React 真的是太灵活了,写它就感觉像是在写原生 JavaScript 一样,一个功能你可以有多种实现方式,例如你要实现动态样式,只要你愿意去做,你会有很多种解决方案,这可能也就是 React 会比 Vue 相对来说比较难一点的原因,这或许也就是这么喜欢 React 的原因了吧,毕竟它可是我见一个爱一个的技术之一🤣🤣🤣
也正是因为这个原因,在 React 中编写一个组件就给我们编写一个组件提供了多种方式,那么在接下来的文章中我们就来讲解一下这几种组件的设计模式。
Mixin设计模式
在上一篇文章中有讲解到了 JavaScript 中的 Mixin,如果对这个设计模式不太理解的可以通过这篇文章进行学习 来学习一下 JavaScript 中的 Mixin
如何在多个组件之间共享代码,是开发者们在学习 React 是最先问的问题之一,你可以使用组件组合来实现代码重构,你也可以定义一个组件并在其他几个组件中使用它。
如何用组合来解决某个模式并不是显而易见的,React 受函数式编程的影响,但是它进入了由面向对象库主导的领域(hooks 出现以前),为了解决这个问题,React 团队在这加上了 Mixin,它的目标就是当你不确定如何使用组合解决想用的问题时,为你提供一种在组件之间重用代码。
React 最主流构建 Component 的方法是利用 createClass 创建,顾名思义,就是创造一个包含 React 方法 Class 类。
Mixin危害
在 React 官方文档 Mixins Considered Harmful 中提到了 Mixin 带来的危害,主要有以下几个方面:
Mixin 可能会相互依赖,相互耦合,不利于代码维护;
- 不同的
Mixin 中的方法可能会相互冲突;
Mixin非常多时,组件是可以感知到的,甚至还要为其做相关处理,这样会给代码造成滚雪球式的复杂性;
装饰器模式
装饰器是一种特殊的声明,可以附加到类声明、方法、访问器、属性或参数上,装饰者使用 @+函数名 形式来修改类的行为。如果你对装饰器不太了解,你可以通过这一篇文章 TS的装饰器你再学不会我可就要报警了哈 进行学习。
现在我们来看看在 React 中怎么使用装饰器,我们现在有这样的一个需求,就是为被装饰的页面或组件设置统一的背景颜色和自定义颜色,完整代码具体如下:
import React, { Component } from "react";
interface Params {
background: string;
size?: number;
}
function Controller(params: Params) {
return function (
WrappedComponent: React.ComponentClass,
): React.ComponentClass {
WrappedComponent.prototype.render = function (): React.ReactNode {
return <div>但使龙城飞将在,不教胡马度阴山</div>;
};
return class Page extends Component {
render(): React.ReactNode {
const { background, size = 16 } = params;
return (
<div style={{ backgroundColor: background, fontSize: size }}>
<WrappedComponent {...this.props}></WrappedComponent>
</div>
);
}
};
};
}
@Controller({ background: "pink", size: 100 })
class App extends Component {
render(): React.ReactNode {
return <div>牛逼</div>;
}
}
export default App;
这段代码的具体输出如下所示:
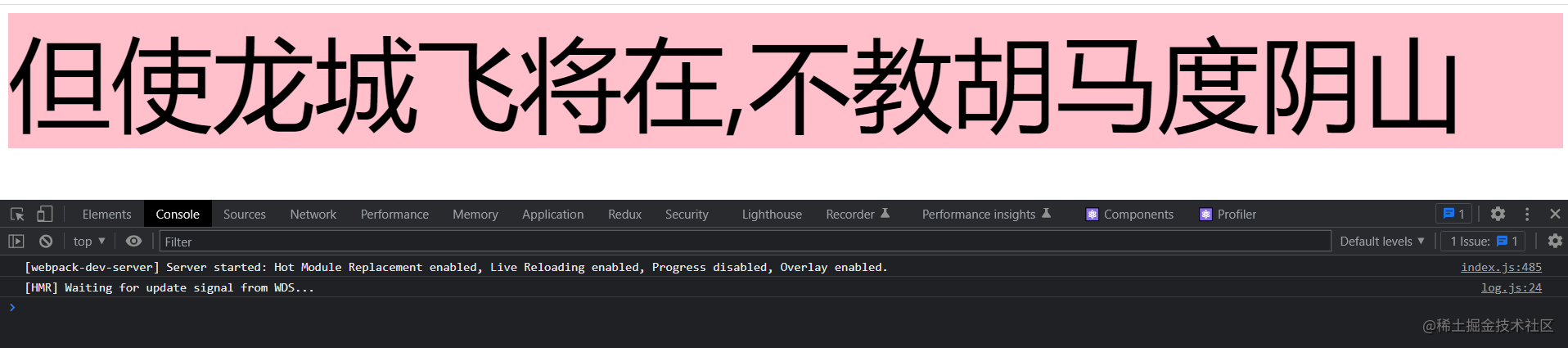
在上面的代码中,Controller 装饰器会接收 App 组件,其中 WrappedComponent 就是我们的 App 组件,在这里我们通过修改原型方法 render 将其的返回值修改了,并对其进行了一层包裹。
所以 App 组件在使用了类装饰器,不仅可以修改了原来的 DOM,还对外层多加了一层包裹,理解起来就是接收需要装饰的类为参数,返回一个新的内部类。恰与 HOC 的定义完全一致。所以,可以认为作用在类上的 decorator 语法糖简化了高阶组件的调用。
