Vue 中处理页面数据有两种交互方式:
- 骨架屏:加载时提供骨架屏,加载失败展示错误页面和重试按钮,需要维护加载状态数据,适用于注重用户体验的精细页面
- 消息弹窗:加载过程中展示 loading 遮罩,失败时弹出错误消息提示,不需要维护加载状态数据,适用于后台管理系统等不太看重用户体验的页面,或者提交数据的场景
本文适用于骨架屏类的页面数据加载场景。
痛点描述
我们日常加载页面数据时,可能需要维护 loading 状态,就像这样:
<template>
<el-table v-loading="loading" :data="tableData"></el-table>
</template>
<script>
export default {
data() {
return {
tableData: [],
loading: false,
}
},
methods: {
async getTableData() {
this.loading = true
try {
this.tableData = await this.$http.get("/user/list");
} finally {
this.loading = false;
}
},
},
}
</script>
其实加载函数本来可以只有一行代码,但为了维护 loading 状态,让我们的加载函数变得复杂。如果还要维护成功和失败状态的话,加载函数还会变得更加复杂。
export default {
data() {
return {
tableData: [],
loading: false,
success: false,
error: false,
errmsg: "",
}
},
methods: {
async getTableData() {
this.loading = true;
this.success = false;
this.error = false;
try {
this.user = await this.$http.get("/user/list");
this.success = true;
} catch (err) {
this.error = true;
this.errmsg = err.message;
} finally {
this.loading = false;
}
},
},
}
如果页面有多个数据要加载,比如表单页面中有多个下拉列表数据,那么这些状态属性会变得特别多,代码量会激增。
export default {
data() {
return {
yearList: [],
yearListLoading: false,
yearListLoaded: false,
