








实现一个支持@的输入框
近期产品期望在后台发布帖子或视频时,需要添加 @用户 的功能,以便用户收到通知,例如“xxx在xxx提及了您!”。然而,现有的开源库未能满足我们的需求,例如 ant-design 的 Mentions 组件:

但是不难发现跟微信飞书对比下,有两个细节没有处理。
- @用户没有高亮
- 在删除时没有当做一个整体去删除,而是单个字母删除,首先不谈用户是否想要整体删除,在这块有个模糊查询的功能,如果每删一个字母之后去调接口查询数据库造成一些不必要的性能开销,哪怕加上防抖。
然后也是找了其他的库都没达到产品的期望效果,那么好,自己实现一个,先看看最终实现的效果:

封装之后使用:
<AtInput
height={150}
onRequest={async (searchStr) => {
const { data } = await UserFindAll({ nickname: searchStr });
return data?.list?.map((v) => ({
id: v.uid,
name: v.nickname,
wechatAvatarUrl: v.wechatAvatarUrl,
}));
}}
onChange={(content, selected) => {
setAtUsers(selected);
}}
/>
那么实现这么一个输入框大概有以下几个点:
- 高亮效果
- 删除/选中用户时需要整体删除
- 监听@的位置,复制给弹框的坐标,联动效果
- 最后我需要拿到文本内容,并且需要拿到@那些用户,去做表单提交
大多数文本输入框我们会使用input,或者textarea,很明显以上1,2两点实现不了,antd也是使用的textarea,所以也是没有实现这两个效果。所以这块使用富文本编辑,设置contentEditable,将其变为可编辑去做。输入框以及选择器的dom就如下:
<div style={{ height, position: 'relative' }}>
{/* 编辑器 */}
<div
id="atInput"
ref={atRef}
className={'editorDiv'}
contentEditable
onInput={editorChange}
onClick={editorClick}
/>
{/* 选择用户框 */}
<SelectUser
options={options}
visible={visible}
cursorPosition={cursorPosition}
onSelect={onSelect}
/>
</div>
实现思路:
- 监听输入@,唤起选择框。
- 截取@xxx的xxx作为搜素的关键字去查询接口
- 选择用户后需要将原先输入的 @xxx 替换成 @姓名,并且将@的用户缓存起来
- 选择文本框中的姓名时需要变为整体选中状态,这块依然可以给标签设置为不可编辑状态就可实现,contentEditable=false,即可实现整体删除,在删除的同时需要将当前用户从之前缓存的@过的用户数组删除
- 那么可以拿到输入框的文本,@的用户, 最后将数据抛给父组件就完成了
以上提到了监听@文本变化,通常绑定onChange事件就行,但是还有一种用户通过点击移动光标,这块需要绑定change,click两个时间,他们里边的逻辑基本一样,只需要额外处理点击选中输入框中用户时,整体选中g功能,那么代码如下:
const onObserveInput = () => {
let cursorBeforeStr = '';
const selection: any = window.getSelection();
if (selection?.focusNode?.data) {
cursorBeforeStr = selection.focusNode?.data.slice(0, selection.focusOffset);
}
setFocusNode(selection.focusNode);
const lastAtIndex = cursorBeforeStr?.lastIndexOf('@');
setCurrentAtIdx(lastAtIndex);
if (lastAtIndex !== -1) {
getCursorPosition();
const searchStr = cursorBeforeStr.slice(lastAtIndex + 1);
if (!StringTools.isIncludeSpacesOrLineBreak(searchStr)) {
setSearchStr(searchStr);
fetchOptions(searchStr);
setVisible(true);
} else {
setVisible(false);
setSearchStr('');
}
} else {
setVisible(false);
}
};
const selectAtSpanTag = (target: Node) => {
window.getSelection()?.getRangeAt(0).selectNode(target);
};
const editorClick = async (event) => {
onObserveInput();
// 判断当前标签名是否为span 是的话选中当做一个整体
if (e.target.localName === 'span') {
selectAtSpanTag(e.target);
}
};
const editorChange = (event) => {
const { innerText } = event.target;
setContent(innerText);
onObserveInput();
};
每次点击或者文本改变时都会去调用onObserveInput,以上onObserveInput该方法中主要做了以下逻辑:
- 在此之前需要先了解 Selection的一些方法
- 通过getSelection方法可以获取光标的偏移位置,那么可以截取光标之前的字符串,并且使用lastIndexOf从后向前查找最后一个“@”符号,并记录他的下标,那么有了【光标之前的字符串】,【@的下标】就可以拿到到@之后用于过滤用户的关键字,并将其缓存起来。
- 唤起选择器,并通过关键字去过滤用户。这块涉及到一个选择器的位置,直接使用window.getSelection()?.getRangeAt(0).getBoundingClientRect()去获取光标的位置拿到的是光标相对于窗口的坐标,直接用这个坐标会有问题,比如滚动条滚动时,这个选择器发生位置错乱,所以这块同时去拿输入框的坐标,去做一个相减,这样就可以实现选择器跟着@符号联动的效果。
const getCursorPosition = () => {
// 坐标相对浏览器的坐标
const { x, y } = window.getSelection()?.getRangeAt(0).getBoundingClientRect() as any;
// 获取编辑器的坐标
const editorDom = window.document.querySelector('#atInput');
const { x: eX, y: eY } = editorDom?.getBoundingClientRect() as any;
// 光标所在位置
setCursorPosition({ x: x - eX, y: y - eY });
};
选择器弹出后,那么下面就到了选择用户之后的流程了,
/**
* @param id 唯一的id 可以uid
* @param name 用户姓名
* @param color 回显颜色
* @returns
*/
const createAtSpanTag = (id: number | string, name: string, color = 'blue') => {
const ele = document.createElement('span');
ele.className = 'at-span';
ele.style.color = color;
ele.id = id.toString();
ele.contentEditable = 'false';
ele.innerText = `@${name}`;
return ele;
};
/**
* 选择用户时回调
*/
const onSelect = (item: Options) => {
const selection = window.getSelection();
const range = selection?.getRangeAt(0) as Range;
// 选中输入的 @关键字 -> @郑
range.setStart(focusNode as Node, currentAtIdx!);
range.setEnd(focusNode as Node, currentAtIdx! + 1 + searchStr.length);
// 删除输入的 @关键字
range.deleteContents();
// 创建元素节点
const atEle = createAtSpanTag(item.id, item.name);
// 插入元素节点
range.insertNode(atEle);
// 光标移动到末尾
range.collapse();
// 缓存已选中的用户
setSelected([...selected, item]);
// 选择用户后重新计算content
setContent(document.getElementById('atInput')?.innerText as string);
// 关闭弹框
setVisible(false);
// 输入框聚焦
atRef.current.focus();
};
选择用户的时候需要做的以下以下几点:
- 删除之前的@xxx字符
- 插入不可编辑的span标签
- 将当前选择的用户缓存起来
- 重新获取输入框的内容
- 关闭选择器
- 将输入框重新聚焦
最后
在选择的用户或者内容发生改变时将数据抛给父组件
const getAttrIds = () => {
const spans = document.querySelectorAll('.at-span');
let ids = new Set();
spans.forEach((span) => ids.add(span.id));
return selected.filter((s) => ids.has(s.id));
};
/** @的用户列表发生改变时,将最新值暴露给父组件 */
useEffect(() => {
const selectUsers = getAttrIds();
onChange(content, selectUsers);
}, [selected, content]);
完整组件代码
输入框主要逻辑代码:
let timer: NodeJS.Timeout | null = null;
const AtInput = (props: AtInputProps) => {
const { height = 300, onRequest, onChange, value, onBlur } = props;
// 输入框的内容=innerText
const [content, setContent] = useState<string>('');
// 选择用户弹框
const [visible, setVisible] = useState<boolean>(false);
// 用户数据
const [options, setOptions] = useState<Options[]>([]);
// @的索引
const [currentAtIdx, setCurrentAtIdx] = useState<number>();
// 输入@之前的字符串
const [focusNode, setFocusNode] = useState<Node | string>();
// @后关键字 @郑 = 郑
const [searchStr, setSearchStr] = useState<string>('');
// 弹框的x,y轴的坐标
const [cursorPosition, setCursorPosition] = useState<Position>({
x: 0,
y: 0,
});
// 选择的用户
const [selected, setSelected] = useState<Options[]>([]);
const atRef = useRef<any>();
/** 获取选择器弹框坐标 */
const getCursorPosition = () => {
// 坐标相对浏览器的坐标
const { x, y } = window.getSelection()?.getRangeAt(0).getBoundingClientRect() as any;
// 获取编辑器的坐标
const editorDom = window.document.querySelector('#atInput');
const { x: eX, y: eY } = editorDom?.getBoundingClientRect() as any;
// 光标所在位置
setCursorPosition({ x: x - eX, y: y - eY });
};
/**获取用户下拉列表 */
const fetchOptions = (key?: string) => {
if (timer) {
clearTimeout(timer);
timer = null;
}
timer = setTimeout(async () => {
const _options = await onRequest(key);
setOptions(_options);
}, 500);
};
useEffect(() => {
fetchOptions();
// if (value) {
// /** 判断value中是否有at用户 */
// const atUsers: any = StringTools.filterUsers(value);
// setSelected(atUsers);
// atRef.current.innerHTML = value;
// setContent(value.replace(/<\/?.+?\/?>/g, '')); //全局匹配内html标签)
// }
}, []);
const onObserveInput = () => {
let cursorBeforeStr = '';
const selection: any = window.getSelection();
if (selection?.focusNode?.data) {
cursorBeforeStr = selection.focusNode?.data.slice(0, selection.focusOffset);
}
setFocusNode(selection.focusNode);
const lastAtIndex = cursorBeforeStr?.lastIndexOf('@');
setCurrentAtIdx(lastAtIndex);
if (lastAtIndex !== -1) {
getCursorPosition();
const searchStr = cursorBeforeStr.slice(lastAtIndex + 1);
if (!StringTools.isIncludeSpacesOrLineBreak(searchStr)) {
setSearchStr(searchStr);
fetchOptions(searchStr);
setVisible(true);
} else {
setVisible(false);
setSearchStr('');
}
} else {
setVisible(false);
}
};
const selectAtSpanTag = (target: Node) => {
window.getSelection()?.getRangeAt(0).selectNode(target);
};
const editorClick = async (e?: any) => {
onObserveInput();
// 判断当前标签名是否为span 是的话选中当做一个整体
if (e.target.localName === 'span') {
selectAtSpanTag(e.target);
}
};
const editorChange = (event: any) => {
const { innerText } = event.target;
setContent(innerText);
onObserveInput();
};
/**
* @param id 唯一的id 可以uid
* @param name 用户姓名
* @param color 回显颜色
* @returns
*/
const createAtSpanTag = (id: number | string, name: string, color = 'blue') => {
const ele = document.createElement('span');
ele.className = 'at-span';
ele.style.color = color;
ele.id = id.toString();
ele.contentEditable = 'false';
ele.innerText = `@${name}`;
return ele;
};
/**
* 选择用户时回调
*/
const onSelect = (item: Options) => {
const selection = window.getSelection();
const range = selection?.getRangeAt(0) as Range;
// 选中输入的 @关键字 -> @郑
range.setStart(focusNode as Node, currentAtIdx!);
range.setEnd(focusNode as Node, currentAtIdx! + 1 + searchStr.length);
// 删除输入的 @关键字
range.deleteContents();
// 创建元素节点
const atEle = createAtSpanTag(item.id, item.name);
// 插入元素节点
range.insertNode(atEle);
// 光标移动到末尾
range.collapse();
// 缓存已选中的用户
setSelected([...selected, item]);
// 选择用户后重新计算content
setContent(document.getElementById('atInput')?.innerText as string);
// 关闭弹框
setVisible(false);
// 输入框聚焦
atRef.current.focus();
};
const getAttrIds = () => {
const spans = document.querySelectorAll('.at-span');
let ids = new Set();
spans.forEach((span) => ids.add(span.id));
return selected.filter((s) => ids.has(s.id));
};
/** @的用户列表发生改变时,将最新值暴露给父组件 */
useEffect(() => {
const selectUsers = getAttrIds();
onChange(content, selectUsers);
}, [selected, content]);
return (
<div style={{ height, position: 'relative' }}>
{/* 编辑器 */}
<div id="atInput" ref={atRef} className={'editorDiv'} contentEditable onInput={editorChange} onClick={editorClick} />
{/* 选择用户框 */}
<SelectUser options={options} visible={visible} cursorPosition={cursorPosition} onSelect={onSelect} />
</div>
);
};
选择器代码
const SelectUser = React.memo((props: SelectComProps) => {
const { options, visible, cursorPosition, onSelect } = props;
const { x, y } = cursorPosition;
return (
<div
className={'selectWrap'}
style={{
display: `${visible ? 'block' : 'none'}`,
position: 'absolute',
left: x,
top: y + 20,
}}
>
<ul>
{options.map((item) => {
return (
<li
key={item.id}
onClick={() => {
onSelect(item);
}}
>
<img src={item.wechatAvatarUrl} alt="" />
<span>{item.name}</span>
</li>
);
})}
</ul>
</div>
);
});
export default SelectUser;
以上就是实现一个支持@用户的输入框功能,就目前而言,比较死板,不支持自定义颜色,自定义选择器等等,未来,可以进一步扩展功能,例如添加@用户的高亮样式定制、支持键盘快捷键操作等,从而提升用户体验和功能性。
来源:juejin.cn/post/7357917741909819407
Vue.js 自动路由:告别手动配置,让开发更轻松!
在使用 Vue.js 开发项目的时候,我最头疼的就是创建路由,尤其是项目越来越大的时候,管理 route.ts 或 route.js 文件简直是一场噩梦!
我曾经做过一个页面超级多的项目,每新增一个页面就要更新路由,删除页面也要更新路由文件,不然就会报错,真是烦死人了!
所以,我开始寻找自动生成路由的方法。我在网上搜了很久,但大部分结果都是针对 Webpack 和 Vue 2 的,很难找到适合我的方案。最后,我在 Vue 的 GitHub 仓库的讨论区里提问,终于找到了答案!
那就是 Unplugin Vue Router! 它可以为 Vue 3 实现基于文件的自动路由,而且支持 TypeScript,设置起来也超级简单! 虽然官方说它还在实验阶段,但用起来已经很方便了。
创建项目,安装插件
首先,我们创建一个新的 Vue 项目。 相信大家都很熟悉用 Vue CLI 创建项目了,这里就不赘述了,不熟悉的小伙伴可以去看看 Vue.js 官网的快速入门指南。
pnpm create vue@latest
我创建项目的时候选择了 TypeScript 和 Vue Router,这样它就会自动生成一些页面和路由。
然后,进入项目目录,安装依赖。我最近开始用 pnpm 来管理依赖,感觉还不错。
pnpm add -D unplugin-vue-router
接下来,更新 vite.config.ts 文件, 注意要把插件放在第 0 个位置 。
import { fileURLToPath, URL } from "node:url";
import VueRouter from "unplugin-vue-router/vite";
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
VueRouter({
/* options */
}),
// ⚠️ Vue must be placed after VueRouter()
vue(),
],
resolve: {
alias: {
"@": fileURLToPath(new URL("./src", import.meta.url)),
},
},
});
然后,更新 env.d.ts 文件,让编辑器能够识别插件的类型。
/// <reference types="vite/client" />
/// <reference types="unplugin-vue-router/client" />
最后,更新路由文件 src/router/index.ts 。
import { createRouter, createWebHistory } from "vue-router";
import { routes, handleHotUpdate } from "vue-router/auto-routes";
const router = createRouter({
history: createWebHistory(import.meta.env.BASE_URL),
routes,
});
if (import.meta.hot) {
handleHotUpdate(router);
}
export default router;
创建页面,自动生成路由
现在,我们可以创建 src/pages 目录了,在这个目录下创建的 Vue 组件会自动变成路由和页面,就像 Nuxt 一样方便!
我们先在 src\pages\about.vue 创建一个关于页面:
<template>
<div>This is the about page</div>
</template>
然后在 src\pages\index.vue 创建首页:
<template>
<div>This is Home Page</div>
</template>
运行 pnpm dev 启动开发服务器,点击 “Home” 链接就会跳转到首页,点击 “About” 链接就会跳转到关于页面。
怎么样,是不是很方便? 如果你不熟悉路由文件夹结构,可以看看这个文档: uvr.esm.is/guide/file-…
动态路由
我们再来试试创建带参数的动态路由。在 src/pages/blog/[id].vue 创建一个组件,内容如下:
<script setup>
const { id } = useRoute().params;
</script>
<template>
<div>This is the blog post with id: {{ id }}</div>
</template>
再次运行 pnpm dev ,然后访问 http://localhost:5173/blog/6 ,你就会看到以下内容:

是不是很神奇? 希望这篇简短的博客能帮助你在 Vue.js 的旅程中更轻松地创建路由!
来源:juejin.cn/post/7401354593588199465
JS类型判断的四种方法,你掌握了吗?
引言
JavaScript中有七种原始数据类型和几种引用数据类型,本文将清楚地介绍四种用于类型判断的方法,分别是typeOf、instanceOf、Object.prototype.toString.call()、Array.isArray(),并介绍其使用方法和判定原理。
typeof
- 可以准确判断除
null之外的所有原始类型,null会被判定成object function类型可以被准确判断为function,而其他所有引用类型都会被判定为object
let s = '123' // string
let n = 123 // number
let f = true // boolean
let u = undefined // undefined
let nu = null // null
let sy = Symbol(123) // Symbol
let big = 1234n // BigInt
let obj = {}
let arr = []
let fn = function() {}
let date = new Date()
console.log(typeof s); // string typeof后面有无括号都行
console.log(typeof n); // number
console.log(typeof f); // boolean
console.log(typeof u); // undefined
console.log(typeof(sy)); // symbol
console.log(typeof(big)); // bigint
console.log(typeof(nu)); // object
console.log(typeof(obj)); // object
console.log(typeof(arr)); // object
console.log(typeof(date)); // object
console.log(typeof(fn)); // function
判定原理
typeof是通过将值转换为二进制之后,判断其前三位是否为0:都是0则为object,反之则为原始类型。因为原始类型转二进制,前三位一定不都是0;反之引用类型被转换成二进制前三位一定都是0。
null是原始类型却被判定为object就是因为它在机器中是用一长串0来表示的,可以把这看作是一个史诗级的bug。
所以用typeof判断接收到的值是否为一个对象时,还要注意排除null的情况:
function isObject() {
if(typeof(o) === 'object' && o !== null){
return true
}
return false
}
你丢一个值给typeof,它会告诉你这个字值是什么类型,但是它无法准确告诉你这是一个Array或是Date,若想要如此精确地知道一个对象类型,可以用instanceof告诉你是否为某种特定的类型
instanceof
只能精确地判断引用类型,不能判断原始类型
console.log(obj instanceof Object);// true
console.log(arr instanceof Array);// true
console.log(fn instanceof Function);// true
console.log(date instanceof Date);// true
console.log(s instanceof String);// false
console.log(n instanceof Number);// false
console.log(arr instanceof Object);// true
判定原理
instanceof既能把数组判定成Array,又能把数组判定成Object,究其原因是原型链的作用————顺着数组实例 arr 的隐式原型一直找到了 Object 的构造函数,看下面的代码:
arr.__proto__ = Array.prototype
Array.prototype.__proto__ = Object.prototype
所以我们就知道了,instanceof能准确判断出一个对象是否为某种类型,就是依靠对象的原型链来查找的,一层又一层地判断直到找到null为止。
手写instanceOf
根据这个原理,我们可以手写出一个instanceof:
function myinstanceof(L, R) {
while(L != null) {
if(L.__proto__ === R.prototype){
return true;
}
L = L.__proto__;
}
return false;
}
console.log(myinstanceof([], Array)) // true
console.log(myinstanceof({}, Object)) // true
对象的隐式原型 等于 构造函数的显式原型!可看文章 给我三分钟,带你完全理解JS原型和原型链前言
Object.prototype.toString.call()
可以判断任何数据类型
在浏览器上执行这三段代码,会得到'[object Object]','[object Array]','[object Number]'
var a = {}
Object.prototype.toString.call(a)
var a = {}
Object.prototype.toString.call(a)
var a = 123
Object.prototype.toString.call(a)
原型上的toString的内部逻辑
调用Object.prototype.toString的时候执行会以下步骤: 参考官方文档:带注释的 ES5
- 如果此值是
undefined类型,则返回‘[object Undefined]’ - 如果此值是
null类型,则返回‘[object Null]’ - 将 O 作为
ToObject(this)的执行结果。toString执行过程中会调用一个ToObject方法,执行一个类似包装类的过程,我们访问不了这个方法,是JS自己用的 - 定义一个
class作为内部属性[[class]]的值。toString可以读取到这个值并把这个值暴露出来让我们看得见 - 返回由
"[object"和class和"]"组成的字符串
为什么结合call就能准确判断值类型了呢?
① 首先我们要知道Object.prototype.toString(xxx)往括号中不管传递什么返回结果都是'[object Object]',因为根据上面五个步骤来看,它内部会自动执行ToObject()方法,xxx会被执行一个类似包装类的过程然后转变成一个对象。所以单独一个Object.prototype.toString(xxx)不能用来判定值的类型
② 其次了解call方法的核心原理就是:比如foo.call(obj),利用隐式绑定的规则,让obj对象拥有foo这个函数的引用,从而让foo函数的this指向obj,执行完foo函数内部逻辑后,再将foo函数的引用从obj上删除掉。手搓一个call的源码就是这样的:
// call方法只允许被函数调用,所以它应该是放在Function构造函数的显式原型上的
Function.prototype.mycall = function(context) {
// 判断调用我的那个哥们是不是函数体
if (typeof this !== 'function') {
return new TypeError(this+ 'is not a function')
}
// this(函数)里面的this => context对象
const fn = Symbol('key') // 定义一个独一无二的fn,防止使用该源码时与其他fn产生冲突
context[fn] = this // 让对象拥有该函数 context={Symbol('key'): foo}
context[fn]() // 触发隐式绑定
delete context[fn]
}
③ 所以Object.prototype.toString.call(xxx)就相当于 xxx.toString(),把toString()方法放在了xxx对象上调用,这样就能精准给出xxx的对象类型
toString方法有几个版本:
{}.toString()得到由"[object" 和 class 和 "]" 组成的字符串
[].toString()数组的toString方法重写了对象上的toString方法,返回由数组内部元素以逗号拼接的字符串
xx.toString()返回字符串字面量,比如
let fn = function(){};
console.log( fn.toString() ) // "function () {}"
Array.isArray(x)
只能判断是否是数组,若传进去的x是数组,返回true,否则返回false
总结
typeOf:原始类型除了null都能准确判断,引用类型除了function能准确判断其他都不能。依靠值转为二进制后前三位是否为0来判断
instanceOf:只能把引用类型丢给它准确判断。顺着对象的隐式原型链向上比对,与构造函数的显式原型相等返回true,否则false
Object.prototype.toString.call():可以准确判断任何类型。要了解对象原型的toString()内部逻辑和call()的核心原理,二者结合才有精准判定的效果
Array.isArray():是数组则返回true,不是则返回false。判定范围最狭窄
来源:juejin.cn/post/7403288145196580904
学TypeScript必然要了解declare
背景
declare关键字是为了服务TypeScript的。TypeScript是什么在这里就不多介绍了,但是我们要知道ts文件是需要TypeScript编译器转换为js文件才可以执行,并且在编译阶段就会进行类型检查。但是在TypeScript中并不支持js可识别的所有类型,例如我们使用第三方库JQuery,我们通过一下方法获取一个id为‘foo’的标签元素。
$('#foo');
// or
jQuery('#foo');
然而在ts文件中,使用底下就会爆出一条红线提示到:Cannot find name '$'

因此,需要declare来声明,告诉TypeScript编译器该标识符已存在,通过编译时的检查并在开发时提供类型提示。
定义
在 TypeScript 中,declare关键字告诉编译器存在一个对象(并且可以在代码中引用)。它向 TypeScript 编译器声明该对象。简而言之,它允许开发人员使用在其他地方声明的对象。
注:编译器不会将declare语句编译为 JavaScript。对比下面两段代码:
// declare声明了一个名为 myGlobal 的全局变量,并指定其类型为 any。
// 该声明并不会生成真正的 JavaScript 代码,而只是告诉 TypeScript 编译器该变量存在。
declare var myGlobal: any;
// 给 myGlobal 赋值为 42。
myGlobal = 42;
console.log(myGlobal); // 42
// 直接声明了一个名为 myGlobal 的全局变量,并指定其类型为 any。这会生成真正的 JavaScript 代码。
var myGlobal: any;
// 给 myGlobal 赋值为 42。
myGlobal = 42;
console.log(myGlobal); // 42
使用
- declare var 声明全局变量
- declare function 声明全局方法
- declare class 声明全局类
- declare enum 声明全局枚举类型
- declare namespace 声明(含有子属性的)全局对象
- declare global 扩展全局变量
- declare module 扩展模块
声明文件
通常,在使用第三方库或模块时,有两种方式引入声明文件:
- 全局声明:如果第三方库或模块是全局可访问的,你可以在整个项目的任何地方直接使用它们,而无需显式导入。此时,你只需要确保在 TypeScript 项目中正确引入了相应的声明文件。一般情况下,TypeScript 会自动查找并加载全局声明文件。如果没有自动加载,你可以使用 /// 的方式在具体的源文件中将声明文件引入。
- 模块导入:如果第三方库或模块是通过模块化方式提供的,你需要使用 import 语句将其导入到你的代码中,同时也需要确保相应的声明文件被正确引入。在这种情况下,你可以使用 import 或 require 来引入库,并且不需要显式地引入声明文件,因为 TypeScript 编译器会根据模块的导入语句自动查找和加载相应的声明文件。
有很多第三方库提供了声明文件,可以在packages.json文件中查看。types表示类型声明文件是哪一个。

可以使用 @types 统一管理第三方库的声明文件。@types 的使用方式很简单,直接用 npm 安装对应的声明模块即可,以 jQuery 举例:
npm install @types/jquery --save-dev
来源:juejin.cn/post/7402811318816702515
厉害了,不用js就能实现文字中间省略号
今天发现一个特别有意思的效果,并进行解析,就是标题的效果
参考链接
如果要实现这个功能,我想很多人第一时间想到的都是用js去计算dom容器和文字之间是否溢出吧?但今天带来一个用css实现的效果,不用自己计算,只需要寥寥几行(bushi)就可以实现让人头疼的文字中间省略号功能。
实现思路
1. 简单实现
在用css实现的时候我们不妨用这个思路想想,设置一个当前显示文字span伪元素的width为50%,浮动到当前span上面,并且设置direction: rtl; 显示右边文字,不就可以很简单的实现这个功能了?让我们试试:
<style>
.wrap {
width: 200px;
border: 1px solid white;
}
.test-title {
display: block;
color: white;
overflow: hidden;
height: 20px;
}
.test-title::before {
content: attr(title);
width: 50%;
float: right;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
}
</style>
<body>
<div class="wrap">
<span class="test-title" title="这是一行文字文字文字文字文字文字文字文字文字文字文字文字文字">
这是一行文字文字文字文字文字文字文字文字文字文字文字文字文字
</span>
</div>
</body>
💡 此处应有图
2. 优化效果
在上面我们已经看到,其实效果我们已经实现了,现在文字中间已经有了省略号了!但是这其中其实有一个弊端不知道大家有没有发现,那就是文本不溢出的情况呢?伪元素是不是会一直显示在上面?这该怎么办?难道我们需要用js监听文本不溢出的情况然后手动隐藏吗?
既然是用css来进行实现,那么我们当然不能用这种方式了。这里原作者用了一种很取巧,但也很好玩的一种方法,让我们来看看吧!
既然我们上面实现的是文本溢出的情况,那么当文本不溢出的时候我们直接显示文字不就行了?你可能想说:“这不是废话吗?但我现在不就是不知道怎么判断吗? ”。hhhhh对,那我们就要用css来想想,css该怎么判断呢?我就不卖关子了,让我们想想,我们给文本的容器添加一个固定宽度,那么当文本溢出的时候会发生什么呢?是不是会换行,高度变大呢,那么当我们设置两个文本元素,一个是正常样式,一个是我们上方的溢出样式。等文本不溢出没换行的时候,显示正常样式,当文本溢出高度变大的时候显示溢出样式可以吗?让我们试试吧
<!DOCTYPE html>
<html lang="en">
<head>
<style>
body {
background: #333;
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
margin: 0;
font-size: 14px;
}
.wrap {
width: 300px;
background: #333;
/* 设置正常行高,并隐藏溢出画面 */
height: 2em;
overflow: hidden;
line-height: 2;
position: relative;
text-align: -webkit-match-parent;
resize: horizontal;
}
.normal-title {
/* 设置最大高度为双倍行高使其可以换行 */
display: block;
max-height: 4em;
}
.test-title {
position: relative;
top: -4em;
display: block;
color: white;
overflow: hidden;
height: 2em;
text-align: justify;
background: inherit;
overflow: hidden;
}
.test-title::before {
content: attr(title);
width: 50%;
float: right;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
direction: rtl;
}
</style>
</head>
<body>
<div class="wrap">
<span class="normal-title">这是一行文字文字文字文字文字文字文字文字文字文字文字文字文字</span>
<span class="test-title" title="这是一行文字文字文字文字文字文字文字文字文字文字文字文字文字">
这是一行文字文字文字文字文字文字文字文字文字文字文字文字文字
</span>
</div>
</body>
</html>
大家都试过了吧?那让我们来讲一下这段代码的实现:
实现方式:简单来说这段代码实现的就是一个覆盖的效果,normal-title元素平常是普通高度(1em),等到换行之后就会变成2em,那么我们的溢出样式test-title怎么实现的覆盖呢?这主要依赖于test-title的top属性,让我们这样子想,当normal-title高度为1em的时候,test-title的top为-2em,那么这时候因为wrap的hidden效果,所以test-title是看不到的。那么当normal-title的高度为2em的时候呢?test-title刚好就会覆盖到normal-title上面,所以我们刚好可以看到test-title的省略号效果。
这就是完整的实现过程和方式,css一些取巧的判断方式总会让我们大开眼界,不断学习,方得始终。
来源:juejin.cn/post/7401812292211081226
1. 使用openai api实现一个智能前端组件
0. 注意
本文只是提供一个思路,由于现在大模型正在飞速发展,整个生态在不久的将来或许会发生巨大的变化,文章中的代码仅供参考。
1. 一个简单的示例

假设当前时间是2023年12月28日,时间段选择器通过理解用户输入表述,自动设置值。
可以看到组件正确理解了用户想要设置的时间。
2.原理简介
graph TD
输入文字描述 --> 请求语言模型接口 --> 处理语言模型响应 --> 功能操作
其实原理很简单,就是通过代码的方式问模型问题,然后让他回答。这和我们使用chatgpt一样的。
3. 实现
输入描述就不说了,就是输入框。关键在于请求和处理语言模型的接口。
最简单的就是直接使用api请求这些大模型的官方接口,但是我们需要处理各种平台之间的接口差异和一些特殊问题。这里我使用了一个开发语言模型应用的框架LangChain。
3.1. LangChain
简单的说,这是一个面向语言处理模型的编程框架,从如何输入你的问题,到如何处理回答都有规范的工具来实现。
// 这是一个最简单的例子
import { OpenAI } from "langchain/llms/openai";
import { ChatOpenAI } from "langchain/chat_models/openai";
// 初始化openai模型
const llm = new OpenAI({
temperature: 0.9,
});
// 准备一个输入文本
const text =
"What would be a good company name for a company that makes colorful socks?";
// 输入文本,获取响应
const llmResult = await llm.predict(text);
//=> 响应一段文本:"Feetful of Fun"
整个框架主要就是下面三个部分组成:
graph LR
A["输入模板(Prompt templates)"] --- B["语言模型(Language models)"] --- C["输出解释器(Output parsers)"]
Prompt templates:输入模板分一句话(not chat)和对话(chat)模式,区别就是输入一句话和多句话,而且对话模式中每句话有角色区分是谁说的,比如人类、AI、系统。这里简单介绍一下非对话模式下怎么创建输入模板。
import { PromptTemplate } from "langchain/prompts";
// 最简单的模板生成,使用fromTemplate传入一句话
// 可以在句子中加入{}占位符表示变量
const oneInputPrompt = PromptTemplate.fromTemplate(
`You are a naming consultant for new companies.
What is a good name for a company that makes {product}?`
);
// 也可以直接实例化设置
const twoInputPrompt = new PromptTemplate({
inputVariables: ["adjective"],
template: "Tell me a {adjective} joke.",
});
// 如果你想要这样和模型对话
// 先给出几个例子,然后在问问题
Respond to the users question in the with the following format:
Question: What is your name?
Answer: My name is John.
Question: What is your age?
Answer: I am 25 years old.
Question: What is your favorite color?
Answer:
// 可以使用FewShotPromptTemplate
// 创建一些模板,字段名随便你定
const examples = [
{
input:
"Could the members of The Police perform lawful arrests?",
output: "what can the members of The Police do?",
},
{
input: "Jan Sindel's was born in what country?",
output: "what is Jan Sindel's personal history?",
},
];
// 输入模板,包含变量就是模板要填充的
const prompt = `Human: {input}\nAI: {output}`;
const examplePromptTemplate = PromptTemplate.fromTemplate(prompt);
// 创建example输入模板
const fewShotPrompt = new FewShotPromptTemplate({
examplePrompt: examplePromptTemplate,
examples,
inputVariables: [], // no input variables
});
console.log(
(await fewShotPrompt.formatPromptValue({})).toString()
);
// 输出
Human: Could the members of The Police perform lawful arrests?
AI: what can the members of The Police do?
Human: Jan Sindel's was born in what country?
AI: what is Jan Sindel's personal history?
// 还有很多可以查询官网
Language models: 语言模型同样分为LLM(大语言模型)和chat模型,其实两个差不多,就是输入多少和是否可以连续对话的区别。
import { OpenAI } from "langchain/llms/openai";
const model = new OpenAI({ temperature: 1 });
// 可以添加超时
const resA = await model.call(
"What would be a good company name a company that makes colorful socks?",
{ timeout: 1000 } // 1s timeout
);
// 注册一些事件回调
const model = new OpenAI({
callbacks: [
{
handleLLMStart: async (llm: Serialized, prompts: string[]) => {
console.log(JSON.stringify(llm, null, 2));
console.log(JSON.stringify(prompts, null, 2));
},
handleLLMEnd: async (output: LLMResult) => {
console.log(JSON.stringify(output, null, 2));
},
handleLLMError: async (err: Error) => {
console.error(err);
},
},
],
});
// 还有一些配置可以参考文档
Output parsers: 顾名思义就是处理输出的模块,当语言模型回答了一段文字程序是很难提取出有用信息的, 我们通常需要模型返回一个程序可以处理的答案,比如JSON。虽然叫输出解释器,实际上是在输入信息中加入一些额外的提示,让模型能够按照需求格式输出。
// 这里用StructuredOutputParser,结构化输出解释器为例
// 使用StructuredOutputParser创建一个解释器
// 定义了输出有两个字段answer、source
// 字段的值是对这个字段的描述在
const parser = StructuredOutputParser.fromNamesAndDescriptions({
answer: "answer to the user's question",
source: "source used to answer the user's question, should be a website.",
});
// 使用RunnableSequence,批量执行任务
const chain = RunnableSequence.from([
// 输入包含了两个变量,一个是结构化解释器的“格式说明”,一个是用户的问题
PromptTemplate.fromTemplate(
"Answer the users question as best as possible.\n{format_instructions}\n{question}"
),
new OpenAI({ temperature: 0 }),
parser,
]);
// 与模型交互
const response = await chain.invoke({
question: "What is the capital of France?",
format_instructions: parser.getFormatInstructions(),
});
// 响应 { answer: 'Paris', source: 'https://en.wikipedia.org/wiki/Paris' }
// 输入的模板是这样
Answer the users question as best as possible. // 这句话就是prompt的第一句
// 下面一大段是StructuredOutputParser自动加上的,大概就是告诉模型json的标准格式应该是什么
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {{"properties": {{"foo": {{"title": "Foo", "description": "a list of strings", "type": "array", "items": {{"type": "string"}}}}}}, "required": ["foo"]}}}}
the object {{"foo": ["bar", "baz"]}} is a well-formatted instance of the schema. The object {{"properties": {{"foo": ["bar", "baz"]}}}} is not well-formatted.
Here is the output schema:
```
{"type":"object","properties":{"answer":{"type":"string","description":"answer to the user's question"},"sources":{"type":"array","items":{"type":"string"},"description":"sources used to answer the question, should be websites."}},"required":["answer","sources"],"additionalProperties":false,"$schema":"http://json-schema.org/draft-07/schema#"}
```
// 这段就是调用的时候传入的问题
What is the capital of France?
// 还有很多不同的解释器
// 如StringOutputParser字符串输出解释器
// JsonOutputFunctionsParser json函数输出解释器等等
除了这三部分,还有一些方便程序操作的一些功能模块,比如记录聊天状态的Memory模块,知识库模块Retrieval等等,这些官网有比较完整的文档,深度的使用后面再来探索。
3.2. 简单版本
// 初始化语言模型
// 这里使用的openai
const llm = new OpenAI({
openAIApiKey: import.meta.env.VITE_OPENAI_KEY,
temperature: 0,
});
function App() {
const [res, setRes] = useState<string>();
const [from] = Form.useForm();
return (
<>
<div>结果:{res}</div>
<Form wrapperCol={{ span: 6 }} form={from}>
<Form.Item label="输入描述">
<Input.Search
onSearch={async (value) => {
setRes("正在请求");
// 直接对话模型
const text =
`现在是${dayjs().format("YYYY-MM-DD")},${value},开始结束时间是什么。请用这个格式回答{startTime: '开始时间', endTime: '结束时间'}`;
// 简单预测文本
const llmResult = await llm.predict(text);
const response = JSON.parse(llmResult)
// 解析
const { startTime, endTime } = response;
// 设置
from.setFieldsValue({
times: [dayjs(startTime), dayjs(endTime)],
});
setRes(llmResult)
}}
enterButton={<Button type="primary">确定</Button>}
/>
</Form.Item>
<Form.Item label="时间段" name="times">
<DatePicker.RangePicker />
</Form.Item>
</Form>
</>
);
}
export default App;
前面虽然能实现功能,但是有很多边界条件无法考虑到,比如有的模型无法理解你这个返回格式是什么意思,或者你有很多个字段那你就要写一大串输入模板。
3.3. 使用结构化输出解释器
// 修改一下onSearch
setRes("正在请求");
// 定义输出有两个字段startTime、endTime
const parser = StructuredOutputParser.fromNamesAndDescriptions({
startTime: "开始时间,格式是YYYY-MM-DD HH:mm:ss",
endTime: "结束时间,格式是YYYY-MM-DD HH:mm:ss",
});
const chain = RunnableSequence.from([
// 输入模板
PromptTemplate.fromTemplate(
`{format_instructions}\n现在是${dayjs().format(
"YYYY-MM-DD"
)},{question},开始结束时间是什么`
),
llm,
parser,
]);
const response = await chain.invoke({
question: value,
// 把输出解释器的提示放入输入模板中
format_instructions: parser.getFormatInstructions(),
});
// 这个时候经过结构化解释器处理,返回的就是json
setRes(JSON.stringify(response));
const { startTime, endTime } = response;
from.setFieldsValue({
times: [dayjs(startTime), dayjs(endTime)],
});
对于大型一点的项目,使用langChain的api可以更规范的组织我们的代码。
// 完整代码
import { OpenAI } from "langchain/llms/openai";
import { useState } from "react";
import {
PromptTemplate,
} from "langchain/prompts";
import { StructuredOutputParser } from "langchain/output_parsers";
import { RunnableSequence } from "langchain/runnables";
import { Button, DatePicker, Form, Input } from "antd";
import "dayjs/locale/zh-cn";
import dayjs from "dayjs";
const llm = new OpenAI({
openAIApiKey: import.meta.env.VITE_OPENAI_KEY,
temperature: 0,
});
function App() {
const [res, setRes] = useState<string>();
const [from] = Form.useForm();
return (
<>
<div>结果:{res}</div>
<Form wrapperCol={{ span: 6 }} form={from}>
<Form.Item label="输入描述">
<Input.Search
onSearch={async (value) => {
setRes("正在请求");
const parser = StructuredOutputParser.fromNamesAndDescriptions({
startTime: "开始时间,格式是YYYY-MM-DD HH:mm:ss",
endTime: "结束时间,格式是YYYY-MM-DD HH:mm:ss",
});
const chain = RunnableSequence.from([
PromptTemplate.fromTemplate(
`{format_instructions}\n现在是${dayjs().format(
"YYYY-MM-DD"
)},{question},开始结束时间是什么`
),
llm,
parser,
]);
const response = await chain.invoke({
question: value,
format_instructions: parser.getFormatInstructions(),
});
setRes(JSON.stringify(response));
const { startTime, endTime } = response;
from.setFieldsValue({
times: [dayjs(startTime), dayjs(endTime)],
});
}}
enterButton={<Button type="primary">确定</Button>}
/>
</Form.Item>
<Form.Item label="时间段" name="times">
<DatePicker.RangePicker />
</Form.Item>
</Form>
</>
);
}
export default App;
4.总结
这篇文章只是我初步使用LangChain的一个小demo,在智能组件上面,大家其实可以发挥更大的想象去发挥。还有很多组件可以变成自然语言驱动的。
随着以后大模型的小型化,专门化,我相信肯定会涌现更多的智能组件。
来源:juejin.cn/post/7317440781588840486
Vue.js 自动路由:告别手动配置,让开发更轻松!
在使用 Vue.js 开发项目的时候,我最头疼的就是创建路由,尤其是项目越来越大的时候,管理 route.ts 或 route.js 文件简直是一场噩梦!
我曾经做过一个页面超级多的项目,每新增一个页面就要更新路由,删除页面也要更新路由文件,不然就会报错,真是烦死人了!
所以,我开始寻找自动生成路由的方法。我在网上搜了很久,但大部分结果都是针对 Webpack 和 Vue 2 的,很难找到适合我的方案。最后,我在 Vue 的 GitHub 仓库的讨论区里提问,终于找到了答案!
那就是 Unplugin Vue Router! 它可以为 Vue 3 实现基于文件的自动路由,而且支持 TypeScript,设置起来也超级简单! 虽然官方说它还在实验阶段,但用起来已经很方便了。
创建项目,安装插件
首先,我们创建一个新的 Vue 项目。 相信大家都很熟悉用 Vue CLI 创建项目了,这里就不赘述了,不熟悉的小伙伴可以去看看 Vue.js 官网的快速入门指南。
pnpm create vue@latest
我创建项目的时候选择了 TypeScript 和 Vue Router,这样它就会自动生成一些页面和路由。
然后,进入项目目录,安装依赖。我最近开始用 pnpm 来管理依赖,感觉还不错。
pnpm add -D unplugin-vue-router
接下来,更新 vite.config.ts 文件, 注意要把插件放在第 0 个位置 。
import { fileURLToPath, URL } from "node:url";
import VueRouter from "unplugin-vue-router/vite";
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
VueRouter({
/* options */
}),
// ⚠️ Vue must be placed after VueRouter()
vue(),
],
resolve: {
alias: {
"@": fileURLToPath(new URL("./src", import.meta.url)),
},
},
});
然后,更新 env.d.ts 文件,让编辑器能够识别插件的类型。
/// <reference types="vite/client" />
/// <reference types="unplugin-vue-router/client" />
最后,更新路由文件 src/router/index.ts 。
import { createRouter, createWebHistory } from "vue-router";
import { routes, handleHotUpdate } from "vue-router/auto-routes";
const router = createRouter({
history: createWebHistory(import.meta.env.BASE_URL),
routes,
});
if (import.meta.hot) {
handleHotUpdate(router);
}
export default router;
创建页面,自动生成路由
现在,我们可以创建 src/pages 目录了,在这个目录下创建的 Vue 组件会自动变成路由和页面,就像 Nuxt 一样方便!
我们先在 src\pages\about.vue 创建一个关于页面:
<template>
<div>This is the about page</div>
</template>
然后在 src\pages\index.vue 创建首页:
<template>
<div>This is Home Page</div>
</template>
运行 pnpm dev 启动开发服务器,点击 “Home” 链接就会跳转到首页,点击 “About” 链接就会跳转到关于页面。
怎么样,是不是很方便? 如果你不熟悉路由文件夹结构,可以看看这个文档: uvr.esm.is/guide/file-…
动态路由
我们再来试试创建带参数的动态路由。在 src/pages/blog/[id].vue 创建一个组件,内容如下:
<script setup>
const { id } = useRoute().params;
</script>
<template>
<div>This is the blog post with id: {{ id }}</div>
</template>
再次运行 pnpm dev ,然后访问 http://localhost:5173/blog/6 ,你就会看到以下内容:
是不是很神奇? 希望这篇简短的博客能帮助你在 Vue.js 的旅程中更轻松地创建路由!
来源:juejin.cn/post/7401354593588199465
学TypeScript必然要了解declare
背景
declare关键字是为了服务TypeScript的。TypeScript是什么在这里就不多介绍了,但是我们要知道ts文件是需要TypeScript编译器转换为js文件才可以执行,并且在编译阶段就会进行类型检查。但是在TypeScript中并不支持js可识别的所有类型,例如我们使用第三方库JQuery,我们通过一下方法获取一个id为‘foo’的标签元素。
$('#foo');
// or
jQuery('#foo');
然而在ts文件中,使用底下就会爆出一条红线提示到:Cannot find name '$'