高阶组件
HOC 高阶组件模式是 React 比较常用的一种包装强化模式之一,你也可以看作 React 对装饰模式的一种实现,高阶组件就是一个函数,并且该函数接收一个组件作为参数,并返回一个新的组件,它是一种设计模式,这种设计模式是由 React 自身的特性产生的结果。
高阶组件主要解决了以下问题,具体如下:
复用逻辑: 高阶组件就像是一个加工 React 组件的工厂,你需要向该工厂提供一个坯子,它可以批量地对你送进来的组件进行加工,包装处理,还可以根据你的需求定制不同的产品;
强化props: 高阶组件返回的组件,可以劫持上一层传过来的 props,染回混入新的 props,来增强组件的功能;
控制渲染: 劫持渲染是 hoc 中的一个特性,在高阶组件中,你可以对原来的组件进行条件渲染,节流渲染,懒加载等功能;
HOC的实现方式
常用的高阶组件有两种方式,它们分别是 正向属性代理 和 反向继承,接下来我们来看看这两者的区别。
正向属性代理
所谓正向属性代理,就是用组件包裹一层代理组件,在代理组件上,我们可以代理所有传入的 props,并且觉得如何渲染。实际上这种方式生成的高阶组件就是原组件的父组件,父组件对子组件进行一系列强化操作,上面那个装饰器的例子就是一个 HOC 正向属性代理的实现方式。
对比原生组件增强的项主要有以下几个方面:
可操作所有传入的props: 可以对其传入的 props 进行条件渲染,例如权限控制等;
- 可以操作组件的生命周期;
- 可操作组件的
static 方法,但是需要手动处理,或者引入第三方库;
- 获取
refs;
- 抽象
state;
反向继承
反向继承其实是一个函数接收一个组件作为参数传入,并返回了一个继承自该传入的组件的类,并且在该类的 render() 方法中返回 super.render() 方法,能通过 this 访问到源组件的生命周期、props、state、render等,相比属性代理它能操作更多的属性。
两者区别
- 属性代理是从组合的角度出发,这样有利于从外部操作被包裹的组件,可以操作的对象是
props,或者加一层拦截器或者控制器等;
- 方向继承则是从继承的角度出发,是从内部去操作被包裹的组件,也就是可以操作组件内部的
state,生命周期,render 函数等;
具体实例代码如下所示:
function Controller(WrapComponent: React.ComponentClass) {
return class extends WrapComponent {
public state: State;
constructor(props: any) {
super(props);
this.state = {
nickname: "moment",
};
}
render(): React.ReactNode {
return super.render();
}
};
}
interface State {
nickname: string;
}
@Controller
class App extends Component {
public state: State = {
nickname: "你小子",
};
render(): React.ReactNode {
return <div>{this.state.nickname}</div>;
}
}
反向继承主要有以下优点:
- 可以获取组件内部状态,比如
state,props,生命周期和事件函数;
- 操作由
render() 输出的 React 组件;
- 可以继承静态属性,无需对静态属性和方法进行额外的处理;
反向继承也存在缺点,它和被包装的组件强耦合,需要知道被包装的组件内部的状态,具体是做什么,如果多个反向继承包裹在一起,状态会被覆盖。
HOC的实现
HOC 的实现方式按照上面讲到的两个分类一样,来分别讲解这两者有什么写法。
操作 props
该功能由属性代理实现,它可以对传入组件的 props 进行增加、修改、删除或者根据特定的 props 进行特殊的操作,具体实现代码如下所示:
import React, { Component } from "react";
interface Params {
background: string;
size?: number;
}
function Controller(params: Params) {
return function (
WrappedComponent: React.ComponentClass,