yearListError: false,
yearListErrmsg: "",
deptList: [],
deptListLoading: false,
deptListLoaded: false,
deptListError: false,
deptListErrmsg: "",
tableData: [],
tableDataLoading: false,
tableDataLoaded: false,
tableDataError: false,
tableDataErrmsg: ""
}
}
}
其实我们可以根据加载函数的状态来自动维护这些状态数据,这次我们要实现的目标就是自动维护这些状态数据,并将它们放到对应函数的属性上。看看这样改进后的代码:
<template>
<div v-if="tableData.success">
</div>
<div v-else-if="tableData.loading">
</div>
<div v-else-if="tableData.error">
</div>
</template>
<script>
export default {
data() {
return {
tableData: []
}
},
methods: {
async getTableData() {
this.tableData = await this.$http.get("/user/list");
},
}
}
</script>
加载函数变得非常纯净,data 中也不需要定义一大堆状态数据,非常舒适。
Mixin 设计
基本用法
我们需要指定一下 methods 中的哪些方法是用来加载数据的,我们只需要对这些加载数据的方法添加状态属性。根据我之前在文章《我可能发现了Vue Mixin的正确用法——动态Mixin》中的看法,可以使用函数形式的 mixin 来指定。
export default {
mixins: [asyncStatus('getTableData')],
methods: {
async getTableData() {},
},
}
指定多个方法
也可以用数组指定多个方法名。
export default {
mixins: [asyncStatus([
'getDeptList',
'getYearList',
'getTableData'
])],
}
自动扫描所有方法
如果不传参数,则通过遍历的方式,给所有组件实例方法加上状态属性。
export default {
mixins: [asyncStatus()]
}
全局注入
虽然给所有的组件实例方法加上状态属性是没必要的,但也不影响。而且这有个好处,就是可以注册全局 mixin。
