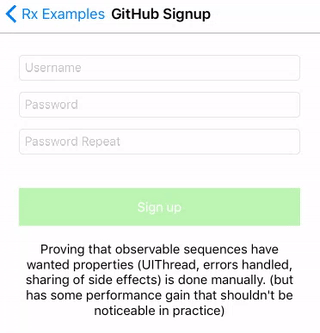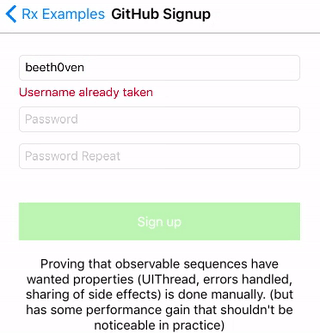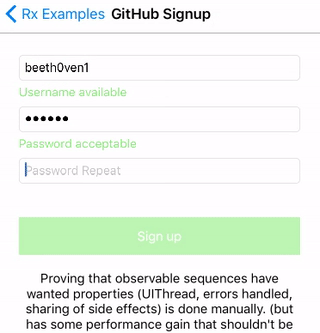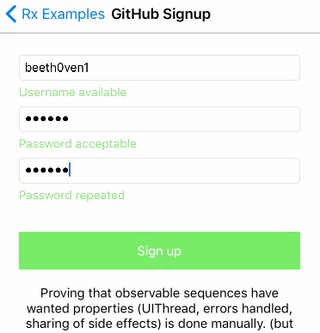
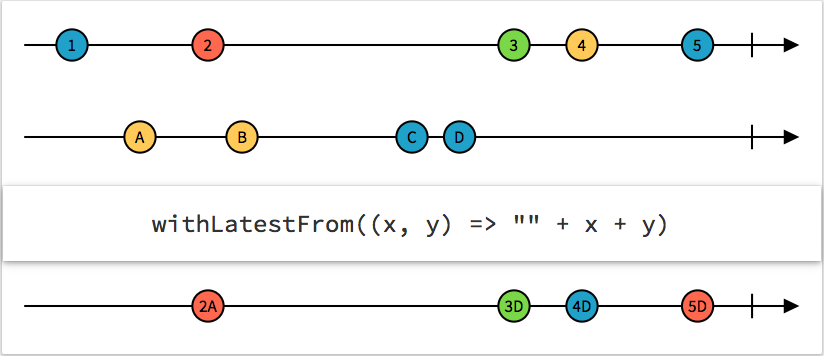
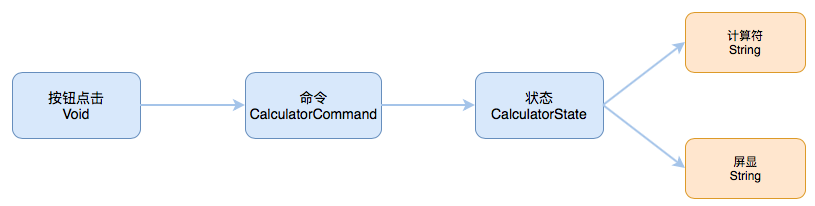
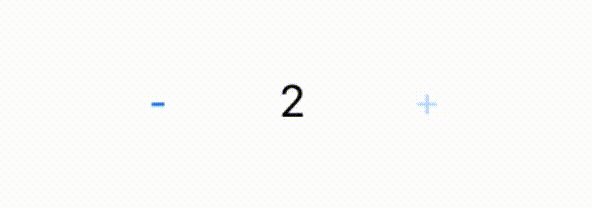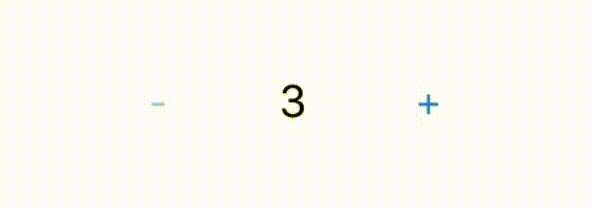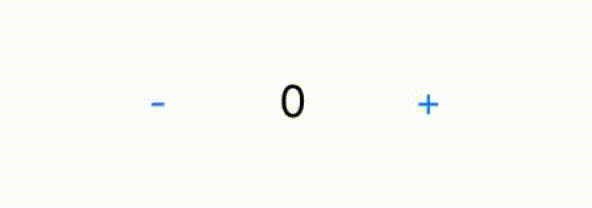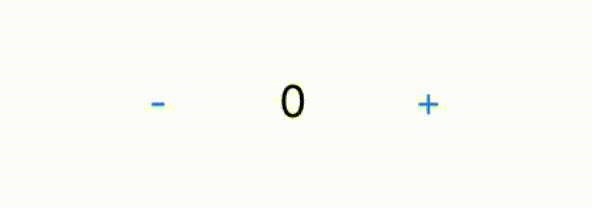Calculator - 计算器
1 + 2 + 3 = 6

