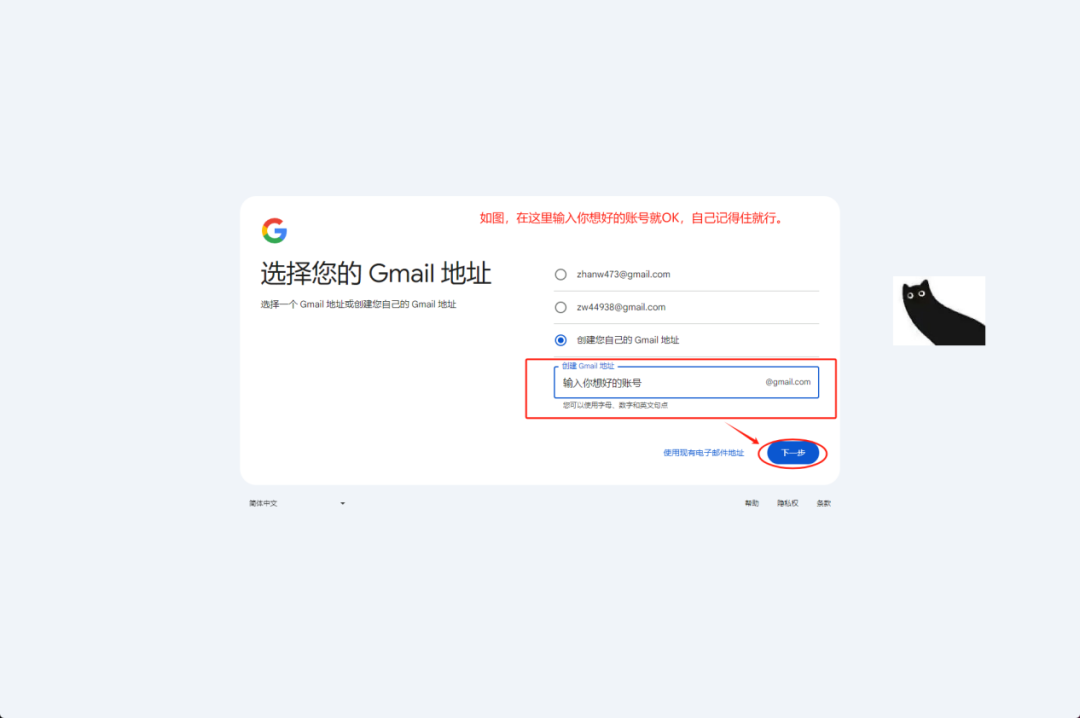
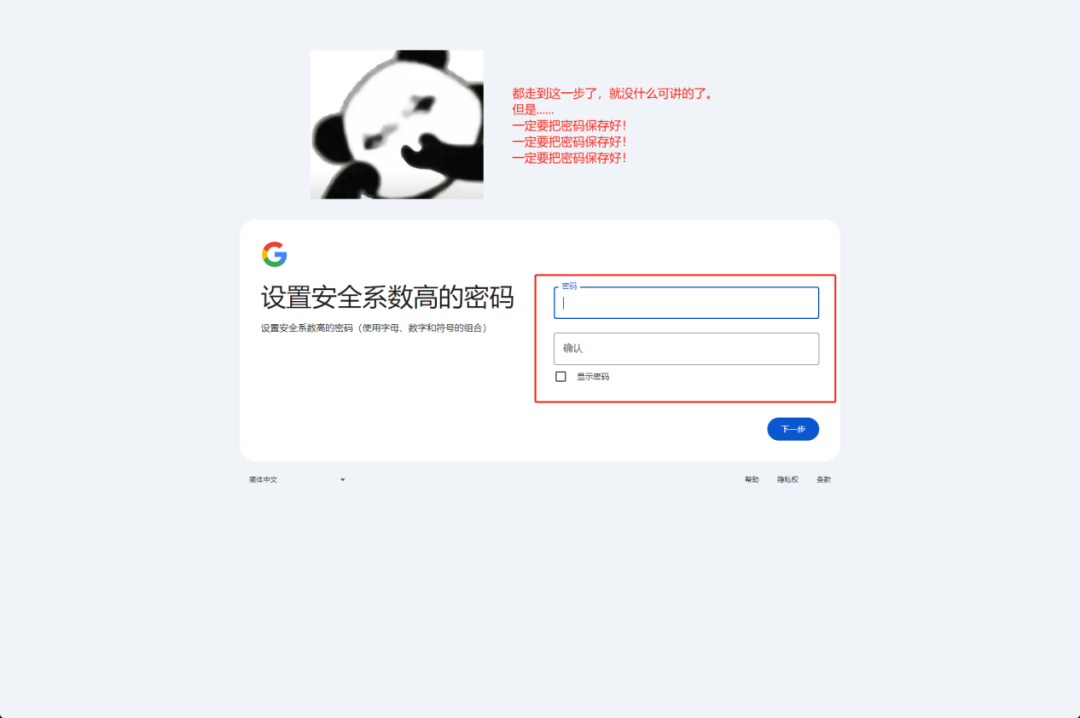
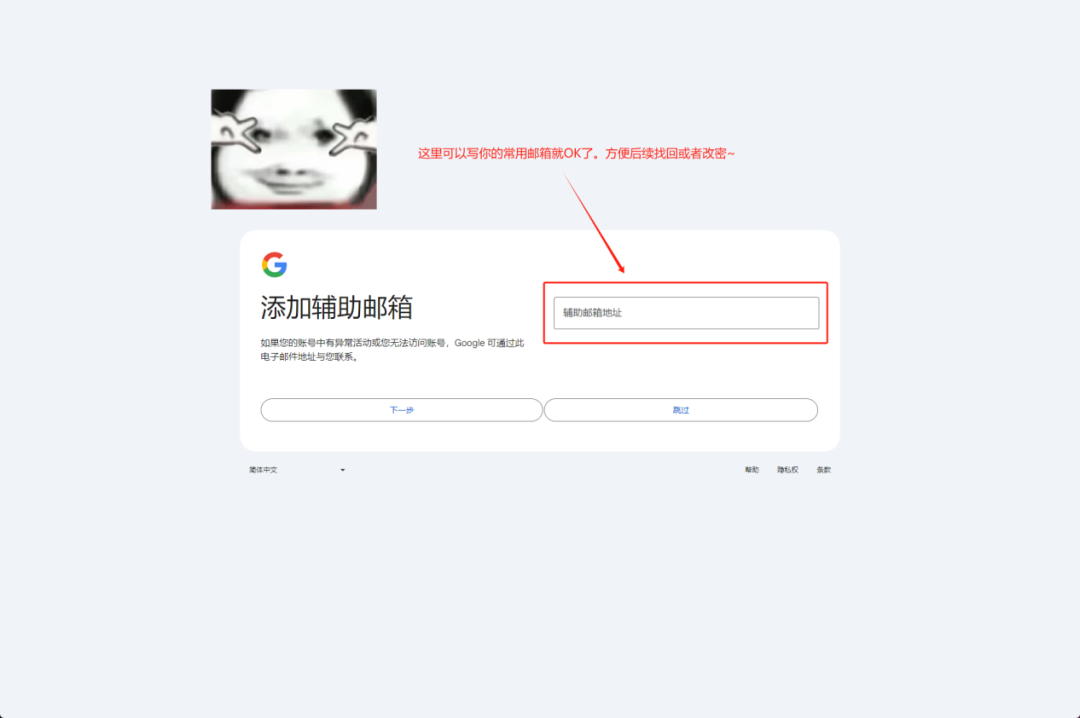
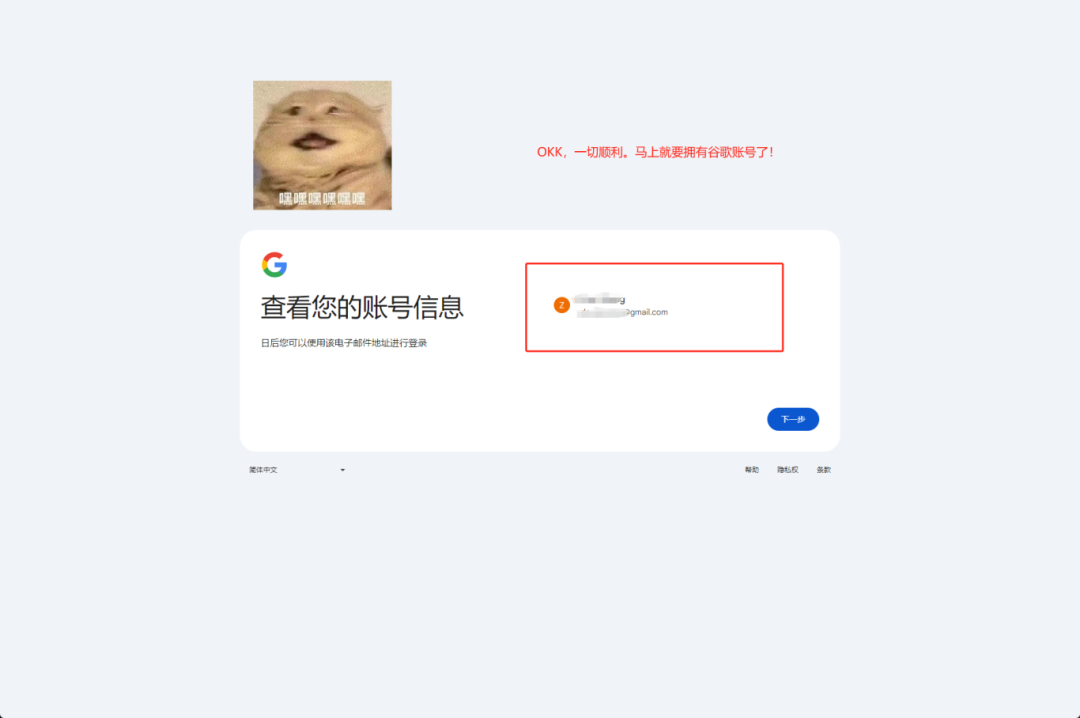
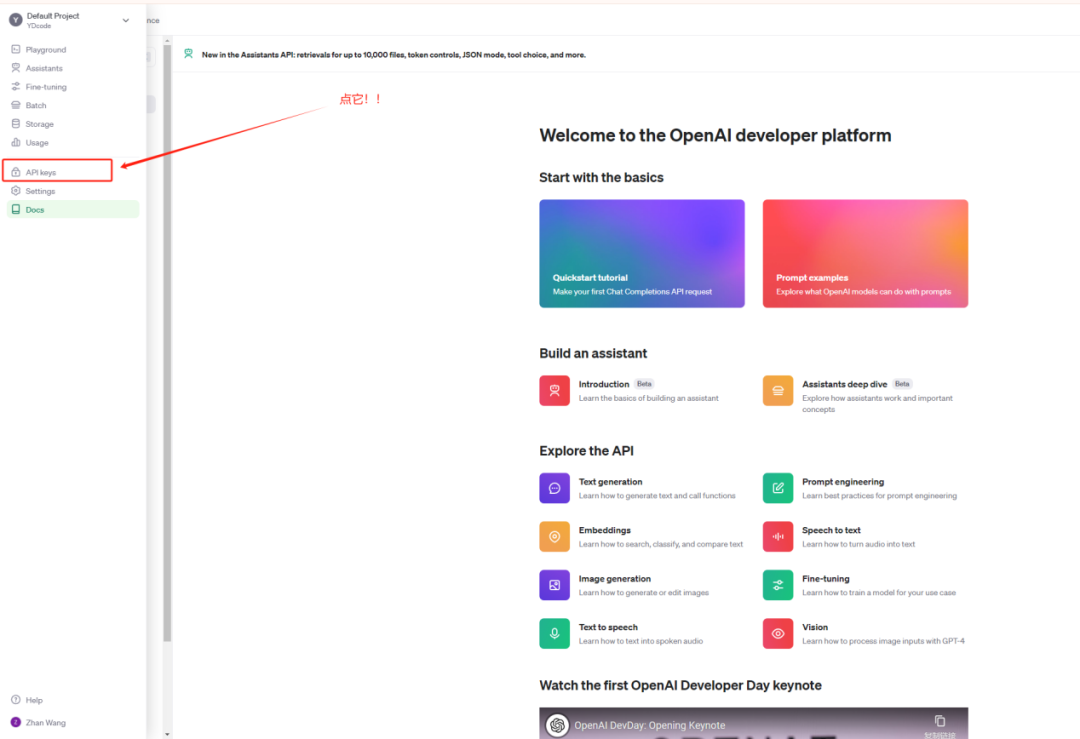
