国破山河在,城春草木深。 ——杜甫·春望
今日周一,在下与诸位同道中人一起来讨论一个话题:当一个前端空闲的时候会做些什么。
🤯是独自深耕论坛,钻研学术?
👯还是三两闲聊打趣,坐而论道?
💆♂️亦或是闭目养神,神游天地?
作为一名优秀的(摆子、摸鱼、切图...)前端开发者,在下在空闲时间最喜欢做的还是钻研(混)前端技术(工作量)。
新的一周,新的开始,上篇文章中有同学批评在下说不够“玩”,那么这周就“简单”画一个鼠标精灵再交予各位“玩一玩”吧。
说明一下:在下说的玩,是写一遍嗷
温馨提示:文章较长,图片较多,不耐看的同学可以先去文末玩一玩在下的“大眼”,不满足了再去创造属于各位自己的鼠标精灵
以下是这周“玩具”的简单介绍:
- 名称:大眼
- 生辰:发文时间的昨天(2022-08-15)
- 性别:随意
- 情绪:发怒/常态
- 状态:休眠/工作中
- 简介:没啥特别的,大眼就干一件事,就是盯着你的鼠标,以防你找不到鼠标了。不过大眼有起床气,而且非常懒散,容易犯困。
大眼生活照:

接下来请各位跟随在下的节奏,一步一步把自己的“大眼”创造出来。
👀 画“大眼”先画圆
老话说“画人先画骨”,同样画大眼也得先画它的骨,嗯......也就是个圆,没错,就是个普通的圆
在下的笔法还是老套路,先给他一个容器。
<div class="eyeSocket"></div>
给大眼容器添加一些必要的样式
body {
width: 100vw;
height: 100vh;
overflow: hidden;
background-color: #111;
}
.eyeSocket {
position: absolute; // 浮动居中
left: calc(50% - 75px);
top: calc(50% - 75px);
width: 150px; // 固定宽度
aspect-ratio: 1; // 长宽比 1:1 如果浏览器不支持该属性,换成 height: 150px 也一样
border-radius: 50%;
border: 4px solid rgb(41, 104, 217);
z-index: 1;
}
效果:

然后就是另外两个圆和一些阴影效果,由于另外两个圆没有特殊的动效,所以在下使用两个伪元素来实现
.eyeSocket::before,
.eyeSocket::after {
content: "";
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%); // 居中
border-radius: 50%;
box-sizing: border-box; // css3盒子模型
}
.eyeSocket::before {
width: calc(100% + 20px);
height: calc(100% + 20px);
border: 6px solid #02ffff;
}
.eyeSocket::after {
width: 100%;
height: 100%;
border: 4px solid rgb(35, 22, 140);
box-shadow: inset 0px 0px 30px rgb(35, 22, 140);
}
效果:

👀 画龙需点睛
大眼的眼球画好了,之后就需要给它点上眼睛,喜欢什么样的眼睛因人而异,在下就选择这种分割线来作为大眼的眼仁。
为了方便做一些过渡效果,在下使用echarts来完成这个眼仁。
首先在下需要各位通过任何方式引入echarts库,然后给眼仁一个容器,并初始化echarts画布。
<div class="eyeSocket">
<div id="eyeball"></div>
</div>
#eyeball {
width: 100%;
height: 100%;
}
let eyeball = document.getElementById('eyeball');
let eyeballChart = echarts.init(eyeball);
function getEyeballChart() {
eyeballChart.setOption({
series: [
{
type: 'gauge',
radius: '-20%',
clockwise: false,
startAngle: '0',
endAngle: '270',
splitNumber: 3,
detail: false,
axisLine: {
show: false,
},
axisTick: false,
splitLine: {
show: true,
length: 12,
lineStyle: {
shadowBlur: 20,
shadowColor: 'rgb(0, 238, 255)',
shadowOffsetY: '0',
color: 'rgb(0, 238, 255)',
width: 4,
}
},
axisLabel: false
},
{
type: 'gauge',
radius: '-20%',
clockwise: false,
startAngle: '45',
endAngle: '315',
splitNumber: 3,
detail: false,
axisLine: {
show: false,
},
axisTick: false,
splitLine: {
show: true,
length: 12,
lineStyle: {
shadowBlur: 20,
shadowColor: 'rgb(0, 238, 255)',
shadowOffsetY: '0',
color: 'rgb(0, 238, 255)',
width: 4,
}
},
axisLabel: false
}
]
})
}
getEyeballChart();
效果:

眼仁就这么轻轻松松的画好了,对于常用echarts的同学可以说是轻而易举,对吧。
同时一个静态的大眼也创建完毕,接下来就要给大眼赋予生命了。
再次提醒:长文,而且代码量多,建议抽思路看即可。
✨ 生命仪式:休眠状态
赋予生命是神圣的,她需要一个过程,所以在下从最简单的开始——休眠状态。
在下给大眼设计的休眠状态,就是闭着眼睛睡觉,其实不露出眼仁同时有节奏的呼吸(缩放)罢了,相比于整个生命仪式来说,还是比较简单的,只需要修改大眼外框的大小即可。
呼吸
这里在下采用的是css转换+动画的方式
<div class="eyeSocket eyeSocketSleeping">
<div id="eyeball"></div>
</div>
.eyeSocketSleeping {
animation: sleeping 6s infinite;
}
@keyframes sleeping {
0% {
transform: scale(1);
}
50% {
transform: scale(1.2);
}
100% {
transform: scale(1);
}
}

闭眼
搞定了呼吸,但是睁着眼睛怎么睡得着?
所以接下来在下要帮助大眼把眼睛闭上,这时候咱们前面给眼睛设置负数radius的好处就来了(其实是在下设计好的),因为分割线是从内向外延伸的,所以此时只需要慢慢减小分割线的高度,即可实现眼睛慢慢缩小的效果,即在下给大眼设计的闭眼效果。
实现的效果是:大眼慢慢闭上眼睛(分割线缩小至0),然后开始呼吸
直接上代码
<div class="eyeSocket" id='bigEye'> // 去掉 eyeSocketSleeping 样式,添加id
<div id="eyeball"></div>
</div>
let bigEye = document.getElementById('bigEye');
let leftRotSize = 0;
let ballSize = 12;
let rotTimer;
function getEyeballChart() {
eyeballChart.setOption({
series: [
{
startAngle: `${0 + leftRotSize * 5}`,
endAngle: `${270 + leftRotSize * 5}`,
splitLine: {
length: ballSize,
},
},
{
startAngle: `${45 + leftRotSize * 5}`,
endAngle: `${315 + leftRotSize * 5}`,
splitLine: {
length: ballSize,
}
},
}
]
})
}
function toSleep() {
clearInterval(rotTimer);
rotTimer = setInterval(() => {
getEyeballChart()
if (ballSize > 0) {
ballSize -= 0.1;
} else {
bigEye.className = 'eyeSocket eyeSocketSleeping';
}
leftRotSize === 360 ? (leftRotSize = 0) : (leftRotSize += 0.1);
}, 10);
}
getEyeballChart();
toSleep()
旋转实现原理:(看过在下第一篇动效的同学对旋转的实现原理应该不陌生)
修改每个圈的起始角度(startAngle)和结束角度(endAngle),并不断刷新视图,
增加度数为逆时针旋转,减去度数为顺时针旋转
如此一来就实现了眼睛缩小消失,然后开始呼吸的过程,同时咱们的大眼也进入了生命仪式之休眠状态(乱入的鼠标有点烦);

✨ 生命仪式:起床气状态
在下相信,在座(站?蹲?)的各位同僚身边或者自身都存在一些小毛病,譬如咱们的大眼,它不但懒,喜欢睡觉,甚至叫醒它还会生气,通俗讲就是有起床气。
心理学上说有种说法是:情绪会让你接近生命的本真。
生命不就是情绪的结合嘛,没有情绪怎么能称之为生命的呢?
在设计之前我们还有点准备工作,就是让大眼先处于休眠状态。
<div class="eyeSocket eyeSocketSleeping" id='bigEye'> // 添加休眠
<div id="eyeball"></div>
</div>
let ballSize = 0;
唤醒
然后我们需要唤醒大眼,所以首先我们需要添加唤醒动作——点击事件;
let bigEye = document.getElementById('bigEye');
let leftRotSize = 0;
let ballSize = 0;
let rotTimer;
let isSleep = true;
bigEye.addEventListener('click', () => {
if (!isSleep) return;
clickToWeakup();
})
function clickToWeakup() {
isSleep = false;
bigEye.className = 'eyeSocket';
clearInterval(rotTimer);
rotTimer = setInterval(() => {
getEyeballChart()
ballSize <= 12 && (ballSize += 0.1);
leftRotSize === 360 ? (leftRotSize = 0) : (leftRotSize += 0.1);
}, 10);
}
这样点一下大眼它就苏醒了过来:

生气
但是!
这是一个没有情绪的大眼,而在下需要的是一个有起床气的大眼,所以这样的大眼咱们不要!
退格←...退格←...退格←...退格←...退格←...退格←......
......
慢点慢点,也不是全都不要了,咱们只需要修改一下他唤醒以后的操作,给他添加上起床气不就行了?
接着来吧:
首先我们把代表了大眼常态的蓝色系抽离出来,使用css变量代替,然后再苏醒后给他添加成代表生气的红色系
body {
width: 100vw;
height: 100vh;
overflow: hidden;
background-color: #111;
perspective: 1000px;
--c-eyeSocket: rgb(41, 104, 217);
--c-eyeSocket-outer: #02ffff;
--c-eyeSocket-outer-shadow: transparent;
--c-eyeSocket-inner: rgb(35, 22, 140);
}
.eyeSocket {
border: 4px solid var(--c-eyeSocket);
box-shadow: 0px 0px 50px var(--c-eyeSocket-outer-shadow);
transition: border 0.5s ease-in-out, box-shadow 0.5s ease-in-out;
}
.eyeSocket::before,
.eyeSocket::after {
transition: all 0.5s ease-in-out;
}
.eyeSocket::before {
border: 6px solid var(--c-eyeSocket-outer);
}
.eyeSocket::after {
border: 4px solid var(--c-eyeSocket-inner);
box-shadow: inset 0px 0px 30px var(--c-eyeSocket-inner);
}
let ballColor = 'transparent';
function getEyeballChart() {
eyeballChart.setOption({
series: [
{
splitLine: {
lineStyle: {
shadowColor: ballColor,
color: ballColor,
}
},
},
{
splitLine: {
lineStyle: {
shadowColor: ballColor,
color: ballColor,
}
}
},
}
]
})
}
function setAngry() {
document.body.style.setProperty('--c-eyeSocket', 'rgb(255,187,255)');
document.body.style.setProperty('--c-eyeSocket-outer', 'rgb(238,85,135)');
document.body.style.setProperty('--c-eyeSocket-outer-shadow', 'rgb(255, 60, 86)');
document.body.style.setProperty('--c-eyeSocket-inner', 'rgb(208,14,74)');
ballColor = 'rgb(208,14,74)';
}
function setNormal() {
document.body.style.setProperty('--c-eyeSocket', 'rgb(41, 104, 217)');
document.body.style.setProperty('--c-eyeSocket-outer', '#02ffff');
document.body.style.setProperty('--c-eyeSocket-outer-shadow', 'transparent');
document.body.style.setProperty('--c-eyeSocket-inner', 'rgb(35, 22, 140)');
ballColor = 'rgb(0,238,255)';
}
function clickToWeakup() {
isSleep = false;
bigEye.className = 'eyeSocket';
setAngry();
clearInterval(rotTimer);
rotTimer = setInterval(() => {
getEyeballChart()
ballSize <= 50 && (ballSize += 1);
leftRotSize === 360 ? (leftRotSize = 0) : (leftRotSize += 0.5);
}, 10);
}
bigEye.addEventListener('click', () => {
if (!isSleep) return;
clickToWeakup();
})
大眼生气长这样:

更生气
不知道在座(站?蹲擦?)各位是如何看待,但是在下看来,大眼这样好像还不够生气。
没错还不够生气,如何让大眼起来更生气呢,生气到发火如何?
嗦干酒干!
在下这里采用的是svg滤镜的方法,svg滤镜的属性和使用方法非常繁多,在下使用得也不是很娴熟,本文中在下就不赘述了,网上冲浪有许多技术大牛讲的非常好,希望各位勉励自己。emmmm......然后来教会在下,记得给在下留言文章地址
在下使用的是feTurbulence来形成噪声,然后用feDisplacementMap替换来给大眼添加粒子效果,因为feDisplacementMap会混合掉元素,所以在下需要给大眼新增一个大眼替身来代替大眼被融合。
创建大眼替身
<div class="filter"> // 添加滤镜的元素
<div class="eyeSocket" id='eyeFilter'> // 大眼替身
</div>
</div>
.filter {
width: 100%;
height: 100%;
}
.eyeSocket,
.filter .eyeSocket {
}

