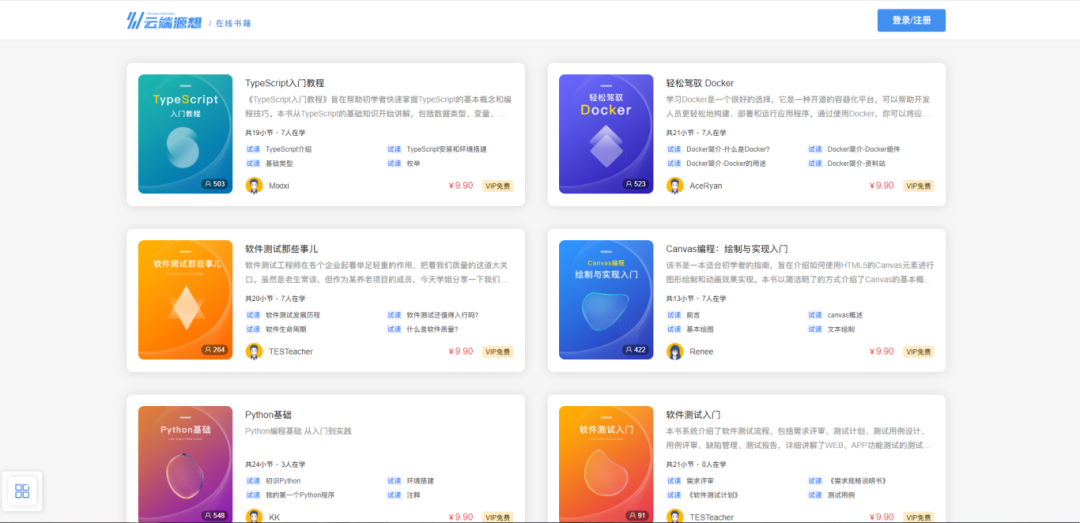
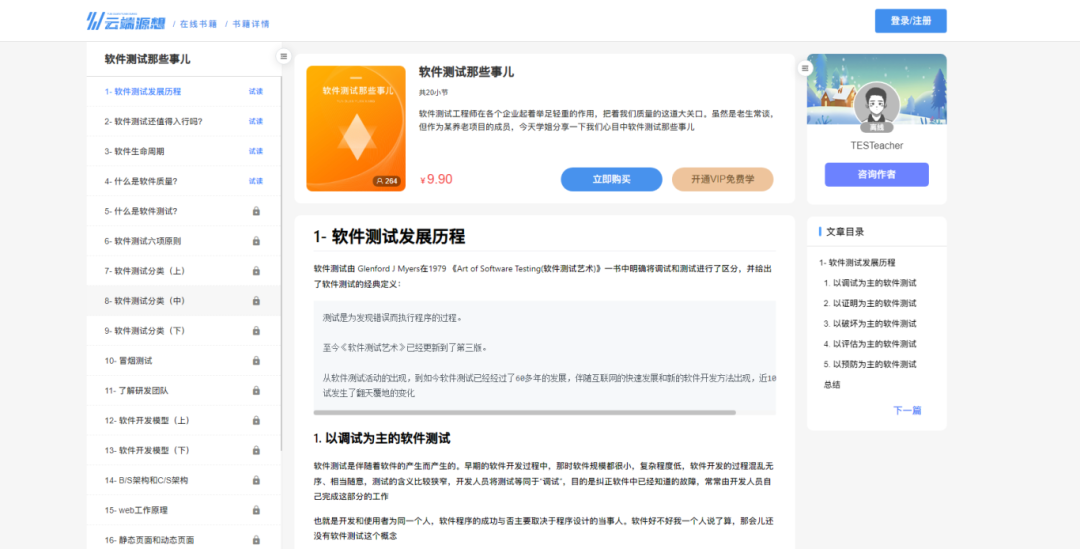
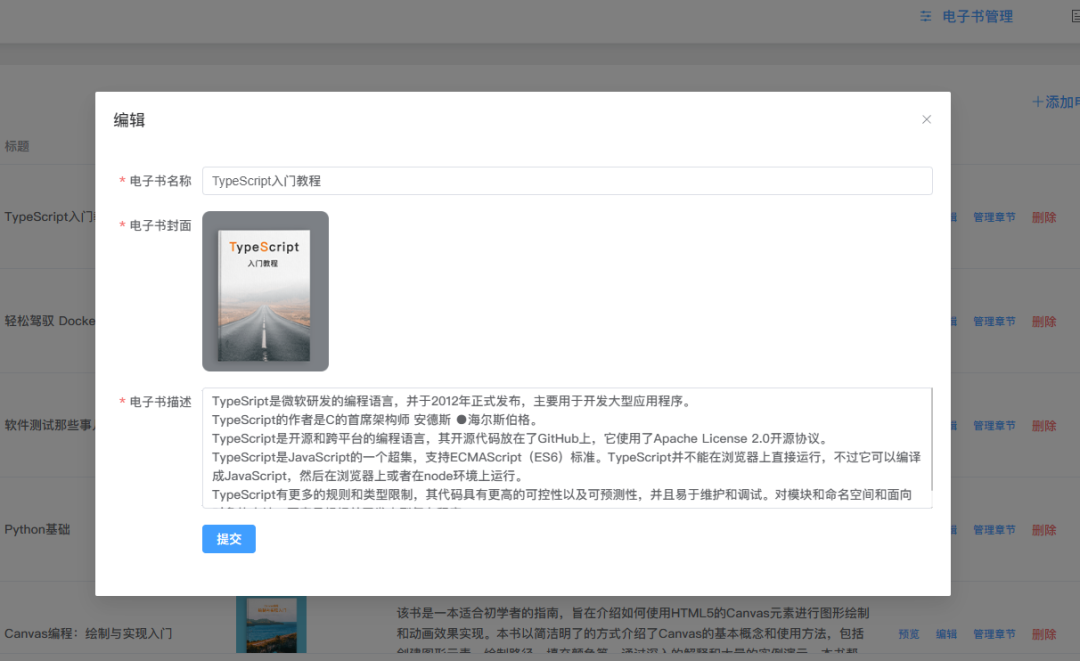
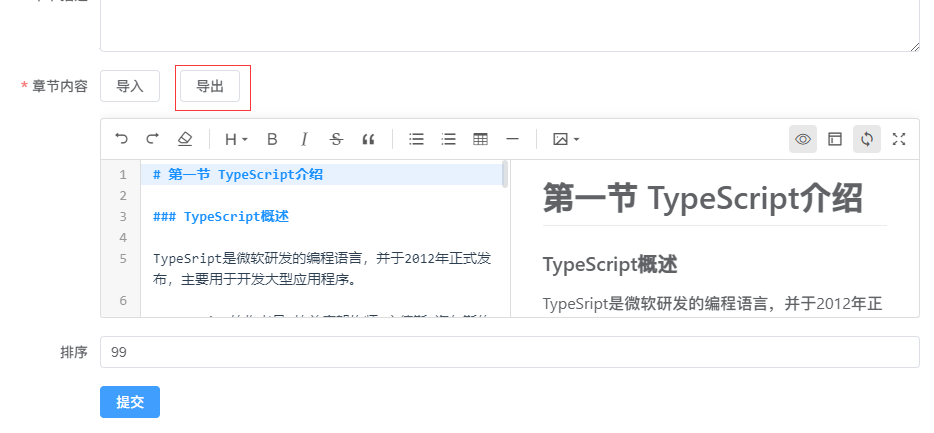
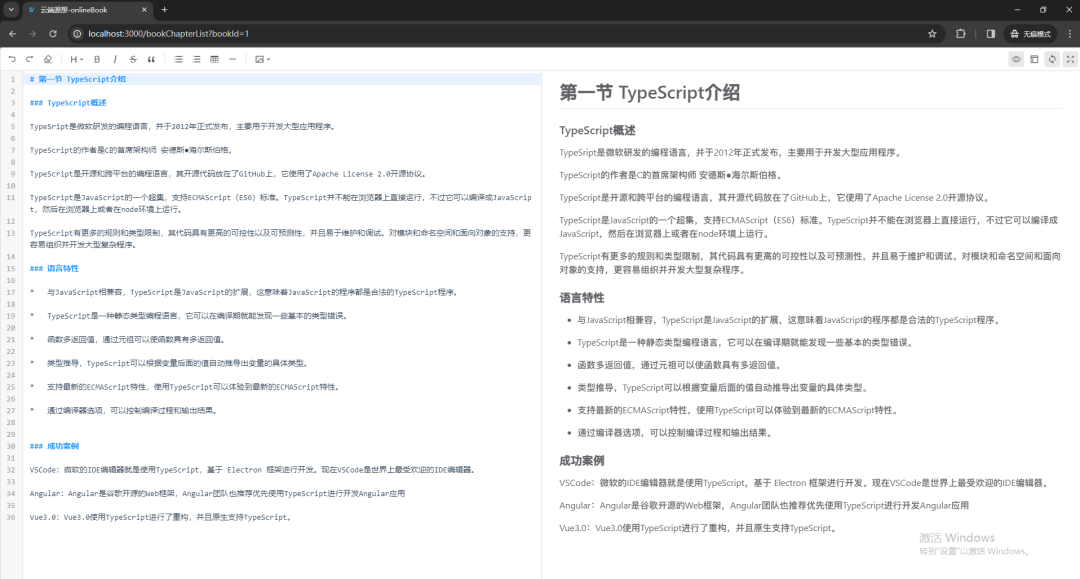
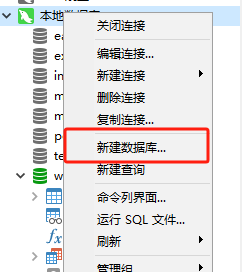
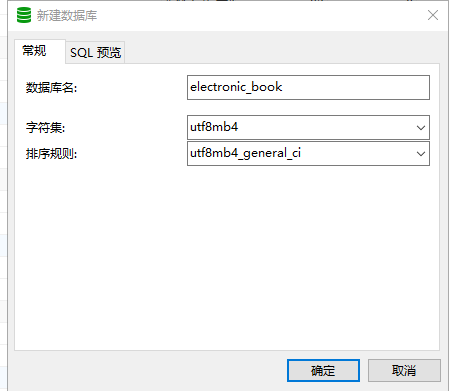
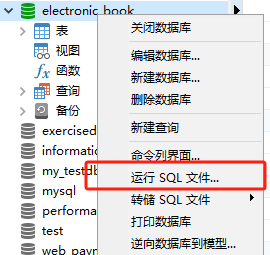
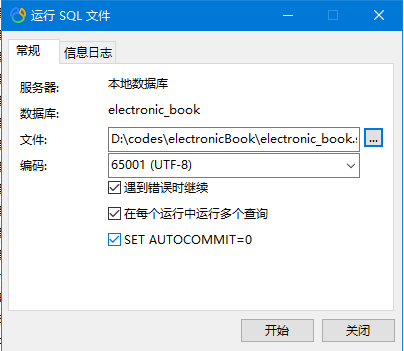
H5 下拉刷新如何实现
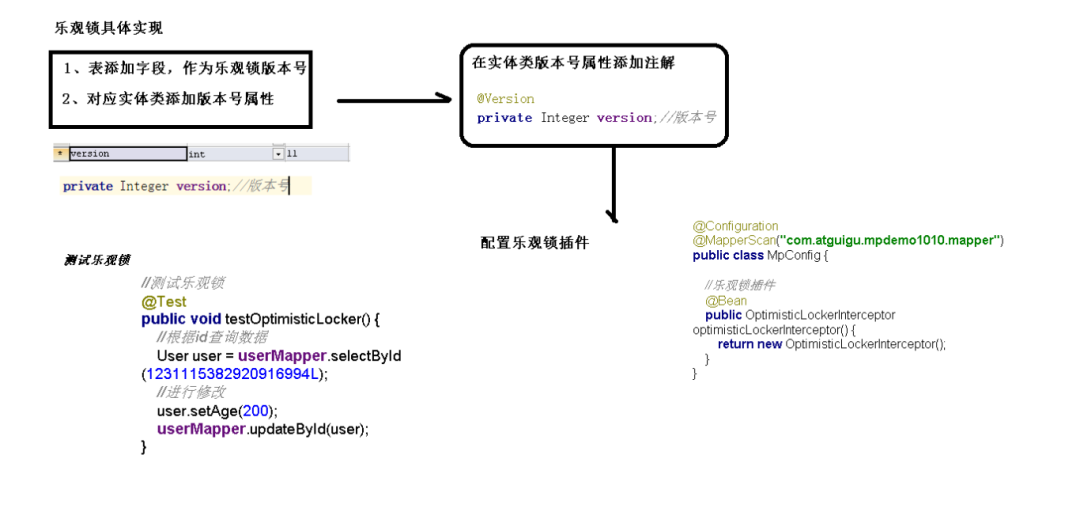
最近我需要做一个下拉刷新的功能,实现功能后我发现,它需要处理的情况还蛮多,于是我整理了这篇文章。
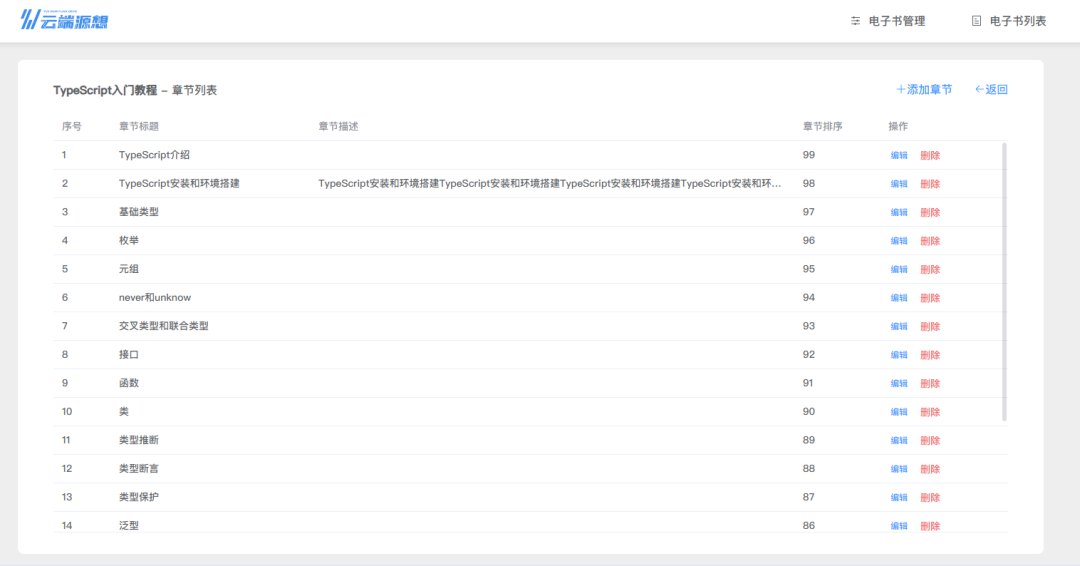
下图是我实现的效果,分为三步:开始下拉时,屏幕顶部会出现加载动画;加载过程中,屏幕顶部高度保持不变;加载完成后,加载动画隐藏。

