








前几天组员遇到h5跳转微信小程序的功能,由于时间关系,我这边接手实现这个功能。
遇到问题点
- 微信内部跳转怎么实现?
- 外部浏览器或者app打开链接如何跳转?
微信内部跳转怎么实现
使用 wx-open-launch-weapp 这边标签进行跳转,使用这个标签跳转小程序,需要满足3个条件
- 首先 wx.config 授权,公众号设置 > 功能设置 > js安全域名设置
- 域名设置,静态资源托管
- 小程序需要关联这个公众号 设置 > 基本设置 > 相关公众号
h5上代码源码
<html>
<head>
<title>打开小程序</title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, user-scalable=no, initial-scale=1, maximum-scale=1">
<script>
window.onerror = e => {
console.error(e)
alert('发生错误' + e)
}
</script>
<!-- 引入jQuery -->
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.js"></script>
<!-- weui 样式 -->
<link rel="stylesheet" href="https://res.wx.qq.com/open/libs/weui/2.4.1/weui.min.css"></link>
<!-- 调试用的移动端 console -->
<script src="https://cdn.jsdelivr.net/npm/eruda"></script>
<script>eruda.init();</script>
<!-- 公众号 JSSDK -->
<script src="https://res.wx.qq.com/open/js/jweixin-1.6.0.js"></script>
<!-- 云开发 Web SDK -->
<script src="https://res.wx.qq.com/open/js/cloudbase/1.1.0/cloud.js"></script>
<script>
const baseUrl ="/pages/biddingCenter/index"
function getQueryVariable(variable)
{
var query = window.location.search.substring(1);
var vars = query.split("&");
for (var i=0;i<vars.length;i++) {
var pair = vars[i].split("=");
if(pair[0] == variable){return pair[1];}
}
return(false);
}
function docReady(fn) {
if (document.readyState === 'complete' || document.readyState === 'interactive') {
fn()
} else {
document.addEventListener('DOMContentLoaded', fn);
}
}
var version = 'trial'
var fetchData = new Promise((resolve, reject) => {
// 获取签名,timestamp、nonceStr、signature
$.ajax({
url: "xxxxxxx",
dataType: "json",
method: 'get',
data: { xxx },
success: function (res) {
console.log("WeChatConfig", res);
if (res.data) {
var data = res.data; // 根据实际情况返还的数据进行赋值
console.log(999, data)
resolve(data);
}
},
error: function (error) {
console.error('error-->', error)
return reject(error)
}
})
});
docReady(async function() {
var ua = navigator.userAgent.toLowerCase()
var isWXWork = ua.match(/wxwork/i) == 'wxwork'
var isWeixin = !isWXWork && ua.match(/MicroMessenger/i) == 'micromessenger'
var isMobile = false
var isDesktop = false
if (navigator.userAgent.match(/(phone|pad|pod|iPhone|iPod|ios|iPad|Android|Mobile|IEMobile)/i)) {
isMobile = true
} else {
isDesktop = true
}
console.warn('ua', ua)
console.warn(ua.match(/MicroMessenger/i) == 'micromessenger')
var m = ua.match(/MicroMessenger/i)
console.warn(m && m[0] === 'micromessenger')
if (isWeixin) {
var containerEl = document.getElementById('wechat-web-container')
containerEl.classList.remove('hidden')
containerEl.classList.add('full', 'wechat-web-container')
var launchBtn = document.getElementById('launch-btn')
launchBtn.addEventListener('ready', function (e) {
launchBtn.setAttribute('env-version',version)
launchBtn.setAttribute('path', baseUrl)
console.log('开放标签 ready')
})
launchBtn.addEventListener('launch', function (e) {
console.log('开放标签 success')
})
launchBtn.addEventListener('error', function (e) {
console.log('开放标签 fail', e.detail)
})
await fetchData.then(res=> {
wx.config({
// debug: true, // 调试时可开启
appId: res.appId,
timestamp: res.timestamp, // 必填,填任意数字即可
nonceStr: res.nonceStr, // 必填,填任意非空字符串即可
signature: res.signature, // 必填,填任意非空字符串即可
jsApiList: ['chooseImage'], // 安卓上必填一个,随机即可
