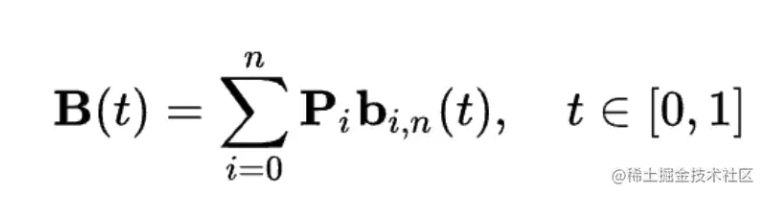











本文章只做技术探讨, 请勿用于非法用途。
目标网站
近期为了深刻学习法律知识, 需要来下载一些法律条文相关的内容。
本文通过 某法宝网站来下载数据 http://www.pkulaw.com/。
网站分析
文章内容

详情页图片
可以看到下载的方式还蛮多的, 尝试复制全文, 得到内容保留原格式, 所以我选择使用复制全文的方式来得到文章内容。
同时详情页没有看到明显的反扒措施, 不需要特殊处理。
列表页

最终决定通过专题分类来获取所有的数据, 然后调试分析接口参数, 这里没有什么加密的参数, 确定需要关注的参数如下:
{
"Aggs.SpecialType": "", // 专题类型(编号)
"VerifyCodeResult": "", // 验证码值(后边讲解)
"Pager.PageIndex": "2", // 页码
"RecordShowType": "List", // 显示方式(List 方式显示所有数据, 保持该值即可)
"Pager.PageSize": 100, // 每页的数量(最大 100)
}
这里仅列出了需要关注的参数, 其他参数保持原值即可(需要的话可以自己调试对比参数值确定意义), 当 pageSize 设置为 100 时, 第 3 页之后的数据需要验证码才能查看。
验证码
为方便分析验证码的校验方式, 推荐使用无痕模式来调试, 获取验证码之前清空一次 cookie。



可以看到验证码的流程为:
- 请求验证码, 并返回 set-cookie 。
- 携带该 cookie 信息并校验验证码, 通过后得到 code。
- 携带 code 请求数据, 得到数据。
开整
确定了问题后, 就可以开始了, 一个一个解决。
文章内容
确定了要用复制的方式来得到数据, 那就分析下他的复制干了点啥。

查看他的页面元素, 发现了这两个东西, 全局搜索后很容易定位到处理函数(找不到的话刷新页面)。

然后接着定位这个 toCopyFulltext() 函数。

找到这个就对了, 然后可以看代码他是用的 jQuery 的选择器来做的, 我们只能来仿造一个页面结构来用它, 这里推荐使用 cheerio(nodejs) 库来做(jsdom 应该也可以?)。

伪造后直接调用就大功告成。
列表页
这个问题不大, 问题主要在于验证码。

通过查看页面元素可以得到专题编号。
验证码
请求
// 验证码图片请求返回结果
{
"errcode": 0,
"y": 131,
"array": "14,12,11,7,6,2,13,15,9,8,16,0,1,3,4,18,17,5,19,10",
"imgx": 300,
"imgy": 200,
"small": "data:image/jpg;base64,...", // 滑块图片
"normal": "data:image/jpg;base64,..." // 背景图片
}

得到的 base64 可以用 python 的 PIL 库来解析出来。

然后我解析出来的图片就是这个样子, 基本上就确定了这验证码就是老朋友了, 我们先来把他还原。
还是简单解释一下这个, 图片被切割为了上下两部分, 每个部分又被切割为了 10 等份, 原图为 300x200, 也就是说这里被切割为 20 张 30x100 的图片, 然后打乱顺序拼接后返回, 我们需要先完成切割然后再按正确的顺序来拼接还原。
"errcode": 0,
"y": 131,
"array": "14,12,11,7,6,2,13,15,9,8,16,0,1,3,4,18,17,5,19,10", // 图片的正确顺序
"imgx": 300, // 图片宽
"imgy": 200, // 图片高
"small": "data:image/jpg;base64,...", // 滑块图片
"normal": "data:image/jpg;base64,..." // 背景图片


还原后的图片就是这个样子了。
校验
// 校验接口请求参数
{
"act": "check",
"point": "197", // 缺口位置
"timespan": "1067", // 滑动耗时
"datelist": "1,1692848585282|10,1692848585288|20,1692848585295|34,1692848585305|50,1692848585312|58,1692848585320|74,1692848585328|90,1692848585338|95,1692848585344|107,1692848585355|117,1692848585360|124,1692848585371|126,1692848585376|130,1692848585388|133,1692848585393|136,1692848585404|137,1692848585409|138,1692848585416|139,1692848585425|139,1692848585433|140,1692848585441|140,1692848585449|140,1692848585457|141,1692848585465|141,1692848585473|141,1692848585481|142,1692848585489|142,1692848585498|142,1692848585506|143,1692848585514|143,1692848585522|143,1692848585530|144,1692848585539|145,1692848585546|146,1692848585554|146,1692848585562|149,1692848585572|151,1692848585579|154,1692848585589|157,1692848585596|160,1692848585604|161,1692848585611|164,1692848585621|167,1692848585627|170,1692848585639|172,1692848585643|174,1692848585655|177,1692848585659|179,1692848585667|181,1692848585676|182,1692848585683|184,1692848585692|185,1692848585699|186,1692848585710|187,1692848585716|188,1692848585724|189,1692848585732|189,1692848585740|190,1692848585748|191,1692848585758|192,1692848585764|192,1692848585773|193,1692848585781|194,1692848585789|195,1692848585797|195,1692848585806|196,1692848585813|196,1692848585821|197,1692848585829|197,1692848585839|197,1692848585845|197,1692848585855|197,1692848586219"
} // 滑动轨迹(位置,时间戳)
需要解决的参数为 point(缺口位置) 及 datelist(滑动轨迹)。
point

推荐使用 ddddocr 库来识别, 准确率还可以吧, 挺方便的。
datelist

轨迹方面自己设计算法来吧, 这里可以作为一个参考, 他的 datelist 的长度不固定, 一般也就是一百多些轨迹点吧, 可以通过调整参数来达到效果, 反正就是多测试吧, 这个方法大概有 百分之九十 左右的通过率吧, 暂时够用。
VerifyCodeResult
// 校验请求成功后返回数据
{
"state": 0,
"info": "正确",
"data": 197
}
// VerifyCodeResult: YmRmYl8xOTc=
解决了验证码, 惊喜的发现还是不咋对, 这个返回的 data 明显长得和要用的 VerifyCodeResult 不太像, 就接着来找。

全局搜索, 找到两个 js 文件, 都打上断点来调试。

可以看到我们成功断到, 并得到是由 (new Base64).encode("bdfb_" + y) 这种方式来生成的 code 值, 这个 y 值就是上一步返回的 data, 接下来只需要把 Base64 的代码那里扣下来, 或者自己实现就行了, 方便些, 这里直接抠下来了, 然后拿到 code 带上验证码请求返回的 cookie, 就能正常拿到数据了。
结语
整体来说不算困难, 没有什么加密啊混淆啊之类的东西, 确定方向之后很快就能搞定了, 用来练手还是很不错的, 有什么问题欢迎交流, 不知道这个得几年啊。。。
请洒潘江,各倾陆海云
作者:Glommer尔。
来源:juejin.cn/post/7270702261293039635