本文为稀土掘金技术社区首发签约文章,30 天内禁止转载,30 天后未获授权禁止转载,侵权必究!
业务中涉及图片的制作和审核功能,审核人员需要在图片中进行标注,并说明存在的问题,标注过程中需要支持放大缩小,移动等交互,将业务剥离,这个需求,可以定义为实现一个图片标注功能。
实现这个功能并不容易,其涉及的前端知识点众多,本文带领大家从零到一,亲手实现一个,支持缩放,移动,编辑的图片标注功能,文字描述是抽象的,眼见为实,实现效果如下所示:

技术方案
这里涉及两个关键功能,一个是绘制,包括缩放和旋转,一个是编辑,包括选取和修改尺寸,涉及到的技术包括,缩放,移动,和自定义形状的绘制(本文仅实现矩形),绘制形状的选取,改变尺寸和旋转角度等。
从大的技术选型来说,有两种实现思路,一种是 canvas,一种是 dom+svg,下面简单介绍下两种思路和优缺点。
canvas 可以方便实现绘制功能,但编辑功能就比较困难,当然这可以使用库来实现,这里我们考虑自己亲手实现功能。
- 优点:
- 性能较好,尤其是在处理大型图片和复杂图形时。
- 支持更复杂的图形绘制和像素级操作。
- 一旦图形绘制在 Canvas 上,就不会受到 DOM 的影响,减少重绘和回流。
- 缺点:
- 交互相对复杂,需要手动管理图形的状态和事件。
- 对辅助技术(如屏幕阅读器)支持较差。
- 可能遇到的困难:
- 实现复杂的交互逻辑(如选取、移动、修改尺寸等)可能比较繁琐。
- 在缩放和平移时,需要手动管理坐标变换和图形重绘。
dom+svg 也可以实现功能,缩放和旋转可以借助 css3 的 transform。
- 优点:
- 交互相对简单,可以利用 DOM 事件系统和 CSS。
- 对辅助技术支持较好,有助于提高可访问性。
- 缺点:
- 在处理大型图片和复杂图形时,性能可能不如 Canvas。
- SVG 元素数量过多时,可能会影响页面性能。
- 可能遇到的困难:
- 在实现复杂的图形和效果时,可能需要较多的 SVG 知识和技巧。
- 管理大量的 SVG 元素和事件可能会使代码变得复杂。
总的来说,如果对性能有较高要求,或需要进行复杂的图形处理和像素操作,可以选择基于 Canvas 的方案。否则可以选择基于 DOM + SVG 的方案。在具体实现时,可以根据项目需求和技术栈进行选择。
下面我们选择基于 canvas 的方案,通过例子,一步一步实现完成功能,让我们先从最简单的开始。
渲染图片
本文我们不讲解 canvas 基础,如果你不了解 canvas,可以先在网上找资料,简单学习下,图片的渲染非常简单,只用到一个 API,这里我们直接给出代码,示例如下:
这里我们提前准备一个 canvas,宽高设定为 1000*700,这里唯一的一个知识点就是要在图片加载完成后再绘制,在实战中,需要注意绘制的图片不能跨域,否则会绘制失败。
<body>
<div>
<canvas id="canvas1" width="1000" height="700"></canvas>
</div>
<script>
const canvas1 = document.querySelector('#canvas1');
const ctx1 = canvas1.getContext('2d');
let width = 1000;
let height = 700;
let img = new Image();
img.src = './bg.png';
img.onload = function () {
draw();
};
function draw() {
console.log('draw');
ctx1.drawImage(img, 0, 0, width, height);
}
</script>
</body>
现在我们已经成功在页面中绘制了一张图片,这非常简单,让我们继续往下看吧。
缩放
实现图片缩放功能,我们需要了解两个关键的知识点:如何监听缩放事件和如何实现图片缩放。
先来看第一个,我用的是 Mac,在 Mac 上可以通过监听鼠标的滚轮事件来实现缩放的监听。当用户使用鼠标滚轮时,会触发 wheel 事件,我们可以通过这个事件的 deltaY 属性来判断用户是向上滚动(放大)还是向下滚动(缩小)。
可以看到在 wheel 事件中,我们修改了 scale 变量,这个变量会在下面用到。这里添加了对最小缩放是 1,最大缩放是 3 的限制。
document.addEventListener(
'wheel',
function (event) {
if (event.ctrlKey) {
// detect pinch
event.preventDefault(); // prevent zoom
if (event.deltaY < 0) {
console.log('Pinching in');
if (scale < 3) {
scale = Math.min(scale + 0.1, 3);
draw();
}
} else {
console.log('Pinching out');
if (scale > 1) {
scale = Math.max(scale - 0.1, 1);
draw();
}
}
}
},
{ passive: false }
);
图片缩放功能,用到了 canvas 的 scale 函数,其可以修改绘制上下文的缩放比例,示例代码如下:
我们添加了clearRect函数,这用来清除上一次绘制的图形,当需要重绘时,就需要使用clearRect函数。
这里需要注意开头和结尾的 save 和 restore 函数,因为我们会修改 scale,如果不恢复的话,其会影响下一次绘制,一般在修改上下文时,都是通过 save 和 restore 来复原的。
let scale = 1;
function draw() {
console.log('draw');
ctx1.clearRect(0, 0, width, height);
ctx1.save();
ctx1.scale(scale, scale);
ctx1.drawImage(img, 0, 0, width, height);
ctx1.restore();
}
这里稍微解释一下 scale 函数,初次接触,可能会不太好理解。在 Canvas 中使用 scale 函数时,重要的是要理解它实际上是在缩放绘图坐标系统,而不是直接缩放绘制的图形。当你调用 ctx.scale(scaleX, scaleY) 时,你是在告诉 Canvas 之后的所有绘图操作都应该在一个被缩放的坐标系统中进行。
这意味着,如果你将缩放比例设置为 2,那么在这个缩放的坐标系统中,绘制一个宽度为 50 像素的矩形,实际上会在画布上产生一个宽度为 100 像素的矩形。因为在缩放的坐标系统中,每个单位长度都变成了原来的两倍。
因此,当我们谈论 scale 函数时,重点是要记住它是在缩放整个绘图坐标系统,而不是单独的图形。这就是为什么在使用 scale 函数后,所有的绘图操作(包括位置、大小等)都会受到影响。
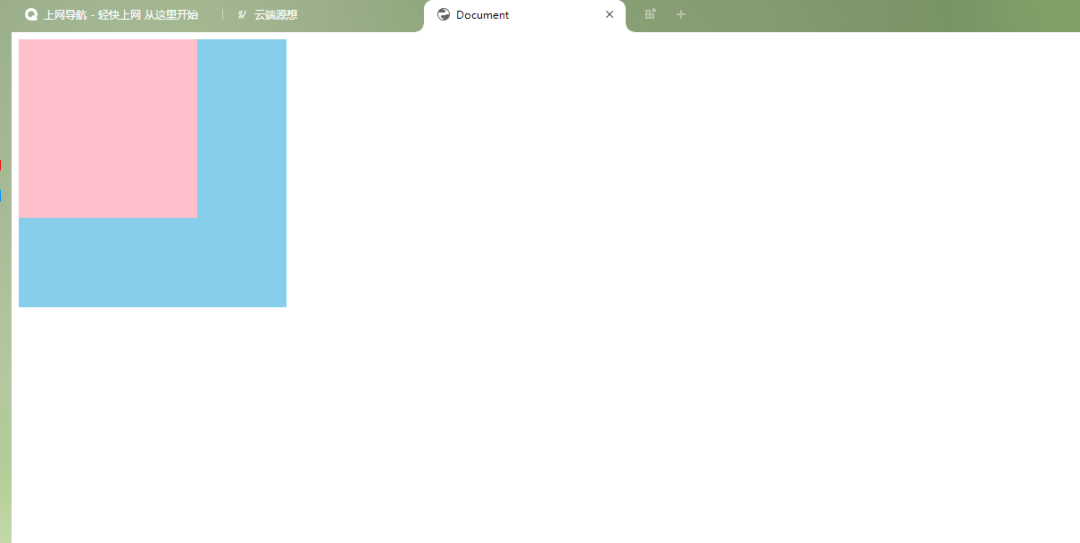
现在我们已经实现了图片的缩放功能,效果如下所示:

鼠标缩放
细心的你可能发现上面的缩放效果是基于左上角的,基于鼠标点缩放意味着图片的缩放中心是用户鼠标所在的位置,而不是图片的左上角或其他固定点。这种缩放方式更符合用户的直觉,可以提供更好的交互体验。
为了实现这种效果,可以使用 tanslate 来移动原点,canvas 中默认的缩放原点是左上角,具体方法是,可以在缩放前,将缩放原点移动到鼠标点的位置,缩放后,再将其恢复,这样就不会影响后续的绘制,实现代码如下所示:
let scaleX = 0;
let scaleY = 0;
function draw() {
ctx1.clearRect(0, 0, width, height);
ctx1.save();
// 注意这行1
ctx1.translate(scaleX, scaleY);
ctx1.scale(scale, scale);
// 注意这行2
ctx1.translate(-scaleX, -scaleY);
ctx1.drawImage(img, 0, 0, width, height);
ctx1.restore();
}
scaleX 和 scaleY 的值,可以在缩放的时候设置即可,如下所示:
// zoom
document.addEventListener(
'wheel',
function (event) {
if (event.ctrlKey) {
if (event.deltaY < 0) {
if (scale < 3) {
// 注意这里两行
scaleX = event.offsetX;
scaleY = event.offsetY;
scale = Math.min(scale + 0.1, 3);
draw();
}
}
// 省略代码
}
},
{ passive: false }
);
现在我们已经实现了图片的鼠标缩放功能,效果如下所示:

移动视口
先解释下放大时,可见区域的概念,好像叫视口吧
当处于放大状态时,会导致图像只能显示一部分,此时需要能过需要可以移动可见的图像,
这里选择通过触摸板的移动,也就是 wheel 来实现移动视口
通过 canvas 的 translate 来实现改变视口
在图片放大后,整个图像可能无法完全显示在 Canvas 上,此时只有图像的一部分(即可见区域)会显示在画布上。这个可见区域也被称为“视口”。为了查看图像的其他部分,我们需要能够移动这个视口,即实现图片的平移功能。
在放大状态下,视口的大小相对于整个图像是固定的,但是它可以在图像上移动以显示不同的部分。你可以将视口想象为一个固定大小的窗口,你通过这个窗口来观察一个更大的图像。当你移动视口时,窗口中显示的图像部分也会相应改变。
为了实现移动视口,我们可以通过监听触摸板的移动事件(也就是 wheel 事件)来改变视口的位置。当用户通过触摸板进行上下或左右滑动时,我们可以相应地移动视口,从而实现图像的平移效果。
我们可以使用 Canvas 的 translate 方法来改变视口的位置。translate 方法接受两个参数,分别表示沿 x 轴和 y 轴移动的距离。在移动视口时,我们需要更新图片的位置,并重新绘制图像以反映新的视口位置。
代码改动如下所示:
let translateX = 0;
let translateY = 0;
function draw() {
// 此处省略代码
// 改变视口
ctx1.translate(translateX, translateY);
ctx1.drawImage(img, 0, 0, width, height);
ctx1.restore();
}
// translate canvas
