








实现一个微信录音功能过程
功能原型图
其实就是微信发送语音的功能。没有转文字的功能。
拆解需求
根据原型图可以很容易的得出我们需要做的内容包括下面三个部分:
接入微信的语音SDK
调用微信SDK的API逻辑
界面和交互的实现
其中第一点和第二点属于业务逻辑部分,第三点属于交互逻辑部分。对于业务逻辑和交互逻辑的关系在我的另外一篇文章描述过,我在vue中是这样拆分组件的 - 掘金 (juejin.cn)
从原型图可以分析出如下的流程图:
评估时间
第三事情是评估时间。在接到这个需求的时候,我们需要假设我们在此之前没有接入过微信相关的SDK,并以此为前提进行工期的评估。
可以将该用户故事拆分为如下任务:
微信语音SDK的技术调研(0.5天)
输出开发设计文档(0.5天)
接入微信语音SDK(0.5天)
编码(1天)
自测(0.5天)
随后将上面的时间都乘以2! 自此才可以将估算的工期上报给产品。多年的经验告诉自己,自己一开始估算的工期从来没够过。自行估算的时候,幻想的是在工作的时候能够一直保持专注。
就我自己而言,做不到,上班不可能不摸鱼!也是必须要摸鱼的。乘以2才是刚够而已。
代码实现
都说在实现代码之前要先设计,谋定而后动。我是这样做的,先想好文件夹创建,然后到文件的创建,再到具体文件中写出大体的框架。
需求并不复杂,只是一个界面中的一个模块。所以我只需要一个Record.vue来承载界面,一个use-record-layout.js来承载业务逻辑,以及一个use-record-interact.js来承接交互逻辑。
|__im-record
|__Record.vue
|__use-record-layout.js
|__use-record-interact.js为了便于说明,将这个聊天的界面简化如下:
<script setup>
import { useNamespace } from "@/use-namespace";
const ns = useNamespace('chat')
</script>
<template>
<header :class="ns.b('header')"></header>
<main :class="ns.b('main')">
<section :class="[ns.b('record'), ns.w('record', 'toast')]">
<div :class="ns.w('record', 'speak')"></div>
<div :class="ns.w('record', 'pause')"></div>
</section>
</main>
<footer :class="ns.w('button', 'wrap')">
<button :class="ns.b('button')">
<span>
按住 说话
</span>
</button>
</footer>
</template>通过上面的代码片段可知,我们的主要的界面在section标签的record部分。
use-record-layout.js的主题代码如下:
const recordStyle = {
default: { }, // 默认样式/确定发送录音
recording: { }, // 录音中
pause: { }, // 暂停录音
cancel: { } // 取消录音
}
const init = () => {
initEvent()
initStyle()
}
const initStyle = () => {
recordStyle.default.is = true
}
const initEvent = () => {
el.addEventListener('touchstart', handleTouchstart)
el.addEventListener('touchmove', handleTouchmove)
el.addEventListener('touchend', handleTouchend)
}
const axis = {
posStart: 0, // 初始化起点坐标
posMove: 0 // 初始化滑动坐标
}
const handleTouchstart = (event) => {
event.preventDefault()
axis.posStart = event.touches[0].pageY
recordStyle.recording.is = true
}
const handleTouchmove = (event) => {
event.preventDefault()
axis.posMove = event.targetTouches[0].pageY
const diffMove = axis.posMove - axis.posStart
if (diffMove > DEFAULT_AXIS) {
recordStyle.recording.is = true
}
}
const handleTouchend = (event) => {
event.preventDefault()
recordStyle.default.is = true
}
init()其中recordStyle是交互的结果,在这个需求当中,我们的界面的四种变化都对应其中一个的样式。
use-record-interact.js也很简单,注册微信录音功能 ➡️
const wx = 'wx'
const useRecordInteract = () => {
const isAuth = localStorage.getItem('allowWxRecord')
// 获取录音权限
const authRecord = () => {
if (!isAuth) {
wx.startRecord()
return
}
return isAuth
}
// 停止录音
const stopRecord = () => {}
// 上传录音
const uploadRecord = () => {}
}交互逻辑和业务逻辑的联动通过recordStyle对象的存取属性来实现,代码片段如下:
const interact = useRecordInteract()
const recordStyle = {
default: {
_is: false,
get is() {
return this._is
},
set is(value) {
this._is = value
if (value) {
this.recording.is = false
this.pause.is = false
this.cancel.is = false
interact.uploadRecord()
}
}
},
//...
}实现了业务逻辑和交互逻辑的分离。
作者:砂糖橘加盐
来源:juejin.cn/post/7201491839815745597
真的有必要用微前端框架么?
前言
最近公司项目在用qiankun构建微前端的应用,深深体会到微前端的魅力,无框架限制,主应用统一管理,弹窗的统一位置等。如果是刚开始就植入微前端还好,不过基本上都是后期老项目植入微前端,各种拆分模块,也是一件很头疼的事情。
基石
我们为什么要用微前端
大的应用体量维护成本是很高的,拆分成单独的模块,由主应用处理登录等通用逻辑,子应用来只负责模块的业务实现,这样不管资源加载、按需加载、人员维护成本降低、增量升级、独立部署都有很好的体检提升。当然前提是体量非常大的web应用可以这么做,但是开始做的时候你会很头疼各种拆解带来的不确定性,但是长痛不如短痛。
Why Not Iframe
下面是我从qiankun文档摘抄的:
iframe 最大的特性就是提供了浏览器原生的硬隔离方案,不论是样式隔离、js 隔离这类问题统统都能被完美解决。那么为什么不用iframe呢 ?
- url 不同步。浏览器刷新 iframe url 状态丢失等(本地缓存不就行了?)
- UI 不同步,DOM 结构不共享(主应用控制不就行了?子应用通过postMessage传递数据给父应用)
- 一次性加载,慢!(个人感觉就是项目体积小了!跟iframe有啥区别么?)
- 全局上下文完全隔离,内存变量不共享。(当然这里通过postMessage是可以实现通信的!)
所以其实用iframe就够了,微前端是不是有点kpi的味道呢?当然学习下源码还是对自己有提升的,万一iframe没有,是不是可以手撸一个呢?
源码入口
最核心的就是手动加载loadMicroApp、registerMicroApps注册微应用,start开始构建这3个api,但其实qiankun的核心是基于single-spa框架封装的, 我们看下single-spa做了些什么,以及single-spa内部核心api的registerApplication做了什么
single-spa
single-spa是一个框架,用于将多个JavaScript微前端组合在一个前端应用程序中。使用单一页面中心构建前端可以带来许多好处,例如:
- 在同一页面上使用多个框架而无需刷新页面(React,AngularJS,Angular,Ember或你正在使用的任何框架)
- 独立部署您的微前端
- 使用新框架编写代码,无需重写现有应用
- 延迟加载代码可缩短初始加载时间
registerApplication 注册应用
export function reroute (pendingPromises = [], eventArguments) {
//...
const {
appsToUnload,
appsToUnmount,
appsToLoad,
appsToMount,
} = getAppChanges(); //返回不同生命周期的队列
//记录基础的应用信息
let appsThatChanged,
navigationIsCanceled = false,
oldUrl = currentUrl,
newUrl = (currentUrl = window.location.href);
//这里根据是否已挂载做处理
if (isStarted()) {
//....
} else {
appsThatChanged = appsToLoad;
return loadApps();
}
//加载apps
function loadApps () {
return Promise.resolve().then(() => {
const loadPromises = appsToLoad.map(toLoadPromise);
return (
Promise.all(loadPromises)
.then(callAllEventListeners)
// there are no mounted apps, before start() is called, so we always return []
.then(() => [])
.catch((err) => {
callAllEventListeners();
throw err;
})
);
});
}
//根据app状态改变发布对应的事件
function performAppChanges () {
return Promise.resolve().then(() => {
// https://github.com/single-spa/single-spa/issues/545
window.dispatchEvent(
new CustomEvent(
appsThatChanged.length === 0
? "single-spa:before-no-app-change"
: "single-spa:before-app-change",
getCustomEventDetail(true)
)
);
//...做了大量的自定义事件以及卸载事件
}
//....
}
复制代码说实话这里的源码很绕,这里只摘取最关键的,在registerApplication内部,将qiankun的registerMicroApps的参数传入做些兼容判断,然后调用了一个核心的reroute方法, 这里删除了不必要的干扰信息,说白了single-spa做了spa的生命周期的管理,每个应用有单独的html做页面的加载,但是环境的隔绝是需要qiankun做的
getAppChanges 状态管理
export function getAppChanges () {
const appsToUnload = [],
appsToUnmount = [],
appsToLoad = [],
appsToMount = [];
// We re-attempt to download applications in LOAD_ERROR after a timeout of 200 milliseconds
const currentTime = new Date().getTime();
apps.forEach((app) => {
const appShouldBeActive =
app.status !== SKIP_BECAUSE_BROKEN && shouldBeActive(app);
switch (app.status) {
case LOAD_ERROR:
if (appShouldBeActive && currentTime - app.loadErrorTime >= 200) {
appsToLoad.push(app);
}
break;
case NOT_LOADED:
case LOADING_SOURCE_CODE:
if (appShouldBeActive) {
appsToLoad.push(app);
}
break;
case NOT_BOOTSTRAPPED:
case NOT_MOUNTED:
if (!appShouldBeActive && getAppUnloadInfo(toName(app))) {
appsToUnload.push(app);
} else if (appShouldBeActive) {
appsToMount.push(app);
}
break;
case MOUNTED:
if (!appShouldBeActive) {
appsToUnmount.push(app);
}
break;
// all other statuses are ignored
}
});
return { appsToUnload, appsToUnmount, appsToLoad, appsToMount };
}
复制代码getAppChange返回了应用一旦改变那么不同生命周期的队列会更新
registerMicroApps注册微应用
简单的看下用法,qiankun的核心api并不多
registerMicroApps注册微应用中,传入apps的信息,如name、路由匹配规则、container挂载dom等,和生命周期的钩子lifeCycles。核心的应用状态管理在single-spa中,而qiankun在外层又做了统一的上层的主应用封装。这里比较重要的是loadApp,里面统一处理解决了全局变量混入的问题也就是沙箱隔离,样式隔离等。下面是loadApp的一部分核心逻辑
环境隔离
1. 全局变量的隔离
createSandboxContainer 创建沙箱
这里核心就是createSandboxContainer的用法,这里简单讲下几个核心的参数,initialAppWarpperGetter用于处理检查是否有无包裹的dom元素,scpredCSS是代表样式是否已经被隔离状态, useLooseSandbox和speedySandbox处理不同状态的沙箱。
,在里面核心的方法是patchAtBootstrapping做了不同的沙箱隔离方式的隔绝处理
patchAtBootstrapping 启动器
patchAtBootstrapping中的策略者模式,我们可以看到有3种沙箱的处理方式,legacyProxy、Proxy、Snapshot,并分别对应了pathLooseSandbox、pathStrictSandbox、patchLooseSandbox,下面简单解析下原理,理解即可。
Snapshot沙箱隔离
先将主应用的window拷贝一份,一旦微应用切换到主应用做回退,如果微应用切换,那么会提前生成微应用的diff过程的对象,然后回退。而缺陷就是diff属性量一旦过大会性能不好
Legacy沙箱隔离
那么与Snapshot最大的不同是用了Proxy来处理,set做记录,一旦应用切换就回退,相对于我不断循环遍历diff,性能好了不少
Proxy沙箱隔离
前面两种应用场景在于都是一个路由对应一个微应用,那么如果是多个微应用同时出现在一个页面中,那么环境是不是不可控了呢。这种情况就不能在window直接操作,而是要每个应用都要有一个独立的fakeWindow,这样区分环境后,数据处理尽量在fakeWindow上处理,而不是原生window
Proxy模式的核心的我们看下pathStrictSandbox源码
pathStrictSandbox 严格模式
Proxy代理模式的沙箱,通过Object.defineProperty来拦截对象属性,但是不可枚举可写入, 这样每次切换应用我都重新获取新的nativeGlobal
nativeGlobal 全局对象
export const nativeGlobal = new Function('return this')();
复制代码通过new Function来更安全的返回全局对象
2. DOM的隔离
很明显这里是通过ShadowDOM来实现dom的隔离,我们常见的比如video、audio标签内部都是可以看到shadowDOM实现的,同时我们也可以看到做了兼容性的处理
3. 样式隔离
scopedCSS代表是否要隔离css,如果要隔离首先去判断将微应用的根元素挂载qiankun的属性标记,然后遍历所有style标签,css.process对每个内部的样式属性名做了模块化的处理,而appInstanceId就是做微应用样式隔离的id区分
通信
import-html-entry
qiankun用的是import-html-entry这个库的execSceipts方法来请求获得并解析脚本的,然后直接把html插入到容器里,所以应用间需要允许跨域才行,在importEntry你可以发现他使用了浏览器空闲的api,requestIdleCallback以及为基础实现预加载prefetch
initGlobalState 全局状态
我们主要看下initGlobalState,通过emitGlobal来触发更新全局状态,从上图可以看出核心通过deps发布订阅模式来管理每个微应用,然后更新状态。返回的onGlobalChange和setGlobalState来监听变化和触发通知。状态管理还是比较简单的。
总结
花了几天时间看了源码,收获还是挺大的,微前端其实主要有3个的核心点在于应用通信、应用的生命周期及状态管理、沙箱环境隔离。相对来说iframe足够满足我们业务需求了,微前端提供了一种思路还是不错的,但是真的有必要用qiankun么?
链接:https://juejin.cn/post/7201282972967944250
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
JavaScript 预编译
预编译发生在什么时候
预编译发生在函数执行的前一刻
一. 预编译的抽象理解
函数声明整体提升
变量,声明提升
举个例子
<script type="text/javascript">
test();
function test() {
console.log('我是test');
}
a = 10;
var a;
console.log(a);
</script>这里控制台能正常输出就是因为在预编译时将函数的声明整体和变量的声明提升到了代码的最顶部,所以代码中先调用函数或者是先给变量赋值再声明都没有问题,当然这是抽象的概念,记住这个已经能解决8-90%的变成问题了,如果你想了解具体的流程,可以接着往下看。
二. 局部函数预编译过程
创建AO(Activation Object)对象
找形参和变量声明,将变量和形参名作为AO对象的属性名,默认值为undefind
将实参值和形参相关联
找函数声明,值为其函数体
例子一
<script type="text/javascript">
function test(a) {
var b = 10;
function c() {
}
}
test(1);
</script>根据过程来我们可以得出右边的AO对象中的数值,a最终保存的是1,因为第三步需要把形参和实参相关联
例子二
<script type="text/javascript">
function test(a) {
var a = 10;
function a() {
}
}
test(1);
</script>对象中同名的属性会只保留一个,所以经过第二步寻找变量声明和形参的时候,AO对象中会有一个a,且默认值为undefind,经过第三步实参值和形参相关联后,a的值变为1,经过第四步找函数声明的时候发现有个名字为a的函数,AO中本身就有a的属性名了,所以这个时候会将a的函数体赋值给AO中的a。
如果上面的例子能够搞懂的话,咱们就可以接着玩一个题
例子三
<script type="text/javascript">
function test(a) {
console.log(a);
var a = 10;
console.log(a);
function a() {
consoel.log('这是函数a');
}
}
test(1);
</script>如果你心中的结果跟答案一致,说明已经清楚了局部函数预编译的四个步骤了
到test函数执行之前AO对象中a的值为a的函数体这个应该没有什么问题吧?所以第一个log打印出来的是a的函数体,第二个log之前由于有var a = 10;,这个经过变量的声明提升后可以看做是a = 10;,走到这里这里AO中的a被赋值为10,所以第二个log打印的就是10。
二. 全局函数预编译过程
创建GO(Global Object)对象
找变量声明,将变量名作为GO对象的属性名,默认值为undefind
找函数声明,值为其函数体
全局函数的过程跟局部函数差不多,由于全局函数没有形参和实参的传递,所以省略了一个步骤。
例子四
<script type="text/javascript">
console.log(a);
var a = 1111;
console.log(a);
function a() {
console.log('这里是a函数');
}
</script>这里例子四的输出和转化结果跟例子三差不多,只不过是AO对象变成了GO对象。
例子五
<script type="text/javascript">
console.log(a);
var a = 10;
function a(a) {
console.log(a);
}
a(1);
</script>这里可以看看第二个log打印的是什么,还是会报错?
第一个log打印a函数的函数体没有问题吧?第二个log为什么会报错呢?因为GO对象中保存的a属性在第一次log的时候保存的是a的函数体,但是下面有个a=10;*的赋值,这个时候GO中的a就被修改成10了,后面调用*a(1)*函数的时候,找到GO中的a,这个时候a是number数字而不是函数,所以会报错说*a is not a function。
例子六
<script type="text/javascript">
var a = 1;
var b = 2;
function test(a) {
var a;
console.log(a); // 输出10
a = 100;
console.log(a); // 输出100
console.log(b); // 输出2
}
test(10);
console.log(a); // 输出1
</script>看看例子六的输出结果是不是符合自己的心里预期。我们都知道函数内部有变量会优先使用自身内部的变量,其实也可以转化成AO和GO来理解。 第一个log输出的时候找到自身的AO中有属性a,且这个值是实参传递过来的,所以是10。 第二个log由于前面有a=100所以a被赋值成了100。 第三个log会找自己的AO,发现自己的AO里没有这个b属性,就会去找到父函数的AO,由于这里父函数是全局函数了,所以就去找GO里有没有b属性,有的话就输出了GO里的b的值,所以是2。(如果这里GO中也没有b属性的话,就会报b is not defined的错误了) 第四个log输出的就是自身AO也就是GO中的a属性的值了。
看完这几个例子相信你应该对预编译有个比较清晰的认识了,这里的面试题很多,但是万变不离其中,我们只需要把AO和GO分析出来,那么就可以清晰的了解到函数运行过程中每一步的每个属性值分别是什么了。
作者:Charlin丶
来源:juejin.cn/post/7200681438315642941
心血来潮,这次我用代码“敲”木鱼
技术栈
面对这种寿命短,后期也基本不需要维护的项目(更没有复杂的网络请求一说),本篇文章直接使用原生JavaScript进行开发。或者您也可以尝试一下低代码
关于低代码,您大可放心的阅读此篇干货文章《低代码都做了什么?(为什么?怎么实现Low-Code?)》
至于TypeScript,您可以通过《谈谈写TypeScript实践而来的心得体会》这篇文章快速上手或进阶TS
实现
页面布局
图中右侧标出了三个部分:
img标签用于指定木鱼的图片url地址,在木鱼进行缩放时,对该标签增加/删除css类名即可- 每次敲击时所产生的文字由
p标签生成,且所有的p标签都存在于div标签之下 audio标签会在敲击时播放声音
本篇文章不会涉及具体的Html、Css部分。如有疑问,请在此项目的GitHub中找到答案
逻辑部分
准备工作
通过JavaScript获取要操作的真实dom
const dom = {
// 木鱼
woodenFish: document.querySelector("img"),
// 文字浮层
text: document.querySelector(".w-f-c-text"),
// 音频
audio: document.querySelector("audio")
}
复制代码木鱼缩放
这里的思路是敲击时给img追加一个带有css animation的样式类,该animation的作用是让木鱼进行一次缩放,例如
.w-f-c-i-size {
/** 这里的animation只会执行一次缩放,所以后面会通过增加/删除该类名来达到可以进行n次缩放的效果 */
animation: wooden-fish-size 0.3s;
}
@keyframes wooden-fish-size {
0% {
transform: scale(1);
}
50% {
transform: scale(0.9);
}
100% {
transform: scale(1);
}
}
复制代码样式搞定之后,通过原生JavaScript提供的dom classList进行css样式类名的增加与删除。dom classList共有四个方法:
add:在指定节点上增加一个样式类名remove:在指定节点上删除一个样式类名toggle:在指定节点A上若已有样式类名a,则将a删除;若没有样式类名a,则添加类名areplace:将指定节点上的样式类名替换为另一个样式类名。效果同String##replace一致
const woodenFish = {
// 封装一个用于增加/删除类名的方法
className(type) {
dom.woodenFish.classList[type]("w-f-c-i-size")
},
size() {
this.className("add")
setTimeout(() => this.className("remove"), 300)
}
}
复制代码size方法用于进行一次木鱼的缩放。调用该方法时,首先为img标签增加类w-f-c-i-size,在300毫秒后,再将该类名移除
为什么是300毫秒?因为css animation的持续时间为300毫秒
需要注意的是,size方法中的this为woodenFish对象,所以this.className就相当于woodenFish.className
关于this或其它JavaScript的问题,您可以在《JavaScript每日一题》专栏中找到对应的题目进行练习
文字浮层
const woodenFish = {
className() {},
size() {},
createText() {
const p = document.createElement("p")
p.innerText = "功德+1"
dom.text.appendChild(p)
}
}
复制代码createText方法用于创建一个p标签,该标签的文字内容为“功德+1”,随后将该标签追加在div下即可
小tip:JSX(或react)中书写HTML类型的注释
博主在此刻书写document.createElement这个原生方法时,突然想到了最近用到的一个原生属性outerHTML,该属性与innerHTML的区别就不再赘述。在JSX中书写html类型的注释,使用大括号的形式({/** */})是不可以的,因为在编译时这些东西都会被扔掉,此时可以使用由React提供的dangerouslySetInnerHTML属性,但体验感不太好。所以可以使用ouertHTML配合ref来解决,vue同理,例如:
const HtmlComment: FC<HtmlCommentType> = ({ children }) => {
const virtual = useRef<HTMLSpanElement>(null)
useEffect(() => {
virtual.current!.outerHTML = `<!-- ${children} -->`
}, [])
return <span ref={virtual} />
}
复制代码H5控制手机震动
const vibrate = () => {
const navigator = window.navigator
if (!("vibrate" in navigator)) return
navigator.vibrate =
navigator.vibrate ||
navigator.webkitVibrate ||
navigator.mozVibrate ||
navigator.msVibrate
if (!navigator.vibrate) return
// 上面的代码全是进行兼容性判断,只有下面这一行是发起手机震动的API
navigator.vibrate(300)
}
复制代码像发起手机震动这类Api,首先就要进行兼容性判断,所以上面vibrate方法的90%部分都在进行兼容性判断。注意,window.navigator提供了一个用于发起设备震动的方法,即window.navigator.vibrate
window.navigator.vibrate方法的参数:
- 一个
number类型的值
这种方式表示震动持续多长时间,例如window.navigator.vibrate(300),则表示震动持续300毫秒
- 一个
number类型的数组
这种方式表示震动、暂停间隔的时间。例如window.navigator.vibrate([100, 30, 100]),则表示先震动100毫秒,随后暂停30毫秒,然后再震动100毫秒
window.navigator.vibrate方法在震动成功时返回true,否则返回false
vibrate兼容性
浏览器全屏操作
const toggleFullScreen = () => {
if (!document.fullscreenElement)
return document.documentElement.requestFullscreen()
if (!document.exitFullscreen) return
document.exitFullscreen()
}
document.addEventListener("keydown", (e) =>
e.keyCode == 13 ? toggleFullScreen() : false
)
复制代码toggleFullScreen方法会在全屏或非全屏之间来回切换,用到了以下属性/方法:
document.fullscreenElement返回当前正在以全屏模式显示的元素,如果没有,则返回nulldocument.documentElement.requestFullscreen用于发起全屏请求。若全屏请求成功,则该函数返回成功的Promise对象,否则返回失败的Promise对象。
在全屏成功时,全屏显示的元素会触发fullscreenchange事件;类似于输入框在输入时会触发onchange事件
document.exitFullscreen方法用于使当前元素退出全屏模式
随后为document绑定keydown事件,如果按下了回车键,则在全屏/非全屏之间切换,否则不做出任何操作
音频事件操作
之前博主在写播放器的时候就发现音频的属性、方法、事件很多很多,所以此处只列举两个本项目中用到的方法
play()使播放开始pause()使播放暂停
制作完成
通过以上几个步骤就已经完成了所有要用到的东西,最后只需为木鱼注册“敲击”事件即可
dom.woodenFish.addEventListener("click", () => {
// 木鱼缩放
woodenFish.size()
// 创建文字浮层
woodenFish.createText()
// 播放敲击木鱼的声音
dom.audio.play()
// 发起手机震动
vibrate()
})
复制代码文末
从一次心血来潮,到自己从0至1完成这个简单而有趣的小项目,无论是技术角度,还是个人收获角度来讲,都是收获满满!现在您可以通过以下两个地址来 “功德+1” :
由于时间匆忙,文中错误之处在所难免,敬请读者斧正。如果您觉得本篇文章还不错,欢迎点赞收藏和关注,我们下篇文章见!
链接:https://juejin.cn/post/7199660596735164475
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
z-index不生效?让我们来掀开它的面具
前言
hi大家好,我是小鱼,今天复习的是z-index。之前以为自己很了解它,可是在工作中总会遇到一些不思其解的问题,后来去深入学习了层叠上下文、层叠等级、层叠顺序,才发现z-index只是其中的一叶小舟,今天就一起来看看它背后到底隐藏着什么。
z-index
.container {
z-index: auto | <integer> ;
}
复制代码z-index属性是允许给一个负值的。z-index属性支持 CSS3animation动画。- 在 CSS 2.1 的时候,需要配合
position属性且值不为static时使用。
这个属性大家应该都很熟悉了,指定了元素及其子元素的 在 Z 轴上面的顺序,而 Z 轴上面的顺序 可以决定当元素发生覆盖的时候,哪个元素在上面。 z-index值大的元素会覆盖较低的。
不知道大家在工作中有没有遇到过这种情况,明明给其设置了z-index并且也设置了position不为static,但是样式并不是你所想的那样。可能这里大家对z-index不太了解,判断元素在Z轴上的顺序,不仅仅是z-index值的大小,接下来给大家解释层叠上下文、层叠等级和层叠顺序。
层叠上下文
层叠上下文(stacking context),是HTML中一个三维的概念。如果一个元素含有层叠上下文,我们可以理解为这个元素在Z轴上就“高人一等”。
大家应该都玩过王者荣耀,里面的段位就是一个层级概念。你可以把「层叠上下文」理解为上了最强王者的人,还有很多没上王者的人,我们可以看成是菜鸡。那王者选手和菜鸡之间就形成了一个差距,这个差距也就是在Z轴上的距离,王者选手离荣耀王者就更近了一步,这里的“荣耀王者”可以看成是我们的屏幕观察者。
这样抽象解释完大家应该明白了什么是层叠上下文。继续往下看↓
层叠等级
层叠等级(stacking level),决定了同一个层叠上下文中元素在Z轴上的显示顺序。这里又牵扯出一个level,那么这个等级指的又是什么呢?
所有的元素都有层叠等级,包括层叠上下文元素,层叠上下文元素的层叠等级可以理解为是什么普通王者,无双,荣耀传奇之类。然后,对于普通元素的层叠等级,我们的探讨仅仅局限在当前层叠上下文元素中。为什么呢?因为否则没有意义。
还是回到王者荣耀,元素具有层叠上下文就相当于是王者段位,但是王者里面又分为普通王者,无双王者和荣耀王者还有传奇王者,那我们如果拿普通王者的韩信和传奇王者的韩信相比较实际上是没有意义的,那不吊打吗,那他牛不牛逼是由段位决定的(排除一些意外情况哈哈哈)。
层叠上下文的创建
说白了就是一个元素如何才能变成层叠上下文元素?
层叠上下文是由一些特点的CSS属性创建的,分为三点:
- 页面根元素天生具有层叠上下文,称之为“根层叠上下文”。
- 普通元素设置
position属性为非static值并设置z-index属性为具体数值,产生层叠上下文。 - 其他CSS3中的新属性也可以
flex容器的子元素,且z-index值不为auto- grid 容器的子元素,且 z-index 值不为
auto opacity属性值小于 1 的元素transform属性值不为none的元素filter属性值不为none的元素isolation属性值为isolate的元素-webkit-overflow-scrolling属性值为touch的元素;
简单写两个例子
栗子一
.box1,.box2 {
position: relative;
width: 100px;
height: 100px;
}
.a,.c {
width: 100px;
height: 100px;
position: absolute;
font-size: 20px;
padding: 5px;
color: white;
border: 1px solid rgb(119, 119, 119);
}
.a {
background-color: rgb(0, 163, 168);
z-index: 1;
}
.c {
background-color: rgb(0, 168, 84);
z-index: 2;
left: 50px;
top: -50px;
}
<div class="box1">
<div class="a">A</div>
</div>
<div class="box2">
<div class="c">C</div>
</div>
复制代码
因为box1,box2都没有设置
z-index,所以没有创建层叠上下文,所以其子元素都处于‘根层叠上下文’中,在同一个层叠上下文领域,层叠水平值大的那一个覆盖小的那一个。
栗子2
只帖了修改部分
.box1 {
z-index: 2;
}
.box2 {
z-index: 1;
}
.a {
background-color: rgb(0, 163, 168);
z-index: 1;
}
.b {
background-color: rgb(21, 84, 180);
z-index: 2;
left: 50px;
top: 50px;
}
.c {
background-color: rgb(0, 168, 84);
z-index: 999;
left: 100px;
top: 50px;
}
复制代码
大家可以发现我们给C盒子设置的
z-index为999远大于A、B两个盒子,效果却出现在他俩下面。那是因为给两个父盒子分别设置了z-index,创建了两个不同的层叠上下文,而box1的z-index值大,所以排在上面,这里验证了层叠等级。
栗子3
有一个父元素绝对定位,它有一个子元素也是绝对定位,父元素z-index大于子元素z-index,为何子元素还是在父元素的上面?如何让这个子元素放在父元素的下面。
.parent {
width: 100%;
height: 500px;
background-color: rgb(243, 151, 45);
position: absolute;
z-index: 1;
}
.child {
width: 20%;
height: 150px;
background-color: rgb(211, 56, 56);
position: absolute;
z-index: 0;
}
<div class="parent">
<div class="child">C</div>
</div>
复制代码效果却是这样
解决方案
因为父元素和子元素之间,z-index是无法对比的,同级之间的z-index才能对比。可以考虑换一种方式,两个div做同级,外面包一层父元素,根据共同的父元素定位、做层级区分就可以。
父元素不指定 z-index, 而子元素 z-index 为 -1
结论
普通元素的层叠等级优先由层叠上下文决定,所以,层叠等级的比较只有在当前层叠上下文元素中才有意义。
层叠顺序
层叠顺序(stacking order),表示元素发生层叠时候有着特定的垂直显示顺序,注意,这里跟上面两个不一样,上面的层叠上下文和层叠等级是概念,而这里的层叠顺序是规则。
上图↓
在不考虑CSS3的情况下,当元素发生层叠时,层叠顺序遵循上面图中的规则。
这里稍微解释下为什么内联元素的层叠顺序要比浮动元素和块状元素都高?有些同学可能觉得浮动元素和块状元素要更屌一点,图中我标注了内联样式是内容,因为网页中最重要的是内容,文字和浮动图片的时候优先确保显示文字。
层叠准则
- 谁大谁上: 当具有明显层叠等级的时候,在同一个层叠上下文领域,
z-indx大的那一个覆盖小的那一个。 - 后来居上: 当元素的层叠等级一致、层叠顺序相同的时候,在DOM流中处于后面的元素会覆盖前面的元素。
栗子4
.box1,.box2 {
position: relative;
width: 100px;
height: 100px;
}
.box1 {
z-index: 0;
}
.box2 {
z-index: 0;
}
.a,.c {
width: 100px;
height: 100px;
position: absolute;
font-size: 20px;
padding: 5px;
color: white;
border: 1px solid rgb(119, 119, 119);
}
.a {
background-color: rgb(0, 163, 168);
z-index: 999;
}
.c {
background-color: rgb(0, 168, 84);
z-index: 1;
left: 50px;
top: -50px;
}
<div class="box1">
<div class="a">A</div>
</div>
<div class="box2">
<div class="c">C</div>
</div>
复制代码
上面给两个父盒子都设置了
z-index为0,这里要注意z-index一旦变成数值,哪怕是0,都会创建一个层叠上下文。当然层叠规则就发生了变化,子元素的层叠顺序比较变成了优先比较其父级的层叠上下文的层叠顺序,尽管a盒子的z-index为999。又由于两个父级都是z-index:0,层叠顺序这一块一样大,这个时候就遵循后来居上原则,根据DOM流中的位置决定谁在上面。也可以说子元素上面的z-index失效了!
end
回顾自己以前使用z-index都不太规范或者滥用,以后一定改正!
链接:https://juejin.cn/post/7158409848692932621
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为什么有公司规定所有接口都用Post?
看到这个标题,你肯定觉得离谱。怎么会有公司规定所有接口都用Post,是架构菜还是开发菜。这可不是夸大其词,这样的公司不少。
在特定的情况下,规定使用Post可以减少不少的麻烦,一起看看。
Answer the question
我们都知道,get请求一半用来获取服务器信息,post一般用来更新信息。get请求能做的,post都能做,get请求不能做的,post也都能做。
如果你的团队都是大佬,或者有着良好的团队规范,所有人都在平均水平线之上,并且有良好的纠错机制,那基本不会制定这样的规则。
但如果团队成员水平参差不齐,尤其是小团队,创业团队,常常上来就开干,没什么规范,纯靠开发者个人素质决定代码质量,这样的团队就不得不制定这样的规范。
毕竟可以减少非常多的问题,Post不用担心URL长度限制,也不会误用缓存。通过一个规则减少了出错的可能,这个决策性价比极高。
造成的结果:公司有新人进来,什么lj公司,还有这种要求,回去就在群里讲段子。
实际上都是有原因的。
有些外包公司或者提供第三方接口的公司也会选择只用Post,就是图个方便。
最佳实践
可能各位大佬都懂了哈,我还是给大家科普下,GET、POST、PUT、DELETE,他们的区别和用法。
GET
GET 方法用于从服务器检索数据。这是一种只读方法,因此它没有改变或损坏数据的风险,使用 GET 的请求应该只被用于获取数据。
GET API 是幂等的。 每次发出多个相同的请求都必须产生相同的结果,直到另一个 API(POST 或 PUT)更改了服务器上资源的状态。
POST
POST 方法用于将实体提交到指定的资源,通常导致在服务器上的状态变化或创建新资源。POST既不安全也不幂等,调用两个相同的 POST 请求将导致两个不同的资源包含相同的信息(资源 ID 除外)。
PUT
主要使用 PUT API更新现有资源(如果资源不存在,则 API 可能决定是否创建新资源)。
DELETE
DELETE 方法删除指定的资源。DELETE 操作是幂等的。如果您删除一个资源,它会从资源集合中删除。
| GET | POST | PUT | DELETE | |
|---|---|---|---|---|
| 请求是否有主体 | 否 | 是 | 是 | 可以有 |
| 成功的响应是否有主体 | 是 | 是 | 否 | 可以有 |
| 安全 | 是 | 否 | 否 | 否 |
| 幂等 | 是 | 否 | 是 | 是 |
| 可缓存 | 是 | 否 | 否 | 否 |
| HTML表单是否支持 | 是 | 是 | 否 | 否 |
来源:https://juejin.cn/post/7129685508589879327
异步阻塞IO是什么鬼?
这篇文章我们来聊一个很简单,但是很多人往往分不清的一个问题,同步异步、阻塞非阻塞到底怎么区分?
开篇先问大家一个问题:IO多路复用是同步IO还是异步IO?
先思考一下,再继续往下读。
巨著《Unix网络编程》将IO模型划分为5种,分别是
- 阻塞IO
- 非阻塞IO
- IO复用
- 信号驱动IO
- 异步IO
个人认为这么分类并不是很好,因为从字面上理解阻塞IO和非阻塞IO就已经是数学意义上的全集了,怎么又冒出了后边3种模型,会给初学者带来一些困扰。
接下来进入正文。
文章首发于公众号:「蝉沐风的码场」
1. 一个简单的IO流程
让我们先摒弃我们原本熟知的各种IO模型流程图,先看一个非常简单的IO流程,不涉及任何阻塞非阻塞、同步异步概念的图。
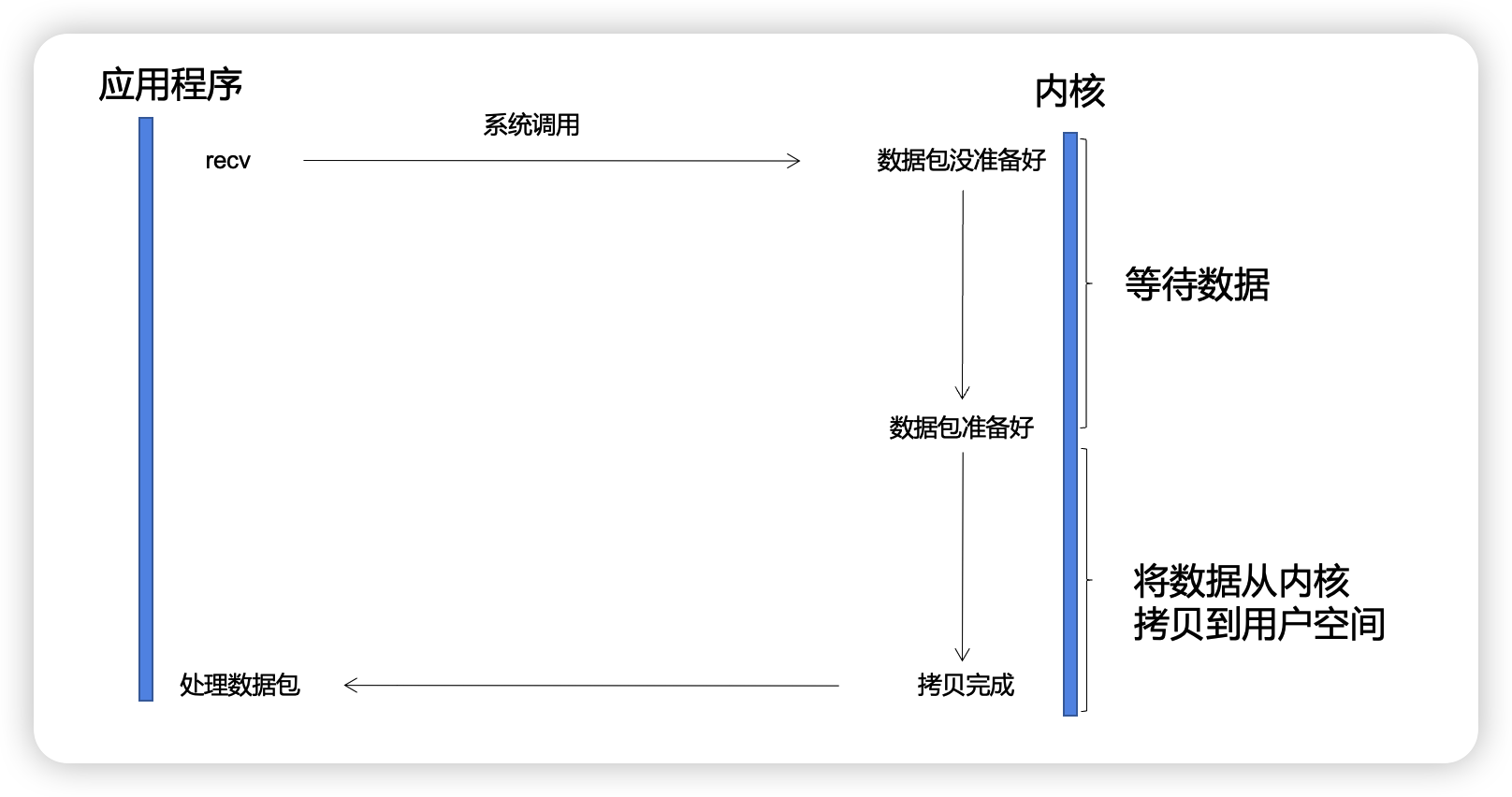
客户端发起系统调用之后,内核的操作可以被分成两步:
等待数据
此阶段网络数据进入网卡,然后网卡将数据放到指定的内存位置,此过程CPU无感知。然后经过网卡发起硬中断,再经过软中断,内核线程将数据发送到socket的内核缓冲区中。
数据拷贝
数据从socket的内核缓冲区拷贝到用户空间。
2. 阻塞与非阻塞
阻塞与非阻塞在API上区别在于socket是否设置了SOCK_NONBLOCK这个参数,默认情况下是阻塞的,设置了该参数则为非阻塞。

2.1 阻塞
假设socket为阻塞模式,则IO调用如下图所示。
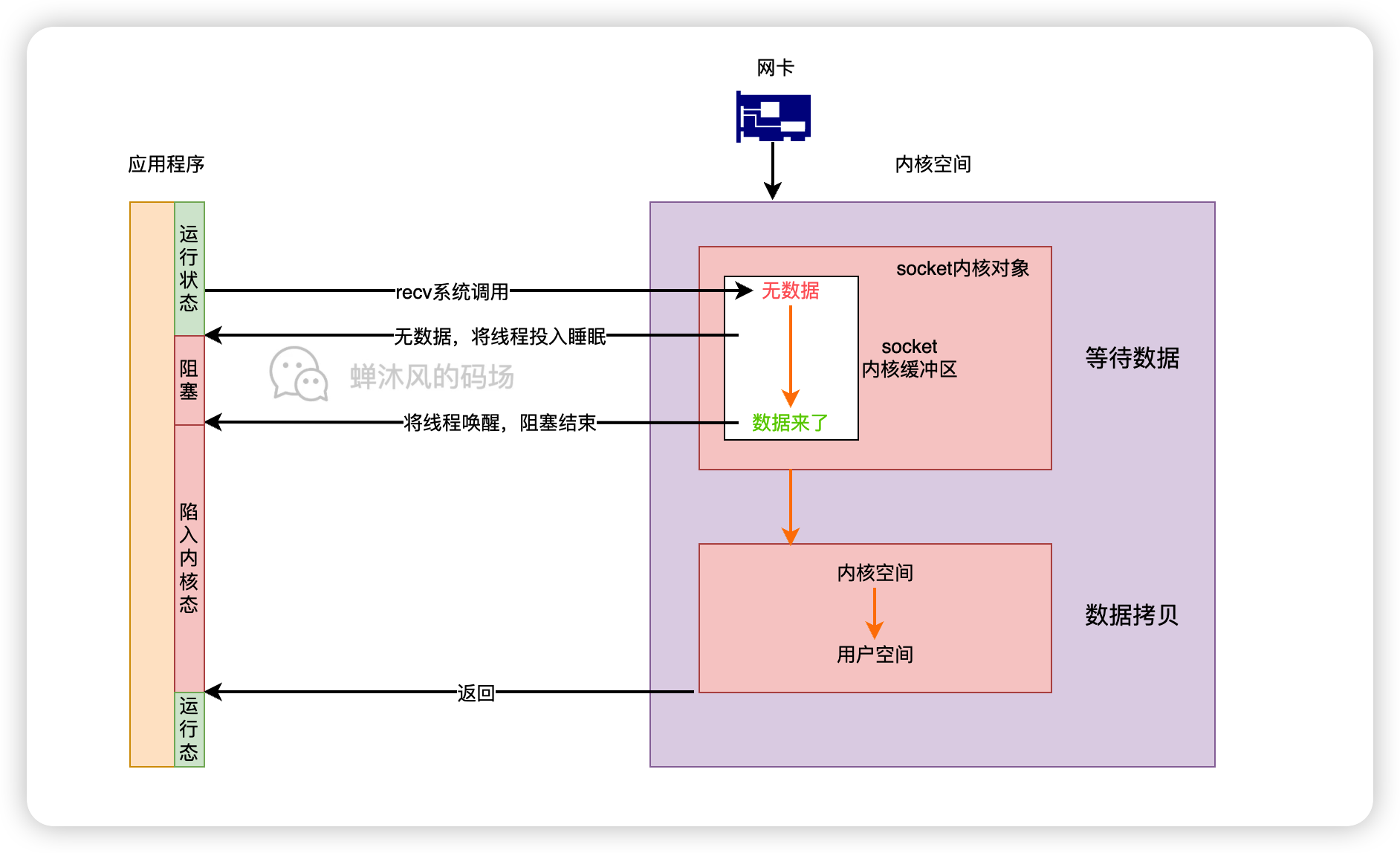
当处于运行状态的用户线程发起recv系统调用时,如果socket内核缓冲区内没有数据,则内核会将当前线程投入睡眠,让出CPU的占用。
直到网络数据到达网卡,网卡DMA数据到内存,再经过硬中断、软中断,由内核线程唤醒用户线程。
此时socket的数据已经准备就绪,用户线程由用户态进入到内核态,执行数据拷贝,将数据从内核空间拷贝到用户空间,系统调用结束。此阶段,开发者通常认为用户线程处于等待(称为阻塞也行)状态,因为在用户态的角度上,线程确实啥也没干(虽然在内核态干得累死累活)。
2.2 非阻塞
如果将socket设置为非阻塞模式,调用便换了一副光景。
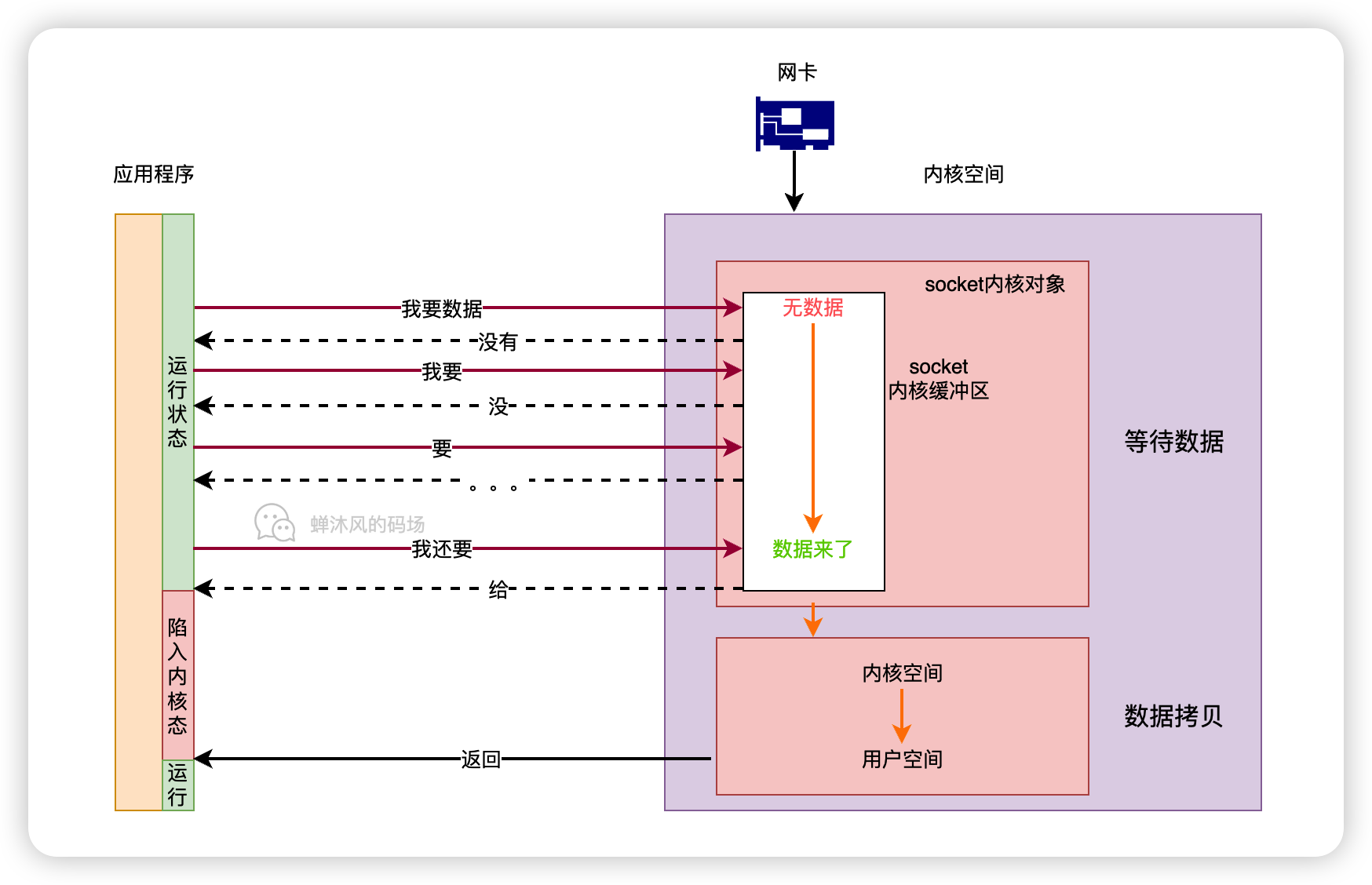
用户线程发起系统调用,如果socket内核缓冲区中没有数据,则系统调用立即返回,不会挂起线程。而线程会继续轮询,直到socket内核缓冲区内有数据为止。
如果socket内核缓冲区内有数据,则用户线程进入内核态,将数据从内核空间拷贝到用户空间,这一步和2.1小节没有区别。
3. 同步与异步
同步和异步主要看请求发起方对消息结果的获取方式,是主动获取还是被动通知。区别主要体现在数据拷贝阶段。
3.1 同步
同步我们其实已经见识过了,2.1节和2.2节中的数据拷贝阶段其实都是同步!
