密一串密钥,生成哈希值,用户扫码绑定,然后每次将这个验证码提交给服务器进行比对即可
每次使用都要看一下验证码,感觉有点烦
服务器和手机进行绑定,是同一把密钥,每次输入都找半天。一旦用户更换手机,就必须生成全新的密钥。
总结
参考资料
来源:juejin.cn/post/7413322738315378697
Spring Boot整合Kafka+SSE实现实时数据展示
2024年3月10日
知识积累
为什么使用Kafka?
不使用Rabbitmq或者Rocketmq是因为Kafka是Hadoop集群下的组成部分,对于大数据的相关开发适应性好,且当前业务场景下不需要使用死信队列,不过要注意Kafka对于更新时间慢的数据拉取也较慢,因此对与实时性要求高可以选择其他MQ。
使用消息队列是因为该中间件具有实时性,且可以作为广播进行消息分发。
为什么使用SSE?
使用Websocket传输信息的时候,会转成二进制数据,产生一定的时间损耗,SSE直接传输文本,不存在这个问题
由于Websocket是双向的,读取日志的时候,如果有人连接ws日志,会发送大量异常信息,会给使用段和日志段造成问题;SSE是单向的,不需要考虑这个问题,提高了安全性
另外就是SSE支持断线重连;Websocket协议本身并没有提供心跳机制,所以长时间没有数据发送时,会将这个连接断掉,因此需要手写心跳机制进行实现。
此外,由于是长连接的一个实现方式,所以SSE也可以替代Websocket实现扫码登陆(比如通过SSE的超时组件在实现二维码的超时功能,具体实现我可以整理一下)
另外,如果是普通项目,不需要过高的实时性,则不需要使用Websocket,使用SSE即可
代码实现
Java代码
pom.xml引入SSE和Kafka
<!-- SSE,一般springboot开发web应用的都有 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- kafka,最主要的是第一个,剩下两个是测试用的 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.4.0</version>
</dependency>
application.properties增加Kafka配置信息
# KafkaProperties
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=community-consumer-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
配置Kafka信息
@Configuration
public class KafkaProducerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String bootstrapServers;
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
配置controller,通过web方式开启效果
@RestController
@RequestMapping(path = "sse")
public class KafkaSSEController {
private static final Map<String, SseEmitter> sseCache = new ConcurrentHashMap<>();
@Resource
private KafkaTemplate<String, String> kafkaTemplate;
@Resource
private SseEmitter sseEmitter;
/**
* @param message
* @apiNote 发送信息到Kafka主题中
*/
@PostMapping("/send")
public void sendMessage(@RequestBody String message) {
kafkaTemplate.send("my-topic", message);
}
/**
* 监听Kafka数据
*
* @param message
*/
@KafkaListener(topics = "my-topic", groupId = "my-group-id")
public void consume(String message) {
System.out.println("Received message: " + message);
//使用接口建立起sse连接后,监听到kafka消息则会发送给对应链接
SseEmitter sseEmitter = sseCache.get(id); if (sseEmitter != null) { sseEmitter.send(content); }
}
/**
* 连接sse服务
*
* @param id
* @return
* @throws IOException
*/
@GetMapping(path = "subscribe", produces = {MediaType.TEXT_EVENT_STREAM_VALUE})
public SseEmitter push(@RequestParam("id") String id) throws IOException {
// 超时时间设置为5分钟,用于演示客户端自动重连
SseEmitter sseEmitter = new SseEmitter(5_60_000L);
// 设置前端的重试时间为1s
// send(): 发送数据,如果传入的是一个非SseEventBuilder对象,那么传递参数会被封装到 data 中
sseEmitter.send(SseEmitter.event().reconnectTime(1000).data("连接成功"));
sseCache.put(id, sseEmitter);
System.out.println("add " + id);
sseEmitter.send("你好", MediaType.APPLICATION_JSON);
SseEmitter.SseEventBuilder data = SseEmitter.event().name("finish").id("6666").data("哈哈");
sseEmitter.send(data);
// onTimeout(): 超时回调触发
sseEmitter.onTimeout(() -> {
System.out.println(id + "超时");
sseCache.remove(id);
});
// onCompletion(): 结束之后的回调触发
sseEmitter.onCompletion(() -> System.out.println("完成!!!"));
return sseEmitter;
}
/**
* http://127.0.0.1:8080/sse/push?id=7777&content=%E4%BD%A0%E5%93%88aaaaaa
* @param id
* @param content
* @return
* @throws IOException
*/
@ResponseBody
@GetMapping(path = "push")
public String push(String id, String content) throws IOException {
SseEmitter sseEmitter = sseCache.get(id);
if (sseEmitter != null) {
sseEmitter.send(content);
}
return "over";
}
@ResponseBody
@GetMapping(path = "over")
public String over(String id) {
SseEmitter sseEmitter = sseCache.get(id);
if (sseEmitter != null) {
// complete(): 表示执行完毕,会断开连接
sseEmitter.complete();
sseCache.remove(id);
}
return "over";
}
}
前端方式
<html>
<head>
<script>
console.log('start')
const clientId = "your_client_id_x"; // 设置客户端ID
const eventSource = new EventSource(`http://localhost:9999/v1/sse/subscribe/${clientId}`); // 订阅服务器端的SSE
eventSource.onmessage = event => {
console.log(event.data)
const message = JSON.parse(event.data);
console.log(`Received message from server: ${message}`);
};
// 发送消息给服务器端 可通过 postman 调用,所以下面 sendMessage() 调用被注释掉了
function sendMessage() {
const message = "hello sse";
fetch(`http://localhost:9999/v1/sse/publish/${clientId}`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(message)
});
console.log('dddd'+JSON.stringify(message))
}
// sendMessage()
</script>
</head>
</html>
来源:juejin.cn/post/7356770034180898857
看了Kubernetes 源码后,我的Go水平突飞猛进
接口方式隐藏传入参数的细节
当方法的入参是一个结构体的时候,内部去调用时会看到入参过多的细节,这个时候可以将入参隐式转成结构,让内部只看到需要的方法即可。
type Kubelet struct{}
func (kl *Kubelet) HandlePodAdditions(pods []*Pod) {
for _, pod := range pods {
fmt.Printf("create pods : %s\n", pod.Status)
}
}
func (kl *Kubelet) Run(updates <-chan Pod) {
fmt.Println(" run kubelet")
go kl.syncLoop(updates, kl)
}
func (kl *Kubelet) syncLoop(updates <-chan Pod, handler SyncHandler) {
for {
select {
case pod := <-updates:
handler.HandlePodAdditions([]*Pod{&pod})
}
}
}
type SyncHandler interface {
HandlePodAdditions(pods []*Pod)
}
这里我们可以看到 Kubelet 本身有比较多的方法:
- syncLoop 同步状态的循环
- Run 用来启动监听循环
- HandlePodAdditions 处理Pod增加的逻辑
由于 syncLoop 其实并不需要知道 kubelet 上其他的方法,所以通过 SyncHandler 接口的定义,让 kubelet 实现该接口后,外面作为参数传入给 syncLoop ,它就会将类型转换为 SyncHandler 。
经过转换后 kubelet 上其他的方法在入参里面就看不到了,编码时就可以更加专注在 syncLoop 本身逻辑的编写。
但是这样做同样会带来一些问题,第一次研发的需求肯定是能满足我们的抽象,但是随着需求的增加和迭代,我们在内部需要使用 kubelet 其他未封装成接口的方法时,我们就需要额外传入 kubelet 或者是增加接口的封装,这都会增加我们的编码工作,也破坏了我们最开始的封装。
分层隐藏设计是我们设计的最终目的,在代码设计的过程中让一个局部关注到它需要关注的东西即可。
接口封装方便Mock测试
通过接口的抽象,我们在测试的时候可以把不关注的内容直接实例化成一个 Mock 的结构。
type OrderAPI interface {
GetOrderId() string
}
type realOrderImpl struct{}
func (r *realOrderImpl) GetOrderId() string {
return ""
}
type mockOrderImpl struct{}
func (m *mockOrderImpl) GetOrderId() string {
return "mock"
}
这里如果测试的时候不需要关注 GetOrderId 的方法是否正确,则直接用 mockOrderImpl 初始化 OrderAPI 即可,mock的逻辑也可以进行复杂编码
func TestGetOrderId(t *testing.T) {
orderAPI := &mockOrderImpl{} // 如果要获取订单id,且不是测试的重点,这里直接初始化成mock的结构体
fmt.Println(orderAPI.GetOrderId())
}
gomonkey 也同样能进行测试注入,所以如果以前的代码没能够通过接口封装也同样可以实现mock,而且这种方式更加强大
patches := gomonkey.ApplyFunc(GetOrder, func(orderId string) Order {
return Order{
OrderId: orderId,
OrderState: delivering,
}
})
return func() {
patches.Reset()
}
使用 gomonkey 能够更加灵活的进行 mock , 它能直接设置一个方法的返回值,而接口的抽象只能够处理结构体实例化出来的内容。
接口封装底层多种实现
iptables 、ipvs等的实现就是通过接口的抽象来实现,因为所有网络设置都需要处理 Service 和 Endpoint ,所以抽象了 ServiceHandler 和 EndpointSliceHandler
// ServiceHandler 是一个抽象接口,用于接收有关服务对象更改的通知。
type ServiceHandler interface {
// OnServiceAdd 在观察到创建新服务对象时调用。
OnServiceAdd(service *v1.Service)
// OnServiceUpdate 在观察到现有服务对象的修改时调用。
OnServiceUpdate(oldService, service *v1.Service)
// OnServiceDelete 在观察到现有服务对象的删除时调用。
OnServiceDelete(service *v1.Service)
// OnServiceSynced 一旦所有初始事件处理程序都被调用并且状态完全传播到本地缓存时调用。
OnServiceSynced()
}
// EndpointSliceHandler 是一个抽象接口,用于接收有关端点切片对象更改的通知。
type EndpointSliceHandler interface {
// OnEndpointSliceAdd 在观察到创建新的端点切片对象时调用。
OnEndpointSliceAdd(endpointSlice *discoveryv1.EndpointSlice)
// OnEndpointSliceUpdate 在观察到现有端点切片对象的修改时调用。
OnEndpointSliceUpdate(oldEndpointSlice, newEndpointSlice *discoveryv1.EndpointSlice)
// OnEndpointSliceDelete 在观察到现有端点切片对象的删除时调用。
OnEndpointSliceDelete(endpointSlice *discoveryv1.EndpointSlice)
// OnEndpointSlicesSynced 一旦所有初始事件处理程序都被调用并且状态完全传播到本地缓存时调用。
OnEndpointSlicesSynced()
}
然后通过 Provider 注入即可,
type Provider interface {
config.EndpointSliceHandler
config.ServiceHandler
}
这个也是我在做组件的时候用的最多的一种编码技巧,通过将类似的操作进行抽象,能够在替换底层实现后,上层代码不发生改变。
封装异常处理
我们开启协程之后如果不对异常进行捕获,则会导致协程出现异常后直接 panic ,但是每次写一个 recover 的逻辑做全局类似的处理未免不太优雅,所以通过封装 HandleCrash 方法来实现。
package runtime
var (
ReallyCrash = true
)
// 全局默认的Panic处理
var PanicHandlers = []func(interface{}){logPanic}
// 允许外部传入额外的异常处理
func HandleCrash(additionalHandlers ...func(interface{})) {
if r := recover(); r != nil {
for _, fn := range PanicHandlers {
fn(r)
}
for _, fn := range additionalHandlers {
fn(r)
}
if ReallyCrash {
panic(r)
}
}
}
这里既支持了内部异常的函数处理,也支持外部传入额外的异常处理,如果不想要 Crash 的话也可以自己进行修改。
package runtime
func Go(fn func()) {
go func() {
defer HandleCrash()
fn()
}()
}
要起协程的时候可以通过 Go 方法来执行,这样也避免了自己忘记增加 panic 的处理。
waitgroup的封装
import "sync"
type Gr0up struct {
wg sync.WaitGr0up
}
func (g *Gr0up) Wait() {
g.wg.Wait()
}
func (g *Gr0up) Start(f func()) {
g.wg.Add(1)
go func() {
defer g.wg.Done()
f()
}()
}
这里最主要的是 Start 方法,内部将 Add 和 Done 进行了封装,虽然只有短短的几行代码,却能够让我们每次使用 waitgroup 的时候不会忘记去对计数器增加一和完成计数器。
信号量触发逻辑封装
type BoundedFrequencyRunner struct {
sync.Mutex
// 主动触发
run chan struct{}
// 定时器限制
timer *time.Timer
// 真正执行的逻辑
fn func()
}
func NewBoundedFrequencyRunner(fn func()) *BoundedFrequencyRunner {
return &BoundedFrequencyRunner{
run: make(chan struct{}, 1),
fn: fn,
timer: time.NewTimer(0),
}
}
// Run 触发执行 ,这里只能够写入一个信号量,多余的直接丢弃,不会阻塞,这里也可以根据自己的需要增加排队的个数
func (b *BoundedFrequencyRunner) Run() {
select {
case b.run <- struct{}{}:
fmt.Println("写入信号量成功")
default:
fmt.Println("已经触发过一次,直接丢弃信号量")
}
}
func (b *BoundedFrequencyRunner) Loop() {
b.timer.Reset(time.Second * 1)
for {
select {
case <-b.run:
fmt.Println("run 信号触发")
b.tryRun()
case <-b.timer.C:
fmt.Println("timer 触发执行")
b.tryRun()
}
}
}
func (b *BoundedFrequencyRunner) tryRun() {
b.Lock()
defer b.Unlock()
// 可以增加限流器等限制逻辑
b.timer.Reset(time.Second * 1)
b.fn()
}
写在最后
感谢你读到这里,如果想要看更多 Kubernetes 的文章可以订阅我的专栏: juejin.cn/column/7321… 。
来源:juejin.cn/post/7347221064429469746
Go 重构:尽量避免使用 else、break 和 continue
今天,我想谈谈相当简单的事情。我不会发明什么,但我在生产代码中经常看到这样的事情,所以我不能回避这个话题。
我经常要解开多个复杂的 if else 结构。多余的缩进、过多的逻辑只会加深理解。首先,这篇文章的主要目的是让代码更透明、更易读。不过,在某些情况下还是必须使用这些操作符。
else 操作
例如,我们有简单的用户处理程序:
func handleRequest(user *User) {
if user != nil {
showUserProfilePage(user)
} else {
showLoginPage()
}
}
如果没有提供用户,则需要将收到的请求重定向到登录页面。If else 似乎是个不错的决定。但我们的主要任务是确保业务逻辑单元在任何输入情况下都能正常工作。因此,让我们使用提前返回来实现这一点。
func handleRequest(user *User) {
if user == nil {
return showLoginPage()
}
showUserProfilePage(user)
}
逻辑是一样的,但是下面的做法可读性会更强。
break 操作
对我来说,Break 和 Continue 语句总是可以分解的信号。
例如,我们有一个简单的搜索任务。找到目标并执行一些业务逻辑,或者什么都不做。
func processData(data []int, target int) {
for i, value := range data {
if value == target {
performActionForTarget(data[i])
break
}
}
}
你应该始终记住,使用 break 操作符并不能保证整个数组都会被处理。这对性能有好处,因为我们丢弃了不必要的迭代,但对代码支持和可读性不利。因为我们永远不知道程序会在列表的开头还是结尾停止。
在某些情况下,带有子任务的简单功能可能会破坏这段代码。
func processData(data []int, target int, subtask int) {
for i, value := range data {
if value == subtask {
performActionForSubTarget(data[i])
}
if value == target {
performActionForTarget(data[i])
break
}
}
}
这样我们实际上可以拆出一个 find 的方法:
func processData(data []int, target int, subTarget int) {
found := findTarget(data, target)
if found > notFound {
performActionForTarget(found)
}
found = findTarget(data, subTarget)
if found > notFound {
performActionForSubTarget(found)
}
}
const notFound = -1
func findTarget(data []int, target int) int {
if len(data) == 0 {
return notFound
}
for _, value := range data {
if value == target {
return value
}
}
return notFound
}
同样的逻辑,但是拆分成更细粒度的方法,也有精确的返回语句,可以很容易地通过测试来实现。
continue 操作
该操作符与 break 类似。为了正确阅读代码,您应该牢记它对操作顺序的具体影响。
func processWords(words []string, substring string) {
for _, word := range words {
if !strings.Contains(word, substring) {
continue
}
// do some buisness logic
performAction(word)
}
}
Continue 使得这种简单的流程变得有点难以理解。
让我们写得更简洁些:
func processWords(words []string, substring string) {
for _, word := range words {
if strings.Contains(word, substring) {
performAction(word)
}
}
}
来源:juejin.cn/post/7290931758786756669
Innodb之buffer pool 图文详解
介绍
数据通常都是持久化在磁盘中的,innodb如果在处理客户端的请求时直接访问磁盘,无论是IO压力还是响应速度都是无法接受的;所以innodb在处理请求时,如果需要某个页的数据就会把整个页都加载到缓存中,数据页会长时间待在缓存中,根据一定策略进行淘汰,后续如果在缓存中的数据就不需要再次加载数据页了,这样即可提高响应时间又可以节省磁盘IO.
buffer pool
上述介绍中我们有提到一个缓存,这个缓存就指的是buffer pool,通过innodb_buffer_pool_size进行设置它的大小,默认为128MB,最小为5MB;可以根据各自线上机器的情况来设置它的大小,设置几个G甚至上百个G都是合理的。
内部组成

buffer pool中包含数据页、索引页、change buffer、自适应hash等内容;数据页、索引页在buffer pool中占用了大部分,不能简单的认为缓冲池中只有数据页和索引页;change buffer在较老的版本中叫insert buffer,后面对其进行了升级形成了现在的change buffer;自适应hash可以方便我们快速查询数据;锁信息、数据字典都是占用比较小的一部分;以上就是buffer pool的内部组成。
页数据
数据页、索引页数据在mysql启动的时候,会直接给申请一块连续的内存空间;如图:

上图中的缓冲页对应的就是磁盘中的数据,默认每个页大小为16KB,并且innodb为每个缓冲页都创建了一些控制块,每个控制块占用大小是800字节左右,需要额外付出百分之5的内存,它记录页所属的表空间编号、页号、缓存页在buffer pool中的地址、链表节点信息等。内存中间可能会有碎片进行对齐。
注意:这里只有缓冲页占用的空间是计算在buffer pool中的。
free链表
根据上面的图可以了解到,buffer pool中有一堆缓冲页,但innodb从磁盘中读取数据页时,由于不能直接知道哪些缓冲页是空闲的、哪些页已经被使用了,导致了不知道把要读取的数据页存放到哪里;此时就引入了一个free链表的概念。如图:

上图中可以看到free链表靠一个free节点连接到控制块中,其中free头节点仅占用40字节空间,但它也不计算在buffer pool中;有了这个free链表后每当需要从磁盘中加载一个页到buffer pool中时就可以从free链表上取一个控制块,把控制块所需信息填充上,同时把从磁盘上加载的数据放到对应的缓冲页上,并把该控制块从free链表中移除。此时就把磁盘中的页加载到内存中了,后续查询数据时就会优先查询该内存页,但每次查询时没办法立刻知道该页是在内存中还是磁盘中,上述操作后还会把这个页信息放到一个散列表中,以(表空间号+页号)作为key,以控制块地址作为value。
flush链表
上述介绍了读数据时通过优先读取内存页可以提高我们的响应速度以及节省磁盘io,那么如果是写数据呢?其实在innodb中,更改也会优先在内存中更改,在后续会根据一定规则(会在后续redolog文章中详细介绍)进行刷盘,在刷盘时只需要刷被更改的缓冲页即可,那么哪些缓存页被更改了innodb是不知道的,此时innodb就设计了flush链表,它和free链表几乎一样,如图:

当需要刷盘时会从flush链表中拿出一部分控制块对应的缓冲页进行刷盘,刷盘后控制块会从flush链表中移除,并放到free链表中。
LRU链表
由于buffer pool的内存区域是有限的,如果当来不及刷盘时内存就不够用了;此时innodb采用了LRU淘汰策略,标准的LRU算法:
- 如果数据页已经被加载到buffer pool中了,则直接把对应的控制块移动到LRU链表的头部;
- 如果数据页不在buffer pool中,则从磁盘中加载到buffer pool中,并把其对应的控制块放到LRU头部;此时内存空间已经满了的话,就会从链表中移除最后一个内存页。
但直接采用lru方案,在内存较小或者临时一次性加载到内存中的页过多时会把真正的热点数据刷掉。如预读和全表扫描。
- 线性预读:如果顺序访问的某个区的页面数超过
innodb_read_ahead_threshold(默认值为56)就会触发一次异步预加载下一个区中的全部页到内存中; - 随机预读:如果某个区的13个连续的页都被加载到young区前1/4的位置中,会触发一次异步预加载本区中的全部页到内存中;
- 全表扫描:把整张表的数据都加载到内存中。
为了解决上述问题,innodb对这个淘汰策略做了一点改变。如图:

innodb根据innodb_old_blocks_pct(默认37)参数把整个lru分成一定比例,具体的淘汰策略:
- 当数据页第一次加载进来时会先放到old head处,当链表满时会把old tail刷盘并从链表中移除。
- 当再次使用一个数据页时,并且该页在old区,会先判断在old区的停留时间是否超过
innodb_old_blocks_time(默认1000ms),如果超过则把该数据页移动到young head处,反之移动到old head处。 - 当再次使用一个数据页时,并且该页young区为了节省移动的操作,会判断该缓冲页是否在young区前1/4中,如果在就不进行移动,如果不在则移动到young head处。
多buffer pool实例
对于buffer pool设置很大内存的实例,由于操作各种链表都需要进行加锁这样就比较影响整体的性能,为了提高并发处理能力,可以通过innodb_buffer_pool_instances来设置buffer pool的实例个数。在mysql5.7.5版本中,会以chunk为单位向系统申请内存空间,每个buffer pool中包含了N个chunk。如图:

可以通过innodb_buffer_pool_chunk_size(默认128M)来设置chunk的大小,只能在启动前设置好,启动后可以更改innodb_buffer_pool_size的大小,但必须时innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances的整数倍。
自适应hash
对于b+数来讲,整体的查询时间复杂度为O(logN),而innodb为了进一步提升性能,引入了自适应hash,对热点数据可以做到O(1)的时间复杂度就可以定位到数据在具体哪个页中。
innodb会自动根据访问频率和模式自动为某些热点页在内存中建立自适应哈希索引,规则:
- 模式:例如有一个联合索引(a,b);查询条件
where a = xxx与where a = xxx and b = xxx这就属于两种模式,如果交叉使用这两种查询,不会为其建立自适应哈希索引;
- 频率:使用一种默认访问的次数大于Math.min(100,页中数据/16)。
根据官方数据,启动自适应哈希索引读写速度可以提升2倍,辅助索引的连接性能可以提升5倍。
总结
通过上述的介绍,希望能帮助大家对buffer pool有一个基础的了解,想进一步深入了解可以通过执行show engine innodb status观察下各种参数,通过对每个参数的细致研究可以全方面的掌握buffer pool。
创作不易,觉得文章写得不错帮忙点个赞吧!如转载请标明出处~
来源:juejin.cn/post/7413196978601295899
为什么很多人不推荐你用JWT?
为什么很多人不推荐你用JWT?
如果你经常看一些网上的带你做项目的教程,你就会发现 有很多的项目都用到了JWT。那么他到底安全吗?为什么那么多人不推荐你去使用。这个文章将会从全方面的带你了解JWT 以及他的优缺点。
什么是JWT?
这个是他的官网JSON Web Tokens - jwt.io
这个就是JWT

JWT 全称JSON Web Token
如果你还不熟悉JWT,不要惊慌!它们并不那么复杂!
你可以把JWT想象成一些JSON数据,你可以验证这些数据是来自你认识的人。
当然如何实现我们在这里不讲,有兴趣的可以去自己了解。
下面我们来说一下他的流程:
- 当你登录到一个网站,网站会生成一个JWT并将其发送给你。
- 这个JWT就像是一个包裹,里面装着一些关于你身份的信息,比如你的用户名、角色、权限等。
- 然后,你在每次与该网站进行通信时都会携带这个JWT。
- 每当你访问一个需要验证身份的页面时,你都会把这个JWT带给网站。
- 网站收到JWT后,会验证它的签名以确保它是由网站签发的,并且检查其中的信息来确认你的身份和权限。
- 如果一切都通过了验证,你就可以继续访问受保护的页面了。

为什么说JWT很烂?
首先我们用JWT应该就是去做这些事情:
- 用户注册网站
- 用户登录网站
- 用户点击并执行操作
- 本网站使用用户信息进行创建、更新和删除 信息
这些事情对于数据库的操作经常是这些方面的
- 记录用户正在执行的操作
- 将用户的一些数据添加到数据库中
- 检查用户的权限,看看他们是否可以执行某些操作
之后我们来逐步说出他的一些缺点
大小
这个方面毋庸置疑。
比如我们需要存储一个用户ID 为xiaou
如果存储到cookie里面,我们的总大小只有5个字节。
如果我们将 ID 存储在 一个 JWT 里。他的大小就会增加大概51倍

这无疑就增大了我们的宽带负担。
冗余签名
JWT的主要卖点之一就是其加密签名。因为JWT被加密签名,接收方可以验证JWT是否有效且可信。
但是,在过去20年里几乎每一个网络框架都可以在使用普通的会话cookie时获得加密签名的好处。
事实上,大多数网络框架会自动为你加密签名(甚至加密!)你的cookie。这意味着你可以获得与使用JWT签名相同的好处,而无需使用JWT本身。
实际上,在大多数网络身份验证情况下,JWT数据都是存储在会话cookie中的,这意味着现在有两个级别的签名。一个在cookie本身上,一个在JWT上。
令牌撤销问题
由于令牌在到期之前一直有效,服务器没有简单的方法来撤销它。
以下是一些可能导致这种情况危险的用例。
注销并不能真正使你注销!
想象一下你在推特上发送推文后注销了登录。你可能会认为自己已经从服务器注销了,但事实并非如此。因为JWT是自包含的,将在到期之前一直有效。这可能是5分钟、30分钟或任何作为令牌一部分设置的持续时间。因此,如果有人在此期间获取了该令牌,他们可以继续访问直到它过期。
可能存在陈旧数据
想象一下用户是管理员,被降级为权限较低的普通用户。同样,这不会立即生效,用户将继续保持管理员身份,直到令牌过期。
JWT通常不加密
因此任何能够执行中间人攻击并嗅探JWT的人都拥有你的身份验证凭据。这变得更容易,因为中间人攻击只需要在服务器和客户端之间的连接上完成
安全问题
对于JWT是否安全。我们可以参考这个文章
JWT (JSON Web Token) (in)security - research.securitum.com
同时我们也可以看到是有专门的如何攻击JWT的教程的
高级漏洞篇之JWT攻击专题 - FreeBuf网络安全行业门户
总结
总的来说,JWT适合作为单次授权令牌,用于在两个实体之间传输声明信息。
但是,JWT不适合作为长期持久数据的存储机制,特别是用于管理用户会话。使用JWT作为会话机制可能会引入一系列严重的安全和实现上的问题,相反,对于长期持久数据的存储,更适合使用传统的会话机制,如会话cookie,以及建立在其上的成熟的实现。
但是写了这么多,我还是想说,如果你作为自己开发学习使用,不考虑安全,不考虑性能的情况下,用JWT是完全没有问题的,但是一旦用到生产环境中,我们就需要避免这些可能存在的问题。
来源:juejin.cn/post/7365533351451672612
把哈希表换成 tire 树,居然为公司省下了几千万
你有没有想过,仅仅省下1%的计算资源,能为一家大公司带来多大的影响?你可能觉得,1%听起来微不足道,完全不值得一提。但今天我们聊一下一个技术优化点,就是关于如何通过微小的优化,Cloudflare这样的大型网络公司如何省下了大量的计算资源,背后还有不少值得我们学习的智慧。

你也在为计算资源头疼吗?
如果你是个开发者,尤其是负责维护大规模服务的开发者,你一定对计算资源的消耗有深刻的体会。无论是服务器的 CPU 使用率还是内存消耗,甚至是网络带宽,稍有不慎就可能让成本暴增。而且,问题不止是花钱那么简单,资源浪费还会拖慢你的系统,影响用户体验,最终给公司带来巨大的损失。
我要说的是 Cloudfllare 公司的案例,它不是什么宏大的技术革新或颠覆性的变革,而是从一些不起眼的小地方着手,积少成多,最终实现了1%的节省。这背后到底有什么诀窍?我们一起来看看。
1. 换个数据结构,省时又省力
在Cloudflare的案例中,他们的第一个关键优化是引入了更高效的数据结构。在大规模的数据处理中,数据结构的选择往往是决定性能的关键因素。
他们提到了将原有的哈希表结构换成了更适合他们需求的trie(字典树)结构。
下述是然来的 hash 表结构
// PERF: heavy function: 1.7% CPU time
pub fn clear_internal_headers(request_header: &mut RequestHeader) {
INTERNAL_HEADERS.iter().for_each(|h| {
request_header.remove_header(h);
});
}

这是优化之后的版本
pub fn clear_internal_headers(request_header: &mut RequestHeader) {
let to_remove = request_header
.headers
.keys()
.filter_map(|name| INTERNAL_HEADER_SET.get(name))
.collect::<Vec<_>>();
to_remove.int0_iter().for_each(|k| {
request_header.remove_header(k);
});

可以看到,他是先构造了一颗 tire 树,然后在进行操作
那么,为什么是trie呢?因为它能更高效地存储和处理特定类型的数据,特别是字符串相关的操作。每次的字符串查找、匹配操作都能变得更加快速,减少了不必要的计算消耗。

这就好比我们平时在超市找商品,如果货架排布得井井有条,一目了然,那么找起东西来肯定又快又省力。
2. 不只是省电,它还能加速系统响应
有时候,节省计算资源并不仅仅体现在电费账单上,它还直接影响系统的响应时间。你有没有遇到过访问一个网站时,页面加载缓慢,让你心急如焚?这很大程度上与后台的计算效率有关。
Cloudflare在优化trie结构后,明显提升了系统的响应速度。

举个通俗的例子,如果原本的哈希表是一个在黑夜中摸索东西的场景,那优化后的trie结构就是在白天找东西——路径明确,操作直观,不浪费多余的时间。这种提升,虽然看起来只是毫秒级的,但在每天处理数以亿计的请求时,省下来的时间就变得非常可观了。
3. 别小看每一次小改动
也许你会问:“这1%的优化,真有那么重要吗?” Cloudflare给出的答案是肯定的。别看只是1%,但在他们这种大规模系统中,每天的请求数以亿计,这1%就意味着节省了大量的服务器计算资源。试想,如果你每天的电费能减少1%,一年下来呢?这可是一笔不小的费用。
而且,从另一个角度看,任何微小的改动都有可能是更大优化的开始。Cloudflare的工程师们通过这次的优化,深入分析了系统中的其他潜在问题,发掘出更多可以提升的地方。这就像是修车时,你发现一个小问题,结果一修就发现了更多的隐患,最后车子不仅恢复了正常,还比以前跑得更快。
4. 现在,从你的小项目开始优化吧
当然,Cloudflare的规模可能让很多普通开发者觉得遥不可及,但这并不意味着我们不能从中学到东西。你手上的小项目同样可以从数据结构、代码效率等方面着手进行优化。
比如,如果你正在处理大量的字符串数据,不妨考虑一下是否可以用trie这种结构来提升效率。或者你可以先从代码的性能分析开始,看看有没有哪个部分的计算特别耗时。通过一点点的优化,哪怕最终只提升了1%,也会让你长期受益。不过,注意,过早优化,依然是万恶之源,先使用优雅的代码实现,上线后做性能瓶颈分析才是正道,换句话说,一个只有 10 几个 PV的地方,那么是再好的数据结构和算法,也很难体现出商业成本上的价值。
5. 未来的路:每一秒都很重要
在如今这个对速度要求极高的互联网时代,每一秒、甚至每一毫秒的节省都至关重要。你以为的“小改动”,可能就是让你的服务脱颖而出的关键。
Cloudflare通过这些小优化,每天节省的计算资源不仅让他们的服务更加高效,也给其他同行树立了一个榜样:技术上的进步不一定是依靠大刀阔斧的改革,有时候,从细微处着手,能带来同样惊人的效果。
不知道,你是否也开始思考自己项目中的那些“隐形”问题了呢?或许,你已经意识到了一些可以优化的地方,但还没来得及动手。那为什么不从今天开始,试着优化一两个小地方呢?也许下次的1%提升,就来自于你的一点点努力。
这个世界上没有小优化,只有还没被发现的优化。
来源:juejin.cn/post/7412848251844280360
用rust写个flutter插件并上传 pub.dev
今天收到一个需求,要求在flutter端把任意类型的图片,转换成bmp类型的图片,然后把 bmp位图发送到条码打印机,生成的 bmp图片是 1 位深度的,只有黑白两种像素颜色
包已经上传到 pub.dev,pub.dev/packages/ld…
效果图