document.addEventListener(
"wheel",
function (event) {
if (!event.ctrlKey) {
// console.log("translate", event.deltaX, event.deltaY);
event.preventDefault();
translateX -= event.deltaX;
translateY -= event.deltaY;
draw();
}
},
{ passive: false }
);
在这个示例中,translateX 和 translateY 表示视口的位置。当用户通过触摸板进行滑动时,我们根据滑动的方向和距离更新视口的位置,并重新绘制图像。通过这种方式,我们可以实现图像的平移功能,允许用户查看图像的不同部分。
现在我们已经实现了移动视口功能,效果如下所示:

绘制标注
为了便于大家理解,这里我们仅实现矩形标注示例,实际业务中可能存在各种图形的标记,比如圆形,椭圆,直线,曲线,自定义图形等。
我们先考虑矩形标注的绘制问题,由于 canvas 是位图,我们需要在 js 中存储矩形的数据,矩形的存储需要支持坐标,尺寸,旋转角度和是否在编辑中等。因为可能存在多个标注,所以需要一个数组来存取标注数据,我们将标注存储在reacts中,示例如下:
let rects = [
{
x: 650,
y: 350,
width: 100,
height: 100,
isEditing: false,
rotatable: true,
rotateAngle: 30,
},
];
下面将 rects 渲染到 canvas 中,示例代码如下:
代码扩机并不复杂,比较容易理解,值得一提的rotateAngle的实现,我们通过旋转上下文来实现,其旋转中心是矩形的图形的中心点,因为操作上线文,所以在每个矩形绘制开始和结束后,要通过save和restore来恢复之前的上下文。
isEditing表示当前的标注是否处于编辑状态,在这里编辑中的矩形框,我们只需设置不同的颜色即可,在后面我们会实现编辑的逻辑。
function draw() {
// 此处省略代码
ctx1.drawImage(img, 0, 0, width, height);
rects.forEach((r) => {
ctx1.strokeStyle = r.isEditing ? 'rgba(255, 0, 0, 0.5)' : 'rgba(255, 0, 0)';
ctx1.save();
if (r.rotatable) {
ctx1.translate(r.x + r.width / 2, r.y + r.height / 2);
ctx1.rotate((r.rotateAngle * Math.PI) / 180);
ctx1.translate(-(r.x + r.width / 2), -(r.y + r.height / 2));
}
ctx1.strokeRect(r.x, r.y, r.width, r.height);
ctx1.restore();
});
ctx1.restore();
}
现在我们已经实现了标注绘制功能,效果如下所示:

添加标注
为了在图片上添加标注,我们需要实现鼠标按下、移动和抬起时的事件处理,以便在用户拖动鼠标时动态地绘制一个矩形标注。同时,由于视口可以放大和移动,我们还需要进行坐标的换算,确保标注的位置正确。
首先,我们需要定义一个变量 drawingRect 来存储正在添加中的标注数据。这个变量将包含标注的起始坐标、宽度和高度等信息:
let drawingRect = null;
接下来,我们需要实现鼠标按下、移动和抬起的事件处理函数:
mousedown中我们需要记录鼠标按下时,距离视口左上角的坐标,并将其记录到全局变量startX和startY中。
mousemove时,需要更新当前在绘制矩形的数据,并调用draw完成重绘。
mouseup时,需要处理添加操作,将矩形添加到rects中,在这里我做了一个判断,如果矩形的宽高小于 1,则不添加,这是为了避免在鼠标原地点击时,误添加图形的问题。
let startX = 0;
let startY = 0;
canvas1.addEventListener('mousedown', (e) => {
startX = e.offsetX;
startY = e.offsetY;
const { x, y } = computexy(e.offsetX, e.offsetY);
console.log('mousedown', e.offsetX, e.offsetY, x, y);
drawingRect = drawingRect || {};
});
canvas1.addEventListener('mousemove', (e) => {
// 绘制中
if (drawingRect) {
drawingRect = computeRect({
x: startX,
y: startY,
width: e.offsetX - startX,
height: e.offsetY - startY,
});
draw();
return;
}
});
canvas1.addEventListener('mouseup', (e) => {
if (drawingRect) {
drawingRect = null;