注:把同步的流程画在阻塞和非阻塞的第二阶段,并不是说阻塞和非阻塞的第二阶段只能搭配同步手段!
同步指的是数据到达socket内核缓冲区之后,由用户线程参与到数据拷贝过程中,直到数据从内核空间拷贝到用户空间。
因此,IO多路复用,对于应用程序而言,仍然只能算是一种同步,因为应用程序仍然花费时间等待IO结果,等待期间CPU要么用于遍历文件描述符的状态,要么用于休眠等待事件发生。
以select为例,用户线程发起select调用,会切换到内核空间,如果没有数据准备就绪,则用户线程阻塞到有数据来为止,select调用结束。结束之后用户线程获取到的只是「内核中有N个socket已经就绪」的这么一个信息,还需要用户线程对着1024长度的描述符数组进行遍历,才能获取到socket中的数据,这就是同步。
举个生活中的例子,我们给物流客服打电话询问我们的包裹是否已到达,如果未到达,我们就先睡一会儿,等到了之后客服给我们打电话把我们喊起来,然后我们屁颠屁颠地去快递驿站拿快递。这就是同步阻塞。
如果我们不想睡,就一直打电话问,直到包裹到了为止,然后再屁颠屁颠地去快递驿站拿快递。这就是同步非阻塞。
问题就是,能不能直接让物流的人把快递直接送到我家,别让我自己去拿啊!这就是异步。
3.2 理想的异步
我们理想中的完美异步应该是用户进程发起非阻塞调用,内核直接返回结果之后,用户线程可以立即处理下一个任务,只需要IO完成之后通过信号或回调函数的方式将数据传递给用户线程。如下图所示。
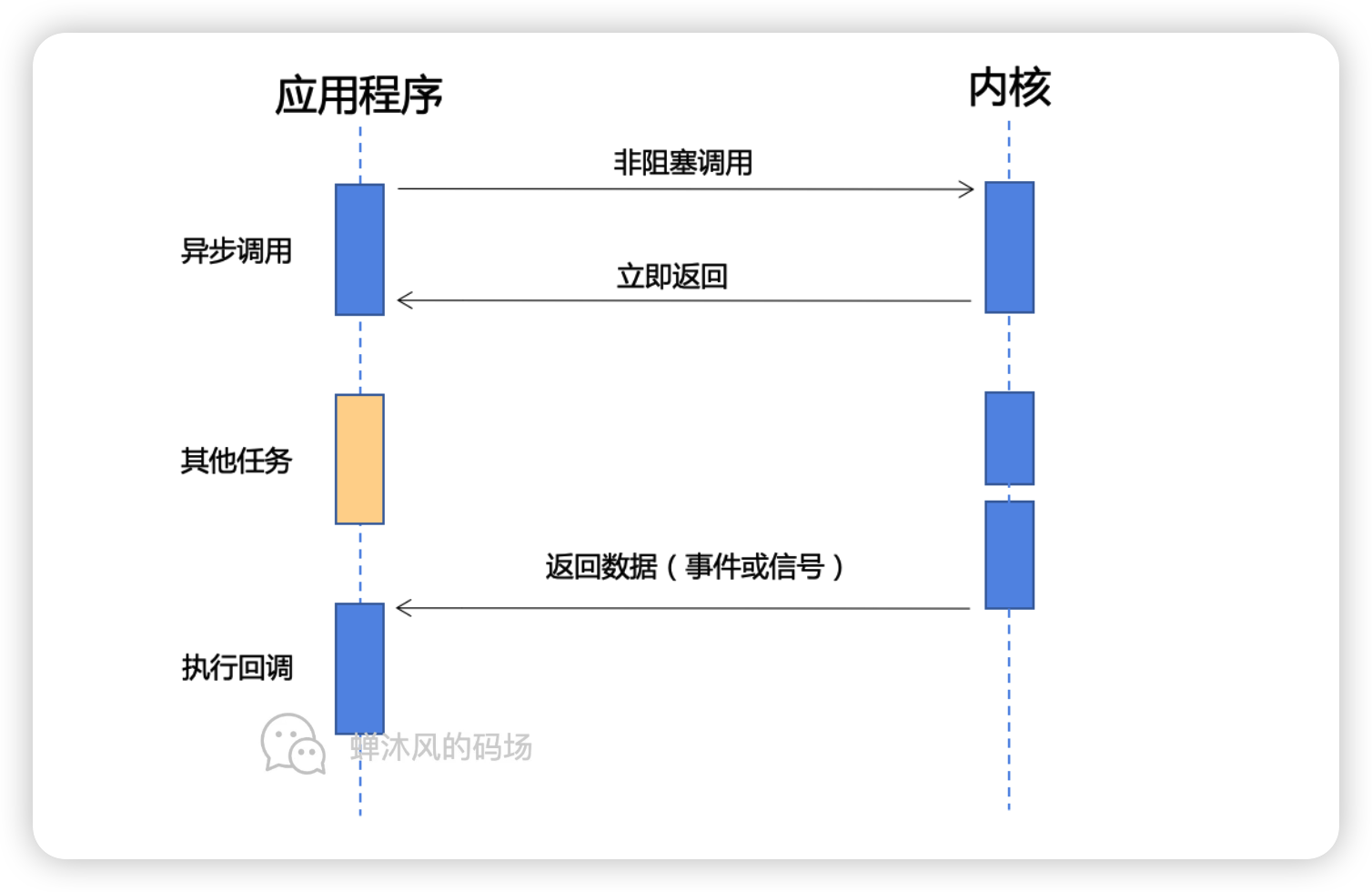
因此,在理想的异步环境下,数据准备阶段和数据拷贝阶段都是由内核完成的,不会对用户线程进行阻塞,这种内核级别的改进自然需要操作系统底层的功能支持。
3.3 现实的异步
现实比理想要骨感一些。
Linux内核并没有太惹眼的异步IO机制,这难不倒各路大神,比如Node的作者采用多线程模拟了这种异步效果。
比如让某个主线程执行主要的非IO逻辑操作,另外再起多个专门用于IO操作的线程,让IO线程进行阻塞IO或者非阻塞IO加轮询的方式来完成数据获取,通过IO线程和主线程之间通信进行数据传递,以此来实现异步。
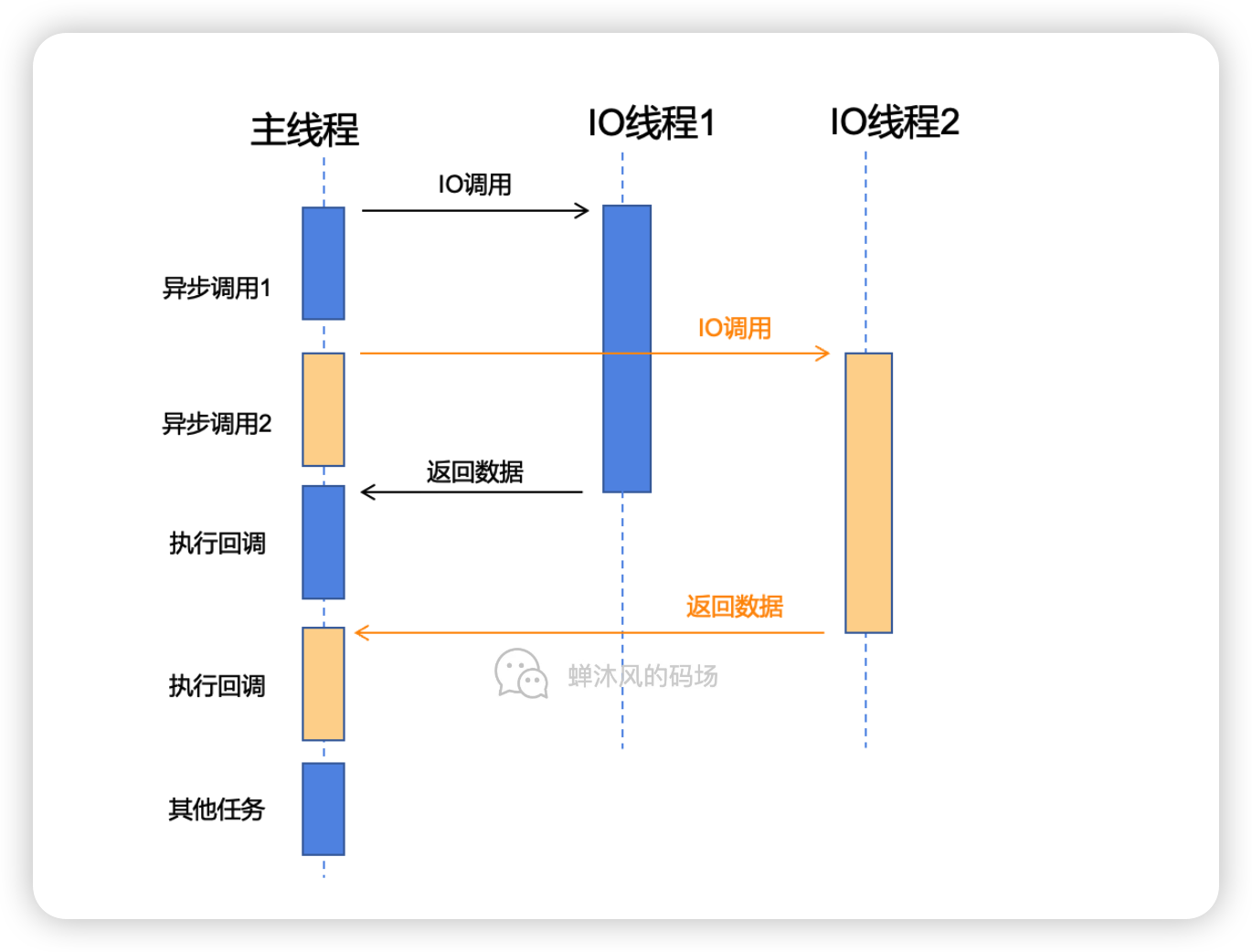
还有一种方案是Windows上的IOCP,它在某种程度上提供了理想的异步,其内部依然采用的是多线程的原理,不过是内核级别的多线程。
遗憾的是,用Windows做服务器的项目并不是特别多,期待Linux在异步的领域上取得更大的进步吧。
4. 异步阻塞?
说完了同步异步、阻塞非阻塞,一个很自然的操作就是对他们进行排列组合。
- 同步阻塞
- 同步非阻塞
- 异步非阻塞
- 异步阻塞
但是异步阻塞是什么鬼?按照上文的解释,该IO模型在第一阶段应该是用户线程阻塞,等待数据;第二阶段应该是内核线程(或专门的IO线程)处理IO操作,然后把数据通过事件或者回调的方式通知用户线程,既然如此,那么第一步的阻塞完全没有必要啊!非阻塞调用,然后继续处理其他任务岂不是更好。
因此,压根不存在异步阻塞这种模型哦~
5. 千万分清主语是谁
最后给各位提个醒,和别人讨论阻塞非阻塞的时候千万要带上主语。
如果我问你,epoll是阻塞还是非阻塞?你怎么回答?
应该说,epoll_wait这个函数本身是阻塞的,但是epoll会将socket设置为非阻塞。因此单纯把epoll认为阻塞是太委屈它,认为其是非阻塞又抬举它。
具体关于epoll的说明可以参见IO多路复用中的epoll部分。
链接:https://juejin.cn/post/7199809805362495546
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你还在傻傻的npm run serve吗?快来尝尝这个!
背景
大家在日常开发中应该经常会有需要切换不同环境地址的情况。当一个项目代码切换环境地址时,vue-cli没有能够感知文件的变化,所以代理的还是旧的地址,所以通常我们需要执行npm run serve进行项目重跑,而项目重跑往往意味着长时间的等待,非常痛苦!
方案调研
事实上,其实我们只是需要重启webpack为我们启动的proxy代理服务,或许能够从webpack的代理服务插件中找到解决方法。
从webpack官网可以看到proxy服务其实是由
http-proxy-middleware提供的,或许我们能够从中找到解决方法。
初步方案
在http-proxy-middleware的配置选项中,除了我们常见的target,还有router。router返回一个字符串的服务地址,当两个选项都配置了的情况下,会优先使用router函数的返回值,只有当router的返回值不可用时,才会使用target的值。
我们可以利用这一点来重新配置我们的项目代码。参考文档在这里
// vue.config.js
const { defineConfig } = require('@vue/cli-service')
const { proxy } = require('./environments/proxy.js')
module.exports = defineConfig({
devServer:{
proxy
},
})
复制代码// proxy.js
const fs = require('fs')
const path = require('path')
const encoding = 'utf-8'
const getContent = filename => {
const dir = path.resolve(process.cwd(), 'environments')
return fs.readFileSync(path.resolve(dir, filename), { encoding })
}
const jsonParse = obj => { return Function('"use strict";return (' + obj + ')')() }
const getConfig = () => { try {
return jsonParse(getContent('proxy-config.json'))
} catch (e) { return {} } }
module.exports = {
proxy: {
// 接口匹配规则自行修改
'/api': {
// 这里必须要有字符串来进行占位
// 如果报错Invaild Url,将target改成有效的url字符串即可,如http://localhost:9001
target: 'that must have a empty placeholder',
changeOrigin: true,
router: () => (getConfig() || {}).target || ''
}
}
}
复制代码// proxy-config.json
{ "target": "http://localhost:9001" }
复制代码自此,当我们需要修改环境地址时,只需要修改proxy-config.json文件便能够实时生效,不再需要npm run serve!
重点代码分析
实现代码中其实最主要的就是getContent这个方法,我们项目在每次发起http请求时都会调用router中的函数,而getContent则会通过node的fs服务,对我们的环境地址文件进行实时读取,从而指向我们最新修改的环境地址。
方案总结
在按照参考文档配置了项目代码之后,我们发现确实能够及时指向新的环境地址,再也不需要重启代码,不需要长时间的等待了。但是,我们多了两个需要维护的文件,每次我们修改环境地址时,不仅需要修改config中的api,还需要修改proxy-config.json中的target!
有没有可能在只需要修改config文件的情况下,实现代理地址动态修改呢?
方案优化
从上面的重点代码分析中,可以看到只要我们可以在router函数执行时,拿到正确的config文件中导出的api属性的值,也可以实现同样的效果!
这是不是意味着只要我们在函数中对config文件进行require请求,读取api的值,再return出去就能及时修改代理指向了呢?
没错,你会发现无论你怎么修改,函数内require取到的api永远是不变的,还是服务刚启动时的环境地址。
参考源码可以知道,这是因为我们在使用require请求文件信息时,node会解析出我们传入的字符串的文件路径的绝对路径,并且以绝对路径为键值,对该文件进行缓存。
因此,如果我们在执行require函数时打断点进行观察的话,会发现require上面有一个cache缓存了已经加载过的文件。
这也恰恰说明了只要我们能够删除掉文件保存在require中的缓存,我们就能够拿到最新的文件内容,那么我们也可以据此得出我们的最终优化方案。
// vue.config.js
const hotRequire = modulePath => {
// require.resolve可以通过相对路径获取绝对路径
// 以绝对路径为键值删除require中的对应文件的缓存
delete require.cache[require.resolve(modulePath)]
// 重新获取文件内容
const target = require(modulePath)
return target
}
...
proxy: {
'/api': {
// 如果router有效优先取router返回的值
target: 'that must have a empty placeholder',
changeOrigin: true,
// 每次发起http请求都会执行router函数
router: () => (hotRequire('./src/utils/config') || {}).api || '',
ws: true,
pathRewrite: {
'^/api': ''
}
}
}
复制代码自此,我们项目修改环境地址将不在需要重启项目,也不需要维护额外的文件夹,再也不需要痛苦等待了!
来源:https://juejin.cn/post/7198696282336313400
从 微信 JS-SDK 认识 JSBridge
前言
前段时间由于要实现 H5 移动端拉取微信卡包并同步卡包数据的功能,于是在项目中引入了 微信 JS-SDK(jweixin) 相关包实现功能,但也由此让我对其产生了好奇心,于是打算好好了解下相关的内容,通过查阅相关资料发现这其实属于 JSBridge 的一种实现方式。
因此,只要了解 JSBridge 就能明白 微信 JS-SDK 是怎么一回事。

为什么需要 JSBridge?
相信大多数人都有相同的经历,第一次了解到关于 JSBridge 都是从 微信 JS-SDK(WeiXinJSBridge) 开始,当然如果你从事的是 Hybrid 应用 或 React-Native 开发的话相信你自然(应该、会)很了解。
其实 JSBridge 早就出现并被实际应用了,如早前桌面应用的消息推送等,而在移动端盛行的时代已经越来越需要 JSBridge,因为我们期望移动端(Hybrid 应用 或 React-Native)能做更多的事情,其中包括使用 客户端原生功能 提供更好的 交互 和 服务 等。
然而 JavaScript 并不能直接调用和它不同语言(如 Java、C/C++ 等)提供的功能特性,因此需要一个中间层去实现 JavaScript 与 其他语言 间的一个相互协作,这里通过一个 Node 架构来进行说明。
Node 架构

核心内容如下:
顶层 Node Api
- 提供 http 模块、流模块、fs文件模块等等,
可以通过 JavaScript 直接调用
- 提供 http 模块、流模块、fs文件模块等等,
中间层 Node Bindings
- 主要是使 JavaScript 和 C/C++ 进行通信,原因是 JavaScript 无法直接调用 C/C++ 的库(libuv),需要一个中间的桥梁,node 中提供了很多 binding,这些称为
Node bindings
- 主要是使 JavaScript 和 C/C++ 进行通信,原因是 JavaScript 无法直接调用 C/C++ 的库(libuv),需要一个中间的桥梁,node 中提供了很多 binding,这些称为
底层 V8 + libuv
- v8 负责解释、执行顶层的 JavaScript 代码
- libuv 负责提供 I/O 相关的操作,其主要语言是
C/C++语言,其目的就是实现一个 跨平台(如 Windows、Linux 等)的异步 I/O 库,它直接与操作系统进行交互
这里不难发现 Node Bindings 就有点类似 JSBridge 的功能,所以 JSBridge 本身是一个很简单的东西,其更多的是 一种形式、一种思想。
为什么叫 JSBridge?
Stack Overflow 联合创始人 Jeff Atwood 在 2007 年的博客《The Principle of Least Power》中认为 “任何可以使用 JavaScript 来编写的应用,并最终也会由 JavaScript 编写”,后来 JavaScript 的发展确实非常惊人,现在我们可以基于 JavaScript 来做各种事情,比如 网页、APP、小程序、后端等,并且各种相关的生态越来越丰富。
作为 Web 技术逻辑核心的 JavaScript 自然而然就需要承担与 其他技术 进行『桥接』的职责,而且任何一个 移动操作系统 中都会包含 运行 JavaScript 的容器环境,例如 WebView、JSCore 等,这就意味着 运行 JavaScript 不用像运行其他语言时需要额外添加相应的运行环境。
JSBridge应用在国内真正流行起来则是因为 微信 的出现,当时微信的一个主要功能就是可以在网页中通过JSBridge来实现 内容分享。
JSBridge 能做什么?
举个最常见的前端和后端的例子,后端只提供了一个查找接口,但是没有提供更新接口,那么对于前端来讲就是再想实现更新接口,也是没有任何法子的!
同样的,JSBridge 能做什么得看原生端给 JavaScript 提供调用 Native 什么功能的接口,比如通过 微信 JS-SDK 网页开发者可借助微信使用 拍照、选图、语音、位置 等手机系统的能力,同时可以直接使用 微信分享、扫一扫、卡券、支付 等微信特有的能力。
JSBridge 作为 JavaScript 与 Native 之间的一个 桥梁,表面上看是允许 JavaScript 调用 Native 的功能,但其核心是建立 Native 和 非 Native 间消息 双向通信 通道。

双向通信的通道:
JavaScript 向 Native 发送消息:
- 调用 Native 功能
- 通知 Native 当前 JavaScript 的相关状态等
Native 向 JavaScript 发送消息:
- 回溯调用结果
- 消息推送
- 通知 JavaScript 当前 Native 的状态等
JSBridge 是如何实现的?
JavaScript 的运行需要 JS 引擎的支持,包括 Chrome V8、Firefox SpiderMonkey、Safari JavaScriptCore 等,总之 JavaScript 运行环境 是和 原生运行环境 是天然隔离的,因此,在 JSBridge 的设计中我们可以把它 类比 成 JSONP 的流程:
- 客户端通过
JavaScript定义一个回调函数,如:function callback(res) {...},并把这个回调函数的名称以参数的形式发送给服务端 - 服务端获取到
callback并携带对应的返回数据,以JS脚本形式返回给客户端 - 客户端接收并执行对应的
JS脚本即可
JSBridge 实现 JavaScript 调用的方式有两种,如下:
JavaScript调用NativeNative调用JavaScript
在开始分析具体内容之前,还是有必要了解一下前置知识 WebView。
WebView 是什么?
WebView 是 原生系统 用于 移动端 APP 嵌入 Web 的技术,方式是内置了一款高性能 webkit 内核浏览器,一般会在 SDK 中封装为一个 WebView 组件。
WebView 具有一般 View 的属性和设置外,还对 url 进行请求、页面加载、渲染、页面交互进行增强处理,提供更强大的功能。
WebView 的优势 在于当需要 更新页面布局 或 业务逻辑发生变更 时,能够更便捷的提供 APP 更新:
- 对于
WebView而言只需要修改前端部分的Html、Css、JavaScript等,通知用户端进行刷新即可 - 对于
Native而言需要修改前端内容后,再进行打包升级,重新发布,通知用户下载更新,安装后才可以使用最新的内容
微信小程序中的 WebView
小程序的主要开发语言是 JavaScript ,其中 逻辑层 和 渲染层 是分开的,分别运行在不同的线程中,而其中的渲染层就是运行在 WebView 上:
| 运行环境 | 逻辑层 | 渲染层 |
|---|---|---|
| iOS | JavaScriptCore | WKWebView |
| 安卓 | V8 | chromium 定制内核 |
| 小程序开发者工具 | NWJS | Chrome WebView |

在开发过程中遇到的一个 坑点 就是:
- 在真机中,需要实现同一域名下不同子路径的应用实现数据交互(纯前端操作,不涉及接口),由于同域名且是基于同一个页面进行跳转的(当然只是看起来是),而且这个数据是 临时数据,因此觉得使用
sessionStorage实现数据交互是很合适的 - 实际上从 A 应用 跳转到 B 应用 中却无法获取对应的数据,而这是因为 sessionStorage 是基于当前窗口的会话级的数据存储,移动端浏览器 或 微信内置浏览器 中在跳转新页面时,可能打开的是一个新的 WebView,这就相当于我们在浏览器中的一个新窗口中进行存储,因此是没办法读取在之前的窗口中存储的数据
JavaScript 调用 Native — 实现方案一
通过 JavaScript 调用 Native 的方式,又会分为:
- 注入 API
- 劫持 URL Scheme
- 弹窗拦截
【 注入 API 】
核心原理:
- 通过
WebView提供的接口,向JavaScript的上下文(window)中注入 对象 或者 方法 - 允许
JavaScript进行调用时,直接执行相应的Native代码逻辑,实现JavaScript调用Native
这里不通过 iOS 的 UIWebView 和 WKWebView 注入方式来介绍了,感兴趣可以自行查找资料,咱们这里直接通过 微信 JS-SDK 来看看。

当通过 的方式引入 JS-SDK 之后,就可以在页面中使用和 微信相关的 API,例如:
// 微信授权
window.wx.config(wechatConfig)
// 授权回调
window.wx.ready(function () {...})
// 异常处理
window.wx.error(function (err) {...})
// 拉起微信卡包
window.wx.invoke('chooseInvoice', invokeConf, function (res) {...})如果通过其内部编译打包后的代码(简化版)来看的话,其实不难发现:
- 其中的
this(即参数e)此时就是指向全局的window对象 - 在代码中使用的
window.wx实际上是e.jWeixin也是其中定义的N对象 - 而在
N对象中定义的各种方法实际上又是通过e.WeixinJSBridge上的方法来实际执行的 e.WeixinJSBridge就是由 微信内置浏览器 向window对象中注入WeiXinJsBridge接口实现的!(function (e, n) {
'function' == typeof define && (define.amd || define.cmd)
? define(function () {
return n(e)
})
: n(e, !0)
})(this, function (e, n) {
...
function i(n, i, t) {
e.WeixinJSBridge
? WeixinJSBridge.invoke(n, o(i), function (e) {
c(n, e, t)
})
: u(n, t)
}
if (!e.jWeixin) {
var N = {
config(){
i(...)
},
ready(){},
error(){},
...
}
return (
S.addEventListener(
'error',callback1,
!0
),
S.addEventListener(
'load',callback2,
!0
),
n && (e.wx = e.jWeixin = N),
N
)
}
})
【 劫持 URL Scheme 】
URL Scheme 是什么?
URL Scheme 是一种特殊的 URL,一般用于在 Web 端唤醒 App(或是跳转到 App 的某个页面),它能方便的实现 App 间互相调用(例如 QQ 和 微信 相互分享讯息)。
URL Scheme 的形式和 普通 URL(如:https://www.baidu.com)相似,主要区别是 protocol 和 host 一般是对应 APP 自定义的。
通常当 App 被安装后会在系统上注册一个 自定义的 URL Scheme,比如 weixin:// 这种,所以我们在手机浏览器里面访问这个 scheme 地址,系统就会唤起对应的 App。
例如,当在浏览器中访问 weixin:// 时,浏览器就会询问你是否需要打开对应的 APP:

劫持原理
Web 端通过某种方式(如 iframe.src)发送 URL Scheme 请求,之后 Native 拦截到请求并根据 URL Scheme 和 携带的参数 进行对应操作。
例如,对于谷歌浏览器可以通过 chrome://version/、chrome://chrome-urls/、chrome://settings/ 定位到不同的页面内容,假设 跳转到谷歌的设置页并期望当前搜索引擎改为百度,可以这样设计 chrome://settings/engine?changeTo=baidu&callbak=callback_id:
- 谷歌客户端可以拦截这个请求,去解析对应参数
changeTo来修改默认引擎 - 然后通过
WebView上面的callbacks对象来根据callback_id进行回调
以上只是一个假设哈,并不是说真的可以这样去针对谷歌浏览器进行修改,当然它要是真的支持也不是不可以。
是不是感觉确实和 JSONP 的流程很相似呀 ~ ~【 弹窗拦截 】
弹窗拦截核心:利用弹窗会触发 WebView 相应事件来实现的。
一般是在通过拦截 Prompt、Confirm、Alert 等方法,然后解析它们传递过来的消息,但这种方法存在的缺陷就是 iOS 中的 UIWebView 不支持,而且 iOS 中的 WKWebView 又有更好的 scriptMessageHandler,因此很难统一。
Native 调用 JavaScript — 实现方案二
Native 调用 JavaScript 的方式本质就是 执行拼接 JavaScript 字符串,这就好比我们通过 eval() 函数来执行 JavaScript 字符串形式的代码一样,不同的系统也有相应的方法执行 JavaScript 脚本。
Android
在 Android 中需要根据版本来区分:
安卓 4.4 之前的版本使用
loadUrl()loadUrl()不能获取JavaScript执行后的结果,这种方式更像在的href属性中编写的JavaScript代码webView.loadUrl("javascript:foo()")
安卓 4.4 以上版本使用
evaluateJavascript()webView.evaluateJavascript("javascript:foo()", null);IOS
UIWebView中通常使用stringByEvaluatingJavaScriptFromStringresults = [self.webView stringByEvaluatingJavaScriptFromString:"foo()"];WKWebView中通常使用evaluateJavaScript[self.webView evaluateJavaScript:@"document.body.offsetHeight;" completionHandler:^(id _Nullable response, NSError * _Nullable error) {
// 获取返回值
}];最后
来源:segmentfault.com/a/1190000043417038
开始!使用node搭建一个小页面
介绍
这个小demo是Node.js, Express, MongoDB & More: The Complete Bootcamp系列课程的第一个demo,本篇文章主要介绍实现过程以及可能带来的思考。
完成展示
首页
详情页面
前置知识
首先我们需要了解一些知识,以便完成这个demo
fs
首先是node对文件的操作,也就是fs模块。本文只介绍一些简单的操作,大部分是例子中需要用到的方法。想要了解更多可以去API文档去查找。
首先引入fs模块:const fs = require("fs");
readFileSync
const textIn = fs.readFileSync("./txt/append.txt", "utf-8");
复制代码上面代码展示的是readFileSync的使用,两个参数中,第一个参数是要读取文件的位置,第二个参数是编码格式encoding。如果指定encoding返回一个字符串,否则返回一个Buffer。
writeFileSync
fs.writeFileSync("./txt/output.txt", textOut);
复制代码writeFileSync毫无疑问是写文件,第一个参数为写文件的地址,第二个参数是写入的内容。
readFile、writeFile
上面的两个API都是同步的读写操作。但是nodeJs作为一个单线程的语言,在很多时候,使用同步的操作会造成不必要的拥堵。例如等待用户输入这类I/O操作,就会浪费很多时间。所以 js中有异步的方式解决这类问题,nodejs也一样。通过回调的方式来解决。
fs.readFile("./txt/append.txt", "utf-8", (err, data) => {
fs.writeFile("./txt/final.txt", `${data}`, (err) => {
console.log("ok");
});
});
复制代码http
createServer
http.createServer(requestListener);
复制代码http.createServer() 方法创建一个HTTP Server 对象,参数requestListener为每次服务器收到请求时要执行的函数。
server.listen(8001, "127.0.0.1", () => {
console.log("Listening to requests on port 8001");
});
复制代码上面表代码表示监听8001端口。
url
url.parse
这个模块可以很好的处理URL信息。比如当我们请求http://127.0.0.1:8001/product?id=0的时候通过url.parse可以获取到很多信息。如下图:
实现过程
对于已经给出的完成页面,我们可以看到在切换页面时URL的变化,所以我们需要得到用户请求时的 URL地址,并根据地址展示不同的页面。所以我们通过path模块得到pathname,进行处理。
对于不同的请求,我们返回不同的界面。首先对于Overview page界面,由于它的类型是 html界面,所以我们通过writeHead将它的Content-type设置为text/html。
res.writeHead(200, {
"Content-type": "text/html",
});
复制代码其他的几个返回html的页面也是同样的处理。由于前端界面已经给出,我们只需要读取JSON里面的数据,并将模板字符串替换即可。最后我们通过res.end(output)返回替换后的页面。
总结
通过这一个小页面的练习,可以学习到node对文件的操作以及HTTP模块的操作。并对后端有了初步的认识。
链接:https://juejin.cn/post/7171295946372972557
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一篇文章告诉你 <按钮> 如何选择,div button 还是a?
前言
当你要创建一个可点击的元素时,是使用 a标签 、button按钮 还是 div 等其他不同的元素?
// 🚩
export function MyButton() {
return <div onClick={...}>点击我</div>
}
//❓
export function MyButton() {
return <button onClick={...}>点击我</button>
}
//❓
export function MyButton() {
return <a onClick={...}>点击我</a>
}
复制代码出人意料的是大多数人都会选择div,这似乎与我们所学的很不一样。
这篇文章将展开对比三者的区别,并做了一个总结,这对于你工作或者面试的时候是很有帮助的。
div
让我们首先弄清楚一件事
您不应该将 div 用于可点击的元素(至少在 99% 的情况下)。
为什么?
严格上来说, div != 按钮。 div 只是一个通用容器,缺少一些可正确点击的元素应具备的特性,例如:
- Div 不可聚焦,例如,
tab键不会像设备上的任何其他按钮那样聚焦 div。 - 屏幕阅读器和其他辅助设备不会将 div 识别为可点击元素。
- Div 不会将某些键输入(如空格键或返回键)转换为获得焦点时的点击。
但是,您可以使用 tabindex="0" 和 role=”button” 等几个属性解决其中一些问题:
// 🚩 试着将 div 改造成像 button一样...
export function MyButton() {
function onClick() { ... }
return (
<div
className="my-button"
tabindex="0" // 让div 能聚焦
role="button" // 屏幕阅读器和其他辅助设备 识别可点击
onClick={onClick}
onKeydown={(event) => {
// 聚焦时监听 回车键和空格键
if (event.key === "Enter" || event.key === "Space") {
onClick()
}
}}
>
点击我
</div>
)
}
复制代码是的,我们需要确保设置聚焦状态的样式,以便用户反馈该元素也被聚焦。我们必须确保这通过了所有问题可访问性,例如:
.my-button:focus-visible {
outline: 1px solid blue;
}
复制代码如果要还原所有细微且关键的按钮行为,并手动实现,需要大量工作。
button
The beauty of the button tag is it behaves just like any other button on your device, and is exactly what users and accessibility tools expect.
button 标签的美妙之处在于它的行为与您设备上的任何其他 button 一样,并且正是用户和辅助工具所期望的。
它是可聚焦的、可访问的、可键盘输入的,具有兼容的焦点状态样式!
// ✅
export function MyButton() {
return (
<button onClick={...}>
点击我
</button>
)
}
复制代码有几个我们需要注意的问题。
button 的问题
我一直对按钮最大的烦恼是它们的样式。
例如,给按钮一个浅紫色背景:
<button class="my-button">
Click me
</button>
<style>
/* 🤢 */
.my-button {
background-color: purple;
}
</style>
复制代码这看起来就像 Windows 95 一样的样式。
这就是为什么我们都喜欢 div。它们没有额外的样式或默认行为。它们的工作和外观每次都完全符合预期。
你可以说, appearance: none 会重置外观!但是这并不能完全按照您的想法进行。
<button class="my-button">
Click me
</button>
<style>
.my-button {
appearance: none; /* 🤔 */
background-color: purple;
}
</style>
复制代码它仍然是这样:
重置 button 的样式
没错,我们必须对每一个样式属性逐行重置:
/* ✅ */
button {
padding: 0;
border: none;
outline: none;
font: inherit;
color: inherit;
background: none
}
复制代码这就是一个样式和行为都像 div 的按钮,它仍然使用浏览器的默认焦点样式。
您的另一种选择是使用 all: unset 恢复一个简单属性中的无特殊样式:
/* ✅ */
button { all: unset; }
button:focus-visible { outline: 1px solid var(--your-color); }
复制代码但是不要忘记添加您自己的焦点状态;例如,您的品牌颜色的轮廓具有足够的对比度。
修复 button 行为属性
使用 button 标签时需要注意最后一个问题。
默认情况下, form 内的任何按钮都被视为提交按钮,单击时将提交表单。
function MyForm() {
return (
<form onSubmit={...}>
...
<button type="submit">Submit</button>
{/* 🚩 点击 "Cancel"仍然会提交表单! */}
<button onClick={...}>Cancel</button>
</form>
)
}
复制代码没错,按钮的默认 type 属性是 submit 。很奇怪。而且很烦人。
要解决此问题,除非您的按钮实际上是为了提交表单,否则请始终向其添加 type="button" ,如下所示:
export function MyButton() {
return (
<button
type="button" // ✅
onClick={...}>
Click me
</button>
)
}
复制代码现在我们的按钮将不再尝试找到它们最接近的 form parent 并提交它。
哇,配置一个简单的按钮几乎变得奇怪了。
a标签 链接
这是大部分人也不注意的一点。我们使用按钮链接到其他页面:
// 🚩
function MyLink() {
return (
<button
type="button"
onClick={() => {
location.href = "/"
}}
>
Don't do this
</button>
)
}
复制代码使用 点击事件 链接到页面的按钮的一些问题:
- 它们不可抓取,因此对 SEO 非常不利。
- 用户无法在新标签页或窗口中打开此链接;例如,右键单击在新选项卡中打开。
因此,我们不要使用按钮进行导航。这就是我们需要 a 标签。
// ✅
function MyLink() {
return (
<a href="/">
Do this for links
</button>
)
}
复制代码a 标签具有按钮的所有上述优点——可访问、可聚焦、可键盘输入——而且它们没有一堆默认的样式!
那我们是否应该将它们用于任何可点击的东西为我们自己省去一些麻烦?
// 🚩
function MyButton() {
return (
<a onClick={...}>
Do this for links
</a>
)
}
复制代码不行
这是因为没有 href属性 的 a 标签不再像按钮一样工作。没错,当它 href 属性有值时,才有完整的按钮行为,例如可聚焦... 。
所以,我们一定要坚持使用按钮作为按钮,使用锚点作为链接。
把 button 和 a 结合起来
我非常喜欢的是将这些规则封装在一个组件中,这样你就可以只使用你的 MyButton 组件,
如果你 提供一个 URL,它就会变成一个链接,否则就是一个按钮就像这样:
// ✅
function MyButton(props) {
if (props.href) {
return <a className="my-button" {...props} />
}
return <button type="button" className="my-button" {...props} />
}
// 渲染出一个 <a href="/">
<MyButton href="/">Click me</MyButton>
// 渲染出 <button type="button">
<MyButton onClick={...}>Click me</MyButton>
复制代码这样,无论按钮的用途是单击处理程序还是指向另一个页面的链接,我们都可以获得一致的开发人员体验和用户体验。
总结
对于链接,使用带有
href属性的a标签,
对于所有其他按钮,使用带有
type="button"的button标签。
需要一个点击容器,就用
div标签
链接:https://juejin.cn/post/7197995910566740025
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CSS简单实现一幅新春对联
前言
今年过年家里没有贴春联,这两天在网上看到一幅对联,觉得写得挺好的, 上联——只生欢喜不生愁;下联——此心安处是吾家; 横批——平安喜乐, 因此使用css简单实现这幅新春对联。
具体实现
页面先做一个简单描述,首先页面中间有一个大门,然后在大门两侧实现春联的上下联,大门的上面实现春联的横批,再做一个打开大门,出现兔年祝福图片的效果。
效果展示:(毛笔字体文件没有线上的资源,所以字体没有效果) code.juejin.cn/pen/7197022…
页面整体布局:
<div class="wrapper">
<div class="container">
<div class="title">平安喜乐</div>
<div class="content">
<h1>此心安处是吾家</h1>
<div class="door">
<div class="door-l"></div>
<div class="door-r"></div>
<!-- 送福图片 -->
<img src="/4034970a304e251fb44609698ce95a1c7e3e536c.webp" alt="" class="pic">
</div>
<h1>只生欢喜不生愁</h1>
</div>
</div>
</div>1. 大门的实现
大门的总体宽高都设置成350px,设置视角(perspective:1000px), 大门打开的时候呈现一种3D的视觉感受。
大门分成左右两部分门扇,使用绝对定位控制左右的位置,并使用transform-origin属性设置大门旋转动画的基点,默认情况下,元素的动作参考点(基点)为元素盒子的中心(center),这里设置左边门扇的transform-origin: left,左门扇以左边基点旋转;右边门扇的transform-origin: right,右门扇以右边基点旋转。
大门门扇的圆形门环使用伪元素实现,使用hover属性实现当鼠标移到大门上时,大门的门扇分别旋转一定的角度,实现打开大门的效果
兔年祝福图片使用绝对定位控制在大门的居中位置,并设置层级最低,当打开大门图片慢慢变大
.door {
width: 350px;
height: 350px;
border: 2px solid #333;
margin: 0 auto;
position: relative;
perspective: 1000px;
}
.door .pic{
position: absolute;
top: 50%;
left: 50%;
width: 70%;
object-fit: cover;
transform: translate(-50%,-50%);
z-index: -1;
transition: all 0.3s ease-in;
}
.door-l,
.door-r {
width: 50%;
height: 100%;
background-color: #e1b12c;
position: absolute;
top: 0;
transition: all 0.5s;
}
.door-l {
left: 0;
border-right: 1px solid #000;
transform-origin: left;
}
.door-r {
right: 0;
border-left: 1px solid #000;
transform-origin: right;
}
.door-l::before,
.door-r::before {
content: "";
border: 1px solid #000;
width: 20px;
height: 20px;
position: absolute;
top: 50%;
border-radius: 50%;
transform: translateY(-50%);
}
.door-l::before {
right: 5px;
}
.door-r::before {
left: 5px;
}
.door:hover .door-l {
transform: rotateY(-120deg);
}
.door:hover .door-r {
transform: rotateY(120deg);
}
.door:hover .pic{
width: 100%;
}2. 春联的实现
春联一般是用毛笔写的,因此在网上找了一款毛笔字体下载下来,并引入到样式中,并给春联设置红色的背景
网上下载下来的毛笔字体为trueType格式(.ttf,Windows和Mac上常见的字体格式,是一种原始格式,没有为网页进行优化处理),需要转换成Web Open Font格式(.woff,针对网页进行特殊优化,是Web字体中最佳格式)。可以在这个网站上传字体进行转换
@font-face 用于设置自定义字体,可以自定义字体名称。两个必要属性:
font-family:给引入的字体起一个名称,注意:名字不要和那些专属的名称起冲突了,比如:微软雅黑。
src:自定义字体的路径,一般采用相对路径去使用。
@font-face {
font-family: 'YFJLXS8';
src: url('./font.woff2') format('woff2'),
url('./font.woff') format('woff');
font-weight: normal;
font-style: normal;
}
* {
margin: 0;
padding: 0;
box-sizing: border-box
}
.wrapper {
height: 100vh;
font-family: 'YFJLXS8', 'Courier New', Courier, monospace;
padding: 50px;
overflow: hidden;
background: #ccc;
}
.content {
display: flex;
align-items: center;
justify-content: center;
width: 44%;
margin: 20px auto;
}
h1 {
font-size: 40px;
font-weight: 700;
width: 5vw;
color: #000;
line-height: 1;
text-align: center;
background-color: #d63031;
padding: 20px 0;
}
.title{
width: 20%;
font-size: 40px;
font-weight: 700;
text-align: center;
margin: 0 auto;
background-color: #d63031;
}作者:sherlockkid7
来源:juejin.cn/post/7196994373237866553
详解css中伪元素::before和::after和创意用法
伪类和伪元素
首先我们需要搞懂两个概念,伪类和伪元素,像我这种没有系统全面性的了解过css的人来说,突然一问我伪类和伪元素的区别我还真不知道,我之前一直以为这两个说法指的是一个东西,就是我题目中的提到的那两个::before和::after。偶然间才了解到,原来指的是两个东西
伪类
w3cSchool对于伪类的定义是”伪类用于定义元素的特殊状态“。向我们常用到的:link、:hover、:active、:first-child等都是伪类,全部伪类比较多,大家感兴趣的话可以去官方文档了解一下
伪元素
至于伪元素,w3cSchool的定义是”CSS 伪元素用于设置元素指定部分的样式“,光看定义我是搞不懂,其实我们只要记住有哪些东西就好了,伪元素共有5个,分别是::before、::after、::first-letter、::first-line和::selection
伪类和伪元素可以叠加使用,如
.sbu-btn:hover::before,本文后面示例部分也会用到此种用法。
::first-letter主要用于为文本的首字母添加特殊样式
注意:
::first-letter伪元素只适用于块级元素。
::first-line 伪元素用于向文本的首行添加特殊样式。
注意:
::first-line伪元素只能应用于块级元素。
::selection 伪元素匹配用户选择的元素部分。也就是给我们鼠标滑动选中的部分设置样式,它可以设置以下属性
colorbackgroundcursoroutline
以上几种我们简单了解一下就可以了,也不在我们今天的讨论范围之内,今天我们来着重了解一下::before和::after,相信大家在工作中都或多或少的用过,但很少有人真的去深入的了解过他们,本文是我对我所知的关于他们用法的一个总结,如有缺漏,欢迎补充。
用法及示例
::before用于在元素内容之前插入一些内容,::after用于在元素内容之后插入一些内容,其他方面的都相同。写法就是只要在想要添加的元素选择器后面加上::before或::after即可,有些人会发现,写一个冒号和两个冒号都可以有相应的效果,那是因为在css3中,w3c为了区分伪类和伪元素,用双冒号取代了伪元素的单冒号表示法,所以我们以后在写伪元素的时候尽量使用双冒号。
不同于其他伪元素,::before和::after在使用的时候必须提供content属性,可以为字符串和图片,也可以是空,但不能省略该属性,否则将不生效。
给指定元素前添加内容
这个用法是最基础也是最常用的,比如我们可以给一个或多个元素前面或者后面添加想要的文字
<div class="class1">
<p class="q">你的名字是?</p>
<p class="a">张三</p>
<p class="q">你的名字是?</p>
<p class="a">张三</p>
<p class="q">你的名字是?</p>
<p class="a">张三</p>
</div>.class1::before {
content: '问卷';
font-size: 30px;
}
.class1 .q::before {
content: '问题:'
}
.class1 .a::before {
content: '回答:'
}
当然也可以添加形状,默认的是行内元素,如果有需要,我们可以把它变为块级元素
<div class="class2">
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
<div class="news-item">今天天气为多云</div>
</div>
.news-item::before {
content: '';
display: inline-block;
width: 16px;
height: 16px;
background: rgb(96, 228, 255);
margin-right: 8px;
border-radius: 50%;
}我们也可以使用它来添加图片
<div class="class3">
<p class="text1">阅读和写作同样重要</p>
<p class="text1">阅读和写作同样重要</p>
<p class="text1">阅读和写作同样重要</p>
<p class="text1">阅读和写作同样重要</p>
</div>
.class3 .text1::before {
content: url(https://lf3-cdn-tos.bytescm.com/obj/static/xitu_juejin_web/e08da34488b114bd4c665ba2fa520a31.svg);
}不过这一方法的缺点就是,不能调整图片大小,如果我们需要使用伪元素添加图片的话,建议通过给伪元素设置背景图片的方式设置
结合clear属性清除浮动
我们都知道清除浮动的一种方式就是给一个空元素设置clear:both属性,但在页面里添加过多的空元素一方面代码不够简洁,另一方面也不便于维护,所以我们可以通过给伪元素设置clear:both属性的方法更好的实现我们想要的效果
禁用网页ctrl+f搜索
有些时候,我们不想要用户使用ctrl+f搜索我们网页内的内容,必须在一些文字识别的网页小游戏里,我们又不想把文字做成图片,那么就可以使用这个属性,使用::before和::after渲染出来的文字,不可选中也不能搜索。当然这个低版本浏览器的兼容性我木有试,谷歌浏览器和safari是可以实现不能选中不可搜索的效果的。
拿上面的示例进行尝试,可以看到,我们使用伪元素添加的[问题]两个字,就无法使用浏览器的搜索工具搜到。
制作一款特殊的鼠标滑入滑出效果
这个效果还是之前一个朋友从某网站看到之后问我能不能实现,我去那个网站查看了代码学会的,觉得很有趣,特意分享给大家。
可以先看一下效果
这里附上源码和在线演示
.h-button {
z-index: 1;
position: relative;
overflow: hidden;
}
.h-button::before,
.h-button::after {
content: "";
width: 0;
height: 100%;
position: absolute;
filter: brightness(.9);
background-color: inherit;
z-index: -1;
}
.h-button::before {
left: 0;
}
.h-button:after {
right: 0;
transition: width .5s ease;
}
.h-button:hover::before {
width: 100%;
transition: width .5s ease;
}
.h-button:hover::after {
width: 100%;
background-color: transparent;
}这里我做了一些改进,就是鼠标滑入之后的颜色是对按钮本身颜色进行一定的变换得来的,这样我们就无需对每一个按钮单独设置鼠标滑入时候的颜色了,全局时候的时候只需要对目标按钮添加一个类名h-button就可以,更加的方便简单,当然,如果大家觉得这样的颜色不好看的话,还是可以自行设置,或者修改一我对颜色的处理方式
这个效果的实现思路其实很简单,就是使用::before和::after给目标按钮添加两个伪元素,然后使用定位让他们重合在一起,再通过改变两者的宽度实现的。
首先是创建两个伪元素,宽高都和目标元素一致,我这里的背景色由于是对按钮本身颜色进行处理得来的,所以给他们设置的背景色是沿用父级背景色,如果你想单独设置这里可以分别设置为自己想要的颜色。
.h-button {
z-index: 1;
position: relative;
overflow: hidden;
}
.h-button::before,
.h-button::after {
content: "";
width: 0;
height: 100%;
position: absolute;
filter: brightness(.9);
background-color: inherit;
z-index: -1;
}我们的实现原理是通过改变伪元素的宽度实现,所以我们需要第一个伪元素的定位以左边为准,从而实现鼠标移入时色块从左往右出现的效果,而第二个伪元素的定位以右为准,从而实现鼠标移出时色块从左往右消失的效果。
这里可以看到,我们在没有给第一个伪元素的初始状态添加过渡效果,那是因为它只需要在从鼠标移出的时候展示动画即可,在鼠标移出的时候需要瞬间消失,所以在初始状态不需要添加过渡效果,而第二个伪元素恰恰相反,它在鼠标滑入的时候不需要展示动画效果,在鼠标滑入也就是回归初始状态的时候需要展示动画效果,所以我们需要在最开始的时候就添加上过渡效果。
.h-button::before {
left: 0;
}
.h-button::after {
right: 0;
transition: width .5s ease;
}两个伪元素的初始宽度都为0,鼠标滑入的时候,让两个伪元素宽度都变为100%,由于鼠标滑入时我们并不需要第二个伪元素出现,所以这里我们给它的背景颜色设置为透明,这样就可以实现鼠标滑入时只展示第一个伪元素宽度从0到100%的动画,而鼠标移出时第一个伪元素宽度变为0,因为没有过渡效果,所以它的宽度会瞬间变为0,然后展示第二个色块宽度从100%到0的动画效果。
.h-button:hover::before {
width: 100%;
transition: width .5s ease;
}
.h-button:hover::after {
width: 100%;
background-color: transparent;
}伪元素能实现的创意用法还有很多,如果大家有不同的用法,欢迎分享,希望本篇文章可以对大家有所帮助。
作者:十里青山
来源:juejin.cn/post/7163867155639828488
团队的技术分享又轮到我了,分享点啥才能显得牛逼又有趣?
