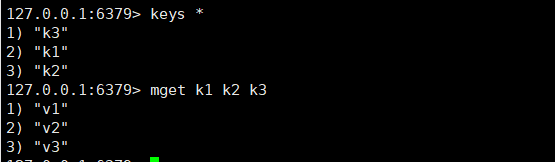
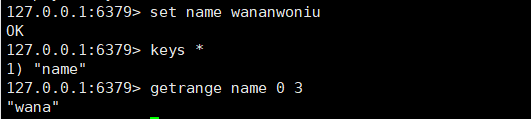
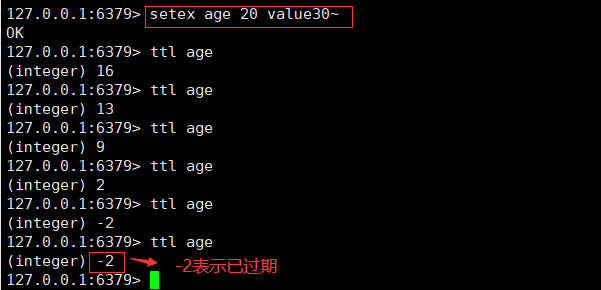
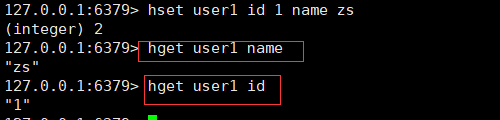
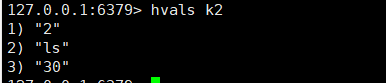
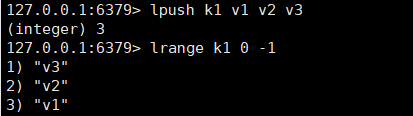
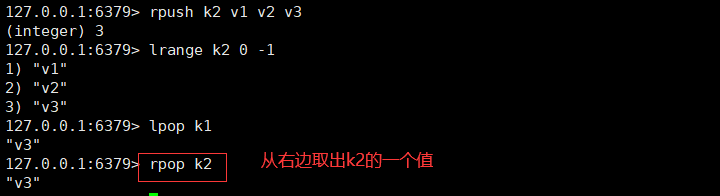
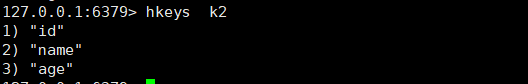1、onPullDownRefresh下拉刷新不生效
pages.json对应的style中enablePullDownRefresh设置为true,开启下拉刷新
{
"path" : "pages/list/list",
"style" :
{
"navigationBarTitleText": "页面标题名称",
"enablePullDownRefresh": true
}
}
2、onReachBottom上拉加载不生效
page中css样式设置了height:100%;
修改为height:auto;即可
3、onPageScroll生命周期不触发
最外层css样式设置了以下样式
height: 100%;
overflow: scroll;
4、onBackPress监听页面返回生命周期
使用场景:APP手机左滑返回时控制执行某些操作,不直接返回上一页(例如:弹框打开时关闭弹框)
注意事项
1、onBackPress上不可使用async,会导致无法阻止默认返回
2、支付宝小程序只有真机可以监听到非navigateBack引发的返回事件(使用小程序开发工具时不会触发onBackPress),不可以阻止默认返回行为
3、只有在该函数中返回值为 true 时,才表示不执行默认的返回,自行处理此时的业务逻辑
4、当不阻止页面返回却直接调用页面路由相关接口(如:uni.switchTab)时,可能会导致页面显示异常,可以通过延迟调用路由相关接口解决
5、H5 平台,顶部导航栏返回按钮支持 onBackPress(),浏览器默认返回按键及Android手机实体返回键不支持 onBackPress()
6、暂不支持直接在自定义组件中配置该函数,目前只能是在页面中来处理。
//场景1:弹框打开时,返回执行关闭弹框
//html
"searchPop" type="right" @change="popupChange">
<view class="popup-con">1111view>
//js
export default {
data() {
return {
boxShow: false
}
},
onBackPress(options) {
if( this.boxShow ){
this.$refs.searchPop.close();
return true
}
//其他情况执行默认返回
},
methods: {
popupChange(e) {
this.boxShow = e.show;
},
}
}
//场景2,多级返回时
export default {
data() {
return {
boxShow: false
}
},
onBackPress(options) {
if( this.boxShow ){
this.$refs.searchPop.close();
return true
}else{
if (options.from === 'navigateBack') {
return false;
}
uni.navigateBack({
delta: 2
});
}
},
methods: {
popupChange(e) {
this.boxShow = e.show;
},
}
}
5、遮罩层不能遮底部导航栏
应用场景:APP升级弹框提示
uni文档api界面——交互反馈中uni.showModal可以遮罩底部导航栏;
uni.showToast(OBJECT)、uni.showLoading(OBJECT)都无法遮罩底部导航栏;
目前可以采用两种方式解决:自定义底部导航栏、打开时隐藏底部导航栏
方法一:自定义底部导航栏
1、在app.vue页面的onLaunch生命周期中隐藏原生底部
onLaunch: function() {
console.log('App Launch')
uni.hideTabBar();
}
2、自己封装tab组件
<template>
<view class="foot-bar">
<view v-if="hasBorder" class="foot-barBorder">view>
<view class="foot-con">
<view class="foot-list" v-for="(item,index) in tabList" :key="index" @tap="tabJump(index,item.pagePath)">
