一、布局
1、首页
(1)头部
iconfont的使用和代码优化
- iconfont.css中修改路径
- 引入iconfont.css import
text-align: center(文字水平居中)
优化:
- 变量复用:src/assets/styles/varibles.styl中定义变量 $变量名=值。在style中引入样式,@import(样式中引入样式需加@符号)
- 路径名过长:在css中引入其他的css想使用@符号,必须在@符号前加上~(@表示src目录)
- 路径别名:
build/webpack.base.conf.js->resolve->alias->创建别名
resolve: {
extensions: ['.js', '.vue', '.json'],
alias: {
'vue$': 'vue/dist/vue.esm.js',
'@': resolve('src'),
'styles': resolve('src/assets/styles'),
'common':resolve('src/common')
}
}
报错原因:修改webpack中的内容后需要重启服务器
(2)轮播图
Swiper插件原理
Swiper是一款基于JavaScript的开源滑动插件,可以用于制作各种类型的轮摇图、滑动菜单、图片预览等。Swiper 的原理主要是通过监听用户的手势操作来实现滑动效果,同时利用CSS3动画和过渡效果来实现平滑的过渡和动画效果。
- 监听手势操作
Swiper通过监听用户的手势操作来实现滑动效果,具体包括touchstart、touchmove.touchend符事件。在touchstart 事件中,Swiper记录下用户的触摸起始位置及时间,touchmove事件中,Swiper根据用户移动的距离和时间计算出滑动速度和方向,从而控制滑动的行为;touchend事件中,Swiper根据滑动的距离和速度来判断是否进行下一张图片的切换。
- 切换图片
Swiper通过获取当前显示的图片索引及方向来计算出下一张图片的索引,并通过CSS3过渡效果来实现平滑的图片切换。同时,Swiper可以支持多种不同的切换效果,包括淡入淡出、渐变、滑动、翻转等,
- 响应式设计
Swiper支持响应式设计,可以根据不同的设备尺寸和屏幕方向来自动调整轮播图的大小和样式,从而提供更好的用户体验。同时,Swiper还支持自定义参数配置,可以灵活地控制轮播图的各种属性和行为。
问题
网速慢时图片没有加载出来造成的抖动(使用padding-bottom占位):
overflow: hidden
height:0
padding-bottom: 31.25% //高宽比
显示分页:
<swiper :options="swiperOption" v-if="showSwiper">
<swiper-slide v-for="item of list" :key="item.id">
<img class="swiper-img" :src="item.imgUrl" alt="">
</swiper-slide>
<div class="swiper-pagination" slot="pagination"></div>
</swiper>
export default {
name: 'HomeSwiper',
props: {
list:Array
},
data() {
return {
swiperOption: {
pagination: ".swiper-pagination",
loop: true,
autoplay: 3000
},
}
},
computed: {
showSwiper() {
return this.list.length;
}
}
}
样式穿透
- 引入第三方组件库(如element-ui、element-plus),修改第三方组件库的样式。
- 样式文件中使用了 scoped 属性,但是为了确保每个组件之间不存在相互影响所以不能去除
.wrapper >>> .swiper-pagination-bullet
background-color: #fff
插槽slot
通过slot插槽将页面中具体的数据传递给swiper组件,希望组件的内容可以被父组件定制的时候,使用slot向组件传递内容。
(3)图标区域
图标的轮播实现
使用computed计算功能实现图标的多页显示(容量为8,多出来的的图标换页显示):
computed: {
pages () {
const pages = [];
this.list.forEach((item, index) => {
const page = Math.floor(index/8);
if (!pages[page]){
pages[page] = []
}
pages[page].push(item)
});
return pages
},
showIcon() {
return this.list.length
}
}
优化:
(1)希望文字过多时有…提示:
css中添加:
overflow: hidden
white-space:nowrap
text-overflow:ellipsis
(2)重复代码封装:
借助stylus提供的mixin对代码进行封装:
src/assets/varibles.styl中定义ellipse方法,在css中@import 文件,直接使用ellipse()
mixin(混入)
它提供了一种非常灵活的方式,来分发 Vue 组件中的可复用功能。
使用场景: 不同组件中经常会用到一些相同或相似的代码,这些代码的功能相对独立。可以通过mixin 将相同或相似的代码提出来。
缺点:
- 变量来源不明确
- 多 mixin 可能会造成命名冲突(解决方式:Vue 3的组合API)
- mixin 和组件出现多对多的关系,使项目复杂度变高。
(4)推荐
text-indent:文字缩进
使用ellipsis()不起作用:父元素添加min-width: 0
(5)周末游
(6)Ajax获取首页数据
