一、以前封装的遗憾点
主要集中在如下2点上:
总而言之,就是需要写很多模板代码。
不必编写模版代码的一个最大好处就是: 写的代码越少,出错的概率越小.
1.1 Loading的处理
对于封装二,虽然解耦比封装一更彻底,但是关于Loading这里我觉得还是有遗憾。
试想一下:如果Activity中业务很多、逻辑复杂,存在很多个网络请求,在需要网络请求的地方都要手动去showLoading() ,然后在 observer() 中手动调用 stopLoading()。
假如Activity中代码业务复杂,存在多个api接口,这样Activity中就存在很多个与loading有关的方法。
此外,如果一个网络请求的showLoading()方法和dismissLoading()方法相隔很远。会导致一个顺序流程的割裂。
请求开始前showLoading() ---> 请求网络 ---> 结束后stopLoading(),这是一个完整的流程,代码也应该尽量在一起,一目了然,不应该割裂存在。
如果代码量一多,以后维护起来,万一不小心删除了某个showLoading()或者stopLoading(),也容易导致问题。
还有就是每次都要手动调用这两个方法,麻烦。
1.2 重复的LiveData声明
个人认为常用的网络请求分为两大类:
举个常见的例子,看下面这个页面:
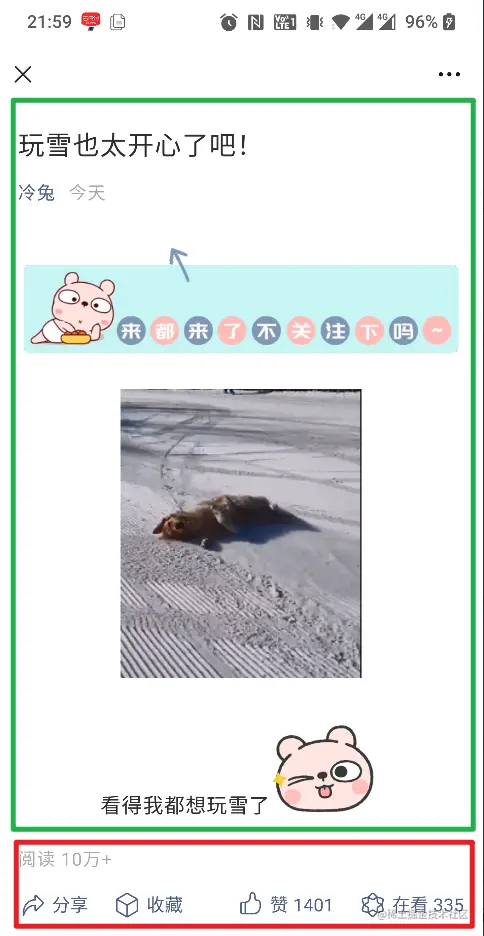
用户一进入这个页面,绿色框里面内容基本不会变化,(不去纠结微信这个页面是不是webview之类的),这种ui其实是不需要设置一个LiveData去监听的,因为它几乎不会再更新了。
典型的还有:点击登录按钮,成功后就进去了下一个页面。
但是红色的框里面的ui不一样,需要实时刷新数据,也就用到LiveData监听,这种情况下观察者订阅者模式的好处才真正展示出来。并且从其他页面过来,LiveData也会把最新的数据自动更新。
对于用完即丢的网络请求,LoginViewModel会存在这种代码:
// LoginViewModel.kt
val loginLiveData = MutableLiveData<User?>()
val logoutLiveData = MutableLiveData<Any?>()
val forgetPasswordLiveData = MutableLiveData<User?>(
并且对应的Activity中也需要监听这3个LiveData。
这种模板代码让我写的很烦。
用了Flow优化后,完美的解决这2个痛点。
“Talk is cheap. Show me the code.”