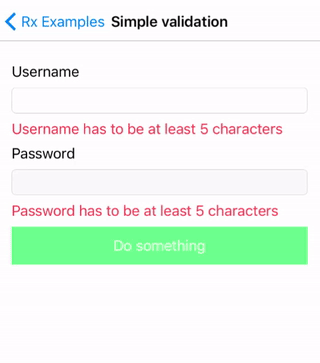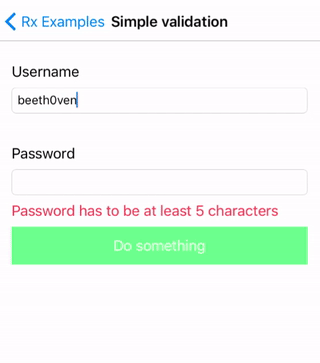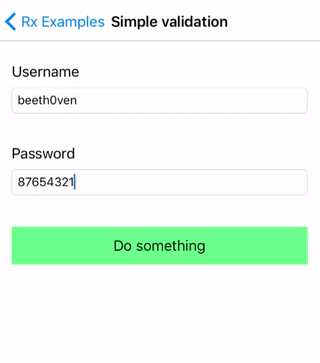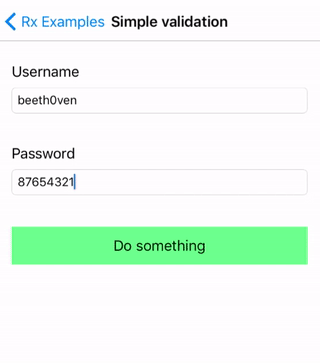
这是一个计算器应用程序,你可以在这里下载这个例子。
简介
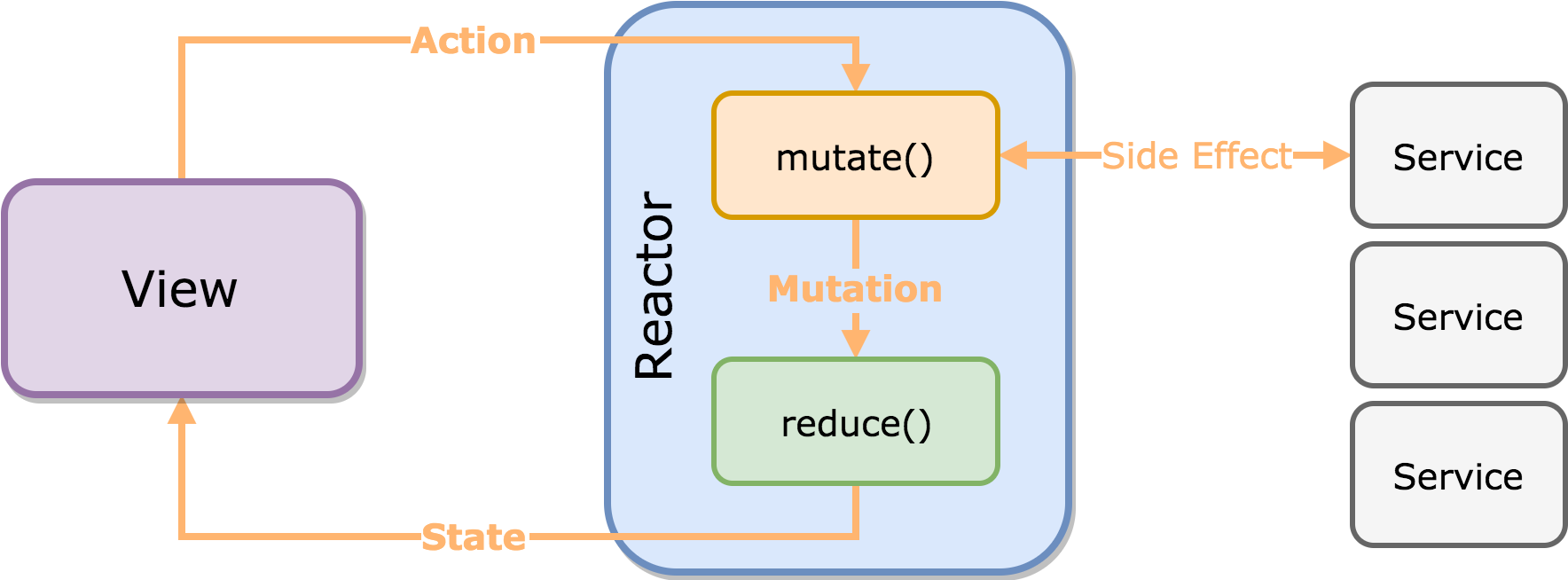
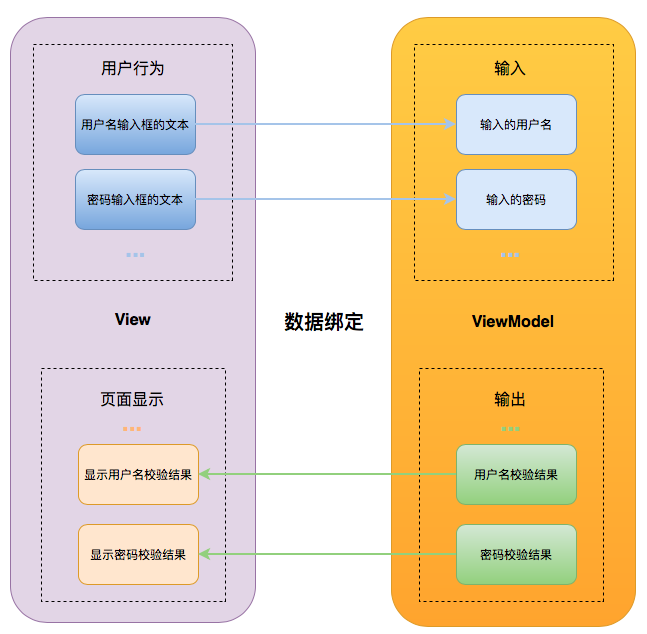
这里的计算器是用响应式编程写的,而且它还用到了 RxFeedback 架构。它比较适合有经验的 RxSwift 使用者学习。接下来我们就来介绍一下这个应用程序是如何实现的。
整体结构
class CalculatorViewController: ViewController {
@IBOutlet weak var lastSignLabel: UILabel!
