








Kotlin协程,我学“废”了
Kotlin协程
Kotlin协程(本文讲解的协程都是基于Kotlin讲解的,其他语言的协程不在本文章的讨论范围)目前很流行的一款用于异步任务处理的库,都知道它处理异步任务特别好用,但是很少人去探究它背后的原理。还有一点,由于它是用于处理异步任务的,很多人将协程与线程做对比,也有一些人将协程与Rxjava做对比。这篇文章将从最简单的用法开始,层层递进的讲解以下知识点:
- 如何使用使用协程,以及协程中的一些重要概念
- 协程怎么处理异步任务和并发任务
- 挂起函数是什么
- 协程底层是怎么实现挂起-恢复的
- 协程是怎么做线程切换的
如何使用使用协程,以及协程中的一些重要概念
首先先介绍一下怎么开启一个协程,在Android开发中,如果是在Activity或者Fragment中,那么可以通过以下这种方式开启一个协程。
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launch{
//这里面就是协程
}
}
}
然而我们肯定不止在Activity或者Fragment中去使用协程,那么其他地方怎么去开启协程呢?要搞清楚这一点,就要知道lifecycleScope是什么,lifecycleScope是一个实现了CoroutineScope类的一个实例。CoroutineScope翻译过来就是协程作用域,到这里我们就清楚了,要开启一个协程,首先就要有一个协程作用域。通过协程作用域的实例去启动一个协程。 在Android开发中呢,很多时候不需要我们自己创建协程作用域,因为android中有很多拓展属性。比方上面说的Activity和Fragment中有lifecycleScope,ViewModel中有viewModelScope,可以直接使用这些拓展属性去开启一个协程。那其他地方怎么去创建一个协程作用域呢?首先就是可以通过MainScope()去创建一个主线程下协程作用域,还有可以通过CoroutineScope(Dispatchers.IO)去创建一个IO线程下的协程作用域。如下
// demo1
val scope = MainScope()
scope.launch{
Log.d(TAG,Thread.currentThread().name) // 打印main
}
// demo2
val scope2 = CoroutineScope(Dispatchers.IO)
scope2.launch {
Log.d(TAG,Thread.currentThread().name) // 打印DefaultDispatcher-worker-1
}
上面的这段代码还有一个地方没有讲清楚CoroutineScope(Dispatchers.IO)里面的参数是什么?其实CoroutineScope(context: CoroutineContext)接收的是一个CoroutineContext实例,CoroutineContext翻译过来就是协程的上下文的意思。
协程上下文是各种不同元素的集合。其中元素包含了了一个CoroutineDispatcher,即协程调度器。它确定了相关的协程在哪个线程或哪些线程上执行。协程调度器可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。 比如上述的例子通过demo1里面的MainScope()协程作用域开启的协程,协程是运行在主线程里面的。demo2的协程就是运行在io线程里面的。即使是在通过MainScope()开启的协程,依旧可以指定线程。啥意思,看如下这个例子,launch里面多了Dispatchers.IO这个参数
val scope = MainScope()
val job = scope.launch(Dispatchers.IO){
Log.d(TAG,Thread.currentThread().name) //打印 DefaultDispatcher-worker-1
}
这里面打印的就不是主线程了,而是IO线程了。看到这里明白了吗?协程调度器才是真正决定协程在哪个线程运行的关键,而协程作用域只是给这个协程提供了一个生命周期的管理而已。它并不能真正决定协程运行在哪一个线程。那么demo1打印main的现象怎么解释?因为launch函数如果不传协程的上下文,它就默认是协程作用域里面的上下文,而MainScope()默认的上下文里面的调度器就是Dispatchers.Main.
总结对比一下上面讲述的几个概念: 协程作用域:主要负责管理协程的生命周期。 协程上下文:由各种元素组成,其中一个元素是协程调度器。 协程调度器:定了相关的协程在哪个线程或哪些线程上执行。
协程如何处理异步任务和并发任务
上面说了这么多概念,好像很厉害的样子,但是听完之后也就听完了,啥也没学会。比如他如何处理异步任务?就一个普通的场景,去网络上请求数据,然后在前台显示。协程里面该怎么做,如下
class MainActivity : AppCompatActivity() {
val TAG = MainActivity::class.java.name
var text = "hello"
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// 步骤一,通过lifecycleScope开启一个协程
lifecycleScope.launch{
//步骤二 调用耗时任务
changeText()
//步骤三 打印结果
Log.d(TAG,text) // 最终打印结果 hello Coroutine,这段代码在Main线程
}
}
// changeText 在IO线程模拟一个耗时任务,注意这里的suspend关键字,标识这个函数是挂起函数,什么是挂起函数后面会讲
private suspend fun changeText(){
// 通过withContext将协程运行的线程切换到IO线程,然后在IO线程里面做耗时处理,并改变text
withContext(Dispatchers.IO){
delay(1000)
text = "$text Coroutine"
}
}
}
以上就是简单处理一个耗时任务的例子。看上去是不是很神奇,明明切换了线程,Log.d(TAG,text)这段代码不会先执行吗?可以肯定的告诉你,不会。这就是协程相比于线程的优势,用同步的代码方式去完成异步任务。而能完成这一切都与挂起函数有关。这是简单的任务,如果是多任务呢?比如说,任务一在IO线程任务二在UI线程,任务三又在IO线程任务四又回来了UI线程:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launch{
task1() // io线程执行耗时任务
task2() // ui线程执行界面更新
task3() // io线程执行耗时任务
task4() // ui线程执行界面更新
}
}
private suspend fun task1(){
withContext(Dispatchers.IO){
delay(1000)
}
}
private suspend fun task2(){
withContext(Dispatchers.Main){
}
}
private suspend fun task3(){
withContext(Dispatchers.IO){
delay(1000)
}
}
private suspend fun task4(){
withContext(Dispatchers.Main){
}
}
task1->task2->task3->task4会依次按照顺序执行。没有回调函数,直接明了。
还有一种比较复杂的情况就是,如果a,b,c三个任务,a,b任务的结果用于c任务的参数,那应该怎么做?我们先想一下如果是不用协程我们改怎么做,很多人说用rxjava。确实rxjava可以比较简单的实现我们上面的功能。如果只用线程来做的话是不是很麻烦,因为我们不知道任务a,b哪一个更快或者哪一个更忙,这样的任务用线程来管控的话,会非常麻烦,所以我们在代码里面可以会先a执行完,在执行b,然后再执行c,这样做的话,效率就会很低了。而且任务如果有10个呢(这当然是比较极端的情况了)。那么当当是用线程写起来可读性就很差了,这不是要写10次回调?
那么在协程中如何去做呢?如下:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
lifecycleScope.launch{
val time = measureTimeMillis{
// ① 通过async启动一个协程,async 返回一个 Deferred —— 一个轻量级的非阻塞 future, 这代表了一个将会在稍后提供结果的 promise。你可以使用 .await() 在一个延期的值上得到它的最终结果
val firstName = async(Dispatchers.IO) { getFirstName() }
val second = async(Dispatchers.IO) { getSecondName() }
// 通过await()得到结果,getFirstName() 与getSecondName()是并发的
val name = firstName.await() + " - " +second.await()
val friend = withContext(Dispatchers.IO){
getFriend(name)
}
Log.d(TAG,friend) // John - Tom Amy
}
Log.d(TAG,"$time") // 2000ms右一般2050左右,不到3000ms
}
}
private suspend fun getFirstName():String{
delay(1000)
return "John"
}
private suspend fun getSecondName():String{
delay(1000)
return "Tom"
}
private suspend fun getFriend(name:String):String{
delay(1000)
return "$name Amy"
}
以上就是协程中如何处理异步和做并发了。
总结:
1、在Android中,可以开启一个主线程作用域的协程,然后需要切线程的时候通过withContext去切换线程,耗时任务放到IO线程中去执行,并且将耗时任务通过suspend声明为挂起函数。完成以上步骤就可以在协程中,用同步方式的代码去实现简单的异步任务了。
2、如果要并发任务,可以通过async关键字开启一个新的协程,然后之后通过.await()拿到结果。
挂起函数是什么
通过以上的讲解,我们仅仅是知道怎么使用协程,怎么去使用协程完成并发任务,我们还不知道协程为什么能够用同步的代码方式去完成异步任务。要想知道这个,就从一个关键字说起,那就是suspend关键字,被suspend关键字标记的函数叫挂起函数。
首先先来看一下什么是CPS。Suspending functions are implemented via Continuation-Passing-Style (CPS). Every suspending function and suspending lambda has an additional Continuation parameter that is implicitly passed to it when it is invoked.
这段话什么意思呢?它的意思是说挂起函数都会经过CPS转换的,CPS转换之后呢会有一个额外的参数Continuation,当调用这个挂起函数的时候,会传递给这个挂起函数。
什么意思呢?来看代码:
// 注释1
private suspend fun getFirstName():String //kotlin代码
//注释2
private fun <T> getFirstName(continuation: Continuation<T>):Any? //经过CPS转化后的代码,多了一个Continuation类型的参数,而这个参数就类似一个callback接口的作用
/** 这是Continuation的定义
*Here is the definition of the standard library interface Continuation
*(defined in kotlinx.coroutines package), which represents a generic callback:
*/
interface Continuation<in T> {
val context: CoroutineContext
fun resumeWith(result: Result<T>)
}
从注释1到注释2的过程,就是CPS的过程。函数类型由原来的 suspend()->String 变成了Continuation->Any?
那么Continuation是什么,它是一个类似于callback的东西,里面的resumeWith函数,就类似于callBack里面的回调函数,那么这个
Continuation指的是哪一部分呢?
它大概会转换成下面这个样子
lifecycleScope.launch{
task1(object: Continuation<Unit>{
override fun resumeWith(result: Result<Unit>) {
// 也就是说,等到task1,执行完成之后才会执行到task2,task3与task4
task2() // ui线程执行界面更新
task3() // io线程执行耗时任务
task4() // ui线程执行界面更新
}
override val context: CoroutineContext
get() = TODO("Not yet implemented")
}) // io线程执行耗时任务
}
以上大概就是有关挂起函数的讲解了。
简单总结一下:在kotlin中,如果用suspend声明的函数,称为挂起函数。挂起函数的原理其实就是CPS转换。挂起函数并没有切换线程的功能,将函数声明为挂起函数,只是做一个标记,让编译器去做CPS转换,这个CPS转换对开发者来说是无感知的,所以我们能以同步的方式去实现异步的任务。
协程如何去实现挂起-恢复的
通过以上的讲解,我们知道了协程是如何工作了,但是我们还是不知道协程如果去实现这些功能的,首先看一段代码,跟着这一段代码,我们一步一步去讲解协程是如何实现挂起-恢复的。
fun testCoroutine() {
lifecycleScope.launch {
val firstName = getFirstName()
Log.d(TAG, firstName)
}
Log.d(TAG, "主线程继续执行")
}
private suspend fun getFirstName(): String {
var name = ""
withContext(Dispatchers.IO) {
delay(1000)
name = "hello"
}
return name
}
以上代码的执行步骤如下: 1、在主线程中开启一个协程
2、通过withContext切换了线程去做耗时任务,同时主线程打印“主线程继续执行”
3、耗时任务执行完成,并且在主线程将值赋给firstName,主线程打印firstname
如下:
在执行代码1的时候,在IO线程做耗时任务,这时候主线程的代码块2是不执行的,代码块2被挂起了,但是主线程的代码块3这时候是执行的,代码块1里面的耗时任务执行完成之后,主线程2里面的代码会被恢复,然后继续执行完成
现在的难点在于:
协程如何做挂起和恢复。
首先我们将delay()(这个delay()只是代表了耗时任务,但是他会增加我们阅读反编译代码的难度)这段代码删除,然后反编译一下。这里我就不直接贴反编译的代码了,因为直接贴反编译的代码,它的可读性太差了。它反编译之后大概如下:
public final void testCoroutine() {
BuildersKt.launch$default((CoroutineScope)LifecycleOwnerKt.getLifecycleScope(this), (CoroutineContext)null, (CoroutineStart)null, (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object result) { // 状态机状态的切换
suspendLable = IntrinsicsKt.getCOROUTINE_SUSPENDED(); // 是否要挂起
switch(this.label) {
case 0:
this.label = 1;
funtionSuspend = var4.getFirstName(this); //是否为挂起函数,注意这里的this
if (suspendLable == funtionSuspend) {
return suspendLable; //如果是挂起函数,那么直接return,return之后就可以执行 这段代码 Log.d(this.TAG, "主线程继续执行");
}
break;
case 1:
finalResult = result;
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
String firstName = (String)finalResult;
return Unit.INSTANCE;
}
}), 3, (Object)null);
Log.d(this.TAG, "主线程继续执行");
}
private final Object getFirstName(Continuation var1) {
Object $result = ((<undefinedtype>)$continuation).result;
Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
final ObjectRef name;
switch(label) {
case 0:
name = "";
CoroutineContext var10000 = (CoroutineContext)Dispatchers.getIO(); //切换线程
Function2 var10001 = (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object var1) {
switch(this.label) {
case 0:
name= "hello";
return Unit.INSTANCE;
}
}
});
break;
case 1:
name = (ObjectRef)((<undefinedtype>)$continuation).L$0;
ResultKt.throwOnFailure($result);
break;
}
return name;
}
编译后的代码大概就是这样,这种利用label进行状态判断的代码,也叫状态机机制,其实协程就是通过状态机去实现挂起恢复的一个过程。在testCoroutine,我们能够清楚的看到,如果在线程中执行了一个挂起函数,那么他就会直接return掉。这里也解释了为什么在执行挂起函数的时候,协程外的主线程会执行了。
if (suspendLable == funtionSuspend) {
return suspendLable; //如果是挂起函数,那么直接return,return之后就可以执行 这段代码 Log.d(this.TAG, "主线程继续执行");
}
那怎么办恢复呢?恢复的代码在反编译的代码中是没有呈现出来的,他其实是通过执行了invokeSuspend函数来进行恢复的。再一次执行invokeSuspend的时候,这时候它的label就不是0了,而是1了,所以他会执行- finalResult = result;然后跳出switch语句,并且执行String firstName = (String)finalResult;语句。这样一整个流程就结束了。协程的挂起与恢复。
总结:协程的挂起与恢复是通过状态机去实现的。每一个挂起点都是一种状态,协程恢复只是跳转到下一个状态,挂起点将执行过程分割成多个片段,利用状态机的机制保证各个片段按顺序执行。
协程是如何做线程切换的:
那么现在还剩下最后一个问题,协程的底层是怎么做线程切换的呢?其实在刚刚的反编译代码中就可以看出,协程它的底层是通过Dispatchers去切换线程的,那么它是怎么切换的呢?要研究这个问题就要从最开始的launch{}的源码开始了,今天当然不会去纠结源码的实现细节,我们知道底层切换线程是怎么做的就好了。
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
第一个参数 context 是协程上下文,在讲述协程概念的时候有提到过 第二个参数 start 此处我们没有传值则使用默认值,代表启动方式默认值为立即执行。 第三个参数 block 是协程真正执行的代码块,即launch{}花括号中的代码块。
launch{}里面做了什么?
1、创建一个新的协程上下文。
2、再创建一个Continuation,默认情况下是StandaloneCoroutine
3、启动Continuation
首先来看:newCoroutineContext
public actual fun CoroutineScope.newCoroutineContext(context: CoroutineContext): CoroutineContext {
val combined = coroutineContext + context // 将launch方法传入的context与CoroutineScope中的context组合起来
val debug = if (DEBUG) combined + CoroutineId(COROUTINE_ID.incrementAndGet()) else combined
return if (combined !== Dispatchers.Default && combined[ContinuationInterceptor] == null)
debug + Dispatchers.Default else debug // 如果combined中没有拦截器,会传入一个默认的拦截器,即Dispatchers.Default
}
再来看启动Continuation
coroutine.start(start, coroutine, block)
->AbstractCoroutine.start()
->CoroutineStart.invoke()
->block.startCoroutineCancellable()
->createCoroutineUnintercepted(receiver, completion).intercepted().resumeCancellableWith(Result.success(Unit), onCancellation)
最终会执行到我们的最后一行最后一行也是分析的重点。
首先创建一个协程,并链式调用intercepted()和resumeCancellableWith()方法。createCoroutineUnintercepted()这个方法目前看不到源码的实现,不过不影响我们后面的分析,先看intercepted()
public actual fun <T> Continuation<T>.intercepted(): Continuation<T> =
(this as? ContinuationImpl)?.intercepted() ?: this
public fun intercepted(): Continuation<Any?> =
intercepted
?: (context[ContinuationInterceptor]?.interceptContinuation(this) ?: this)
.also { intercepted = it }
//上面讲解newCoroutineContext的时候,讲解到有一个默认的Dispatchers.Default是CoroutineDispatcher,所以这里最终会调用到CoroutineDispatcher的interceptContinuation()
public final override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
DispatchedContinuation(this, continuation)
所以,我们可以发现这里其实就是创建的一个DispatchedContinuation,并且将原来的协程放入的DispatchedContinuation中。
最后看一下resumeCancellableWith这里很明显了,调用的是DispatchedContinuation的resumeCancellableWith。
@Suppress("NOTHING_TO_INLINE")
inline fun resumeCancellableWith(
result: Result<T>,
noinline onCancellation: ((cause: Throwable) -> Unit)?
) {
val state = result.toState(onCancellation)
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_CANCELLABLE
dispatcher.dispatch(context, this)
} else {
executeUnconfined(state, MODE_CANCELLABLE) {
if (!resumeCancelled(state)) {
resumeUndispatchedWith(result)
}
}
}
}
来看一下这段代码,如果需要切换线程,那么调用dispatcher.dispatch方法,如果不需要,直接运行在原来的线程上。
那么接下来就是要看一下dispatcher是怎么切换线程的了,DispatchedContinuation提供了四种实现,我们接下来只看Dispatchers.IO
最终会调用的ExperimentalCoroutineDispatcher的dispatch方法
override fun dispatch(context: CoroutineContext, block: Runnable): Unit =
try {
coroutineScheduler.dispatch(block)
} catch (e: RejectedExecutionException) {
// CoroutineScheduler only rejects execution when it is being closed and this behavior is reserved
// for testing purposes, so we don't have to worry about cancelling the affected Job here.
DefaultExecutor.dispatch(context, block)
}
而这里的coroutineScheduler是一个Executor。看到这里,我们就大概知道协程是怎么做一个线程切换了,它的底层是通过线程池去做线程的切换的。这是Dispatchers.IO的实现,如果是Dispatchers.Main的,它的底层是通过handler去做的一个线程切换。
Android Hook告诉你 如何启动未注册的Activity
前言
Android Hook 插件化其实已经不是什么新鲜的技术了,不知你有没有想过,支付宝中那么多小软件:淘票票 ,火车票等软件,难道是支付宝这个软件自己编写的吗?那不得写个十年,软件达到几十G,但是并没有,玩游戏时那么多的皮肤包肯定时用户使用哪个就下载哪个皮肤包。
一 未在配置文件中注册的Activity可以启动吗?
从0学的时候就知道Activity必须在配置文件中注册,否则无法启动且报错。但是Hook告诉你的是,未在配置文件中注册Activity是可以启动的,惊不惊喜?意不意外?
通过本文你可以学到:
1.通过对startActivity方法进行Hook,实现为startActivity方法添加日志。
1.1 通过对Instrumentation进行Hook
1.2 通过对AMN进行Hook
2.如何启动一个未在配置文件中注册的Activity实现插件化
本片文章基础建立在 Java反射机制和App启动流程解析,建议不太了解的小伙伴可以先移步至这两篇文章。
二 对startActivity方法进行Hook
通过对查阅startActivity的源码可以看出startActivity最终都会走到startActivityFoResult方法中
public void startActivityForResult(Intent intent, int requestCode, Bundle options) {
if(this.mParent == null) {
ActivityResult ar = this.mInstrumentation.execStartActivity(this, this.mMainThread.getApplicationThread(), this.mToken, this, intent, requestCode, options);
if(ar != null) {
this.mMainThread.sendActivityResult(this.mToken, this.mEmbeddedID, requestCode, ar.getResultCode(), ar.getResultData());
}
if(requestCode >= 0) {
this.mStartedActivity = true;
}
} else if(options != null) {
this.mParent.startActivityFromChild(this, intent, requestCode, options);
} else {
this.mParent.startActivityFromChild(this, intent, requestCode);
}
}
通过mInstrumentation.execStartActivity调用(ps:详细的源码解析已在上篇文章中讲解),再看mInstrumentation.execStartActivity方法源码如下:
public Instrumentation.ActivityResult execStartActivity(Context who, IBinder contextThread, IBinder token, Activity target, Intent intent, int requestCode, Bundle options) {
IApplicationThread whoThread = (IApplicationThread)contextThread;
if(this.mActivityMonitors != null) {
Object e = this.mSync;
synchronized(this.mSync) {
int N = this.mActivityMonitors.size();
for(int i = 0; i < N; ++i) {
Instrumentation.ActivityMonitor am = (Instrumentation.ActivityMonitor)this.mActivityMonitors.get(i);
if(am.match(who, (Activity)null, intent)) {
++am.mHits;
if(am.isBlocking()) {
return requestCode >= 0?am.getResult():null;
}
break;
}
}
}
}
try {
intent.setAllowFds(false);
intent.migrateExtraStreamToClipData();
int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent, intent.resolveTypeIfNeeded(who.getContentResolver()), token, target != null?target.mEmbeddedID:null, requestCode, 0, (String)null, (ParcelFileDescriptor)null, options);
checkStartActivityResult(var16, intent);
} catch (RemoteException var14) {
;
}
return null;
}
最终会交给 int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent,...处理,所以如果我们想对startActivity方法进行Hook,可以从这两个地方入手(其实不止这两个地方,我们只讲解着两个地方,下面使用的反射封装类也在上篇文章中给出)。
- 2.1 对mInstrumentation进行Hook
在Activity.class类中定义了私有变量
private Instrumentation mInstrumentation;
我们首先要做的就是修改这个私有变量的值,在执行方法前打印一行日志,首先我们通过反射来获取这一私有变量。
Instrumentation instrumentation = (Instrumentation) Reflex.getFieldObject(Activity.class,MainActivity.this,"mInstrumentation");
我们要做的是将这个Instrumentation替换成我们自己的Instrumentation,所以下面我们新建MyInstrumentation继承自Instrumentation,并且MyInstrumentation的execStartActivity方法不变。
public class MyInstrumentation extends Instrumentation {
private Instrumentation instrumentation;
public MyInstrumentation(Instrumentation instrumentation) {
this.instrumentation = instrumentation;
}
public ActivityResult execStartActivity(Context who, IBinder contextThread, IBinder token, Activity target, Intent intent, int requestCode, Bundle options) {
Log.d("-----","啦啦啦我是hook进来的!");
Class[] classes = {Context.class,IBinder.class,IBinder.class,Activity.class,Intent.class,int.class,Bundle.class};
Object[] objects = {who,contextThread,token,target,intent,requestCode,options};
Log.d("-----","啦啦啦我是hook进来的!!");
return (ActivityResult) Reflex.invokeInstanceMethod(instrumentation,"execStartActivity",classes,objects);
}
我们直接通过反射调用这个方法 参数就是 Class[] classes = {Context.class,IBinder.class,IBinder.class,Activity.class,Intent.class,int.class,Bundle.class}与方法名中一致
(ActivityResult) Reflex.invokeInstanceMethod(instrumentation,"execStartActivity",classes,objects)
如果我们这里不调用它本身的execStartActivity方法的话,那么startActivity就无效了。
然后我们将自定义的替换为原来的Instrumentation
Reflex.setFieldObject(Activity.class,this,"mInstrumentation",instrumentation1);
完整代码就是
Instrumentation instrumentation = (Instrumentation) Reflex.getFieldObject(Activity.class,MainActivity.this,"mInstrumentation");
MyInstrumentation instrumentation1 = new MyInstrumentation(instrumentation);
Reflex.setFieldObject(Activity.class,this,"mInstrumentation",instrumentation1);
运行日志如下:
这个时候我们就成功的Hook了startActivity方法
2.2 对AMN进行Hook
execStartActivity方法最终会走到ActivityManagerNative.getDefault().startActivity方法
try {
intent.setAllowFds(false);
intent.migrateExtraStreamToClipData();
int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent, intent.resolveTypeIfNeeded(who.getContentResolver()), token, target != null?target.mEmbeddedID:null, requestCode, 0, (String)null, (ParcelFileDescriptor)null, options);
checkStartActivityResult(var16, intent);
} catch (RemoteException var14) {
;
}
你可能会说上面说过了啊,替换ActivityManagerNative.getDefault(),重写startActivity方法,我们来看ActivityManagerNative.getDefault()
public static IActivityManager getDefault() {
return (IActivityManager)gDefault.get();
}
public final T get() {
synchronized(this) {
if(this.mInstance == null) {
this.mInstance = this.create();
}
return this.mInstance;
}
}
可以看出IActivityManager是一个接口,gDefault.get()返回的是一个泛型,上述方案我们无法入手,所以我们这里要用动态代理方案
我们定义一个AmsHookHelperUtils类,在AmsHookHelperUtils类中处理反射代码
gDefault是个final静态类型的字段,首先我们获取gDefault字段
Object gDefault = Reflex.getStaticFieldObject("android.app.ActivityManagerNative","gDefault");
gDefault是 Singleton<IActivityManager>类型的对象,Singleton是一个单例模式
public abstract class Singleton<T> {
private T mInstance;
public Singleton() {
}
protected abstract T create();
public final T get() {
synchronized(this) {
if(this.mInstance == null) {
this.mInstance = this.create();
}
return this.mInstance;
}
}
}
接下里我们来取出mInstance字段
Object mInstance = Reflex.getFieldObject("android.util.Singleton",gDefault,"mInstance");
然后创建一个代理对象
Class<?> classInterface = Class.forName("android.app.IActivityManager");
Object proxy = Proxy.newProxyInstance(classInterface.getClassLoader(),
new Class<?>[]{classInterface},new AMNInvocationHanlder(mInstance));
我们的代理对象就是new AMNInvocationHanlder(mInstance),(ps:代理模式分为静态代理和动态代理,如果对代理模式不了解可以百度一波,也可以关注我,等待我的代理模式相关文章)
public class AMNInvocationHanlder implements InvocationHandler {
private String actionName = "startActivity";
private Object target;
public AMNInvocationHanlder(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (method.getName().equals(actionName)){
Log.d("---","啦啦啦我是hook AMN进来的");
return method.invoke(target,args);
}
return method.invoke(target,args);
}
}
所有的代理类都要实现InvocationHandler接口,在invoke方法中method.invoke(target,args);表示的就是 执行被代理对象所对应的方法。因为AMN Singleton做的事情比较多,所以这里只对startActivity方法hook
if (method.getName().equals(actionName)){
Log.d("---","啦啦啦我是hook AMN进来的");
return method.invoke(target,args);
}
然后我们将gDefault字段替换为我们的代理类
Reflex.setFieldObject("android.util.Singleton",gDefault,"mInstance",proxy);
AmsHookHelperUtils方法整体如下:
public class AmsHookHelperUtils {
public static void hookAmn() throws ClassNotFoundException {
Object gDefault = Reflex.getStaticFieldObject("android.app.ActivityManagerNative","gDefault");
Object mInstance = Reflex.getFieldObject("android.util.Singleton",gDefault,"mInstance");
Class<?> classInterface = Class.forName("android.app.IActivityManager");
Object proxy = Proxy.newProxyInstance(classInterface.getClassLoader(),
new Class<?>[]{classInterface},new AMNInvocationHanlder(mInstance));
Reflex.setFieldObject("android.util.Singleton",gDefault,"mInstance",proxy);
}
}
我们调用AmsHookHelperUtils.hookAmn();然后启动一个新的Activity,运行日志如下:
这样我们就成功Hook了AMN的getDefault方法。
2.3 如何启动一个未注册的Activity
如何启动一个未注册的Activity,首先我们了解Activity的启动流程,App的启动流程已经在上篇文章中讲解了,APP启动流程解析,还不了解的小伙伴,可先移步至上篇文章。假设现在MainActivity,Main2Activity,Main3Activity,其中Main3Activity未注册,我们在MainActivity中启动Main3Activity,当启动Main3Activity的时候,AMS会在配置文件中检查,是否有Main3Activity的配置信息如果不存在则报错,存在则启动Main3Activity。
所以我们可以做的是,将要启动的Activity发送给AMS之前,将要启动的Activity替换未已经注册Activity Main2Activity,这样AMS就可以检验通过,当AMS要启动目标Activity的时候再将Main2Activity替换为真正要启动的Activity。
首先我们按照上面逻辑先对startActivity方法进行Hook,这里采用对AMN Hook的方式。和上述代码一样,不一样的地方在于mInstance的代理类不同。
新建一个AMNInvocationHanlder1对象同样继承自InvocationHandler,只拦截startActivity方法。
if (method.getName().equals(actionName)){}
在这里我们要做的就是将要启动的Main3Activity替换为Main2Activity,这样能绕过AMS的检验,首先我们从目标方法中取出目标Activity。
Intent intent;
int index = 0;
for (int i = 0;i<args.length;i++){
if (args[i] instanceof Intent){
index = i;
break;
}
}
你可能会问你怎么知道args中一定有intent类的参数,因为invoke方法中最终会执行
return method.invoke(target,args);
表示会执行原本的方法,而我们来看原本的startActivity方法如下:
int var16 = ActivityManagerNative.getDefault().startActivity(whoThread, intent, intent.resolveTypeIfNeeded(who.getContentResolver()), token, target != null?target.mEmbeddedID:null, requestCode, 0, (String)null, (ParcelFileDescriptor)null, options);
所以我们说args中肯定有个intent类型的参数,获取真实目标Activity之后,我们获取目标的包名
intent = (Intent) args[index];
String packageName = intent.getComponent().getPackageName();
新建一个Intent 将intent设置为 冒充者Main2Activity的相关信息
Intent newIntent = new Intent();
ComponentName componentName = new ComponentName(packageName,Main2Activity.class.getName());
newIntent.setComponent(componentName);
args[index] = newIntent;
这样目标Activity就被替换成了Main2Activity,不过这个冒充者还要将原本的目标携带过去,等待真正打开的时候再替换回来,否则就真的启动这个冒充者了
newIntent.putExtra(AmsHookHelperUtils.TUREINTENT,intent);
这个时候我们调用这个方法什么都不做,这个时候启动Main3Activity
startActivity(new Intent(this,Main3Activity.class));
显示的其实是Main2Activity,如图所示:
这样说明我们的冒充者已经成功替换了真实目标,所以我们接下来要在启动的时候,将冒充者再重新替换为目标者,ActivityThread通过mH发消息给AMS
synchronized(this) {
Message msg = Message.obtain();
msg.what = what;
msg.obj = obj;
msg.arg1 = arg1;
msg.arg2 = arg2;
this.mH.sendMessage(msg);
}
AMS收到消息后进行处理
public void handleMessage(Message msg) {
ActivityThread.ActivityClientRecord data;
switch(msg.what) {
case 100:
Trace.traceBegin(64L, "activityStart");
data = (ActivityThread.ActivityClientRecord)msg.obj;
data.packageInfo = ActivityThread.this.getPackageInfoNoCheck(data.activityInfo.applicationInfo, data.compatInfo);
ActivityThread.this.handleLaunchActivity(data, (Intent)null);
Trace.traceEnd(64L);
mH是Handler类型的消息处理类,所以sendMessage方法会调用callback,Handler消息处理机制可看我之前一篇博客
深入理解Android消息机制,所以我们可以对callback字段进行Hook。如果不明白怎么办?关注我!
新建hookActivityThread方法,首先我们获取当前的ActivityThread对象
Object currentActivityThread = Reflex.getStaticFieldObject("android.app.ActivityThread", "sCurrentActivityThread");
然后获取对象的mH对象
Handler mH = (Handler) Reflex.getFieldObject(currentActivityThread, "mH");
将mH替换为我们的自己自定义的MyCallback。
Reflex.setFieldObject(Handler.class, mH, "mCallback", new MyCallback(mH));
自定义MyCallback首先 Handler.Callback接口,重新处理handleMessage方法
@Override
public boolean handleMessage(Message msg) {
switch (msg.what) {
case 100:
handleLaunchActivity(msg);
break;
default:
break;
}
mBase.handleMessage(msg);
return true;
}
我们获取传递过来的目标对象
Object obj = msg.obj;
Intent intent = (Intent) Reflex.getFieldObject(obj, "intent");
然后从目标对象中取出携带过来的真实对象,并将intent修改为真实目标对象的信息,这样就可以启动真实的目标Activity
Intent targetIntent = intent.getParcelableExtra(AmsHookHelperUtils.TUREINTENT);
intent.setComponent(targetIntent.getComponent());
MyCallbackt如下
**
* Created by Huanglinqing on 2019/4/30.
*/
public class MyCallback implements Handler.Callback {
Handler mBase;
public MyCallback(Handler base) {
mBase = base;
}
@Override
public boolean handleMessage(Message msg) {
switch (msg.what) {
case 100:
handleLaunchActivity(msg);
break;
default:
break;
}
mBase.handleMessage(msg);
return true;
}
private void handleLaunchActivity(Message msg) {
Object obj = msg.obj;
Intent intent = (Intent) Reflex.getFieldObject(obj, "intent");
Intent targetIntent = intent.getParcelableExtra(AmsHookHelperUtils.TUREINTENT);
intent.setComponent(targetIntent.getComponent());
}
}
这个时候再启动未注册的Main3Activity,就可以成功启动了
startActivity(new Intent(this,Main3Activity.class));
这样我们就成功的启动了未注册Activity
作者:黄林晴_阿黄哥
链接:https://juejin.cn/post/7052520889379880968
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
CTO 说了,用错 @Autowired 和 @Resource 的人可以领盒饭了
介绍
今天使用Idea写代码的时候,看到之前的项目中显示有warning的提示,去看了下,是如下代码?
@Autowire
private JdbcTemplate jdbcTemplate;
提示的警告信息
Field injection is not recommended Inspection info: Spring Team recommends: "Always use constructor based dependency injection in your beans. Always use assertions for mandatory dependencies".
这段是Spring工作组的建议,大致翻译一下:
属性字段注入的方式不推荐,检查到的问题是:Spring团队建议:"始终在bean中使用基于构造函数的依赖项注入,始终对强制性依赖项使用断言"
如图
Field注入警告
注入方式
虽然当前有关Spring Framework(5.0.3)的文档仅定义了两种主要的注入类型,但实际上有三种:
基于构造函数的依赖注入
public class UserServiceImpl implents UserService{
private UserDao userDao;
@Autowire
public UserServiceImpl(UserDao userDao){
this.userDao = userDao;
}
}
基于Setter的依赖注入
public class UserServiceImpl implents UserService{
private UserDao userDao;
@Autowire
public serUserDao(UserDao userDao){
this.userDao = userDao;
}
}
基于字段的依赖注入
public class UserServiceImpl implents UserService{
@Autowire
private UserDao userDao;
}
基于字段的依赖注入方式会在Idea当中吃到黄牌警告,但是这种使用方式使用的也最广泛,因为简洁方便.您甚至可以在一些Spring指南中看到这种注入方法,尽管在文档中不建议这样做.(有点执法犯法的感觉)
如图
Spring自己的文档
基于字段的依赖注入缺点
对于有final修饰的变量不好使
Spring的IOC对待属性的注入使用的是set形式,但是final类型的变量在调用class的构造函数的这个过程当中就得初始化完成,这个是基于字段的依赖注入做不到的地方.只能使用基于构造函数的依赖注入的方式
掩盖单一职责的设计思想
我们都知道在OOP的设计当中有一个单一职责思想,如果你采用的是基于构造函数的依赖注入的方式来使用Spring的IOC的时候,当你注入的太多的时候,这个构造方法的参数就会很庞大,类似于下面.
当你看到这个类的构造方法那么多参数的时候,你自然而然的会想一下:这个类是不是违反了单一职责思想?.但是使用基于字段的依赖注入不会让你察觉,你会很沉浸在@Autowire当中
public class VerifyServiceImpl implents VerifyService{
private AccountService accountService;
private UserService userService;
private IDService idService;
private RoleService roleService;
private PermissionService permissionService;
private EnterpriseService enterpriseService;
private EmployeeService employService;
private TaskService taskService;
private RedisService redisService;
private MQService mqService;
public SystemLogDto(AccountService accountService,
UserService userService,
IDService idService,
RoleService roleService,
PermissionService permissionService,
EnterpriseService enterpriseService,
EmployeeService employService,
TaskService taskService,
RedisService redisService,
MQService mqService) {
this.accountService = accountService;
this.userService = userService;
this.idService = idService;
this.roleService = roleService;
this.permissionService = permissionService;
this.enterpriseService = enterpriseService;
this.employService = employService;
this.taskService = taskService;
this.redisService = redisService;
this.mqService = mqService;
}
}
与Spring的IOC机制紧密耦合
当你使用基于字段的依赖注入方式的时候,确实可以省略构造方法和setter这些个模板类型的方法,但是,你把控制权全给Spring的IOC了,别的类想重新设置下你的某个注入属性,没法处理(当然反射可以做到).
本身Spring的目的就是解藕和依赖反转,结果通过再次与类注入器(在本例中为Spring)耦合,失去了通过自动装配类字段而实现的对类的解耦,从而使类在Spring容器之外无效.
隐藏依赖性
当你使用Spring的IOC的时候,被注入的类应当使用一些public类型(构造方法,和setter类型方法)的方法来向外界表达:我需要什么依赖.但是基于字段的依赖注入的方式,基本都是private形式的,private把属性都给封印到class当中了.
无法对注入的属性进行安检
基于字段的依赖注入方式,你在程序启动的时候无法拿到这个类,只有在真正的业务使用的时候才会拿到,一般情况下,这个注入的都是非null的,万一要是null怎么办,在业务处理的时候错误才爆出来,时间有点晚了,如果在启动的时候就暴露出来,那么bug就可以很快得到修复(当然你可以加注解校验).
如果你想在属性注入的时候,想根据这个注入的对象操作点东西,你无法办到.我碰到过的例子:一些配置信息啊,有些人总是会配错误,等到了自己测试业务阶段才知道配错了,例如线程初始个数不小心配置成了3000,机器真的是狂叫啊!这个时候就需要再某些Value注入的时候做一个检测机制.
结论
通过上面,我们可以看到,基于字段的依赖注入方式有很多缺点,我们应当避免使用基于字段的依赖注入.推荐的方法是使用基于构造函数和基于setter的依赖注入.对于必需的依赖项,建议使用基于构造函数的注入,以使它们成为不可变的,并防止它们为null。对于可选的依赖项,建议使用基于Setter的注入
作者:MarkerHub
链接:https://juejin.cn/post/7053664705507753991
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
我为大家带来了二十张登录界面?!!!
我为大家带来了二十张登录界面😎!!!这次给大家带来了20张Web登录界面,真的是辛辛苦苦收集了好久,如果有喜欢的不妨给我点个赞吧,感谢!
以下所有设计图均来自网络,如有侵权,请联系我删除,感谢各位分享~
本人最喜欢的一张😎:(大家在评论区投票选出最喜欢的一张吧)
按钮的圆角让我看了真的是身心愉悦,简约却又不是高雅!
其他的十九张😍:
1.这一款我也是吹爆,层次非常明显,颜色令人舒适,各位觉得怎么样呢?
2.这张就是经典款,左侧突出自己网页的主题,右侧是一个简约的登录,这张非常实用,只需将左侧的图片一换即可!
3. 这就很像校园的网站,这样的配色突出校园青春气息,登录框与背景的交叠凸显层次
4.这一款可是上榜2020年6月的设计榜,层次相当丰富,主题也很突出,不愧是上榜的作品
5.哇塞当时看到这一款的时候,我是惊讶到的,这款色彩和层次是真的丰富🤩!!!
6.这款也是相当的好,一款卡通风格的旅游网页,用于游戏的官网也可以(例如原神),个人很喜欢
7.这篇也是很通用的网页,不过右边的圆角登录框也是比较有特色的
8.这一款乍一看很普通,但是当你关注到了细节时,它的背景分块真的是很好,爱了爱了
9.这一款是相较于其他有很大不同的,它更多的是在展示自己的界面美,没有去注意功能的突出,这样别具一格的其实也很不错!
10.以蓝色为底色,利用圆角层次分明,也突出了功能,很适合电商网页
11.这一款除了背景有点留白太多,其他还是很不错的,换一下背景就可以直接商用了~
12.也是一如往常的好,乍一看是很常规,但是当你细看的时候,它对于输入框的处理还是很到位的
13.这一款就比较有特色的,左侧一个轮播图用于展示网页与业务的特点,右侧的输入框与背景交叠丰富了层次,很棒的作品!
14.这款就是介绍自己app的一个网页,也是很不错,但是不知道为啥图片有点糊😭
15.这款黑色与紫色交融,满满的高级感!
16.这一款也在设计榜上,不过,我水平不够,没有欣赏到它的美,蓝色的底色(好了我真是编不下去啦哈哈,原作者看到的话不要打我,这只能证明我的审美不够)
17.漫威蜘蛛侠咱就不用多说了吧,懂得都懂,5星通过👌
18.唯美风格,相当舒服了,很适合一些助睡眠的网页🌙
19.外星风格,我觉得可以卖玩具了哈哈😝
每一张都是设计师辛辛苦苦设计的,每一张都很棒,感谢!!!
作者:阿Tya
链接:https://juejin.cn/post/7015042594396700709
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
【Flutter App】GetX框架的实践
正在做的这款App是一个打卡软件,旨在让用户能够更好地坚持自己所设置的目标,坚持自己的初心。
由于项目还只是在前期阶段,目前根据需要建立了以下结构:
参考了部分官方插件以及结合官方getX文档中建议的目录:
暂时没有对state分离出来一层的想法。 以下是各层详细内容:
在使用GetX的时候,往往每次都是用需要手动实例化一个控制器final controller = Get.put(CounterController());,如果每个界面都要实例化一次,有些许麻烦。使用Binding 能解决上述问题,可以在项目初始化时把所有需要进行状态管理的控制器进行统一初始化,直接使用Get.find()找到对应的GetxController使用。
- 可以将路由、状态管理器和依赖管理器完全集成
- 这里介绍2种使用方式,推荐第一种使用getx的命名路由的方式
- 不使用binding,不会对功能有任何的影响。
- 第一种:使用命名路由进行Binding绑定
/// 入口类
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
/// 这里使用 GetMaterialApp
/// 初始化路由
return GetMaterialApp(
initialRoute: RouteConfig.onePage,
getPages: RouteConfig.getPages,
);
}
}
/// 路由配置
class RouteConfig {
static const String onePage = "/onePage";
static const String twoPage = "/twoPage";
static final List<GetPage> getPages = [
GetPage(
name: onePage,
page: () => const OnePage(),
binding: OnePageBinding(),
),
// GetPage(
// name: twoPage,
// page: () => TwoPage(),
// binding: TwoPageBinding(),
// ),
];
}
/// binding层
class OnePageBinding extends Bindings {
@override
void dependencies() {
Get.lazyPut(() => CounterController());
}
}
/// 逻辑层
class CounterController extends GetxController{
var count = 0;
/// 自增方法
void increase(){
count++;
update();
}
}
- 第二种:使用initialBinding初始化所有的Binding
/// 入口类
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return GetMaterialApp(
/// 初始化所有的Binding
initialBinding: AllControllerBinding(),
home: const OnePage(),
);
}
}
/// 所有的Binding层
class AllControllerBinding extends Bindings {
@override
void dependencies() {
Get.lazyPut(() => CounterController());
///Get.lazyPut(() => OneController());
///Get.lazyPut(() => TwoController());
}
}
作者:_Archer
链接:https://juejin.cn/post/7042904386799927332
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
android Handler架构思考
前言
写这篇文章不是为了分析Handler怎么使用,目的是想从设计的角度来看Handler的演进过程,以及为什么会出现Looper,MessageQueue,Handler,Message这四个类。
一.线程通信的本质?
线程区别于进程的主要因素在于,线程之间是共享内存的。在android系统中,堆中的对象可以被所有线程访问。因此无论是哪种线程通信方式,考虑到性能问题,一定会选用持有对方线程的某个对象来实现通信。
1.1 AsyncTask
public AsyncTask(@Nullable Looper callbackLooper) {
mHandler = callbackLooper == null || callbackLooper == Looper.getMainLooper()
? getMainHandler()
: new Handler(callbackLooper);
mWorker = new WorkerRunnable() {
public Result call() throws Exception {
mTaskInvoked.set(true);
Result result = null;
try {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
//noinspection unchecked
result = doInBackground(mParams);
Binder.flushPendingCommands();
} catch (Throwable tr) {
mCancelled.set(true);
throw tr;
} finally {
postResult(result);
}
return result;
}
};
mFuture = new FutureTask(mWorker) {
@Override
protected void done() {
try {
postResultIfNotInvoked(get());
} catch (InterruptedException e) {
android.util.Log.w(LOG_TAG, e);
} catch (ExecutionException e) {
throw new RuntimeException("An error occurred while executing doInBackground()",
e.getCause());
} catch (CancellationException e) {
postResultIfNotInvoked(null);
}
}
};
}
private Result postResult(Result result) {
@SuppressWarnings("unchecked")
Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult(this, result));
message.sendToTarget();
return result;
}
从用法可以看出,AsyncTask也是间接通过handler机制实现从当前线程给Looper所对应线程发送消息的,如果不传,默认选的就是主线程的Looper。
1.2 Handler
借助ThreadLocal获取thread的Looper,传输message进行通信。本质上也是持有对象线程的Looper对象。
public Handler(@Nullable Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
public final boolean post(@NonNull Runnable r) {
return sendMessageDelayed(getPostMessage(r), 0);
}
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
1.3 View.post(Runnable)
public boolean post(Runnable action) {
final AttachInfo attachInfo = mAttachInfo;
if (attachInfo != null) {
return attachInfo.mHandler.post(action);
}
// Postpone the runnable until we know on which thread it needs to run.
// Assume that the runnable will be successfully placed after attach.
getRunQueue().post(action);
return true;
}
getRunQueue().post(action)仅仅是在没有attachToWindow之前缓存了Runnable到数组中
private HandlerAction[] mActions;
public void postDelayed(Runnable action, long delayMillis) {
final HandlerAction handlerAction = new HandlerAction(action, delayMillis);
synchronized (this) {
if (mActions == null) {
mActions = new HandlerAction[4];
}
mActions = GrowingArrayUtils.append(mActions, mCount, handlerAction);
mCount++;
}
}
等到attachToWindow时执行,因此本质上也是handler机制进行通信。
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
....
// Transfer all pending runnables.
if (mRunQueue != null) {
mRunQueue.executeActions(info.mHandler);
mRunQueue = null;
}
....
}
1.4 runOnUiThread
public final void runOnUiThread(Runnable action) {
if (Thread.currentThread() != mUiThread) {
mHandler.post(action);
} else {
action.run();
}
}
通过获取UIThread的handler来通信。
从以上分析可以看出,android系统的四种常见通信方式本质上都是通过Handler技术进行通信。
二.handler解决什么问题?
handler解决线程通信问题,以及线程切换问题。本质上还是共享内存,通过持有其他线程的Looper来发送消息。
我们常提的Handler技术通常包括以下四部分
- Handler
- Looper
- MessageQueue
- Message
三.从架构的演进来看Handler
3.1 原始的线程通信
String msg = "hello world";
Thread thread = new Thread(){
@Override
public void run() {
super.run();
System.out.println(msg);
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
System.out.println(msg);
}
};
thread1.start();
3.2 结构化数据支持
为了发送结构化数据,因此设计了Message
Message msg = new Message();
Thread thread = new Thread(){
@Override
public void run() {
super.run();
msg.content = "hello";
System.out.println(msg);
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
System.out.println(msg);
}
};
thread1.start();
3.3 持续通信支持
Message msg = new Message();
Thread thread = new Thread(){
@Override
public void run() {
for (;;){
msg.content = "hello";
}
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
for (;;){
System.out.println(msg.content);
}
}
};
thread1.start();
通过无限for循环阻塞线程,Handler中对应的是Looper。
3.4 线程切换支持
上述方法都只能是thread1接受改变,而无法通知thread。因此设计了Handler, 同时封装了发送和接受消息的方法.
class Message{
String content = "123";
String from = "hch";
}
abstract class Handler{
public void sendMessage(Message message){
handleMessage(message);
}
public abstract void handleMessage(Message message);
}
Message msg = new Message();
Thread thread = new Thread(){
@Override
public void run() {
for (;;){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
msg.content = "hello";
if (handler != null){
handler.sendMessage(msg);
}
}
}
};
thread.start();
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
handler = new Handler(){
@Override
public void handleMessage(Message message) {
System.out.println(message.content);
}
};
}
};
thread1.start();
3.5 对于线程消息吞吐量的支持
abstract class Handler{
BlockingDeque messageQueue = new LinkedBlockingDeque<>();
public void sendMessage(Message message){
messageQueue.add(message);
}
public abstract void handleMessage(Message message);
}
...
Thread thread1 = new Thread(){
@Override
public void run() {
super.run();
handler = new Handler(){
@Override
public void handleMessage(Message message) {
if (!handler.messageQueue.isEmpty()){
System.out.println(messageQueue.pollFirst().content);
}
}
};
}
};
thread1.start();
增加消息队列MessageQueue来缓存消息,处理线程按顺序消费。形成典型的生产者消费者模型。
3.6 对于多线程的支持
上述模型最大的不便之后在于Handler的申明和使用,通信线程双方必须能够非常方便的获取到相同的Handler。
同时考虑到使用线程的便利性,我们不能限制Handler在某个固定的地方申明。如果能够非常方便的获取到对应线程的消息队列,然后往里面塞我们的消息,那该多么美好。
因此Looper和ThreadLocal闪亮登场。
- Looper抽象了无限循环的过程,并且将MessageQueue从Handler中移到Looper中。
- ThreadLocal将每个线程通过ThreadLocalMap将Looper与Thread绑定,保证能够通过任意Thread获取到对应的Looper对象,进而获取到Thread所需的关键MessageQueue.
//ThreadLocal获取Looper
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
//Looper写入到ThreadLocal
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
// 队列抽象
private Looper(boolean quitAllowed) {
mQueue = new MessageQueue(quitAllowed);
mThread = Thread.currentThread();
}
//Handler获取Looper
public Handler(@Nullable Callback callback, boolean async) {
if (FIND_POTENTIAL_LEAKS) {
final Class klass = getClass();
if ((klass.isAnonymousClass() || klass.isMemberClass() || klass.isLocalClass()) &&
(klass.getModifiers() & Modifier.STATIC) == 0) {
Log.w(TAG, "The following Handler class should be static or leaks might occur: " +
klass.getCanonicalName());
}
}
mLooper = Looper.myLooper();
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
mQueue = mLooper.mQueue;
mCallback = callback;
mAsynchronous = async;
}
3.7 google对于Handler的无奈妥协
思考一个问题,由于Handler可以在任意位置定义,sendMessage到对应的线程可以通过线程对应的Looper--MessageQueue来执行,那handleMessage的时候,如何能找到对应的Handler来处理呢?我们可没有好的办法能直接检索到每个消息对应的Handler
两种解决思路
- 通过公共总线,比如定义Map
- 通过消息带Message来携带属性target到对应线程,当消息被消费后,可以通过Message来获得Handler.
第一种方式的问题比较明显,公共总线需要手动维护它的生命周期,google采用的是第二种方式。
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,
long uptimeMillis) {
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
3.8.妥协造成Handler泄露问题的根源
由于Message持有了Handler的引用,当我们通过内部类的形式定义Handler时,持有链为
Thread->MessageQueue->Message->Handler->Activity/Fragment
长生命周期的Thread持有了短生命周期的Activity.
