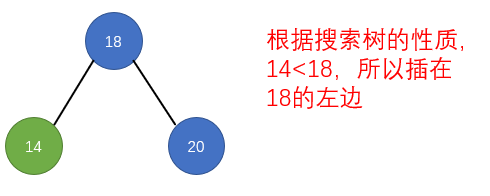
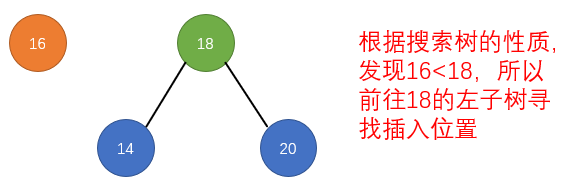
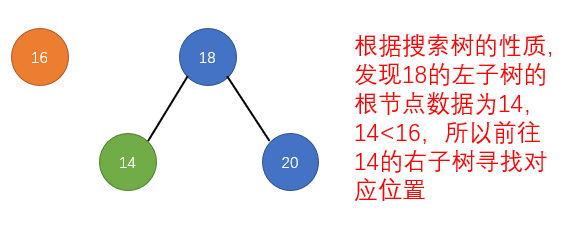
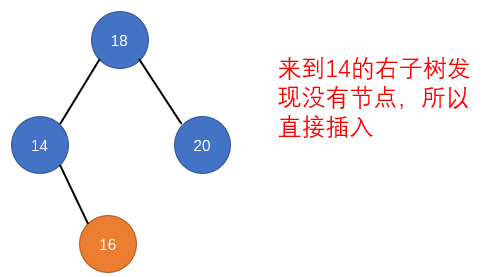
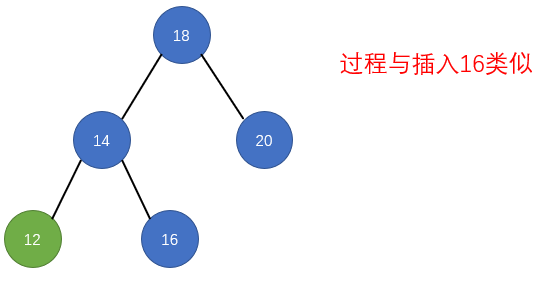
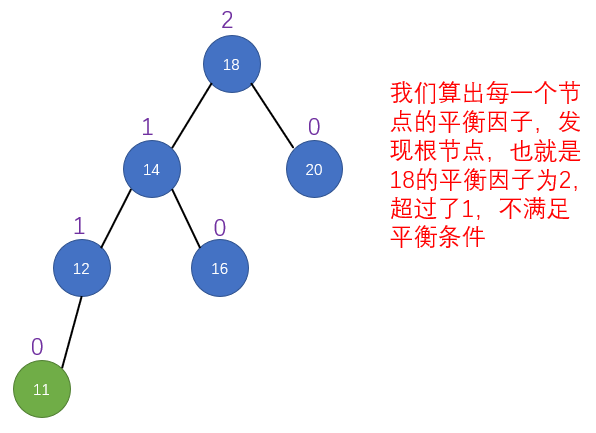
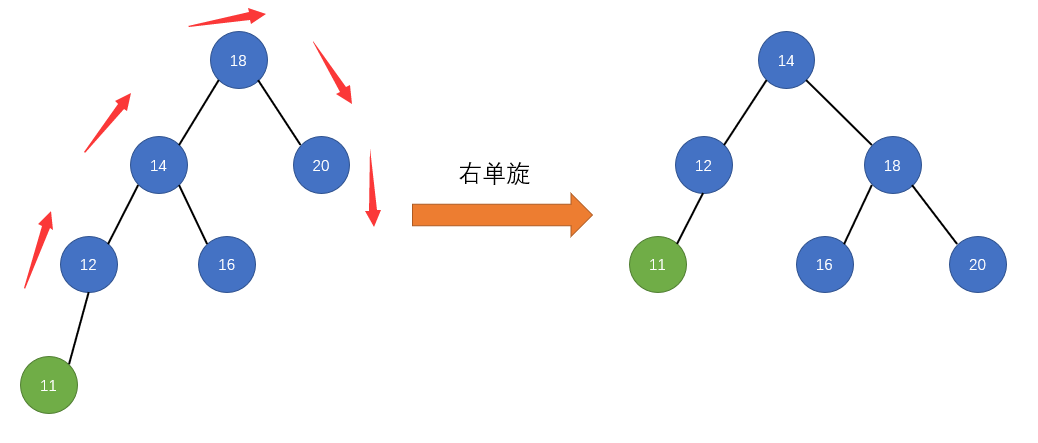
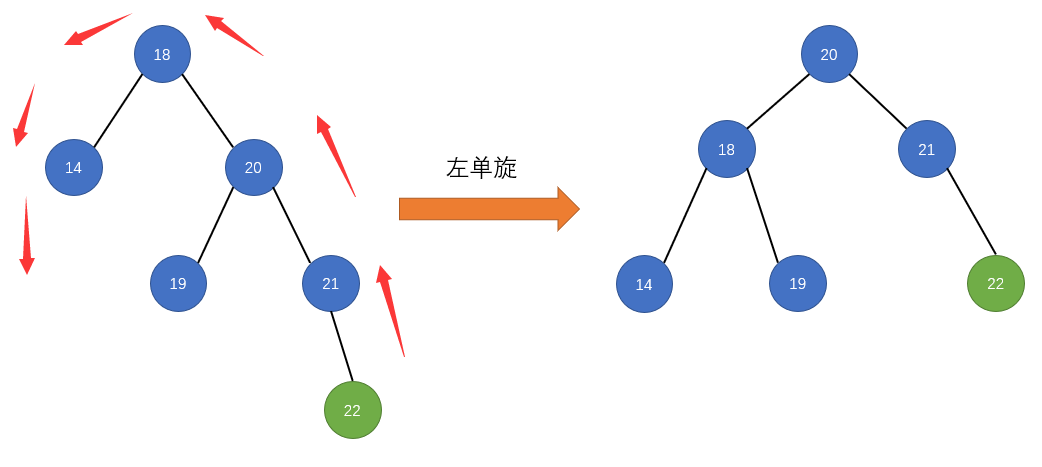
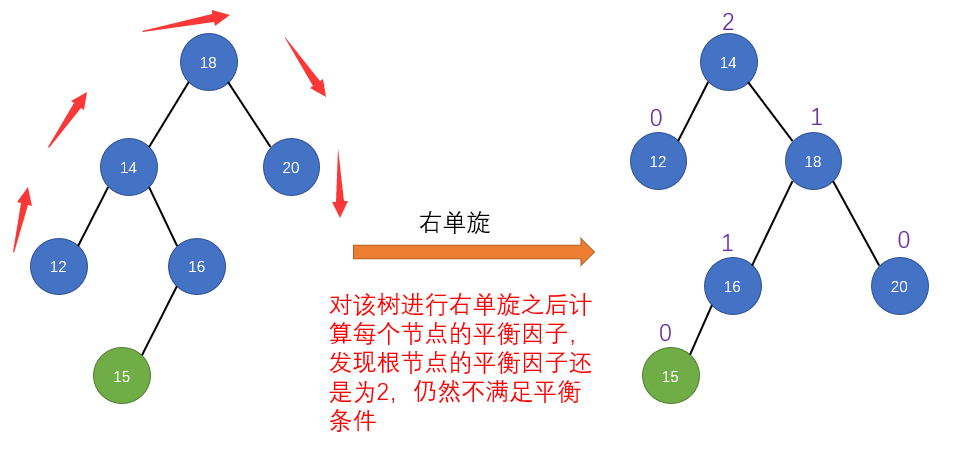
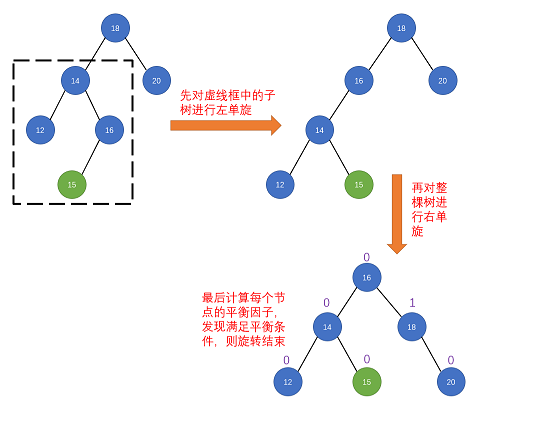
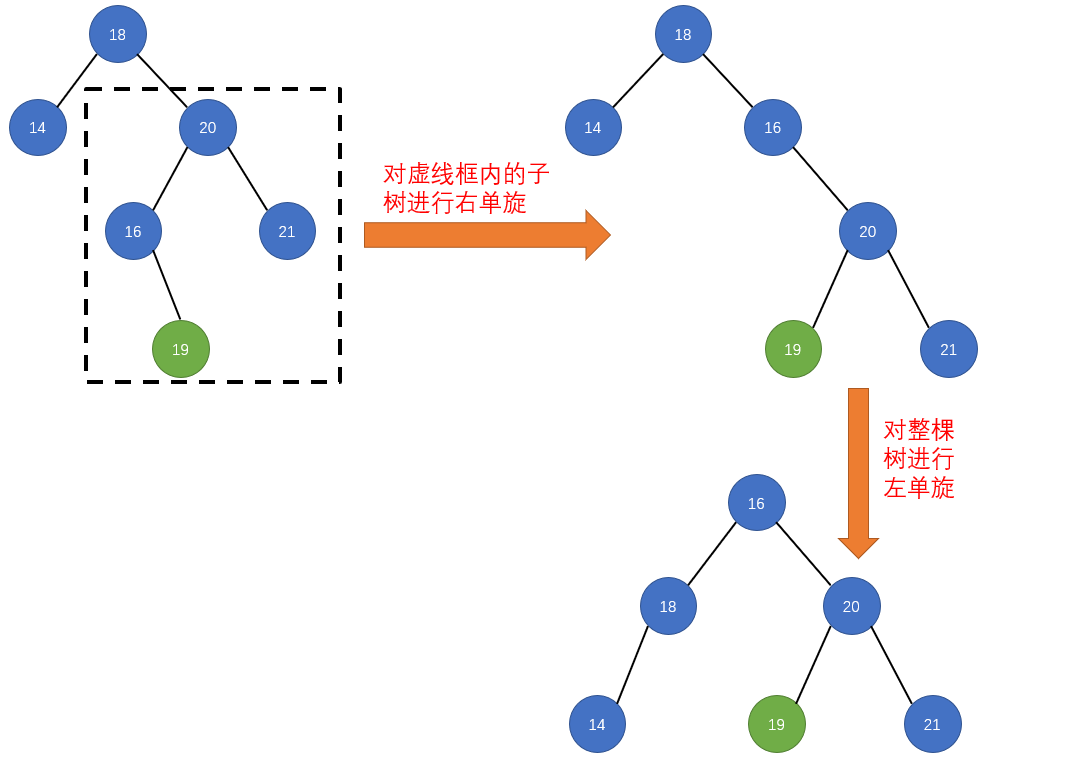
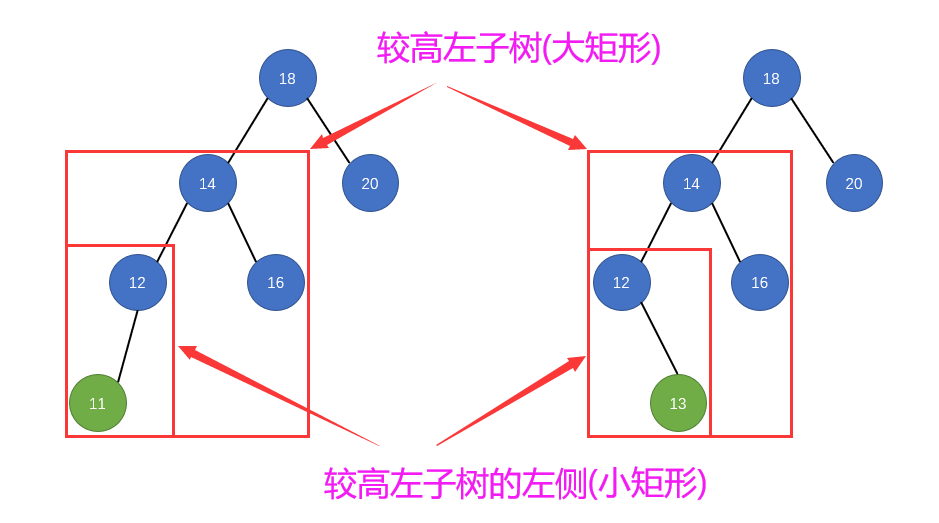
public LoopScrollView(Context context) {
this(context, null);
}
public LoopScrollView(Context context, AttributeSet attrs) {
super(context, attrs);
setOverScrollMode(OVER_SCROLL_ALWAYS);
try {
@SuppressLint("DiscouragedPrivateApi")
Field field =HorizontalScrollView.class.getDeclaredField("mScroller");
field.setAccessible(true);
loopScroller = new LoopScroller(getContext());
field.set(this, loopScroller);
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
protected void onLayout(boolean changed, int l, int t, int r, int b) {
super.onLayout(changed, l, t, r, b);
if(changed||animator==null){
buildAnimation();
}
}
private void buildAnimation() {
if(animator!=null){
animator.cancel();
animator=null;
}
animator = ValueAnimator.ofInt(getWidth() - getPaddingRight() - getPaddingLeft());
animator.setDuration(5*1000);
animator.setRepeatCount(-1);
animator.setInterpolator(new LinearInterpolator());
animator.addUpdateListener(new ValueAnimator.AnimatorUpdateListener() {