): React.ComponentClass {
WrappedComponent.prototype.render = function (): React.ReactNode {
return <div>但使龙城飞将在,不教胡马度阴山</div>;
};
return class Page extends Component {
render(): React.ReactNode {
const { background, size = 16 } = params;
return (
<div style={{ backgroundColor: background, fontSize: size }}>
<WrappedComponent {...this.props}></WrappedComponent>
</div>
);
}
};
};
}
@Controller({ background: "pink", size: 100 })
class App extends Component {
render(): React.ReactNode {
return <div>牛逼</div>;
}
}
export default App;
抽离state控制组件更新
高阶组件可以将 HOC 的 state 配合起来,控制业务组件的更新,在下面的代码中,我们将 input 的 value 提取到 HOC 中进行管理,使其变成受控组件,同时不影响它使用 onChange 方法进行一些其他操作,具体代码如下所示:
function Controller(WrappedComponent) {
return class extends React.Component {
constructor(props) {
super(props);
this.state = {
name: "",
};
this.onChange = this.onChange.bind(this);
}
onChange = (event) => {
this.setState({
name: event.target.value,
});
};
render() {
const newProps = {
value: this.state.name,
};
return (
<WrappedComponent
onChange={() => this.onChange}
{...this.props}
{...newProps}
/>
);
}
};
}
class App extends React.Component {
render() {
return (
<div>
<h1>{this.props.value}</h1>
<input name="name" {...this.props} />
</div>
);
}
}
export default Controller(App);
获取 Refs 实例
使用高阶组件后,获取到的 ref 实例实际上是最外层的容器组件,而非原组件,但是很多情况下我们需要用到原组件的 ref,我们先来看下面的代码,具体代码如下所示:
function Controller(WrappedComponent) {
return class Page extends React.Component {
render() {
const { ref, ...rest } = this.props;
return <WrappedComponent {...rest} ref={ref} />;
}
};
}
class Input extends React.Component {
render() {
return <input />;
}
}
class App extends React.Component {
constructor(props) {
super(props);
this.ref = React.createRef();
}
componentDidMount() {
console.log(this.ref);
}
render() {
return <Input ref={this.ref} />;
}
}
export default Controller(App);
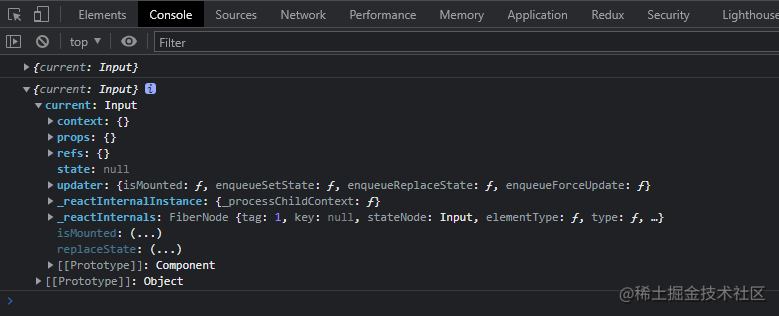
通过查看控制台输出,你会发现获取到的是整个 Input 组件,那么有什么办法可以获取到 input 这个真实的 DOM 呢?
