
















































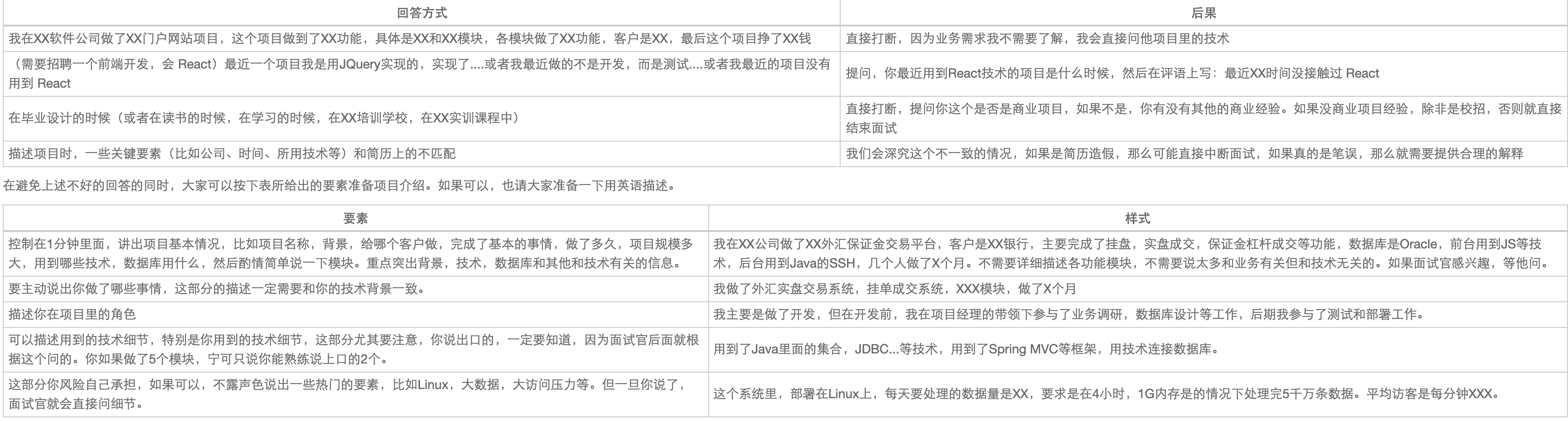
写
这种写方法只能一个字节一个字节的写;
注意把要关闭的流写在try括号中,省去了代码中finally关闭的过程,以下例子均是。
private static void ioWrite() {
try (OutputStream outputStream = new FileOutputStream("./demo.txt")) {
outputStream.write('a');
outputStream.write('b');
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
读
这种读方法只能一个字节一个字节的写;
private static void ioRead() {
try (InputStream inputStream = new FileInputStream("./demo.txt")) {
System.out.println((char)inputStream.read());
System.out.println((char)inputStream.read());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
带缓存的读
private static void ioBufferedRead() {
try (InputStream inputStream = new FileInputStream("./demo.txt");
Reader reader = new InputStreamReader(inputStream);
BufferedReader bufferedReader = new BufferedReader(reader)) {
System.out.println(bufferedReader.readLine());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
带缓存的写
注意需要
bufferedOutputStream.flush()需要写流数据,但是该方法会在流关闭前被自动调用,因此在try中写了流对象后,可以省去这一步。 此外注意,该方法会覆盖原来文件的内容而不是追加。
private static void ioBufferedWrite() {
try (OutputStream outputStream = new FileOutputStream("./demo.txt");
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(outputStream)) {
bufferedOutputStream.write('a');
bufferedOutputStream.write('q');
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
带缓存的读写
private static void ioWriteRead() {
try (
InputStream inputStream = new BufferedInputStream(new FileInputStream("./demo.txt"));
OutputStream outputStream = new BufferedOutputStream(new FileOutputStream("./demoNew.txt"))) {
byte[] data = new byte[1024];
int read;
while ((read = inputStream.read(data)) != -1) {
outputStream.write(data, 0, read);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
IO在网络中实现通信
private static void ioNetDemo() {
try (Socket socket = new Socket("yanfriends.com", 80);
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {
writer.write("GET / HTTP/1.1\n" +
"Host: http://www.yanfriends.com\n\n");
writer.flush();
String message;
while ((message = reader.readLine()) != null) {
System.out.println(message);
}
} catch (IOException e) {
e.printStackTrace();
}
}
NIO
NIO(New IO)库于JDK1.4引入,目的和IO一致但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
对比IO:
| IO | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
流和缓存
Java IO是面向流的,这意味着是一次性从流中读取一批数据,这些数据并不会缓存在任何地方,并且对于在流中的数据是不支持在数据中前后移动。如果需要在这些数据中移动(为什么要移动,可以多次读取),则还是需要将这部分数据先缓存在缓冲区中。
NIO采用的是面向缓冲区的方式,有些不同,数据会先读取到缓冲区中以供稍后处理。在buffer中是可以方便地前移和后移,这使得在处理数据时可以有更大的灵活性。但是需要检查buffer是否包含需要的所有数据以便能够将其完整地处理,并且需要确保在通过channel往buffer读数据的时候不能够覆盖还未处理的数据。
阻塞非阻塞
IO流是阻塞式的,当线程调用其read()或write()方法时线程会阻塞,直到完成了数据的读写,在读写的过程中线程是什么都做不了的。
NIO提供了一种非阻塞模式,使得线程向channel请求读数据时,只会获取已经就绪的数据,并不会阻塞以等待所有数据都准备好(IO就是这样做),这样在数据准备的阶段线程就能够去处理别的事情。对于非阻塞式写数据是一样的。线程往channel中写数据时,并不会阻塞以等待数据写完,而是可以处理别的事情,等到数据已经写好了,线程再处理这部分事情。当线程在进行IO调用并且不会进入阻塞的情况下,这部分的空余时间就可以花在和其他channel进行IO交互上。也就是说,这样单个线程就能够管理多个channel的输入和输出了。
Selector
Java NIO中的Selector允许单个线程监控多个channel,可以将多个channel注册到一个Selector中,然后可以"select"出已经准备好数据的channel,或者准备好写入的channel。这个selector机制使得单个线程同时管理多个channel变得更容易。
采用NIO的API调用方式和IO是不一样的,与直接从InputStream中读取字节数据不同,在NIO中,数据必须要先被读到buffer中,然后再从那里进行后续的处理。
读例子
当线程在进行IO调用并且不会进入阻塞的情况下,这部分的空余时间就可以花在和其他channel进行IO交互上。也就是说,这样单个线程就能够管理多个channel的输入和输出了。
private static void nioRead() {
try {
RandomAccessFile file = new RandomAccessFile("./demo.txt", "r");
FileChannel channel = file.getChannel();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
channel.read(byteBuffer);
byteBuffer.flip();
System.out.println(Charset.defaultCharset().decode(byteBuffer));
byteBuffer.clear();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
NIO在网络中实现通信
private static void nioNetDemo() {
try {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(80));
serverSocketChannel.configureBlocking(false);
Selector selector = Selector.open();
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select();
for (SelectionKey key : selector.selectedKeys()) {
if (key.isAcceptable()) {
SocketChannel socketChannel = serverSocketChannel.accept();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
while (socketChannel.read(byteBuffer) != -1) {
byteBuffer.flip();
socketChannel.write(byteBuffer);
byteBuffer.clear();
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
Okio
Okio的优势
Java IO的读写,缓冲区的存在必然涉及copy的过程,而如果涉及双流操作,比如从一个输入流读入,再写入到一个输出流,在缓冲存在的情况下,数据走向是:
- 从输入流读出到缓冲区
- 从输入流缓冲区copy到 b[]
- 将 b[] copy 到输出流缓冲区
- 输出流缓冲区读出数据到输出流
这种操作存在着冗余copy操作,Okio应运而生。除此之外,Okio还简化出了一套对开发者更加友好的API,弥补了IO/NIO使用不方便的缺点。
Segment
