
















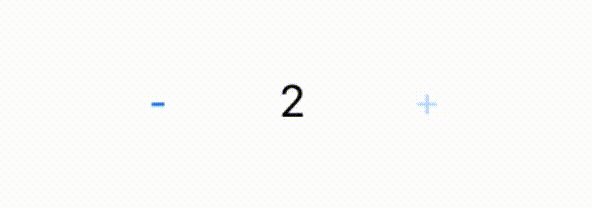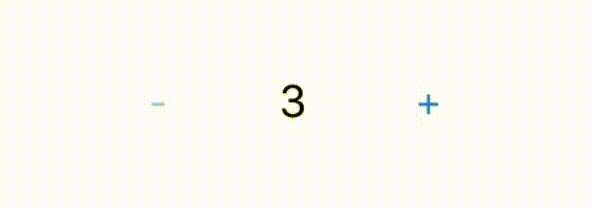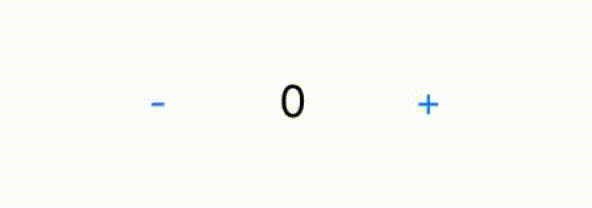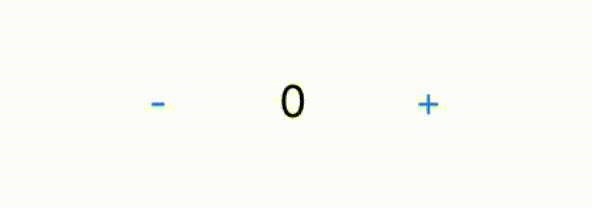

















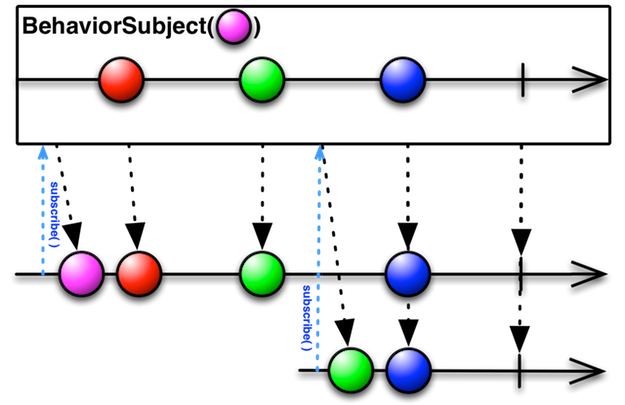
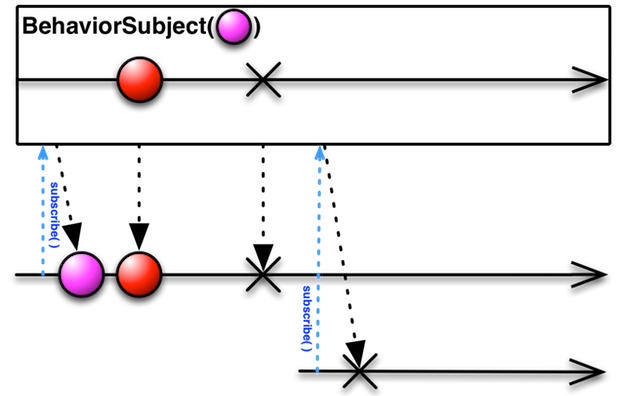

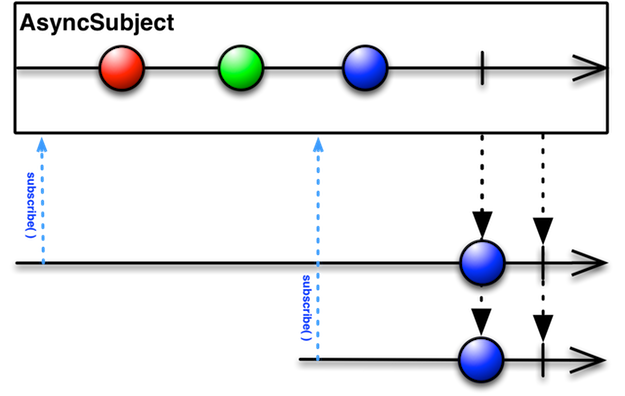
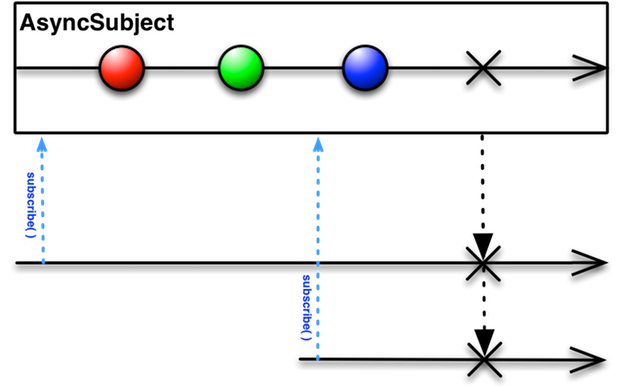


前言
前面的文章讲述了同步和异步的底层分析步骤,今天来讲GCD实际的应用相关的函数及原理,主要是:栅栏函数,信号量,线程组和Dispatch_source
栅栏函数
- 栅栏函数有一个比较直接的效果:
控制任务的执行顺序,导致同步的效果。 - 栅栏函数有两种:
dispatch_barrier_asyncdispatch_barrier_sync
下面通过案例来分析他们的作用:
dispatch_barrier_async
先来看看异步栅栏的案例:
- (void)testAsync_barrier {
dispatch_queue_t concurrent = dispatch_queue_create("wushuang.concurrent", DISPATCH_QUEUE_CONCURRENT);
NSLog(@" 开始啦 ~ ");
dispatch_async(concurrent, ^{
sleep(1);
NSLog(@"1");
});
dispatch_async(concurrent, ^{
sleep(1);
NSLog(@"2");
});
