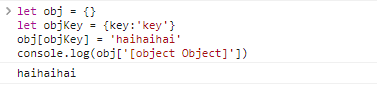

前言
七夕节马上就要到了,作为拥有对象(没有的话,可以选择 new 一个出来)的程序员来说,肯定是需要有一点表示才行的。用钱能买到的东西不一定能表达咱们的心意,但是用心去写的代码,还能让对象每天看到那才是最正确的选择。
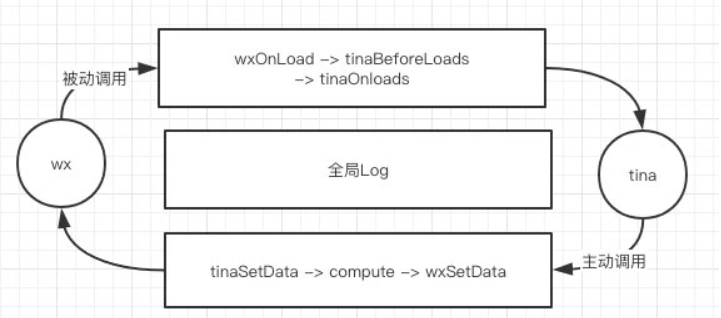
除了手机之外,在电脑上使用浏览器搜索想要的东西是最常用的功能了,所以就需要一个打开即用的搜索框,而且还能表达心意的chrome标签页来让 TA 随时可用。
新建项目
由于我们是做chrome标签页,所以新建的项目不需要任何框架,只需要最简单的HTML、js、css即可。
在任意地方新建一个文件夹chrome
在chrome目录下新建一个manifest.json文件
配置chrome插件
{
"name": "Every Day About You",
"description": "Every Day About You",
"version": "1.0",
"manifest_version": 2,
"browser_action": {
"default_icon": "ex_icon.png"
},
"permissions": [
"activeTab"
],
"content_scripts": [
{
"matches": [
""
],
"js": [
"demo.js",
"canvas.js"
],
"run_at": "document_start"
}
],
"chrome_url_overrides": {
"newtab": "demo.html"
},
"offline_enabled": true,
}
复制代码- name:扩展名称,加载扩展程序时显示的名称。
- description:描述信息,用于描述当前扩展程序,限132个字符。
- version:扩展程序版本号。
- manifest_version:manifest文件版本号。chrome18开始必须为2。
- browser_action:设置扩展程序的图标。
- permissions:需要申请的权限,这里使用tab即可。
- content_scripts:指定在页面中运行的js和css及插入时机。
- chrome_url_overrides:新标签页打开的html文件。
- offline_enabled:脱机运行。
还有很多配置项可以在chrome插件开发文档中查询到,这里因为不需要发布到chrome商店中,所以只需要配置一些固定的数据项。
新建HTML和JS
在配置项中的content_scripts和chrome_url_overrides中分别定义了html文件和js文件,所以我们需要新建这两个文件,名称对应即可。
HTML背景
没有哪个小天使可以拒绝来自程序猿霸道的满屏小心心好吗? 接下来我来教大家做一个飘满屏的爱心。
html>
<html>
<head>
<meta charset="utf-8">
<title>Every Day About Youtitle>
<script src="http://libs.baidu.com/jquery/1.10.2/jquery.min.js">script>
<script type="text/javascript" src="canvas.js" >script>
head>
<body>
<canvas id="c" style="position: absolute;z-index: -1;text-align: center;">canvas>
body>
html>
复制代码- 这里引入的 jquery 是 百度 的CDN(matches中配置了可以使用所有的URL,所以CDN是可以使用外部链接的。)
- canvas.js中主要是针对爱心和背景色进行绘画。
canvas
$(document).ready(function () {
var canvas = document.getElementById("c");
var ctx = canvas.getContext("2d");
var c = $("#c");
var w, h;
var pi = Math.PI;
var all_attribute = {
num: 100, // 个数
start_probability: 0.1, // 如果数量小于num,有这些几率添加一个新的
size_min: 1, // 初始爱心大小的最小值
size_max: 2, // 初始爱心大小的最大值
size_add_min: 0.3, // 每次变大的最小值(就是速度)
size_add_max: 0.5, // 每次变大的最大值
opacity_min: 0.3, // 初始透明度最小值
opacity_max: 0.5, // 初始透明度最大值
opacity_prev_min: .003, // 透明度递减值最小值
opacity_prev_max: .005, // 透明度递减值最大值
light_min: 0, // 颜色亮度最小值
light_max: 90, // 颜色亮度最大值
};
var style_color = find_random(0, 360);
var all_element = [];
window_resize();
function start() {
window.requestAnimationFrame(start);
style_color += 0.1;
//更改背景色hsl(颜色值,饱和度,明度)
ctx.fillStyle = 'hsl(' + style_color + ',100%,97%)';
ctx.fillRect(0, 0, w, h);