二、集成Flow之后的用法
2.1 请求自带Loading&&不需要监听数据变化
需求:
不需要监听数据变化,对应上面的用完即丢
不需要在ViewModel中声明LiveData成员对象
发起请求之前自动showLoading(),请求结束后自动stopLoading()
类似于点击登录按钮,finish 当前页面,跳转到下一个页面
TestActivity 中示例代码:
// TestActivity.kt
private fun login() {
launchWithLoadingAndCollect({mViewModel.login("username", "password")}) {
onSuccess = { data->
showSuccessView(data)
}
onFailed = { errorCode, errorMsg ->
showFailedView(code, msg)
}
onError = {e ->
e.printStackTrace()
}
}
}
TestViewModel 中代码:
// TestViewModel中代码
suspend fun login(username: String, password: String): ApiResponse<User?> {
return repository.login(username, password)
}
2.2 请求不带Loading&&不需要声明LiveData
需求:
// TestActivity.kt
private fun getArticleDetail() {
launchAndCollect({ mViewModel.getArticleDetail() }) {
onSuccess = {
showSuccessView()
}
onFailed = { errorCode, errorMsg ->
showFailedView(code, msg)
}
onDataEmpty = {
showEmptyView()
}
}
}
TestViewModel 中代码和上面一样,这里就不写了。
是不是非常简单,一个方法搞定,将Loading的逻辑都隐藏了,再也不需要手动写 showLoading() 和 stopLoading()。
并且请求的结果直接在回调里面接收,直接处理,这样请求网络和结果的处理都在一起,看起来一目了然,再也不需要在 Activity 中到处找在哪监听的 LiveData。
同样,它跟 LiveData 一样,也会监听 Activity 的生命周期,不会造成内存泄露。因为它是运行在Activity 的 lifecycleScope 协程作用域中的。
2.3 需要监听数据变化
需求:
TestActivity 中示例代码:
// TestActivity.kt
class TestActivity : AppCompatActivity(R.layout.activity_api) {
private fun initObserver() {
mViewModel.wxArticleLiveData.observeState(this) {
onSuccess = { data: List<WxArticleBean>? ->
showSuccessView(data)
}
onDataEmpty = { showEmptyView() }
onFailed = { code, msg -> showFailedView(code, msg) }
onError = { showErrorView() }
}
}
private fun requestNet() {
// 需要Loading
launchWithLoading {
mViewModel.requestNet()
}
}
}
ViewModel 中示例代码:
class ApiViewModel : ViewModel() {
private val repository by lazy { WxArticleRepository() }
val wxArticleLiveData = StateMutableLiveData<List<WxArticleBean>>()
suspend fun requestNet() {
wxArticleLiveData.value = repository.fetchWxArticleFromNet()
}
}
本质上是通过FLow来调用LiveData的setValue()方法,还是LiveData的使用。虽然可以完全用 Flow 来实现,但是我觉得这里用 Flow 的方式麻烦,不容易懂,还是怎么简单怎么来。
这种方式其实跟上篇文章中的封装二差不多,区别就是不需要手动调用Loading有关的方法。
三、拆封装
如果不抽取通用方法是这样写的:
// TestActivity.kt
private fun login() {
lifecycleScope.launch {
flow {
emit(mViewModel.login("username", "password"))
}.onStart {
showLoading()
}.onCompletion {
dismissLoading()
}.collect { response ->
when (response) {
is ApiSuccessResponse -> showSuccessView(response.data)
is ApiEmptyResponse -> showEmptyView()
is ApiFailedResponse -> showFailedView(response.errorCode, response.errorMsg)
is ApiErrorResponse -> showErrorView(response.error)
}
}
}
}
简单介绍下Flow:
Flow类似于RxJava,操作符都跟Rxjava差不多,但是比Rxjava简单很多,kotlin通过flow来实现顺序流和链式编程。
flow关键字大括号里面的是方法的执行,结果通过emit发送给下游。
onStart表示最开始调用方法之前执行的操作,这里是展示一个 loading ui;
onCompletion表示所有执行完成,不管有没有异常都会执行这个回调。
collect表示执行成功的结果回调,就是emit()方法发送的内容,flow必须执行collect才能有结果。因为是冷流,对应的还有热流。
更多的Flow知识点可以参考其他博客和官方文档。
这里可以看出,通过Flow完美的解决了loading的显示与隐藏。
我这里是在Activity中都调用flow的流程,这样我们扩展BaseActivity即可。
为什么扩展的是BaseActivity?
