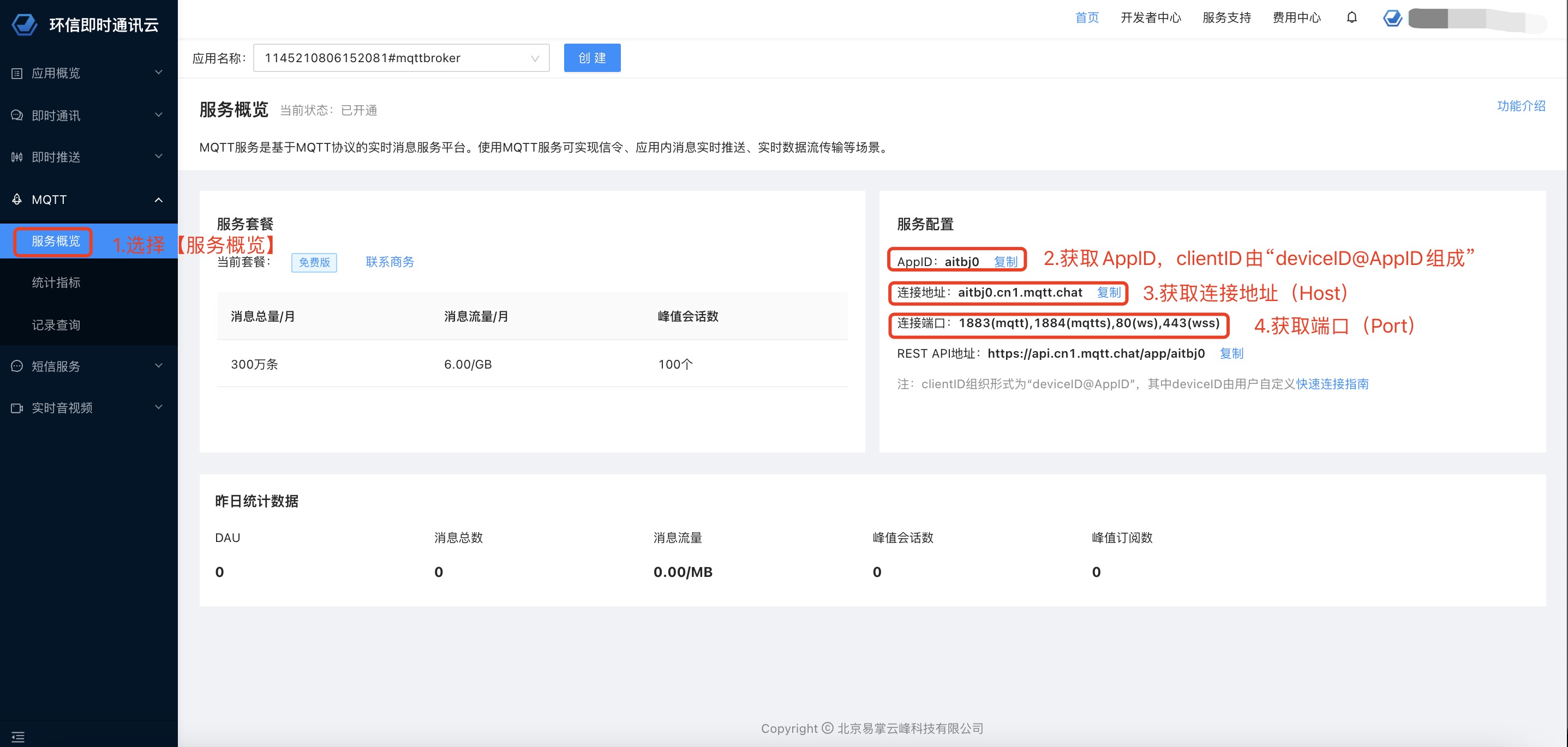
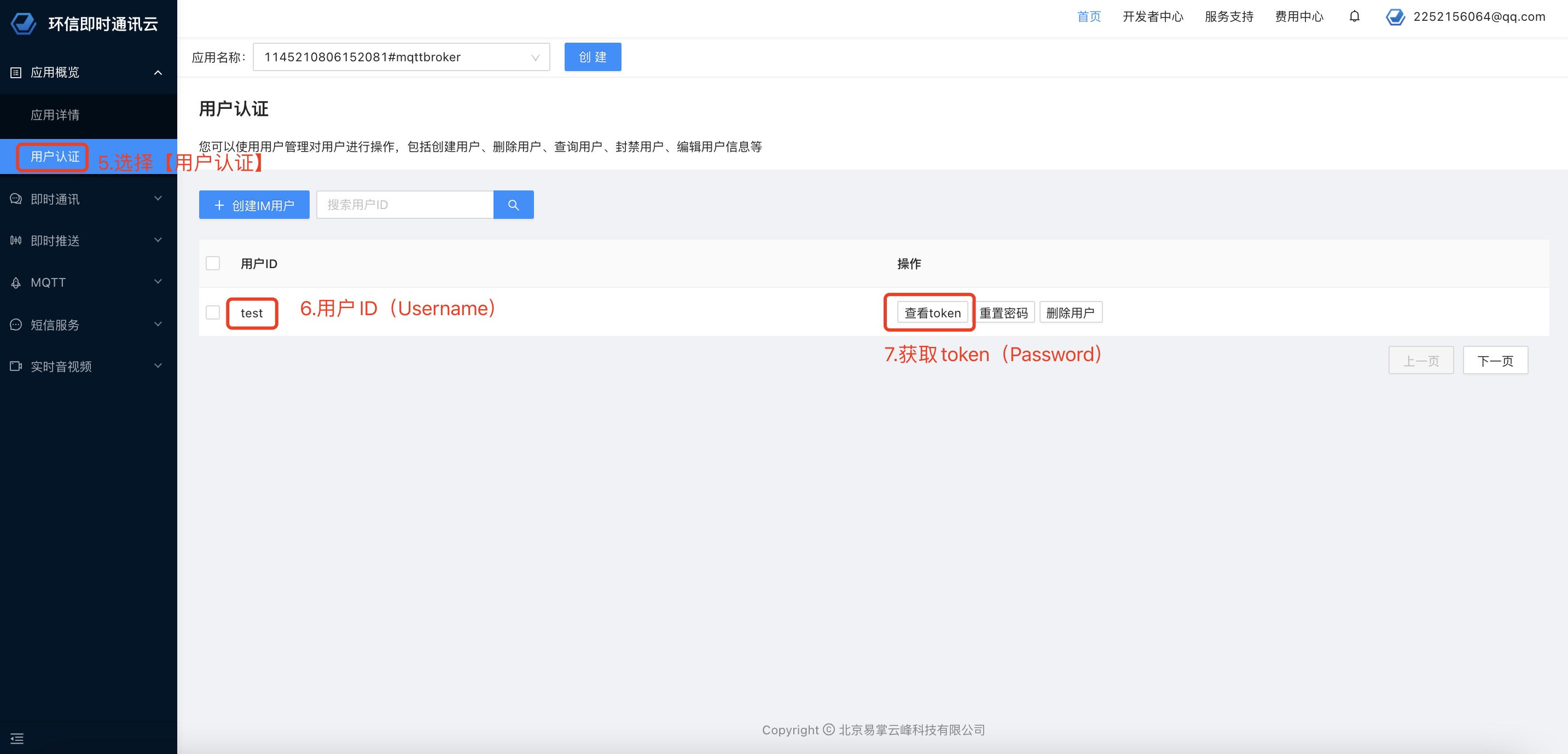
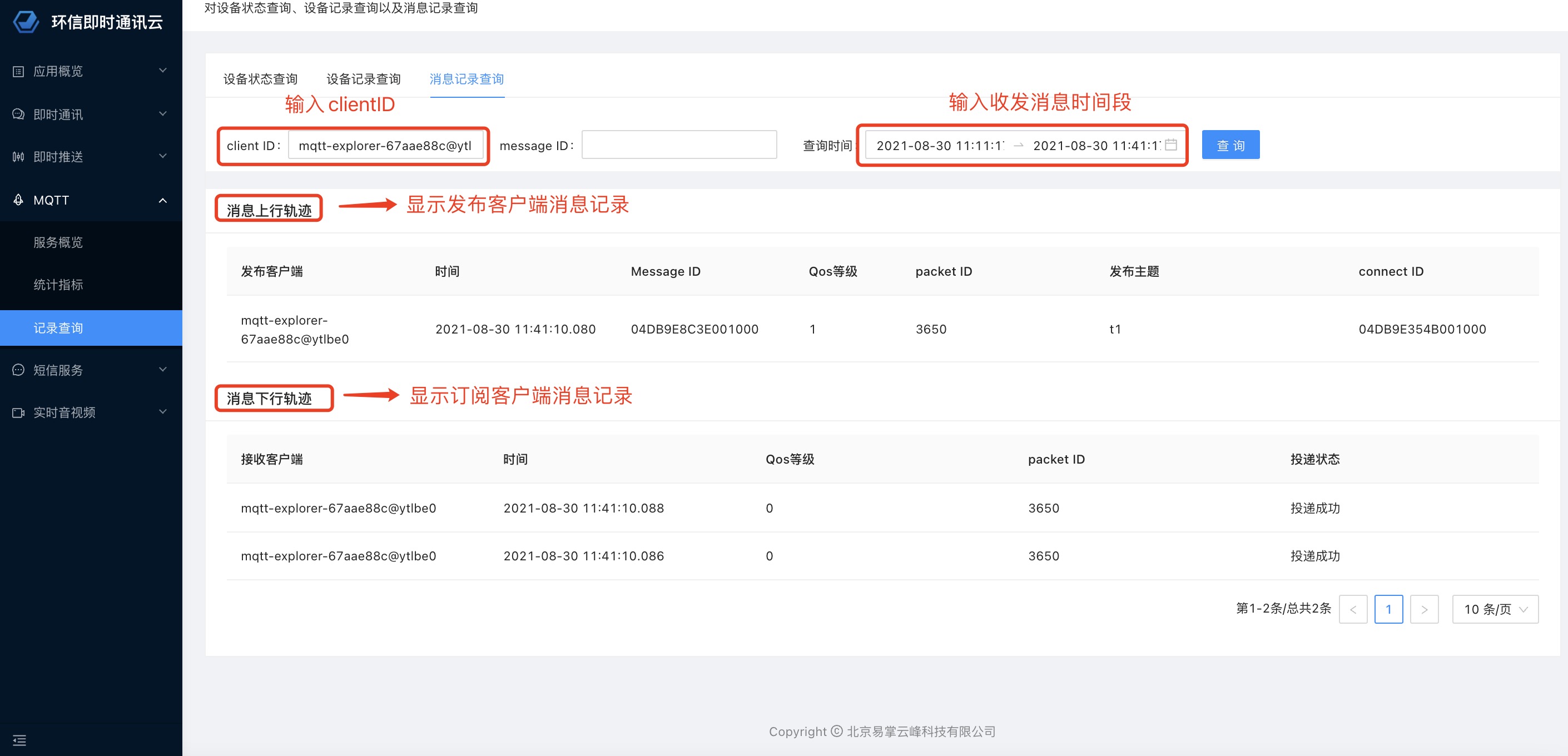