解决方式: 使用静态内部类定义Handler,静态内部类不持有外部类的引用,所以使用静态的handler不会导致activity的泄露。
四.总结
- 1.线程通信本质上通过共享内存来实现
- 2.android系统常用的四种通信方式,实际都采用Handler实现
- 3.Handler机制包含四部分Handler,MessageQueue,Message,Looper,它是架构演进的结果。
- 4.Handler泄露本质是由于长生命周期的对象Thead间接持有了短生命周期的对象造成。
作者:八道
链接:https://juejin.cn/post/7045473726929829918
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android架构学习之路一-漫谈
架构是什么
对于架构,我也有些一知半解,读了一些架构相关的文章,结合实际项目经历,有了自己的一些理解。
关于架构是什么?这点可以顾名思义去看,架构=架+构,即整体的一个架子和各个组件之间的组合结构。当然可能不同的程序员对于项目架构的风格和习惯不一样,但是底层的思想应该都是类似的,诸如我们可能听到起了茧子的“关注点分离”,“低耦合高内聚”,“可扩展可复用易维护”等等,听完这些话,感觉自己懂了,又感觉啥也不懂,好像有所收获了,准备开始写代码的时候,脑子里想的可能又是“工期太赶了,就这样写吧,反正干完这几票就跑路了”。
架构离我们并不远,反而在我们的实际开发中无处不在,它是一个很笼统的概念,上至框架选型,组件化等,下至业务代码,设计模式都能称为架构的一部分。对于架构学习而言,我觉得首先得对面向对象(抽象,继承,多态等)及设计原则有一定的理解,进而结合 Android 常用的一些架构如 MVVM, MVP, MVI 等思想,基础与理论理解清楚了,架构就在日常的开发中,多思考,多结合理论与实际,一点一点地积累起来了。
一起吐槽
我想每个程序员在写代码的时候可能都有这些历程(夸张):
- 这坨代码谁写的,怎么要这样写啊,我这个需求该怎么加代码!
- (尝试在shit山上小心地走,并添加新代码)写的好难受,shit越改越chou了...
- 算了,爷来重构一下,结束掉一切吧!
- 重构的一天:我曰,这个地方怎么埋了个雷,我来排一下;哇,怎么这里还有奇怪的逻辑,哼哧哼哧问了之前的同事说是PM改的需求;哎,爱咋地咋地。
- Several days later -> git revert -> 下班
- 在原来的shit山上再拉一坨,OK,很稳定,提测。
新员工整天都想着重构,而经验丰富的老人早就知道能不动别人的代码就不动的(doge),shit都是互相的,你来我往才能生生不息。写代码嘛,就讲究一个礼尚往来~
背后的原因令人XX
吐槽不是针对某个人,这种现象其实也挺正常的,因为技术在发展和迭代,业务也在丰富和重构,所以在当时看起来,这块代码是很优秀的,只不过由于一步一步的发展,以及一些历史包袱(PM: ??),慢慢的原先的架构可能就跟不上业务需求了,毕竟,架构不是一成不变的,业务在发展,技术在迭代,熵增很正常。到了一定的地步,评估好成本和收入,老老实实提需求重构吧。
当然,虽说随着业务的发展,熵增是必然情况,但是也得注意自己的代码质量呀,毕竟大家应该都不想被后面的同事接手的时候偷偷吐槽你的shit太chou了吧,除非真的抱着干完这一票就溜溜球的想法(doge)。
简而言之原因可以分为两种:
- 产品的发展,技术的更新迭代
- 每个人的代码习惯可能不一样,比较参差
怎么做
学好面向对象
听说即使是许多年的老 Java 人,可能在开发中也不怎么注意面向对象的思想,我也经常疏忽这点,啊不对,我不算老 Java 人(囧)。
关于面向对象和面向过程的区别,网上很多介绍的,随便抄了一份:
- 面向对象:面向对象是一种风格,会以类作为代码的基本单位,通过对象访问,并拥有
封装、继承、抽象、多态四种特性作为基石,可让其更为智能。 - 面向过程:分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了,更侧重于功能的设计。
在开始做需求的时候,先别急着写代码,思考一下这个需求的本质是干嘛,用面向对象的思想去抽象这个过程,不是直接搞几个类就可以了的。
举个栗子,之前在老东家的时候做过后台启动的需求,当时的情况是这样子的:针对不同的 Android 版本,可能有一种或者多种不同的启动方式,需要分版本挨个尝试。直截了当的方式是 if else 从头到尾一路火花带闪电,但是觉得这样子肯定是比较难以维护的,所以就把每种启动方式都抽象成了一个 Starter 类:
abstract class Starter {
// 做后台启动的事情
abstract fun handle(context: Context, intent: Intent)
// 是否满足特定Android版本和业务场景等
abstract fun satisfy(): Boolean
}
然后把这些启动方式串起来,通过类似责任链的设计模式去工作,具体代码不贴了,有兴趣可以看看之前的文章: 实战|Android后台启动Activity实践之路。可能现在看当时的代码,会觉得有些稚嫩,但程序员不就是得一直进步的嘛~
接着就是那些常用的面向对象设计模式了,讲道理这些设计模式是很有用的,另外还有面向对象的六大设计原则,这些网上应该很多很多的文章都会讲,此处就不赘述了。
设计架构
前面已经提过随着技术和业务的发展,架构也在一步一步迭代,比如说一开始的单体架构,把用户界面,业务逻辑,数据管理都糅合到一起,到后面根据业务和技术拆分结构,如 MVC, MVP, MVVM, MVI 这些,以及模块化和组件化,服务注册和发现等等,另外还有比较复杂的 Clean 架构,Android 版的 Redux 架构之类的等等。多的一批,哎,好卷。
有时候会产生疑问,这么多新的东西冒出来到底是技术必需的迭代还是由于 OKR, KPI 太卷了(doge)。但能怎么着哦,还是得哼哧哼哧学习。这些文章计划在后面慢慢整理,就当给我年初补充的flag 两年半,加油Android|2021年终总结 吧!
不过架构再多,也都是为业务服务的,没有什么完美的架构,适合当前需求的才是最好的。
写在最后
写代码的时候,记得三思而后行,想一想你写的代码是不是在它该在的位置,是不是以该有的形式存在的。
架构不是一蹴而就的,希望我们有一天的时候,能够从自己写的代码中找到架构的成就感,而不是干几票就跑路的想法,这个系列应该会一直更新,记录我在架构之路上学习的脚印儿,一件一件扒开架构神秘的面纱。
作者:苍耳叔叔
链接:https://juejin.cn/post/7052201118092230669
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2022年为什么要使用Flutter构建应用程序?
今天每个人都想构建一个应用程序,但是谁又能责怪他们呢?事实上,如今每个人都拥有智能手机,它已迅速成为我们白天最常使用的工具。当我们没有它们时,我们会感到缺少一些东西,我们甚至把它们带到洗手间,我们甚至想不出没有它们,如何出门。无论我们喜欢与否,它对我们生活都在进行最快,最积极的影响,而这要归功于应用程序。
应用有一种特殊的方式来吸引用户,而其他事物则没有。这里给大家顺便带一下,我之前写过的一篇文章你想好,如何为你的应用做推广了吗?这可能是由于其漂亮的用户界面,经过深思熟虑的用户体验或完美的可用性。这就是为什么编程可以被认为是一门艺术的全部原因,而Flutter在这里为我们提供了这条道路。
什么是Flutter?
"Flutter是Google的UI工具包,用于从单个代码库为移动,Web和桌面构建美观,可以的应用程序。
Flutter是一个跨平台框架,使开发人员能够从单个代码库在不同的平台上编程。 这为桌面带来了很多优势。
以下是关于Flutter的一些最特点:
- 它是开源的
- 它有一个清晰的文档和一个伟大的社区
- 由谷歌开发
- 它有一个适合一切的小部件
- 提高开发人员的工作效率
- 一个单一的代码库来统治它们
为什么跨平台如此重要?
跨平台开发允许创建与多个操作系统兼容的软件应用程序。通过这种方式,该技术克服了为每个平台构建唯一代码的原始开发困难。
当然,今天开发一个应用程序意味着出现在两个相关操作系统上:Android和iOS。 在过去,这意味着拥有两个代码,两个团队和两倍的成本。多亏了跨平台,我们可以让一个团队从一个代码库为多个平台创建一个应用程序。
毫无疑问,Flutter并不是唯一的跨平台解决方案,我们可以继续讨论其他人如何尝试采取不同的方向,但这是另一篇文章。但是,有一件事是肯定的,那就是:跨平台将继续存在。 这也是2022年为什么要学习Flutter的理由
单个代码库,单个技术栈。
为了继续我要去的地方,如果管理应用程序的开发是困难的,想象一下管理两种不同技术的开发。每个更改都必须在两种不同的技术中编码和批准。团队必须分为两个,iOS团队和Android团队。这就是为什么让一个团队在单个代码库中工作更有益的原因。
Flutter 擅长的地方
*任何软件开发人员都熟悉这个概念,因为我们做出的每一个选择都决定了优点和缺点。因此,再次选择Flutter在您的项目中有利有弊。
在本文中,我想提供有关它的信息,以便在适合您的项目时进行权衡。以下是它的一些好处:
缩短上市时间
Flutter 是一项出色的原型设计技术 - 不仅是 MVP ,还包括具有实际产品功能的应用程序。通过使用Flutter,您将为两个平台(iOS和Android)构建一个应用程序,这可以大大减少开发时间,从而可以更快地将您推向市场。此外,基本上将小部件用于所有内容的可能性以及具有大量可用库的可能性是加快速度的另一个重要因素。
单个开发团队
通过使用Flutter,你可以拥有一个开发团队,而不需要有两个iOS和Android专家团队。您不必担心同步两台计算机,两个代码库,您可以简单地同时在两个平台上发布。
降低开发成本
拥有一个开发团队还有其他好处 ,例如大大降低成本。 这对任何想要构建应用程序的人来说都非常有吸引力,因为进入应用程序市场的经济门槛较低。使其具有成本效益
但是等等,上面说了这么多好处,有什么不利吗
什么时候使用Flutter不方便?
当然,在某些情况下,Flutter并不完全适合您的项目。当这种情况发生时,我们必须简单地接受它,并选择原生开发或其他选择。
例如,如果你的应用需要并且完全依赖于某些特定的硬件设备密集型功能,你可能想要找出是否存在某种Flutter插件。但是,由于它非常新,我强烈建议您进行概念验证,需求分析,以降低技术不是障碍的风险。
此外,还有一些Flutter尚未到达的地方,例如增强现实和3D游戏。在这些情况下,Unity 可能更适合您的项目。请记住,您始终可以尽可能使用 Flutter,然后对于特定的事情使用 native 或 Unity。请记住,将 Flutter 与原生集成始终是一个可用的选项。
想学习另一个技术?
如果你对学习另一种技术有想法,我明白了。但是,请在这里继续等我,让我向您展示它到目前为止是如何演变的:
Flutter的测试版于2018年3月推出,并于2018年12月首次上线。从那时起 ,Flutter稳固了其在市场上的地位,并继续高速崛起。
Flutter社区也在不断发展。Flutter受到大型市场参与者和顶级公司的信任 ,如Google Ads,丰田,还有国内的很多大厂等等。 ,
关于这点你可以去检查你的手机的应用程序,相信会发现很多关于Flutter的踪迹。
最后:
自信地迁移到 Flutter
可以肯定地说,Flutter 有着光明的未来。所以,如果你一直生活在一块石头下并且还没有听说过它,现在就去看看。这是官网flutter.dev/
就我的使用来说,Flutter 不仅达到了我的期望,而且超出了我的期望。这无疑是一项我们从头到尾都爱上的技术。它使我们能够在创纪录的时间内高效地构建应用程序。
这就是我信任 Flutter 的原因。我相信它的未来。我也愿意为此推广Flutter。
作者:大前端之旅
链接:https://juejin.cn/post/7051828127227609124
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我们对 DiffUtil 的使用可能被带偏了
我们对 DiffUtil 的使用可能被带偏了
前面都是我的流水账, 觉得看起来很没劲的, 可以直接跳转到本质小节,.
DiffUtil 的优势
我在最初接触 DiffUtil 时, 心中便对它有颇多的好感, 包括:
- 算法听提来就很nb, 一定是个好东西;
- 简化了
RecyclerView的刷新逻辑, 无须关心该调用notifyItemInserted还是notifyItemChanged, 一律submitList就完事了(虽然notifyDataSetChanged也能做到, 但是性能拉胯, 而且没有动画); LiveData或者Flow监听单一List数据源时, 往往很难知道, 整个List中到底哪些数据项被更新了, 只能调用notifyDataSetChanged方法, 而DiffUtil恰好就能解决这个问题, 无脑submitList就完事了.
DiffUtil 代码示例
使用 DiffUtil 时, 代码大致如下:
data class Item (
var id: Long = 0,
var data: String = ""
)
class DiffAdapter : RecyclerView.Adapter<DiffAdapter.MyViewHolder>() {
// AsyncListDiffer 类位于 androidx.recyclerview.widget 包下
// 这里以 AsyncListDiffer 的使用来举例, 使用 ListAdapter 或者直接用 DiffUtil, 也存在后面的问题
private val differ = AsyncListDiffer<Item>(this, object : DiffUtil.ItemCallback<Item>() {
override fun areItemsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem.id == newItem.id
}
override fun areContentsTheSame(oldItem: Item, newItem: Item): Boolean {
// Kotlin中的 == 运算符, 相当于 Java 中调用 equals 方法
return oldItem == newItem
}
private val payloadResult = Any()
override fun getChangePayload(oldItem: Item, newItem: Item): Any {
// payload 用于Item局部字段更新的时候使用,具体用法可以自行搜索了解
// 当检测到同一个Item有更新时, 会调用此方法
// 此方法默认返回null, 此时会触发Item的更新动画, 表现为Item会闪一下
// 当返回值不为null时, 可以关闭Item的更新动画
return payloadResult
}
})
class MyViewHolder(val view: View):RecyclerView.ViewHolder(view){
private val dataTv:TextView by lazy{ view.findViewById(R.id.dataTv) }
fun bind(item: Item){
dataTv.text = item.data
}
}
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): MyViewHolder {
return MyViewHolder(LayoutInflater.from(parent.context).inflate(
R.layout.item_xxx,
parent,
false
))
}
override fun onBindViewHolder(holder: MyViewHolder, position: Int) {
holder.bind(differ.currentList[position])
}
override fun getItemCount(): Int {
return differ.currentList.size
}
public fun submitList(newList: List<Item>) {
differ.submitList(newList)
}
}
val dataList = mutableListOf<Item>(item1, item2)
differ.submitList(dataList)
以上代码的关键在于以下两个方法的实现, 作用分别是:
areItemsTheSame(oldItem: Item, newItem: Item):比较两个 Item 是否表示同一项数据;areContentsTheSame(oldItem: Item, newItem: Item):比较两个 Item 的数据是否相同.
DiffUtil 的踩坑过程
上述示例代码很看起来简单, 也比较好理解, 当我们尝试添加一条数据时:
val dataList = mutableListOf<Item>(item1, item2)
differ.submitList(dataList)
// 增加数据
dataList.add(item3)
differ.submitList(dataList)
发现 item3 并未在界面上显示出来, 怎么回事呢? 我们来看 AsyncListDiffer 关键代码的实现:
public void submitList(@Nullable final List<T> newList) {
submitList(newList, null);
}
public void submitList(@Nullable final List<T> newList, @Nullable final Runnable commitCallback) {
// ...省略无关代码
// 注意这里是 Java 代码, 正在比较 newList 与 mList 是否为同一个引用
if (newList == mList) {
// nothing to do (Note - still had to inc generation, since may have ongoing work)
if (commitCallback != null) {
commitCallback.run();
}
return;
}
// ...省略无关代码
mConfig.getBackgroundThreadExecutor().execute(new Runnable() {
@Override
public void run() {
final DiffUtil.DiffResult result = DiffUtil.calculateDiff(new DiffUtil.Callback() {
// ...省略 newList 和 mList 的 Diff 算法比较代码
});
// ...省略无关代码
mMainThreadExecutor.execute(new Runnable() {
@Override
public void run() {
if (mMaxScheduledGeneration == runGeneration) {
latchList(newList, result, commitCallback);
}
}
});
}
});
}
void latchList(
@NonNull List<T> newList,
@NonNull DiffUtil.DiffResult diffResult,
@Nullable Runnable commitCallback) {
// ...省略无关代码
mList = newList;
// 将结果更新到具体的
diffResult.dispatchUpdatesTo(mUpdateCallback);
// ...省略无关代码
}
可以看到, 单参数的 submitList 方法会调用 双参数的 submitList 方法, 重点在于双参数的submitList 方的实现:
- 首先检查新提交的
newList与内部持有的mList的引用是否相同, 如果相同, 就直接返回; - 如果不同的引用, 就对
newList和mList做Diff算法比较, 并生成比较结果DiffUtil.DiffResult; - 最后通过
latchList方法将newList赋值给mList, 并将Diff算法的结果DiffUtil.DiffResult应用给mUpdateCallback.
最后的
mUpdateCallback, 其实就是上述示例代码中, 创建AsyncListDiffer对象时, 传入的RecyclerView.Adapter对象, 这里就不贴代码了.
浅拷贝
分析代码后, 我们可以知道, 每次 submitList 时, 必须传入不同的 List 对象, 否者方法内部不会做 Diff 算法比较, 而是直接返回, 界面也不会刷新. 需要要不同的 List 是吧? 哪还不简单, 我创建一个新的 List 不就行了?
于是我们修改一下 submitList 方法:
class DiffAdapter : RecyclerView.Adapter<DiffAdapter.MyViewHolder>() {
private val differ = AsyncListDiffer<Item>(this, object : DiffUtil.ItemCallback<Item>() {
override fun areItemsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem.id == newItem.id
}
override fun areContentsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem == newItem
}
})
// ...省略无关代码
public fun submitList(newList: List<Item>) {
// 创建一个新的 List, 再调用 submitList
differ.submitList(newList.toList())
}
}
相应的测试代码也变成了:
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 增加数据
dataList.add(item3)
diffAdapter.submitList(dataList)
// 删除数据
dataList.removeAt(0)
diffAdapter.submitList(dataList)
// 更新数据
dataList[1].data = "最新的数据"
diffAdapter.submitList(dataList)
运行代码后发现, 单独运行"增加数据"和"删除数据"的测试代码, 表现都是正常的, 唯独"更新数据"单独运行时, 界面毫无反应.
其实仔细想想也能明白, 虽然我们调用 differ.submitList(newList.toList()) 方法时, 确实对 List 做了一份拷贝, 但却是浅拷贝, 真正在运行 Diff 算法比较时, 其实是同一个 Item 对象在自己和自己比较(areContentsTheSame 方法参数的 oldItem 和 newItem 为同一个对象引用), 也就判定为没有数据更新.
data class 的 copy
有的同学,可能有话要说: "你应该在更新 data 字段时, 应该调用 copy 方法, 拷贝一个新的对象, 更新新的值后, 再把原始的 Item 替换掉!".
于是就有了以下代码:
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
dataList[0] = dataList[0].copy(data = "最新的数据")
diffAdapter.submitList(dataList)
运行代码后, "更新数据"也变得正常了, 当业务比较简单时, 也就到此为止了, 没有新的坑来踩了. 但如果业务比较复杂时, 更新数据的代码可能是这样的:
data class InnerItem(
val innerData: String = ""
)
data class Item(
val id: Long = 0,
val data: String = "",
val innerItem: InnerItem = InnerItem()
)
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
val item = dataList[0]
// 内部的数据也不能直接赋值, 需要拷贝一份, 否者和上面的情况类似了
val innerNewItem = item.innerItem.copy(innerData = "内部最新的数据")
dataList[0] = item.copy(innerItem = innerNewItem)
diffAdapter.submitList(dataList)
好像稍微有些复杂的样子, 那如果我们嵌套再深一些呢? 我里面还嵌套了一个List呢? 就要依次递归copy, 代码好像就比较复杂了.
此时我们再回想起开篇提到的 DiffUtil 第 2 点优势要打个疑问了. 本来以为会简化代码, 反而使代码变得更复杂了, 我还不如手动赋值, 然后自己去调用 notifyItemXxx , 代码怕是要简单一些.
深拷贝
于是乎, 为了避免递归copy, 导致更新数据的代码变得过于复杂, 就有了深拷贝的方案. 我管你套了几层, 我先深拷贝一份, 我直接对深拷贝的数据进行修改, 然后直接设置回去, 代码如下:
data class InnerItem(
var innerData: String = ""
)
data class Item(
val id: Long = 0,
var data: String = "",
var innerItem: InnerItem = InnerItem()
)
val diffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
dataList[0] = dataList[0].deepCopy().apply {
innerItem.innerData = "内部最新的数据"
}
diffAdapter.submitList(dataList)
代码看上去又变得简洁了许多, 我们的关注点又来到了深拷贝的如何实现:
利用 Serializable 或者 Parcelable 即可实现对象深拷贝, 具体可自行搜索.
- 使用
Serializable, 代码看起来比较简单, 但是性能稍差; - 使用
Parcelable, 性能好, 但是需要生成更多额外的代码, 看起来不够简洁;
其实选择 Serializable 或者 Parcelable 都无所谓, 看个人喜好即可. 关键在于实现了 Serializable 或者 Parcelable 接口后, Item 中的数据类型会被限制, 要求 Item 中所有的直接或间接字段也必须实现 Serializable Parcelable 接口, 否者就会序列化失败.
比如说, Item 中就不能声明类型为 android.text.SpannableString 的字段(用于显示富文本), 因为 SpannableString 既没有实现 Serializable 接口, 也没有实现 Parcelable 接口.
本质
回过头去, 我们再来审视一下 DiffUtil 两个核心方法:
areItemsTheSame(oldItem: Item, newItem: Item): 比较两个 Item 是否表示同一项数据;
areContentsTheSame(oldItem: Item, newItem: Item): 比较两个 Item 的数据是否相同.
先问个问题, 这两个方法分别为了实现什么目的呢, 或者说他们在算法中起的作用是什么?
简单, 就算不懂 DiffUtil 算法实现(其实是我不懂 o( ̄▽ ̄)o ), 也能猜到, 仅凭 areItemsTheSame 方法我们就能实现以下三种操作:
- itemRemove
- itemInsert
- itemMove
而最后一种 itemChange 操作, 需要 areItemsTheSame 方法先返回 true, 然后调用 areContentsTheSame 方法返回 false, 才能判定为 itemChange 操作, 这也和此方法的注释说明相对应:
This method is called only if {@link #areItemsTheSame(T, T)} returns {@code true} for these items.
所以, areContentsTheSame 方法的作用, 仅仅是为了判定 Item 用于界面显示的部分是否有更新, 而不一定需要调用 equals 方法来全量比较两个item的所有字段. 其实 areContentsTheSame 方法的代码注释也有说明:
This method to check equality instead of {@link Object#equals(Object)} so that you can change its behavior depending on your UI.
For example, if you are using DiffUtil with a {@link RecyclerView.Adapter RecyclerView.Adapter}, you should return whether the items' visual representations are the same.
你会发现, 网上很多教程的代码示例就是用的 equals 来判定数据是否被修改, 然后基于 equals 的比较前提, 更新数据的时候, 又是递归copy, 又是深拷贝, 其实是被带偏了, 思想被限制住了.
改进办法
既然 areItemsTheSame 方法仅用于判定 Item 用于显示的部分是否有更新, 从而判定 itemChange 操作, 那我们完全可以新起一个 contentId 字段, 用于标识内容的唯一性, areItemsTheSame 方法的实现也仅比较 contentId , 代码看起来像这样:
private val contentIdCreator = AtomicLong()
abstract class BaseItem(
open val id: Long,
val contentId: Long = contentIdCreator.incrementAndGet()
)
data class InnerItem(
var innerData: String = ""
)
data class ItemImpl(
override val id: Long,
var data: String = "",
var innerItem: InnerItem = InnerItem()
) : BaseItem(id)
class DiffAdapter : RecyclerView.Adapter<DiffAdapter.MyViewHolder>() {
private val differ = AsyncListDiffer<Item>(this, object : DiffUtil.ItemCallback<Item>() {
override fun areItemsTheSame(oldItem: Item, newItem: Item): Boolean {
return oldItem.id == newItem.id
}
override fun areContentsTheSame(oldItem: Item, newItem: Item): Boolean {
// contentId不一致时, 就认为此Item数据有更新
return oldItem.contentId == newItem.contentId
}
private val payloadResult = Any()
override fun getChangePayload(oldItem: Item, newItem: Item): Any {
// payload 用于Item局部字段更新的时候使用,具体用法可以自行搜索了解
// 当检测到同一个Item有更新时, 会调用此方法
// 此方法默认返回null, 此时会触发Item的更新动画, 表现为Item会闪一下
// 当返回值不为null时, 可以关闭Item的更新动画
return payloadResult
}
})
// ... 省略无关代码
public fun submitList(newList: List<Item>) {
// 创建新的List的浅拷贝, 再调用submitList
differ.submitList(newList.toList())
}
}
val diffAdapter: DiffAdapter = ...
val dataList = mutableListOf<Item>(item1, item2)
diffAdapter.submitList(dataList)
// 更新数据
// 仅需copy外层的数据,保证contentId不一致即可, 内部嵌套的数据仅需直接赋值即可
// 由于ItemImpl继承自BaseItem, 当执行ItemImpl.copy方法时, 会调用父类BaseItem的构造方法, 生成新的contentId
dataList[0] = dataList[0].copy().apply {
data = "最新的数据"
innerItem.innerData = "内部最新的数据"
}
diffAdapter.submitList(dataList)
因为 areContentsTheSame 方法执行时,需要不同的两个对象比较,所以有字段更新时,还是需要通过 copy 方法生成新的对象.
这种方式存在误判的可能, 因为
ItemImpl中的一些字段的更新可能不会影响到界面的显示, 此时areContentsTheSame方法应该返回false. 但个人认为这种情况是少数, 误判是可以接受的, 代价仅仅只会额外多更新了一次界面 item 而已.
其实, 了解了本质后, 我们还可以根据自己的业务需求按自己的方式来定制. 比如说用Java该怎么办? 我们也许可以这么做:
class Item{
int id;
boolean isUpdate; // 此字段用于标记此Item是否有更新
String data;
}
class JavaDiffAdapter extends RecyclerView.Adapter<JavaDiffAdapter.MyViewHolder>{
public void submitList(List<Item> dataList){
differ.submitList(new ArrayList<>(dataList));
}
@NonNull
@Override
public MyViewHolder onCreateViewHolder(@NonNull ViewGroup parent, int viewType) {
return new MyViewHolder(LayoutInflater.from(parent.getContext()).inflate(
R.layout.item_xxx,
parent,
false
));
}
@Override
public void onBindViewHolder(@NonNull MyViewHolder holder, int position) {
// 绑定一次数据后, 将需要更新的标识赋值为false
differ.getCurrentList().get(position).isUpdate = false;
holder.bind(differ.getCurrentList().get(position));
}
@Override
public int getItemCount() {
return differ.getCurrentList().size();
}
class MyViewHolder extends RecyclerView.ViewHolder{
private TextView dataTv;
public MyViewHolder(View itemView) {
super(itemView);
dataTv = itemView.findViewById(R.id.dataTv);
}
private void bind(Item item){
dataTv.setText(item.data);
}
}
private AsyncListDiffer<Item> differ = new AsyncListDiffer<Item>(this, new DiffUtil.ItemCallback<Item>() {
@Override
public boolean areItemsTheSame(@NonNull Item oldItem, @NonNull Item newItem) {
return oldItem.id == newItem.id;
}
@Override
public boolean areContentsTheSame(@NonNull Item oldItem, @NonNull Item newItem) {
// 通过读取isUpdate来确定数据是否有更新
return !newItem.isUpdate;
}
private final Object payloadResult = new Object();
@Nullable
@Override
public Object getChangePayload(@NonNull Item oldItem, @NonNull Item newItem) {
// payload 用于Item局部字段更新的时候使用,具体用法可以自行搜索了解
// 当检测到同一个Item有更新时, 会调用此方法
// 此方法默认返回null, 此时会触发Item的更新动画, 表现为Item会闪一下
// 当返回值不为null时, 可以关闭Item的更新动画
return payloadResult;
}
});
}
// 更新数据
List<Item> dataList = ...;
Item target = dataList.get(0);
// 标识数据有更新
target.isUpdate = true;
target.data = "新的数据";
adapter.submitList(dataList);
最后
其实, 如果我们的 List<Item> 来源于 Room, 其实没有这么多麻烦事, 直接调用 submitList 即可, 不用考虑这里提到的问题, 因为 Room 数据有更新时, 会自动生成新的 List<Item>, 里面的每项 Item 也是新的, 具体代码示例可参考 AsyncListDiffer 或者 ListAdapter 类的顶部的注释. 需要注意的是数据更新太频繁时, 会不会生成了太多的临时对象.
作者:水花DX
链接:https://juejin.cn/post/7054930375675478023
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
快速实现分布式session?厉害了
我们在开发一个项目时通常需要登录认证,常用的登录认证技术实现框架有Spring Security和shiro
Spring Security
Spring Security是一个功能强大且高度可定制的身份验证和访问控制框架。它是保护基于spring的应用程序的事实上的标准。
Spring Security是一个专注于为Java应用程序提供身份验证和授权的框架。与所有Spring项目一样,Spring Security的真正强大之处在于它可以很容易地扩展以满足定制需求,并且Spring Security和spring更加适配贴合,我们工作中常常使用到Spring Security。
Apache Shiro
Apache Shiro 是 Java 的一个安全框架。目前,使用 Apache Shiro 的人越来越多,因为它相当简单,对比Spring Security,可能没有 Spring Security 做的功能强大,但是在实际工作时可能并不需要那么复杂的东西,所以使用小而简单的 Shiro 就足够了。
不足:
这些都是认证技术框架,在单体应用中都是常用的技术框架,但是在分布式中,应用可能要部署多份,这时通过nginx分发请求,但是每个单体应用都要可能重复验证,因为他们的seesion数据是放在他们自己服务中的。
Session作用
Session是客户端与服务器通讯会话跟踪技术,服务器与客户端保持整个通讯的会话基本信息。
客户端在第一次访问服务端的时候,服务端会响应一个sessionId并且将它存入到本地cookie中,在之后的访问会将cookie中的sessionId放入到请求头中去访问服务器。
spring-session
Spring Session是Spring的项目之一,Spring Session把servlet容器实现的httpSession替换为spring-session,专注于解决session管理问题。
Spring Session提供了集群Session(Clustered Sessions)功能,默认采用外置的Redis来存储Session数据,以此来解决Session共享的问题。
spring-session提供对用户session管理的一系列api和实现。提供了很多可扩展、透明的封装方式用于管理httpSession/WebSocket的处理。
支持功能
- 轻易把session存储到第三方存储容器,框架提供了redis、jvm的map、mongo、gemfire、hazelcast、jdbc等多种存储session的容器的方式。这样可以独立于应用服务器的方式提供高质量的集群。
- 同一个浏览器同一个网站,支持多个session问题。 从而能够很容易地构建更加丰富的终端用户体验。
- Restful API,不依赖于cookie。可通过header来传递jessionID 。控制session id如何在客户端和服务器之间进行交换,这样的话就能很容易地编写Restful API,因为它可以从HTTP 头信息中获取session id,而不必再依赖于cookie
- WebSocket和spring-session结合,同步生命周期管理。当用户使用WebSocket发送请求的时候
分布式seesion实战
步骤1:依赖包
因为是web应用。我们加入springboot的常用依赖包web,加入SpringSession、redis的依赖包,移支持把session存储在redis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>
这里因为是把seesion存储在redis,这样每个服务登录都是去查看redis中数据进行验证的,所有是分布式的。
这里要引入spring-session-data-redis和spring-boot-starter-redis
步骤2:配置文件
spring.application.name=spring-boot-redis
server.port=9090
# 设置session的存储方式,采用redis存储
spring.session.store-type=redis
# session有效时长为15分钟
server.servlet.session.timeout=PT15M
## Redis 配置
## Redis数据库索引
spring.redis.database=1
## Redis服务器地址
spring.redis.host=127.0.0.1
## Redis服务器连接端口
spring.redis.port=6379
## Redis服务器连接密码(默认为空)
spring.redis.password=
步骤3:实现逻辑
初始化用户数据
@Slf4j
@RestController
@RequestMapping(value = "/user")
public class UserController {
Map<String, User> userMap = new HashMap<>();
public UserController() {
//初始化1个用户,用于模拟登录
User u1=new User(1,"user1","user1");
userMap.put("user1",u1);
}
}
这里就不用使用数据库了,初始化两条数据代替数据库,用于模拟登录
登录
@GetMapping(value = "/login")
public String login(String username, String password, HttpSession session) {
//模拟数据库的查找
User user = this.userMap.get(username);
if (user != null) {
if (!password.equals(user.getPassword())) {
return "用户名或密码错误!!!";
} else {
session.setAttribute(session.getId(), user);
log.info("登录成功{}",user);
}
} else {
return "用户名或密码错误!!!";
}
return "登录成功!!!";
}
登录接口,根据用户名和密码登录,这里进行验证,如果验证登录成功,使用 session.setAttribute(session.getId(), user);把相关信息放到session中。
查找用户
/**
* 通过用户名查找用户
*/
@GetMapping(value = "/find/{username}")
public User find(@PathVariable String username) {
User user=this.userMap.get(username);
log.info("通过用户名={},查找出用户{}",username,user);
return user;
}
模拟通过用户名查找用户
获取session
/**
*拿当前用户的session
*/
@GetMapping(value = "/session")
public String session(HttpSession session) {
log.info("当前用户的session={}",session.getId());
return session.getId();
}
退出登录
/**
* 退出登录
*/
@GetMapping(value = "/logout")
public String logout(HttpSession session) {
log.info("退出登录session={}",session.getId());
session.removeAttribute(session.getId());
return "成功退出!!";
}
这里退出时,要把session中的用户信息删除。
步骤4:编写session拦截器
session拦截器的作用:验证当前用户发来的请求是否有携带sessionid,如果没有携带,提示用户重新登录。
@Configuration
public class SecurityInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws IOException {
HttpSession session = request.getSession();
//验证当前session是否存在,存在返回true true代表能正常处理业务逻辑
if (session.getAttribute(session.getId()) != null){
log.info("session拦截器,session={},验证通过",session.getId());
return true;
}
//session不存在,返回false,并提示请重新登录。
response.setCharacterEncoding("UTF-8");
response.setContentType("application/json; charset=utf-8");
response.getWriter().write("请登录!!!!!");
log.info("session拦截器,session={},验证失败",session.getId());
return false;
}
}
步骤5:把拦截器注入到拦截器链中
@Slf4j
@Configuration
public class SessionCofig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new SecurityInterceptor())
//排除拦截的2个路径
.excludePathPatterns("/user/login")
.excludePathPatterns("/user/logout")
//拦截所有URL路径
.addPathPatterns("/**");
}
}
步骤6:测试
登录user1用户:http://127.0.0.1:9090/user/login?username=user1&password=user1
查询user1用户session:http://127.0.0.1:9090/user/session
退出登录: http://127.0.0.1:9090/user/logout
登录后查看redis中数据:
seesion数据已经保存到redis了,到这里我们就整合了使用spring-seesion实现分布式seesion功能。
作者:小伙子vae
链接:https://juejin.cn/post/7054913351503052813
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
你真的了解反射吗?
1. 啥是反射
1.初识反射
刚开始学反射的时候,我是一脸懵逼的,这玩意真的是“抽象的妈妈给抽象开门-抽象到家了。”
为什么创建对象要先获取 Class 对象?这不多此一举吗?我直接 new 一下不是更简单吗?
什么是程序运行时获取类的属性和方法?平时都是程序编译出错了再修改代码,我为什么要考虑程序运行时的状态?
我平时开发也用不到,学这玩意有啥用?
后来学了注解、spring、SpringMVC 等技术之后,发现反射无处不在。
2.JVM 加载类
我们写的 java 程序要放到 JVM 中运行,所以要学习反射,首先需要了解 JVM 加载类的过程。
1.我们写的 .java 文件叫做源代码。
2.我们在一个类中写了一个 main 方法,然后点击 IDEA 的 run 按钮,JVM 运行时会触发 jdk 的 javac 指令将源代码编译成 .class 文件,这个文件又叫做字节码文件。
3.JVM 的类加载器(你可以理解成一个工具)通过一个类的全限定名来获取该类的二进制字节流,然后将该 class 文件加载到 JVM 的方法区中。
4.类加载器加载一个 .class 文件到方法区的同时会在堆中生成一个唯一的 Class 对象,这个 Class 包含这个类的成员变量、构造方法以及成员方法。
5.这个 Class 对象会创建与该类对应的对象实例。
所以表面上你 new 了一个对象,实际上当 JVM 运行程序的时候,真正帮你创建对象的是该类的 Class 对象。
也就是说反射其实就是 JVM 在运行程序的时候将你创建的所有类都封装成唯一一个 Class 对象。这个 Class 对象包含属性、构造方法和成员方法。你拿到了 Class 对象,也就能获取这三个东西。
你拿到了反射之后(Class)的属性,就能获取对象的属性名、属性类别、属性值,也能给属性设置值。
你拿到了反射之后(Class)的构造方法,就能创建对象。
你拿到了反射之后(Class)的成员方法,就能执行该方法。
3.反射的概念
JAVA 反射机制是在程序运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为 java 语言的反射机制。
知道了 JVM 加载类的过程,相信你应该更加深入的了解了反射的概念。
反射:JVM 运行程序 --> .java 文件 --> .class 文件 --> Class 对象 --> 创建对象实例并操作该实例的属性和方法
接下来我就讲一下反射中的相关类以及常用方法。
2. Class 对象
获取 Class 对象
先建一个 User 类:
public class User {
private String name = "知否君";
public String sex = "男";
public User() {
}
public User(String name, String sex) {
this.name = name;
this.sex = sex;
}
public void eat(){
System.out.println("人要吃饭!");
}
private void run(){
System.out.println("人要跑步!");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
}获取 Class 对象的三种方式:
1. Class.forName("全类名")
全类名:包名+类名
Class userClass = Class.forName("com.xxl.model.User");
2. 类名.class
Class userClass = User.class;
3. 对象.getClass()
User user = new User();
Class userClass = user.getClass();
尽管有三种方式获取 Class 对象,但是我们一般采用上述第一种方式。
拿到 Class 对象之后,我们就可以操作与它相关的方法了。
3. 获取类名
1.获取完整类名:包名+类名
getName()
Class userClass = Class.forName("com.xxl.model.User");
String name = userClass.getName();
System.out.println(name);
打印结果:
2.获取简单类名:不包括包名
getSimpleName()
Class userClass = Class.forName("com.xxl.model.User");
String simpleName = userClass.getSimpleName();
System.out.println(simpleName);
打印结果:
4. 属性
4.1 获取属性
1.获取所有公有属性:public 修饰
getFields()
Class userClass = Class.forName("com.xxl.model.User");
Field[] fields = userClass.getFields();
for (Field field : fields) {
System.out.println(field);
}
打印结果:
2.获取单个公有属性
getField("属性名")
Class userClass = Class.forName("com.xxl.model.User");
Field field = userClass.getField("sex");
System.out.println(field);
打印结果:
3.获取所有属性:公有+私有
getDeclaredFields()
Class userClass = Class.forName("com.xxl.model.User");
Field[] fields = userClass.getDeclaredFields();
for (Field field : fields) {
System.out.println(field);
}
打印结果:
4.获取单个属性:公有或者私有
getDeclaredField("属性名")
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
Field sexField = userClass.getDeclaredField("sex");
System.out.println(nameField);
System.out.println(sexField);
打印结果:
4.2 操作属性
1.获取属性名称
getName()
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
System.out.println(nameField.getName());
打印结果:
2.获取属性类型
getType()
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
System.out.println(nameField.getType());
打印结果:
3.获取属性值
get(object)
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("sex");
User user = new User();
System.out.println(nameField.get(user));
打印结果:
注: 通过反射不能直接获取私有属性的值,但是可以通过修改访问入口来获取私有属性的值。
设置允许访问私有属性:
field.setAccessible(true);
例如:
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
nameField.setAccessible(true);
User user = new User();
System.out.println(nameField.get(user));
打印方法:
4.设置属性值
set(object,"属性值")
Class userClass = Class.forName("com.xxl.model.User");
Field nameField = userClass.getDeclaredField("name");
nameField.setAccessible(true);
User user = new User();
nameField.set(user,"张无忌");
System.out.println(nameField.get(user));
打印结果:
5. 构造方法
1.获取所有公有构造方法
getConstructors()
Class userClass = Class.forName("com.xxl.model.User");
Constructor[] constructors = userClass.getConstructors();
for (Constructor constructor : constructors) {
System.out.println(constructor);
}
打印结果:
2.获取与参数类型匹配的构造方法
getConstructor(参数类型)
Class userClass = Class.forName("com.xxl.model.User");
Constructor constructor = userClass.getConstructor(String.class, String.class);
System.out.println(constructor);
打印结果:
6. 成员方法
6.1获取成员方法
1.获取所有公共方法
getMethods()
Class userClass = Class.forName("com.xxl.model.User");
Method[] methods = userClass.getMethods();
for (Method method : methods) {
System.out.println(method);
}
打印结果:
我们发现,打印结果除了自定义的公共方法,还有继承自 Object 类的公共方法。
2.获取某个公共方法
getMethod("方法名", 参数类型)
Class userClass = Class.forName("com.xxl.model.User");
Method method = userClass.getMethod("setName", String.class);
System.out.println(method);
打印结果:
3.获取所有方法:公有+私有
getDeclaredMethods()
Class userClass = Class.forName("com.xxl.model.User");
Method[] declaredMethods = userClass.getDeclaredMethods();
for (Method method : declaredMethods) {
System.out.println(method);
}
打印结果:
4.获取某个方法:公有或者私有
getDeclaredMethod("方法名", 参数类型)
Class userClass = Class.forName("com.xxl.model.User");
Method method = userClass.getDeclaredMethod("run");
System.out.println(method);
打印结果:
6.2 执行成员方法
invoke(object,"方法参数")
Class userClass = Class.forName("com.xxl.model.User");
Method method = userClass.getDeclaredMethod("eat");
User user = new User();
method.invoke(user);
打印结果:
注: 通过反射不能直接执行私有成员方法,但是可以设置允许访问。
设置允许执行私有方法:
method.setAccessible(true);
7. 注解
1.判断类上或者方法上时候包含某个注解
isAnnotationPresent(注解名.class)
例如:
Class userClass = Class.forName("com.xxl.model.User");
if(userClass.isAnnotationPresent(Component.class)){
Component annotation = (Component)userClass.getAnnotation(Component.class);
String value = annotation.value();
System.out.println(value);
};
2.获取注解
getAnnotation(注解名.class)
例如:
Class userClass = Class.forName("com.xxl.model.User");
// 获取类上的注解
Annotation annotation1 = userClass.getAnnotation(Component.class);
Method method = userClass.getMethod("eat");
// 获取方法上的某个注解
Annotation annotation2 = userClass.getAnnotation(Component.class);
8. 创建类的实例
1.通过 Class 实例化对象
Class.newInstance()
Class userClass = Class.forName("com.xxl.model.User");
User user = (User)userClass.newInstance();
System.out.println("姓名:"+user.getName()+" 性别:"+user.getSex());
打印结果:
2.通过构造方法实例化对象
constructor.newInstance(参数值)
Class userClass = Class.forName("com.xxl.model.User");
Constructor constructor = userClass.getConstructor(String.class, String.class);
User user = (User)constructor.newInstance\("李诗情", "女"\);
System.out.println("姓名:"+user.getName()+" 性别:"+user.getSex());
打印结果:
9. 反射案例
有一天技术总监对张三说:"张三,听说你最近学反射了呀。那你设计一个对象的工厂类给我看看。"
张三心想:"哟,快过年了,领导这是要给我涨工资啊。这次我一定好好表现一次。"
5分钟过后,张三提交了代码:
public class ObjectFactory {
public static User getUser() {
User user = null;
try {
Class userClass = Class.forName("com.xxl.model.User");
user = (User) userClass.newInstance();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
return user;
}
public static UserService getUserService() {
UserService userService = null;
try {
Class userClass = Class.forName("com.xxl.service.impl.UserServiceImpl");
userService = (UserService) userClass.newInstance();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
}
return userService;
}
}
技术总监瞄了一眼代码,对张三说:"你这个工厂类存在两个问题。"
1.代码存在大量冗余。如果有一万个类,你是不是要写一万个静态方法?
2.代码耦合度太高。如果这些类存放的包路径发生改变,你再用 forName()获取 Class 对象是不是就会有问题?你还要一个个手动改代码,然后再编译、打包、部署。。你不觉得麻烦吗?
“发散你的思维想一下,能不能只设计一个静态类,通过传参的方式用反射创建对象,传递的参数要降低和工厂类的耦合度。顺便提醒你一下,可以参考一下 JDBC 获取数据库连接参数的方式。”
张三一听:"不愧是总监啊,醍醐灌顶啊!等我 10 分钟。"
10 分钟后,张三再次提交了代码:
object.properties
user=com.xxl.model.User
userService=com.xxl.service.impl.UserServiceImpl
ObjectFactory
public class ObjectFactory {
private static Properties objectProperty = new Properties();
// 静态方法在类初始化时执行,且只执行一次
static{
try {
InputStream inputStream = ObjectFactory.class.getResourceAsStream("/object.properties");
objectProperty.load(inputStream);
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static Object getObject(String key){
Object object = null;
try {
Class objectClass = Class.forName(objectProperty.getProperty(key));
object = objectClass.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return object;
}
}
测试方法:
@Test
void testObject() {
User user = (User)ObjectFactory.getObject("user");
UserService userService = (UserService)ObjectFactory.getObject("userService");
System.out.println(user);
System.out.println(userService);
}
执行结果:
总监看后连连点头,笑着对张三说:“用 properties 文件存放类的全限定名降低了代码的耦合度,通过传参的方式使用反射创建对象又降低了代码的冗余性,这次改的可以。"
"好啦,今晚项目要上线,先吃饭去吧,一会还要改 bug。”
张三:"..........好的总监。"
10. 反射的作用
我们或多或少都听说过设计框架的时候会用到反射,例如 Spring 的 IOC
就用到了工厂模式和反射来创建对象,BeanUtils 的底层也是使用反射来拷贝属性。所以反射无处不在。
尽管我们日常开发几乎用不到反射,但是我们必须要搞懂反射的原理,因为它能帮我们理解框架设计的原理。
作者:知否技术
链接:https://juejin.cn/post/7055090668619694094
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
HashMap除了死循环之外,还有什么问题?
本篇的这个问题是一个开放性问题,HashMap 除了死循环之外,还有其他什么问题?总体来说 HashMap 的所有“问题”,都是因为使用(HashMap)不当才导致的,这些问题大致可以分为两类:
- 程序问题:比如 HashMap 在 JDK 1.7 中,并发插入时可能会发生死循环或数据覆盖的问题。
- 业务问题:比如 HashMap 无序性造成查询结果和预期结果不相符的问题。
接下来我们一个一个来看。
1.死循环问题
死循环问题发生在 JDK 1.7 版本中,形成的原因是 JDK 1.7 HashMap 使用的是头插法,那么在并发扩容时可能就会导致死循环的问题,具体产生的过程如下流程所示。
HashMap 正常情况下的扩容实现如下图所示:
旧 HashMap 的节点会依次转移到新 HashMap 中,旧 HashMap 转移的顺序是 A、B、C,而新 HashMap 使用的是头插法,所以最终在新 HashMap 中的顺序是 C、B、A,也就是上图展示的那样。有了这些前置知识之后,咱们来看死循环是如何诞生的?
