
高级线程应用之栅栏、信号量、调度组以及source(二)
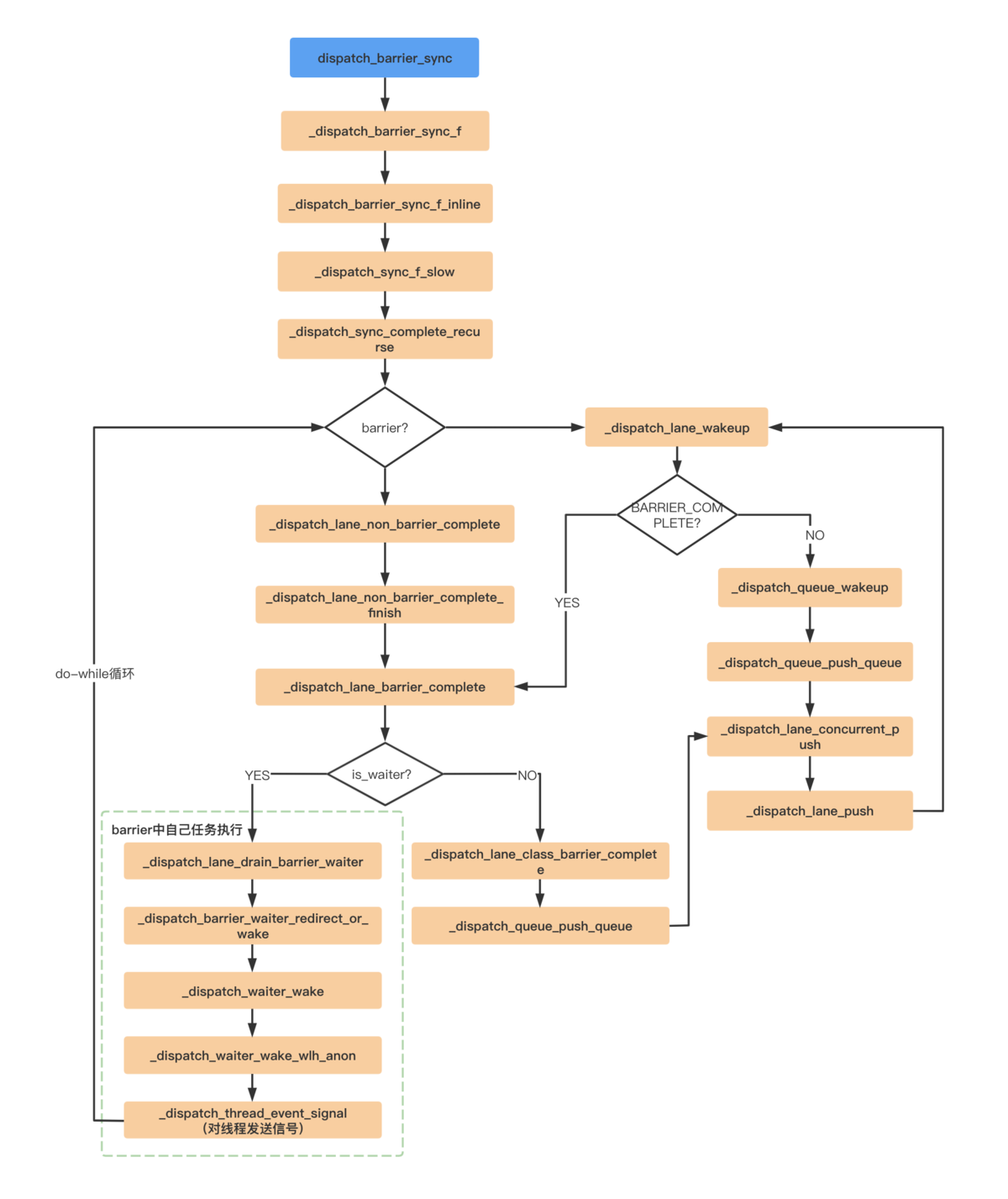
1.2.1.2 _dispatch_lane_non_barrier_complete
static void
_dispatch_lane_non_barrier_complete(dispatch_lane_t dq,
dispatch_wakeup_flags_t flags)
{
......
_dispatch_lane_non_barrier_complete_finish(dq, flags, old_state, new_state);
}其中是对_dispatch_lane_non_barrier_complete_finish的调用。
DISPATCH_ALWAYS_INLINE
static void
_dispatch_lane_non_barrier_complete_finish(dispatch_lane_t dq,
dispatch_wakeup_flags_t flags, uint64_t old_state, uint64_t new_state)
{
if (_dq_state_received_override(old_state)) {
// Ensure that the root queue sees that this thread was overridden.
_dispatch_set_basepri_override_qos(_dq_state_max_qos(old_state));
}
if ((old_state ^ new_state) & DISPATCH_QUEUE_IN_BARRIER) {
if (_dq_state_is_dirty(old_state)) {
//走_dispatch_lane_barrier_complete逻辑
return _dispatch_lane_barrier_complete(dq, 0, flags);
}
if ((old_state ^ new_state) & DISPATCH_QUEUE_ENQUEUED) {
if (!(flags & DISPATCH_WAKEUP_CONSUME_2)) {
_dispatch_retain_2(dq);
}
dispatch_assert(!_dq_state_is_base_wlh(new_state));
_dispatch_trace_item_push(dq->do_targetq, dq);
return dx_push(dq->do_targetq, dq, _dq_state_max_qos(new_state));
}
if (flags & DISPATCH_WAKEUP_CONSUME_2) {
_dispatch_release_2_tailcall(dq);
}
}走的是_dispatch_lane_barrier_complete逻辑:
DISPATCH_NOINLINE
static void
_dispatch_lane_barrier_complete(dispatch_lane_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags)
{
dispatch_queue_wakeup_target_t target = DISPATCH_QUEUE_WAKEUP_NONE;
dispatch_lane_t dq = dqu._dl;
if (dq->dq_items_tail && !DISPATCH_QUEUE_IS_SUSPENDED(dq)) {
struct dispatch_object_s *dc = _dispatch_queue_get_head(dq);
//串行队列
if (likely(dq->dq_width == 1 || _dispatch_object_is_barrier(dc))) {
if (_dispatch_object_is_waiter(dc)) {
//栅栏中的任务逻辑
return _dispatch_lane_drain_barrier_waiter(dq, dc, flags, 0);
}
} else if (dq->dq_width > 1 && !_dispatch_object_is_barrier(dc)) {
return _dispatch_lane_drain_non_barriers(dq, dc, flags);
}
if (!(flags & DISPATCH_WAKEUP_CONSUME_2)) {
_dispatch_retain_2(dq);
flags |= DISPATCH_WAKEUP_CONSUME_2;
}
target = DISPATCH_QUEUE_WAKEUP_TARGET;
}
uint64_t owned = DISPATCH_QUEUE_IN_BARRIER +
dq->dq_width * DISPATCH_QUEUE_WIDTH_INTERVAL;
//执行栅栏后续的代码
return _dispatch_lane_class_barrier_complete(dq, qos, flags, target, owned);
}_dispatch_lane_drain_barrier_waiter执行栅栏函数中的任务。_dispatch_lane_class_barrier_complete执行栅栏函数后续的代码。
调用_dispatch_lane_drain_barrier_waiter执行栅栏函数中的任务:
static void
_dispatch_lane_drain_barrier_waiter(dispatch_lane_t dq,
struct dispatch_object_s *dc, dispatch_wakeup_flags_t flags,
uint64_t enqueued_bits)
{
......
return _dispatch_barrier_waiter_redirect_or_wake(dq, dc, flags,
old_state, new_state);
}直接调用_dispatch_barrier_waiter_redirect_or_wake:
static void
_dispatch_barrier_waiter_redirect_or_wake(dispatch_queue_class_t dqu,
dispatch_object_t dc, dispatch_wakeup_flags_t flags,
uint64_t old_state, uint64_t new_state)
{
......
return _dispatch_waiter_wake(dsc, wlh, old_state, new_state);
}调用_dispatch_waiter_wake:
static void
_dispatch_waiter_wake(dispatch_sync_context_t dsc, dispatch_wlh_t wlh,
uint64_t old_state, uint64_t new_state)
{
dispatch_wlh_t waiter_wlh = dsc->dc_data;
if ((_dq_state_is_base_wlh(old_state) && !dsc->dsc_from_async) ||
_dq_state_is_base_wlh(new_state) ||
waiter_wlh != DISPATCH_WLH_ANON) {
_dispatch_event_loop_wake_owner(dsc, wlh, old_state, new_state);
}
if (unlikely(waiter_wlh == DISPATCH_WLH_ANON)) {
//走这里
_dispatch_waiter_wake_wlh_anon(dsc);
}
}调用_dispatch_waiter_wake_wlh_anon:
static void
_dispatch_waiter_wake_wlh_anon(dispatch_sync_context_t dsc)
{
if (dsc->dsc_override_qos > dsc->dsc_override_qos_floor) {
_dispatch_wqthread_override_start(dsc->dsc_waiter,
dsc->dsc_override_qos);
}
//执行
_dispatch_thread_event_signal(&dsc->dsc_event);
}其中是对线程发送信号。
对于_dispatch_root_queue_wakeup而言:
void
_dispatch_root_queue_wakeup(dispatch_queue_global_t dq,
DISPATCH_UNUSED dispatch_qos_t qos, dispatch_wakeup_flags_t flags)
{
if (!(flags & DISPATCH_WAKEUP_BLOCK_WAIT)) {
DISPATCH_INTERNAL_CRASH(dq->dq_priority,
"Don't try to wake up or override a root queue");
}
if (flags & DISPATCH_WAKEUP_CONSUME_2) {
return _dispatch_release_2_tailcall(dq);
}
}内部没有对barrier的处理,所以全局队列栅栏函数无效。
因为全局队列不仅有你的任务,还有其它系统的任务。如果加barrier不仅影响你自己的任务还会影响系统的任务。对于全局队列而言栅栏函数就是个普通的异步函数。
整个流程如下:
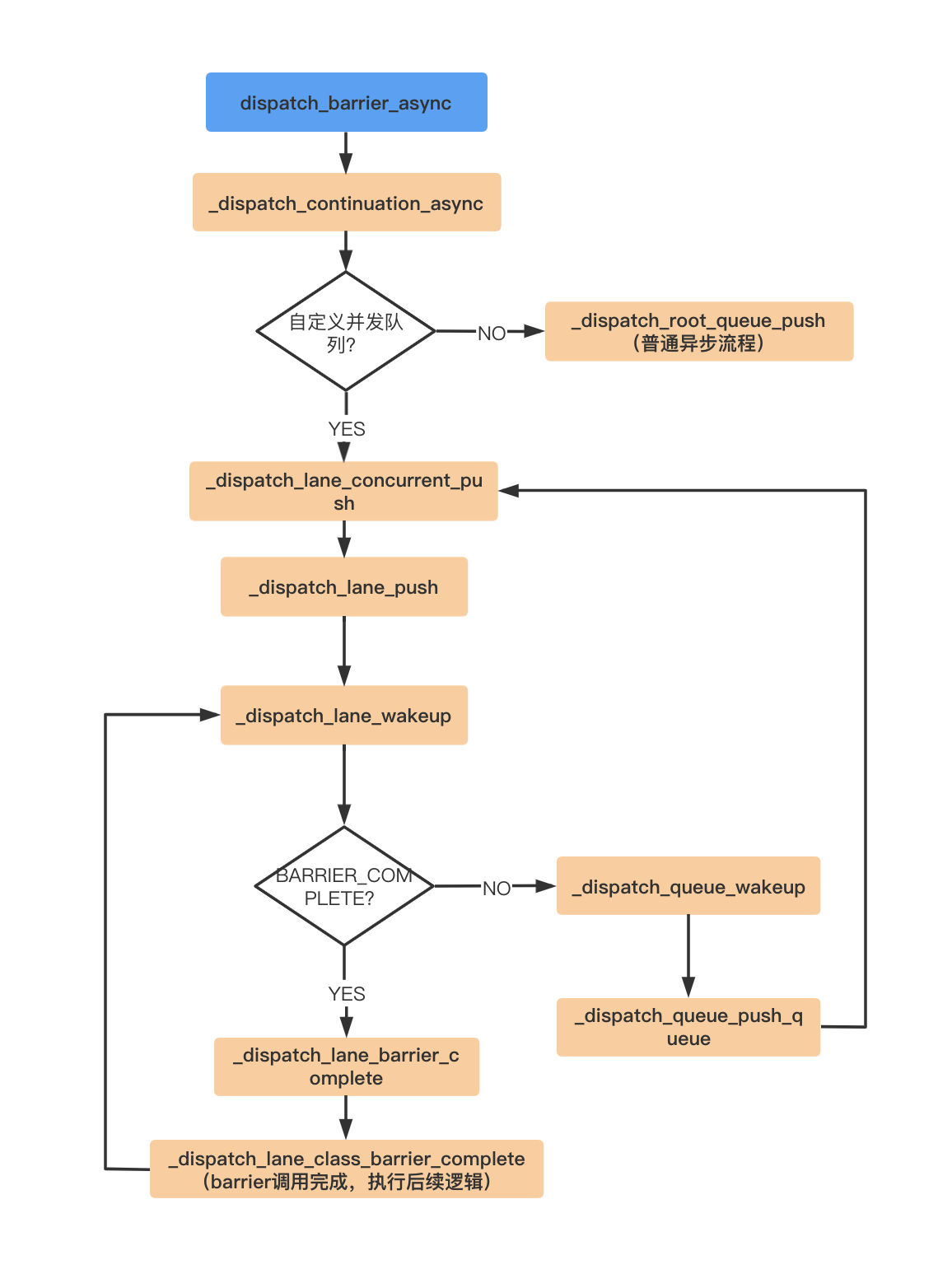
1.2.2 dispatch_barrier_async
dispatch_barrier_async源码如下:
void
dispatch_barrier_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_BARRIER;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
_dispatch_continuation_async(dq, dc, qos, dc_flags);
}调用的是_dispatch_continuation_async:
static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc);
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos);
}调用了dx_push,对应的自定义队列是_dispatch_lane_concurrent_push。全局队列是_dispatch_root_queue_push。
_dispatch_lane_concurrent_push:
void
_dispatch_lane_concurrent_push(dispatch_lane_t dq, dispatch_object_t dou,
dispatch_qos_t qos)
{
if (dq->dq_items_tail == NULL &&
!_dispatch_object_is_waiter(dou) &&
!_dispatch_object_is_barrier(dou) &&
_dispatch_queue_try_acquire_async(dq)) {
return _dispatch_continuation_redirect_push(dq, dou, qos);
}
_dispatch_lane_push(dq, dou, qos);
}断点跟踪走的是_dispatch_lane_push:
DISPATCH_NOINLINE
void
_dispatch_lane_push(dispatch_lane_t dq, dispatch_object_t dou,
dispatch_qos_t qos)
{
dispatch_wakeup_flags_t flags = 0;
struct dispatch_object_s *prev;
if (unlikely(_dispatch_object_is_waiter(dou))) {
return _dispatch_lane_push_waiter(dq, dou._dsc, qos);
}
dispatch_assert(!_dispatch_object_is_global(dq));
qos = _dispatch_queue_push_qos(dq, qos);
prev = os_mpsc_push_update_tail(os_mpsc(dq, dq_items), dou._do, do_next);
if (unlikely(os_mpsc_push_was_empty(prev))) {
_dispatch_retain_2_unsafe(dq);
flags = DISPATCH_WAKEUP_CONSUME_2 | DISPATCH_WAKEUP_MAKE_DIRTY;
} else if (unlikely(_dispatch_queue_need_override(dq, qos))) {
_dispatch_retain_2_unsafe(dq);
flags = DISPATCH_WAKEUP_CONSUME_2;
}
os_mpsc_push_update_prev(os_mpsc(dq, dq_items), prev, dou._do, do_next);
if (flags) {
//栅栏函数走这里。
//#define dx_wakeup(x, y, z) dx_vtable(x)->dq_wakeup(x, y, z)
//dx_wakeup 对应 dq_wakeup 自定义全局队列对应 _dispatch_lane_wakeup,全局队列对应 _dispatch_root_queue_wakeup
return dx_wakeup(dq, qos, flags);
}
}栅栏函数走_dispatch_lane_wakeup逻辑:
void
_dispatch_lane_wakeup(dispatch_lane_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags)
{
dispatch_queue_wakeup_target_t target = DISPATCH_QUEUE_WAKEUP_NONE;
if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) {
return _dispatch_lane_barrier_complete(dqu, qos, flags);
}
if (_dispatch_queue_class_probe(dqu)) {
target = DISPATCH_QUEUE_WAKEUP_TARGET;
}
//走这里
return _dispatch_queue_wakeup(dqu, qos, flags, target);
}继续断点走_dispatch_queue_wakeup逻辑:
void
_dispatch_queue_wakeup(dispatch_queue_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags, dispatch_queue_wakeup_target_t target)
{
......
if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) {
......