@IBOutlet weak var resultLabel: UILabel!
@IBOutlet weak var allClearButton: UIButton!
@IBOutlet weak var changeSignButton: UIButton!
@IBOutlet weak var percentButton: UIButton!
@IBOutlet weak var divideButton: UIButton!
@IBOutlet weak var multiplyButton: UIButton!
@IBOutlet weak var minusButton: UIButton!
@IBOutlet weak var plusButton: UIButton!
@IBOutlet weak var equalButton: UIButton!
@IBOutlet weak var dotButton: UIButton!
@IBOutlet weak var zeroButton: UIButton!
@IBOutlet weak var oneButton: UIButton!
@IBOutlet weak var twoButton: UIButton!
@IBOutlet weak var threeButton: UIButton!
@IBOutlet weak var fourButton: UIButton!
@IBOutlet weak var fiveButton: UIButton!
@IBOutlet weak var sixButton: UIButton!
@IBOutlet weak var sevenButton: UIButton!
@IBOutlet weak var eightButton: UIButton!
@IBOutlet weak var nineButton: UIButton!
override func viewDidLoad() {
let commands: Observable<CalculatorCommand> = Observable.merge([
allClearButton.rx.tap.map { _ in .clear },
changeSignButton.rx.tap.map { _ in .changeSign },
percentButton.rx.tap.map { _ in .percent },
divideButton.rx.tap.map { _ in .operation(.division) },
multiplyButton.rx.tap.map { _ in .operation(.multiplication) },
minusButton.rx.tap.map { _ in .operation(.subtraction) },
plusButton.rx.tap.map { _ in .operation(.addition) },
equalButton.rx.tap.map { _ in .equal },
dotButton.rx.tap.map { _ in .addDot },
zeroButton.rx.tap.map { _ in .addNumber("0") },
oneButton.rx.tap.map { _ in .addNumber("1") },
twoButton.rx.tap.map { _ in .addNumber("2") },
threeButton.rx.tap.map { _ in .addNumber("3") },
fourButton.rx.tap.map { _ in .addNumber("4") },
fiveButton.rx.tap.map { _ in .addNumber("5") },
sixButton.rx.tap.map { _ in .addNumber("6") },
sevenButton.rx.tap.map { _ in .addNumber("7") },
eightButton.rx.tap.map { _ in .addNumber("8") },
nineButton.rx.tap.map { _ in .addNumber("9") }
])
let system = Observable.system(
CalculatorState.initial,
accumulator: CalculatorState.reduce,
scheduler: MainScheduler.instance,
feedback: { _ in commands }
)
.debug("calculator state")
.share(replay: 1)
system.map { $0.screen }
.bind(to: resultLabel.rx.text)
.disposed(by: disposeBag)
system.map { $0.sign }
.bind(to: lastSignLabel.rx.text)
.disposed(by: disposeBag)
}