引言
新年好,我是飞叶_程序员。
见过我这个ID的朋友们肯定都知道,作为前端,我主要通过 B站up主 的身份来来进行社区交流的。 虽然主要的交流渠道不是掘金、segmentfault这样的技术站点,但与在掘金活跃的大佬们遇到的问题其实是一样的。
那就是我们需要经常阅读技术文章、技术资讯,保持和丰富自己的知识储备,不然怎么给别人分享知识呢? 这是我作为一个创作者和分享者 和 广大其他创作者们遇到的共性问题。
那作为一线的开发者,其实也有技术分享的需要,我相信大家的技术团队都是需要技术分享的。 而技术分享一般都是通过轮流进行的,也不能逮着团队里的几个人一直薅羊毛对吧。
那轮到你技术分享的时候,你是否会苦恼于不知道该分享点啥呢?
你是否担心:万一我分享的东西其他人都已经知道了,显得自己不够牛逼呢?
我想这些问题,归根到底是不知道去哪里获取技术资讯的问题。
如果你手里有大量的技术站点,他们能给你提供大量的高质量技术文章,在里面找到一篇值得分享的内容应该就不难了。
回顾2022年,我在B站发布了100多个技术视频,平均约每周两个,现在看起来都不可思议。 哪有那么多可以分享的内容啊!
前端森林
实际上我能分享那么多,得益于我收录了一些英文站点。尤其是有一些技术周刊。
我的灵感来源都是他们。不是凭空产生的。
过年期间我一直在想着把我收藏的这些站点公开出来,让其他人和创作者们也不再有技术分享的苦恼。 所以创建了一个开源项目,叫awesome-fe-sites,GitHub, 并把它部署在了fesites.netlify.app。
他的作用是收录前端资讯类站点,周刊类网站,高质量个人博客和技术团队博客,在线服务类/工具类网站等。
slogan:前端网站,尽收眼底。
同时也希望它也可以解放你的浏览器书签栏。
参与贡献
不知道你有没有一些私藏的高质量的前端站点,如果你希望把它贡献出来,欢迎PR。
另外这个站点是通过qwik这个很新的前端框架搭建的,对qwik感兴趣的话,也可以看看这个项目的代码。
作者:飞叶_前端
来源:juejin.cn/post/7193136620948684860
不修改任何现有源代码,将项目从 webpack 迁移到 vite
背景
之前将公司项目开发环境从 webpack 迁移到 vite,实现了 dev 环境下使用 vite、打包使用 webpack 的共存方案。本文将讲述开发环境下 vue3 项目打包器从 webpack 迁移到 vite 过程中的所遇问题、解决方案、迁移感受,以及如何不修改任何源码完成迁移。
迁移的前提及目标
我们之前的项目大概有 10w+ 行代码,开发环境下冷启动所花费的时间大概 1 分钟多,所以迁移到 vite 就是看中了它的核心价值:快!但是迁移到 vite,也会伴随着风险:代码改动及回归成本。
作为一个大型的已上线项目,它的线上稳定性的一定比我们工程师开发时多减少一些项目启动时间的价值要高,所以如果迁移带来了很多线上问题,那便得不偿失了。
所以我们迁移过程中有前提也有目标:
- 前提:不因为迁移打包工具引发线上问题
- 目标:实现开发环境下的快速启动
方案
有了上述前提和目标,那我们的方案就可以从这两方面思考入手了。
- 如何能确保实现前提?我们已有了稳定版本,那只要保证源代码不改动,线上的打包工具 webpack 及配置也不改动,就可以确保实现前提。
- 如何实现目标?vite 的快主要是体现在开发环境,打包使用的 rollup 相比 webpack 速度上并无太明显的优势,所以我们只要开发环境下使用 vite 启动就可以实现目标。
由此得出最终方案:不改动任何现有源代码,开发环境使用 vite,线上打包使用 webpack。
迁移过程
安装 vite 及进行基础配置
- 在终端执行下述命令,安装 vite 相关基础依赖:
yarn add vite @vitejs/plugin-vue vite-plugin-html -D
复制代码
- 因为 vite 的 html 模板文件需要显示引入入口的
.js/.ts文件,同时有一些模板变量上面的区别,为了完全不影响线上打包,在/public目录下新建一个index.vite.html文件。将/public/index.html文件的内容拷贝进来并添加入口文件的引用(/src/main.ts指向项目的入口文件):
<!DOCTYPE html>
<html lang="">
<!-- other code... -->
<body>
<!-- other code... -->
<div id="app"></div>
+ <script type="module" src="/src/main.ts"></script>
</body>
</html>
复制代码
- 新增
vite.config.js,内容如下:
import { defineConfig } from 'vite';
import vue from '@vitejs/plugin-vue';
import { createHtmlPlugin } from 'vite-plugin-html';
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
createHtmlPlugin({
minify: true,
/**
* After writing entry here, you will not need to add script tags in `index.html`, the original tags need to be deleted
* @default src/main.ts
*/
entry: 'src/main.ts',
/**
* If you want to store `index.html` in the specified folder, you can modify it, otherwise no configuration is required
* @default index.html
*/
template: 'public/index.vite.html',
}),
]
});
复制代码
- 在
package.json的scripts里新增一条 vite 开发启动的指令:
{
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint",
+ "vite": "vite"
}
}
复制代码
到这里,我们基本的配置就已经完成了,现在可以通过 npm run vite 来启动 vite 开发环境了,只不过会有一大堆的报错,我们根据可能遇到的问题一个个去解决。
问题及解决方案
HtmlWebpackPlugin 变量处理
报错: htmlWebpackPlugin is not defined
是因为之前在 webpack 的 HtmlWebpackPlugin 插件中配置了变量,而 vite 中没有这个插件,所以缺少这个变量。
我们先前安装了 vite-plugin-html 插件,所以可以在这个插件中配置变量来代替:
- 将
index.vite.html中所有的htmlWebpackPlugin.options.xxx修改为xxx,如:
<!DOCTYPE html>
<html lang="">
<head>
- <title><%= htmlWebpackPlugin.options.title %></title>
+ <title><%= title %></title>
</head>
</html>
复制代码
- 在
vite.config.js中添加如下内容:
export default defineConfig({
plugins: [
createHtmlPlugin({
+ inject: {
+ data: {
+ title: '我的项目',
+ },
+ },
}),
]
});
复制代码
其他的 html 中未定义的变量亦可以通过此方案来解决。
alias 配置
报错:Internal server error: Failed to resolve import "@/ok.ts" from "src/main.ts". Does the file exist?
通常我们的项目都会在 alias 中将 src 目录配置为 @ 来便于引用,所以遇到这个报错我们需要再 vite.config.js 中将之前 webpack 的 alias 配置补充进来(同时 vite 中 css 等样式文件的 alias 不需要加 ~ 前缀,所以也需要配置下 ~@):
import { defineConfig } from 'vite';
import path from 'path';
export default defineConfig({
resolve: {
alias: {
'@': path.resolve(__dirname, './src'),
'~@': path.resolve(__dirname, './src'),
// 其他的 alias 配置...
}
},
});
复制代码css 全局变量
报错:Internal server error: [less] variable @primaryColor is undefined
是因为项目在 less 文件中定义了变量,并在 webpack 的配置中通过 style-resources-loader 将其设置为了全局变量。我们可以在 vite.config.js 中添加如下配置引入文件将其设置为全局变量:
// vite.coonfig.js
export default defineConfig({
css: {
preprocessorOptions: {
less: {
additionalData: `@import "src/styles/var.less";`
},
},
},
});
复制代码环境变量
报错:ReferenceError: VUE_APP_HOST is not defined
这是因为项目中在 .env.local 文件中设置了以 VUE_APP_XXX 开头的环境变量,我们通过可以通过在 vite.config.js 的 define 中定义为全局变量:
// vite.config.js
export default defineConfig({
define: {
'process.env': {
NODE_ENV: import.meta.env,
APP_NAME: '我的项目名称',
},
+ VUE_APP_HOST: '"pinyin-pro.com"', // 这里需要注意定义为一个字符串
},
})
复制代码process 未定义
报错: ReferenceError: process is not defined
这是因为 webpack 启动时会根据 node 环境将代码中的 process 变量会将值给替换,而 vite 未替换该变量,所以在浏览器环境下会报错。
我们可以通过在 vite.config.js 中将 process.env 定义成一个全局变量,将相应的属性给配置好:
// vite.config.js
export default defineConfig({
define: {
'process.env': {
NODE_ENV: import.meta.env,
APP_NAME: '我的项目名称',
},
},
})
复制代码使用 JSX
报错:Uncaught ReferenceError: React is not defined
这是因为 react16 版本之后,babel 默认会将 .jsx/.tsx 语法转换为 react 函数,而我们需要以 vue 组件的方式来解析 .jsx/.tsx 文件,需要通过新的插件来解决:
- 安装
@vitejs/plugin-vue-jsx插件:
yarn add @vitejs/plugin-vue-jsx -D
复制代码
- 在
vite.config.js文件中引入插件:
// others
import vueJsx from '@vitejs/plugin-vue-jsx';
// https://vitejs.dev/config/
export default defineConfig({
plugins: [
vue(),
vueJsx(),
// others...
],
});
复制代码
CommonJS 不识别
报错:ReferenceError: require is not defined
这是因为项目中通过 require() 引入了图片,webpack 支持 commonjs 语法,而 vite 开发环境是 esmodule 不支持 require。可以通过 @originjs/vite-plugin-commonjs 插件,它能解析 require 进行语法转换以支持同样效果:
- 安装
@originjs/vite-plugin-commonjs插件:
yarn add @originjs/vite-plugin-commonjs -D
复制代码
- 在
vite.config.js中引入插件:
import { viteCommonjs } from '@originjs/vite-plugin-commonjs'
export default defineConfig({
plugins: [
viteCommonjs()
]
})
复制代码
多模块导入
报错:Uncaught ReferenceError: require is not defined
这个报错注意比前面的 ReferenceError: require is not defined 多了一个 Uncaught,是因为 @originjs/vite-plugin-commonjs 并不是对所有的 require 进行了转换,我们项目中还通过 webpack 提供的 require.context 进行了多模块导入。要解决这个问题可以通过 @originjs/vite-plugin-require-context 插件实现:
- 安装
@originjs/vite-plugin-require-context插件:
yarn add @originjs/vite-plugin-require-context -D
复制代码
- 在
vite.config.js中引入插件:
import ViteRequireContext from '@originjs/vite-plugin-require-context'
export default defineConfig({
plugins: [
ViteRequireContext()
]
})
复制代码
其他 webpack 配置
其他的一些 webpack 配置例如 devServer 以及引用的一些 loader 和 plugin,只需要参考 vite 文档一一修改就行,由于各个团队的项目配置不同,我在这里就不展开了。需要注意的是,因为是开发环境下使用 vite,只需要适配开发环境的 webpack 配置就行,打包优化等不需要处理。
潜在隐患
上述方案中,我们通过不修改源代码 + 打包依然使用 webpack,保证了现有项目线上的稳定性:但还有一个潜在隐患:随着项目后期的迭代,因为开发环境是 vite,打包是 webpack,可能因为两种打包工具的不同导致开发和打包产物表现不同的缺陷。例如一旦你开发环境使用了 import.meta.xxx,打包后立马就会报错。
写在最后
我们当时采用此方案是因为 vite 刚发布没太久,用于正式环境有不少坑,而现在 vite 已经成为一款比较成熟的打包工具了,如果要迁移的话还是建议开发和打包都采用 vite,这种方面可以作为 webpack 迁移 vite 的短期过渡方案使用。(我们的项目现在打包也迁移到了 vite 了)
另外我们要明确,作为公司项目稳定性是第一位的,技术方案的变更需要明确能给项目带来收益。例如 webpack 迁移的 vite,是明确能够大幅优化开发环境的等待时间成本,而非看到别人都在用随大流而用。如果已知项目后期发展规模不会太大,当前项目启动时间也不长,就没有迁移的必要了。
上述迁移过程中遇到的坑只是针对我们的项目,没能包含全部的迁移坑点,大家有其他的遇到问题欢迎分享一起讨论。
最后推荐一个工具,可以将项目一键 webpack 迁移到 vite: webpack-to-vite
链接:https://juejin.cn/post/7197222701220053047
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
10000+条数据的内容滚动功能如何实现?
遇到脑子有问题的产品经理该怎么办?如果有这么一个需求要你在一个可视区范围内不间断循环滚动几千上万条数据你会怎么去实现?
且不说提这个需求的人是不是脑子有问题,这个需求能不能实现?肯定是可以的,把数据请求回来渲染到页面写个滚动样式就好了。抛开这样一次性请求上万条数据合不合理不讲,一万条数据渲染到页面上估计都要卡死了吧。那有没有更好的方法呢? 当然有
分析一波思路
我们分批次请求数据,比如可视化区域展示的是20条数据,那我们就一次只请求30条,然后把请求回来的数据保存起来,定义一个滚动的数组,把第一次请求的30条数据赋值给它。后面每当有一条数据滚出可视区域我们就把它删掉,然后往尾部新增一条,让滚动数组始终保持30条的数据,这样渲染在页面上的数据始终只有30条而不是一万条。文字描述太生硬我们上代码
首先定义两个数组,一个滚动区域的数组scrollList,一个总数据的数组totalList,模拟一个异步请求的方法和获取数据的方法。
<script lang="ts" setup>
import { nextTick, ref } from "vue";
type cellType = {
id: number,
title: string,
}
interface faceRequest {
data: cellType,
total: number
}
// 总数据的数组
const totalList = ref<Array<cellType>>([]);
// 滚动的数组
const scrollList = ref<Array<cellType>>([]);
// 数据是否全部加载完毕
let loading: Boolean = false
// 模拟异步请求
const request = () => {
return new Promise<faceRequest>((resolve: any, reject: any) => {
let data: Array<cellType> = []
// 每次返回30条数据
for (let i = 0; i < 30; i++) {
data.push({
id: totalList.value.length + i,
title: 'cell---' + (totalList.value.length + i)
});
}
let total = 10000// 数据的总数
resolve({ data, total })
})
}
const getData = () => {
request().then(res => {
totalList.value = totalList.value.concat(res.data)
// 默认获取第一次请求回来的数据
if (totalList.value.length <= 30) {
scrollList.value = scrollList.value.concat(res.data)
}
// 当前请求的数量小于总数则继续请求
if (totalList.value.length < res.total) {
getData()
} else {
loading = true
}
})
}
getData()
</script>
复制代码上面写好了数据的获取处理,接下来写一下页面
<template>
<div class="div">
<div :style="styleObj" @mouseover="onMouseover" @mouseout="onMouseout" ref="divv">
<div v-for="item in scrollList" :key="item.id" @click="onClick(item)">
<div class="cell">{{ item.title }}</div>
</div>
</div>
</div>
</template>
<script lang="ts" setup>
// 滚动样式
const styleObj = ref({
transform: "translate(0px, 0px)",
});
</script>
<style scoped>
.div {
width: 500px;
height: 500px;
background-color: aquamarine;
overflow: hidden;
}
.cell {
height: 30px;
}
</style>
复制代码现在页面跟数据的前提条件都写好,下面就是数据逻辑的处理了,也就是这篇文章的重点
- 获取页面上单条数据的总体高度
- 设置定时器使页面不停的滚动
- 当一条数据滚动出视图范围时调用处理数据的方法并且重置滚动高度为0
const divv = ref();
// 当前滚动高度
const ScrollHeight = ref<number>(0);
// 储存定时器
const setInt = ref();
// 内容滚动
const roll = () => {
nextTick(() => {
let offsetHeight = divv.value.childNodes[1].offsetHeight
setInt.value = setInterval(() => {
if (ScrollHeight.value == offsetHeight) {
onDel();
ScrollHeight.value = 0;
}
ScrollHeight.value++;
styleObj.value.transform = `translate(0px, -${ScrollHeight.value}px)`;
}, 10);
})
};
onMounted(() => {
roll()
})
复制代码处理数据的方法
- 保存需要被删除的数据
- 删除超出视窗的数据
- 获取总数组的数据添加到滚动数组的最后一位
- 将被删除的数组数据添加到总数组最后面,
- 当滚动到最后一条数据时重置下标为0,使得数据首位相连不断循环
let index = 29;// 每次请求的数量-1,例如每次请求30条数据则为29
const onDel = () => {
index++;
if (loading) {
// 当滚动到最后一条数据时重置下标为0
if (index == totalList.value.length) {
index = 0;
}
scrollList.value.shift();
scrollList.value.push(totalList.value[index]);
} else {
if (index == totalList.value.length) {
index = 0;
}
// 保存需要被删除的数据
let value = scrollList.value[0]
// 删除超出视窗的数据
scrollList.value.shift();
// 获取总数组的数据添加到滚动数组的最后一位
scrollList.value.push(totalList.value[index]);
// 将被删除的数组数据添加到总数组最后面
totalList.value.push(value)
}
};
复制代码到这里代码就写好了,接下来让我们看看效果怎么样
总结
在我们开发的过程中会遇到各种各样天马行空的需求,尤其会遇到很多不合理的需求,这时候我们就要三思而后行,
想清楚能不能不做?
能不能下次再做?
能不能让同事去做?
链接:https://juejin.cn/post/7169940462357184525
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CSS动画篇之404动画
当前页面无法访问,可能没有权限或已删除。 作为一个从事互联网行业的你是不是见过各种各种的404页面,今天刚好发现一个比较有趣的404页面,如上图所示,是不是感觉挺炫酷呢,本文将和大家分享一下实现原理。
前言
看到上面的404你的第一感觉会是这么做呢?
来,UI同学给我上GIF。
当然这种方式对于前端同学来说肯定是最简单的实现方式,单纯的加载一张图片即可。
但是对于一个有追求的前端,绝对不会答应这么干,加载一张GIF图片的成本太高了,网络差的情况下会导致白屏时间过长,所以我们尽可能的用代码实现,减少这种不必要的网络请求。
实现
当你仔细看这个动画的时候可以发现其实主体只有一个标签,内容就是404,另外的几个动画都是基于这个主体实现,所以我们先写好这个最简单的html代码。
<h1 data-t="404">404</h1>
复制代码细心的同学应该看到了我们自定义了一个熟悉data-t,这个我们后续在css中会用到,接下来实现主体的动画效果,主要的动画效果就是让主体抖动并增加模糊的效果,代码实现如下所示。
h1 {
text-align: center;
width: 100%;
font-size: 6rem;
animation: shake .6s ease-in-out infinite alternate;
}
@keyframes shake {
0% {
transform: translate(-1px)
}
10% {
transform: translate(2px, 1px)
}
30% {
transform: translate(-3px, 2px)
}
35% {
transform: translate(2px, -3px);
filter: blur(4px)
}
45% {
transform: translate(2px, 2px) skewY(-8deg) scaleX(.96);
filter: blur(0)
}
50% {
transform: translate(-3px, 1px)
}
}
复制代码接下来增加主体动画后面子两个子动画内容,基于伪元素实现,伪元素的内容通过上面html中自定义data-t获取,主要还用了clip中的rect,具体css代码如下。
h1:before {
content: attr(data-t);
position: absolute;
left: 50%;
transform: translate(-50%,.34em);
height: .1em;
line-height: .5em;
width: 100%;
animation: scan .5s ease-in-out 275ms infinite alternate,glitch-anim .3s ease-in-out infinite alternate;
overflow: hidden;
opacity: .7;
}
@keyframes glitch-anim {
0% {
clip: rect(32px,9999px,28px,0)
}
10% {
clip: rect(13px,9999px,37px,0)
}
20% {
clip: rect(45px,9999px,33px,0)
}
30% {
clip: rect(31px,9999px,94px,0)
}
40% {
clip: rect(88px,9999px,98px,0)
}
50% {
clip: rect(9px,9999px,98px,0)
}
60% {
clip: rect(37px,9999px,17px,0)
}
70% {
clip: rect(77px,9999px,34px,0)
}
80% {
clip: rect(55px,9999px,49px,0)
}
90% {
clip: rect(10px,9999px,2px,0)
}
to {
clip: rect(35px,9999px,53px,0)
}
}
@keyframes scan {
0%,20%,to {
height: 0;
transform: translate(-50%,.44em)
}
10%,15% {
height: 1em;
line-height: .2em;
transform: translate(-55%,.09em)
}
}
复制代码伪元素after的动画与before中的一致,只是部分参数改动,如下所示。
h1:after {
content: attr(data-t);
position: absolute;
top: -8px;
left: 50%;
transform: translate(-50%,.34em);
height: .5em;
line-height: .1em;
width: 100%;
animation: scan 665ms ease-in-out .59s infinite alternate,glitch-anim .3s ease-in-out infinite alternate;
overflow: hidden;
opacity: .8
}
复制代码总结
到此为止我们的功能就实现完成啦,看完代码是不是感觉并没有很复杂,又为我们的页面性能提升了大大的一步。
完整的代码可以访问codepen查看 👉 codepen-404
链接:https://juejin.cn/post/7091848998830473230
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
老板说:把玉兔迎春图实现高亮
前言
兔年来临,老板意气风发的说:我们的系统登录页要换做玉兔迎春的背景页,而且用户
ctrl+f搜索【玉兔迎春】关键字时,图片要高亮。
新的一年,祝大家身体健康、Bug--
一、明确需求
将系统的登录页面背景换做如上图【玉兔迎春】。
而且,用户可以通过搜索关键字【玉兔迎春】让背景图的文字进行高亮。
下面我们进行分析一下。
二、进行分析
接到该需求的时候,心里是这样子的。
于是,老板像是看穿我的疑惑时,语重心长的对我们说:我们要给用户一个焕然一新的感觉。
疯狂点点头,并想好如何让图片里面的文字进行高亮的对策。
静下来思考片刻,其实不是很难。
2.1 思路
我们只需要盖一层div在图片上,然后设置文字透明,浏览器ctrl+f搜索的时候,会给文字他高亮黄的颜色,我们就可以看到文字了。
盖的这层div,里面包含着我们的文字。
那么,难点就是怎么从图片获取文字出来。
其实这个技术,有个专业词语来描述,叫ocr识别技术。
2.2 ocr
ocr,其实也叫“光学字符识别技术”,是最为常见的、也是目前最高效的文字扫描技术,它可以从图片或者PDF中识别和提取其中的文字内容,输出文本文档,方便验证用户信息,或者直接进行内容编辑。
揭秘该技术:实现文字识别?从图片到文字的过程发生了什么?
分别是输入、图像与处理、文字检测、文本识别,及输出。每个过程都需要算法的深度配合,因此从技术底层来讲,从图片到文字输出,要经历以下的过程:
1、图像输入:读取不同图像格式文件;
2、图像预处理:主要包括图像二值化,噪声去除,倾斜校正等;
3、版面分析:将文档图片分段落,分行;
4、字符切割:处理因字符粘连、断笔造成字符难以简单切割的问题;
5、字符特征提取:对字符图像提取多维特征;
6、字符识别:将当前字符提取的特征向量与特征模板库进行模板粗分类和模板细匹配,识别出字符;
7、版面恢复:识别原文档的排版,按原排版格式将识别结果输出到文本文档;
8、后处理校正: 根据特定的语言上下文的关系,对识别结果进行校正。
2.3 应用
随着ocr技术的成熟,不少软件已经出了该功能。
比如:微信、qq、语雀等等。
还有一些试卷试题,都会用到ocr识别技术。
还有一些技术文档,实现自定义搜索功能,表格关键字高亮。
老板这次需求:把玉兔迎春图实现高亮。
和如上实现的技术思路类似。
我们也可以自定义颜色,加个span标签给其想要的样式。
三、使用
当然,我们可能并不关心底层的实现,只关心怎么怎么去使用。
我们可以调用百度API:文字提取技术
还可以使用java的tesseract-ocr库,其实就是文字的训练。
所以会有个弊端,就是文件可能会有点大,存放着大量文字。
后记
在一个需求的产生之后,我们如果没什么思路,可以借鉴一下,目前市场上有没有类似的技术的沉淀,从而实现需求。
最后,望大家的新的一年,工作顺利,身体健康。
玉兔迎春啦🐇🧨🐇🏮🐇~
👍 如果对您有帮助,您的点赞是我前进的润滑剂。
作者:Dignity_呱
来源:juejin.cn/post/7186459084303335481
一个有趣的交互效果的实现
效果分析
最近在做项目,碰到了这样一个需求,就是页面有一个元素,这个元素可以在限定的区域内进行拖拽,拖拽完成吸附到左边或者右边,并且在滚动页面的时候,这个元素要半隐状态,停止滚动的时候恢复到原来的位置。如图所示:
根据视频所展示的效果,我们得出了我们需要实现的效果主要有2个部分:
拖拽并吸附
滚动半隐元素
那么如何实现这2个效果呢?我们一个效果一个效果的来分析。
ps: 由于这里采用的是react技术栈,所以这里以react作为讲解
首先对于第一个效果,我们要想实现拖拽,有2种方式,第一种就是html5提供的拖拽api,还有一种就是监听鼠标的mousedown,mousemove和mouseup事件,由于这里兼容的移动端,所以我采用的是第二种实现方法。
思路是有了,接下来我想的就是将这三个事件封装一下,写成一个hook函数,这样方便调用,也方便扩展。
对于拖拽的实现,我们只需要在鼠标按下的时候,记录一下横坐标x和纵坐标y,在鼠标拖动的时候用当前拖动的横坐标x和横坐标y去与鼠标按下的时候的横坐标x与y坐标相减就可以得到拖动的偏移坐标,而这个偏移坐标就是我们最终要使用到的坐标。
在鼠标按下的时候,我们还需要减去元素本身所在的left偏移和top偏移,这样计算出来的坐标才是正确的。
然后,由于元素需要通过设置偏移来改变位置,因此我们需要将元素脱离文档流,换句话说就是元素使用定位,这里我采用的是固定定位。
hooks函数的实现
基于以上思路,一个任意拖拽功能实现的hooks函数就结构就成型了。
当然由于我们需要限定范围,这时候我们可以思考会有2个方向上的限定,即水平方向和垂直方向上的限定。除此之外,我们还需要提供一个默认的坐标值,也就是说元素默认应该是在哪个位置上。现在我们用伪代码来表示一下这个函数的结构,代码如下:
const useLimitDrag = (el,options,container) => {
//核心代码
}
export default useLimitDrag;参数类型
这个hooks函数有3个参数,第一个参数自然是需要拖拽的元素,第二个参数则是配置对象,而第三个参数则是限定的容器元素。拖拽的元素和容器元素都是属于dom元素,在react中,我们还可以传递ref来表示一个dom元素,所以这两个参数,我们可以约定一下类型定义。我们先来定义元素的类型如下:
export type ElementType = Element | HTMLElement | null;dom元素的类型就是Element | HTMLElement这2个类型,现在我们知道react的ref可以传递dom元素,并且我们还可以传入一个函数当作参数,所以基于这个类型,我们又额外的扩展了参数的类型,也方便配置。让我们继续写下如下代码:
import type { RefObject } from 'react';
export type RefElementType = RefObject<ElementType>;
export type FunctionElementType = () => ElementType;这样el和container元素的类型就一目了然,我们再定义一个类型简单合并一下这两个类型,代码如下:
export type ParamType = RefElementType | FunctionElementType;接下来,让我们看配置对象,配置对象主要有2个地方,第一个就是默认值,第二个则是限定方向,因此我们约定了3个参数,islimitX,isLimitY,defaultPosition,并且配置对象都应该是可选的,我们可以使用Partial内置泛型将这个类型包裹一下,ok,来看看代码吧。
export type OptionType = Partial<{
isLimitX: boolean,
isLimitY: boolean,
defaultPosition: {
x: number,
y: number
}
}>;嗯现在,我们可以修改一下以上的核心函数了,代码如下:
const useLimitDrag = (el: ParamType,options: OptionType,container?: ParamType) => {
//核心代码
}
export default useLimitDrag;返回值类型
下一步,我们需要确定我们返回的值,首先肯定是当前被计算出来的x和y坐标,其次由于我们这个需求还有一个吸附效果,这个吸附效果是什么意思呢?就是说,以屏幕的中间作为划分界限为左右两部分,当拖动的x坐标大于中间,那么就吸附到最右边,否则就吸附到最左边。
根据这个需求,我们可以将坐标分为最大x坐标,最小x坐标以及中间的x坐标,当然由于需求只提到了水平方向上的吸附,垂直方向上并没有,但是为了考虑扩展,与之对应的我们同样要分成最大y坐标,最小y坐标以及中间的y坐标。
最后,我们还可以返回一个是否正在拖动中,方便我们做额外的操作。根据描述,以上的代码我们也就可以构造如下:
export type PositionType = Partial<{ x: number, y: number, isMove: boolean, maxX: number, maxY: number, minX: number, minY: number, centerX: number, centerY: number }>;
//
const useLimitDrag = (el: ParamType,options: OptionType,container?: ParamType): PositionType => {
//核心代码
}
export default useLimitDrag;核心代码实现第一步---判断当前环境
最基本的结构搭建好了,接下来第一步,我们要做什么?首先当然是判断当前环境是否表示移动端啊。那么如何判断呢?浏览器提供了一个navigator对象,通过这个对象的userAgent属性我们就可以判断,这个属性是一个很长的字符串,但是我们可以从其中一些值看出一些端倪,在移动端的环境中,通常都会看到iPhone|iPod|Android|ios这些字符串值,比如在iphone手机中就会有iPhone字符串,同理android也是。所以我们就可以通过写一个正则表达式来匹配这些字符串,如果有这些字符串就代表是移动端环境,否则就是pc浏览器环境,代码如下:
const isMobile = navigator.userAgent.match(/(iPhone|iPod|Android|ios)/i);我们为什么要判断是否是移动端环境?因为在移动端环境,我们通常监听的是触摸事件,即touchstart,touchmove与touchend,而非mousedown,mousemove和mouseup。所以下一行代码自然就是定义好事件呢。如下:
const eventType = isMobile ? ['touchstart', 'touchmove', 'touchend'] : ['mousedown', 'mousemove', 'mouseup'];核心代码实现第二步---一些初始化工作
下一步,我们通过useRef方法来存储拖拽元素和限定拖拽容器元素。代码如下:
const element = useRef<ElementType>();
const containerElement = useRef<ElementType>();接着我们获取配置对象的值,然后我们定义最大边界的值,代码如下:
const { isLimitX, isLimitY,defaultPosition } = option;
const globalWidthHeight = {
offsetWidth: window.innerWidth,
offsetHeight: window.innerHeight
}随后,我们用一个变量代表鼠标是否按下的状态,这样做的目的是让拖拽变得更丝滑流畅一些,而不容易出问题,然后我们用useState定义返回的值,再定义一个对象存储鼠标按下时的x坐标和y坐标的值。代码如下:
let isStart = false;
const [position, setPosition] = useState<PositionType>({
x: defaultPosition?.x,
y: defaultPosition?.y,
maxX: 0,
maxY: 0,
centerX: 0,
centerY: 0,
minX: 0,
minY: 0
});
const [isMove, setIsMove] = useState(false);
const downPosition = {
x:0,
y:0
}另外为了确保拖动在限定区域内,我们需要设置滚动截断的样式,让元素不能在出现滚动条后还能拖动,因为这样会出现问题。我们定义一个方法用来设置,代码如下:
const setOverflow = () => {
const limitEle = (containerElement.current || document.body) as HTMLElement;
if (isLimitX) {
limitEle.style.overflowX = 'hidden';
} else {
limitEle.style.overflowX = '';
}
if (isLimitY) {
limitEle.style.overflowY = 'hidden';
} else {
limitEle.style.overflowY = '';
}
}这个方法也就比较好理解了,如果使用的时候传入isLimitX那么就设置overflowX为hidden,否则不设置,y方向同理。
核心代码的实现第三步---监听事件
接下来,我们在react的钩子函数中监听事件,此时有了一个选择就是钩子函数我们使用useEffect还是useLayoutEffect呢?要决定使用哪个,我们需要知道这两个钩子函数的区别,这个超出了本文范围,不提及,可以查阅相关资料了解,这里我选择的是useLayoutEffect。
在钩子函数的回调函数中,我们首先将拖拽元素和容器元素存储下来,然后如果拖拽元素不存在,我们就不执行后续事件,回调函数返回一个函数,在该函数中我们移除对应的事件。代码如下:
useLayoutEffect(() => {
element.current = typeof el === 'function' ? el() : el.current;
containerElement.current = typeof containerRef === 'function' ? containerRef() : containerRef?.current;
if (!element.current) {
return;
}
element.current.addEventListener(eventType[0], onStartHandler);
return () => {
element.current?.removeEventListener(eventType[0], onStartHandler);
}
}, []);核心代码实现第四步---拖动开始事件回调
接下来,我们来看一下onStartHandler函数的实现,在这个函数中,我们主要其实就是存储按下时候的坐标值,并且设置状态以及拖拽元素的鼠标样式和滚动截断的样式,随后当然是监听拖动和拖动结束事件,代码如下:
const onStartHandler = useCallback((e:Event) => {
isStart = true;
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = 'move';
}
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
downPosition.x = clientX - target.offsetLeft;
downPosition.y = clientY - target.offsetTop;
setOverflow();
window.addEventListener(eventType[1], onMoveHandler);
window.addEventListener(eventType[2], onUpHandler);
}, []);pc端是可以直接从事件对象中拿出来坐标,可是在移动端我们要通过一个changedTouches属性,这个属性是一个伪数组,第一项就是我们要获取到的坐标值。
接下来就是拖动事件的回调函数以及拖动结束的回调函数的实现了。
核心代码实现第五步---拖动事件回调
这是一个最核心实现的回调,我们在这个函数当中是要计算坐标的,首先当然是根据isStart状态来确定是否执行后续逻辑,其次,还要获取到当前拖拽元素,因为我们要根据这个拖拽元素的宽高做坐标的计算,另外还要获取到容器元素,如果没有提供容器元素,那么就是我们最开始定义的globalWidthHeight中取,然后获取鼠标按下时的x和y坐标值,将当前移动的x坐标和y坐标分别与按下时相减,就是我们的移动x坐标和y坐标,如果有设置isLimitX和isLimitY,我们还要额外设置滚动截断样式,并且我们通过将0和moveX以及最大值(也就是屏幕或者是容器元素的宽高减去拖拽元素的宽高)得到我们的最终的moveX和moveY值。
最后,我们将最终的moveX和moveY用react的状态存储起来即可。代码如下:
const onMoveHandler = useCallback((e: Event) => {
if (!isStart) {
return;
}
setOverflow();
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
if (!element.current) {
return;
}
const { offsetWidth, offsetHeight} = element.current as HTMLElement;
const { offsetWidth: containerWidth, offsetHeight: containerHeight } = (containerElement.current as HTMLElement ||globalWidthHeight);
const { x,y } = downPosition;
const moveX = clientX - x,
moveY = clientY - y;
const data = {
x: isLimitX ? Math.max(0, Math.min(containerWidth - offsetWidth, moveX)) : moveX,
y: isLimitY ? Math.max(0, Math.min(containerHeight - offsetHeight, moveY)) : moveY,
minX: 0,
minY: 0,
maxX: containerWidth - offsetWidth,
maxY: containerHeight - offsetHeight,
centerX: (containerWidth - offsetWidth) / 2,
centerY: (containerHeight - offsetHeight) / 2
}
setIsMove(true);
setPosition(data);
}, []);核心代码实现第六步--拖动结束回调
最后在拖动结束后,我们需要重置我们做的一些操作,比如样式溢出截断,再比如移除事件的监听,以及恢复鼠标的样式等。代码如下:
const onUpHandler = useCallback(() => {
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = '';
}
isStart = false;
setIsMove(false);
const limitEle = (containerElement.current || document.body) as HTMLElement;
limitEle.style.overflowX = '';
limitEle.style.overflowY = '';
window.removeEventListener(eventType[1], onMoveHandler);
window.removeEventListener(eventType[2],onUpHandler);
}, []);到此为止,我们的第一个效果核心实现就已经算是完成大半部分了,最后我们再把需要用到的状态值返回出去。代码如下:
return {
...position,
isMove
}合并以上的代码,就成了我们最终的hooks函数,代码如下:
import { useState, useCallback, useLayoutEffect, useRef } from 'react';
import type { RefObject } from 'react';
export type ElementType = Element | HTMLElement | null;
export type RefElementType = RefObject<ElementType>;
export type FunctionElementType = () => ElementType;
export type ParamType = RefElementType | FunctionElementType;
export type PositionType = Partial<{ x: number, y: number, isMove: boolean, maxX: number, maxY: number, minX: number, minY: number, centerX: number, centerY: number }>;
export type OptionType = Partial<{
isLimitX: boolean,
isLimitY: boolean,
defaultPosition: {
x: number,
y: number
}
}>;
const useAnyDrag = (el: ParamType, option: OptionType = { isLimitX: true, isLimitY: true,defaultPosition:{ x:0,y:0 } }, containerRef?: ParamType): PositionType => {
const isMobile = navigator.userAgent.match(/(iPhone|iPod|Android|ios)/i);
const eventType = isMobile ? ['touchstart', 'touchmove', 'touchend'] : ['mousedown', 'mousemove', 'mouseup'];
const element = useRef<ElementType>();
const containerElement = useRef<ElementType>();
const { isLimitX, isLimitY,defaultPosition } = option;
const globalWidthHeight = {
offsetWidth: window.innerWidth,
offsetHeight: window.innerHeight
}
let isStart = false;
const [position, setPosition] = useState<PositionType>({
x: defaultPosition?.x,
y: defaultPosition?.y,
maxX: 0,
maxY: 0,
centerX: 0,
centerY: 0,
minX: 0,
minY: 0
});
const [isMove, setIsMove] = useState(false);
const downPosition = {
x:0,
y:0
}
const setOverflow = () => {
const limitEle = (containerElement.current || document.body) as HTMLElement;
if (isLimitX) {
limitEle.style.overflowX = 'hidden';
} else {
limitEle.style.overflowX = '';
}
if (isLimitY) {
limitEle.style.overflowY = 'hidden';
} else {
limitEle.style.overflowY = '';
}
}
const onStartHandler = useCallback((e:Event) => {
isStart = true;
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = 'move';
}
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
downPosition.x = clientX - target.offsetLeft;
downPosition.y = clientY - target.offsetTop;
setOverflow();
window.addEventListener(eventType[1], onMoveHandler);
window.addEventListener(eventType[2], onUpHandler);
}, []);
const onMoveHandler = useCallback((e: Event) => {
if (!isStart) {
return;
}
setOverflow();
const event: Touch | MouseEvent = e instanceof TouchEvent ? e.changedTouches[0] : e as MouseEvent;
const { clientX, clientY } = event;
if (!element.current) {
return;
}
const { offsetWidth, offsetHeight} = element.current as HTMLElement;
const { offsetWidth: containerWidth, offsetHeight: containerHeight } = (containerElement.current as HTMLElement || globalWidthHeight);
const { x,y } = downPosition;
const moveX = clientX - x,
moveY = clientY - y;
const data = {
x: isLimitX ? Math.max(0, Math.min(containerWidth - offsetWidth, moveX)) : moveX,
y: isLimitY ? Math.max(0, Math.min(containerHeight - offsetHeight, moveY)) : moveY,
minX: 0,
minY: 0,
maxX: containerWidth - offsetWidth,
maxY: containerHeight - offsetHeight,
centerX: (containerWidth - offsetWidth) / 2,
centerY: (containerHeight - offsetHeight) / 2
}
setIsMove(true);
setPosition(data);
}, []);
const onUpHandler = useCallback(() => {
const target = element.current as HTMLElement;
if (target) {
target.style.cursor = '';
}
isStart = false;
setIsMove(false);
const limitEle = (containerElement.current || document.body) as HTMLElement;
limitEle.style.overflowX = '';
limitEle.style.overflowY = '';
window.removeEventListener(eventType[1], onMoveHandler);
window.removeEventListener(eventType[2],onUpHandler);
}, []);
useLayoutEffect(() => {
element.current = typeof el === 'function' ? el() : el.current;
containerElement.current = typeof containerRef === 'function' ? containerRef() : containerRef?.current;
if (!element.current) {
return;
}
element.current.addEventListener(eventType[0], onStartHandler);
return () => {
element.current?.removeEventListener(eventType[0], onStartHandler);
}
}, []);
return {
...position,
isMove
}
}
export default useAnyDrag;接下来我们来看第二个效果的实现。
半隐效果的实现分析
第二个效果实现的难点在哪里?我们都知道监听元素的滚动事件可以知道用户正在滚动页面,可是我们并不知道用户是否停止了滚动,而且也没有相关的事件或者是API能够让我们去监听用户停止了滚动,那么难点就在这里,如何知道用户是否停止了滚动。
要解决这个问题,我们还得从滚动事件中作文章,我们知道如果用户一直在滚动页面的话,滚动事件就会一直触发,假设我们在该事件中延迟个数百毫秒执行某个操作,是否就代表用户停止了滚动,然后我们可以执行相应的操作?
幸运的是,我从这里找到了答案,还真的是这么做。
如此一来,这个效果我们就实现了一大半了,我们实现一个useIsScroll函数,然后返回一个布尔值代表用户是否正在滚动和停止滚动两种状态,为了完成额外的操作,我们还可以返回一个用户滚动停止时的当前元素距离文档顶部的一个距离,也就是scrollTop。
如此一来,这个函数的实现就比较简单了,还是在react钩子函数中监听滚动事件,然后执行修改状态值的操作。但是现在还有一个问题,那就是我们如何去存储状态?
