开发目标:快速搭建nestjs项目本地环境,并测试本地打包方便后期部署到服务器。
项目准备:node环境、npm依赖、docker
- 创建项目并启动
- 使用typeorm连接mysql
- 使用class-validate校验入参
- 使用全局filter处理异常,使用全局interceptor处理成功信息
- 使用ioredis连接redis
- 使用swaager文档
- 使用docker-compose打包并运行
- 总结
一、创建项目并启动
1、全局安装nestjs并创建项目
npm i -g @nestjs/cli
nest new nest-demo
2、使用热更新模式运行项目
npm run start:dev
此时访问 http://localhost:3000就可以看到 Hello World!
3、使用cli一键生成一个user模块
nest g resource system/user
选择REST API和自动生成CURD
4、设置全局api前缀
src/main.ts
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.setGlobalPrefix('api');
await app.listen(3000);
}
bootstrap();
更多nestjs入门教程查看:# 跟随官网学nestjs之入门
二、使用typeorm连接并操作mysq
1、安装依赖
npm i @nestjs/typeorm typeorm mysql @nestjs/config -S
2、在src下创建 config/env.ts 用来判断当前环境,抛出配置文件地址
src/config/env.ts
import * as fs from 'fs';
import * as path from 'path';
const isProd = process.env.NODE_ENV == 'prod';
function parseEnv() {
const localEnv = path.resolve('.env');
const prodEnv = path.resolve('.env.prod');
if (!fs.existsSync(localEnv) && !fs.existsSync(prodEnv)) {
throw new Error('缺少环境配置文件');
}
const filePath = isProd && fs.existsSync(prodEnv) ? prodEnv : localEnv;
return { path: filePath };
}
export default parseEnv();
3、在src下创建.env配置文件
src/.env
PORT=9000
DB_HOST=localhost
DB_PORT=3306
DB_USER=demo_user
DB_PASSWD=123456
DB_DATABASE=demo_db
4、在app.module内挂载全局配置和mysql
src/app.module.ts
import { Module } from '@nestjs/common';
import { AppController } from './app.controller';
import { TypeOrmModule } from '@nestjs/typeorm';
import { ConfigService, ConfigModule } from '@nestjs/config';
import envConfig from './config/env';
import { AppService } from './app.service';
import { UserModule } from './system/user/user.module';
@Module({
imports: [
ConfigModule.forRoot({
isGlobal: true,
envFilePath: [envConfig.path],
}),
TypeOrmModule.forRootAsync({
imports: [ConfigModule],
inject: [ConfigService],
useFactory: async (configService: ConfigService) => ({
type: 'mysql',
host: configService.get('DB_HOST', 'localhost'),
port: configService.get<number>('DB_PORT', 3306),
username: configService.get('DB_USER', 'root'),
password: configService.get('DB_PASSWORD', '123456'),
database: configService.get('DB_DATABASE', 'test_db'),
entities: ['dist/**/*.entity{.ts,.js}'],
timezone: '+08:00',
synchronize: true,
autoLoadEntities: true,
}),
}),
UserModule,
],
controllers: [AppController],
providers: [AppService],
})
export class AppModule {}
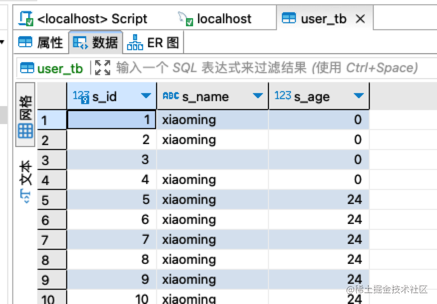
5、定义userEntity实体
src/system/user/entities/user.entity.ts
import { Entity, Column, PrimaryGeneratedColumn } from 'typeorm';
@Entity('user_tb')
export class UserEntity {
@PrimaryGeneratedColumn()
s_id: string;
@Column({ type: 'varchar', length: 20, default: '', comment: '名称' })
s_name: string;
@Column({ type: 'int', default: 0, comment: '年龄' })