func formatResult(_ result: String) -> String {
if result.hasSuffix(".0") {
return result.substring(to: result.index(result.endIndex, offsetBy: -2))
} else {
return result
}
}
}
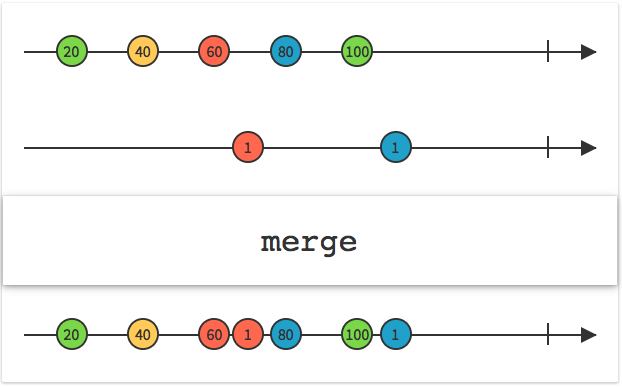
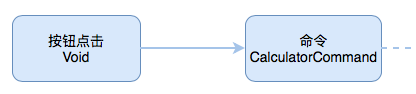
首先合成出一个命令序列,它是通过按钮点击转换过来的:
let commands: Observable<CalculatorCommand> = Observable.merge([
allClearButton.rx.tap.map { _ in .clear },
changeSignButton.rx.tap.map { _ in .changeSign },
percentButton.rx.tap.map { _ in .percent },
divideButton.rx.tap.map { _ in .operation(.division) },
multiplyButton.rx.tap.map { _ in .operation(.multiplication) },
minusButton.rx.tap.map { _ in .operation(.subtraction) },
plusButton.rx.tap.map { _ in .operation(.addition) },
equalButton.rx.tap.map { _ in .equal },
dotButton.rx.tap.map { _ in .addDot },
zeroButton.rx.tap.map { _ in .addNumber("0") },
oneButton.rx.tap.map { _ in .addNumber("1") },
twoButton.rx.tap.map { _ in .addNumber("2") },
threeButton.rx.tap.map { _ in .addNumber("3") },
fourButton.rx.tap.map { _ in .addNumber("4") },
fiveButton.rx.tap.map { _ in .addNumber("5") },
sixButton.rx.tap.map { _ in .addNumber("6") },
sevenButton.rx.tap.map { _ in .addNumber("7") },
eightButton.rx.tap.map { _ in .addNumber("8") },
nineButton.rx.tap.map { _ in .addNumber("9") }
])
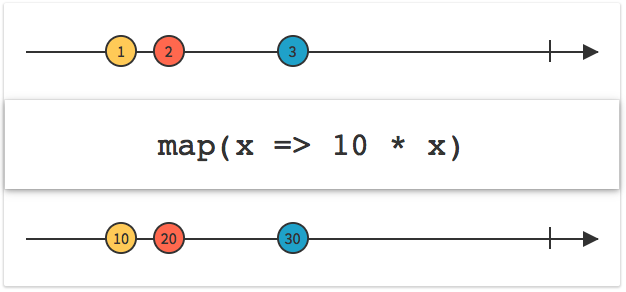
通过使用 map 方法将按钮点击事件转换为对应的命令。如:将 allClearButton 点击事件转换为清除命令,将 plusButton 点击事件转换为相加命令,将 oneButton 点击事件转换为添加数字1命令。最后使用 merge 操作符将这些命令合并。于是就得到了我们所需要的命令序列。
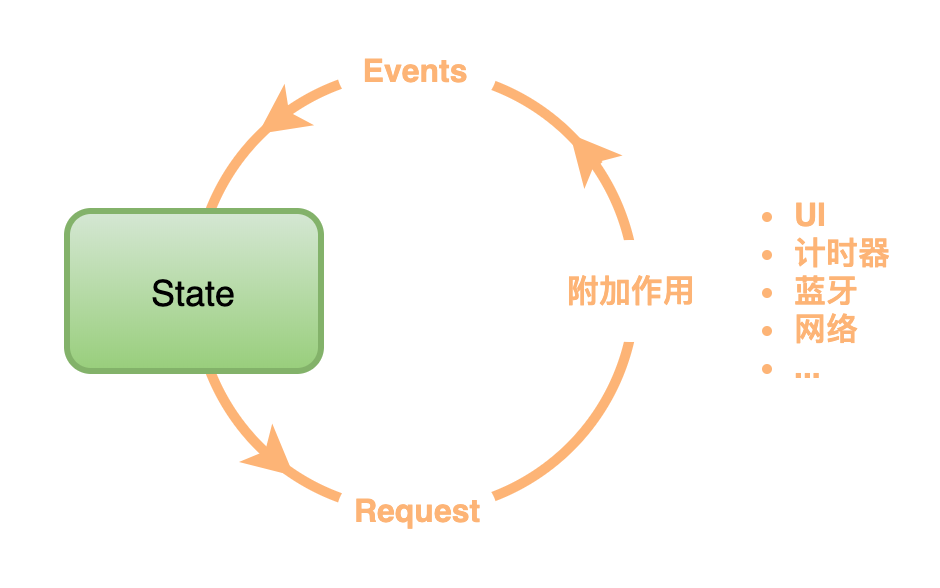
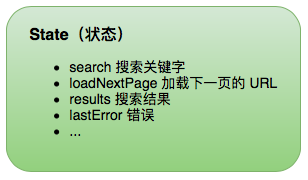
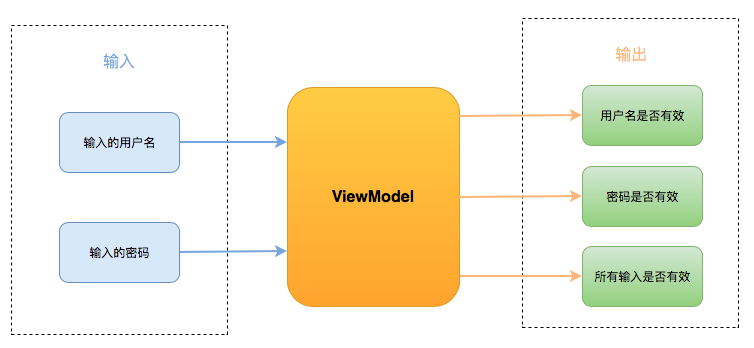
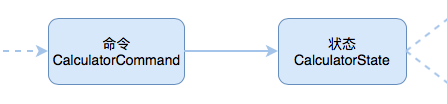
几乎每个页面都是有状态的。我们通过命令序列来对状态进行修改,然后产生一个新的状态。例如,刚进页面后,点击了按钮 1 。那么初始状态为 0,在执行添加数字1命令后,状态就更新为 1。通过这种变换方式,就可以生成一个状态序列:
let system = Observable.system(
CalculatorState.initial,
accumulator: CalculatorState.reduce,
scheduler: MainScheduler.instance,
feedback: { _ in commands }
)
.debug("calculator state")
.share(replay: 1)
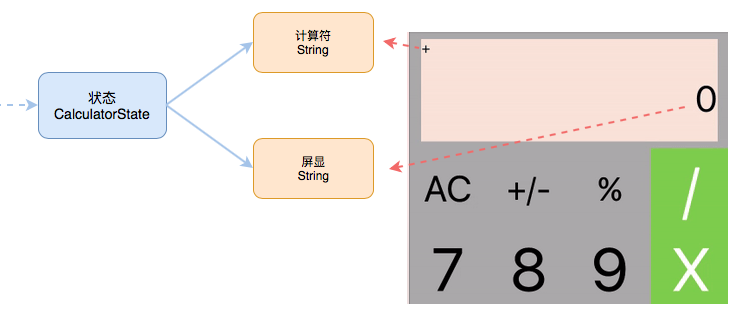
由命令序列触发,对页面状态进行更新,在用更新后的状态组成一个序列。这就是我们所需要的状态序列。接下来我们用这个状态序列来控制页面显示:
system.map { $0.screen }
.bind(to: resultLabel.rx.text)
.disposed(by: disposeBag)
system.map { $0.sign }
.bind(to: lastSignLabel.rx.text)
.disposed(by: disposeBag)