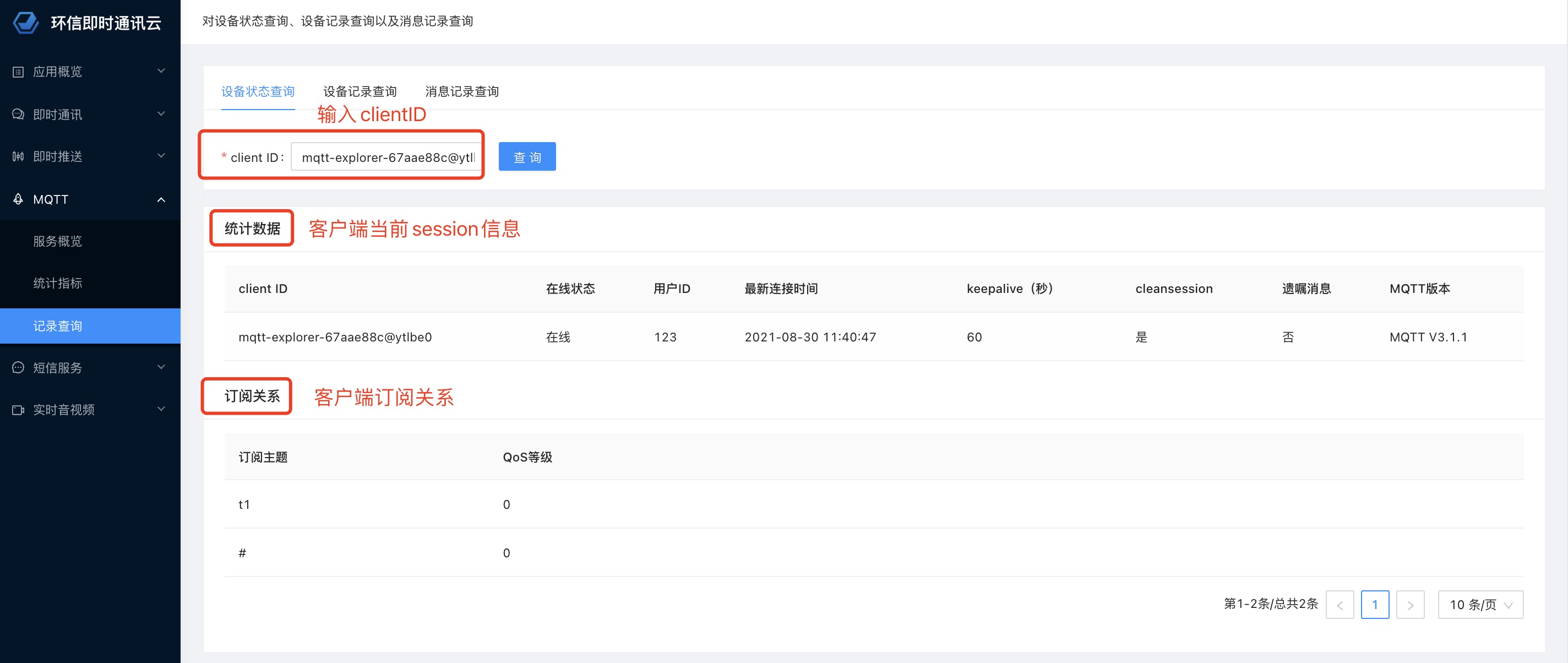
大家好,这次给大家换换口味,我们来点不一样的东西。请不要理解歪了🐶。
上周六和昊神的一聊,然后就有了这篇文章。
通过H5实现3D全景是挺平常的事情了,通过three.js可以很容易实现一个全景图。