核心代码实现第一步--解决状态存储的响应式
如果使用useState来存储的话,似乎并没有达到响应式,好在react还提供了一个useRef函数,这个是一个响应式的,我们可以基于这个hooks函数结合useReducer函数来封装一个useGetSet函数,这个函数也在这里有总结到,感兴趣的可以去看看。
这个函数的实现其实也不难,主要就是利用useReducer的第二个参数强行去更新状态值,然后返回更新后的状态值。代码如下:
export const useGetSet = <T>(initialState:T):[() => T,(s:T) => void] => {
const state = useRef<T>(initialState);
const [,update] = useReducer(() => Object.create(null),{});
const updateState = (newState: T) => {
state.current = newState;
update();
}
return useMemo(() => [
() => state.current,
updateState
],[])
}核心代码实现第二步--构建hooks函数
接下来我们来看这个hooks函数,很明显这个hooks函数有2个参数,第一个则是监听滚动事件的滚动元素,第二个则是一个延迟时间。滚动元素的类型与前面的拖拽函数保持一致,我们来详细看看。
const useIsScroll = <T extends HTMLElement>(el: Window | T | (() => T) = window,throlleTime:number = 300): {
isScroll: boolean,
scrollTop: number
} => {
//核心代码
}需要注意这里设置了默认值,el默认值时window对象,throlleTime默认值时300
接下来我们就是使用useSetGet方法存储状态,定义一个timer用于延迟函数定时器,然后监听滚动事件,在事件的回调函数中执行相应的修改状态值的操作,最后就是返回这两个状态值即可。代码如下:
const useIsScroll = <T extends HTMLElement>(el: Window | T | (() => T) = window,throlleTime:number = 300): {
isScroll: boolean,
scrollTop: number
} => {
const [isScroll,setIsScroll] = useGetSet(false);
const [scrollTop,setScrollTop] = useGetSet(0);
const timer = useRef<ReturnType<typeof setTimeout> | null>(null);
const onScrollHandler = useCallback(() => {
setIsScroll(true);
setScrollTop(window.scrollY);
if(timer.current){
clearTimeout(timer.current);
}
timer.current = setTimeout(() => {
setIsScroll(false);
},throlleTime)
},[])
useLayoutEffect(() => {
const ele = typeof el === 'function' ? (el as () => T)() : el;
if(!ele){
return;
}
ele.addEventListener('scroll',onScrollHandler,false);
return () => {
ele.removeEventListener('scroll',onScrollHandler,false);
}
},[]);
return {
isScroll: isScroll(),
scrollTop: scrollTop()
};
}整个hooks函数代码实现起来简单明了,所以也没什么难点,只要理解到了思路,就很简单了。
两个hooks函数的使用
核心功能我们已经实现了,接下来使用起来也比较简单,样式代码如下:
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body,html {
height: 100%;
}
body {
overflow:auto;
}
.App {
position: relative;
}
.overHeight {
height: 3000px;
}
.drag {
position: fixed;
width: 150px;
height: 150px;
border: 3px solid #2396ef;
background: linear-gradient(135deg,#efac82 10%,#da5b0c 90%);
z-index: 2;
left: 0;
top: 0;
}
.transition {
transition: all 1.2s ease-in-out;
}组件代码如下:
import useAnyDrag from "./hooks/useAnyDrag";
import './App.css';
import useIsScroll from "./hooks/useIsScroll";
import { createRef } from "react";
const App = () => {
// 这里是使用核心代码
const { x, y, isMove, centerX, minX, maxX } = useAnyDrag(() => document.querySelector('#drag'));
//这里是使用核心代码
const {isScroll} = useIsScroll();
const scrollElement = createRef<HTMLDivElement>();
const getLeftPosition = () => {
if (!x || !centerX || isMove) {
return x;
}
if (x <= centerX) {
return minX || 0;
} else {
return maxX;
}
}
const scrollPosition = () => {
if (typeof getLeftPosition() === 'number') {
if (getLeftPosition() === 0) {
return -((scrollElement.current?.offsetWidth || 0) / 2);
} else {
return getLeftPosition() as number + (scrollElement.current?.offsetWidth || 0) / 2;
}
}
return 0;
}
return (
<div className="App">
<div className="overHeight"></div>
<div className={`${ isScroll ? 'drag transition' : 'drag'}`}
style={{ left: (isScroll ? scrollPosition() : getLeftPosition()) + 'px', top: y + 'px' }}
id="drag"
ref={scrollElement}
></div>
</div>
)
}
export default App;结语
经过以上的分析,我们就完成了这样一个需求,感觉实现完了之后,还是收获满满的,总结一下我学到了什么。
拖拽事件的监听以及拖拽坐标的计算
滚动事件的监听以及react响应式状态的实现
移动端环境与pc环境的判断
如何知道用户停止了滚动
本文就到此为止了,感谢大家观看,最后贴一下在线demo如下所示。
作者:夕水
来源:juejin.cn/post/7163153386911563813
动态适配 web 终端的尺寸
使Xterminal组件自适应容器
通过 xtermjs 所创建的终端大小是由cols、rows这两个配置项的来决定,虽然你可以通过 CSS 样式来让其产生自适应效果,但是这种情况下字体会变得模糊变形等、会出现一系列的问题,要解决这个问题我们还是需要使用cols、rows这两个值来动态设置。
红色部分则是通过cols和rows属性控制,我们可以很明显的看到该终端组件并没有继承父元素的宽度以及高度,而实际的宽度则是通过cols、rows两个属性控制的。
如何动态设置cols和rows这两个参数。
我们去看官方官方文档的时候,会注意到,官方有提供几个插件供我们使用。
而xterm-addon-fit: 可以帮助我们来让 web 终端实现宽度自适应容器。目前的话行数还不行,暂时没有找到好的替代方案,需要动态的计算出来,关于如何计算可以参数 vscode 官方的实现方案。
引入xterm-addon-fit,在我们的案例中,加入下面这两行:
动态计算行数
想要动态计算出行数的话,就需要获取到一个dom元素的高度:
动态计算尺寸的方法。
const terminalReact: null | HTMLDivElement = terminalRef.current // 100% * 100%
const xtermHelperReact: DOMRect | undefined = terminalReact?.querySelector(".xterm-helper-textarea")!.getBoundingClientRect()
const parentTerminalRect = terminalReact?.getBoundingClientRect()
const rows = Math.floor((parentTerminalRect ? parentTerminalRect.height : 20) / (xtermHelperReact ? xtermHelperReact.height : 1))
const cols = Math.floor((parentTerminalRect ? parentTerminalRect.width : 20) / (xtermHelperReact ? xtermHelperReact.width : 1))
// 调用resize方法,重新设置大小
termRef.current.resize(cols, rows)
复制代码我们可以考虑封装成一个函数,只要父亲组件的大小发生变化,就动态适配一次。
链接:https://juejin.cn/post/7160332506015727629
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Backbone前端框架解读
一、 什么是Backbone
在前端的发展道路中,前端框架元老之一jQuery对繁琐的DOM操作进行了封装,提供了链式调用、各类选择器,屏蔽了不同浏览器写法的差异性,但是前端开发过程中依然存在作用域污染、代码复用度低、冗余度高、数据和事件绑定烦琐等痛点。
5年后,Backbone横空出世,通过与Underscore、Require、Handlebar的整合,提供了一个轻量和友好的前端开发解决方案,其诸多设计思想对于后续的现代化前端框架发展起到了举足轻重的作用,堪称现代前端框架的基石。
通过对Backbone前端框架的学习,让我们领略其独特的设计思想。
二、 核心架构
按照MVC框架的定义,MVC是用来将应用程序分为三个主要逻辑组件的架构模式:模型,视图和控制器。这些组件被用来处理一个面向应用的特定开发。 MVC是最常用的行业标准的Web开发框架,以创建可扩展的项目之一。 Backbone.js为复杂WEB应用程序提供模型(models)、集合(collections)、视图(views)的结构。
◦ 其中模型用于绑定键值数据,并通过RESRful JSON接口连接到应用程序;
◦ 视图用于UI界面渲染,可以声明自定义事件,通过监听模型和集合的变化执行相应的回调(如执行渲染)。
如图所示,当用户与视图层产生交互时,控制层监听变化,负责与数据层进行数据交互,触发数据Change事件,从而通知视图层重新渲染,以实现UI界面更新。更进一步,当数据层发生变化时,由Backbone提供了数据层和服务器数据共享同步的能力。
其设计思想主要包含以下几点:
◦数据绑定(依赖渲染模板引擎)、事件驱动(依赖Events)
◦视图组件化,并且组件有了生命周期的概念
◦前端路由配置化,实现页面局部刷新
这些创新的思想,在现代前端框架中进一步得到了继承和发扬。
三、 部分源码解析
Backbone极度轻量,编译后仅有几kb,贯穿其中的是大量的设计模式:工厂模式、观察者模式、迭代器模式、适配器模式……,代码流畅、实现过程比较优雅。按照功能拆分为了Events、Model、Collection、Router、History、View等若干模块,这里摘取了部分精彩源码进行了解析,相信对我们的日常代码开发也有一定指导作用:
(1)迭代器
EventsApi起到一个迭代器分流的作用,对多个事件进行解析拆分,设计的非常经典,执行时以下用法都是合法的:
◦用法一:传入一个名称和回调函数的对象
modal.on({
"change": change_callback,
"remove": remove_callback
})◦用法二:使用空格分割的多个事件名称绑定到同一个回调函数上
model.on("change remove", common_callback)实现如下:
var eventsApi = function(iteratee, events, name, callback, opts) {
var i = 0, names;
if(name && typeof name === 'object') {
// 处理第一种用法
if(callback !== void 0 && 'context' in opts && opts.context === void 0) opts.context = callback;
for(names = _.keys(names); i < names.length; i++) events = eventsApi(iteratee, events, names[i], name[names[i]], opts);
} else if(name && eventSplitter.test(name)) {
// 处理第二种用法
for(names = name.split(eventSplitter); i < names.length; i++) events = iteratee(events, names[i], callback, opts);
} else {
events = iteratee(events, name, callback, opts);
}
return events;
}(2)监听器
用于一个对象监听另外一个对象的事件,例如,在A对象上监听在B对象上发生的事件,并且执行A的回调函数:
A.listenTo(B, "b", callback)实际上这个功能用B对象来监听也可以实现:
B.on("b", callback, A)这么做的好处是,方便对A创建、销毁逻辑的代码聚合,并且对B的侵入程度较小。实现如下:
Events.listenTo = function(obj, name, callback) {
if(!obj) return this;
var id = obj._listenId || (obj._listenId = _.uniqueId('l'));
// 当前对象的所有监听对象
var listeningTo = this._listeningTo || (this._listeningTo = {});
var listening = listeningTo[id];
if(!listening) {
// 创建自身监听id
var thisId = this._listenId || (this._listenId = _.uniqueId('l'));
listening = listeningTo[id] = {obj: obj, objId: id, id: thisId, listeningTo: listeningTo, count: 0};
}
// 执行对象绑定
internalOn(obj, name, callback, this, listening);
return this;
}(3)Model值set
通过option-flags兼容赋值、更新、删除等操作,这么做的好处是融合公共逻辑,简化代码逻辑和对外暴露api。实现如下:
set: function(key, val, options) {
if(key == null) return this;
// 支持两种赋值方式: 对象或者 key\value
var attrs;
if(typeof key === 'object') {
attrs = key;
options = val;
} else {
(attrs = {})[key] = val;
}
options || (options = {});
……
var unset = options.unset;
var silent = options.silent;
var changes = [];
var changing = this._changing; // 处理嵌套set
this._changing = true;
if(!changing) {
// 存储变更前的状态快照
this._previousAttributes = _.clone(this.attributes);
this.changed = {};
}
var current = this.attributes;
var changed = this.changed;
var prev = this._previousAttributes;
for(var attr in attrs) {
val = attrs[attr];
if(!_.isEqual(current[attr], val)) changes.push(attr);
// changed只存储本次变化的key
if(!_.isEqual(prev[attr], val)) {
changed[attr] = val;
} else {
delete changed[attr]
}
unset ? delete current[attr] : (current[attr] = val)
}
if(!silent) {
if(changes.length) this._pending = options;
for(var i=0; i<changes.length; i++) {
// 触发 change:attr 事件
this.trigger('change:' + changes[i], this, current[changes[i]], options);
}
}
if(changing) return this;
if(!silent) {
// 处理递归change场景
while(this._pending) {
options = this._pending;
this._pending = false;
this.trigger('change', this, options);
}
}
this._pending = false;
this._changing = false;
return this;
}四、 不足(对比react、vue)
对比现代前端框架,由于Backbone本身比较轻量,对一些内容细节处理不够细腻,主要体现在:
◦视图和数据的交互关系需要自己分类编写逻辑,需要编写较多的监听器
◦监听器数量较大,需要手动销毁,维护成本较高
◦视图树的二次渲染仅能实现组件整体替换,并非增量更新,存在性能损失
◦路由切换需要自己处理页面更新逻辑
五、为什么选择Backbone
看到这里,你可能有些疑问,既然Backbone存在这些缺陷,那么现在学习Backbone还有什么意义呢?
首先,对于服务端开发人员,Backbone底层依赖underscore/lodash、jQuery/Zepto,目前依然有很多基于Jquery和Velocity的项目需要维护,会jQuery就会Backbone,学习成本低;通过Backbone能够学习用数据去驱动View更新,优化jQuery的写法;Backbone面对对象编程,符合Java开发习惯。
其次,对于前端开发人员,能够学习其模块化封装库类函数,提升编程技艺。Backbone的组件化开发,和现代前端框架有很多共通之处,能够深入理解其演化历史。
作者:京东零售 陈震
来源:juejin.cn/post/7197075558941311035
一篇文章带你掌握Flex布局的所有用法
Flex 布局目前已经非常流行了,现在几乎已经兼容所有浏览器了。在文章开始之前我们需要思考一个问题:我们为什么要使用 Flex 布局?
其实答案很简单,那就是 Flex 布局好用。一个新事物的出现往往是因为旧事物不那么好用了,比如,如果想让你用传统的 css 布局来实现一个块元素垂直水平居中你会怎么做?实现水平居中很简单,margin: 0 auto就行,而实现垂直水平居中则可以使用定位实现:
<div class="container">
<div class="item"></div>
</div>
.container {
position: relative;
width: 300px;
height: 300px;
background: red;
}
.item {
position: absolute;
background: black;
width: 50px;
height: 50px;
margin: auto;
left: 0;
top: 0;
bottom: 0;
right: 0;
}或者
.item {
position: absolute;
background: black;
width: 50px;
height: 50px;
margin: auto;
left: calc(50% - 25px);
top: calc(50% - 25px);
}但是这样都显得特别繁琐,明明可以一个属性就能解决的事情没必要写这么麻烦。而使用 Flex 则可以使用 place-content 属性简单的实现(place-content 为 justify-content 和 align-content 简写属性)
.container {
width: 300px;
height: 300px;
background: red;
display: flex;
place-content: center;
}
.item {
background: black;
width: 50px;
height: 50px;
}接下来的本篇文章将会带领大家一起来探讨Flex布局
基本概念
我们先写一段代码作为示例(部分属性省略)
html
<div class="container">
<div class="item">flex项目</div>
<div class="item">flex项目</div>
<div class="item">flex项目</div>
<div class="item">flex项目</div>
</div>
.container {
display: flex;
width: 800px;
gap: 10px;
}
.item {
color: #fff;
}flex 容器
我们可以将一个元素的 display 属性设置为 flex,此时这个元素则成为flex 容器比如container元素
flex 项目
flex 容器的子元素称为flex 项目,比如item元素
轴
flex 布局有两个轴,主轴和交叉轴,至于哪个是主轴哪个是交叉轴则有flex 容器的flex-direction属性决定,默认为:flex-direction:row,既横向为主轴,纵向为交叉轴,
flex-direction还可以设置其它三个属性,分别为row-reverse,column,column-reverse。
row-reverse
column
column-reverse
从这里我们可以看出 Flex 轴的方向不是固定不变的,它受到flex-direction的影响
不足空间和剩余空间
当 Flex 项目总宽度小于 Flex 容器宽度时就会出现剩余空间
当 Flex 项目总宽度大于 Flex 容器宽度时就会出现不足空间
Flex 项目之间的间距
Flex 项目之间的间距可以直接在 Flex 容器上设置 gap 属性即可,如
<div class="container">
<div class="item">A</div>
<div class="item">B</div>
<div class="item">C</div>
<div class="item">D</div>
</div>
.container {
display: flex;
width: 500px;
height: 400px;
gap: 10px;
}
.item {
width: 150px;
height: 40px;
}Flex 属性
flex属性是flex-grow,flex-shrink,flex-basis三个属性的简写。下面我们来看下它们分别是什么。
flex-basis可以设定 Flex 项目的大小,一般主轴为水平方向的话和 width 解析方式相同,但是它不一定是 Flex 项目最终大小,Flex 项目最终大小受到flex-grow,flex-shrink以及剩余空间等影响,后面文章会告诉大家最终大小的计算方式flex-grow为 Flex 项目的扩展系数,当 Flex 项目总和小于 Flex 容器时就会出现剩余空间,而flex-grow的值则可以决定这个 Flex 项目可以分到多少剩余空间flex-shrink为 Flex 项目的收缩系数,同样的,当 Flex 项目总和大于 Flex 容器时就会出现不足空间,flex-shrink的值则可以决定这个 Flex 项目需要减去多少不足空间
既然flex属性是这三个属性的简写,那么flex属性简写方式分别代表什么呢?
flex属性可以为 1 个值,2 个值,3 个值,接下来我们就分别来看看它们代表什么意思
一个值
如果flex属性只有一个值的话,我们可以看这个值是否带单位,带单位那就是flex-basis,不带就是flex-grow
.item {
flex: 1;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: 0;
}
.item {
flex: 30px;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: 30px;
}两个值
当flex属性有两个值的话,第一个无单位的值就是flex-grow,第一个无单位的值则是flex-shrink,有单位的就是flex-basis
.item {
flex: 1 2;
/* 相当于 */
flex-grow: 1;
flex-shrink: 2;
flex-basis: 0;
}
.item {
flex: 30px 2;
/* 相当于 */
flex-grow: 2;
flex-shrink: 1;
flex-basis: 30px;
}三个值
当flex属性有三个值的话,第一个无单位的值就是flex-grow,第一个无单位的值则是flex-shrink,有单位的就是flex-basis
.item {
flex: 1 2 10px;
/* 相当于 */
flex-grow: 1;
flex-shrink: 2;
flex-basis: 10px;
}
.item {
flex: 30px 2 1;
/* 相当于 */
flex-grow: 2;
flex-shrink: 1;
flex-basis: 30px;
}
.item {
flex: 2 30px 1;
/* 相当于 */
flex-grow: 2;
flex-shrink: 1;
flex-basis: 30px;
}另外,flex 的值还可以为initial,auto,none。
initial
initial 为默认值,和不设置 flex 属性的时候表现一样,既 Flex 项目不会扩展,但会收缩,Flex 项目大小有本身内容决定
.item {
flex: initial;
/* 相当于 */
flex-grow: 0;
flex-shrink: 1;
flex-basis: auto;
}auto
当 flex 设置为 auto 时,Flex 项目会根据自身内容确定flex-basis,既会拓展也会收缩
.item {
flex: auto;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: auto;
}none
none 表示 Flex 项目既不收缩,也不会扩展
.item {
flex: none;
/* 相当于 */
flex-grow: 0;
flex-shrink: 0;
flex-basis: auto;
}Flex 项目大小的计算
首先看一下 flex-grow 的计算方式
flex-grow
面试中经常问到: 为什么 flex 设置为 1 的时候,Flex 项目就会均分 Flex 容器? 其实 Flex 项目设置为 1 不一定会均分容器(后面会解释),这里我们先看下均分的情况是如何发生的
同样的我们先举个例子
<div>
<div>Xiaoyue</div>
<div>June</div>
<div>Alice</div>
<div>Youhu</div>
<div>Liehuhu</div>
</div>
.container {
display: flex;
width: 800px;
}
.item {
flex: 1;
font-size: 30px;
}flex 容器总宽度为 800px,flex 项目设置为flex:1,此时页面上显示
我们可以看到每个项目的宽度为 800/5=160,下面来解释一下为什么会均分:
首先
.item {
flex: 1;
/* 相当于 */
flex-grow: 1;
flex-shrink: 1;
flex-basis: 0;
}因为flex-basis为 0,所有 Flex 项目扩展系数都是 1,所以它们分到的剩余空间都是一样的。下面看一下是如何计算出最终项目大小的
这里先给出一个公式:
Flex项目弹性量 = (Flex容器剩余空间/所有flex-grow总和)\*当前Flex项目的flex-grow
其中Flex项目弹性量指的是分配给 Flex 项目多少的剩余空间,所以 Flex 项目的最终宽度为
flex-basis+Flex项目弹性量。
根据这个公式,上面的均分也就很好理解了,因为所有的flex-basis为 0,所以剩余空间就是 800px,每个 Flex 项目的弹性量也就是(800/1+1+1+1+1)*1=160,那么最终宽度也就是160+0=160
刚刚说过 flex 设置为 1 时 Flex 项目并不一定会被均分,下面就来介绍一下这种情况,我们修改一下示例中的 html,将第一个 item 中换成一个长单词
<div>
<div>Xiaoyueyueyue</div>
<div>June</div>
<div>Alice</div>
<div>Youhu</div>
<div>Liehu</div>
</div>此时会发现 Flex 容器并没有被均分
因为计算出的灵活性 200px 小于第一个 Flex 项目的min-content(217.16px),此时浏览器会采用 Flex 项目的min-content作为最终宽度,而后面的 Flex 项目会在第一个 Flex 项目计算完毕后再进行同样的计算
我们修改一下 flex,给它设置一个 flex-basis,看下它计算之后的情况
.item {
text-align: center;
flex: 1 100px;
}因为每个项目的flex-basis都是 100px,Flex 容器剩余空间为800-500=300px,所以弹性量就是(300/5)*1=60px,最终宽度理论应该为100+60=160px,同样的因为第一个 Flex 项目的min-content为 217.16px,所以第一个 Flex 项目宽度被设置为 217.16px,最终表现和上面一样
我们再来看一下为什么第 2,3,4,5 个 Flex 项目宽度为什么是 145.71px
当浏览器计算完第一个 Flex 项目为 217.16px 后,此时的剩余空间为800-217.16-100*4=182.84,第 2 个 Flex 项目弹性量为(182.84/1+1+1+1)*1=45.71,所以最终宽度为100+45.71=145.71px,同样的后面的 Flex 项目计算方式是一样的,但是如果后面再遇到长单词,假如第五个是长单词,那么不足空间将会发生变化,浏览器会将第五个 Flex 项目宽度计算完毕后再回头进行一轮计算,具体情况这里不再展开
所以说想要均分 Flex 容器 flex 设置为 1 并不能用在所有场景中,其实当 Flex 项目中有固定宽度元素也会出现这种情况,比如一张图片等,当然如果你想要解决这个问题其实也很简单,将 Flex 项目的min-width设置为 0 即可
.item {
flex: 1 100px;
min-width: 0;
}flex-grow 为小数
flex-grow 的值不仅可以为正整数,还可以为小数,当为小数时也分为两种情况:所有 Flex 项目的 flex-grow 之和小于等于 1 和大于 1,我们先看小于等于 1 的情况,将例子的改成
<div>
<div>Acc</div>
<div>Bc</div>
<div>C</div>
<div>DDD</div>
<div>E</div>
</div>
.item:nth-of-type(1) {
flex-grow: 0.1;
}
.item:nth-of-type(2) {
flex-grow: 0.2;
}
.item:nth-of-type(3) {
flex-grow: 0.2;
}
.item:nth-of-type(4) {
flex-grow: 0.1;
}
.item:nth-of-type(5) {
flex-grow: 0.1;
}效果如图
我们可以发现项目并没有占满容器,它的每个项目的弹性量计算方式为
Flex项目弹性量=Flex容器剩余空间*当前Flex项目的flex-grow
相应的每个项目的实际宽度也就是flex-basis+弹性量,首先先不设置 flex-grow,我们可以看到每个项目的 flex-basis 分别为: 51.2 , 33.88 , 20.08 , 68.56 , 16.5
所以我们可以计算出 Flex 容器的剩余空间为800-51.2 -33.88 - 20.08 - 68.56 - 16.5=609.78,这样我们就可以算出每个项目的实际尺寸为
A: 实际宽度 = 51.2 + 609.78*0.1 = 112.178
B: 实际宽度 = 33.88 + 609.78*0.2 = 155.836
...
下面看下 flex-grow 之和大于 1 的情况,将例子中的 css 改为
.item:nth-of-type(1) {
flex-grow: 0.1;
}
.item:nth-of-type(2) {
flex-grow: 0.2;
}
.item:nth-of-type(3) {
flex-grow: 0.3;
}
.item:nth-of-type(4) {
flex-grow: 0.4;
}
.item:nth-of-type(5) {
flex-grow: 0.5;
}此时的效果为
可以看出 Flex 项目是占满容器的,它的计算方式其实和 flex-grow 为正整数时一样
Flex项目弹性量 = (Flex容器剩余空间/所有flex-grow总和)\*当前Flex项目的flex-grow
所以我们可以得出一个结论: Flex 项目的 flex-grow 之和小于 1,Flex 项目不会占满 Flex 容器
flex-shrink
flex-shrink 其实和 flex-grow 基本一样,就是扩展变成了收缩,flex-grow 是项目比例增加容器剩余空间,而 flex-shrink 则是比例减去容器不足空间
修改一下我们的例子:
.item {
flex-basis: 200px;
/* 相当于 */
flex-shrink: 1;
flex-grow: 0;
flex-basis: 200px;
}此时项目的总宽度200*5=1000px已经大于容器总宽度800px,此时计算第一个项目的不足空间就是800-200*5=-200px,第二个项目的不足空间则是800-第一个项目实际宽度-200*4,依次类推
最终计算公式其实和 flex-grow 计算差不多
Flex项目弹性量 = (Flex容器不足空间/所有flex-shrink总和)*当前Flex项目的flex-shrink
只不过,所以上面例子每个项目可以计算出实际宽度为
第一个 Flex 项目: 200+((800-200x5)/5)*1 = 160px
第二个 Flex 项目: 200+((800-160-200x4)/4)*1 = 160px
第三个 Flex 项目: 200+((800-160-160-200x3)/3)*1 = 160px
第四个 Flex 项目: 200+((800-160-160-160-200x2)/2)*1 = 160px
第五个 Flex 项目: 200+((800-160-160-160-160-200x1)/1)*1 = 160px
如果 Flex 项目的min-content大于flex-basis,那么最终的实际宽度将会取该项目的min-content,比如改一下例子,将第一个 Flex 项目改成长单词
<div>
<div>XiaoyueXiaoyue</div>
<div>June</div>
<div>Alice</div>
<div>Youhu</div>
<div>Liehu</div>
</div>可以看出浏览器最终采用的是第一个 Flex 项目的min-content作为实际宽度,相应的后面 Flex 项目的宽度会等前一个 Flex 项目计算完毕后在进行计算
比如第二个 Flex 项目宽度= 200+((800-228.75-200x4)/4)*1 = 142.81px
flex-shrink 为小数
同样的 flex-shrink 也会出现小数的情况,也分为 Flex 项目的 flex-shrink 之和小于等于 1 和大于 1 两种情况,如果大于 1 和上面的计算方式一样,所以我们只看小于 1 的情况,将我们的例子改为
.item {
flex-basis: 200px;
flex-shrink: 0.1;
}效果为
此时我们会发现 Flex 项目溢出了容器,所以我们便可以得出一个结论:Flex 项目的 flex-shrink 之和小于 1,Flex 项目会溢出 Flex 容器
下面看一下它的计算公式
Flex项目弹性量=Flex容器不足空间*当前Flex项目的flex-shrink
Flex项目实际宽度=flex-basis + Flex项目弹性量
比如上面例子的每个 Flex 项目计算结果为
第一个 Flex 项目宽度 = 200+(800-200x5)x0.1=180px,但是由于它本身的min-content为 228.75,所以最终宽度为 228.75
第二个 Flex 项目宽度 =200-(800-228.75-200x4)x0.1=117.125
第三个 Flex 项目宽度...
Flex 的对齐方式
Flex 中关于对齐方式的属性有很多,其主要分为两种,一是主轴对齐方式:justify-,二是交叉轴对齐方式:align-
首先改一下我们的例子,将容器设置为宽高为 500x400 的容器(部分属性省略)
<div>
<div>A</div>
<div>B</div>
<div>C</div>
</div>
.container {
display: flex;
width: 500px;
height: 400px;
}
.item {
width: 100px;
height: 40px;
}主轴对齐属性
这里以横向为主轴,纵向为交叉轴
justify-content
justify-content的值可以为:
flex-start 默认值,主轴起点对齐
flex-end 主轴终点对齐
left 默认情况下和 flex-start 一致
right 默认情况下和 flex-end 一致
center 主轴居中对齐
space-between 主轴两端对齐,并且 Flex 项目间距相等
space-around 项目左右周围空间相等
space-evenly 任何两个项目之间的间距以及边缘的空间相等
交叉轴对齐方式
align-content
align-content 属性控制整个 Flex 项目在 Flex 容器中交叉轴的对齐方式
注意设置 align-content 属性时候必须将 flex-wrap 设置成 wrap 或者 wrap-reverse。它可以取得值为
stretch 默认值,当我们 Flex 元素不设置高度的时候,默认是拉伸的
比如将 Flex 元素宽度去掉
.item {
width: 100px;
}flex-start 位于容器开头,这个和 flex-direction:属性有关,默认在顶部
flex-end 位于容器结尾
center 元素居中对齐
space-between 交叉轴上下对齐,并且 Flex 项目上下间距相等
此时我们改下例子中 Flex 项目的宽度使其换行,因为如果 Flex 项目只有一行,那么 space-between 与 flex-start 表现一致
.item {
width: 300px;
}space-around 项目上下周围空间相等
space-evenly 任何两个项目之间的上下间距以及边缘的空间相等
align-items
align-items 属性定义 flex 子项在 flex 容器的当前行的交叉轴方向上的对齐方式。它与 align-content 有相似的地方,它的取值有
stretch 默认值,当我们 Flex 元素不设置高度的时候,默认是拉伸的
center 元素位于容器的中心,每个当前行在图中已经框起来
flex-start 位于容器开头
flex-end 位于容器结尾
baseline 位于容器的基线上
比如给 A 项目一个 padding-top
.item:nth-of-type(1) {
padding-top: 50px;
}没设置 baseline 的表现
设置 baseline 之后
通过上面的例子我们可以发现,如果想要整个 Flex 项目垂直对齐,在只有一行的情况下,align-items 和 align-content 设置为 center 都可以做到,但是如果出现多行的情况下 align-items 就不再适用了
align-self
上面都是给 Flex 容器设置的属性,但是如果想要控制单个 Flex 项目的对齐方式该怎么办呢?
其实 Flex 布局中已经考虑到了这个问题,于是就有个 align-self 属性来控制单个 Flex 项目在 Flex 容器侧交叉轴的对齐方式。
align-self 和 align-items 属性值几乎是一致的,比如我们将整个 Flex 项目设置为 center,第二个 Flex 项目设置为 flex-start
.container {
display: flex;
width: 500px;
height: 400px;
align-items: center;
}
.item {
width: 100px;
height: 40px;
}
.item:nth-of-type(2) {
align-self: flex-start;
}注意,除了以上提到的属性的属性值,还可以设置为 CSS 的关键词如 inherit 、initial 等
交叉轴与主轴简写
place-content
place-content` 为 `justify-content` 和 `align-content` 的简写形式,可以取一个值和两个值,如果设置一个值那么 `justify-content` 和 `align-content` 都为这个值,如果是两个值,第一个值为 `align-content`,第二个则是 `justify-content到这里关于Flex布局基本已经介绍完了,肯定会有些细枝末节没有考虑到,这可能就需要我们在平时工作和学习中去发现了
作者:东方小月
来源:https://juejin.cn/post/7197229913156796472
我竟然完美地用js实现默认的文本框粘贴事件
前言:本文实际是用js移动控制光标的位置!解决了网上没有可靠教程的现状
废话连篇
默认情况对一个文本框粘贴,应该会有这样的功能:
粘贴文本后,光标不会回到所有文本的最后位置,而是在粘贴的文本之后
将选中的文字替换成粘贴的文本
但是由于需求,我们需要拦截粘贴的事件,对剪贴板的文字进行过滤,这时候粘贴的功能都得自己实现了,而一旦自己实现,上面2个功能就不见了,我们就需要还原它。
面对这样的需求,我们肯定要控制移动光标,可是现在的网上环境真的是惨,千篇一律的没用代码...于是我就发表了这篇文章。
先上代码
<textarea id="text" style="width: 996px; height: 423px;"></textarea>
<script>
// 监听输入框粘贴事件
document.getElementById('text').addEventListener('paste', function (e) {
e.preventDefault();
let clipboardData = e.clipboardData.getData('text');
// 这里写你对剪贴板的私货
let tc = document.querySelector("#text");
tc.focus();
const start = (tc.value.substring(0,tc.selectionStart)+clipboardData).length;
if(tc.selectionStart != tc.selectionEnd){
tc.value = tc.value.substring(0,tc.selectionStart)+clipboardData+tc.value.substring(tc.selectionEnd)
}else{
tc.value = tc.value.substring(0,tc.selectionStart)+clipboardData+tc.value.substring(tc.selectionStart);
}
// 重新设置光标位置
tc.selectionEnd =tc.selectionStart = start
});
</script>怎么理解上述两个功能?
第一个解释:
比如说现在文本框有:
染念真的很生气
如果我们现在在真的后面粘贴不要,变成
染念真的不要很生气|
拦截后的光标是在生气后面,但是我们经常使用发现,光标应该出现在不要的后面吧!
就像这样:
染念真的不要|很生气
第2个解释:
染念真的不要很生气
我们全选真的的同时粘贴求你,拦截后会变成
染念真的求你不要很生气|
但默认应该是:
染念求你|不要很生气
代码分析
针对第2个问题,我们应该先要获取默认的光标位置在何处,tc.selectionStart是获取光标开始位置,tc.selectionEnd是获取光标结束位置。
为什么这里我写了一个判断呢?因为默认时候,我们没有选中一块区域,就是把光标人为移动到某个位置(读到这里,光标在位置后面,现在人为移动到就是前面,这个例子可以理解不?),这个时候两个值是相等的。
233|333
^--^
1--4
tc.selectionEnd=4,tc.selectionStart = 4
如果相等,说明就是简单的定位,tc.value = tc.value.substring(0,tc.selectionStart)+clipboardData+tc.value.substring(tc.selectionStart);,tc.value.substring(0,tc.selectionStart)获取光标前的内容,tc.value.substring(tc.selectionStart)是光标后的内容。
如果不相等,说明我们选中了一个区域(光标选中一块区域说明我们选中了一个区域),代码只需要在最后获取光标后的内容这的索引改成tc.selectionEnd
|233333|
^------^
1------7
tc.selectionEnd=7,tc.selectionStart = 1
在获取光标位置之前,我们应该先使用tc.focus();聚焦,使得光标回到文本框的默认位置(最后),这样才能获得位置。
针对第1个问题,我们就要把光标移动到粘贴的文本之后,我们需要计算位置。
获得这个位置,一定要在tc.value重新赋值之前,因为这样的索引都没有改动。
const start = (tc.value.substring(0,tc.selectionStart)+clipboardData).length;这个代码和上面解释重复,很简单,我就不解释了。
最后处理完了,重新设置光标位置,tc.selectionEnd =tc.selectionStart = start,一定让selectionEnd和selectionStart相同,不然选中一个区域了。
如果我们在value重新赋值之后获取(tc.value.substr(0,tc.selectionStart)+clipboardData).length,大家注意到没,我们操作的是tc.value,value已经变了,这里的重新定位光标开始已经没有任何意义了!
作者:染念
来源:dyedd.cn/943.html
闭包用多了会造成内存泄露 ?
闭包,是JS中的一大难点;网上有很多关于闭包会造成内存泄露的描述,说闭包会使其中的变量的值始终保持在内存中,一般都不太推荐使用闭包
而项目中确实有很多使用闭包的场景,比如函数的节流与防抖
那么闭包用多了,会造成内存泄露吗?
场景思考
以下案例: A 页面引入了一个 debounce 防抖函数,跳转到 B 页面后,该防抖函数中闭包所占的内存会被 gc 回收吗?
该案例中,通过变异版的防抖函数来演示闭包的内存回收,此函数中引用了一个内存很大的对象 info(42M的内存),便于明显地对比内存的前后变化
注:可以使用 Chrome 的 Memory 工具查看页面的内存大小:
场景步骤:
1) util.js 中定义了 debounce 防抖函数
// util.js`
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
export const debounce = (fn, time) => {
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};2) A 页面中引入并使用该防抖函数
import { debounce } from './util';
mounted() {
this.debounceFn = debounce(() => {
console.log('1');
}, 1000)
}抓取 A 页面内存:
57.1M
3) 从 A 页面跳转到 B 页面,B 页面中没有引入该 debounce 函数
问题: 从 A 跳转到 B 后,该函数所占的内存会被释放掉吗?
此时,抓取 B 页面内存:
58.1M
刷新 B 页面,该页面的原始内存为:
16.1M
结论: 前后对比发现,从 A 跳转到 B 后,B 页面内存增大了 42M,证明该防抖函数所占的内存没有被释放掉,即造成了内存泄露
为什么会这样呢? 按理说跳转 B 页面后,A 页面的组件都被销毁掉了,那么 A 页面所占的内存应该都被释放掉了啊😕
我们继续对比测试
4) 如果把 info 对象放到 debounce 函数内部,从 A 跳转到 B 后,该防抖函数所占的内存会被释放掉吗?
// util.js`
export const debounce = (fn, time) => {
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};按照步骤 4 的操作,重新从 A 跳转到 B 后,B 页面抓取内存为16.1M,证明该函数所占的内存被释放掉了
为什么只是改变了 info 的位置,会引起内存的前后变化?
要搞懂这个问题,需要理解闭包的内存回收机制
闭包简介
闭包:一个函数内部有外部变量的引用,比如函数嵌套函数时,内层函数引用了外层函数作用域下的变量,就形成了闭包。最常见的场景为:函数作为一个函数的参数,或函数作为一个函数的返回值时
闭包示例:
function fn() {
let num = 1;
return function f1() {
console.log(num);
};
}
let a = fn();
a();上面代码中,a 引用了 fn 函数返回的 f1 函数,f1 函数中引入了内部变量 num,导致变量 num 滞留在内存中
打断点调试一下
展开函数 f 的 Scope(作用域的意思)选项,会发现有 Local 局部作用域、Closure 闭包、Global 全局作用域等值,展开 Closure,会发现该闭包被访问的变量是 num,包含 num 的函数为 fn
总结来说,函数 f 的作用域中,访问到了fn 函数中的 num 这个局部变量,从而形成了闭包
所以,如果真正理解好闭包,需要先了解闭包的内存引用,并且要先搞明白这几个知识点:
函数作用域链
执行上下文
变量对象、活动对象
函数的内存表示
先从最简单的代码入手,看下变量是如何在内存中定义的
let a = '小马哥'这样一段代码,在内存里表示如下
在全局环境 window 下,定义了一个变量 a,并给 a 赋值了一个字符串,箭头表示引用
再定义一个函数
let a = '小马哥'
function fn() {
let num = 1
}内存结构如下:
特别注意的是,fn 函数中有一个 [[scopes]] 属性,表示该函数的作用域链,该函数作用域指向全局作用域(浏览器环境就是 window),函数的作用域是理解闭包的关键点之一
请谨记:函数的作用域链是在创建时就确定了,JS 引擎会创建函数时,在该对象上添加一个名叫作用域链的属性,该属性包含着当前函数的作用域以及父作用域,一直到全局作用域
函数在执行时,JS 引擎会创建执行上下文,该执行上下文会包含函数的作用域链(上图中红色的线),其次包含函数内部定义的变量、参数等。在执行时,会首先查找当前作用域下的变量,如果找不到,就会沿着作用域链中查找,一直到全局作用域
垃圾回收机制浅析
现在各大浏览器通常用采用的垃圾回收有两种方法:标记清除、引用计数
这里重点介绍 "引用计数"(reference counting),JS 引擎有一张"引用表",保存了内存里面所有的资源(通常是各种值)的引用次数。如果一个值的引用次数是0,就表示这个值不再用到了,因此可以将这块内存释放
上图中,左下角的两个值,没有任何引用,所以可以释放
如果一个值不再需要了,引用数却不为0,垃圾回收机制无法释放这块内存,从而导致内存泄漏
判断一个对象是否会被垃圾回收的标准: 从全局对象 window 开始,顺着引用表能找到的都不是内存垃圾,不会被回收掉。只有那些找不到的对象才是内存垃圾,才会在适当的时机被 gc 回收
分析内存泄露的原因
回到最开始的场景,当 info 在 debounce 函数外部时,为什么会造成内存泄露?
进行断点调试
展开 debounce 函数的 Scope选项,发现有两个 Closure 闭包对象,第一个 Closure 中包含了 info 对象,第二个 Closure 闭包对象,属于 util.js 这个模块
内存结构如下:
当从 A 页面切换到 B 页面时,A 页面被销毁,只是销毁了 debounce 函数当前的作用域,但是 util.js 这个模块的闭包却没有被销毁,从 window 对象上沿着引用表依然可以查找到 info 对象,最终造成了内存泄露
当 info 在 debounce 函数内部时,进行断点调试
其内存结构如下:
当从 A 页面切换到 B 页面时,A 页面被销毁,同时会销毁 debounce 函数当前的作用域,从 window 对象上沿着引用表查找不到 info 对象,info 对象会被 gc 回收
闭包内存的释放方式
1、手动释放(需要避免的情况)
如果将闭包引用的变量定义在模块中,这种会造成内存泄露,需要手动释放,如下所示,其他模块需要调用 clearInfo 方法,来释放 info 对象
可以说这种闭包的写法是错误的 (不推荐), 因为开发者需要非常小心,否则稍有不慎就会造成内存泄露,我们总是希望可以通过 gc 自动回收,避免人为干涉
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
export const debounce = (fn, time) => {
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};
export const clearInfo = () => {
info = null;
};2、自动释放(大多数的场景)
闭包引用的变量定义在函数中,这样随着外部引用的销毁,该闭包就会被 gc 自动回收 (推荐),无需人工干涉
export const debounce = (fn, time) => {
let info = {
arr: new Array(10 * 1024 * 1024).fill(1),
timer: null
};
return function (...args) {
info.timer && clearTimeout(info.timer);
info.timer = setTimeout(() => {
fn.apply(this, args);
}, time);
};
};结论
综上所述,项目中大量使用闭包,并不会造成内存泄漏,除非是错误的写法
绝大多数情况,只要引用闭包的函数被正常销毁,闭包所占的内存都会被 gc 自动回收。特别是现在 SPA 项目的盛行,用户在切换页面时,老页面的组件会被框架自动清理,所以我们可以放心大胆的使用闭包,无需多虑
理解了闭包的内存回收机制,才算彻底搞懂了闭包。以上关于闭包的理解,如果有误,欢迎指正 🌹
参考链接:
浏览器是怎么看闭包的。
JavaScript 内存泄漏教程
JavaScript闭包(内存泄漏、溢出以及内存回收),超直白解析
作者:海阔_天空
来源:juejin.cn/post/7196636673694285882
字节前端监控实践
简述
Slardar 前端监控自18年底开始建设以来,从仅仅作为 Sentry 的替代,经历了一系列迭代和发展,目前做为一个监控解决方案,已经应用到抖音、西瓜、今日头条等众多业务线。
据21年下旬统计,Slardar 前端监控(Web + Hybrd) 工作日晚间峰值 qps 300w+,日均处理数据超过千亿条。
本文,我将针对在这一系列的发展过程中,字节内部监控设计和迭代遇到的落地细节设计问题,管中窥豹,向大家介绍我们团队所思考和使用的解决方案。
他们主要围绕着前端监控体系建设的一些关键问题展开。也许大家对他们的原理早已身经百战见得多了,不过当实际要落地实现的时候,还是有许多细节可以再进一步琢磨的。
如何做好 JS 异常监控
JS 异常监控本质并不复杂,浏览器早已提供了全局捕获异常的方案。
window.addEventListenr('error', (err) => {
report(normalize(err))
});
window.addEventListenr('unhandledrejection', (rejection) => {
report(normalize(rejection))
});
复制代码但捕获到错误仅仅只是相关工作的第一步。在我看来,JS 异常监控的目标是:
开发者迅速感知到 JS 异常发生
通过监控平台迅速定位问题
开发者能够高效的处理问题,并统计,追踪问题的处理进度
在异常捕获之外,还包括堆栈的反解与聚合,处理人分配和报警这几个方面。
堆栈反解: Sourcemap
大家都知道 Script 脚本在浏览器中都是以明文传输并执行,现代前端开发方案为了节省体积,减少网络请求数,不暴露业务逻辑,或从另一种语言编译成 JS。都会选择将代码进行混淆和压缩。在优化性能,提升用户体验的同时,也为异常的处理带来了麻烦。
在本地开发时,我们通常可以清楚的看到报错的源代码堆栈,从而快速定位到原始报错位置。而线上的代码经过压缩,可读性已经变得非常糟糕,上报的堆栈很难对应到原始的代码中。 Sourcemap 正是用来解决这个问题的。
简单来说,Sourcemap 维护了混淆后的代码行列到原代码行列的映射关系,我们输入混淆后的行列号,就能够获得对应的原始代码的行列号,结合源代码文件便可定位到真实的报错位置。
Sourcemap 的解析和反解析过程涉及到 VLQ 编码,它是一种将代码映射关系进一步压缩为类base64编码的优化手段。
在实际应用中,我们可以把它直接当成黑盒,因为业界已经为我们提供了方便的解析工具。下面是一个利用 mozila 的 sourcemap 库进行反解的例子。
以上代码执行后通常会得到这样的结果,实际上我们的在线反解服务也就是这样实现的
当然,我们不可能在每次异常发生后,才去生成 sourcemap,在本地或上传到线上进行反解。这样的效率太低,定位问题也太慢。另一个方案是利用 sourcemappingURL 来制定sourcemap 存放的位置,但这样等于将页面逻辑直接暴露给了网站使用者。对于具有一定规模和保密性的项目,这肯定是不能接受的。
//# sourceMappingURL=http://example.com/path/hello.js.map
复制代码为了解决这个问题,一个自然的方案便是利用各种打包插件或二进制工具,在构建过程中将生成的 sourcemap 直接上传到后端。Sentry 就提供了类似的工具,而字节内部也是使用相似的方案。
通过如上方案,我们能够让用户在发版构建时就可以完成 sourcemap 的上传工作,而异常发生后,错误可以自动完成解析。不需要用户再操心反解相关的工作了。
堆栈聚合策略
当代码被成功反解后,用户已经可以看到这一条错误的线上和原始代码了,但接下来遇到的问题则是,如果我们只是上报一条存一条,并且给用户展示一条错误,那么在平台侧,我们的异常错误列表会被大量的重复上报占满,
对于错误类型进行统计,后续的异常分配操作都无法正常进行。
在这种情况下,我们需要对堆栈进行分组和聚合。也就是,将具有相同特征的错误上报,归类为统一种异常,并且只对用户暴露这种聚合后的异常。
堆栈怎么聚合效果才好呢?我们首先可以观察我们的JS异常所携带的信息,一个异常通常包括以下部分
name: 异常的 Type,例如 TypeError, SyntaxError, DOMError
Message:异常的相关信息,通常是异常原因,例如
a.b is not defined.Stack (非标准)异常的上下文堆栈信息,通常为字符串
那么聚合的方案自然就出来了,利用某种方式,将 error 相关的信息利用提取为 fingerprint,每一次上报如果能够获得相同的 fingerprint,它们就可以归为一类。那么问题进一步细化为:如何利用 Error 来保证 fingerprint 的区分尽量准确呢?
如果跟随标准,我们只能利用 name + message 作为聚合依据。但在实践过程中,我们发现这是远远不够的。如上所示,可以看到这两个文件发生的位置是完全不同的,来自于不同的代码段,但由于我们只按照 name + message 聚合。它们被错误聚合到了一起,这样可能造成我们修复了其中一个错误后。误以为相关的所有异常都被解决。
因此,很明显我们需要利用非标准的 error.stack 的信息来帮我们解决问题了。在这里我们参考了 Sentry 的堆栈聚合策略:
除了常规的 name, message, 我们将反解后的 stacktrace 进一步拆分为一系列的 Frame,每一个 Frame 内我们重点关注其调用函数名,调用文件名以及当前执行的代码行(图中的context_line)。
Sentry 将每一个拆分出的部分都称为一个 GroupingComponent,当堆栈反解完毕后,我们首先自上而下的递归检测,并自下而上的生成一个个嵌套的 GroupingComponent。最后,在顶层调用 GroupingComponent.getHash() 方法, 得到一个最终的哈希值,这就是我们最终求得的 fingerprint。
相较于message+name, 利用 stacktrace 能够更细致的提取堆栈特征,规避了不同文件下触发相同 message 的问题。因此获得的聚合效果也更优秀。这个策略目前在字节内部的工作效果良好,基本上能够做到精确的区分各类异常而不会造成混淆和错误聚合。
处理人自动分配策略
异常已经成功定位后,如果我们可以直接将异常分配给这行代码的书写者或提交者,可以进一步提升问题解决的效率,这就是处理人自动分配所关心的,通常来说,分配处理人依赖 git blame 来实现。
一般的团队或公司都会使用 Gitlab / Github 作为代码的远端仓库。而这些平台都提供了丰富的 open-api 协助用户进行blame,
我们很自然的会联想到,当通过 sourcemap 解出原始堆栈路径后,如果可以结合调用 open-api,获得这段代码所在文件的blame历史, 我们就有机会直接在线上确定某一行的可能的 author / commitor 究竟是谁。从而将这个异常直接分配给他。
思路出来了,那么实际怎么落地呢?
我们需要几个信息
线上报错的项目对应的源代码仓库名,如
toutiao-fe/slardar线上报错的代码发生的版本,以及与此版本关联的 git commit 信息,为什么需要这些信息呢?
默认用来 blame 的文件都是最新版本,但线上跑的不一定是最新版本的代码。不同版本的代码可能发生行的变动,从而影响实际代码的行号。如果我们无法将线上版本和用来 blame 的文件划分在统一范围内,则很有可能自动定位失败。
因此,我们必须找到一种方法,确定当前 blame 的文件和线上报错的文件处于同一版本。并且可以直接通过版本定位到关联的源代码 commit 起止位置。这样的操作在 Sentry 的官方工具 Sentry-Cli 中亦有提供。字节内部同样使用了这种方案。
通过 相关的 二进制工具,在代码发布前的脚本中提供当前将要发布的项目的版本和关联的代码仓库信息。同时在数据采集侧也携带相同的版本,线上异常发生后,我们就可以通过线上报错的版本找到原始文件对应的版本,从而精确定位到需要哪个时期的文件了。
异常报警
当异常已经成功反解和聚合后,当用户访问监控平台,已经可以观察并处理相关的错误,不过到目前为止,异常的发生还无法触及开发者,问题的解决依然依靠“走查”行为。这样的方案对严重的线上问题依然是不够用,因此我们还需要主动通知用户的手段,这就是异常报警。
在字节内部,报警可以分为宏观报警,即针对错误指标的数量/比率的报警,以及微观报警,即针对新增异常的报警。
宏观报警
宏观报警是数量/比率报警, 它只是统计某一类指标是否超出了限定的阈值,而不关心它具体是什么。因此默认情况下它并不会告诉你报警的原因。只有通过归因维度或者下文会提到的 微观(新增异常)报警 才能够知晓引发报警的具体原因
关于宏观报警,我们有几个关键概念
第一是样本量,用户数阈值: 在配置比率指标时。如果上报量过低,可能会造成比率的严重波动,例如错误率 > 20%, 的报警下,如果 JS 错误数从 0 涨到 1, 那就是比率上涨到无限大从而造成没有意义的误报。如果不希望被少量波动干扰,我们设置了针对错误上报量和用户数的最低阈值,例如只有当错误影响用户数 > 5 时,才针对错误率变化报警。
第二是归因维度: 对于数量,比率报警,仅仅获得一个异常指标值是没什么意义的,因为我们无法快速的定位问题是由什么因素引发的,因此我们提供了归因维度配置。例如,通过对 JS 异常报警配置错误信息归因,我们可以在报警时获得引发当前报警的 top3 关键错误和增长最快的 top3 错误信息。
第三是时间窗口,报警运行频率: 如上文所说,报警是数量,比率报警,而数量,比率一定有一个统计范围,这个就是通过 时间窗口 来确定的。而报警并不是时时刻刻盯着我们的业务数据的,可以理解为利用一个定时器来定期检查 时间窗口 内的数据是否超出了我们定义的阈值。而这个定时器的间隔时间,就是 报警运行频率。通过这种方式,我们可以做到类实时的监测异常数据的变化,但又没有带来过大的资源开销。
微观报警(新增异常)
相较于在意宏观数量变化的报警,新增异常在意每一个具体问题,只要此问题是此前没有出现过的,就会主动通知用户。
同时,宏观报警是针对数据的定时查找,存在运行频率和时间窗口的限制,实时性有限。微观报警是主动推送的,具有更高的实时性。
微观报警适用于发版,灰度等对新问题极其关注,并且不方便在此时专门配置相关数量报警的阶段。
如何判断“新增”?