融合
<div class="filter">
<div class="eyeSocket" id='eyeFilter'>
</div>
</div>
<svg width="0">
<filter id='filter'>
<feTurbulence baseFrequency="1">
<animate id="animate1" attributeName="baseFrequency" dur="1s" from="0.5" to="0.55" begin="0s;animate1.end">
</animate>
<animate id="animate2" attributeName="baseFrequency" dur="1s" from="0.55" to="0.5" begin="animate2.end">
</animate>
</feTurbulence>
<feDisplacementMap in="SourceGraphic" scale="50" xChannelSelector="R" yChannelSelector="B" />
</filter>
</svg>
.filter {
width: 100%;
height: 100%;
filter: url('#filter');
}
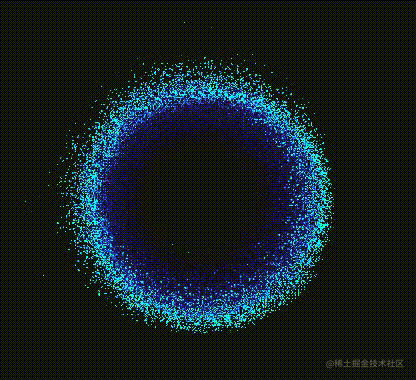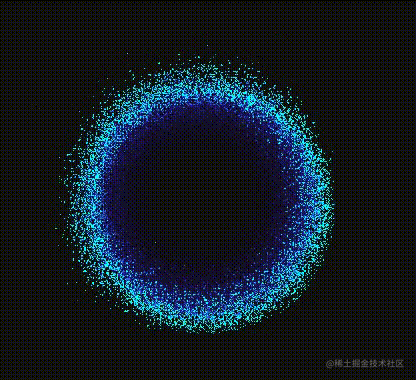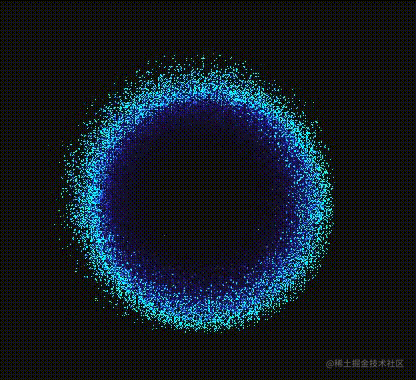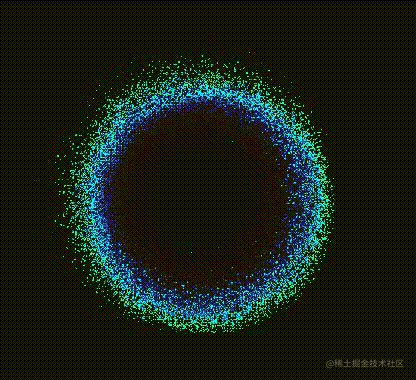
芜湖~果然献祭了一只“大眼”出来的效果看起来确实还不错哈?确实看起来酷炫多了,不愧是**“献祭”**啊!
真眼出现
既然粒子效果已经产生,咱们的真实大眼也就不需要躲躲藏藏了,该站出来获取这粒子“光环”了!
大眼:哈!

额......
其实......
也挺好看的嘛,不是吗?毕竟不是献祭的真正的大眼,毕竟是个替身,效果没有本体好也是很正常的对吧。
本质上是因为feDisplacementMap设置了scale属性的原因。
feDisplacementMap其实就是一个位置替换滤镜,通过就是改变元素和图形的像素位置的进行重新映射,然后替换一个新的位置,形成一个新的图形。
而scale就是替换公式计算后偏移值相乘的比例,影响着图形的偏移量和呈现的效果。
但是话虽如此,咱这个光环不能真的就这么戴着呀,咱们还需要对光环的位置进行一些微调。
.filter .eyeSocket {
left: calc(50% - 92px);
top: calc(50% - 92px);
}