1.生成插件包
crates.io地址: crates.io/crates/frb_…
安装命令
cargo install frb_plugin_tool
使用很简单,输入frb_plugin_tool即可

按照提示输入插件名
创建后的项目目录大概像这样

2. 编写 rust代码
我这里图片转 bmp工具用的是rust image这个包
添加依赖
cd rust && cargo add image
然后在 src/api目录下添加image.rs文件
use std::{io::Cursor, time::Instant};
use bytesize::ByteSize;
use humantime::format_duration;
use image::{GrayImage, Luma};
use indicatif::ProgressBar;
use log::debug;
use super::entitys::{LddImageType, ResizeOpt};
///任意图像转 1 位深度的数据
pub fn convert_to_1bit_bmp(
input_data: &[u8],
image_type: LddImageType,
resize: Option<ResizeOpt>,
is_apply_ordered_dithering: Option<bool>,
) -> Vec<u8> {
let use_ordered_dithering = is_apply_ordered_dithering.map_or(false, |v| v);
let start = Instant::now();
debug!("开始转换,数据大小:{:?}", ByteSize(input_data.len() as u64));
let mut img =
image::load(Cursor::new(input_data), image_type.int0()).expect("Failed to load image");
if let Some(size) = resize {
debug!("开始格式化尺寸:{:?}", size);
img = img.resize(size.width, size.height, size.filter.int0());
debug!("✅格式化尺寸完成");
}
let mut gray_img = img.to_luma8(); // 转换为灰度图像
if use_ordered_dithering {
debug!("✅使用 h4x4a 抖动算法");
gray_img = apply_ordered_dithering(&gray_img);
}
let (width, height) = gray_img.dimensions();
let row_size = ((width + 31) / 32) * 4; // 每行字节数 4 字节对齐
let mut bmp_data = vec![0u8; row_size as usize * height as usize];
// 创建进度条
let progress_bar = ProgressBar::new(height as u64);
// 二值化处理并填充 BMP 数据(1 位深度)
let threshold = 128;
for y in 0..height {
let inverted_y = height - 1 - y; // 倒置行顺序
for x in 0..width {
let pixel = gray_img.get_pixel(x, y)[0];
if pixel >= threshold {
bmp_data[inverted_y as usize * (row_size as usize) + (x / 8) as usize] |=
1 << (7 - (x % 8));
}
}
progress_bar.inc(1); // 每处理一行,进度条增加一格
}
progress_bar.finish_with_message("Conversion complete!");
// BMP 文件头和 DIB 信息头
let file_size = 14 + 40 + 8 + bmp_data.len(); // 文件头 + DIB 头 + 调色板 + 位图数据
let bmp_header = vec![
0x42,
0x4D, // "BM"
(file_size & 0xFF) as u8,
((file_size >> 8) & 0xFF) as u8,
((file_size >> 16) & 0xFF) as u8,
((file_size >> 24) & 0xFF) as u8,
0x00,
0x00, // 保留字段
0x00,
0x00, // 保留字段
54 + 8,
0x00,
0x00,
0x00, // 数据偏移(54 字节 + 调色板大小)
];
let dib_header = vec![
40,
0x00,
0x00,
0x00, // DIB 头大小(40 字节)
(width & 0xFF) as u8,
((width >> 8) & 0xFF) as u8,
((width >> 16) & 0xFF) as u8,
((width >> 24) & 0xFF) as u8,
(height & 0xFF) as u8,
((height >> 8) & 0xFF) as u8,
((height >> 16) & 0xFF) as u8,
((height >> 24) & 0xFF) as u8,
1,
0x00, // 颜色平面数
1,
0x00, // 位深度(1 位)
0x00,
0x00,
0x00,
0x00, // 无压缩
0x00,
0x00,
0x00,
0x00, // 图像大小(可为 0,表示无压缩)
0x13,
0x0B,
0x00,
0x00, // 水平分辨率(2835 像素/米)
0x13,
0x0B,
0x00,
0x00, // 垂直分辨率(2835 像素/米)
0x02,
0x00,
0x00,
0x00, // 调色板颜色数(2)
0x00,
0x00,
0x00,
0x00, // 重要颜色数(0 表示所有颜色都重要)
];
// 调色板(黑白)
let palette = vec![
0x00, 0x00, 0x00, 0x00, // 黑色
0xFF, 0xFF, 0xFF, 0x00, // 白色
];
// 将所有部分组合成 BMP 文件数据
let mut bmp_file_data = Vec::with_capacity(file_size);
bmp_file_data.extend(bmp_header);
bmp_file_data.extend(dib_header);
bmp_file_data.extend(palette);
bmp_file_data.extend(bmp_data);
let duration = start.elapsed(); // 计算耗时
debug!(
"✅转换完成,数据大小:{:?},耗时:{}",
ByteSize(bmp_file_data.len() as u64),
format_duration(duration)
);
bmp_file_data
}
// 有序抖动矩阵(4x4 Bayer 矩阵)
const DITHER_MATRIX: [[f32; 4]; 4] = [
[0.0, 8.0, 2.0, 10.0],
[12.0, 4.0, 14.0, 6.0],
[3.0, 11.0, 1.0, 9.0],
[15.0, 7.0, 13.0, 5.0],
];
//h4x4a 抖动算法
fn apply_ordered_dithering(image: &GrayImage) -> GrayImage {
let (width, height) = image.dimensions();
let mut dithered_image = GrayImage::new(width, height);
for y in 0..height {
for x in 0..width {
let pixel = image.get_pixel(x, y)[0];
let threshold = DITHER_MATRIX[(y % 4) as usize][(x % 4) as usize] / 16.0 * 255.0;
let new_pixel_value = if pixel as f32 > threshold { 255 } else { 0 };
dithered_image.put_pixel(x, y, Luma([new_pixel_value]));
}
}
dithered_image
}
生成 dart代码,在项目根目录下执行
flutter_rust_bridge_codegen generate
会在dart lib下生成对应的文件

在项目中使用
编写 example , main.dart.
import 'dart:io';
import 'dart:typed_data';
import 'package:file_picker/file_picker.dart';
import 'package:flutter/material.dart';
import 'package:ldd_bmp/api/entitys.dart';
import 'package:ldd_bmp/api/image.dart';
import 'package:ldd_bmp/ldd_bmp.dart';
import 'dart:async';
import 'package:path_provider/path_provider.dart';
const reSize = ResizeOpt(
width: 200,
height: 200,
filter: LddFilterType.nearest,
);
Future<void> main() async {
await bmpSdkInit();
runApp(const MyApp());
}
class MyApp extends StatefulWidget {
const MyApp({super.key});
@override
State<MyApp> createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
File? file;
Uint8List? bmpData;
@override
void initState() {
super.initState();
}
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text('Native Packages'),
),
body: SingleChildScrollView(
child: Column(
children: [
FilledButton(onPressed: selectFile, child: const Text('选择文件')),
if (file != null)
Image.file(
file!,
width: 200,
height: 200,
),
ElevatedButton(
onPressed: file == null
? null
: () async {
final bts = await file!.readAsBytes();
bmpData = await convertTo1BitBmp(
inputData: bts,
imageType: LddImageType.jpeg,
isApplyOrderedDithering: true,
resize: const ResizeOpt(
width: 200,
height: 200,
filter: LddFilterType.nearest,
));
setState(() {});
},
child: const Text("转换")),
ElevatedButton(
onPressed: bmpData == null
? null
: () {
saveImageToFile(bmpData!);
},
child: const Text("保存图片"))
],
),
),
floatingActionButton: bmpData != null
? ConstrainedBox(
constraints:
const BoxConstraints(maxHeight: 300, maxWidth: 300),
child: Card(
elevation: 10,
child: Padding(
padding: const EdgeInsets.all(8.0),
child: Column(
children: [
const Text('转换结果'),
Image.memory(bmpData!),
],
),
),
),
)
: null,
),
);
}
Future<void> selectFile() async {
setState(() {
file = null;
});
FilePickerResult? result = await FilePicker.platform.pickFiles();
if (result != null) {
file = File(result.files.single.path!);
setState(() {});
} else {
// User canceled the picker
}
}
}
Future<void> saveImageToFile(Uint8List imageData) async {
// 获取应用程序的文档目录
final directory = await getApplicationDocumentsDirectory();
// 设置文件路径和文件名
final filePath = '${directory.path}/image.bmp';
// 创建一个文件对象
final file = File(filePath);
// 将Uint8List数据写入文件
await file.writeAsBytes(imageData);
print('Image saved to $filePath');
}

转换速度还是挺快的,运行效果

上传到 pub.dev
这个包已经上传到仓库了,可以直接使用
pub.dev/packages/ld…
来源:juejin.cn/post/7412486655862734874
Java 语法糖,你用过几个?
你好,我是猿java。
这篇文章,我们来聊聊 Java 语法糖。
什么是语法糖?
语法糖(Syntactic Sugar)是编程语言中的一种设计概念,它指的是在语法层面上对某些操作提供更简洁、更易读的表示方式。这种表示方式并不会新增语言的功能,而只是使代码更简洁、更直观,便于开发者理解和维护。
语法糖的作用:
- 提高代码可读性:语法糖可以使代码更加贴近自然语言或开发者的思维方式,从而更容易理解。
- 减少样板代码:语法糖可以减少重复的样板代码,使得开发者可以更专注于业务逻辑。
- 降低出错率:简化的语法可以减少代码量,从而降低出错的概率。
因此,语法糖不是 Java 语言特有的,它是很多编程语言设计中的一些语法特性,这些特性使代码更加简洁易读,但并不会引入新的功能或能力。
那么,Java中有哪些语法糖呢?
Java 语法糖
1. 自动装箱与拆箱
自动装箱和拆箱 (Autoboxing and Unboxing)是 Java 5 引入的特性,用于在基本数据类型和它们对应的包装类之间自动转换。
// 自动装箱
Integer num = 10; // 实际上是 Integer.valueOf(10)
// 自动拆箱
int n = num; // 实际上是 num.intValue()
2. 增强型 for 循环
增强型 for 循环(也称为 for-each 循环)用于遍历数组或集合。
int[] numbers = {1, 2, 3, 4, 5};
for (int number : numbers) {
System.out.println(number);
}
3. 泛型
泛型(Generics)使得类、接口和方法可以操作指定类型的对象,提供了类型安全的检查和消除了类型转换的需要。
List<String> list = new ArrayList<>();
list.add("Hello");
String s = list.get(0); // 不需要类型转换
4. 可变参数
可变参数(Varargs)允许在方法中传递任意数量的参数。
public void printNumbers(int... numbers) {
for (int number : numbers) {
System.out.println(number);
}
}
printNumbers(1, 2, 3, 4, 5);
5. try-with-resources
try-with-resources 语句用于自动关闭资源,实现了 AutoCloseable 接口的资源会在语句结束时自动关闭。
try (BufferedReader br = new BufferedReader(new FileReader("file.txt"))) {
System.out.println(br.readLine());
} catch (IOException e) {
e.printStackTrace();
}
6. Lambda 表达式
Lambda 表达式是 Java 8 引入的特性,使得可以使用更简洁的语法来实现函数式接口(只有一个抽象方法的接口)。
List<String> list = Arrays.asList("a", "b", "c");
list.forEach(s -> System.out.println(s));
7. 方法引用
方法引用(Method References)是 Lambda 表达式的一种简写形式,用于直接引用已有的方法。
list.forEach(System.out::println);
8. 字符串连接
从 Java 5 开始,Java 编译器会将字符串的连接优化为 StringBuilder 操作。
String message = "Hello, " + "world!"; // 实际上是 new StringBuilder().append("Hello, ").append("world!").toString();
9. Switch 表达式
Java 12 引入的 Switch 表达式使得 Switch 语句更加简洁和灵活。
int day = 5;
String dayName = switch (day) {
case 1 -> "Sunday";
case 2 -> "Monday";
case 3 -> "Tuesday";
case 4 -> "Wednesday";
case 5 -> "Thursday";
case 6 -> "Friday";
case 7 -> "Saturday";
default -> "Invalid day";
};
10. 类型推断 (Type Inference)
Java 10 引入了局部变量类型推断,通过 var 关键字来声明变量,编译器会自动推断变量的类型。
var list = new ArrayList<String>();
list.add("Hello");
这些语法糖使得 Java 代码更加简洁和易读,但需要注意的是,它们并不会增加语言本身的功能,只是对已有功能的一种简化和封装。
总结
本文,我们介绍了 Java 语言中的一些语法糖,从上面的例子可以看出,Java 语法糖只是一些简化的语法,可以使代码更简洁易读,而本身并不增加新的功能。
学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
来源:juejin.cn/post/7412672643633791039
BOE·IPC电竞大赛暨BOE无畏杯S2完美收官 BOE(京东方)竖立电竞产业生态新标杆
在开幕环节,高文宝博士表示:“电竞是年轻人的活动,年轻人有着活跃的思想和强大的创造力。近年来,BOE(京东方)通过BOE无畏杯和ChinaJoy等活动加深了和年轻人的沟通,与年轻人成为了真诚的伙伴和挚友,在这个过程中,BOE(京东方)也激发了新的创造灵感,做出更好更惊艳的产品。未来BOE(京东方)还会持续在技术、产品、活动等方面,与合作伙伴一起带来异彩纷呈的电竞体验,带动电竞产业链的价值提升,助力中国电竞再创高峰。”
今年举办的BOE无畏杯总决赛活动上,BOE(京东方)还特别打造"Best of Esports电竞高阶联盟"产品展区,集中展现了联盟伙伴们最新的电竞产品和尖端技术。依托于BOE(京东方)自主研发的ADS Pro、a-MLED等创新技术赋能,AGON爱攻 AG275QZW显示器支持260Hz超高刷新率,以1ms GTG疾速响应时间为玩家提供高帧率、低延迟的游戏画质,确保流畅丝滑的游戏体验;ROG枪神8 Plus超竞版笔记本,支持60-240Hz动态调频刷新率及3ms极速响应,玩家操作无比顺畅……一系列电竞黑科技产品凭借高清流畅的显示画面和酷炫的科技外观吸引了现场粉丝纷纷体验,为观众们呈现了一场融合竞技与科技的盛宴。
总决赛现场更是异彩纷呈,现场Coser开场秀、无畏契约水友赛等丰富的互动环节点燃了现场观众的热情,更有BOE无畏契约战队对战JDG无畏契约战队表演赛,BOE战队面对职业战队分毫不让、竞出风采,让决赛前的氛围达到了高潮。在总决赛启动仪式上,BOE(京东方)副总裁刘毅、虎牙直播商业化副总裁焦阳、京东集团3C数码事业群电脑组件业务部总经理蔡欣洋一起揭开BOE无畏杯《无畏契约》2024挑战赛总决赛的帷幕,总决赛最终在上一届亚军津门飞鹰战队与CCG战队的较量中展开对决,经过3局激战,CCG队获得最终胜利,拿下本届赛事的冠军。
多年来,BOE(京东方)以技术创新为驱动,通过高刷新率、护眼科技等技术产品优势、广泛的合作以及强大的品牌影响力,从技术、产品、生态等多个方面助力电竞产业发展,获得了众多全球一线客户的支持和好评,引领了整个电竞产业的升级和变革。未来,BOE(京东方)将继续秉持"Powered by BOE"的生态理念,充分发挥"Best of Esports电竞高阶联盟"在全业态布局、资源聚合和技术领先等方面的优势,通过持续不断的技术创新和产业链整合,为我国电竞生态贡献力量,为数字经济的高质量发展注入新的动力。
收起阅读 »Mysql中各种日志、缓冲区都是干嘛的?
介绍
本篇文章主要以innodb存储引擎为主;在了解mysql的过程中经常能听到它内部有各种log以及缓冲区,他们在mysql中具有重要作用,例如binlog可以进行主从恢复,undo log可以进行数据回滚等。这篇文章主要讲解在mysql运气期间每个区域都是用来做什么的。
写入数据流程
对于mysql来讲,读写任何数据都是在内存中进行操作的;下图为mysql写入数据的详细流程:

- 写入undo log,为了实现回滚的功能,在写入真实数据前需要记录它的回滚日志,防止写入完数据后无法进行回滚;
- 写入
buffer pool或change buffer,在缓存中记录下数据内容; - 为了防止mysql崩溃内存中的数据丢失,此时会记录下redo log,记录redo log时也是写入它的buffer,通过不同的刷盘策略刷入到磁盘redo log文件中;
- 为了实现主从同步,数据恢复功能,mysql提供了binlog日志,写入完redo log后写binlog文件;
- 为了使binlog和redo log保持数据一致,这里采用的二阶段提交,写入binlog成功会再在redo log buffer中写入commit;
- 对redo log进行刷盘,这里有三种刷盘策略,介绍一下刷盘策略;
- 对buffer pool中的数据进行刷盘。
undo log
undo log记录事务开始前的数据状态,它主要用于数据回滚和实现MVCC:
- 回滚操作:undo log记录了事务开始前的数据状态,当事务需要回滚时,以便可以恢复到原始状态。
- 多版本并发控制(MVCC) :在读取历史数据时,undo log允许读取到事务开始前的数据版本,从而实现非锁定读取。
MVCC的具体实现可以查看:MVCC实现
buffer pool
innodb中无论是查询还是写绝大部分都是在buffer pool中进行操作的,它相当于innodb的缓存区,可以通过show engine innodb status来查看buffer pool的使用情况;可以通过innodb_buffer_pool_size来设置buffer pool的大小,线上不要吝啬给几个G内存都是正常的,但无论给多大内存都会有不够的时候,innodb采用了变种的LRU算法对数据页进行淘汰;如下图:

传统的LRU算法当碰到扫描一张大表时可能会直接把buffer pool中的所有页都更换为该表的数据,但这张表可能就使用一次,并不是热点数据;
innodb为了避免这种场景发生,会把整个buffer pool按照 5:3分成了young区域和old区域;其中绿色区域就是young区域也就是热点数据区域,紫色区域就是old区域也就是冷数据区域;整体的淘汰流程为:
- 如果想访问绿色区域内的数据,会把访问页直接放在young head处;
- 如果想访问一个不存在的页,会把tail页淘汰掉,并且把新访问的数据页插入在old head处;
- 如果访问old区域的数据页,并且这个数据页在LRU链表中存在的时间超过了
innodb_old_blocks_time(默认1000毫秒),就把它移动到yound head处; - 如果访问old区域的数据页,并且这个数据页在LRU链表中存在的时间短于
innodb_old_blocks_time,把该页移动到old head处。
在上图中可以看到除了LRU链表还有一个Flush链表,它是用来管理脏页的;在写入数据时绝大部分都会先写入buffer pool中,再更改buffer pool中的页数据时,该页就变成了脏页,此时就会被加入到flush链表中,定时会把flush中的脏页刷到.idb数据文件中。
change buffer
在介绍buffer pool时用的是绝大部分操作,是因为在innodb中还存在change buffer,还有一部分操作是写入change buffer的。change buffer的定义是当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,innodb会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中加载这个数据页了,如果有查询需要访问这个数据页的时候,再将数据页读到内存中,然后执行change buffer中与这个页有关的操作,这样就能保证这个数据的正确性。change buffer用的是buffer pool中的内存,可以通过innodb_change_buffer_max_size来设置它占用buffer pool的内存比例。使用change buffer的前提条件是该数据页还没被加载到buffer pool中,并且如果是根据唯一索引进行更新,由于要检查数据的唯一性,必须把数据页加载到buffer pool中是无法享受change buffer带来的收益的。
redo log 与 redo log buffer
redo log是为了防止由于mysql异常退出导致buffer pool中还未持久化的数据丢失而诞生的;
它也是一个环形文件写数据写满时会覆盖历史的数据,它记录了数据页的物理变化,并且是顺序写入的提升了写入的性能;当mysql重启时可以使用redo log来恢复数据。
每次写redo log时并不是直接写入redo log文件,而是写入redo log buffer中,通过三种刷盘策略把数据同步到redo log中,可以通过innodb_flush_log_at_trx_commit参数来控制刷盘的时机
- 0:事务提交时,日志缓冲(log buffer)被写入到日志文件,但并不立即刷新到磁盘。日志文件的刷新操作由后台线程每隔一秒执行一次;
- 1:事务提交时,日志缓冲被写入到日志文件,并立即刷新到磁盘;
- 2:事务提交时,日志缓冲被写入到日志文件,但不立即刷新到磁盘。而是每秒由后台线程将日志文件刷新到磁盘。
如果对数据的正确性要求很高应该设置为1。
注:第一张图流程中,在第5步有二次commit,在数据恢复如果发现一个事务没有commit,则去binlog日志中查询,如果发现binlog中有相应数据则直接恢复,如果没有则丢弃。
binlog
binlog为了高效地记录和传输数据更改信息,它采用了二进制格式存储数据库的更改操作,这样还可以占用更小的存储空间;它可以实现数据恢复、数据同步等功能。默认mysql是关闭binlog日志的,可以通过
在[mysqlId]部分中设置log-bin和server-id来开启binlog日志。它也是在事务提交时才进行数据记录,它有以下三种数据格式:
- Statement:记录每一条执行的sql,但由于mysql中存在一些函数,例如一些随机生成函数,此时数据同步时会发生同步过去的数据不一致;
- Row:记录每行被修改成什么,这样可以解决statement带来的数据不一致问题,但由于记录的太详细如果出现了全表更新,那记录的数据量就会特别大;
- Mixed:Statement和Row的混合体,mysql会根据执行的每一条具体的SQL语句来区别对待记录的日志格式。
总结
为了实现更高的性能,在innodb中的任何操作都是优先在内存中操作的;为了支持数据的数据回滚、MVVC引入了undo log,进而可以实现查询历史版本或数据回滚;同时为了防止异常退出导致的数据丢失引入了redo log;为了支持数据同步等功能mysql引入了binlog日志。这就是各个区域的作用,由于篇幅原因本篇文章只对每个区域做了简单介绍,后续会写各个区域详细内容的文章。
创作不易,觉得文章写得不错帮忙点个赞吧!如转载请标明出处~
来源:juejin.cn/post/7411489477283856419
用SQL写游戏,可能吗?看看大佬是如何使用 SQL 写一个俄罗斯方块亮瞎你的钛合金狗眼的!
大家好,今天我要带你们一起来开开眼界。你知道SQL吗?就是那个我们平时用来和数据库打交道的语言——查询数据、插入数据、删除数据,嗯,数据库管理员的必备技能。但你能想象到有人用SQL做了什么吗?他用SQL做了一款俄罗斯方块!对,就是那个曾经风靡全球的经典游戏。

你可能会想,“这怎么可能?SQL不就是查查数据嘛,最多写点复杂的查询语句,能做游戏?”其实我一开始也是这个想法,但看了这个项目后,真的不得不感叹程序员的脑洞太大了!这篇文章就来和你聊聊,这个疯狂的项目到底是怎么实现的,以及为什么这个看似“不务正业”的尝试背后,可能藏着编程世界的一些终极奥秘。
还是先上一下项目地址吧:
1. Turing完备性,SQL到底有多强大?
首先,让我们聊聊一个稍微专业一点的概念:图灵完备性(Turing completeness) 。简单来说,如果一门编程语言是图灵完备的,那它理论上可以实现任何计算。我们平时接触的编程语言,比如Python、Java、C++,都是图灵完备的。但SQL呢?你可能想象不到,SQL也是图灵完备的,这意味着它也具备和其他编程语言一样的能力,只是我们平时大多只用它进行数据库操作。

项目的开发者正是看中了SQL的图灵完备性,才想出了用它来实现俄罗斯方块这个创意。虽然SQL天生并不是为游戏设计的,但通过一些巧妙的设计,开发者硬是把这个“不可能的任务”完成了。不得不说,这不仅仅是技术上的一种挑战,更是一种极致的创意和智慧的碰撞。
2. 用SQL写游戏,可能吗?
接下来,你可能很好奇了,具体怎么实现的呢?其实,开发者在SQL中用了一些非常“刁钻”的技巧。他利用了SQL中的递归查询(Common Table Expressions,简称CTE)和一些复杂的数学操作,来模拟俄罗斯方块的游戏逻辑。
WITH RECURSIVE t(i) AS (
-- non-recursive term
SELECT 1
UNION ALL
-- recursive term
SELECT i + 1 -- takes i of the previous row and adds 1
FROM t -- self-reference that enables recursion
WHERE i < 5 -- when i = 5, the CTE stops
)
SELECT *
FROM t;
i
----
1
2
3
4
5
(5 rows)
举个简单的例子,当俄罗斯方块下落时,我们需要判断它是否与底部或其他方块发生碰撞。通常这种逻辑我们会在游戏开发中使用循环来处理,而在SQL中,开发者通过递归查询来实现类似的循环效果。每次查询都相当于让方块“动”一下,并判断它是否碰到边界。
-- without i appended
...
-> Memoize (loops=999)
...
Hits: 998 Misses: 1 ...
-> Function Scan on dblink input (loops=1) -- only called once
...
-- with i appended
...
-> Nested Loop (loops=999)
-> WorkTable Scan on main main_1 (loops=999)
-> Function Scan on dblink input (loops=999) -- called every iteration
...
虽然说这个过程比传统的编程语言要复杂得多,但实际上,通过SQL,也能够非常清晰地描述出游戏的规则和状态变化。这其实也证明了图灵完备性的一个非常有趣的应用场景——我们可以用SQL来做的不仅仅是数据库操作,甚至是一些我们平时想都不敢想的事情。
3. 疯狂背后的深思:编程的边界在哪里?
或许你会觉得,用SQL做一个俄罗斯方块游戏纯粹是“哗众取宠”,为了博取眼球,没什么实际意义。但深入思考一下,这个项目实际上揭示了编程的一些非常深刻的哲学问题:编程的边界在哪里?
我们习惯性地把SQL、Python、Java等语言分门别类,用它们来解决不同类型的问题。但这个项目提醒我们,编程的真正边界,或许并不是由语言的设计来决定的,而是由开发者的想象力来定义的。一个看似“不合适”的工具,通过创意和技巧,也可以实现出乎意料的结果。这或许也是编程最迷人之处:没有什么是绝对不可能的。
4. 我们可以从这些疯狂的想法中能学到什么?
看完这个项目,你可能会想,“那我能从中学到什么呢?” 其实,除了技术上的启发之外,这个项目还给我们提供了一些更为重要的思维方式。
第一点,敢于挑战常规。 当我们学习编程时,往往会被一些固定的思维框架束缚住,比如SQL只能用于数据库操作,JavaScript才是做前端的。但这个项目告诉我们,有时候打破常规、尝试一些看似不可能的事情,可能会有意外的收获。
第二点,深入理解工具的本质。 学习一门编程语言不仅仅是掌握语法和基本操作,更重要的是理解它背后的能力和局限。这个项目通过SQL的图灵完备性展示了它的潜力,这种对工具的深刻理解,往往能帮助我们在关键时刻找到突破口。
第三点,保持对编程的好奇心。 编程是一门技术,但同时也是一门艺术。正如这位开发者一样,保持好奇心,不断尝试新东西,能够让我们在编程的世界里走得更远。
5. 最后,尝试一下吧!
看完了这篇文章,我猜你可能已经对这个项目充满了好奇。那就别犹豫了,去看看GitHub项目,甚至可以自己动手试试。即使你并不是SQL的高手,但通过这个项目,你一定能收获一些不一样的编程灵感。毕竟,编程的世界永远充满了无限可能,而这些可能性,就等待着你去探索和创造。
最后送你一句话:编程的乐趣,不在于完成任务,而在于不断发现和实现那些看似不可能的创意!
来源:juejin.cn/post/7411354460969222159
只因把 https 改成 http,带宽减少了 70%!
起因
是一个高并发的采集服务上线后,100m的上行很快就被打满了。
因为这是一条专线,并且只有这一个服务在使用,所以可以确定就是它导致的。
但是!这个请求只是一个 GET 请求,同时并没有很大的请求体,这是为什么呢?
于是使用 charles 重新抓包后发现,一个 request 的请求居然要占用 1.68kb 的大小!
其中TLS Handshake 就占了 1.27kb。

这种情况下,需要的上行带宽就是:1.68*20000/1024*8=262.5mbps
也就说明100mbps的上行为何被轻松打满
TLS Handshake是什么来头,竟然如此大?
首先要知道HTTPS全称是:HTTP over TLS,每次建立新的TCP连接通常需要进行一次完整的TLS Handshake。在握手过程中,客户端和服务器需要交换证书、公钥、加密算法等信息,这些数据占用了较多的字节数。
TLS Handshake的内容主要包括:
- 客户端和服务器的随机数
- 支持的加密算法和TLS版本信息
- 服务器的数字证书(包含公钥)
- 用于生成对称密钥的“Pre-Master Secret”
这个过程不仅耗时,还会消耗带宽和CPU资源。
因此想到最粗暴的解决方案也比较简单,就是直接使用 HTTP,省去TLS Handshake的过程,那么自然就不会有 TLS 的传输了。
那么是否真的有效呢?验证一下就知道。
将请求协议改成 http 后:

可以看到请求头确实不包含 TLS Handshake了!
整个请求只有 0.4kb,节省了 70% 的大小
目标达成
因此可以说明:在一些不是必须使用 https 的场景下,使用 http 会更加节省带宽。
同时因为减少了加密的这个过程,可以观察到的是,在相同的并发下,服务器的负载有明显降低。
那么问题来了
如果接口必须使用 https那怎么办呢?
当然还有另外一个解决方案,那就使用使用 Keep-Alive。
headers 中添加 Connection: keep-alive 即可食用。
通过启用 Keep-Alive,
可以在同一TCP连接上发送多个HTTPS请求,
而无需每次都进行完整的TLS Handshake,
但第一次握手时仍然需要传输证书和完成密钥交换。
对于高并发的场景也非常适用。
要注意的是
keep-alive 是有超时时间的,超过时间连接会被关闭,再次请求需要重新建立链接。
Nginx 默认的 keep-alive 超时是 75 秒,
Apache HTTP 服务器 通常默认的 keep-alive 超时是 5 秒。
ps:
如果你的采集程序使用了大量的代理 ip那么 keep-alive 的效果并不明显~~
最好的还是使用 http
来源:juejin.cn/post/7409138396792881186
多人游戏帧同步策略

介绍解决该问题的基本概念和常见解决方案。
- Lockstep state update 锁步状态更新
- Client prediction 客户端预测
- server reconcilation 服务端和解
多人游戏的运作方式
游戏程序的玩家当前状态随时间和玩家的输入会进行变化。也就是说游戏是有状态的程序。多人游戏也不例外,但由于多人玩家之间存在交互,复杂性会更高。
例如贪吃蛇游戏,我们假设它的操作会发送到服务器,那它的核心游戏逻辑应该是:
- 客户端读取用户输入改变蛇的方向,也可以没有输入,然后发送给服务端
- 服务端接收消息,根据消息改变蛇的方向,将蛇的“头”移动一个单位空间
- 服务端检查蛇是否撞到了墙壁或者自己,如果撞到了游戏结束,给客户端发送响应消息,更新客户端的画面。如果没有撞到,则继续接收客户端发送的消息,同时也要响应给客户端消息,告诉客户端,蛇目前的状态。
服务端接收该消息做出对应的动作,这个过程会以固定的间隔运行。每一次循环都被称为 frame 或 tick。
客户端将解析服务端发送的消息,也就是每一帧的动作,渲染到游戏华中中。
锁步状态更新
为了确保所有客户端都同步帧,最简单的方法是让客户端以固定的间隔向服务器发送更新。发送的消息包含用户的输入,当然也可以发送 no user input。
服务器收集“所有用户”的输入后,就可以生成下一次 frame 帧。

上图演示了客户端与服务端的交互过程。T0 ~ T1 时间段,客户端保持等待,或者说空闲状态,直到服务器响应 frame,等待时间的大小取决于网络质量,约 50 毫秒到 500 毫秒,人眼能够注意到任何超过 100 毫秒的延迟,因此这个等待时间对于某些游戏来说是不可接受的。
锁步状态更新,还有一个问题。游戏的延迟来自最慢的用户 。

上图有两个客户端。客户端 B 的网络比较差,A 和 B 都在 T0 时间点向服务器发送了用户输入,A 的请求在 T1 到达服务端,B 的请求在 T2 到达服务端,前面我们提到,服务器需要收集“所有用户”的请求后才开始工作,因此需要到 T2 时间点才开始生成 frame。
因为 Client B 比较慢,我们“惩罚”了所有的玩家。
假如我们不等待所有客户端的用户输入,低延迟玩家又会获得优势,因为它的输入到达服务器的时间更短,会更快处理。例如,两个玩家 A、B 同时互相射击预期是同时死亡,但是 A 玩家延迟比 B 玩家更低,因此在处理 B 玩家的用户输入时,A 玩家已经干掉 B 玩家了。
小结一下,锁步状态更新存在的问题,如下。
- 游戏画面是否卡顿,取决于最慢的玩家
- 客户端需要等待来自服务器的响应,否则不会渲染画面
- 连接非常活跃,客户端需要定期发送一些无用的心跳包,以便服务器可以确定它拥有生成 frame 所需的所有信息
回合制类型的游戏大多数使用这种方法,因为玩家确实需要等待,例如《炉石传说》。
对于慢节奏的游戏,少量延迟也是可以接受的,例如《QQ农场》。
但是对于快节奏的游戏,锁步状态更新的这些问题都是致命的,不可能操纵游戏人物进入某一个建筑,500 毫秒后,我才能进入。我们一起来看看下一种方法。
客户端预测
客户端预测,在玩家的计算机上,运行游戏逻辑,来模拟游戏的行为,而不是等待服务器更新。
例如我们生成 Tn 时间点的游戏状态,我们需要 Tn-1 时间点的所有玩家状态和 Tn-1 时间点所有玩家的输入。
假设,我们现在的固定频率为 1 s,每 1s 需要给服务器发送一个请求,获取玩家状态并更新玩家的状态。

