







前言
亲爱的小伙伴,你好!我是 嘟老板。我们使用 Vue 开发页面时,经常需要在

为了提高代码的可读性,JS与CSS一样,也提供了注释功能。JS中的注释主要有两种,分别是单行注释和多行注释。
在编程的世界里,注释是那些默默无闻的英雄,它们静静地站在代码的背后,为后来的维护者、为未来的自己,甚至是为那些偶然间翻阅你代码的开发者提供着不可或缺的信息。

今天,我们就来深入探讨JavaScript中的注释,让我们的代码不仅能够运行,还能够“说话”。
JavaScript注释是用来解释代码的,不会被浏览器执行。它们可以帮助其他开发者理解代码的功能和目的。
注释就像是给代码穿上了一件华丽的外衣,让我们的代码更加优雅、易读。如下图中的例子所示:
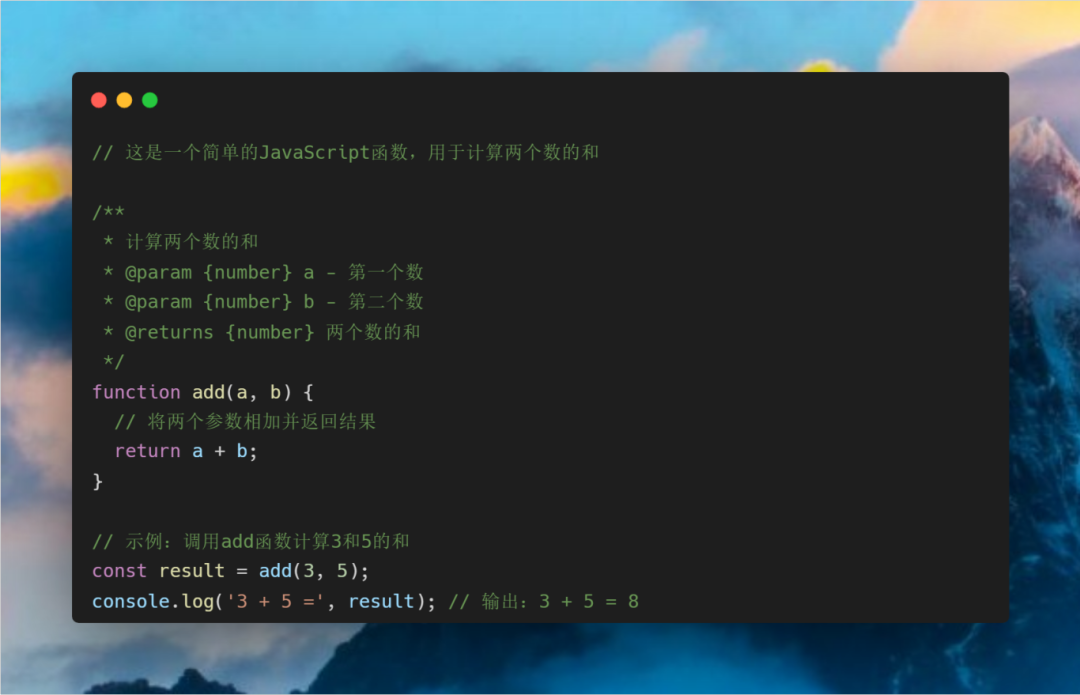
在JavaScript中,有两种类型的注释:单行注释和多行注释。下面分别讲解这两种注释的含义和使用。
单行注释: 使用两个斜杠(//)开头,后面的内容直到该行结束都被视为注释。例如:
// 这是一个单行注释
console.log("Hello, World!"); // 这也是一个单行注释
它适用于简短的注释,比如对某一行代码的快速说明。
多行注释: 使用斜杠星号(/)开头,星号斜杠(/)结尾,中间的内容都被视为注释。
例如:
/*
这是一个多行注释
可以跨越多行
*/
console.log("Hello, World!");
这种注释可以跨越多行,适合用于函数描述、复杂的算法解释或者临时屏蔽代码块。
注意: 在HTML文件中,如果需要将JavaScript代码嵌入到<script>标签中,可以使用以下方法来添加多行注释:
<script>
<!--
这是一个多行注释
可以跨越多行
-->
console.log("Hello, World!");
</script>
通过注释,我们可以解释代码的功能和作用,让其他程序员更容易理解我们的代码。
// 这是一个求和函数
function sum(a, b) {
return a + b;
}
我们可以使用注释来标记代码的状态,例如TODO、FIXME等,提醒自己或其他程序员注意这些问题。
// TODO: 优化这个函数的性能
function slowFunction() {
// ...
}
当我们需要暂时禁用某段代码时,可以使用注释将其包裹起来,而不是直接删除。
// function oldFunction() {
// // ...
// }
想要快速入门前端开发吗?推荐一个前端开发基础课程,这个老师讲的特别好,零基础学习无压力,知识点结合代码,边学边练,可以免费试看试学,还有各种辅助工具和资料,非常适合新手!
点这里前往学习哦!
注释虽好,但过多或不当的注释反而会成为阅读代码的障碍。我们在写注释时也要注意以下几点:
简洁明了: 注释应该简单明了,能够快速传达信息。
适当使用: 不要过度使用注释,只有在必要的时候才添加。
保持一致: 在团队开发中,要遵循统一的注释规范,以便于团队成员之间的沟通。
适时更新: 随着代码的变更,记得更新相关的注释。
JavaScript注释是我们编程过程中的得力助手,它们不仅能够帮助我们更好地理解代码,还能提高代码的可读性和可维护性。让我们一起学会使用注释,让我们的代码更加精彩!
收起阅读 »前半年接了一个划线需求,一直没空总结下。微信公众号和微信读书等读书类应用都有此功能,但前者只对部分用户开放了,并且没有长期运营。
这次只谈下划线技术实现本身。
可以看到,微信公众号划线过程会弹出一个灰色面板,面板上有划线(这次需求改为了点赞)按钮:


这个需求乍看可能会觉得没那么复杂,但细细分析后会发现有较长的交互流程和逻辑链:

其中有几个会影响整体逻辑的关键点需要关注:
window 上提供了 Selection 对象,它代表页面中的文本选区,可能横跨多个元素。文本选区由用户拖拽鼠标经过文字而产生。调用 Selection.toString() 方法会返回被选中区域中的纯文本。
var selObj = window.getSelection();
var range = selObj.getRangeAt(0);
Selection 对象所对应的是用户所选择的 ranges(区域)
var selObj = window.getSelection();
var range = selObj.getRangeAt(0);
渲染划线有两种方式:
1 在划线range对象的首尾dom的位置,插入线段的dom标签;
优点:划线的点击不需要计算点击位置,直接在插入dom上绑定事件即可;
缺点:对原页面结构有入侵,改变了dom结构,可能引发其他问题;
2 绝对定位,相对于整篇文章;
优点:完全增量,对原页面没有入侵;
缺点:需要计算点击位置;
我选择的第二种,原因是为了不影响原有页面逻辑,这样项目风险也是最小的。那么具体怎么实现呢?
range对象提供了一个 getClientRects 方法,表示 range 在屏幕上所占的区域。这个列表相当于汇集了范围中所有元素调用 Element.getClientRects() 方法所得的结果。用拿到的位置信息进行绝对定位即可。
rectList = range.getClientRects()
我们把用户所有划线range对象和其产生的位置信息都存入到一个list中。
pageRangeList.push({
range,
rectInfo
})
我们分析下整个交互过程:
有两个主要的交互事件,一是点击划线,二是滑动选区。
处理点击事件,我们拿到点击事件的位置,和存放的 pageRangeList 进行位置比较,得出用户点击的是哪个range对象。
// 点击事件
const {pageX, pageY} = event;
const lineHeight = 23;
const {range} = rectInfo.some(rect => {
const {left, right, realY} = rect;
return pageX < left && pageX > left && pageY > realY
})
this.selection.removeAllRanges();
this.selection.addRange();
选区事件我选择的是 selectionchange,需要加防抖和节流处理。
如果你选的是 touchend 安卓系统会点问题。
如第2点核心逻辑中所说,在滑词过程中,需要比较位置关系,我们直接使用Range.compareBoundaryPoints方法即可。返回值 0 、-1 、1 分别代表不同的位置关系。
const compare = range.compareBoundaryPoints(Range.START_TO_END, sourceRange);
序列化是整个需求的重点,序列化是指将交互产生的划线转化成某种数据结构能存储在服务器上,反序列化是指如何将server下发的序列化数据转化成非序列化的划线。
两者是两个相反的过程,当我们确定了序列化方案,其实也就知道了反序列化了。
刚开始我观察文章都会拆分段落,如按P标签或某一个class类名来划分段落,于是计划用段落信息,告诉 server 划线在第几段的第几个字。
interface data {
startParagraph: 1,
startIndex: 22,
endParagraph: 2,
endIndex: 15
}
但后来发现有一些抓取的文章根本内容很混乱,且没有特定的段落,强行识别复杂度极高。(如下图)所以此方案不可行。

前面的方案不可能的原因是,识别段落信息复杂度不可控,那么我们可以绕过段落信息,去识别全文第几个字。
interface data {
startCharacters: 122,
endCharacters: 166
}
具体方式是用Range,圈选文章开头到当前dom,形成一个新Range,再调用range.toString查看字数即可。
const range = new Range();
range.setStart(pageContainer, 0);
range.setEnd(curEndContainer, endOffset);
const str = range.toString();
这里注意,由于 Javascript 在大多宿主环境下没有递归的尾调用优化,所以我采用了手动创建栈来进行 dfs:
dfs({
node = this.content,
}) {
const stack = [];
if (!node) {
return;
}
stack.push(node);
while (stack.length) {
const item = stack.pop();
const children = item.childNodes;
for (let i = children.length - 1; i >= 0; i--) {
stack.push( [i]);
}
}
}
我记得2021年的时候做过聊天功能,那时业务也只限微信小程序
那时候的心路历程是:
卧槽,让我写一个聊天功能这么高大上??
嗯?这么简单,不就画画页面来个轮询吗,加个websocket也还行吧
然后,卧槽?这查看历史聊天记录什么鬼,页面闪一下不太好啊,真的能做到微信的那种效果吗
然后一堆调研加测试,总算在小程序中查看历史记录没那么鬼畜了,但是总是感觉不是最佳解决方案。
那时打出的子弹,一直等到现在击中了我
最近又回想到了这个痛点,于是网上想看看有没有大佬发解决方案,结果还真被我找到了。

上才艺~~~

常规写法加载历史记录拼接到聊天主体的顶部后,滚动条会回到顶部、不在原聊天页面
直接上图

而我们以往的解决方案也只是各种利用缓存、scroll的滚动定位把回到顶部的滚动条重新拉回加载历史记录前的位置,好让我们可以继续在原聊天页面。
但即使我们做了很多优化,也会有安卓和苹果部分机型适配问题,还是不自然,可能会出现页面闪动。
其实吧,解决方案只有两行css代码~~~
想优雅顺滑的在聊天框里查看历史记录,这两行css代码就是flex的这个翻转属性
dispaly:flex;
flex-direction: column-reverse
灵感来源~~~

小伙伴可以看到,在加载更多数据时
滚动条位置没变、加载数据后还是原聊天页面的位置
这不就是我们之前的痛点吗~~~
所以,我们只需要翻转位置,用这个就可以优雅流畅的实现微信的加载历史记录啦
flex-direction: column-reverse
官方的意思:指定Flex容器中子元素的排列方向为列(从上到下),并且将其顺序反转(从底部到顶部)
如果感觉还是抽象,不好理解的话,那就直接上图,不加column-reverse的样子

加了column-reverse的样子

至此,我们用column-reverse再搭配data数据的位置处理就完美解决加载历史记录的历史性问题啦
代码放最后啦~~~
因为用了翻转,数据少的时候会出现上图的问题
只需要.mainArea加上height:100%
然后额外写个适配盒子就行
flex-grow: 1;
flex-shrink: 1;

这一part是因为我用了uniapp里 scroll-view组件导致的坑以及解决方案,小伙伴们没用这个组件的可忽略~~~
如下图,.mainArea使用了height:100%后,继承了父级高度后scroll-view滚动条消失了。

.mainArea去掉height:100%后scroll-view滚动条出现,但是第一屏数据过多时不会滚动到底部展示最新信息

解决方案:第一屏手动进行滚动条置顶
scrollBottom() {
if (this.firstLoad) return;
// 第一屏后不触发
this.$nextTick(() => {
const query = uni.createSelectorQuery().in(this);
query
.select("#mainArea")
.boundingClientRect((data) => {
console.log(data);
if (data.height > +this.chatHeight) {
this.scrollTop = data.height; // 填写个较大的数
this.firstLoad = true;
}
})
.exec();
});
},
使用koa自己搭一个websocket服务端

package.json
{
"name": "websocketapi",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"koa": "^2.14.2",
"koa-router": "^12.0.1",
"koa-websocket": "^7.0.0"
}
}
koa-tcp.js
const koa = require('koa')
const Router = require('koa-router')
const ws = require('koa-websocket')
const app = ws(new koa())
const router = new Router()
/**
* 服务端给客户端的聊天信息格式
* {
id: lastid,
showTime: 是否展示时间,
time: nowDate,
type: type,
userinfo: {
uid: this.myuid,
username: this.username,
face: this.avatar,
},
content: {
url:'',
text:'',
w:'',
h:''
},
}
消息数据队列的队头为最新消息,以次往下为老消息
客户端展示需要reverse(): 客户端聊天窗口最下面需要为最新消息,所以队列尾部为最新消息,以此往上为老消息
*/
router.all('/websocket/:id', async (ctx) => {
// const query = ctx.query
console.log(JSON.stringify(ctx.params))
ctx.websocket.send('我是小服,告诉你连接成功啦')
ctx.websocket.on('message', (res) => {
console.log(`服务端收到消息, ${res}`)
let data = JSON.parse(res)
if (data.type === 'chat') {
ctx.websocket.send(`我也会说${data.text}`)
}
})
ctx.websocket.on('close', () => {
console.log('服务端关闭')
})
})
// 将路由中间件添加到Koa应用中
app.ws.use(router.routes()).use(router.allowedMethods())
app.listen(9001, () => {
console.log('socket is connect')
})
切到server目录下yarn
然后执行nodemon koa-tcp.js
没有nodemon的小伙伴要装一下

代码区
聊天页面的核心代码如下(包含data数据的位置处理和与服务端联动)
这篇文章我尽力把我的笔记和想法放到这了,希望对小伙伴有帮助。
到这里,想给小伙伴分享两句话
现在搞不清楚的事,不妨可以先慢下来,不要让自己钻到牛角尖了
一些你现在觉得解决不了的事,可能需要换个角度
欢迎转载,但请注明来源。
最后,希望小伙伴们给我个免费的点赞,祝大家心想事成,平安喜乐。

装饰器模式可在不改变现有对象解构的基础上,动态地为对象添加功能。var plane = {
fire: function () {
console.log("普通子弹");
},
};
var missleDecorator = function () {
console.log("发射导弹");
};
var atomDecorator = function () {
console.log("发射原子弹");
};
var fire1 = plane.fire;
plane.fire = function () {
fire1();
missleDecorator();
};
var fire2 = plane.fire;
plane.fire = function () {
fire2();
atomDecorator();
};
plane.fire();
/**
普通子弹
发射导弹
发射原子弹
*/
function a(){
console.log(1);
}
// 改写:
function a(){
console.log(1);
// 新功能
console.log(2);
}
AOP 来装饰函数。Function.prototype.before = function (beforeFn) {
var _self = this;
return function () {
beforeFn.apply(this, arguments);
return _self.apply(this, arguments);
};
};
Function.prototype.after = function (afterFn) {
var _self = this;
return function () {
var ret = _self.apply(this, arguments);
afterFn.apply(this, arguments);
return ret;
}
}
// before 和 after 函数都接收一个函数作为参数,这个函数也就是新添加的函数(里面也就是要添加的新功能逻辑)。
// 而before 和 after 函数区别在于在是原函数之前执行还是之后执行。
Function.prototype.before = function (beforeFn) {
var _self = this;
return function () {
beforeFn.apply(this, arguments);
return _self.apply(this, arguments);
};
};
Function.prototype.after = function (afterFn) {
var _self = this;
return function () {
var ret = _self.apply(this, arguments);
afterFn.apply(this, arguments);
return ret;
}
}
var o1 = function(){
console.log('1');
}
var o2 = function(){
console.log('2');
}
var o3 = function(){
console.log('3');
}
var desctor = o1.after(o2);
desctor = desctor.after(o3);
desctor(); // 1 2 3
/**
var desctor = o1.after(o2);
desctor = desctor.after(o3);
desctor();
1
2
3
var desctor = o1.before(o2);
desctor = desctor.before(o3);
desctor();
3
2
1
var desctor = o1.after(o2);
desctor = desctor.before(o3);
desctor();
3
1
2
var desctor = o1.before(o2);
desctor = desctor.after(o3);
desctor();
2
1
3
*/
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>AOP日志上报</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<script src="https://unpkg.com/vue@3.2.20/dist/vue.global.js"></script>
</head>
<body>
<div id="app">
<button class="btn" @click="handler">Button</button>
<p id="tt">{{message}}</p>
</div>
</body>
</html>
<script type="text/javascript">
// log report
const { reactive, ref, createApp } = Vue;
const app = createApp({
setup() {
const message = ref("未点击");
const count = ref(0);
Function.prototype.before = function (beforeFn) {
var _self = this;
return function () {
beforeFn.apply(this, arguments);
return _self.apply(this, arguments);
};
};
Function.prototype.after = function (afterFn) {
var _self = this;
return function () {
var ret = _self.apply(this, arguments);
afterFn.apply(this, arguments);
return ret;
};
};
function handler() {
message.value = `已点击${++count.value}`;
}
handler = handler.after(log);
function log() {
message.value = message.value + "-----> log reported";
console.log("log report");
}
return {
message,
handler,
};
},
});
app.mount("#app");
</script>
{
name: 'xxxx',
password: 'xxxx',
}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>AOP动态参数</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<script src="https://unpkg.com/vue@3.2.20/dist/vue.global.js"></script>
</head>
<body>
<div id="app">{{message}}</div>
</body>
</html>
<script type="text/javascript">
const { reactive, ref, createApp } = Vue;
const app = createApp({
setup() {
const message = ref("empty params");
Function.prototype.before = function (beforeFn) {
var _self = this;
return function () {
beforeFn.apply(this, arguments);
return _self.apply(this, arguments);
};
};
Function.prototype.after = function (afterFn) {
var _self = this;
return function () {
var ret = _self.apply(this, arguments);
afterFn.apply(this, arguments);
return ret;
};
};
function ajax(type, url, params){
message.value = `${type} ----> ${url} -----> ${JSON.stringify(params)}`;
}
function getToken(){
// do something
return 'token';
}
ajax = ajax.before(function(type, url, params){
params.token = getToken();
})
ajax('get', 'https://www.baidu.com/userinfo', {name: 'se', password: 'xsdsd'});
return {
message,
};
},
});
app.mount("#app");
</script>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>AOP表单验证</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<script src="https://unpkg.com/vue@3.2.20/dist/vue.global.js"></script>
</head>
<body>
<div id="app">
<label>
姓名:
<input
type="text"
v-model="data.name"
placeholder="请输入姓名"
/>
</label>
<label>
密码:
<input
type="text"
v-model="data.pass"
placeholder="请输入密码"
/>
</label>
<p v-if="data.name || data.pass">{{data.name + '/' + data.pass}} ----after-----> {{data.message}}</p>
<hr>
<button @click="submitBtn">submit</button>
</div>
</body>
</html>
<script type="text/javascript">
const { reactive, ref, createApp, watchEffect } = Vue;
const app = createApp({
setup() {
const data = reactive({
name: "",
pass: "",
message: "",
});
Function.prototype.before = function (beforeFn) {
var _self = this;
return function () {
if (beforeFn.apply(this, arguments) === false) return;
return _self.apply(this, arguments);
};
};
function valid() {
if (!data.name || !data.pass) {
alert("用户名或密码不能为空");
return false;
}
}
function formSubmit() {
console.log("data ------>", data);
data.message = `${data.name} ------- ${data.pass}`;
}
formSubmit = formSubmit.before(valid);
function submitBtn() {
formSubmit();
}
return {
data,
submitBtn,
};
},
});
app.mount("#app");
</script>
曾探大佬的《JavaScript 设计模式与开发实践》。文章仅做个人学习总结和知识汇总之前写过一篇文章 我理想中的低代码开发工具的形态,已经吐槽了各种封装 xxxForm,xxxTable 的行为,这里就不啰嗦了。今天再来看看我的工具达到了什么程度。
多图预警。。。






目前我们没有写一行代码,就已经达到了如下的效果

下面是一部分生成的代码
import { reactive, ref } from 'vue'
import { IFetchTableListResult } from './api'
interface ITableListItem {
/**
* 决算单状态
*/
settlementStatus: string
/**
* 主合同编号
*/
mainContractNumber: string
/**
* 客户名称
*/
customerName: string
/**
* 客户手机号
*/
customerPhone: string
/**
* 房屋地址
*/
houseAddress: string
/**
* 工程管理
*/
projectManagement: string
/**
* 接口返回的数据,新增字段不需要改 ITableListItem 直接从这里取
*/
apiResult: IFetchTableListResult['result']['records'][0]
}
interface IFormData {
/**
* 决算单状态
*/
settlementStatus?: string
/**
* 主合同编号
*/
mainContractNumber?: string
/**
* 客户名称
*/
customerName?: string
/**
* 客户手机号
*/
customerPhone?: string
/**
* 工程管理
*/
projectManagement?: string
}
interface IOptionItem {
label: string
value: string
}
interface IOptions {
settlementStatus: IOptionItem[]
}
const defaultOptions: IOptions = {
settlementStatus: [],
}
export const defaultFormData: IFormData = {
settlementStatus: undefined,
mainContractNumber: undefined,
customerName: undefined,
customerPhone: undefined,
projectManagement: undefined,
}
export const useModel = () => {
const filterForm = reactive<IFormData>({ ...defaultFormData })
const options = reactive<IOptions>({ ...defaultOptions })
const tableList = ref<(ITableListItem & { _?: unknown })[]>([])
const pagination = reactive<{
page: number
pageSize: number
total: number
}>({
page: 1,
pageSize: 10,
total: 0,
})
const loading = reactive<{ list: boolean }>({
list: false,
})
return {
filterForm,
options,
tableList,
pagination,
loading,
}
}
export type Model = ReturnType<typeof useModel>
这就是用模板生成的好处,有规范,随时可以改,而封装 xxxForm,xxxTable 就是一个黑盒。
下面大致说一下原理

首先是写好一个个模版,vscode 插件读取指定目录下模版显示到界面上

每个模版下可能包含如下内容:

选择模版后,进入动态表单配置界面

动态表单是读取 config/schema.json 里的内容进行动态渲染的,目前支持 amis、form-render、formily

配置表单是为了生成 JSON 数据,然后根据 JSON 数据生成代码。所以最终还是无法避免的使用私有的 DSL ,但是生成后的代码是没有私有 DSL 的痕迹的。生成代码本质是 JSON + EJS 模版引擎编译 src 目录下的 ejs 文件。
为了加快表单的配置,可以自定义脚本进行操作

这部分内容是读取 config/preview.json 内容进行显示的

选择对应的脚本方法后,插件会动态加载 script/index.js 脚本,并执行里面对应的方法

以 initColumnsFromImage 方法为例,这个方法是读取剪贴板里的图片,然后使用百度 OCR 解析出文本,再使用文本初始化表单
initColumnsFromImage: async (lowcodeContext) => {
context.lowcodeContext = lowcodeContext;
const res = await main.handleInitColumnsFromImage();
return res;
},
export async function handleInitColumnsFromImage() {
const { lowcodeContext } = context;
if (!lowcodeContext?.clipboardImage) {
window.showInformationMessage('剪贴板里没有截图');
return lowcodeContext?.model;
}
const ocrRes = await generalBasic({ image: lowcodeContext!.clipboardImage! });
env.clipboard.writeText(ocrRes.words_result.map((s) => s.words).join('\r\n'));
window.showInformationMessage('内容已经复制到剪贴板');
const columns = ocrRes.words_result.map((s) => ({
slot: false,
title: s.words,
dataIndex: s.words,
key: s.words,
}));
return { ...lowcodeContext.model, columns };
}
反正就是可以根据自己的需求定义各种各样的脚本。比如使用 ChatGPT 翻译 JSON 里的指定字段,可以看我的上一篇文章 TypeChat、JSONSchemaChat实战 - 让ChatGPT更听你的话
再比如要实现把中文翻译成英文,然后英文使用驼峰语法,这样就可以将中文转成英文代码变量,下面是实现的效果

选择对应的命令菜单后 vscode 插件会加载对应模版里的脚本,然后执行里面的 onSelect 方法。

main.ts 代码如下
import { env, window, Range } from 'vscode';
import { context } from './context';
export async function bootstrap() {
const clipboardText = await env.clipboard.readText();
const { selection, document } = window.activeTextEditor!;
const selectText = document.getText(selection).trim();
let content = await context.lowcodeContext!.createChatCompletion({
messages: [
{
role: 'system',
content: `你是一个翻译家,你的目标是把中文翻译成英文单词,请翻译时使用驼峰格式,小写字母开头,不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面用户输入的内容`,
},
{
role: 'user',
content: selectText || clipboardText,
},
],
});
content = content.charAt(0).toLowerCase() + content.slice(1);
window.activeTextEditor?.edit((editBuilder) => {
if (window.activeTextEditor?.selection.isEmpty) {
editBuilder.insert(window.activeTextEditor.selection.start, content);
} else {
editBuilder.replace(
new Range(
window.activeTextEditor!.selection.start,
window.activeTextEditor!.selection.end,
),
content,
);
}
});
}
使用了 ChatGPT。
再来看看,之前生成管理后台 CURD 页面的时候,连 mock 也一起生成了,主要逻辑放在了 complete 方法里,这是插件的一个生命周期函数。

因为 mock 服务在另一个项目里,所以需要跨目录去生成代码,这里我在 mock 服务里加了个接口返回 mock 项目所在的目录
.get(`/mockProjectPath`, async (ctx, next) => {
ctx.body = {
status: 200,
msg: '',
result: __dirname,
};
})
生成代码的时候请求这个接口,就知道往哪个目录生成代码了
const mockProjectPathRes = await axios
.get('http://localhost:3001/mockProjectPath', { timeout: 1000 })
.catch(() => {
window.showInformationMessage(
'获取 mock 项目路径失败,跳过更新 mock 服务',
);
});
if (mockProjectPathRes?.data.result) {
const projectName = workspace.rootPath
?.replace(/\\/g, '/')
.split('/')
.pop();
const mockRouteFile = path.join(
mockProjectPathRes.data.result,
`${projectName}.js`,
);
let mockFileContent = `
import KoaRouter from 'koa-router';
import proxy from '../middleware/Proxy';
import { delay } from '../lib/util';
const Mock = require('mockjs');
const { Random } = Mock;
const router = new KoaRouter();
router{{mockScript}}
module.exports = router;
`;
if (fs.existsSync(mockRouteFile)) {
mockFileContent = fs.readFileSync(mockRouteFile).toString().toString();
const index = mockFileContent.lastIndexOf(')') + 1;
mockFileContent = `${mockFileContent.substring(
0,
index,
)}{{mockScript}}\n${mockFileContent.substring(index)}`;
}
mockFileContent = mockFileContent.replace(/{{mockScript}}/g, mockScript);
fs.writeFileSync(mockRouteFile, mockFileContent);
try {
execa.sync('node', [
path.join(
mockProjectPathRes.data.result
.replace(/\\/g, '/')
.replace('/src/routes', ''),
'/node_modules/eslint/bin/eslint.js',
),
mockRouteFile,
'--resolve-plugins-relative-to',
mockProjectPathRes.data.result
.replace(/\\/g, '/')
.replace('/src/routes', ''),
'--fix',
]);
} catch (err) {
console.log(err);
}
mock 项目也可以通过 vscode 插件快速创建和使用

上面展示的模版都放在了 github.com/lowcode-sca… 仓库里,照着 README 步骤做就可以使用了。
众所周知,小程序的渲染性能一直被广大开发者诟病,2023年中旬,小程序团队正式发布了 skyline 渲染引擎,Skyline,旨在替代 WebView 作为小程序的渲染层,以提供更优秀的渲染性能和诸多增强特性,让小程序能达到原生的体验。
非常好,那么就是说我们可以在小程序上体验类原生的特性啦!这下谁敢再说小程序是屎?
在用了一段时间,主要尝试了canvas、手势组件动画等功能,惊奇的发现,小程序做的这个 skyline 渲染引擎,是一陀超大的屎。
噢!腾讯,你小子好啊,研究了这么长时间,跑我这排宿便了是吧?


自己写的样式和iconfont样式给我报了很多坨警告,能用吗?能用,但是我是屎我需要恶心你,我必须得给你点警告。
除了控制台脏了之外,还有各种各样数不清的 bug。比如,地图的bindregionchange失效,而你去论坛发帖,他们只会说:"未复现"、"写片段"、"你试试",发文时实测依然没有修复😅。
铺垫了这么多,实属无奈,我也不想说这么多,只是这口屎憋在嘴里,臭的难受。我本以为出淤泥而不染已经很难得了,没想到在这屎坑里还有大佬栽培了一朵精美绝伦的白莲花,它就是 lspriv/wx-calendar ,github链接:github.com/lspriv/wx-c…。
看到这么牛逼的组件,只有区区一百来个 star。
牛逼不牛逼,直接看效果:

它还同时支持 skyline 和 webview 下渲染。

每个场景都是丝滑过渡的,元素到元素的联合动画。看的出来,这个日历是有很重的 MIUI 风格的,如果不是右上角的小程序胶囊,我甚至以为是某手机的自带日历。

依赖 skyline 的 worklet 动画,组件做到了跟手、丝滑,且符合直觉的动画。
lspriv/wx-calendar 需要使用npm下载并构建,然后引入组件使用。
npm i @lspriv/wx-calendar
然后需要使用微信开发者工具构建 npm
{
"usingComponents": {
"calendar": "@lspriv/wx-calendar"
}
}
id="calendar" bindload="handleLoad" />
作者十分聪明,给 lspriv/wx-calendar 预留了插件接口,开发者可以根据自身需求,写扩展功能。
源码中 src>plugins>lunar.ts 是一个内置插件,实现了农历、节气、闰年等功能。
目前为止,还没有看到有第二个人为作者贡献插件。
目前还有很多基础功能还没有开发,比如
总的来说,这是一款不可多得的组件,即使在PC端,也是不常见的。在小程序的层层阻挠下能开发出如此的组件,实属不易。

tips: 文末有完整示例代码。
领导:『小S啊,我们有个新需求🥸,需要在预览的资源上添加水印,让服务端来加水印成本太高了,在前端渲染的时候把水印加上可以吗🤨?』
小S:『加水印啊,简简单单🤏。我们项目使用的是 Vue3,使用自定义指令一下就可以加好了。领导你看我操作!』
小S说着,就把生产力工具打开了。手速熟练🤠的启动了项目。
小S:『领导你看😈,我先在项目自定义指令的文件夹下新建一个自定义水印指令文件 - watermark.ts。在需要添加水印的目标 Dom 挂载时,创建一个 canvas 节点,canvas 的宽高自然要跟 Dom 的大小一样啦,层级也必须是最高的。然后我再给 canvas 里画上水印内容,最后再给 canvas 挂载到目标节点。当然啦,目标节点销毁时也要把 canvas 销毁掉。』
小S一边讲,一边就在生产力工具中敲🫳出了代码。
import type { Directive, App } from 'vue';
import { nextTick } from 'vue';
const watermarkDirective: Directive = {
// 在绑定元素的父组件
// 及他自己的所有子节点都挂载完成后调用
async mounted(el, binding) {
await createWatermark(el, binding.value.text);
},
// 绑定元素的父组件卸载后调用
unmounted(el) {
removeWatermark(el);
},
};
/** 创建水印 */
async function createWatermark(el, text: string) {
const canvasEl = document.createElement('canvas');
const newCanvas = !el.querySelector('canvas');
canvasEl.id = 'watermark-canvas';
canvasEl.style.position = 'absolute';
canvasEl.style.top = '0';
canvasEl.style.left = '0';
canvasEl.style.zIndex = '99';
canvasEl.style.pointerEvents = 'none';
el.appendChild(canvasEl);
canvasEl.width = window.screen.width;
canvasEl.height = window.screen.height;
const ctx = canvasEl.getContext('2d');
ctx.rotate((-20 * Math.PI) / 180); //旋转角度
ctx.font = '24px serif';
ctx.fillStyle = 'rgba(180, 180, 180, 0.3)';
ctx.textAlign = 'left';
ctx.textBaseline = 'middle';
for (let i = -canvasEl.width / 100; i < canvasEl.width / 100; i++) {
for (let j = -canvasEl.height / 200; j < canvasEl.height / 200; j++) {
ctx.fillText(text, i * 300, j * 300);
}
}
}
async function removeWatermark(el) {
await nextTick();
const canvasEl = el.querySelector('#watermark-canvas');
if (canvasEl) {
canvasEl.remove();
}
}
export default watermarkDirective;
小S得意😏的抖着腿,侧身向领导讲到:『这样就可以生成水印啦! 撒花🥳🥳🥳』。
领导🫲🫱:『你这样是可以实现了,但是也仅仅可以防一下小白,稍微懂点前端知识的人,都可以 F12 把控制台打开,选中水印节点,给它哐哐哐删掉。』
小S听了,一拍脑门:『是哦,我怎么没想到呢!嗯……』小S陷入了沉思,如何防止被删掉呢?小S脑子转了3圈后:『领导,我知道怎么做了!DOM3 Event 规范中有一个 MutationObserver,这个接口可以监视 DOM 进行监视,只要我的水印被删掉了,我就赶紧再生成一个水印!』
小S立刻转身,一边思索🤔着逻辑,一边在生产力工具中继续完善:
小S心里想到:『在目标节点挂载,首次添加 canvas 时,我给目标节点添加 MutationObserver 监听,并把实例化的监视器放在目标节点的自定义属性上,监听它的子节点,如果监听到子节点水印被删除,我就再新建一个水印 canvas,插入到目标节点中,对了,还要考虑到我主动删除水印的操作。水印节点也要加监视,不然手动改一下水印的CSS样式,就可以把水印给隐藏掉了。emmm……最后在 目标节点卸载时把监听移除掉。』
小S搞好了,转身给领导讲道:『领导,搞定了!使用的时候只需要引入自定义指令,在需要加水印的节点添加参数就可以啦』
<template>
<div v-watermark="watermarkOption">
<img src="xxxx">
</div>
</template>
<script setup lang="ts">
// @ts-ignore
import vWatermark from '/@/directives/watermark';
const watermarkOption = {
text: '小S水印'
}
</script>
领导看着小S加好水印,笑😼着说:『针不错,这就去给你涨工资!』
小S听了,连忙摇头🙀道:『领导,不用,不用,这都是前端切图仔的基本功!』
END
完整示例代码
import type { Directive, App } from 'vue';
import { nextTick } from 'vue';
const watermarkDirective: Directive = {
// 在绑定元素的父组件
// 及他自己的所有子节点都挂载完成后调用
async mounted(el, binding) {
await createWatermark(el, binding.value.text);
},
// 绑定元素的父组件卸载后调用
unmounted(el) {
removeWatermark(el);
},
};
async function createWatermark(el, text: string) {
const canvasEl = el.querySelector('canvas') || document.createElement('canvas');
const newCanvas = !el.querySelector('canvas');
if (!el.dataset.mutationObserverParent) {
const mutationObserver = new MutationObserver((records) =>
parentCheckWatermark(records, el, text),
);
mutationObserver.observe(el, {
childList: true,
});
el.dataset.mutationObserverParent = mutationObserver;
}
canvasEl.id = 'watermark-canvas';
canvasEl.style.position = 'absolute';
canvasEl.style.top = '0';
canvasEl.style.left = '0';
canvasEl.style.zIndex = '99';
canvasEl.style.pointerEvents = 'none';
newCanvas && el.appendChild(canvasEl);
canvasEl.width = window.screen.width * 3;
canvasEl.height = window.screen.height * 3;
const ctx = canvasEl.getContext('2d');
if (!ctx) return;
ctx.rotate((-20 * Math.PI) / 180); //旋转角度
ctx.font = '24px serif';
ctx.fillStyle = 'rgba(180, 180, 180, 0.3)';
ctx.textAlign = 'left';
ctx.textBaseline = 'middle';
for (let i = -canvasEl.width / 100; i < canvasEl.width / 100; i++) {
for (let j = -canvasEl.height / 200; j < canvasEl.height / 200; j++) {
ctx.fillText(text, i * 300, j * 300);
}
}
if (newCanvas) {
// 水印属性监听
const mutationObserver = new MutationObserver(() => canvasCheckWatermark(el, text));
mutationObserver.observe(canvasEl, {
attributes: true,
});
el.dataset.mutationObserverCanvas = mutationObserver;
}
}
/** 检查水印是否被删除 */
async function parentCheckWatermark(records, el, text) {
// 主动删除水印不处理
if (el.dataset.focusRemove) return;
const removedNodes = records[0].removedNodes;
let hasDelWatermark = false;
removedNodes.forEach((el) => {
if (el.id === 'watermark-canvas') {
hasDelWatermark = true;
}
});
// 水印被删除了
hasDelWatermark && createWatermark(el, text);
}
/** 检查水印属性是否变化了 */
async function canvasCheckWatermark(el, text) {
// 防止多次触发
if (el.dataset.canvasRending) return;
el.dataset.canvasRending = 'rending';
// 水印canvas属性变化了,重新创建
await createWatermark(el, text);
el.dataset.canvasRending = '';
}
async function removeWatermark(el) {
el.dataset.focusRemove = true;
el.dataset.mutationObserverParent?.disconnect?.();
await nextTick();
const canvasEl = el.querySelector('#watermark-canvas');
if (canvasEl) {
canvasEl.dataset.mutationObserverCanvas?.disconnect?.();
canvasEl.remove();
}
}
export default watermarkDirective;
如何修改第三方npm包?
有这样一种场景:如果你在开发过程中,发现某个npm包有Bug,应该怎么办?
第一选择当然是向原作者提issue,或者Fork该仓库代码,修改以后,提交合并请求。
但这种情况有个严重的问题,就是耗时,如果遇到严格的作者,或者不活跃的作者,时间线可能会拉得很长。你的项目未必能等这么长时间。
还有一种可能是,你修改的代码并不具备普适性,只有你的业务场景能用到,合并被拒的概率会大大增加。
总而言之,如果能修改npm包的源包,再好不过,如果不行,则需要有个临时方案,或者替代方案。
这时,又有下面两种情况:
下面,详细介绍下这两种不同方案。
patch-package是一个用于修复第三方依赖包的工具,使用方式非常简单。
它支持npm和yarn v1,如果是yarn v2+或者pnpm,则使用自带的patch方案(下文会介绍pnpm方案)。
安装:
$ npm i patch-package
$ yarn add patch-package postinstall-postinstall
如果只是前端使用,可以添加--dev或-D参数。如果是后端使用,为保障生产模式(会去除devDendencies依赖)也能正常使用,就不要加了。
在node_modules中找到你要修改的npm包,修改内容后,就可以运行patch-package创建patch文件了。
$ npx patch-package package-name # 使用npm
$ yarn patch-package package-name # 使用yarn
运行后会在项目根目录下创建一个patches文件夹,并生成一个名为package-name+version.patch的文件。将该patch文件提交至版本控制中,即可在之后应用该补丁了。
以我修改的verdaccio为例,会生成一个verdaccio+4.4.0.patch的文件,内容大致如下:
diff --git a/node_modules/verdaccio/build/index.js b/node_modules/verdaccio/build/index.js
index 3a79eaa..d00974b 100644
--- a/node_modules/verdaccio/build/index.js
+++ b/node_modules/verdaccio/build/index.js
@@ -5,6 +5,8 @@ Object.defineProperty(exports, "__esModule", {
});
exports.default = void 0;
+console.log('---------------')
+
var _bootstrap = require("./lib/bootstrap");
完成上述操作后,最后在package.json的scripts中加入"postinstall": "patch-package"。
"scripts": {
"postinstall": "patch-package"
}
这样当其他同事拉下代码,运行npm install或是yarn install命令时,便会自动为依赖包打上我们的补丁了。
简单来说,这个方案的原理就是记录补丁的代码与位置,利用npm的hook(
postinstall会在npm install后触发),在安装完依赖以后,触发相应的脚本,将补丁覆盖到node_modules对应的包里。
当然,补丁是对应具体版本的,需要锁定版本号。这样的缺点是如果要升级的话,还得重新来一遍,不过不是有Bug或性能问题,通常不必追求新的版本。
pnpm的patch自称灵感来自yarn的类似命令。由于yarn v2可能走了邪路,我们就不介绍了。
首先,执行pnpm patch 。该命令会将指定的软件包提取到一个可以随意编辑的临时目录中。
完成修改后, 运行pnpm patch-commit ( 是之前提取的临时目录,这个临时目录会长到你根本记不住,不过不用担心,命令行里会有完备的提示) 以生成一个补丁文件,并提供patchedDependencies 字段注册到你的项目中。
比如,我想修改一个is-even的包:
pnpm patch is-even
You can now edit the following folder: /private/var/folders/sq/0jfgh1js6cs8_31df82hx3jw0000gn/T/29ba74c7c7ffd7aa157831c6436d3738
Once you're done with your changes, run "pnpm patch-commit /private/var/folders/sq/0jfgh1js6cs8_31df82hx3jw0000gn/T/29ba74c7c7ffd7aa157831c6436d3738"
按照提示,打开这个文件夹,加一行代码:

执行上面控制台的提示:
pnpm patch-commit /private/var/folders/sq/0jfgh1js6cs8_31df82hx3jw0000gn/T/e103de90617a18eee7942d1df35a2c48
Packages: -1
-
Progress: resolved 5, reused 6, downloaded 0, added 1, done
这时你会发现package.json中多了一段内容:
"pnpm": {
"patchedDependencies": {
"is-even@1.0.0": "patches/is-even@1.0.0.patch"
}
}
根目录下,也多了个文件夹patches,打开以后,你就能找到添加的代码:

打开node_modules/is-even/index.js,可以看到已经多了我们添加的代码:

删除node_modules,重新pnpm i安装依赖,仍然与现在一样,这就代表成功了。
整个流程下来,我们看得出来相比于patch-package,要稍微复杂点儿,但也是可以接受的。
注意:patches目录是一定得提交到git的。
上面说过,如果要修改的代码较多,或者不具备修改条件,这时就需要修改源码。
到GitHub上找到npm包的源码,Fork该项目,修改代码后,再修改包名,重新发布,比如你要修改的包是lodash,可以修改为awesome-lodash,在应用代码中更换引用。
本来这个方案没什么好说的,但有一种情况,如果你修改的是个底层包,也就是说并不是你的应用代码中直接引用的,而是你引用的npm包A所依赖的,甚至可能同时被包B依赖的,这时就比较尴尬了,你不可能再去修改A和B的源码,那就太不值当了。
pnpm提供了一种别名(Aliases)的能力。
假设你发布了一个名为awesome-lodash的新包,并使用lodash作为别名来安装它:
$ pnpm add lodash@npm:awesome-lodash
不需要更改代码,所有的lodash引用都被解析到了awesome-lodash。
就这么简单,上面说的问题就解决了。
再说点儿题外话,有时你会想要在项目中使用一个包的两个不同版本,很简单:
$ pnpm add lodash1@npm:lodash@1
$ pnpm add lodash2@npm:lodash@2
现在,您可以通过 require('lodash1') 引入第一个版本的 lodash 并通过 require('lodash2') 引入第二个。
与pnpm的钩子结合使用功能会更加强大,比如你想将node_modules里所有的lodash引用也替换为awesome-lodash,你可以用下面的.pnpmfile.cjs 轻松实现:
function readPackage(pkg) {
if (pkg.dependencies && pkg.dependencies.lodash) {
pkg.dependencies.lodash = 'npm:awesome-lodash@^1.0.0'
}
return pkg
}
module.exports = {
hooks: {
readPackage
}
}
pnpm功能非常强大,后面我会再详细写篇文章介绍下。
在开发过程中发现npm包的Bug,首先向原作者提交issue或Fork代码修改后提交合并请求。但遇到不活跃或拒绝修改的情况,项目等待时间会很长。这时可以使用补丁方案或换日方案进行解决。
补丁方案中,如果是npm或yarn v1,可以使用patch-package工具包处理;如果是yarn v2或pnpm,可以使用各自的patch命令。
换日方案,则是修改源码,发布新的npm包后,利用pnpm的别名功能,将所有依赖原npm包的地方,全部替换为新的包。
这种场景在日常开发中还是比较常见的,这里为大家提供一种思路。当然,如果真是个Bug,别忘了提issue或PR,为开源贡献自己的一份力量,在与作者的沟通交流中,相信你也能受益匪浅。
点赞 + 收藏 === 学会🤣🤣🤣
首先明确一点,localStorage是同步的
localStorage 是 Web Storage API 的一部分,它提供了一种存储键值对的机制。localStorage 的数据是持久存储在用户的硬盘上的,而不是内存。这意味着即使用户关闭浏览器或电脑,localStorage 中的数据也不会丢失,除非主动清除浏览器缓存或者使用代码删除。
当你通过 JavaScript 访问 localStorage 时,浏览器会从硬盘中读取数据或向硬盘写入数据。然而,在读写操作期间,数据可能会被暂时存放在内存中,以提高处理速度。但主要的特点是它的持久性,以及它不依赖于会话的持续性。
是的,硬盘确实是一个 IO 设备,而大部分与硬盘相关的操作系统级IO操作确实是异步进行的,以避免阻塞进程。不过,在 Web 浏览器环境中,localStorage 的API是设计为同步的,即使底层的硬盘读写操作有着IO的特性。
js代码在访问 localStorage 时,浏览器提供的API接口通常会处于js执行线程上下文中直接调用。这意味着尽管硬盘是IO设备,当一个js执行流程访问 localStorage 时,它将同步地等待数据读取或写入完成,该过程中js执行线程会阻塞。
这种同步API设计意味着开发者在操作 localStorage 时不需要考虑回调函数或者Promise等异步处理模式,可以按照同步代码的方式来编写。不过,这也意味着如果涉及较多数据的读写操作时,可能对性能产生负面影响,特别是在主线程上,因为它会阻塞UI的更新和其他js的执行。
localStorage 实现同步存储的方式就是阻塞 JavaScript 的执行,直到数据的读取或者写入操作完成。这种同步操作的实现可以简单概述如下:
localStorage 的操作,比如 localStorage.getItem('key') 或 localStorage.setItem('key', 'value'),这个调用发生在 js 的单个线程上。在同步的 localStorage 操作期间,由于 js 的单线程性质,整个线程会阻塞,即不会执行其他任何js代码,也不会进行任何渲染操作,直到 localStorage 调用返回。
localStorage,存储大量数据在用户的设备上,这可能导致设备存储空间迅速耗尽,也可能侵犯用户的隐私。localStorage 的操作是阻塞的。如果网站能够存储大量数据,就会加剧读写操作对页面性能的影响。localStorage 存储的是字符串形式的数据,不是为存储大量或结构化数据设计的。当尝试存储过多数据时,效率会降低。localStorage,但出于跨浏览器兼容性的考虑,开发者通常会假设这个限制。虽然它们提供了更大的存储空间和更丰富的功能,但确实潜在地也可能被滥用。但是与相比 localStorage 增加了一些特性用来降低被滥用的风险:
IndexedDB 是一个异步API,即使它被用来处理更大量的数据,也不会像 localStorage 那样阻塞主线程,从而避免了对页面响应性的直接影响。IndexedDB 提供的存储容量比 localStorage 大得多,但它也不是无限的。浏览器会为 IndexedDB 设定一定的存储配额,这个配额可能基于可用磁盘空间的一个百分比或者是一个事先设定的限额。配额超出时,浏览器会拒绝更多的存储请求。IndexedDB 的数据库形式允许有组织的存储和更容易的数据管理。用户或开发者可以更容易地查看和清理占用的数据。IndexedDB 存储时,可能会在数据库大小增长到一定阈值时,提示用户是否允许继续存储,而不是一开始就分配一个很大的空间。最近参与了个微信小程序的项目,有个长列表模块 我在自测的时候(测试人员居然没发现,可能懒得加载那么多数据去验证),发现当列表加载加载500条以上的时候,会有一个 Dom limit exceeded, please check if there's any mistake you've made.(超过了Dom限制,请检查你是否犯了任何错误) 渲染报错,页面会白屏,所以猜测小程序的Dom节点应该是有最高限制的。
网上查了很多资料,查到了Dom节点确实有渲染限制,有位大神还晒出了源码 如下图,限制最高16000个节点

之前只知道 包大小 限制、域名需要配置不然限制、各种授权api限制,没想到 dom节点数量还要限制 居然还有这种骚操作

不过想想也算合理,因为小程序 小程序,小才行,哈哈,资源也不可能无限大,为的就是让你在有限的资源内完成强大的功能。
上文图中 代码 左上角显示版本是2019年的,那现在都2023年了,会不会有所改进呢,为了搞清楚现在到底限制多少节点,实验一波。


测试结果如上面两张图 Dom限制数量没变还是 16000个节点,但实际可新增的 渲染节点为 15999个 ,你要是问为啥,那我告诉你,因为小程序默认根标签 page 也占用一个,一个字 牛!!

既然找了原因,就要想办法解决,经过一番深思熟虑(面向百度思考),总结了以下几个解决方案。
毕竟平台是人家的,规则都是人家定的,那么就得按照规则去开发,下图是官方推荐说明(也是评分标准),单页面节点尽量不超过1000个节点,嵌套不超过30层,子节点不超过60个

动动你灵活嘴皮子,看看能不能说服 产品 说服老板,就这标准 爱做不做,爱谁谁
长列表 数据过多、dom节点过多 确实有性能问题,但谁让需求是刚需呢,看了下网上的方案 五花八门,有利用swiper 始终只展示固定数量的 swiper-item的 根据当前的 index 显示第几页数据。还有有自己写算法动态显示的。也有很多现成的组件
核心原理 我总结了下就是,只渲染显示在屏幕的数据(为了减少白页面和滑动更丝滑,要再当前屏幕的前后再分别多渲染一屏幕),实现就是监听 scroll 事件,并且重新计算需要渲染的数据,不需要渲染的数据留一个空的 view 空白占位元素。
具体实现方案就不在这里展开了,留下几个已经实现的链接地址
可以扫码体验下腾讯官方新闻小程序的 渲染效率 感觉很哇塞
Skyline 渲染引擎] list-view注意点: 列表布局容器,仅支持作为 scroll-view 自定义模式下的直接子节点或组件直接子节点
解释下,就是要注意2点
1 scroll-view要设置自定义模式 type="custom"
2 list-view要作为 scroll-view 直接子节点(不然会失去效果)
示例代码如下
<scroll-view type="custom">
<list-view>
...
循环列表逻辑
...
</list-view>
</scroll-view>在编程的世界里,数据是构建一切的基础。而在JavaScript中,变量就是存储数据的容器。它们就像是我们生活中的盒子,可以装下各种物品,让我们在需要的时候随时取用。
今天,就让我们一起揭开变量的神秘面纱,探索它们的概念、使用规则,以及那些令人头疼的错误。
变量,顾名思义,是可以变化的量。在JavaScript中,变量是用来存储数据的,这些数据可以是数字、字符串、对象等等。想象一下,如果没有变量,我们的程序就会变得非常死板,无法灵活地处理和交换信息。
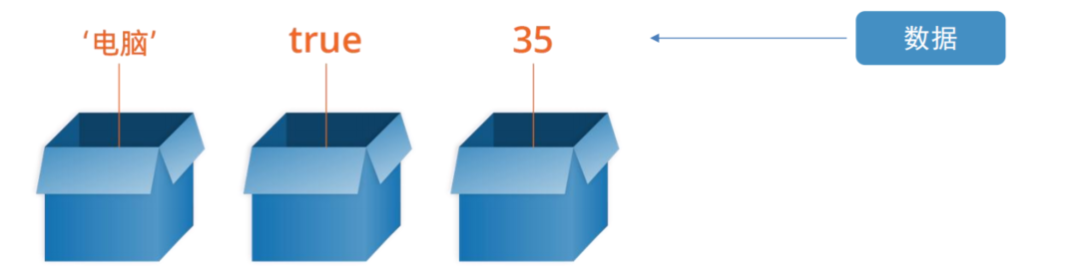
注意: 变量不是数据本身,它们仅仅是一个用于存储数值的容器。可以理解为是一个个用来装东西的纸箱子。
要想使用变量,首先需要创建变量(也称为声明变量或者定义变量),JavaScript中通常使用var关键字或者let关键字进行变量的声明操作。
语法:
var age; //声明一个名为age的变量
let name; //声明一个名为name的变量
举例:
let age
声明出来后的变量是没有值的,我们需要对声明出来的变量进行赋值操作。
变量赋值的语法为:
var age; //声明一个名为age的变量
age = 18; //为该个age变量赋值为18
定义了一个变量后,你就能够初始化它(赋值)。在变量名之后跟上一个“=”,然后是数值。

注意: 是通过变量名来获得变量里面的数据。
变量初始化就相当于声明变量和变量赋值操作的结合,声明变量并为其初始化。
变量初始化语法为:
var age = 18; //声明变量age并赋值为18
案例如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>变量的使用</title>
</head>
<body>
<script>
// 1. 声明一个年龄变量
let age
// 2. 赋值
age = 18
console.log(age)
// 3. 声明的同时直接赋值 变量的初始化
let age2 = 18
// 小案例
let num = 20
let uname = 'pink老师'
console.log(num)
console.log(uname)
</script>
</body>
</html>
变量赋值后,还可以通过简单地给它一个不同的值来更新它。

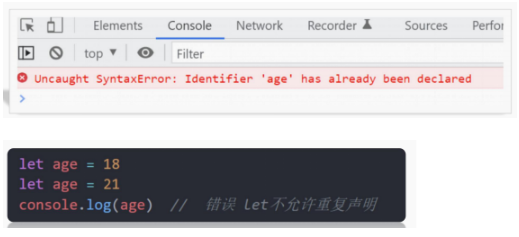
注意: let 不允许多次声明一个变量。
案例如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>变量的使用更新</title>
</head>
<body>
<script>
// 1 声明的同时直接赋值 变量的初始化
// let age = 18
// age = 19
// // let age = 19
// console.log(age)
// 2. 声明多个变量
// let age = 18, uname = '迪丽热巴'
// console.log(age, uname)
</script>
</body>
</html>
语法:多个变量中间用逗号隔开
let age=18,uname='pink'
**说明:**看上去代码长度更短,但并不推荐这样。为了更好的可读性,请一行只声明一个变量。
输入用户名案例:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>输入用户名案例</title>
</head>
<body>
<script>
// 输出用户名案例
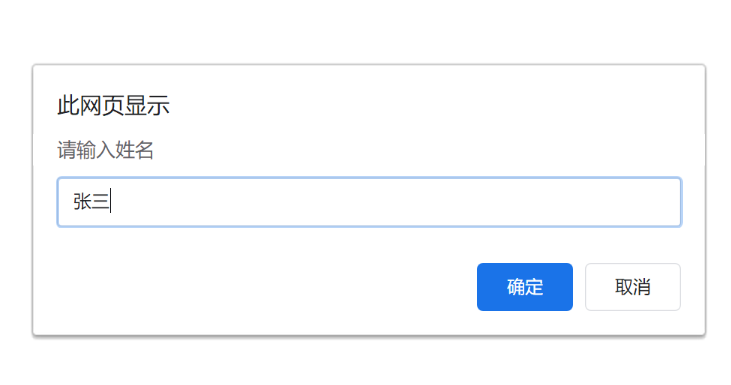
// 1. 用户输入
// prompt('请输入姓名')
// 2. 内部处理保存数据
let uname = prompt('请输入姓名')
// 3. 打印输出
document.write(uname)
</script>
</body>
</html>
变量可以先使用再声明(不合理)。
var声明过的变量可以重复声明(不合理)。
比如变量提升、全局变量、没有块级作用域等等
let声明的变量不会被提升,即在声明之前引用let声明的变量系统会直接报错,直接阻断程序的运行。
let不可以在同一个作用域下重复声明同一个变量,如果用let重复声明同一个变量,那么这时候就会报错。
用let声明的变量支持块级作用域,在es6提出块级作用域的概念之前,作用域只存在函数里面,或者全局。而es6提出的块级作用域则是一个大括号就是一个块级作用域,该变量只能在块级作用域里使用,否则就会报错。
注意:
var 在现代开发中一般不再使用它,只是我们可能在老版程序中看到它。
let 是为了解决 var 的一些问题而出现的,以后声明变量我们统一使用 let。
案例如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>let和var的区别</title>
</head>
<body>
<script>
// var可以重复声明,后面声明的覆盖前面的
var num1
var num1 = 10
var num1= 20
console.log(num1)
// let不能重复声明,直接编译不通过
// let num
// let num = 20
// let num = 10
// console.log(num)
</script>
</body>
</html>
规则: 必须遵守,不遵守报错 (法律层面)
不能用关键字(有特殊含义的字符,JavaScript 内置的一些英语词汇,例如:let、var、if、for等)
只能用下划线、字母、数字、$组成,且数字不能开头
字母严格区分大小写,如 Age 和 age 是不同的变量
**规范:**建议,不遵守不会报错,但不符合业内通识 (道德层面)
起名要有意义
遵守小驼峰命名法:第一个单词首字母小写,后面每个单词首字母大写。例:userName。
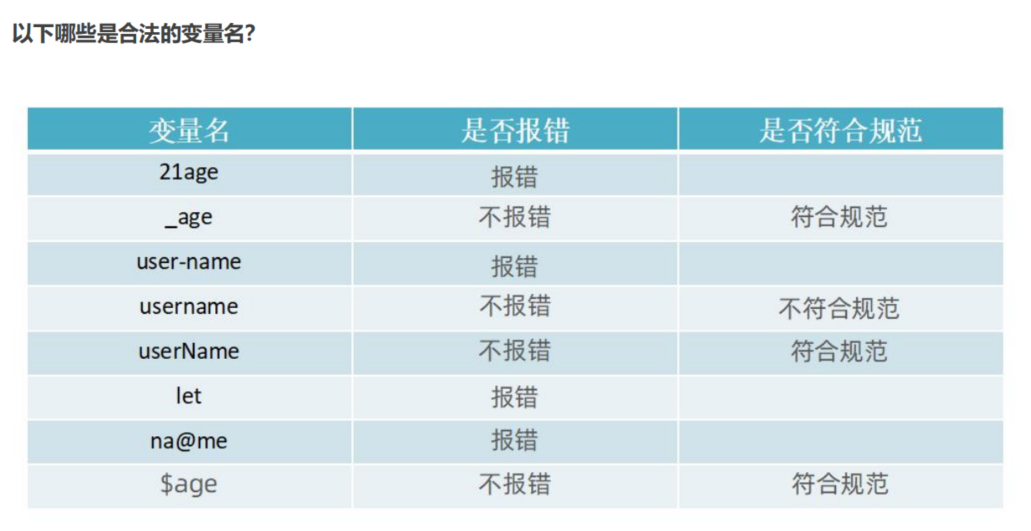
案例如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>变量的命名规范</title>
</head>
<body>
<script>
// let if = 10
let num1$_ = 11
// let nav-bar = 11
// let 1num = 10
//严格区分大小写
let pink = '老师'
let Pink = '演员'
console.log(pink, Pink)
</script>
</body>
</html>
严格模式是一种限制性更强的JavaScript运行环境。在严格模式下,一些不安全或容易出错的行为会被禁止。
JavaScript在设计之初,并不强制要求申明变量,如果一个变量没有申明就被使用,那么该变量就自动被声明为全局变量。
在同一个页面的不同的JavaScript文件中,如果都不声明,将造成变量污染。
ECMA在后续规范中推出了strict模式,在strict模式下运行的JavaScript代码,强制要求申明变量,否则报错。启用strict模式的方法是在JavaScript代码的第一行写上:
'use strict';
这是一个字符串,不支持strict模式的浏览器会把它当做一个字符串语句执行,支持strict模式的浏览器将开启strict模式运行JavaScript。
想要快速入门前端开发吗?推荐一个前端开发基础课程,这个老师讲的特别好,零基础学习无压力,知识点结合代码,边学边练,可以免费试看试学,还有各种辅助工具和资料,非常适合新手!点这里前往学习哦!
如果浏览器不报错,说明你的浏览器太古老了,需要尽快升级。
'use strict';
// 如果浏览器支持strict模式,下面的代码将报ReferenceError错误:
abc = 'Hello, world';
console.log(abc);
有时候,我们希望某些变量的值在程序运行过程中保持不变。这时,可以使用const关键字来声明一个常量。
const是ES6引入的一个新特性,用于声明常量。常量一旦被声明并赋值后,其值就不能被改变。这为我们提供了一种保护机制,确保某些值不会被意外修改。
使用场景:当某个变量永远不会改变的时候,就可以使用 const 来声明,而不是let。
命名规范:和变量一致
注意: 常量不允许重新赋值,声明的时候必须赋值(初始化)
案例如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>常量</title>
</head>
<body>
<script>
// 1.声明常量,使用常量
const PI = 3.14
console.log(PI)
//不允许更改值
//PI = 3.15
// 2. 常量声明的时候必须赋值
//const G
</script>
</body>
</html>
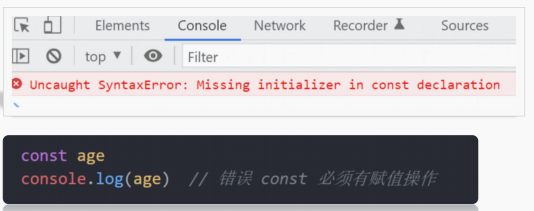
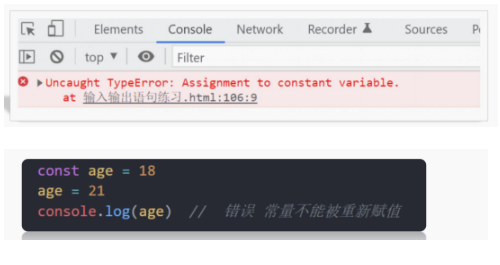
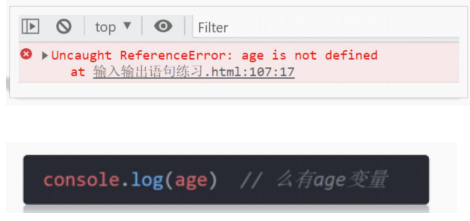
分析:
提示 age变量没有定义过。
很可能 age 变量没有声明和赋值。
或者我们输出变量名和声明的变量不一致引起的(简单说写错变量名了)。
分析:
提示 “age”已经声明。
很大概率是因为重复声明了一个变量。
注意let 或者const 不允许多次声明同一个变量。
变量是JavaScript编程的基础,掌握了变量的声明和使用,就能更好地理解和编写代码。希望这篇文章能帮助你更好地理解和使用变量,让你的编程之路更加顺畅。
记住,实践是最好的老师,多写代码,多尝试,你会发现,原来变量的世界,也可以如此精彩!
如果觉得本文对你有所帮助,别忘了点赞和分享哦!
故事的起因是这样的, 一个前端开发人员(也算是挺有名的,ariakit.org的作者, wrodPress的前维护者)在社交媒体上发了这么一条帖子。

短短几天就有了51.8万次的view。 简单的文案:又是使用 TypeScript 的一天.。表达了对Typescript的又爱又恨😂。在目前的前端市场上,Typescript已经成为标配,ts强大的类型检查机制给我们带来了非常多的好处(代码质量,强大的可维护性,代码即注释),但是其槽点也很多, 很多奇奇怪怪的问题(相信不仅是我一个人这么觉得),繁多的配置项组合,稍不注意就会引起页面爆红,代码量增多和代码组织也会引起一定的负担。但在这些并不能撼动Typescript 在目前前端社区中的地位,在开发项目中一般还是会选择typescript。
话说回到这个帖子上,这个帖子发出来之后迅速引起发酵,被很多大佬转发和引用,下面的评论很多都是wait, what, why happen?类似的语气😂,有很多给出建议,比如换种写法, 重启下Typescript server试试,也有很多开发爱好者希望作者能提供一个例子来复现,他们也想看看是什么问题,看能不能尝试解决这个有趣的例子。
(ps: 在ts中有很多奇怪的东西,特别是在和编辑器配合的时候,有些时候不能判断出来是否是个bug?还是我们代码写的有问题?还是设计如此?还是编辑器的问题?还是版本兼容问题?仅代表个人看法)
后来有大佬根据作者提供的信息复现出来了样板例子 :
declare function hasOwnPropertyextends AnyObject>(
object: T,
prop: keyof any,
): prop is keyof T;
type EffectCallback = () => void;
declare const useSafeLayoutEffect: (effect: EffectCallback) => void;
type AnyObject = Record<string, any>;
export type State = AnyObject;
type AnyFunction = (...args: any) => any;
type BivariantCallbackextends AnyFunction> = {
bivarianceHack(...args: Parameters): ReturnType;
}["bivarianceHack"];
type SetStateAction = T | BivariantCallback<(prevState: T) => T>;
interface StoreState> {
getState(): S;
setStateextends keyof S>(key: K, value: SetStateAction): void;
}
export function useStoreProps<
S extends State,
P extends Partial,
K extends keyof S,
>(store: Store, props: P, key: K) {
const value = hasOwnProperty(props, key) ? props[key] : undefined;
useSafeLayoutEffect(() => {
if (value === undefined) return;
value;
// ^?
if (value === undefined) return; // toggle this to see the magic
value;
// ^?
store.setState(key, value);
});
}
将鼠标放到倒数第八行上显示value的类型:
const value: P[K] & ({} | null)
但是将鼠标放到倒数第五行时显示的value类型:
const value: P[K] & {}
真是见了鬼了。同样的操作复制了一遍,显示的类型却不一样?是的,这很Typescript😏。
issue的地址在这。

这个提出issue的哥们就是复现样板例子的人,看的出来他应该是个狂热的技术爱好者,执行力也很强,从问作者要出现这种情况的代码仓库可以是否可以公开 ==> 复现样板例子 ==> 给Typescript提出issue(还尝试了自己能不能解决),执行力power👍。
在提出issue之后立即就被官方定位是一个bug, 而且Typescript之父还给出了一个简化版可复现的例子:
function f1extends Record<string, any>, K extends keyof T>(x: T[K] | undefined) {
if (x === undefined) return;
x; // T[K] & ({} | null)
if (x === undefined) return;
x; // T[K] & {}
}
通过上面的例子发现null被意外的消除了。
ahejlsberg(ts之父) 写了一个规范化null和undefined在类型系统中的表现的函数解决了这个问题。

至此issue被关闭。
我们打开palyground的nightly版本,可以发现这个问题被解决, 错误不在显示了。
这是无意间从网上看到,然后从问题追溯到问题被一步步的解决。从帖子中可以看出来现在大部分用Typescript写项目的人又爱又恨的普遍状态。不管你是多菜的菜鸟也能感受到ts给日益庞大的前端项目带来的好处,不管你是多厉害的大牛也是会遇到一些奇怪的错误。随着Typescript的普及,社区中有很多不同的声音,有热爱者,有反对者,也有随波逐流者,但这也代表Typescript在社区中展现的旺盛生命力。质疑也好,热爱也罢,我觉得ts会越来越好。
在如今的互联网时代,网页源码的保护显得尤为重要,特别是前端代码,几乎就是明文展示,很容易造成源码泄露,黑客和恶意用户往往会利用浏览器的开发者工具来窃取网站的敏感信息。为了有效防止用户打开浏览器的Web开发者工具面板,今天推荐一个不错的npm库,可以帮助开发者更好地保护自己的网站源码,本文将介绍该库的功能和使用方法。
npm库名称:disable-devtool,github地址:github.com/theajack/disable-devtool。从f12按钮,右键单击和浏览器菜单都可以禁用Web开发工具。
🚀 一行代码搞定禁用web开发者工具
该库有以下特性:
使用该库非常简单,只需按照以下步骤进行操作:
推荐使用这种方式安装使用,使用script脚本可以被代理单独拦截掉从而无法执行。
npm i disable-devtool
import DisableDevtool from 'disable-devtool';
DisableDevtool(options);
<script disable-devtool-auto src='https://cdn.jsdelivr.net/npm/disable-devtool'>script>
或者通过版本引用:
<script disable-devtool-auto src='https://cdn.jsdelivr.net/npm/disable-devtool@x.x.x'>script>
<script disable-devtool-auto src='https://cdn.jsdelivr.net/npm/disable-devtool@latest'>script>
options中的参数与说明如下,各方面的配置相当完善。
interface IConfig {
md5?: string; // 绕过禁用的md5值,默认不启用绕过禁用
url?: string; // 关闭页面失败时的跳转页面,默认值为localhost
tkName?: string; // 绕过禁用时的url参数名称,默认为 ddtk
ondevtoolopen?(type: DetectorType, next: Function): void; // 开发者面板打开的回调,启用时url参数无效,type 为监测模式, next函数是关闭当前窗口
ondevtoolclose?(): void; // 开发者面板关闭的回调
interval?: number; // 定时器的时间间隔 默认200ms
disableMenu?: boolean; // 是否禁用右键菜单 默认为true
stopIntervalTime?: number; // 在移动端时取消监视的等待时长
clearIntervalWhenDevOpenTrigger?: boolean; // 是否在触发之后停止监控 默认为false, 在使用ondevtoolclose时该参数无效
detectors?: Array<DetectorType>; // 启用的检测器 检测器详情
clearLog?: boolean; // 是否每次都清除log
disableSelect?: boolean; // 是否禁用选择文本 默认为false
disableCopy?: boolean; // 是否禁用复制 默认为false
disableCut?: boolean; // 是否禁用剪切 默认为false
disablePaste: boolean; // 是否禁用粘贴 默认为false
ignore?: (string|RegExp)[] | null | (()=>boolean); // 某些情况忽略禁用
disableIframeParents?: boolean; // iframe中是否禁用所有父窗口
timeOutUrl?: // 关闭页面超时跳转的url;
}
enum DetectorType {
Unknown = -1,
RegToString = 0, // 根据正则检测
DefineId, // 根据dom id检测
Size, // 根据窗口尺寸检测
DateToString, // 根据Date.toString 检测
FuncToString, // 根据Function.toString 检测
Debugger, // 根据断点检测,仅在ios chrome 真机情况下有效
Performance, // 根据log大数据性能检测
DebugLib, // 检测第三方调试工具 eruda 和 vconsole
};
<script
disable-devtool-auto
src='https://cdn.jsdelivr.net/npm/disable-devtool'
md5='xxx'
url='xxx'
tk-name='xxx'
interval='xxx'
disable-menu='xxx'
detectors='xxx'
clear-log='true'
disable-select='true'
disable-copy='true'
disable-cut='true'
disable-paste='true'
>script>
ondevtoolopen 事件的回调参数就是被触发的监测模式。可以在 ondevtoolopen 里执行业务逻辑,比如做数据上报、用户行为分析等。
DisableDevtool({
ondevtoolopen(type, next){
alert('Devtool opened with type:' + type);
next();
}
});
该库中使用 key 与 md5 配合的方式使得开发者可以在线上绕过禁用。
流程如下:
先指定一个 key a(该值不要记录在代码中),使用 md5 加密得到一个值 b,将b作为 md5 参数传入,开发者在访问 url 的时候只需要带上url参数 ddtk=a,便可以绕过禁用。
disableDevtool对象暴露了 md5 方法,可供开发者加密时使用:
DisableDevtool.md5('xxx');
更多细节可查阅官方文档,中文文档地址:https://github.com/theajack/disable-devtool/blob/master/README.cn.md
尽管该库可以有效地禁用浏览器的开发者工具面板,但仍然需要注意以下几点:
为了进一步加强网页源码的安全性,我们可以采取以下额外措施:
保护网页源码的安全性对于Web开发至关重要。通过使用npm库disable-devtool,并结合其他安全措施,我们可以有效地降低用户访问和修改源代码的风险。但是绝对的安全是不存在的,因此定期更新和加强安全性措施也是必要的。
嗨,大家好,我是徐小夕,之前一直在研究可视化零代码相关的技术实践,也做了很多可视化搭建的产品,比如:
最近在研发智能搭建系统(WEP)的时候发现一款非常好用的可视化拖拽插件——draggable。它在 github 上有17.4k star,提供了很多非常精美的拖拽案例, 我们使用它可以轻松实现可视化拖拽,组件排序,网格拖拽等效果,而且浏览器兼容性也非常不错,原生 javascript 开发, 可以轻松集成到 react, vue 等主流框架中。
接下来我就和大家一起介绍一下这款开源插件。

我们可以使用如下方式安装:
# yarn add shopify/draggable
pnpm add shopify/draggable
在项目里使用:
import {
Draggable,
Sortable,
Droppable,
Swappable,
} from 'shopify/draggable'
github地址: https://github.com/Shopify/draggable
接下来我就来和大家分享几个非常有价值的使用案例。

代码实现:
// eslint-disable-next-line import/no-unresolved
import {Draggable} from '@shopify/draggable';
// eslint-disable-next-line shopify/strict-component-boundaries
import Plate from '../../components/Plate';
export default function Home() {
const containerSelector = '#Home .PlateWrapper';
const container = document.querySelector(containerSelector);
if (!container) {
return false;
}
const draggable = new Draggable(container, {
draggable: '.Plate',
});
const plates = new Plate(container);
// --- Draggable events --- //
draggable.on('drag:start', (evt) => {
plates.setThreshold();
plates.setInitialMousePosition(evt.sensorEvent);
});
draggable.on('drag:move', (evt) => {
// rAF seems to cause the animation to get stuck?
// requestAnimationFrame(() => {});
plates.dragWarp(evt.source, evt.sensorEvent);
});
draggable.on('drag:stop', () => {
plates.resetWarp();
});
return draggable;
}

代码如下:
// eslint-disable-next-line import/no-unresolved
import {Draggable} from '@shopify/draggable';
function translateMirror(mirror, mirrorCoords, containerRect) {
if (mirrorCoords.top < containerRect.top || mirrorCoords.left < containerRect.left) {
return;
}
requestAnimationFrame(() => {
mirror.style.transform = `translate3d(${mirrorCoords.left}px, ${mirrorCoords.top}px, 0)`;
});
}
function calcOffset(offset) {
return offset * 2 * 0.5;
}
export default function DragEvents() {
const toggleClass = 'PillSwitch--isOn';
const containers = document.querySelectorAll('#DragEvents .PillSwitch');
if (containers.length === 0) {
return false;
}
const draggable = new Draggable(containers, {
draggable: '.PillSwitchControl',
delay: 0,
});
let isToggled = false;
let initialMousePosition;
let containerRect;
let dragRect;
let dragThreshold;
let headings;
let headingText;
// --- Draggable events --- //
draggable.on('drag:start', (evt) => {
initialMousePosition = {
x: evt.sensorEvent.clientX,
y: evt.sensorEvent.clientY,
};
});
draggable.on('mirror:created', (evt) => {
containerRect = evt.sourceContainer.getBoundingClientRect();
dragRect = evt.source.getBoundingClientRect();
const containerRectQuarter = containerRect.width / 4;
dragThreshold = isToggled ? containerRectQuarter * -1 : containerRectQuarter;
headings = {
source: evt.originalSource.querySelector('[data-switch-on]'),
mirror: evt.mirror.querySelector('[data-switch-on]'),
};
headingText = {
on: headings.source.dataset.switchOn,
off: headings.source.dataset.switchOff,
};
});
draggable.on('mirror:move', (evt) => {
evt.cancel();
const offsetX = calcOffset(evt.sensorEvent.clientX - initialMousePosition.x);
const offsetY = calcOffset(initialMousePosition.y - evt.sensorEvent.clientY);
const offsetValue = offsetX > offsetY ? offsetX : offsetY;
const mirrorCoords = {
top: dragRect.top - offsetValue,
left: dragRect.left + offsetValue,
};
translateMirror(evt.mirror, mirrorCoords, containerRect);
if (isToggled && offsetValue < dragThreshold) {
evt.sourceContainer.classList.remove(toggleClass);
headings.source.textContent = headingText.off;
headings.mirror.textContent = headingText.off;
isToggled = false;
} else if (!isToggled && offsetValue > dragThreshold) {
evt.sourceContainer.classList.add(toggleClass);
headings.source.textContent = headingText.on;
headings.mirror.textContent = headingText.on;
isToggled = true;
}
});
const triggerMouseUpOnESC = (evt) => {
if (evt.key === 'Escape') {
draggable.cancel();
}
};
draggable.on('drag:start', () => {
document.addEventListener('keyup', triggerMouseUpOnESC);
});
return draggable;
}

源码地址: https://github.com/Shopify/draggable/tree/master/examples/src/content/Droppable/UniqueDropzone

源码地址: https://github.com/Shopify/draggable/tree/master/examples/src/content/Sortable/SimpleList

源码地址: https://github.com/Shopify/draggable/tree/master/examples/src/content/Sortable/Transformed

源码地址: https://github.com/Shopify/draggable/tree/master/examples/src/content/Sortable/MultipleContainers

源码地址:https://github.com/Shopify/draggable/tree/master/examples/src/content/Swappable/Floated

源码地址: https://github.com/Shopify/draggable/tree/master/examples/src/content/Plugins/SortAnimation
当然还有很多有意思的拖拽案例, 大家也可以去体验一下。
今天就分享到这啦,祝大家节日快乐, 博学!
如果有收获,记得点赞 + 再看哦, 欢迎在评论区评论, 分享你的收藏干货~
早期的页面使用了左右布局。左侧宽度固定,右侧宽度自适应。未使用vm、em、百分比等进行屏幕适配。所有的尺寸(宽度、高度、边框宽度、字体大小等)全部使用的px进行开发。导致只有常用的显示屏尺寸显示较为正常,但是小屏幕显示不正常。
正常显示屏的分辨率是1920 * 1080【假如缩放比例为100%】。在此尺寸下显示正常的布局和展示,如果修改分辨率为1360 * 768。则正常显示的字体等有一种放大的效果。

如果想要同1920的显示屏同样的显示效果,则需要在index.html中设置:
@media(max-width: 1440px) {
html {
zoom: 90%;
}
}

但是有一个弊端,字体会变模糊。
很多小屏幕推荐的缩放比例是150%。
此时根据dpr进行适配
@media (-webkit-min-device-pixel-ratio: 1.5) {
html {
zoom: 0.67
}
}
注意,在此设置下,如果系统中有根据pageX, pageY进行定位时,需要额外处理。
if (window.devicePixelRatio == 1.5) {
x = x/0.67;
y = y/0.67;
}
李经理在使用飞书时无意中发现,飞书竟然支持一键复制网页内容到剪贴板的功能。
他立即叫来了公司的前端开发小王,兴致勃勃地说:
"小王啊,你看,飞书的这个功能多方便!我们公司的协同办公系统是不是也可以实现类似的功能?这样用户体验一定能得到很大提升!"
小王看着李经理充满expectant的眼神, 虽然内心已经吐槽"就这点功能至于吗", 但表面上还是恭恭敬敬地回答:
"老板英明,这个功能确实很实用。技术上应该不难实现,主要就是用Clipboard API写几行代码的事。我这就去安排!"

回到工位后,小王苦笑着摇摇头,找来相关文档开始翻阅,暗暗发誓一定要把这个"划时代"的功能做好.
小王找来了领导说的飞书文档复制网页内容的功能, 如下:

小王思考了片刻…
要实现这个功能, 要拆分为4个步骤:
由于小王的业务只需要复制固定区域的div, 所以第一步可以忽略, 简化成:
const element = document.getElementById("target");
时间已经很晚了, 小王咳了一杯咖啡, 继续奋战. 小王苦思冥想, 要怎么把div转换成 canvas. 他琢磨:
小王这时候已经觉得很累了, 于是索性打开浏览器搜索, 结果第一页就看到了: html2canvas. 他看了一眼, github 29K stars. 他查看了一下调用api:
html2canvas(document.body).then(function(canvas) {
document.body.appendChild(canvas);
});
它正是小王需要的!
于是小王在项目中命令行输入:
npm install --save html2canvas
然后小王在业务代码中敲下了:
function copyDivToImage() {
const element = document.getElementById("target");
html2canvas(element).then(canvas => {
// canvas 拿到了, 然后呢
}
}
小王犹豫, 为什么要转成二进制图像呢, 我直接复制 base64 字符不行吗. 不过很快, 小王就意识到了, 剪贴版API 不支持base64字符串的类型. 于是他翻开 mdn 文档:
HTMLCanvasElement: toBlob() method - Web APIs | MDN (mozilla.org)
function copyDivToImage() {
const element = document.getElementById("target");
html2canvas(element).then(canvas => {
canvas.toBlob(
(blob) => {
// 复制文件到剪贴板
},
"image/jpeg", // 文件的格式
1 // 图像压缩质量 0-1
);
});
}
这一步小王已经先前看过 MDN 文档了, ClipboardItem - Web APIs | MDN (mozilla.org) 可以直接调用浏览器的 navigator api :
function copyDivToImage() {
const element = document.getElementById("target");
html2canvas(element).then(canvas => {
canvas.toBlob(
(blob) => {
// 复制文件到剪贴板
try {
await navigator.clipboard.write([
// eslint-disable-next-line no-undef
new ClipboardItem({
[blob.type]: blob
})
]);
console.log("图像已成功复制到剪贴板");
} catch (err) {
console.error("无法复制图像到剪贴板", err);
}
},
"image/jpeg", // 文件的格式
1 // 图像压缩质量 0-1
);
});
}
所有代码已经就绪, 小王随即启动项目, 运行他刚刚编写好的完美的代码. 不出所料, 他遇到了挫折:

小王看到这个报错, 完全没有头绪, 幸好有多年的开发经验, 他遇到这种问题的时候并没有慌张, 内心想, “第一次跑通常这样!”. 随即他打开百度搜索, 有一个回答引起了小王的注意:

原来, 小王是在 http 环境调试的, 他修改了代理的配置, 换成了 https 环境下调试本地代码.
然而让小王没有想到的是, 程序还是没有如期运行, 小王遇到了第二个挫折:

小王崩溃了 “这是什么鬼. 明明都是按照API文档写的!”

原来, 浏览器剪贴板对 jpeg的支持不大好, 于是小王把 canvas.toBlob() 的参数改成了 "image/png”.
他再次运行代码, 他成功了:

小王欣喜地把这个消息告诉了李经理.
功夫不负有心人,凭借扎实的JavaScript功底,小王很快就实现了一个简洁优雅的"一键复制"功能,并成功集成到公司的协同办公系统中。
李经理在看到小王的杰作后非常满意,当即表扬了小王的能力和效率,并承诺会在年终绩效考核中给予小王优秀评级,同时还暗示未来会给小王升职加薪的机会。小王听后喜上眉梢,他明白自己的努力和才能得到了老板的认可。
这次经历不仅巩固了小王在公司中的地位,更坚定了他在前端开发领域继续钻研的决心。他暗自庆幸,幸亏当初学习JavaScript时没有偷懒,才能在关键时刻派上用场,赢得了老板的青睐。
从此以后,小王在技术方面更加勤奋刻苦,也更加善于捕捉用户需求和痛点,设计出更多优秀的功能和体验。他逐渐成长为团队中不可或缺的核心成员,并最终如愿晋升为高级前端开发工程师,走上了实现自我价值和理想的康庄大道。
JavaScript是一种轻量级的编程语言,通常用于网页开发,以增强用户界面的交互性和动态性。然而在HTML中,有多种方法可以嵌入和使用JavaScript代码。本文就带大家深入了解如何在HTML中使用JavaScript。
要在HTML中使用JavaScript,我们需要使用<script>标签。这个标签可以放在<head>或<body>部分,但通常我们会将其放在<body>部分的底部,以确保在执行JavaScript代码时,HTML文档已经完全加载。
使用 <script> 标签有两种方式:
直接在页面中嵌入 JavaScript 代码和包含外部 JavaScript 文件。
包含在 <script> 标签内的 JavaScript 代码在浏览器总按照从上至下的顺序依次解释。
所有 <script> 标签都会按照他们在 HTML 中出现的先后顺序依次被解析。
HTML为 <script> 定义了几个属性:
1)async: 可选。表示应该立即下载脚本,但不妨碍页面中其他操作。该功能只对外部 JavaScript 文件有效。
如果给一个外部引入的js文件设置了这个属性,那页面在解析代码的时候遇到这个<script>的时候,一边下载该脚本文件,一边异步加载页面其他内容。
2)defer: 可选。表示脚本可以延迟到整个页面完全被解析和显示之后再执行。该属性只对外部 JavaScript 文件有效。
3)src: 可选。表示包含要执行代码的外部文件。
4)type: 可选。表示编写代码使用的脚本语言的内容类型,目前在客户端,type属性值一般使用 text/javascript。
不过这个属性并不是必需的,如果没有指定这个属性,则其默认值仍为text/javascript。
内部JavaScript是将JavaScript代码放在HTML文档的<script>标签中。这样可以将JavaScript代码与HTML代码分离,使结构更清晰,易于维护。
在使用<script>元素嵌入JavaScript代码时,只须为<script>指定type属性。然后,像下面这样把JavaScript代码直接放在元素内部即可:
<script type="text/javascript">
function sayHi(){
alert("Hi!");
}
</script>
如果没有指定script属性,则其默认值为text/javascript。
包含在<script>元素内部的JavaScript代码将被从上至下依次解释。在解释器对<script>元素内部的所有代码求值完毕以前,页面中的其余内容都不会被浏览器加载或显示。
在使用<script>嵌入JavaScript代码的过程中,当代码中出现"</script>"字符串时,由于解析嵌入式代码的规则,浏览器会认为这是结束的</script>标签。可以通过转义字符“\”写成</script>来解决这个问题。
外部JavaScript是将JavaScript代码放在单独的.js文件中,然后在HTML文档中通过<script>标签的src属性引用这个文件。这种方法可以使代码更加模块化,便于重用和共享。
如果要通过<script>元素来包含外部JavaScript文件,那么src属性就是必需的。
这个属性的值是一个指向外部JavaScript文件的链接。
<script type="text/javascript" src="example.js"></script>
外部文件example.js将被加载到当前页面中。
外部文件只须包含通常要放在开始的<script>和结束的</script>之间的那些JavaScript代码即可。
与解析嵌入式JavaScript代码一样,在解析外部JavaScript文件(包括下载该文件)时,页面的处理也会暂时停止。
注意: 带有src属性的<script>元素不应该在其<script>和</script>标签之间再包含额外的JavaScript代码。如果包含了嵌入的代码,则只会下载并执行外部脚本文件,嵌入的代码会被忽略。
通过<script>元素的src属性还可以包含来自外部域的JavaScript文件。它的src属性可以是指向当前HTML页面所在域之外的某个域中的完整URL。
<script type="text/javascript" src="http://www.somewhere.com/afile.js"></script>
于是,位于外部域中的代码也会被加载和解析。
在HTML中,所有的<script>标签会按照它们出现的先后顺序被解析。在不使用defer和async属性的情况下,只有当前面的<script>标签中的代码解析完成后,才会开始解析后面的<script>标签中的代码。
通常,所有的<script>标签应该放在页面的<head>标签中,这样可以将外部文件(包括CSS和JavaScript文件)的引用集中放置。
然而,如果将所有的JavaScript文件都放在<head>标签中,会导致浏览器在呈现页面内容之前必须下载、解析并执行所有JavaScript代码,这可能会造成明显的延迟,导致浏览器窗口在加载过程中出现空白。
为了避免这种延迟问题,现代Web应用程序通常会将所有的JavaScript引用放置在<body>标签中的页面内容的后面。这样做可以确保在解析JavaScript代码之前,页面的内容已经完全呈现在浏览器中,从而加快了打开网页的速度。
JavaScript 解析过程包括两个阶段:预处理(也称预编译)和执行。
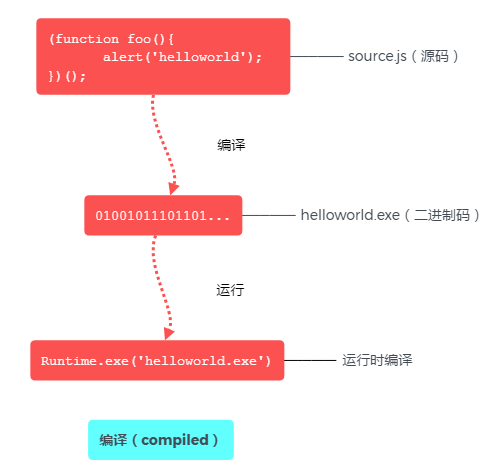
在编译期,JavaScript 解析器将完成对 JavaScript 代码的预处理操作,把 JavaScript 代码转换成字节码;
在执行期,JavaScript 解析器把字节码生成二进制机械码,并按顺序执行,完成程序设计的任务。
HTML 文档在浏览器中的解析过程是:按照文档流从上到下逐步解析页面结构和信息。
JavaScript 代码作为嵌入的脚本应该也算做 HTML 文档的组成部分,所以 JavaScript 代码在装载时的执行顺序也是根据 <script> 标签出现的顺序来确定。
想要快速入门前端开发吗?推荐一个前端开发基础课程,这个老师讲的特别好,零基础学习无压力,知识点结合代码,边学边练,可以免费试看试学,还有各种辅助工具和资料,非常适合新手!点这里前往学习哦!
当 JavaScript 引擎解析脚本时候,他会在与编译期对所有声明的变量和函数预先进行处理。当 JavaScript 解析器执行下面脚本时不会报错。
alert(a); //返回值 undefined
var a = 1;
alert(a); //返回值 1
由于变量声明是在预编译期被处理的,在执行期间对于所有的代码来说,都是可见的,但是执行上面代码,提示的值是 undefined 而不是 1。
因为变量初始化过程发生在执行期,而不是预编译期。在执行期,JavaScript 解析器是按照代码先后顺序进行解析的,如果在前面代码行中没有为变量赋值,则 JavaScript 解析器会使用默认值 undefined 。
由于第二行中为变量 a 赋值了,所以在第三行代码中会提示变量 a 的值为 1,而不是 undefined。
fun(); //调用函数,返回值1
function fun(){
alert(1);
}
函数声明前调用函数也是合法的,并能够正确解析,所以返回值是 1。但如果是下面这种方式则 JavaScript 解释器会报错。
fun(); //调用函数,返回语法错误
var fun = function(){
alert(1);
}
上面的这个例子中定义的函数仅作为值赋值给变量 fun 。在预编译期,JavaScript 解释器只能够为声明变量 fun 进行处理,而对于变量 fun 的值,只能等到执行期时按照顺序进行赋值,自然就会出现语法错误,提示找不到对象 fun。
总结: 声明变量和函数可以在文档的任意位置,但是良好的习惯应该是在所有 JavaScript 代码之前声明全局变量和函数,并对变量进行初始化赋值。在函数内部也是先声明变量,后引用。
通过今天的分享,相信大家已经对JavaScript在HTML中的应用有了一定的了解。这只是冰山一角,JavaScript的潜力远不止于此。
希望这篇文章能激发大家对编程的热情,让我们一起在编程的世界里探索更多的可能性!
欢迎关注本专栏,会经常分享一些简单实用的技巧!
感谢各位大佬点赞!关注我,学习实用前端知识!
在前端开发中,我们经常遇见这样的开发需求,实现下列以此排布的卡片,这些卡片宽度一般是固定的,

并且在不同大小的屏幕宽度下自动换行。

实现这样的一个需求其实不难,我们很容易想到设置一个安全宽度(如下图绿色),然后进行弹性布局。

一个很容易写出的代码是这样的:
使用flex弹性布局,我们很看似轻松的实现了需求。但是,当我们将卡片数量减少一个,问题就出现了
由于我们使用了justify-content: space-between;的布局方式,4,5卡片左右对称布局,这显然不符合我们的要求!

聪明的人,可能会把justify-content: space-between改成align-content: space-between

这样的确会让卡片以此排列,但是没了右边距!因此,你可能会手动加上右边距
你会尴尬的发现换行了,因为两个卡片的宽度加元素的右边距之和大于你设置的安全宽度了!

当然,你可以让每个卡片的右边距小一点,这样不会换行,但是,右边的元素永远无法贴边了!

想解决上的问题,也有很多方法。
如果永远是第3n的元素是最后一列,这个问题非常容易解决:
.container{
display: flex;
width:630px;
align-content: space-between;
flex-flow: wrap;
.crad{
height:100px;
background: blueviolet;
width:200px;
margin-bottom: 16px;
margin-right: 16px;
&:nth-child(3n) {
margin-right: 0;
}
}
}
4n,5n,6n我们都可以用这样的方式解决!
但如果安全宽度是变化的(630px不固定),比如随着浏览器尺寸的变化,每行的卡片数量也变化,上述方式就无法解决了。

此时,我们可以用下面的方法:
我们可以在绿色盒子外在套一个红色盒子,超出红色盒子的部分隐藏即可
代码如下

上述代码中,我们的container元素设置了width: calc(100% + 16px)保证其比父元素多出16px的容错边距,然后我们给红色盒子设置了overflow: hidden,就避免了滚动条出现。
完美解决了这个布局问题!
最近需要做一个关于自动解析矢量瓦片链接地址的内部Demo,这个demo比较简单,所以没有准备引入任何的第三方UI库,所以遇到了一个小问题,toast提示怎么做?
如果像往常一样,我肯定直接用 alert 了,但是一是 alert 会中断体验,不够友好,二是不适用于多个提示共同出现,三是无法区分提示类型,所以我就想着找一个体积小的三方库来实现,但是找来找去,发现没有一个库能入我法眼。
在网上搜索,好像独立的 toast 插件停留在了 jq 时代,靠前的 toast 库居然是 bootstrap 的。所以我决定自己写一个,又小巧,又易用的 toast 插件。
延续 autofit.js 的传统,我依然准备用纯 js 实现,以达到极致的体积、极致的兼容性。此外,还编写了d.ts,支持TS。
autolog.js 诞生了。

它由两部分构成,一个极简单的js,和一个极简单的css。gzip后体积是1.40kb。
在线体验:larryzhu-dev.github.io/autoLarryPa…
const autolog = {
log(text, type = "log", time = 2500) {
if (typeof type === "number") {
time = type;
type = "log";
}
let mainEl = getMainElement();
let el = document.createElement("span");
el.className = `autolog-${type}`;
el.innerHTML = text;
mainEl.appendChild(el);
setTimeout(() => {
el.classList.add("hide");
}, time - 500);
setTimeout(() => {
mainEl.removeChild(el);
el = null;
}, time);
},
};
function getMainElement() {
let mainEl = document.querySelector("#autolog");
if (!mainEl) {
mainEl = document.createElement("div");
mainEl.id = "autolog";
document.body.appendChild(mainEl);
}
return mainEl;
}
export default autolog;
以上是 autolog.js的全部 js 代码。可以看到只导出了一个 log 方法,而调用此方法,也只需要必填一个参数。
我来讲一下这段代码干了一件什么事
最重要的在于css部分,css承载了最重要的显示逻辑。
@font-face {
font-family: "iconfont"; /* Project id 4507845 */
src: url("//at.alicdn.com/t/c/font_4507845_4ys40xqhy9u.woff2?t=1713154951707")
format("woff2"),
url("//at.alicdn.com/t/c/font_4507845_4ys40xqhy9u.woff?t=1713154951707")
format("woff"),
url("//at.alicdn.com/t/c/font_4507845_4ys40xqhy9u.ttf?t=1713154951707")
format("truetype");
}
#autolog {
display: flex;
flex-direction: column;
align-items: center;
justify-content: flex-start;
pointer-events: none;
width: 100vw;
height: 100vh;
position: fixed;
left: 0;
top: 0;
z-index: 9999999;
cursor: pointer;
transition: 0.2s;
}
#autolog span {
pointer-events: auto;
width: max-content;
animation: fadein 0.4s;
animation-delay: 0s;
border-radius: 6px;
padding: 10px 20px;
box-shadow: 0 0 10px 6px rgba(0, 0, 0, 0.1);
margin: 4px;
transition: 0.2s;
z-index: 9999999;
font-size: 14px;
height: max-content;
background-color: #fafafa;
color: #333;
font-family: "iconfont" !important;
font-size: 16px;
font-style: normal;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
#autolog span::before {
padding-right: 4px;
}
#autolog span.autolog-warn,
#autolog span.autolog-warning {
background-color: #fffaec;
color: #e29505;
}
#autolog span.autolog-warn::before,
#autolog span.autolog-warning::before {
content: "\e682";
}
#autolog span.autolog-error {
background-color: #fde7e7;
color: #d93025;
}
#autolog span.autolog-error::before {
content: "\e66f";
}
#autolog span.autolog-info {
background-color: #e6f7ff;
color: #0e6eb8;
}
#autolog span.autolog-info::before {
content: "\e668";
}
#autolog span.autolog-success,
#autolog span.autolog-ok,
#autolog span.autolog-done {
background-color: #e9f7e7;
color: #1a9e2c;
}
#autolog span.autolog-success::before,
#autolog span.autolog-ok::before,
#autolog span.autolog-done::before {
content: "\e67f";
}
#autolog span.hide {
opacity: 0;
pointer-events: none;
transform: translateY(-10px);
height: 0;
padding: 0;
margin: 0;
}
@keyframes fadein {
0% {
opacity: 0;
transform: translateY(-10px);
}
100% {
opacity: 1;
transform: translateY(0);
}
}
css部分正正好好 100 行代码,从上到下分别是:iconfont 字体图标链接、主容器样式、各类型提示框的样式、退场类,入场动画。
由此可见,你也可以重写这些css,为他们添加不同的 icon、颜色。
没有什么巧妙的设计,也没有什么精致的构思,朴实无华的一百多行代码而已,希望这些代码可以帮到各位。
使用也非常简单,只需引入两个文件。
npm i autolog.js
在js中引入
import 'autolog.js/autolog.css'
在css中引入
@import url('autolog.js/autolog.css');
import aotolog from "autolog.js";
autolog.log("Hi,this is a normal tip");
autolog.log("Hello World", "success", 2500);
// 其中 "success" 和 2500 都是可选项
Github Link:github.com/LarryZhu-de…
NPM Link:http://www.npmjs.com/package/aut…


从构思到上线的全过程,开发中遇到一些未知问题,也都通过查阅资料和源码一一解决,小记一下望对正在使用或即将使用Nextjs开发的你们有所帮助。
就挺有意思,域名,技术栈和平台的折腾史
hexo搭建了个静态博客,部署在github pagesvue,nodejs,mongodb三件套,使用nginx部署在云服务器上nextjs为基础框架,部署在vercel上因为日常开发离不开终端,正好也有重写博客的想法,打算开发一个不只是看的博客网站,所以模仿终端风格开发了Yucihent。
nextjs 更多技术栈
选用nextjs是因为next13更新且稳定了App Router和一些其他新特性。
简约为主,首页为类终端风格,prompt样式参考了starship,也参考过ohmyzsh themes,选用starship因为觉得更好看。
通过手动输入或点击列出的命令进行交互,目前可交互的命令有:
help 查看更多list和ls 列出可用命令clear 清空所有输出posts 列出所有文章about 关于我后续会新增一些命令,增加交互的趣味。
基于
tailwind的dark mode和next-themes
首先将tailwind的dark mode设置为class,目的是将暗黑模式的切换设置为手动,而不是跟随系统。
// tailwind.config.js
module.exports = {
darkMode: 'class'
}
新建ThemeProvider组件,用到next-themes提供的ThemeProvider,需要在文件顶部使用use client,因为createContext只在客户端组件使用。
'use client'
import { ThemeProvider as NextThemeProvider } from 'next-themes'
import type { ThemeProviderProps } from 'next-themes/dist/types'
export default function ThemeProvider({
children,
...props
}: ThemeProviderProps) {
return <NextThemeProvider {...props}>{children}</NextThemeProvider>
}
在app/layout.tsx中使用ThemeProvider,设置attribute为class,这是必要的。
<ThemeProvider attribute="class">{children}</ThemeProvider>
next-themes提供了useTheme,解构出theme和setTheme用于手动设置主题。
综上基本实现暗黑模式切换,但你会在控制台看到此报错信息:Warning: Extra attributes from the server: class,style,虽然它并不影响功能,但终究是个报错。
作为第三方包,可能存在水合不匹配的问题,经查阅资料,禁用ThemeProvider组件预渲染消除报错。
资料:
const NoSSRThemeProvider =
dynamic(() => import('@/components/ThemeProvider'), {
ssr: false
})
<NoSSRThemeProvider attribute="class">{children}</NoSSRThemeProvider>
由输入和输出组件组成,输入的结果添加到输出list中

定义打字间隔100ms,对键入的命令for处理,定时器中根据遍历的索引延迟赋值。
const autoTyping = (cmd: string) => {
const interval = 100 // ms
for (let i = 0; i < cmd.length; i++) {
setTimeout(
() => {
setCmd((prev) => prev + cmd.charAt(i))
},
interval * (i + 1)
)
}
}
定义外层容器ref为containerRef,键入命令后都自动滚动到页面底部,使用了scrollIntoViewapi,作用是让调用这个api的容器始终在页面可见,block参数设置为end表示垂直方向末端对其即最底端。
const containerRef = useRef<HTMLDivElement>(null)
useEffect(() => {
containerRef.current?.scrollIntoView({
behavior: 'smooth',
block: 'end'
})
}, [typedCmds])
何为
mdx?即给md添加了jsx支持,功能更强大的md,在nextjs中通过@next/mdx解析.mdx文件,它会将md和react components转成html
安装相关包,后两者作为@next/mdx的peerDependencies
@next/mdx@mdx-js/loader@mdx-js/react在next.config.js新增createMDX配置
// next.config.js
import createMDX from '@next/mdx'
const nextConfig = {}
const withMDX = createMDX()
export default withMDX(nextConfig)
接着在应用根目录下新建mdx-components.tsx
// mdx-components.tsx
import type { MDXComponents } from 'mdx/types'
export function useMDXComponents(components: MDXComponents): MDXComponents {
return {
...components
}
}
在app目录下使用.mdx文件,useMDXComponents组件是必要的,
需要注意的是此文件命名上有一定规范只能命名为mdx-components,不能为其他名称,也不可为MdxComponents,从@next/mdx源码中可以看出会去应用根目录查找mdx-components。
// @next/mdx部分源码
config.resolve.alias['next-mdx-import-source-file'] = [
'private-next-root-dir/src/mdx-components',
'private-next-root-dir/mdx-components',
'@mdx-js/react'
]
至此就可以在app中使用mdx。
为mdx解析成的html添加样式
解析mdx为html,但并没有样式,所以我们借助@tailwindcss/typography来为其添加样式,在tailwind.config.js使用该插件。
// tailwind.config.js
module.exports = {
plugins: [require('@tailwindcss/typography')]
}
在外层标签上添加prose的className,prose-invert用于暗黑模式。
<article className="prose dark:prose-invert">{mdx}</article>
综上我们实现了对mdx的样式支持,然而有一点是@tailwindcss/typography并不会对mdx代码块中代码进行高亮。
写文章或多或少都有代码,高亮是必不可少,那么
react-syntax-highlighter该上场了
定义一个CodeHighligher组件
// CodeHighligher.tsx
import { Prism as SyntaxHighlighter } from 'react-syntax-highlighter'
import {
oneDark,
oneLight
} from 'react-syntax-highlighter/dist/cjs/styles/prism'
import { useTheme } from 'next-themes'
export default function CodeHighligher({
lang,
code
}: {
lang: string
code: string
}) {
const { theme } = useTheme()
return (
<SyntaxHighlighter
language={lang?.replace(/\language-/, '') || 'javascript'}
style={theme === 'light' ? oneLight : oneDark}
customStyle={{
padding: 20,
fontSize: 15,
fontFamily: 'var(--font-family)'
}}
>
{code}
</SyntaxHighlighter>
)
}
react-syntax-highlighter高亮代码可用hljs和prism,我在这使用的prism,两者都有众多代码高亮主题可供选择,lang如果没标注则默认设置为javascript也可以简写为js,值得注意的是如果是使用hljs,则必须写javascript,不可简写为js,否则代码高亮失败,这一点prism更加友好。
同时可通过useTheme实现亮色,暗色模式下使用不同代码高亮主题。
组件写好了,该如何使用?上面讲到过mdx的解析,在useMDXComponents重新渲染pre标签。
// mdx-components.tsx
import type { MDXComponents } from 'mdx/types'
import CodeHighligher from '@/components/CodeHighligher'
export function useMDXComponents(components: MDXComponents): MDXComponents {
return {
pre: ({ children }) => {
const { className, children: code } = props
return <CodeHighligher lang={className} code={code} />
}
}
}
mdx文件中代码块会被解析成pre标签,可以对pre标签返回值作进一步处理,即返回高亮组件,这样可实现对代码高亮,当然高亮主题很多,选自己喜欢的。
文章一些信息如标题,描述,日期,作者等都作为文章的元数据,使用
yaml语法定义
---
title: '文章标题'
description: '文章描述'
date: '2020-01-01'
---
@next/mdx默认不会按照yaml语法解析,这会被解析成h2标签,然而我们并不希望元数据被解析成h2标签作为内容展示,更希望拿这类数据做其他处理,
为了正确解析yaml,需要借助remark-frontmatter来实现。
使用该插件,注意需要修改next配置文件名为next.config.mjs,因为remark-frontmatter只支持ESM规范。
// next.config.mjs
import createMDX from '@next/mdx'
import frontmatter from 'remark-frontmatter'
const nextConfig = {}
const withMDX = createMDX({
options: {
remarkPlugins: [frontmatter]
}
})
export default withMDX(nextConfig)
yaml被正确解析了那么我们可以使用gray-matter来获取文章元数据
由于app目录是运行在nodejs runtime下,基本思路是用nodejs的fs模块去读取文章目录即mdxs/posts,读取该目录下的所有文章放在一个list中。
使用fs.readdirSync读取文章目录内容,但是这仅仅是拿到文章名称的集合。
const POST_PATH = path.join(process.cwd(), 'mdxs/posts')
// 文章名称集合
export function getPostList() {
return fs.readdirSync(POST_PATH).map((name) => name.replace(/\.mdx/, ''))
}
文章列表中展示的是标题而不是名称,标题作为文章的元数据,通过gray-matter的readapi读取文件可获取(也可以使用fs.readFileSync) read返回data和content的对象,
data是元数据信息,content则是文章内容。
export function getPostMetaList() {
const posts = getPostList()
return posts.map((post) => {
const {
data: { title, description, date }
} = matter.read(path.join(POST_PATH, `${post}.mdx`))
// 使用fs.readFileSync
// const post = fs.readFileSync(path.join(POST_PATH, `${post}.mdx`), 'utf-8')
// const {
// data: { title, description, date }
// } = matter(post)
return {
slug: post,
title,
description,
date
}
})
}
上述方法中我们拿到了所有文章标题,描述信息,日期的list,根据list渲染文章列表。
文章列表中使用Link跳转到详情,通过dynamic动态加载文章对应的mdx文件
export default function LoadMDX(props: Omit<PostMetaType, 'description'>) {
const { slug, title, date } = props
const DynamicMDX = dynamic(() => import(`@/mdxs/posts/${slug}.mdx`), {
loading: () => <p>loading...</p>
})
return (
<>
<div className="mb-12">
<h1 className="mb-5 font-[600]">{title}</h1>
<time className="my-0">{date}</time>
</div>
<DynamicMDX />
</>
)
}
优化文章列表跳转详情的速度
在文章详情组件导出generateStaticParams方法,这个方法在构建时静态生成路由,而不是在请求时按需生成路由,一定程度上提高了访问详情页速度
export async function generateStaticParams() {
const posts = await fetch('https://.../posts').then((res) => res.json())
return posts.map((post) => ({
slug: post.slug
}))
}
项目是部署在vercel,使用github登录后我们新建一个项目,点进去后会看到Import Git Repository,导入对应仓库即可,也可使用vercel提供的模版新建一个,后续我们每次提交代码都会自动化部署。

有自己域名的可以在Domains中添加,然后去到你买域名的地方添加对应DNS解析即可。
开发中遇到了一些坑:
next-themes报错Warning: Extra attributes from the server: class,style,通过issues和看文档,最终找到了方案mdx-components组件的命名,经多次测试发现只能命名为mdx-components,阅读@next/mdx的源码也验证了hljs,mdx中的代码块写的js,部署到线上后发现代码并没有高亮,然后改用了prism正常高亮,react-syntax-highlighter源码发现hljs的语言集合中并没有js,所以无法正确解析,只能写成javascript,而prism两者写法都支持posts命令是运行在客户端组件中,fs无法使用,因此获取文章的方案使用fetch请求apiremark-frontmatter解析yaml无法和mdxRs: true同时使用,否则解析失败。添加此配置项表示使用基于rust的解析器来解析mdx,可能是还未支持的缘故module.exports = withMDX({
experimental: {
mdxRs: true
}
})
后续更新:
Weekly周刊模块,关注前端技术的更新


这样看是不是一目了然呢~ 😏
如上👆gif👆效果可以理解为👉 以鼠标位置为圆心,产生的背景圆,与box的间隙产生的交叉
boxes区域出现,是不是需要判断鼠标位置来添加粉色背景圆呢 ❓box 才会有 粉色背景圆,box 以外的部分是没有颜色的,这个又如何解决呢 ❓给每个box添加背景圆,背景圆位置 根据鼠标位置变化,👇 如下所示 👇


背景圆大小固定(比如200px),圆心位置如何确定呢?
👉 初始位置 (0,0) ,参照系则是参考box左上角;
👉 动态变化的位置取(clientX - left, clientY - top)。left 和 top 即 box 元素相对浏览器视口的位置,通过 getBoundingClientRect 方法获取
👉 取差值(clientX - left, clientY - top)也很好理解,因为伪元素位置是参照box左上的位置变化,这样就能在 差值(绝对值) < 半径 的时候出现在 box间隙内

box 添加伪元素 before,设置伪元素宽高均大于父元素,效果上类似于伪元素覆盖了box,同时设置偏移量 inset为负值,实现 “居中覆盖”(这样就能留出一个"空隙", 即👆gif👆中粉色圆填充before 与 box 中间空白的部分)200px 的圆形,圆心位置记为 --x 和 --y,通过css变量传入,颜色自定义即可(demo中采用的是rgba(245,158,11,.7) 到 transparent 的渐变)--x 和 --y 的获取 👀(mouseX, mouseY)calBoxesPosition方法获取每个box 的位置 (left,top) 并记录差值 (mouseX - left, mouseY - top)(mouseX, mouseY) 变动的时候重新触发 calBoxesPosition 方法即可calBoxesPosition 后,在不滑动页面的情况下,每个box位置相对固定,可以缓存下来位置信息,避免该函数内部频繁调用 getBoundingClientRect 引发的性能问题造成卡顿滑动页面的时候,可以将记录box位置信息的字段重置为(0,0),再移动鼠标重新触发 calBoxesPosition 即可PS: 不太会使用掘金的代码片段,不知道如何引入第三方库😅,如果验证代码, @vueuse/core 和 tailwindcss请自行安装🫠
(等我查一下怎么使用,再回来贴个代码片段~ ⏰@ 4-17 14:56 )
threejs的每个版本都有一些差异,在api和threejs项目文件夹下面,本案列使用的版本
npm i three@0.153.0
项目的目录结构如下:
03-fulldemo
└───css
│───main.css
│
└───draco
│───gltf——存放Google Draco解码器插件
│
└───models——存放模型
│───ferrari.glb——模型文件,可以是glb也可以是gltf格式
│───ferrari_ao.png——模型贴图,这个图片是阴影效果
│
└───textures——纹理材质
│───venice_sunset_1k.hdr——将其用作场景的环境映射或者用来创建基于物理的材质
│
创建对应的html文件并引入相应的环境
<!DOCTYPE html>
<html lang="en">
<head>
<title>three.js webgl - materials - car</title>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, user-scalable=no, minimum-scale=1.0, maximum-scale=1.0">
<link type="text/css" rel="stylesheet" href="./css/main.css">
<style>
body {
color: #bbbbbb;
background: #333333;
}
a {
color: #08f;
}
.colorPicker {
display: inline-block;
margin: 0 10px
}
</style>
</head>
<body>
<!--设置三个按钮,用于切换车身、轮毂、玻璃的颜色-->
<div id="info">
<span class="colorPicker"><input id="body-color" type="color" value="#ff0000"></input><br/>Body</span>
<span class="colorPicker"><input id="details-color" type="color" value="#ffffff"></input><br/>Details</span>
<span class="colorPicker"><input id="glass-color" type="color" value="#ffffff"></input><br/>Glass</span>
</div>
<!--要渲染3D的容器-->
<div id="container"></div>
<script type="importmap">
{
"imports": {
"three": "./node_modules/three/build/three.module.js",
"three/addons/": "./node_modules/three/examples/jsm/"
}
}
</script>
<script type="module">
import * as THREE from 'three';
//用于显示屏幕渲染帧率的面板
import Stats from 'three/addons/libs/stats.module.js';
//相机控件OrbitControls实现旋转缩放预览效果。
import { OrbitControls } from 'three/addons/controls/OrbitControls.js';
//加载GLTF文件格式的加载器,用于加载外部为gltf的文件
import { GLTFLoader } from 'three/addons/loaders/GLTFLoader.js';
//Draco是一个用于压缩和解压缩 3D 网格和点云的开源库
import { DRACOLoader } from 'three/addons/loaders/DRACOLoader.js';
//RGBELoader可以将HDR图像加载到Three.js应用程序中
import { RGBELoader } from 'three/addons/loaders/RGBELoader.js';
//下面的代码就是JS渲染逻辑代码
</script>
</body>
</html>
在css/main.css文件中我们的代码如下
body {
margin: 0;
background-color: #000;
color: #fff;
font-family: Monospace;
font-size: 13px;
line-height: 24px;
overscroll-behavior: none;
}
a {
color: #ff0;
text-decoration: none;
}
a:hover {
text-decoration: underline;
}
button {
cursor: pointer;
text-transform: uppercase;
}
#info {
position: absolute;
top: 0px;
width: 100%;
padding: 10px;
box-sizing: border-box;
text-align: center;
-moz-user-select: none;
-webkit-user-select: none;
-ms-user-select: none;
user-select: none;
pointer-events: none;
z-index: 1; /* TODO Solve this in HTML */
}
a, button, input, select {
pointer-events: auto;
}
.lil-gui {
z-index: 2 !important; /* TODO Solve this in HTML */
}
@media all and ( max-width: 640px ) {
.lil-gui.root {
right: auto;
top: auto;
max-height: 50%;
max-width: 80%;
bottom: 0;
left: 0;
}
}
#overlay {
position: absolute;
font-size: 16px;
z-index: 2;
top: 0;
left: 0;
width: 100%;
height: 100%;
display: flex;
align-items: center;
justify-content: center;
flex-direction: column;
background: rgba(0,0,0,0.7);
}
#overlay button {
background: transparent;
border: 0;
border: 1px solid rgb(255, 255, 255);
border-radius: 4px;
color: #ffffff;
padding: 12px 18px;
text-transform: uppercase;
cursor: pointer;
}
#notSupported {
width: 50%;
margin: auto;
background-color: #f00;
margin-top: 20px;
padding: 10px;
}
效果如下图:

在项目中我们添加一个carInit函数进行动画的初始化
...省略之前代码
//下面的代码就是JS渲染逻辑代码
let scene, renderer, grid, camera;
function initCar(){
//里面就开始进行3D场景的搭建
}
//执行初始化函数
initCar()
上面的函数设计用于执行我们所有3d业务代码。
/**
* (1)获取要渲染的容器
*/
const container = document.getElementById('container');
/**
* (2)创建场景对象Scene
*/
//创建一个场景对象,用来模拟3d世界
scene = new THREE.Scene();
//设置一个场景的背景颜色
scene.background = new THREE.Color(0x333333);
//这个类中的参数定义了线性雾。也就是说,雾的密度是随着距离线性增大的
scene.fog = new THREE.Fog("red", 10, 15);
background:这个属性用于设置我们场景的背景颜色,0x333333默认采用深灰来作为我们初始颜色
fog:定义了线性雾,类似于在背景指定位置设置雾化的效果,让背景看起来更加模糊,凸显空旷效果。
/**
* (3)坐标格辅助对象. 坐标格实际上是2维线数组.
*/
//创建网格对象,参数1:大小,参数2:网格细分次数,参数3:网格中线颜色,参数4:网格线条颜色
grid = new THREE.GridHelper(40, 40, 0xffffff, 0xffffff);
//网格透明度
grid.material.opacity = 1;
grid.material.depthWrite = false;
grid.material.transparent = true;
scene.add(grid);
坐标格辅助对象GridHelper可以在3D场景中定义坐标格出现。后续我们会在坐标格上面放我们的模型进行展示
代码编写完毕后,最终渲染出来的坐标格效果如下:

/**
* (4)创建透视相机
* 参数一:摄像机视锥体垂直视野角度
* 参数二:摄像机视锥体长宽比
* 参数三:摄像机视锥体近端面
* 参数四:摄像机视锥体远端面
*/
camera = new THREE.PerspectiveCamera(40, window.innerWidth / window.innerHeight, 0.3, 100);
camera.position.set(0, 1.4, - 4.5);
任何一个3D渲染效果都需要相机来成像
这一投影模式被用来模拟人眼所看到的景象,它是3D场景的渲染中使用得最普遍的投影模式
透视相机最大的特点就是满足近大远小的效果。
/**
* (5)创建一个渲染器
*/
renderer = new THREE.WebGLRenderer({ antialias: true });
renderer = new THREE.WebGLRenderer({ antialias: true });
//设置设备像素比。通常用于避免HiDPI设备上绘图模糊
renderer.setPixelRatio(window.devicePixelRatio);
//设置渲染出来的画布范围
renderer.setSize(window.innerWidth, window.innerHeight);
container.appendChild(renderer.domElement);
renderer.render(scene, camera);
有了场景、相机、坐标格辅助,我们想要让画面能够呈现出来,那就得有渲染器。
相当于你拍照需要将画面呈现到交卷上面。
其中renderer.render(scene, camera); 这段代码就是在进行渲染器的渲染。
如果render在指定频率内不断被调用,那就意味着可以不断拍照,不断渲染。可以实现动态切换效果
当执行完上面的代码后,你需要确保调用了carInit这个函数,页面就可以渲染出对应的效果了

说明:
0x333333效果为深灰色。0xffffff效果为灰色。对应的各种参数,当你在学习的时候都都可以进行调整。一遍调整就能看懂参数和最终渲染的效果差异。
当你把fog的颜色调整为跟背景一样的时候,你会发现画面上就类似产生了迷雾效果,让3D背景更加立体
scene.fog = new THREE.Fog(0x333333, 10, 15);
效果如下:

你也可以继续设置网格线条的透明度,让网格线不那么抢眼
grid.material.opacity = 0.3;
效果如下:

是不是整个画面看起来3D立体效果会更强一些,背景看起来更深邃一些。
threejs官方给我们提供了一个类,OrbitControls(轨道控制器)可以使得相机围绕目标进行轨道运动。
换句话说,引入了OrbitControls后,我们可以操作鼠标来控制页面上动态效果。
比如:鼠标滚动、鼠标点击、鼠标左右滑动效果。
代码如下:
...省略了 【(5)创建一个渲染器】
/**
* (6)开启OrbitControls控件,可以支持鼠标操作图像
*/
controls = new OrbitControls(camera, container);
//你能够将相机向外移动多少(仅适用于PerspectiveCamera),其默认值为Infinity
controls.maxDistance = 9;
//你能够垂直旋转的角度的上限,范围是0到Math.PI,其默认值为Math.PI
controls.maxPolarAngle = THREE.MathUtils.degToRad(90);
controls.target.set(0, 0.5, 0);
controls.update();
加入上面代码后,我们还要继续优化代码
在carInit函数后面在添加一个render函数,用于执行渲染
function initCar(){
/**
* (5)创建一个渲染器
*/
renderer = new THREE.WebGLRenderer({ antialias: true });
renderer = new THREE.WebGLRenderer({ antialias: true });
renderer.setPixelRatio(window.devicePixelRatio);
renderer.setSize(window.innerWidth, window.innerHeight);
container.appendChild(renderer.domElement);
//注释掉这句话
//renderer.render(scene, camera);
//调用一次render函数进行渲染
render()
}
function render(){
renderer.render(scene, camera);
requestAnimationFrame(render)
}
效果实现如下:

既然要加载外部模型,那我们肯定需要通过模型软件来设计对应的模型。本案列不讲解如何设计模型,我使用threejs官方提供的模型来进行展示。
我们常用的模型格式如下:
OBJ 是一种常见的纯文本模型格式,支持存储模型的几何信息(顶点、面)和材质信息(纹理坐标、法线等)。可以通过OBJLoader来加载和解析OBJ格式的模型。
FBX 是由Autodesk开发的一种常用的二进制模型格式,支持存储模型的几何信息、材质、动画等。可以通过FBXLoader来加载和解析FBX格式的模型。
GLTF 是一种基于JSON的开放标准,用于存储和传输三维模型和场景。GLTF格式支持几何信息、材质、骨骼动画、节点层次结构等,并且通常具有较小的文件大小。可以通过GLTFLoader来加载和解析GLTF格式的模型。
STL 是一种常用的三维打印文件格式,用于存储模型的几何信息。STL 文件通常包含三角形面片的列表,用于定义模型的外观。可以通过STLLoader来加载和解析STL格式的模型。
GLB是GL Transmission Format(gltf)的二进制版本,GLB格式将模型的几何信息、材质、骨骼动画、节点层次结构等存储在单个二进制文件中,通常具有较小的文件大小和更高的加载性能.
本案列采用glb格式来加载外部模型。
因为案列中使用glb模型数据采用了Draco来进行压缩,所以我们需要引入DRACOLoader来解析我们的模型
(1)引入DRACOLoader加载模型
/**
* (7)汽车模型相关的内容
* DRACOLoader 主要用于解析使用 Draco 压缩的 GLB 模型,而不是所有的 GLB 模型都使用了 Draco 压缩
*/
const dracoLoader = new DRACOLoader();
//配置加载器的位置,这个需要提前下载到项目中
dracoLoader.setDecoderPath('./draco/gltf/');
const loader = new GLTFLoader();
//设置GLTFLoader加载器使用DRACO来解析我们的模型数据
loader.setDRACOLoader(dracoLoader);
并不是所有的模型都需要Draco来进行加载,取决于你的模型在设计导出的时候是否用了Draco来进行压缩。
./draco/gltf/目录下面的文件如下:代码可以从gitee上面下载

当你已经创建了`const loader = new GLTFLoader();这个类实例后,我们就可以加载模型了
/**
* (8)加载glb模型
*/
loader.load('./models/gltf/ferrari.glb', function (gltf) {
//获取到模型的数据
const carModel = gltf.scene.children[0];
//将模型添加到3D场景中
scene.add(carModel);
});
render()
加载的效果如下:

模型已经加载成功了,但是你会发现他在整个背景中是黑色的。当然模型本身是有材质贴图的,车身默认是红色的。
之所以产生这个效果那是因为我们现在缺少一个非常重要的元素,那就是光照。
你试想一下,一个物体在没有任何光源的情况下,呈现出来的就是黑色的效果。如果你的场景背景也是黑色,那根本看不到效果。
我们设置光源的时候主要有两个部分
设置环境光
/**
* (9)添加光影效果
*/
//创建环境光
var ambient = new THREE.AmbientLight("blue");
scene.add(ambient);
环境光的颜色为blue,效果如下:

环境光为blue的情况下,模型表面反射出来的颜色就是蓝色,一般金属材质和玻璃材质反射的效果更佳明显。所以轮毂和车辆挡风玻璃效果会更强烈一些。
设置点光源
/**
* (9)添加光影效果
*/
//创建环境光
var ambient = new THREE.AmbientLight("blue");
scene.add(ambient);
//创建点光源
var point = new THREE.PointLight("#fff");
//设置点光源位置
point.position.set(0, 300, 0);
//点光源添加到场景中
scene.add(point);
效果如下:

此刻我们基本上完成了模型的渲染,环境光蓝色默认替换为黑色,这样车辆立体感会更强一些
//环境光
var ambient = new THREE.AmbientLight("#000");
效果如下:

HDR(High Dynamic Range)文件是一种存储图像高动态范围信息的文件格式。
HDR可以理解成一张真实世界的图片或者设计者想要的灯光效果。
他的作用主要如下:
也就说在本案列中如果我们想要获取更加真实的照明效果,我们可以使用设计师导出的hdr文件。将这个文件作为3D场景(Scene)的环境贴图
/**
* (2)创建场景对象Scene
*/
scene = new THREE.Scene();
scene.background = new THREE.Color(0x333333);
//通过RGBELoader加载hdr文件,它是一种图像格式,将其用作场景的环境映射或者用来创建基于物理的材质
scene.environment = new
RGBELoader().load('textures/equirectangular/venice_sunset_1k.hdr');
scene.environment.mapping = THREE.EquirectangularReflectionMapping;
scene.fog = new THREE.Fog(0x333333, 10, 15);
删除我们(9)添加光影效果中我们自己的光影效果
/**
* (9)添加光影效果
*/
//创建环境光
//var ambient = new THREE.AmbientLight("blue");
//scene.add(ambient);
//创建点光源
//var point = new THREE.PointLight("#fff");
//设置点光源位置
//point.position.set(0, 300, 0);
//点光源添加到场景中
//scene.add(point);
这样渲染下来我们物体在场景中显示的会更加自然

不管你用hdr文件来作为环境贴图,还是采用光源设置来设计,我们都可以让模型在3D场景中更方便的显示出来。
目前我们已经将模型渲染出来了,但是你会发现不管是车身、轮毂、还是玻璃材质跟我们想要的真实车辆材质是有区别的。比如你希望玻璃透明的、反光的。车身的漆面是可以反光的。模型在设计的时候使用默认材质。我们想要进行材质的替换。
/**
* (8)加载glb模型
* 并设置不同部位的材质。
*/
//物理网格材质(MeshPhysicalMaterial)
//车漆,碳纤,被水打湿的表面的材质需要在面上再增加一个透明的
const bodyMaterial = new THREE.MeshPhysicalMaterial({
color: 0xff0000, metalness: 1.0, roughness: 0.5, clearcoat: 1.0, clearcoatRoughness: 0.03
});
//汽车轮毂的材质,采用了标准网格材质,threejs解析gltf模型,会用两种材质PBR材质去解析
const detailsMaterial = new THREE.MeshStandardMaterial({
color: 0xffffff, metalness: 1.0, roughness: 0.5
});
//汽车玻璃的材质
const glassMaterial = new THREE.MeshPhysicalMaterial({
color: 0xffffff, metalness: 0.25, roughness: 0, transmission: 1.0
});
loader.load('./models/gltf/ferrari.glb', function (gltf) {
//获取到模型的数据
const carModel = gltf.scene.children[0];
//将模型添加到3D场景中
scene.add(carModel);
});
材质创建了过后,接下来我们就可以将材质加载了到模型中了。
loader.load('./models/gltf/ferrari.glb', function (gltf) {
//获取到模型的数据
const carModel = gltf.scene.children[0];
//获取模型中指定的模块,将默认材质替换为我们自定义材质
carModel.getObjectByName('body').material = bodyMaterial;
//轮毂的材质替换
carModel.getObjectByName('rim_fl').material = detailsMaterial;
carModel.getObjectByName('rim_fr').material = detailsMaterial;
carModel.getObjectByName('rim_rr').material = detailsMaterial;
carModel.getObjectByName('rim_rl').material = detailsMaterial;
////座椅的材质
carModel.getObjectByName('trim').material = detailsMaterial;
//玻璃的材质替换
carModel.getObjectByName('glass').material = glassMaterial;
scene.add(carModel);
});
上面的代码分别是获取模型中车身区域(body),获取轮毂区域(rim_fl、rim_fr、rim_rr、rim_rl)、座椅区域(trim)、玻璃区域(glass)
将我们自己创建的材质拿去替换默认材质实现加载渲染。
效果如下:

替换过后的模型,更有金属质感和玻璃质感。材质对应的颜色你们都可以自己进行替换。
(2)给车底盘添加阴影效果
车底盘是没有阴影效果的,我们可以使用图片来进行模型贴图,让底盘有阴影效果会更加立体。
贴图的图片为png,图片由设计师出的
效果如下:

创建一个材质对象,并使用这张图片作为贴图
loader.load('./models/gltf/ferrari.glb', function (gltf) {
//获取到模型的数据
const carModel = gltf.scene.children[0];
//获取模型中指定的模块,将默认材质替换为我们自定义材质
carModel.getObjectByName('body').material = bodyMaterial;
//轮毂的材质替换
carModel.getObjectByName('rim_fl').material = detailsMaterial;
carModel.getObjectByName('rim_fr').material = detailsMaterial;
carModel.getObjectByName('rim_rr').material = detailsMaterial;
carModel.getObjectByName('rim_rl').material = detailsMaterial;
//座椅的材质
carModel.getObjectByName('trim').material = detailsMaterial;
//玻璃的材质替换
carModel.getObjectByName('glass').material = glassMaterial;
// shadow阴影效果图片
const shadow = new THREE.TextureLoader().load( './models/gltf/ferrari_ao.png' );
// 创建一个材质模型
const mesh = new THREE.Mesh(
new THREE.PlaneGeometry(0.655 * 4, 1.3 * 4),
new THREE.MeshBasicMaterial({
map: shadow, blending: THREE.MultiplyBlending, toneMapped: false, transparent: true
})
);
mesh.rotation.x = - Math.PI / 2;
mesh.renderOrder = 2;
carModel.add(mesh);
scene.add(carModel);
});
效果如下:

通过效果图能看出,车辆底部是有阴影效果的,让整个3D效果渲染更加立体。
轮毂和网格地板我们都要动画加载
网格需要进行平移,按照z的反方向进行移动。
轮毂需要按照x轴的方向进行旋转
代码如下:
let wheels = []
function initCar(){
loader.load('./models/gltf/ferrari.glb', function (gltf) {
//获取到模型的数据
const carModel = gltf.scene.children[0];
...省略代码
//将车轮的模块保存到数组中,后面可以设置动画效果
wheels.push(
carModel.getObjectByName('wheel_fl'),
carModel.getObjectByName('wheel_fr'),
carModel.getObjectByName('wheel_rl'),
carModel.getObjectByName('wheel_rr')
);
scene.add(carModel);
});
}
上面的代码将轮毂模块获取到过后,放入到wheels数组中。
接下来在render函数中进行动画控制
function render() {
controls.update();
//performance.now()是一个用于测量代码执行时间的方法。它返回一个高精度的时间戳,表示自页面加载以来的毫秒数
const time = - performance.now() / 1000;
//控制车轮的动画效果
for (let i = 0; i < wheels.length; i++) {
wheels[i].rotation.x = time * Math.PI * 2;
}
//控制网格的z轴移动
grid.position.z = - (time) % 1;
renderer.render(scene, camera);
requestAnimationFrame(render)
}
通过上面的代码我们已经能够实现轮毂和网格的动画效果了
实现颜色切换就必须绑定js的事件。
三个按钮,我们都绑定点击事件,并获取对应的颜色
function initCar(){
...省略代码
/**
* (10)切换车身颜色
* 获取到指定的按钮,得到你选中的颜色,并将颜色设置给我们自己的模型对象
*/
const bodyColorInput = document.getElementById('body-color');
bodyColorInput.addEventListener('input', function () {
bodyMaterial.color.set(this.value);
});
const detailsColorInput = document.getElementById('details-color');
detailsColorInput.addEventListener('input', function () {
detailsMaterial.color.set(this.value);
});
const glassColorInput = document.getElementById('glass-color');
glassColorInput.addEventListener('input', function () {
glassMaterial.color.set(this.value);
});
}
当我们将上面的代码实现后,切换颜色就完成分了。
只要修改bodyMaterial材质对象的颜色,页面刷新的时候就可以应用成功。
JavaScript,简称JS,是一种轻量级的解释型编程语言,它是网页开发中不可或缺的三剑客之一,与HTML和CSS并肩作战,共同构建起我们浏览的网页。
今天我们就来了解一下JavaScript,看看它在我们的web前端开发中扮演着什么样的角色。
JavaScript(简称“JS”)是一种具有函数优先的轻量级,解释型或即时编译型的编程语言。它以其作为开发Web页面的脚本语言而闻名,但也被广泛应用于非浏览器环境中。
JavaScript是一种基于原型编程、多范式的动态脚本语言,支持面向对象、命令式、声明式和函数式编程范式。

JavaScript最初由Netscape公司的Brendan Eich于1995年为网景导航者浏览器设计并实现。由于Netscape与Sun的合作,Netscape管理层希望该语言在外观上看起来像Java,因此得名为JavaScript。
JavaScript的标准是ECMAScript。截至2012年,所有浏览器都完整地支持ECMAScript 5.1,旧版本的浏览器至少支持ECMAScript 3标准。
2015年6月17日,ECMA国际组织发布了ECMAScript的第六版,正式名称为ECMAScript 2015,但通常被称为ECMAScript 6或ES2015。

JavaScript目前是互联网上最流行的脚本语言。这门语言不仅可用于HTML和Web开发,还可以广泛用于服务器、PC、笔记本电脑、平板电脑和智能手机等设备。
让你的网页动起来,比如轮播图、下拉菜单等。

在数据提交到服务器之前,进行即时的客户端验证。
通过AJAX技术,实现页面的局部更新,无需刷新整个页面。
创建复杂的网页游戏,或是简单的互动元素。
利用浏览器提供的API,访问地理位置、摄像头、本地存储等。
使用如React Native、Electron等框架,开发跨平台的移动应用和桌面应用。
Node.js的出现让JavaScript也能在服务器端大展拳脚。
ECMAScript,描述了该语言的语法和基本对象。
文档对象模型(DOM),描述处理网页内容的方法和接口。
浏览器对象模型(BOM),描述与浏览器进行交互的方法和接口
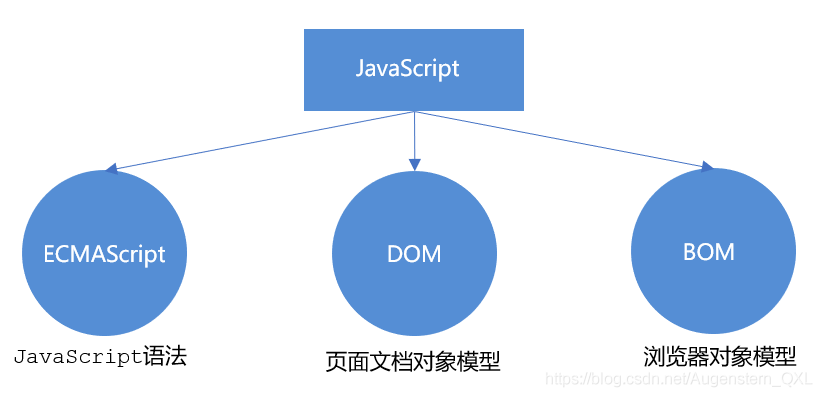
ECMAScript是一种由Ecma国际(前身为欧洲计算机制造商协会)在标准ECMA-262中定义的脚本语言规范。这种语言在万维网上应用广泛,它往往被称为JavaScript或JScript,但实际上后两者是ECMA-262标准的实现和扩展。
简单来说:
ECMAScript JavaScript是的核心,是规范标准。
描述了语言的基本语法(var、for、if、array等)和数据类型(数字、字符串、布尔、函数、对象(obj、[]、{}、null)、未定义)。
文档对象模型 (DOM) 是HTML和XML文档的编程接口。它提供了对文档的结构化的表述,并定义了一种方式可以使从程序中对该结构进行访问,从而改变文档的结构,样式和内容。
DOM 将文档解析为一个由节点和对象(包含属性和方法的对象)组成的结构集合。
简言之,它会将web页面和脚本或程序语言连接起来。
可以理解为:
DOM Document Object Model文档对象模型,可以去操作网页。
指的是XML和HTML的页面,当你创建一个页面并且加载到Web浏览器中,DOM就在幕后悄然而生,它会把你编写的网页文档转换成一个文档对象。
js对象大致可以分为以下三种:
用户定义对象,例如:var obj = {}
内置对象,无需创建,可直接使用,例如:Array、Math和Data等
宿主对象,浏览器提供的对象,例如:window、document
DOM中主要关注的就是document,document对象的主要功能就是处理网页内容。
代表着加载到浏览器窗口的当前网页,可以利用JavaScript对它进行读取。
浏览器对象模型,操作浏览器。
Browser Object Model 浏览器对象模型提供了独立与内容的、可以与浏览器窗口进行互动的对象结构,BOM由多个对象构成,其中代表浏览器窗口的window对象是BOM的顶层对象,其他对象都是该对象的子对象。
JavaScript是一种功能强大的编程语言,它的特点主要包括以下几点,在这里大家只需要了解一下就可以了。
客户端脚本语言: JavaScript通常在用户的浏览器上运行,用于实现动态内容和用户界面的交互性。
弱类型语言: JavaScript不要求开发者在编程时明确指定变量的类型,类型会在运行时自动转换。
面向对象: JavaScript支持面向对象的编程模式,允许创建对象和定义它们之间的交互。
事件驱动: JavaScript能够响应用户的操作(如点击、输入等),这使得它非常适合构建交互式的Web应用。
跨平台: JavaScript代码可以在几乎所有的现代浏览器上运行,无论是Windows、macOS还是Linux操作系统。
动态性: JavaScript是一种动态语言,可以在运行时改变其结构和行为。
可扩展性: JavaScript可以通过添加新的函数和属性来扩展其内置对象的功能。
宽松语法: JavaScript的语法相对宽松,使得编程更加灵活,但也可能导致错误。
单线程与异步处理: JavaScript在浏览器中是单线程执行的,但它通过事件循环和回调函数等机制实现了异步处理。
基于原型的继承: 不同于传统的类继承,JavaScript使用的是基于原型的继承方式。
核心组成部分: JavaScript的核心由ECMAScript、DOM(文档对象模型)和BOM(浏览器对象模型)组成。
多范式: JavaScript支持多种编程范式,包括过程式、面向对象和函数式编程。
总的来说,JavaScript的这些特点使其成为了Web开发中不可或缺的一部分,同时也适用于服务端编程(如Node.js)和其他非浏览器环境。
你是不是厌倦了一成不变的编程模式?想要突破自我,挑战新技术想要突破自我,挑战新技术?却迟迟找不到可以练手的项目实战?是不是梦想打造一个属于自己的支付系统?那么,恭喜你,云端源想免费实战直播——《VUE3+SpringBoot搭建移动支付功能(第1期)》即将开启,点击前往获取源码!
在HTML文件中,可以在<head>或<body>标签中添加<script>标签,然后在<script>标签中编写JavaScript代码。这种方式适合较小的脚本或者是测试阶段的代码。
例如:
<!DOCTYPE html>
<html>
<head>
<title>页内样式示例</title>
<script>
// 在这里编写JavaScript代码
</script>
</head>
<body>
// 页面内容
</body>
</html>
步骤一:在js文件夹中创建一个Xxx.js文件。
步骤二:在Xxxx.js文件中编写JavaScript代码。
步骤三:在HTML文件的<head>标签中通过<script src="Xxxx.js"></script>进行引入。
例如:
<!DOCTYPE html>
<html>
<head>
<title>页外样式示例</title>
<script src="Xxxx.js"></script>
</head>
<body>
// 页面内容
</body>
</html>
需要注意的是,引入时路径要正确,如果是当前目录则直接写文件名,如果是上级目录则需要使用./来指定路径。
页外样式写到<head>中,可以让它早点加载、早点完成。
而页内样式写到<body>结束标签之前,可以让HTML代码先渲染内容,然后再执行JavaScript代码。
随着Web技术的发展,JavaScript也在不断进化。ES6引入了类、模块、箭头函数等新特性,未来的JavaScri
pt将更加强大、简洁。作为前端开发的基石,也是全栈开发的重要工具,JavaScript的重要性不言而喻。
现在,你是否已经迫不及待想要开启自己的JavaScript学习之旅了呢?记住,每一位大师都是从基础开始的,不要害怕犯错,因为每一个错误都是通往成功的阶梯。
拿起你的键盘,打开你的浏览器,让我们一起在JavaScript的海洋中遨游,发现编程的无穷魅力吧!
收起阅读 »什么是安全区域?
自从苹果推出了惊艳的iPhone X,智能手机界就正式步入了全面屏的新纪元。然而,这一革新也带来了一个特别的问题——那就是屏幕顶部的“刘海”和底部的“黑条”区域。这些区域犹如手机的“神秘面纱”,遮挡了一部分屏幕,给开发者带来了新的挑战。
Android似乎对iPhone的设计情有独钟,纷纷效仿这种全面屏的潮流。于是,越来越多的Android手机也开始有了这个安全区域的概念。
在这个背景下,移动端安全区域适配变得尤为重要。开发者们需要巧妙地调整应用的布局和界面,确保内容不会被这些特殊区域遮挡,同时保持应用的美观和易用性。
安全区域定义为视图中未被导航栏、选项卡栏、工具栏或视图控制器可能提供的其他视图覆盖的区域。

如上图所示,安全区域为中间蓝色部分,也就是说我们在页面布局时应该保证页面内容在蓝色安全区域内。
所以对于这类机型,你如果不特殊处理,那么它将会是这样的:

这样就会导致底部输入框的交互受影响
在处理安全区域之前,我们需要先来了解viewport-fit属性,这是解决问题的关键。
iOS带来问题的同时也带来了解决问题的方法,为了适配 iPhoneX等全面屏机型 对现有 viewport meta 标签进行了扩展,用于设置视觉视口的大小来控制裁剪区域。
<meta name="viewport" content="width=device-width,initial-scale=1, user-scalable=0, viewport-fit=cover">
该属性包含三个值:
在非矩形显示器上(比如手表)设置视口边界框的大小时,我们必须考虑以下因素:
contain

当使用viewport-fit: contain时,初始视口将应用于显示器的最大内接矩形。
cover

当使用viewport-fit: cover时,初始视口将应用于显示器的外接矩形。
为了解决安全区域问题,iOS 11 新增了一个新的 CSS 函数env()和四个预定义的环境变量
iOS 11 中提供的 env() 函数名为 constant()。从 Safari 技术预览版 41 和 iOS 11.2 beta 开始,constant() 已被删除并替换为 env()。如有必要,您可以使用 CSS 后备机制来支持这两个版本,但以后应该更喜欢使用 env()。 —— 来自webkit文档
上面的意思是从iOS12开始不再支持使用constant函数,所以为了兼容处理,我们应该这样写:
body {
padding-bottom: constant(safe-area-inset-bottom); /* 兼容 iOS < 11.2 */
padding-bottom: env(safe-area-inset-bottom); /* 兼容 iOS >= 11.2 */
}
使用该函数的前提是必须设置meta标签viewport-fit=cover ,并且对于不支持 env() 的浏览器,浏览器将会忽略它。
第一步:
修改页面布局方式
<meta name="viewport" content="width=device-width,initial-scale=1, user-scalable=0, viewport-fit=cover">
第二步:
底部适配
.keyboard_foot {
padding-bottom: constant(safe-area-inset-bottom);
padding-bottom: env(safe-area-inset-bottom);
}

这样安全区域问题就解决了!
《前端暴走团》,喜欢请抱走~大家好,我是团长林语冰。

当当当当~惊不惊喜,意不意外,相信大家已经注意到 Node 官网的偷偷变帅了!
Node 最近可谓意气风发,不仅重新设计了新官网,还有新设计的吉祥物助阵。
今天,让我们一起来深度学习 Node 官方博客,携手 Node 团队一起回顾重新设计官网的这段旅程。

免责声明
本文属于是语冰的直男翻译了属于是,略有删改,仅供粉丝参考。英文原味版请传送 Diving int0 the Node.js Website Redesign。
Node 官方网站诞生已经超过 14 岁了。下载和文档主页的设计首次在 2011 年底崭露头角。这是 Node 0.6 的陈年旧事。

从那时起,Node 官网的规模随着项目需要与日俱增,包含了 1600 多页。在巅峰时期,它拥有大约 20 种国际化语言。Node 的域名(nodejs.org)每月处理 30 亿个请求,传输的数据量为 2 千兆字节。
Node 官网首次尝试重新设计于 2019 年开始。工作从新的域名(nodejs.dev)和新存储库起步。蓦然回首,这可能从一开始就冥冥之中注定了该项目的失败。
简而言之,这个代码库不是社区或贡献者的常驻之地,也不存在已建立的贡献者工作流程。为生活奔走忙碌的人们自愿贡奉献自己的时间,但并不想学习第二套工具。该项目无法维持蒸蒸日上所需的领导力。
2022 年,团队回归现有的存储库,考虑如何重建站点。Node 的旧版代码库开始在各个维度上显示出它的老龄化。Node 旧版官网的设计已经 out 了。Node 旧版网站的内部结构很难扩展,而且文档也很少。
Node 团队仔细考虑了技术堆栈。正在进行的重新设计的第一阶段涉及 nextra,这是一个优秀的 Next 静态站点生成器。但随着网站的发展,我们发现自己经常“打破” nextra 的惯例,依赖于 nextra 抽象的底层 Next 模式和强大工具。
Next 是一个自然选择的进化过程,以其灵活性和强大功能而赫赫有名。举个栗子,Node 新网站仍然是为了终端用户速度和基础托管独立性而静态构建的,但利用 Next 的增量静态重新生成,来获取版本发布等动态内容。
我们与 Vercel 强强联手。当 Node 新官网的规模在静态导出时使 webpack 的内存管理紧张时,它们提供了直接支持。我们在公开发布之前对新版本进行了 Beta 测试,这是该框架的真实压力测试。
2023 年 4 月,我们进行了一次小型切换。拉取请求有 1600 个文件,将 GitHub UI 推向了渲染能力的极限。Node 新官网的基建会发生变化,但外观、内容和创作体验将保持不变。
这是一个重要的里程碑 —— 证明我们可以一边开飞机、一边修飞机。
OpenJS 基金会慷慨解囊,全力资助 Node 团队与设计师一起进行重新设计。
设计师为 Node 新官网带来了现代化设计,其中包括用户体验流程、暗/亮模式、页面布局、移动视口注意事项和组件细分。

接下来是将设计实现为代码,重点放在基础设计元素和结构化组件层次结构的顺序构建上。我们从第一天起就构建了组件的变体,并从一开始就考虑了国际化。我们选择使用 Tailwind CSS,但重点是设计令牌和应用 CSS。
Orama 搜索将网站的所有内容让用户触手可及。它们对我们的静态内容进行索引,并以闪电般的速度提供 API 内容、学习材料、博客文章等结果。很难想象如果没有这个强大的搜索功能,Node 爱好者该如何方便的查阅文档。
Node 旧版官网已经国际化为近 20 种语言。虽然但是,一系列不幸的事件导致我们重置了所有翻译。
我们利用 Sentry 提供错误报告、监控和诊断工具。这对于识别问题和为我们的用户提供更好的体验大有助益。
Vercel 和 Cloudflare 支持可确保网站快速可靠。我们还通过 GitHub Actions 投资了 CI/CD 管道,为贡献者提供实时反馈。这包括使用 Chromatic、Lighthouse 结果进行视觉回归测试,确保网站质量保持较高水平。

重新设计工作与 2023 年 9 月的庆典开源日以及下个月的黑客啤酒节不谋而合。我们通过将“良好的第一个 issue”作为离散的开发任务来为这些事件做好准备。就庆典开源日而言,我们还提供了现场指导,以便与会者能够以落地公关结束这一天。
仅在庆典开源日期间,就有 28 位作者提出了 40 个 PR(拉取请求)。黑客啤酒节又收到了 26 个 PR。

开源项目的好坏取决于它的文档。在此过程中,我们迭代或引入了:
新代码非常注重内联代码和配置注释、关注点分离,以及明确定义的常量。整个过程中使用 TS 可以辅助贡献者理解数据的形状和函数的预期行为。
本次重新设计为 Node 官网的新时代奠定了基础。但工作还有待完成:
许多人和组织为实现重新设计做出了大大小小的贡献。我们要感谢:
本期话题是 —— 你觉得 Node 的新官网颜值如何、体验如何?欢迎在本文下方自由言论,文明共享。
坚持阅读,自律打卡,每天一次,进步一点。
做前端的同学在平常的工作中,很多时候都会接触到各种指示器,这次我就接到一个等级指示器的需求:
RecyclerView横向滚动,item之间有分割线,中间的item会被放大,边上的item会有一定的透明度进行淡化,滚动时要将等级变更回调给外界进行处理,停止滚动后被选中的item需要居中。

在LevelRecyclerView初始化时设置一个横向的LinearLayoutManager
init {
layoutManager = LinearLayoutManager(context, HORIZONTAL, false)
}
设置基本的数据源与adapter
private fun initRecycler() {
val list = mutableListOf<Int>()
list.add(R.drawable.icon_vip_level_0)
list.add(R.drawable.icon_vip_level_1)
list.add(R.drawable.icon_vip_level_2)
list.add(R.drawable.icon_vip_level_3)
list.add(R.drawable.icon_vip_level_4)
list.add(R.drawable.icon_vip_level_5)
list.add(R.drawable.icon_vip_level_6)
list.add(R.drawable.icon_vip_level_7)
list.add(R.drawable.icon_vip_level_8)
list.add(R.drawable.icon_vip_level_9)
list.add(R.drawable.icon_vip_level_10)
rv_level.adapter = object : CommonAdapter<Int>(this, R.layout.level_item, list) {
override fun convert(holder: ViewHolder, t: Int, position: Int) {
holder.setImageResource(R.id.iv_image, t)
holder.setOnClickListener(R.id.iv_image) {
rv_level.smoothScrollToPosition(position)
}
}
}
}
效果图:

创建一个LevelDividerItemDecoration类继承ItemDecoration,构造参数需要传入分割线的水平长度与高度,分割线的颜色为可选参数,重写getItemOffsets与onDraw方法,熟悉ItemDecoration的同学可能会觉得onDraw方法有点眼熟,因为我这个onDraw是在DividerItemDecoration上修改的
class LevelDividerItemDecoration @JvmOverloads constructor(
private val itemDividerHorizontalMargin : Int,
private val dividerHeight : Int,
dividerColor : Int = Color.parseColor("#3A3A3C")
) : ItemDecoration() {
//分割线Drawable
private val mDivider = ColorDrawable(dividerColor)
//分割线绘制区域
private val mBounds = Rect()
/**
* 计算item的分割线需要的尺寸,就是一个偏移量,可简单看成外边距
*/
override fun getItemOffsets(outRect: Rect, view: View, parent: RecyclerView, state: RecyclerView.State) {
//上下不需要分割线设置为0,左右则是将构造时传入的itemDividerHorizontalMargin设置进去
outRect.set(itemDividerHorizontalMargin, 0, itemDividerHorizontalMargin, 0)
}
/**
* 绘制分割线
*/
override fun onDraw(canvas: Canvas, parent: RecyclerView, state: RecyclerView.State) {
super.onDraw(canvas, parent, state)
canvas.save()
val top = (parent.height - dividerHeight) / 2
val bottom = top + dividerHeight
if (parent.clipToPadding) {
canvas.clipRect(parent.paddingLeft, top, parent.width - parent.paddingRight, bottom)
}
val childCount = parent.childCount
for (i in 0 until childCount) {
val item = parent.getChildAt(i)
//获取item的Rect,包含它的外边距(包含上面设置进去的偏移量)
parent.layoutManager!!.getDecoratedBoundsWithMargins(item, mBounds)
//左边分割线
mDivider.setBounds(mBounds.left, top, mBounds.left + itemDividerHorizontalMargin, bottom)
mDivider.draw(canvas)
//右边分割线
mDivider.setBounds(mBounds.right - itemDividerHorizontalMargin, top, mBounds.right, bottom)
mDivider.draw(canvas)
}
canvas.restore()
}
}
在init中添加到LevelRecyclerView
addItemDecoration(LevelDividerItemDecoration(
UIUtil.dip2px(context, 16.0),
UIUtil.dip2px(context, 4.0)))
效果图:

这时候RecyclerView可以随意滚动,给它添加一个PagerSnapHelper,让RecyclerView停下来时,item可以自动居中
在内部添加一个PagerSnapHelper,并在init时设置依附于LevelRecyclerView
private val mSnapHelper = PagerSnapHelper()
init {
mSnapHelper.attachToRecyclerView(this)
layoutManager = mLayoutManager
}
效果图:

这时又发现首尾的item,由于滚不到RecyclerView的中间,无法被选中,于是优化LevelDividerItemDecoration的计算与绘制,调整首尾item的分割线长度,使它们可以滚动到RecyclerView的中间
class LevelDividerItemDecoration @JvmOverloads constructor(
private val itemDividerHorizontalMargin : Int,
private val dividerHeight : Int,
dividerColor : Int = Color.parseColor("#3A3A3C")
) : ItemDecoration() {
//分割线Drawable
private val mDivider = ColorDrawable(dividerColor)
//分割线绘制区域
private val mBounds = Rect()
/**
* 计算item的分割线需要的尺寸,就是一个偏移量,可简单看成外边距
*/
override fun getItemOffsets(outRect: Rect, view: View, parent: RecyclerView, state: RecyclerView.State) {
val parentWidth = parent.measuredWidth
val itemWidth = view.layoutParams.width
val lastPosition = parent.adapter?.itemCount?.minus(1) ?: 0
//针对首尾两个item计算它们的左右边距,用parentWidth - itemWidth再除2,可以使item刚好到达RecyclerView的中间
when (parent.getChildAdapterPosition(view)) {
0 -> {
outRect.set(((parentWidth - itemWidth) * 0.5).toInt(), 0, itemDividerHorizontalMargin, 0)
}
lastPosition -> {
outRect.set(itemDividerHorizontalMargin, 0, ((parentWidth - itemWidth) * 0.5).toInt(), 0)
}
else -> outRect.set(itemDividerHorizontalMargin, 0, itemDividerHorizontalMargin, 0)
}
}
/**
* 绘制分割线
*/
override fun onDraw(canvas: Canvas, parent: RecyclerView, state: RecyclerView.State) {
super.onDraw(canvas, parent, state)
canvas.save()
val top = (parent.height - dividerHeight) / 2
val bottom = top + dividerHeight
if (parent.clipToPadding) {
canvas.clipRect(parent.paddingLeft, top, parent.width - parent.paddingRight, bottom)
}
//RecyclerView宽度
val parentWidth = parent.measuredWidth
val childCount = parent.childCount
for (i in 0 until childCount) {
val item = parent.getChildAt(i)
//item宽度
val itemWidth = item.measuredWidth
//获取item的Rect,包含它的外边距(包含上面设置进去的偏移量)
parent.layoutManager!!.getDecoratedBoundsWithMargins(item, mBounds)
//左边分割线
if (i == 0 && mBounds.width() > itemWidth + itemDividerHorizontalMargin * 2) {
mDivider.setBounds(0, top, mBounds.right - itemWidth - itemDividerHorizontalMargin, bottom)
} else {
mDivider.setBounds(mBounds.left, top, mBounds.left + itemDividerHorizontalMargin, bottom)
}
mDivider.draw(canvas)
//右边分割线
if (i == childCount - 1 && mBounds.width() > itemWidth + itemDividerHorizontalMargin * 2) {
mDivider.setBounds(mBounds.left + itemWidth + itemDividerHorizontalMargin, top, parentWidth, bottom)
} else {
mDivider.setBounds(mBounds.right - itemDividerHorizontalMargin, top, mBounds.right, bottom)
}
mDivider.draw(canvas)
}
canvas.restore()
}
}
效果图:

定义一个等级回调接口
interface OnLevelChangeListener {
fun onLevelChange(position : Int)
}
添加OnScrollListener,在滚动过程中做了一些计算,每个方法都写了注释,具体看下面代码↓
addOnScrollListener(object : OnScrollListener() {
//系数最大值
private val maxFactor = .45F
/**
* RecyclerView滚动
*/
override fun onScrolled(recyclerView: RecyclerView, dx: Int, dy: Int) {
super.onScrolled(recyclerView, dx, dy)
val first = mLayoutManager.findFirstVisibleItemPosition()
val last = mLayoutManager.findLastVisibleItemPosition()
val parentCenter = recyclerView.width / 2F
for (i in first..last) {
setItemTransform(i, parentCenter)
}
changeSnapView()
}
/**
* RecyclerView滚动状态改变
*/
override fun onScrollStateChanged(recyclerView: RecyclerView, newState: Int) {
if (newState == SCROLL_STATE_IDLE) {
changeSnapView()
}
}
/**
* 对item进行各种变换
* 目前是缩放与透明度变换
*/
private fun setItemTransform(position : Int, parentCenter : Float) {
mLayoutManager.findViewByPosition(position)?.run {
val factor = calculationViewFactor(left.toFloat(), width.toFloat(), parentCenter)
val scale = 1 + factor
scaleX = scale
scaleY = scale
alpha = 1 - maxFactor + factor
}
}
/**
* 计算当前item的缩放与透明度系数
* item的中心离recyclerView的中心越远,系数越小(负相关)
*/
private fun calculationViewFactor(left: Float, width : Float, parentCenter : Float) : Float {
val viewCenter = left + width / 2
val distance = abs(viewCenter - parentCenter) / width
return max(0F, (1F - distance) * maxFactor)
}
/**
* 修改当前居中的item,把当前等级回调给外界
*/
private fun changeSnapView() {
mSnapHelper.findSnapView(mLayoutManager)?.let {
mLayoutManager.getPosition(it).let { position ->
if (lastPosition != position) {
lastPosition = position
levelListener?.onLevelChange(position)
}
}
}
}
})
给LevelRecyclerView设置等级回调监听
rv_level.levelListener = object : LevelRecyclerView.OnLevelChangeListener {
override fun onLevelChange(position: Int) {
Log.e("levelListener","levelListener $position")
tv_level.text = "等级:$position"
}
}
效果图:
方法的原实现其实就是LinearLayoutManager内部创建了一个LinearSmoothScroller去进行滚动,现在我们创建一个CenterSmoothScroller类去继承LinearSmoothScroller,重写它的calculateDtToFit方法,calculateDtToFit用于计算滚动距离,而calculateSpeedPerPixel计算滚动速度
class CenterSmoothScroller(context: Context?) : LinearSmoothScroller(context) {
override fun calculateDtToFit(viewStart: Int, viewEnd: Int, boxStart: Int,
boxEnd: Int, snapPreference: Int): Int {
return boxStart + (boxEnd - boxStart) / 2 - (viewStart + (viewEnd - viewStart) / 2)
}
override fun calculateSpeedPerPixel(displayMetrics: DisplayMetrics?): Float {
return super.calculateSpeedPerPixel(displayMetrics) * 3F
}
}
override fun smoothScrollToPosition(position : Int) {
if (position == lastPosition) return
if (position < 0 || position >= (adapter?.itemCount ?: 0)) return
mLayoutManager.startSmoothScroll(
CenterSmoothScroller(context).apply {
targetPosition = position
}
)
}
到这里就完成了对整个LevelRecyclerView的开发了,实现了文章开头的动画效果
10分钟过去了,这个简单的LevelRecyclerView你拿下没有?
觉得不错的话,就不要吝啬你的点赞!
需要整份代码的话,下面链接自提。
代码链接 : github.MyCustomView
最近接了一个需求,需要实现不同登录人员可以自定义首页模块卡片。简单来说,就是实现首页看板模块的增添与拖拉拽,效果如下:

原生js是支持拖拉拽的,只需要将拖拽的元素的 draggable 属性设置成 "true"即可,然后就是调用相应的函数即可。
但是,原生js功能不够完善,使用起来需要改造的地方很多,因此,选用成熟的第三方插件比较好。
我们的主项目采用的是vue3,,经过一系列对比,最终选择了 vue-draggable-next这个插件。
vue-draggable-next
vue-draggable-next的周下载量月3万左右,可以看出是一个比较靠谱的插件。

它的使用方式npmj上也介绍的很详细:
如果英文的使用Api看起来比较难受,网上还有中文的使用文档:
vue.draggable.next 中文文档 - itxst.com
这个插件也有vue2版本和纯js版本,其他框架也是也是可以完美使用的。
根据我们的需求,我们应该实现的是分组拖拽,假设我们有三列,那我们要实现的就是这A、B、C三列数据相互拖拽。

我们看看中文官网给的示例:
看起来很容易,我们只需要写多个draggable标签,每个draggable标签写入相同的组名即可。
回到代码中,要想实现一个三列可拖拉拽的模块列表,我们首先需要引入组件
<script lang="ts" setup>
import { VueDraggableNext } from 'vue-draggable-next'
// ....
</script>
然后定义一个数组储存数据:
<script lang="ts" setup>
import { VueDraggableNext } from 'vue-draggable-next'
const moduleList = ref([
{
"columnIndex": 1,
"moduleDetail": [
{ "moduleCode": "deviation", "moduleName": "控制失调空间",},
{ "moduleCode": "meeting_pending", "moduleName": "会议待办",},
{ "moduleCode": "abnormal_events", "moduleName": "异常事件", },
{ "moduleCode": "audit_matters", "moduleName": "事项审批",}
],
},
{
"columnIndex": 2,
"moduleDetail": [
{ "moduleCode": "air_conditioning_terminal", "moduleName": "空调末端", }
],
},
{
"columnIndex": 3,
"moduleDetail": [
{ "moduleCode": "run_broadcast", "moduleName": "运行播报",},
{"moduleCode": "my_schedule", "moduleName": "我的日程", },
{ "moduleCode": "cold_station", "moduleName": "冷站",}
],
}
])
</script>
最后,在代码中我们使用v-for循环渲染即可
<div v-for="moduleColumn in moduleList " :key="moduleColumn.columnIndex" class="box">
<VueDraggableNext :list="moduleColumn.moduleDetail" group="column" >
<div v-for="(item, index) in moduleColumn.moduleDetail " :key="item.moduleCode" class="drag-item">
<!-- 模块内容 -->
</div>
</VueDraggableNext>
</div>
注意上面的html结构,我们循环渲染了三列VueDraggableNext标签,每个VueDraggableNext标签内部又通过v-for="(item, index) in moduleColumn.moduleDetail渲染了这个拖拽列内部的所有模块。我们通过group="column" 让每个VueDraggableNext组件的组名相同,实现了三个拖拽标签之间的模块互相拖拉拽。
正常情况小,我们肯定是希望在某个组件的固定位置才能拖动组件,因此我们需要使用到拖拽组件的handle属性。
vue.draggable.next属性说明:
| handle | :handle=".mover" 只有当鼠标在class为mover类的元素上才能触发拖到事件 |
|---|
根据属性说明,我们的代码实现起来也非常容易了。
<div v-for="moduleColumn in moduleList " :key="moduleColumn.columnIndex" class="box">
<VueDraggableNext :list="moduleColumn.moduleDetail" handle=".move" group="column">
<div v-for="(item, index) in moduleColumn.moduleDetail " :key="item.moduleCode" class="drag-item">
<div class="move">
拖拽区域
</div>
<!-- 模块内容 -->
</div>
</VueDraggableNext>
</div>
实际开发中,我么一定会根据接口或者操作动态的更改列表,代码层也就是更改moduleList的值。非常幸运的是,如果你按照上面的方式写代码,当你拖拉拽完毕后,上面的moduleList值会自动更改,我们不用做任何处理!!!这么看,数据的增删改根本不是问题。
实际开发中,我们可能会遇到一个问题,就是如何动态的去渲染组件,如果你熟悉vue,使用动态组件component就可以实现。
首先,我们需要定义一个模块列表
import MeetingPending from '../components/meetingPending.vue'
import AbnormalEvents from '../components/abnormalEvents/index.vue'
import MySchedule from '../components/mySchedule.vue'
import TransactionApproval from '../components/transactionApproval.vue'
import RunningBroadcast from '../components/runningBroadcast.vue'
import CodeSite from '../components/codeSite/index.vue'
import MismatchSpace from '../components/mismatchSpace/index.vue'
import AirDevice from '../components/airDevice/index.vue'
// !全量模块选择列表
export const allModuleList = [
{ moduleCode: 'meeting_pending', label: '会议待办', component: MeetingPending },
{ moduleCode: 'my_schedule', label: '我的日程', component: MySchedule },
{ moduleCode: 'audit_matters', label: '事项审批', component: TransactionApproval },
{ moduleCode: 'abnormal_events', label: '异常事件', component: AbnormalEvents },
{ moduleCode: 'deviation', label: '控制失调空间', component: MismatchSpace },
{ moduleCode: 'run_broadcast', label: '运行播报', component: RunningBroadcast },
{ moduleCode: 'cold_station', label: '冷站', component: CodeSite },
{ moduleCode: 'air_conditioning_terminal', label: '空调末端', component: AirDevice }
]
然后根据moduleCode做匹配,动态渲染即可
<div v-for="moduleColumn in moduleList " :key="moduleColumn.columnIndex" class="box">
<VueDraggableNext :list="moduleColumn.moduleDetail" handle=".move" group="column">
<div v-for="(item, index) in moduleColumn.moduleDetail " :key="item.moduleCode" class="drag-item">
<div class="move">
拖拽区域
</div>
<component :is="getComponentsByCode(item.moduleCode)" ></component>
</div>
</VueDraggableNext>
</div>
如果上面的功能不满足你的需求,我们可以使用这个组件的其他属性,完成更多意想不到的效果
如果下面的属性说明未能完全看明,可以看左边的对应的菜单查看详细说明和例子。
| 属性名称 | 说明 |
|---|---|
| group | 如果一个页面有多个拖拽区域,通过设置group名称可以实现多个区域之间相互拖拽 或者 { name: "...", pull: [true, false, 'clone', array , function], put: [true, false, array , function] } |
| sort | 是否开启排序,如果设置为false,它所在组无法排序 |
| delay | 鼠标按下多少秒之后可以拖拽元素 |
| touchStartThreshold | 鼠标按下移动多少px才能拖动元素 |
| disabled | :disabled= "true",是否启用拖拽组件 |
| animation | 拖动时的动画效果,如设置animation=1000表示1秒过渡动画效果 |
| handle | :handle=".mover" 只有当鼠标在class为mover类的元素上才能触发拖到事件 |
| filter | :filter=".unmover" 设置了unmover样式的元素不允许拖动 |
| draggable | :draggable=".item" 样式类为item的元素才能被拖动 |
| ghost-class | :ghost-class="ghostClass" 设置拖动元素的占位符类名,你的自定义样式可能需要加!important才能生效,并把forceFallback属性设置成true |
| chosen-class | :ghost-class="hostClass" 被选中目标的样式,你的自定义样式可能需要加!important才能生效,并把forceFallback属性设置成true |
| drag-class | :drag-class="dragClass"拖动元素的样式,你的自定义样式可能需要加!important才能生效,并把forceFallback属性设置成true |
| force-fallback | 默认false,忽略HTML5的拖拽行为,因为h5里有个属性也是可以拖动,你要自定义ghostClass chosenClass dragClass样式时,建议forceFallback设置为true |
| fallback-class | 默认false,克隆选中元素的样式到跟随鼠标的样式 |
| fallback-on-body | 默认false,克隆的元素添加到文档的body中 |
| fallback-tolerance | 按下鼠标移动多少个像素才能拖动元素,:fallback-tolerance="8" |
| scroll | 默认true,有滚动区域是否允许拖拽 |
| scroll-fn | 滚动回调函数 |
| scroll-fensitivity | 距离滚动区域多远时,滚动滚动条 |
| scroll-speed | 滚动速度 |
传送门:vue.draggable.next 中文文档 - itxst.com
关联文章:如何实现模块的锚点定位及闪烁提示:juejin.cn/post/734622…

随着小程序项目的不断迭代升级,避免不了体积越来越大。微信限制主包最多2M,然而我们的项目引入了直播插件直接占了1.1M,导致必须采用一些手段去优化。下面介绍一下优化思路和终极解决方案。
我相信几乎所有人都能想到的方案,基本上这个方案就能解决问题。具体如何实现可以参照官方文档这里不做过多说明。(基础能力 / 分包加载 / 使用分包 (qq.com)),但是有时候你会发现分包之后好像主包变化不是很大,这是为什么呢?

图片是最好解决的,除了tabbar用到的图标,其余都放在云上就好了,例如oss和obs。而且放在云上还有个好处就是背景图片无需担心引入不成功。
这部分可以采用tabbar页面都在放在一个文件夹下,比如一共有4个tab,那么一个文件夹下就只存放这4个页面。其余tabbar的子页面一律采用分包。
独立分包是小程序中一种特殊类型的分包,可以独立于主包和其他分包运行。从独立分包中页面进入小程序时,不需要下载主包。当用户进入普通分包或主包内页面时,主包才会被下载。
但是使用的时候需要注意:
app.wxss 对独立分包无效,应避免在独立分包页面中使用 app.wxss 中的样式;App 只能在主包内定义,独立分包中不能定义 App,会造成无法预期的行为;
我们自己写的代码就算再多,其实增加的kb并不大。大部分大文件主要源于第三方依赖,那么有没有办法像webpack中的externals一样,当进入这个页面的时候再去异步加载js文件而不被打包呢(说白了就是CDN)
其实解决方案就是we-script,他允许我们使用CDN方式加载js文件。这样就不会影响打包体积了。
npm install --save we-script"usingComponents": {"we-script": "we-script"}<we-script src="url1" />构建后可能会出现依赖报错,解决的方式就是将编译好的文件手动拖入miniprogram_npm文件夹中,主要是三个文件夹:we-script,acorn,eval5
最后成功解决了主包文件过大的问题,只要是第三方依赖,都可以通过这个办法去加载。
感谢阅读,希望来个三连支持下,转载记得标注原文地址~
面试官:看你简历上做过图片或文件批量下载,那么假如我一次性下载几十个,如何去控制并发请求的?
让我想想,额~, 选中ID,循环请求?,八嘎!肯定不是那么沙雕的做法,这样做服务器直接崩溃啦!突然灵光一现,请求池!!!
我:利用Promise模拟任务队列,从而实现请求池效果。
面试官:大佬!
废话不多说,正文开始:
众所周知,浏览器发起的请求最大并发数量一般都是6~8个,这是因为浏览器会限制同一域名下的并发请求数量,以避免对服务器造成过大的压力。
首先让我们来模拟大量请求的场景
const ids = new Array(100).fill('')
console.time()
for (let i = 0; i < ids.length; i++) {
console.log(i)
}
console.timeEnd()

一次性并发上百个请求,要是配置低一点,又或者带宽不够的服务器,直接宕机都有可能,所以我们前端这边是需要控制的并发数量去为服务器排忧解难。
先进先出就是队列,push一个的同时就会有一个被shift。我们看下面的动图可能就会更加的理解:

我们接下来的操作就是要模拟上图的队列行为。
export const handQueue = (
reqs // 请求数量
) => {}
接受一个参数reqs,它是一个数组,包含需要发送的请求。函数的主要目的是对这些请求进行队列管理,确保并发请求的数量不会超过设定的上限。
const dequeue = () => {
while (current < concurrency && queue.length) {
current++;
const requestPromiseFactory = queue.shift() // 出列
requestPromiseFactory()
.then(() => { // 成功的请求逻辑
})
.catch(error => { // 失败
console.log(error)
})
.finally(() => {
current--
dequeue()
});
}
}
这个函数用于从请求池中取出请求并发送。它在一个循环中运行,直到当前并发请求数current达到最大并发数concurrency或请求池queue为空。对于每个出队的请求,它首先增加current的值,然后调用请求函数requestPromiseFactory来发送请求。当请求完成(无论成功还是失败)后,它会减少current的值并再次调用dequeue,以便处理下一个请求。
return (requestPromiseFactory) => {
queue.push(requestPromiseFactory) // 入队
dequeue()
}
函数返回一个函数,这个函数接受一个参数requestPromiseFactory,表示一个返回Promise的请求工厂函数。这个返回的函数将请求工厂函数加入请求池queue,并调用dequeue来尝试发送新的请求,当然也可以自定义axios,利用Promise.all统一处理返回后的结果。
const enqueue = requestQueue(6) // 设置最大并发数
for (let i = 0; i < reqs.length; i++) { // 请求
enqueue(() => axios.get('/api/test' + i))
}

我们可以看到如上图所示,请求数确实被控制了,只有有请求响应成功的同时才会有新的请求进来,极大的降低里服务器的压力,后端的同学都只能喊6。
import axios from 'axios'
export const handQueue = (
reqs // 请求总数
) => {
reqs = reqs || []
const requestQueue = (concurrency) => {
concurrency = concurrency || 6 // 最大并发数
const queue = [] // 请求池
let current = 0
const dequeue = () => {
while (current < concurrency && queue.length) {
current++;
const requestPromiseFactory = queue.shift() // 出列
requestPromiseFactory()
.then(() => { // 成功的请求逻辑
})
.catch(error => { // 失败
console.log(error)
})
.finally(() => {
current--
dequeue()
});
}
}
return (requestPromiseFactory) => {
queue.push(requestPromiseFactory) // 入队
dequeue()
}
}
const enqueue = requestQueue(6)
for (let i = 0; i < reqs.length; i++) {
enqueue(() => axios.get('/api/test' + i))
}
}
前端开发的核心构建在三大基石技术上:HTML、CSS和JavaScript。回想起多年前,前端开发者常被戏称为“切图仔”,但就是这样的角色,通过精湛的CSS技巧,能够实现各种复杂的交互和特效,展现出前所未有的网页魔法。这是那些专注于服务端开发的工程师所难以企及的领域。因此,前端工程师这一职业逐渐崭露头角,早期的培训班甚至设立了专门的课程来传授这些技能。然而,随着时间的推移,UI组件库和框架变得越来越普及,HTML和JavaScript的重要性依旧被人们所认可,但CSS技能却逐渐被边缘化,甚至有所忽视。在一次代码走查中,发现一个拥有三四年前端开发经验的同事,连CSS最基本的类型选择器都掌握不熟练。这一现象令人感到忧虑。
在一次对 useState 的使用场景进行治理的过程中。发现了一段感觉很无语的代码。代码我简化一下如下所示:
import React, { useState } from 'react';
import { Input } from 'antd';
import type { FC } from 'react';
import styles from './index.less';
const Test: FC = () => {
const [isFocus, setIsFocus] = useState(false);
return (
<Input
className={isFocus ? styles['input-focus'] : styles.input}
onFocus={() => {
setIsFocus(true);
}}
onBlur={() => {
setIsFocus(false);
}}
/>
);
};
export default Test;
.input-focus{
background: #f2f3f;
}
这段代码的目的是根据输入框的焦点状态(聚焦或失去焦点)来改变其样式,逻辑上没有问题。
我找到编写这段代码的同事询问:“为什么需要定义一个isFocus状态呢?”
他看了代码良久,有些疑惑地解释说:“这是为了追踪输入框的聚焦状态,从而在聚焦时改变背景色。”
“这个状态还有其他用途吗?”我追问。
“没有,就这个作用。有问题吗?”他回答。
我继续探询:“不使用isFocus状态,我们还能达到同样的效果吗?”
他思考了一会儿:“如果不添加类名来标识输入框的聚焦状态,我们怎么区分呢?”
我提出了另一种方案:“我们能不能仅用CSS来实现这个效果?”
他迟疑了一下:“但是CSS怎么能识别输入框是否聚焦呢?”
我提醒他:“你有没有试过使用伪类选择器?”
“伪类?我通常只用类选择器。”他回答。
我解释道:“我们可以使用:focus伪类来实现这个效果。你可以先回去继续你的工作。”
我继续审查了这位同事的其他代码,发现他对CSS的理解似乎并不深入。例如,为了实现列表的斑马纹效果,理应直接使用:nth-child(odd)和:nth-child(even)选择器,但他却通过在遍历过程中判断索引是奇数还是偶数来分别添加不同的类选择器实现这一效果。此外,他同时使用了float: left和position: absolute,这在布局中是矛盾的组合。他还通过JavaScript动态添加类选择器来改变输入框提示文字的字体颜色,还一直重复定义color和font-size而不懂这些可以继承。
我不确定这是否反映了他的态度问题或是能力问题,在现在只出不进,内部消化的环境下,我默默地记录下这些,以便将来作为评估的参考。
也许会有人觉得我要求的太苛刻,也许这位同事只是忘记了有这几个CSS选择器。的确,CSS选择器的种类众多,达到60多种,可能会让人难以记住每一个。然而,重点并不在于能否一一背诵每个选择器,而在于理解它们各自的功能和使用场景。这样,当面对特定的样式需求时,我们可以轻松地查找并应用最合适的选择器来实现目标效果。
最基本的元素选择器、类选择器、和ID选择器因其简洁直观而被频繁使用。但是,深入探索那些不那么显眼的选择器——如通配符选择器、组合选择器、属性选择器、伪类选择器、和伪元素选择器——同样至关重要。这些选择器赋予了我们更精细的控制权,使得我们能够创造出更加复杂和细腻的视觉效果。
总之,我们不必强迫自己记住所有CSS选择器。更为重要的是认识到CSS选择器的多样性和强大之处。这种认识使我们能够在遇到具体的样式挑战时,知道如何寻找解决方案,从而更高效地运用CSS优化我们的代码。
为了真正理解这些选择器,我们需要思考它们被设计出来的原因——它们是如何帮助我们更好地控制样式,应对各种布局和视觉挑战的。这种深入的理解方式,远比简单的记忆更为重要和有效。
伪类选择器在CSS中的存在有着重要的意义和作用。它们提供了一种方式来选择HTML文档中无法通过简单选择器(如元素选择器、类选择器或ID选择器)直接选择的元素。伪类选择器的设计初衷和主要用途包括以下几点:
伪类选择器允许开发者根据用户与页面的交互来改变元素的样式,而不需要改变HTML代码。例如,:hover伪类可以用来改变鼠标悬停在链接或按钮上时的样式,:focus伪类用于当元素获得焦点时(比如输入框被点击时),而:active伪类则用于元素被激活(通常是被点击)的瞬间。这些都是基于用户行为的动态变化,通过CSS直接实现,无需JavaScript介入,提高了网页的交互性和用户体验。
伪类选择器还可以用来选择处于特定位置的元素,例如第一个子元素、最后一个子元素或者是父元素的唯一子元素。这对于设计复杂的布局和样式非常有用,尤其是在处理列表、表格和导航菜单时。例如,:first-child、:last-child、:nth-child()等伪类选择器,它们提供了一种灵活的方式来选择和样式化这些特定位置的元素。
虽然属性选择器(如[attribute=value])可以用来基于元素的属性选择元素,但某些伪类选择器(如:checked)提供了更为简便的方式来选择具有特定属性的元素。例如,:checked伪类选择器可以选择所有选中的复选框和单选按钮,这对于创建自定义表单控件的样式非常有用。
伪类选择器还可以增强网页的可访问性。例如,:focus伪类可以用来为获得焦点的元素定义明显的样式,这对于键盘导航用户来说非常重要。通过提供视觉反馈,用户可以更容易地识别当前交互的元素,从而提高网站的可访问性。
使用伪类选择器,开发者可以在不增加额外HTML标记的情况下,实现复杂的样式和布局。这有助于保持HTML代码的简洁和语义化,同时还可以减少页面的大小和提高加载速度。
总之,伪类选择器为CSS提供了强大的功能,使得开发者能够以更细致和动态的方式控制网页的样式。它们是现代网页设计中不可或缺的工具,使得网页能够响应用户的交互,同时保持代码的整洁和高效。
伪元素选择器在CSS中的引入,为网页设计和内容表现提供了更加丰富和灵活的手段。伪元素选择器允许开发者访问并样式化一个元素的特定部分,或者在文档树中虚拟地创建新的元素,而这些通常不能通过HTML直接实现。伪元素选择器的存在有几个重要的原因和用途:
伪元素选择器使得开发者能够访问并样式化元素的特定部分,比如第一行文本、第一个字母、或者元素之前和之后的内容。例如,::first-line 和 ::first-letter 伪元素分别允许开发者为元素的第一行文本和第一个字母设置特定的样式。这在打造具有吸引力的排版和阅读体验时非常有用。
通过使用 ::before 和 ::after 伪元素,开发者可以在元素的内容之前或之后插入新的内容或装饰,而不需要修改HTML代码。这种方法非常适合添加图标、装饰性元素或者是为元素添加特殊的前缀或后缀,同时保持HTML的清晰和语义化。
伪元素选择器也常被用于创建特殊的视觉效果,比如自定义的清除浮动方法(使用 ::after 清除浮动),或者是设计复杂的背景装饰和形状。这些都可以通过伪元素以及结合CSS的其他特性(如background、border、box-shadow等)来实现。
使用伪元素可以在不增加额外HTML元素的情况下实现复杂的设计,这有助于减少DOM的大小,从而提高网页的性能。通过减少页面加载时需要解析的HTML标签数量,可以加快页面的渲染速度。
通过使用伪元素来添加装饰性内容或样式,开发者可以避免在HTML中添加非语义化的标记。这有助于保持HTML文档的清晰和语义化,使得文档的结构更加明确,也更容易被搜索引擎优化(SEO)和屏幕阅读器理解。
总之,伪元素选择器为CSS提供了强大的功能,使得开发者能够以更细致和动态的方式控制网页的样式和内容。它们是现代网页设计中不可或缺的工具,允许开发者在不牺牲HTML语义化的前提下,实现复杂和创新的设计。
属性选择器在CSS中的引入提供了一种强大的方式来根据元素的属性及其值来选择元素,从而应用特定的样式。这种选择器的存在和使用有几个关键的原因和优势:
在复杂的网页设计中,开发者可能需要对具有特定属性或属性值的元素应用样式,而不是仅基于元素类型、类或ID。属性选择器使得这种精确选择成为可能。例如,可以选择所有设置了target="_blank"属性的<a>标签,并为它们应用特定的样式,以提示用户这些链接将在新窗口中打开。
属性选择器增加了CSS规则的灵活性,允许开发者基于元素的属性和属性值来创建复杂的选择条件。这意味着开发者可以在不修改HTML结构的情况下,通过CSS实现更多的设计需求和响应式布局。
使用属性选择器,开发者可以避免在HTML中过度使用类或ID,从而简化HTML结构并提高样式的可维护性。当需要基于相同属性的元素应用统一的样式时,只需在CSS中定义一次相应的属性选择器规则,而不是在HTML中为每个元素重复添加类或ID。
属性选择器可以用来增强文档的语义化和可访问性。例如,通过选择具有特定role属性的元素并为它们应用样式,开发者可以帮助提高网页对于屏幕阅读器等辅助技术的可访问性。
在某些情况下,开发者可能希望仅在元素具有特定属性或属性值时才应用样式。属性选择器使得这种条件样式化成为可能,无需额外的类或ID,也无需使用JavaScript。这种方式非常适合实现基于特定数据属性(data-*属性)的样式变化。
示例
假设我们想为所有含有特定属性data-tooltip的元素添加一个工具提示样式,我们可以使用如下CSS规则:
[data-tooltip] {
position: relative;
cursor: pointer;
}
[data-tooltip]:before {
content: attr(data-tooltip);
/* 更多的样式规则来定义工具提示的外观 */
}
这个示例展示了如何仅通过CSS和HTML属性来实现一个简单的工具提示功能,无需修改HTML结构或使用JavaScript。
总之,属性选择器为CSS提供了更多的选择和样式化能力,增加了样式表的灵活性和可维护性,同时促进了更好的文档结构和语义化。
组合选择器在CSS中扮演着至关重要的角色,它们提供了一种强大的机制来选择具有特定关系的元素,从而允许开发者以更精细、更具体的方式应用样式。组合选择器的存在和使用主要基于以下几个原因:
在复杂的网页布局中,仅使用简单选择器(如元素选择器、类选择器或ID选择器)往往难以精确地定位到特定的元素。组合选择器通过定义元素之间的关系(如父子关系、相邻关系等),使得开发者可以更精确地选择到目标元素。这种精确性对于实现特定的布局和样式效果至关重要。
使用组合选择器,可以避免在HTML中过度使用类或ID来达到样式目的,从而使得CSS的结构更加清晰和简洁。这种方法有助于提高代码的可维护性和可读性,同时减少了因重复定义样式而导致的冗余。
组合选择器提供了一种方式来实现基于特定元素关系的复杂样式设计。例如,开发者可以使用子选择器(>)来仅为特定父元素的直接子元素应用样式,或使用相邻兄弟选择器(+)来为紧跟在特定元素后的兄弟元素应用样式。这种灵活性使得开发者能够创造出更加动态和富有层次感的页面布局和视觉效果。
通过使用组合选择器,开发者可以为特定的元素关系定义样式,而不是针对特定的类或ID。这种做法增加了样式的可复用性,因为相同的组合选择器样式可以在不同的HTML结构中被复用,只要这些结构符合选择器定义的元素关系。
组合选择器的使用有助于保持HTML代码的语义化,因为它们允许开发者基于元素之间的自然关系来应用样式,而不是强迫添加额外的类或ID。这样不仅使得HTML结构更加清晰,也有助于搜索引擎优化(SEO)和提高网站的可访问性。
示例
假设我们想为一个列表中的第一个项目添加特殊样式,我们可以使用子选择器和伪类选择器的组合来实现这一点:
ul > li:first-child {
color: red;
}
这个示例展示了如何使用组合选择器来精确选择并样式化特定的元素,而无需为该元素添加额外的类或ID。
总之,组合选择器是CSS中不可或缺的一部分,它们通过定义元素之间的关系增强了选择器的功能,使得开发者能够以更灵活、更高效的方式设计和实现网页样式。
针对这个问题有两个思路
方式一:纯前端
每次打包发版时都使用webpack构建一个version.json文件,文件里的内容是一个随机的字符串(我用的是时间戳),每次打包都会自动更新这个文件。
项目中,通过监听点击事件来请求version.json文件。使用本地缓存将上一次生成的字符串存储起来,和本次请求过来的字符串进行对比;若字符串不一样,则说明有项目有新内容更新,提供用户刷新或清除缓存(我使用的)
方式二:前后端配合
在每个请求头加上发版的版本号,和保留在客户端的上一次版本号进行对比,如果不一致则强制刷新,刷新后保存当前版本号
实现:
1、webpack构建生成一个json文件,在项目目录下新建一个plugins的文件夹,新建version-webpack-plugin.js文件
webpack4****等高版本构建方式
/** Customized plug-in: Generate version number json file */const fs = require("fs");class VersionPlugin { apply(compiler) { // emit is an asynchronous hook, use tapAsync to touch it, you can also use tapPromise/tap (synchronous) compiler.hooks.emit.tap("Version Plugin", (compilation) => { const outputPath = compiler.path || compilation.options.output.path; const versionFile = outputPath + "/version.json"; const timestamp = Date.now(); // timestamp as version number const content = `{"version": "${timestamp}"}`; /** Returns true if the path exists, false otherwise */ if (!fs.existsSync(outputPath)) { // Create directories synchronously. Returns undefined or the path to the first directory created if recursive is true. This is the synchronous version of fs.mkdir(). fs.mkdirSync(outputPath, { recursive: true }); } // Generate json file fs.writeFileSync(versionFile, content, { encoding: "utf8", flag: "w", }); }); }}module.exports = { VersionPlugin };
webpack3
低版本构建方式
/** Customized plug-in: Generate version number json file */const fs = require('fs')class VersionPlugin { apply(compiler) { compiler.plugin('done', function () { // Copy the logic of the file, and the file has been compiled. const outputPath = compiler.outputPath const versionFile = outputPath + '/version.json' const timestamp = Date.now() // 时间戳作为版本号 const content = `{"version": "${timestamp}"}` /** Returns true if the path exists, false otherwise. */ if (!fs.existsSync(outputPath)) { // Create directories synchronously. Returns undefined or the path to the first directory created if recursive is true. This is the synchronous version of fs.mkdir(). fs.mkdirSync(outputPath, { recursive: true }) } // Generate json file fs.writeFileSync(versionFile, content, { encoding: 'utf8', flag: 'w' }) }) }}module.exports = { VersionPlugin }
2、在vue.config.js中使用这个plugin
const { VersionPlugin } = require('./src/plugin/version-webpack-plugin')
config.plugins.push(new VersionPlugin())

3、在每次执行webpack构建命令,都会在dist目录下生成一个version.json文件,里面有一个字段叫version,值是构建时的时间戳,每次构建都会生成一个新的时间戳。


4、发起ajax请求,请求version.json文件获取version时间戳,和本地保存的上一次的时间戳做比较,如果不一样,则进行对应的操作。/business/version.json,business是我项目的前缀,改成你自己的项目地址,能请求到version.json文件就行。
import axios from 'axios'import i18n from '@/i18n'import UpdateMessage from '@/components/common/UpdateProject/index.js'export function reloadVersion() { axios.get(window.location.origin + '/mobile/version.json?v=' + Date.now()).then(rsp => { let mobileVersion = localStorage.getItem('mobileVersion') let onlineVersion = rsp.data.version if (!mobileVersion) { localStorage.setItem('mobileVersion', onlineVersion) return } if (onlineVersion) { if (mobileVersion !== onlineVersion) { UpdateMessage.success({ title: i18n.t('bulk.pleaseWait'), msg: i18n.t('common.updateRemind') }) setTimeout(() => { UpdateMessage.close() localStorage.setItem('mobileVersion', onlineVersion) window.location.reload(); }, 2000); } } })}
5、请求发起的时机,可以使用定时器或者在切换页面的时候进行校验版本。根据自己的实际情况选择合适的调用时机。
async mounted() { process.env.NODE_ENV !== 'development' && window.addEventListener('mousedown', this.handleonmousedown);},beforeDestroy() { window.removeEventListener('mousedown', this.handleonmousedown)},
handleonmousedown() { reloadVersion()}
以某网站如下的电影《2012》为例。
在这个网站上面,电影2012是以一系列几秒的ts格式来播放的,所以没办法直接复制视频地址来下载整部电影。看如下截图:

并且,每段ts还是加密的,单独下载ts文件是无法播放的,需要解密,如下图:

那要怎样才能下载完整的解密后的视频呢?下面分几步进行说明。
1、首先,获取该电影所有的ts列表,和加密方式及密钥:
要用chrome浏览器打开该网址,然后右击,点击检查,然后重新刷新页面,然后根据如下截图查看:

点击“index.m3u8”这个请求,然后根据如下截图:

能够得出该电影的所有ts列表,并且加密方式是“AES-128”,密钥是enc.key的请求中,iv是16字节长度的0 。 现查看enc.key请求如下:

发现是乱码(有些网站不是乱码,而是字符串)。乱码是因为该密钥是二进制的,需要用查看hex工具来获取16进制的密钥。
先下载该“enc.key”到本地,然后用hex工具查看16进制值。mac系统可以用如下查看:

可以得出该密钥的16进制为:7be5d74d56af87838c3b98f1a2febf8f
2、根据ts列表,用php来实现多进程快速下载
下载所有ts文件有很多方法,可以手动一个个下载,但是因为太多,所以这个方法会比较麻烦。可以用php脚本来快速下载。
创建个1.php文件,用来下载ts文件。写入如下内容:
<?php
function my_file_get_contents($url) {
$arrContextOptions = [
'ssl' => [
'verify_peer' => false,
'verify_peer_name' => false,
]
];
return file_get_contents($url, false, stream_context_create($arrContextOptions));
}
for ($i=$argv[1]; $i <= $argv[2]; $i++) {
echo $i.'...'.PHP_EOL;
$f = $i.'.ts';
if (file_exists($f)) {
continue;
}
// 下面的链接要改成“index.m3u8”这里面相对应的ts链接
$data = my_file_get_contents('https://hnts.ymuuy.com:65/hls/200/20240110/2077/plist'.$i.'.ts');
file_put_contents($f, $data);
}
然后,再创建个2.php文件,用来创建下载命令。写入如下内容:
<?php
// 882要改成改成“index.m3u8”这里面最大数字的ts链接后的数字
for ($i=1; $i<=882; $i+=20) {
$tmp = $i+20;
if ($tmp > 882) {
$tmp = 882;
}
echo 'php 1.php '.$i.' '.$tmp.' &'.PHP_EOL;
}
然后,运行如下命令:

生成了可以多进程下载ts文件的命令行,然后复制生成的命令,在终端运行如下:

可以看到,已经在快速下载了,分为了882/20=44个进程来同时快速下载。
可以用如下命令来查看下载进度:
while true
do
du -sh `pwd`; ls |wc -l;sleep 1;
done
显示如下:

会显示出当前下载的大小,和下载的总ts数。
注意,全部都下载完后,要查看下有没有大小为0的ts文件,这些是下载失败的文件,删除后,重新运行下下载命令即可。
3、所有文件都下载完后,要开始解密并合并了
同样也是用php脚本来解密,保存下面脚本为decrypt.php:
<?php
// 如果“enc.key”的密钥是二进制的话,就用下面这行
$key = hex2bin("7be5d74d56af87838c3b98f1a2febf8f");
// 如果“enc.key”的密钥是字符串的话,就用下面这行
// $key = 'Cibz2Dp3bCnzlmVx';
// 原样复制“index.m3u8”里面的IV的0x后面的部分
$iv = hex2bin("00000000000000000000000000000000");
$decrypted_file = 'output.ts'; // 最终要保存的文件
// 882改为ts总数
for ($i=1; $i<=882; $i++) {
echo $i,'...',PHP_EOL;
$encrypted_file = $i.'.ts';
$data = file_get_contents($encrypted_file);
$decrypted_data = openssl_decrypt($data, 'AES-128-CBC', $key, OPENSSL_RAW_DATA, $iv);
file_put_contents($decrypted_file, $decrypted_data, FILE_APPEND);
}
echo "解密成功,已保存为:".$decrypted_file;
运行如下命令:


这样,就成功的解密并合并为了output.ts文件,用支持ts的播放器就可以播放此电影了。
有问题这边留言探讨下~
如果要在 JS 中找一个用的最多的函数,那一定就是console.log,在前端进行调试时,大家都屡试不爽,都喜欢用的函数。但是在生产环境中使用console.log之类的打印日志,这就会造成内存的泄漏了,这是我们不可以忽视的一个点。
为什么会造成内存泄漏呢?接下来我们来分析分析。
先来这样的一个场景
<body>
<h1 id="app" @click="handleClick"> Hello, console.log</h1>
<script>
const h1 = document.getElementById('app');
h1.addEventListener('click', () => {
const arr = new Array(100000).fill(0);
console.log(arr);
})
</script>
</body>
每当我们点击一次<h1>元素时,就会创建了一个包含 100000 个元素的数组,并将其输出到控制台中。

我们知道打印在控制台上的数组,我们是可以将它展开来看见更加详细的内容的,所以造成内存泄漏的原因是什么呢?
按照过程,点击一下,触发一个事件处理函数,待这个函数执行完之后,里面的生成的数组按道理是要销毁掉的,但是因为经过了打印,控制台里面需要保持对这个数组的引用, 不然的话我们就不能展开数组,查看里面的内容了,所以它会一直保存,随着我们点击次数的增多,这样的数组引用次数越来越多,于是就造成了内存泄漏。
接下来我们借助Performance来具体的展示一下是不是这样的情况。
在进行前我们先进行一下垃圾回收(图片中小扫把就是垃圾回收),释放一下内存以便为了更好的观察console.log带来的内存泄漏,然后点击几次h1元素,打印数组,最后再进行一次垃圾回收。

我们就可以看到,即使我们最后点了垃圾回收,还是存在一部分东西没有被回收,也是占用着内存的,这里指的就是我们打印在控制台的数组了。

我们来个不打印数组的情况看看(操作过程和前面一样,这里只展示最后的结果)

这时我们就可以观察到,内存的增长和下降都是很正常的,每当我们点击一次h1元素,就执行一次事件处理函数,导致内存的占用,可是执行完之后,内存就立马释放出来了。最后点击一次垃圾回收,内存的占用也就和刚刚开始时一样了。
那么说,我们不打开控制台不就不会造成内容泄漏了?那确实,在谷歌浏览器中会进行特殊的处理,并不会造成内存泄漏,但是在别的浏览器中,情况就不一样了。
看完这篇文章,我们一定要注意不要在生产环境中使用console.log!不要在生产环境中使用console.log!不要在生产环境中使用console.log!重要的事情说三遍。
但是在开发环境中我们要使用console.log来调试代码怎么办呢?那就需要在打包到生产环境时,把这个console.log给去掉,手动删的话又太麻烦了,这时就可以借助terser工具来帮助我们了。
好的,今日分享到此结束,最后感谢小伙伴的阅读。
大家好,我是杨成功。
自从《前端开发实战派》出版以后,好多买过的小伙伴都联系我,问我有没有电子书?纸质书在公司看不方便,一些现成的代码没办法复制。
确实没有电子版,我也听大家的建议上微信读书,结果那边审核没通过。我想不行我自己搞一个电子书呗,给买了纸书的朋友免费阅读,方便他们随时查阅。
经过一番调研,VitePress 的 UI 我最喜欢,扩展性也非常好,所以就用它来搭建。
在一个空文件夹下,使用命令生成项目:
$ npx vitepress init
全部使用默认选项,生成结构如下:

图中的 .vitepress/config.mts 就是 VitePress 的配置文件。另外三个 .md 文件是 Markdown 内容,VitePress 会根据文件名自动生成路由,并将文件内容转换为 HTML 页面。
为了代码更优雅,一般会把 Markdown 文件放在 docs 目录下。只需要添加一个配置:
// config.mts
export default defineConfig({
srcDir: 'docs',
});
改造后的目录结构是这样:

安装依赖并运行项目:
$ yarn add vitepress vue
$ yarn run docs:dev
电子书的内容不完全对外开放,只有买过纸书的人才能阅读。和掘金小册差不多,只能看部分内容,登录或购买后才能解锁全部章节。
而 VitePress 是一个静态站点生成器,默认只解析 Markdown。要想实现上述的功能,必须用到纯 Vue 组件,这需要通过扩展默认主题来实现。
扩展默认主题,也就是扩展 VitePress 的原始 Vue 组件,达到自定义的效果。
遵循这个思路,我们需要扩展的内容如下:
当然了还需要接入几个接口:
扩展默认主题,首先要创建一个 .vitepress/theme 文件夹,用来存放主题的组件、样式等代码。该文件夹下新建 index.ts 表示主题入口文件。
入口文件导出主题配置:
// index.ts
import Layout from './Layout.vue';
export default {
Layout,
enhanceApp({ app, router, siteData }) {
// ...
},
};
上面代码导入了一个 Layout.vue,这个组件是自定义布局组件:
<!-- Layout.vue -->
<script setup>
import DefaultTheme from 'vitepress/theme';
const { Layout } = DefaultTheme;
</script>
<template>
<Layout>
<template #nav-bar-content-after>
<button>登录</button>
</template>
</Layout>
</template>
为啥需要这个组件呢?因为该组件是项目根组件,可以从两个方面扩展:
(1)使用自定义插槽。
Layout 组件提供了许多插槽,允许我们在页面的多处位置插入内容。比如上面代码中的 nav-bar-content-after 插槽,会在头部组件右侧插入登录按钮。
具体有哪些插槽,详见这里。
(2)做全局初始化。
当刷新页面时,需要做一些初始化操作,比如调用接口、监听某些状态等。
这个时候可以使用 Vue 的各种钩子函数,比如 onMounted:
// Layout.vue
<script setup>
import { onMounted } from 'vue';
onMounted(() => {
console.log('初始化、请求接口');
});
</script>
VitePress 的内容组件,会把所有 Markdown 内容渲染出来。但是如果用户没有登录,我们不允许展示内容,而是提示用户登录,就像掘金小册这样:

定制内容组件,核心是在内容渲染的区域加一个判断:如果用户登录且验证通过,渲染内容即可;否则,展示类似上图的提示登录界面。
接下来我翻了 VitePress 的源码,找到了这个名为 VPDoc.vue 的组件:
在上方组件大概 46 行,我找到了内容渲染区域:

就在这个位置,添加一个判断,就达到我们想要的效果了:
<main class="main">
<Content
class="vp-doc"
v-if="isLogin"
:class="[
pageName,
theme.externalLinkIcon && 'external-link-icon-enabled'
]"
/>
<div v-else>
<h4>登录后阅读全文</h4>
<button>去登录</button>
</div>
</main>
那怎么让这个修改生效呢?
VitePress 提供了一个 重写内部组件 的方案。将 VPDoc.vue 组件拷贝到本地,按照上述方法修改,重命名为 CusVPDoc.vue。
在配置文件 .vitepress/config.ts 中添加重写逻辑:
// config.ts
export default defineConfig({
vite: {
resolve: {
alias: [
{
find: /^.*\/VPDoc\.vue$/,
replacement: fileURLToPath(new URL('./components/CusVPDoc.vue', import.meta.url)),
},
],
},
},
});
这样便实现了自定义内容组件,电子书截图如下:

添加自定义页面,首先要创建一个自定义组件。
以登录页面为例,创建一个自定义组件 CusLogin.vue,编写登录页面和逻辑,然后将其注册为一个全局组件。在 Markdown 页面文件中,直接使用这个组件。
注册全局组件的方法,是在主题入口文件中添加以下配置:
// .vitepress/theme/index.ts
import CusLogin from './components/CusLogin.vue'
export default {
...
enhanceApp({ app}) {
app.component("CusLogin", CusLogin); // 注册全局组件
// ...
},
} satisfies Theme;
最后,新建 Markdown 文件 login.md,写入内容如下:
---
layout: page
---
<CusLogin />
现在访问路由 “/login” 就可以看到自定义登录页面了。

涉及到用户登录,那么必然会涉及在多个组件中共享登录信息。
如果要做完全的状态管理,不用说,安装 Pinia 并经过一系列配置,可以实现。但是我们的需求只是共享登录信息,完全没必要再装一套 Pinia,使用 组合式函数 就可以了。
具体怎么实现,在另一篇文章 Vue3 新项目,没必要再用 Pinia 了! 中有详细介绍。
自定义页面,总是需要一个 UI 框架。上面的登录页面中,我使用了 Bootstrap。
Vitepress 使用 UI 框架有一个限制:必须兼容 SSR。因为 Vitepress 本质上使用了 Vue 的服务端渲染功能,在构建期间生成多个 HTML 页面,并不是常见的单页面应用。
这意味着,Vue 组件只有在 beforeMount 或 mounted 钩子中才能访问 DOM API。
而 Bootstrap 不需要打包构建就可以使用 UI,非常适合 Vitepress。
首先安装 Bootstrap:
$ yarn add bootstrap
然后在主题入口文件中引入 Sass 和 JS 文件:
import 'bootstrap/scss/bootstrap-cus.scss';
import 'bootstrap/dist/js/bootstrap.bundle.min.js';
按常理说,这样就可以了,但是实际运行会报错:找不到某个 DOM API。
还记得那个限制吗?必须兼容 SSR!因此不能直接引入 JS 文件。
解决方法是在自定义布局组件 Layout.vue 中通过异步的方式引入:
// .vitepress/theme/Layout.vue
onMounted(() => {
import('bootstrap/dist/js/bootstrap.bundle.min.js');
});
这样就大功告成了,你可以使用 Bootstrap 中丰富的 UI。
最终的电子书效果:《前端开发实战派》,欢迎点评。
最后留一个思考题:Vitepress 支持主题切换,Bootstrap 也分浅色和深色主题;切换 Vitepress 主题时,如何同步更改 Bootstrap 的主题呢?
前端功能问题系列文章,点击上方合集↑
大家好,我是大澈!
本文约2100+字,整篇阅读大约需要3分钟。
本文主要内容分三部分,如果您只需要解决问题,请阅读第一、二部分即可。如果您有更多时间,进一步学习问题相关知识点,请阅读至第三部分。
感谢关注微信公众号:“程序员大澈”,然后加入问答群,从此让解决问题的你不再孤单!
为了提高用户对页面链接分享的体验,需要对分享链接做一些处理。
以 Telegram(国外某一通讯软件) 为例,当在 Telegram 上分享已做过处理的链接时,它会自动尝试获取链接的预览信息,包括标题、描述和图片。
如此当接收者看到时,可以立即获取到分享链接的一些重要信息。这有助于接收者更好地了解链接的内容,决定是否点击查看详细内容。

对于URL分享预览这个功能问题,在项目中挺常用的,只不过今天我们是以一些框架分享API的底层原理角度来讲的。
实现这种功能的关键,是在分享的链接中嵌入适当的元数据信息,应用软件会自动解析,请求分享链接的预览信息,并根据返回的元数据生成预览卡片。
对于国内的应用软件,目前我试过抖音,它可以实现分享和复制粘贴都自动解析,而微信、QQ等只能实现分享的自动解析。
对于国外的应用软件,我只实验过Telegram,它可以实现分享和复制粘贴都自动解析,但我想Facebook、Twitter、Instagram这些应用应该也都是可以的。
实现URL链接的分享预览,你可以使用 Open Graph协议或 Twitter Cards,然后在 HTML 的 标签中,添加以下 meta 标签来定义链接预览的信息。
使用时,将所有meta全部复制过去,然后根据需求进行自定义即可。
还要注意两点,确保你页面的服务器正确配置了 SSL 证书,以及确保链接的URL有效(即:服务器没有做白名单限制)。
<head>
<meta property="og:title" content="预览标题">
<meta property="og:description" content="预览描述">
<meta property="og:image:width" content="图片宽度">
<meta property="og:image:height" content="图片高度">
<meta property="og:image" content="预览图片的URL">
<meta property="og:url" content="链接的URL">
<meta name="twitter:card" content="summary">
<meta name="twitter:title" content="预览标题">
<meta name="twitter:description" content="预览描述">
<meta property="twitter:image:width" content="图片宽度">
<meta property="twitter:image:height" content="图片高度">
<meta name="twitter:image" content="预览图片的URL">
<meta name="twitter:url" content="链接的URL">
head>
下面我们做一些概念的整理、总结和学习。
Open Graph协议是一种用于在社交媒体平台上定义和传递网页元数据的协议。它由 Facebook 提出,并得到了其他社交媒体平台的支持和采纳。Open Graph 协议旨在标准化网页上的元数据,使网页在社交媒体上的分享和预览更加一致和可控。
通过在网页的 HTML 标签中添加特定的 meta 标签,使用 Open Graph 协议可以定义和传递与网页相关的元数据信息,如标题、描述、图片等。这些元数据信息可以被社交媒体平台解析和使用,用于生成链接预览、分享内容和提供更丰富的社交图谱。
使用 Open Graph 协议,网页的所有者可以控制链接在社交媒体上的预览内容,确保链接在分享时显示的标题、描述和图片等信息准确、有吸引力,并能够准确传达链接的主题和内容。这有助于提高链接的点击率、转化率和用户体验。
Open Graph 协议定义了一组标准的 meta 标签属性,如 og:title、og:description、og:image 等,用于提供链接预览所需的元数据信息。通过在网页中添加这些 meta 标签并设置相应的属性值,可以实现链接预览在社交媒体平台上的一致展示。
需要注意的是,Open Graph 协议是一种开放的标准,并不限于 Facebook 平台。其他社交媒体平台,如 Twitter、LinkedIn 等,也支持使用 Open Graph 协议定义和传递网页元数据,以实现链接预览的一致性。

Twitter Cards 是一种由 Twitter 推出的功能,它允许网站所有者在他们的网页上定义和传递特定的元数据,以便在 Twitter 上分享链接时生成更丰富和吸引人的预览卡片。通过使用 Twitter Cards,网页链接在 Twitter 上的分享可以展示标题、描述、图片、链接和其他相关信息,以提供更具吸引力和信息丰富的链接预览。
Twitter Cards 提供了多种类型的卡片,以适应不同类型的内容和需求。以下是 Twitter Cards 的一些常见类型:
Summary Card:Summary Card 类型的卡片包含一个标题、描述和可选的图片。它适用于分享文章、博客帖子等内容。Summary Card with Large Image:Summary Card with Large Image 类型的卡片与 Summary Card 类型类似,但图片尺寸更大,更突出地展示在卡片上。App Card:App Card 类型的卡片用于分享移动应用程序的信息。它包含应用的名称、图标、描述和下载按钮,以便用户可以直接从预览卡片中下载应用。Player Card:Player Card 类型的卡片用于分享包含媒体播放器的内容,如音频文件、视频等。它允许在预览卡片上直接播放媒体内容。通过在网页的 HTML 标签中添加特定的 meta 标签,使用 Twitter Cards 可以定义和传递与链接预览相关的元数据信息,如标题、描述、图片、链接等。这些元数据信息将被 Twitter 解析和使用,用于生成链接预览卡片。
使用 Twitter Cards 可以使链接在 Twitter 上的分享更加吸引人和信息丰富,提高链接的点击率和用户参与度。它为网站所有者提供了更多控制链接在 Twitter 上展示的能力,并提供了一种更好的方式来呈现他们的内容。


建立这个平台的初衷:
在深入探讨CSS变形动画之前,让我们先探讨一下掌握它之后你可以实现哪些有趣的效果。
学习了CSS变形动画之后,你将能够为你的网页添加引人注目的动态效果,例如创建一个立体的3D魔方,或者设计一个引人入胜的旋转菜单。

这些仅仅是众多可能性中的一小部分,但或许可以勾起我们的学习兴趣。
CSS变形动画是利用CSS3的transform属性创建的动画效果。它可以使元素旋转、缩放、倾斜甚至翻转,让静态的网页元素动起来,为用户带来更加丰富的交互体验。
首先我们要学习的变形动画,想达到在上图中出现的3D效果单纯的X与Y两个轴是实现不了的,还需要加入一条纵深轴,即Y轴的参与才有一个3D的视觉感受。
那么如何来理解X,Y,Z这三条轴的关系呢?可以看一下下面这张图。
X轴代表水平轴
Y轴代表垂直轴
Z轴代表纵深轴
X和Y轴都非常好理解,怎么理解这个Z轴呢?
CSS的中文名称叫做层叠样式表,那么它肯定是一层一层的。之前学习过z-index就是用来设置层的优先级,优先级越高越在上面,也可以理解为离我们肉眼越近,它把优先级低的层给盖住了,所以Z轴可以理解为我们观察的视角与被观察物体之间的一条轴。
Z轴数值越大,说明观测距离越远。
Z轴的数值可以无限大,所以设置的时候一定要小心。
使用 transform 来控制元素变形操作,包括控制移动、旋转、倾斜、3D转换等。
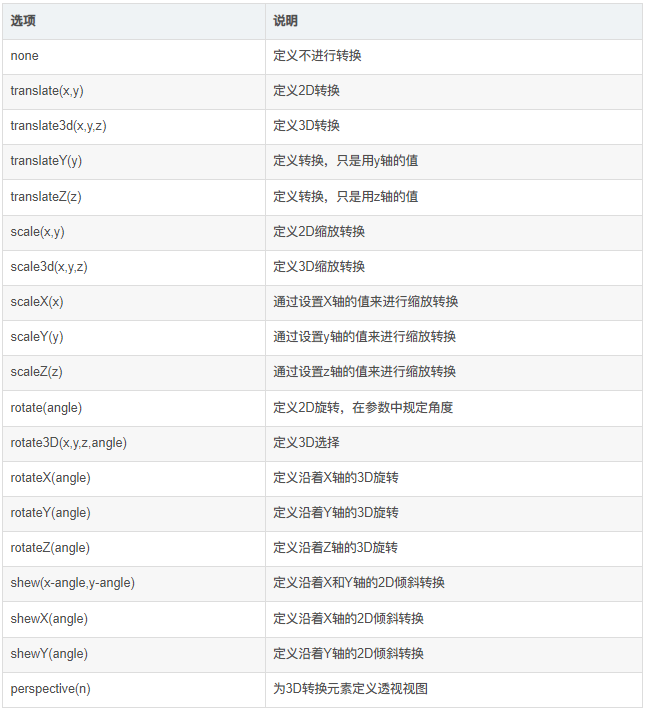
下面我们通过一些例子来演示一下,比较常用的变形操作:
translate()函数可以将元素向指定的方向移动,类似于position中的relative。或以简单的理解为,使用translate()函数,可以把元素从原来的位置移动,而不影响在X、Y轴上的任何Web组件。
想象一下,当你滚动页面时,一个元素平滑地从一个位置滑向另一个位置,这种流畅的过渡效果可以大大提升用户体验。
translate我们分为三种情况:
1)translate(x,y)水平方向和垂直方向同时移动(也就是X轴和Y轴同时移动)
2)translateX(x)仅水平方向移动(X轴移动)
3)translateY(Y)仅垂直方向移动(Y轴移动)
实例演示: 通过translate()函数将元素向Y轴下方移动50px,X轴右方移动100px。
HTML代码:
<div class="wrapper">
<div>我向右向下移动</div>
</div>
CSS代码:
.wrapper {
width: 200px;
height: 200px;
border: 2px dotted red;
margin: 20px auto;
}
.wrapper div {
width: 200px;
height: 200px;
line-height: 200px;
text-align: center;
background: orange;
color: #fff;
-webkit-transform: translate(50px,100px);
-moz-transform:translate(50px,100px);
transform: translate(50px,100px);
}
演示结果:

旋转rotate()函数通过指定的角度参数使元素相对原点进行旋转。旋转不仅可以是固定的度数,还可以是动态变化的,创造出无限的可能性。
它主要在二维空间内进行操作,设置一个角度值,用来指定旋转的幅度。如果这个值为正值,元素相对原点中心顺时针旋转;如果这个值为负值,元素相对原点中心逆时针旋转。如下图所示:
HTML代码:
<div class="wrapper">
<div></div>
</div>
CSS代码:
.wrapper {
width: 200px;
height: 200px;
border: 1px dotted red;
margin: 100px auto;
}
.wrapper div {
width: 200px;
height: 200px;
background: orange;
-webkit-transform: rotate(45deg);
transform: rotate(45deg);
}
演示结果:
扭曲skew()函数能够让元素倾斜显示。这种效果常常用于模拟速度感或者倾斜的视觉效果。
它可以将一个对象以其中心位置围绕着X轴和Y轴按照一定的角度倾斜。这与rotate()函数的旋转不同,rotate()函数只是旋转,而不会改变元素的形状。skew()函数不会旋转,而只会改变元素的形状。
Skew()具有三种情况:
1)skew(x,y)使元素在水平和垂直方向同时扭曲(X轴和Y轴同时按一定的角度值进行扭曲变形);
第一个参数对应X轴,第二个参数对应Y轴。如果第二个参数未提供,则值为0,也就是Y轴方向上无斜切。
2)skewX(x)仅使元素在水平方向扭曲变形(X轴扭曲变形);
3)skewY(y)仅使元素在垂直方向扭曲变形(Y轴扭曲变形)。
示例演示:通过skew()函数将长方形变成平行四边形。
HTML代码:
<div class="wrapper">
<div>我变成平形四边形</div>
</div>
CSS代码:
.wrapper {
width: 300px;
height: 100px;
border: 2px dotted red;
margin: 30px auto;
}
.wrapper div {
width: 300px;
height: 100px;
line-height: 100px;
text-align: center;
color: #fff;
background: orange;
-webkit-transform: skew(45deg);
-moz-transform:skew(45deg)
transform:skew(45deg);
}
演示结果:
缩放 scale()函数 让元素根据中心原点对对象进行缩放。这不仅可以用来模拟放大镜效果,还可以创造出元素的进入和退出动画,比如一个图片慢慢缩小直至消失。
缩放 scale 具有三种情况:
1) scale(X,Y)使元素水平方向和垂直方向同时缩放(也就是X轴和Y轴同时缩放)。

例如:
div:hover {
-webkit-transform: scale(1.5,0.5);
-moz-transform:scale(1.5,0.5)
transform: scale(1.5,0.5);
}
注意:Y是一个可选参数,如果没有设置Y值,则表示X,Y两个方向的缩放倍数是一样的。
2)scaleX(x)元素仅水平方向缩放(X轴缩放)
3)scaleY(y)元素仅垂直方向缩放(Y轴缩放)
HTML代码:
<div class="wrapper">
<div>我将放大1.5倍</div>
</div>
CSS代码:
.wrapper {
width: 200px;
height: 200px;
border:2px dashed red;
margin: 100px auto;
}
.wrapper div {
width: 200px;
height: 200px;
line-height: 200px;
background: orange;
text-align: center;
color: #fff;
}
.wrapper div:hover {
opacity: .5;
-webkit-transform: scale(1.5);
-moz-transform:scale(1.5)
transform: scale(1.5);
}
演示结果:
注意: scale()的取值默认的值为1,当值设置为0.01到0.99之间的任何值,作用使一个元素缩小;而任何大于或等于1.01的值,作用是让元素放大。
想要快速入门前端开发吗?推荐一个前端开发基础课程,这个老师讲的特别好,零基础学习无压力,知识点结合代码,边学边练,可以免费试看试学,还有各种辅助工具和资料,非常适合新手!点这里前往学习哦!
matrix() 是一个含六个值的(a,b,c,d,e,f)变换矩阵,用来指定一个2D变换,相当于直接应用一个[a b c d e f]变换矩阵。就是基于水平方向(X轴)和垂直方向(Y轴)重新定位元素。
此属性值使用涉及到数学中的矩阵,我在这里只是简单的说一下CSS3中的transform有这么一个属性值,如果需要深入了解,需要对数学矩阵有一定的知识。
示例演示:通过matrix()函数来模拟transform中translate()位移的效果。
HTML代码:
<div class="wrapper">
<div></div>
</div>
CSS代码:
.wrapper {
width: 300px;
height: 200px;
border: 2px dotted red;
margin: 40px auto;
}
.wrapper div {
width:300px;
height: 200px;
background: orange;
-webkit-transform: matrix(1,0,0,1,50,50);
-moz-transform:matrix(1,0,0,1,50,50);
transform: matrix(1,0,0,1,50,50);
}
演示结果:

任何一个元素都有一个中心点,默认情况之下,其中心点是居于元素X轴和Y轴的50%处。如下图所示:

在没有重置transform-origin改变元素原点位置的情况下,CSS变形进行的旋转、位移、缩放,扭曲等操作都是以元素自己中心位置进行变形。
但很多时候,我们可以通过transform-origin来对元素进行原点位置改变,使元素原点不在元素的中心位置,以达到需要的原点位置。
transform-origin取值和元素设置背景中的background-position取值类似,如下表所示:
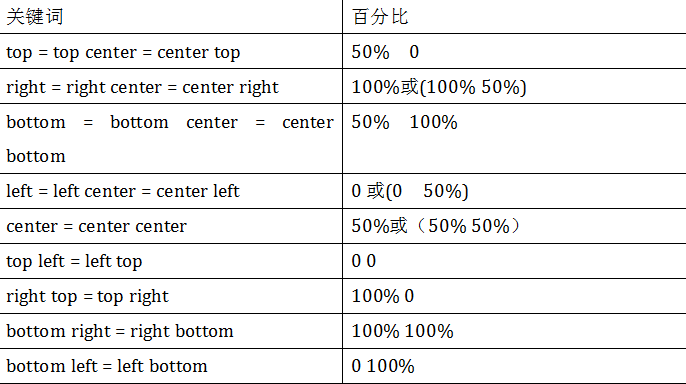
示例演示:
通过transform-origin改变元素原点到左上角,然后进行顺时旋转45度。
HTML代码:
<<div class="wrapper">
<div>原点在默认位置处</div>
</div>
<div class="wrapper transform-origin">
<div>原点重置到左上角</div>
</div>
CSS代码:
.wrapper {
width: 300px;
height: 300px;
float: left;
margin: 100px;
border: 2px dotted red;
line-height: 300px;
text-align: center;
}
.wrapper div {
background: orange;
-webkit-transform: rotate(45deg);
transform: rotate(45deg);
}
.transform-origin div {
-webkit-transform-origin: left top;
transform-origin: left top;
}
演示结果:
以上就是css动画中几种基本的变形技巧了,掌握这些我们可以操控我们的网页元素实现我们想要的一些基本动画效果。
在这个充满创造力的时代,CSS变形动画是每个前端开发者必备的技能。它不仅能提升用户体验,更能激发设计师和开发者的创意火花。所以,不妨尝试一下,让你的网页动起来,给用户留下深刻的印象吧!
收起阅读 »个人或个体户,如何免费使用微信小程序授权,快速登录进系统内部?
微信授权登录好处:
可能有的人会问,为何不用微信公众号授权登录?原因很简单,因为一年要300元,小公司得省钱啊!
所有的步骤里包含四个对象,分别是本地后台、本地微信小程序、本地网页、以及第三方微信后台
本地后台调用微信后台的https://api.weixin.qq.com/cgi-bin/token接口,get请求,拿到返回的access_token;本地后台根据拿到的access_token,调用微信后台的https://api.weixin.qq.com/wxa/getwxacodeunlimit接口,得到二维码图片文件,将其输出传递给本地网页显示本地微信小程序扫本地网页的二维码图片,跳转至小程序登录页面,通过wx.login方法,在success回调函数内得到code值,并将该值传递给本地后台本地后台拿到code值后,调用微信后台的https://api.weixin.qq.com/sns/jscode2session接口,get请求,得到用户登录的openid即可。
注意点:
- 上面三个微信接口
/cgi-bin/token、/getwxacodeunlimit、/jscode2session必须由本地后台调用,微信小程序那边做了前端限制;
本地网页如何得知本地微信小程序已扫码呢?
本地微信小程序将code,通过A接口,将值传给后台,后台拿到openid后,再将成功结果返回给本地微信小程序;同时,本地网页不断地轮询A接口,等待后台拿到openid后,便显示登录成功页面。
Page({
data: {
theme: wx.getSystemInfoSync().theme,
scene: "",
jsCode: "",
isLogin: false,
loginSuccess: false,
isChecked: false,
},
onLoad(options) {
const that = this;
wx.onThemeChange((result) => {
that.setData({
theme: result.theme,
});
});
if (options !== undefined) {
if (options.scene) {
wx.login({
success(res) {
if (res.code) {
that.setData({
scene: decodeURIComponent(options.scene),
jsCode: res.code,
});
}
},
});
}
}
},
handleChange(e) {
this.setData({
isChecked: Boolean(e.detail.value[0]),
});
},
formitForm() {
const that = this;
if (!this.data.jsCode) {
wx.showToast({
icon: "none",
title: "尚未微信登录",
});
return;
}
if (!this.data.isChecked) {
wx.showToast({
icon: "none",
title: "请先勾选同意用户协议",
});
return;
}
wx.showLoading({
title: "正在加载",
});
let currentTimestamp = Date.now();
let nonce = randomString();
wx.request({
url: `A接口?scene=${that.data.scene}&js_code=${that.data.jsCode}`,
header: {},
method: "POST",
success(res) {
wx.hideLoading();
that.setData({
isLogin: true,
});
if (res.statusCode == 200) {
that.setData({
loginSuccess: true,
});
} else {
if (res.statusCode == 400) {
wx.showToast({
icon: "none",
title: "无效请求",
});
} else if (res.statusCode == 500) {
wx.showToast({
icon: "none",
title: "服务内部错误",
});
}
that.setData({
loginSuccess: false,
});
}
},
fail: function (e) {
wx.hideLoading();
wx.showToast({
icon: "none",
title: e,
});
},
});
},
});
scene为随机生成的8位数字
let isInit = true
function loginWx() {
isInit = false
refreshQrcode()
}
function refreshQrcode() {
showQrLoading = true
showInfo = false
api.get('/qrcode').then(qRes => {
if (qRes.status == 200) {
imgSrc = `${BASE_URL}${qRes.data}`
pollingCount = 0
startPolling()
} else {
showToast = true
toastMsg = '二维码获取失败,请点击刷新重试'
showInfo = true
}
}).finally(() => {
showQrLoading = false
})
}
// 开始轮询
// 1000毫秒轮询一次
function startPolling() {
pollingInterval = setInterval(function () {
pollDatabase()
}, 1000)
}
function pollDatabase() {
if (pollingCount >= maxPollingCount) {
clearInterval(pollingInterval)
showToast = true
toastMsg = '二维码已失效,请刷新'
showInfo = true
return
}
pollingCount++
api.get('/result').then(res => {
if (res.status == 200) {
clearInterval(pollingInterval)
navigate('/os', { replace: true })
} else if (res.status == 408) {
clearInterval(pollingInterval)
showToast = true
toastMsg = '二维码已失效,请刷新'
showInfo = true
}
})
}
html的部分代码如下所示
<button class="btn" on:click={loginWx}>微信登录</button>
<div id="qrcode" class="relative mt-10">
{#if imgSrc}
<img src={imgSrc} alt="二维码图片"/>
{/if}
{#if showQrLoading}
<div class="mask absolute top-0 left-0 w-full h-full z-10">
<Loading height="12" width="12"/>
</div>
{/if}
</div>
若需要完整代码,或想知道如何申请微信小程序,欢迎大家关注或私信我哦~~

家里有一条狗🐶,很喜欢乘人不备睡沙发🛋️,恰好最近刚搬家 + 狗迎来了掉毛期 不想让沙发上很多毛。所以希望能识别到狗,然后播放“gun 下去”的音频📣。
const stream = await navigator.mediaDevices.getUserMedia({
// video: { facingMode: "environment" }, // 摄像头后置
video: { facingMode: "user" },
});
const videoElement = document.getElementById("camera-stream");
videoElement.srcObject = stream;
let dogDetector;
async function loadDogDetector() {
// 加载预训练的SSD MobileNet V2模型
const model = await cocoSsd.load();
dogDetector = model; // 将加载好的模型赋值给dogDetector变量
}
videoElement.addEventListener("play", async () => {
requestAnimationFrame(processVideoFrame);
});
async function processVideoFrame() {
if (!videoElement.paused && !videoElement.ended) {
canvas.width = videoElement.videoWidth;
canvas.height = videoElement.videoHeight;
ctx.drawImage(videoElement, 0, 0, canvas.width, canvas.height);
// 获取当前帧图像数据
const imageData = ctx.getImageData(0, 0, canvas.width, canvas.height);
// 对帧执行预测
let predictionClasses = "";
const predictions = await dogDetector.detect(imageData);
// 处理预测结果,比如检查是否有狗被检测到
for (const prediction of predictions) {
predictionClasses += `${prediction.class}\n`; // 组装识别的物体名称
if (prediction.class === "dog") {
// 播放声音
playDogBarkSound();
}
}
nameContainer.innerText = predictionClasses.trim(); // 移除末尾的换行符
requestAnimationFrame(processVideoFrame);
}
}
async function playDogBarkSound() {
if (playing) return;
playing = true;
const audio = new Audio(dogBarkSound);
audio.addEventListener("ended", () => {
playing = false;
});
audio.volume = 0.5; // 调整音量大小
await audio.play();
}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Mobile Dog Detector</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@4.17.0/dist/tf.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd@2.2.3/dist/coco-ssd.min.js"></script>
<style>
#camera-stream {
width: 200px;
height: auto;
}
#name {
height: 200px;
overflow-y: auto;
font-family: Arial, sans-serif;
}
</style>
</head>
<body>
<video id="camera-stream" autoplay playsinline></video>
<div id="name" style="height: 200px"></div>
<script>
let playing = false;
let dogDetector;
async function loadDogDetector() {
// 加载预训练的SSD MobileNet V2模型
const model = await cocoSsd.load();
dogDetector = model; // 将加载好的模型赋值给dogDetector变量
console.log("dogDetector", dogDetector);
startCamera();
}
// 调用函数加载模型
loadDogDetector();
async function startCamera() {
const stream = await navigator.mediaDevices.getUserMedia({
// video: { facingMode: "environment" }, // 摄像头后置
video: { facingMode: "user" },
});
const nameContainer = document.getElementById("name");
const videoElement = document.getElementById("camera-stream");
videoElement.srcObject = stream;
const canvas = document.createElement("canvas");
const ctx = canvas.getContext("2d");
videoElement.addEventListener("play", async () => {
requestAnimationFrame(processVideoFrame);
});
async function processVideoFrame() {
if (!videoElement.paused && !videoElement.ended) {
canvas.width = videoElement.videoWidth;
canvas.height = videoElement.videoHeight;
ctx.drawImage(videoElement, 0, 0, canvas.width, canvas.height);
const imageData = ctx.getImageData(
0,
0,
canvas.width,
canvas.height
);
let predictionClasses = "";
const predictions = await dogDetector.detect(imageData);
for (const prediction of predictions) {
predictionClasses += `${prediction.class}\n`;
if (prediction.class === "dog") {
// 修改为检测到狗时播放声音
playDogBarkSound();
}
}
nameContainer.innerText = predictionClasses.trim();
requestAnimationFrame(processVideoFrame);
}
}
async function playDogBarkSound() {
if (playing) return;
playing = true;
const audio = new Audio("./getout.mp3");
audio.addEventListener("ended", () => {
playing = false;
});
audio.volume = 0.5; // 调整音量大小
await audio.play();
}
}
</script>
</body>
</html>
效果很好👍,用旧手机开启摄像头后,检测到狗就播放声音了。
但是,家里夫人直接做了一个围栏晚上给狗圈起来了🚫

该方案通过以下步骤实现了一个基于网页的实时物体检测系统,专门用于识别画面中的狗并播放特定音频以驱赶它离开沙发。具体实现过程包括以下几个核心部分:
使用浏览器提供的 navigator.mediaDevices.getUserMedia API 获取用户授权后调用手机摄像头,并将视频流设置给 video 元素展示。
使用 TensorFlow.js 和预训练的 COCO-SSD MobileNet V2 模型进行对象检测,加载模型后赋值给 dogDetector 变量。
处理视频流与图像识别:
监听 video 元素的播放事件,通过 requestAnimationFrame 循环逐帧处理视频。
将当前视频帧绘制到 canvas 上,然后从 canvas 中提取图像数据传入模型进行预测。
在模型返回的预测结果中,如果检测到“dog”,则触发播放音频函数。
定义一个异步函数 playDogBarkSound 来播放指定的音频文件,确保音频只在前一次播放结束后才开始新的播放。
使用旧 Android 手机安装 Termux,创建本地 HTTP 服务器运行项目代码。
上传项目文件至 Termux 目录下并通过访问 localhost:8000 启动应用。
通过以上技术整合,最终实现了在旧手机上部署一个能够实时检测画面中狗的网页应用,并在检测到狗时播放指定音频。
华为云生成obs链接时,可以做配置。
预览的下载的一般我们播放本地视频都是使用vedio标签,但是vedio标签只支持三种视频格式:MP4、WebM、Ogg,对于在线视频直接使用vedio不支持播放。
故,上述 2 中的视频,在vedio中不支持播放,浏览器访问链接,直接就下载了。
流协议: 流协议就是在两个通信系统之间传输多媒体文件的一套规则,它定义了视频文件将如何分解为小数据包以及它们在互联网上传输的顺序,RTMP与 RTSP 是比较常见的流媒体协议。
HLS: HLS (HTTP Live Streaming)是Apple的动态码率自适应技术。主要用于PC和Apple终端的音视频服务。包括一个m3u(8)的索引文件,TS媒体分片文件和key加密串文件。参考:HLS。简单来说,HLS是一种协议,如果你的视频源是http://xxxx.m3u8这种,就选择这种协议,.m3u8是个文本文件,直播时,他的内容实时变更,内部指向一个或多个.ts文件。
HTTP-FLV: HTTP-FLV 是将音视频数据以 FLV 文件格式进行封装,再将 FLV 格式数据封装在 HTTP 协议中进行传输的一种流媒体传输方式。HTTP-FLV 的实现原理: HTTP-FLV 利用 HTTP/1.1 分块传输机制发送 FLV 数据。虽然直播服务器无法知道直播流的长度,但是 HTTP/1.1 分块传输机制可以不填写 conten-length 字段而是携带 Transfer-Encoding: chunked 字段,这样客户端就会一直接受数据。参考:FLV 和 HTTP-FLV。
简单来说就是你的视频源是直播且是xxxx.flv,就选择这种协议播放。还有个websocket-flv,是基于websocket的。
RTMP与RTSP: 什么是RTMP 和 RTSP?它们之间有什么区别?
H264(AVC)与H265(HEVC): 都是视频编码,是视频压缩格式,由于视频本身的码流太大,所以需要经过压缩然后再通过网络进行传输,其中H265是H264的升级版,很多播放器无法播放H265视频。
vue2的系统,本来用xgplayer 版本:2.32.5。无奈本地可以展示,测试环境不能用,报错不明显,粗略看了一下是插件底层,内部报错,故放弃xgpalyer插件。
ps.我在vue3的系统中,用过xgpalyer插件,挺好用的
优点如下:
然后,我就换了 dppalyer插件来展示。点击查看中文文档
这个插件,我去github查了一下,15k星星,用的人还是挺多,但是,个人感觉不如 xgplayer好用。
安装npm install dplayer --save
在页面中引用
import DPlayer from 'dplayer';
const dp = new DPlayer(options);
dpplayer实现是通过生成iframe页面,将视频嵌套到其中。
刚开始给容器写了样式,宽100% 高100%,结果它不能自适应屏幕,很难受。后面我强行定宽420px。高度自动获取当前容器高度,定了一个最大高度。
但其实没有用,它会根据宽度,自己按比例缩放高度。
所以我在视频渲染出来后,自动调了一下全屏功能dpPlayer.fullScreen.request('web');
勉强解决了这个问题。
贴一下我的完整代码
<template>
<div class="vedio-wrapper" :style="{'max-height': winH}">
<el-empty v-if="!player" description="暂无数据"></el-empty>
<div :id="id" allowfullscreen="allowfullscreen" />
</div>
</template>
<script>
import DPlayer from 'dplayer';
import { getParam } from '@/utils/utils'
import {
getBucketObsFileUrl
} from '@/api/common'
export default {
name: 'previewMedia',
components:{},
data() {
return {
winH: '300px',
id: 'dpPlayerDom',
player: null
}
},
created() {
const winH = window.innerHeight
this.winH = winH + 'px'
},
mounted() {
this.getFileUrl()
},
methods: {
async getFileUrl() {
try {
const filePath = getParam('filePath')
const type = getParam('type') ? parseInt(getParam('type')) : 1
if (!filePath) return
const params = {
objectKey: filePath,
type
}
const data = await getBucketObsFileUrl(params);
this.setVedioplayerConfig(data)
} catch (e) {
console.error(e)
}
},
setVedioplayerConfig(url) {
if (!url) return
const tmpConfig = {
container: document.getElementById('dplayer'),
screenshot: false,
video: {
url: url,
thumbnails: 'thumbnails.jpg',
},
contextmenu: []
}
this.$nextTick(() => {
tmpConfig.container = document.getElementById(this.id)
const dpPlayer = new DPlayer(tmpConfig);
this.player = dpPlayer
dpPlayer.fullScreen.request('web');
})
}
}
}
</script>
<style scoped lang="scss">
.vedio-wrapper {
width: 400px;
height: 100%;
margin: 0 auto;
}
</style>
随着现代网页设计的不断演进,传统的布局方式已经逐渐不能满足设计师和开发者们对于高效、灵活且强大布局系统的追求。而CSS Grid网格布局,正是在这样的背景下应运而生的。
今天,我们就来深入探讨CSS Grid布局的魅力所在,带你解锁这项强大的设计工具,让网页布局变得更加简单和高效。
CSS Grid布局,简称为Grid,是CSS的一个二维布局系统,它能够处理行和列,使得网页布局变得更加直观和强大。与传统的布局方式相比,Grid能够轻松实现复杂的页面结构,而无需繁琐的浮动、定位或是使用多个嵌套容器。
Grid网格布局是一种基于网格的布局系统,它允许我们通过定义行和列的大小、位置和排列方式来创建复杂的网页布局。
这与之前讲到的flex一维布局不相同。
设置display:grid/inline-grid的元素就是网格布局容器,这样就能触发浏览器渲染引擎的网格布局算法。
<div>
<div class="item item-1">
<p></p >
</div>
<div class="item item-2"></div>
<div class="item item-3"></div>
</div>
上述代码实例中,.container元素就是网格布局容器,.item元素就是网格的项目,由于网格元素只能是容器的顶层子元素,所以p元素并不是网格元素。
首先,我们来了解一下CSS Grid布局的核心概念:
设置了display: grid;的元素成为容器。它是由一组水平线和垂直线交叉构成,就如同我们所在的地区是由小区和各个路构成。
容器内的直接子元素,称为项目。
划分行和列的线条,可以想象成坐标轴。正常情况下n行会有n+1根横向网格线,m列有m+1根纵向网格线。比如田字就好像是一个三条水平线和三条垂直线构成的网格元素。
上图是一个 2 x 3 的网格,共有3根水平网格线和4根垂直网格线。
即两个水平网格线之间的空间,也就是水平轨道,就好比我们面朝北边东西方向横向排列的楼房称为行。
即两个垂直网格线之间的空间,也就是垂直轨道,也就是南北方向排列的楼房。
由水平线和垂直线交叉构成的每个区域称为单元格,网络单元格是CSS网格中的最小单元。也就是说东西和南北方向的路交叉后划分出来的土地区域。
两条相邻网格线之间的空间。
四条网格线围成的空间,可以是行或列。本质上,网格区域一定是矩形的。例如,不可能创建T形或L形的网格区域。
CSS Grid网格布局的主要属性包括:
display:设置元素为网格容器或网格项。
grid-template-columns 和 grid-template-rows:用于定义网格的列和行的大小。
grid-column-gap 和 grid-row-gap:用于定义网格的列和行的间距。
grid-template-areas:用于定义命名区域,以便在网格中引用。
grid-auto-flow:用于控制网格项的排列方式,可以是行(row)或列(column)。
grid-auto-columns 和 grid-auto-rows:用于定义自动生成的列和行的大小。
grid-column-start、grid-column-end、grid-row-start 和 grid-row-end:用于定义网格项的位置。
justify-items、align-items 和 place-items:用于对齐网格项。
grid-template:一个复合属性,用于一次性定义多个网格布局属性。
下面将详细介绍这些属性的概念及作用:
通过给元素设置:display:grid | inline-grid,可以让一个元素变成网格布局元素。
语法:
display: grid | inline-grid;
display: grid:表示把元素定义为块级网格元素,单独占一行;
display:inline-grid:表示把元素定义为行内块级网格元素,可以和其他块级元素在同一行。
grid-template-columns和grid-template-rows:用于定义网格的列和行的大小。
grid-template-columns 属性设置列宽
grid-template-rows 属性设置行高
.wrapper {
display: grid;
/* 声明了三列,宽度分别为 200px 200px 200px */
grid-template-columns: 200px 200px 200px;
grid-gap: 5px;
/* 声明了两行,行高分别为 50px 50px */
grid-template-rows: 50px 50px;
}
以上表示固定列宽为 200px 200px 200px,行高为 50px 50px。
上述代码可以看到重复写单元格宽高,我们也可以通过使用repeat()函数来简写重复的值。
第一个参数是重复的次数
第二个参数是重复的值
所以上述代码可以简写成:
.wrapper {
display: grid;
grid-template-columns: repeat(3,200px);
grid-gap: 5px;
grid-template-rows:repeat(2,50px);
}
除了上述的repeact关键字,还有:
auto-fill: 表示自动填充,让一行(或者一列)中尽可能的容纳更多的单元格。
grid-template-columns: repeat(auto-fill, 200px)
表示列宽是 200 px,但列的数量是不固定的,只要浏览器能够容纳得下,就可以放置元素。
fr: 片段,为了方便表示比例关系。
grid-template-columns: 200px 1fr 2fr
表示第一个列宽设置为 200px,后面剩余的宽度分为两部分,宽度分别为剩余宽度的 1/3 和 2/3。
minmax: 产生一个长度范围,表示长度就在这个范围之中都可以应用到网格项目中。第一个参数就是最小值,第二个参数就是最大值。
minmax(100px, 1fr)
表示列宽不小于100px,不大于1fr。
auto: 由浏览器自己决定长度。
grid-template-columns: 100px auto 100px
表示第一第三列为 100px,中间由浏览器决定长度。
grid-column-gap和grid-row-gap,用于定义网格的列间距和行间距。grid-gap 属性是两者的简写形式。
grid-row-gap: 10px 表示行间距是 10px
grid-column-gap: 20px 表示列间距是 20px
grid-gap: 10px 20px 等同上述两个属性
grid-auto-flow,用于控制网格项的排列方式,可以是行(row)或列(column)。
划分网格以后,容器的子元素会按照顺序,自动放置在每一个网格。
顺序就是由grid-auto-flow决定,默认为行,代表"先行后列",即先填满第一行,再开始放入第二行。

当修改成column后,放置变为如下:

justify-items、align-items和place-items,用于定义网格项目的对齐方式。
justify-items 属性设置单元格内容的水平位置(左中右)
align-items 属性设置单元格的垂直位置(上中下)
.container {
justify-items: start | end | center | stretch;
align-items: start | end | center | stretch;
}
属性对应如下:
start:对齐单元格的起始边缘
end:对齐单元格的结束边缘
center:单元格内部居中
stretch:拉伸,占满单元格的整个宽度(默认值)
place-items属性是align-items属性和justify-items属性的合并简写形式。
justify-content属性是整个内容区域在容器里面的水平位置(左中右)
align-content属性是整个内容区域的垂直位置(上中下)
.container {
justify-content: start | end | center | stretch | space-around | space-between | space-evenly;
align-content: start | end | center | stretch | space-around | space-between | space-evenly;
}
两个属性的写法完全相同,都可以取下面这些值:
start - 对齐容器的起始边框
end - 对齐容器的结束边框
center - 容器内部居中
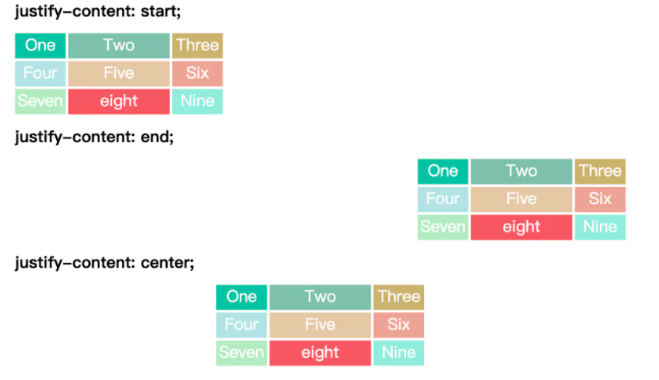
space-around - 每个项目两侧的间隔相等。所以,项目之间的间隔比项目与容器边框的间隔大一倍。
space-between - 项目与项目的间隔相等,项目与容器边框之间没有间隔。
space-evenly - 项目与项目的间隔相等,项目与容器边框之间也是同样长度的间隔。
stretch - 项目大小没有指定时,拉伸占据整个网格容器。
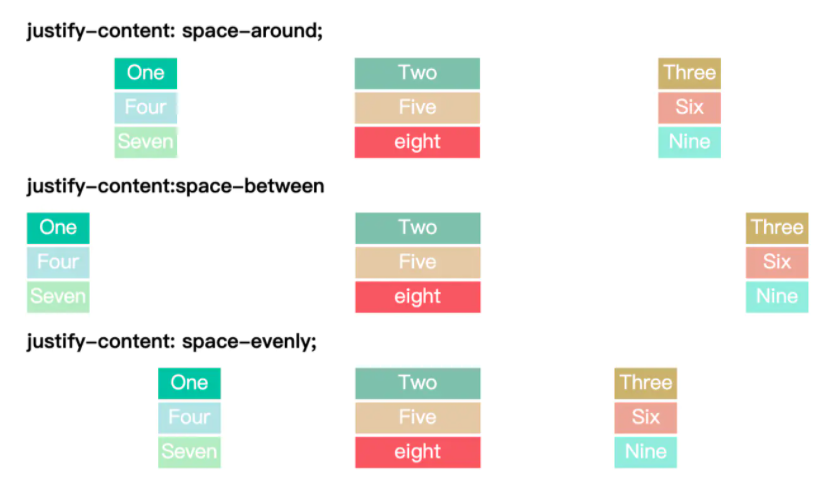
有时候,一些项目的指定位置,在现有网格的外部,就会产生显示网格和隐式网格。
比如网格只有3列,但是某一个项目指定在第5行。这时,浏览器会自动生成多余的网格,以便放置项目。超出的部分就是隐式网格。
而grid-auto-rows与grid-auto-columns就是专门用于指定隐式网格的宽高。
指定网格项目所在的四个边框,分别定位在哪根网格线,从而指定项目的位置。
grid-column-start 属性:左边框所在的垂直网格线
grid-column-end 属性:右边框所在的垂直网格线
grid-row-start 属性:上边框所在的水平网格线
grid-row-end 属性:下边框所在的水平网格线
<style>
#container{
display: grid;
grid-template-columns: 100px 100px 100px;
grid-template-rows: 100px 100px 100px;
}
.item-1 {
grid-column-start: 2;
grid-column-end: 4;
}
</style>
<div id="container">
<div class="item item-1">1</div>
<div class="item item-2">2</div>
<div class="item item-3">3</div>
</div>
通过设置grid-column属性,指定1号项目的左边框是第二根垂直网格线,右边框是第四根垂直网格线。

grid-area 属性指定项目放在哪一个区域。
.item-1 {
grid-area: e;
}
意思为将1号项目位于e区域
grid-area属性一般与上述讲到的grid-template-areas搭配使用。
想要快速入门前端开发吗?推荐一个前端开发基础课程,这个老师讲的特别好,零基础学习无压力,知识点结合代码,边学边练,可以免费试看试学,还有各种辅助工具和资料,非常适合新手!
点这里前往学习哦!
justify-self属性设置单元格内容的水平位置(左中右),跟justify-items属性的用法完全一致,但只作用于单个项目。
align-self属性设置单元格内容的垂直位置(上中下),跟align-items属性的用法完全一致,也是只作用于单个项目。
.item {
justify-self: start | end | center | stretch;
align-self: start | end | center | stretch;
}
这两个属性都可以取下面四个值。
start:对齐单元格的起始边缘。
end:对齐单元格的结束边缘。
center:单元格内部居中。
stretch:拉伸,占满单元格的整个宽度(默认值)
CSS Grid网格布局的应用场景非常广泛,包括但不限于:
CSS Grid网格布局可以轻松创建出复杂的网页布局,如多列布局、不规则布局等。
CSS Grid网格布局可以轻松实现响应式设计,通过调整网格的大小和间距,可以适应不同的屏幕尺寸。
CSS Grid网格布局也可以用于创建复杂的组件布局,如卡片布局、轮播图布局等。
总的来说,CSS Grid网格布局是一种强大的布局工具,可以帮助网页设计者轻松创建出各种复杂的网页布局。
CSS Grid布局为我们提供了一个全新的视角来思考页面布局,它让复杂布局的实现变得简单明了。随着浏览器支持度的提高,未来的网页设计将更加灵活和富有创意。
掌握了CSS Grid布局,你就已经迈出了成为前端设计高手的重要一步。不断实践,不断探索,你会发现更多Grid的神奇之处。
收起阅读 »外包项目结束后,代码交给我公司需要存起来,因为后期还会有迭代开发任务,以后的事情肯定是我们公司内部来维护了,那就需要把代码运行起来,这过程中运行前端项目遇到的几个问题和处理过程简单记录下。
主要问题是,外包公司建有自己UI组件库,所有里面很多包是他们npm私有仓库的托管,我们无法访问到他们的私服仓库,思路是从 node_modules中 把私有包迁移到我们公司自己内网仓库
我拿到的两个项目代码,共有两个项目代码,下面这是web的代码,处理思路是一样的

因为观察到项目中有 node_modules ,因为外包公司是把整个项目文件都拷贝过来了,里面还包括 .git 目录,如果能直接运行起来,那万事大吉。
显示看下图,是运行报错的,缺少包和相关命令,所以我们还是得自己来重新安装 node_modules ,但是问题是私有包如何解决?

我们尝试重新直接安装包,安装失败,因为访问不到私有仓库域名

我们公司也是用verdaccio搭建过私有仓库的,所以要把外包项目的私有包上传到我们公司内部
通过判定看到下图的包在 http://www.npmjs.com/ 中查找不到,所以下面这些 @iios前缀的包是需要迁移到包

我们从 node_modules 中拷贝出来这些文件夹

观察到所有包都是完整的,都有package.json文件

这里这么多包,如果简化可以使用lerna或者shell脚本来统一处理版本问题,但是我们简化就按个包执行推送命令即可

后续所有包同理操作即可

后面就不一一列举了,检查verdaccio是否推送成功

现在私有包都上传完成了,所以需要回到主项目,安装包就行了,但是因为有私有包,于是需要执行 .npmrc 规定各种包的安装路径

这一步是我习惯,在package.json中,版本号固定写死,而不是 ^前缀开头自动更新此版本
而且更重要的是,外包项目已经在线上运行,万一以后要三方包变化导致一些莫名其妙问题就很麻烦,锁定版本号是非常有必要的,才能以后很久之后打开发布代码也是没有问题的




一切都搞完了,重新运行成功



百度「弱智吧」是个神奇的地方,在这里人人都说自己是弱智,但大多聪明得有点过了头。最近几年,弱智吧的年度总结文章都可以顺手喜提百度贴吧热度第一名。所谓总结,其实就是给当年吧里的弱智发言排个名。

随着十几年的发展,越来越多的弱智文学也有了奇怪的风格,有心灵鸡汤,有现代诗,甚至有一些出现了哲学意义。

引发 AI 革命的大模型因为缺乏数据,终于盯上了弱智吧里无穷无尽的「数据集」。有人把这些内容拿出来训练了 AI,认真评测对比一番,还别说,效果极好。


COIG-CQIA 数据集介绍
为了保证数据质量以及多样性,本文从中国互联网内的优质网站和数据资源中手动选择了数据源。这些来源包括社区问答论坛、、内容创作平台、考试试题等。此外,该数据集还纳入了高质量的中文 NLP 数据集,以丰富任务的多样性。具体来说,本文将数据源分为四种类型:社交媒体和论坛、世界知识、NLP 任务和考试试题。




实验结果





文章最后有效果图
在小程序上绘制 40000+ 的点位。
众所周知小程序的 map 组件性能低下,同时渲染几百个 marker 就会卡顿,一旦加上 callout 弹窗,这个数量可能会降到几十个,如果使用了 自定义弹窗(custom-callout) 会更卡,所以渲染 4w+ 的点,用常规方法是不可能实现的。
按需加载即按屏幕坐标加载,只显示视野范围内的点位,需要后端配合在接口中新增 bbox(Bounding box) 参数,再从数据库中查出范围内的点。
小程序端需要使用视野变化监听方法实时更新,虽然请求和渲染频繁,但是在缩放等级较大时,有很高的性能:
<map bindregionchange="regionChanged" markers="{{markers}}">
regionChanged(e){
this.data.bbox = [ [e.detail.region.southwest.longitude, e.detail.region.southwest.latitude],
[e.detail.region.northeast.longitude, e.detail.region.northeast.latitude],
]
// 执行获取点、渲染点的操作
}
需要注意的是,目前的微信版本(8.0.47),基础库3.3.4该方法不可用,见 微信开放社区
如果遇到 bindregionchange 不可用时,可以用 bind:touchend 方法代替,手动获取范围
setBbox() {
mapCtx = wx.createMapContext('map', this)
mapCtx.getRegion({
success: (res) => {
let bbox = [
[res.southwest.longitude, res.southwest.latitude],
[res.northeast.longitude, res.northeast.latitude],
]
// 执行获取点、渲染点的操作
})
})
}
使用了按需渲染后,在缩放等级较大时,已经可以有很好的效果,移动屏幕时基本可以秒加载出新的点,同时清除掉屏幕范围外的点。
然而,在点位多的时候,我们收到了 setData 长度超出的报错,页面也异常卡顿。
小程序的 setData 方法最多只能更新 1M 的数据,超过这个数据会报错,并严重卡顿,即使不超过,在数据量较大时,也会非常卡顿,为了解决这个问题,我们不能再使用 setData 去渲染数据。
小程序提供了专门渲染点的方法: addMarkers
在 // 执行获取点、渲染点的操作处,使用该方法,并设置 clear: true 。这样就达到了上面说的,更新点时,旧的点会被清除。
然而,这并没有解决根本问题,我们现在可以做到渲染远远大于1M的数据,并渲染时不会报错,但是由于小程序 map 组件的渲染策略,我们的点会一个一个渲染上去,我们知道更新 canvas 代价是很大的,尤其是像 marker 这种携带很多必要信息的东西。
这里我们尝试将 marker 携带的参数压缩到极致,仅保留经纬度、颜色状态信息、id、callout,效果依然差强人意。
并且,由于小程序 marker 的 callout 不是互斥的,且没有给我们预留参数去设置这一点,所以在我们切换 marker 选中状态时,需要把 marker 数组完全遍历一遍,移除其他的 callout , 并添加新的 callout,这个开销也是巨大不可接受的。
为了解决切换 marker 选中状态时的开销问题,我们想了一个绝妙的主意,就是将 marker 数组中的 callout 完全移除,只保留 id 等必要字段,在点击时,添加一个新的带 callout 点上去,盖住原来的点,这样看起来就是原有的点被选中了,这样既压缩了 marker 携带参数,又解决了切换选中时必须遍历 marker 数组的问题。
height: 20,
width: 17,
iconPath: this.data.markerIcons[this.getMarkerType(item)],
latitude: item.point[1],
longitude: item.point[0],
id: this.getUniqueNumber(item.uid), //id 必须是数字
storeCode: item.uid,
//callout:{...} // 不要此项
customCallout: {} //必须加,不然会有一个没有内容的弹窗,这个可以阻止默认弹窗弹出
经过上面的优化,我们的小程序已经可以高性能的显示点位了,但是当缩放等级低时(12以下),点位多起来了,我们目前的方法就显得力不从心了。
如果点位无限多,我们又该如何优化呢?
聚合指的是将临近的点位聚合成一个大点,从而达到渲染点数变少、提高性能的方法。
此方法经过实测,发现当点达到一定量级的时候,用了反而比不用还卡,因为每当你缩放地图时,都需要计算聚合,当计算压力大于渲染压力时,聚合反而成了一种负担,而不是优化了。
所以我们不用聚合。
小程序提供了付费功能:个性化图层,可以上传海量数据并生成一个小程序支持加载的图层。遗憾的是这种方法只适合静态数据,对于经常需要变动的数据,这种方法的实时性得不到保证,只能通过手动在后台更新数据。
所以此方案也不可用。
小程序 map 是不支持瓦片(个性化图层除外)加载的,但是我们知道,瓦片就是一张图片而已,那么小程序可以在地图上放图片吗,答案是可以:addGroundOverlay
我们决定朝着此方案努力,请看下文。
首先到 geoserver官网 下载geoserver本体,geoserver是为数不多几个推荐 windows 平台的大型工具软件,下载前注意,geoserver对 jdk 版本有要求,版本不一致会导致 geoserver 启动失败等问题。

我们的服务器是 linux ,所以下载了linux版本,到服务器找个位置 直接 unzip 就可以了。
安装完之后,需要先编辑 start.ini 调整一个合适的空闲端口,作为后面web端管理页面的地址端口。别忘了在防火墙开启此端口。
最后在 bin 中有一个 startup.sh , 使用 nohup 命令设置后台运行。
此时在浏览器输入服务器地址和你刚刚设置的端口号,最后加上 /geoserver,即可看到geoserver的管理页面。

初始用户名密码:admin geoserver
登录完成后可以看到全部功能

点击数据存储 -> 添加新的数据存储,即可添加数据并发布图层。
可以看到支持 PostGis,使用 PostGis 作为数据源,图层会实时更新,也就是说,当数据变化时,无需任何代码和人工干预。
当数据源添加完成后,需要新建一个图层,并指定为刚刚新建的数据源。
此时,在图层预览页面即可看到刚刚创建的图层了,当然此时的图层使用的是默认样式,需要编写SLD(xml格式)的样式文件去指定样式,这对于我们来说无疑是一种负担。
好在 geoserver 有 css 插件,安装此插件并重启geoserver,即可使用 css 编写图层样式。
* {
mark-size:8px;
}
[control_sts == 1] {
mark:url("https://entropy.xxx.cn/xx/dotgreen.png");
}
[control_sts == 0] {
mark:url("https://entropy.xxx.cn/xx/dotgray.png");
}
可以看到,它与标准css还是有一些差异的,像mark、mark-size在标准css中是不存在的。
指定样式后,在图层预览页面,可以看到效果

打开控制台,可以看到网络请求中的地址长这样:
http://xxx:8089/geoserver/cite/wms?SERVICE=WMS&VERSION=1.1.1&REQUEST=GetMap&FORMAT=image%2Fpng&TRANSPARENT=true&STYLES&LAYERS=cite%3Axc_store_geo&exceptions=application%2Fvnd.ogc.se_inimage&SRS=EPSG%3A4326&WIDTH=670&HEIGHT=768&BBOX=114.4720458984375%2C37.7874755859375%2C118.1524658203125%2C42.0062255859375
放到浏览器窗口打开,发现是一张png图片,那么我们刚好可以使用小程序的 addGroundOverlay 添加到地图上。
SERVICE: WMS
VERSION: 1.1.1
REQUEST: GetMap
FORMAT: image/png
TRANSPARENT: true
STYLES:
LAYERS: xx:xxxx
exceptions: application/vnd.ogc.se_inimage
SRS: EPSG:4326
WIDTH: 670
HEIGHT: 768
BBOX: 114.4720458984375,37.7874755859375,118.1524658203125,42.0062255859375
看一下这些参数,出了 BBOX ,其他的写固定值就可以了。
这里注意,宽高值,需要设置为小程序中地图元素的大小,单位是 px。
比较简单,直接看代码:
setTileImage(params: { LAYERS: string[], BBOX: string, SCREEN_WIDTH: number, SCREEN_HEIGHT: number, CQL_FILTER: string }) {
mapCtx = wx.createMapContext('map', this)
this.removeTileImage().then(() => {
for (let index in params.LAYERS) {
let id = +(9999 + index)
!this.data.groundOverlayIds.includes(id) && this.data.groundOverlayIds.push(id)
let data: any = {
id: +(9999 + index),
zIndex: 999,
src: `http://xxx:8089/geoserver/cite/wms?SERVICE=WMS&VERSION=1.1.1&REQUEST=GetMap&LAYERS=${params.LAYERS[index]}&STYLES=&exceptions=application/vnd.ogc.se_inimage&FORMAT=image/png&TRANSPARENT=true&FORMAT_OPTIONS=antialias:full&SRS=EPSG:4326&BBOX=${params.BBOX}&WIDTH=${params.SCREEN_WIDTH * 2}&HEIGHT=${params.SCREEN_HEIGHT * 2}&CQL_FILTER=${params.CQL_FILTER}`,
bounds: {
southwest: {
latitude: +params.BBOX.split(',')[1],
longitude: +params.BBOX.split(',')[0]
},
northeast: {
latitude: +params.BBOX.split(',')[3],
longitude: +params.BBOX.split(',')[2]
}
}
}
mapCtx.addGroundOverlay({
...data,
})
}
})
},
我这里封装了一个可以接受多个图层的方法,这里值得注意的是,我没有使用 updateGroundOverlay 方法去更新图层,而是先使用 removeGroundOverlay 移除,再重新添加的,这是因为updateGroundOverlay有一个bug,我不说,你可以自己试试。

至此已经完全实现了小程序的海量点的渲染,无论点有多少,我们都只需要渲染一张图片而已,性能好的一批。
pnpm create vite react-starter --template react-swc-tspnpm ipnpm i @types/node -Dnpmrcregistry = "https://registry.npmmirror.com/"
"engines": {
"node": ">=16.0.0"
},
eslint 处理代码规范,prettier 处理代码风格
eslint 选择只检查错误不处理风格,这样 eslint 就不会和 prettier 冲突
react 官网有提供一个 hook 的 eslint (eslint-plugin-react-hooks),用处不大就不使用了
pnpm i eslint -Deslint --init(如果没eslint,可以全局安装一个,然后使用npx eslint --init)- To check syntax and find problems //这个选项是eslint默认选项,这样就不会和pretter起风格冲突
- JavaScript modules (import/export)
- React
- YES
- Browser
- JSON
- Yes
- pnpm
eslintrc.json->rules里配置不用手动引入 react,和配置不可以使用 any"rules": {
//不用手动引入react
"react/react-in-jsx-scope": "off",
//使用any报错
"@typescript-eslint/no-explicit-any": "error",
}
.vscode>settings.json,配置后 vscode 保存时自动格式化代码风格比如写了一个 var a = 100,会被自动格式化为 const a = 100
{
"editor.codeActionsOnSave": {
// 每次保存的时候将代码按照 eslint 格式进行修复
"source.fixAll.eslint": true,
//自动格式化
"editor.formatOnSave": true
}
}
.eslintignore,eslint 会自动过滤 node_modulesdist
eslint格式化命令,后面使用 lint-staged 提交代码的时候需要配置为什么上面有 vscode 自动 eslint 格式化,还需要命令行: 因为命令行能一次性爆出所有警告问题,便于找到位置修复
npx eslint . --fix//用npx使用项目里的eslint,没有的话也会去使用全局的eslint
eslint . --fix //全部类型文件
eslint . --ext .ts,.tsx --fix //--ext可以指定文件后缀名s
eslintrc.json 里配置
"env": {
"browser": true,
"es2021": true,
"node": true // 因为比如配置vite的时候会使用到
},
prettier 格式化风格,因为使用 tailwind,使用 tailwind 官方插件
pnpm i prettier prettier-plugin-tailwindcss -D.prettierrc.json注释要删掉,prettier 的配置文件 json 不支持注释
{
"singleQuote": true, // 单引号
"semi": false, // 分号
"trailingComma": "none", // 尾随逗号
"tabWidth": 2, // 两个空格缩进
"plugins": ["prettier-plugin-tailwindcss"] //tailwind插件
}
.prettierignoredist
pnpm-lock.yaml
.vscode>settings.json,配置后 vscode 保存时自动格式化代码风格{
"editor.codeActionsOnSave": {
// 每次保存的时候将代码按照 eslint 格式进行修复
"source.fixAll.eslint": true
},
//自动格式化
"editor.formatOnSave": true,
//风格用prettier
"editor.defaultFormatter": "esbenp.prettier-vscode"
}
prettier命令行可以让之前没有格式化的错误一次性暴露出来
npx prettier --write .//使用Prettier格式化所有文件
记得要初始化一个 git 仓库,husky 能执行 git hook,在 commit 的时候对文件进行操作
sudo pnpm dlx husky-init
pnpm install
npx husky add .husky/commit-msg 'npx --no -- commitlint --edit "$1"',commit-msg 使用 commitlint
npx husky add .husky/pre-commit "npm run lint-staged",pre-commit 使用 lint-staged
提交规范参考:http://www.conventionalcommits.org/en/v1.0.0/
pnpm i @commitlint/cli @commitlint/config-conventional -D.commitlintrc.json{ extends: ['@commitlint/config-conventional'] }
pnpm i -D lint-staged package.json"scripts": {
"dev": "vite",
"build": "tsc && vite build",
"preview": "vite preview",
"prepare": "husky install",
"lint-staged": "npx lint-staged"//新增,对应上面的husky命令
},
.lintstagedrc.json{
"*.{ts,tsx,json}": ["prettier --write", "eslint --fix"],
"*.css": ["stylelint --fix", "prettier --write"]
}
如果有兼容性考虑,需要使用 legacy 插件,vite 也有 vscode 插件,也可以下载使用
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react-swc'
import path from 'path'
// https://vitejs.dev/config/
export default defineConfig({
esbuild: {
drop: ['console', 'debugger']
},
css: {
// 开css sourcemap方便找css
devSourcemap: true
},
plugins: [react()],
server: {
// 自动打开浏览器
open: true,
proxy: {
'/api': {
target: 'https://xxxxxx',
changeOrigin: true,
rewrite: (path) => path.replace(/^\/api/, '')
}
}
},
resolve: {
// 配置别名
alias: { '@': path.resolve(__dirname, './src') }
},
//打包路径变为相对路径,用liveServer打开,便于本地测试打包后的文件
base: './'
})
pnpm i rollup-plugin-visualizer -D
pnpm i @vitejs/plugin-legacy -D,实际遇到了再看官网用
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react-swc'
import { visualizer } from 'rollup-plugin-visualizer'
import legacy from '@vitejs/plugin-legacy'
import path from 'path'
// https://vitejs.dev/config/
export default defineConfig({
css: {
// 开css sourcemap方便找css
devSourcemap: true
},
plugins: [
react(),
visualizer({
open: false // 打包完成后自动打开浏览器,显示产物体积报告
}),
//考虑兼容性,实际遇到了再看官网用
legacy({
targets: ['ie >= 11'],
additionalLegacyPolyfills: ['regenerator-runtime/runtime']
})
],
server: {
// 自动打开浏览器
open: true
},
resolve: {
// 配置别名
alias: { '@': path.resolve(__dirname, './src') }
},
//打包路径变为相对路径,用liveServer打开,便于本地测试打包后的文件
base: './'
})
pnpm dev --hosth去 help 帮助,再按c就可以 clear console{
"compilerOptions": {
"target": "ESNext",
"useDefineForClassFields": true,
"lib": ["DOM", "DOM.Iterable", "ESNext"],
"allowJs": false,
"skipLibCheck": true,
"esModuleInterop": false,
"allowSyntheticDefaultImports": true,
"strict": true,
"forceConsistentCasingInFileNames": true,
"module": "ESNext",
"moduleResolution": "Node",
"resolveJsonModule": true,
"isolatedModules": true,
"noEmit": true,
"jsx": "react-jsx",
"baseUrl": "./",
"paths": {
"@/*": ["src/*"]
}
},
"include": ["src"],
"references": [{ "path": "./tsconfig.node.json" }]
}
pnpm i react-router-domrouter->index.tsimport { lazy } from 'react'
import { createBrowserRouter } from 'react-router-dom'
const Home = lazy(() => import('@/pages/home'))
const router = createBrowserRouter([
{
path: '/',
element: <Home></Home>
}
])
export default router
main.tsximport { RouterProvider } from 'react-router-dom'
import ReactDOM from 'react-dom/client'
import './global.css'
import router from './router'
ReactDOM.createRoot(document.getElementById('root') as HTMLElement).render(
<RouterProvider router={router} />
)
pnpm i zustand import { create } from 'zustand'
interface appsState {
nums: number
setNumber: (nums: number) => void
}
const useAppsStore = create<appsState>((set) => ({
nums: 0,
setNumber: (num) => {
return set(() => ({
nums: num
}))
}
}))
export default useAppsStore
import Button from '@/comps/custom-button'
import useAppsStore from '@/store/app'
const ZustandDemo: React.FC = () => {
const { nums, setNumber } = useAppsStore()
const handleNum = () => {
setNumber(nums + 1)
}
return (
<div className="p-10">
<h1 className="my-10">数据/更新</h1>
<Button click={handleNum}>点击事件</Button>
<h1 className="py-10">{nums}</h1>
</div>
)
}
export default ZustandDemo
pnpm i antdpnpm i tailwindcss autoprefixer postcss
tailwind.config.cjs
// 打包后会有1kb的css用不到的,没有影响
// 用了antd组件关系也不大,antd5的样式是按需的
/** @type {import('tailwindcss').Config} */
module.exports = {
darkMode: 'class',
content: ['./index.html', './src/**/*.{js,ts,jsx,tsx}'],
theme: {
extend: {
// colors: {
// themeColor: '#ff4132',
// textColor: '#1a1a1a'
// },
// 如果写自适应布局,可以指定设计稿为1000px,然后只需要写/10的数值
// fontSize: {
// xs: '3.3vw',
// sm: '3.9vw'
// }
}
},
plugins: []
}
postcss.config.cjs
module.exports = {
plugins: {
tailwindcss: {},
autoprefixer: {}
}
}
我喜欢新建一个 apply.css 引入到全局
@tailwind base;
@tailwind components;
@tailwind utilities;
.margin-center {
@apply mx-auto my-0;
}
.flex-center {
@apply flex justify-center items-center;
}
.absolute-center {
@apply absolute top-1/2 left-1/2 -translate-x-1/2 -translate-y-1/2;
}
这个封装仅供参考,TS 类型有点小问题
// 可以传入这些配置
interface BaseOptions {
method?: string
credentials?: RequestCredentials
headers?: HeadersInit
body?: string | null
}
// 请求方式
type HttpMethod = 'GET' | 'POST' | 'PUT' | 'PATCH' | 'DELETE' | 'HEAD'
// 第一层出参
interface ResponseObject {
ok: boolean
error: boolean
status: number
contentType: string | null
bodyText: string
response: Response
}
// 请求头类型
type JSONHeader = {
Accept: string
'Content-Type': string
}
// 创建类
class Request {
private baseOptions: BaseOptions = {}
// 根据传入的 baseOptions 做为初始化参数
constructor(options?: BaseOptions) {
this.setBaseOptions(options || {})
}
public setBaseOptions(options: BaseOptions): BaseOptions {
this.baseOptions = options
return this.baseOptions
}
// 也提供获取 baseOption 的方法
public getBaseOptions(): BaseOptions {
return this.baseOptions
}
// 核心请求 T 为入参类型,ResponseObject 为出参类型
public request<T>(
method: HttpMethod,
url: string,
data?: T, //支持使用get的时候配置{key,value}的query参数
options?: BaseOptions //这里也有个 base 的 method
): Promise<ResponseObject> {
// 默认 baseOptions
const defaults: BaseOptions = {
method
// credentials: 'same-origin'
}
// 收集最后要传入的配置
const settings: BaseOptions = Object.assign(
{},
defaults,
this.baseOptions,
options
)
// 如果 method 格式错误
if (!settings.method || typeof settings.method !== 'string')
throw Error('[fetch-json] HTTP method missing or invalid.')
// 如果 url 格式错误
if (typeof url !== 'string')
throw Error('[fetch-json] URL must be a string.')
// 支持大小写
const httpMethod = settings.method.trim().toUpperCase()
// 如果是GET
const isGetRequest = httpMethod === 'GET'
// 请求头
const jsonHeaders: Partial<JSONHeader> = { Accept: 'application/json' }
// 如果不是 get 设置请求头
if (!isGetRequest && data) jsonHeaders['Content-Type'] = 'application/json'
// 收集最后的headers配置
settings.headers = Object.assign({}, jsonHeaders, settings.headers)
// 获取query参数的key
const paramKeys = isGetRequest && data ? Object.keys(data) : []
// 获取query参数的值
const getValue = (key: keyof T) => (data ? data[key] : '')
// 获取query key=value
const toPair = (key: string) =>
key + '=' + encodeURIComponent(getValue(key as keyof T) as string)
// 生成 key=value&key=value 的query参数
const params = () => paramKeys.map(toPair).join('&')
// 收集最后的 url 配置
const requestUrl = !paramKeys.length
? url
: url + (url.includes('?') ? '&' : '?') + params()
// get没有body
settings.body = !isGetRequest && data ? JSON.stringify(data) : null
// 做一层res.json()
const toJson = (value: Response): Promise<ResponseObject> => {
// 拿到第一次请求的值
const response = value
const contentType = response.headers.get('content-type')
const isJson = !!contentType && /json|javascript/.test(contentType)
const textToObj = (httpBody: string): ResponseObject => ({
ok: response.ok,
error: !response.ok,
status: response.status,
contentType: contentType,
bodyText: httpBody,
response: response
})
const errToObj = (error: Error): ResponseObject => ({
ok: false,
error: true,
status: 500,
contentType: contentType,
bodyText: 'Invalid JSON [' + error.toString() + ']',
response: response
})
return isJson
? // 如果是json,用json()
response.json().catch(errToObj)
: response.text().then(textToObj)
}
// settings做一下序列化
const settingsRequestInit: RequestInit = JSON.parse(
JSON.stringify(settings)
)
// 最终请求fetch,再通过then就能取到第二层res
return fetch(requestUrl, settingsRequestInit).then(toJson)
}
public get<T>(
url: string,
params?: T,
options?: BaseOptions
): Promise<ResponseObject> {
return this.request<T>('GET', url, params, options)
}
public post<T>(
url: string,
resource: T,
options?: BaseOptions
): Promise<ResponseObject> {
return this.request<T>('POST', url, resource, options)
}
public put<T>(
url: string,
resource: T,
options?: BaseOptions
): Promise<ResponseObject> {
return this.request<T>('PUT', url, resource, options)
}
public patch<T>(
url: string,
resource: T,
options?: BaseOptions
): Promise<ResponseObject> {
return this.request<T>('PATCH', url, resource, options)
}
public delete<T>(
url: string,
resource: T,
options?: BaseOptions
): Promise<ResponseObject> {
return this.request<T>('DELETE', url, resource, options)
}
}
const request = new Request()
export { request, Request }
request.ts
import axios from 'axios'
import { AxiosInstance } from 'axios'
import { errorHandle, processData, successHandle } from './resInterceptions'
import { defaultRequestInterception } from './reqInterceptions'
const TIMEOUT = 5 * 1000
class Request {
instance: AxiosInstance
constructor() {
this.instance = axios.create()
this.init()
}
private init() {
this.setDefaultConfig()
this.reqInterceptions()
this.resInterceptions()
}
private setDefaultConfig() {
this.instance.defaults.baseURL = import.meta.env.VITE_BASE_URL
this.instance.defaults.timeout = TIMEOUT
}
private reqInterceptions() {
this.instance.interceptors.request.use(defaultRequestInterception)
}
private resInterceptions() {
this.instance.interceptors.response.use(processData)
this.instance.interceptors.response.use(successHandle, errorHandle)
}
}
export default new Request().instance
reqInterceptions.ts
import type { InternalAxiosRequestConfig } from 'axios'
const defaultRequestInterception = (config: InternalAxiosRequestConfig) => {
// TODO: 全局请求拦截器: 添加token
return config
}
export { defaultRequestInterception }
resInterceptions.ts
import { AxiosError, AxiosResponse } from 'axios'
import { checkStatus } from './checkStatus'
const processData = (res: AxiosResponse) => {
// TODO:统一处理数据结构
return res.data
}
const successHandle = (res: AxiosResponse) => {
// TODO:处理一些成功回调,例如请求进度条
return res.data
}
const errorHandle = (err: AxiosError) => {
if (err.status) checkStatus(err.status)
else return Promise.reject(err)
}
export { processData, successHandle, errorHandle }
checkStatus.ts
export function checkStatus(status: number, msg?: string): void {
let errMessage = ''
switch (status) {
case 400:
errMessage = `${msg}`
break
case 401:
break
case 403:
errMessage = ''
break
// 404请求不存在
case 404:
errMessage = ''
break
case 405:
errMessage = ''
break
case 408:
errMessage = ''
break
case 500:
errMessage = ''
break
case 501:
errMessage = ''
break
case 502:
errMessage = ''
break
case 503:
errMessage = ''
break
case 504:
errMessage = ''
break
case 505:
errMessage = ''
break
default:
}
if (errMessage) {
// TODO:错误提示
// createErrorModal({title: errMessage})
}
}
api.ts
import request from '@/services/axios/request'
import { ReqTitle } from './type'
export const requestTitle = (): Promise<ReqTitle> => {
return request.get('/api/一个获取title的接口')
}
type.ts
export type ReqTitle = {
title: string
}
pnpm i mobx mobx-react-litemodel->index.tsimport { makeAutoObservable } from 'mobx'
const store = makeAutoObservable({
count: 1,
setCount: (count: number) => {
store.count = count
}
})
export default store
import store from '@/model'
import { Button } from 'antd'
import { observer, useLocalObservable } from 'mobx-react-lite'
const Home: React.FC = () => {
const localStore = useLocalObservable(() => store)
return (
<div>
<Button>Antd</Button>
<h1>{localStore.count}</h1>
</div>
)
}
export default observer(Home)
pnpm i conventional-changelog-cli -D
第一次先执行conventional-changelog -**p** angular -**i** CHANGELOG.md -s -r 0全部生成之前的提交信息
配置个脚本,版本变化打 tag 的时候可以使用
"scripts": {
"changelog": "conventional-changelog -p angular -i CHANGELOG.md -s"
}
editorConfig,可以同步编辑器差异,其实大部分工作 prettier 做了,需要下载 editorConfig vscode 插件
有编辑器差异的才配置一下,如果团队都是 vscode 就没必要了
editorconfig#不再向上查找.editorconfig
root = true
# *表示全部文件
[*]
#编码
charset = utf-8
#缩进方式
indent_style = space
#缩进空格数
indent_size = 2
#换行符lf
end_of_line = lf
stylelint 处理 css 更专业,但是用了 tailwind 之后用处不大了
pnpm i -D stylelint stylelint-config-standard.stylelintrc.json{
"extends": "stylelint-config-standard"
}
.vscode>settings.json,配置后 vscode 保存时自动格式化 css{
"editor.codeActionsOnSave": {
"source.fixAll.eslint": true, // 每次保存的时候将代码按照 eslint 格式进行修复
"source.fixAll.stylelint": true //自动格式化stylelint
},
"editor.formatOnSave": true, //自动格式化
"editor.defaultFormatter": "esbenp.prettier-vscode" //风格用prettier
}
stylelint命令行npx stylelint "**/*.css" --fix//格式化所有css,自动修复css
vconsole(h5)pnpm i vconsole -Dmain.tsx里新增import VConsole from 'vconsole'
new VConsole({ theme: 'dark' })
pnpm remove antdpnpm add antd-mobilepnpm i postcss-px-to-viewport -Dpostcss.config.cjsmodule.exports = {
plugins: {
'postcss-px-to-viewport': {
landscape: false, // 是否添加根据 landscapeWidth 生成的媒体查询条件 @media (orientation: landscape)
landscapeUnit: 'vw', // 横屏时使用的单位
landscapeWidth: 568, // 横屏时使用的视口宽度
unitToConvert: 'px', // 要转化的单位
viewportWidth: 750, // UI设计稿的宽度
unitPrecision: 5, // 转换后的精度,即小数点位数
propList: ['*'], // 指定转换的css属性的单位,*代表全部css属性的单位都进行转换
viewportUnit: 'vw', // 指定需要转换成的视窗单位,默认vw
fontViewportUnit: 'vw', // 指定字体需要转换成的视窗单位,默认vw
selectorBlackList: ['special'], // 指定不转换为视窗单位的类名,
minPixelValue: 1, // 默认值1,小于或等于1px则不进行转换
mediaQuery: true, // 是否在媒体查询的css代码中也进行转换,默认false
replace: true, // 是否转换后直接更换属性值
exclude: [/node_modules/] // 设置忽略文件,用正则做目录名匹配
}
}
}
在上一篇文章前端监控究竟有多重要?大家了解了前端监控系统的重要性以及前端监控的组成部分、常见的监控指标、埋点方式。
接下来这篇文章我们就来详细学习一下前端监控系统中的,异常监控。
想要进行异常监控之前,肯定先要了解有哪些异常才能进行监控。
一般来说,浏览器端的异常分为两种类型:
而这里面我们又有各自的差异
先来说说JavaScript的错误类型,ECMA-262 定义了 7 种错误类型,说明如下:
EvalError :eval() 函数的相关的错误RangeError :使用了超出了 JavaScript 的限制或范围的值。ReferenceError: 引用了未定义的变量或对象TypeError: 类型错误URIError: URI操作错误SyntaxError: 语法错误 (这个错误WebIDL中故意省略,保留给ES解析器使用)Error: 普通异常,通常与 throw 语句和 try/catch 语句一起使用,利用属性 name 可以声明或了解异常的类型,利用message 属性可以设置和读取异常的详细信息。如果想更详细了解可以看详细错误罗列这篇文章
![]() 、
、Flex 布局是一种新型的 CSS 布局模式,它主要用于弹性盒子布局。相比于传统的布局方式,它更加灵活,易于调整,也更加适应不同的设备和屏幕尺寸。
下面我们就来详细解析 Flex 布局及其属性,帮助大家深入理解和运用 Flex 布局。
在介绍Flex布局之前,我们不得不提到它的前辈——浮动和定位。它们曾是布局的主力军,但随着响应式设计的兴起,它们的局限性也愈发明显。
Flex布局的出现,正是为了解决这些局限性,它允许我们在一个容器内对子元素进行灵活的排列、对齐和空间分配。
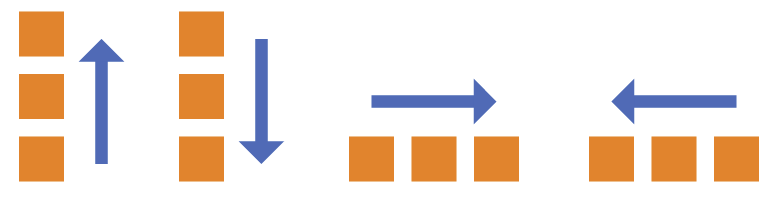
Flex全称为 “Flexible Box Layout”,即 “弹性盒布局”,旨在提供一种更有效的方式来布局、对齐和分配容器中项目之间的空间,即使它们的大小未知或动态变化。
声明定义
容器里面包含着项目元素,使用 display:flex 或 display:inline-flex 声明为弹性容器。
.container {
display: flex | inline-flex;
}
flex布局的作用
在父内容里面垂直居中一个块内容。
使容器的所有子项占用等量的可用宽度/高度,而不管有多少宽度 / 高度可用。
使多列布局中的所有列采用相同的高度,即使它们包含的内容量不同。
要理解Flex布局,我们必须先了解几个核心概念:
容器(Container):设置了display: flex;的元素成为Flex容器。容器内的子元素自动成为Flex项目。
.container{
display: flex;
}
<div class="container">
<div class="item"> </div>
<div class="item">
<p class="sub-item"> </p>
</div>
<div class="item"> </div>
</div>
上面代码中, 最外层的 div 就是容器,内层的三个 div 就是项目。
注意: 项目只能是容器的顶层子元素(直属子元素),不包含项目的子元素,比如上面代码的 p 元素就不是项目。flex布局只对项目生效。
主轴是Flex项目的排列方向,交叉轴则是垂直于主轴的方向。
主轴(main axis)
沿其布置子容器的从 main-start 开始到 main-end ,请注意,它不一定是水平的;这取决于 flex-direction 属性(见下文), main size 是它可放置的宽度,是容器的宽或高,取决于 flex-direction。
交叉轴(cross axis)
垂直于主轴的轴称为交叉轴,它的方向取决于主轴方向,是主轴写满一行后另起一行的方向,从 cross-start 到 cross-end , cross size 是它可放置的宽度,是容器的宽或高,取决于 flex-direction。
容器的属性主要包括:
flex-direction:定义了主轴的方向,可以是水平或垂直,以及其起始和结束的方向。
flex-wrap:决定了当容器空间不足时,项目是否换行。
flex-flow:这是flex-direction和flex-wrap的简写形式。
justify-content:设置项目在主轴上的对齐方式。
align-items:定义了项目在交叉轴上的对齐方式。
align-content:定义了多根轴线时,项目在交叉轴上的对齐方式。
gap row-gap、column-gap:设置容器内项目间的间距。
定义主轴的方向,也就是子项目元素排列的方向。
row (默认):从左到右 ltr ;从右到左 rtl
row-reverse :从右到左 ltr ;从左到右 rtl
column: 相同, row 但从上到下
column-reverse: 相同, row-reverse 但从下到上
.container {
flex-direction: row | row-reverse | column | column-reverse;
}
设置子容器的换行方式,默认情况下,子项目元素都将尝试适合一行nowrap。
nowrap (默认)不换行
wrap 一行放不下时换行
wrap-reverse 弹性项目将从下到上换行成多行
.container {
flex-wrap: nowrap | wrap | wrap-reverse;
}
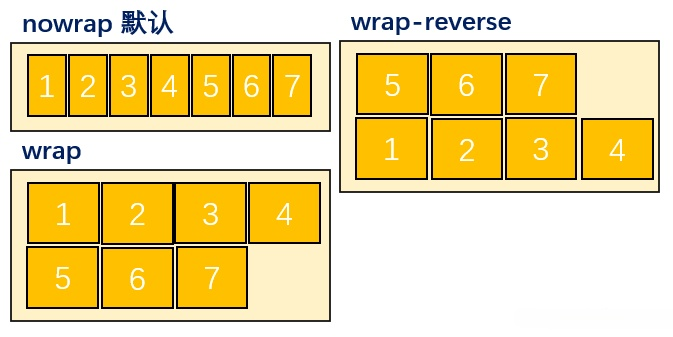
flex-direction 和 flex-wrap 属性的简写,默认值为 row nowrap。
.container {
flex-flow: column wrap;
}
取值情况:

justify-c ontent 决定子元素在主轴方向上的对齐方式,默认是 flex-start。
.container {
justify-content: flex-start | flex-end | center | space-between | space-around | space-evenly | start | end | left | right ... + safe | unsafe;
}
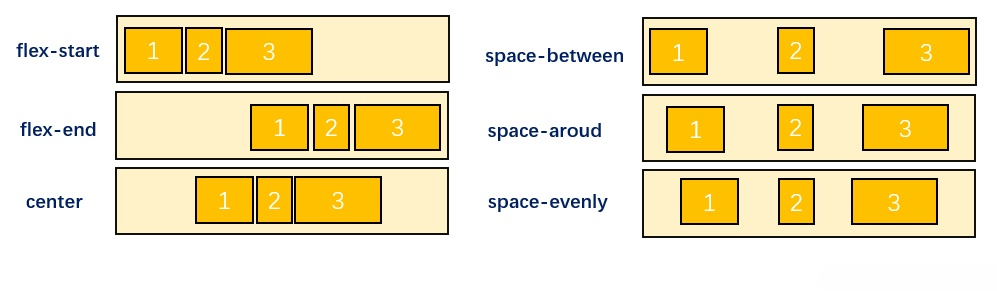
align-items 决定子元素在交叉轴方向上的对齐方式,默认是 stretch。
.container {
align-items: stretch | flex-start | flex-end | center | baseline | first baseline | last baseline | start | end | self-start | self-end + ... safe | unsafe;
}
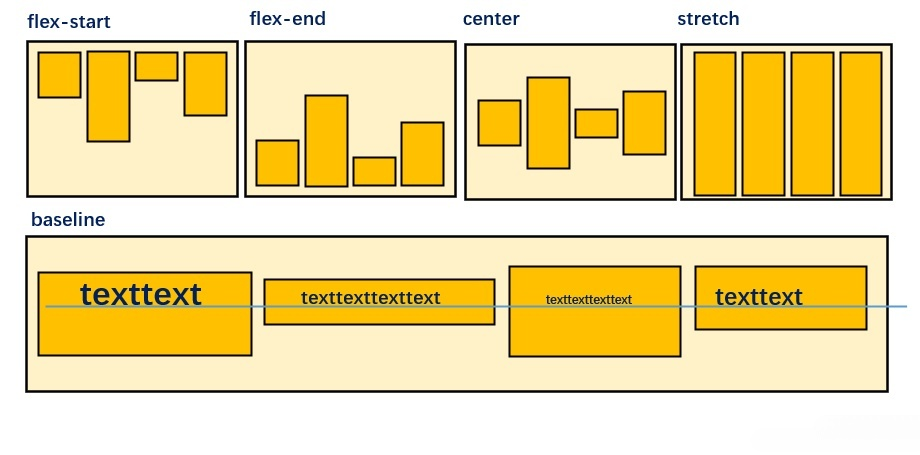
align-content属性定义了多根轴线的对齐方式。如果项目只有一根轴线,该属性不起作用。
flex-start:与交叉轴的起点对齐。
flex-end:与交叉轴的终点对齐。
center:与交叉轴的中点对齐。
space-between:与交叉轴两端对齐,轴线之间的间隔平均分布。
space-around:每根轴线两侧的间隔都相等。所以,轴线之间的间隔比轴线与边框的间隔大一倍。
stretch(默认值):轴线占满整个交叉轴。
.container {
align-content: flex-start | flex-end | center | space-between | space-around | space-evenly | stretch | start | end | baseline | first baseline | last baseline + ... safe | unsafe;
}
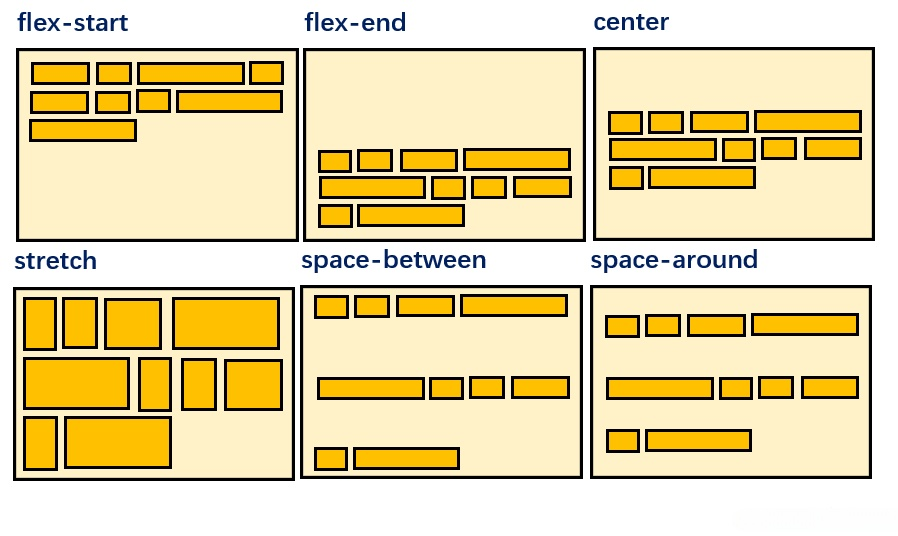
设置容器内项目之间的间距,只控制项目与项目的间距,对项目与容器的间距不生效。
.container {
display: flex;
...
gap: 10px;
gap: 10px 20px; /* row-gap column gap */
row-gap: 10px;
column-gap: 20px;
}
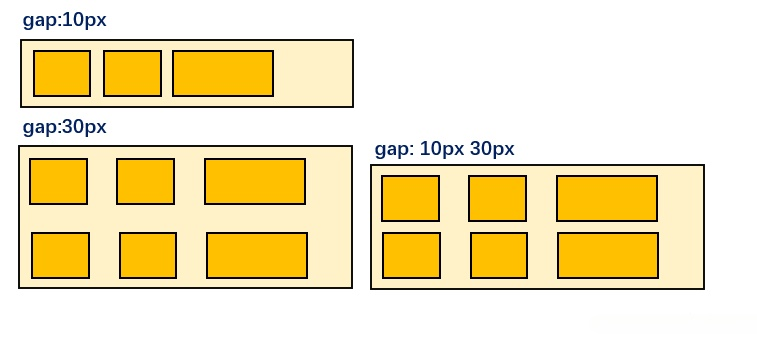
这设置的是最小间距,因为 just-content 导致的间距变大。

项目item 的属性包括:
order:指定了项目的排列顺序。
flex-grow:定义了在有可用空间时的放大比例。
flex-shrink:定义了在空间不足时的缩小比例。
flex-basis:指定了项目在分配空间前的初始大小。
flex:这是flex-grow、flex-shrink和flex-basis的简写形式。
align-self:允许单个项目独立于其他项目在交叉轴上对齐。
每个子容器的order属性默认为0
通过设置order属性值,改变子容器的排列顺序
可以是负值,数值越小的话,排的越靠前
.item1 {
order: 3; /* default is 0 */
}

在容器主轴上存在剩余空间时, flex-grow才有意义。
定义的是可放大的能力,0 (默认)禁止放大,大于 0 时按占的比重分放大,负数无效。
.container{
border-left:1.2px solid black;
border-top:1.2px solid black;
border-bottom: 1.2px solid black;
width: 100px;
height: 20px;
display: flex;
}
.item{
border-right:1.2px solid black;
width: 20px;height: 20px;
}
.item1{
/* 其他的都是0,这一个是1,1/1所以能所有剩下的空间都是item1的 */
flex-grow: 1; /* default 0 */
}
<div>
<div class="item item1" style="background-color: #7A42A8;"></div>
<div style="background-color: #8FAADC;"></div>
<div style="background-color: #DAE3F3;"></div>
</div>

当容器主轴 “空间不足” 且 “禁止换行” 时, flex-shrink才有意义。
定义的是可缩小的能力,1 (默认)等大于 0 的按比例权重收缩, 0 为禁止收缩,负数无效。
.container{
width: 100px;
height: 20px;
display: flex;
flex-wrap: nowrap;
}
.item{
width: 50px;height: 20px;
}
.item1{/*收缩权重1/3,总空间50,所以它占33.33,为原本的2/3*/
flex-shrink: 1; /* default 1 */
}
.item2{/*收缩权重2/3,总空间50,所以它占16.67,为原本的1/3*/
flex-shrink: 2; /* default 1 */
}
.item3{
flex-shrink: 0; /* default 1 */
}
<div>
<div class="item item1" style="background-color: #7A42A8;"></div>
<div class="item item2" style="background-color: #8FAADC;"></div>
<div class="item item3" style="background-color: #DAE3F3;"></div>
</div>

flex-basis 指定了 flex 元素在主轴方向上的初始尺寸,它可以是长度(例如 20% 、 5rem 等)或关键字。felx-wrap根据它计算是否换行,默认值为 auto ,即项目的本来大小。它会覆盖原本的width 或 height。
.item {
flex-basis: <length> | auto; /* default auto */
}
flex-grow , flex-shrink 和 flex-basis 组合的简写,默认值为 0 1 auto。
.item {
flex: none | [ <'flex-grow'> <'flex-shrink'>? || <'flex-basis'> ]
}
取值情况: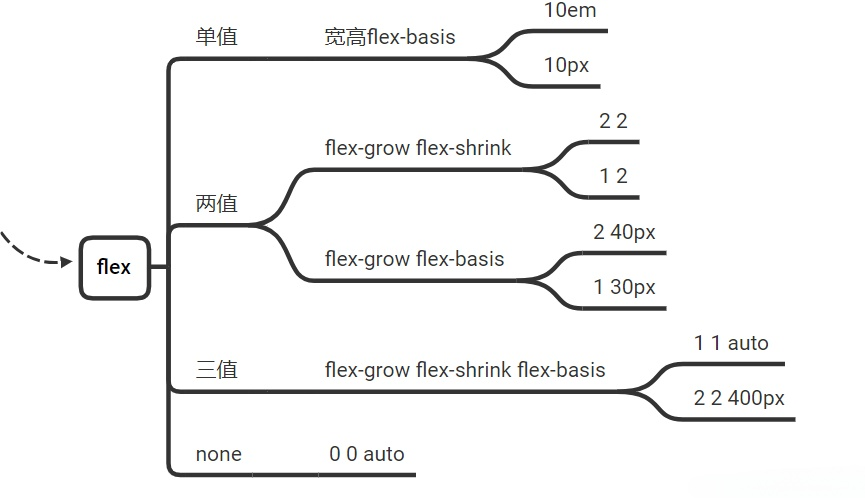
这允许为单个弹性项目覆盖默认的交叉轴对齐方式 align-items。
.item {
align-self: auto | flex-start | flex-end | center | baseline | stretch;
}
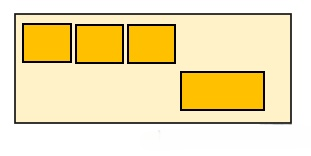
注意: flexbox布局和原来的布局是两个概念,部分css属性在flexbox盒子里面不起作用,eg:float , clear 和 vertical-align 等等。
想要快速入门前端开发吗?推荐一个前端开发基础课程,这个老师讲的特别好,零基础学习无压力,知识点结合代码,边学边练,可以免费试看试学,还有各种辅助工具和资料,非常适合新手!
点这里前往学习哦!
让我们通过一个简单的例子来实践一下Flex布局的魅力。假设我们有6张图片,我们希望在不同的屏幕尺寸下,它们能够自适应排列。
对于包含图片的容器,首先将其display属性设置为flex,从而启用Flex布局。
根据设计需求,可以通过设置flex-direction属性来确定图片的排列方向。例如,如果希望图片在小屏幕上水平排列,可以设置flex-direction: row;如果希望图片垂直排列,则设置flex-direction: column。
使用justify-content和align-items属性来调整图片的对齐方式。例如,如果想让图片在主轴上均匀分布,可以设置justify-content: space-around;如果想让图片在交叉轴上居中对齐,可以设置align-items: center。
如果需要图片在小屏幕上换行显示,可以添加flex-wrap: wrap属性。
通过调整flex-grow、flex-shrink和flex-basis属性来优化空间分配。例如,可以设置图片的flex-basis为calc(100% / 3 - 20px),这样每张图片会占据三分之一的宽度减去20像素的间距。
示例代码如下:
<!DOCTYPE html>
<html>
<head>
<style>
.image-grid {
display: flex;
flex-wrap: wrap;
justify-content: space-around;
}
.image-grid img {
flex-basis: calc(100% / 3 - 20px);
}
@media screen and (max-width: 800px) {
.image-grid img {
flex-basis: calc(100% / 2 - 20px);
}
}
@media screen and (max-width: 400px) {
.image-grid img {
flex-basis: calc(100% - 20px);
}
}
</style>
</head>
<body>
<div>
<img src="image1.jpg" alt="Image 1">
<img src="image2.jpg" alt="Image 2">
<img src="image3.jpg" alt="Image 3">
<img src="image4.jpg" alt="Image 4">
<img src="image5.jpg" alt="Image 5">
<img src="image6.jpg" alt="Image 6">
</div>
</body>
</html>
将上述代码保存为一个HTML文件,并将image1.jpg、image2.jpg等替换为你自己的图片路径。然后在浏览器中打开该HTML文件,你将看到一个响应式的图片网格布局,图片会根据屏幕尺寸自适应排列。
Flex布局以其简洁明了的属性和强大的适应性,已经成为现代网页设计不可或缺的工具。掌握了Flex布局,你将能够轻松应对各种复杂的页面布局需求,让你的设计更加灵活、美观。现在,就打开你的代码编辑器,开始你的Flex布局之旅吧!
收起阅读 »autofit.js 发布马上要一年了,也收获了一批力挺用户,截至目前它在github上有1k 的 star,npm 上有超过 13k 的下载量。
这篇文章主要讲从设计稿到落地开发大屏应用,大道至简,这篇文章能帮助各位潇洒自如的开发大屏。
分析设计稿之前先吐槽一下大屏这种展现形式,这简直就是自欺欺人、面子工程的最直接的诠释,是吊用没有,只为了好看,如果设计的再不好看啊,这就纯纯是屎。在我的理解中,这就像把PPT放到了web端,仅此而已。
但是王哥告诉我:"你看似没有用的东西,其实都有用,很多想真正做出有用的产品的企业,没钱,就要先把面子工程做好,告诉别人他们要做一件什么事,这样投资人才会看到,后面才有机会发展。"

上图展示了一个传统意义上且比较普遍的大屏形态,分为四个部分,分别是
头部经常放标题、功能菜单、时间、天气
左右面板承载了各种数字和报表,还有视频、轮播图等等
中间部分一般放地图,这其中又分假地图(一张图片)、图表地图(如echarts)、地图引擎(如:leaflet、mapbox、高德、百度)。或者有的还会放3D场景,一般有专门的同事去做3D场景,然后导入到web端。
大屏的设计通常的分辨率是 1920*1080 的,这也是迄今为止应用最广泛的显示器配置,当然也有基于客户屏幕做的异形分辨率,这就五花八门了。
但是万变不离其宗,分辨率的变化不会影响它的基本结构,根据上面的图,我们可以快速构建结构代码
<div class='Box'>
<div class="header"></div>
<div class="body">
<div class="leftPanel"></div>
<div class="mainMap"></div>
<div class="rightPanel"></div>
</div>
</div>
上面的代码实现了最简单的上下(Box)+左右(body)的布局结构,完全不需要任何定位策略。
要实现上图的效果,只需最简单的CSS即可完成布局。
大屏虽然是屎,但是是一种可玩性很强的项目,想的越复杂,做起来就越复杂,想的越简单,做起来就越简单。
可以疯狂封装炫技,因为大屏里面的可玩组件简直太多了,且涵盖的太全了,想怎么玩都可以,包括但不限于 各类图表库的封装(echarts、highCharts、vChart)、轮播图(swiper)、地图引擎、视频库(包括直播流)等等。
如果想简单,甚至可以不用封装,可以看到结构甚至简单到不用CSS几行就可以搭建出基本框架,只把header、leaftPanel、rightPanel、map封装一下就可以了。
这里还有一个误区,就是大家都喜欢把 大型的组件库 拉到大屏里来用,结果做完了发现好像只用了一个 toast 和一个下拉组件,项目打包后却增大了几十倍的体积,其实像这种简单的组件,完全可以手写,或者找小的独立包来用,一方面会减小体积,不至于让项目臃肿,另一方面可以锻炼自己的手写能力,这才是有必要的封装。
目前主流的适配方案,依然是 rem 方案,其原理就是根据根元素的 font-size 自动计算大小,但是此方法需要手动计算 rem 值,或者使用第三方插件如postcss等,但是此方案还有一个弊端,就是无法向下兼容,因为浏览器中最小的文字大小是12px。
vh/vw方案就不再赘述了,原理基本和 rem/em 相似,都涉及到单位的转换。
主要讲一下使用 autofit.js 如何快速实现适配。
首先 autofit.js 不支持 elementUI(plus)、ant-design等组件库,具体是不支持包含popper.js的组件,popper.js 在计算弹出层位置时,不会考虑 scale 后的元素的视觉大小,所以会造成弹出元素的位置偏移。
其次,不支持 百度地图,百度地图对窗口缩放事件没有任何处理,有同学反馈说,即使使用了resize属性,百度地图在和autofit.js共同使用时,也会有事件热区偏移的问题。而且百度地图使用 bd-09 坐标系,和其他图商不通用,引擎的性能方面也差点意思,个人不推荐在开发中使用百度地图。
然后一些拖拽库,如甘特图插件,可能也不支持,他们在计算鼠标位置时同样没有考虑 scale 后的元素的视觉大小。
不支持的单位:vh、vw、rem、em
让我诧异的是,老有人问我该用什么单位,主要徘徊在 px 和 % 之间,加群的同学多数是因为用了相对单位,导致留白了。不过人各有所长,跟着各位大佬我也学到了很多。
看下图

假如有两个宽度为1000的元素,他们内部都有一个子元素,第一个用百分比设置为 width:50%;left:1% , 第二个设置为 wdith:500px;left:10px 。此时,只要外部的1000px的容器宽度不变,这两个内部元素在视觉上是一模一样的,且在实际数值上也是一模一样的,他们宽度都为500px,距离左侧10px。
但是如果外部容器变大了,来看一下效果:

在样式不变的情况下,仅改变外部容器大小,差异就出来了,由上图可知,50%的元素依然占父元素的一半,实际宽度变成了 1000px,距离左侧的实际距离变成了 20px。
这当然不难理解,百分比单位是根据 最近的、有确定大小的父级元素计算的。
所以,应该用什么单位其实取决于想做什么,举个例子:在1920*1080基础上开发,中间的地图写成了宽度为 500px ,这在正常情况下,看起来没有任何问题,它大概占屏幕的 26%,当屏幕分辨率达到4096*2160时,它在屏幕上只占 12%,看起来就是缩在一角。而当你设置宽度为26%时,无论显示器如何变化,它始终占屏幕26%。
autofit.js 所干的事,就是把1000px 变成了 2000px或者把2000px变成了1000px,并给它设置了一个合适的缩放大小。
背景或各种图片按需设置 object-fit: cover;即可
图表如echarts一般推荐使用百分比,且监听窗口变化事件做resize()
再次感慨,大道至简,事情往往没有那么复杂,祝各位前程似锦。
最近开发项目时,常碰到“用户在一定时间内无任何操作时,跳转到某个页面”的需求。
网上冲浪后,也没有找到一个比较好的js封装去解决这个问题,从而决定自己实现。
首先,我们要知道什么是空闲?用户一定时间内,没有对网页进行任何操作,则当前网页为空闲状态。
用户操作网页,无非就是通过鼠标、键盘两个输入设备(暂不考虑手柄等设备)。因而我们可以监听相应的输入事件,来判断网页是否空闲(用户是否有操作网页)。
mousemove;mousedown;以下代码,简单实现了一个判断网页空闲的方法:
const onIdleDetection = (callback, timeout = 15, immediate = false) => {
let pageTimer;
const onClearTimer = () => {
pageTimer && clearTimeout(pageTimer);
pageTimer = undefined;
};
const onStartTimer = () => {
onClearTimer();
pageTimer = setTimeout(() => {
callback();
}, timeout * 1000);
};
const startDetection = () => {
onStartTimer();
document.addEventListener('mousedown', onStartTimer);
document.addEventListener('mousemove', onStartTimer);
};
const stopDetection = () => {
onClearTimer();
document.removeEventListener('mousedown', onStartTimer);
document.removeEventListener('mousemove', onStartTimer);
};
const restartDetection = () => {
onClearTimer();
onStartTimer();
};
if (immediate) {
startDetection();
}
return {
startDetection,
stopDetection,
restartDetection
};
};
也许你注意到了,我并没有针对onStartTimer事件进行防抖,那这是不是会对性能有影响呢?
是的,肯定有那么点影响,那我为啥不添加防抖呢?
这是因为添加防抖后,形成了setTimeout嵌套,嵌套setTimeout会有精度问题(参考)。
或许你还会说,非活动标签页(网页被隐藏)的setTimeout的执行和精度会有问题(参考非活动标签的超时)。
确实存在以上问题,接下来我们就来一一解决吧!
我们可以通过添加一个变量记录开始执行时间,当下一次执行与当前的时间间隔小于某个值时直接退出函数,从而解决这个问题(节流思想应用)。
const onIdleDetection = (callback, timeout = 15, immediate = false) => {
let pageTimer;
// 记录开始时间
let beginTime = 0;
const onStartTimer = () => {
// 触发间隔小于100ms时,直接返回
const currentTime = Date.now();
if (pageTimer && currentTime - beginTime < 100) {
return;
}
onClearTimer();
// 更新开始时间
beginTime = currentTime;
pageTimer = setTimeout(() => {
callback();
}, timeout * 1000);
};
const onClearTimer = () => {
pageTimer && clearTimeout(pageTimer);
pageTimer = undefined;
};
const startDetection = () => {
onStartTimer();
document.addEventListener('mousedown', onStartTimer);
document.addEventListener('mousemove', onStartTimer);
};
const stopDetection = () => {
onClearTimer();
document.removeEventListener('mousedown', onStartTimer);
document.removeEventListener('mousemove', onStartTimer);
};
const restartDetection = () => {
onClearTimer();
onStartTimer();
};
if (immediate) {
startDetection();
}
return {
startDetection,
stopDetection,
restartDetection
};
};
我们可以监听visibilitychange事件,在页面隐藏时移除延时器,然后页面显示时继续计时,从而解决这个问题。
/**
* 网页空闲检测
* @param {() => void} callback 空闲时执行,即一定时长无操作时触发
* @param {number} [timeout=15] 时长,默认15s,单位:秒
* @param {boolean} [immediate=false] 是否立即开始,默认 false
* @returns
*/
const onIdleDetection = (callback, timeout = 15, immediate = false) => {
let pageTimer;
let beginTime = 0;
const onClearTimer = () => {
pageTimer && clearTimeout(pageTimer);
pageTimer = undefined;
};
const onStartTimer = () => {
const currentTime = Date.now();
if (pageTimer && currentTime - beginTime < 100) {
return;
}
onClearTimer();
beginTime = currentTime;
pageTimer = setTimeout(() => {
callback();
}, timeout * 1000);
};
const onPageVisibility = () => {
// 页面显示状态改变时,移除延时器
onClearTimer();
if (document.visibilityState === 'visible') {
const currentTime = Date.now();
// 页面显示时,计算时间,如果超出限制时间则直接执行回调函数
if (currentTime - beginTime >= timeout * 1000) {
callback();
return;
}
// 继续计时
pageTimer = setTimeout(() => {
callback();
}, timeout * 1000 - (currentTime - beginTime));
}
};
const startDetection = () => {
onStartTimer();
document.addEventListener('mousedown', onStartTimer);
document.addEventListener('mousemove', onStartTimer);
document.addEventListener('visibilitychange', onPageVisibility);
};
const stopDetection = () => {
onClearTimer();
document.removeEventListener('mousedown', onStartTimer);
document.removeEventListener('mousemove', onStartTimer);
document.removeEventListener('visibilitychange', onPageVisibility);
};
const restartDetection = () => {
onClearTimer();
onStartTimer();
};
if (immediate) {
startDetection();
}
return {
startDetection,
stopDetection,
restartDetection
};
};
通过以上代码,我们就完整地实现了一个网页空闲状态检测的方法。
chrome浏览器其实提供了一个Idle DetectionAPI,来实现网页空闲状态的检测,但是这个API还是一个实验性特性,并且Firefox与Safari不支持。API参考
为了提升浏览器加载页面资源的性能,对于js、css、图片等静态资源,web服务器往往会通过Cache-Control、ETag/If--Match、Last-Modified/If-Modified-Since、Pragma、Expires、Date、Age等头部来控制、管理、检测这类资源对缓存机制的使用情况。同时,为了使新版本的js、css等资源立即生效,一种比较通行的做法是为js、css这些文件名添加一个hash值。这样当js、css内容发生变化时,浏览器获取的是不同的js、css文件。在这种情况下,旧版本的index.html文件可能是这样的:
<!DOCTYPE html>
<html>
<head>
<meta charset=utf-8>
<title>测试</title>
<meta http-equiv=X-UA-Compatible content="IE=Edge">
<meta name=viewport content="width=device-width,minimum-scale=1,maximum-scale=1">
<link href=/static/css/main.4656e35c1e8d4345f5bf.css rel=stylesheet>
</head>
<style>
html, body {
width: 100%;
}
</style>
<body>
<div id=newMain></div>
<script type=text/javascript src=/static/js/main-4656e35c1e8d4345f5bf.js></script>
</body>
</html>
当项目的js、css内容发生了变化时,新版本的index.html文件内容变成这样的(js和css文件名携带了新的hash值1711528240049):
<!DOCTYPE html>
<html>
<head>
<meta charset=utf-8>
<title>测试</title>
<meta http-equiv=X-UA-Compatible content="IE=Edge">
<meta name=viewport content="width=device-width,minimum-scale=1,maximum-scale=1">
<link href=/static/css/main.1711528240049.css rel=stylesheet>
</head>
<style>
html, body {
width: 100%;
}
</style>
<body>
<div id=newMain></div>
<script type=text/javascript src=/static/js/main-1711528240049.js></script>
</body>
</html>
因为index.html文件一般会设置为不缓存,这样用户每次访问首页时,都会从web服务器重新获取index.html,然后根据index.html中的资源文件是否变化,从而决定是否使用缓存的文件。这样既能让用户立即获取最新的js、css等静态资源文件,又能充分地使用缓存。index.html的响应头大概长这样:

但是为了保证系统的高可用,web后端往往由多个实例提供服务,用户请求会在多个服务实例间进行负载均衡。而系统升级过程中,会存在多个版本共存的现象。这时,如果用户从旧版本实例上获取了index.html文件,然后再去获取旧版本的js、css文件(main-4656e35c1e8d4345f5bf.js和main.4656e35c1e8d4345f5bf.css),但是请求却分发到了新版本服务实例上,这时因为新版本服务实例只有main-1711528240049.js和main.1711528240049.css文件,就会导致访问失败。反过来,如果从新版本实例上获取了index.html文件,在请求相应的js、css文件时,也可能被分发到旧版本实例上,也导致访问失败。
解决方法:
1)首先,改造一下index.html文件中引用js、css等静态资源的路径,添加一个版本号,如v1、v2,这样index.html文件对js、css的引用变为:
<link href=/static/v1/css/main.1711528240049.css rel=stylesheet>
<script type=text/javascript src=/static/v1/js/main-1711528240049.js></script>
2)使用灰度发布策略升级系统,具体步骤如下(假设系统包含A、B两个服务实例)
/static/v1的请求负载均衡分发到A、B两个服务实例/static/v2的请求分发到服务实例A。这时,从服务实例A上获取的index.html文件引发的后续js、css请求,都会分发到服务实例A,从服务实例B上获取的index.html文件引发的后续js、css请求,都会分发到服务实例B
一个开放、互助、协作、创意的社区