看看,看看!这不就顺眼多了吗,献祭了替身,所以尺寸都是非常契合的,而且共用了样式,所以当大眼生气的时候,光环也会跟着生气。
这下光环也有了,看起来的确比之前更生气了。
但是我们还需要对大眼做一些细微的调整,因为大眼在常规状态下并不需要这个光环,睡着的时候光环在旁边“滋啦滋啦”不吵的慌么,所以我们还需要把常态下的大眼光环给消除掉。
在下采用的是不透明度opacity来控制,当大眼处于生气状态时,光环为不透明;处于常规状态时光环透明不可见。
.filter .eyeSocket {
opacity: 0; // 默认状态下不透明度为0
left: calc(50% - 92px);
top: calc(50% - 92px);
transition: all 0.5s ease-in-out; // 添加过渡效果,值得注意的是不能丢了原本的过渡效果,所以这里使用all
}
let eyeFilter = document.getElementById('eyeFilter');
function clickToWeakup() {
eyeFilter.style.opacity = '1';
}
deathEye.addEventListener('click', () => {
if (!isSleep) return;
clickToWeakup();
})
这样设置完,一个更生气的大眼就这样出现了:
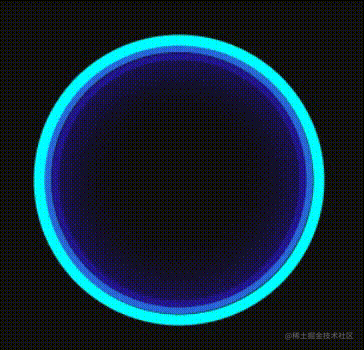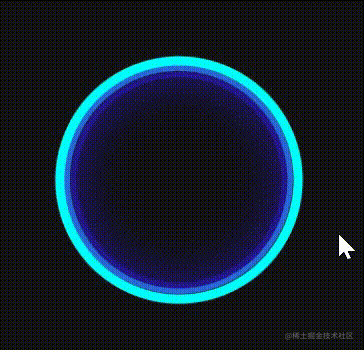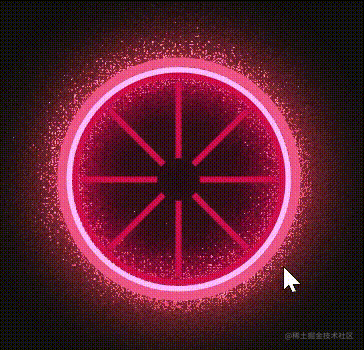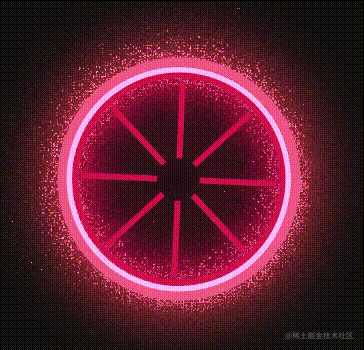
更更生气
不知看到这样发火的大眼,各位是不是已经满足于此。
但是在下认为不,在下觉得一个真正足够生气的大眼,不只局限于自己生气,还需要找人发泄!!
所以在下还给大眼添加了一些大眼找人的动效(当然是找不到的,它这么笨)。
其实就是让大眼左右旋转,通过css转换来实现。
<div class="eyeSocket eyeSocketSleeping" id='bigEye'>
<div id="eyeball"></div>
</div>
<div class="filter">
<div class="eyeSocket" id='eyeFilter'>
</div>
</div>
<svg width="0">
...
</svg>
body {
perspective: 1000px;
}
.eyeSocketLooking {
animation: lookAround 2.5s; // 添加动画,只播放一次
}
@keyframes lookAround {
0% {
transform: translateX(0) rotateY(0);
}
10% {
transform: translateX(0) rotateY(0);
}
40% {
transform: translateX(-70px) rotateY(-30deg);
}
80% {
transform: translateX(70px) rotateY(30deg);
}
100% {
transform: translateX(0) rotateY(0);
}
}
let bigEye = document.getElementById('bigEye');
let eyeFilter = document.getElementById('eyeFilter');
function clickToWeakup() {
eyeFilter.className = bigEye.className = 'eyeSocket eyeSocketLooking';
}
bigEye.addEventListener('click', () => {
if (!isSleep) return;
clickToWeakup();
})
看看大眼在找什么?