因此,需要declare来声明,告诉TypeScript编译器该标识符已存在,通过编译时的检查并在开发时提供类型提示。
定义
在 TypeScript 中,declare关键字告诉编译器存在一个对象(并且可以在代码中引用)。它向 TypeScript 编译器声明该对象。简而言之,它允许开发人员使用在其他地方声明的对象。
注:编译器不会将declare语句编译为 JavaScript。对比下面两段代码:
// declare声明了一个名为 myGlobal 的全局变量,并指定其类型为 any。
// 该声明并不会生成真正的 JavaScript 代码,而只是告诉 TypeScript 编译器该变量存在。
declare var myGlobal: any;
// 给 myGlobal 赋值为 42。
myGlobal = 42;
console.log(myGlobal); // 42
// 直接声明了一个名为 myGlobal 的全局变量,并指定其类型为 any。这会生成真正的 JavaScript 代码。
var myGlobal: any;
// 给 myGlobal 赋值为 42。
myGlobal = 42;
console.log(myGlobal); // 42
使用
- declare var 声明全局变量
- declare function 声明全局方法
- declare class 声明全局类
- declare enum 声明全局枚举类型
- declare namespace 声明(含有子属性的)全局对象
- declare global 扩展全局变量
- declare module 扩展模块
声明文件
通常,在使用第三方库或模块时,有两种方式引入声明文件:
- 全局声明:如果第三方库或模块是全局可访问的,你可以在整个项目的任何地方直接使用它们,而无需显式导入。此时,你只需要确保在 TypeScript 项目中正确引入了相应的声明文件。一般情况下,TypeScript 会自动查找并加载全局声明文件。如果没有自动加载,你可以使用 /// 的方式在具体的源文件中将声明文件引入。
- 模块导入:如果第三方库或模块是通过模块化方式提供的,你需要使用 import 语句将其导入到你的代码中,同时也需要确保相应的声明文件被正确引入。在这种情况下,你可以使用 import 或 require 来引入库,并且不需要显式地引入声明文件,因为 TypeScript 编译器会根据模块的导入语句自动查找和加载相应的声明文件。
有很多第三方库提供了声明文件,可以在packages.json文件中查看。types表示类型声明文件是哪一个。

可以使用 @types 统一管理第三方库的声明文件。@types 的使用方式很简单,直接用 npm 安装对应的声明模块即可,以 jQuery 举例:
npm install @types/jquery --save-dev
来源:juejin.cn/post/7402811318816702515
前端如何将git的信息打包进html
为什么要做这件事
- 定制化项目我们没有参与或者要临时更新客户的包的时候,需要查文档才知道哪个是最新分支
- 当测试环境打包的时候,不确定是否是最新的包,需要点下功能看是否是最新的代码,不能直观的看到当前打的是哪个分支
- 多人开发的时候,某些场景下可能被别人覆盖了,需要查下jenkins或者登录服务器看下
实现效果
如下,当打开F12,可以直观的看到打包日期、分支、提交hash、提交时间

如何做
主要是借助 git-revision-webpack-plugin的能力。获取到git到一些后,将这些信息注入到变量中,html读取这个变量即可
1. 安装dev的依赖
npm install --save-dev git-revision-webpack-plugin
2. 引入依赖并且初始化
const { GitRevisionPlugin } = require('git-revision-webpack-plugin')
const gitRevisionPlugin = new GitRevisionPlugin()
3. 注入变量信息
我这里用的是vuecli,可直接在chainWebpack中注入,当然你可以使用DefinePlugin进行声明
config.plugin('html').tap((args) => {
args[0].banner = {
date: dayjs().format('YYYY-MM-DD HH:mm:ss'),
branch: gitRevisionPlugin.branch(),
commitHash: gitRevisionPlugin.commithash(),
lastCommitDateTime: dayjs(gitRevisionPlugin.lastcommitdatetime()).format('YYYY-MM-DD HH:mm:ss'),
}
return args
});
4. 使用变量
在index.html的头部插入注释
<!-- date <%= htmlWebpackPlugin.options.banner.date %> -->
<!-- branch <%= htmlWebpackPlugin.options.banner.branch %> -->
<!-- commitHash <%= htmlWebpackPlugin.options.banner.commitHash %> -->
<!-- lastCommitDateTime <%= htmlWebpackPlugin.options.banner.lastCommitDateTime %> -->
5. 查看页面
6. 假如你用的是vuecli
当你使用的是vuecli,构建完后会发现index.html上这个注释丢失了
原因如下
vueCLi 对html的打包用的html-webpack-plugin,默认在打包的时候会把注释删除掉

修改vuecli的配置如下可以解决,将removeComments设置为false即可
module.exports = {
// 其他配置项...
chainWebpack: config => {
config
.plugin('html')
.tap(args => {
args[0].minify = {
removeComments: false,
// 其他需要设置的参数
};
return args;
});
},
};
7. 假如你想给qiankun的子应用添加一些git的注释信息,可以在meta中添加
<meta name="description"
content="Date:<%= htmlWebpackPlugin.options.banner.date %>,Branch:<%= htmlWebpackPlugin.options.banner.branch %>,commitHash: <%= htmlWebpackPlugin.options.banner.commitHash %>,lastCommitDateTime:<%= htmlWebpackPlugin.options.banner.lastCommitDateTime %>">
渲染在html上如下,也可以快速的看到子应用的构建时间和具体的分支

总结
- 借助git-revision-webpack-plugin的能力读取到git的一些信息
- 将变量注入在html中或者使用DefinePlugin进行声明变量
- 读取变量后显示在html上或者打印在控制台上可以把关键的信息保留,方便我们排查问题
来源:juejin.cn/post/7403185402347634724
码农的畅想:年入10个小目标
本文将以自己真实的创业项目为例,给大家分享如何写一个用于融资的BP(商业计划书)。
使命愿景
我们为小型艺培机构或个体老师提供好用的招生引流工具和教学课件,让老师能够更加专注教学和提升服务体验。
- 使命:让天下没有难做的艺术培训,通过艺术培训提升人类的幸福感。
- 愿景:成为艺培行业的贝壳(线下培训蜗牛艺术中心类似链家,线上平台艺培助理类似贝壳),实现年营收一百亿。
产品及服务
线下业务为蜗牛艺术中心,以提供融合了绘本阅读、艺术创作和图形编程的跨学科美育培训为主,同时也开设书法、舞蹈和音乐等品类的培训。
线上业务为艺培助理,是美术、音乐和舞蹈等培训机构教研、招生及运营的好帮手,引流产品为3D画展,现金产品为海报设计,利润产品为课程加盟。
- 载体:小程序、网页应用和APP。
- 服务:3D展厅、海报设计、拼团招生和课程加盟。
- 策略:移动端优先,通过海报设计和课程研发大赛获取目标用户,借助AIGC技术提升生产力,用产品力说话,靠口碑裂变。
团队
- 陈XX:创始人 CEO 产研负责人 美团技术专家 毕业于交大和某军校 曾在798当过美术馆长 有5年以上线下艺培经验。
- 杨XX:运营合伙人 毕业于交大和暨南大学,和创始人认识了16年 并一起经营了一家跨境电商服务公司,实现年营收500多万。
- 熊XX:教研合伙人 清华美院硕士和美育研究所委员 曾任探月学院美育教研负责人 和创始人认识了10年,三年前就一起尝试过创业,拥有15年艺培经验。
财务顾问:xxx,创始人的亲戚,曾任上市公司董事长助理,北大光华管理学院硕士。
行业背景
从21年底开始,国家大力限制学科培训,并于23年底教育部下发通知要大力推进跨学科美育,艺术教育将迎来大爆发,2025年的市场规模将由之前预期的2000亿增长为3000亿。
虽然新生儿的人口相比高峰下降了近一半,但艺术教育中偏兴趣的低龄目标学生(2到12岁),五年内也能维持在一个亿左右,而偏应试的大龄目标学生(12到19岁),也有一个亿左右,还有正在高速发展的成人艺培培训。
所以,整个艺培市场的规模,还能保持年复20%左右的增长,未来五年至少能达到5000亿(仅考虑低龄艺培市场,若人均5000元,渗透率50%即可达到)。
存在痛点
但由于经济下行,家长对课程和服务体验的要求越来越高,艺培机构普遍招生很难,急需技术赋能传统教育机构,提升产品服务标准程度、提高管理效率和坪效、缩短回本周期,技术的完善应用,将给予连锁教育机构实现标准化、规模化的机会。
相比学科培训,艺培的标准化要难很多,而且做服务的天花板很低,最多只能达到10亿的级别,巨头看不上,小团队又搞不定,目前还没有平台能够给艺培机构,提供系统化的通用解决方案,简化机构的日常工作,让机构能够更多的关注学生及家长,做好最核心的教学服务。
近几年,移动互联网发展已经非常成熟,服务艺培机构招生运营某个环节的软件,在市面上已经有了很多,不论是拼团招生的工具,还是海报设计的平台,或是校区管理的saas软件,都只能部分解决艺培机构的需求。
竞品及我们的优势
从海报设计看,有稿定设计、美图设计室、创客贴、爱设计、图怪兽等知名的设计平台,只有稿定设计的艺培模板素材相对丰富,但都不是专门面向艺培机构的,模板和素材不够丰富,且机构使用海报模板后,还需结合自己的招生运营方案做较大调整。我们提供的海报都是我们线下培训门店真实用于招生的海报,并且通过设计大赛,让用户也能为其他用户提供海报及素材,所以使用海报模板后,只需简单改一改品牌、logo和图片即可投入使用。
从3D展厅看,目前很多公司提供的展厅以面向政府企业的宣传为主,比如党建展览、历史回顾等,多数不支持实时在3D模型中去动态加载图片,使用成本比较高。我们提供3D展厅,是专门面向艺培机构的,可以实时动态修改画展中的作品,只要在后台替换了图片,系统无需上线,用户再次打开,展现的就是最新作品,我们可以做到一个展厅最低只需10元,甚至可以作为免费引流的工具。
从拼团招生看,市面上有很多第三方的招生公司,他们一般提供的方案是198元6次课,学生购买拼团课的钱,机构一分钱也拿不到,并且课次太多,机构的转化率也不高。我通过师训教会机构自己按照流程去组织拼团活动即可,我们的收费不到竞品的十分之一,甚至为了引流,可以完全免费。
从课程加盟看,目前市面美术做的比较好的有本来计画和小央美,但他们提供的都是传统的美术课程,并且软件使用的是第三方的课件系统,用户体验比较差;我们提供的是教育部23年底倡导的跨学科美育课程,不仅课程辨识度高,而且我们将艺术创作与绘本阅读及图形编程结合,其他机构很难模仿。
项目现状及展望
当前,线下培训方向:我们已经在深圳开了一家门店并实现盈利,近期正在郑州和北京各开一家分店(都有一定学生基础,基于已有的店进行跨学科升级),招聘了5个全职的美术老师和3个实习生;线上培训方向:艺培助理的小程序和网站均已上线,海报设计、拼团招生和3D展厅均已正式投入使用,近期正在接入一个合作的课程加盟老师,将带来一千个种子用户,日活突破一千(每天都需使用课件进行备课和上课)。
接下来的计划是,先融资500到1000万,组建10人的产研团队,根据种子用户的反馈,优化系统和收费方案,组织海报设计和课程研发大赛,实现线上业务月营收突破一百万;同时,在多个大城市打造10家线下培训旗舰店,实现月营收突破200万,为开展师训和课程加盟做好准备。
后续将会根据发展进行多轮融资,不断完善艺培助理的功能和服务,比如打造社区、增加招聘板块、提供短视频、支持直播等,为1000万个学生提供个性化的3D展厅(每个每年20元),发展100万个艺培助理会员(年费300元),同时在大城市开设100家直营门店,并为5000家艺培机构提供课程加盟,年营收达到:100020万+ 100300万 + 300100万 + 50004万 = 10亿。
资金及项目规划
- 股权架构:创始人 45% 联合创始人 25% 运营合伙人+技术合伙人20% 其他员工股权池 10%。
- 融资需求:500~1000万,出让20%的股权。
- 资金使用:50%用于搭建产研团队,30%用于为海报设计和课程制作大赛提供奖金,20%用于投放广告。
- 未来融资:一年后实现月营收100万,启动A轮融资2000~5000万,扩大规模,实现月营收一千万,三年后启动B轮融资一到三亿元,实现月营收五千万,五年后启动C轮融资,业务多元化,实现月营收一亿以上。
总结
小富靠勤,大富靠命。要坚信,命运永远掌握在自己手中。
随着这两年大模型技术的突飞猛进,很多简单重复的智力工作将被AI替代,大家将有更多的时间去丰富自己的精神需要,艺培行业的市场规模一定可以超过万亿。
如今,美术在线培训的美术宝和钢琴在线培训的vip陪练,都已经实现了年营收超过20亿,我们作为oMo模式的先行者,未来五年实现年营收10个亿只是个小目标。
我相信,这个商业计划能够实现的可能性很大的,在此分享给大家,即使我没有实现,肯定也会有其他人可以实现。
来源:juejin.cn/post/7376925694613274674
还在用 来当作空格?别忽视他对样式的影响!
许久没有更新博客了,今天就抽空来分享下之前遇到个有意思的现象~
奇怪的现象,被换行的单词
在一次新需求完工之后,进行国际化样式优化时,我发现了一个奇怪的现象:即使页面元素有word-wrap:break-word; 样式属性,单词也照样会被直接裁断换行。

这又是为什么嘞?细细分析页面元素,突然发现或许这与之前的踩过的坑:特殊的不换行空格有关?!
来复现吧!
那我们马上就来试一试!
<style>
.normal_style{
width:70px;
height:200px;
margin-right:150px;
border:1px solid red;
/* 👇表示 如果一个单词超出行长度,要截取换行,其他默认;👇 */
word-wrap:break-word;
}
</style>
<div style="display:flex;">
<div class='normal_style'>This is a long a long sentence</div>
<div class='normal_style'>This is a long a long sentence</div>
</div>

很明显,单词直接被强行换行拆分了!
那会不会是页面解析的时候,把 连同其他单词一起,当作一长串单词来处理了,所以才不换行的嘞?
你知道空格转义符有几种写法吗?
那我们就再来试试!不使用 转而使用其他空格转义符呢?
其实除了 ,还有其他很多种空格转义符。
1. 半角空格
 
它才是典型的“半角空格”,全称是En Space,en是字体排印学的计量单位,为em宽度的一半。根据定义,它等同于字体度的一半(如16px字体中就是8px)。名义上是小写字母n的宽度。此空格传承空格家族一贯的特性:透明的,此空格有个相当稳健的特性,就是其占据的宽度正好是1/2个中文宽度,而且基本上不受字体影响。
2. 全角空格
 
从这个符号到下面, 我们就很少见到了, 它叫“全角空格”,全称是Em Space,em是字体排印学的计量单位,相当于当前指定的点数。例如,1 em在16px的字体中就是16px。此空格也传承空格家族一贯的特性:透明的,此空格也有个相当稳健的特性,就是其占据的宽度正好是1个中文宽度,而且基本上不受字体影响。
3. 窄空格
 
窄空格,全称是Thin Space。我们不妨称之为“瘦弱空格”,就是该空格长得比较瘦弱,身体单薄,占据的宽度比较小。它是em之六分之一宽。
4. 零宽不连字
‌
它叫零宽不连字,全称是Zero Width Non Joiner,简称“ZWNJ”,是一个不打印字符,放在电子文本的两个字符之间,抑制本来会发生的连字,而是以这两个字符原本的字形来绘制。Unicode中的零宽不连字字符映射为“”(zero width non-joiner,U+200C),HTML字符值引用为:
5. 零宽连字
‍
它叫零宽连字,全称是Zero Width Joiner,简称“ZWJ”,是一个不打印字符,放在某些需要复杂排版语言(如阿拉伯语、印地语)的两个字符之间,使得这两个本不会发生连字的字符产生了连字效果。零宽连字符的Unicode码位是U+200D (HTML: )。
再次尝试复现- 
<style>
.normal_style{
width:70px;
height:200px;
margin-right:150px;
border:1px solid red;
/* 👇表示 如果一个单词超出行长度,要截取换行,其他默认;👇 */
word-wrap:break-word;
}
</style>
<div style="display:flex;">
<div class='normal_style'>This is a long a long sentence</div>
<div class='normal_style'>This is a long a long sentence</div>
<div class='normal_style'>This is a long a long sentence</div>
</div>

我们可以看到   进行转义的话,单词截取换行是正常的!所以,真凶就是 特殊的不换行空格!
如何修订?
因为这个提示框是使用公司自制的 UI 组件实现的,而之所以使用 进行转义是为了修订XSS注入。(对,这个老东西现在没人维护,还是我去啃源码加上的,使用了公共的转义方法)。最后就简单去修改这个公共方法吧!使用了最贴近 宽度的空格转义符: !
来源:juejin.cn/post/7403953367766859828
数据大屏的解决方案
1. 使用缩放比例适配各种设备(适用16*9比例的屏幕分辨率)
- 封装一个获取缩放比例的工具函数
/**
* 大屏效果需要满足16:9的屏幕比例,才能达到完美的大屏适配效果
* 其他比例的大屏效果,不能铺满整个屏幕
* @param {*} w 设备宽度 默认 1920
* @param {*} h 设备高度 默认 1080
* @returns 返回值是缩放比例
*/
export function getScale(w = 1920, h = 1080) {
const ww = window.innerWidth / w
const wh = window.innerHeight / h
return ww < wh ? ww : wh
}
- 在
vue中使用方案如下
<template>
<div class="full-screen-container">
<div id="screen">
大屏展示的内容
</div>
</div>
</template>
<script>
import { getScale } from "@/utils/tool";
import screenfull from "screenfull";
export default {
name: "cockpit",
mounted() {
if (screenfull && screenfull.enabled && !screenfull.isFullscreen) {
screenfull.request();
}
this.setFullScreen();
},
methods: {
setFullScreen() {
const screenNode = document.getElementById("screen");
// 非标准设备(笔记本小于1920,如:1366*768、mac 1432*896)
if (window.innerWidth < 1920) {
screenNode.style.left = "50%";
screenNode.style.transform = `scale(${getScale()}) translate(-50%, 0)`;
} else if (window.innerWidth === 1920) {
// 标准设备 1920 * 1080
screenNode.style.left = 0;
screenNode.style.transform = `scale(1) translate(0, 0)`;
} else {
// 大屏设备(4K 2560*1600)
screenNode.style.left = "50%";
screenNode.style.transform = `scale(${getScale()}) translate(-50%, 0)`;
}
// 监听视口变化
window.addEventListener("resize", () => {
if (window.innerWidth === 1920) {
screenNode.style.left = 0;
screenNode.style.transform = `scale(1) translate(0, 0)`;
} else {
screenNode.style.left = "50%";
screenNode.style.transform = `scale(${getScale()}) translate(-50%, 0)`;
}
});
},
},
};
</script>
<style lang="scss">
.full-screen-container {
width: 100vw;
height: 100vh;
display: flex;
flex-direction: column;
background-color: #131a2b;
#screen {
position: fixed;
width: 1920px;
height: 1080px;
top: 0;
transform-origin: left top;
color: #fff;
}
}
</style>
- mac设备上的屏幕分辨率,在适配的时候,可能不是那么完美,以短边缩放为准,所以宽度到达百分之百后,高度不会铺满
- 1432*896 13寸mac本
- 2560*1600
4k屏幕
2. 使用第三方插件来实现数据大屏(mac设备会产生布局错落)
- 建议在全屏容器内使用百分比搭配flex进行布局,以便于在不同的分辨率下得到较为一致的展示效果。
- 使用前请注意将
body的margin设为0,否则会引起计算误差,全屏后不能完全充满屏幕。 - 使用方式
1. npm install @jiaminghi/data-view
2. yarn add @jiaminghi/data-view
// 在vue项目中的main.js入口文件,将自动注册所有组件为全局组件
import {fullScreenContainer} from '@jiaminghi/data-view'
Vue.use(fullScreenContainer)
<template>
<dv-full-screen-container>
要展示的数据大屏内容
这里建议高度使用百分比来布局,而且要考虑mac设备适配问题,防止百分比发生布局错乱
需要注意的点是,一个是宽度,一个是字体大小,不产生换行
</dv-full-screen-container>
</template>
<script>
import screenfull from "screenfull";
export default {
name: "cockpit",
mounted() {
if (screenfull && screenfull.enabled && !screenfull.isFullscreen) {
screenfull.request();
}
}
};
</script>
<style lang="scss">
#dv-full-screen-container {
width: 100vw;
height: 100vh;
display: flex;
flex-direction: column;
background-color: #131a2b;
}
</style>
- 插件地址
3. 效果图

来源:juejin.cn/post/7372105071573663763
从编程语言的角度,JS 是不是一坨翔?一个来自社区的暴力观点
给前端以福利,给编程以复利。大家好,我是大家的林语冰。
00. 写在前面
毋庸置疑,JS 的历史包袱确实罄竹难书。用朱熹的话说,天不生 ES6,JS 万古如长夜。
就技术细节而言,ES6 之前,JS 保留了若干臭名昭著的反人类设计,包括但不限于:
typeof null的抽象泄露==的无理要求undefined不是关键词- 其他雷区......
幸运的是,ES5 的“阉割模式”(strict mode)把一大坨 JS 的反人类设计都屏蔽了,后 ES6 时代的 JS 焕然一新。
所以,本期我们就从编程语言的宏观设计来思考,先不纠结 JS 极端情况的技术瑕疵,探讨一下 JS 作为地球上人气最高的编程语言,设计哲学上到底有何魅力?

免责声明:上述统计数据来源于 GitHub 社区,可能存在统计学偏差,仅供粉丝参考。
01. 标准化
编程语言人气排行榜屈居亚军的是 Python,那我们就用 JS 来打败 Python。
根据 MDN 电子书,JS 的核心语言是 ECMAScript,是一门由 ECMA TC39 委员会标准化的编程语言。并不是所有的编程语言都有标准化流程,JS 恰好是“天选之子”,后 ES6 的提案流程也相对稳定,虽然最近突然增加了 stage 2.7,但整体标准化无伤大雅。
值得一提的是,JS 的标准是向下兼容的,用户友好。JS 的大多数技术债务已经诉诸“阉割模式”禁用,而向下兼容则避免了近未来的 ESNext 出现主版本级别的破坏性更新。
举个栗子,ES2024 最新支持的数组分组提案,出于兼容性考虑,提案一度从 Array.prototype.group() 修改为 Object.groupBy()。

可以看到,JS 的向下兼容设计正是为了防止和某些遗留代码库产生命名冲突,降低迁移成本。
换而言之,JS 不会像 Python 2 升级 Python 3 那样,让用户承担语言迭代伴生的兼容性税,学习成本和心智负担相对较小。
02. 动态类型
编程语言人气排行榜屈居季军的是 TS,那我们就用 JS 来打败 TS。
JS 和 TS 都是 ECMAScript 的超集,TS 则是 JS 的超集。简而言之,TS ≈ JS + 静态类型系统。
JS 和 TS 区别在于动态类型 vs 静态类型,不能说孰优孰劣,只能说各有千秋。我的个人心证是,静态类型对于工程化生态而言不可或缺,比如 IDE 或 Linting,但对于编程应用则不一定,因为没有静态类型,JS 也能开发 Web App。

可以看到,因为 TS 是 JS 的超集,所以虽然没有显式的类型注解,上述代码也可作为 TS 代码,只不过 TS 和 JS 类型检查的粒度和时机并不一致。
一个争论点在于,静态类型的编译时检查有利于服务大型项目,但其实在大型项目中,一般会诉诸单元测试保障代码质量和回归测试。严格而言,静态类型之于大型项目的充要条件并不成立。
事实上,剥离静态类型注解的源码,恰恰体现了编程的本质和逻辑,这也是后来的静态类型语言偏爱半自动化的智能类型系统,因为有的类型注解可能是画蛇添足,而诉诸智能的类型推论可以解放程序猿的生产力。
03. 面向对象
编程语言人气排行榜第四名是 Java,那我们就用 JS 来打败 Java。
作为被误解最深的语言,前 ES6 的 JS 有一个普遍的误区:JS 不是面向对象语言,原因在于 ES5 没有 class。
这种“思想钢印”哪里不科学呢?不科学的地方在于,面向对象编程是面向对象,而不是 面向类。换而言之,类不是面向对象编程的充要条件。
作为经典的面向对象语言,Java 不同于 C艹,不支持多继承。如果说多继承的 C艹 是“面向对象完备”的,那么能且仅能支持单继承的 Java,其面向对象也一定有不完备的地方,需要诉诸其他机制来弥补。
JS 的面向对象是不同于经典类式继承的原型机制,为什么无类、原型筑基的 JS 也能实现多继承的 C艹 的“面向对象完备”呢?搞懂这个问题,才能深入理解“对象”的本质。

可以看到,JS 虽然没有类,但也通过神秘机制具备面向对象的三大特征。如果说 JS 不懂类,那么经典面向对象语言可能不懂面向对象编程,只懂“面向类编程”。
JS 虽然全称 JavaScript,但其实和 Java 一龙一猪,原型筑基的 JS 没有类也问题不大。某种意义上,类可以视为 JS 实现面向对象的语法糖。很多人知道封装、继承和多态的面向对象特性,但不知道面向对象的定义和思想,所以才会把类和“面向对象完备”等同起来,认为 JS 不是面向对象的语言。
04. 异步编程
编程语言人气排行榜第五名是 C#,那我们就用 JS 来打败 C#。
一般认为,JS 是一门单线程语言,有且仅有一个主线程。JS 有一个基于事件循环的并发模型,这个模型与 C# 语言等模型一龙一猪。
在 JS 中,当一个函数执行时,只有在它执行完毕后,JS 才会去执行任何其他的代码。换而言之,函数执行不会被抢占,而是“运行至完成”(除了 ES6 的生成器函数)。这与 C 语言不同,在 C 语言中,如果函数在线程中运行,它可能在任何位置被终止,然后在另一个线程中运行其他代码。
单线程的优势在于,大部分情况下,JS 不需要考虑多线程某些让人头大的复杂处理。因为我只会 JS,所以无法详细说明多线程的痛点,比如竞态、死锁、线程间通信(消息、信道、队列)、Actor 模型等。
但 JS 的单线程确实启发了其他支持多线程的语言,比如阮一峰大大的博客提到,Python 的 asyncio 模块只存在一个线程,跟 JS 一样。

在异步编程方面,JS 的并发模型其实算是奇葩,因为主流的编程语言都支持多线程模型,所以学习资料可以跨语言互相借鉴,C# 关于多线程的文档就有 10 页,而单线程的 JS 就像非主流的孤勇者,很多异步的理论都用不上,所以使用起来较为简单。
05. 高潮总结
JS 自诞生以来就是一种混合范式的“多面手语言”,这是 JS 二十年来依然元气满满的根本原因。
举个栗子,你可能已经见识过“三位一体”的神奇函数了:

可以看到,在 ES6 之前,JS 中的函数其实身兼数职,正式由于 JS 是天生支持混合范式导致的。
前 JS 时代的先驱语言部分是单范式语言,比如纯粹的命令式过程语言 C 语言无法直接支持面向对象编程,而 C艹 11、Java 8 等经典面向对象语言则渐进支持函数式编程等。
后 JS 时代的现代编程语言大都直接拥抱混合范式设计,比如 TypeScript 和 Rust 等。作为混合范式语言,JS 是一种原型筑基、动态弱类型的脚本语言,同时支持面向对象编程、函数式编程、异步编程等编程范式或编程风格。
粉丝请注意,你可能偶尔会看到“JS 是一门解释型语言”的说法,其实后 ES6 时代的 JS 已经不再是纯粹的解释型语言了,也可能是 JIT(即时编译)语言,这取决于宿主环境中 JS 引擎或运行时的具体实现。
值得一提的是,混合范式语言的优势在于博采众家之长,有助于塑造攻城狮的开放式编程思维和心智模型;缺陷在于不同于单范式语言,混合范式语言可能支持了某种编程范式,但没有完全支持。(PS:编程范式完备性的判定边界是模糊的,所以偶尔也解读为风格或思维。)
因此,虽然 JS 不像 PHP 一样是地球上最好的语言,但 JS 作为地表人气最高的语言,背后是有深层原因的。
参考文献
- 阮一峰日志:ruanyifeng.com/blog/2019/1…
- MDN:developer.mozilla.org
- C# 异步编程:learn.microsoft.com/zh-cn/dotne…
来源:juejin.cn/post/7392787221097545780
此生最佩服数学家
大家好啊,我是董董灿。
之前在和不少小伙伴聊天时,都时不时的提到,搞人工智能尤其是搞算法,数学是一座很难跨过去的砍,数学太难了。

我本身也不是数学专业的,在搞AI算法的过程中,也确实遇到了很多数学问题。
用大学学的那点线性代数、概率论和微积分的知识,来推一些枯燥的数学公式,就好像是拄着拐杖去跑马拉松,虽然查查资料磨蹭磨蹭也能弄出来,但是感觉很费劲。
数学真的就是算法的基石,数学能力强、抽象能力强的人,有时候在学算法时,就像降维打击,他们会从很不可思议的角度来论证,某某算法确实是好的。
我之前见过一个同事,中科大少年班毕业,数学专业的(数学水平很高,至少比我高),有一次在和他讨论某个算法的实现时,他全程用一种我听不懂的话在说,我当时是记了一些关键字,回到工位查了很久很久。
被打击了。
数学公式和理论对我而言是枯燥的,但是数学故事是有趣的。今天,就说一个与数学相关的故事,号称“数学史上的三次危机”。
很早就听说过这个说法了,前几天在查概率论相关的资料时,突然想起来,分享一下。
在很多数学专业的学生来看,这种说法并不严谨。在中外文献中,并不存在所谓的“数学史上的三次危机”,这种说法更多的出现在科普文章以及流行度较高的民间科学杂志上。
1、第一次数学危机:长方形的对角线是什么?
在古希腊时期,毕达哥拉斯学派统治的年代,人们对于数学的认识就是:一切都是数字,这里说的数字,是我们现在理解的有理数,也就是1、2、3这种。
那时的人们认为,万事万物都可以用有理数来衡量,在一个数轴上,任何一个点都可以用一个确定的有理数字来表示。
可突然有一天,一个人站出来说,边长为 1 的正方形的对角线,在数轴上就表示不出来。

人们慌了,毕达哥拉斯学派更慌了。
对这个问题他们百思不得其解,随着问题传播的越来越广,人们开始担心,引以为傲的“一切都是数字”的数学理论,是不是有可能是错误的。
这引起了第一次数学理论基础的危机。
毕达哥拉斯学派,不允许这种不和谐的声音出现,来诋毁自己的地位,但是,当时的他们又解决不了这个问题。
于是,他们秉着解决不了这个人提出的问题,就解决了这个人的原则,把提出这个问题的人解决了。
这次危机持续了很久,直到人们提出了无理数,并且接受了无理数的存在,第一次数学危机才得以解决。
2、第二次数学危机:兔子到底能不能追上乌龟?
这是关于龟兔赛跑的故事。
有人说,如果乌龟先跑,兔子后跑。
当兔子跑到乌龟已跑出距离的一半时,乌龟又前进了一段距离,而当兔子又跑到这一段距离的时候,乌龟此时又前进了一段距离,就这样无穷无尽的跑下去,兔子永远也追不上乌龟。
这就是“龟兔赛跑”悖论,这个悖论直接导致了当时数学界的恐慌。
悖论很反直觉,但是好像又无懈可击。

人们钻研了很久,却始终找不出问题出在什么地方。
当时的人们认为:数学完了,这么简单的问题都解决不了,数学根本不靠谱。
这就好像现在有人告诉你,高铁永远追不上骑自行车的人,但是你又没办法反驳一样。
明知是错的,我却无能为力。
这便是人们津津乐道的第二次数学危机,并且直接导致了无穷与极限的发展,以及后来微积分思想的发展。
到现在,无穷级数和微积分的数学根基已经很牢固了,但是如果回过头来,如果你想反驳一下这个悖论,你应该怎么说呢?
或许你可以这么说:
世界上没有这样的兔子和乌龟,可以活无穷长的时间,这是因为时间是不可能无穷拆分的。
那如果有人继续反驳问你,你怎么证明时间是不可以无穷拆分的呢?
你就说,那是物理学家的事,不是数学家的事,让物理学家思考去吧。
反正,在无穷与极限的概念的发展中,这次危机也算是渡过了。
3、第三次数学危机:理发师该不该给自己理发
一个村子里有个理发师,突然有一天这个理发师贴了一个公告说:我只给这个村子里不给自己理发的人理发。
然后有个人跑上门问他:那你自己的头发应该谁来理呢?
理发师懵了。
如果他给自己理发,那他就不是不给自己理发的人,他就不应该给自己理发。
如果他不给自己理发,那么他就是不给自己理发的人,他就应该给自己理发。

也就说,如果存在两个互相独立的集合,一个是给自己理发的人,一个是不给自己理发的人,那么理发师属于哪个集合呢?
这就是著名的罗素悖论。
这个悖论的威力在于,当时一个著名的数学家要发表一本数学著作,在收到罗素关于这个悖论的描述后尴尬地说:我以为数学的大厦已经盖好了,没想到地基还这么不牢固。
这个问题通俗点讲就是,你可以说出一件事,如果这件事是真的,那么它就是假的,如果他是假的,那么他就是真的。
数学里的自相矛盾,然而它却符合康托尔关于集合的定义。
这个问题的解决好像是一位大佬级别的数学家,在研究了一段时间后说:不存在这样理发师,他说的话不能当做数学公理,从源头上解决了这个问题。
但是这个悖论促进促进了集合论的进一步发展。
三次数学危机,每一次都让人惶恐不安,但事实却是,每一次都极大的促进了当时数学理论的发展。
好啦,故事就分享到这。
说回AI,AI的发展绝对离不开数学,这也是为什么华为愿意花大价钱雇佣很多数学家、物理学家搞基础研究,阿里每年搞全球数学竞赛,吸纳全球数学精英。
三体里有句话,如果一旦外星文明打来,我们能与之拼一拼的绝对不是火箭大炮,而是基础物理学理论,核弹都得益于数学物理,更何况其他呢。
如果此时你正在高数课堂上,请你打起精神好好听课,没准未来拯救世界的重任就落到了你的肩上。🙃
一直很膜拜数学、物理大佬,如果有数学物理专业的大佬,可在下面留言,让小弟膜拜下~
来源:juejin.cn/post/7294619778987622411
你真的了解圣杯和双飞翼布局吗?
前言
圣杯和双飞翼布局作为面试常考的题目之一,相信大家肯定都会有着自己的一套知识储备,但是,你真的了解这两种经典布局吗?本文将介绍这两种经典布局产生的来龙去脉,以及实现这两种布局的一些方式,希望大家能够喜欢。
为什么需要圣杯和双飞翼布局
大家思考一个问题,这样一种布局,你该怎么处理呢?

常规情况下,我们的布局思路应该这样写,从上到下,从左到右:
<div>header</div>
<div>
<div>left</div>
<div>main</div>
<div>right</div>
</div>
<div>footer</div>
这样的三栏布局也没有什么问题,但是我们要知道一个网站的主要内容就是中间的部分,比如像掘金:

那么对于用户来说,他们当然是希望最中间的部分首先加载出来的,能看到最重要的内容,但是因为浏览器加载dom的机制是按顺序加载的,浏览器从HTML文档的开头开始,逐步解析并构建文档对象模型,所以,我们想让main首先加载出来的话,那就将它前置,然后通过一些CSS的样式,将其继续展示出上面的三栏布局的样式:
<div>header</div>
<div>
<div>main</div>
<div>left</div>
<div>right</div>
</div>
<div>footer</div>
这就是所谓的圣杯布局,最早是Matthew Levine 在2006年1月30日在In Search of the Holy Grail 这篇文章中提出来的;
那么完整的效果、实现代码如下:

<style>
.header,
.footer {
width: 100%;
height: 200px;
background-color: pink;
}
.container {
padding: 0 100px 0 100px;
overflow: hidden;
}
.col {
position: relative;
float: left;
height: 400px;
}
.left {
background-color: green;
width: 100px;
margin-left: -100%;
left: -100px;
}
.main {
width: 100%;
background-color: blue;
}
.right {
width: 100px;
background-color: green;
margin-left: -100px;
right: -100px;
}
</style>
<div class="header">header</div>
<div class="container">
<div class="main col">main</div>
<div class="left col">left</div>
<div class="right col">right</div>
</div>
<div class="footer">footer</div>
如上述代码所示,,使用了相对定位、浮动和负值margin,将left和right装到main的两侧,所以顾名:圣杯;
但是呢,圣杯是有问题的,在某些特殊的场景下,比如说,left和right盒子的宽度过宽的情况下,圣杯就碎掉了,比如将上述代码的left和right盒子的宽度改为以500px为基准:
<style>
.header,
.footer {
width: 100%;
height: 200px;
background-color: pink;
}
.container {
padding: 0 500px 0 500px;
overflow: hidden;
}
.col {
position: relative;
float: left;
height: 400px;
}
.left {
background-color: green;
width: 500px;
margin-left: -100%;
left: -500px;
}
.main {
width: 100%;
background-color: blue;
}
.right {
width: 500px;
background-color: green;
margin-left: -500px;
right: -500px;
}
</style>
<div class="header">header</div>
<div class="container">
<div class="main col">main</div>
<div class="left col">left</div>
<div class="right col">right</div>
</div>
<div class="footer">footer</div>
正常情况下,布局还是依然正常,只是两侧宽了而已:

但是我们将整个窗口缩小,圣杯就碎掉了:

原因是因为 padding: 0 500px 0 500px;,当整个窗口的最大宽度已经小于左右两边的padding共1000px,left和right就被挤下去了;
于是针对这种情况,淘宝UED的玉伯大大提出来了双飞翼布局,效果和圣杯布局一样,只是他将其比作一只鸟,左翅膀、中间、右翅膀;
相比于圣杯布局,双飞翼布局在原有的main盒子再加了一层div:
<div>header</div>
<div>
<div><div>main</div></div>
<div>left</div>
<div>right</div>
</div>
<div>footer</div>
实际的效果和代码如下,哪怕再怎么缩,都不会被挤下去:

<style>
.header,
.footer {
width: 100%;
height: 200px;
background-color: pink;
}
.container {
padding: 0;
overflow: hidden;
}
.col {
float: left;
height: 400px;
}
.left {
background-color: green;
width: 500px;
margin-left: -100%;
}
.main {
width: 100%;
background-color: blue;
}
.main-in {
margin: 0 500px 0 500px;
}
.right {
width: 500px;
background-color: green;
margin-left: -500px;
}
</style>
<div class="header">header</div>
<div class="container">
<div class="main col">
<div class="main-in">main</div>
</div>
<div class="left col">left</div>
<div class="right col">right</div>
</div>
<div class="footer">footer</div>
圣杯布局实现方式补充
上面介绍了一种圣杯布局的实现方式,这里再介绍一种用绝对定位的,这种方法其实也能避免上述说的当左右两侧的盒子过于宽时,圣杯被挤破的情况:
<style>
.header,
.footer {
width: 100%;
height: 200px;
background-color: pink;
}
.container {
position: relative;
padding: 0 100px;
}
.col {
height: 400px;
}
.left {
background-color: green;
width: 100px;
position: absolute;
left: 0;
top: 0;
}
.main {
width: 100%;
background-color: blue;
}
.right {
width: 100px;
background-color: green;
position: absolute;
right: 0;
top: 0;
}
</style>
<div class="header">header</div>
<div class="container">
<div class="main col">main</div>
<div class="left col">left</div>
<div class="right col">right</div>
</div>
<div class="footer">footer</div>
双飞翼布局实现方式补充
也是使用绝对定位的:
<style>
.header,
.footer {
width: 100%;
height: 200px;
background-color: pink;
}
.container {
position: relative;
}
.col {
height: 400px;
}
.left {
background-color: green;
width: 500px;
position: absolute;
top: 0;
left: 0;
}
.main {
width: calc(100% - 1000px);
background-color: blue;
margin-left: 500px;
}
.main-in {
/* margin: 0 500px 0 500px; */
}
.right {
width: 500px;
background-color: green;
position: absolute;
top: 0;
right: 0;
}
</style>
<div class="header">header</div>
<div class="container">
<div class="main col">
<div class="main-in">main</div>
</div>
<div class="left col">left</div>
<div class="right col">right</div>
</div>
<div class="footer">footer</div>
其它普通的三列布局的实现
flex布局实现
<style>
* {
padding: 0;
margin: 0;
}
.header,
.footer {
width: 100%;
height: 200px;
background-color: blue;
}
.container {
display: flex;
}
.left {
width: 100px;
height: 300px;
background-color: pink;
}
.main {
flex: 1;
width: 100%;
height: 300px;
background-color: green;
}
.right {
width: 100px;
height: 300px;
background-color: pink;
}
</style>
<div class="header">header</div>
<div class="container">
<div class="left col">left</div>
<div class="main col">main</div>
<div class="right col">right</div>
</div>
<div class="footer">footer</div>
绝对定位实现
<style>
* {
padding: 0;
margin: 0;
}
.header,
.footer {
width: 100%;
height: 200px;
background-color: blue;
}
.container {
position: relative;
padding: 0 100px;
}
.left {
width: 100px;
height: 300px;
background-color: pink;
position: absolute;
top: 0;
left: 0;
}
.main {
width: 100%;
height: 300px;
background-color: green;
}
.right {
width: 100px;
height: 300px;
background-color: pink;
position: absolute;
top: 0;
right: 0;
}
</style>
<div class="header">header</div>
<div class="container">
<div class="left col">left</div>
<div class="main col">main</div>
<div class="right col">right</div>
</div>
<div class="footer">footer</div>
总结
现在真正了解到圣杯布局、双飞翼布局和普通三列布局的思想了吗?虽然它们三者最终的效果可能一样,但是实际的思路,优化也都不一样,希望能对你有所帮助!!!!感谢支持
来源:juejin.cn/post/7405467437564428299
前端中的“+”连接符,居然有鲜为人知的强大功能!
故事背景:"0"和"1"布尔判断
这几天开发,遇到一个问题:根据后端返回的isCritical判断页面是否展示【关键标签】