在之前的例子中我们可以通过 props 传递,一层一层传递给 input 原生组件来获取,具体代码如下:
class Input extends React.Component {
render() {
return <input ref={this.props.inputRef} />;
}
}
注意,因为传参不能传 ref,所以这里要修改一下
当然你也可以利用父组件的回调,具体代码如下:
class App extends React.Component {
constructor(props) {
super(props);
this.ref = React.createRef();
}
componentDidMount() {
console.log(this.ref);
}
render() {
return <Input inputRef={(e) => (this.ref = e)} />;
}
}
最终的代码如下图所示,这里展示了以上两个方法具体代码,如下图所示:
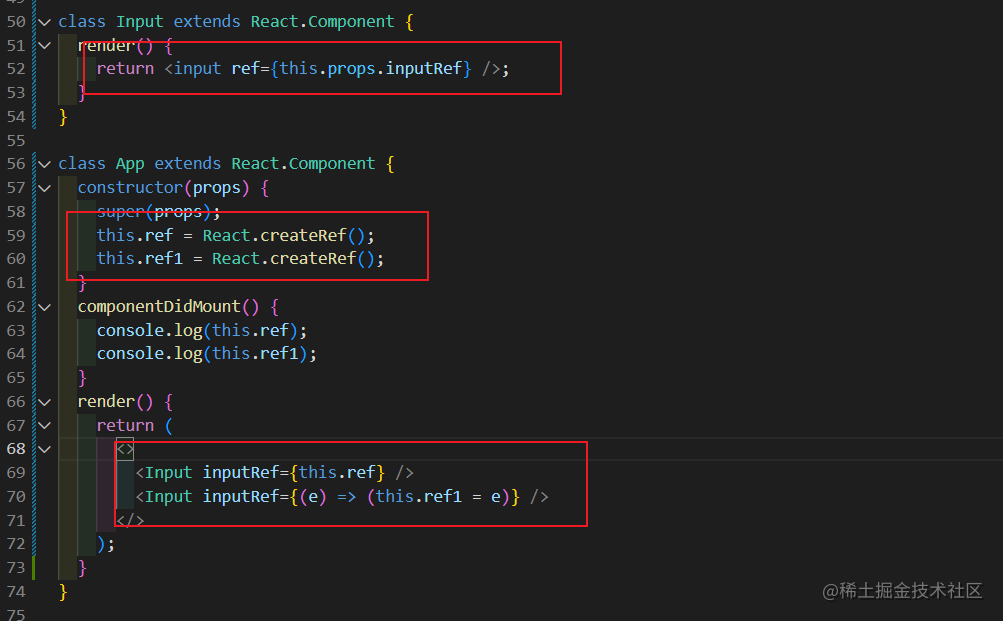
通过查看浏览器输出,两者都能成功输出原生的 ref 实例
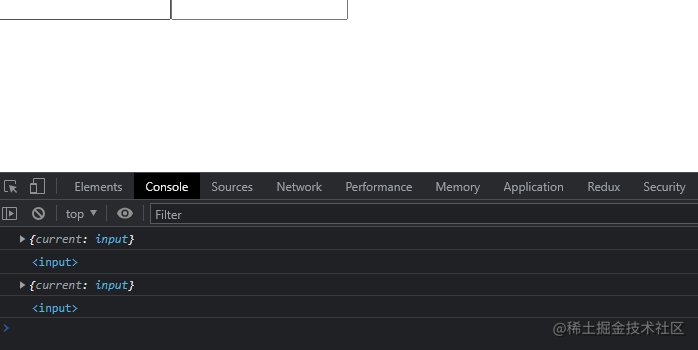
React 给我们提供了一个 forwardRef 来帮助我们进行 refs 传递,这样我们在高阶组件上获取的 ref 实例就是原组件的 ref 了,而不需要手动传递,我们只需要修改一下 Input 组件代码即可,具体如下:
const Input = React.forwardRef((props, ref) => {
return <input type="text" ref={ref} />;
});
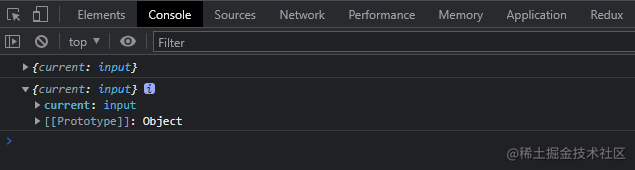
这样我们就获取到了原始组件的 ref 实例啦!