1.1 死循环执行流程一
死循环是因为并发 HashMap 扩容导致的,并发扩容的第一步,线程 T1 和线程 T2 要对 HashMap 进行扩容操作,此时 T1 和 T2 指向的是链表的头结点元素 A,而 T1 和 T2 的下一个节点,也就是 T1.next 和 T2.next 指向的是 B 节点,如下图所示:
1.2 死循环执行流程二
死循环的第二步操作是,线程 T2 时间片用完进入休眠状态,而线程 T1 开始执行扩容操作,一直到线程 T1 扩容完成后,线程 T2 才被唤醒,扩容之后的场景如下图所示:
从上图可知线程 T1 执行之后,因为是头插法,所以 HashMap 的顺序已经发生了改变,但线程 T2 对于发生的一切是不可知的,所以它的指向元素依然没变,如上图展示的那样,T2 指向的是 A 元素,T2.next 指向的节点是 B 元素。
1.3 死循环执行流程三
当线程 T1 执行完,而线程 T2 恢复执行时,死循环就建立了,如下图所示:
因为 T1 执行完扩容之后 B 节点的下一个节点是 A,而 T2 线程指向的首节点是 A,第二个节点是 B,这个顺序刚好和 T1 扩完容完之后的节点顺序是相反的。T1 执行完之后的顺序是 B 到 A,而 T2 的顺序是 A 到 B,这样 A 节点和 B 节点就形成死循环了,这就是 HashMap 死循环导致的原因。
1.4 解决方案
使用线程安全的容器来替代 HashMap,比如 ConcurrentHashMap 或 Hashtable,因为 ConcurrentHashMap 的性能远高于 Hashtable,因此推荐使用 ConcurrentHashMap 来替代 HashMap。
2.数据覆盖问题
数据覆盖问题发生在并发添加元素的场景下,它不止出现在 JDK 1.7 版本中,其他版本中也存在此问题,数据覆盖产生的流程如下:
- 线程 T1 进行添加时,判断某个位置可以插入元素,但还没有真正的进行插入操作,自己时间片就用完了。
- 线程 T2 也执行添加操作,并且 T2 产生的哈希值和 T1 相同,也就是 T2 即将要存储的位置和 T1 相同,因为此位置尚未插入值(T1 线程执行了一半),于是 T2 就把自己的值存入到当前位置了。
- T1 恢复执行之后,因为非空判断已经执行完了,它感知不到此位置已经有值了,于是就把自己的值也插入到了此位置,那么 T2 的值就被覆盖了。
具体执行流程如下图所示。
2.1 数据覆盖执行流程一
线程 T1 准备将数据 k1:v1 插入到 Null 处,但还没有真正的执行,自己的时间片就用完了,进入休眠状态了,如下图所示:
2.2 数据覆盖执行流程二
线程 T2 准备将数据 k2:v2 插入到 Null 处,因为此处现在并未有值,如果此处有值的话,它会使用链式法将数据插入到下一个没值的位置上,但判断之后发现此处并未有值,那么就直接进行数据插入了,如下图所示:
2.3 数据覆盖执行流程三
线程 T2 执行完成之后,线程 T1 恢复执行,因为线程 T1 之前已经判断过此位置没值了,所以会直接插入,此时线程 T2 插入的值就被覆盖了,如下图所示:
2.4 解决方案
解决方案和第一个解决方案相同,使用 ConcurrentHashMap 来替代 HashMap 就可以解决此问题了。
3.无序性问题
这里的无序性问题指的是 HashMap 添加和查询的顺序不一致,导致程序执行的结果和程序员预期的结果不相符,如以下代码所示:
HashMap<String, String> map = new HashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
});
我们添加的顺序:
我们期望查询的顺序和添加的顺序是一致的,然而以上代码输出的结果却是:
执行结果和我们预期结果不相符,这就是 HashMap 的无序性问题。我们期望输出的结果是 Hello,Java 1、2、3、4、5,而得到的顺序却是 2、1、4、3、5。
解决方案
想要解决 HashMap 无序问题,我们只需要将 HashMap 替换成 LinkedHashMap 就可以了,如下代码所示:
LinkedHashMap<String, String> map = new LinkedHashMap<>();
// 添加元素
for (int i = 1; i <= 5; i++) {
map.put("2022-" + i, "Hello,Java:" + i);
}
// 查询元素
map.forEach((k, v) -> {
System.out.println(k + ":" + v);
});以上程序的执行结果如下图所示:
总结
本文演示了 3 个 HashMap 的经典问题,其中死循环和数据覆盖是发生在并发添加元素时,而无序问题是添加元素的顺序和查询的顺序不一致的问题,这些问题本质来说都是对 HashMap 使用不当才会造成的问题,比如在多线程情况下就应该使用 ConcurrentHashMap,想要保证插入顺序和查询顺序一致就应该使用 LinkedHashMap,但刚开始时我们对 HashMap 不熟悉,所以才会造成这些问题,不过了解了它们之后,就能更好的使用它和更好的应对面试了。
作者:Java中文社群
链接:https://juejin.cn/post/7055084070790758436
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 启动优化杂谈 | 另辟蹊径
新年快乐
新年伊始,万象更新,虾哥开卷,天下无敌。
首先感谢各位大佬的支持,今年终于喜提掘金优秀作者了。
给各位大佬跪了,祝各位安卓同学新年快乐啊。
开篇
先介绍下徐公大佬的文章,如果有前置需要的话建议看下这个系列。
启动优化这个系列都可以好好看看,感谢徐公大佬。
本文将不发表任何关于 有向无环图(DAG) 相关,会更细致的说一些我自己的奇怪的观点,以及从一些问题出发,介绍如何做一些有意思的调整。
当前仓库还处于一个迭代状态中,并不是一个特别稳定的状态,所以文章更多的是给大家打开一些小思路。
有想法的同学可以留言啊,我个人感觉一个迭代库才是可以持续演进的啊。
demo 地址 AndroidStartup
demo中很多代码参考了android-startup,感谢这位大佬,u1s1这位大佬很强啊。
Task粒度
这一点其实蛮重要的,相信很多人在接入启动框架之后,更多的事情是把原来可以用的代码,直接用几个Task的把之前的代码包裹起来,之后然后这样就相当于完成了简单的启动框架接入了。
其实这个基本算是违背了启动框架设计的初衷了。我先抛出一个观点,启动框架并不会真实帮你加快多少启动速度,他解决的场景只是让你的sdk的初始化更加的有序,让你可以在长时间的迭代过程中,可以更加稳妥的添加一些新的sdk。
举个栗子,当你的埋点框架依赖了网络库,abtest配置中心也依赖了网络库,然后网络库则依赖了dns等等,之后所有的业务依赖了埋点配置中心图片库等等sdk的初始化完成之后。
当然还是有极限情况下会出现依赖成环问题,这个时候可能就需要开发同学手动的把这个依赖问题给解决了 比如特殊情况网络库需要唯一id,上报库依赖了网络库,而上报库又依赖了唯一id,唯一id又需要进行数据上报
所以我个人的看法启动框架的粒度应该细化到每个sdk的初始化,如果粒度可以越细致当然就越好了。其实一般的启动框架都会对每个task的耗时进行统计的,这样我们后续在跟进对应的问题也会变的更简便,比如查看某些的任务耗时是否增加了啊之类的。
当前我们在设计的时候可能会把一个sdk的初始化拆分成三个部分去做,就是为了去解决这种依赖成环的问题。
子线程间的等待
之前发现项目内的启动框架只保证了放入线程的时候的顺序是按照dag执行的。如果只有主线程和池子大小为1线程池的情况下,这种是ok的。但是如果多线程并发的情况下,这个就变成了一个危险操作了。
所以我们需要在并发场景下加上一个等待的情况下,一定要等到依赖的任务完成了之后,才能继续向下执行初始化代码。
机制的话还是使用CountDownLatch,当依赖的任务都执行完成之后,await会被释放,继续向下执行。而设计上我还是采取了装饰者,不需要使用方更改原始的逻辑就能继续使用了。
代码如下,主要就是一次任务完成的分发,之后发现当前的依赖是有该任务的则latch-1. 当latch到0的情况下就会释放当前线程了。
class StartupAwaitTask(val task: StartupTask) : StartupTask {
private var dependencies = task.dependencies()
private lateinit var countDownLatch: CountDownLatch
private lateinit var rightDependencies: List
var awaitDuration: Long = 0
override fun run(context: Context) {
val timeUsage = SystemClock.elapsedRealtime()
countDownLatch.await()
awaitDuration = (SystemClock.elapsedRealtime() - timeUsage) / 1000
KLogger.i(
TAG, "taskName:${task.tag()} await costa:${awaitDuration} "
)
task.run(context)
}
override fun dependencies(): MutableList {
return dependencies
}
fun allTaskTag(tags: HashSet) {
rightDependencies = dependencies.filter { tags.contains(it) }
countDownLatch = CountDownLatch(rightDependencies.size)
}
fun dispatcher(taskName: String) {
if (rightDependencies.contains(taskName)) {
countDownLatch.countDown()
}
}
override fun mainThread(): Boolean {
return task.mainThread()
}
override fun await(): Boolean {
return task.await()
}
override fun tag(): String {
return task.tag()
}
override fun onTaskStart() {
task.onTaskStart()
}
override fun onTaskCompleted() {
task.onTaskCompleted()
}
override fun toString(): String {
return task.toString()
}
companion object {
const val TAG = "StartupAwaitTask"
}
}
这个算是一个能力的补充完整,也算是多线程依赖必须要完成的一部分。
同时将依赖模式从class变更成tag的形式,但是这个地方还没完成最后的设计,当前还是有点没想好的。主要是解决组件化情况下,可以更随意一点。
线程池关闭
这里是我个人考虑哦,当整个启动流程结束之后,默认情况下是不是应该考虑把线程池关闭了呢。我发现很多都没有写这些的,会造成一些线程使用的泄漏问题。
fun dispatcherEnd() {
if (executor != mExecutor) {
KLogger.i(TAG, "auto shutdown default executor")
mExecutor.shutdown()
}
}
代码如上,如果当前线程池并不是传入的线程池的情况下,考虑执行完毕之后关闭线程池。
dsl + 锚点
因为我既是开发人员,同时也是框架的使用方。所以我自己在使用的过程中发现原来的设计上问题还是很多的,我自己想要插入一个在所有sdk完成之后的任务非常不方便。
然后我就考虑这部分通过dsl的方式去写了动态添加task。kotlin是真的很香,如果后续开发没糖我估计就是个废人了。
我就是死从这里跳下去,卧槽语法糖真香。
fun Application.createStartup(): Startup.Builder = run {
startUp(this) {
addTask {
simpleTask("taskA") {
info("taskA")
}
}
addTask {
simpleTask("taskB") {
info("taskB")
}
}
addTask {
simpleTask("taskC") {
info("taskC")
}
}
addTask {
simpleTaskBuilder("taskD") {
info("taskD")
}.apply {
dependOn("taskC")
}.build()
}
addTask("taskC") {
info("taskC")
}
setAnchorTask {
MyAnchorTask()
}
addTask {
asyncTask("asyncTaskA", {
info("asyncTaskA")
}, {
dependOn("asyncTaskD")
})
}
addAnchorTask {
asyncTask("asyncTaskB", {
info("asyncTaskB")
}, {
dependOn("asyncTaskA")
await = true
})
}
addAnchorTask {
asyncTaskBuilder("asyncTaskC") {
info("asyncTaskC")
sleep(1000)
}.apply {
await = true
dependOn("asyncTaskE")
}.build()
}
addTaskGroup { taskGroup() }
addTaskGroup { StartupTaskGroupApplicationKspMain() }
addMainProcTaskGroup { StartupTaskGroupApplicationKspAll() }
addProcTaskGroup { StartupProcTaskGroupApplicationKsp() }
}
}
这种DSL写法适用于插入一些简单的任务,可以是一些没有依赖的任务,也可以是你就是偷懒想这么写。好处就是可以避免自己用继承等的形式去写过多冗余的代码,然后在这个启动流程内能看到自己做了些什么事情。
一般等到项目稳定之后,会设立几个锚点任务。他们的作用是后续任务只要挂载到锚点任务之后执行即可,定下一些标准,让后续的同学可以更快速的接入。
我们会把这些设置成一些任务组设置成基准,比如说是网络库,图片库,埋点框架,abtest等等,等到这些任务完成之后,别的业务代码就可以在这里进行初始化了。这样就不需要所有人都写一些基础的依赖关系,也可以让开发同学舒服一点点。
怎么又成环了
在之前的排序阶段,存在一个非常鬼畜的问题,如果你依赖的任务并不在当前的图中存在,就会报出依赖成环问题,但是你并不知道是因为什么原因成环的。
这个就非常不方便开发同学调试问题了,所以我增加了前置任务有效性判断,如果不存在的则会直接打印Log日志,也增加了debugmode,如果测试情况下可以直接已任务不存在的崩溃结束。
ksp
我想偷懒所以用ksp生成了一些代码,同时我希望我的启动框架也可以应用于项目的组件化和插件化中,这样反正就是牛逼啦。
启动任务分组
当前完成的一个功能就是通过注解+ksp生成一个启动任务的分组,这次ksp的版本我们采用的是1.5.30的版本,同时api也有了一些变更。
之前在ksp的文章说过process死循环的问题,最近和米忽悠乌蝇哥交流(吹牛)的时候发现,系统提供一个finish方法,因为process的时候只要有类生成就会重新出发process方法,导致stackoverflow,所以后续代码生成可以考虑迁移到新方法内。
class StartupProcessor(
val codeGenerator: CodeGenerator,
private val logger: KSPLogger,
val moduleName: String
) : SymbolProcessor {
private lateinit var startupType: KSType
private var isload = false
private val taskGroupMap = hashMapOf>()
private val procTaskGroupMap =
hashMapOf>>>()
override fun process(resolver: Resolver): List {
logger.info("StartupProcessor start")
val symbols = resolver.getSymbolsWithAnnotation(StartupGroup::class.java.name)
startupType = resolver.getClassDeclarationByName(
resolver.getKSNameFromString(StartupGroup::class.java.name)
)?.asType() ?: kotlin.run {
logger.error("JsonClass type not found on the classpath.")
return emptyList()
}
symbols.asSequence().forEach {
add(it)
}
return emptyList()
}
private fun add(type: KSAnnotated) {
logger.check(type is KSClassDeclaration && type.origin == Origin.KOTLIN, type) {
"@JsonClass can't be applied to $type: must be a Kotlin class"
}
if (type !is KSClassDeclaration) return
//class type
val routerAnnotation = type.findAnnotationWithType(startupType) ?: return
val groupName = routerAnnotation.getMember("group")
val strategy = routerAnnotation.arguments.firstOrNull {
it.name?.asString() == "strategy"
}?.value.toString().toValue() ?: return
if (strategy.equals("other", true)) {
val key = groupName
if (procTaskGroupMap[key] == null) {
procTaskGroupMap[key] = mutableListOf()
}
val list = procTaskGroupMap[key] ?: return
list.add(type.toClassName() to (routerAnnotation.getMember("processName")))
} else {
val key = "${groupName}${strategy}"
if (taskGroupMap[key] == null) {
taskGroupMap[key] = mutableListOf()
}
val list = taskGroupMap[key] ?: return
list.add(type.toClassName())
}
}
private fun String.toValue(): String {
var lastIndex = lastIndexOf(".") + 1
if (lastIndex <= 0) {
lastIndex = 0
}
return subSequence(lastIndex, length).toString().lowercase().upCaseKeyFirstChar()
}
// 开始代码生成逻辑
override fun finish() {
super.finish()
// logger.error("className:${moduleName}")
try {
taskGroupMap.forEach { it ->
val generateKt = GenerateGroupKt(
"${moduleName.upCaseKeyFirstChar()}${it.key.upCaseKeyFirstChar()}",
codeGenerator
)
it.value.forEach { className ->
generateKt.addStatement(className)
}
generateKt.generateKt()
}
procTaskGroupMap.forEach {
val generateKt = GenerateProcGroupKt(
"${moduleName.upCaseKeyFirstChar()}${it.key.upCaseKeyFirstChar()}",
codeGenerator
)
it.value.forEach { pair ->
generateKt.addStatement(pair.first, pair.second)
}
generateKt.generateKt()
}
} catch (e: Exception) {
logger.error(
"Error preparing :" + " ${e.stackTrace.joinToString("\n")}"
)
}
}
}
class StartupProcessorProvider : SymbolProcessorProvider {
override fun create(
environment: SymbolProcessorEnvironment
): SymbolProcessor {
return StartupProcessor(
environment.codeGenerator,
environment.logger,
environment.options[KEY_MODULE_NAME] ?: "application"
)
}
}
fun String.upCaseKeyFirstChar(): String {
return if (Character.isUpperCase(this[0])) {
this
} else {
StringBuilder().append(Character.toUpperCase(this[0])).append(this.substring(1)).toString()
}
}
const val KEY_MODULE_NAME = "MODULE_NAME"
其中processor被拆分成两部分,SymbolProcessorProvider负责构造,SymbolProcessor则负责处理ast逻辑。以前的initapi 被移动到SymbolProcessorProvider中了。
逻辑也比较简单,收集注解,然后基于注解的入参生成一个taskGroup逻辑。这个组会被我手动加入到启动流程内。
未完成
另外我想做的一件事就是通过注解来去生成一个Task任务,然后通过不同的注解的排列组合,组合出一个新的task任务。
这部分功能还在设计中,后续完成之后再给大家水一篇好了。
调试组件
这部分是我最近设计的重中之重了。当接了启动框架这个活之后,更多的时候你是需要去追溯启动变慢的问题的,我们把这种情况叫做劣化。如何快速定位劣化问题也是启动框架所需要关心的。
一开始我们打算通过日志上报,之后在版本发布之后重新推导线上的任务耗时,但是因为计算出来的是平均值,而且我们的自动化测试同学每个版本发布前都会跑自动化case,观察启动时间的状况,如果时间均值变长就会来通知我们,这个时候看埋点数据其实挺难发现问题的。
核心原因还是我想偷懒,因为排查问题必须要基于之前的版本和当前版本进行对比,比较各个task之间的耗时状况,我们当前大概应该有30+的启动任务,这尼玛不是要了我老命了吗。
所以我和我大佬沟通了下,就对这部分进行了立项,打算折腾一个调试工具,可以记录下启动任务的耗时,还有启动任务的列表,通过本地对比的形式,可以快速推导出出现问题任务,方便我们快速定位问题。
小贴士 调试工具的开发最好不要有太多的依赖 然后通过debug 的buildtype来加入 所以使用了contentprovider来初始化
启动时间轴
江湖上一直流传着我的外号-ui大湿,在下也不是浪得虚名,ui大湿画出来的图形那叫一个美如画啊。
这部分原理比较简单,我们把当前启动任务的数据进行了收集,然后根据线程名进行分发,记录任务开始和结束的节点,然后通过图形化进行展示。
如果你第一时间看不懂,可以参考下自选股列表,每一列都是代表一个线程执行的时间轴。
启动顺序是否变更
我们会在每次启动的时候将当前启动的顺序进行数据库记录,然后通过数据库找出和当前hashcode不一样的任务,然后比对下用textview的形式展示出来,方便测试同学反馈问题。
这个地方的原理的,我是将整个启动任务通过字符串拼接,然后生成一个字符串,之后通过字符串的hashcode作为唯一标识符,不同字符串生成的hashcode也是不同的。
这里有个傻事就是我一开始对比的是stringbuilder的hashcode,然后发现一样的任务竟然值变更了,我真傻真的。
别问,问就是ui大湿,textview不香?
平均任务耗时
这个地方的数据库设计让我思考了好一会,之后我按照天为维度,之后记录时间和次数,然后在渲染的时候取出均值。
之后把之前的历史数据取出来,然后进行汇总统计,之后重新生成list,一个当前task下面跟随一个历史的task。然后进行牛逼的ui渲染。
这个时候你要喷了啊,为什么你全部都是textview还自称ui大湿啊。
虾扯蛋你听过吗,没错就是这样的。
总结
卷来,天不生我逮虾户,卷道万古长如夜。
与诸君共勉。
真的总结
UI方面我后续还是会进行迭代的,毕竟第一个版本丑陋不堪主要是想完成数据的手机,而且开发看起来也不是特别显眼,后面可能会把差异部分直接输出。
做大做强,搞一波大新闻。
作者:究极逮虾户
链接:https://juejin.cn/post/7048516748768706567
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
SpringBoot 三大开发工具,你都用过么?
1、SpringBoot Dedevtools
他是一个让SpringBoot支持热部署的工具,下面是引用的方法
要么在创建项目的时候直接勾选下面的配置:
要么给springBoot项目添加下面的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
idea修改完代码后再按下 ctrl + f9 使其重新编译一下,即完成了热部署功能
eclipse是按ctrl + s保存 即可自动编译
如果你想一修改代码就自动重新编译,无需按ctrl+f9。只需要下面的操作:
1.在idea的setting中把下面的勾都打上
2.进入pom.xml,在build的反标签后给个光标,然后按Alt+Shift+ctrl+/
3.然后勾选下面的东西,接着重启idea即可
2、Lombok
Lombok是简化JavaBean开发的工具,让开发者省去构造器,getter,setter的书写。
在项目初始化时勾选下面的配置,即可使用Lombok
或者在项目中导入下面的依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
使用时,idea还需要下载下面的插件:
下面的使用的例子
@AllArgsConstructor
//全参构造器
@NoArgsConstructor
//无参构造器
@Data//getter + setterpublic
class User {
private Long id;
private String name;
private Integer age;
private String email;
}
3、Spring Configuration Processor
该工具是给实体类的属性注入开启提示,自我感觉该工具意义不是特别大!
因为SpringBoot存在属性注入,比如下面的实体类:
@Component
@ConfigurationProperties(prefix = "mypet")
public class Pet {
private String nickName;
private String strain;
public String getNickName() {
return nickName;
}
public void setNickName(String nickName) {
this.nickName = nickName;
}
public String getStrain() {
return strain;
}
public void setStrain(String strain) {
this.strain = strain;
}
@Override public String toString() {
return "Pet [nickName=" + nickName + ", strain=" + strain + "]";
}
}
想要在application.properties和application.yml中给mypet注入属性,却没有任何的提示,为了解决这一问题,我们在创建SpringBoot的时候勾选下面的场景:
或者直接在项目中添加下面的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
并在build的标签中排除对该工具的打包:(减少打成jar包的大小)
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins></build>
作者:终码一生
链接:https://juejin.cn/post/7054436849804132382
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
过年想要红包?年前你先把咱们的红包系统上线了呗!
红包分类
产品需求设计分为两类红包,个人红包,群红包。群红包又分为专属、均分、群手气三种。分别适应不同的场景。如下图所示:
红包实现
发红包流程:
1、用户进入发红包界面发起请求;
2、服务端接受到请求后,对用户的红包金额进行冻结(前提用户事先开通余额账户)。
3、是否余额充足(兜底教研),如果充足发红包成功,并且生成红包记录,如果不充足提示错误信息。
4、推送最终结果给用户,如果发成功了会推两条消息,一个是发送人告诉用户红包发成功了,且推送群/个人立即领取。
5、如果红包发成功后,发一个延迟1天的 MQ 消息,做一个超期未退款处理。把冻结账户的钱返还给用户。
领红包流程:
当用户收到红包的推送过后,用户就可以通过该消息,进行红包的领取。
1、参数状态判断,判断红包是否过期,红包是否领完,红包是否重复领取等逻辑;
2、生成红包领取记录;
3、生成红包入账记录,对领取者上账。生成余额流水,并且增加余额流水。
4、减少发红包者的冻结余额,完成红包领取流程。
红包高并发
高并发设计
对于群手气红包肯定会存在并发问题,比如微信群红包领取的时候。一个 200 人的群同时来领取1个 200 元,10 人可以领取的红包,从用户的发起可能到领取基本是在 1-2 秒内领完。
怎么样保证既能高效的领取,又能保证金额都能正确,且不会记错账。我们采用的方案就是“一快一慢”的方案。
1、对于群红包的场景,我们首先会将红包金额提前计算。然后存储到 Redis 中 Key : redpacket:amount_list:#{id}存储的结构是一个 List 集合。
2、 每次领取的时候我们会做一个 rpop操作,获取到红包的金额。由于这块是redis 操作,是非常高效的。
3、为了保证数据的持久性、可靠性。我们会生成一个领取记录到 mysql 数据库中持久化。
4、然后发送红包领取成功的消息出去,在记账服务中进行订阅,异步入账。
具体的流程如下:
幂等性保证
为了保证领取过程用户有序的领取,且保证一个用户只能领取成功一次,如果第二次来领取,咱们就提示已经领取过了,不能重复领取。这是我们在高并发场景下必须严保证的问题。当时我们选择的是通过分布式锁的方式来解决的,锁的 key 设计如下:
redpacket:amount_list:#{id}_#{user_id}
这样设计的好处就是能够保证一当前分布式系统中,当前只能一个有效的请求进入正真的处理逻辑中。
兜底保障:
1、在领取记录表中增加 user_id, redpacket_id 为唯一索引。
2、对红包的剩余金额做乐观锁更新(可以使用 tk.mapper 的 @Version)。
可拓展性设计
为了保证可拓展性的设计,我们当时采用的是 策略 + 模板方法的设计模型进行低耦合设计。
手气红包金额计算
我们采用的是中位数随机算法(大致的逻辑就是控制一个中位数的值最大金额,最小金额的区间不能超过中位数的浮动水位线),更多的随机算法,大家可以参阅:为啥春节抢红包总不是手气最佳?看完微信抢红包算法你就明白了!
金额随机代码
public class RedPacketUtils {
private static final Random random = new Random();
/**
* 根据总数分割个数及限定区间进行数据随机处理
* 数列浮动阀值为0.95
*
* @param totalMoney - 被分割的总数
* @param splitNum - 分割的个数
* @param min - 单个数字下限
* @param max - 单个数字上限
* @return - 返回符合要求的数字列表
*/
public static List<BigDecimal> genRandomList(BigDecimal totalMoney, Integer splitNum, BigDecimal min, BigDecimal max) {
totalMoney = totalMoney.multiply(new BigDecimal(100));
min = min.multiply(new BigDecimal(100));
max = max.multiply(new BigDecimal(100));
List<Integer> li = genRandList(totalMoney.intValue(), splitNum, min.intValue(), max.intValue(), 0.95f);
List<BigDecimal> randomList = new CopyOnWriteArrayList<>();
for (Integer v : li) {
BigDecimal randomVlue = new BigDecimal(v).divide(new BigDecimal(100));
randomList.add(randomVlue);
}
randomList = randomArrayList(randomList);
return randomList;
}
/**
* 根据总数分割个数及限定区间进行数据随机处理
*
* @param total - 被分割的总数
* @param splitNum - 分割的个数
* @param min - 单个数字下限
* @param max - 单个数字上限
* @param thresh - 数列浮动阀值[0.0, 1.0]
*/
public static List<Integer> genRandList(int total, int splitNum, int min, int max, float thresh) {
assert total >= splitNum * min && total <= splitNum * max : "请校验红包参数设置的合理性";
assert thresh >= 0.0f && thresh <= 1.0f;
// 平均分配
int average = total / splitNum;
List<Integer> list = new ArrayList<>(splitNum);
int rest = total - average * splitNum;
for (int i = 0; i < splitNum; i++) {
if (i < rest) {
list.add(average + 1);
} else {
list.add(average);
}
}
// 如果浮动阀值为0则不进行数据随机处理
if (thresh == 0) {
return list;
}
// 根据阀值进行数据随机处理
int randOfRange = 0;
int randRom = 0;
int nextIndex = 0;
int nextValue = 0;
int surplus = 0;//多余
int lack = 0;//缺少
for (int i = 0; i < splitNum - 1; i++) {
nextIndex = i + 1;
int itemThis = list.get(i);
int itemNext = list.get(nextIndex);
boolean isLt = itemThis < itemNext;
int rangeThis = isLt ? max - itemThis : itemThis - min;
int rangeNext = isLt ? itemNext - min : max - itemNext;
int rangeFinal = (int) Math.ceil(thresh * (Math.min(rangeThis, rangeNext) + 100));
randOfRange = random.nextInt(rangeFinal);
randRom = isLt ? 1 : -1;
int iValue = list.get(i) + randRom * randOfRange;
nextValue = list.get(nextIndex) + randRom * randOfRange * -1;
if (iValue > max) {
surplus += (iValue - max);
list.set(i, max);
} else if (iValue < min) {
list.set(i, min);
lack += (min - iValue);
} else {
list.set(i, iValue);
}
list.set(nextIndex, nextValue);
}
if (nextValue > max) {
surplus += (nextValue - max);
list.set(nextIndex, max);
}
if (nextValue < min) {
lack += (min - nextValue);
list.set(nextIndex, min);
}
if (surplus - lack > 0) {//钱发少了 给低于max的凑到max
for (int i = 0; i < list.size(); i++) {
int value = list.get(i);
if (value < max) {
int tmp = max - value;
if (surplus >= tmp) {
surplus -= tmp;
list.set(i, max);
} else {
list.set(i, value + surplus);
return list;
}
}
}
} else if (lack - surplus > 0) {//钱发多了 给超过高于min的人凑到min
for (int i = 0; i < list.size(); i++) {
int value = list.get(i);
if (value > min) {
int tmp = value - min;
if (lack >= tmp) {
lack -= tmp;
list.set(i, min);
} else {
list.set(i, min + tmp - lack);
return list;
}
}
}
}
return list;
}
/**
* 打乱ArrayList
*/
public static List<BigDecimal> randomArrayList(List<BigDecimal> sourceList) {
if (sourceList == null || sourceList.isEmpty()) {
return sourceList;
}
List<BigDecimal> randomList = new CopyOnWriteArrayList<>();
do {
int randomIndex = Math.abs(new Random().nextInt(sourceList.size()));
randomList.add(sourceList.remove(randomIndex));
} while (sourceList.size() > 0);
return randomList;
}
public static void main(String[] args) {
Long startTi = System.currentTimeMillis();
List<BigDecimal> li = genRandomList(new BigDecimal(100000), 26000, new BigDecimal(2), new BigDecimal(30));
li = randomArrayList(li);
BigDecimal total = BigDecimal.ZERO;
System.out.println("======total=========total:" + total);
System.out.println("======size=========size:" + li.size());
Long endTi = System.currentTimeMillis();
System.out.println("======耗时=========:" + (endTi - startTi) / 1000 + "秒");
}
}作者:心城以北
链接:https://juejin.cn/post/7054561013839953956
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
SpringBoot:如何优雅地进行参数传递、响应数据封装、异常处理?
在项目开发中,接口与接口之间、前后端之间的数据传输都使用 JSON 格式。
1 fastjson使用
阿里巴巴的 fastjson是目前应用最广泛的JSON解析框架。本文也将使用fastjson。
1.1 引入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.35</version>
</dependency>
2 统一封装返回数据
在web项目中,接口返回数据一般要包含状态码、信息、数据等,例如下面的接口示例:
import com.alibaba.fastjson.JSONObject;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
/**
* @author guozhengMu
* @version 1.0
* @date 2019/8/21 14:55
* @description
* @modify
*/
@RestController
@RequestMapping(value = "/test", method = RequestMethod.GET)
public class TestController {
@RequestMapping("/json")
public JSONObject test() {
JSONObject result = new JSONObject();
try {
// 业务逻辑代码
result.put("code", 0);
result.put("msg", "操作成功!");
result.put("data", "测试数据");
} catch (Exception e) {
result.put("code", 500);
result.put("msg", "系统异常,请联系管理员!");
}
return result;
}
}
这样的话,每个接口都这样处理,非常麻烦,需要一种更优雅的实现方式。
2.1 定义统一的JSON结构
统一的 JSON 结构中属性包括数据、状态码、提示信息,其他项可以自己根据需要添加。一般来说,应该有默认的返回结构,也应该有用户指定的返回结构。由于返回数据类型无法确定,需要使用泛型,代码如下:
public class ResponseInfo<T> {
/**
* 状态码
*/
protected String code;
/**
* 响应信息
*/
protected String msg;
/**
* 返回数据
*/
private T data;
/**
* 若没有数据返回,默认状态码为 0,提示信息为“操作成功!”
*/
public ResponseInfo() {
this.code = 0;
this.msg = "操作成功!";
}
/**
* 若没有数据返回,可以人为指定状态码和提示信息
* @param code
* @param msg
*/
public ResponseInfo(String code, String msg) {
this.code = code;
this.msg = msg;
}
/**
* 有数据返回时,状态码为 0,默认提示信息为“操作成功!”
* @param data
*/
public ResponseInfo(T data) {
this.data = data;
this.code = 0;
this.msg = "操作成功!";
}
/**
* 有数据返回,状态码为 0,人为指定提示信息
* @param data
* @param msg
*/
public ResponseInfo(T data, String msg) {
this.data = data;
this.code = 0;
this.msg = msg;
}
// 省略 get 和 set 方法
}
2.2 使用统一的JSON结构
我们封装了统一的返回数据结构后,在接口中就可以直接使用了。如下:
import com.example.demo.model.ResponseInfo;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
/**
* @author guozhengMu
* @version 1.0
* @date 2019/8/21 14:55
* @description
* @modify
*/
@RestController
@RequestMapping(value = "/test", method = RequestMethod.GET)
public class TestController {
@RequestMapping("/json")
public ResponseInfo test() {
try {
// 模拟异常业务代码
int num = 1 / 0;
return new ResponseInfo("测试数据");
} catch (Exception e) {
return new ResponseInfo(500, "系统异常,请联系管理员!");
}
}
}
如上,接口的返回数据处理便优雅了许多。针对上面接口做个测试,启动项目,通过浏览器访问:localhost:8096/test/json,得到响应结果:
{"code":500,"msg":"系统异常,请联系管理员!","data":null}
3 全局异常处理
3.1 系统定义异常处理
新建一个 ExceptionHandlerAdvice 全局异常处理类,然后加上 @RestControllerAdvice 注解即可拦截项目中抛出的异常,如下代码中包含了几个异常处理,如参数格式异常、参数缺失、系统异常等,见下例:
@RestControllerAdvice
@Slf4j
public class ExceptionHandlerAdvice {
// 参数格式异常处理
@ExceptionHandler({IllegalArgumentException.class})
@ResponseStatus(HttpStatus.BAD_REQUEST)
public ResponseInfo badRequestException(IllegalArgumentException exception) {
log.error("参数格式不合法:" + e.getMessage());
return new ResponseInfo(HttpStatus.BAD_REQUEST.value() + "", "参数格式不符!");
}
// 权限不足异常处理
@ExceptionHandler({AccessDeniedException.class})
@ResponseStatus(HttpStatus.FORBIDDEN)
public ResponseInfo badRequestException(AccessDeniedException exception) {
return new ResponseInfo(HttpStatus.FORBIDDEN.value() + "", exception.getMessage());
}
// 参数缺失异常处理
@ExceptionHandler({MissingServletRequestParameterException.class})
@ResponseStatus(HttpStatus.BAD_REQUEST)
public ResponseInfo badRequestException(Exception exception) {
return new ResponseInfo(HttpStatus.BAD_REQUEST.value() + "", "缺少必填参数!");
}
// 空指针异常
@ExceptionHandler(NullPointerException.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public ResponseInfo handleTypeMismatchException(NullPointerException ex) {
log.error("空指针异常,{}", ex.getMessage());
return new JsonResult("500", "空指针异常");
}
@ExceptionHandler(Exception.class)
@ResponseStatus(value = HttpStatus.INTERNAL_SERVER_ERROR)
public JsonResult handleUnexpectedServer(Exception ex) {
log.error("系统异常:", ex);
return new JsonResult("500", "系统发生异常,请联系管理员");
}
// 系统异常处理
@ExceptionHandler(Throwable.class)
@ResponseStatus(HttpStatus.INTERNAL_SERVER_ERROR)
public ResponseInfo exception(Throwable throwable) {
log.error("系统异常", throwable);
return new ResponseInfo(HttpStatus.INTERNAL_SERVER_ERROR.value() + "系统异常,请联系管理员!");
}
}
- @RestControllerAdvice 注解包含了 @Component 注解,说明在 Spring Boot 启动时,也会把该类作为组件交给 Spring 来管理。
- @RestControllerAdvice 注解包含了 @ResponseBody 注解,为了异常处理完之后给调用方输出一个 JSON 格式的封装数据。
- @RestControllerAdvice 注解还有个 basePackages 属性,该属性用来拦截哪个包中的异常信息,一般我们不指定这个属性,我们拦截项目工程中的所有异常。
- 在方法上通过 @ExceptionHandler 注解来指定具体的异常,然后在方法中处理该异常信息,最后将结果通过统一的 JSON 结构体返回给调用者。
- 但在项目中,我们一般都会比较详细地去拦截一些常见异常,拦截 Exception 虽然可以一劳永逸,但是不利于我们去排查或者定位问题。实际项目中,可以把拦截 Exception 异常写在 GlobalExceptionHandler 最下面,如果都没有找到,最后再拦截一下 Exception 异常,保证输出信息友好。
下面我们通过一个接口来进行测试:
@RestController
@RequestMapping(value = "/test", method = RequestMethod.POST)
public class TestController {
@RequestMapping("/json")
public ResponseInfo test(@RequestParam String userName, @RequestParam String password) {
try {
String data = "登录用户:" + userName + ",密码:" + password;
return new ResponseInfo("0", "操作成功!", data);
} catch (Exception e) {
return new ResponseInfo("500", "系统异常,请联系管理员!");
}
}
}
接口调用,password这项故意空缺:
作者:MarkerHub
链接:https://juejin.cn/post/7054843436431572999
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
建议收藏 | SpringBoot 元数据配置原来可以这么拓展!
一、背景
最近在调试reactive-steams源码的时候看到spring-boot源码包里面的
spring-configuration-metadata.json
additional-spring-configuration-metadata.json
说实话主要是metadata吸引了我,因为最近在调整引擎元数据管理确实折腾了很久。
查了官方的资料发现这里也是 SpringBoot 提供的元数据配置拓展,但是这里的元数据不是只在 Spring bean 管理的元数据类似。
▐ 官方解释
访问地址:docs.spring.io/spring-boot…
简单点可以理解为这类元数据的配置时为了让我们在使用 IDEA 开发的过程中,使用application.properties或者 application.yml配置的时候更有注释说明,更方便我们开发使用。
▐ 官方案例
以我们常用的 logging 配置为例
元数据配置
- 定义配置
二、应用实例
▐ 插件工厂配置定义
配置元数据文件位于 jar 下面。META-INF/spring-configuration-metadata.json它们使用简单的 JSON 格式,其中的项目分类在“groups”或“properties”下
{
"properties": [
{
"name": "plugin-cache.basePackage",
"type": "java.lang.String",
"description": "文档扫描包路径。"
},
{
"name": "plugin-cache.title",
"type": "java.lang.String",
"description": "Plugin Cache 插件工厂"
},
{
"name": "plugin-cache.description",
"type": "java.lang.String",
"description": "插件工厂描述"
},
{
"name": "plugin-cache.version",
"type": "java.lang.String",
"defaultValue": "V1.0",
"description": "版本。"
}
]
}
大部分元数据文件是在编译时通过处理所有带注释的项目自动生成的
@ConfigurationProperties 可以查看先前的文章
@EnableConfigurationProperties 的工作原理
参考下面 properties 表格进行配置上的理解。
deprecation 每个 properties 元素的属性中包含的 JSON 对象可以包含以下属性:
▐ 插件工厂配置注入
@Data
@Component
@ConfigurationProperties(PluginCacheProperties.PREFIX)
class PluginCacheProperties {
public static final String PREFIX = "plugin-cache";
/**
* 文档扫描包路径
*/
private String basePackage = "";
/**
* Plugin Cache 插件工厂
*/
private String title = "Plugin Cache 插件工厂";
/**
* 服务文件介绍
*/
private String description = "插件缓存说明";
/**
* 版本
*/
private String version = "V1.0";
/**
* 默认编码
*/
private String charset="UTF-8";
}
▐ 配置应用
三、总结
对于元数据配置,理解起来不难!主要为了组件库为了让使用者更加优化使用提供的一套 IDEA 提示说明。借此我们在开放私有组件或者插件的时候在对于配置项可对外提供开放能力,可以根据元数据配置来完善 IDEA 提示说明。这样其他人用起来的时候能很快知道对应的参数的配置类型以及相关的配置属性说明。总结本篇文章希望对从事相关工作的同学能够有所帮助或者启发
作者:码农架构
链接:https://juejin.cn/post/7052894468474847245
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
【小声团队】 - 我们为什么选择了Flutter Desktop
本文由小声团队出品,小声团队是一个专注于音频&音乐技术的初创团队,深度使用Flutter构建跨平台应用,希望与大家一起共同探索Flutter在桌面端&移动端的可能性。
背景
我们计划研发一款全功能跨平台的音乐制作平台(DAW),从立项之初我们就已经明确了全平台的支持计划(即Windows / MacOS / Linux / iOS / Android ) ,也因此我们也是以这个为目标来寻找技术解决方案,经过一段时间的研究与学习,大致确定了几个可选项,内部的调研结果如下(本结果仅代表团队内部认知,如有差异还请包涵):
| 技术方案 | 性能 | 研发效率 | 跨平台兼容性 | 扩展能力 | 原生代码交互能力 |
|---|---|---|---|---|---|
| HTML5 | 低 | 高 | 高 | 低 | 低 |
| QT | 高 | 极低 | 高 | 高 | 高 |
| React Native | 中 | 高 | 低 | 中 | 中 |
| Flutter | 高 | 高 | 高 | 中 | 高 |
为什么不使用基于HTML5打造的技术栈?
HTML5是众所周知的最易上手的跨平台UI解决方案,并且产业成熟,有众多可选的框架与开源组件可直接使用。但是DAW作为一款专业生产力工具并不适合完全在浏览器环境中运行,比如第三方插件系统浏览器则无法支撑,另外在内存资源上的使用也不是很便捷,通常一个音乐工程可能需要占据数G内存,运行时需要维护数万个对象,这对于Javascript来说还是浏览器来说都是很严重的负担。
从另一个方面来看,就算我们需要以一种阉割的形式支持Web,那么WASM技术则是我们更佳的选择。
因此,我们不考虑基于HTML5的技术方案。
为什么不选择QT & GTK 等老牌原生高性能框架?
在传统技术上来看,QT是最符合我们需求的技术方案,很多老牌工具厂商背后也都是基于QT技术栈完成。QT在运行效率上而言无疑是最佳的选择,我们的主要顾虑在对于CPP的掌控能力与研发效率,UI开发与引擎开发有一个很大的根本区别在于引擎开发通常使用单元测试来完成逻辑验证,而UI则很难使用单元测试来验证UI效果,也很少看到有团队真的依赖单元测试的方式来进行UI开发,而QT没有像Webpack类似的hot reload技术,UI的验证效率会非常的低下,甚至于不是我们一个小团队可以承受得起的。
而CPP也是入门门槛极高的编程语言,我们对于QT方案也存疑,但是没有完全放弃。
Flutter 的什么特性吸引了我们
- Flutter使用基于Skia绘图引擎直接构建组件,操作系统只需要提供像素级的绘图能力即可,因此也就保证了跨平台的UI一致性(像素级一致),而对React Native的兼容性吐槽一直充斥着社区。
- Dart对于UI开发也是非常舒服的。
- 对象默认引用传递。
- 支持HOT Reload。这为开发效率带来本质的提升,使得Flutter研发效率不弱于HTML5
- AOT支持,生产级代码运行效率飞升,不逊色于原生应用的表现。
- FFI 支持 。 可以直接与原生C & Cpp代码进行交互而几乎没有任何性能损失。
- Web 支持。 Flutter 即可直接编译到Web运行,这也为我们提供Web服务打下了可能性。
Flutter的这些特性都是直击我们需求的,所以我们决定尝试使用Flutter来构建我们的平台。
结论
如果你也在寻找一个技术技术方案兼顾研发效率与运行时效率,那么Flutter应该是一个很不错的选择。
作者:小声团队
链接:https://juejin.cn/post/7040289136787324958
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
10分钟用Flutter写出摸鱼桌面版App
起因
摸鱼是不可能摸鱼的,这辈子都不会摸鱼。
缘起是 郭佬 分享了一则微博:share.api.weibo.cn/share/26900…
顿时这个念头划过了我的脑海:好东西,但是我用的是 MacBook,不能用这个应用。但是貌似我可以自己写一个?
准备工作
年轻最需要的就是行动力,想到就干,尽管我此刻正在理顺 DevFest 的讲稿,但丝毫不妨碍我用 10 分钟写一个 App。于是我打出了一套组合拳:
flutter config --enable-macos-desktopflutter create --platforms=macos touch_fish_on_macos
一个支持 macOS 的 Flutter 项目就创建好了。(此时大约过去了 1 分钟)
开始敲代码
找到资源
我们首先需要一张高清无码的 图片,这里你可以在网上进行搜寻,有一点需要注意的是,使用 LOGO 要注意使用场景带来的版权问题。找到图片后,丢到 assets/apple-logo.png,并在 pubspec.yaml 中加上资源引用:
flutter:
use-material-design: true
+ assets:
+ - assets/apple-logo.png
思考布局
我们来观察一下 macOS 的启动画面,有几个要点:
- LOGO 在屏幕中间,固定大小约为 100dp;
- LOGO 与进度条间隔约 100 dp;
- 进度条高度约 5dp,宽度约 200dp,圆角几乎完全覆盖高度,值部分为白色,背景部分为填充色+浅灰色边框。
(别问我为什么这些东西能观察出来,问就是天天教 UI 改 UI。)
确认了大概的布局模式,接下来我们开始搭布局。(此时大约过去了 2 分钟)
实现布局
首先将 LOGO 居中、着色、设定宽度为 100,上下间隔 100:
return Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
const Spacer(),
Padding(
padding: const EdgeInsets.symmetric(vertical: 100),
child: Image.asset(
'assets/apple-logo.png',
color: CupertinoColors.white, // 使用 Cupertino 系列的白色着色
width: 100,
),
),
const Spacer(),
],
),
);
然后在下方放一个相对靠上的进度条:
return Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
const Spacer(),
Padding(
padding: const EdgeInsets.symmetric(vertical: 100),
child: Image.asset(
'assets/apple-logo.png',
color: CupertinoColors.white, // 使用 Cupertino 系列的白色
width: 100,
),
),
Expanded(
child: Container(
width: 200,
alignment: Alignment.topCenter, // 相对靠上中部对齐
child: DecoratedBox(
border: Border.all(color: CupertinoColors.systemGrey), // 设置边框
borderRadius: BorderRadius.circular(10), // 这里的值比高大就行
),
child: ClipRRect(
borderRadius: BorderRadius.circular(10), // 需要进行圆角裁剪
child: LinearProgressIndicator(
value: 0.3, // 当前的进度值
backgroundColor: CupertinoColors.lightBackgroundGray.withOpacity(.3),
color: CupertinoColors.white,
minHeight: 5, // 设置进度条的高度
),
),
),
),
],
),
);
到这里你可以直接 run,一个静态的界面已经做好了。(此时大约过去了 4 分钟)
打开 App,你已经可以放在一旁挂机了,老板走到你的身边,可能会跟你闲聊更新的内容。但是,更新界面不会动,能称之为更新界面? 当老板一而再再而三地从你身边经过,发现还是这个进度的时候,也许就已经把你的工资划掉了,或者第二天你因为进办公室在椅子上坐下而被辞退。
那么下一步我们就要思考如何让它动起来。
思考动画
来看看启动动画大概是怎么样的:
- 开始是没有进度条的;
- 进度条会逐级移动、速度不一定相等。
基于以上两个条件,我设计了一种动画处理方式:
- 构造分段的时长 (
Duration),可以自由组合由多个时长; - 动画通过时长的数量决定每个时长最终的进度;
- 每段时长控制起始值到结束值的间隔。
只有三个条件,简单到起飞,开动!(此时大约过去了 5 分钟)
实现动画
开局一个 AnimationController:
class _HomePageState extends State<HomePage> with SingleTickerProviderStateMixin {
/// 巧用 late 初始化,节省代码量
late final AnimationController _controller = AnimationController(vsync: this);
/// 启动后等待的时长
Duration get _waitingDuration => const Duration(seconds: 5);
/// 分段的动画时长
List<Duration> get _periodDurations {
return <Duration>[
const Duration(seconds: 5),
const Duration(seconds: 10),
const Duration(seconds: 4),
];
}
/// 当前进行到哪一个分段
final ValueNotifier<int> _currentPeriod = ValueNotifier<int>(1);
接下来实现动画方法,采用了递归调用的方式,减少调用链的控制:
@override
void initState() {
super.initState();
// 等待对应秒数后,开始进度条动画
Future.delayed(_waitingDuration).then((_) => _callAnimation());
}
Future<void> _callAnimation() async {
// 取当前分段
final Duration _currentDuration = _periodDurations[currentPeriod];
// 准备下一分段
currentPeriod++;
// 如果到了最后一个分段,取空
final Duration? _nextDuration = currentPeriod < _periodDurations.length ? _periodDurations.last : null;
// 计算当前分段动画的结束值
final double target = currentPeriod / _periodDurations.length;
// 执行动画
await _controller.animateTo(target, duration: _currentDuration);
// 如果下一分段为空,即执行到了最后一个分段,重设当前分段,动画结束
if (_nextDuration == null) {
currentPeriod = 0;
return;
}
// 否则调用下一分段的动画
await _callAnimation();
}
以上短短几行代码,就完美的实现了进度条的动画操作。(此时大约过去了 8 分钟)
最后一步,将动画、分段二者与进度条绑定,在没进入分段前不展示进度条,在动画开始后展示对应的进度:
ValueListenableBuilder<int>(
valueListenable: _currentPeriod,
builder: (_, int period, __) {
// 分段为0时,不展示
if (period == 0) {
return const SizedBox.shrink();
}
return DecoratedBox(
decoration: BoxDecoration(
border: Border.all(color: CupertinoColors.systemGrey),
borderRadius: BorderRadius.circular(10),
),
child: ClipRRect(
borderRadius: BorderRadius.circular(10),
child: AnimatedBuilder( // 使用 AnimatedBuilder,在动画进行时触发更新
animation: _controller,
builder: (_, __) => LinearProgressIndicator(
value: _controller.value, // 将 controller 的值绑定给进度
backgroundColor: CupertinoColors.lightBackgroundGray.withOpacity(.3),
color: CupertinoColors.white,
minHeight: 5,
),
),
),
);
},
大功告成,总共用时 10 分钟,让我们跑起来看看效果。(下图 22.1 M)
这还原度,谁看了不迷糊呢?🤩从此开启上班摸鱼之路...
打包发布
发布正式版的 macOS 应用较为复杂,但我们可以打包给自己使用,只需要一行命令即可:flutter build macos。
成功后,产物将会输出在 build/macos/Build/Products/Release/touch_fish_on_macos.app,双击即可使用。
结语
至此,一个简单的能在 macOS 上运行的摸鱼 Flutter App 就这么开发完成了。完整的 demo 可以访问我的仓库:github.com/AlexV525/fl… 。你可以给它提一些需求,我觉得这样一款软件还是挺有意思的。
可能大多数人都没有想到,编写一个 Flutter 应用,跑在 macOS 上,能有这么简单。当然,看似短暂的 10 分钟并没有包括安装环境、搜索素材、提交到 git 的时间,但在这个时间范围内,完成相关的事情也是绰绰有余。
希望这篇文章能激起你学习 Flutter 的兴趣,或是在桌面端尝试 Flutter 的兴趣,又或是挑战自己编程速度的兴趣(别说 10 分钟不可能,实际上我用的时间还要更少)。
作者:AlexV525
链接:https://juejin.cn/post/7042349287560183816
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter(一)Hello, Flutter!
1. 移动端开发演变过程
1.1 原生开发
原生应用程序是指某一个移动平台(比如iOS或安卓)所特有的应用,使用相应平台支持的开发工具和语言,直接调用系统SDK API。
Android原生应用:使用Java或Kotlin直接调用Android SDK开发的应用程序;
iOS原生应用:通过Objective-C或Swift语言直接调用iOS SDK开发的应用程序。
主要优势:
可直接无障碍的访问平台全部功能;
速度快、性能高、可以实现复杂动画及绘制,整体用户体验好;
主要缺点:
开发成本高;不同平台必须维护不同代码,人力成本、测试成本大;
内容固定,动态化弱,大多数情况下,有新功能更新时只能发版,但应用上架、审核是需要周期的,这对高速变化的互联网时代来说是很难接受的;
针对动态化和开发成本两个问题,诞生了一些跨平台的动态化框架。👇👇👇👇👇👇
1.2 跨平台技术简介
这里的跨平台指Android和iOS两个平台。根据其原理,主要分为三类:
H5+原生(Cordova、Ionic、微信小程序)=> Hybrid/混合开发
原理:APP需要动态变化的内容通过H5来实现,进一步通过原生的网页加载控件WebView (Android)或WKWebView(iOS)来加载。
WebView实质上是一个浏览器内核,其JavaScript依然运行在一个权限受限的沙箱中,所以对于大多数系统能力都没有访问权限,如无法访问文件系统、不能使用蓝牙等。所以,对于H5不能实现的功能,都需要原生去做。
核心:混合框架会在原生代码中预先实现一些访问系统能力的API, 暴露给WebView以供JavaScript调用,让WebView成为JavaScript与原生API之间通信的桥梁,主要负责JavaScript与原生之间传递调用消息 => JsBridge(WebView JavaScript Bridge)
JavaScript开发+原生渲染 (React Native、Weex、快应用)
这里主要介绍下 React Native 特点
和 React 原理相似,支持响应式编程,开发者只需关注状态转移,不需要关注UI绘制;
React 和 React Native 主要的区别在于虚拟DOM映射的对象是什么:
React中虚拟DOM最终会映射为浏览器DOM树;
RN中虚拟DOM会通过 JavaScriptCore 映射为原生控件树。(两步)
第一步:布局消息传递; 将虚拟DOM布局信息传递给原生;
第二步:原生根据布局信息通过对应的原生控件渲染控件树;
优点:
采用Web开发技术栈,社区庞大、上手快、开发成本相对较低。
原生渲染,性能相比H5提高很多。
动态化较好,支持热更新。
不足:
渲染时需要JavaScript和原生之间通信,在有些场景如拖动可能会因为通信频繁导致卡顿;
JavaScript为脚本语言,执行时需要JIT(Just In Time),执行效率和AOT(Ahead Of Time)代码仍有差距;
由于渲染依赖原生控件,不同平台的控件需要单独维护。
( RN架构升级,进行中,解决频繁和原生通信的瓶颈问题。)
自绘UI+原生(QT for mobile、Flutter)
QT for mobile(是移动端开发跨平台自绘引擎的先驱,也是烈士。)
Flutter 👇👇👇👇👇👇
2. Flutter 介绍
Flutter 是 Google 推出并开源的移动应用框架,主打跨平台、高保真、高性能。
2.1 跨平台自绘引擎
Flutter 与用于构建应用程序的其他框架不同,是因为 Flutter 既不使用 WebView 也不使用操作系统的原生控件。相反,Flutter 自己实现了自绘引擎。这样不仅能保证一套代码可以同时运行在 IOS 和 Android 平台上,还保证了 Android 和 IOS 上 UI 的一致性,而且也可以避免对原生控件依赖带来的限制和高昂的成本维护,也不用和native层做过多的通信,大大提高性能。
Flutter 使用 Skia 作为其2D渲染引擎,Skia 是一个 Google 的2D图形处理函数,包含字符、坐标转换,以及点阵图都有高效能且简介的表现,Skia 是跨平台的,并提供了非常友好的 API ,目前 Google Chrome 浏览器和 Android 均采用 Skia 作为其绘图引擎。
目前 Flutter 默认支持 Android、IOS、Fuchsia(Google新的自研操作系统)、鸿蒙四个移动平台,也支持 Web 开发(Flutter for web)、 PC 、小程序的开发。
2.2 采用Dart语言
这是一个很有意思也很有争议的问题,Flutter为什么选择Dart语言?