我们在 异常自动分配章节讲到了,我们的业务代码都是可以关联一个版本概念的。实际上版本不仅和源代码有关,也可以关联到某一类错误上。
在这里我们同样也可以基于版本视角判断“新增错误”。
对于新增异常的判断,针对两种不同场景做了区分
对于指定版本、最新版本的新增异常报警,我们会分析该报警的 fingerprint 是否为该版本代码中首次出现。
而对于全体版本,我们则将"首次”的范围增加了时间限制,因为对于某个错误,如果在长期没有出现后又突然出现,他本身还是具有通知的意义的,如果不进行时间限制,这个错误就不会通知到用户,可能会出现信息遗漏的情况。
如何做好性能监控?
如果说异常处理是前端监控体系60分的分界线,那么性能度量则是监控体系能否达到90分的关键。一个响应迟钝,点哪儿卡哪儿的页面,不会比点开到处都是报错的页面更加吸引人。页面的卡顿可能会直接带来用户访问量的下降,进而影响背后承载的服务收入。因此,监控页面性能并提升页面性能也是非常重要的。针对性能监控,我们主要关注指标选取,品质度量 、瓶颈定位三个关键问题。
指标选取
指标选取依然不是我们今天文章分享的重点。网上关于 RUM 指标,Navigation 指标的介绍和采集方式已经足够清晰。通常分为两个思路:
RUM (真实用户指标) -> 可以通过 Web Vitals (github.com/GoogleChrom…*
页面加载指标 -> NavigationTiming (ResourceTiming + DOM Processing + Load) 可以通过 MDN 相关介绍学习。这里都不多赘述。
瓶颈定位
收集到指标只是问题的第一步,接下来的关键问题便是,我们应该如何找出影响性能问题的根因,并且针对性的进行修复呢?
慢会话 + 性能时序分析
如果你对“数据洞察/可观测性”这个概念有所了解,那么你应该对 Kibana 或 Datadog 这类产品有所耳闻。在 kibana 或 Datadog 中都能够针对每一条上传的日志进行详细的追溯。和详细的上下文进行关联,让用户的体验可被观测,通过多种筛选找到需要用户的数据。
在字节前端的内部建设中,我们参考了这类数据洞察平台的消费思路。设计了数据探索能力。通过数据探索,我们可以针对用户上报的任意维度,对一类日志进行过滤,而不只是获得被聚合过的列表信息数据。这样的消费方式有什么好处呢?
我们可以直接定位到一条具体日志,找到一个现实的 data point 来分析问题
这种视图的状态是易于保存的,我们可以将找到的数据日志通过链接发送给其他人,其他用户可以直接还原现场。
对于性能瓶颈,在数据探索中,可以轻松通过针对某一类 PV 上报所关联的性能指标进行数值筛选。也可以按照某个固定时段进行筛选,从而直接获得响应的慢会话。这样的优势在于我们不用预先设定一个“慢会话阈值”,需要哪个范围的数据完全由我们自己说了算。例如,通过对 FCP > 3000ms 进行筛选,我们就能够获得一系列 FCP > 3s 的 PV 日志现场。
在每次 PV 上报后,我们会为数据采集的 SDK 设置一个全局状态,比如 view_id, 只要没有发生新的页面切换,当前的 view_id 就会保持不变。
而后续的一系列请求,异常,静态资源上报就可以通过 view_id 进行后端的时序串联。形成一张资源加载瀑布图。在瀑布图中我们可以观察到各类性能指标和静态资源加载,网络请求的关系。从而检测出是否是因为某些不必要的或者过大的资源,请求导致的页面性能瓶颈。这样的瀑布图都是一个个真实的用户上报形成的,相较于统计值产生的甘特图,更能帮助我们解决实际问题。
结合Longtask + 用户行为分析
通过指标过滤慢会话,并且结合性能时序瀑布图分析,我们能够判断出当前页面中是否存在由于网络或过大资源因素导致的页面加载迟缓问题
但页面的卡顿不一定全是由网络因素造成的。一个最简单的例子。当我在页面的 head 中插入一段非常耗时的同步脚本(例如 while N 次),则引发页面卡顿的原因就来自于代码执行而非资源加载。
针对这种情况,浏览器同样提供了 Longtask API 供我们收集这类占据主线程时间过长的任务。
同样的,我们将这类信息一并收集,并通过上文提到的 view_id 串联到一次页面访问中。用户就可以观察到某个性能指标是否受到了繁重的主线程加载的影响。若有,则可利用类似 lighthouse 的合成监控方案集中检查对应页面中是否存在相关逻辑了。
受限于浏览器所收集到的信息,目前的 longtask 我们仅仅只能获得它的执行时间相关信息。而无法像开发者面板中的 performance 工具一样准确获取这段逻辑是由那段代码引发的。如果我们能够在一定程度上收集到longtask触发的上下文,则可定位到具体的慢操作来源。
此外,页面的卡顿不一定仅仅发生在页面加载阶段,有时页面的卡顿会来自于页面的一次交互,如点击,滚动等等。这类行为造成的卡顿,仅仅依靠 RUM / navigation 指标是无法定位的。如果我们能够通过某种方式(在PPT中已经说明),对操作行为计时。并将操作计时范围内触发的请求,静态资源和longtask上报以同样的瀑布图方式收敛到一起。则可以进一步定位页面的“慢操作”,从而提升页面交互体验。
如下图所示,我们可以检查到,点击 slardar_web 这个按钮 / 标签带来了一系列的请求和 longtask,如果这次交互带来了一定的交互卡顿。我们便可以集中修复触发这个点击事件所涉及的逻辑来提升页面性能表现。
品质度量
当我们采集到一个性能指标后,针对这样一个数字,我们能做什么?
我们需要结论:好还是不好?
实际上我们通常是以单页面为维度来判定指标的,以整站视角来评判性能的优劣的置信度会受到诸多因素影响,比如一个站点中包含轻量的登陆页和功能丰富的中后台,两者的性能要求和用户的容忍度是不一致的,在实际状况下两者的绝对性能表现也是不一致的。而简单平均只会让我们观察不到重点,页面存在的问题数据也可能被其他的页面拉平。
其次,指标只是冷冰冰的数据,而数据想要发挥作用,一定需要参照系。比如,我仅仅提供 FMP = 4000ms,并不能说明这个页面的性能就一定需要重点关注,对于逻辑较重的PC页面,如数据平台,在线游戏等场景,它可能是符合业务要求的。而一个 FMP = 2000ms的页面则性能也不一定好,对于已经做了 SSR 等优化的回流页。这可能远远达不到我们的预期。
一个放之四海而皆准的指标定义是不现实的。不同的业务场景有不同的性能基准要求。我们可以把他们转化为具体的指标基准线。
通过对于现阶段线上指标的分布,我们可以可以自由定义当前站点场景下针对某个指标,怎样的数据是好的,怎样的数据是差的。
基准线应用后,我们便可以在具体的性能数据产出后,直观的观察到,在什么阶段,某些指标的表现是不佳的,并且可以集中针对这段时间的性能数据日志进行排查。
一个页面总是有多个性能指标的,现在我们已经知道了单个性能指标的优劣情况,如何整体的判断整个页面,乃至整个站点的性能状况,落实到消费侧则是,我们如何给一个页面的性能指标评分?
如果有关注过 lighthouse 的同学应该对这张图不陌生。
lighthouse 通过 google 采集到的大量线上页面的性能数据,针对每一个性能指标,通过对数正态分布将其指标值转化成 百分制分数。再通过给予每个指标一定的权重(随着 lighthouse 版本更迭), 计算出该页面性能模块的一个“整体分数”。在即将上线的“品质度量”能力中,我们针对 RUM 指标,异常指标,以及资源加载指标均采取了类似的方案。
我们通常可以给页面的整体性能分数再制定一个基准分数,当上文所述的性能得分超过分数线,才认为该页面的性能水平是“达标”的。而整站整体的达标水平,则可以利用整站达标的子页面数/全站页面数来计算,也就是达标率,通过达标率,我们可以非常直观的迅速找到需要优化的性能页面,让不熟悉相关技术的运营,产品同学也可以定期巡检相关页面的品质状况。
如何做好请求 / 静态资源监控?
除了 JS 异常和页面的性能表现以外,页面能否正常的响应用户的操作,信息能否正确的展示,也和 api 请求,静态资源息息相关。表现为 SLA,接口响应速度等指标。现在主流的监控方案通常是采用手动 hook相关 api 和利用 resource timing 来采集相关信息的。
手动打点通常用于请求耗时兜底以及记录请求状态和请求响应相关信息。
对于 XHR 请求: 通过 hook XHR 的 open 和 send 方法, 获取请求的参数,在 onreadystatechange 事件触发时打点记录请求耗时。
// 记录 method
hookObjectProperty(XMLHttpRequest.prototype, 'open', hookXHROpen);
// hook onreadystateChange,调用前后打点计算
hookObjectProperty(XMLHttpRequest.prototype, 'send', hookXHRSend);
复制代码
对于fetch请求,则通过 hook Fetch 实现
hookObjectProperty(global, 'fetch', hookFetch)
复制代码
第二种则是 resourceTiming 采集方案
静态资源上报:
pageLoad 前:通过 performance.getEntriesByType 获取 resource 信息
pageLoad后:通过 PerformanceObserver 监控 entryType 为 resource 的资源
const callback = (val, i, arr, ob) => // ... 略
const observer = new PerformanceObserver((list, ob) => {
if (list.getEntries) {
list.getEntries().forEach((val, i, arr) => callback(val, i, arr, ob))
} else {
onFail && onFail()
}
// ...
});
observer.observe({ type: 'resource', buffered: false })
复制代码
手动打点的优势在于无关兼容性,采集方便,而 Resource timing 则更精准,并且其记录中可以避开额外的事件队列处理耗时
如何理解和使用 resource timing 数据?
我们现在知道 ResourceTiming 是更能够反映实际资源加载状况的相关指标,而在工作中,我们经常遇到前端请求上报时间极长而后端对应接口日志却表现正常的情况。这通常就可能是由使用单纯的打点方案计算了太多非服务端因素导致的。影响一个请求在前端表现的因素除了服务端耗时以外,还包括网络,前端代码执行排队等因素。我们如何从 ResourceTiming 中分离出这些因素,从而更好的对齐后端口径呢?
第一种是 Chrome 方案(阿里的 ARMS 也采用的是这种方案):
它通过将线上采集的 ResoruceTiming 和 chrome timing 面板的指标进行类比还原出一个近似的各部分耗时值。他的简单计算方式如图所示。
不过 chrome 实际计算 timing 的方式不明,这种近似的方式不一定能够和 chrome 的面板数据对的上,可能会被用户质疑数据不一致。
第二种则是标准方案: 规范划分阶段,这种划分是符合 W3C 规范的格式,其优势便在于其通用性好,且数据一定是符合要求的而不是 chrome 方案那种“近似计算”。不过它的缺陷是阶段划分还是有点太粗了,比如用户无法判断出浏览器排队耗时,也无法完全区分网络下载和下载完成后的资源加载阶段。只是简单的划分成了 Request / Response 阶段,给用户理解和分析带来了一定成本
在字节内部,我们是以标准方案为主,chrome方案为辅的,用户可以针对自己喜好的那种统计方式来对齐指标。通常来说,和服务端对齐耗时阶段可以利用标准方案的request阶段减去severtiming中的cdn,网关部分耗时来确定。
接下来我们再谈谈采集 SDK 的设计。
SDK 如何降低侵入,减少用户性能损耗?体积控制和灵活使用可以兼得吗?
常需要尽早执行,其资源加载通常也会造成一定的性能影响。更大的资源加载可能会导致更慢的 Load,LCP,TTI 时间,影响用户体验。
为了进一步优化页面加载性能,我们采用了 JS Snippets 来实现异步加载 + 预收集。
异步加载主要逻辑
首先,如果通过 JS 代码创建 script 脚本并追加到页面中,新增的 script 脚本默认会携带 async 属性,这意味着这这部分代码将通过async方式延迟加载。下载阶段不会阻塞用户的页面加载逻辑。从而一定程度的提升用户的首屏性能表现。
预收集
试想一下我们通过 npm 或者 cdn 的方式直接引入监控代码,script必须置于业务逻辑最前端,这是因为若异常先于监控代码加载发生,当监控代码就位时,是没有办法捕获到历史上曾经发生过的异常的。但将script置于前端将不可避免的对用户页面造成一定阻塞,且用户的页面可能会因此受到我们监控 sdk 服务可用性的影响。
为了解决这个问题,我们可以同步的加载一段精简的代码,在其中启动 addEventListener 来采集先于监控主要逻辑发生的错误。并存储到一个全局队列中,这样,当监控代码就位,我们只需要读取全局队列中的缓存数据并上报,就不会出现漏报的情况了。
更进一步:事件驱动与插件化
方案1. 2在大部分情况下都已经比较够用了,但对于字节的某些特殊场景却还不够。由于字节存在大量的移动端页面,且这些页面对性能极为敏感。因而对于第三方库的首包体积要求非常苛刻,同时,也不希望第三方代码的执行占据主线程太长时间。
此外,公司内也有部分业务场景特殊,如 node 场景,小程序场景,electron,如果针对每一种场景,都完全重新开发一套新的监控 SDK,有很大的人力重复开发的损耗。
如果我们能够将 SDK 的框架逻辑做成平台无关的,而各个数据监控,收集方案都只是以插件形式存在,那么这个 SDK 完全是可插拔的,类似 Sentry 所使用的 integration 方案。用户甚至可以完全不使用任何官方插件,而是通过自己实现相关采集方案,来做到项目的定制化。
关于框架设计可以参见下图
我们把整个监控 SDK 看作一条流水线(Client),接受的是用户配置(config)(通过 ConfigManager),收集和产出的是具体事件(Event, 通过 Plugins)。流水线是平台无关的,它不关心处理的事件是什么,也不关心事件是从哪来的。它其实是将这一系列的组件交互都抽象为 client 上的事件,从而使得数据采集器能够介入数据流转的每个阶段
Client 通过 builder 包装事件后,转运给 Sender 负责批处理,Sender 最终调用 Transporter 上报。Transporter 是平台强相关的,例如 Web 使用 xhr 或 fetch,node 则使用 request 等。 同时,我们利用生命周期的概念设置了一系列的钩子,可以让用户可以在适当阶段处理流水线上的事件。例如利用 beforeSend 钩子去修改即将被发送的上报内容等。
当整体的框架结构设计完后,我们就可以把视角放到插件上了。由于我们将框架设置为平台无关的,它本身只是个数据流,有点像是一个精简版的 Rx.js。而应用在各个平台上,我们只需要根据各个平台的特性设计其对应的采集或数据处理插件。
插件方案某种意义上实现了 IOC,用户不需要关心事件怎么处理,传入的参数是哪里来的,只需要利用传入的参数去获取配置,启动自己的插件等。如下这段JS采集器代码,开发插件时,我们只需要关心插件自身相关的逻辑,并且利用传入 client 约定的相关属性和方法工作就可以了。不需要关心 client 是怎么来的,也不用关心 client 什么时候去执行它。
当我们写完了插件之后,它要怎么才能被应用在数据采集和处理中呢?为了达成降低首包大小的目标,我们将插件分为同步和异步两种加载方式。
可以预收集的监控代码都不需要出现在首包中,以异步插件方式接入
无法做到预收集的监控代码以同步形式和首包打在一起,在源码中将client传入,尽早启动,保证功能稳定。
3. 异步插件采用约定式加载,用户在使用层面是完全无感的。我们通过主包加载时向在全局初始化注册表和注册方法,在读取用户配置后,拉取远端插件加载并利用全局注册方法获取插件实例,最后传入我们的 client 实现代码执行。
经过插件化和一系列 SDK 的体积改造后,我们的sdk 首包体积降低到了从63kb 降低到了 34 kb。
总结
本文主要从 JS 异常监控,性能监控和请求,静态资源监控几个细节点讲述了 Slardar 在前端监控方向所面临关键问题的探索和实践,希望能够对大家在前端监控领域或者将来的工作中产生帮助。其实前端监控还有许多方面可以深挖,例如如何利用拨测,线下实验室数据采集来进一步追溯问题,如何捕获白屏等类崩溃异常,如何结合研发流程来实现用户无感知的接入等等。
作者:字节架构前端
来源:https://juejin.cn/post/7195496297150709821
一个炫酷的头像悬停效果
本文翻译自 A Fancy Hover Effect For Your Avatar,略有删改,有兴趣可以看看原文。
你知道当一个人的头像从一个圆圈或洞里伸出来时的那种效果吗?本文将使用一种很简洁的方式实现该悬停效果,可以用在你的头像交互上面。
看到了吗?我们将制作一个缩放动画,其中头像部分似乎从它所在的圆圈中钻出来了。是不是很酷呢?接下来让我们一起一步一步地构建这个动画交互效果。
HTML:只需要一个元素
是的,只需要一个img图片标签即可,本次练习的挑战性部分是使用尽可能少的代码。如果你已经关注我一段时间了,你应该习惯了。我努力寻找能够用最小、最易维护的代码实现的CSS解决方案。
<img src="" alt="">首先我们需要一个带有透明背景的正方形图像文件,以下是本次案例使用的图像。
在开始CSS之前,让我们先分析一下效果。悬停时图像会变大,所以我们肯定会在这里使用transform:scale。头像后面有一个圆圈,径向渐变应该可以达到这个效果。最后我们需要一种在圆圈底部创建边框的方法,该边框将不受整体放大的影响且是在视觉顶层。
放大效果
放大的效果,增加transform:scale,这个比较简单。
img:hover {
transform: scale(1.35);
}上面说过背景是一个径向渐变。我们创建一个径向渐变,但是两个颜色之间不要有过渡效果,这样使得它看起来像我们画了一个有实线边框的圆。
img {
--b: 5px; /* border width */
background:
radial-gradient(
circle closest-side,
#ECD078 calc(99% - var(--b)),
#C02942 calc(100% - var(--b)) 99%,
#0000
);
}注意CSS变量,--b,在这里它表示“边框”的宽度,实际上只是用于定义径向渐变红色部分的位置。
下一步是在悬停时调整渐变大小,随着图像的放大,圆需要保持大小不变。由于我们正在应用scale变换,因此实际上需要减小圆圈的大小,否则它会随着化身的大小而增大。
让我们首先定义一个CSS变量--f,它定义了“比例因子”,并使用它来设置圆的大小。我使用1作为默认值,因为这是图像和圆的初始比例,我们从圆转换。
现在我们必须将背景定位在圆的中心,并确保它占据整个高度。我喜欢把所有东西都直接简写在 background 属性,代码如下:
background: radial-gradient() 50% / calc(100% / var(--f)) 100% no-repeat;背景放置在中心( 50%),宽度等于calc(100%/var(--f)),高度等于100%。
当 --f 等于 1 时是我们最初的比例。同时,渐变占据容器的整个宽度。当我们增加 --f,元素的大小会增长但是渐变的大小将减小。
越来越接近了!我们在顶部添加了溢出效果,但我们仍然需要隐藏图像的底部,这样它看起来就像是跳出了圆圈,而不是整体浮在圆圈前面。这是整个过程中比较复杂的部分,也是我们接下来要做的。
下边框
第一次尝试使用border-bottom属性,但无法找到一种方法来匹配边框的大小与圆的大小。如图所示,相信你能看出来无法实现我们想要的效果:
实际的解决方案是使用outline属性。不是border。outline可以让我们创造出很酷的悬停效果。结合 outline-offset 偏移量,我们就可以实现所需要的效果。
其核心是在图像上设置一个outline轮廓并调整其偏移量以创建下边框。偏移量将取决于比例因子,与渐变大小相同。outline-offset 偏移量看起来相对比较复杂,这里对计算方式进行了精简,有兴趣的可以看看原文。
img {
--s: 280px; /* image size */
--b: 5px; /* border thickness */
--c: #C02942; /* border color */
--f: 1; /* initial scale */
border-radius: 0 0 999px 999px;
outline: var(--b) solid var(--c);
outline-offset: calc((1 / var(--f) - 1) * var(--s) / 2 - var(--b));
}因为我们需要一个圆形的底部边框,所以在底部添加了一个边框圆角,使轮廓与渐变的弯曲程度相匹配。
现在我们需要找到如何从轮廓中删除顶部,也就是上图中挡住头像的那根线。换句话说,我们只需要图像的底部轮廓。首先,在顶部添加空白和填充,以帮助避免顶部头像的重叠,这通过增加padding即可实现:
padding-top: calc(var(--s)/5)这里还有一个注意点,需要添加 content-box 值添加到 background:
background:
radial-gradient(
circle closest-side,
#ECD078 calc(99% - var(--b)),
var(--c) calc(100% - var(--b)) 99%,
#0000
) 50%/calc(100%/var(--f)) 100% no-repeat content-box;这样做是因为我们添加了padding填充,并且我们只希望将背景设置为内容框,因此我们必须显式地定义出来。
CSS mask
到了最后一部分!我们要做的就是藏起一些碎片。为此,我们将依赖于 CSS mask 属性,当然还有渐变。
下面的图说明了我们需要隐藏的内容或需要显示的内容,以便更加准确。左图是我们目前拥有的,右图是我们想要的。绿色部分说明了我们必须应用于原始图像以获得最终结果的遮罩内容。
我们可以识别mask的两个部分:
底部的圆形部分,与我们用来创建化身后面的圆的径向渐变具有相同的维度和曲率
顶部的矩形,覆盖轮廓内部的区域。请注意轮廓是如何位于顶部的绿色区域之外的-这是最重要的部分,因为它允许剪切轮廓,以便只有底部部分可见
最终的完整css如下,对有重复的代码进行抽离,如--g,--o:
img {
--s: 280px; /* image size */
--b: 5px; /* border thickness */
--c: #C02942; /* border color */
--f: 1; /* initial scale */
--_g: 50% / calc(100% / var(--f)) 100% no-repeat content-box;
--_o: calc((1 / var(--f) - 1) * var(--s) / 2 - var(--b));
width: var(--s);
aspect-ratio: 1;
padding-top: calc(var(--s)/5);
cursor: pointer;
border-radius: 0 0 999px 999px;
outline: var(--b) solid var(--c);
outline-offset: var(--_o);
background:
radial-gradient(
circle closest-side,
#ECD078 calc(99% - var(--b)),
var(--c) calc(100% - var(--b)) 99%,
#0000) var(--_g);
mask:
linear-gradient(#000 0 0) no-repeat
50% calc(-1 * var(--_o)) / calc(100% / var(--f) - 2 * var(--b)) 50%,
radial-gradient(
circle closest-side,
#000 99%,
#0000) var(--_g);
transform: scale(var(--f));
transition: .5s;
}
img:hover {
--f: 1.35; /* hover scale */
}下面的一个演示,直观的说明mask的使用区域。中间的框说明了由两个渐变组成的遮罩层。把它想象成左边图像的可见部分,你就会得到右边的最终结果:
最后
搞定!我们不仅完成了一个流畅的悬停动画,而且只用了一个<img>元素和不到20行的CSS技巧!如果我们允许自己使用更多的HTML,我们能简化CSS吗?当然可以。但我们是来学习CSS新技巧的!这是一个很好的练习,可以探索CSS渐变、遮罩、outline属性的行为、转换以及其他许多内容。
在线效果
实例里面是流行的CSS开发人员的照片。有兴趣的同学可以展示一下自己的头像效果。
看完本文如果觉得有用,记得点个赞支持,收藏起来说不定哪天就用上啦~
作者:南城FE
来源:juejin.cn/post/7196747356796518460
React和Vue谁会淘汰谁?
在我的技术群里大家经常会聊一些宏观的技术问题,就比如:
Vue和React,最终谁会被淘汰?
这样的讨论,到最后往往会陷入技术的细枝末节的比较,比如:
对比两者响应式的实现原理
对比两者的运行时性能
很多程序员朋友,会觉得:
技术问题,就应该从技术的角度找到答案
但实际上,一些大家纠结的技术问题,往往跟技术本身无关。
谁才是框架的最终赢家?
讨论React和Vue谁会淘汰谁?这个问题,就像10年前,一个康师傅信徒和一个统一信徒争论:
哪家泡面企业最终会被淘汰呢?
他们把争论的重点放在口味的对比、面饼分量的对比等等,最终谁也无法说服谁。
实际我们最后知道了,外卖App的崛起,对泡面企业形成了降维打击。
回到框架这个问题上,在前端框架流行之前,前端最流行的开发库是jQuery,他是命令式编程的编程范式。
取代jQuery的并不是另一个更优秀的jQuery,而是声明式编程的前端框架。
同样的,取代前端框架的,不会是另一个更优秀的前端框架,而是另一种更适合web开发的编程范式。
那在前端框架这个领域内部,React和Vue最终谁会淘汰谁呢?
我的答案是:
谁也不会淘汰谁。
任何框架最核心的竞争力,不是性能,也不是生态是否繁荣,而是开发者用的是否顺手,也就是开发模式是否合理。
React发明了JSX这种开发模式,并持续教育了开发者3年,才让社区接受这种开发模式
这种发明开发模式,再教育开发者的行为,也只有meta这种大公司才办得到。
而Vue则直接使用了模版语法这种现成的开发模式。这种模式已经被广大后端工程师验证过是最好上手的web开发模式。
所以像后端工程师或者编程新人会很容易上手Vue。
经过多年迭代,他们各自的开发模式已经变成了事实上的前端框架DSL标准。
这会为他们带来两个好处:
开发模式是个主观偏好,不存在优劣
所以他们谁也无法淘汰谁,只能说React的开发模式受众范围更广而已。
后来者会永远居于他们的阴影之下
新的框架如果无法在编程范式上突破,那么为了抢占Vue或React的市场份额,只能遵循他们的开发模式,因为这样开发者才能无痛迁移。
比如最近两年比较优秀的新框架,svelte是Vue的开发模式,Solid.js 是React的开发模式
在同样的开发模式下,占市场主导地位的框架可以迅速跟进那些竞争者的优秀特性。
比如Vue就准备开发一个类似Svelte的版本。
一句话总结就是:
你是无法在我的BGM中击败我的
总结
总体来说,在新的web编程范式流行之前,React、Vue还会长期霸占开发者喜欢的前端框架前列。
在此过程中,会出现各种新框架,他们各有各的特点,但是,都很难撼动前者的地位。
作者:魔术师卡颂
来源:juejin.cn/post/7190550643386351653
记一次浏览器播放实时监控rtsp视频流的解决历程(利用Ffmpeg + node.js + websocket + flv.js实现)
背景
笔者目前在做一个智慧楼宇的产品(使用react开发的),在交付项目的时候,遇到了需要在浏览器端播放rtsp视频流的场景,而浏览器端是不能直接播放rtsp视频流的,原本打算让客户方提供flv格式的视频流 鉴于项目现场的环境以及种种原因,客户方只能提供rtsp视频流,所以就只能自己解决了。
于是乎,去网上随便一搜就搜到了Ffmpeg + node.js + websocket + flv.js的解决方案,但是真正自己实现下来,遇到了几个棘手的问题,例如:莫名其妙的报错,部分监控视频转换失败,不能转码h265格式的视频等等(本文会介绍自己遇到的问题以及解决方案)。
涉及到的技术点
ffmpeg:ffmpeg是一个转码工具,将rtsp视频里转换成flv格式的视频流
node.js
websocket
flv.js
node.js端
用到的关键库
@ffmpeg-installer/ffmpeg
自动为当前node服务所在的平台安装适合的ffmpeg,无需自己再去手动下载、安装配置了。通过该库安装的ffmpeg,其路径在node_modules/@ffmpeg-installer/darwin-x64/ffmpeg (我用的是mac,自动安装的是darwin-x64,不同平台不一样)
fluent-ffmpeg
该库是对ffmpeg 命令的封装,简化了命令的使用流程,原生ffmpeg的命令是比较复杂难懂的。
完整可复制直接运行的node代码
const ffmpegPath = require('@ffmpeg-installer/ffmpeg'); // 自动为当前node服务所在的系统安装ffmpeg
const ffmpeg = require('fluent-ffmpeg');
const express = require('express');
const webSocketStream = require('websocket-stream/stream');
const expressWebSocket = require('express-ws');
ffmpeg.setFfmpegPath(ffmpegPath.path);
/**
* 创建一个后端服务
*/
function createServer() {
const app = express();
app.use(express.static(__dirname));
expressWebSocket(app, null, {
perMessageDeflate: true
});
app.ws('/rtsp/', rtspToFlvHandle);
app.get('/', (req, response) => {
response.send('当你看到这个页面的时候说明rtsp流媒体服务正常启动中......');
});
app.listen(8100, () => {
console.log('转换rtsp流媒体服务启动了,服务端口号为8100');
});
}
/**
* rtsp 转换 flv 的处理函数
* @param ws
* @param req
*/
function rtspToFlvHandle(ws, req) {
const stream = webSocketStream(ws, {
binary: true,
browserBufferTimeout: 1000000
}, {
browserBufferTimeout: 1000000
});
// const url = req.query.url;
const url = new Buffer(req.query.url, 'base64').toString(); // 前端对rtsp url进行了base64编码,此处进行解码
console.log('rtsp url:', url);
try {
ffmpeg(url)
.addInputOption(
'-rtsp_transport', 'tcp',
'-buffer_size', '102400'
)
.on('start', (commandLine) => {
// commandLine 是完整的ffmpeg命令
console.log(commandLine, '转码 开始');
})
.on('codecData', function (data) {
console.log(data, '转码中......');
})
.on('progress', function (progress) {
// console.log(progress,'转码进度')
})
.on('error', function (err, a, b) {
console.log(url, '转码 错误: ', err.message);
console.log('输入错误', a);
console.log('输出错误', b);
})
.on('end', function () {
console.log(url, '转码 结束!');
})
.addOutputOption(
'-threads', '4', // 一些降低延迟的配置参数
'-tune', 'zerolatency',
'-preset', 'ultrafast'
)
.outputFormat('flv') // 转换为flv格式
.videoCodec('libx264') // ffmpeg无法直接将h265转换为flv的,故需要先将h265转换为h264,然后再转换为flv
.withSize('50%') // 转换之后的视频分辨率原来的50%, 如果转换出来的视频仍然延迟高,可按照文档上面的描述,自行降低分辨率
.noAudio() // 去除声音
.pipe(stream);
} catch (error) {
console.log('抛出异常', error);
}
}
createServer();react 前端
用到的关键库
flv.js
用于前端播放flv格式视频库
完整可直接复制使用的react组件
import React, { useEffect, useRef } from 'react';
import './FlvVideoPlayer.scss';
import flvjs from 'flv.js';
import { Button } from '@alifd/next';
interface FlvVideoPlayerProps {
url?: string; // rtsp 的url
isNeedControl?: boolean;
fullScreenRef?: any; // 方便组件外部调用全屏方法的ref
}
const FlvVideoPlayer = React.forwardRef<any, FlvVideoPlayerProps>(({ isNeedControl, url, fullScreenRef }, ref) => {
const videoDomRef = useRef<any>();
const playerRef = useRef<any>(); // 储存player的实例
React.useImperativeHandle(ref, () => ({
requestFullscreen,
}));
useEffect(() => {
if (videoDomRef.current) {
if (fullScreenRef) {
fullScreenRef.current[url] = requestFullscreen;
}
// const url = `${videoUrl}/rtsp/video1/?url=${url}`;
playerRef.current = flvjs.createPlayer({
type: 'flv',
isLive: true,
url,
});
playerRef.current.attachMediaElement(videoDomRef.current);
try {
playerRef.current.load();
playerRef.current.play();
} catch (error) {
console.log(error);
}
}
return () => {
destroy();
};
}, [url]);
/**
* 全屏方法
*/
const requestFullscreen = () => {
if (videoDomRef.current) {
(videoDomRef.current.requestFullscreen && videoDomRef.current.requestFullscreen()) ||
(videoDomRef.current.webkitRequestFullScreen && videoDomRef.current.webkitRequestFullScreen()) ||
(videoDomRef.current.mozRequestFullScreen && videoDomRef.current.mozRequestFullScreen()) ||
(videoDomRef.current.msRequestFullscreen && videoDomRef.current.msRequestFullscreen());
}
};
/**
* 销毁flv的实例
*/
const destroy = () => {
if (playerRef.current) {
playerRef.current.pause();
playerRef.current.unload();
playerRef.current.detachMediaElement();
playerRef.current.destroy();
playerRef.current = null;
}
};
return (
<>
<Button type="primary" onClick={requestFullscreen}>
全屏按钮
</Button>
<video controls={isNeedControl} ref={videoDomRef} className="FlvVideoPlayer" loop />
</>
);
});
export default FlvVideoPlayer;组件用到的url
本地开发时
本地开发时,node服务是启动在自己电脑上,所以node服务的地址就是 ws://127.0.0.1:8100,为了防止在传rtsp地址的过程中出现参数丢失的情况,故采用window.btoa()方法对rtsp进行base64编码一下,又由于node端代码中监听的是/rtsp/,故完整的组件的url是
ws://127.0.0.1:8100/rtsp?url=${window.btoa('rtsp地址')}部署线上
直接将服务器ip替换掉127.0.0.1即可
提供一个测试的rtsp地址
rtsp://wowzaec2demo.streamlock.net/vod/mp4:BigBuckBunny_115k.mp4遇到的问题
1. rtsp地址中存在?拼接的参数,传到后端丢失
错误详情
An error occured: ffmpeg exited with code 1: rtsp://... Server returned 404 Not Found原因
完整的url是ws://127.0.0.1:8100/rtsp?url=${window.btoa('rtsp地址')},如果rtsp地址中再含有?拼接参数的话,那么就会出现两个?,传到node端之后,会被express去除掉rtsp地址中的?