if (all_element.length < all_attribute.num && Math.random() < all_attribute.start_probability) {
all_element.push(new ready_run);
}
all_element.map(function (line) {
line.to_step();
})
}
function ready_run() {
this.to_reset();
}
function arc_heart(x, y, z, m) {
//绘制爱心图案的方法,参数x,y是爱心的初始坐标,z是爱心的大小,m是爱心上升的速度
y -= m * 10;
ctx.moveTo(x, y);
z *= 0.05;
ctx.bezierCurveTo(x, y - 3 * z, x - 5 * z, y - 15 * z, x - 25 * z, y - 15 * z);
ctx.bezierCurveTo(x - 55 * z, y - 15 * z, x - 55 * z, y + 22.5 * z, x - 55 * z, y + 22.5 * z);
ctx.bezierCurveTo(x - 55 * z, y + 40 * z, x - 35 * z, y + 62 * z, x, y + 80 * z);
ctx.bezierCurveTo(x + 35 * z, y + 62 * z, x + 55 * z, y + 40 * z, x + 55 * z, y + 22.5 * z);
ctx.bezierCurveTo(x + 55 * z, y + 22.5 * z, x + 55 * z, y - 15 * z, x + 25 * z, y - 15 * z);
ctx.bezierCurveTo(x + 10 * z, y - 15 * z, x, y - 3 * z, x, y);
}
ready_run.prototype = {
to_reset: function () {
var t = this;
t.x = find_random(0, w);
t.y = find_random(0, h);
t.size = find_random(all_attribute.size_min, all_attribute.size_max);
t.size_change = find_random(all_attribute.size_add_min, all_attribute.size_add_max);
t.opacity = find_random(all_attribute.opacity_min, all_attribute.opacity_max);
t.opacity_change = find_random(all_attribute.opacity_prev_min, all_attribute.opacity_prev_max);
t.light = find_random(all_attribute.light_min, all_attribute.light_max);
t.color = 'hsl(' + style_color + ',100%,' + t.light + '%)';
},
to_step: function () {
var t = this;
t.opacity -= t.opacity_change;
t.size += t.size_change;
if (t.opacity <= 0) {
t.to_reset();
return false;
}
ctx.fillStyle = t.color;
ctx.globalAlpha = t.opacity;
ctx.beginPath();
arc_heart(t.x, t.y, t.size, t.size);
ctx.closePath();
ctx.fill();
ctx.globalAlpha = 1;
}
}
function window_resize() {
w = window.innerWidth;
h = window.innerHeight;
canvas.width = w;
canvas.height = h;
}
$(window).resize(function () {
window_resize();
});
//返回一个介于参数1和参数2之间的随机数
function find_random(num_one, num_two) {
return Math.random() * (num_two - num_one) + num_one;
}
start();
});
复制代码- 因为使用了jquery的CDN,所以我们在js中就可以直接使用 $(document).ready方法
土豪金色的标题
为了时刻展示出对 TA 的爱,我们除了在背景中体现出来之外,还可以再文字中体现出来,所以需要取一个充满爱意的标题。
<body>
<canvas id="c" style="position: absolute;z-index: -1;text-align: center;">canvas>
<div class="middle">
<h1 class="label">Every Day About Youh1>
div>
body>
复制代码
复制代码- 这里引入了
googleapis中的字体样式。 - 给label一个背景,并使用了动画效果。
- 这个就是文字后面的静态图片,可以另存为然后使用的哦~
百度搜索框
对于你心爱的 TA 来说,不管干什么估计都得用百度直接搜出来,就算是看个优酷、微博都不会记住域名,都会直接去百度一下,所以我们需要在标签页中直接集成百度搜索。让 TA 可以无忧无虑的搜索想要的东西。
由于现在百度搜索框不能直接去站长工具中获取了,所以我们可以参考掘金标签页插件中的百度搜索框。
根据掘金的标签页插件我们可以发现,输入结果之后,直接跳转到百度的网址,并在url后面携带了一个 wd 的参数,wd 也就是我们输入的内容了。