Vue.mixin(asyncStatus())
默认注入的属性
我们默认注入的状态字段有4个:
loading 是否正在加载中
success 是否加载成功
error 是否加载失败
exception 加载失败时抛出的错误对象
指定注入的属性名
当然,为了避免命名冲突,可以传入第二个参数,来指定添加的状态属性名。
export default {
mixins: [asyncStatus('getTableData', {
loading: 'isLoading',
error: 'hasError',
exception: 'errorObj',
success: false,
})]
}
随意传入参数
由于第一个参数和第二个参数的形式没有重叠,所以省略第一个参数也是可行的。
export default {
mixins: [asyncStatus({
loading: 'isLoading',
error: 'hasError',
exception: 'errorObj',
success: false,
})]
}
总结
总结一下,我们需要使用函数形式来实现 mixin,函数接收两个参数,并且两个参数都是可选的。
export function asyncStatus(methods, alias) {}
函数返回真正的 mixin 对象,为组件中的异步方法维护并注入状态属性。
Mixin 实现
注入属性的时机
实现这个 mixin 是有一定难度的,首先要找准注入属性的时机。我们希望尽可能早往方法上注入属性,至少在执行 render 函数之前,以便在加载状态变化时可以重现渲染,但又需要在组件方法初始化之后。
所以,你需要熟悉 Vue 的组件渲染流程。在 Vue2 的源码中有这样一段组件初始化代码:
Vue.prototype._init = function (options?: Object) {
initLifecycle(vm);
initEvents(vm);
initRender(vm);
callHook(vm, "beforeCreate");
initInjections(vm);
initState(vm);
initProvide(vm);
callHook(vm, "created");
};
而其中的 initState 方法的源码如下:
export function initState (vm: Component) {
vm._watchers = []
const opts = vm.$options
if (opts.props) initProps(vm, opts.props)