int lastValue;
@Override
public void onAnimationUpdate(ValueAnimator animation) {
int value= (int) animation.getAnimatedValue();
int scrollByX=value-lastValue;
// Log.i("zzz","scroll by x="+scrollByX);
scrollByX=Math.max(0,scrollByX);
if(userUp) {
scrollBy(scrollByX, 0);
}
lastValue=value;
}
});
animator.addListener(new AnimatorListenerAdapter() {
@Override
public void onAnimationEnd(Animator animation) {
super.onAnimationEnd(animation);
}
@Override
public void onAnimationStart(Animator animation) {
super.onAnimationStart(animation);
}
});
animator.start();
}
static class LoopScroller extends OverScroller{
public LoopScroller(Context context) {
super(context);
}
@Override
public void fling(int startX, int startY, int velocityX, int velocityY, int minX, int maxX, int minY, int maxY, int overX, int overY) {
super.fling(startX, startY, velocityX, velocityY, Integer.MIN_VALUE,Integer.MAX_VALUE, minY, maxY, 0, overY);
}
}
public interface ModelLoader<Model, Data> {
class LoadData<Data> {
//数据加载的key
public final Key sourceKey;
public final List<Key> alternateKeys;
//获取数据的接口,对应获取不同类型的数据实现
public final DataFetcher<Data> fetcher;
//创建LoadData 对象
@Nullable
LoadData<Data> buildLoadData(@NonNull Model model, int width, int height,
@NonNull Options options);
//判断当前的ModelLoader是否能够处理这个model
boolean handles(@NonNull Model model);
}
DataFetcher: 用于进行数据加载,不同的类型有不同的DataFetcher
SourceGenerator远程数据加载过程
@Override
public boolean startNext() {
//...