首先我会讲解下拉的原理、根据原理写出初始代码;然后我会说明代码存在的缺陷、解决缺陷并做些额外优化;最后我会给出完整代码,并做一个总结。
下拉的原理

如图所示,蓝色框代表视口,绿色框代表容器,橙色框代表加载动画。最开始时,加载动画处于视口外;开始下拉之后,容器向下移动,加载动画从上方进入视口;结束下拉后,容器又开始向上移动,加载动画也从上方退出视口。
下拉基础代码
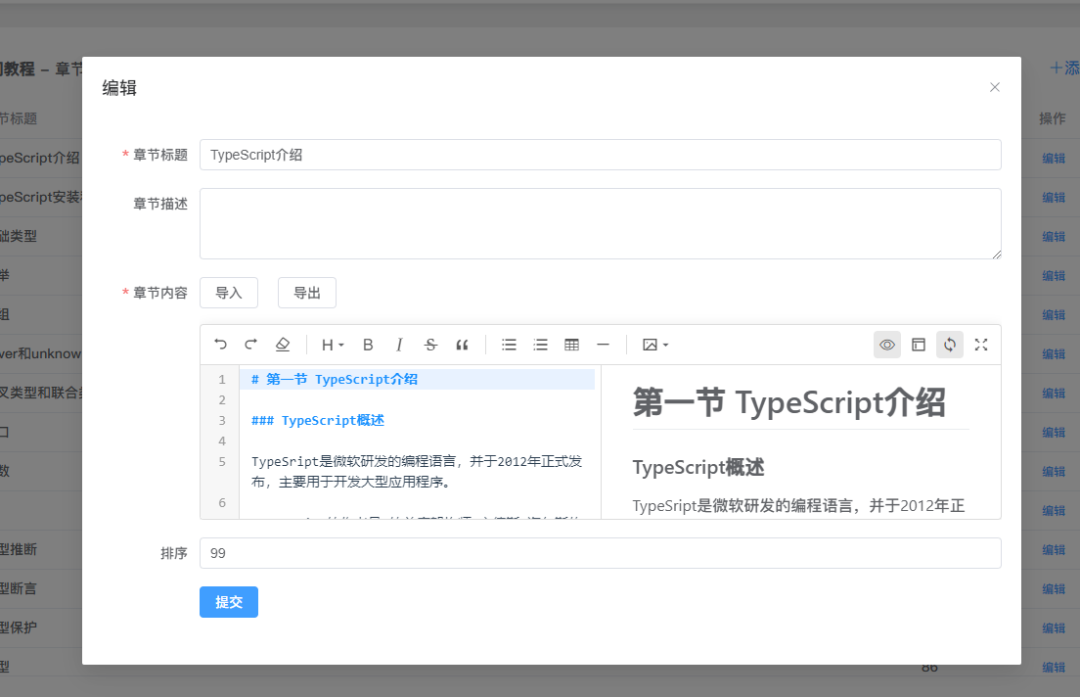
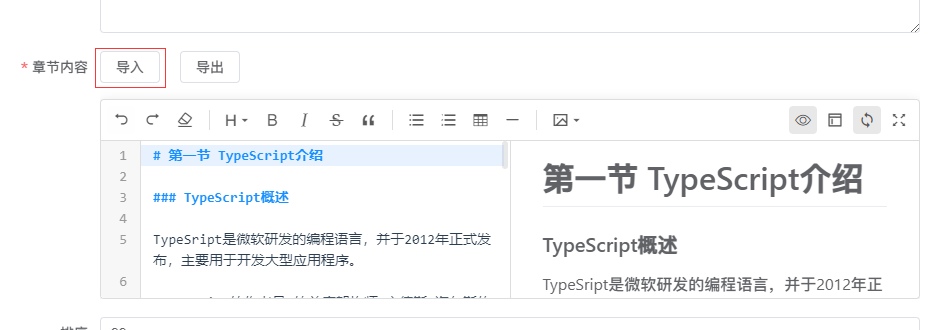
知道原理,我们现在开始写实现代码,首先是布局的代码:
布局代码
我们把 box 元素当作容器,把 loader-box,loader-box + loading 元素当作动画,至于 h1 元素不需要关注,我们只把它当作操作提示。
<div id="box">
<div class="loader-box">
<div id="loading"></div>
</div>
<h1>下拉刷新 ↓</h1>
</div>
loader-box 的高度是 80px,按上一节原理中的分析,初始时我们需要让 loader-box 位于视口上方,因此 CSS 代码中我们需要把它的位置向上移动 80px。