① 开发效率高。Dart运行时和编译器支持Flutter两个关键特性的组合:
基于JIT的快读开发周期:Flutter在开发阶段采用JIT模式。这样就避免了每次改动都要进行编译,极大节省了开发时间;并且在iOS和Android模拟器或真机上可以实现毫秒级热重载,并且不会丢失状态。
基于AOT的发布包:Flutter 在发布时间可以通过AOT生成高效的ARM代码以保证应用性能。而JavaScript则不具有这个能力(虽然可以通过打包工具实现)。
目前,程序主要有两种运行方式:静态编译与动态解释。
静态编译:在执行前全部被翻译为机器码
👉 AOT(Ahead of time)即“提前编译”; AOT程序的典型代表是用C/C++开发的应用,他们必须在执行前编译成机器码; 动态解释(解释执行)则是一句一句边翻译边运行
👉 JIT(Just-in-time)即“即时编译”。 JIT的代表则非常多,如JavaScript、Python等。
事实上,所有脚本语言都支持JIT模式。但需要注意的是,JIT和AOT 指的是程序运行方式,和编译语言并非强相关,有些语言既可以以JIT方式运行也可以以AOT方式运行,如Java、Python,他们可以在第一次执行时编译成中间字节码,然后在之后执行时可以直接执行字节码,也许有人会说,中间字节码并非机器码,在程序执行时仍需动态将字节码转换成机器码,是的,这没有错,不过通常我们区分是否为AOT的标准就是看代码在执行前是否需要编译,只要需要编译,无论其编译产物是字节码还是机器码,都属于AOT(不必纠结于概念,概念是为了传达精神而发明的,理解原理即可)。
② 高性能。Flutter提供流畅、高保真的UI体验,为了实现这一点,Flutter中需要能够在每个动画帧中运行大量的代码。这意味着需要一种既能提供高性能的语言,而不会出现丢帧的周期性暂停的问题,而Dart支持AOT,在这一点上可以比JavaScript做的更好。
③ 类型安全。由于Dart 是类型安全的语言,支持静态类型检查,所以可以在编译前发现一些类型错误,并排除潜在问题。这一点对于前端开发者极具吸引力,为了解决JavaScript弱类型的缺点,前端社区出现了很多给JavaScript代码添加静态类型检测的扩展语言和工具,如:微软的TypeScript、Facebook的Flow。而 Dart 本身就支持静态类型,这是他的一个重要优势。
④ 快速内存分配。Flutter框架使用函数式流,这使得它在很大程度上依赖底层内存分配器。因此,拥有一个能够有效的处理琐碎任务的内存分配器将显得十分重要。但其实在内存分配上Dart并没有超越JavaScript,只是Flutter需要,Dart 恰好满足。
⑤ Dart 团队就在 Flutter身边。Dart 语言也是谷歌推出的,由于有Dart团队的积极投入,Flutter团队可以获得更多、更方便的支持。
例如:Dart 最初并没有提供原生二进制文件的工具链(这对于实现可预测的高性能有很大帮助),但是现在它实现了,因为 Dart 团队专门为 Flutter 构建了它。 Dart VM 之前已经针对吞吐量进行了优化,但团队现在正忙于优化VM的延迟,这对于Flutter的工作负载更为重要。
2.3 高性能
Flutter 高性能主要是靠以上刚刚介绍的两点来保证的:
① 采用 Dart 语言开发。Dart 在 JIT(即时编译)模式下,速度与 JavaScript 基本持平,但是 Dart 支持 AOT,当以 AOT 模式运行时,JavaScript 就远远追不上了。速度的提升对高帧率下的数据计算很有帮助。
② 使用自己的渲染引擎来绘制 UI,布局数据由 Dart 语言直接控制,在布局过程中不需要像 RN 那样要在 JavaScript 和 Native 之间通信,这在一些滑动拖动场景下有明显优势,因为在滑动和拖动过程中往往都会引起布局发生变化,所以 JavaScript 需要在 Native 之间不停的同步布局信息,这和在浏览器中要 JavaScript 频繁操作 DOM 所带来的问题是相同的,都会带来比较大的性能开销。
2.4 响应式框架
借鉴 React 响应式的 UI 框架设计思想。中心思想是用 widget 构建你的 UI。 Widget 描述了他们的视图在给定其当前配置和状态时应该看起来像什么。当 widget 的状态发生变化时,widget 会重新构建 UI,Flutter 会对比前后变化的不同, 来确定底层渲染树从一个状态转换到下一个状态所需的最小更改(类似于 React/Vue 中虚拟 DOM 的 diff 算法)。
2.5 多端编译
2.5.1 移动端
打包 Android 并发布手机商店 👉 VSCode
打包命令
flutter build apk
发布:
注册各大应用市场开发者账号
创建要发布的app信息
按照流程上传
打包 IOS 并发布 Apple Store 👉 XCode
打包命令
flutter build ios
发布:
注册 Apple 开发者
创建要发布的app信息
配置钥匙串
在xcode配置apple stoer的证书和bundle id
xcode>Product>Archive>Distribute App
2.5.2 Web端
Flutter 2.x
检查是否支持web开发 $ flutter devices
打包命令
flutter build web --web-renderer html # 打开速度最快,兼容性好
flutter build web # 打开速度一般,兼容性好
flutter build web --web-renderer canvaskit # 打开速度最慢,兼容性好
部署:直接部署到服务器上即可
3. Flutter 框架结构
3.1 移动架构
3.1.1 Framework 框架层
框架层。这是一个纯dart实现的响应式框架,它实现了一套基础库。
底下两层(Foundation、Animation、Painting、Gestures)在Google的一些视频中被合并为一个Dart UI层,对应的是Flutter中的dart:ui包,它是Flutter引擎暴露的底层UI库,提供动画、手势及绘制能力。
Rendering 层,是一个抽象层,它依赖于 Dart UI ,这一层会构建一个UI树,当UI有变化时,会计算出有变化的部分,然后更新UI树,最终将UI树绘制到屏幕上,这个过程类似于React中的虚拟dom。Rendering层可以说是Flutter UI 框架的核心,它除了确定每个UI元素的位置、大小之外,还要调用底层dart:ui进行坐标变化和绘制。
Widgets层是Flutter提供的一套基础组件
Material 和 Cupertino 是 Flutter 提供的两种视觉风格的组件库,Material 安卓风格,Cupertino 是IOS风格。
实际开发过程中,主要都是和最上面的Widgets、Material/Cupertino两层打交道。
3.1.2 Engine 引擎层
纯C++实现的SDK,为Flutter的核心,提供了Flutter核心API的底层实现。其中包括了Dart运行时、Skia引擎、文字排版引擎等,是连接框架和系统(Android/IOS)的桥梁。在代码调用dart:ui库时,调用最终会走到Engine层,然后实现真正的绘制逻辑。
3.1.3 Embedder 嵌入层
嵌入层基本是由平台对应的语言来实现的。例如:在Android上,是由Java和C++ 来实现的,IOS是由Object-C和Object-C++来实现的。
嵌入层为Flutter提供了一个入口,Flutter系统是通过该入口访问底层系统提供的服务,例如输入法、绘制surface等。
3.2 Web端架构
3.3 移动端开发方式架构比较
4. 移动端开发对比
4.1 方案对比
4.2 性能对比
感兴趣 这里 有详细的性能对比介绍,不赘述。
5. Flutter 周边——调试工具
Flutter日志 和 print(); 是比较常用的检查数据的调试方法,但是不支持图形化界面、布局等的检查。👇👇👇👇👇👇
5.1 inspector 插件
可视化和浏览Flutter Widget树的工具。查看渲染树,了解布局信息。
5.2 Dev Tools
5.3 UME
字节 Flutter Infra 团队推出的开源 应用内 调试工具。
Pub.dev 发布地址
pub.flutter-io.cn/packages/fl…
GitHub 开源地址
github.com/bytedance/f…
功能 => UI 检查、代码查看、日志查看、性能工具 ...
服务于 => 设计师、产品经理、研发工程师或质量工程师 ...
- UI 检查插件包。点选 widget 获取 widget 基本信息、代码所在目录、widget 层级结构、RenderObject 的 build 链与描述的能力,颜色拾取与对齐标尺在视觉验收环节提供有力帮助。
- 代码查看插件。允许用户输入关键字,进行模糊匹配,对任意代码内容的查看能力。
- 日志查看。日志信息可通过统一面板提供筛选、导出等。
- 性能检测包。提供了当前 VM 对象实例数量与内存占用大小等信息。
6. Flutter 周边——学习路线
6.1 学习社区
Flutter 中文网 👉 入门文档
Flutter 中文社区 👉 入门文档
咸鱼Flutter 👉 可借鉴的架构方案
掘进Flutter 👉 专业性强的博客
StackOverflow 👉 问答社区,我遇到的flutter的问题,这里的答案最靠谱
源码及注释 👉 🙋♂️🙋♂️🙋♂️🙋♂️🙋♂️🙋♂️ 最方便开发时查找
6.2 学习路线
1、准备期
- 目标:
通过学习 Dart 基本语法,了解 Flutter 中的 Dart 的基本使用;
学习 Flutter 提供的基础布局和基本内容组件,完成基本页面展示。
技术点:
Dart语法
Flutter 基础组件
Material Design
Cupertino
Flutter 事件处理
Flutter 页面跳转
2、入门期
**目标:**了解 Flutter 盒模型,手势,动画等
学习资料:
3、进阶期
目标:掌握 Dart 中的 Stream,能将 Flutter 中的状态管理使用 Stream 或者其他的响应式编程的思想开发
技术点:
Dart异步
Generator
Stream
Flutter 中的 StreamBuilder
Bloc
Provider
学习资料:
6.3 学习开源项目
UI组件集项目 FlutterUnit
7. Flutter 周边——JS2Flutter
JS 转 Dart => JS2Flutter
作者:得到前端团队
链接:https://juejin.cn/post/7052902682285047821
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一兜糖 APP :用 Flutter 链接关于家的一切
一兜糖家居,成立于2009年,2015年获得腾讯系战略投资,截至2020年平台已累积3000万装修用户、5万设计师和10万经销商。自成立以来,我们通过「找灵感——学知识——做决策」全路径的优质内容输出,帮助用户提高消费决策的效率;通过门店线上化、口碑线上化和获客线上化,帮助品牌全面种草;通过内容、社群及用户资源,全面释放设计师价值,帮助设计师提高选品及获客效率。通过链接关于家的一切,我们希望让家变得有温度。
说重点
一兜糖 APP 在 2020 年开始尝试使用 Flutter 重构 iOS / Android 应用,使用 4 个月时间逐步迁移至 Flutter 工作流上。然后又使用一个月的时间,将 H5 以及微信小程序迁移到 MPFlutter 上。\
在重构完成后,一兜糖仅使用一套代码,便完成了在 iOS / Android / H5 / 微信小程序四端的部署,提升近四倍开发效率。
本文将与您分享一兜糖在重构过程中遇到的问题和解决方案。
一兜糖 APP 重构前的问题
2015 年,一兜糖家居开始发行 Android / iOS 两个平台的 APP,经过五年多的打磨,APP 内容日渐丰富,风格也越来越贴近用户使用习惯。直至 2020 年 4 月份,一兜糖家居 APP 均采用原生(Swift / Java)开发的方式进行,随着业务的快速增长以及五年多的技术迭代,面临的问题也越来越多。
- Android / iOS 两个平台开发进度不统一,实现效果差异性较大,随着业务需求的累积,差异越来越大。
- 项目日常维护开发所需人力越来越多,开发成本越来越高,Android / iOS 需要开发人员分别进行开发,同一个功能需要双倍的工作量来完成,如果把 H5 / 小程序涵括在内,同一个功能甚至需要四倍的工作量。
- 将近五年的技术变更,冗余代码越来越多,导致项目的编译时长越来越长,往往一个小小的变动,都要经过漫长的等待时间后才能看到改动后的效果。
为了解决以上问题,2020 年 4 月,一兜糖 APP 开发团队决定对 APP 进行重构,希望重构能够实现快速开发,减少两个平台的差异等问题。而此时,市面上 APP 开发方案除了原生开发,跨平台方案也已经相对成熟,使用哪种技术重构 APP 成为一兜糖移动团队需要面临的第一个抉择。
原生 VS 跨平台
原生开发的方式,两个平台的开发人员分别进行开发,可以以一种很高效的方式调度系统资源,性能更加优秀。缺点也很明显:
- 同一个业务却需要对两个平台分别进行开发,增加开发成本,业务代码无法在两个平台上复用。
- 重构时间只有短短的两个月,如果要以原生的方式对 APP 进行整体重构,不现实,人力不足也会增加重构失败的风险。
- 两个平台的差异性大,无法给不同平台的用户提供一致的使用体验。
- 原生开发的方式,需要分别开发相应的需求,后续的测试流程,也需要测试人员分别对相应平台进行测试,增加测试成本。
而跨平台方案则完美解决了以上问题,一兜糖 APP 开发团队尝试使用 Flutter 跨平台方案重构 APP。
为什么选择 Flutter
市面上跨平方技术方案除 Flutter 之外,还有多种其他技术,为何最终定型 Flutter 呢?团队主要从以下几点考虑。
节省人力
跨平台方案能够有效减少适配多个平台所带来的工作量,提高业务代码的复用率,原本需要两个平台开发人员一起开发的工作,现在只需要投入一半的人力即可完成需求。同样是跨平台方案,React Native 则需要投入更多的精力用于 UI 兼容等琐碎的事项。
性能上限
相比其他跨平台方案,Flutter 通过 Skia 引擎渲染 UI 视图,这种渲染方式其性能上限非常接近原生。也因为 Flutter 的自绘引擎设计,跨平台 UI 一致性得以保证,因 iOS / Android 系统升级而导致的适配问题更少,可维护性更高,开发人员也可以更专注于业务开发而无需担心平台兼容问题。
声明式 UI
有别于命令式编程,Flutter 使用声明式 UI 设计。使用声明式 UI,开发人员只需要描述当前的 UI 状态,无须关注不同 UI 状态之间的转换,状态转换的相关逻辑则交由 Flutter 框架处理。这无疑提高了开发人员的效率,开发人员可以更加专注于页面的结构。
热重载
在调试模式下,Flutter 支持运行时编译即热重载功能。热重载模块首先扫描工程中发生改动的文件,接着将发生变化的 Dart 代码编译转化为 Dart Kernel 文件,然后将增量的 Dart Kernel 文件发送给 Dart VM,Dart VM 则将接收到的增量文件与原本的 Dart Kernel 文件合并,重新加载合并后的 Dart Kernel 文件,最后在确认 Dart VM 资源加载成功后,重置 UI 线程,完成 Widget 的重建工作。
热重载对于页面的改动,无需重新启动 APP 即可呈现。可以保存页面的视图状态,对于一些在页面栈很深情况,无需为恢复视图栈而重复大量调试步骤,节省调试复杂交互界面的时间。
Flutter 生态
Flutter 开发社区生态活跃,开发中遇到的问题基本都可以在开发社区上找到解决方案。
开工大吉
我们按照以下步骤重构应用
- 统一中心思想,做好全员培训工作。
- 设计应用架构,以渐进式的方式过渡到 Flutter 工作流。
- 逐步重构,有计划地重构。
- 拆除旧有代码。
全员培训工作
在重构工作开始时,除 TL 外,团队成员均无 Flutter / Dart 开发经验。
重构工作的关键在于人,我们通过数次重要的会议,告知团队成员目前面临的困境,以及使用 Flutter 重构能为团队带来的收益,并鼓励团队成员尽快学习 Flutter / Dart,让成员感知该技术的便利性。
通过2~3周的学习,团队成员均已上手 Flutter,具备重构条件。
渐进式地过渡到 Flutter
一兜糖家居 APP 已经迭代了五年多,使用 Flutter 重构 APP 的时候,会面临另一个抉择:是以原生为主,Flutter 为辅还是以 Flutter 为主,原生为辅?
市面上大部分 APP 使用 Flutter 的过程中,都是小范围使用 Flutter,绝大部分功能以原生的方式实现,新功能则尝试使用 Flutter 进行开发。这样对 APP 的改动及影响会保持在一个很小的范围,然而这对于开发人员来说却不够友好,调试的时候,需要在原生模块和 Flutter 模块来回切换,比较麻烦;原生项目唤起 Flutter 页面时,也需要大量的资源支持,这同样不利于提升 APP 的性能。因此,一兜糖移动团队决定以 Flutter 为主,原生为辅 的方式重构 APP。
而对于 Android/iOS 这两个已经迭代了五年的原生项目,一下子舍弃原有的代码显然不太现实,我们先创建一个新的 Flutter 项目(ydt_flutter),将原本的两个原生项目(iOS / Android)迁移到新建的 ydt_flutter 项目目录下。
完成这一步后,即可开始将功能从原生往 Flutter 的方向迁移了。但如果直接在 lib 目录下开发的话,会有以下几个问题:
开发阶段编译项目的时候,会将原生冗余的代码也编译进去,造成第一次编译项目时需要经过漫长的等待。
不利于项目的迁移,原本高度耦合的项目代码会对重构中的 Flutter 项目造成干扰,也导致调试链的增长。
因此,在将两个原生项目迁移到 ydt_flutter 下后,在该目录下又创建了一个 common 模块(纯 Flutter 项目),后续重构的工作全部放在该模块下进行。这样做的好处是可以区分出 Flutter 重构后的项目和原本的原生项目,还可以简化调试工作,降低了两个项目的耦合度。后续相应的业务模块完成后,返回原生项目将相关的业务代码移除即可,一步步的将项目迁移到 Flutter 上。
逐步重构,有计划地重构。
接下来,是开发团队使用 4 个月的时间,逐步以模块为单位,重构应用。\
我们的应用是内容平台应用,在重构的过程中也同时顺带地配合设计组的同事重新整理了 APP 的 UI 风格,统一整理出 ListItemWidget(列表类型的组件) & WaterfallItem(瀑布流类型的组件)。该 APP 最核心的场景是各类列表与内容详情页,我们可以通过 CustomScrollView 的方式,以搭积木的方法,拼接出所有页面。
CustomScrollView + ListItem + WaterfallItem
通过这种方式,配合 GraphQL 下发的数据,我们拼接出了一个完整的内容应用。在这个过程中,Flutter 的一切皆 Widget 的思想,为重构提供了非常大的便利。
拆除旧有代码
在完成重构以后,便是将原有的原生代码删除,直至拆除上面提到的渐进式架构。
收益
重构对开发团队来说是一件高风险高收益的事,重构过程需要对旧业务进行整理,不仅要填上遗留的暗坑,同时还要避免新坑出现。好处也显而易见,可以解决绝大部分原本令人头痛的问题。
借助 Flutter 的诸多优秀特性,四个月时间,一兜糖家居 APP 重构成功。经过将近一年的线上运营,APP 总体使用和用户反馈良好。借助 CustomScrollView + ListItem + Waterfall,有一些小需求甚至无需发版即可将新改动呈现在用户面前。
重构后的 APP 中 Flutter 覆盖场景超过 90%。Dart 语法对比原生开发所使用的开发语言,语法更加简洁,如 await & async 可以有效的避免原生开发中处处可见的回调地狱,代码逻辑更加清晰。这些新特性,帮助开发人员减少 40% 的日常业务开发时间,所需的人力成本也降为原来的一半,开发效率提升 50%。
因为 Flutter 跨平台的优越性,不仅可以缩短开发周期,后续的测试周期也可以相应缩短,只需编写一次 Flutter 的自动化测试用例,而无需分别对 Android/iOS 编写测试用例,测试效率提升的同时降低测试成本。不仅如此,APP 交付给 UI 设计师阶段,也可以大大节省设计师 UI 走查的时间,走查效率提升 50%。
使用 Flutter 开发后,各开发相关的流程所需成本都显著降低,流程也同步简化了不少。接下来,一兜糖移动开发团队将会致力于将 Flutter 覆盖 APP 中 95% 以上的场景。
额外收获
对于 H5 和 微信小程序,一兜糖团队也尝试使用 MPFlutter 进行重构、迁移。
MPFlutter 是一个跨平台的 Flutter 开发框架,致力于推广 Flutter 至官方未能涉足的领域,如微信小程序。
借助 MPFlutter,一兜糖只用了一个月时间,简单修改一些关键的节点代码,便将应用部署到 H5 和微信小程序中。
体验一兜糖应用
如果您对一兜糖的成果感兴趣,不妨现在就通过以下方式体验。
- 在 AppStore 或各大安卓应用商店,搜索『一兜糖』下载应用。
- 在微信搜索『一兜糖』体验小程序。
- 点击 h5.yidoutang.com/v6/ ,体验一兜糖 H5 网站。
如果您正考虑如何装修新房,或者想知道屋主们的生活状态,欢迎持续使用一兜糖 APP。
作者:PonyCui
链接:https://juejin.cn/post/7039588712597946381
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Google 推荐使用 MVI 架构?卷起来了~
前言
前段时间写了一些介绍MVI架构的文章,不过软件开发上没有最好的架构,只有最合适的架构,同时众所周知,Google推荐的是MVVM架构。相信很多人都会有疑问,我为什么不使用官方推荐的MVVM,而要用你说的这个什么MVI架构呢?
不过我这几天查看Android的应用架构指南,发现谷歌推荐的最佳实践已经变成了单向数据流动 + 状态集中管理,这不就是MVI架构吗?
看起来Google已经开始推荐使用MVI架构了,大家也有必要开始了解一下Android应用架构指南的最新版本了~
本文主要基于Android应用架构指南,感兴趣的也可以直接查看原文
总体架构
两个架构原则
Android的架构设计原则主要有两个
分离关注点
要遵循的最重要的原则是分离关注点。一种常见的错误是在一个 Activity 或 Fragment 中编写所有代码。这些基于界面的类应仅包含处理界面和操作系统交互的逻辑。
总得来说,Activity或Fragment中的代码应该尽量精简,尽量将业务逻辑迁移到其它层
通过数据驱动界面
另一个重要原则是您应该通过数据驱动界面(最好是持久性模型)。数据模型独立于应用中的界面元素和其他组件。
这意味着它们与界面和应用组件的生命周期没有关联,但仍会在操作系统决定从内存中移除应用的进程时被销毁。
数据模型与界面元素,生命周期解耦,因此方便复用,同时便于测试,更加稳定可靠。
推荐的应用架构
基于上一部分提到的常见架构原则,每个应用应至少有两个层:
- 界面层 - 在屏幕上显示应用数据。
- 数据层 - 提供所需要的应用数据。
您可以额外添加一个名为“网域层”的架构层,以简化和复用使用界面层与数据层之间的交互
如上所示,各层之间的依赖关系是单向依赖的,网域层,数据层不依赖于界面层
界面层
界面的作用是在屏幕上显示应用数据,并响应用户的点击。每当数据发生变化时,无论是因为用户互动(例如按了某个按钮),还是因为外部输入(例如网络响应),界面都应随之更新,以反映这些变化。
不过,从数据层获取的应用数据的格式通常不同于UI需要展示的数据的格式,因此我们需要将数据层数据转化为页面的状态
因此界面层一般分为两部分,即UI层与State Holder,State Holder的角色一般由ViewModel承担
数据层的作用是存储和管理应用数据,以及提供对应用数据的访问权限,因此界面层必须执行以下步骤:
- 获取应用数据,并将其转换为
UI可以轻松呈现的UI State。 - 订阅
UI State,当页面状态发生改变时刷新UI - 接收用户的输入事件,并根据相应的事件进行处理,从而刷新
UI State - 根据需要重复第 1-3 步。
主要是一个单向数据流动,如下图所示:
因此界面层主要需要做以下工作:
- 如何定义
UI State。 - 如何使用单向数据流 (
UDF),作为提供和管理UI State的方式。 - 如何暴露与更新
UI State - 如何订阅
UI State
如何定义UI State
如果我们要实现一个新闻列表界面,我们该怎么定义UI State呢?我们将界面需要的所有状态都封装在一个data class中。
与之前的MVVM模式的主要区别之一也在这里,即之前通常是一个State对应一个LiveData,而MVI架构则强调对UI State的集中管理
data class NewsUiState(
val isSignedIn: Boolean = false,
val isPremium: Boolean = false,
val newsItems: List<NewsItemUiState> = listOf(),
val userMessages: List<Message> = listOf()
)
data class NewsItemUiState(
val title: String,
val body: String,
val bookmarked: Boolean = false,
...
)
以上示例中的UI State定义是不可变的。这样的主要好处是,不可变对象可保证即时提供应用的状态。这样一来,UI便可专注于发挥单一作用:读取UI State并相应地更新其UI元素。因此,切勿直接在UI中修改UI State。违反这个原则会导致同一条信息有多个可信来源,从而导致数据不一致的问题。
例如,如上中来自UI State的NewsItemUiState对象中的bookmarked标记在Activity类中已更新,那么该标记会与数据层展开竞争,从而产生多数据源的问题。
UI State集中管理的优缺点
在MVVM中我们通常是多个数据流,即一个State对应一个LiveData,而MVI中则是单个数据流。两者各有什么优缺点?
单个数据流的优点主要在于方便,减少模板代码,添加一个状态只需要给data class添加一个属性即可,可以有效地降低ViewModel与View的通信成本
同时UI State集中管理可以轻松地实现类似MediatorLiveData的效果,比如可能只有在用户已登录并且是付费新闻服务订阅者时,您才需要显示书签按钮。您可以按如下方式定义UI State:
data class NewsUiState(
val isSignedIn: Boolean = false,
val isPremium: Boolean = false,
val newsItems: List<NewsItemUiState> = listOf()
){
val canBookmarkNews: Boolean get() = isSignedIn && isPremium
}
如上所示,书签的可见性是其它两个属性的派生属性,其它两个属性发生变化时,canBookmarkNews也会自动变化,当我们需要实现书签的可见与隐藏逻辑,只需要订阅canBookmarkNews即可,这样可以轻松实现类似MediatorLiveData的效果,但是远比MediatorLiveData要简单
当然,UI State集中管理也会有一些问题:
- 不相关的数据类型:
UI所需的某些状态可能是完全相互独立的。在此类情况下,将这些不同的状态捆绑在一起的代价可能会超过其优势,尤其是当其中某个状态的更新频率高于其他状态的更新频率时。 UiState diffing:UiState对象中的字段越多,数据流就越有可能因为其中一个字段被更新而发出。由于视图没有diffing机制来了解连续发出的数据流是否相同,因此每次发出都会导致视图更新。当然,我们可以对LiveData或Flow使用distinctUntilChanged()等方法来实现局部刷新,从而解决这个问题
使用单向数据流管理UI State
上文提到,为了保证UI中不能修改状态,UI State中的元素都是不可变的,那么如何更新UI State呢?
我们一般使用ViewModel作为UI State的容器,因此响应用户输入更新UI State主要分为以下几步:
ViewModel会存储并公开UI State。UI State是经过ViewModel转换的应用数据。UI层会向ViewModel发送用户事件通知。ViewModel会处理用户操作并更新UI State。- 更新后的状态将反馈给
UI以进行呈现。 - 系统会对导致状态更改的所有事件重复上述操作。
举个例子,如果用户需要给新闻列表加个书签,那么就需要将事件传递给ViewModel,然后ViewModel更新UI State(中间可能有数据层的更新),UI层订阅UI State订响应刷新,从而完成页面刷新,如下图所示:
为什么使用单向数据流动?
单向数据流动可以实现关注点分离原则,它可以将状态变化来源位置、转换位置以及最终使用位置进行分离。
这种分离可让UI只发挥其名称所表明的作用:通过观察UI State变化来显示页面信息,并将用户输入传递给ViewModel以实现状态刷新。
换句话说,单向数据流动有助于实现以下几点:
- 数据一致性。界面只有一个可信来源。
- 可测试性。状态来源是独立的,因此可独立于界面进行测试。
- 可维护性。状态的更改遵循明确定义的模式,即状态更改是用户事件及其数据拉取来源共同作用的结果。
暴露与更新UI State
定义好UI State并确定如何管理相应状态后,下一步是将提供的状态发送给界面。我们可以使用LiveData或者StateFlow将UI State转化为数据流并暴露给UI层
为了保证不能在UI中修改状态,我们应该定义一个可变的StateFlow与一个不可变的StateFlow,如下所示:
class NewsViewModel(...) : ViewModel() {
private val _uiState = MutableStateFlow(NewsUiState())
val uiState: StateFlow<NewsUiState> = _uiState.asStateFlow()
...
}
这样一来,UI层可以订阅状态,而ViewModel也可以修改状态,以需要执行异步操作的情况为例,可以使用viewModelScope启动协程,并且可以在操作完成时更新状态。
class NewsViewModel(
private val repository: NewsRepository,
...
) : ViewModel() {
private val _uiState = MutableStateFlow(NewsUiState())
val uiState: StateFlow<NewsUiState> = _uiState.asStateFlow()
private var fetchJob: Job? = null
fun fetchArticles(category: String) {
fetchJob?.cancel()
fetchJob = viewModelScope.launch {
try {
val newsItems = repository.newsItemsForCategory(category)
_uiState.update {
it.copy(newsItems = newsItems)
}
} catch (ioe: IOException) {
// Handle the error and notify the notify the UI when appropriate.
_uiState.update {
val messages = getMessagesFromThrowable(ioe)
it.copy(userMessages = messages)
}
}
}
}
}
在上面的示例中,NewsViewModel 类会尝试进行网络请求,然后更新UI State,然后UI层可以对其做出适当反应
订阅UI State
订阅UI State很简单,只需要在UI层观察并刷新UI即可
class NewsActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.uiState.collect {
// Update UI elements
}
}
}
}
}
UI State实现局部刷新
因为MVI架构下实现了UI State的集中管理,因此更新一个属性就会导致UI State的更新,那么在这种情况下怎么实现局部刷新呢?
我们可以利用distinctUntilChanged实现,distinctUntilChanged只有在值发生变化了之后才会回调刷新,相当于对属性做了一个防抖,因此我们可以实现局部刷新,使用方式如下所示
class NewsActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.STARTED) {
// Bind the visibility of the progressBar to the state
// of isFetchingArticles.
viewModel.uiState
.map { it.isFetchingArticles }
.distinctUntilChanged()
.collect { progressBar.isVisible = it }
}
}
}
}
当然我们也可以对其进行一定的封装,给Flow或者LiveData添加一个扩展函数,令其支持监听属性即可,使用方式如下所示
class MainActivity : AppCompatActivity() {
private fun initViewModel() {
viewModel.viewStates.run {
//监听newsList
observeState(this@MainActivity, MainViewState::newsList) {
newsRvAdapter.submitList(it)
}
//监听网络状态
observeState(this@MainActivity, MainViewState::fetchStatus) {
//..
}
}
}
}
关于MVI架构下支持属性监听,更加详细地内容可见:MVI 架构更佳实践:支持 LiveData 属性监听
网域层
网域层是位于界面层和数据层之间的可选层。
网域层负责封装复杂的业务逻辑,或者由多个ViewModel重复使用的简单业务逻辑。此层是可选的,因为并非所有应用都有这类需求。因此,您应仅在需要时使用该层。
网域层具有以下优势:
- 避免代码重复。
- 改善使用网域层类的类的可读性。
- 改善应用的可测试性。
- 让您能够划分好职责,从而避免出现大型类。
我感觉对于常见的APP,网域层似乎并没有必要,对于ViewModel重复的逻辑,使用util来说一般就已足够
或许网域层适用于特别大型的项目吧,各位可根据自己的需求选用,关于网域层的详细信息可见:developer.android.com/jetpack/gui…
数据层
数据层主要负责获取与处理数据的逻辑,数据层由多个Repository组成,其中每个Repository可包含零到多个Data Source。您应该为应用处理的每种不同类型的数据创建一个Repository类。例如,您可以为与电影相关的数据创建 MoviesRepository 类,或者为与付款相关的数据创建 PaymentsRepository 类。当然为了方便,针对只有一个数据源的Repository,也可以将数据源的代码也写在Repository,后续有多个数据源时再做拆分
数据层跟之前的MVVM架构下的数据层并没用什么区别,这里就不多介绍了,关于数据层的详细信息可见:developer.android.com/jetpack/gui…
总结
相比老版的架构指南,新版主要是增加了网域层并修改了界面层,其中网域层是可选的,各位各根据自己的项目需求使用。
而界面层则从MVVM架构变成了MVI架构,强调了数据的单向数据流动与状态的集中管理。相比MVVM架构,MVI架构主要有以下优点
- 强调数据单向流动,很容易对状态变化进行跟踪和回溯,在数据一致性,可测试性,可维护性上都有一定优势
- 强调对
UI State的集中管理,只需要订阅一个ViewState便可获取页面的所有状态,相对MVVM减少了不少模板代码 - 添加状态只需要添加一个属性,降低了
ViewModel与View层的通信成本,将业务逻辑集中在ViewModel中,View层只需要订阅状态然后刷新即可
当然在软件开发中没有最好的架构,只有最合适的架构,各位可根据情况选用适合项目的架构,实际上在我看来Google在指南中推荐使用MVI而不再是MVVM,很可能是为了统一Android与Compose的架构。因为在Compose中并没有双向数据绑定,只有单向数据流动,因此MVI是最适合Compose的架构。
当然如果你的项目中没有使用DataBinding,或许也可以开始尝试一下使用MVI,不使用DataBinding的MVVM架构切换为MVI成本不高,切换起来也比较简单,在易用性,数据一致性,可测试性,可维护性等方面都有一定优势,后续也可以无缝切换到Compose。
作者:程序员江同学
链接:https://juejin.cn/post/7048980213811642382
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
聊下与 hash 有关的加密
聊下与 hash 有关的加密
hash 的简单概述
奥.自己百度去吧 百度比我说的详细.
咱们在这介绍一下 hash 的特点
注意看啊 重点来了
1.算法是公开的(怎么算的不重要,腻友不是数学家)
2.对相同数据运算,得到的结果是一样的
3.对不同数据运算,如MD5得到的结果默认是128位,32个字符(16进制标识)
4.逆运算的可能约等于0
5.可称之为信息指纹,是用来做数据识别
hash (MD5)加密的用途
1.用户密码的加密
比如客户端用户密码设置为 123456 ,通过 MD5加密的结果是e10adc3949ba59abbe56e057f20f883e
然后把这个e10adc3949ba59abbe56e057f20f883e发送给服务器,服务器储存的就是e10adc3949ba59abbe56e057f20f883e . 这个时候就算服务器被攻击,数据库泄露,别人拿到的也是一段加密后的结果.是不是这样就安全了
觉得安全了的同学罚站半小时. 看特点 ,上述第二条, 对相同数据运算,得到的结果是一样的!
这个意思就是说. 通过穷举字符组合的方式,创建了明文密文对应查询数据库,创建的记录约90万亿条,占用硬盘超过500TB! 这些都是 MD5加密前和加密后的数据!
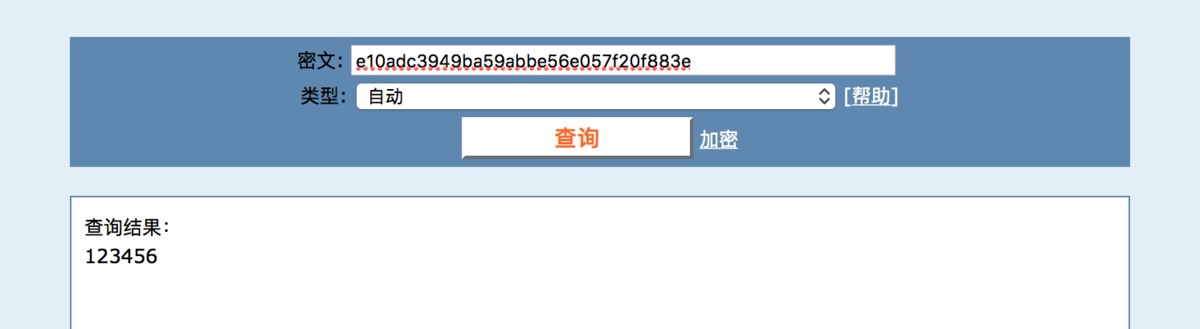
看吧. 一些常用或者常规通过 MD5加密已经可以通过第三方直接查询的到了
既然 MD5这么不安全,为什么这种加密还如此风靡 . 咱们接着往下看
这个时候有经验的同学应该知道怎么办了.有一种 md5的保护.叫加盐
什么是加盐呢 .举个栗子 用户的密码是123456吧. 这在程序里是个字符串吧.字符串拼接大家都会吧 比如用户密码后边都拼接一个 handsomezuyu. 哎? 试试看
123456handsomezuyu md5 后的结果是9a9a83b884f51deb88944461075dc538
咱们在用这个结果去解密试试
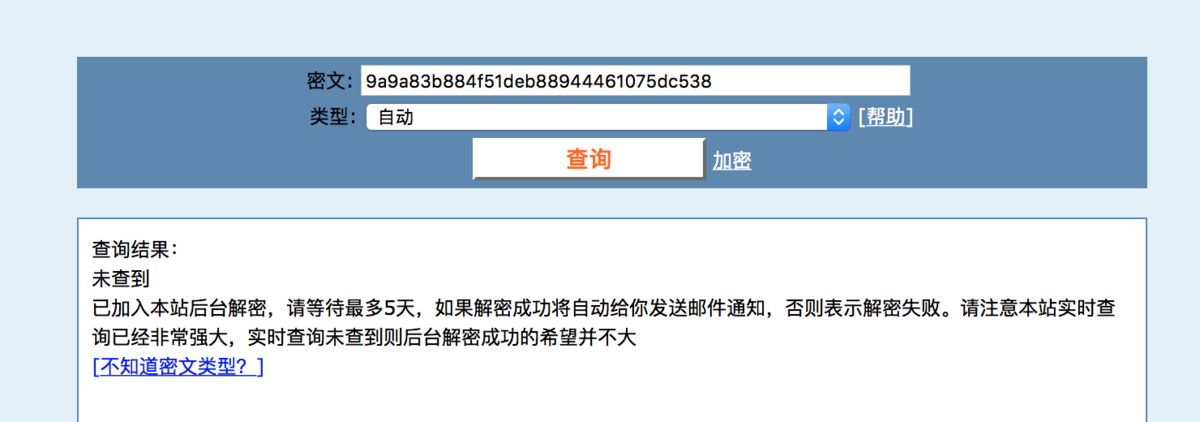
这个handsomezuyu就是盐了. 当然盐也可以是coolzuyu 也可以是excellentzuyu 也可以是 goodzuyu. 都可以都可以.
查不到了吧. 厉害了吧. 可以了吧.这招还行吧. 既简单又实用.都学会了吧.
(注意一下这个方法的缺点.参与这个项目的人都知道这个盐的值吧.那么如果有一天某位参与这个项目开发的同事因为在聚餐的时候放了个屁被开除了.额.... 是吧.那他如果想搞事... 好了.当然也有避免这种情况发生的措施,咱们这篇闲聊中先不讲.)
2.搜索引擎
嗯?这个时候可能有些小可爱就要问了.搜索引擎?哈希?
咱们就简单说一下搜索引擎与哈希的关系
比如你百度搜 "帅逼 zuyu" 和" zuyu 帅逼" 这两个关键词
出现的结果如果没有"帅逼 zuyu"直接关联的内容.那么搜索过后呈现的内容是一样的
因为搜索时引擎会拆词 ,关键字会被拆成" 帅逼 "和"zuyu"两个词 .然后得到两个词的哈希值.然后在对位相加. 无论顺序是怎么样的.对位相加后的结果都一样吧!所以就会出现了我上边说的内容一样的现象. 当然这只是一小部分关系,里边还有很多更复杂的算法和逻辑.这儿咱们就不一一标出了(呵呵,我也不知道)
3.版权/云盘
唉?版权?有点懵?版权还能和hash有关系?
咱们就先说说版权.比如腾讯视频上. 你拍了一段视频然后上传 ,紧接着上传成功 .这个时候腾讯视频就记录下了这个视频的 hash值.并且认定这个版权是你的. 其他人在上传相同的视频之后就会提示该视频已存在等类似的提示信息(如果你通过下载或者修改格式等各方便因素影响.即使视频内容完全一样, hash 值也有可能不同)
那云盘呢.云盘和 hash 有啥 关系呢.
举个栗子奥.百度云大家应该都用过对吧,而且你不仅用过,你用来干嘛我也知道.嗯,看懂这句话的都是同道中人. 好.咱们说回原题. 你们上传一些学习资料的时候有没有遇到过一种现象呢?
不是和谐啊! 不是和谐! 不是和谐!!!
秒传! 对吧 .一个挺大的文件 就秒传上去了.这就是和 hash的关系了. 百度云盘在你上传某国学习资料的时候,会先去拿到你这个文件对应的 hash 值. 如果云盘服务器就会做一个 hash 值的对比 .如果 hash 只能匹配的到,那就是服务器有相同的数据. 然后服务器只不过就是在你的账号里加了一条数据而已 .并不是真的把这个学习资料传上去. 当你下载一些学习资料的时候或者上传一些学习资料的时候 . 也遇到过提示你这个学习资料因为某种原因不可以下载了吧. 是吧.也是这个道理.
所以阿.这个时候知道原理了.那是不是就是可以避免一些不开心的事情了(压缩会改变 hash 值.修改文件名字不会改变 hash 值.翻录或者剪辑视频会改变 hash 值) 好 ,刹车.
来,回想一下, 我上边说特点. 第五条 可称之为信息指纹,是用来做数据识别. 理解了吧
至于特点的第一条. 算法是公开的 .咱们了解就好
至于特点的第三条.对不同数据运算,如MD5得到的结果默认是128位,32个字符(16进制标识)到更像是一种规则
至于特点的第四条.逆运算的可能约等于0 .简单解释一下就是说目前人们所熟知的知识范畴内 hash 就是不可逆运算
Kotlin invoke约定,让Kotlin代码更简洁
前言
最近看到DSL这个东西,不由的觉得里面可以利用Kotlin的一些特性能简化代码,所以具体来看看它是如何实现的。
正文
首先一上来就说原理或许对于不熟悉Kotlin的来说会感觉有点突兀,所以我准备从头梳理一下。
约定
Kotlin的约定我们在平时开发中肯定用到过,不过我们没有仔细去注意这个名词而已。约定的概念就是:使用与常规方法调用语法不同的、更简洁的符号,调用着有着特殊命名的函数。
这里提取2个关键点,一个是更简洁的符号调用,一个是特殊命名的函数。说白了就是让函数调用更加简洁。
比如我们最熟悉的集和调用 [index] 来 替代 get(index),我们自己也来定义个类,来实现一下这个约定:
data class TestBean(val name: String,val age: Int){
//定义非常简单 使用operator重载运算符get方法
operator fun get(index : Int): Any{
return when(index) {
0 -> name
1 -> age
else -> name
}
}
}
然后我们在使用时:
//这里就可以使用 [] 来替换 get来简化调用方法了
val testBean = TestBean("zyh",20)
testBean.get(0)
testBean[0]
invoke约定
和上面的get约定一样,[] 就是调用 get 方法的更简洁的方式,这里有个invoke约定,它的作用就是让对象像函数一样调用方法,下面直接来个例子:
data class TestBean(val name: String,val age: Int){
//重载定义invoke方法
operator fun invoke() : String{
return "$name - $age"
}
}
定义完上面代码后,我们来进行使用:
val testBean = TestBean("zyh",20)
//正常调用
testBean.invoke()
//约定后的简化调用
testBean()
这里会发现testBean对象可以调用invoke方法是正常调用,但是也可以testBean()直接来调用invoke方法,这就是invoke约定的作用,让调用invoke方法更简单。
invoke约定和函数式类型
既然了解了invoke约定,我们来和lambda结合起来。
对于lambda有点疑惑的可以查看文章:
我们知道函数类型其实就是实现了FunctionN接口的类,然后当函数类型是函数类型时,这时传递给它一个lambda,lambda就会被编译成FunctionN的匿名内部类(当然是非内联的),然后调用lambda就变成了一次FunctionN接口的invoke调用。
还是看个例子代码:
//定义代码
class TestInvoke {
//高阶函数类型变量
private var mSingleListener: ((Int) -> Unit)? = null
//设置变量
public fun setSingleListener(listener:((Int) -> Unit)?){
this.mSingleListener = listener
}
//
fun testRun() {
//调用invoke函数
mSingleListener?.invoke(100)
//使用invoke约定,省去invoke
if (mSingleListener != null){
mSingleListener!!(100)
}
}
}
定义完上面回调变量后,我们来使用这个回调,由于我们知道高阶函数其实是实现了FunctionN接口的类,也就是实现了:
//注意,这里接口的方法就是invoke
public interface Function1<in P1, out R> : Function<R> {
/** Invokes the function with the specified argument. */
public operator fun invoke(p1: P1): R
}
那我也就可以直接使用下面代码来传递参数:
val function1 = object: Function1<Int,Unit> {
override fun invoke(p1: Int) {
Logger.d("$p1")
}
}
testInvoke.setSingleListener(function1)
这里看起来合情合理,因为在testRun函数中我们调用了invoke函数,把100当做参数,然后这个100会被回调到function1中,但是我们传递lambda时呢:
val testInvoke = TestInvoke()
testInvoke.setSingleListener { returnInt ->
Logger.d("$returnInt")
}
上面代码传递lambda和传递一个类的实例效果是一样的,只不过这里只是一段代码块,没有显示的调用invoke啥的,所以这就是一个特性,当lambda被用作参数被函数调用时,也就可以看成是一次invoke的自动调用。
invoke在DSL中的实践:Gradle依赖
这里我们为什么要说这个invoke依赖呢,很大的原因就是它在一些DSL中有很好的用法,这里我们就来看个Gradle依赖的使用。
我们很常见下面代码:
dependencies {
implementation 'androidx.core:core-ktx:1.6.0'
implementation 'androidx.appcompat:appcompat:1.3.1'
//...
}
这里我们都很习以为常,感觉这里很像配置项,而不像是代码,其实这个也是一段代码,只不过是这种风格。那这种风格如何实现呢,我们来简单实现一下:
class DependencyHandler{
//编译库
fun compile(libString: String){
Logger.d("add $libString")
}
//定义invoke方法
operator fun invoke(body: DependencyHandler.() -> Unit){
body()
}
}
上面代码写完后,我们便可以有下面3种调用方式:
val dependency = DependencyHandler()
//调用invoke
dependency.invoke {
compile("androidx.core:core-ktx:1.6.0")
}
//直接调用
dependency.compile("androidx.core:core-ktx:1.6.0")
//带接受者lambda方式
dependency{
compile("androidx.core:core-ktx:1.6.0")
}
由此可见,上面代码第三种方式便是我们在Gradle配置文件中常见的一种,这里其实就2个关键点,一个是定义invoke函数,一个是定义带接受者的lambda,调用时省去this即可。
总结
其实关于invoke约定和带接受者lambda的写法现在越来越流行了,比如之前的anko库,现在的compose库都是这种声明式的写法,看完原理后,就会发现其实还是很方便的。
后续开始研究compose的时候,再来补充一波。
作者:元浩875
链接:https://juejin.cn/post/7047028786969346079
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
android充电架构的分析
前言
目前android设备越来越多,对于快速充电和长时间待机的需求就不言而喻。对应于此的就是各大手机厂商不断突破大功率充电新闻频繁的出现。在个人目前遇到的快充方案中,基本上在大的架构下属于同一种类型。故分析记录下来。
基本原理
充电简单粗暴点来说就是把电流灌到电池里面去。那么最简单的方法就是直接拿一个电源接在电池的正负极。只要电源电压高于电池电压就可以把电流灌进去。就如同直接打开水龙头开关接水一样。
但是这样会存在很多问题。例如:电池此时的电压很小,电源电压很高,一怼上电池上的电流就会变得非常大,很可能烧坏电池。所以需要根据电池的电压来调节输入电源的电压。这样又会出现充一会后就调一下电压,太麻烦了。因此可以使用计算机来完成这些动作,通过一颗锂电池充放电芯片来管理充放电的过程。
使用锂电池充电芯片,整个充电过程大致分成了三个阶段:分别是预充、恒流、恒压。
上图是各个阶段电池电流,电压的状态。
但是该方案存在转化效率较低的问题,特别是在大功率的情况下,损耗太大。因此在手机里不常采用这个方案,不过无论怎样,基本的充电曲线还是和上图保持一致的。
基本硬件架构
现在手机充电的基本架构如下图所示
电源输入
首先是电源的输入。目前手机上输入电源普遍支持有线和无线两种方式。在该架构下并不是简单让电源输入一个固定电压完成充电。而在由ap在不同阶段调节输入电源的功率。因此电源的提供需要支持调压的过程。现在在无线中常使用qi协议,而有线中常使用pd协议。
充电模块
充电模块现在主要由main charger(充电芯片)和charger pump(电荷泵芯片)构成,因为charger pump在大电流的情况下效率很高。整个充电过程依旧和上面的充电曲线基本一致。只不过此时的cc阶段和前半段的cv阶段由charger pump来完成,其余的由main charger来完成
main charger芯片在自身集成了数字逻辑,所以可以自动的切换各个阶段。而charger pump则不是这样,它只是一个模拟器件,我们可以把它理解成一个开关(经过它以后电流升一倍,电压降一半。譬如输入10v,5a输出就是5v,10a)
故在使用过程中通过ap的程序来模拟充电阶段。比如我们规定在cc阶段下的电流是6a,而此时ap采集到的电流是4a。那我们就通过协议去增大电源的输入;采集到的电流大于6a则降低电源的输入。
电量计模块
电量计模块主要是获取电池的电量信息。然后上层可以获得电池剩余电量百分比等。
软件架构
android手机内核采用的是linux内核,android有很多层。单单对于充电功能来说可以把它分为2层,一层是kernel里的驱动和逻辑实现,另一层是上层。android界面上显示和充电相关的信息就需要从kernel这一层拿。
在内核中一切皆文件,那对于充电这部分来说也不例外。上层获取的信息都是从/sys/class/power supply路径获取的。这个路径是由代码决定的(源码路径:/system/core/healthd/BatteryMonitor.cpp)
在充电信息发生改变的时候kernel就会调用uevent,上层就会接收到,然后执行下面的函数更新状态。
bool BatteryMonitor::update(void) {
bool logthis;
initBatteryProperties(&props);
if (!mHealthdConfig->batteryPresentPath.isEmpty())
props.batteryPresent = getBooleanField(mHealthdConfig->batteryPresentPath);
else
props.batteryPresent = mBatteryDevicePresent;
props.batteryLevel = mBatteryFixedCapacity ?
mBatteryFixedCapacity :
getIntField(mHealthdConfig->batteryCapacityPath);
props.batteryVoltage = getIntField(mHealthdConfig->batteryVoltagePath) / 1000;
if (!mHealthdConfig->batteryCurrentNowPath.isEmpty())
props.batteryCurrent = getIntField(mHealthdConfig->batteryCurrentNowPath) / 1000;
if (!mHealthdConfig->batteryFullChargePath.isEmpty())
props.batteryFullCharge = getIntField(mHealthdConfig->batteryFullChargePath);
if (!mHealthdConfig->batteryCycleCountPath.isEmpty())
props.batteryCycleCount = getIntField(mHealthdConfig->batteryCycleCountPath);
if (!mHealthdConfig->batteryChargeCounterPath.isEmpty())
props.batteryChargeCounter = getIntField(mHealthdConfig->batteryChargeCounterPath);
props.batteryTemperature = mBatteryFixedTemperature ?
mBatteryFixedTemperature :
getIntField(mHealthdConfig->batteryTemperaturePath);
std::string buf;
if (readFromFile(mHealthdConfig->batteryStatusPath, &buf) > 0)
props.batteryStatus = getBatteryStatus(buf.c_str());
if (readFromFile(mHealthdConfig->batteryHealthPath, &buf) > 0)
props.batteryHealth = getBatteryHealth(buf.c_str());
if (readFromFile(mHealthdConfig->batteryTechnologyPath, &buf) > 0)
props.batteryTechnology = String8(buf.c_str());
unsigned int i;
double MaxPower = 0;
for (i = 0; i < mChargerNames.size(); i++) {
String8 path;
path.appendFormat("%s/%s/online", POWER_SUPPLY_SYSFS_PATH,
mChargerNames[i].string());
if (getIntField(path)) {
path.clear();
path.appendFormat("%s/%s/type", POWER_SUPPLY_SYSFS_PATH,
mChargerNames[i].string());
switch(readPowerSupplyType(path)) {
case ANDROID_POWER_SUPPLY_TYPE_AC:
props.chargerAcOnline = true;
break;
case ANDROID_POWER_SUPPLY_TYPE_USB:
props.chargerUsbOnline = true;
break;
case ANDROID_POWER_SUPPLY_TYPE_WIRELESS:
props.chargerWirelessOnline = true;
break;
default:
KLOG_WARNING(LOG_TAG, "%s: Unknown power supply type\n",
mChargerNames[i].string());
}
path.clear();
path.appendFormat("%s/%s/current_max", POWER_SUPPLY_SYSFS_PATH,
mChargerNames[i].string());
int ChargingCurrent =
(access(path.string(), R_OK) == 0) ? getIntField(path) : 0;
path.clear();
path.appendFormat("%s/%s/voltage_max", POWER_SUPPLY_SYSFS_PATH,
mChargerNames[i].string());
int ChargingVoltage =
(access(path.string(), R_OK) == 0) ? getIntField(path) :
DEFAULT_VBUS_VOLTAGE;
double power = ((double)ChargingCurrent / MILLION) *
((double)ChargingVoltage / MILLION);
if (MaxPower < power) {
props.maxChargingCurrent = ChargingCurrent;
props.maxChargingVoltage = ChargingVoltage;
MaxPower = power;
}
}
}
logthis = !healthd_board_battery_update(&props);
if (logthis) {
char dmesgline[256];
size_t len;
if (props.batteryPresent) {
snprintf(dmesgline, sizeof(dmesgline),
"battery l=%d v=%d t=%s%d.%d h=%d st=%d",
props.batteryLevel, props.batteryVoltage,
props.batteryTemperature < 0 ? "-" : "",
abs(props.batteryTemperature / 10),
abs(props.batteryTemperature % 10), props.batteryHealth,
props.batteryStatus);
len = strlen(dmesgline);
if (!mHealthdConfig->batteryCurrentNowPath.isEmpty()) {
len += snprintf(dmesgline + len, sizeof(dmesgline) - len,
" c=%d", props.batteryCurrent);
}
if (!mHealthdConfig->batteryFullChargePath.isEmpty()) {
len += snprintf(dmesgline + len, sizeof(dmesgline) - len,
" fc=%d", props.batteryFullCharge);
}
if (!mHealthdConfig->batteryCycleCountPath.isEmpty()) {
len += snprintf(dmesgline + len, sizeof(dmesgline) - len,
" cc=%d", props.batteryCycleCount);
}
} else {
len = snprintf(dmesgline, sizeof(dmesgline),
"battery none");
}
snprintf(dmesgline + len, sizeof(dmesgline) - len, " chg=%s%s%s",
props.chargerAcOnline ? "a" : "",
props.chargerUsbOnline ? "u" : "",
props.chargerWirelessOnline ? "w" : "");
KLOG_WARNING(LOG_TAG, "%s\n", dmesgline);
}
healthd_mode_ops->battery_update(&props);
return props.chargerAcOnline | props.chargerUsbOnline |
props.chargerWirelessOnline;
}
很显然可以从code看出,通过该路径下文件夹里的type文件的值,来获得不同的信息。
例如
此时我进入到test_usb节点下,type为usb。然后online节点则表示usb连接是否在线,此时为1,则表示usb连接,充电图标会亮起来。
然后通过命令echo 0 > online ,强制将该值写为0。充电图标消失。
故在手机端充电相关的开发基本围绕着power supply架构展开的。下面依次从kernel到上层应用进行分析。
作者:Air-Liu
链接:https://juejin.cn/post/7047081152372277262
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android编译插桩操作字节码
1. 概念
什么是编译插桩
顾名思义,所谓的编译插桩就是在代码编译期间修改已有的代码或者生成新代码。我们项目中的 Dagger、ButterKnife或者kotlin都用到了编译插桩技术。
要理解编译插桩,我们要先知道在Android中.java 文件是怎么编译的。
如上图所示,demo.java通过javac命令编译成demo.class文件,然后通过字节码文件编译器将class文件打包成.dex。
我们今天要说的插桩,就是在class文件转为.dex之前修改或者添加代码。
2. 场景
我们什么时候会用到它呢?