if (opts.methods) initMethods(vm, opts.methods)
if (opts.data) {
initData(vm)
} else {
observe(vm._data = {}, true )
}
if (opts.computed) initComputed(vm, opts.computed)
if (opts.watch && opts.watch !== nativeWatch) {
initWatch(vm, opts.watch)
}
}
所以总结一下 Vue 组件的初始化流程:
- 执行
beforeCreate
- 挂载
props
- 挂载
methods
- 执行并挂载
data
- 挂载
computed
- 监听
watch
- 执行
created
我们必须在 methods 初始化之后开始注入属性,否则方法还没挂载到组件实例上。可以选择的是 data 或者 created。为了尽早注入,我们应该选择在 data 中注入。
export function asyncStatus(methods, alias) {
return {
data() {
return {}
}
}
}
处理参数
由于参数的形式比较自由,我们需要处理并统一一下参数形式。我们把 methods 处理成数组形式,并取出 alias 中指定注入的状态属性名。
export function asyncStatus(methods, alias = {}) {
if (typeof methods === 'object' && !Array.isArray(methods)) {
alias = methods
}
if (typeof methods === 'string') {
methods = [methods]
}
if (!Array.isArray(methods)) {
methods = []
}
const getKey = (name) =>
typeof alias[name] === 'string' || alias[name] === false
? alias[name]
: name
const loadingKey = getKey('loading')
const successKey = getKey('success')
const errordKey = getKey('error')
const exceptionKey = getKey('exception')
}
遍历组件方法
没有传入 methods 的时候,需要遍历组件上定义的所有方法。办法是遍历 this.$options.methods 上的所有属性名,这样遍历出的结果会包含从 mixins 中引入的方法。