.loader-box {
position: relative;
top: -80px;
height: 80px;
}
loader-box 中的 loader 是纯 CSS 的加载动画。我们利用 border 画出的一个圆形边框,左、上、右边框是浅灰色,下边框是深灰色:

#loader {
width: 25px;
height: 25px;
border: 3px solid #ddd;
border-radius: 50%;
border-bottom: 3px solid #717171;
transform: rotate(0deg);
}
开始刷新时,我们给 loader 元素增加一个动画,让它从 0 度到 360 度无限旋转,就实现了加载动画:

#loader.loading {
animation: loading 1s linear infinite;
}
@keyframes loading {
from { transform: rotate(0deg); }
to { transform: rotate(360deg); }
}
逻辑代码
看完布局代码,我们再看逻辑代码。逻辑代码中,我们要监听用户的手指滑动、实现下拉手势。我们需要用到三个事件:
- touchstart 代表触摸开始;
- touchmove 代表触摸移动;
- touchend 代表触摸结束。
从 touchstart 和 touchmove 事件中我们可以获取手指的坐标,比如 event.touches[0].clientX 是手指相对视口左边缘的 X 坐标,event.touches[0].clientY 是手指相对视口上边缘的 Y 坐标;从 touchend 事件中我们则无法获得 clientX 和 clientY。
我们可以先记录用户手指 touchstart 的 clientY 作为开始坐标,记录用户最后一次触发 touchmove 的 clientY 作为结束坐标,二者相减就得到手指移动的距离 distanceY。
设置手指移动多少距离,容器就移动多少距离,就得到了我们的逻辑代码:
const box = document.getElementById('box')
const loader = document.getElementById('loader')
let startY = 0, endY = 0, distanceY = 0
function start(e) {
startY = e.touches[0].clientY
}
function move(e) {
endY = e.touches[0].clientY