在 T0 时间点,客户端将用户的输入发送到服务器,用于获取 T1 时间点的游戏状态。在 T1 时间点,客户端已经可以渲染画面了,实际上客户端的响应是在 T3 时刻,也就是说客户端没有等待来自服务器的响应。
使用这个方法,需要满足一些前置条件:
- 客户端拥有游戏运行逻辑所需的所有条件
- 玩家状态的更新逻辑是确定性的,即没有随机性,或者可以以某种方式保证确定性,例如客户端和服务器使用同样的公式以及随机种子,可以保证具有随机性的同时,产生的结果具有确定性。这样保证了客户端和服务器在给定相同输入的情况下产生相同的游戏状态
满足这两点,客户端预测的结果也不一定总是对的。就比如刚提到的,使用相同的公式以及相同的随机种子,进行伪随机算法,但不同平台的浮点计算,可能会存在微小的差异。
再设想一个场景,如下图。

客户端 A 尝试使用 T0 时间点的信息模拟 T1 时间点上的游戏状态,但客户端 B 也在 T0 时间点提交了用户输入,客户端 A 并不知道这个用户输入。
这意味着客户端 A 对 T1 时间的预测将是错误的是,但!由于客户端 A 仍然从服务器接收 T1 时间点的状态,因此客户端有机会在 T3 时间点修正错误。
客户端需要知道,自己的预测是否正确,以及如何修正错误。
修正错误通常叫做 Reconcilation 和解。
需要根据上下文来实现和解部分,下面我们通过一个简单的例子来理解这个概念。这个例子只是抛弃我们的预测,并将其游戏状态替换为服务器响应的正确状态。
- 客户端需要维护 2 个缓冲区,一个用于预测 PredictionBuffer,一个用于用户输入 InputBuffer 。它们是预测这个行为需要的上下文,请记住,预测 Tn 时刻,需要 Tn-1 的状态和 Tn-1 时刻的用户输入。它们一开始都为空

- 玩家点击鼠标,移动游戏角色到下一个位置。此时,玩家输入的移动信息 Input 0 存储在 InputBuffer 中,客户端将生成预测 Prediction 1,存储在 PredictionBuffer 中,预测将展示在玩家画面中

- 客户端收到服务器响应的 State0 ,发现与客户端的预测不匹配,我们将Prediction 1 替换为 State 0,并使用 Input 0 和 State 0 重新计算,得到 Prediction 2,这个重新计算的过程,就是 Reconcilation 和解

- 和解后,我们从缓冲区中删除 State 0 和 Input 0

这种和解的方式有一个明显的缺点,如果服务器响应的游戏状态和客户端预测差异太大,则游戏画面可能会出现错误。例如我们预测敌人在 T0 时间点向南移动,但在 T3 时间点,我们意识到它在向北移动,然后通过使用服务器的响应进行和解,敌人将从北“飞到”正确的位置。
有一些方法可以解决此问题,这里不展开讨论,感兴趣可以搜一下实体插值 Entity Interpolation。
小结一下,客户端预测技术,让客户端以自己的更新频率运行,与服务器的更新频率无关,所以服务器如果出现阻塞,不会影响客户端的帧。
但它也带来复杂性,如下。
- 需要在客户端处理更多的状态和逻辑,比如我们前面提到的缓冲区和预测逻辑
- 需要和解来自服务器的状态(正确的游戏状态)与预测之前的冲突
还给我们带来了敌人从南飞到北的问题。
目前为止,我们都在讨论客户端,接下来看看服务端如何解决帧同步。
服务端和解
利用服务端解决帧同步问题,首先需要解决的是网络延迟带来的问题。如下图。

用户 A 在 T 处进行了操作(比如按下了一个技能键),该操作应该在 T+20ms 处理,但由于延迟,服务器在 T+120ms 才接收到输入。
在游戏中,用户做出指定操作后,应该立即有反应。立即有反应,这个立即是多久,取决于游戏的类型,比如之前我们提到的回合制,它的立即可能是几十秒。我们可以通过 T + X,表示立即反应的时间,T 代表用户的输入时刻,X 代表的是延迟。X 可以为 0,这代表真正的立即 :-)
解决这个问题的思路,与之前客户端预测中使用的办法类似,就是通过客户端的用户输入,来和解服务器中的玩家游戏状态。
所有的用户输入,都需要时间戳进行标记,该时间戳用于告诉服务器,什么时刻处理此用户输入。

为什么在同一水平线上,Client A 的时间是 Time X,而 Server 的时间是 Time Y?
因为客户端和服务端独立运行,通常时间会有所不同,在多人游戏中,我们可以特殊处理其中的差异。在特殊处理时,我们应该使客户端的时间大于服务端的时间,因为这样可以存在更大的灵活性
上图演示了一个客户端与服务端之间的交互。
- 客户端发送带有时间戳的输入。客户端告诉服务器在 X 时间点应该发生用户输入的效果
- 服务端在 Y 时间点收到请求
- 在 Y+1 时间点,即红色框的地方,服务端开始和解,服务端将 X 时间点的用户输入应用于最新的游戏状态,以保证 X 的 Input 发生在 X 时间点
- 服务端发送响应,该响应中包含时间戳
服务端和解部分(上图红色底色部分),主要维护 3 个部分,如下。
- GameStateHistory,在一定时间范围内玩家在游戏中的状态
- ProcessedUserInput,在一定时间范围内处理的用户输入的历史记录
- UnprocessedUserInput,已收到但未处理的用户输入,也是在一定的时间内
服务端和解过程,如下。
- 当服务端收到来自用户的输入时,首先将其放入 UnprocessedUserInput 中
- 等待服务端开始同步帧,检查 UnprocessedUserInput 中是否存在任何早于当前帧的用户输入
- 如果没有,只需要将最新的 GameState 更新为当前用户的输入,并执行游戏逻辑,然后广播到客户端
- 如果有,则表示之前生成的某些游戏状态由于缺少部分用户输入而出错,需要和解,也就是更正。首先需要找到最早的,未处理的用户输入,假设它在时间 N 上,我们需要从 GameStateHistory 中获取时间 N 对应的 GameState 以及从 ProcessedUserInput 获取时间 N 上用户的输入
- 使用这 3 条数据,就可以创建一个准确的游戏状态,然后将未处理的输入 N 移动到 ProcessingUserInput,用于之后的和解
- 更新 GameStateHistory 中的游戏状态
- 重复步骤 4 ~ 6,直到从 N 的时间点到最新的游戏状态
- 服务端将最新帧广播给所有玩家
我并没有做过这些工作,分享的知识都是我对它感兴趣,在网上看了许多经验后整理的。
来源:juejin.cn/post/7277489569958821900
如何让你喜欢的原神角色陪你写代码
如何让你喜欢的原神角色陪你写代码
每天上班,脑子里面就想着一件事,原神,啊不对,VsCode!启动!(doge 狗头保命),那么如何将这两件事情结合起来呢?特别是原神里面有那么多我喜欢的角色。
最终效果预览
- 右下角固定一只小可爱
- 全屏一只小可爱


省流直接抄作业版
vscode下载background插件

- 第一次使用这个插件会提示
vscode已损坏让你restart vscode,不要慌,因为插件底层是改 vscode 的样式 - 需要管理员权限,如果你安装到了 C 盘
copy下面的配置到你的settings.json文件
2.1 右下角固定图片配置
{
"background.customImages": [
"https://upload-bbs.miyoushe.com/upload/2023/02/24/196231062/8540249f2c0dd72f34c8236925ef45bc_3880538836005347690.png",
"https://user-images.githubusercontent.com/41776735/163673800-0e575aa3-afab-405b-a833-212474a51adc.png"
],
"background.enabled": true,
"background.style": {
"content": "''",
"width": "30%",
"height": "30%",
"opacity": 0.3,
"position": "absolute",
"bottom": "0",
"right": "7%",
"z-index": "99999",
"background-repeat": "no-repeat",
"background-size": "contain",
"pointer-events": "none"
},
"background.useDefault": false,
"background.useFront": true
}
2.2 全屏图片配置
{
"background.customImages": ["https://upload-bbs.miyoushe.com/upload/2024/01/15/196231062/1145c3a2f56b2f789a9be086b546305d_3972870625465222006.png"],
"background.enabled": true,
"background.style": {
"content": "''",
"pointer-events": "none",
"position": "absolute",
"z-index": "99999",
"height": "100%",
"width": "100%",
"background-repeat": "no-repeat",
"background-size": "cover",
"background-position": "content",
"opacity": 0.3
},
"background.useDefault": false,
"background.useFront": true
}
详细说明版
第一步,你还是需要下载 background 这个插件。
background插件的官方中文文档
第二步,配置解析
我们看官方文档里面,有两个配置是需要说明一下的
background.customImages:
- 是一个数组,默认是用第一张图片做背景图,在分屏的时候第二屏就用的是数组的第二个元素,以此类推
- 支持 https 协议和本地的 file 协议
- 因为我有公司机器和自己电脑,所以本地协议不太适用我,但是我之前一直用的是本地协议,并且下面会教大家如何白嫖图床
background.style:
- 作为一个前端,看到上面的内容是不是十分的熟悉,其实这个插件的底层原理就是去改 vscode 的 css,所以你可以想想成一个需求,在一个界面上显示一张图片,css 可以怎么写,背景图就可以是啥样的
- 如果你看不懂 css 代码,你可以直接复制我上面提供的两种配置,一个全屏的,一个是在右下角固定一小只的
- 如果你觉得背景图太亮了,有点看不清代码,你可以修改
background.style.opacity这个属性,降低图片的透明度。 - 发现最新版本支持
background.interval来轮播背景图了
高清社死图片
OK,其实到这就没啥了,但是到这里和原神好像并没有什么太大的关系,那现在我就教你怎么白嫖米游社的图床,并且获取高清的原神图片
- 第一步,你需要有一个米游社的账号,当然,玩原神的不能没有吧
- 第二步,随便找个帖子进行评论回复,如果你怕麻烦别人,可以自己发一贴
- 第三步:新标签页打开
- 到这里,你就能白嫖米游社的图床了,如果你是评论的自己的图片,新标签页打开之后,删除 url 中
?后面所有的内容,就可以得到原图 https 的链接了 - 但是又遇到一个问题,我就是很喜欢米游社的图片,但是图片的分辨率太低了怎么办?
- 提供两个用 ai 来放大图片的网站
- waifu2x.udp.jp/
- bigjpg.com/
- 把图片放大之后,在用上面白嫖图床的方法就可以了


最后
水一期,求三连 + 可以在评论区分享你的背景图嘛
来源:juejin.cn/post/7324143986759303194
NestJs: 定时任务+redis实现阅读量功能
抛个砖头
不知道大家用了这么久的掘金,有没有对它文章中的阅读量的实现有过好奇呢?

想象一下,你每次打开一篇文章时,都会有一个数字告诉你多少人已经读过这篇文章。那么这个数字是怎么得出来的呢?
有些人可能会认为,每次有人打开文章,数字就加1,不是很简单吗? 起初我也以为这样,哈哈(和大家站在同一个高度),但(好了,我不说了,继续往下看吧!)
引个玉
文章阅读量的统计看似简单,实则蕴含着巧妙的逻辑和高效的技术实现。我们想要得到的阅读量,并非简单的页面刷新次数,而是真正独立阅读过文章的人数。因此,传统的每次页面刷新加1的方法显然不够准确,它忽略了用户的重复访问。
同时,阅读作为一个高频操作,如果每次都直接写入数据库,无疑会给数据库带来巨大的压力,甚至可能影响到整个系统的性能和稳定性。这就需要我们寻找一种既能准确统计阅读量,又能减轻数据库压力的方法。
Redis,这个高性能的内存数据库,为我们提供了解决方案。我们可以利用Redis的键值对存储特性,将用户ID和文章ID的组合作为键,设置一个短暂的过期时间,比如15分钟。当用户首次访问文章时,我们在Redis中为这个键设置一个值,表示该用户已经阅读过这篇文章。如果用户在15分钟内再次访问,我们可以直接判断该键是否存在,如果存在,则不再增加阅读量,否则进行增加。
这种方法的优点在于,它能够准确地统计出真正阅读过文章的人数,而不是简单的页面刷新次数。同时,通过将阅读量先存储在Redis中,我们避免了频繁地写入数据库,从而大大减轻了数据库的压力。
最后,我们还需要考虑如何将Redis中的阅读量最终写入数据库。由于数据库的写入操作相对较重,我们不宜频繁进行。因此,我们可以选择在业务低峰期,比如凌晨2到4点,使用定时任务将Redis中的阅读量批量写入数据库。这样,既保证了阅读量的准确统计,又避免了频繁的数据库写入操作,实现了高效的系统运行。
思路梳理
- 😎Redis 助力阅读量统计,方法超好用!✨
- 🧐在 Redis 存用户和文章关系,轻松解决多次无效阅读!👏
- 💪定时任务来帮忙,Redis 数据写入数据库,不再
那么接下来就是实现环节
代码层面
项目使用的后端框架为NestJS
配置下redis
一、安装redis plugin
npm install --save redis
二、创建redis模块

三、初始化连接redis相关配置
@Module({
providers: [
RedisService,
{
provide: 'REDIS_CLIENT',
async useFactory(configService: ConfigService) {
console.log(configService.get('redis_server_host'));
const client = createClient({
socket: {
host: configService.get('redis_server_host'),
port: configService.get('redis_server_port'),
},
database: configService.get('redis_server_db'),
});
await client.connect();
return client;
},
inject: [ConfigService],
},
],
exports: [RedisService],
})
Redis是一个Key-Value型数据库,可以用作数据库,所有的数据以Key-Value的形式存在服务器的内存中,其中Value可以是多种数据结构,如字符串(String)、哈希(hashes)、列表(list)、集合(sets)和有序集合(sorted sets)等类型
在这里会用到字符串和哈希两种。
创建文章表和用户表
我的项目中创建有post.entity和user.entity这两个实体表,并为post文章表添加以下

这三个字段,在这里我们只拿 阅读量 说事。
访问文章详情接口-阅读量+1
/**
* @description 增加阅读量
* @param id
* @returns
*/
@Get('xxx/:id')
@RequireLogin()
async frontIncreViews(@Param('id') id: string, @Req() _req: any,) {
console.log('frontFindOne');
return await this.postService.frontIncreViews(+id, _req?.user);
}
前文已经说过,同一个用户多次刷新,如果不做处理,就会产生多次无效的阅读量。 因此,为了避免这种情况方式,我们需要为其增加一个用户文章id组合而成的标记,并设置在有效时间内不产生多次阅读量。
那么,有的掘友可能会产生一个疑问,如果用户未登录,那么以游客的身份去访问文章就不产生阅读记录了吗?
其实同理!
在我的项目中只是,要求需要用户登录后才能访问,
那么我这就会以 userID_postID_ 来组成标识区分用户和文章罢了。
而如果想以游客身份,我们可以获取用户 IP_postID 这样的组合来做标识即可
接下来说下postService中调用的frontIncreViews方法
直接贴代码:
const res = await this.redisService.hashGet(`post_${id}`);
if (res.viewCount === undefined) {
const post = await this.postRepository.findOne({ where: { id } });
post.viewCount++;
await this.postRepository.update(id, { viewCount: post.viewCount });
await this.redisService.hashSet(`post_${id}`, {
viewCount: post.viewCount,
likeCount: post.likeCount,
collectCount: post.collectCount,
});
// 在用户访问文章的时候在 redis 存一个 10 分钟过期的标记,有这个标记的时候阅读量不增加
await this.redisService.set(`user_${user.id}_post_${id}`, 1, 10);
return post.viewCount;
} else {
const flag = await this.redisService.get(`user_${user.id}_post_${id}`);
console.log(flag);
if (flag) {
return res.viewCount;
}
await this.redisService.hashSet(`post_${id}`, {
...res,
viewCount: +res.viewCount + 1,
});
await this.redisService.set(`user_${user.id}_post_${id}`, 1, 10);
return +res.viewCount + 1;
}
}
- 从Redis获取文章阅读量:
const res = await this.redisService.hashGet(`post_${id}`);
使用Redis的哈希表结构,从键post_${id}中获取文章的信息,其中可能包含阅读量(viewCount)、点赞数(likeCount)和收藏数(collectCount)。
2. 检查Redis中是否存在阅读量:
if (res.viewCount === undefined) {
如果Redis中没有阅读量数据,说明这篇文章的阅读量还没有被初始化。
3. 从数据库中获取文章并增加阅读量:
const post = await this.postRepository.findOne({ where: { id } });
post.viewCount++;
await this.postRepository.update(id, { viewCount: post.viewCount });
从数据库中获取文章,然后增加阅读量,并更新数据库中的文章阅读量。
4. 将更新后的文章信息存回Redis:
await this.redisService.hashSet(`post_${id}`, {
viewCount: post.viewCount,
likeCount: post.likeCount,
collectCount: post.collectCount,
});
将更新后的文章信息(包括新的阅读量、点赞数和收藏数)存回Redis的哈希表中。
5. 设置用户访问标记:
await this.redisService.set(`user_${user.id}_post_${id}`, 1, 10);
在用户访问文章时,在Redis中设置一个带有10分钟过期时间的标记,用于防止在10分钟内重复增加阅读量。
6. 返回阅读量:
return post.viewCount;
返回更新后的阅读量。
7. 如果Redis中存在阅读量:
} else {
const flag = await this.redisService.get(`user_${user.id}_post_${id}`);
console.log(flag);
如果Redis中存在阅读量数据,则检查用户是否已经访问过该文章。
8. 检查用户访问标记:
if (flag) {
return res.viewCount;
}
如果用户已经访问过该文章(标记存在),则直接返回当前阅读量,不增加。
9. 如果用户未访问过文章:
await this.redisService.hashSet(`post_${id}`, {
...res,
viewCount: +res.viewCount + 1,
});
await this.redisService.set(`user_${user.id}_post_${id}`, 1, 10);
return +res.viewCount + 1;
如果用户未访问过该文章,则增加阅读量,并重新设置用户访问标记。然后返回更新后的阅读量。
简而言之,目的是在用户访问文章时,确保文章阅读量只增加一次,即使用户在短时间内多次访问。
NestJS使用定时任务包,实现redis数据同步到数据库中
有的掘友可能疑问,既然已经用redis来做阅读量记录了,为什么还要同步到数据库中,前文开始的时候,就已经提到过了,一旦我们的项目重启, redis 数据就没了,而数据库却有着“数据持久性的优良品质”。不像redis重启后,又是个新生儿。但是它们的互补,又是1+1大于2的那种。
好了,不废话了
一、引入定时任务包 @nestjs/schedule
npm install --save @nestjs/schedule
在 app.module.ts 引入

二、创建定时任务模块和服务
nest g module task
nest g service task

你可以在同一个服务里面声明多个定时任务方法。在 NestJS 中,使用 @nestjs/schedule 库时,你只需要在服务类中为每个定时任务方法添加 @Cron() 装饰器,并指定相应的 cron 表达式。以下是一个示例,展示了如何在同一个服务中声明两个定时任务:
import { Injectable } from '@nestjs/common';
import { Cron, CronExpression } from '@nestjs/schedule';
@Injectable()
export class TasksService {
// 第一个定时任务,每5秒执行一次
@Cron(CronExpression.EVERY_5_SECONDS)
handleEvery5Seconds() {
console.log('Every 5 seconds task executed');
}
// 第二个定时任务,每10秒执行一次
@Cron(CronExpression.EVERY_10_SECONDS)
handleEvery10Seconds() {
console.log('Every 10 seconds task executed');
}
}
三、实现定时任务中同步文章阅读量的任务
更新文章的阅读数据
await this.postService.flushRedisToDB();
// 查询出 key 对应的值,更新到数据库。 做定时任务的时候加上
async flushRedisToDB() {
const keys = await this.redisService.keys(`post_*`);
console.log(keys);
for (let i = 0; i < keys.length; i++) {
const key = keys[i];
const res = await this.redisService.hashGet(key);
const [, id] = key.split('_');
await this.postRepository.update(
{
id: +id,
},
{
viewCount: +res.viewCount,
},
);
}
}
- 从 Redis 获取键:
const keys = await this.redisService.keys(post_*);: 使用 Redis 服务的keys方法查询所有以post_开头的键,并将这些键存储在keys数组中。
console.log(keys);: 打印出所有查询到的键。 - 遍历 Redis 键:
使用
for循环遍历所有查询到的键。 - 从 Redis 获取哈希值:
const res = await this.redisService.hashGet(key);: 对于每一个键,使用 Redis 服务的hashGet方法获取其对应的哈希值,并将结果存储在res中。 - 解析键以获取 ID:
const [, id] = key.split('_');: 将键字符串按照_分割,并取出第二个元素(索引为 1)作为id。这假设键的格式是post_<id>。 - 更新数据库:
使用
postRepository.update方法更新数据库中的记录。
{ id: +id, }: 指定要更新的记录的id。+id是将id字符串转换为数字。
{ viewCount: +res.viewCount, }: 指定要更新的字段及其值。这里将viewCount字段更新为 Redis 中存储的值,并使用+res.viewCount将字符串转换为数字。
等到第二天,哈,数据就同步来了
访问:

而产生的后台数据:

抛出问题
如果能看到这里的掘友,若能接下这个问题,说明你已经掌握了吖
问题1:
如何实现一个批量返回redis键值对的方法(这个方法问题2需要用到)
问题2:
用户查询文章列表的时候,如何整理数据后返回文章阅读量呈现给用户查看
来源:juejin.cn/post/7355554711166271540
领导问我:为什么一个点赞功能你做了五天?
公众号:【可乐前端】,每天3分钟学习一个优秀的开源项目,分享web面试与实战知识。
前言
可乐是一名前端切图仔,最近他们团队需要做一个文章社区平台。由于人手不够,前后端部分都是由前端同学来实现,后端部分用的技术栈是 nest.js 。
某一个周一,领导希望做一个给文章点赞的功能,在文章列表页与文章详情页需要看到该文章的点赞总数,以及当前登录的用户有没有对该文章点赞,即用户与文章的点赞关系。
交代完之后,领导就去出差了。等领导回来时已是周五,他问可乐:这期的需求进展如何?
可乐回答:点赞的需求我做完了,其他的还没开始。
领导生气的说:为什么点赞这样的一个小功能你做了五天才做完???
可乐回答:领导息怒。。请听我细细道来
往期文章
- 切图仔做全栈:React&Nest.js 社区平台(一)——基础架构与邮箱注册、JWT 登录实现
- 切图仔做全栈:React&Nest.js社区平台(二)——👋手把手实现优雅的鉴权机制
- React&Nest.js全栈社区平台(三)——🐘对象存储是什么?为什么要用它?
- React&Nest.js社区平台(四)——✏️文章发布与管理实战
- React&Nest.js全栈社区平台(五)——👋封装通用分页Service实现文章流与详情
初步设计
对于上面的这个需求,我们提炼出来有三点最为重要的功能:
- 获取点赞总数
- 获取用户的点赞关系
- 点赞/取消点赞
所以这里容易想到的是在文章表中冗余一个点赞数量字段 likes ,查询文章的时候一起把点赞总数带出来。
| id | content | likes |
|---|---|---|
| 1 | 文章A | 10 |
| 2 | 文章B | 20 |
然后建一张 article_lile_relation 表,建立文章点赞与用户之间的关联关系。
| id | article_id | user_id | value |
|---|---|---|---|
| 1 | 1001 | 2001 | 1 |
| 2 | 1001 | 2002 | 0 |
上面的数据就表明了 id 为 2001 的用户点赞了 id 为 1001 的文章; id 为 2002 的用户对 id 为 1001 的文章取消了点赞。
这是对于这种关联关系需求最容易想到的、也是成本不高的解决方案,但在仔细思考了一番之后,我放弃了这种方案。原因如下:
- 由于首页文章流中也需要展示用户的点赞关系,这里获取点赞关系需要根据当前文章
id、用户id去联表查询,会增加数据库的查询压力。 - 有关于点赞的信息存放在两张表中,需要维护两张表的数据一致性。
- 后续可能会出现对摸鱼帖子点赞、对用户点赞、对评论点赞等需求,这样的设计方案显然拓展性不强,后续再做别的点赞需求时可能会出现大量的重复代码。
基于上面的考虑,准备设计一个通用的点赞模块,以拓展后续各种业务的点赞需求。
表设计
首先来一张通用的点赞表, DDL 语句如下:
CREATE TABLE `like_records` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`target_id` int(11) DEFAULT NULL,
`type` int(4) DEFAULT NULL,
`created_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`updated_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`value` int(4) DEFAULT '0',
PRIMARY KEY (`id`),
KEY `like_records_target_id_IDX` (`target_id`,`user_id`,`type`) USING BTREE,
KEY `like_records_user_id_IDX` (`user_id`,`target_id`,`type`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
解释一下上面各个字段的含义:
id:点赞记录的主键iduser_id:点赞用户的idtarget_id:被点赞的文章idtype:点赞类型:可能有文章、帖子、评论等value:是否点赞,1点赞,0取消点赞created_time:创建时间updated_time:更新时间
前置知识
在设计好数据表之后,再来捋清楚这个业务的一些特定属性与具体实现方式:
- 我们可以理解这是一个相对来说读比写多的需求,比如你看了
10篇掘金的文章,可能只会对1篇文章点赞 - 应该设计一个通用的点赞模块,以供后续各种点赞需求的接入
- 点赞数量与点赞关系需要频繁地获取,所以需要读缓存而不是读数据库
- 写入数据库与同步缓存需考虑数据一致性
所以可乐针对这样的业务特性上网查找了一些资料,发现有一些前置知识是他所欠缺的,我们一起来看看。
mysql事务
mysql 的事务是指一系列的数据库操作,这些操作要么全部成功执行,要么全部失败回滚。事务是用来确保数据库的完整性、一致性和持久性的机制之一。
在 mysql 中,事务具有以下四个特性,通常缩写为 ACID :
- 原子性: 事务是原子性的,这意味着事务中的所有操作要么全部成功执行,要么全部失败回滚。
- 一致性: 事务执行后,数据库从一个一致的状态转换到另一个一致的状态。这意味着事务执行后,数据库中的数据必须满足所有的约束、触发器和规则,保持数据的完整性。
- 隔离性: 隔离性指的是多个事务之间的相互独立性。即使有多个事务同时对数据库进行操作,它们之间也不会相互影响,每个事务都感觉到自己在独立地操作数据库。
mysql通过不同的隔离级别(如读未提交、读已提交、可重复读和串行化)来控制事务之间的隔离程度。 - 持久性: 持久性指的是一旦事务被提交,对数据库的改变将永久保存,即使系统崩溃也不会丢失。
mysql通过将事务的提交写入日志文件来保证持久性,以便在系统崩溃后能够恢复数据。
这里以商品下单创建订单并扣除库存为例,演示一下 nest+typeorm 中的事务如何使用:
import { Injectable } from '@nestjs/common';
import { InjectEntityManager } from '@nestjs/typeorm';
import { EntityManager } from 'typeorm';
import { Order } from './order.entity';
import { Product } from './product.entity';
@Injectable()
export class OrderService {
constructor(
@InjectEntityManager()
private readonly entityManager: EntityManager,
) {}
async createOrderAndDeductStock(productId: number, quantity: number): Promise<Order> {
return await this.entityManager.transaction(async transactionalEntityManager => {
// 查找产品并检查库存是否充足
const product = await transactionalEntityManager.findOne(Product, productId);
if (!product || product.stock < quantity) {
throw new Error('Product not found or insufficient stock');
}
// 创建订单
const order = new Order();
order.productId = productId;
order.quantity = quantity;
await transactionalEntityManager.save(order);
// 扣除库存
product.stock -= quantity;
await transactionalEntityManager.save(product);
return order;
});
}
}
this.entityManager.transaction 创建了一个事务,在异步函数中,如果发生错误, typeorm 会自动回滚事务;如果没有发生错误,typeorm 会自动提交事务。
在这个实例中,尝试获取库存并创建订单和减库存,如果任何一个地方出错异常抛出,则事务就会回滚,这样就保证了多表间数据的一致性。
分布式锁
分布式锁是一种用于在分布式系统中协调多个节点并保护共享资源的机制。在分布式系统中,由于涉及多个节点并发访问共享资源,因此需要一种机制来确保在任何给定时间只有一个节点能够访问或修改共享资源,以防止数据不一致或竞争条件的发生。
对于同一个用户对同一篇文章频繁的点赞/取消点赞请求,可以加分布式锁的机制,来规避一些问题:
- 防止竞态条件: 点赞/取消点赞操作涉及到查询数据库、更新数据库和更新缓存等多个步骤,如果不加锁,可能会导致竞态条件,造成数据不一致或错误的结果。
- 保证操作的原子性: 使用分布式锁可以确保点赞/取消点赞操作的原子性,即在同一时间同一用户只有一个请求能够执行操作,从而避免操作被中断或不完整的情况发生。
- 控制并发访问: 加锁可以有效地控制并发访问,限制了频繁点击发送请求的数量,从而减少系统负载和提高系统稳定性。
在 redis 中实现分布式锁通常使用的是基于 SETNX 命令和 EXPIRE 命令的方式:
- 使用
SETNX命令尝试将lockKey设置为lockValue,如果lockKey不存在,则设置成功并返回1;如果lockKey已经存在,则设置失败并返回0。 - 如果
SETNX成功,说明当前客户端获得了锁,可以执行相应的操作;如果SETNX失败,则说明锁已经被其他客户端占用,当前客户端需要等待一段时间后重新尝试获取锁。 - 为了避免锁被永久占用,可以使用
EXPIRE命令为锁设置一个过期时间,确保即使获取锁的客户端在执行操作时发生故障,锁也会在一定时间后自动释放。
async getLock(key: string) {
const res = await this.redis.setnx(key, 'lock');
if (res) {
// 10秒锁过期
await this.redis.expire(key, 10);
}
return res;
}
async unLock(key: string) {
return this.del(key);
}
redis中的set结构
redis 中的 set 是一种无序集合,用于存储多个不重复的字符串值,set 中的每个成员都是唯一的。
我们存储点赞关系的时候,需要用到 redis 中的 set 结构,存储的 key 与 value 如下:
article_1001:[uid1,uid2,uid3]
这就表示文章 id 为 1001 的文章,有用户 id 为 uid1 、 uid2 、 uid3 这三个用户点赞了。
常用的 set 结构操作命令包括:
SADD key member [member ...]: 将一个或多个成员加入到集合中。SMEMBERS key: 返回集合中的所有成员。SISMEMBER key member: 检查成员是否是集合的成员。SCARD key: 返回集合元素的数量。SREM key member [member ...]: 移除集合中一个或多个成员。SPOP key [count]: 随机移除并返回集合中的一个或多个元素。SRANDMEMBER key [count]: 随机返回集合中的一个或多个元素,不会从集合中移除元素。SUNION key [key ...]: 返回给定所有集合的并集。SINTER key [key ...]: 返回给定所有集合的交集。SDIFF key [key ...]: 返回给定所有集合的差集。
下面举几个点赞场景的例子
- 当用户
id为uid1给文章id为1001的文章点赞时:sadd 1001 uid1 - 当用户
id为uid1给文章id为1001的文章取消点赞时:srem 1001 uid1 - 当需要获取文章
id为1001的点赞数量时:scard 1001
redis事务
在 redis 中,事务是一组命令的有序序列,这些命令在执行时会被当做一个单独的操作来执行。即事务中的所有命令要么全部执行成功,要么全部执行失败,不存在部分执行的情况。
以下是 redis 事务的主要命令:
- MULTI: 开启事务,在执行
MULTI命令后,后续输入多个命令来组成一个事务。 - EXEC: 执行事务,在执行
EXEC命令时,redis会执行客户端输入的所有事务命令,如果事务中的所有命令都执行成功,则事务执行成功,返回事务中所有命令的执行结果;如果事务中的某个命令执行失败,则事务执行失败,返回空。 - DISCARD: 取消事务,在执行
DISCARD命令时,redis会取消当前事务中的所有命令,事务中的命令不会被执行。 - WATCH: 监视键,在执行
WATCH命令时,redis会监听一个或多个键,如果在执行事务期间任何被监视的键被修改,事务将会被打断。
比如说下面的代码给集合增加元素,并更新集合的过期时间,可以如下使用 redis 的事务去执行它:
const pipeline = this.redisService.multi();
const setKey = this.getSetKey(targetId, type);
if (value === ELike.LIKE) {
pipeline.sadd(setKey, userId);
} else {
pipeline.srem(setKey, userId);
}
pipeline.expire(setKey, this.ttl);
await pipeline.exec();
流程图设计
在了解完这些前置知识之后,可乐开始画一些实现的流程图。
首先是点赞/取消点赞接口的流程图:

简单解释下上面的流程图:
- 先尝试获取锁,获取不到的时候等待重试,保证接口与数据的时序一致。
- 判断这个点赞关系是否已存在,比如说用户对这篇文章已经点过赞,其实又来了一个对此篇文章点赞的请求,直接返回失败
- 开启
mysql的事务,去更新点赞信息表,同时尝试去更新缓存,在缓存更新的过程中,会有3次的失败重试机会,如果缓存更新都失败,则回滚mysql事务;整体更新失败 mysql更新成功,缓存也更新成功,则整个操作都成功
然后是获取点赞数量和点赞关系的接口

简单解释下上面的流程图:
- 首先判断当前文章
id对应的点赞关系是否在redis中存在,如果存在,则直接从缓存中读取并返回 - 如果不存在,此时加锁,准备读取数据库并更新
redis,这里加锁的主要目的是防止大量的请求一下子打到数据库中。 - 由于加锁的时候,可能很多接口已经在等待,所以在锁释放的时候,再加多一次从
redis中获取的操作,此时redis中已经有值,可以直接从缓存中读取。
代码实现
在所有的设计完毕之后,可以做最后的代码实现了。分别来实现点赞操作与点赞数量接口。这里主要关注 service 层的实现即可。
点赞/取消点赞接口
async toggleLike(params: {
userId: number;
targetId: number;
type: ELikeType;
value: ELike;
}) {
const { userId, targetId, type, value } = params;
const LOCK_KEY = `${userId}::${targetId}::${type}::toggleLikeLock`;
const canGetLock = await this.redisService.getLock(LOCK_KEY);
if (!canGetLock) {
console.log('获取锁失败');
await wait();
return this.toggleLike(params);
}
const record = await this.likeRepository.findOne({
where: { userId, targetId, type },
});
if (record && record.value === value) {
await this.redisService.unLock(LOCK_KEY);
throw Error('不可重复操作');
}
await this.entityManager.transaction(async (transactionalEntityManager) => {
if (!record) {
const likeEntity = new LikeEntity();
likeEntity.targetId = targetId;
likeEntity.type = type;
likeEntity.userId = userId;
likeEntity.value = value;
await transactionalEntityManager.save(likeEntity);
} else {
const id = record.id;
await transactionalEntityManager.update(LikeEntity, { id }, { value });
}
const isSuccess = await this.tryToFreshCache(params);
if (!isSuccess) {
await this.redisService.unLock(LOCK_KEY);
throw Error('操作失败');
}
});
await this.redisService.unLock(LOCK_KEY);
return true;
}
private async tryToFreshCache(
params: {
userId: number;
targetId: number;
type: ELikeType;
value: ELike;
},
retry = 3,
) {
if (retry === 0) {
return false;
}
const { targetId, type, value, userId } = params;
try {
const pipeline = this.redisService.multi();
const setKey = this.getSetKey(targetId, type);
if (value === ELike.LIKE) {
pipeline.sadd(setKey, userId);
} else {
pipeline.srem(setKey, userId);
}
pipeline.expire(setKey, this.ttl);
await pipeline.exec();
return true;
} catch (error) {
console.log('tryToFreshCache error', error);
await wait();
return this.tryToFreshCache(params, retry - 1);
}
}
可以参照流程图来看这部分实现代码,基本实现就是使用 mysql 事务去更新点赞信息表,然后去更新 redis 中的点赞信息,如果更新失败则回滚事务,保证数据的一致性。
获取点赞数量、点赞关系接口
async getLikes(params: {
targetId: number;
type: ELikeType;
userId: number;
}) {
const { targetId, type, userId } = params;
const setKey = this.getSetKey(targetId, type);
const cacheExsit = await this.redisService.exist(setKey);
if (!cacheExsit) {
await this.getLikeFromDbAndSetCache(params);
}
const count = await this.redisService.getSetLength(setKey);
const isLike = await this.redisService.isMemberOfSet(setKey, userId);
return { count, isLike };
}
private async getLikeFromDbAndSetCache(params: {
targetId: number;
type: ELikeType;
userId: number;
}) {
const { targetId, type, userId } = params;
const LOCK_KEY = `${targetId}::${type}::getLikesLock`;
const canGetLock = await this.redisService.getLock(LOCK_KEY);
if (!canGetLock) {
console.log('获取锁失败');
await wait();
return this.getLikeFromDbAndSetCache(params);
}
const setKey = this.getSetKey(targetId, type);
const cacheExsit = await this.redisService.exist(setKey);
if (cacheExsit) {
await this.redisService.unLock(LOCK_KEY);
return true;
}
const data = await this.likeRepository.find({
where: {
targetId,
userId,
type,
value: ELike.LIKE,
},
select: ['userId'],
});
if (data.length !== 0) {
await this.redisService.setAdd(
setKey,
data.map((item) => item.userId),
this.ttl,
);
}
await this.redisService.unLock(LOCK_KEY);
return true;
}
由于读操作相当频繁,所以这里应当多使用缓存,少查询数据库。读点赞信息时,先查 redis 中有没有,如果没有,则从 mysql 同步到 redis 中,同步的过程中也使用到了分布式锁,防止一开始没缓存时请求大量打到 mysql 。
同时,如果所有文章的点赞信息都同时存在 redis 中,那 redis 的存储压力会比较大,所以这里会给相关的 key 设置一个过期时间。当用户重新操作点赞时,会更新这个过期时间。保障缓存的数据都是相对热点的数据。
通过组装数据,获取点赞信息的返回数据结构如下:

返回一个 map ,其中 key 文章 id , value 里面是该文章的点赞数量以及当前用户是否点赞了这篇文章。
前端实现
文章流列表发生变化的时候,可以监听列表的变化,然后去获取点赞的信息:
useEffect(() => {
if (!article.list) {
return;
}
const shouldGetLikeIds = article.list
.filter((item: any) => !item.likeInfo)
.map((item: any) => item.id);
if (shouldGetLikeIds.length === 0) {
return;
}
console.log("shouldGetLikeIds", shouldGetLikeIds);
getLikes({
targetIds: shouldGetLikeIds,
type: 1,
}).then((res) => {
const map = res.data;
const newList = [...article.list];
for (let i = 0; i < newList.length; i++) {
if (!newList[i].likeInfo && map[newList[i].id]) {
newList[i].likeInfo = map[newList[i].id];
}
}
const newArticle = { ...article };
newArticle.list = newList;
setArticle(newArticle);
});
}, [article]);

点赞操作的时候前端也需要加锁,接口执行完毕了再把锁释放。
<Space
onClick={(e) => {
e.stopPropagation();
if (lockMap.current?.[item.id]) {
return;
}
lockMap.current[item.id] = true;
const oldValue = item.likeInfo.isLike;
const newValue = !oldValue;
const updateValue = (value: any) => {
const newArticle = { ...article };
const newList = [...newArticle.list];
const current = newList.find(
(_) => _.id === item.id
);
current.likeInfo.isLike = value;
if (value) {
current.likeInfo.count++;
} else {
current.likeInfo.count--;
}
setArticle(newArticle);
};
updateValue(newValue);
toggleLike({
targetId: item.id,
value: Number(newValue),
type: 1,
})
.catch(() => {
updateValue(oldValue);
})
.finally(() => {
lockMap.current[item.id] = false;
});
}}
>
<LikeOutlined
style={
item.likeInfo.isLike ? { color: "#1677ff" } : {}
}
/>
{item.likeInfo.count}
</Space>

解释
可乐:从需求分析考虑、然后研究网上的方案并学习前置知识,再是一些环境的安装,最后才是前后端代码的实现,领导,我这花了五天不过份吧。
领导(十分无语):我们平台本来就没几个用户、没几篇文章,本来就是一张关联表就能解决的问题,你又搞什么分布式锁又搞什么缓存,还花了那么多天时间。我不管啊,剩下没做的需求你得正常把它正常做完上线,今天周五,周末你也别休息了,过来加班吧。
最后
以上就是本文的全部内容,如果你觉得有意思的话,点点关注点点赞吧~
来源:juejin.cn/post/7349437605858066443
昨天晚上,RPC 线程池被打满了,原因哭笑不得
大家好,我是五阳。
1. 故障背景
昨天晚上,我刚到家里打开公司群,就看见群里有人讨论:线上环境出现大量RPC请求报错,异常原因:被线程池拒绝。虽然异常量很大,但是异常服务非核心服务,属于系统旁路,服务于数据核对任务,即使有大量异常,也没有实际的影响。
原来有人在线上刷数据,产生了大量 binlog,数据核对任务的请求量大幅上涨,导致线程池被打满。因为并非我负责的工作内容,也不熟悉这部分业务,所以没有特别留意。
第二天我仔细思考了一下,觉得疑点很多,推导过程过于简单,证据链不足,最终结论不扎实,问题根源也许另有原因。
1.1 疑点
- 请求量大幅上涨, 上涨前后请求量是多少?
- 线程池被打满, 线程池初始值和最大值是多少,线程池队列长度是多少?
- 线程池拒绝策略是什么?
- 影响了哪些接口,这些接口的耗时波动情况?
- 服务的 CPU 负载和 GC情况如何?
- 线程池被打满的原因仅仅是请求量大幅上涨吗?
带着以上的几点疑问,第二天一到公司,我就迫不及待地打开各种监控大盘,开始排查问题,最后还真叫我揪出问题根源了。
因为公司的监控系统有水印,所以我只能陈述结论,不能截图了。
2. 排查过程
2.1 请求量的波动情况
- 单机 RPC的 QPS从 300/s 涨到了 450/s。
- Kafka 消息 QPS 50/s 无 明显波动。
- 无其他请求入口和 无定时任务。
这也能叫请求量大幅上涨,请求量增加 150/s 能打爆线程池?就这么糊弄老板…… ,由此我坚定了判断:故障另有根因
2.2 RPC 线程池配置和监控
线上的端口并没有全部被打爆,仅有 1 个 RPC 端口 8001 被打爆。所以我特地查看了8001 的线程池配置。
- 初始线程数 10
- 最大线程数 1024(数量过大,配置的有点随意了)
- 队列长度 0
- 拒绝策略是抛出异常立即拒绝。
- 在 20:11到 20:13 分,线程从初始线程数10,直线涨到了1024 。
2.3 思考
QPS 450次/秒 需要 1024 个线程处理吗?按照我的经验来看,只要接口的耗时在 100ms 以内,不可能需要如此多的线程,太蹊跷了。
2.4 接口耗时波动情况
- 接口 平均耗时从 5.7 ms,增加到 17000毫秒。
接口耗时大幅增加。后来和他们沟通,他们当时也看了接口耗时监控。他们认为之所以平均耗时这么高,是因为RPC 请求在排队,增加了处理耗时,所以监控平均耗时大幅增长。
这是他们的误区,错误的地方有两个。
- 此RPC接口线程池的队列长度为 0,拒绝策略是抛出异常。当没有可用线程,请求会即被拒绝,请求不会排队,所以无排队等待时间。
- 公司的监控系统分服务端监控和调用端监控,服务端的耗时监控不包含 处理连接的时间,不包含 RPC线程池排队的时间。仅仅是 RPC 线程池实际处理请求的耗时。 RPC 调用端的监控包含 RPC 网络耗时、连接耗时、排队耗时、处理业务逻辑耗时、服务端GC 耗时等等。
他们误认为耗时大幅增加是因为请求在排队,因此忽略了至关重要的这条线索:接口实际处理阶段的性能严重恶化,吞吐量大幅降低,所以线程池大幅增长,直至被打满。
接下来我开始分析,接口性能恶化的根本原因是什么?
- CPU 被打满?导致请求接口性能恶化?
- 频繁GC ,导致接口性能差?
- 调用下游 RPC 接口耗时大幅增加 ?
- 调用 SQL,耗时大幅增加?
- 调用 Redis,耗时大幅增加
- 其他外部调用耗时大幅增加?
2.5 其他耗时监控情况
我快速的排查了所有可能的外部调用耗时均没有明显波动。也查看了机器的负载情况,cpu和网络负载 均不高,显然故障的根源不在以上方向。
- CPU 负载极低。在故障期间,cpu.busy 负载在 15%,还不到午高峰,显然根源不是CPU 负载高。
- gc 情况良好。无 FullGC,youngGC 1 分钟 2 次(younggc 频繁,会导致 cpu 负载高,会使接口性能恶化)
- 下游 RPC 接口耗时无明显波动。我查看了服务调用 RPC 接口的耗时监控,所有的接口耗时无明显波动。
- SQL 调用耗时无明显波动。
- 调用 Redis 耗时无明显波动。
- 其他下游系统调用无明显波动。(如 Tair、ES 等)
2.6 开始研究代码
为什么我一开始不看代码,因为这块内容不是我负责的内容,我不熟悉代码。
直至打开代码看了一眼,恶心死我了。代码非常复杂,分支非常多,嵌套层次非常深,方法又臭又长,堪称代码屎山的珠穆朗玛峰,多看一眼就能吐。接口的内部分支将近 10 个,每个分支方法都是一大坨代码。
这个接口是上游 BCP 核对系统定义的 SPI接口,属于聚合接口,并非单一职责的接口。看了 10 分钟以后,还是找不到问题根源。因此我换了问题排查方向,我开始排查异常 Trace。
2.7 从异常 Trace 发现了关键线索
我所在公司的基建能力还是很强大的。系统的异常 Trace 中标注了各个阶段的处理耗时,包括所有外部接口的耗时。如SQL、 RPC、 Redis等。
我发现确实是内部代码处理的问题,因为 trace 显示,在两个 SQL 请求中间,系统停顿长达 1 秒多。不知道系统在这 1 秒执行哪些内容。我查看了这两个接口的耗时,监控显示:SQL 执行很快,应该不是SQL 的问题
机器也没有发生 FullGC,到底是什么原因呢?
前面提到,故障接口是一个聚合接口,我不清楚具体哪个分支出现了问题,但是异常 Trace 中指明了具体的分支。
我开始排查具体的分支方法……, 然而捏着鼻子扒拉了半天,也没有找到原因……
2.8 山穷水复疑无路,柳暗花明又一村
这一坨屎山代码看得我实在恶心,我静静地冥想了 1 分钟才缓过劲。
- 没有外部调用的情况下,阻塞线程的可能性有哪些?
- 有没有加锁? Synchiozed 关键字?
于是我按着关键字搜索Synchiozed关键词,一无所获,代码中基本没有加锁的地方。
马上中午了,肚子很饿,就当我要放弃的时候。随手扒拉了一下,在类的属性声明里,看到了 Guava限流器。
激动的心,颤抖的手
private static final RateLimiter RATE_LIMITER = RateLimiter.create(10, 20, TimeUnit.SECONDS);
限流器:1 分钟 10次调用。
于是立即查看限流器的使用场景,和异常 Trace 阻塞的地方完全一致。
嘴角出现一丝很容易察觉到的微笑。

破案了,真相永远只有一个。
3. 问题结论
Guava 限流器的阈值过低,每秒最大请求量只有10次。当并发量超过这个阈值时,大量线程被阻塞,RPC线程池不断增加新线程来处理新的请求,直到达到最大线程数。线程池达到最大容量后,无法再接收新的请求,导致大量的后续请求被线程池拒绝。
于是我开始建群、摇人。把相关的同学,还有老板们,拉进了群里。把相关截图和结论发到了群里。
由于不是紧急问题,所以我开开心心的去吃午饭了。后面的事就是他们优化代码了。
4. 思考总结
4.1 八股文不是完全无用,有些八股文是有用的
有人质疑面试为什么要问八股文? 也许大部分情况下,大部分八股文是没有用的,然而在排查问题时,多知道一些八股文是有助于排查问题的。
例如要明白线程池的原理、要明白 RPC 的请求处理过程、要知道影响接口耗时的可能性有哪些,这样才能带着疑问去追踪线索。
4.2 可靠好用的监控系统,能提高排查效率
这个问题排查花了我 1.5 小时,大部分时间是在扒拉代码,实际查看监控只用了半小时。如果没有全面、好用的监控,线上出了问题真的很难快速定位根源。
此外应该熟悉公司的监控系统。他们因为不清楚公司监控系统,误认为接口监控耗时包含了线程池排队时间,忽略了 接口性能恶化 这个关键结论,所以得出错误结论。
4.2 排查问题时,要像侦探一样,不放过任何线索,确保证据链完整,逻辑通顺。
故障发生后第一时间应该是止损,其次才是排查问题。
出现故障后,故障制造者的心理往往处于慌乱状态,逻辑性较差,会倾向于为自己开脱责任。这次故障后,他们给定的结论就是:因为请求量大幅上涨,所以线程池被打满。 这个结论逻辑不通。没有推导过程,跳过了很多推导环节,所以得出错误结论,掩盖了问题的根源~
其他人作为局外人,逻辑性会更强,可以保持冷静状态,这是老板们的价值所在,他们可以不断地提出问题,在回答问题、质疑、继续排查的循环中,不断逼近事情的真相。
最终一定要重视证据链条的完整。别放过任何线索。
出现问题不要慌张,也不要吃瓜嗑瓜子。行动起来,此时是专属你的柯南时刻
我是五阳,关注我,追踪更多我在大厂的工作经历和大型翻车现场。
来源:juejin.cn/post/7409181068597313573
别再混淆了!一文带你搞懂@Valid和@Validated的区别
上篇文章我们简单介绍和使用了一下Springboot的参数校验,同时也用到了 @Valid 注解和 @Validated 注解,那它们之间有什么不同呢?
区别
先总结一下它们的区别:
- 来源
- @Validated :是Spring框架特有的注解,属于Spring的一部分,也是JSR 303的一个变种。它提供了一些 @Valid 所没有的额外功能,比如分组验证。
- @Valid:Java EE提供的标准注解,它是JSR 303规范的一部分,主要用于Hibernate Validation等场景。
- 注解位置
- @Validated : 用在类、方法和方法参数上,但不能用于成员属性。
- @Valid:可以用在方法、构造函数、方法参数和成员属性上。
- 分组
- @Validated :支持分组验证,可以更细致地控制验证过程。此外,由于它是Spring专有的,因此可以更好地与Spring的其他功能(如Spring的依赖注入)集成。
- @Valid:主要支持标准的Bean验证功能,不支持分组验证。
- 嵌套验证
- @Validated :不支持嵌套验证。
- @Valid:支持嵌套验证,可以嵌套验证对象内部的属性。
这些理论性的东西没什么好说的,记住就行。我们主要看分组和嵌套验证是什么,它们怎么用。
实操阶段
话不多说,通过代码来看一下分组和嵌套验证。
为了提示友好,修改一下全局异常处理类:
@RestControllerAdvice
public class GlobalExceptionHandler {
/**
* 参数校检异常
* @param e
* @return
*/
@ExceptionHandler(value = MethodArgumentNotValidException.class)
public ResponseResult handle(MethodArgumentNotValidException e) {
BindingResult bindingResult = e.getBindingResult();
StringJoiner joiner = new StringJoiner(";");
for (ObjectError error : bindingResult.getAllErrors()) {
String code = error.getCode();
String[] codes = error.getCodes();
String property = codes[1];
property = property.replace(code ,"").replaceFirst(".","");
String defaultMessage = error.getDefaultMessage();
joiner.add(property+defaultMessage);
}
return handleException(joiner.toString());
}
private ResponseResult handleException(String msg) {
ResponseResult result = new ResponseResult<>();
result.setMessage(msg);
result.setCode(500);
return result;
}
}
分组校验
分组验证是为了在不同的验证场景下能够对对象的属性进行灵活地验证,从而提高验证的精细度和适用性。一般我们在对同一个对象进行保存或修改时,会使用同一个类作为入参。那么在创建时,就不需要校验id,更新时则需要校验用户id,这个时候就需要用到分组校验了。
对于定义分组有两点要特别注意:
- 定义分组必须使用接口。
- 要校验字段上必须加上分组,分组只对指定分组生效,不加分组不校验。
有这样一个需求,在创建用户时校验用户名,修改用户时校验用户id。下面对我们对这个需求进行一个简单的实现。
- 创建分组
CreationGr0up 用于创建时指定的分组:
public interface CreationGr0up {
}
UpdateGr0up 用于更新时指定的分组:
public interface UpdateGr0up {
}
- 创建用户类
创建一个UserBean用户类,分别校验 username 字段不能为空和id字段必须大于0,然后加上CreationGr0up和 UpdateGr0up 分组。
/**
* @author 公众号-索码理(suncodernote)
*/
@Data
public class UserBean {
@NotEmpty( groups = {CreationGr0up.class})
private String username;
@Min(value = 18)
private Integer age;
@Email(message = "邮箱格式不正确")
private String email;
@Min(value = 1 ,groups = {UpdateGr0up.class})
private Long id;
}
- 创建接口
在ValidationController 中新建两个接口 updateUser 和 createUser:
@RestController
@RequestMapping("validation")
public class ValidationController {
@GetMapping("updateUser")
public UserBean updateUser(@Validated({UpdateGr0up.class}) UserBean userBean){
return userBean;
}
@GetMapping("createUser")
public UserBean createUser(@Validated({CreationGr0up.class}) UserBean userBean){
return userBean;
}
}
- 测试
先对 createUser接口进行测试,我们将id的值设置为0,也就是不满足id必须大于0的条件,同样 username 不传值,即不满足 username 不能为空的条件。  通过测试结果我们可以看到,虽然id没有满足条件,但是并没有提示,只提示了username不能为空。
通过测试结果我们可以看到,虽然id没有满足条件,但是并没有提示,只提示了username不能为空。
再对 updateUser接口进行测试,条件和测试 createUser接口的条件一样,再看测试结果,和 createUser接口测试结果完全相反,只提示了id最小不能小于1。 
至此,分组功能就演示完毕了。
嵌套校验
介绍嵌套校验之前先看一下两个概念:
- 嵌套校验(Nested Validation) 指的是在验证对象时,对对象内部包含的其他对象进行递归验证的过程。当一个对象中包含另一个对象作为属性,并且需要对这个被包含的对象也进行验证时,就需要进行嵌套校验。
- 嵌套属性指的是在一个对象中包含另一个对象作为其属性的情况。换句话说,当一个对象的属性本身又是一个对象,那么这些被包含的对象就可以称为嵌套属性。
有这样一个需求,在保存用户时,用户地址必须要填写。下面来简单看下示例:
- 创建地址类 AddressBean
在AddressBean 设置 country和city两个属性为必填项。
@Data
public class AddressBean {
@NotBlank
private String country;
@NotBlank
private String city;
}
- 修改用户类,将AddressBean作为用户类的一个嵌套属性
特别提示:想要嵌套校验生效,必须在嵌套属性上加 @Valid 注解。
@Data
public class UserBean {
@NotEmpty(groups = {CreationGr0up.class})
private String username;
@Min(value = 18)
private Integer age;
private String email;
@Min(value = 1 ,groups = {UpdateGr0up.class})
private Long id;
//嵌套验证必须要加上@Valid
@Valid
@NotNull
private AddressBean address;
}
- 创建一个嵌套校验测试接口
@PostMapping("nestValid")
public UserBean nestValid(@Validated @RequestBody UserBean userBean){
System.out.println(userBean);
return userBean;
}
- 测试
我们在传参时,只传 country字段,通过响应结果可以看到提示了city 字段不能为空。 
可以看到使用了 @Valid 注解来对 Address 对象进行验证,这会触发对其中的 Address 对象的验证。通过这种方式,可以确保嵌套属性内部的对象也能够参与到整体对象的验证过程中,从而提高验证的完整性和准确性。
总结
本文介绍了@Valid注解和@Validated注解的不同,同时也进一步介绍了Springboot 参数校验的使用。不管是 JSR-303、JSR-380又或是 Hibernate Validator ,它们提供的参数校验注解都是有限的,实际工作中这些注解可能是不够用的,这个时候就需要我们自定义参数校验了。下篇文章将介绍一下如何自定义一个参数校验器。
来源:juejin.cn/post/7344958089429434406
Jenkins:运维早搞定了,但我就是想偷学点前端CI/CD!
前言:运维已就绪,但好奇心作祟
- 背景故事: 虽然前端开发人员平时可能不会直接操控Jenkins,运维团队已经把这一切搞得井井有条。然而,你的好奇心驱使你想要深入了解这些自动化的流程。本文将带你一探究竟,看看Jenkins如何在前端项目中发挥作用。
- 目标介绍: 了解Jenkins如何实现从代码提交到自动部署的全过程,并学习如何配置和优化这一流程。
- 背景故事: 虽然前端开发人员平时可能不会直接操控Jenkins,运维团队已经把这一切搞得井井有条。然而,你的好奇心驱使你想要深入了解这些自动化的流程。本文将带你一探究竟,看看Jenkins如何在前端项目中发挥作用。
- 目标介绍: 了解Jenkins如何实现从代码提交到自动部署的全过程,并学习如何配置和优化这一流程。
Jenkins基础与部署流程
1. Jenkins到底是个什么东西?
- Jenkins简介: Jenkins是一个开源的自动化服务器,用于持续集成和持续交付。它能够自动化各种开发任务,提高开发效率和软件质量。
- 核心功能: Jenkins可以自动化构建、测试和部署任务,帮助开发团队实现快速、高效的开发流程。
- Jenkins简介: Jenkins是一个开源的自动化服务器,用于持续集成和持续交付。它能够自动化各种开发任务,提高开发效率和软件质量。
- 核心功能: Jenkins可以自动化构建、测试和部署任务,帮助开发团队实现快速、高效的开发流程。
2. 自动化部署流程详解
- 流程概述: 本文将重点介绍前端自动化部署的完整流程,包括代码提交、构建、打包、部署等步骤。具体流程如下:
- 代码提交:
- 开发人员通过
git push 将代码提交到远程仓库。
- 触发Jenkins自动构建:
- Jenkins配置为在代码提交时自动触发构建任务。
- 拉取代码仓库代码:
- Jenkins从仓库拉取最新代码。
- 构建打包:
- Jenkins运行构建命令(如
npm run build),将源代码编译成可部署版本。
- 生成dist文件:
- 构建生成
dist 文件夹,包含打包后的静态资源。
- 压缩dist文件:
- 使用压缩工具(如
tar 或 zip)将 dist 文件夹压缩成 dist.tar 或 dist.zip。
- 迁移到指定环境目录下:
- 将压缩包迁移到目标环境目录(如
/var/www/project/)。
- 删除旧dist文件:
- 删除目标环境目录下旧的
dist 文件,以确保保留最新版本。
- 解压迁移过来的dist.tar:
- 在目标环境目录下解压新的
dist.tar 文件。
- 删除dist.tar:
- 解压后删除压缩包,节省存储空间。
- 部署成功:
- 自动化流程完成,新的前端版本已经成功部署。
- 流程概述: 本文将重点介绍前端自动化部署的完整流程,包括代码提交、构建、打包、部署等步骤。具体流程如下:
- 代码提交:
- 开发人员通过
git push将代码提交到远程仓库。
- 开发人员通过
- 触发Jenkins自动构建:
- Jenkins配置为在代码提交时自动触发构建任务。
- 拉取代码仓库代码:
- Jenkins从仓库拉取最新代码。
- 构建打包:
- Jenkins运行构建命令(如
npm run build),将源代码编译成可部署版本。
- Jenkins运行构建命令(如
- 生成dist文件:
- 构建生成
dist文件夹,包含打包后的静态资源。
- 构建生成
- 压缩dist文件:
- 使用压缩工具(如
tar或zip)将dist文件夹压缩成dist.tar或dist.zip。
- 使用压缩工具(如
- 迁移到指定环境目录下:
- 将压缩包迁移到目标环境目录(如
/var/www/project/)。
- 将压缩包迁移到目标环境目录(如
- 删除旧dist文件:
- 删除目标环境目录下旧的
dist文件,以确保保留最新版本。
- 删除目标环境目录下旧的
- 解压迁移过来的dist.tar:
- 在目标环境目录下解压新的
dist.tar文件。
- 在目标环境目录下解压新的
- 删除dist.tar:
- 解压后删除压缩包,节省存储空间。
- 部署成功:
- 自动化流程完成,新的前端版本已经成功部署。
- 代码提交:
准备工作
话不多说干就完了!!!
安装git
yum install -y git
查看是否安装成功
git --version
 生成秘钥
生成秘钥
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
查看公钥
cat ~/.ssh/id_rsa.pub
 将公钥添加到GitHub或其他代码库的SSH Keys
将公钥添加到GitHub或其他代码库的SSH Keys

yum install -y git
查看是否安装成功
git --version
生成秘钥
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"
查看公钥
cat ~/.ssh/id_rsa.pub
将公钥添加到GitHub或其他代码库的SSH Keys
Docker安装
直接查看 菜鸟教程
安装完之后,配置docker镜像源详情参考 24年6月国内Docker镜像源失效解决办法...
编辑 /etc/resolv.conf 文件:
sudo vim /etc/resolv.conf
添加或修改以下行以使用 Cloudflare 的 DNS 服务器:
nameserver 1.1.1.1
nameserver 1.0.0.1
创建完成的docker-hub镜像输出示例:
 查看docker相关的rpm源文件是否存在
查看docker相关的rpm源文件是否存在
rpm -qa |grep docker
作用
rpm -qa:列出所有已安装的 RPM 包。grep docker:筛选出包名中包含 docker 的条目。
示例输出  启动Docker服务:
启动Docker服务:
- 启动Docker服务并设置为开机自启:
sudo systemctl start docker
sudo systemctl enable docker
直接查看 菜鸟教程
安装完之后,配置docker镜像源详情参考 24年6月国内Docker镜像源失效解决办法...
编辑 /etc/resolv.conf 文件:
sudo vim /etc/resolv.conf
添加或修改以下行以使用 Cloudflare 的 DNS 服务器:
nameserver 1.1.1.1
nameserver 1.0.0.1
创建完成的docker-hub镜像输出示例:
查看docker相关的rpm源文件是否存在
rpm -qa |grep docker
作用
rpm -qa:列出所有已安装的 RPM 包。grep docker:筛选出包名中包含docker的条目。
示例输出 启动Docker服务:
- 启动Docker服务并设置为开机自启:
sudo systemctl start docker
sudo systemctl enable docker
Docker安装Docker Compose
Docker Compose 可以定义和运行多个 Docker 容器应用的工具。它允许你使用一个单独的文件(通常称为 docker-compose.yml)来配置应用程序的服务,然后使用该文件快速启动整个应用的所有服务。
第一步,下载安装
curl -L https://get.daocloud.io/docker/compose/releases/download/v2.4.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
第二步,查看是否安装成功
docker-compose -v

第三步,给/docker/jenkins_home 目录设置最高权限,所有用户都具有读、写、执行这个目录的权限。(等建了/docker/jenkins_home目录之后设置)
chmod 777 /docker/jenkins_home
Docker Compose 可以定义和运行多个 Docker 容器应用的工具。它允许你使用一个单独的文件(通常称为 docker-compose.yml)来配置应用程序的服务,然后使用该文件快速启动整个应用的所有服务。
第一步,下载安装
curl -L https://get.daocloud.io/docker/compose/releases/download/v2.4.1/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
第二步,查看是否安装成功
docker-compose -v
第三步,给/docker/jenkins_home 目录设置最高权限,所有用户都具有读、写、执行这个目录的权限。(等建了/docker/jenkins_home目录之后设置)
chmod 777 /docker/jenkins_home
创建Docker相关文件目录
可以命令创建或者相关shell可视化工具创建, 命令创建如下:
mkdir /docker
mkdir /docker/compose
mkdir /docker/jenkins_home
mkdir /docker/nginx
mkdir /docker/nginx/conf
mkdir /docker/html
mkdir /docker/html/dev
mkdir /docker/html/release
mkdir /docker/html/pro
创建docker-compose.yml、nginx.conf配置文件
cd /docker/compose touch docker-compose.yml
cd /docker/nginx/conf touch nginx.conf
完成后目录结构如下: 