安装axios,引入axios
import axios from 'axios'
methods: {
getHomeInfo() {
axios.get('/api/index.json?city='+this.city)
.then(this.getHomeInfoSucc);
},
getHomeInfoSucc(res) {
res = res.data;
if (res.ret && res.data) {
const data = res.data
this.swiperList = data.swiperList
this.iconList = data.iconList
this.recommendList = data.recommendList
this.weekendList = data.weekendList
}
}
}
转发机制(开发环境的转发)
- 只有static文件夹下的内容才可以被外部访问到
- 现在用的是本地模拟的接口地址,假如代码要上线,肯定不能填成这样的一个地址,那么就需要在上线之前把这块儿的东西都重新替换成API这种格式,上线之前去改动代码儿是有风险的
- 转发机制:webpack-dev-server提供 proxyTable 配置项,config/index.js 中proxyTable
module.exports = {
dev: {
assetsSubDirectory: 'static',
assetsPublicPath: '/',
proxyTable: {
'/api':{
target: 'http://localhost:8080',
pathRewrite: {
'^/api': '/static/mock'
}
}
}
}
- 整个首页发送一个ajax请求而不是每个组件发送一个
(7)首页父子组件数据传递
父->子:属性传值,子组件props:{}接收
轮播图默认显示最后一张图
原因:
还没有接收ajax数据时,swiper接收的数据是一个空数组,当接受ajax数据后, swiperList变成真正的数据项。再传给home-swiper这个组件的时候,它才获取到新的数据,然后重新渲染了新数据对应的很多的幻灯片。因为swiper的初始化创建是根据空数组创建的,所以会导致默认显示的是所有的这个页面中的最后一个页面。
解决:
让swiper的初次创建由完整的数据来创建,而不是由那个空数组来创建。只需要写一个v-if,再写一个list.length。当传递过来的list是个空数组的时候,v-if的值是false,所以swiper不会被创建。只有等真正的数据过来了之后才会被创建。由于模板中尽量少出现逻辑性代码,所以创建一个计算属性computed,计算 list.length。
取消轮播图自动播放:autoplay: false
2、城市选择页
(1)路由配置
路由跳转:
import Vue from 'vue'
import Router from 'vue-router'
import Home from '../pages/home/Home'
import City from '../pages/city/City'
import Detail from '../pages/detail/Detail'
Vue.use(Router)
export default new Router({
routes: [{
path: '/',
name: 'Home',
component: Home
},
{
path: '/city',
name: 'City',
component: City
},
{
path: '/detail/:id',
name: 'Detail',
component: Detail
}
],
scrollBehavior (to, from, savedPosition) {
return { x: 0, y: 0 }
}
})
使用:
<router-link to="/city">
<div class="header-right">
{{this.city}}
<span class="iconfont arrow-icon"></span>
</div>
</router-link>
(2)搜索框
定义一个keyword数据,与搜索框使用v-model做双向数据绑定。
<div class="search">
<input v-model="keyword" class="search-input" type="text" placeholder="输入城市名或拼音" />
</div>
City.vue父组件向Search.vue组件传值(cities),Search.vue接收cities
使用watch监听keyword的改变(使用节流)
解决匹配城市过多无法滚动问题
import Bscroll,在mounted中创建一个BScroll, this.scroll = new BScroll(this.$refs.search),通过$ref获取需要滚动的元素。
<div class="search-content" ref="search" v-show="keyword">
<ul>
<li class="search-item border-bottom" v-for="item in list" :key="item.id" @click="handleCityClick(item.name)">{{item.name}}</li>
<li class="search-item border-bottom" v-show="hasNoData">没有找到匹配数据</li>
</ul>
</div>
优化
1.解决删除输入列表依然存在的问题:v-show = "keyword"
2.没有找到匹配项时,显示“没有找到匹配数据”:v-show = "!this.list.length"
双向数据绑定原理(搜索时使用)
概念:
Vue 中双向绑定是一个指令v-model,可以绑定一个响应式数据到视图,同时视图的变化能改变该值。v-model是语法糖,默认情况下相当于:value和@input(v-bind:value,v-on:input),使用v-model可以减少大量繁琐的事件处理代码,提高开发效率。
使用:
通常在表单项上使用v-model,还可以在自定义组件上使用,表示某个值的输入和输出控制。
原理:
v-model是一个指令,双向绑定实际上是Vue 的编译器完成的,通过输出包含v-model模版的组件渲染函数,实际上还是value属性的绑定及input事件监听,事件回调函数中会做相应变量的更新操作。
(3)列表
引入区块滚动
子元素使用float,父元素开启BFC(overflow:hidden)去除高度塌陷。
使列表区域无法滚动(position:absolute + overflow:hidden),然后使用better-scroll插件
better-scroll
- 安装better-scroll包。
- 需要 better-scroll 包裹的所有元素最外层需要使用一个div包裹,并设置一个ref属性方便创建scroll。
- 创建scroll
<div class="list" ref="wrapper">list中的元素<div>
import Bscroll from 'better-scroll'
mounted() {
this.scroll = new Bscroll(this.$refs.wrapper)
}
$ref
ref属性:获取DOM。
在vue中ref可以以属性的形式添加给标签或者组件:
- ref 写在标签上时:this.$refs.ipt 获取的是添加了ref="ipt"标签对应的dom元素;
- ref 写在组件上时:this.$refs['component'] 获取到的是添加了ref="component"属性的这个组件。
$refs 是所有注册过 ref 的集合(对象);若是遍历的ref,则对应$refs是个数组集合
注意:$refs不是响应式的,只在组件渲染完成之后才填充。所以想要获取DOM数据的更新要使用 this.$nextTick()
字母表和城市列表字母的联动
兄弟组件传值:
Alphabet组件将值传递给父组件City.vue,父组件将值传递给子组件List.vue实现字母表和城市列表字母的联动。
为每个字母绑定一个onclick事件,在方法中使用this.$emit向外传递change事件。
<template>
<ul class="list" >
<li class="item" v-for="key in letters"
:key="key"
:ref="key"
@touchstart="handleTouchStart"
@touchmove="handleTouchMove"
@touchend="handleTouchEnd"
@click="handleLetterClick"
>
{{key}}
</li>
</ul>
</template>
methods: {
handleLetterClick (e) {
this.$emit("change", e.target.innerText);
}
}
父组件
<city-alphabet :cities="cities" @change="handleLetterChange"></city-alphabet>
data () {
return {
letter: ''
}
},
methods: {
handleLetterChange (letter) {
this.letter = letter;
}
}
<city-list :cities="cities" :hot="hotCities" :letter="letter"></city-list>
props: {
hot: Array,
cities: Object,
letter: String
},
使用watch监听letter变化,当letter发生变化时,调用this.scroll.scrollToElement()方法将区域自动滚动到指定区域,在template中给每一个area区域加一个:ref='key',通过this.$refs[this.letter][0]获取值为this.letter的DOM元素。
<div class="area" v-for="(item, key) in cities" :key="key" :ref="key" >
<div class="title border-topbottom">{{ key }}</div>
<div class="item-list">
<div class="item border-bottom" v-for="innerItem in item" :key="innerItem.id" @click="handleCityClick(innerItem.name)">{{innerItem.name}}</div>
</div>
</div>
watch: {
letter () {
if (this.letter) {
const element = this.$refs[this.letter][0]
this.scroll.scrollToElement(element)
}
}
}
上下拖拽字母表touch
为字母表绑定三个事件:
@touchstart="handleTouchStart" //手指开始触摸时设置this.touchStatus = true
@touchmove="handleTouchMove" //在true时对触摸事件做处理
@touchend="handleTouchEnd" //手指结束触摸时设置this.touchStatus = false
computed: {
letters () {
const letters = [];
for (let i in this.cities){
letters.push(i);
}
return letters;
}
},
