








项目开发时越来越卡?多半是桶文件用多了!
前言
无论是开发性能优化还是生产性能优化如果你想找资料那真是一抓一大把,而且方案万变不离其宗并已趋于成熟,但是有一个点很多人没有关注到,在铺天盖地的性能优化文章中几乎很少出现它的影子,它就是桶文件(barrel files),今天我们就来聊一聊。
虽然大家都没怎么提及过,但是你肯定都或多或少地在项目中使用过,而且还对你的项目产生不小的影响!
那么什么是桶文件?
无论是开发性能优化还是生产性能优化如果你想找资料那真是一抓一大把,而且方案万变不离其宗并已趋于成熟,但是有一个点很多人没有关注到,在铺天盖地的性能优化文章中几乎很少出现它的影子,它就是桶文件(barrel files),今天我们就来聊一聊。
虽然大家都没怎么提及过,但是你肯定都或多或少地在项目中使用过,而且还对你的项目产生不小的影响!
那么什么是桶文件?
桶文件 barrel files
桶文件是一种将多个模块的导出汇总到一个模块中的方式。具体来说,桶文件本身是一个模块文件,它重新导出其他模块的选定导出。
原始文件结构
// demo/foo.ts
export class Foo {}
// demo/bar.ts
export class Bar {}
// demo/baz.ts
export class Baz {}
不使用桶文件时的导入方式:
import { Foo } from '../demo/foo';
import { Bar } from '../demo/bar';
import { Baz } from '../demo/baz';
使用桶文件导出(通常是 index.ts)后:
// demo/index.ts
export * from './foo';
export * from './bar';
export * from './baz';
使用桶文件时的导入方式:
import { Foo, Bar, Baz } from '../demo';
是不是很熟悉,应该有很多人经常这么写吧,尤其是封装工具时 utils/index。
还有这种形式的桶文件:
// components/index.ts
export { default as Button } from './Button';
export { default as Input } from './Input';
export { default as Select } from './Select';
export {foo} from './foo';
export {bar} from './bar';
export {baz} from './baz';
这都是大家平常很常用到的形式,那么用桶文件到底怎么了?
桶文件是一种将多个模块的导出汇总到一个模块中的方式。具体来说,桶文件本身是一个模块文件,它重新导出其他模块的选定导出。
原始文件结构
// demo/foo.ts
export class Foo {}
// demo/bar.ts
export class Bar {}
// demo/baz.ts
export class Baz {}
不使用桶文件时的导入方式:
import { Foo } from '../demo/foo';
import { Bar } from '../demo/bar';
import { Baz } from '../demo/baz';
使用桶文件导出(通常是 index.ts)后:
// demo/index.ts
export * from './foo';
export * from './bar';
export * from './baz';
使用桶文件时的导入方式:
import { Foo, Bar, Baz } from '../demo';
是不是很熟悉,应该有很多人经常这么写吧,尤其是封装工具时 utils/index。
还有这种形式的桶文件:
// components/index.ts
export { default as Button } from './Button';
export { default as Input } from './Input';
export { default as Select } from './Select';
export {foo} from './foo';
export {bar} from './bar';
export {baz} from './baz';
这都是大家平常很常用到的形式,那么用桶文件到底怎么了?
桶文件的优缺点
先来说结论:
优点:
- 集中管理,简化代码
- 统一命名,利于多人合作
缺点:
- 增加编译、打包时间
- 增加包体积
- 不必要的性能和内存消耗
- 降低代码可读性
嗯,有没有激起你的好奇心?我们一个一个来解释。
先来说结论:
优点:
- 集中管理,简化代码
- 统一命名,利于多人合作
缺点:
- 增加编译、打包时间
- 增加包体积
- 不必要的性能和内存消耗
- 降低代码可读性
嗯,有没有激起你的好奇心?我们一个一个来解释。
增加编译、打包时间
桶文件对打包工具的影响
我们都知道 tree-shaking ,他可以在打包时分析出哪些模块和代码没有用到,从而在打包时将这些没有用到的部分移除,从而减少包体积。
以 rollup 为例,tree-shaking 的实现原理(其他大同小异)是:
1.静态分析
- Tree-shaking 基于 ES Module 的静态模块结构进行分析
- 通过分析 import/export 语句,构建模块依赖图
- 标记哪些代码被使用,哪些未被使用
- 使用 /#PURE/ 和 /@NO_SIDE_EFFECTS/ 注释来标记未使用代码
- 死代码消除
- 移除未使用的导出
- 移除未使用的纯函数
- 保留有副作用的代码
我们都知道 tree-shaking ,他可以在打包时分析出哪些模块和代码没有用到,从而在打包时将这些没有用到的部分移除,从而减少包体积。
以 rollup 为例,tree-shaking 的实现原理(其他大同小异)是:
1.静态分析
- Tree-shaking 基于 ES Module 的静态模块结构进行分析
- 通过分析 import/export 语句,构建模块依赖图
- 标记哪些代码被使用,哪些未被使用
- 使用 /#PURE/ 和 /@NO_SIDE_EFFECTS/ 注释来标记未使用代码
- 死代码消除
tree-shaking 实现流程
- 模块分析阶段
// 源代码
import { a, b } from './module'
console.log(a)
// 分析:b 未被使用
- 构建追踪
// 构建依赖图
module -> a -> used
module -> b -> unused
- 代码生成
// 最终只保留使用的代码
import { a } from './module'
console.log(a)
更多细节可以看我的另一篇文章关于tree-shaking,这不是这篇文章的重点 。
接着说回来,为什么桶文件会增加编译、打包时间?
如果你使用支持 tree-shaking 的打包工具,那么在打包时打包工具需要分析每个模块是否被使用,而桶文件作为入口整合了模块并重新导出,所以会增加分析的复杂度,你重导出的模块越多,它分析的时间就越长。
那有聪明的小伙伴就会问,既然 tree-shaking 分析、标记、删除无用代码会降低打包效率,那我关闭 tree-shaking 功能怎么样?
我只能说,不怎么样,有些情况你关闭 tree-shaking 后,打包时间反而更长。为啥?
关闭 Tree Shaking 意味着 Rollup 会直接将所有模块完整打包,即使某些模块中的代码未被使用。结果是:
- 打包体积增大:更多的代码需要进行语法转换、压缩等步骤。
- I/O 操作增加:较大的输出文件需要更多时间写入磁盘。
- 模块合并工作量增加:Rollup 在关闭 Tree Shaking 时仍会尝试将模块合并到一个文件中(尤其是 output.format 为 iife 或 esm 时)。
所以,虽然 Tree Shaking 的静态分析阶段可能较慢,但其最终生成的 bundle 通常更小、更优化,反而会减少后续步骤(如 压缩 和 代码生成)的负担。
又跑题了,我其实想说的是,问题不在于是否开启 tree-shaking,而在于你使用了桶文件,导致打包工具苦不堪言。
这个很好理解,你就想下面的桶文件重导出了100个模块,相当于这个文件里包含了100个模块的代码,解析器肯定一视同仁每一行代码都得照顾到,但其实你就用了其中一个方法 import { Foo } from '../demo';,想想都累...
// demo/index.ts
export * from './foo';
export * from './bar';
export * from './baz';
...
下面这两种形式,比上面的稍微强点
// components/index.ts
export { default as Button } from './Button';
export { default as Input } from './Input';
export { default as Select } from './Select';
假设 ./Button 文件导出多个具名导出和一个默认导出,那么这段代码意味着只使用其中的默认导出,而 export * 则是照单全收。
export {foo} from './foo';
export {bar} from './bar';
export {baz} from './baz';
同理,假设 ./foo 中有100个具名导出,这行代码就只使用了其中的 foo。
即使这比export * 强,但是当重导出的模块较多较复杂时对打包工具依然负担不小。
好难啊。。。,那到底要怎么样打包工具才舒服?
最佳建议
- 包或者模块支持通过具体路径引入即所谓的“按需导入” 如:
import Button from 'antd/es/button';
import Divider from 'antd/es/divider';
- 包或者模块支持通过具体路径引入即所谓的“按需导入” 如:
import Button from 'antd/es/button';
import Divider from 'antd/es/divider';
不知道有没有人用过 babel-plugin-import,它的工作原理大概就是
import { Button, Divider } from 'antd';
帮你转换为
import Button from 'antd/es/button';
import Divider from 'antd/es/divider';
- 减少或避免使用桶文件,将模块按功能细粒度分组,且要控制单个文件的导出数量
例如:
import {formatTime} from 'utils/timeUtils';
import {formatNumber} from 'utils/numberUtils';
import {formatMoney} from 'utils/moneyUtils';
...
而不是使用桶文件统一导出
import { formatTime, formatNumber, formatMoney } from 'utils/index';
其实这和生产环境的代码拆分一个意思,你把一个项目的所有代码都放在一个文件里搞个几M,浏览器下载和解析肯定是慢的
另外,不止打包阶段,本地开发也是一样的,无论是 vite 还是 webpack ,桶文件都会影响解析编译速度,你的桶文件搞得很多很复杂页面初始加载时间就会很长。
这一点 vite 的官方文档中也有说明。

增加包体积
有的小伙伴可能想,桶文件只影响开发和打包时的体验?那没事,我不差那点时间。
肯定没那么简单,桶文件也会影响打包后产物的体积,这就切实影响到用户侧的体验了。
如果你在打包时没有刻意关注 treeshaking 的效果,或者压根就没开启,那么你无形之中就打包了很多无用代码进最终产物里去了,这就是桶文件带来的坑。
如果你有计划的想要优化打包体积,那么桶文件会额外给你带来很多心智负担,你要一边看着打包产物一边调试打包工具的各种配置,以确保打包结果符合你的预期。
// components/utils/index.ts (桶文件)
export * from './chart'; // 依赖 echarts
export * from './format'; // 纯工具函数
export * from './i18n'; // 依赖 i18next
export * from './storage'; // 浏览器 API
// 使用桶文件
import { formatDate } from 'components/utils';
// 可能导致加载所有依赖
上面的代码,即使开启了 tree-shaking ,打包工具也无能为力。
好在较新版本的 Rollup 已针对export * from 进行了优化,只要最终代码路径中没有实际使用的导出项,它仍会尝试移除这些未使用的代码。但在以下场景下仍可能有问题:
- 模块间有副作用:如果重新导出的模块执行了副作用代码(如修改全局变量),Rollup 会保留这些模块。
- 与 CommonJS 混用:如果被导入模块是 CommonJS 格式,Tree Shaking 可能会受到限制。
想了解完整的影响 treeshaking 的场景点这里传送 Rollup 的 Tree Shaking
不仅 vite,rollup官网也说明了使用桶文件导入的弊端。

总之就是,使用桶文件如果不开 treeshaking,那么打包产物体积大,开了treeshaking也没办法做到完美(目前),你还得多花很多心思去分析优化,就没必要嘛。
不必要的性能和内存消耗
// demo/index.ts
export * from './foo';
export * from './bar';
export * from './baz';
...
// demo/index.ts
export * from './foo';
export * from './bar';
export * from './baz';
...
这点就很好理解了,即使你只 import {foo} from 'demo/index'使用了一个模块,其他模块也是被初始化了的,这些初始化是没有任何意义的,但是却可能拖累你的初始加载速度、增加内存占用。
同理,他也会影响你的IDE的性能,例如代码检查、补全等,或者测试框架 jest 等。
降低代码可读性
这一点见仁见智,我个人觉得桶文件增加了追踪实现的复杂性,当然大部分情况我们使用IDE是可以直接跳转到对应文件或者搜索的,不然用桶文件真的很抓狂。
// 使用桶文件
import { something } from '@/utils';
// 难以知道 something 的具体来源
// 直接导入更清晰
import { something } from '@/utils/atool';
总结
看到这里快去你的项目里检查一下,你可能做一个很小的改动就能让旁边小伙伴刮目相看:你做了what?这个项目怎么突然快了这么多?
桶文件实际上产生的影响并不小,只有少量桶文件在您的代码中通常是没问题的,但当每个文件夹都有一个时,问题就大了。
如果的项目是一个广泛使用桶文件的项目,现在可以应用一项免费的优化,使许多任务的速度提高 60-80%,让你的IDE和构建工具减减负:
删除所有桶文件!
来源:juejin.cn/post/7435492245912551436
程序员裸辞创业, 都混的咋样了?
嗨, 大家好, 我是徐小夕.
没错, 我已经辞职快一年了, 目前在全职创业, 今天会和大家系统的分享一下接近一年的创业历程, 能“劝退”一个是一个!
写这篇文章主要有两个目的, 一个是对自己创业做个阶段性复盘, 另一个目的是给一些在筹备创业的小伙伴, 一些客观而有参考性的建议.
因为我发现最近几个月很多技术小伙伴都在咨询我创业的事情, 我突然有点不知所措, 心想现在创业行情都这么“好”了吗? 于是我我看了一眼技术社区的画风, 仿佛他们读懂了我的疑惑:

已有先辈们做出了“总结”......
就我自己亲身做互联网软件创业来说, 确实不太“易”.
接下来就分享一下我这一年的创业历程.
裸辞后为什么选择创业
两个字: 执念!
因为之前一直在深耕低代码可视化领域, 对可视化搭建产品有很大的执念, 所以辞职的首要目标就是要做一款高价值的可视化搭建产品.
虽然在之前的公司工作非常愉快, 不管是薪资还是和同事们的相处, 感觉都非常nice, 但是心里总是有一个“坎”, 想要去迈过.
也可能是为了让即将到来的30岁, 不留遗憾吧~
很多朋友认识我大多通过技术社区里我做的技术分享和技术文章, 在开源领域, 我也做了很多可视化相关的开源项目, 从而树立了一定的技术影响力:

由于自己坚持做技术分享和写文章已经3年多了, 积累了大概 10w 的粉丝, 所以这也为自己创业做了一定的“用户”保障.(你做的产品一定要有原始用户)
总结一下, 决定我创业的原因有以下3个核心要素:
- 技术积累
- 资金积累
- 粉丝积累
如果大家想创业, 尤其是从事互联网创业, 我觉得得好好思考上面3点, 缺一勿“创”.
毕竟刚才在说话的间隙, 我又刷到一波高赞的文章, 和我的文章遥相呼应:

再来聊聊创业收入.
由于我们的创业方向主要是给企业提供可视化解决方案, 加上最近大环境又不太好, 很多企业的预算都在降低, 所以我们产品价格定位在企业可以接受的较低档位.
10个月时间, 收入6位数+.
好在我们是轻资本创业, 后面会通过提高产品价值和市场力, 来提高产品盈利能力.
创业过程中的酸甜苦辣
之前在网上看到有个大V说: 创业最可怕的事是,一开始就看到了终点那个举着胜利旗帜的人不会是你。
直到真正创业了, 我才感同身受. 因为你的每一个决策都决定着产品的未来走向, 意味着你需要为你的决策付出时间, 精力, 财力, 和人情.
1. 产品研发的血泪史

当时听到“自由无价”这个词, 用来形容独立开发者和自由职业者时, 觉得非常'cool', 直到自己亲身下场创业, 才发现自由是“相对的”, 创业没成功之前, 你是绝对不自由的.
也许关注可视化搭建项目的朋友知道我之前开源了一个零代码的项目——H5-Dooring, 今年一直在做Saas版的零代码产品, 让不懂技术的朋友也能通过拖拽的方式使用搭建平台来低成本制作页面.
从1月到6月, 我们几个小伙伴兵分两路, 一路给客户做定制开发, 一路迭代我们自己的低代码平台, 基本上天天熬夜coding, 测试, 同时还要兼顾用户反馈的需求和 bug.
由于大家都没有市场销售经验, 所以我自然而然的担起了这个责任.

除了要做技术研发, 我硬挤出了一部分时间来做内容宣传, 学习视频剪辑, 录制产品宣传视频和视频教程, 然后客户确定购买后我还需要给客户做技术培训, 帮助客户快速上手可视化搭建方案的技术研发.
所以说, 我也终于理解为什么说创业者都得是多面手了, 因为大部分事情都要亲力亲为!
再来聊聊软件产品的发布上线经验.
因为Dooring线上产品有近2万用户, 所以产品的更新迭代都极为谨慎, 我们一般在凌晨12点发布新版本, 这也就是意味着我们需要为发版“疯狂”. 由于没有专业测试, 我们都得自测, 当然百密总有一疏, 也出现几次线上bug导致用户受到了影响, 好在我们及时修复了, 才避免了损失.
这里的经验教训就是, 需要根据自己用户的属性, 来沉淀适合产品自身的迭代周期和BUG追溯机制.
凌晨发版是国内企业的不二选择......
这些都是创业过程中需要经历的冰山一角, 还有很多困难等着各位, 比如攻克技术难题, 风险管控, 成本等, 这些会不断考验着创业者的心智.
一次失败的百度广告

百度广告也许是我们做的最亏的一次投资.
Dooring零代码 其实有做3个月的百度广告, 当时主要是为了提高搜索权重和用户曝光, 来提高转化, 于是我们商量之后投了几万的百度广告.
由于百度是竞价机制, 在投放期间, 我们发现搜索关键词排名还是没有在第一页, 搜索排名基本上被“大公司”垄断, 投的钱越多你的位置越靠前, 我们当时的底线就是用户检索关键词后我们的网站只要在第一页就行了, 后面发现还是差强人意.
所以对于小公司, 做百度广告基本效果很小, 如果没有几十万上百万的投入, 很难有实际效果.
所以我们后面果断放弃了百度广告, 转而从内容侧和网站自身SEO来提高搜索曝光度. 大家对百度广告, 怎么看呢? 欢迎留言区留下你的经验分享~
学会做一名销售
说实话, 程序员创业, 营销或者销售能力是一个短板. 然而企业的基础目标就是“卖货”, 要想把自己产品销售出去, 就必须得懂客户市场.
当然销售能力也是我在创业过程中遇到的短板.
今年参加了很多线下的分享会, 有关于AI的, 也有创业的, 也认识了很多的创业者, 他们大多都有技术背景, 但是我发现发展比较好的企业基本上都是极度重视用户需求和体验的, 他们建立了各种渠道来挖掘用户需求和用户反馈, 从而改进优化自己的产品,让更多的用户来主动帮它“代言” .
往往是那种死磕技术但是忽视真正的用户体验的产品, 虽然技术虽强, 但是在使用产品初期, 就把大部分用户“劝退”了.
很多技术人更倾向于把技术做好, 以技术思维来设计产品. 但是产品光有技术是不行的, 还得懂客户, 懂用户体验, 我们需要把自己假想成产品的“客户”, 如果“客户”都觉得这个有价值, 有购买意愿, 这个产品才能更好的成单.
这里举一个大家都比较熟悉的例子——雷军的小米SU7.

虽然小米不是第一个造车, 但是一场汽车发布会下来, 却让一众老牌车企“洗面”.
当时也看了很多博主分享小米汽车爆单的原因, 其中最重要的就是用户体验. 在发布会上雷总真的是吊足了观众的胃口和对年轻人第一辆“xx车”的期望, 其爆款的背后是小米对大量用户诉求的思考, 并融入到了产品的设计中.
虽然我个人对这种产品模式不太苟同, 但是有一点是比较赞同的, 就是: 创业者要做一个懂客户的金牌销售.
国内的客户关系管理涉及到方方面面, 作为创业者一定要考虑客户关系的维护和管理.
这里分享我的几个创业经验:
- 建立客户群(需求挖掘和市场洞察)
- 建立产品用户群(提高产品体验, 获取产品体验数据)
- 做好数据埋点(进一步分析产品决策, 用户属性)
- 持续迭代产品
- 在不影响大方向的前提下, 市场反馈优于技术实现
- 做好产品营销(不要指望客户主动来找你)
打造竞争壁垒
我觉得AI盛行的当下, 小团队做互联网产品创业, 在不融资的情况下, 你的唯二的竞争壁垒就是:
- 铁粉基数
- 产品垂直度
因为任何软件技术都能被复制, 只要有足够的资金, 那如何才能和这些喜欢 copy 的公司竞争呢?
第一个就是你的粉丝基数, 如果你有大量的粉丝, 那么你已经成功一半了, 因为你有了第一批可能会帮你传播的用户, 并且能很快确定在当前行业的影响力.(当然后续的口碑也非常重要, 为了保证粉丝不会倒戈~)
其次我觉得就是你的创业项目得在垂直细分领域做的足够优秀, 至少达到Top3的水平. 不然很难在这个领域获取可持续的客户, 所以需要做深一个垂直细分领域, 这样才能形成一定的竞争壁垒.
说到这里, 还在规划做互联网创业的技术小伙伴们, 是否觉得有一丝丝压力了?
不急, 我来继续复盘.
短期收益 or 长期收益?
再来聊聊一个比较实际的话题, 就是创业的收益.
当然创业的方式有很多很多种, 有短期收益模式的, 比如说卖课, 广告等, 也有长期才能获取收益的, 比如做独立产品, 而我创业的方向是走长期收益的方向——做独立产品.
我相信很多技术圈友想创业的方向都是自研产品, 但是有一个现实的问题就是, 你的收益周期可能是3个月, 半年, 1年, 甚至更久. 而投入的成本来说也比较大, 比如服务器, 研发成本, 设计资源, 营销投入等.
我们在做可视化搭建产品的过程中(比如Dooring, flowmix系列), 累计投入超过了20w, 还不包含人工研发成本. 虽然目前已经盈利, 但是还是需要持续的投入, 而且要做好半年不盈利的准备.
所以对于想独立做产品创业的小伙伴, 大家一定要慎重, 如果都具备了我上面说的条件, 大家再入局, 不然会非常“惨烈”的.
创业这一年, 都做了什么
接下来到了文章的“高潮”部分, 聊聊从1月到10月, 我们做了哪些可视化搭建产品.
1.Dooring零代码搭建平台

2. Dooring智图, 在线图片设计平台

- 橙子试卷, 表单问卷搭建平台

4. flowmix/docx 多模态文档编辑引擎

5. flowmix/flow 多模态工作流设计器

未来的规划
后续还是会持续在可视化零代码领域做深耕, 同时借助AI技术, 让应用搭建门槛降到最低.
如果创业不达预期, 我可能也会像下面的博主一样, 继续在职场中卷卷卷啦!

如果大家有好的创业想法, 或者想有一些技术交流, 欢迎随时和我沟通, 也可以在留言区和大家分享哦~
来源:juejin.cn/post/7425600234523131956
微信的消息订阅,就是小程序有通知,可以直接发到你的微信上
给客户做了一个信息发布的小程序,今天客户提要求说希望用户发布信息了以后,他能收到信息,然后即时给用户审核,并且要免费,我就想到了微信的订阅消息。之前做过一次,但是忘了,这次记录一下,还是有一些坑的。
一 先申请消息模版
先去微信公众平台,申请消息模版

在uni-app 里面下载这个插件uni-subscribemsg
 我的原则就是有插件用插件,别自己造轮子。而且这个插件文档很好
我的原则就是有插件用插件,别自己造轮子。而且这个插件文档很好
根据文档定义一个message.js 云函数
这个其实文档里面都有现成的代码,但我还是贴一下自己的吧。
'use strict';
const uidObj = require('uni-id');
const {
Controller
} = require('uni-cloud-router');
// 引入uni-subscribemsg公共模块
const UniSubscribemsg = require('uni-subscribemsg');
// 初始化实例
let uniSubscribemsg = new UniSubscribemsg({
dcloudAppid: "填你的应用id",
provider: "weixin-mp",
});
module.exports = class messagesController extends Controller {
// 发送消息
async send() {
let response = { code: 1, msg: '发送消息失败', datas: {} };
const {
openid,
data,
} = this.ctx.data;
// 发送订阅消息
let resdata = await uniSubscribemsg.sendSubscribeMessage({
touser: openid,// 就是用户的微信id,决定发给他
template_id: "填你刚刚申请的消息模版id",
page: "pages/tabbar/home", // 小程序页面地址
miniprogram_state: "developer", // 跳转小程序类型:developer为开发版;trial为体验版;formal为正式版;默认为正式版
lang: "zh_CN",
data: {
thing1: {
value: "信息审核通知"// 消息标题
},
thing2: {
value: '你有新的内容需要审核' // 消息内容
},
number3: {
value: 1 // 未读数量
},
thing4: {
value: '管理员' // 发送人
},
time7: {
value: data.time // 发送时间
}
}
});
response.code = 0;
response.msg = '发送消息成功';
response.datas = resdata;
return response;
}
}
四 让用户主动订阅消息
微信为了防止打扰用户,需要用户订阅消息,并且每次订阅只能发送一次,不过我取巧,在用户操作按钮上偷偷加订阅方法,让用户一直订阅,我就可以一直发
// 订阅
dingYue() {
uni.requestSubscribeMessage({
tmplIds: ["消息模版id"], // 改成你的小程序订阅消息模板id
success: (res) => {
if (res['消息模版id'] == 'accept') {
}
}
});
},
五 讲一下坑
我安装了那个uni-app 的消息插件,但是一直报错找不到那个模块。原来是unicloud 云函数要主动关联公共模块,什么意思呢,直接上图。

 又是一个人的前行
又是一个人的前行
如果你喜欢我的文章,可以关注我的公众号,九月有风,上面更新更及时
来源:juejin.cn/post/7430353222685048859
「差生文具多」增大IDE字体,增大显示器
🍄 大家好,我是风筝
🌍 个人博客:【古时的风筝】。
本文目的为个人学习记录及知识分享。如果有什么不正确、不严谨的地方请及时指正,不胜感激。
每一个赞都是我前进的动力。
公众号:「古时的风筝」
上个月发“微博”的时候说IDE字体已经从 16号调到18号了,主要是一到换季的时候就有点鼻炎,导致眼睛也不舒服,看电脑时间长了就很累,结果我就给字体调大了。
你别说,该认怂就得认怂,调大了不丢人,字体一大果然就没那么累了。刚毕业的时候用12号字,后来改14号,再后来16号,这不,转眼18号字了,如果过两年还写代码的话,就奔着20号去了。

但是问题还是有的,我一般情况下是不怎么用外接显示器的,16寸写代码感觉够用了,除非要做一些大块儿内容的比对,否则,我的外接显示器就是一张风景图,搁旁边就剩下赏心悦目的作用了。
但是这18号字体一上,如果开着控制台的话,一屏也就能显示20行代码了。我之所以用 MacBook Pro,很大的一个原因就是显示屏,但是公司的外接显示器应该是 2K 显示器里最便宜的了,显示效果跟苹果比差了一大截。

看到我发的“微博”后,几个朋友就在群里聊起显示器来,最后一致认为苹果 Studio Display 是最好的显示器,唯一的缺点就是太贵了,最低的27寸 11499起,这你受的了吗?
一个醉心研究显示器和机械键盘的朋友让我看看明基(BenQ)RD280U,说是专业的编程显示器,而且护眼这一块儿做的特别到位,他说,你不是最关心这个吗,肯定对路。他说入手不想要的话可以转给他,他正好想把之前的华为显示器换了呢。
我查了一晚上资料后,这款显示器有两点最吸引我的地方:
- 它为编程场景专门做过定制设计,保证开发的时候能有更好的体验。
- 有专业的护眼硬件滤蓝光设置,看评论说用起来眼睛真的不累。
然后它就来了,28寸4K,好大一个箱子。快递小哥说这箱子还挺沉,我说是啊,一个显示器怎么这么大这么沉,快递小哥也有点儿惊讶。
拆开后,一个大箱子里面套了一个小箱子,但是是真的沉,好不夸张的说得有20多斤,料真足啊。

但是安装很方便,直接把底座扣上就好了。

这是显示器的上桌效果,28寸,实话说已经很大了,再大的话,全屏写代码就有点儿费脖子了。

一般的显示器都是27寸 16:9 比例的,但是 RD280U 是3:2的,这样显示器更高一点,能多显示几行代码。

目前市面上特殊屏幕比的显示器商家很少,有成本、市场等很多原因,但也有很多程序员喜欢用方一点的屏幕,RD这款考虑到了,还挺贴心。对于我来说,这倒是小事,反正屏幕够大,也不差那几行代码。我最关心的还是显示效果,代码显示的清不清楚。
用惯了苹果的屏幕,其他的显示器一眼就能看出来清晰不清晰,结果,果然没让我失望。文字显示非常清晰,效果非常好。

专门的编码主题
这个显示器内置了几种模式,其中就包括专门的编码主题,一个是深色主题、一个是亮色主题,写代码的时候就直接调成这俩模式就行了。看电影、读书也有专门的主题。

同时还有个专门的背光灯,晚上写代码就直接开背光灯就可以了,不用再单独开个台灯了,也不用开着室内灯了,有时候思路真的不能被打断,晚上背光灯亮起来就不用着急去开灯了,而且氛围感也不错。

另外,在晚上开启猫头鹰模式,也就是夜间保护模式,可以自动调节亮度,在搭配上深色模式,晚上写代码也很舒服。

反光处理
它对定点光源的反光效果处理的也很好,左边是 MacBook Pro,右边是 RD280U,效果还是很明显的。

但是建议写代码、看视频还是不要在强光下,总是对眼睛不好的。
用软件助手直接控制
与显示器配套的还有一个软件控制工具,叫做 「Display Pilot 2」,通过这个软件可以直接更改色彩主题、亮度。
还可以开启 MoonHalo ,MoonHalo 就是背光灯,还有夜间保护、智慧蓝光,还附赠个桌面分区的功能。

软件助手里还有一个 Flow 功能,可以自定义固定时间段里我想要的显示器色彩模式、护眼功能开启状态和其他参数。比如我晚上八点想看会电子书提前设置好Flow, 到点就直接切换了,非常丝滑。
还有一个用处
我家小朋友最近正在学习认表,我就给做了一个认表的网页,没事儿可以拿着大屏练习几分钟。
地址: http://www.moonkite.cn/clock-study…

点击暂停,表盘就会停止,这时候就可以让他看看是几点了,然后点击显示按钮就会出现刚才暂停的时刻。

有小孩子的可以拿来用一用。
然后顺道改了改,做了一个在线时钟,不用大屏的时候可以看时间用。

来源:juejin.cn/post/7436036522019143707
anime,超强JS动画库和它的盈利模式
大家好,我是农村程序员,独立开发者,前端之虎陈随易。

前面分享了开源编辑器 wangEditor 维护九年终停更,隐藏大佬接大旗的故事。
本文呢,分享开源项目进行商业化盈利的故事。
这个项目叫做 anime,是一个 JavaScript 动画库,目前有 50k star。
我们先来看看它的效果。




怎么样?是不是大呼过瘾。
而这,只是 anime 的冰山一角,更多案例,可以访问下方官网查看。
github:https://github.com/juliangarnier/anime

anime 的第一次提交时间是 2016年6月27日,到如今 8年 来,一共提交了 752次,平均每年提交 100次,核心代码 1300行 左右。
从数据上来看,并不亮眼,但是从功能上来说,确是极其优秀。
目前,anime v4 版本已经可以使用了。
v4 版本的功能特点如下:
- 新的 ES 模块优先 API。
- 主要性能提升和减少内存占用。
- 内置类型定义!
- 用于检查和加速动画工作流程的 GUI 界面。
- 带有标签的改进时间轴、更多时间位置语法选项、对子项的循环/方向支持等等!。
- 用于创建附加动画的新附加合成模式。
- 新的可配置内置功能:‘linear(x,x,x)’、‘in(x)’、‘out(x)’、‘inOut(x)’、‘outIn(x)’。
- 更好的 SVG 工具,包括改进的形状变形、线条绘制和运动路径实用程序。
- 支持 CSS 变量动画。
- 能够从特定值进行动画处理。
- 可链接的实用程序函数可简化动画工作流程中的常见任务。
- 新的 Timer 实用程序类,可用作 setInterval 和 setTimeout 的替代方案。
- 超过 300 个测试,使开发过程更轻松且无错误。
- 全新的文档,具有新设计和更深入的解释。
- 新的演示和示例。
可以看到,新版进行了大量的优化和升级。
但是呢,目前只提供给赞助的用户使用。

最低档赞助是 10美元/月,目标是 120个 赞助,目前已经积累了 117个 赞助。
也就是说,每个月都会有至少 1170美元 的赞助收入,折合人民币 8400元/月。
不知道作者所在地区的生活水平怎么样,这个赞助收入,对于生存问题,基本能够胜任了。
我们很多时候都在抱怨开源赚不到钱,那么开源盈利的方案也是有很多的,比如:
- 旧版免费,新版付费使用。
- 源码免费,文档或咨询付费。
- 开源免费,定制服务付费。
希望我们的开源环境更加友好,让更多人可以解决他们的问题,也要让开源作者获得应有的回报。
来源:juejin.cn/post/7435959580506914816
Flutter 新一代混合栈管理框架(已适配HarmonyOS Next)
简介
Fusion 是新一代的混合栈管理框架,用于 Flutter 与 Native 页面统一管理,并支持页面通信、页面生命周期监听等功能。Fusion 即 融合,我们的设计初衷就是帮助开发者在使用 Flutter 与 Native 进行混合开发时尽量感受不到两者的隔阂,提升开发体验。此外,Fusion 彻底解决了混合开发过程中普遍存在的黑屏、白屏、闪屏等问题,更加适合重视用户体验的App使用。
从 4.0 开始,Fusion 已完成纯鸿蒙平台(HarmonyOS Next/OpenHarmony,以下简称 HarmonyOS)的适配,开发者可以在Android、iOS、HarmonyOS上得到完全一致的体验。(HarmonyOS 的 Flutter SDK 可以在这里获取)
| OS | Android | iOS | HarmonyOS |
|---|---|---|---|
| SDK | 5.0(21)+ | 11.0+ | 4.1(11)+ |
Fusion 采用引擎复用方案,在 Flutter 与 Native 页面多次跳转情况下,APP 始终仅有一份 FlutterEngine 实例,因此拥有更好的性能和更低的内存占用。
Fusion 也是目前仅有的支持混合开发时应用在后台被系统回收后,所有Flutter页面均可正常恢复的混合栈框架。
开始使用
0、准备
在开始前需要按照 Flutter 官方文档,将 Flutter Module 项目接入到 Android、iOS、HarmonyOS 工程中。
1、初始化
Flutter 侧
使用 FusionApp 替换之前使用的 App Widget,并传入所需路由表,默认路由表和自定义路由表可单独设置也可同时设置。
void main() {
runApp(FusionApp(
// 默认路由表
routeMap: routeMap,
// 自定义路由表
customRouteMap: customRouteMap,
));
}
// 默认路由表,使用默认的 PageRoute
// 使用统一的路由动画
final Map<String, FusionPageFactory> routeMap = {
'/test': (arguments) => TestPage(arguments: arguments),
kUnknownRoute: (arguments) => UnknownPage(arguments: arguments),
};
// 自定义路由表,可自定义 PageRoute
// 比如:某些页面需要特定的路由动画则可使用该路由表
final Map<String, FusionPageCustomFactory> customRouteMap = {
'/mine': (settings) => PageRouteBuilder(
opaque: false,
settings: settings,
pageBuilder: (_, __, ___) => MinePage(
arguments: settings.arguments as Map<String, dynamic>?)),
};
P.S: kUnknownRoute表示未定义路由
注意:如果项目使用了 flutter_screenutil,需要在 runApp 前调用 Fusion.instance.install(),没有使用 flutter_screenutil则无须该步骤。
void main() {
Fusion.instance.install();
runApp(FusionApp(
// 默认路由表
routeMap: routeMap,
// 自定义路由表
customRouteMap: customRouteMap,
));
}
Android 侧
在 Application 中进行初始化,并实现 FusionRouteDelegate 接口
class MyApplication : Application(), FusionRouteDelegate {
override fun onCreate() {
super.onCreate()
Fusion.install(this, this)
}
override fun pushNativeRoute(name: String?, arguments: Map<String, Any>?) {
// 根据路由 name 跳转对应 Native 页面
}
override fun pushFlutterRoute(name: String?, arguments: Map<String, Any>?) {
// 根据路由 name 跳转对应 Flutter 页面
// 可在 arguments 中存放参数判断是否需要打开透明页面
}
}
iOS 侧
在 AppDelegate 中进行初始化,并实现 FusionRouteDelegate 代理
@UIApplicationMain
@objc class AppDelegate: UIResponder, UIApplicationDelegate, FusionRouteDelegate {
func application(
_ application: UIApplication,
didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?
) -> Bool {
...
Fusion.instance.install(self)
...
return true
}
func pushNativeRoute(name: String?, arguments: Dictionary<String, Any>?) {
// 根据路由 name 跳转对应 Native 页面
}
func pushFlutterRoute(name: String?, arguments: Dictionary<String, Any>?) {
// 根据路由 name 跳转对应 Flutter 页面
// 可在 arguments 中存放参数判断是否需要打开透明页面
// 可在 arguments 中存放参数判断是 push 还是 present
}
}
HarmonyOS 侧
在 UIAbility 中进行初始化,并实现 FusionRouteDelegate 代理
export default class EntryAbility extends UIAbility implements FusionRouteDelegate {
private static TAG = 'EntryAbility'
private mainWindow: window.Window | null = null
private windowStage: window.WindowStage | null = null
override async onCreate(want: Want, launchParam: AbilityConstant.LaunchParam): Promise<void> {
await Fusion.instance.install(this.context, this)
GeneratedPluginRegistrant.registerWith(Fusion.instance.defaultEngine!)
}
pushNativeRoute(name: string, args: Map<string, Object> | null): void {
// 根据路由 name 跳转对应 Native 页面
}
pushFlutterRoute(name: string, args: Map<string, Object> | null): void {
// 根据路由 name 跳转对应 Flutter 页面
// 可在 arguments 中存放参数判断是否需要打开透明页面
}
}
2、Flutter 容器
普通页面模式
Android 侧
通过 FusionActivity(或其子类) 创建 Flutter 容器,启动容器时需要使用 Fusion 提供的 buildFusionIntent 方法,其中参数 transparent 需设为 false。其 xml 配置参考如下(如果使用 FusionActivity 则不用配置):
<activity
android:name=".CustomFusionActivity"
android:configChanges="orientation|keyboardHidden|keyboard|screenSize|smallestScreenSize|locale|layoutDirection|fontScale|screenLayout|density|uiMode"
android:exported="false"
android:hardwareAccelerated="true"
android:launchMode="standard"
android:theme="@style/FusionNormalTheme"
android:windowSoftInputMode="adjustResize" />
iOS 侧
通过 FusionViewController (或其子类)创建 Flutter 容器,push 和 present 均支持。FusionViewController 默认隐藏了 UINavigationController。
在 iOS 中需要处理原生右滑退出手势和 Flutter 手势冲突的问题,解决方法也很简单:只需在自定义的 Flutter 容器中实现 FusionPopGestureHandler 并在对应方法中启用或者关闭原生手势即可,这样可以实现如果当前 Flutter 容器存在多个 Flutter 页面时,右滑手势是退出 Flutter 页面,而当 Flutter 页面只有一个时则右滑退出 Flutter 容器。
// 启用原生手势
func enablePopGesture() {
// 以下代码仅做演示,不可直接照搬,需根据APP实际情况自行实现
navigationController?.interactivePopGestureRecognizer?.isEnabled = true
}
// 关闭原生手势
func disablePopGesture() {
// 以下代码仅做演示,不可直接照搬,需根据APP实际情况自行实现
navigationController?.interactivePopGestureRecognizer?.isEnabled = false
}
HarmonyOS 侧
通过 FusionEntry(或其子类) 创建 Flutter 容器,启动容器时需要使用 Fusion 提供的 buildFusionParams 方法,也可直接使用 FusionPage。默认全屏模式。
const params = buildFusionParams(name, args, false, backgroundColor)
this.mainLocalStorage?.setOrCreate('params', params)
router.pushNamedRoute({name: FusionConstant.FUSION_ROUTE_NAME})
透明页面模式
Android 侧
使用方式与普通页面模式相似,只是buildFusionIntent 方法的参数 transparent 需设为 true,其 xml 配置参考如下:
<activity
android:name=".TransparentFusionActivity"
android:configChanges="orientation|keyboardHidden|keyboard|screenSize|smallestScreenSize|locale|layoutDirection|fontScale|screenLayout|density|uiMode"
android:exported="false"
android:hardwareAccelerated="true"
android:launchMode="standard"
android:theme="@style/FusionTransparentTheme"
android:windowSoftInputMode="adjustResize" />
iOS 侧
使用方式与普通页面模式相似:
let fusionVc = CustomViewController(routeName: name, routeArguments: arguments, transparent: true)
navController?.present(fusionVc, animated: false)
HarmonyOS 侧
使用方式与普通页面模式相似:
const params = buildFusionParams(name, args, true, backgroundColor)
this.windowStage?.createSubWindow(FusionConstant.TRANSPARENT_WINDOW, (_, win) => {
const record: Record<string, Object> = {
'params': params
}
win.loadContentByName(FusionConstant.FUSION_ROUTE_NAME, new LocalStorage(record))
win.showWindow()
})
Flutter 侧
同时Flutter页面背景也需要设置为透明
子页面模式
子页面模式是指一个或多个 Flutter 页面同时嵌入到 Native 容器中的场景,如:使用Tab切换Flutter和原生页面,Fusion 支持多个 Flutter 页面嵌入同一个 Native 容器中
Android 侧
使用 FusionFragment 以支持子页面模式,创建 FusionFragment 对象需要使用 buildFusionFragment 方法
iOS 侧
与页面模式一样使用 FusionViewController
HarmonyOS 侧
与页面模式一样使用 FusionEntry,配合 buildFusionParams方法配置参数
自定义容器背景色
默认情况下容器的背景为白色,这是因为考虑到绝大多数的页面都是使用白色背景,但如果打开的首个Flutter页面的背景是其他颜色,比如夜间模式下页面为深灰色,此时是为了更好的视觉效果,可以自定义容器的背景色与首个Flutter页面的背景色一致。
Android 侧
在 buildFusionIntent 和 buildFusionFragment方法中参数 backgroundColor 设为所需背景色
iOS 侧
在创建 FusionViewController (或其子类)对象时,参数 backgroundColor 设为所需背景色
HarmonyOS 侧
在 buildFusionParams方法中参数 backgroundColor 设为所需背景色
3、路由API(FusionNavigator)
- push:将对应路由入栈,Navigator.pushNamed 与之等同,根据FusionRouteType分为以下几种方式:
- flutter模式: 在当前Flutter容器中将指定路由对应的Flutter页面入栈,如果没有则跳转kUnknownRoute对应Flutter页面
- flutterWithContainer模式: 创建一个新的Flutter容器,并将指定路由对应的Flutter页面入栈,如果没有则跳转kUnknownRoute对应Flutter页面。即执行FusionRouteDelegate的pushFlutterRoute
- native模式: 将指定路由对应的Native页面入栈,即执行FusionRouteDelegate的pushNativeRoute
- adaption模式: 自适应模式,默认类型。首先判断该路由是否是Flutter路由,如果不是则进入native模式,如果是再判断当前是否是页面是否是Flutter容器,如果是则进入flutter模式,如果不是则进入flutterWithContainer模式
- pop:在当前Flutter容器中将栈顶路由出栈,Navigator.pop 与之等同
- maybePop:在当前Flutter容器中将栈顶路由出栈,可被WillPopScope拦截
- replace:在当前Flutter容器中将栈顶路由替换为对应路由,Navigator.pushReplacementNamed 与之等同
- remove:在当前Flutter容器中移除对应路由
路由跳转与关闭等操作既可使用FusionNavigator的 API,也可使用Navigator中与之对应的API(仅上述提到的部分)
4、Flutter Plugin 注册
在 Android 和 iOS 平台上框架内部会自动注册插件,无须手动调用 GeneratedPluginRegistrant.registerWith 进行注册,但 HarmonyOS 必须手动调用该方法。
5、自定义 Channel
如果需要 Native 与 Flutter 进行通信,则需要自行创建 Channel,创建 Channel 方式如下(以 MethodChannel 为例):
Android 侧
①、与容器无关的方法
在 Application 中进行注册
val channel = Fusion.defaultEngine?.dartExecutor?.binaryMessenger?.let {
MethodChannel(
it,
"custom_channel"
)
}
channel?.setMethodCallHandler { call, result ->
}
②、与容器相关的方法
在自实现的 FusionActivity、FusionFragmentActivity、FusionFragment 上实现 FusionMessengerHandler 接口,在 configureFlutterChannel 中创建 Channel,在 releaseFlutterChannel 释放 Channel
class CustomActivity : FusionActivity(), FusionMessengerHandler {
override fun configureFlutterChannel(binaryMessenger: BinaryMessenger) {
val channel = MethodChannel(binaryMessenger, "custom_channel")
channel.setMethodCallHandler { call, result ->
}
}
override fun releaseFlutterChannel() {
channel?.setMethodCallHandler(null)
channel = null
}
}
iOS 侧
①、与容器无关的方法
在 AppDelegate 中进行注册
var channel: FlutterMethodChannel? = nil
if let binaryMessenger = Fusion.instance.defaultEngine?.binaryMessenger {
channel = FlutterMethodChannel(name: "custom_channel", binaryMessenger: binaryMessenger)
}
channel?.setMethodCallHandler { (call: FlutterMethodCall, result: @escaping FlutterResult) in
}
②、与容器相关的方法
在自实现的 FusionViewController 上实现 FusionMessengerHandler 协议,在协议方法中创建 Channel
class CustomViewController : FusionViewController, FusionMessengerHandler {
func configureFlutterChannel(binaryMessenger: FlutterBinaryMessenger) {
channel = FlutterMethodChannel(name: "custom_channel", binaryMessenger: binaryMessenger)
channel?.setMethodCallHandler { (call: FlutterMethodCall, result: @escaping FlutterResult) in
}
}
func releaseFlutterChannel() {
channel?.setMethodCallHandler(nil)
channel = nil
}
}
HarmonyOS 侧
①、与容器无关的方法
在 UIAbility 中进行注册
const binaryMessenger = Fusion.instance.defaultEngine?.dartExecutor.getBinaryMessenger()
const channel = new MethodChannel(binaryMessenger!, 'custom_channel')
channel.setMethodCallHandler({
onMethodCall(call: MethodCall, result: MethodResult): void {
}
})
②、与容器相关的方法
在自实现的 FusionEntry 上实现 FusionMessengerHandler 接口,在 configureFlutterChannel 中创建 Channel,在 releaseFlutterChannel 释放 Channel
export default class CustomFusionEntry extends FusionEntry implements FusionMessengerHandler, MethodCallHandler {
private channel: MethodChannel | null = null
configureFlutterChannel(binaryMessenger: BinaryMessenger): void {
this.channel = new MethodChannel(binaryMessenger, 'custom_channel')
this.channel.setMethodCallHandler(this)
}
onMethodCall(call: MethodCall, result: MethodResult): void {
result.success(`Custom Channel:${this}_${call.method}`)
}
releaseFlutterChannel(): void {
this.channel?.setMethodCallHandler(null)
this.channel = null
}
}
BasicMessageChannel 和 EventChannel 使用也是类似
P.S.: 与容器相关的方法是与容器生命周期绑定的,如果容器不可见或者销毁了则无法收到Channel消息。
6、生命周期
应用生命周期监听:
- ①、在 Flutter 侧任意处注册监听皆可,并
implementsFusionAppLifecycleListener - ②、根据实际情况决定是否需要注销监听
void main() {
...
FusionAppLifecycleBinding.instance.register(MyAppLifecycleListener());
runApp(const MyApp());
}
class MyAppLifecycleListener implements FusionAppLifecycleListener {
@override
void onBackground() {
print('onBackground');
}
@override
void onForeground() {
print('onForeground');
}
}
FusionAppLifecycleListener 生命周期回调函数:
- onForeground: 应用进入前台会被调用(首次启动不会被调用,Android 与 iOS 保持一致)
- onBackground: 应用退到后台会被调用
页面生命周期监听:
- ①、在需要监听生命周期页面的 State 中
implementsFusionPageLifecycleListener - ②、在 didChangeDependencies 中注册监听
- ③、在 dispose 中注销监听
class LifecyclePage extends StatefulWidget {
const LifecyclePage({Key? key}) : super(key: key);
@override
State<LifecyclePage> createState() => _LifecyclePageState();
}
class _LifecyclePageState extends State<LifecyclePage>
implements FusionPageLifecycleListener {
@override
Widget build(BuildContext context) {
return Container();
}
@override
void didChangeDependencies() {
super.didChangeDependencies();
FusionPageLifecycleBinding.instance.register(this);
}
@override
void onPageVisible() {}
@override
void onPageInvisible() {}
@override
void onForeground() {}
@override
void onBackground() {}
@override
void dispose() {
super.dispose();
FusionPageLifecycleBinding.instance.unregister(this);
}
}
PageLifecycleListener 生命周期回调函数:
- onForeground: 应用进入前台会被调用,所有注册了生命周期监听的页面都会收到
- onBackground: 应用退到后台会被调用,所有注册了生命周期监听的页面都会收到
- onPageVisible: 该 Flutter 页面可见时被调用,如:从 Native 页面或其他 Flutter 页面
push到该 Flutter 页面时;从 Native 页面或其他 Flutter 页面pop到该 Flutter 页面时;应用进入前台时也会被调用。 - onPageInvisible: 该 Flutter 页面不可见时被调用,如:从该 Flutter 页面
push到 Native 页面或其他 Flutter 页面时;如从该 Flutter 页面pop到 Native 页面或其他 Flutter 页面时;应用退到后台时也会被调用。
7、全局通信
支持消息在应用中的传递,可以指定 Native 还是 Flutter 或者全局接收和发送。
注册消息监听
Flutter侧
- ①、在需要监听消息的类中
implementsFusionNotificationListener,并复写onReceive方法,该方法可收到发送过来的消息 - ②、在合适时机注册监听
- ③、在合适时机注销监听
class TestPage extends StatefulWidget {
@override
State<TestPage> createState() => _TestPageState();
}
class _TestPageState extends State<TestPage> implements FusionNotificationListener {
@override
void onReceive(String name, Map<String, dynamic>? body) {
}
@override
void didChangeDependencies() {
super.didChangeDependencies();
FusionNotificationBinding.instance.register(this);
}
@override
void dispose() {
super.dispose();
FusionNotificationBinding.instance.unregister(this);
}
}
Native侧
- ①、在需要监听消息的类中实现 FusionNotificationListener 接口,并复写
onReceive方法,该方法可收到发送过来的消息 - ②、在适当时机使用
FusionNotificationBinding的register方法注册监听 - ③、在适当时机使用
FusionNotificationBinding的unregister方法注销监听
发送消息
三端均可使用FusionNavigator 的 sendMessage 方法来发送消息,根据使用FusionNotificationType 不同类型有不同效果:
- flutter: 仅 Flutter 可以收到
- native: 仅 Native 可以收到
- global(默认): Flutter 和 Native 都可以收到
8、返回拦截
在纯 Flutter 开发中可以使用WillPopScope组件拦截返回操作,Fusion 也完整支持该功能,使用方式与在纯 Flutter 开发完全一致,此外使用FusionNavigator.maybePop的操作也可被WillPopScope组件拦截。
9、状态恢复
Fusion 支持 Android 和 iOS 平台 APP 被回收后 Flutter 路由的恢复。
来源:juejin.cn/post/7329573765087019034
明明 3 行代码即可轻松实现,Promise 为何非要加塞新方法?
给前端以福利,给编程以复利。大家好,我是大家的林语冰。
00. 观前须知
地球人都知道,JS 中的异步编程是 单线程 的,和其他多线程语言的三观一龙一猪。因此,虽然其他语言的异步模式彼此互通有无,但对 JS 并不友好,比如 Actor 模型等。
这并不是说 JS 被异步社区孤立了,只是因为 JS 天生和多线程八字不合。你知道的,要求 JS 使用多线程,就像要求香菜恐惧症患者吃香菜一样离谱。本质上而言,这是刻在 JS 单线程 DNA 里的先天基因,直接决定了 JS 的“异步性状”。有趣的是,如今 JS 也变异出若干多线程的使用场景,只是比较非主流。
ES6 之后,JS 的异步编程主要基于 Promise 设计,比如人气爆棚的 fetch API 等。因此,最新的 ES2024 功能里,又双叒叕往 Promise 加塞了新型静态方法 Promise.withResolvers(),也就见怪不怪了。