用 state.screen 来控制 resultLabel 的显示内容。用 state.sign 来控制 lastSignLabel 的显示内容。
Calculator
控制器主要负责数据绑定,而整个计算器的大脑在 Calculator.swift 文件内。
State:
这个页面主要有三种状态:
enum CalculatorState {
case oneOperand(screen: String)
case oneOperandAndOperator(operand: Double, operator: Operator)
case twoOperandsAndOperator(operand: Double, operator: Operator, screen: String)
}
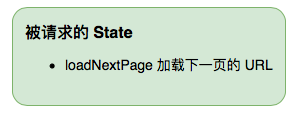
- oneOperand 一个操作数,例如:进入页面后,输入
1 时的状态 - oneOperandAndOperator 一个操作数和一个运算符,例如:进入页面后,输入
1 + 时的状态 - twoOperandsAndOperator 两个操作数和一个运算符,例如:进入页面后,输入
1 + 2 时的状态
Command:
这个计算器提供七种命令:
enum Operator {
case addition
case subtraction
case multiplication
case division
}
enum CalculatorCommand {
case clear
case changeSign
case percent
case operation(Operator)
case equal
case addNumber(Character)
case addDot
}
- clear 清除,重置
- changeSign 改变正负号
- percent 百分比
- operation 四则运算
- equal 等于
- addNumber 输入数字
- addDot 输入 “.”
reduce:
当命令产生时,将它应用到当前状态上,然后生成新的状态:

extension CalculatorState {
static func reduce(state: CalculatorState, _ x: CalculatorCommand) -> CalculatorState {
switch x {
case .clear:
return CalculatorState.initial
case .addNumber(let c):
return state.mapScreen { $0 == "0" ? String(c) : $0 + String(c) }
case .addDot:
return state.mapScreen { $0.range(of: ".") == nil ? $0 + "." : $0 }
case .changeSign:
return state.mapScreen { "\(-(Double($0) ?? 0.0))" }
case .percent:
return state.mapScreen { "\((Double($0) ?? 0.0) / 100.0)" }
case .operation(let o):
switch state {
case let .oneOperand(screen):
return .oneOperandAndOperator(operand: screen.doubleValue, operator: o)
case let .oneOperandAndOperator(operand, _):
return .oneOperandAndOperator(operand: operand, operator: o)
case let .twoOperandsAndOperator(operand, oldOperator, screen):
return .twoOperandsAndOperator(operand: oldOperator.perform(operand, screen.doubleValue), operator: o, screen: "0")
}
case .equal:
switch state {
case let .twoOperandsAndOperator(operand, operat, screen):
let result = operat.perform(operand, screen.doubleValue)
return .oneOperand(screen: String(result))
default:
return state
}
}
}
}
- clear 重置当前状态
- addNumber, addDot, changeSign, percent 只需要更改屏显即可
- operation 需要根据当前状态来确定如何变化状态。
- 如果只有一个操作数,就添加操作符。
- 如果有一个操作数和操作符,就替换操作符。
- 如果有两个操作数和一个操作符,将他们的计算结果作为操作数保留,然后加入新的操作符,以及一个操作数 0.