因为startLoading()和stopLoading()在BaseActivity中。😂
3.1 解决 flow 的 Loading 模板代码
fun <T> BaseActivity.launchWithLoadingGetFlow(block: suspend () -> ApiResponse<T>): Flow<ApiResponse<T>> {
return flow {
emit(block())
}.onStart {
showLoading()
}.onCompletion {
dismissLoading()
}
}
这样每次调用launchWithLoadingGetFlow方法,里面就实现了 Loading 的展示与隐藏,并且会返回一个 FLow 对象。
下一步就是处理 flow 结果collect里面的模板代码。
3.2 声明结果回调类
class ResultBuilder<T> {
var onSuccess: (data: T?) -> Unit = {}
var onDataEmpty: () -> Unit = {}
var onFailed: (errorCode: Int?, errorMsg: String?) -> Unit = { _, _ -> }
var onError: (e: Throwable) -> Unit = { e -> }
var onComplete: () -> Unit = {}
}
各种回调按照项目特性删减即可。
3.3 对ApiResponse对象进行解析
private fun <T> parseResultAndCallback(response: ApiResponse<T>,
listenerBuilder: ResultBuilder<T>.() -> Unit) {
val listener = ResultBuilder<T>().also(listenerBuilder)
when (response) {
is ApiSuccessResponse -> listener.onSuccess(response.response)
is ApiEmptyResponse -> listener.onDataEmpty()
is ApiFailedResponse -> listener.onFailed(response.errorCode, response.errorMsg)
is ApiErrorResponse -> listener.onError(response.throwable)
}
listener.onComplete()
}
上篇文章这里的处理用的是继承LiveData和Observer,这里就不需要了,毕竟继承能少用就少用。
3.4 最终抽取方法
将上面的步骤连起来如下:
fun <T> BaseActivity.launchWithLoadingAndCollect(block: suspend () -> ApiResponse<T>,
listenerBuilder: ResultBuilder<T>.() -> Unit) {
lifecycleScope.launch {
launchWithLoadingGetFlow(block).collect { response ->
parseResultAndCallback(response, listenerBuilder)
}
}
}
3.5 将Flow转换成LiveData对象
获取到的是Flow对象,如果想要变成LiveData,Flow原生就支持将Flow对象转换成不可变的LiveData对象。
val loginFlow: Flow<ApiResponse<User?>> =
launchAndGetFlow(requestBlock = { mViewModel.login("UserName", "Password") })
val loginLiveData: LiveData<ApiResponse<User?>> = loginFlow.asLiveData()
调用的是 Flow 的asLiveData()方法,原理也很简单,就是用了livedata的扩展函数:
@JvmOverloads
fun <T> Flow<T>.asLiveData(
context: CoroutineContext = EmptyCoroutineContext,
timeoutInMs: Long = DEFAULT_TIMEOUT
): LiveData<T> = liveData(context, timeoutInMs) {
collect {
emit(it)
}
}
这里返回的是LiveData<ApiResponse<User?>>对象,如果想要跟上篇文章一样用StateLiveData,在observe的回调里面监听不同状态的callback。
以前的方式是继承,有如下缺点:
- 必须要用
StateLiveData,不能用原生的LiveData,侵入性很强
- 不只是继承
LiveData,还要继承Observer,麻烦
- 为了实现这个,写了一堆的代码
这里用 Kotlin 扩展实现,直接扩展 LiveData:
@MainThread
inline fun <T> LiveData<ApiResponse<T>>.observeState(
owner: LifecycleOwner,
listenerBuilder: ResultBuilder<T>.() -> Unit
) {
val listener = ResultBuilder<T>().also(listenerBuilder)
observe(owner) { apiResponse ->
when (apiResponse) {
is ApiSuccessResponse -> listener.onSuccess(apiResponse.response)
is ApiEmptyResponse -> listener.onDataEmpty()
is ApiFailedResponse -> listener.onFailed(apiResponse.errorCode, apiResponse.errorMsg)
is ApiErrorResponse -> listener.onError(apiResponse.throwable)
}
listener.onComplete()
}
}
感谢Flywith24开源库提供的思路,感觉自己有时候还是在用Java的思路在写Kotlin。
3.6 进一步完善
很多网络请求的相关并不是只有 loading 状态,还需要在请求前和结束后处理一些特定的逻辑。
这里的方式是:直接在封装方法的参数加 callback,默认用是 loading 的实现。
fun <T> BaseActivity.launchAndCollect(
requestBlock: suspend () -> ApiResponse<T>,
startCallback: () -> Unit = { showLoading() },
completeCallback: () -> Unit = { dismissLoading() },
listenerBuilder: ResultBuilder<T>.() -> Unit
)
四、针对多数据来源
虽然项目中大部分都是单一数据来源,但是也偶尔会出现多数据来源,多数据源结合Flow的操作符,也非常的方便。
示例
假如同一份数据可以从数据库获取,可以从网络请求获取,TestRepository的代码如下:
// TestRepository.kt
suspend fun fetchDataFromNet(): Flow<ApiResponse<List<WxArticleBean>>> {
val response = executeHttp { mService.getWxArticle() }
return flow { emit(response) }.flowOn(Dispatchers.IO)
}
suspend fun fetchDataFromDb(): Flow<ApiResponse<List<WxArticleBean>>> {
val response = getDataFromRoom()
return flow { emit(response) }.flowOn(Dispatchers.IO)
Repository中的返回不再直接返回实体类,而是返回flow包裹的实体类对象。
为什么要这么做?