// 如果绘制的矩形太小,则不添加,防止原地点击时添加矩形
// 如果反向绘制,则调整为正向
const width = Math.abs(e.offsetX - startX);
const height = Math.abs(e.offsetY - startY);
if (width > 1 || height > 1) {
const newrect = computeRect({
x: Math.min(startX, e.offsetX),
y: Math.min(startY, e.offsetY),
width,
height,
});
rects.push(newrect);
draw();
}
return;
}
});
下面我们来重点讲讲上面的computexy和computeRect函数,由于视口可以放大和移动,我们需要将鼠标点击时的视口坐标换算为 Canvas 坐标系的坐标。
宽高的计算比较简单,只需要将视口坐标除以缩放比例即可得到。但坐标的计算并不简单,这里通过视口坐标,直接去推 canvas 坐标是比较困难的,我们可以求出 canvas 坐标计算视口坐标的公式,公式推导如下:
vx: 视口坐标
x: canvas坐标
scale: 缩放比例
scaleX: 缩放原点
translateX: 视口移动位置
我们x会在如下视口操作后进行渲染成vx:
1: ctx1.translate(scaleX, scaleY);
2: ctx1.scale(scale, scale);
3: ctx1.translate(-scaleX, -scaleY);
4: ctx1.translate(translateX, translateY);
根据上面的步骤,每一步vx的推演如下:
1: vx = x + scaleX
2: vx = x * scale + scaleX
3: vx = x * scale + scaleX - scaleX * scale
4: vx = x * scale + scaleX - scaleX * scale + translateX * scale
通过上面 vx 和 x 的公式,我们可以计算出来 x 和 vx 的关系如下,我在这里走了很多弯路,导致计算的坐标一直不对,不要试图通过 vx 直接推出 x,一定要通过上面的公式来推导:
x = (vx - scaleX * (1 - scale) - translateX * scale) / scale
理解了上面坐标和宽高的计算公式,下面的代码就好理解了:
function computexy(x, y) {
const xy = {
x: (x - scaleX * (1 - scale) - translateX * scale) / scale,
y: (y - scaleY * (1 - scale) - translateY * scale) / scale,
};
return xy;
}
function computewh(width, height) {
return {
width: width / scale,
height: height / scale,
};
}
function computeRect(rect) {
const cr = {
...computexy(rect.x, rect.y),
...computewh(rect.width, rect.height),
};
return cr;
}
最后,我们需要一个函数来绘制标注矩形:
function draw() {
// 此处省略代码
if (drawingRect) {
ctx1.strokeRect(
drawingRect.x,
drawingRect.y,
drawingRect.width,
drawingRect.height
);
}
ctx1.restore();
}
现在我们已经实现了添加标注功能,效果如下所示:

选取标注
判断选中,将视口坐标,转换为 canvas 坐标,遍历矩形,判断点在矩形内部
同时需要考虑点击空白处,清空选中状态
选中其他元素时,清空上一个选中的元素
渲染选中状态,选中状态改变边的颜色,为了明显,红色变为绿色
要是先选取元素的功能,关键要实现的判断点在矩形内部,判断点在矩形内部的逻辑比较简单,我们可以抽象为如下函数:
function poInRect({ x, y }, rect) {
return (
x >= rect.x &&
x <= rect.x + rect.width &&
y >= rect.y &&
y <= rect.y + rect.height
);
}
在点击事件中,我们拿到的是视口坐标,首先将其转换为 canvas 坐标,然后遍历矩形数组,判断是否有中选的矩形,如果有的话将其存储下来。
还需要考虑点击新元素时,和点击空白时,重置上一个元素的选中态的逻辑,代码实现如下所示:
canvas1.addEventListener('mousedown', (e) => {
startX = e.offsetX;
startY = e.offsetY;
const { x, y } = computexy(e.offsetX, e.offsetY);
const pickRect = rects.find((r) => {
return poInRect({ x, y }, r);
});
if (pickRect) {