可以这个链接来查看,three.js来实现的,戳👇three.js全景图DEMO链接。
其实我们通过CSS3也能实现类似的效果,而且性能上更好,兼容性更好,支持低端机型。
是不是很惊讶,CSS居然也能做这种事情?

好了,放放手上的事情,花10多分钟专心致志🐶,羽飞老师的课开始了。
注意⚠️:建议PC端观摩,因为有挺多例子需要查看后理解更好,不过也不太影响,为手机同学准备了比较多的gif图,准备地好疲乏🥱。
由于本文重点在最后章,文中借用了一些DEMO方便快速带入,可能有所纰漏,欢迎各位大佬拍砖🧱、吐槽💬。
〇 背景
17年双十一前夕,其实也前不了多少天(大家都懂),产品找到我,说要做它,赶在双十一前上线,然后就有了它🐶。
开门见山,直接甩上成品给大家看看。

那......我就开动啦。我们先看看成品是长啥样的。
可以查看这个,👇CSS全景图DEMO链接。

或者通过如上CSS全景图DEMO二维码进行尝试。
如果是“尊贵”的苹果手机用户🐶,在iOS13以上需要允许陀螺仪才可,如下图,得点击屏幕授权通过。iOS13之前都是默认开启的,苹果真的是一点不考虑向下兼容🥲,有点霸道呀。
扯远了扯远了,收。
这个时候大家就可以通过旋转手机或拖拽来查看整个全景图了。

是不是还挺神奇的?不是?

还是不是?🐶。🦢🦢🦢,不能向苹果学习🐶。
回来回来,接下来讲讲原理,先看看前置知识点。
〇 前置知识
看问题先看全貌,我们先来了解下如题中所提的天空盒子是什么概念。
天空盒子
天空盒子其实通俗的理解,可以理解如果把你放到天空中,上下前后左右都是蓝色的天空。而这个天空可以简单的用六边形来实现。
如下图所示,六边组成了一个封闭空间。
如果把你放到这个空间里,然后把每个空间的墙壁弄成天蓝色,而且每面都是纯蓝天色,这样你就分辨不出自己是不是在天上,还是只是在一个封闭的天空盒子里。
细思极恐,让人想到了缸中之脑,没听过的同学可以看看百度百科的缸中之脑解释。
好了,回归主题👻。这样一个天空盒子就形成了一个全景空间图。
那CSS是要怎么才能实现一个天空盒子呢?我们继续。