s_age: number;
}
6、user.module内引入entity实体
import { Module } from '@nestjs/common';
import { UserService } from './user.service';
import { UserController } from './user.controller';
// 引入typeorm和Enetiy实例
import { TypeOrmModule } from '@nestjs/typeorm';
import { UserEntity } from './entities/user.entity';
@Module({
imports: [TypeOrmModule.forFeature([UserEntity])],
controllers: [UserController],
providers: [UserService],
})
export class UserModule {}
7、在控制器user.controller修改api地址
@Post('create')
create(@Body() createUserDto: CreateUserDto) {
return this.userService.create(createUserDto);
}
地址拼接为:全局前缀api+模块user+自定义create = localhost:3000/api/user/crtate
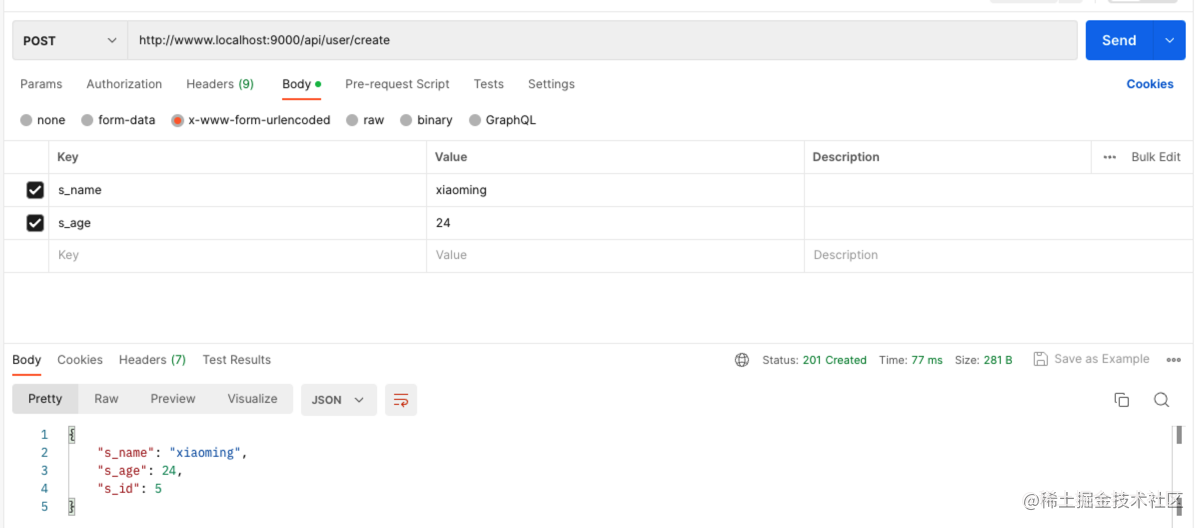
三、使用class-validato校验入参
1、安装依赖
npm i class-validator class-transformer -S
2、配置校验规则
src/system/user/dto/create-user.dto.ts
import { IsNotEmpty } from 'class-validator';
export class CreateUserDto {
@IsNotEmpty({ message: '名称不能为空' })
readonly s_name: string;
}

更多校验规则查看:git文档
四、使用filter全局错误过滤、interceptor全局成功过滤
1、使用cli自动生成过滤器
nest g filter common/http-exception
nest g interceptor common/transform
2、编写过滤器
src/common/http-exception/http-exception.filter.ts
import {
ArgumentsHost,
Catch,
ExceptionFilter,
HttpException,
} from '@nestjs/common';
@Catch(HttpException)
export class HttpExceptionFilter implements ExceptionFilter {
catch(exception: HttpException, host: ArgumentsHost) {
const ctx = host.switchToHttp();
const response = ctx.getResponse();
const status = exception.getStatus();
let resultMessage = exception.message;
try {
const exceptionResponse = exception.getResponse() as any;
if (Object.hasOwnProperty.call(exceptionResponse, 'message')) {
resultMessage = exceptionResponse.message;
}
} catch (e) {}
const errorResponse = {
data: null,
message: resultMessage,
code: '9999',
};
response.status(status);
response.header('Content-Type', 'application/json; charset=utf-8');
response.send(errorResponse);
}
}
src/common/transform/transform.interceptor.ts
import {
CallHandler,
ExecutionContext,
Injectable,
NestInterceptor,
} from '@nestjs/common';
import { map, Observable } from 'rxjs';
@Injectable()
export class TransformInterceptor implements NestInterceptor {
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
return next.handle().pipe(
map((data) => {
return {
data,
code: '0000',
msg: '请求成功',
};
}),
);
}
}
3、在main.ts里挂载
import { HttpExceptionFilter } from './common/http-exception/http-exception.filter';
import { TransformInterceptor } from './common/transform/transform.interceptor';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
app.useGlobalFilters(new HttpExceptionFilter());
app.useGlobalInterceptors(new TransformInterceptor());
await app.listen(3000);
}
bootstrap();
手动抛出异常错误只需在service的方法里