- 日志埋点
- 性能监控
- 权限控制
- 代码替换
- 代码调试
- 等等...
3. 插桩工具介绍
AspectJ
AspectJ 是老牌 AOP(Aspect-Oriented Programming)框架。其主要优势是成熟稳定,使用者也不需要对字节码文件有深入的理解。
ASM
ASM 最初起源于一个博士的研究项目,在 2002 年开源,并从 5.x 版本便开始支持 Java 8。并且,ASM 是诸多 JVM 语言钦定的字节码生成库,它在效率与性能方面的优势要远超其它的字节码操作库如 javassist、AspectJ。其主要优势是内存占用很小,运行速度快,操作灵活。但是上手难度大,需要对 Java 字节码有比较充分的了解。
本文使用 ASM 来实现简单的编译插桩效果,接下来我们是想一个小需求,
4. 实践
1. 创建AsmDemo项目,其中只有一个MainActivity
2.创建自定义gradle插件
删除module中main文件夹下所有目录,新建groovy跟java目录。
gradle插件是用groovy编写的,所以groovy文件存放.groovy文件,java目录中存放asm相关类。
清空build.gradle文件内容,改为如下内容:
plugins {
id 'groovy'
id 'maven'
}
dependencies {
implementation gradleApi()
implementation localGroovy()
implementation 'com.android.tools.build:gradle:3.5.4'
}
group = "demo.asm.plugin"
version = "1.0.0"
uploadArchives {
repositories {
mavenDeployer {
repository(url: uri("../asm_lifecycle_repo"))
}
}
}
3.创建LifeCyclePlugin文件
package demo.asm.plugin
import org.gradle.api.Plugin
import org.gradle.api.Project
public class LifeCyclePlugin implements Plugin {
@Override
void apply(Project target) {
println("hello this is my plugin")
}
}
LifeCyclePlugin实现了Plugin接口,但我们在app中使用此插件的时候,LifeCyclePlugin的apply插件会被调用。
接着创建properties文件:
首先在main下面创建resources/META-INF/gradle-plugins目录,然后在gradle-plugins中创建demo.asm.lifecycle.properties,并填入如下内容:
implementation-class=demo.asm.plugin.LifeCyclePlugin
其中文件名demo.asm.lifecycle就是我们插件的名称,后续我们需要在app的build.gradle文件中引用此插件。
好了,现在我们的插件已经写完了,我们把他部署到本地仓库中来测试一下。发布地址在上述build.grale文件中repository属性配置。我将其配置在asm_lifecycle_repo目录中。
我们在 Android Studio 的右边栏找到 Gradle 中点击 uploadArchives,执行 plugin 的部署任务,构建成功后,本地会出现一个repo目录,就是我们自定义的插件。
我们测试一下demo.asm.lifecycle。
首先在项目根目录的build.gradle文件中添加
buildscript {
ext.kotlin_version = '1.4.32'
repositories {
google()
mavenCentral()
maven { url 'asm_lifecycle_repo' } //需要添加的内容
}
dependencies {
classpath "com.android.tools.build:gradle:3.5.4"
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:1.4.32"
classpath 'demo.asm.plugin:asm_lifecycle_plugin:1.0.0' //需要添加的内容
}
}
然后在app的build.gradle中添加
id 'demo.asm.lifecycle'
然后我们执行命令./gradlew clean assembleDebug,可以看到hello this is my plugin 正确输出,说明我们自定义的gradle插件可以使用。
然后我们来自定义transform,来遍历.class文件
这部分功能主要依赖 Transform API。
4.自定义transform
什么是 Transform ?
Transform 可以被看作是 Gradle 在编译项目时的一个 task,在 .class 文件转换成 .dex 的流程中会执行这些 task,对所有的 .class 文件(可包括第三方库的 .class)进行转换,转换的逻辑定义在 Transform 的 transform 方法中。实际上平时我们在 build.gradle 中常用的功能都是通过 Transform 实现的,比如混淆(proguard)、分包(multi-dex)、jar 包合并(jarMerge)。
创建LifeCycleTransfrom文件,内容如下:
package demo.asm.plugin
import com.android.build.api.transform.QualifiedContent
import com.android.build.api.transform.Transform
import com.android.build.api.transform.TransformException
import com.android.build.api.transform.TransformInput
import com.android.build.api.transform.TransformInvocation
import com.android.build.gradle.internal.pipeline.TransformManager
import joptsimple.internal.Classes
/**
* Transform 主要作用是检索项目编译过程中的所有文件。通过这几个方法,我们可以对自定义 Transform 设置一些遍历规则,
*/
public class LifeCycleTransform extends Transform {
/**
* 设置我们自定义的 Transform 对应的 Task 名称。Gradle 在编译的时候,会将这个名称显示在控制台上。
* 比如:Task :app:transformClassesWithXXXForDebug。
* @return
*/
@Override
String getName() {
return "LifeCycleTransform"
}
/**
* 在项目中会有各种各样格式的文件,通过 getInputType 可以设置 LifeCycleTransform 接收的文件类型,
* 此方法返回的类型是 Set 集合。
* 此方法有俩种取值
* 1.CLASSES:代表只检索 .class 文件;
* 2.RESOURCES:代表检索 java 标准资源文件。
* @return
*/
@Override
Set getInputTypes() {
return TransformManager.CONTENT_CLASS
}
/**
* 这个方法规定自定义 Transform 检索的范围,具体有以下几种取值:
* EXTERNAL LIBRARIES 只有外部库
* PROJECT 只有项目内容
* PROJECT LOCAL DEPS 只有项目的本地依赖(本地jar )
* PROVIDED ONLY 只提供本地或远程依赖项
* SUB PROJECTS 只有子项目。
* SUB PROJECTS LOCAL DEPS 只有子项目的本地依赖项(本地jar)。
* TESTED CODE 由当前变量(包括依赖项)测试的代码
* @return
*/
@Override
Set getScopes() {
return TransformManager.PROJECT_ONLY
}
/**
* isIncremental() 表示当前 Transform 是否支持增量编译,我们不需要增量编译,所以直接返回 false 即可。
* @return
*/
@Override
boolean isIncremental() {
return false
}
/**
* 最重要的方法,在这个方法中,可以获取到俩个数据的流向
* inputs:inputs 中是传过来的输入流,其中有两种格式,一种是 jar 包格式,一种是 directory(目录格式)。
* outputProvider:outputProvider 获取到输出目录,最后将修改的文件复制到输出目录,这一步必须做,否则编译会报错。
*
* @param transformInvocation
* @throws TransformException* @throws InterruptedException* @throws IOException
*/
@Override
void transform(TransformInvocation transformInvocation) throws TransformException, InterruptedException, IOException {
Collection tis = transformInvocation.inputs
tis.forEach(ti -> {
ti.directoryInputs.each {
File file = it.file
if (file) {
file.traverse {
println("find class:" + it.name)
}
}
}
})
}
}
然后将我们将自定义的transform注册到我们定义好的plugin中,LifeCyclePlugin代码修改如下:
package demo.asm.plugin
import com.android.build.gradle.AppExtension
import org.gradle.api.Plugin
import org.gradle.api.Project
public class LifeCyclePlugin implements Plugin {
@Override
void apply(Project target) {
println("hello this is my plugin")
def android = target.extensions.getByType(AppExtension)
println "======register transform ========"
LifeCycleTransform transform = new LifeCycleTransform()
android.registerTransform(transform)
}
}
然后再次执行./gradlew clean assembleDebug,可以看到项目中所有的.class文件都被输出了
5.使用 ASM,插入字节码到 Activity 文件
ASM 是一套开源框架,其中几个常用的 API 如下:
ClassReader:负责解析 .class 文件中的字节码,并将所有字节码传递给 ClassWriter。
ClassVisitor:负责访问 .class 文件中各个元素,还记得上一课时我们介绍的 .class 文件结构吗?ClassVisitor 就是用来解析这些文件结构的,当解析到某些特定结构时(比如类变量、方法),它会自动调用内部相应的 FieldVisitor 或者 MethodVisitor 的方法,进一步解析或者修改 .class 文件内容。
ClassWriter:继承自 ClassVisitor,它是生成字节码的工具类,负责将修改后的字节码输出为 byte 数组。
添加 ASM 依赖
在asm_demo_plugin的build.gradle中添加asm依赖
dependencies {
implementation gradleApi()
implementation localGroovy()
implementation 'com.android.tools.build:gradle:3.5.4'
implementation 'org.ow2.asm:asm:8.0.1'//需要添加的依赖
implementation 'org.ow2.asm:asm-commons:8.0.1'//需要添加的依赖
}
在main/java下面创建包 demo/asm/asm目录并添加如下代码:
import org.objectweb.asm.ClassVisitor;
import org.objectweb.asm.MethodVisitor;
import org.objectweb.asm.Opcodes;
/**
* Created by zhangzhenrui
*/
public class LifeCycleClassVisitor extends ClassVisitor {
private String className = "";
private String superName = "";
public void visit(int version, int access, String name, String signature, String superName, String[] interfaces) {
super.visit(version, access, name, signature, superName, interfaces);
this.className = name;
this.superName = superName;
}
public MethodVisitor visitMethod(int access, String name, String descriptor, String signature, String[] exceptions) {
System.out.println("classVisitor methodName" + name + ",supername" + superName);
MethodVisitor mv = cv.visitMethod(access, name, descriptor, signature, exceptions);
if (superName.equals("android/support/v7/app/AppCompatActivity")) {
if (name.equals("onCreate")) {
return new LifeCycleMethodVisitor(className, name, mv);
}
}
return mv;
}
public void visitEnd() {
super.visitEnd();
}
public LifeCycleClassVisitor(ClassVisitor classVisitor) {
super(Opcodes.ASM5, classVisitor);
}
}
import org.objectweb.asm.MethodVisitor;
import org.objectweb.asm.Opcodes;
/**
* Created by zhangzhenrui
*/
class LifeCycleMethodVisitor extends MethodVisitor {
private String className;
private String methodName;
public LifeCycleMethodVisitor(String className, String methodName, MethodVisitor methodVisitor) {
super(Opcodes.ASM5, methodVisitor);
this.className = className;
this.methodName = methodName;
}
public void visitCode() {
super.visitCode();
System.out.println("methodVistor visitorCode");
mv.visitLdcInsn("TAG");
mv.visitLdcInsn(className + "------>" + methodName);
mv.visitMethodInsn(Opcodes.INVOKESTATIC, "android/util/Log", "e", "(Ljava/lang/String;Ljava/lang/String;)I", false);
mv.visitInsn(Opcodes.POP);
}
}
然后修改LifeCycleTransform的transform函数如下:
@Override
void transform(TransformInvocation transformInvocation) throws TransformException, InterruptedException, IOException {
Collection transformInputs = transformInvocation.inputs
TransformOutputProvider outputProvider = transformInvocation.outputProvider
transformInputs.each { TransformInput transformInput ->
transformInput.directoryInputs.each { DirectoryInput directoryInput ->
File file = directoryInput.file
if (file) {
file.traverse(type: FileType.FILES, namefilter: ~/.*.class/) { File item ->
ClassReader classReader = new ClassReader(item.bytes)
if (classReader.itemCount != 0) {
System.out.println("find class:" + item.name + "classReader.length:" + classReader.getItemCount())
ClassWriter classWriter = new ClassWriter(classReader, ClassWriter.COMPUTE_MAXS)
ClassVisitor classVisitor = new LifeCycleClassVisitor(classWriter)
classReader.accept(classVisitor, ClassReader.EXPAND_FRAMES)
byte[] bytes = classWriter.toByteArray()
FileOutputStream outputStream = new FileOutputStream(item.path)
outputStream.write(bytes)
outputStream.close()
}
}
}
def dest = outputProvider.getContentLocation(directoryInput.name, directoryInput.contentTypes, directoryInput.scopes, Format.DIRECTORY)
FileUtils.copyDirectory(directoryInput.file, dest)
}
}
}
重新部署我们的插件后,重新运行主项目,可以看到:
MainActivity------>onCreate
但是我们没有在MainActivity中写一行代码,这样就实现了动态注入日志的功能
5.总结
本篇文章主要讲述了在Android中使用asm动态操作字节码的流程,其中涉及到的技术点有
- 自定义gradle插件
- transform的使用
- asm的使用
收起阅读 »
Android技能树点亮计划--Java反射与动态代理
简介
Java的反射是指程序在运行期可以拿到一个对象的所有信息
使用
反射主要分为以下几个步骤
1. 获取Class对象
JVM在加载类的时候,会为每个类生成一个独一无二的Class对象
获取方式有以下几种
//name = Test.class.getDeclaredField("name");
//name = test.getClass().getDeclaredField("name");
name = Class.forName("com.example.app.MainActivity$Test").getDeclaredField("name");
2. 操作fileds
Test test = new Test("xxx");
Field name;
try {
//name = Test.class.getDeclaredField("name");
//name = test.getClass().getDeclaredField("name");
name = Class.forName("com.example.app.MainActivity$Test").getDeclaredField("name");
name.setAccessible(true);
Log.d("test", (String)name.get(test));
} catch (NoSuchFieldException | IllegalAccessException | ClassNotFoundException e) {
e.printStackTrace();
}
class Test {
private String name;
public Test(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
getDeclaredField :获取本类的任何field
getField:获取本类和基类的public field
获取基类非public值,只能通过基类class的getDeclaredField
3. 调用method
// 无参数的方法
Method getName = Class.forName("com.example.app.MainActivity$Test").getMethod("getName");
Log.d("test", (String)getName.invoke(test));
// 有参数的方法
Method setName = Class.forName("com.example.app.MainActivity$Test").getMethod("setName", String.class);
setName.invoke(test, "sdaasda");
Log.d("test", test.getName());
动态代理
在程序运行期动态创建某个interface的实例,通过动态代理可以实现一个方法/类的hook
比如hook点击事件
public class HookOnClickListenerHelper {
public static View.OnClickListener hook(Context context, final View v) {//
return (OnClickListener)Proxy.newProxyInstance(v.getClass().getClassLoader(),
new Class[] {OnClickListener.class},
new ProxyHandler(new ProxyOnClickListener()));
}
static class ProxyHandler implements InvocationHandler {
private View.OnClickListener listener;
public ProxyHandler(OnClickListener listener) {
this.listener = listener;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return method.invoke(listener, args);
}
}
static class ProxyOnClickListener implements View.OnClickListener {
@Override
public void onClick(View v) {
Log.d("HookSetOnClickListener", "点击事件被hook到了");
}
}
}
findViewById(R.id.service).setOnClickListener(HookOnClickListenerHelper.hook(this, findViewById(R.id.service)))
实践
目标:动态代理应用版本号的返回
分析:
动态代理的实现相对来说是简单的,困难的部分在于通过读源码了解到功能是如何实现的,通过代理哪个类可以修改目标代码的返回
- Android是如何获取应用版本号的?
通过getPackageManager()的getPackageInfo()
PackageManager pm = getPackageManager();
PackageInfo pi = pm.getPackageInfo(getPackageName(), 0);
versionName = pi.versionName;
versioncode = pi.versionCode;
- getPackageManager()如何获取 ?
getPackageManager在Context中实现,Context是一个abstract Class,所有的实现都在 ContextImpl中,通过ContextImpl我们发现getPackageManager()是从 ActivityThread.getPackageManager()拿到的
// ContextImp.java
@Override
public PackageManager getPackageManager() {
if (mPackageManager != null) {
return mPackageManager;
}
final IPackageManager pm = ActivityThread.getPackageManager();
if (pm != null) {
// Doesn't matter if we make more than one instance.
return (mPackageManager = new ApplicationPackageManager(this, pm));
}
return null;
}
- ActivityThread如何获取?
ActivityThread内部有静态方法currentActivityThread()来获取
// ActivityThread.java
public static ActivityThread currentActivityThread() {
return sCurrentActivityThread;
}
- ActivityThread中的packageManager怎么获取?
在ActivityThread中定义了sPackageManager,通过它我们就能拿到sPackageManager
public static IPackageManager getPackageManager() {
if (sPackageManager != null) {
//Slog.v("PackageManager", "returning cur default = " + sPackageManager);
return sPackageManager;
}
IBinder b = ServiceManager.getService("package");
//Slog.v("PackageManager", "default service binder = " + b);
sPackageManager = IPackageManager.Stub.asInterface(b);
//Slog.v("PackageManager", "default service = " + sPackageManager);
return sPackageManager;
}
代理:
获取ActivityThread
// 获取ActivityThread
activityThreadClz = Class.forName("android.app.ActivityThread");
Method currentActivityThread = activityThreadClz.getDeclaredMethod("currentActivityThread");
currentActivityThread.setAccessible(true);
Object activityThread = currentActivityThread.invoke(null);
获取packageManager
// 获取packageManager
Field packageManagerField = activityThreadClz.getDeclaredField("sPackageManager");
packageManagerField.setAccessible(true);
final Object packageManager = packageManagerField.get(activityThread);
动态代理,处理getPackageInfo方法
// 动态代理处理数据
Class<?> packageManagerClazz = Class.forName("android.content.pm.IPackageManager", false, getClassLoader());
Object proxy = Proxy.newProxyInstance(getClassLoader(), new Class[] {packageManagerClazz},
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = method.invoke(packageManager, args);
if ("getPackageInfo".equals(method.getName())) {
PackageInfo packageInfo = (PackageInfo)result;
packageInfo.versionName = "sdsds";
}
return result;
}
});
给packManger设置hook的对象
//hook sPackageManager
packageManagerField.set(activityThread, proxy);
测试:
//越早 hook 越好,推荐在 attachBaseContext 调用
PackageManager pm = getPackageManager();
try {
PackageInfo pi = pm.getPackageInfo(getPackageName(), 0);
Log.d(TAG, pi.versionName);
} catch (NameNotFoundException e) {
e.printStackTrace();
}
作者:悠二
链接:https://juejin.cn/post/7046353293240434724
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
由于包名引发的惨案(安装 apk 闪退,拍照闪退,manifest》Provider》authorities导致的)
我们项目原本是这样的,在项目开始之初定的报名是 com.b.c ,然后为了让用户能成功从 1.0 升级到 2.0 ,在项目要开发完成以后改了包名 com.a.b,由于直接改整个项目目录结果并不简单,于是我们直接改了 app/build.gradle 下的 applicationId ,改成了最新的 com.a.b 。之前在编写程序内升级的时候,在 AndroidManifest.xml 中编写的 <provider> 是下面这样的:
<provider
android:name="androidx.core.content.FileProvider"
android:authorities="com.b.c.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/file_paths" />
</provider>
在使用的过程中是这样的(部分代码):
Uri uri = FileProvider.getUriForFile(context, context.getPackageName() + ".fileprovider", apk);
我们项目中包含有 react-native 代码,同时装了不少插件,其中一个插件 react-native-webview 的 AndroidManifest.xml 中也定义了 <provider> ,是这样的:
<provider
android:name=".RNCWebViewFileProvider"
android:authorities="${applicationId}.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/file_provider_paths" />
</provider>
之前我们的升级一直都很完美,每一次都很成功;有一天我们领导决定抛弃 react-native ,全部改用 h5 ,于是我就负责把 react-native 相关的代码从项目中删除,删除的过程非常愉快与自然,删除成功以后我验证了删除部分的相关功能,发现一切正常。
很快项目迎来了更新,一切都那么理所当然,用户正常升级,删除的 react-native 并没有给项目带来问题,随着时间的推进,很快第二批功能开发完毕,即将迎来再一次的更新,我认为这次更新内容少,还加上测试也测试通过,应该没啥问题,但是坏消息在第二天早上发生了,大面积的升级失败,闪退率直线上升,于是我们根据现象尝试复现,发现这是必现的 bug 。
在这个时候我很高兴,但也很悲伤,高兴的是 bug 是百分之百复现,悲伤的是,由于我的原因让用户体验急剧下滑,我知道,目前要做的是用最快的速度修复 bug ,让更少的人“受伤”。
通过我的排查,发现是包名导致的,因为报错信息直指报错的那一行,信息提示:
Caused by: java.lang.IllegalArgumentException: Couldn't find meta-data for provider with authority com.a.b.fileprovider
于是我看了看 AndroidManifest.xml 文件,发现我们的 <provider> 中 authorities 是写死的 com.b.c.fileprovider ,我知道出现问题的原因就是在这里,于是我就将配置改成下面这样:
<provider
android:name="androidx.core.content.FileProvider"
android:authorities="${applicationId}.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/file_paths" />
</provider>
改完以后赶快打了一个补救包,上传了上去,我认为问题已经解决,但是我们没有找到原因,首先要定位的是什么代码导致的这个问题,为什么以前可以,于是开始查看提交记录和合并记录,最终定位到是因为 react-native 的删除导致的,但是又产生了一个问题,为什么我删除 react-native 会导致这个问题,等我还在纠结的时候,突然反馈 app 拍照功能不能使用,这个功能是我们 app 的核心功能,一下从原来的无伤大雅变成了遍体鳞伤,这下整个部门都在问什么原因,于是我赶快放下脑中的疑惑,开始去项目的茫茫大海中寻找答案,我知道答案就在那里,也就是跟包相关的,于是根据问题,我检查了跟包相关的代码,发现在拍照的地方由于要保存,代码(部分)如下:
private const val authorities = "com.b.a.fileprovider"
FileProvider.getUriForFile(requireContext(), authorities, file)
我知道是由于我之前把 AndroidManifest.xml 改了以后导致的。于是我就把相关的代码都检查了一遍,确定都跟包名想通了,我才打包给测试,测试完成以后才再一次上线。
这下问题都被我解决了,只不过脑袋里面仍然有很多疑惑,之前我从 react-native 开发的时候由于看原生代码比较困难,现在我觉得我能找到这个问题的最终答案,于是开始了我的寻找问题之旅。
首先回到刚才的问题,为啥删除 react-native 会对包名造成影响呢,于是我开始复原删除之前,通过递减删除的方式排查,看看到底是那一行删除导致的。
其实认真看到这里的小伙伴肯定知道,并不是 react-native 的问题,而是本身我们代码编写的有问题,所以准确的说是 react-native 的什么代码屏蔽了问题。其中 react-native 嵌入原生是根据集成到现有原生应用引入的。在使用排除法的过程中,发现在 app/build.gradle 中配置:
apply from: file("../../node_modules/@react-native-community/cli-platform-android/native_modules.gradle"); applyNativeModulesAppBuildGradle(project)
是这行代码导致的,于是我尝试看这个 native_modules.gradle 文件,首先我从构造函数看起,其实我不会 groovy 语言,只是我大致看了看发现跟 java 差不多,所以上面的代码大差不差能够看懂,先看构造:
ReactNativeModules(Logger logger, File root) {
this.logger = logger
this.root = root
def (nativeModules, packageName) = this.getReactNativeConfig()
this.reactNativeModules = nativeModules
this.packageName = packageName
}
这里有 packageName ,于是我就想是不是因为执行这个 this.getReactNativeConfig() 修改了 packageName ,其实我一直不相信会修改包名,但是我不敢确定,毕竟我刚接触 android 不久。于是我就继续看这个函数的实现:
ArrayList<HashMap<String, String>> getReactNativeConfig() {
if (this.reactNativeModules != null) return this.reactNativeModules
ArrayList<HashMap<String, String>> reactNativeModules = new ArrayList<HashMap<String, String>>()
def cliResolveScript = "console.log(require('react-native/cli').bin);"
String[] nodeCommand = ["node", "-e", cliResolveScript]
def cliPath = this.getCommandOutput(nodeCommand, this.root)
String[] reactNativeConfigCommand = ["node", cliPath, "config"]
def reactNativeConfigOutput = this.getCommandOutput(reactNativeConfigCommand, this.root)
def json
try {
json = new JsonSlurper().parseText(reactNativeConfigOutput)
} catch (Exception exception) {
throw new Exception("Calling `${reactNativeConfigCommand}` finished with an exception. Error message: ${exception.toString()}. Output: ${reactNativeConfigOutput}");
}
def dependencies = json["dependencies"]
def project = json["project"]["android"]
if (project == null) {
throw new Exception("React Native CLI failed to determine Android project configuration. This is likely due to misconfiguration. Config output:\n${json.toMapString()}")
}
dependencies.each { name, value ->
def platformsConfig = value["platforms"];
def androidConfig = platformsConfig["android"]
if (androidConfig != null && androidConfig["sourceDir"] != null) {
this.logger.info("${LOG_PREFIX}Automatically adding native module '${name}'")
HashMap reactNativeModuleConfig = new HashMap<String, String>()
reactNativeModuleConfig.put("name", name)
reactNativeModuleConfig.put("nameCleansed", name.replaceAll('[~*!\'()]+', '_').replaceAll('^@([\\w-.]+)/', '$1_'))
reactNativeModuleConfig.put("androidSourceDir", androidConfig["sourceDir"])
reactNativeModuleConfig.put("packageInstance", androidConfig["packageInstance"])
reactNativeModuleConfig.put("packageImportPath", androidConfig["packageImportPath"])
this.logger.trace("${LOG_PREFIX}'${name}': ${reactNativeModuleConfig.toMapString()}")
reactNativeModules.add(reactNativeModuleConfig)
} else {
this.logger.info("${LOG_PREFIX}Skipping native module '${name}'")
}
}
return [reactNativeModules, json["project"]["android"]["packageName"]];
}
}
发现这里实际上是从 nodejs 执行结果拿到的信息,而执行的 js 文件的位置在 rn项目/node_modules/react-native/node_modules/@react-native-community/cli/build/index.js 下,这里是具体执行的 js 文件,前面还有一个 js 文件,只不过没有代码,就是执行这里面的 run 方法:
async function run() {
try {
await setupAndRun();
} catch (e) {
handleError(e);
}
}
接着看 setupAndRun() 函数:
async function setupAndRun() {
if (process.argv.includes('config')) {
_cliTools().logger.disable();
}
_cliTools().logger.setVerbose(process.argv.includes('--verbose')); // We only have a setup script for UNIX envs currently
if (process.platform !== 'win32') {
const scriptName = 'setup_env.sh';
const absolutePath = _path().default.join(__dirname, '..', scriptName);
try {
_child_process().default.execFileSync(absolutePath, {
stdio: 'pipe',
});
} catch (error) {
_cliTools().logger.warn(
`Failed to run environment setup script "${scriptName}"\n\n${_chalk().default.red(
error,
)}`,
);
_cliTools().logger.info(
`React Native CLI will continue to run if your local environment matches what React Native expects. If it does fail, check out "${absolutePath}" and adjust your environment to match it.`,
);
}
}
for (const command of _commands.detachedCommands) {
attachCommand(command);
}
try {
const config = (0, _config.default)();
_cliTools().logger.enable();
for (const command of [..._commands.projectCommands, ...config.commands]) {
attachCommand(command, config);
}
} catch (error) {
if (error.message.includes("We couldn't find a package.json")) {
_cliTools().logger.enable();
_cliTools().logger.debug(error.message);
_cliTools().logger.debug(
'Failed to load configuration of your project. Only a subset of commands will be available.',
);
} else {
throw new (_cliTools().CLIError)(
'Failed to load configuration of your project.',
error,
);
}
}
_commander().default.parse(process.argv);
if (_commander().default.rawArgs.length === 2) {
_commander().default.outputHelp();
}
if (
_commander().default.args.length === 0 &&
_commander().default.rawArgs.includes('--version')
) {
console.log(pkgJson.version);
}
}
经过我打印日志,最终发现是 _commander().default.parse(process.argv) 这行代码返回给 groovy 的,但是我发现这行代码也只是读取配置的,跟修改不相关,于是我就开始假设,有没有可能是 groovy 最终修改,只是从 js 拿到相关的信息,于是我就直接把拿到的值进行修改,也就是 native_modules.gradle 里面的 this.getReactNativeConfig 函数返回值,于是我做了修改了:
ArrayList<HashMap<String, String>> getReactNativeConfig() {
if (this.reactNativeModules != null) return this.reactNativeModules
ArrayList<HashMap<String, String>> reactNativeModules = new ArrayList<HashMap<String, String>>()
def dependencies = new JsonSlurper().parseText('{"react-native-webview":{"root":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview","name":"react-native-webview","platforms":{"ios":{"sourceDir":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview/ios","folder":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview","pbxprojPath":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview/ios/RNCWebView.xcodeproj/project.pbxproj","podfile":null,"podspecPath":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview/react-native-webview.podspec","projectPath":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview/ios/RNCWebView.xcodeproj","projectName":"RNCWebView.xcodeproj","libraryFolder":"Libraries","sharedLibraries":[],"plist":[],"scriptPhases":[]},"android":{"sourceDir":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview/android","folder":"/Users/wujingyue/Works/yq-bss-tour-rn/node_modules/react-native-webview","packageImportPath":"import com.reactnativecommunity.webview.RNCWebViewPackage;","packageInstance":"new RNCWebViewPackage()"}},"assets":[],"hooks":{},"params":[]}}')
dependencies.each { name, value ->
def platformsConfig = value["platforms"];
def androidConfig = platformsConfig["android"]
if (androidConfig != null && androidConfig["sourceDir"] != null) {
this.logger.info("${LOG_PREFIX}Automatically adding native module '${name}'")
HashMap reactNativeModuleConfig = new HashMap<String, String>()
reactNativeModuleConfig.put("name", name)
reactNativeModuleConfig.put("nameCleansed", name.replaceAll('[~*!\'()]+', '_').replaceAll('^@([\\w-.]+)/', '$1_'))
reactNativeModuleConfig.put("androidSourceDir", androidConfig["sourceDir"])
reactNativeModuleConfig.put("packageInstance", androidConfig["packageInstance"])
reactNativeModuleConfig.put("packageImportPath", androidConfig["packageImportPath"])
this.logger.trace("${LOG_PREFIX}'${name}': ${reactNativeModuleConfig.toMapString()}")
reactNativeModules.add(reactNativeModuleConfig)
} else {
this.logger.info("${LOG_PREFIX}Skipping native module '${name}'")
}
}
// 这儿直接返回我想要的值 com.a.b
return [reactNativeModules, "com.a.b"];
}
}
其中 dependencies 变量的值远不止这些,很多个。首先我让 dependencies 的值是一个空值,也就是 new JsonSlurper().parseText('{}') ,然后我发现居然不行了,也就是升级闪退,之前是可以的;于是我根据这个现象提出假设,是由于这个字符串中的某一个插件导致的,于是我就根据这个假设开始把一个个插件放入其中进行测试,最后发现 react-native-webview ,你不知道的是 react-native-webview 是最后一个插件,我把前面所有的都测试了,真的是又喜又悲,终于我把范围进一步缩小了,接下来,我就开始对插件 react-native-webview 的代码进行检查。
我最喜欢的还是“注释法”,也就是经典的“排除法”,我首先把所有代码都注释掉,只剩下空壳,发现仍然可以正常安装,说明不是在代码上,然后我再对插件的 build.gradle 采用“注释法”,结果还是可以,说明不是在这里,这时我感觉到无力,但是这个时候我突然想到“山重水复疑无路,柳暗花明又一村”,于是我开始对整个插件的每个文件进行检查,然后一个文件出现在我眼前 AndroidManifest.xml ,我打开看了看,看到了这个插件也定义了 <provider> 。而且是正确的方式,于是我又提出假设来解释现象,如果 AndroidManifest.xml 最终采用的是插件 react-native-webview 的 <provider> ,那么就能解释这个原因了,但这仅仅是假设,我得在实践中证明我的假设是正确的。
首先我尝试修改 react-native-webview 插件中的 AndroidManifest.xml 下的 authorities ,我首先修改成跟项目的相同,结果闪退,符合我得猜想,说明项目的确会进行合并,于是我开始翻阅文档进一步证明我的结论,首先我看了看 AndroidManifest.xml 配置相关的文档 ,我看到了下面这句描述,也就是代表 authorities 支持多个。
android:authorities
一个或多个 URI 授权方的列表,这些 URI 授权方用于标识内容提供程序提供的数据。列出多个授权方时,用分号将其名称分隔开来。为避免冲突,授权方名称应遵循 Java 样式的命名惯例(如com.example.provider.cartoonprovider)。通常,它是实现提供程序的ContentProvider子类的名称。
没有默认值。必须至少指定一个授权方。
第一次看到这个我没想到啥,只不过后面文档让我想到了这个,然后做了验证,最终找到了答案。首先是同事找到了合并多个清单文件这个,证实了 AndroidManifest.xml 会合并的假设,然后又看到了这个检查合并后的清单并查找冲突:
然后我去看了看我们的项目,发现了这个,并且我看了看合并后的内容,发现 react-native-webview 的在最后,也就是会替换项目中 authorities ,但是我仔细看了看这个文件,发现下面还有定义的 authorities ,也就是说,如果是覆盖是说不通的,因为后面的 authorities 就会导致报错,但是实际上并没有,于是我尝试修改使用的地方,把 FileProvider.getUriForFile(requireContext(), authorities, file) 中的第二个参数改成这些定义的,发现仍然能成功,也就是说我们定义的所有这些都会生效,于是我想到了上面的那句被我标记为红色的话,发现一切迷雾都解开了。
到这里可以说结束了,但我在想为啥会这样设计呢?我最后想到的答案是,对于那些插件来说,他并不知道别人项目中的 authorities 定义,那怎么保证插件可以到处使用呢,答案很显然,那就是多个生效,插件不需要知道项目中是怎样定义的,只需要使用自己插件中定义好的。
作者:吴敬悦
链接:https://juejin.cn/post/7044044227063316488
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Activity基础知识—四大组件
Activity
Activity的生命周期
真的没什么难度,大家自行了解。
有些会问到横竖屏切换的生命周期。
Activity A 启动 Activity B,然后B再返回A,他们的生命周期怎么走
需要考虑一下B是不是透明的,透明盒不透明生命周期是不一样的。
需要考虑 B 的启动模式,不同的启动模式会有一定的区别。
Activity在走了哪个生命周期之后会显示出来
onResume()
简单来说就是:在onResume回调之后,会创建一个 ViewRootImpl ,有了它之后应用端就可以和 WMS 进行双向调用了。
Activity的启动模式有哪些
没什么难度,大家自行了解。
Activity的启动流程
1、点击桌面App图标,Launcher进程采用Binder IPC(AMS)向system_server进程发起startActivity请求;
2、system_server进程接收到请求后,向zygote进程发送创建进程的请求;
3、Zygote进程fork出新的子进程,即App进程;
4、App进程,通过Binder IPC向sytem_server进程发起attachApplication请求;
5、system_server进程在收到请求后,进行一系列准备工作后,再通过binder IPC向App进程发送scheduleLaunchActivity请求;
6、App进程的binder线程(ApplicationThread)在收到请求后,通过handler向主线程发送LAUNCH_ACTIVITY消息;
7、主线程在收到Message后,通过发射机制创建目标Activity,并回调Activity.onCreate()等方法。
Fragment的生命周期,Fragment和Activity之间的传参
需要区别Fragment和Activity之间的生命周期
1.Activity–onCreate();
2.Fragment–onAttach();
3.Fragment–onCreate();
4.Fragment–onCreateView();
5.Fragment–onActivityCreated();
接着是这样的:
6.Activity–onStart();
7.Fragment–onStart();
8.Activity–onResume();
9.Fragment–onResume();
当销毁的时候
10.Fragment–onPause();
11.Activity–onPause();
12.Fragment–onStop();
13.Activity–onStop();
14.Fragment–onDestroyView();
15.Fragment–onDestroy();
16.Fragment–onDetach();
17.Activity–onDestroy();
Service
Service的生命周期
IntentService和Service区别
IntentService内部实现了一个线程,可以去执行耗时操作
HandlerThread
继承自Thread,内部创建了一个Looper
Service和Thread的区别还有优缺点
Service 是android的一种机制Service 是运行在主进程的 main 线程上的。
Thread会开辟一个线程去执行它是分配CPU的基本单位。
进程的几种类型
前台进程
可视进程
服务进程
后台进程
Broadcast
有哪几类广播
普通广播(自定义广播)
系统广播
有序广播
粘性广播
应用内广播
LocalBroadcast的实现原理
ContentProvider
作者:OnlyTerminator
链接:https://juejin.cn/post/7044108847119597575
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
leetcode-最接近的三数之和
往常周末都是睡懒觉,今天早起去体检了。每年都是到了体检的时候,才会想起来身体才是革命的本钱吧。还好都不是什么大问题,最大的问题就是自己没有坚持锻炼。
先立个Flag,每周至少有5天,专门锻炼30分钟以上吧。先把标准定的低一点,能做到最重要,不然都是5分钟热情,过了几天这个目标就抛在脑后了吧。
当然,说起坚持,一个比较好的方法是定期review,如果有1天没做到,也不要觉得反正已经没做到,破罐子破摔,后面根本就不再做的。每天坚持是每天新的挑战,能够比之前的自己坚持做更久,就是自己的突破。
每天做1题算法题,也是上个月立下的Flag,虽然已经倒了,还是希望后面能多坚持,毕竟进一寸就有进一寸的欢喜。今天继续刷leetcode第16题,跟昨天的题目非常类似,昨天要求3个数之和=0,今天要求是跟target偏离最小。
题目
给定一个包括 n 个整数的数组
nums和 一个目标值target。找出nums中的三个整数,使得它们的和与target最接近。返回这三个数的和。假定每组输入只存在唯一答案。
示例
输入: nums = [-1,2,1,-4], target = 1
输出: 2
解释: 与 target 最接近的和是 2 (-1 + 2 + 1 = 2) 。
思路
跟昨天的题目是非常类似的,首先肯定还是排序。
排序后,假定一个最小值a,然后从a右边的数里面找出2个b和c,使得abs(a+b+c-target)的值最小。因为a右边的数组也是有序的,这时候找b和c其实也不需要2层for循环来遍历,可以使用双指针,分别指向剩余数组的最小和最大,如果a+b+c-target小于0,就让最小值往右边走一个,如果a+b+c-target大于0,就让最大值往左边走一个。
Java版本代码
class Solution {
public int threeSumClosest(int[] nums, int target) {
int len = nums.length;
int ans = 3001;
Arrays.sort(nums);
for (int i = 0; i < len -2; i++) {
if (i > 0 && nums[i] == nums[i-1]) {
continue;
}
int start = i + 1;
int end = len - 1;
while (start < end) {
int sum = nums[i] + nums[start] + nums[end];
if (sum == target) {
ans = sum;
return ans;
}
if (Math.abs(sum - target) < Math.abs(ans - target)) {
ans = sum;
}
if (sum > target) {
end--;
} else if (sum < target) {
start++;
}
}
}
return ans;
}
}作者:podongfeng
链接:https://juejin.cn/post/6993689125320654855
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android正确的保活方案,不要掉进保活需求死循环陷进
在开始前,还是给大家简单介绍一下,以前出现过的一些黑科技:
大概在6年前Github中出现过一个叫MarsDaemon,这个库通过双进程守护的方式实现保活,一时间风头无两。好景不长,进入 Android 8.0时代之后,这个库就废掉了。
最近2年Github上面出来一个Leoric 感兴趣的可以去看一下源码,谁敢用在生产环境呢,也就自己玩玩的才会用吧(不能因为保活而导致手机卡巴斯基),我没有试过这个,我想说的是:黑科技能黑的了一时,能黑的了一世吗?
没有规矩,不成方圆,要提升产品的存活率,最终还是要落到产品本身上面来,尊重用户,提升用户体验才是正道。
以前我也是深受保活需求的压迫,最近发现QQ群里有人又提到了如何保活,那么我们就来说一说,如何来正确保活App?
Android 8.0之后: 加强了应用后台限制,当时测试过一组数据:
应用处于前台,启动一个前台Service,里面使用JobScheduler启动定时任务(
30秒触发一次),
此时手机锁屏,前10分钟内,定时任务都是正常执行;
大概在12分钟左右,发现应用进程就被kill掉了,解锁屏幕,app也不在前台了;
各大国产手机厂商底层都经过自己魔改,自家都有自己的一套自启动管理,小米手机更乱(当时有个神隐模式的概念,那也是杀后台高手),只能说当时Android手机各种性能方面都不足,各家都会有自己的一套省电模式,以此来达到省电和提高手机性能,Android 系统变得越来越完善,但是厂商定制的自启动、省电模式还在,所以我们要做保活。
1.Android 8.0之前-常用的保活方案
1.开启一个前台Service
2.Android 6.0+ 忽略电池优化开关(稍后会有代码)
3.无障碍服务(只针对有用这个功能的app,如支付宝语音增强提醒用了它)
2.Android 8.0之后-常用的保活方案
1.开启一个前台Service(可以加上,单独启用的话无法满足保活需求)
2.Android 6.0+ 忽略电池优化开关(稍后会有代码)
3.无障碍服务(只针对有用这个功能的app,如支付宝语音增强提醒用了它)
4.应用自启动权限(最简单的方案是针对不同系统提供教程图片-让用户自己去打开)
5.多任务列表窗口加锁(提供GIF教程图片-让用户自己去打开)
6.多任务列表窗口隐藏App(仅针对有这方面需求的App)
7.应用后台高耗电(仅针对Vivo手机)
3.保活方案实现步骤
(1). 前台Service
//前台服务
class ForegroundCoreService : Service() {
override fun onBind(intent: Intent?): IBinder? = null
private var mForegroundNF:ForegroundNF by lazy {
ForegroundNF(this)
}
override fun onCreate() {
super.onCreate()
mForegroundNF.startForegroundNotification()
}
override fun onStartCommand(intent: Intent?, flags: Int, startId: Int): Int {
if(null == intent){
//服务被系统kill掉之后重启进来的
return START_NOT_STICKY
}
mForegroundNF.startForegroundNotification()
return super.onStartCommand(intent, flags, startId)
}
override fun onDestroy() {
mForegroundNF.stopForegroundNotification()
super.onDestroy()
}
}
//初始化前台通知,停止前台通知
class ForegroundNF(private val service: ForegroundCoreService) : ContextWrapper(service) {
companion object {
private const val START_ID = 101
private const val CHANNEL_ID = "app_foreground_service"
private const val CHANNEL_NAME = "前台保活服务"
}
private var mNotificationManager: NotificationManager? = null
private var mCompatBuilder:NotificationCompat.Builder?=null
private val compatBuilder: NotificationCompat.Builder?
get() {
if (mCompatBuilder == null) {
val notificationIntent = Intent(this, MainActivity::class.java)
notificationIntent.action = Intent.ACTION_MAIN
notificationIntent.addCategory(Intent.CATEGORY_LAUNCHER)
notificationIntent.flags = Intent.FLAG_ACTIVITY_NEW_TASK or Intent.FLAG_ACTIVITY_RESET_TASK_IF_NEEDED
//动作意图
val pendingIntent = PendingIntent.getActivity(
this, (Math.random() * 10 + 10).toInt(),
notificationIntent, PendingIntent.FLAG_UPDATE_CURRENT
)
val notificationBuilder: NotificationCompat.Builder = NotificationCompat.Builder(this,CHANNEL_ID)
//标题
notificationBuilder.setContentTitle(getString(R.string.notification_content))
//通知内容
notificationBuilder.setContentText(getString(R.string.notification_sub_content))
//状态栏显示的小图标
notificationBuilder.setSmallIcon(R.mipmap.ic_coolback_launcher)
//通知内容打开的意图
notificationBuilder.setContentIntent(pendingIntent)
mCompatBuilder = notificationBuilder
}
return mCompatBuilder
}
init {
createNotificationChannel()
}
//创建通知渠道
private fun createNotificationChannel() {
mNotificationManager =
getSystemService(Context.NOTIFICATION_SERVICE) as NotificationManager
//针对8.0+系统
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
val channel = NotificationChannel(
CHANNEL_ID,
CHANNEL_NAME,
NotificationManager.IMPORTANCE_LOW
)
channel.lockscreenVisibility = Notification.VISIBILITY_PUBLIC
channel.setShowBadge(false)
mNotificationManager?.createNotificationChannel(channel)
}
}
//开启前台通知
fun startForegroundNotification() {
service.startForeground(START_ID, compatBuilder?.build())
}
//停止前台服务并清除通知
fun stopForegroundNotification() {
mNotificationManager?.cancelAll()
service.stopForeground(true)
}
}
(2).忽略电池优化(Android 6.0+)
1.我们需要在AndroidManifest.xml中声明一下权限
<uses-permission android:name="android.permission.REQUEST_IGNORE_BATTERY_OPTIMIZATIONS" />
2.通过Intent来请求忽略电池优化的权限(需要引导用户点击)
//在Activity的onCreate中注册ActivityResult,一定要在onCreate中注册
//监听onActivityForResult回调
mIgnoreBatteryResultContract = registerForActivityResult(ActivityResultContracts.StartActivityForResult()) { activityResult ->
//查询是否开启成功
if(queryBatteryOptimizeStatus()){
//忽略电池优化开启成功
}else{
//开启失败
}
}
通过Intent打开忽略电池优化弹框:
val intent = Intent(Settings.ACTION_REQUEST_IGNORE_BATTERY_OPTIMIZATIONS)
intent.data = Uri.parse("package:$packageName")
//启动忽略电池优化,会弹出一个系统的弹框,我们在上面的
launchActivityResult(intent)
查询是否成功开启忽略电池优化开关:
fun Context.queryBatteryOptimizeStatus():Boolean{
val powerManager = getSystemService(Context.POWER_SERVICE) as PowerManager?
return if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.M) {
powerManager?.isIgnoringBatteryOptimizations(packageName)?:false
} else {
true
}
}
(3).无障碍服务
看官方文档:创建自己的无障碍服务
它也是一个Service,它的优先级比较高,提供界面增强功能,初衷是帮助视觉障碍的用户或者是可能暂时无法与设备进行全面互动的用户完成操作。
可以做很多事情,使用了此Service,在6.0+不需要申请悬浮窗权限,直接使用WindowManager.LayoutParams.TYPE_ACCESSIBILITY_OVERLAY 挺方便的
(仅针对有需要此服务的app,可以开启增强后台保活)
(4).自启动权限(即:白名单管理列表页面)
是系统给用户自己去打开“自启动权限”开关的入口,我们需要针对不同的手机厂商和系统版本,弹出提示引导用户是否前去打开“自启动权限”
有的手机厂商叫:白名单管理,有的叫:自启动权限,两个是一个概念;
点击查看跳转到『手机自启动设置页面』完整代码
(需要注意:如果是代码控制跳转,无法保证永远可以调整,系统升级可能就给你屏蔽了,
最简单的方法是:显示一个如何找到自启动页面的引导图,下面以华为手机为例:)
华为手机-自启动管理
(5).多任务列表窗口加锁
可以针对不同手机厂商,显示引导用户,开启App窗口加锁之后,点击清理加速不会导致应用被kill
华为手机窗口加锁-教程图
(6).多任务列表窗口隐藏App窗口
刚刚上面多任务窗口加锁完,再提示用户去App里面把隐藏App窗口开关打开,这样用户就不会在多任务列表里面把App窗口给手抖划掉
多任务窗口中『隐藏App窗口』,可以用如下代码控制:
(这个也只是针对有这方面需求App提供的一种增强方案罢了:因为隐藏了窗口,用户就不会去想他,不会去手痒去划掉它)
//在多任务列表页面隐藏App窗口
fun hideAppWindow(context: Context,isHide:Boolean){
try {
val activityManager: ActivityManager = context.getSystemService(Context.ACTIVITY_SERVICE) as ActivityManager
//控制App的窗口是否在多任务列表显示
activityManager.appTasks[0].setExcludeFromRecents(isHide)
}catch (e:Exception){
.....