获取原组件的 static 方法
当待处理的组件为 class 组件时,通过属性代理实现的高阶组件可以获取到原组件的 static 方法,具体实现代码如下所示:
function Controller(WrappedComponent) {
return class Page extends React.Component {
componentDidMount() {
WrappedComponent.moment();
}
render() {
const { ref, ...rest } = this.props;
return <WrappedComponent {...rest} ref={ref} />;
}
};
}
class App extends React.Component {
static moment() {
console.log("你好骚啊");
}
render() {
return <div>你小子</div>;
}
}
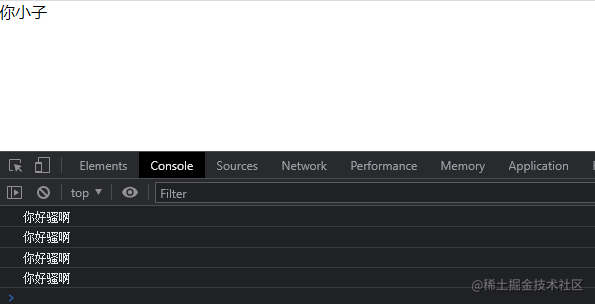
export default Controller(App);
你好骚啊 正常输出
反向继承操作 state
因为我们高阶组件继承了传入组件,那么就是能访问到this了,有了 this 我们就能操作和读取 state,也就不用像属性代理那么复杂还要通过 props 回调来操作 state。
反向继承的基本实现方法就是原组件继承 Component,再在高阶组件中通过把原组件传参,再生成一个继承自原组件的组件。
具体实例代码如下所示:
function Controller(WrappedComponent) {
return class Page extends WrappedComponent {
componentDidMount() {
console.log(`组件挂载时 this.state 的状态为`, this.state);
setTimeout(() => {
this.setState({ nickname: "你个叼毛" });
}, 1000);
}
render() {
return super.render();
}
};
}
class App extends React.Component {
constructor() {
super();
this.state = {
nickname: "你小子",
};
}
render() {
return <h1>{this.state.nickname}</h1>;
}
}
export default Controller(App);
代码具体输出如下图所示,当组件挂载完成之后经过一秒,state 状态发生改变:
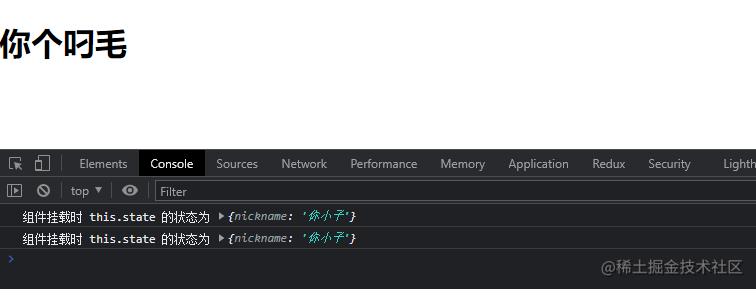
劫持原组件生命周期
因为反向继承方法实现的是高阶组件继承原组件,而返回的新组件属于原组件的子类,子类的实例方法会覆盖父类的,具体实例代码如下所示:
function Controller(WrappedComponent) {
return class Page extends WrappedComponent {
componentDidMount() {
console.log("生命周期方法被劫持啦");
}
render() {
return super.render();
}
};
}
class App extends React.Component {
componentDidMount() {