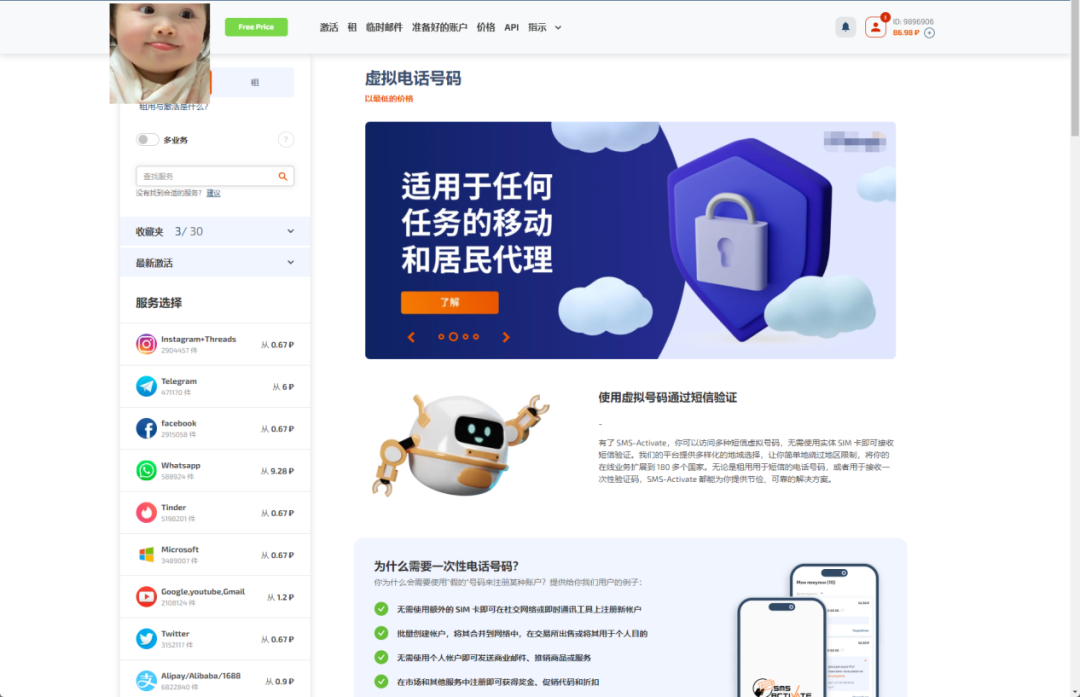
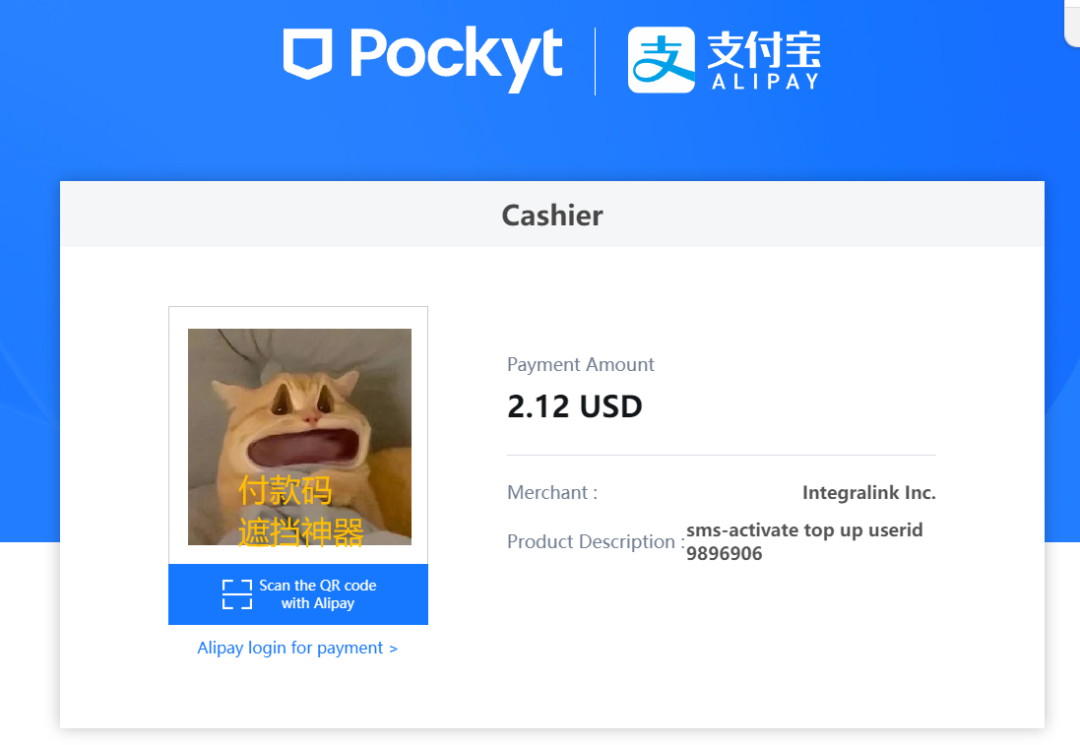
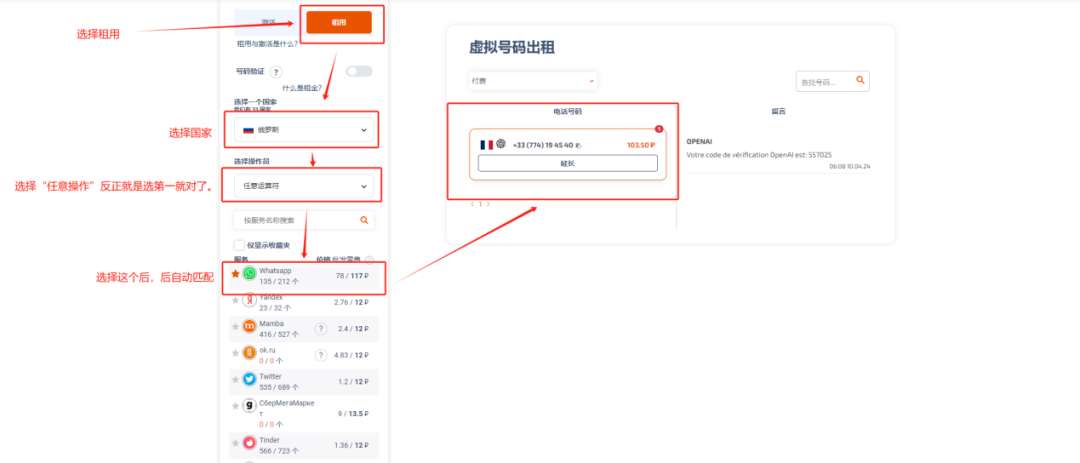
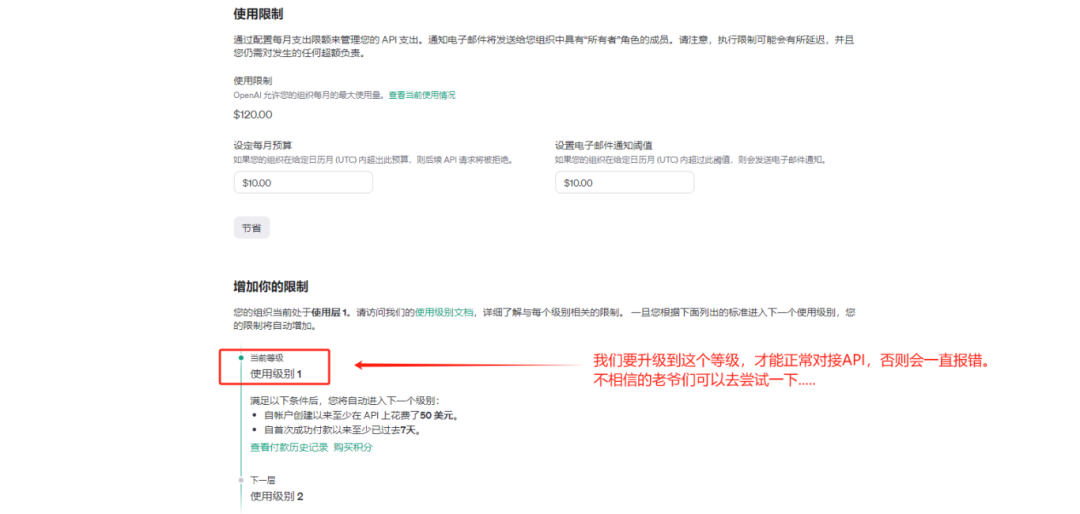