可以命令创建或者相关shell可视化工具创建, 命令创建如下:
mkdir /docker
mkdir /docker/compose
mkdir /docker/jenkins_home
mkdir /docker/nginx
mkdir /docker/nginx/conf
mkdir /docker/html
mkdir /docker/html/dev
mkdir /docker/html/release
mkdir /docker/html/pro
创建docker-compose.yml、nginx.conf配置文件
cd /docker/compose touch docker-compose.yml
cd /docker/nginx/conf touch nginx.conf
完成后目录结构如下:
编写nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
gzip on;
#dev环境
server {
#监听的端口
listen 8001;
server_name localhost;
#设置日志
access_log logs/dev.access.log main;
#定位到index.html
location / {
#linux下HTML文件夹,就是你的前端项目文件夹
root /usr/share/nginx/html/dev/dist;
# root /home/html/dev/dist;
#输入网址(server_name:port)后,默认的访问页面
index index.html;
try_files $uri $uri/ /index.html;
}
}
#release环境
server {
#监听的端口
listen 8002;
server_name localhost;
#设置日志
access_log logs/release.access.log main;
#定位到index.html
location / {
#linux下HTML文件夹,就是你的前端项目文件夹
root /usr/share/nginx/html/release/dist;
# root /home/html/release/dist;
#输入网址(server_name:port)后,默认的访问页面
index index.html;
try_files $uri $uri/ /index.html;
}
}
#pro环境
server {
#监听的端口
listen 8003;
server_name localhost;
#设置日志
access_log logs/pro.access.log main;
#定位到index.html
location / {
#linux下HTML文件夹,就是你的前端项目文件夹
root /usr/share/nginx/html/pro/dist;
# root /home/html/pro/dist;
#输入网址(server_name:port)后,默认的访问页面
index index.html;
try_files $uri $uri/ /index.html;
}
}
# include /etc/nginx/conf.d/*.conf;
}
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
gzip on;
#dev环境
server {
#监听的端口
listen 8001;
server_name localhost;
#设置日志
access_log logs/dev.access.log main;
#定位到index.html
location / {
#linux下HTML文件夹,就是你的前端项目文件夹
root /usr/share/nginx/html/dev/dist;
# root /home/html/dev/dist;
#输入网址(server_name:port)后,默认的访问页面
index index.html;
try_files $uri $uri/ /index.html;
}
}
#release环境
server {
#监听的端口
listen 8002;
server_name localhost;
#设置日志
access_log logs/release.access.log main;
#定位到index.html
location / {
#linux下HTML文件夹,就是你的前端项目文件夹
root /usr/share/nginx/html/release/dist;
# root /home/html/release/dist;
#输入网址(server_name:port)后,默认的访问页面
index index.html;
try_files $uri $uri/ /index.html;
}
}
#pro环境
server {
#监听的端口
listen 8003;
server_name localhost;
#设置日志
access_log logs/pro.access.log main;
#定位到index.html
location / {
#linux下HTML文件夹,就是你的前端项目文件夹
root /usr/share/nginx/html/pro/dist;
# root /home/html/pro/dist;
#输入网址(server_name:port)后,默认的访问页面
index index.html;
try_files $uri $uri/ /index.html;
}
}
# include /etc/nginx/conf.d/*.conf;
}
编写docker-compose.yml
networks:
frontend:
external: true
services:
docker_jenkins:
user: root # root权限
restart: always # 重启方式
image: jenkins/jenkins:lts # 使用的镜像
container_name: jenkins # 容器名称
ports: # 对外暴露的端口定义
- 8999:8080
- 50000:50000
environment:
- TZ=Asia/Shanghai ## 设置时区 否则默认是UTC
#- "JENKINS_OPTS=--prefix=/jenkins_home"
## 自定义 jenkins 访问前缀(设置了的话访问路径就为你的ip:端口/jenkins_home,反之则直接为ip:端口)
volumes: # 卷挂载路径
- /docker/jenkins_home/:/var/jenkins_home
# 挂载到容器内的jenkins_home目录
# docker-compose up 就会自动生成一个jenkins_home文件夹
- /usr/local/bin/docker-compose:/usr/local/bin/docker-compose
docker_nginx_dev:
restart: always
image: nginx
container_name: nginx_dev
ports:
- 8001:8001
volumes:
- /docker/nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- /docker/html:/usr/share/nginx/html
- /docker/nginx/logs:/var/log/nginx
docker_nginx_release:
restart: always
image: nginx
container_name: nginx_release
ports:
- 8002:8002
volumes:
- /docker/nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- /docker/html:/usr/share/nginx/html
- /docker/nginx/logs:/var/log/nginx
environment:
- TZ=Asia/Shanghai
docker_nginx_pro:
restart: always
image: nginx
container_name: nginx_pro
ports:
- 8003:8003
volumes:
- /docker/nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- /docker/html:/usr/share/nginx/html
- /docker/nginx/logs:/var/log/nginx
networks:
frontend:
external: true
services:
docker_jenkins:
user: root # root权限
restart: always # 重启方式
image: jenkins/jenkins:lts # 使用的镜像
container_name: jenkins # 容器名称
ports: # 对外暴露的端口定义
- 8999:8080
- 50000:50000
environment:
- TZ=Asia/Shanghai ## 设置时区 否则默认是UTC
#- "JENKINS_OPTS=--prefix=/jenkins_home"
## 自定义 jenkins 访问前缀(设置了的话访问路径就为你的ip:端口/jenkins_home,反之则直接为ip:端口)
volumes: # 卷挂载路径
- /docker/jenkins_home/:/var/jenkins_home
# 挂载到容器内的jenkins_home目录
# docker-compose up 就会自动生成一个jenkins_home文件夹
- /usr/local/bin/docker-compose:/usr/local/bin/docker-compose
docker_nginx_dev:
restart: always
image: nginx
container_name: nginx_dev
ports:
- 8001:8001
volumes:
- /docker/nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- /docker/html:/usr/share/nginx/html
- /docker/nginx/logs:/var/log/nginx
docker_nginx_release:
restart: always
image: nginx
container_name: nginx_release
ports:
- 8002:8002
volumes:
- /docker/nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- /docker/html:/usr/share/nginx/html
- /docker/nginx/logs:/var/log/nginx
environment:
- TZ=Asia/Shanghai
docker_nginx_pro:
restart: always
image: nginx
container_name: nginx_pro
ports:
- 8003:8003
volumes:
- /docker/nginx/conf/nginx.conf:/etc/nginx/nginx.conf
- /docker/html:/usr/share/nginx/html
- /docker/nginx/logs:/var/log/nginx
启动Docker-compose
cd /docker/compose
docker-compose up -d
此时就会自动拉取jenkins镜像与Nginx镜像
查看运行状态
docker-compose ps -a
示例输出

cd /docker/compose
docker-compose up -d
此时就会自动拉取jenkins镜像与Nginx镜像
查看运行状态
docker-compose ps -a
示例输出
验证Nginx
在/docker/html/dev/dist目录下新建index.html,文件内容如下:
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Hello Nginxtitle>
head>
<body>
<h1>Hello Nginxh1>
body>
html>
浏览器打开,输入服务器地址:8001看到下面的页面说明nginx配置没问题,同样的操作可测试下8002端口和8003端口

在/docker/html/dev/dist目录下新建index.html,文件内容如下:
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Hello Nginxtitle>
head>
<body>
<h1>Hello Nginxh1>
body>
html>
浏览器打开,输入服务器地址:8001看到下面的页面说明nginx配置没问题,同样的操作可测试下8002端口和8003端口
验证Jenkins
浏览器输入服务器地址:8999
 查看jenkins初始密码
查看jenkins初始密码
docker logs jenkins

安装插件


浏览器输入服务器地址:8999
查看jenkins初始密码
docker logs jenkins
安装插件
安装Publish Over SSH、NodeJS
【Dashboard】——>【Manage Jenkins】——>【Plugins】——>【Available plugins】,搜索Publish Over SSH、NodeJS,安装后重启。 

- Publish Over SSH配置远程服务器
 找到
找到SSH Servers

 点击
点击Test Configuration显示successs则成功,之后再Apply并且Save。

- NodeJS配置
 找到
找到Nodejs 
坑点!!! 使用阿里云镜像 否则会容易报错


阿里云node镜像地址
https://mirrors.aliyun.com/nodejs-release/

【Dashboard】——>【Manage Jenkins】——>【Plugins】——>【Available plugins】,搜索Publish Over SSH、NodeJS,安装后重启。
- Publish Over SSH配置远程服务器
找到SSH Servers
点击Test Configuration显示successs则成功,之后再Apply并且Save。
- NodeJS配置
找到Nodejs
坑点!!! 使用阿里云镜像 否则会容易报错
阿里云node镜像地址
https://mirrors.aliyun.com/nodejs-release/
添加凭据
添加凭据,也就是GitHub或者其他远程仓库的凭据可以是账号密码也可以是token,方便之后使用。话不多说,Lets go!

 我这里使用的是
我这里使用的是ssh,原因用账号密码拉不下来源码不知道为啥

添加凭据,也就是GitHub或者其他远程仓库的凭据可以是账号密码也可以是token,方便之后使用。话不多说,Lets go!
我这里使用的是ssh,原因用账号密码拉不下来源码不知道为啥
创建Job

选择自由风格 
- 配置
git仓库地址 
- 构建环境 在 Jenkins 中将 Node.js 和 npm 的 bin 文件夹添加到
PATH 中,否则可能就会报错。 
- 选择
nodejs版本


- 创建
shell命令


- 自动部署到对应环境项目目录:上面打包到了Jenkins中的workspace中,但是我们设置的项目环境路径跟这个不同,比如开发环境项目目录是
/docker/html/dev/dist/,所以需要打包后,把dist文件内容推送到/docker/html/dev/dist/目录下- 修改一下上面的
shell脚本
#!/bin/bash
echo "Node版本:"
node -v
pnpm i
echo "依赖安装成功"
pnpm build
echo "打包成功"
rm -rf dist.tar # 每次构建删除已存在的dist压缩包
tar -zcvf dist.tar ./dist #将dist文件压缩成dist.tar
echo $PATH
- 然后
Add build step选择Send files or execute commands over SSH,Send files or execute
- 通过SSH连接到远程服务器执行命令和发送文件:
选择自由风格
- 配置
git仓库地址 - 构建环境 在 Jenkins 中将 Node.js 和 npm 的 bin 文件夹添加到
PATH中,否则可能就会报错。 - 选择
nodejs版本
- 创建
shell命令
- 自动部署到对应环境项目目录:上面打包到了Jenkins中的workspace中,但是我们设置的项目环境路径跟这个不同,比如开发环境项目目录是
/docker/html/dev/dist/,所以需要打包后,把dist文件内容推送到/docker/html/dev/dist/目录下- 修改一下上面的
shell脚本
#!/bin/bash
echo "Node版本:"
node -v
pnpm i
echo "依赖安装成功"
pnpm build
echo "打包成功"
rm -rf dist.tar # 每次构建删除已存在的dist压缩包
tar -zcvf dist.tar ./dist #将dist文件压缩成dist.tar
echo $PATH
- 然后
Add build step选择Send files or execute commands over SSH,Send files or execute - 通过SSH连接到远程服务器执行命令和发送文件:
- 修改一下上面的
 ps:
ps:脚本解释
cd /docker/html/dev- 切换到
/docker/html/dev目录。这是你要进行操作的工作目录。
- 切换到
rm -rf dist/- 递归地删除
dist/目录及其所有内容。这是为了确保旧的dist目录被完全移除。
- 递归地删除
tar zxvf dist.tar- 解压
dist.tar文件,并将其中的内容解压到当前目录下。通常,dist.tar会包含dist/目录,解压后就会生成一个新的dist/目录。
- 解压
rm dist.tar- 解压完成后,删除
dist.tar文件。这样可以节省存储空间并清理不再需要的压缩包。
- 解压完成后,删除
至此全部配置完成
- 测试ci/cd 点击
Build Now开始构建

查看构建中任务的Console Output,日志出现Finished: SUCCESS即为成功

预览产物: 
其他配置
GitHub webHooks配置

payload URL 为:http://ip:jenkins端口/github-webhook/ 
在Github webHooks创建好后,到jenkins中开启触发器  这样配置完后在push到相应分支就会自动构建发布
这样配置完后在push到相应分支就会自动构建发布
其他的个性化配置例如:钉钉通知、邮箱通知、pipeline配置等等就不做学习了,毕竟运维的事,我也学不会。😊😊
完结撒花🎉🎉🎉
来源:juejin.cn/post/7407333344889896998
多用户抢红包,如何保证只有一个抢到
前言
在一个百人群中,群主发了个红包,设置的3个人瓜分。如何能够保证只有3个人能抢到。100个人去抢,相当于就是100个线程去争夺这3个资源,如果处理不好,可能就会发生“超卖”,产生脏数据,威胁系统的正常运行。
当100个人同时去抢,也就是线程1,线程2,线程3...,此时线程1和线程2已经抢到了,就还剩一个红包了,而此时线程3和线程4同时发出抢红包的命令,线程3查询数据库发现还剩1个,抢下成功,而线程3还未修改库存时,线程4也来读取,发现还剩一个,也抢成功。结果这就发生“超卖”,红包被抢了4个,数据库一看红包剩余为-1。

解决思路
为了保证资源的安全,不能让多个用户同时访问到资源,也就是需要互斥的访问共有资源,同一时刻只能让一个用户访问,也就是给共享资源加上一个悲观锁,只有拿到锁的线程才能正常访问资源,拿不到锁的线程也不能让他一直等着,直接返回用户让他稍后重试。
JVM本地锁
JVM本地锁由ReentrantLock或synchronized实现
//抢红包方法加锁
public synchronized void grabRedPaper(){
...业务处理
}
不过这种同步锁粒度太大,我们需要的是针对抢同一红包的用户互斥,而这种方式是所有调用grabRedPaper方法的线程都需要等待,即限制所有人抢红包操作,效率低且不符合业务需求。每个红包应该都有一个唯一性ID,在单个红包上加锁效率就会高很多,也是单进程常用的使用方式。
private Map<String, Object> lockMap = new HashMap<>();
//抢红包方法
public void grabRedPaper(String redPaperId) {
Object lock = getLock(redPaperId);
synchronized (lock) {
// 在这里进行对业务的互斥访问操作
}
}
//获取红包ID锁对象
private Object getLock(String redPaperId) {
if (!lockMap.containsKey(redPaperId)) {
lockMap.put(redPaperId, new Object());
}
return lockMap.get(redPaperId);
}

Redis分布式锁
但当我们使用分布式系统中,一个业务功能会打包部署到多台服务器上,也就是会有多个进程来尝试获取共享资源,本地JVM锁也就无法完成需求了,所以我们需要第三方统一控制资源的分配,也就是分布式锁。

分布式锁一般一般需要满足四个基本条件:
- 互斥:同一时刻,只能有一个线程获取到资源。
- 可重入:获取到锁资源后,后续还能继续获取到锁。
- 高可用:锁服务一个宕机后还能有另一个接着服务;再者即使发生了错误,一定时间内也能自动释放锁,避免死锁发生。
- 非阻塞:如果获取不到锁,不能无限等待。
有关分布式锁的具体实现我之前的文章有讲到Java实现Redis分布式锁 - 掘金 (juejin.cn)
Mysql行锁
再者我们还可以通过Mysql的行锁实现,SELECT...FOR UPDATE,这种方式会将查询时的行锁住,不允许其他事务修改,直到读取完毕。将行锁和修改红包剩余数量放在一个事务中,也能做到互斥。不过这种做法效率较差,不推荐使用。
总结
| 方案 | 实现举例 | 优点 | 缺点 |
|---|---|---|---|
| JVM本地锁 | synchronized | 实现简单,性能较好 | 只能在单个 JVM 进程内使用,无法用于分布式环境 |
| Mysql行锁 | SELECT...FOR UPDATE | 保证并发情况下的隔离性,避免出现脏数据 | 增加了数据库的开销,特别是在高并发场景下;对应用程序有一定的侵入性,需要在 SQL 语句中正确使用锁定机制。 |
| 分布式锁 | Redis分布式锁 | 可用于分布式,性能较高 | 实现相对复杂,需要考虑锁的续租、释放等问题。 |
来源:juejin.cn/post/7398038222985543692
二维码扫码登录业务详解
二维码扫码登录业务详解
前言
二维码登录 顾名思义 重要是在于登录这俩个字
登录简单点来说可以概括为俩点
- 告诉系统
我是谁 - 向系统证明
我是谁
下面我们就会围绕着这俩点来展开详细说明
原理解析
其实大部分的二维码 都是一个url地址
我们以掘金扫码登录为例来进行剖析

我们进行一个解析

我们可以发现她实际就是这样的一个url
所以说 我们二维码的一个操作 做出来的就是一个url地址
那么我们知道这个后 我们就可以来进行一个流程的解析。
就是一个这样简单的流程

流程概述
简单来说氛围下面的步骤:
- PC端:进入二维码登录页面,请求服务端获取二维码的ID。
- 服务端:生成二维码ID,并将其与请求的设备绑定后,返回有效的二维码ID。
- PC端:根据二维码ID生成二维码图片,并展示出来。
- 移动端:扫描二维码,解析出二维码ID。
- 移动端:使用移动端的token和二维码ID请求服务端进行登录。
- 服务端:解析验证请求,绑定用户信息,并返回给移动端一个用于二次确认的临时token。
- PC端:展示二维码为“待确认”状态。
- 移动端:使用二维码ID、临时token和移动端的token进行确认登录。
- 服务端:验证通过后,修改二维码状态,并返回给PC端一个登录的token。
下面我们来用一个python的代码来描述一下这个过程。
首先是服务端:
from flask import Flask, request, jsonify
import uuid
import time
app = Flask(__name__)
# 存储二维码ID和对应的设备信息以及临时token
qr_code_store = {}
temporary_tokens = {}
@app.route('/generate_qr', methods=['POST'])
def generate_qr():
device_id = request.json['device_id']
qr_id = str(uuid.uuid4())
qr_code_store[qr_id] = {'device_id': device_id, 'timestamp': time.time(), 'status': 'waiting'}
return jsonify({'qr_id': qr_id})
@app.route('/scan_qr', methods=['POST'])
def scan_qr():
qr_id = request.json['qr_id']
token = request.json['token']
if qr_id in qr_code_store:
qr_code_store[qr_id]['status'] = 'scanned'
temp_token = str(uuid.uuid4())
temporary_tokens[temp_token] = {'qr_id': qr_id, 'timestamp': time.time()}
return jsonify({'temp_token': temp_token})
return jsonify({'error': 'Invalid QR code'}), 400
@app.route('/confirm_login', methods=['POST'])
def confirm_login():
qr_id = request.json['qr_id']
temp_token = request.json['temp_token']
mobile_token = request.json['mobile_token']
if temp_token in temporary_tokens and temporary_tokens[temp_token]['qr_id'] == qr_id:
login_token = str(uuid.uuid4())
qr_code_store[qr_id]['status'] = 'confirmed'
return jsonify({'login_token': login_token})
return jsonify({'error': 'Invalid confirmation'}), 400
if __name__ == '__main__':
app.run(debug=True)
之后来看PC端:
import requests
import json
# 1. 请求生成二维码ID
response = requests.post('http://localhost:5000/generate_qr', json={'device_id': 'PC_device'})
qr_id = response.json()['qr_id']
# 2. 根据二维码ID生成二维码图片 (此处省略,可以使用第三方库生成二维码图片)
print(f"QR Code ID: {qr_id}")
# 7. 显示二维码进入“待确认”状态
print("QR Code Status: Waiting for confirmation")
之后再来看移动端的代码:
import requests
# 4. 扫描二维码,解析出二维码ID
qr_id = '解析出的二维码ID'
token = '移动端token'
# 5. 请求服务端进行登录
response = requests.post('http://localhost:5000/scan_qr', json={'qr_id': qr_id, 'token': token})
temp_token = response.json()['temp_token']
# 8. 使用二维码ID、临时token和移动端的token进行确认登录
response = requests.post('http://localhost:5000/confirm_login', json={'qr_id': qr_id, 'temp_token': temp_token, 'mobile_token': token})
login_token = response.json().get('login_token')
if login_token:
print("登录成功!")
else:
print("登录失败!")
这样一个简单的二维码登录的流程就出来了
案例解析
了解了流程之后我们来看看其他大型网站是如何实施的 这里拿哔哩哔哩来举例。
我们可以看到她的那个json实例
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"url": "",
"refresh_token": "",
"timestamp": 0,
"code": 86101,
"message": "未扫码"
}
}
我们可以发现他是不断的去发送这个请求 每过1s大概

之后当我们扫描后发现已经变成等待确认

当我们确认后 他会返回

和我们说的流程大概的相同
来源:juejin.cn/post/7389952503041884170
数据无界,存储有方:MinIO,为极致性能而生!
MinIO: 数据宇宙的超级存储引擎,解锁云原生潜能- 精选真开源,释放新价值。

概览
MinIO,这一高性能分布式对象存储系统的佼佼者,正以开源的力量重塑企业数据存储的版图。它设计轻巧且完全兼容Amazon S3接口,成为连接全球开发者与企业的桥梁,提供了一个既强大又灵活的数据管理平台。超越传统存储桶的范畴,MinIO是专为应对大规模数据挑战而生,尤其适用于AI深度学习、大数据分析等高负载场景,其单个对象高达5TB的存储容量设计,确保了数据密集应用运行无阻,流畅高效。
无论是部署于云端、边缘计算环境还是本地服务器,MinIO展现了极高的适配性和灵活性。它以超简单的安装步骤、直观的管理界面以及平滑的扩展能力,极大地降低了企业构建复杂数据架构的门槛。利用MinIO,企业能够快速部署数据湖,以集中存储海量数据,便于分析挖掘;构建高效的内容分发网络(CDN),加速内容的全球分发;或建立可靠的备份存储方案,确保数据资产的安全无虞。
MinIO的特性还包括自动数据分片、跨区域复制、以及强大的数据持久性和高可用性机制,这些都为数据的全天候安全与访问提供了坚实保障。此外,其微服务友好的架构,使得集成到现有的云原生生态系统中变得轻而易举,加速了DevOps流程,提升了整体IT基础设施的响应速度和灵活性。

主要功能
你可以进入官方网站下载体验:min.io/download

- 高性能存储
- 优化的I/O路径:MinIO通过精心设计的I/O处理逻辑,减少了数据访问的延迟,确保了数据读写操作的高速执行。
- 并发设计:支持高并发访问,能够有效利用多核处理器,即使在高负载情况下也能维持稳定的吞吐量,特别适合处理大数据量的读写请求。
- 裸机级性能:通过底层硬件的直接访问和资源高效利用,使得在普通服务器上也能达到接近硬件极限的存储性能,为PB级数据的存储与处理提供强大支撑。

- 分布式架构
- 多节点部署:允许用户根据需求部署多个节点,形成分布式存储集群,横向扩展存储容量和处理能力。
- 纠删码技术:采用先进的纠删码(Erasure Coding)代替传统的RAID,即使在部分节点故障的情况下,也能自动恢复数据,确保数据的完整性和服务的连续性,提高了系统的容错能力。
- 高可用性与持久性:通过跨节点的数据复制或纠删码,确保数据在不同地理位置的多个副本,即使面临单点故障,也能保证数据的不间断访问,满足严格的SLA要求。

- 全面的S3兼容性
- 无缝集成:MinIO完全兼容Amazon S3 API,这意味着现有的S3应用程序、工具和库可以直接与MinIO对接,无需修改代码。
- 迁移便利:企业可以从AWS S3或任何其他S3兼容服务平滑迁移至MinIO,降低迁移成本,加速云原生应用的部署进程。

- 安全与合规
- 加密传输:支持SSL/TLS协议,确保数据在传输过程中加密,防止中间人攻击,保障数据通信安全。
- 访问控制:提供细粒度的访问控制列表(ACLs)和策略管理,实现用户和群体的权限分配,确保数据访问权限的严格控制。
- 审计与日志:记录详细的系统活动日志,便于监控和审计,符合GDPR、HIPAA等国际安全标准和法规要求。


- 简易管理与监控
- 直观Web界面:用户可通过Web UI进行集群配置、监控和日常管理,界面友好,操作简便。
- Prometheus集成:集成Prometheus监控系统,实现存储集群的实时性能监控和告警通知,帮助管理员及时发现并解决问题,确保系统稳定运行。

信息
截至发稿概况如下:
- 软件地址:github.com/minio/minio
- 软件协议:AGPL 3.0
- 编程语言:
| 语言 | 占比 |
|---|---|
| Go | 99.0% |
| Other | 1.0% |
- 收藏数量:44.3K
面对不断增长的数据管理挑战,MinIO不仅是一个存储解决方案,更是企业在数字化转型旅程中的核心支撑力量,助力各行各业探索数据价值的无限可能。无论是优化存储成本、提升数据处理效率,还是确保数据安全与合规,MinIO持续推动技术边界,邀请每一位技术探索者加入其活跃的开源社区,共同参与讨论,贡献智慧,共同塑造数据存储的未来。
尽管MinIO凭借其卓越的性能与易于使用的特性在存储领域独树一帜,但面对数据量的指数级增长和环境的日益复杂,一系列新挑战浮出水面。首要任务是在海量数据中实现高效的数据索引与查询机制,确保信息的快速提取与分析。其次,在混合云及多云部署的趋势下,如何平滑实现数据在不同平台间的迁移与实时同步,成为提升业务连续性和灵活性的关键。再者,数据安全虽为根基,但在成本控制上也不可忽视,优化存储策略,在强化防护的同时降低开支,实现存储经济性与安全性的完美平衡,是当前亟待探讨与解决的课题。这些问题不仅考验着技术的极限,也为MinIO及其用户社区带来了新的研究方向与实践机遇。
热烈欢迎各位在评论区分享交流心得与见解!!!
来源:juejin.cn/post/7363570869065498675
数字签名 Signature
这一章,我们将简单的介绍以太坊中的数字签名ECDSA,以及如何利用它发放NFT白名单。代码中的ECDSA库由OpenZeppelin的同名库简化而成。
数字签名
如果你用过opensea交易NFT,对签名就不会陌生。下图是小狐狸(metamask)钱包进行签名时弹出的窗口,它可以证明你拥有私钥的同时不需要对外公布私钥。

以太坊使用的数字签名算法叫双椭圆曲线数字签名算法(ECDSA),基于双椭圆曲线“私钥-公钥”对的数字签名算法。它主要起到了三个作用:
- 身份认证:证明签名方是私钥的持有人。
- 不可否认:发送方不能否认发送过这个消息。
- 完整性:消息在传输过程中无法被修改。
ECDSA合约
ECDSA标准中包含两个部分:
- 签名者利用
私钥(隐私的)对消息(公开的)创建签名(公开的)。 - 其他人使用
消息(公开的)和签名(公开的)恢复签名者的公钥(公开的)并验证签名。 我们将配合ECDSA库讲解这两个部分。本教程所用的私钥,公钥,消息,以太坊签名消息,签名如下所示:
私钥: 0x227dbb8586117d55284e26620bc76534dfbd2394be34cf4a09cb775d593b6f2b
公钥: 0xe16C1623c1AA7D919cd2241d8b36d9E79C1Be2A2
消息: 0x1bf2c0ce4546651a1a2feb457b39d891a6b83931cc2454434f39961345ac378c
以太坊签名消息: 0xb42ca4636f721c7a331923e764587e98ec577cea1a185f60dfcc14dbb9bd900b
签名: 0x390d704d7ab732ce034203599ee93dd5d3cb0d4d1d7c600ac11726659489773d559b12d220f99f41d17651b0c1c6a669d346a397f8541760d6b32a5725378b241c
创建签名
1. 打包消息: 在以太坊的ECDSA标准中,被签名的消息是一组数据的keccak256哈希,为bytes32类型。我们可以把任何想要签名的内容利用abi.encodePacked()函数打包,然后用keccak256()计算哈希,作为消息。我们例子中的消息是由一个address类型变量和一个uint256类型变量得到的:
/*
* 将mint地址(address类型)和tokenId(uint256类型)拼成消息msgHash
* _account: 0x5B38Da6a701c568545dCfcB03FcB875f56beddC4
* _tokenId: 0
* 对应的消息msgHash: 0x1bf2c0ce4546651a1a2feb457b39d891a6b83931cc2454434f39961345ac378c
*/
function getMessageHash(address _account, uint256 _tokenId) public pure returns(bytes32){
return keccak256(abi.encodePacked(_account, _tokenId));
}

2. 计算以太坊签名消息: 消息可以是能被执行的交易,也可以是其他任何形式。为了避免用户误签了恶意交易,EIP191提倡在消息前加上"\x19Ethereum Signed Message:\n32"字符,并再做一次keccak256哈希,作为以太坊签名消息。经过toEthSignedMessageHash()函数处理后的消息,不能被用于执行交易:
/**
* @dev 返回 以太坊签名消息
* `hash`:消息
* 遵从以太坊签名标准:https://eth.wiki/json-rpc/API#eth_sign[`eth_sign`]
* 以及`EIP191`:https://eips.ethereum.org/EIPS/eip-191`
* 添加"\x19Ethereum Signed Message:\n32"字段,防止签名的是可执行交易。
*/
function toEthSignedMessageHash(bytes32 hash) internal pure returns (bytes32) {
// 哈希的长度为32
return keccak256(abi.encodePacked("\x19Ethereum Signed Message:\n32", hash));
}
处理后的消息为:
以太坊签名消息: 0xb42ca4636f721c7a331923e764587e98ec577cea1a185f60dfcc14dbb9bd900b

3-1. 利用钱包签名: 日常操作中,大部分用户都是通过这种方式进行签名。在获取到需要签名的消息之后,我们需要使用metamask钱包进行签名。metamask的personal_sign方法会自动把消息转换为以太坊签名消息,然后发起签名。所以我们只需要输入消息和签名者钱包account即可。需要注意的是输入的签名者钱包account需要和metamask当前连接的account一致才能使用。
因此首先把例子中的私钥导入到小狐狸钱包,然后打开浏览器的console页面:Chrome菜单-更多工具-开发者工具-Console。在连接钱包的状态下(如连接opensea,否则会出现错误),依次输入以下指令进行签名:
ethereum.enable()
account = "0xe16C1623c1AA7D919cd2241d8b36d9E79C1Be2A2"
hash = "0x1bf2c0ce4546651a1a2feb457b39d891a6b83931cc2454434f39961345ac378c"
ethereum.request({method: "personal_sign", params: [account, hash]})
在返回的结果中(Promise的PromiseResult)可以看到创建好的签名。不同账户有不同的私钥,创建的签名值也不同。利用教程的私钥创建的签名如下所示:
0x390d704d7ab732ce034203599ee93dd5d3cb0d4d1d7c600ac11726659489773d559b12d220f99f41d17651b0c1c6a669d346a397f8541760d6b32a5725378b241c

3-2. 利用web3.py签名: 批量调用中更倾向于使用代码进行签名,以下是基于web3.py的实现。
from web3 import Web3, HTTPProvider
from eth_account.messages import encode_defunct
private_key = "0x227dbb8586117d55284e26620bc76534dfbd2394be34cf4a09cb775d593b6f2b"
address = "0x5B38Da6a701c568545dCfcB03FcB875f56beddC4"
rpc = 'https://rpc.ankr.com/eth'
w3 = Web3(HTTPProvider(rpc))
#打包信息
msg = Web3.solidityKeccak(['address','uint256'], [address,0])
print(f"消息:{msg.hex()}")
#构造可签名信息
message = encode_defunct(hexstr=msg.hex())
#签名
signed_message = w3.eth.account.sign_message(message, private_key=private_key)
print(f"签名:{signed_message['signature'].hex()}")
运行的结果如下所示。计算得到的消息,签名和前面的案例一致。
消息:0x1bf2c0ce4546651a1a2feb457b39d891a6b83931cc2454434f39961345ac378c
签名:0x390d704d7ab732ce034203599ee93dd5d3cb0d4d1d7c600ac11726659489773d559b12d220f99f41d17651b0c1c6a669d346a397f8541760d6b32a5725378b241c
验证签名
为了验证签名,验证者需要拥有消息,签名,和签名使用的公钥。我们能验证签名的原因是只有私钥的持有者才能够针对交易生成这样的签名,而别人不能。
4. 通过签名和消息恢复公钥: 签名是由数学算法生成的。这里我们使用的是rsv签名,签名中包含r, s, v三个值的信息。而后,我们可以通过r, s, v及以太坊签名消息来求得公钥。下面的recoverSigner()函数实现了上述步骤,它利用以太坊签名消息 _msgHash和签名 _signature恢复公钥(使用了简单的内联汇编):
// @dev 从_msgHash和签名_signature中恢复signer地址
function recoverSigner(bytes32 _msgHash, bytes memory _signature) internal pure returns (address){
// 检查签名长度,65是标准r,s,v签名的长度
require(_signature.length == 65, "invalid signature length");
bytes32 r;
bytes32 s;
uint8 v;
// 目前只能用assembly (内联汇编)来从签名中获得r,s,v的值
assembly {
/*
前32 bytes存储签名的长度 (动态数组存储规则)
add(sig, 32) = sig的指针 + 32
等效为略过signature的前32 bytes
mload(p) 载入从内存地址p起始的接下来32 bytes数据
*/
// 读取长度数据后的32 bytes
r := mload(add(_signature, 0x20))
// 读取之后的32 bytes
s := mload(add(_signature, 0x40))
// 读取最后一个byte
v := byte(0, mload(add(_signature, 0x60)))
}
// 使用ecrecover(全局函数):利用 msgHash 和 r,s,v 恢复 signer 地址
return ecrecover(_msgHash, v, r, s);
}
参数分别为:
// 以太坊签名消息
_msgHash:0xb42ca4636f721c7a331923e764587e98ec577cea1a185f60dfcc14dbb9bd900b
// 签名
_signature:0x390d704d7ab732ce034203599ee93dd5d3cb0d4d1d7c600ac11726659489773d559b12d220f99f41d17651b0c1c6a669d346a397f8541760d6b32a5725378b241c