methods: {
handleLetterClick (e) {
this.$emit("change", e.target.innerText);
},
handleTouchStart () {
this.torchStatus = true;
},
handleTouchMove (e) {
if (this.torchStatus) {
if (this.timer){
clearTimeout(this.timer)
}
this.timer = setTimeout(() => {
const touchY = e.touches[0].clientY - 79;
const index = Math.floor((touchY - this.startY) / 20);
if (index >= 0 && index < this.letters.length){
this.$emit('change', this.letters[index]);
}
}, 16)
}
},
handleTouchEnd () {
this.torchStatus = false
}
}
优化
1、将字母A到头部下沿的距离的计算放在updated生命周期钩子函数中
初始时cities值为0,当Ajax获取数据后,cities的值才发生变化,AlphaBet才被渲染出来, 当往alphabet里面传的数据发生变化的时候,alphabet这个组件儿就会重新渲染。之后,updated这个生命周期钩子就会被执行。这个时候,页面上已经展示出了城市字母列表里所有的内容,去获取A这个字母所在的dom对应的offsettop的值就没有任何的问题了。
2、节流
如果timer已经存在,去除timmer(即上一次的事件还未执行完毕又出发了下一次事件,就用下一次事件覆盖上一次的事件)。
否则就创建一个timer,将操作延迟16ms执行,如果上一个操作间隔小于16ms,则清除上一个操作,直接执行这次操作,减少handleTouchMove的使用频率。
3、使用Vuex实现首页和城市选择页面的数据共享
- 安装vuex
- 创建src/store/index.js文件
import Vue from 'vue'
import Vuex from 'vuex'
import state from './state'
import mutations from './mutations'
Vue.use(Vuex)
export default new Vuex.Store({
state,
mutations
})
- main.js中引入store
import store from './store'
- 在mainjs中创建根实例时将store传入,store会被派发到每个子组件中,每个子组件中都可以使用
this.$store获取到 store。
new Vue({
el: '#app',
router,
store,
components: { App },
template: '<App/>'
})
(1)Vuex
概念
Vuex 是 Vue 专用的状态管理库,它以全局方式集中管理应用的状态,并以相应的规则保证状态以一种可预测的方式发生变化。主要解决的问题是多组件之间状态共享。
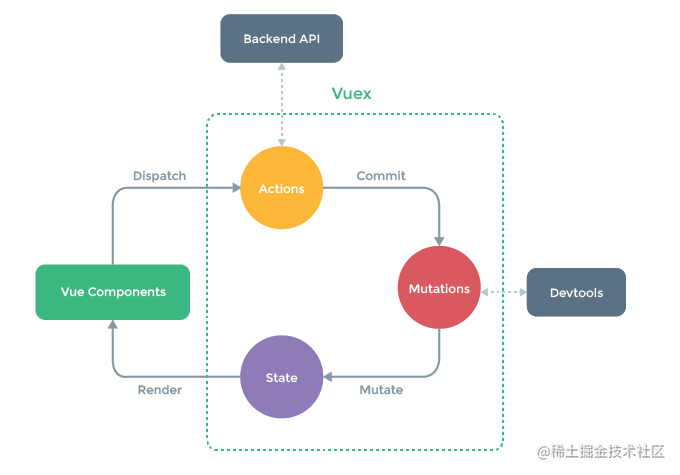
核心概念
- State:存放核心数据
- Action:异步方法
- Mutation:同步的对数据的改变
- Getter:类似于计算属性,提供新的数据,避免数据的冗余
- Module:模块化,拆分
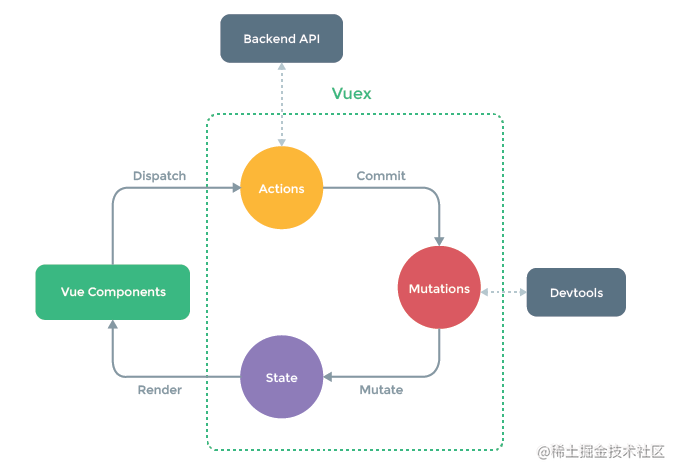
项目中Vuex的使用
- state存放当前城市CurCity
- 为每个城市元素都绑定一个
onclick事件(获取改变的city),点击城市
- 在List组件中调用
dispatch方法->触发Action
- 在store/index.js中增加一个
actions对象(接收city),使用commit调用mutation
mutations中,令state.city = city,完成
this.$store.dispatch('changeCity', city)
actions: {
changeCity (ctx, city) {
ctx.commit('changeCity', city)
}
},
mutations: {
changeCity (state, city) {
state.city = city;
try {
localStorage.city = city
} catch (e) {}
}
}
(2)单页面与多页面
实现单页面跳转的方式
- 标签实现
<a href="#/xxx" />
<router-link to="/xxx" />
- 函数实现
- 传统的window.location.href
- 使用vue-router中的router对象 (点击城市后自动跳转到首页)
step1 定义一个实现onclik事件的组件
<a onClick={this.goTo} />
step2 在goTo函数中实现跳转
goTo = () => {
window.location.href = "#/xxx"
this.$router.push('/');
}
项目中,点击城市后跳转到首页:this.$router.push
methods: {
handleCityClick (city) {
this.$router.push('/');
}
},
(3)localStorage(state和mutations中使用)
let defaultCity = "上海"
try {
if (localStorage.city){
defaultCity = localStorage.city
}
}catch (e) {}
export default{
city: defaultCity
}
export default{
changeCity (state, city) {