//loop _dispatch_lane_wakeup //_dq_state_merge_qos
return _dispatch_lane_class_barrier_complete(upcast(dq)._dl, qos,
flags, target, DISPATCH_QUEUE_SERIAL_DRAIN_OWNED);
}
if (target) {
......
#if HAVE_PTHREAD_WORKQUEUE_QOS
} else if (qos) {
......
if (likely((old_state ^ new_state) & enqueue)) {
...... //_dispatch_queue_push_queue断点断不住,断它内部断点
return _dispatch_queue_push_queue(tq, dq, new_state);
}
#if HAVE_PTHREAD_WORKQUEUE_QOS
if (unlikely((old_state ^ new_state) & DISPATCH_QUEUE_MAX_QOS_MASK)) {
if (_dq_state_should_override(new_state)) {
return _dispatch_queue_wakeup_with_override(dq, new_state,
flags);
}
}
#endif // HAVE_PTHREAD_WORKQUEUE_QOS
done:
if (likely(flags & DISPATCH_WAKEUP_CONSUME_2)) {
return _dispatch_release_2_tailcall(dq);
}
}这里断点走了_dispatch_queue_push_queue逻辑(_dispatch_queue_push_queue本身断不住,断它内部断点):
static inline void
_dispatch_queue_push_queue(dispatch_queue_t tq, dispatch_queue_class_t dq,
uint64_t dq_state)
{
#if DISPATCH_USE_KEVENT_WORKLOOP
if (likely(_dq_state_is_base_wlh(dq_state))) {
_dispatch_trace_runtime_event(worker_request, dq._dq, 1);
return _dispatch_event_loop_poke((dispatch_wlh_t)dq._dq, dq_state,
DISPATCH_EVENT_LOOP_CONSUME_2);
}
#endif // DISPATCH_USE_KEVENT_WORKLOOP
_dispatch_trace_item_push(tq, dq);
//_dispatch_lane_concurrent_push
return dx_push(tq, dq, _dq_state_max_qos(dq_state));
}内部走的是_dispatch_lane_concurrent_push逻辑,这里又继续走了_dispatch_lane_push的逻辑了,在这里就造成了循环等待。当队列中任务执行完毕后_dispatch_lane_wakeup中就走_dispatch_lane_barrier_complete逻辑了。
可以通过
barrier前面的任务加延迟去验证。直接断点_dispatch_lane_barrier_complete,当前面的任务执行完毕后就进入_dispatch_lane_barrier_complete断点了。
_dispatch_lane_barrier_complete源码如下:
static void
_dispatch_lane_barrier_complete(dispatch_lane_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags)
{
......
return _dispatch_lane_class_barrier_complete(dq, qos, flags, target, owned);
}走了_dispatch_lane_class_barrier_complete逻辑:
static void
_dispatch_lane_class_barrier_complete(dispatch_lane_t dq, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags, dispatch_queue_wakeup_target_t target,
uint64_t owned)
{
......
again:
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
......
} else if (unlikely(_dq_state_is_dirty(old_state))) {
......
flags |= DISPATCH_WAKEUP_BARRIER_COMPLETE;
//自定义并行队列 _dispatch_lane_wakeup
return dx_wakeup(dq, qos, flags);
});
} else {
new_state &= ~DISPATCH_QUEUE_MAX_QOS_MASK;
}
});
......
}调用走的是_dispatch_lane_wakeup:
void
_dispatch_lane_wakeup(dispatch_lane_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags)
{
dispatch_queue_wakeup_target_t target = DISPATCH_QUEUE_WAKEUP_NONE;
if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) {
//barrier完成了就走这里的逻辑,barrier之前的任务执行完毕。
return _dispatch_lane_barrier_complete(dqu, qos, flags);
}
if (_dispatch_queue_class_probe(dqu)) {
target = DISPATCH_QUEUE_WAKEUP_TARGET;
}
//走这里
return _dispatch_queue_wakeup(dqu, qos, flags, target);
}这个时候就又走到了_dispatch_lane_barrier_complete。
DISPATCH_WAKEUP_BARRIER_COMPLETE状态是在_dispatch_lane_resume中进行变更的:
_dispatch_root_queue_push内部并没有对barrier的处理,与全局队列逻辑一致。所以barrier函数传递全局队列无效。
整个过程如下:
作者:HotPotCat
链接:https://www.jianshu.com/p/84153e072f44
