
让生成式 AI 触手可及:火山引擎推出 NVIDIA NIM on VKE 最佳部署实践
技术行业近来对大语言模型(LLM)的关注正开始转向生产环境的大规模部署,将 AI 模型接入现有基础设施以优化系统性能,包括降低延迟、提高吞吐量,以及加强日志记录、监控和安全性等。然而这一路径既复杂又耗时,往往需要构建专门的平台和流程。
在部署 AI 模型的过程中,研发团队通常需要执行以下步骤:
环境搭建与配置:首先需要准备和调试运行环境,这包括但不限于 CUDA、Python、PyTorch 等依赖项的安装与配置。这一步骤往往较为复杂,需要细致地调整各个组件以确保兼容性和性能。
模型优化与封装:接下来进行模型的打包和优化,以提高推理效率。这通常涉及到使用 NVIDIA TensorRT 软件开发套件或 NVIDIA TensorRT-LLM 库等专业工具来优化模型,并根据性能测试结果和经验来调整推理引擎的配置参数。这一过程需要深入的 AI 领域知识,并且工具的使用具有一定的学习成本。
模型部署:最后,将优化后的模型部署到生产环境中。对于非容器化环境,资源的准备和管理也是一个需要精心策划的环节。
为了简化上述流程并降低技术门槛,火山引擎云原生团队推出基于 VKE 的 NVIDIA NIM 微服务最佳实践。通过结合 NIM 一站式模型服务能力,以及火山引擎容器服务 VKE 在成本节约和极简运维等方面的优势,这套开箱即用的技术方案将帮助企业更加快捷和高效地部署 AI 模型。
AI 微服务化:NVIDIA NIM
NVIDIA NIM 是一套经过优化的企业级生成式 AI 微服务,它包括推理引擎,通过 API 接口对外提供服务,帮助企业和个人开发者更简单地开发和部署 AI 驱动的应用程序。
NIM 使用行业标准 API,支持跨多个领域的 AI 用例,包括 LLM、视觉语言模型(VLM),以及用于语音、图像、视频、3D、药物研发、医学成像等的模型。同时,它基于 NVIDIA Triton™ Inference Server、NVIDIA TensorRT™、NVIDIA TensorRT-LLM 和 PyTorch 构建,可以在加速基础设施上提供最优的延迟和吞吐量。
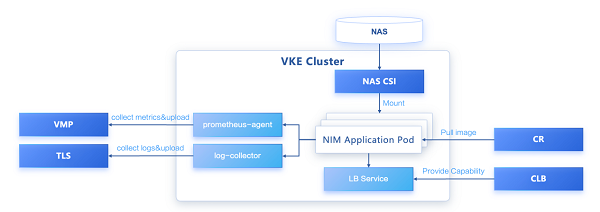
为了进一步降低复杂度,NIM 将模型和运行环境做了解耦,以容器镜像的形式为每个模型或模型系列打包。其在 Kubernetes 内的部署形态如下:

NVIDIA NIM on Kubernetes
火山引擎容器服务 VKE(Volcengine Kubernetes Engine)通过深度融合新一代云原生技术,提供以容器为核心的高性能 Kubernetes 容器集群管理服务,可以为 NIM 提供稳定可靠高性能的运行环境,实现模型使用和运行的强强联合。
同时,模型服务的发布和运行也离不开发布管理、网络访问、观测等能力,VKE 深度整合了火山引擎高性能计算(ECS/裸金属)、网络(VPC/EIP/CLB)、存储(EBS/TOS/NAS)、弹性容器实例(VCI)等服务,并与镜像仓库、持续交付、托管 Prometheus、日志服务、微服务引擎等云产品横向打通,可以实现 NIM 服务构建、部署、发布、监控等全链路流程,帮助企业更灵活、更敏捷地构建和扩展基于自身数据的定制化大型语言模型(LLMs),打造真正的企业级智能化、自动化基础设施。
NVIDIA NIM on VKE 部署流程
下面,我们将介绍 NIM on VKE 的部署流程,助力开发者快速部署和访问 AI 模型。
准备工作
部署 NVIDIA NIM 前,需要做好如下准备:
1. VKE 集群中已安装 csi-nas / prometheus-agent / vci-virtual-kubelet / cr-credential-controller 组件
2. 在 VKE 集群中使用相适配的 VCI GPU 实例规格,具体软硬件支持情况可以查看硬件要求
3. 创建 NAS 实例,作为存储类,用于模型文件的存储
4. 创建 CR(镜像仓库) 实例,用于托管 NIM 镜像
5. 开通 VMP(托管 Prometheus)服务
6. 向 NVIDIA 官方获取 NIM 相关镜像的拉取权限(下述以 llama3-8b-instruct:1.0.0 为例),并生成 API Key
部署
1. 在国内运行 NIM 官方镜像时,为了避免网络访问影响镜像拉取速度,可以提前拉取相应 NIM 镜像并上传到火山引擎镜像仓库 CR,操作步骤如下:

2. Download the code locally, go to the Helm Chart directory of the code, and push Helm Chart to Container Registry (Helm version > 3.7):
下载代码到本地,进入到代码的 helm chart 目录中,把 helm chart 推送到镜像仓库(helm 版本大于 3.7):

3. 在 vke 的应用中心的 helm 应用中选择创建 helm 应用,并选择对应 chart,集群信息,并点击 values.yaml 的编辑按钮进入编辑页
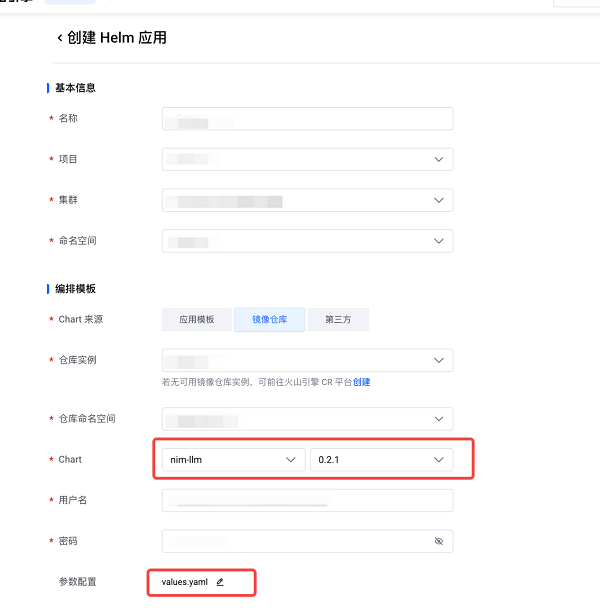
4. 覆盖 values 内容为如下值来根据火山引擎环境调整参数配置,提升部署性能,点击确定完成参数改动,再继续在部署页点击确定完成部署

5. 若 Pod 日志出现如下内容或者 Pod 状态变成 Ready,说明服务已经准备好:

6. 在 VKE 控制台获取 LB Service 地址(Service 名称为-nim-llm)

7. 访问 NIM 服务

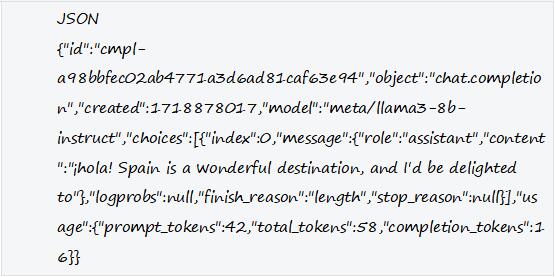
The output is as follows:
会有如下输出:
监控
NVIDIA NIM 在 Grafana Dashboard 上提供了丰富的观测指标,详情可参考 Observability
在 VKE 中,可通过如下方法搭建 NIM 监控:
1. 参考文档搭建 Grafana:https://www.volcengine.com/docs/6731/126068
2. 进入 Grafana 中,在 dashboard 菜单中选择 import:
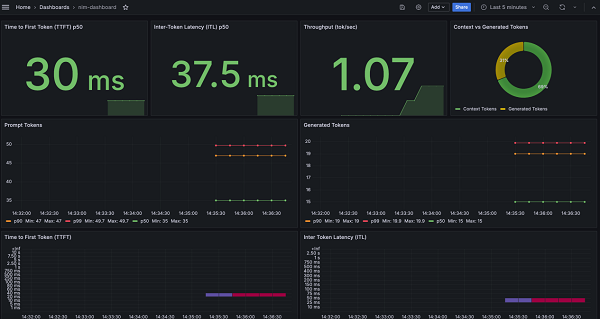
3. 观测面板效果如下:
结语
相比构建大模型镜像,基于 VKE 使用 NVIDIA NIM 部署和访问模型有如下优点:
● 易用性:NIM 提供了预先构建好的模型容器镜像,用户无需从头开始构建和配置环境,配合 VKE 与 CR 的应用部署能力,极大简化了部署过程
● 性能优化:NIM 的容器镜像是经过优化的,可以在 NVIDIA GPU 上高效运行,充分利用 VCI 的硬件性能
● 模型选择:NIM 官方提供了多种大语言模型,用户可以根据需求选择合适的模型,部署在 VKE 中仅需对values.yaml 配置做修改即可
● 自动更新:通过 NGC,NIM 可以自动下载和更新模型,用户无需手动管理模型版本
● 可观测性:NIM 内置了丰富的观测指标,配合 VKE 与 VMP 观测能力开箱即用
目前火山引擎容器服务 VKE 已开放个人用户使用,为个人和企业用户提供高性能、高可靠、极致弹性的企业级容器管理能力,结合 NIM 强大易用的模型部署服务,进一步帮助开发者快速部署 AI 模型,并提供高性能、开箱即用的模型 API 服务。(作者:李双)