export function asyncStatus(methods, alias = {}) {
return {
data() {
if (!Array.isArray(methods)) {
methods = Object.keys(this.$options.methods)
}
return {}
}
}
}
维护加载状态
需要注意的是,只有响应式对象上的属性才会被监听,也就是说,只有响应式对象上的属性值变化才能引起组件的重新渲染。所以我们必须创建一个响应式对象,把加载状态维护进去。这可以通过 Vue.observable() 这个API来创建。
export function asyncStatus(methods, alias = {}) {
return {
data() {
for (const method of methods) {
if (typeof this[method] === 'function') {
const status = Vue.observable({})
loadingKey && Vue.set(status, loadingKey, false)
successKey && Vue.set(status, successKey, false)
errorKey && Vue.set(status, errorKey, false)
exceptionKey && Vue.set(status, exceptionKey, false)
const setStatus = (key, value) => key && (status[key] = value)
}
}
return {}
}
}
}
我们把加载状态维护到 status 中。
export function asyncStatus(methods, alias = {}) {
return {
data() {
for (const method of methods) {
if (typeof this[method] === 'function') {
const fn = this[method]
let loadId = 0
this[method] = (...args) => {
const currentId = ++loadId
setStatus(loadingKey, true)
setStatus(successKey, false)
setStatus(errorKey, false)
setStatus(exceptionKey, null)
try {
const result = fn.call(this, ...args)