问题在于,我发现这个新方法居然只要 3 行代码就能实现!奥卡姆剃刀原则告诉我们, 若无必要,勿增实体。那么这个鸡肋的新方法是否违背了奥卡姆剃刀原则呢?我决定先质疑、再质疑。
当然,作为应试教育的漏网之鱼,我很擅长批判性思考,不会被第一印象 PUA。经过三天三夜的刻意练习,机智如我发现新方法果然深藏不露。所以,本期我们就一起来深度学习 Promise 新方法的技术细节。
01. 静态工厂方法
Promise.withResolvers() 源自 tc39/proposal-promise-with-resolvers 提案,是 Promise 类新增的一个 静态工厂方法。
静态的意思是,该方法通过 Promise 类调用,而不是通过实例对象调用。工厂的意思是,我们可以使用该方法生成一个 Promise 实例,而无须求助于传统的构造函数 + new 实例化。

可以看到,这类似于 Promise.resolve() 等语法糖。区别在于,传统构造函数实例化的对象状态可能不太直观,而这里的 promise 显然处于待定状态,此外还“买一送二”,额外附赠一对用于改变 promise 状态的“变态函数” —— resolve() 和 reject()。
ES2024 之后,该方法可以作为一道简单的异步笔试题 —— 请你在一杯泡面的时间里,实现一下 Promise.withResolvers()。
如果你是我的粉丝,根本不慌,因为新方法的基本原理并不复杂,参考我下面的实现,简单给面试官表演一下就欧了。

可以看到,这个静态工厂方法的实现难点在于,如何巧妙地将变态函数暴露到外部作用域,其实核心逻辑压缩后有且仅有 3 行代码。
这就引发了本文开头的质疑:新方法是否多此一举?难道负责 JS 标准化的 tc39 委员会也有绩效考核,还是确实存在某些不为人知的极端情况?
02. 技术细节
通过对新方法进行苏格拉底式的“灵魂拷问”和三天三夜的深度学习,我可以很有把握地说,没人比我更懂它。
首先,与传统的构造函数实例化不同,新方法支持无参构造,我们不需要在调用时传递任何参数。

可以看到,构造函数实例化要求传递一个执行器回调,偷懒不传则直接报错,无法顺利实例化。
其次,变态函数的设计更加自由。

可以看到,传统的构造函数中,变态函数能且仅能作为局部变量使用,无法在构造函数外部调用。而新方法同时返回实例及其变态函数,这意味着实例和变态函数处于同一级别的作用域。
那么,这个设计上的小细节有何黑科技呢?
假设我们想要一个 Promise 实例,但尚未知晓异步任务的所有细节,我们期望先将变态函数抽离出来,再根据业务逻辑灵活调用,请问阁下如何应对?
ES2024 之前,我们可以通过 作用域提升 来“曲线救国”,举个栗子:

可以看到,这种方案的优势在于,诉诸作用域提升,我们不必把所有猫猫放在一个薛定谔的容器里,在构造函数中封装一大坨“代码屎山”;其次,变态函数不被限制在构造函数内部,随时随地任你调用。
该方案的缺陷则在于,某些社区规范鼓励“const 优先”的代码风格,即 const 声明优先,再按需修改为 let 声明。
这里的变态函数被迫使用 let 声明,这意味着存在被愣头青意外重写的隐患,但为了缓存赋值,我们一开始就不能使用 const 声明。从防御式编程的角度,这可能不太鲁棒。
因此,Promise.withResolvers() 应运而生,该静态工厂方法允许我们:
- 无参构造
const优先- 自由变态
03. 设计动机
在某些需要封装 Promise 风格的场景中,新方法还能减少回调函数的嵌套,我把这种代码风格上的优化称为“去回调化”。
举个栗子,我们可以把 Node 中回调风格的 API 转换为 Promise 风格,以 fs 模块为例:

可以看到,由于使用了传统的构造函数实例化,在封装 readFile() 的时候,我们被迫将其嵌套在构造函数内部。
现在,我们可以使用新方法来“去回调化”。

可以看到,传统构造函数嵌套的一层回调函数就无了,整体实现更加扁平,减肥成功!
粉丝请注意,很多 Node API 现在也内置了 Promise 版本,现实开发中不需要我们手动封装,开箱即用就欧了。但是这种封装技巧是通用的。
举个栗子,瞄一眼 MDN 电子书搬运过来的一个更复杂的用例,将 Node 可读流转换为异步可迭代对象。

可以看到,井然有序的代码中透露着一丝无法形容的优雅。我脑补了一下如何使用传统构造函数来实现上述功能,现在还没缓过来......
04. 高潮总结
从历史来看,Promise.withResolvers() 并非首创,bluebird 的 Promise.defer() 或 jQuery 的 $.defer() 等库就提供了同款功能,ES2024 只是换了个名字“新瓶装旧酒”,将其标准化为内置功能。
但是,Promise.withResolvers() 的标准化势在必行,比如 Vite 源码中就自己手动封装了同款功能。

无独有偶,Axios、Vue、TS、React 等也都在源码内部“反复造轮子”,像这种回头率超高的代码片段我们称之为 boilerplate code(样板代码)。
重复乃编程之大忌,既然大家都要写,不如大家都别写,让 JS 自己写,牺牲小我,成全大家。编程里的 DRY 原则就是让我们不要重复,因为很多 bug 就是重复导致的,而且不好统一管理和维护,《ES6 标准入门教程》科普的 魔术字符串 就是其中一种反模式。
兼容性方面,我也做过临床测试了,主流浏览器广泛支持。

总之,Promise.withResolvers() 通过将样板代码标准化,达到了消除重复的目的,原生实现除了性能更好,是一个性价比较高的静态工厂方法。
参考文献
- GitHub:github.com/tc39/propos…
- MDN:developer.mozilla.org/en-US/docs/…
- bluebird:bluebirdjs.com/docs/deprec…
粉丝互动
本期话题是:你觉得新方法好评几颗星,为什么?你可以在本文下方自由言论,文明科普。
欢迎持续关注“前端俱乐部”,给前端以福利,给编程以复利。
坚持阅读的小伙伴可以给自己点赞!谢谢大家的点赞,掰掰~

来源:juejin.cn/post/7391745629876469760
商品 sku 在库存影响下的选中与禁用
分享一下,最近使用 React 封装的一个 Skus 组件,主要用于处理商品的sku在受到库存的影响下,sku项的选中和禁用问题;
需求分析
需要展示商品各规格下的sku信息,以及根据该sku的库存是否为空,判断是否禁用该sku的选择。

以下讲解将按照我的 Skus组件 来,我这里放上我组件库中的线上 demo 和码上掘金的一个 demo 供大家体验;由于码上掘金导入不了组件库,我就上传了一份开发组件前的一份类似的代码,功能和代码思路是差不多的,大家也可以自己尝试写一下,可能你的思路会更优;
码上掘金
传入的sku数据结构
需要传入的商品的sku数据类型大致如下:
type SkusProps = {
/** 传入的skus数据列表 */
data: SkusItem[]
// ... 其他的props
}
type SkusItem = {
/** 库存 */
stock?: number;
/** 该sku下的所有参数 */
params: SkusItemParam[];
};
type SkusItemParam = {
name: string;
value: string;
}
转化成需要的数据类型:
type SkuStateItem = {
value: string;
/** 与该sku搭配时,该禁用的sku组合 */
disabledSkus: string[][];
}[];
生成数据
定义 sku 分类
首先假装请求接口,造一些假数据出来,我这里自定义了最多 6^6 = 46656 种 sku。

下面的是自定义的一些数据:
const skuData: Record<string, string[]> = {
'颜色': ['红','绿','蓝','黑','白','黄'],
'大小': ['S','M','L','XL','XXL','MAX'],
'款式': ['圆领','V领','条纹','渐变','轻薄','休闲'],
'面料': ['纯棉','涤纶','丝绸','蚕丝','麻','鹅绒'],
'群体': ['男','女','中性','童装','老年','青少年'],
'价位': ['<30','<50','<100','<300','<800','<1500'],
}
const skuNames = Object.keys(skuData)
页面初始化
- checkValArr: 需要展示的sku分类是哪些;
- skusList: 接口获取的skus数据;
- noStockSkus: 库存为零对应的skus(方便查看)。
export default () => {
// 这个是选中项对应的sku类型分别是哪几个。
const [checkValArr, setCheckValArr] = useState<number[]>([4, 5, 2, 3, 0, 0]);
// 接口请求到的skus数据
const [skusList, setSkusList] = useState<SkusItem[]>([]);
// 库存为零对应的sku数组
const [noStockSkus, setNoStockSkus] = useState<string[][]>([])
useEffect(() => {
const checkValTrueArr = checkValArr.filter(Boolean)
const _noStockSkus: string[][] = [[]]
const list = getSkusData(checkValTrueArr, _noStockSkus)
setSkusList(list)
setNoStockSkus([..._noStockSkus])
}, [checkValArr])
// ....
return <>...</>
}
根据上方的初始化sku数据,生成一一对应的sku,并随机生成对应sku的库存。
getSkusData 函数讲解
先看总数(total)为当前需要的各sku分类的乘积;比如这里就是上面传入的 checkValArr 数组 [4,5,2,3] 共 120种sku选择。对应的就是 skuData 中的 [颜色前四项,大小前五项,款式前两项,面料前三项] 即下图的展示。

遍历 120 次,每次生成一个sku,并随机生成库存数量,40%的概率库存为0;然后遍历 skuNames 然后找到当前对应的sku分类即 [颜色,大小,款式,面料] 4项;
接下来就是较为关键的如何根据 sku的分类顺序 生成对应的 120个相应的sku。
请看下面代码中注释为 LHH-1 的地方,该 value 的获取是通过 indexArr 数组取出来的。可以看到上面 indexArr 数组的初始值为 [0,0,0,0] 4个零的索引,分别对应 4 个sku的分类;
- 第一次遍历:
indexArr: [0,0,0,0] -> skuName.forEach -> 红,S,圆领,纯棉
看LHH-2标记处: 索引+1 -> indexArr: [0,0,0,1];
- 第二次遍历:
indexArr: [0,0,0,1] -> skuName.forEach -> 红,S,圆领,涤纶
看LHH-2标记处: 索引+1 -> indexArr: [0,0,0,2];
- 第三次遍历:
indexArr: [0,0,0,2] -> skuName.forEach -> 红,S,圆领,丝绸
看LHH-2标记处: 由于已经到达该分类下的最后一个,所以前一个索引加一,后一个重新置为0 -> indexArr: [0,0,1,0];
- 第四次遍历:
indexArr: [0,0,1,0] -> skuName.forEach -> 红,S,V领,纯棉
看LHH-2标记处: 索引+1 -> indexArr: [0,0,1,1];
- 接下来的一百多次遍历跟上面的遍历同理

function getSkusData(skuCategorys: number[], noStockSkus?: string[][]) {
// 最终生成的skus数据;
const skusList: SkusItem[] = []
// 对应 skuState 中各 sku ,主要用于下面遍历时,对 product 中 skus 的索引操作
const indexArr = Array.from({length: skuCategorys.length}, () => 0);
// 需要遍历的总次数
const total = skuCategorys.reduce((pre, cur) => pre * (cur || 1), 1)
for(let i = 1; i <= total; i++) {
const sku: SkusItem = {
// 库存:60%的几率为0-50,40%几率为0
stock: Math.floor(Math.random() * 10) >= 4 ? Math.floor(Math.random() * 50) : 0,
params: [],
}
// 生成每个 sku 对应的 params
let skuI = 0;
skuNames.forEach((name, j) => {
if(skuCategorys[j]) {
// 注意:LHH-1
const value = skuData[name][indexArr[skuI]]
sku.params.push({
name,
value,
})
skuI++;
}
})
skusList.push(sku)
// 注意: LHH-2
indexArr[indexArr.length - 1]++;
for(let j = indexArr.length - 1; j >= 0; j--) {
if(indexArr[j] >= skuCategorys[j] && j !== 0) {
indexArr[j - 1]++
indexArr[j] = 0
}
}
if(noStockSkus) {
if(!sku.stock) {
noStockSkus.at(-1)?.push(sku.params.map(p => p.value).join(' / '))
}
if(indexArr[0] === noStockSkus.length && noStockSkus.length < skuCategorys[0]) {
noStockSkus.push([])
}
}
}
return skusList
}
Skus 组件的核心部分的实现
初始化数据
需要将上面生成的数据转化为以下结构:
type SkuStateItem = {
value: string;
/** 与该sku搭配时,该禁用的sku组合 */
disabledSkus: string[][];
}[];
export default function Skus() {
// 转化成遍历判断用的数据类型
const [skuState, setSkuState] = useState<Record<string, SkuStateItem>>({});
// 当前选中的sku值
const [checkSkus, setCheckSkus] = useState<Record<string, string>>({});
// ...
}
将初始sku数据生成目标结构
根据 data (即上面的假数据)生成该数据结构。
第一次遍历是对skus第一项进行的,会生成如下结构:
const _skuState = {
'颜色': [{value: '红', disabledSkus: []}],
'大小': [{value: 'S', disabledSkus: []}],
'款式': [{value: '圆领', disabledSkus: []}],
'面料': [{value: '纯棉', disabledSkus: []}],
}
第二次遍历则会完整遍历剩下的skus数据,并往该对象中填充完整。
export default function Skus() {
// ...
useEffect(() => {
if(!data?.length) return
// 第一次对skus第一项的遍历
const _checkSkus: Record<string, string> = {}
const _skuState = data[0].params.reduce((pre, cur) => {
pre[cur.name] = [{value: cur.value, disabledSkus: []}]
_checkSkus[cur.name] = ''
return pre
}, {} as Record<string, SkuStateItem>)
setCheckSkus(_checkSkus)
// 第二次遍历
data.slice(1).forEach(item => {
const skuParams = item.params
skuParams.forEach((p, i) => {
// 当前 params 不在 _skuState 中
if(!_skuState[p.name]?.find(params => params.value === p.value)) {
_skuState[p.name].push({value: p.value, disabledSkus: []})
}
})
})
// ...接下面
}, [data])
}
第三次遍历主要用于为每个 sku的可点击项 生成一个对应的禁用sku数组 disabledSkus ,只要当前选择的sku项,满足该数组中的任一项,该sku选项就会被禁用。之所以保存这样的一个二维数组,是为了方便后面点击时的条件判断(有点空间换时间的概念)。
遍历 data 当库存小于等于0时,将当前的sku的所有参数传入 disabledSkus 中。
例:第一项 sku(红,S,圆领,纯棉)库存假设为0,则该选项会被添加到 disabledSkus 数组中,那么该sku选择时,勾选前三个后,第四个 纯棉 的勾选会被禁用。

export default function Skus() {
// ...
useEffect(() => {
// ... 接上面
// 第三次遍历
data.forEach(sku => {
// 遍历获取库存需要禁用的sku
const stock = sku.stock!
// stockLimitValue 是一个传参 代表库存的限制值,默认为0
// isStockGreaterThan 是一个传参,用来判断限制值是大于还是小于,默认为false
if(
typeof stock === 'number' &&
isStockGreaterThan ? stock >= stockLimitValue : stock <= stockLimitValue
) {
const curSkuArr = sku.params.map(p => p.value)
for(const name in _skuState) {
const curSkuItem = _skuState[name].find(v => curSkuArr.includes(v.value))
curSkuItem?.disabledSkus?.push(
sku.params.reduce((pre, p) => {
if(p.name !== name) {
pre.push(p.value)
}
return pre
}, [] as string[])
)
}
}
})
setSkuState(_skuState)
}, [data])
}
遍历渲染 skus 列表
根据上面的 skuState,生成用于渲染的列表,渲染列表的类型如下:
type RenderSkuItem = {
name: string;
values: RenderSkuItemValue[];
}
type RenderSkuItemValue = {
/** sku的值 */
value: string;
/** 选中状态 */
isChecked: boolean
/** 禁用状态 */
disabled: boolean;
}
export default function Skus() {
// ...
/** 用于渲染的列表 */
const list: RenderSkuItem[] = []
for(const name in skuState) {
list.push({
name,
values: skuState[name].map(sku => {
const isChecked = sku.value === checkSkus[name]
const disabled = isChecked ? false : isSkuDisable(name, sku)
return { value: sku.value, disabled, isChecked }
})
})
}
// ...
}
html css 大家都会,以下就简单展示了。最外层遍历sku的分类,第二次遍历遍历每个sku分类下的名称,第二次遍历的 item(类型为:RenderSkuItemValue),里面会有sku的值,选中状态和禁用状态的属性。
export default function Skus() {
// ...
return list?.map((p) => (
<div key={p.name}>
{/* 例:颜色、大小、款式、面料 */}
<div>{p.name}</div>
<div>
{p.values.map((sku) => (
<div
key={p.name + sku.value}
onClick={() => selectSkus(p.name, sku)}
>
{/* classBem 是用来判断当前状态,增加类名的一个方法而已 */}
<span className={classBem(`sku`, {active: sku.isChecked, disabled: sku.disabled})}>
{/* 例:红、绿、蓝、黑 */}
{sku.value}
</span>
</div>
))}
</div>
</div>
))
}
selectSkus 点击选择 sku
通过 checkSkus 设置 sku 对应分类下的 sku 选中项,同时触发 onChange 给父组件传递一些信息出去。
const selectSkus = (skuName: string, {value, disabled, isChecked}: RenderSkuItemValue) => {
const _checkSkus = {...checkSkus}
_checkSkus[skuName] = isChecked ? '' : value;
const curSkuItem = getCurSkuItem(_checkSkus)
// 该方法主要是 sku 组件点击后触发的回调,用于给父组件获取到一些信息。
onChange?.(_checkSkus, {
skuName,
value,
disabled,
isChecked: disabled ? false : !isChecked,
dataItem: curSkuItem,
stock: curSkuItem?.stock
})
if(!disabled) {
setCheckSkus(_checkSkus)
}
}
getCurSkuItem 获取当前选中的是哪个sku
isInOrder.current是用来判断当前的 skus 数据是否是整齐排列的,这里当成true就好,判断该值的过程就不放到本文了,感兴趣可以看 源码。
由于sku是按顺序排列的,所以只需按顺序遍历上面生成的 skuState,找出当前sku选中项对应的索引位置,然后通过 乘 就可以直接得出对应的索引位置。这样的好处是能减少很多次遍历。
如果直接遍历原来那份填充所有 sku 的 data 数据,则需要很多次的遍历,当sku是 6^6 时, 则每次变换选中的sku时最多需要 46656 * 6 (data总长度 * 里面 sku 的 params) 次。
const getCurSkuItem = (_checkSkus: Record<string, string>) => {
const length = Object.keys(skuState).length
if(!length || Object.values(_checkSkus).filter(Boolean).length < length) return void 0
if(isInOrder.current) {
let skuI = 0;
// 由于sku是按顺序排列的,所以索引可以通过计算得出
Object.keys(_checkSkus).forEach((name, i) => {
const index = skuState[name].findIndex(v => v.value === _checkSkus[name])
const othTotal = Object.values(skuState).slice(i + 1).reduce((pre, cur) => (pre *= cur.length), 1)
skuI += index * othTotal;
})
return data?.[skuI]
}
// 这样需要遍历太多次
return data.find(s => (
s.params.every(p => _checkSkus[p.name] === getSkuParamValue(p))
))
}
isSkuDisable 判断该 sku 是否是禁用的
该方法是在上面 遍历渲染 skus 列表 时使用的。
- 开始还未有选中值时,需要校验 disabledSkus 的数组长度,是否等于该sku参数可以组合的sku总数,如果相等则表示禁用。
- 判断当前选中的 sku 还能组成多少种组合。例:当前选中
红,S,而isSkuDisable方法当前判断的 sku 为款式 中的 圆领,则还有三种组合红\S\圆领\纯棉,红\S\圆领\涤纶和红\S\圆领\丝绸。 - 如果当前判断的 sku 的
disabledSkus数组中存在这三项,则表示该 sku 选项会被禁用,无法点击。
const isCheckValue = !!Object.keys(checkSkus).length
const isSkuDisable = (skuName: string, sku: SkuStateItem[number]) => {
if(!sku.disabledSkus.length) return false
// 1.当一开始没有选中值时,判断某个sku是否为禁用
if(!isCheckValue) {
let checkTotal = 1;
for(const name in skuState) {
if(name !== skuName) {
checkTotal *= skuState[name].length
}
}
return sku.disabledSkus.length === checkTotal
}
// 排除当前的传入的 sku 那一行
const newCheckSkus: Record<string, string> = {...checkSkus}
delete newCheckSkus[skuName]
// 2.当前选中的 sku 一共能有多少种组合
let total = 1;
for(const name in newCheckSkus) {
if(!newCheckSkus[name]) {
total *= skuState[name].length
}
}
// 3.选中的 sku 在禁用数组中有多少组
let num = 0;
for(const strArr of sku.disabledSkus) {
if(Object.values(newCheckSkus).every(str => !str ? true : strArr.includes(str))) {
num++;
}
}
return num === total
}
至此整个商品sku从生成假数据到sku的选中和禁用的处理的核心代码就完毕了。还有更多的细节问题可以直接查看 源码 会更清晰。
来源:juejin.cn/post/7313979106890842139
筑牢湾区网络安全防线!Coremail亮相大湾区网络安全大会
11月7-8日,大湾区网络安全大会在广州隆重举行。Coremail作为邮件行业领导者,受邀参会并亮相多场论坛,与现场嘉宾围绕网络安全的前沿话题与挑战展开深入交流与探讨。
本次大会以“共建网络安全,对话数字未来”为主题,聚焦信息技术应用创新、人工智能攻防对抗技术、AI+关键信息基础设施保护、数字安全创新等热点话题。通过多场行业论坛与主题演讲,全面展示网络安全技术的最新成果与未来趋势,激发参会者的创新思维,共同推动网络安全技术的持续进步与创新发展。

汇聚新动能 彰显邮件创新硬实力
世界经济数字化转型是大势所趋,人工智能、区块链、5G等新技术广泛应用,对邮件领域有着怎么样的启发和新尝试?
本届大会上,Coremail重点展示了邮件系统国产化实践与创新成果,以及AI+邮件的创新应用。通过多媒体展示互动与现场讲解直观、全面地为与会者呈现了Coremail在邮件领域的硬实力和新案例。

在大会的评选活动中,CACTER邮件安全网关解决方案不负众望,荣获“信息网络安全建设优秀案例”奖项。

解构新趋势探索邮件安全新篇章
11月7日,2024年大湾区信息技术应用创新产业发展论坛大幕拉开,Coremail副总裁吴秀诚以“信创环境下邮件数据安全的探索与实践”为主题,分享了Coremail在信创邮件升级和数据安全防护方面的探索经验和先进产品。

近年来,数据安全越来越被重视,而邮件系统承载着大量数据的内外往来,是企业至关重要的基础设施。据Coremail与奇安信联合发布的《2023中国企业邮箱安全性研究报告》数据显示,2023年国内共收发各类电子邮件约7798.5亿封,其中垃圾邮件占比54.2%。随着AI技术的广泛应用,网络安全问题更加多样化,攻击者正利用AI使钓鱼邮件变得更加丰富和逼真,严重威胁数据安全。

△数据显示,2023年基于 AI 的攻击和诈骗邮件增长了1000%。在2024年第一季度中,企业邮件攻击和诈骗邮件数量同比增长59.9%
Coremail 25年来一直致力于邮件及邮件安全领域的技术研究与创新,为各行业用户提供综合的整体电子邮件安全解决方案,目前在我国的邮件终端使用用户量超10亿。作为国内安全邮件的先行者,Coremail积极相应《网络数据安全管理条例》,推出首款覆盖网络安全保险保障的云邮箱产品,覆盖多种常见邮件安全风险领域的保障。在安全防护层面,Coremail基于多年的邮件系统研发、服务经验,提供全面、多机制的保护策略,构建AI安全防御体系。
另一方面,Coremail也在积极探索AI赋能高效办公,推出AI大模型整合方案,将邮箱能力解耦调用,以邮箱桥接大模型,实现智能化和自动化。

聚焦AI+把脉邮件安全新态势
11月8日,网络与数据安全分论坛开讲,Coremail高级安全解决方案专家刘骞发表“拥抱AI:探索AI大模型在邮件反钓鱼领域中的应用潜力”主题演讲,分享了Coremail在AI大模型融合邮件防护应用的探索。

电子邮件作为日常工作和商务沟通的重要工具,其安全性直接关系到企业和个人的利益。然而,邮件系统面临着内部泄密、外部攻击等多种安全威胁,对于不同威胁场景,Coremail针对性提供了不同防护策略,以保障邮件使用安全。
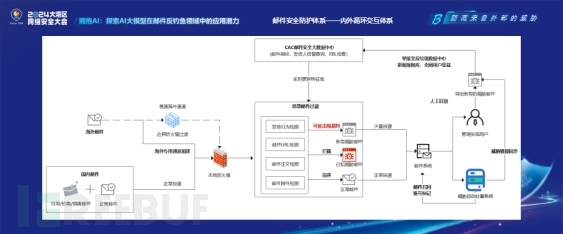
近几年,AI成为行业顶流,Coremail CACTER邮件安全人工智能实验室也在不断探索新技术在邮件安全防护中的可能性,通过深入研究与实践,发现AI在反钓鱼领域多个场景中均能发挥其优势。今年,Coremail AI实验室引入清华智谱ChatGLM大语言模型,进一步提升钓鱼邮件检测能力。

与文本大模型相比,多模态大模型能够处理更丰富的信息数据源,如文本、图像、音频等,不仅能进行文本理解,还能模拟视觉分析,处理图片和链接落地页等多媒体内容,为钓鱼检测提供更全面的支持。CACTER AI实验室正积极探索多模态大模型在邮件安全领域的应用,以进一步提升对钓鱼邮件的识别率和对新型攻击手段的适应性。
当前,人工智能正与千行百业深度融合,成为社会及经济结构革新的关键支柱。Coremail将持续深化邮件技术的自主创新和数智化转型,探索更多新技术与邮件的有机融合,为各行业数字化升级赋能!
收起阅读 »如果你没有必须要离职的原因,我建议你在忍忍
自述
本人成都,由于一些原因我在八月离职了,因为我终于脱离了那个压抑的环境,我没有自己想象中的那么开心,我离职的那天,甚至后面很长的一段时间;离职后的我回了一趟家,刚好在最热的那几天,在家躺了几天,然后又出去逛了逛,玩了差不多一个月吧!我觉得心情逐渐恢复了;然后开始慢慢的投递简历。
前期
刚投递简历那会,基本上每天都是耍耍哒哒的投递;有面试就去面试,没有面试就在家刷抖音也不看看面试题,可能我找工作的状态还在几年前或者还没从上家公司的状态中走出来,也有可能我目前有一点存款不是特别焦虑,所以也没认真的找。
就这样刷刷哒哒的又过了半月,然后有许多朋友跟我说他们被裁员了,问他们的打算是怎么样的:有的人休息了两三天就开始了找工作当中,而有的人就玩几个月再说。
休息两三天就开始找工作的人基本上都是有家庭有小孩的,反之基本上都是单身。
在跟他们聊天的过程中发现,有些人半年没找到工作了,也有一些人一年都没有找到工作了。可能是年级大了、也可能是工资不想要的太低吧!但是工作机会确实比原来少很多。
在听了大家的话以后,我觉得我差不多也该认真找工作了,我开始逐渐投递简历。
疯狂投递简历
我在9月的下旬开始了简历的修改以及各大招聘App的下载,拉钩、智联、boos以及一下小程序的招聘软件(记不住名字了,因为没啥效果);在我疯狂的投递了几天以后我迎来了第一家面试,是一个线上面试;刚一来就给了我迎头一棒,或许我只忙着修改简历和投递简历去了,没有去背面试题吧(网上说现在都问场景题,所以没准备);
具体的问题我记不全了,但是我记得这么一个问题,面试官问:“深克隆有哪些方法”,我回答的是递归,然后他说还有吗?我直接呆住说不知道了。然后我们就结束了面试,最后他跟我说了这么一句话:“现在的市场行情跟原来没法比,现在的中级基本上要原来的高级的水平,现在的初级也就是原来的中级的水平,所以问的问题会比原来难很多,你可以在学习一下,看你的简历是很不错的;至少简历是这样的。”
当这个面试结束以后我想了想发现是这样的,不知是我还没有接受或者说还没有进入一个面试的状态,还是因为我不想上班的原因,导致我连一些基本的八股文都不清楚,所以我决定开始学习。
给准备离职或者已经离职的朋友们一个忠告:“做任何事情都需提前准备,至少在找工作上是这样的。”
学习
我去看了招聘网站的技术要求(想了解下企业需要的一些技术),不看不知道一看吓一跳,真的奇葩层出不穷,大概给大家概述一下:
- 开发三班倒:分为早中晚班
- 要你会vue+react+php+java等技术(工资8-12)
- 要你会基本的绘画(UI)以及会后端的一些工作,目前这些都需要你一个人完成
- 要你会vue+react+fluter;了解electron以及3d等
- 还有就是你的项目跟我们的项目不一致的。
我看到这些稀奇古怪的玩意有点失望,最终我选择了fabricjs进行学习,最开始的时候就是在canvas上画了几个矩形,感觉挺不错的;然后我就想这不是马上快要国庆了吗?我就想用fabric做一个制作头像的这么一个工具插件,在经过两天的开发成功将其制作了出来,并且发布到了网站上(插件tools),发布第一天就有使用的小伙伴给我提一些宝贵的建议了,然后又开始了调整,现在功能也越来越多;
fabricjs在国内的资料很少,基本上就那么几篇文章,没有办法的我就跑去扒拉他们的源码看,然后拷贝需要的代码在修修改改(毕竟比较菜只能这样....);然后在学习fabric的时候也会去学习一些基本知识,比如:js内置方法、手写防抖节流、eventloop、闭包(一些原理逻辑)、深拷贝、内存回收机制等等。
在学习的过程中很难受,感觉每天都是煎熬;每次都想在床上躺着,但是想想还是放弃了,毕竟没有谁会喜欢一个懒惰的人...
在战面试(HR像是刷KPI)
在有所准备的情况下再去面试时就得心应手了,基本上没有太多的胆怯,基本上问啥都知道一些,然后就在面试的时候随机应变即可,10月我基本上接到的面试邀请大概有10多家,然后有几家感觉工资低了就没去面试,去面试了的应该有7/8家的样子,最终只要一家录取。
说说其中一家吧(很像刷KPI的一家):这是一家做ai相关的公司,公司很大,看资料显示时一家中外合资的企业,进去以后先开始了一轮笔试题(3/4页纸),我大概做了50分钟的样子;我基本上8层都答对了(因为他的笔试题很多我都知道嘛,然后有一些还写了几个解决方案的),笔试完了以后,叫我去机试;机试写接口;而且还是在规定的一个网站写(就给我一个网站,然后说写一个接口返回正确结果就行;那个网站我都不会用);我在哪儿磨磨蹭蹭了10多分钟以后,根据node写了一个接口给了hr;然后HR说你这个在我们网站上不能运行。我站起来就走了...
其实我走的原因还有一个,就是他们另一个HR对带我进来的这个HR说:你都没有协调好研发是否有时间,就到处招面试...
是否离职
如果你在你现在这公司还能呆下去的情况下,我建议你还是先呆呆看吧!目前这个市场行情很差,你看到我有10来个面试,但是你知道嘛?我沟通了多少:
- boos沟通了差不多800-900家公司,邀请我投递简历的只有100家左右。邀请我面试的只有8/9家。
- 智联招聘我投递了400-600家,邀请我面试的只有1家。
- 拉钩这个不说了基本上没有招聘的公司(反反复复就那几家);投递了一个月后有一家叫我去面试的,面试了差不多50来分钟;交谈的很开心,他说周一周二给我回复,结果没有回复,我发消息问;也没有回复;看招聘信息发现(邀约面试800+)
我离职情非得已,愿诸君与我不同;如若您已离职,愿您早日找到属于自己的路,不一定是打工的路;若你在职,请在坚持坚持;在坚持的同时去做一些对未来有用的事情,比如:副业、耍个男女朋友、拓展一下圈子等等。
后续的规划
在经历了这次离职以后,我觉得我的人生应该进行好好的规划了;不能为原有的事物所影响,不能为过去所迷茫;未来还很长,望诸君互勉;
未来的计划大致分为几个方向:
- 拓展自己的圈子(早日脱单)
- 学习开发鸿蒙(我已经在做了,目前开发的app在审核),发布几款工具类app(也算是为国内唯一的系统贡献一些微弱的力量吧!)
- 持续更新我在utools上的绘图插件
- 学习投资理财(最近一月炒股:目前赚了4000多了)
- 持续更新公众号(前端雾恋)、掘金等网站技术文章
结尾
我们的生活终将回归正轨,所有的昨天也将是历史,不必遗憾昨天,吸取教训继续前进。再见了...
来源:juejin.cn/post/7435289649273569334
轻量级Nacos来了!占用资源极低,性能炸裂!
Nacos作为一款非常流行的微服务注册中心,我们在构建微服务项目时往往会使用到它。最近发现一款轻量级的Nacos项目r-nacos,占用内存极低,性能也很强大,分享给大家。本文就以我的mall-swarm微服务电商实战项目为例,来聊聊它在项目中的使用。
r-nacos简介
r-nacos是一款使用rust实现的nacos服务,对比阿里的nacos来说,可以提供相同的注册中心和配置中心功能。同时它占用的内存更小,性能也很优秀,能提供更稳定的服务。
下面是r-nacos管理控制台使用的效果图,大家可以参考下:

mall-swarm项目简介
由于之后我们需要用到mall-swarm项目,这里简单介绍下它。 mall-swarm项目(11k+star)是一套微服务商城系统,基于2024最新微服技术栈,涵盖Spring Cloud Alibaba、Spring Boot 3.2、JDK17、Kubernetes等核心技术。mall-swarm在电商业务的基础集成了注册中心、配置中心、监控中心、网关等系统功能。
- Github地址:github.com/macrozheng/…
- Gitee地址:gitee.com/macrozheng/…
- 教程网站:cloud.macrozheng.com
项目演示:

安装
r-nacos支持Windows下的exe文件安装,也支持Linux下的Docker环境安装,这里以Docker安装为例。
- 首先通过如下命令下载r-nacos的Docker镜像:
docker pull qingpan/rnacos:stable
- 安装完成后通过如下命令运行r-nacos容器;
docker run --name rnacos -p 8848:8848 -p 9848:9848 -p 10848:10848 -d qingpan/rnacos:stable
- 接下来就可以访问r-nacos的控制台了,默认管理员账号密码为
admin:admin,访问地址:http://192.168.3.101:10848/rnacos/

项目实战
接下来就以我的mall-swarm微服务电商实战项目为例,来讲解下它的使用。由于mall-swarm项目中各个服务的配置与运行都差不多,这里以mall-admin模块为例。
- 首先我们需要下载mall-swarm项目的代码,下载完成后修改项目的
bootstrap-dev.yml文件,将其中的nacos连接地址改为r-nacos的地址,项目地址:github.com/macrozheng/…
spring:
cloud:
nacos:
discovery:
server-addr: http://192.168.3.101:8848
config:
server-addr: http://192.168.3.101:8848
file-extension: yaml

- 接下来在r-nacos的
配置列表中添加mall-admin-dev.yaml配置,该配置下项目的config目录下;


- 之后把mall-admin模块运行起来,此时在
r-nacos的服务列表功能中就可以看到注册好的服务了;

- 接下来把其他模块的配置也添加到r-nacos的配置列表中去;

- 再运行其他模块,最终
服务列表显示如下;

- 之后通过网关就可以访问到mall-swarm项目的在线API文档了,访问地址:http://localhost:8201/doc.html

- 这里我们再把mall-swarm项目的后台管理系统前端项目
mall-admin-web给运行起来;

- 最后我们再把mall-swarm项目的前台商城系统前端项目
mall-app-web给运行起来,发现都是可以正常从网关调用API的。

其他使用
r-nacos除了提供了基本的注册中心和配置中心功能,还提供了一些其他的实用功能,这里我们一起来了解下。
- 如果你想添加一些其他访问的用户,或者修改admin用户的信息,可以使用
用户管理功能;

- 如果你想对r-nacos中配置信息进行导入导出,可以使用
数据迁移功能;

- 如果你想对r-nacos中的运行状态进行监控,你可以使用
系统监控功能,监控还是挺全的。

性能压测
r-nacos的性能还是非常好的,这里有个r-nacos官方提供的性能压测结果表,大家可以参考下。

对比Nacos
个人感觉对比阿里的nacos,占用的内存资源减少了非常多,运行不到10M内存,而nacos需要900M,服务器资源不宽裕的小伙伴可以尝试下它。

总结
今天以我的mall-swarm微服务电商实战项目为例,讲解了r-nacos的使用。从功能上来说r-nacos是完全可以替代nacos的,而且它占用内存资源非常低,性能也很强大,感兴趣的小伙伴可以尝试下它!
项目地址
来源:juejin.cn/post/7434185097300475919
既生@Primary,何生@Fallback
个人公众号:IT周瑜,十二年Java开发和架构经验,一年大模型应用开发经验,爱好研究源码,比如Spring全家桶源码、MySQL源码等,同时也喜欢分享技术干货,期待你的关注
最近闲着的时候在看Spring 6.2的源码,发现了一些新特性,比如本文要介绍的@Fallback注解。
相信大家都知道@Primary注解,而@Fallback相当于是@Primary的反向补充。
Spring在进行依赖注入时,会根据属性的类型去Spring容器中匹配Bean,但有可能根据类型找到了多个Bean,并且也无法根据属性名匹配到Bean时,就会报错,比如expected single matching bean but found 2,此时,就可以利用@Primary来解决。
加了@Primary的Bean表示是同类型多个Bean中的主Bean,换句话说,如果Spring根据类型找到了多个Bean,会选择其中加了@Primary的Bean来进行注入,因此,同类型的多个Bean中只能有一个加了@Primary,如果有多个也会报错more than one 'primary' bean found。
比如以下代码会使用orderService1来进行注入:
@Bean
@Primary
public OrderService orderService1() {
return new OrderService();
}
@Bean
public OrderService orderService2() {
return new OrderService();
}
而加了@Fallback注解的Bean为备选Bean,比如以下代码会使用orderService2来进行依赖注入:
@Bean
@Fallback
public OrderService orderService1() {
return new OrderService();
}
@Bean
public OrderService orderService2() {
return new OrderService();
}
因为orderService1加了@Fallback注解,相当于备胎,只有当没有其他Bean可用时,才会用orderService1这个备胎,有其他Bean就会优先用其他Bean。
@Primary和@Fallback都是用在依赖注入时根据类型找到了多个Bean的场景中:
- @Primary比较强势,它在说:“直接用我就可以了,不用管其他Bean”
- @Fallback比较弱势,它在说:“先别用我,先用其他Bean”
如果根据类型只找到一个Bean就用不着他两了,另外,同类型多个Bean中@Primary的Bean只能有一个,但可以有多个@Fallback。
大家觉得@Fallback注解怎么样?
实际上,@Primary和@Fallback两个注解的源码实现在同一个方法中,源码及注释如下,感兴趣的同学可以看看:
protected String determinePrimaryCandidate(Map<String, Object> candidates, Class<?> requiredType) {
String primaryBeanName = null;
// First pass: identify unique primary candidate
// 先找@Primary注解的Bean
// candidates就是根据类型找到的多个Bean,key为beanName, Value为bean对象
for (Map.Entry<String, Object> entry : candidates.entrySet()) {
String candidateBeanName = entry.getKey();
Object beanInstance = entry.getValue();
if (isPrimary(candidateBeanName, beanInstance)) {
if (primaryBeanName != null) {
boolean candidateLocal = containsBeanDefinition(candidateBeanName);
boolean primaryLocal = containsBeanDefinition(primaryBeanName);
// 找到多个@Primary会报错
if (candidateLocal == primaryLocal) {
throw new NoUniqueBeanDefinitionException(requiredType, candidates.size(),
"more than one 'primary' bean found among candidates: " + candidates.keySet());
}
else if (candidateLocal) {
primaryBeanName = candidateBeanName;
}
}
else {
// 找到一个@Primary注解的Bean就先存着,看是不是还有其他@Primay注解的Bean
primaryBeanName = candidateBeanName;
}
}
}
// Second pass: identify unique non-fallback candidate
// 没有@Primary注解的Bean情况下,才找没有加@Fallback注解的,加了@Fallback注解的Bean会被过滤掉
if (primaryBeanName == null) {
for (String candidateBeanName : candidates.keySet()) {
// 判断是否没有加@Fallback
if (!isFallback(candidateBeanName)) {
// 如果有多个Bean没有加@Fallback,会返回null,后续会根据属性名从多个bean中进行匹配,匹配不到就会报错
if (primaryBeanName != null) {
return null;
}
primaryBeanName = candidateBeanName;
}
}
}
return primaryBeanName;
}
来源:juejin.cn/post/7393311009686192147
Java程序员必知的9个SQL优化技巧
大多数的接口性能问题,很多情况下都是SQL问题,在工作中,我们也会定期对慢SQL进行优化,以提高接口性能。这里总结一下常见的优化方向和策略。
避免使用select *,减少查询字段
不要为了图省事,直接查询全部的字段,尽量查需要的字段,特别是复杂的SQL,能够避免很多不走索引的情况。这也是最基本的方法。
检查执行计划,是否走索引
检查where和order by字段是否有索引,根据表的数据量和现有索引,考虑是否增加索引或者联合索引。 然而,索引并不是越多越好,原因有以下几点:
- 存储空间:每个索引都会占用额外的存储空间。如果为表中的每一列都创建索引,那么这些索引的存储开销可能会非常大,尤其是在大数据集上。
- 索引重建增加开销:当数据发生变更(如插入、更新或删除)时,相关的索引也需要进行更新,以确保数据的准确性和查询效率。这意味着更多的索引会导致更慢的写操作。
- 选择性:选择性是指索引列中不同值的数量与表中记录数的比率。选择性高的列(即列中有很多唯一的值)更适合创建索引。对于选择性低的列(如性别列,其中只有“男”和“女”两个值),创建索引可能不会产生太大的查询性能提升。
- 过度索引:当表中存在过多的索引时,可能会导致数据库优化器在选择使用哪个索引时变得困难。这可能会导致查询性能下降,因为优化器可能选择了不是最优的索引。
因此,在设计数据库时,需要根据查询需求和数据变更模式来仔细选择需要创建索引的列。通常建议只为经常用于查询条件、排序和连接的列创建索引,并避免为选择性低的列创建索引。
避免使用or连接
假设我们有一个数据表employee,包含以下字段:id, name, age。 原始查询使用OR操作符来筛选满足name为'John'或age为30的员工:
SELECT * FROM employee WHERE name = 'John' OR age = 30;
使用UNION操作符来实现同样的筛选:
SELECT * FROM employee WHERE name = 'John'
UNION
SELECT * FROM employee WHERE age = 30;
UNION操作符先查询满足name为'John'的记录,然后查询满足age为30的记录,并将两个结果集合并起来。这样可以减少查询的数据量,提高查询效率。 需要注意的是,UNION操作符会去除重复的记录。如果想要保留重复的记录,可以使用UNION ALL操作符,例如: 判断两条记录是否为重复记录的标准是通过比较每个字段的值来确定的。
SELECT * FROM employee WHERE name = 'John'
UNION ALL
SELECT * FROM employee WHERE age = 30;
在使用UNION代替OR时,还需要注意查询语句的语义是否与原始查询相同。有些情况下,OR可能会产生更准确的结果,因此在使用UNION时需谨慎考虑语义问题。
减少in和not in的使用
说实话,这种情况有点难。实际工作中,使用in的场景很多,但是要尽量避免in后面的数据范围,范围太大的时候,要考虑分批处理等操作。
对于连续的数值,可以考虑使用between and 代替。
避免使用左模糊查询
在工作中,对于姓名、手机号、名称等内容,经常会遇到模糊查询的场景,但是要尽量避免左模糊,这种SQL无法使用索引。
- 左模糊查询: 假设我们有一个数据表customer,包含字段name,我们想要查询名字以"J"开头的客户:
SELECT * FROM customer WHERE name LIKE 'J%';
- 右模糊查询: 继续使用上述customer表,我们想要查询名字以"n"结尾的客户:
SELECT * FROM customer WHERE name LIKE '%n';
注意,在某些数据库中,对于右模糊查询,可能需要使用转义符号(如""),以防止通配符被误解。
- 全模糊查询: 还是使用上述customer表,我们想要查询名字中包含"son"的客户:
SELECT * FROM customer WHERE name LIKE '%son%';
连接查询join替代子查询
假设我们有两个表:订单表(orders)和客户表(customers)。 订单表包含了订单号(order_id)、客户ID(customer_id)和订单金额(amount),而客户表包含了客户ID(customer_id)和客户姓名(customer_name)。
我们要找出所有订单金额大于1000美元的客户姓名:
SELECT customer_name
FROM customers
WHERE customer_id IN (SELECT DISTINCT customer_id FROM orders WHERE amount > 1000);
以上查询首先在订单表中挑选出所有金额大于1000美元的客户ID,然后使用这个子查询的结果来过滤客户表并获取客户姓名。
使用 JOIN 来替代子查询的方式:
SELECT DISTINCT c.customer_name
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
WHERE o.amount > 1000;
改造后的查询通过使用 INNER JOIN 将客户表和订单表连接在一起,然后使用 WHERE 子句来过滤出金额大于1000美元的订单。
这种改造不仅使查询更加简洁,而且可能还会提高查询的性能。JOIN 操作通常比子查询的效率更高,特别是在处理大型数据集时。
join的优化
JOIN 是 SQL 查询中的一个操作,用于将两个或多个表连接在一起。JOIN 操作有几种类型,包括 LEFT JOIN、RIGHT JOIN 和 INNER JOIN。要选用正确的关联方式,确保查询内容的正确性。
- INNER JOIN(内连接):内连接返回满足连接条件的行,即两个表中相关联的行组合。只有在两个表中都存在匹配的行时,才会返回结果。
SELECT *
FROM table1
INNER JOIN table2 ON table1.column = table2.column;
- LEFT JOIN(左连接):左连接返回左侧表中的所有行,以及右侧表中满足连接条件的行。如果右表中没有匹配的行,则返回 NULL 值。在用left join关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。
SELECT *
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;
- RIGHT JOIN(右连接):右连接返回右侧表中的所有行,以及左侧表中满足连接条件的行。如果左表中没有匹配的行,则返回 NULL 值。
SELECT *
FROM table1
RIGHT JOIN table2 ON table1.column = table2.column;
需要注意的是,LEFT JOIN 和 RIGHT JOIN 是对称的,只是左右表的位置不同。INNER JOIN 则是返回共同匹配的行。
这些不同类型的 JOIN 可以灵活地根据查询需求选择使用。INNER JOIN 用于获取两个表中的匹配行,LEFT JOIN 和 RIGHT JOIN 用于获取一个表中的所有行以及另一个表中的匹配行。使用 JOIN 可以将多个表连接在一起,使我们能够根据关联的列获取相关的数据,并更有效地处理复杂的查询需求。但是使用的时候要特别注意,左右表的关联关系,是一对一、一对多还是多对多,对查询的结果影响很大。
gr0up by 字段优化
假设我们要计算每个客户的订单总金额,原始的查询可能如下所示:
SELECT customer_id, SUM(amount) AS total_amount
FROM orders
GR0UP BY customer_id;
在这个查询中,我们使用 GR0UP BY 字段 customer_id 对订单进行分组,并使用 SUM 函数计算每个客户的订单总金额。
为了优化这个查询,我们可以考虑以下几种方法:
- 索引优化:
- 确保在 customer_id 字段上创建索引,以加速 GR0UP BY 和 WHERE 子句的执行。
- 如果查询还包含其他需要的字段,可以考虑创建聚簇索引,将相关的字段放在同一个索引中,以减少查询的IO操作。
- 使用覆盖索引:
- 如果查询中只需要使用 customer_id 和 amount 两个字段,可以创建一个覆盖索引,它包含了这两个字段,减少了查找其他字段的开销。
- 子查询优化:
- 如果订单表很大,可以先使用子查询将数据限制在一个较小的子集上,然后再进行 GR0UP BY 操作。例如,可以先筛选出最近一段时间的订单,然后再对这些订单进行分组。
- 条件优化:
- 使用WHERE条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。而不是在分组后使用having过滤数据。
深分页limit优化
深分页通常指的是在处理大量数据时,用户需要浏览远离首页的页面,例如第100页、第1000页等。这种场景下,如果简单地一次性加载所有数据并进行分页,会导致性能问题,包括内存消耗、数据库查询效率等。
我们日常使用较多的分页一般是用的PageHelper插件,SQL如下:
select id,name from table_name where N个条件 limit 100000,10;
它的执行流程:
- 先去二级索引过滤数据,然后找到主键ID
- 通过ID回表查询数据,取出需要的列
- 扫描满足条件的100010,丢弃前面100000条,返回
这里很明显的不足就是只需要拿10条,但是却多回表了100000次。
可采用的策略:主要是使用子查询、关联查询、范围查询和标签记录法这四种方法,当然对于深分页问题,一般都是比较麻烦了,都需要采用标签记录法来改造代码。
标签记录法:就是记录上次查询的最大ID,再请求下一页的时候带上,从上次的下一条数据开始开始,前提是有序的。 主要需要对代码进行改造:
public Page- fetchPageByKey(Long lastKey, int pageSize) {
// lastKey是上一页最后一项的主键
// 查询数据库,获取主键大于lastKey的pageSize条记录
List- items = itemRepository.findByPrimaryKeyGreaterThan(lastKey, pageSize);
// 如果没有更多数据,可以设置下一个lastKey为空或特定值(如-1)
Long nextLastKey = items.isEmpty() ? null : items.get(items.size() - 1).getId();
return new Page<>(items, nextLastKey);
}
来源:juejin.cn/post/7368377525859008522
把java接口写在数据库里(groovy)
业务复杂多变?那把接口写在数据库里吧,修改随改随用!本文使用了Groovy脚本,不了解的可以自行了解,直接上菜。
- 引入依赖
<dependency>
<groupId>org.codehaus.groovygroupId>
<artifactId>groovy-allartifactId>
<version>2.5.16version>
<type>pomtype>
dependency>
- 创建测试接口
public interface InterfaceA {
/**
* 执行规则
*/
void testMethod();
}
- resource目录下创建.groovy实现上面的接口
@Slf4j
class GroovyInterfaceAImpl implements InterfaceA {
@Override
void testMethod() {
log.info("我是groovy编写的InterfaceA接口实现类中的接口方法")
GroovyScriptService groovyScriptService = SpringUtils.getBean(GroovyScriptService.class)
GroovyScript groovyScript = Optional.ofNullable(groovyScriptService.getOne(new QueryWrapper()
.eq("name", "groovy编写的java接口实现类")
.eq("version", 1))).orElseThrow({ -> new RuntimeException("没有查询到脚本") })
log.info("方法中进行了数据库查询,数据库中的groovy脚本是这个:{}", "\n" + groovyScript.getScript())
}
}
- mysql数据库中建个表groovy_script
 5. 将刚才编写的.groovy文件内容存入数据库
5. 将刚才编写的.groovy文件内容存入数据库
@RunWith(SpringRunner.class)
@SpringBootTest
public class GroovyTest {
@Resource
private GroovyScriptService groovyScriptService;
@Test
public void test01() {
GroovyScript groovyScript = new GroovyScript();
groovyScript.setScript("package groovy\n" +
"\n" +
"import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper\n" +
"import com.demo.groovy.entity.GroovyScript\n" +
"import com.demo.groovy.service.GroovyScriptService\n" +
"import com.demo.groovy.service.InterfaceA\n" +
"import com.demo.groovy.util.SpringUtils\n" +
"import groovy.util.logging.Slf4j\n" +
"\n" +
"\n" +
"@Slf4j\n" +
"class GroovyInterfaceAImpl implements InterfaceA {\n" +
"\n" +
" @Override\n" +
" void testMethod() {\n" +
" log.info("我是groovy编写的InterfaceA接口实现类中的接口方法")\n" +
" GroovyScriptService groovyScriptService = SpringUtils.getBean(GroovyScriptService.class)\n" +
" GroovyScript groovyScript = Optional.ofNullable(groovyScriptService.getOne(new QueryWrapper()\n" +
" .eq("name", "groovy编写的java接口实现类")\n" +
" .eq("version", 1))).orElseThrow({ -> new RuntimeException("没有查询到脚本") })\n" +
" log.info("方法中进行了数据库查询,数据库中的groovy脚本是这个:{}", "\n" + groovyScript.getScript())\n" +
" }\n" +
"}");
groovyScript.setVersion(1);
groovyScript.setName("groovy编写的java接口实现类");
groovyScriptService.save(groovyScript);
}
}
- 从数据读取脚本,GroovyClassLoader加载脚本为Class(注意将Class对象进行缓存)
@Service("groovyScriptService")
@Slf4j
public class GroovyScriptServiceImpl extends ServiceImpl<GroovyScriptServiceMapper, GroovyScript> implements GroovyScriptService {
private static final Map<String, Md5Clazz> SCRIPT_MAP = new ConcurrentHashMap<>();
@Override
public Object getInstanceFromDb(String name, Integer version) {
//查询脚本
GroovyScript groovyScript = Optional.ofNullable(baseMapper.selectOne(new QueryWrapper<GroovyScript>()
.eq("name", name)
.eq("version", version))).orElseThrow(() -> new RuntimeException("没有查询到脚本"));
//将groovy脚本转换为java类对象
Class clazz = getClazz(name + version.toString(), groovyScript.getScript());
Object instance;
try {
instance = clazz.newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
return instance;
}
private Class getClazz(String scriptKey, String scriptText) {
String md5Hex = DigestUtil.md5Hex(scriptText);
Md5Clazz md5Script = SCRIPT_MAP.getOrDefault(scriptKey, null);
if (md5Script != null && md5Hex.equals(md5Script.getMd5())) {
log.info("从缓存获取的Clazz");
return md5Script.getClazz();
} else {
CompilerConfiguration config = new CompilerConfiguration();
config.setSourceEncoding("UTF-8");
GroovyClassLoader groovyClassLoader = new GroovyClassLoader(Thread.currentThread().getContextClassLoader(), config);
try {
Class clazz = groovyClassLoader.parseClass(scriptText);
SCRIPT_MAP.put(scriptKey, new Md5Clazz(md5Hex, clazz));
groovyClassLoader.clearCache();
log.info("groovyClassLoader parseClass");
return clazz;
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
groovyClassLoader.close();
} catch (IOException e) {
log.error("close GroovyClassLoader error", e);
}
}
}
}
@Data
private static class Md5Clazz {
private String md5;
private Class clazz;
public Md5Clazz(String md5, Class clazz) {
this.md5 = md5;
this.clazz = clazz;
}
}
}
- 测试
@RestController
@RequestMapping("/test")
@Slf4j
public class GroovyTestController {
@Resource
private GroovyScriptService groovyScriptService;
@GetMapping("")
public String testGroovy() {
InterfaceA interfaceA = (InterfaceA) groovyScriptService.getInstanceFromDb("groovy编写的java接口实现类", 1);
interfaceA.testMethod();
return "ok";
}
}
- 接口方法被执行。想要修改接口的话在idea里面把groovy文件编辑好更新到数据库就行了,即时生效。