CSS 3D坐标系
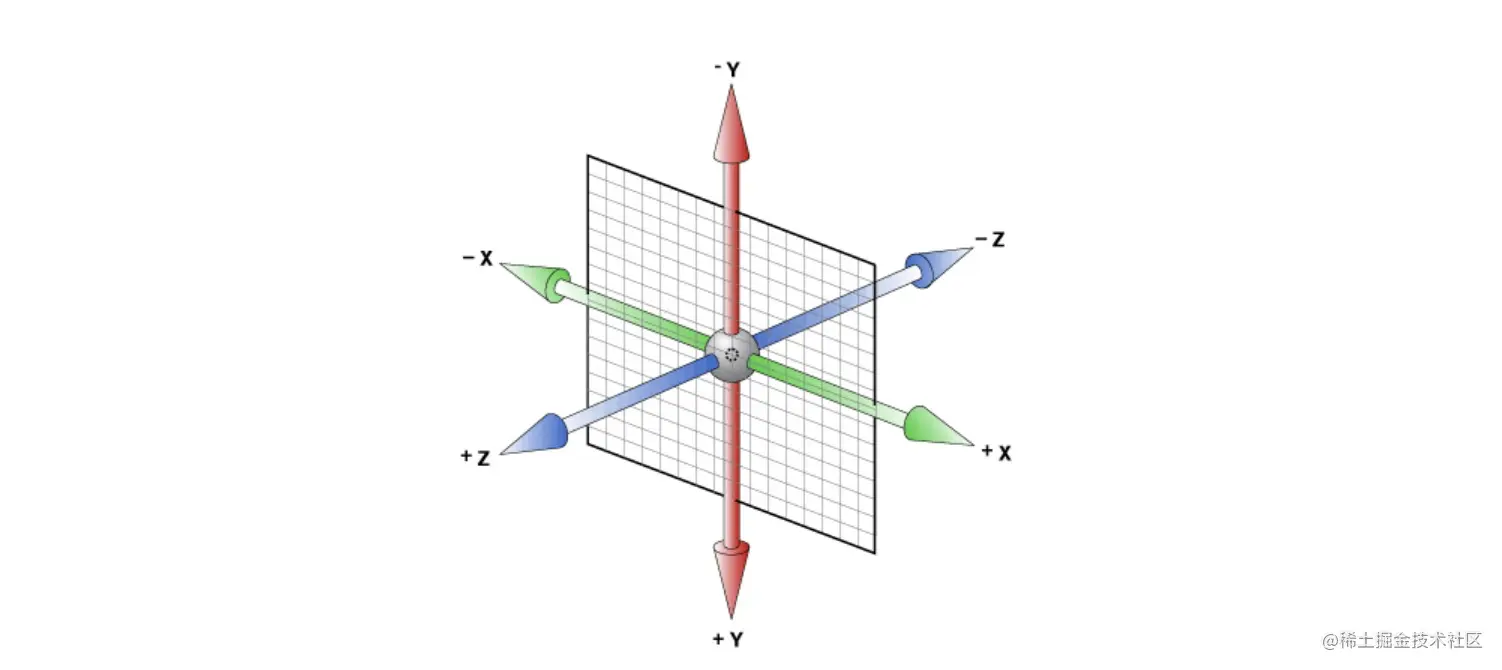
先来了解一下坐标系的概念。
从二维“反降维”到三维,需要理解下这个坐标系。
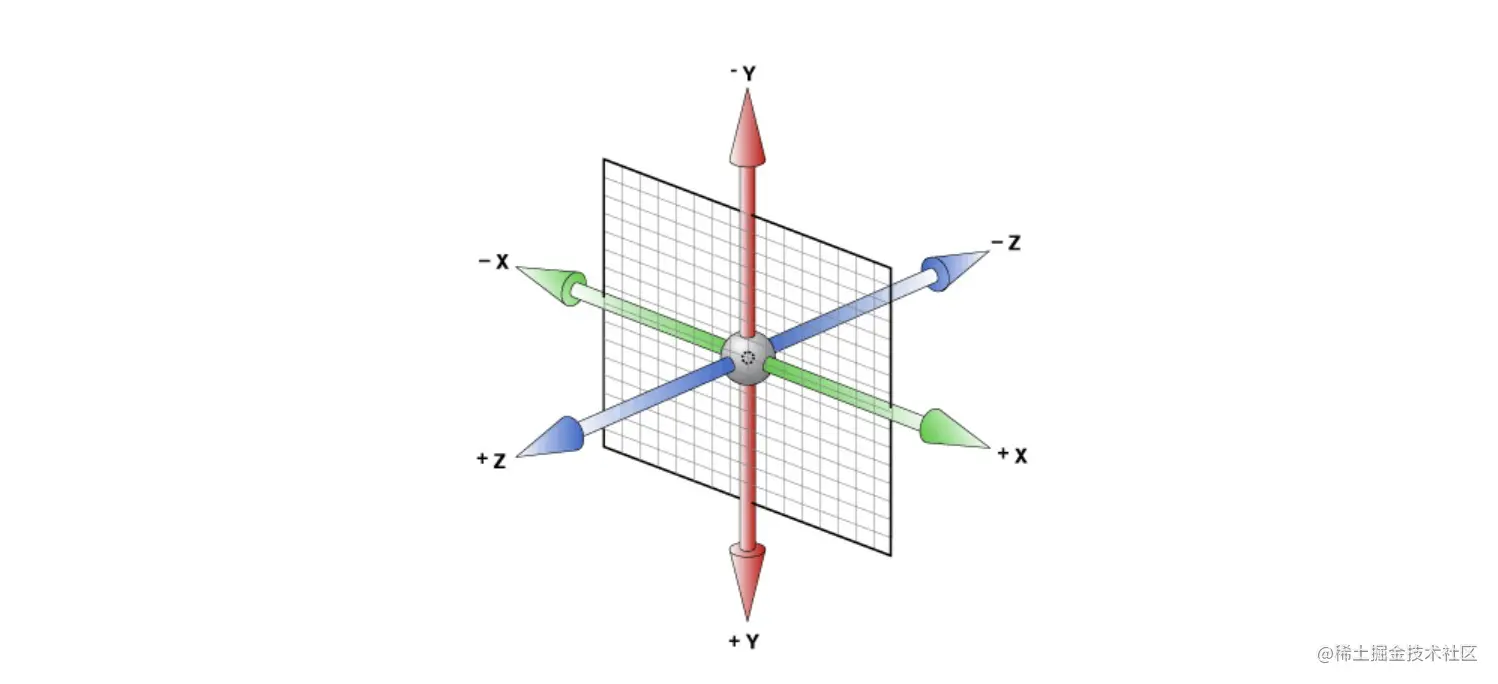
我们可以看到增加一个Z纬度的线,平面就变3D了。
这里需要注意的是CSS3D中,上下轴是Y轴,左右轴是X轴,前后轴是Z轴。可以简单理解为在原有竖着的面对我们的平面中,在X和Y轴中间强行插入一根直线,与Y轴和X轴都成90度,这根直线就是Z轴。
通过上面的处理,这样就形成了一个空间坐标系。
这有什么用呢?

大家可能有点懵逼,感觉二维都没搞定,突然要搞三维了。
可以先看看这个3D坐标系的DEMO,👇链接在此,可以先随意把玩把玩。
可以看到途中绿色线就是Z轴,红色就是X轴,蓝色就是Z轴。
多玩一玩就有点感觉啦,是不是感觉逐渐有了3D空间的感觉。
没有?

其他同学们,不要他了,我们继续。

不管你了,辛苦做了好久的DEMO🐶。继续继续。
如果想深入了解此CSS 3D坐标系演示的DEMO,源码可以查看这里,👇链接在此。
说到CSS 3D,肯定离不开CSS3D transform,下面开始学习。
CSS 3D transform
3D transform字面意思翻译过来为三维变换。
3D rotate
我们先从rotate 3d(旋转)开始,这个能辅助我们理解3D坐标系。
rotate X
单杠运动员,如果正面对着我们,就是可以理解为围着X转。

rotate Y
围着钢管转,就可以理解为围着Y轴在转。
rotate Z
如果我们正面对着摩天轮,其实摩天轮就在围着Z轴在做运动,中间那个白点,可以理解为Z轴从这个圆圈穿透过去的点。
如果还没理解的同学,可以通过之前的CSS3D DEMO,👇链接在此,辅助理解3D rotate。
理解了3D rotate后,可以辅助我们理解三维坐标系。下面我们开始讲解perspective,有一些理解的难度哦。

perspective
perspective是做什么用的呢?字面意思是视角、透视的意思。
有一种我们从小到大看到的想象,可能我们都并不在意了,就是现实生活中的透视。比如同样的电线杆,会进高远低。其实这个现象是有一些规律的:近大远小、近实远虚、近宽远窄。
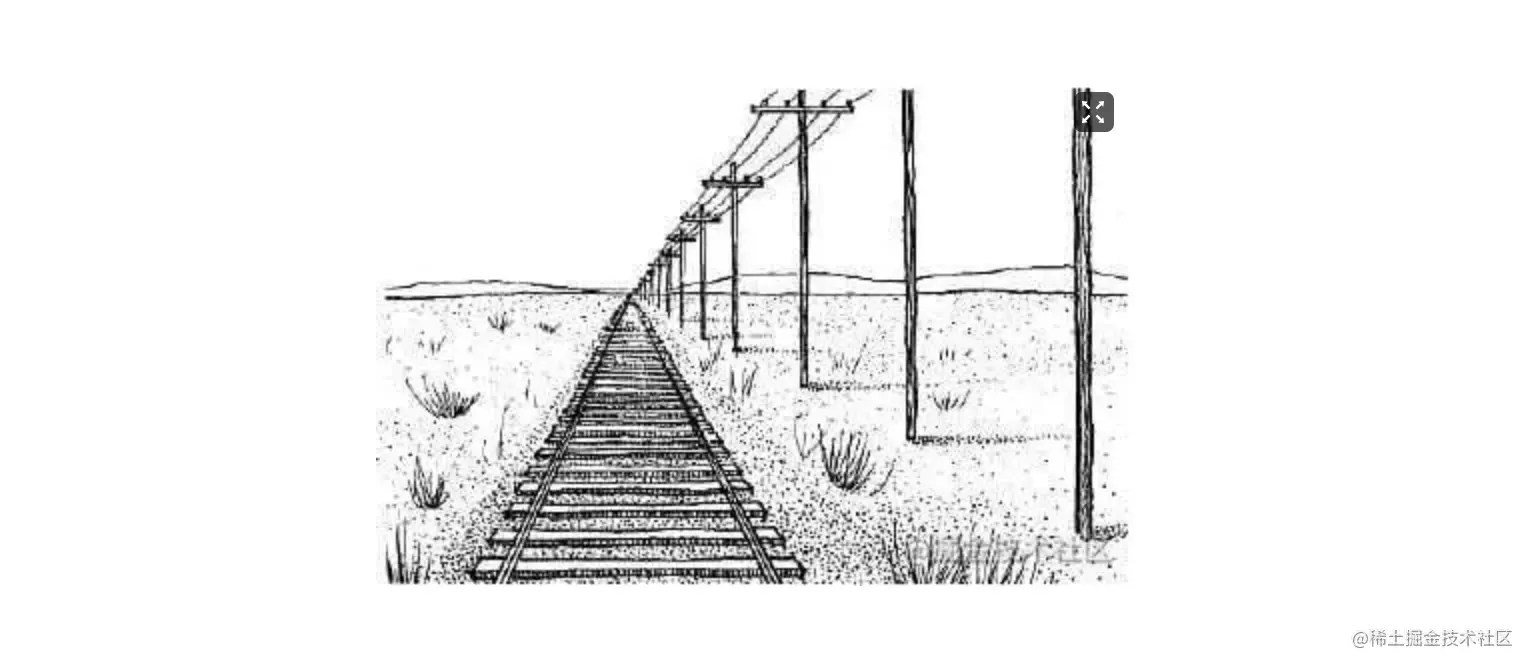
因此在素描、建筑的行业,都会通过一种透视的方式来表达现实世界的3D模型。
而我们在计算机世界怎么表达3D呢?
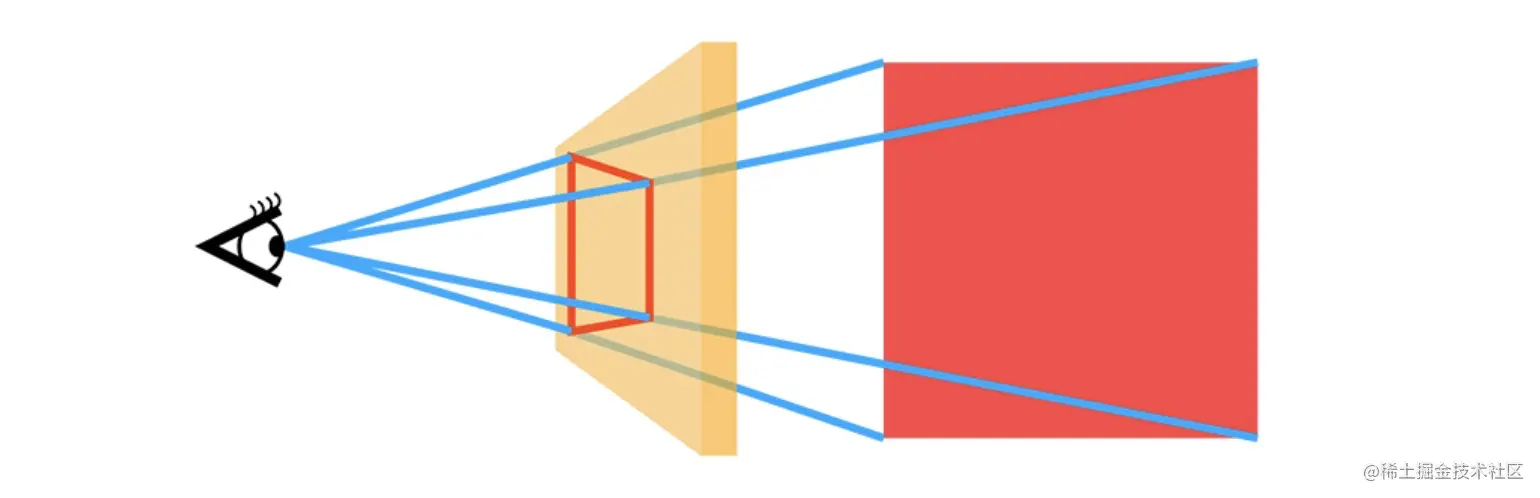
上方图可以辅助大家理解3D的透视perspective,黄色的是电脑或手机屏幕,红色是屏幕里的方块。
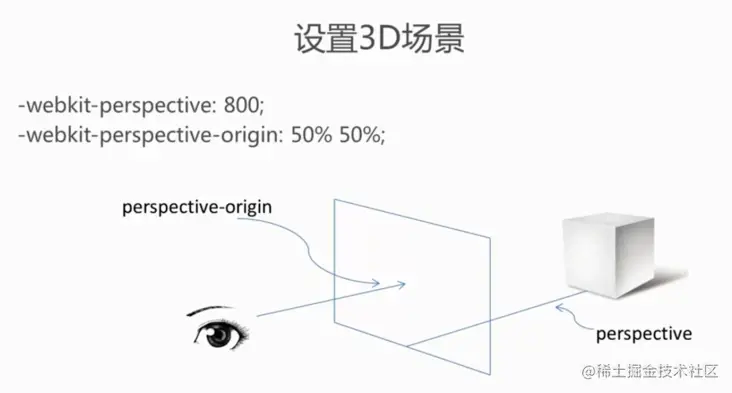
再看看上面这个二维图,可以看到,perspective: 800,代表3D物体距离屏幕(中间那个平面)是800px。
这里还有个概念,perspective-origin,可以看到上面perspective-origin是50% 50%,可以理解为眼睛视角的中心点,分别在x轴、y轴(x轴50%,y轴50%)交叉处。

没事没事,如果上面这些还不够你理解的,可以看看下面这张图。再不懂就不管你了🐶。
「下图来自:CSS 3D - Scrolling on the z-axis | CSS | devNotes」
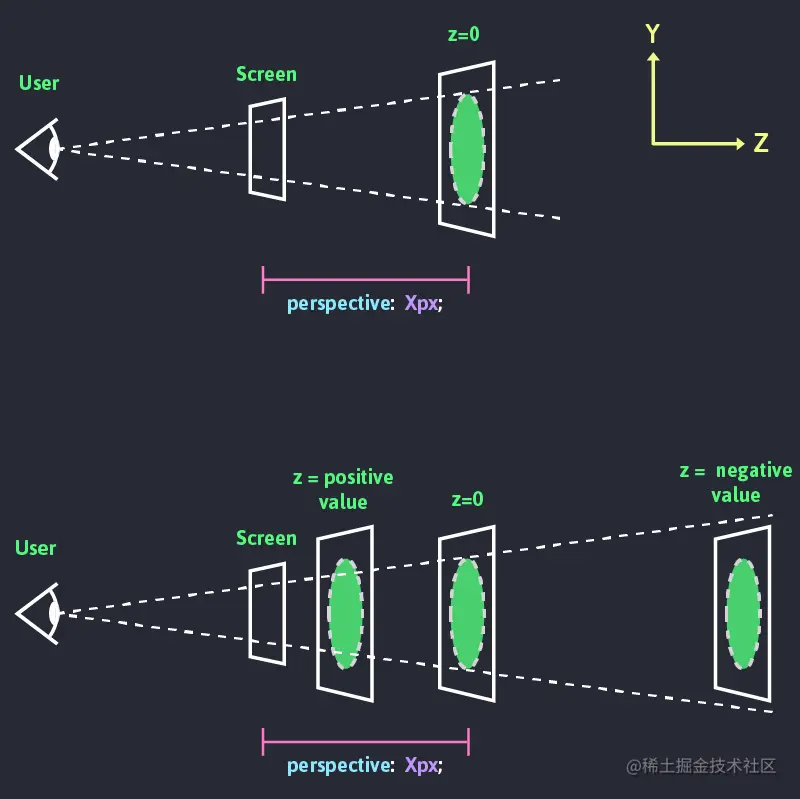
上图里的Z就是Z轴的值。Z轴如果是正数的离屏幕更近,如果是负数离屏幕更远。
而Z轴的远近和translateZ分不开,下面来讲解translateZ。

translateZ
这个属性可以帮助我们理解perspective。
可以通过translate的DEMO进行把玩把玩,有助于理解,戳👇DEMO链接在此。
translateZ实现了CSS3D世界空间的近大远小。
看一下这个例子,平面上的translateZ的变换,戳👇DEMO链接在此。

比如,我们设置元素perspective为201px,则其子元素的translateZ值越小,则看着越小;如果translateZ值越大,则看着越大。当translateZ为200px的时候,该元素会撑满屏幕,当超过201px时候,该元素消失了,跑到我们眼睛后面了。
平面上的translateZ感受完了,来试试三维下的,看看这个DEMO,戳👇链接在此。
上图中,如果把perspective往左拖,可以发现front面会离我们越来越远,如果往右拖,反之。
通过这么一节,基本translateZ的作用,大家应该都能理解到位了,还没有?回头看看🐶。

模拟现实3D空间
其实计算机的3D世界就是现实3D世界的模拟。而和计算机的3D世界中,构建3D空间概念很相近的现实场景,是摄像。我们可以考虑一下如果你去拍照,会有几个要素?
第一个:镜头,第二个:拍摄的环境的空间,第三个:要拍摄的物件。
「下图来自搞懂 CSS 3D,你必须理解 perspective(视域)」
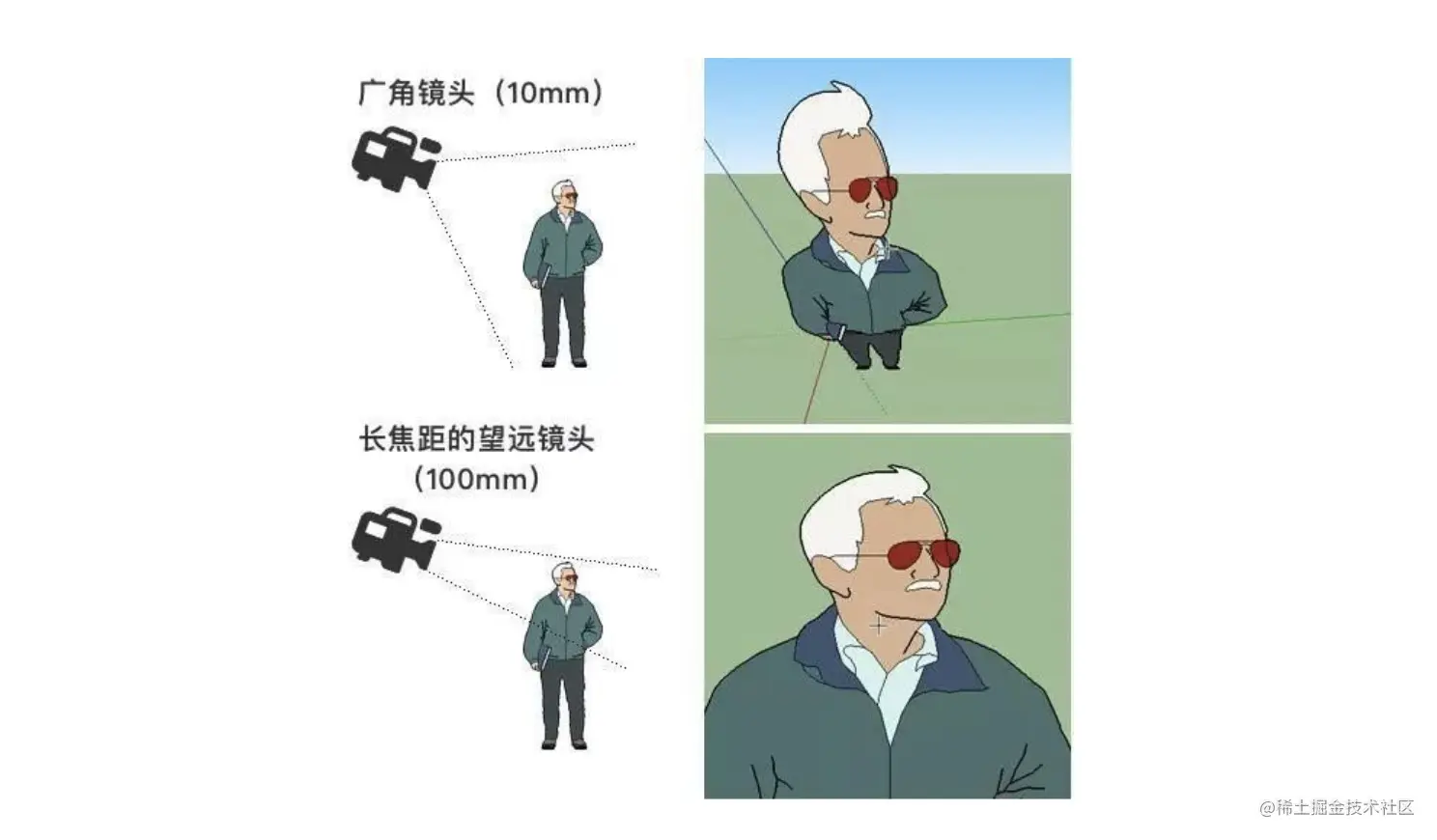
而在CSS的3D世界,我们也需要去模仿这三要素。我们用三层div来表示,第一层是摄像镜头、第二层是立体空间或也可叫舞台,第三层是立体空间内的元素。
大致的HTML代码如下。
<div class="camera">
<div class="space">
<div class="box">
</div>
</div>
</div>
下面就是真枪实弹地干了。

〇 实现天空盒子
已经知道了足够的前置知识,我们来简单实现一下天空盒子。
六面盒子
需要生成前后、左右、上下六个面。首先我们想一下第一面前面应该怎么放?
前面墙
假设我们在天空盒子(是一个正方体1024px*1024px),我们在正方体里面的中心点,那我们要往前面的墙上贴一张图,需要做什么?
我们回顾下坐标系。
你可以想象自己站在x轴和y轴交叉的中心点,即你在正方体的中心点。则你的前面的墙就是在z为-512px处,因为是前面,我们无需对这个墙进行旋转。
<html>
<head>
<title>CSS3D天空盒子</title>
<style>
html,
body {
margin: 0;
overflow: hidden;
background-color: #ccc;
}
.camera {
perspective: 512px;
perspective-origin:50% 50%;
}
.space {
width: 1024px;
height: 1024px;
margin: 0 auto;
transform-style: preserve-3d;
}
.space img {
width: 1024px;
height: 1024px;
position: absolute;
}
.space .front {
/* 正面的图无需旋转 */
transform: rotateZ(0) rotateY(0) rotateZ(0) translateZ(-512px);
}
</style>
</head>
<body>
<div class="camera" id="camera">
<div class="space">
<img class="front" src="//yun.dui88.com/tuia/junhehe/skybox/front.jpg" alt="" />
</div>
</div>
</body>
</html>
生成如下页面,演示代码地址:。

可以看到第一张图被放在了前面。
左面墙
从前面墙放上一张图,然后转向左面墙,需要几步走?

第一步,需要让平面与前面的墙垂直,这个时候我们需要把左面的图绕着Y轴旋转90度。
左面墙的图本应该放在X轴的-512px位置,但由于做了旋转,所以左面墙对应的坐标系也做了绕着Y轴向下旋转了90度。如果我们想把左侧的图放到对应的位置,我们需要让其在Z轴的-512px位置。
因此代码如下。
<html>
<head>
<title>CSS3D天空盒子</title>
<style>
html,
body {
margin: 0;
overflow: hidden;
background-color: #ccc;
}
.camera {
perspective: 512px;
perspective-origin:50% 50%;
}
.space {
width: 1024px;
height: 1024px;
margin: 0 auto;
transform-style: preserve-3d;
}
.space img {
width: 1024px;
height: 1024px;
position: absolute;
}
.space .front {
/* 正面的图无需旋转 */
transform: rotateZ(0) rotateY(0) rotateZ(0) translateZ(-512px);
}
.space .left {
transform: rotateY(90deg) translateZ(-512px);
}
</style>
</head>
<body>
<div class="camera" id="camera">
<div class="space">
<img class="front" src="//yun.dui88.com/tuia/junhehe/skybox/front.jpg" alt="" />
<img class="left" src="//yun.dui88.com/tuia/junhehe/skybox/left.jpg" alt="" />
</div>
</div>
</body>
</html>
生成的页面如下,演示代码地址。

可以看到左面墙确实生成在了前面墙的左侧。
底面
类似前面墙、左面墙,我们把底面,做了绕着X轴旋转90度,然后沿着Y轴走-512px。
代码如下。
<html>
<head>
<title>CSS3D天空盒子</title>
<style>
html,
body {
margin: 0;
overflow: hidden;
background-color: #ccc;
}
.camera {
perspective: 512px;
perspective-origin:50% 50%;
}
.space {
width: 1024px;
height: 1024px;
margin: 0 auto;
transform-style: preserve-3d;
}
.space img {
width: 1024px;
height: 1024px;
position: absolute;
}
.space .front {
/* 正面的图无需旋转 */
transform: rotateZ(0) rotateY(0) rotateZ(0) translateZ(-512px);
}
.space .left {
transform: rotateY(90deg) translateZ(-512px);
}
.space .bottom {
transform: rotateX(90deg) translateZ(-512px);
}
</style>
</head>
<body>
<div class="camera" id="camera">
<div class="space">
<img class="front" src="//yun.dui88.com/tuia/junhehe/skybox/front.jpg" alt="" />
<img class="left" src="//yun.dui88.com/tuia/junhehe/skybox/left.jpg" alt="" />
<img class="bottom" src="//yun.dui88.com/tuia/junhehe/skybox/bottom.jpg" alt="" />
</div>
</div>
</body>
</html>
生成页面如下,演示代码地址。

可以看到我们底部也有了,看看所有面集成后是什么样。

所有面
类似上面的操作,我们把六个面补全,下面我们就把六个面都集合起来。
<html>
<head>
<title>CSS3D天空盒子</title>
<style>
html,
body {
overflow: hidden;
margin: 0;
}
.camera {
perspective: 512px;
perspective-origin:50% 50%;
}
.space {
width: 1024px;
height: 1024px;
margin: 0 auto;
transform-style: preserve-3d;
}
.space img {
width: 1024px;
height: 1024px;
position: absolute;
}
.space .front {
/* 正面的图无需旋转 */
transform: rotateZ(0) rotateY(0) rotateZ(0) translateZ(-512px);
}
.space .back {
transform: rotateY(180deg) translateZ(-512px);
}
.space .left {
transform: rotateY(90deg) translateZ(-512px);
}
.space .right {
transform: rotateY(-90deg) translateZ(-512px);
}
.space .bottom {
transform: rotateX(90deg) translateZ(-512px);
}
.space .top {
transform: rotateX(-90deg) translateZ(-512px);
}
</style>
</head>
<body>
<div class="camera" id="camera">
<div class="space">
<img class="front" src="//yun.dui88.com/tuia/junhehe/skybox/front.jpg" alt="" />
<img class="back" src="//yun.dui88.com/tuia/junhehe/skybox/back.jpg" alt="" />
<img class="left" src="//yun.dui88.com/tuia/junhehe/skybox/left.jpg" alt="" />
<img class="right" src="//yun.dui88.com/tuia/junhehe/skybox/right.jpg" alt="" />
<img class="bottom" src="//yun.dui88.com/tuia/junhehe/skybox/bottom.jpg" alt="" />
<img class="top" src="//yun.dui88.com/tuia/junhehe/skybox/top.jpg" alt="" />
</div>
</div>
</body>
</html>
生成页面如下,演示代码地址。