distanceY = endY - startY
box.style = `
transform: translateY(${distanceY}px);
transition: all 0.3s linear;
`
}
function end() {
setTimeout(() => {
box.style = `
transform: translateY(0);
transition: all 0.3s linear;
`
loader.className = 'loading'
}, 1000)
}
box.addEventListener('touchstart', start)
box.addEventListener('touchmove', move)
box.addEventListener('touchend', end)
逻辑代码实现一个简陋的下拉效果,当然现在还有很多缺陷。

简陋下拉效果的 6 个缺陷
之前我们实现了简陋的下拉效果,它还需要解决 6 个缺陷,才能算一个完善的功能。
没有最小、最大距离限制
第一个缺陷是,下拉没有做最小、最大距离的限制。
通常来说,我们下拉屏幕时,距离太小应该不能触发刷新,距离太大也不行,下滑到一定距离后,就应该无法继续下滑。
因此我们可以给下拉设置最小距离限制 DISTANCE_Y_MIN_LIMIT、最大距离限制 DISTANCE_Y_MAX_LIMIT。如果 touchend 中发现下拉距离小于最小距离,直接不触发加载;如果 touchmove 中下拉距离超过最大距离,页面只向下移动最大距离。
解决缺陷关键代码如下:
const DISTANCE_Y_MAX_LIMIT = 150
DISTANCE_Y_MIN_LIMIT = 80
function move(e) {
endY = e.touches[0].clientY
distanceY = endY - startY
if (distanceY > DISTANCE_Y_LIMIT) {
distanceY = DISTANCE_Y_LIMIT
}
box.style = `
transform: translateY(${distanceY}px);
transition: all 0.3s linear;
`
}
function end() {
if (distanceY < DISTANCE_Y_MIN_LIMIT) {
box.style = `
transform: translateY(0px);
transition: all 0.3s linear;
`
return
}
...