为了用神奇的flow操作符来处理。
flow组合操作符
combine操作符可以连接两个不同的Flow。
merge操作符用于将多个流合并。
zip操作符会分别从两个流中取值,当一个流中的数据取完,zip过程就完成了。
关于 Flow 的基础操作符,徐医生大神的这篇文章已经写的很棒了,这里就不多余的写了。
根据操作符的示例可以看出,就算返回的不是同一个对象,也可以用操作符进行处理。
几年前刚开始学RxJava时,好几次都是入门到放弃,操作符太多了,搞的也很懵逼,Flow 真的比它简单太多了。
五、flow的奇淫技巧
flowWithLifecycle
需求:
Activity 的 onSume() 方法中请求最新的地理位置信息。
以前的写法:
// TestActivity.kt
override fun onResume() {
super.onResume()
getLastLocation()
}
override fun onDestory() {
super.onDestory()
// 释放获取定位的代码,防止内存泄露
}
这种写法没问题,也很正常,但是用了 Flow 之后,有一种新的写法。
用了 flow 的写法:
// TestActivity.kt
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
getLastLocation()
}
@ExperimentalCoroutinesApi
@SuppressLint("MissingPermission")
private fun getLastLocation() {
if (LocationPermissionUtils.isLocationProviderEnabled() && LocationPermissionUtils.isLocationPermissionGranted()) {
lifecycleScope.launch {
SharedLocationManager(lifecycleScope)
.locationFlow()
.flowWithLifecycle(lifecycle, Lifecycle.State.RESUMED)
.collect { location ->
Log.i(TAG, "最新的位置是:$location")
}
}
}
}
在onCreate中书写该函数,然后 flow 的链式调用中加入:
.flowWithLifecycle(lifecycle, Lifecycle.State.RESUMED)
flowWithLifecycle能监听 Activity 的生命周期,在 Activity 的onResume开始请求位置信息,onStop 时自动停止,不会导致内存泄露。
flowWithLifecycle 会在生命周期进入和离开目标状态时发送项目和取消内部的生产者。
这个api需要引入 androidx.lifecycle:lifecycle-runtime-ktx:2.4.0-rc01依赖库。
callbackFlow
有没有发现5.1中调用获取位置信息的代码很简单?
SharedLocationManager(lifecycleScope)
.locationFlow()
.flowWithLifecycle(lifecycle, Lifecycle.State.RESUMED)
.collect { location ->
Log.i(TAG, "最新的位置是:$location")
}
几行代码解决获取位置信息,并且任何地方都直接调用,不要写一堆代码。
这里就是用到callbackFlow,简而言之,callbackFlow就是将callback回调代码变成同步的方式来写。
这里直接上SharedLocationManager的代码,具体细节自行 Google,因为这就不是网络框架的内容。
这里附上主要的代码:
@ExperimentalCoroutinesApi
@SuppressLint("MissingPermission")
private val _locationUpdates: SharedFlow<Location> = callbackFlow<Location> {
val callback = object : LocationCallback() {
override fun onLocationResult(result: LocationResult?) {
result ?: return
Log.d(TAG, "New location: ${result.lastLocation}")
trySend(result.lastLocation)
}
}
Log.d(TAG, "Starting location updates")
fusedLocationClient.requestLocationUpdates(
locationRequest,callback,Looper.getMainLooper())
.addOnFailureListener { e ->close(e)}
awaitClose {
Log.d(TAG, "Stopping location updates")
fusedLocationClient.removeLocationUpdates(callback)
}
}.shareIn(
externalScope,
replay = 0,
started = SharingStarted.WhileSubscribed()
)
完整代码见:GitHub
总结
上一篇文章# 两种方式封装Retrofit+协程,实现优雅快速的网络请求
加上这篇的 flow 网络请求封装,一共是三种对Retrofit+协程的网络封装方式。
对比下三种封装方式:
封装一 (对应分支oneWay) 传递ui引用,可按照项目进行深度ui定制,方便快速,但是耦合高
封装二 (对应分支master) 耦合低,依赖的东西很少,但是写起来模板代码偏多
封装三 (对应分支dev) 引入了新的flow流式编程(虽然出来很久,但是大部分人应该还没用到),链式调用,loading 和网络请求以及结果处理都在一起,很多时候甚至都不要声明 LiveData 对象。
第二种封装我在公司的商业项目App中用了很长时间了,涉及几十个接口,暂时没遇到什么问题。
第三种是我最近才折腾出来的,在公司的新项目中(还没上线)使用,也暂时没遇到什么问题。
如果某位大神看到这篇文章,有不同意见,或者发现封装三有漏洞,欢迎指出,不甚感谢!
项目地址
FastJetpack
项目持续更新...