openTagList:['wx-open-launch-weapp'], // 填入打开小程序的开放标签名
})
})
} else if (isDesktop) {
// 在 pc 上则给提示引导到手机端打开
var containerEl = document.getElementById('desktop-web-container')
containerEl.classList.remove('hidden')
containerEl.classList.add('full', 'desktop-web-container')
} else {
var containerEl = document.getElementById('public-web-container')
containerEl.classList.remove('hidden')
containerEl.classList.add('full', 'public-web-container')
var c = new cloud.Cloud({
// 必填,表示是未登录模式
identityless: true,
// 资源方 AppID
resourceAppid: 'wxaabe7e5d652fc1d8',
// 资源方环境 ID
resourceEnv: 'cloud1-7gnlxfema33074ec',
})
await c.init()
console.log(c)
window.c = c
var buttonEl = document.getElementById('public-web-jump-button')
var buttonLoadingEl = document.getElementById('public-web-jump-button-loading')
try {
await openWeapp(() => {
console.log('dui')
buttonEl.classList.remove('weui-btn_loading')
buttonLoadingEl.classList.add('hidden')
})
} catch (e) {
console.log(e,'cuo')
buttonEl.classList.remove('weui-btn_loading')
buttonLoadingEl.classList.add('hidden')
throw e
}
}
})
async function openWeapp(onBeforeJump) {
var c = window.c
const res = await c.callFunction({
name: 'public',
data: {
action: 'getUrlScheme',
},
})
if (onBeforeJump) {
onBeforeJump()
}
location.href = res.result.openlink
}
</script>
<style>
.hidden {
display: none;
}
.full {
position: absolute;
top: 0;
bottom: 0;
left: 0;
right: 0;
}
.public-web-container {
display: flex;
flex-direction: column;
align-items: center;
}
.public-web-container p {
position: absolute;
top: 40%;
}
.public-web-container a {
position: absolute;
bottom: 40%;
}
.wechat-web-container {
display: flex;
flex-direction: column;
align-items: center;
}
.wechat-web-container p {
position: absolute;
top: 40%;
}
.wechat-web-container wx-open-launch-weapp {
position: absolute;
bottom: 40%;
left: 0;
right: 0;
display: flex;
flex-direction: column;
align-items: center;
}
.desktop-web-container {
display: flex;
flex-direction: column;
align-items: center;
}
.desktop-web-container p {
position: absolute;
top: 40%;
}
</style>
</head>
<body>
<div class="page full">
<div id="public-web-container" class="hidden">
<p class="">正在打开 “ 小程序”...</p>
<a id="public-web-jump-button" href="javascript:" class="weui-btn weui-btn_primary weui-btn_loading" onclick="openWeapp()">
<span id="public-web-jump-button-loading" class="weui-primary-loading weui-primary-loading_transparent"><i class="weui-primary-loading__dot"></i></span>
小程序
</a>
</div>
<div id="wechat-web-container" class="hidden">
<p class="">点击以下按钮打开 “小程序”</p>
<!-- 跳转小程序的开放标签。文档 https://developers.weixin.qq.com/doc/offiaccount/OA_Web_Apps/Wechat_Open_Tag.html -->
<wx-open-launch-weapp id="launch-btn" username="gh_36a8dca79910" path="/pages/biddingCenter/index" env-version="trial">
<template>
<button style="width: 200px; height: 45px; text-align: center; font-size: 17px; display: block; margin: 0 auto; padding: 8px 24px; border: none; border-radius: 4px; background-color: #07c160; color:#fff;">打开小程序</button>
</template>
</wx-open-launch-weapp>
</div>
<div id="desktop-web-container" class="hidden">
<p class="">请在手机打开网页链接</p>
</div>
</div>
</body>
</html>
以上第二点后面会讲到
以上功能满足基本可以在微信内部打开小程序了,但是实际上,我们url可能是其他app,短信,或者浏览器里面打开的
外部app或者短信跳转怎么实现
首先我这边是uni-app实现的
- 第一步在项目根目录项目新建functions这个文件夹,然后到