dispatch_barrier_async(concurrent, ^{
NSLog(@"——————— 大栅栏 ———————");
});
dispatch_async(concurrent, ^{
NSLog(@"3");
});
dispatch_async(concurrent, ^{
NSLog(@"4");
});
NSLog(@" ~~ 你过来呀 ~~ ");
}
复制代码- 为了更直接的观察,在栅栏前面的异步函数里加上了
sleep,打印结果如下:
- 从打印结果可以看出来,栅栏函数拦住的是同一个线程中的任务,并
不会阻塞线程
dispatch_barrier_sync
再来看看同步栅栏:
- (void)testSync_barrier {
dispatch_queue_t concurrent = dispatch_queue_create("wushuang.concurrent", DISPATCH_QUEUE_CONCURRENT);
NSLog(@" 开始啦 ~ ");
dispatch_async(concurrent, ^{
sleep(1);
NSLog(@"1");
});
dispatch_async(concurrent, ^{
sleep(1);
NSLog(@"2");
});
dispatch_barrier_sync(concurrent, ^{
NSLog(@"——————— 同步大栅栏 ———————");
});
dispatch_async(concurrent, ^{
NSLog(@"3");
});
dispatch_async(concurrent, ^{
NSLog(@"4");
});
NSLog(@" ~~ 你过来呀 ~~ ");
}
复制代码先看看打印结果:
- 从结果中能够看出来,同步栅栏函数也拦住的是同一个队列中的任务,但
会阻塞线程
全局队列栅栏
我们平常用的栅栏函数都是创建的并发队列,那么使用在全局队列使用呢?