if (result instanceof Promise) {
return result
.then((res) => {
if (loadId === currentId) {
setStatus(loadingKey, false)
setStatus(successKey, true)
}
return res
})
.catch((err) => {
if (loadId === currentId) {
setStatus(loadingKey, false)
setStatus(errorKey, true)
setStatus(exceptionKey, err)
}
throw err
})
}
setStatus(loadingKey, false)
setStatus(successKey, true)
return result
} catch (err) {
setStatus(loadingKey, false)
setStatus(errorKey, true)
setStatus(exceptionKey, err)
throw err
}
}
}
}
return {}
}
}
}
注入状态属性
其实需要注入的属性都在 status 中,可以把它们作为访问器属性添加到对应的方法上。
export function asyncStatus(methods, alias = {}) {
return {
data() {
for (const method of methods) {
if (typeof this[method] === 'function') {
const status = Vue.observable({})
this[method] = (...args) => {}
Object.keys(status).forEach((key) => {
Object.defineProperty(this[method], key, {
get() {
return status[key]
}
})
})
Object.setPrototypeOf(this[method], fn)
}
}
return {}
}
}
}
完整代码
最后整合一下完整的代码。
import Vue from 'vue'
export default function asyncMethodStatus(methods, alias = {}) {
if (typeof methods === 'object' && !Array.isArray(methods)) {
alias = methods
}