本文简单给大家提供一种思路,希望能对大家有所帮助,如有不当之处还请大家指正。本人之前在项目中用的比较多的是Groovyshell,执行的是一些代码片段,而GroovyClassLoader则可以加载整个脚本为Class,Groovy对于java开发者来说还是比较友好的,上手容易。
来源:juejin.cn/post/7397013935106048051
Android Activity 之间共享的 ViewModel
Android Activity 之间共享的 ViewModel
- 提供一个 Application 作用域的 ViewModel 去实现
- 要尽量避免被滥用
- 按需考虑加数据销毁、资源释放的逻辑
AppSharedViewModel
class AppSharedViewModel: ViewModel() {
var testLiveData = MutableLiveData(0)
}
class AppApplication : Application(), ViewModelStoreOwner {
companion object {
private lateinit var sInstance: AppApplication
fun getInstance() = sInstance
}
override fun onCreate() {
super.onCreate()
sInstance = this
}
private val appSharedViewModelStore by lazy {
ViewModelStore()
}
override fun getViewModelStore(): ViewModelStore {
return appSharedViewModelStore
}
}
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
//使用
val appSharedViewModel = ViewModelProvider(AppApplication.getInstance())[AppSharedViewModel::class.java]
}
让 AppSharedViewModel 继承自 AndroidViewModel
class AppSharedViewModel(application: Application) : AndroidViewModel(application) {
var testLiveData = MutableLiveData(0)
}
- 方案1
改写 ViewModel 创建获取的地方传入 AndroidViewModelFactory 实例
val appSharedViewModel = ViewModelProvider(
AppApplication.getInstance(),
ViewModelProvider.AndroidViewModelFactory.getInstance(AppApplication.getInstance())
)[AppSharedViewModel::class.java]
- 方案2
改写 Application 实现 HasDefaultViewModelProviderFactory 接口,因为 ViewModelProvider 构造方法里有调用 ViewModelProvider.AndroidViewModelFactory.defaultFactory 方法传入 ViewModelStoreOwner 去判断处理 HasDefaultViewModelProviderFactory 接口的逻辑
class AppApplication : Application(), ViewModelStoreOwner, HasDefaultViewModelProviderFactory {
companion object {
private lateinit var sInstance: AppApplication
fun getInstance() = sInstance
}
override fun onCreate() {
super.onCreate()
sInstance = this
}
private val appSharedViewModelStore by lazy {
ViewModelStore()
}
override fun getViewModelStore(): ViewModelStore {
return appSharedViewModelStore
}
override fun getDefaultViewModelProviderFactory(): ViewModelProvider.Factory {
return ViewModelProvider.AndroidViewModelFactory.getInstance(this)
}
}
来源:juejin.cn/post/7380579037113237554
utf8和utf8mb4有什么区别?
utf8或者utf-8是大家常见的一个词汇,它是一种信息的编码格式,特别是不同开发平台的系统进行对接的时候,编码一定要对齐,否则就容易出现乱码。
什么是编码?
先说说什么是编码。编码就像我们日常生活中的语言,不同的地方说不同的话,编码就是计算机用来表示这些“话”的一种方式。比如我们使用汉字来说话,计算机用二进制数来表示这些汉字的方式,就是编码。
utf8就是这样一种编码格式,正式点要使用:UTF-8,utf8是一个简写形式。
为什么需要utf8?
在计算机早期,主要使用ASCII编码,只能表示128个字符,汉字完全表示不了。后来,才出现了各种各样的编码方式,比如GB2312、GBK、BIG5,但这些编码只能在特定的环境下使用,不能全球通用。
UTF-8就像一个万能翻译官,它的全称是“Unicode Transformation Format - 8 bit”,注意这里不是说UTF-8只能使用8bit来表示一个字符,实际上UTF-8能表示世界上几乎所有的字符。
它的特点是:
- 变长编码:一个字符可以用1到4个字节表示,英文字符用1个字节(8bit),汉字用3个字节(24bit)。
- 向后兼容ASCII:ASCII的字符在UTF-8中还是一个字节,这样就兼容了老系统。
- 节省空间:对于英文字符,UTF-8比其他多字节编码更省空间。
UTF-8适用于网页、文件系统、数据库等需要全球化支持的场景。
经常接触代码的同学应该还经常能看到 Unicode 这个词,它和编码也有很大的关系,其实Unicode是一个字符集标准,utf8只是它的一种实现方式。Unicode 作为一种字符集标准,为全球各种语言和符号定义了唯一的数字码位(code points)。其它的Unicode实现方式还有UTF-16和UTF-32:
- UTF-16 使用固定的16位(2字节)或者变长的32位(4字节,不在常用字符之列)来编码 Unicode 字符。
- UTF-32 每一个字符都直接使用固定长度的32位(4字节)编码,不论字符的实际数值大小。这会消耗更多的存储空间,但是所有字符都可以直接索引访问。

图片来源:src: javarevisited.blogspot.com/2015/02/dif…
utf8mb4又是什么?
utf8mb4并不常见,它是UTF-8的一个扩展版本,专门用于MySQL数据库。MySQL在 5.5.3 之后增加了一个utf8mb4的编码,mb4就是最多4个字节的意思(most bytes 4),它主要解决了UTF-8不能表示一些特殊字符的问题,比如Emoji表情,这在论坛或者留言板中也经常用到。大家使用小红书时应该见过各种各样的表情符号,小红书后台也可能使用utf8mb4保存它们。
编码规则和特点:
- 最多4个字节:utf8mb4中的每个字符最多用4个字节表示。
- 支持更多字符:能表示更多的Unicode字符,包括Emoji和其他特殊符号。
utf8和utf8mb4的比较
存储空间
- 数据库:utf8mb4每个字符最多用4个字节,比UTF-8多一个字节,存储空间会增加。
- 文件:类似的,文件用utf8mb4编码也会占用更多的空间。
性能影响
- 数据库:utf8mb4的查询和索引可能稍微慢一些,因为占用更多的空间和内存。
- 网络传输:utf8mb4编码的字符会占用更多的带宽,传输速度可能会稍慢。
不过因为实际场景中使用的utf8mb4的字符也不多,其实对存储空间和性能的影响很小,大家基本没有必要因为多占用了一些空间和流量,而不是用utf8mb4。
只是我们在定义字段长度、规划数据存储空间、网络带宽的时候,要充分考虑4字节带来的影响,预留好足够的空间。
实战选择
在实际开发中,选择编码要根据具体需求来定。如果你的网站或者应用需要支持大量的特殊字符和Emoji,使用utf8mb4是个不错的选择。如果主要是英文和普通中文文本,utf8足够应付。
注意为了避免乱码问题,前端、后端、数据库都应该使用同一种编码,比如utf8,具体到编码时就是要确保数据库连接、网页头部、文件读写都设置为相同的编码。
另外还需要注意Windows和Linux系统中使用UTF-8编码的文件可能是有差别的,Windows中的UTF-8文件可能会携带一个BOM头,方便系统进行识别,但是Linux中不需要这个头,所以如果要跨系统使用这个文件,特别是程序脚本,可能需要在Linux中去掉这个头。
以上就是本文的主要内容,如有问题欢迎留言讨论。
关注萤火架构,加速技术提升!
来源:juejin.cn/post/7375504338758025254
黑神话:悟空——揭秘风灵月影的技术魔法
作为一名“手残党”,你是否常常因为复杂的操作和高难度的游戏内容而感到沮丧?不用担心,《黑神话:悟空》不仅仅是为硬核玩家准备的,它同样为我们这些操作不那么娴熟的玩家提供了无比精彩的游戏体验。
本文将带你深入探讨《黑神话:悟空》背后的技术原理,揭示风灵月影团队如何通过创新的技术手段,让每一位玩家,无论技术水平如何,都能在游戏中找到属于自己的乐趣。我们将揭秘那些让你在游戏中感受到无比真实和沉浸的细节,从逼真的角色动画到动态的环境效果,每一个细节都展示了团队的卓越才能和对游戏品质的追求。让我们一同走进这场技术与艺术的盛宴,感受《黑神话:悟空》背后的科技魔法,了解这些技术如何让你在游戏中无论是战斗还是探索,都能享受到极致的体验。
我的黑神话悟空数值

欢迎加入宗门
风灵月影修改器
Attach一个游戏进程,黑神话悟空进程名固定

Attach一个进程之后,可以修改对应的游戏数值

使用方式上每次启动游戏都要启动风灵月影,重启的游戏风铃月影也会重新Attach进程。
游戏修改器的工作原理
游戏修改器的技术原理主要涉及对游戏内存的实时修改和对游戏数据的动态调整。以下是修改器的主要技术原理和工作机制:
内存修改
- 内存扫描:修改器首先会扫描游戏进程的内存空间,找到存储特定游戏数据(如生命值、金钱、资源等)的内存地址。
- 地址定位:通过反复扫描和比较内存数据的变化,确定具体的内存地址。例如,玩家在游戏中增加或减少金钱,修改器会通过这些变化找到金钱的内存地址。
- 数据修改:一旦找到目标内存地址,修改器会直接修改该地址处的数据。例如,将生命值地址的数据修改为一个极大值,从而实现无限生命。
动态链接库(DLL)注入
- DLL注入:修改器可以通过将自定义的DLL文件注入到游戏进程中,来拦截和修改游戏的函数调用。
- 函数劫持:通过劫持游戏的关键函数,修改器可以在函数执行前后插入自定义代码。例如,拦截角色受伤的函数调用,将伤害值修改为零,从而实现无敌效果。
- 实时调整:DLL注入还可以实现对游戏数据的实时监控和调整,确保修改效果持续生效。
调试工具
- 调试接口:一些高级修改器使用调试工具(如Cheat Engine)提供的调试接口,直接与游戏进程交互。
- 断点调试:通过设置断点,修改器可以在特定代码执行时暂停游戏,进行数据分析和修改。
- 汇编指令修改:修改器可以修改游戏的汇编指令,改变游戏的逻辑。例如,将减血指令修改为加血指令。
数据文件修改
- 配置文件:一些游戏的关键数据存储在配置文件中(如INI、XML等),修改器可以直接修改这些文件来改变游戏设置。
- 存档文件:修改器可以修改游戏的存档文件,直接改变游戏进度和状态。例如,增加存档中的金钱数量或解锁所有关卡。
反作弊机制
- 反检测:为了避免被游戏的反作弊机制检测到,修改器通常会使用一些反检测技术,如代码混淆、动态加密等。
- 隐蔽操作:修改器可能会模拟正常的用户操作,避免直接修改内存或数据,降低被检测到的风险。
以上是游戏修改器的主要技术原理。通过这些技术,修改器能够对游戏进行各种修改和调整,提供丰富的功能来提升玩家的游戏体验。然而,使用修改器时应注意相关法律和游戏规定,避免影响游戏的公平性和他人体验。
blog.csdn.net/m0_74942241… (可部分阅读)
代码示例
以下是一个简单的内存扫描示例:
#include <windows.h>
#include <iostream>
#include <vector>
// 扫描目标内存
std::vector<LPVOID> ScanMemory(HANDLE hProcess, int targetValue) {
std::vector<LPVOID> addresses;
MEMORY_BASIC_INFORMATION mbi;
LPVOID address = 0;
while (VirtualQueryEx(hProcess, address, &mbi, sizeof(mbi))) {
if (mbi.State == MEM_COMMIT && (mbi.Protect == PAGE_READWRITE || mbi.Protect == PAGE_WRITECOPY)) {
SIZE_T bytesRead;
std::vector<BYTE> buffer(mbi.RegionSize);
if (ReadProcessMemory(hProcess, address, buffer.data(), mbi.RegionSize, &bytesRead)) {
for (SIZE_T i = 0; i < bytesRead - sizeof(targetValue); ++i) {
if (memcmp(buffer.data() + i, &targetValue, sizeof(targetValue)) == 0) {
addresses.push_back((LPVOID)((SIZE_T)address + i));
}
}
}
}
address = (LPVOID)((SIZE_T)address + mbi.RegionSize);
}
return addresses;
}
int main() {
DWORD processID = 1234; // 替换为目标进程的实际PID
int targetValue = 100; // 要查找的值
HANDLE hProcess = OpenTargetProcess(processID);
if (hProcess) {
std::vector<LPVOID> addresses = ScanMemory(hProcess, targetValue);
for (auto addr : addresses) {
std::cout << "Found value at address: " << addr << std::endl;
ModifyMemory(hProcess, addr, 999); // 修改内存
}
CloseHandle(hProcess);
}
return 0;
}
修改目标进程的内存
#include <windows.h>
#include <iostream>
// 打开目标进程
HANDLE OpenTargetProcess(DWORD processID) {
HANDLE hProcess = OpenProcess(PROCESS_ALL_ACCESS, FALSE, processID);
if (hProcess == NULL) {
std::cerr << "Failed to open process. Error: " << GetLastError() << std::endl;
}
return hProcess;
}
// 查找目标内存地址(假设我们已经知道地址)
void ModifyMemory(HANDLE hProcess, LPVOID address, int newValue) {
SIZE_T bytesWritten;
if (WriteProcessMemory(hProcess, address, &newValue, sizeof(newValue), &bytesWritten)) {
std::cout << "Memory modified successfully." << std::endl;
} else {
std::cerr << "Failed to modify memory. Error: " << GetLastError() << std::endl;
}
}
int main() {
DWORD processID = 1234; // 替换为目标进程的实际PID
LPVOID targetAddress = (LPVOID)0x00ABCDEF; // 替换为目标内存地址
int newValue = 999; // 要写入的新值
HANDLE hProcess = OpenTargetProcess(processID);
if (hProcess) {
ModifyMemory(hProcess, targetAddress, newValue);
CloseHandle(hProcess);
}
return 0;
}
以下是一个使用内联钩子实现函数劫持的简单示例(基于Windows平台):
#include <windows.h>
// 原始函数类型定义
typedef int (WINAPI *MessageBoxAFunc)(HWND, LPCSTR, LPCSTR, UINT);
// 保存原始函数指针
MessageBoxAFunc OriginalMessageBoxA = NULL;
// 自定义函数
int WINAPI HookedMessageBoxA(HWND hWnd, LPCSTR lpText, LPCSTR lpCaption, UINT uType) {
// 修改参数或执行其他逻辑
lpText = "This is a hooked message!";
// 调用原始函数
return OriginalMessageBoxA(hWnd, lpText, lpCaption, uType);
}
// 设置钩子
void SetHook() {
// 获取原始函数地址
HMODULE hUser32 = GetModuleHandle("user32.dll");
OriginalMessageBoxA = (MessageBoxAFunc)GetProcAddress(hUser32, "MessageBoxA");
// 修改函数头部指令
DWORD oldProtect;
VirtualProtect(OriginalMessageBoxA, 5, PAGE_EXECUTE_READWRITE, &oldProtect);
*(BYTE*)OriginalMessageBoxA = 0xE9; // JMP指令
*(DWORD*)((BYTE*)OriginalMessageBoxA + 1) = (DWORD)HookedMessageBoxA - (DWORD)OriginalMessageBoxA - 5;
VirtualProtect(OriginalMessageBoxA, 5, oldProtect, &oldProtect);
}
int main() {
// 设置钩子
SetHook();
// 测试钩子
MessageBoxA(NULL, "Original message", "Test", MB_OK);
return 0;
}
CheatEngine
上述通过代码的方式成本比较高,我们通过工具修改内存值和函数劫持
http://www.cheatengine.org/downloads.p…
使用教程 blog.csdn.net/CYwxh0125/a…

如何实现自动扫描
风灵月影如何实现自动修改值,不需要每次搜索变量内存地址?
猜想1:变量内存地址固定?
经过测试发现不是
猜想2:通过变量字符串搜索?
算了不猜了,直接问GPT,发现应该是通过指针内存扫描的方式。
指针扫描适合解决的问题
指针扫描是一种高级技术,用于解决动态内存地址变化的问题。在某些应用程序(特别是游戏)中,内存地址在每次运行时可能会变化,这使得简单的内存扫描方法难以长期有效地找到目标变量。指针扫描通过查找指向目标变量的指针链,可以找到一个稳定的基址(静态地址),从而解决动态内存地址变化的问题。
1. 动态内存分配
许多现代应用程序和游戏使用动态内存分配,导致每次运行时同一变量可能位于不同的内存地址。指针扫描可以找到指向这些变量的指针链,从而定位到一个稳定的基址。
2. 多次重启后的地址稳定性
通过指针扫描找到的静态基址和指针链,即使在应用程序或系统重启后,仍然可以有效地找到目标变量的位置。这样,用户无需每次重新扫描内存地址。
3. 多级指针
有些变量可能通过多级指针间接引用。指针扫描可以处理这种情况,通过多级指针链找到最终的目标变量。
指针扫描的基本步骤
以下是使用 Cheat Engine 进行指针扫描的基本步骤:
1. 初始扫描
首先,使用普通的内存扫描方法找到目标变量的当前内存地址。例如,假设在游戏中找到当前金钱值的地址是 0x00ABCDEF。
2. 指针扫描
- 在找到的内存地址上右键单击,选择“指针扫描此地址”。
- Cheat Engine 会弹出一个指针扫描窗口。在窗口中设置扫描参数,例如最大指针级别和偏移量。
- 点击“确定”开始扫描。Cheat Engine 会生成一个包含可能的指针路径的列表。
3. 验证指针路径
- 重启游戏或应用程序,再次找到目标变量的当前内存地址。
- 使用新的内存地址进行指针扫描,验证之前找到的指针路径是否仍然有效。
- 通过多次验证,找到一个稳定的指针路径。
4. 使用指针路径
- 在 Cheat Engine 中保存指针路径。
- 以后可以直接使用这个指针路径来访问目标变量,无需每次重新扫描。
示例:使用 Cheat Engine 进行指针扫描
假设你在游戏中找到了当前金钱值的地址 0x00ABCDEF,并想通过指针扫描找到一个稳定的基址。
1. 初始扫描
- 启动 Cheat Engine 并附加到游戏进程。
- 使用普通的内存扫描方法找到当前金钱值的地址
0x00ABCDEF。
2. 指针扫描
- 右键单击找到的地址
0x00ABCDEF,选择“指针扫描此地址”。 - 在弹出的指针扫描窗口中,设置最大指针级别为 5(可以根据需要调整),偏移量保持默认。
- 点击“确定”开始扫描。
3. 验证指针路径
- 重启游戏,重新找到当前金钱值的地址(假设新的地址是
0x00DEF123)。 - 使用新的地址进行指针扫描,验证之前找到的指针路径是否仍然有效。
- 通过多次验证,找到一个稳定的指针路径。例如,指针路径可能是
[game.exe+0x00123456] + 0x10 + 0x20。
4. 使用指针路径
- 在 Cheat Engine 中保存这个指针路径。
- 以后可以直接使用这个指针路径来访问金钱值,无需每次重新扫描。
注意事项
- 指针级别:指针级别越高,扫描时间越长,但也能处理更复杂的多级指针情况。根据实际需要设置合适的指针级别。
- 验证指针路径:指针路径需要多次验证,以确保其稳定性和可靠性。重启游戏或应用程序,重新扫描并验证指针路径。
- 性能影响:指针扫描可能会对系统性能产生一定影响,特别是在大型游戏或应用程序中。建议在合适的环境下进行扫描。
通过以上步骤,指针扫描技术可以帮助用户找到稳定的基址,解决动态内存地址变化的问题,从而实现更可靠的内存修改。
来源:juejin.cn/post/7426389669527207936
WebStorm现在免费啦!
前言
就在昨天1024程序员节,JetBrains突然宣布WebStorm现在对非商业用途免费啦。以后大家再也不用费尽心思的去找破解方法了,并且公告中的关于非商业用途定义也很有意思。
加入欧阳的高质量vue源码交流群、欧阳平时写文章参考的多本vue源码电子书
为什么免费
在公告中的原话是:
我们希望新的许可模式将进一步降低使用 IDE 的门槛,帮助大家学习、成长并保持创造力。
欧阳个人还是觉得现在大家都在使用vscode或者Cursor。
如果我不想付费,那么我会选择开源的vscode,安装上插件后体验完全不输于WebStorm。
如果我想付费获得更好的体验,那么为什么不使用AI加持的Cursor呢?
前段时间网上有很多吸引人眼球的段子,比如:
我6岁的儿子使用
Cursor开发了一个个人网站
又或者:
我是一名UI设计师,使用
Cursor轻松的开发了一个APP
欧阳也一直在使用Cursor,虽然没有网上那些段子那样把Cursor吹的那么神。但是对于开发来说Cursor是真的很好用,经常觉得Cursor比我更知道我接下来应该写什么代码。如果我选择付费,为什么不考虑更加好用的Cursor呢?
不管是免费还是付费市场,vscode系的IDE已经占据了很大的比例。欧阳个人觉得WebStorm为了能够重新占据市场,所以选择推出非商业用途免费的WebStorm
非商业和商业有什么区别
非商业和商业的WebStorm区别只有一个,Code With Me 功能。如果是非商业的WebStorm里面的Code With Me 是社区版。
Code With Me是一个协作工具,允许多个开发者实时共享代码和协作编程。通过这项功能,用户可以在WebStorm、Rider等IDE中与他人共同编辑代码、进行调试和解决问题。
这个是Code With Me社区版和非社区版的区别:

如何判断是否是非商业
公告中的原文是:
商业产品是指有偿分发或提供、或者作为您的商业活动的一部分使用的产品。 但某些类别被明确排除在这一定义之外。 常见的非商业用例包括学习和自我教育、任何形式的内容创作、开源代码和业余爱好开发。
这不就是完全靠自觉吗?不需要证明我是用于非商业,欧阳觉得这是故意为之。
小公司使用Webstorm的非商业模式进行业务开发,人家看不上你,所以懒得搭理你。就像是以前在小公司里面使用破解版本的webstorm开发一样。
但是在公告中明确有写:
如果您使用非商业许可证,将无法选择退出匿名使用情况统计信息收集。 我们使用此类信息改进我们的产品。 这一规定与我们的抢先体验计划 (EAP) 类似,并符合我们的隐私政策。
意思是如果你使用了非商业版本,那么JetBrains就能拿到你的数据。
如果在大公司里面使用非商业模式进行业务开发,那么Webstorm在拿到数据的情况下就是一告一个准。就像是大公司里面禁止使用破解版本的webstorm开发业务一样,欧阳个人觉得有点像是钓鱼。
如何使用非商业版
使用方式很简单,首先从官网下载安装包。然后在对话框中选择非商业模式,如下图:

接着勾选协议,点击开始非商业使用,如下图:

此时会在浏览器中新开页面让你登录,登录方式有很多种:比如谷歌、GitHub、微信等。这里欧阳选择的是谷歌登录,如下图:

最后就成功啦,非商业有效期是一年,一年后会自动续订。

总结
WebStorm推出的非商业版免费对于开发者来说肯定是好事,特别是一些使用WebStorm的独立开发,还有小公司里面的开发,但是大公司里面想使用非商业版就需要三思了。
来源:juejin.cn/post/7429381641700048923
程序员攻占小猿口算,炸哭小学生!
小学生万万没想到,做个加减乘除的口算练习题,都能被大学生、博士生、甚至是程序员大佬们暴打!

最近这款拥有 PK 功能的《小猿口算》App 火了,谁能想到,本来一个很简单的小学生答题 PK,竟然演变为了第四次忍界大战!

刚开始还是小学生友好 PK,后面突然涌入一波大学生来踢馆,被网友称为 “大学生炸鱼”;随着战况愈演愈烈,硕士生和博士生也加入了战场,直接把小学生学习软件玩成了电子竞技游戏,谁说大一就不是一年级了?这很符合当代大学生的精神状态。

然而,突然一股神秘力量出现,是程序员带着科技加入战场! 自动答题一秒一道 ,让小学生彻底放弃,家长们也无可奈何,只能在 APP 下控诉严查外挂。

此时很多人还没有意识到,小学生口算 PK,已经演变为各大高校和程序员之间的算法学术交流竞赛!

各路大神连夜改进算法,排行榜上的数据也是越发离谱,甚至卷到了 0.1 秒一道题!

算法的演示效果,可以看我发的 B 站视频。
接口也是口,算法也是算,这话没毛病。
这时,官方不得不出手来保护小学生了,战况演变为官方和广大程序员的博弈。短短几天,GitHub 上开源的口算脚本就有好几页,程序员大神们还找到了多种秒速答题的方案。

官方刚搞了加密,程序员网友马上就成功解密,以至于 网传 官方不得不高价招募反爬算法工程师,我建议直接把这些开源大佬招进去算了。

实现方法
事情经过就是这样,我相信朋友们也很好奇秒答题目背后的实现原理吧,这里我以 GitHub 排名最高的几个脚本项目为例,分享 4 种实现方法。当然,为了给小学生更好的学习体验,这里我就不演示具体的操作方法了,反正很快也会被官方打压下去。
方法 1、OCR 识别 + 模拟操作
首先使用模拟器在电脑上运行 App,运用 Python 读取界面上特定位置的题目,然后运用 OCR 识别技术将题目图片识别为文本并输入给算法程序来答题,最后利用 Python 的 pyautogui 库来模拟人工点击和输入答案。
这种方法比较好理解,应用范围也最广,但缺点是识别效果有限,如果题目复杂一些,准确度就不好保证了。
详见开源仓库:github.com/ChaosJulien…

方法 2、抓包获取题目和答案
通过 Python 脚本抓取 App 的网络请求包,从中获取题目和答案,然后通过 ADB(Android Debug Bridge)模拟滑动操作来自动填写答案。然而,随着官方升级接口并加密数据,这种方法已经失效。
详见开源仓库:github.com/cr4n5/XiaoY…

方法 3、抓包 + 修改答案
这个方法非常暴力!首先通过抓包工具拦截口算 App 获取题目数据和答案的网络请求,然后修改请求体中的答案全部为 “1”,这样就可以通过 ADB 模拟操作,每次都输入 1 就能快速完成答题。 根据测试可以达到接近 0 秒的答题时间!
但是这个方法只对练习场有效,估计是练习场的答题逻辑比较简单,且没有像 PK 场那样的复杂校验。
详见开源仓库:github.com/cr4n5/XiaoY…

方法 4、修改 PK 场的 JavaScript 文件
这种方法就更暴力了!在 PK 场模式下,修改 App 内部的 JavaScript 文件来更改答题逻辑。通过分析 JavaScript 响应中的 isRight 函数,找到用于判定答案正确与否的逻辑,然后将其替换为 true,强制所有答案都判定为正确,然后疯狂点点点就行了。
详见开源仓库:github.com/cr4n5/XiaoY…

能这么做是因为 App 在开发时采用了混合 App 架构,一些功能是使用 WebView 来加载网页内容的。而且由于 PK 场答题逻辑是在前端进行验证,而非所有请求都发送到服务器进行校验,才能通过直接修改前端 JS 文件绕过题目验证。
官方反制
官方为了保护小学生学习的体验,也是煞费苦心。
首先加强了用户身份验证和管理,防止大学生炸鱼小学生;并且为了照顾大学生朋友,还开了个 “巅峰对决” 模式,让俺们也可以同实力竞技 PK。

我建议再增加一个程序员模式,也给爱玩算法的程序员一个竞技机会。
其实从技术的角度,要打击上述的答题脚本,并不难。比如检测 App 运行环境,发现是模拟器就限制答题;通过改变题目的显示方式来对抗 OCR 识别;通过随机展示部分 UI, 让脚本无法轻易通过硬编码的坐标点击正确的答案;还可以通过分析用户的答题速度和操作模式来识别脚本,比如答题速度快于 0.1 秒的用户,显然已经超越了人类的极限。
0.0 秒的这位朋友,是不是有点过分(强大)了?

但最关键的一点是,目前 App 的判题逻辑是在前端负责处理的,意味着题目答案的验证可以在本地进行,而不必与服务器通信,这就给了攻击者修改前端文件的机会。虽然官方通过接口加密和行为分析等手段加强了防御,但治标不治本,还是将判题逻辑转移到服务端,会更可靠。
当然,业务流程改起来哪有那么快呢?
不过现在的局面也不错,大学生朋友快乐了,程序员玩爽了,口算 App 流量赢麻了,可谓是皆大欢喜!
等等,好像有哪里不对。。。别再欺负我们的小学生啦!

更多
来源:juejin.cn/post/7425121392738140214
技术大佬 问我 订单消息乱序了怎么办?
技术大佬 :佩琪,最近看你闷闷不乐了,又被虐了?
佩琪:(⊙o⊙)…,又被大佬发现了。这不最近出去面试都揉捏的像一个麻花了嘛
技术大佬 :哦,这次又是遇到什么难题了?
佩琪: 由于和大佬讨论过消息不丢,消息防重等技能(见
kafka 消息“零丢失”的配方 和技术大佬问我 订单消息重复消费了 怎么办?
),所以在简历的技术栈里就夸大似的写了精通kafka消息中间件,然后就被面试官炮轰了里面的细节
佩琪: 其中面试官给我印象深刻的一个问题是:你们的kafka消息里会有乱序消费的情况吗?如果有,是怎么解决的了?
技术大佬 :哦,那你是怎么回答的了?
佩琪:我就是个crud boy,根本不知道啥是顺序消费啥是乱序消费,所以就回答说,没有
技术大佬 :哦,真是个诚实的孩子;然后呢?
佩琪:然后面试官就让我回家等通知了,然后就没有然后了。。。。
佩琪 : 对了大佬,什么是消息乱序消费了?
技术大佬 :消息乱序消费,一般指我们消费者应用程序不按照,上游系统 业务发生的顺序,进行了业务消息的颠倒处理,最终导致消费业务出错。
佩琪 :低声咕噜了下你这说的是人话吗?大声问答:这对我的小脑袋有点抽象了,大佬能举个实际的栗子吗?
技术大佬 :举个上次我们做的促销数据同步的栗子吧,大概流程如下:

技术大佬 :上次我们做的促销业务,需要在我们的运营端后台,录入促销消息;然后利用kafka同步给三方业务。在业务流程上,是先新增促销信息,然后可能删除促销信息;但是三方消费端业务接受到的kafka消息,可能是先接受到删除促销消息;随后接受到新增促销消息;这样不就导致了消费端系统和我们系统的促销数据不一致了嘛。所以你是消费方,你就准备接锅吧,你不背锅,谁背锅了?
佩琪 :-_-||,此时佩琪心想,锅只能背一次,坑只能掉一次。赶紧问到:请问大佬,消息乱序了后,有什么解决方法吗?
技术大佬 : 此时抬了抬眼睛,清了清嗓子,面露自信的微笑回答道。一般都是使用顺序生产,顺序存储,顺序消费的思想来解决。
佩琪 :摸了摸头,能具体说说,顺序生产,顺序存储,顺序消费吗?
技术大佬 : 比如kafka,一般建议同一个业务属性数据,都往一个分区上发送;而kafka的一个分区只能被一个消费者实例消费,不能被多个消费者实例消费。
技术大佬 : 也就是说在生产端如果能保证 把一个业务属性的消息按顺序放入同一个分区;那么kakfa中间件的broker也是顺序存储,顺序给到消费者的。而kafka的一个分区只能被一个消费者消费;也就不存在多线程并发消费导致的顺序问题了。
技术大佬 :比如上面的同步促销消息;不就是两个消费者,拉取了不同分区上的数据,导致消息乱序处理,最终数据不一致。同一个促销数据,都往一个分区上发送,就不会存在这样的乱序问题了。
佩琪 :哦哦,原来是这样,我感觉这方案心理没底了,大佬能具体说说这种方案有什么优缺点吗?
技术大佬 :给你一张图,你学习下?
| 优点 | 缺点 |
|---|---|
| 生产端实现简单:比如kafka 生产端,提供了按指定key,发送到固定分区的策略 | 上游难保证严格顺序生产:生产端对同一类业务数据需要按照顺序放入同一个分区;这个在应用层还是比较的难保证,毕竟上游应用都是无状态多实例,多机器部署,存在并发情况下执行的先后顺序不可控 |
| 消费端实现也简单 :kafka消费者 默认就是单线程执行;不需要为了顺序消费而进行代码改造 | 消费者处理性能会有潜在的瓶颈:消费者端单线程消费,只能扩展消费者应用实例来进行消费者处理能力的提升;在消息较多的时候,会是个处理瓶颈,毕竟干活的进程上限是topic的分区数。 |
| 无其它中间件依赖 | 使用场景有取限制:业务数据只能指定到同一个topic,针对某些业务属性是一类数据,但发送到不同topic场景下,则不适用了。比如订单支付消息,和订单退款消息是两个topic,但是对于下游算佣业务来说都是同一个订单业务数据 |
佩琪 :大佬想偷懒了,能给一个 kafka 指定 发送到固定分区的代码吗?
技术大佬 :有的,只需要一行代码,你要不自己动手尝试下?
KafkaProducer.send(new ProducerRecord[String,String](topic,key,msg),new Callback(){} )
topic:主题,这个玩消息的都知道,不解释了
key: 这个是指定发送到固定分区的关键。一般填写订单号,或者促销ID。kafka在计算消息该发往那个分区时,会默认使用hash算法,把相同的key,发送到固定的分区上
msg: 具体消息内容
佩琪 :大佬,我突然记起,上次我们做的 订单算佣业务了,也是利用kafka监听订单数据变化,但是为什么没有使用固定分区方案了?
技术大佬 : 主要是我们上游业务方:把订单支付消息,和订单退款消息拆分为了两个topic,这个从使用固定分区方案的前提里就否定了,我们不能使用此方案。
佩琪 :哦哦,那我们是怎么去解决这个乱序的问题的了?
技术大佬 :主要是根据自身业务实际特性;使用了数据库乐观锁的思想,解决先发后至,后发先至这种数据乱序问题。
大概的流程如下图:

佩琪 :摸了摸头,大佬这个自身业务的特性是啥了?
技术大佬 :我们算佣业务,主要关注订单的两个状态,一个是订单支付状态,一个是订单退款状态。
订单退款发生时间肯定是在订单支付后;而上游订单业务是能保证这两个业务在时间发生上的前后顺序的,即订单的支付时间,肯定是早于订单退款时间。所以主要是利用订单ID+订单更新时间戳,做为数据库佣金表的更新条件,进行数据的乱序处理。
佩琪 : 哦哦,能详细说说 这个数据库乐观锁是怎么解决这个乱序问题吗?
技术大佬 : 比如:当佣金表里订单数据更新时间大于更新条件时间 就放弃本次更新,表明消息数据是个老数据;即查询时不加锁;
技术大佬 :而小于更新条件时间的,表明是个订单新数据,进行数据更新。即在更新时 利用数据库的行锁,来保证并发更新时的情况。即真实发生修改时加锁。
佩琪 :哦哦,明白了。原来一条带条件更新的sql,就具备了乐观锁思想。
技术大佬 :我们算佣业务其实是只关注佣金的最终状态,不关注中间状态;所以能用这种方式,保证算佣数据的最终一致性,而不用太关注订单的中间状态变化,导致佣金的中间变化。
总结
要想保证消息顺序消费大概有两种方案

固定分区方案
1、生产端指定同一类业务消息,往同一个分区发送。比如指定发送key为订单号,这样同一个订单号的消息,都会发送同一个分区
2、消费端单线程进行消费
乐观锁实现方案
如果上游不能保证生产的顺序;可让上游加上数据更新时间;利用唯一ID+数据更新时间,+乐观锁思想,保证业务数据处理的最终一致性。
原创不易,请 点赞,留言,关注,收藏 4暴击^^
天冷了,多年不下雪的北京,下了一场好大的雪。如果暴击不能让您动心,请活动下小手
佩琪正在参与 掘金2023年度人气创作者打榜中,感谢掘友们的支持,为佩琪助助力,也是对我文章输出的鼓励和支持 ~ ~ 万分感谢 activity.juejin.cn/rank/2023/w…
来源:juejin.cn/post/7303833186068086819
冷板凳30年,离职时75岁!看完老爷子的简历,我失眠了
0x01
前几天,科技圈又一个爆款新闻相信不少同学都已经看到了。
那就是77岁的计算机科学家,同时也是一位享誉全球的人工智能专家 Geoffrey Hint0n 和 John J. Hopfield 一起,拿到了2024年诺贝尔物理学奖,以表彰他们通过人工神经网络实现机器学习的奠基性发现和发明。

消息一出,在科技届引起了一阵广泛的关注和讨论,以至于不少同学都发出感叹,“AI法力无边”、“人工智能终于不止是技术,而是科学了”。
而提到 Hint0n 这个名字,对于学习和从事AI人工智能和机器学习等领域的同学来说,应该都非常熟悉了。
Hint0n 是一位享誉全球的人工智能专家,被誉为“神经网络之父”、“深度学习的鼻祖”、“人工智能教父”等等,在这个领域一直以来都是最受尊崇的泰斗之一。

而上一次 Hint0n 站在聚光灯下则是5年前,彼时的 Hint0n 刚拿下2018年度图灵奖。
至此,AI教父 Hint0n 也成为了图灵奖和诺贝尔奖的双料得主!
0x02
大多人都是因为近年大火的AI才了解的Hint0n,但是他之前的人生经历也是相当富有戏剧性的。
1947年,Geoffrey Hint0n出生于英国温布尔登的一个知识分子家庭。

他的父亲Howard Everest Hint0n是一个研究甲壳虫的英国昆虫学家,而母亲Margaret Clark则是一名教师。
除此之外,他的高曾祖父George Boole还是著名的逻辑学家,也是现代计算科学的基础布尔代数的发明人,而他的叔叔Colin Clark则是一个著名的经济学家。
可以看到,Hint0n家庭里的很多成员都在学术和研究方面都颇有造诣。
当然,在这样的氛围下长大的Hint0n,其成长压力也是可想而知的。
1970年,23岁的Hint0n获得了实验心理学的学士学位。但是,令谁也没有想到的是,毕业后这位“学二代”由于找不到科研的意义,他竟然先跑去当了一段时间的木匠。
不过这个经历并没有帮助他消除自己的阶段性迷茫,他一直希望真正理解大脑的运作原理,渴望更深入的理论研究,于是经历过一番思想斗争后又下决心重返学术殿堂,投身于人工智能领域。
直到 1978 年,他终于获得了爱丁堡大学人工智能学博士学位,而此时的他也已经 31 岁了。
那个年代做深度学习的研究可以说是妥妥的冷板凳,因为你要知道当时的AI正值理论萌芽阶段,Hint0n所主张和研究的深度学习派更是不太为关注和认可。
那面对这一系列冷漠甚至反对,唯有纯粹的相信与热爱才能将这个领域深耕了数十年,直到后来 AI 时代的来临。
而这一切,Hint0n 都做到了。
0x03
Hint0n主要从事神经网络和机器学习的研究,在AI领域做出过许多重要贡献,其中最著名的当属他在神经网络领域所做的研究工作。

他在20世纪80年代就已经开启了反向传播算法(Back Propagation, BP算法)的研究,并将其应用于神经网络模型的训练中。这一算法被广泛应用于语音识别、图像识别和自然语言处理等领域。

除此之外,Hint0n还在卷积神经网络(Convolutional Neural Networks,CNN)、深度置信网络(Deep Belief Networks,DBN)、递归神经网络(Recursive Neural Networks,RNN)、胶囊网络(Capsule Network)等领域做出了重要贡献。
2013年,Hint0n加入Google,同时把机器学习相关的很多技术带进了谷歌,同时融合到谷歌的多项业务之中。

2019年3月,ACM公布了2018年度的图灵奖得主。
图灵奖大家都知道,是计算机领域的国际最高奖项,也被誉为“计算机界的诺贝尔奖”。
而Hint0n则与蒙特利尔大学计算机科学教授Yoshua Bengio和Meta首席AI科学家Yann LeCun一起因为研究神经网络而获得了该年度的图灵奖,以表彰他们在对应领域所做的杰出贡献。

除此之外,Hint0n在他的学术生涯中发表了数百篇论文,这些论文中提出了许多重要的理论和方法,涵盖了人工智能、机器学习、神经网络、计算机视觉等多个领域。
而且他的论文被引用的次数也是惊人,这对于这些领域的研究和发展都产生了重要的影响。

0x04
除了自身在机器学习方面的造诣很高,Hint0n同时也是一个优秀的老师。
当年为了扩大深度学习的圈子,Hint0n曾在多伦多大学成立过研究中心,专门接收有兴趣从事相关研究的年轻人,以至于现如今AI圈“半壁江山”都是他的“门生”。

Hint0n带过很多大牛学生,其中不少都被像苹果、Google等这类硅谷科技巨头所挖走,在对应的公司里领导着人工智能相关领域的研究。
这其中最典型的就是Ilya Sutskever,他是Hint0n的学生,同时他也是最近大名鼎鼎的OpenAI公司的联合创始人和首席科学家。

聊到这里,不得不感叹大佬们的创造力以及对这个领域所作出的贡献,同时也期待大佬们后续给大家带来更多精彩的故事。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7425848834456961051
前端自动化部署的极简方案
打开服务器连接,找到文件夹,删掉,找到打包的目录,ctrl + C, ctrl + v 。。。。
烦的要死。。内网开发,node 的 ssh2 依赖库一时半会还导不进来。
索性,自己写一个!
原生 NodeJS 代码,不需要引用任何第三方库 win10 及以上版本,系统自带ssh 命令行工具,如果没有,需要自行安装
首先,需要生成本地秘钥;
ssh-keygen
执行上述命令后,系统会提示你输入文件保存位置和密码,如果你想使用默认位置和密码,直接按回车接受即可。这将在默认的SSH目录~/.ssh/下生成两个文件:id_rsa(私钥)和id_rsa.pub(公钥)
开启服务端使用秘钥登录
一般文件位置位于 /etc/ssh/sshd_config 中,
找到下面两行 ,取消注释,值改为 yes
RSAAuthentication yes
PubkeyAuthentication yes
将秘钥添加到服务端:
打开服务端文件 /root/.ssh/authorized_keys 将公钥 粘贴到新的一行中
重启服务端 ssh 服务
sudo service ssh restart
编写自动化上传脚本(nodejs 脚本)
// 创建文件 ./build/Autoactic.js
const { exec, spawn } = require('child_process');
const fs= require('fs');
// C:/Users/admin/.ssh/server/ServiceOptions.json
// 此处储存本地连接服务端相关配置数据(目的为不将秘钥暴露给 Git 提交代码)
// {
// 服务端关键字(记录为哪个服务器)
// "Test90": {
// 服务器登录用户名
// "Target": "root@255.255.255.255",
// 本地证书位置(秘钥)
// "Pubkey": "C:/User/admin/.shh/server/file"
// }
// }
// 温馨提示 本机储存的秘钥需要调整权限,需要删除除了自己以外其他的全部用户
const ServiceOption = Json.parse(fs.readFileSync("C:/Users/admin/.ssh/server/ServiceOptions.json"), "utf-8");
// 本地项目文件路径(dist 打包后的实际路径)
const LocalPath = "D:/Code/rmgm/jilinres/jprmcrm/dev/admin/dist";
// 服务端项目路径
const ServerPath = "/home/rmgmuser/web/pmr";
// 运行单行命令 (scp 命令,上传文件使用)
const RunSSHCode = function (code) {
return new Promise((resolve, reject) => {
const process = exec(code, (error, sodut, stderr) => {
if (error) {
console.error(`执行错误: ${error}`)
reject();
return;
};
console.log(`sodut:${sodut}`);
if (stderr) {
console.error(`stderr:${stderr}`)
};
if (process && !process.killed){
process.kill();
};
setTimeout(()=>{
resolve();
},10);
})
})
}
// 执行服务端命令 (执行 ssh 命令行)
const CommandHandle(command) {
return new Promise((resolve, reject) => {
const child = spawn('ssh', ['-i', ServiceOption.Test90.Pubkey, '-o', 'StrictHostKeyChecking=no', ServiceOption.Test90.Target], {
stdio: ['pipe']
});
child.on('close',(err)=>{
console.log(`--close--:${err}`);
if (err === 0) {
setTimeout(()=>{ resolve() },10)
} else {
reject();
}
})
child.on('error',(err)=>{
console.error(`--error--:${err}`)
});
console.log(`--command--:${command}`);
child.stdin.end(command);
child.stdout.on('data',(data)=>{
console.log(`Stdout:${data}`);
})
child.stderr.on('data',(data)=>{
console.log(`Stdout:${data}`);
})
}
};
// 按照顺序执行代码
!(async function (CommandHandle, RunSSHCode){
try {
console.log(`创建文件夹 => ${ServerPath}`);
await CommandHandle(`mkdir -p ${ServerPath}`);
console.log(`创建文件夹 => ${ServerPath} => 完成`);
console.log(`删除历史文件 => ${ServerPath}`);
await CommandHandle(`find ${ServerPath} -type d -exec rm -rf {} +`);
console.log(`删除历史文件 => ${ServerPath} => 完成`);
console.log(`上传本地文件 => 从 本地 ${LocalPath} 到 服务端 ${ServerPath}`);
await RunSSHCode(`scp -i ${serviceOption.Test90.pubkey} -r ${LocalPath}/ ${serviceOption.Test90.Target}:${ServerPath}/`);
console.log(`上传本地文件 => 从 本地 ${LocalPath} 到 服务端 ${ServerPath} => 完成`);
// 吉林环境个性配置 非必须(更改访问权限)
console.log(`更改访问权限 => ${ServerPath}`);
await CommandHandle(`chown -R rmgmuser:rmgmuser ${ServerPath}`);
console.log(`更改访问权限 => ${ServerPath} => 完成`);
} catch (error) {
console.error(`---END---`, error)
}
})(CommandHandle, RunSSHCode)
更改打包命令:
// package.json
{
// ....
"scripts": {
// .....
"uploadFile" : "node ./build/Autoactic.js"
// 原始的 build 改为 prebuild 命令
"preBuild" : "vue-cli-service build --mode production"
// npm 按顺序运行多个命令行
"build" : "npm run preBuild && npm run uploadFile"
// .....
}
//...
}
效果 打包结束后,直接上传到服务端。
有特殊需求,例如重启服务等,可自行添加。
来源:juejin.cn/post/7431591478508748811
居然还能这么画骑车线路?:手绘骑行路线 和 起始点途径点规划 导出GPX数据
写在前面
众所周知啊骑行🚲是一项非常健康、锻炼身体素质、拓宽视野的一项运动,在如今的2024年啊,越来越多的小孩年轻人等等各类人群都加入了骑行这项运动,哈哈本人也不例外😲,像今年的在中国举办的环广西更是加深了国内的骑行氛围,那导播的运镜水平相比去年越来越有观赏性。

在骑行过程中,其中一些想记录自己骑行数据的骑友会选择一些子骑行软件啊,比如像行者、Strva、捷安特骑行等等这些子,功能都非常丰富,他们都会有路线规划这个功能,大部分规划的方案我知道的大概分为 起始点规划、起始+途径点规划、GPX文件导入这三个主要功能前二者都是靠输入明确地点来确定路线,对于没有明确骑行目的地、选择困难症的一些朋友想必是一大考验,于是我就在想可不可以在地图上画一个大概的线路来生成地图?答案是可以的!
技术分析
灵感来自高德app中运动的大栏中有一个跑步线路规划这一功能,其中的绘制路线就是我们想要的功能,非常方便在地图上画一个大概的线路,然后自动帮你匹配道路上,但是高德似乎没有道路匹配得API?
但是!他有线路纠偏这个功能,这个API大概的功能就是把你历史行进过的线路纠偏到线路上,我们可以将画好得线路模拟出一段行驶轨迹,模拟好方向角、时间和速度,就可以了,这就是我们下面要做得手绘线路这个功能,规划线路那肯定不能只有这一种这么单一啦,再加上一个支持添加途径点得线路规划功能岂不美哉?
效果截图和源码地址
UI截图

导出效果截图

仓库地址 : github.com/zuowenwu/Li…
手绘线路+线路纠偏 代码实现
首先是要明确画线的操作,分三步:按下、画线和抬起的操作:
this.map.on("touchstart", (e) => {});// 准备画线
this.map.on("touchend", (e) => {});// 结束画线
this.map.on("touchmove");// 画线中
最重要的代码是画线的操作,此时我们设置为地图不可拖动,然后记录手指在地图上的位置即可:
//路径
this.path = []
// 监听滑动配合节流(这里节流是为了减少采样过快避免造成不必要的开销)
this.map.on("touchmove",_.throttle((e) => {
// 点
const position = [e.lnglat.lng, e.lnglat.lat];
// 数组长度为0则第一个点为起点marker
if (!this.path.length) {
this.path.push(position);
new this.AMap.Marker({ map: this.map, position: position });
return;
}
//满足两点创建线
if (this.path.length == 1) {
this.path.push(position);
this.line = new this.AMap.Polyline({
map: this.map,
path: this.path,
strokeColor: "#FF33FF",
strokeWeight: 6,
strokeOpacity: 0.5,
});
return;
}
//添加path
if (this.path.length > 1) {
this.path.push(position);
this.line.setPath(this.path);
}
}, 30)
);
线连接好了,可以导出了!。。吗?那肯定不是,手指在屏幕上画线肯定会和道路有很大的偏差的,我们可以使用高德的线路纠偏功能,因为该功能需要方向角、速度和时间,我们可以把刚刚模拟的线路path设置一下:
let arr = this.path.map((item, index) => {
// 默认角度
let angle = 0;
// 初始时间戳
let tm = 1478031031;
// 和下一个点的角度
if (this.path[index + 1]) {
// 计算与正北方向的夹角
const north = turf.bearing(turf.point([item[0], item[1]]), turf.point([item[0], item[1] + 1]));
// 使用正北方向的点
angle = north < 0 ? (360 + north) : north;
}
return {
x: item[0], //经度
y: item[1],//维度
sp: 10,//速度
ag: Number(angle).toFixed(0),//与正北的角度
tm: !index ? tm : 1 + index,//时间
};
});
这里的数据格式就是这样的:
要注意一下,第一个tm是初始的时间戳,后面都是在[index-1]+距离上次的时间,角度则是与正北方向的夹角而不是和上一个点的夹角,这里我差点弄混淆了

然后使用线路纠偏:
graspRoad.driving(arr, (error, result) => {
if (!error) {
var path2 = [];
var newPath = result.data.points;
for (var i = 0; i < newPath.length; i += 1) {
path2.push([newPath[i].x, newPath[i].y]);
}
var newLine = new this.AMap.Polyline({
path: path2,
strokeWeight: 8,
strokeOpacity: 0.8,
strokeColor: "#00f",
showDir: true,
});
this.map.add(newLine);
}
});
绿色是手动画的线,蓝色是纠偏到道路上的线,可以看的出来效果还是很不错的

OK!接下来是导出手机或者码表使用的GPX格式文件的代码,这里使用插件geojson-to-gpx,直接npm i geojson-to-gpx即可,然后导入使用,代码如下:
import GeoJsonToGpx from "@dwayneparton/geojson-to-gpx";
// 转为GeoJSON
const geoJSON = turf.lineString(this.path);
const options = {
metadata: {
name: "导出为GPX",
author: {
name: "XiaoZuoOvO",
},
},
};
//转为geoJSON
const gpxLine = GeoJsonToGpx(geoJSON, options);
const gpxString = new XMLSerializer().serializeToString(gpxLine);
const link = document.createElement("a");
link.download = "高德地图路线绘制.gpx";
const blob = new Blob([gpxString], { type: "text/xml" });
link.href = window.URL.createObjectURL(blob);
link.click();
ElMessage.success("导出PGX成功");
好的,以上就是手绘线路的大概功能!接下来是我们的线路规划功能。
起终点和定义途径点的线路规划 代码实现
虽然说这个功能大多骑行软件都有,但是我们要做就做好用的,支持添加途径点,我们这里使用高德的线路规划2.0,这个API支持添加途径点,再配合上elementplus的el-autocomplete配合搜索,搜索地点使用搜索POI2.0来搜索地点,以下是代码实现,完整代码在github
//html
<el-autocomplete
:prefix-icon="Location"
v-model.trim="start"
:trigger-on-focus="false"
clearable
size="large"
placement="top-start"
:fetch-suggestions="querySearch"
@select="handleSelectStart"
placeholder="起点" />
//js
//搜索地点函数
const querySearch = async (queryString, cb) => {
if (!queryString) return;
const res = await inputtips(queryString);//inputtips是封装好的
if (res.status == "1") {
const arr = res.tips.map((item) => {
return {
value: item.name,
name: item.name,
district: item.district,
address: item.address,
location: item.location,
};
});
cb(arr);
return;
}
};
//自行车路径规划函数
const plan = async () => {
path = [];
const res = await driving({
origin: startPositoin.value,//起点
destination: endPosition.value,//终点
cartype: 1, //电动车/自行车
waypoints: means.value.map((item) => item.location).join(";"),//途径点
});
if (res.status == "1") {
res.route.paths[0].steps.map((item) => {
const linestring = item.polyline;
path = path.concat(
linestring.split(";").map((item) => {
const arr = item.split(",");
return [Number(arr[0]), Number(arr[1])];
})
);
});
}
};
//......................完整代码见github..............................
搜索和规划效果截图:

以上就是手绘线路和途径点起点终点两个功能,接下来我们干个题外事,我们优化一下高德的 setCenter 和 setFitView,高德的动画太过于线性,我们这里模仿一下cesium和mapbox的效果,使用丝滑贝塞尔曲线来插值过度,配合高德Loca镜头动画
动画效果优化
首先是写一个setCenter,使用的时候传入即可,效果图和代码:

export function panTo(center, map, loca) {
const curZoom = map.getZoom();
const curPitch = map.getPitch();
const curRotation = map.getRotation();
const curCenter = [map.getCenter().lng, map.getCenter().lat];
const targZoom = 17;
const targPitch = 45;
const targRotation = 0;
const targCenter = center;
const route = [
{
pitch: {
value: targPitch,
duration: 2000,
control: [
[0, curPitch],
[1, targPitch],
],
timing: [0.420, 0.145, 0.000, 1],
},
zoom: {
value: targZoom,
duration: 2500,
control: [
[0, curZoom],
[1, targZoom],
],
timing: [0.315, 0.245, 0.405, 1.000],
},
rotation: {
value: targRotation,
duration: 2000,
control: [
[0, curRotation],
[1, targRotation],
],
timing: [1.000, 0.085, 0.460, 1],
},
center: {
value: targCenter,
duration: 1500,
control: [curCenter, targCenter],
timing: [0.0, 0.52, 0.315, 1.0],
},
},
];
// 如果用户有操作则停止动画
map.on("mousewheel", () => {
loca.animate.stop();
});
loca.viewControl.addAnimates(route, () => {});
loca.animate.start();
}
接下来是setFitView:

export function setFitView(center, zoom, map, loca) {
const curZoom = map.getZoom();
const curPitch = map.getPitch();
const curRotation = map.getRotation();
const curCenter = [map.getCenter().lng, map.getCenter().lat];
const targZoom = zoom;
const targPitch = 0;
const targRotation = 0;
const targCenter = center;
const route = [
{
pitch: {
value: targPitch,
duration: 1000,
control: [
[0, curPitch],
[1, targPitch],
],
timing: [0.23, 1.0, 0.32, 1.0],
},
zoom: {
value: targZoom,
duration: 2500,
control: [
[0, curZoom],
[1, targZoom],
],
timing: [0.13, 0.31, 0.105, 1],
},
rotation: {
value: targRotation,
duration: 1000,
control: [
[0, curRotation],
[1, targRotation],
],
timing: [0.13, 0.31, 0.105, 1],
},
center: {
value: targCenter,
duration: 1000,
control: [curCenter, targCenter],
timing: [0.13, 0.31, 0.105, 1],
},
},
];
// 如果用户有操作则停止动画
map.on("mousewheel", () => {
loca.animate.stop();
});
loca.viewControl.addAnimates(route, () => {});
loca.animate.start();
}
export function getFitCenter(points) {
let features = turf.featureCollection(points.map((point) => turf.point(point)));
let center = turf.center(features);
return [center.geometry.coordinates[0], center.geometry.coordinates[1]];
}
export function setFitCenter(points, map) {
const center = getFitCenter(points);
}
//使用
setFitView(getFitCenter(path), getFitZoom(map, path), map, loca);
结束
先贴上仓库地址:
github.com/zuowenwu/Li…
最后送几张自己拍的照片吧哈哈哈


来源:juejin.cn/post/7430616540804153394
Flutter 中在单个屏幕上实现多个列表

今天,我将提供一个实际的示例,演示如何在单个页面上实现多个列表,这些列表可以水平排列、网格格式、垂直排列,甚至是这些常用布局的组合。
下面是要做的:
实现
让我们从创建一个包含产品所有属性的产品模型开始。
class Product {
final String id;
final String name;
final double price;
final String image;
const Product({
required this.id,
required this.name,
required this.price,
required this.image,
});
factory Product.fromJson(Map json) {
return Product(
id: json['id'],
name: json['name'],
price: json['price'],
image: json['image'],
);
}
}
现在,我们将设计我们的小部件以支持水平、垂直和网格视图。
创建一个名为 HorizontalRawWidget 的新窗口小部件类,定义水平列表的用户界面。
import 'package:flutter/material.dart';
import 'package:multiple_listview_example/models/product.dart';
class HorizontalRawWidget extends StatelessWidget {
final Product product;
const HorizontalRawWidget({Key? key, required this.product})
: super(key: key);
@override
Widget build(BuildContext context) {
return Padding(
padding: const EdgeInsets.only(
left: 15,
),
child: Container(
width: 125,
decoration: BoxDecoration(
color: Colors.white, borderRadius: BorderRadius.circular(12)),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Padding(
padding: const EdgeInsets.fromLTRB(5, 5, 5, 0),
child: ClipRRect(
borderRadius: BorderRadius.circular(12),
child: Image.network(
product.image,
height: 130,
fit: BoxFit.contain,
),
),
),
Expanded(
child: Padding(
padding: const EdgeInsets.all(8.0),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Expanded(
child: Text(product.name,
maxLines: 2,
overflow: TextOverflow.ellipsis,
style: const TextStyle(
color: Colors.black,
fontSize: 12,
fontWeight: FontWeight.bold)),
),
Row(
crossAxisAlignment: CrossAxisAlignment.end,
children: [
Text("\$${product.price}",
style: const TextStyle(
color: Colors.black, fontSize: 12)),
],
),
],
),
),
)
],
),
),
);
}
}
设计一个名为 GridViewRawWidget 的小部件类,定义单个网格视图的用户界面。
import 'package:flutter/material.dart';
import 'package:multiple_listview_example/models/product.dart';
class GridViewRawWidget extends StatelessWidget {
final Product product;
const GridViewRawWidget({Key? key, required this.product}) : super(key: key);
@override
Widget build(BuildContext context) {
return Container(
padding: const EdgeInsets.all(5),
decoration: BoxDecoration(
color: Colors.white, borderRadius: BorderRadius.circular(10)),
child: Column(
children: [
AspectRatio(
aspectRatio: 1,
child: ClipRRect(
borderRadius: BorderRadius.circular(10),
child: Image.network(
product.image,
fit: BoxFit.fill,
),
),
)
],
),
);
}
}
最后,让我们为垂直视图创建一个小部件类。
import 'package:flutter/material.dart';
import 'package:multiple_listview_example/models/product.dart';
class VerticalRawWidget extends StatelessWidget {
final Product product;
const VerticalRawWidget({Key? key, required this.product}) : super(key: key);
@override
Widget build(BuildContext context) {
return Container(
margin: const EdgeInsets.symmetric(horizontal: 15, vertical: 5),
padding: const EdgeInsets.symmetric(horizontal: 10, vertical: 10),
color: Colors.white,
child: Row(
children: [
Image.network(
product.image,
width: 78,
height: 88,
),
const SizedBox(
width: 15,
),
Expanded(
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Text(
product.name,
style: const TextStyle(fontSize: 12, color: Colors.black, fontWeight: FontWeight.bold),
),
SizedBox(
height: 5,
),
Text("\$${product.price}",
style: const TextStyle(color: Colors.black, fontSize: 12)),
],
),
)
],
),
);
}
}
现在是时候把所有的小部件合并到一个屏幕中了,我们先创建一个名为“home_page.dart”的页面,在这个页面中,我们将使用一个横向的 ListView、纵向的 ListView 和 GridView。
import 'package:flutter/material.dart';
import 'package:multiple_listview_example/models/product.dart';
import 'package:multiple_listview_example/utils/product_helper.dart';
import 'package:multiple_listview_example/views/widgets/gridview_raw_widget.dart';
import 'package:multiple_listview_example/views/widgets/horizontal_raw_widget.dart';
import 'package:multiple_listview_example/views/widgets/title_widget.dart';
import 'package:multiple_listview_example/views/widgets/vertical_raw_widget.dart';
class HomePage extends StatelessWidget {
const HomePage({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
List products = ProductHelper.getProductList();
return Scaffold(
backgroundColor: const Color(0xFFF6F5FA),
appBar: AppBar(
centerTitle: true,
title: const Text("Home"),
),
body: SingleChildScrollView(
child: Container(
padding: const EdgeInsets.symmetric(vertical: 20),
child: Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
const TitleWidget(title: "Horizontal List"),
const SizedBox(
height: 10,
),
SizedBox(
height: 200,
child: ListView.builder(
shrinkWrap: true,
scrollDirection: Axis.horizontal,
itemCount: products.length,
itemBuilder: (BuildContext context, int index) {
return HorizontalRawWidget(
product: products[index],
);
}),
),
const SizedBox(
height: 10,
),
const TitleWidget(title: "Grid View"),
Container(
padding:
const EdgeInsets.symmetric(horizontal: 15, vertical: 10),
child: GridView.builder(
gridDelegate:
const SliverGridDelegateWithFixedCrossAxisCount(
crossAxisCount: 2,
crossAxisSpacing: 13,
mainAxisSpacing: 13,
childAspectRatio: 1),
itemCount: products.length,
shrinkWrap: true,
physics: const NeverScrollableScrollPhysics(),
itemBuilder: (BuildContext context, int index) {
return GridViewRawWidget(
product: products[index],
);
}),
),
const TitleWidget(title: "Vertical List"),
ListView.builder(
itemCount: products.length,
shrinkWrap: true,
physics: const NeverScrollableScrollPhysics(),
itemBuilder: (BuildContext context, int index) {
return VerticalRawWidget(
product: products[index],
);
}),
],
),
),
),
);
}
}
我使用了一个 SingleChildScrollView widget 作为代码中的顶部根 widget,考虑到我整合了多个布局,如水平列表、网格视图和垂直列表,我将所有这些 widget 包装在一个 Column widget 中。
挑战在于如何处理多个滚动部件,因为在上述示例中有两个垂直滚动部件:一个网格视图和一个垂直列表视图。为了禁用单个部件的滚动行为, physics 属性被设置为 const NeverScrollableScrollPhysics()。取而代之的是,使用顶层根 SingleChildScrollView`` 来启用整个内容的滚动。此外,SingleChildScrollView上的shrinkWrap属性被设置为true`,以确保它能紧紧包裹其内容,只占用其子控件所需的空间。
Github 链接:github.com/tarunaronno…
来源:juejin.cn/post/7302070112638468147
flutter3-douyin:基于flutter3.x+getx+mediaKit短视频直播App应用
经过大半个月的爆肝式开发输出,又一个跨端新项目Flutter-Douyin短视频正式完结了。

flutter3_douyin基于最新跨平台技术flutter3.19.2开发手机端仿抖音app实战项目。

实现了类似抖音全屏沉浸式上下滑动视频、左右滑动切换页面模块,直播间进场/礼物动画,聊天等模块功能。

使用技术
- 编辑器:vscode
- 技术框架:flutter3.19.2+dart3.3.0
- 路由/状态插件:get: ^4.6.6
- 本地缓存服务:get_storage: ^2.1.1
- 图片预览插件:photo_view: ^0.14.0
- 刷新加载:easy_refresh^3.3.4
- toast轻提示:toast^0.3.0
- 视频套件:media_kit: ^1.1.10+1


项目结构

前期需要配置好flutter和dart sdk环境。如果使用vscode编辑器,可以安装一些flutter语法插件。

更多的开发api资料,大家可以去官网查阅就行。
flutter.dev/
flutter.cn/
pub.flutter-io.cn/
http://www.dartcn.com/





该项目涉及到的技术知识还是蛮多的。下面主要介绍一些短视频及直播知识,至于其它知识点,大家可以去看看之前分享的flutter3聊天项目文章。
http://www.cnblogs.com/xiaoyan2017…
http://www.cnblogs.com/xiaoyan2017…
flutter主入口lib/main.dart
import 'dart:io';
import 'package:flutter/material.dart';
import 'package:get/get.dart';
import 'package:get_storage/get_storage.dart';
import 'package:media_kit/media_kit.dart';
import 'utils/index.dart';
// 引入布局模板
import 'layouts/index.dart';
import 'binding/binding.dart';
// 引入路由管理
import 'router/index.dart';
void main() async {
// 初始化get_storage
await GetStorage.init();
// 初始化media_kit
WidgetsFlutterBinding.ensureInitialized();
MediaKit.ensureInitialized();
runApp(const MyApp());
}
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return GetMaterialApp(
title: 'FLUTTER3 DYLIVE',
debugShowCheckedModeBanner: false,
theme: ThemeData(
colorScheme: ColorScheme.fromSeed(seedColor: const Color(0xFFFE2C55)),
useMaterial3: true,
// 修正windows端字体粗细不一致
fontFamily: Platform.isWindows ? 'Microsoft YaHei' : null,
),
home: const Layout(),
// 全局绑定GetXController
initialBinding: GlobalBindingController(),
// 初始路由
initialRoute: Utils.isLogin() ? '/' : '/login',
// 路由页面
getPages: routePages,
// 错误路由
// unknownRoute: GetPage(name: '/404', page: Error),
);
}
}
flutter3自定义底部凸起导航

采用 bottomNavigationBar 组件实现页面模块切换。通过getx状态管理联动控制底部导航栏背景颜色。导航栏中间图标/图片按钮,使用了 Positioned 组件实现功能。
return Scaffold(
backgroundColor: Colors.grey[50],
body: pageList[pageCurrent],
// 底部导航栏
bottomNavigationBar: Theme(
// Flutter去掉BottomNavigationBar底部导航栏的水波纹
data: ThemeData(
splashColor: Colors.transparent,
highlightColor: Colors.transparent,
hoverColor: Colors.transparent,
),
child: Obx(() {
return Stack(
children: [
Container(
decoration: const BoxDecoration(
border: Border(top: BorderSide(color: Colors.black54, width: .1)),
),
child: BottomNavigationBar(
backgroundColor: bottomNavigationBgcolor(),
fixedColor: FStyle.primaryColor,
unselectedItemColor: bottomNavigationItemcolor(),
type: BottomNavigationBarType.fixed,
elevation: 1.0,
unselectedFontSize: 12.0,
selectedFontSize: 12.0,
currentIndex: pageCurrent,
items: [
...pageItems
],
onTap: (index) {
setState(() {
pageCurrent = index;
});
},
),
),
// 自定义底部导航栏中间按钮
Positioned(
left: MediaQuery.of(context).size.width / 2 - 15,
top: 0,
bottom: 0,
child: InkWell(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
// Icon(Icons.tiktok, color: bottomNavigationItemcolor(centerDocked: true), size: 32.0,),
Image.asset('assets/images/applogo.png', width: 32.0, fit: BoxFit.contain,)
// Text('直播', style: TextStyle(color: bottomNavigationItemcolor(centerDocked: true), fontSize: 12.0),)
],
),
onTap: () {
setState(() {
pageCurrent = 2;
});
},
),
),
],
);
}),
),
);
flutter3实现抖音滑动效果


return Scaffold(
extendBodyBehindAppBar: true,
appBar: AppBar(
forceMaterialTransparency: true,
backgroundColor: [1, 2, 3].contains(pageVideoController.pageVideoTabIndex.value) ? null : Colors.transparent,
foregroundColor: [1, 2, 3].contains(pageVideoController.pageVideoTabIndex.value) ? Colors.black : Colors.white,
titleSpacing: 1.0,
leading: Obx(() => IconButton(icon: Icon(Icons.menu, color: tabColor(),), onPressed: () {},),),
title: Obx(() {
return TabBar(
controller: tabController,
tabs: pageTabs.map((v) => Tab(text: v)).toList(),
isScrollable: true,
tabAlignment: TabAlignment.center,
overlayColor: MaterialStateProperty.all(Colors.transparent),
unselectedLabelColor: unselectedTabColor(),
labelColor: tabColor(),
indicatorColor: tabColor(),
indicatorSize: TabBarIndicatorSize.label,
unselectedLabelStyle: const TextStyle(fontSize: 16.0, fontFamily: 'Microsoft YaHei'),
labelStyle: const TextStyle(fontSize: 16.0, fontFamily: 'Microsoft YaHei', fontWeight: FontWeight.w600),
dividerHeight: 0,
labelPadding: const EdgeInsets.symmetric(horizontal: 10.0),
indicatorPadding: const EdgeInsets.symmetric(horizontal: 5.0),
onTap: (index) {
pageVideoController.updatePageVideoTabIndex(index); // 更新索引
pageController.jumpToPage(index);
},
);
}),
actions: [
Obx(() => IconButton(icon: Icon(Icons.search, color: tabColor(),), onPressed: () {},),),
],
),
body: Column(
children: [
Expanded(
child: Stack(
children: [
/// 水平滚动模块
PageView(
// 自定义滚动行为(支持桌面端滑动、去掉滚动条槽)
scrollBehavior: PageScrollBehavior().copyWith(scrollbars: false),
scrollDirection: Axis.horizontal,
controller: pageController,
onPageChanged: (index) {
pageVideoController.updatePageVideoTabIndex(index); // 更新索引
setState(() {
tabController.animateTo(index);
});
},
children: [
...pageModules
],
),
],
),
),
],
),
);





flutter实现直播功能

// 商品购买动效
Container(
...
),
// 加入直播间动效
const AnimationLiveJoin(
joinQueryList: [
{'avatar': 'assets/images/logo.png', 'name': 'andy'},
{'avatar': 'assets/images/logo.png', 'name': 'jack'},
{'avatar': 'assets/images/logo.png', 'name': '一条咸鱼'},
{'avatar': 'assets/images/logo.png', 'name': '四季平安'},
{'avatar': 'assets/images/logo.png', 'name': '叶子'},
],
),
// 送礼物动效
const AnimationLiveGift(
giftQueryList: [
{'label': '小心心', 'gift': 'assets/images/gift/gift1.png', 'user': 'Jack', 'avatar': 'assets/images/avatar/uimg2.jpg', 'num': 12},
{'label': '棒棒糖', 'gift': 'assets/images/gift/gift2.png', 'user': 'Andy', 'avatar': 'assets/images/avatar/uimg6.jpg', 'num': 36},
{'label': '大啤酒', 'gift': 'assets/images/gift/gift3.png', 'user': '一条咸鱼', 'avatar': 'assets/images/avatar/uimg1.jpg', 'num': 162},
{'label': '人气票', 'gift': 'assets/images/gift/gift4.png', 'user': 'Flower', 'avatar': 'assets/images/avatar/uimg5.jpg', 'num': 57},
{'label': '鲜花', 'gift': 'assets/images/gift/gift5.png', 'user': '四季平安', 'avatar': 'assets/images/avatar/uimg3.jpg', 'num': 6},
{'label': '捏捏小脸', 'gift': 'assets/images/gift/gift6.png', 'user': 'Alice', 'avatar': 'assets/images/avatar/uimg4.jpg', 'num': 28},
{'label': '你真好看', 'gift': 'assets/images/gift/gift7.png', 'user': '叶子', 'avatar': 'assets/images/avatar/uimg7.jpg', 'num': 95},
{'label': '亲吻', 'gift': 'assets/images/gift/gift8.png', 'user': 'YOYO', 'avatar': 'assets/images/avatar/uimg8.jpg', 'num': 11},
{'label': '玫瑰', 'gift': 'assets/images/gift/gift12.png', 'user': '宇辉', 'avatar': 'assets/images/avatar/uimg9.jpg', 'num': 3},
{'label': '私人飞机', 'gift': 'assets/images/gift/gift16.png', 'user': 'Hison', 'avatar': 'assets/images/avatar/uimg10.jpg', 'num': 273},
],
),
// 直播弹幕+商品讲解
Container(
margin: const EdgeInsets.only(top: 7.0),
height: 200.0,
child: Row(
crossAxisAlignment: CrossAxisAlignment.end,
children: [
Expanded(
child: ListView.builder(
padding: EdgeInsets.zero,
itemCount: liveJson[index]['message']?.length,
itemBuilder: (context, i) => danmuList(liveJson[index]['message'])[i],
),
),
SizedBox(
width: isVisibleGoodsTalk ? 7 : 35,
),
// 商品讲解
Visibility(
visible: isVisibleGoodsTalk,
child: Column(
...
),
),
],
),
),
// 底部工具栏
Container(
margin: const EdgeInsets.only(top: 7.0),
child: Row(
...
),
),

flutter直播通过 SlideTransition 组件实现直播进场动画。
return SlideTransition(
position: animationFirst ? animation : animationMix,
child: Container(
alignment: Alignment.centerLeft,
margin: const EdgeInsets.only(top: 7.0),
padding: const EdgeInsets.symmetric(horizontal: 7.0,),
height: 23.0,
width: 250,
decoration: const BoxDecoration(
gradient: LinearGradient(
begin: Alignment.centerLeft,
end: Alignment.centerRight,
colors: [
Color(0xFF6301FF), Colors.transparent
],
),
borderRadius: BorderRadius.horizontal(left: Radius.circular(10.0)),
),
child: joinList!.isNotEmpty ?
Text('欢迎 ${joinList![0]['name']} 加入直播间', style: const TextStyle(color: Colors.white, fontSize: 14.0,),)
:
Container()
,
),
);
class _AnimationLiveJoinState extends State<AnimationLiveJoin> with TickerProviderStateMixin {
// 动画控制器
late AnimationController controller = AnimationController(
vsync: this,
duration: const Duration(milliseconds: 500), // 第一个动画持续时间
);
late AnimationController controllerMix = AnimationController(
vsync: this,
duration: const Duration(milliseconds: 1000), // 第二个动画持续时间
);
// 动画
late Animation<Offset> animation = Tween(begin: const Offset(2.5, 0), end: const Offset(0, 0)).animate(controller);
late Animation<Offset> animationMix = Tween(begin: const Offset(0, 0), end: const Offset(-2.5, 0)).animate(controllerMix);
Timer? timer;
// 是否第一个动画
bool animationFirst = true;
// 是否空闲
bool idle = true;
// 加入直播间数据列表
List? joinList;
@override
void initState() {
super.initState();
joinList = widget.joinQueryList!.toList();
runAnimation();
animation.addListener(() {
if(animation.status == AnimationStatus.forward) {
debugPrint('第一个动画进行中');
idle = false;
setState(() {});
}else if(animation.status == AnimationStatus.completed) {
debugPrint('第一个动画结束');
animationFirst = false;
if(controllerMix.isCompleted || controllerMix.isDismissed) {
timer = Timer(const Duration(seconds: 2), () {
controllerMix.forward();
debugPrint('第二个动画开始');
});
}
setState(() {});
}
});
animationMix.addListener(() {
if(animationMix.status == AnimationStatus.forward) {
setState(() {});
}else if(animationMix.status == AnimationStatus.completed) {
animationFirst = true;
controller.reset();
controllerMix.reset();
if(joinList!.isNotEmpty) {
joinList!.removeAt(0);
}
idle = true;
// 执行下一个数据
runAnimation();
setState(() {});
}
});
}
void runAnimation() {
if(joinList!.isNotEmpty) {
// 空闲状态才能执行,防止添加数据播放状态混淆
if(idle == true) {
if(controller.isCompleted || controller.isDismissed) {
setState(() {});
timer = Timer(Duration.zero, () {
controller.forward();
});
}
}
}
}
@override
void dispose() {
controller.dispose();
controllerMix.dispose();
timer?.cancel();
super.dispose();
}
}
以上只是介绍了一部分知识点,限于篇幅就先介绍这么多,希望有所帮助~
juejin.cn/post/731918…

来源:juejin.cn/post/7349542148733960211
我穿越回2013年,拿到一台旧电脑,只为给Android2.3设备写一个时钟程序
昨天收拾屋子,翻出一台 lenovo A360e ,其搭载联了发科单核芯片(MT6567)的3G智能(Android 2.3.6)手机,上市于2012年,于2017年停产。其屏幕尺寸为3.5英寸,分辨率是480x320像素。具备重力感应、光线感应和距离传感器。
然而,现在是2024年。几乎没有什么应用可以在Android2.3上面跑了。
所以,打开 AndroidStudio,新建一个项目。

完犊子了,最低只支持Android5.0!
好吧,我立刻坐进时光机,穿越到2013年,拿到当年我的一台旧电脑。上面有Android2.2的开发环境。
新建一个 Android 2.2 的项目。

接下来就是 xml 布局。对于习惯 jetpack components的人来讲,xml布局简直就是一坨屎。但是没办法,为了能在 Android 2.3 上面跑,只好硬着头搞了。
首先画一个简单的布局图:

看起来有点复杂,其实一点也不简单。
但是,可以先做上下结构:

<FrameLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="#000"
tools:context="org.deviceartist.clock.FullscreenActivity" >
<LinearLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:orientation="vertical" >
</LinearLayout>
</FrameLayout>
然后在下面的结构中,再分出一个左右结构:

<FrameLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="#000"
tools:context="org.deviceartist.clock.FullscreenActivity" >
<LinearLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:orientation="vertical" >
<LinearLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:gravity="center_horizontal" >
</LinearLayout>
<LinearLayout
android:layout_width="match_parent"
android:layout_height="250sp"
android:gravity="center_vertical" >
</LinearLayout>
</LinearLayout>
</FrameLayout>
然后按照布局图写 xml 的 layout 文件:
<FrameLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:background="#000"
tools:context="org.deviceartist.clock.FullscreenActivity" >
<LinearLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:orientation="vertical" >
<LinearLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:gravity="center_horizontal" >
<TextView
android:id="@+id/tab1"
android:layout_width="50sp"
android:layout_height="30sp"
android:layout_weight="1"
android:gravity="left"
android:padding="0dp"
android:text="STAT"
android:textColor="@color/green"
android:textSize="22sp" />
<TextView
android:id="@+id/tab2"
android:layout_width="50sp"
android:layout_height="30sp"
android:layout_weight="1"
android:gravity="center"
android:padding="0dp"
android:text="INV"
android:textColor="@color/green"
android:textSize="22sp" />
<TextView
android:id="@+id/tab3"
android:layout_width="50sp"
android:layout_height="30sp"
android:layout_weight="2"
android:gravity="center"
android:padding="0dp"
android:text="DATA"
android:textColor="@color/green"
android:textSize="22sp" />
<TextView
android:id="@+id/tab4"
android:layout_width="50sp"
android:layout_height="30sp"
android:layout_weight="1"
android:gravity="center"
android:padding="0dp"
android:text="MAP"
android:textColor="@color/green"
android:textSize="22sp" />
<TextView
android:id="@+id/tab5"
android:layout_width="50sp"
android:layout_height="30sp"
android:layout_weight="1"
android:gravity="right"
android:padding="0dp"
android:text="TERMUX"
android:textColor="@color/green"
android:textSize="22sp" />
</LinearLayout>
<LinearLayout
android:layout_width="match_parent"
android:layout_height="250sp"
android:gravity="center_vertical" >
<TextView
android:id="@+id/textViewTime"
android:layout_width="210sp"
android:layout_height="200sp"
android:textSize="100sp" />
<TextView
android:id="@+id/textViewTimeS"
android:gravity="center"
android:layout_width="50sp"
android:layout_height="150sp"
android:textSize="20sp" />
<org.deviceartist.clock.MyCanvas
android:id="@+id/myCanvas"
android:layout_width="200sp"
android:layout_height="200sp" />
</LinearLayout>
</LinearLayout>
</FrameLayout>
相应的 java 代码
package org.deviceartist.clock;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.Timer;
import org.deviceartist.clock.util.SystemUiHider;
import android.annotation.SuppressLint;
import android.annotation.TargetApi;
import android.app.Activity;
import android.graphics.Typeface;
import android.os.Build;
import android.os.Bundle;
import android.os.Handler;
import android.view.MotionEvent;
import android.view.View;
import android.view.View.OnClickListener;
import android.view.Window;
import android.view.WindowManager;
import android.widget.Button;
import android.widget.TextView;
public class FullscreenActivity extends Activity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
requestWindowFeature(Window.FEATURE_NO_TITLE);
if (Build.VERSION.SDK_INT < 16) {
getWindow().setFlags(WindowManager.LayoutParams.FLAG_FULLSCREEN,WindowManager.LayoutParams.FLAG_FULLSCREEN);
}
setContentView(R.layout.activity_fullscreen);
Typeface typeface = Typeface.createFromAsset(this.getAssets(), "fonts/font.ttf");
final TextView textViewTime = (TextView) findViewById(R.id.textViewTime);
final TextView textViewTimeS = (TextView) findViewById(R.id.textViewTimeS);
final MyCanvas c = (MyCanvas) findViewById(R.id.myCanvas);
textViewTime.setTextColor(0xff5CB31D);
textViewTime.setTypeface(typeface);
textViewTimeS.setTextColor(0xff5CB31D);
textViewTimeS.setTypeface(typeface);
final Handler handler = new Handler();
Runnable runnable = new Runnable(){
@Override
public void run() {
String currentTime = new SimpleDateFormat("HH\nmm",Locale.getDefault()).format(new Date());
textViewTime.setText(currentTime);
String currentTimeS = new SimpleDateFormat("ss",Locale.getDefault()).format(new Date());
textViewTimeS.setText(currentTimeS);
handler.postDelayed(this, 1000);
}
};
handler.postDelayed(runnable, 0);
final Handler handler2 = new Handler();
Runnable runnable2 = new Runnable(){
@Override
public void run() {
c.next();
handler.postDelayed(this, 100);
}
};
handler2.postDelayed(runnable2, 100);
}
}
知识点:
1、定时器
final Handler handler = new Handler();
Runnable runnable = new Runnable(){
@Override
public void run() {
//todo
}
};
handler.postDelayed(runnable, 0);
2、Canvas画布就是自定义的View类
关键代码:
package org.deviceartist.clock;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.Locale;
import android.content.Context;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.graphics.Canvas;
import android.graphics.Color;
import android.graphics.Matrix;
import android.graphics.Paint;
import android.os.Handler;
import android.util.AttributeSet;
import android.view.View;
public class MyCanvas extends View {
private Paint paint;
Canvas canvas;
public MyCanvas(Context context) {
super(context);
init();
}
public MyCanvas(Context context, AttributeSet attrs) {
super(context, attrs);
init();
}
public MyCanvas(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
init();
}
private void init() {
paint = new Paint();
paint.setColor(0xff5CB31D);
paint.setStyle(Paint.Style.FILL);
}
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
}
}
全部代码:
package org.deviceartist.clock;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.Locale;
import android.content.Context;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.graphics.Canvas;
import android.graphics.Color;
import android.graphics.Matrix;
import android.graphics.Paint;
import android.os.Handler;
import android.util.AttributeSet;
import android.view.View;
public class MyCanvas extends View {
private int index = 0;
ArrayList<Bitmap> bitmaps = new ArrayList<>();
Bitmap voltage;
Bitmap nuclear;
Bitmap shield;
Bitmap aim;
Bitmap gun;
Bitmap helmet;
private Paint paint;
Canvas canvas;
public MyCanvas(Context context) {
super(context);
init();
// TODO Auto-generated constructor stub
}
public MyCanvas(Context context, AttributeSet attrs) {
super(context, attrs);
init();
}
public MyCanvas(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
init();
}
private void init() {
voltage = BitmapFactory.decodeResource(getResources(),
R.drawable.voltage);
nuclear = BitmapFactory.decodeResource(getResources(),
R.drawable.nuclear);
shield = BitmapFactory.decodeResource(getResources(),
R.drawable.shield);
aim = BitmapFactory.decodeResource(getResources(),
R.drawable.aim);
gun = BitmapFactory.decodeResource(getResources(),
R.drawable.gun);
helmet = BitmapFactory.decodeResource(getResources(),
R.drawable.helmet);
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy1));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy2));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy3));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy4));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy5));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy6));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy7));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy8));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy9));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy10));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy11));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy12));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy13));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy14));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy15));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy16));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy17));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy18));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy19));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy10));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy11));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy12));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy13));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy14));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy15));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy16));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy17));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy18));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy19));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy20));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy21));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy22));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy23));
bitmaps.add(BitmapFactory.decodeResource(getResources(),
R.drawable.boy24));
paint = new Paint();
paint.setColor(0xff5CB31D); // 设置圆形的颜色
paint.setStyle(Paint.Style.FILL); // 设置填充样式
}
void next() {
index += 1;
index += 1;
if (index == 24) {
index = 0;
}
invalidate();
}
protected void onDraw(Canvas canvas) {
this.canvas = canvas;
super.onDraw(canvas);
Bitmap bitmap = bitmaps.get(index);
int w = bitmap.getWidth();
int h = bitmap.getHeight();
// 获取View的中心点坐标
int x = getWidth() / 2 - w/2;
int y = getHeight() / 2 - h/2;
canvas.drawBitmap(bitmap, x, y, paint);
canvas.drawLine(10, 20, 55, 20, paint);
canvas.drawLine(55, 20, 90, 70, paint);
canvas.drawBitmap(shield, 10, 30, paint);
canvas.drawLine(50, getHeight()/2, 100, getHeight()/2, paint);
canvas.drawText("98%", 50, getHeight()/2-10, paint);
canvas.drawBitmap(voltage, 10, getHeight()/2-30, paint);
canvas.drawLine(10, getHeight()-30, 90, getHeight()-30, paint);
canvas.drawLine(90, getHeight()-30, 100, getHeight()-80, paint);
canvas.drawBitmap(gun, 10, getHeight()-90, paint);
canvas.drawLine(getWidth()-30, 20, getWidth(), 20, paint);
canvas.drawLine(getWidth()-30, 20, getWidth()-90, 70, paint);
canvas.drawBitmap(aim, getWidth()-40, 30, paint);
canvas.drawLine(getWidth()-110, getHeight()/2, getWidth()-50, getHeight()/2, paint);
canvas.drawText("9.9", getWidth()-80, getHeight()/2-10, paint);
canvas.drawBitmap(nuclear, getWidth()-50, getHeight()/2-30, paint);
canvas.drawLine(getWidth()-100, getHeight()-80, getWidth()-70, getHeight()-30, paint);
canvas.drawLine(getWidth()-70, getHeight()-30, getWidth(), getHeight()-30, paint);
canvas.drawBitmap(helmet, getWidth()-70, getHeight()-90, paint);
}
}
最终效果

源码地址:
git.sr.ht/~devicearti…
来源:juejin.cn/post/7431455141084528650
用js手撸了一个zip saver
背景介绍
最近公司有个需求,要在浏览器端生成一大堆的 word 文件并保存到本地。
生成 word 文件直接用了docx这个库,嗖的一下很快就搞定了。但是交付给需求方的时候他们却说生成的文件乱糟糟的放在下载目录里面他们看着烦,而且还要手动整理每一批文件,问我能不能搞成一个压缩包。我一听这个要求,心想:不就是调的包的事吗,二话不说马上就答应了。
然而,,,,,
搜了很久,也没有找到直接马上就可以用的 js 库来将一大堆文件直接变成一个压缩包。又搜了一下 zip 的文件格式内容,发现好像不是很复杂。那就自己来搞一个包吧。
最近公司有个需求,要在浏览器端生成一大堆的 word 文件并保存到本地。
生成 word 文件直接用了docx这个库,嗖的一下很快就搞定了。但是交付给需求方的时候他们却说生成的文件乱糟糟的放在下载目录里面他们看着烦,而且还要手动整理每一批文件,问我能不能搞成一个压缩包。我一听这个要求,心想:不就是调的包的事吗,二话不说马上就答应了。
然而,,,,,
搜了很久,也没有找到直接马上就可以用的 js 库来将一大堆文件直接变成一个压缩包。又搜了一下 zip 的文件格式内容,发现好像不是很复杂。那就自己来搞一个包吧。
太长不看?直接用 zip-saver
一、zip 文件格式简介
zip 文件大致可以分成三个个部分:
- 文件部分
- 文件部分包含了所有的文件内容,每个文件都有一个文件头,文件头包含了文件的元信息,比如文件名、文件大小、文件的压缩方式等等。
- 中央目录部分
- 中央目录部分包含了所有文件的元信息,比如文件名、文件大小、文件的压缩方式等等。
- 目录结束标识 - 目录结束标识标识了中央目录部分的结束。包含了中央目录的开始位置、中央目录的大小等信息。
 图片来自:en.wikipedia.org/wiki/ZIP_(f…
图片来自:en.wikipedia.org/wiki/ZIP_(f…
对于每一个文件,他在 zip 中包含三部分
- 本地文件头( Local File Header)-- 图片来自:goodapple.top/archives/70…

- 文件内容
- 数据描述符( Data descriptor)-- 图片来自:goodapple.top/archives/70…
zip 文件大致可以分成三个个部分:
- 文件部分
- 文件部分包含了所有的文件内容,每个文件都有一个文件头,文件头包含了文件的元信息,比如文件名、文件大小、文件的压缩方式等等。
- 中央目录部分
- 中央目录部分包含了所有文件的元信息,比如文件名、文件大小、文件的压缩方式等等。
- 目录结束标识 - 目录结束标识标识了中央目录部分的结束。包含了中央目录的开始位置、中央目录的大小等信息。 图片来自:en.wikipedia.org/wiki/ZIP_(f…
对于每一个文件,他在 zip 中包含三部分
- 本地文件头( Local File Header)-- 图片来自:goodapple.top/archives/70…
- 文件内容
- 数据描述符( Data descriptor)-- 图片来自:goodapple.top/archives/70…

数据描述符是可选的,当本地文件头中没有指明 CRC-32 校验码和压缩前后的长度时,才需要数据描述符
中央目录区的数据构成是这样的 -- 图片来自:goodapple.top/archives/70…

目录结束标识的数据构成是这样的 -- 图片来自:goodapple.top/archives/70…

二、代码实现
有了上面的信息之后,不难想到生成一个 zip 文件的步骤:
- 生成文件部分
- 构造固定的文件信息头
- 追加文件内容
- 计算文件的 CRC32 校验码
- 生成数据描述符
- 生成中央目录部分
- 构造固定的中央文件信息头
- 计算文件的偏移量
- 生成目录结束标识
- 构造固定的目录结束标识
- 计算中央目录的大小和偏移
1. 生成本地文件头(local file header)
根据local file header的结构,我们很容易得知:一个local file header 的大小是 30 + n + m 个字节
其中n是文件名的长度,m是扩展字段的长度,在这里我们不考虑扩展字段,那么最终大小就是30 + n
在js中我可以直接用Uint8Array来存储一个字节,又因为 zip 是采用小端序,为了方便操作, 那么local file header变量就可以这样定义:
const length = 30 + filenameLength
const localFileHeaderBytes = new Uint8Array(length)
// 使用DataView可以更方便的操作小端序数据
const localFileHeaderDataView = new DataView(localFileHeaderBytes.buffer)
定义完 local file header 变量后我们就可以往里面塞一些东西了
// local file header 的起始固定值为 0x04034b50
// setUint第一个参数为偏移量,第二个参数是值,第三个参数为true表示以小端序存储
localFileHeaderDataView.setUint32(0, 0x04034b50, true)
// 设置最低要求的版本号为 0x14
localFileHeaderDataView.setUint16(4, 0x0014, true)
// 设置通用标志位为 0x0808
// 0x0808 使用UTF-8编码且文件头中不包含CRC32和文件大小信息
localFileHeaderDataView.setUint16(6, 0x0808, true)
// 设置压缩方式为 0x0000 表示不压缩
localFileHeaderDataView.setUint16(8, 0x0000, true)
// 设置最后修改时间, 这里假设最后修改时间为当前时间
const lastModified = new Date().getTime()
// last modified time
localFileHeader.setUint16(
10,
(date.getUTCHours() << 11) |
(date.getUTCMinutes() << 5) |
(date.getUTCSeconds() / 2)
)
// last modified date
localFileHeader.setUint16(
12,
date.getUTCDate() |
((date.getUTCMonth() + 1) << 5) |
((date.getUTCFullYear() - 1980) << 9)
)
// 设置文件名的长度,这里假设文件名已经转换成了字节数组nameBytes
localFileHeaderDataView.setUint16(26, nameBytes.length, true)
// 设置文件名
localFileHeaderBytes.set(nameBytes, 30)
到此,一个local file header就生成好了
2. 文件内容追加
文件内容追加这一步很简单,这里我们不考虑压缩文件,直接将文件转为Uint8Array 并计算文件的 CRC32 校验码,然后追加到local file header后面即可
const crc = new CRC32()
// 获取file数据备用
const fileBytes = await file.arrayBuffer()
crc.append(fileBytes)
3. 数据描述符(Data descriptor)生成
数据描述符用来表示文件压缩与的结束,根据他的编码格式,他包含的信息只有四个:固定的标识符、CRC-32校验码,压缩前的大小,压缩后的大小,这里我们暂且不考虑数据的压缩, 要生成他也很简单:
const dataDescriptor = new Uint8Array(16)
const dataDescriptorDataView = new DataView(dataDescriptor.buffer)
// 0x08074b50 是数据描述符的固定标识字段
dataDescriptorDataView.setUint32(0, 0x08074b50, true)
// CRC-32校验码
dataDescriptorDataView.setUint32(4, crc.value, true)
// 压缩前的大小
dataDescriptorDataView.setUint32(8, fileBytes.length, true)
// 压缩后的大小
dataDescriptorDataView.setUint32(12, fileBytes.length, true)
至此,一个文件在zip中所有的信息就已经都可以生成了,接下来就需要生成中央目录信息了
4. 中央目录区生成
根据上面的图,我们知道, 中央目录区也是由一个一个的文件头组成,每一个文件头对对应着一个真实文件的信息,每个文件信息大小是46 + n + m + k,其中n是文件名称的大小,m是扩展字段的大小,k是文件注释的大小。 在这里,我们可以暂时不必管扩展字段,先计算一下中央目录区的总大小:
// 假设有一个文件列表为flieList
const wholeLength = flieList.reduce((acc, file) => {
// 文件名长度
const nameBufferLength = textEncoder.encode(file.name).length
// 假设文件有注释字段comment
const commentBufferLength = textEncoder.encode(file.comment).length
// 累加起来
return acc + 46 + nameBufferLength + commentBufferLength
}, 0)
然后,创建一个变量存储中央目录区的数据
const centraHeader = new Uint8Array(wholeLength)
const centraHeaderDataView = new DataView(dataDescriptor.buffer)
接下来就可以通过循环,将所有文件的信息都写入中央目录区
// 假设有这样一个数据结构存储了文件的信息
type FileZipInfo = {
localFileHeader: Uint8Array
fileBytes: Uint8Array
dataDescriptor: Uint8Array
filename: string
fileComment: string
}
// offset表示中央目录信息中,当前文件相对于中央目录起始位置的偏移
// entryOffset 表示一个文件的信息(本地文件头+文件数据+数据描述符)相对于整个zip文件起始位置的偏移
let entryOffset = 0
for (
let i = 0, offset = 0;
i < fileZipInfoList.length;
i++
) {
const fileZipInfo = fileZipInfoList[i]
// 设置固定标识符号
centraHeaderDataView.setUint32(offset, 0x02014b50, true)
// 设置压缩版本号
centraHeaderDataView.setUint16(offset + 4, 0x0014, true)
// 因为中央目录信息中的文件数据一大部份都是本地文件头数据的冗余,所以可以直接复制过来使用
centraHeader.set(fileZipInfo.localFileHeader.slice(4, 30), offset + 6)
const textEncoder = new TextEncoder()
// 注释长度
const commentBuffer = textEncoder.encode(fileZipInfo.fileComment)
centraHeaderDataView.setUint16(offset + 32, commentBuffer.length, true)
// 对应的本地文件头在整个zip文件中的偏移
centraHeaderDataView.setUint32(offset + 42, entryOffset, true)
// 文件名
const filenameBuffer = textEncoder.encode(fileZipInfo.filename)
centraHeaderDataView.setUint16(filenameBuffer, offset + 46)
// 扩展字段暂时不管,下一个直接设置文件注释
bufferDataView.set(commentBuffer, offset + 46 + filenameBuffer.length)
// 更新offset的值
// 下一个中央目录中的文件的offset的值为此次生成的文件信息大小 + 当前的offset
// 也就是
offset = offset + 46 + commentBuffer.length + filenameBuffer.length
// entryOffset 的值累加为当前文件信息在整个zip文件中的大小 + 当前的 entryOffset
entryOffset += fileZipInfo.localFileHeader.length + fileZipInfo.fileBytes.length + fileZipInfo.dataDescriptor.length
}
最后,再生成 目录结束标识
// 目录结束标识的大小为22 + 注释信息(注释信息先忽略)
const eocdBytes = new Uint8Array(22)
const eocdDataView = new DataView(eocd.buffer)
// 固定标识值
eocdDataView.setUint32(eocdOffset, 0x06054b50, true)
// 和分卷有关的数据都可以忽略,他主要是为了处理一个zip文件跨磁盘存储的问题,现在基本没有这种场景
// 当前分卷号
eocdDataView.setUint16(4, 0, true)
// 中央目录开始分卷号
eocdDataView.setUint16(6, 0, true)
// 当前分卷的总文件数量
eocdDataView.setUint16(8, fileZipInfoList.length, true)
// 总文件数量
eocdDataView.setUint16(10, fileZipInfoList.length, true)
// 中央目录的总大小
eocdDataView.setUint32(12, wholeLength, true)
// 中央目录在整个zip文件中的目录偏移
eocdDataView.setUint32(16, entryOffset, true)
// 最后是注释的信息,先忽略
5. 拼接完整数据
完成了上面所有的步骤之后,我们只需要把数据都拼接起来就可以了
// 所有文件数据都存储在 fileZipInfoList中
// 组合文件数据
const fileBytesList = fileZipInfoList.map(fileZipInfo => {
return new Uint8Array([
...fileZipInfo.localFileHeader,
...fileZipInfo.fileBytes,
...fileZipInfo.dataDescriptor
])
})
const zipBlob = new Blob([
...fileBytesList,
centraHeader,
eocdBytes
],{
type: 'application/zip'
})
ok,搞定!
6. 完整的实现
三、总结
经过上面的步骤,我们就可以生成一个zip文件了,当然,这里只是一个简单的实现,zip文件格式还有很多细节,比如压缩算法、加密压缩等等,这里都没有涉及到,后面有时间再来完善吧。
参考资料:
来源:juejin.cn/post/7430660826900185097
用Flutter写可以,但架构可不能少啊
一个平台语言的开发优秀与否,取决于两个维度,一是语言的设计,这是语言天然的优劣,另一个测试程序员。
后者决定的东西太多太多了,如果后者对于某个平台类型的语言开发使用不当,那将导致非常严重的后果,屎山的形成、开发排期的无限增大、稳定性差到太平洋等等问题。
我之前写过一个Fluter的项目,但是写时Flutter还没有发布正式版本,到今天Flutter已经成为一棵参天大树,无数的同僚前辈已经用Flutter密谋生计。这两天看了一下相关的语法、技术, 决定对其进行二次熟悉。
从哪方面入手,成了我的第一个问题,看文档?记不住,看视频? 没时间,做项目?没需求(相关的)。所以决定探究一下开篇的问题,如何在新语言领域做好开发。
进来我一直在关注架构方面的技术,到没想着成为架构师(因为我太菜),只是想成为一个懂点架构的程序员,让自己的代码有良好的扩展性、维护性、可读性、健壮性,以此来洗涤自我心灵,让自己每天过的舒服点,因为好的代码看起来确实会让人心情愉悦,让领导喜笑颜开,让钱包增厚那么一奶奶。
一、 常见的Flutter 架构模式
其实还是老生常谈的几个问题,最终的目的就是: “高内聚,低耦合”,满足这个条件 让程序运行就可以了。
Fluter中常见的架构模式有以下几种:
- MVC(Model-View-Controller): 这是一种传统的软件设计架构,将应用程序分为模型(Model)、视图(View)和控制器(Controller)三个部分。在 Flutter 中,你可以使用类似于
StatefulWidget、State和其他 Dart 类来实现 MVC 架构。 - MVVM(Model-View-ViewModel): MVVM 是一种流行的设计模式,将视图(View)、模型(Model)和视图模型(ViewModel)分离。在 Flutter 中,你可以使用类似于
Provider、GetX、Riverpod等状态管理库来实现 MVVM 架构。 - Bloc(Business Logic Component): Bloc 是一种基于事件驱动的架构,用于管理应用程序的业务逻辑和状态。它将应用程序分为视图、状态和事件三个部分,并使用流(Stream)来处理数据流。Flutter 官方推荐使用
flutter_bloc库来实现 Bloc 架构。 - Redux: Redux 是一种状态管理模式,最初是为 Web 应用程序设计的,但也可以在 Flutter 中使用。它通过单一不可变的状态树来管理应用程序的状态,并使用纯函数来处理状态变化。在 Flutter 中,你可以使用
flutter_redux或provider与redux库结合使用来实现 Redux 架构。 - GetX: GetX 是一个轻量级的、高性能的状态管理和路由导航库,它提供了一个全面的解决方案,包括状态管理、依赖注入、路由导航等。GetX 非常适合中小型 Flutter 应用程序的开发,可以减少代码量并提高开发效率。
当然MVP也不是不行。
对于Flutter来讲不仅有熟悉的MXXX, 还有几种新的模式。今天就先从最简单的MVC模式开始探究。
二、MVC架构实现Flutter开发
什么是MVC这里简单复习一下:
MVC(Model-View-Controller)是一种软件设计架构,用于将应用程序分为三个主要组件:模型(Model)、视图(View)和控制器(Controller)。这种架构的目的是将应用程序的逻辑部分与用户界面部分分离,以便于管理和维护。
以下是 MVC 架构中各组件的功能和作用:
- 模型(Model): 模型是应用程序的数据和业务逻辑部分。它负责管理数据的状态和行为,并提供对数据的操作接口。模型通常包括数据存储、数据验证、数据处理等功能。模型与视图和控制器相互独立,不直接与用户界面交互。
- 视图(View): 视图是应用程序的用户界面部分,负责向用户展示数据和接收用户输入。视图通常包括界面布局、样式设计、用户交互等功能。视图与模型和控制器相互独立,不直接与数据交互。
- 控制器(Controller): 控制器是模型和视图之间的中介,负责处理用户输入和更新模型数据。它接收用户的操作请求,并根据需要调用模型的方法来执行相应的业务逻辑,然后更新视图以反映数据的变化。控制器与模型和视图都有联系,但它们之间不直接通信。
在Flutter中 M无关紧要,只需要参与整个逻辑,让代码统一就可以了,封装一个对应的base,管理释放资源啊 公共数据也是可以的。
2.1 设计base
首先使用命令在Flutter项目中创建一个base, 创建时按照Flutter的工程类型做好组件的职责选择: Flutter工程中,通常有以下几种工程类型,下面分别简单概述下:
1. Flutter Application
标准的Flutter App工程,包含标准的Dart层与Native平台层
2. Flutter Module
Flutter组件工程,仅包含Dart层实现,Native平台层子工程为通过Flutter自动生成的隐藏工程
3. Flutter Plugin
Flutter平台插件工程,包含Dart层与Native平台层的实现
4. Flutter Package
Flutter纯Dart插件工程,仅包含Dart层的实现,往往定义一些公共Widget
很明显 我们需要的base 创建为package 即可:
flutter create -t package base
然后在项目的pubspec.yaml 中的
dependencies:
flutter:
sdk: flutter
base: //此处添加配置
path: ../base
- base 结构