}
}
(7).应用后台高耗电(Vivo手机独有)
开启的入口:“设置”>“电池”>“后台高耗电”>“找到xxxApp打开开关”
vivo允许后台高耗电
最后还是奉劝那些,仍然执着于找寻黑科技的开发者,醒醒吧,太阳晒屁股了。
如果说你的App用户群体不是普通用户,是专门给一些玩机大神们用的,都可以root手机的话,那么直接 move 到系统目录 priv/system/app 即可, 即使被用户强杀也会自动重新拉起。
作者:Halifax
链接:https://juejin.cn/post/7003992225575075876
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android 优雅处理重复点击(建议收藏)
一般手机上的 Android App,主要的交互方式是点击。用户在点击后,App 可能做出在页面内更新 UI、新开一个页面或者发起网络请求等操作。Android 系统本身没有对重复点击做处理,如果用户在短时间内多次点击,则可能出现新开多个页面或者重复发起网络请求等问题。因此,需要对重复点击有影响的地方,增加处理重复点击的代码。
之前的处理方式
之前在项目中使用的是 RxJava 的方案,利用第三方库 RxBinding 实现了防止重复点击:
fun View.onSingleClick(interval: Long = 1000L, listener: (View) -> Unit) {
RxView.clicks(this)
.throttleFirst(interval, TimeUnit.MILLISECONDS)
.subscribe({
listener.invoke(this)
}, {
LogUtil.printStackTrace(it)
})
}
但是这样有一个问题,比如使用两个手指同时点击两个不同的按钮,按钮的功能都是新开页面,那么有可能会新开两个页面。因为 Rxjava 这种方式是针对单个控件实现防止重复点击,不是多个控件。
现在的处理方式
现在使用的是时间判断,在时间范围内只响应一次点击,通过将上次单击时间保存到 Activity Window 中的 decorView 里,实现一个 Activity 中所有的 View 共用一个上次单击时间。
fun View.onSingleClick(
interval: Int = SingleClickUtil.singleClickInterval,
isShareSingleClick: Boolean = true,
listener: (View) -> Unit
) {
setOnClickListener {
val target = if (isShareSingleClick) getActivity(this)?.window?.decorView ?: this else this
val millis = target.getTag(R.id.single_click_tag_last_single_click_millis) as? Long ?: 0
if (SystemClock.uptimeMillis() - millis >= interval) {
target.setTag(
R.id.single_click_tag_last_single_click_millis, SystemClock.uptimeMillis()
)
listener.invoke(this)
}
}
}
private fun getActivity(view: View): Activity? {
var context = view.context
while (context is ContextWrapper) {
if (context is Activity) {
return context
}
context = context.baseContext
}
return null
}
参数 isShareSingleClick 的默认值为 true,表示该控件和同一个 Activity 中其他控件共用一个上次单击时间,也可以手动改成 false,表示该控件自己独享一个上次单击时间。
mBinding.btn1.onSingleClick {
// 处理单次点击
}
mBinding.btn2.onSingleClick(interval = 2000, isShareSingleClick = false) {
// 处理单次点击
}
其他场景处理重复点击
间接设置点击
除了直接在 View 上设置的点击监听外,其他间接设置点击的地方也存在需要处理重复点击的场景,比如说富文本和列表。
为此将判断是否触发单次点击的代码抽离出来,单独作为一个方法:
fun View.onSingleClick(
interval: Int = SingleClickUtil.singleClickInterval,
isShareSingleClick: Boolean = true,
listener: (View) -> Unit
) {
setOnClickListener { determineTriggerSingleClick(interval, isShareSingleClick, listener) }
}
fun View.determineTriggerSingleClick(
interval: Int = SingleClickUtil.singleClickInterval,
isShareSingleClick: Boolean = true,
listener: (View) -> Unit
) {
...
}
直接在点击监听回调中调用 determineTriggerSingleClick 判断是否触发单次点击。下面拿富文本和列表举例。
富文本
继承 ClickableSpan,在 onClick 回调中判断是否触发单次点击:
inline fun SpannableStringBuilder.onSingleClick(
listener: (View) -> Unit,
isShareSingleClick: Boolean = true,
...
): SpannableStringBuilder = inSpans(
object : ClickableSpan() {
override fun onClick(widget: View) {
widget.determineTriggerSingleClick(interval, isShareSingleClick, listener)
}
...
},
builderAction = builderAction
)
这样会有一个问题, onClick 回调中的 widget,就是设置富文本的控件,也就是说如果富文本存在多个单次点击的地方, 就算 isShareSingleClick 值为 false,这些单次点击还是会共用设置富文本控件的上次单击时间。
因此,这里需要特殊处理,在 isShareSingleClick 为 false 的时候,创建一个假的 View 来触发单击事件,这样富文本中多个单次点击 isShareSingleClick 为 false 的地方都有一个自己的假的 View 来独享上次单击时间。
class SingleClickableSpan(
...
) : ClickableSpan() {
private var mFakeView: View? = null
override fun onClick(widget: View) {
if (isShareSingleClick) {
widget
} else {
if (mFakeView == null) {
mFakeView = View(widget.context)
}
mFakeView!!
}.determineTriggerSingleClick(interval, isShareSingleClick, listener)
}
...
}
在设置富文本的地方,使用设置 onSingleClick 实现单次点击:
mBinding.tvText.movementMethod = LinkMovementMethod.getInstance()
mBinding.tvText.highlightColor = Color.TRANSPARENT
mBinding.tvText.text = buildSpannedString {
append("normalText")
onSingleClick({
// 处理单次点击
}) {
color(Color.GREEN) { append("clickText") }
}
}
列表
列表使用 RecyclerView 控件,适配器使用第三方库 BaseRecyclerViewAdapterHelper。
Item 点击:
adapter.setOnItemClickListener { _, view, _ ->
view.determineTriggerSingleClick {
// 处理单次点击
}
}
Item Child 点击:
adapter.addChildClickViewIds(R.id.btn1, R.id.btn2)
adapter.setOnItemChildClickListener { _, view, _ ->
when (view.id) {
R.id.btn1 -> {
// 处理普通点击
}
R.id.btn2 -> view.determineTriggerSingleClick {
// 处理单次点击
}
}
}
数据绑定
使用 DataBinding 的时候,有时会在布局文件中直接设置点击事件,于是在 View.onSingleClick 上增加 @BindingAdapte 注解,实现在布局文件中设置单次点击事件,并对代码做出调整,这个时候需要将项目中 listener: (View) -> Unit 替换成 listener: View.OnClickListener。
@BindingAdapter(
*["singleClickInterval", "isShareSingleClick", "onSingleClick"],
requireAll = false
)
fun View.onSingleClick(
interval: Int? = SingleClickUtil.singleClickInterval,
isShareSingleClick: Boolean? = true,
listener: View.OnClickListener? = null
) {
if (listener == null) {
return
}
setOnClickListener {
determineTriggerSingleClick(
interval ?: SingleClickUtil.singleClickInterval, isShareSingleClick ?: true, listener
)
}
}
在布局文件中设置单次点击:
<androidx.appcompat.widget.AppCompatButton
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="@string/btn"
app:isShareSingleClick="@{false}"
app:onSingleClick="@{()->viewModel.handleClick()}"
app:singleClickInterval="@{2000}" />
在代码中处理单次点击:
class YourViewModel : ViewModel() {
fun handleClick() {
// 处理单次点击
}
}
总结
对于直接在 View 上设置点击的地方,如果需要处理重复点击使用 onSingleClick,不需要处理重复点击则使用原来的 setOnClickListener。
对于间接设置点击的地方,如果需要处理重复点击,则使用 determineTriggerSingleClick 判断是否触发单次点击。
项目地址
作者:Misdirection
链接:https://juejin.cn/post/7041397338950074375
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
【Flutter App】GetX框架的实践
正在做的这款App是一个打卡软件,旨在让用户能够更好地坚持自己所设置的目标,坚持自己的初心。
由于项目还只是在前期阶段,目前根据需要建立了以下结构:
参考了部分官方插件以及结合官方getX文档中建议的目录:
暂时没有对state分离出来一层的想法。 以下是各层详细内容:
在使用GetX的时候,往往每次都是用需要手动实例化一个控制器final controller = Get.put(CounterController());,如果每个界面都要实例化一次,有些许麻烦。使用Binding 能解决上述问题,可以在项目初始化时把所有需要进行状态管理的控制器进行统一初始化,直接使用Get.find()找到对应的GetxController使用。
- 可以将路由、状态管理器和依赖管理器完全集成
- 这里介绍三种使用方式,推荐第一种使用getx的命名路由的方式
- 不使用binding,不会对功能有任何的影响。
- 第一种:使用命名路由进行Binding绑定
/// 入口类
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
/// 这里使用 GetMaterialApp
/// 初始化路由
return GetMaterialApp(
initialRoute: RouteConfig.onePage,
getPages: RouteConfig.getPages,
);
}
}
/// 路由配置
class RouteConfig {
static const String onePage = "/onePage";
static const String twoPage = "/twoPage";
static final List<GetPage> getPages = [
GetPage(
name: onePage,
page: () => const OnePage(),
binding: OnePageBinding(),
),
// GetPage(
// name: twoPage,
// page: () => TwoPage(),
// binding: TwoPageBinding(),
// ),
];
}
/// binding层
class OnePageBinding extends Bindings {
@override
void dependencies() {
Get.lazyPut(() => CounterController());
}
}
/// 逻辑层
class CounterController extends GetxController{
var count = 0;
/// 自增方法
void increase(){
count++;
update();
}
}
- 第二种:使用initialBinding初始化所有的Binding
/// 入口类
class MyApp extends StatelessWidget {
const MyApp({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return GetMaterialApp(
/// 初始化所有的Binding
initialBinding: AllControllerBinding(),
home: const OnePage(),
);
}
}
/// 所有的Binding层
class AllControllerBinding extends Bindings {
@override
void dependencies() {
Get.lazyPut(() => CounterController());
///Get.lazyPut(() => OneController());
///Get.lazyPut(() => TwoController());
}
}
作者:_Archer
链接:https://juejin.cn/post/7042904386799927332
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Gradle 与 AGP 构建 API: 配置您的构建文件
欢迎阅读全新的 MAD Skills 系列 之 Gradle 及 Android Gradle plugin API 的第一篇文章。我们将在本文中了解 Android 构建系统的工作方式以及 Gradle 的基础知识。
我们将会从 Gradle 的构建阶段开始,讨论如何使用 AGP (Android Gradle Plugin) 的配置选项自定义您的构建,并讨论如何使您的构建保持高效。如果您更喜欢通过视频了解此内容,请在 此处 查看。
通过了解构建阶段的工作原理及配置 Android Gradle plugin 的配置方法,可以帮您基于项目的需求自定义构建。让我们回到 Android Studio,一起看看构建系统是如何工作的吧。
Gradle 简介
Gradle 是一个通用的自动化构建工具。当然,您可以使用 Gradle 来构建 Android 项目,但实际上您可以使用 Gradle 来构建任何类型的软件。
Gradle 支持单一或多项目构建。如果要将项目配置为使用 Gradle,您需要在项目文件夹中添加 build.gradle 文件。
在多项目层级结构中,根项目中会包含一个 settings.gradle 文件,其中列出了构建中包含的其他项目。Android 使用多项目构建来帮您模块化应用。
△ Android 项目结构与 build.gradle 及 settings.gradle 文件
由于插件的存在,Gradle 可以处理不同类型的项目,比如 Android 或 Java。这些插件会包含预定义的功能,用于配置和构建特定类型的项目。
例如,为了构建 Android 项目,您需要使用 Android Gradle 插件配置您的 Gradle 构建文件。无论当前的 Android 项目是应用还是依赖库,Android Gradle 插件都知道如何对其进行构建和打包。
Task (任务)
Gradle 的构建流程围绕名为 Task (任务) 的工作单元展开。您可以通过终端查看 Task 列表,或通过启用 Android Studio Gradle 面板中的 Task 列表来查看任务。
△ Gradle Task 列表
这些 Task 可以接收输入、执行某些操作,并根据执行的操作产生输出。
Android Gradle Plugin 定义了自己的 Task,并且知道构建 Android 项目时,需要以何种顺序执行这些 Task。
Gradle 构建文件由许多不同的部分组成。Gradle 的配置语法被称为 Gradle DSL,其为开发者定义了配置插件的方式。Gradle 会解析 build.gradle 文件中的 android DSL 块并创建 AGP DSL 对象,例如 ApplicationExtension 和 BuildType。
典型的 Android 项目会包含一个顶层 Gradle 构建文件。Android 项目中的每个模块又分别有一个 Gradle 构建文件。在示例项目中,我仅有一个应用模块。
在模块层的 build.gradle 文件中,我需要声明和应用构建项目所需的插件。为了让 Gradle 知道我正在构建 Android 项目,我需要应用 com.android.application 或 com.android.library 插件。这两个插件分别定义了如何配置和构建 Android 应用和依赖库。在本例中,我要构建的是 Android 应用项目,所以我需要应用 com.android.application 插件。由于我需要使用 Kotlin,所以在示例中也应用了 kotlin.android 插件。
plugins {
id 'com.android.application'
id 'org.jetbrains.kotlin.android'
}
Android Gradle Plugin 提供了它自己的 DSL,您可以用它配置 AGP,并使该配置在构建时应用于 Task。
想要配置 Android Gradle Plugin,您需要使用 android 块。在该代码块中,您可以为不同的构建类型 (如 debug 或 release) 定义 SDK 版本、工具版本、应用详情及其它一些配置。如需了解更多有关 gradle 如何使用这些信息来创建变体,以及您可以使用哪些其他选项,请参阅 构建文档:
android {
compileSdk 31
defaultConfig {
applicationId "com.example.myapp"
minSdk 21
targetSdk 31
versionCode 1
versionName "1.0"
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android-optimize.txt'), 'proguard-rules.pro'
}
}
compileOptions {
sourceCompatibility JavaVersion.VERSION_1_8
targetCompatibility JavaVersion.VERSION_1_8
}
kotlinOptions {
jvmTarget = '1.8'
}
}
在下一部分中,您可以定义依赖。Gradle 的依赖管理支持兼容 Maven 与 Ivy 的仓库,以及来自文件系统的本地二进制文件。
dependencies {
implementation 'androidx.core:core-ktx:1.7.0'
implementation 'com.google.android.material:material:1.4.0'
implementation 'androidx.lifecycle:lifecycle-runtime-ktx:2.4.0'
testImplementation 'junit:junit:4.13.2'
androidTestImplementation 'androidx.test.ext:junit:1.1.3'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.4.0'
}
构建阶段
Gradle 分三个阶段评估和运行构建,分别是 Initialization (初始化)、Configuration (配置) 和 Execution (执行),更多请参阅 Gradle 文档。
在 Initialization (初始化) 阶段,Gradle 会决定构建中包含哪些项目,并会为每个项目创建 Project实例。为了决定构建中会包含哪些项目,Gradle 首先会寻找 settings.gradle 来决定此次为单项目构建还是多项目构建。
在 Configuration (配置) 阶段,Gradle 会评估构建项目中包含的所有构建脚本,随后应用插件、使用 DSL 配置构建,并在最后注册 Task,同时惰性注册它们的输入。
需要注意的是,无论您请求执行哪个 Task,配置阶段都会执行。为了保持您的构建简洁高效,请避免在配置阶段执行任何耗时操作。
最后,在 Execution (执行) 阶段,Gradle 会执行构建所需的 Task 集合。
下篇文章中,在编写我们自己的插件时,我们将深入剖析这些阶段。
Gradle DSL 支持使用 Groovy 与 Kotlin 脚本编写构建文件。到目前为止,我都在使用 Groovy DSL 脚本来配置此工程的构建。您可以在下面看到分别由 Kotlin 和 Groovy 编写的相同构建文件。注意 Kotlin 脚本文件名后缀为 ".kts"。
△ Kotlin 与 Groovy 脚本对比
从 Groovy 迁移到 Kotlin 或其他配置脚本的方法,不会改变您执行 Task 的方式。
总结
以上便是本文的全部内容。Gradle 与 Android Gradle Plugin 有许多可以让您自定义构建的功能。在本文中,您已经了解了 Gradle Task、构建阶段、配置 AGP 以及使用 DSL 配置构建的基础知识。
作者:Android_开发者
链接:https://juejin.cn/post/7044011519591317534
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
当 Adapter 遇上 Kotlin DSL,无比简单的调用方式
早在去年的时候我就提到过使用工厂的方式获取 Adapter 而不是为每个 Adapter 定义一个类文件。这样的好处是,对于不是那么复杂的 Adapter 可以节省大量的代码,提升开发效率和解放双手,同时更好的支持多类型布局效果。
1、Kotlin DSL 和 Adapter 工厂方法
可以把 Kotlin DSL 当作构建者使用。这里有一篇不错的文章,想了解的可以阅读下,
http://www.ximedes.com/2020-04-21/…
Kotlin DSL 是拓展函数的延申,比如我们常用的 with 等函数就是函数的拓展,
public inline fun <T, R> with(receiver: T, block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return receiver.block()
}
这里是泛型 T 的拓展。这里的 T 可以类比到 Java 构建者模式中的 Builder,通过方法接收外部参数之后调用 build() 方法创建一个最终的对象即可。
对于 Adapter 工厂方法,之前我是通过如下方式使用的,
fun <T> getAdapter(
@LayoutRes itemLayout:Int,
converter: (helper: BaseViewHolder, item: T) -> Unit,
data: List<T>
): Adapter<T> = Adapter(itemLayout, converter, data)
class Adapter<T>(
@LayoutRes private val layout: Int,
private val converter: (helper: BaseViewHolder, item: T) -> Unit,
val list: List<T>
): BaseQuickAdapter<T, BaseViewHolder>(layout, list) {
override fun convert(helper: BaseViewHolder, item: T) {
converter(helper, item)
}
}
也就是每次想要得到 Adapter 的时候只要调用 getAdapter() 方法即可。这种封装方式比较简陋,支持的功能有限。后来慢慢采用了 Kotlin DSL 之后,我封装了 Kotlin DSL 风格的工厂方法。采用 Kotlin DSL 风格之后更加优雅和方便快捷,同时更好的支持多类型布局效果。
2、使用
2.1 引入依赖
首先,该项目依赖于 BRVAH,所以,你需要引入该库之后才可以使用。BRVAH 可以说是目前开源的最好用的 Adapter,我们没必要再另起炉灶自己再造轮子。这个框架设计最好地方在于通过 SpareArray 收集了 ViewHolder 控件,从而避免了自定义 ViewHolder,这是我们框架设计的基础思想。
该项目已经上传到了 MavenCentral,你需要先在项目中引入该仓库,
allprojects {
repositories {
mavenCentral()
}
}
然后在项目中添加如下依赖,
implementation "com.github.Shouheng88:xadapter:${latest_version}"
2.2 使用 Adapter 工厂方法
使用 xAdapter 之后,当你需要定义一个 Adapter 的时候,你无需单独创建一个类文件,只需要通过 createAdapter() 方法获取一个 Adapter,
adapter = createAdapter {
withType(Item::class.java, R.layout.item_eyepetizer_home) {
// Bind data with viewholder.
onBind { helper, item ->
helper.setText(R.id.tv_title, item.data.title)
helper.setText(R.id.tv_sub_title, item.data.author?.name + " | " + item.data.category)
helper.loadCover(requireContext(), R.id.iv_cover, item.data.cover?.homepage, R.drawable.recommend_summary_card_bg_unlike)
helper.loadRoundImage(requireContext(), R.id.iv_author, item.data.author?.icon, R.mipmap.eyepetizer, 20f.dp2px())
}
// Item level click and long click events.
onItemClick { _, _, position ->
adapter?.getItem(position)?.let {
toast("Clicked item: " + it.data.title)
}
}
}
}
在这种新的调用方式中,你需要通过 withType() 方法指定数据类型及其对应的布局文件,然后在 onBind() 方法中即可实现数据到 ViewHolder 的绑定操作。这里的 onBind() 方法的使用与 BRVAH 中的 convert() 方法使用一致,可以通过阅读该库了解如何使用。总之,xAapter 在 BRVAH 的基础上做了二次封装,可以说,比简单更简单。
xAdapter 支持为每个 ViewHolder 绑定点击和长按事件,同时也支持为 ViewHolder 上的某个单独的 View 添加点击和长按事件。使用方式如上所示,只需要添加 onItemClick() 方法并实现自己的逻辑即可。其他的点击事件可以参考项目的示例代码。
效果,
2.3 使用多类型 Adapter
多类型 Adapter 的使用方式非常简单,类似于上面的调用方式,只需要在 createAdapter() 内再添加一个 withType() 方法即可。下面是一个写起来可能相当复杂的 Adapter,但是采用了 xAdpater 的调用方式之后,一切变得非常简单,
private fun createAdapter() {
adapter = createAdapter {
withType(MultiTypeDataGridStyle::class.java, R.layout.item_list) {
onBind { helper, item ->
val rv = helper.getView<RecyclerView>(R.id.rv)
rv.layoutManager = GridLayoutManager(context, 3)
val adapter = createSubAdapter(R.layout.item_home_page_data_module_1, 1)
rv.adapter = adapter
adapter.setNewData(item.items)
}
}
withType(MultiTypeDataListStyle1::class.java, R.layout.item_home_page_data_module_2) {
onBind { helper, item ->
converter.invoke(helper, item)
}
onItemClick { _, _, position ->
(adapter?.getItem(position) as? MultiTypeDataListStyle1)?.let {
toast("Clicked style[2] item: " + it.item.data.title)
}
}
}
withType(MultiTypeDataListStyle2::class.java, R.layout.item_list) {
onBind { helper, item ->
val rv = helper.getView<RecyclerView>(R.id.rv)
rv.layoutManager = LinearLayoutManager(context, RecyclerView.HORIZONTAL, false)
val adapter = createSubAdapter(R.layout.item_home_page_data_module_4, 3)
rv.adapter = adapter
adapter.setNewData(item.items)
}
}
withType(MultiTypeDataListStyle3::class.java, R.layout.item_home_page_data_module_3) {
onBind { helper, item ->
converter.invoke(helper, item)
}
onItemClick { _, _, position ->
(adapter?.getItem(position) as? MultiTypeDataListStyle3)?.let {
toast("Clicked style[4] item: " + it.item.data.title)
}
}
}
}
}
xAdapter 对多类型布局方式的支持是在 BRVAH 之上进行的改造,在这种封装方式中,数据类无需实现任何类和接口。Adpater 内部通过 Class 区分各个 ViewHolder.
效果,
总结
相对于为各种类型的数据定义 Adapter 的使用方式,以上封装方式的优势是:
- 借助 BRVAH 的优势,封装了大量的方法,进一步简化了 Adapter 的使用;
- 通过工厂和 DSL 封装,简化了调用 Adapter 的方式,你无需为数据类型定义 Adapter 文件,减少了项目中需要维护的代码和类文件数量;
- 通过以上封装,使用 Adapter 更加简洁,节省了大量的代码,提升开发效率和解放双手;
- 自由地在单一类型布局和多类型布局之间进行切换,但是少了没必要的工厂方法。
当有更加简洁的使用方式的时候,继续采用复杂的调用方式无异于抱残守缺,对于程序员而言,做这种重复而没有太大价值的工作,付出再多的汗水都不值得同情。以上是部分功能和代码的展示,可以通过阅读源码了解更多。后续我参考其他优秀的库的设计思想,支持更多 Adapter 特性的封装来实现快速调用。
项目已开源,感兴趣的可以直接阅读项目源码,源码地址:github.com/Shouheng88/…
作者:shouheng
链接:https://juejin.cn/post/7006530777995296782
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
我用Flutter写了一个上班摸鱼应用
网上最近看到了个摸鱼应用,还挺好玩的。
我打算自己用flutter写了一个
之前我有用flutter制作过mobile应用,但是没有在desktop尝试过;毕竟2.0大更新,我这里就在这试手一下,并说说flutter的体验.
当前flutter环境 2.8
增加flutter desktop支持 (默认项目之存在ios,android项目包)
flutter config --enable-<platform>-desktop
我这里是mac,因此platform=macos,详细看flutter官网
代码十分简单,UI部分就不讲了
在摸鱼界面,我是用了 Bloc 做倒计时计算逻辑,默认摸鱼时长15分钟
MoYuBloc() : super(MoyuInit()) {
on(_handleMoyuStart);
on(_handleUpdateProgress);
on(_handleMoyuEnd);
}
摸鱼开始事件处理
// handle moyu start action
FutureOr<void> _handleMoyuStart(
MoyuStarted event, Emitter<MoyuState> emit) async {
if (_timer != null && _timer!.isActive) {
_timer?.cancel();
}
final totalTime = event.time;
int progressTime = state is MoyuIng ? (state as MoyuIng).progressTime : 0;
_timer = Timer.periodic(const Duration(seconds: 1), (timer) {
add(MoyuProgressUpdated(totalTime, ++progressTime));
if (progressTime >= totalTime) {
timer.cancel();
add(MoyuEnded());
}
});
emit(MoyuIng(progress: 0, progressTime: 0));
}
摸鱼进度更新
// handle clock update
FutureOr<void> _handleUpdateProgress(
MoyuProgressUpdated event, Emitter<MoyuState> emit) async {
final totalTime = event.totalTime;
final progressTime = event.progressTime;
emit(
MoyuIng(progress: progressTime / totalTime, progressTime: progressTime),
);
}
摸鱼结束,释放结束事件
// handle clock end
FutureOr<void> _handleMoyuEnd(
MoyuEnded event, Emitter<MoyuState> emit) async {
emit(MoyuFinish());
}
总结3个event (摸鱼开始,进程更新,摸鱼结束)
abstract class MoyuEvent {}
class MoyuStarted extends MoyuEvent {
final int time;
final System os;
MoyuStarted({required this.time, required this.os});
}
class MoyuProgressUpdated extends MoyuEvent {
final int totalTime;
final int progressTime;
MoyuProgressUpdated(this.totalTime, this.progressTime);
}
class MoyuEnded extends MoyuEvent {
MoyuEnded();
}
其中3个state (摸鱼初始,正在摸鱼,摸鱼结束)
abstract class MoyuState {}
class MoyuInit extends MoyuState {}
class MoyuIng extends MoyuState {
final double progress;
final int progressTime;
MoyuIng({required this.progress, required this.progressTime});
}
class MoyuFinish extends MoyuState {}
启动摸鱼使用, 记录总时长和消耗时间,计算进度百分比,更新UI进度条
下面是界面更新逻辑
BlocConsumer<MoYuBloc, MoyuState>(
builder: (context, state) {
if (state is MoyuIng) {
final progress = state.progress;
return _moyuIngView(progress);
} else if (state is MoyuFinish) {
return _replayView();
}
return const SizedBox();
},
listener: (context, state) {},
listenWhen: (pre, cur) => pre != cur,
),
很简单 最重要的是进度状态,其次结束后是否重新摸鱼按钮
构建运行flutter应用
flutter run -d macos
最后结果展示
总结下flutter desktop使用
- 简单上手,按着官网走基本没问题,基本上没踩上什么雷,可能项目比较简单
- 构建流程简单,hot reload强大
- 性能强大,启动速度很快,并且界面无顿挫感
比较遗憾的事desktop电脑构建系统独立,mac环境下无法构建windows应用,有点小遗憾.
项目完全开源 可以前往GitHub查看 不要忘点个star😊
作者:1vau
链接:https://juejin.cn/post/7042864240817864740
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
丢掉丑陋的 toast,会动的 toast 更有趣!
前言
我们通常会用 toast(也叫吐司)来显示提示信息,例如网络请求错误,校验错误等等。大多数 App的 toast 都很简单,简单的半透明黑底加上白色文字草草了事,比如下面这种.
说实话,这种toast 的体验很糟糕。假设是新手用户,他们并不知道 toast 从哪里出来,等出现错误的时候,闪现出来的时候,可能还没抓住内容的重点就消失了(尤其是想截屏抓错误的时候,更抓狂)。这是因为一个是这种 toast 一般比较小,而是动效非常简单,用来提醒其实并不是特别好。怎么破?本篇来给大家介绍一个非常有趣的 toast 组件 —— motion_toast。
motion_toast 介绍
从名字就知道,motion_toast 是支持动效的,除此之外,它的颜值还很高,下面是它的一个示例动图,仔细看那个小闹钟图标,是在跳动的哦。这种提醒效果比起常用的 toast 来说醒目多了,也更有趣味性。
下面我们看看 motion_toast 的特性:
- 可以通过动画图标实现动效;
- 内置了成功、警告、错误、提醒和删除类型;
- 支持自定义;
- 支持不同的主题色;
- 支持 null safety;
- 心跳动画效果;
- 完全自定义的文本内容;
- 内置动画效果;
- 支持自定义布局(LTR 和 RTL);
- 自定义持续时长;
- 自定义展现位置(居中,底部或顶部);
- 支持长文本显示;
- 自定义背景样式;
- 自定义消失形式。
可以看到,除了能够开箱即用之外,我们还可以通过自定义来丰富 toast 的样式,使之更有趣。
示例
介绍完了,我们来一些典型的示例吧,首先在 pubspec.yaml 中添加依赖motion_toast: ^2.0.0(最低Dart版本需要2.12)。
最简单用法
只需要一行代码搞定!其他参数在 success 的命名构造方法中默认了,因此使用非常简单。
MotionToast.success(description: '操作成功!').show(context);
其他内置的提醒
内置的提醒也支持我们修改默认参数进行样式调整,如标题、位置、宽度、显示位置、动画曲线等等。
// 错误提示
MotionToast.error(
description: '发生错误!',
width: 300,
position: MOTION_TOAST_POSITION.center,
).show(context);
//删除提示
MotionToast.delete(
description: '已成功删除',
position: MOTION_TOAST_POSITION.bottom,
animationType: ANIMATION.fromLeft,
animationCurve: Curves.bounceIn,
).show(context);
// 信息提醒(带标题)
MotionToast.info(
description: '这是一条提醒,可能会有很多行。toast 会自动调整高度显示',
title: '提醒',
titleStyle: TextStyle(fontWeight: FontWeight.bold),
position: MOTION_TOAST_POSITION.bottom,
animationType: ANIMATION.fromBottom,
animationCurve: Curves.linear,
dismissable: true,
).show(context);
不过需要注意的是,一个是 dismissable 参数只对显示位置在底部的有用,当在底部且dismissable为 true 时,点击空白处可以让 toast 提前消失。另外就是显示位置 position 和 animationType 是存在某些互斥关系的。从源码可以看到底部显示的时候,animationType不能是 fromTop,顶部显示的时候 animationType 不能是 fromBottom。
void _assertValidValues() {
assert(
(position == MOTION_TOAST_POSITION.bottom &&
animationType != ANIMATION.fromTop) ||
(position == MOTION_TOAST_POSITION.top &&
animationType != ANIMATION.fromBottom) ||
(position == MOTION_TOAST_POSITION.center),
);
}
自定义 toast
自定义其实就是使用 MotionToast 构建一个实例,其中,description,icon 和 primaryColor参数是必传的。自定义的参数很多,使用的时候建议看一下源码注释。
MotionToast(
description: '这是自定义 toast',
icon: Icons.flag,
primaryColor: Colors.blue,
secondaryColor: Colors.green[300],
descriptionStyle: TextStyle(
color: Colors.white,
),
position: MOTION_TOAST_POSITION.center,
animationType: ANIMATION.fromRight,
animationCurve: Curves.easeIn,
).show(context);
下面对自定义的一些参数做一下解释:
icon:图标,IconData 类,可以使用系统字体图标;primaryColor:主颜色,也就是大的背景底色;secondaryColor:辅助色,也就是图标和旁边的竖条的颜色;descriptionStyle:toast 文字的字体样式;title:标题文字;titleStyle:标题文字样式;toastDuration:显示时长;backgroundType:背景类型,枚举值,共三个可选值,transparent,solid和lighter,默认是lighter。lighter其实就是加了一层白色底色,然后再将原先的背景色(主色调)加上一定的透明度叠加到上面,所以看起来会泛白。onClose:关闭时回调,可以用于出现多个错误时依次展示,或者是关闭后触发某些动作,如返回上一页。
总结
看完之后,是不是觉得以前的 toast 太丑了?用 motion_toast来一个更有趣的吧。另外,整个 motion_toast 的源码并不多,有兴趣的可以读读源码,了解一下toast 的实现也是不错的。
作者:岛上码农
链接:https://juejin.cn/post/7042301322376265742
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android 使用 Span 打造丰富多彩的文本
1.引言
在开发过程中经常需要使用文本,有时候需要对一段文字中的部分文字进行特殊的处理,如改变其中部分文字的大小、颜色、加下划线等,这个时候使用Span就能方便地解决这些问题。本文将主要介绍SpannableStringBuilder和各种Span的使用。
2.SpannableStringBuilder的基本用法
新建一个SpannableStringBuilder对象的操作如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
SpannableStringBuilder的setSpan()方法如下:
//what:各种文本Span,如BackgroundColorSpan、ForegroundColorSpan等
//start:应用Span的文本的开始位置索引
//end:应用Span的文本的结束位置索引
//flags:标志
public void setSpan(Object what, int start, int end, int flags) {
setSpan(true, what, start, end, flags, true/*enforceParagraph*/);
}
3.使用Span给文本添加效果
3.1 AbsoluteSizeSpan
此Span用来改变文本的绝对大小,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new AbsoluteSizeSpan(60),3,9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.2 BackgroundColorSpan
此Span用来改变文本的背景颜色大小,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new BackgroundColorSpan(Color.GREEN),3,9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.3 ClickableSpan
此Span用来给文本添加点击效果,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new ClickableSpan() {
@Override
public void onClick(@NonNull View widget) {
Toast.makeText(MainActivity.this,"ClickableSpan",Toast.LENGTH_SHORT).show();
}
}, 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
tv_content.setMovementMethod(LinkMovementMethod.getInstance());
tv_content.setHighlightColor(Color.TRANSPARENT);
3.4 DrawableMarginSpan
此Span用来给段落添加drawable和padding,这个padding指的是drawable和文本之间的距离,默认值是0,Span要从文本的起始位置设置,否则Span将不会渲染或者错误地渲染,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
Drawable drawable = AppCompatResources.getDrawable(MainActivity.this,R.drawable.ic_launcher);
builder.setSpan(new DrawableMarginSpan(drawable,30), 0, builder.length(), Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.5 DynamicDrawableSpan
此Span使用drawable替换文本内容,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new DynamicDrawableSpan() {
@Override
public Drawable getDrawable() {
Drawable drawable =
AppCompatResources.getDrawable(MainActivity.this,R.drawable.ic_launcher);
drawable.setBounds(0,0,drawable.getIntrinsicWidth(),drawable.getIntrinsicHeight());
return drawable;
}
}, 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.6 ForegroundColorSpan
此Span可以用来改变文本的颜色,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new ForegroundColorSpan(Color.GREEN), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.7 IconMarginSpan
此Span可以在文本开始的地方添加位图,而且可以在位图和文本之间设置padding,padding的默认值是0px,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
Bitmap bitmap = BitmapFactory.decodeResource(getResources(), R.drawable.ic_launcher);
builder.setSpan(new IconMarginSpan(bitmap,30), 0, builder.length(), Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.8 ImageSpan
此Span可以使用Drawable替换文本,创建ImageSpan的构造方法有很多,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new ImageSpan(MainActivity.this,R.drawable.ic_launcher), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.9 MaskFilterSpan
此Span可以给文本设置MaskFilter,例如给文本设置模糊效果,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
MaskFilter maskFilter = new BlurMaskFilter(10f, BlurMaskFilter.Blur.NORMAL);
builder.setSpan(new MaskFilterSpan(maskFilter), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.10 QuoteSpan
此Span可以在文本开始的地方添加一个垂直的线条,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new QuoteSpan(Color.GREEN), 0, builder.length(), Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.11 RelativeSizeSpan
此Span可以按一定的比例缩放文本的大小,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new RelativeSizeSpan(2.0f), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.12 ScaleXSpan
此Span以一定的系数在水平方向缩放文本的大小,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new ScaleXSpan(2.5f), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.13 StrikethroughSpan
此Span可以在文本上添加下划线,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new StrikethroughSpan(), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.14 StyleSpan
此Span可以设置文本的样式,可用的样式有Typeface.NORMAL、Typeface.BOLD、Typeface.ITALIC、Typeface.BOLD_ITALIC,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new StyleSpan(Typeface.BOLD), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.15 SubscriptSpan
此Span可以将文本的基线移动到更低的地方,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new SubscriptSpan(), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.16 SuperscriptSpan
此Span可以将文本的基线移动到更高的地方,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new SuperscriptSpan(), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
3.17 UnderlineSpan()
此Span可以在文本下面添加下划线,示例如下:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new UnderlineSpan(), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
4.多个Span组合使用
Span不但可以单独使用,还可以组合在一起使用,以下示例演示了如何同时加粗文字,改变文字的颜色和添加下滑线:
SpannableStringBuilder builder = new SpannableStringBuilder("Hello World!");
builder.setSpan(new UnderlineSpan(), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
builder.setSpan(new ForegroundColorSpan(Color.GREEN), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
builder.setSpan(new StyleSpan(Typeface.BOLD), 3, 9, Spannable.SPAN_EXCLUSIVE_INCLUSIVE);
tv_content.setText(builder);
5.总结
Span的功能相当丰富,如改变文本颜色、大小、添加点击效果、加下划线等功能,本文介绍了经常用到的各种Span,Span支持单独使用和组合使用,使用它能够对文本进行各种灵活的操作,去实现个性化的需求。
作者:i小灰
链接:https://juejin.cn/post/7043064985848643591
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
看完这篇Broadcast你还不会,来找我
看完这篇文章,你将明白以下内容:
- broadcast是什么,使用场景
- Android中广播的分类
- 广播的注册方式
- 本地广播优点、原理
- 广播的安全
1.1 什么是 BroadcastReceiver
- 是四大组件之一, 主要用于接收
app发送的广播 - 内部通信实现机制:通过
android系统的Binder机制.
1.2 广播分类
1.2.1 无序广播
- 也叫标准广播,是一种完全异步
执行的广播。
- 在广播发出之后,所有广播接收器几乎都会在同一时刻接收到这条广播消息,它们之间没有任何先后顺序,广播的效率较高。
优点:完全异步, 逻辑上可被任何接受者收到广播,效率高缺点:接受者不能将处理结果交给下一个接受者, 且无法终止广播.
1.2.2 有序广播
是一种同步执行的广播。
在广播发出之后,同一时刻只有一个广播接收器能够收到这条广播消息,当其逻辑执行完后该广播接收器才会继续传递。
调用
SendOrderedBroadcast()方法来发送广播,同时也可调用abortBroadcast()方法拦截该广播。可通过<intent-filter>标签中设置android:property属性来设置优先级,未设置时按照注册的顺序接收广播。
有序广播接受器间可以互传数据。
当广播接收器收到广播后,当前广播也可以使用
setResultData方法将数据传给下一个接收器。
使用
getStringExtra函数获取广播的原始数据,通过getResultData方法取得上个广播接收器自己添加的数据,并可用abortBroadcast方法丢弃该广播,使该广播不再被别的接收器接收到。
总结
- 按被接收者的优先级循序传播
A > B > C, - 每个都有权终止广播, 下一个就得不到
- 每一个都可进行修改操作, 下一个就得到上一个修改后的结果.
1.2.3 最终广播者
Context.sendOrderedBroadcast ( intent , receiverPermission , resultReceiver , scheduler , initialCode , initialData , initialExtras )时我们可以指定resultReceiver为最终广播接收者.- 如果比他优先级高的接受者不终止广播, 那么他的
onReceive会执行两次 - 第一次是正常的接收
- 第二次是最终的接收
- 如果优先级高的那个终止广播, 那么他还是会收到一次最终的广播
1.2.4 常见的广播接收者运用场景
- 开机启动,
sd卡挂载, 低电量, 外拨电话, 锁屏等 - 比如根据产品经理要求, 设计播放音乐时, 锁屏是否决定暂停音乐.
1.3 BroadcastReceiver 的种类
1.3.1 广播作为 Android 组件间的通信方式,如下使用场景:
对前一部分 “ 请描述一下
BroadcastReceiver” 进行展开补充
APP内部的消息通信。- 不同
APP之间的消息通信。 Android系统在特定情况下与 APP 之间的消息通信。- 广播使用了观察者模式,基于消息的发布 / 订阅事件模型。广播将广播的发送者和接受者极大程度上解耦,使得系统能够方便集成,更易扩展。
- BroadcastReceiver 本质是一个全局监听器,用于监听系统全局的广播消息,方便实现系统中不同组件间的通信。
- 自定义广播接收器需要继承基类
BroadcastReceiver,并实现抽象方法onReceive ( context, intent )。默认情况下,广播接收器也是运行在主线程,因此onReceiver()中不能执行太耗时的操作( 不超过10s),否则将会产生ANR问题。onReceiver()方法中涉及与其他组件之间的交互时,可以使用发送Notification、启动Service等方式,最好不要启动Activity。
1.3.2 系统广播
Android系统内置了多个系统广播,只要涉及手机的基本操作,基本上都会发出相应的系统广播,如开机启动、网络状态改变、拍照、屏幕关闭与开启、电量不足等。在系统内部当特定时间发生时,系统广播由系统自动发出。- 常见系统广播
Intent中的Action为如下值:
- 短信提醒:
android.provider.Telephony.SMS_RECEIVED - 电量过低:
ACTION_BATIERY_LOW - 电量发生改变:
ACTION_BATTERY_CHANGED - 连接电源:
ACTION_POWER_CO
- 从
Android 7.0开始,系统不会再发送广播ACTION_NEW_PICTURE和ACTION_NEW_VIDEO,对于广播CONNECTIVITY_ACTION必须在代码中使用registerReceiver方法注册接收器,在AndroidManifest文件中声明接收器不起作用。 - 从
Android 8.0开始,对于大多数隐式广播,不能在AndroidManifest文件中声明接收器。
1.3.3 局部广播
- 局部广播的发送者和接受者都同属于一个
APP - 相比于全局广播具有以下优点:
- 其他的
APP不会受到局部广播,不用担心数据泄露的问题。 - 其他
APP不可能向当前的APP发送局部广播,不用担心有安全漏洞被其他APP利用。 - 局部广播比通过系统传递的全局广播的传递效率更高。
Android v4包中提供了LocalBroadcastManager类,用于统一处理 APP 局部广播,使用方式与全局广播几乎相同,只是调用注册 / 取消注册广播接收器和发送广播偶读方法时,需要通过LocalBroadcastManager类的getInstance()方法获取的实例调用。
1.4 BroadcastReceiver 注册方式
1.4.1 静态注册
在 AndroidManifest.xml 文件中配置。
<receiver android:name=".MyReceiver" android:exported="true">
<intent-filter>
<!-- 指定该 BroadcastReceiver 所响应的 Intent 的 Action -->
<action android:name="android.intent.action.INPUT_METHOD_CHANGED"
<action android:name="android.intent.action.BOOT_COMPLETED" />
</intent-filter>
</receiver>
- 两个重要属性需要关注:
android: exported其作用是设置此BroadcastReceiver能否接受其他APP发出的广播 ,当设为false时,只能接受同一应用的的组件或具有相同user ID的应用发送的消息。这个属性的默认值是由BroadcastReceiver中有无Intent-filter决定的,如果有Intent-filter,默认值为true,否则为false。android: permission如果设置此属性,具有相应权限的广播发送方发送的广播才能被此BroadcastReceiver所接受;如果没有设置,这个值赋予整个应用所申请的权限。
1.4.2 动态注册
- 调用
Context的registerReceiver ( BroadcastReceiver receiver , IntentFilter filter )方法指定。
1.5 在 Mainfest 和代码如何注册和使用 BroadcastReceiver ? ( 一个 action 是重点 )
1.5.1 使用文件注册 ( 静态广播 )
只要
app还在运行,那么会一直收到广播消息
演示:
- 一个
app里: 自定义一个类继承BroadcastReceiver然后要求重写onReveiver方法
public class MyBroadCastReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
Log.d("MyBroadCastReceiver", "收到信息,内容是 : " + intent.getStringExtra("info") + "");
}
}
- 清单文件注册,并设置
Action, 就那么简单完成接收准备工作
<receiver android:name=".MyBroadCastReceiver">
<intent-filter>
<action android:name="myBroadcast.action.call"/>
</intent-filter>
</receiver>
1.5.2 代码注册 ( 动态广播 )
当注册的
Activity或者Service销毁了那么就会接收不到广播.
演示:
- 在和广播接受者相同的
app里的MainActivity添加一个注册按钮 , 用来注册广播接收者 - 设置意图过滤,添加
Action
//onCreate创建广播接收者对象
mReceiver = new MyBroadCastReceiver();
//注册按钮
public void click(View view) {
IntentFilter intentFilter = new IntentFilter();
intentFilter.addAction("myBroadcast.action.call");
registerReceiver(mReceiver, intentFilter);
}
- 销毁的时候取消注册
@Override
protected void onDestroy() {
unregisterReceiver(mReceiver);
super.onDestroy();
}
1.5.3 在另一个 app , 定义一个按钮, 设置意图, 意图添加消息内容, 意图设置 action( ... ) 要匹配 , 然后发送广播即可.
public void click(View view) {
Intent intent = new Intent();
intent.putExtra("info", "消息内容");
intent.setAction("myBroadcast.action.call");
sendBroadcast(intent);
}
- 运行两个
app之后:
- 静态注册的方法: 另一
app直接发广播就收到了 - 动态注册的方法: 自己的
app先代码注册,然后另一个app直接发广播即可.
1.6 BroadcastReceiver 的实现原理是什么?
Android中的广播使用了设计模式中的观察者模式:基于消息的发布 / 订阅事件模型。
模型中主要有
3个角色:
- 消息订阅者( 广播接收者 )
- 消息发布者( 广播发布者 )
- 消息中心(
AMS,即Activity Manager Service)
1.6.1 原理:
- 广播接收者通过
Binder机制在AMS(Activity Manager Service) 注册; - 广播发送者通过
Binder机制向AMS发送广播; AMS根据广播发送者要求,在已注册列表中,寻找合适的BroadcastReceiver( 寻找依据:IntentFilter / Permission);AMS将广播发送到BroadcastReceiver相应的消息循环队列中;- 广播接收者通过消息循环拿到此广播,并回调
onReceive()方法。 - 需要注意的是:广播的发送和接受是异步的,发送者不会关心有无接收者或者何时收到。
1.7 本地广播
- 本地广播机制使得发出的广播只能够在应用程序的内部进行传递,并且广播接收器也只能接受来自本应用程序发出的广播,则安全性得到了提高。
- 本地广播主要是使用了一个
LocalBroadcastManager来对广播进行管理,并提供了发送广播和注册广播接收器的方法。 - 开发者只要实现自己的
BroadcastReceiver子类,并重写onReceive ( Context context, Intetn intent )方法即可。 - 当其他组件通过
sendBroadcast()、sendStickyBroadcast()、sendOrderBroadcast()方法发送广播消息时,如果该BroadcastReceiver也对该消息“感兴趣”,BroadcastReceiver的onReceive ( Context context, Intetn intent )方法将会被触发。 - 使用步骤:
- 调用 LocalBroadcastManager.getInstance() 获得实例
- 调用 registerReceiver() 方法注册广播
- 调用 sendBroadcast() 方法发送广播
- 调用 unregisterReceiver() 方法取消注册
1.7.1 注意事项:
- 本地广播无法通过静态注册方式来接受,相比起系统全局广播更加高效。
- 在广播中启动
Activity时,需要为Intent加入FLAG_ACTIVITY_NEW_TASK标记,否则会报错,因为需要一个栈来存放新打开的Activity。 - 广播中弹出
Alertdialog时,需要设置对话框的类型为TYPE_SYSTEM_ALERT,否则无法弹出。 - 不要在
onReceiver()方法中添加过多的逻辑或者进行任何的耗时操作,因为在广播接收器中是不允许开启线程的,当onReceiver()方法运行了较长时间而没有结束时,程序就会报错。
1.8 Sticky Broadcast 粘性广播
- 如果发送者发送了某个广播,而接收者在这个广播发送后才注册自己的 Receiver ,这时接收者便无法接收到刚才的广播
- 为此
Android引入了StickyBroadcast,在广播发送结束后会保存刚刚发送的广播(Intent),这样当接收者注册完Receiver后就可以继续使用刚才的广播。 - 如果在接收者注册完成前发送了多条相同
Action的粘性广播,注册完成后只会收到一条该Action的广播,并且消息内容是最后一次广播内容。 - 系统网络状态的改变发送的广播就是粘性广播。
- 粘性广播通过
Context的sendStickyBroadcast ( Intent )接口发送,需要添加权限 uses-permission android:name=”android.permission.BROADCAST_STICKY”- 也可以通过
Context的removeStickyBroadcast ( Intent intent )接口移除缓存的粘性广播
1.9 LocalBroadcastManager 详解
1.9.1 特点:
- 使用它发送的广播将只在自身APP内传播,因此你不必担心泄漏隐私数据;
- 其他
APP无法对你的APP发送该广播,因为你的APP根本就不可能接收到非自身应用发送的该广播,因此你不必担心有安全漏洞可以利用; - 比系统的全局广播更加高效。
1.9.2 源码分析 :
LocalBroadcastManager内部协作主要是靠这两个Map集合:MReceivers和MActions,当然还有一个 List 集合MPendingBroadcasts,这个主要就是存储待接收的广播对象。LocalBroadcastManager高效的原因主要是因为它内部是通过Handler实现的,它的sendBroadcast()方法含义并非和我们平时所用的一样,它的sendBroadcast()方法其实是通过handler发送一个Message实现的;- 既然它内部是通过
Handler来实现广播的发送的,那么相比于系统广播通过Binder实现那肯定是更高效了,同时使用Handler来实现,别的应用无法向我们的应用发送该广播,而我们应用内发送的广播也不会离开我们的应用;
1.9.3 BroadcastReceiver 安全问题
BroadcastReceiver设计的初衷是从全局考虑可以方便应用程序和系统、应用程序之间、应用程序内的通信,所以对单个应用程序而言BroadcastReceiver是存在安全性问题的 ( 恶意程序脚本不断的去发送你所接收的广播 ) 。为了解决这个问题LocalBroadcastManager就应运而生了。LocalBroadcastManager是Android Support包提供了一个工具,用于在同一个应用内的不同组件间发送Broadcast。LocalBroadcastManager也称为局部通知管理器,这种通知的好处是安全性高,效率也高,适合局部通信,可以用来代替Handler更新UI
1.9.4 广播的安全性
Android系统中的广播可以跨进程直接通信,会产生以下两个问题:
- 其他
APP可以接收到当前APP发送的广播,导致数据外泄。 - 其他
APP可以向当前APP放广播消息,导致APP被非法控制。
- 发送广播
- 发送广播时,增加相应的
permission,用于权限验证。 - 在
Android 4.0及以上系统中发送广播时,可以使用setPackage()方法设置接受广播的包名。 - 使用局部广播。
- 接受广播
- 注册广播接收器时,增加相应的
permission,用于权限验证。 - 注册广播接收器时,设置
android:exported的值为false。
- 使用局部广播
- 发送广播时,如果增加了
permission - 那接受广播的
APP必须申请相应权限,这样才能收到对应的广播,反之亦然。
1.9.5 使用 BroadcastReceiver 的好处
- 因广播数据在本应用范围内传播,你不用担心隐私数据泄露的问题。
- 不用担心别的应用伪造广播,造成安全隐患。
- 相比在系统内发送全局广播,它更高效。
1.10 如何让自己的广播只让指定的 app 接收?
- 在发送广播的
app端,自定义定义权限, 那么想要接收的另外app端必须声明权限才能收到.
- 权限, 保护层级是普通正常.
- 用户权限
<permission android:name="broad.ok.receiver" android:protectionLevel="normal"/>
<uses-permission android:name="broad.ok.receiver" />
- 发送广播的时候加上权限字符串
public void click(View view) {
Intent intent = new Intent();
intent.putExtra("info", "消息内容");
intent.setAction("myBroadcast.action.call");
sendBroadcast(intent, "broad.ok.receiver");
//sendOrderedBroadcast(intent,"broad.ok.receiver");
}
- 其他app接收者想好获取广播,必须声明在清单文件权限
<uses-permission android:name="broad.ok.receiver"/>
1.11 广播的优先级对无序广播生效吗?
- 优先级对无序也生效.
1.12 动态注册的广播优先级谁高?
- 谁先注册,谁就高
1.13 如何判断当前的 BrodcastReceiver 接收到的是有序还是无序的广播?