throw new HttpException('message', HttpStatus.BAD_REQUEST)
五、使用idredis连接redis
1、安装依赖
npm i ioredis -S
2、在.env文件添加reids配置
REDIS_HOST=localhost
REIDS_PORT=6379
REIDS_PASSWD=
REIDS_DB=3
3、在common目录下创建cache模块,连接redis
nest g mo cache common && nest g s cache common
src/common/cache/cache.service.ts
import { Injectable, Logger } from '@nestjs/common';
import { Redis } from 'ioredis';
import { ConfigService } from '@nestjs/config';
@Injectable()
export class CacheService {
public client;
constructor(private readonly configService: ConfigService) {
this.getClient();
}
async getClient() {
const client = new Redis({
host: this.configService.get('REDIS_HOST', 'localhost'),
port: this.configService.get<number>('REIDS_PORT', 6379),
password: this.configService.get('REIDS_PASSWD', ''),
db: this.configService.get<number>('REIDS_DB', 3),
});
client.on('connect', () =>
Logger.log(
`redis连接成功,端口${this.configService.get<number>(
'REIDS_PORT',
3306,
)}`,
),
);
client.on('error', (err) => Logger.error('Redis Error', err));
this.client = client;
}
public async set(key: string, val: string, second?: number) {
const res = await this.client.set(key, val, 'EX', second);
return res === 'OK';
}
public async get(key: string) {
const res = await this.client.get(key);
return res;
}
}
在cache.module内抛出service
src/common/cache/cache.module.ts
@Module({
providers: [CacheService],
exports: [CacheService],
})
4、在user.module内引入cacheModule并在user.service内使用
src/system/user/user.module.ts
import { CacheModule } from 'src/common/cache/cache.module';
@Module({
imports: [CacheModule],
controllers: [UserController],
providers: [UserService],
})
export class UserModule {}
src/system/user/user.service.ts
import { CacheService } from '@src/common/cache/cache.service';
@Injectable()
export class UserService {
constructor(
private readonly cacheService: CacheService,
) {}
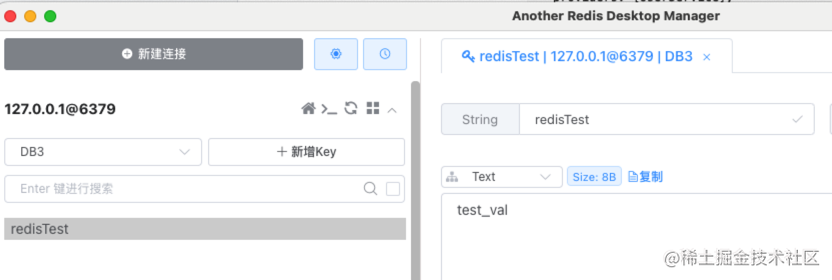
async create(createUserDto: CreateUserDto) {
const redisTest = await this.cacheService.get('redisTest');
Logger.log(redisTest, 'redisTest');
if (!redisTest) {
await this.setRedis();
return this.create(createUserDto);
}
...
}
async setRedis() {
const res = await this.cacheService.set(
'redisTest',
'test_val',
12 * 60 * 60,
);
if (!res) {
Logger.log('redis保存失败');
} else {
Logger.log('redis保存成功');
}
}
}

六、使用swagger生成文档
1、安装依赖
npm i @nestjs/swagger swagger-ui-express -S
2、在main.ts引入并配置
import { SwaggerModule, DocumentBuilder } from '@nestjs/swagger';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
const options = new DocumentBuilder()
.setTitle('nest-demo example')
.setDescription('The nest demo API description')
.setVersion('1.0')
.build();
const document = SwaggerModule.createDocument(app, options);
SwaggerModule.setup('swagger', app, document);
...