我们发现看不到后方墙(背面墙)。所以我们打算把整个场景转起来。

盒子旋转
怎么才能把盒子进行旋转?这里需要对六面墙所在的场景,也即是它们上一层的元素。
我们给.cube加上一个动画效果,绕着Y轴钢管舞🐶,回忆起前置知识里的钢管舞没?
<html>
<head>
<title>CSS3D天空盒子</title>
<style>
html,
body {
overflow: hidden;
margin: 0;
}
.camera {
perspective: 512px;
perspective-origin:50% 50%;
}
.space {
width: 1024px;
height: 1024px;
margin: 0 auto;
transform-style: preserve-3d;
}
.space img {
width: 1024px;
height: 1024px;
position: absolute;
}
.space .front {
/* 正面的图无需旋转 */
transform: rotateZ(0) rotateY(0) rotateZ(0) translateZ(-512px);
}
.space .back {
transform: rotateY(180deg) translateZ(-512px);
}
.space .left {
transform: rotateY(90deg) translateZ(-512px);
}
.space .right {
transform: rotateY(-90deg) translateZ(-512px);
}
.space .bottom {
transform: rotateX(90deg) translateZ(-512px);
}
.space .top {
transform: rotateX(-90deg) translateZ(-512px);
}
@keyframes rot {
0% {
transform: rotateY(0deg)
}
10% {
transform: rotateY(90deg)
}
25% {
transform: rotateY(90deg)
}
35% {
transform: rotateY(180deg)
}
50% {
transform: rotateY(180deg)
}
60% {
transform: rotateY(270deg)
}
75% {
transform: rotateY(270deg)
}
85% {
transform: rotateY(360deg)
}
100% {
transform: rotateY(360deg)
}
}
/*为立方体加上帧动画*/
.space {
animation: rot 8s ease-out 0s infinite forwards;
}
</style>
</head>
<body>
<div class="camera" id="camera">
<div class="space">
<img class="front" src="//yun.dui88.com/tuia/junhehe/skybox/front.jpg" alt="" />
<img class="back" src="//yun.dui88.com/tuia/junhehe/skybox/back.jpg" alt="" />
<img class="left" src="//yun.dui88.com/tuia/junhehe/skybox/left.jpg" alt="" />
<img class="right" src="//yun.dui88.com/tuia/junhehe/skybox/right.jpg" alt="" />
<img class="bottom" src="//yun.dui88.com/tuia/junhehe/skybox/bottom.jpg" alt="" />
<img class="top" src="//yun.dui88.com/tuia/junhehe/skybox/top.jpg" alt="" />
</div>
</div>
</body>
</html>
生成页面动画效果如下,这次用的手机拍摄的更真实一些😂,虽然有点糊,演示代码地址。

既然能自动旋转,我们是不是可以考虑用手动旋转呢?

手动旋转
大概原理,就是手动拖拽(手机是touchmove,PC是mousemove),拖拽过去走的多少路程,计算出角度,然后把这个角度通过DOM设置(这个过程通过requestAnimationFrame不停地轮询设置)。
启动手动拖拽的代码。
var curMouseX = 0;
var curMouseY = 0;
var lastMouseX = 0;
var lastMouseY = 0;
if (isAndroid || isiOS) {
document.addEventListener('touchstart', mouseDownHandler);
document.addEventListener('touchmove', mouseMoveHandler);
} else {
document.addEventListener('mousedown', mouseDownHandler);
document.addEventListener('mousemove', mouseMoveHandler);
}
function mouseDownHandler(evt) {
lastMouseX = evt.pageX || evt.targetTouches[0].pageX;
lastMouseY = evt.pageY || evt.targetTouches[0].pageY;
}
function mouseMoveHandler(evt) {
curMouseX = evt.pageX || evt.targetTouches[0].pageX;
curMouseY = evt.pageY || evt.targetTouches[0].pageY;
}
具体的不分析了,不是本次的重点。有兴趣的可以直接看代码深入。
且由于我们想使用在手机上,因此做了rem的适配,适配在手机端。
生成页面动画效果如下,演示代码地址。
上面是手机录制的旋转视频。既然我们能通过手触旋转,那我们肯定也可以进行陀螺仪旋转。
陀螺仪旋转
大致原理也是如上,把手动拖拽换成了陀螺仪旋转,然后计算旋转角度。
启动陀螺仪的代码。
window.addEventListener('deviceorientation', motionHandler, false)
function motionHandler(event) {
var x = event.beta;
var y = event.gamma;
}
自开头所说,陀螺仪在IOS13+下需要授权。
var isiOS = !!u.match(/\(i[^;]+;( U;)? CPU.+Mac OS X/); // ios??
if (isiOS) {
permission()
}
function permission () {
if ( typeof( DeviceMotionEvent ) !== "undefined" && typeof( DeviceMotionEvent.requestPermission ) === "function" ) {
// (optional) Do something before API request prompt.
DeviceMotionEvent.requestPermission()
.then( response => {
// (optional) Do something after API prompt dismissed.
if ( response == "granted" ) {
window.addEventListener( "devicemotion", (e) => {
// do something for 'e' here.
})
}
})
.catch( console.error )
} else {
alert( "请使用手机浏览器" );
}
}
下面是手机录制展示陀螺仪的例子,生成页面动画效果如下,演示代码地址。
这里想深入的同学,可以看一下代码,和上面一样不是本文的重点就不分析了。
有没有感觉写了这么多代码,感觉跟写纯JS操作DOM似的,有没有类似JQuery之类的库呢?

css3d-engine
上面只是实现了平行旋转,要实现任意角度旋转,我们是基于css3d-engine做了实现。
这一节只是带过,理解了大概的原理后,结合例子去学习这个库还是非常快的。
部分示例代码
文章第一个DEMO就是以这个库为基础进行实践的,地址在这里:github.com/shrekshrek/…。
创建stage,stage是舞台,是整个场景的根。
var s = new C3D.Stage();
创建一个天空盒子的例子,控制各面的素材。
//创建1个立方体放入场景
var c = new C3D.Skybox();
c.size(1024).position(0, 0, 0).material({
front: {image: "images/cube_FR.jpg"},
back: {image: "images/cube_BK.jpg"},
left: {image: "images/cube_LF.jpg"},
right: {image: "images/cube_RT.jpg"},
up: {image: "images/cube_UP.jpg"},
down: {image: "images/cube_DN.jpg"},
}).update();
s.addChild(c);
Tween制作动效
第一个DEMO中动效,是通过Tween.js实现的,地址在这里:github.com/sole/tween.…。
为什么DOM元素会有动效,也是因为属性值的变化,而Tween可以控制属性值在一段时间内按规定的规律变化。
下面是一个Tween的示例。
var coords = { x: 0, y: 0 };
var tween = new TWEEN.Tween(coords)
.to({ x: 100, y: 100 }, 1000)
.onUpdate(function() {
console.log(this.x, this.y);
})
.start();
requestAnimationFrame(animate);
function animate(time) {
requestAnimationFrame(animate);
TWEEN.update(time);
}
在最后再体验一下整个处理好后的DEMO,重新感受一下。

具体的完整版DEMO的源码在此,有兴趣的可以深入研究,由于是之前早几年做的DEMO,代码比较乱,还请见谅,地址在此:github.com/fly0o0/css3…。