boolean started = false;
while (!started && hasNextModelLoader()) {
loadData = helper.getLoadData().get(loadDataListIndex++);
if (loadData != null
&& (helper.getDiskCacheStrategy().isDataCacheable(loadData.fetcher.getDataSource())
|| helper.hasLoadPath(loadData.fetcher.getDataClass()))) {
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
/**
* Make a standard toast to display using the specified looper.
* If looper is null, Looper.myLooper() is used. // 1. 注意这一句话
* @hide
*/
public static Toast makeText(@NonNull Context context, @Nullable Looper looper,
@NonNull CharSequence text, @Duration int duration) {
// 2. 构造toast实例,有传入looper,此处looper为null
Toast result = new Toast(context, looper);
LayoutInflater inflate = (LayoutInflater)
context.getSystemService(Context.LAYOUT_INFLATER_SERVICE);
View v = inflate.inflate(com.android.internal.R.layout.transient_notification, null);
TextView tv = (TextView)v.findViewById(com.android.internal.R.id.message);
tv.setText(text);
// 重点
// 2.判断looper == null,这里我们从上面传入的时候就是null,所以会进到里面去。
if (looper == null) {
// Use Looper.myLooper() if looper is not specified.
// 3.然后会调用Looper.myLooper这个函数,也就是会从ThreadLocal<Looper> sThreadLocal 去获取当前线程的looper。
// 如果ThreadLocal这个不太清楚的可以先去看看handler源码分析相关的内容了解一下。
looper = Looper.myLooper();
if (looper == null) {
// 4.这就是报错信息的根源点了!!
// 没有获取到当前线程的looper的话,就会抛出这个异常。
// 所以分析到这里,就可以明白为什么在子线程直接toast会抛出这个异常
// 而在子线程中创建了looper就不会抛出异常了。
throw new RuntimeException(
"Can't toast on a thread that has not called Looper.prepare()");
}
}
// 5.这里不重点讲toast是如何展示出来的源码了,主要都在TN这个类里面,
// Toast与TN中间有涉及aidl跨进程的调用,这些可以看看源码。
// 大致就是:我们的show方法实际是会往这个looper里面放入message的,
// looper.loop()会阻塞、轮循,
// 当looper里面有Message的时候会将message取出来,
// 然后会通过handler的handleMessage来处理。
mHandler = new Handler(looper, null) {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
// .... 省略代码
case SHOW: // 显示,与WindowManager有关,这部分源码不做说明了,可以自己看看,就在TN类里面。
case HIDE: // 隐藏
case CANCEL: // 取消
}
}
};
}
总结
从第1点可以看到会创建TN的实例,并传入looper,此时的looper还是null。
进入TN的构造函数可以看到会有looper是否为null的判断,并且在当looper为null时,会从当前线程去获取looper(第3点,Looper.myLooper()),如果还是获取不到,刚会抛出我们开头说的这个异常信息:Can't toast on a thread that has not called Looper.prepare()。
而不能直接在子线程程中toast的原因是:子线程中没有创建looper的话,去通过Looper.myLooper()获取到的为null,就会throw new RuntimeException(
"Can't toast on a thread that has not called Looper.prepare()");
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
最大容量为2^30
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
链表元素数量进化成红黑树的阈值为8,数组元素大于64时,链表元素超过8就会进化为红黑树
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
至于为什么选8,在之前有一段很长的注释里面有说明,可以看一下原文如下:
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
链表树能进化成树时最小的数组长度,只有数组长度打到这个值链表才可能进化成树
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
重要的内部类
链表Node<K,V>
定义的链表Node类,next有木有很熟悉,单向链表
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
红黑树TreeNode<K,V>
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
HashMap的put方法
实际上调用的是putVal方法
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
接下来看看putVal方法
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
//数组原来不为空
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//初始化,申明HashMap的时候指定了初始容量
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//初始化,申明HashMap的时候没有指定初始容量
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
你可以给事务添加 tag 标签,然后从栈中弹出操作,但是仅仅是一个 main -> Events -> Details(id=123) 的操作流程就相当繁琐了。
同样的,一旦你将一个 Fragment 放进回退栈中,我个人不知道它的生命周期开始做什么。我曾经遇到过一个后台中的 fragment 被调用四次 onCreateView() 方法,我甚至不知道究竟怎么了。而没有位于回退栈中的 Fragments 是可以被预见的。它们的动画支持有点古怪,但至少它们还能使用。
Duplicate class com.ta.utdid2.a.a.a found in modules jetified-alicloud-android-utdid-2.5.1-proguard (com.aliyun.ams:alicloud-android-utdid:2.5.1-proguard) and jetified-utdid-1.5.2.1 (com.umeng.umsdk:utdid:1.5.2.1)
随着容器编排(Container Orchestration)、微服务(Micro Services)、云技术(Cloud Technology)等在 IT 行业不断盛行,2009 年诞生于 Google 的 Golang(Go 语言,简称 Go)越来越受到软件工程师的欢迎和追捧,成为如今炙手可热的后端编程语言。在用 Golang 开发的软件项目列表中,有 Docker(容器技术)、Kubernetes(容器编排)这样的颠覆整个 IT 行业的明星级产品,也有像 Prometheus(监控系统)、Etcd(分布式存储)、InfluxDB(时序数据库)这样的强大实用的知名项目。当然,Go 语言的应用领域也绝不局限于容器和分布式系统。如今很多大型互联网企业在大量使用 Golang 构建后端 Web 应用,例如今日头条、京东、七牛云等;长期被 Python 统治的框架爬虫领域也因为简单而易用的爬虫框架 Colly 的崛起而不断受到 Golang 的挑战。Golang 已经成为了如今大多数软件工程师最想学习的编程语言。下图是 HackerRank 在 2020 年调查程序员技能的相关结果。
那么,**Go 语言真的是后端开发人员的救命良药呢?它是否能够有效提高程序员们的技术实力和开发效率,从而帮助他们在职场上更进一步呢?Go 语言真的值得我们花大量时间深入学习么?**本文将详细介绍 Golang 的语言特点以及它的优缺点和适用场景,带着上述几个疑问,为读者分析 Go 语言的各个方面,以帮助初入 IT 行业的程序员以及对 Go 感兴趣的开发者进一步了解这个热门语言。
Golang 简介
Golang 诞生于互联网巨头 Google,而这并不是一个巧合。我们都知道,Google 有一个 20% 做业余项目(Side Project)的企业文化,允许工程师们能够在轻松的环境下创造一些具有颠覆性创新的产品。而 Golang 也正是在这 20% 时间中不断孵化出来。Go 语言的创始者也是 IT 界内大名鼎鼎的行业领袖,包括 Unix 核心团队成员 Rob Pike、C 语言作者 Ken Thompson、V8 引擎核心贡献者 Robert Griesemer。Go 语言被大众所熟知还是源于容器技术 Docker 在 2014 年被开源后的爆发式发展。之后,Go 语言因为其简单的语法以及迅猛的编译速度受到大量开发者的追捧,也诞生了很多优秀的项目,例如 Kubernetes。