点击下载放入刚刚的functions下面,然后再 manifest.json 下面
"mp-weixin" : {
"appid" : "xxxxx",
"cloudfunctionRoot": "./functions/", // 这一行就是标记云函数目录的字段
"setting" : {
"urlCheck" : false
},
"usingComponents" : true,
"permission" : {}
}
这个时候编译项目在编译之后的小程序项目是没有functions 这个文件夹的,我们这个时候需要在vue.config.js
const path = require('path')
const CopyWebpackPlugin = require('copy-webpack-plugin')
module.exports = {
configureWebpack: {
plugins: [
new CopyWebpackPlugin({
patterns: [
{
from: path.join(__dirname, 'functions'),
to: path.join(__dirname, 'unpackage/dist', process.env.NODE_ENV === 'production' ? 'build' : 'dev', process.env.UNI_PLATFORM, 'functions')
}
]
})
]
}
}
在终端上面npm install 才行,需要node环境
设置以上代码重新启动编译,在微信工具里面就会出现


右击public上传并部署(云端安装依赖),成功之后打开微信开发工具云开发


会出现刚刚的云函数文件
然后再次点击云函数权限

点击所有用户访问,保存

然后再点击右上角设置>权限设置> 未登录用户访问云资源权限设置打开

以上搞定也只是函数环境搞定,然后还要配置刚刚的函数方法api

只有配置这个才能在index方法里面调用
// 云函数入口文件
const cloud = require('wx-server-sdk')
cloud.init()
// 云函数入口函数
exports.main = async (event, context) => {
const wxContext = cloud.getWXContext()
switch (event.action) {
case 'getUrlScheme': {
return getUrlScheme(event)
}
}
return 'action not found'
}
async function getUrlScheme(event) {
return cloud.openapi.urlscheme.generate({
jumpWxa: {
path:'/pages/index/index', // <!-- replace -->
env_version:'trial',
},
// 如果想不过期则置为 false,并可以存到数据库
isExpire: false,
// 一分钟有效期
expireTime: parseInt(Date.now() / 1000 + 60),
})
}
代码讲到这边会发现之前h5里面调用的 c.callFunction 方法其实调用的就是exports.main 这个导出得方法
然后还需要把h5代码放入


以上就是整个h5跳转微信小程序的过程,需要注意的点事在h5里面 方法返回 res.result.openlink 这个参数需要跳转的url在生产上线过,要不然报错 openapi.urlscheme.generate pagepath 获取不到





