解决方式
在前端对rtsp使用window.btoa方法进行base64编码,在node端使用new Buffer进行解码即可
2. 连接超时
报错截图
原因
部署到客户内网发现的,是两台服务网络不通造成的
解决方式
找运维解决
3. CPU飚到100%,卡顿
错误详情
监控视频采用分页显示,每页8个监控视频,切换到下一页的时候,上一页转换监控视频的ffmpeg进程,仍然存在,没有被kill掉。所以ffmpeg的进程不停地增加,导致CPU占用100%
原因
封装flvjs 的react组件中,在组件卸载的时候,没有把flvjs的实例销毁掉,导致进程不会被自动kill掉
解决方式
组件卸载的时候,将flvjs的实例销毁掉
4. 不能转码h265视频流
错误详情
Video codec hevc not compatible with flv 。Could not write header for output file #0 (incorrect codec parameters ?): Function not implemented原因
有些监控摄像头的视频格式是 hevc h265, flv不支持,需要先将h265转化至h264格式
解决方式
node端代码中。ffmpeg添加 videoCodec('libx264') 配置即可
优化 ffmpeg 低延迟配置参数
'-threads', '4'
'-tune', 'zerolatency'
'-preset', 'ultrafast'
更新
当我把ffmpeg配置参数中的输出分辨率配置移除后,目前的延时在1~2s左右
作者:huisiyu
来源:juejin.cn/post/7124188097617051685
vue-video-player 播放m3u8视频流
该问题网上答案较少,翻阅github得到想要的答案,在此记录一下
首先,为了减少包体积,在组件中局部引入vue-video-player(在main.j s中引入会增加包体积)
播放m3u8需要注意两点:
需要引入videojs并绑定到window上
安装依赖videojs-contrib-hls(
npm i videojs-contrib-hls)并引入sources要指定type为
application/x-mpegURL
代码如下:
<template>
<section>
<video-player :options="options"></video-player>
</section>
</template>
<script>
import { videoPlayer } from 'vue-video-player'
import videojs from 'video.js'
//注意点1:需要引入videojs并绑定到window上
window.videojs = videojs
//注意点2:引入依赖
require('videojs-contrib-hls/dist/videojs-contrib-hls.js')
require('video.js/dist/video-js.css')
require('vue-video-player/src/custom-theme.css')
export default {
name: 'test-video-player',
components: {
videoPlayer
},
data() {
return {
options: {
autoplay: false,
height: '720',
playbackRates: [0.7, 1.0, 1.25, 1.5, 2.0],
sources: [
{
withCredentials: false,
type: 'application/x-mpegURL', //注意点3:这里的type需要指定为 'application/x-mpegURL'
src:
'https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/47252fc26243b079-e992c6c3928c6be2dcb2426c2743ceca-hls_720p_2.m3u8?pkey=ABDuFNTOUnsfYOEZC286rORZhpfh5uaNeFhzffUnwTFoS8-3NBSQEvWcqdKGtIRMgiywklkZvPdU-2avzKUT-I738UJX6urdwxy_ZHp617win7G6ga30Lfvfp2AyAVoUMjhVkiCnKeObrMEPVn4x749wFaigz-mPaWPGAf5uVvR0kbkVIw6x-HZTlgyY6tj-eE_rVnxHvB1XJ01_JhXMVWh70zlJ89EL2wsdPfhrgeLCWQ&safety_id=AAKir561j0mZgTqDfijAYjR6'
}
],
hls: true
}
}
},
computed: {},
methods: {},
created() {}
}
</script>
<style lang="" scoped></style>参考
作者:我只是一个API调用工程师
来源:juejin.cn/post/7080748744592850951
项目没发版却出现了bug,原来是chrome春节前下毒
前言
农历: 腊月二十五
阳历: 2023-01-16
过年和年兽
已经临近过年,公司的迭代版本也已经封版,大家都在一片祥和又掺杂焦虑的气氛中等待春节的到来。 当然,等待的人群里面也有我,吼吼哈嘿。
突然企业微信的一声响,我习惯性的抬头瞅了一眼屏幕,嗯? 来至线上bug群?。
不过因为最近咱前端项目也没有发版,心里多少有点底气的。
于是怀着好奇的心情点开了群消息, 准备看看是什么情况。
结果进群看到是某前端页面元素拖拽功能的位置失效了。晴天霹雳啊,我们有一个类似给运营做自定义活动页面,说是无法拖拽了。然后需要做活动比较紧急,需要尽快修复。
这活脱脱就是跟着春节来的年兽啊。我还没放烟花打年兽,年兽就先朝我冲过来了,那说什么也得较量较量了。
项目背景
我们这个功能是属于一个基础功能,通过npm私有仓库维护版本
这个基础功能呢,很多项目中都在使用。
如果基础功能发了新版本,业务部门不进行升级安装,那么这个业务线的项目也是不会出问题的。所以只要线上出了问题,那么要满足两个条件
1、基础功能进行了发布了npm新版本,且这个版本有问题,
2、业务部门进行了升级,使用了这个新版本
排查问题
一般来说:造成问题的可能性有
有人发过新迭代版本
是不是存在莫名的缓存
有人在以前的版本里面下毒了,然后现在发作了(可能性不大)
经过粗略排查
| 猜测 | 结果 |
|---|---|
| 1、发版导致? | 近期两周,该服务部分未更新,排除 |
| 2、缓存导致 | 已经清理,没用,排除 |
| 3、下毒了 | 看了相关代码,没什么问题,排除 |
问题初见端倪
接着发生了两件事情
1、然后我本地跑了一下项目的时候,在操作的时候,存在报错。
2、一个测试兄弟反馈说他那儿可以正常操作
这他么莫不是浏览器兼容问题了吧。
我去他那看了一下,都是chrome浏览器(这个项目我们只支持到chrome就可以)
这时的我感觉可能问题有点大了,莫不是chrome又调整了吧
点开测试兄弟的版本看了下,是108,而且处于重启就会升级的状态。 我赶紧回到我的工位,打开电脑发现是109。
在看了下那个报错, event.path为undefined, 这里先介绍下path是个什么玩意,他是一个数组,里面记录着从当前节点冒泡到顶层window的所有node节点。我们借助这个功能做了一写事情。。。
这直接被chrome釜底抽薪了。(path属于非标准api, 这些非标准api慎用,说不定什么时候就嘎了)
解决问题
1、问题一
既然是event.path没了,那么我们怎么办呢,首先得找到代替path的方法, 上面我们也说了,path里面记录的是从当前节点冒泡到顶层window的所有node节点(我们是拖拽事件)
那么我们可以自己遍历一下当前节点+他的父节点+父节点的父节点+...+window
let path = [];
let target = event.target;
while(target.parentNode !== null){
path.push(target);
target = target.parentNode;
}
path.push(document, window);
return path;在项目里面试了一下,emm,很稳定。
1、问题二
但是我们又遇到了第二个问题,使用到event.path的项目还比较多,这就日了狗了 如果没有更好的方法,那么我只能挨个项目改,然后测试,然后逐个项目发版
这种原始的方法我们肯定是不会采用的,换个思路,既然event下的path被删除了,那么我们在event对象下追加个一个path属性就可以了
当然我们要记得判断下path属性是否存在,因为有部分用户的chrome是老版本的,我们只对升级后的版本做一些兼容就可以了
if (!Event.prototype.hasOwnProperty("path")){
Object.defineProperties(Event.prototype, {
path: {
get: function(){
var target = this.target;
console.log('target', target)
var path = [];
while(target.parentNode !== null){
path.push(target);
target = target.parentNode;
}
path.push(document, window);
return path;
}
},
composedPath: {
value: function(){
return this.path;
},
writable: true
}
});
}这样,我们只需要在每个项目的根html,通过script引入这个js文件就可以了
反思
如题,这个事情怪chrome吗?其实不能怪的。 1、chrome在之前就已经给出了更新通知,只是我们没有去关注这个事情 2、本身event.path不是标准属性,我们却使用了(其实其他浏览器是没有这个属性的,只是chrome提供了path属性, 虽然现在他删除了) 3、总之还是自己不够警惕,同时使用了不标准的属性,以此为戒,共勉
作者:大鱼敢瞪猫
来源:juejin.cn/post/7193520080808837180
感受Vue3的魔法力量
近半年有幸参与了一个创新项目,由于没有任何历史包袱,所以选择了Vue3技术栈,总体来说感受如下:
• setup语法糖
• 可以通过Composition API(组合式API)封装可复用逻辑,将UI和逻辑分离,提高复用性,view层代码展示更清晰
• 和Vue3更搭配的状态管理库Pinia,少去了很多配置,使用起来更便捷
• 构建工具Vite,基于ESM和Rollup,省去本地开发时的编译步骤,但是build打包时还是会编译(考虑到兼容性)
• 必备VSCode插件Volar,支持Vue3内置API的TS类型推断,但是不兼容Vue2,如果需要在Vue2和Vue3项目中切换,比较麻烦
当然也遇到一些问题,最典型的就是响应式相关的问题
响应式篇
本篇主要借助watch函数,理解ref、reactive等响应式数据/状态,有兴趣的同学可以查看Vue3源代码部分加深理解,
watch数据源可以是ref (包括计算属性)、响应式对象、getter 函数、或多个数据源组成的数组
import { ref, reactive, watch, nextTick } from 'vue'
//定义4种响应式数据/状态
//1、ref值为基本类型
const simplePerson = ref('张三')
//2、ref值为引用类型,等价于:person.value = reactive({ name: '张三' })
const person = ref({
name: '张三'
})
//3、ref值包含嵌套的引用类型,等价于:complexPerson.value = reactive({ name: '张三', info: { age: 18 } })
const complexPerson = ref({ name: '张三', info: { age: 18 } })
//4、reactive
const reactivePerson = reactive({ name: '张三', info: { age: 18 } })
//改变属性,观察以下不同情景下的监听结果
nextTick(() => {
simplePerson.value = '李四'
person.value.name = '李四'
complexPerson.value.info.age = 20
reactivePerson.info.age = 22
})
//情景一:数据源为RefImpl
watch(simplePerson, (newVal) => {
console.log(newVal) //输出:李四
})
//情景二:数据源为'张三'
watch(simplePerson.value, (newVal) => {
console.log(newVal) //非法数据源,监听不到且控制台告警
})
//情景三:数据源为RefImpl,但是.value才是响应式对象,所以要加deep
watch(person, (newVal) => {
console.log(newVal) //输出:{name: '李四'}
},{
deep: true //必须设置,否则监听不到内部变化
})
//情景四:数据源为响应式对象
watch(person.value, (newVal) => {
console.log(newVal) //输出:{name: '李四'}
})
//情景五:数据源为'张三'
watch(person.value.name, (newVal) => {
console.log(newVal) //非法数据源,监听不到且控制台告警
})
//情景六:数据源为getter函数,返回基本类型
watch(
() => person.value.name,
(newVal) => {
console.log(newVal) //输出:李四
}
)
//情景七:数据源为响应式对象(在Vue3中状态都是默认深层响应式的)
watch(complexPerson.value.info, (newVal, oldVal) => {
console.log(newVal) //输出:Proxy {age: 20}
console.log(newVal === oldVal) //输出:true
})
//情景八:数据源为getter函数,返回响应式对象
watch(
() => complexPerson.value.info,
(newVal) => {
console.log(newVal) //除非设置deep: true或info属性被整体替换,否则监听不到
}
)
//情景九:数据源为响应式对象
watch(reactivePerson, (newVal) => {
console.log(newVal) //不设置deep: true也可以监听到
})总结:
在Vue3中状态都是默认深层响应式的(情景七),嵌套的引用类型在取值(get)时一定是返回Proxy响应式对象
watch数据源为响应式对象时(情景四、七、九),会隐式的创建一个深层侦听器,不需要再显示设置deep: true
情景三和情景八两种情况下,必须显示设置deep: true,强制转换为深层侦听器
情景五和情景七对比下,虽然写法完全相同,但是如果属性值为基本类型时是监听不到的,尤其是ts类型声明为any时,ide也不会提示告警,导致排查问题比较费力
所以精确的ts类型声明很重要,否则经常会出现莫名其妙的watch不生效的问题
ref值为基本类型时通过get\set拦截实现响应式;ref值为引用类型时通过将.value属性转换为reactive响应式对象实现;
deep会影响性能,而reactive会隐式的设置deep: true,所以只有明确状态数据结构比较简单且数据量不大时使用reactive,其他一律使用ref
Props篇
设置默认值
type Props = {
placeholder?: string
modelValue: string
multiple?: boolean
}
const props = withDefaults(defineProps<Props>(), {
placeholder: '请选择',
multiple: false,
})双向绑定(多个值)
• 自定义组件
//FieldSelector.vue
type Props = {
businessTableUuid: string
businessTableFieldUuid?: string
}
const props = defineProps<Props>()
const emits = defineEmits([
'update:businessTableUuid',
'update:businessTableFieldUuid',
])
const businessTableUuid = ref('')
const businessTableFieldUuid = ref('')
// props.businessTableUuid、props.businessTableFieldUuid转为本地状态,此处省略
//表切换
const tableChange = (businessTableUuid: string) => {
emits('update:businessTableUuid', businessTableUuid)
emits('update:businessTableFieldUuid', '')
businessTableFieldUuid.value = ''
}
//字段切换
const fieldChange = (businessTableFieldUuid: string) => {
emits('update:businessTableFieldUuid', businessTableFieldUuid)
}• 使用组件
<template>
<FieldSelector
v-model:business-table-uuid="stringFilter.businessTableUuid"
v-model:business-table-field-uuid="stringFilter.businessTableFieldUuid"
/>
</template>
<script setup lang="ts">
import { reactive } from 'vue'
const stringFilter = reactive({
businessTableUuid: '',
businessTableFieldUuid: ''
})
</script>单向数据流
大部分情况下应该遵循【单向数据流】原则,禁止子组件直接修改props,否则复杂应用下的数据流将变得混乱,极易出现bug且难排查
直接修改props会有告警,但是如果props是引用类型,修改props内部值将不会有告警提示,因此应该有团队约定(第5条除外)
如果props为引用类型,赋值到子组件状态时,需要解除引用(第5条除外)
复杂的逻辑,可以将状态以及修改状态的方法,封装成自定义hooks或者提升到store内部,避免props的层层传递与修改
一些父子组件本就紧密耦合的场景下,可以允许修改props内部的值,可以减少很多复杂度和工作量(需要团队约定固定场景)
逻辑/UI解耦篇
利用Vue3的Composition/组合式API,将某种逻辑涉及到的状态,以及修改状态的方法封装成一个自定义hook,将组件中的逻辑解耦,这样即使UI有不同的形态或者调整,只要逻辑不变,就可以复用逻辑。下面是本项目中涉及的一个真实案例-逻辑树组件,UI有2种形态且可以相互转化。
• hooks部分的代码:useDynamicTree.ts
import { ref } from 'vue'
import { nanoid } from 'nanoid'
export type TreeNode = {
id?: string
pid: string
nodeUuid?: string
partentUuid?: string
nodeType: string
nodeValue?: any
logicValue?: any
children: TreeNode[]
level?: number
}
export const useDynamicTree = (root?: TreeNode) => {
const tree = ref<TreeNode[]>(root ? [root] : [])
const level = ref(0)
//添加节点
const add = (node: TreeNode, pid: string = 'root'): boolean => {
//添加根节点
if (pid === '') {
tree.value = [node]
return true
}
level.value = 0
const pNode = find(tree.value, pid)
if (!pNode) return false
//嵌套关系不能超过3层
if (pNode.level && pNode.level > 2) return false
if (!node.id) {
node.id = nanoid()
}
if (pNode.nodeType === 'operator') {
pNode.children.push(node)
} else {
//如果父节点不是关系节点,则构建新的关系节点
const current = JSON.parse(JSON.stringify(pNode))
current.pid = pid
current.id = nanoid()
Object.assign(pNode, {
nodeType: 'operator',
nodeValue: 'and',
// 重置回显信息
logicValue: undefined,
nodeUuid: undefined,
parentUuid: undefined,
children: [current, node],
})
}
return true
}
//删除节点
const remove = (id: string) => {
const node = find(tree.value, id)
if (!node) return
//根节点处理
if (node.pid === '') {
tree.value = []
return
}
const pNode = find(tree.value, node.pid)
if (!pNode) return
const index = pNode.children.findIndex((item) => item.id === id)
if (index === -1) return
pNode.children.splice(index, 1)
if (pNode.children.length === 1) {
//如果只剩下一个节点,则替换父节点(关系节点)
const [one] = pNode.children
Object.assign(
pNode,
{
...one,
},
{
pid: pNode.pid,
},
)
if (pNode.pid === '') {
pNode.id = 'root'
}
}
}
//切换逻辑关系:且/或
const toggleOperator = (id: string) => {
const node = find(tree.value, id)
if (!node) return
if (node.nodeType !== 'operator') return
node.nodeValue = node.nodeValue === 'and' ? 'or' : 'and'
}
//查找节点
const find = (node: TreeNode[], id: string): TreeNode | undefined => {
// console.log(node, id)
for (let i = 0; i < node.length; i++) {
if (node[i].id === id) {
Object.assign(node[i], {
level: level.value,
})
return node[i]
}
if (node[i].children?.length > 0) {
level.value += 1
const result = find(node[i].children, id)
if (result) {
return result
}
level.value -= 1
}
}
return undefined
}
//提供遍历节点方法,支持回调
const dfs = (node: TreeNode[], callback: (node: TreeNode) => void) => {
for (let i = 0; i < node.length; i++) {
callback(node[i])
if (node[i].children?.length > 0) {
dfs(node[i].children, callback)
}
}
}
return {
tree,
add,
remove,
toggleOperator,
dfs,
}
}• 在不同组件中使用(UI1/UI2组件为递归组件,内部实现不再展开)
//组件1
<template>
<UI1
:logic="logic"
:on-add="handleAdd"
:on-remove="handleRemove"
:toggle-operator="toggleOperator"
</UI1>
</template>
<script setup lang="ts">
import { useDynamicTree } from '@/hooks/useDynamicTree'
const { add, remove, toggleOperator, tree: logic, dfs } = useDynamicTree()
const handleAdd = () => {
//添加条件
}
const handleRemove = () => {
//删除条件
}
const toggleOperator = () => {
//切换逻辑关系:且、或
}
</script>
//组件2
<template>
<UI2 :logic="logic"
:on-add="handleAdd"
:on-remove="handleRemove"
:toggle-operator="toggleOperator"
</UI2>
</template>
<script setup lang="ts">
import { useDynamicTree } from '@/hooks/useDynamicTree'
const { add, remove, toggleOperator, tree: logic, dfs } = useDynamicTree()
const handleAdd = () => { //添加条件 }
const handleRemove = () => { //删除条件 }
const toggleOperator = () => { //切换逻辑关系:且、或 }
</script>
Pinia状态管理篇
将复杂逻辑的状态以及修改状态的方法提升到store内部管理,可以避免props的层层传递,减少props复杂度,状态管理更清晰
• 定义一个store(非声明式):User.ts
import { computed, reactive } from 'vue'
import { defineStore } from 'pinia'
type UserInfo = {
userName: string
realName: string
headImg: string
organizationFullName: string
}
export const useUserStore = defineStore('user', () => {
const userInfo = reactive<UserInfo>({
userName: '',
realName: '',
headImg: '',
organizationFullName: ''
})
const fullName = computed(() => {
return `${userInfo.userName}[${userInfo.realName}]`
})
const setUserInfo = (info: UserInfo) => {
Object.assgin(userInfo, {...info})
}
return {
userInfo,
fullName,
setUserInfo
}
})• 在组件中使用
<template>
<div class="welcome" font-JDLangZheng>
<el-space>
<el-avatar :size="60" :src="userInfo.headImg ? userInfo.headImg : avatar"> </el-avatar>
<div>
<p>你好,{{ userInfo.realName }},欢迎回来</p>
<p style="font-size: 14px">{{ userInfo.organizationFullName }}</p>
</div>
</el-space>
</div>
</template>
<script setup lang="ts">
import { useUserStore } from '@/stores/user'
import avatar from '@/assets/avatar.png'
const { userInfo } = useUserStore()
</script>作者:京东云开发者
来源:juejin.cn/post/7193538517480243258
阿里iconfont审核很慢?自己搭建一个,直接从figma上传
iconfont我们前端都认为挺好用的,但设计师经常说:“这玩意真不好,上传个图标审核半天,审核通过了还不会自动上传😡”
不应该呀,我一看,原来是阿里iconfont管理平台的问题;那简单,我不用它不就行了😎
原来的工作流程
“宁花机器10分钟,不花人工1分钟”,在旧流程中,我们可以看到,人工操作的环节足足有6个(听说阿里icon审核也是人工的)。很显然,这是相当低效的流程。看来,除了阿里第三方的审核问题,我们内部原有的图标交付流程也出现了问题😀
怎么解决
先看看有没有可以直接用的方案
转转的方案 和我们想到一块去了,不使用阿里的iconfont管理平台,而是魔改了YIcon;可惜转转暂时没有开源他们方案的想法,但也给予我们一些思路,我们能不能也学着魔改。
除了YIcon,还有一个开源的iconfont管理平台Nicon。他们的优点都是具有完善的管理&鉴权机制,但缺点是代码过于老旧,长时间没人维护。这也意味着要花费较大的人力要魔改,这对于我们是不能接受的。
很幸运的是,figma社区有较为成熟的Figma图标交付方案figma-icon-automation,看到了Shoppee与得物等公司都参考figma-icon-automation来实现了自己一套的图标交付流程,看起来figma插件是目前最优的选择。可是,我们还是希望保留iconfont的使用方式,不然的话改用SVG组件,这个改变成本也是无法接受的。
因此,我们决定修改figma-icon-automation的流程,实现适合我们的iconfont交付方案🚀
新的iconfont交付方案
魔改1: github 改为 gitlab
出于保护设计师的资产
我们存储icons到内网部署的gitlab上,保护了设计资产的同时,也自然不会有第三方来审核图标。
出于iconont权限管理
gitlab可对不同项目分配不同权限,我们不再需要一个iconfont平台来管理权限;同时解决了,可能会没有及时回收离职员工的阿里iconfont平台权限所带来的风险。
出于iconfont项目管理
这个与普通的gitlab项目没什么区别,你可以创建多个iconfont项目对应不同前端项目,每个项目都是独立的。
出于iconfont版本管理
得益于git的强大,我们可以还拥有了版本管理,这是阿里iconfont平台没有给我们带来的;我们可以清楚地追溯到是谁修改/删除了图标,或者及时地回滚iconfont版本。
魔改2: 更加好用的figma插件
基于gitlab官方Figma插件,我们对其进行改造(主要因为可以节省查阅Figma API文档的时间),实现了一款更加适合我们的设计师使用的Figma插件————UpCon,主要功能如下:
支持配置自己公司gitlab域名
使用自定义gitlab域名作为请求的BaseUrl来调用gitlab开放的api,默认为v4版api,支持最新版gitlab。
支持配置project-id,支持存储多个id
通过project-id来管理不同项目,并且通过本地storage存储多个project-id,方便用户快速切换项目
支持配置gitlab access token
通过access token来登录gitlab,同时识别该用户是否具有该project对应的开发权限(无权限用户无法跳转到上传页)
支持自定义选择多个Icons,并实时预览
通过在figma中选择要上传的icon(支持frame与component类型),填写本次提交的信息,即可触发上传。
支持去除颜色上传
我们保留了阿里iconfont平台的去除颜色上传功能,其原理是通过正则修改SVG代码中的color属性为
currentcolor
选择去除颜色后,当前选择的所有icon都会去除颜色,并可实时预览去除颜色后的效果。
校验icon命名
我们会对已上传的icons名称与当前选择icons名称进行对比,重名的icon,会给予橙色边框与tooltip提示。如果你执意要上传,则会覆盖原先的图标。
与之同时,我们对icon命名进行了强制规范,名称中如含有/\:*?"<>|.字符,会给予红色边框提示,并不允许上传
魔改3: 触发Gitlab CI脚本
在figma插件触发上传后,会生成一次commit记录并同时触发Gitlab CI操作。可以通过clone 我们开源的iconfont-build-tools来实现自定义Gitlab CI操作,iconfont-build-tools的主要功能如下:
处理转换SVG代码为iconfont
我们会读取当前项目下的
icons/路径下的所有svg文件(此路径暂不支持修改),将svg代码转换为iconfont.js代码,详细实现代码可查看iconfont-build-tools。
转换svg名称为拼音
我们保留了阿里iconfont平台中,把中文名称自动转为拼音的功能,这一功能大大降低了设计师们的icon命名带来的困扰。
自动生成tag信息并发布新版本
我们还自动把本次git commit的Hash值作为版本tag,并自动发布新版本,这是实现版本管理关键的一步。
自动上传iconfont到CDN
生成的iconfont.js文件可以通过自定义配置来自动上传到自己的CDN,返回的url会自动携带在release信息中,具体的数据格式可查看iconfont-build-tools。
方案开源&计划
目前,我们的方案已经开源了,欢迎大家积极尝试并提出宝贵的建议👍
未来,我们计划给gitlab ci流程中接入微信机器人通知,大家可以持续关注或者star我们的项目😊
Figma UpCon iconfont-build-tools
总结
相比于旧的图标交付流程,新的流程直接把步骤缩减到两步,这大大地提高了我们的效率。而且我们保留许多旧流程的习惯,如依旧使用iconfont方案,upcon中去除颜色功能,build-tools的中文转拼音功能,这些功能的迁移让我们几乎不用花费额外的成本去使用新的流程。
同时我们也希望有更多的用户给予我们正向的反馈,完善此流程,让图标交付变得更简单。
参考链接
figma plugin juejin.cn/post/706816…
得物 IconBot juejin.cn/post/704398…
Shopee IconBot juejin.cn/post/690372…
svgicons2svgfont juejin.cn/post/713711…
iconfont预览 segmentfault.com/a/119000002…
gitlab figma gitlab.com/gitlab-org/…
作者:BlackGoldRoad
来源:juejin.cn/post/7184324458063069245
舍弃传统文档阅读吧!~新一代代码文档神器code-hike
最终效果如图。
起因
相信不少小伙伴阅读过一篇文章:build-your-own-react
这是一篇通俗易懂的从头开始讲述如何创建一个react过程的文章,其中最吸引我的就是这个文章的代码排版方式。将所有代码放置在左侧,随着文档的滚动,左侧代码不断发生变化,不断提示我哪些代码发生了变动。这样的文档方式,是我之前没体验过的船新版本。去作者的gayhub看到正好有开源工具,于是自己搭建了demo,马上惊为天人。所以在这里我要做一个违背祖宗的决定,将其分享给大家。
code-hike简介
codehike.org/ code-hike是一个 mdx的插件,专注于文档写作的组件库。专注于代码的展示,具有以下几个功能:
代码块的展示
支持134种不同的编程语言,基本涵盖了目前市面上的编程语言。
批注和对代码的交互体验
可以看到在code-hike中可以对部分代码进行高亮显示,这部分主要通过force和mark来操作。同时它还允许你在代码块中进行链接,可以点击跳转到页面的其他位置。也可以自定义自己的样式显示。
一系列的code组件
一系列帮你优化code展示的组件,在本文中,将主要使用CH-scrollycoding作为展示。
安装
我们这里以Docusaurus为例作为展示,当然你也可以使用React,vite或其他任意模版或者docs框架作为开始。
我们首先安装docusaurus
npx create-docusaurus@latest my-website classic然后安装hike的相关依赖
cd my-website
npm i @mdx-js/react@2 docusaurus-theme-mdx-v2 @code-hike/mdx配置
首先配置docusaurus.config.js,插入mdx-v2主题
// docusaurus.config.js
const config = {
...
themes: ["mdx-v2"],
...
}然后插入code-hike插件
// docusaurus.config.js
const theme = require("shiki/themes/nord.json")
const {
remarkCodeHike,
} = require("@code-hike/mdx")
const config = {
presets: [
[
"classic",
{
docs: {
beforeDefaultRemarkPlugins: [
[remarkCodeHike, { theme }],
],
sidebarPath: require.resolve("./sidebars.js"),
},
},
],
],
...
}再设置下style
// docusaurus.config.js
...
const config={
theme: {
customCss: [
require.resolve("@code-hike/mdx/styles.css"),
],
},
}
}至此所有配置完成,我的完整配置如下:
// @ts-check
// Note: type annotations allow type checking and IDEs autocompletion
const lightCodeTheme = require("prism-react-renderer/themes/github");
const darkCodeTheme = require("prism-react-renderer/themes/dracula");
const theme = require("shiki/themes/nord.json");
const { remarkCodeHike } = require("@code-hike/mdx");
/** @type {import('@docusaurus/types').Config} */
const config = {
title: "css and js",
tagline: "read everyday",
url: "https://your-docusaurus-test-site.com",
baseUrl: "/",
onBrokenLinks: "throw",
onBrokenMarkdownLinks: "warn",
favicon: "img/favicon.ico",
// GitHub pages deployment config.
// If you aren't using GitHub pages, you don't need these.
organizationName: "facebook", // Usually your GitHub org/user name.
projectName: "docusaurus", // Usually your repo name.
// Even if you don't use internalization, you can use this field to set useful
// metadata like html lang. For example, if your site is Chinese, you may want
// to replace "en" with "zh-Hans".
i18n: {
defaultLocale: "en",
locales: ["en"],
},
presets: [
[
"classic",
/** @type {import('@docusaurus/preset-classic').Options} */
({
docs: {
beforeDefaultRemarkPlugins: [[remarkCodeHike, { theme }]],
sidebarPath: require.resolve("./sidebars.js"),
// Please change this to your repo.
// Remove this to remove the "edit this page" links.
editUrl:
"https://github.com/facebook/docusaurus/tree/main/packages/create-docusaurus/templates/shared/",
},
blog: {
showReadingTime: true,
// Please change this to your repo.
// Remove this to remove the "edit this page" links.
editUrl:
"https://github.com/facebook/docusaurus/tree/main/packages/create-docusaurus/templates/shared/",
},
theme: {
customCss: [
require.resolve("@code-hike/mdx/styles.css"),
require.resolve("./src/css/custom.css"),
],
},
}),
],
],
themes: ["mdx-v2"],
themeConfig:
/** @type {import('@docusaurus/preset-classic').ThemeConfig} */
({
navbar: {
title: "My Site",
logo: {
alt: "My Site Logo",
src: "img/logo.svg",
},
items: [
{
type: "doc",
docId: "intro",
position: "left",
label: "阅读",
},
{ to: "/blog", label: "Blog", position: "left" },
{
href: "https://github.com/facebook/docusaurus",
label: "GitHub",
position: "right",
},
],
},
footer: {
style: "dark",
links: [
{
title: "Docs",
items: [
{
label: "Tutorial",
to: "/docs/intro",
},
],
},
{
title: "Community",
items: [
{
label: "Stack Overflow",
href: "https://stackoverflow.com/questions/tagged/docusaurus",
},
{
label: "Discord",
href: "https://discordapp.com/invite/docusaurus",
},
{
label: "Twitter",
href: "https://twitter.com/docusaurus",
},
],
},
{
title: "More",
items: [
{
label: "Blog",
to: "/blog",
},
{
label: "GitHub",
href: "https://github.com/facebook/docusaurus",
},
],
},
],
copyright: `Copyright © ${new Date().getFullYear()} My Project, Inc. Built with Docusaurus.`,
},
prism: {
theme: lightCodeTheme,
darkTheme: darkCodeTheme,
},
}),
};
module.exports = config;特别注意
因为code hike使用的是mdx2,在此版本有一个破坏性更新,如果遇到以下问题
请找到<!--truncate-->,将其删除
开始自己的demo
将docs下的一个md文件,改为如下的数据
为啥不在掘金贴代码块呢,因为跟掘金的markdown冲突了。。。你得到了如下的效果
这就是一个简单的如我开头展示的效果。
代码标记
这里主要有两个点需要注意 : 第一个是
---三条横线,作为每段展示文档的分割,所以你可以看到我们的每一段都有这个标记
第二个是 focus
这个标记表明了你有哪些代码需要高亮,在demo中使用的是行高亮。一共有两种用法:
你可以写在文件开头,例如```js statement.js focus=6:8,这表示将从文件的开头进行计算,第6-8行 你也可以写在文件内,例如
// focus(1,1)
const result=[]这表示,从标记位置开始的后面的1-1行,也就是第一行
除了这种按照行进行标记,你也可以标记列,例如
// focus[7:12]
result = 40000;它表示从下一行的第7-12个字符。 效果为
作者:im天元
来源:juejin.cn/post/7175000675523887159
vue阻止重复请求(下)
(c)代码
步骤1-通过axios请求拦截器取消重复请求
通过axios请求拦截器,在每次请求前把请求信息和请求的取消方法放到一个map对象当中,并且判断map对象当中是否已经存在该请求信息的请求,如果存在取消上传请求
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/vue/2.6.14/vue.min.js" type="application/javascript"></script>
<script src="https://lf9-cdn-tos.bytecdntp.com/cdn/expire-1-M/axios/0.26.0/axios.min.js" type="application/javascript"></script>
<script src="https://lf3-cdn-tos.bytecdntp.com/cdn/expire-1-M/qs/6.10.3/qs.js" type="application/javascript"></script>
</head>
<body>
<div id="app">
<button @click="onClick1" ref="btn1">请求1</button>
<button @click="onClick2" ref="btn2">请求2</button>
</div>
</body>
<script>
//存储请求信息和取消方法的的map对象
const pendingRequest = new Map();
//根据请求的信息(请求方式,url,请求get/post数据),产生map的key
function getRequestKey(config){
const { method, url, params, data } = config;
return [method, url, Qs.stringify(params), Qs.stringify(data)].join("&");
}
//请求拦截器
axios.interceptors.request.use(
function (config) {
//根据请求的信息(请求方式,url,请求get/post数据),产生map的key
let requestKey = getRequestKey(config)
//判断请求是否重复
if(pendingRequest.has(requestKey)){
//取消上次请求
let cancel = pendingRequest.get(requestKey)
cancel()
//删除请求信息
pendingRequest.delete(requestKey)
}
//把请求信息,添加请求到map当中
// 生成取消方法
config.cancelToken = config.cancelToken || new axios.CancelToken(cancel => {
// 把取消方法添加到map
if (!pendingRequest.has(requestKey)) {
pendingRequest.set(requestKey, cancel)
}
})
return config;
},
(error) => {
return Promise.reject(error);
}
);
let sendPost = function(data){
return axios({
url: 'http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test',
method: 'post',
data
})
}
new Vue({
el: '#app',
mounted() {
this.$refs.btn1.click()
this.$refs.btn2.click()
},
methods: {
// 使用lodash对请求方法做防抖
//这里有问题,只是对每个按钮的点击事件单独做了防抖,但是两个按钮之间做不到防抖的效果
onClick1: async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求1的结果', res.data)
},
onClick2: async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求2的结果', res.data)
},
},
})
</script>
</html>步骤2-通过axios响应拦截器处理请求成功
通过axios的响应拦截器,在请求成功后在map对象当中,删除该请求信息的数据
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/vue/2.6.14/vue.min.js" type="application/javascript"></script>
<script src="https://lf9-cdn-tos.bytecdntp.com/cdn/expire-1-M/axios/0.26.0/axios.min.js" type="application/javascript"></script>
<script src="https://lf3-cdn-tos.bytecdntp.com/cdn/expire-1-M/qs/6.10.3/qs.js" type="application/javascript"></script>
</head>
<body>
<div id="app">
<button @click="onClick1" ref="btn1">请求1</button>
<button @click="onClick2" ref="btn2">请求2</button>
</div>
</body>
<script>
//存储请求信息和取消方法的的map对象
const pendingRequest = new Map();
//根据请求的信息(请求方式,url,请求get/post数据),产生map的key
function getRequestKey(config){
const { method, url, params, data } = config;
return [method, url, Qs.stringify(params), Qs.stringify(data)].join("&");
}
//请求拦截器
axios.interceptors.request.use(
function (config) {
//根据请求的信息(请求方式,url,请求get/post数据),产生map的key
let requestKey = getRequestKey(config)
//判断请求是否重复
if(pendingRequest.has(requestKey)){
//取消上次请求
let cancel = pendingRequest.get(requestKey)
cancel()
//删除请求信息
pendingRequest.delete(requestKey)
}
//把请求信息,添加请求到map当中
// 生成取消方法
config.cancelToken = config.cancelToken || new axios.CancelToken(cancel => {
// 把取消方法添加到map
if (!pendingRequest.has(requestKey)) {
pendingRequest.set(requestKey, cancel)
}
})
return config;
},
(error) => {
return Promise.reject(error);
}
);
//响应拦截器
axios.interceptors.response.use(
(response) => {
//请求成功
//删除请求的信息
let requestKey = getRequestKey(response.config)
if(pendingRequest.has(requestKey)){
pendingRequest.delete(requestKey)
}
return response;
},
(error) => {
return Promise.reject(error);
}
);
let sendPost = function(data){
return axios({
url: 'http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test',
method: 'post',
data
})
}
new Vue({
el: '#app',
mounted() {
this.$refs.btn1.click()
this.$refs.btn2.click()
},
methods: {
// 使用lodash对请求方法做防抖
//这里有问题,只是对每个按钮的点击事件单独做了防抖,但是两个按钮之间做不到防抖的效果
onClick1: async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求1的结果', res.data)
},
onClick2: async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求2的结果', res.data)
},
},
})
</script>
</html>步骤3-通过axios响应拦截器处理请求失败
通过axios的响应拦截器,在请求失败后在map对象当中,删除该请求信息的数据
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/vue/2.6.14/vue.min.js" type="application/javascript"></script>
<script src="https://lf9-cdn-tos.bytecdntp.com/cdn/expire-1-M/axios/0.26.0/axios.min.js" type="application/javascript"></script>
<script src="https://lf3-cdn-tos.bytecdntp.com/cdn/expire-1-M/qs/6.10.3/qs.js" type="application/javascript"></script>
</head>
<body>
<div id="app">
<button @click="onClick1" ref="btn1">请求1</button>
<button @click="onClick2" ref="btn2">请求2</button>
</div>
</body>
<script>
//存储请求信息和取消方法的的map对象
const pendingRequest = new Map();
//根据请求的信息(请求方式,url,请求get/post数据),产生map的key
function getRequestKey(config){
const { method, url, params, data } = config;
return [method, url, Qs.stringify(params), Qs.stringify(data)].join("&");
}
//请求拦截器
axios.interceptors.request.use(
function (config) {
//根据请求的信息(请求方式,url,请求get/post数据),产生map的key
let requestKey = getRequestKey(config)
//判断请求是否重复
if(pendingRequest.has(requestKey)){
//取消上次请求
let cancel = pendingRequest.get(requestKey)
cancel()
//删除请求信息
pendingRequest.delete(requestKey)
}
//把请求信息,添加请求到map当中
// 生成取消方法
config.cancelToken = config.cancelToken || new axios.CancelToken(cancel => {
// 把取消方法添加到map
if (!pendingRequest.has(requestKey)) {
pendingRequest.set(requestKey, cancel)
}
})
return config;
},
(error) => {
return Promise.reject(error);
}
);
//删除请求信息
function delPendingRequest(config){
let requestKey = getRequestKey(config)
if(pendingRequest.has(requestKey)){
pendingRequest.delete(requestKey)
}
}
//响应拦截器
axios.interceptors.response.use(
(response) => {
//请求成功
//删除请求的信息
delPendingRequest(response.config)
return response;
},
(error) => {
//请求失败
//不是取消请求的错误
if (!axios.isCancel(error)){
//服务器报400,500报错,删除请求信息
delPendingRequest(error.config || {})
}
return Promise.reject(error);
}
);
let sendPost = function(data){
return axios({
url: 'http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test',
method: 'post',
data
})
}
new Vue({
el: '#app',
mounted() {
this.$refs.btn1.click()
this.$refs.btn2.click()
},
methods: {
// 使用lodash对请求方法做防抖
//这里有问题,只是对每个按钮的点击事件单独做了防抖,但是两个按钮之间做不到防抖的效果
onClick1: async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求1的结果', res.data)
},
onClick2: async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求2的结果', res.data)
},
},
})
</script>
</html>作者:黄金林
来源:juejin.cn/post/7189231050806001719
vue阻止重复333请求(上)
背景
项目当中前端代码会遇到同一个请求向服务器发了多次的情况,我们要避免服务器资源浪费,同一个请求一定时间只允许发一次请求
思路
(1)如果业务简单,例如同一个按钮防止多次点击,我们可以用定时器做防抖处理
(2)如果业务复杂,例如多个组件通过代码,同一个请求发多次,这个时候防抖已经不好处理了,最好是对重复的ajax请求统一做取消操作
实现
方式1-通过定时器做防抖处理
(a)概述
效果:当用户连续点击多次同一个按钮,最后一次点击之后,过小段时间后才发起一次请求
原理:每次调用方法后都产生一个定时器,定时器结束以后再发请求,如果重复调用方法,就取消当前的定时器,创建新的定时器,等结束后再发请求,工作当中可以用第三方封装的工具函数例如lodash的debounce方法来简化防抖的代码
(b)代码
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/lodash.js/4.17.21/lodash.min.js" type="application/javascript">script>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/vue/2.6.14/vue.min.js" type="application/javascript">script>
<script src="https://lf9-cdn-tos.bytecdntp.com/cdn/expire-1-M/axios/0.26.0/axios.min.js" type="application/javascript">script>
head>
<body>
<div id="app">
<button @click="onClick">请求button>
div>
body>
<script>
// 定义请求接口
function sendPost(data){
return axios({
url: 'https://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test',
method: 'post',
data
})
}
new Vue({
el: '#app',
methods: {
// 调用lodash的防抖方法debounce,实现连续点击按钮多次,0.3秒后调用1次接口
onClick: _.debounce(async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求的结果', res.data)
}, 300),
},
})
script>
html>(c)预览
(d)存在的问题
无法解决多个按钮件的重复请求的发送问题,例如下面两种情况
情况-在点击事件上做防抖
按钮事件间是相互独立的,调用的是不同方法,做不到按钮间防抖效果
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/lodash.js/4.17.21/lodash.min.js" type="application/javascript">script>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/vue/2.6.14/vue.min.js" type="application/javascript">script>
<script src="https://lf9-cdn-tos.bytecdntp.com/cdn/expire-1-M/axios/0.26.0/axios.min.js" type="application/javascript">script>
head>
<body>
<div id="app">
<button @click="onClick1" ref="btn1">请求1button>
<button @click="onClick2" ref="btn2">请求2button>
div>
body>
<script>
let sendPost = function(data){
return axios({
url: 'http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test',
method: 'post',
data
})
}
new Vue({
el: '#app',
mounted() {
this.$refs.btn1.click()
this.$refs.btn2.click()
},
methods: {
// 使用lodash对请求方法做防抖
//这里有问题,只是对每个按钮的点击事件单独做了防抖,但是两个按钮之间做不到防抖的效果
onClick1: _.debounce(async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求1的结果', res.data)
}, 300),
onClick2: _.debounce(async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求2的结果', res.data)
}, 300),
},
})
script>
html>情况2-在接口方法做防抖
按钮间调用的方法是相同的,是可以对方法做防抖处理,但是处理本身对方法做了一次封装,会影响到之前方法的返回值接收,需要对之前的方法做更多处理,变得更加复杂,不推荐
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/lodash.js/4.17.21/lodash.min.js" type="application/javascript">script>
<script src="https://lf26-cdn-tos.bytecdntp.com/cdn/expire-1-M/vue/2.6.14/vue.min.js" type="application/javascript">script>
<script src="https://lf9-cdn-tos.bytecdntp.com/cdn/expire-1-M/axios/0.26.0/axios.min.js" type="application/javascript">script>
head>
<body>
<div id="app">
<button @click="onClick1" ref="btn1">请求1button>
<button @click="onClick2" ref="btn2">请求2button>
div>
body>
<script>
// 使用lodash对请求方法做防抖,
let sendPost = _.debounce(function(data){
//这里有问题,这里的返回值不能作为sendPost方法执行的返回值,因为debounce内部包裹了一层
return axios({
url: 'http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test',
method: 'post',
data
})
}, 300)
new Vue({
el: '#app',
mounted() {
this.$refs.btn1.click()
this.$refs.btn2.click()
},
methods: {
onClick1: async function(){
//这里有问题,sendPost返回值不是promise,而是undefined
let res = await sendPost({username:'zs', age: 20})
console.log('请求1的结果', res)
},
onClick2: async function(){
let res = await sendPost({username:'zs', age: 20})
console.log('请求2的结果', res)
},
},
})
script>
html>方式2-通过取消ajax请求
(a) 概述
直接对请求方法做处理,通过ajax库的api方法把重复的请求给取消掉
(b)原理
原生ajax取消请求
通过调用XMLHttpRequest对象实例的abort方法把请求给取消掉
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
body>
<script>
//原生ajax的语法
let xhr = new XMLHttpRequest();
xhr.open("GET", "http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test?username=zs&age=20", true);
xhr.onload = function(){
console.log(xhr.responseText)
}
xhr.send();
//在谷歌浏览器的低速3g下面测试
//通过XMLHttpRequest实例的abort方法取消请求
setTimeout(() => xhr.abort(), 100);
script>
html>axios取消请求
通过axios的CancelToken对象实例cancel方法把请求给取消掉
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
<script src="https://lf9-cdn-tos.bytecdntp.com/cdn/expire-1-M/axios/0.26.0/axios.min.js" type="application/javascript">script>
head>
<body>
body>
<script>
/*axios的取消的语法*/
// 方式1-通过axios.CancelToken.source产生cancelToken和cancel方法
/*
const source = axios.CancelToken.source();
axios.get('http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test', {
params: {username: 'zs', age: 20},
cancelToken: source.token
}).then(res=>{
console.log('res', res.data)
}).catch(err=>{
console.log('err', err)
})
//在谷歌浏览器的低速3g下面测试
//通过调用source的cancel方法取消
setTimeout(() => source.cancel(), 100);
*/
/**/
// 方式2-通过new axios.CancelToken产生cancelToken和cancel方法
let cancelFn
const cancelToken = new axios.CancelToken(cancel=>{
cancelFn = cancel
});
axios.get('http://nodejs-cloud-studio-demo-bkzxs.nodejs-cloud-studio-demo.50185620.cn-hangzhou.fc.devsapp.net/test', {
params: {username: 'zs', age: 20},
cancelToken: cancelToken
}).then(res=>{
console.log('res', res.data)
}).catch(err=>{
console.log('err', err)
})
//在谷歌浏览器的低速3g下面测试
//通过调用cancelFn方法取消
setTimeout(() => cancelFn(), 100);
script>
html>作者:黄金林
来源:juejin.cn/post/7189231050806001719
集成环信uni-app sdk遇到的问题及解决方法
1. 打包问题
问题描述:
a. 打包h5后报错 [system] API connectSocket is not yet implemented
b. 打包后登录时请求token有问题。
解决方案:如果打包h5平台出现以上两种情况,可以看下打包时想优化包体积大小是否有开启【摇钱树】具体配置如图:
ps: 不了解该配置的可以看下uniapp的官方文档介绍,附上链接https://uniapp.dcloud.io/collocation/manifest?id=treeshaking
问题原因:如果开启这个配置项,打包后所有uni没用到的方法都不会打包进去,这样就会导致SDK内部 uni去用request请求就拿不到,这样后续token就会有问题,或者识别不到scoket api等报错。
2. uniapp运行真机报错 【addEventListener is not defind】

解决方案:升级到4.1.0的uni sdk即可。
问题原因:addEventListener 这个是监听浏览器网络变化的,移动端下不支持,所以提示未定义,但实际上并不会影响其他功能,在后续的版本也修复了下该报错~
3. 参考demo报错【this.setData is not a function】如图: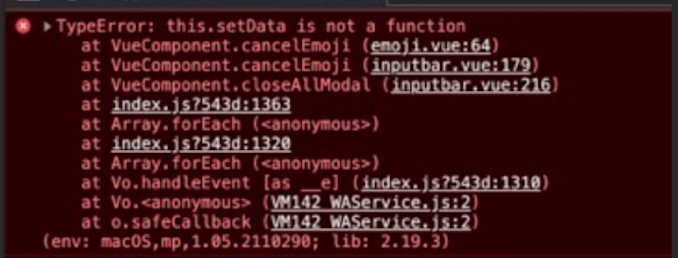
集成过程中可能疑惑this.setData应该是小程序中的方法,为什么uni中会有,是因为demo中有对该方法重写通过minxin,具体在main.js文件中体现,如下图:
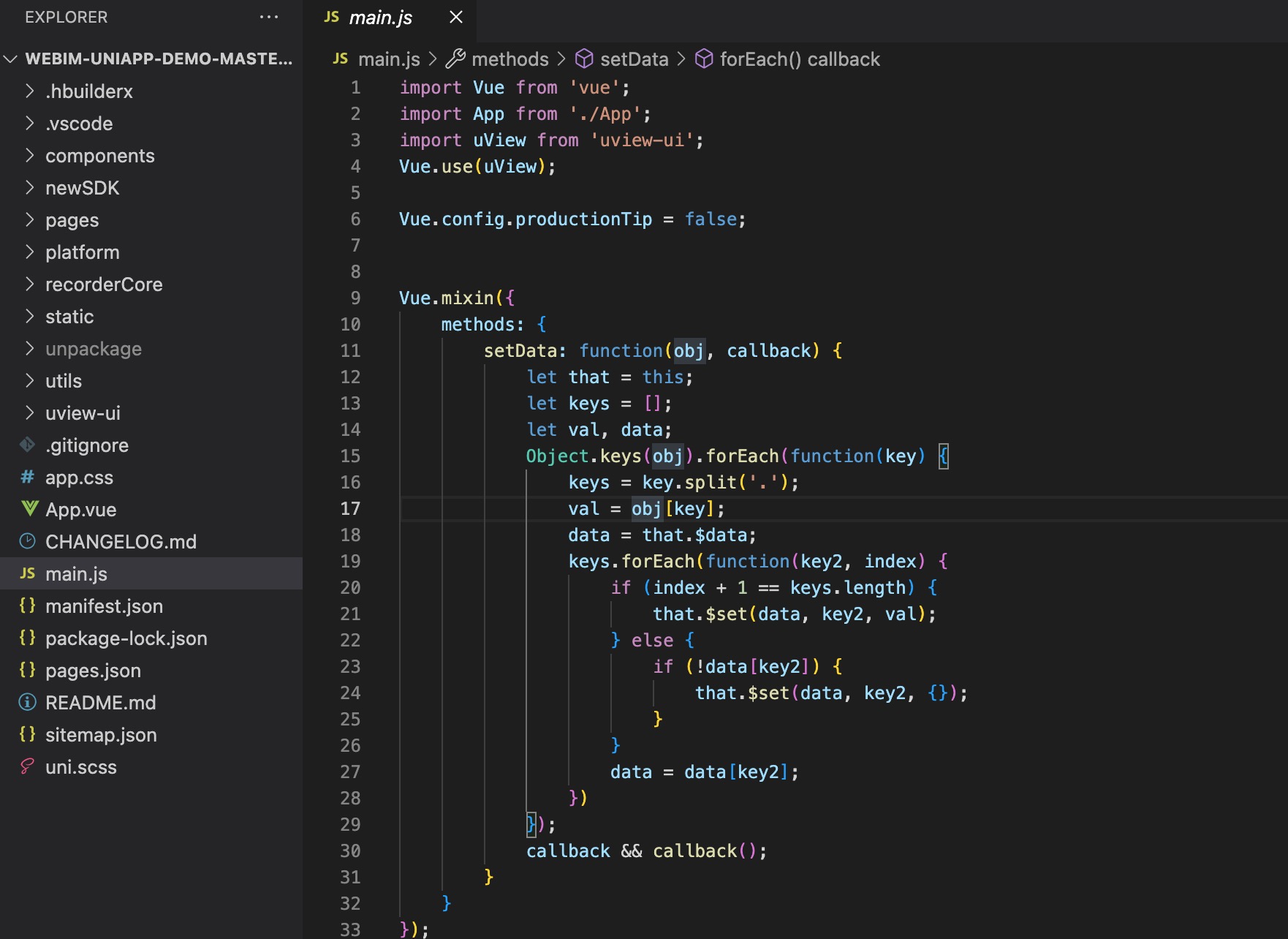
所以如果参照demo报此错可以看下这块是否有复制过来呢~
4. uniapp运行h5发送语音报错
目前的录音实现依赖uni.getRecorderManager()方式, 是不支持 H5的 可以参考下这个文章
https://en.uniapp.dcloud.io/api/media/record-manager.html#getrecordermanager
5. 登录报错 elapse 如图:
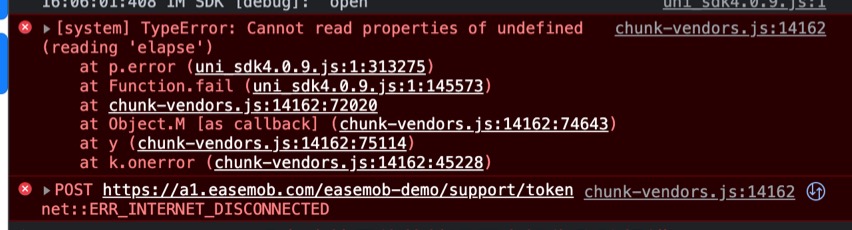
解决方案:1)看下当前是否有链接网络 2)是否有开启vpn
6. uni-app中有时会用到nvue组件,订阅事件将会在nvue中失效,所以如果有发布订阅事件需求推荐使用,uni.$emit发布,uni.$on监听。
今天问题就分享到这里啦,感谢大家的阅读!
收起阅读 »Vue PC前端扫码登录
需求描述
目前大多数PC端应用都有配套的移动端APP,如微信,淘宝等,通过使用手机APP上的扫一扫功能去扫页面二维码图片进行登录,使得用户登录操作更方便,安全,快捷。
思路解析
PC 扫码原理?
扫码登录功能涉及到网页端、服务器和手机端,三端之间交互大致步骤如下:
网页端展示二维码,同时不断的向服务端发送请求询问该二维码的状态;
手机端扫描二维码,读取二维码成功后,跳转至确认登录页,若用户确认登录,则服务器修改二维码状态,并返回用户登录信息;
网页端收到服务器端二维码状态改变,则跳转登录后页面;
若超过一定时间用户未操作,网页端二维码失效,需要重新刷新生成新的二维码。
前端功能实现
如何生成二维码图片?
二维码内容是一段字符串,可以使用uuid 作为二维码的唯一标识;
使用qrcode插件 import QRCode from 'qrcode'; 把uuid变为二维码展示给用户
import {v4 as uuidv4} from "uuid"
import QRCode from "qrcodejs2"
let timeStamp = new Date().getTime() // 生成时间戳,用于后台校验有效期
let uuid = uuidv4()
let content = `uid=${uid}&timeStamp=${timeStamp}`
this.$nextTick(()=> {
const qrcode = new QRCode(this.$refs.qrcode, {
text: content,
width: 180,
height: 180,
colorDark: "#333333",
colorlight: "#ffffff",
correctLevel: QRCode.correctLevel.H,
render: "canvas"
})
qrcode._el.title = ''如何控制二维码的时效性?
使用前端计时器setInterval, 初始化有效时间effectiveTime, 倒计时失效后重新刷新二维码
export default {
name: "qrCode",
data() {
return {
codeStatus: 1, // 1- 未扫码 2-扫码通过 3-过期
effectiveTime: 30, // 有效时间
qrCodeTimer: null // 有效时长计时器
uid: '',
time: ''
};
},
methods: {
// 轮询获取二维码状态
getQcodeStatus() {
if(!this.qsCodeTimer) {
this.qrCodeTimer = setInterval(()=> {
// 二维码过期
if(this.effectiveTime <=0) {
this.codeStatus = 3
clearInterval(this.qsCodeTimer)
this.qsCodeTimer = null
return
}
this.effectiveTime--
}, 1000)
}
},
// 刷新二维码
refreshCode() {
this.codeStatus = 1
this.effectiveTime = 30
this.qsCodeTimer = null
this.generateORCode()
}
},前端如何获取服务器二维码的状态?