View部分按照Flutter的常用开发模式(可变状态组件)设计为state + view 组合成View
他们的关系如下图:

代码:
2.1.1 base 代码
- model;
abstract class MvcBaseModel {
void dispose();
}
- controller
abstract class MvcBaseController {
late M _model;
final _dataUpdatedController = StreamController.broadcast();
MvcBaseController() {
_model = createModel();
}
void updateData(M model) {
_dataUpdatedController.add(model);
}
M createModel();
StreamController get streamController => _dataUpdatedController;
M get model => _model;
}
- view. (view)
abstract class MvcBaseView extends MvcBaseController> extends StatefulWidget {
final C controller;
const MvcBaseView({Key? key, required this.controller});
@override
State<StatefulWidget> createState() {
print("create state ${controller.streamController == null}");
MvcBaseState mvcBaseState = create();
mvcBaseState.createStreamController(controller.streamController);
return mvcBaseState;
}
MvcBaseState create();
}
- view(state)
abstract class MvcBaseState extends MvcBaseModel, T extends StatefulWidget>
extends State<T> {
late StreamController<M> streamController;
late StreamSubscription<M> _streamSubscription;
@override
Widget build(BuildContext context);
@override
void initState() {
super.initState();
print("init state");
_streamSubscription = this.streamController.stream.listen((event) {
setState(() {
observer(event);
});
});
}
void createStreamController(StreamController<M> streamController) => this.streamController = streamController;
void observer(M event);
@override
void dispose() {
_streamSubscription.cancel();
streamController.close();
super.dispose();
}
}
三、使用Demo
- 入口:
void main() => runApp(MyApp());
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(primarySwatch: Colors.blue),
home: CounterView(controller: CounterController()),
);
}
}
- view + state
class CounterView extends MvcBaseView<CounterController> {
const CounterView({super.key,required CounterController controller})
: super(controller: controller);
@override
MvcBaseState<MvcBaseModel, StatefulWidget> create() => _CounterViewState();
}
class _CounterViewState extends MvcBaseState<CounterModel, CounterView> {
var count = 0;
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('Counter App (MVC)'),
),
body: Center(
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
const Text(
'Counter Value = :',
style: TextStyle(fontSize: 20),
),
Text(
'${count}',
style: const TextStyle(fontSize: 50, fontWeight: FontWeight.bold),
),
const SizedBox(height: 20),
ElevatedButton(
onPressed: () {
debugPrint("---11-->");
// setState(() {
widget.controller.incrementCounter();
// });
},
child: Text('Test Add111'))
],
),
),
);
}
@override
void observer(CounterModel event) {
count = event.counter;
}
}
- model
class CounterModel extends MvcBaseModel{
int _counter = 0;
int get counter => _counter;
increment() {
_counter++;
}
@override
void dispose() {
}
}
- controller
class CounterController extends MvcBaseController
@override
CounterModel createModel() => CounterModel();
void incrementCounter() {
model.increment();
updateData(model);
}
int get counter => model.counter;
}
四: 总结
通过实现基于MVC架构的Flutter应用程序,我们可以看到以下几点:
- 模型(Model)的作用: 模型负责管理应用程序的数据状态和行为。在我们的示例中,CounterModel负责管理计数器的数值状态,并提供了增加计数器数值的方法。
- 控制器(Controller)的作用: 控制器是模型和视图之间的中介,负责处理用户输入并更新模型数据。在示例中,CounterController接收用户点击事件,并调用CounterModel的方法来增加计数器数值,然后通知视图更新数据。
- 视图(View)的作用: 视图是应用程序的用户界面部分,负责向用户展示数据和接收用户输入。在示例中,CounterView负责展示计数器的数值,并提供了一个按钮来触发增加计数器数值的操作。
- MVC架构的优势: MVC架构能够将应用程序的逻辑部分与用户界面部分分离,使得代码结构更清晰,易于维护和扩展。通过单独管理模型、视图和控制器,我们可以更好地组织代码,并实现高内聚、低耦合的设计原则。
- 基础组件的设计: 我们设计了一个基础组件库,包括模型(MvcBaseModel)、控制器(MvcBaseController)、视图(MvcBaseView)和视图状态(MvcBaseState)。这些基础组件可以帮助我们快速构建符合MVC架构的Flutter应用程序,并实现模块化、可复用的代码结构。
通过理解和应用MVC架构,我们可以更好地组织和管理Flutter应用程序的代码,提高代码质量和开发效率。同时,我们也可以通过学习和探索其他架构模式,如MVVM、Bloc、Redux等,来丰富我们的架构设计思路,进一步提升应用程序的性能和用户体验。
后续将探索MVVM等其他架构模式。
来源:juejin.cn/post/7366557738266558498
决定了,做一个纯前端的pptx预览库
大家好,我是前端林叔。
今年我github的vue-office文档预览库star已经达到了3600+,不过这个库没什么技术含量,只不过是站在前人的肩膀上简单封装了下。目前该库包含了word(docx)、excel(xls、xlsx)和pdf的预览,唯独缺少ppt文档的预览,很多朋友都提过,能不能做一个ppt的预览库,我一直也在纠结。
为什么迟迟不做ppt的预览库
说到底,还是收益的问题,我做这件事的收益到底是什么?
一般来说做一个开源库我们会有以下几个收益:
- 证明自己的技术实力,在找工作时增加自己的竞争力(回答面试官经常问的那个问题,怎么证明你的技术深度?)
- 锻炼自己的技术能力,做一个好的开源项目需要一定的技术功底,在实战中提升自己是最快的方式
- 反哺开源社区,用爱发电,提升社区知名度
- 做得好了还可以考虑商业化赚钱
我迟迟没有做这件事就是没有想好我到底要什么,而且今年一直在忙着写掘金小册,也确实没有时间,另外就是在做vue-office库的时候,真切的感觉到,用爱发电是不长久的,如果没有利益驱动,是很难坚持下去的,试问,在如今行情这么不好的情况下,怎么平衡工作和自己的业余爱好,每个周末都去免费解决用户的问题,谁能长久地坚持下去呢?
为什么又决定做了
最近正好小册已经完结了(估计最近就会上线),自己也闲下来了,突然感觉失去了方向,不知道做啥了,整个人都变得迷茫,而且能预期到明年裁员的大刀就要砍到自己头上了,也要为后面的面试做下准备了,毕竟年龄大了,没有拿得出手的技术作品,想必后面也是很难的,把近期想做的事情排了个优先级,觉得这个事情还是比较重要的,于是决定开干!
但对于选择开源还是闭源纠结了很久,开源的话比较容易积累star,但主要还是精神支持,对长期利益来看是好的;不过开源后代码很容易被人拷贝改做他用,将自己辛辛苦苦几个月的成果免费拿走,还是不太甘心(这里忏悔下自己的格局)。我最终决定还是闭源,打赏一定金额(比如50以上)可以索取源码,源码不得用于开源,仅做学习和自己项目使用,后期可以考虑开发企业版,通过license授权。
这么做肯定会被人骂的,不过没办法,免费的事情实在坚持不下去了。当然了,只是不免费开放源码,使用都是免费的,会把最终的库发布到npm。
可行性
对于pptx格式的文件,实际上可以看做一个压缩文件,我们把任意一个pptx文件的后缀改为zip,然后解压,就可以看到pptx文件的内容,大部分都是xml文件,我们可以通过分析这个xml中的内容来获取ppt文档的信息,文档符合Microsoft Open XML(简称OOXML)规范。而对于.ppt格式的文件则无法获取其具体格式,所以本库只支持.pptx格式的文件。

说起来容易,不过由于xml的格式比较晦涩难懂,分析过程还是非常痛苦的,下面是ppt中单个幻灯片的xml,可以体会下其中的复杂度。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<p:sld xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:p="http://schemas.openxmlformats.org/presentationml/2006/main">
<p:cSld>
<p:bg>
<p:bgPr>
<a:solidFill>
<a:schemeClr val="accent2">
<a:alpha val="34902"/>
</a:schemeClr>
</a:solidFill>
<a:effectLst/>
</p:bgPr>
</p:bg>
<p:spTree>
<p:nvGrpSpPr>
<p:cNvPr id="1" name=""/>
<p:cNvGrpSpPr/>
<p:nvPr/>
</p:nvGrpSpPr>
<p:grpSpPr>
<a:xfrm>
<a:off x="0" y="0"/>
<a:ext cx="0" cy="0"/>
<a:chOff x="0" y="0"/>
<a:chExt cx="0" cy="0"/>
</a:xfrm>
</p:grpSpPr>
<p:pic>
<p:nvPicPr>
<p:cNvPr id="2" name="图片 1">
<a:extLst>
<a:ext uri="{FF2B5EF4-FFF2-40B4-BE49-F238E27FC236}">
<a16:creationId xmlns:a16="http://schemas.microsoft.com/office/drawing/2014/main"
id="{92992223-295D-7122-C034-29375CD12672}"/>
</a:ext>
</a:extLst>
</p:cNvPr>
<p:cNvPicPr>
<a:picLocks noChangeAspect="1"/>
</p:cNvPicPr>
<p:nvPr/>
</p:nvPicPr>
<p:blipFill>
<a:blip r:embed="rId2"/>
<a:stretch>
<a:fillRect/>
</a:stretch>
</p:blipFill>
<p:spPr>
<a:xfrm>
<a:off x="1270000" y="635000"/>
<a:ext cx="1485900" cy="787400"/>
</a:xfrm>
<a:prstGeom prst="rect">
<a:avLst/>
</a:prstGeom>
</p:spPr>
</p:pic>
<p:pic>
<p:nvPicPr>
<p:cNvPr id="5" name="图片 4">
<a:extLst>
<a:ext uri="{FF2B5EF4-FFF2-40B4-BE49-F238E27FC236}">
<a16:creationId xmlns:a16="http://schemas.microsoft.com/office/drawing/2014/main"
id="{D071BB10-9D98-FEF0-768B-8E826152F476}"/>
</a:ext>
</a:extLst>
</p:cNvPr>
<p:cNvPicPr>
<a:picLocks noChangeAspect="1"/>
</p:cNvPicPr>
<p:nvPr/>
</p:nvPicPr>
<p:blipFill rotWithShape="1">
<a:blip r:embed="rId3"/>
<a:srcRect r="46000"/>
<a:stretch/>
</p:blipFill>
<p:spPr>
<a:xfrm>
<a:off x="0" y="0"/>
<a:ext cx="685800" cy="1270000"/>
</a:xfrm>
<a:prstGeom prst="rect">
<a:avLst/>
</a:prstGeom>
</p:spPr>
</p:pic>
<p:sp>
<p:nvSpPr>
<p:cNvPr id="3" name="矩形 2">
<a:extLst>
<a:ext uri="{FF2B5EF4-FFF2-40B4-BE49-F238E27FC236}">
<a16:creationId xmlns:a16="http://schemas.microsoft.com/office/drawing/2014/main"
id="{FC6BFD96-7710-5D5C-0E6D-5647BB89F8D0}"/>
</a:ext>
</a:extLst>
</p:cNvPr>
<p:cNvSpPr/>
<p:nvPr/>
</p:nvSpPr>
<p:spPr>
<a:xfrm>
<a:off x="7002462" y="2264229"/>
<a:ext cx="3110366" cy="522514"/>
</a:xfrm>
<a:prstGeom prst="rect">
<a:avLst/>
</a:prstGeom>
</p:spPr>
<p:style>
<a:lnRef idx="2">
<a:schemeClr val="accent1">
<a:shade val="15000"/>
</a:schemeClr>
</a:lnRef>
<a:fillRef idx="1">
<a:schemeClr val="accent1"/>
</a:fillRef>
<a:effectRef idx="0">
<a:schemeClr val="accent1"/>
</a:effectRef>
<a:fontRef idx="minor">
<a:schemeClr val="lt1"/>
</a:fontRef>
</p:style>
<p:txBody>
<a:bodyPr rtlCol="0" anchor="ctr"/>
<a:lstStyle/>
<a:p>
<a:pPr algn="ctr"/>
<a:endParaRPr kumimoji="1" lang="zh-CN" altLang="en-US">
<a:ln>
<a:solidFill>
<a:srgbClr val="FF0000"/>
</a:solidFill>
</a:ln>
</a:endParaRPr>
</a:p>
</p:txBody>
</p:sp>
</p:spTree>
<p:extLst>
<p:ext uri="{BB962C8B-B14F-4D97-AF65-F5344CB8AC3E}">
<p14:creationId xmlns:p14="http://schemas.microsoft.com/office/powerpoint/2010/main" val="760063892"/>
</p:ext>
</p:extLst>
</p:cSld>
<p:clrMapOvr>
<a:masterClrMapping/>
</p:clrMapOvr>
</p:sld>
怎么做好这个库
就像我在我的掘金小册中说的那样,做前端开发,首先要做的就是设计,必须先编写设计文档,然后再开发,现在我也是这么做的。
第一步:分析pptx中每个xml的含义

第二步:整体架构设计
我把这个库分成了三层(我在小册中提到的分层思维)

- PPTX Reader层:负责读取pptx中的内容,将其转为便于理解的格式,也就是自己定义的PPTX的对象
- PPTX Render层:负责进行pptx单个幻灯片的渲染,入参为上一步得到的PPTX对象,不同的渲染方式实现不同的渲染对象,比如我们可以开发一个HtmlRender,将其渲染成为html格式,或者开发一个Canvas Render将其渲染成为Canvas,而不是写死,这样扩展性也更好一些(小册中提到的前端扩展方法)
- PPTX Preview层:负责整个pptx文件的预览,比如是采用左右翻页展示还是一下把pptx的幻灯片都展示出来,都由这个层来决定。
其中文件读取是非常复杂的,面对这种复杂的大型项目,必须考虑采用面向对象的方式来组织代码(也是小册中提到的),我将 PPTX Reader层细化为如下几个类。
- PPTX: pptx类,存储pptx文档的信息,比如缩略图,尺寸大小等信息
- Theme: 主题类,存储pptx的主题信息
- Slide: 单个幻灯片类,存储幻灯片信息
- PicNode:图片类,用它表示幻灯片中的一个图片
- ShapeNode:形状类,用它表示幻灯片中的一个一个形状
- Node:不同节点的基类
- ...

第三步:搭建代码仓库
这次决定还是采用monorepo方式组织代码,其中技术栈包括 turbo + ts + jest单测 + rollup打包 + eslint 等。
目前进展
目前正在开发 PPTX Reader 层的相关代码,争取元旦前完成PPTX中基础功能的预览,有什么心得和进展随时给大家同步。
感兴趣的同学可以关注我或者仓库,小册近期也要上线了,到时候大家多关注支持。
来源:juejin.cn/post/7418389059287908404
为什么使用fetch时,有两个await?
为什么使用fetch时,有两个await?
提问
// first await
let response = await fetch("/some-url")
// second await
let myObject = await response.json()
你以前在使用fetch时,见过这两个await对吗?
有没有思考过,这是为什么?
思考
我们在浏览器中使用异步编程来,处理需要时间才能完成的任务(也就是异步任务),这样我们就不会阻塞用户界面。
等待 fetch 是有道理的。因为我们最好不要阻止 UI!
但是,我们到底为什么需要呢 await response.json() ?
解析 JSON 应该不会花费很长时间。 事实上,我们经常调用 JSON.parse("{"key": "value"}") ,这是一个同步调用。 那么,为什么 response.json() 返回 promise 而不是我们真正想要的呢?
这是怎么回事?
摘自 MDN 关于 Fetch API 的文章
https://developer.mozilla.org/en-US/docs/Web/API/Fetch_API#concepts_and_usage
fetch() 方法接受一个强制性参数,即你想要获取的资源的路径。 它返回一个 Promise,该 Promise 解析为该请求的 Response — 只要服务器使用 Headers 响应 — 即使服务器响应是 HTTP 错误状态。
因此,fetch 会在必须完全接收 body 之前解析响应。
查看前面的代码:
let response = await fetch("/some-url")
// At this point,
// 1. the client has received the headers
// 2. the body is (probably) still making its way over.
let myObject = await response.json()
// At this point,
// 1. the client has received the body
// 2. the client has tried to parse the body
// as json with the goal of making a JavaScript object
很明显,在整个正文到达之前访问 headers 是多么有用。
根据状态代码或其中一个标头,我们可能会决定根本不读取正文。
而 body 在 headers 之后到达实际上是我们已经习惯的。这就是浏览器中一切的工作方式。
HTML 通过网络缓慢发送,图像、字体等也是如此。
我想我只是被方法的名称弄糊涂了: response.json() .
有一个简单的节点服务器来演示这一点。相关代码都在这里
YouTube视频演示在这
http://www.youtube.com/watch?v=Ki6…
来源:juejin.cn/post/7432269413405769762
性能对比:为什么 Set.has() 比 Array.includes() 更快?
在 JavaScript 开发中,检查某个元素是否存在于集合中是一个常见的操作。对于这个任务,我们通常会使用两种方法:Set.has() 和 Array.includes()。尽管它们都能实现查找功能,但在性能上存在显著差异。今天我们就来探讨一下,为什么 Set.has() 通常比 Array.includes() 更快,特别是在查找大量元素时。
数据结构的差异:
SetvsArray
首先,要理解性能差异,我们需要了解
Set和Array在JavaScript中的底层实现原理。它们使用了不同的数据结构,这对查找操作的效率有着直接影响。
Set:哈希表的魔力
Set是一种集合数据结构,旨在存储唯一的值。JavaScript中的Set通常使用 哈希表 来实现。在哈希表中,每个元素都有一个唯一的哈希值,这个哈希值用于快速定位和访问该元素。这意味着,当我们使用Set.has()来检查某个元素时,JS引擎能够直接计算该元素的哈希值,从而迅速确定元素是否存在。查找操作的时间复杂度是O(1),即无论集合中有多少个元素,查找的时间几乎是恒定的。
Array:顺序遍历
与
Set不同,Array是一种有序的列表结构,元素按插入顺序排列。在数组中查找元素时,Array.includes()方法必须遍历数组的每一个元素,直到找到目标元素或确认元素不存在。这样,查找操作的时间复杂度是O(n),其中n是数组中元素的个数。也就是说,随着数组中元素数量的增加,查找所需的时间将线性增长。
性能差异:什么时候该用哪个?
在实际开发中,我们通常会选择根据数据的特性来选择
Set.has()或Array.includes()。但是,理解它们的性能差异有助于我们做出更加明智的决策。
小型数据集
对于较小的集合,性能差异可能不那么明显。在这种情况下,无论是
Set.has()还是Array.includes(),都能以接近常数时间完成操作,因为数据集本身就很小。因此,在小数据集的情况下,开发者更关心的是易用性和代码的简洁性,而不是性能。
例如,以下是对小型数据集的查找操作:
// 小型数据集
const smallSet = new Set([1, 2, 3, 4, 5]);
console.log(smallSet.has(3)); // true
const smallArray = [1, 2, 3, 4, 5];
console.log(smallArray.includes(3)); // true
在这个示例中,
Set.has()和Array.includes()都能快速找到元素3,两者的性能差异几乎不明显。

Set.has(Code 1)和 Array.includes(Code 2)代码性能分析。数据来源:CodePerf
大型数据集
当数据集变得更大时,
Set.has()的优势变得尤为明显。如果我们使用Array.includes()在一个包含上百万个元素的数组中查找一个目标元素,时间复杂度将变为O(n),查找时间会随着数组的大小而增长。
而
Set.has()在面对大数据集时,性能依然保持在O(1),因为它利用了哈希表的高效查找特性。下面是两个在大数据集下性能对比的例子:
// 大型数据集
const largeArray = Array.from({ length: 1000000 }, (_, i) => i);
const largeSet = new Set(largeArray);
const valueToFind = 999999;
console.time("Set.has");
console.log(largeSet.has(valueToFind)); // true
console.timeEnd("Set.has");
console.time("Array.includes");
console.log(largeArray.includes(valueToFind)); // true
console.timeEnd("Array.includes");
在这个例子中,当数据集非常大时,
Set.has()显示了明显的性能优势,而Array.includes()的执行时间会随着数组的大小而显著增加。

Set.has(Code 1)和 Array.includes(Code 2)代码性能分析。数据来源:CodePerf
重复元素的影响
Set本身就是一个集合,只允许存储唯一的元素,因此它天然会去除重复的元素。如果你在一个包含大量重复元素的数组中查找某个值,使用Set可以提高性能。因为在将数组转换为Set后,我们不必担心查找操作的冗余计算。
// 数组中有重复元素
const arrayWithDuplicates = [1, 2, 3, 1, 2, 3];
const uniqueSet = new Set(arrayWithDuplicates);
// 使用 Set 查找
console.log(uniqueSet.has(2)); // true
何时选择
Array.includes()
尽管
Set.has()在查找时的性能更优,但这并不意味着Array.includes()就没有用武之地。对于小型数据集、对顺序有要求或需要保留重复元素的场景,Array.includes()仍然是一个非常合适的选择。例如,数组保持元素的插入顺序,或者你需要查找重复元素时,数组仍然是首选。
总结
Set.has()性能较好,特别是在处理大型数据集时,其查找时间接近O(1)。Array.includes()在小型数据集或元素顺序敏感时可以正常工作,但随着数据量的增加,其时间复杂度为O(n)。- 在需要频繁查找元素且数据量较大的情况下,建议使用
Set。 - 对于较小数据集或有顺序要求的操作,
Array.includes()仍然是一个合适的选择。 - 因为构造
Set的过程本身就是遍历的过程,所以如果只用来查询一次的话,可以使用Array.includes()。但如果需要频繁查询,则建议使用Set,尤其是在处理较大的数据集时,性能优势更加明显。
通过理解这两种方法的性能差异,我们可以在编写
JavaScript程序时更加高效地处理数据查找操作,选择合适的数据结构来提升应用的性能。
来源:juejin.cn/post/7433458585147342882
基于Flutter实现的小说阅读器——BITReader ,相信我你也可以变成光!

前言
最近感觉自己有点颓废,左思右想后觉得不能这样浪费时间,天天来摆烂。受到了群友的激励以及最近自己喜欢看小说。就想我能不能自己也做一款小说阅读器出来呢。在最开始的时候花了一段时间写了一个版本。当时用的是一个开源的接口,当我写好后使用了两天接口挂了我就只有大眼瞪小眼了。之后在 FlutterCandies里面咨询了群友,发现了一种使用外部提供书籍数据源的方法可以避免数据来源挂掉,说干就干vscode启动!
项目地址
项目介绍
当前功能包含:
- 源搜索:使用内置数据来源进行搜索数据(后续更新:用户可以自行导入来源进行源搜索
- 收藏书架
- 阅读历史记录
- 阅读设置:字号设置,字体颜色更改,自定义阅读背景(支持调色板自定义选择,支持image设置为背景
- 主题设置:支持九种颜色的主题样式
- 书籍详情:展示书籍信息以及章节目录等书籍信息
支持平台
| 平台 | 是否支持 |
|---|---|
| Android | ✅ |
| IOS | ✅ |
| Windows | ✅ |
| MacOS | ✅ |
| Web | ❌ |
| Linux | ❌ |
项目截图





mac运行截图

windows运行截图

项目结构
lib
├── main.dart -- 入口
├── assets -- 本地资源生成
├── base -- 请求状态、页面状态
├── db -- 数据缓存
├── icons -- 图标
├── net -- 网络请求、网络状态
├── n_pages
├── detail -- 详情页
├── home -- 首页
├── search -- 全网搜索搜索页
├── history -- 历史记录
├── read -- 小说阅读
└── like -- 收藏书架
├── pages 已废弃⚠
├── home -- 首页
├── novel -- 小说阅读
├── search -- 全网搜索
├── category -- 小说分类
├── detail_novel -- 小说详情
├── book_novel -- 书架、站源
└── collect_novel -- 小说收藏
├── route -- 路由
└── theme -- 主题管理
└── themes -- 主题颜色-9种颜色
├── tools -- 工具类 、解析工具、日志、防抖。。。
└── widget -- 自定义组件、工具 、加载、状态、图片 等。。。。。。
阅读器主要包含的模块
- 阅读显示:文本解析,对文本进行展示处理
- 数据解析: 数据源的解析,以及数据来源的解析(目前只支持简单数据源格式解析、后续可能会更新更多格式解析
- 功能:阅读翻页样式、字号、背景、背景图、切换章节、收藏、历史记录、本地缓存等
阅读显示
阅读文本展示我用的是extended_text因为支持自定义效果很好。
实现的效果把文本中 “ ” 引用起来的文本自定义成我自己想要的效果样式。
class MateText extends SpecialText {
MateText(
TextStyle? textStyle,
SpecialTextGestureTapCallback? onTap, {
this.showAtBackground = false,
required this.start,
required this.color,
}) : super(flag, '”', textStyle, onTap: onTap);
static const String flag = '“';
final int start;
final Color color;
/// whether show background for @somebody
final bool showAtBackground;
@override
InlineSpan finishText() {
final TextStyle textStyle =
this.textStyle?.copyWith(color: color) ?? const TextStyle();
final String atText = toString();
return showAtBackground
? BackgroundTextSpan(
background: Paint()..color = Colors.blue.withOpacity(0.15),
text: atText,
actualText: atText,
start: start,
///caret can move int0 special text
deleteAll: true,
style: textStyle,
recognizer: (TapGestureRecognizer()
..onTap = () {
if (onTap != null) {
onTap!(atText);
}
}))
: SpecialTextSpan(
text: atText,
actualText: atText,
start: start,
style: textStyle,
recognizer: (TapGestureRecognizer()
..onTap = () {
if (onTap != null) {
onTap!(atText);
}
}));
}
}
class NovelSpecialTextSpanBuilder extends SpecialTextSpanBuilder {
NovelSpecialTextSpanBuilder({required this.color});
Color color;
set setColor(Color c) => color = c;
@override
SpecialText? createSpecialText(String flag,
{TextStyle? textStyle,
SpecialTextGestureTapCallback? onTap,
int? index}) {
if (flag == '') {
return null;
} else if (isStart(flag, AtText.flag)) {
return AtText(
textStyle,
onTap,
start: index! - (AtText.flag.length - 1),
color: color,
);
} else if (isStart(flag, MateText.flag)) {
return MateText(
textStyle,
onTap,
start: index! - (MateText.flag.length - 1),
color: color,
);
}
// index is end index of start flag, so text start index should be index-(flag.length-1)
return null;
}
}
数据解析编码格式转换
首先数据是有不同的编码格式,否则我们直接展示可能会导致乱码问题。
先把数据给根据查找到的编码类型来做单独的处理转换。
/// 解析html数据 解码 不同编码
static String parseHtmlDecode(dynamic htmlData) {
String resultData = gbk.decode(htmlData);
final charset = ParseSourceRule.parseCharset(htmlData: resultData) ?? "gbk";
if (charset.toLowerCase() == "utf-8" || charset.toLowerCase() == "utf8") {
resultData = utf8.decode(htmlData);
}
return resultData;
}
static String? parseCharset({
required String htmlData,
}) {
Document document = parse(htmlData);
List<Element> metaTags = document.getElementsByTagName('meta').toList();
for (Element meta in metaTags) {
String? charset = meta.attributes['charset'];
String content = meta.attributes['content'] ??
""; //<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
if (charset != null) {
return charset;
}
List<String> parts = content.split(';');
for (String part in parts) {
part = part.trim();
if (part.startsWith('charset=')) {
return part.split('=').last.trim();
}
}
}
return null;
}
数据结构解析-代码太多只展示部分
Document document = parse(htmlData);
//
List<Element> rootNodes = [];
if (rootSelector != null && rootSelector.isNotEmpty) {
//
List<String> rootParts = rootSelector.split(RegExp(r'[@>]'));
String initialPart = rootParts[0].trim();
//
if (initialPart.startsWith('class.')) {
String className = initialPart.split('.')[1];
rootNodes = document.getElementsByClassName(className).toList();
} else if (initialPart.startsWith('.')) {
String className = initialPart.substring(1);
rootNodes = document.getElementsByClassName(className).toList();
} else if (initialPart.startsWith('#')) {
String idSelector = initialPart.substring(1);
rootNodes = document.querySelectorAll('#$idSelector').toList();
} else if (initialPart.startsWith('id.')) {
String idSelector = initialPart.split('.')[1];
var element = document.querySelector('#$idSelector');
if (element != null) {
rootNodes.add(element);
}
} else if (initialPart.contains(' ')) {
String idSelector = initialPart.replaceAll(' ', ">");
var element = document.querySelector(idSelector);
if (element != null) {
rootNodes.add(element);
}
} else {
rootNodes = document.getElementsByTagName(initialPart).toList();
}
存储工具类 - 部分代码
/// shared_preferences
class PreferencesDB {
PreferencesDB._();
static final PreferencesDB instance = PreferencesDB._();
SharedPreferencesAsync? _instance;
SharedPreferencesAsync get sps => _instance ??= SharedPreferencesAsync();
/*** APP相关 ***/
/// 主题外观模式
///
/// system(默认):跟随系统 light:普通 dark:深色
static const appThemeDarkMode = 'appThemeDarkMode';
/// 多主题模式
///
/// default(默认)
static const appMultipleThemesMode = 'appMultipleThemesMode';
/// 字体大小
///
///
static const fontSize = 'fontSize';
/// 字体粗细
static const fontWeight = 'fontWeight';
/// 设置-主题外观模式
Future<void> setAppThemeDarkMode(ThemeMode themeMode) async {
await sps.setString(appThemeDarkMode, themeMode.name);
}
/// 获取-主题外观模式
Future<ThemeMode> getAppThemeDarkMode() async {
final String themeDarkMode =
await sps.getString(appThemeDarkMode) ?? 'system';
return darkThemeMode(themeDarkMode);
}
/// 设置-多主题模式
Future<void> setMultipleThemesMode(String value) async {
await sps.setString(appMultipleThemesMode, value);
}
/// 获取-多主题模式
Future<String> getMultipleThemesMode() async {
return await sps.getString(appMultipleThemesMode) ?? 'default';
}
/// 获取-fontsize 大小 默认18
Future<double> getNovelFontSize() async {
return await sps.getDouble(fontSize) ?? 18;
}
/// 设置 -fontsize 大小
Future<void> setNovelFontSize(double size) async {
await sps.setDouble(fontSize, size);
}
/// 设置-多主题模式
Future<void> setNovelFontWeight(NovelReadFontWeightEnum value) async {
await sps.setString(fontWeight, value.id);
}
/// 获取-多主题模式
Future<String> getNovelFontWeight() async {
return await sps.getString(fontWeight) ?? 'w300';
}
}
最后
特别鸣谢FlutterCandies糖果社区,也欢迎加入我们的大家庭。让我们一起学习共同进步
免责声明:本项目提供的源代码仅用学习,请勿用于商业盈利。
来源:juejin.cn/post/7433306628994940979
对于 Flutter 快速开发框架的思考

要打造一个Flutter的快速开发框架,首先要思考的事情是一个快速开发框架需要照顾到哪些功能点,经过2天的思考,我大致整理了一下需要的能力:
- 状态管理:很明显全局状态管理是不可或缺的,这个在前端领域上,几乎是一种不容置疑的方案沉淀,他就像人体的血液循环系统,连接了每个区域角落。
- 网络请求管理:这个是标配了,对外的窗口,一般来讲做选型上需要注意可以支持请求拦截,支持响应拦截,以及错误处理机制,方便做重试等等。
- 路由管理:可以说很多项目路由混乱不堪,导致难以维护,和这个功能脱不了干系,一般来讲,需要支持到页面参数传递,路由守卫的能力。
- UI组件库:在Flutter上,可能不太需要考虑这个,因为Flutter本身自己就是已这个为利刃的行家了,不过现在有些企业发布了自己的UI库,觉得可以跟一下。
- 数据持久化:对于用户的一些设置,个性化配置,通常需要存在本地。而且,有时候,我们在做性能优化的时候,需要缓存网络请求到本地,以便,可以实现秒开页面,因此这依然也是一个不可获取的基础模块。
- 依赖注入:很多情况下,为了便于管理和使用应用中的服务和数据模型,我们需要这个高级能力,但是属于偏高级点的能力了,所以是一个optional的,你可以不考虑。
- 国际化:支持多语言开发,现在App一般都还是挺注重这块的,而且最好是立项的时候就考虑进来,为后续的出海做准备,因为这个越到后面,处理起来工作量越大。
- 测试框架:支持单元测试、组件测试和集成测试,保证业务质量,自动化发现问题。
- 调试工具:帮助开发者快速定位和解决问题,排查性能问题。
- CI/CD集成:支持持续集成和持续部署的解决方案,简化应用的构建、测试和发布过程。
那么,基于上面的分析,我就开始做了一些选型,这里基本上就是按照官方Flutter Favorites ,里面推荐的来选了。因为这些建议的库都是目前Flutter社区中比较流行和受欢迎的,能够提供稳定和高效的开发体验。
1. 状态管理:Riverpod

- 库名: flutter_riverpod
- 描述: 一个提供编译时安全、测试友好和易于组合的状态管理库。
- 选择理由: Riverpod 是 Provider 的升级版,提供更好的性能和灵活性,但是说哪个更好,其实不能一概而论,毕竟不同的人会有不同的编码习惯,当然这里可以设计得灵活一些,具体全局状态管理可以替换,即便你想使用 GetX,或者是 flutter_bloc 也是 OK 的。
@riverpod
Future boredSuggestion(BoredSuggestionRef ref) async {
final response = await http.get(
Uri.https('boredapi.com/api/activit…'),
);
final json = jsonDecode(response.body);
return json['activity']! as String;
}
class Home extends ConsumerWidget {
@override
Widget build(BuildContext context, WidgetRef ref) {
final boredSuggestion = ref.watch(boredSuggestionProvider);
// Perform a switch-case on the result to handle loading/error states
return boredSuggestion.when(
loading: () => Text('loading'),
error: (error, stackTrace) => Text('error: $error'),
data: (data) => Text(data),
);
}
}
2. 网络请求管理:Dio
- 库名: dio
- 描述: 一个强大的Dart HTTP客户端,支持拦截器、全局配置、FormData、请求取消等。
- 选择理由: Dio 支持Restful API、拦截器和全局配置,易于扩展和维护。这个已经是老牌的网络请求库了,稳定的很,且支持流式传输,访问大模型也丝毫不马虎。
final rs = await dio.get(
url,
options: Options(responseType: ResponseType.stream), // Set the response type tostream.
);
print(rs.data.stream); // Response stream.
3. 路由管理:routemaster
- 库名: routemaster
- 描述: 提供声明式路由解决方案,支持参数传递、路由守卫等。
- 选择理由: url的方式访问,简化了路由管理的复杂度。
'/protected-route': (route) =>
canUserAccessPage()
? MaterialPage(child: ProtectedPage())
: Redirect('/no-access'),
4. UI组件库:tdesign_flutter
- 库名: tdesign_flutter
- 描述: 腾讯TDesign Flutter技术栈组件库,适合在移动端项目中使用。。
- 选择理由: 样式比原生的稍微好看且统一一些,大厂维护,减少一些在构建UI方面的复杂性。
5. 数据持久化:Hive

- 库名: hive
- 描述: 轻量级且高性能的键值对数据库。
- 选择理由: Hive 提供了高性能的读写操作,无需使用SQL即可存储对象。
var box = Hive.box('myBox');
box.put('name', 'David');
var name = box.get('name');
print('Name: $name');
6. 依赖注入:GetIt
- 库名: get_it
- 描述: 一个简单的服务注入,用于依赖注入。
- 选择理由: GetIt 提供了灵活的依赖注入方式,易于使用且性能高效。
final getIt = GetIt.instance;
void setup() {
getIt.registerSingleton(AppModel());
// Alternatively you could write it if you don't like global variables
GetIt.I.registerSingleton(AppModel());
}
MaterialButton(
child: Text("Update"),
onPressed: getIt().update // given that your AppModel has a method update
),
7. 国际化和本地化:flutter_localization
- 库名: flutter_localization
- 描述: Flutter官方提供的国际化和本地化支持。
- 选择理由: 官方支持,集成简单,覆盖多种语言。
8. 测试和调试:flutter_test, mockito
- 库名: flutter_test (内置), mockito
- 描述: flutter_test提供了丰富的测试功能,mockito用于模拟依赖。
- 选择理由: flutter_test是Flutter的官方测试库,mockito可以有效地模拟类和测试行为。
9. 日志系统:logger
- 库名: logger
- 描述: 提供简单而美观的日志输出。
- 选择理由: logger支持不同级别的日志,并且输出格式清晰、美观。
10. CI/CD集成
CI/CD集成通常涉及外部服务,如GitHub Actions、Codemagic等,而非Flutter库。
目录规划
前面已经做完了选型,下来我们可以确立一下我们快速开发框架的目录结构,我们给框架取名为fdflutter,顾名思义,就是fast development flutter,如下:
fdflutter/
├── lib/
│ ├── core/
│ │ ├── api/
│ │ │ └── api_service.dart
│ │ ├── di/
│ │ │ └── injection_container.dart
│ │ ├── localization/
│ │ │ └── localization_service.dart
│ │ ├── routing/
│ │ │ └── router.dart
│ │ └── utils/
│ │ └── logger.dart
│ ├── data/
│ │ ├── datasources/
│ │ │ ├── local_datasource.dart
│ │ │ └── remote_datasource.dart
│ │ └── repositories/
│ │ └── example_repository.dart
│ ├── domain/
│ │ ├── entities/
│ │ │ └── example_entity.dart
│ │ └── usecases/
│ │ └── get_example_data.dart
│ ├── presentation/
│ │ ├── pages/
│ │ │ └── example_page.dart
│ │ └── providers/
│ │ └── example_provider.dart
│ └── main.dart
├── test/
│ ├── data/
│ ├── domain/
│ └── presentation/
├── pubspec.yaml
└── README.md
在这个结构中,我保持了核心功能、数据层、领域层和表示层的划分:
- core/api/: 使用Dio来实现ApiService,处理所有网络请求。
- core/di/: 使用GetIt来实现依赖注入,注册和获取依赖。
- core/localization/: 使用flutter_localization来实现本地化服务。
- core/routing/: 使用routemaster来实现路由管理。
- core/utils/: 使用logger来实现日志记录。
- data/: 数据层包含数据源和仓库,用于获取和管理数据。
- domain/: 领域层包含实体和用例,用于实现业务逻辑。
- presentation/: 表示层包含页面和Provider,用于显示UI和管理状态。
- test/: 测试目录包含各层的测试代码,使用flutter_test和mockito来编写测试。
我想,感兴趣的朋友们,可以私信我交流,我后续会在 GitHub 上放出该flutter 快速开发框架的 template 地址。
探索代码的无限可能,与老码小张一起开启技术之旅。点关注,未来已来,每一步深入都不孤单。

来源:juejin.cn/post/7340898858556964864
前端啊,拿Lottie炫个动画吧
点赞 + 关注 + 收藏 = 学会了
本文简介
有时候在网页上看到一些很炫酷的小动画,比如loading特效,还能控制这个动画的状态,真的觉得很神奇。
大部分做后端的不想碰前端,做前端的不想碰动画特效。
其实啊,很多时候不需要自己写炫酷的特效,会调用第三方库已经挺厉害的了。比如今天要介绍的 Lottie。

Lottie 是什么?
🔗Lottie官网 airbnb.io/lottie/
Lottie 是一个适用于 Android、iOS、Web 和 Windows 的库,它可以解析使用 Bodymovin 导出为 JSON 的 Adobe After Effects 动画,并在移动设备和 Web 上本地渲染它们!
After Effects 是什么?Bodymovin 又是什么?
别怕,这些我也不会。作为前端,我会拿别人做好的东西来用😁
简单来说,Lottie 是 Airbnb 开发的动画库,特别适合前端开发人员。它可以轻松实现复杂的动画效果,不需要手写大量代码,只需引入现成的 JSON 文件即可。
今天不讲iOS,不讲Android,只讲如何在前端使用 Lottie。
安装 Lottie Web
要在前端项目中使用 Lottie,要么用 CDN 的方式引入,要么通过 NPM 下载。
CDN
在这个网址可以找到 Lottie 的各个版本的JS文件: cdnjs.com/libraries/b…

我使用的是 5.12.2 这个版本
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
#lottie {
width: 200px;
height: 200px;
}
</style>
</head>
<body>
<div id="lottie"></div>
<script src="https://cdnjs.cloudflare.com/ajax/libs/bodymovin/5.12.2/lottie.min.js"></script>
<script>
var animation = lottie.loadAnimation({
container: document.getElementById('lottie'), // 渲染动画的容器
renderer: 'svg', // 渲染方式
loop: true, // 是否循环
autoplay: true, // 是否自动播放
path: './Animation_1.json' // 动画 JSON 文件的路径
});
</script>
</body>
</html>
Animation_1.json 是我下载的一个动画文件,这个文件我放在同级目录里。这个动画文件在哪可以下载我接下来会介绍。这里先了解一下 CDN 的方式怎么引入 Lottie 即可。
NPM
用下面这个命令将 Lottie 下载到你的项目里。
npm install lottie-web
动画资源下载
前面介绍到,动画是用 AE 做好,然后用 Bodymovin 插件将动画转换成一个 JSON 文件,前端就可以使用 lottie-web 将这个 JSON 文件的内容转换成图像渲染到浏览器页面上。
如果想要现成的动画资源可以在这些地方找找
- lottiefiles:lottiefiles.com/
- iconfont的lottie模块:http://www.iconfont.cn/lotties/ind…
- Creattie:creattie.com/
- Lottielab(自己编辑、下载):http://www.lottielab.com/
我这里也给大家准备了一个动画文件,大家可以拿它来练手。
- 【百度网盘】链接: pan.baidu.com/s/1Qnp3BAAT… 提取码: d7gt
- 【阿里云盘】链接:http://www.alipan.com/s/sfMVak2Xh… 提取码:35kw
实现第一个 Lottie 动画
我通过 React 脚手架创建了一个 React 项目来举例说明如何使用 Lottie,在 Vue 里的用法也是一样的。

import React, { useEffect, useRef } from 'react';
import lottie from 'lottie-web';
import animationData from './assets/animations/Animation.json';
function App() {
const containerRef = useRef(null);
useEffect(() => {
const anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: true,
autoplay: true,
animationData: animationData
});
}, []);
return <div ref={containerRef} style={{width: "300px", height: "300px"}}></div>;
}
export default App;
在 HTML 文件中,创建一个容器,用于放置 Lottie 动画。在这个例子中我创建了一个宽和高都是 300px 的 div 元素。
然后引入 lottie-web 以及放在前端项目里的 Animation.json 动画文件。
最后调用 lottie.loadAnimation() 来启动动画。它将一个对象作为唯一参数。
container:动画容器,这个例子通过React提供的语法获取到DOM元素。renderer:渲染方式,可选svg、canvas和html。loop:是否循环播放。autoplay:是否自动播放。animationData:本地的动画数据的对象。
这里需要注意,animationData 接收的动画对象是存放在前端项目的 JSON 文件,如果你的动画文件是存在别的服务器,需要通过一个 URL 引入的话就不能用 animationData 来接收了,而是要改成 path。
const anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: true,
autoplay: true,
path: 'https://lottie.host/68bd36a3-b21d-4909-9b61-9be6b0947943/gInO8owFG1.json'
});
Lottie 常用功能
播放、暂停、停止
控制动画的播放、暂停、停止是很常用的功能。
- 播放:使用
play()方法。顾名思义就是让动画动起来。 - 暂停:使用
pause()方法。暂停可以让动画在当前帧停下来。可以这么理解,你在看视频一个10秒的短视频,播放到第7秒的时候你按了“暂停”,画面就停在第7秒的地方了。 - 停止:使用
stop()方法。停止和暂停都是让动画停下来,而停止会让动画返回第1帧画面的地方停下来。

import lottie from 'lottie-web';
import React, { useEffect, useRef } from 'react';
import animationData from './assets/animations/Animation.json';
function App() {
const containerRef = useRef(null);
let anim = null
useEffect(() => {
anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: true,
autoplay: true,
animationData: animationData,
});
}, []);
// 播放动画
function play() {
anim.play()
}
// 暂停动画
function pause() {
anim.pause()
}
// 停止动画
function stop() {
anim.stop()
}
return <>
<div ref={containerRef} style={{width: "300px", height: "300px"}}></div>
<button onClick={play}>播放</button>
<button onClick={pause}>暂停</button>
<button onClick={stop}>停止</button>
</>;
}
export default App;
代码放这,建议自己运行起来体验一下。
设置动画播放速度
使用 setSpeed() 方法可以设置动画的播放速度,传入一个数字即可。默认的播放速度是1。

// 省略部分代码
// 2倍速度播放
anim.setSpeed(2)
这个参数支持正数(包括非整数)、0、负数。
- 大于1的正数:比默认速度快
- 大于0小于1:比默认速度慢
- 0:画面停止在第一帧不动了
- 小于0大于-1:动画倒放,而且速度比默认值慢
- -1:动画倒放,速度和默认值一样
- 小于-1:动画倒放,速度比默认值快
设置动画播放方向
这里说的播放方向指的是「正着放」还是「倒着放」。前面用 setSpeed() 方法可以做到这点。但还有一个叫 setDirection() 的方法也能做到。
setDirection() 接收一个数字参数,这个参数大于等于0时是正着播放,负数时是倒着播放。通常情况下,想倒着播放会传入 -1。

// 省略部分代码
anim.setDirection(-1)
看,面是吐出来的。
设置动画进度
通过 goToAndStop() 方法可以控制动画跳转到指定帧或时间并停止。
goToAndStop(value, isFrame) 接收2个参数。
value:数值,表示要跳转到的帧数或时间点。isFrame:布尔值,默认为false。如果设置为true,则value参数表示帧数;如果设置为false,则value参数表示时间(以毫秒为单位)。

function goToAndStop() {
anim.goToAndStop(1000, false)
}
return <>
<div ref={containerRef} style={{width: "300px", height: "300px"}}></div>
<button onClick={goToAndStop}>跳转到1秒</button>
</>;
如果 goToAndStop 第二个参数为 true 则表示要跳转到指定帧数,这个值不能超过动画的总帧数。
销毁动画实例
有些场景在某个时刻需要将动画元素删除掉,比如在数据加载时需要显示 loading,数据加载成功或者失败后需要隐藏 loading,此时可以用 destroy 将 Lottie 动画实例销毁掉。
// 省略部分代码
anim.destroy()
动画监听事件
动画有很多个状态,比如动画数据加载完成/失败、动画播放结束、循环下一次播放、进入新的一帧。Lottie 为我们提供了几个常用的监听方法。
而要监听这些事件,需要在 lottie 实例上用 addEventListener 方法绑定各个事件。
动画数据加载情况
监听动画数据(JSON文件)加载成功或者失败,可以用这两个方法。
data_ready:数据加载成功后执行。data_failed:数据加载失败后执行。
需要注意,这两个方法只适用 path 的方式加载数据时触发。animationData 加载的是本地数据,并不会触发这两个方法。
// 省略部分代码
let anim = null;
useEffect(() => {
anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: true,
autoplay: true,
path: 'https://lottie.host/68bd36a3-b21d-4909-9b61-9be6b0947943/gInO8owFG1.json'
});
anim.addEventListener('data_ready', () => {
console.log('数据加载完成');
});
anim.addEventListener('data_failed', () => {
console.log('数据加载失败');
})
}, []);
初始配置完成后
在数据加载前,还可以通过 config_ready 监听初始化配置的完成情况。
要让 config_ready 生效,同样需要通过 path 的方式加载数据。
config_ready 的执行顺序排在 data_ready 之前。
// 省略部分代码
let anim = null;
useEffect(() => {
anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: true,
autoplay: true,
path: 'https://lottie.host/68bd36a3-b21d-4909-9b61-9be6b0947943/gInO8owFG1.json'
});
anim.addEventListener('data_ready', () => {
console.log('数据加载完成');
});
anim.addEventListener('config_ready', () => {
console.log('初始化成功');
});
}, []);
动画播放结束
当动画播放结束时,会触发 complete 事件。
如果 loop 为 true 的话时不会触发 complete 的,因为一直循环的话动画是没有结束的那天。
// 省略部分代码
let anim = null;
useEffect(() => {
anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: false,
autoplay: true,
animationData: animationData,
});
anim.addEventListener('complete', () => {
console.log('动画播完了');
});
}, []);
动画循环播放结束
当 loop 为 true 时,每循环播放完一次就会触发 loopComplete 事件。
// 省略部分代码
let anim = null;
useEffect(() => {
anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: true,
autoplay: true,
animationData: animationData,
});
anim.addEventListener('loopComplete', () => {
console.log('循环结束,准备进入下一次循环');
});
}, []);
当你通过 pause() 暂停了动画,过一阵用 play() 继续播放,也会等这次动画完整播放完才会触发 loopComplete。
进入新的一帧
一个动画由很多个画面组成,每个画面都属于1帧。动画每进入一帧时都会触发 enterFrame 事件。
// 省略部分代码
let anim = null;
useEffect(() => {
anim = lottie.loadAnimation({
container: containerRef.current,
renderer: 'svg',
loop: true,
autoplay: true,
animationData: animationData,
// path: 'https://lottie.host/68bd36a3-b21d-4909-9b61-9be6b0947943/gInO8owFG1.json'
});
anim.addEventListener('enterFrame', () => {
console.log('进入新帧');
});
}, []);
自己手写一个动画JSON?
手写 Lottie 的 JSON 动画文件相对复杂,因为需要对 Lottie 的 JSON 结构有较深入的理解。Lottie 的 JSON 文件基于 Bodymovin 插件输出的格式,主要包含静态资源、图层、形状以及帧动画信息。
由于相对复杂,所以不建议真的自己手写,这会显得你很傻。
Lottie JSON 文件由多个部分组成,主要包括:
assets:动画中使用的资源(图片等)。layers:动画中的每一层(类似于 Photoshop 图层)。shapes:定义图形、路径等基本元素及其动画。animations:定义每一帧的动画数据,包括位置、缩放、透明度等。
太复杂的元素我确实手写不出来,只能写一个简单的圆形从左向右移动演示一下。

{
"v": "5.6.10", // Lottie 版本
"fr": 30, // 帧率 (Frames per second)
"ip": 0, // 动画开始帧 (In Point)
"op": 60, // 动画结束帧 (Out Point)
"w": 500, // 画布宽度
"h": 500, // 画布高度
"nm": "circle animation",// 动画名称
"ddd": 0, // 是否是 3D 动画
"assets": [], // 静态资源(如图片等)
"layers": [ // 动画的图层
{
"ddd": 0, // 图层是否是 3D
"ind": 1, // 图层索引
"ty": 4, // 图层类型,4 代表形状图层
"nm": "circle", // 图层名称
"sr": 1, // 图层的播放速度
"ks": { // 图层的关键帧属性(动画数据)
"o": { // 不透明度动画
"a": 0, // 不透明度动画为 0,表示不设置动画
"k": 100 // 不透明度固定为 100%
},
"r": { // 旋转动画
"a": 0, // 不设置动画
"k": 0 // 旋转角度为 0
},
"p": { // 位置动画 (Position)
"a": 1, // a 为 1 表示位置有动画
"k": [
{
"i": { "x": 0.667, "y": 1 }, // 起始位置插值
"o": { "x": 0.333, "y": 0 }, // 终止位置插值
"n": "0p667_1_0p333_0", // 插值模式名称
"t": 0, // 起始帧
"s": [50, 250, 0], // 起始位置 (x: 50, y: 250)
"e": [450, 250, 0], // 结束位置 (x: 450, y: 250)
"to": [66.66667, 0, 0], // 起始插值控制点
"ti": [-66.66667, 0, 0] // 终止插值控制点
},
{ "t": 60 } // 在 60 帧时结束动画
]
},
"a": { // 锚点动画(用于旋转或缩放中心)
"a": 0,
"k": [0, 0, 0] // 锚点固定在 (0, 0)
},
"s": { // 缩放动画 (Scale)
"a": 0,
"k": [100, 100, 100] // 保持 100% 缩放
}
},
"ao": 0, // 自动定向
"shapes": [ // 图形数组,定义图层中的形状
{
"ty": "el", // 图形类型 'el' 代表 ellipse(椭圆/圆形)
"p": { // 椭圆的中心点
"a": 0,
"k": [0, 0]
},
"s": { // 椭圆的大小
"a": 0,
"k": [100, 100] // 圆的宽和高为 100px
},
"nm": "ellipse"
},
{
"ty": "st", // 图形类型 'st' 代表 stroke(描边)
"c": { // 描边颜色
"a": 0,
"k": [1, 0, 0, 1] // 红色 [R: 1, G: 0, B: 0, Alpha: 1]
},
"o": { // 描边不透明度
"a": 0,
"k": 100
},
"w": { // 描边宽度
"a": 0,
"k": 10
},
"lc": 1, // 线帽样式
"lj": 1, // 线接样式
"ml": 4 // 折线限制
}
],
"ip": 0, // 图层开始帧
"op": 60, // 图层结束帧
"st": 0, // 图层起始时间
"bm": 0 // 混合模式
}
]
}
v: 表示 Lottie 动画的版本。fr: 帧率,表示每秒多少帧。在这个示例中,每秒播放 30 帧。ip和op: 分别代表动画的起始帧和结束帧。本例中,动画从第 0 帧开始,到第 60 帧结束。layers: 图层数组。每个图层包含ks(关键帧属性),用于控制位置、缩放、旋转等动画参数。
ty: 4: 图层类型为形状图层。p: 定义了位置动画,从帧 0 开始,圆形从 (50, 250) 移动到 (450, 250) 的位置,表示从画布左侧移动到右侧。
shapes: 定义了图形的属性。
el: 表示一个椭圆形,即我们定义的圆形。st: 表示圆形的描边,颜色为红色,宽度为 10px。
以上就是本文的全部内容,如果本文对你有帮助,欢迎转发给你的朋友。

点赞 + 关注 + 收藏 = 学会了
来源:juejin.cn/post/7430690608711647232
什么年代了?还不懂为什么一定要在团队项目开发中去使用 TypeScript ?

为什么要去使用 TypeScript ?
一直以来 TypeScript 的存在都备受争议,很多人认为他加重了前端开发的负担,特别是在它的严格类型系统和 JavaScript 的灵活性之间的矛盾上引发了不少讨论。
支持者认为 TypeScript 提供了强类型检查、丰富的 IDE 支持和更好的代码重构能力,从而提高了大型项目的代码质量和可维护性。
然而,也有很多开发者认为 TypeScript 加重了开发负担,带来了不必要的复杂性,尤其是在小型项目或快速开发场景中,它的严格类型系统可能显得过于繁琐,限制了 JavaScript 本身的动态和自由特性
但是随着项目规模的增大和团队协作的复杂性增加,TypeScript 的优势也更加明显。因为你不可能指望团队中所有人的知识层次和开发习惯都达到同一水准!你也不可能保证团队中的其他人都能够完全正确的使用你封装的组件、函数!
在大型项目中我们往往会封装到很多工具函数、组件等等,我们不可能在使用到组件时跑去看这个组件的实现逻辑,而
TypeScript的类型提示正好弥补了这一点。通过明确的类型注解,TypeScript可以在代码中直接提示每个组件的输入输出、参数类型和预期结果,让开发者只需在 IDE 中悬停或查看提示信息,就能了解组件的用途和使用方式,而不需要翻阅具体实现逻辑。
这时你可能会说,使用
JSDoc也能够实现类似的效果。的确,JSDoc可以通过注释的形式对函数、参数、返回值等信息进行详细描述,甚至可以生成文档。
然而,
JSDoc依赖于开发者的自觉维护,且其检查和提示能力远不如TypeScript强大和全面。TypeScript的类型系统是在编译阶段强制执行的,这意味着所有类型定义都是真正的 “硬性约束”,能在代码运行前捕获错误,而不仅仅是提示。
在实际开发中,
JSDoc的确能让我们知道参数类型,但它只是一种 “约定” ,而不是真正的约束。这意味着,如果同事在使用工具函数时不小心写错了类型,比如传了字符串而不是数字,JSDoc只能通过注释告诉你正确的使用方法,却无法在你出错时立即给出警告。
然而在
TypeScript中,类型系统会在代码编写阶段实时检查。比如,你定义的函数要求传入数字类型的参数,如果有人传入了字符串,IDE 立刻会报错提醒你,防止错误进一步传播。
所以,TypeScript 的价值就在于它提供了一层代码保护,让代码有了“硬约束”,团队在开发过程中更加节省心智负担,显著提升开发体验和生产力,少出错、更高效。
接下来我们来使用 TypeScript 写一个基础的防抖函数作为示例。通过类型定义和参数注解,我们不仅能让防抖函数更加通用且类型安全,还能充分利用 TypeScript 的类型检查优势,从而提高代码的可读性和可维护性。
这样的实现方式将有效地降低潜在的运行时错误,特别是在大型项目中,可以使团队成员之间的协作能够更加顺畅,并且避免一些低级问题。

功能点讲解
防抖函数的主要功能是:在指定的延迟时间内,如果函数多次调用,只有最后一次调用会生效。这一功能尤其适合优化用户输入等高频事件。
防抖函数的核心功能
- 函数执行的延迟控制:函数调用后不立即执行,而是等待一段时间。如果在等待期间再次调用函数,之前的等待会被取消,重新计时。
- 立即执行选项:有时我们希望函数在第一次调用时立即执行,然后在延迟时间内避免再次调用。
- 取消功能:我们还希望在某些情况下手动取消延迟执行的函数,比如当页面卸载或需要重新初始化时。
第一步:编写函数框架
在开始封装防抖函数之前,我们首先应该想到的就是要写一个函数,假设这个函数名叫 debounce。我们先创建它的基本框架:
function debounce() {
// 函数的逻辑将在这里编写
}
这一步非常简单,先定义一个空函数,这个函数就是我们的防抖函数。在后续步骤中,我们会逐步向这个函数中添加功能。
第二步:添加基本的参数
防抖函数的第一个功能是控制某个函数的执行,因此,我们需要传递一个需要防抖的函数。其次,防抖功能依赖于一个延迟时间,这意味着我们还需要添加一个用于设置延迟的参数。
让我们扩展一下 debounce 函数,为它添加两个基本的参数:
func:需要防抖的目标函数。duration:防抖的延迟时间,单位是毫秒。
function debounce(func: Function, duration: number) {
// 函数的逻辑将在这里编写
}
func是需要防抖的函数。每当防抖函数被调用时,我们实际上是在控制这个func函数的执行。duration是延迟时间。这个参数控制了在多长时间后执行目标函数。
第三步:为防抖功能引入定时器逻辑
防抖的核心逻辑就是通过定时器(setTimeout),让函数执行延后。那么我们需要用一个变量来保存这个定时器,以便在函数多次调用时可以取消之前的定时器。
function debounce(func: Function, duration: number) {
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
}
let timer: ReturnType<typeof setTimeout> | null = null:我们使用一个变量timer来存储定时器的返回值。clearTimeout(timer):每次调用防抖函数时,都会清除之前的定时器,这样就保证了函数不会被立即执行,直到等待时间结束。setTimeout:在指定的延迟时间后执行传入的目标函数func,并传递原始参数。
为什么写成了 ReturnType<typeof setTimeout> | null 这样的类型 ?
在 JavaScript 中,setTimeout 是一个内置函数,用来设置一个延迟执行的任务。它的基本语法如下:
let id = setTimeout(() => {
console.log("Hello, world!");
}, 1000);
setTimeout 返回一个定时器 ID(在浏览器中是一个数字),这个 ID 用来唯一标识这个定时器。如果你想取消定时器,你可以使用 clearTimeout(id),其中 id 就是这个返回的定时器 ID。
ReturnType<T>是 TypeScript 提供的一个工具类型,它的作用是帮助我们获取某个函数类型的返回值类型。我们通过泛型T来传入一个函数类型,然后ReturnType<T>就会返回这个函数的返回值类型。在这里我们可以用它来获取setTimeout函数的返回类型。
为什么需要使用 ReturnType<typeof setTimeout> ?
由于不同的 JavaScript 运行环境中,setTimeout 的返回值类型是不同的:
- 在浏览器中,
setTimeout返回的是一个数字 ID。 - 在Node.js 中,
setTimeout返回的是一个对象(Timeout对象)。
为了兼容不同的环境,我们需要用 ReturnType<typeof setTimeout> 来动态获取 setTimeout 返回的类型,而不是手动指定类型(比如 number 或 Timeout)。
let timer: ReturnType<typeof setTimeout>;
这里 ReturnType<typeof setTimeout> 表示我们根据 setTimeout 的返回值类型自动推导出变量 timer 的类型,不管是数字(浏览器)还是对象(Node.js),TypeScript 会自动处理。
为什么需要设置联合类型 | null ?
在我们的防抖函数实现中,定时器 timer 并不是一开始就设置好的。我们需要在每次调用防抖函数时动态设置定时器,所以初始状态下,timer 的值应该是 null。
使用 | null 表示联合类型,它允许 timer 变量既可以是 setTimeout 返回的值,也可以是 null,表示目前还没有设置定时器。
let timer: ReturnType<typeof setTimeout> | null = null;
ReturnType<typeof setTimeout>:表示timer可以是setTimeout返回的定时器 ID。| null:表示在初始状态下,timer没有定时器,它的值为null。
第四步:返回一个新函数
在防抖函数 debounce 中,我们希望当它被调用时,返回一个新的函数。这是防抖函数的核心机制,因为每次调用返回的新函数,实际上是在控制目标函数 func 的执行。
具体的想法是这样的:我们并不直接执行传入的目标函数 func,而是返回一个新函数,这个新函数在被调用时会受到防抖的控制。
因此,我们要修改 debounce 函数,使它返回一个新的函数,真正控制 func 的执行时机。
function debounce(func: Function, duration: number) {
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
return function () {
// 防抖逻辑将在这里编写
};
}
- 返回新函数:当
debounce被调用时,它返回一个新函数。这个新函数是每次调用时执行防抖逻辑的入口。 - 为什么返回新函数? :因为我们需要在每次事件触发时(例如用户输入时)执行防抖操作,而不是直接执行传入的目标函数
func。
第五步:清除之前的定时器
为了实现防抖功能,每次调用返回的新函数时,我们需要先清除之前的定时器。如果之前有一个定时器在等待执行目标函数,我们应该将其取消,然后重新设置一个新的定时器。
这个步骤的关键就是使用 clearTimeout(timer) 。
function debounce(func: Function, duration: number) {
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
return function () {
if (timer) {
clearTimeout(timer); // 清除之前的定时器
}
// 下面将设置新的定时器
};
}
if (timer):我们检查timer是否有值。如果它有值,说明之前的定时器还在等待执行,我们需要将其清除。clearTimeout(timer):这就是清除之前的定时器,防止之前的调用被执行。这个操作非常关键,因为它确保了只有最后一次调用(在延迟时间后)才会真正触发目标函数。
第六步:设置新的定时器
现在我们需要在每次调用返回的新函数时,重新设置一个新的定时器,让它在指定的延迟时间 duration 之后执行目标函数 func。
这时候就要使用 setTimeout 来设置定时器,并在延迟时间后执行目标函数。
function debounce(func: Function, duration: number) {
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
return function () {
if (timer) {
clearTimeout(timer); // 清除之前的定时器
}
timer = setTimeout(() => {
func(); // 延迟后调用目标函数
}, duration);
};
}
setTimeout:我们使用setTimeout来设置一个新的定时器,定时器将在duration毫秒后执行传入的目标函数func。func():这是目标函数的实际执行点。定时器到达延迟时间时,它会执行目标函数func。timer = setTimeout(...):我们将定时器的 ID 存储在timer变量中,以便后续可以使用clearTimeout(timer)来清除定时器。
第七步:支持参数传递
接下来是让这个防抖函数能够接受参数,并将这些参数传递给目标函数 func。
为了实现这个功能,我们需要用到 ...args 来捕获所有传入的参数,并在执行目标函数时将这些参数传递过去。
function debounce(func: Function, duration: number) {
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
return function (...args: any[]) { // 接收传入的参数
if (timer) {
clearTimeout(timer); // 清除之前的定时器
}
timer = setTimeout(() => {
func(...args); // 延迟后调用目标函数,并传递参数
}, duration);
};
}
...args: any[]:这表示新函数可以接收任意数量的参数,并将这些参数存储在args数组中。func(...args):当定时器到达延迟时间后,调用目标函数func,并将args中的所有参数传递给它。这确保了目标函数能接收到我们传入的所有参数。
到这里,我们一个基本的防抖函数的实现。这个防抖函数实现了以下基本功能:
- 函数执行的延迟控制:每次调用时,都重新设置定时器,确保函数不会立即执行,而是在延迟结束后才执行。
- 多参数支持:通过
...args,防抖函数能够接收多个参数,并将它们传递给目标函数。 - 清除之前的定时器:在每次调用时,如果定时器已经存在,先清除之前的定时器,确保只有最后一次调用才会生效。
但是,这样就完了吗?
在当前的实现中,
debounce函数的定义是debounce(func: Function, duration: number),其中func: Function用来表示目标函数。这种定义虽然可以工作,但它存在明显的缺陷和不足之处,尤其是在 TypeScript 强调类型安全的情况下。
缺陷 1:缺乏参数类型检查
Function 是一种非常宽泛的类型,它允许目标函数接收任何类型、任意数量的参数。因此定义目标函数 func 为 Function 类型意味着 TypeScript 无法对目标函数的参数类型进行任何检查。
const debounced = debounce((a: number, b: number) => {
console.log(a + b);
}, 200);
debounced("hello", "world"); // 这里不会报错,参数类型不匹配,但仍会被调用
在这个例子中,我们定义了一个目标函数,期望它接受两个数字类型的参数,但在实际调用时却传入了两个字符串。
这种情况下 TypeScript 不会提示任何错误,因为 Function 类型没有对参数类型进行限制。这种类型检查的缺失可能导致运行时错误或者逻辑上的错误。
缺陷 2:返回值类型不安全
同样,定义 func 为 Function 类型时,TypeScript 无法推断目标函数的返回值类型。这意味着防抖函数不能保证目标函数的返回值是符合预期的类型,可能导致返回值在其他地方被错误使用。
const debounced = debounce(() => {
return "result";
}, 200);
const result = debounced(); // TypeScript 不知道返回值类型,认为是 undefined

在这个例子中,虽然目标函数明确返回了一个字符串 "result",但 debounced 函数的返回值类型未被推断出来,因此 TypeScript 会认为它的返回值是 void 或 undefined,即使目标函数实际上返回了 string。
缺陷 3:缺乏目标函数的签名限制
由于 Function 类型允许任何形式的函数,因此 TypeScript 也无法检查目标函数的参数个数和类型是否匹配。这种情况下,如果防抖函数返回的新函数接收了错误数量或类型的参数,可能导致函数行为异常或意外的运行时错误。
const debounced = debounce((a: number) => {
console.log(a);
}, 200);
debounced(1, 2, 3); // TypeScript 不会报错,但多余的参数不会被使用
虽然目标函数只期望接收一个参数,但在调用时传入了多个参数。TypeScript 不会进行任何警告或报错,因为 Function 类型允许这种宽泛的调用,这可能会导致开发者误以为这些参数被使用。
总结 func: Function 的缺陷
- 缺乏参数类型检查:任何数量、任意类型的参数都可以传递给目标函数,导致潜在的参数类型错误。
- 返回值类型不安全:目标函数的返回值类型无法被推断,导致 TypeScript 无法确保返回值的类型正确。
- 函数签名不受限制:没有对目标函数的参数个数和类型进行检查,容易导致逻辑错误或参数使用不当。
这些缺陷使得代码在类型安全性和健壮性上存在不足,可能导致运行时错误或者隐藏的逻辑漏洞。
下一步的改进
为了解决这些缺陷,我们可以通过泛型的方式为目标函数添加类型限制,确保目标函数的参数和返回值类型都能被准确地推断和检查。这会是我们接下来要进行的优化。
第八步:使用泛型优化
为了克服 func: Function 带来的缺陷,我们可以通过 泛型 来优化防抖函数的类型定义,确保目标函数的参数和返回值都能在编译时进行类型检查。使用泛型不仅可以解决参数类型和返回值类型的检查问题,还可以提升代码的灵活性和安全性。
如何使用泛型进行优化?
我们将通过引入两个泛型参数来改进防抖函数的类型定义:
A:表示目标函数的参数类型,可以是任意类型和数量的参数,确保防抖函数在接收参数时能进行类型检查。R:表示目标函数的返回值类型,确保防抖函数返回的值与目标函数一致。
function debounce<A extends any[], R>(
func: (...args: A) => R, // 使用泛型 A 表示参数,R 表示返回值类型
duration: number // 延迟时间,以毫秒为单位
): (...args: A) => R { // 返回新函数,参数类型与目标函数相同,返回值类型为 R
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
let lastResult: R; // 存储目标函数的返回值
return function (...args: A): R { // 返回的新函数,参数类型由 A 推断
if (timer) {
clearTimeout(timer); // 清除之前的定时器
}
timer = setTimeout(() => {
lastResult = func(...args); // 延迟后调用目标函数,并存储返回值
}, duration);
return lastResult; // 返回上一次执行的结果,如果尚未执行则返回 undefined
};
}
A extends any[]:A表示目标函数的参数类型,A是一个数组类型,能够适应目标函数接收多个参数的场景。通过泛型,防抖函数能够根据目标函数的签名推断出参数类型并进行检查。R:R表示目标函数的返回值类型,防抖函数能够确保返回值类型与目标函数一致。如果目标函数返回值类型为string,防抖函数也会返回string,这样可以防止返回值类型不匹配。lastResult:用来存储目标函数的最后一次返回值。每次调用目标函数时会更新lastResult,并在调用时返回上一次执行的结果,确保防抖函数返回正确的返回值。
泛型优化后的优点:
- 类型安全的参数传递:
通过泛型A,防抖函数可以根据目标函数的签名进行类型检查,确保传入的参数与目标函数一致,避免参数类型错误。
const debounced1 = debounce((a: number, b: string) => {
console.log(a, b);
}, 300);
debounced1(42, "hello"); // 正确,参数类型匹配
debounced1("42", 42); // 错误,类型不匹配

- 返回值类型安全:
泛型R确保了防抖函数的返回值与目标函数的返回值类型一致,防止不匹配的类型被返回。
const debounced = debounce(() => {
return "result";
}, 200);
const result = debounced(); // 返回值为 string
console.log(result); // 输出 "result"

- 支持多参数传递:
泛型A表示参数类型数组,这意味着目标函数可以接收多个参数,防抖函数会将这些参数正确传递给目标函数。而如果防抖函数返回的新函数接收了错误数量或类型的参数,会直接报错提示。
const debounced = debounce((name: string, age: number) => {
return `${name} is ${age} years old.`;
}, 300);
const result = debounced("Alice", 30);
console.log(result); // 输出 "Alice is 30 years old."

第九步:添加 cancel 方法并处理返回值类型
在前面的步骤中,我们已经实现了一个可以延迟执行的防抖函数,并且支持参数传递和返回目标函数的结果。
但是,由于防抖函数的执行是异步延迟的,因此在初次调用时,防抖函数可能无法立即返回结果。因此函数的返回值我们需要使用 undefined 来表示目标函数的返回结果可能出现还没生成的情况。
除此之外,我们还要为防抖函数添加一个 cancel 方法,用于手动取消防抖的延迟执行。
为什么需要 cancel 方法?
在一些场景下,可能需要手动取消防抖操作,例如:
- 用户取消了操作,不希望目标函数再执行。
- 某个事件或操作已经不再需要处理,因此需要取消延迟中的函数调用。
为了解决这些需求,cancel 方法可以帮助我们在定时器还未触发时,清除定时器并停止目标函数的执行。
// 定义带有 cancel 方法的防抖函数类型
type DebouncedFunction<A extends any[], R> = {
(...args: A): R | undefined; // 防抖函数本身,返回值可能为 R 或 undefined
cancel: () => void; // `cancel` 方法,用于手动清除防抖
};
// 实现防抖函数
function debounce<A extends any[], R>(
func: (...args: A) => R, // 泛型 A 表示参数类型,R 表示返回值类型
duration: number // 延迟时间
): DebouncedFunction<A, R> { // 返回带有 cancel 方法的防抖函数
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
let lastResult: R | undefined; // 用于存储目标函数的返回值
// 防抖逻辑的核心函数
const debouncedFn = function (...args: A): R | undefined {
if (timer) {
clearTimeout(timer); // 清除之前的定时器
}
// 设置新的定时器
timer = setTimeout(() => {
lastResult = func(...args); // 延迟后执行目标函数,并存储返回值
}, duration);
// 返回上一次的结果或 undefined
return lastResult;
};
// 添加 `cancel` 方法,用于手动取消防抖
debouncedFn.cancel = function () {
if (timer) {
clearTimeout(timer); // 清除定时器
timer = null; // 重置定时器
}
};
return debouncedFn; // 返回带有 `cancel` 方法的防抖函数
}
- 返回值类型
R | undefined:
R:代表目标函数的返回值类型,例如number或string。undefined:在防抖函数的首次调用或目标函数尚未执行时,返回undefined,表示结果尚未生成。lastResult用于存储目标函数上一次执行的结果,防抖函数在每次调用时会返回该结果,或者在尚未执行时返回undefined。
cancel方法:
cancel方法的作用是清除当前的定时器,防止目标函数在延迟时间结束后被执行。- 通过调用
clearTimeout(timer),我们可以停止挂起的防抖操作,并将timer重置为null,表示当前没有挂起的定时器。
让我们来看一个具体的使用示例,展示如何使用防抖函数,并在需要时手动取消操作。
// 定义一个简单的目标函数
const debouncedLog = debounce((message: string) => {
console.log(message);
return message;
}, 300);
// 第一次调用防抖函数,目标函数将在 300 毫秒后执行
debouncedLog("Hello"); // 如果不取消,300ms 后会输出 "Hello"
// 手动取消防抖,目标函数不会执行
debouncedLog.cancel();
在这个示例中:
- 调用
debouncedLog("Hello"):会启动一个 300 毫秒的延迟执行,目标函数计划在 300 毫秒后执行,并输出"Hello"。 - 调用
debouncedLog.cancel():会清除定时器,目标函数不会执行,避免了不必要的操作。
第十步:将防抖函数作为工具函数单独放在一个 ts 文件中并添加 JSDoc 注释
在编写好防抖函数之后,下一步是将其作为一个工具函数放入单独的 .ts 文件中,以便在项目中重复使用。同时,我们可以为函数添加详细的 JSDoc 注释,方便使用者了解函数的作用、参数、返回值及用法。
1. 将防抖函数放入单独的文件
首先,我们可以创建一个名为 debounce.ts 的文件,并将防抖函数的代码放在其中。
// debounce.ts
export type DebouncedFunction<A extends any[], R> = {
(...args: A): R | undefined; // 防抖函数本身,返回值可能为 R 或 undefined
cancel: () => void; // `cancel` 方法,用于手动清除防抖
};
/**
* 创建一个防抖函数,确保在最后一次调用后,目标函数只会在指定的延迟时间后执行。
* 防抖函数可以防止某个函数被频繁调用,例如用户输入事件、滚动事件或窗口调整大小等场景。
*
* @template A - 函数接受的参数类型。
* @template R - 函数的返回值类型。
* @param {(...args: A) => R} func - 需要防抖的目标函数。该函数将在延迟时间后执行。
* @param {number} duration - 延迟时间(以毫秒为单位)。在这个时间内,如果再次调用函数,将重新计时。
* @returns {DebouncedFunction<A, R>} 一个防抖后的函数,该函数包括一个 `cancel` 方法用于清除防抖。
*
* @example
* const debouncedLog = debounce((message: string) => {
* console.log(message);
* return message;
* }, 300);
*
* debouncedLog("Hello"); // 300ms 后输出 "Hello"
* debouncedLog.cancel(); // 取消防抖,函数不会执行
*/
export function debounce<A extends any[], R>(
func: (...args: A) => R,
duration: number
): DebouncedFunction<A, R> {
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
let lastResult: R | undefined; // 存储目标函数的返回值
const debouncedFn = function (...args: A): R | undefined {
if (timer) {
clearTimeout(timer); // 清除之前的定时器
}
timer = setTimeout(() => {
lastResult = func(...args); // 延迟后执行目标函数,并存储返回值
}, duration);
return lastResult; // 返回上次执行的结果,如果尚未执行则返回 undefined
};
debouncedFn.cancel = function () {
if (timer) {
clearTimeout(timer); // 清除定时器,防止目标函数被执行
timer = null; // 重置定时器
}
};
return debouncedFn;
}
2. 详细的 JSDoc 注释说明
通过添加 JSDoc 注释,能够为函数使用者提供清晰的文档信息,说明防抖函数的功能、参数类型、返回值类型,以及如何使用它。
JSDoc 注释的结构说明:
@template A, R:说明泛型A是函数接受的参数类型,R是目标函数的返回值类型。@param:解释函数的输入参数,说明func是目标函数,duration是防抖的延迟时间。@returns:说明返回值是一个带有cancel方法的防抖函数,函数返回值类型是R | undefined。@example:为函数提供示例,展示防抖函数的典型用法,包括取消防抖操作。
使用 JSDoc 生成文档
通过在 .ts 文件中添加 JSDoc 注释,可以借助 TypeScript 编辑器或 IDE(如 VSCode/Webstorm)自动生成代码提示和函数文档说明,提升开发体验。
例如,当开发者在使用 debounce 函数时,可以自动看到函数的说明和参数类型提示:

回顾:泛型防抖函数的最终效果
通过前面各个步骤的优化,我们已经构建了一个类型安全的防抖函数,结合泛型实现了以下关键功能:
- 类型安全的参数传递:
通过泛型A,防抖函数能够根据目标函数的签名进行参数类型检查,确保传入的参数与目标函数的类型一致。如果传入的参数类型不匹配,TypeScript 将在编译时报错,避免运行时的潜在错误。
const debounced1 = debounce((a: number, b: string) => {
console.log(a, b);
}, 300);
debounced1(42, "hello"); // 正确,参数类型匹配
debounced1("42", 42); // 错误,类型不匹配
在上面的例子中,TypeScript 会检查参数类型,确保传入的参数符合预期的类型。错误的参数类型会被及时捕捉。
- 返回值类型安全:
泛型R确保防抖函数的返回值与目标函数的返回值类型保持一致。TypeScript 可以根据目标函数的返回值类型推断防抖函数的返回值,防止不匹配的类型被返回。
const debounced = debounce(() => {
return "result";
}, 200);
const result = debounced(); // 返回值为 string
console.log(result); // 输出 "result"

在这个例子中,debounce返回的防抖函数的返回值类型为string或者undefind,因为在防抖函数的实现中,目标函数是延迟执行的,因此在初次调用或在延迟期间,debounced函数返回的结果可能尚未生成,与目标函数的返回值类型预期一致。 - 支持多参数传递:
泛型A表示目标函数的参数类型数组,这意味着防抖函数可以正确传递多个参数,并确保类型安全。如果传入了错误数量或类型的参数,TypeScript 会提示开发者进行修正。
const debounced = debounce((name: string, age: number) => {
return `${name} is ${age} years old.`;
}, 300);
const result = debounced("Alice", 30);
console.log(result); // 输出 "Alice is 30 years old."
在这个例子中,防抖函数正确地将多个参数传递给目标函数,并输出目标函数的正确返回值。传入的参数数量或类型不正确时,TypeScript 会发出报错提示。
总结
至此,我们完整实现并优化了一个类型安全的防抖函数,并通过泛型确保参数和返回值的类型安全。此外,我们还详细讲解了如何为防抖函数添加 cancel 方法,并处理延迟执行的返回值 R | undefined。最后,我们将防抖函数封装在一个单独的 TypeScript 文件中,并为其添加了 JSDoc 注释,使其成为一个可复用的工具函数。
通过这种方式,防抖函数不仅功能强大,还能在编译时提供类型检查,减少运行时的潜在错误。TypeScript 的类型系统帮助我们提升了代码的安全性和健壮性。
最后,我们给出完整的的代码如下:
// debounce.ts
export type DebouncedFunction<A extends any[], R> = {
(...args: A): R | undefined; // 防抖函数本身,返回值可能为 R 或 undefined
cancel: () => void; // `cancel` 方法,用于手动清除防抖
};
/**
* 创建一个防抖函数,确保在最后一次调用后,目标函数只会在指定的延迟时间后执行。
* 防抖函数可以防止某个函数被频繁调用,例如用户输入事件、滚动事件或窗口调整大小等场景。
*
* @template A - 函数接受的参数类型。
* @template R - 函数的返回值类型。
* @param {(...args: A) => R} func - 需要防抖的目标函数。该函数将在延迟时间后执行。
* @param {number} duration - 延迟时间(以毫秒为单位)。在这个时间内,如果再次调用函数,将重新计时。
* @returns {DebouncedFunction<A, R>} 一个防抖后的函数,该函数包括一个 `cancel` 方法用于清除防抖。
*
* @example
* const debouncedLog = debounce((message: string) => {
* console.log(message);
* return message;
* }, 300);
*
* debouncedLog("Hello"); // 300ms 后输出 "Hello"
* debouncedLog.cancel(); // 取消防抖,函数不会执行
*/
export function debounce<A extends any[], R>(
func: (...args: A) => R,
duration: number
): DebouncedFunction<A, R> {
let timer: ReturnType<typeof setTimeout> | null = null; // 定时器变量
let lastResult: R | undefined; // 存储目标函数的返回值
const debouncedFn = function (...args: A): R | undefined {
if (timer) {
clearTimeout(timer); // 清除之前的定时器
}
timer = setTimeout(() => {
lastResult = func(...args); // 延迟后执行目标函数,并存储返回值
}, duration);
return lastResult; // 返回上次执行的结果,如果尚未执行则返回 undefined
};
debouncedFn.cancel = function () {
if (timer) {
clearTimeout(timer); // 清除定时器,防止目标函数被执行
timer = null; // 重置定时器
}
};
return debouncedFn;
}
来源:juejin.cn/post/7431889821168812073
为什么一个文件的代码不能超过300行?
先说观点:在进行前端开发时,单个文件的代码行数推荐最大不超过300行,而超过1000行的都可以认为是垃圾代码,需要进行重构。
为什么是300
当然,这不是一个完全精准的数字,你一个页面301行也并不是什么犯天条的大罪,只是一般情况下,300行以下的代码可读性会更好。
起初,这只是林叔根据自己多年的工作经验拍脑袋拍出来的一个数字,据我观察,常规的页面开发,或者说几乎所有的前端页面开发,在进行合理的组件化拆分后,页面基本上都能保持在300行以下,当然,一个文件20行也并没有什么不妥,这里只是说上限。
但是拍脑袋得出的结论是不能让人信服的,于是林叔突发奇想想做个实验,看看这些开源大佬的源码文件都是多少行,于是我开发了一个小脚本。给定一个第三方的源文件所在目录,读取该目录下所有文件的行数信息,然后统计该库下文件的最长行数、最短行数、平均行数、小于500行/300行/200行/100行的文件占比。
脚本实现如下,感兴趣的可以看一下,不感兴趣的可以跳过看统计结果。统计排除了css样式文件以及测试相关文件。
const fs = require('fs');
const path = require('path');
let fileList = []; //存放文件路径
let fileLengthMap = {}; //存放每个文件的行数信息
let result = { //存放统计数据
min: 0,
max: 0,
avg: 0,
lt500: 0,
lt300: 0,
lt200: 0,
lt100: 0
}
//收集所有路径
function collectFiles(sourcePath){
const isFile = function (filePath){
const stats = fs.statSync(filePath);
return stats.isFile()
}
const shouldIgnore = function (filePath){
return filePath.includes("__tests__")
|| filePath.includes("node_modules")
|| filePath.includes("output")
|| filePath.includes("scss")
|| filePath.includes("style")
}
const getFilesOfDir = function (filePath){
return fs.readdirSync(filePath)
.map(file => path.join(filePath, file));
}
//利用while实现树的遍历
let paths = [sourcePath]
while (paths.length){
let fileOrDirPath = paths.shift();
if(shouldIgnore(fileOrDirPath)){
continue;
}
if(isFile(fileOrDirPath)){
fileList.push(fileOrDirPath);
}else{
paths.push(...getFilesOfDir(fileOrDirPath));
}
}
}
//获取每个文件的行数
function readFilesLength(){
fileList.forEach((filePath) => {
const data = fs.readFileSync(filePath, 'utf8');
const lines = data.split('\n').length;
fileLengthMap[filePath] = lines;
})
}
function statisticalMin(){
let min = Infinity;
Object.keys(fileLengthMap).forEach((key) => {
if (min > fileLengthMap[key]) {
min = fileLengthMap[key];
}
})
result.min = min;
}
function statisticalMax() {
let max = 0;
Object.keys(fileLengthMap).forEach((key) => {
if (max < fileLengthMap[key]) {
max = fileLengthMap[key];
}
})
result.max = max;
}
function statisticalAvg() {
let sum = 0;
Object.keys(fileLengthMap).forEach((key) => {
sum += fileLengthMap[key];
})
result.avg = Math.round(sum / Object.keys(fileLengthMap).length);
}
function statisticalLt500() {
let count = 0;
Object.keys(fileLengthMap).forEach((key) => {
if (fileLengthMap[key] < 500) {
count++;
}
})
result.lt500 = (count / Object.keys(fileLengthMap).length * 100).toFixed(2) + '%';
}
function statisticalLt300() {
let count = 0;
Object.keys(fileLengthMap).forEach((key) => {
if (fileLengthMap[key] < 300) {
count++;
}
})
result.lt300 = (count / Object.keys(fileLengthMap).length * 100).toFixed(2) + '%';
}
function statisticalLt200() {
let count = 0;
Object.keys(fileLengthMap).forEach((key) => {
if (fileLengthMap[key] < 200) {
count++;
}
})
result.lt200 = (count / Object.keys(fileLengthMap).length * 100).toFixed(2) + '%';
}
function statisticalLt100() {
let count = 0;
Object.keys(fileLengthMap).forEach((key) => {
if (fileLengthMap[key] < 100) {
count++;
}
})
result.lt100 = (count / Object.keys(fileLengthMap).length * 100).toFixed(2) + '%';
}
//统计
function statistics(){
statisticalMin();
statisticalMax();
statisticalAvg();
statisticalLt500();
statisticalLt300();
statisticalLt200();
statisticalLt100();
}
//打印
function print(){
console.log(fileList)
console.log(fileLengthMap)
console.log('最长行数:', result.max);
console.log('最短行数:', result.min);
console.log('平均行数:', result.avg);
console.log('小于500行的文件占比:', result.lt500);
console.log('小于300行的文件占比:', result.lt300);
console.log('小于200行的文件占比:', result.lt200);
console.log('小于100行的文件占比:', result.lt100);
}
function main(path){
collectFiles(path);
readFilesLength();
statistics();
print();
}
main(path.resolve(__dirname,'./vue-main/src'))
利用该脚本我对Vue、React、ElementPlus和Ant Design这四个前端最常用的库进行了统计,结果如下:
| 库 | 小于100行占比 | 小于200行占比 | 小于300行占比 | 小于500行占比 | 平均行数 | 最大行数 | 备注 |
|---|---|---|---|---|---|---|---|
| vue | 60.8% | 84.5% | 92.6% | 98.0% | 112 | 1000 | 仅1个模板文件编译的为1000行 |
| react | 78.0% | 92.0% | 94.0% | 98.0% | 96 | 1341 | 仅1个JSX文件编译的为1341行 |
| element-plus | 73.6% | 90.9% | 95.8% | 98.8 | 75 | 950 | |
| ant-design | 86.9% | 96.7% | 98.7% | 99.5% | 47 | 722 |
可以看出95%左右的文件行数都不超过300行,98%的都低于500行,而每个库中超过千行以上的文件最多也只有一个,而且还都是最复杂的模板文件编译相关的代码,我们平时写的业务代码复杂度远远小于这些优秀的库,那我们有什么理由写出那么冗长的代码呢?
从这个数据来看,林叔的判断是正确的,代码行数推荐300行以下,最好不超过500行,禁止超过1000行。
为什么不要超过300
现在,请你告诉我,你见过最难维护的代码文件是什么样的?它们有什么特点?
没错,那就是大,通常来说,难维护的代码会有3个显著特点:耦合严重、可读性差、代码过长,而代码过长是难以维护的最重要的原因,就算耦合严重、可读性差,只要代码行数不多,我们总还能试着去理解它,但一旦再伴随着代码过长,就超过我们大脑(就像计算机的CPU和内存)的处理上限了,直接死机了。
这是由于我们的生理结构决定的,大脑天然就喜欢简单的事物,讨厌复杂的事物,不信咱们做个小测试,试着读一遍然后记住下面的几个字母:
F H U T L P
怎么样,记住了吗?是不是非常简单,那我们再来看下下面的,还是读一遍然后记住:
J O Q S D R P M B C V X
这次记住了吗?这才12个字母而已,而上千行的代码中,包含各种各样的调用关系、数据结构等,为了搞懂一个功能可能还要跳转好几个函数,这么复杂的信息,是不是对大脑的要求有点过高了。
代码行数过大通常是难以维护的最大原因。
怎么不超过300
现在前端组件化编程这么流行,这么方便,我实在找不出还要写出超大文件的理由,我可以"武断"地说,凡是写出大文件的同学,都缺乏结构化思维和分治思维。
面向结构编程,而不是面向细节编程
以比较简单的官网开发为例,喜欢面向细节编程的同学,可能得实现是这样的:
<div>
<div class="header">
<img src="logo.png"/>
<h1>网站名称h1>
div>
<div class="main-content">
<div class="banner">
<ul>
<li><img src="banner1.png">li>
ul>
div>
<div class="about-us">
div>
div>
div>
其中省略了N行代码,通常他们写出的页面都非常的长,光Dom可能都有大几百行,再加上JS逻辑以及CSS样式,轻松超过1000行。
现在假如领导让修改"关于我们"的相关代码,我们来看看是怎么做的:首先从上往下阅读代码,在几千行代码中找到"关于我们"部分的DOM,然后再从几千行代码中找到相关的JS逻辑,这个过程中伴随着鼠标的反复上下滚动,眼睛像扫描仪一样一行行扫描,生怕错过了某行代码,这样的代码维护起来无疑是让人痛苦的。
面向结构开发的同学实现大概是这样的:
<div>
<Header/>
<main>
<Banner/>
<AboutUs/>
<Services/>
<ContactUs/>
main>
<Footer/>
div>
我们首先看到的是页面的结构、骨架,如果领导还是让我们修改"关于我们"的代码,你会怎么做,是不是毫不犹豫地就进入AboutUs组件的实现,无关的信息根本不会干扰到你,而且AboutUs的逻辑都集中在组件内部,也符合高内聚的编程原则。
特别是关于表单的开发,面向细节编程的情况特别严重,也造成表单文件特别容易变成超大文件,比如下面这个图,在一个表单中有十几个表单项,其中有一个选择商品分类的下拉选择框。

面向细节编程的同学喜欢直接把每个表单项的具体实现,杂糅在表单组件中,大概如下这样:
这还只是一个非常简单的表单项,你看看,就增加了这么多细节,如果是比较复杂点的表单项,其代码就更多了,这么多实现细节混合在这里,你能轻易地搞明白每个表单项的实现吗?你能说清楚这个表单组件的主线任务吗?
面向结构编程的同学会把它抽取为表单项组件,这样表单组件中只需要关心表单初始化、校验规则配置、保存逻辑等应该表单组件处理的内容,而不再呈现各种细节,实现了关注点的分离。
分而治之,大事化小
在进行复杂功能开发时,应该首先通过结构化思考,将大功能拆分为N个小功能,具体每个小功能怎么实现,先不用关心,在结构搭建完成后,再逐个问题击破。
仍然以前面提到的官网为例,首先把架子搭出来,每个子组件先不要实现,只要用一个简单的占位符占个位就行。
<div>
<Header/>
<main>
<Banner/>
<AboutUs/>
<Services/>
<ContactUs/>
main>
<Footer/>
div>
每个子组件刚开始先用个Div占位,具体实现先不管。
架子搭好后,再去细化每个子组件的实现,如果子组件很复杂,利用同样的方式将其拆分,然后逐个实现。相比上来就实现一个超大的功能,这样的实现更加简单可执行,也方便我们看到自己的任务进度。
可以看到,我们实现组件拆分的目的,并不是为了组件的复用(复用也是组件化拆分的一个主要目的),而是为了更好地呈现功能的结构,实现关注点的分离,增强可读性和可维护性,同时通过这种拆分,将复杂的大任务变成可执行的小任务,更容易完成且能看到进度。
总结
前端单个文件代码建议不超过300行,最大上限为500行,严禁超过100行。
应该面向结构编程,而不是面向细节编程,要能看到一个组件的主线任务,而不被其中的实现细节干扰,实现关注点分离。
将大任务拆分为可执行的小任务,先进行占位,后逐个实现。
来源:juejin.cn/post/7431575865152618511
太强了!这个js库有200多个日期时间函数

笔者在多年的职业生涯中,用过很多 js 日期时间操作库,如今唯爱这一个,它就是 date-fns。
这是一个拥有 200多个 日期时间函数的集合,堪称日期时间中的 Lodash。
支持按需导出,最大可能地降低打包体积,也支持函数式,链式调用风格。
当前维护非常积极,star 数 35k,提交了 2000多次,近 400个 代码贡献者,被超过 400万 个项目所依赖使用。
2024年9月份发布了 v4 大版本,支持不同时区的时间操作和互转等,特点如下图。

话不多说,看几个示例:
格式化
import { format, formatDistance, formatRelative, subDays } from 'date-fns';
format(new Date(), "'Today is a' eeee");
//=> "Today is a Saturday"
formatDistance(subDays(new Date(), 3), new Date(), { addSuffix: true });
//=> "3 days ago"
formatRelative(subDays(new Date(), 3), new Date());
//=> "last Friday at 7:26 p.m."
国际化
import { formatRelative, subDays } from 'date-fns';
import { es, ru } from 'date-fns/locale';
formatRelative(subDays(new Date(), 3), new Date());
//=> "last Friday at 7:26 p.m."
formatRelative(subDays(new Date(), 3), new Date(), { locale: es });
//=> "el viernes pasado a las 19:26"
formatRelative(subDays(new Date(), 3), new Date(), { locale: ru });
//=> "в прошлую пятницу в 19:26"
组合与函数式
import { addYears, formatWithOptions } from 'date-fns/fp';
import { eo } from 'date-fns/locale';
const addFiveYears = addYears(5);
const dateToString = formatWithOptions({ locale: eo }, 'D MMMM YYYY');
const dates = [
new Date(2017, 0, 1),
new Date(2017, 1, 11),
new Date(2017, 6, 2)
];
const toUpper = (arg) => String(arg).toUpperCase();
const formattedDates = dates.map(addFiveYears).map(dateToString).map(toUpper);
//=> ['1 JANUARO 2022', '11 FEBRUARO 2022', '2 JULIO 2022']
可以看到,这操作,非常地 Lodash!

不过呢,官方文档,笔者每次查看都感觉有点不方便。
所以,特意根据官方文档制作了一份中文文档,点击查看 date-fns 中文文档。

不过,笔者目前还没翻译完毕,还在持续进行中,感兴趣的朋友可以先提前关注一下,也欢迎与我微信交流探讨。
那么关于 date-fns 的安利,基本就结束了,本身就是一个函数库而已,没有太多可以细说的地方。
由于笔者比较八卦,我们来看一看 date-fns 周边的数据和信息。
日期时间的操作,是一个非常基础且重要的领域。

果不其然地,这个项目的赞助者非常之多,不乏很多出名的产品和公司。

截至目前,共收到了近 23 万美元的赞助。

项目的发起者是 Sasha,是一个独立开发者,自2017年起,就一直全职在做开源项目,目前和一家人生活在新加坡。
笔者发现,国外的独立开发者,不依托于公司而具备赚钱和生存能力的人有不少。
这确实是一个非常不错的生活方式,可以自由地选择自己觉得舒适的生活。
笔者目前也是独立开发者,2024年,是笔者做自由职业的地 4 第四年,做全职独立开发的第1年,目前超过 10 个产品有或多或少的收益。
如果对独立开发感兴趣,欢迎与我交流探讨。
来源:juejin.cn/post/7432588086418948131
小项目自动化部署用 Jenkins 太麻烦了怎么办
导读
本文介绍用 Webhooks 代替 Jenkins 更简单地实现自动化部署。不论用 Jenkins 还是 Webhooks,都需要一定的服务端基础。
Webhooks 的使用更简单,自然功能就不如 Jenkins 丰富,因此更适合小项目。
背景
笔者一直在小厂子做小项目,只做前端的时候,部署项目就是 npm run build 然后压缩发给后端。后来到另一个小厂子做全栈,开始自己部署,想着捣鼓一下自动化部署。
Jenkins 是最流行的自动化部署工具,但是弄到一半我头都大了。我只是想部署一个小项目而已,结果安装、配置、启动 Jenkins 这工作量好像比我手动部署还大呢,必须找个更简单的办法才行。果然经过一番捣鼓,发现 Webhooks 又简单又实用,更适合我们小厂子小项目。
原理
首先我们的项目应该都放在 Git 平台上,主流的 Git 平台上都有 Webhooks。它的作用是:在你推送代码、发布版本等操作时,自动向你提供的地址发一个请求。
你的服务器收到这个请求后,要做的事情就是调用一段事先写好的脚本。这段脚本的任务是拉取最新代码、安装依赖(可选)、打包项目、重新启动项目。
这样当你在 Git 平台上发布版本后,服务器就会自动部署最新代码了。
实现
实现步骤可以和上面的原理反着来:先写好脚本,然后启动服务,最后创建 Webhooks。
在此之前,你的服务器需要先安装 Git,并能够拉取你的代码。这部分内容很常规,看官可以在其他地方搜到。
1. 自动部署脚本
Nuxt
自动部署脚本就是代替我们手动打包、部署的工作。在 Linux 中,它应该写在一个 .sh 文件里。我的前端项目用 Nuxt 开发,脚本主要内容如下:
# 进入项目文件
cd /usr/local/example
# 拉取最新代码
git pull
# 打包
npm run build
# 重启服务
pm2 reload ecosystem.config.js
你可以在 Git 上随便更新点内容,然后在 XShell 或其他工具打开服务器控制台,执行这段代码,然后到线上版本看更新有没有生效。
笔记一开始经过了一番折腾,发现最好得记录部署日志,那样方便排查问题。完整脚本如下:
# 日志文件路径
LOG_FILE="/usr/local/example/$(date).txt"
# 记录开始时间
echo "Deployment started at $(date)" > $LOG_FILE
# 进入项目文件
cd /usr/local/example
# 拉取最新代码
git pull >> $LOG_FILE 2>&1
# 打包
npm run build >> $LOG_FILE 2>&1
# 重启服务
pm2 reload ecosystem.config.js >> $LOG_FILE 2>&1
# 记录结束时间
echo "Deployment finished at $(date)" >> $LOG_FILE
Eggjs
笔者后端用了 Eggjs,其自动部署脚本如下:
# 日志文件
LOG_FILE="/usr/local/example/$(date).txt"
# 记录开始时间
echo "Deployment started at $(date)" > $LOG_FILE
# 进入项目文件
cd /usr/local/example
# 拉取最新代码
git pull >> $LOG_FILE 2>&1
# Egg 没有重启命令,要先 stop 再 start
npm stop >> $LOG_FILE 2>&1
npm start >> $LOG_FILE 2>&1
# 记录结束时间
echo "Deployment finished at $(date)" >> $LOG_FILE
Eggjs 项目没有构建的步骤,其依赖要事先安装好。因此如果开发过程中安装了新依赖,记得到服务端安装一下。
Midwayjs
由于 Eggjs 对 TypeScript 的支持比较差,笔者后来还用了 Midwayjs 来开发服务端,其脚本如下:
# 日志文件
LOG_FILE="/usr/local/example/$(date).txt"
# 记录开始时间
echo "Deployment started at $(date)" > $LOG_FILE
# 进入项目文件
cd /usr/local/example
# 拉取最新代码
git pull >> $LOG_FILE 2>&1
# 重装依赖
export NODE_ENV=development
npm install >> $LOG_FILE 2>&1
# 构建
npm run build >> $LOG_FILE 2>&1
# 移除开发依赖
npm prune --omit=dev >> $LOG_FILE 2>&1
# 启动服务
npm start >> $LOG_FILE 2>&1
# 记录结束时间
echo "Deployment finished at $(date)" >> $LOG_FILE
Midwayjs 的自动部署脚本比较特殊:在 npm install 之前需要先指定环境为 development,那样才会安装所有依赖,否则会忽略 devDependencies 中的依赖,导致后面的 npm run build 无法执行。这点也是费了笔者好长时间才排查清楚,因为它在 XShell 里执行的时候默认的环境就是 development,但是到了 Webhooks 调用的时候又变成了 product。
2. 启动一个独立的小服务
上面这些脚本,应该由一个独立的小服务来执行。笔者一开始让项目的 Eggjs 服务来执行,也就是想让 Eggjs 服务自动部署自己,就失败了。原因是:脚本在执行到 npm stop 时,Eggjs 服务把自己关掉了,自然就执行不了 npm start。
笔者启动了一个新的 Eggjs 服务来实现这个功能,使用其他语言、框架同理。其中执行脚本的控制器代码如下:
const { Controller } = require('egg');
const { exec } = require('child_process');
class EggController extends Controller {
async index() {
const { ctx } = this;
try {
// 执行 .sh 脚本
await exec('sh /usr/local/example/egg.sh');
ctx.body = {
'msg': 'Deployment successful'
};
} catch (error) {
ctx.body = {
'msg': 'Deployment failed:' + JSON.stringify(error)
};
}
}
}
module.exports = EggController;
如果启动成功,你应该可以在 Postman 之类的工具上发起这个控制器对应的请求,然后成功执行里面的 .sh 脚本。
注意这些请求必须是 POST 请求。
3. 到 Git 平台创建 Webhooks
笔者用的是GitCode,其他平台类似。到代码仓库 -> 项目设置 -> WebHook 菜单 -> 新建 Webhook:

- URL:上面独立小服务的请求地址;
- Token:在 Git 平台生成即可;
- 事件类型:我希望是发布版本的时候触发,所以选
Tag推送事件。
创建好之后,激活这个 hook,然后随便提交些新东西,到代码仓库 -> 代码 -> 创建发行版:


填写版本号、版本描述后,滑到底部,勾选“最新版本”,点击发布按钮。

这样就能触发前面创建的 WebHook,向你的独立小服务发送请求,小服务就会去调用自动部署脚本。
怎么样,是不是比 Jenkins 简单太多了。当然功能也比 Jenkins 简单太多,但是对小厂子小项目来说,也是刚好够用。
来源:juejin.cn/post/7406238334215520291
增强 vw/rem 移动端适配,适配宽屏、桌面端、三折屏

vw 和 rem 是两个神奇的 CSS 长度单位,认识它们之前,我一度认为招聘广告上的“像素级还原”是一种超能力,我想具备这种能力的人,一定专业过硬、有一双高分辨率的深邃大眼睛。
时间一晃,入坑两年,我敏捷地移动有点僵硬不算过硬的小手,将一些固定的 px 尺寸复制到代码,等待编译阶段的 vw/rem 转换,刷新浏览器的功夫,完美还原的界面映入眼前,我推了推眼镜,会心一笑。多亏了 vw 和 rem。
TLDR:极简配置 postcss-mobile-forever 增强 vw 的宽屏可访问性,限制视图最大宽度。
用 vw 和 rem 适配移动端视图的结果是一致的,都会得到一个随屏幕宽度变化的等比例伸缩视图。一般使用 postcss-px-to-viewport 做 vw 适配,使用 postcss-px2rem 配合 amfe-flexible 做 rem 适配。由于 rem 适配的原理是模仿 vw,所以后面关于适配的增强,一律使用 vw 适配做对比。
vw 适配有一些优点(同样 rem):
- 加速开发效率;
- 像素级还原设计稿;
- 也许更容易被自动生成。
但是 vw 适配也不完美,它引出了下面的问题:
- 开发过程机械化,所有元素是固定的宽高,不考虑响应式设计,例如不使用
flex、grid布局; - 助长不规范化,不关注细节,只关注页面还原度和开发速度,例如在非按钮元素的
<div>上添加点击事件; - 桌面端难以访问,包容性降低。
前两个问题,也许要抛弃 vw、回归响应式布局才能解决,在日常开发时,我们要约束自己以开发桌面端的标准来开发移动端页面,改善这两个问题。
马克·吐温在掌握通过密西西比河的方法之后,发现这条河已经失去了它的美丽——总会丢掉一些东西,但是在艺术中比较不受重视的东西同时也被创造出来了。让我们不要再注意丢掉了什么,而是注意获得了什么。 ——《禅与摩托车的维修艺术》
后面,我们将关注第三点,介绍如何在保持现状(vw 适配)的情况下,尽可能提高不同屏幕的包容性,至少让我们在三折屏的时代能得到从前 1 倍的体验,而不是 1/3。
| 移动端 | 桌面端 |
|---|---|
 |  |
上面是一个页面分别在手机和电脑上展示的截图,可以看到左图移动端的右上角没有隐藏分享按钮,所以用户是允许(也应该允许)被分享到桌面端访问的,可惜,当用户准备享受大屏震撼的时候,真的被震撼了:他不知道这个页面的技术细节是神奇的 vw,也不知道他只能用鼠标小心地拖动浏览器窗口边缘,直到窗口窄得和手机一样,最崩溃的是,当他得意地按下了浏览器的缩小按钮,页面像冰冷的机器纹丝不动,浇灭了他的最后一点自信。
限制最大宽度
由于 vw 是视口单位,因此当屏幕变宽,vw 元素也会变大,无限变宽,无限变大。
现在假设在一张宽度 600 像素的设计图上,有一个宽度 60px 的元素,最终通过工具,它会被转为 10vw。这个 10vw 元素是任意伸缩的,但是现在我希望,当屏幕宽度扩大到 700px 后,停止元素的放大。
出现了一堆枯燥的数字,不用担心,后面还有一波,请保持耐心。
首先计算 10vw 在宽 700 像素的屏幕上,应该是多少像素:60 * 700 / 600 = 70。通过最大宽度(700px)和标准宽度(600px)的比例,乘以元素在标准宽度时的尺寸(60px),得到了元素的最大尺寸 70px。
接着结合 CSS 函数:min(10vw, 70px),这样元素的宽度将被限制在 70px 以内,小于这个宽度时会以 10vw 等比伸缩。
除了上面的作为正数的尺寸,可能还会有用于方位的负数,负数的情况则使用 CSS 函数 max(),下面的代码块是一个具体实现:
/**
* 限制大小的 vw 转换
* @param {number} n
* @param {number} idealWidth 标准/设计稿/理想宽度,设计稿的宽度
* @param {number} maxWidth 表示伸缩视图的最大宽度
*/
function maxVw(n, idealWidth = 600, maxWidth = 700) {
if (n === 0) return n;
const vwN = Math.round(n * 100 / idealWidth);
const maxN = Math.round(n * maxWidth / idealWidth);
const cssF = n > 0 ? "min" : "max";
return `${cssF}(${vwN}vw, ${maxN}px)`;
}
矫正视图外的元素位置
上一节提供的方法,包容了限制最大宽度尺寸的大部分情况,但是如果不忘像素级还原的❤️初心,就会找到一些漏洞。
下面是一个图例,移动端页面提供了 Top 按钮用于帮助用户返回顶部,按照上一节的方法,Top 按钮会出现在中央移动端视图之外、右边的空白区域中,而不是矫正回中央移动端视图的右下角。

假设 Top 按钮的样式是这样的:
.top {
position: fixed;
right: 30px;
bottom: 30px;
/* ... */
}
按照标准宽度 600、最大宽度 700,上面的 30px 都被转换成了 min(5vw, 35px),bottom 没错,但 right 需要矫正。
对照上面右图矫正过的状态,right 的值 = 右半边的空白长度 + Top 按钮到居中视图右边框的长度 = 桌面端视图的一半 - 视图中线到 Top 按钮的右边框长度。
沿着第二个等号后面的思路,fixed 定位时桌面端视图一半的尺寸即为 50%,中线到 Top 按钮右边框的长度,分两种情况:
- 在屏幕宽度大于最大宽度 700 时,为 700 / 2 - 30 * 700 / 600,即为
315px(其中 700 / 2 是中线到移动端右边框长度,30 * 700 / 600 是屏宽 600 时的30px在屏宽 700 时的尺寸); - 在屏幕宽度小于最大宽度 700 时,为 (600 / 2 - 30) / 600,即为
45%。
结合 calc()、min() 和上面得到的 50%、315px、45%,参考第二个等式,可以得到 right 的新值为 calc(50% - min(315px, 45%))。当尺寸大于移动端视图的一半时,会出现负数的情况,这时使用 max() 替换 min()。
上面的计算方法是一种符合预期的稳定的方法,另一种方法是强制设置移动端视图的根元素成为包含块,设置之后,
right: min(5vw, 35px)将不再基于浏览器边框,而是基于移动端视图的边框。
postcss-mobile-forever
上面介绍了增强 vw 以包容移动端视图在宽屏展示的两个方面,除了介绍的这些,还有一点点边角情况,例如:
- 逻辑属性的判断和转换;
- 矫正
fixed定位时和包含块宽度有关的vw和%尺寸; - 矫正
fixed定位时left与right的vw和%尺寸; - 为移动端视图添加居中样式;
- 各种情况的判断和转换方法选择。
postcss-mobile-forever 是一个 PostCSS 插件,利用 mobile-forever 这些工作可以在编译阶段完成,上面举了那么多例子,汇总成一份 mobile-forever 配置就是:
{
"viewportWidth": 700,
"appSelector": "#app",
"maxDisplayWidth": 600
}
上面是 mobile-forever 用户使用最多的模式,max-vw-mode,此外还提供:
- mq-mode,media-query 媒体查询模式,生成可访问性更高的样式,同样限制最大宽度,但是避免了
vw带来的无法通过桌面端浏览器缩放按钮缩放页面的问题,也提供了更高的浏览器兼容性; - vw-mode,朴素地将固定尺寸转为 vw 伸缩页面,不限制最大宽度。
postcss-mobile-forever 相比 postcss-px-to-viewport 提供了更多的模式,包容了宽屏展示,相比 postcss-px2rem,无需加载 JavaScript,不为项目引入复杂度,即使用户禁用了 js,也能正常展示页面。
scale-view 提供运行时的转换方法。
优秀的模版
postcss-mobile-forever 的推广离不开开源模版的支持、尝试与反馈,下面是这些优秀的模版,它们为开发者提供了更多元的选项,为用户提供了更包容的产品:
- vue3-vant-mobile,一个基于 Vue 3 生态系统的移动 web 应用模板,帮助你快速完成业务开发。【查看在线演示】
- vue3-vant4-mobile,基于Vue3.4、Vite5、Vant4、Pinia、Typescript、UnoCSS等主流技术开发,集成 Dark Mode(暗黑)模式和系统主题色,且持久化保存,集成 Mock 数据,包括登录/注册/找回/keep-alive/Axios/useEcharts/IconSvg 等其他扩展。你可以在此之上直接开发你的业务代码!【查看在线演示】
- fantastic-mobile,一款自成一派的移动端 H5 框架,支持多款 UI 组件库,基于 Vue3。【查看在线演示】
增强后的 vw/rem 看起来已经完成了适配宽屏的任务,不过回想最初的另外两个问题,机械化的开发过程与不规范化的开发细节,没有解决。作为一名专业的前端开发工程师,请考虑使用响应式设计开发你的下一个项目,为三折屏带来 3 倍的用户体验吧。
来源:juejin.cn/post/7431558902171484211
前端进阶必须会的Zod !
大家好,我是白露。
今天我想和大家分享一个我最近在使用的TypeScript库 —— Zod。简单来说,Zod是一个用于数据验证的库,它可以让你的TypeScript代码更加安全和可靠。
最近几个月我一直在使用Zod,发现它不仅解决了我长期以来的一些痛点,还大大提高了我的开发效率。我相信,这个库也能帮助到许多和我有同样困扰的TypeScript开发者们。
1. 为什么需要Zod?
作为一个热爱TypeScript的程序员,我一直在寻找能够增强类型安全性的方法。
最近几年,我主要使用TypeScript进行开发。原因很简单:TypeScript提供了优秀的静态类型检查,特别是对于大型项目来说,它的类型系统可以帮助我们避免许多潜在的运行时错误。
然而,尽管TypeScript的类型系统非常强大,但它仍然存在一些局限性。特别是在处理运行时数据时,TypeScript的静态类型检查无法完全保证数据的正确性。这就是我开始寻找额外的数据验证解决方案的原因。
在这个过程中,我尝试了多种数据验证库,如Joi、Yup等。但它们要么缺乏与TypeScript的良好集成,要么使用起来过于复杂。直到我发现了Zod,它完美地解决了我的需求。
2. Zod是什么?
Zod是一个TypeScript优先的模式声明和验证库。它允许你创建复杂的类型安全验证模式,并在运行时执行这些验证。Zod的设计理念是"以TypeScript类型为先",这意味着你定义的每个Zod模式不仅可以在运行时进行验证,还可以被TypeScript编译器用来推断类型。
使用Zod的主要优势包括:
- 类型安全: Zod提供了从运行时验证到静态类型推断的端到端类型安全。
- 零依赖: Zod没有任何依赖项,这意味着它不会给你的项目增加额外的包袱。
- 灵活性: Zod支持复杂的嵌套对象和数组模式,可以处理几乎任何数据结构。
- 可扩展性: 你可以轻松地创建自定义验证器和转换器。
- 性能: Zod经过优化,可以处理大型和复杂的数据结构,而不会影响性能。
3. 如何使用Zod?
让我们通过一些实际的例子来看看如何使用Zod。
3.1 基本类型验证
import { z } from 'zod';
// 定义一个简单的字符串模式
const stringSchema = z.string();
// 验证
console.log(stringSchema.parse("hello")); // 输出: "hello"
console.log(stringSchema.parse(123)); // 抛出 ZodError
3.2 对象验证
const userSchema = z.object({
name: z.string(),
age: z.number().min(0).max(120),
email: z.string().email(),
});
type User = z.infer<typeof userSchema>; // 自动推断类型
const user = {
name: "Alice",
age: 30,
email: "alice@example.com",
};
console.log(userSchema.parse(user)); // 验证通过
3.3 数组验证
const numberArraySchema = z.array(z.number());
console.log(numberArraySchema.parse([1, 2, 3])); // 验证通过
console.log(numberArraySchema.parse([1, "2", 3])); // 抛出 ZodError
4. Zod的高级用法
Zod不仅可以处理基本的类型验证,还可以处理更复杂的场景。
4.1 条件验证
const personSchema = z.object({
name: z.string(),
age: z.number(),
drivingLicense: z.union([z.string(), z.null()]).nullable(),
}).refine(data => {
if (data.age < 18 && data.drivingLicense !== null) {
return false;
}
return true;
}, {
message: "未成年人不能持有驾-照",
});
4.2 递归模式
const categorySchema: z.ZodType<Category> = z.lazy(() => z.object({
name: z.string(),
subcategories: z.array(categorySchema).optional(),
}));
type Category = z.infer<typeof categorySchema>;
4.3 自定义验证器
const passwordSchema = z.string().refine(password => {
// 至少8个字符,包含大小写字母和数字
const regex = /^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,}$/;
return regex.test(password);
}, {
message: "密码必须至少8个字符,包含大小写字母和数字",
});
5. Zod与前端框架的集成
Zod可以很好地与各种前端框架集成。
这里我们以React为例,看看如何在React应用中使用Zod进行表单验证。
import { z } from 'zod';
import { useForm } from 'react-hook-form';
import { zodResolver } from '@hookform/resolvers/zod';
const schema = z.object({
username: z.string().min(3).max(20),
email: z.string().email(),
password: z.string().min(8),
});
type FormData = z.infer<typeof schema>;
function SignupForm() {
const { register, handleSubmit, formState: { errors } } = useForm<FormData>({
resolver: zodResolver(schema),
});
const onSubmit = (data: FormData) => {
console.log(data);
};
return (
<form onSubmit={handleSubmit(onSubmit)}>
<input {...register("username")} placeholder="Username" />
{errors.username && <span>{errors.username.message}</span>}
<input {...register("email")} placeholder="Email" />
{errors.email && <span>{errors.email.message}</span>}
<input {...register("password")} type="password" placeholder="Password" />
{errors.password && <span>{errors.password.message}</span>}
<button type="submit">Sign Up</button>
</form>
);
}
6. Zod与数据库的结合
Zod不仅可以用于前端验证,还可以与后端数据库模式定义完美结合。以下是一个使用Prisma和Zod的例子:
import { z } from 'zod';
import { Prisma } from '@prisma/client';
const userSchema = z.object({
id: z.number().optional(),
name: z.string().min(3),
email: z.string().email(),
age: z.number().min(18),
createdAt: z.date().optional(),
updatedAt: z.date().optional(),
});
type User = z.infer<typeof userSchema>;
// 使用Zod模式来定义Prisma模型
const userModel: Prisma.UserCreateInput = userSchema.omit({ id: true, createdAt: true, updatedAt: true }).parse({
name: "John Doe",
email: "john@example.com",
age: 30,
});
// 现在可以安全地将这个对象传递给Prisma的create方法
// prisma.user.create({ data: userModel });
7. Zod的性能优化
虽然Zod非常强大,但在处理大型数据结构时,可能会遇到性能问题。以下是一些优化建议:
- 延迟验证: 对于大型对象,考虑使用
z.lazy()来延迟验证。 - 部分验证: 使用
z.pick()或z.omit()来只验证需要的字段。 - 缓存模式: 如果你频繁使用相同的模式,考虑缓存它们。
- 异步验证: 对于复杂的验证逻辑,考虑使用异步验证器。
8. Zod vs 其他验证库
Zod并不是市场上唯一的验证库。让我们简单比较一下Zod与其他流行的验证库:
- Joi: Joi是一个功能强大的验证库,但它不是TypeScript优先的,这意味着你需要额外的工作来获得类型推断。
- Yup: Yup与Zod非常相似,但Zod的API设计更加直观,而且性能通常更好。
- Ajv: Ajv是一个高性能的JSON Schema验证器,但它的API相对复杂,学习曲线较陡。
- class-validator: 这是一个基于装饰器的验证库,非常适合与TypeORM等ORM一起使用,但它需要使用实验性的装饰器特性。
相比之下,Zod提供了一个平衡的解决方案:它是TypeScript优先的,性能优秀,API直观,并且不需要任何实验性特性。
总而言之,通过使用Zod,你可以:
- 减少运行时错误
- 提高代码的可读性和可维护性
- 自动生成TypeScript类型
- 简化前后端之间的数据验证逻辑
开始使用Zod吧,让你的TypeScript代码更安全、更强大!
写了这么多,大家不点赞或者star一下,说不过去了吧?
延伸阅读
来源:juejin.cn/post/7426923218952847412
threejs做特效:实现物体的发光效果-EffectComposer详解!
简介与效果概览
各位大佬给个赞,感谢呢!
threejs的开发中,实现物体发光效果是一个常见需求,比如实现楼体的等待照明

要想实现这样的效果,我们只需要了解一个效果合成器概念:EffectComposer。
效果合成器能够合成各种花里胡哨的效果,好比是一个做特效的AE,本教程,我们将使用它来实现一个简单的发光效果。
如图,这是我们将导入的一个模型
 .
.
我们要给他赋予灵魂,实现下面的发光效果 
顺带的,我们要实现物体的自动旋转、一个简单的性能监视器、一个发光参数调节的面板
技术方案
原生html框架搭建
借助threejs实现一个物体发光效果非常简单,首先我们使用html搭建一个简单的开发框架
参考官方起步文档:three.js中文网
<!DOCTYPE html>
<html lang="en">
<head>
<title>three.js物体发光效果</title>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, user-scalable=no, minimum-scale=1.0, maximum-scale=1.0" />
<link type="text/css" rel="stylesheet" href="./main.css" />
<style>
#info>* {
max-width: 650px;
margin-left: auto;
margin-right: auto;
}
</style>
</head>
<body>
<div id="container"></div>
<script type="importmap">
{
"imports": {
"three": "https://unpkg.com/three@0.163.0/build/three.module.js",
"three/addons/": "https://unpkg.com/three@0.163.0/examples/jsm/"
}
}
</script>
<script type="module">
import * as THREE from "three";
import { OrbitControls } from "three/addons/controls/OrbitControls.js";
import { GLTFLoader } from "three/addons/loaders/GLTFLoader.js";
</script>
</body>
</html>
上述代码中,我们采用type="importmap"的方式引入了threejs开发 的一些核心依赖,"three"是开发的最基本依赖;在Three.js中,"addons" 通常指的是一些附加功能或扩展模块,它们提供了额外的功能,可以用于增强或扩展Three.js的基本功能。
在type="module"中,我们引入了threejs的一些基础依赖,OrbitControls轨道控制器和GLTFLoader模型加载器。
实现模型的加载
我们将下载好的模型放在文件根目录
http://www.yanhuangxueyuan.com/threejs/examples/models/gltf/PrimaryIonDrive.glb
基于threejs的基础知识,我们先实现模型的加载与渲染
<script type="module">
import * as THREE from "three";
import { OrbitControls } from "three/addons/controls/OrbitControls.js";
import { GLTFLoader } from "three/addons/loaders/GLTFLoader.js";
init()
function init() {
const container = document.getElementById("container");
// WebGL渲染器
// antialias是否执行抗锯齿。默认为false.
renderer = new THREE.WebGLRenderer({ antialias: true });
// 设置设备像素比。通常用于避免HiDPI设备上绘图模糊
renderer.setPixelRatio(window.devicePixelRatio);
renderer.setSize(window.innerWidth, window.innerHeight);
// 设置色调映射 这个属性用于在普通计算机显示器或者移动设备屏幕等低动态范围介质上,模拟、逼近高动态范围(HDR)效果。
renderer.toneMapping = THREE.ReinhardToneMapping;
container.appendChild(renderer.domElement);
// 创建新的场景对象。
const scene = new THREE.Scene();
// 创建透视相机
camera = new THREE.PerspectiveCamera(
40,
window.innerWidth / window.innerHeight,
1,
100
);
camera.position.set(-5, 2.5, -3.5);
scene.add(camera);
// 创建轨道控制器
const controls = new OrbitControls(camera, renderer.domElement);
controls.maxPolarAngle = Math.PI * 0.5;
controls.minDistance = 3;
controls.maxDistance = 8;
// 添加了一个环境光
scene.add(new THREE.AmbientLight(0xcccccc));
// 创建了一个点光源
const pointLight = new THREE.PointLight(0xffffff, 100);
camera.add(pointLight);
// 模型加载
new GLTFLoader().load("./PrimaryIonDrive.glb", function (gltf) {
const model = gltf.scene;
scene.add(model);
const clip = gltf.animations[0];
renderer.render(scene, camera);
});
}
</script>
现在,我们的页面中就有了下面的场景

接下来,我们实现模型的发光效果添加。
模型发光效果添加
实现模型的发光效果,实际是EffectComposer效果合成器实现的。
官方定义:用于在three.js中实现后期处理效果。该类管理了产生最终视觉效果的后期处理过程链。 后期处理过程根据它们添加/插入的顺序来执行,最后一个过程会被自动渲染到屏幕上。
简单来说,EffectComposer效果合成器只是一个工具,它可以将多种效果集成,进行渲染。我们来看一个伪代码:
import { EffectComposer } from "three/addons/postprocessing/EffectComposer.js";
// 创建效果合成器
composer = new EffectComposer(renderer);
composer.addPass(发光效果);
composer.addPass(光晕效果);
composer.addPass(玻璃磨砂效果
// 渲染
composer.render();
它的实现过程大致如上述代码。要实现发光效果,我们需要先熟悉三个Pass。
import { RenderPass } from "three/addons/postprocessing/RenderPass.js";
import { UnrealBloomPass } from "three/addons/postprocessing/UnrealBloomPass.js";
import { OutputPass } from "three/addons/postprocessing/OutputPass.js";
- RenderPass: 渲染通道是用于传递渲染结果的对象。RenderPass是EffectComposer中的一个通道,用于将场景渲染到纹理上。(固定代码,相当于混合效果的开始)
- UnrealBloomPass: 这是一个用于实现逼真的辉光效果的通道。它模拟了逼真的辉光,使得场景中的亮部分在渲染后产生耀眼的辉光效果。(不同效果有不同的pass)
- OutputPass: OutputPass是EffectComposer中的一个通道,用于将最终渲染结果输出到屏幕上。(固定代码,相当于混合效果的结束)
现在,我们完整的实现发光效果
<script type="module">
import * as THREE from "three";
import { OrbitControls } from "three/addons/controls/OrbitControls.js";
import { GLTFLoader } from "three/addons/loaders/GLTFLoader.js";
import { EffectComposer } from "three/addons/postprocessing/EffectComposer.js";
import { RenderPass } from "three/addons/postprocessing/RenderPass.js";
import { UnrealBloomPass } from "three/addons/postprocessing/UnrealBloomPass.js";
import { OutputPass } from "three/addons/postprocessing/OutputPass.js";
let camera;
let composer, renderer;
const params = {
threshold: 0,
strength: 1,
radius: 0,
exposure: 1,
};
init();
function init() {
const container = document.getElementById("container");
// WebGL渲染器
// antialias是否执行抗锯齿。默认为false.
renderer = new THREE.WebGLRenderer({ antialias: true });
// 设置设备像素比。通常用于避免HiDPI设备上绘图模糊
renderer.setPixelRatio(window.devicePixelRatio);
renderer.setSize(window.innerWidth, window.innerHeight);
// 设置色调映射 这个属性用于在普通计算机显示器或者移动设备屏幕等低动态范围介质上,模拟、逼近高动态范围(HDR)效果。
renderer.toneMapping = THREE.ReinhardToneMapping;
container.appendChild(renderer.domElement);
// 创建新的场景对象。
const scene = new THREE.Scene();
// 创建透视相机
camera = new THREE.PerspectiveCamera(
40,
window.innerWidth / window.innerHeight,
1,
100
);
camera.position.set(-5, 2.5, -3.5);
scene.add(camera);
// 创建轨道控制器
const controls = new OrbitControls(camera, renderer.domElement);
controls.maxPolarAngle = Math.PI * 0.5;
controls.minDistance = 3;
controls.maxDistance = 8;
// 添加了一个环境光
scene.add(new THREE.AmbientLight(0xcccccc));
// 创建了一个点光源
const pointLight = new THREE.PointLight(0xffffff, 100);
camera.add(pointLight);
// 创建了一个RenderPass对象,用于将场景渲染到纹理上。
const renderScene = new RenderPass(scene, camera);
// 创建了一个UnrealBloomPass对象,用于实现辉光效果。≈
const bloomPass = new UnrealBloomPass(
new THREE.Vector2(window.innerWidth, window.innerHeight),
1.5,
0.4,
0.85
);
// 设置发光参数,阈值、强度和半径。
bloomPass.threshold = params.threshold;
bloomPass.strength = params.strength;
bloomPass.radius = params.radius;
// 创建了一个OutputPass对象,用于将最终渲染结果输出到屏幕上。
const outputPass = new OutputPass();
// 创建了一个EffectComposer对象,并将RenderPass、UnrealBloomPass和OutputPass添加到渲染通道中。
composer = new EffectComposer(renderer);
composer.addPass(renderScene);
composer.addPass(bloomPass);
composer.addPass(outputPass);
// 模型加载
new GLTFLoader().load("./PrimaryIonDrive.glb", function (gltf) {
const model = gltf.scene;
scene.add(model);
const clip = gltf.animations[0];
animate();
});
}
function animate() {
requestAnimationFrame(animate);
// 通过调用 render 方法,将场景渲染到屏幕上。
composer.render();
}
</script>
现在,我们就实现发光的基本效果了!

实现物体的自动旋转动画
现在,我们实现一下物体自身的旋转动画

AnimationMixer是three中的动画合成器,使用AnimationMixer可以解析到模型中的动画数据
// 模型加载
new GLTFLoader().load("./PrimaryIonDrive.glb", function (gltf) {
const model = gltf.scene;
scene.add(model);
//创建了THREE.AnimationMixer 对象,用于管理模型的动画。
mixer = new THREE.AnimationMixer(model);
//从加载的glTF模型文件中获取动画数据。
//这里假设模型文件包含动画数据,通过 gltf.animations[0] 获取第一个动画片段。
const clip = gltf.animations[0];
// 使用 mixer.clipAction(clip) 创建了一个动画操作(AnimationAction),并立即播放该动画
mixer.clipAction(clip.optimize()).play();
animate();
});
实现动画更新
let clock;
clock = new THREE.Clock();
function animate() {
requestAnimationFrame(animate);
//使用了 clock 对象的 getDelta() 方法来获取上一次调用后经过的时间,即时间间隔(delta)。
const delta = clock.getDelta();
//根据上一次更新以来经过的时间间隔来更新动画。
//这个方法会自动调整动画的播放速度,使得动画看起来更加平滑,不受帧率的影响
mixer.update(delta);
// 通过调用 render 方法,将场景渲染到屏幕上。
composer.render();
}
完整代码
<script type="module">
import * as THREE from "three";
import { OrbitControls } from "three/addons/controls/OrbitControls.js";
import { GLTFLoader } from "three/addons/loaders/GLTFLoader.js";
import { EffectComposer } from "three/addons/postprocessing/EffectComposer.js";
import { RenderPass } from "three/addons/postprocessing/RenderPass.js";
import { UnrealBloomPass } from "three/addons/postprocessing/UnrealBloomPass.js";
import { OutputPass } from "three/addons/postprocessing/OutputPass.js";
let camera, stats;
let composer, renderer, mixer, clock;
const params = {
threshold: 0,
strength: 1,
radius: 0,
exposure: 1,
};
init();
function init() {
const container = document.getElementById("container");
clock = new THREE.Clock();
// WebGL渲染器
// antialias是否执行抗锯齿。默认为false.
renderer = new THREE.WebGLRenderer({ antialias: true });
// .....
// 模型加载
new GLTFLoader().load("./PrimaryIonDrive.glb", function (gltf) {
const model = gltf.scene;
scene.add(model);
mixer = new THREE.AnimationMixer(model);
const clip = gltf.animations[0];
mixer.clipAction(clip.optimize()).play();
animate();
});
}
function animate() {
requestAnimationFrame(animate);
const delta = clock.getDelta();
mixer.update(delta);
// 通过调用 render 方法,将场景渲染到屏幕上。
composer.render();
}
</script>
优化屏幕缩放逻辑
init{
// ....
window.addEventListener("resize", onWindowResize);
}
function onWindowResize() {
const width = window.innerWidth;
const height = window.innerHeight;
camera.aspect = width / height;
camera.updateProjectionMatrix();
renderer.setSize(width, height);
composer.setSize(width, height);
}
添加参数调节面板
在Three.js中,GUI是一个用于创建用户界面(UI)控件的库。具体来说,GUI库允许你在Three.js应用程序中创建交互式的图形用户界面元素,例如滑块、复选框、按钮等,这些元素可以用于控制场景中的对象、相机、光源等参数。
我们借助这个工具实现如下发光效果调试面板 
import { GUI } from "three/addons/libs/lil-gui.module.min.js";
init{
// ....
// 创建一个GUI实例
const gui = new GUI();
// 创建一个名为"bloom"的文件夹,用于容纳调整泛光效果的参数
const bloomFolder = gui.addFolder("bloom");
// 在"bloom"文件夹中添加一个滑块控件,用于调整泛光效果的阈值参数
bloomFolder
.add(params, "threshold", 0.0, 1.0)
.onChange(function (value) {
bloomPass.threshold = Number(value);
});
// 在"bloom"文件夹中添加另一个滑块控件,用于调整泛光效果的强度参数
bloomFolder
.add(params, "strength", 0.0, 3.0)
.onChange(function (value) {
bloomPass.strength = Number(value);
});
// 在根容器中添加一个滑块控件,用于调整泛光效果的半径参数
gui
.add(params, "radius", 0.0, 1.0)
.step(0.01)
.onChange(function (value) {
bloomPass.radius = Number(value);
});
// 创建一个名为"tone mapping"的文件夹,用于容纳调整色调映射效果的参数
const toneMappingFolder = gui.addFolder("tone mapping");
// 在"tone mapping"文件夹中添加一个滑块控件,用于调整曝光度参数
toneMappingFolder
.add(params, "exposure", 0.1, 2)
.onChange(function (value) {
renderer.toneMappingExposure = Math.pow(value, 4.0);
});
window.addEventListener("resize", onWindowResize);
}
添加性能监视器

import Stats from "three/addons/libs/stats.module.js";
init{
stats = new Stats();
container.appendChild(stats.dom);
// ...
}
function animate() {
requestAnimationFrame(animate);
const delta = clock.getDelta();
mixer.update(delta);
stats.update();
// 通过调用 render 方法,将场景渲染到屏幕上。
composer.render();
}
在Three.js中,Stats是一个性能监视器,用于跟踪帧速率(FPS)、内存使用量和渲染时间等信息。
完整demo代码
html
<!DOCTYPE html>
<html lang="en">
<head>
<title>three.js物体发光效果</title>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, user-scalable=no, minimum-scale=1.0, maximum-scale=1.0" />
<link type="text/css" rel="stylesheet" href="./main.css" />
<style>
#info>* {
max-width: 650px;
margin-left: auto;
margin-right: auto;
}
</style>
</head>
<body>
<div id="container"></div>
<script type="importmap">
{
"imports": {
"three": "https://unpkg.com/three@0.163.0/build/three.module.js",
"three/addons/": "https://unpkg.com/three@0.163.0/examples/jsm/"
}
}
</script>
<script type="module">
import * as THREE from "three";
import Stats from "three/addons/libs/stats.module.js";
import { GUI } from "three/addons/libs/lil-gui.module.min.js";
import { OrbitControls } from "three/addons/controls/OrbitControls.js";
import { GLTFLoader } from "three/addons/loaders/GLTFLoader.js";
import { EffectComposer } from "three/addons/postprocessing/EffectComposer.js";
import { RenderPass } from "three/addons/postprocessing/RenderPass.js";
import { UnrealBloomPass } from "three/addons/postprocessing/UnrealBloomPass.js";
import { OutputPass } from "three/addons/postprocessing/OutputPass.js";
let camera, stats;
let composer, renderer, mixer, clock;
const params = {
threshold: 0,
strength: 1,
radius: 0,
exposure: 1,
};
init();
function init() {
const container = document.getElementById("container");
stats = new Stats();
container.appendChild(stats.dom);
clock = new THREE.Clock();
// WebGL渲染器
// antialias是否执行抗锯齿。默认为false.
renderer = new THREE.WebGLRenderer({ antialias: true });
// 设置设备像素比。通常用于避免HiDPI设备上绘图模糊
renderer.setPixelRatio(window.devicePixelRatio);
renderer.setSize(window.innerWidth, window.innerHeight);
// 设置色调映射 这个属性用于在普通计算机显示器或者移动设备屏幕等低动态范围介质上,模拟、逼近高动态范围(HDR)效果。
renderer.toneMapping = THREE.ReinhardToneMapping;
container.appendChild(renderer.domElement);
// 创建新的场景对象。
const scene = new THREE.Scene();
// 创建透视相机
camera = new THREE.PerspectiveCamera(
40,
window.innerWidth / window.innerHeight,
1,
100
);
camera.position.set(-5, 2.5, -3.5);
scene.add(camera);
// 创建轨道控制器
const controls = new OrbitControls(camera, renderer.domElement);
controls.maxPolarAngle = Math.PI * 0.5;
controls.minDistance = 3;
controls.maxDistance = 8;
// 添加了一个环境光
scene.add(new THREE.AmbientLight(0xcccccc));
// 创建了一个点光源
const pointLight = new THREE.PointLight(0xffffff, 100);
camera.add(pointLight);
// 创建了一个RenderPass对象,用于将场景渲染到纹理上。
const renderScene = new RenderPass(scene, camera);
// 创建了一个UnrealBloomPass对象,用于实现辉光效果。≈
const bloomPass = new UnrealBloomPass(
new THREE.Vector2(window.innerWidth, window.innerHeight),
1.5,
0.4,
0.85
);
// 设置发光参数,阈值、强度和半径。
bloomPass.threshold = params.threshold;
bloomPass.strength = params.strength;
bloomPass.radius = params.radius;
// 创建了一个OutputPass对象,用于将最终渲染结果输出到屏幕上。
const outputPass = new OutputPass();
// 创建了一个EffectComposer对象,并将RenderPass、UnrealBloomPass和OutputPass添加到渲染通道中。
composer = new EffectComposer(renderer);
composer.addPass(renderScene);
composer.addPass(bloomPass);
composer.addPass(outputPass);
// 模型加载
new GLTFLoader().load("./PrimaryIonDrive.glb", function (gltf) {
const model = gltf.scene;
scene.add(model);
mixer = new THREE.AnimationMixer(model);
const clip = gltf.animations[0];
mixer.clipAction(clip.optimize()).play();
animate();
});
const gui = new GUI();
const bloomFolder = gui.addFolder("bloom");
bloomFolder
.add(params, "threshold", 0.0, 1.0)
.onChange(function (value) {
bloomPass.threshold = Number(value);
});
bloomFolder
.add(params, "strength", 0.0, 3.0)
.onChange(function (value) {
bloomPass.strength = Number(value);
});
gui
.add(params, "radius", 0.0, 1.0)
.step(0.01)
.onChange(function (value) {
bloomPass.radius = Number(value);
});
const toneMappingFolder = gui.addFolder("tone mapping");
toneMappingFolder
.add(params, "exposure", 0.1, 2)
.onChange(function (value) {
renderer.toneMappingExposure = Math.pow(value, 4.0);
});
window.addEventListener("resize", onWindowResize);
}
function onWindowResize() {
const width = window.innerWidth;
const height = window.innerHeight;
camera.aspect = width / height;
camera.updateProjectionMatrix();
renderer.setSize(width, height);
composer.setSize(width, height);
}
function animate() {
requestAnimationFrame(animate);
const delta = clock.getDelta();
mixer.update(delta);
stats.update();
// 通过调用 render 方法,将场景渲染到屏幕上。
composer.render();
}
</script>
</body>
</html>
main.css
body {
margin: 0;
background-color: #000;
color: #fff;
font-family: Monospace;
font-size: 13px;
line-height: 24px;
overscroll-behavior: none;
}
a {
color: #ff0;
text-decoration: none;
}
a:hover {
text-decoration: underline;
}
button {
cursor: pointer;
text-transform: uppercase;
}
#info {
position: absolute;
top: 0px;
width: 100%;
padding: 10px;
box-sizing: border-box;
text-align: center;
-moz-user-select: none;
-webkit-user-select: none;
-ms-user-select: none;
user-select: none;
pointer-events: none;
z-index: 1; /* TODO Solve this in HTML */
}
a, button, input, select {
pointer-events: auto;
}
.lil-gui {
z-index: 2 !important; /* TODO Solve this in HTML */
}
@media all and ( max-width: 640px ) {
.lil-gui.root {
right: auto;
top: auto;
max-height: 50%;
max-width: 80%;
bottom: 0;
left: 0;
}
}
#overlay {
position: absolute;
font-size: 16px;
z-index: 2;
top: 0;
left: 0;
width: 100%;
height: 100%;
display: flex;
align-items: center;
justify-content: center;
flex-direction: column;
background: rgba(0,0,0,0.7);
}
#overlay button {
background: transparent;
border: 0;
border: 1px solid rgb(255, 255, 255);
border-radius: 4px;
color: #ffffff;
padding: 12px 18px;
text-transform: uppercase;
cursor: pointer;
}
#notSupported {
width: 50%;
margin: auto;
background-color: #f00;
margin-top: 20px;
padding: 10px;
}
总结
通过本教程,我想现在你对效果合成器一定有了更深入的了解,现在,我们在看看官网的定义:
用于在three.js中实现后期处理效果。该类管理了产生最终视觉效果的后期处理过程链。 后期处理过程根据它们添加/插入的顺序来执行,最后一个过程会被自动渲染到屏幕上
结合代码,我想现在理解其它非常容易
<script type="module">
import * as THREE from "three";
import { EffectComposer } from "three/addons/postprocessing/EffectComposer.js";
import { RenderPass } from "three/addons/postprocessing/RenderPass.js";
import { UnrealBloomPass } from "three/addons/postprocessing/UnrealBloomPass.js";
import { OutputPass } from "three/addons/postprocessing/OutputPass.js";
function init() {
// 1【渲染开始】创建了一个RenderPass对象,用于将场景渲染到纹理上。
const renderScene = new RenderPass(scene, camera);
// 2【需要合成的中间特效】创建了一个UnrealBloomPass对象,用于实现辉光效果。≈
const bloomPass = new UnrealBloomPass(
new THREE.Vector2(window.innerWidth, window.innerHeight),
1.5,
0.4,
0.85
);
// 【特效设置】设置发光参数,阈值、强度和半径。
bloomPass.threshold = params.threshold;
bloomPass.strength = params.strength;
bloomPass.radius = params.radius;
// 3【效果输出】创建了一个OutputPass对象,用于将最终渲染结果输出到屏幕上。
const outputPass = new OutputPass();
// 4【特效合并】创建了一个EffectComposer对象,并将RenderPass、UnrealBloomPass和OutputPass添加到渲染通道中。
composer = new EffectComposer(renderer);
composer.addPass(renderScene);
composer.addPass(bloomPass);
composer.addPass(outputPass);
}
function animate() {
requestAnimationFrame(animate);
// 5【渲染特效】通过调用 render 方法,将场景渲染到屏幕上。
composer.render();
}
</script>
来源:juejin.cn/post/7355055084822446095
go的生态真的一言难尽
前言
标题党了,原生go很好用,只不过我习惯了java封装大法。最近在看golang,因为是javaer,所以突发奇想,不如开发一个类似于 Maven 或 Gradle 的构建工具来管理 Go 项目的依赖,众所周知,构建和发布是一个复杂的任务,但通过合理的设计和利用现有的工具与库,可以实现一个功能强大且灵活的工具。
正文分为两部分:项目本身和如何使用
一、项目本身
1. 项目需求分析
核心需求
- 依赖管理:
- 解析和下载 Go 项目的依赖。
- 支持依赖版本控制和冲突解决。
- 构建管理:
- 支持编译 Go 项目。
- 支持跨平台编译。
- 支持自定义构建选项。
- 发布管理:
- 打包构建结果。
- 支持发布到不同的平台(如 Docker Hub、GitHub Releases)。
- 任务管理:
- 支持定义和执行自定义任务(如运行测试、生成文档)。
- 插件系统:
- 支持扩展工具的功能。
可选需求
- 缓存机制:缓存依赖和构建结果以提升速度。
- 并行执行:支持并行下载和编译。
2. 技术选型
2.1 编程语言
- Go 语言:由于我们要构建的是 Go 项目的构建工具,选择 Go 语言本身作为开发语言是合理的。
2.2 依赖管理
- Go Modules:Go 自带的依赖管理工具已经很好地解决了依赖管理的问题,可以直接利用 Go Modules 来解析和管理依赖。
2.3 构建工具
- Go 标准库:Go 的标准库提供了强大的编译和构建功能(如
go build,go install等命令),可以通过调用这些命令或直接使用相关库来进行构建。
2.4 发布工具
- Docker:对于发布管理,可能需要集成 Docker 来构建和发布 Docker 镜像。
- upx:用于压缩可执行文件。
2.5 配置文件格式
- YAML 或 TOML:选择一种易于阅读和编写的配置文件格式,如 YAML 或 TOML。
3. 系统架构设计
3.1 模块划分
- 依赖管理模块:
- 负责解析和下载项目的依赖。
- 构建管理模块:
- 负责编译 Go 项目,支持跨平台编译和自定义构建选项。
- 发布管理模块:
- 负责将构建结果打包和发布到不同平台。
- 任务管理模块:
- 负责定义和执行自定义任务。
- 插件系统:
- 提供扩展点,允许用户编写插件来扩展工具的功能。
3.2 系统流程
- 初始化项目:读取配置文件,初始化项目环境。
- 依赖管理:解析依赖并下载。
- 构建项目:根据配置文件进行项目构建。
- 执行任务:执行用户定义的任务(如测试)。
- 发布项目:打包构建结果并发布到指定平台。
4. 模块详细设计与实现
4.1 依赖管理模块
4.1.1 设计
利用 Go Modules 现有的功能来管理依赖。可以通过 go list 命令来获取项目的依赖:
4.1.2 实现
package dependency
import (
"fmt"
"os/exec"
)
// ListDependencies 列出项目所有依赖
func ListDependencies() ([]byte, error) {
cmd := exec.Command("go", "list", "-m", "all")
return cmd.Output()
}
// DownloadDependencies 下载项目所有依赖
func DownloadDependencies() error {
cmd := exec.Command("go", "mod", "download")
output, err := cmd.CombinedOutput()
if err != nil {
return fmt.Errorf("download failed: %s", output)
}
return nil
}
4.2 构建管理模块
4.2.1 设计
调用 Go 编译器进行构建,支持跨平台编译和自定义构建选项。
4.2.2 实现
package build
import (
"fmt"
"os/exec"
"runtime"
"path/filepath"
)
// BuildProject 构建项目
func BuildProject(outputDir string) error {
// 设置跨平台编译参数
var goos, goarch string
switch runtime.GOOS {
case "windows":
goos = "windows"
case "linux":
goos = "linux"
default:
goos = runtime.GOOS
}
goarch = "amd64"
output := filepath.Join(outputDir, "myapp")
cmd := exec.Command("go", "build", "-o", output, "-ldflags", "-X main.version=1.0.0")
output, err := cmd.CombinedOutput()
if err != nil {
return fmt.Errorf("build failed: %s", output)
}
fmt.Println("Build successful")
return nil
}
4.3 发布管理模块
4.3.1 设计
打包构建结果并发布到不同平台。例如,构建 Docker 镜像并发布到 Docker Hub。
4.3.2 实现
package release
import (
"fmt"
"os/exec"
)
// BuildDockerImage 构建 Docker 镜像
func BuildDockerImage(tag string) error {
cmd := exec.Command("docker", "build", "-t", tag, ".")
output, err := cmd.CombinedOutput()
if err != nil {
return fmt.Errorf("docker build failed: %s", output)
}
fmt.Println("Docker image built successfully")
return nil
}
// PushDockerImage 推送 Docker 镜像
func PushDockerImage(tag string) error {
cmd := exec.Command("docker", "push", tag)
output, err := cmd.CombinedOutput()
if err != nil {
return fmt.Errorf("docker push failed: %s", output)
}
fmt.Println("Docker image pushed successfully")
return nil
}
5. 任务管理模块
允许用户定义和执行自定义任务:
package task
import (
"fmt"
"os/exec"
)
type Task func() error
func RunTask(name string, task Task) {
fmt.Println("Running task:", name)
err := task()
if err != nil {
fmt.Println("Task failed:", err)
return
}
fmt.Println("Task completed:", name)
}
func TestTask() error {
cmd := exec.Command("go", "test", "./...")
output, err := cmd.CombinedOutput()
if err != nil {
return fmt.Errorf("tests failed: %s", output)
}
fmt.Println("Tests passed")
return nil
}
6. 插件系统
可以通过动态加载外部插件或使用 Go 插件机制来实现插件系统:
package plugin
import (
"fmt"
"plugin"
)
type Plugin interface {
Run() error
}
func LoadPlugin(path string) (Plugin, error) {
p, err := plugin.Open(path)
if err != nil {
return nil, err
}
symbol, err := p.Lookup("PluginImpl")
if err != nil {
return nil, err
}
impl, ok := symbol.(Plugin)
if !ok {
return nil, fmt.Errorf("unexpected type from module symbol")
}
return impl, nil
}
5. 示例配置文件
使用 YAML 作为配置文件格式,定义项目的构建和发布选项:
name: myapp
version: 1.0.0
build:
options:
- -ldflags
- "-X main.version=1.0.0"
release:
docker:
image: myapp:latest
tag: v1.0.0
tasks:
- name: test
command: go test ./...
6. 持续改进
后续我将持续改进工具的功能和性能,例如:
- 增加更多的构建和发布选项。
- 优化依赖管理和冲突解决算法。
- 提供更丰富的插件。
二、如何使用
1. 安装构建工具
我已经将构建工具发布到 GitHub 并提供了可执行文件,用户可以通过以下方式安装该工具。
1.1 使用安装脚本安装
我将提供一个简单的安装脚本,开发者可以通过 curl 或 wget 安装构建工具。
使用 curl 安装
curl -L https://github.com/yunmaoQu/GoForge/releases/download/v1.0.0/install.sh | bash
使用 wget 安装
wget -qO- https://github.com//yunmaoQu/GoForge/releases/download/v1.0.0/install.sh | bash
1.2 手动下载并安装
如果你不想使用自动安装脚本,可以直接从 GitHub Releases 页面手动下载适合你操作系统的二进制文件。
- 访问 GitHub Releases 页面。
- 下载适合你操作系统的二进制文件:
- Linux:
GoForge-linux-amd64 - macOS:
GoForge-darwin-amd64 - Windows:
GoForge-windows-amd64.exe
- Linux:
- 将下载的二进制文件移动到系统的 PATH 路径(如
/usr/local/bin/),并确保文件有执行权限。
# 以 Linux 系统为例
mv GoForge-linux-amd64 /usr/local/bin/GoForge
chmod +x /usr/local/bin/GoForge
2. 创建 Go 项目并配置构建工具
2.1 初始化 Go 项目
假设你已经有一个 Go 项目或你想创建一个新的 Go 项目。首先,初始化 Go 模块:
mkdir my-go-project
cd my-go-project
go mod init github.com/myuser/my-go-project
2.2 创建 build.yaml 文件
在项目根目录下创建 build.yaml 文件,这个文件类似于 Maven 的 pom.xml 或 Gradle 的 build.gradle,用于配置项目的依赖、构建任务和发布任务。
示例 build.yaml
project:
name: my-go-project
version: 1.0.0
dependencies:
- name: github.com/gin-gonic/gin
version: v1.7.7
- name: github.com/stretchr/testify
version: v1.7.0
build:
output: bin/my-go-app
commands:
- go build -o bin/my-go-app main.go
tasks:
clean:
command: rm -rf bin/
test:
command: go test ./...
build:
dependsOn:
- test
command: go build -o bin/my-go-app main.go
publish:
type: github
repo: myuser/my-go-project
token: $GITHUB_TOKEN
assets:
- bin/my-go-app
配置说明:
- project: 定义项目名称和版本。
- dependencies: 列出项目的依赖包及其版本号。
- build: 定义构建输出路径和构建命令。
- tasks: 用户可以定义自定义任务(如
clean、test、build等),并可以配置任务依赖关系。 - publish: 定义发布到 GitHub 的配置,包括发布的仓库和需要发布的二进制文件。
3. 执行构建任务
构建工具允许你通过命令行执行各种任务,如构建、测试、清理、发布等。以下是一些常用的命令。
3.1 构建项目
执行以下命令来构建项目。该命令会根据 build.yaml 文件中定义的 build 任务进行构建,并生成二进制文件到指定的 output 目录。
GoForge build
构建过程会自动执行依赖任务(例如 test 任务),确保在构建之前所有测试通过。
3.2 运行测试
如果你想单独运行测试,可以使用以下命令:
GoForge test
这将执行 go test ./...,并运行所有测试文件。
3.3 清理构建产物
如果你想删除构建生成的二进制文件等产物,可以运行 clean 任务:
GoForge clean
这会执行 rm -rf bin/,清理 bin/ 目录下的所有文件。
3.4 列出所有可用任务
如果你想查看所有可用的任务,可以运行:
GoForge tasks
这会列出 build.yaml 文件中定义的所有任务,并显示它们的依赖关系。
4. 依赖管理
构建工具会根据 build.yaml 中的 dependencies 部分来处理 Go 项目的依赖。
4.1 安装依赖
当执行构建任务时,工具会自动解析依赖并安装指定的第三方库(类似于 go mod tidy)。
你也可以单独运行以下命令来手动处理依赖:
GoForge deps
4.2 更新依赖
如果你需要更新依赖版本,可以在 build.yaml 中手动更改依赖的版本号,然后运行 mybuild deps 来更新依赖。
5. 发布项目
构建工具提供了发布项目到 GitHub 等平台的功能。根据 build.yaml 中的 publish 配置,你可以将项目的构建产物发布到 GitHub Releases。
5.1 配置发布相关信息
确保你在 build.yaml 中正确配置了发布信息:
publish:
type: github
repo: myuser/my-go-project
token: $GITHUB_TOKEN
assets:
- bin/my-go-app
- type: 发布的目标平台(GitHub 等)。
- repo: GitHub 仓库路径。
- token: 需要设置环境变量
GITHUB_TOKEN,用于认证 GitHub API。 - assets: 指定发布时需要上传的二进制文件。
5.2 发布项目
确保你已经完成构建,并且生成了二进制文件。然后,你可以执行以下命令来发布项目:
GoForge publish
这会将 bin/my-go-app 上传到 GitHub Releases,并生成一个新的发布版本。
5.3 测试发布(Dry Run)
如果你想在发布之前测试发布流程(不上传文件),可以使用 --dry-run 选项:
GoForge publish --dry-run
这会模拟发布过程,但不会实际上传文件。
6. 高级功能
6.1 增量构建
构建工具支持增量构建,如果你在 build.yaml 中启用了增量构建功能,工具会根据文件的修改时间戳或内容哈希来判断是否需要重新构建未被修改的部分。
build:
output: bin/my-go-app
incremental: true
commands:
- go build -o bin/my-go-app main.go
6.2 插件机制
你可以通过插件机制来扩展构建工具的功能。例如,你可以为工具增加自定义的任务逻辑,或在构建生命周期的不同阶段插入钩子。
在 build.yaml 中定义插件:
plugins:
- name: custom-task
path: plugins/custom-task.go
编写 custom-task.go,并实现你需要的功能。
7. 调试和日志
如果你在使用时遇到了问题,可以通过以下方式启用调试模式,查看详细的日志输出:
GoForge --debug build
这会输出工具在执行任务时的每一步详细日志,帮助你定位问题。
总结
通过这个构建工具,你可以轻松管理 Go 项目的依赖、构建过程和发布任务。以下是使用步骤的简要总结:
- 安装构建工具:使用安装脚本或手动下载二进制文件。
- 配置项目:创建
build.yaml文件,定义依赖、构建任务和发布任务。 - 执行任务:通过命令行执行构建、测试、清理等任务。
- 发布项目:将项目的构建产物发布到 GitHub 或其他平台。
来源:juejin.cn/post/7431545806085423158
白嫖微信OCR,实现批量提取图片中的文字
微信自带的OCR使用比较方便,且准确率较高,但是唯一不足的是需要手动截图之后再识别,无法批量操作,这里我们借助wechat-ocr这一开源工具,实现批量读取文件夹下的所有图片并提取文本的功能。下面介绍下操作步骤。
1. 安装wechat-ocr这个库
这里我们使用的是GoBot这一自动化工具(如对该软件感兴趣,可以关注公众号:RPA二师兄),他提供的可视化安装依赖的功能。打开依赖包管理的Tab页,在Python包名称处填写wechat-ocr,然后点击安装,就能完成wechat-ocr的安装,安装完成之后可以切换到管理已安装模块的Tab,可以看到已经成功安装。