很难受的是,后端的isCritical的枚举值是字符串
”0“: 非关键
”1“ :关键
这意味着前端得自己转换一下,于是我写出了这样的代码
// html
<van-icon v-if="getCriticalStatus(it.isCritical)" color="#E68600"/>
// js
const getCriticalStatus = (critical: string) => {
if (critical.value === "1") return true;
return false;
}
我以为我这样写很简单了,没想到同事看到后,说我这样写麻烦了,于是给我改了一下代码
// html
<van-icon v-if="+it.isCritical" color="#E68600"/>
我大惊失色脱水缩合,这就行了?看来,我还是小看"+"运算符了!
"+"的常见使用场景
前端对"+"连字符一定不陌生,它的算术运算符功能和字符串连接功能,我们用脚趾头也能敲出来。
算术运算符
在 JavaScript 中,+ 是最常见的算术运算符之一,可以用来执行加法运算。
let a = 5;
let b = 10;
let sum = a + b;
// sum的值为15
字符串连接符
+ 还可以用来连接字符串。
let firstName = "石";
let lastName = "小石";
let fullName = firstName + " " + lastName; // fullName的值为"石小石"
如果是数字和字符连接,它会把数字转成字符
const a = 1
const b = "2"
const c = a + b; // c的值为字符串"12"
"+"的高级使用场景
除了上述的基本使用场景,其实它还有一些冷门但十分使用的高级使用场景。
URL编码中的空格
在 URL 编码中,+ 字符可以表示空格,尤其是在查询字符串中。
http://shixiaoshi.com/search?query=hello+world
上面的代码中,hello+world 表示查询 hello world,其中的 + 会被解码为一个空格。
但要注意的是,现代 URL 编码规范中推荐使用 %20 表示空格,而不是 +。
一元正号运算符
+ 的高级用法,再下觉得最牛逼的地方就是可以作为一元运算符使用!
+ 作为一元运算符时,可以将一个值转换为数字(如果可能的话)。
let str = "123";
let num = +str;
// num的值为123,类型为number
这一用法在处理表单输入时特别有用,因为表单输入通常是字符串类型。
let inputValue = "42";
let numericValue = +inputValue; // 将字符串转换为数字42
那么回到文章开头的问题,我们看看下面的代码为什么可以生效
// html
<van-icon v-if="getCriticalStatus(it.isCritical)" color="#E68600"/>
// js
const getCriticalStatus = (critical: string) => {
if (critical.value === "1") return true;
return false;
}
// html 优化后的代码
<van-icon v-if="+it.isCritical" color="#E68600"/>
由于it.isCritical的值是字符"0"或"1",通过"+it.isCritical"转换后,其值是数字0或1,而恰好0可以当false使用,1可以当true使用!因此,上述代码可以生效!
JavaScript 中的类型转换规则会将某些值隐式转换为布尔值:
- 假值 :在转换为布尔值时被视为
false的值,包括:false、0(数字零)、-0(负零)、""(空字符串)、null、undefined、NaN(非数字)
- 真值 :除了上述假值外,所有其他值在转换为布尔值时都被视为
true。
一元正号运算符的原理
通过上文,我们知道:当使用 + 操作符时,JavaScript 会尝试把目标值转换为数字,它遵循以下规则:。
转换规则
数字类型:
如果操作数是数字类型,一元正号运算符不会改变其值。
例如:+5 还是 5。
// 数字类型
console.log(+5); // 5(数字)
字符串类型:
如果字符串能够被解析为有效的数字,则返回相应的数字。
如果字符串不能被解析为有效的数字(如含有非数字字符),则返回 NaN(Not-a-Number)。
例如:+"123" 返回 123,+"abc" 返回 NaN。
// 字符串类型
console.log(+"42"); // 42
console.log(+"42abc"); // NaN
布尔类型:
true 会被转换为 1。
false 会被转换为 0。
// 布尔类型
console.log(+true); // 1
console.log(+false); // 0
null:
null 会被转换为 0。
// null
console.log(+null); // 0
undefined:
undefined 会被转换为 NaN。
// undefined
console.log(+undefined); // NaN
对象类型:
对象首先会通过内部的 ToPrimitive 方法被转换为一个原始值,然后再进行数字转换。通常通过调用对象的 valueOf 或 toString 方法来实现,优先调用 valueOf。
// 对象类型
console.log(+{}); // NaN
console.log(+[]); // 0
console.log(+[10]); // 10
console.log(+["10", "20"]); // NaN
底层原理
不重要,简单说说:
在 JS引擎内部,执行一元正号运算符时,实际调用了 ToNumber 抽象操作,这个操作试图将任意类型的值转换为数字。ToNumber 操作依据 ECMAScript 规范中的规则,将不同类型的值转换为数字。
总结
一元正号运算符 + 是一个简便的方法,用于将非数字类型转换为数字。
如果你们后端返回字符串0和1,你需要转换成布尔值,使用"+"简直不要太爽
// isCritical 是字符串"0"或"1"
<van-icon v-if="+isCritical" color="#E68600"/>
或者处理表单输入时用
let inputValue = "42";
let value = +inputValue; // 将字符串转换为数字42
来源:juejin.cn/post/7402076531294863360
还在封装 xxxForm,xxxTable 残害你的同事?试试这个工具
之前写过一篇文章 我理想中的低代码开发工具的形态,已经吐槽了各种封装 xxxForm,xxxTable 的行为,这里就不啰嗦了。今天再来看看我的工具达到了什么程度。
多图预警。。。
以管理后台一个列表页为例

选择对应的模板

截图查询区域,使用 OCR 初始化查询表单的配置

截图表头,使用 OCR 初始化 table 的配置

使用 ChatGPT 翻译中文字段

生成代码

效果
目前我们没有写一行代码,就已经达到了如下的效果

下面是一部分生成的代码
import { reactive, ref } from 'vue'
import { IFetchTableListResult } from './api'
interface ITableListItem {
/**
* 决算单状态
*/
settlementStatus: string
/**
* 主合同编号
*/
mainContractNumber: string
/**
* 客户名称
*/
customerName: string
/**
* 客户手机号
*/
customerPhone: string
/**
* 房屋地址
*/
houseAddress: string
/**
* 工程管理
*/
projectManagement: string
/**
* 接口返回的数据,新增字段不需要改 ITableListItem 直接从这里取
*/
apiResult: IFetchTableListResult['result']['records'][0]
}
interface IFormData {
/**
* 决算单状态
*/
settlementStatus?: string
/**
* 主合同编号
*/
mainContractNumber?: string
/**
* 客户名称
*/
customerName?: string
/**
* 客户手机号
*/
customerPhone?: string
/**
* 工程管理
*/
projectManagement?: string
}
interface IOptionItem {
label: string
value: string
}
interface IOptions {
settlementStatus: IOptionItem[]
}
const defaultOptions: IOptions = {
settlementStatus: [],
}
export const defaultFormData: IFormData = {
settlementStatus: undefined,
mainContractNumber: undefined,
customerName: undefined,
customerPhone: undefined,
projectManagement: undefined,
}
export const useModel = () => {
const filterForm = reactive<IFormData>({ ...defaultFormData })
const options = reactive<IOptions>({ ...defaultOptions })
const tableList = ref<(ITableListItem & { _?: unknown })[]>([])
const pagination = reactive<{
page: number
pageSize: number
total: number
}>({
page: 1,
pageSize: 10,
total: 0,
})
const loading = reactive<{ list: boolean }>({
list: false,
})
return {
filterForm,
options,
tableList,
pagination,
loading,
}
}
export type Model = ReturnType<typeof useModel>
这就是用模板生成的好处,有规范,随时可以改,而封装 xxxForm,xxxTable 就是一个黑盒。
原理
下面大致说一下原理

首先是写好一个个模版,vscode 插件读取指定目录下模版显示到界面上

每个模版下可能包含如下内容:

选择模版后,进入动态表单配置界面

动态表单是读取 config/schema.json 里的内容进行动态渲染的,目前支持 amis、form-render、formily

配置表单是为了生成 JSON 数据,然后根据 JSON 数据生成代码。所以最终还是无法避免的使用私有的 DSL ,但是生成后的代码是没有私有 DSL 的痕迹的。生成代码本质是 JSON + EJS 模版引擎编译 src 目录下的 ejs 文件。
为了加快表单的配置,可以自定义脚本进行操作

这部分内容是读取 config/preview.json 内容进行显示的

选择对应的脚本方法后,插件会动态加载 script/index.js 脚本,并执行里面对应的方法

以 initColumnsFromImage 方法为例,这个方法是读取剪贴板里的图片,然后使用百度 OCR 解析出文本,再使用文本初始化表单
initColumnsFromImage: async (lowcodeContext) => {
context.lowcodeContext = lowcodeContext;
const res = await main.handleInitColumnsFromImage();
return res;
},
export async function handleInitColumnsFromImage() {
const { lowcodeContext } = context;
if (!lowcodeContext?.clipboardImage) {
window.showInformationMessage('剪贴板里没有截图');
return lowcodeContext?.model;
}
const ocrRes = await generalBasic({ image: lowcodeContext!.clipboardImage! });
env.clipboard.writeText(ocrRes.words_result.map((s) => s.words).join('\r\n'));
window.showInformationMessage('内容已经复制到剪贴板');
const columns = ocrRes.words_result.map((s) => ({
slot: false,
title: s.words,
dataIndex: s.words,
key: s.words,
}));
return { ...lowcodeContext.model, columns };
}
反正就是可以根据自己的需求定义各种各样的脚本。比如使用 ChatGPT 翻译 JSON 里的指定字段,可以看我的上一篇文章 TypeChat、JSONSchemaChat实战 - 让ChatGPT更听你的话
再比如要实现把中文翻译成英文,然后英文使用驼峰语法,这样就可以将中文转成英文代码变量,下面是实现的效果

选择对应的命令菜单后 vscode 插件会加载对应模版里的脚本,然后执行里面的 onSelect 方法。

main.ts 代码如下
import { env, window, Range } from 'vscode';
import { context } from './context';
export async function bootstrap() {
const clipboardText = await env.clipboard.readText();
const { selection, document } = window.activeTextEditor!;
const selectText = document.getText(selection).trim();
let content = await context.lowcodeContext!.createChatCompletion({
messages: [
{
role: 'system',
content: `你是一个翻译家,你的目标是把中文翻译成英文单词,请翻译时使用驼峰格式,小写字母开头,不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面用户输入的内容`,
},
{
role: 'user',
content: selectText || clipboardText,
},
],
});
content = content.charAt(0).toLowerCase() + content.slice(1);
window.activeTextEditor?.edit((editBuilder) => {
if (window.activeTextEditor?.selection.isEmpty) {
editBuilder.insert(window.activeTextEditor.selection.start, content);
} else {
editBuilder.replace(
new Range(
window.activeTextEditor!.selection.start,
window.activeTextEditor!.selection.end,
),
content,
);
}
});
}
使用了 ChatGPT。
再来看看,之前生成管理后台 CURD 页面的时候,连 mock 也一起生成了,主要逻辑放在了 complete 方法里,这是插件的一个生命周期函数。

因为 mock 服务在另一个项目里,所以需要跨目录去生成代码,这里我在 mock 服务里加了个接口返回 mock 项目所在的目录
.get(`/mockProjectPath`, async (ctx, next) => {
ctx.body = {
status: 200,
msg: '',
result: __dirname,
};
})
生成代码的时候请求这个接口,就知道往哪个目录生成代码了
const mockProjectPathRes = await axios
.get('http://localhost:3001/mockProjectPath', { timeout: 1000 })
.catch(() => {
window.showInformationMessage(
'获取 mock 项目路径失败,跳过更新 mock 服务',
);
});
if (mockProjectPathRes?.data.result) {
const projectName = workspace.rootPath
?.replace(/\\/g, '/')
.split('/')
.pop();
const mockRouteFile = path.join(
mockProjectPathRes.data.result,
`${projectName}.js`,
);
let mockFileContent = `
import KoaRouter from 'koa-router';
import proxy from '../middleware/Proxy';
import { delay } from '../lib/util';
const Mock = require('mockjs');
const { Random } = Mock;
const router = new KoaRouter();
router{{mockScript}}
module.exports = router;
`;
if (fs.existsSync(mockRouteFile)) {
mockFileContent = fs.readFileSync(mockRouteFile).toString().toString();
const index = mockFileContent.lastIndexOf(')') + 1;
mockFileContent = `${mockFileContent.substring(
0,
index,
)}{{mockScript}}\n${mockFileContent.substring(index)}`;
}
mockFileContent = mockFileContent.replace(/{{mockScript}}/g, mockScript);
fs.writeFileSync(mockRouteFile, mockFileContent);
try {
execa.sync('node', [
path.join(
mockProjectPathRes.data.result
.replace(/\\/g, '/')
.replace('/src/routes', ''),
'/node_modules/eslint/bin/eslint.js',
),
mockRouteFile,
'--resolve-plugins-relative-to',
mockProjectPathRes.data.result
.replace(/\\/g, '/')
.replace('/src/routes', ''),
'--fix',
]);
} catch (err) {
console.log(err);
}
mock 项目也可以通过 vscode 插件快速创建和使用

上面展示的模版都放在了 github.com/lowcode-sca… 仓库里,照着 README 步骤做就可以使用了。
来源:juejin.cn/post/7315242945454735414
领导:你加的水印怎么还能被删掉的,扣工资!
故事是这样的
领导:小李,你加的水印怎么还能被删掉的?这可是关乎公司信息安全的大事!这种疏忽怎么能不扣工资呢?
小李:领导,请您听我解释一下!我确实按照常规的方法加了水印,可是……
领导:(打断)但是什么?难道这就是你对公司资料的保护吗?
小李:我也不明白,按理说水印是无法删除的,我会再仔细检查一下……
领导:我不能容忍这样的失误。这种安全隐患严重影响了我们的机密性。
小李焦虑地试图解释,但领导的目光如同刀剑一般锐利。他决定,这次一定要找到解决方法,否则,这将是一场职场危机……

水印组件
小李想到antd中有现成的水印组件,便去研究了一下。即使删掉了水印div,水印依然存在,因为瞬间又生成了一个相同的水印div。他一瞬间想到了解决方案,并开始了重构水印组件。

原始代码
//app.vue
<template>
<div>
<Watermark text="前端百事通">
<div class="content"></div>
</Watermark>
</div>
</template>
<script setup>
import Watermark from './components/Watermark.vue';
</script>
<style scoped>
.content{
width: 400px;
height: 400px;
background-color: aquamarine;
}
</style>
//watermark.vue
<template>
<div ref="watermarkRef" class="watermark-container">
<slot>
</slot>
</div>
</template>
<script setup>
import { onMounted, ref } from 'vue';
const watermarkRef=ref(null)
const props = defineProps({
text: {
type: String,
default: '前端百事通'
},
fontSize: {
type: Number,
default: 14
},
gap: {
type: Number,
default: 50
},
rotate: {
type: Number,
default: 45
}
})
onMounted(() => {
addWatermark()
})
const addWatermark = () => {
const { rotate, gap, text, fontSize } = props
const color = 'rgba(0, 0, 0, 0.3)'; // 可以从props中传入
const watermarkContainer = watermarkRef.value;
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
const font=fontSize+'px DejaVu Sans Mono'
// 设置水印文字的宽度和高度
const metrics = context.measureText(text);
const canvasWidth=metrics.width+gap
canvas.width=canvasWidth
canvas.height=canvasWidth
// 绘制水印文字
context.translate(canvas.width/2,canvas.height/2)
context.rotate((-1 * rotate * Math.PI / 180));
context.fillStyle = color;
context.font=font
context.textAlign='center'
context.textBaseline='middle'
context.fillText(text,0,0)
// 将canvas转为图片
const url = canvas.toDataURL('image/png');
// 创建水印元素并添加到容器中
const watermarkLayer = document.createElement('div');
watermarkLayer.style.position = 'absolute';
watermarkLayer.style.top = '0';
watermarkLayer.style.left = '0';
watermarkLayer.style.width = '100%';
watermarkLayer.style.height = '100%';
watermarkLayer.style.pointerEvents = 'none';
watermarkLayer.style.backgroundImage = `url(${url})`;
watermarkLayer.style.backgroundRepeat = 'repeat';
watermarkLayer.style.zIndex = '9999';
watermarkContainer.appendChild(watermarkLayer);
}
</script>
<style>
.watermark-container {
position: relative;
width: 100%;
height: 100%;
overflow: auto;
}
</style>
防篡改思路
- 监听删除dom操作,在删除dom操作的瞬间重新生成一个相同的dom元素
- 监听修改dom样式操作
- 不能使用onMounted,改为watchEffect进行监听操作
使用MutationObserver监听整个区域
let ob
onMounted(() => {
ob=new MutationObserver((records)=>{
console.log(records)
})
ob.observe(watermarkRef.value,{
childList:true,
attributes:true,
subtree:true
})
})
onUnmounted(()=>{
ob.disconnect()
})
在删除水印div之后,打印一下看看records是什么。

在修改div样式之后,打印一下records

很明显,如果是删除,我们就关注removedNodes字段,如果是修改,我们就关注attributeName字段。
onMounted(() => {
ob=new MutationObserver((records)=>{
for(let item of records){
//监听删除
for(let ele of item.removedNodes){
if(ele===watermarkDiv){
generateFlag.value=!generateFlag.value
return
}
}
//监听修改
if(item.attributeName==='style'){
generateFlag.value=!generateFlag.value
return
}
}
})
ob.observe(watermarkRef.value,{
childList:true,
attributes:true,
subtree:true
})
})
watchEffect(() => {
//generateFlag的用处是让watchEffect收集这个依赖
//通过改变generateFlag的值来重新调用生成水印的函数
generateFlag.value
if(watermarkRef.value){
addWatermark()
}
})

最终,小李向领导展示了新的水印组件,取得了领导的认可和赞许,保住了工资。
全剧终。
文章同步发表于前端百事通公众号,欢迎关注!
来源:juejin.cn/post/7362309246556356647
终于搞懂类型声明文件.d.ts和declare了,原来用处如此大
项目中的.d.ts和declare
最近开发项目,发现公司代码里都有一些.d.ts后缀的文件

还有一些奇奇怪怪的declare代码

秉持着虚心学习的态度,我向同事请教了这些知识点,发现这些东西居然蛮重要的。于是,我根据自己的理解,把这些知识简单总结一下。
类型声明文件.d.ts
为什么需要 .d.ts 文件?
如果我们在ts项目中使用第三方库时,如果这个库内置类型声明文件.d.ts,我们在写代码时可以获得对应的代码补全、接口提示等功能。
比如,我们在index.ts中使用aixos时:

当我们引入axios时,ts会检索aixos的package.json文件,并通过其types属性查找类型声明文件,查找到index.d.ts这个文件后,就会根据其内部配置进行语法提示。

但是如果某个库没有内置类型声明文件时,我们使用这个库,不会获得Ts的语法提示,甚至会有类型报错警告

像这种没有内置类型声明文件的,我们就可以自己创建一个xx.d.ts的文件来自己声明,ts会自动读取到这个文件里面的内容的。比如,我们在index.ts中使用"vue-drag",会提示缺少声明文件。
由于这个库没有@types/xxxx声明包,因此,我们可以在项目内自定义一个vueDrag.d.ts声明文件。
// vueDrag.d.ts
declare module 'vue-drag'
这个时候,就不会报错了,没什么警告了。
第三方库的默认类型声明文件
当我们引入第三方库时,ts会自动检索aixos的package.json文件,并通过其types属性查找类型声明文件,查找到index.d.ts这个文件后,就会根据其内部配置进行语法提示。比如,我们刚才说的axios

- "typings"与"types"具有相同的意义,也可以使用它。
- 主声明文件名是index.d.ts并且位置在包的根目录里(与index.js并列),你就不需要使用"types"属性指定了。
第三方库的@types/xxxx类型声明文件
如express这类框架,它们的开发时Ts还没有流行,自然没有使用Ts进行开发,也自然不会有ts的类型声明文件。如果你想引入它们时也获得Ts的语法提示,就需要引入它们对应的声明文件npm包了。
使用声明文件包,不用重构原来的代码就可以在引入这些库时获得Ts的语法提示
比如,我们安装express对应的声明文件包后,就可以获得相应的语法提示了。
npm i --save-dev @types/express

@types/express包内的声明文件

.d.ts声明文件
通过上述的几个示例,我们可以知道.d.ts文件的作用和@types/xxxx包一致,@type/xxx需要下载使用,而.d.ts是我们自己创建在项目内的。
.d.ts文件除了可以声明模块,也可以用来声明变量。
例如,我们有一个简单的 JavaScript 函数,用于计算两个数字的总和:
// math.js
const sum = (a, b) => a + b
export { sum }
TypeScript 没有关于函数的任何信息,包括名称、参数类型。为了在 TypeScript 文件中使用该函数,我们在 d.ts 文件中提供其定义:
// math.d.ts
declare function sum(a: number, b: number): number
现在,我们可以在 TypeScript 中使用该函数,而不会出现任何编译错误。
.ts 是标准的 TypeScript 文件。其内容将被编译为 JavaScript。
*.d.ts 是允许在 TypeScript 中使用现有 JavaScript 代码的类型定义文件,其不会编译为 JavaScript。
shims-vue.d.ts
shims-vue.d.ts 文件的主要作用是声明 Vue 文件的模块类型,使得 TypeScript 能够正确地处理 .vue 文件,并且不再报错。通常这个文件会放在项目的根目录或 src 目录中。
shims-vue.d.ts 文件的内容一般长这样:
// shims-vue.d.ts
declare module '*.vue' {
import { DefineComponent } from 'vue';
const component: DefineComponent<{}, {}, any>;
export default component;
}
declare module '*.vue': 这行代码声明了一个模块,匹配所有以.vue结尾的文件。*是通配符,表示任意文件名。import { DefineComponent } from 'vue';: 引入 Vue 的DefineComponent类型。这是 Vue 3 中定义组件的类型,它具有良好的类型推断和检查功能。const component: DefineComponent<{}, {}, any>;: 定义一个常量component,它的类型是DefineComponent,并且泛型参数设置为{}表示没有 props 和 methods 的基本 Vue 组件类型。any用来宽泛地表示组件的任意状态。export default component;: 将这个组件类型默认导出。这样,当你在 TypeScript 文件中导入.vue文件时,TypeScript 就知道导入的内容是一个 Vue 组件。
declare
.d.ts 文件中的顶级声明必须以 “declare” 或 “export” 修饰符开头。
通过declare声明的类型或者变量或者模块,在include包含的文件范围内,都可以直接引用而不用去import或者import type相应的变量或者类型。
- declare声明一个类型
declare type Asd {
name: string;
}
- declare声明一个模块
declare module '*.css';
declare module '*.less';
declare module '*.png';
.d.ts文件顶级声明declare最好不要跟export同级使用,不然在其他ts引用这个.d.ts的内容的时候,就需要手动import导入了
在.d.ts文件里如果顶级声明不用export的话,declare和直接写type、interface效果是一样的,在其他地方都可以直接引用
declare type Ass = {
a: string;
}
type Bss = {
b: string;
};
来源:juejin.cn/post/7402891257196691468
前端:金额高精度处理
Decimal 是什么
想必大家在用js 处理 数字的 加减乘除的时候,或许都有遇到过 精度不够 的问题,还有那些经典的面试题 0.2+0.1 !== 0.3,
至于原因,那就是 js 计算底层用的是 IEEE 754 ,精度上有限制,
那么Decimal.js 就是帮助我们解决 js中的精度失准的问题。
原理
- 它的原理就是将数字用字符串表示,字符串在计算机中可以说是无限的。
- 并使用基于字符串的算术运算,以避免浮点数运算中的精度丢失。它使用了一种叫做十进制浮点数算术(Decimal Floating Point Arithmetic)的算法来进行精确计算。
- 具体来说,decimal.js库将数字表示为一个字符串,其中包含整数部分、小数部分和一些其他的元数据。它提供了一系列的方法和运算符,用于执行精确的加减乘除、取模、幂运算等操作。
精度丢失用例
const a = 31181.82
const b = 50090.91
console.log(a+b) //81272.73000000001
Decimal 的引入 与 加减乘除
- 如何引入
npm install --save decimal.js // 安装
import Decimal from "decimal.js" // 具体文件中引入
- 加
let a = 1
let b = 6
// a 与 b 可以是 任何类型,Decimal 内部会自己处理兼容
// 下面两种都可以 可以带 new 也不可以不带 new(推荐带new)
let res = new Decimal(a).add(new Decimal(b))
let res = Decimal(a).add(Decimal(b))
- 减
let a = "4"
let b = "8"
// a 与 b 可以是 任何类型,Decimal 内部会自己处理兼容
// 下面两种都可以 可以带 new 也不可以不带 new
let res = new Decimal(a).sub(new Decimal(b))
let res = Decimal(a).sub(Decimal(b))
- 乘
let a = 1
let b = 6
// a 与 b 可以是 任何类型,Decimal 内部会自己处理兼容
// 下面两种都可以 可以带 new 也不可以不带 new
let res = new Decimal(a).mul(new Decimal(b))
let res = Decimal(a).mul(Decimal(b))
- 除
let a = 1
let b = 6
// a 与 b 可以是 任何类型,Decimal 内部会自己处理兼容
// 下面两种都可以 可以带 new 也不可以不带 new
let res = new Decimal(a).div(new Decimal(b))
let res = Decimal(a).div(Decimal(b))
注意
上面的结果是 一个 Decimal 对象,你可以转换成 Number 或则 String
let res = Decimal(a).div(Decimal(b)).toNumber() // 结果转换成 Number
let res = Decimal(a).div(Decimal(b)).toString() // 结果转换成 String
关于保存几位小数相关
//查看有几位小数 (注意不计算 小数点 最后 末尾 的 0)
y = new Decimal(987000.000)
y.sd() // '3' 有效位数
y.sd(true) // '6' 总共位数
// 保留 多少个位数 (小数位 会补0)
x = 45.6
x.toPrecision(5) // '45.600'
// 保留 多少位有效位数(小数位 不会补0,是计算的有效位数)
x = new Decimal(9876.5)
x.toSignificantDigits(6) // '9876.5' 不会补0 只是针对有效位数
// 保留几位小数 , 跟 js 中的 number 一样
toFixed
x = 3.456
// 向下取整
x.toFixed(2, Decimal.ROUND_DOWN) // '3.45' (舍入模式 向上0 向下1 四舍五入 4,7)
// 向上取整
Decimal.ROUND_UP
//四舍五入
ROUND_HALF_UP //(主要)
// 使用例子
let num2 = 0.2
let num3 = 0.1
let res = new Decimal(num2).add(new Decimal(num3)).toFixed(2, Decimal.ROUND_HALF_UP)
console.log(res); //返回值是字符串类型
超过 javascript 允许的数字
如果使用超过 javascript 允许的数字的值,建议传递字符串而不是数字,以避免潜在的精度损失。
new Decimal(1.0000000000000001); // '1'
new Decimal(88259496234518.57); // '88259496234518.56'
new Decimal(99999999999999999999); // '100000000000000000000'
new Decimal(2e308); // 'Infinity'
new Decimal(1e-324); // '0'
new Decimal(0.7 + 0.1); // '0.7999999999999999'
可读性
与 JavaScript 数字一样,字符串可以包含下划线作为分隔符以提高可读性。
x = new Decimal("2_147_483_647");
其它进制的数字
如果包含适当的前缀,则也接受二进制、十六进制或八进制表示法的字符串值。
x = new Decimal("0xff.f"); // '255.9375'
y = new Decimal("0b10101100"); // '172'
z = x.plus(y); // '427.9375'
z.toBinary(); // '0b110101011.1111'
z.toBinary(13); // '0b1.101010111111p+8'
x = new Decimal(
"0b1.1111111111111111111111111111111111111111111111111111p+1023"
);
// '1.7976931348623157081e+308'
最后:希望本篇文章能帮到您!
来源:juejin.cn/post/7405153695507234867
视差滚动效果实现
视差滚动是一种在网页设计和视频游戏中常见的视觉效果技术,它通过在不同速度上移动页面或屏幕上的多层图像,创造出深度感和动感。
这种效果通过前景、中景和背景以不同的速度移动来实现,使得近处的对象看起来移动得更快,而远处的对象移动得较慢。

在官网中适当的使用视差效果,可以增加视觉吸引力,提高用户的参与度,从而提升网站和品牌的形象。本文通过JavaScript、CSS多种方式并在React框架下进行了视差效果的实现,供你参考指正。
实现方式
1、background-attachment
通过配置该 CSS 属性值为fixed可以达到背景图像的位置相对于视口固定,其他元素正常滚动的效果。但该方法的视觉表现单一,没有纵深,缺少动感。
.parallax-box {
width: 100%;
height: 100vh;
background-image: url("https://picsum.photos/800");
background-size: cover;
background-attachment: fixed;
display: flex;
justify-content: center;
align-items: center;
}

2、Transform 3D
在 CSS 中使用 3D 变换效果,通过将元素划分至不同的纵深层级,在滚动时相对视口不同距离的元素,滚动所产生的位移在视觉上就会呈现越近的元素滚动速度越快,相反越远的元素滚动速度就越慢。
为方便理解,你可以想象正开车行驶在公路上,汽车向前移动,你转头看向窗外,近处的树木一闪而过,远方的群山和风景慢慢的渐行渐远,逐渐的在视野中消失,而天边的太阳却只会在很长的一段距离细微的移动。

.parallax {
perspective: 1px; /* 设置透视效果,为3D变换创造深度感 */
overflow-x: hidden;
overflow-y: auto;
height: 100vh;
}
.parallax__group {
transform-style: preserve-3d; /* 保留子元素3D变换效果 */
position: relative;
height: 100vh;
}
.parallax__layer {
position: absolute;
inset: 0;
display: flex;
justify-content: center;
align-items: center;
}
/* 背景层样式,设置为最远的层 */
.parallax__layer--back {
transform: translateZ(-2px) scale(3);
z-index: 1;
}
/* 中间层样式,设置为中等距离的层 */
.parallax__layer--base {
transform: translateZ(-1px) scale(2);
z-index: 2;
}
/* 前景层样式,设置为最近的层 */
.parallax__layer--front {
transform: translateZ(0px);
z-index: 3;
}
实现原理

通过设置 perspective 属性,为整个容器创建一个 3D 空间。
使用 transform-style: preserve-3d 保持子元素的 3D 变换效果。
将内容分为多个层(背景、中间、前景),使用 translateZ() 将它们放置在 3D 空间的不同深度。
对于较远的层(如背景层),使用 scale() 进行放大,以补偿由于距离产生的视觉缩小效果。
当用户滚动页面时,由于各层位于不同的 Z 轴位置,它们会以不同的速度移动,从而产生视差效果。
3、ReactScrollParallax
想得到更炫酷的滚动视差效果,纯 CSS 的实现方式就会有些吃力。
如下是在 React 中实现示例,通过监听滚动事件,封装统一的视差组件,来达到多样的动画效果。

const Parallax = ({ children, effects = [], speed = 1, style = {} }) => {
// 状态hooks:用于存储动画效果的当前值
const [transform, setTransform] = useState("");
useEffect(() => {
if (!Array.isArray(effects) || effects.length === 0) {
console.warn("ParallaxElement: effects should be a non-empty array");
return;
}
const handleScroll = () => {
// 计算滚动进度
const scrollProgress =
(window.scrollY /
(document.documentElement.scrollHeight - window.innerHeight)) *
speed;
let transformString = "";
// 处理每个效果
effects.forEach((effect) => {
const { property, startValue, endValue, unit = "" } = effect;
const value =
startValue +
(endValue - startValue) * Math.min(Math.max(scrollProgress, 0), 1);
switch (property) {
case "translateX":
case "translateY":
transformString += `${property}(${value}${unit}) `;
break;
case "scale":
transformString += `scale(${value}) `;
break;
case "rotate":
transformString += `rotate(${value}${unit}) `;
break;
// 更多的动画效果...
default:
console.warn(`Unsupported effect property: ${property}`);
}
});
// 更新状态
setTransform(transformString);
};
window.addEventListener("scroll", handleScroll);
// 初始化位置
handleScroll();
return () => {
window.removeEventListener("scroll", handleScroll);
};
}, [effects, speed]);
// 渲染带有计算样式的子元素
return <div style={{ ...style, transform }}>{children}</div>;
};
在此基础上你可以添加缓动函数使动画效果更加平滑;以及使用requestAnimationFrame获得更高的动画性能。
requestAnimationFrame 带来的性能提升
同步浏览器渲染周期:requestAnimationFrame 会在浏览器下一次重绘之前调用指定的回调函数。这确保了动画更新与浏览器的渲染周期同步,从而产生更流畑的动画效果。
提高性能:与使用 setInterval 或 setTimeout 相比,requestAnimationFrame 可以更高效地管理动画。它只在浏览器准备好进行下一次重绘时才会执行,避免了不必要的计算和重绘。
优化电池使用:在不可见的标签页或最小化的窗口中,requestAnimationFrame 会自动暂停,这可以节省 CPU 周期和电池寿命。
适应显示器刷新率:requestAnimationFrame 会自动适应显示器的刷新率。这意味着在 60Hz、120Hz 或其他刷新率的显示器上,动画都能保持流畑。
避免丢帧:由于与浏览器的渲染周期同步,使用 requestAnimationFrame 可以减少丢帧现象,特别是在高负荷情况下。
更精确的时间控制:requestAnimationFrame 提供了一个时间戳参数,允许更精确地控制动画的时间。
4、组件库方案
在当前成熟的前端生态中,想要获得精彩的视差动画效果,你可以通过现有的开源组件库来高效的完成开发。
以下是一些你可以尝试的主流组件库:
引用参考
How to create parallax scrolling with CSS
来源:juejin.cn/post/7406161967617163301
阶层必然会分化,但维度不只有金钱
前言
Hi 你好,我是东东拿铁,一个在“玩游戏”的后端程序员。
先问大家一个问题,如果阶层分化是必然的,你还会有玩下去人生这个“无限游戏”的动力吗?
让我们从一个游戏说起。
1996年,通过计算机建模理解社会演化的思潮在学术界正兴,美国布鲁金斯学会的艾伯斯坦和阿克斯特尔设计了一个关于财富分配的游戏,命名为“糖人世界”(Sugarscape)。

他们设计出一个模拟的地形图,深色区域含糖量高,浅色区域含糖量少,而白色区域则不产糖,对应资源富裕区、有限区、贫困区和沙漠区。
糖在被吃掉以后过一段时间会再长出来。然后他们会随机丢一些小糖人上去——这些小糖人遵循几个简单规则:
- 看四周6个方格,找到含糖量最高的区域,移动过去吃糖;
- 每天会消耗一定的糖(新陈代谢),如果消耗大于产出,则会死掉出局;
- 每个糖人的天赋、视力和新陈代谢是随机的。有人天生视力好,别人看1格,自己看4格,比较占优势;有人则比别人消耗少,别人每天消耗2格,他只要1格,可理解为体力好。还有一些天生富二代,携带更多糖出生。
一开始的时候,大家都差不多,最富裕的24个人有10块糖;但跑着跑着,不均衡开始出现。在第189回合以后,贫富差距出现了,最富裕的2人有225块糖,而有131个人只有1块。

注:横轴为财富数,纵轴为人数。
具体细节大家可以自行了解,但游戏告诉我们一个结论:在一个流动、开放的社会里,阶层分化是稳定且可预期的。
游戏如此,现实世界也如此。
阶级分化
我看过一部分书,比如《皮囊》、《活着》、《许三观卖血记》、《兄弟》,也听过很多耳熟能详的作品比如《平凡的世界》、《人世间》,我特别喜欢类似的作品。
虽然自己出生在城市,生活的时代早已和历史上的时代有所不同,也不需要为物质、精神需求所忧虑,但在某些时候,却又能感同身受。
因为这些优秀的作品背后有一个共性,就是关注普通人的生活与命运。
投射现实,我们大概率属于拥有更少糖的那部分小糖人。
比如,出生时拥有的糖不够多,又或者生在离糖山更远的地方。
当然,现实生活比游戏复杂的多,但我们能做的事情,也比小糖人能做的多。
比如
- 小糖人无法学习,我们可以
- 小糖人走到糖山,需要走很多步,但是我们有网络,交通工具
- 游戏中的糖山,是不会移动的,但是我们时代和机会是在不断变化的
所以,阶层固化是必然的,但是个体的命运却不是。
阶级分化,到底是分化了什么。
我之前肤浅的认为,阶级分化,无非就是财富的分化。
我有一个很有钱的阿姨,她的女儿比我小一些,之前一起吃饭的时候,聊起买衣服的话题。有一个服装品牌叫“优衣库”,大家应该都听过。经济实惠,质量虽然赶不上大品牌,但也还可以,我现在去商场也会习惯性的去优衣库逛逛。
有一次一起吃饭,我记着我们聊到优衣库的时候,她面露难色的说了一句:“优衣库的衣服能穿吗。”
毕竟平常接触到的非常有钱的人的机会不多,即使十年过去了,这件事给正在上学的我留下的印象非常深刻。
毕竟我们就是要让一部分人先富起来,先富带动后富,所以分化就是财富的分化。
心智
最近在看古典老师的书《跃迁》,这本书里举的一个例子,让我对分化,有了不一样的看法。
原文如下:
我在当GRE老师的时候,曾经教过收费很高的一对一英语私教班,学生家长一般分成两种:一种是真的很有钱,不在乎钱的家长;有一些则是收入中等,希望孩子有出息,一咬牙花大价钱的家长。对于前者,我倾尽全力让自己对得起这个价格;对于后者,我则更加苦口婆心,小心谨慎,偶尔还开个小灶,我知道这些钱对这个家庭意味着什么。
每次,我都会跟接孩子的家长聊聊孩子的学习进度。我会说“你们家孩子词汇量还不够,要把这6000词汇尽快背完,然后阅读分才会好。”这个时候,我经常收到两种回答。那些中产阶层家庭的家长会说:“听到没有!要听古典老师的话!回去好好背,好不好?”孩子温顺地点头。而有些真正聪明的家长则会笑着说:“古典老师,我们家孩子就是不爱背单词,但是他喜欢阅读。我们进度不需要那么赶,你能不能陪他多读点儿有趣的英文书?”后面这种回答,震撼了我。
这段描述给我了非常大的冲击,毕竟教育是每一个人都会经历的,我不禁回忆起了我上学的时候,想想看,如果当我们遇到单词量不够的时候,父母怎么面对这个问题,我们又是如何面对这个问题呢?
无论是初中、高中、还是大学,在我想提高单词量的时候,我会选择打开常用词汇的小册子,打开当时很流行的什么“百词斩”等app,开始背单词。
父母应该会问,单词背的怎么样了,老师布置的任务都完成了吗?
所以最后我印象最深的词汇就是“abandon”。
我从初中开始便开始住校,直到大学毕业,住校的时间足足有十年。初中、高中寄宿制的生活,接受的是军事化、填鸭式的教育,我们只管上课、做题,如果你表示不满,老师就会让你去操场跑几圈。
直到近几年我才明白,我才知道住校期间的那段学习,有多么的低效。
现在我也当了父亲,有了孩子后,我时常在考虑,相比于我们这一代的放养式教育,我应该如何把我学会的技巧、方法和道理传递给孩子,让他更高效的成长。
比如我教会他100种背单词的技巧,告诉他艾宾浩斯遗忘曲线记忆法?还是便利贴贴满冰箱让他实时看到,利用碎片化时间记忆?还是让他像我一样借助一些APP辅助记忆?
在我眼里这些技巧确实是对的,也都是有一定效果的,但是孩子真的能够听进去,学会这些吗?我总是感觉到,这并不是父母能做到最好的。
我之前肤浅的认为,阶级分化,无非就是财富的分化,毕竟我们就是要让一部分人先富起来,带动后富,所以分化的就是分化的财富。
而古典老师的这个例子,让我看到了不同阶级的家庭,对于背单词这件事情不一样的选择。
前者,被动接受,按部就班,最后成长成为一个优秀的员工。
后者,主动选择,试图寻找最高效的方式,创造一些传统教育教不会的学习思维。
父母在做,孩子在看。
教育与学习,不同家庭会有如此大的差异,那么个人成长呢,工作、甚至人生选择呢,不同的思维又会对我们产生多大的影响呢?
看到这里,你是否对阶级分化有了不一样的看法,我发现分化的不仅是财富,还有心智。
影响心智的因素
是什么导致了心智的分化?看了许多书,也看过很多大佬给出的建议和方法,我想从两个方面来聊聊,一个是自控力,一个是思维带宽。
自控力
先从自控力说起,自控力是什么,《自控力》中是这样定义的:
自控力是控制自己的注意力、情绪和欲望的能力,由 “我要做”“我不要”“我想要” 这三种力量组成。
我要做:是为了更好的未来做自己不喜欢的事情的能力,比如坚持学习、完成工作任务等;
我不要:是即使面对诱惑也能说 “不” 的能力,像抵制美食、视频的诱惑等;
我想要:是记住自己真正想要的东西的能力,它能让我们在面对短期诱惑时,不忘长期目标。
你如果白天面临较多需要自控的事情,比如美食、工作、阅读等,下班回到家一旦自控力耗尽,就很容易放纵,开始打游戏、刷视频。
一次放纵对于富人来说也许不算是损失,对于穷人来说则会浪费很多宝贵的机会。
普通人并非不懂得延迟满足,只是他们对自己延迟满足的肌肉的操控力,早就被诱惑消耗得所剩无几。
刚刚在我写着这篇文章,不自觉地拿起了手机刷小红书,幸亏写的是这个主题,我及时的意识到又把我拉了回来。
但是,《自控力》书中还提到了“自控力肌肉”这个概念,的角度解释过这个问题。自控力如肌肉,用多了会疲劳。
说一个最近的例子,上周孩子睡觉一直很晚,几乎要到晚上十点多才能入睡,为了保证阅读时间,晚上收拾完看书,睡觉的时候几乎都在十二点以后了。
但实际上,我能够看书的时间依然很少,我总会用“我都这么晚看书了,不如先放松一下”的心态,开始去刷视频或者一些别的东西,然而回过神来,一个小时就过去了。
思维带宽
《稀缺》这本书中提出了“思维带宽”的概念,思维带宽是指心智的容量,它由认知能力和执行控制力构成。
当你处于稀缺状态时,无论是时间稀缺、金钱稀缺还是其他资源稀缺,你的注意力会高度集中在稀缺的事物上,这就导致心智容量被过度占据。
这种情况下,你用于处理其他事务的认知能力和执行控制力就会减弱。
例如,普通人可能会因过于关注当下的金钱问题,而在做决策时忽视了对未来的投资和规划;工作忙碌的人可能因专注于眼前的紧急任务,而忽略了重要但不紧急的事情,如锻炼身体、陪伴家人等。
如果总想着怎么换个大房子,怎么换个好车子,哪里有时间思考什么个人发展、儿女教育呢?发展战略显然才是核心。如果说贫穷是一种“思维带宽”的稀缺,注意力资源就变得非常重要,提升认知时大部分都是反人性的,需要巨大的带宽。
所以,如果你注意力稀缺,即使你知道要做些什么,也会陷入战术勤奋、战略懒惰的困局。
在《贫穷的本质》这本书里,作者阿比吉特和埃斯特观察到很多捐赠者的本意,是希望穷人将捐款用在教育、健康上,实际却往往被花在了消费品、奢侈品上,因为穷人和富人处于不同的自控力和心智资源层面。
如果把这种根据社会学尺度观察到的贫富现象平移到我们身边,就会发现,其实贫穷早就不是一个财富数字,而是一种稀缺的心理状态。
正视自控力,提升思维带宽
幸运的是,上面的两种能力,都是可以通过训练来提升的。
对于自控力,我们可以通过如下方式训练我们的自控力肌肉:
- 训练大脑,比如冥想、深呼吸等方式
- 调整生活方式,比如充足的睡眠、健康的饮食、充足的锻炼
- 改变思维方式,比如接纳自己的情绪,而不是压抑。养成成长型思维等
甚至,我们还可以借助一些工具,比如Flora等。