前端向服务端发送二维码状态查询请求,通常使用轮询的方式
定时轮询:间隔1s 或特定时段发送请求,通过调用setInterval(), clearInterval()来停止;
长轮询:前端判断接收到的返回结果,若二维码仍未被扫描,则会继续发送查询请求,直至状态发生变化(失效或扫码成功)
Websocket:前端在生成二维码后,会与后端建立连接,一旦后端发现二维码状态变化,可直接通过建立的连接主动推送信息给前端。
使用长轮询实现:
// 获取后台状态
async checkQRcodeStatus() {
const res = await checkQRcode({
uid: this.uid,
time: this.time
})
if(res && res.code == 200) {
let codeStatus - res.codeStatus
this.codeStatus = codeStatus
let loginData = res.loginData
switch(codeStatus) {
case 3:
console.log("二维码过期")
clearInterval(this.qsCodeTimer)
this.qsCodeTimer = null
this.effectiveTime = 0
break;
case 2:
console.log("扫码通过")
clearInterval(this.qsCodeTimer)
this.qsCodeTimer = null
this.$emit("login", loginData)
break;
case 1:
console.log("未扫码")
this.effectiveTime > 0 && this.checkQRcodeStatus()
break;
default:
break;
}
}
},参考资料:
作者:前端碎碎念
来源:juejin.cn/post/7179821690686275621
环信web、uniapp、微信小程序sdk报错详解---注册篇(一)
项目场景:
记录对接环信sdk时遇到的一系列问题,总结一下避免大家再次踩坑。这里主要针对于web、uniapp、微信小程序在对接环信sdk时遇到的问题。注册篇(一)
在初始化完成之后,就卡在了第一步注册用户,注册用户居然报错401,上截图
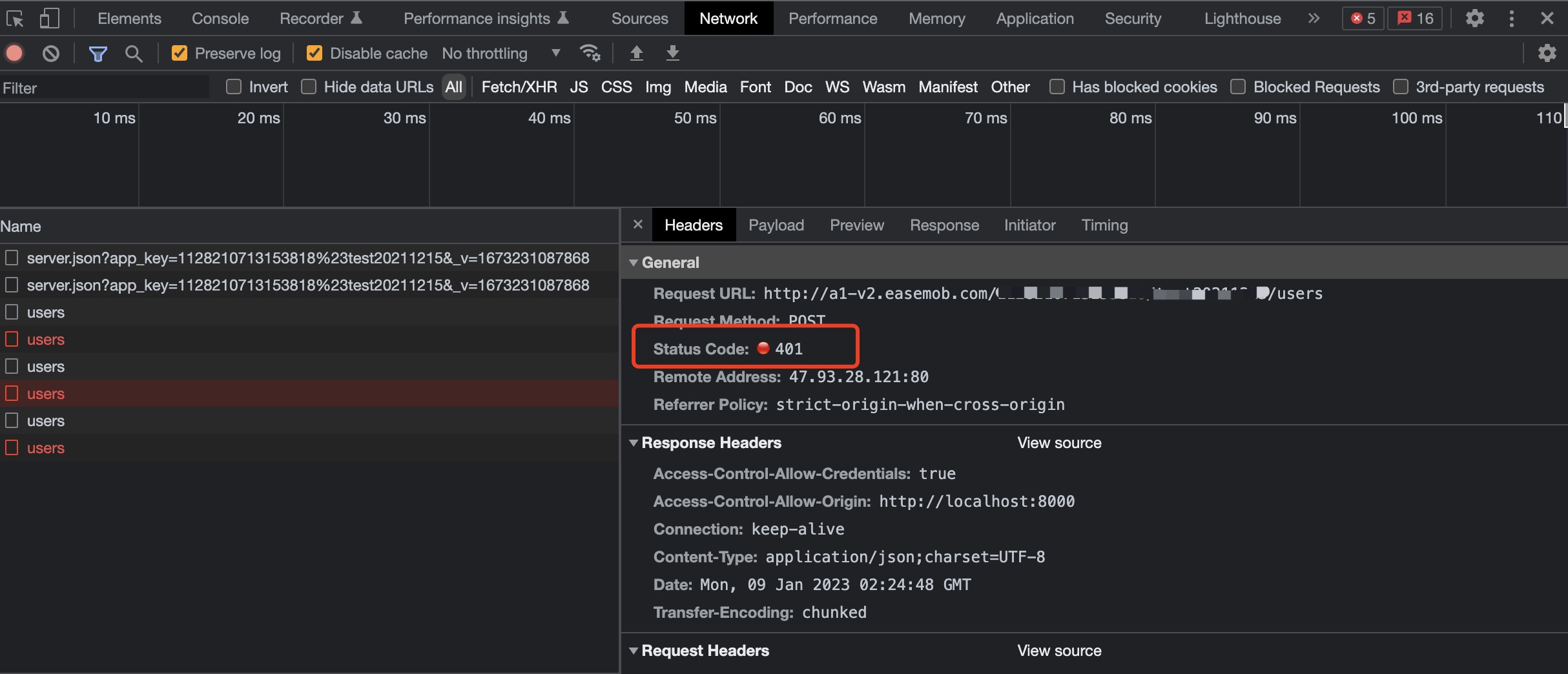

原因分析:
从console控制台输出及network请求返回入手分析
可以看到报错描述Open registration doesn't allow, so register user need token,也就是注册用户需要token,知道问题所在就比较好解决了
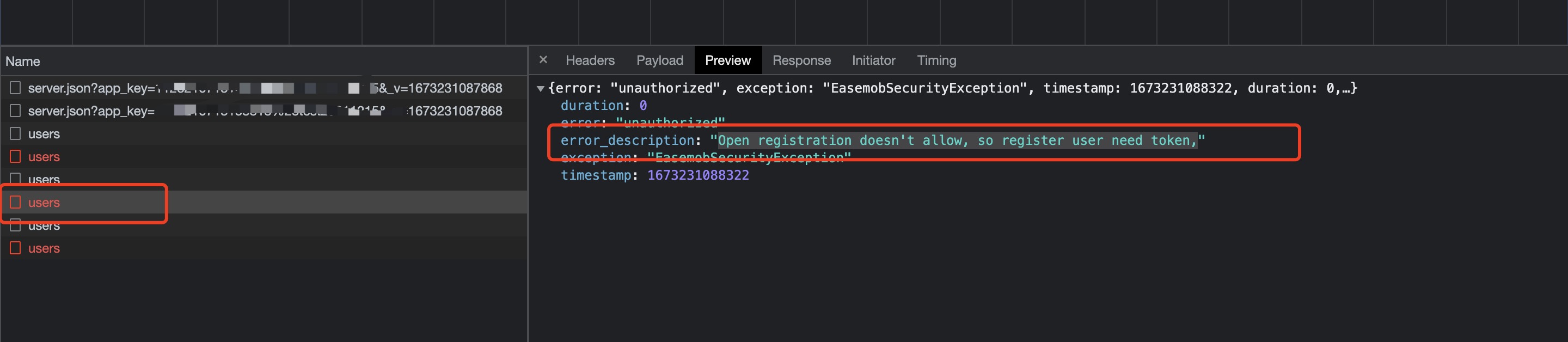

解决方案:
解决思路,文档描述
文档描述:若支持SDK注册,需登录环信即时通讯云控制台 (https://console.easemob.com/app/im-service/detail),选择即时通讯 > 服务概览,将 设置下的用户注册模式设置为开放注册。可见文档地址:http://docs-im-beta.easemob.com/document/web/overview.html#sdk-%E6%B3%A8%E5%86%8C
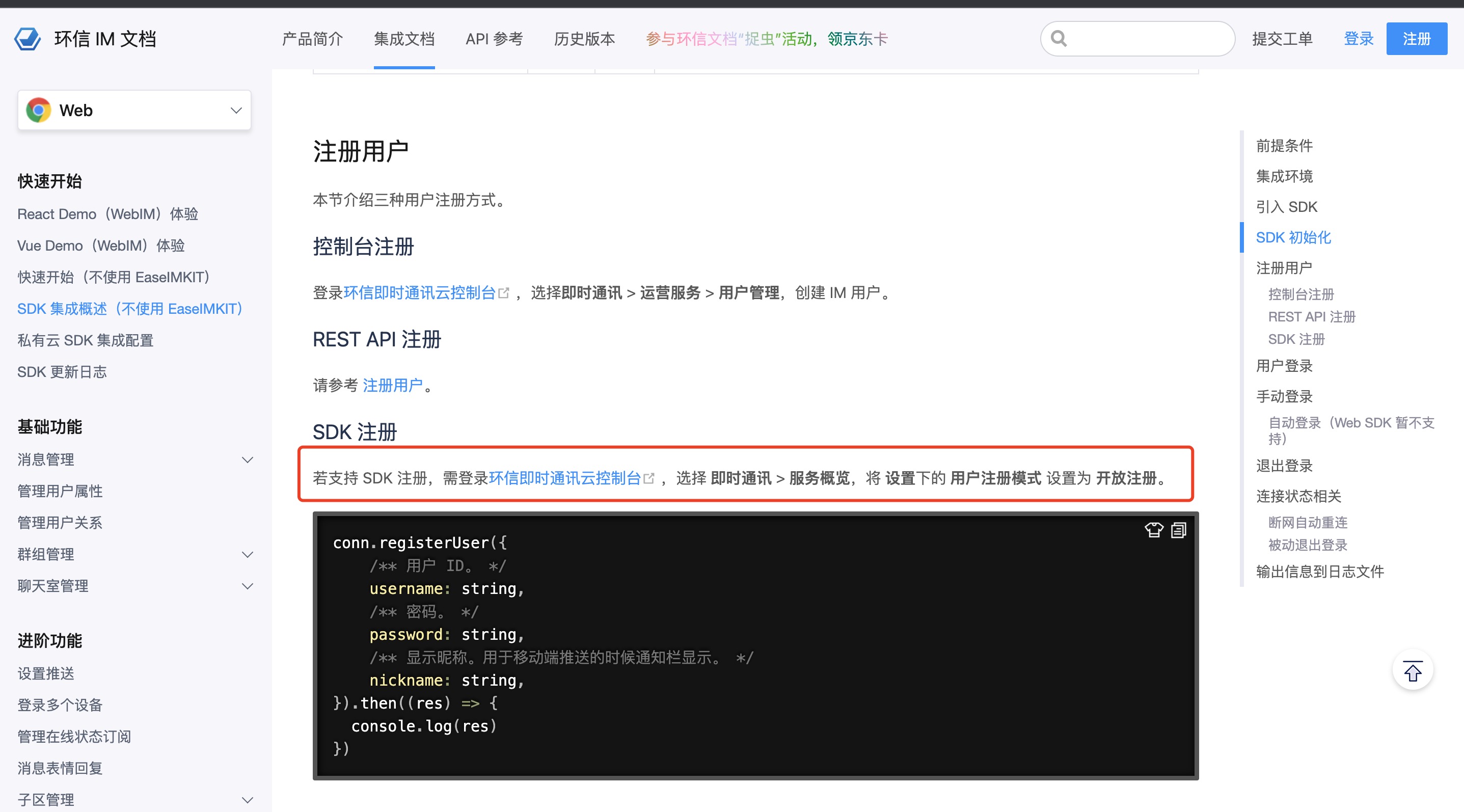
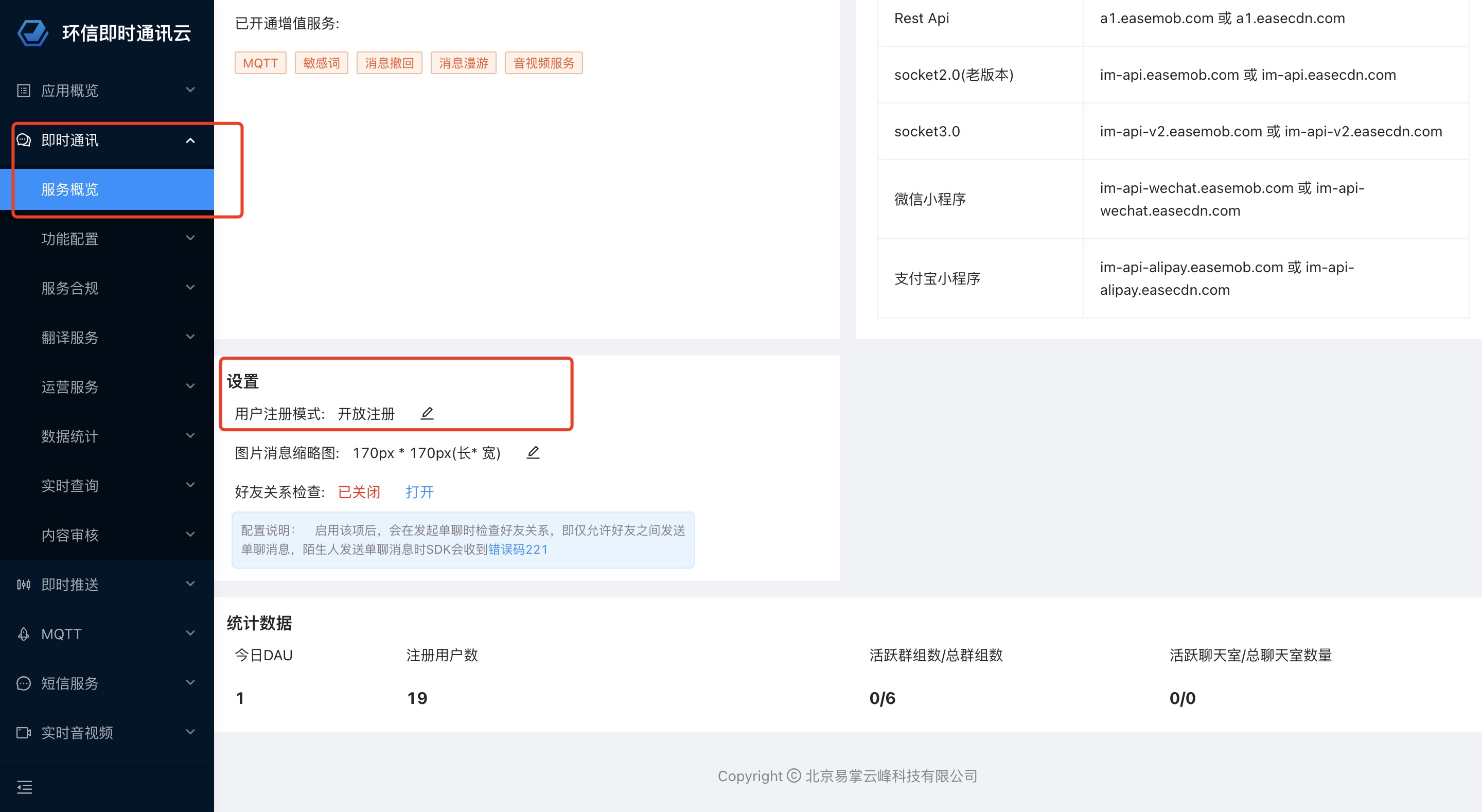
拓展:
上文提到的用户注册模式是什么
据了解,环信的用户注册模式分为两种,一种是授权注册,一种是开放注册,这两种注册模式在即时通讯>服务概览>设置>用户注册模式可以看到,但是这两种注册模式有什么区别呢?
以下是环信文档对于开放注册和授权注册的解释,文档地址:http://docs-im-beta.easemob.com/document/server-side/account_system.html#%E5%BC%80%E6%94%BE%E6%B3%A8%E5%86%8C%E5%8D%95%E4%B8%AA%E7%94%A8%E6%88%B7

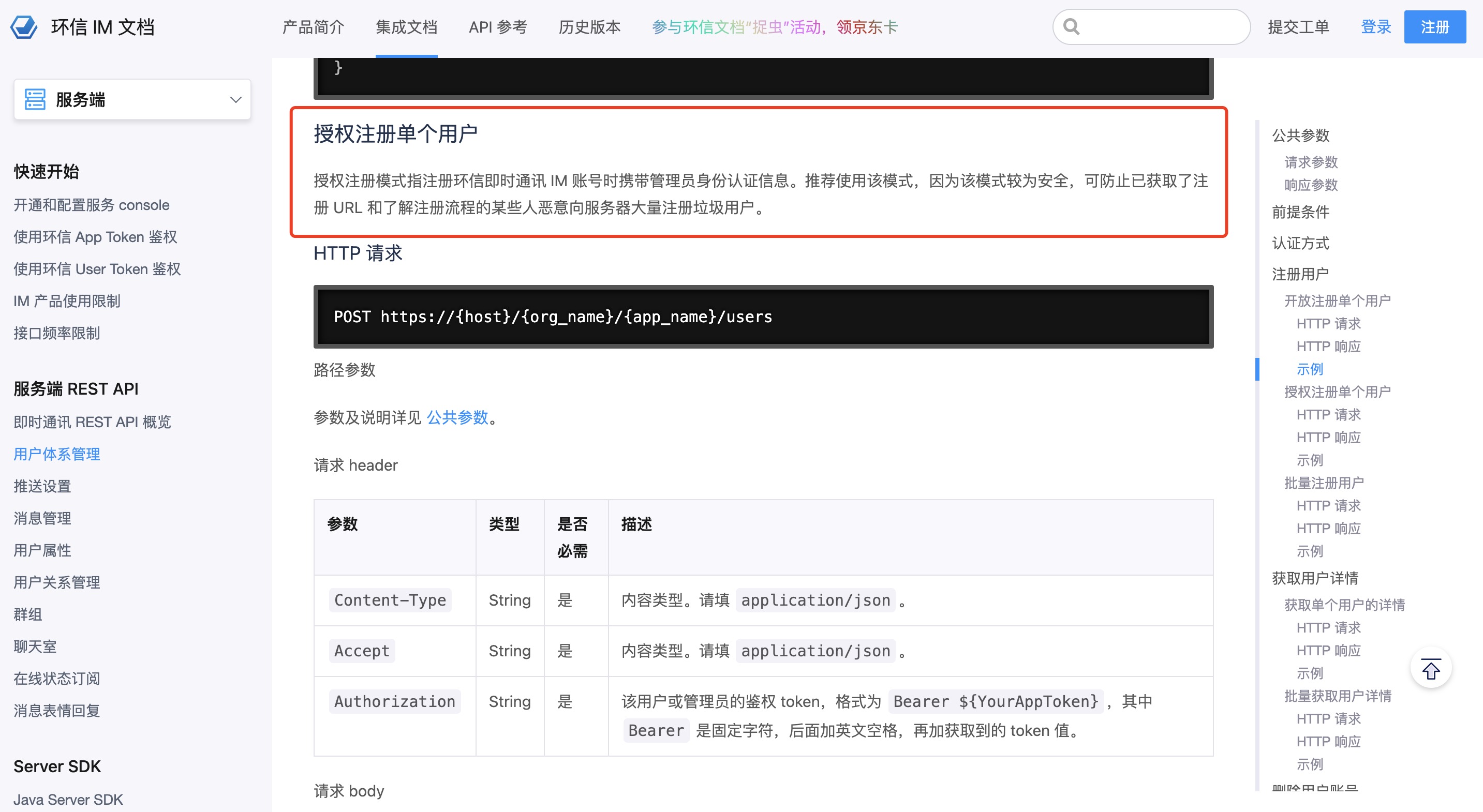
通俗解释就是授权注册比开放注册增加了token认证,授权注册更安全,但是如果在端上启用授权注册会比较麻烦,还需要自己封装请求,我这边建议大家注册还是交给后端同事来搞吧~~~~
react的useState源码分析
前言
简单说下为什么React选择函数式组件,主要是class组件比较冗余、生命周期函数写法不友好,骚写法多,functional组件更符合React编程思想等等等。更具体的可以拜读dan大神的blog。其中Function components capture the rendered values这句十分精辟的道出函数式组件的优势。
但是在16.8之前react的函数式组件十分羸弱,基本只能作用于纯展示组件,主要因为缺少state和生命周期。本人曾经在hooks出来前负责过纯函数式的react项目,所有状态处理都必须在reducer中进行,所有副作用都在saga中执行,可以说是十分艰辛的经历了。在hooks出来后我在公司的一个小中台项目中使用,落地效果不错,代码量显著减少的同时提升了代码的可读性。因为通过custom hooks可以更好地剥离代码结构,不会像以前类组件那样在cDU等生命周期堆了一大堆逻辑,在命令式代码和声明式代码中有一个良性的边界。
useState在React中是怎么实现的
Hooks take some getting used to — and especially at the boundary of imperative and declarative code.
如果对hooks不太了解的可以先看看这篇文章:前情提要,十分简明的介绍了hooks的核心原理,但是我对useEffect,useRef等钩子的实现比较好奇,所以开始啃起了源码,下面我会结合源码介绍useState的原理。useState具体逻辑分成三部分:mountState,dispatch, updateState
hook的结构
首先的是hooks的结构,hooks是挂载在组件Fiber结点上memoizedState的
//hook的结构
export type Hook = {
memoizedState: any, //上一次的state
baseState: any, //当前state
baseUpdate: Update<any, any> | null, // update func
queue: UpdateQueue<any, any> | null, //用于缓存多次action
next: Hook | null, //链表
};renderWithHooks
在reconciler中处理函数式组件的函数是renderWithHooks,其类型是:
renderWithHooks(
current: Fiber | null, //当前的fiber结点
workInProgress: Fiber,
Component: any, //jsx中用<>调用的函数
props: any,
refOrContext: any,
nextRenderExpirationTime: ExpirationTime, //需要在什么时候结束
): any在renderWithHooks,核心流程如下:
//从memoizedState中取出hooks
nextCurrentHook = current !== null ? current.memoizedState : null;
//判断通过有没有hooks判断是mount还是update,两者的函数不同
ReactCurrentDispatcher.current =
nextCurrentHook === null
? HooksDispatcherOnMount
: HooksDispatcherOnUpdate;
//执行传入的type函数
let children = Component(props, refOrContext);
//执行完函数后的dispatcher变成只能调用context的
ReactCurrentDispatcher.current = ContextOnlyDispatcher;
return children;useState构建时流程
mountState
在HooksDispatcherOnMount中,useState调用的是下面的mountState,作用是创建一个新的hook并使用默认值初始化并绑定其触发器,因为useState底层是useReducer,所以数组第二个值返回的是dispatch。
type BasicStateAction<S> = (S => S) | S;
function mountState<S>(
initialState: (() => S) | S,
){
const hook = mountWorkInProgressHook();
//如果入参是func则会调用,但是不提供参数,带参数的需要包一层
if (typeof initialState === 'function') {
initialState = initialState();
}
//上一个state和基本(当前)state都初始化
hook.memoizedState = hook.baseState = initialState;
const queue = (hook.queue = {
last: null,
dispatch: null,
eagerReducer: basicStateReducer, // useState使用基础reducer
eagerState: (initialState: any),
});
//返回触发器
const dispatch: Dispatch<
//useState底层是useReducer,所以type是BasicStateAction
(queue.dispatch = (dispatchAction.bind(
null,
//绑定当前fiber结点和queue
((currentlyRenderingFiber: any): Fiber),
queue,
): any));
return [hook.memoizedState, dispatch];
}mountWorkInProgressHook
这个函数是mountState时调用的构建hook的方法,在初始化完毕后会连接到当前hook.next(如果有的话)
function mountWorkInProgressHook(): Hook {
const hook: Hook = {
memoizedState: null,
baseState: null,
queue: null,
baseUpdate: null,
next: null,
};
if (workInProgressHook === null) {
// 列表中的第一个hook
firstWorkInProgressHook = workInProgressHook = hook;
} else {
// 添加到列表的末尾
workInProgressHook = workInProgressHook.next = hook;
}
return workInProgressHook;
}dispatch分发函数
在上面我们提到,useState底层是useReducer,所以返回的第二个参数是dispatch函数,其中的设计十分巧妙。
假设我们有以下代码:
相关参考视频讲解:进入学习
const [data, setData] = React.useState(0)
setData('first')
setData('second')
setData('third')在第一次setData后, hooks的结构如上图
在第二次setData后, hooks的结构如上图
在第三次setData后, hooks的结构如上图
在正常情况下,是不会在dispatcher中触发reducer而是将action存入update中在updateState中再执行,但是如果在react没有重渲染需求的前提下是会提前计算state即eagerState。作为性能优化的一环。
function dispatchAction<S, A>(
fiber: Fiber,
queue: UpdateQueue<S, A>,
action: A,
) {
const alternate = fiber.alternate;
{
flushPassiveEffects();
//获取当前时间并计算可用时间
const currentTime = requestCurrentTime();
const expirationTime = computeExpirationForFiber(currentTime, fiber);
const update: Update<S, A> = {
expirationTime,
action,
eagerReducer: null,
eagerState: null,
next: null,
};
//下面的代码就是为了构建queue.last是最新的更新,然后last.next开始是每一次的action
// 取出last
const last = queue.last;
if (last === null) {
// 自圆
update.next = update;
} else {
const first = last.next;
if (first !== null) {
update.next = first;
}
last.next = update;
}
queue.last = update;
if (
fiber.expirationTime === NoWork &&
(alternate === null || alternate.expirationTime === NoWork)
) {
// 当前队列为空,我们可以在进入render阶段前提前计算出下一个状态。如果新的状态和当前状态相同,则可以退出重渲染
const lastRenderedReducer = queue.lastRenderedReducer; // 上次更新完后的reducer
if (lastRenderedReducer !== null) {
let prevDispatcher;
if (__DEV__) {
prevDispatcher = ReactCurrentDispatcher.current; // 暂存dispatcher
ReactCurrentDispatcher.current = InvalidNestedHooksDispatcherOnUpdateInDEV;
}
try {
const currentState: S = (queue.lastRenderedState: any);
// 计算下次state
const eagerState = lastRenderedReducer(currentState, action);
// 在update对象中存储预计算的完整状态和reducer,如果在进入render阶段前reducer没有变化那么可以服用eagerState而不用重新再次调用reducer
update.eagerReducer = lastRenderedReducer;
update.eagerState = eagerState;
if (is(eagerState, currentState)) {
// 在后续的时间中,如果这个组件因别的原因被重渲染且在那时reducer更变后,仍有可能重建这次更新
return;
}
} catch (error) {
// Suppress the error. It will throw again in the render phase.
} finally {
if (__DEV__) {
ReactCurrentDispatcher.current = prevDispatcher;
}
}
}
}
scheduleWork(fiber, expirationTime);
}
}useState更新时流程
updateReducer
因为useState底层是useReducer,所以在更新时的流程(即重渲染组件后)是调用updateReducer的。
function updateState<S>(
initialState: (() => S) | S,
): [S, Dispatch<BasicStateAction<S>>] {
return updateReducer(basicStateReducer, (initialState: any));
}所以其reducer十分简单
function basicStateReducer<S>(state: S, action: BasicStateAction<S>): S {
return typeof action === 'function' ? action(state) : action;
}我们先把复杂情况抛开,跑通updateReducer流程
function updateReducer(
reducer: (S, A) => S,
initialArg: I,
init?: I => S,
){
// 获取当前hook,queue
const hook = updateWorkInProgressHook();
const queue = hook.queue;
queue.lastRenderedReducer = reducer;
// action队列的最后一个更新
const last = queue.last;
// 最后一个更新是基本状态
const baseUpdate = hook.baseUpdate;
const baseState = hook.baseState;
// 找到第一个没处理的更新
let first;
if (baseUpdate !== null) {
if (last !== null) {
// 第一次更新时,队列是一个自圆queue.last.next = queue.first。当第一次update提交后,baseUpdate不再为空即可跳出队列
last.next = null;
}
first = baseUpdate.next;
} else {
first = last !== null ? last.next : null;
}
if (first !== null) {
let newState = baseState;
let newBaseState = null;
let newBaseUpdate = null;
let prevUpdate = baseUpdate;
let update = first;
let didSkip = false;
do {
const updateExpirationTime = update.expirationTime;
if (updateExpirationTime < renderExpirationTime) {
// 优先级不足,跳过这次更新,如果这是第一次跳过更新,上一个update/state是newBaseupdate/state
if (!didSkip) {
didSkip = true;
newBaseUpdate = prevUpdate;
newBaseState = newState;
}
// 更新优先级
if (updateExpirationTime > remainingExpirationTime) {
remainingExpirationTime = updateExpirationTime;
}
} else {
// 处理更新
if (update.eagerReducer === reducer) {
// 如果更新被提前处理了且reducer跟当前reducer匹配,可以复用eagerState
newState = ((update.eagerState: any): S);
} else {
// 循环调用reducer
const action = update.action;
newState = reducer(newState, action);
}
}
prevUpdate = update;
update = update.next;
} while (update !== null && update !== first);
• if (!didSkip) {
• newBaseUpdate = prevUpdate;
• newBaseState = newState;
• }
• // 只有在前后state变了才会标记
• if (!is(newState, hook.memoizedState)) {
• markWorkInProgressReceivedUpdate();
• }
• hook.memoizedState = newState;
• hook.baseUpdate = newBaseUpdate;
• hook.baseState = newBaseState;
queue.lastRenderedState = newState;
}
const dispatch: Dispatch<A> = (queue.dispatch: any);
return [hook.memoizedState, dispatch];
}
export function markWorkInProgressReceivedUpdate() {
didReceiveUpdate = true;
}
后记
作为系列的第一篇文章,我选择了最常用的hooks开始,抛开提前计算及与react-reconciler的互动,整个流程是十分清晰易懂的。mount的时候构建钩子,触发dispatch时按序插入update。updateState的时候再按序触发reducer。可以说就是一个简单的redux。
作者:flyzz177
来源:juejin.cn/post/7184636589564231735
IM会话列表刷新优化思考
背景
脱离业务场景讲技术方案都是耍流氓
最近接手了IM的业务,一上来就来了几个大需求,搞得有点手忙脚乱。在做需求的过程中发现,我们的会话列表(RecyclerView)居然每次更新都是notifyDataSetChanged(),因为IM的刷新频率是非常高的
大家可以想象一下微信消息列表,每来1条消息,就全局调用notifyDataSetChanged。
这里瞎猜一下,可能由于历史原因,之前设计的同学也是不得已而为之。既然发现了这个问题,那么我们如何来进行优化呢?
IM列表跟普通列表的区别
有序性:列表中的Item按时间排序,或者其他规则(置顶也是修改时间实现)
唯一性:每个会话都是唯一的,不存在重复
单item更新频率高:可以参考微信的会话列表
DiffUtil
首先想到的是DiffUtil,它用来比较两个数据集,寻找出旧数据集->新数据集的最小变化量
实现思路:
获取原始会话数据,进行排序,去重操作
采用DiffUtil自动计算新老数据集差异,自动完成定向刷新
这里只摘取DiffUtil关键使用部分,至于高级用法和更高级的用法不再赘述
class DiffMsgCallBack: DiffUtil.Callback() {
private val oldData: MutableList<MsgItem> = mutableListOf()
private val newData: MutableList<MsgItem> = mutableListOf()
//老数据集size
override fun getOldListSize(): Int {
return oldData.size
}
//新数据集size
override fun getNewListSize(): Int {
return newData.size
}
/**
* 比较的是position,被DiffUtil调用,用来判断两个对象是否是相同的Item
* 例如,如果你的Item有唯一的id字段,这个方法就 判断id是否相等
*/
override fun areItemsTheSame(oldItemPosition: Int, newItemPosition: Int): Boolean {
return oldData[oldItemPosition].id == newData[newItemPosition].id
}
/**
* 用来检查 两个item是否含有相同的数据,当前item的内容是否发生了变化,这个方法仅仅在areItemsTheSame()返回true时,才调用
*/
override fun areContentsTheSame(oldItemPosition: Int, newItemPosition: Int): Boolean {
if (oldData[oldItemPosition].id != newData[newItemPosition].id){
return false
}
if (oldData[oldItemPosition].content != newData[newItemPosition].content){
return false
}
if (oldData[oldItemPosition].time != newData[newItemPosition].time){
return false
}
return true
}
/**
* 高级用法:实现部分(partial)绑定的方法,需要配合onBindViewHolder的3个参数的方法
* 更高级用法:AsyncListDiffer+ListAdapter
*
*/
override fun getChangePayload(oldItemPosition: Int, newItemPosition: Int): Any? {
return super.getChangePayload(oldItemPosition, newItemPosition)
}SortedList
当我以为DiffUtil已经可以满足需求的时候,无意间又发现了一个SortedList。
SortedList是一个有序列表(数据集)的实现,可以保持ItemData都是有序的,并(自动)通知列表(RecyclerView)(数据集)中的更改。
搭配RecyclerView使用,去重,有序,自动定向刷新
这里也只摘取关键使用部分,具体用法不再详解
class SortListCallBack(adapter: RecyclerView.Adapter<*>?) : SortedListAdapterCallback<MsgItem>(adapter) {
/**
* 排序条件,实现排序的逻辑
*/
override fun compare(o1: MsgItem?, o2: MsgItem?): Int {
o1 ?: return -1
o2 ?: return -1
return o1.time - o2.time
}
/**
* 和DiffUtil方法一致,用来判断 两个对象是否是相同的Item。
*/
override fun areItemsTheSame(item1: MsgItem?, item2: MsgItem?): Boolean {
return item1?.id == item2?.id
}
/**
* 和DiffUtil方法一致,返回false,代表Item内容改变。会回调mCallback.onChanged()方法;
* 相同:areContentsTheSame+areItemsTheSame
*/
override fun areContentsTheSame(oldItem: MsgItem?, newItem: MsgItem?): Boolean {
if (oldItem?.id != newItem?.id){
return false
}
if (oldItem?.content != newItem?.content){
return false
}
if (oldItem?.time != newItem?.time){
return false
}
return true
}
/**
* 高级用法:实现部分绑定的方法,需要配合onBindViewHolder的3个参数的方法
*/
override fun getChangePayload(item1: MsgItem?, item2: MsgItem?): Any? {
return super.getChangePayload(item1, item2)
}
}对比
DiffUtil和SortedList是非常相似的,修改过数据后,内部持有的回调接口都是同一个:androidx.recyclerview.widget.ListUpdateCallback
/**
* An interface that can receive Update operations that are applied to a list.
* <p>
* This class can be used together with DiffUtil to detect changes between two lists.
*/
public interface ListUpdateCallback {
void onInserted(int position, int count);
void onRemoved(int position, int count);
void onMoved(int fromPosition, int toPosition);
void onChanged(int position, int count, @Nullable Object payload);DiffUtil计算出Diff或者SortedList察觉出数据集有改变后,会回调ListUpdateCallback接口的这四个方法,DiffUtil和SortedList提供的默认Callback实现中,都会通知Adapter完成定向刷新。 这就是自动定向刷新的原理
总结
DiffUtil比较两个数据源(一般是List)的差异(Diff),Callback中比对时传递的参数是 position
SortedList能完成数据集的排序和去重,Callback中比对时,传递的参数是ItemData
都能完成自动定向刷新 + 部分绑定,一种自动定向刷新的手段
DiffUtil: 检测不出重复的,会被认为是新增的
DiffUtil高级用法支持子线程中处理数据,而SortList不支持
理想与现实
2种方案都有了,是不是可以进行IM会话列表的优化了呢,答案是不能
业务需求迭代,牵一发而动全身
祖传代码,无人敢动,更别说优化了
有时候我们写代码会想着后面再优化一下,然而很多时候都不会给你优化的机会,除非重大需求变动,所以一开始设计框架的时候就要结合业务场景尽量设计的更加合理
参考文章:blog.csdn.net/zxt0601/art…
作者:掀乱书页的风
来源:juejin.cn/post/7183517773790707769
前端白屏的检测方案,让你知道自己的页面白了
前言
页面白屏,绝对是让前端开发者最为胆寒的事情,特别是随着 SPA 项目的盛行,前端白屏的情况变得更为复杂且棘手起来( 这里的白屏是指页面一直处于白屏状态 )
要是能检测到页面白屏就太棒了,开发者谁都不想成为最后一个知道自己页面白的人😥
web-see 前端监控方案,提供了 采样对比+白屏修正机制 的检测方案,兼容有骨架屏、无骨架屏这两种情况,来解决开发者的白屏之忧
知道页面白了,然后呢?
web-see 前端监控,会给每次页面访问生成一个唯一的uuid,当上报页面白屏后,开发者可以根据白屏的uuid,去监控后台查询该id下对应的代码报错、资源报错等信息,定位到具体的源码,帮助开发者快速解决白屏问题
白屏检测方案的实现流程
采样对比+白屏修正机制的主要流程:
1、页面中间取17个采样点(如下图),利用 elementsFromPoint api 获取该坐标点下的 HTML 元素
2、定义属于容器元素的集合,如 ['html', 'body', '#app', '#root']
3、判断17这个采样点是否在该容器集合中。说白了,就是判断采样点有没有内容;如果没有内容,该点的 dom 元素还是容器元素,若17个采样点都没有内容则算作白屏
4、若初次判断是白屏,开启轮询检测,来确保白屏检测结果的正确性,直到页面的正常渲染
采样点分布图(蓝色为采样点):
如何使用
import webSee from 'web-see';
Vue.use(webSee, {
dsn: 'http://localhost:8083/reportData', // 上报的地址
apikey: 'project1', // 项目唯一的id
userId: '89757', // 用户id
silentWhiteScreen: true, // 开启白屏检测
skeletonProject: true, // 项目是否有骨架屏
whiteBoxElements: ['html', 'body', '#app', '#root'] // 白屏检测的容器列表
});下面聊一聊具体的分析与实现
白屏检测的难点
1) 白屏原因的不确定
从问题推导现象虽然能成功,但从现象去推导问题却走不通。白屏发生时,无法和具体某个报错联系起来,也可能根本没有报错,比如关键资源还没有加载完成
导致白屏的原因,大致分两种:资源加载错误、代码执行错误
2) 前端渲染方式的多样性
前端页面渲染方式有多种,比如 客户端渲染 CSR 、服务端渲染 SSR 、静态页面生成 SSG 等,每种模式各不相同,白屏发生的情况也不尽相同
很难用一种统一的标准去判断页面是否白了
技术方案调研
如何设计出一种,在准确性、通用型、易用性等方面均表现良好的检测方案呢?
本文主要讨论 SPA 项目的白屏检测方案,包括有无骨架屏的两种情况
方案一:检测根节点是否渲染
原理很简单,在当前主流 SPA 框架下,DOM 一般挂载在一个根节点之下(比如 <div id="app"></div> ),发生白屏后通常是根节点下所有 DOM 被卸载,该方法通过检测根节点下是否挂载 DOM,若无则证明白屏
这是简单明了且有效的方案,但缺点也很明显:其一切建立在 白屏 === 根节点下 DOM 被卸载 成立的前提下,缺点是通用性较差,对于有骨架屏的情况束手无策
方案二:Mutation Observer 监听 DOM 变化
通过此 API 监听页面 DOM 变化,并告诉我们每次变化的 DOM 是被增加还是删除
但这个方案有几个缺陷
1)白屏不一定是 DOM 被卸载,也有可能是压根没渲染,且正常情况也有可能大量 DOM 被卸载
2)遇到有骨架屏的项目,若页面从始至终就没变化,一直显示骨架屏,这种情况 Mutation Observer 也束手无策
方案三:页面截图检测
这种方式是基于原生图片对比算法处理白屏检测的 web 实现
整体流程:对页面进行截图,将截图与一张纯白的图片做对比,判断两者是否足够相似
但这个方案有几个缺陷:
1、方案较为复杂,性能不高;一方面需要借助 canvas 实现前端截屏,同时需要借助复杂的算法对图片进行对比
2、通用性较差,对于有骨架屏的项目,对比的样张要由纯白的图片替换成骨架屏的截图
方案四:采样对比
该方法是对页面取关键点,进行采样对比,在准确性、易用性等方面均表现良好,也是最终采用的方案
对于有骨架屏的项目,通过对比前后获取的 dom 元素是否一致,来判断页面是否变化(这块后面专门讲解)
采样对比代码:
// 监听页面白屏
function whiteScreen() {
// 页面加载完毕
function onload(callback) {
if (document.readyState === 'complete') {
callback();
} else {
window.addEventListener('load', callback);
}
}
// 定义外层容器元素的集合
let containerElements = ['html', 'body', '#app', '#root'];
// 容器元素个数
let emptyPoints = 0;
// 选中dom的名称
function getSelector(element) {
if (element.id) {
return "#" + element.id;
} else if (element.className) {// div home => div.home
return "." + element.className.split(' ').filter(item => !!item).join('.');
} else {
return element.nodeName.toLowerCase();
}
}
// 是否为容器节点
function isContainer(element) {
let selector = getSelector(element);
if (containerElements.indexOf(selector) != -1) {
emptyPoints++;
}
}
onload(() => {
// 页面加载完毕初始化
for (let i = 1; i <= 9; i++) {
let xElements = document.elementsFromPoint(window.innerWidth * i / 10, window.innerHeight / 2);
let yElements = document.elementsFromPoint(window.innerWidth / 2, window.innerHeight * i / 10);
isContainer(xElements[0]);
// 中心点只计算一次
if (i != 5) {
isContainer(yElements[0]);
}
}
// 17个点都是容器节点算作白屏
if (emptyPoints == 17) {
// 获取白屏信息
console.log({
status: 'error'
});
}
}
}白屏修正机制
若首次检测页面为白屏后,任务还没有完成,特别是手机端的项目,有可能是用户网络环境不好,关键的JS资源或接口请求还没有返回,导致的页面白屏
需要使用轮询检测,来确保白屏检测结果的正确性,直到页面的正常渲染,这就是白屏修正机制
白屏修正机制图例:
轮询代码:
// 采样对比
function sampling() {
let emptyPoints = 0;
……
// 页面正常渲染,停止轮询
if (emptyPoints != 17) {
if (window.whiteLoopTimer) {
clearTimeout(window.whiteLoopTimer)
window.whiteLoopTimer = null
}
} else {
// 开启轮询
if (!window.whiteLoopTimer) {
whiteLoop()
}
}
// 通过轮询不断修改之前的检测结果,直到页面正常渲染
console.log({
status: emptyPoints == 17 ? 'error' : 'ok'
});
}
// 白屏轮询
function whiteLoop() {
window.whiteLoopTimer = setInterval(() => {
sampling()
}, 1000)
}骨架屏
对于有骨架屏的页面,用户打开页面后,先看到骨架屏,然后再显示正常的页面,来提升用户体验;但如果页面从始至终都显示骨架屏,也算是白屏的一种
骨架屏示例:
骨架屏的原理
无论 vue 还是 react,页面内容都是挂载到根节点上。常见的骨架屏插件,就是基于这种原理,在项目打包时将骨架屏的内容直接放到 html 文件的根节点中
有骨架屏的html文件:
骨架屏的白屏检测
上面的白屏检测方案对有骨架屏的项目失灵了,虽然页面一直显示骨架屏,但判断结果页面不是白屏,不符合我们的预期
需要通过外部传参明确的告诉 SDK,该页面是不是有骨架屏,如果有骨架屏,通过对比前后获取的 dom 元素是否一致,来实现骨架屏的白屏检测
完整代码:
/**
* 检测页面是否白屏
* @param {function} callback - 回到函数获取检测结果
* @param {boolean} skeletonProject - 页面是否有骨架屏
* @param {array} whiteBoxElements - 容器列表,默认值为['html', 'body', '#app', '#root']
*/
export function openWhiteScreen(callback, { skeletonProject, whiteBoxElements }) {
let _whiteLoopNum = 0;
let _skeletonInitList = []; // 存储初次采样点
let _skeletonNowList = []; // 存储当前采样点
// 项目有骨架屏
if (skeletonProject) {
if (document.readyState != 'complete') {
sampling();
}
} else {
// 页面加载完毕
if (document.readyState === 'complete') {
sampling();
} else {
window.addEventListener('load', sampling);
}
}
// 选中dom点的名称
function getSelector(element) {
if (element.id) {
return '#' + element.id;
} else if (element.className) {
// div home => div.home
return ('.' + element.className.split(' ').filter(item => !!item).join('.'));
} else {
return element.nodeName.toLowerCase();
}
}
// 判断采样点是否为容器节点
function isContainer(element) {
let selector = getSelector(element);
if (skeletonProject) {
_whiteLoopNum ? _skeletonNowList.push(selector) : _skeletonInitList.push(selector);
}
return whiteBoxElements.indexOf(selector) != -1;
}
// 采样对比
function sampling() {
let emptyPoints = 0;
for (let i = 1; i <= 9; i++) {
let xElements = document.elementsFromPoint(
(window.innerWidth * i) / 10,
window.innerHeight / 2
);
let yElements = document.elementsFromPoint(
window.innerWidth / 2,
(window.innerHeight * i) / 10
);
if (isContainer(xElements[0])) emptyPoints++;
// 中心点只计算一次
if (i != 5) {
if (isContainer(yElements[0])) emptyPoints++;
}
}
// 页面正常渲染,停止轮训
if (emptyPoints != 17) {
if (skeletonProject) {
// 第一次不比较
if (!_whiteLoopNum) return openWhiteLoop();
// 比较前后dom是否一致
if (_skeletonNowList.join() == _skeletonInitList.join())
return callback({
status: 'error'
});
}
if (window._loopTimer) {
clearTimeout(window._loopTimer);
window._loopTimer = null;
}
} else {
// 开启轮训
if (!window._loopTimer) {
openWhiteLoop();
}
}
// 17个点都是容器节点算作白屏
callback({
status: emptyPoints == 17 ? 'error' : 'ok',
});
}
// 开启白屏轮训
function openWhiteLoop() {
if (window._loopTimer) return;
window._loopTimer = setInterval(() => {
if (skeletonProject) {
_whiteLoopNum++;
_skeletonNowList = [];
}
sampling();
}, 1000);
}
}如果不通过外部传参,SDK 能否自己判断是否有骨架屏呢? 比如在页面初始的时候,根据根节点上有没有子节点来判断
因为这套检测方案需要兼容 SSR 服务端渲染的项目,对于 SSR 项目来说,浏览器获取 html 文件的根节点上已经有了 dom 元素,所以最终采用外部传参的方式来区分
总结
这套白屏检测方案是从现象推导本质,可以覆盖绝大多数 SPA 项目的应用场景
小伙们若有其他检测方案,欢迎多多讨论与交流 💕
作者:海阔_天空
来源:juejin.cn/post/7176206226903007292
前端常见登录方案梳理
前端登录有很多种方式,我们来挑一些常见的方案先梳理一下,后续再补充更多的。
账号密码登录
在系统数据库中已经有了账号密码,或者通过注册渠道生成了账号和密码,此时可以直接通过账号密码登录,只要账号密码正确就认为身份合法,可以换到系统访问的 token,用于后续业务鉴权。
验证码登录
比如手机验证码,邮箱验证码等等。用户首先提供手机号/邮箱,后端根据会话信息生成一个特定的码下发到用户的手机或者邮箱(通过运营商提供的能力)。
用户得到这个码后填入登录表单,随手机号/邮箱一并发给后端,后端拿到手机号/邮箱、码后,与会话信息做校验,确认身份信息是否合法。
如果一致就检查数据库中是否有这个手机号/邮箱,有的话就不用创建用户了,直接通过登录;没有的话就说明是新用户,可以先创建用户,绑定好手机号/邮箱,然后通过登录。
第三方授权
比如微信授权,github授权之类的,可以通过OAuth授权得到访问对方开放API的能力。
OAuth 协议读起来很复杂,其实本质上就是:
我是开发者,有个自己的业务系统。
用户想图方便,希望通过一些常用的平台(比如微信,支付宝等)登录到我的业务系统。
但是这也不是你想用就能用的,我首先要去三方平台登记一下我的应用,比如注册一个微信公众号,公众号再绑定我的业务域名(验证所有权),可能还要交个费做微信认证之类的。
交了保护费后(经过上面的操作),我的业务系统就是某三方平台的合法应用了,就可以使用某三方平台的开放接口了。
此时用户来到我的业务系统客户端,点击微信一键登录。
然后我的业务系统就会按照微信的规矩生成一些鉴权需要的信息,拉起微信的中间页(如果是手机客户端,那可能就是通过 SDK 拉起手机微信)让用户授权。
用户同意授权,微信的中间页鉴权成功后,就会给我的客户端返回一个 code 之类的回调信息,客户端需要把这个 code 传给后端。
后端拿到这个 code 可以去微信服务器换取 access_token,基于这个 access_token,可以获取微信用户基本开放信息和帮助用户实现基础开放功能等。
后端也可以基于此封装自定义的登录态返给客户端,如有必要,也可以生成用户表中的记录。
此时我就认为这个用户是通过微信合法登录到我的系统中了。
有些字段或者信息之类的可能会描述得不够精确,但是整个鉴权的思路大概就是这样。
微信小程序登录
wx.login + code2Session 无感登录
如果你的业务系统需要鉴权大部分接口,但是又不想让用户一打开小程序就去输入啥或者点啥按钮登录,那么无感登录是比较适合的。
关键是找到能唯一标识用户身份的东西,openid 或者 unionid 就不错。那么怎么无感得到这些?wx.login + code2Session 值得拥有。
小程序前端 wx.login 得到用户登录凭证 code(目前说的有效期是五分钟),然后把 code 传给服务端,服务端调用微信服务的 auth.code2Session,使用 code 换取 openid、unionid、session_key 等信息,session_key 相当于是当前用户在微信的会话标识,我们可以基于此自定义登录态再返回给前端,前端拿着登录态再访问后端的业务接口。
getPhonenumber授权手机号登录
当指定 button 组件的 open-type 为 getPhoneNumber 时,可以拉起手机号授权,手机号某种程度上可以标识用户身份,自然也可以用来做登录。
旧版方案中,getPhonenumber得到的 e 对象中有 encryptedData, iv 字段,传给后端,根据解密算法能得到手机号和区号等信息。手机号也相当于是一种可以唯一标识用户的信息(虽然一个人可以有多个手机号,不过宽松点来说也可以用来标识用户),自然可以用来生成用户表记录,后续再与其他信息做关联即可。
但是旧版方案已经不建议使用了,目前 getPhonenumber得到的 e 对象中有 code 字段,这个 code 和 wx.login 得到的 code 不是同一回事。我们把这个 code 传给后端,后端再调用 phonenumber.getPhoneNumber得到手机号信息。
接着再封装登录态返回给前端即可。
微信公众号登录
首先分析一下渠道,在微信环境中,用户可能会直接通过链接访问 H5,也可能通过公众号菜单进入 H5。
微信公众号网页提供了授权方案,具体可以参考这个网页授权文档。
授权有两种形式,snsapi_base 和 snsapi_userinfo。
这个授权是支持无感的,具体见这个解释。
关于特殊场景下的静默授权
上面已经提到,对于以snsapi_base为 scope 的网页授权,就静默授权的,用户无感知;
对于已关注公众号的用户,如果用户从公众号的会话或者自定义菜单进入本公众号的网页授权页,即使是 scope 为snsapi_userinfo,也是静默授权,用户无感知。
这基本上就是说,如果是 snsapi_base 方式,目的主要是取 token 和 openid,用来做后续业务鉴权,那就是无感的。
如果是 snsapi_userinfo 方式,除了拿鉴权信息,还要要拿头像昵称等信息,可能需要用户授权,不过只要关注了该公众号,也可以不出现授权中间页,也是无感的。
下面说下具体的交互形式。
snsapi_base 场景下,需要绑定一个回调地址,交互形式是:
根据标准格式提供链接:
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=snsapi_base&state=STATE#wechat_redirect你可以在公众号菜单跳转这个标准链接,或者通过其他网页跳转这个链接。这个链接是个微信鉴权的中间页,如果鉴权没问题就会回调到 REDIRECT_URI 对应的业务系统页面,也就是用户真正前往的网页,用户能感知到的就是网页的进度条加载了两次,然后就到目标页面了,基本上是无感的。
页面在回调时会在 querystring 上携带 code 参数。前端在这个页面拿到 code 后,可以传给后端,后端就可以调下面这个接口得到 token 信息,然后封装出登录态返给前端。
https://api.weixin.qq.com/sns/oauth2/access_token?appid=APPID&secret=SECRET&code=CODE&grant_type=authorization_code具体实现时,不一定要在页面层级上完成 code 换 token 的操作,也可以在应用层级上实现。
后续可以根据需要进行 refreshToken。
snsapi_userinfo 场景下,也是跳一个标准链接。与 snsapi_base 场景相比,除了 scope 参数不一样,其他都一样。跳转这个标准链接时会根据有没有关注公众号决定是否要拉起授权中间页面。
https://open.weixin.qq.com/connect/oauth2/authorize?appid=APPID&redirect_uri=REDIRECT_URI&response_type=code&scope=snsapi_userinfo&state=STATE#wechat_redirect接着也可以根据 code 换 token,进行必要的 refreshToken。
最重要的是,在 scope=snsapi_userinfo 场景下,还可以发起获取用户信息的请求,这才是它与 snsapi_base 的本质区别。如果 scope 不符合要求,则无法通过调用下面的接口得到用户信息。
https://api.weixin.qq.com/sns/userinfo?access_token=ACCESS_TOKEN&openid=OPENID&lang=zh_CN还有一些公告调整内容要注意一下:
结语
好了,前端常见的一些登录方式先整理到这里,实际上还有很多种方案还没提到,比如生物认证登录,运营商验证登录等等,后面再补充,只要是双方互相认可的方案,并且能标识用户身份,不管是严格的还是宽松的,都可以拿来做认证使用,具体还要根据你的业务特性决定。
作者:Tusi
来源:juejin.cn/post/7172026468535369735
给你的网站接入 github 提供的第三方登录
什么年代了还在用传统账号密码登录?没钱买手机号验证码组合?直接把鉴权和用户系统全盘托出依赖第三方(又不是不能用),省去鉴权系列 SQL 攻击、密码加密、CSRF 攻击、XSS 攻击,老板再也不用担心黑产盗号了(我们的系统根本没有号)
要实现上面的功能就得接入第三方登录,接下来就随着文章一起试试吧!
github
本章节将使用 github 作为第三方登录服务提供商
github 不愧是阿美力卡之光,极其简便的操作即可开启你的第三方登录之旅,经济又实惠,你可以通过快捷链接进入创建 OAuth 应用界面,也可以按照下面的顺序
然后填写相应的信息
生成你的密钥(Client secrets),就可以去试试第三方登录了
组合 URL
您可以在线查看本章节源代码
这里我使用的是 express-generator 去生成项目,并且前后端分离,在选项上不需要 HTML 渲染器
npx express --no-view your-project-path && cd your-project-path前端部分简单设置一下跳转验证
<html>
<body>
<div>
第三方登录
<br />
<button onclick="handleGithubLoginClick()">github</button>
</div>
</body>
<script>
const handleGithubLoginClick = () => {
const state = Math.floor(Math.random() * Math.pow(10, 8));
localStorage.setItem("state", state);
window.open(
`https://github.com/login/oauth/authorize?client_id=b351931efd1203b2230e&redirect_uri=http://localhost:8080&state=${state}`,
"_blank"
);
};
</script>
</html>其中有三个比较重要的 params
redirect_uri 默认是注册 OAuth 应用(Register a new OAuth application)是填写的授权回调 URL(Authorization callback URL)
而对于 state 就在前端用随机字符串模拟,通常此类加密的敏感数据会再后端生成,而这里为了方便演示就采用了前端生成
详细参数请参考文档
鉴权验证
登录之后就可以进行相对应的验证,比如输入账号密码、授权、Github 客户端验证
成功鉴权后会再新弹出的页面重定向至 redirect_uri
注意要在属于用户操作的范畴下,比如点击按钮的操作,去使用 window.open(strUrl, strWindowName, [strWindowFeatures]) 这种方式去跳转鉴权,否则像 window.open("https://github.com...", "_blank") 这种常见的写法,会报错
浏览器会以为是弹窗式广告,所以我推荐使用直接在当前窗口跳转的方法,而不是选择新开窗口或者浮动窗口
window.location.href = "https://github.com/login/oauth/authorize?client_id=b351931efd1203b2230e&redirect_uri=http://localhost:8080";处理回调
通过用户授权时,Github 的响应如下
GET redirect_uri参数
| 名称 | 类型 | 说明 |
|---|---|---|
code | string | 鉴权通过的响应代码 |
state | string | 请求第三方登录时防 csrf 凭证 |
state 参数负责安全非常重要,想要快速通关的选手可以跳过这部分
对于这里的 state 处理可以分为前端处理和后端处理
前端处理
当 redirect_uri 是前端路由时,可以将之前提交的 state 从 localStorage 或者 sessionStorage 中取出,验证是否一致,再去向后端请求并带上 state 和 code
优点
无需缓存
state
缺点
需要防止
XSS的DOM型攻击
后端处理
当 redirect_uri 是后端时,后端需要持有 state 的缓存,具体做法可以在前端处理第三方登录时同步随机生成的 state,并在后端缓存
优点
不需要防止
XSS的DOM型攻击
缺点
需要缓存
state
科普:早期 token 其实就是这里的 state
获取 token
第三方登录从本质上来讲就是获取到 token,在安全的拿到 code 和 state 之后,需要向 github 发送获取 token 请求,其文档如下
POST https://github.com/login/oauth/access_token参数
| 名称 | 类型 | 说明 |
|---|---|---|
client_id | string | 必填。 从 GitHub 收到的 OAuth App 的客户端 ID。 |
client_secret | string | 必填。 从 GitHub 收到的 OAuth App 的客户端密码。 |
code | string | 必填。 收到的作为对步骤 1 的响应的代码。 |
redirect_uri | string | 用户获得授权后被发送到的应用程序中的 URL。 |
响应
| 名称 | 类型 | 说明 |
|---|---|---|
access_token | string | github 的 token |
scope | string | 参考文档 |
token_type | string | token 类型 |
注意因为 client_secret 属于私钥,所以该请求必须放在后端,不能在前端请求!否则会失去登录的意义
const { default: axios } = require("axios");
const express = require("express");
const router = express.Router();
router.post("/redirect", function (req, res, next) {
const { code } = req.body;
axios({
method: "POST",
url: "https://github.com/login/oauth/access_token",
headers: {
"Accept": "application/json",
},
timeout: 60 * 1000,
data: {
client_id: "your_client_id",
client_secret: "your_client_secret",
code,
},
})
.then((response) => {
res.send(response.data);
})
.catch((e) => {
res.status(404);
});
});
module.exports = router;注意,由于 github 的服务器在国外,所以这个请求非常容易超时或者失效,建议做好对应的处理(或者设置一个比较长的时间)
最后拿到对应的 token
总结
如果还没有了解过第三方登录的同学可以试试,毕竟不需要审核,有对应的 github 账号就行,截至写完文章的现在,我仍然没有通过微博第三方登录的审核/(ㄒoㄒ)/~~
参考资料
作者:2分钟速写快排
来源:juejin.cn/post/7181114761394782269
electron-egg 当代桌面开发框架,轻松入门electron
当前技术社区中出现了各种下一代技术或框架,却很少有当代可以用的,于是electron-egg就出现了。
它愿景很大:希望所有开发者都能学会桌面软件开发
当前桌面软件技术有哪些?
| 语言 | 技术 | 优点 | 缺点 |
|---|---|---|---|
| C# | wpf | 专业的桌面软件技术,功能强大 | 学习成本高 |
| Java | swing/javaFx | 跨平台和语言流行 | GUI库少,界面不美观 |
| C++ | Qt | 跨平台,功能和类库丰富 | 学习成本高 |
| Swift | 无 | 非跨平台,文档不友好,UI库少 | |
| JS | electron | 跨平台,入门简单,UI强大,扩展性强 | 内存开销大,包体大。 |
为什么使用electron?