Okio使用Segment来作为数据存储手段。Segment 实际上也是对 byte[] 进行封装,再通过各种属性来记录各种状态。在交换时,如果可以,将Segment整体作为数据传授媒介,这样就没有具体数据的copy过程,而是交换了对应的Segment引用。Segment通过Buffer进行缓冲管理,在Buffer.write()里,通过移动引用而不是真实数据,是减少数据copy进而交换数据的关键。
Segment的数据结构如下:
final class Segment {
// 默认容量
static final int SIZE = 8192;
// 最小分享数据量
static final int SHARE_MINIMUM = 1024;
// 存储具体数据的数组
final byte[] data;
// 有效数据索引起始位置
int pos;
// 有效数据索引结束位置
int limit;
// 指示Segment是否为共享状态
boolean shared;
// 指示当前Segment是否为数据拥有者,与shared互斥
// 默认构造函数的Segment owner为true,当把数据分享
// 出去时,被分享的Segment的owner标记为false
boolean owner;
// 指向下一个Segment
Segment next;
// 指向前一个Segment
Segment prev;
}
Okio的依赖链接
private static void okioRead() {
try (BufferedSource source = Okio.buffer(Okio.source(new File("./demo.txt")))) {
System.out.println(source.readUtf8Line());
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) { // AIO Asynchronous I/O
e.printStackTrace();
}
}
Android+Okio实例
下面利用OkHttp和Okio实现一个下载网络图片的简单例子:
File file = new File(getCacheDir() + "/demoImg.jpg");
OkHttpClient client = new OkHttpClient();
final Request request = new Request.Builder()
.url("https://avatar.csdnimg.cn/7/E/5/1_lucasxu01.jpg")
.build();
client.newCall(request)
.enqueue(new Callback() {
@Override
public void onFailure(@NotNull Call call, @NotNull IOException e) {
v.post(new Runnable() {
@Override
public void run() {
Toast.makeText(MainActivity.this, "下载出错", Toast.LENGTH_SHORT).show();
}
});
}
@Override
public void onResponse(@NotNull Call call, @NotNull Response response) {
try (BufferedSink sink = Okio.buffer(Okio.sink(apk))) {
sink.write(response.body().bytes());
} catch (IOException e) {
e.printStackTrace();
}
v.post(new Runnable() {
@Override
public void run() {
Toast.makeText(MainActivity.this, "下载成功", Toast.LENGTH_SHORT).show();
}
});
}
});
小结
Okio核心竞争力为,增强了流于流之间的互动,使得当数据从一个缓冲区移动到另一个缓冲区时,可以不经过copy能达到:
- 以Segment作为存储结构,真实数据以类型为byte[]的成员变量data存在,并用其它变量标记数据状态,在需要时,如果可以,移动Segment引用,而非copy data数据
- Segment在Segment线程池中以单链表存在以便复用,在Buffer中以双向链表存在存储数据,head指向头部,是最老的数据
- Segment能通过slipt()进行分割,可实现数据共享,能通过compact()进行合并。由Buffer来进行数据调度,基本遵守 “大块数据移动引用,小块数据进行copy” 的思想
- Source 对应输入流,Sink 对应输出流
- TimeOut 以达到在期望时间内完成IO操作的目的,同步超时在每次IO操作中检查耗时,异步超时开启另一线程间隔时间检查耗时
Okio并没有打算优化底层IO方式以及替代原生IO方式,Okio优化了缓冲策略以减轻内存压力和性能消耗,并且对于部分IO场景,提供了更友好的API,而更多的IO场景,该记的还得记。























{kind=link}