- (void)testGlobalBarrier {
dispatch_queue_t global = dispatch_get_global_queue(0, 0);
NSLog(@" 开始啦 ~ ");
dispatch_async(global, ^{
sleep(1);
NSLog(@"1");
});
dispatch_async(global, ^{
sleep(1);
NSLog(@"2");
});
dispatch_barrier_async(global, ^{
NSLog(@"——————— 大栅栏 ———————");
});
dispatch_async(global, ^{
NSLog(@"3");
});
dispatch_async(global, ^{
NSLog(@"4");
});
NSLog(@" ~~ 你过来呀 ~~ ");
}
复制代码- 打印结果如下:
- 结果什么也没有拦住,说明全局队列比较特殊。
疑问:
1. 为什么栅栏函数可以控制任务
2. 为什么栅栏函数在全局队列不起作用
- 带着这两个疑问,我们去源码 libdispatch-1271.120.2中探索下
底层源码
- 以
dispatch_barrier_sync来分析,搜索跟流程最终会进入_dispatch_barrier_sync_f_inline方法
- 通过符号断点调试,发现最终会走
_dispatch_sync_f_slow方法,同时设置DC_FLAG_BARRIER标记,再跟进
- 再根据下符号断点,确定走
_dispatch_sync_invoke_and_complete_recurse方法,并且将DC_FLAG_BARRIER参数传入
- 进入
_dispatch_sync_function_invoke_inline方法能够发现是_dispatch_client_callout方法,也就是栅栏函数的调用,但我们研究的核心是为什么会控制任务,通过下符号断点发现,栅栏函数执行后会走_dispatch_sync_complete_recurse方法
- 于是跟进
_dispatch_sync_complete_recurse方法
static void
_dispatch_sync_complete_recurse(dispatch_queue_t dq, dispatch_queue_t stop_dq,
uintptr_t dc_flags)
{
bool barrier = (dc_flags & DC_FLAG_BARRIER);
do {
if (dq == stop_dq) return;
if (barrier) {
dx_wakeup(dq, 0, DISPATCH_WAKEUP_BARRIER_COMPLETE);
} else {
_dispatch_lane_non_barrier_complete(upcast(dq)._dl, 0);
}
dq = dq->do_targetq;
barrier = (dq->dq_width == 1);
} while (unlikely(dq->do_targetq));
}
复制代码- 此处是一个
do-while循环,首先dc_flags传入的是DC_FLAG_BARRIER,所以(dc_flags & DC_FLAG_BARRIER)一定有值的,于是在循环中会走dx_wakeup,去唤醒队列中的任务,唤醒完成后也就是栅栏结束,就会走_dispatch_lane_non_barrier_complete函数,也就是继续栅栏之后的流程。 - 再查看此时
dx_wakeup函数,此时flag传入为DISPATCH_WAKEUP_BARRIER_COMPLETE
_dispatch_lane_wakeup
- 并发流程
_dispatch_root_queue_wakeup中,根据flag判断会走_dispatch_lane_barrier_complete方法:
- 当串行或者栅栏时,会调用
_dispatch_lane_drain_barrier_waiter阻塞任务,直到确认当前队列前面任务执行完就会继续后面任务的执行
_dispatch_root_queue_wakeup
void
_dispatch_root_queue_wakeup(dispatch_queue_global_t dq,
DISPATCH_UNUSED dispatch_qos_t qos, dispatch_wakeup_flags_t flags)
{
if (!(flags & DISPATCH_WAKEUP_BLOCK_WAIT)) {
DISPATCH_INTERNAL_CRASH(dq->dq_priority,
"Don't try to wake up or override a root queue");
}
if (flags & DISPATCH_WAKEUP_CONSUME_2) {
return _dispatch_release_2_tailcall(dq);
}
}
复制代码- 全局并发队列源码中什么没做,此时的栅栏相当于一个普通的异步并发函数
没起作用,为什么呢?全局并发是系统创建的并发队列,如果阻塞可能会导致系统任务出现问题,所以在使用栅栏函数时,不能使用全部并发队列
总结
- 栅栏函数可以阻塞当前线程的任务,达到控制任务的效果,但只能在
创建的并发队列中使用
- 栅栏函数可以阻塞当前线程的任务,达到控制任务的效果,但只能在
- 栅栏函数也可以在多读单写的场景中使用
- 栅栏函数只能在当前线程使用,如果多个线程就会起不到想要的效果
信号量
- 在
程序员的自我修养中这本书的26页,有对二元信号量的讲解,它只有0和1两个状态,多元信号量简称信号量 GCD中的信号量dispatch_semaphore_t中主要有三个函数:
dispatch_semaphore_create:创建信号dispatch_semaphore_wait:等待信号dispatch_semaphore_signal:释放信号
案例分析
- (void)testDispatchSemaphore {
dispatch_queue_t global = dispatch_get_global_queue(0, 0);
dispatch_semaphore_t semaphore = dispatch_semaphore_create(0);
NSLog(@"~~ 开始 ~~");
dispatch_async(global, ^{
NSLog(@"~~ 0 ~~");
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
NSLog(@"~~ 1 ~~");
});
dispatch_async(global, ^{
NSLog(@"~~ 2 ~~");
sleep(2);
dispatch_semaphore_signal(semaphore);
NSLog(@"~~ 3 ~~");
});
NSLog(@" ~~ 你过来呀 ~~ ");
}
复制代码- 运行结果如下:
- 从打印结果中可以看出来,在先走了一个异步任务所以打印了
0,但是由于没有信号,所以在dispatch_semaphore_wait就原地等待,导致1没法执行,此时第二个异步任务执行了就打印了2,然后dispatch_semaphore_signal释放信号,之后1就可以打印了
源码解读
再来看看源码分析
dispatch_semaphore_create
- 首先如果信号为小于
0,则返回一个DISPATCH_BAD_INPUT类型对象,也就是返回个_Nonnull - 如果信号
大于等于0,就会对dispatch_semaphore_t对象dsema进行一些赋值,并返回dsema对象
dispatch_semaphore_wait
intptr_t
dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout)
{
long value = os_atomic_dec2o(dsema, dsema_value, acquire);
if (likely(value >= 0)) {
return 0;
}
return _dispatch_semaphore_wait_slow(dsema, timeout);
}
复制代码- 等待信号主要是通过
os_atomic_dec2o函数对信号进行自减,当值大于等于0时返回0 - 当值
小于0时,会走_dispatch_semaphore_wait_slow方法
_dispatch_semaphore_wait_slow
当设置了
timeout(超时时间),则会根据类型进行相关操作,本文使用的是DISPATCH_TIME_FOREVER,此时调用_dispatch_sema4_wait进行等待处理:
- 这里主要是一个
do-while循环里队等待信号,当不满足条件后才会跳出循环,所以会出现一个等待的效果
- 这里主要是一个
dispatch_semaphore_signal
intptr_t
dispatch_semaphore_signal(dispatch_semaphore_t dsema)
{
long value = os_atomic_inc2o(dsema, dsema_value, release);
if (likely(value > 0)) {
return 0;
}
if (unlikely(value == LONG_MIN)) {
DISPATCH_CLIENT_CRASH(value,
"Unbalanced call to dispatch_semaphore_signal()");
}
return _dispatch_semaphore_signal_slow(dsema);
}
复制代码- 发送信号主要是通过
os_atomic_inc2o对信号进行自增,如果自增后的结果大于0,就返回0 - 如果
自增后还是小于0,就会走到_dispatch_semaphore_signal_slow方法
_dispatch_semaphore_signal_slow
intptr_t
_dispatch_semaphore_signal_slow(dispatch_semaphore_t dsema)
{
_dispatch_sema4_create(&dsema->dsema_sema, _DSEMA4_POLICY_FIFO);
_dispatch_sema4_signal(&dsema->dsema_sema, 1);
return 1;
}
复制代码- 这里有个
_dispatch_sema4_signal函数进行缓慢发送信号
调度组
- 调度组最直接的作用就是:
控制任务的执行顺序,Api主要有以下几个方法:
dispatch_group_create:创建组dispatch_group_async:进组任务dispatch_group_notify:组任务执行完毕的通知dispatch_group_enter:进组dispatch_group_leave:出组dispatch_group_wait:等待组任务时间
案例分析
dispatch_group_async
- (void)testDispatchGroup1 {
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t globalQueue = dispatch_get_global_queue(0, 0);
dispatch_group_async(group, globalQueue, ^{
sleep(1);
NSLog(@"1");
});
NSLog(@"2");
dispatch_group_async(group, globalQueue, ^{
sleep(1);
NSLog(@"3");
});
NSLog(@"4");
dispatch_group_notify(group, globalQueue, ^{
NSLog(@"5");
});
NSLog(@"~~ 6 ~~");
}
复制代码- 讲任务
1和3放到组任务,然后将5任务放到dispatch_group_notify中执行,输出结果如下:
- 输出结果可以得出结论:
调度组不会阻塞线程
- 组任务
执行没有顺序,相当于异步并发队列
- 组任务
- 组任务执行完后才会执行
dispatch_group_notify任务
- 组任务执行完后才会执行
dispatch_group_wait
- 将任务
1和3分别放到两个任务组,然后在下面执行dispatch_group_wait等待10秒
- 将任务
- (void)testDispatchGroup1 {
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t globalQueue = dispatch_get_global_queue(0, 0);
dispatch_group_async(group, globalQueue, ^{
sleep(5);
NSLog(@"1");
});
NSLog(@"2");
dispatch_group_async(group, globalQueue, ^{
sleep(5);
NSLog(@"3");
});
dispatch_time_t time = dispatch_time(DISPATCH_TIME_NOW, NSEC_PER_SEC * 10);
dispatch_group_wait(group, time);
NSLog(@"~~ 6 ~~");
}
复制代码- 输出结果如下:
发现等待的是10秒,但5秒后任务执行完,立即执行任务6
- 在将等待时间改成
3秒:
- 在将等待时间改成
这里是等3秒,发现组任务还没执行完就去执行6任务
- 总结:
dispatch_group_wait的作用是阻塞调度组之外的任务:
- 当等待时间结束时,组任务还没完成,就结束阻塞执行其他任务
- 当组任务完成,等待时间还未结束时,会结束阻塞执行其他任务
进组 + 出组
- (void)testDispatchGroup2 {
dispatch_group_t group = dispatch_group_create();
dispatch_queue_t globalQueue = dispatch_get_global_queue(0, 0);
dispatch_group_enter(group);
dispatch_async(globalQueue, ^{
sleep(1);
NSLog(@"1");
dispatch_group_leave(group);
});
NSLog(@"2");
dispatch_group_enter(group);
dispatch_async(globalQueue, ^{
sleep(1);
NSLog(@"3");
dispatch_group_leave(group);
});
dispatch_group_notify(group, globalQueue, ^{
NSLog(@"4");
});
NSLog(@"5");
}
复制代码进组+出组的案例基本和上面的一致,只是将进组任务拆分成进组+出组,执行结果如下:
输出结果和
dispatch_group_async基本一致,说明他们两个作用相同
进组+出组组合有几个 注意事项,他们必须是成对出现,必须先进组后出组,否则会出现以下问题:
- 如果少一个
dispatch_group_leave,则dispatch_group_notify不会执行
- 如果少一个
- 如果少一个
dispatch_group_enter,则任务执行完会走notify但不成对的dispatch_group_leave处会崩溃
- 如果少一个
- 如果先
leave后enter,此时会直接崩溃在leave处
- 如果先
疑问:
1. 调度组是如何达到流程控制的?
2. 为什么进组+出组要搭配使用,且效果和dispatch_group_async是一样的?
3. 为什么先dispatch_group_leave会崩溃?