console.log("原组件");
}
render() {
return <h1>你小子</h1>;
}
}
export default Controller(App);
代码的具体输出如下图所示:
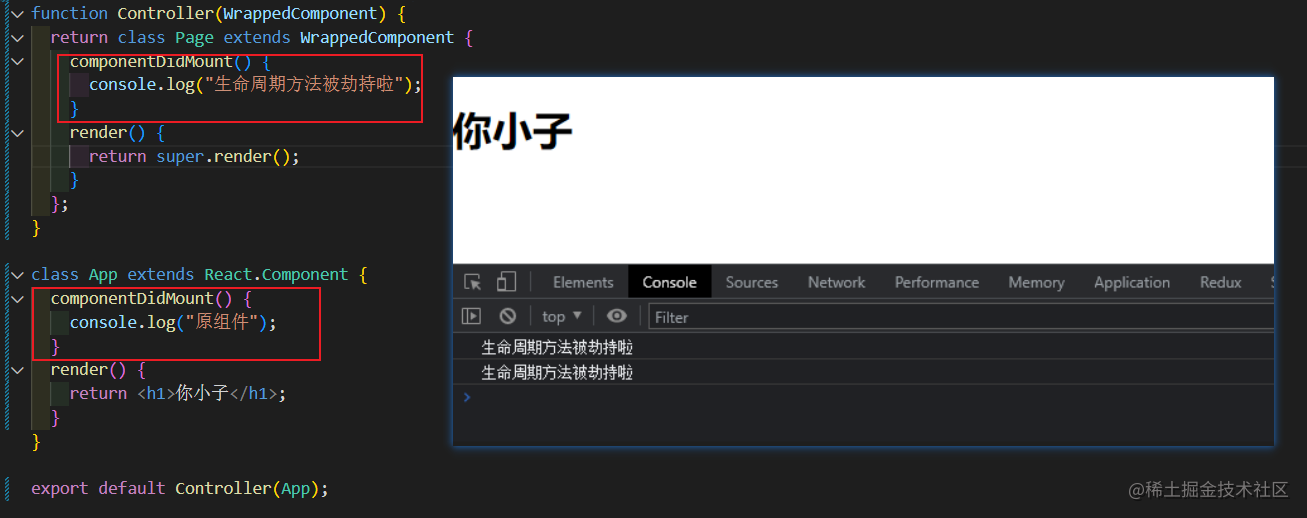
render props 模式
render props 的核心思想是通过一个函数将组件作为 props 的形式传递给另外一个函数组件。函数的参数由容器组件提供,这样的好处就是将组件的状态提升到外层组件中,具体实例代码如下所示:
const Home = (props) => {
console.log(props);
const { children } = props;
return <div>{children}</div>;
};
const App = () => {
return (
<div>
<Home admin={true}>
<h1>你小子</h1>
<h1>小黑子</h1>
</Home>
</div>
);
};
export default App;
具体的代码运行结果如下图所示:
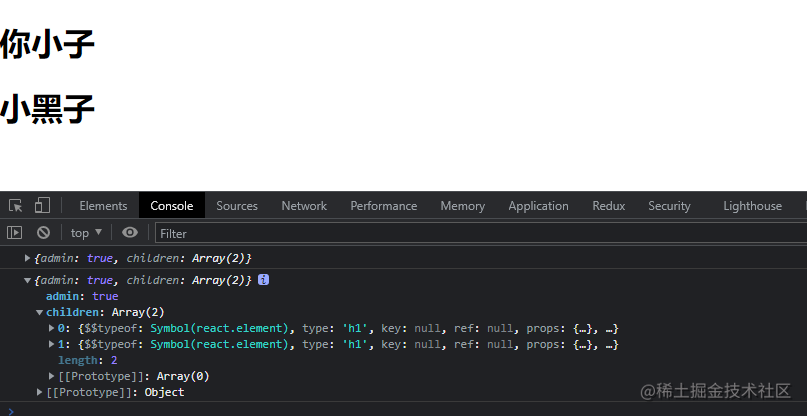
虽然这样能实现效果,但是官方说这是一个傻逼行为,因此官方更推荐使用 React 官方提供的 Children 方法,具体实例代码如下所示:
const Home = (props) => {
console.log(props);
const { children } = props;
return <div>{React.Children.map(children, (node) => node)}</div>;
};
const App = () => {
return (
<div>
<Home admin={true}>
<h1>你小子</h1>
<h1>小黑子</h1>
</Home>
</div>
);
};
export default App;
具体更多信息请参考 官方文档
实际上,我们经常使用的 context 就是使用的 render props 模式。
反向状态回传
这个组件的设计模式很叼很骚,就是你可以通过 render props 中的状态,提升到当前组件中也就是把容器组件内的状态,传递给父组件,具体示例代码如下所示:
import React, { useRef, useEffect } from "react";
const Home = (props) => {
console.log(props);
const dom = useRef();
const getDomRef = () => dom.current;
const handleClick = () => {
console.log("小黑子");
};
const { children } = props;
return (
<div ref={dom}>
<div>{children({ getDomRef, handleClick })}</div>
<div>{React.Children.map(children, (node) => node)}</div>
</div>
);
};
const App = () => {
const childRef = useRef(null);
useEffect(() => {
const dom = childRef.current();