<img v-if="index!=selectedIndex" class="foot-icon" :src="'/'+item.iconPath" mode="heightFix" />
<img v-else class="foot-icon" :src="'/'+item.selectedIconPath" mode="heightFix" />
<text v-if="index!=selectedIndex" :style="textStyle">{{item.text}}text>
<text v-else :style="textSelectStyle">{{item.text}}text>
view>
view>
view>
template>
<script>
export default {
name: "tabBar",
props: {
hasBorder: {
type: Boolean,
default: false
},
selectedIndex:{
type:[String,Number],
default:0
},
textStyle: {
type: Object,
default () {
return {
color:'#999'
}
}
},
textSelectStyle:{
type: Object,
default () {
return {
color: 'rgb(0, 122, 255)'
}
}
}
},
data() {
return {
tabList: [{
"pagePath": "pages/tabBar/component/component",
"iconPath": "static/component.png",
"selectedIconPath": "static/componentHL.png",
"text": "内置组件"
},
{
"pagePath": "pages/tabBar/API/API",
"iconPath": "static/api.png",
"selectedIconPath": "static/apiHL.png",
"text": "接口"
}, {
"pagePath": "pages/tabBar/extUI/extUI",
"iconPath": "static/extui.png",
"selectedIconPath": "static/extuiHL.png",
"text": "扩展组件"
}, {
"pagePath": "pages/tabBar/template/template",
"iconPath": "static/template.png",
"selectedIconPath": "static/templateHL.png",
"text": "模板"
}
]
};
},
methods:{
tabJump(index,url){
if( index == this.selectedIndex ){
return
}
uni.switchTab({
url: '/' + url
})
}
}
}
script>
<style lang="scss" scoped>
.foot-bar {
position: fixed;
left: 0px;
right: 0px;
bottom: 0px;
z-index: 998;
width: 100vw;
.foot-barBorder {
position: absolute;
left: 0px;
right: 0px;
top: -1px;
width: 100vw;
height: 1px;
background-color: #eee;
}
.foot-con {
background-color: #fff;
width: 100vw;
height: 50px;
display: flex;
flex-direction: row;
align-items: center;
.foot-list {
flex: 1;
display: flex;
flex-direction: column;
align-items: center;
.foot-icon{
width: auto;
height:30px;
}
text{
font-size: 12px;
}
}
}
}
style>
3、需要底部导航的页面引入组件,当前页面是导航栏第几个,selectedIndex就等于几,从0开始
<template>
<view>
<TabBar :selectedIndex="0">TabBar>
view>
template>
<script>
import TabBar from "@/components/tabBar/tabBar";
export default {
components:{
TabBar
},
data() {
return {}
}
}
script>