}
bootstrap();
此时访问http://wwww.localhost:9000/swagge就可以看到文档
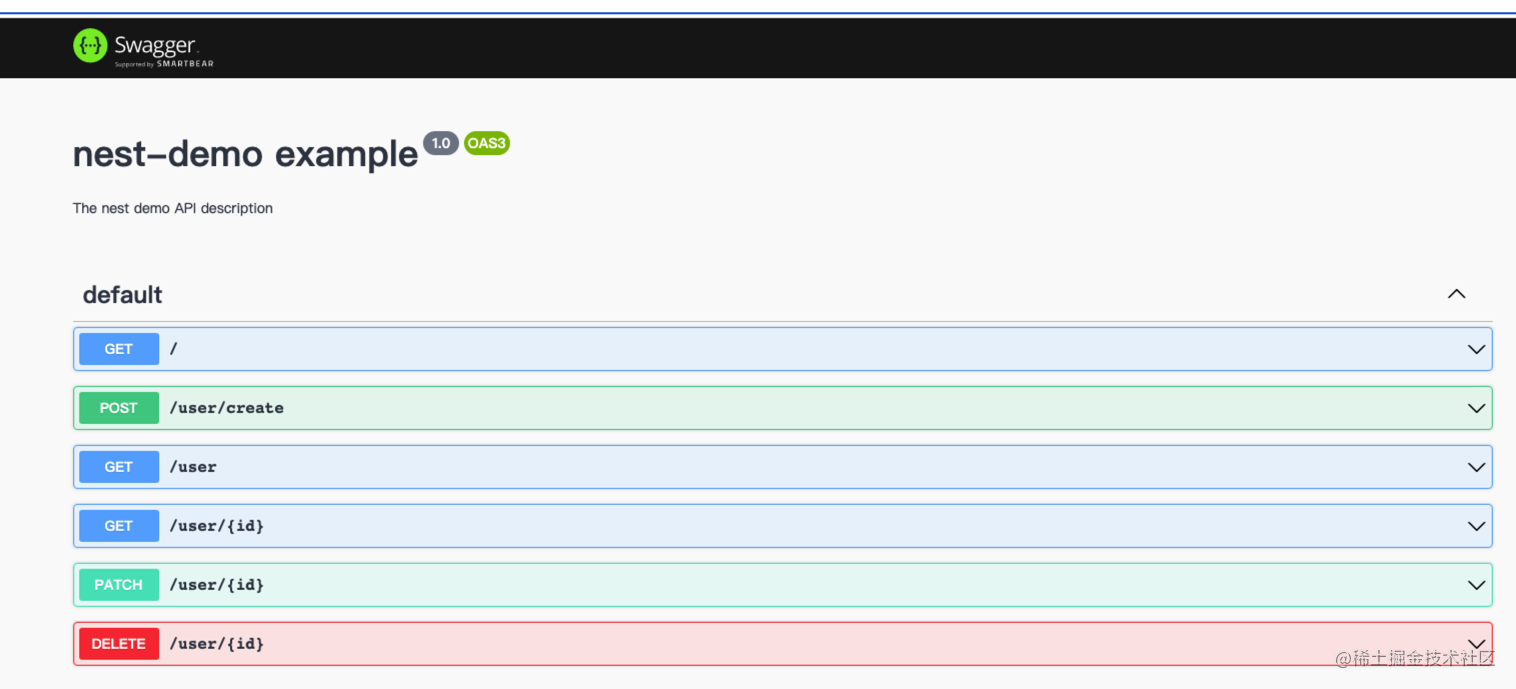
3、在控制器为业务模块和api打上标签
src/system/user/user.controller.ts
import { ApiTags, ApiOperation } from '@nestjs/swagger';
@ApiTags('user')
@Controller('user')
export class UserController {
constructor(private readonly userService: UserService) {}
@ApiOperation({
summary: '创建用户',
})
@Post('create')
create(@Body() createUserDto: CreateUserDto) {
return this.userService.create(createUserDto);
}
}
4、在dto内为字段设置名称
src/system/user/dto/create-user.dto.ts
import { ApiProperty } from '@nestjs/swagger';
export class CreateUserDto {
@ApiProperty({ type: 'string', example: '用户名称' })
@IsNotEmpty({ message: '名称不能为空' })
readonly s_name: string;
@ApiProperty({ type: 'number', example: '用户年龄' })
readonly s_age: number;
}
这时刷新浏览器,就能看到文档更新了
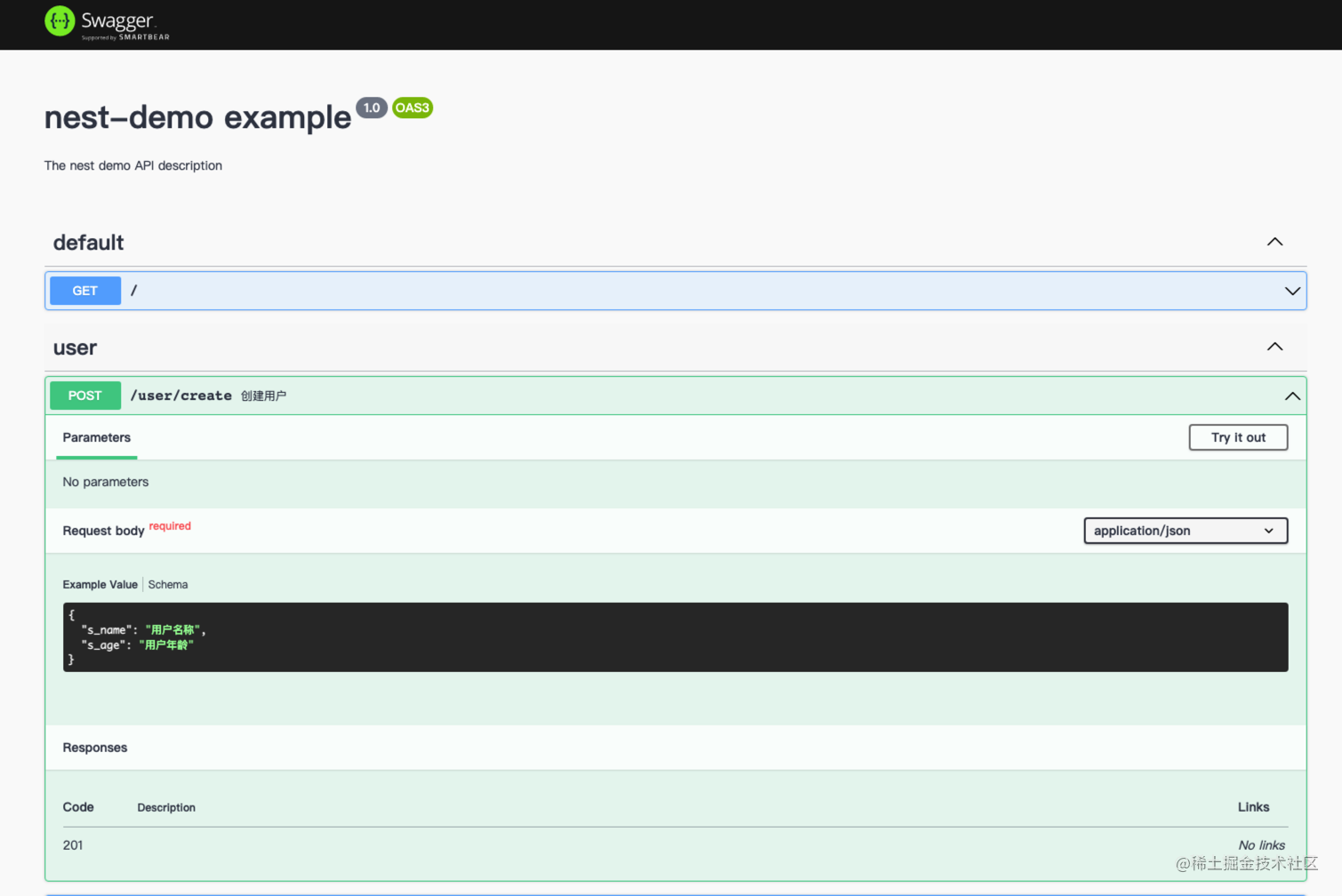
更多swaager配置查看:官方文档
七、使用docker-compose自动部署到本地docker
1、在根目录下创建docker-compose.yml
version: "3.0"
services:
redis_demo:
container_name: redis_demo
image: daocloud.io/library/redis:6.0.3-alpine3.11
command: redis-server --appendonly yes
ports:
- 6379:6379
restart: on-failure
volumes:
- ./deploy/redis/db:/data
- ./deploy/redis/conf/redis.conf:/usr/local/etc/redis/redis.conf
- ./deploy/redis/logs:/logs
environment:
- TZ=Asia/Shanghai
networks:
- my-server_demo
mysql_demo:
container_name: mysql_demo
image: daocloud.io/library/mysql:8.0.20
ports:
- 3306:3306
restart: on-failure
environment:
MYSQL_DATABASE: demo_db
MYSQL_ROOT_PASSWORD: 123456
MYSQL_USER: demo_user
MYSQL_PASSWORD: 123456
MYSQL_ROOT_HOST: '%'
volumes:
- ./deploy/mysql/db:/var/lib/mysql
- ./deploy/mysql/conf/my.cnf:/etc/my.cnf
- ./deploy/mysql/init:/docker-entrypoint-initdb.d/
networks:
- my-server_demo
server_demo:
container_name: server_demo
build:
context: .