带着问题我们去源码中探索究竟
原理分析
dispatch_group_creat
dispatch_group_t
dispatch_group_create(void)
{
return _dispatch_group_create_with_count(0);
}
复制代码dispatch_group_create方法会调用_dispatch_group_create_with_count方法,并传入参数0
static inline dispatch_group_t
_dispatch_group_create_with_count(uint32_t n)
{
dispatch_group_t dg = _dispatch_object_alloc(DISPATCH_VTABLE(group),
sizeof(struct dispatch_group_s));
dg->do_next = DISPATCH_OBJECT_LISTLESS;
dg->do_targetq = _dispatch_get_default_queue(false);
if (n) {
os_atomic_store2o(dg, dg_bits,
(uint32_t)-n * DISPATCH_GROUP_VALUE_INTERVAL, relaxed);
os_atomic_store2o(dg, do_ref_cnt, 1, relaxed); // <rdar://22318411>
}
return dg;
}
复制代码- 方法的核心是创建
dispatch_group_t对象dg,并对它的do_next和do_targetq参数进行赋值,然后调用os_atomic_store2o进行存储
dispatch_group_enter
void
dispatch_group_enter(dispatch_group_t dg)
{
// The value is decremented on a 32bits wide atomic so that the carry
// for the 0 -> -1 transition is not propagated to the upper 32bits.
uint32_t old_bits = os_atomic_sub_orig2o(dg, dg_bits,
DISPATCH_GROUP_VALUE_INTERVAL, acquire);
uint32_t old_value = old_bits & DISPATCH_GROUP_VALUE_MASK;
if (unlikely(old_value == 0)) {
_dispatch_retain(dg); // <rdar://problem/22318411>
}
if (unlikely(old_value == DISPATCH_GROUP_VALUE_MAX)) {
DISPATCH_CLIENT_CRASH(old_bits,
"Too many nested calls to dispatch_group_enter()");
}
}
复制代码主要调用os_atomic_sub_orig2o进行自减操作,也就是由0 -> -1,这块和信号量的操作很像,但没有wait的步骤
dispatch_group_leave
void
dispatch_group_leave(dispatch_group_t dg)
{
// The value is incremented on a 64bits wide atomic so that the carry for
// the -1 -> 0 transition increments the generation atomically.
uint64_t new_state, old_state = os_atomic_add_orig2o(dg, dg_state,
DISPATCH_GROUP_VALUE_INTERVAL, release);
uint32_t old_value = (uint32_t)(old_state & DISPATCH_GROUP_VALUE_MASK);
if (unlikely(old_value == DISPATCH_GROUP_VALUE_1)) {
old_state += DISPATCH_GROUP_VALUE_INTERVAL;
do {
new_state = old_state;
if ((old_state & DISPATCH_GROUP_VALUE_MASK) == 0) {
new_state &= ~DISPATCH_GROUP_HAS_WAITERS;
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
} else {
// If the group was entered again since the atomic_add above,
// we can't clear the waiters bit anymore as we don't know for
// which generation the waiters are for
new_state &= ~DISPATCH_GROUP_HAS_NOTIFS;
}
if (old_state == new_state) break;
} while (unlikely(!os_atomic_cmpxchgv2o(dg, dg_state,
old_state, new_state, &old_state, relaxed)));
return _dispatch_group_wake(dg, old_state, true);
}
if (unlikely(old_value == 0)) {
DISPATCH_CLIENT_CRASH((uintptr_t)old_value,
"Unbalanced call to dispatch_group_leave()");
}
}
复制代码通过os_atomic_add_orig2o进行自增(-1 ~ 0)得到old_state = 0
DISPATCH_GROUP_VALUE_MASK 0x00000000fffffffcULL
DISPATCH_GROUP_VALUE_1 DISPATCH_GROUP_VALUE_MASK
复制代码
old_value等于old_state & DISPATCH_GROUP_VALUE_MASK等于0,此时old_value != DISPATCH_GROUP_VALUE_1,再由于判断是unlikely,所以会进入if判断
- 由于
DISPATCH_GROUP_VALUE_INTERVAL = 4,所以此时old_state = 4,再进入do-while循环,此时会走else判断new_state &= ~DISPATCH_GROUP_HAS_NOTIFS= 4 & ~2 = 4,这时old_state和new_state相等,然后跳出循环执行_dispatch_group_wake方法,也就是唤醒dispatch_group_notify方法
- 由于
- 假如
enter两次,则old_state=-1,加上4后为3,也就是在do-while循环时,new_state = old_state = 3。然后new_state &= ~DISPATCH_GROUP_HAS_NOTIFS = 3 & ~2 = 1,然后不等与old_state会再进行循环,当再次进行leave自增操作后,新的循环判断会走到_dispatch_group_wake函数进行唤醒
- 假如
dispatch_group_notify
static inline void
_dispatch_group_notify(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dsn)
{
uint64_t old_state, new_state;
dispatch_continuation_t prev;
dsn->dc_data = dq;
_dispatch_retain(dq);
prev = os_mpsc_push_update_tail(os_mpsc(dg, dg_notify), dsn, do_next);
if (os_mpsc_push_was_empty(prev)) _dispatch_retain(dg);
os_mpsc_push_update_prev(os_mpsc(dg, dg_notify), prev, dsn, do_next);
if (os_mpsc_push_was_empty(prev)) {
os_atomic_rmw_loop2o(dg, dg_state, old_state, new_state, release, {
new_state = old_state | DISPATCH_GROUP_HAS_NOTIFS;
if ((uint32_t)old_state == 0) {
os_atomic_rmw_loop_give_up({
return _dispatch_group_wake(dg, new_state, false);
});
}
});
}
}
复制代码主要是通过os_atomic_rmw_loop2o进行do-while循环判断,知道old_state == 0时就会走_dispatch_group_wake唤醒,也就是会去走block执行
- 此时还有一个问题没有解决,就是
dispatch_group_async为什么和进组+出组效果一样,再来分析下源码
dispatch_group_async
void
dispatch_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_block_t db)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME | DC_FLAG_GROUP_ASYNC;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, db, 0, dc_flags);
_dispatch_continuation_group_async(dg, dq, dc, qos);
}
复制代码这个函数内容比较熟悉,与异步的函数很像,但此时dc_flags = DC_FLAG_CONSUME | DC_FLAG_GROUP_ASYNC,然后走进_dispatch_continuation_group_async函数:
static inline void
_dispatch_continuation_group_async(dispatch_group_t dg, dispatch_queue_t dq,
dispatch_continuation_t dc, dispatch_qos_t qos)
{
dispatch_group_enter(dg);
dc->dc_data = dg;
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);
}
复制代码这里我们看到了dispatch_group_enter,但是没有看到leave函数,我猜想肯定在block执行的地方会执行leave,不然不能确保组里任务执行完,于是根据global类型的dq_push = _dispatch_root_queue_push最终找到_dispatch_continuation_invoke_inline函数
如果是普通异步类型会走到_dispatch_client_callout函数,如果是DC_FLAG_GROUP_ASYNC组类型,会走_dispatch_continuation_with_group_invoke函数
static inline void
_dispatch_continuation_with_group_invoke(dispatch_continuation_t dc)
{
struct dispatch_object_s *dou = dc->dc_data;
unsigned long type = dx_type(dou);
if (type == DISPATCH_GROUP_TYPE) {
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);