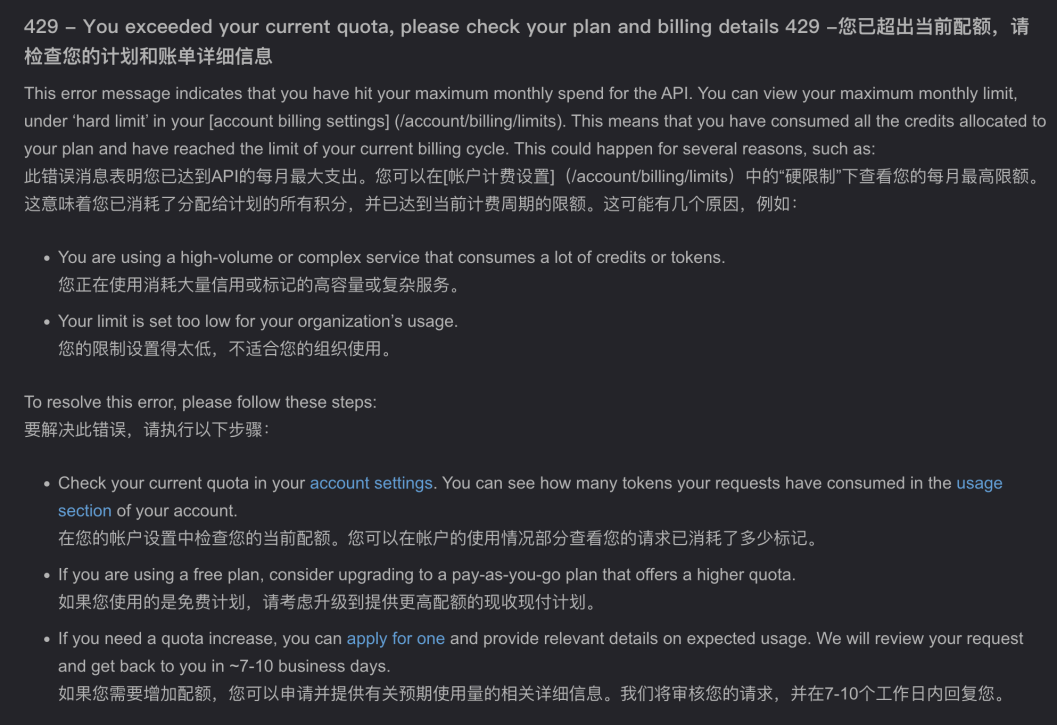
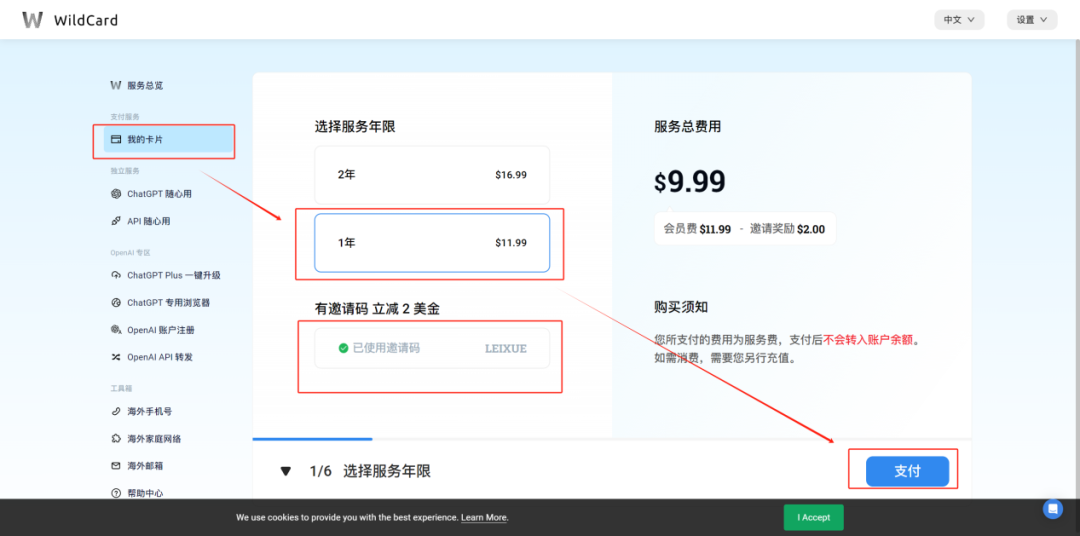
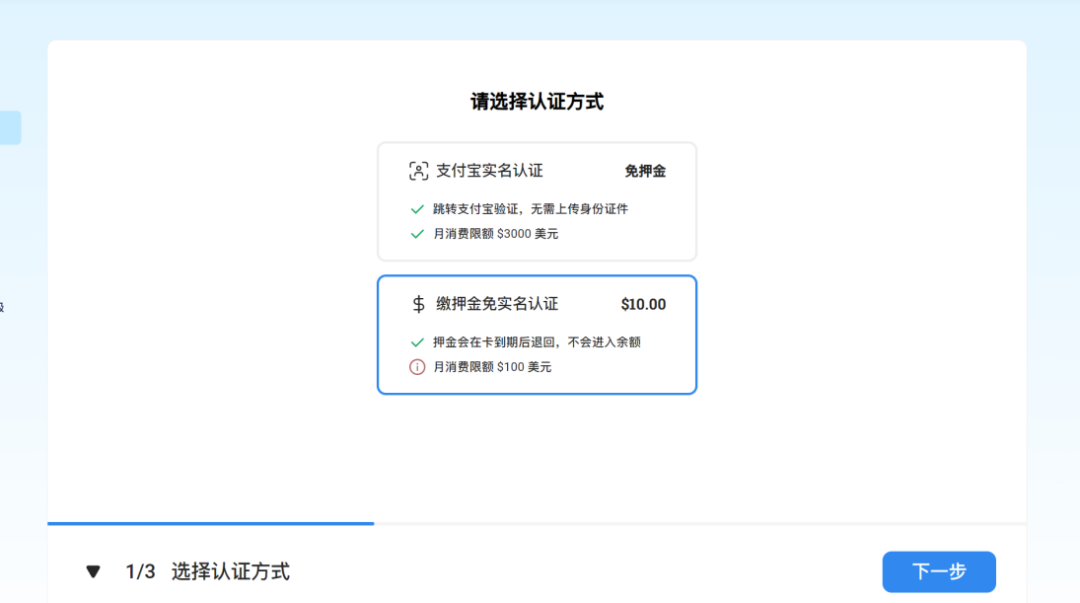
囧途开始
四月初的时候,阿宇问我:“老三,五一去泰国不?”
其实那一阵状态“水深火热”,没什么太多玩的心思,但是一想到小卡拉米一把年纪了,还没出过国,这次不去,下次又不知道什么时候了。
“去他妈的,整!”
订好机票,简单做个攻略。四月三十号,上海下着雨,浦东机场,还有几分凉意,但是此时的我,已经开始畅想那头的曼谷有多么火热。
万万没想到,飞机延误!延了三次!原本五点开的飞机,到了差不多八点,还没动静,而且最后一次航司没有给出任何官方通知和说明。我心想:“今天不会走不了,要打道回府吧?”