对于思维带宽,我们也有不少方法,避免稀缺,提升我们的思维带宽
- 进行时间规划,避免紧急重要的任务投入太多时间。对重要不紧急的事情,每周固定留出一部分时间,避免因为时间带来的负担
- 对于支出制定预算,明确收支范围,避免因为财务紧张陷入金钱稀缺的状态
- 学会留白,拒绝不重要的活动、聚会,而是什么都不做,让自己自由思考、放松等,或者是拒绝一份996的工作
- 培养正确的认知,认识到稀缺对于我们心态的影响,当真的面临时间、金钱的压力时,提醒自己不要陷入狭隘的视角,从更广阔的角度去看问题
方法很多,就不一一列举了。
说在最后
好了,文章到这里就要结束了,感谢你能看到最后。
从看到小糖人游戏带给我的结论时,我先是感到无奈与不甘,因为这个结论,对于一个普通人来说,实在是太让人失望了。
洋洋洒洒这么多,还是想给自己泼一盆冷水,那便是我们即使不断的提升我们的心智,我们大大大概率也不能够拥有完全足够的财富。
我只能说,通过心智的不断提升,即使财富无法追上那20%的人们,也可以在思维、心智上完成跃迁。只有这样,财富或许才会到来。
因为相信,所以看见,让我们继续玩人生这个无限游戏吧。
来源:juejin.cn/post/7405889205476032552
为什么vue:deep、/deep/、>>>样式能穿透到子组件
为什么vue:deep、/deep/、>>>样式能穿透到子组件
在scoped标记的style中,只要涉及三方组件,那deep符号会经常被使用,用来修改外部组件的样式。
小试牛刀
不使用deep
要想修改三方组件样式,只能添加到scoped之外,弊端是污染了全局样式,后续可能出现样式冲突。
<style lang="less">
.container {
.el-button {
background: #777;
}
}
使用 /deep/ deprecated
.container1 {
/deep/ .el-button {
background: #000;
}
}
使用 >>> deprecated
.container2 >>> .el-button {
background: #222;
}
当在vue3使用/deep/或者>>>、::v-deep,console面板会打印警告信息:
the >>> and /deep/ combinators have been deprecated. Use :deep() instead.
由于/deep/或者>>>在less或者scss中存在兼容问题,所以不推荐使用了。
使用:deep
.container3 {
:deep(.el-button) {
background: #444;
}
}
那么问题来了,如果我按以下的方式嵌套deep,能生效吗?
.container4 {
:deep(.el-button) {
:deep(.el-icon) {
color: #f00;
}
}
}
源码解析
/deep/或>>>会被编译为什么
编译后的代码为:
.no-deep .container1[data-v-f5dea59b] .el-button { background: #000; }
源代码片段:
if (
n.type === 'combinator' &&
(n.value === '>>>' || n.value === '/deep/')
) {
n.value = ' '
n.spaces.before = n.spaces.after = ''
warn(
`the >>> and /deep/ combinators have been deprecated. ` +
`Use :deep() instead.`,
)
return false
}
当vue编译样式时,先将样式解析为AST对象,例如deep/ .el-button会被解析为Selector对象,/deep/ .el-button解析后生成的Selector包含的字段:
{ type: 'combinator', value: '/deep/' }
然后将n.value由/deep/替换为空 。所以转换出来的结果,.el-button直接变为.container下的子样式。
:deep会被编译为什么?
编译后的代码:
.no-deep .container3[data-v-f5dea59b] .el-button { background: #444; }
源代码片段:
// .foo :v-deep(.bar) -> .foo[xxxxxxx] .bar
let last: selectorParser.Selector['nodes'][0] = n
n.nodes[0].each(ss => {
selector.insertAfter(last, ss)
last = ss
})
// insert a space combinator before if it doesn't already have one
const prev = selector.at(selector.index(n) - 1)
if (!prev || !isSpaceCombinator(prev)) {
selector.insertAfter(
n,
selectorParser.combinator({
value: ' ',
}),
)
}
selector.removeChild(n)
还是以.container4 :deep(.el-button)为例,当解析到:deep符号式,selector快照为

parent为.container4 :deep(.el-button),当前selector的type正好为伪类标识pseudo,nodes节点包含一个.el-button。
经过递归遍历,生成的selector结构为.container4 :deep(.el-button).el-button,
最后一行代码selector.removeChild(n)会将:deep(.el-button)移出,所以输出的最终样式为.container4 .el-button。
如果样式为:deep(.el-button) { :deep(.el-icon) { color: #f00 } },当遍历.el-icon时找不到ancestor,所以直接将:deep(.el-icon)作为其icon时找不到ancestor,其结果为:
.no-deep .container4[data-v-f5dea59b] .el-button :deep(.el-icon) { color: #f00; }
因此,deep是不支持嵌套的。
结尾
插个广告,麻烦各位大佬为小弟开源项目标个⭐️,点点关注:
- react-native-mapa, react native地图组件库
- mapboxgl-syncto-any,三维地图双屏联动
来源:juejin.cn/post/7397285315822632997
前端经理岗的面试技巧
本人最早是2017年,开始在上市公司作为高级经理,管理大前端团队,包括安卓、iOS和前端工程师,但这么多年过去了,我的管理工作还有很多需要改进的地方。
不管我是继续创业,还是去上班,我都需要考虑前端团队管理的事情。所以,本文我将结合过去多年的前端管理实践和面试经历,分享我对前端管理的思考、前端管理的高频面试题和一些学习资料。
关于前端经理岗的思考
在我成为程序员之前,我是北京军区38集团军某部的指挥军官,在部队最多时管理过130多人,在聚焦谈前端经理岗之前,我先放大聊一下管理。
什么是管理
管理是一个多维度的过程,既有对项目的管理,也有对人员的管理,还有向上管理、同级管理、自我管理和向下管理。
对于前端经理岗的管理,需要以人员管理为主,但也要以项目管理为本,而前端架构岗,则以项目管理为主,但需兼顾人员管理。
狭义的管理是指一定组织中的管理者,通过计划、组织、领导、协调和控制等手段,对组织所拥有的资源进行有效的整合和利用,以达成组织既定目标的过程。
技术团队管理的方法论
技术团队的管理是指运用一系列的管理原则和实践,对技术人员进行组织、指导和协调,以实现团队目标的过程。
技术团队管理的关键在于平衡技术发展、团队建设和业务需求之间的关系,确保团队的高效运作和创新能力的持续发展。
通过询问国内几个主流的大模型和查阅相关的资料,我最推荐的是一个美团同事在团队管理方面的总结的方法论。
他不仅在IGT、腾讯和新美大工作期间,参加了各种培训和大佬分享,平时还阅读了二十多本团队管理有关的书籍,并且在美团也做了多年的技术团队管理。
他采用的是自底向上方式,先是将所有知识打碎,然后重新归类汇总。先列举出了六十多种实践或方法,然后将它们划分成不同模块,并且思考这些模块之间的关系,最终建立一个相对完整且自洽的体系。
他将团队管理的整个体系分为两个维度,十个模块。有了这个体系,我们就能够以更高的视角,来看待团队管理中的各种事务,并且有针对性地加以改善。

上面的图,只是列了一下技术管理相关工作大纲,但要开展好管理工作,推荐的还是 PDCA 管理,这是美国质量管理专家休哈特博士首先提出的,由戴明采纳、宣传,也被称为“戴明环”。
它是全面质量管理所应遵循的科学程序,不仅在质量管理体系中运用,也适用于一切循序渐进的管理工作。它通过循环不断地进行计划(plan)、执行(do)、检查(check)和处理(ack) ,以达到不断完善过程和提高结果的目标。
PDCA 的管理可以总结为四阶段及八步骤:
- P阶段--计划:即根据顾客的要求和组织的方针,为提供结果建立必要的目标和过程。
- 步骤一:选择课题,分析现状,找出问题
- 步骤二:设定目标,分析产生问题的原因
- 步骤三:提出各种方案并确定最佳方案,区分主因和次因
- 步骤四:根据已知的内外部信息,设计出具体的行动方法、方案
- D阶段--执行:即按照预定的计划、标准,努力实现预期目标的过程。
- 步骤五:设计出具体的行动方法、方案,进行布局,采取有效的行动
- C阶段--检查:即确认实施方案是否达到了目标。
- 步骤六:效果检查,检查验证、评估效果
- A阶段--处理
- 步骤七:对已被证明的有成效的措施,要进行标准化,以便以后的执行和推广。
- 步骤八:问题总结,处理遗留问题,为开展新一轮的PDCA循环提供依据。
我在 PDCA 上加了扩展,变成了 O + PDCA + R:其中 O 是机会,只有发现并抓住了机会,才能开展 PDCA 的管理过程;而 R 则是Review,需要结合周报、月报、季度和年终总结定期进行总结复盘。
我的管理复盘
先谈一下我对管理认知:管理可以理解为管人理事的缩写,其中管人,包括选用育留开;而理事,则包括对公司及部门的战略理解,所负责或参与项目的规划、实施和复盘,整体的质量、效率和体验的提升。
因为我是国防生,大学期间就开始接受部队系统的管理培训,所以看了很多管理相关的书籍,我的管理理念和风格依然受部队的管理很大。
很多人会误解部队的管理是简单粗暴的命令式管理,但我党我军管理的精髓是民主集中制,既有民主,又要确保集中,注重以身作则、平等待人和思想工作。
所以,我实际工作中,不管是直线管理团队,还是通过项目管理相关同事,都会坚持民主集中制的原则,倡导用规则管理团队,并鼓励大家从团队出发,完善或提出规则,让大家都能参与到管理中。
大家若能参与到团队管理规则的制定,并且管理者能否以身作则,奖惩公平,树立起规则的权威,这样的团队才比较容易做到上下同心,营造出平等、自驱、高效和快乐的团队氛围,团队业绩也会更好。
管理团队的前期,我一般会制定三个原则:
- 每周跑一个3公里(女生只需1.5公里);
- 每周抄写10个英语词汇(每月安排一个同学提供);
- 每周写一篇技术博客或学习笔记。
做不到的需要交10元团建费(一般由女同学负责管理),在每周的技术分享会上用来买水果糕点吃。
制定第一个原则的考虑是,很多码农缺乏运动,身体亚健康的比例很高,另外对男女生的要求不同,也是让大家知道待人着想。而第二个原则呢,则是现在技术更新很快,很多新技术及遇到的问题,只有英文资料。最后呢,则是提升大家的写作基本功和让大家养成持续学习的习惯。
这三个原则执行起来后,我就会鼓励部分同学提出一些新的管理规则,然后在周会上提出,大家匿名表决,对于规则的完善建议也是如此,比如参加会议迟到也要交10元团建费或加一些奖励的规则。
回顾过去几年的管理工作,我觉得《高效能力的七个习惯》对我的启示很大,要想做好前端团队的管理,先从做好自我管理入手,然后主动做好向上管理,接着兼顾组织目标和团队个人目标做好向下管理,但也不要忘了关注协作方相关的管理工作。
一般一个月以后,团队能够按照规则良好管理起来后,我就会把重心过渡到核心项目的管理和架构上面,既会做前沿技术的调研,又会参与一些紧急项目的代码开发。
对我来说,我不愿成为一个官僚式的纯管理者,而是要主动拥抱前沿技术,具备大型复杂项目的管理和架构能力,这样在职场上才能保持持续的竞争力。
前端经理岗的高频面试题
这几年不管我是面试开发岗,还是前端经理岗或总监岗,有一些共同问题高频出现,但不同的岗位回答各有侧重,才能提升通过面试的概率。
本节我既会针对一些高频的共同问题,也会针对只有前端经理这个岗位才可能遇到的问题,分享一些我的思考。
请先做一下自我介绍?
不管是面试什么行业或什么岗位,也不管是第几轮面试,我们面试需要回答的第一个问题就是介绍自己。
很多人都会简单准备一个自我介绍,并且每次面试的介绍都一样。要想面试过程更顺利,我们最好根据面试公司的业务、岗位要求、面试官等情况,适当地调整自我介绍。
比如面试腾讯TEG 大模型的开发岗,我会这么介绍自己:我是XXX,从XX毕业已经12年了,最开始在外企以开发操作系统为主,16年开始转型做大前端开发和架构工作,技术栈以react 为主(因为JD说了项目用的是react),19年开始自学深度学习,过去三年都在做模型应用开相关的工作,特别是在美团,从零实现了一个web推理引擎。
而面试另外一个上市公司的管理岗,我则会这么介绍自己:我是XXX,从XX毕业后,一直都从事管理相关的工作,最开始在外企做操作系统时,负责团队的新人培训和团建工作,2016年进入互联网行业后,在做好项目架构和管理的基础上,还经常需要做团队管理,最多时管理过35人的大前端团队,既有前端开发、也有安卓和iOS开发,因为在部队接受过系统的指挥军官培训,我的管理遵循毛主席提出的民主集中制原则,以团队共同制定的规则管理各项工作,团队良好运转后,我会把精力聚焦在项目架构优化和研发质量和效率的提升上。
如何克服管理遇到的挑战?
技术团队管理面临的挑战多种多样,包括但不限于沟通不畅、资源分配不合理、团队成员技能不匹配、项目延期等,在面试的过程中,我们挑选一两个例子进行展开即可。
最难凝聚的,是人心:信任和凝聚力是团队成功的基石。每个团队成员都有自己的思想和需求,如何将这些不同的个体凝聚成一个有战斗力的集体,是每位管理者必须面对的挑战。管理者需要倾听员工的声音,尊重他们的意见,关心他们的成长。只有当员工感到被尊重和重视时,他们才会真心投入到工作中,与团队共同进退。
最难驾驭的,是情绪:管理者不仅是团队的领航者,更是情绪的调控者。一个稳定、积极的情绪状态能够激发团队的士气,反之,则可能引发团队的动荡。情绪的传染力极强,管理者的每一次情绪失控都可能成为团队士气的“病毒”。
最难把握的,是人性:孔子说:“己所不欲,勿施于人。” 管理者应将心比心,尊重员工的个人价值和需求。同时,通过合理的激励机制,激发员工的积极性和创造力。人性是不变的,但人心是流动的。管理者需要通过不断观察和学习,把握员工的心理变化,适时调整管理策略。
最难管理的,是期望:员工和上级都对管理者有着不同的期望,这些期望往往难以完全满足。上级领导希望团队能够不断超越,达成更高的业绩目标,而员工则希望得到更多的关注和支持。管理者需要深入了解各方的期望,并制定合理的策略来满足他们。
最难摆正的,是心态:管理者需要摆正自己的心态,从“保姆”转变为“教练”。通过引导和激励,帮助团队成员提升自我管理的能力,而不是替他们解决所有问题。应给予团队成长的空间和时间,而不是急于求成。
最难排解的,是委屈:管理者需要有宽广的胸襟,能够承受来自各方的压力和误解。在管理的过程中,管理者常常处于上下夹击的境地,既要面对上级的高要求,又要应对下属的期望和不满。应有谦逊和自省的精神,面对挑战和压力时,能够坦然接受,积极寻求解决方案。
分享你工作中最大的成果?
技术管理的最大成果不仅体现在项目交付或技术创新上,更在于其对整个组织的长远影响。可以从以下角度挑一两个展开:
- 业务项目:带领团队按时、按预算、高质量完成了一个或多个关键项目,满足了业务需求和客户期望,并通过技术驱动,促进了公司业务增长,如增加了用户数量、提升了用户活跃度或实现了收入增长。
- 技术创新:推动了技术创新,如引入新的技术栈、开发新的产品功能或改进现有的技术方案,从而提升了产品的竞争力和市场份额。
- 流程优化:改进了开发和运维流程,如引入敏捷开发、持续集成/持续部署(CI/CD)等,提高了工作效率和产品质量,在面对突发事件或危机时,能够迅速做出反应,采取有效措施,最大限度地减少了损失,并从中恢复过来。
- 人才培养:建立了积极向上的团队文化,增强了团队的凝聚力和员工的归属感,通过培训和指导,成功地培养了技术和管理方面的后备人才,为公司未来的发展打下了坚实的基础。
如何去做好这个管理岗位?
朝哪个方向走,判断的核心是深刻理解市场、业务的趋势。这其中,要对技术的未来做判断,对产品的未来做判断,相对而言,大部分人都能看到技术的发展趋势,困难的是判断未来的产品形态。
要有效地管理前端团队,需要从团队组建与选拔、技能提升与培训、项目管理与协作、质量控制与测试以及团队氛围与文化等多个方面入手。
通过明确团队目标、合理分配任务、持续培训、建立有效的沟通机制和加强团队文化建设,可以提升团队的整体效率和协作能力。
回答这个问题时,最好以互动问答的方式进行,多向面试官了解相关的情况,然后针对岗位职责和存在问题,进行适当的展开。
你为何离职?之后有何规划
回答离职原因和后续规划的问题时,重要的是要保持诚实、积极,并展现出你对新机会的热情和期待。
离职原因
- 诚实但策略性:选择离职原因时,应避免负面评价前雇主,而是强调个人成长和职业发展的需求。
- 具体原因与改进:即使是因为薪资、工作环境或领导问题离职,也应表达出你从中学到了什么,以及你如何准备在新工作中避免类似问题。
后续规划
- 职业目标:清晰地表达你的职业目标,展示你对前端技术领域的热情和承诺。
- 技能提升:强调你计划如何继续提升自己的技能,包括学习新技术和参与项目实践 。
- 对新机会的期望:表达你对新公司的期望,包括你希望在新角色中实现的目标和对公司的贡献。
通过上述策略,你不仅可以有效地回答离职原因和后续规划的问题,还能够给面试官留下一个积极、有目标的印象。
相关的学习资料
主要推荐一些我阅读过的书籍或看过的视频。
书籍:
- 《高效能人士的七个习惯》
- 《卓有成效的管理者》
- 《领导梯队》
- 《重新定义团队:谷歌如何工作》
- 《OKR工作法》
视频:
总结
人,是企业最宝贵的财富,甚至更胜于商业模式。管理能力的核心包含两方面,一是针对人,对人性的了解程度以及沟通能力。二是对事,是否有强大的统筹规划协调能力。
这是对于广义上管理能力的定义,对于技术团队,其本身有一些特殊性,所以在管理技术团队的时候,要充分考虑到这些特殊性。
管理是一件很复杂的事情,但是我认为管理技术团队相对并不复杂,可能是大多数技术人员都还是比较单纯吧。
技术团队的管理者,特别是中层管理者,其实就是个夹心层,经常受夹包气。其实你想想,作为一个承上启下的职位,压力同时来自于下面和上面,收夹包气也就正常了。
但是如果我们能够科学的规划任务,坚持以事驱动人,事前做计划,事中做追踪,事后做分析,调动团队积极性,我想再困难的任务也能够分解成一个一个不困难的小任务,分而破之。
对于团队内的一些声音和反馈的问题,能够耐心倾听、加以思考和用心解决,成员自然能够很好地完成管理者布置的任务。
关于面试相关话题,欢迎大家在评论区或加我微信交流:waxyysys82。
来源:juejin.cn/post/7396575930964934708
程序员:全栈的痛你不知道
上周一个同事直接对我开喷,骂我无能,说:“你怎么一个人就搞不定所有系统呢?”,我半支烟纵横IT江湖14余年,还是第一次被人这么嫌弃。
事情缘由
某公司的业务线特别多,有个业务线前后端项目共计上百个,半支烟带着1个大前端、1个Android外包、1个iOS外包在支撑业务线的发展。
突然,有一天大前端同事有事不在,运营同事找到我开发功能,我说要等等,我现在一个人搞不懂所有的端口。此时,运营同事一着急就上头,直接质问我,为什么你不能一个人搞定所有端口?
我当时立马怒怼,我说我一个人确实无法同时搞定IT基建、搞定后端、搞定H5、搞定Android、搞定 iOS、搞定PC、搞定小程序、搞定自动化爬虫。如果觉得我无能,你可以找个全部能搞定的过来。
然后,就是各种撕逼......
这个事情对我还是很触动,倒不是说跟同时互撕了一顿。只是觉得,现在的IT环境真的是看的人后背发凉,不但机会少,对人的要求还特别的高。
在想想前些时间,某高校降低要求大量扩招计算机专业学生,简直是坑学生啦。
全栈的优势
半支烟2010年毕业于计算机专业,工作14余年,后端干过JAVA、Python、Golang,大前端干过React、Vue、Android、iOS,还搞过IT基建运维。
半支烟对全栈还算有些理解,下面说说全栈的优势吧。
个人觉得,最好的技能人才是一专多能,这个绝对毋庸置疑。就是要在某个领域精通之后,在别的领域持续开花结果。说到底还是要做一个全栈的技术人。
全栈的优势非常多,比如:
- 在中小企业,一个人胜任多个岗位,可保饭碗无忧。
- 全栈人解决问题更快,因为全栈人的视角更加全面。
- 可以做一个独立开发者。
- 可以从事各种副业。
- 如果还会懂一些产品运营,那直接可以开个赚钱的小公司了。
全栈的痛
虽然全栈有一些优点,但是全栈的痛点也非常明显,比如:
- 全栈人要学习的技能或者知识非常多,但人的精力是有限的,无法真正做到每个技能栈都非常熟悉。
- 全栈人找工作会招人嫌弃,尤其是大厂会觉得你不是专业的螺丝钉,经常用某个领域的一些八股文去否定你。
- 很对人虽说是全栈,但是没有站在解决问题的角度去思考,而只是作为一个会多个技术栈的工具人。这样的思想其实偏离了全栈的初衷。
个人建议
个人觉得,全栈对个人职业发展很有优势,我建议在精通一个领域后做一个全栈人。
我这里说的全栈,不只是IT技术栈,还有更多的是产品运营思维。任何时候全栈人都应该用解决问题、推动事情往前发展的思维去做事。
当前大环境不乐观,未来也未必乐观,中小企业都偏向找全栈人,大公司偏向找专业高级螺丝钉。虽说背点八股文对找工作有优势,但是将来将一文不值。
因为AI发展太迅速了,获取知识已经变更更加便捷。我更不建议做一个高级螺丝钉,那样只会成为工具人,最后失业时一无所有。
我建议,不管你在哪里企业,自己的成长要放在第一位。
尤其在当下这个AI时代,可以让IT人更轻松的成为全栈人,我们应该把握机会,让自己成为一个优秀的超级个体,努力搞出点自己的事业来。
来源:juejin.cn/post/7406254193433100351
8年前端总结和感想
8年前端总结和感想
本文是我前端工作 8 年的一些总结和感想
主要记录下个人点滴、前端知识点、场景应用、未来的憧憬以及个人规划,供自己以后查漏补缺,也欢迎同道朋友交流学习。
自我介绍
我是一名工作在非知名公司的 8 年前端,双非普通本科,自动化专业(非计算机)。目前也在努力的提升自己,积极找工作状态。虽然工作已经 8 年了,但没待过超 10 人的前端团队,更没有开发过千万级、亿级流量的应用的经历,也是一种遗憾。
16 年才工作那会儿使用原生 JS 和 JQ 比较多,经常写 CSS 动画,主要做企业建站,自学了 PHP 和 ReactNative,还学过 krpano 的使用;17 年到 19 年,主要使用 react、 React Native做 H5 和 跨端开发,也维护过老 NG2.x 项目;19年到22年主要使用 vue、react 做hybrid APP及小程序,自学了electron、node、MongoDB;22 年至今主要从事 B 端的开发,C端也有部分,也主要是 react 和 vue 相关技术栈;
前端应用场景
前端是直面浏览器的,也可以说是直面用户的,我们的应用场景远广泛于后端,用到的 UI 组件库、插件、基础框架、基础语言也非常繁杂,所以在面试和自我学习提升的时候需要准备的东西非常多,有种学不动的感觉。
常见的应用场景就是 PC 浏览器,需要我们掌握一些兼容不同版本和不同浏览器的知识点,一般采取渐进增强或者优雅降级去处理;当然现在很多公司已经不做IE的兼容了,复杂度降低很多;同时大部分新项目都会使用 postcss 去 autoprefixer,给 css 加兼容的前缀。其他的就是做后台的表单为主了,用的基本上都是 antd design 或 element ui。当然复杂点的要涉及到网页编辑器、Low Code、No Code等。
另一个主要场景就是手机浏览器和 APP 了,H5 WebAPP 会遇到 Android、IOS的一些样式和行为需要兼容、列表和图片懒加载问题,还有调用原生的 SDK 进行地图、OCR、拍照、扫一扫等功能进行开发;为了更好的体验,还会选择 RN、flutter 进行跨端开发;复杂的处理场景一般涉及原生端,例如聊天室、直播等。
另一个场景就是小程序,其实还是写H5,主要是使用微信或者支付宝等相关 SDK 去实现,看官网就行了,文档也比较全。
还有一些是做 H5 小游戏,要求数学逻辑思维和算法更好点,初级一点的用 canvas+css3 去做,好一点的用游戏引擎去做,一般是 egret、 Laya、 createjs、 threejs、 cocos。
还有一些场景是做TV端的,有的是基于PC浏览器的,有些是套壳APP,一般使用 AntV、 echarts做图表数据展示,3D一般用 threejs去做。
还有一些做桌面应用的,一般来说桌面应用大多基于 C,但一些简单应用前端可以使用 electron 去进行桌面端开发,一般也用于大屏可视化,做数据展示的,当然我们熟悉的 vscode 也基于 electron 开发。
还有一些是做 AR、 VR、 3D全景图的,一般使用 WebGL3D引擎:threejs、 babylon.js、 playcanvas等,还可以用 css3d-engine、 krpano、 pano2vr去做。
还有一些场景是做 web3 的 DAPP(去中心化应用程序),大部分是做区块链和数字藏品的,推荐的技术是 Solidity、 web3.js、 Ethers.js。
前端网络
我们前端不管是开发 PC、 H5、小程序、 HyBrid App 还是其他应用,始终离不开是浏览器和 web-view,与浏览器交互就要了解基础的 HTTP、网络安全、 nginx方面的知识。
浏览器
浏览器的发展简史和市场份额竞争有空可以自行了解,首先我们要了解计算机架构:
- 底层是机器硬件结构:简单的来说就是电脑主机+各种
IO设备;复杂的来说有用于输入的鼠标键盘,用于输出的显示器、打印等设备,用于控制计算机的控制器和 CPU(核心大脑),用于存储的硬盘、内存,用于计算的CPU和GPU; - 中层是操作系统:常见的就是
Windows、MAC OS、Linux、CentOS,手机就是安卓和 IOS(当然还有华为的鸿蒙);可以了解内存分配、进程和线程管理等方面知识。 - 上层就是我们最熟悉的应用程序:有系统自带的核心应用程序、浏览器、各个公司和开发者开发的各种应用。
前端开发必要了解的就是chrome浏览器,可以说大部分开发基于此浏览器去做的。需要了解 进程和线程 概念、了解 chrome 多进程架构(浏览器主进程、GPU进程、网络进程、渲染进程、插件进程)。
其中最主要的是要了解主进程,包含多个线程:GUI渲染线程、JS引擎线程(V8引擎)、定时触发器线程、事件线程、异步HTTP请求线程。其中 V8 引擎又是核心,需要了解其现有架构:

了解 JS 编译成机器可以识别的机器码的过程:简单的说就是把 JS 通过 Lexer 词法分析器分解成一系列词法 tokens,再通过 Parser 语法分析为语法树 AST,再通过 Bytecode Generator 把语法树转成二进制代码 Bytecode,二进制代码再通过实时编译 JST 编译成机器能识别的汇编代码 MachineCode 去执行。

代码的执行必然会占用大量的内存,那如何自动的把不需要使用的变量回收就叫作 GC 垃圾回收,有空可以了解其算法和回收机制。
HTTP
对于Http,我们前端首先需要了解其网络协议分层: OSI七层协议、 TCP/IP四层协议 和 五层协议,这有助于我们了解应用层和传输层及网络层的工作流程;同时我们也要了解应用层的核心 http1.0、 http1.1、 http2.0 及 https 的区别;还要了解传输层的 TCP、 UDP、 webSocket。
- 在前后端交互方面必须了解
GET和POST的请求方式,以及浏览器返回状态200、3xx、4xx、5xx的区别;还有前后端通信传输的request header头、响应报文体response body,通信的session和cookie。 - 网络安全方面需要了解
https,了解非对称算法rsa和对称算法des,登录认证的JWT(JSON Web Token);同时也需要了解怎么防范XSS、CSRF、SQL注入、URL跳转漏洞、点击劫持和OS命令注入攻击。
Nginx
我们的网页都是存储在 web 服务器上的,公司一般都会进行 nginx 的配置,可以对资源进行 gzip 压缩,redirect 重定向,解决 CROS 跨域问题,配置 history 路由拦截。技术方面,我们还要了解其安装、常用命令、反向代理、正向代理和负载均衡。
前端三剑客
前端简单的说就是在写 html、 css 和 js 的,一般来说 js 我们会更多关注,其实 html 和 css 也大有用处。
HTML
html 的历史可以自行了解,我们需要更关注 文档声明、各种 标签元素、 块级元素及非块级元素、 语义化、 src与href的区别、 WebStorage和 HTML5的新特性。复杂的页面和功能会更依赖于我们的 canvas。
css
css 方面主要了解布局相关 盒子模型、 position、 伪类和伪元素、 css选择器优先级、 各种 水平垂直居中方法、 清除浮动、 CSS3新特性、 CSS动画、 响应式布局相关的 rem、 flex、 @media。当然也有部分公司非常重视用户的交互体验和 UI 效果,那会更依赖我们 CSS3 的使用。
JS
js 在现代开发过程中确实是最重要的,我们更关心其底层原理、使用的方法、异步的处理及 ES6 的使用。
- 在底层方面我们需要了解其
作用域及作用域链、闭包、this绑定、原型和原型链、继承和类、属性描述符defineProperty和事件循环Event Loop。
可以详看我写的javascript随笔
- 在使用方面我们需要了解
值和类型的判断、内置类型的null、undefined、boolean、number、string、object和symbol,其中对象类型是个复杂类型,数组、函数、Date、RegExp等都是一个对象;数组的各种 API 是我们开发中最常用的,了解Dom操作的API也是必要的。 ES6方面要了解let、const声明、块作用域、解构赋值、箭头函数、class、promise、async await、Set、WeakSet、Map、WeakMap、proxy和Reflect。
可以详看我写的(ES6+)随笔
TypeScript在前端的使用越来越广泛,如果要搞NodeJS基本上是标配了,而且也是大厂的标配,还是有必要学习下的。要了解TypeScript的安装配置、基本语法、Type、泛型<T>、Class、Interface、Enum、命名空间和模块。
可以详看我写的typescript随笔
前端框架
我们在开发过程中直接操作 dom 已经不多了,有的公司可能还要部分维护 JQ,但大多都在使用 React、 Vue、 Angular这三个基础前端框架,很多其他跨平台框架及 UI 组件库都基于此,目前来说国内 React 和 Vue 是绝对的主流,我本人就更擅长React。
React
开发 react,也就是在写 all in js,或者说是 JSX,那就必须了解其底层 JSX 是如何转化成虚拟节点 VDom 的。在转换 jsx 转换成 VDom,VDom在转换成真实 Dom,react 的底层做了很多优化,其中大家熟悉的就是 Fiber、 diff、 生命周期 以及 事件绑定。
那我们写 react 都是在写组件化的东西, 组件通信的各种方式也是需要了解的;还要了解 PureComponent、 memo、 forwardRef等组件类的方法;了解 createElement、 cloneElement、 createContext等工具类的方法;了解 useState、 useEffect、 useMemo、 useCallback、 useRef等hooks的使用;还有了解 高阶组件HOC 及自定义 hooks。
了解 react16、 react17、 react18做了哪些优化。
Vue
vue 方面,我们需要了解 MVVM 原理、 template的解析、数据的 双向绑定、vue2 和 vue3 的响应式原理、其数据更新的 diff 算法;使用方面要了解其生命周期、组件通信的各种方式和 vue3 的新特性。
前端工程化
上面写到了前端框架,在使用框架开发的过程中,我们必不可少的在整个开发过程向后端看齐,工程化的思想也深入前端。代码提交时可以使用git的钩子hooks进行流水线的自动化拉取,然后使用 webpack、 rollup、 gulp以及 vite 进行代码编译打包,最后使用 jenkins、 AWS、 阿里云效等平台进行自动化部署,完成整个不同环境的打包部署流程。
可以详看我写的webpack随笔 和 使用rollup搭建工具库并上传npm
webpack
在代码编译打包这块儿, webpack是最重要的,也是更复杂的,所以我们有必要多了解它。
在基础配置方面,我们要了解 mode、 entry、 output、 loader 和 plugin,其中 loader 和 plugin 是比较复杂的,webpack 默认只支持 js,那意味着要使用 es6 就要用 babel-loader,css 方面要配置 css-loader、 style-loader、 less-loader、 sass-loader等,图片文件等资源还要配置 file-loader;
plugin 方面要配置 antd 的相关配置、清空打包目录的 clean-webpack-plugin、多线程打包的 HappyPack、分包的 splitChunks 等等配置。
在不同环境配置方面要基于 cross-env 配置 devServer 和 sourcemap。
在构建优化方面要配置按需加载、 hash、 cache、 noParse、 gzip压缩、 tree-shaking 和 splitChunks等。
幸运的是,现在很多脚手架都自动的帮你配置了很多,并且支持你选择什么模版去配置。
环境部署
环境部署方面,第一家公司我用的软件 FileZilla 进行手动上传 FTP 服务器,虽然也没出过啥错,但不智能,纯依靠人工,如果项目多,时间匆忙,很容易部署错环境,而且还要手动备份数据。后面学了点终端命令,使用 SSH 远程上传文件,其实还没有软件上传来的直接,也容易出错。后面换了公司,也用上了 CI/CD 持续集成,其本质就是平台帮你自动的执行配置好的命令,有 git 拉取代码的命令、npm run build的打包命令,最后 SSH 远程存到服务器的目录文件,并重启 nginx 的 web 服务器。
CI/CD 可让持续自动化和持续监控贯穿于应用的整个生命周期(从集成和测试阶段,到交付和部署)。
后端服务
为了更好的完成整个应用,了解后端技术也是必要的,我们可以从 nodejs、MongoDB、MySQL 等入手。如果有余力,了解 java、c#、c++ 也可以帮助我们更好的开发安卓和 IOS 应用。前后端都通了话,不管对于我们工作、面试、接活儿或者做独立开发者都是很必要的。
node
node 这方面,我们了解常用模块和 Event Loop 是必要的,框架可以选择 express、 koa、 egg,还有我最近刚学的NestJS也非常不错。
形而上学
了解完上面的文章,基本上你就了解了整个前端大体的开发流程、所需的知识点、环境的部署、线上网络安全。但如果需要进阶且不局限于前端和后端,我们需要了解数据结构、 设计模式、 算法 和 英语。
数据结构
常见的数据结构有8种: 数组、 栈、 队列、 链表、 树、 散列表、 堆 和 图。
可以详看我写的算法随笔-数据结构(栈)
可以详看我写的算法随笔-数据结构(队列)
设计模式
设计模式方面我们需要了解:
- 六大原则:
单一职责原则、开放封闭原则、里氏替换原则、依赖倒置原则、接口隔离原则和迪米特原则(最少知道原则) - 创建型设计模式:
单例模式、原型模式、工厂模式、抽象工厂模式和建造者模式 - 结构型设计模式:
适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式和享元模式 - 行为型设计模式:
观察者模式、迭代器模式、策略模式、模板方法模式、职责链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式和解释器模式
算法
算法方面我们需要了解:
- 基础概念:
时间复杂度和空间复杂度 - 排序方法:初级排序的
选择排序、插入排序和冒泡排序,高级排序的快速排序、归并排序、堆排序 - 搜索:
深度优先搜索和广度优先搜索 - 其他:
递归、分治、回溯、动态规划和贪心算法
可以详看我写的算法随笔-基础知识
英语
学生时代,觉得英语离我们挺远,进社会就用不到了。现在发现学好英语非常有用,我们可以入职福利待遇比较好的外企、可以更好的看懂文档、甚至起个文件名和变量名都好的多。最近我也在用多邻国学英语,目标是能进行简单的商务交流和国外旅游,还能在未来辅导下孩子英语作业。
前端未来
目前,初级前端确实饱和了,各个公司对前端已经不像我入职第一家公司那样简单就可以找到工作的了,尤其是在这个各种卷的环境里,我们不得不多学习更多前端方面的知识。对于初学者,我建议更多的了解计算机基础、js原理、框架的底层;对于已经工作一俩年想提升的,不妨多学点跨端、跨平台技术,还有后端的一些技术;对于工作多年想让未来路子更宽的,不得不内卷的学习更多的应用场景所需要的知识。
关于AI,我觉得并不是会代替我们的工具,反而缩小了我们和资深前端的距离。我们可以借助AI翻译国外的一些技术文档,学习更新的技术;可以帮我们进行代码纠错;还可以帮助我们实现复杂的算法和逻辑;善用 AI,让它成为我们的利器;
感想和个人规划
前端很复杂,并不是像很多后端所说的那么简单,处理的复杂度和应对多样的客户群都是比较大的挑战。资深的前端能很快的完成任务需求开发、并保证代码质量,并搭建更好的基础架构,但就业行情的不景气让我一度很迷茫,我们大龄程序员的出路在哪里,经验就不值钱了嘛?
对于未来,我会更多的学习英语、学习后端,向独立开发者转型。
谨以此文,献给未来的自己和同道中人!
来源:juejin.cn/post/7387420922809942035
市场行情再差,也不要选择996,它真的会吞噬你
前言
最近,一连有两个朋友和我聊天,说新公司996,自己很犹豫,是不是应该换个工作。
我的回答是,快走,一秒都不要犹豫。
但在目前市场行情不佳的情况下,似乎也很难让人下定决心放弃一份已有的工作。
恰巧,我也曾经入职过一家996的公司,而且也只有这么一家。我想把这段经历分享出来,希望能对你有一点点帮助。
重复的工作,会限制人的视野。其实在世界上,还存在着无法想象的广袤天地。
满怀憧憬
2019年,我终于决定从当前的小公司离职,准备换一家更大规模的公司。
经过几轮面试,没想到很顺利的拿到一家公司的offer,涨薪50%,单纯从薪资角度来说,达到了我的预期,及时入职前,HR给我说,我们这边996,你是否能够接受,我也很果断的接了offer。
那时候想法很简单,谁给的钱多,我就去哪里。初入职场的我们,大概率都是这么想的。
由于换工作换的很快,我还没来得及搬家,前公司坐标丰台区,并且我住的地方离地铁站很远,需要坐公交车。
早上七点,起床洗漱,抓紧时间下楼去赶7:20的公交车。七点四十坐上地铁,在八点五十左右到达望京附近,一路小跑在九点前完成打卡。
前面也说了,既然是996,晚上九点才能下班,事实上九点公司根本没人走,但是我是刚入职,自然不会跟着他们一起加班。下班后打车回家,一般在十点半到家,结束一天的工作。
太可怕了,我除了睡觉,剩下的时间不是在上班,就是在上班的路上。
上班第二天,联系了自如的管家,我早下班去看了周边三个地方的房子,准备搬到这附近来,最后还交了定金,这样每天起码能省下通勤的时间。
大家可以看到,这时候我还是很想留下来的,但接下来的两天,我便意识到,此地不宜久留。
为了加班而加班
上面讲过,因为我是新人,加上住的地方离着公司很远,所以我都是九点就赶紧下班跑了。
和我同时进入公司的还有一个哥们,就叫他阿文吧。
阿文挺平易近人,对待工作也挺踏实。他告诉我他就住在离公司两三公里的地方,所以即使是新人,他下班都是和他们那些老员工一起下班。
那么老员工下班是几点呢,他说一般大家都是11点才走,然后第二天早上再晚点来公司,而他依然会九点按时上班。
中午吃饭的时候,大家普遍也是坐着不动,等到12点半才陆陆续续去楼下吃饭。
第一周的周六加班,我七点下班了。周一的时候,阿文告诉我,周六他加班到11点才走。
我是一个不会把工作往后拖的人,有工作就抓紧完成,但问题是白天的时间大家感觉也不是很忙,虽然是996,入职一周了,没有人强调过接下来项目的紧迫性,手头的工作也是一些边边角角的功能。
此时的我已经心里交瘁了,一周的早起晚归,加上比较迷茫的工作内容,已经让我有了要辞职的想法。
接下来的一周,依然是熟悉的内耗与纠结,同时也感到迷茫,如果在这里996下去,对自己的职业生涯,能有帮助吗?
最终,入职半个月后,我决定离开这家公司。

996背后是什么
开头说到,996的公司直到今天依然存在,甚至存在于一些外包公司。
大部分实行996的公司,背后一定处于基建建设差、管理能力不足,战略目标不清的状态。为了兜底,强制实行996试图弥补这两个缺陷。
作为一个开发人员,你对自己一天中高效的工作时间,心里是有一定的预估的。
以我和之前身边同事为例,仅从代码产出的角度来说,一天高效写代码4-5小时,已经相当不错了。
长期加班,强制实行996,一定会出现无效加班的现象。因为持续的加班,会触发我们基因中的“调节回路”,降低我们的效率。
调节回路具体是什么,可以看下我之前写的这篇文章。四个字解释明白,常常说的程序员35岁危机,到底说的是什么?
996可怕的不是长达12小时(可能更多)在公司的时间,可怕的是996会极大的丧失我们对于新事物的接受力,影响我们的思考能力。
关注研发效能
软件开发是一个创造性很高的过程,开发者之间的效率相差很大。就比如,10x程序员的生产效率可以达到普通开发者的10倍。其实,不仅是个人,团队间的效率相差也很大。相比工作时长而言,我们更应该关注的是研发效能。
研发效能,是团队能够持续为用户产生有效价值的效率,包括有效性
(Effectiveness)、效率(Efficiency)和可持续性(Sustainability)三方面。简单来说,就是开发者是否能够长期既快又准地产生用户价值。
软件开发流程本质上就是一套流水线,比如需求设计、技术设计、开发、构建、测试、发布、部署、验证。
其中,流水线的每一套流程都可以细化拆分,找到提高效能的方式。
举个例子,不知道你有没有过部署服务的经验,最基础的部署方式,是手动在本地打包,通过工具把打包的程序上传,替换,再重启服务。
但随着服务器数量越来越多,手动的方式会占用大量时间。
部署的方式也持续在升级,从虚拟化到容器化,再到容器编排,开发人员可以轻松的管理大规模的容器集群。
假设不关注效能,只是招人、996来完成日益增长的大规模部署,得需要多少人来完成这件事呢?
说在最后
好了,文章到这里就要结束了,感谢你能看到最后。
有些人,工作对于他们而言,只是在固定的时间出现在固定的地点,做着固定的事情——重复,重复,再重复。他们或许想的是,“就这样吧,反正也没的选”。
高效的完成工作,留出更多时间给自己。
来源:juejin.cn/post/7398150089556606988
同事一行代码,差点给我整破防了!
大家好,我是多喝热水。
最近开发公司项目的时候遇到一个哭笑不得的问题,知道真相的我差点破防!
还原现场
周一开周会的时候正常评审需求,在演示的过程中发生了一点小插曲,我们的聚合搜索功能它不能正常使用了,搜到的内容还是首次加载的数据,如下:

看到这种情况,我下意识的以为是后端返回的数据的问题,所以结束会议后我就着手排查了,如下:

结果发现后端的数据是没问题的,这我就很奇怪了,其他的 tab 都能正常展示数据,为什么就只有综合出现了问题?

开始排查
因为这个无限滚动组件是我封装的,所以我猜测会不会是这个组件出了什么问题?
但经过排查我发现,这个组件接收到的数据是没问题的。
那就很奇怪了,我传递的参数是正确的,后端返回的数据也是没问题的,凭什么你不能正常渲染?
直到我看到了这一行代码,我沉默了:

woc,你小子在代码里下毒!

看到这里我基本上可以确定就是这个 index 搞的鬼,在我尝试把它修改成 item.id 后,搜索功能就能正常使用了,如下:

问题复盘
为什么用 id 就正常了?
这里涉及到 React 底层 diff 算法的优化,有经验的小伙伴应该知道,React 源码中判断两个节点是否是同一个节点就是通过这个 key 属性来判断的,key 相同的话会直接复用旧的节点,如下:

这也就解释了为什么切换 tab 后列表中始终都是旧数据,因为我们使用了 index 作为 key,而 index 它是会重复的,新 index 和旧 index 对比,两者相等,React 就直接复用了旧的节点!
但 id 就不一样了,id 我们可以确保它就是唯一的,不会发生重复!
哎,排查问题半小时,解决问题只花 3 秒钟,我 tm.....

这个故事告诉我们:
一定不要在循环节点的时候使用 index 作为 key!
一定不要在循环节点的时候使用 index 作为 key!
一定不要在循环节点的时候使用 index 作为 key!
养成好习惯,特别是这种数据会动态变化的场景!!!
来源:juejin.cn/post/7391744516111564852
切!我又不是第一次没人要🤡

我和你一样都经历过 家里蹲 狗都嫌 的尴尬时期,每天早上起来拿着手机不断刷着招聘软件,
海投几百份还是杳无音讯,在BOSS直拒、前程堪忧、失联招聘、猎空之间反复横跳...
还经历了十分灰暗的阶段,焦虑导致出现躯体化反应(头痛、严重失眠、吃不下东西等)
整夜整夜睡不着,躺下脑子都是工作、面试、人生选择带来的压力
不想出门社交,害怕面试。
其实,我想跟你说:裸辞并不是终点。
1.裸辞/辞职并不是终点
当我扛着我的键盘收拾东西离开工位,第一次对辞职的 “人走茶凉” 有了实感,
下午六点跟对我很好的前辈们告了别,公司离地铁有点远,和往常不一样,天还没黑,有黄昏相伴
三号线还是这么挤 还有点闷。

算起来这是第二次辞职,但第一次辞职找了一个礼拜就顺利入职了
,这次好像有点久,今年大家都在说被裁员、大环境差,同学领证成家的也不少。
我意识到人与人的节奏不同,而我好像又一次走到了岔路口,上一次这么慌张还是在高考前
即便我从来没后悔过离职这个决定,但还是会因为面试带来的压力感到局促不安
每次离职就像是一场查漏补缺的大考,对勇气,对储蓄,对知识点的大考
唯有拆迁和认亲能打破这场突如其来的考验。。。啊不是。。。我想说:
唯有行动能打破僵局!!

行动!!!去吃个冰淇淋!!。。。果然有灵感了

短暂的欢愉后,是与台灯的昼夜相守,与简历的交织缠绵
(简历编。。不是。。写不出来呀!!!)