方法二:打开时隐藏底部导航栏,关闭时打开导航栏
uni.hideTabBar();uni.showTabBar(); 官方文档


6、条件编译的正确写法
语法:以 #ifdef 或 #ifndef 加 %PLATFORM% 开头,以 #endif 结尾
- #ifdef:if defined 仅在某平台存在
- #ifndef:if not defined 除了某平台均存在
- %PLATFORM%:平台名称
//仅出现在 App 平台下的代码
#ifdef APP-PLUS
需条件编译的代码
#endif
//除了 H5 平台,其它平台均存在的代码
#ifndef H5
需条件编译的代码
#endif
在 H5 平台或微信小程序平台存在的代码
#ifdef H5 || MP-WEIXIN
需条件编译的代码
#endif
//css样式中
page{
padding-top:24rpx;
/* #ifdef H5 */
padding-top:34rpx;
/* #endif */
}
//.vue页面中
<template>
<view>NFC扫码view>
template>
//page.json页面中
//json文件中
//API 的条件编译
//生命周期中
//methods方法中
mounted(){
// #ifdef APP-PLUS
//APP更新
this.checkUpdate();
//#endif
}
7、限制input输入类型,replace不生效
//不生效代码
"Code" type="number" placeholder="请输入号码" clearable trim="all" :inputBorder="false" @input="gunChange" maxlength="11">
methods:{
gunChange(e){
this.addForm.oilGunCode = e.replace(/[^\d]/g, '');
},
}
使用v-model绑定值时,replace回显不生效;将v-model修改为:value即可生效;
//生效代码
all" :inputBorder="false" @input="gunChange" maxlength="11">
限制只能输入数字:/[^\d]/g 或 /\D/g (但无法限制0开头)
限制只能输入大小写字母、数字、下划线:/[^\w_]/g
限制只能输入小写字母、数字、下划线:/[^a-z0-9_]/g
限制只能输入数字和点:/[^\d.]/g
限制只能输入中文:/[^\u4e00-\u9fa5]/g
限制只能输入英文(大小写均可):/[^a-zA-Z]/g
去除空格:/\s+/g
8、常见的登录验证
"name" placeholder="请输入用户名" clearable trim="all" maxlength="11">
<uni-easyinput v-model="tell" placeholder="请输入手机号" clearable trim="all" maxlength="11">uni-easyinput>
methods:{
submitHandle(){
//姓名 2-5为的汉字
var reg0 = /^[\u4e00-\u9fa5]{2,5}$/,
//用户名正则,4到16位(字母,数字,下划线,减号)
var reg = /^[a-zA-Z0-9_-]{4,16}$/;
//密码强度正则,最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
var reg2 = /^.*(?=.{6,})(?=.*\d)(?=.*[A-Z])(?=.*[a-z])(?=.*[!@#$%^&*? ]).*$/;
//Email正则
var reg3 = /^([A-Za-z0-9_\-\.])+\@([A-Za-z0-9_\-\.])+\.([A-Za-z]{2,4})$/;
//手机号正则
var reg4 = /^((13[0-9])|(14[5|7])|(15([0-3]|[5-9]))|(18[0,5-9]))\d{8}$/;
//身-份-证号(18位)正则
var reg5 = /^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/;
//车牌号正则
var reg6 = /^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/;
if( !reg.test(this.name) ){
uni.showToast(
title:'用户名格式不正确!'
)
}
},
} 作者:CRMEB技术团队
来源:juejin.cn/post/7272185503822086203
来源:juejin.cn/post/7272185503822086203






































































 代码如下:
代码如下: