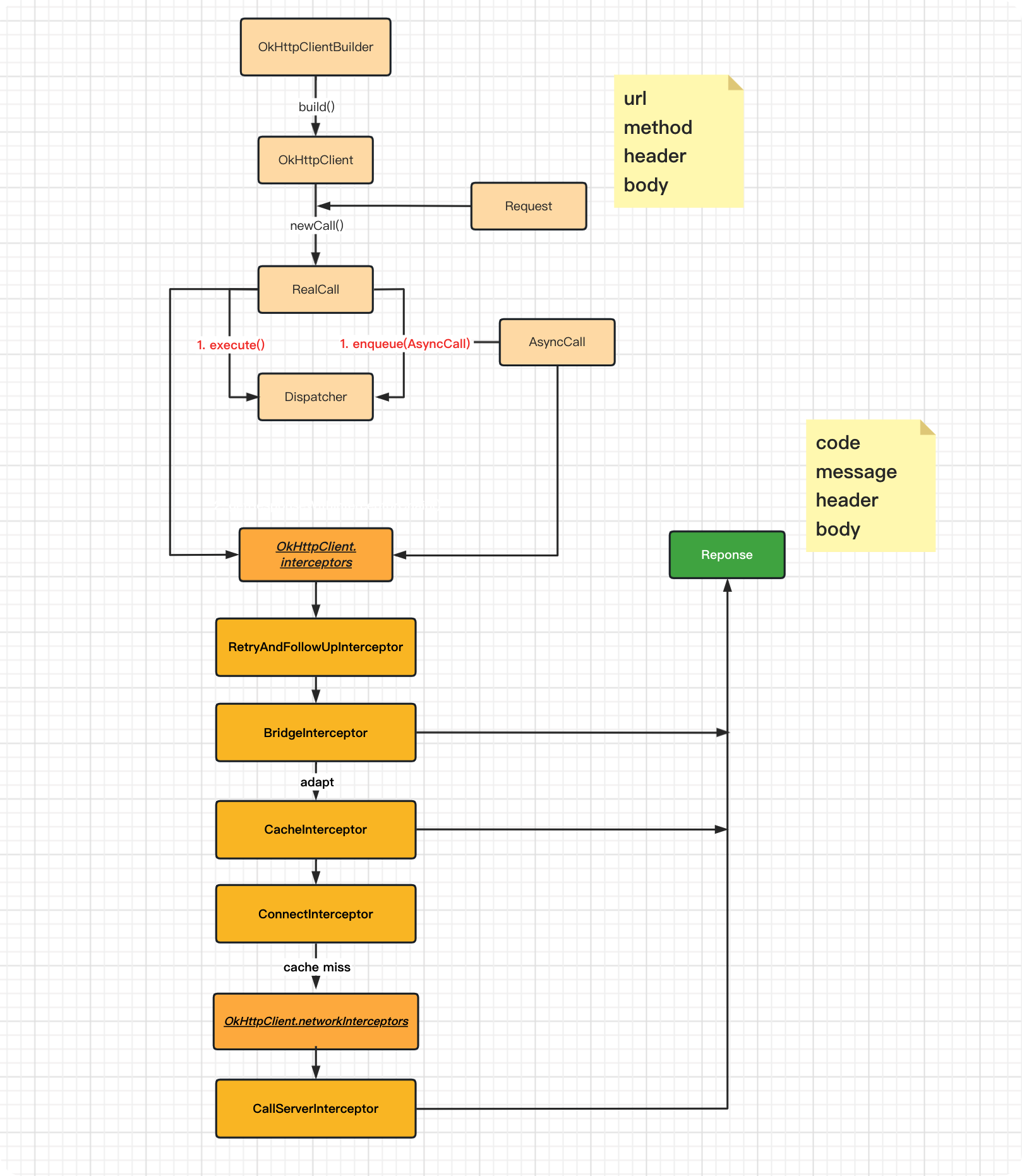
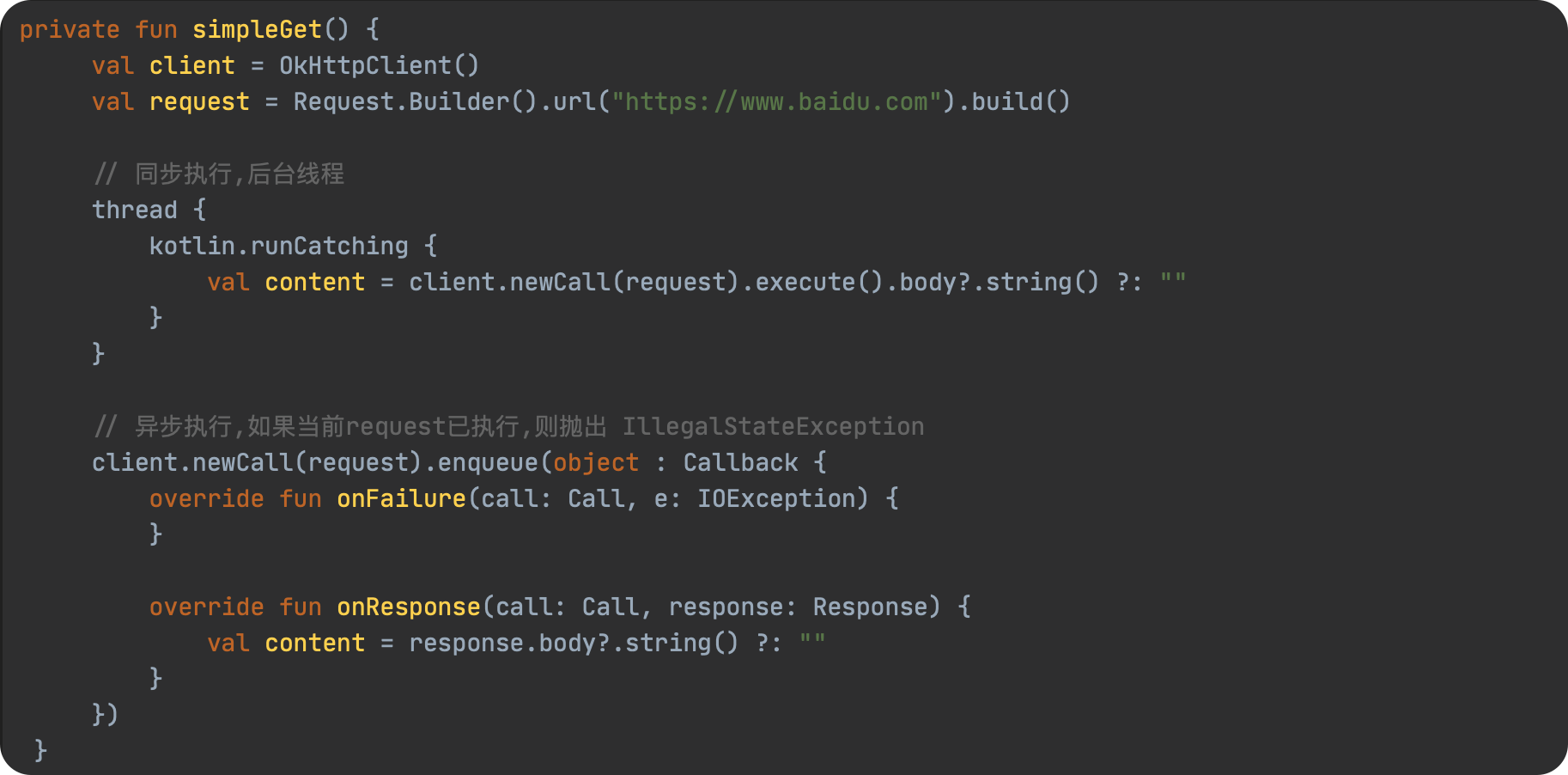
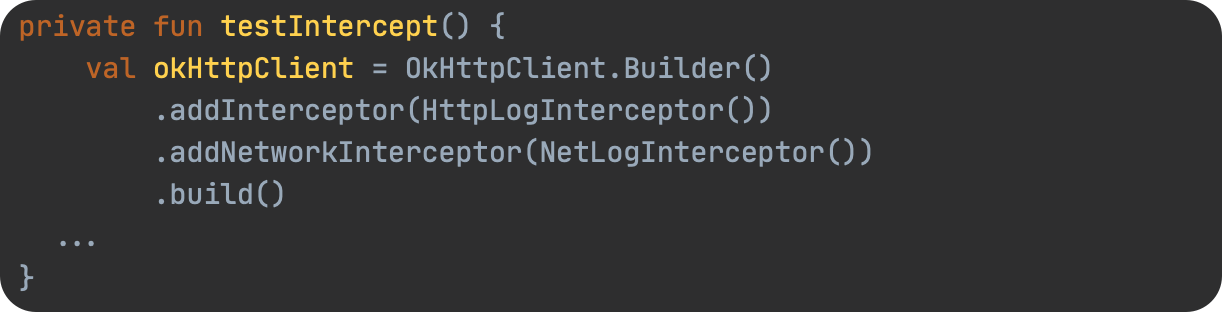
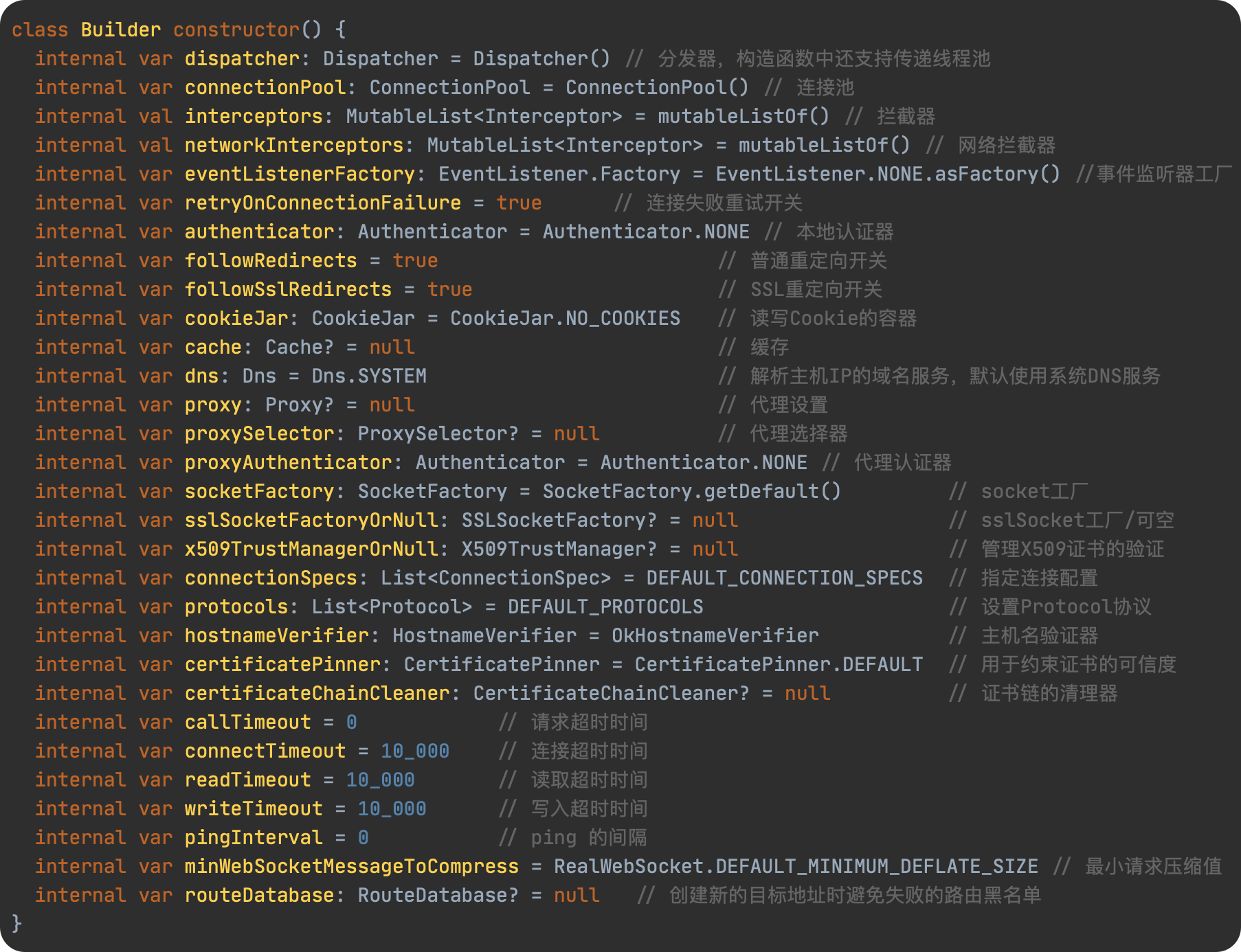
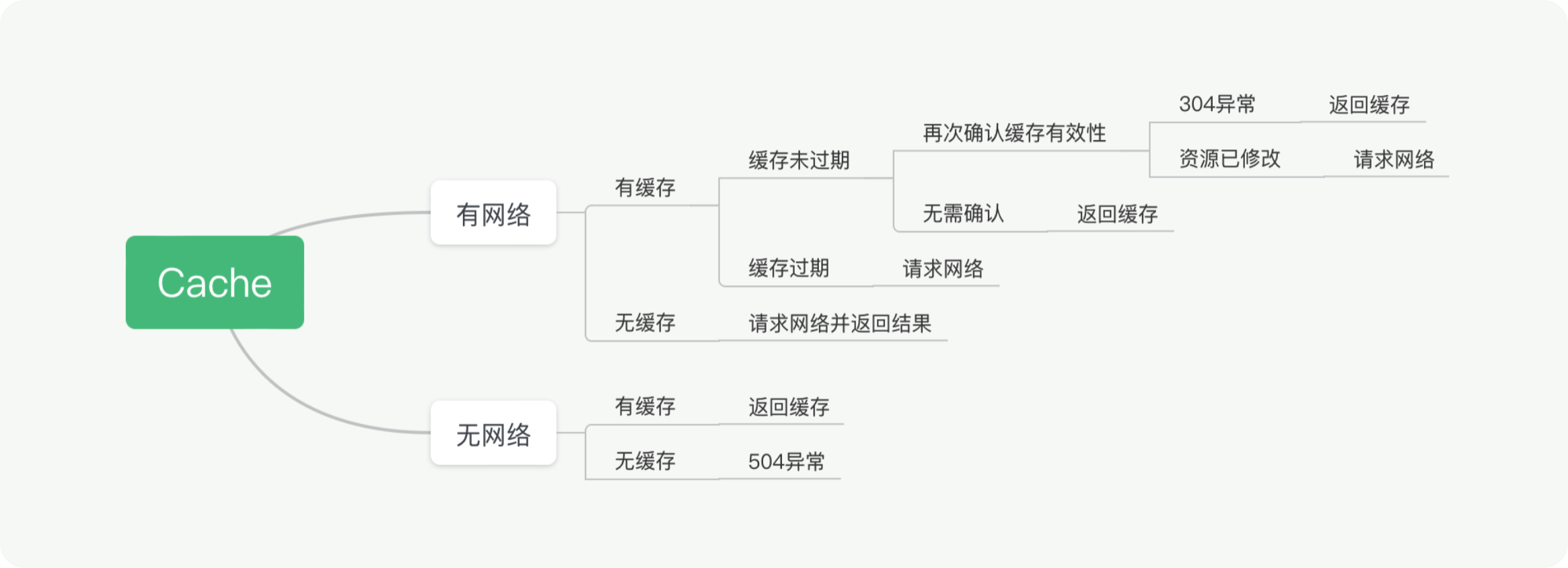
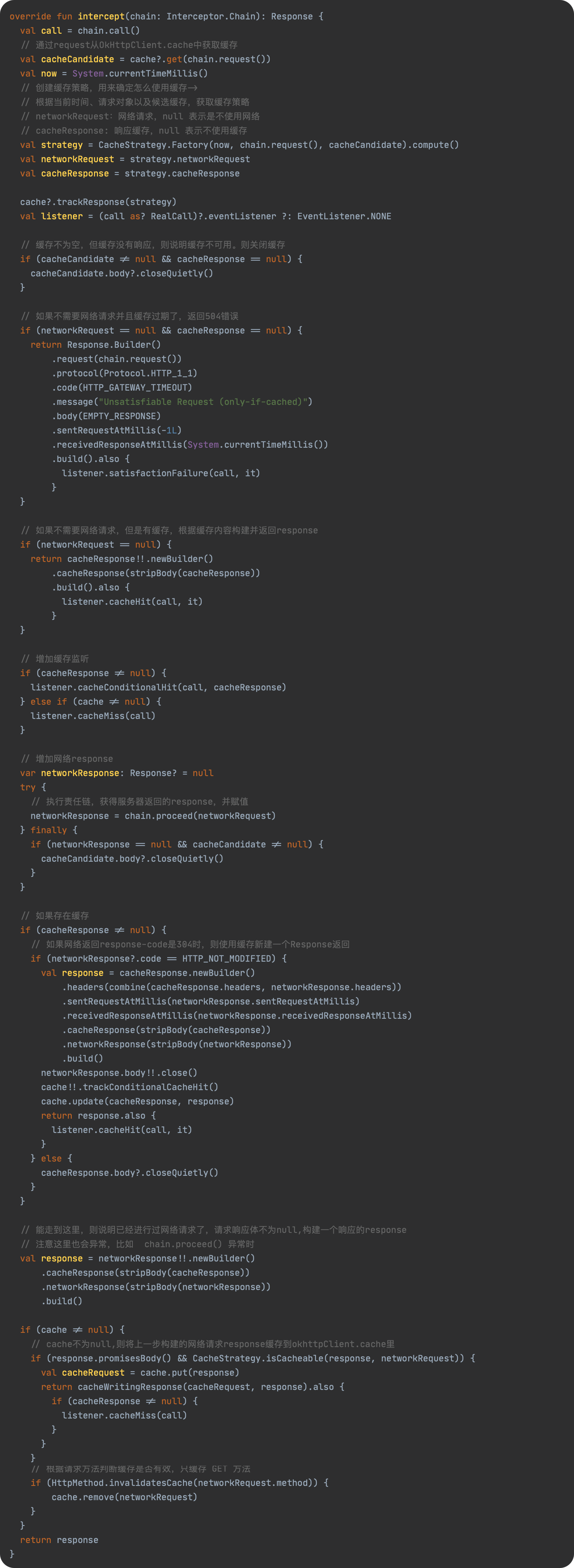
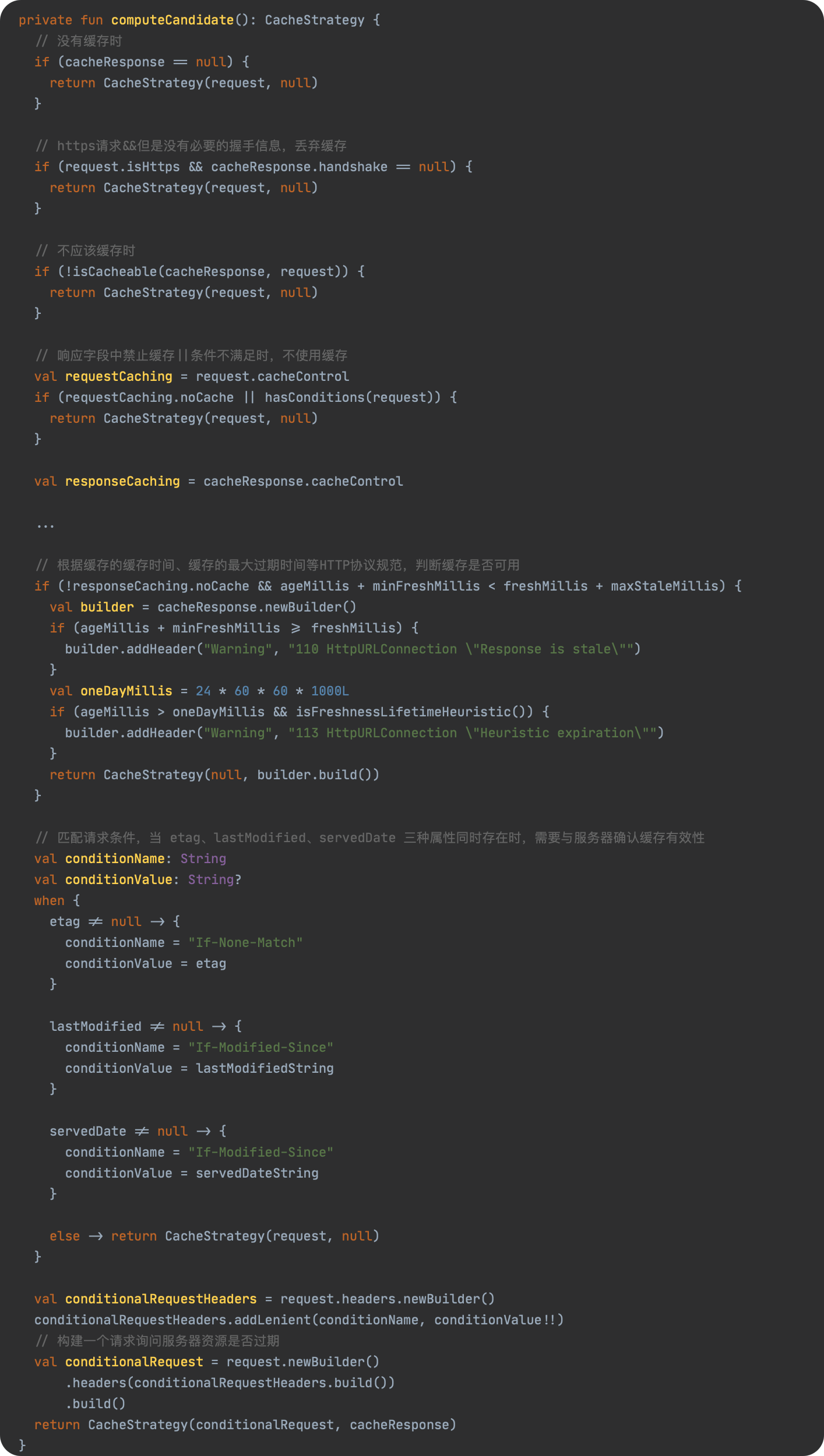
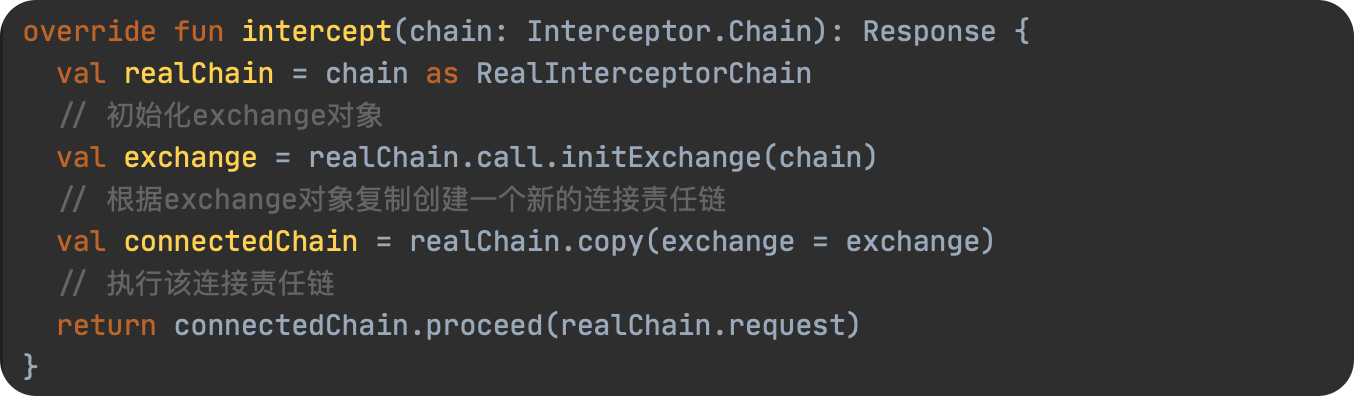
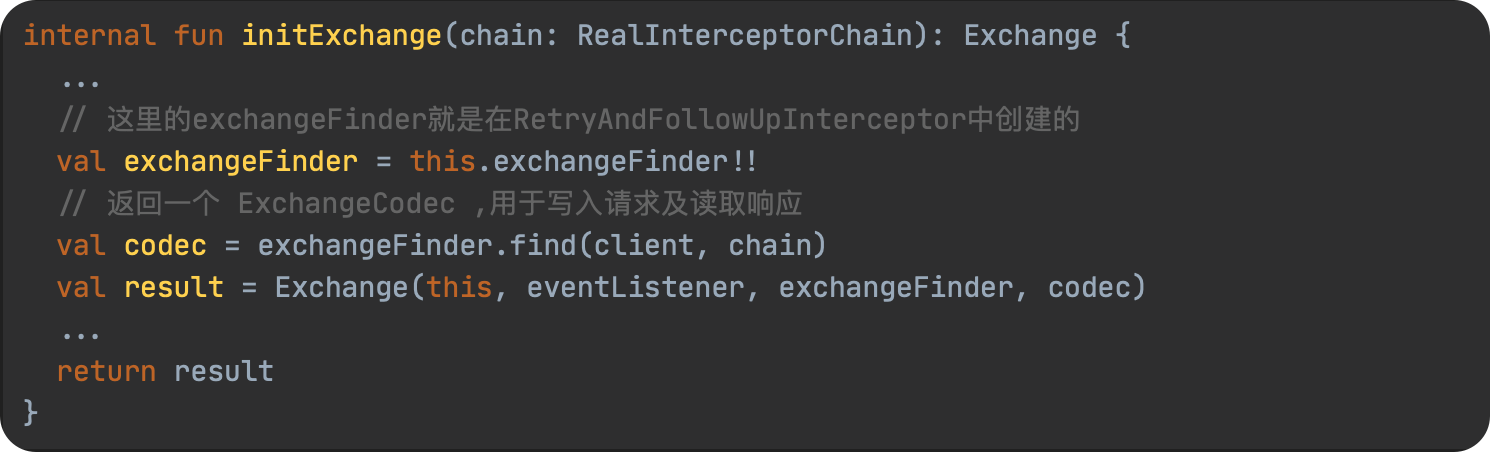
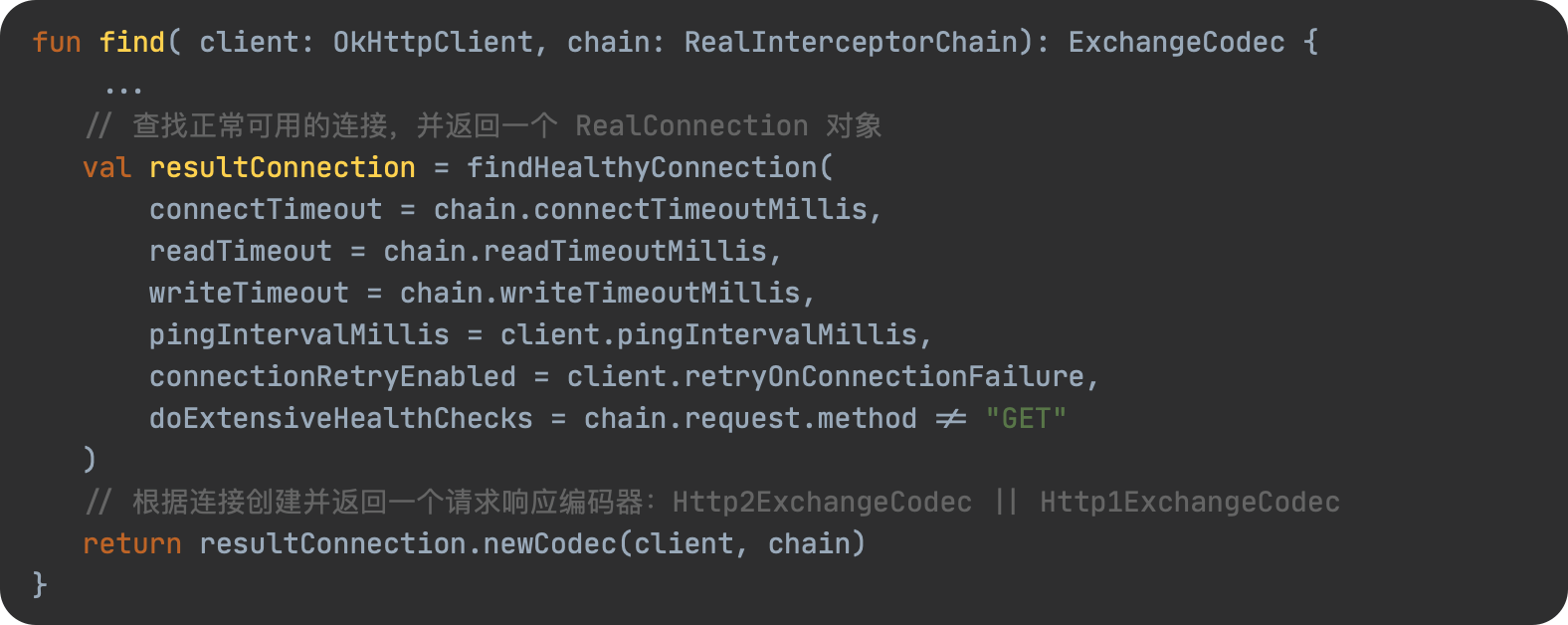
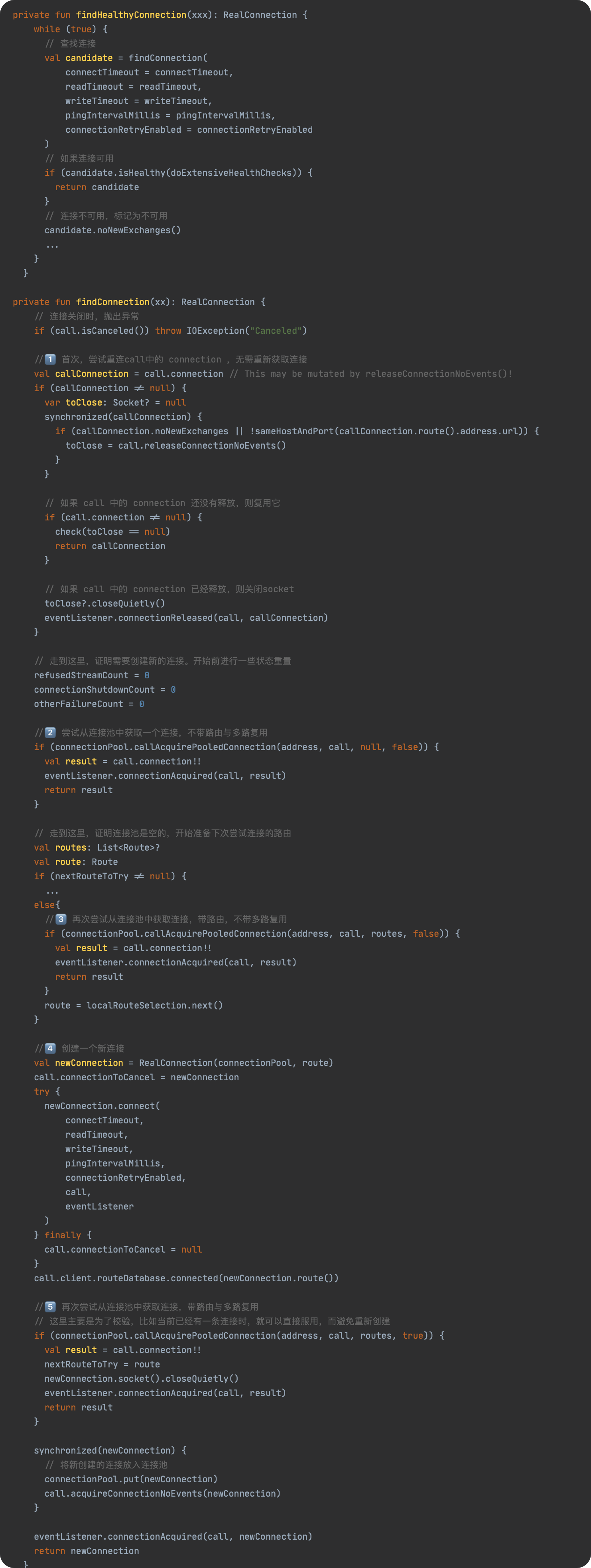
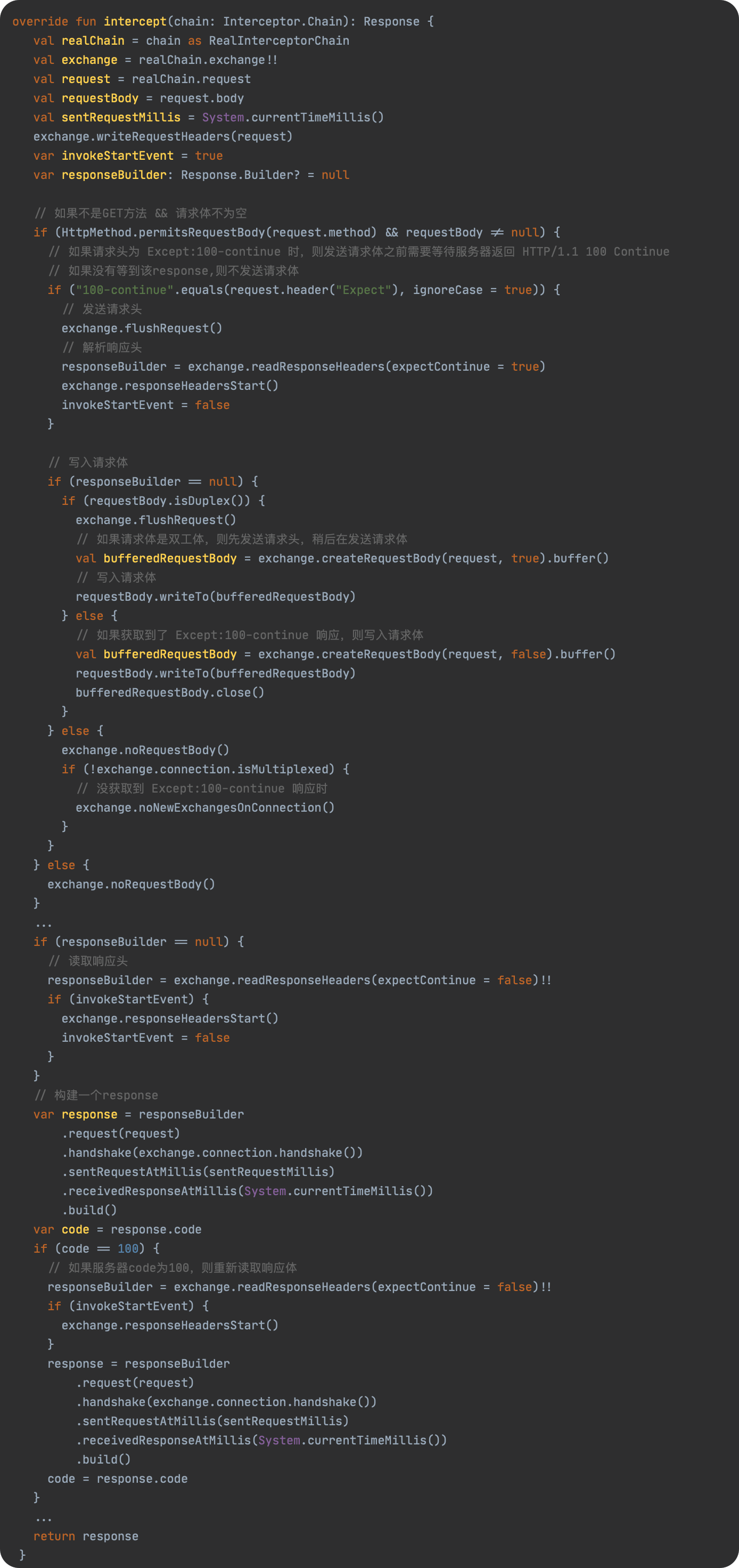
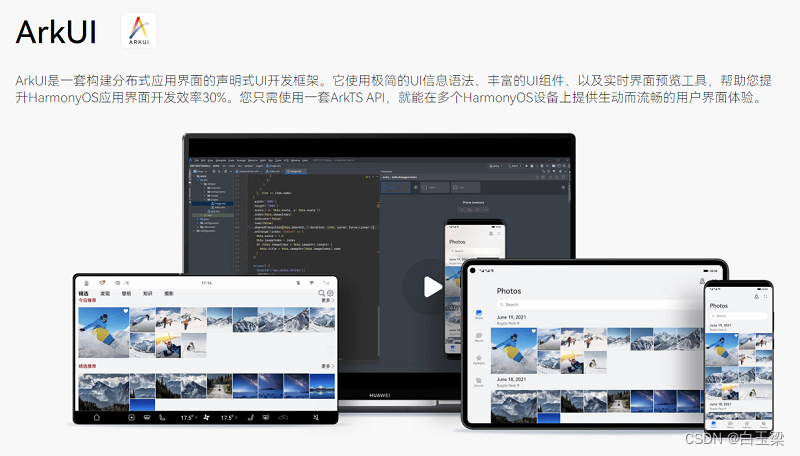
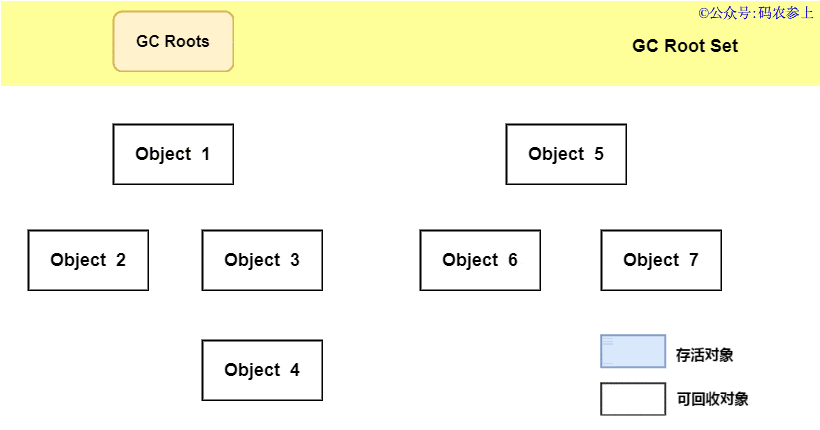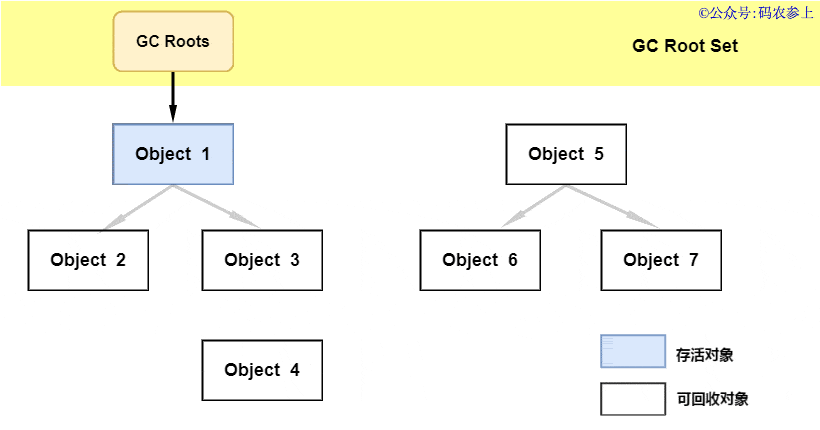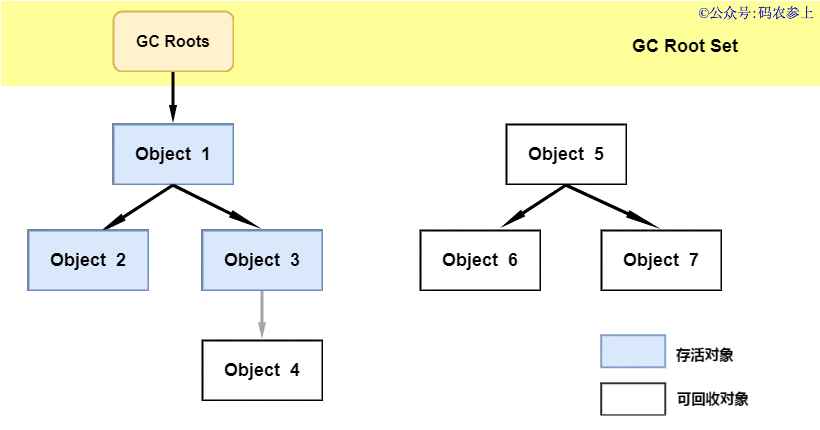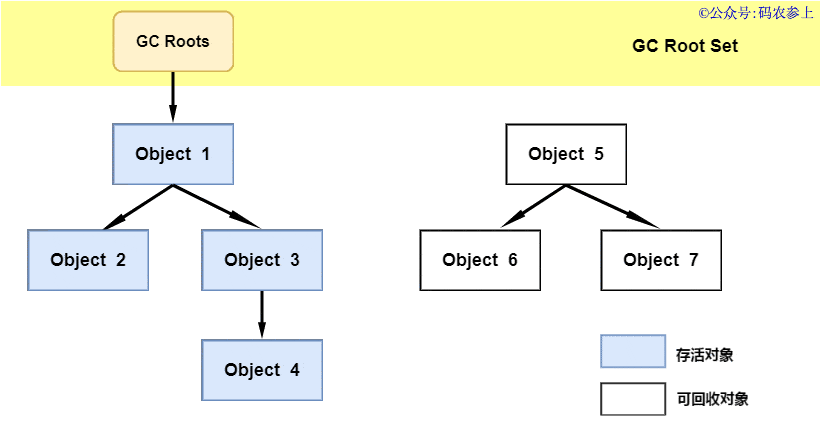
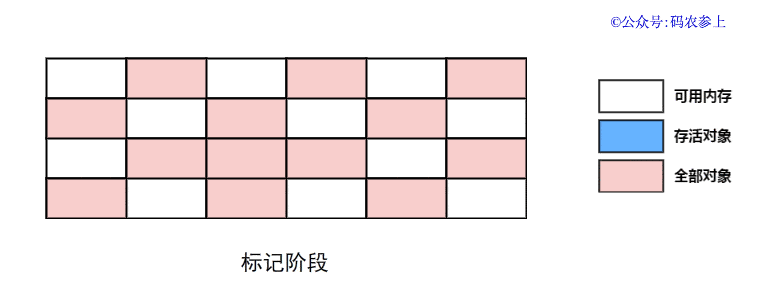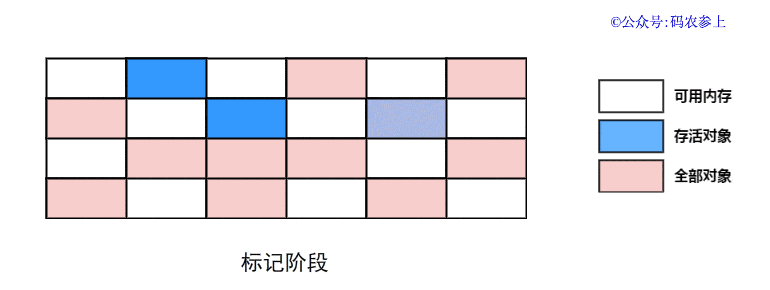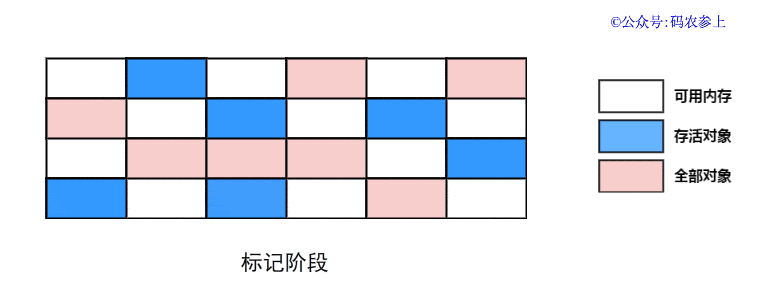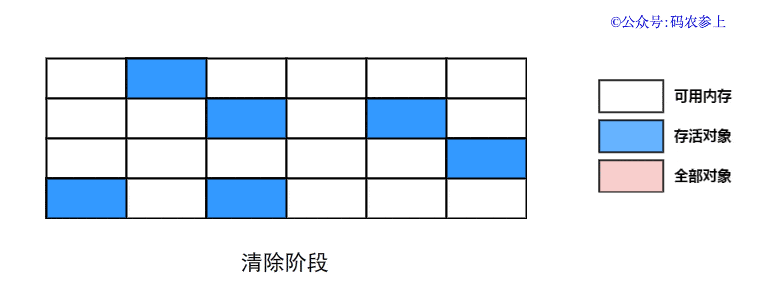
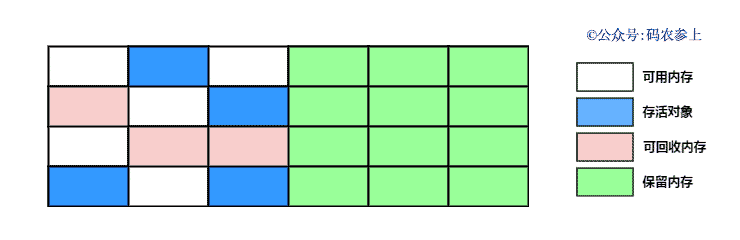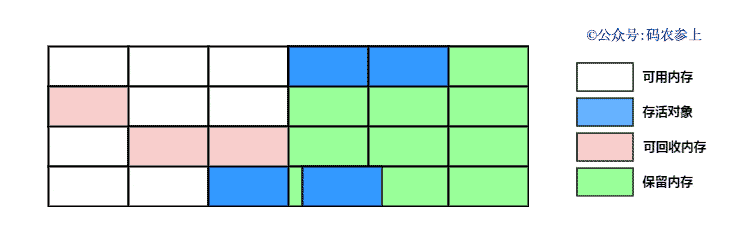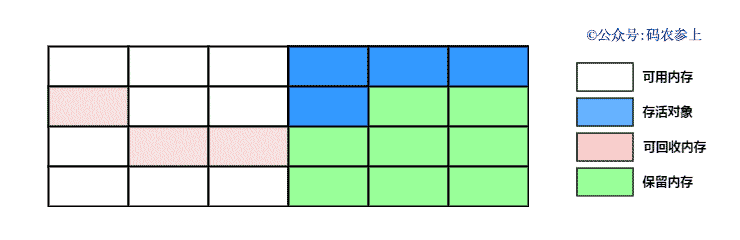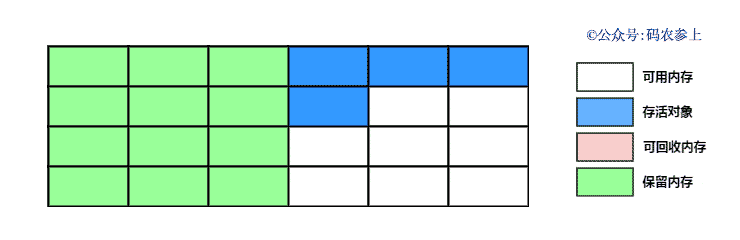
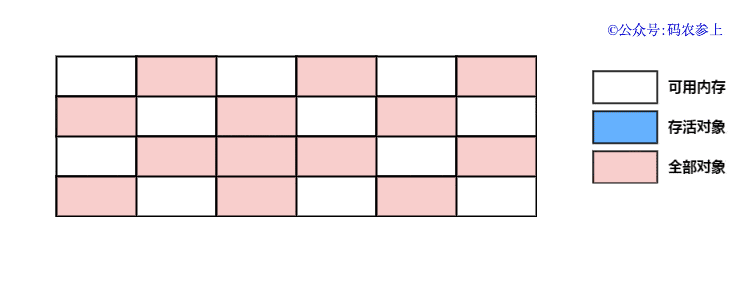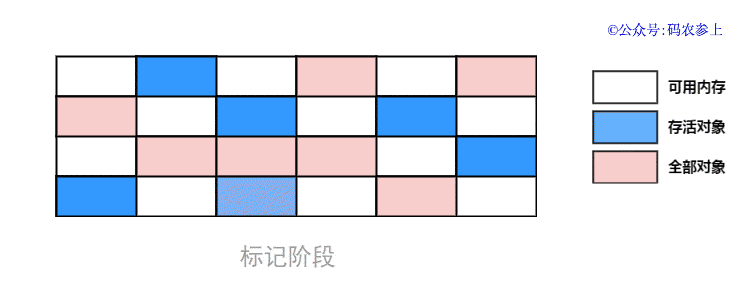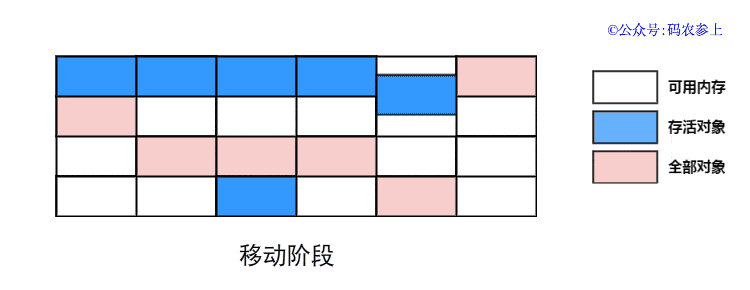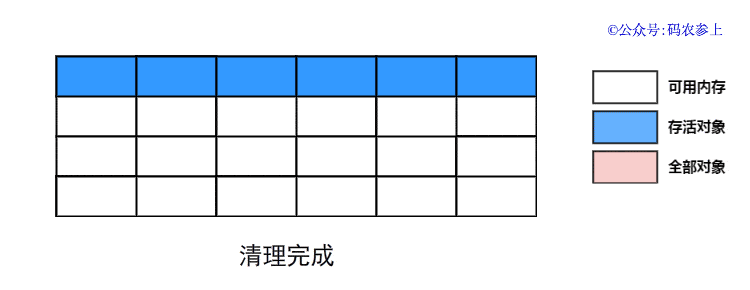
SPL(Structured Process Language)是一个开源结构化数据计算引擎,本身提供了不依赖数据库的强大计算能力,SPL内置了很多高性能算法,尤其是对关联运算做了优化,对不同的关联场景采用不同的手段,可以大幅提升关联性能,从而不用宽表也能实时关联以满足多维分析时效性的需要。同时,SPL还提供了高性能存储,配合高效算法可以进一步发挥性能优势。
SEL ECT ct1.area,o.emp_id,sum(o.amount) somt FROM orders o JOIN customer c ON o.cus_id = c.cus_id JOIN city ct1 ON c.city_id = ct1.city_id JOIN employee e ON o.emp_id = e.emp_id JOIN city ct2 ON e.city_id = ct2.city_id WHERE ct2.area = 'east' AND year(o.order_date)= 2022 GRO UP BY ct1.area, o.emp_id
SEL ECT cus_id.city_id.area,emp_id,sum(amount) somt FROM orders WHERE emp_id.city_id.area == "east"ANDyear(order_date)== 2022 BY cus_id.city_id.area,emp_id
JVMTIAgent是一个利用JVMTI暴露出来的接口提供了代理启动时加载(Agent On Load)、代理通过Attach形式加载(Agent On Attach)和代理卸载(Agent On Unload)功能的动态库。而Instrument Agent可以理解为一类JVMTIAgent动态库,别名是JPLISAgent(Java Programming Language Instrumentation Services Agent),也就是专门为Java语言编写的插桩服务提供支持的代理。
2.2.3 启动时和运行时加载Instrument Agent过程
2.3 那些年JVM和HotSwap之间的“相爱相杀”
围绕着Method Body的HotSwap JVM一直在进行改进。从1.4版本开始,JPDA引入HotSwap机制(JPDA Enhancements),实现Debug时的Method Body的动态性。大家可参考文档:enhancements1.4 。 1.5版本开始通过JVMTI实现的java.lang.instrument(Java Platform SE 8)的Premain方式,实现Agent方式的动态性(JVM启动时指定Agent)。大家可参考文档:package-summary。
1.6版本又增加Agentmain方式,实现运行时动态性(通过The Attach API 绑定到具体VM)。大家可参考文档:package-summary 。基本实现是通过JVMTI的retransformClass/redefineClass进行method、body级的字节码更新,ASM、CGLib基本都是围绕这些在做动态性。但是针对Class的HotSwap一直没有动作(比如Class添加method、添加field、修改继承关系等等),为什么会这样呢?因为复杂度过高,且没有很高的回报。
User ClassLoader是框架自定义的ClassLoader统称,例如Jetty项目是WebAppclassLoader。其中Urlclasspath为当前项目的lib文件件下,例如Spring Boot项目也是从当前项目BOOT-INF/lib/路径中加载CLass等等,不同框架的自定义位置稍有不同。所以针对此类情况,Agent必须拿到用户的自定义Classloader,如果是常规方式启动的,比如普通Spring XML项目,借助Plus(美团内部服务发布平台)发布,此类没有自定义Classloader,是默认AppClassLoader,所以Agent在用户项目启动过程中,借助字节码增强的方式来获取到真正的用户Classloader。
booleanisPrime=number>0; // 计算number的平方根为k,可以减少一半的计算量 intk= (int) Math.sqrt(number); for (inti=2; i<=k; i++) { if (number%i==0) { isPrime=false; break; } } returnisPrime;
二、对称加密和非对称加密
假如 Alice 时而需要给北漂搬砖的 Bob 发一些信息,为了安全起见两个人相互协商了一个加密的方式。比如 Alice 发送了一个银行卡密码 142857 给 Bob,Alice 会按照与 Bob 的协商方式,把 142857 * 2 = 285714 的结果传递给 Bob,之后 Bob 再通过把信息除以2拿到结果。
定理 1 令 a 为整数, d 为正整数, 则存在唯一的整数 q 和 r, 满足 0⩽r<d, 使得 a=dq+r.
当 r=0 时, 我们称 d 整除 a, 记作 d∣a; 否则称 d 不整除 a, 记作 d∤a
整除有以下基本性质:
定理 2 令 a, b, c 为整数, 其中 a≠0a≠0. 则:
对任意整数 m,n,如果 a∣b 且 a∣c, 则 a∣(mb + nc)
如果 a∣b, 则对于所有整数 c 都有 a∣bc
如果 a∣b 且 b∣c, 则 a∣c
1.2 模算术
在数论中我们特别关心一个整数被一个正整数除时的余数. 我们用 a mod m = b表示整数 a 除以正整数 m 的余数是 b. 为了表示两个整数被一个正整数除时的余数相同, 人们又提出了同余式(congruence).
定义 1 如果 a 和 b 是整数而 m 是正整数, 则当 m 整除 a - b 时称 a 模 m 同余 b. 记作 a ≡ b(mod m)
a ≡ b(mod m) 和 a mod m= b 很相似. 事实上, 如果 a mod m = b, 则 a≡b(mod m). 但他们本质上是两个不同的概念. a mod m = b 表达的是一个函数, 而 a≡b(mod m) 表达的是两个整数之间的关系.
模算术有下列性质:
定理 3 如果 m 是正整数, a, b 是整数, 则有
(a+b)mod m=((a mod m)+(b mod m)) mod m
ab mod m=(a mod m)(b mod m) mod m
根据定理3, 可得以下推论
推论 1 设 m 是正整数, a, b, c 是整数; 如果 a ≡ b(mod m), 则 ac ≡ bc(mod m)
证明 ∵ a ≡ b(mod m), ∴ (a−b) mod m=0 . 那么
(ac−bc) mod m=c(a−b) mod m=(c mod m⋅(a−b) mod m) mod m=0
∴ ac ≡ bc(mod m)
需要注意的是, 推论1反之不成立. 来看推论2:
推论 2 设 m 是正整数, a, b 是整数, c 是不能被 m 整除的整数; 如果 ac ≡ bc(mod m) , 则 a ≡ b(mod m)
证明 ∵ ac ≡ bc(mod m) , 所以有
(ac−bc)mod m=c(a−b)mod m=(c mod m⋅(a−b)mod m) mod m=0
∵ c mod m≠0 ,
∴ (a−b) mod m=0,
∴a ≡ b(mod m) .
2. 最大公约数
如果一个整数 d 能够整除另一个整数 a, 则称 d 是 a 的一个约数(divisor); 如果 d 既能整除 a 又能整除 b, 则称 d 是 a 和 b 的一个公约数(common divisor). 能整除两个整数的最大整数称为这两个整数的最大公约数(greatest common divisor).
定义 2 令 a 和 b 是不全为零的两个整数, 能使 d∣ad∣a 和 d∣bd∣b 的最大整数 d 称为 a 和 b 的最大公约数. 记作 gcd(a,b)
定理 4贝祖定理 如果整数 a, b 不全为零, 则 gcd(a,b)是 a 和 b 的线性组合集 {ax+by∣x,y∈Z}中最小的元素. 这里的 x 和 y 被称为贝祖系数
证明 令 A={ax+by∣x,y∈Z}. 设存在 x0x0, y0y0 使 d0d0 是 A 中的最小正元素, d0=ax0+by0 现在用 d0去除 a, 这就得到唯一的整数 q(商) 和 r(余数) 满足
又 0⩽r<d0, d0 是 A 中最小正元素
∴ r=0 , d0∣a.
同理, 用 d0d0 去除 b, 可得 d0∣b. 所以说 d0 是 a 和 b 的公约数.
设 a 和 b 的最大公约数是 d, 那么 d∣(ax0+by0)即 d∣d0
∴∴ d0 是 a 和 b 的最大公约数.
我们可以对辗转相除法稍作修改, 让它在计算出最大公约数的同时计算出贝祖系数.
defgcd(a, b): ifb==0: returna, 1, 0 d, x, y = gcd(b, a% b) returnd, y, x- (a/b) *y
3. 线性同余方程
现在我们来讨论求解形如 ax≡b(modm) 的线性同余方程. 求解这样的线性同余方程是数论研究及其应用中的一项基本任务. 如何求解这样的方程呢? 我们要介绍的一个方法是通过求使得方程 ¯aa≡1(mod m) 成立的整数 ¯a. 我们称 ¯a 为 a 模 m 的逆. 下面的定理指出, 当 a 和 m 互素时, a 模 m 的逆必然存在.
定理 5 如果 a 和 m 为互素的整数且 m>1, 则 a 模 m 的逆存在, 并且是唯一的.
证明 由贝祖定理可知, ∵ gcd(a,m)=1 , ∴ 存在整数 x 和 y 使得 ax+my=1 这蕴含着 ax+my≡1(modm) ∵ my≡0(modm), 所以有 ax≡1(modm)
∴ x 为 a 模 m 的逆.
这样我们就可以调用辗转相除法 gcd(a, m) 求得 a 模 m 的逆.
a 模 m 的逆也被称为 a 在模m乘法群 Z∗m 中的逆元. 这里我并不想引入群论, 有兴趣的同学可参阅算法导论
求得了 a 模 m 的逆 ¯a 现在我们可以来解线性同余方程了. 具体的做法是这样的: 对于方程 ax≡b(modm)a , 我们在方程两边同时乘上 ¯a, 得 ¯aax≡¯ab(modm)
应用层是网络应用程序和网络协议存放的分层,因特网的应用层包括许多协议,例如我们学 web 离不开的 HTTP,电子邮件传送协议 SMTP、端系统文件上传协议 FTP、还有为我们进行域名解析的 DNS 协议。应用层协议分布在多个端系统上,一个端系统应用程序与另外一个端系统应用程序交换信息分组,我们把位于应用层的信息分组称为 报文(message)。
因特网的网络层负责将称为 数据报(datagram) 的网络分层从一台主机移动到另一台主机。网络层一个非常重要的协议是 IP 协议,所有具有网络层的因特网组件都必须运行 IP 协议,IP 协议是一种网际协议,除了 IP 协议外,网络层还包括一些其他网际协议和路由选择协议,一般把网络层就称为 IP 层,由此可知 IP 协议的重要性。
链路层
现在我们有应用程序通信的协议,有了给应用程序提供运输的协议,还有了用于约定发送位置的 IP 协议,那么如何才能真正的发送数据呢?为了将分组从一个节点(主机或路由器)运输到另一个节点,网络层必须依靠链路层提供服务。链路层的例子包括以太网、WiFi 和电缆接入的 DOCSIS 协议,因为数据从源目的地传送通常需要经过几条链路,一个数据包可能被沿途不同的链路层协议处理,我们把链路层的分组称为 帧(frame)
浏览器正式的名字叫做 Web Broser,顾名思义,就是检索、查看互联网上网页资源的应用程序,名字里的 Web,实际上指的就是 World Wide Web,也就是万维网。
我们在地址栏输入URL(即网址),浏览器会向DNS(域名服务器,后面会说)提供网址,由它来完成 URL 到 IP 地址的映射。然后将请求你的请求提交给具体的服务器,在由服务器返回我们要的结果(以HTML编码格式返回给浏览器),浏览器执行HTML编码,将结果显示在浏览器的正文。这就是一个浏览器发起请求和接受响应的过程。
Web 服务器
Web 服务器的正式名称叫做 Web Server,Web 服务器一般指的是网站服务器,上面说到浏览器是 HTTP 请求的发起方,那么 Web 服务器就是 HTTP 请求的应答方,Web 服务器可以向浏览器等 Web 客户端提供文档,也可以放置网站文件,让全世界浏览;可以放置数据文件,让全世界下载。目前最主流的三个Web服务器是Apache、 Nginx 、IIS。
IP 协议的全称是 Internet Protocol 的缩写,它主要解决的是通信双方寻址的问题。IP 协议使用 IP 地址 来标识互联网上的每一台计算机,可以把 IP 地址想象成为你手机的电话号码,你要与他人通话必须先要知道他人的手机号码,计算机网络中信息交换必须先要知道对方的 IP 地址。(关于 TCP 和 IP 更多的讨论我们会在后面详解)
DNS
你有没有想过为什么你可以通过键入 http://www.google.com 就能够获取你想要的网站?我们上面说到,计算机网络中的每个端系统都有一个 IP 地址存在,而把 IP 地址转换为便于人类记忆的协议就是 DNS 协议。
DNS 的全称是域名系统(Domain Name System,缩写:DNS),它作为将域名和 IP 地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
URI / URL
我们上面提到,你可以通过输入 http://www.google.com 地址来访问谷歌的官网,那么这个地址有什么规定吗?我怎么输都可以?AAA.BBB.CCC 是不是也行?当然不是的,你输入的地址格式必须要满足 URI 的规范。
GET 获取资源,GET 方法用来请求访问已被 URI 识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回;
POST 传输实体,虽然 GET 方法也可以传输主体信息,但是便于区分,我们一般不用 GET 传输实体信息,反而使用 POST 传输实体信息,
PUT 传输文件,PUT 方法用来传输文件。就像 FTP 协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求 URI 指定的位置。