_dispatch_trace_item_complete(dc);
dispatch_group_leave((dispatch_group_t)dou);
} else {
DISPATCH_INTERNAL_CRASH(dx_type(dou), "Unexpected object type");
}
}
复制代码此时,当类型是DISPATCH_GROUP_TYPE时,就会先执行_dispatch_client_callout,然后执行dispatch_group_leave,至此前面的问题全部解决
信号源Dispatch_source
- 信号源
Dispatch_source是一个尽量不占用资源,且CPU负荷非常小的Api,它不受Runloop影响,是和Runloop平级的一套Api。主要有以下几个函数组成:
dispatch_source_create:创建信号源
dispatch_source_set_event_handler:设置信号源回调
dispatch_source_merge_data:源时间设置数据
dispatch_source_get_data:获取信号源数据
dispatch_resume:继续
dispatch_suspend:挂起
- 在任一线程上调用函数
dispatch_source_merge_data后,会执行Dispatch Source事先定义好的句柄(可以理解为一个block),这个过程叫Custom event用户事件,是Dispatch Source支持处理的一种事件
信号源类型
- 创建源
dispatch_source_t
dispatch_source_create(dispatch_source_type_t type,
uintptr_t handle,
uintptr_t mask,
dispatch_queue_t _Nullable queue);
复制代码
- 第一个参数是
dispatch_source_type_t类型的type,然后handle和mask都是uintptr_t类型的,最后要传入一个队列
- 第一个参数是
- 使用方法:
dispatch_source_t source = dispatch_source_create(DISPATCH_SOURCE_TYPE_DATA_ADD, 0, 0, dispatch_get_main_queue());
复制代码
- 源的类型
dispatch_source_type_t:
DISPATCH_SOURCE_TYPE_DATA_ADD:用于ADD合并数据
DISPATCH_SOURCE_TYPE_DATA_OR:用于按位或合并数据
DISPATCH_SOURCE_TYPE_DATA_REPLACE:跟踪通过调用dispatch_source_merge_data获得的数据的分派源,新获得的数据值将替换尚未交付给源处理程序 的现有数据值
DISPATCH_SOURCE_TYPE_MACH_SEND:用于监视Mach端口的无效名称通知的调度源,只能发送没有接收权限
DISPATCH_SOURCE_TYPE_MACH_RECV:用于监视Mach端口的挂起消息
DISPATCH_SOURCE_TYPE_MEMORYPRESSURE:用于监控系统内存压力变化
DISPATCH_SOURCE_TYPE_PROC:用于监视外部进程的事件
DISPATCH_SOURCE_TYPE_READ:监视文件描述符以获取可读取的挂起字节的分派源
DISPATCH_SOURCE_TYPE_SIGNAL:监控当前进程以获取信号的调度源
DISPATCH_SOURCE_TYPE_TIMER:基于计时器提交事件处理程序块的分派源
DISPATCH_SOURCE_TYPE_VNODE:用于监视文件描述符中定义的事件的分派源
DISPATCH_SOURCE_TYPE_WRITE:监视文件描述符以获取可写入字节的可用缓冲区空间的分派源。
定时器
下面使用Dispatch Source来封装一个定时器
- (void)testTimer {
self.timer = dispatch_source_create(DISPATCH_SOURCE_TYPE_TIMER, 0, 0, dispatch_get_global_queue(0, 0));
dispatch_time_t startTime = dispatch_time(DISPATCH_TIME_NOW, 0);
dispatch_source_set_timer(self.timer, startTime, 1 * NSEC_PER_SEC, 0);
__block int a = 0;
dispatch_source_set_event_handler(self.timer, ^{
a++;
NSLog(@"a 的 值 %d", a);
});
dispatch_resume(self.timer);
self.isRunning = YES;
}
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event {
if (self.isRunning) {
dispatch_suspend(self.timer);
// dispatch_source_cancel(self.timer);
self.isRunning = NO;
NSLog(@" 中场休息下~ ");
} else {
dispatch_resume(self.timer);
self.isRunning = YES;
NSLog(@" 继续喝~ ");
}
}
复制代码输出结果如下:
- 创建定时器
dispatch_source_create时,一定要用属性或者实例变量接收,不然定时器不会执行 dispatch_source_set_timer的第二个参数start是从什么时候开始,第三个参数interval是时间间隔,leeway是计时器的纳秒偏差- 计时器停止有两种:
dispatch_resume:计时器暂停但一直在线,可以唤醒dispatch_source_cancel:计时器释放,执行dispatch_resume唤醒,会崩溃