<div class="search">
<input id="input" type="text">
<button>百度一下button>
div>
复制代码
复制代码.search {
width: 750px;
height: 50px;
margin: auto;
display: flex;
justify-content: center;
align-content: center;
min-width: 750px;
position: relative;
}
input {
width: 550px;
height: 40px;
border-right: none;
border-bottom-left-radius: 10px;
border-top-left-radius: 10px;
border-color: #f5f5f5;
/* 去除搜索框激活状态的边框 */
outline: none;
}
input:hover {
/* 鼠标移入状态 */
box-shadow: 2px 2px 2px #ccc;
}
input:focus {
/* 选中状态,边框颜色变化 */
border-color: rgb(78, 110, 242);
}
.search span {
position: absolute;
font-size: 23px;
top: 10px;
right: 170px;
}
.search span:hover {
color: rgb(78, 110, 242);
}
button {
width: 100px;
height: 44px;
background-color: rgb(78, 110, 242);
border-bottom-right-radius: 10px;
border-top-right-radius: 10px;
border-color: rgb(78, 110, 242);
color: white;
font-size: 14px;
}
复制代码关于 TA
这里可以放置你们之间的一些生日,纪念日等等,也可以放置你想放置的任何浪漫,仪式感满满~
如果你不记得两个人之间的纪念日,那就换其他的日子吧。比如你和 TA 闺蜜的纪念日也可以。
<body>
<canvas id="c" style="position: absolute;z-index: -1;text-align: center;">canvas>
<div class="middle">
<h1 class="label">Every Day About Youh1>
<div class="time">
<span>
<div id="d">
00
div>
Love day
span> <span>
<div id="h">
00
div>
First Met
span> <span>
<div id="m">
00
div>
birthday
span> <span>
<div id="s">
00
div>
age
span>
div>
div>
<script type="text/javascript" src="demo.js">script>
body>
复制代码- 这里我定义了四个日期,恋爱纪念日、相识纪念日、TA 的生日、TA 的年龄。
- 在页面最后引用了一个js文件,主要是等待页面渲染完成之后调用js去计算日期的逻辑。
恋爱纪念日
var date1 = new Date('2019-10-07')
var date2 = new Date()
var s1 = date1.getTime(),
s2 = date2.getTime();
var total = (s2 - s1) / 1000;
var day = parseInt(total / (24 * 60 * 60)); //计算整数天数
const d = document.getElementById("d");
d.innerHTML = getTrueNumber(day);
复制代码相识纪念日
var date1 = new Date('2019-09-20')
var date2 = new Date()
var s1 = date1.getTime(),
s2 = date2.getTime();
var total = (s2 - s1) / 1000;
var day = parseInt(total / (24 * 60 * 60)); //计算整数天数
h.innerHTML = getTrueNumber(day);
复制代码公共方法(将计算出来的日子转为绝对值)
const getTrueNumber = x => (x < 0 ? Math.abs(x) : x);
复制代码由于生日和年龄的计算代码有些多,所以放在码上掘金中展示了。
添加到chrome浏览器中
开发完成之后,所有的文件就是这样的了,里面的icon可以根据自己的喜好去设计或者网上下载。
使用chrome浏览器打开:chrome://extensions/ 即可跳转到添加扩展程序页面。
- 打开右上角的开发者模式
- 点击加载已解压的扩展程序
- 选择自己的chrome标签页项目目录即可
总结一下
为了让心爱的 TA 开心,作为程序员的我们可谓是煞费苦心呀!!
在给对象安装插件的时候,发现了一个小问题,可能是chrome版本原因,导致jquery的cdn无法直接引用,所以可能需要手动把jquery保存到项目文件中,然后在manifest.json配置js的地方把jquery的js加上即可。
码上掘金中我已经把jquery的代码、canvas的代码、计算纪念日的代码都放进去了,可以直接复制到自己项目中哦!!!
七夕节快到了,祝愿天下有情人终成眷属!
来源:juejin.cn/post/7122332008252080142