正忐忑间,通知飞机起飞!哦吼,晚了三个多小时,但是终于飞了!望着上海的的灯光渐渐模糊,这下终于要曼谷见了。

当天的气候不太友好,航程中,经历了三次颠簸。到了凌晨,终于抵达了曼谷,按照原定计划,找到接机司机,直奔芭提雅。

在去的路上,我们讨论了一下要不要订酒店,合计了一下,到了那先整点夜市小烧烤,再马杀鸡一下解解乏,酒店这事,不着急。
经历了两个多小时的路程,终于到达了芭提雅,这时候发现,我们去的那片地方,怎么都是灯火灰暗,说好的夜市小烧烤呢?哥俩累了,要不先把酒店顶了,携程再一看,明明曼谷看还有很多房间,这回附近的酒店都满了。要不先找个马杀鸡店?哥俩茫然地转在街上,芭提雅的热浪、下水道的恶臭,冲面而来,转了一圈,发现马杀鸡店也都打烊了,哥俩大眼瞪小眼,一时相对无言。
携程是拉了,要不试试美团吧?抱着试一试的态度,用美团搜了一下,哎,发现几百米远的一个酒店有房间,订!顺着高德,一路导航了过去。进了一个疑似前台的大厅,结果一看,没有人,什么情况?

赶紧打电话问问,电话打通,用我多年来一直稳定磕碜的英语,开始磕磕巴巴地咨询:
“We we… book en… your room on meituan er website,we en are in the the the…hotel, but there is no body.”
对面也回复了一堆话,英语也不是很好,当然主要是我听力也差,只听懂了一点点:
“Do you in the hotel?”
"Ah yes."
……
又鸡同鸭讲了一阵,阿宇又接过去掰扯了一会,还是没掰扯明白。
我接过来,只能说,一时无言,“We need help.”,她也想帮我,但她回复的我都听不懂,唉,挂了吧,哥俩这个酒店看样子是住不上了。
我看了眼大堂的沙发,心想,要不哥俩就在这凑合一宿得了。结果,接电话的那个前台大姐找过来了!
Madam,你就是我们的光!
原来酒店的前台就在对面,我还埋怨高德又缺德了,导错了地方,结果领完房卡,发现住房还真差不多真就在高德导航到的位置——我也知道为什么前台大姐会知道要出来找我们,看起来不是第一次了。
此时,已经是凌晨三点了,洗漱洗漱,躺在床上,凌晨三点半。
再规划规划第二天的行程,订订酒店,凌晨四点,奔波了大半天的三某,终于睡了。

第二天不太早,老三在一阵饿意中醒来,得出去找点吃的,不知道吃什么,找个711吧,去的途中,发现有一条小路,看着是通向海边,先去海边看看吧,结果路边的小棚子里,跳出了三只狗子,一阵狂吠,奔着我而来,没感受到芭提雅人的热情,先感受到了芭提雅狗的”热情“,我随手抄起一根棍子,今天非得让你们尝点中国的颜色。
——狗主人出来了,我扔掉棍子,算了,今天先放你们一马,以后好好做狗。

随便吃点东西,回去准备换酒店,我突然反应过来,我们看了半天地图,要住海边,要离今天去的真理寺近,选来选去,阿宇重新订的,不就是现在这家吗?我俩真是热昏了头,这还不如直接续呢,瞅瞅这破酒店,哪有海景?
换房间吧,先住着,放下东西,到了前台,正在办手续,我往外面瞟一眼,大海!这个酒店还真的是海景酒店!酒店的楼下,泳池,海滩,在往侧前方一看,真理寺也赫然在目——芭提雅的热辣假期要开始了!


芭提雅
海滩午餐
一天没怎么正经吃饭的老三和阿宇,决定中午得找个餐厅好好吃一顿,刷了会大众点评,本来想去附近的一个海鲜市场,但是阿宇不能吃海鲜,找了另外一家评分不错的餐厅Surf & Turf Beach Club & Restaurant,这家餐厅在海边,吹着海风,看着大海和沙滩,用餐心情非常美妙。

服务员阿姨不太会英文,对着菜单,像两个看图学字的小学生一样,我们点了饮料和餐,整体上还是没让人失望的。
菠萝炒饭色泽金黄,味道清甜,混杂着坚果、果干、肉松,口感非常丰富,我们一致认为,这是目前为止,吃过的最好吃的菠萝饭。

冬阴功汤,一口下去——嗯,泰国味儿!酸辣鲜三种口味汇聚,咖喱和辣椒的辣,柠檬的酸,在口腔里交相奏响,互相融合。
点之前,服务员阿姨特意提示了我“辣”,我还忐忑了一下,结果发现这种辣和我想象的辣不一样。怎么形容呢,如果说国内的菜,比如川菜的辣是一种干燥的辣,这里的辣是一种湿润的辣。
路边马杀鸡
来了泰国,怎么能不体验一下“马杀鸡”呢?吃过午饭,天气正热,下午的行程还早,穿过烫脚的街头,找到了路边的一家按摩店。
价格看起来很合算,按!我选了肩背按摩。

先洗个脚——咱这也算两只脚踏进洗脚界了。换好衣服,趴在塌板上,来自中国的面团,要被泰国的师傅揉搓了。

先刷油,精油滴在背上,有一点辛辣的感觉,让我想起了以前尝试用过的泰王油。上好油,开始反复揉搓,师傅的手、肘、膝都是这次“白案面点制作”的工具。
和中式按摩相比,泰式按摩要轻柔很多,这种轻柔是恰到好处的轻柔,既能感受到力量的渗透,又不会感觉到很痛。最后,师傅拉扯一下手指,就像是把面团给拉长,结束了这次下厨。打开店门,走进芭提雅滚烫的天气离,中国的面团”下锅“了。
真理寺
下午去了一片海滩之隔的真理寺,直线距离很近,但是真要去的话,得绕很长一段路。

进入真理寺之前,工作人员给我们发了顶安全帽,去过很多景点,真理寺是第一个需要戴安全帽参观的。为什么呢?因为真理寺还在施工。
真理寺始建于1981年,历经多年建设,至今仍然没有完工。它是纯木制结构,所有的构造都采用卡榫结构,雕塑都是纯手工打造,虽然它被称之为寺,但其实不是一座寺庙,而是一件艺术品。

真理寺的修建耗时弥久,似乎不知道它到底会什么时候结束,但是和真正的真理相比,又不一样,毕竟真理寺总有一天修完,但是真理是无穷无尽的。

环绕真理寺的时候,在一个台阶上看到两只稚嫩的小奶猫正在打闹,真理是有生命力的,这两只小猫比我们离”真理“更近。

真理寺在一座宁静的海滩,从一汪孔洞看过去,一枝白花,开在绿的大海旁,远处的天是蓝的,光洒进来,滴在老的木头上。
真理寺内的雕塑风格各异,能看出来一些佛教和印度教的风格,我们参观的时候,刚好有一个旅游团,蹭到了一点导游的解说,导游说到:”……观世音菩萨……孔子“,这两个熟悉的名字引起了我的注意,仔细一看,还真有这样的雕塑,真理寺真是一个多国家、多宗教的文化汇聚地。

在真理寺还看到了大象,不过这大象驮着人,看起来很温顺的样子,希望以后有机会能看看野生的大象吧。

芭提雅落日
在真理寺结束地比较早,天气又比较热,回到了我们的海景酒店休息,下了水,在蓝色的泳池里休息扑腾了一会。
天色渐晚,太阳没那么晒人,躺在沙滩的躺椅上,喝口冰凉的啤酒,吃点水果,吹着海风,看着太阳慢慢变成橘色。

没忍住下海泡了一会,在温热的海水里,看着太阳慢慢落到海平面之下,这一刻,感到格外松弛。


蒂芬妮人妖秀
日落不是芭提雅一天生活的结束,夜晚才刚刚开始。
来了芭提雅,怎么能不看人妖秀,芭提雅知名度最高的是蒂芬妮人妖秀。蒂芬妮的场馆,白色的礼堂风格,喷泉闪着不同的颜色。