if (editRect && pickRect !== editRect) {
// 选择了其他矩形
editRect.isEditing = false;
editRect = null;
}
pickRect.isEditing = true;
editRect = pickRect;
draw();
} else {
if (editRect) {
editRect.isEditing = false;
editRect = null;
draw();
}
drawingRect = drawingRect || {};
}
});
现在我们已经实现了选取标注功能,效果如下所示:

移动
接下来是移动,也就是通过拖拽来改变已有图形的位置
首先需要一个变量来存取当前被拖拽元素,在 down 和 up 时更新这个元素
要实现拖拽,需要一点小技巧,在点击时,计算点击点和图形左上角的坐标差,在每次 move 时,用当前坐标减去坐标差即可
不要忘了将视口坐标,换算为 canvas 坐标哦
接下来,我们将实现通过拖拽来改变已有标注的位置的功能。这需要跟踪当前被拖拽的标注,并在鼠标移动时更新其位置。
首先,我们需要一个变量来存储当前被拖拽的标注:
let draggingRect = null;
在鼠标按下时(mousedown 事件),我们需要判断是否点击了某个标注,并将其设置为被拖拽的标注,并在鼠标抬起时(mouseup 事件),将其置空。
要实现完美的拖拽效果,需要一点小技巧,在点击时,计算点击点和图形左上角的坐标差,将其记录到全局变量shiftX和shiftY,关键代码如下所示。
let shiftX = 0;
let shiftY = 0;
canvas1.addEventListener('mousedown', (e) => {
const { x, y } = computexy(e.offsetX, e.offsetY);
if (pickRect) {
// 计算坐标差
shiftX = x - pickRect.x;
shiftY = y - pickRect.y;
// 标记当前拖拽元素
draggingRect = pickRect;
draw();
}
});
canvas1.addEventListener('mouseup', (e) => {
if (draggingRect) {
// 置空当前拖拽元素
draggingRect = null;
return;
}
});
在鼠标移动时(mousemove 事件),如果有标注被拖拽,则更新其位置,关键代码如下所示。
canvas1.addEventListener('mousemove', (e) => {
const { x, y } = computexy(e.offsetX, e.offsetY);
// 当前正在拖拽矩形
if (draggingRect) {
draggingRect.x = x - shiftX;
draggingRect.y = y - shiftY;
draw();
return;
}
});
现在我们已经实现了移动功能,效果如下所示:

修改尺寸
为了实现标注尺寸的修改功能,我们可以在标注的四个角和四条边的中点处显示小方块作为编辑器,允许用户通过拖拽这些小方块来改变标注的大小。
首先,我们需要实现编辑器的渲染逻辑。我们可以在 drawEditor 函数中添加代码来绘制这些小方块。
在这里,我们使用 computeEditRect 函数来计算标注的八个编辑点的位置,并在 drawEditor 函数中绘制这些小方块,关键代码如下所示:
在这个例子中,我们只展示了上边中间编辑点的处理逻辑,其他编辑点的处理逻辑类似。
function computeEditRect(rect) {
let width = 10;
let linelen = 16;
return {
t: {
type: "t",
x: rect.x + rect.width / 2 - width / 2,
y: rect.y - width / 2,
width,
height: width,
},
b: {// 代码省略},
l: {// 代码省略},
r: {// 代码省略},
tl: {// 代码省略},
tr: {// 代码省略},
bl: {// 代码省略},
br: {// 代码省略},
};
}
function drawEditor(rect) {
ctx1.save();
const editor = computeEditRect(rect);
ctx1.fillStyle = "rgba(255, 150, 150)";
// 绘制矩形
for (const r of Object.values(editor)) {
ctx1.fillRect(r.x, r.y, r.width, r.height);
}
ctx1.restore();
}
function draw() {
rects.forEach((r) => {
// 添加如下代码
if (r.isEditing) {
drawEditor(r);
}
});
}
接下来,我们需要实现拖动这些编辑点来改变标注大小的功能。首先,我们需要在鼠标按下时判断是否点击了某个编辑点。
在这里,我们使用 poInEditor 函数来判断鼠标点击的位置是否接近某个编辑点。如果是,则设置 startEditRect, dragingEditor, editorShiftXY 来记录正在调整大小的标注和编辑点。