state.city = city;
try {
localStorage.city = city
} catch (e) {}
}
}
(4)keep-alive优化网页性能
每次切换回组件时,组件就会被重新渲染,mounted生命周期钩子就会被重新执行,ajax数据就会被重新获取,导致性能低。
<keep-alive>
<router-view/>
</keep-alive>
使用keep-alive后会多出两个生命周期钩子函数activated和deactivated
activated在每次切换回组件时调用,因此可以在activated中定义方法,在城市切换时重新发送ajax请求。
4、景点详情页
(1)动态路由及banner分支
为recommend组件的li标签外部包裹一个router-link标签,li标签样式改变,解决方式:
将li标签直接替换为router-link标签, 加入一个tag=“li”的属性,动态绑定::to = "'/detail/' + item.id",在router/index.js设置Detail路由
<router-link tag="li"
class="item border-bottom"
v-for="item in list"
:key="item.id"
:to="'/detail/' + item.id">
</router-link>
{
path: '/detail/:id',
name: 'Detail',
component: Detail
}
图片底部渐变效果:
background-image: linear-gradient(top, rgba(0, 0, 0, 0), rgba(0, 0, 0, 0.8))
(2)公用图片画廊组件拆分
将画廊组件变成一个公用组件src/common/gallary/Gallary.vue
画廊组件:图片轮播+页码显示
使用swiper插件实现轮播功能,使用swiper插件的 paginationType:
‘bullets’ 圆点(默认)
‘fraction’ 分式
‘progress’ 进度条
‘custom’ 自定义
创建路径别名,重启服务器。
一开始将gallary显示为隐藏状态,再次显示时计算宽度出现问题,swiper无法正确显示,解决:
data () {
return {
showGallary: true,
swiperOptions: {
pagination: '.swiper-pagination',
paginationType: 'fraction',
observeParents:true,
observer:true,
loop:true,
autoplay: false
}
}
}
(3)实现header渐隐渐现效果
methods: {
handleScroll () {
const top = document.documentElement.scrollTop;
if (top > 60){
const opacity = top / 140;
opacity > 1 ? 1 : opacity;
this.opacityStyle = {
opacity
};
this.showAbs = false;
}
else{
this.showAbs = true
}
}
},
activated () {
window.addEventListener('scroll', this.handleScroll)
},
(4)对全局事件的解绑(window对象)
deactivated () {
window.removeEventListener('scroll', this.handleScroll)
}
(5)使用递归组件实现详情页列表
(6)使用Ajax获取动态数据
获得动态路由参数(id)并将其传递给后端、
getDetailInfo () {
axios.get('/api/detail.json',{
params: {
id: this.lastRouteId
}
}).then(this.handleGetDetailInfoSucc)
}
(7)组件跳转时页面定位
scrollBehavior (to, from, savedPosition) {
return { x: 0, y: 0 }
}
(8)在项目中加入基础动画
在点击画廊组件时增加渐隐渐现的动画效果
//FadeAnimation.vue
<template>
<transition>
<slot></slot>
</transition>
</template>
<script>
export default{
name: "FadeAnimation"
}
</script>
<style lang="stylus" scoped>
@import '~styles/varibles.styl'
.v-enter, .v-leave-to
opacity: 0
.v-enter-active, .v-leave-active
transition: opacity .5s
</style>
common-gallary 作为插槽插入到fade-animation中:
<fade-animation>
<common-gallary
:imgs="bannerImgs"
v-show="showGallary"
@close="handleGallaryClose"
>
</common-gallary>
</fade-animation>
二、优化
- 网速慢时图片没有加载出来造成的抖动(使用padding-bottom占位)
- 重复代码封装:借助stylus提供的mixin对代码进行封装
- 节流:触摸滑动字母表&搜索框中输入
- keep-alive
- 对全局事件解绑
作者:树上结了个小橙子
来源:juejin.cn/post/7222627262399365180










 它可以代表从1920往下的分辨率
它可以代表从1920往下的分辨率