5. 对比公钥并验证签名: 接下来,我们只需要比对恢复的公钥与签名者公钥_signer是否相等:若相等,则签名有效;否则,签名无效:
/**
* @dev 通过ECDSA,验证签名地址是否正确,如果正确则返回true
* _msgHash为消息的hash
* _signature为签名
* _signer为签名地址
*/
function verify(bytes32 _msgHash, bytes memory _signature, address _signer) internal pure returns (bool) {
return recoverSigner(_msgHash, _signature) == _signer;
}
参数分别为:
_msgHash:0xb42ca4636f721c7a331923e764587e98ec577cea1a185f60dfcc14dbb9bd900b
_signature:0x390d704d7ab732ce034203599ee93dd5d3cb0d4d1d7c600ac11726659489773d559b12d220f99f41d17651b0c1c6a669d346a397f8541760d6b32a5725378b241c
_signer:0xe16C1623c1AA7D919cd2241d8b36d9E79C1Be2A2

利用签名发放白名单
NFT项目方可以利用ECDSA的这个特性发放白名单。由于签名是链下的,不需要gas。方法非常简单,项目方利用项目方账户把白名单发放地址签名(可以加上地址可以铸造的tokenId)。然后mint的时候利用ECDSA检验签名是否有效,如果有效,则给他mint。
SignatureNFT合约实现了利用签名发放NFT白名单。
状态变量
合约中共有两个状态变量:
signer:公钥,项目方签名地址。mintedAddress是一个mapping,记录了已经mint过的地址。
函数
合约中共有4个函数:
- 构造函数初始化
NFT的名称和代号,还有ECDSA的签名地址signer。 mint()函数接受地址address,tokenId和_signature三个参数,验证签名是否有效:如果有效,则把tokenId的NFT铸造给address地址,并将它记录到mintedAddress。它调用了getMessageHash(),ECDSA.toEthSignedMessageHash()和verify()函数。getMessageHash()函数将mint地址(address类型)和tokenId(uint256类型)拼成消息。verify()函数调用了ECDSA库的verify()函数,来进行ECDSA签名验证。
contract SignatureNFT is ERC721 {
address immutable public signer; // 签名地址
mapping(address => bool) public mintedAddress; // 记录已经mint的地址
// 构造函数,初始化NFT合集的名称、代号、签名地址
constructor(string memory _name, string memory _symbol, address _signer)
ERC721(_name, _symbol)
{
signer = _signer;
}
// 利用ECDSA验证签名并mint
function mint(address _account, uint256 _tokenId, bytes memory _signature)
external
{
bytes32 _msgHash = getMessageHash(_account, _tokenId); // 将_account和_tokenId打包消息
bytes32 _ethSignedMessageHash = ECDSA.toEthSignedMessageHash(_msgHash); // 计算以太坊签名消息
require(verify(_ethSignedMessageHash, _signature), "Invalid signature"); // ECDSA检验通过
require(!mintedAddress[_account], "Already minted!"); // 地址没有mint过
_mint(_account, _tokenId); // mint
mintedAddress[_account] = true; // 记录mint过的地址
}
/*
* 将mint地址(address类型)和tokenId(uint256类型)拼成消息msgHash
* _account: 0x5B38Da6a701c568545dCfcB03FcB875f56beddC4
* _tokenId: 0
* 对应的消息: 0x1bf2c0ce4546651a1a2feb457b39d891a6b83931cc2454434f39961345ac378c
*/
function getMessageHash(address _account, uint256 _tokenId) public pure returns(bytes32){
return keccak256(abi.encodePacked(_account, _tokenId));
}
// ECDSA验证,调用ECDSA库的verify()函数
function verify(bytes32 _msgHash, bytes memory _signature)
public view returns (bool)
{
return ECDSA.verify(_msgHash, _signature, signer);
}
}
总结
这一讲,我们介绍了以太坊中的数字签名ECDSA,如何利用ECDSA创建和验证签名,还有ECDSA合约,以及如何利用它发放NFT白名单。代码中的ECDSA库由OpenZeppelin的同名库简化而成。
- 由于签名是链下的,不需要
gas,因此这种白名单发放模式比Merkle Tree模式还要经济; - 但由于用户要请求中心化接口去获取签名,不可避免的牺牲了一部分去中心化;
- 额外还有一个好处是白名单可以动态变化,而不是提前写死在合约里面了,因为项目方的中心化后端接口可以接受任何新地址的请求并给予白名单签名。
来源:juejin.cn/post/7376324160484327424
我写了个ffmpeg-spring-boot-starter 使得Java能剪辑视频!!
最近工作中在使用FFmpeg,加上之前写过较多的SpringBoot的Starter,所以干脆再写一个FFmpeg的Starter出来给大家使用。
首先我们来了解一下FFmpeg能干什么,FFmpeg 是一个强大的命令行工具和库集合,用于处理多媒体数据。它可以用来做以下事情:
- 解码:将音频和视频从压缩格式转换成原始数据。
- 编码:将音频和视频从原始数据压缩成各种格式。
- 转码:将一种格式的音频或视频转换为另一种格式。
- 复用:将音频、视频和其他流合并到一个容器中。
- 解复用:从一个容器中分离出音频、视频和其他流。
- 流媒体:在网络上传输音频和视频流。
- 过滤:对音频和视频应用各种效果和调整。
- 播放:直接播放媒体文件。
FFmpeg支持广泛的编解码器和容器格式,并且由于其开源性质,被广泛应用于各种多媒体应用程序中,包括视频会议软件、在线视频平台、编辑软件等。
例如

作者很喜欢的一款截图软件ShareX就使用到了FFmpeg的功能。
现在ffmpeg-spring-boot-starter已发布,maven地址为
ffmpeg-spring-boot-starter

那么如何使用ffmpeg-spring-boot-starter 呢?
第一步,新建一个SpringBoot项目
SpringBoot入门:如何新建SpringBoot项目(保姆级教程)
第二步,在pom文件里面引入jar包
<dependency>
<groupId>io.gitee.wangfugui-ma</groupId>
<artifactId>ffmpeg-spring-boot-starter</artifactId>
<version>${最新版}</version>
</dependency>
第三步,配置你的ffmpeg信息
在yml或者properties文件中配置如下信息
ffmpeg.ffmpegPath=D:\\ffmpeg-7.0.1-full_build\\bin\\
注意这里要配置为你所安装ffmpeg的bin路径,也就是脚本(ffmpeg.exe)所在的目录,之所以这样设计的原因就是可以不用在系统中配置环境变量,直接跳过了这一个环节(一切为了Starter)
第四步,引入FFmpegTemplate
@Autowired
private FFmpegTemplate ffmpegTemplate;
在你的项目中直接使用Autowired注解注入FFmpegTemplate即可使用
第五步,使用FFmpegTemplate
execute(String command)
- 功能:执行任意FFmpeg命令,捕获并返回命令执行的输出结果。
- 参数:
command- 需要执行的FFmpeg命令字符串。 - 返回:命令执行的输出结果字符串。
- 实现:使用
Runtime.getRuntime().exec()启动外部进程,通过线程分别读取标准输出流和错误输出流,确保命令执行过程中的所有输出都被记录并可被进一步分析。 - 异常:抛出
IOException和InterruptedException,需在调用处妥善处理。
FFmpeg执行器,这是这里面最核心的方法,之所以提供这个方法,是来保证大家的自定义的需求,例如FFmpegTemplate中没有封装的方法,可以灵活自定义ffmpeg的执行参数。
convert(String inputFile, String outputFile)
- 功能:实现媒体文件格式转换。
- 参数:
inputFile- 待转换的源文件路径;outputFile- 转换后的目标文件路径。 - 实现:构建FFmpeg命令,调用FFmpeg执行器完成媒体文件格式的转换。
就像这样:
@Test
void convert() {
ffmpegTemplate.convert("D:\\video.mp4","D:\\video.avi");
}
extractAudio(String inputFile)
- 功能:精确提取媒体文件的时长信息。
- 参数:
inputFile- 需要提取时长信息的媒体文件路径。 - 实现:构造特定的FFmpeg命令,仅请求媒体时长数据,直接调用FFmpeg执行器并解析返回的时长值。
就像这样:
@Test
void extractAudio() { System.out.println(ffmpegTemplate.extractAudio("D:\\video.mp4"));
}
copy(String inputFile, String outputFile)
- 功能:执行流复制,即在不重新编码的情况下快速复制媒体文件。
- 参数:
inputFile- 源媒体文件路径;outputFile- 目标媒体文件路径。 - 实现:创建包含流复制指令的FFmpeg命令,直接调用FFmpeg执行器,以达到高效复制的目的。
就像这样:
@Test
void copy() {
ffmpegTemplate.copy("D:\\video.mp4","D:\\video.avi");
}
captureVideoFootage(String inputFile, String outputFile, String startTime, String endTime)
- 功能:精准截取视频片段。
- 参数:
inputFile- 源视频文件路径;outputFile- 截取片段的目标文件路径;startTime- 开始时间;endTime- 结束时间。 - 实现:构造FFmpeg命令,指定视频片段的开始与结束时间,直接调用FFmpeg执行器,实现视频片段的精确截取。
@Test
void captureVideoFootage() {
ffmpegTemplate.captureVideoFootage("D:\\video.mp4","D:\\cut.mp4","00:01:01","00:01:12");
}
scale(String inputFile, String outputFile, Integer width, Integer height)
- 功能:调整媒体文件的分辨率。
- 参数:
inputFile- 源媒体文件路径;outputFile- 输出媒体文件路径;width- 目标宽度;height- 目标高度。 - 实现:创建包含分辨率调整指令的FFmpeg命令,直接调用FFmpeg执行器,完成媒体文件分辨率的调整。
@Test
void scale() {
ffmpegTemplate.scale("D:\\video.mp4","D:\\video11.mp4",640,480);
}
cut(String inputFile, String outputFile, Integer x, Integer y, Integer width, Integer height)
- 功能:实现媒体文件的精确裁剪。
- 参数:
inputFile- 源媒体文件路径;outputFile- 裁剪后媒体文件路径;x- 裁剪框左上角X坐标;y- 裁剪框左上角Y坐标;width- 裁剪框宽度;height- 裁剪框高度。 - 实现:构造FFmpeg命令,指定裁剪框的坐标与尺寸,直接调用FFmpeg执行器,完成媒体文件的精确裁剪。
@Test
void cut() {
ffmpegTemplate.cut("D:\\video.mp4","D:\\video111.mp4",100,100,640,480);
}
embedSubtitle(String inputFile, String outputFile, String subtitleFile)
- 功能:将字幕文件内嵌至视频中。
- 参数:
inputFile- 视频文件路径;outputFile- 输出视频文件路径;subtitleFile- 字幕文件路径。 - 实现:构造FFmpeg命令,将字幕文件内嵌至视频中,直接调用FFmpeg执行器,完成字幕的内嵌操作。
@Test
void embedSubtitle() {
ffmpegTemplate.embedSubtitle("D:\\video.mp4","D:\\video1211.mp4","D:\\srt.srt");
}
merge(String inputFile, String outputFile)
- 功能: 通过外部ffmpeg工具将多个视频文件合并成一个。
- 参数:
inputFile: 包含待合并视频列表的文本文件路径。outputFile: 合并后视频的输出路径。
是这样用的:
@Test
void merge() {
ffmpegTemplate.merge("D:\\mylist.txt","D:\\videoBig.mp4");
}
注意,这个mylist.txt文件长这样:

后续版本考虑支持
- 添加更多丰富的api
- 区分win和Linux环境(脚本执行条件不同)
- 支持在系统配置环境变量(用户如果没有配置配置文件的ffmpegPath信息可以自动使用环境变量)

来源:juejin.cn/post/7391326728461647872
微信公众号推送消息笔记
根据业务需要,开发一个微信公众号的相关开发,根据相关开发和整理总结了一下相关的流程和需要,进行一些整理和总结分享给大家,最近都在加班和忙碌,博客已经很久未更新了,打气精神,再接再厉,申请、认证公众号的一系列流程就不在这里赘述了,主要进行的是技术的分享,要达到的效果如下图:

开发接入
首先说明我这里用的是PHP开发语言来进行的接入,设置一个url让微信公众号的服务回调这个url,在绑定之前需要一个token的验证,设置不对会提示token不正确的提示
官方提供的测试Url工具:developers.weixin.qq.com/apiExplorer…
private function checkSignature()
{
$signature = isset($_GET["signature"]) ? $_GET["signature"] : '';
$timestamp = isset($_GET["timestamp"]) ? $_GET["timestamp"] : '';
$nonce = isset($_GET["nonce"]) ? $_GET["nonce"] : '';
$echostr = isset($_GET["echostr"]) ? $_GET["echostr"] : '';
$token = 'klsg2024';
$tmpArr = array($token, $timestamp, $nonce);
sort($tmpArr, SORT_STRING);
$tmpStr = implode( $tmpArr );
$tmpStr = sha1( $tmpStr );
if( $tmpStr == $signature ){
return $echostr;
}else{
return false;
}
}
在设置的地方调用: 微信公众号的 $echostr 和 自定义的匹配上说明调用成功了
public function console(){
//关注公众号推送
$posts = $this->posts;
if(!isset($_GET['openid'])){
$res = $this->checkSignature();
if($res){
echo $res;
return true;
}else{
return false;
}
}
}
设置access_token
公众号的开发的所有操作的前提都是先设置access_token,在于验证操作的合法性,所需要的token在公众号后台的目录中获取:公众号-设置与开发-基本设置 设置和查看:
#POST https://api.weixin.qq.com/cgi-bin/token
{
"grant_type": "client_credential",
"appid": "开发者ID(AppID)",
"secret": "开发者密码(AppSecret)"
}
返回的access_token,过期时间2个小时,Http url 返回结构如下:
{
"access_token": "82_W8kdIcY2TDBJk6b1VAGEmA_X_DLQnCIi5oSZBxVQrn27VWL7kmUCJFVr8tjO0S6TKuHlqM6z23nzwf18W1gix3RHCw6uXKAXlD-pZEO7JcAV6Xgk3orZW0i2MFMNGQbAEARKU",
"expires_in": 7200
}
为了方便起见,公众号平台还开放了一个稳定版的access_token,参数略微有不同。
POST https://api.weixin.qq.com/cgi-bin/stable_token
{
"grant_type": "client_credential",
"appid": "开发者ID(AppID)",
"secret": "开发者密码(AppSecret)",
"force_refresh":true
}
自定义菜单
第一个疑惑是公众号里的底部菜单 是怎么搞出来的,在官方文档中获取到的,如果公众号后台没有设置可以根据自定义菜单来进行设置。
1、创建菜单,参数自己去官方文档上查阅
POST https://api.weixin.qq.com/cgi-bin/menu/create?access_token=ACCESS_TOKEN
2、查询菜单接口,文档和调试工具给的有点不一样,我使用的是调试工具给出的url
GET https://api.weixin.qq.com/cgi-bin/menu/get?access_token=ACCESS_TOKEN
3、删除菜单
GET https://api.weixin.qq.com/cgi-bin/menu/delete?access_token=ACCESS_TOKEN
事件拦截
在公众号的开发后台里会设置一个Url,每次在操作公众号时都会回调接口,用事件去调用和处理,操作公众号后,微信公众平台会请求到设置的接口上,公众号的openid 比较重要,是用来识别用户身份的唯一标识,openid即当前用户。
{
"signature": "d43a23e838e2b580ca41babc78d5fe78b2993dea",
"timestamp": "1721273358",
"nonce": "1149757628",
"openid": "odhkK64I1uXqoUQjt7QYx4O0yUvs"
}
用户进行相关操作时,回调接口会收到这样一份请求,都是用MsgType和Event去区分,下面是关注的回调:
{
"ToUserName": "gh_d98fc9c8e089",
"FromUserName": "用户openID",
"CreateTime": "1721357413",
"MsgType": "event",
"Event": "subscribe",
"EventKey": []
}
下面是点击菜单跳转的回调:
{
"ToUserName": "gh_d98fc9c8e089",
"FromUserName": "用户openID",
"CreateTime": "1721381657",
"MsgType": "event",
"Event": "VIEW",
"EventKey": "https:\/\/zhjy.rchang.cn\/api\/project_audit\/getOpenid?type=1",
"MenuId": "421351906"
}
消息推送
消息能力是公众号中最核心的能力,我们这次主要分享2个,被动回复用户消息和模板推送能力。
被动回复用户消息
被动回复用户消息,把需要的参数拼接成xml格式的,我觉得主要是出于安全上的考虑作为出发点。
<xml>
<ToUserName><![CDATA[toUser]]></ToUserName>
<FromUserName><![CDATA[fromUser]]></FromUserName>
<CreateTime>12345678</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA[你好]]></Content>
</xml>
在php代码里的实现即为:
protected function subscribe($params)
{
$time = time();
$content = "欢迎的文字";
$send_msg = '<xml>
<ToUserName><![CDATA['.$params['FromUserName'].']]></ToUserName>
<FromUserName><![CDATA['.$params['ToUserName'].']]></FromUserName>
<CreateTime>'.time().'</CreateTime>
<MsgType><![CDATA[text]]></MsgType>
<Content><![CDATA['.$content.']]></Content>
</xml>';
echo $send_msg;
return false;
}
模板推送能力
模版推送的两个关键是申请了模版,还有就是模版的data需要和模版中的一致,才能成功发送,模版设置和申请的后台位置在 广告与服务-模版消息
public function project_message()
{
$touser = '发送人公众号openid';
$template_id = '模版ID';
$url = 'https://api.weixin.qq.com/cgi-bin/message/template/send?access_token=' . $this->access_token;
$details_url = '点开链接,需要跳转的详情url';
$thing1 = '模版里定义的参数';
$time2 = '模版里定义的参数';
$const3 = '模版里定义的参数';
$send_data = [
'touser' => $touser,
'template_id' => $template_id,
'url' => $details_url,
'data' => [
'thing1' => ['value' => $thing1],
'time2' => ['value' => $time2],
'const3' => ['value' => $const3],
]
];
$result = curl_json($url, $send_data);
}
错误及解决方式
1、公众号后台: 设置与开发-安全中心-IP白名单 把IP地址加入白名单即可。
{
"errcode": 40164,
"errmsg": "invalid ip 47.63.30.93 ipv6 ::ffff:47.63.30.93, not in whitelist rid: 6698ef60-27d10c40-100819f9"
}
2、模版参数不正确时,接口返回
{
"errcode": 47003,
"errmsg": "argument invalid! data.time5.value invalid rid: 669df26e-538a8a1a-15ab8ba4"
}
3、access_token不正确
{
"errcode": 40001,
"errmsg": "invalid credential, access_token is invalid or not latest, could get access_token by getStableAccessToken, more details at https://mmbizurl.cn/s/JtxxFh33r rid: 669df2f1-74be87a6-05e77d20"
}
4、access_token超过调用次数
{
"errcode": 45009,
"errmsg": "reach max api daily quota limit, could get access_token by getStableAccessToken, more details at https:\/\/mmbizurl.cn\/s\/JtxxFh33r rid: 669e5c4c-2bb4e05f-61d6917c"
}
文档参考
公众号开发文档首页: developers.weixin.qq.com/doc/offiacc…
分享一个微信公众号的调试工具地址,特别好用 : mp.weixin.qq.com/debug/
来源:juejin.cn/post/7394392321988575247
一文揭秘:火山引擎云基础设施如何支撑大模型应用落地
2024年被普遍认为是“大模型落地应用元年”,而要让大模型真正落地应用到企业的生产环节中,推理能力至关重要。所谓“推理能力”,即大模型利用输入的新数据,一次性获得正确结论的过程。除模型本身的设计外,还需要强大的硬件作为基础。
在8月21日举办的2024火山引擎AI创新巡展上海站活动上,火山引擎云基础产品负责人罗浩发表演讲,介绍了火山引擎AI全栈云在算力升级、资源管理、性能和稳定性等方面做出的努力,尤其是分享了针对大模型推理问题的解决方案。
罗浩表示,在弹性方面,与传统的云原生任务相比,推理任务,以及面向AI native应用,由于其所对应的底层资源池更加复杂,因此面临的弹性问题也更加复杂。传统的在线任务弹性,主要存在于CPU、内存、存储等方面,而AI native应用的弹性问题,则涉及模型弹性、GPU弹性、缓存弹性,以及RAG、KV Cache等机制的弹性。
同时,由于底层支撑算力和包括数据库系统在内的存储都发生了相应的变化,也导致对应的观测体系和监控体系出现不同的变化,带来新的挑战。
在具体应对上,火山引擎首先在资源方面,面向不同的需求,提供了更多类型的多达几百种计算实例,包括推理、训练以及不同规格推理和训练的实例类型,同时涵盖CPU和GPU。
在选择实例时,火山引擎应用了自研的智能选型产品,当面训练场景或推理场景时,在给定推理引擎,以及该推理引擎所对应的模型时,都会给出更加适配的GPU或CPU实例。该工具也会自动探索模型参数,包括推理引擎性能等,从而找到最佳匹配实例。
最后,结合整体资源调度体系,可以通过容器、虚拟机、Service等方式,满足对资源的需求。
而在数据领域,目前在训练场景,最主要会通过TOS、CFS、VPFS支持大模型的训练和分发,可以看到所有的存储、数据库等都在逐渐转向高维化,提供了对应的存储和检索能力。

在数据安全方向,当前的存储数据,已经有了更多内容属性,企业和用户对于数据存储的安全性也更加在意。对此,火山引擎在基础架构层面提供全面的路审计能力,可通过专区形式,支持从物理机到交换机,再到专属云以及所有组件的对应审计能力。
对此,罗浩以火山引擎与游戏公司沐瞳的具体合作为例给予了解释。在对移动端游戏里出现的语言、行为进行审计和审核时,大量用到各种各样的云基础,以及包括大模型在内的多种AI产品,而火山引擎做到了让所有的产品使用都在同一朵云上,使其在整体调用过程当中,不出现额外的流量成本,也使整体调用延时达到最优化。
另外,在火山引擎与客户“美图”合作的案例中,在面对新年、元旦、情人节等流量高峰时,美图通过火山引擎弹性的资源池,同时利用火山潮汐的算力,使得应用整体使用GPU和CPU等云资源时,成本达到最优化。
罗浩最后表示,未来火山引擎AI全栈云在算力、资源管理、性能及稳定性等方面还将继续探索,为AI应用在各行业的落地,奠定更加坚实的基础,为推动各行业智能化和数字化转型的全新助力。(作者:李双)
收起阅读 »逻辑删除用户账号合规吗?
事情的起因是这样:
有一个小伙伴说自己用某电动车 App,由于种种原因后来注销了账号,注销完成之后,该 App 提示 “您的账户已删除。与您的账户关联的所有个人数据也已永久删除”。当时当他重新打开 App 之后,发现账户名变为了 unknown,邮箱和电话变成了账号的
uid@delete.account.品牌.com。更炸裂的是,这个 App 此时还是可以正常控制电动车,可以查看定位、电量、客服记录、维修记录等等信息。
小伙伴觉得心塞,感觉被这个 App 耍了,明明就没有删除个人信息,却信誓旦旦的说数据已经永久删除了。
其实咱们做后端服务的小伙伴都知道,基本上都是逻辑删除,很少很少有物理删除。
大部分公司可能都是把账号状态标记为删除,然后踢用户下线;有点良心的公司除了将账号状态标记为删除,还会将用户信息脱敏;神操作公司则把账号状态标记为删除,但是忘记踢用户下线。
于是就出现了咱们小伙伴遇到的场景了。
逻辑删除这事,其实不用看代码,就从商业角度稍微分析就知道不可能是物理删除。比如国内很多 App 对新用户都会送各种优惠券、代金券等等,如果物理删除岂不是意味着可以反复薅平台羊毛。
当然这个是各个厂的实际做法,那么这块有没有相关规定呢?松哥专门去查看了一下相关资料。

根据 GB/T 35273 中的解释,我挑两段给大家看下。
首先文档中解释了什么是删除:

去除用户个人信息的行为,使其保持不可被检索、访问的状态。
理论上来说,逻辑删除也能够实现用户信息不可被检索和访问。
再来看关于用户注销账户的规范:

删除个人信息或者匿名化处理。
从这两处解释大家可以看到,平台逻辑删除用户信息从合规上来说没有问题。
甚至可能物理删除了反而有问题。
比如张三注册了一个聊天软件实施诈骗行为,骗到钱了光速注销账号,平台也把张三的信息删除了,最后取证找不到人,在目前这种情况下,平台要不要背锅?如果平台要背锅,那你说平台会不会就真把张三信息给清空了?
对于这个小伙伴的遭遇,其实算是一个系统 BUG,账户注销,应该强制退出登录,退出之后,再想登录肯定就登录不上去了,所以也看不到自己之前的用户信息了。
小伙伴们说说,你们的系统是怎么处理这种场景的呢?
来源:juejin.cn/post/7407274895929638964
localhost和127.0.0.1的区别是什么?
今天在网上逛的时候看到一个问题,没想到大家讨论的很热烈,就是标题中这个:
localhost和127.0.0.1的区别是什么?

前端同学本地调试的时候,应该没少和localhost打交道吧,只需要执行 npm run 就能在浏览器中打开你的页面窗口,地址栏显示的就是这个 http://localhost:xxx/index.html
可能大家只是用,也没有去想过这个问题。
联想到我之前合作过的一些开发同学对它们俩的区别也没什么概念,所以我觉得有必要普及下。
localhost是什么呢?
localhost是一个域名,和大家上网使用的域名没有什么本质区别,就是方便记忆。
只是这个localhost的有效范围只有本机,看名字也能知道:local就是本地的意思。
张三和李四都可以在各自的机器上使用localhost,但获取到的也是各自的页面内容,不会相互打架。
从域名到程序
要想真正的认清楚localhost,我们还得从用户是如何通过域名访问到程序说起。
以访问百度为例。
1、当我们在浏览器输入 baidu.com 之后,浏览器首先去DNS中查询 baidu.com 的IP地址。
为什么需要IP地址呢?打个比方,有个人要寄快递到你的公司,快递单上会填写:公司的通讯地址、公司名称、收件人等信息,实际运输时快递会根据通信地址进行层层转发,最终送到收件人的手中。网络通讯也是类似的,其中域名就像公司名称,IP地址就像通信地址,在网络的世界中只有通过IP地址才能找到对应的程序。
DNS就像一个公司黄页,其中记录着每个域名对应的IP地址,当然也有一些域名可能没做登记,就找不到对应的IP地址,还有一些域名可能会对应多个IP地址,DNS会按照规则自动返回一个。我们购买了域名之后,一般域名服务商会提供一个域名解析的功能,就是把域名和对应的IP地址登记到DNS中。
这里的IP地址从哪里获取呢?每台上网的电脑都会有1个IP地址,但是个人电脑的IP地址一般是不行的,个人电脑的IP地址只适合内网定位,就像你公司内部的第几栋第几层,公司内部人明白,但是直接发给别人,别人是找不到你的。如果你要对外部提供服务,比如百度这种,你就得有公网的IP地址,这个IP地址一般由网络服务运营商提供,比如你们公司使用联通上网,那就可以让联通给你分配一个公网IP地址,绑定到你们公司的网关服务器上,网关服务器就像电话总机,公司内部的所有网络通信都要通过它,然后再在网关上设置转发规则,将网络请求转发到提供网络服务的机器上。
2、有了IP地址之后,浏览器就会向这个IP地址发起请求,通过操作系统打包成IP请求包,然后发送到网络上。网络传输有一套完整的路由协议,它会根据你提供的IP地址,经过路由器的层层转发,最终抵达绑定该IP的计算机。
3、计算机上可能部署了多个网络应用程序,这个请求应该发给哪个程序呢?这里有一个端口的概念,每个网络应用程序启动的时候可以绑定一个或多个端口,不同的网络应用程序绑定的端口不能重复,再次绑定时会提示端口被占用。通过在请求中指定端口,就可以将消息发送到正确的网络处理程序。
但是我们访问百度的时候没有输入端口啊?这是因为默认不输入就使用80和443端口,http使用80,https使用443。我们在启动网络程序的时候一定要绑定一个端口的,当然有些框架会自动选择一个计算机上未使用的端口。

localhost和127.0.0.1的区别是什么?
有了上边的知识储备,我们就可以很轻松的搞懂这个问题了。
localhost是域名,上文已经说过了。
127.0.0.1 呢?是IP地址,当前机器的本地IP地址,且只能在本机使用,你的计算机不联网也可以用这个IP地址,就是为了方便开发测试网络程序的。我们调试时启动的程序就是绑定到这个IP地址的。
这里简单说下,我们经常看到的IP地址一般都是类似 X.X.X.X 的格式,用"."分成四段。其实它是一个32位的二进制数,分成四段后,每一段是8位,然后每一段再转换为10进制的数进行显示。
那localhost是怎么解析到127.0.0.1的呢?经过DNS了吗?没有。每台计算机都可以使用localhost和127.0.0.1,这没办法让DNS来做解析。
那就让每台计算机自己解决了。每台计算机上都有一个host文件,其中写死了一些DNS解析规则,就包括 localhost 到 127.0.0.1 的解析规则,这是一个约定俗成的规则。
如果你不想用localhost,那也可以,随便起个名字,比如 wodehost,也解析到 127.0.0.1 就行了。
甚至你想使用 baidu.com 也完全可以,只是只能自己自嗨,对别人完全没有影响。
域名的等级划分
localhost不太像我们平常使用的域名,比如 http://www.juejin.cn 、baidu.com、csdn.net, 这里边的 www、cn、com、net都是什么意思?localhost为什么不需要?
域名其实是分等级的,按照等级可以划分为顶级域名、二级域名和三级域名...
顶级域名(TLD):顶级域名是域名系统中最高级别的域名。它位于域名的最右边,通常由几个字母组成。顶级域名分为两种类型:通用顶级域名和国家顶级域名。常见的通用顶级域名包括表示工商企业的.com、表示网络提供商的.net、表示非盈利组织的.org等,而国家顶级域名则代表特定的国家或地区,如.cn代表中国、.uk代表英国等。
二级域名(SLD):二级域名是在顶级域名之下的一级域名。它是由注册人自行选择和注册的,可以是个性化的、易于记忆的名称。例如,juejin.cn 就是二级域名。我们平常能够申请到的也是这种。目前来说申请 xxx.com、xxx.net、xxx.cn等等域名,其实大家不太关心其顶级域名com\net\cn代表的含义,看着简短好记是主要诉求。
三级域名(3LD):三级域名是在二级域名之下的一级域名。它通常用于指向特定的服务器或子网。例如,在blog.example.com中,blog就是三级域名。www是最常见的三级域名,用于代表网站的主页或主站点,不过这只是某种流行习惯,目前很多网站都推荐直接使用二级域名访问了。
域名级别还可以进一步细分,大家可以看看企业微信开放平台这个域名:developer.work.weixin.qq.com,com代表商业,qq代表腾讯,weixin代表微信,work代表企业微信,developer代表开发者。这种逐层递进的方式有利于域名的分配管理。
按照上边的等级定义,我们可以说localhost是一个顶级域名,只不过它是保留的顶级域,其唯一目的是用于访问当前计算机。
多网站共用一个IP和端口
上边我们说不同的网络程序不能使用相同的端口,其实是有办法突破的。
以前个人博客比较火的时候,大家都喜欢买个虚拟主机,然后部署个开源的博客程序,抒发一下自己的感情。为了挣钱,虚拟主机的服务商会在一台计算机上分配N多个虚拟主机,大家使用各自的域名和默认的80端口进行访问,也都相安无事。这是怎么做到的呢?
如果你有使用Nginx、Apache或者IIS等Web服务器的相关经验,你可能会接触到主机头这个概念。主机头其实就是一个域名,通过设置主机头,我们的程序就可以共用1个网络端口。
首先在Nginx等Web程序中部署网站时,我们会进行一些配置,此时在主机头中写入网站要使用的域名。
然后Nginx等Web服务器启动的时候,会把80端口占为己有。
然后当某个网站的请求到达Nginx的80端口时,它会根据请求中携带的域名找到配置了对应主机头的网络程序。
然后再转发到这个网络程序,如果网络程序还没有启动,Nginx会把它拉起来。
私有IP地址
除了127.0.0.1,其实还有很多私有IP地址,比如常见的 192.168.x.x。这些私有IP地址大部分都是为了在局域网内使用而预留的,因为给每台计算机都分配一个独立的IP不太够用,所以只要局域网内不冲突,大家就可劲的用吧。你公司可以用 192.168.1.1,我公司也可以用192.168.1.1,但是如果你要访问我,就得通过公网IP进行转发。
大家常用的IPv4私有IP地址段分为三类:
A类:从10.0.0.0至10.255.255.255
B类:从172.16.0.0至172.31.255.255
C类:从192.168.0.0至192.168.255.255。
这些私有IP地址仅供局域网内部使用,不能在公网上使用。
--
除了上述三个私有的IPv4地址段外,还有一些保留的IPv4地址段:
用于本地回环测试的127.0.0.0至127.255.255.255地址段,其中就包括题目中的127.0.0.1,如果你喜欢也可以给自己分配一个127.0.0.2的IP地址,效果和127.0.0.1一样。
用于局域网内部的169.254.0.0至169.254.255.255地址段,这个很少接触到,如果你的电脑连局域网都上不去,可能会看到这个IP地址,它是临时分配的一个局域网地址。
这些地址段也都不能在公网上使用。
--
近年来,还有一个现象,就是你家里或者公司里上网时,光猫或者路由器对外的IPv4地址也不是公网IP了,这时候获得的可能是一个类似 100.64.x.x 的地址,这是因为随着宽带的普及,运营商手里的公网IP也不够了,所以运营商又加了一层局域网,而100.64.0.0 这个网段是专门分给运营商做局域网用的。如果你使用阿里云等公有云,一些云产品的IP地址也可能是这个,这是为了将客户的私有网段和公有云厂商的私有网段进行有效的区分。
--
其实还有一些不常见的专用IPv4地址段,完整的IP地址段定义可以看这里:http://www.iana.org/assignments…