- 在
onReceiver方法里,直接调用判断方法得返回值
public void onReceive(Context context, Intent intent) {
Log.d("MyBroadCastReceiver", "收到信息,内容是 : " + intent.getStringExtra("info") + "");
boolean isOrderBroadcast = isOrderedBroadcast();
}
1.14 BroadcastReceiver 不能执行耗时操作
- 一方面
BroadcastReceiver一般处于主线程。- 耗时操作会导致
ANR
- 另一方面
BroadcastReceiver启动时间较短。- 如果一个进程里面只存在一个
BroadcastReceiver组件。并且在其中开启子线程执行耗时任务。 - 系统会认为该进程是优先级最低的空进程。很容易将其杀死。
总结
本文对
BroadcastReceiver和ContentProvider的 知识进行了详尽的总结,如果有可以补充的知识点,欢迎大家在评论区指出。
希望大家通过本次阅读都能有所收获。
作者:captain_p
链接:https://juejin.cn/post/7043334283842781192
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
让 Flutter 在鸿蒙系统上跑起来
前言
鸿蒙系统 (HarmonyOS)是华为推出的一款面向未来、面向全场景的分布式操作系统。在传统单设备系统能力的基础上,鸿蒙提出了基于同一套系统能力、适配多种终端形态的分布式理念。自 2020 年 9 月 HarmonyOS 2.0 发布以来,华为加快了鸿蒙系统大规模落地的步伐,预计 2021 年底,鸿蒙系统会覆盖包括手机、平板、智能穿戴、智慧屏、车机在内数亿台终端设备。对移动应用而言,新的系统理念、新的交互形式,也意味着新的机遇。如果能够利用好鸿蒙的开发生态及其特性能力,可以让应用覆盖更多的交互场景和设备类型,从而带来新的增长点。
与面临的机遇相比,适配鸿蒙系统带来的挑战同样巨大。当前手机端,尽管鸿蒙系统仍然支持安卓 APK 安装及运行,但长期来看,华为势必会抛弃 AOSP,逐步发展出自己的生态,这意味着现有安卓应用在鸿蒙设备上将会逐渐变成“二等公民”。然而,如果在 iOS 及 Android 之外再重新开发和维护一套鸿蒙应用,在如今业界越来越注重开发迭代效率的环境下,所带来的开发成本也是难以估量的。因此,通过打造一套合适的跨端框架,以相对低的成本移植应用到鸿蒙平台,并利用好该系统的特性能力,就成为了一个非常重要的选项。
在现有的众多跨端框架当中,Flutter 以其自渲染能力带来的多端高度一致性,在新系统的适配上有着突出的优势。虽然Flutter 官方并没有适配鸿蒙的计划,但经过一段时间的探索和实践,美团外卖 MTFlutter 团队成功实现了 Flutter 对于鸿蒙系统的原生支持。
这里也要提前说明一下,因为鸿蒙系统目前还处于Beta版本,所以这套适配方案还没有在实际业务中上线,属于技术层面比较前期的探索。接下来本文会通过原理和部分实现细节的介绍,分享我们在移植和开发过程中的一些经验。希望能对大家有所启发或者帮助。
背景知识和基础概念介绍
在适配开始之前,我们要明确好先做哪些事情。先来回顾一下 Flutter 的三层结构:
在 Flutter 的架构设计中,最上层为框架层,使用 Dart 语言开发,面向 Flutter 业务的开发者;中间层为引擎层,使用 C/C++ 开发,实现了 Flutter 的渲染管线和 Dart 运行时等基础能力;最下层为嵌入层,负责与平台相关的能力实现。显然我们要做的是将嵌入层移植到鸿蒙上,确切地说,我们要通过鸿蒙原生提供的平台能力,重新实现一遍 Flutter 嵌入层。
对于 Flutter 嵌入层的适配,Flutter 官方有一份不算详细的指南,实际操作起来成本很高。由于鸿蒙的业务开发语言仍然可用 Java,在很多基础概念上与 Android 也有相似之处(如下表所示),我们可以从 Android 的实现入手,完成对鸿蒙的移植。
Flutter 在鸿蒙上的适配
如前文所述,要完成 Flutter 在新系统上的移植,我们需要完整实现 Flutter 嵌入层要求的所有子模块,而从能力支持角度,渲染、交互以及其他必要的原生平台能力是保证 Flutter 应用能够运行起来的最基本的要素,需要优先支持。接下来会依次进行介绍。
1. 渲染流程打通
我们再来回顾一下 Flutter 的图像渲染流程。如图所示,设备发起垂直同步(VSync)信号之后,先经过 UI 线程的渲染管线(Animate/Build/Layout/Paint),再经过 Raster 线程的组合和栅格化,最终通过 OpenGL 或 Vulkan 将图像上屏。这个流程的大部分工作都由框架层和引擎层完成,对于鸿蒙的适配,我们主要关注的是与设备自身能力相关的问题,即:
(1) 如何监听设备的 VSync 信号并通知 Flutter 引擎?
(2) OpenGL/Vulkan 用于上屏的窗口对象从何而来?
VSync 信号的监听及传递
在 Flutter 引擎的 Android 实现中,设备的 VSync 信号通过 Choreographer 触发,它产生及消费流程如下图所示:
Flutter 框架注册 VSync 回调之后,通过 C++ 侧的 VsyncWaiter 类等待 VSync 信号,后者通过 JNI 等一系列调用,最终 Java 侧的 VsyncWaiter 类调用 Android SDK 的 Choreographer.postFrameCallback 方法,再通过 JNI 一层层传回 Flutter 引擎消费掉此回调。Java 侧的 VsyncWaiter 核心代码如下:
@Override
public void asyncWaitForVsync(long cookie) {
Choreographer.getInstance()
.postFrameCallback(
new Choreographer.FrameCallback() {
@Override
public void doFrame(long frameTimeNanos) {
float fps = windowManager.getDefaultDisplay().getRefreshRate();
long refreshPeriodNanos = (long) (1000000000.0 / fps);
FlutterJNI.nativeOnVsync(
frameTimeNanos, frameTimeNanos + refreshPeriodNanos, cookie);
}
});
}
在整个流程中,除了来自 Android SDK 的 Choreographer 以外,大多数逻辑几乎都由 C++ 和 Java 的基础 SDK 实现,可以直接在鸿蒙上复用,问题是鸿蒙目前的 API 文档中尚没有开放类似 Choreographer 的能力。所以现阶段我们可以借用鸿蒙提供的类似 iOS Grand Central Dispatch 的线程 API,模拟出 VSync 的信号触发与回调:
@Override
public void asyncWaitForVsync(long cookie) {
// 模拟每秒 60 帧的屏幕刷新间隔:向主线程发送一个异步任务, 16ms 后调用
applicationContext.getUITaskDispatcher().delayDispatch(() -> {
float fps = 60; // 设备刷新帧率,HarmonyOS 未暴露获取帧率 API,先写死 60 帧
long refreshPeriodNanos = (long) (1000000000.0 / fps);
long frameTimeNanos = System.nanoTime();
FlutterJNI.nativeOnVsync(frameTimeNanos, frameTimeNanos + refreshPeriodNanos, cookie);
}, 16);
};
渲染窗口的构建及传递
在这一部分,我们需要在鸿蒙系统上构建平台容器,为 Flutter 引擎的图形渲染提供用于上屏的窗口对象。同样,我们参考 Flutter for Android 的实现,看一下 Android 系统是怎么做的:
Flutter 在 Android 上支持 Vulkan 和 OpenGL 两种渲染引擎,篇幅原因我们只关注 OpenGL。抛开复杂的注册及调用细节,本质上整个流程主要做了三件事:
- 创建了一个视图对象,提供可用于直接绘制的 Surface,将它通过 JNI 传递给原生侧;
- 在原生侧获取 Surface 关联的本地窗口对象,并交给 Flutter 的平台容器;
- 将本地窗口对象转换为 OpenGL ES 可识别的绘图表面(EGLSurface),用于 Flutter 引擎的渲染上屏。
接下来我们用鸿蒙提供的平台能力实现这三点。
a. 可用于直接绘制的视图对象
鸿蒙系统的 UI 框架提供了很多常用视图组件(Component),比如按钮、文字、图片、列表等,但我们需要抛开这些上层组件,获得直接绘制的能力。借助官方 媒体播放器开发指导 文档,可以发现鸿蒙提供了 SurfaceProvider 类,它管理的 Surface 对象可以用于视频解码后的展示。而 Flutter 渲染与视频上屏从原理上是类似的,因此我们可以借用 SurfaceProvider 实现 Surface 的管理和创建:
// 创建一个用于管理 Surface 的容器组件
SurfaceProvider surfaceProvider = new SurfaceProvider(context);
// 注册视图创建回调
surfaceProvider.getSurfaceOps().get().addCallback(surfaceCallback);
// ... 在 surfaceCallback 中
@Override
public void surfaceCreated(SurfaceOps surfaceOps) {
Surface surface = surfaceOps.getSurface();
// ...将 surface 通过 JNI 交给 Native 侧
FlutterJNI.onSurfaceCreated(surface);
}
b. 与 Surface 关联的本地窗口对象
鸿蒙目前开放的 Native API 并不多,在官方文档中我们可以比较容易地找到 Native_layer API。根据文档的说明,Native API 中的 NativeLayer 对象刚好对应了 Java 侧的 Surface 类,借助 GetNativeLayer 方法,我们实现了两者之间的转化:
// platform_view_android_jni_impl.cc
static void SurfaceCreated(JNIEnv* env, jobject jcaller, jlong shell_holder, jobject jsurface) {
fml::jni::ScopedJavaLocalFrame scoped_local_reference_frame(env);
// 通过鸿蒙 Native API 获取本地窗口对象 NativeLayer
auto window = fml::MakeRefCounted(
GetNativeLayer(env, jsurface));
ANDROID_SHELL_HOLDER->GetPlatformView()->NotifyCreated(std::move(window));
}
c. 与本地窗口对象关联的 EGLSurface
在 Android 的 AOSP 实现中,EGLSurface 可通过 EGL 库的 eglCreateWindowSurface 方法从本地窗口对象 ANativeWindow 创建而来。对于鸿蒙而言,虽然我们没有从公开文档找到类似的说明,但是 鸿蒙标准库 默认支持了 OpenGL ES,而且鸿蒙 SDK 中也附带了 EGL 相关的库及头文件,我们有理由相信在鸿蒙系统上,EGLSurface 也可以通过此方法从前一步生成的 NativeLayer 转化而来,在之后的验证中我们也确认了这一点:
// window->handle() 即为之前得到的 NativeLayer
EGLSurface surface = eglCreateWindowSurface(
display, config_, reinterpret_cast(window->handle()),
attribs);
//...交给 Flutter 渲染管线
2. 交互能力实现
交互能力是支撑 Flutter 应用能够正常运行的另一个基本要求。在 Flutter 中,交互包含了各种触摸事件、鼠标事件、键盘录入事件的传递及消费。以触摸事件为例,Flutter 事件传递的整个流程如下图所示:
iOS/Android 的原生容器通过触摸事件的回调 API 接收到事件之后,会将其打包传递至引擎层,后者将事件传发给 Flutter 框架层,并完成事件的消费、分发和逻辑处理。同样,整个流程的大部分工作已经由 Flutter 统一,我们要做的仅仅是在原生容器上监听用户的输入,并封装成指定格式交给引擎层而已。
在鸿蒙系统上,我们可以借助平台提供的 多模输入 API,实现多种类型事件的监听:
flutterComponent.setTouchEventListener(touchEventListener); // 触摸及鼠标事件
flutterComponent.setKeyEventListener(keyEventListener); // 键盘录入事件
flutterComponent.setSpeechEventListener(speechEventListener); // 语音录入事件
对于事件的封装处理,可以复用 Android 已有逻辑,只需要关注鸿蒙与 Android 在事件处理上的对应关系即可,比如触摸事件的部分对应关系:
3. 其他必要的平台能力
为了保证 Flutter 应用能够正常运行,除了最基本的渲染和交互外,我们的嵌入层还要提供资源管理、事件循环、生命周期同步等平台能力。对于这些能力 Flutter 大多都在嵌入层的公共部分有抽象类声明,只需要使用鸿蒙 API 重新实现一遍即可。
比如资源管理,引擎提供了 AssetResolver 声明,我们可以使用鸿蒙 Rawfile API 来实现:
class HAPAssetMapping : public fml::Mapping {
public:
HAPAssetMapping(RawFile* asset) : asset_(asset) {}
~HAPAssetMapping() override { CloseRawFile(asset_); }
size_t GetSize() const override { return GetRawFileSize(asset_); }
const uint8_t* GetMapping() const override {
return reinterpret_cast(GetRawFileBuffer(asset_));
}
private:
RawFile* const asset_;
FML_DISALLOW_COPY_AND_ASSIGN(HAPAssetMapping);
};
对于事件循环,引擎提供了 MessageLoopImpl 抽象类,我们可以使用鸿蒙 Native_EventHandler API 实现:
// runner_ 为鸿蒙 EventRunnerNativeImplement 的实例
void MessageLoopHarmony::Run() {
FML_DCHECK(runner_ == GetEventRunnerNativeObjForThread());
int result = ::EventRunnerRun(runner_);
FML_DCHECK(result == 0);
}
void MessageLoopHarmony::Terminate() {
int result = ::EventRunnerStop(runner_);
FML_DCHECK(result == 0);
}
对于生命周期的同步,鸿蒙的 Page Ability 提供了完整的生命周期回调(如下图所示),我们只需要在对应的时机将状态上报给引擎即可。
当以上这些能力都准备好之后,我们就可以成功把 Flutter 应用跑起来了。以下是通过 DevEco Studio 运行官方 flutter gallery 应用的截图,截图中 Flutter 引擎已经使用鸿蒙系统的平台能力进行了重写:
借由鸿蒙的多设备支持能力,此应用甚至可在 TV、车机、手表、平板等设备上运行:
总结和展望
通过上述的构建和适配工作,我们以极小的开发成本实现了 Flutter 在鸿蒙系统上的移植,基于 Flutter 开发的上层业务几乎不做任何修改就可以在鸿蒙系统上原生运行,为迎接鸿蒙系统后续的大规模推广也提前做好了技术储备。
当然,故事到这里并没有结束。在最基本的运行和交互能力之上,我们更需要关注 Flutter 与鸿蒙自身生态的结合:如何优雅地适配鸿蒙的分布式技术?如何用 Flutter 实现设备之间的快速连接、资源共享?现有的众多 Flutter 插件如何应用到鸿蒙系统上?未来 MTFlutter 团队将在这些方面做更深入的探索,因为解决好这些问题,才是真正能让应用覆盖用户生活的全场景的关键。
作者:美团技术团队
链接:https://juejin.cn/post/6920862050952413197
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter PlatformView 在闲鱼直播业务中的实践
背景
闲鱼近期实现了端上直播间的 Flutter 技术重构,验证和拓展了 Flutter 在音视频领域的业务边界。因为直播丰富的玩法和可变的交互,通常我们会在直播间页面覆盖一层互动层,用于处理和展示业务互动行为。这一互动层,通常是由 H5/Weex 等技术来实现的,以满足动态性和业务投放的需求。因为其背后有着一整套配套的解决方案和能力,显然在 Flutter 场景下,复用或移植成熟的 Native 能力是比较好的解决方案,PlatformView 是最适合用于实现该组件的技术,这也是我们采用的方案。
什么是 PlatformView?
PlatformView 技术是 Flutter 提供的一种能够将 Native 组件嵌入到 Flutter 页面中的能力,有了这种能力,一些 Native 上非常成熟的功能组件,例如地图、广告页面、WebView 就可以很方便地和 Flutter 结合,在 Flutter 页面上展示。
实现技术上,iOS 中,PlatformView 的 Native View 会被加入到 Flutter 的 UI 视图层级中,这种方式称之为 Hybrid Composition;而 Android 支持使用 VirtualDisplay 和 Hybrid Composition 两种模式,前者将 Native View 绘制到内存中,然后和 Flutter Widget 一起渲染到 Flutter 页面中,后者和 iOS 上类似。闲鱼目前在 Android 中使用的是 VirtualDisplay 这种模式。
直播间互动层组件
互动层是一个覆盖整个直播间的组件,隶属于某一特定的直播间,可以跟随该直播间上下翻页滑动,一般情况下处于直播间 View 层级的最上层,这样才能做到可以在直播间任意位置布局任意的元素并展示。它是一个背景透明的组件,当用户点击互动层上的元素时,由互动层来进行响应交互,而当用户点击透明区域时,事件会穿透互动层,由下面层级上最合适的组件来进行响应,不影响正常的直播间功能。这就要求我们对该组件的事件分发进行一些处理。这里主要的处理方案是,获取用户的点击位置坐标点,判断组件该像素点的透明度,根据一定的阈值来区分究竟是该由谁来响应。以 iOS 为例,我们知道 iOS 的事件响应分为两个阶段:第一阶段用于寻找最佳响应者,即在 View Tree 上不断调用 hitTest 和 pointInside 方法进行检测,第二阶段才是真正响应事件。所以对于 iOS 实现来说 ,我们只要干预第一阶段,重写该互动层 View 的 pointInside 方法增加上我们的透明度判断逻辑,就可以实现。Android 也是进行类似的处理。
PlatformView 互动层的事件分发问题
虽然通过 PlatformView 可以很方便地嵌入互动层 Native View,但在这个场景下事件处理遇到了一些麻烦。通常情况下,如果嵌入的 PlatformView 是一个正常响应事件的组件,那一般不会有问题,但由上面的分析可知,我们需要对事件进行特殊处理,因为互动层 PlatformView 处于整个直播间的最上层,所以正常情况下,所有它下面的 Flutter 组件都无法响应事件。我们可以将 PlatformView 的 hitTestBehavior 设置为 PlatformViewHitTestBehavior.transparent,这样可以将事件穿透到下面其他的 Flutter 组件,但是互动层本身就无法响应事件了。
PlatformView 有两个身份,一个是作为 Native View,另外一个是作为 Flutter 组件树上的一个节点(Widget),因此它上面的事件由两部分共同配合处理。
所以我们需要先探究一下 Flutter 框架是如何处理 PlatformView 在 Native 和 Flutter 两侧的事件分发和控制的,下面以 iOS 为例来进行具体分析。
PlatformView 事件响应分析
由 UI 层级图和下面的源码可以看出,PlatformView 是 FlutterView 的 subView。源码中的 embeded_view 是我们真正提供给 Flutter 的 Native View,它会传递给 FlutterTouchInterceptingView 的构造方法,成为其 subView,FlutterTouchInterceptingView 又是 ChildClippingView 的 subView。
FlutterTouchInterceptingView
这几个 view 中,FlutterTouchInterceptingView 是 Flutter 用来控制和处理 PlatformView 事件的关键。Flutter 需要有这个一个View 来拦截事件,因为事件毕竟是从 Native 传递给 Flutter 的,而 PlatformView 本身也是个 Native View,如果不对作用在 PlatformView 上的事件进行拦截的话,PlatformView 自身就会消化掉事件,而 Flutter 侧则感知不到也没法控制了。
FlutterTouchInterceptingView 的 frame 和 embededView 保持一致,并作为其 superView,根据 iOS 的事件传递规则,FlutterTouchInterceptingView 会先接收到事件。由注释可知,FlutterTouchInterceptingView 实现了两个能力:一是它会延迟或者阻止事件到达 embededView;二是它会将所有的事件直接转发给 FlutterView。而这两点,分别是由 DelayingGestureRecognizer 和 ForwardingGestureRecognizer 这两个手势来完成的。
DelayingGestureRecognizer
DelayingGestureRecognizer 需要延迟其他事件响应,并且将除了 ForwardingGestureRecognizer 之外的其他手势都失效。
DelayingGestureRecognizer 是添加在 embededView 的 superView(FlutterTouchInterceptingView) 上的手势(Gesture),之所以能够起作用拦截 embededView 的手势和事件,原因在于 iOS 的手势识别优先级高于普通的事件响应,且响应链一旦确定,每次事件响应,整条响应链上手势的 delegate 方法都会被调用,用于确定最终可以识别的手势。如下图,如果触摸了 View4,确定 View 4 为最佳响应者,则从 View4 到 rootView 上的所有手势(gesture2、gesture3、gesture4、gesture5)的 delegate 方法都会被调用。
ForwardingGestureRecognizer
ForwardingGestureRecognizer 的实现就很简单了,它重写了事件的相关处理方法,将事件直接转发。
因为 PlatformView 也作为 Flutter Widget Tree 的一个节点,事件转发到 Flutter 之后,遵循 Flutter 的事件处理机制,和其他手势一起在竞技场(Arena)中角逐是否能够响应。最终如果竞争成功,事件该由 PlatformView 来响应,则 FlutterTouchInterceptingView 的 releaseGesture 方法会被调用,DelayingGestureRecognizer 手势会被置成 Failed 状态,其他事件就可以开始响应。相应地如果竞争失败,那么 FlutterTouchInterceptingView 的 blockGesture 方法会被调用,DelayingGestureRecognizer 手势会被置成 Ended 状态,这表明事件被它响应并且完成了,其他手势或者 View 响应者就不会再响应该事件了。
解决事件分发问题
由上面 iOS 上的的事件原理可知,Flutter 主要是通过 DelayingGestureRecoginzer 和 ForwardingGestureRecoginizer 这两个手势来干预和控制 PlatformView 上 Native 的事件分发行为。所以可以想到,如果没有这两个事件,事件的响应又会和我们熟悉的 Native 流程一致。
所以想要自定义 PlatformView 事件分发,在 iOS 上我们可以这么做:
1.根据需要设置 PlatformView Widget 的 hitTestBehavior 参数;
2.重写 PlatformView 的 pointInside 方法,在里面增加控制 Flutter 这两个手势的逻辑。因为 hitTest 寻找最佳响应者的过程一定在响应链响应之前,所以此处对 Flutter 手势的处理,不会影响事件转发给 Flutter 后的处理逻辑。
具体到直播互动场景来说,为了能让事件在大多数情况下能够被互动层下面的组件响应,在 Flutter 侧 PlatformView Widget 的 hitTestBehavior 需要设置为 PlatformViewHitTestBehavior.transparent,目的是为了让 PlatformView Widget 之下的 Flutter Widget 可以响应事件。重写 PlatformView 的 pointInside,如果透明度判断认为该由互动层来响应,则禁用 Flutter 的这两个手势;如果不该由互动层响应(即该由其他 Flutter 组件来响应),则恢复这两个手势响应,不影响正常的逻辑。相关实现代码如下:
因为 DelayingGestureRecoginzer 和 ForwardingGestureRecoginizer 这两个手势是定义在 FlutterTouchInterceptingView 中,而 FlutterTouchInterceptingView 是我们互动层 Native View 的 superView,所以代码中的 self.fluttterForwardGestureRecognizer 和 self.flutterDelayingGestureRecognizer 可以通过反射、循环遍历 superView 的手势列表来获取到。
关于 Android 上的处理
因为 Android 上 PlatfromView 采用了 VirtualDisplay 方案实现的,所以 FlutterView 和 PlatfromView 并不是真正处于同一个 ViewTree 中,因而在这个问题的处理上面和 iOS 略有不同,但原理相通。这里简单的说一下Android 上面的情况。
PlatformView 原本的设计中是由 FlutterView 接收 Android 的原生 TouchEvent,然后转化为 Flutter 中用于事件处理的 Event,再分发给 Flutter中 的 Widget。当 PlatformView 的 Widget(AndroidView)接收到事件后,会再次将事件转化为 Android 的 TouchEvent,然后转给 Native 的 PlatformView 实现 View。如图:
我们可以在 FlutterView 外面再套一层用于事件处理的 View(EventInterceptView),该 View 会优先接收到事件,然后根据实际需要,决定事件转发给 FlutterView 还是 PlatformView。如图:
通过上述方案,我们在 iOS 和 Android 两端都可以做到在 PlatformView 互动层中实现透明度判断逻辑,并交给正确的响应者(Flutter 组件或者 Native View)来进行事件响应。使用 PlatformView 也让我们最大限度地复用了直播互动层背后对应的一整套解决方案,业务能力和使用体验都达到了和 Native 原生实现一样的效果。
写在最后
PlatformView 提供了在 Flutter 页面中嵌入 Native View 的能力,方便了很多业务场景和功能的实现,但 PlatformView 技术也还存在一些问题,例如使用了 PlatformView 在某些场景下可能会导致图片、视频的纹理错乱等。闲鱼在直播业务中第一次在生产环境中使用了 PlatformView 技术,也解决了一些已知问题,但仍有很多问题是我们还没有发现和解决的,后续我们也会继续在这方面进行研究,探索使用 PlatformView 的最佳实践!
作者:传道士
链接:https://juejin.cn/post/7027079414940712991
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
IdleHandler你会用吗?记一次IdleHandler使用误区,导致ANR
1. 示例
问题抛出,当引入线上ANR抓取工具后,发现了不少IdleHandler带来的问题。堆栈具体见下图
思考为什么idleHandler会带来这样的问题呢,或许你会觉得是单个消息执行时间过长导致的。那么请看示例,项目本身代码较为复杂,简化代码如下:
- 工具类
/**
* 添加任务到IdleHandler
*
* @param runnable runnable
*/
public static void run(Runnable runnable) {
IUiRunnable uiRunnable = new IUiRunnable(runnable);
Looper.getMainLooper().getQueue().addIdleHandler(uiRunnable);
}
- 使用工具类
public class MainActivity extends AppCompatActivity {
public static final String TAG = "idleHandler";
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
}
@Override
protected void onResume() {
super.onResume();
Log.e(TAG, "onResume: start");
//1 //关键代码处 延迟 3s执行的delay msg
new Handler().postDelayed(new Runnable() {
@Override
public void run() {
Log.e(TAG, "delay: msg");
startService(new Intent(MainActivity.this, MyService.class));
}
}, 3000);
//关键代码处 添加到IdleHandler里的三个任务
UIManager.run(() -> test(1));
UIManager.run(() -> test(2));
UIManager.run(() -> test(3));
}
//延迟任务
private void test(final int i) {
try {
Log.e(TAG, "queueIdle:test start " + i);
Thread.sleep(3000);
Log.e(TAG, "queueIdle:test end " + i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
让我们来猜猜下面代码的输出顺序。再回看一下代码,肯定以为是下面这样对吧?
如果你觉得上面的输出没问题,那就更需要继续读下去了
这里把真实log截出来:
what??delay3000ms为什么失效了。而是Idle消息先执行了。
为什么呢?不慌遇到这种问题我们肯定要通过IdleHandler机制的源码,来找答案了。
2. 源码分析
//MessageQueue.java
Message next() {
// Return here if the message loop has already quit and been disposed.
// This can happen if the application tries to restart a looper after quit
// which is not supported.
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
int pendingIdleHandlerCount = -1; // -1 only during first iteration
int nextPollTimeoutMillis = 0;
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
nativePollOnce(ptr, nextPollTimeoutMillis);
...
// If first time idle, then get the number of idlers to run.
// Idle handles only run if the queue is empty or if the first message
// in the queue (possibly a barrier) is due to be handled in the future.
//1 执行时机
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
//2 copy副本
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
//3 逐个执行
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
//4 是否移除当前idleHandler
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
// Reset the idle handler count to 0 so we do not run them again.
pendingIdleHandlerCount = 0;
// While calling an idle handler, a new message could have been delivered
// so go back and look again for a pending message without waiting.
nextPollTimeoutMillis = 0;
}
}
//5 外部调用添加idleHandler
public void addIdleHandler(@NonNull IdleHandler handler) {
if (handler == null) {
throw new NullPointerException("Can't add a null IdleHandler");
}
synchronized (this) {
mIdleHandlers.add(handler);
}
}
鉴于next()方法比较长且相关介绍也比较多,这里不细说。
注释1处,这里是IdleHandler执行时机,即主线程无消息或者未到执行时机(空闲时间)。
注释2处,可以看到mPendingIdleHandlers相当于copy了mIdleHandlers中的内容,由注释5处可以看到我们调用addIdleHandler()添加的任务都存进了mIdleHandlers。
注释3处,这里循环意味着要一次性处理之前添加的全部IdleHandler任务,如果我们短时内调用了多次addIdleHandler(),意味着这些idle msg将被拿出来逐个执行;而且要全部处理掉,才可以继续执行原消息队列的消息,如果idle msg很耗时,便会出现前面的主线程的postDelay任务执行时间就非常不可靠了;同理如果期间有触摸事件发生,那极有可能会因为得不到及时处理而导致ANR发生。赶紧检查下自己的项目中是否有此类问题。
注释4处,控制本次的IdleHandler是会被再次调用还是单次调用呢,是由queueIdle()方法的返回值决定,这点是我们该利用起来的。
上面的工具方法初衷是好的,提供接口暴露给各业务侧在某个需要的时刻将非紧急任务延迟加载,进而减少卡顿,但用起来却没有那么丝滑,甚至导致ANR,希望大家理解后能够避开这个坑。
3.安全用法
IdleHandler再介绍
- 这里再赘述下IdleHandler作用,我们都知道在做启动性能优化的时候,要尽可能多地减少启动阶段主线程任务。对一些启动阶段非必须且一定要在主线程里完成的任务,我们可以在应用启动完成之后再去加载。正是考虑到这些google官方提供了IdleHandler机制来告诉我们线程空闲时机。
利用IdleHandler设计的工具类
直接使用IdleHandler,肯定不太符合博主这种“大项目”的编码风格,简单封装是必要,方便我们做些功能定制,下面给大家说下项目中的工具类。
- 正确的方法 将启动过程中非紧急的主线程任务全部放进uiTasks里,然后逐个执行,切记单个消息耗时不要太长。
private static List<Runnable> uiTasks = new ArrayList<>();
public static UIPoolManager addTask(Runnable runnable) {
tasks.add(runnable);
return this;
}
public static UIManager runUiTasks() {
NullHelper.requireNonNull(uiTasks);
IUiTask iUiTask = new IUiTask() {
@Override
public boolean queueIdle() {
if (!uiTasks.isEmpty()) {
Runnable task = uiTasks.get(0);
task.run();
uiTasks.remove(task);
}
//逐次取一个任务执行 避免占用主线程过久
return !uiTasks.isEmpty();
}
};
Looper.myQueue().addIdleHandler(iUiTask);
return this;
}
替换成上面的方法再试一遍。
@Override
protected void onResume() {
super.onResume();
Log.e(TAG, "onResume: start");
//1
new Handler().postDelayed(new Runnable() {
@Override
public void run() {
Log.e(TAG, "delay: msg");
startService(new Intent(MainActivity.this, MyService.class));
}
}, 3000);
UIManager.addTask(() -> test(1));
UIManager.addTask(() -> test(2));
UIManager.addTask(() -> test(3));
UIManager.runUiTasks();
}
得到最初希望的时序结果:
作者:Lphoenix
链接:https://juejin.cn/post/7041576680648867877
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Android系统启动-Zygote进程
本篇文章基于Android6.0源码分析
相关源码文件:
/system/core/rootdir/init.rc
/system/core/rootdir/init.zygote64.rc
/frameworks/base/cmds/app_process/App_main.cpp
/frameworks/base/core/jni/AndroidRuntime.cpp
/frameworks/base/core/java/com/android/internal/os/
- ZygoteInit.java
- Zygote.java
- ZygoteConnection.java
/frameworks/base/core/java/android/net/LocalServerSocket.java
/system/core/libutils/Threads.cpp
Zygote进程启动前的概述
通过init.rc的文件解析会启动zygote相关的服务从而启动zygote进程。通过import导入决定启动哪种类型的zygote服务脚本,这里分为32位和64位架构的zygote服务脚本
import /init.${ro.zygote}.rc
在/system/core/rootdir目录中有四个zygote相关的服务脚本
init.zygote32.rc // 支持32位的zygote
init.zygote32_64.rc // 即支持32位也支持64位的zygote,其中以32位为主,64位为辅
init.zygote64.rc // 支持64位的zygote
init.zygote64_32.rc // 即支持64位也支持32位的zygote,其中以64位为主,32位为辅
下面我们分析只分析64位的zygote服务脚本的Android初始化语言:
service zygote /system/bin/app_process64 -Xzygote /system/bin --zygote --start-system-server
class main
socket zygote stream 660 root system
onrestart write /sys/android_power/request_state wake
onrestart write /sys/power/state on
onrestart restart media
onrestart restart netd
writepid /dev/cpuset/foreground/tasks
zygote进程的执行程序为/system/bin/app_process64中,其中参数为:-Xzygote /system/bin --zygote --start-system-server,classname为main 。除了在Init进程解析时创建Zygote进程,在servicemanager、surfaceflinger、systemserver进程被杀时Zygote进程也会进行重启。
其中/system/bin/app_process64的映射的执行文件为:/frameworks/base/cmds/app_process/app_main.cpp
Zygote进程启动
如图1所示,zygote进程启动时会先启动app_main类的main()方法:
// 参数argv为 : -Xzygote /system/bin --zygote --start-system-server
int main(int argc, char* const argv[])
{
// 创建一个AppRuntime实例,AppRuntime 继承 AndoirdRuntime
AppRuntime runtime (argv[0], computeArgBlockSize(argc, argv));
//忽略第一个参数
argc--;
argv++;
// 解析参数并对变量赋值
bool zygote = false;
bool startSystemServer = false;
bool application = false;
String8 niceName;
String8 className;
++i; // Skip unused "parent dir" argument.
while (i < argc) {
const char * arg = argv [i++];
if (strcmp(arg, "--zygote") == 0) {
// 参数中有--zygote
zygote = true;
niceName = ZYGOTE_NICE_NAME;
} else if (strcmp(arg, "--start-system-server") == 0) {
// 参数中有--start-system-server
startSystemServer = true;
} else if (strcmp(arg, "--application") == 0) {
application = true;
} else if (strncmp(arg, "--nice-name=", 12) == 0) {
niceName.setTo(arg + 12);
} else if (strncmp(arg, "--", 2) != 0) {
className.setTo(arg);
break;
} else {
--i;
break;
}
}
if (zygote) {
//如果zygote为true,则调用AndroidRuntime的start方法,并传入了"com.android.internal.os.ZygoteInit"参数
runtime.start("com.android.internal.os.ZygoteInit", args, zygote);
} else if (className) {
runtime.start("com.android.internal.os.RuntimeInit", args, zygote);
} else {
fprintf(stderr, "Error: no class name or --zygote supplied.\n");
app_usage();
LOG_ALWAYS_FATAL("app_process: no class name or --zygote supplied.");
return 10;
}
}
在app_main的mian()方法中,主要是根据zygote的脚本的参数进行解析,在解析到有--zygote字符后,则确定执行AndroidRuntime.start方法,并且第一个参数传为com.android.internal.os.ZygoteInit。
AndroidRuntime.start()
在此方法中,主要做了三件事:
· 创建虚拟机实例
· JNI方法的注册
· 调用参数的main()方法
// 这里的className为:com.android.internal.os.ZygoteInit
void AndroidRuntime::start(const char* className, const Vector<String8>& options, bool zygote)
{
/* start the virtual machine */
JniInvocation jni_invocation;
jni_invocation.Init(NULL);
JNIEnv * env;
// 1. 创建虚拟机
if (startVm(& mJavaVM, &env, zygote) != 0) {
return;
}
onVmCreated(env);
// 2. JNI方法注册
if (startReg(env) < 0) {
ALOGE("Unable to register all android natives\n");
return;
}
// 解析classname参数
//将"com.android.internal.os.ZygoteInit"转换为"com/android/internal/os/ZygoteInit"
char * slashClassName = toSlashClassName(className);
jclass startClass = env->FindClass(slashClassName);
if (startClass == NULL) {
} else {
// 得到ZygoteInit的main方法
jmethodID startMeth = env->GetStaticMethodID(startClass, "main",
"([Ljava/lang/String;)V");
if (startMeth == NULL) {
} else { env ->
// 3. 执行ZygoteInit的main方法
CallStaticVoidMethod(startClass, startMeth, strArray);
}
}
free(slashClassName);
}
对start方法进行了一些删减后,主要是通过startVm 创建虚拟机,通过startReg(env)进行JNI方法注册,最后解析className参数,去执行ZygoteInit.main方法。下面将逐一分析这三种状态。
1. 创建虚拟机实例
startVm:
int AndroidRuntime::startVm(JavaVM** pJavaVM, JNIEnv** pEnv, bool zygote)
{
// ...
// JNI检测功能
bool checkJni = false;
property_get("dalvik.vm.checkjni", propBuf, "");
if (strcmp(propBuf, "true") == 0) {
checkJni = true;
} else if (strcmp(propBuf, "false") != 0) {
/* property is neither true nor false; fall back on kernel parameter */
property_get("ro.kernel.android.checkjni", propBuf, "");
if (propBuf[0] == '1') {
checkJni = true;
}
}
ALOGD("CheckJNI is %s\n", checkJni ? "ON" : "OFF");
if (checkJni) {
addOption("-Xcheck:jni");
}
// /虚拟机产生的trace文件,主要用于分析系统问题,路径默认为/data/anr/traces.txt
parseRuntimeOption("dalvik.vm.stack-trace-file", stackTraceFileBuf, "-Xstacktracefile:");
//对于不同的软硬件环境,这些参数往往需要调整、优化,从而使系统达到最佳性能
parseRuntimeOption("dalvik.vm.heapstartsize", heapstartsizeOptsBuf, "-Xms", "4m");
parseRuntimeOption("dalvik.vm.heapsize", heapsizeOptsBuf, "-Xmx", "16m");
parseRuntimeOption(
"dalvik.vm.heapgrowthlimit",
heapgrowthlimitOptsBuf,
"-XX:HeapGrowthLimit="
);
parseRuntimeOption("dalvik.vm.heapminfree", heapminfreeOptsBuf, "-XX:HeapMinFree=");
parseRuntimeOption("dalvik.vm.heapmaxfree", heapmaxfreeOptsBuf, "-XX:HeapMaxFree=");
parseRuntimeOption(
"dalvik.vm.heaptargetutilization",
heaptargetutilizationOptsBuf,
"-XX:HeapTargetUtilization="
);
// ...
// 初始化虚拟机
if (JNI_CreateJavaVM(pJavaVM, pEnv, & initArgs) < 0) {
ALOGE("JNI_CreateJavaVM failed\n");
return -1;
}
return 0;
}
startVm方法里面有很多代码,但主要分为三步,第一步是检测,第二步是软硬件参数的设置,第三步是初始化虚拟机。
2. JNI方法的注册
startReg
int AndroidRuntime::startReg(JNIEnv* env)
{
androidSetCreateThreadFunc((android_create_thread_fn) javaCreateThreadEtc);
ALOGV("--- registering native functions ---\n");
env->PushLocalFrame(200);
//进程JNI方法的注册
if (register_jni_procs(gRegJNI, NELEM(gRegJNI), env) < 0) { env ->
PopLocalFrame(NULL);
return -1;
}
env->PopLocalFrame(NULL);
return 0;
}
// 这里的array[]是gRegJNI,它是一个映射了很多方法的数组
static int register_jni_procs(const RegJNIRec array[], size_t count, JNIEnv* env)
{
// 执行很多映射的方法
for (size_t i = 0; i < count; i++) {
if (array[i].mProc(env) < 0) {
return -1;
}
}
return 0;
}
startReg方法是对JNI方法的注册,它通过一个有很多宏定义的数组,并执行数组定义的方法,进行对JNI和Java层方法一一映射。
3. 调用ZygoteInit.main方法
在AndroidRuntime.start()方法的最后,通过反射执行了其ZygoteInit.main()方法。
if (startClass == NULL) {
} else {
// 得到ZygoteInit的main方法
jmethodID startMeth = env->GetStaticMethodID(startClass, "main",
"([Ljava/lang/String;)V");
if (startMeth == NULL) {
} else { env ->
// 3. 执行ZygoteInit的main方法
CallStaticVoidMethod(startClass, startMeth, strArray);
}
}
通过反射去执行ZygoteInit.main方法,也是第一次进入java语言的世界。所以AndroidRuntime的start方法做了三件事,一是初始化虚拟机,二是JNI方法的注册,三是通过反射执行ZygoteInit.main方法。
ZygoteInit.main
Zygote进程用于创建管理framework层的SystemServer进程,还用于创建App进程,就是应用App启动创建进程时,是由Zygote进程创建的,并且Zygote创建子进程将使用copy on write的技术,就是子进程直接继承父进程的现有的资源,在子进程对于共有的资源是读时共享,写时复制。
ZygoteInit.main方法中主要做了四件事:
· 注册服务端的socket,用于接收创建子进程的信息
· 提前预加载类和资源,用于子进程共享
· 创建SystemServer进程,其管理着framework层
· 循环监听服务socket,创建子进程
public static void main(String argv[])
{
try {
// 创建服务端Soctet,用于接收创建子进程信息
registerZygoteSocket(socketName);
// 提前预加载类和资源
preload();
// gc操作
gcAndFinalize();
// 创建SystemServer进程
if (startSystemServer) {
startSystemServer(abiList, socketName);
}
// 用服务socket监听创建进程信息,并创建子进程
runSelectLoop(abiList);
closeServerSocket();
} catch (MethodAndArgsCaller caller) {
caller.run();
} catch (RuntimeException ex) {
Log.e(TAG, "Zygote died with exception", ex);
closeServerSocket();
throw ex;
}
}
通过registerZygoteSocket方法去创建服务端的socket,preload()方法去提前加载类和资源,startSystemServer方法去创建SystemServer进程去管理framework层,runSelectLoop方法循环监听创建子进程。
1. 注册服务端Socket
registerZygoteSocket
private static void registerZygoteSocket(String socketName)
{
if (sServerSocket == null) {
int fileDesc;
final String fullSocketName = ANDROID_SOCKET_PREFIX + socketName;
try {
String env = System . getenv (fullSocketName);
fileDesc = Integer.parseInt(env);
} catch (RuntimeException ex) {
throw new RuntimeException (fullSocketName + " unset or invalid", ex);
}
try {
// 创建服务端的socket
FileDescriptor fd = new FileDescriptor();
fd.setInt$(fileDesc);
sServerSocket = new LocalServerSocket (fd);
} catch (IOException ex) {
throw new RuntimeException (
"Error binding to local socket '" + fileDesc + "'", ex);
}
}
}
创建一个服务端的socket用于接口多个客户端的信息接收,在后面的runSelectLoop方法用于监听服务端的socket信息,以便创建子进程。
2. 预加载资源
preload
static void preload()
{
preloadClasses(); //预加载位于/system/etc/preloaded-classes文件中的类
preloadResources(); //预加载资源,包含drawable和color资源
preloadOpenGL(); //预加载OpenGL
preloadSharedLibraries(); //预加载"android","compiler_rt","jnigraphics"这3个共享库
preloadTextResources(); //预加载 文本连接符资源
WebViewFactory.prepareWebViewInZygote(); //仅用于zygote进程,用于内存共享的进程
}
preloadClasses()方法通过Class.forName()反射的方法去加载类,preloadResources方法主要是加载位于com.android.internal.R.array.preloaded_drawables和com.android.internal.R.array.preloaded_color_state_lists的资源。
提前加载资源的好处是,在复制创建子进程时,提前加载好的资源可以给子进程直接使用,不用第二次创建,但不好的地方是每个创建的子进程都有拥有很多资源,而不管是否需要。
3. 启动SystemServer进程
startSystemServer
private static boolean startSystemServer(String abiList, String socketName)
throws MethodAndArgsCaller, RuntimeException
{
// 通过数组保存创建systemserver进程的信息
String args [] = {
"--setuid=1000",
"--setgid=1000",
"--setgroups=1001,1002,1003,1004,1005,1006,1007,1008,1009,1010,1018,1021,1032,3001,3002,3003,3006,3007",
"--capabilities=" + capabilities + "," + capabilities,
"--nice-name=system_server",
"--runtime-args",
"com.android.server.SystemServer",
};
ZygoteConnection.Arguments parsedArgs = null;
int pid;
try {
parsedArgs = new ZygoteConnection . Arguments (args);
ZygoteConnection.applyDebuggerSystemProperty(parsedArgs);
ZygoteConnection.applyInvokeWithSystemProperty(parsedArgs);
// 创建systemserver进程
pid = Zygote.forkSystemServer(
parsedArgs.uid, parsedArgs.gid,
parsedArgs.gids,
parsedArgs.debugFlags,
null,
parsedArgs.permittedCapabilities,
parsedArgs.effectiveCapabilities
);
} catch (IllegalArgumentException ex) {
throw new RuntimeException (ex);
}
/* pid==0 则是子进程,就是systemserver */
if (pid == 0) {
if (hasSecondZygote(abiList)) {
waitForSecondaryZygote(socketName);
}
// 完成system_server进程剩余的工作
handleSystemServerProcess(parsedArgs);
}
return true;
}
通过Zygote.forkSystemServer去创建SystemServer进程,其进程是管理着framework的,我们将在下一篇分析SystemServer进程进程的启动。
4. 循环等待孵化进程
runSelectLoop
private static void runSelectLoop(String abiList) throws MethodAndArgsCaller
{
// FileDescriptor数组
ArrayList<FileDescriptor> fds = new ArrayList<FileDescriptor>();
// ZygoteConnection数组
ArrayList<ZygoteConnection> peers = new ArrayList<ZygoteConnection>();
//sServerSocket是socket通信中的服务端,即zygote进程。保存到fds[0]
fds.add(sServerSocket.getFileDescriptor());
peers.add(null);
while (true) {
// StructPollfd数组,并将相应位置fds的值赋值
StructPollfd[] pollFds = new StructPollfd[fds.size()];
for (int i = 0; i < pollFds.length; ++i) {
pollFds[i] = new StructPollfd ();
pollFds[i].fd = fds.get(i);
pollFds[i].events = (short) POLLIN;
}
try {
//处理轮询状态,当pollFds有事件到来则往下执行,否则阻塞在这里
Os.poll(pollFds, -1);
} catch (ErrnoException ex) {
throw new RuntimeException ("poll failed", ex);
}
for (int i = pollFds.length - 1; i >= 0; --i) {
//采用I/O多路复用机制,当接收到客户端发出连接请求 或者数据处理请求到来,则往下执行;
// 否则进入continue,跳出本次循环。
if ((pollFds[i].revents & POLLIN) == 0) {
continue;
}
if (i == 0) {
ZygoteConnection newPeer = acceptCommandPeer (abiList);
peers.add(newPeer);
fds.add(newPeer.getFileDesciptor());
} else {
//i>0,则代表通过socket接收来自对端的数据,并执行相应操作
boolean done = peers.get (i).runOnce();
if (done) {
peers.remove(i);
fds.remove(i);
}
}
}
}
}
在runSelectLoop方法中有一个轮询的状态,如果有事件接收则会去执行runOnce()的方法操作:
boolean runOnce() throws ZygoteInit.MethodAndArgsCaller
{
String args [];
Arguments parsedArgs = null;
FileDescriptor[] descriptors;
try {
//读取socket客户端发送过来的参数列表
args = readArgumentList();
descriptors = mSocket.getAncillaryFileDescriptors();
} catch (IOException ex) {
Log.w(TAG, "IOException on command socket " + ex.getMessage());
closeSocket();
return true;
}
if (args == null) {
// EOF reached.
closeSocket();
return true;
}
try {
//将binder客户端传递过来的参数,解析成Arguments对象格式
parsedArgs = new Arguments (args);
...