Go 语言相对于其他传统热门编程语言来说,有很多优点,特别是其高效编译速度和天然并发特性,让其成为快速开发分布式应用的首选语言。Go 语言是静态类型语言,也就是说 Go 语言跟 Java、C# 一样需要编译,而且有完备的类型系统,可以有效减少因类型不一致导致的代码质量问题。因此,Go 语言非常适合构建对稳定性和灵活性均有要求的大型 IT 系统,这也是很多大型互联网公司用 Golang 重构老代码的重要原因:传统的静态 OOP 语言(例如 Java、C#)稳定性高但缺乏灵活性;而动态语言(例如 PHP、Python、Ruby、Node.js)灵活性强但缺乏稳定性。因此,“熊掌和鱼兼得” 的 Golang,受到开发者们的追捧是自然而然的事情,毕竟,“天下苦 Java/PHP/Python/Ruby 们久矣“。
Golang 还有很多帮你节省代码的地方。你可以发现 Go 中不会强制要求用 new 这个关键词来生成某个类(Class)的新实例(Instance)。而且,对于公共和私有属性(变量和方法)的约定不再使用传统的 public 和 private 关键词,而是直接用属性变量首字母的大小写来区分。下面一些例子可以帮助读者理解这些特点。
// 公共方法
public String PublicMethod() {
return "This can be called by external modules";
}
// 私有方法
public String privateMethod() {
return "This can only be called in SomeClass";
}
}
...
// Application.java
public Application {
public static void main(String[] args) {
// 生成实例
SomeClass someInstance = new SomeClass("hello", "world");
}
}
可以看到,在 Java 代码中除了容易看花眼的多层花括号以外,还充斥着大量的 public、private、static、this 等修饰用的关键词,显得异常啰嗦;而 Golang 代码中则靠简单的约定,例如首字母大小写,避免了很多重复性的修饰词。当然,Java 和 Go 在类型系统上还是有一些区别的,这也导致 Go 在处理复杂问题显得有些力不从心,这是后话,后面再讨论。总之,结论就是 Go 的语法在静态类型编程语言中非常简洁。
内置并发编程
Go 语言之所以成为分布式应用的首选,除了它性能强大以外,其最主要的原因就是它天然的并发编程。这个并发编程特性主要来自于 Golang 中的协程(Goroutine)和通道(Channel)。下面是使用协程的一个例子。
func asyncTask() {
fmt.Printf("This is an asynchronized task")
}
func syncTask() {
fmt.Printf("This is a synchronized task")
}
func main() {
go asyncTask() // 异步执行,不阻塞
syncTask() // 同步执行,阻塞
go asyncTask() // 等待前面 syncTask 完成之后,再异步执行,不阻塞
}
可以看到,关键词 go 加函数调用可以让其作为一个异步函数执行,不会阻塞后面的代码。而如果不加 go 关键词,则会被当成是同步代码执行。如果读者熟悉 JavaScript 中的 async/await、Promise 语法,甚至是 Java、Python 中的多线程异步编程,你会发现它们跟 Go 异步编程的简单程度不是一个量级的!
异步函数,也就是协程之间的通信可以用 Go 语言特有的通道来实现。下面是关于通道的一个例子。
func longTask(signal chan int) {
// 不带参数的 for
// 相当于 while 循环
for {
// 接收 signal 通道传值
v := <- signal
// 实现 Move 方法
func (h *Human) Move() {
fmt.Printf("Moving with two legs")
}
// ==== 定义 Human End ====
可以看到,虽然 Go 语言可以定义接口,但跟 Java 不同的是,Go 语言中没有显示声明接口实现(Implementation)的关键词修饰语法。在 Go 语言中,如果要继承一个接口,你只需要在结构体中实现该接口声明的所有方法。这样,对于 Go 编译器来说你定义的类就相当于继承了该接口。在这个例子中,我们规定,只要既能吃(Eat)又能活动(Move)的东西就是动物(Animal)。而狗(Dog)和人(Human)恰巧都可以吃和动,因此它们都被算作动物。这种依靠实现方法匹配度的继承方式,就是鸭子类型:如果一个动物看起来像鸭子,叫起来也像鸭子,那它一定是鸭子。这种鸭子类型相对于传统 OOP 编程语言显得更灵活。但是,后面我们会讨论到,这种编程方式会带来一些麻烦。
错误处理
Go 语言的错误处理是臭名昭著的啰嗦。这里先给一个简单例子。
package main
import "fmt"
func isValid(text string) (valid bool, err error){
if text == "" {
return false, error("text cannot be empty")
}
return text == "valid text", nil
}
func validateForm(form map[string]string) (res bool, err error) {
for _, text := range form {
valid, err := isValid(text)
if err != nil {
return false, err
}
if !valid {
return false, nil
}
}
return true, nil
}
当然,这里并不是说用 Golang 写后端就完全是一个正确的选择。笔者在工作中会用到 Java 和 C#,用了各自的主流框架(SpringBoot 和 .Net Core)之后,发现这两门传统 OOP 语言虽然语法啰嗦,但它们的语法特性很丰富,特别是泛型,能够轻松应对一些逻辑复杂、重复性高的业务需求。因此,笔者认为在考虑用 Go 来编写后端 API 时候,可以提前调研一下 Java 或 C#,它们在写后端业务功能方面做得非常棒。
总结
本篇文章从 Go 语言的主要语法特性入手,循序渐进分析了 Go 语言作为后端编程语言的优点和缺点,以及其在实际软件项目开发中的试用场景。笔者认为 Go 语言与其他语言的主要区别在于语法简洁、天然支持并发、面向接口编程、错误处理等方面,并且对各个语言特性在正反两方面进行了分析。最后,笔者根据之前的分析内容,得出了 Go 语言作为后端开发编程语言的适用场景,也就是分布式应用、网络爬虫以及后端API。当然,Go 语言的实际应用领域还不限于此。实际上,不少知名数据库都是用 Golang 开发的,例如时序数据库 Prometheus 和 InfluxDB、以及有 NewSQL 之称的 TiDB。此外,在机器学习方面,Go 语言也有一定的优势,只是目前来说,Google 因为 Swift 跟 TensorFlow 的意向合作,似乎还没有大力推广 Go 在机器学习方面的应用,不过一些潜在的开源项目已经涌现出来,例如 GoLearn、GoML、Gorgonia 等。
在理解 Go 语言的优势和适用场景的同时,我们必须意识到 Go 语言并不是全能的。它相较于其他一些主流框架来说也有一些缺点。开发者在准备采用 Go 作为实际工作开发语言的时候,需要全面了解其语言特性,从而做出最合理的技术选型。就像打网球一样,不仅需要掌握正反手,还要会发球、高压球、截击球等技术动作,这样才能把网球打好。
// Operator == and hashCode not shown. For details, see note below. // ···
}
voidmain(){ final v = Vector(2, 3); final w = Vector(2, 2);
assert(v + w == Vector(4, 5));
assert(v - w == Vector(0, 1));
}
注:重写==,也需要重写 Object hashCodegetter
classPerson{ final String firstName, lastName;
Person(this.firstName, this.lastName);
// Override hashCode using strategy from Effective Java, // Chapter 11. @override
int get hashCode {
int result = 17;
result = 37 * result + firstName.hashCode;
result = 37 * result + lastName.hashCode; return result;
}
// You should generally implement operator == if you // override hashCode. @override
bool operator ==(dynamic other) { if (other is! Person) returnfalse;
Person person = other; return (person.firstName == firstName &&
person.lastName == lastName);
}
}
void main() { var p1 = Person('Bob', 'Smith'); var p2 = Person('Bob', 'Smith'); var p3 = 'not a person';
assert(p1.hashCode == p2.hashCode);
assert(p1 == p2);
assert(p1 != p3);
}
// collection If Widgetbuild(BuildContext context) { returnRow( children: [
IconButton(icon: Icon(Icons.menu)),
Expanded(child: title),
if (!isAndroid)
IconButton(icon: Icon(Icons.search)),
],
);
}
// Collect For var command = [
engineDartPath,
frontendServer, for (var root in fileSystemRoots) "--filesystem-root=$root", for (var entryPoint in entryPoints) if (fileExists("lib/$entryPoint.json")) "lib/$entryPoint",
mainPath
];
classCounterextendsStatefulWidget{ // This class is the configuration for the state. It holds the // values (in this case nothing) provided by the parent and used by the build // method of the State. Fields in a Widget subclass are always marked "final".
void_increment(){
setState(() { // This call to setState tells the Flutter framework that // something has changed in this State, which causes it to rerun // the build method below so that the display can reflect the // updated values. If you change _counter without calling // setState(), then the build method won't be called again, // and so nothing would appear to happen.
_counter++;
});
}
@override Widget build(BuildContext context){ // This method is rerun every time setState is called, for instance // as done by the _increment method above. // The Flutter framework has been optimized to make rerunning // build methods fast, so that you can just rebuild anything that // needs updating rather than having to individually change // instances of widgets. return Row(
children: [
RaisedButton(
onPressed: _increment,
child: Text('Increment'),
),
Text('Count: $_counter'),
],
);
}
}
A widget that by default does a FadeTransition between a new widget and the widget previously set on the AnimatedSwitcher as a child.
If they are swapped fast enough (i.e. before duration elapses), more than one previous child can exist and be transitioning out while the newest one is transitioning in.
If the "new" child is the same widget type and key as the "old" child, but with different parameters, then AnimatedSwitcher will not do a transition between them, since as far as the framework is concerned, they are the same widget and the existing widget can be updated with the new parameters. To force the transition to occur, set a Key on each child widget that you wish to be considered unique (typically a ValueKey on the widget data that distinguishes this child from the others).
/**
* [TwoWayConverter] class contains the definition on how to convert from an arbitrary type [T]
* to a [AnimationVector], and convert the [AnimationVector] back to the type [T]. This allows
* animations to run on any type of objects, e.g. position, rectangle, color, etc.
*/
interface TwoWayConverter<T, V : AnimationVector> {
/**
* Defines how a type [T] should be converted to a Vector type (i.e. [AnimationVector1D],
* [AnimationVector2D], [AnimationVector3D] or [AnimationVector4D], depends on the dimensions of
* type T).
*/
val convertToVector: (T) -> V
/**
* Defines how to convert a Vector type (i.e. [AnimationVector1D], [AnimationVector2D],
* [AnimationVector3D] or [AnimationVector4D], depends on the dimensions of type T) back to type
* [T].
*/
val convertFromVector: (V) -> T
}
val value by animateFloatAsState(
targetValue = 1f,
animationSpec = keyframes {
durationMillis = 375
0.0f at 0 with LinearOutSlowInEasing // for 0-15 ms
0.2f at 15 with FastOutLinearInEasing // for 15-75 ms
0.4f at 75 // ms
0.4f at 225 // ms
}
)
snapTo(targetValue: T)
androidx.compose.animation.core.Animatable
public final suspend fun snapTo(
targetValue: T
): Unit
Animatable 还提供了一个 snapTo(targetValue) 的函数,这个函数允许直接设置它内部持有的 value 值,此过程不会产生任何动画,正在进行的动画也会被取消,某些场景可能需要动画开始前有一个初始值,可以使用此函数。
一种更方便的使用方式:animate*AsState
设置某一个属性的目标值,当对应属性值发生变化后,自动触发动画,过度到对应值。
This Composable function is overloaded for different parameter types such as Float, Color, Offset, etc. When the provided targetValue is changed, the animation will run automatically. If there is already an animation in-flight when targetValue changes, the on-going animation will adjust course to animate towards the new target value.
compose 提供了这几个覆盖基本场景的函数:
animateFloatAsState
animateDpAsState
animateSizeAsState
animateOffsetAsState
animateRectAsState
animateIntAsState
animateIntOffsetAsState
animateIntSizeAsState
@Composable
fun Demo() {
var flag by remember { mutableStateOf(false) }
Box(
Modifier.fillMaxSize().background(Color.DarkGray),
contentAlignment = Alignment.Center
) {
val size by animateDpAsState(if (flag) 32.dp else 96.dp) { valueOnAnimateEnd ->
// 可以设置动画结束的监听函数,回调动画结束时对应属性的目标值
Log.i(TAG, "size animate finished with $valueOnAnimateEnd")
}
Row(
Modifier
.size(size)
.background(Color.Magenta)
.clickable { flag = !flag }
) {}
}
}
/**
* ... ...
*
* [animateDpAsState] returns a [State] object. The value of the state object will continuously be
* updated by the animation until the animation finishes.
*
* Note, [animateDpAsState] cannot be canceled/stopped without removing this composable function
* from the tree. See [Animatable] for cancelable animations.
*
* @sample androidx.compose.animation.core.samples.DpAnimationSample
*
* @param targetValue Target value of the animation
* @param animationSpec The animation that will be used to change the value through time. Physics animation will be used by default.
* @param finishedListener An optional end listener to get notified when the animation is finished.
* @return A [State] object, the value of which is updated by animation.
*/
@Composable
fun animateDpAsState(
targetValue: Dp,
animationSpec: AnimationSpec<Dp> = dpDefaultSpring,
finishedListener: ((Dp) -> Unit)? = null
): State<Dp> {
return animateValueAsState(
targetValue,
Dp.VectorConverter,
animationSpec,
finishedListener = finishedListener
)
}
查看 animateIntAsState 的实现:
/**
* ... ...
*
* [animateIntAsState] returns a [State] object. The value of the state object will continuously be
* updated by the animation until the animation finishes.
*
* Note, [animateIntAsState] cannot be canceled/stopped without removing this composable function
* from the tree. See [Animatable] for cancelable animations.
*
* @param targetValue Target value of the animation
* @param animationSpec The animation that will be used to change the value through time. Physics
* animation will be used by default.
* @param finishedListener An optional end listener to get notified when the animation is finished.
* @return A [State] object, the value of which is updated by animation.
*/
@Composable
fun animateIntAsState(
targetValue: Int,
animationSpec: AnimationSpec<Int> = intDefaultSpring,
finishedListener: ((Int) -> Unit)? = null
): State<Int> {
return animateValueAsState(
targetValue, Int.VectorConverter, animationSpec, finishedListener = finishedListener
)
}
这是一个基于 State 的实现,联系 Compose 中对于数据的封装和订阅方式,可以理解为当程序的某一个行为触发动画启动后,compose 会自主启动,并根据时间来计算对应的属性应该是什么值,再通过 State 返回,Composable 函数在一次次 recompose 行为中不断通过 State 获取到该属性的最新值,并刷新到界面上,知道这个值变化到目标值状态,更新也就结束了。也就是动画结束。
val animatable = remember { Animatable(targetValue, typeConverter) }
val listener by rememberUpdatedState(finishedListener)
val animSpec by rememberUpdatedState(animationSpec)
@Composable
fun Demo() {
var flag by remember { mutableStateOf(false) }
Box(
Modifier
.fillMaxSize()
.background(Color.DarkGray),
contentAlignment = Alignment.Center
) {
val size by animateDpAsState(if (flag) 32.dp else 96.dp) { valueOnAnimateEnd ->
// 可以设置动画结束的监听函数,回调动画结束时对应属性的目标值
Log.i(TAG, "size animate finished with $valueOnAnimateEnd")
}
val color by animateColorAsState(
targetValue = if (flag) MaterialTheme.colors.primary else MaterialTheme.colors.secondary
)
Row(
Modifier
.size(size)
.background(color)
.clickable { flag = !flag }
) {}
}
}
@Composable
fun Demo() {
var flag by remember { mutableStateOf(false) }
Box(
Modifier
.fillMaxSize()
.background(Color.DarkGray),
contentAlignment = Alignment.Center
) {
val transition = updateTransition(flag)
val size = transition.animateDp { if (it) 32.dp else 96.dp }
val color = transition.animateColor { if (it) MaterialTheme.colors.primary else MaterialTheme.colors.secondary }
Row(
Modifier
.size(size.value)
.background(color.value)
.clickable { flag = !flag }
) {}
}
}
这样当 flag 触发 transition 状态改变时,size 和 color 的值就可以同时在 transition 内部进行计算,性能又节省了亿点点🤏🏻
@Composable
fun <T> updateTransition(
targetState: T,
label: String? = null
): Transition<T> {
val transition = remember { Transition(targetState, label = label) }
transition.animateTo(targetState)
DisposableEffect(transition) {
onDispose {
// Clean up on the way out, to ensure the observers are not stuck in an in-between
// state.
transition.onTransitionEnd()
}
}
return transition
}
class A<T> {
}
fun <T> T.toString(): String {
}
// 约束上界
class Collection<T : Number, R : CharSequence> : Iterable<T> {
}
fun <T : Iterable> T.toString() {
}
// 多重约束
fun <T> T.eat() where T : Animal, T : Fly {
}
// fastjson
inline fun <reified T : Any> parseObject(json: String) {
JSON.parseObject(json, T::class.java)
}
// gson
inline fun <reified T : Any> fromJson(json: String) {
Gson().fromJson(json, T::class.java)
}
// 获取 bundle 中的 Serializable
inline fun <reified T> Bundle?.getSerializableOrNull(key: String): T? {
return this?.getSerializable(key) as? T
}
// start activity
inline fun <reified T : Context> Context.startActivity() {
startActivity(Intent(this, T::class.java))
}
(3) 协变(out)和逆变(in)
java 中 List 是不变的,下面的操作不被允许。
List<String> strList = new ArrayList<>();
List<Object> objList = strList;
但是 kotlin 中 List 是协变的,可以做这个操作。
public interface List<out E> : Collection<E> { ... }
val strList = arrayListOf<String>()
val anyList: List<Any> = strList
注意这里赋值之后 anyList 的类型还是 List<Any> , 如果往里添加数据,那个获取的时候就没法用 String 接收了,这是类型不安全的,所以协变是不允许写入的,是只读的。在 kotlin 中用 out 表示协变,用 out 声明的参数类型不能作为方法的参数类型,只能作为返回类型,可以理解成“生产者”。相反的,kotlin 中用 in 表示逆变,只能写入,不能读取,用 in 声明的参数类型不能作为返回类型,只能用于方法参数类型,可以理解成 “消费者”。
public interface List<out E> : Collection<E> {
public operator fun get(index: Int): E
}
public interface MutableList<E> : List<E>, MutableCollection<E> {
public operator fun set(index: Int, element: E): E
}
调用操作符: invoke 是调用操作符函数名,调用操作符函数可以写成函数调用表达式。
val a = {}
a() => a.invoke()
a(i, j) => a.invoke(i, j)
变量 block: (Int) -> Unit 调用的时候可以写成 block.invoke(2),也可以写成 block(2),原因是重载了 invoke 函数:
public interface Function1<in P1, out R> : Function<R> {
/** Invokes the function with the specified argument. */
public operator fun invoke(p1: P1): R
}
class A(var name: String? = null) {
operator fun getValue(thisRef: Any?, property: KProperty<*>): String? = name
operator fun setValue(thisRef: Any?, property: KProperty<*>, name: String?) {
this.name = name
}
}
// 翻译
var b by A() =>
val a = A()
var b:String?
get() = a.getValue(this, ::b)
set(value) = a.setValue(this, ::b, value)
class A(var name: String? = null) : ReadWriteProperty<Any?, String?>{
override fun getValue(thisRef: Any?, property: KProperty<*>): String? {
return name
}
override fun setValue(thisRef: Any?, property: KProperty<*>, value: String?) {
this.name = value
}
}
class ALoader : PropertyDelegateProvider<Any?, A> {
override operator fun provideDelegate(thisRef: Any?, property: KProperty<*>) : A {
property.run {
when {
isConst -> {}
isLateinit -> {}
isFinal -> {}
isSuspend -> {}
!property.name.startsWith("m") -> {}
}
}
return A()
}
}
// 翻译
var b by ALoader() =>
val a = ALoader().provideDelegate(this, this::b)
var b: String?
get() = a.getValue(this, ::b)
set(value) = a.setValue(this, ::b, value)
// kotlin
class A {
companion object {
const val TAG = "A"
@JvmStatic
fun newInstance() = A()
}
}
// 编译后
public final class A {
@NotNull
public static final String TAG = "A";
@NotNull
public static final A.Companion Companion = new A.Companion((DefaultConstructorMarker)null);
@JvmStatic
@NotNull
public static final A newInstance() {
return Companion.newInstance();
}
public static final class Companion {
@JvmStatic
@NotNull
public final A newInstance() {
return new A();
}
Get.snackbar(
"Hey i'm a Get SnackBar!",
"It's unbelievable! I'm using SnackBar without context, without boilerplate, without Scaffold, it is something truly amazing!",
icon: Icon(Icons.alarm),
shouldIconPulse: true,
barBlur: 20,
isDismissible: true,
duration: Duration(seconds: 3),
backgroundColor: Colors.red);
具体的属性,大家可以点击进去看下源码配置
Dialogs
效果:
Get.defaultDialog(
onConfirm: () => print("Ok"),
buttonColor: Colors.white,
middleText: "Dialog made in 3 lines of code");
这里需要借助一个“BaseSingleFragment”来实现,这是因为我不能违背 ActivityManagerService 的规则,依然需要通过 startActivityForResult 和 onActivityResult 来实现,所以我们这里通过一个不可见(没有界面)的 Fragment ,将这个过程封装起来,代码如下:
classBaseSingleFragment : Fragment() {
/**
* 生成启动对应Activity的Intent,因为指定要启动的Activity,如何启动,传递参数,所以由具体的使用位置来实现这个Intent
*
* 使用者必须实现这个lambda,否则直接抛出一个异常
*/ var intentGenerator: ((context: Context) -> Intent) = { throw RuntimeException("you should provide a intent here to start activity")
}
/**
* 解析目标Activity返回的结果,有具体实现者解析,并回传
*
* 使用者必须实现这个lambda,否则直接抛出一个异常
*/ var resultParser: (resultCode: Int, data: Intent?) -> Unit = { resultCode, data -> throw RuntimeException("you should parse result data yourself")
}
companion object { const val REQUEST_CODE_GET_RESULT = 100
}
override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState)
val context = requireContext()
startActivityForResult(intentGenerator.invoke(context), REQUEST_CODE_GET_RESULT)
}
/**
* add current fragment to FragmentManager
*/
fun addToActivity(fragmentManager: FragmentManager) {
fragmentManager.beginTransaction().add(this, this::class.simpleName)
.commitAllowingStateLoss()
}
/**
* remove current fragment from FragmentManager
*/
fun removeFromActivity(fragmentManager: FragmentManager) {
fragmentManager.beginTransaction().remove(this).commitAllowingStateLoss()
}
}
当然,这是一个 suspend 方法,java是不支持协程的,而现实情况是,很多项目都有中途集成Kotlin的,有很多遗留的java代码,对于这种情况,我们需要提供相应的java实现吗?The answer is no. Java 代码同样可以调用 suspend 方法,调用方式如下:
btnEditByCoroutine.setOnClickListener((view) -> {
String content = tvContent.getText().toString().trim();
EditActivity.editContent(MainActivityJava.this, content, new Continuation<String>() { @NotNull @Override public CoroutineContext getContext() { return EmptyCoroutineContext.INSTANCE;
}
在业务层,单表查询出数据后,作为条件给下一个单表查询。也就是子查询。 会担心子查询出来的结果集太多。mysql 对 in 的数量没有限制,但是
mysql 限制整条 sql 语句的大小。通过调整参数 max_allowed_packet ,可以修改一条 sql 的最大值。建议在业务上做好处理,限制一次查询出来的结果集是能接受的。
关联查询的好处时候可以做分页,可以用副表的字段做查询条件,在查询的时候,将副表匹配到的字段作为结果集,用主表去 in 它,但是问题来了,如果匹配到的数据量太大就不行了,也会导致返回的分页记录跟实际的不一样,解决的方法可以交给前端,一次性查询,让前端分批显示就可以了,这种解决方案的前提是数据量不太,因为 sql 本身长度有限。
google play现在强制所有上传的应用都使用aab,Google Play 会使用您的 AAB 针对每种设备配置生成并提供经过优化的 APK,因此只会下载特定设备所需的代码和资源来运行您的应用。假如一个AAB是90MB在google play上下载耗费的流量可能也就50MB,但是这种方案对性能上没有任何的影响只是减少了下载流量可能会增加一些转换率。具体文档可以参考官方文档。这里有必要说一下AAB还有更多又去的玩法比如使用AAB实现插件化(对模块拆分还是非常有帮助的),对不同地区实现不同的业务然后使用google play进行分发
android {
...
defaultConfig {
...
ndk {
// Specifies the ABI configurations of your native
// libraries Gradle should build and package with your APK.