let startEditRect = null;
let dragingEditor = null;
let editorShiftX = 0;
let editorShiftY = 0;
function poInEditor(point, rect) {
const editor = computeEditRect(rect);
if (!editor) return;
for (const edit of Object.values(editor)) {
if (poInRect(point, edit)) {
return edit;
}
}
}
canvas1.addEventListener('mousedown', (e) => {
startX = e.offsetX;
startY = e.offsetY;
const { x, y } = computexy(e.offsetX, e.offsetY);
if (editRect) {
const editor = poInEditor({ x, y }, editRect);
if (editor) {
// 调整大小
startEditRect = { ...editRect };
dragingEditor = editor;
editorShiftX = x - editor.x;
editorShiftY = y - editor.y;
return;
}
}
});
然后,在鼠标移动时,我们需要根据拖动的编辑点来调整标注的大小。
在这个例子中,我们只展示了上边中间编辑点的处理逻辑,其他编辑点的处理逻辑类似。通过拖动不同的编辑点,我们可以实现标注的不同方向和维度的大小调整。
canvas1.addEventListener('mousemove', (e) => {
const { x, y } = computexy(e.offsetX, e.offsetY);
// 如果存在编辑中的元素
if (editRect) {
const editor = poInEditor({ x, y }, editRect);
// 调整大小中
if (dragingEditor) {
const moveX = (e.offsetX - startX) / scale;
const moveY = (e.offsetY - startY) / scale;
switch (dragingEditor.type) {
case 't':
editRect.y = startEditRect.y + moveY;
editRect.height = startEditRect.height - moveY;
break;
}
draw();
return;
}
}
});
现在我们已经实现了修改尺寸功能,效果如下所示:

旋转
实现旋转编辑器的渲染按钮,在顶部增加一个小方块的方式来实现,
旋转图形会影响选中图形的逻辑,即点在旋转图形里的判断,这块的逻辑需要修改
接下来实现旋转逻辑,会涉及 mousedown 和 mousemove
接下来介绍旋转,这一部分会有一定难度,涉及一些数学计算,而且旋转逻辑会修改多出代码,下面我们依次介绍。
旋转涉及两大块功能,一个是旋转编辑器,一个是旋转逻辑,我们先来看旋转编辑器,我们可以在标注的顶部增加一个用于旋转的小方块作为旋转编辑器,如下图所示:

下面修改我们的drawEditor和computeEditRect函数,增加渲染逻辑,涉及一个方块和一条线的渲染。
其中rotr就是顶部的方块,rotl是那条竖线。
function computeEditRect(rect) {
let width = 10;
let linelen = 16;
return {
...(rect.rotatable
? {
rotr: {
type: 'rotr',
x: rect.x + rect.width / 2 - width / 2,
y: rect.y - width / 2 - linelen - width,
width,
height: width,
},
rotl: {
type: 'rotl',
x1: rect.x + rect.width / 2,
y1: rect.y - linelen - width / 2,
x2: rect.x + rect.width / 2,
y2: rect.y - width / 2,
},
}
: null),
};
}
function drawEditor(rect) {
ctx1.save();
const editor = computeEditRect(rect);
ctx1.fillStyle = 'rgba(255, 150, 150)';
const { rotl, rotr, ...rects } = editor;
// 绘制旋转按钮
if (rect.rotatable) {
ctx1.fillRect(rotr.x, rotr.y, rotr.width, rotr.height);
ctx1.beginPath();
ctx1.moveTo(rotl.x1, rotl.y1);
ctx1.lineTo(rotl.x2, rotl.y2);
ctx1.stroke();
}
// 绘制矩形
// ...