蒂芬妮秀禁止摄影,所以只拍了开幕和谢幕。抛开猎奇的成分,单纯从表演的角度来看,我觉得蒂芬妮秀的艺术水平很高。

演员都称得上是端庄典雅,尤其是每场得领舞,我不知道这是不是就是所谓得”人妖皇后“,身材笔挺、面容姣好,超模的风范、专业的歌舞水平。
演出的节目,风格形式也非常多样,歌舞剧、独舞、现代舞、民族舞……全场大概有三十个节目,每个节目都有不一样的特点。很多节目看得出来,是迎合了游客的审美,包含了不同国家的歌舞形式,泰国、美国、中国、印度、越南、朝鲜……
我印象里特别深刻的节目有两个。
一个是“菊花台”,当《菊花台》的音乐响起,演员表演起了中国风的舞蹈,整个剧院充满了中国观众的欢呼,剧院是懂怎么撩拨观众的。
另外一个,也是全场印象最深刻的一个,是“对唱”,“男演员”戴礼帽,穿礼服,声音清澈,灯光熄灭,“女演员”迅速登场,声音妩媚。
我最开始以为这是两个演员,切换的时候,一个演员钻到幕布后,另外一个演员钻出来。瞪大眼睛,我想看看到底怎么换的,不对——这好像是一个演员!
灯光打开,谜底揭晓,果然是一个演员,左边身子穿着男礼服,右边身子穿着女礼服,左面示人,男声开唱,右边示人,女声开唱。
演员快速左右转身,男女声切换自如,全场充满了欢呼。
这位表演者唱什么我没听懂,但听出来了情绪非常激亢,甚至挺出来了愤怒。“人妖”这个群体,对自己的认同到底是男还是女呢?是向左,还认为自己是男,还是向右,认为自己是女?或者正面对人,雌雄莫辨?
来泰国的路上,我看了一些书,我以前以为人妖在泰国有悠久的历史,后来发现,”人妖“是现代的产物。
芭提雅曾经只是个小渔村,为什么后来逐渐能逐渐成为度假胜地呢?因为美国来过,确切说美国海军陆战队来过。二战后,泰国倒向美国,成为美国反共的桥头堡,芭提雅就曾经是美国海军陆战队的驻地,它也因此而兴。
人妖同样也因此而来,驻扎的美国大兵给芭提雅的市场带来了消费,当然也包括成人市场,因为汇率物价等等方面的差异,美国大兵指甲缝里漏出的一点油,都可能会改变一个泰国的贫穷家庭。有些家庭,家里只有儿子,穷得实在受不了了怎么办呢?如果儿子长的还算清秀,那就牙一咬,送去做变性手术,去挣美国大兵的钱,没想到有些美国大兵还挺喜欢,因为不用担心怀孕。
富可能使人变坏,穷可能使人变态。人妖的来源,算是穷的没办法的办法。

蒂芬妮秀落幕后,演员会站在小广场上,招徕游客合影,一次100泰铢。歌舞秀中的艺术感,终究还是变成生活的真实感,这不是艺术,这是生意。

这是一条不能回头的路,演员得在年轻的时候尽可能挣到养老的钱——如果有老可养的话,因为注射激素过多,通常很难长寿。
到了三十岁以后,雄性激素的分泌难以抑制,TA们的男性特征会越来越明显,难以遮掩,TA们也会被老板无情地抛弃。我在蒂芬妮的前台,看到售货员,化妆、穿裙子、踩高跟,但是男性特征已经无法遮掩,检票员也是如此,剧场的一个内场管理员,留了美式的油头,乍一看是一个“小哥”,仔细一看也发现步态和声音不太对劲。
整个蒂芬妮秀才几个工作人员,其他人都去哪了呢?而且,蒂芬妮的演员,绝对都是百里挑一的,那剩下的九十九呢?曲终人落幕,台上永远会有人,谁会知道离开台子的人呢。
风俗步行街
芭提雅的夜生活,还有一个地方,是一定要去看一看的,那就是风月步行街。坐着双条车,穿行在中滩天海滩旁的长街,风月步行街到了。

刚到街口,五色的灯光,喧闹的人声,嘈杂的音乐铺面而来。

街边的夜店灯红酒绿,街边的女郎穿着清凉性感,招徕客人的皮条客穿梭其间。


路上的行人来来往往,有的走着走着,脚就不听使唤地就拐进了街边的一家店,成为喝着、唱着、跳着的人群中的一员。

——欲望在这条街上流淌。
真是万恶的资本主义啊!唉,怎么这就到头了,阿宇,你拉我回去干什么?
格兰岛
如果想在芭提雅体验一下热带小岛风情,那么格兰岛是个不错的选择。
从芭提雅的码头登船,大概过了半个小时,在海船的摇晃中,一座小岛渐渐映入眼帘,青的山下,红瓦的房子,和蓝的海界限分明。

在燥热的风里,登上Tawaen观景点,浅蓝色的天空下,白色的沙滩渐渐变得湿润,绿色的海,渐渐变成深深的墨绿。

下到Tawaen海滩,满是戏水的游客,男男女女,各个国家。

Tawaen的水上项目很多,我选择了4个项目,摩托艇+香蕉船+浮潜+滑翔伞。
摩托艇,之前在秦皇岛试过,这里再试一次,感觉是海水更清,浪更大,不到一会,全身上下都湿透了。
看到了香蕉船,那必须尝试一下,为什么呢?因为想起了NBA的”香蕉船兄弟“,对了,最后带完香蕉船的小哥,一定会推荐玩一下”翻船“,拉着香蕉船的快艇,最后会控制让香蕉船翻掉,所有人都落到水里。

可惜坐船的时候只有我一个人,如果“支付四狗”组合能齐聚,那大可Cosplay一下香蕉船兄弟,对了,我们也要翻船的。

试了下浮潜,体验一般。作为一个旱鸭子,只能在水里乱扑腾,一不小心,就是原地打陀螺,头埋进水里,满眼都是绿色,海水往耳朵里,顺着缝隙往口鼻里流。当然,如果会游泳,应该体验会很不错,同船会游泳的一些伙计,开心地都流连忘返。在会游泳之前,我应该是不会再玩这个项目了。

最期待的的是滑翔伞,远远地看着,人像风筝一样在天上飘着。

上了快艇,两位师傅都很皮,一个师傅话多、活泼,我们一上船,“中国人?”肯定之后,这位师傅放起了音乐《我们不一样》,放着放着他也跟着在船头唱了起来“我们不一样,每个人有不同的境遇…”唱着唱着还跳了起来。

另一位师傅看起来稳重一点,安静地掌着舵。但是快艇开起来之后,就不是那么回事了,这位师傅喜欢开“快船”,快艇在海上速度拉满,还玩起了漂移。
很快,开始滑翔,第一位勇士上了天,小船上充满了欢呼声。第二位,第三位,第四…快乐戛然而止,船抛锚了。
两个师傅尝试了半天,都没能打响快艇,抛锚的小船,就像一块木板,在海浪中飘摇晃荡,我终于体会到什么叫“海上孤舟”,我们只是在海滩上,想想如果远洋抛锚,那该多么绝望。最后另外一艘快艇过来救了我们,拖着抛锚的快艇回了码头。

又想起了皮师傅之前唱的歌:“我们不一样,我们的船会Done”……下次有机会再玩吧。
伴随着半斜的太阳,从码头乘船离开了格兰岛。看着身后的格兰岛越来越远,又回到了暮色中的芭提雅。



曼谷
大皇宫
来到曼谷的第一站,直奔大皇宫,大皇宫在泰国的地位,就相当于中国的故宫,去了曼谷不去大皇宫,就像是去了北京不去故宫。

但是去的时候不赶巧,大皇宫似乎在接待什么团体,暂时不开放。第二天再去大皇宫,终于开放了,而且免费。

一座大皇宫,一部泰国近代史。
泰国的历史不算悠久,它有四个王朝,素可泰王朝、阿瑜陀耶王朝、吞武里王朝、曼谷王朝,大皇宫就是曼谷王朝的皇宫,也称作拉玛王朝,在现在的泰国仍然延续,目前在位的是拉玛十世。

拉玛王朝创立于公元1782年,此时的中国处于清朝乾隆年间,拉玛一世初建大皇宫,后来历代泰王逐渐完善。

大皇宫的建筑风格很混搭,既有传统的东南亚风格,白墙红瓦,也有宗教元素,金灿灿的舍利塔,华丽的佛堂。西洋风格同样也非常浓厚,很多建筑都被珐琅点缀,有些建筑完全是欧式风格。
这是因为大皇宫后来的完善,同样伴随着拉玛王朝的动荡与变革,资本主义殖民浪潮兴起,泰国虽然没有沦为殖民地,但是却沦为了半殖民地。和宗主国清国被人用坚船利炮打开国门不一样,从拉玛四世开始,泰国主动打开了国门。