dockerfile: Dockerfile
ports:
- 9003:9003
restart: on-failure
networks:
- my-server_demo
depends_on:
- redis_demo
- mysql_demo
networks:
my-server_demo:
2、在根目录创建Dockerfile文件
FROM daocloud.io/library/node:14.7.0
ENV TZ=Asia/Shanghai \
DEBIAN_FRONTEND=noninteractive
RUN ln -fs /usr/share/zoneinfo/${TZ} /etc/localtime && echo ${TZ} > /etc/timezone && dpkg-reconfigure --frontend noninteractive tzdata && rm -rf /var/lib/apt/lists/*
RUN mkdir -p /app
WORKDIR /app
COPY . ./
RUN npm config set registry https://registry.npm.taobao.org/
COPY package.json /app/package.json
RUN rm -rf /app/package-lock.json
RUN cd /app && rm -rf /app/node_modules && npm install
RUN cd /app && rm -rf /app/dist && npm run build
CMD npm run start:prod
EXPOSE 9003
3、修改.env.prod正式环境配置
PORT=9003
HOST=localhost
DB_HOST=mysql_demo
DB_PORT=3306
DB_USER=demo_user
DB_PASSWD=123456
DB_DATABASE=demo_db
REDIS_HOST=redis_demo
REIDS_PORT=6379
REIDS_PASSWD=
REIDS_DB=3
4、修改main.ts启动端口
import { ConfigService } from '@nestjs/config';
async function bootstrap() {
const app = await NestFactory.create(AppModule);
const configService = app.get(ConfigService);
const PORT = configService.get<number>('PORT', 9000);
const HOST = configService.get('HOST', 'localhost');
await app.listen(PORT, () => {
Logger.log(`服务已经启动,接口请访问:http://wwww.${HOST}:${PORT}`);
});
}
bootstrap();
5、前台运行打包
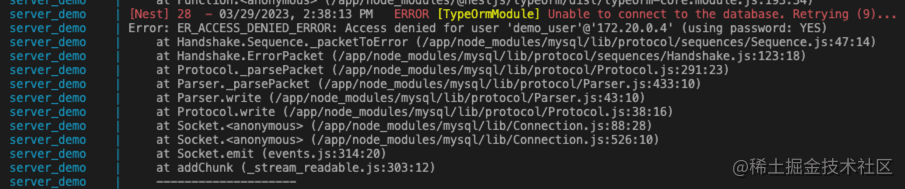
docker-compose up
运行完成后大概率会报错,因为我们使用的mysql账号没有权限,所以需要进行设置
// 进入mysql容器命令
docker ecex -it mysql_demo /bin/bash
// 登录mysql
mysql -uroot -p123456
// 查询数据库后进入mysql查询数据表
show databases;
use mysql;
show tables;
// 查看user表中的数据
select User,Host from user;
// 刚创建的用户表没有我们设置连接的用户和host,所以需要创建
CREATE USER 'demo_user'@'%' IDENTIFIED BY '123456';
// 给创建的用户赋予权限
GRANT ALL ON *.* TO 'demo_user'@'%';
// 刷新权限
flush privileges;
如果还报错修改下密码即可

ALTER USER 'demo_user'@'%' IDENTIFIED WITH mysql_native_password BY '123456';
此时项目应该能正常启动并成功访问


6、切换后台运行
docker-compose up -d
八、总结
docker-compose up正常用来测试本地打包,和第一次构建redis、mysql容器,后续需要在本地运行开发模式只需保证redis、mysql容器正常运行即可,如需再次打包,删除server容器和镜像再次执行即可
docker ps -a
docker rm server_demo
docker images
docker rmi nest-demo_server_demo
docker-compose up -d
本地开发模式只需关闭server容器,然后在项目内只需 start:dev即可
docker stop server_demo
npm run start:dev
作者:jjggddb
来源:juejin.cn/post/7215844385614528549