}
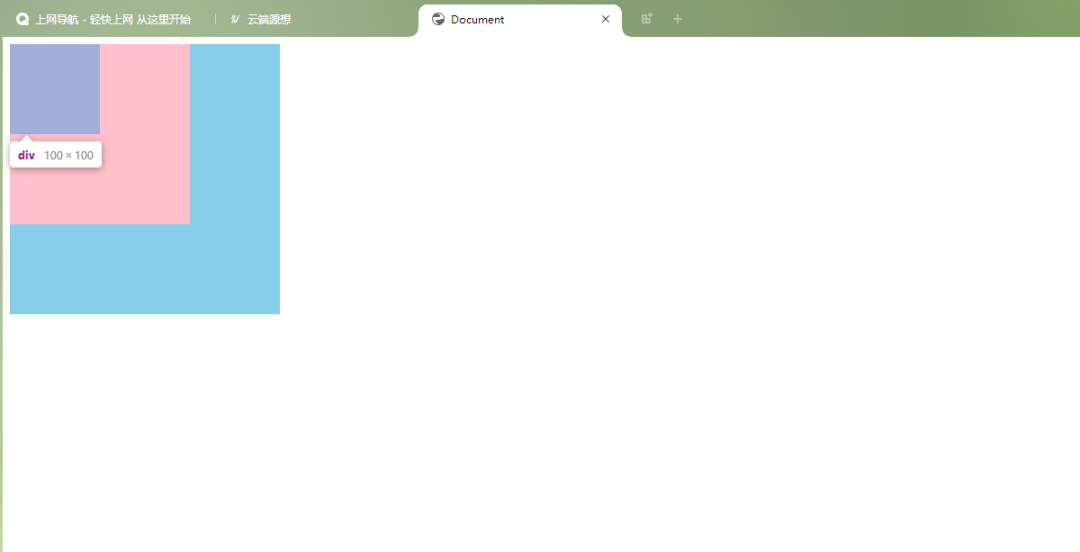
在实现旋转逻辑之前,先来看一个问题,如下图所示,当我们在绿色圆圈区按下鼠标时,在我们之前的逻辑中,也会触发选中状态。

这是因为我们判断点在矩形内部的逻辑,并未考虑旋转的问题,我们的矩形数据存储了矩形旋转之前的坐标和旋转角度,如下所示。
let rects = [
{
x: 650,
y: 350,
width: 100,
height: 100,
isEditing: false,
rotatable: true,
rotateAngle: 30,
},
];
解决这个问题有两个思路,一个是将旋转后矩形的四个点坐标计算出来,这种方法比较麻烦。另一个思路是逆向的,将要判断的点,以矩形的中点为中心,做逆向旋转,计算出其在 canvas 中的坐标,这个坐标,可以继续参与我们之前点在矩形内的计算。
关键代码如下所示,其中rotatePoint是计算 canvas 中的坐标,poInRotRect判断给定点是否在旋转矩形内部。
// 将点绕 rotateCenter 旋转 rotateAngle 度
function rotatePoint(point, rotateCenter, rotateAngle) {
let dx = point.x - rotateCenter.x;
let dy = point.y - rotateCenter.y;
let rotatedX =
dx * Math.cos((-rotateAngle * Math.PI) / 180) -
dy * Math.sin((-rotateAngle * Math.PI) / 180) +
rotateCenter.x;
let rotatedY =
dy * Math.cos((-rotateAngle * Math.PI) / 180) +
dx * Math.sin((-rotateAngle * Math.PI) / 180) +
rotateCenter.y;
return { x: rotatedX, y: rotatedY };
}
function poInRotRect(
point,
rect,
rotateCenter = {
x: rect.x + rect.width / 2,
y: rect.y + rect.height / 2,
},
rotateAngle = rect.rotateAngle
) {
if (rotateAngle) {
const rotatedPoint = rotatePoint(point, rotateCenter, rotateAngle);
const res = poInRect(rotatedPoint, rect);
return res;
}
return poInRect(point, rect);
}
接下来实现旋转逻辑,这需要改在 mousedown 和 mousemove 事件,实现拖动时的实时旋转。
在 mousedown 时,判断如果点击的是旋转按钮,则将当前矩形记录到全局变量rotatingRect。
canvas1.addEventListener('mousedown', (e) => {
startX = e.offsetX;
startY = e.offsetY;
const { x, y } = computexy(e.offsetX, e.offsetY);
if (editRect) {
const editor = poInEditor({ x, y }, editRect);
if (editor) {
// 调整旋转
if (editor.type === 'rotr') {
rotatingRect = editRect;
prevX = e.offsetX;
prevY = e.offsetY;
return;
}
// 调整大小
}
}
});
在 mousemove 时,判断如果是位于旋转按钮上,则计算旋转角度。
canvas1.addEventListener('mousemove', (e) => {
// 绘制中
const { x, y } = computexy(e.offsetX, e.offsetY);
// 当前正在拖拽矩形
// 如果存在编辑中的元素
if (editRect) {
const editor = poInEditor({ x, y }, editRect);