if (typeof methods === 'string') {
methods = [methods]
}
const getKey = (name) =>
typeof alias[name] === 'string' || alias[name] === false
? alias[name]
: name
const loadingKey = getKey('loading')
const successKey = getKey('success')
const errorKey = getKey('error')
const exceptionKey = getKey('exception')
return {
data() {
if (!Array.isArray(methods)) {
methods = Object.keys(this.$options.methods)
}
for (const method of methods) {
if (typeof this[method] === 'function') {
const fn = this[method]
let loadId = 0
const status = Vue.observable({})
loadingKey && Vue.set(status, loadingKey, false)
successKey && Vue.set(status, successKey, false)
errorKey && Vue.set(status, errorKey, false)
exceptionKey && Vue.set(status, exceptionKey, false)
const setStatus = (key, value) => key && (status[key] = value)
this[method] = (...args) => {
const currentId = ++loadId
setStatus(loadingKey, true)
setStatus(successKey, false)
setStatus(errorKey, false)
setStatus(exceptionKey, null)
try {
const result = fn.call(this, ...args)
if (result instanceof Promise) {
return result
.then((res) => {
if (loadId === currentId) {
setStatus(loadingKey, false)
setStatus(successKey, true)
}
return res
})
.catch((err) => {
if (loadId === currentId) {
setStatus(loadingKey, false)
setStatus(errorKey, true)
setStatus(exceptionKey, err)
}
throw err
})
}
setStatus(loadingKey, false)
setStatus(successKey, true)
return result
} catch (err) {
setStatus(loadingKey, false)
setStatus(errorKey, true)
setStatus(exceptionKey, err)
throw err
}
}
Object.keys(status).forEach((key) => {
Object.defineProperty(this[method], key, {
get() {
return status[key]
}
})
})
Object.setPrototypeOf(this[method], fn)
}
}
return {}
}
}
}
作者:cxy930123
来源:juejin.cn/post/7249724085147254845



















































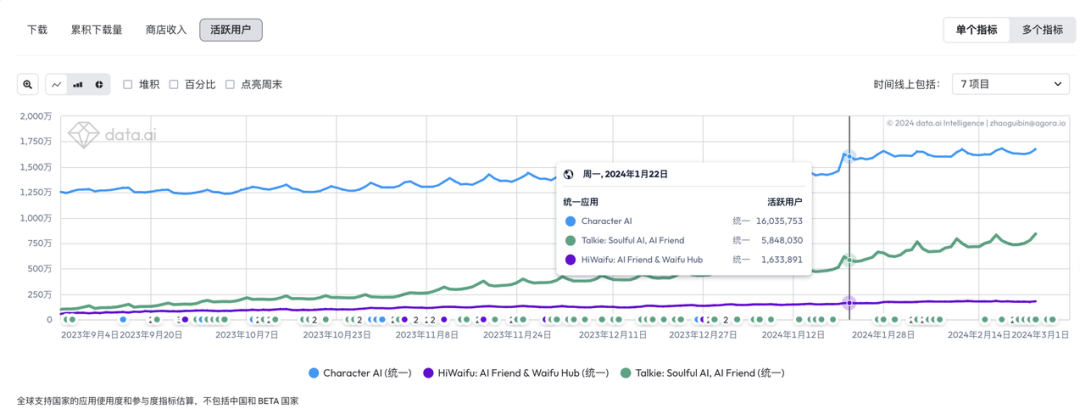
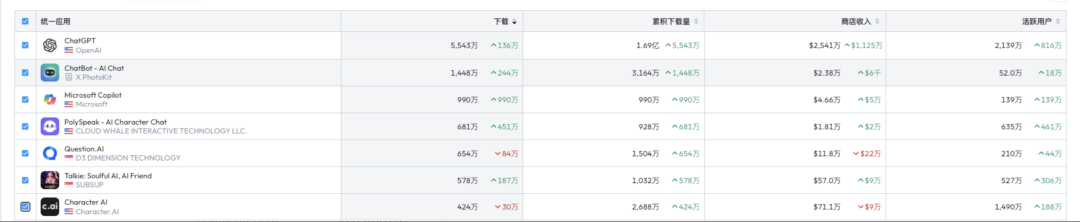
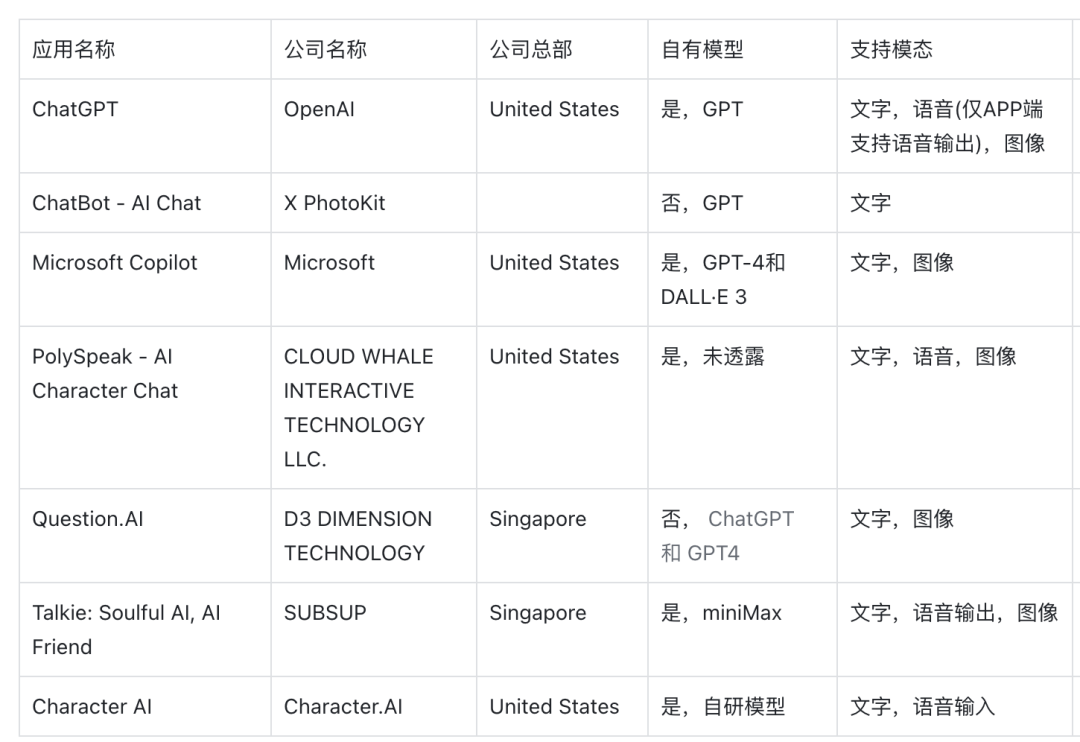
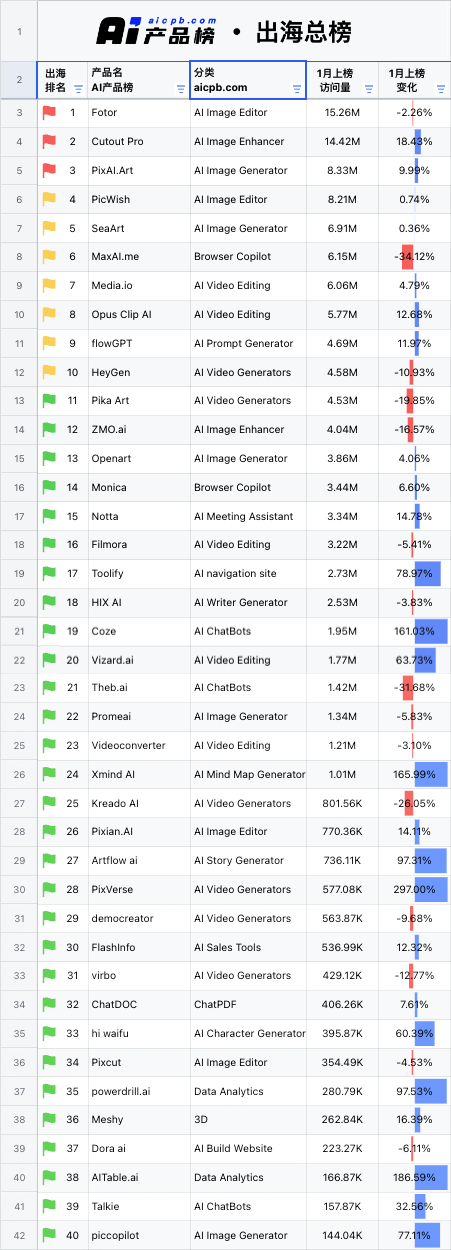

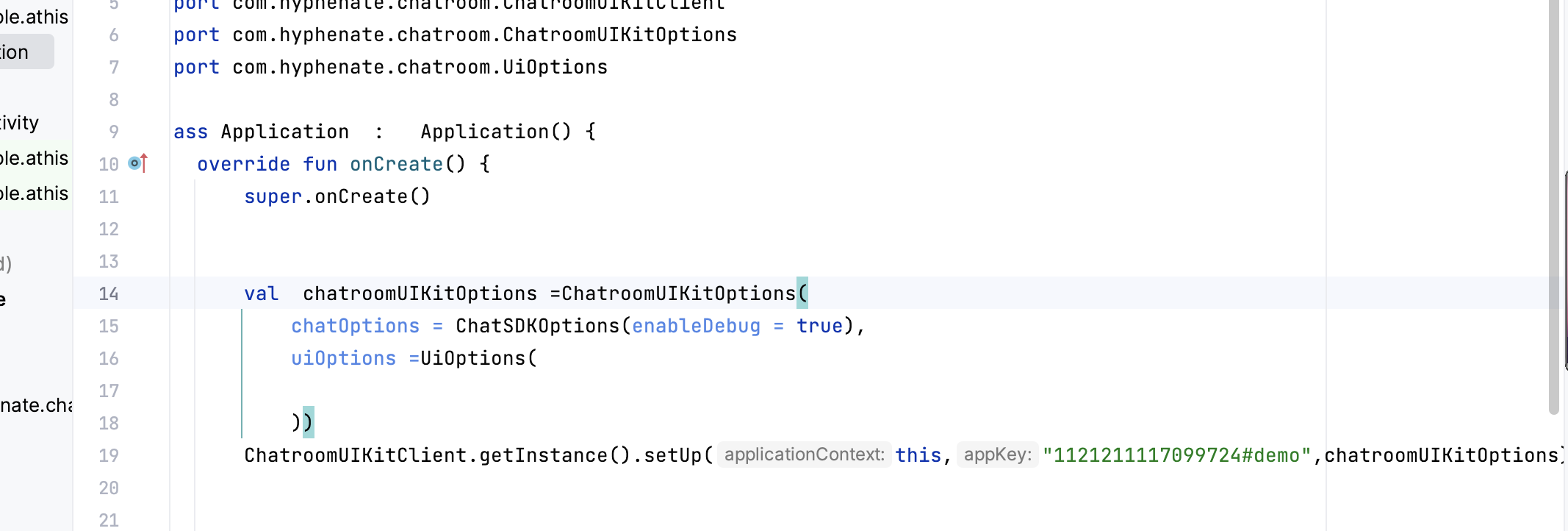
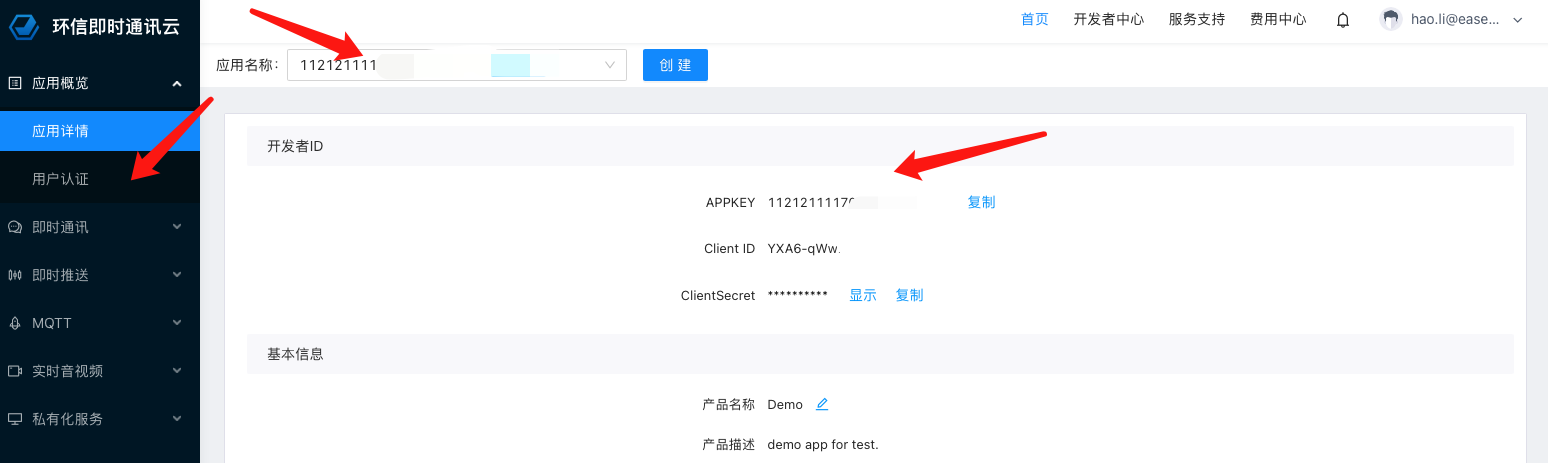
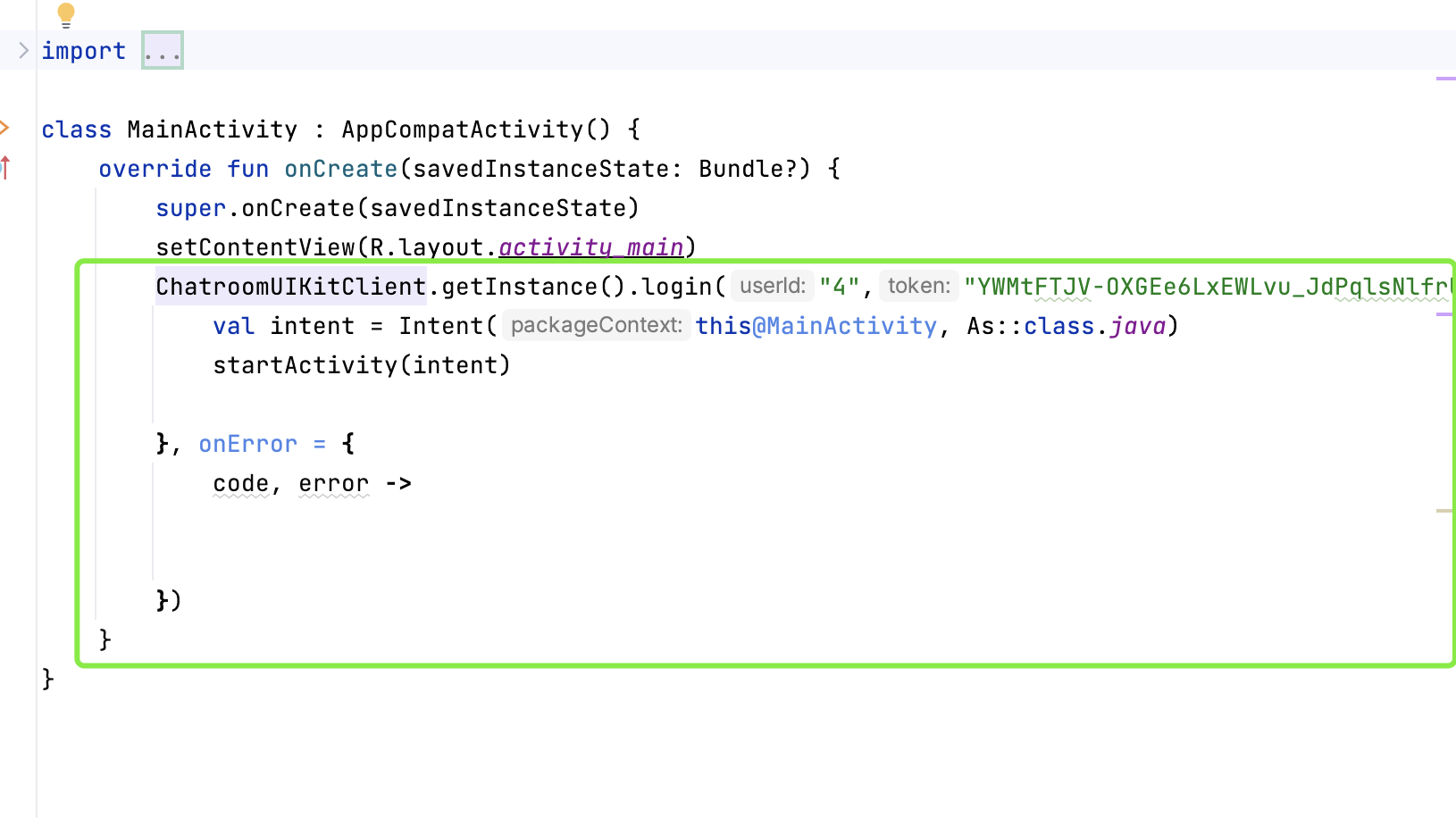
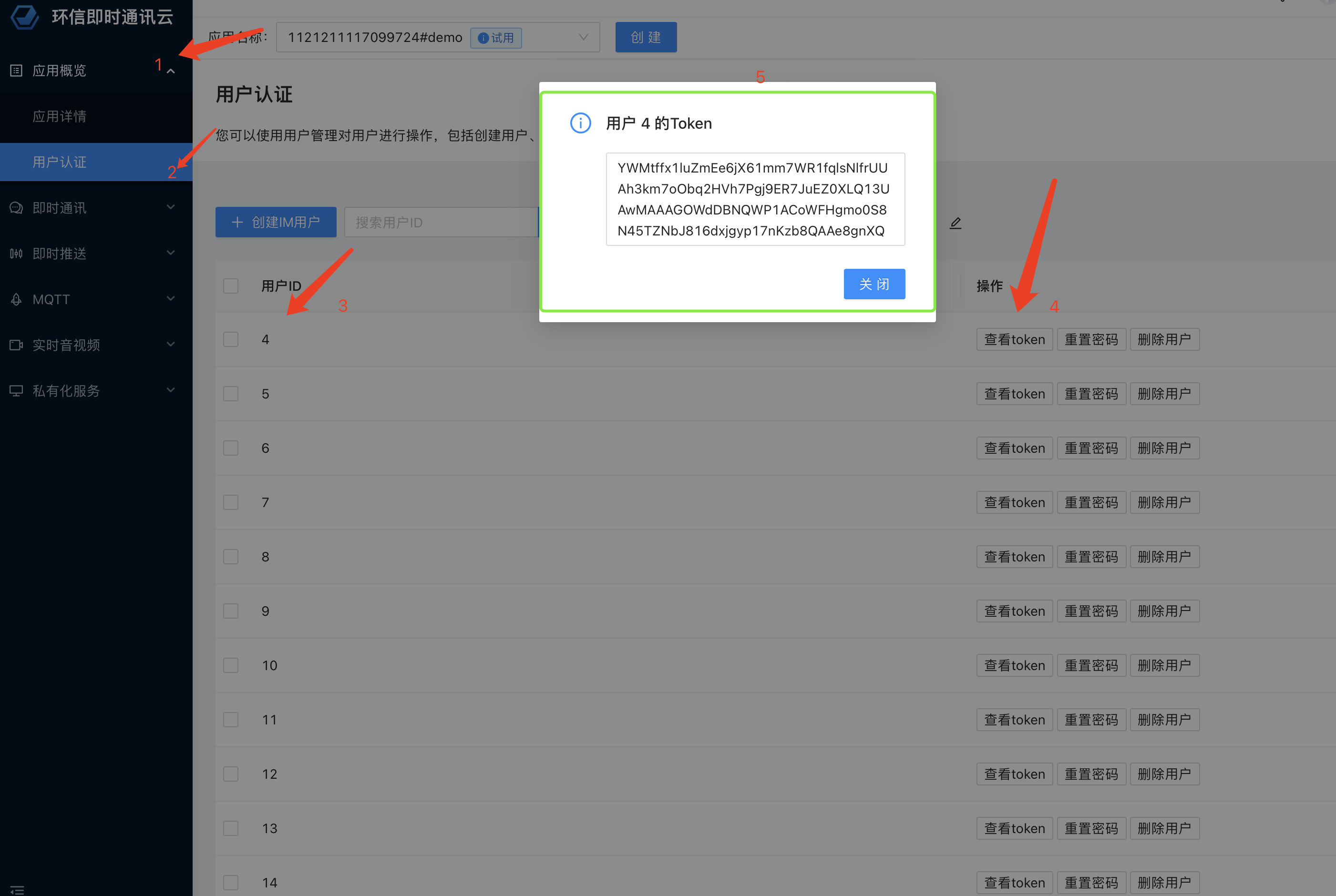







 昨晚做了一个梦,梦到了好多小伙伴,大家一起去爬山,因为还有几个妹子一起,所以我就像孙悟空一样这棵树爬一下,那棵树吊一下,以至于今天早上醒来后,全身酸痛,差点班都不想去上,此刻,打着字,手依然是酸痛的。
昨晚做了一个梦,梦到了好多小伙伴,大家一起去爬山,因为还有几个妹子一起,所以我就像孙悟空一样这棵树爬一下,那棵树吊一下,以至于今天早上醒来后,全身酸痛,差点班都不想去上,此刻,打着字,手依然是酸痛的。