但是,鉴于 HTTP 的 PUT 方法自身不带验证机制,任何人都可以上传文件 , 存在安全性问题,因此一般的 W eb 网站不使用该方法。若配合 W eb 应用程序的验证机制,或架构设计采用REST(REpresentational State Transfer,表征状态转移)标准的同类 Web 网站,就可能会开放使用 PUT 方法。
HEAD 获得响应首部,HEAD 方法和 GET 方法一样,只是不返回报文主体部分。用于确认 URI 的有效性及资源更新的日期时间等。
DELETE 删除文件,DELETE 方法用来删除文件,是与 PUT 相反的方法。DELETE 方法按请求 URI 删除指定的资源。
OPTIONS 询问支持的方法,OPTIONS 方法用来查询针对请求 URI 指定的资源支持的方法。
public class MainTest { public static AtomicInteger num = new AtomicInteger(0); public static void main(String[] args) throws InterruptedException { Runnable runnable=()->{ for (int i = 0; i < 1000000000; i++) { num.getAndAdd(1); } System.out.println(Thread.currentThread().getName()+"执行结束!"); }; Thread t1 = new Thread(runnable); Thread t2 = new Thread(runnable); t1.start(); t2.start(); Thread.sleep(1000); System.out.println("num = " + num); } }
public test.StewardTipCategory(java.lang.String,java.util.Map<java.lang.Integer, java.util.List<java.lang.String>>)『C1』public test.StewardTipCategory(java.lang.String,java.util.List<test.StewardTipItem>)『C2』
publicclassAccessibleObjectimplements AnnotatedElement { ...... // NOTE: for security purposes, this field must not be visible booleanoverride; publicbooleanisAccessible() { returnoverride; } publicvoidsetAccessible(booleanflag) throwsSecurityException { ...... } ...... }
publicObjectinvoke(Objectobj, Object... args){ // 是否要进行安全检查 if (!override) { // 进行快速验证是否是 Public 方法 if (!Reflection.quickCheckMemberAccess(clazz, modifiers)) { // 返回调用这个方法的 Class Class<?> caller = Reflection.getCallerClass(); // 做权限访问的校验,缓存调用这个方法的 Class,避免下次在做检查 checkAccess(caller, clazz, obj, modifiers); } } ...... returnma.invoke(obj, args); }
字段 override 提供给子类去重写,它的值决定了是否要进行安全检查,如果要进行安全检查,则会执行 quickCheckMemberAccess() 快速验证是否是 Public 方法,避免调用 getCallerClass()。
如果是 Public 方法,避免做安全检查,所以我们在代码中不调用 setAccessible(true) 方法,也不会抛出异常
如果不是 Public 方法则会调用 getCallerClass() 获取调用这个方法的 Class,执行 checkAccess() 方法进行安全检查。
// it is necessary to perform somewhat expensive security checks. // A more complicated security check cache is needed for Method and Field // The cache can be either null (empty cache) volatileObjectsecurityCheckCache; // 缓存调用这个方法的 Class voidcheckAccess(Class<?>caller, Class<?>clazz, Objectobj, intmodifiers){ ...... Objectcache=securityCheckCache; // read volatile if(cache==调用这个方法的Class){ return; // ACCESS IS OK } slowCheckMemberAccess(caller, clazz, obj, modifiers, targetClass); ...... } voidslowCheckMemberAccess(Class<?>caller, Class<?>clazz, Objectobj, intmodifiers,Class<?>targetClass){ Reflection.ensureMemberAccess(caller, clazz, obj, modifiers); Objectcache=调用这个方法的Class securityCheckCache=cache; // 缓存调用这个方法的 Class }
Remove method breakpoints and consider using the regular line breakpoints.
删除方法断点并考虑使用常规的 line breakpoints。
官方还是很贴心的,怕你不知道怎么 Remove 还专门补充了一句:
To verify that you don't have any method breakpoints open .idea/workspace.xml file in the project root directory (or .iws file if you are using the old project format) and look for any breakpoints inside the method_breakpoints node.
minId = min(id) maxId = max(id) for(int i = minId; i<= maxId; i+=pageSize){ sele ct * from table_demo where type = ? and id between i and i+ pageSize; }
优化 GROU P BY
提高 GROU P BY 语句的效率, 可以通过将不需要的记录在 GROU P BY 之前过滤掉.下面两个查询返回相同结果但第二个明显就快了许多。
低效:
sele ct job , avg(sal) from table_demo grou p by job having job = ‘manager'
高效:
sele ct job , avg(sal) from table_demo where job = ‘manager' grou p by job
范围查询
联合索引中如果有某个列存在范围(大于小于)查询,其右边的列是否还有意义?
expla in sele ct count(1) from statement where org_code='1012' and trade_date_time >= '2019-05-01 00:00:00' and trade_date_time<='2020-05-01 00:00:00' expla in sele ct * from statement where org_code='1012' and trade_date_time >= '2019-05-01 00:00:00' and trade_date_time<='2020-05-01 00:00:00' limit 0, 100 expla in sele ct * from statement where org_code='1012' and trade_date_time >= '2019-05-01 00:00:00' and trade_date_time<='2020-05-01 00:00:00'
SELE CT id,....,creator,modifier,create_time,update_time FROM statement WHERE (account_number = 'XXX' AND create_time >= '2022-04-24 06:03:44' AND create_time <= '2022-04-24 08:03:44' AND dc_flag = 'C') ORDER BY trade_date_time DESC,id DESC LIMIT 0,1000;
优化前:SQL 执行超时被 kill 了
SELE CT id,....,creator,modifier,create_time,upda te_time FROM statement WHERE (account_number = 'XXX' AND create_time >= '2022-04-24 06:03:44' AND create_time <= '2022-04-24 08:03:44' AND dc_flag = 'C') ORDER BY create_time DESC,id DESC LIMIT 0,1000;
优化后:执行总行数为:6 行,耗时 34ms。
MySQL使不使用索引与所查列无关,只与索引本身,where条件,order by 字段,grou p by 字段有关。索引的作用一个是查找,一个是排序。
业务拆分
sele ct * from order where status='S' and update_time < now-5min limit 500
date = now; minDate = now - 10 days while(date > minDate) { sele ct * from order where order_date={#date} and status='S' and upda te_time < now-5min limit 500 date = data + 1 }
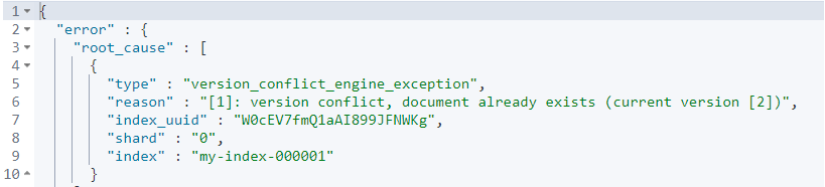
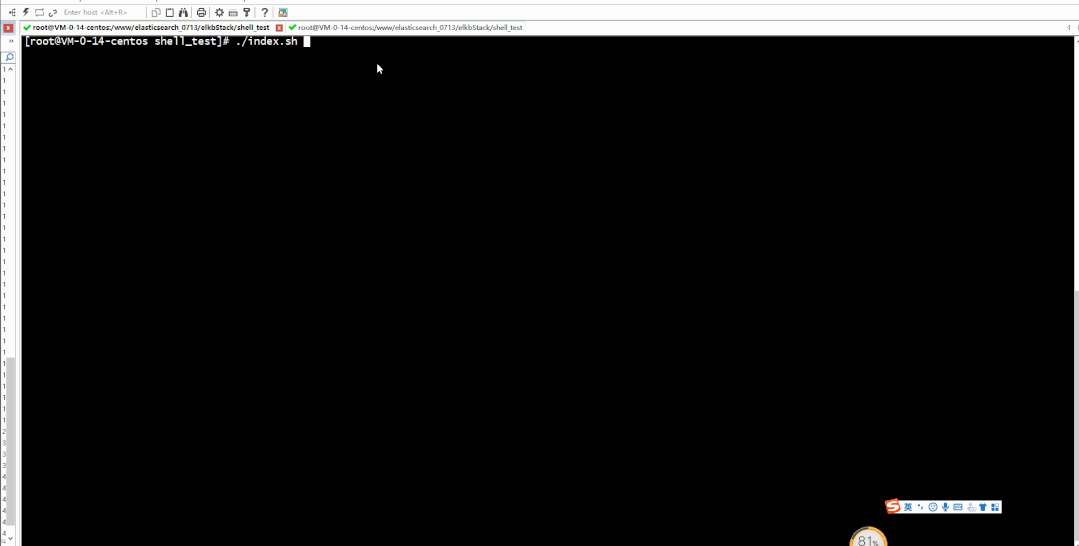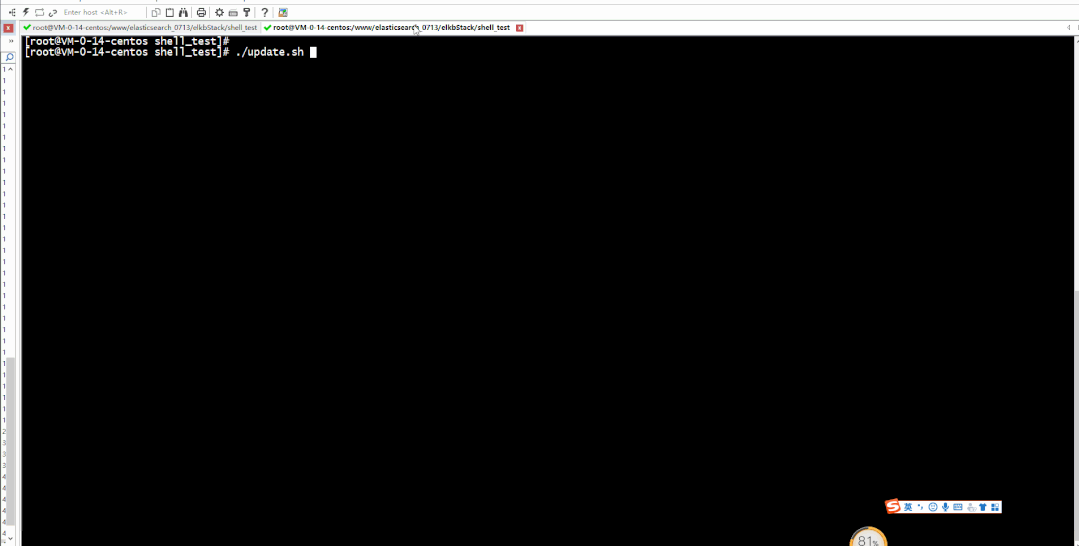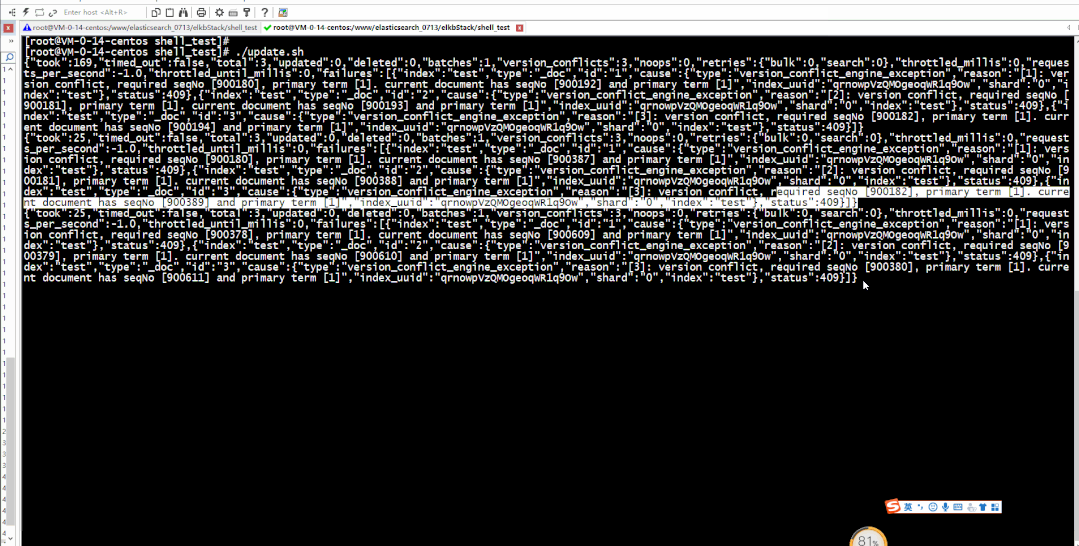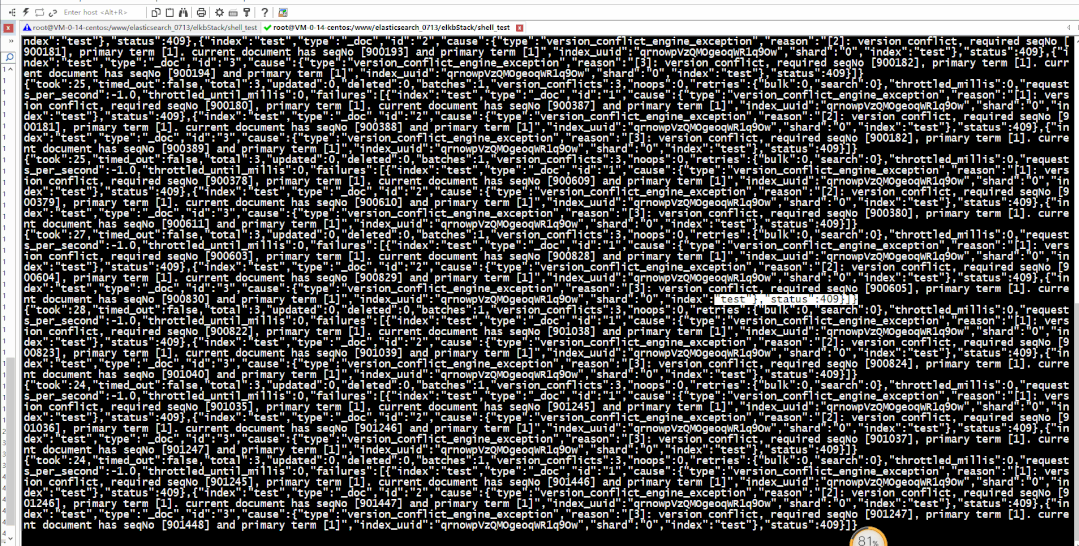
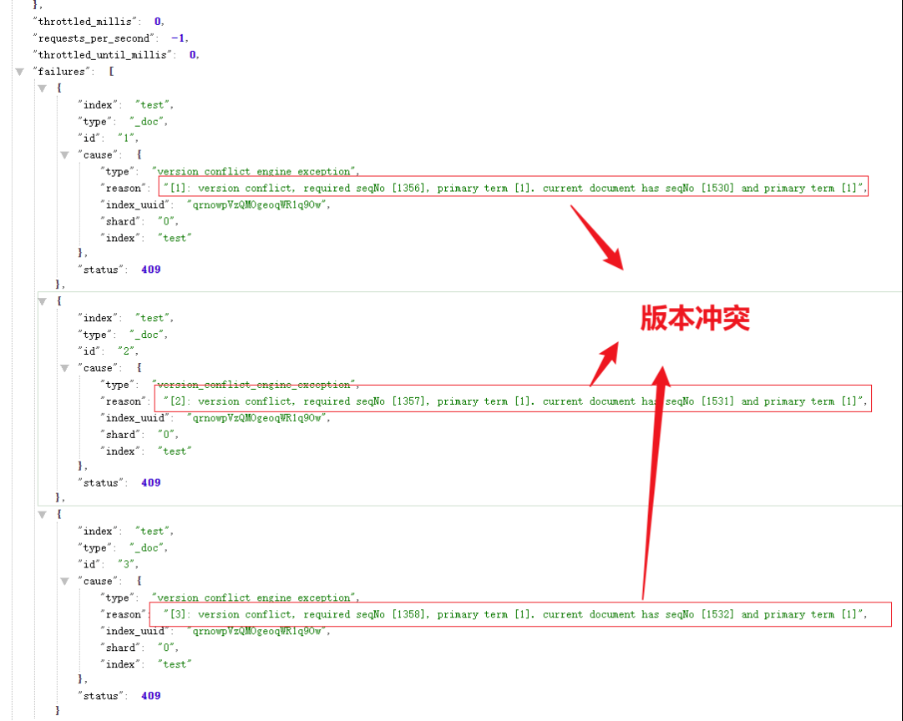
另外,值得注意的是,根据所使用的哈希算法,此方法理论上可能会导致 id 值的[哈希冲突数](https://en.wikipedia.org/wiki/Collision(computer_science))不为零,这在理论上可能导致两个不相同的文档映射到相同的_id,因此导致这些文档之一丢失。对于大多数实际情况,哈希冲突的可能性可能非常低。对不同哈希函数的详细分析不在本博客的讨论范围之内,但是应仔细考虑指纹过滤器中使用的哈希函数,因为它将影响提取性能和哈希冲突次数。
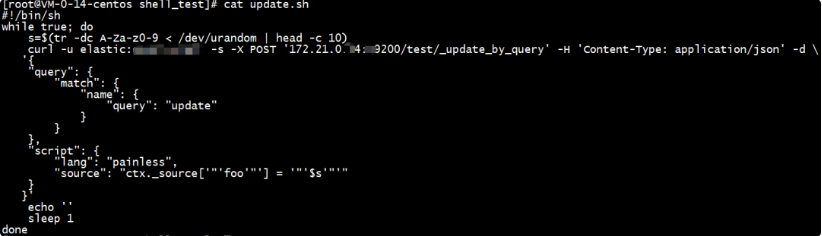
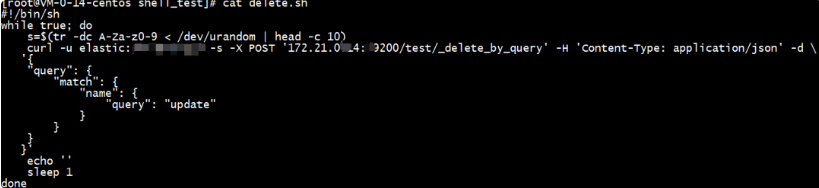
下面给出了使用指纹过滤器对现有索引进行重复数据删除的简单 Logstash 配置。
input { # Read all documents from Elasticsearch elasticsearch { hosts => "localhost" index => "stocks" query => '{ "sort": [ "_doc" ] }' } } # This filter has been updated on February 18, 2019 filter { fingerprint { key => "1234ABCD" method => "SHA256" source => ["CAC", "FTSE", "SMI"] target => "[@metadata][generated_id]" concatenate_sources => true # <-- New line added since original post date } } output { stdout { codec => dots } elasticsearch { index => "stocks_after_fingerprint" document_id => "%{[@metadata][generated_id]}" } }
#!/usr/local/bin/python3 importhashlib fromelasticsearchimportElasticsearch es = Elasticsearch(["localhost:9200"]) dict_of_duplicate_docs = {} # The following line defines the fields that will be # used to determine if a document is a duplicate keys_to_include_in_hash = ["CAC", "FTSE", "SMI"] # Process documents returned by the current search/scroll defpopulate_dict_of_duplicate_docs(hits): foriteminhits: combined_key = "" formykeyinkeys_to_include_in_hash: combined_key += str(item['_source'][mykey]) _id = item["_id"] hashval = hashlib.md5(combined_key.encode('utf-8')).digest() # If the hashval is new, then we will create a new key # in the dict_of_duplicate_docs, which will be # assigned a value of an empty array. # We then immediately push the _id onto the array. # If hashval already exists, then # we will just push the new _id onto the existing array dict_of_duplicate_docs.setdefault(hashval, []).append(_id) # Loop over all documents in the index, and populate the # dict_of_duplicate_docs data structure. defscroll_over_all_docs(): data = es.search(index="stocks", scroll='1m', body={"query": {"match_all": {}}}) # Get the scroll ID sid = data['_scroll_id'] scroll_size = len(data['hits']['hits']) # Before scroll, process current batch of hits populate_dict_of_duplicate_docs(data['hits']['hits']) whilescroll_size>0: data = es.scroll(scroll_id=sid, scroll='2m') # Process current batch of hits populate_dict_of_duplicate_docs(data['hits']['hits']) # Update the scroll ID sid = data['_scroll_id'] # Get the number of results that returned in the last scroll scroll_size = len(data['hits']['hits']) defloop_over_hashes_and_remove_duplicates(): # Search through the hash of doc values to see if any # duplicate hashes have been found forhashval, array_of_idsindict_of_duplicate_docs.items(): iflen(array_of_ids) >1: print("********** Duplicate docs hash=%s **********"%hashval) # Get the documents that have mapped to the current hashval matching_docs = es.mget(index="stocks", doc_type="doc", body={"ids": array_of_ids}) fordocinmatching_docs['docs']: # In this example, we just print the duplicate docs. # This code could be easily modified to delete duplicates # here instead of printing them print("doc=%s\n"%doc) defmain(): scroll_over_all_docs() loop_over_hashes_and_remove_duplicates() main()