2. 编写调用代码
这里我们直接给出代码,只需要创建一个代码流程,将我们给的代码复制进去就可以了。
from package import variables as glv #全局变量,例如glv['test']
from robot_base import log_util
import robot_basic
from robot_base import log_util
import os
import re
from wechat_ocr.ocr_manager import OcrManager, OCR_MAX_TASK_ID
def main(args):
#输入参数使用示例
# if args is :
# 输入参数1 = ""
#else:
# 输入参数1 = args.get("输入参数1", "")
log_util.Logger.info(args)
init_ocr_manger(args['微信安装目录'])
ocr_manager.DoOCRTask(args['待识别图片路径'])
while ocr_manager.m_task_id.qsize() != OCR_MAX_TASK_ID:
pass
global ocr_result
return ocr_result
ocr_result = {}
ocr_manager =
def ocr_result_callback(img_path:str, results:dict):
log_util.Logger.info(results)
ocr_result = results
def init_ocr_manger(wechat_dir):
wechat_dir = find_wechat_path(wechat_dir)
wechat_ocr_dir = find_wechatocr_exe()
global ocr_manager
if ocr_manager is :
ocr_manager = OcrManager(wechat_dir)
# 设置WeChatOcr目录
ocr_manager.SetExePath(wechat_ocr_dir)
# 设置微信所在路径
ocr_manager.SetUsrLibDir(wechat_dir)
# 设置ocr识别结果的回调函数
ocr_manager.SetOcrResultCallback(ocr_result_callback)
# 启动ocr服务
ocr_manager.StartWeChatOCR()
def find_wechat_path(wechat_dir):
# 定义匹配版本号文件夹的正则表达式
version_pattern = re.compile(r'\[\d+\.\d+\.\d+\.\d+\]')
path_temp = os.listdir(wechat_dir)
for temp in path_temp:
# 下载是正则匹配到[3.9.10.27]
# 使用正则表达式匹配版本号文件夹
if version_pattern.match(temp):
wechat_path = os.path.join(wechat_dir, temp)
if os.path.isdir(wechat_path):
return wechat_path
def find_wechatocr_exe():
# 获取APPDATA路径
appdata_path = os.getenv("APPDATA")
if not appdata_path:
print("APPDATA environment variable not found.")
return
# 定义WeChatOCR的基本路径
base_path = os.path.join(appdata_path, r"Tencent\WeChat\XPlugin\Plugins\WeChatOCR")
# 定义匹配版本号文件夹的正则表达式
version_pattern = re.compile(r'\d+')
try:
# 获取路径下的所有文件夹
path_temp = os.listdir(base_path)
except FileNotFoundError:
print(f"The path {base_path} does not exist.")
return
for temp in path_temp:
# 使用正则表达式匹配版本号文件夹
if version_pattern.match(temp):
wechatocr_path = os.path.join(base_path, temp, 'extracted', 'WeChatOCR.exe')
if os.path.isfile(wechatocr_path):
return wechatocr_path
# 如果没有找到匹配的文件夹,返回
return
然后点击流程参数,创建流程的输入参数

3. 调用OCR识别的方法,实现批量的文字提取
使用调用流程组件,填写对应的参数,即可实现图片文字的提取了。

来源:juejin.cn/post/7432193949765287962
uni-app的这个“地雷”坑,我踩了
距离上次的 uni-app-x 文章已有一月有余,在此期间笔者又“拥抱”了 uni-app,使用 uni-app 开发微信小程序。
与使用 uni-app-x 相比个人感觉 uni-app 在开发体验上更流畅,更舒服一些,这可能得益于 uni-app 相对成熟,且与标准的前端开发相差不大。至少在 IDE 的选择上比较自由,比如可以选择 VSCode 或者 WebStorm,笔者习惯了 Jetbrains 家的 IDE,自然选择了 WebStorm。
虽说 uni-app 相对成熟,但是笔者还是踩到了“地雷式”的巨坑,下面且听我娓娓道来。
附:配套代码。
什么样的坑
先描述下是什么样的坑。简单来说,我有一个动态的 style 样式,伪代码如下:
<view v-for="(c, ci) in 10" :key="ci" :style="{ height: `${50}px` }">
{{ c }}
</view>
理论上编译到小程序应该如下:
<view style="height: 50px">1</view>
但是,实际上编译后却是:
<view style="height: [object Object]">1</view>
最后导致样式没有生效。
着手排查
先网上搜索一番,基本上千篇一律的都是 uni-app 编程成微信小程序时 style 不支持对象的形式,需要在对象外包一层数组,需要做如下修改:
<view :style="[{ height: `${50}px` }]"></view>
但是,这种方式对我无效。
然后开始了漫长的排查之旅,对比之前的项目是使用的对象形式对动态 style 进行的赋值也没有遇到这样问题,最后各种尝试至深夜一点多也没有解决,浪费我大好的“青春”。
没有解决问题实在是不甘心啊,于是第二天上午继续排查,观察 git 提交记录,没有发现什么异常的代码,然后开始拉新分支一个一个的 commit 回滚代码,然后再把回滚的代码手敲一遍再一点点的编译调试对比,这真的是浪费时间与精力的一件事,最终也是功夫不负有心人,终于锁定了一个 commit 提交,在这个 commit 后出现了上述问题。
为什么要回滚代码?因为在之前的代码中都是以对象形式为动态 style 赋值的。
现在可以着重的“攻击”这个 commit 上的代码了,仿佛沉溺在水中马上就要浮出水面可以呼一口气。这个 commit 上的代码不是很多,其中就包含上述的伪代码。最后,经过仔细的审查这个 commit 上的代码也没有发现什么异常的代码逻辑,好像突然没有了力气又慢慢沉入了水底。
反正是经过了各种尝试,其中历程真是一把鼻涕一把泪,不提也罢。
也不知是脑子不好使还是最后的倔强,突发奇想的修改了上述伪代码中 v-for 语句中的 c 变量命名:
<view v-for="(a, ci) in 10" :key="ci" :style="{ height: `${50}px` }">
{{ a }}
</view>
妈耶,奇迹发生了,动态 style 编译后正常了,样式生效了。随后又测试了一些其他的命名,如:A,b,B,C,d,D,i,I,这些都编译后正常,唯独命名为小写的 c 后,编译后不正常还是 [object Object] 的形式。
如果,现在,你迫不及待的去新建个 uni-app 项目来验证笔者所言是否属实,那么不好意思,你大概率不会踩到这个坑。
但是,如果你在动态 style 中再多加一个 css 属性,代码如下:
<view
v-for="(c, ci) in 5"
:key="ci"
:style="{
height: `${50}px`,
marginTop: `${10}px`,
}"
>
{{ c }}
</view>
那么你会发现第一个 height 属性生效了,然而新加的 marginTop 属性却是 [object Object]。
如果你再多加几个属性,你会发现它们都生效了,唯独第二个属性是失效的。
如果你在这个问题 view 代码前面使用过 v-for 且使用过动态 style 且动态 style 中有字符串模板,那么你会发现问题 view 变正常了。
总结
本文记录了笔者排查 uni-app 动态 style 失效的心路历程,虽然问题得到了解决,但是没有深入研究产生此问题的本质原因,总结起来就是菜,还得多练。
深夜对着星空感叹,这种坑也能被我踩到,真是时也命也。
来源:juejin.cn/post/7416554802254364708
写了一个字典hook,瞬间让组员开发效率提高20%!!!
1、引言
在项目的开发中,发现有很多地方(如:选择器、数据回显等)都需要用到字典数据,而且一个页面通常需要请求多个字典接口,如果每次打开同一个页面都需要重新去请求相同的数据,不但浪费网络资源、也给开发人员造成一定的工作负担。最近在用 taro + react 开发一个小程序,所以就写一个字典 hook 方便大家开发。
2、实现过程
首先,字典接口返回的数据类型如下图所示:

其次,在没有实现字典 hook 之前,是这样使用 选择器 组件的:
const [unitOptions, setUnitOptions] = useState([])
useEffect(() => {
dictAppGetOptionsList(['DEV_TYPE']).then((res: any) => {
let _data = res.rows.map(item => {
return {
label: item.fullName,
value: item.id
}
})
setUnitOptions(_data)
})
}, [])
const popup = (
<PickSelect
defaultValue=""
open={unitOpen}
options={unitOptions}
onCancel={() => setUnitOpen(false)}
onClose={() => setUnitOpen(false)}
/>
)
每次都需要在页面组件中请求到字典数据提供给 PickSelect 组件的 options 属性,如果有多个 PickSelect 组件,那就需要请求多次接口,非常麻烦!!!!!
既然字典接口返回的数据格式是一样的,那能不能写一个 hook 接收不同属性,返回不同字典数据呢,而且还能 缓存 请求过的字典数据?
当然是可以的!!!
预想一下如何使用这个字典 hook?
const { list } = useDictionary('DEV_TYPE')
const { label } = useDictionary('DEV_TYPE', 1)
const { label } = useDictionary('DEV_TYPE', 1, '、')
从上面代码中可以看到,第一个参数接收字典名称,第二个参数接收字典对应的值,第三个参数接收分隔符,而且后两个参数是可选的,因此根据上面的用法来写我们的字典 hook 代码。
interface dictOptionsProps {
label: string | number;
value: string | number | boolean | object;
disabled?: boolean;
}
interface DictResponse {
value: string;
list: dictOptionsProps[];
getDictValue: (value: string) => string
}
let timer = null;
const types: string[] = [];
const dict: Record<string, dictOptionsProps[]> = {}; // 字典缓存
// 因为接收不同参数,很适合用函数重载
function useDictionary(type: string): DictResponse;
function useDictionary(
type: string | dictOptionsProps[],
value: number | string | Array<number | string>,
separator?: string
): DictResponse;
function useDictionary(
type: string | dictOptionsProps[],
value?: number | string | Array<string | number>,
separator = ","
): DictResponse {
const [options, setOptions] = useState<dictOptionsProps[]>([]); // 字典数组
const [dictValue, setDictValue] = useState(""); // 字典对应值
const init = () => {
if (!dict[type] || !dict[type].length) {
dict[type] = [];
types.push(type);
// 当多次调用hook时,获取所有参数,合成数组,再去请求,这样可以避免多次调用接口。
timer && clearTimeout(timer);
timer = setTimeout(() => {
dictAppGetOptionsList(types.slice()).then((res) => {
for (const key in dictRes.data) {
const dictList = dictRes.data[key].map((v) => ({
label: v.description,
value: v.subtype,
}));
dict[type] = dictList
setOptions(dictList) // 注意这里会有bug,后面有说明的
}
});
}, 10);
} else {
typeof type === "string" ? setOptions(dict[type]) : setOptions(type);
}
};
// 获取字典对应值的中文名称
const getLabel = useCallback(
(value) => {
if (value === undefined || value === null || !options.length) return "";
const values = Array.isArray(value) ? value : [value];
const items = values.map((v) => {
if (typeof v === "number") v = v.toString();
return options.find((item) => item.value === v) || { label: value };
});
return items.map((v) => v.label).join(separator);
},
[options]
)
useEffect(() => init(), [])
useEffect(() => setDictValue(getLabel(value)), [options, value])
return { value: dictValue, list: options, getDictValue: getLabel };
}
初步的字典hook已经开发完成,在 Input 组件中添加 dict 属性,去试试看效果如何。
export interface IProps extends taroInputProps {
value?: any;
dict?: string; // 字典名称
}
const CnInput = ({
dict,
value,
...props
}: IProps) => {
const { value: _value } = dict ? useDictionary(dict, value) : { value };
return <Input value={_value} {...props} />
}
添加完成,然后去调用 Input 组件
<CnInput
readonly
dict="DEV_ACCES_TYPE"
value={formData?.accesType}
/>
<CnInput
readonly
dict="DEV_SOURCE"
value={formData?.devSource}
/>
没想到,翻车了
会发现,在一个页面组件中,多次调用 Input 组件,只有最后一个 Input 组件才会回显数据

这个bug是怎么出现的呢?原来是 setTimeout 搞的鬼,在 useDictionary hook 中,当多次调用 useDictionary hook 的时候,为了能拿到全部的 type 值,请求一次接口拿到所有字典的数据,就把字典接口放在 setTimeout 里,弄成异步的逻辑。但是每次调用都会清除上一次的 setTimeout,只保存了最后一次调用 useDictionary 的 setTimeout ,所以就会出现上面的bug了。
既然知道问题所在,那就知道怎么去解决了。
解决方案: 因为只有调用 setOptions 才会引起页面刷新,为了不让 setTimeout 清除掉 setOptions,就把 setOptions 添加到一个更新队列中,等字典接口数据回来再去执行更新队列就可以了。
let timer = null;
const queue = []; // 更新队列
const types: string[] = [];
const dict: Record<string, dictOptionsProps[]> = {};
function useDictionary2(type: string): DictResponse;
function useDictionary2(
type: string | dictOptionsProps[],
value: number | string | Array<number | string>,
separator?: string
): DictResponse;
function useDictionary2(
type: string | dictOptionsProps[],
value?: number | string | Array<string | number>,
separator = ","
): DictResponse {
const [options, setOptions] = useState<dictOptionsProps[]>([]);
const [dictValue, setDictValue] = useState("");
const getLabel = useCallback(
(value) => {
if (value === undefined || value === null || !options.length) return "";
const values = Array.isArray(value) ? value : [value];
const items = values.map((v) => {
if (typeof v === "number") v = v.toString();
return options.find((item) => item.value === v) || { label: value };
});
return items.map((v) => v.label).join(separator);
},
[options]
);
const init = () => {
if (typeof type === "string") {
if (!dict[type] || !dict[type].length) {
dict[type] = [];
const item = {
key: type,
exeFunc: () => {
if (typeof type === "string") {
setOptions(dict[type]);
} else {
setOptions(type);
}
},
};
queue.push(item); // 把 setOptions 推到 更新队列(queue)中
types.push(type);
timer && clearTimeout(timer);
timer = setTimeout(async () => {
const params = types.slice();
types.length = 0;
try {
let dictRes = await dictAppGetOptionsList(params);
for (const key in dictRes.data) {
dict[key] = dictRes.data[key].map((v) => ({
label: v.description,
value: v.subtype,
}));
}
queue.forEach((item) => item.exeFunc()); // 接口回来了再执行更新队列
queue.length = 0; // 清空更新队列
} catch (error) {
queue.length = 0;
}
}, 10);
} else {
typeof type === "string" ? setOptions(dict[type]) : setOptions(type);
}
}
};
useEffect(() => init(), []);
useEffect(() => setDictValue(getLabel(value)), [options, value]);
return { value: dictValue, list: options, getDictValue: getLabel };
}
export default useDictionary;
修复完成,再去试试看~

不错不错,已经修复,嘿嘿~
这样就可以愉快的使用 字典 hook 啦,去改造一下 PickSelect 组件
export interface IProps extends PickerProps {
open: boolean;
dict?: string;
options?: dictOptionsProps[];
onClose: () => void;
}
const Base = ({
dict,
open = false,
options = [],
onClose = () => { },
...props
}: Partial<IProps>) => {
// 如果不传 dict ,就拿 options
const { list: _options } = dict ? useDictionary(dict) : { list: options };
return <Picker.Column>
{_options.map((item) => {
return (
<Picker.Option
value={item.value}
key={item.value as string | number}
>
{item.label}
</Picker.Option>
);
})}
</Picker.Column>
在页面组件调用 PickSelect 组件

效果:

这样就只需要传入 dict 值,就可以轻轻松松获取到字典数据啦。不用再手动去调用字典接口啦,省下来的时间又可以愉快的摸鱼咯,哈哈哈
最近也在写 vue3 的项目,用 vue3 也实现一个吧。
// 定时器
let timer = 0
const timeout = 10
// 字典类型缓存
const types: string[] = []
// 响应式的字典对象
const dict: Record<string, Ref<CnPage.OptionProps[]>> = {}
// 请求字典选项
function useDictionary(type: string): Ref<CnPage.OptionProps[]>
// 解析字典选项,可以传入已有字典解析
function useDictionary(
type: string | CnPage.OptionProps[],
value: number | string | Array<number | string>,
separator?: string
): ComputedRef<string>
function useDictionary(
type: string | CnPage.OptionProps[],
value?: number | string | Array<number | string>,
separator = ','
): Ref<CnPage.OptionProps[]> | ComputedRef<string> {
// 请求接口,获取字典
if (typeof type === 'string') {
if (!dict[type]) {
dict[type] = ref<CnPage.OptionProps[]>([])
if (type === 'UNIT_LIST') {
// 单位列表调单独接口获取
getUnitListDict()
} else if (type === 'UNIT_TYPE') {
// 单位类型调单独接口获取
getUnitTypeDict()
} else {
types.push(type)
}
}
// 等一下,人齐了才发车
timer && clearTimeout(timer)
timer = setTimeout(() => {
if (types.length === 0) return
const newTypes = types.slice()
types.length = 0
getDictionary(newTypes).then((res) => {
for (const key in res.data) {
dict[key].value = res.data[key].map((v) => ({
label: v.description,
value: v.subtype
}))
}
})
}, timeout)
}
const options = typeof type === 'string' ? dict[type] : ref(type)
const label = computed(() => {
if (value === undefined || value === null) return ''
const values = Array.isArray(value) ? value : [value]
const items = values.map(
(value) => {
if (typeof value === 'number') value = value.toString()
return options.value.find((v) => v.value === value) || { label: value }
}
)
return items.map((v) => v.label).join(separator)
})
return value === undefined ? options : label
}
export default useDictionary
感觉 vue3 更简单啊!
到此结束!如果有错误,欢迎大佬指正~
来源:juejin.cn/post/7377559533785022527
什么?Flutter 又要凉了? Flock 是什么东西?
今天突然看到这个消息,突然又有一种熟悉的味道,看来这个月 Flutter “又要凉一次了”:

起因 flutter foundation 决定 fork Flutter 并推出 Flock 分支用于自建维护,理由是:
foundation 推测 Flutter 团队的劳动力短缺,因为 Flutter 需要维护 Android、iOS、Mac、Window、Linux、Web 等平台,但是 Flutter团队的规模仅略有增加。
在 foundation 看来,保守估计全球至少有 100 万 Flutter 相关开发者,而 Flutter 团队的规模大概就只有 50+ 人,这个比例并不健康。
问题在于这个数据推测就很迷,没有数据来源的推测貌似全靠“我认为”。。。。
另外 foundation 做这个决定,还因为 Flutter 官方团队对其 6 个支持的平台中,有 3 个处于维护模式(Window、Mac、Linux),所以他们无法接受桌面端的现场,因为他们认为桌面端很可能是 Flutter 最大的未开发价值。
关于这点目前 PC 端支持确实缓慢,但也并没有完全停止,如果关注 PC issue 的应该看到, Mac 的 PlatformView 和 WebView 支持近期才初步落地。
而让 foundation 最无法忍受的是,issue 的处理还有 pr 的 merge 有时候甚至可能会积累数年之久。
事实上这点确实成立,因为 Flutter 在很多功能上都十分保守,同时 issue 量大且各平台需求多等原因,很多能力的支持时间跨度多比较长,例如 「Row/Column 即将支持 Flex.spacing」 、「宏编程支持」 、「支持 P3 色域」 等这些都是持续了很久才被 merge 的 feature 。
所以 Flutter 的另外一个支持途径是来自社区 PR,但是 foundation 表示 Flutter 的代码 Review 和审计工作缓慢,并且沟通困难,想法很难被认可等,让 foundation 无法和 Flutter 官方有效沟通。
总结起来,在 foundation 的角度是,Flutter 官方团队维护 Flutter 不够尽心尽力。
所以他们决定,创建 Flutter 分支,并称为 Flock:意寓位 “Flutter+”。
不过 foundation 表示,他们其实并不想也不打算分叉 Flutter 社区,Flock 将始终与 Flutter 保持同步。
Flock 的重点是添加重要的错误修复和全新的社区功能支持,例如 Flutter 团队不做的,或者短期不会实现:

并且 Flock 的目的是招募一个比 Flutter 团队大得多的 PR 审查团队,从而加快 PR 的审计和推进。
所以看起来貌似这是一件好事,那么为什么解读会是“崩盘”和“内斗”?大概还是 Flutter 到时间凉了,毕竟刚刚过完 Flutter 是十周年生日 ,凉一凉也挺好的。

来源:juejin.cn/post/7431032490284236839
BOE(京东方)2024年前三季度净利润三位数增长 “屏之物联”引领企业高质发展
10月30日,京东方科技集团股份有限公司(京东方A:000725;京东方B:200725)发布2024年第三季度报告,前三季度公司实现营业收入1437.32亿元,较去年同期增长13.61%;归属于上市公司股东净利润33.10亿元,同比大幅增长223.80%。其中,第三季度实现营业收入503.45亿元,较去年同期增长8.65%;归属于上市公司股东净利润10.26亿元,同比增长258.21%。BOE(京东方)凭借稳健的经营策略和行业领先的技术优势,在保持半导体显示产业龙头地位的同时,持续推动“1+4+N+生态链”在各个细分市场的深度布局与成果落地,不断深化“屏之物联”战略在多业态场景的转化应用。面向下一个三十年,BOE(京东方)积极推动构建产业发展“第N曲线”,打造新的业务增长极,持续激发产业生态活力。
不仅业绩表现亮眼,BOE(京东方)还不断加大在前沿技术领域和物联网转型方面的投入与探索,为全球显示及物联网产业的未来发展注入新的活力。第三季度,BOE(京东方)全球创新伙伴大会成功举办,全面展示公司在前沿技术领域的重要突破以及物联网转型创新成果,并重磅发布了企业创新发展的战略升维“第N曲线”理论。这一理论不仅承载着企业文化的深厚底蕴,更是对核心优势资源的深度拓展,在“第N曲线”理论指导下,BOE(京东方)已在玻璃基、钙钛矿等新兴领域重点布局,其中,钙钛矿光伏电池中试线从设备搬入到首批样品产出,历时仅38天,创造了行业新记录,这一突破性进展标志着BOE(京东方)在钙钛矿光伏产业化道路上迈出了重要一步,以卓越的实力和高效的速度着力打造“第N曲线”关键增长极,持续引领行业走向智能化、可持续化发展。
稳居半导体显示领域龙头地位,技术创新引领行业发展
2024年前三季度,BOE(京东方)凭借前瞻性的全球市场布局,持续稳固半导体显示领域的龙头地位,不仅专利申请量保持全球领先,更有自主研发的ADS Pro顶尖技术引领行业发展,在柔性AMOLED市场也持续突破,各类技术创新成果丰硕。据市场调研机构Omdia数据显示,BOE(京东方)显示屏整体出货量和五大主流应用领域液晶显示屏出货量稳居全球第一。在专利方面,BOE(京东方)累计自主专利申请已超9万件,其中发明专利超90%,海外专利超30%,技术与产品创新能力稳步提升。同时,BOE(京东方)持续展现强大的创新实力和市场影响力,BOE(京东方)自主研发的、独有的液晶显示领域顶流技术ADS Pro,不仅是目前全球出货量最高的主流液晶显示技术,也是应用最广的硬屏液晶显示技术。凭借高环境光对比度、全视角无色偏、高刷新率和动态画面优化等方面的卓越性能表现,ADS Pro技术成为客户高端旗舰产品的首选,市场出货量和客户采纳度遥遥领先,展现了液晶显示技术蓬勃的生命力,更是极大推动了全球显示产业的良性健康发展。在柔性显示领域,2024年前三季度,BOE(京东方)柔性AMOLED产品出货量进一步增加,荣耀Magic6系列搭载BOE(京东方)首发的OLED低功耗解决方案,开启柔性OLED低功耗全新时代,获得市场和客户的广泛赞誉;与OPPO一加客户联合发布全新2K+LTPO全能高端屏幕标志着柔性显示的又一次全面技术革新,凭借在画质、性能及护眼等多方面的显著提升,再次定义高端柔性OLED屏幕行业新标准。同时,BOE(京东方)加快AMOLED产业布局,投建的国内首条第8.6代AMOLED生产线从开工到封顶仅用183天,以科学、高效、高质的速度树立行业新标杆,推动OLED显示产业快速迈进中尺寸发展阶段。
“1+4+N”业务布局成果显著,打造多元化发展格局
在持续深耕显示行业的同时,BOE(京东方)始终坚持创新发展,“1+4+N+生态链”业务也在创新技术的赋能下展现出全新活力,各个细分市场成果显著。BOE(京东方)物联网创新业务在智慧终端和系统方案两大领域持续高速发展,智慧终端领域,BOE(京东方)正式发布“Smart GOAL”业务目标,致力于打造软硬融合、服务全球、一站式、高效敏捷、绿色低碳的智造体系,并在白板、拼接、电子价签(ESL)等细分市场出货量保持全球第一(数据来源:迪显、Omdia等);系统方案领域,BOE(京东方)持续深耕智慧园区、智慧金融等多个物联网细分场景,积极拓展人机交互协同新边界。在传感业务方面,BOE(京东方)光幕技术及MEMS传感等技术加速赋能奇瑞汽车,推进汽车智能化转型;发布国内首个《乘用车用电子染料液晶调光玻璃技术规范》团体标准,并在智慧视窗领域超额完成极氪首款标配车型调光窗的量产交付,实现订单量增长200%,开启光幕技术创新与应用的新篇章;同时还在工业传感器领域导入6家战略客户,未来将在项目合作及产品研发等方面开展广泛合作。在MLED业务方面, BOE(京东方)MLED珠海项目全面启动,标志着公司在MLED领域进一步深入布局,为全球MLED市场的拓展奠定了坚实基础。在智慧医工业务方面,BOE(京东方)强化科技与医学相结合,打通“防治养”全链条,持续推动医疗健康服务的智慧化升级,成都京东方智慧医养社区正式投入运营,创新医养融合模式,成为BOE(京东方)布局智慧医养领域的重要里程碑;合肥京东方医院加入胸部肿瘤长三角联盟,携手优质专家资源造福当地患者;BOE(京东方)健康研究院与山西省肿瘤医院合作开展NK细胞治疗膀胱癌的临床研究,助力医疗技术创新。
BOE(京东方)还以“N”业务为着力点,为不同行业提供软硬融合的整体解决方案,包括智慧车载、数字艺术、AI+、超高清显示、智慧能源等多个细分领域,打造业务增长新曲线。在车载领域,BOE(京东方)持续保持车载显示屏出货量及出货面积全球第一(数据来源:Omdia),智能座舱产品全面应用到长安汽车、吉利汽车、蔚来、理想等全球各大主流汽车品牌中。在数字艺术领域,艺云科技在裸眼3D显示技术等方面取得新突破,裸眼3D屏亮相国家博物馆,艺云数字艺术中心(王府井)、艺云数字艺术中心(宜宾)正式开馆,创新显示技术为多个领域增光添彩。在AI+领域,BOE(京东方)已将人工智能技术产品、服务、解决方案应用于制造、办公、医疗、零售等细分场景,依托自主研发的人工智能平台及衍生技术集,打造AI良率分析系统、AI显示知识问答系统、显示工业大模型等,大幅度提高生产效率。在超高清领域,BOE(京东方)中联超清通过8K超高清显示技术、超薄全贴合电子站牌和户外LCD广告屏等产品,赋能合肥高新区公交站升级、成都双流国际机场T1航站楼,助力交通出行智能化服务水平大幅提升。在绿色发展方面,BOE(京东方)能源业务在工业、商业、园区等多个场景下加速推进零碳综合能源服务,成功落地多个能源托管项目和碳资产管理项目,助力社会实现二氧化碳减排约33万吨。
值得一提的是,BOE(京东方)在全球化布局与品牌建设的道路上也迈出了更加坚实的步伐。“你好,BOE”、《BOE解忧实验室》两大营销IP持续大热,BOE(京东方)年度标志性品牌活动“你好,BOE”首站亮相海外,助力中国非物质文化遗产艺术展览落地法国巴黎,向世界展示中国科技的创新活力;在上海北外滩盛大启幕的“你好,BOE”SUPER O SPACE影像科技展以“艺术x科技”为主题为观众带来了一场视觉盛宴,成为BOE(京东方)“屏之物联”战略赋能万千应用场景的又一次生动展现;《BOE解忧实验室》奇遇发现季节目以全网4.58亿传播的辉煌成绩,成为2024年度硬核技术科普综艺及科技企业破圈营销典范。2024年是体育大年,在巴黎全球体育盛会举办期间,BOE(京东方)还与联合国教科文组织(UNESCO)在法国巴黎总部签订合作协议,成为首个支持联合国“科学十年”的中国科技企业,更助力中国击剑队出征巴黎,在科技、体育、文化等多个维度树立中国科技企业出海的全新范式。
在新技术、新消费、新场景的多重驱动下,2024年前三季度,BOE(京东方)保持了稳健的发展态势,不断创新前沿技术成果,丰富多元应用场景,为半导体显示产业高质升维发展注入源源不断的动能。未来,BOE(京东方)将继续秉承“屏之物联”战略,以稳健的经营、前瞻性的技术研发和持续应用创新,携手全球合作伙伴共同构建“Powered by BOE”产业价值创新生态,推动显示技术、物联网技术与数字技术的深度融合,为显示行业高质量发展贡献力量,共创智慧美好未来。
BOE(京东方)全新一代发光器件赋能iQOO 13 全面引领柔性显示行业性能新高度
10月30日,备受瞩目的iQOO最新旗舰机——被誉为“性能之光”的iQOO 13在深圳震撼发布。该款机型由BOE(京东方)独供6.82英寸超旗舰2K LTPO直屏,行业首发搭载全新一代Q10发光器件,在画面表现、护眼舒适度及性能功耗方面均达到行业领先水准,并以“直屏超窄边”的设计为用户呈现了前所未有的视觉体验,将直板手机的产品性能推向了全新高度。此次BOE(京东方)携手vivo旗下iQOO品牌联合打造旗舰新品,既体现了以“Powered by BOE”的生态携手合作伙伴联合创新的强大成果,还彰显了BOE(京东方)在柔性显示领域的强大技术优势和引领实力。

在画面表现方面,得益于BOE(京东方)全新发光器件,iQOO 13实现了屏幕性能的全面提升。该款机型全局峰值亮度提升12.5%,可达1800nit,局部峰值亮度更是达到4500nit,即使在强光照射下屏幕内容也清晰可见;在极端温度环境(-10℃至45℃)下,屏幕的偏色现象减少50%以上,确保用户无论身处何种复杂环境下,都能享受到始终一致的卓越屏幕观看体验。此外,iQOO 13屏幕还实现了15%的拖影减轻效果,搭配其高达144Hz的刷新率,无论是观看高清视频还是畅玩大型游戏,都能呈现流畅无阻、细腻入微的视觉效果。
在性能及功耗领域,借助BOE(京东方)领先的屏幕技术加持,iQOO 13的触控技术全新飞跃,实现了更为灵敏的触控体验,响应速度也达到了前所未有的快捷。在确保高度灵敏操作的同时,iQOO 13还通过BOE(京东方)全新迭代升级的Q10核心发光器件,成功将屏幕显示功耗降低10%,寿命提升33%,从而实现续航能力的全面跃升。这一系列改进不仅提升了能效比,更带来了更为精细化的表现,为用户带来更加出色的使用体验。
在护眼舒适度方面,作为首款将2K分辨率与类自然偏光完美结合的产品,iQOO 13的表现同样出色,搭载BOE(京东方)OLED圆偏振光护眼技术,此项技术能够通过模拟自然光线在进入人眼时在多个方向上的均匀分布特性,还原自然光所带来的舒适、健康体验,从而显著减轻长时间使用手机所带来的用眼疲劳问题。同时,iQOO 13还配备BOE(京东方)至高2592Hz全亮度高频PWM调光方案,在各种光线环境下都能确保屏幕的稳定性,可有效降低屏幕频闪对眼睛造成的潜在危害。
根据Omdia数据显示,截至2024年上半年,京东方柔性OLED出货量已连续多年稳居国内第一,全球第二,柔性OLED相关专利申请超3万件。目前,BOE(京东方)柔性显示终端解决方案已应用于多款国内外头部品牌的高端旗舰机型,并持续拓展至笔记本、车载、可穿戴等丰富场景。
作为领先的物联网创新企业,BOE(京东方)多年来始终秉持对技术的尊重和对创新的坚持,通过“Powered by BOE”的生态构建与合作伙伴联合创新,引领中国柔性OLED产业不断迈向新高度。未来,BOE(京东方)将秉持“屏之物联”战略,联动上下游生态链伙伴,共同探索更多柔性显示应用场景,为全球亿万用户带来屏联万物的美好“视”界。
收起阅读 »买了个mini主机当服务器
虽然有苹果的电脑,但是在安装一些软件的时候,总想着能不能有一个小型的服务器,免得各种设置导致 Mac 出现异常。整体上看了一些小型主机,也看过苹果的 Mac mini,但是发现它太贵了,大概要 3000 多,特别是如果要更高配置的话,价格会更高,甚至更贵。所以,我就考虑一些别的小型主机。也看了一些像 NUC 这些服务器,但是觉得还是太贵了。于是我自己去淘宝搜索,找到了这一款 N100 版的主机。
成本的话,由于有折扣,所以大概是 410 左右,然后自己加了个看上去不错的内存条花了 300 左右。硬盘的话我自己之前就有,所以总成本大概是 700 左右。大小的话,大概是一台手机横着和竖着的正方形大小,还带 Wi-Fi,虽然不太稳定。

一、系统的安装
系统我看是支持windows,还有现在Ubuntu,但是我这种选择的是centos stream 9, 10的话我也找过,但是发现很多软件还有不兼容。所以最终还是centos stream 9。
1、下载Ventoy软件
去Ventoy官网下载Ventoy软件(Download . Ventoy)如下图界面

2、制作启动盘
选择合适的版本以及平台下载好之后,进行解压,解压出来之后进入文件夹,如下图左边所示,双击打开Ventoy2Disk.exe,会出现下图右边的界面,选择好自己需要制作启动盘的U盘,然后点击安装等待安装成功即可顺利制作成功启动U盘。
3、centos安装
直接取官网,下载完放到u盘即可。

它的BIOS是按F7启动,直接加载即可。

之后就是正常的centos安装流程了。
二、连接wifi
因为是用作服务器的,所以并没有给它配置个专门的显示器,只要换个网络,就连不上新的wifi了,这里可以用网线连接路由器进行下面的操作即可。
在 CentOS 系统中,通过命令行连接 Wi-Fi 通常需要使用 nmcli(NetworkManager 命令行工具)来管理网络连接。nmcli 是 NetworkManager 的一个命令行接口,可以用于创建、修改、激活和停用网络连接。以下是如何使用 nmcli 命令行工具连接 Wi-Fi 的详细步骤。
步骤 1: 检查网络接口
首先,确认你的 Wi-Fi 网络接口是否被检测到,并且 NetworkManager 是否正在运行。
nmcli device status
输出示例:
DEVICE TYPE STATE CONNECTION
wlp3s0 wifi disconnected --
enp0s25 ethernet connected Wired connection 1
lo loopback unmanaged --
在这个示例中,wlp3s0 是 Wi-Fi 接口,它当前处于未连接状态。
步骤 2: 启用 Wi-Fi 网卡
如果你的 Wi-Fi 网卡是禁用状态,可以通过以下命令启用:
nmcli radio wifi on
验证 Wi-Fi 是否已启用:
nmcli radio
步骤 3: 扫描可用的 Wi-Fi 网络
使用 nmcli 扫描附近的 Wi-Fi 网络:
nmcli device wifi list
你将看到可用的 Wi-Fi 网络列表,每个网络都会显示 SSID(网络名称)、安全类型等信息。
步骤 4: 连接到 Wi-Fi 网络
使用 nmcli 命令连接到指定的 Wi-Fi 网络。例如,如果你的 Wi-Fi 网络名称(SSID)是 MyWiFiNetwork,并且密码是 password123,你可以使用以下命令连接:
nmcli device wifi connect 'xxxxxx' password 'xxxxx'
你应该会看到类似于以下输出,表明连接成功:
Device 'wlp3s0' successfully activated with 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx'.
步骤 5: 验证连接状态
验证网络连接状态:
nmcli connection show
查看当前连接的详细信息:
nmcli device show wlp3s0
三、VNC远程连接
桌面还是偶尔需要用一下的,虽然用的不多。
root@master:~# dnf install -y tigervnc-server
root@master:~# vncserver
bash: vncserver: command not found...
Install package 'tigervnc-server' to provide command 'vncserver'? [N/y] y
* Waiting in queue...
* Loading list of packages....
The following packages have to be installed:
dbus-x11-1:1.12.20-8.el9.x86_64 X11-requiring add-ons for D-BUS
tigervnc-license-1.14.0-3.el9.noarch License of TigerVNC suite
tigervnc-selinux-1.14.0-3.el9.noarch SELinux module for TigerVNC
tigervnc-server-1.14.0-3.el9.x86_64 A TigerVNC server
tigervnc-server-minimal-1.14.0-3.el9.x86_64 A minimal installation of TigerVNC server
Proceed with changes? [N/y] y
* Waiting in queue...
* Waiting for authentication...
* Waiting in queue...
* Downloading packages...
* Requesting data...
* Testing changes...
* Installing packages...
WARNING: vncserver has been replaced by a systemd unit and is now considered deprecated and removed in upstream.
Please read /usr/share/doc/tigervnc/HOWTO.md for more information.
You will require a password to access your desktops.
getpassword error: Inappropriate ioctl for device
Password:
之后在mac开启屏幕共享就可以了


四、docker 配置
docker安装我以为很简单,没想到这里是最难的一步了。安装完docker之后,总是报错:
Error response from daemon: Get "https://registry-1.docker.io/v2/": context deadline exceeded
即使改了mirrors也毫无作用
{
"registry-mirrors": [
"https://ylce84v9.mirror.aliyuncs.com"
]
}
看起来好像是docker每次pull镜像都要访问一次registry-1.docker.io,但是这个网址国内已经无法连接了,各种折腾,这里只贴一下代码吧,原理就就不讲了(懂得都懂)。

sslocal -c /etc/猫代理.json -d start
curl --socks5 127.0.0.1:1080 http://httpbin.org/ip
sudo yum -y install privoxy
vim /etc/systemd/system/docker.service.d/http-proxy.conf
[Service]
Environment="HTTP_PROXY=http://127.0.0.1:8118"
/etc/systemd/system/docker.service.d/https-proxy.conf
[Service]
Environment="HTTPS_PROXY=http://127.0.0.1:8118"
最后重启docker
systemctl start privoxy
systemctl enable privoxy
sudo systemctl daemon-reload
sudo systemctl restart docker

五、文件共享
sd卡好像读取不了,只能换个usb转换器
fdisk -l
mount /dev/sdb1 /mnt/usb/sd
在CentOS中设置文件共享,可以使用Samba服务。以下是配置Samba以共享文件的基本步骤:
- 安装Samba
sudo yum install samba samba-client samba-common
- 设置共享目录
编辑Samba配置文件
/etc/samba/smb.conf,在文件末尾添加以下内容:
[shared]
path = /path/to/shared/directory
writable = yes
browseable = yes
guest ok = yes
- 设置Samba密码
为了允许访问,需要为用户设置一个Samba密码:
sudo smbpasswd -a your_username
- 重启Samba服务
sudo systemctl restart smb.service
sudo systemctl restart nmb.service
- 配置防火墙(如果已启用)
允许Samba通过防火墙:
sudo firewall-cmd --permanent --zone=public --add-service=samba
sudo firewall-cmd --reload
现在,您应该能够从网络上的其他计算机通过SMB/CIFS访问共享。在Windows中,你可以使用\\centos-ip\shared,在Linux中,你可以使用smbclient //centos-ip/shared -U your_username

参考:
https://猫代理help.github.io/猫代理/linux.html
来源:juejin.cn/post/7430460789067055154
开发小同学的骚操作,还好被我发现了
大家好,我是程序员鱼皮。今天给朋友们还原一个我们团队真实的开发场景。
开发现场
最近我们编程导航网站要开发 用户私信 功能,第一期要做的需求很简单:
- 能让两个用户之间 1 对 1 单独发送消息
- 用户能够查看到消息记录
- 用户能够实时收到消息通知

这其实是一个双向实时通讯的场景,显然可以使用 WebSocket 技术来实现。
团队的后端开发小 c 拿到需求后就去调研了,最后打算采用 Spring Boot Starter 快速整合 Websocket 来实现,接受前端某个用户传来的消息后,转发到接受消息的用户的会话,并在数据库中记录,便于用户查看历史。
小 c 的代码写得还是不错的,用了一些设计模式(像策略模式、工厂模式)对代码进行了一些抽象封装。虽然在我看来对目前的需求来说稍微有点过度设计,但开发同学有自己的理由和想法,表示尊重~

前端同学小 L 也很快完成了开发,并且通过了产品的验收。
看似这个需求就圆满地完成了,但直到我阅读前端同学的代码时,才发现了一个 “坑”。

这是前端同学小 L 提交的私信功能代码,看到这里我就已经发现问题了,朋友们能注意到么?

解释一下,小 L 引入了一个 nanoid 库,这个库的作用是生成唯一 id。看到这里,我本能地感到疑惑:为什么要引入这个库?为什么前端要生成唯一 id?
难道。。。是作为私信消息的 id?
果不其然,通过这个库在前端给每个消息生成了一个唯一 id,然后发送给后端。

后端开发的同学可能会想:一般情况下不都是后端利用数据库的自增来生成唯一 id 并返回给前端嘛,怎么需要让前端来生成呢?
这里小 L 的解释是,在本地创建消息的时候,需要有一个 id 来追踪状态,不会出现消息没有 id 的情况。
首先,这么做的确 能够满足需求 ,所以我还是通过了代码审查;但严格意义上来说,让前端来生成唯一 id 其实不够优雅,可能会有一些问题。
前端生成 id 的问题
1)ID 冲突:同时使用系统的前端用户可能是非常多的,每个用户都是一个客户端,多个前端实例可能会生成相同的 ID,导致数据覆盖或混乱。
2)不够安全:切记,前端是没有办法保证安全性的!因为攻击者可以篡改或伪造请求中的数据,比如构造一个已存在的 id,导致原本的数据被覆盖掉,从而破坏数据的一致性。
要做这件事成本非常低,甚至不需要网络攻击方面的知识,打开 F12 浏览器控制台,重放个请求就行实现:

3)时间戳问题:某些生成 id 的算法是依赖时间戳的,比如当前时间不同,生成的 id 就不同。但是如果前端不同用户的电脑时间不一致,就可能会生成重复 id 或无效 id。比如用户 A 电脑是 9 点时生成了 id = 06030901,另一个用户 B 电脑时间比 A 慢了一个小时,现在是 8 点,等用户 B 电脑时间为 9 点的时候,可能又生成了重复 id = 06030901,导致数据冲突。这也被称为 “分布式系统中的全局时钟问题”。
明确前后端职责
虽然 Nanoid 这个库不依赖时间戳来生成 id,不会受到设备时钟不同步的影响,也不会因为时间戳重复而导致 ID 冲突。根据我查阅的资料,生成大约 10 ^ 9 个 ID 后,重复的可能性大约是 10 ^ -17,几乎可以忽略不计。但一般情况下,我个人会更建议将业务逻辑统一放到后端实现,这么做的好处有很多:
- 后端更容易保证数据的安全性,可以对数据先进行校验再生成 id
- 前端尽量避免进行复杂的计算,而是交给后端,可以提升整体的性能
- 职责分离,前端专注于页面展示,后端专注于业务,而不是双方都要维护一套业务逻辑
我举个典型的例子,比如前端下拉框内要展示一些可选项。由于选项的数量并不多,前端当然可以自己维护这些数据(一般叫做枚举值),但后端也会用到这些枚举值,双方都写一套枚举值,就很容易出现不一致的情况。推荐的做法是,让后端返回枚举值给前端,前端不用重复编写。

所以一般情况下,对于 id 的生成,建议统一交给后端实现,可以用雪花算法根据时间戳生成,也可以利用数据库主键生成自增 id 或 UUID,具体需求具体分析吧~
来源:juejin.cn/post/7376148503087169562