}
加载动画没有停留在视口顶部
第二个缺陷是,下拉没有让加载动画停留在视口顶部。
我们可以把 end 函数加以改造,在数据还没有加载完成时(用 setTimeout 模拟的),让加载动画 style 的 translateY 一直是 80px,translateY(80px) 可以和 初始 CSS 的 top: -80px; 相互抵消,让动画在未刷新完成前停留在视口顶部。
function end() {
...
box.style = `
transform: translateY(80px);
transition: all 0.3s linear;
`
loader.className = 'loading'
setTimeout(() => {
box.style = `
transform: translateY(0px);
transition: all 0.3s linear;
`
loader.className = ''
}, 1000)
}
重复触发
第三个缺陷是,下拉可以重复触发。
正常来说,如果我们已经下拉过,数据正在加载中时,我们不能继续下拉。
我们可以增加一个加载锁 loadLock。当加载锁开启时,start,move 和 end 事件都不会触发。
let loadLock = false
function start(e) {
if (loadLock) { return }
...
}
function move(e) {
if (loadLock) { return }
...
}
function end(e) {
if (loadLock) { return }
...
setTimeout(() => {
...
loadLock = true
...
}, 1000)
}
没有限制方向
第四个缺陷是,没有限制方向。
目前我们的代码,用户上拉也能触发。我们可以增加判断,当 endY - startY 小于 0 时,阻止 touchmove 和 touchend 的逻辑。
function move(e) {
...
if (endY - startY < 0) { return }
...
}
function end() {
if (endY - startY < 0) { return }
...
}
你可能会疑惑,为什么我宁愿写多个判断拦截,也不取消监听事件。这是因为一旦取消监听事件,我们需要考虑在一个合适的时间重新监听,这会把问题变得更复杂。
没有阻止原生滚动
第五个缺陷时,我们在加载数据时没有阻止原生滚动。
虽然我们已经阻止了重复下拉,touchmove 和 touchend 事件被拦截了,但是 H5 原生滚动还能用。
我们可以在刷新时给 body 设置一个 overflow: hidden; 属性,刷新结束后清除 overflow: hidden,这样就可以阻止原生滚动。
body.overflowHidden {
overflow: hidden;
}
const body = document.body
function end() {
...
box.style = `
transform: translateY(80px);
transition: all 0.3s linear;
`
loader.className = 'loading'
body.className = 'overflowHidden'
setTimeout(() => {
...
box.style = `
transform: translateY(0px);
transition: all 0.3s linear;
`
loader.className = ''
body.className = ''
}, 1000)
}
没有阻止 iOS 橡皮筋效果
第 6 个缺陷是,没有阻止 iOS 的橡皮筋效果。
iOS 浏览器默认滑动时有一个橡皮筋效果,我们需要阻止它,避免影响我们的下拉手势。阻止方式就是给监听器设置 passive: false。
function addTouchEvent() {
box.addEventListener('touchstart', start, { passive: false })
box.addEventListener('touchmove', move, { passive: false })
box.addEventListener('touchend', end, { passive: false })
}
addTouchEvent()
解决完 6 个缺陷后,我们已经得到无缺陷的下拉刷新功能,但离丝滑的下拉刷新还有一段距离。我们还可以做一些优化,让下拉刷新更完善。
优化
我们可以做两个优化,第一个优化是添加阻尼效果:
增加阻尼效果
所谓阻尼效果,就是下拉过程我们可以感受到一股阻力的存在,虽然我们下拉力度是一样的,但距离的增加速度变慢了。用物理术语表示的话,就是加速度变小了。
体现到代码上,我们可以设置一个百分比,百分比会随着下拉距离增加而减少,把百分比乘以距离当作最后的距离。
代码中百分比 percent 设为 (100 - distanceY * 0.5) / 100,当 distanceY 越来越大时,百分比 percent 越来越小,最后再把 distanceY * percent 赋值给 distanceY。
function move(e) {
...
distanceY = endY - startY
let percent = (100 - distanceY * 0.5) / 100
percent = Math.max(0.5, percent)
distanceY = distanceY * percent
if (distanceY > DISTANCE_Y_MAX_LIMIT) {
distanceY = DISTANCE_Y_MAX_LIMIT
}
...