dom.style.background = "red";
dom.style.fontSize = "100px";
}, [childRef]);
return (
<div>
<Home admin={true}>
{({ getDomRef, handleClick }) => {
childRef.current = getDomRef;
return <div onClick={handleClick}>你小子</div>;
}}
</Home>
</div>
);
};
export default App;
在运行代码之后,我们首先点击一下 div 元素,具体有如下输出,请看下图:
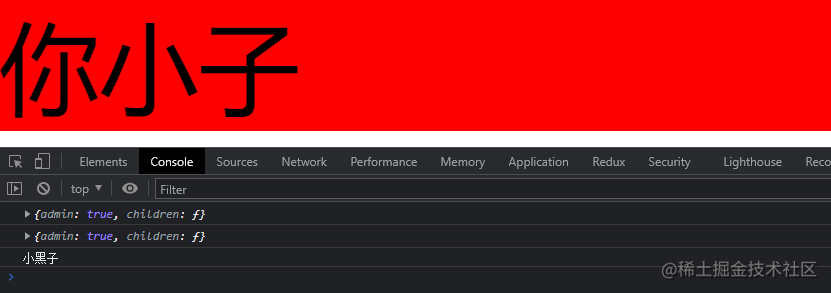
你会看到成功的在父组件操作到了子组件的 ref 实例了,还获取到了子组件的 handleClick 函数并成功调用了。
提供者模式
考虑一下这个场景,就好像爷爷要给孙子送吃的,按照之前的例子中,要通过 props 的方式把吃的送到孙子手中,你首先要经过儿子手中,再由儿子传给孙子,那万一儿子偷吃了呢?孙子岂不是饿死了.....
为了解决这个问题,React 提供了 Context 提供者模式,它可以直接跳过儿子直接把吃的送到孙子手上,具体实例代码如下所示:
import React, { createContext, useContext } from "react";
const ThemeContext = createContext({ nickname: "moment" });
const Foo = () => {
const theme = useContext(ThemeContext);
return <h1>{theme.nickname}</h1>;
};
const Home = () => {
const theme = useContext(ThemeContext);
return <h1>{theme.nickname}</h1>;
};
const App = () => {
const theme = useContext(ThemeContext);
return (
<div>
{
<ThemeContext.Provider
value={{
nickname: "你小子",
}}
>
<Foo />
</ThemeContext.Provider>
}
{
<ThemeContext.Provider
value={{
nickname: "首页",
}}
>
<Home />
</ThemeContext.Provider>
}
<div>{theme.nickname}</div>
</div>
);
};
export default App;
代码输出如下图所示:
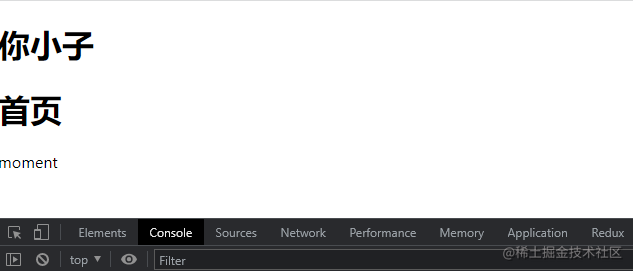
到这里本篇文章也就结束了,Hooks 的就不讲啦,在这篇文章中有讲到一点,喜欢的可以看看 如何优雅设地计出不可维护的 React 组件
参考资料
总结
不管是使用高阶组件、render props、context亦或是 Hooks,它们都有不同的使用场景,不能说哪个好用,哪个不好用,这就要根据到你的业务场景了,最后不得不说,React,你是真的骚啊......
最后希望这篇文章对你有帮助,如果错漏,欢迎留言指出,最后祝大嘎假期快来!
作者:Moment
来源:juejin.cn/post/7230461901356154940