拉玛四世主动派遣留学生到欧洲学习军事政治法律,并对国内的政治经济进行了改革。拉玛四世的继任者,也就是著名的朱拉隆功大帝,是个更激进的改革者,少年即位的朱拉隆功,组织了一些王室和贵族青年,自称为“少年暹罗”,在“进步”和“改革”的主题下争辩和前进。
“少年暹罗”的意思,是把他们的对手暗喻为“老年暹罗”, 立志要把他们扫进故纸堆。朱拉隆功的改革是成功的,所以他成为泰国五大帝之一。
这跟大皇宫的建筑风格有什么关系呢?《泰国史》里写了这么一段:
在19世纪70年代,朱拉隆功建造了一座新的宫殿,采用意大利风格的设计,但是在顶部采用了暹罗式的屋顶,以取悦传统主义者。1907年,这种妥协就被抛弃了,国王修建了带有强烈古典主义风格的阿南达沙玛空御座厅(Ananta Samakhom throne hall),采用了卡雷拉大理石、米兰的花岗岩、德国的铜和维也纳的陶瓷。整座建筑成为通往旧城区北部的新的王室宫邸区的入口,那是一片欧式风格的宫殿群,以及为其他王室家族成员建造的宅邸。国王和贵族们进口了许多欧洲的小摆设来装点这些新房子。
泰国宫廷和欧洲联系越来越紧密,体现在建筑风格,就是有很多欧化的地方。对了,从《泰国通史》看到比较有意思的一个点,拉玛王朝的前四位国王都有中文名:郑华、郑佛、郑福、郑明,拉玛五世也就是朱拉隆功开始,没有中文名,朱拉隆功即位于1868年,此时的中国属于清朝的同治年间。

大皇宫也有血色,年轻的拉玛八世在大皇宫饮弹身亡,泰王是自杀还是他杀?行刺者是谁?已经成了历史谜案。拉玛八世的弟弟普密蓬·阿杜德即位,命运的改变总是这么突然,年轻的普密蓬应该是个热爱自由的人,在瑞士留学的时候,他因为飙车失去了一只眼睛。

如果没有兄长的遇刺,他也许会成为一个风流贵族,也许泰国会是另外一个样子。命运把他推到他该在的位置,他做的非常好,正如他的名字泰文的意思,“无与伦比的能力”,可以说是名副其实。
他影响了几乎整个泰国的现代史,军政府、民选政府……在每次政治危机的时候,普密蓬都会在恰当的时候出手,来保证政局的基本稳定。他亲近民众,是泰国民众非常热爱的”父亲“。
也正是由于拉玛八世的遇刺,王室认为大皇宫不详,搬到了其它地方,所以我们今天才有机会参观大皇宫。
郑王庙
郑王庙和大皇宫大概一水之隔,它纪念的是一个传奇国王——郑信大帝。

郑信大帝的一生,是一个传奇,也如同一部跌宕起伏的戏剧。
他的前半生比起爽文不遑多让,郑信的父亲郑镛是潮州人,因为谋生,孤身来到泰国。郑镛从贩水果的小贩做起,逐渐发达,承包赌税,也籍着这个关系,郑信被过继给当时的财政大臣昭披耶却克里。从贫民到大亨,两代完成阶层晋升,郑镛已经足够励志,但是他的儿子更加传奇。

青年郑信,成为北方的一个城主。泰缅战争爆发,阿瑜陀耶王朝灭亡,属于郑信的舞台却搭建好了。郑信率兵赴京勤王,参与了出城出击,但是遭遇了失败,在撤退到城下的时候,发现已经被阻拦在外,进退无据之中,郑信毅然带兵突围,没想到阿瑜陀耶城亡,郑信生。

王朝乱世之中,郑信逐渐崛起,他先是在泰国南部站稳脚跟,又团结各方力量,挥师北上,收复阿瑜陀耶城。
1768年1月4日,郑信加冕为吞武里王。
郑信和吞武里王朝的落幕也很突然,阿瑜陀耶城发生骚动,郑信派遣大臣披耶讪镇压,披耶讪却被叛军说服,加入了叛军。此时吞武里空虚,叛军长驱直入,王宫卫队不支,郑信不得已退位,出家为僧。

此时听闻国内政变的远征军主帅,郑信的女婿通銮,回国平乱,平乱之后的第二天,郑信身亡,死于紫檀木棍的击打之下——这是帝王的死法。
通銮,也就是拉玛一世,他让我想起了另外一个历史人物——司马懿,郑信出家为僧按照惯例可以免死,司马懿同样指洛水为誓,一定会放过曹爽——政治也许有时候不能讲道德吧。
对了,这位拉玛一世的中文名叫郑华,在对宗主国清国的国书中,他自称郑信的儿子。
郑信大帝的一生,在绝境中奋起,在最辉煌时戛然而止,让人不得不感概历史和命运的无常。
拳赛
来到泰国,我最大的愿望就是看一场泰拳赛,泰国有两大知名泰拳场,伦披尼和迦南隆,可以说是泰拳圣地,几乎所有泰拳手都梦想披上这两个拳场的金腰带。
伦披尼经历了一次搬迁,目前在曼谷郊区,迦南隆,在曼谷市区,在某些app上,被翻译成那差达慕,我一开始还吃惊,点评拳赛,竟然没有迦南隆,原来是这个翻译闹了乌龙。
这次我选择是更远的伦披尼,是因为周五,伦披尼和One冠军赛合作,有ONE周五格斗夜比赛。ONE冠军赛是是目前世界排名第二、东南亚排名第一的综合格斗赛事,当然,地处东南亚,ONE冠军赛自然也免不了泰拳比赛,甚至目前ONE的踢拳赛事同样开始迅猛发力。
能在泰拳两大圣地之一的伦披尼,看一场顶级的现代格斗赛事,实在是一件无比快乐的事情。
ONE格斗夜
我已经有六七年没到现场看比赛了,经历了两个小时的拥堵路程,我们终于赶到了伦披尼。
领票,进场,坐到座位上,音乐、灯光,现场的欢呼声,我感觉开始兴奋起来了———It's Time!

开局的第一场比赛,日本选手VS白俄罗斯选手,日本选手有很浓重的空手道风格的意味,站立更强一些,几次打晃白俄罗斯选手,但是白俄罗斯选手的摔柔更胜一筹,在第三回后半段,裸绞终结了日本选手。第一场比赛就出现了终结,太兴奋了!

还有一场日本vs泰国的比赛,日本选手身高臂展更有优势,一度压制了泰国选手,肘法给泰国选手的脸开了一个大口子,泰国选手血流满面,苦苦支撑,我以为这场比赛就这么结束了,没想到泰国选手抓住一个漏洞,前手摆拳命中,日本选手重重倒地不起,赛事方赶紧用担架把日本选手抬走。我觉得这场是整个比赛最残酷的一场,赢的人血流满面,输的人担架抬走。

联合主赛同样精彩,一个年轻的黎巴嫩选手,挑战老牌的泰拳王,这个泰拳王应该是个明星选手,出场的时候全场欢呼,还现场表演了一段拜师舞,没想到场上局势风云突变,年轻选手,一开始就凶猛发力,老拳王显然有些慢热,没有进入节奏,第一回合就被击倒了两次,虽然最后依靠老道的经验,撑到了最后,但还是一致判定负。
现场还有很多精彩的比赛,现场看比赛和隔着屏幕看比赛,完全是不同的感觉,现场的欢呼声,选手的打击声,再好的摄影设备都制造不出来这样的临场感,去了现场,才能真正感受到现场的热烈!看比赛的时候,我完全兴奋起来了,呐喊,嘶吼,赛事结束后嗓子都是哑的。
只能说:过瘾,下次还看!
ONE巅峰赛
ONE格斗夜的赛事结束之后,我突然发现周六的早上还有一场比赛,ONE巅峰赛,这场比赛有一场金腰带的卫冕战,而且最重要的是,这一场有三位中国选手:胡勇、魏锐、张立鹏,两场MMA赛事,一场踢拳赛事。
尤其是魏锐VS秋元皓贵的这场比赛,让我想起了之前我非常喜欢的选手邱建良,带着前世界第一的势头,打入了ONE冠军赛,结果第一场被秋元皓贵阻击,至今还没有再次复出比赛。这场,毫无疑问,是一场恩怨局,这样的机会可遇不可求,我一定要来现场,一定要亲眼看到魏锐击败秋元皓贵。
晚上回到酒店已经差不多两点,我完全兴奋地睡不着,一早五点,我又起床到了伦披尼现场,这次现场摆放了一条金腰带,金腰带在前,谁能拒绝合影呢?