}
利用角度判断用户下拉意图
第二个优化是利用角度判断用户下拉意图。
下图展示了两种用户下拉的情况,β 角度比 α 角度小,角度越小用户下拉意图越明显、误触的可能性更小。

我们可以利用反三角函数求出角度来判断下拉意图。
JavaScript 中,反正切函数是 Math.atan(),需要注意的是,反正切函数算出的是弧度,我们还需要将它乘以 180 / π 才能获取角度。
下面的代码中,我们做了一个限制,只有角度小于 40 时,我们才认为用户的真实意图是想要下拉刷新。
const DEG_LIMIT = 40
function move(e) {
...
distanceY = endY - startY
distanceX = endX - startX
const deg = Math.atan(Math.abs(distanceX) / distanceY)
* (180 / Math.PI)
if (deg > DEG_LIMIT) {
[startY, startX] = [endY, endX]
return
}
...
}
代码示例
你可以在 codepen 中查看效果,web 端需要按 F12 用手机浏览器打开。

总结
本文讲解了下拉的原理、并根据原理写出初始代码。在初始代码的基础上,我解决了 6 个缺陷、做了 2 个优化,实现了一个完善的下拉刷新效果。
来源:juejin.cn/post/7340836136208859174




















































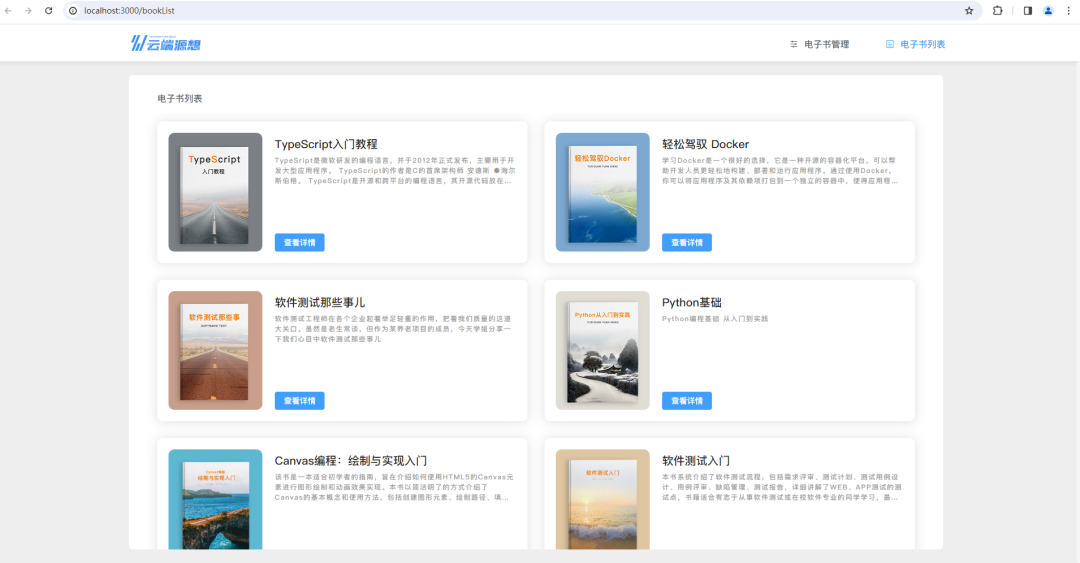














































































































 新方案加上课程Id排序方式以后,搜索结果和原方案一致。
新方案加上课程Id排序方式以后,搜索结果和原方案一致。






























































 `
`