某某说:我们的应用要兼容多个平台,原生开发效率低,各平台研发人员不足,我们没有资源。
也许你觉得只是中小公司没有资源,no!大公司更没有资源。因为软件体量越大,所需研发人员越多。再加上需要多平台支持的话,研发人员更是指数级增长的。
我们来看看QQ团队负责人最近的回应吧:
“感谢大家对新版桌面QQ NT的使用和关注,今年QQ团队启动了QQ的架构升级计划,第一站就是解决目前桌面端迭代慢的问题,我们使用新架构从前到后对QQ代码进行了重构,而其中选择使用Electron作为新版QQ桌面端UI跨平台解决方案,是基于提升研发效率、框架成熟度、团队技术及人才积累等几个方面综合考虑的结果。”
也许electron的缺点很明显,但它的投入产出比却是最高的。
所以,对企业而言,效率永远是第一位的。不要用程序员的思维去思考产品。
哪些企业或软件在使用electron?
国内:抖音客户端、百度翻译、阿里云盘、B站客户端、迅雷、网易有道云、QQ(doing) 等
国外:vscode、Slack、Atom、Discord、Skype、WhatsApp、等
你的软件用户体量应该没有上面这些公司多吧?所以你还有什么可担心的呢?
开发者 / 决策者不要去关心性能、包体大小这些东西,当你的产品用户少时,它没意义;当你的产品用户多时,找nb的人把它优化。
聊聊electron-egg框架
EE是一个业务框架;就好比 Spring之于java,thinkphp之于php,nuxt.js之于vue;electron只提供了基础的函数和api,但你写项目的时候,业务和代码工程化是需要自己实现的,ee就提供了这个工程化能力。
特性
🍄 跨平台:一套代码,可以打包成windows版、Mac版、Linux版、国产UOS、Deepin、麒麟等
🌹 简单高效:只需学习 js 语言
🌱 前端独立:理论上支持任何前端技术,如:vue、react、html等等
🌴 工程化:可以用前端、服务端的开发思维,来编写桌面软件
🍁 高性能:事件驱动、非阻塞式IO
🌷 功能丰富:配置、通信、插件、数据库、升级、打包、工具... 应有尽有
🌰 安全:支持字节码加密、压缩混淆加密
💐 功能demo:桌面软件常见功能,框架集成或提供demo
谁可以使用electron-egg?
前端、服务端、运维、游戏等技术人员皆可使用。我相信在你的工作生涯中,或多或少都接触过js,恭喜你,可以入门了。
为什么各种技术栈的开发者都能使用electron-egg?
这与它的架构有关。
第一:前端独立
你可以用vue、react、angular等开发框架;也可用antdesign、layui、bootstrap等组件库;或者你用cococreater开发游戏也行; 框架只需要最终构建的资源(html/css/js)。
第二:工程化-MVC编程模式
如果你是java、php、python等后端开发者,不懂js那一套编程模式怎么办?
没关系,框架已经为你提供了MVC(controller/service/model/view),是不是很熟悉?官方提供了大量业务场景demo,直接开始撸代码吧。
开箱即用
编程方法、插件、通信、日志、数据库、调试、脚本工具、打包工具等开发需要的东西,框架都已经提供好了,你只需要专注于业务的实现。
十分钟体验
安装
# 下载
git clone https://gitee.com/dromara/electron-egg.git
# 安装依赖
npm install
# 启动
npm run start效果
界面中的功能是demo,方便初学者入门。
项目案例
EE框架已经应用于医疗、学校、政务、股票交易、ERP、娱乐、视频、企业等领域客户端
以下是部分开发者使用electron-egg开发的客户端软件,请看效果
后语
仓库地址,欢迎给项目点赞!
gitee : gitee.com/dromara/ele… 2300+
github : github.com/dromara/ele… 500+
关于 Dromara
Dromara 是由国内顶尖的开源项目作者共同组成的开源社区。提供包括分布式事务,流行工具,企业级认证,微服务RPC,运维监控,Agent监控,分布式日志,调度编排等一系列开源产品、解决方案与咨询、技术支持与培训认证服务。技术栈全面开源共建、 保持社区中立,致力于为全球用户提供微服务云原生解决方案。让参与的每一位开源爱好者,体会到开源的快乐。
Dromara开源社区目前拥有10+GVP项目,总star数量超过十万,构建了上万人的开源社区,有成千上万的个人及团队在使用Dromara社区的开源项目。
electron-egg已加入dromara组织。
作者:哆啦好梦
来源:juejin.cn/post/7181279242628366397
纯 JS 简单实现类似 404 可跳跃障碍物页面
废话开篇:一些 404 页面为了体现趣味性会添加一些简单的交互效果。 这里用纯 JS 简单实现类似 404 可跳跃障碍物页面,内容全部用 canvas 画布实现。
一、效果展示
二、画面拆解
1、绘制地平线
地平线这里就是简单的一条贯穿屏幕的线。
2、绘制红色精灵
绘制红色精灵分为两部分:
(1)上面圆
(2)下面定点与上面圆的切线。
绘制结果:
进行颜色填充,再绘制中小的小圆,绘制结果:
(3)绘制障碍物
这里绘制的是一个黑色的长方形。最后的实现效果:
三、逻辑拆解
1、全局定时器控制画布重绘
创建全局的定时器。
它有两个具体任务:
(1)全局定时刷新重置,将画布定时擦除之前的绘制结果。
(2)全局定时器刷新动画重绘新内容。
2、精灵跳跃动作
在接收到键盘 “空格” 点击的情况下,让精灵起跳一定高度,到达顶峰的时候进行回落,当然这里设计的是匀速。
3、障碍物移动动作
通过定时器,重绘障碍物从最右侧移动到最左侧。
4、检测碰撞
在障碍物移动到精灵位置时,进行碰撞检测,判断障碍物最上端的左、右顶点是否在精灵的内部。
5、绘制提示语
提示语也是用 canvas 绘制的,当障碍物已移动到左侧的时候进行,结果判断。如果跳跃过程中无碰撞,就显示 “完美跳跃~”,如果调跃过程中有碰撞,就显示 “再接再厉”。
四、代码讲解
1、HTML
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<script src="./wsl404.js"></script>
</head>
<body>
<div id="content">
<canvas id="myCanvas">
</canvas>
</div>
</body>
<script>
elves.init();
</script>
</html>2、JS
(function WSLNotFoundPage(window) {
var elves = {};//精灵对象
elves.ctx = null;//画布
elves.width = 0;//屏幕的宽度
elves.height = 0;//屏幕的高度
elves.point = null;//精灵圆中心
elves.elvesR = 20;//精灵圆半径
elves.runloopTargets = [];//任务序列(暂时只保存跳跃)
elves.upDistance = 50;//当前中心位置距离地面高度
elves.upDistanceInitNum = 50;//中心位置距离地面高度初始值
elves.isJumping = false;//是否跳起
elves.jumpTarget = null;//跳跃任务
elves.jumpTop = false;//是否跳到最高点
elves.maxCheckCollisionWith = 0;//碰撞检测的最大宽度尺寸
elves.obstaclesMovedDistance = 0;//障碍物移动的距离
elves.isCollisioned = false;//是否碰撞过
elves.congratulationFont = 13;//庆祝文字大小
elves.congratulationPosition = 40;//庆祝文字位移
elves.isShowCongratulation = false;//是否展示庆祝文字
elves.congratulationContent = "完美一跃~";
elves.congratulationColor = "red";
//初始化
elves.init = function(){
this.drawFullScreen("content");
this.drawElves(this.upDistance);
this.keyBoard();
this.runloop();
}
//键盘点击事件
elves.keyBoard = function(){
var that = this;
document.onkeydown = function whichButton(event)
{
if(event.keyCode == 32){
//空格
that.elvesJump();
}
}
}
//开始跑圈
elves.runloop = function(){
var that = this;
setInterval(function(){
//清除画布
that.cleareAll();
//绘制障碍物
that.creatObstacles();
if(that.isJumping == false){
//未跳起时重绘精灵
that.drawElves(that.upDistanceInitNum);
}
//绘制地面
that.drawGround();
//跳起任务
for(index in that.runloopTargets){
let target = that.runloopTargets[index];
if(target.isRun != null && target.isRun == true){
if(target.runCallBack){
target.runCallBack();
}
}
}
//碰撞检测
that.checkCollision();
//展示庆祝文字
if(that.isShowCongratulation == true){
that.congratulation();
}
},10);
}
//画布
elves.drawFullScreen = function (id){
var element = document.getElementById(id);
this.height = window.screen.height - 200;
this.width = window.screen.width;
element.style.width = this.width + "px";
element.style.height = this.height + "px";
element.style.background = "white";
this.getCanvas("myCanvas",this.width,this.height);
}
elves.getCanvas = function(id,width,height){
var c = document.getElementById(id);
this.ctx = c.getContext("2d");
//锯齿修复
if (window.devicePixelRatio) {
c.style.width = this.width + "px";
c.style.height = this.height + "px";
c.height = height * window.devicePixelRatio;
c.width = width * window.devicePixelRatio;
this.ctx.scale(window.devicePixelRatio, window.devicePixelRatio);
}
};
//绘制地面
elves.drawGround = function() {
// 设置线条的颜色
this.ctx.strokeStyle = 'gray';
// 设置线条的宽度
this.ctx.lineWidth = 1;
// 绘制直线
this.ctx.beginPath();
// 起点
this.ctx.moveTo(0, this.height / 2.0 + 1);
// 终点
this.ctx.lineTo(this.width,this.height / 2.0);
this.ctx.closePath();
this.ctx.stroke();
}
//绘制精灵
elves.drawElves = function(upDistance){
//绘制圆
var angle = Math.acos(this.elvesR / upDistance);
this.point = {x:this.width / 3,y : this.height / 2.0 - upDistance};
this.ctx.fillStyle = "#FF0000";
this.ctx.lineWidth = 1;
this.ctx.beginPath();
this.ctx.arc(this.point.x,this.point.y,this.elvesR,Math.PI / 2 + angle,Math.PI / 2 - angle,false);
//绘制切线
var bottomPoint = {x:this.width / 3,y : this.point.y + this.upDistanceInitNum};
let leftPointY = this.height / 2.0 - (upDistance - Math.cos(angle) * this.elvesR);
let leftPointX = this.point.x - (Math.sin(angle) * this.elvesR);
var leftPoint = {x:leftPointX,y:leftPointY};
let rightPointY = this.height / 2.0 - (upDistance - Math.cos(angle) * this.elvesR);
let rightPointX = this.point.x + (Math.sin(angle) * this.elvesR);
var rightPoint = {x:rightPointX,y:rightPointY};
this.maxCheckCollisionWith = (rightPointX - leftPointX) * 20 / (upDistance - Math.cos(angle) * this.elvesR);
this.ctx.moveTo(bottomPoint.x, bottomPoint.y);
this.ctx.lineTo(leftPoint.x,leftPoint.y);
this.ctx.lineTo(rightPoint.x,rightPoint.y);
this.ctx.closePath();
this.ctx.fill();
//绘制小圆
this.ctx.fillStyle = "#FFF";
this.ctx.lineWidth = 1;
this.ctx.beginPath();
this.ctx.arc(this.point.x,this.point.y,this.elvesR / 3,0,Math.PI * 2,false);
this.ctx.closePath();
this.ctx.fill();
}
//清除画布
elves.cleareAll = function(){
this.ctx.clearRect(0,0,this.width,this.height);
}
//精灵跳动
elves.elvesJump = function(){
if(this.isJumping == true){
return;
}
this.isJumping = true;
if(this.jumpTarget == null){
var that = this;
this.jumpTarget = {type:'jump',isRun:true,runCallBack:function(){
let maxDistance = that.upDistanceInitNum + 55;
if(that.jumpTop == false){
if(that.upDistance > maxDistance){
that.jumpTop = true;
}
that.upDistance += 1;
} else if(that.jumpTop == true) {
that.upDistance -= 1;
if(that.upDistance < 50) {
that.upDistance = 50;
that.jumpTop = false;
that.jumpTarget.isRun = false;
that.isJumping = false;
}
}
that.drawElves(that.upDistance);
}};
this.runloopTargets.push(this.jumpTarget);
} else {
this.jumpTarget.isRun = true;
}
}
//绘制障碍物
elves.creatObstacles = function(){
let obstacles = {width:20,height:20};
if(this.obstaclesMovedDistance != 0){
this.ctx.clearRect(this.width - obstacles.width - this.obstaclesMovedDistance + 0.5, this.height / 2.0 - obstacles.height,obstacles.width,obstacles.height);
}
this.obstaclesMovedDistance += 0.5;
if(this.obstaclesMovedDistance >= this.width + obstacles.width) {
this.obstaclesMovedDistance = 0;
//重置是否碰撞
this.isCollisioned = false;
}
this.ctx.beginPath();
this.ctx.fillStyle = "#000";
this.ctx.moveTo(this.width - obstacles.width - this.obstaclesMovedDistance, this.height / 2.0 - obstacles.height);
this.ctx.lineTo(this.width - this.obstaclesMovedDistance,this.height / 2.0 - obstacles.height);
this.ctx.lineTo(this.width - this.obstaclesMovedDistance,this.height / 2.0);
this.ctx.lineTo(this.width - obstacles.width - this.obstaclesMovedDistance, this.height / 2.0);
this.ctx.closePath();
this.ctx.fill();
}
//检测是否碰撞
elves.checkCollision = function(){
var obstaclesMarginLeft = this.width - this.obstaclesMovedDistance - 20;
var elvesUpDistance = this.upDistanceInitNum - this.upDistance + 20;
if(obstaclesMarginLeft > this.point.x - this.elvesR && obstaclesMarginLeft < this.point.x + this.elvesR && elvesUpDistance <= 20) {
//需要检测的最大范围
let currentCheckCollisionWith = this.maxCheckCollisionWith * elvesUpDistance / 20;
if((obstaclesMarginLeft < this.point.x + currentCheckCollisionWith / 2.0 && obstaclesMarginLeft > this.point.x - currentCheckCollisionWith / 2.0) || (obstaclesMarginLeft + 20 < this.point.x + currentCheckCollisionWith / 2.0 && obstaclesMarginLeft + 20 > this.point.x - currentCheckCollisionWith / 2.0)){
this.isCollisioned = true;
}
}
//记录障碍物移动到精灵左侧
if(obstaclesMarginLeft + 20 < this.point.x - this.elvesR && obstaclesMarginLeft + 20 > this.point.x - this.elvesR - 1){
if(this.isCollisioned == false){
//跳跃成功,防止检测距离内重复得分置为true,在下一次循环前再置为false
this.isCollisioned = true;
//庆祝
if(this.isShowCongratulation == false) {
this.congratulationContent = "完美一跃~";
this.congratulationColor = "red";
this.isShowCongratulation = true;
}
} else {
//鼓励
if(this.isShowCongratulation == false) {
this.isShowCongratulation = true;
this.congratulationColor = "gray";
this.congratulationContent = "再接再厉~";
}
}
}
}
//庆祝绘制文字
elves.congratulation = function(){
this.congratulationFont += 0.1;
this.congratulationPosition += 0.1;
if(this.congratulationFont >= 30){
//重置
this.congratulationFont = 13;
this.congratulationPosition = 30;
this.isShowCongratulation = false;
return;
}
this.ctx.fillStyle = this.congratulationColor;
this.ctx.font = this.congratulationFont + 'px "微软雅黑"';
this.ctx.textBaseline = "bottom";
this.ctx.textAlign = "center";
this.ctx.fillText( this.congratulationContent, this.point.x, this.height / 2.0 - this.upDistanceInitNum - this.congratulationPosition);
}
window.elves = elves;
})(window)五、总结与思考
逻辑注释基本都写在代码里,里面的一些计算可能会绕一些。
作者:头疼脑胀的代码搬运工
来源:juejin.cn/post/7056610619490828325
关于自建组件库的思考
很多公司都会有自己的组件库,但是在使用起来都不尽如人意,这里分享下我自己的一些观点和看法
问题思考
在规划这种整个团队都要用的工具之前要多思考,走一步想一步的方式是不可取的
首先,在开发一个组件库之前先要明确以下几点:
目前现状
不自建的话会有哪些问题,为什么不用 antd/element
哪些人提出了哪些的问题
分析为什么会出现这些问题
哪些问题是必须解决的,哪些是阶段推进的
期望目标
组件库的定位是什么
自建组件库是为了满足什么场景
阶段目标是什么
最终期望达到什么效果
具体实现
哪些问题用哪些方法来解决
关于后续迭代是怎么考虑的
目前现状
仅仅是因为前端开发为了部分代码或者样式不用重复写就封装一个组件甚至组件库是一件很搞笑的事情,最终往往会出现以下问题:
代码分散但是却高耦合,存在很多职责不明确
封装过于死板,且暴露的属性职责不明确
可维护性低,无法应对不断变化的需求
可靠性低,对上游数据不做错误处理,对下游使用者不做兼容处理
最后没法迭代,因为代码质量及版本问题,连原始开发者都改不动的,相关使用者怨声载道,然后又重构一遍,还是同样的设计思路,只不过基于已知业务场景改了写法,然后过一段时间又成为一个新的历史包袱。。。
当你为了方便改别人的代码而选择 fork 别人的组件库下来简单改改再输出时,难道你觉得别人不会对“你写的”这个组件库持同样的看法么?
你会发现,如果仅仅以一个业务员的角度去寻求解决办法的话,最后往往不能够得到其他业务员的认可的~
组件库的存在目的是为了提高团队的工作效率,不是单纯为了个别人能少写代码,前者才是目的,后者只是其中一种实现方式(这句话自己悟吧)
期望目标
一个合格的组件库应该要让使用者感受到两点:
约束(为什么只能这样传嘛?)
方便(只要这样传就可以耶~)
不合格的组件库往往只关注后者,但是其实前者更加重要
在能实现甲方的需求前提下,约束的树立会让团队对某一问题形成一个固有的解决方案,这个使用过程会促成惯性的产生
同时,这个惯性一旦建立,就能促成两个结果:
弥合了人与人之间的差异
提高了交流效率(不单单是开发,还包括设计、产品、测试等一条工作链路上的相关人)
要知道的是,团队合作过程中,效率最低的环节永远是沟通,一个好的团队不是全员大神,而是做什么事情以一个整体,每个人步调趋于一致,这样效率才高~
具体实现
编写一个公共库需要考虑很多东西,下面主要分三点来阐述
逻辑的分割
避免一次性、不通用、没必要的封装
不允许出现相互跨级或交叉引用的情况,应形成明确的上下级关系
被抽离的逻辑代码应该尽可能的“独立“,避免变成”谁也离不开谁”
逻辑的封装
对于一个管理平台框架来说,宗旨是让开发少写代码、产品少写文档,不需要每次有新业务都要重复产出
对于开发来说,具体有两点:
大部分情况下,能拷贝下 demo 即可实现各类交互效果
小部分情况下,组件能提供其他更多的可能以满足特殊需求
封装过程中,仅暴露关键属性,提供多种可能,并且以比较常用的值作为“默认值”并明确定义,即可满足“大部分需求只需无脑引用,同时小部分的特殊需求也能被满足”
维护与开发
作为一个上游的 UI 库,要充分考虑下游使用者的情况
做到升级后保证下游大部分情况下不需要改动
组件的新增、删除、修改要有充分的理由(需求或 bug),并且要遵循最小影响原则
组件的设计要充分考虑日后可能发生的变化
未来展望
仅靠一个 UI 框架难以解决问题,对于未来的想法有分成三个阶段:
UI 库,沉淀稳定高效的组件
代码片段生成器,收集业务案例代码
页面生成器,输出有效模版
这里更多面向的是中后台项目的解决方案
总结
组件库输出约束和统一解决办法,前者通过抚平团队中个体的差异来提高团队的沟通效率,后者通过形成工作惯性来提高团队的工作效率
作者:tellyourmad
来源:juejin.cn/post/7063017892714905608
不就是代码缩进吗?别打起来啊
免战申明
本文不讨论两种缩进方式的优劣,只提供一种能够同时兼容大家关于缩进代码风格的解决方案
字符缩进,2还是4?
很久之前,组内开发时发现大家的tab.size不一样,有的伙伴表示都能接受,有的伙伴习惯使用2字符缩进,有的伙伴习惯4字符缩进,导致开发起来很痛苦,一直在寻找兼容大家代码风格的办法,今天终于研究出一种解决方案(不一定适用所有人)。
工具准备
vscode
prettierrc插件
解决方案
首先设置"editor.tabSize"为自己习惯的tabSize
设置tab按下时不插入空格"editor.insertSpaces": false
项目根目录下创建.prettierrc(可添加到.gitignore),设置"useTabs": true
{
"printWidth": 180,
"semi": true,
"singleQuote": true,
//使用tab进行格式化
"useTabs": true
}设置展示效果"editor.renderWhitespace": "selection"
最终效果
可以看到,编辑器内设置不同的代码缩进,展示效果不同,但最终提交的代码风格一致。 (小缺陷:对于强制要求使用空格代替tab的情况不适用)
作者:断律绎殇
来源:juejin.cn/post/7095001798120833061
面试官:你如何实现大文件上传
提到大文件上传,在脑海里最先想到的应该就是将图片保存在自己的服务器(如七牛云服务器),保存在数据库,不仅可以当做地址使用,还可以当做资源使用;或者将图片转换成base64,转换成buffer流,但是在javascript这门语言中不存在,但是这些只适用于一些小图片,对于大文件还是束手无策。
一、问题分析
如果将大文件一次性上传,会发生什么?想必都遇到过在一个大文件上传、转发等操作时,由于要上传大量的数据,导致整个上传过程耗时漫长,更有甚者,上传失败,让你重新上传!这个时候,我已经咬牙切齿了。先不说上传时间长久,毕竟上传大文件也没那么容易,要传输更多的报文,丢包也是常有的事,而且在这个时间段万不可以做什么其他会中断上传的操作;其次,前后端交互肯定是有时间限制的,肯定不允许无限制时间上传,大文件又更容易超时而失败....
一、解决方案
既然大文件上传不适合一次性上传,那么将文件分片散上传是不是就能减少性能消耗了。
没错,就是分片上传。分片上传就是将大文件分成一个个小文件(切片),将切片进行上传,等到后端接收到所有切片,再将切片合并成大文件。通过将大文件拆分成多个小文件进行上传,确实就是解决了大文件上传的问题。因为请求时可以并发执行的,这样的话每个请求时间就会缩短,如果某个请求发送失败,也不需要全部重新发送。
二、具体实现
1、前端
(1)读取文件
准备HTML结构,包括:读取本地文件(input类型为file)、上传文件按钮、上传进度。
<input type="file" id="input">
<button id="upload">上传</button>
<!-- 上传进度 -->
<div style="width: 300px" id="progress"></div>JS实现文件读取:
监听input的change事件,当选取了本地文件后,打印事件源可得到文件的一些信息:
let input = document.getElementById('input')
let upload = document.getElementById('upload')
let files = {}//创建一个文件对象
let chunkList = []//存放切片的数组
// 读取文件
input.addEventListener('change', (e) => {
files = e.target.files[0]
console.log(files);
//创建切片
//上传切片
})观察控制台,打印读取的文件信息如下:
(2)创建切片
文件的信息包括文件的名字,文件的大小,文件的类型等信息,接下来可以根据文件的大小来进行切片,例如将文件按照1MB或者2MB等大小进行切片操作:
// 创建切片
function createChunk(file, size = 2 * 1024 * 1024) {//两个形参:file是大文件,size是切片的大小
const chunkList = []
let cur = 0
while (cur < file.size) {
chunkList.push({
file: file.slice(cur, cur + size)//使用slice()进行切片
})
cur += size
}
return chunkList
}切片的核心思想是:创建一个空的切片列表数组chunkList,将大文件按照每个切片2MB进行切片操作,这里使用的是数组的Array.prototype.slice()方法,那么每个切片都应该在2MB大小左右,如上文件的大小是8359021,那么可得到4个切片,分别是[0,2MB]、[2MB,4MB]、[4MB,6MB]、[6MB,8MB]。调用createChunk函数,会返回一个切片列表数组,实际上,有几个切片就相当于有几个请求。
调用创建切片函数:
//注意调用位置,不是在全局,而是在读取文件的回调里调用
chunkList = createChunk(files)
console.log(chunkList);观察控制台打印的结果:
(3)上传切片
上传切片的个关键的操作:
第一、数据处理。需要将切片的数据进行维护成一个包括该文件,文件名,切片名的对象,所以采用FormData对象来进行整理数据。FormData 对象用以将数据编译成键值对,可用于发送带键数据,通过调用它的append()方法来添加字段,FormData.append()方法会将字段类型为数字类型的转换成字符串(字段类型可以是 Blob、File或者字符串:如果它的字段类型不是 Blob 也不是 File,则会被转换成字符串类。
第二、并发请求。每一个切片都分别作为一个请求,只有当这4个切片都传输给后端了,即四个请求都成功发起,才上传成功,使用Promise.all()保证所有的切片都已经传输给后端。
//数据处理
async function uploadFile(list) {
const requestList = list.map(({file,fileName,index,chunkName}) => {
const formData = new FormData() // 创建表单类型数据
formData.append('file', file)//该文件
formData.append('fileName', fileName)//文件名
formData.append('chunkName', chunkName)//切片名
return {formData,index}
})
.map(({formData,index}) =>axiosRequest({
method: 'post',
url: 'http://localhost:3000/upload',//请求接口,要与后端一一一对应
data: formData
})
.then(res => {
console.log(res);
//显示每个切片上传进度
let p = document.createElement('p')
p.innerHTML = `${list[index].chunkName}--${res.data.message}`
document.getElementById('progress').appendChild(p)
})
)
await Promise.all(requestList)//保证所有的切片都已经传输完毕
}
//请求函数
function axiosRequest({method = "post",url,data}) {
return new Promise((resolve, reject) => {
const config = {//设置请求头
headers: 'Content-Type:application/x-www-form-urlencoded',
}
//默认是post请求,可更改
axios[method](url,data,config).then((res) => {
resolve(res)
})
})
}
// 文件上传
upload.addEventListener('click', () => {
const uploadList = chunkList.map(({file}, index) => ({
file,
size: file.size,
percent: 0,
chunkName: `${files.name}-${index}`,
fileName: files.name,
index
}))
//发请求,调用函数
uploadFile(uploadList)
})2、后端
(1)接收切片
主要工作:
第一:需要引入multiparty中间件,来解析前端传来的FormData对象数据;
第二:通过path.resolve()在根目录创建一个文件夹--qiepian,该文件夹将存放另一个文件夹(存放所有的切片)和合并后的文件;
第三:处理跨域问题。通过setHeader()方法设置所有的请求头和所有的请求源都允许;
第四:解析数据成功后,拿到文件相关信息,并且在qiepian文件夹创建一个新的文件夹${fileName}-chunks,用来存放接收到的所有切片;
第五:通过fse.move(filePath,fileName)将切片移入${fileName}-chunks文件夹,最后向前端返回上传成功的信息。
//app.js
const http = require('http')
const multiparty = require('multiparty')// 中间件,处理FormData对象的中间件
const path = require('path')
const fse = require('fs-extra')//文件处理模块
const server = http.createServer()
const UPLOAD_DIR = path.resolve(__dirname, '.', 'qiepian')// 读取根目录,创建一个文件夹qiepian存放切片
server.on('request', async (req, res) => {
// 处理跨域问题,允许所有的请求头和请求源
res.setHeader('Access-Control-Allow-Origin', '*')
res.setHeader('Access-Control-Allow-Headers', '*')
if (req.url === '/upload') { //前端访问的地址正确
const multipart = new multiparty.Form() // 解析FormData对象
multipart.parse(req, async (err, fields, files) => {
if (err) { //解析失败
return
}
console.log('fields=', fields);
console.log('files=', files);
const [file] = files.file
const [fileName] = fields.fileName
const [chunkName] = fields.chunkName
const chunkDir = path.resolve(UPLOAD_DIR, `${fileName}-chunks`)//在qiepian文件夹创建一个新的文件夹,存放接收到的所有切片
if (!fse.existsSync(chunkDir)) { //文件夹不存在,新建该文件夹
await fse.mkdirs(chunkDir)
}
// 把切片移动进chunkDir
await fse.move(file.path, `${chunkDir}/${chunkName}`)
res.end(JSON.stringify({ //向前端输出
code: 0,
message: '切片上传成功'
}))
})
}
})
server.listen(3000, () => {
console.log('服务已启动');
})通过node app.js启动后端服务,可在控制台打印fields和files:
(2)合并切片
第一:前端得到后端返回的上传成功信息后,通知后端合并切片:
// 通知后端去做切片合并
function merge(size, fileName) {
axiosRequest({
method: 'post',
url: 'http://localhost:3000/merge',//后端合并请求
data: JSON.stringify({
size,
fileName
}),
})
}
//调用函数,当所有切片上传成功之后,通知后端合并
await Promise.all(requestList)
merge(files.size, files.name)第二:后端接收到合并的数据,创建新的路由进行合并,合并的关键在于:前端通过POST请求向后端传递的合并数据是通过JSON.stringify()将数据转换成字符串,所以后端合并之前,需要进行以下操作:
解析POST请求传递的参数,自定义函数
resolvePost,目的是将每个切片请求传递的数据进行拼接,拼接后的数据仍然是字符串,然后通过JSON.parse()将字符串格式的数据转换为JSON对象;接下来该去合并了,拿到上个步骤解析成功后的数据进行解构,通过
path.resolve获取每个切片所在的路径;自定义合并函数
mergeFileChunk,只要传入切片路径,切片名字和切片大小,就真的将所有的切片进行合并。在此之前需要将每个切片转换成流stream对象的形式进行合并,自定义函数pipeStream,目的是将切片转换成流对象,在这个函数里面创建可读流,读取所有的切片,监听end事件,所有的切片读取完毕后,销毁其对应的路径,保证每个切片只被读取一次,不重复读取,最后将汇聚所有切片的可读流汇入可写流;最后,切片被读取成流对象,可读流被汇入可写流,那么在指定的位置通过
createWriteStream创建可写流,同样使用Promise.all()的方法,保证所有切片都被读取,最后调用合并函数进行合并。
if (req.url === '/merge') { // 该去合并切片了
const data = await resolvePost(req)
const {
fileName,
size
} = data
const filePath = path.resolve(UPLOAD_DIR, fileName)//获取切片路径
await mergeFileChunk(filePath, fileName, size)
res.end(JSON.stringify({
code: 0,
message: '文件合并成功'
}))
}
// 合并
async function mergeFileChunk(filePath, fileName, size) {
const chunkDir = path.resolve(UPLOAD_DIR, `${fileName}-chunks`)
let chunkPaths = await fse.readdir(chunkDir)
chunkPaths.sort((a, b) => a.split('-')[1] - b.split('-')[1])
const arr = chunkPaths.map((chunkPath, index) => {
return pipeStream(
path.resolve(chunkDir, chunkPath),
// 在指定的位置创建可写流
fse.createWriteStream(filePath, {
start: index * size,
end: (index + 1) * size
})
)
})
await Promise.all(arr)//保证所有的切片都被读取
}
// 将切片转换成流进行合并
function pipeStream(path, writeStream) {
return new Promise(resolve => {
// 创建可读流,读取所有切片
const readStream = fse.createReadStream(path)
readStream.on('end', () => {
fse.unlinkSync(path)// 读取完毕后,删除已经读取过的切片路径
resolve()
})
readStream.pipe(writeStream)//将可读流流入可写流
})
}
// 解析POST请求传递的参数
function resolvePost(req) {
// 解析参数
return new Promise(resolve => {
let chunk = ''
req.on('data', data => { //req接收到了前端的数据
chunk += data //将接收到的所有参数进行拼接
})
req.on('end', () => {
resolve(JSON.parse(chunk))//将字符串转为JSON对象
})
})
}还未合并前,文件夹如下图所示:
合并后,文件夹新增了合并后的文件:
作者:来碗盐焗星球
来源:juejin.cn/post/7177045936298786872
我最喜欢高效学习前端的两种方式
先说结论:
看经典书
看官方文档
为什么是经典书籍
我买过很多本计算机、前端、JavaScript方面的书,在这方面也踩过一些坑,分享下我的经验。
在最早我也买过亚马逊的kindle,kindle的使用体验还不错,能达到和纸书差不多的阅读体验,而且很便携,但由于上面想看的书很多都没有,又懒得去折腾,所以后来就卖了。
之后就转到了纸书上,京东经常搞100减50的活动,买了很多的书,这些书有的只翻了几页,有的翻来覆去看了几遍。
翻了几页的也有两种情况,一种是内容质量太差,完全照抄文档,而且还是过时的文档,你们都知道,前端的技术更新是比较快的,框架等更新也很快,所以等书出版了,技术可能就已经翻篇了。
另一种就是过于专业的,比较复杂难懂,比如编译原理,深入了解计算机系统 算法(第4版)等这种计算机传世经典之作。
纸书其实也有缺点,它真的是太沉了,如果要是出差的话想要带几本书的话,都得去考虑考虑,带多了是真的重。
还有就是在搬家的时候,真的就是噩梦,我家里有将近100本的纸书,每次搬家真的就是累死了。
所以最近一两年我都很少买纸书了,如果有需要我都会尽量选择电子版。
电子版书走到哪里都能看,不会有纸书那么多限制,唯一缺点可能就是没有纸书那股味道。
还有就是电子书平台的问题,一个平台的书可能不全,比如我就有微信图书和京东这两个,这也和听歌看剧一样,想看个东西,还得去多个平台,如果要是能够统一的话就好了。
还有就是盗版的pdf,这个我也看过,有一些已经买不到的书,没办法只能去网上寻找资源了。建议大家如果能支持正版,还是支持正版,如果作者赚不到钱,慢慢就没有人愿意创作优质内容,久而久之形成了恶性循环。
看经典书学习前端,是非常好的方式之一,因为书是一整套系统的内容,它不同于网上的碎片化文章。同时好书也是经过成千上万人验证后的,我们只需选择对的就可以了。
我推荐几本我读过的比较好的前端方面的书
javascript高级程序设计
你不知道的javascript 上 中 下卷
狼书 卷1 卷2
关于计算机原理方面的书
编码:隐匿在计算机软硬件背后的语言
算法图解
图解http
大话数据结构
上面的书都是我买过,看过的,可能还有我不知道的,欢迎在评论中留言
这些书都有一些共同的特征,就是能经过时间的检验,不会过时,可以重复的去阅读,学习。
为什么是官方API文档
除了经典书之外,就是各种语言、框架的官方文档,这里一定注意是“官方文档”,因为百度里面搜索的结果里,有很多镜像的文档网站,官方第一时间发布的更新,他们有时并不能及时同步,所以接受信息就比人慢一步。所以一定要看“官方文档”。
比如要查询javascript、css的内容,就去mdn上查看。要去看nodejs就去nodejs的官网,要去看react、vue框架就去官网。尽量别去那些第三方网站。
作者:小帅的编程笔记
来源:juejin.cn/post/7060102025232515086
JS封装覆盖水印
废话开篇:简单实现一个覆盖水印的小功能,水印一般都是添加在图片上,然后直接加载处理过的图片url即可,这里并没有修改图片,而是直接的在待添加水印的 dom 上添加一个 canvas 蒙版。
一、效果
处理之前
DIV
IMG
处理之后
DIV
IMG
这里添加 “水印”(其实并不是真正的水印) 到 DIV 的时候按钮点击事件并不会因为有蒙版遮挡而无法点击
二、JS 代码
class WaterMark{
//水印文字
waterTexts = []
//需要添加水印的dom集合
needAddWaterTextElementIds = null
//保存添加水印的dom
saveNeedAddWaterMarkElement = []
//初始化
constructor(waterTexts,needAddWaterTextElementIds){
if(waterTexts && waterTexts.length != 0){
this.waterTexts = waterTexts
} else {
this.waterTexts = ['水印文字哈哈哈哈','2022-12-08']
}
this.needAddWaterTextElementIds = needAddWaterTextElementIds
}
//开始添加水印
startWaterMark(){
const self = this
if(this.needAddWaterTextElementIds){
this.needAddWaterTextElementIds.forEach((id)=>{
let el = document.getElementById(id)
self.saveNeedAddWaterMarkElement.push(el)
})
} else {
this.saveNeedAddWaterMarkElement = Array.from(document.getElementsByTagName('img'))
}
this.saveNeedAddWaterMarkElement.forEach((el)=>{
self.startWaterMarkToElement(el)
})
}
//添加水印到到dom对象
startWaterMarkToElement(el){
let nodeName = el.nodeName
if(['IMG','img'].indexOf(nodeName) != -1){
//图片,需要加载完成进行操作
this.addWaterMarkToImg(el)
} else {
//普通,直接添加
this.addWaterMarkToNormalEle(el)
}
}
//给图片添加水印
async addWaterMarkToImg(img){
if(!img.complete){
await new Promise((resolve)=>{
img.onload = resolve
})
}
this.addWaterMarkToNormalEle(img)
}
//给普通dom对象添加水印
addWaterMarkToNormalEle(el){
const self = this
let canvas = document.createElement('canvas')
canvas.width = el.width ? el.width : el.clientWidth
canvas.height = el.height ? el.height : el.clientHeight
let ctx = canvas.getContext('2d')
let maxSize = Math.max(canvas.height, canvas.width)
let font = (maxSize / 25)
ctx.font = font + 'px "微软雅黑"'
ctx.fillStyle = "rgba(195,195,195,1)"
ctx.textAlign = "left"
ctx.textBaseline = "top"
ctx.save()
let angle = -Math.PI / 10.0
//进行平移,计算平移的参数
let translateX = (canvas.height) * Math.tan(Math.abs(angle))
let translateY = (canvas.width - translateX) * Math.tan(Math.abs(angle))
ctx.translate(-translateX / 2.0, translateY / 2.0)
ctx.rotate(angle)
//起始坐标
let x = 0
let y = 0
//一组文字之间间隔
let sepY = (font / 2.0)
while(y < canvas.height){
//当前行的y值
let rowCurrentMaxY = 0
while(x < canvas.width){
let totleMaxX = 0
let currentY = 0
//绘制水印
this.waterTexts.forEach((text,index)=>{
currentY += (index * (sepY + font))
let rect = self.drawWater(ctx,text,x,y + currentY)
let currentMaxX = (rect.x + rect.width)
totleMaxX = (currentMaxX > totleMaxX) ? currentMaxX: totleMaxX
rowCurrentMaxY = currentY
})
x = totleMaxX + 20
}
//重置x,y值
x = 0
y += (rowCurrentMaxY + (sepY + font + (canvas.height / 5)))
}
ctx.restore()
//添加canvas
this.addCanvas(canvas,el)
}
//绘制水印
drawWater(ctx,text,x,y){
//绘制文字
ctx.fillText(text,x,y)
//计算尺度
let textRect = ctx.measureText(text)
let width = textRect.width
let height = textRect.height
return {x,y,width,height}
}
//添加canvas到当前标签的父标签上
addCanvas(canvas,el){
//创建div(canvas需要依赖一个div进行位置设置)
let warterMarDiv = document.createElement('div')
//关联水印dom对象
el.warterMark = warterMarDiv
//添加样式
this.resetCanvasPosition(el)
//添加水印
warterMarDiv.appendChild(canvas)
//添加到父标签
el.parentElement.insertBefore(warterMarDiv,el)
}
//重新计算位置
resetCanvasPosition(el){
if(el.warterMark){
//设置父标签的定位
el.parentElement.style.cssText = `position: relative;`
//设施水印载体的定位
el.warterMark.style.cssText = 'position: absolute;top: 0px;left: 0px;pointer-events:none'
}
}
}用法
<div>
<!-- 待加水印的IMG -->
<img style="width: 100px;height: auto" src="" alt="">
</div>
let waterMark = new WaterMark()
waterMark.startWaterMark();ctx.save() 与 ctx.restore() 其实在这里的作用不是很大,但还是添加上了,目的是保存添加水印前的上下文,跟结束绘制后恢复水印前的上下文,这样,这些斜体字只在这两行代码之间生效,下面如果再绘制其他,那么,将不受影响。
防止蒙版水印遮挡底层按钮或其他事件,需要添加 pointer-events:none 属性到蒙版标签上。
添加水印的标签外需要添加一个 父标签 ,这个 父标签 的作用就是添加约束 蒙版canvas 的位置,这里想通过 MutationObserver 观察 body 的变化来进行更新 蒙版canvas 的位置,这个尝试失败了,因为复杂的布局只要变动会都在这个回调里触发。因此,直接在添加水印的标签外需要添加一个 父标签 ,用这个 父标签 来自动约束 蒙版canvas 的位置。
MutationObserver 逻辑如下,在监听回调里可以及时修改布局或者其他操作(暂时放弃)。
var MutationObserver = window.MutationObserver || window.webkitMutationObserver || window.MozMutationObserver;
var mutationObserver = new MutationObserver(function (mutations) {
//修改水印位置
})
mutationObserver.observe(document.getElementsByTagName('body')[0], {
childList: true, // 子节点的变动(新增、删除或者更改)
attributes: true, // 属性的变动
characterData: true, // 节点内容或节点文本的变动
subtree: true // 是否将观察器应用于该节点的所有后代节点
})图片的大小只有在加载完成之后才能确定,所以,对于 IMG 的操作,需要观察它的 complete 事件。
三、总结与思考
用 canvas ctx.drawImage(img, 0, 0) 进行绘制,再将 canvas.toDataURL('image/png') 生成的 url 加载到之前的图片上,也是一种方式,但是,有时候会因为图片的原因导致最后的合成图片的 base64 数据是空,所以,直接增加一个蒙版,本身只是为了显示,并不是要生成真正的合成图片。实现了简单的伪水印,没有特别复杂的代码,代码拙劣,大神勿笑。
作者:头疼脑胀的代码搬运工
来源:juejin.cn/post/7174695149195231293