开局两场速杀
首局终结获胜,在拳赛里是很少见的,终结一般发生在选手体能下降和伤害累积之后,但是今天的比赛,开场的两局都是首回合终结速胜。
今天比赛的第一场是泰拳比赛,在第一回合的后段,先是一个摆拳,打晃,接着一个击腹的直拳,选手痛苦倒地,这一拳应该是岔气了。
第二场比赛是无道服的巴西柔术比赛,日本选手上场之后,很快就被巴西选手压制,拿背裸绞一气呵成,几秒,裁判试了一下,日本选手胳膊已经软了,赶紧终止比赛。巴西选手在赛后抑制不住地哭泣,巴西柔术比赛,需要一点欣赏的门槛,所以纯巴西柔术选手很难接到商业比赛,很难赚到钱,平时生活很艰难,所以也能理解为什么巴西选手忍不住哭泣。
为了三位中国选手的比赛而来,加上状态不佳,中间的几场比赛,都没有上一场那么高的兴致。
胡勇被克制
终于来了,第一位出场的中国选手是胡勇,伴随着中文的出场音乐,全场响起了巨大的欢呼声,能在异国他乡,为本国的选手加油助威,这是一件多么令人激动的事!
现场的声音非常整齐,一位大哥自发担当了”领喊“的角色,他喊”胡勇“,现场的中国观众跟着一起喊”加油“,”胡勇……加油“的声音响彻整个场馆。
胡勇的脚下移动比较灵活,能看出,他以前应该是有散打的背景,他的站立比对手出色,开局几次重击对手。
对手随后调整了策略,坚决要和胡勇打地面,对手的摔柔水平在胡勇之上,每一次防守,胡勇都得拼尽全力,几次被拖入地面,被拿到了很深的把位,现场的中国观众心都揪了起来。

最终三局战罢,胡勇点数落败。胡勇还很年轻,还有时间能继续完善和提高自己,加油!
魏锐稳健取胜
这是我最期待的比赛,魏锐是我特别佩服的一个选手,已过而立之年,家庭圆满,带的徒弟都成了冠军,他的职业生涯,武林风金腰带、勇士的荣耀金腰带、还有最具含金量的K1金腰带,功成名就,他已经不需要证明什么了。但是在职业生涯暮年,他还是选择了走出国门,挑战自己,继续冲击ONE的金腰带,这就是真正的武者意气!

这场也是一场复仇局,对手秋元皓贵,曾经击败过邱建良,这次魏锐前来,也有为好兄弟复仇的意味。魏锐是是非常有名字的选手,他出场的时候,全场的欢呼像海啸一样。

伴随着同样整齐的”魏锐……加油“的声音,比赛开始。魏锐赛前说,针对秋元的技术特点,他已经找到了应对的办法,果然所言非虚。魏锐灵活的脚下移动,让秋元皓贵根本打不出他习惯的快速组合,到了第二回合,秋元皓贵甚至顶着伤害,硬往前压,给魏锐造成了一些麻烦,但是魏锐经验丰富、拳商很高,进行了调整,加强移动和迎击,整场比赛,基本上没见到秋元像往常一样的高速组合。

就这样,三局战罢,在异国他乡的赛场上,魏锐一致判定击败了秋元皓贵,向着金腰带又迈进了一步。

裁判举起魏锐的手的时候,我满脑子和嘶吼的只有四个字:”魏锐牛逼!“
张立鹏憾负
张立鹏是老牌的MMA选手,曾经也打进过UFC,这次他遇到了不小的麻烦,他的对手赛前超重,协议之下,张立鹏选择了接下比赛。
果然,临场,对手的维度比张立鹏要大一号,在地面的缠斗中,张立鹏在力量上劣势太大,根本压不住对手,而且体能消耗地过快,到了第三回合,完全是强撑着打完,中间有一些好机会,因为体能不足都没有抓住。

最终,对手一致判定获胜。
张立鹏因为体能消耗过度,被轮椅推离现场,希望他能尽快恢复,早日拿下下一场胜利。
这场有个彩蛋,目前在UFC排名最高的中国男子选手宋亚东也来到了现场,作为张立鹏的边角,希望中国MMA的未来越来越好!

射击
来泰国,有第二件必做的事情,就是体验射击,因为没有提前预订,去不了最推荐的海军射击俱乐部,我选择了陆军俱乐部。
带着兴奋过后的眩晕,我来到了陆军射击俱乐部,下午两点开门,经历了一阵等待之后,领到了我的子弹,黄橙橙,亮晶晶。

等待的时间,看着里面正在射击的游客,耳边传来了鞭炮一样的声音,震得耳朵嗡嗡的。

终于轮到我了,我选择的套餐是三款手枪,教练帮忙上子弹上膛,我接枪瞄准,想起之前看的一点教程,身子往前压——后来看视频,嗯,怎么是勾着头的,好丑,以后有机会动作练漂亮一点。

开枪,手枪的后坐力不大,但是射击的时候,枪会往上跳,一开始,空靶了若干次,后来强打精神,努力瞄准,终于上靶了,甚至还蒙中了一发靶心。

这次射击体验呢,整体感觉是隔靴搔痒,瞄准、扣动扳机,多少感觉有点麻木,当然也可能和我此时头脑已经昏沉有关。
我买了五十发子弹,本来以为不少,打完却觉得意犹未尽。最后离开的时候,旁边的步枪靶场,一声巨响,我的耳朵瞬间轰鸣,回头一看,原来是有个大哥在打霰弹枪。

没有哪个男人不爱枪,希望以后有机会能更深度地体验甚至学习射击。
感受
人生意义就是体验,我们回忆的时候,永远只会回忆自己体验过的东西,看一万个短视频,看一百本书,不如一次滚烫的沙滩来的记忆深刻。
泰国这个国家给我的感受,就是混杂,各种东西混杂,有寺庙的肃穆,有海岛的宁静、有拳赛的刺激,有红灯区的放荡…就像冬阴功汤,一下子把各种味道混杂在了一起。
在芭提雅和曼谷的街头,也能感受到泰国的贫富差距,大街时不时能看到几辆超跑,但更多的是坐在路边的乞丐,那天阿宇查了一下泰国王室的财富,他惊讶了一下,我也是——殿堂之下有杂草。
泰国很自由,但我觉得太过自由不是一件好事,大麻店、红灯区…这类声色刺激的东西,其实就像是表面能看到的纱布,底下不知道隐藏着多少溃烂的伤口,感谢我们的国家,社会主义铁拳,压得这些东西抬不了头。
最后,世界这么大,还是要去看看!
参考
- 《泰国常识》
- 《泰国通史》
- 《爱上泰国:你的色彩惊艳了我的时光》
- 《泰国史》
- 《泰国攻略》



















































































































 专业渲染软件 Octane。
专业渲染软件 Octane。