向左看时,Y轴偏移量为-70px,同时按Y轴旋转-30°
向右看时,Y轴偏移量为70px,同时Y轴旋转30°
✨ 生命仪式:自我调整状态
这个状态非常好理解,大眼虽然有起床气,但是也仅限于起床对吧,总不能一直让它生气,气坏了咋办,带着情绪工作,效果也不好不是吗。
所以我们还需要给它一点时间,让它自我调整一下,恢复成正常状态。
这个自我调整状态就是一个从生气状态变回常态的过程,在这个过程中,大眼需要将生气状态的红色系切换为常态的蓝色系,同时红眼也会慢慢褪去恢复正常。
其实这个自我调整状态还是属于唤醒状态中,只是需要放在起床气状态之后。
这里在下采纳了上文中有位同学给的建议,监听动画结束事件webkitAnimationEnd,然后将自我调整放在动画结束以后。
同时这里也有两个步骤:
- 退出起床气状态;
- 变回常态
为了保证两个步骤的先后顺序,可以使用Promise来实现。不懂Promise的同学可以先去学习一下,在下也讲不清楚哈哈哈哈。
bigEye.addEventListener('webkitAnimationEnd', () => {
new Promise(res => {
clearInterval(rotTimer);
rotTimer = setInterval(() => {
getEyeballChart();
ballSize > 0 && (ballSize -= 0.5);
leftRotSize === 360 ? (leftRotSize = 0) : (leftRotSize += 0.1);
if (ballSize === 0) {
clearInterval(rotTimer);
res();
}
}, 10);
}).then(() => {
eyeFilter.style.opacity = '0';
eyeFilter.className = bigEye.className = 'eyeSocket';
setNormal();
rotTimer = setInterval(() => {
getEyeballChart();
ballSize <= 12 && (ballSize += 0.1);
leftRotSize === 360 ? (leftRotSize = 0) : (leftRotSize += 0.1);
}, 10);
})
})
添加了这样一个监听事件后,咱们的大眼就已经具备了自我调整的能力了:
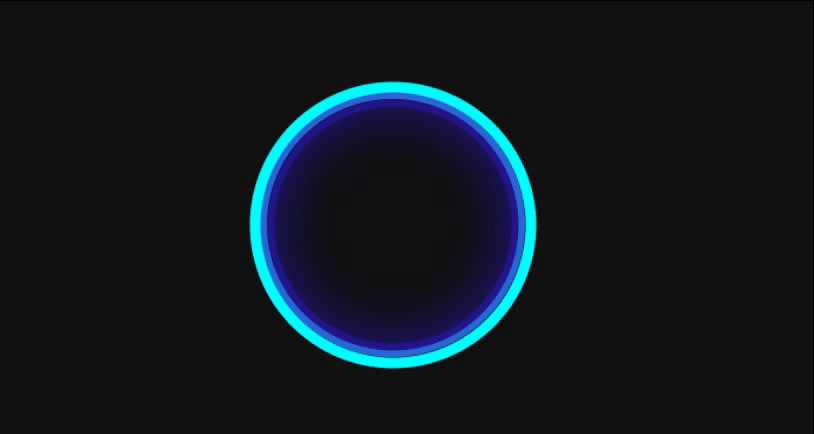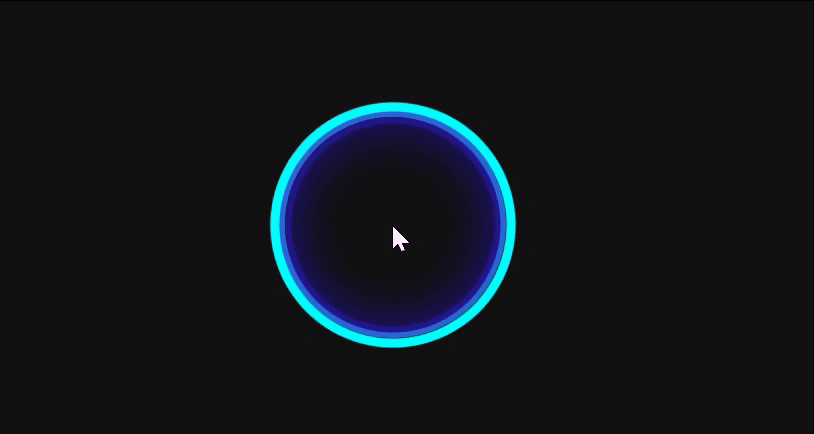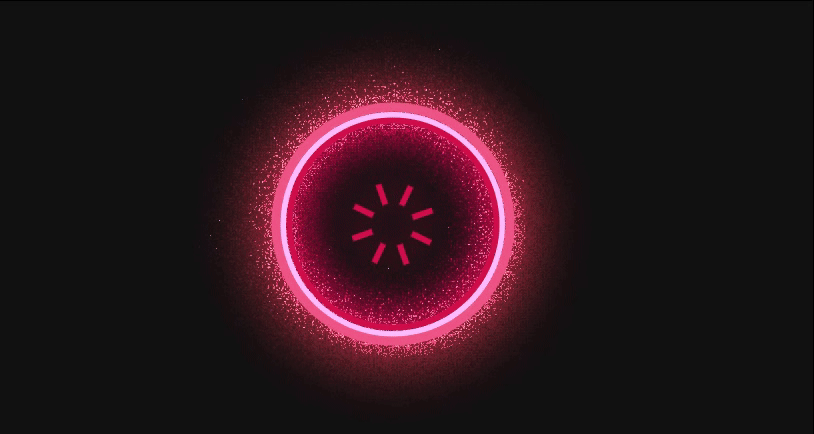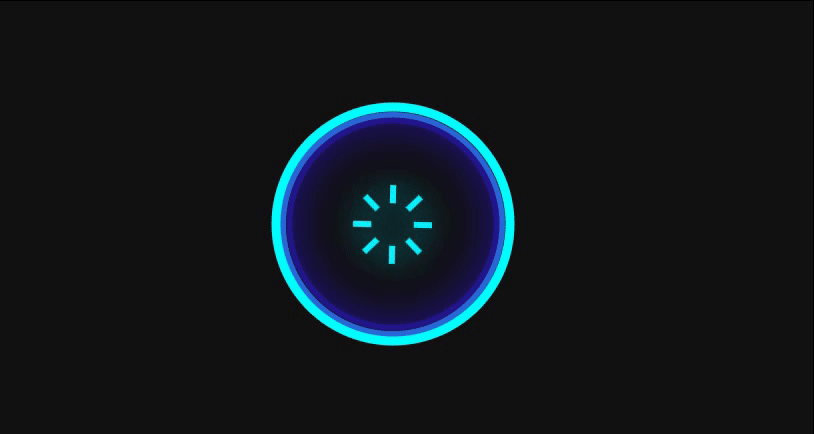
✨ 生命仪式:工作状态
接下来就到了大眼重中之重的环节,也就是大眼的工作状态。
在下给大眼的工作非常简单,就是单纯的盯住在下的鼠标,如果各位想给各自的大眼一些其他的功能,可以自己发挥。
盯住鼠标,不只是说说而已,那么怎么样才能让大眼表现出他已经盯住了呢?
在下的思路是:
- 以大眼的位置为原点建立一个直角坐标系
- 然后通过监听鼠标移动事件,获取鼠标所在位置,计算出鼠标处于大眼坐标系的坐标。
- 将整个视口背景以X轴和Y轴进行等分成无数个旋转角度,通过鼠标坐标的数值和正负来调整大眼眼框和眼睛的Y轴和Z轴旋转,从而达到盯住鼠标的目的。
好的,咱们理清思路,接下来就是付诸于行动。
function focusOnMouse(e) {
{
let clientWidth = document.body.clientWidth;
let clientHeight = document.body.clientHeight;
let origin = [clientWidth / 2, clientHeight / 2];
let mouseCoords = [e.clientX - origin[0], origin[1] - e.clientY];
let eyeXDeg = mouseCoords[1] / clientHeight * 80;
let eyeYDeg = mouseCoords[0] / clientWidth * 60;
bigEye.style.transform = `rotateY(${eyeYDeg}deg) rotateX(${eyeXDeg}deg)`;
eyeball.style.transform = `translate(${eyeYDeg / 1.5}px, ${-eyeXDeg / 1.5}px)`;
}
}
注意: 如果觉得旋转角度不够大,可以调整代码中的80和60,最大可以到180,也就是完全朝向,但是由于大眼终归是一个平面生物,如果旋转度数过大,就很容易穿帮,如果旋转角度为180,大眼就会在某个方向完全消失看不见(因为大眼没有厚度,这个也许是可以优化的点),所以个人喜好调整吧。
咱们来看看大眼工作时的飒爽英姿:

✨ 生命仪式:懒惰状态
顾名思义,懒惰状态就是......懒惰状态。
在下给大眼设计的懒惰状态就是当在下的鼠标超过30秒没有移动时,大眼就会进入休眠状态。
所以生命仪式的最后收尾其实非常的轻松,没有大量的代码,只需要添加一个定时器,然后修改休眠状态的代码,将大眼的所有参数初始化即可。
let sleepTimer;
function toSleep() {
document.body.removeEventListener('mousemove', focusOnMouse);
bigEye.style.transform = `rotateY(0deg) rotateX(0deg)`;
eyeball.style.transform = `translate(0px, 0px)`;
}
function focusOnMouse(e) {
if (sleepTimer) clearTimeout(sleepTimer);
sleepTimer = setTimeout(() => {
toSleep();
}, 30000);
}
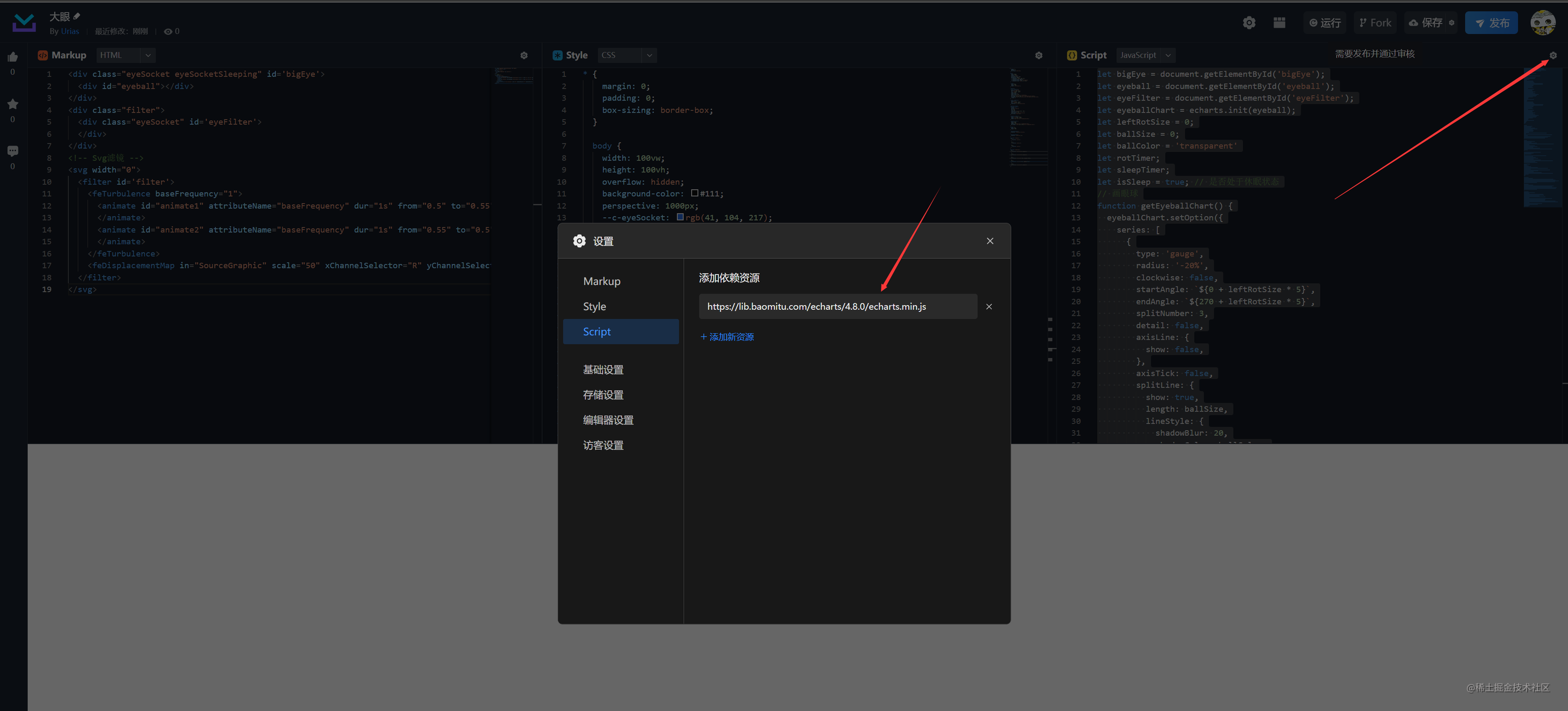
感谢上次掘金官方的提醒,在下把线上代码贴在这,在下文笔较差,看不下去的同学可以直接过来玩一玩,感兴趣再去创建自己的大眼。(没有点运行的不要来问我为什么出不来!!!)

如果自己在码上掘金动手的同学记得不要忘记添加echarts资源
💐 结语
好家伙,原来再写一遍大眼会这么累,这次是真真正正的“玩”了一天,有功夫的各位同僚也可以去玩一玩,于在下的基础上进行完善,创造出属于各位自己的大眼。当然如果有一些比较好玩的动效也可以留言告知在下,当下次混工作量时在下可以有东西写。
就这样!

作者:Urias
来源:juejin.cn/post/7132409301380890660