console.log('mousemove', editor);
// 旋转中
if (rotatingRect) {
const relativeAngle = getRelativeRotationAngle(
computexy(e.offsetX, e.offsetY),
computexy(prevX, prevY),
{
x: editRect.x + editRect.width / 2,
y: editRect.y + editRect.height / 2,
}
);
console.log('relativeAngle', relativeAngle);
editRect.rotateAngle += (relativeAngle * 180) / Math.PI;
prevX = e.offsetX;
prevY = e.offsetY;
draw();
return;
}
// 调整大小中
}
});
将拖拽移动的距离,转换为旋转的角度,涉及一些数学知识,其原理是通过上一次鼠标位置和本次鼠标位置,计算两个点和旋转中心(矩形的中心)三个点,形成的夹角,示例代码如下:
function getRelativeRotationAngle(point, prev, center) {
// 计算上一次鼠标位置和旋转中心的角度
let prevAngle = Math.atan2(prev.y - center.y, prev.x - center.x);
// 计算当前鼠标位置和旋转中心的角度
let curAngle = Math.atan2(point.y - center.y, point.x - center.x);
// 得到相对旋转角度
let relativeAngle = curAngle - prevAngle;
return relativeAngle;
}
现在我们已经实现了旋转功能,效果如下所示:

总结
在本文中,我们一步一步地实现了一个功能丰富的图片标注工具。从最基本的图片渲染到复杂的标注编辑功能,包括缩放、移动、添加标注、选择标注、移动标注、修改标注尺寸、以及标注旋转等,涵盖了图片标注工具的核心功能。
通过这个实例,我们可以看到,实现一个前端图片标注工具需要综合运用多种前端技术和知识,包括但不限于:
- Canvas API 的使用,如绘制图片、绘制形状、图形变换等。
- 鼠标事件的处理,如点击、拖拽、滚轮缩放等。
- 几何计算,如点是否在矩形内、旋转角度的计算等。
希望这个实例能够为你提供一些启发和帮助,让你在实现自己的图片标注工具时有一个参考和借鉴。
更进一步
站在文章的角度,到此为止,下面让我们站在更高的维度思考更进一步的可能,我们还能继续做些什么呢?
在抽象层面,我们可以考虑将图片标注工具的核心功能进行进一步的抽象和封装,将其打造成一个通用的开源库。这样,其他开发者可以直接使用这个库来快速实现自己的图片标注需求,而无需从零开始。为了实现这一目标,我们需要考虑以下几点:
- 通用性:库应该支持多种常见的标注形状和编辑功能,以满足不同场景的需求。
- 易用性:提供简洁明了的 API 和文档,使得开发者能够轻松集成和使用。
- 可扩展性:设计上应该留有足够的灵活性,以便开发者可以根据自己的特定需求进行定制和扩展。
- 性能优化:注重性能优化,确保库在处理大型图片或复杂标注时仍能保持良好的性能。
在产品层面,我们可以基于这个通用库,进一步开发成一个功能完备的图片标注工具,提供开箱即用的体验。这个工具可以包括以下功能:
- 多种标注类型:支持矩形、圆形、多边形等多种标注类型。
- 标注管理:提供标注的增加、删除、编辑、保存等管理功能。
- 导出和分享:支持导出标注结果为各种格式,如 JSON、XML 等,以及分享给他人协作编辑。
- 用户界面:提供友好的用户界面,支持快捷键操作,提高标注效率。
- 集成与扩展:支持与其他系统或工具的集成,提供 API 接口和插件机制,以便进行功能扩展。
通过不断地迭代和优化,我们可以使这个图片标注工具成为业界的标杆,为用户提供高效便捷的标注体验。
感谢您的阅读和关注!希望这篇文章能够为您在前端开发中实现图像标注功能提供一些有价值的见解和启发。如果您有任何问题、建议或想要分享自己的经验,欢迎在评论区留言交流。让我们一起探索更多前端技术的可能性,不断提升我们的技能和创造力!
本文示例源码:github.com/yanhaijing/…
本文示例预览:yanhaijing.com/imagic/demo…