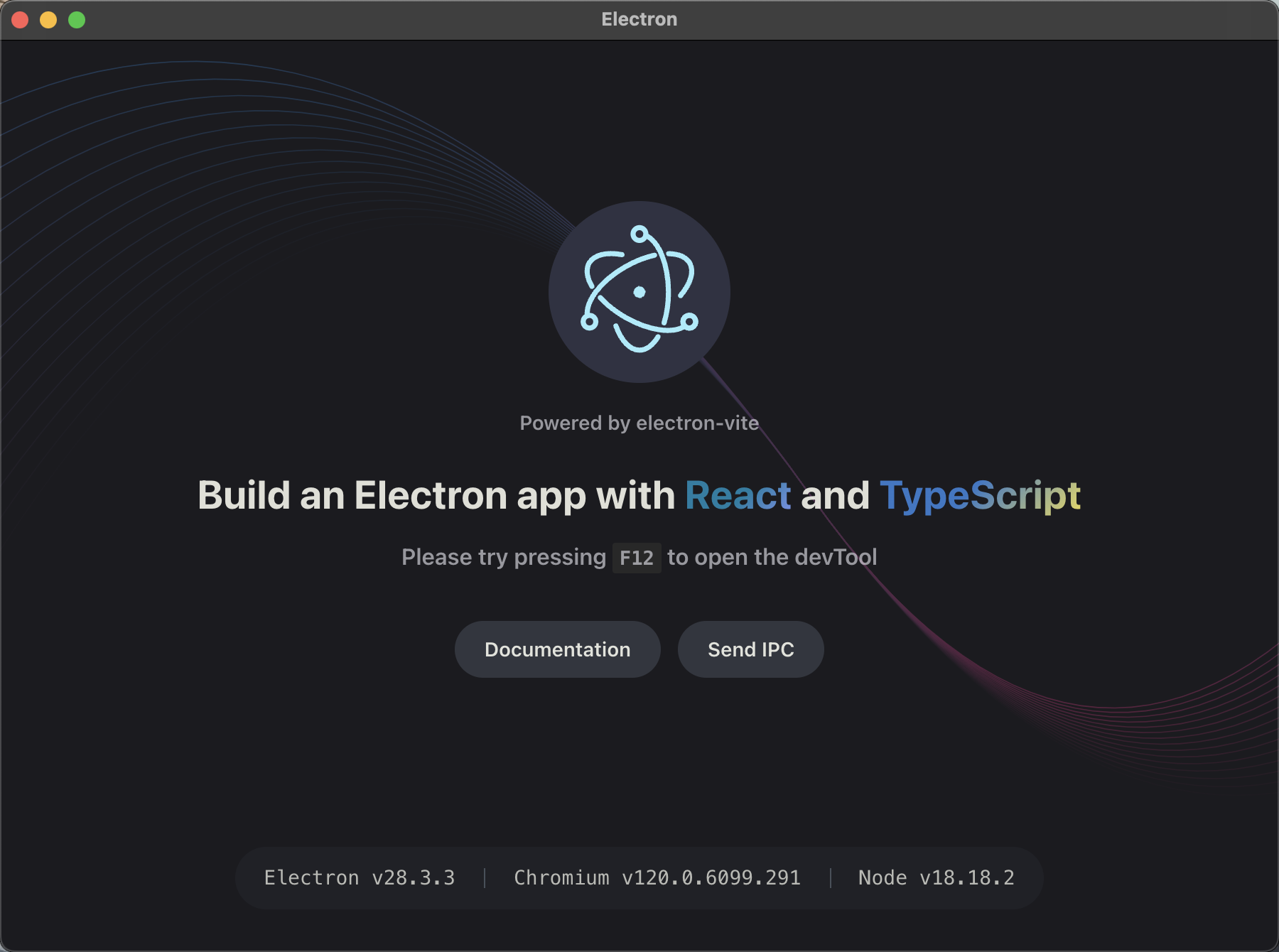
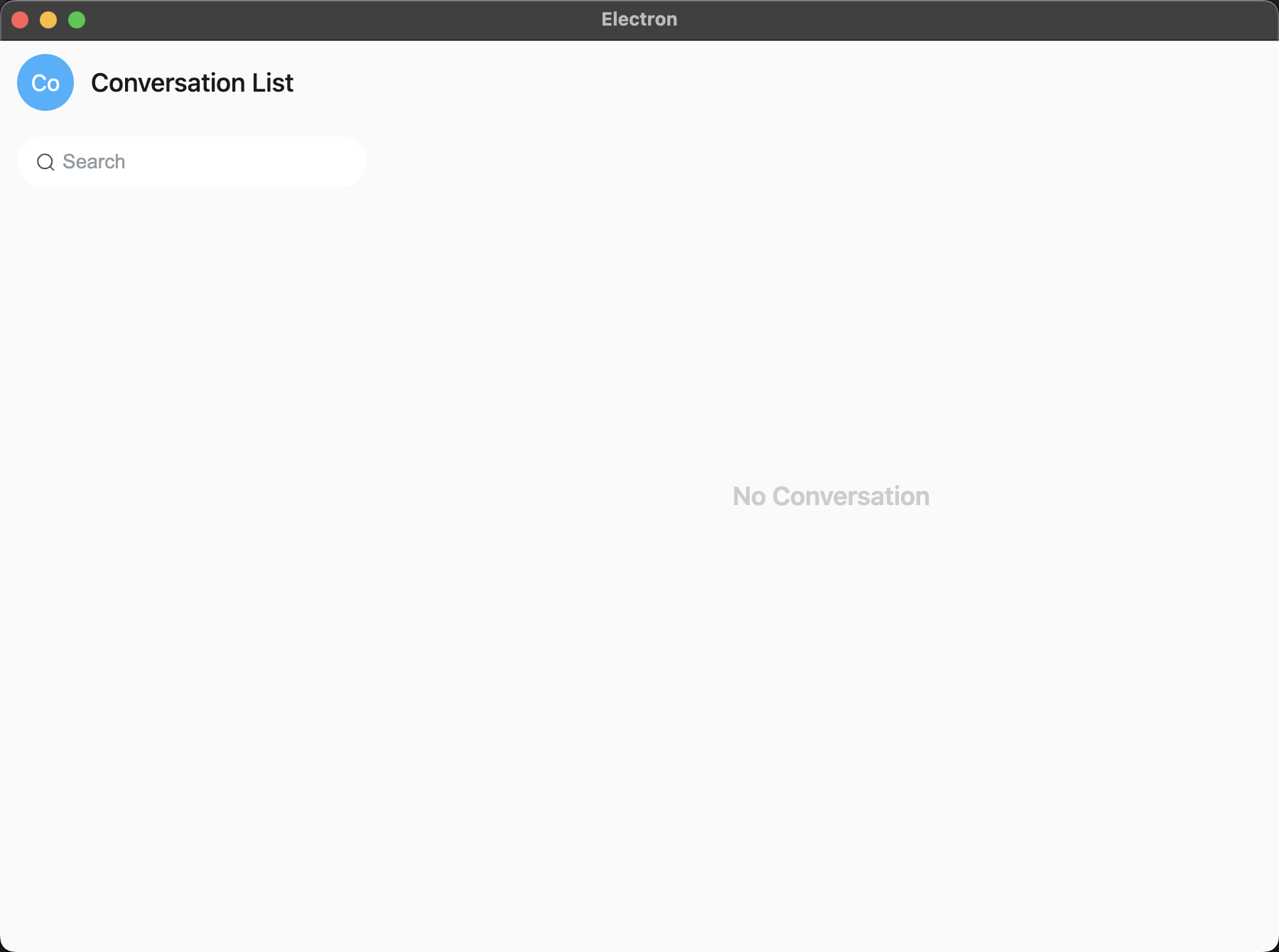