反复改了几版之后确实多了一些“打招呼”的机会,但是实际面试机会还是屈指可数呀,
切!又不是第一次没人要🤡,拒绝我的多的去了,得从巴黎排到广州...
继续努力,等待运气,厚积薄发

2.当知识脱离了考试,真理和美丽才慢慢浮现
2.1 心态调整(分享一下最近对我有帮助的书)
- 《见识》 - 吴军
这是第一年出来工作,遇上了很好的领导送我的书,每当迷茫的时候再拿出来翻翻有了不一样的感悟,很多我们看上去非做不可的事情,其实想通了并没有那么重要,无论在职场上还是在生活中,提高效率都需要从拒绝伪工作开始,有些苦是可以不用吃的,苦难并非造就人类。
幸福是目的,成功是手段
- 《意志力》 - 罗伊·鲍迈斯特
技术行业的人都知道学习是个漫长/终身的事情,跟考公考研短期爆发式集中不同,我们更需要坚持、长期一点点做下去,我认识到所有人的意志力都是有限的,使用就会消耗,压力也并非与动力画等号,人也跟机器一样需要“充电”和合理分配,每个人的节奏和身体承受能力也不同。
- 《被讨厌的勇气》 - 岸见一郎、古贺史健编著
在心情动荡的时期,这本书就像开了一盏加热灯一样在一旁无声陪伴,那会我就像婴儿一样无意识地紧紧抓着自己的头发,直到我睁开眼看见了、意识到了,放下禁锢着工作、生活、交友的课题的手,更能轻松地赶路了。
生活的方式千千万,人生的意义,由我自己决定
- 《法律常识全知道》 - 李桥
读书的时候没有一门跟社会接轨的课程,毕业了也一直专研技术,导致一毕业不知道劳动合同/租房有什么坑,把仲裁和维权看得过于艰难,法律条例密密麻麻 一时间不知从何下手,这本书就很适合我这种来一线城市打工没什么社会经验的小白,用简单的案例植入“NPC游戏”攻略,和《影响力》这本书加一起简直就是进城防骗指南哈哈哈
免费法律援助电话:12348
2.2 前端学习路线图:

各位摸鱼的小伙伴下次见,这篇便是我的2023年终总结:
裸辞不是终点,唯有行动才能打破僵局,当知识脱离了考试,真理和美丽才慢慢浮现。
参考资料:
来源:juejin.cn/post/7312304122535133220
这两年,我把28年以来欠的亏都吃完了...
前言
很长一段时间没有总结一下过去几个月的状态了,今天思绪万千,脑海中浮现了很多经历和生活片段,我把它记录下来。顺便今天聊一聊认知突破,分享我在买房这段时间吃过的亏,也希望作为你的前车之鉴。
买房
21年底的时候,那时刚好毕业三年,也正是互联网公司996最流行的阶段,由于平时我不怎么花钱,也很少买衣服,上网买东西是个矛盾体,需要花很多时间对比,经常看了一件东西很久,最后又不买。加上比较高强度的工作状态,两点一线,可以说是没时间花钱,再加上自己把钱都拿去理财了,也赚了几万块,最后一共攒了几十万下来。我从小就立志要走出农村,而且认为以后有女朋友结婚也要房子,加上当时花比较多时间在理财上面,那时候其实行情已经不好了,工作上没什么突破,比较迷茫,于是想着干脆就把钱花出去了,自己也就有动力去搞各种路子尝试赚钱。在没有经过任何对比之后就在佛山买了一套房子,房价正是高峰的时候,于是我成功站岗!因为这个契机,躲过了持续了2年多的低迷股市,却没躲过低迷的房地产。
while(true) { 坑++ }
我买的是期房,当时不知道期房会有这么多坑,比如期间不确定开发商会不会破产,我这个开发商(龙光)就差点破产了,房产证无着落,相当于花了200w买了一个无证的房子,这辈子就算是搭进去了。
对于整个购房过程也是很懵逼,对流程完全不熟悉,当时去翻了政府规划文件,看那个地段后续有没有涨价空间,然后跟着亲戚介绍的销售转圈圈,当时说给我免3年物业费,合计也有几万块。在签合同之前销售都有说可以给到,但由于第一次没有录音,导致在签合同的时候销售反口,不承认,我们也没有证据,最后吃了哑巴亏。
开始的时候谈好了一个价格167w,然后销售私下打电话给我洗脑说我给点辛苦费1.5w,他可以向领导申请多几万块优惠。我知道这是他们的销售套路,但是架不住给我优惠5w啊,中间反复拉扯最后说给他8k,采用线下现金交易的方式。这一次我有录音了,因为私底下交易没有任何痕迹,也不合法,所以留了一手,也成为我后面维权时争取话语权的基础。
中介佣金是很乐观的,当时由于我亲戚推荐我去,销售承诺税前有4w,当时看中这个返佣也促使我火急火燎的交了定金。现在3年过去了,这个佣金依旧没有到账,我一度怀疑是中介搞ABC套路把我这个钱💰吃了,其他邻居的推荐佣金都到了账,加上现在地产商没钱了,同时跟那个亲戚有些过节,这个返佣更是遥遥无期。最后通过上面的录音获得了一丝话语权,知道了这个钱还在开发商手上,一直没有拨款下来到中介公司。下面是部分聊天记录:

不接受微信语音沟通,文字可以留给自己思考的时间,同时也更好收集证据。

然后去找相关人员把信息拉出来给我看,显示开发商未付款状态,这个状态维持2年了,目前看来只能再等下去。

签合同的时候,有个律师所说是协助我们签合同、备案、办房产证等各种边缘工作,糊里糊涂交了700元律师费,不交不行,甚至律师所连发票都没有给,而我都没有意识到这个最基本的法律法规问题。现在交房了可以办理房产证了,拿证下来也就80块登记费,居然收我700,其他业主有些是600多,400多,顿时觉得智商受到了侮辱,看了网上铁头各种打假的视频,我觉得自己也应该勇敢发声。现在也在收集商家各种违规证据,提交给相关部门解决。



后面市场监督管理局收到投诉,应该是有协商,意识到没有给我们发票,过来几天之后才把发票补过来,开票日期不是付款时候的2022年,而是2024年,明显属于偷税了。目前跟他要发票的应该只有我,估算2300多户业主都没有开发票的。
当时我首付需要50w,自己手上不够,我爸干建筑一辈子,辛苦供我们两个孩子上了大学,山上建了两层楼,手里没钱。我妈是一辈子没打过工,消极派,说出来没几句好话,家里不和睦的始作俑者,更不可能有钱支持。所以我还有20w是首付贷,也就是跟开发商借的,利率10%,这个利息很高了。销售当时说可以优惠到5%,但是优惠金额是补贴到总房价里面去,其实这也是他们的一种销售套路,这亏我也吃了,2年之后我连本带息还24w。当时认为自己应该一年左右能还完,但是实际远远高估自己的能力,买完房子接着我爸又生病在医院待了几个月,前后花了十几万,人生一下子跌入了谷底。
从头再来
后面2023一年,夫妻出去创业,很多人不赞同,期间遇到了不少小人诋毁我们两夫妻,当时我老婆还在怀孕,但我们最后都熬过来了,还生了一个儿子,6斤多。期间一年赚了十几万,但是开支也大,加上父母要养,我爸还要吃药,房子要供,最后还是选择了先稳定下来,我重新回到了职场,空窗一年后在这个环境下拿了一个还不错的offer,同时也想自己沉淀一下。
自从有了宝宝之后,生活似乎都往好的方面发展,出版社找我出书,为了契合自己的职业发展,我选择了写书《NestJS全栈开发秘籍》,从2023年11月份开始,迄今快半年了,在收尾阶段,希望尽快与各位读者们见面。同时,等了3年的房子也收房了,由于是高层,质量相对其他邻居好,没有出现成片天花掉下来或者漏水的情况。我们经常都说他是天使宝宝,是来报恩的。
由于我们公司技术部门是属于后勤支持性质的,技术变化不大,Vue2+微前端和React管理系统那一套,没有太多的新技术扩展,意味着不确定也大。业务发展不好考虑的是减少这些部门的开支,所以不出意外最近也迎来了降薪。这不是最可怕的,对于我们技术人来讲,最可怕的是我认为在业务中成长停滞了,或者没有业务来锻炼技术,所以在业余时间也选择了参与一些开源项目,如hello-alog开源算法书的代码贡献,并且这也是选择写书的原因。很简单地说,当下一个面试官问到我的时候,我不可能什么都讲不出来,最经典的问题就是:在这个公司期间你做过最有成就感的事情是什么?现在,我有了答案!
哲学
我的人生哲学是不断改变,拥抱不确定性!这么看来,我的确在这些年上了不少当,吃了不少亏,把自己搞的很累,甚至连累到家里人。但,用我老婆经常说的一句话:人生这么长,总是要经历点什么,再说现在也没有很差。的确,不断将自己处于变化之中,当不确定性降临到普罗大众时,我们唯一的优势,就是更加从容!
总结
人们还在行走,我们的故事还在继续~

来源:juejin.cn/post/7349136892333981711
火山引擎谭待:没必要将AI和云对立,大模型是“云2.0”的组成部分
8月21日,2024火山引擎AI创新巡展(上海站)如期举行。火山引擎总裁谭待在媒体采访中表示,大模型是云的构成部分,不应把AI和云对立起来。否则,AI很容易演化为项目制商业模式,很难做大做强。
谭待认为,在公共云上调用大模型API,本质仍是云端PaaS,只是相较于DevOps等PaaS的重要程度更高、Workload更大,或者也可以叫“云2.0”。
谭待表示,大模型时代,火山引擎的定位没有变,仍是云服务厂商。但在当前时代,云服务厂商要在做好降本增效,通过规模优势把成本降低的同时,做好大模型,助力企业做好创新。
以往,企业决策者很难评估云的质量优劣,只能看看PPT。但在当前,评价大模型的优劣,下载APP体验即可得到最直观的了解。
对于大模型的具体应用,许多细分场景,如文档、客服等等,企业可以慢慢应用到自身实际运用中去,而没必要“一步到位”上大系统,这样一来,无论在可感知性、可量化性,还是决策的容易性方面,都会更高,从而真正加速大模型的落地。
对于媒体提出的“云计算市场格局是否已相对清晰”的问题,谭待表达了不同看法。他认为,2012年到2013年的中国电商市场,当时大部分的观点也认为市场格局已相对固化,但随着新的业态不断涌现,如今的电商市场仍然竞争激烈。
谭待表示,随着数字化的GDP占比越来越高,云对于数字化转型和发展也越来越重要,企业未来一定会用到云,而今天中国的云市场只有几千亿的规模,还远没有见顶。他预判,未来的中国云市场发展到万亿规模,只是时间问题,并且一定是多云成为主流。
云市场的本质是规模经济,规模大意味着更强的竞争力、更好的弹性、更低的成本。火山引擎决定进入云市场,很重要的一点是因为“内外复用”,火山引擎与抖音是资源并池的,两者相加的规模,在中国排在前列,火山引擎完全有信心越做越好。
同时,火山引擎还要抓住AI这一重大技术变革机遇,目前在用户量层面,豆包APP是中国最大的AIGC应用,而对于大模型来说,只有更多的用户使用量,才能锻炼出最好的技术。
谭待表示目前全球大模型价格已处于合理价位,有利于真正促进应用生态繁荣。尽管单价较低,但随着日均tokens的不断攀升,特别是多模态模型的普及,客户的各类场景中都会出现Agent,tokens的消耗量会非常大,从而创造很大价值,即使按现在的价格来看,也是非常有吸引力的市场。(作者:李双)
收起阅读 »前端开发,不应止于前端
重新思考前端开发以及自己未来的规划。先说结论,再展开。
- 烂程序员关心的是代码,好的程序员关心的是数据结构和它们之间的关系。—— Torvalds
- 编程也是内容创作,认清自己是哪个层级的创作者。
亲身经历
公司在去年选择了一款 Plasmic 这个低码平台,希望未来由业务部的人来使用低码平台构建页面,由开发部的人负责研究平台的使用方法、解决复杂的问题。后来,公司有 100+ 个问卷需要制作,并且这个业务是在内网中,不方便使用第三方的表单服务。这 100 个问卷中,有几十个在另一个 Vue 系统中有实现过,还有一些可能需要新增。我推荐让开发部来写这部分代码,但领导还是决定让业务部门的人使用低码平台(基于 NextJS)来构建。理由是这些问卷在另一个 Vue 中有实现过(我实现的),照着页面抄就行了。
在业务部的人经过一个星期的折腾之后,做了几十个问卷,最终因为难以维护而停止。这几十个问卷每个都是单独的页面,每个页面都需要对接口,需要一个问题一个问题的拖拽然后配置。在检查的时候,出现了各种各样的问题,量表出现问题时,还得一个问题一个问题的排查,排查起来不如重做。更何况,业务部的人也不会排查页面,她们没有什么编程基础。
这个问题并不难解决,只是这个决策让人有点令人匪夷所思。我的解决步骤大致分为两个步骤:将 NextJS 中的 Form 的编辑变成声明式的、对 Vue 中的 Form 进行迁移。
将 Form 的编辑变成声明式的,也就是用 JSON 来配置。例如在 Vue 中可以使用 FormCreate、在 NextJS 中可以使用 nice-form-react。我其实并不喜欢拖拽式的低码,拖拽之后再通过点击来配置其实很费时间,在经过我的实践发现,这种声明式的配置配合 GPT 来使用非常妙,只需要把配置相关的要求告诉他,就可以让他完成大部分的工作。前两天发现有类似的文章:低代码与大语言模型的探索实践。把编写 Form 页面变成编写 JSON 文件,复杂度直线下降。业务部的人可以直接通过 ChatGPT 生成 JSON,我只需要给他们一个工具来校验和展示 JSON 所对应的量表即可。
将 Vue 中的 Form 转换到 Next 中,有些人可能会考虑思考 FormCreate 底层的逻辑,然后在 NextJS 中再实现一遍,这样就能无缝迁移。并不需要这么做,这么做工作量非常大,只需要看数据结构怎么转换即可。
总结:Vue 中的 FormCreate 经过了魔改,支持根据题目算分。在 NextJS 先实现类似的声明式构建的机制,然后再将数据库中的 JSON 配置进行转换。
最终,加上业务部的配合,使用 GPT 来生成 JSON 文件,两三天的时间就全部迁移完成。大胆预测一下,拖拽式低码平台后面会被懂 DSL 的平台所替代,利用语义化的 DSL 配合大语言模型,效率应该会非常高。
重新思考前端开发
Linux 的创始人 Torvalds 曾说过一句话:“烂程序员关心的是代码,好的程序员关心的是数据结构和它们之间的关系”。
上面的声明式的 Form 工具是我构建的,由业务部的人来使用,当他们有什么需求的时候,我能很容易知道现有的结构能否实现。将 React 想象成一个更复杂的声明式的 Form 工具,那么熟悉它底层原理的人应该也可以拓展它的边界。
于是我尝试着阅读了一些 React 相关的源码,根据《🚀 万字好文 —— 手把手教你实现史上功能最丰富的简易版 react》构建了一个 mini-react。理解了 React 本质上是 DSL + 高效更新树的算法。JSX 作为 DSL 来引入组件化和简化树形结构的编写,Fiber 树和 Diff 算法来高效的更新树。
沿着树形结构稍微发散一下,就知道为什么会有 React Native 了。在网页中使用 DOM 树,在安卓中使用 View,在 IOS 中使用 UIView,这些都可以被称为布局树。当然除了更新视图,还有很多需要兼容的问题,例如:
我还继续沿着树形结构去探索 React 的可能性,想到了 Svg、Canvas、Three.js 这几种技术。我并不是特别了解这几种技术,只是简单的 check 是否有人将 React 用于这些方向,最后发现 React Three Fiber 这个项目。Three.js 中需要渲染场景树,Fiber 树现有的逻辑为什么不能用,非常好奇作者是如何将 Fiber 应用于 Three.js、为什么需要再实现一个 Fiber。
学会用 React 写页面非常简单,从零基础开始学,最多几天就能写出基本的页面,最麻烦的可能就是调 CSS,但是这些问题的复杂度都并不高,多搜索多尝试多问 GPT,基本也花不了多长时间就能解决。
但如果我们遇到的需求是制作 Su7 在线预览、制作 Win98 在线版、制作 Figma(通过 Webasmbly 与浏览器 Canvas 交互,让用户在浏览器端体验到了 Native 软件能力),那我们应该怎么办?薪资水平上不去的原因有部分原因就是这个了吧。我想到的解决方案是:重视源码阅读、重视数据结构和算法、甚至重视底层的数学。虽然上大学的时候就一直听说这句话,但是一直感悟不深。
在我重视了源码阅读之后,开始尝试去阅读 React 源码,然后顺着树形数据结构更新这个核心概念,延展出了 React Three Fiber。假设将时间线往前移动几年,并且我的设计和开发能力足够,可能我就成为了 React Three Fiber 的 Creator。也就是说,我顺着这样的思路再往后学习,可能也会发现一些新的场景,然后做出一些还不错的工具。
在 React 源码中有很多对于树这种数据结构的操作,让我重拾了对数据结构和算法的乐趣。在了解到还有 React Three Fiber 之后,我意识到常见的 Web 页面只是 2D 上交互,未来可能还有很多 3D 交互(比如在 Vision Pro 上),我想自学一下计算机图形学(在这之前可能得补一下线性代数、物理的光学)。好像挺多人推荐 GAMES101: 现代计算机图形学入门 这门课的。
内容创作者
作为一个前端开发者,有时候会逛到一些特别好看官网,就会特别羡慕这些开发者那么强。如:ONEUPSTUDIO、GSAP。后面我发现,网站好看与否很大程度上取决于设计师,软件好不好用取决于产品,功能能否实现取决于程序员。
开发者的职责是用代码将他们的想法表达出来,或者制作更好的工具帮助他们去创作和表达。工具之间的区别在于表现力、使用场景和使用范围大小,并且这些工具通常都是声明式的。设计师能使用 Webflow 这样的软件开开发出好看的网页,但是前端开发不一定能做到。作为程序员,最好的做法是制作更好的工具,如果直接表达想法,就会写出维护性和拓展性很差的代码。就像我上面提到的 Form,我应该提供一些制作 Form 的工具,而不是一个页面一个页面的绘制。
我们常见的 CSS 就是表现力非常强大的工具集,里面包含了 Table、Flex、Grid 等等工具。在没有 Flex 的时候,我们可以用 table-cell 这种这种的办法来实现垂直居中,但是在很多场景下使用起来比较麻烦,这就是工具的表现力差。后来引入 Flex,可以轻松的实现垂直居中。
程序员也是一种内容创作者,我大致的划分了一下互联网上的内容创作者,大致有如下的观点(不一定准确):
- 内容创作者可以大致分为:数学/物理、框架/库、软件/游戏/网页、视频/图片/文字
- 内容创作者如果从上到下排布,创作人数会呈现金字塔形状,从上到下创作难度从高到低、内容的数量会由少到多。
- 上层创作者为下层创作者提供基础设施(声明式的工具),并且可以简化下层创作的难度,但有可能会让下层创作者失去工作。
我在写 mini-react 的时候,相当于自己处于「框架/库」的内容创作者,我尝试直接在 codepen 中找一些有意思的作品,然后尽量去提供相关的机制(渲染、Diff、Hook)。作为「框架/库」的内容创作的的时候,可以很容易分析出整个软件的边界,我能知道 mini-react 能否做到某些功能。具体的页面绘制可以交给另一个层级的内容创作者,也可以尝试去复用他们的作品。
不同人有不同的喜好和擅长点。我很喜欢好看的软件,但我在绘画和艺术方面没有非常高的热情 Passion,往「数学/物理」这个方向去拓展应该会更适合我。有些人可能喜欢画画,会往「视频/图片/文字」这个方向,最终成为设计师。
过早优化是万恶之源
“过早优化是万恶之源”来源于 Donald Knuth 的《计算机编程艺术》一书,其原话是:
The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.
真正的问题在于程序员在错误的地方和错误的时间花费了太多时间去关注效率;过早优化是万恶之源(或至少是大多数问题的根源)。
在学习 mini-react 的时候,我想到了一些问题:
- React 中还有很多种 API 和配置,那我是不是要都实现一遍?
- React 有很多优化手段,我是否都要看看?
答案都是“不”。通过 React 能实现的网页,用 JQuery 也能实现。这些优化手段和 API 是通常都针对非常具体的场景,其通用性是比较低的。在掌握了整个 React 的核心原理之后,遇到这些场景再去学习会更好。它们大多也是基于核心原理去拓展的,理解起来并不会非常耗时间。比如 React Hooks 和 Fiber 树紧密关联。
半年计划
用以终为始的眼光来看,我十年之后还会在现在这家公司吗?答案是绝对不会。不在沉默中死亡,就在沉默中爆发。继续在公司苟着也只是将问题隐藏起来,所以还是决定了离职。
现在找工作难度越来越大,前端更是重灾区,一个岗位可能几十个人投。在这种环境下,调整好自己的心态比较关键。苦思冥想后,想到了一句可以让自己保持 Passion 的话:“找不到工作这段时间就是提升能力,找到工作就是幸运的”。
最近看到一篇博文非常喜欢,这里转载一下《前端开发的瓶颈与未来之路》 中的一段文字:
我在 2018 年有幸参加了 TypeScirpt 的推广大会,TypeScript 的作者 Anders Hejlsberg 亲自主讲。一位将近 60 岁的程序员在讲台上滔滔不绝的讲技术方案,TS 的设计理念。你真的很难想像这样一位处于「知天命」阶段的老头子(实际上很年轻)讲的东西。
QA 环节有个年轻小伙问到 Anders「在中国做程序员很累、很难应该怎么坚持下去(类似这样的描述,细节记不清楚了)」的问题。
Anders 几乎毫不犹豫的说出了「Passion」这个单词。我瞬间就被打动了。因为在此之前我对于「激情」这个词的认识还停留在成功人士的演讲说辞层面,当 Anders 亲口说出 Passion 一词的时候,让人感觉真的是一字千金。
这里还有一些我非常喜欢的文章,给大家推荐一下:
来源:juejin.cn/post/7399273700117479474
一个普通人的27岁
致工作三年即将27岁的自己
这是一篇自己的碎碎念、即回顾自己以前的成长经历、也小小的持有一下对未来的期待。
我是一个双非本科从事于Java开发的一名普普通通的码农、不同于大多数人的27岁、大部分人在这个年龄都已经工作了4/5年、而我也恰恰刚刚满三年而已。
读书
小时候的记忆很模糊、很少关于有父母的记忆、从小的印象就是他们在很远的地方打工、那边还有一个从未谋面的哥哥、小时候的记忆更多是和爷爷奶奶在一起,爷爷在我记事起、他就很忙、很少在家里也或许是我不记事或者缺少了这部分的记忆。
在小时候的记忆里、住在茅草屋里面、那个时候家里还没有完全通电、印象里经常点煤油灯、这个时间段应该是02/03年的时候、记忆里这个时候家里养了一头牛、是一头老黄牛。家里在需要耕田播种的时候、不管风吹日晒、都能看见爷爷在田里一边驾驭着黄牛、嘴边一直在说什么、应该是教导牛牛该怎么走以便使的犁田犁的更好。记不清了、只知道每次遇到下雨的时候、爷爷披着蓑衣带着一个草帽、颇有一些武林大侠的气息。
那个时候家里有一条很凶很凶的狗、幺爷爷家里还是一条白猫、年龄比我那个时候都大。这条很凶的狗已经不记得长啥样了、甚至什么时候去世的都没有印象。
关于这条狗不多的记忆就是、它很凶、但凡看见我们在地坝(四川话:门前小院的意思、通常用于晒一些农作物的地方、或者夜晚乘凉的地方)里面打闹。它都会狂吠不止、这是对它的一个记忆。
还有一个记忆就是,记得是在某一个夏天、在屋后发现了一只野兔、这个时候不记得是不是爸妈在家了、全家都在追这个野兔、追了好久、这条狗也在追、有一个画面就是在我小时候的眼里那个农田的岸边很高、这个直接就从岸边往下面的田里跳下去、连续跳了好几个这样的梯田、那个姿势在我眼里好帅好帅、现在都记得很清楚。最后这个野兔是被抓住了、炸了酥肉、那个味道真的很香、现在都记忆深刻。毕竟小时候家里都是吃猪油、用很小很小的一块、煎出油炒菜。
幺爷爷在的猫是条白猫,印象里是一条抓老鼠的好手、但是不知道它什么死的、只记得大概有十三岁左右。
奶奶有风湿心脏病、那个时候总会吃一些药和一些偏方、记忆里有这么一幕、爷爷把刚出生的小狗狗杀掉、给奶奶治病、嘴馋的我也要吃、结果吃了一口就闷住了。
奶奶在我的记忆里有个画面就是我不想去读书、在上学的路上跑到了一个斜坡上、就如同那个时候黑白电视机上播放的游击战争片一样、以为自己躲在这里他们指定找不到、当然了最后肯定少不了一顿打。印象里只被奶奶打了这一次。
奶奶是在06年走的、不到六十岁。记忆特别深,当时哥哥从东北回老家也快一年了、那是在一个夜晚、哥哥先去睡了、我和其他堂哥堂姐在家里看电视、电视里播放的是洪金宝主演的、是一部战争片、大概就是他们去越南救什么人、有一个人在飞机上跳伞的时候说要倒数十个数、然后打开伞、结果这个嘴吃的人没数到就摔死了。里面有个画面用草杀人、后面还依葫芦画瓢学过这个东西。
奶奶走的时候、爷爷是第一个发现的、我记得爷爷发现之后、我去把哥哥喊醒了、然后我就一直在哭。虽然当时不知道死亡意味着什么、就是在哭、那个时候我上三年级了。奶奶走的那天的天气很好、我还记得我捡了一个螺母回家、后来我把这个螺母扔掉了、当时就想如果不捡这个螺母就好了、奶奶就不会走了。
第一次见哥哥的时候是在一个夏天、爸妈把他从东北送了回来、打算让他家里面读书、当然读书的地方现在已经垮掉了。那个时候家里的公路还是泥巴路、泥巴路大概还是前一年挖机采挖的、挖坏了几个秧田。他们在回来的前一年、写了一封信寄回来、内容是什么记不住了、只记得有一封信、分别向爷爷奶奶以及我都写了点东西。初次见面的时候很陌生、眼前这个和我差不多高有点黑的就是我哥、我的关注并没有在他的身上、更多的是他们提的袋子里面、因为有一袋子糖。
当然了小时候的记忆还有几个画面、就埋藏在心里吧、为什么说上面的狗狗很凶、因为他在我堂姐的脸上留下了印子、现在都能看见。
奶奶走掉之后、我和我哥就去了东北、因为家里没人会做饭了。就去东北读书、东北的记忆说不上多好、校园霸凌确实存在、我也是被霸凌的那一员、我不像我哥哥那样、他们总是有勇气、那个时候的我没有。
在东北这三年、父母总是在吵架打架、住在平房里面、附近都是和父母一样的体力劳动者、他们一闹附近的人都会知道。我们的右边住了一个也是一个外出务工者、他们的有个女儿、比我和我哥都大、长得很白。在我们的左边也是一户外地务工者、不过是东三省的、不是四川的、这家的女主人好像很贤惠很好看、长得也很白。
在这期间、四川发生了很大的一件事、汶川地震、当时我记得我和附近的小孩偷偷跑去上网、结果附近的网吧都没网、然后回家就看到电视上到处都在播放新闻、去上学的时候、学校组织了捐款、我捐了五块钱。
小学结束之后、过完了六年级的暑假我就被送回到了老家、走的时候是和爸爸在工地上的工友一路的、正好他要回家。他和我们是一个地方的,记得大概是午饭后、叫了一辆出租车、我就和这个工友上了车、爸爸的这个工友坐在了副驾、我坐在了后排、送行的人有几个、车窗升起、行驶了一段路后、眼泪就落下了、大概知道了以后又不会在爸妈身边了、也不知道为什么没有哭出声、就和电视里面一样。这就是小学的记忆。
大概走了三四天、回到家了、就开始上初中了。
报名的时候见到了很多小学同学、他们很容易就认出我来了、然而我并没有很快的认出他们、他们说我五官没什么变化、很好认。
初中是在一所民办初中读的、我们这边的公立学校很水、很乱、上课打牌抽烟都存在、老师也不会管。而且离我们也很远。民办学校离我家很近、这里的校长和附近的家长都很熟悉、自然而然的就去读了、自然而然的也会听到这样的交代、娃儿不听话不好好读书就整哦。初中的算是目前为止的小高光、因为那个时候自己还算聪明、成绩也还算可以、被当着升学的苗子重点关注。当然最后也还算争气、以A+1的成绩考进县一中、我们这一届也还算争气、有一个去了同济大学、算是历史最好的一届了,当然这个学校现在也垮了。
高中的时候流传出了一个梗、你的数学不会是体育老师教的吧、那个时候会自嘲、我初中的时候、不止是数学是体育老师教的、历史和物理也是体育老师教的、这个老师还没上过高中。
高中是lol很火的时候、那个时候脱离了棍棒教育的我、理所当然的沉迷了进去、高一上学期还好、棍棒教育的习惯还在、期末考试全年级2000多人我考了200名左右、班上第五名好像。
学习态度的变化不止是因为lol、还记得当时班上有个人说我很努力、所以成绩这样、当时不知道是脑子抽了还是咋了就认为别人在说我笨、然后就慢慢放弃了之前的学习方式、再加上联盟的影响、自然而然的成绩一落千丈、后来也就去复读了。
复读这一年没什么特别的记忆、涨了几十分、去了一所双非学校。还是没有做到高一班主任说的那样、你好好读上个一本不成问题。当时学校的升学率是前60名可以上川大的程度、200名左右上一个一本好像确实不是什么问题。但也确实没做到。
上了大学就和大部分人一样、加部门、当班干部、实际上就是混吃等死。不同的是大二那年、由于初中埋下的病因、做了双侧股骨头置换手术、这一下就把家里面掏空了、手术是在北京做的、花了20+、是在18年、三月一号做的左腿三月14号下午14:17做的右腿、刚检测出来的时候很崩溃、出了诊室就哭了、因为知道这么大笔钱家里出不起、当时借住在北京的姐姐家,在十五楼窗口处、恐惧战胜了勇气、没有跳下去。
查出来的时候就告知了父母、父母当时在深圳上班、我一个人去的北京找的姐姐、父亲先赶过来、看见父亲憔悴的面庞、自己也彻底取消了跳下去的想法、太憔悴了、没见过这个样子的父亲、也无法去想象如果跳了父亲会咋样、只知道那个时候父亲的头发白了很多、然后开始秃头了。
做手术的那几天恰逢过年期间、医院的人很多、见识了人生百态、有的人痛苦呻吟着想活下去,有的人沉默不语想离开人世,坐在轮椅上的时候、被推出去透透风、看见了一个和我一般大的人、少了一条腿,那个时候心里想着都是苦命人。不同于大一暑假工被晒的黢黑的我,在学校看到一个老外、老外的黑衬托出我的白,那个时候由于被晒的黢黑心情很糟糕,见到这个交换生之后得到了极大的安慰。
因为这个手术需要人照顾、学校是上下铺、因此休学一年、手术很顺利、在我们眼里是一个天大的事情、在医生眼里如果一个小手术一般、就和普通的感冒差不多。术后也会恢复的很好、有一段时间是长短腿、走路一瘸一拐的、过了两个多月吧就彻底正常了。到目前为止至少没什么问题。唱跳rap不打篮球。
后面的大学时光就很平平无奇、本以为就和之前的师兄师姐一样正常大学然后毕业、后面就遇到了口罩事件、在学校都没有好好学习、在家里怎么可能会好好学习、真的是在混吃等死、大学期间没有什么特别的记忆、唯一的印象就是大一老校区是一群室友、大二搬到新校区、又换了一批室友、寝室从原来和其他专业的混寝、变成了同专业的混寝、但是由于休学一年、复学的时候又被安排到新的寝室、又换了一批室友、读了一年这一批室友毕业了、我大四的时候又换了一批室友。也就是一年一批室友。也算是独一份了。不过后面的都没怎么联系了。
这就是整个读书生涯了。还有很多画面就埋藏在心底吧。
工作
毕业之后、第一年认识了一个老师、养鱼达人、第一次约她出来玩、就问我用什么去接他、给了刚毕业的我一个暴击。于是呼在工作上加把力,从刚毕业的几千块不到一年的时间就破万了。也就是在22年左右吧。这个时候总觉得自己谈恋爱应该有点底气了。可在24年又给了我一个暴击。也就是今年。
在整个22年里面、由于工作还行、有大量的自由时间、在b上学习了尚硅谷的mysql和jvm课程、在慕课网上学习Java高并发课程、还算充实、虽然工作上用到的不多。
在22年、养了一只猫取名壹贰、是只三花、很粘人,也很喜欢、但我把它放在老家了。我的头像就是它很可爱吧。
在23年里、由于之前的学习累积、总觉得要记录一下、避免用的时候又到处找、就开始了写博客这个过程、博客更新的速度很稳定、生活节奏也很稳定、每天下班之后、买菜回家做晚饭和第二天中午的午餐、厨艺和刀工得到了大涨,每天晚上还能学习两小时、从周末开始选题、工作日开始编码、验证写博客、一切都有条不紊的进行着,生活节奏很稳定、窗外的阳光也很温暖。
23年发生了一件事、就是爷爷走了、遗憾的是没有带个孙媳妇回去让他看一眼、爷爷是五月份走的、守灵的那个晚上、睡在爷爷旁边、没有丝毫的害怕、下葬的那一天、没有哭但全是遗憾。至此带我长大的两个人都离开了人世。
在23年11月份的时候、认识了一个菇凉、她的名字很好听、长得也很好看、她的生活多姿多彩、现在都觉得她活得很多姿多彩。就和大家想的那样、慢慢的喜欢上了这个人、好巧不巧的是她对我也有点点意思吧、然后就约着出来玩、一起看电影、一起跨年等等、初期总是美好的、回忆也是。她不会做饭、总是吃外卖、我会让她点菜然后我做好了带给她吃、无论什么时候会送她回家然后自己再回家、每次见面都会给她准备一点零食或者小惊喜、理所当然的我们在一起了、直到过完年之后的某一个周末、我朋友约我们出去玩、在晚上回来的时候、我朋友买了房子(和女朋友一起买的)、刚好又说到这个问题、我就说了一句以后我们也一起买、用公积金带款、然后就因为这个问题讨论了一周、直到最后的分手。
具体的细节问题就不说了。我工作三年攒了一些钱、家里修房子我出了一点钱。一时间我家肯定是拿不出来的、我想让他给我点时间、结果不愿意、她之前有过很长一段时间的恋情被分手、大概是害怕再浪费时间、也能理解。
刚分手那段时间、感觉像是丢了半条命。心态很崩溃、觉得自己很差劲、一眼望到了头、好像也成不了家。掘金的更新速度就能看出来影响,虽然在一起的时间不长、三月份分的手、到现在为止有些时候都会因为这件事emo。
分手之前很喜欢做饭、分手之后再也没做过饭、看着那些为了给她做菜买的调味品以及打包盒、总是别有一番滋味、有时候总觉得自己要是当时做的再好一点就好了。在这期间看了一些心理学相关的书、也学会了一些调整自己的方法。
分手这段时间里、激情消费买了辆车、自驾去了一趟若尔盖大草原、草原很好看、自此身上的积蓄被自己花得差不多了。不止如此、由于工作上没有任何发展、总是干一些和Java无关的事情、甚至打算让我做嵌入式开发和大模型这一类工作,职业发展也看到了头。
整理生活这段时间丢了很多东西、总感觉自己也把自己丢了、好在慢慢的把自己拼好重新捡起来了。
下一个月也就马上27岁了、看着身边同龄的人要么成家、要么即将成家、要么事业有成、自己还是孤家寡人,多多少少也很羡慕。
站在生活这条十字路口、迷茫、彷徨、不安、焦虑每隔一段时间都会出现在自己身边、好在自己的调整能力得到了极大的提升、看书总归是有用的。
古人云:三十而立、至少现在看来、在这有限的时间里很难立起来了、但总要去试试、说不定就成了呢。
未来会是什么样子的呢?不知道,能把自己的生活过好就已经很不错了。感知幸福是一种能力、感知焦虑也是。
对生活的感悟如同总有千言万语、却有一种如鲠在喉的感觉。不知道命运会给我带来什么样的生活?不管怎么样都坦然接受吧。期待吗?期待吧。
写到这里、感受万千、内心细腻的人总是容易伤春悲秋。
回顾过往、就如同这篇文字一样、普普通通平平无奇、都无法用鸡肋来形容。但相信生活不会辜负每一个好好生活的人、始终对未来抱有期待与憧憬。不管最终如何、终将相信我们都会过上自己想要的生活。
最后给自己定一个目标吧:
- 坚持写博客、写到35岁,我相信自己会一直从事计算机行业的!
- 健健康康的活到退休。
窗外的天空很蓝、阳光很温暖、最近的心情也很好、希望您也是。
谢谢您能看到这里,祝君心想事成、万事顺遂。
来源:juejin.cn/post/7396609176744886310
fabric.js 实现服装/商品定制预览效果
大家好,我是秦少卫,vue-fabric-editor 开源图片编辑项目的作者,很多开发者有问过我如何使用 fabric.js 实现商品定制的预览效果,今天跟大家分享一下实现思路。
预览图:



简单介绍大部分开发这类产品的开发者,都会提到一个关键词叫做 POD ,按需定制,会通过设计工具简单的对产品进行颜色、图片的修改后,直接下单,获得自己独一无二的商品。
POD是什么?
按需定制(Print On Demand,简称POD),是一种订单履约方式,卖家提前设计好商品模板上架到销售平台,出单后,同步订到给供应商进行生产发货。
使用 fabric.js 实现商品定制预览,有 4 种实现方式
方式一:镂空 PNG 素材
这种方式最简单方便,只需要准备镂空的png素材,将图层放置在顶部不可操作即可,定制的图案在图层底部,进行拖拽修改即可,优点是简单方便,缺点是只能针对一个部位操作。

方式二:png阴影 + 色块 + 图案叠加
如果要进一步实现多个部位的定制设计,不同部位使用不同的定制图,第一种方案就无法满足了,那么可以采用透明阴影 + 色块叠加图案的方式来实现多个位置的定制。
例如这样的商品,上下需要 2 张不同的定制图案。

我们需要准备透明的阴影素材在最上方,下方添加色块区域并叠加图案:



最底部放上原始的图片即可。

方式三:SVG + 图案/颜色填充
fabric.js 支持导入 svg图片,如果是SVG形式的设计文件,只需要导入到编辑器中,对不同区域修改颜色或者叠加图案就可以。

方式四:平面图 + 3D 贴图
最后一种是平面图设计后,将平面图贴图到 3D 模型,为了效果更逼真,需要增加光源、法线等贴图,从实现上并不会太复杂,只是运营成本比较高,每一个 SKU 都需要做一个 3D模型。

参考 Demo:

结束
以上就是fabric.js 实现服装/商品定制预览效果的 4 种思路,如果你正在开发类似产品,也可以使用开源项目快速构建你的在线商品定制工具。

来源:juejin.cn/post/7403245452215386150
前端转产品一年总结!
截止至本月,我从前端研发转岗为产品经理已经一年左右了,这篇文章就讲讲我这一年中的一些经验和总结。希望能为同样身为前端也有想法转产品的你提供一点帮助。
为什么转产品
工作原因
我是22年毕业的,在刚刚毕业的那段时间,我还是对前端开发很有热情的,经常把工作中的一些内容给总结成文章在掘金发布,而且开发时我会比其他人更加注重整体的代码质量和实现的完整度,毕竟也要写文章嘛,输出倒逼输入。但是随着工作年限的增加(其实也没多少),我渐渐的感觉公司的业务没有什么挑战性了,而且最开始同事们还比较注重代码质量,但随着业务越来越复杂,排期越来越紧张,代码质量慢慢的就开始妥协了。
而且有一些功能实现方式比我想象的复杂很多,但是他们依然执着的要引用一些我不认可的框架或者库,代码这件事大家应该清楚,写的爽是很重要的,如果一个项目的实现都是我不喜欢的实现方式,为了一些虚无缥缈的性能优化把代码写的很复杂。
不知道大家有没有用过 SWR 这个请求库,我曾经写过一篇文章介绍这个工具 《都什么时代还在发传统请求?来看看 SWR 如何用 React Hook 实现优雅请求》,这是我很喜欢的一个请求库。它可以帮助我们在组件中获取请求数据时,不用在父组件获取后一个个通过 props 传递,而是直接在子组件中获取请求数据,并且不用重复请求。
但我有个同事认为直接使用 SWR 性能不好,因为每个组件都调用 hook 去请求,虽然 SWR key 是一样的,那肯定有个判重机制,这个判重机制对性能有影响。我当时就很无语,我说判重机制不就是用避免重复请求这件事情的嘛。更无语的是,他的解决方法时在父组件中使用 react context 创建上下文,通过 SWR 获取数据,将 SWR 中的数据传入 Context,然后在子组件中消费 Context。我当时就觉得这种写法就是恶心,脱裤子放屁行为,这么写何必用 SWR,直接用 Axios 请求后传子组件得了,为什么不直接在子组件里面调用 SWR 拿数据?
后面我与他掰扯,说我们按照 SWR 官方文档的方式来用就好了,无需多此一举,他的观点是 “SWR 又不是 React 官方的。他们的用法也不见得合适”,其他前端同事也没有很大异议,后续就是那段代码依然合并进去了,而且后续他都是这么写的。除此还有很多在 js 代码中使用单字母简写的变量,问就是跟xxx语言学的,我个人是觉得前端项目的变量名还是写全称,尽可能完整,让代码可读性更强,但我也懒得去争了,一旦大家的代码规范不同,那对我来说写代码就是很难受的一件事情了。关于这件事情我希望能在评论区看到大家的看法。
职业规划
其次是职业规划,这个倒不是说我最初就决定了想走产品这条路,而是我不太想一直走前端的路子了。我最初之所以选择前端开发的岗位,是由于我的大学专业是计算机相关,并且在我毕业前有过一段创业的经历,在那段经历中我担任的就是产品经理+前端开发的角色,因此找工作时也自然而然的投递前端相关的岗位。
但慢慢的,我在工作中感受不到前端技术很大的热情,脑袋里的灵感越来越少,工作上的代码写起来越来越乏味,而且社区里还是各种面试拷打,八股文,算法题最吃香。我是真的很讨厌八股文,我知道基础对于前端来说很重要,但还是讨厌,想到一旦要跳槽就要重拾八股文,我就觉得真的很无聊,所以我心理也埋下了要转产品的种子。
兴趣驱动
前面有讲到我在大学期间有创业过一阵子,当时我们一边做外包项目,一边做自己的一些校园产品,不论是网页还是移动端的产品,各个主流组件库都门清儿,而且也画过原型图,对一个产品从零到一的流程比较清晰,自己也对设计一个优秀的产品有执念,虽然至今还不算完成,但毕竟如果一件事情能让你有成就感,那么它就会推着你向前走。
怎么转的产品
在去年八月份,我们公司的产品要做一个大版本的迭代,很多功能都需要重新设计实现。在一个新产品诞生的初期,研发是依赖非常产品经理的产品文档,而产品经理则需要进行产品调研,概念设计等等流程才能写出一份产品方案,这就导致了产品有很大的产品方案设计的工作量,而研发只能先做一些基础框架搭建,写写技术方案,一旦这些简单工作做完就必须停下来等产品出文档,十几个研发两三天没活儿干,对于一个企业来说肯定是无法接受的。因此我们的领导就开始招聘产品经理,与此同时也在内部会议时主动问到有没有愿意尝试一下产品的工作。我本身就与公司里的产品比较熟悉,又有这么一个机会,于是我就毛遂自荐,并且当时在会上主动提出参与的也就我一个,于是就顺理成章的开始了研发向产品的转变。
遇到的问题
相信点进这篇文章的同学,有很多都是有过转岗为产品的想法的,那么我就说说从我自身出发,在从研发转为产品之后遇到了哪些问题是我没有意料到的。
专业知识
当研发时,每一次产品需求评审会上,我会去看这次新增了什么概念,思考这个需求如何实现,产品画的原型图交互流程有没有可以优化的地方,似乎自己对需求的理解能力还是很强的,也能够理解业务。
例如一个微信朋友圈的功能,产品经理提出放在发现页面,然后单击右上角加号可以选择照片发布,长按加号可以直接发布文字,那么我就会想长按这个操作是不是不够直观呢,会不会有用户很长时间了都没有发现这里是可以长按直接发布文字的?于是我就提出问题与产品探讨,长此以往,我会觉得我们的产品有时候考虑问题也不是特别全面嘛,给了我一种我上也行的错觉。
到了实际转变为产品经理后,你就会发现你要做的不只是思考朋友圈的发布是从个入口进去,而是老板给了你一个需求,是用户如何在微信中分享自己的动态。那这时候你就要想:
- “我是不是加一个类似 QQ 空间的功能?这个功能就叫动态?还是空间?还是叫微博?还是叫圈子?”
- “这个功能要放在我的页面还是聊天页面,还是说新增一个底部栏?”
- “这个功能和微博或 QQ 空间有什么本质上的不同?”
或者评审时有同事或领导问你“为什么要叫朋友圈?我觉得叫朋友圈我完全 get 不到是什么意思?”,你应该如何应对?
我在刚刚转产品的初期几乎每次评审都是心惊胆颤,因为我很难接住同事问的问题,而且我也不是一个性格刚猛的人,可以接受讨论但不太喜欢很激烈的争论。这个问题出在两个方面:
一是刚刚转产品,我对于过往的一些概念只是了解但没有深入了解。例如领导问道:“xxx功能为什么要这么设计?”,这个功能并不是一个新功能,而是一个存在已久的功能,但是设计上有些许不合理,但是你并不清楚这个功能具体的上下文,那么人家一问,我也只能支支吾吾。这样的经历在有过几次后就会给人一种你不够专业的感觉,你连系统里的功能设计都不清楚,你还配当产品经理?
二是对自己的职责定位及权限边界还不够清晰,以上面朋友圈的例子来说,我觉得我拍板不了朋友圈具体的名称,我得去找更有经验的同事一起讨论,虽然同事会给你提供意见参考,最终的决定还是得你来做。在方案评审时,发现领导对朋友圈这个概念设计有很多疑问,例如问你:“为什么不参考竞品?”,“这个入口放在发现页也太隐蔽了吧,我作为用户完全不会点进去?”
诸如此类的问题,刚开始我是完全接不住的,总是想着领导说的也有道理,那我就按照他的想法改吧。这样一来,领导提出的意见一旦比较尖锐,你就只能顺从,说明你没有自己的想法,没有自己的主见,即使有想法也不能坚持。尤其是你还没有足够的经验,更容易被人质疑。此时如果没有一颗大心脏,没有一个非常全面的调研和思考,就容易变得很不自信,从而丧失对产品这个岗位的工作热情。
刚刚转产品的那个月我非常煎熬,每次做方案和评审前都特别紧张,有时候睡觉前都在想要是每天同事问了这个问题要怎么回答?
与研发的对接的边界
在我还是前端的时候,我单纯的认为很多边界情况就是需要前端去考虑的,例如页面的加载状态是骨架屏还是加载动画,表单字段在输入时是失焦时触发表单验证还是点击提交按钮时触发表单验证,返回上一个页面是否需要保留页面状态,文本溢出时的省略效果如何。
但当我自己转为产品后,似乎这些情况还是得我来考虑,每天需要面对各种研发提出的各种组件边界情况如何处理,很多边界情况如果你的文档中没有写,那么研发可能就不考虑了,不做任何处理,直到问题被领导或用户发现了,这时候只要你文档中没有提,那多半就要背锅了。一个你自认为通用的空数据页,你这个页面画了图,那个页面没有画空页面的图,那么研发就可以理所当然的在这个页面没有数据时啥都不展示。
这个现象主要出现在产品初期。随着产品迭代到一定程度,产品团队和研发团队通常会达成共识。此时前端的组件已经覆盖了大多数边界场景,产品团队也了解研发团队可能在哪些地方容易疏忽,因此需要特别强调这些方面。
时间分配
前面讲到研发会时不时找你对各种事情,这就导致了你平时可能很少有大段的时间专注于做一件事,每天上午研发问几个小问题,下午问几个小问题,一天就这么过去了。相比于写代码,有时思路清晰的话就可以一整天都在写,遇到问题了再停下来查一查想一想,相对来说还是会有大片的时间去做事。
对于我个人来说,有时候一个需求给到我,我可能一时半会儿没有一个好的思路,这时候你即便怎么想,怎么查都很难有突破,但有时你睡个午觉,或者放空一下,就突然有解决方向了。这导致了我做为产品经理时比较少进入心流状态,我需要思考,需要头脑风暴,但有时候想不出来也不能僵在那儿,而一件事情悬而未决又让我很难受,就容易有焦虑的情绪。
职业规划的变化
虽然很多人说技术人员越老越不吃香,产品就不一样了,可以积累经验,未来的道路也更加广阔,有机会走的更远。话虽如此,但实际上对于前端开发来说,基本上工作的两三年就基本上对整体的前端技术栈有个深入使用的经验,无非就是 React 和 Vue 以及相关的生态,,再深入点就是一些特殊协议或者可视化方面的更深入的技术,在跳槽时,只要技术栈匹配基本都可以尝试。但是产品经理的话,通常都会要求有同个赛道的经验,例如做社交产品的公司,当然希望找有社交产品经验的产品经理,而产品的赛道可就多了
前端转产品的优势
前面提了这么多研发转产品可能遇到的问题,也不能光抽巴掌不喂糖,所以下面再讲下前端转产品的优势,这些点大家可能会更有共鸣一些。
技术背景
关于这一点,有很多网上的文章唱反调说你有研发背景,肯定满脑子技术思维,做产品的时候创新能力肯定不行,你被你技术背景束缚啦。
这一点从我个人出发,我只能说产品懂技术绝对是一个优势,无论是从功能设计,到与研发沟通,天然的少了一层隔阂,尤其我们公司的产品是基础软件,用户群体本身就是相对懂技术的人。刚刚转为产品经理时,产品相关专业能力虽然不足,考虑事情不周全,但是懂技术起码给你兜了底,你不会有过于天马行空的想法,研发在你面前不能也信口开河,大致的实现成本,排期时间你能够做到心里有数。
前端思维
前端思维和技术背景还是有些不同的,前端和后端对产品的理解方向有些不同,前端偏向交互,后端更偏向业务。因此这里我将技术背景和前端思维分开讲。
不同公司使用的原型工具可能不同,我们公司是直接由产品来出高保真原型,因此我们使用的工具是 Figma,
在我转岗产品一个月左右 《👨💻 Figma 协作设计工具:前端开发者视角快速上手指南》 我就写了一篇关于 Figma 的使用文章,我认为我的 Figma 上手速度是非常快的,这可能由两方面的因素。
- 一是我大学的时候就有自学平面设计,对于 PPT,PS 这类创意类工具的使用方式比较了解。
- 二就是前端思维了,因为做原型其实和用代码写页面的思路是一致的,你看到了一个页面,首先你会想这个页面会由哪些组件组成,这些组件是否已经实现过了?如果没有实现过是否可以抽离到组件库进行复用?
Figma 这个工具是我转产品后,公司才开始使用的,因此大家都不熟悉,那么交互设计的大头就落在我身上,我就拉着我们的 UI 同学一起搭建了一个组件库,这个组件库中包含了常用的所有表单组件,表格组件,还有一些页面组件,其中我根据过往的经验为组件配置了很多参数和插槽,保证插件的拓展性。
如果我没有前端相关的经验,我敢肯定从头要去了解这套组件体系,并熟练的去构建出一套兼容性好的组件库。是要花很多时间的。
后续我们还用上了 Figma 的分支管理功能,这一点和 Git 的分支管理也有些许类似,逻辑上的快速迁移学习为我上手相关工具增速了很多。
对未来的思考
虽然在当前公司已经当了一年的产品经理了,大部分的事情都可以轻松 cover,也算是处于舒适圈了,但是心里还是会焦虑,毕竟目前只是身处一个小公司,而且在产品方面的专业能力又难以评估,网上想要学习关于产品经理的相关专业知识几乎都是卖课的,而且我愈发觉得产品相关的知识不是看任何书籍或课程可以快速提升的,产品经理相关的能力以及可能碰到的问题都是要在解决实际需求的过程中去提升,而且专业的能力与产品的赛道息息相关,你在一个赛道的积累可能换个赛道就派不上用场了,因此还是得持续学习,让自己不论做什么行业都能保持竞争力。
代码的话现在偶尔写写自己感兴趣的小项目,只是没那么多了,公司内偶尔也需要我去支援研发。如果大家有有意思的小项目,小比赛欢迎拉我一起去折腾(不做外包)。
来源:juejin.cn/post/7395559155686604809
哭了,朋友当韭菜被割惨了
最近我的朋友,被某些知识付费坑得很惨。全程毫无干货可言。内容仅仅只适用于初级、或者说部分中级的程序员。为此,我的朋友交了大几千的学费,却收获甚微。
当然,你可能说,是你的朋友问题啊?你朋友烂泥扶不上墙,学习方法不对,别人都有很多成功的案例。什么offer收到手酸,外包入大厂。
我买这些课就是为了学习,入门一些语言。知识付费很合理呀!!
于是我跟我朋友在微信彻夜长谈,有了如下分析
先说结论
请擦亮你的慧眼,你的一分一毫来之不易。不到迫不得已,才当学费
为什么这么说?
首先,不管你是想就业,还是想学习一些新的技术,网上都有例子,github上也会有前沿的项目提供学习。
| 类型 | 结论 |
|---|---|
| 学习新技术 | 某项技术开源出来,作为技术的布道者,恨不得你免费过去学习,然后你再发一篇文章,越来越多人学习你的技术。 |
| 就业 | 简历包装无非就是抄抄抄,抄别人的优秀代码。github开源项目就非常合适 |
其次,你学费,一定要做到利益最大化。必须要有以下两点
- 能学到大部分人都学不到的技术亮点。记住,是大部分人,一定要做到差异化
- 能学到优秀的学习方法,push你前进。
开启慧眼
现在市面的学习机构,鱼龙混杂。,B站大学,某识xin球,某ke时jian 甚至,在某音上,都有那种连麦做模拟面试,然后引导你付费学习。
就业环境不好,买方市场竞争激烈,某些人就抓住你的焦虑心理,坑你一把。回想你的求学生涯,是否也有类似被坑经历?醒醒吧,少年。能救你的,只有你自己。
当然,小海也会有潜龙。不可否认,知识付费为我们提供了便利性。
- 原本散乱无章的知识点,人家给你整理好了,你尽管就是学习,实践
- 面对焦虑,你觉得很迷茫,需要一个人指点你前进
- 能认识更多同样诉求的人,为以后学习,就业,甚至做生意提供可能
但是,某些不法分子,就是抓住你的这个心理,疯狂ge你韭菜。什么10块钱知识手册,19.9面试题,100块钱的项目视频。天天一大早,就转发一些公众号到你群上,dddd。
这些内容,不是说没有用。我们讨论适合人群,这类东西不适合中高级程序员。
说那么多,你得学会判断这个人是不是大佬
你都可以简历包装,为什么‘大佬’就不会是被包装的
那就稍微整理一下,哪些是真大佬,伪大佬
真伪大佬
| 某佬 | 博客 | 开源项目 | 学习人群 | 是否顺眼 |
|---|---|---|---|---|
| 伪大佬 | 面试题居多,很多基础内容,没有干货 | 无,或者很少。动不动就是商城,博客 | 应届生占比较多 | 可能顺眼 |
| 真大佬 | 博客、论坛内容干货。整理分类完善,你能学到东西 | 有,某些大项目的贡献,同时也有优秀开源项目 | 应届生,中高级都有 | 大多数不顺眼,因为实在优秀 |
就学习人群做一个说明
- 在就业容易程度上,相对于初中高级别的程序员,应届生无论从考察的内容,招聘的人数。都会容易丢丢。
- 他说跟着他学,offer赢麻了。但是其中,找到工作的大多数都是应届生
就这些点,我们其实可以能判断个大概了。
记住,你想知识付费。一定要摸清他的底细,不能认为他说得都是对的。人家也是会包装的
你的hello world
或许每个程序员的第一行代码,都是
print("hello world")
我想说的是,请你记住你的初心。
- 转行过来当程序员,就是为了狠狠赚他一笔
- 喜欢写代码,苦中作乐
情况每个人都不太一样,这里不细说。明白你是谁,你还是否有动力能坚持下去。明白这一点,远比你在迷茫的时候病急乱投医更为重要,请勿过度焦虑
为此,后面会说一下如何学习,以及找工作如何不被骗
力量大会
事关钱包的问题,我们都得谨慎谨慎。就业市场那恶劣,朋友找不到工作还被坑了一把。骗子实在可恶。请你先自身强大,先自己找出问题,不花冤枉钱,避免传销式编程
如有雷同,纯属巧合,没有针对任何人,也没有动某些人的饭碗。
来源:juejin.cn/post/7357231056288055336
揭秘小米手机被疯狂吐槽的存储扩容技术

前段时间,在小米14的发布会上,雷布斯公布了名为“Xiaomi Ultra Space存储扩容”的技术,号称可以在512G的手机中再搞出来16G,256G的手机中再搞出8G。对于普通用户来说,能多得一些存储空间,无异是个很好的福利,不过也有网友说这是以损害存储使用寿命为代价的,那么真相到底如何呢?这篇文章我就从技术角度来给大家详细分析下。
认识闪存
首先让我们来了解一些手机存储的基本知识。
手机存储使用的是闪存技术,其本质和U盘、固态硬盘都是一样的。
在闪存中读写的基本单位是页(Page),比页更大的概念是块(Block),一个块会包含很多页。
虽然读写的基本单位都是页,但是写实际操作的很可能是块,这是为什么呢?
这要从删除谈起,在闪存中删除数据时不会立即删除页上的数据,而只是给页打上一个空闲的标签。这是因为谁也不知道这个页什么时候会再写入数据,这样处理起来比较简单快速。
再看写操作,如果写入分配的页是因为删除而空闲的,数据并不能立即写入,根据闪存的特性,此时需要先把页上之前存储的数据擦除,然后才能写入;但是闪存中擦除操作的基本单位是块,此时就需要先把整个块中的有效数据读出来,然后再擦除块,最后再向块中写入修改后的整块数据;这整个操作称为“读-改-写”。当然如果写入分配的页是空白的,并不需要先进行擦除,此时直接写入就可以了。
预留空间
小米这次抠出来的存储空间来源于一个称为“预留空间”的区域,它的英文全称是Over Provisio,简称 OP。
那么“预留空间”是什么呢?我将通过5个方面来介绍它的用途,让大家近距离认识下。
提高写入速度
在上面介绍闪存的基本知识时,我们谈到闪存的写操作存在一种“读-改-写”的情况,因为额外的读和擦除操作,这种方法的耗时相比单纯的写入会增加不少,闪存使用的时间越长,空白的空间越少,这种操作越容易出现,闪存的读写性能下降的越快。
为了提升写入的性能,我们可以先将新数据写入到预留空间,此时上层系统就可以认为已经写入完成,然后我们在后台将预留空间中的新数据和原数据块中需要保留的数据合并到一个新的数据块中,这样就避免了频繁的读-修改-写操作,从而可以大大提高写入速度。
垃圾回收和整理
在上面介绍闪存的基本知识时,我们还谈到删除数据并不是立即清除空间,而是给数据页打一个标签,这样做的效率比较高。这样做就像我们标记了垃圾,但是并没有把它们运走,时间久了,这些垃圾会占用很多的空间。这些垃圾空间就像一个个的小碎片,所以有时也把这个问题称为碎片化问题。
虽然我们可以通过“读-改-写”操作来重新利用这些碎片空间,包括通过异步的“读-改-写”操作来提升上层应用的写入效率,但无疑还是存在写入的难度,实际写入之前还是要先进行擦除。
为了解决上述问题,聪明的设计师们又想到了新办方法:让存储器在后台自动检测、自动整理存储中的数据碎片,而不是等到写入数据时再进行整理。
考虑到闪存的读擦写特性,当需要移除数据块中部分碎片或者将不同数据碎片合并时,就得把需要保留的数据先放到一个临时空间中,以免数据出现丢失,待存储中的数据块准备好之后再重新写入,预留空间就可以用作这个临时空间。
磨损均衡
闪存中每个块的写入次数都是有限制的,超过这个限制,块就可能会变得不可靠,不能再被使用。这就是我们通常所说的闪存的磨损。
为了尽可能延长闪存的使用寿命,我们需要尽量均匀地使用所有的闪存块,确保每个块的使用频率大致相同。这就是磨损均衡的主要目标。
假设我们发现块A的使用频率过高,我们需要将它的数据移动到没怎么用过的块B去,以达到磨损均衡的目的。首先,我们需要读取块A中的数据,然后将这些数据暂时存储到预留空间。然后,我们擦除块A,将它标记为空闲。最后,我们从预留空间中取出数据,写入到块B。实际上,磨损均衡的策略比这更复杂,不仅仅是看使用频率,还需要考虑其他因素,比如块的寿命,数据的重要性等。
可以看到,预留空间在这个过程中起到了临时存储数据的作用。
不过你可能会问,为什么不直接将块A的数据复制到块B,而需要一个临时空间?
这是因为在实际操作中直接复制块A的数据到块B会带来一些问题和限制。
假如直接进行这种数据复制,那么在数据从块A复制到块B的过程中,块A和块B中都会存在一份相同的数据,如果有其他进程在这个过程中访问了这份数据,可能会产生数据一致性的问题。此外,如果移动过程中发生意外中断,如电源故障,可能会导致数据在块B中只复制了一部分,而块A中的数据还未被擦除,这样就可能导致数据丢失或者数据不一致的问题。
而如果我们使用预留空间,也就是引入一个第三方,就可以缓解这些问题。我们先将数据从块A复制到预留空间,然后擦除块A,最后再将预留空间中的数据写入到块B。在这个过程中,我们可以借助预留空间来实现一些原子性的机制,来保证数据不会丢失和数据的一致性。
错误校正
预留空间还可以用来存储错误校正码(ECC)。如果在读取数据时发现有错误,可以用错误校正码来修复这些错误,提高数据的可靠性。
很多同学可能也不了解这个错误校正码的来龙去脉,这里多说几句。
我们知道计算机中的数据最终都是二进制的0和1,0和1使用硬件比较好表达,比如我们使用高电压表示1,低电压表示0。但是硬件有时候会出错,本来写进去的是1,读出来的却是0。为了解决这个问题,设计师们就搞出来个错误校正码,这个校正码是使用某些算法基于要存储的数据算出来的,存储数据的时候把它一起保存起来。读取数据的时候再使用相同的算法进行计算,如果两个校正码对不上,就说明存储的数据出现错误了。然后ECC算法可以通过计算知道是哪一位出现了错误,改正它就可以恢复正确的数据了。
注意ECC能够修正的二进制位数有限,因为可以修复的位数越多,额外需要的存储空间也越大,具体能修复几位要考虑出现坏块的概率以及数据的重要性。
坏块管理
当闪存单元变为坏块时,预留空间可以提供新的闪存单元来替代坏块,此时读取对应数据时不再访问坏块,而是通过映射表转到预留空间中读取,从而保证数据的存储和读取不受影响,提高了固态硬盘的可靠性和耐用性。
综上所述,预留空间在提升固态硬盘性能,延长其使用寿命,提高数据的可靠性等方面发挥着重要的作用。
小米的优化
根据公开资料,小米将预留空间的占比从6.9%压缩到了约3%。
那么小米是怎么做到的呢?以下是官方说法:
小米在主机端也基于文件管理深度介入了 UFS 的资源管理,通过软件实现“数据非必要不写入(UFS)”,通过软件 + 固件实现“写入数据非必要不迁移”,减少写入量的同时也实现了更好的 wear-leveling 和 WAF
还有一张图:

优化解读
这里用了一些术语,文字也比较抽象,我这里解读下:
UFS(Universal Flash Storage)即通用闪存存储,可以理解为就是手机中的存储模块。
“数据非必要不写入(UFS)”也就是先把数据写入到缓冲区,然后等收到足够的数据之后(比如1页),再写入闪存单元,这样就可以减少闪存单元的擦写次数,自然就能延长闪存单元的使用寿命,推迟坏块的产生。这个缓冲区类似于计算机的内存,如果突然掉电可能会丢失一部分数据,但是对于手机来说,突然掉电这个情况发生的几率极低,所以小米在这里多缓存点数据对数据丢失的影响很小,不过还是需要注意缓冲空间有限,这个值也不能太大,具体多少小米应该经过大量测试之后做了评估。
“写入数据非必要不迁移” 没有细说怎么做的,大概率说的是优化磨损均衡、垃圾回收和整理策略,没事别瞎整理,整理的时候尽量少擦写,目的还是延长闪存单元的使用寿命。
“增加坏块预留” 小米可以根据用户的使用情况调整坏块预留区的大小,比如用户是个重度手机使用狂,他用1年相当于别人用4年,小米系统就会增加坏块预留区,以应对擦写次数增加带来的坏块几率增加。注意这个调整是在云端实现的,如果手机不联网,这个功能还用不上。
wear-leveling:就是上面提到的磨损均衡,小米优化了均衡算法,减少擦写。
WAF:写放大,Write Amplification Factor,缩写WAF。写放大就是上面提到的“读-改-写”操作引起的,因为擦除必须擦掉整个块的数据,所以上层系统只需要写一个页的情况下,底层存储可能要重写一个块,从页到块放大了写操作的数据量。因为闪存的寿命取决于擦除次数,所以写放大会影响到闪存的使用寿命。
概括来说就是,小米从存储的预留空间中抠出来一部分作为用户存储,不过预留空间的减小,意味着坏块管理、错误纠正等可以使用的空间变小,这些空间变小会减少存储的使用寿命,所以小米又通过各种算法延缓了手机存储的磨损速度,如此则对大家的使用没有什么影响,而用户又能多得一些存储空间。
小米的测试结果
对于大家担心小米手机存储的寿命问题,小米手机系统软件部总监张国全表示:“按照目前重度用户的模型来评估,在每天写入40GB数据的条件下, 256GB的扩容芯片依然可以保证超过10年, 512GB可以超过20年,请大家放心。”
同时一般固态硬盘往往都拥有5年的质保,而很多消费者往往会5年之内更换手机。因此按着这个寿命数据来看,普通消费者并不用太担心“扩容芯片”的寿命问题。所以如果你的手机用不了10年,可以不用担心这个问题。
当然更多的测试细节,小米并没有透漏,比如读写文件的大小等。不过按照小米的说法,存储的供应商也做了测试,没有什么问题。这个暂时只能相信小米是个负责任的企业,做好了完备的测试。
最后小米搞了这个技术,申请了专利,但是又把标准和技术方案贡献给了UFS协会,同时还要求存储芯片厂商设置了半年的保护期,也就是说技术可以分享给大家,但是请大家体谅下原创的辛苦,所以半年后其它手机厂商才能用上。
大家猜一下半年后其它手机厂商会跟进吗?
来源:juejin.cn/post/7297423930225639465
差生文具多,这么些年,为了写代码我花了多少钱?
背景
转眼写代码有10多年了,林林总总花费了很多的钱,现在主要按照4大件来盘点下我都买了啥。
电脑

acer 4741g ¥4500+

这是我入门时的一款电脑,整体配置在当时还是属于中等的。

当时用的编辑器还是notepad++,在这个配置下,还是可以愉快的编码的。
mac air 2013 ¥8800+



当时被苹果的放进信封的广告创意所折服,这也是我的第一台apple,在之后就一直用苹果了。到手后的感觉是,薄,确实薄,大概只有我宏基的1/3-1/4厚。
当时apple的简洁,快速,很少的配置,让我在环境变量上苦苦挣扎的心酸得以释放。以后也不用比较各种笔记本参数了
mac book pro13 2015 ¥9000+


当时买这台的原因是因为air进水了,经常死机,修了2次后,又坏了。一怒之下,直接买了一台。
换了新的retina屏之后,色彩质量和效果都提升了不少,对比原来的air性能也是拉升了超级多。但是因为是16上半年买的,所以没体验到toch bar,到现在都没体验过。。。
这是我真正意义上的第一台十分满意的电脑,大概是当时的理想型了。
公司电脑
2016年下半年进了一家创业公司,公司配置了mac book pro,比我的配置还高,所以之后一直就是用公司的。
2021年换新公司,公司配了thinkpad,又一次开始用win。然后又被win各种打败,有时又有了换回mac的想法。
当前–mac book pro14 2021 ¥21999

主要入手的原因是公司的电脑我觉得太慢了。当时开发小程序,脚手架是公司自己的,每次打包都是全量的,没有缓存。所以每次打包短则7,8分钟,长则10多分钟。加上切分支/安装依赖(如果两个分支依赖版本不同,需要强制更新),导致我每天花费大量的时间等待上。
同事早于我入手了M1,反馈巨好,于是我也买了,想着配置拉的满点,但是还是高估了自己的钱包,低估了苹果的价格,只能退而求其次的选择了中档配置。

每次看着低低的负载,都是满满的安全感。

另外m1是支持stable diffusion的,所以偶尔我也会炼丹
显示器

dell U2424H ¥1384

其实在写代码之前也买过几台显示器,但是以程序员视角来说,第一台是这台。原因是当时公司也是这个型号,主要是能旋转,谁能拒绝一台自由旋转的显示器呢?

而且dell的质量和做工都不错,在当时是十分喜欢的。
小米 Redmi 27 ¥789.9

dell那台显示器是放在家里的,公司也需要显示器,而且自带设备每个月可以补贴100,所以就入手了这款,原因无他:便宜,也够大。
但是用久了,发现也有些问题。例如失真等,但是真的便宜,
厂家送寄,但因为合作内容没谈拢,本周寄回
键盘
当前-cherry G80-3000 ¥689

一把真正可以用到包浆的键盘,大多数看到这个键盘的感觉应该都是黄色,而不是原本的白色,不知道是不是材质的问题,极其容易变黄。同时由于键帽又不变黄,所以呈现了诡异的脏脏的颜色。
因为本身机械键盘的高度,所以建议加个手托比较好。各种轴也齐全,任君选择。
目前这个键盘在家里游戏了,毕竟是个全键盘
当前–京造C2 ¥253

选择这个键盘的原因嘛,同事有了,并且是一个带灯的键盘。手感比cherry硬一些,但还属于是能接受的程度,整体延迟比较低(也可能是因为有线的原因)。目前是在办公室使用的一款,当前这篇文章就是用这个敲出来的。
鼠标

总览
鼠标其实留在手边的不太多,大多数都是消耗品了,这么些年,各种有用过。大概用了不下10个鼠标,我只挑2个重点的说吧。
微软ie 3.0 ¥359

这是我用过最好的鼠标,没有之一。握感极佳,用久了也不累,比其他的鼠标都舒服万分。
当前–apple magic trapad ¥899

mac用户的最终归属就是板子,如果你刚开始用mac,那么建议直接用板子吧。支持原生手势操作,各种mac本身触控板的事情都完美适用,真正的跟你的电脑和为一体。
欢迎评论区留言你的设备
如上所述,我这年的大头是电脑,消耗品是鼠标、,那么你都花了多少钱呢?
来源:juejin.cn/post/7395473411651682343
30岁之前透支,30岁之后还债。
前言
看到不少私信问我为啥没有更新了,我没有一一回复,实在是身体抱恙,心情沉重,加上应付于工作,周旋于家庭,自然挤压了自我空间。
今天思来想去,重新执键,决定久违地又一次写点分享,奉劝大家珍惜身体,愉悦生活。
愉悦二字说来容易,但各位都一样,奔波于现实,劳累于生活,岂是三言两语就能改变的。
病来如山倒
我又病了,有些意外和突然的,令我措手不及。
一天早上我起来,脖子有些酸,就伸手揉揉捏捏,忽然发现脖颈左侧有一个肿块,仔细拿捏,发现竟然是在里面,而且硬邦邦的,伴有轻微的疼痛感。
当时早上对着镜子拍下来的肿块,我还保留了照片。

立马便一身冷汗冒出,我从未经历过这样的事情,去年身体毕竟出过问题,两相叠加之下,内心更是难以描述。
因为是周一,怀着忐忑的心情去上班了,接下来一直都有些神经兮兮,觉得自己身体出了大问题。
之前我有文章讲过自己去年其实已经检查出血脂的问题,停更半年之久,调养了一番,才真正感觉到身体有所恢复,根据我发文的日期可见一二。
恢复更新的这段时间,报复式地写作和分享,一度不知不觉地排到榜单第二,今天登录看了一下,居然还在月榜前三没下来,也是意外。
话说回来,人一旦身体冒出点病痛,整个心情都显得低沉萎靡,很快就能在方方面面反应出来。
我是硬着头皮上班的,抽空网上查了下好让自己有个心理准备。
百度一搜便是绝症,这是很多年前就知道的,但病急乱投医果然是人之本性,我毅然决然还是搜了。
然后,各种甲状腺之类的就来了,再搜,淋巴瘤也来了,再搜,好家伙,直接恶性肿瘤十有八九了。
面对未知而产生的接近绝望的心情,想必不少人有类似经验。
比如我,下意识先想到的竟然不是我是不是要完蛋了,而是想到自己是家中独子,父母年迈身体有恙,妻子操劳,孩子尚小,家中主要经济来源也是我。
我一旦倒下,实在不敢想,往深了一想各种负面因子都蜂拥而来。
我不知道有多少人和我的性格相似,就是身体出了这种未知的问题,一面觉得应该去医院看看,一面又怕折腾来去最后拿到最不可接受的结果,可能不知道反而能活久一点,大概就是这种心情了。
是的,我大体是个胆子还算大的人,也猛然间抗拒去医院了。
不去医院的结果,就是你每天都在意这个肿块,每天都要摸摸它是不是变小了,是不是消失了,每天都小心呵护着它,甚至还想对它说说话倾诉一下,像是自己偷养的小情人一样。
只盼着某天睡觉醒来,用手一摸,哈哈没有了这样。
我就是差不多一个月都这样惶惶不可终日地度过,直到这周六才被妻子赶去医院做了检查。
透支和还债
30岁之前透支,30岁之后还债。
说来好笑,摸到肿块的第二天吧,还有朋友私信找我合作,换做平时,我肯定欣然接受,并开始设计文稿。
但身体有问题,一切都索然无味了,再次真切地体会到这种被现实打碎一切欲望的撕裂感。

为什么我30岁之后身体慢慢开始出现各种问题,这两年我有静下心来思考过。
到底还是30岁之前透支太多了,30岁之后你依然养成30岁之前的生活习惯,无异于自杀行为。
我把身体比作一根橡皮筋,它大概只能扯那么长,我长期将它扯那么那么长,我以为它没事,直到有一次我将它扯那么那么那么长,砰的一声它就断了。
我们都无法知道自己的这根橡皮筋到底能扯多长,只要它没断,我们都觉得它还能扯很长,代价就是,只需断一次,你再也无法重来了。
30岁之前,我努力学习各种知识,熬夜那是家常便饭,睡一觉便生龙活虎。
我就像以前上学的三好学生一样,在学校我扎扎实实,放学了我还进补习班,补习班回来了我还上网学知识。
回头想想,真特么离谱啊,我上学都没这样,走上社会了竟然付出了之前在学校几倍的努力。
早知如此,我好好上学读书最后进入一个更优质的圈子,不就少走很多弯路了吗,但是谁又会听当年的老师和父母一番肺腑之言呢。
埋怨过去没有什么意义,只能偶尔借着都市小说幻想一下带着记忆重生回校园的自己。
细数下来,我30岁之前熬过的夜比我加的班还多,我不是天天加班,但好像真的天天熬夜。
可我身体一点问题都没有,我觉得自己不是那种被命运抛弃的人,内心一直这么侥幸,你是不是也和我一样呢。
30岁之后,该来的还是来了,32岁那年,我有一次咳嗽入院,反复高烧,退了又发烧,医生一度以为是新冠,或结核,或白血病什么的,后来全部检查了都不是,发现就是普通的肺部感染。
每天两瓶抗病毒的点滴,大概半个月才逐渐恢复,人都瘦脱相了,这是我人生头一次住院,躺在病床上像废人一样。
等到33岁也就是去年,偶然头晕了一次,那种眩晕,天旋地转,犯恶心,怎么站怎么坐怎么躺都不行,真正要死的感觉。
后面我一度以为是年纪轻轻得了高血压,结果查了下是血脂的问题,还不算严重,但继续下去很可能会变成一些心脑血管疾病。
我难以置信,这可都是老年病啊,我一个30几岁的程序员说来就来了?
调养半年多,肉眼可见身体有好转,我又开始没忍住熬夜了,想做自己的课题,想分享更多的东西,这些都要花时间,而且包括一些其他领域的内容,想得太多,自然花的时间就多。
一不小心就连续熬了一个多月,平均每晚都是2点左右躺下,有时中午还不午休,刷手机找素材。
终于,脖子上起了肿块,让我整个人都蒙圈了,觉得一切努力都是在玩弄自己,忽然间什么都没意思了。
我尽量把这种感受描述出来,希望你们能看明白,真切体会一二。
为什么30岁之后我一熬夜就有问题出现,说白了,30岁之前透支了已经,一来是身体负荷达到临界,二来养成了多年的坏习惯,一时想改还改不过来。
30岁之前真别玩弄自己的身体了xdm,橡皮筋断了就真断了,接不上了,接上了也没以前的弹性了。
健康取决于自律和心情
对于程序员来说,健康取决于两点:自律和心情。
30岁之前,请学会自律,学习时间自律,生活作息自律,一日三餐自律,养成这样的习惯,30岁之后的你会受益匪浅。
自律真的很难,我就是一个很难做到的人,我有倔强地适应过,却又悲哀地失败了。
就像你是一个歇斯底里的人,忽然让你温文尔雅,你又能坚持多久呢。
我用很多鸡汤说服过自己,对于已经30几岁的我来说,也只能维持一段时间。
想看的多,想玩的多,想学的也多,时间是真不够啊,真想向天再借五百年。
我应该算是幸运的那一类,至少我这般透支身体,我还活着,也没用余生去直面绝望。
我用这两年的身体故障给自己上了重要的一课,人死如灯灭。
如果能重来,我一定会学习时间规划,我一定会把每天的时间安排的好好的。
我一定会保证一日三餐不落下,少吃外卖,多吃水果蔬菜。
我一定会保证每晚充足的睡眠,早睡早起,绝不熬夜。
我一定会每天下班和放假抽出一些时间运动和锻炼。
我不是说给自己听的,因为我已经透支了。
我是说给在看文章的你们听的,还年轻点的,还没透支的,请用我的现在当做你可能更坏的未来,早点醒悟,为时不晚。
自律很难,但不自律可能等死,这个选择一点也不难。
工作压力大,作为程序员是避免不了的,所以我以前有劝过大家,薪水的重要性只占一半,你应该追寻一份薪水尚可,但压力一定在承受范围内的工作,这是我认为在国内对于程序员来说相对友好的途径。
我进入IT行业目前为止的整个生涯中,学习阶段听到过传智播客张孝祥老师的猝死,工作阶段听说过附近的4396游戏公司里面30多岁程序员猝死,今年又听到了左耳朵耗子先生的离世。
我想着,那一天,离我和你还有多远。
心情真的很重要,至少能快速反应在身体上。
当我这周六被妻子劝说去检查的时候,我内心一直是紧张的,妻子没去,就在家陪着孩子,跟我说你自己去吧,如果有坏消息就别回复了,等回来再说,如果没什么事那就发个微信。
我想我理解她的意思了,点了点头就骑车去了医院。
医院真不是什么好地方,我就是给医院干活的,我全身上下都讨厌这里。
最煎熬的时间是做彩超前的一个多小时,因为人太多,我得排队,盯着大屏上的号序,我脑子里想了很多事情,甚至连最坏的打算都想好了。
人就很奇怪,越是接近黑暗,越是能回忆起非常多的往事,连高中打篮球挥洒汗水的模样和搞笑的投篮姿势都能想起来。
喊到我的时候,我心跳了一下,然后麻木地进去了,躺下的时候,医生拿着仪器对着我的脖子扫描,此时的我是近一个月以来第一次内心平静,当真好奇怪的感觉。
随着医生一句:没什么事,就一个淋巴结。
犹如审判一般,我感觉一下无罪释放了。
当时听到这句话简直犹如天籁,这会儿想起来还感觉毛孔都在欢快地愉悦。
我问她不是什么肿瘤或甲状腺吧,她说不是,就一个正常的淋巴结,可能是炎症导致了增生,这种一般3个多月至半年才会完全消掉。
这是当时拍的结果

拿给主任医师看了之后,对方也说一点事没有,只是告诫我别再熬夜了。
我不知道人生还会给我几次机会,但我从20几岁到30几岁,都没有重视过这个问题,也没有认真思考过。
直到最近,我才发现,活着真好。
当晚是睡得最踏实的一晚,一点梦都没做,中途也没醒,一觉到天亮。
更离谱的是,早上我摸了一下脖子,竟然真的小了点,这才短短一天,说了都没人信。
我头一次相信,心情真的会影响身体,你心情好了,身体的器官和血液仿佛都欢腾了起来。
如何保持一个好心情,原来这般重要,我拿自己的身体给大家做实验了,有用!
希望大家每天在自律的基础上保持好心情,不负年华,不负自己。
总结
xdm,好好活着,快乐活着。
来源:juejin.cn/post/7300564263344128051
三个月内遭遇的第二次比特币勒索
早前搭过一个wiki (可点击wiki.dashen.tech 查看),用于"团队协作与知识分享".把游客账号给一位前同事,其告知登录出错.

用我记录的账号密码登录,同样报错; 打开数据库一看,疑惑全消.

To recover your lost Database and avoid leaking it: Send us 0.05 Bitcoin (BTC) to our Bitcoin address 3F4hqV3BRYf9JkPasL8yUPSQ5ks3FF3tS1 and contact us by Email with your Server IP or Domain name and a Proof of Payment. Your Database is downloaded and backed up on our servers. Backups that we have right now: mm_wiki, shuang. If we dont receive your payment in the next 10 Days, we will make your database public or use them otherwise.
(按照今日比特币价格,0.05比特币折合人民币4 248.05元..)
大多时候不使用该服务器上安装的mysql,因而账号和端口皆为默认,密码较简单且常见,为在任何地方navicat也可连接,去掉了ip限制...对方写一个脚本,扫描各段ip地址,用常见的几个账号和密码去"撞库",几千几万个里面,总有一两个能得手.
被窃取备份而后删除的两个库,一个是来搭建该wiki系统,另一个是用来亲测mysql主从同步,详见此篇,价值都不大
实践告诉我们,不要用默认账号,不要用简单密码,要做ip限制。…
- 登录服务器,登录到mysql:
mysql -u root -p

- 修改密码:
尝试使用如下语句来修改
set password for 用户名@yourhost = password('新密码');
结果报错;查询得知是最新版本更改了语法,需用
alter user 'root'@'localhost' identified by 'yourpassword';

成功~
但在navicat里,原连接依然有效,而输入最新的密码,反倒是失败

打码部分为本机ip
在服务器执行
-- 查询所有用户
select user from mysql.user;
再执行
select host,user,authentication_string from mysql.user;

user及其后的host组合在一起,才构成一个唯一标识;故而在user表中,可以存在同名的root
使用
alter user 'root'@'%' identified by 'xxxxxx';
注意主机此处应为%
再使用
select host,user,authentication_string from mysql.user;
发现 "root@%" 对应的authentication_string已发生改变;
在navicat中旧密码已失效,需用最新密码才可登录
参考:
这不是第一次遭遇"比特币勒索",在四月份,收到了这么一封邮件:

后来证明这是唬人的假消息,但还是让我学小扎,把Mac的摄像头覆盖了起来..
来源:juejin.cn/post/7282666367239995392
让生成式 AI 触手可及:火山引擎推出 NVIDIA NIM on VKE 最佳部署实践
技术行业近来对大语言模型(LLM)的关注正开始转向生产环境的大规模部署,将 AI 模型接入现有基础设施以优化系统性能,包括降低延迟、提高吞吐量,以及加强日志记录、监控和安全性等。然而这一路径既复杂又耗时,往往需要构建专门的平台和流程。
在部署 AI 模型的过程中,研发团队通常需要执行以下步骤:
环境搭建与配置:首先需要准备和调试运行环境,这包括但不限于 CUDA、Python、PyTorch 等依赖项的安装与配置。这一步骤往往较为复杂,需要细致地调整各个组件以确保兼容性和性能。
模型优化与封装:接下来进行模型的打包和优化,以提高推理效率。这通常涉及到使用 NVIDIA TensorRT 软件开发套件或 NVIDIA TensorRT-LLM 库等专业工具来优化模型,并根据性能测试结果和经验来调整推理引擎的配置参数。这一过程需要深入的 AI 领域知识,并且工具的使用具有一定的学习成本。
模型部署:最后,将优化后的模型部署到生产环境中。对于非容器化环境,资源的准备和管理也是一个需要精心策划的环节。
为了简化上述流程并降低技术门槛,火山引擎云原生团队推出基于 VKE 的 NVIDIA NIM 微服务最佳实践。通过结合 NIM 一站式模型服务能力,以及火山引擎容器服务 VKE 在成本节约和极简运维等方面的优势,这套开箱即用的技术方案将帮助企业更加快捷和高效地部署 AI 模型。
AI 微服务化:NVIDIA NIM
NVIDIA NIM 是一套经过优化的企业级生成式 AI 微服务,它包括推理引擎,通过 API 接口对外提供服务,帮助企业和个人开发者更简单地开发和部署 AI 驱动的应用程序。
NIM 使用行业标准 API,支持跨多个领域的 AI 用例,包括 LLM、视觉语言模型(VLM),以及用于语音、图像、视频、3D、药物研发、医学成像等的模型。同时,它基于 NVIDIA Triton™ Inference Server、NVIDIA TensorRT™、NVIDIA TensorRT-LLM 和 PyTorch 构建,可以在加速基础设施上提供最优的延迟和吞吐量。
为了进一步降低复杂度,NIM 将模型和运行环境做了解耦,以容器镜像的形式为每个模型或模型系列打包。其在 Kubernetes 内的部署形态如下:

NVIDIA NIM on Kubernetes
火山引擎容器服务 VKE(Volcengine Kubernetes Engine)通过深度融合新一代云原生技术,提供以容器为核心的高性能 Kubernetes 容器集群管理服务,可以为 NIM 提供稳定可靠高性能的运行环境,实现模型使用和运行的强强联合。
同时,模型服务的发布和运行也离不开发布管理、网络访问、观测等能力,VKE 深度整合了火山引擎高性能计算(ECS/裸金属)、网络(VPC/EIP/CLB)、存储(EBS/TOS/NAS)、弹性容器实例(VCI)等服务,并与镜像仓库、持续交付、托管 Prometheus、日志服务、微服务引擎等云产品横向打通,可以实现 NIM 服务构建、部署、发布、监控等全链路流程,帮助企业更灵活、更敏捷地构建和扩展基于自身数据的定制化大型语言模型(LLMs),打造真正的企业级智能化、自动化基础设施。
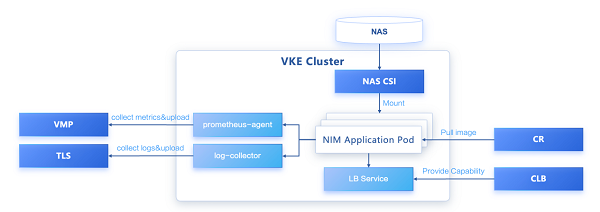
NVIDIA NIM on VKE 部署流程
下面,我们将介绍 NIM on VKE 的部署流程,助力开发者快速部署和访问 AI 模型。
准备工作
部署 NVIDIA NIM 前,需要做好如下准备:
1. VKE 集群中已安装 csi-nas / prometheus-agent / vci-virtual-kubelet / cr-credential-controller 组件
2. 在 VKE 集群中使用相适配的 VCI GPU 实例规格,具体软硬件支持情况可以查看硬件要求
3. 创建 NAS 实例,作为存储类,用于模型文件的存储
4. 创建 CR(镜像仓库) 实例,用于托管 NIM 镜像
5. 开通 VMP(托管 Prometheus)服务
6. 向 NVIDIA 官方获取 NIM 相关镜像的拉取权限(下述以 llama3-8b-instruct:1.0.0 为例),并生成 API Key
部署
1. 在国内运行 NIM 官方镜像时,为了避免网络访问影响镜像拉取速度,可以提前拉取相应 NIM 镜像并上传到火山引擎镜像仓库 CR,操作步骤如下:

2. Download the code locally, go to the Helm Chart directory of the code, and push Helm Chart to Container Registry (Helm version > 3.7):
下载代码到本地,进入到代码的 helm chart 目录中,把 helm chart 推送到镜像仓库(helm 版本大于 3.7):

3. 在 vke 的应用中心的 helm 应用中选择创建 helm 应用,并选择对应 chart,集群信息,并点击 values.yaml 的编辑按钮进入编辑页
4. 覆盖 values 内容为如下值来根据火山引擎环境调整参数配置,提升部署性能,点击确定完成参数改动,再继续在部署页点击确定完成部署

5. 若 Pod 日志出现如下内容或者 Pod 状态变成 Ready,说明服务已经准备好:

6. 在 VKE 控制台获取 LB Service 地址(Service 名称为

7. 访问 NIM 服务

The output is as follows:
会有如下输出:
监控
NVIDIA NIM 在 Grafana Dashboard 上提供了丰富的观测指标,详情可参考 Observability
在 VKE 中,可通过如下方法搭建 NIM 监控:
1. 参考文档搭建 Grafana:https://www.volcengine.com/docs/6731/126068
2. 进入 Grafana 中,在 dashboard 菜单中选择 import:
3. 观测面板效果如下:
结语
相比构建大模型镜像,基于 VKE 使用 NVIDIA NIM 部署和访问模型有如下优点:
● 易用性:NIM 提供了预先构建好的模型容器镜像,用户无需从头开始构建和配置环境,配合 VKE 与 CR 的应用部署能力,极大简化了部署过程
● 性能优化:NIM 的容器镜像是经过优化的,可以在 NVIDIA GPU 上高效运行,充分利用 VCI 的硬件性能
● 模型选择:NIM 官方提供了多种大语言模型,用户可以根据需求选择合适的模型,部署在 VKE 中仅需对values.yaml 配置做修改即可
● 自动更新:通过 NGC,NIM 可以自动下载和更新模型,用户无需手动管理模型版本
● 可观测性:NIM 内置了丰富的观测指标,配合 VKE 与 VMP 观测能力开箱即用
目前火山引擎容器服务 VKE 已开放个人用户使用,为个人和企业用户提供高性能、高可靠、极致弹性的企业级容器管理能力,结合 NIM 强大易用的模型部署服务,进一步帮助开发者快速部署 AI 模型,并提供高性能、开箱即用的模型 API 服务。(作者:李双)
收起阅读 »uniapp-实现安卓app水印相机
写在前面的话:最近要配合项目输出带水印的图片,之前的实现的方式是调uniapp封装好的相机,然后在图片输出的时候用canvas,把水印绘制上去,但是老感觉没有水印相机看着舒服.改成了现在的这种方式。
1.相机实现
水印相机实现有两种方式,在小程序端可以用camera来实现,但在安卓端不支持camera,使用uniapp的live-pusher来实现相机。
而live-pusher推荐使用nvue来做,好处是
- nvue也可一套代码编译多端。
- nvue的cover-view比vue的cover-view更强大,在视频上绘制元素更容易。如果只考虑App端的话,不用cover-view,任意组件都可以覆盖组件,因为nvue没有层级问题。
- 若需要视频内嵌在swiper里上下滑动(类抖音、映客首页模式),App端只有nvue才能实现 当然nvue相比vue的坏处是css写法受限,如果只开发微信小程序,不考虑App,那么使用vue页面也是一样的。
- App平台:使用
<live-pusher/>组件,打包 App 时必须勾选 manifest.json->App 模块权限配置->LivePusher(直播推流) 模块。


上代码!
<template>
<view class="live-camera" :style="{ width: windowWidth, height: windowHeight }">
<view class="preview" :style="{ width: windowWidth, height: windowHeight }">
<live-pusher
id="livePusher"
ref="livePusher"
class="livePusher"
mode="FHD"
beauty="0"
whiteness="0"
:aspect="aspect"
min-bitrate="1000"
audio-quality="16KHz"
device-position="back"
:auto-focus="true"
:muted="true"
:enable-camera="true"
:enable-mic="false"
:zoom="false"
@statechange="statechange"
:style="{ width: windowWidth, height: windowHeight }"
></live-pusher>
<!--这里修改水印的样式-->
<cover-view class="remind">
<text class="remind-text" style="">{{ message }}</text>
<text class="remind-text" style="">经度:1002.32</text>
<text class="remind-text" style="">纬度:1002.32</text>
</cover-view>
</view>
<view class="menu">
<!--底部菜单区域背景-->
<cover-image class="menu-mask" src="/static/live-camera/bar.png"></cover-image>
<!--返回键-->
<cover-image class="menu-back" @tap="back" src="/static/live-camera/back.png"></cover-image>
<!--快门键-->
<cover-image class="menu-snapshot" @tap="snapshot" src="/static/live-camera/shutter.png"></cover-image>
<!--反转键-->
<cover-image class="menu-flip" @tap="flip" src="/static/live-camera/flip.png"></cover-image>
</view>
</view>
</template>
<script>
let _this = null;
export default {
data() {
return {
dotype: 'watermark',
message: '水印相机', //水印内容
poenCarmeInterval: null, //打开相机的轮询
aspect: '2:3', //比例
windowWidth: '', //屏幕可用宽度
windowHeight: '', //屏幕可用高度
camerastate: false, //相机准备好了
livePusher: null, //流视频对象
snapshotsrc: null //快照
};
},
onLoad(e) {
_this = this;
if (e.dotype != undefined) this.dotype = e.dotype;
this.initCamera();
},
onReady() {
this.livePusher = uni.createLivePusherContext('livePusher', this);
this.startPreview(); //开启预览并设置摄像头
this.poenCarme();
},
methods: {
//轮询打开
poenCarme() {
//#ifdef APP-PLUS
if (plus.os.name == 'Android') {
this.poenCarmeInterval = setInterval(function () {
console.log(_this.camerastate);
if (!_this.camerastate) _this.startPreview();
}, 2500);
}
//#endif
},
//初始化相机
initCamera() {
uni.getSystemInfo({
success: function (res) {
_this.windowWidth = res.windowWidth;
_this.windowHeight = res.windowHeight;
let zcs = _this.aliquot(_this.windowWidth, _this.windowHeight);
_this.aspect = _this.windowWidth / zcs + ':' + _this.windowHeight / zcs;
console.log('画面比例:' + _this.aspect);
}
});
},
//整除数计算
aliquot(x, y) {
if (x % y == 0) return y;
return this.aliquot(y, x % y);
},
//开始预览
startPreview() {
this.livePusher.startPreview({
success: (a) => {
console.log(a);
}
});
},
//停止预览
stopPreview() {
this.livePusher.stopPreview({
success: (a) => {
_this.camerastate = false; //标记相机未启动
}
});
},
//状态
statechange(e) {
//状态改变
console.log(e);
if (e.detail.code == 1007) {
_this.camerastate = true;
} else if (e.detail.code == -1301) {
_this.camerastate = false;
}
},
//返回
back() {
uni.navigateBack();
},
//抓拍
snapshot() {
this.livePusher.snapshot({
success: (e) => {
_this.snapshotsrc = e.message.tempImagePath;
_this.stopPreview();
_this.setImage();
uni.navigateBack();
}
});
},
//反转
flip() {
this.livePusher.switchCamera();
},
//设置
setImage() {
let pages = getCurrentPages();
let prevPage = pages[pages.length - 2]; //上一个页面
//直接调用上一个页面的setImage()方法,把数据存到上一个页面中去
prevPage.$vm.setImage({ path: _this.snapshotsrc, dotype: this.dotype });
}
}
};
</script>
<style lang="scss">
.live-camera {
justify-content: center;
align-items: center;
.preview {
justify-content: center;
align-items: center;
.remind {
position: absolute;
bottom: 180rpx;
left: 20rpx;
width: 130px;
z-index: 100;
.remind-text {
color: #dddddd;
font-size: 40rpx;
text-shadow: #fff 1px 0 0, #fff 0 1px 0, #fff -1px 0 0, #fff 0 -1px 0;
}
}
}
.menu {
position: absolute;
left: 0;
bottom: 0;
width: 750rpx;
height: 180rpx;
z-index: 98;
align-items: center;
justify-content: center;
.menu-mask {
position: absolute;
left: 0;
bottom: 0;
width: 750rpx;
height: 180rpx;
z-index: 98;
}
.menu-back {
position: absolute;
left: 30rpx;
bottom: 50rpx;
width: 80rpx;
height: 80rpx;
z-index: 99;
align-items: center;
justify-content: center;
}
.menu-snapshot {
width: 130rpx;
height: 130rpx;
z-index: 99;
}
.menu-flip {
position: absolute;
right: 30rpx;
bottom: 50rpx;
width: 80rpx;
height: 80rpx;
z-index: 99;
align-items: center;
justify-content: center;
}
}
}
</style>
2.水印图片绘制
图片水印返回上一页用<canvas>添加水印
<template>
<view class="page">
<view style="height: 80rpx;"></view>
<navigator class="buttons" url="../camera/watermark/watermark"><button type="primary">打开定制水印相机</button></navigator>
<view style="height: 80rpx;"></view>
<view>拍摄结果预览图,见下方</view>
<image class="preview" :src="imagesrc" mode="aspectFit" style="width:710rpx:height:710rpx;margin: 20rpx;"></image>
<canvas id="canvas-clipper" canvas-id="canvas-clipper" type="2d" :style="{width: canvasSiz.width+'px',height: canvasSiz.height+'px',position: 'absolute',left:'-500000px',top: '-500000px'}" />
</view>
</template>
<script>
var _this;
export default {
data() {
return {
windowWidth:'',
windowHeight:'',
imagesrc: null,
canvasSiz:{
width:188,
height:273
}
};
},
onLoad() {
_this= this;
this.init();
},
methods: {
//设置图片
setImage(e) {
console.log(e);
//显示在页面
//this.imagesrc = e.path;
if(e.dotype =='idphoto'){
_this.zjzClipper(e.path);
}else if(e.dotype =='watermark'){
_this.watermark(e.path);
}else{
_this.savePhoto(e.path);
}
},
//添加照片水印
watermark(path){
uni.getImageInfo({
src: path,
success: function(image) {
console.log(image);
_this.canvasSiz.width =image.width;
_this.canvasSiz.height =image.height;
//担心尺寸重置后还没生效,故做延迟
setTimeout(()=>{
let ctx = uni.createCanvasContext('canvas-clipper', _this);
ctx.drawImage(
path,
0,
0,
image.width,
image.height
);
//具体位置如需和相机页面上一致还需另外做计算,此处仅做大致演示
ctx.setFillStyle('white');
ctx.setFontSize(40);
ctx.fillText('live-camera', 20, 100);
//再来加个时间水印
var now = new Date();
var time= now.getFullYear()+'-'+now.getMonth()+'-'+now.getDate()+' '+now.getHours()+':'+now.getMinutes()+':'+now.getMinutes();
ctx.setFontSize(30);
ctx.fillText(time, 20, 140);
ctx.draw(false, () => {
uni.canvasToTempFilePath(
{
destWidth: image.width,
destHeight: image.height,
canvasId: 'canvas-clipper',
fileType: 'jpg',
success: function(res) {
_this.savePhoto(res.tempFilePath);
}
},
_this
);
});
},500)
}
});
},
//保存图片到相册,方便核查
savePhoto(path){
this.imagesrc = path;
//保存到相册
uni.saveImageToPhotosAlbum({
filePath: path,
success: () => {
uni.showToast({
title: '已保存至相册',
duration: 2000
});
}
});
},
//初始化
init(){
let _this = this;
uni.getSystemInfo({
success: function(res) {
_this.windowWidth = res.windowWidth;
_this.windowHeight = res.windowHeight;
}
});
}
}
};
</script>
<style lang="scss">
.page {
width: 750rpx;
justify-content: center;
align-items: center;
flex-direction:column;
display: flex;
.buttons {
width: 600rpx;
}
}
</style>

来源:juejin.cn/post/7399983106750447627
前端如何做截图?
一、 背景
页面截图功能在前端开发中,特别是营销场景相关的需求中, 是比较常见的。比如截屏分享,相对于普通的链接分享,截屏分享具有更丰富的展示、更多的信息承载等优势。最近在需求开发中遇到了相关的功能,所以调研了相关的实现和原理。
二、相关技术
前端要实现页面截图的功能,现在比较常见的方式是使用开源的截图npm库,一般使用比较多的npm库有以下两个:
- dom-to-image: github.com/tsayen/dom-…
- html2canvas: github.com/niklasvh/ht…
以上两种常见的npm库,对应着两种常见的实现原理。实现前端截图,一般是使用图形API重新绘制页面生成图片,基本就是SVG(dom-to-image)和Canvas(html2canvas)两种实现方案,两种方案目标相同,即把DOM转为图片,下面我们来分别看看这两类方案。
三、 dom-to-image
dom-to-image库主要使用的是SVG实现方式,简单来说就是先把DOM转换为SVG然后再把SVG转换为图片。
(一)使用方式
首先,我们先来简单了解一下dom-to-image提供的核心api,有如下一些方法:
- toSvg (dom转svg)
- toPng (dom转png)
- toJpeg (dom转jpg)
- toBlob (dom转二进制格式)
- toPixelData (dom转原始像素值)
如需要生成一张png的页面截图,实现代码如下:
import domtoimage from "domtoimage"
const node = document.getElementById('node');
domtoimage.toPng(node,options).then((dataUrl) => {
const img = new Image();
img.src = dataUrl;
document.body.appendChild(img);
})
toPng方法可传入两个参数node和options。
node为要生成截图的dom节点;options为支持的属性配置,具体如下:filter,backgroundColor,width,height,style,quality,imagePlaceholder,cacheBust。
(二)原理分析
dom to image的源码代码不是很多,总共不到千行,下面就拿toPng方法做一下简单的源码解析,分析一下其实现原理,简单流程如下:

整体实现过程用到了几个函数:
- toPng(调用draw,实现canvas=>png )
- Draw(调用toSvg,实现dom=>canvas)
- toSvg(调用cloneNode和makeSvgDataUri,实现dom=>svg)
- cloneNode(克隆处理dom和css)
- makeSvgDataUri(实现dom=>svg data:url)
- toPng
toPng函数比较简单,通过调用draw方法获取转换后的canvas,利用toDataURL转化为图片并返回。
function toPng(node, options) {
return draw(node, options || {})
.then((canvas) => canvas.toDataURL());
}
- draw
draw函数首先调用toSvg方法获得dom转化后的svg,然后将获取的url形式的svg处理成图片,并新建canvas节点,然后借助drawImage()方法将生成的图片放在canvas画布上。
function draw(domNode, options) {
return toSvg(domNode, options)
// 拿到的svg是image data URL, 进一步创建svg图片
.then(util.makeImage)
.then(util.delay(100))
.then((image) => {
// 创建canvas,在画布上绘制图像并返回
const canvas = newCanvas(domNode);
canvas.getContext("2d").drawImage(image, 0, 0);
return canvas;
});
// 新建canvas节点,设置一些样式的options参数
function newCanvas(domNode) {
const canvas = document.createElement("canvas");
canvas.width = options.width || util.width(domNode);
canvas.height = options.height || util.height(domNode);
if (options.bgcolor) {
const ctx = canvas.getContext("2d");
ctx.fillStyle = options.bgcolor;
ctx.fillRect(0, 0, canvas.width, canvas.height);
}
return canvas;
}
}
- toSvg
- toSvg函数实现从dom到svg的处理,大概步骤如下:
- 递归去克隆dom节点(调用cloneNode函数)
- 处理字体,获取所有样式,找到所有的@font-face和内联资源,解析并下载对应的资源,将资源转为dataUrl给src使用。把上面处理完的css rules放入中,并把标签加入到clone的节点中去。
- 处理图片,将img标签的src的url和css中backbround中的url,转为dataUrl使用。
- 获取dom节点转化的dataUrl数据(调用makeSvgDataUri函数)
function toSvg(node, options) {
options = options || {};
// 处理imagePlaceholder、cacheBust值
copyOptions(options);
return Promise.resolve(node)
.then((node) =>
// 递归克隆dom节点
cloneNode(node, options.filter, true))
// 把字体相关的csstext放入style
.then(embedFonts)
// clone处理图片,将图片链接转换为dataUrl
.then(inlineImages)
// 添加options里的style放入style
.then(applyOptions)
.then((clone) =>
// node节点转化成svg
makeSvgDataUri(clone,
options.width || util.width(node),
options.height || util.height(node)));
// 处理一些options的样式
function applyOptions(clone) {
...
return clone;
}
}
- cloneNode
cloneNode函数主要处理dom节点,内容比较多,简单总结实现如下:
- 递归clone原始的dom节点,其中, 其中如果有canvas将转为image对象。
- 处理节点的样式,通过getComputedStyle方法获取节点元素的所有CSS属性的值,并将这些样式属性插入新建的style标签上面, 同时要处理“:before,:after”这些伪元素的样式, 最后处理输入内容和svg。
function cloneNode(node, filter, root) {
if (!root && filter && !filter(node)) return Promise.resolve();
return Promise.resolve(node)
.then(makeNodeCopy)
.then((clone) => cloneChildren(node, clone, filter))
.then((clone) => processClone(node, clone));
function makeNodeCopy(node) {
// 将canvas转为image对象
if (node instanceof HTMLCanvasElement) return util.makeImage(node.toDataURL());
return node.cloneNode(false);
}
// 递归clone子节点
function cloneChildren(original, clone, filter) {
const children = original.childNodes;
if (children.length === 0) return Promise.resolve(clone);
return cloneChildrenInOrder(clone, util.asArray(children), filter)
.then(() => clone);
function cloneChildrenInOrder(parent, children, filter) {
let done = Promise.resolve();
children.forEach((child) => {
done = done
.then(() => cloneNode(child, filter))
.then((childClone) => {
if (childClone) parent.appendChild(childClone);
});
});
return done;
}
}
function processClone(original, clone) {
if (!(clone instanceof Element)) return clone;
return Promise.resolve()
.then(cloneStyle)
.then(clonePseudoElements)
.then(copyUserInput)
.then(fixSvg)
.then(() => clone);
// 克隆节点上的样式。
function cloneStyle() {
...
}
// 提取伪类样式,放到css
function clonePseudoElements() {
...
}
// 处理Input、TextArea标签
function copyUserInput() {
...
}
// 处理svg
function fixSvg() {
...
}
}
}
- makeSvgDataUri
首先,我们需要了解两个特性:
- SVG有一个元素,这个元素的作用是可以在其中使用具有其它XML命名空间的XML元素,换句话说借助标签,我们可以直接在SVG内部嵌入XHTML元素,举个例子:
<svg xmlns="http://www.w3.org/2000/svg">
<foreignObject width="120" height="50">
<body xmlns="http://www.w3.org/1999/xhtml">
<p>文字。</p>
</body>
</foreignObject>
</svg>
可以看到标签里面有一个设置了xmlns=“http://www.w3.org/1999/xhtml”…标签,此时标签及其子标签都会按照XHTML标准渲染,实现了SVG和XHTML的混合使用。
- XMLSerializer对象能够把一个XML文档或Node对象转化或“序列化”为未解析的XML标记的一个字符串。
基于以上特性,我们再来看一下makeSvgDataUri函数,该方法实现node节点转化为svg,就用到刚刚提到的两个重要特性。
首先将dom节点通过
XMLSerializer().serializeToString() 序列化为字符串,然后在
标签 中嵌入转换好的字符串,foreignObject 能够在 svg
内部嵌入XHTML,再将svg处理为dataUrl数据返回,具体实现如下:
function makeSvgDataUri(node, width, height) {
return Promise.resolve(node)
.then((node) => {
// 将dom转换为字符串
node.setAttribute("xmlns", "http://www.w3.org/1999/xhtml");
return new XMLSerializer().serializeToString(node);
})
.then(util.escapeXhtml)
.then((xhtml) => `<foreignObject x="0" y="0" width="100%" height="100%">${xhtml}</foreignObject>`)
// 转化为svg
.then((foreignObject) =>
// 不指定xmlns命名空间是不会渲染的
`<svg xmlns="http://www.w3.org/2000/svg" width="${width}" height="${height}">${
foreignObject}</svg>`)
// 转化为data:url
.then((svg) => `data:image/svg+xml;charset=utf-8,${svg}`);
}
四、 html2canvas
html2canvas库主要使用的是Canvas实现方式,主要过程是手动将dom重新绘制成canvas,因此,它只能正确渲染可以理解的属性,有许多CSS属性无法正确渲染。
支持的CSS属性的完整列表:
html2canvas.hertzen.com/features/
浏览器兼容性:
Firefox 3.5+ Google Chrome Opera 12+ IE9+ Edge Safari 6+
官方文档地址:
html2canvas.hertzen.com/documentati…
(一)使用方式
// dom即是需要绘制的节点, option为一些可配置的选项
import html2canvas from 'html2canvas'
html2canvas(dom, option).then(canvas=>{
canvas.toDataURL()
})
常用的option配置:

全部配置文档:
html2canvas.hertzen.com/configurati…
(二)原理分析
html2canvas的内部实现相对dom-to-image来说要复杂一些, 基本原理是读取DOM元素的信息,基于这些信息去构建截图,并呈现在canvas画布中。
其中重点就在于将dom重新绘制成canvas的过程,该过程整体的思路是:遍历目标节点和目标节点的子节点,遍历过程中记录所有节点的结构、内容和样式,然后计算节点本身的层级关系,最后根据不同的优先级绘制到canvas画布中。
由于html2canvas的源码量比较大,可能无法像dom-to-image一样详细的分析,但还是可以大致了解一下整体的流程,首先可以看一下源码中src文件夹中的代码结构,如下图:

简单解析一下:
- index:入口文件,将dom节点渲染到一个canvas中,并返回。
- core:工具函数的封装,包括对缓存的处理函数、Context方法封装、日志模块等。
- css:对节点样式的处理,解析各种css属性和特性,进行处理。
- dom:遍历dom节点的方法,以及对各种类型dom的处理。
- render:基于clone的节点生成canvas的处理方法。
基于以上这些核心文件,我们来简单了解一下html2canvas的解析过程, 大致的流程如下:

- 构建配置项
在这一步会结合传入的options和一些defaultOptions,生成用于渲染的配置数据renderOptions。在过程中会对配置项进行分类,比如resourceOptions(资源跨域相关)、contextOptions(缓存、日志相关)、windowOptions(窗口宽高、滚动配置)、cloneOptions(对指定dom的配置)、renderOptions(render结果的相关配置,包括生成图片的各种属性)等,然后分别将各类配置项传到下接下来的步骤中。
- clone目标节点并获取样式和内容
在这一步中,会将目标节点到指定的dom解析方法中,这个过程会clone目标节点和其子节点,获取到节点的内容信息和样式信息,其中clone dom的解析方法也是比较复杂的,这里不做详细展开。获取到目标节点后,需要把克隆出来的目标节点的dom装载到一个iframe里,进行一次渲染,然后就可以获取到经过浏览器视图真实呈现的节点样式。
- 解析目标节点
目标节点的样式和内容都获取到了之后,就需要把它所承载的数据信息转化为Canvas可以使用的数据类型。在对目标节点的解析方法中,递归整个DOM树,并取得每一层节点的数据,对于每一个节点而言需要绘制的部分包括边框、背景、阴影、内容,而对于内容就包含图片、文字、视频等。在整个解析过程中,对目标节点的所有属性进行解析构造,转化成为指定的数据格式,基础数据格式可见以下代码:
class ElementContainer {
// 所有节点上的样式经过转换计算之后的信息
readonly styles: CSSParsedDeclaration;
// 节点的文本节点信息, 包括文本内容和其他属性
readonly textNodes: TextContainer[] = [];
// 当前节点的子节点
readonly elements: ElementContainer[] = [];
// 当前节点的位置信息(宽/高、横/纵坐标)
bounds: Bounds;
flags = 0;
...
}
具体到不同类型的元素如图片、IFrame、SVG、input等还会extends ElementContainer拥有自己的特定数据结构,在此不详细贴出。
- 构建内部渲染器
把目标节点处理成特定的数据结构之后,就需要结合Canvas调用渲染方法了,Canvas绘图需要根据样式计算哪些元素应该绘制在上层,哪些在下层,那么这个规则是什么样的呢?这里就涉及到CSS布局相关的一些知识。
默认情况下,CSS是流式布局的,元素与元素之间不会重叠。不过有些情况下,这种流式布局会被打破,比如使用了浮动(float)和定位(position)。因此需要需要识别出哪些脱离了正常文档流的元素,并记住它们的层叠信息,以便正确地渲染它们。
那些脱离正常文档流的元素会形成一个层叠上下文。元素在浏览器中渲染时,根据W3C的标准,所有的节点层级布局,需要遵循层叠上下文和层叠顺序的规则,具体规则如下:

在了解了元素的渲染需要遵循这个标准后,Canvas绘制节点的时候,需要生成指定的层叠数据,就需要先计算出整个目标节点里子节点渲染时所展现的不同层级,构造出所有节点对应的层叠上下文在内部所表现出来的数据结构,具体数据结构如下:
// 当前元素
element: ElementPaint;
// z-index为负, 形成层叠上下文
negativeZIndex: StackingContext[];
// z-index为0、auto、transform或opacity, 形成层叠上下文
zeroOrAutoZIndexOrTransformedOrOpacity: StackingContext[];
// 定位和z-index形成的层叠上下文
positiveZIndex: StackingContext[];
// 没有定位和float形成的层叠上下文
nonPositionedFloats: StackingContext[];
// 没有定位和内联形成的层叠上下文
nonPositionedInlineLevel: StackingContext[];
// 内联节点
inlineLevel: ElementPaint[];
// 不是内联的节点
nonInlineLevel: ElementPaint[];
基于以上数据结构,将元素子节点分类,添加到指定的数组中,解析层叠信息的方式和解析节点信息的方式类似,都是递归整棵树,收集树的每一层的信息,形成一颗包含层叠信息的层叠树。
- 绘制数据
基于上面两步构造出的数据,就可以开始调用内部的绘制方法,进行数据处理和绘制了。使用节点的层叠数据,依据浏览器渲染层叠数据的规则,将DOM元素一层一层渲染到canvas中,其中核心具体源码如下:
async renderStackContent(stack: StackingContext): Promise<void> {
if (contains(stack.element.container.flags, FLAGS.DEBUG_RENDER)) {
debugger;
}
// 1. the background and borders of the element forming the stacking context.
await this.renderNodeBackgroundAndBorders(stack.element);
// 2. the child stacking contexts with negative stack levels (most negative first).
for (const child of stack.negativeZIndex) {
await this.renderStack(child);
}
// 3. For all its in-flow, non-positioned, block-level descendants in tree order:
await this.renderNodeContent(stack.element);
for (const child of stack.nonInlineLevel) {
await this.renderNode(child);
}
// 4. All non-positioned floating descendants, in tree order. For each one of these,
// treat the element as if it created a new stacking context, but any positioned descendants and descendants
// which actually create a new stacking context should be considered part of the parent stacking context,
// not this new one.
for (const child of stack.nonPositionedFloats) {
await this.renderStack(child);
}
// 5. the in-flow, inline-level, non-positioned descendants, including inline tables and inline blocks.
for (const child of stack.nonPositionedInlineLevel) {
await this.renderStack(child);
}
for (const child of stack.inlineLevel) {
await this.renderNode(child);
}
// 6. All positioned, opacity or transform descendants, in tree order that fall int0 the following categories:
// All positioned descendants with 'z-index: auto' or 'z-index: 0', in tree order.
// For those with 'z-index: auto', treat the element as if it created a new stacking context,
// but any positioned descendants and descendants which actually create a new stacking context should be
// considered part of the parent stacking context, not this new one. For those with 'z-index: 0',
// treat the stacking context generated atomically.
//
// All opacity descendants with opacity less than 1
//
// All transform descendants with transform other than none
for (const child of stack.zeroOrAutoZIndexOrTransformedOrOpacity) {
await this.renderStack(child);
}
// 7. Stacking contexts formed by positioned descendants with z-indices greater than or equal to 1 in z-index
// order (smallest first) then tree order.
for (const child of stack.positiveZIndex) {
await this.renderStack(child);
}
}
在renderStackContent方法中,首先对元素本身调用renderNodeContent和renderNodeBackgroundAndBorders进行渲染处理。
然后处理各个分类的子元素,如果子元素形成了层叠上下文,就调用renderStack方法,这个方法内部继续调用了renderStackContent,这就形成了对于层叠上下文整个树的递归。
如果子元素是正常元素没有形成层叠上下文,就直接调用renderNode,renderNode包括两部分内容,渲染节点内容和渲染节点边框背景色。
async renderNode(paint: ElementPaint): Promise<void> {
if (paint.container.styles.isVisible()) {
// 渲染节点的边框和背景色
await this.renderNodeBackgroundAndBorders(paint);
// 渲染节点内容
await this.renderNodeContent(paint);
}
}
其中renderNodeContent方法是渲染一个元素节点里面的内容,其可能是正常元素、文字、图片、SVG、Canvas、input、iframe,对于不同的内容也会有不同的处理。
以上过程,就是html2canvas的整体内部流程,在了解了大致原理之后,我们再来看一个更为详细的源码流程图,对上述流程进行一个简单的总结。
五、 常见问题总结
在使用html2canvas的过程中,会有一些常见的问题和坑,总结如下:
(一)截图不全
要解决这个问题,只需要在截图之前将页面滚动到顶部即可:
document.documentElement.scrollTop = 0;
document.body.scrollTop = 0;
(二)图片跨域
插件在请求图片的时候会有图片跨域的情况,这是因为,如果使用跨域的资源画到canvas中,并且资源没有使用CORS去请求,canvas会被认为是被污染了,canvas可以正常展示,但是没办法使用toDataURL()或者toBlob()导出数据,详情可参考:developer.mozilla.org/en-US/docs/…
解决方案:在img标签上设置crossorigin,属性值为anonymous,可以开启CROS请求。当然,这种方式的前提还是服务端的响应头Access-Control-Allow-Origin已经被设置过允许跨域。如果图片本身服务端不支持跨域,可以使用canvas统一转成base64格式,方法如下。
function getUrlBase64_pro( len,url ) {
//图片转成base64
var canvas = document.createElement("canvas"); //创建canvas DOM元素
var ctx = canvas.getContext("2d");
return new Promise((reslove, reject) => {
var img = new Image();
img.crossOrigin = "Anonymous";
img.onload = function() {
canvas.height = len;
canvas.width = len;
ctx.drawImage(img, 0, 0, len, len);
var dataURL = canvas.toDataURL("image/");
canvas = null;
reslove(dataURL);
};
img.onerror = function(err){
reject(err)
}
img.src = url;
});
}
(三)截图与当前页面有区别
方式一:如果要从渲染中排除某些elements,可以向这些元素添加data-html2canvas-ignore属性,html2cnavas会将它们从渲染中排除,例如,如果不想截图iframe的部分,可以如下:
html2canvas(ele,{
useCORS: true,
ignoreElements: (element: any) => {
if (element.tagName.toLowerCase() === 'iframe') {
return element;
}
return false;
},
})
方式二:可以将需要转化成图片的部分放在一个节点内,再把整个节点,透明度设置为0, 其他部分层级设置高一些,即可实现截图指定区域。
六、 小结
本文针对前端截图实现的方式,对两个开源库dom-to-image和html2canvas的使用和原理进行了简单的使用方式、实现原理方面,进行介绍和分析。
参考资料:
1.dom-to-image原理
2.html2image原理简述
3.浏览器端网页截图方案详解
4.html2canvas
5.html2canvas实现浏览器截图的原理(包含源码分析的通用方法)
来源:juejin.cn/post/7400319811358818340
好好的短链,url?1=1为啥变成了url???1=1
运营小伙伴突然找到我们说,我们的一个短链有三个?
第一反应就是不可能,但是事实胜于雄辩,还真的就是和运营小伙伴说的一模一样。
到底发生了什么呢?跟着我一起Review一下。
一、URL结构
1.1 URL概述
URL(统一资源定位符)是一个用于标识互联网上资源的地址。一个典型的URL结构通常包括以下几个部分:

- 协议(Scheme) :也称为"服务方式",位于URL的开头,指定了浏览器与服务器之间通信的方式。常见的协议有
http(超文本传输协议)、https(安全超文本传输协议)、ftp(文件传输协议)等。 - 子域名(Subdomain) :可选部分,位于域名之前,通常用于区分不同的服务或组织。例如,在
sub.example.com中,sub是子域名。 - 域名(Domain Name) :URL的核心部分,用于唯一标识一个网站。通常是一个组织或公司的名字,如
example.com。 - 端口号(Port) :可选部分,用于指定服务器上的特定服务。如果省略,浏览器将使用默认端口,例如
http和https的默认端口是80和443。 - 路径(Path) :指定服务器上的资源位置。路径可以包含多个部分,用斜杠
/分隔。例如,在/path/to/resource中,path/to/resource是资源的路径。 - 查询字符串(Query String) :可选部分,位于路径之后,用于传递额外的参数或数据。查询字符串以问号
?开始,后面跟着一系列的参数,参数之间用和号&分隔。例如,在?key1=value1&key2=value2中,key1和key2是参数名,value1和value2是对应的值。 - 片段标识符(Fragment Identifier) :可选部分,用于指向页面内的特定部分。片段标识符以井号
#开始,通常用于锚点链接。例如,在#section2中,section2是页面内的一个锚点。
1.2 URL示例
示例:一个完整的URL示例可能是下面这样的
https://www.xxx.com:8080/path/to/resource?key1=value1&key2=value2#section2
在上面的示例中,详细拆解如下:
https是协议。
http://www.xxx.com是域名。
8080是端口号。
/path/to/resource是路径。
key1=value1&key2=value2是查询字符串。
#section2是片段标识符。
二、URL的意义
URL(统一资源定位符)的意义在于它提供了一种标准化的方法来标识和访问互联网上的资源。它是互联网的基础构件之一,它不仅使得资源的定位和访问变得简单,还支持了互联网的组织、导航、安全和分享等多种功能。以下是URL的几个关键意义:

这些意义做开发的都懂,不懂的就自己百度吧,这里不做赘述。
三、硬菜:url?1=1为啥变成了url???1=1
3.1 故事背景
我们有一个自己的短链项目,用户访问短链的时候,我们自己服务器会进行重定向,这样的好处是分享出去的链接都是很短的,会有效提升用户的使用体验。
短链触发和服务器的交互流程如下:
sequenceDiagram
用户->>+短链: 点击
短链->>+服务器: 请求
服务器->>+服务器: 找到映射的长链地址
服务器->>+用户: 重定向到长链
用户->>+长链: 请求并得到响应
3.2 事故现场
上面弄清楚了短链的基本触发流程,那我我们看看到底发生了什么。
- 客户端事故现场截图

从这个截图就可以明显的看出,这里有三个?,这是不合理的...
- 数据库存储的事故现场数据截图

哎,数据库里面只有一个问号吧?
3.3 问题分析和解决方案
- 问题分析
上面数据库看着正常的,别着急,咱们换个方式看看,我们执行下面这个SQL看看数据存储的实际长度是多少。
SELECT
LENGTH(
CONVERT ( full_link USING utf8 )) AS actual_length
FROM
t_short_link
WHERE
id = '0fcc75b3e1b243c4b36d71b1d58b3b41';
执行结果:

上面sql执行实际得到的长度是52,但是我们长链的实际长度却是49,那么问题就出来了,数据库里面多了两个我们肉眼看不见的字符,三个问号就是这个来的
- 解决方案
从上面分析了事故现场,我们已经知道是多了两个字符了,删掉即可。
注意:因为数据库看不到,所以不能直接编辑,可以选择一些可以看到的编辑器编辑之后更新,例如notepad++。
3.4 额外发现
在写文章的时候,我将连接复制到了掘金的MD编辑器,发现这里也是暴露了问题,上面提到的解决方案,大家也是可以复制进来然后删除多余字符的。

四、总结
程序员大多数都非常自信,相信自己的代码没有bug,相信有bug也不是我的问题,有的时候怼天怼地。
但是真的遇到问题,需要三思而后行,谋定而后动;是不是自己的问题,先检查检查,避免后面发现是自己的问题很尴尬。
希望本文对您有所帮助。如果有任何错误或建议,请随时指正和提出。
同时,如果您觉得这篇文章有价值,请考虑点赞和收藏。这将激励我进一步改进和创作更多有用的内容。
感谢您的支持和理解!
来源:juejin.cn/post/7399985723674394633
折腾我2周的分页打印和下载pdf

1.背景
一开始接到任务需要打印html,之前用到了vue-print-nb-jeecg来处理Vue2一个打印的问题,现在是遇到需求要在Vue3项目里面去打印十几页的打印和下载为pdf,难点和坑就在于我用的库vue3-print-nb来做分页打印预览,下载pdf后面介绍
2.预览打印实现
<div id="printMe" style="background:red;">
<p>葫芦娃,葫芦娃</p>
<p>一根藤上七朵花 </p>
<p>小小树藤是我家 啦啦啦啦 </p>
<p>叮当当咚咚当当 浇不大</p>
<p> 叮当当咚咚当当 是我家</p>
<p> 啦啦啦啦</p>
<p>...</p>
</div>
<button v-print="'#printMe'">Print local range</button>
因为官方提供的方案都是DOM加载完成后然后直接打印,但是我的需求是需要点击打印的时候根据id渲染不同的组件然后渲染DOM,后面仔细看官方文档,有个beforeOpenCallback方法在打印预览之前有个钩子,但是这个钩子没办法确定我接口加载完毕,所以我的思路就是用户先点击我写的点击按钮事件,等异步渲染完毕之后,我再同步触发真正的打印预览按钮,这样就变相解决了我的需求。
坑
- 没办法处理接口异步渲染数据展示DOM进行打印操作
- 在布局相对定位的时候在谷歌浏览器会发现有布局整体变小的问题(后续用zoom处理的)
3.掉头发之下载pdf
下载pdf这种需求才是我每次去理发店不敢让tony把我头发打薄的原因,我看了很多技术文章,结合个人业务情况,采取的方案是html2canvas把html转成canvas然后转成图片然后通过jsPDF截取图片分页最后下载到本地。本人秉承着不生产水,只做大自然的搬运工的匠人精神,迅速而又果断的从社区来到社区去,然后找到了适配当前业务的逻辑代码(实践出真知)。
import html2canvas from 'html2canvas'
import jsPDF, { RGBAData } from 'jspdf'
/** a4纸的尺寸[595.28,841.89], 单位毫米 */
const [PAGE_WIDTH, PAGE_HEIGHT] = [595.28, 841.89]
const PAPER_CONFIG = {
/** 竖向 */
portrait: {
height: PAGE_HEIGHT,
width: PAGE_WIDTH,
contentWidth: 560
},
/** 横向 */
landscape: {
height: PAGE_WIDTH,
width: PAGE_HEIGHT,
contentWidth: 800
}
}
// 将元素转化为canvas元素
// 通过 放大 提高清晰度
// width为内容宽度
async function toCanvas(element: HTMLElement, width: number) {
if (!element) return { width, height: 0 }
// canvas元素
const canvas = await html2canvas(element, {
// allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true // 允许跨域
})
// 获取canvas转化后的宽高
const { width: canvasWidth, height: canvasHeight } = canvas
// html页面生成的canvas在pdf中的高度
const height = (width / canvasWidth) * canvasHeight
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0)
return { width, height, data: canvasData }
}
/**
* 生成pdf(A4多页pdf截断问题, 包括页眉、页脚 和 上下左右留空的护理)
* @param param0
* @returns
*/
export async function outputPDF({
/** pdf内容的dom元素 */
element,
/** 页脚dom元素 */
footer,
/** 页眉dom元素 */
header,
/** pdf文件名 */
filename,
/** a4值的方向: portrait or landscape */
orientation = 'portrait' as 'portrait' | 'landscape'
}) {
if (!(element instanceof HTMLElement)) {
return
}
if (!['portrait', 'landscape'].includes(orientation)) {
return Promise.reject(
new Error(`Invalid Parameters: the parameter {orientation} is assigned wrong value, you can only assign it with {portrait} or {landscape}`)
)
}
const [A4_WIDTH, A4_HEIGHT] = [PAPER_CONFIG[orientation].width, PAPER_CONFIG[orientation].height]
/** 一页pdf的内容宽度, 左右预设留白 */
const { contentWidth } = PAPER_CONFIG[orientation]
// eslint-disable-next-line new-cap
const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation
})
// 一页的高度, 转换宽度为一页元素的宽度
const { width, height, data } = await toCanvas(element, contentWidth)
// 添加
function addImage(
_x: number,
_y: number,
pdfInstance: jsPDF,
base_data: string | HTMLImageElement | HTMLCanvasElement | Uint8Array | RGBAData,
_width: number,
_height: number
) {
pdfInstance.addImage(base_data, 'JPEG', _x, _y, _width, _height)
}
// 增加空白遮挡
function addBlank(x: number, y: number, _width: number, _height: number) {
pdf.setFillColor(255, 255, 255)
pdf.rect(x, y, Math.ceil(_width), Math.ceil(_height), 'F')
}
// 页脚元素 经过转换后在PDF页面的高度
const { height: tFooterHeight, data: headerData } = footer ? await toCanvas(footer, contentWidth) : { height: 0, data: undefined }
// 页眉元素 经过转换后在PDF的高度
const { height: tHeaderHeight, data: footerData } = header ? await toCanvas(header, contentWidth) : { height: 0, data: undefined }
// 添加页脚
async function addHeader(headerElement: HTMLElement) {
headerData && pdf.addImage(headerData, 'JPEG', 0, 0, contentWidth, tHeaderHeight)
}
// 添加页眉
async function addFooter(pageNum: number, now: number, footerElement: HTMLElement) {
if (footerData) {
pdf.addImage(footerData, 'JPEG', 0, A4_HEIGHT - tFooterHeight, contentWidth, tFooterHeight)
}
}
// 距离PDF左边的距离,/ 2 表示居中
const baseX = (A4_WIDTH - contentWidth) / 2 // 预留空间给左边
// 距离PDF 页眉和页脚的间距, 留白留空
const baseY = 15
// 除去页头、页眉、还有内容与两者之间的间距后 每页内容的实际高度
const originalPageHeight = A4_HEIGHT - tFooterHeight - tHeaderHeight - 2 * baseY
// 元素在网页页面的宽度
const elementWidth = element.offsetWidth
// PDF内容宽度 和 在HTML中宽度 的比, 用于将 元素在网页的高度 转化为 PDF内容内的高度, 将 元素距离网页顶部的高度 转化为 距离Canvas顶部的高度
const rate = contentWidth / elementWidth
// 每一页的分页坐标, PDF高度, 初始值为根元素距离顶部的距离
const pages = [rate * getElementTop(element)]
// 获取该元素到页面顶部的高度(注意滑动scroll会影响高度)
function getElementTop(contentElement) {
if (contentElement.getBoundingClientRect) {
const rect = contentElement.getBoundingClientRect() || {}
const topDistance = rect.top
return topDistance
}
}
// 遍历正常的元素节点
function traversingNodes(nodes) {
for (const element of nodes) {
const one = element
/** */
/** 注意: 可以根据业务需求,判断其他场景的分页,本代码只判断表格的分页场景 */
/** */
// table的每一行元素也是深度终点
const isTableRow = one.classList && one.classList.contains('ant4-table-row')
// 对需要处理分页的元素,计算是否跨界,若跨界,则直接将顶部位置作为分页位置,进行分页,且子元素不需要再进行判断
const { offsetHeight } = one
// 计算出最终高度
const offsetTop = getElementTop(one)
// dom转换后距离顶部的高度
// 转换成canvas高度
const top = rate * offsetTop
const rateOffsetHeight = rate * offsetHeight
// 对于深度终点元素进行处理
if (isTableRow) {
// dom高度转换成生成pdf的实际高度
// 代码不考虑dom定位、边距、边框等因素,需在dom里自行考虑,如将box-sizing设置为border-box
updateTablePos(rateOffsetHeight, top)
}
// 对于普通元素,则判断是否高度超过分页值,并且深入
else {
// 执行位置更新操作
updateNormalElPos(top)
// 遍历子节点
traversingNodes(one.childNodes)
}
updatePos()
}
}
// 普通元素更新位置的方法
// 普通元素只需要考虑到是否到达了分页点,即当前距离顶部高度 - 上一个分页点的高度 大于 正常一页的高度,则需要载入分页点
function updateNormalElPos(top) {
if (top - (pages.length > 0 ? pages[pages.length - 1] : 0) >= originalPageHeight) {
pages.push((pages.length > 0 ? pages[pages.length - 1] : 0) + originalPageHeight)
}
}
// 可能跨页元素位置更新的方法
// 需要考虑分页元素,则需要考虑两种情况
// 1. 普通达顶情况,如上
// 2. 当前距离顶部高度加上元素自身高度 大于 整页高度,则需要载入一个分页点
function updateTablePos(eHeight: number, top: number) {
// 如果高度已经超过当前页,则证明可以分页了
if (top - (pages.length > 0 ? pages[pages.length - 1] : 0) >= originalPageHeight) {
pages.push((pages.length > 0 ? pages[pages.length - 1] : 0) + originalPageHeight)
}
// 若 距离当前页顶部的高度 加上元素自身的高度 大于 一页内容的高度, 则证明元素跨页,将当前高度作为分页位置
else if (
top + eHeight - (pages.length > 0 ? pages[pages.length - 1] : 0) > originalPageHeight &&
top !== (pages.length > 0 ? pages[pages.length - 1] : 0)
) {
pages.push(top)
}
}
// 深度遍历节点的方法
traversingNodes(element.childNodes)
function updatePos() {
while (pages[pages.length - 1] + originalPageHeight < height) {
pages.push(pages[pages.length - 1] + originalPageHeight)
}
}
// 对pages进行一个值的修正,因为pages生成是根据根元素来的,根元素并不是我们实际要打印的元素,而是element,
// 所��要把它修正,让其值是以真实的打印元素顶部节点为准
const newPages = pages.map(item => item - pages[0])
// 根据分页位置 开始分页
for (let i = 0; i < newPages.length; ++i) {
// 根据分页位置新增图片
addImage(baseX, baseY + tHeaderHeight - newPages[i], pdf, data!, width, height)
// 将 内容 与 页眉之间留空留白的部分进行遮白处理
addBlank(0, tHeaderHeight, A4_WIDTH, baseY)
// 将 内容 与 页脚之间留空留白的部分进行遮白处理
addBlank(0, A4_HEIGHT - baseY - tFooterHeight, A4_WIDTH, baseY)
// 对于除最后一页外,对 内容 的多余部分进行遮白处理
if (i < newPages.length - 1) {
// 获取当前页面需要的内容部分高度
const imageHeight = newPages[i + 1] - newPages[i]
// 对多余的内容部分进行遮白
addBlank(0, baseY + imageHeight + tHeaderHeight, A4_WIDTH, A4_HEIGHT - imageHeight)
}
// 添加页眉
if (header) {
await addHeader(header)
}
// 添加页脚
if (footer) {
await addFooter(newPages.length, i + 1, footer)
}
// 若不是最后一页,则分页
if (i !== newPages.length - 1) {
// 增加分页
pdf.addPage()
}
}
return pdf.save(filename)
}
4.分页的小姿势
如果有需求把打印预览的时候的页眉页脚默认取消不展示,然后自定义页面的边距可以这么设置样式
@page {
size: auto A4 landscape;
margin: 3mm;
}
@media print {
body,
html {
height: initial;
padding: 0px;
margin: 0px;
}
}
5.关于页眉页脚
由于业务是属于比较自定义化的展示,所以我封装成组件,然后根据返回的数据进行渲染到每个界面,然后利用绝对定位放在相同的位置,最后一点小优化就是,公共化提取界面的样式,然后整合为pub.scss然后引入到界面里面,这样即使产品有一定的样式调整,我也可以在公共样式里面去配置和修改,大大的减少本人的工作量。在日常的开发中也是这样,不要去抱怨需求的变动频繁,而是力争在写组件的过程中考虑到组件的健壮性和灵活度,给自己的工作减负,到点下班。
参考文章
来源:juejin.cn/post/7397319113796780042
借助 LocatorJS ,快速定位本地代码
引言
前端coder在刚接触一个新项目时是十分迷茫的,修改一个小 bug 可能要从路由结构入手逐级查找。 LocatorJS 提供了一种更便捷的方式,你只需要按住预设的快捷键选中元素点击,就可以快速打开本地编辑器中的代码,是不是非常神奇?
安装
访问 google 商店进行插件安装 地址
用法
本文以 MacOS 系统为例, Win系统可以用 Control 键替代 options键使用
LocatorJS 是 Chrome 浏览器的一个扩展程序,使用很便捷,只需要进行下面的三个步骤:
- 运行一个本地项目(本文以 LocatorJS源码 的 React 项目为例)
- 打开项目访问本地链接(例如:http://localhost:3348 )
- 按住键盘的 option 键(win系统是 control)后选中某一个元素并点击

这时候,就会跳出一个是否打开的提示,点击 “打开Visual Studio Code” 后 元素所在的本地代码就会通过你的 VsCode (或者其他编辑器) 打开。是不是很神奇,那么它是怎么实现的呢?
原理解读
解读 Chrome 扩展程序,我们先打开 apps/extension/src/pages 路径,可以看到如下几个文件夹:

● Background 是放置后台代码的文件夹,本插件不涉及
● ClientUI 这里只有一行,引入了 @locator/runtime(本插件的核心代码)
● Content 放着插件与浏览器内容页面的代码,与页面代码一起执行
● Popup 文件夹下是点击浏览器插件图标弹出层的代码
4.1 解读 Content/index.ts
Content/index.ts 中最重要的代码是 injectScript 方法,主要做了两件事情,一个是创建了 Script 标签执行了 hook.bundle.js,另一个是将 client.bundle.js 赋值给了 document.documentElement.dataset.locatorClientUrl(通过 Dom 传值),其余代码是一些监听事件
function injectScript() {
const script = document.createElement('script');
// script.textContent = code.default;
script.src = browser.runtime.getURL('/hook.bundle.js');
document.documentElement.dataset.locatorClientUrl =
browser.runtime.getURL('/client.bundle.js');
// This script runs before the <head> element is created,
// so we add the script to <html> instead.
if (document.documentElement) {
document.documentElement.appendChild(script);
if (script.parentNode) {
script.parentNode.removeChild(script);
}
}
}
4.2 解读 hook.bundle.js
hook.bundle.js 是 hook 文件夹下的 index文件打包后的产物,因此我们去·看 apps/extension/src/pages/hook/index.ts 即可
import { installReactDevtoolsHook } from '@locator/react-devtools-hook';
import { insertRuntimeScript } from './insertRuntimeScript';
installReactDevtoolsHook();
insertRuntimeScript();
● installReactDevtoolsHook 会确保你的 react devtools扩展已安装 (没安装就install一个,猜测是仅涉及使用 API 的轻量版(笔者未深究))
● insertRuntimeScript 会对页面生命周期做一个监听,尝试加载 LocatorJS 的 runtime 组件, 在 insertRuntimeScript() 中,看到了这两行:
const locatorClientUrl = document.documentElement.dataset.locatorClientUrl;
delete document.documentElement.dataset.locatorClientUrl;
这个 locatorClientUrl 就是之前在 Content/index.ts 里传值的那个 client.bundle.js,这里笔者简单说下,在尝试加载插件的方法 tryToInsertScript() 第一行判断如下:
if (!locatorClientUrl) {
return 'Locator client url not found';
}
这行判断其实已经可以推测出 client.bundle.js 的重要性了,它加载失败,整个插件直接返回错误信息了。
回过头来看向 ClientUI 文件夹下的 index.tsx 文件:
import '@locator/runtime';
至此,我们已经完成了 locatorJs 的加载逻辑推导,下一步我们讲揭开“定位器”的神秘面纱...
4.3 解读核心代码 runtime 模块
打开 packages/runtime/src/index.ts 文件

在这里我们看到不论是本地加载 runtime,还是浏览器加载扩展的方式都会去执行 initRuntime
initRuntime.ts
packages/runtime/src/initRuntime.ts 的initRuntime

这个文件中声明了一些全局样式,并用 shadow dom 的方式进行了全局的样式隔离,我们关注下底部的这几行代码即可:
// This weird import is needed because:
// SSR React (Next.js) breaks when importing any SolidJS compiled file, so the import has to be conditional
// Browser Extension breaks when importing with "import()"
// Vite breaks when importing with "require()"
if (typeof require !== "undefined") {
// eslint-disable-next-line @typescript-eslint/no-var-requires
const { initRender } = require("./components/Runtime");
initRender(layer, adapter, targets || allTargets);
} else {
import("./components/Runtime").then(({ initRender }) => {
initRender(layer, adapter, targets || allTargets);
});
}
兼容了一下服务端渲染和 SolidJs 的引入方式,引入相对路径下的 ./components/Runtime
核心组件 Runtime.tsx
packages/runtime/src/components/Runtime.tsx
抽丝剥茧,我们终于找到了它的核心组件 Runtime,这是一个使用 SolidJs框架编写的组件,包含了我们选中元素时出现的红框样式,以及所有的事件:

我们重点关注点击事件 clickListener ,最后点击跳转的方法是 goToLinkProps
export function goToLinkProps(
linkProps: LinkProps,
targets: Targets,
options: OptionsStore
) {
const link = buildLink(linkProps, targets, options);
window.open(link, options.getOptions().hrefTarget || HREF_TARGET);
}
采用逆推的方式,看 clickListener 事件里的 LinkProps 是怎样生成的:
function clickListener(e: MouseEvent) {
...
const elInfo = getElementInfo(target, props.adapterId);
if (elInfo) {
const linkProps = elInfo.thisElement.link;
...
}
...
}
同样的方式,我们去看看 getElementInfo 怎么返回的(过程略过),我们以 react 的实现为例,打开
packages/runtime/src/adapters/react/reactAdapter.ts, 查看 getElementInfo 方法
export function getElementInfo(found: HTMLElement): FullElementInfo | null {
const labels: LabelData[] = [];
const fiber = findFiberByHtmlElement(found, false);
if (fiber) {
...
const thisLabel = getFiberLabel(fiber, findDebugSource(fiber)?.source);
...
return {
thisElement: {
box: getFiberOwnBoundingBox(fiber) || found.getBoundingClientRect(),
...thisLabel,
},
...
};
}
return null;
}
前面 goToLinkProps 使用的是 thisElement.link 字段, thisLabel 又依赖于 fiber 字段,等等! 这不是我们 react 玩家的老朋友 fiber 吗,我们查看一下生成它的 findFiberByHtmlElement 方法
export function findFiberByHtmlElement(
target: HTMLElement,
shouldHaveDebugSource: boolean
): Fiber | null {
const renderers = window.__REACT_DEVTOOLS_GLOBAL_HOOK__?.renderers;
const renderersValues = renderers?.values();
if (renderersValues) {
for (const renderer of Array.from(renderersValues) as Renderer[]) {
if (renderer.findFiberByHostInstance) {
const found = renderer.findFiberByHostInstance(target as any);
console.log('found', found)
if (found) {
if (shouldHaveDebugSource) {
return findDebugSource(found)?.fiber || null;
} else {
return found;
}
}
}
}
}
return null;
}
可以看到,这里是直接使用的 window 对象下的 __REACT_DEVTOOLS_GLOBAL_HOOK__ 属性做的处理,我们先打印一下 fiber 查看下生成的结构

惊奇的发现 _debugSource 字段里竟然包含了点击元素所对应本地文件的路径
我们到 goToLinkProps 方法里打印一下跳转的路径发现果然一致,只是实际跳转的路径加上了 vscode:// 开头,进行了协议跳转。
真相解读,_debugOwner 是怎么来的
一路砍瓜切菜终于要接近真相了,回顾代码我们其实只需要搞懂 window.REACT_DEVTOOLS_GLOBAL_HOOK 是怎么来的以及它做了什么,就可以收工了。
- _debugOwner 怎么来的?
_debugOwner是通过 window.REACT_DEVTOOLS_GLOBAL_HOOK 根据 HtmlElement 生成的 fiber 得来的, 它是 React Devtools 插件的全局变量 HOOK,这就是为什么hook.bundle.js要确保安装了 React Devtools - REACT_DEVTOOLS_GLOBAL_HOOK 做了什么
它是通过 @babel/plugin-transform-react-jsx-source 实现的,这个 plugin 可以在创建 fiber 的时候,将元素本地代码的位置信息保存下来,以
_debugSource字段进行抛出
总结
LocatorJs 的 React 方案使用 React Devtools 扩展的全局 Hook,由 @babel/plugin-transform-react-jsx-source plugin 将元素所在代码路径写入 fiber 对象当中,通过 HtmlElement 查找到相对应的 fiber,取得本地代码的路径,随即可实现定位代码并跳转的功能。
结语
本文粗略的讲解了 LocatorJs 在 React 框架的原理实现,算是抛砖引玉,供大家参考。
篇幅原因,略过很多细节,感兴趣的朋友建议看看源码,结合调试学习
我是饮东,欢迎点赞关注,江湖再见
来源:juejin.cn/post/7358274599883653120
太方便了!Arthas,生产问题大杀器
一、一个难查的生产问题
一天,小王发现生产环境上偶发性地出现某接口耗时过高,但在测试环境又无法复现,小王一筹莫展😔。小王“幻想”到:如果有个工具能记录生产上各个函数的耗时该多好,这样一看不就知道时间花在哪了?
这不是幻想,Arthas 已经帮我们解决了这个问题。在介绍它之前,我们先了解下相关背景。
一天,小王发现生产环境上偶发性地出现某接口耗时过高,但在测试环境又无法复现,小王一筹莫展😔。小王“幻想”到:如果有个工具能记录生产上各个函数的耗时该多好,这样一看不就知道时间花在哪了?
这不是幻想,Arthas 已经帮我们解决了这个问题。在介绍它之前,我们先了解下相关背景。
二、动态追踪
现在互联网和大家生活的各个方面都息息相关。相应地,互联网应用的用户规模也变得越来越大。江湖大了,什么风浪都有。开发者们不断被各种诡异问题打扰,接口耗时过大、CPU 占用过高、内存溢出、只有生产环境会报错......
这些问题出现的概率可能是千分之一、乃至万分之一。如果我们能不修改代码、不修改配置、不重启服务,就能看到程序内部在执行什么,这该多好,再大的问题心里也有底了。
动态追踪技术出现了,它诞生于21 世纪初。Sun Microsystems 公司的工程师在解决一个复杂问题时被繁琐的排查过程所困扰,痛定思痛,他们创造了 DTrace 动态跟踪框架。DTrace 奠定了动态追踪的基础,Bryan Cantrill, Mike Shapiro, and Adam Leventhal 三位作者也多次获得行业荣誉。
动态追踪技术出现的时间早,但 Java 语言相关的调试工具链一直不太完善。直到进入移动互联网时代,Java 的发展才进入了快车道。2018 年,Alibaba 开源 Arthas,Java 的动态追踪才真正好用起来。
动态追踪可以看作是构建了一个运行时“只读数据库”,这个数据库内部保存了实时变化的进程运行信息,我们通过调用这个“数据库”开放的接口,就能看到进程内部发生了什么。
经验丰富的读者可能会有疑问,现在微服务都用上了 Skywalking 这样的分布式链路追踪技术,通过它也能分阶段地看到各个部分的执行情况,为什么还需要 Arthas?
Arthas 有两大特点:
- 低侵入;不需要程序中进行额外配置,更不需要手动埋点。
- 功能强大;Arthas 提供了四十多种命令:从查看线程调用链,到查看输入、输出,到反编译代码等,应有尽有。
对于排查接口耗时长这样的情况,Skywalking 可以和 Arthas 配合起来,先用 Skywalking 定位出异常微服务,再用 Arthas 分析单个进程的情况,找到根因。
现在互联网和大家生活的各个方面都息息相关。相应地,互联网应用的用户规模也变得越来越大。江湖大了,什么风浪都有。开发者们不断被各种诡异问题打扰,接口耗时过大、CPU 占用过高、内存溢出、只有生产环境会报错......
这些问题出现的概率可能是千分之一、乃至万分之一。如果我们能不修改代码、不修改配置、不重启服务,就能看到程序内部在执行什么,这该多好,再大的问题心里也有底了。
动态追踪技术出现了,它诞生于21 世纪初。Sun Microsystems 公司的工程师在解决一个复杂问题时被繁琐的排查过程所困扰,痛定思痛,他们创造了 DTrace 动态跟踪框架。DTrace 奠定了动态追踪的基础,Bryan Cantrill, Mike Shapiro, and Adam Leventhal 三位作者也多次获得行业荣誉。
动态追踪技术出现的时间早,但 Java 语言相关的调试工具链一直不太完善。直到进入移动互联网时代,Java 的发展才进入了快车道。2018 年,Alibaba 开源 Arthas,Java 的动态追踪才真正好用起来。
动态追踪可以看作是构建了一个运行时“只读数据库”,这个数据库内部保存了实时变化的进程运行信息,我们通过调用这个“数据库”开放的接口,就能看到进程内部发生了什么。
经验丰富的读者可能会有疑问,现在微服务都用上了 Skywalking 这样的分布式链路追踪技术,通过它也能分阶段地看到各个部分的执行情况,为什么还需要 Arthas?
Arthas 有两大特点:
- 低侵入;不需要程序中进行额外配置,更不需要手动埋点。
- 功能强大;Arthas 提供了四十多种命令:从查看线程调用链,到查看输入、输出,到反编译代码等,应有尽有。
对于排查接口耗时长这样的情况,Skywalking 可以和 Arthas 配合起来,先用 Skywalking 定位出异常微服务,再用 Arthas 分析单个进程的情况,找到根因。
三、Arthas常用场景
相信你对动态追踪有了基本的了解,Arthas 可以理解为动态追踪在 Java 领域落地的具体工具。下面以场景助学,大家可以参考这些方案,因事制宜来解决自己的问题。
Arthas 的安装和基础使用见官方文档:Introduction | arthas。
相信你对动态追踪有了基本的了解,Arthas 可以理解为动态追踪在 Java 领域落地的具体工具。下面以场景助学,大家可以参考这些方案,因事制宜来解决自己的问题。
Arthas 的安装和基础使用见官方文档:Introduction | arthas。
3.1.接口慢/吞吐量低
在文章开头,小王就遇到了这个问题。现在小王依靠老道的排查经验确定了 MathGame 服务肯定有问题,但具体的点却找不到。小王仔细学习了这篇文章,决定用 Arthas 分以下三步来排查:
- profile 明确整体的耗时情况
profile 命令支持为应用生成火焰图,在 Arthas 终端输入以下命令:
# 开始对应用中当前执行的活动采样 30 秒,采样结束后默认会生成 HTML 文件
[arthas@5555]$ profiler start -d 30
打开 HTML 文件能看到这样的结构:

火焰图
MathGame 类下的 run 方法占用了大部分的执行时间,接下来我们看看 run 方法内部的耗时情况。
- trace 详细查看单个调用的内部耗时
[arthas@5555]$ trace --skipJDKMethod false demo.MathGame run
PrintStream 类的 print 方法占据了 87% 的时间,这是 JDK 自带的类,这说明我们程序本身并无耗时问题,但 MathGame 类的 primeFactors 方法抛出了异常,我们可以看看具体的异常,再思考怎么优化。

run方法的trace流
另外,trace 可以选择性地进行调用拦截,比如设置只拦截大于 20ms 的调用:
[arthas@5555]$ trace demo.MathGame run '#cost > 20'
- watch 查看真实的调用数据
拦截 primeFactors 方法抛出的异常:
[arthas@5555]$ watch demo.MathGame primeFactors -e "throwExp"

拦截异常
小王从大到小、逐步分析,找出了问题的原因是 primeFactors 抛出了异常,修正参数后,程序恢复了正常。
在文章开头,小王就遇到了这个问题。现在小王依靠老道的排查经验确定了 MathGame 服务肯定有问题,但具体的点却找不到。小王仔细学习了这篇文章,决定用 Arthas 分以下三步来排查:
- profile 明确整体的耗时情况
profile 命令支持为应用生成火焰图,在 Arthas 终端输入以下命令:
# 开始对应用中当前执行的活动采样 30 秒,采样结束后默认会生成 HTML 文件
[arthas@5555]$ profiler start -d 30
打开 HTML 文件能看到这样的结构:
火焰图MathGame 类下的 run 方法占用了大部分的执行时间,接下来我们看看 run 方法内部的耗时情况。
- trace 详细查看单个调用的内部耗时
[arthas@5555]$ trace --skipJDKMethod false demo.MathGame run
PrintStream 类的 print 方法占据了 87% 的时间,这是 JDK 自带的类,这说明我们程序本身并无耗时问题,但 MathGame 类的 primeFactors 方法抛出了异常,我们可以看看具体的异常,再思考怎么优化。
run方法的trace流另外,trace 可以选择性地进行调用拦截,比如设置只拦截大于 20ms 的调用:
[arthas@5555]$ trace demo.MathGame run '#cost > 20'
- watch 查看真实的调用数据
拦截 primeFactors 方法抛出的异常:
[arthas@5555]$ watch demo.MathGame primeFactors -e "throwExp"
拦截异常
小王从大到小、逐步分析,找出了问题的原因是 primeFactors 抛出了异常,修正参数后,程序恢复了正常。
3.2.CPU 占用过高
CPU 是程序运行的核心计算资源,一旦出现 CPU 占用过高,必定对大部分用户的访问耗时产生影响。针对这类问题,要定位出有问题的线程,并获取该线程当前执行的代码位置。
使用 top + jstack 命令可以定位这类问题(见参考资料三),Arthas 也提供了更便捷的一体化工具:
- 定位目标线程
# 调用线程看板,并刷新数据三次
[arthas@5555]$ dashboard -n 3

示例程序的CPU占用不算高
DashBoard 刷新三次后,在最新状态中发现示例程序里自己的线程 “main” 占用不算高。说明程序运行正常。如果是要排错,这里就要找出 CPU 占用最高的用户线程的 ID。
- 查看目标线程执行的代码位置
# “1” 是上一步定位到的 main 的线程ID
[arthas@5555]$ thread 1

线程正在“睡觉”,没什么大问题。
CPU 是程序运行的核心计算资源,一旦出现 CPU 占用过高,必定对大部分用户的访问耗时产生影响。针对这类问题,要定位出有问题的线程,并获取该线程当前执行的代码位置。
使用 top + jstack 命令可以定位这类问题(见参考资料三),Arthas 也提供了更便捷的一体化工具:
- 定位目标线程
# 调用线程看板,并刷新数据三次
[arthas@5555]$ dashboard -n 3
示例程序的CPU占用不算高DashBoard 刷新三次后,在最新状态中发现示例程序里自己的线程 “main” 占用不算高。说明程序运行正常。如果是要排错,这里就要找出 CPU 占用最高的用户线程的 ID。
- 查看目标线程执行的代码位置
# “1” 是上一步定位到的 main 的线程ID
[arthas@5555]$ thread 1
线程正在“睡觉”,没什么大问题。
3.3 生产环境的效果和测试不一样
有些时候你发现:测试环境正常,但生产就报错了。这类问题主要靠做好上线流程的管控,但也有可能是打包的依赖库出现冲突,造成程序行为不一致。接下来,我们看看怎么用 Arthas 反编译代码,以及怎么对比依赖库的版本。
- 反编译代码
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ jad demo.MathGame

- 查看目标类所属的依赖包
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ sc -d demo.MathGame

目标类所属的包
如果这里是依赖包,code-source 还可以显示所属包的版本。这样就可以对比本地的代码,从而在打包时设置正确的依赖版本。
有些时候你发现:测试环境正常,但生产就报错了。这类问题主要靠做好上线流程的管控,但也有可能是打包的依赖库出现冲突,造成程序行为不一致。接下来,我们看看怎么用 Arthas 反编译代码,以及怎么对比依赖库的版本。
- 反编译代码
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ jad demo.MathGame
- 查看目标类所属的依赖包
# demo.MathGame 是目标类的全限定名
[arthas@5555]$ sc -d demo.MathGame
如果这里是依赖包,code-source 还可以显示所属包的版本。这样就可以对比本地的代码,从而在打包时设置正确的依赖版本。
目标类所属的包
3.4 内存溢出
生产问题中内存溢出也有不小的比例。内存溢出的关键是找出高内存占用的对象。命令行操作会比较麻烦,建议转储 Heap Dump 等文件后,通过 Eclipse Memory Analyzer(MAT) 等工具进行分析。
四、运行 Arthas 报错
在有些运行环境下,Arthas 会出现报错。对于以下两种情况,读者可参照文档解决:
- 不兼容 Skywalking
Compatible-with-other-javaagent-bytecode-processing - Alpine 镜像的容器无法生成火焰图
Alpine容器镜像中生成火焰图错误的其它解决方案
五、参考资料
作者:立子
来源:juejin.cn/post/7308230350374256666
来源:juejin.cn/post/7308230350374256666
SpringBoot 这么实现动态数据源切换,就很丝滑!
大家好,我是小富~
简介
项目开发中经常会遇到多数据源同时使用的场景,比如冷热数据的查询等情况,我们可以使用类似现成的工具包来解决问题,但在多数据源的使用中通常伴随着定制化的业务,所以一般的公司还是会自行实现多数据源切换的功能,接下来一起使用实现自定义注解的形式来实现一下。
基础配置
yml配置
pom.xml文件引入必要的Jar
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.6</version>
</parent>
<groupId>com.dynamic</groupId>
<artifactId>springboot-dynamic-datasource</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<mybatis.plus.version>3.5.3.1</mybatis.plus.version>
<mysql.connector.version>8.0.32</mysql.connector.version>
<druid.version>1.2.6</druid.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- springboot核心包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mysql驱动包 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<version>${mysql.connector.version}</version>
</dependency>
<!-- lombok工具包 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- MyBatis Plus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis.plus.version}</version>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.7</version>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
管理数据源
我们应用ThreadLocal来管理数据源信息,通过其中内容的get,set,remove方法来获取、设置、删除当前线程对应的数据源。
/**
* ThreadLocal存放数据源变量
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
public class DataSourceContextHolder {
private static final ThreadLocal<String> DATASOURCE_HOLDER = new ThreadLocal<>();
/**
* 获取当前线程的数据源
*
* @return 数据源名称
*/
public static String getDataSource() {
return DATASOURCE_HOLDER.get();
}
/**
* 设置数据源
*
* @param dataSourceName 数据源名称
*/
public static void setDataSource(String dataSourceName) {
DATASOURCE_HOLDER.set(dataSourceName);
}
/**
* 删除当前数据源
*/
public static void removeDataSource() {
DATASOURCE_HOLDER.remove();
}
}
重置数据源
创建 DynamicDataSource 类并继承 AbstractRoutingDataSource,这样我们就可以重置当前的数据库路由,实现切换成想要执行的目标数据库。
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import javax.sql.DataSource;
import java.util.Map;
/**
* 重置当前的数据库路由,实现切换成想要执行的目标数据库
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
public DynamicDataSource(DataSource defaultDataSource, Map<Object, Object> targetDataSources) {
super.setDefaultTargetDataSource(defaultDataSource);
super.setTargetDataSources(targetDataSources);
}
/**
* 这一步是关键,获取注册的数据源信息
* @return
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceContextHolder.getDataSource();
}
}
配置数据库
在 application.yml 中配置数据库信息,使用dynamic_datasource_1、dynamic_datasource_2两个数据库
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
master:
url: jdbc:mysql://127.0.0.1:3306/dynamic_datasource_1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 12345
driver-class-name: com.mysql.cj.jdbc.Driver
slave:
url: jdbc:mysql://127.0.0.1:3306/dynamic_datasource_2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 12345
driver-class-name: com.mysql.cj.jdbc.Driver
再将多个数据源注册到DataSource.
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* 注册多个数据源
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@Configuration
public class DateSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource dynamicDatasourceMaster() {
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave")
public DataSource dynamicDatasourceSlave() {
return DruidDataSourceBuilder.create().build();
}
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource createDynamicDataSource() {
Map<Object, Object> dataSourceMap = new HashMap<>();
// 设置默认的数据源为Master
DataSource defaultDataSource = dynamicDatasourceMaster();
dataSourceMap.put("master", defaultDataSource);
dataSourceMap.put("slave", dynamicDatasourceSlave());
return new DynamicDataSource(defaultDataSource, dataSourceMap);
}
}
启动类配置
在启动类的@SpringBootApplication注解中排除DataSourceAutoConfiguration,否则会报错。
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
到这多数据源的基础配置就结束了,接下来测试一下
测试切换
准备SQL
创建两个库dynamic_datasource_1、dynamic_datasource_2,库中均创建同一张表 t_dynamic_datasource_data。
CREATE TABLE `t_dynamic_datasource_data` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`source_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
dynamic_datasource_1.t_dynamic_datasource_data表中插入
insert int0 t_dynamic_datasource_data (source_name) value ('dynamic_datasource_master');
dynamic_datasource_2.t_dynamic_datasource_data表中插入
insert int0 t_dynamic_datasource_data (source_name) value ('dynamic_datasource_slave');
手动切换数据源
这里我准备了一个接口来验证,传入的 datasourceName 参数值就是刚刚注册的数据源的key。
/**
* 动态数据源切换
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@RestController
public class DynamicSwitchController {
@Resource
private DynamicDatasourceDataMapper dynamicDatasourceDataMapper;
@GetMapping("/switchDataSource/{datasourceName}")
public String switchDataSource(@PathVariable("datasourceName") String datasourceName) {
DataSourceContextHolder.setDataSource(datasourceName);
DynamicDatasourceData dynamicDatasourceData = dynamicDatasourceDataMapper.selectOne(null);
DataSourceContextHolder.removeDataSource();
return dynamicDatasourceData.getSourceName();
}
}
传入参数master时:127.0.0.1:9004/switchDataSource/master

传入参数slave时:127.0.0.1:9004/switchDataSource/slave

通过执行结果,我们看到传递不同的数据源名称,已经实现了查询对应的数据库数据。
注解切换数据源
上边已经成功实现了手动切换数据源,但这种方式顶多算是半自动,下边我们来使用注解方式实现动态切换。
定义注解
我们先定一个名为DS的注解,作用域为METHOD方法上,由于@DS中设置的默认值是:master,因此在调用主数据源时,可以不用进行传值。
/**
* 定于数据源切换注解
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DS {
// 默认数据源master
String value() default "master";
}
实现AOP
定义了@DS注解后,紧接着实现注解的AOP逻辑,拿到注解传递值,然后设置当前线程的数据源
import com.dynamic.config.DataSourceContextHolder;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.util.Objects;
/**
* 实现@DS注解的AOP切面
*
* @author 公众号:程序员小富
* @date 2023/11/27 11:02
*/
@Aspect
@Component
@Slf4j
public class DSAspect {
@Pointcut("@annotation(com.dynamic.aspect.DS)")
public void dynamicDataSource() {
}
@Around("dynamicDataSource()")
public Object datasourceAround(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
DS ds = method.getAnnotation(DS.class);
if (Objects.nonNull(ds)) {
DataSourceContextHolder.setDataSource(ds.value());
}
try {
return point.proceed();
} finally {
DataSourceContextHolder.removeDataSource();
}
}
}
测试注解
再添加两个接口测试,使用@DS注解标注,使用不同的数据源名称,内部执行相同的查询条件,看看结果如何?
@DS(value = "master")
@GetMapping("/dbMaster")
public String dbMaster() {
DynamicDatasourceData dynamicDatasourceData = dynamicDatasourceDataMapper.selectOne(null);
return dynamicDatasourceData.getSourceName();
}

@DS(value = "slave")
@GetMapping("/dbSlave")
public String dbSlave() {
DynamicDatasourceData dynamicDatasourceData = dynamicDatasourceDataMapper.selectOne(null);
return dynamicDatasourceData.getSourceName();
}

通过执行结果,看到通过应用@DS注解也成功的进行了数据源的切换。
事务管理
在动态切换数据源的时候有一个问题是要考虑的,那就是事务管理是否还会生效呢?
我们做个测试,新增一个接口分别插入两条记录,其中在插入第二条数据时将值设置超过了字段长度限制,会产生Data too long for column异常。
/**
* 验证一下事物控制
*/
// @Transactional(rollbackFor = Exception.class)
@DS(value = "slave")
@GetMapping("/dbTestTransactional")
public void dbTestTransactional() {
DynamicDatasourceData datasourceData = new DynamicDatasourceData();
datasourceData.setSourceName("test");
dynamicDatasourceDataMapper.insert(datasourceData);
DynamicDatasourceData datasourceData1 = new DynamicDatasourceData();
datasourceData1.setSourceName("testtesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttesttest");
dynamicDatasourceDataMapper.insert(datasourceData1);
}
经过测试发现执行结果如下,即便实现动态切换数据源,本地事务依然可以生效。
- 不加上
@Transactional注解第一条记录可以插入,第二条插入失败 - 加上
@Transactional注解两条记录都不会插入成功
本文案例地址:github.com/chengxy-nds…
来源:juejin.cn/post/7316202800663363594
这个字符串”2*(1+3-4)“的结果是多少
大家好,我是火焱。
前两天,在抖音上刷到一个计算器魔术,很有意思。

于是拿出手机尝试,发现不太对,为什么我的计算器直接把输入的内容都展示出来了?看评论区发现很多人都有类似的问题。

既然自带的计算器不好使,那就用小程序写一个。
产品描述
计算器的显示区只展示当前的数字,如果按了运算符(+ - * /),再输入数字时,展示当前的新数字,不展示之前输入的内容,按等于(=)号后,展示计算结果。
从程序员视角看,按等于(=) 时,我们拿到的是四则运算的字符串,比如:"1 + 2 * 3 - 4",然后通过代码计算这个字符串的结果,那么如何计算呢?
初步尝试
对于 javascript,很容易想到通过 eval 或者 new Function 实现,可是小程序...

既然捷径走不通,那就用逆波兰表达式来解决,我们来看下表达式的三种表示方法。
三种表示
中缀表达式,就是我们常用的表示方式:1 + 2 * 3 - 4
前缀表达式,也叫波兰表达式,是把操作符放到操作数前边,表示成:- + 1 * 2 3 4,由于后缀表达式操作起来比较方便,我们重点看下后缀表达式;
后缀表达式,也叫逆波兰表达式,它是把操作符放到操作数后边,表示成:1 2 3 * + 4 -,有了后缀表达式,我们就可以很容易计算结果了,那如何将中缀表达式转化成后序表达式呢?语言表述比较乏力,直接看代码吧,逻辑比较清晰:
/** 中缀表达式 转 后缀表达式 */
function infixToPostfix(infixExpression) {
let output = [];
// 存放运算符
let stack = [];
for (let i = 0; i < infixExpression.length; i++) {
let char = infixExpression[i];
if (!isOperator(char)) { // char 是数字
output.push(char);
} else { // char 是运算符
while (
// 栈不为空
stack.length > 0 &&
// 栈顶操作符的优先级不小于 char 的优先级
getPrecedence(stack[stack.length - 1]) >= getPrecedence(char)
) {
output.push(stack.pop());
}
stack.push(char);
}
}
// 将剩余的运算符弹出并追加到 output 后边
while (stack.length > 0) {
output.push(stack.pop());
}
return output.join('');
}
结合下图理解一下:
表达式:1 + 2 * 3 - 4

处理括号
带括号的表达式,处理逻辑和不带括号是一样的,只是多了对括号的处理。当遇到右括号时,需要把栈中左括号后面的所有运算符弹出,并追加到 output,举个例子:
计算:2 * ( 1 + 3 - 4)

通过这个例子,我们可以看出,后缀表示法居然不需要括号,更简洁。
好了,现在已经有了后序表达式,我们如何的到计算结果呢?
计算结果
计算这一步其实比较简单,直接上代码吧:
const operators = {
'+': function (a, b) { return a + b; },
'-': function (a, b) { return a - b; },
'*': function (a, b) { return a * b; },
'/': function (a, b) { return a / b; }
};
const stack = [];
postfixTokens.forEach(function (token) {
if (!isNaN(token)) {
stack.push(token);
} else if (isOperator(token)) {
var b = stack.pop();
var a = stack.pop();
stack.push(operators[token](a, b));
}
});
总结
中缀表达式对于人比较友好,而后缀表达式对计算机友好,通过对数字和运算符的编排即可实现带优先级的运算。如果本文对你有帮助,欢迎点赞、评论。
来源:juejin.cn/post/7294441582983528484
鸿蒙next高仿微信来了 我不允许你不会
前言导读
各位同学大家,有段时间没有跟大家见面了,因为最近一直在更新鸿蒙的那个实战课程所以就没有去更新文章实在是不好意思, 所以今天就给大家更新一期实战案例 高仿微信案例 希望帮助到各位同学工作和学习
效果图






特点
- 高仿程度80
- 目前不支持即时通讯功能
- 支持最新的api 12
- 目前做了账号注册和登录自动登录功能入口
具体实现
启动页面
/**
* 创建人:xuqing
* 创建时间:2024年7月14日22:56:15
* 类说明:欢迎页面
*
*/
import router from '@ohos.router';
import { preferences } from '@kit.ArkData';
import CommonConstant from '../common/CommonConstants';
import Logger from '../utils/Logger';
import { httpRequestGet } from '../utils/OkhttpUtils';
import { LoginModel } from '../bean/LoginModel';
let dataPreferences: preferences.Preferences | null = null;
@Entry
@Component
struct Welcome {
async aboutToAppear(){
let options: preferences.Options = { name: 'myStore' };
dataPreferences = preferences.getPreferencesSync(getContext(), options);
let getusername=dataPreferences.getSync('username','');
let getpassword=dataPreferences.getSync('password','');
if(getusername===''||getpassword===''){
router.pushUrl({
url:'pages/LoginPage'
})
}else {
let username:string='username=';
let password:string='&password=';
let netloginurl=CommonConstant.LOGIN+username+getusername+password+getpassword;
httpRequestGet(netloginurl).then((data)=>{
Logger.error("请求数据--->"+ data.toString());
let loginmodel:LoginModel=JSON.parse(data.toString());
if(loginmodel.code===200){
router.pushUrl({
url:'pages/Index'
})
}else{
router.pushUrl({
url:'pages/LoginPage'
})
}
})
}
}
build() {
RelativeContainer(){
Image($r('app.media.weixinbg'))
.width('100%')
.height('100%')
}.height('100%')
.width('100%')
.backgroundColor(Color.Green)
}
}
登录页面
import CommonConstant, * as commonConst from '../common/CommonConstants';
import Logger from '../utils/Logger';
import { httpRequestGet } from '../utils/OkhttpUtils';
import { LoginData, LoginModel} from '../bean/LoginModel';
import prompt from '@ohos.promptAction';
import router from '@ohos.router';
import { preferences } from '@kit.ArkData';
let dataPreferences: preferences.Preferences | null = null;
/**
* 创建人:xuqing
* 创建时间:2024年7月14日17:00:03
* 类说明:登录页面
*
*/
//输入框样式
@Extend(TextInput) function inputStyle(){
.placeholderColor($r('app.color.placeholder_color'))
.height(45)
.fontSize(18)
.backgroundColor($r('app.color.background'))
.width('100%')
.padding({left:0})
.margin({top:12})
}
//线条样式
@Extend(Line) function lineStyle(){
.width('100%')
.height(1)
.backgroundColor($r('app.color.line_color'))
}
//黑色字体样式
@Extend(Text) function blackTextStyle(size?:number ,height?:number){
.fontColor($r('app.color.black_text_color'))
.fontSize(18)
.fontWeight(FontWeight.Medium)
}
@Entry
@Component
struct LoginPage {
@State accout:string='';
@State password:string='';
async login(){
let username:string='username=';
let password:string='&password=';
let netloginurl=CommonConstant.LOGIN+username+this.accout+password+this.password;
Logger.error("请求url"+netloginurl);
await httpRequestGet(netloginurl).then((data)=>{
Logger.error("请求结果"+data.toString());
let loginModel:LoginModel=JSON.parse(data.toString());
let msg=loginModel.msg;
let logindata:LoginData=loginModel.user;
let token=loginModel.token;
let userid=logindata.id;
let options: preferences.Options = { name: 'myStore' };
dataPreferences = preferences.getPreferencesSync(getContext(), options);
if(loginModel.code===200){
Logger.error("登录成功");
dataPreferences.putSync('token',token);
dataPreferences.putSync('id',userid);
dataPreferences.putSync('username',this.accout);
dataPreferences.putSync('password',this.password);
dataPreferences!!.flush()
router.pushUrl({
url:'pages/Index'
})
}else {
prompt.showToast({
message:msg
})
}
})
}
build() {
Column(){
Image($r('app.media.weixinicon'))
.width(48)
.height(48)
.margin({top:100,bottom:8})
.borderRadius(8)
Text('登录界面')
.fontSize(24)
.fontWeight(FontWeight.Medium)
.fontColor($r('app.color.title_text_color'))
Text('登录账号以使用更多服务')
.fontSize(16)
.fontColor($r('app.color.login_more_text_color'))
.margin({bottom:30,top:8})
Row(){
Text('账号').blackTextStyle()
TextInput({placeholder:'请输入账号'})
.maxLength(12)
.type(InputType.Number)
.inputStyle()
.onChange((value:string)=>{
this.accout=value;
}).margin({left:20})
}.justifyContent(FlexAlign.SpaceBetween)
.width('100%')
.margin({top:8})
Line().lineStyle().margin({left:80})
Row(){
Text('密码').blackTextStyle()
TextInput({placeholder:'请输入密码'})
.maxLength(12)
.type(InputType.Password)
.inputStyle()
.onChange((value:string)=>{
this.password=value;
}).margin({left:20})
}.justifyContent(FlexAlign.SpaceBetween)
.width('100%')
.margin({top:8})
Line().lineStyle().margin({left:80})
Button('登录',{type:ButtonType.Capsule})
.width('90%')
.height(40)
.fontSize(16)
.fontWeight(FontWeight.Medium)
.backgroundColor($r('app.color.login_button_color'))
.margin({top:47,bottom:12})
.onClick(()=>{
this.login()
})
Text('注册账号').onClick(()=>{
router.pushUrl({
url:'pages/RegisterPage'
})
}).fontColor($r('app.color.login_blue_text_color'))
.fontSize(12)
.fontWeight(FontWeight.Medium)
}.backgroundColor($r('app.color.background'))
.height('100%')
.width('100%')
.padding({
left:12,
right:12,
bottom:24
})
}
}
主页index
import home from './Home/Home';
import contacts from './Contact/Contacts';
import Discover from './Discover/Discover';
import My from './My/My';
import common from '@ohos.app.ability.common';
import prompt from '@ohos.promptAction';
@Entry
@Component
struct Index {
@State message: string = 'Hello World';
private backTime :number=0;
@State fontColor: string = '#182451'
@State selectedFontColor: string = 'rgb(0,196,104)'
private controller:TabsController=new TabsController();
showtoast(msg:string){
prompt.showToast({
message:msg
})
}
@State SelectPos:number=0;
private positionClick(){
this.SelectPos=0;
this.controller.changeIndex(0);
}
private companyClick(){
this.SelectPos=1;
this.controller.changeIndex(1);
}
private messageClick(){
this.SelectPos=2;
this.controller.changeIndex(2);
}
private myClick(){
this.SelectPos=3;
this.controller.changeIndex(3);
}
onBackPress(): boolean | void {
let nowtime=Date.now();
if(nowtime-this.backTime<1000){
const mContext=getContext(this) as common.UIAbilityContext;
mContext.terminateSelf()
}else{
this.backTime=nowtime;
this.showtoast("再按一次将退出当前应用")
}
return true;
}
// ['微信','通讯录','发现','我']
build() {
Flex({direction:FlexDirection.Column,alignItems:ItemAlign.Center,justifyContent:FlexAlign.Center}){
Tabs({controller:this.controller}){
TabContent(){
home();
}
TabContent(){
contacts();
}
TabContent(){
Discover();
}
TabContent(){
My()
}
}.scrollable(false)
.barHeight(0)
.animationDuration(0)
Row(){
Column(){
Image((this.SelectPos==0?$r('app.media.wetab01'):$r('app.media.wetab00')))
.width(20).height(20)
.margin({top:5})
Text('微信')
.size({width:'100%',height:30}).textAlign(TextAlign.Center)
.fontSize(15)
.fontColor((this.SelectPos==0?this.selectedFontColor:this.fontColor))
}.layoutWeight(1)
.backgroundColor($r('app.color.gray2'))
.height('100%')
.onClick(this.positionClick.bind(this))
Column(){
Image((this.SelectPos==1?$r('app.media.wetab11'):$r('app.media.wetab10')))
.width(20).height(20)
.margin({top:5})
Text('通讯录')
.size({width:'100%',height:30}).textAlign(TextAlign.Center)
.fontSize(15)
.fontColor((this.SelectPos==1?this.selectedFontColor:this.fontColor))
}.layoutWeight(1)
.backgroundColor($r('app.color.gray2'))
.height('100%')
.onClick(this.companyClick.bind(this))
Column(){
Image((this.SelectPos==2?$r('app.media.wetab21'):$r('app.media.wetab20')))
.width(20).height(20)
.margin({top:5})
Text('发现')
.size({width:'100%',height:30}).textAlign(TextAlign.Center)
.fontSize(15)
.fontColor((this.SelectPos==2?this.selectedFontColor:this.fontColor))
}.layoutWeight(1)
.backgroundColor($r('app.color.gray2'))
.height('100%')
.onClick(this.messageClick.bind(this))
Column(){
Image((this.SelectPos==5?$r('app.media.wetab31'):$r('app.media.wetab30')))
.width(20).height(20)
.margin({top:5})
Text('我')
.size({width:'100%',height:30}).textAlign(TextAlign.Center)
.fontSize(15)
.fontColor((this.SelectPos==5?this.selectedFontColor:this.fontColor))
}.layoutWeight(1)
.backgroundColor($r('app.color.gray2'))
.height('100%')
.onClick(this.myClick.bind(this))
}.alignItems(VerticalAlign.Bottom).width('100%').height(60).margin({top:0,right:0,bottom:0,left:0})
}.width('100%')
.height('100%')
}
}
后续目标
- 微信朋友圈
- 聊天菜单(相册,拍摄...)组件栏
- 语音|视频页面
- 支持群聊头像
- 支持图片,红包等聊天内容类型(现已支持图片类型)
- 二维码扫描
最后总结:
因为篇幅有限我也不能整个项目都展开讲,有兴趣的同学能可以关注我B站课程。 后续能我会把这个项目更新到项目里面 供大家学习
B站课程地址:http://www.bilibili.com/cheese/play…
团队介绍
团队介绍:坚果派由坚果等人创建,团队由12位华为HDE以及若干热爱鸿蒙的开发者和其他领域的三十余位万粉博主运营。专注于分享 HarmonyOS/OpenHarmony,ArkUI-X,元服务,仓颉,团队成员聚集在北京,上海,南京,深圳,广州,宁夏等地,目前已开发鸿蒙 原生应用,三方库60+,欢迎进行课程,项目等合作。
来源:juejin.cn/post/7400741845508522019