abiFilters 'armeabi-v7a','arm64-v8a'
}
}
// 耗时统计kt化
class TimingsListener : TaskExecutionListener, BuildListener {
private var startTime: Long = 0L
private var timings = linkedMapOf<String, Long>()
override fun beforeExecute(task: Task) {
startTime = System.nanoTime()
}
override fun afterExecute(task: Task, state: TaskState) {
val ms = TimeUnit.MILLISECONDS.convert(System.nanoTime() - startTime, TimeUnit.NANOSECONDS)
task.path
timings[task.path] = ms
project.logger.warn("${task.path} took ${ms}ms")
}
override fun buildFinished(result: BuildResult) {
project.logger.warn("Task timings:")
timings.forEach {
if (it.value >= 50) {
project.logger.warn("${it.key} cos ms ${it.value}\n")
}
}
}
override fun buildStarted(gradle: Gradle) {
}
override fun settingsEvaluated(settings: Settings) {
}
private void preView(String path) {
File file = new File(path);
//这里只是作为一个file文件进行展示 还有其他的办法进行展示
pdfView.fromFile(file)
.enableSwipe(true) // allows to block changing pages using swipe
.swipeHorizontal(false)
.enableDoubletap(true)
.defaultPage(0)
// allows to draw something on the current page, usually visible in the middle of the screen
.enableAnnotationRendering(false) // render annotations (such as comments, colors or forms)
.password(null)
.scrollHandle(null)
.enableAntialiasing(true) // improve rendering a little bit on low-res screens
// spacing between pages in dp. To define spacing color, set view background
.spacing(0)
.load();
}
//添加TabLayout for (i in tabTextData.indices) {
tabLayout.addTab(tabLayout.newTab())
tabLayout.getTabAt(i)!!.setText(tabTextData[i]).setIcon(tabIconData[i])
public static PlayerType[] values()
{
return (PlayerType[])$VALUES.clone();
}
public static PlayerType valueOf(String name)
{
return (PlayerType)Enum.valueOf(com/cmower/baeldung/enum1/PlayerType, name);
}
private PlayerType(String s, int i)
{
super(s, i);
}
public static final PlayerType TENNIS;
public static final PlayerType FOOTBALL;
public static final PlayerType BASKETBALL;
private static final PlayerType $VALUES[];
static
{
TENNIS = new PlayerType("TENNIS", 0);
FOOTBALL = new PlayerType("FOOTBALL", 1);
BASKETBALL = new PlayerType("BASKETBALL", 2);
$VALUES = (new PlayerType[] {
TENNIS, FOOTBALL, BASKETBALL
});
}
}
看到没?PlayerType 类是 final 的,并且继承自 Enum 类。这些工作我们程序员没做,编译器帮我们悄悄地做了。此外,它还附带几个有用静态方法,比如说 values() 和 valueOf(String name)。
switch (playerType) {
case TENNIS:
return "网球运动员费德勒";
case FOOTBALL:
return "足球运动员C罗";
case BASKETBALL:
return "篮球运动员詹姆斯";
case UNKNOWN:
throw new IllegalArgumentException("未知");
default:
throw new IllegalArgumentException(
"运动员类型: " + playerType);
/**
*This dispatcher shares threads with a [Default][Dispatchers.Default] dispatcher, so using
* `withContext(Dispatchers.IO) { ... }` does not lead to an actual switching to another thread —
* typically execution continues in the same thread.
*/ @JvmStatic publicval IO: CoroutineDispatcher = DefaultScheduler.IO
overridefundispatch(context: CoroutineContext, block: Runnable) { // 只有当调用yield方法时,Unconfined的dispatch方法才会被调用 // yield() 表示当前协程让出自己所在的线程给其他协程运行 val yieldContext = context[YieldContext] if (yieldContext != null) {
yieldContext.dispatcherWasUnconfined = true return
} throw UnsupportedOperationException("Dispatchers.Unconfined.dispatch function can only be used by the yield function. " + "If you wrap Unconfined dispatcher in your code, make sure you properly delegate " + "isDispatchNeeded and dispatch calls.")
}
}
@JvmField val dispatcher: MainCoroutineDispatcher = loadMainDispatcher()
privatefunloadMainDispatcher(): MainCoroutineDispatcher { returntry { val factories = if (FAST_SERVICE_LOADER_ENABLED) {
FastServiceLoader.loadMainDispatcherFactory()
} else { // We are explicitly using the // `ServiceLoader.load(MyClass::class.java, MyClass::class.java.classLoader).iterator()` // form of the ServiceLoader call to enable R8 optimization when compiled on Android.
ServiceLoader.load(
MainDispatcherFactory::class.java,
MainDispatcherFactory::class.java.classLoader
).iterator().asSequence().toList()
}
factories.maxBy { it.loadPriority }?.tryCreateDispatcher(factories)
?: MissingMainCoroutineDispatcher(null)
} catch (e: Throwable) { // Service loader can throw an exception as well
MissingMainCoroutineDispatcher(e)
}
}
internalfunloadMainDispatcherFactory(): List<MainDispatcherFactory> { val clz = MainDispatcherFactory::class.java if (!ANDROID_DETECTED) { return load(clz, clz.classLoader)
}
returntry { val result = ArrayList<MainDispatcherFactory>(2)
createInstanceOf(clz, "kotlinx.coroutines.android.AndroidDispatcherFactory")?.apply { result.add(this) }
createInstanceOf(clz, "kotlinx.coroutines.test.internal.TestMainDispatcherFactory")?.apply { result.add(this) }
result
} catch (e: Throwable) { // Fallback to the regular SL in case of any unexpected exception
load(clz, clz.classLoader)
}
}
Manifest merger failed : Attribute application@name value=(com.example.moduledemo.MainApplication) from AndroidManifest.xml:7:9-40
is also present at [:live] AndroidManifest.xml:11:9-56 value=(com.example.live.LiveApplication).
Suggestion: add 'tools:replace="android:name"' to <application> element at AndroidManifest.xml:6:5-23:19 to override.
社区的小伙伴们,大家好啊,艰难的2020已经过去,随着2021的到来,在新的一年里希望大家都能够需求不变更、准点上下班、代码0 Bug。同时我们DoKit团队也给大家准备了一份特殊的“新年礼物”,没错它就是DoKit For Flutter,它来啦,它带着熟悉的配方来啦。接下来就让我们揭开它神秘的面纱吧。
滴滴做为国内最大的出行平台,早在两年前就有多个内部团队开始在Flutter领域进行尝试。但是在开发过程中,我们遇到了很多调试性问题,如日志、帧率、抓包等。为了解决这些开发测试过程中遇到的各类问题,我们DoKit团队联合滴滴代驾和货运团队,把平时工作过程中沉淀下来的效率工具进行业务剥离和脱敏,并最终打造出DoKit For Flutter,在服务内部业务的同时,也为社区贡献一份力量,这也是滴滴的开源精神。
介绍
DoKit For Flutter是一个DoKit针对Flutter环境的产研工具包,内部集成了各种丰富的小工具,UI、网络、内存、监控等等。DoKit始终站在用户的角度,为用户提供最便利的产研工具。
public static final int STATUS_NORMAL = 0;
public static final int STATUS_OPTIMISTIC = 1;
public static final int STATUS_OPEN = 2;
public static final int STATUS_CLOSE = 4;
public static void testPrint() {
for (int i = 0; i < 5; i++) {
System.out.println("now " + i);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
try (Cost c = new Cost()) {
testPrint();
}
System.out.println("------over-------");
}
执行后输出如下:
now 0
now 1
now 2
now 3
now 4
cost: 55
------over-------
如果代码块抛异常,也会正常输出耗时么?
public static void testPrint() {
for (int i = 0; i < 5; i++) {
System.out.println("now " + i);
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (i == 3) {
throw new RuntimeException("some exception!");
}
}
}
再次输出如下,并没有问题
now 0
now 1
now 2
now 3
cost: 46
Exception in thread "main" java.lang.RuntimeException: some exception!
at com.git.hui.boot.order.Application.testPrint(Application.java:43)
at com.git.hui.boot.order.Application.main(Application.java:50)