- equal 如果当前有两个操作数和一个操作符,将他们的计算结果作为操作数保留。否则什么都不做。
剩下的都是一些辅助代码,接下来我们再来看下全部代码:
ViewController:
class CalculatorViewController: ViewController {
@IBOutlet weak var lastSignLabel: UILabel!
@IBOutlet weak var resultLabel: UILabel!
@IBOutlet weak var allClearButton: UIButton!
@IBOutlet weak var changeSignButton: UIButton!
@IBOutlet weak var percentButton: UIButton!
@IBOutlet weak var divideButton: UIButton!
@IBOutlet weak var multiplyButton: UIButton!
@IBOutlet weak var minusButton: UIButton!
@IBOutlet weak var plusButton: UIButton!
@IBOutlet weak var equalButton: UIButton!
@IBOutlet weak var dotButton: UIButton!
@IBOutlet weak var zeroButton: UIButton!
@IBOutlet weak var oneButton: UIButton!
@IBOutlet weak var twoButton: UIButton!
@IBOutlet weak var threeButton: UIButton!
@IBOutlet weak var fourButton: UIButton!
@IBOutlet weak var fiveButton: UIButton!
@IBOutlet weak var sixButton: UIButton!
@IBOutlet weak var sevenButton: UIButton!
@IBOutlet weak var eightButton: UIButton!
@IBOutlet weak var nineButton: UIButton!
override func viewDidLoad() {
let commands: Observable<CalculatorCommand> = Observable.merge([
allClearButton.rx.tap.map { _ in .clear },
changeSignButton.rx.tap.map { _ in .changeSign },
percentButton.rx.tap.map { _ in .percent },
divideButton.rx.tap.map { _ in .operation(.division) },
multiplyButton.rx.tap.map { _ in .operation(.multiplication) },
minusButton.rx.tap.map { _ in .operation(.subtraction) },
plusButton.rx.tap.map { _ in .operation(.addition) },
equalButton.rx.tap.map { _ in .equal },
dotButton.rx.tap.map { _ in .addDot },
zeroButton.rx.tap.map { _ in .addNumber("0") },
oneButton.rx.tap.map { _ in .addNumber("1") },
twoButton.rx.tap.map { _ in .addNumber("2") },
threeButton.rx.tap.map { _ in .addNumber("3") },
fourButton.rx.tap.map { _ in .addNumber("4") },
fiveButton.rx.tap.map { _ in .addNumber("5") },
sixButton.rx.tap.map { _ in .addNumber("6") },
sevenButton.rx.tap.map { _ in .addNumber("7") },
eightButton.rx.tap.map { _ in .addNumber("8") },
nineButton.rx.tap.map { _ in .addNumber("9") }
])
let system = Observable.system(
CalculatorState.initial,
accumulator: CalculatorState.reduce,
scheduler: MainScheduler.instance,
feedback: { _ in commands }
)
.debug("calculator state")
.share(replay: 1)
system.map { $0.screen }
.bind(to: resultLabel.rx.text)
.disposed(by: disposeBag)
system.map { $0.sign }
.bind(to: lastSignLabel.rx.text)
.disposed(by: disposeBag)
}
func formatResult(_ result: String) -> String {
if result.hasSuffix(".0") {
return result.substring(to: result.index(result.endIndex, offsetBy: -2))
} else {
return result
}
}
}
Calculator:
enum Operator {
case addition
case subtraction
case multiplication
case division
}
enum CalculatorCommand {
case clear
case changeSign
case percent
case operation(Operator)
case equal
case addNumber(Character)
case addDot
}
enum CalculatorState {
case oneOperand(screen: String)
case oneOperandAndOperator(operand: Double, operator: Operator)
case twoOperandsAndOperator(operand: Double, operator: Operator, screen: String)
}
extension CalculatorState {
static let initial = CalculatorState.oneOperand(screen: "0")
func mapScreen(transform: (String) -> String) -> CalculatorState {
switch self {
case let .oneOperand(screen):
return .oneOperand(screen: transform(screen))
case let .oneOperandAndOperator(operand, operat):
return .twoOperandsAndOperator(operand: operand, operator: operat, screen: transform("0"))
case let .twoOperandsAndOperator(operand, operat, screen):
return .twoOperandsAndOperator(operand: operand, operator: operat, screen: transform(screen))
}
}
var screen: String {
switch self {
case let .oneOperand(screen):
return screen
case .oneOperandAndOperator:
return "0"
case let .twoOperandsAndOperator(_, _, screen):
return screen
}
}
var sign: String {
switch self {
case .oneOperand:
return ""
case let .oneOperandAndOperator(_, o):
return o.sign
case let .twoOperandsAndOperator(_, o, _):
return o.sign
}
}
}
extension CalculatorState {
static func reduce(state: CalculatorState, _ x: CalculatorCommand) -> CalculatorState {
switch x {
case .clear:
return CalculatorState.initial
case .addNumber(let c):
return state.mapScreen { $0 == "0" ? String(c) : $0 + String(c) }
case .addDot:
return state.mapScreen { $0.range(of: ".") == nil ? $0 + "." : $0 }
case .changeSign:
return state.mapScreen { "\(-(Double($0) ?? 0.0))" }
case .percent:
return state.mapScreen { "\((Double($0) ?? 0.0) / 100.0)" }
case .operation(let o):
switch state {
case let .oneOperand(screen):
return .oneOperandAndOperator(operand: screen.doubleValue, operator: o)
case let .oneOperandAndOperator(operand, _):
return .oneOperandAndOperator(operand: operand, operator: o)
case let .twoOperandsAndOperator(operand, oldOperator, screen):
return .twoOperandsAndOperator(operand: oldOperator.perform(operand, screen.doubleValue), operator: o, screen: "0")
}
case .equal:
switch state {
case let .twoOperandsAndOperator(operand, operat, screen):
let result = operat.perform(operand, screen.doubleValue)
return .oneOperand(screen: String(result))
default:
return state
}
}
}
}
extension Operator {
var sign: String {
switch self {
case .addition: return "+"
case .subtraction: return "-"
case .multiplication: return "×"
case .division: return "/"
}
}
var perform: (Double, Double) -> Double {
switch self {
case .addition: return (+)
case .subtraction: return (-)
case .multiplication: return (*)
case .division: return (/)
}
}
}
private extension String {
var doubleValue: Double {
guard let double = Double(self) else {
return Double.infinity
}
return double
}
}
参考
TableViewSectionedViewController - 多层级的列表页
演示如何使用 RxDataSources 来布局列表页,你可以在这里下载这个例子。
简介
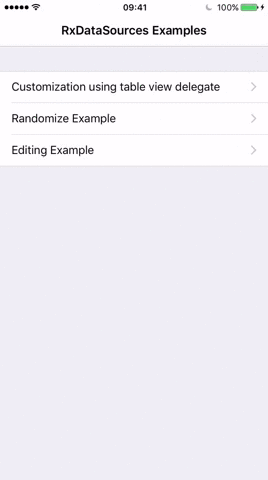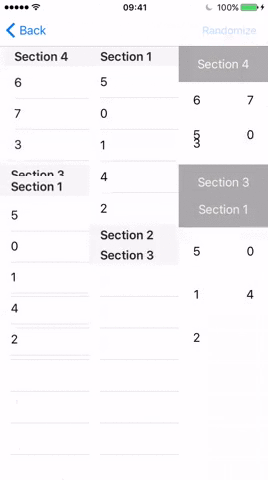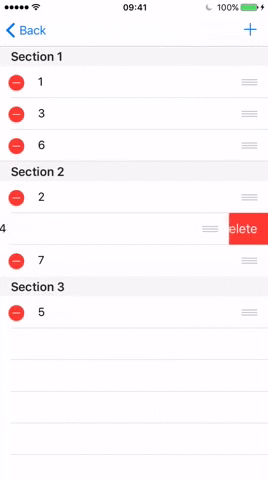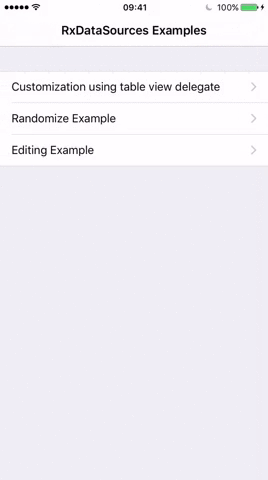
这是一个多层级列表页,它主要需要完成这些需求:
- 每个
Section 显示对应的标题 - 每个
Cell 显示对应的元素以及行号 - 根据
Cell 的 indexPath 控制行高 - 当
Cell 被选中时,显示一个弹框
整体结构
以上这些需求,只需要一页代码就能完成:
class SimpleTableViewExampleSectionedViewController
: ViewController
, UITableViewDelegate {
@IBOutlet weak var tableView: UITableView!
let dataSource = RxTableViewSectionedReloadDataSource<SectionModel<String, Double>>(
configureCell: { (_, tv, indexPath, element) in
let cell = tv.dequeueReusableCell(withIdentifier: "Cell")!