IPv6
你可能也听说过IPv6,因为IPv4可分配的地址太少了,不够用,使用IPv6甚至可以为地球上的每一粒沙子分配一个IP。只是喊了很多年,大家还是喜欢用IPv4,这里边原因很多,这里就不多谈了。
IPv6地址类似:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX:XXXX
它是128位的,用":"分成8段,每个X是一个16进制数(取值范围:0-F),IPv6地址空间相对于IPv4地址有了极大的扩充。比如:2001:0db8:3c4d:0015:0000:0000:1a2f:1a2b 就是一个有效的IPv6地址。
关于IPv6这里就不多说了,有兴趣的可以再去研究下。
关注萤火架构,加速技术提升!
来源:juejin.cn/post/7321049446443417638
前端如何将git的信息打包进html
为什么要做这件事
- 定制化项目我们没有参与或者要临时更新客户的包的时候,需要查文档才知道哪个是最新分支
- 当测试环境打包的时候,不确定是否是最新的包,需要点下功能看是否是最新的代码,不能直观的看到当前打的是哪个分支
- 多人开发的时候,某些场景下可能被别人覆盖了,需要查下jenkins或者登录服务器看下
实现效果
如下,当打开F12,可以直观的看到打包日期、分支、提交hash、提交时间

如何做
主要是借助 git-revision-webpack-plugin的能力。获取到git到一些后,将这些信息注入到变量中,html读取这个变量即可
1. 安装dev的依赖
npm install --save-dev git-revision-webpack-plugin
2. 引入依赖并且初始化
const { GitRevisionPlugin } = require('git-revision-webpack-plugin')
const gitRevisionPlugin = new GitRevisionPlugin()
3. 注入变量信息
我这里用的是vuecli,可直接在chainWebpack中注入,当然你可以使用DefinePlugin进行声明
config.plugin('html').tap((args) => {
args[0].banner = {
date: dayjs().format('YYYY-MM-DD HH:mm:ss'),
branch: gitRevisionPlugin.branch(),
commitHash: gitRevisionPlugin.commithash(),
lastCommitDateTime: dayjs(gitRevisionPlugin.lastcommitdatetime()).format('YYYY-MM-DD HH:mm:ss'),
}
return args
});
4. 使用变量
在index.html的头部插入注释
<!-- date <%= htmlWebpackPlugin.options.banner.date %> -->
<!-- branch <%= htmlWebpackPlugin.options.banner.branch %> -->
<!-- commitHash <%= htmlWebpackPlugin.options.banner.commitHash %> -->
<!-- lastCommitDateTime <%= htmlWebpackPlugin.options.banner.lastCommitDateTime %> -->
5. 查看页面
6. 假如你用的是vuecli
当你使用的是vuecli,构建完后会发现index.html上这个注释丢失了
原因如下
vueCLi 对html的打包用的html-webpack-plugin,默认在打包的时候会把注释删除掉

修改vuecli的配置如下可以解决,将removeComments设置为false即可
module.exports = {
// 其他配置项...
chainWebpack: config => {
config
.plugin('html')
.tap(args => {
args[0].minify = {
removeComments: false,
// 其他需要设置的参数
};
return args;
});
},
};
7. 假如你想给qiankun的子应用添加一些git的注释信息,可以在meta中添加
<meta name="description"
content="Date:<%= htmlWebpackPlugin.options.banner.date %>,Branch:<%= htmlWebpackPlugin.options.banner.branch %>,commitHash: <%= htmlWebpackPlugin.options.banner.commitHash %>,lastCommitDateTime:<%= htmlWebpackPlugin.options.banner.lastCommitDateTime %>">
渲染在html上如下,也可以快速的看到子应用的构建时间和具体的分支

总结
- 借助git-revision-webpack-plugin的能力读取到git的一些信息
- 将变量注入在html中或者使用DefinePlugin进行声明变量
- 读取变量后显示在html上或者打印在控制台上可以把关键的信息保留,方便我们排查问题
来源:juejin.cn/post/7403185402347634724
三个月内遭遇的第二次比特币勒索
早前搭过一个wiki (可点击wiki.dashen.tech 查看),用于"团队协作与知识分享".把游客账号给一位前同事,其告知登录出错.

用我记录的账号密码登录,同样报错; 打开数据库一看,疑惑全消.

To recover your lost Database and avoid leaking it: Send us 0.05 Bitcoin (BTC) to our Bitcoin address 3F4hqV3BRYf9JkPasL8yUPSQ5ks3FF3tS1 and contact us by Email with your Server IP or Domain name and a Proof of Payment. Your Database is downloaded and backed up on our servers. Backups that we have right now: mm_wiki, shuang. If we dont receive your payment in the next 10 Days, we will make your database public or use them otherwise.
(按照今日比特币价格,0.05比特币折合人民币4 248.05元..)
大多时候不使用该服务器上安装的mysql,因而账号和端口皆为默认,密码较简单且常见,为在任何地方navicat也可连接,去掉了ip限制...对方写一个脚本,扫描各段ip地址,用常见的几个账号和密码去"撞库",几千几万个里面,总有一两个能得手.
被窃取备份而后删除的两个库,一个是来搭建该wiki系统,另一个是用来亲测mysql主从同步,详见此篇,价值都不大
实践告诉我们,不要用默认账号,不要用简单密码,要做ip限制。…
- 登录服务器,登录到mysql:
mysql -u root -p

- 修改密码:
尝试使用如下语句来修改
set password for 用户名@yourhost = password('新密码');
结果报错;查询得知是最新版本更改了语法,需用
alter user 'root'@'localhost' identified by 'yourpassword';

成功~
但在navicat里,原连接依然有效,而输入最新的密码,反倒是失败

打码部分为本机ip
在服务器执行
-- 查询所有用户
select user from mysql.user;
再执行
select host,user,authentication_string from mysql.user;

user及其后的host组合在一起,才构成一个唯一标识;故而在user表中,可以存在同名的root
使用
alter user 'root'@'%' identified by 'xxxxxx';
注意主机此处应为%
再使用
select host,user,authentication_string from mysql.user;
发现 "root@%" 对应的authentication_string已发生改变;
在navicat中旧密码已失效,需用最新密码才可登录
参考:
这不是第一次遭遇"比特币勒索",在四月份,收到了这么一封邮件:

后来证明这是唬人的假消息,但还是让我学小扎,把Mac的摄像头覆盖了起来..
来源:juejin.cn/post/7282666367239995392
让生成式 AI 触手可及:火山引擎推出 NVIDIA NIM on VKE 最佳部署实践
技术行业近来对大语言模型(LLM)的关注正开始转向生产环境的大规模部署,将 AI 模型接入现有基础设施以优化系统性能,包括降低延迟、提高吞吐量,以及加强日志记录、监控和安全性等。然而这一路径既复杂又耗时,往往需要构建专门的平台和流程。
在部署 AI 模型的过程中,研发团队通常需要执行以下步骤:
环境搭建与配置:首先需要准备和调试运行环境,这包括但不限于 CUDA、Python、PyTorch 等依赖项的安装与配置。这一步骤往往较为复杂,需要细致地调整各个组件以确保兼容性和性能。
模型优化与封装:接下来进行模型的打包和优化,以提高推理效率。这通常涉及到使用 NVIDIA TensorRT 软件开发套件或 NVIDIA TensorRT-LLM 库等专业工具来优化模型,并根据性能测试结果和经验来调整推理引擎的配置参数。这一过程需要深入的 AI 领域知识,并且工具的使用具有一定的学习成本。
模型部署:最后,将优化后的模型部署到生产环境中。对于非容器化环境,资源的准备和管理也是一个需要精心策划的环节。
为了简化上述流程并降低技术门槛,火山引擎云原生团队推出基于 VKE 的 NVIDIA NIM 微服务最佳实践。通过结合 NIM 一站式模型服务能力,以及火山引擎容器服务 VKE 在成本节约和极简运维等方面的优势,这套开箱即用的技术方案将帮助企业更加快捷和高效地部署 AI 模型。
AI 微服务化:NVIDIA NIM
NVIDIA NIM 是一套经过优化的企业级生成式 AI 微服务,它包括推理引擎,通过 API 接口对外提供服务,帮助企业和个人开发者更简单地开发和部署 AI 驱动的应用程序。
NIM 使用行业标准 API,支持跨多个领域的 AI 用例,包括 LLM、视觉语言模型(VLM),以及用于语音、图像、视频、3D、药物研发、医学成像等的模型。同时,它基于 NVIDIA Triton™ Inference Server、NVIDIA TensorRT™、NVIDIA TensorRT-LLM 和 PyTorch 构建,可以在加速基础设施上提供最优的延迟和吞吐量。
为了进一步降低复杂度,NIM 将模型和运行环境做了解耦,以容器镜像的形式为每个模型或模型系列打包。其在 Kubernetes 内的部署形态如下:

NVIDIA NIM on Kubernetes
火山引擎容器服务 VKE(Volcengine Kubernetes Engine)通过深度融合新一代云原生技术,提供以容器为核心的高性能 Kubernetes 容器集群管理服务,可以为 NIM 提供稳定可靠高性能的运行环境,实现模型使用和运行的强强联合。
同时,模型服务的发布和运行也离不开发布管理、网络访问、观测等能力,VKE 深度整合了火山引擎高性能计算(ECS/裸金属)、网络(VPC/EIP/CLB)、存储(EBS/TOS/NAS)、弹性容器实例(VCI)等服务,并与镜像仓库、持续交付、托管 Prometheus、日志服务、微服务引擎等云产品横向打通,可以实现 NIM 服务构建、部署、发布、监控等全链路流程,帮助企业更灵活、更敏捷地构建和扩展基于自身数据的定制化大型语言模型(LLMs),打造真正的企业级智能化、自动化基础设施。
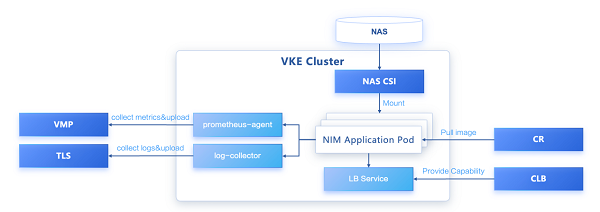
NVIDIA NIM on VKE 部署流程
下面,我们将介绍 NIM on VKE 的部署流程,助力开发者快速部署和访问 AI 模型。
准备工作
部署 NVIDIA NIM 前,需要做好如下准备:
1. VKE 集群中已安装 csi-nas / prometheus-agent / vci-virtual-kubelet / cr-credential-controller 组件
2. 在 VKE 集群中使用相适配的 VCI GPU 实例规格,具体软硬件支持情况可以查看硬件要求
3. 创建 NAS 实例,作为存储类,用于模型文件的存储
4. 创建 CR(镜像仓库) 实例,用于托管 NIM 镜像
5. 开通 VMP(托管 Prometheus)服务
6. 向 NVIDIA 官方获取 NIM 相关镜像的拉取权限(下述以 llama3-8b-instruct:1.0.0 为例),并生成 API Key
部署
1. 在国内运行 NIM 官方镜像时,为了避免网络访问影响镜像拉取速度,可以提前拉取相应 NIM 镜像并上传到火山引擎镜像仓库 CR,操作步骤如下:

2. Download the code locally, go to the Helm Chart directory of the code, and push Helm Chart to Container Registry (Helm version > 3.7):
下载代码到本地,进入到代码的 helm chart 目录中,把 helm chart 推送到镜像仓库(helm 版本大于 3.7):

3. 在 vke 的应用中心的 helm 应用中选择创建 helm 应用,并选择对应 chart,集群信息,并点击 values.yaml 的编辑按钮进入编辑页
4. 覆盖 values 内容为如下值来根据火山引擎环境调整参数配置,提升部署性能,点击确定完成参数改动,再继续在部署页点击确定完成部署

5. 若 Pod 日志出现如下内容或者 Pod 状态变成 Ready,说明服务已经准备好:

6. 在 VKE 控制台获取 LB Service 地址(Service 名称为

7. 访问 NIM 服务

The output is as follows:
会有如下输出:
监控
NVIDIA NIM 在 Grafana Dashboard 上提供了丰富的观测指标,详情可参考 Observability
在 VKE 中,可通过如下方法搭建 NIM 监控:
1. 参考文档搭建 Grafana:https://www.volcengine.com/docs/6731/126068
2. 进入 Grafana 中,在 dashboard 菜单中选择 import:
3. 观测面板效果如下:
结语
相比构建大模型镜像,基于 VKE 使用 NVIDIA NIM 部署和访问模型有如下优点:
● 易用性:NIM 提供了预先构建好的模型容器镜像,用户无需从头开始构建和配置环境,配合 VKE 与 CR 的应用部署能力,极大简化了部署过程
● 性能优化:NIM 的容器镜像是经过优化的,可以在 NVIDIA GPU 上高效运行,充分利用 VCI 的硬件性能
● 模型选择:NIM 官方提供了多种大语言模型,用户可以根据需求选择合适的模型,部署在 VKE 中仅需对values.yaml 配置做修改即可
● 自动更新:通过 NGC,NIM 可以自动下载和更新模型,用户无需手动管理模型版本
● 可观测性:NIM 内置了丰富的观测指标,配合 VKE 与 VMP 观测能力开箱即用
目前火山引擎容器服务 VKE 已开放个人用户使用,为个人和企业用户提供高性能、高可靠、极致弹性的企业级容器管理能力,结合 NIM 强大易用的模型部署服务,进一步帮助开发者快速部署 AI 模型,并提供高性能、开箱即用的模型 API 服务。(作者:李双)
收起阅读 »好好的短链,url?1=1为啥变成了url???1=1
运营小伙伴突然找到我们说,我们的一个短链有三个?
第一反应就是不可能,但是事实胜于雄辩,还真的就是和运营小伙伴说的一模一样。
到底发生了什么呢?跟着我一起Review一下。
一、URL结构
1.1 URL概述
URL(统一资源定位符)是一个用于标识互联网上资源的地址。一个典型的URL结构通常包括以下几个部分:

- 协议(Scheme) :也称为"服务方式",位于URL的开头,指定了浏览器与服务器之间通信的方式。常见的协议有
http(超文本传输协议)、https(安全超文本传输协议)、ftp(文件传输协议)等。 - 子域名(Subdomain) :可选部分,位于域名之前,通常用于区分不同的服务或组织。例如,在
sub.example.com中,sub是子域名。 - 域名(Domain Name) :URL的核心部分,用于唯一标识一个网站。通常是一个组织或公司的名字,如
example.com。 - 端口号(Port) :可选部分,用于指定服务器上的特定服务。如果省略,浏览器将使用默认端口,例如
http和https的默认端口是80和443。 - 路径(Path) :指定服务器上的资源位置。路径可以包含多个部分,用斜杠
/分隔。例如,在/path/to/resource中,path/to/resource是资源的路径。 - 查询字符串(Query String) :可选部分,位于路径之后,用于传递额外的参数或数据。查询字符串以问号
?开始,后面跟着一系列的参数,参数之间用和号&分隔。例如,在?key1=value1&key2=value2中,key1和key2是参数名,value1和value2是对应的值。 - 片段标识符(Fragment Identifier) :可选部分,用于指向页面内的特定部分。片段标识符以井号
#开始,通常用于锚点链接。例如,在#section2中,section2是页面内的一个锚点。
1.2 URL示例
示例:一个完整的URL示例可能是下面这样的
https://www.xxx.com:8080/path/to/resource?key1=value1&key2=value2#section2
在上面的示例中,详细拆解如下:
https是协议。
http://www.xxx.com是域名。
8080是端口号。
/path/to/resource是路径。
key1=value1&key2=value2是查询字符串。
#section2是片段标识符。
二、URL的意义
URL(统一资源定位符)的意义在于它提供了一种标准化的方法来标识和访问互联网上的资源。它是互联网的基础构件之一,它不仅使得资源的定位和访问变得简单,还支持了互联网的组织、导航、安全和分享等多种功能。以下是URL的几个关键意义:

这些意义做开发的都懂,不懂的就自己百度吧,这里不做赘述。
三、硬菜:url?1=1为啥变成了url???1=1
3.1 故事背景
我们有一个自己的短链项目,用户访问短链的时候,我们自己服务器会进行重定向,这样的好处是分享出去的链接都是很短的,会有效提升用户的使用体验。
短链触发和服务器的交互流程如下:
sequenceDiagram
用户->>+短链: 点击
短链->>+服务器: 请求
服务器->>+服务器: 找到映射的长链地址
服务器->>+用户: 重定向到长链
用户->>+长链: 请求并得到响应
3.2 事故现场
上面弄清楚了短链的基本触发流程,那我我们看看到底发生了什么。
- 客户端事故现场截图

从这个截图就可以明显的看出,这里有三个?,这是不合理的...
- 数据库存储的事故现场数据截图

哎,数据库里面只有一个问号吧?
3.3 问题分析和解决方案
- 问题分析
上面数据库看着正常的,别着急,咱们换个方式看看,我们执行下面这个SQL看看数据存储的实际长度是多少。
SELECT
LENGTH(
CONVERT ( full_link USING utf8 )) AS actual_length
FROM
t_short_link
WHERE
id = '0fcc75b3e1b243c4b36d71b1d58b3b41';
执行结果:

上面sql执行实际得到的长度是52,但是我们长链的实际长度却是49,那么问题就出来了,数据库里面多了两个我们肉眼看不见的字符,三个问号就是这个来的
- 解决方案
从上面分析了事故现场,我们已经知道是多了两个字符了,删掉即可。
注意:因为数据库看不到,所以不能直接编辑,可以选择一些可以看到的编辑器编辑之后更新,例如notepad++。
3.4 额外发现
在写文章的时候,我将连接复制到了掘金的MD编辑器,发现这里也是暴露了问题,上面提到的解决方案,大家也是可以复制进来然后删除多余字符的。

四、总结
程序员大多数都非常自信,相信自己的代码没有bug,相信有bug也不是我的问题,有的时候怼天怼地。
但是真的遇到问题,需要三思而后行,谋定而后动;是不是自己的问题,先检查检查,避免后面发现是自己的问题很尴尬。
希望本文对您有所帮助。如果有任何错误或建议,请随时指正和提出。
同时,如果您觉得这篇文章有价值,请考虑点赞和收藏。这将激励我进一步改进和创作更多有用的内容。
感谢您的支持和理解!
来源:juejin.cn/post/7399985723674394633
太方便了!Arthas,生产问题大杀器
一、一个难查的生产问题
一天,小王发现生产环境上偶发性地出现某接口耗时过高,但在测试环境又无法复现,小王一筹莫展😔。小王“幻想”到:如果有个工具能记录生产上各个函数的耗时该多好,这样一看不就知道时间花在哪了?
这不是幻想,Arthas 已经帮我们解决了这个问题。在介绍它之前,我们先了解下相关背景。
一天,小王发现生产环境上偶发性地出现某接口耗时过高,但在测试环境又无法复现,小王一筹莫展😔。小王“幻想”到:如果有个工具能记录生产上各个函数的耗时该多好,这样一看不就知道时间花在哪了?
这不是幻想,Arthas 已经帮我们解决了这个问题。在介绍它之前,我们先了解下相关背景。
二、动态追踪
现在互联网和大家生活的各个方面都息息相关。相应地,互联网应用的用户规模也变得越来越大。江湖大了,什么风浪都有。开发者们不断被各种诡异问题打扰,接口耗时过大、CPU 占用过高、内存溢出、只有生产环境会报错......
这些问题出现的概率可能是千分之一、乃至万分之一。如果我们能不修改代码、不修改配置、不重启服务,就能看到程序内部在执行什么,这该多好,再大的问题心里也有底了。
动态追踪技术出现了,它诞生于21 世纪初。Sun Microsystems 公司的工程师在解决一个复杂问题时被繁琐的排查过程所困扰,痛定思痛,他们创造了 DTrace 动态跟踪框架。DTrace 奠定了动态追踪的基础,Bryan Cantrill, Mike Shapiro, and Adam Leventhal 三位作者也多次获得行业荣誉。
动态追踪技术出现的时间早,但 Java 语言相关的调试工具链一直不太完善。直到进入移动互联网时代,Java 的发展才进入了快车道。2018 年,Alibaba 开源 Arthas,Java 的动态追踪才真正好用起来。
动态追踪可以看作是构建了一个运行时“只读数据库”,这个数据库内部保存了实时变化的进程运行信息,我们通过调用这个“数据库”开放的接口,就能看到进程内部发生了什么。
经验丰富的读者可能会有疑问,现在微服务都用上了 Skywalking 这样的分布式链路追踪技术,通过它也能分阶段地看到各个部分的执行情况,为什么还需要 Arthas?
Arthas 有两大特点:
- 低侵入;不需要程序中进行额外配置,更不需要手动埋点。
- 功能强大;Arthas 提供了四十多种命令:从查看线程调用链,到查看输入、输出,到反编译代码等,应有尽有。
对于排查接口耗时长这样的情况,Skywalking 可以和 Arthas 配合起来,先用 Skywalking 定位出异常微服务,再用 Arthas 分析单个进程的情况,找到根因。
现在互联网和大家生活的各个方面都息息相关。相应地,互联网应用的用户规模也变得越来越大。江湖大了,什么风浪都有。开发者们不断被各种诡异问题打扰,接口耗时过大、CPU 占用过高、内存溢出、只有生产环境会报错......
这些问题出现的概率可能是千分之一、乃至万分之一。如果我们能不修改代码、不修改配置、不重启服务,就能看到程序内部在执行什么,这该多好,再大的问题心里也有底了。
动态追踪技术出现了,它诞生于21 世纪初。Sun Microsystems 公司的工程师在解决一个复杂问题时被繁琐的排查过程所困扰,痛定思痛,他们创造了 DTrace 动态跟踪框架。DTrace 奠定了动态追踪的基础,Bryan Cantrill, Mike Shapiro, and Adam Leventhal 三位作者也多次获得行业荣誉。
动态追踪技术出现的时间早,但 Java 语言相关的调试工具链一直不太完善。直到进入移动互联网时代,Java 的发展才进入了快车道。2018 年,Alibaba 开源 Arthas,Java 的动态追踪才真正好用起来。
动态追踪可以看作是构建了一个运行时“只读数据库”,这个数据库内部保存了实时变化的进程运行信息,我们通过调用这个“数据库”开放的接口,就能看到进程内部发生了什么。
经验丰富的读者可能会有疑问,现在微服务都用上了 Skywalking 这样的分布式链路追踪技术,通过它也能分阶段地看到各个部分的执行情况,为什么还需要 Arthas?
Arthas 有两大特点:
- 低侵入;不需要程序中进行额外配置,更不需要手动埋点。
- 功能强大;Arthas 提供了四十多种命令:从查看线程调用链,到查看输入、输出,到反编译代码等,应有尽有。
对于排查接口耗时长这样的情况,Skywalking 可以和 Arthas 配合起来,先用 Skywalking 定位出异常微服务,再用 Arthas 分析单个进程的情况,找到根因。
三、Arthas常用场景
相信你对动态追踪有了基本的了解,Arthas 可以理解为动态追踪在 Java 领域落地的具体工具。下面以场景助学,大家可以参考这些方案,因事制宜来解决自己的问题。
Arthas 的安装和基础使用见官方文档:Introduction | arthas。
相信你对动态追踪有了基本的了解,Arthas 可以理解为动态追踪在 Java 领域落地的具体工具。下面以场景助学,大家可以参考这些方案,因事制宜来解决自己的问题。
Arthas 的安装和基础使用见官方文档:Introduction | arthas。
3.1.接口慢/吞吐量低
在文章开头,小王就遇到了这个问题。现在小王依靠老道的排查经验确定了 MathGame 服务肯定有问题,但具体的点却找不到。小王仔细学习了这篇文章,决定用 Arthas 分以下三步来排查:
- profile 明确整体的耗时情况
profile 命令支持为应用生成火焰图,在 Arthas 终端输入以下命令:
# 开始对应用中当前执行的活动采样 30 秒,采样结束后默认会生成 HTML 文件
[arthas@5555]$ profiler start -d 30
打开 HTML 文件能看到这样的结构:

火焰图
MathGame 类下的 run 方法占用了大部分的执行时间,接下来我们看看 run 方法内部的耗时情况。
- trace 详细查看单个调用的内部耗时
[arthas@5555]$ trace --skipJDKMethod false demo.MathGame run
PrintStream 类的 print 方法占据了 87% 的时间,这是 JDK 自带的类,这说明我们程序本身并无耗时问题,但 MathGame 类的 primeFactors 方法抛出了异常,我们可以看看具体的异常,再思考怎么优化。

run方法的trace流
另外,trace 可以选择性地进行调用拦截,比如设置只拦截大于 20ms 的调用:
[arthas@5555]$ trace demo.MathGame run '#cost > 20'
- watch 查看真实的调用数据
拦截 primeFactors 方法抛出的异常:
[arthas@5555]$ watch demo.MathGame primeFactors -e "throwExp"

拦截异常
小王从大到小、逐步分析,找出了问题的原因是 primeFactors 抛出了异常,修正参数后,程序恢复了正常。
在文章开头,小王就遇到了这个问题。现在小王依靠老道的排查经验确定了 MathGame 服务肯定有问题,但具体的点却找不到。小王仔细学习了这篇文章,决定用 Arthas 分以下三步来排查:
- profile 明确整体的耗时情况
profile 命令支持为应用生成火焰图,在 Arthas 终端输入以下命令:
# 开始对应用中当前执行的活动采样 30 秒,采样结束后默认会生成 HTML 文件
[arthas@5555]$ profiler start -d 30
打开 HTML 文件能看到这样的结构:
火焰图MathGame 类下的 run 方法占用了大部分的执行时间,接下来我们看看 run 方法内部的耗时情况。
- trace 详细查看单个调用的内部耗时
[arthas@5555]$ trace --skipJDKMethod false demo.MathGame run
PrintStream 类的 print 方法占据了 87% 的时间,这是 JDK 自带的类,这说明我们程序本身并无耗时问题,但 MathGame 类的 primeFactors 方法抛出了异常,我们可以看看具体的异常,再思考怎么优化。
run方法的trace流另外,trace 可以选择性地进行调用拦截,比如设置只拦截大于 20ms 的调用:
[arthas@5555]$ trace demo.MathGame run '#cost > 20'
- watch 查看真实的调用数据
拦截 primeFactors 方法抛出的异常:
[arthas@5555]$ watch demo.MathGame primeFactors -e "throwExp"
拦截异常
小王从大到小、逐步分析,找出了问题的原因是 primeFactors 抛出了异常,修正参数后,程序恢复了正常。
3.2.CPU 占用过高
CPU 是程序运行的核心计算资源,一旦出现 CPU 占用过高,必定对大部分用户的访问耗时产生影响。针对这类问题,要定位出有问题的线程,并获取该线程当前执行的代码位置。
使用 top + jstack 命令可以定位这类问题(见参考资料三),Arthas 也提供了更便捷的一体化工具:
- 定位目标线程
# 调用线程看板,并刷新数据三次
[arthas@5555]$ dashboard -n 3

示例程序的CPU占用不算高
DashBoard 刷新三次后,在最新状态中发现示例程序里自己的线程 “main” 占用不算高。说明程序运行正常。如果是要排错,这里就要找出 CPU 占用最高的用户线程的 ID。
- 查看目标线程执行的代码位置
# “1” 是上一步定位到的 main 的线程ID
[arthas@5555]$ thread 1

线程正在“睡觉”,没什么大问题。
CPU 是程序运行的核心计算资源,一旦出现 CPU 占用过高,必定对大部分用户的访问耗时产生影响。针对这类问题,要定位出有问题的线程,并获取该线程当前执行的代码位置。
使用 top + jstack 命令可以定位这类问题(见参考资料三),Arthas 也提供了更便捷的一体化工具:
- 定位目标线程
# 调用线程看板,并刷新数据三次
[arthas@5555]$ dashboard -n 3
示例程序的CPU占用不算高DashBoard 刷新三次后,在最新状态中发现示例程序里自己的线程 “main” 占用不算高。说明程序运行正常。如果是要排错,这里就要找出 CPU 占用最高的用户线程的 ID。
- 查看目标线程执行的代码位置
# “1” 是上一步定位到的 main 的线程ID
[arthas@5555]$ thread 1
线程正在“睡觉”,没什么大问题。
3.3 生产环境的效果和测试不一样
有些时候你发现:测试环境正常,但生产就报错了。这类问题主要靠做好上线流程的管控,但也有可能是打包的依赖库出现冲突,造成程序行为不一致。接下来,我们看看怎么用 Arthas 反编译代码,以及怎么对比依赖库的版本。
- 反编译代码
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ jad demo.MathGame

- 查看目标类所属的依赖包
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ sc -d demo.MathGame