// fork创建一个新的进程
pid = Zygote.forkAndSpecialize(
parsedArgs.uid, parsedArgs.gid, parsedArgs.gids,
parsedArgs.debugFlags, rlimits, parsedArgs.mountExternal, parsedArgs.seInfo,
parsedArgs.niceName, fdsToClose, parsedArgs.instructionSet,
parsedArgs.appDataDir
);
} catch (ErrnoException ex) {
logAndPrintError(newStderr, "Exception creating pipe", ex);
} catch (IllegalArgumentException ex) {
logAndPrintError(newStderr, "Invalid zygote arguments", ex);
} catch (ZygoteSecurityException ex) {
logAndPrintError(
newStderr,
"Zygote security policy prevents request: ", ex
);
}
try {
if (pid == 0) {
// 处理子进程
IoUtils.closeQuietly(serverPipeFd);
serverPipeFd = null;
handleChildProc(parsedArgs, descriptors, childPipeFd, newStderr);
// should never get here, the child is expected to either
// throw ZygoteInit.MethodAndArgsCaller or exec().
return true;
} else {
// 父进程
IoUtils.closeQuietly(childPipeFd);
childPipeFd = null;
return handleParentProc(pid, descriptors, serverPipeFd, parsedArgs);
}
} finally {
IoUtils.closeQuietly(childPipeFd);
IoUtils.closeQuietly(serverPipeFd);
}
}
所以在runSelectLoop方法中,通过客户端的socket不断的和服务端的socket通信的监听,通过调用起runOnce方法去不断的创建新的进程。
总结
Zygote进程的启动过程主要有:
- 创建虚拟机和JNI方法的注册
- 注册服务Socket和提前加载系统类和资源
- 创建SystemServer进程
- 循环等待孵化进程
作者:ofLJli
链接:https://juejin.cn/post/7041839237582782477
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
NDK系列:JNI基础
1 Java、JNI、C/C++中的数据类型之间的映射关系
JNI是接口,Java与C/C++交互会有一个数据类型的对应,而JNI为此提供了一套中间类型。
2 JNI动态注册与静态注册
2.1 静态注册
步骤:
- 编写Java类,比如StaticRegister.java;
package register.staticRegister;
public class StaticRegister {
public static native String func();//注意native关键字
public static void main(String[] args) {
System.out.println(func());
}
}
- 在.java源文件目录下,命令行输入“javac StaticRegister.java”生成StaticRegister.class文件;
- 在StaticRegister.class所属包所在目录下,命令行执行“javah register.staticRegister.StaticRegister”(完整类名无后缀),在包所在目录生成register_staticRegister_StaticRegister.h头文件;
- 如果是JDK 1.8或以上,以上步骤可简化为一步:在StaticRegister.java目录下,命令行执行 javac -h . StaticRegister.java,直接在当前目录下得到.class文件和.h文件;
- 创建CLion项目并拷贝register_staticRegister_StaticRegister.h文件到项目目录;
- 在CLion项目中添加jni.h头文件和jni_md.h头文件,这两个头文件是JDK自带的,在C:\Program Files\Java\jdk1.8.0_144\include目录下,将这两个头文件拷贝到CLion项目目录;
- 在register_staticRegister_StaticRegister.h中修改#include
为#include "jni.h" ; - 我们其实可以看到,register_staticRegister_StaticRegister.h文件里面就是一个Java方面native方法的一个JNI声明,格式为JNIEXPORT 关键字一 jstring 返回值的JNI类型 JNICALL 关键字二 Java_register_staticRegister_StaticRegister_func Java_全类名_方法名
(JNIEnv *, jclass);如下;
/* DO NOT EDIT THIS FILE - it is machine generated */
#include "jni.h"
/* Header for class register_staticRegister_StaticRegister */
#ifndef _Included_register_staticRegister_StaticRegister
#define _Included_register_staticRegister_StaticRegister
#ifdef __cplusplus
extern "C" {
#endif
/*
* Class: register_staticRegister_StaticRegister
* Method: func
* Signature: ()Ljava/lang/String;
*/
JNIEXPORT jstring JNICALL Java_register_staticRegister_StaticRegister_func
(JNIEnv *, jclass);
#ifdef __cplusplus
}
#endif
#endif
- 编写头文件register_staticRegister_StaticRegister.h对应的register_staticRegister_StaticRegister.c源文件,拷贝并实现register_staticRegister_StaticRegister.h下的函数,如下:
#include "register_staticRegister_StaticRegister.h"
JNIEXPORT jstring JNICALL Java_register_staticRegister_StaticRegister_func
(JNIEnv *env, jclass jobj){
return (*env)->NewStringUTF(env,"Hi Java, this is JNI");
};
- 编写CMakeLists.txt文件,这是库的配置文件。最重要的是最后两个add_library(),其余的都是自动生成的。add_library()声明库的名字、类型和包含的.c&.h文件。SHARED关键字表示创建的库是动态库.dll,STATIC关键字表示创建的库是静态库.a。*注意:库本身有动态库和静态库之分,Java native方法也有静态注册和动态注册之分,二者没有关系。*这里将动态库命名为StaticRegisterLib;
cmake_minimum_required(VERSION 3.15)
project(JNI_C)
set(CMAKE_CXX_STANDARD 14)
add_library(JNI_C SHARED library.cpp library.h)
add_library(StaticRegisterLib SHARED register_staticRegister_StaticRegister.c register_staticRegister_StaticRegister.h)
- 此时CLion项目结构如下图,Build Project生成动态链接库,得到libStaticRegisterLib.dll;
- 在最开始的Java源文件中,添加静态代码块,使用System.load()方法加载该动态链接库,如下:
package register.staticRegister;
public class StaticRegister {
static {
System.load("E:\\_Projects_\\JNI_Projects\\JNI_C\\cmake-build-debug\\libStaticRegisterLib.dll");
}
public static native String func();
public static void main(String[] args) {
System.out.println(func());
}
}
- 在Java侧运行,得到如下效果,Java成功调用了dll中的方法,静态注册完毕。
- 上述过程,我们在JNI中使用Java_PACKAGENAME_CLASSNAME_METHODNAME与Java侧的方法进行匹配,这种方式我们称之为静态注册。
2.2 动态注册
步骤:
- 编写Java类,比如DynamicRegister.java,如下;
package register.dynamicRegister;
public class DynamicRegister {
public static native String func1(String s);
public static native int func2(int[] a);
public static void main(String[] args) {
System.out.println(func1("Hi JNI"));
int[] a = {1,2,3};
System.out.println("该数组有"+func2(a)+"个元素");
}
}
- 在CLion项目中添加jni.h头文件和jni_md.h头文件,这两个头文件是JDK自带的,在C:\Program Files\Java\jdk1.8.0_144\include目录下,将这两个头文件拷贝到CLion项目目录;
- 新建CLion项目,新建C/C++源文件dynamicRegister.c。在该.c文件中,实现两个函数,这两个函数将是native方法在JNI的实现,如下:
#include "jni.h"
jstring f1(JNIEnv *env, jclass jobj){
return (*env)->NewStringUTF(env,"Hi Java");
}
//注意JNI侧数组形参的写法以及如何求数组长度
jint f2(JNIEnv *env, jclass jobj, jintArray arr){
int len = (*env)->GetArrayLength(env,arr);
return len;
}
- 到目前,f1(),f2()与Java侧native方法func1(),func2()还没有任何关联,我们需要手动**管理关联**;
- 首先,我们新建一个以JNINativeMethod结构体为元素的数组,如下:
static const JNINativeMethod mMethods[] = {
{"func1","(Ljava/lang/String;)Ljava/lang/String;",(jstring *)f1},
{"func2","([I)I",(jint *)f2},
};
- 以上数组中每一个元素,都是JNI侧实现方法与Java侧native方法的关联,前两个是Java侧native方法的描述,最后一个是JNI侧函数实现的描述,格式为:
{"Java侧的native方法名","方法的签名",函数指针}
- 我们需要实现jni.h中的JNI_OnLoad()方法,该方法的实现方法是一个模板,如下:
JNIEXPORT jint JNICALL
JNI_OnLoad(JavaVM *vm, void *reserved){
JNIEnv* env = NULL;
//获得 JNIEnv
int r = (*vm)->GetEnv(vm, (void**) &env, JNI_VERSION_1_4);
if( r != JNI_OK){
return -1;
}
jclass mainActivityCls =
(*env)—>FindClass(env,"register/dynamicRegister/DynamicRegister");
// 最后参数是需要注册的native方法的个数,如果小于0则注册失败。
r = (*env)->RegisterNatives(env, mainActivityCls, mMethods, 2);
if(r != JNI_OK ){
return -1;
}
return JNI_VERSION_1_4;
}
- 注意!第一:以上FindClass(env,"register/dynamicRegister/DynamicRegister")中的字符串是Java侧DynamicRegister类的全类名,注意此处的写法"/";第二:RegisterNatives(env, mainActivityCls, mMethods, 2)中的最后一个参数是需要动态注册的方法个数,手动添加注册或者删除注册都需要对应变化,当然可以直接把mMethod[]的长度传进去,一劳永逸,如下:
int cnt = sizeof(mMethods)/ sizeof(mMethods[0]);
r = (*env)->RegisterNatives(env, mainActivityCls, mMethods, cnt);
- 在最开始的Java源文件中,添加静态代码块,使用System.load()方法加载该动态链接库,如下:
package register.dynamicRegister;
public class DynamicRegister {
static {
System.load("E:\\_Projects_\\JNI_Projects\\JNI_C\\cmake-build-debug\\libDynamicRegisterLib.dll");
}
public static native String func1(String s);
public static native int func2(int[] a);
public static void main(String[] args) {
System.out.println(func1("Hi JNI"));
int[] a = {1,2,3};
System.out.println("该数组有"+func2(a)+"个元素");
}
}
- Build Project生成动态链接库,得到libDynamicRegisterLib.dll;
- Java侧运行,效果如下:
- 动态注册完毕。
3 system.load()与system.loadLibrary()
System.load()
System.load()参数必须为库文件的绝对路径,可以是任意路径,例如: System.load("C:\Documents and
Settings\TestJNI.dll"); //Windows
System.load("/usr/lib/TestJNI.so"); //Linux
System.loadLibrary()
System.loadLibrary()参数为库文件名,不包含库文件的扩展名。
System.loadLibrary("TestJNI"); //加载Windows下的TestJNI.dll本地库
System.loadLibrary("TestJNI"); //加载Linux下的libTestJNI.so本地库
注意:TestJNI.dll 或 libTestJNI.so 必须是在JVM属性java.library.path所指向的路径中。
loadLibary需要[配置当前项目的java.library.path路径]
3 JNI上下文与Java签名
3.1 JNI上下文环境
3.1.1 JNIEnv
JNIEnv类型实际上代表了Java环境,通过JNIEnv*指针,JNI函数可以对Java侧的代码进行操作。例如,创建Java类的对象,调用Java对象的方法,获取对象中的属性等。JNIEnv的指针会被传入到JNI侧的native方法的实现函数中,来对Java端的代码进行操作。例如:
jstring f1(JNIEnv *env, jclass jobj){
return (*env)->NewStringUTF(env,"Hi Java");
}
3.1.2 区分jobject与jclass
在JNI侧声明Java native方法的实现的时候,会有两个默认形参(除开native方法自己的传入参数),分别是JNIEnv指针,另外一个是jobject/jclass,这两个的区别在于:
- jobject:如果Java侧的native方法是非静态的,那么传给JNI的第二个参数是类的对象,所有类的对象在JNI侧都是jobject类型。
- jclass:如果Java侧的native方法是静态的,那么传给JNI的第二个参数是类的运行时类,所有运行时类在JNI侧都是jclass类型。
显然,这段JNI代码是native方法在JNI侧的实现,其中先后
- 创建了一个jintArray;
- 调用了Java侧JNICallJavaMethod类的构造方法;
- JNICallJavaMethod类的非静态方法;
- JNICallJavaMethod类的静态方法;
- JNICallJavaMethodNative类的非静态方法。
我们分别分析,以下代码就是上述代码的分别分析。
调用构造函数
步骤:
- 加载类,被调用方法所在类的运行时类,即jclass;
- 获取方法ID,即jmethodID;
- 创建一个类的实例,即jobject;
- 调用方法。
注意:
- MethodName形参直接传""即可;
- 构造函数在Java侧没有返回值,连void都不是;但是,在JNI侧的方法签名中,返回值是void。比如,一个类的默认构造函数的签名是**"()V"**;
- 凡是JNI方法的*GetXxx()*过程,都必须进行异常处理,即使用前判断是否为NULL。
代码:
//todo:调用另一个类的构造函数
jclass jclz1 = NULL;
jclz1 = (*env)->FindClass(env, "JNICallJava/JNICallJavaMethod");
if(jclz1 == NULL){
printf("JNI Side : jclz is NULL.");
return ji;
}
jmethodID jmethodId1 = NULL;
jmethodId1 = (*env)->GetMethodID(env, jclz1, "", "()V");
if(jmethodId1 == NULL){
printf("JNI Side : jmethodId1 is NULL.");
return ji;
}
jobject jobj1 = (*env)->NewObject(env, jclz1, jmethodId1);
(*env)->CallVoidMethod(env, jobj1, jmethodId1);
调用非静态方法
步骤:
- 加载类,被调用方法所在类的运行时类,即jclass;
- 获取方法ID,即jmethodID;
- 创建一个类的实例,即jobject;
- 调用方法。
注意:
- 因为该非静态方法与上述构造方法同属一个类,所以此时可以省去加载运行时类的步骤一,直接用已经获取到的jclass;
- Java侧来说,一个类的对象可以调用多个方法;但是JNI侧的jobject是与jmethodID一一对应的。所以,即使JNI侧调用的不同方法属于同一个类,也需要创建不同的jobject,不能共用;从创建jobject的JNI函数可以看出来:
//jobject与jmethodID是一一对应的关系:
jobject jobj1 = (*env)->NewObject(env, jclz1, jmethodId1);
代码:
//todo:调用另一个类的非静态方法
jmethodID jmethodId2 = NULL;
jmethodId2 = (*env)->GetMethodID(env, jclz1, "func", "(I)I");
if(jmethodId2 == NULL){
return ji;
}
jobject jobj2 = (*env)->NewObject(env, jclz1, jmethodId2);
jint i1 = (*env)->CallIntMethod(env, jobj2, jmethodId2, 5);
printf("JNI Side : func returns %d.\n", i1);
调用静态方法
步骤:
- 加载类,被调用方法所在类的运行时类,即jclass;
- 获取方法ID,即jmethodID;
- 调用方法。
注意:
- 因为该非静态方法与上述构造方法同属一个类,所以此时可以省去加载运行时类的步骤一,直接用已经获取到的jclass;
- 因为静态方法的调用不需要对象实例,所以调用Java静态方法时,不需要jobject。
代码:
//todo:调用另一个类的静态方法
jmethodID jmethodId3 = NULL;
jmethodId3 = (*env)->GetStaticMethodID(env, jclz1, "staticFunc", "([I)I");
if(jmethodId3 == NULL){
printf("JNI Side : jmethodId3 is NULL.");
return ji;
}
jint i2 = (*env)->CallStaticIntMethod(env, jclz1, jmethodId3, jArr);
printf("JNI Side : staticFunc returns %d.\n", i2);
调用native方法所在类的方法
这里以非静态方法为例,因为Java侧方法与native方法在同一个类中,而JNI侧实现native方法时,会传入一个jclass/jobject,分别对应Java侧的native方法声明是static native/native。此时我们可以直接使用传入的jclass,或者利用**(*env)->GetObjectClass(env,jobj)**获取到运行时类。关键在于,调用哪个方法,首先需要加载该方法所在的类到JVM运行时环境中。
代码:
//todo:调用与native方法同属一个类的方法
jclass jclz0 = NULL;
jclz0 = (*env)->GetObjectClass(env, jobj);
if(jclz0 == NULL){
printf("JNI Side : jclz0 is NULL.");
return ji;
}
jmethodID jmethodId4 = NULL;
jmethodId4 = (*env)->GetMethodID(env, jclz0,"func2","()Ljava/lang/String;");
if(jmethodId4 == NULL){
printf("JNI Side : jmethodId4 is NULL.");
return ji;
}
//todo:接收Java方法返回的字符串,并在JNI侧打印
jstring jstr = (jstring)(*env)->CallObjectMethod(env, jobj, jmethodId4);
char *ptr_jstr = (char *)(*env)->GetStringUTFChars(env,jstr,0);
printf("JNI Side : func2 returns %s\n",ptr_jstr);
JNI调用Java方法答疑
JNI侧如何创建整形数组
步骤:
- 声明数组名字与数组长度,即jArr、4;
- 获取数组元素类型(jint型)的指针,通过调用(*env)->GetIntArrayElements(env, jArr, NULL);
- 利用指针,为元素赋值;
- 释放指针资源,数组得以保留。
代码:
//todo:JNI侧创建一个int array
jintArray jArr = (*env)->NewIntArray(env, 4);//步骤1
jint *arr = (*env)->GetIntArrayElements(env, jArr, NULL);//步骤2
arr[0] = 0;//步骤3
arr[1] = 10;
arr[2] = 20;
arr[3] = 30;
(*env)->ReleaseIntArrayElements(env,jArr,arr,0);//步骤4
Java侧方法返回String,JNI调用时如何打印返回值?
步骤:
- 定义jstring变量,并用(jstring)强转jobject;
- 定义字符型指针,并用 (char *)强转;
- 打印。
//todo:接收Java方法返回的字符串,并在JNI侧打印
jstring jstr = (jstring)(*env)->CallObjectMethod(env, jobj, jmethodId4);
char *ptr_jstr = (char *)(*env)->GetStringUTFChars(env,jstr,0);
printf("JNI Side : func2 returns %s\n",ptr_jstr);
JNI侧与Java侧的控制台打印顺序
结论是:
JNI侧的控制台打印一定出现在Java侧程序运行结束之后。
我们可以调试看现象:
两遍I am constructor?
答:在调用构造方法和非静态方法的两个调用过程中,都需要通过(*env)->NewObject(env, jclz, jmethodId)创建与jmethodID一一对应的jobject,所以调用了两次构造函数。
两遍func is called?
答:待解答!
能否脱离native方法的实现来调用Java侧方法?
答:可以,JNI是Java跨平台的实现机制,是Java与原生代码交互的机制。上述的过程我们一般都是在JNI侧的native方法实现中进行的,因为native方法的JNI实现中就有JNIEnv*指针,是获取JNIEnv*最容易的方式,并非唯一方式。如何获取JNIEnv*?待解答!
4.3 JNI处理从Java传来的字符串
Java与C字符串的区别
- Java内部使用的是utf-16 16bit 的编码方式;
- JNI里面使用的utf-8 unicode编码方式,英文是1个字节,中文3个字节;
- C/C++ 使用ASCII编码,中文的编码方式GB2312编码,中文2个字节。
实战代码
//Java:
package JNICallJava;
public class GetSetJavaString {
static {
System.load("E:\\_Projects_\\JNI_Projects\\JNI_C\\cmake-build-debug\\libGetSetJavaStringLib.dll");
}
public static native String func(String s);
public static void main(String[] args) {
String str = func("--Do you enjoy coding?");
System.out.println(str);
}
}
//C:
#include "stdio.h"
#include "jni.h"
JNIEXPORT jstring JNICALL Java_JNICallJava_GetSetJavaString_func
(JNIEnv *,jclass,jstring);//没有用专门的.h文件,此声明可写可不写。
JNIEXPORT jstring JNICALL Java_JNICallJava_GetSetJavaString_func
(JNIEnv *env,jclass jclz,jstring jstr){
const char *chr = NULL;//字符指针定义与初始化分开
jboolean iscopy;//判断jstring转成char指针是否成功
chr = (*env)->GetStringUTFChars(env,jstr,&iscopy);//&iscopy位置一般直接传入NULL就好
if(chr == NULL){
return NULL;//异常处理
}
char buf[128] = {0};//申请空间+初始化
sprintf(buf,"%s\n--Yes, I do.",chr);//字符串拼接
(*env)->ReleaseStringUTFChars(env,jstr,chr);//编程习惯,释放内存
return (*env)->NewStringUTF(env,buf);
}
//CMakeLists.txt
add_library(GetSetJavaStringLib SHARED GetSetJavaString.c)
运行结果
异常处理
上述代码实例中,GetStringUTFChars()方法将JNI的jstring变量转换成C语言能操作的char指针,这个过程可能失败,其实任何转换过程都可能失败,这些过程的目标变量的定义和初始化都需要分开进行,并通过判空进行异常处理。
C语言字符串拼接
在C语言中,没有String,字符串都是字符指针。其拼接过程不像Java等语言那么简单,分为以下过程:
- malloc申请空间
- 初始化
- 拼接字符串
- 释放内存
灵活的静态注册
- 此实战代码中,我们没有想一般的静态注册一样使用Java native产生的.h文件,而是直接在实现JNI方法之前写了一个JNI静态注册,这也是可行的,甚至这个提前的声明注册也是可以不写的。此时我们在CMakeLists.txt中的add_library()中值包含了该.c文件。核心在于add_library()中一定要包含native方法在JNI的实现函数,.h文件更多是Java命令生成的教你怎么写JNI实现的一个辅助,无关紧要。
- JNI无视Java侧的访问控制权限,但会区别静态或非静态。
5 JNI引用
5.1 三种引用
只有当JNI返回值是jobject的引用,才是三种引用之一。
比如(*env)->GetMethodID()返回值就不是引用,是一个结构体。
局部引用
- 绝大部分JNI方法返回的是局部引用;
- 局部引用的作用域或者生命周期始于创建它的本地方法,终止于本地方法的返回;
- 通常在局部引用不再使用时,可以显式使用**DeleteLocalRef()**方法来提前释放它所指向的对象,一边GC回收;
- 局部引用时线程相关的,只能在创建他的线程里面使用,通过全局变量缓存并使用在其他线程是不合法的。
全局引用
调用NewGlobalRef()基于局部引用创建,会阻止GC回收所引用的对象。可以跨方法、跨线程使用。JVM不会自动释放,必须调用DeleteGlobalRef()手动释放。
弱全局引用
调用NewWeakGlobalRef()基于局部引用创建,不会阻止GC回收所引用的对象。可以跨方法、跨线程使用。JVM不会自动释放,必须调用DeleteWeakGlobalRef()手动释放。
5.2 野指针
上一次创建的东西在程序结束的被回收了,但是静态局部变量未释放,不为NULL。
作业1:写代码实现访问java 非静态和静态方法,返回值必须是object类型
作业2:写代码体会野指针异常
作者:乐为
链接:https://juejin.cn/post/7041939942636781576
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
前言
跟我学flutter系列:
跟我学flutter:我们来举个例子通俗易懂讲解dart 中的 mixin
跟我学flutter:我们来举个例子通俗易懂讲解异步(一)ioslate
跟我学flutter:我们来举个例子通俗易懂讲解异步(二)ioslate循环机制
企业级篇目:
跟我学企业级flutter项目:用bloc手把手教你搭建用户认证系统
跟我学企业级flutter项目:dio网络框架增加公共请求参数&header
跟我学企业级flutter项目:如何用dio封装一套企业级可扩展高效的网络层
跟我学企业级flutter项目:如何封装一套易用,可扩展的Hybrid混合开发webview
跟我学企业级flutter项目:手把手教你制作一款低耦合空页面widget
在以flutter为底的app项目中,用户登录,退出等认证必须做在flutter项目里,那么采用何种状态管理,来全局管理用户认证呢?
今天我就借助flutter_bloc这个库来搭建一套可以复用的成熟用户认证系统
搭建前夕准备
一、我们需要了解现有app有多少认证事件,那么常规来说,流程如下:
1、启动app,判断有无token,有token则跳转首页获取数据,无token则跳转需要授权页面如登录页
2、登录页登录,登陆后保存token,跳转首页
3、退出登录,删除token跳转需要授权页
那么总结起来就有三种事件
1、启动事件
2、登录事件
3、退出登录事件
二、那么有了认证事件,我们还需要有几个认证状态,有哪些状态呢,我来梳理一下:
1、在app启动后,需要初始化用户状态,那么用户当前是一个身份需要初始化的状态
2、如果有token,或者用户登录后那么用户就是一个已认证的状态
3、如果用户退出登录,那么用户当前是未认证的状态
三、咱们还需要做一个用户认证接口,接口主要是为了解耦,为了后期扩展能力、接口需要有哪些内容呢继续梳理一下:
1、是否有token,token是决定app是否认证的关键
2、删除token,退出登录需要删除
3、保存token,登录需要保存
4、跳转授权页面
5、跳转非授权页面
准备好如上工作,那么我们开始搭建用户认证系统吧
1、先编写认证事件:
part of 'authentication_bloc.dart';
//App认证事件,一般来说有三种,启动认证,登录认证,退出认证
abstract class AuthenticationEvent extends Equatable {
const AuthenticationEvent();
@override
List get props => [];
}
//App启动事件
class AppStart extends AuthenticationEvent{}
//App登录事件
class LogIn extends AuthenticationEvent{
final String token;
LogIn(this.token);
@override
List get props => [token];
@override
String toString() =>"LoggedIn { token: $token }";
}
//App退出事件
class LogOut extends AuthenticationEvent{}
2、编写认证状态
part of 'authentication_bloc.dart';
/// 认证状态
abstract class AuthenticationState extends Equatable {
const AuthenticationState();
@override
ListKotlin 1.5 新特性 Inline classes,还不了解一下?
Kotlin 1.5 如约而来了。
如果你正在使用Android Studio 4.2.0 、IntelliJ IDEA 2020.3 或更高的版本,近期就会收到 Kotlin 1.5 的Plugin推送了。作为一个大版本,1.5带来了不少新特性,其中最主要的要数inline class了。
早在kotlin 1.3 就已经有了 inline class 的alpha版本。到 1.4.30 进入 beta,如今在 1.5.0 中 终于迎来了 Stable 版本。早期的实验版本的 inline 关键字 在 1.5 中被废弃,转而变为 value关键字
//before 1.5
inline class Password(private val s: String)
//after 1.5 (For JVM backends)
@JvmInline
value class Password(private val s: String)
个人很认同从 inline 变为 value 的命名变化,这使得其用途更为明确:
inline class 主要就是用途就是更好地 "包装" value
有时为了语义更有辨识度,我们会使用自定义class包装一些基本型的value,这虽然提高了代码可读性,但额外的包装会带来潜在的性能损失,基本型的value由于被在包装在其他class中,无法享受到jvm的优化(由堆上分配变为栈上分配)。 而 inline class 在最终生成的字节码中被替换成其 “包装”的 value, 进而提高运行时的性能。
// For JVM backends
@JvmInline
value class Password(private val s: String)
如上,inline class 构造参数中有且只能有一个成员变量,即最终被inline到字节码中的value。
val securePassword = Password("Don't try this in production")
如上,Password实例在字节码中被替换为String类型"Don't try this in production"
PS:如何安装 Kotlin 1.5
- 首先更新IDE的 Kotlin Plugin,如果没收到推送,可以手动方式升级:
Tools > Kotlin > Configure Kotlin Plugin Updates
- 配置languageVersion & apiVersion
compileKotlin {
kotlinOptions {
languageVersion = "1.5"
apiVersion = "1.5"
}
}
经 inline 处理后代码
inline classes 转化为字节码后究竟是怎样的呢?
fun check(password: Password) {
//...
}
fun main() {
val securePassword = Password("Don't try this in production")
check(securePassword)
}
对于Password这个inline class, 字节码反编译的产物如下:
public static final void check_XYhEtbk/* $FF was: check-XYhEtbk*/(@NotNull String password) {
Intrinsics.checkNotNullParameter(password, "password");
}
public static final void main() {
String securePassword = Password.constructor-impl("Don't try this in production");
check-XYhEtbk(securePassword);
}
// $FF: synthetic method
public static void main(String[] var0) {
main();
}
securePassword的类型由Password替换为String- check方法改名为
check_XYhEtbk,签名类型也有 Password 替换 String
可见,无论是变量类型或是函数参数类型,所有的inline classes都被替换为其包装的类型。
名字被混淆处理(check_XYhEtbk)主要有两个目的
- 防止重载函数的参数经过 inline 后出现相同签名的情况
- 防止从Java侧调用到参数经过 inline 后的方法
Inline class 的成员
inline class 具备普通class的所有特性,例如拥有成员变量、方法、初始化块等
@JvmInline
value class Name(val s: String) {
init {
require(s.length > 0) { }
}
val length: Int
get() = s.length
fun greet() {
println("Hello, $s")
}
}
fun main() {
val name = Name("Kotlin")
name.greet() // `greet()`作为static方法被调用
println(name.length) // property getter 也是一个static方法
}
但是,inline class 的成员不能有自己的幕后属性,只能作为代理使用。 inline class的创建的对象在字节码中会被消除,所以这个实例无法拥有自己的状态以及行为,对inline class 实例的方法调用,在实际运行时会变为一格静态方法调用。
Inline class 的继承
interface Printable {
fun prettyPrint(): String
}
@JvmInline
value class Name(val s: String) : Printable {
override fun prettyPrint(): String = "Let's $s!"
}
fun main() {
val name = Name("Kotlin")
println(name.prettyPrint()) // prettyPrint()也是一个 static方法调用
}
inline class 可以实现任意inteface, 但不能继承自class。因为在运行时将无处安放其父类的属性或状态。如果你试图继承另一个Class,IDE会提示错误:Inline class cannot extend classes
自动拆装箱
inline class 在字节码中并非总被消除,有时也是需要存在的。例如当出现在泛型中、或者以 Nullable 类型出现时,此时它会根据情况自动与被包装类型进行转换,实现像Integer与int那样的自动拆装箱
@JvmInline
value class WrappedInt(val value: Int)
fun take(w: WrappedInt?) {
if (w != null) println(w.value)
}
fun main() {
take(WrappedInt(5))
}
如上,take 接受一个 Nulable 的 WrappedInt 后进行 print 处理
public static final void take_G1XIRLQ(@Nullable WrappedInt w) {
if (Intrinsics.areEqual(w, (Object)null) ^ true) {
int var1 = w.unbox_impl();
System.out.println(var1);
}
}
public static final void main() {
take_G1XIRLQ(WrappedInt.box_impl(WrappedInt.constructor_impl(5)));
}
字节码中,take的参数并没有变为Int,而仍然是原始类型 WrappedInt。因此,在 take 的调用处,需要通过box_impl 做装箱处理, 而在take的实现中,通过 unbox_impl 拆箱后再进行print
同理,在泛型方法或者泛型容器中使用 inline class 时,需要通过装箱保证传入其原始类型:
genericFunc(color) // boxed
val list = listOf(color) // boxed
val first = list.first() // unboxed back to primitive
反之,从容器获取 item 时,需要拆箱为被包装类型。
关于自动拆装箱在开发中无需太在意,只要知道有这个特性存在即可。
对比其他类型
与 type aliases 的区别 ?
inline class 与 type aliases 在概念上有点相似,都会在编译后被替换为被代理(包装)的类型, 区别在于
- inline class 本身是实际存在的Class 只是在字节码中被消除了并被替换为被包装类型
- type aliases仅仅是个别名,它的类型就是被代理类的类型。
typealias NameTypeAlias = String
@JvmInline
value class NameInlineClass(val s: String)
fun acceptString(s: String) {}
fun acceptNameTypeAlias(n: NameTypeAlias) {}
fun acceptNameInlineClass(p: NameInlineClass) {}
fun main() {
val nameAlias: NameTypeAlias = ""
val nameInlineClass: NameInlineClass = NameInlineClass("")
val string: String = ""
acceptString(nameAlias) // OK: NameTypeAlias等同String,可以传递
acceptString(nameInlineClass) // Not OK: NameInlineClass 与 String是两个类,不能等同
// 反之亦然:
acceptNameTypeAlias(string) // OK: 传入String也是可以的
acceptNameInlineClass(string) // Not OK: String不等同于NameInlineClass
}
与 data class 的区别 ?
inline class 与 data class 在概念上也很相似,都是对一些数据的包装,但是区别很明显
- inline class 只能有一个成员属性,其主要目的是通过一个额外类型的包装让代码更易用
- data clas 可以有多个成员属性,其主要目的是更高效地处理一组相关数据的集合
使用场景
上面说到, inline class 的目的是通过包装让代码更易用,这个易用性体现在诸多方面:
场景1:提高可读性
fun auth(userName: String, password: String) { println("authenticating $userName.") }
如上, auth的两个参数都是String,缺乏辨识度,即使像下面这样传错了也难以发觉
auth("12345", "user1") //Error
@JvmInline value class Password(val value: String)
@JvmInline value class UserName(val value: String)
fun auth(userName: UserName, password: Password) { println("authenticating $userName.")}
fun main() {
auth(UserName("user1"), Password("12345"))
//does not compile due to type mismatch
auth(Password("12345"), UserName("user1"))
}
使用 inline class 使的参数更具辨识度,避免发生错误
场景2:类型安全(缩小扩展函数作用域)
inline fun <reified T> String.asJson() = jacksonObjectMapper().readValue<T>(this)
String类型的扩展方法asJson可以转化为指定类型T
val jsonString = """{ "x":200, "y":300 }"""
val data: JsonData = jsonString.asJson()
由于扩展函数是top-level的,所有的String类型都可以访问,造成污染
"whatever".asJson<JsonData> //will fail
通过inline class可以将Receiver类型缩小为指定类型,避免污染
@JvmInline value class JsonString(val value: String)
inline fun <reified T> JsonString.asJson() = jacksonObjectMapper().readValue<T>(this.value)
如上,定义JsonString,并为之定义扩展方法。
场景3:携带额外信息
/**
* parses string number into BigDecimal with a scale of 2
*/
fun parseNumber(number: String): BigDecimal {
return number.toBigDecimal().setScale(2, RoundingMode.HALF_UP)
}
fun main() {
println(parseNumber("100.12212"))
}
如上,parseNumber的功能是将任意字符串解析成数字并保留小数点后两位。
如果我们希望通过一个类型将解析前后的值都保存下来然后分别打印,可能首先想到的使用Pair或者data class。但是当这两个值之间是有换算关系时,其实也可以用inline class实现。如下
@JvmInine value class ParsableNumber(val original: String) {
val parsed: BigDecimal
get() = original.toBigDecimal().setScale(2, RoundingMode.HALF_UP)
}
fun getParsableNumber(number: String): ParsableNumber {
return ParsableNumber(number)
}
fun main() {
val parsableNumber = getParsableNumber("100.12212")
println(parsableNumber.parsed)
println(parsableNumber.original)
}
ParsableNumber的包装类型是String,同时通过parsed携带了解析后的值。如前文提到的那样,字节码中,parsed getter 会以static方法的形式存在,因此虽然携带了更多信息,但实际上并不存在这样一个包装类实例:
@NotNull
public static final String getParsableNumber(@NotNull String number) {
Intrinsics.checkParameterIsNotNull(number, "number");
return ParsableNumber.constructor_impl(number);
}
public static final void main() {
String parsableNumber = getParsableNumber("100.12212");
BigDecimal var1 = ParsableNumber.getParsed_impl(parsableNumber);
System.out.println(var1);
System.out.println(parsableNumber);
}
最后
Inline class 是个好工具,在提高代码的可读性、易用性的同时,不会造成性能的损失。 早期由于一直处于试验状态没有被大家所熟知, 随着如今在 Kotlin 1.5 中的转正,相信未来一定会被在更广泛地使用、发掘更多应用场景。
作者:fundroid
链接:https://juejin.cn/post/6959364276557447181
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter 2021 中的按钮
在本文中,我们将介绍令人惊叹的 Flutter 按钮,它们可以帮助所有初学者或专业人士为现代应用程序设计漂亮的 UI。
首先让我告诉你关于 Flutter 中按钮的一件重要事情,在flutter最新版本中以下Buttons在fluter中被废弃了:
| 废弃的 | 推荐的替代 |
|---|---|
| RaisedButton | ElevatedButton |
| OutlineButton | OutlinedButton |
| FlatButton | TextButton |
那么让我们来探索一下 Flutter 中的按钮。
Elevated Button
StadiumBorder
ElevatedButton(
onPressed: (){},
child: Text('Button'),
style: ElevatedButton.styleFrom(
shadowColor: Colors.green,
shape: StadiumBorder(),
padding: EdgeInsets.symmetric(horizontal: 35,vertical: 20)),
)
RoundedRectangleBorder
ElevatedButton(
onPressed: (){},
child: Text('Button'),
style: ElevatedButton.styleFrom(
shadowColor: Colors.green,
shape: RoundedRectangleBorder(
borderRadius: BorderRadius.circular(12),
),
),
),
CircleBorder
ElevatedButton(
onPressed: () {},
child: Text('Button'),
style: ElevatedButton.styleFrom(
shape: CircleBorder(),
padding: EdgeInsets.all(24),
),
)
BeveledRectangleBorder
ElevatedButton(
onPressed: () {},
child: Text('Button'),
style: ElevatedButton.styleFrom(
shape: BeveledRectangleBorder(
borderRadius: BorderRadius.circular(12)
),
),
)
Outlined Button
StadiumBorder
OutlinedButton(
onPressed: () {},
child: Text('Button'),
style: OutlinedButton.styleFrom(
shape: StadiumBorder(),
),
)
RoundedRectangleBorder
OutlinedButton(
onPressed: () {},
child: Text('Button'),
style: OutlinedButton.styleFrom(
shape: BeveledRectangleBorder(
borderRadius: BorderRadius.circular(12),
),
),
)
CircleBorder
OutlinedButton(
onPressed: () {},
child: Text('Button'),
style: OutlinedButton.styleFrom(
shape: CircleBorder(),
padding: EdgeInsets.all(24),
),
)
BeveledRectangleBorder
OutlinedButton(
onPressed: () {},
child: Text('Button'),
style: OutlinedButton.styleFrom(
shape: BeveledRectangleBorder(
borderRadius: BorderRadius.circular(12),
),
),
)作者:传道士
链接:https://juejin.cn/post/7025939451356381197
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
Flutter定制一个ScrollView嵌套webview滚动的效果
场景描述
业务需要在一个滚动布局中嵌入一个webview,但是在Android平台上有一个关于webview高度的bug: 当webview高度过大时会导致Crash甚至手机重启。所以我想到了这样一种布局:最外层是一个ScrollView,内部含有一个定高的可以滚动的webview。这里有两个问题:
- webview怎么滚动
- webview的滚动怎么和外部的ScrollView联动
解决方案
第一个问题可以通过设置gestureRecognizers解决:
gestureRecognizers: [Factory(() => EagerGestureRecognizer())].toSet(),
但是这种方法会导致webview在手势竞争中获胜,外部的ScrollView根本无法获得滚动事件,从而导致webview滚动完全独立于外部ScrollView的滚动,这也是这种布局很少出现的原因。
于是我想到了使用NestedScrollView的方案,但是很明显我需要重新定义,因为我最终想要的效果是这样子的:
OutScrollView 滑动或者Fling时InnerScrollView完全静止。
在滚动InnerScrollView时OutScrollView完全不会滑动,只有在InnerScrollView滑动到边界时才能滑动OutScrollView。如果InnerScrollView Fling, OutScrollView不会Fling,同样的在InnerScrollView边界Fling则会触发OutScrollView的Fling。
下面就是具体方案:
NestedScrollView介入滚动是靠自定义ScrollActivityDelegate开始的,scrollable.dart源码中展示了滚动手势的传递过程:
Scrollable->GestureRecorgnizer->Drag(ScrollDragController)->ScrollActivityDelegate
当用户手指拖动ScrollView时会调用:
ScrollDragController:
@override
void update(DragUpdateDetails details) {
//other codes
delegate.applyUserOffset(offset);
}
当拖动结束时调用:
@override
void end(DragEndDetails details) {
///other codes, goBallistic代表Fling
delegate.goBallistic(velocity);
}
所以自定义ScrollActivityDelegate就是Hook滚动的开始,在NestedScrollView中这个类是_NestedScrollCoordinator, 所以我的思路就是自己定义一个Delegate。下面是魔改的过程:
需要判断InnerScrollView是否在滚动
我强制InnerScrollView必须被我的自定义Widget包裹:
class _NestedInnerScrollChildState extends State<NestedInnerScrollChild> {
@override
Widget build(BuildContext context) {
return Listener(
child: NotificationListener<ScrollEndNotification>(
child: widget.child,
onNotification: (end) {
widget.coordinator._innerTouchingKey = null;
//继续向上冒泡
return false;
},
),
onPointerDown: _startScrollInner,
);
}
void _startScrollInner(_) {
widget.coordinator._innerTouchingKey = widget.scrollKey;
}
}
我使用了Listener onPointerDown 方法来判断用户触摸了inner view, 但是并没有使用onPointerUp或者onPointerCancel来判断滚动结束,原因就是Fling的存在,Fling效果下手指已经离开屏幕但是view可能还在滑动,因此使用ScrollEndNotification这个标记更靠谱。
OutScrollView滑动时完全禁止InnerScrollView的滑动
- applyUserOffset的hook
@override
void applyUserOffset(double delta) {
if (!innerScroll) {
_outerPosition.applyFullDragUpdate(delta);
}
}
- Fling
首先会调用Coordinator的goBallistic方法,然后触发beginActivity方法,我们直接在beginActivity中拦截即可:
///_innerPositions并不是所有innerView的集合,这个后面会讲到
if (innerScroll) {
for (final _NestedScrollPosition position in _innerPositions) {
final ScrollActivity newInnerActivity = innerActivityGetter(position);
position.beginActivity(newInnerActivity);
scrolling = newInnerActivity.isScrolling;
}
}
InnerScrollView和OutScrollView嵌套滑动
- applyUserOffset
借鉴NestedScrollView即可
@override
void applyUserOffset(double delta) {
double remainDelta = innerPositionList.first.applyClampedDragUpdate(delta);
if (remainDelta != 0.0) {
_outerPosition.applyFullDragUpdate(remainDelta);
}
}
- Fling
innerView触发Fling手势的调用链:ScrollDragController会调用ScrollActivityDelegate的goBallistic方法->触发ScrollPosition的beginActivity方法并创建BallisticScrollActivity实例->BallisticScrollActivity实例结合Simulation不断计算滚动距离。
BallisticScrollActivity有个方法:
/// Move the position to the given location.
///
/// If the new position was fully applied, returns true. If there was any
/// overflow, returns false.
///
/// The default implementation calls [ScrollActivityDelegate.setPixels]
/// and returns true if the overflow was zero.
@protected
bool applyMoveTo(double value) {
return delegate.setPixels(value) == 0.0;
}
当这个方法返回false时就会立刻停止滚动,正好NestedScrollView有创建自定义OutBallisticScrollActivity方法,所以我在applyMove那里判断如果是innerView 正在滚动就返回false
@override
bool applyMoveTo(double value) {
if (coordinator.innerScroll) {
return false;
}
// other codes
}
当然,这里也可以加个优化:比如innerView如果在边界触发了Fling就可以放开。
支持多个inner scroll view
outview只能有一个,但是innerView理论上可以有多个,我这里贴下参考的文章链接[:]("Flutter 扩展NestedScrollView (二)列表滚动同步解决 - 掘金 (juejin.cn)")。核心就是在ScrollController attach detach时实现position和ScrollView的绑定。
实现webview的滚动
这里我也是借鉴的大神的思路[:](大道至简:Flutter嵌套滑动冲突解决之路 - V大师在一号线 (vimerzhao.top))
Flutter中所有的滚动View最终都是用Scrollable+Viewport来实现的,Scrollable负责获取滚动手势,距离计算等,而绘制则交给Viewport来实现。翻看viewport.dart相关源码,我贴下paint的方法:
@override
void paint(PaintingContext context, Offset offset) {
if (firstChild == null)
return;
if (hasVisualOverflow && clipBehavior != Clip.none) {
_clipRectLayer.layer = context.pushClipRect(
needsCompositing,
offset,
Offset.zero & size,
_paintContents,
clipBehavior: clipBehavior,
oldLayer: _clipRectLayer.layer,
);
} else {
_clipRectLayer.layer = null;
_paintContents(context, offset);
}
}
void _paintContents(PaintingContext context, Offset offset) {
for (final RenderSliver child in childrenInPaintOrder) {
if (child.geometry!.visible)
context.paintChild(child, offset + paintOffsetOf(child));
}
}
paintOffsetOf(child)就可以简化为滚动导致的绘制偏差。举个栗子:一个viewport高500,内容高度1000,默认绘制[0-500]的内容,当用户向上滑动了100,则绘制[100,600]的内容,这里的100就是paintOffset。
所以我最后创建了一个自定义Viewport,但是Flutter端绘制时paintOffset始终传0,我把真正的offset传递给webview,然后调用window.scrollTo(0,offset)即可实现webview内容的滑动了。简而言之,传统的ScrollView是内容不动,画布在动,而我的方案就是画布不动,但是内容在动。参考代码:[]("inner_scroll_webview.dart (github.com)")
作者:芭比Q达人
链接:https://juejin.cn/post/7041064106094231560
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »
kotlin函数
1.概念
函数是执行操作并可以返回值的离散代码块。在 Kotlin 中,函数是使用 fun 关键字声明的,并且可以使用接收具名值或默认值的参数。与特定类关联的函数称为方法。
- 一个用于执行特定任务的代码块
- 它可以将大型的程序分解为小型的模块
- 使用关键字 fun 来声明
- 可以通过参数接收具名值或默认值
2.函数的组成部分
fun sayHello(text:String) :Unit{
println("hello world!")
}其中 sayHello就是函数名,小括号()内text是函数参数,大括号{}中是函数具体代码,Unit是返回值(当函数没有任何返回的时候,那它的返回值便是Unit。Unit 类型只包含一个值,即:Unit 。返回Unit类型的声明是可选的。)。
以上函数等价于:
fun sayHello(text:String){
println("hello world!")
}2.1函数参数
函数可能会有:
默认参数
必选参数
具名参数
我们重新编写一个 sayHello 函数,这个函数接收一个 String 类型的参数: name,并且会打印出输入的姓名。name 的默认值为 "张三"。
fun sayHello(name: String = "张三") {
println("你好:${name}")
}
sayHello() =>你好:张三
sayHello("李四") =>你好:李四
sayHello(name="王五") =>你好:王五在 main() 函数中,有三种方法可以调用 sayHello() 函数:
- 在调用函数时,使用默认参数;
- 调用函数时,不使用参数名传入 speed;
- 调用函数时,传入名为 speed 的参数。
如果没有为某个参数指定默认值,则该参数为必选参数。
fun sayHello(name: String) {
println("你好:${name}")
}
sayHello() =>编译错误:Kotlin: No value passed for parameter 'name'
sayHello("李四") =>你好:李四
sayHello(name="王五") =>你好:王五为了提升可读性,可以向必选参数传入具名值。就是我们上述代码中的 sayHello(name="王五")调用方式 。
函数可以同时拥有默认参数和必选参数。我们改造一下sayHello函数 。
fun sayHello(name: String, age: Int = 6, sex: String = "男") {
println("你好:${name} ,你的年龄:$age ,你的性别:$sex")
}
sayHello(name = "王五") =>你好:王五,你的年龄:6,你的性别:男
sayHello("王五",sex = "女") =>你好:王五 ,你的年龄:6 ,你的性别:女参数可以通过它们的名称进行传递 (具名参数)。在函数包含大量参数或者默认参数时,具名参数非常方便。默认参数和具名参数可以减少重载并优化代码可读性。
3.紧凑函数
如果一个函数只返回了一个表达式,那么它的大括号可以省略,而函数体可以在 “=” 符号后指定。
fun getSum(x: Int, y: Int): Int { =>完整版
return x + y
}
fun getSum(x: Int, y: Int): Int = x + y =>紧凑版4.Lambda 表达式与高阶函数
Kotlin 中函数是 first-class(头等函数)
- Kotlin 的函数可以储存在变量和数据结构中
- 函数可以作为其他高阶函数的参数和返回值
- 可以使用高阶函数创建新的 “内建” 函数
4.1 Lambda 函数
除了传统的命名函数外,Kotlin 还支持 lambda 表达式。lambda 是用来创建函数的表达式,但不同于声明已命名的函数,以这种方式声明的函数没有名称。lambda 很好用的一点便是可以作为数据传递。在其他编程语言中,lambda 也被称为匿名函数、函数字面量或其他类似的名称。
像具名函数一样,lambda 也可以有参数。对于 lambda 来说,参数 (及其类型,如果需要声明的话) 位于函数箭头 -> 的左侧。要执行的代码在函数箭头的右侧。将 lambda 赋值给变量后,就可以像函数一样调用它。
kotlin可以声明一个存储函数的变量
val getSum = { x: Int, y: Int -> x + y }
println(getSum(1, 2)) =>3其中x,y就是参数。->为函数箭头 ,需要执行的代码再其右侧。其中getSum就是变量名。
4.2高阶函数
高阶函数接收函数作为参数,或以函数作为返回值。
fun getSum(x: Int, y: Int, sum: (Int, Int) -> Int): Int {
return sum(x, y)
}
val sum: (Int, Int) -> Int = { x, y -> x + y }
println(getSum(1, 2, sum)) =>3此段代码中函数体调用了作为第三个参数传入的函数,并将第一个第二个参数传递给该函数。
lambda 的真正作用在于可以使用它们创建高阶函数,高阶函数接收另一个函数作为参数。
使用函数类型可将其实现与使用处分离。
4.3传递函数引用
使用:: 操作符将具名函数作为参数传入另一个函数。
fun sum(x: Int, y: Int): Int {
return x + y
}
println(getSum(1, 2, ::sum)):: 操作符让 Kotlin 知道我们正在将函数引用作为参数传递,这样一来 Kotlin 便不会尝试调用该函数。
在使用高阶函数时,Kotlin 倾向于将接收函数的参数作为函数的最后一个参数。Kotlin 有一个特别的语法,叫做尾随参数调用语法,可以让我们的代码更加简洁。在下面代码中中,我们可以为函数参数传递一个 lambda,而不必将 lambda 放在括号中。
println(getSum(1, 2,{ x, y -> x + y }) )
等价于
println(getSum(1, 2) { x, y -> x + y })Kotlin 内建的许多函数,其声明方式都遵循了尾随参数调用语法。
inline fun repeat(times: Int, action: (Int) -> Unit)
repeat(3) {
println("hello world!")
}AES 前后端加解密方案
AES 前后端加解密方案
背景
最近有一个需求:后端对敏感数据进行加密传输给前端,由前端解密后进行回显。在讨论之后,定下了AES加解密方案
概念
AES: 密码学中的高级加密标准(Advanced Encryption Standard,AES),又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准,是最为常见的对称加密算法
密码说明
AES算法主要有四种操作处理,分别是:
- 密钥轮加(Add Round Key)
- 字节代换层(SubBytes)
- 行位移层(Shift Rows)
- 列混淆层(Mix Column)
主要是讲使用方案,所以这里不说太多废话了,对算法感兴趣的同学移步这里, 讲的非常详细,不过文章里的代码是使用C语言写的,为此找到了github上aes.js 的源码,感兴趣的同学移步这里
前端实现
现在简单说一下前端的实现:
我先找到了github上的源码,看了一下大概800行的样子。本来打算直接改吧改吧,封装成一个加解密的工具方法,直接扔在utils目录里的。本来也很成功的改好了,本地加解密试了一下,效果也很不错。根据github链接上的readme文档说明,封装了如下函数:
// 省略了改完的aes.js的代码。。。
// 加密 text 需要加密的文本 key 密钥
const toAESBytes = (text, key) => {
const textBytes = aesjs.utils.utf8.toBytes(text);
const aesCtr = new aesjs.ModeOfOperation.ctr(key, new aesjs.Counter(5));
const encryptedBytes = aesCtr.encrypt(textBytes);
const encryptedHex = aesjs.utils.hex.fromBytes(encryptedBytes);
console.log('加密后的文本:', encryptedHex);
return encryptedHex;
};
// 解密
const fromAESBytes = (text, key) => {
const encryptedBytes = aesjs.utils.hex.toBytes(text);
const aesCtr = new aesjs.ModeOfOperation.ctr(key, new aesjs.Counter(5));
const decryptedBytes = aesCtr.decrypt(encryptedBytes);
const decryptedText = aesjs.utils.utf8.fromBytes(decryptedBytes);
console.log('解密后的文本:', decryptedText);
return decryptedText;
}
但是这个方法在和后端对接的时候出现了一点偏差,死活也不能将后端加密后的数据成功解密。于是又向后端同学请教了一下,发现原因如下:
在AES加解密算法中,除了加解密的密文,也就是key需要一样之外,还有几样东西也非常重要:
AES 的算法模式需要保持一致
关于算法模式,主要有以下几种:
1. 电码本模式 Electronic Codebook Book (ECB);
2. 密码分组链接模式 Cipher Block Chaining (CBC)
3. 计算器模式Counter (CTR)
4. 密码反馈模式(Cipher FeedBack (CFB)
5. 输出反馈模式Output FeedBack (OFB)
这么看的话,我上面的demo应该使用的就是计算器模式了!关于算法模式的介绍,感兴趣的同学请移步这里
补码方式保持一致
关于补码方式,我查到的以下几种:
1. PKCS5Padding PKCS7Padding的子集,块大小固定为8字节
2. PKCS7Padding 假设数据长度需要填充n(n>0)个字节才对齐,那么填充n个字节,每个字节都是n;如果数据本身就已经对齐了,则填充一块长度为块大小的数据,每个字节都是块大小。
3. ZeroPadding 数据长度不对齐时使用0填充,否则不填充
密钥长度保持一致
AES算法一共有三种密钥长度:128、192、256。这个前后端的密钥长度确实是保持一致的。
加密结果编码方式保持一致
一般情况下,AES加密结果有两种编码方式:base64 和 16进制
所以到底是哪里出了问题呢?后端同学好心发给了我他后端的代码:
/**
* aes 加密 Created by xingxiping on 2017/9/20.
*/
public class AesUtils {
private static final String CIPHER_ALGORITHM = "AES"; // optional value AES/DES/DESede
private AesUtils(){
}
/**
* 加密
*
* @param content
* 源内容
* @param key
* 加密密钥
* @return
*/
public static String encrypt(String content, String key) throws Exception {
Cipher cipher = getCipher(key, Cipher.ENCRYPT_MODE);
byte[] byteContent = content.getBytes(StandardCharsets.UTF_8);
byte[] result = cipher.doFinal(byteContent);
return Base64Utils.encode(result);
}
/**
* 解密
*
* @param content
* 内容
* @param key
* 解密密钥
* @return
*/
public static byte[] decrypt(String content, String key) throws Exception {
Cipher cipher = getCipher(key, Cipher.DECRYPT_MODE);
byte[] bytes = Base64Utils.decode(content);
bytes = cipher.doFinal(bytes);
return bytes;
}
private static Cipher getCipher(String key, int cipherMode) throws NoSuchAlgorithmException, NoSuchPaddingException, InvalidKeyException {
Cipher cipher = Cipher.getInstance(CIPHER_ALGORITHM);
SecretKeySpec secretKey = new SecretKeySpec(key.getBytes(), "AES");
cipher.init(cipherMode, secretKey);
return cipher;
}
}
破案了,后端老哥对加密后的结果进行了base64编码,然后我又仔细去看了一下aes.js源码,根本没有找到base64的影子啊!
于是在查找一翻资料以后,决定使用crypto-j,使用 Crypto-JS 可以非常方便地在 JavaScript 进行 MD5、SHA1、SHA2、SHA3、RIPEMD-160 哈希散列,进行 AES、DES、Rabbit、RC4、Triple DES 加解密。真是方便呀,老规矩,感兴趣的同学可以移步这里
以下是我又一轮的解决步骤:
npm install crypto-js
在utils目录下新建一个文件aes.js
封装如下代码:
// aes 解密
import CryptoJS from 'crypto-js';
// 解密 encryptedStr待解密字符串 pass 密文
export const aesDecode = (encryptedStr, pass) => {
const key = CryptoJS.enc.Utf8.parse(pass); // 通过密钥获取128位的key
const encryptedHexStr = CryptoJS.enc.Base64.parse(encryptedStr); // 解码base64编码结果
const encryptedBase64Str = CryptoJS.enc.Base64.stringify(encryptedHexStr);
const decryptedData = CryptoJS.AES.decrypt(encryptedBase64Str, key, {
mode: CryptoJS.mode.ECB,
padding: CryptoJS.pad.Pkcs7
});
return decryptedData.toString(CryptoJS.enc.Utf8);
}
然后就可以正常调用了!
最后,终于成功解密!
一点点小感悟
在日常工作中真的很少使用算法,对称加密在学校里听起来好像非常简单的样子,但是真的应用到生活中,特别是安全领域,还是非常复杂的。哎,学无止境吧~
感谢大家的阅读!
作者:溜溜球形废物
链接:https://juejin.cn/post/6951368041590423582
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 收起阅读 »