cell.textLabel?.text = "\(element) @ row \(indexPath.row)"
return cell
},
titleForHeaderInSection: { dataSource, sectionIndex in
return dataSource[sectionIndex].model
}
)
override func viewDidLoad() {
super.viewDidLoad()
let dataSource = self.dataSource
let items = Observable.just([
SectionModel(model: "First section", items: [
1.0,
2.0,
3.0
]),
SectionModel(model: "Second section", items: [
1.0,
2.0,
3.0
]),
SectionModel(model: "Third section", items: [
1.0,
2.0,
3.0
])
])
items
.bind(to: tableView.rx.items(dataSource: dataSource))
.disposed(by: disposeBag)
tableView.rx
.itemSelected
.map { indexPath in
return (indexPath, dataSource[indexPath])
}
.subscribe(onNext: { pair in
DefaultWireframe.presentAlert("Tapped `\(pair.1)` @ \(pair.0)")
})
.disposed(by: disposeBag)
tableView.rx
.setDelegate(self)
.disposed(by: disposeBag)
}
// to prevent swipe to delete behavior
func tableView(_ tableView: UITableView, editingStyleForRowAt indexPath: IndexPath) -> UITableViewCellEditingStyle {
return .none
}
func tableView(_ tableView: UITableView, heightForHeaderInSection section: Int) -> CGFloat {
return 40
}
}
我们首先创建一个 dataSource: RxTableViewSectionedReloadDataSource<SectionModel<String, Double>>:
let dataSource = RxTableViewSectionedReloadDataSource<SectionModel<String, Double>>(
configureCell: { (_, tv, indexPath, element) in
let cell = tv.dequeueReusableCell(withIdentifier: "Cell")!
cell.textLabel?.text = "\(element) @ row \(indexPath.row)"
return cell
},
titleForHeaderInSection: { dataSource, sectionIndex in
return dataSource[sectionIndex].model
}
)
通过使用这个辅助类型,我们就不用执行数据源代理方法,而只需要提供必要的配置函数就可以布局列表页了。
第一个函数 configureCell 是用来配置 Cell 的显示,而这里的参数 element 就是 SectionModel<String, Double> 中的 Double。
第二个函数 titleForHeaderInSection 是用来配置 Section 的标题,而 dataSource[sectionIndex].model 就是 SectionModel<String, Double> 中的 String。
然后为列表页订制一个多层级的数据源 items: Observable<[SectionModel<String, Double>]>,用这个数据源来绑定列表页。
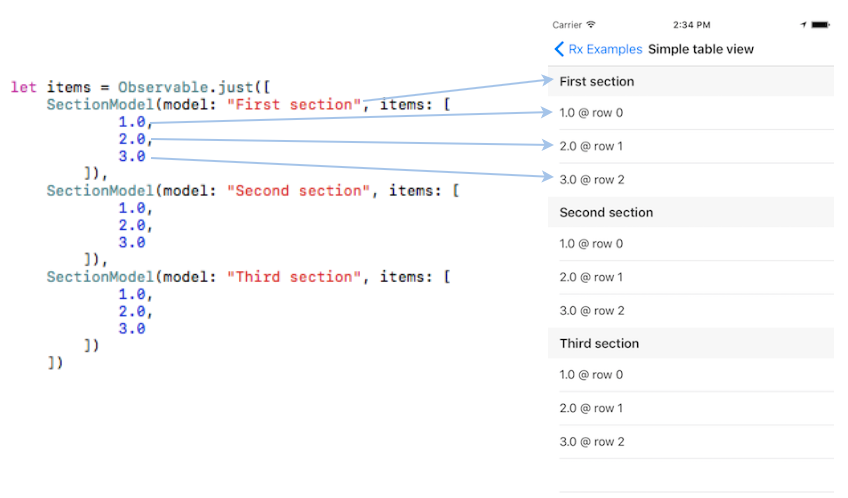
这里 SectionModel<String, Double> 中的 String 是用来显示 Section 的标题。而 Double 是用来绑定对应的 Cell。假如我们的列表页是用来显示通讯录的,并且通讯录通过首字母来分组。那么应该把数据定义为 SectionModel<String, Person>,然后用首字母 String 来显示 Section 标题,用联系人 Person 来显示对应的 Cell。
由于 SectionModel<Section, ItemType> 是一个范型,所以我们可以用它来定义任意类型的 Section 以及 Item。
最后:
override func viewDidLoad() {
super.viewDidLoad()
...
tableView.rx
.setDelegate(self)
.disposed(by: disposeBag)
}
...
func tableView(_ tableView: UITableView, heightForHeaderInSection section: Int) -> CGFloat {
return 40
}
这个是用来控制行高的,tableView.rx.setDelegate(self)... 将自己设置成 tableView 的代理,通过 heightForHeaderInSection 方法提供行高。
参考
收起阅读 »