目标类所属的包
如果这里是依赖包,code-source 还可以显示所属包的版本。这样就可以对比本地的代码,从而在打包时设置正确的依赖版本。
有些时候你发现:测试环境正常,但生产就报错了。这类问题主要靠做好上线流程的管控,但也有可能是打包的依赖库出现冲突,造成程序行为不一致。接下来,我们看看怎么用 Arthas 反编译代码,以及怎么对比依赖库的版本。
- 反编译代码
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ jad demo.MathGame
- 查看目标类所属的依赖包
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ sc -d demo.MathGame
如果这里是依赖包,code-source 还可以显示所属包的版本。这样就可以对比本地的代码,从而在打包时设置正确的依赖版本。
目标类所属的包
3.4 内存溢出
生产问题中内存溢出也有不小的比例。内存溢出的关键是找出高内存占用的对象。命令行操作会比较麻烦,建议转储 Heap Dump 等文件后,通过 Eclipse Memory Analyzer(MAT) 等工具进行分析。
四、运行 Arthas 报错
在有些运行环境下,Arthas 会出现报错。对于以下两种情况,读者可参照文档解决:
- 不兼容 Skywalking
Compatible-with-other-javaagent-bytecode-processing - Alpine 镜像的容器无法生成火焰图
Alpine容器镜像中生成火焰图错误的其它解决方案
五、参考资料
作者:立子
来源:juejin.cn/post/7308230350374256666
来源:juejin.cn/post/7308230350374256666
SpringBoot 这么实现动态数据源切换,就很丝滑!
大家好,我是小富~
简介
项目开发中经常会遇到多数据源同时使用的场景,比如冷热数据的查询等情况,我们可以使用类似现成的工具包来解决问题,但在多数据源的使用中通常伴随着定制化的业务,所以一般的公司还是会自行实现多数据源切换的功能,接下来一起使用实现自定义注解的形式来实现一下。
基础配置
yml配置
pom.xml文件引入必要的Jar
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.6</version>
</parent>
<groupId>com.dynamic</groupId>
<artifactId>springboot-dynamic-datasource</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<mybatis.plus.version>3.5.3.1</mybatis.plus.version>
<mysql.connector.version>8.0.32</mysql.connector.version>
<druid.version>1.2.6</druid.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- springboot核心包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mysql驱动包 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.connector.version}</version>
</dependency>
<!-- lombok工具包 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- MyBatis Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis.plus.version}</version>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
管理数据源
我们应用ThreadLocal来管理数据源信息,通过其中内容的get,set,remove方法来获取、设置、删除当前线程对应的数据源。
/**
* ThreadLocal存放数据源变量
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> DATASOURCE_HOLDER = new ThreadLocal<>();
/**
* 获取当前线程的数据源
*
* @return 数据源名称
*/
public static String getDataSource() {
return DATASOURCE_HOLDER.get();
}
/**
* 设置数据源
*
* @param dataSourceName 数据源名称
*/
public static void setDataSource(String dataSourceName) {
DATASOURCE_HOLDER.set(dataSourceName);
}
/**
* 删除当前数据源
*/
public static void removeDataSource() {
DATASOURCE_HOLDER.remove();
}
}
重置数据源
创建 DynamicDataSource 类并继承 AbstractRoutingDataSource,这样我们就可以重置当前的数据库路由,实现切换成想要执行的目标数据库。
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import javax.sql.DataSource;
import java.util.Map;
/**
* 重置当前的数据库路由,实现切换成想要执行的目标数据库
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
public DynamicDataSource(DataSource defaultDataSource, Map<Object, Object> targetDataSources) {
super.setDefaultTargetDataSource(defaultDataSource);
super.setTargetDataSources(targetDataSources);
}
/**
* 这一步是关键,获取注册的数据源信息
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.getDataSource();
}
}
配置数据库
在 application.yml 中配置数据库信息,使用dynamic_datasource_1、dynamic_datasource_2两个数据库
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
master:
url: jdbc:mysql://127.0.0.1:3306/dynamic_datasource_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 12345
driver-class-name: com.mysql.cj.jdbc.Driver
slave:
url: jdbc:mysql://127.0.0.1:3306/dynamic_datasource_2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 12345
driver-class-name: com.mysql.cj.jdbc.Driver
再将多个数据源注册到DataSource.
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* 注册多个数据源
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@Configuration
public class DateSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource dynamicDatasourceMaster() {
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
public DataSource dynamicDatasourceSlave() {
return DruidDataSourceBuilder.create().build();
}
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource createDynamicDataSource() {
Map<Object, Object> dataSourceMap = new HashMap<>();
// 设置默认的数据源为Master
DataSource defaultDataSource = dynamicDatasourceMaster();
dataSourceMap.put("master", defaultDataSource);
dataSourceMap.put("slave", dynamicDatasourceSlave());
return new DynamicDataSource(defaultDataSource, dataSourceMap);
}
}
启动类配置
在启动类的@SpringBootApplication注解中排除DataSourceAutoConfiguration,否则会报错。
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
到这多数据源的基础配置就结束了,接下来测试一下
测试切换
准备SQL
创建两个库dynamic_datasource_1、dynamic_datasource_2,库中均创建同一张表 t_dynamic_datasource_data。
CREATE TABLE `t_dynamic_datasource_data` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`source_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
dynamic_datasource_1.t_dynamic_datasource_data表中插入
insert int0 t_dynamic_datasource_data (source_name) value ('dynamic_datasource_master');
dynamic_datasource_2.t_dynamic_datasource_data表中插入
insert int0 t_dynamic_datasource_data (source_name) value ('dynamic_datasource_slave');
手动切换数据源
这里我准备了一个接口来验证,传入的 datasourceName 参数值就是刚刚注册的数据源的key。
/**
* 动态数据源切换
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@RestController
public class DynamicSwitchController {
@Resource
private DynamicDatasourceDataMapper dynamicDatasourceDataMapper;
@GetMapping("/switchDataSource/{datasourceName}")
public String switchDataSource(@PathVariable("datasourceName") String datasourceName) {
DataSourceContextHolder.setDataSource(datasourceName);
DynamicDatasourceData dynamicDatasourceData = dynamicDatasourceDataMapper.selectOne(null);
DataSourceContextHolder.removeDataSource();
return dynamicDatasourceData.getSourceName();
}
}
传入参数master时:127.0.0.1:9004/switchDataSource/master

传入参数slave时:127.0.0.1:9004/switchDataSource/slave

通过执行结果,我们看到传递不同的数据源名称,已经实现了查询对应的数据库数据。
注解切换数据源
上边已经成功实现了手动切换数据源,但这种方式顶多算是半自动,下边我们来使用注解方式实现动态切换。
定义注解
我们先定一个名为DS的注解,作用域为METHOD方法上,由于@DS中设置的默认值是:master,因此在调用主数据源时,可以不用进行传值。
/**
* 定于数据源切换注解
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DS {
// 默认数据源master
String value() default "master";
}
实现AOP
定义了@DS注解后,紧接着实现注解的AOP逻辑,拿到注解传递值,然后设置当前线程的数据源
import com.dynamic.config.DataSourceContextHolder;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.util.Objects;
/**
* 实现@DS注解的AOP切面
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@Aspect
@Component
@Slf4j
public class DSAspect {
@Pointcut("@annotation(com.dynamic.aspect.DS)")
public void dynamicDataSource() {
}
@Around("dynamicDataSource()")
public Object datasourceAround(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
DS ds = method.getAnnotation(DS.class);
if (Objects.nonNull(ds)) {
DataSourceContextHolder.setDataSource(ds.value());
}
try {
return point.proceed();
} finally {
DataSourceContextHolder.removeDataSource();
}
}
}
测试注解
再添加两个接口测试,使用@DS注解标注,使用不同的数据源名称,内部执行相同的查询条件,看看结果如何?
@DS(value = "master")
@GetMapping("/dbMaster")
public String dbMaster() {
DynamicDatasourceData dynamicDatasourceData = dynamicDatasourceDataMapper.selectOne(null);
return dynamicDatasourceData.getSourceName();
}

@DS(value = "slave")
@GetMapping("/dbSlave")
public String dbSlave() {
DynamicDatasourceData dynamicDatasourceData = dynamicDatasourceDataMapper.selectOne(null);
return dynamicDatasourceData.getSourceName();
}

通过执行结果,看到通过应用@DS注解也成功的进行了数据源的切换。
事务管理
在动态切换数据源的时候有一个问题是要考虑的,那就是事务管理是否还会生效呢?
我们做个测试,新增一个接口分别插入两条记录,其中在插入第二条数据时将值设置超过了字段长度限制,会产生Data too long for column异常。
/**
* 验证一下事物控制
*/
// @Transactional(rollbackFor = Exception.class)
@DS(value = "slave")
@GetMapping("/dbTestTransactional")
public void dbTestTransactional() {
DynamicDatasourceData datasourceData = new DynamicDatasourceData();
datasourceData.setSourceName("test");
dynamicDatasourceDataMapper.insert(datasourceData);
DynamicDatasourceData datasourceData1 = new DynamicDatasourceData();
datasourceData1.setSourceName("testtesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttest");
dynamicDatasourceDataMapper.insert(datasourceData1);
}
经过测试发现执行结果如下,即便实现动态切换数据源,本地事务依然可以生效。
- 不加上
@Transactional注解第一条记录可以插入,第二条插入失败 - 加上
@Transactional注解两条记录都不会插入成功
本文案例地址:github.com/chengxy-nds…
来源:juejin.cn/post/7316202800663363594
京东企业业务前端监控实践
作者:零售企业业务苏子刚
监控的背景和意义
在现代前端开发中,接入监控系统是一个很重要的环节,它可以帮助开发者、产品、运营了解应用的性能表现,用户的实际体验以及潜在的错误和问题,从而进一步优化用户体验,帮助产品升级迭代。
背景
•应用复杂性增加:随着单页应用(SPA)和渐进式网页应用(PWA)的流行,前端应用变得越来越复杂。
•网页加载性能要求提高:用户对网页加载速度和交互响应的要求越来越高,性能成为影响用户体验的关键因素。
•多样化的设备和网络环境:用户通过各种设备和网络环境访问应用,这些因素都可能影响应用的性能和用户体验。
•敏捷开发和持续部署:敏捷开发和 CI/CD 的实践要求开发团队能够快速的响应问题,并持续改进产品。
意义
•对应用性能监控,提升用户体验:监控页面的加载时间,交互时间等性能指标,帮助团队优化代码,提升用户体验。
•错误追踪,快速定位并解决问题:捕获前端错误和异常,快速定位问题源头,缩短故障的修复时间。
•用户行为分析,指导产品快速迭代:了解用户如何与应用互动,哪些功能用户喜欢,哪些路径导致转化,从而指导产品迭代升级。
•业务指标监控,保证主流程的稳定性:监控关键业务流程,如:购物车、商详、结算页等黄流,确保业务流程的稳定性。
•告警系统,异常情况能够快速响应:通过定时任务自动化巡检/实时监控,当出现性能异常时,能够快速响应。
监控的类别
从上面可看出,通过监控能够促使我们的系统更加健壮、稳定,体验更好。那我们团队也从去年开始逐步将各个应用接入了监控。到目前为止,我们的监控分为两个部分:
•实时监控:成功集成了 SGM 集团内部监控平台,并引入了相应的 SDK 来对前端应用进行实时监控。目前,我们所涉及的 100+ 个应用程序已经完全接入该系统。通过配置有效的告警机制,我们能够及时捕捉并上报线上环境中的错误和异常,确保业务的稳定运行。
•定时任务巡检:实现了定时任务的自动化设置,用于定期执行自动巡检,并自动上报检测结果,还能激活告警系统。通过这种方式,我们能够确保持续监控系统健康状况,并在发现潜在问题时能够迅速响应。
◦使用 Chrome 插件快速创建 UI 测试脚本,随后在 UI啄木鸟平台 上配置定时执行这些脚本进行系统巡检。这一流程实现了自动化的界面测试,确保应用的用户界面按预期工作,同时及时发现并解决潜在的 UI 问题;
◦自主研发一套脚本,这些脚本通过启动一个 Node.js 服务来进行系统巡检。这种方法使我们能够灵活地监控系统性能和功能,及时发现并处理潜在的问题,从而保障系统的稳定运行;
监控整体架构

监控建设实践
实时监控
通过整合 SGM 监控平台和告警系统,我们实现了对所有接入应用的实时监控。一旦检测到异常,系统会立即通过多种方式(如咚咚、邮件、电话等)通知相关团队成员,确保问题能够被迅速发现和解决。为了提高告警的有效性,我们精心设计了告警策略,确保只有真正的异常情况才会触发告警。以下是我们在优化告警设置过程中积累的一些关键经验和建议:
1.精确度与敏感度的平衡:过于敏感的告警会导致频繁的误报,而设置过于宽松则可能错过关键的异常。找到合适的平衡点至关重要。
2.分级告警机制:根据问题的严重程度设置不同级别的告警,以便采取相应的响应措施。紧急问题可以通过电话直接通知,而较为轻微的问题可以通过邮件或即时消息通知。
3.持续优化告警规则:定期回顾和分析告警的准确性和响应情况,根据实际情况调整告警规则,以提高告警的准确性和有效性。
4.明确责任分配:确保每个告警都有明确的责任人,这样一旦发生异常,能够迅速有人响应。
5.培训和意识提升:对团队成员进行定期的培训,提高他们对告警系统的理解和重视,确保每个人都能正确响应告警。
这些经验和建议是我们在实践中不断摸索和尝试的结果,希望能够帮助你们更有效地管理和响应系统告警,确保应用的稳定运行。
WEB端
用户体验
用户体验是指用户在使用网站过程中的整体感受、情绪和态度,它包括与产品交互的全程。对于开发者而言,打造出色的用户体验意味着关注网站的加载速度、视觉稳定性、交互响应时间、渲染性能等关键因素。Google 提出了一系列 Web 性能标准指标,这些指标旨在量化用户体验的不同层面。SGM 性能监控平台紧跟这些标准,对几项关键指标进行监控并提供反馈,以确保用户能够获得流畅且愉悦的网站使用体验。
•LCP:页面加载过程中最大的内容元素(图片、视频等)渲染完成的时间点。也可近似看作是首屏加载时间。Google 标准是 小于等于 2500ms。

最初,我们遵循了 Google 提出的标准来精确设定我们的告警系统。

配置告警后,我们注意到告警频率较高,主要是因为多数系统的实际网页最大内容绘制(LCP)值普遍超过了预期的 2.5s 标准。然而,这些告警并未实质性影响用户的正常使用体验。为了优化告警机制,我们经过仔细评估后,决定将部分系统的 LCP 阈值暂时调整至 5s,并相应调整了告警级别,以更合理地反映系统性能对用户体验的实际影响。
显然,当前调整的 LCP 阈值 5s 并非我们的最终目标。这一调整是基于应用当前的性能状况所做的临时措施,旨在优化告警的频率和质量。我们计划随着对各个应用性能的持续改进,最终将 LCP 阈值恢复至标准的 2.5s。
•CLS:从页面开始加载到生命周期状态更改为隐藏期间发生的所有意外布局偏移的累计得分。Web 给出的性能指标是 < 0.1
•FCP:从网页开始加载到有内容渲染的耗时。标准性能指标 1.8s
•FID:用户首次发出交互指令到页面可以响应为止的时间差。标准性能指标 100ms
•TTFB:客户端接收到服务器返回的第一个字节响应信息的耗时。标准性能指标 1000ms

从最初启用告警到目前决定关闭大部分告警,我们的决策基于以下考虑:
1.用户体验未受显著影响:即使某些性能指标超出了标准值,我们观察到这并未对用户操作网站造成实质性影响。
2.避免告警疲劳:频繁的告警可能导致开发团队对通知产生麻木感,从而忽视那些真正关键的、影响网站健康的告警。
3.指标作为优化参考:这些性能指标更多地被视为优化网站时的参考点,而对用户的直觉体验影响甚微。
4.有针对性的优化:在网站优化过程中,我们会将这些指标作为健康检查的一部分,进行针对性的改进,而无需依赖告警来频繁提醒。
基于这些理由,我们目前选择只对 LCP 指标保持告警启用,以确保关注到可能影响用户加载体验的关键性能问题。
| 健康度指标 | 告警开启 | 标准值 | 优化后值 | 告警阀值 | 告警级别 |
|---|---|---|---|---|---|
| LCP | 开启 | <=2500ms | 针对部分应用 <=5000ms | 1min 内 耗时>=5000ms(持续优化并更新阀值到2500ms) 调用次数:50 连续次数:1次 | 通知 |
| FCP | 关闭 | <=1800ms | - | | - |
| CLS | 关闭 | <=0.1 | - | | - |
| FID | 关闭 | <=100ms | - | | - |
| TTFB | 关闭 | <=1000ms | - | | - |
页面性能
网页性能涉及从加载开始到完全可交互的整个过程,包括页面内容的下载、解析和渲染等多个阶段。在 SGM 监控平台上,我们能够追踪到一系列与页面加载性能相关的指标,如页面加载总时长、DNS 解析时长、DOM 加载完成时间、用户的浏览器和地理分布、首次渲染(白屏)时间、用户行为追踪、性能重现和热力图分析等。这些丰富的数据为我们优化页面性能提供了宝贵的参考。特别是首次渲染时间,或称为白屏时间,是我们监控中特别关注的一个关键指标,因为它直接影响用户的首次印象和整体体验。
•白屏时间:这一指标能够向开发者展示哪些页面出现了白屏现象。在利用此指标之前,我们需要为每个应用单独配置白屏时间的监控参数,以确保准确地捕捉到首次内容呈现的时刻。这有助于我们识别并优化那些影响用户首次加载体验的关键页面。

为了监控白屏时间,我们必须在应用的全局配置中的白屏监控项下,指定每个页面的 URL 及其关键元素。同时,我们还需设定监控的起始时间点和超时阈值。值得注意的是,URL 配置支持正则表达式,这为我们提供了灵活性,以匹配和监控一系列相似的页面路径。

•白屏检测的机制:白屏检测机制的核心在于验证页面上的关键元素是否已经被渲染。所谓关键元素,指的是在配置过程中指定的用于检测的 DOM 元素。这些元素的渲染情况是判断页面是否白屏的依据。
•告警设置:白屏告警功能已经启用,但目前还处于初期阶段,一些功能尚待完善。例如,当前的 URL 配置尚未支持正则表达式匹配。

面对当前的局限性,我们采取了双策略应对。一方面,我们利用白屏告警功能直接监控页面的白屏情况;另一方面,我们通过分析页面加载性能指标中的白屏时间来间接监测潜在的白屏问题。在设置平均耗时时间和告警级别时,我们综合考虑了多个因素,包括用户的网络环境、告警的发生频率以及告警的实际适用性,以确保监控方案的有效性和合理性。
| 网页性能 | 告警开启 | 优化前值 | 优化后值 | 告警阀值 | 告警级别 |
|---|---|---|---|---|---|
| 首包时间 | 关闭 | - | - | - | - |
| 页面完全加载时间 | 关闭 | - | - | - | - |
| 白屏时间 | 开启 | <=5000ms | <=10000ms | 1min 内 耗时>=10000ms,后期采用白屏告警替代 调用次数:30 连续次数:5 次 | 紧急 |
•此外,我们的页面追踪功能包括用户行为回溯、页面性能重现以及行为轨迹热力图,这些工具允许我们从多个维度和场景对用户行为进行深入分析,极大地便利了问题的诊断和排查。
JSError监控
我们通过配置错误关键词来匹配控制台的报错信息。报错阈值的设定可以参考各个项目的 QPS,因为在项目实施了恰当的降级策略后,即便控制台出现报错,页面通常仍能正常访问,不会对用户体验造成影响。因此,这个阈值可以适当设置得较高。
这里需要特别注意 “Script error” 的错误,这种错误给不到任何对我们有用的信息。所以需要采用一定的手段避免出现类似的报错:
•这种错误也称之为跨域错误,所以首先,我们需要开启跨域资源共享功能(CORS)。
<script src="http://xxxdomain.com/home.js" crossorigin></script>
•针对 Vue 项目,由于 Vue 重写了 window.onerror 事件,所以我们需要在 Vue 项目中增加 错误处理:
Vue.config.errorHandler = (err, vm, info)=> {
if (err) {
try {
console.error(err);
window.__sgm__.error(err)
} catch (e) {}
}
};
•在某些情况下,“Script error” 可能是无关紧要的,我们可以选择忽略这类特定的错误。为此,可以关闭这些特定错误的监控,具体的错误可以通过它们的 hash 在错误日志中进行识别和过滤。

| 关键指标 | 关键字(支持正则匹配) | 触发次数 | 告警级别 |
|---|---|---|---|
| js错误 | null、undefined、error、map、filter、style、length... | 周期:1min ,错误次数:50/100/200(可参考 QPS 值设置),连续次数:1次 | 严重 |
API请求监控
这里我们的告警设置主要关注 HTTP 状态码和业务错误码。这两项指标的异常表明我们的应用可能遇到了问题,需要我们迅速进行检查和处理以确保系统的正常运行。
首先,我们必须在应用的监控配置中设定数据采集参数:

| 关键指标 | 错误码 | 业务域名 | 触发次数 | 告警级别 |
|---|---|---|---|---|
| http错误 | !200(Http响应非200报警) | xx1.jd.com xx2.jd.com | 周期:1min 错误次数:1 总调用次数:50 连续次数:1 | 严重 |
| 业务失败码 | errCode(根据实际业务线设置 -1,-2等) |
针对业务失败码:
1.由于现有应用跨不同业务条线存在异常码的差异,我们需要针对每个业务线收集并配置其特定的异常码。
| 应用来源 | 标准响应 | 针对性告警 |
|---|---|---|
| 慧采PC 企业购 | { "code":null, "success":true, "msg":"操作成功", "result":{} } | 业务异常码 code ·-1,-2 ·... |
| 锦礼 | { "code": 000, "data": {}, "msg": "操作成功" } | 业务异常码 code ·! (1000 && 3001等 ) |
| color | | ·-1 echo ·1 echo |
| 其他 | ... | .... |
2、对于新增应用,我们实施了后端服务异常码的标准化。因此,在监控方面,我们只需要配置一套统一的标准来进行监控。
{
"50000X": "程序异常,内部",
"500001": "程序异常,上游",
"500002": "程序异常,xx",
"500003": "程序异常,xx",
...
}
资源错误
这里通常指的是 css、js、图片等资源的加载错误
| 关键指标 | 告警开启 | 告警阀值 | 告警级别 |
|---|---|---|---|
| 资源错误 | 开启 | 周期:1min 错误次数:200(也可参照QPS进行设置) 连续次数:1 | 严重 |
对于图片加载错误,只需在项目中实施适当的降级方案。在应用的监控配置中,我们可以设置为不收集图片错误相关的数据。

再来举个例子:
在企业业务的封闭场景中,例如慧采平台,我们集成了埋点 JavaScript 脚本。然而,由于某些客户的网络环境,导致我们的埋点相关静态资源延迟加载。

治理方案:

自定义上报
每个业务流程的关键节点或核心功能实施了专门的监控措施,以便对任何异常状况进行跟踪、监控并及时上报。
目前,几条业务线已经实施了自定义上报机制,其主要目的包括:
•利用自定义上报来捕获接口异常的详细信息,如入参和出参,以便在线上出现异常时,能够依据上报的数据快速进行问题的诊断和定位。
•在复杂的环境下,准确追踪用户行为导致的错误,并利用上报的信息进行有效的问题排查和定位。
锦礼酷兜: 用户在选择地址后,系统未能根据所选地址提供正确的信息,导致页面加载出现异常。
由于这个 H5 页面被嵌入到用户的 App 内,开发者难以直接复现用户遇到的问题。因此,我们利用监控平台的自定义上报功能来收集相关信息,以辅助进行问题排查。
•上报地址组件返回值

•上报接口入参

•然后根据自定义上报日志查看具体信息

E卡:外部引用资源异常上报(设备指纹,eid 等)
在结算页面提交订单时,系统需要获取设备ID。为此,我们实施了降级方案,并通过自定义上报机制对此过程进行监控,以确保流程的顺利执行。
降级方案:如果获取不到,后端会生成 uuid 给到前端。


企业购注销pc: 我们需要集成科技 SDK,以便在页面上完成用户注销后自动跳转到指定的 URL。上线后,收到客户反馈指出在完成注销流程后页面未能正确跳转。

接口异常: 在接口异常中,添加自定义监控,查看入参和出参信息。

尽管我们已经在应用中引入了自定义监控以便更好地观察和定位问题,但我们仍需进一步细化和规范化这些监控措施。目前,我们正积极对各业务线的功能点进行梳理,以实现更深入的细化监控。我们的目标是为每个业务线、每个应用的关键链路和功能点定制针对各种异常情况的精细化自定义监控(例如,某页面按钮的显示或点击异常)。
| 自定义告警 | 告警开启 | 告警阀值 | 告警级别 |
|---|---|---|---|
| 自定义编码 | 开启 | 1min内 调用次数:50 连续次数:1次 | 警告 |
小程序端
与 Web 端相比,小程序的监控存在一些差异,主要是缺少了如 LCP(最大内容绘制)等特定性能指标。然而,性能问题、JavaScript错误、资源加载错误等其他监控指标仍然可以被捕获。此外,小程序官方和开发者工具都提供了性能检测工具,这些工具便于开发者查看和优化小程序应用的性能。本文将不深入介绍 Web 端的监控指标,而是专注于介绍小程序中独有的监控和分析工具。
小程序官方后台
可以分析接口数据、js 分析等。

利用 SGM 的监控功能结合小程序官方的分析工具,对我们的小程序进行综合优化,是一个有效的策略。
原生应用
基础监控:mPaas、烛龙、SGM
mPaaS:崩溃监控。应用崩溃对用户体验有显著影响,是移动端监控中的一个关键指标。通过不断的监控和优化,京东慧采移动端的崩溃率已经降至较低水平,目前的平均用户崩溃率大约为0.03122%。

烛龙:启动耗时、首屏耗时、启动且首焦耗时、卡顿。为了改善首屏加载时间,京东慧采采用了烛龙监控平台并实施了相应的优化措施。优化后,应用的整体性能显著提升,其中 Android 平台的tp95耗时大约为 2764ms,iOS 平台的tp95耗时大约为1791ms,均达到了较低的水平。


SGM:网络、WebView、原生页面等指标。
业务监控
京东慧采在多个业务模块中,其中登录、商详、订单详情 3 个模块接入了业务监控。
登录:登录接入 SGM 监控平台,自定义了整个流程错误码,并配置了告警规则
(1)600:登录正常流程(必要是可白名单开启)
(2)601:登录防刷验证流程异常监控
(3)602:登录魔方验证流程异常监控
(4)603:登录流程异常监控



商详、订单详情:在商品详情和订单详情页面,我们集成了业务监控 SDK。通过移动配置平台,我们下发了监控规则,以便在接口返回的数据不符合预期时,能够上报错误信息。目前,这些监控信息被上报到崩溃分析平台的自定义异常模块中,以便进行进一步的分析和优化。
(1)接口请求是否成功。
(2)banner 楼层:是否为空、楼层类型是否正常(1 原生)、数据/大小图地址是否为空。
(3)商品信息楼层:是否为空、楼层类型是否正常(2 动态)、数据/商品名称/价格是否为空。
(4)服务楼层:是否为空、楼层类型是否正常(1 原生)、数据/服务信息是否为空。
(5)spu 和物流楼层:是否为空、楼层类型是否正常(1 原生)、数据/sup信息是否为空。
(6)其他:其他/按钮数据/按钮名称是否为空、按钮类型是否正常(排除1/2/3/4/5/6/20000)。
订单详情监控信息:
(1)接口请求是否成功。
(2)基础信息楼层:是否为空、楼层类型是否正常(2 动态)、数据/地址信息是否为空。
(3)商品信息楼层:是否为空、楼层类型是否正常(2 动态)、数据/商品列表是否为空。
(4)支付信息楼层:是否为空、楼层类型是否正常(2 动态)、数据是否为空。
(5)价格楼层:是否为空、楼层类型是否正常(2 动态)、数据是否为空。

定时巡检
定时巡检可以通过两种方法实现:
•利用 UI 啄木鸟平台配置定时执行的任务。
•使用团队开发的自定义脚本,并通过自动启动的服务来执行这些检测任务。
UI 啄木鸟
定时巡检的主要目的是确保每个项目的核心流程在每次迭代中保持稳定。通过配置定时任务,我们能够及时发现并解决线上问题,从而维护系统的稳定性。
什么是 UI 啄木鸟
UI啄木鸟平台,由京东集团-京东科技开发,是一个自动化巡检工具,其主要功能包括:
•Chrome插件:用于录制项目的用户交互步骤。
•定时任务平台:用于在服务器端定期执行已录制的脚本进行巡检。
在使用Chrome插件过程中,我们遇到了一些问题。与京东科技团队沟通后,我们获得了共同开发和升级插件的机会。目前,我们已经添加了新功能并修复了一些已知问题。
1.打开录制和停止录制按钮,分别开启监听和关闭拦截页面事件功能;
2.新增点击录制后保留当前录制步骤功能;
3.在执行事件过程中,禁止再次点击执行,避免执行顺序错乱;
4.点击事件可切换操作类型为 focus 事件,便于监听滚动条滑动;
5.在步骤复现情况下,调整判断元素选择器和屏幕位置的顺序,避免位置出入点击位置错位;
6....
使用chrome扩展程序进行安装即可。

怎么使用
•新建录制脚本

•点击详情,开启录制

•监听步骤

•关联到啄木鸟平台

•啄木鸟平台(调试、配置 Cookie,开启定时任务)

自启动巡检工具
自动化巡检工具能够检测页面上的多种元素和链接,包括 a 标签的外链、接口返回的链接、鼠标悬停元素、点击元素,以及跳转后 URL 的有效性。该工具尤其适合用于频道页,这些页面通常通过投放广告和配置通天塔链接来生成。在大型促销活动期间,我们可以运行脚本来验证广告和通天塔链接的有效性。目前,工具的功能还相对有限,并且对于广告组等特定接口的支持不够通用,这也是我们计划逐步改进和优化的方向。
功能检测
•检测所有 a 标签和所有接口响应数据中包含所有通天塔活动外链是否有效。

{
"cookieThor":"", // 是否依赖cookie等登录态,无需请传空
"urlPattern": "pro\.jd\.com",// 匹配的链接,这里只匹配通天塔
"urls": ["https://b.jd.com/s?entry=newuser"] // 将要检测的url,可填多个
}
运行结果:

•检测鼠标 hover 事件,收集用户交互后的接口响应数据,检测所有活动外联是否有效。

{
"cookieThor": "",
"urlPattern": "///pro.jd.com/",
"urls": [
{
"url": "https://b.jd.com/s?entry=newuser",
"hoverElements": [
{
"item": "#focus-category-id .focus-category-item", // css样式选择器
"target": ".focus-category-item-subtitle"
}
]
}
]
}

•检查 click 事件,收集用户交互后的接口响应数据,检测所有通天塔活动外联是否有效。

{
"cookieThor": "",
"urlPattern": "///pro.jd.com/",
"urls": [
{
"url": "https://b.jd.com/s?entry=newuser",
"clickElements": [
{
"item": "#recommendation-floor .drip-tabs-tab"
}
]
}
]
}

•检测点击后,跳转后的链接有效性。

{
"cookieThor": "",
"urlPattern": "///pro.jd.com/",
"urls": [
{
"url": "https://b.jd.com/s?entry=newuser",
"clickElements": [
{
"item": ".recommendation-product-wrapper .jdb-sku-wrapper"
}
]
}
]
}

检测原理

监控后暴露的问题
•慧采 jsError:
用于埋点数据上报的API,但在一些封闭环境中,由于网络环境,客户可能无法及时访问埋点或指纹识别等 SDK,导致频繁的报错。为了解决这个问题,我们可以通过引入 try...catch 语句来捕获异常,并结合使用队列机制,以确保埋点数据能够在网络条件允许时正常上报。这样既避免了错误的频繁发生,也保障了数据上报的完整性和准确性。
public exposure(exposureId: ExposureId, jsonParam = {}, eventParam = '') {
this.execute(() => {
try {
const exposure = new MPing.inputs.Exposure(exposureId);
exposure.eventParam = eventParam; // 设置click事件参数
exposure.jsonParam = serialize(jsonParam); // 设置json格式事件参数,必须是合法的json字符串
console.log('上报 曝光 info >> ', exposure);
new MPing().send(exposure);
} catch (e) {
console.error(e);
}
});
}
private execute(fn: CallbackFunction) {
if (this._MPing === null) {
this._Queue.push(fn);
} else {
fn();
}
}
•企业购订详异常:


总结
接入前
在过去,我们的应用上线后,对线上运行状况了解不足,错误发生时往往依赖于用户或运营团队的反馈,这使我们常常处于被动应对状态,有时甚至会导致严重的线上问题,如白屏、设备兼容性问题和异常报错等。为了改变这一局面,我们开始寻找和实施解决方案。从去年开始,我们逐步将所有 100+ 应用接入了监控系统,现在我们能够实时监控应用状态,及时发现并解决问题,大大提高了我们的响应速度和服务质量。
接入后
自从接入监控系统后,我们的问题发现和处理方式从被动等待用户反馈转变为了主动监测。现在我们能够即时发现并快速解决问题。此外,我们还利用监控平台对若干应用进行了性能优化,并为关键功能点制定了预先的降级策略,以保障应用的稳定运行。
•页面健康度监控表明,我们目前已有 50+ 个项目的性能评分达到或超过 85 分。通过分析监控数据,我们对每个应用的各个页面进行了详细分析和梳理。在确保流程准确无误的基础上,我们对那些性能较差的页面进行了持续的优化。目前,我们仍在对一些关键但性能表现一般的应用进行进一步的优化工作。


•通过配置 JavaScript 错误和资源错误的告警机制,我们在项目迭代过程中及时解决了多个 JavaScript 问题,有效降低了错误率和告警频率。正如前文所述,对于慧采PC 这类封闭环境,客户公司的网络策略可能会阻止埋点 SDK 和设备指纹等 JavaScript 资源的加载,导致全局变量获取时出现错误。我们通过实施异常捕获和队列机制,不仅规避了部分错误,还确保了埋点数据的准确上报。

•通过收集 HTTP 错误码和业务失败码,并设置相应的告警机制,我们能够在接到告警通知的第一时间内分析并解决问题。例如,我们成功地解决了集团内部遇到的 “color404” 问题等。这种做法加快了问题的响应和解决速度,提高了服务的稳定性和用户满意度。
•自定义监控:通过给接口异常做入参、出参的上报、在关键功能点上报有效信息等,能够在应用出现异常时,快速定位问题并及时修复。

•通过实施定时任务巡检,我们有效地避免了迭代更新上线可能对整个流程造成的影响。同时,巡检工具的使用也确保了外部链接的有效性,进一步保障了应用的稳定运行和用户体验。
规划
监控是一个持续长期的过程,我们致力于不断完善,确保系统的稳定性和安全性。基于现有的监控能力,我们计划实施以下几项优化措施:
1.应用性能提升:我们将持续优化我们的应用,目标是让 90% 以上的应用性能评分达到 90 分以上,并对资源错误和 JavaScript 错误进行有效管理。
2.深化监控细节:我们将扩展监控的深度和广度,确保能够捕捉到所有潜在的异常情况。例如,如果一个仅限采购账号使用的按钮错误地显示了,这应该触发自定义异常上报,并在代码层面实施降级处理。
3.巡检工具升级:我们将继续升级我们的 Chrome 巡检插件,提高其智能化程度和覆盖范围,以保持线上主要流程的健壮性和稳定性。
结尾
我们是企业业务大前端团队,会持续针对各端优化升级我们的监控策略,如果您有任何疑问或者有更好的建议,我们非常欢迎您的咨询和交流。
来源:juejin.cn/post/7400271712359186484