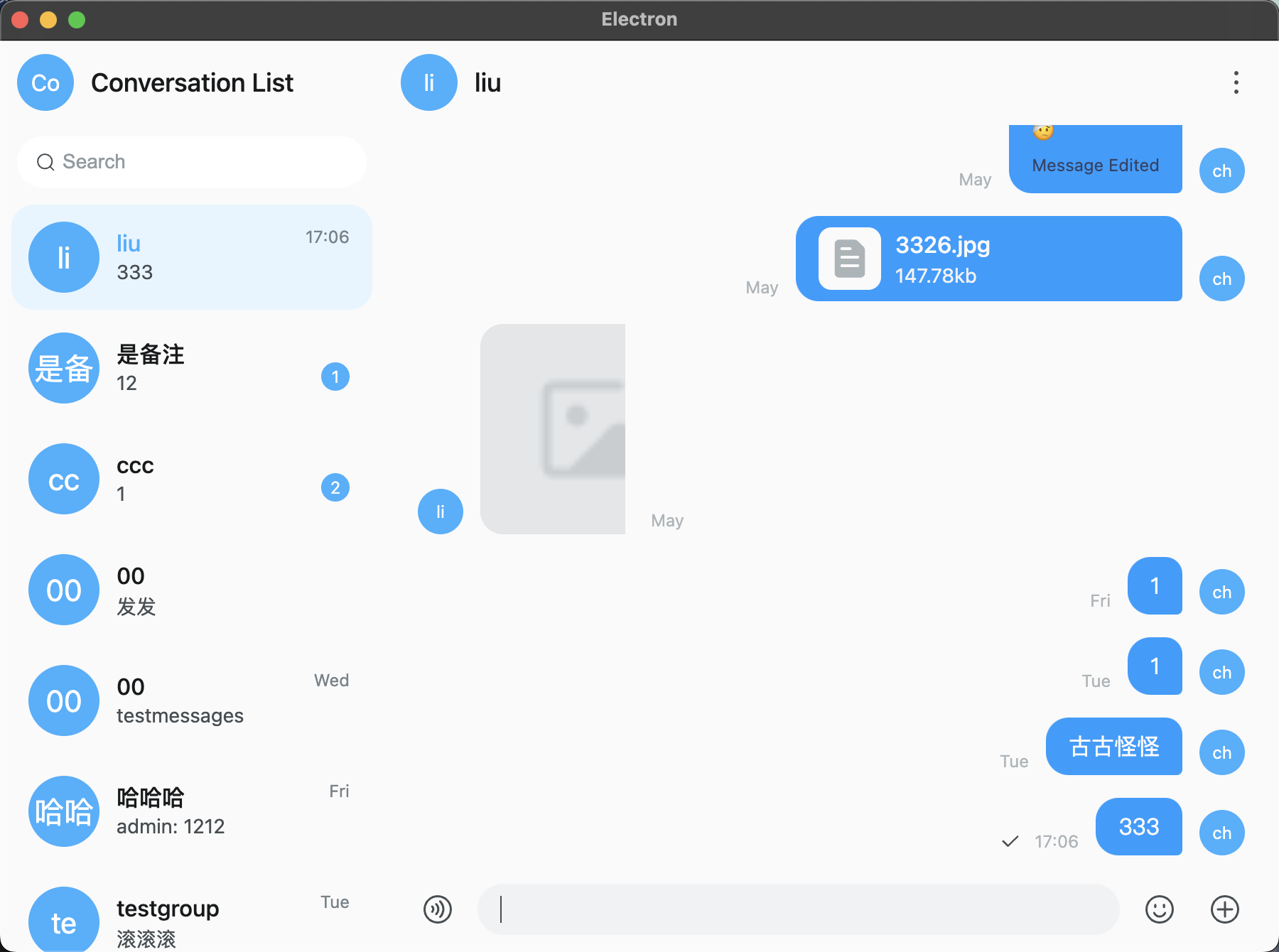


































































 最终效果如下图:
最终效果如下图: 





































































































































































